This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
SQL reference
Vertica offers a robust set of SQL elements that allow you to manage and analyze massive volumes of data quickly and reliably, including:.
Vertica offers a robust set of SQL elements that allow you to manage and analyze massive volumes of data quickly and reliably, including:
-
Language elements such as keywords, operators, expressions, predicates, and hints
-
Data types including complex types
-
Functions including Vertica-specific functions that take advantage of Vertica's unique column-store architecture
-
SQL statements that let you write robust queries to quickly return large volumes of data
1 - System limits
This section describes system limits on the size and number of objects in a Vertica database.
This section describes system limits on the size and number of objects in a Vertica database. In most cases, computer memory and disk drive are the limiting factors.
|
Item |
Maximum |
|
Nodes |
128 (without Vertica assistance) |
|
Database size |
Dependent on maximum disk configuration, approximately:
numFiles*platformFileSize
|
|
Table size |
Smaller of:
-
264 rows per node
-
263 bytes per column
|
|
Row size |
(231) -1
Row size is approximately the sum of its maximum column sizes. For example, a VARCHAR(80) has a maximum size of 80 bytes.
|
|
Key size |
Dependent on row size |
|
Tables/projections per database |
Dependent on physical RAM, as the catalog must fit in memory. |
|
Concurrent connections per node |
Dependent on physical RAM (or threads per process), typically 1024
Default: 50
|
|
Concurrent connections per cluster |
Dependent on physical RAM of a single node (or threads per process), typically 1024 |
|
Columns per table/view |
9800 |
|
Arguments per function call |
9800 |
|
Rows per load |
263 |
|
ROS containers per projection |
1024
See Minimizing partitions.
|
|
Length of fixed-length column |
65000 bytes |
|
Length of variable-length column |
32 MB |
|
Length of basic names |
128 bytes. Basic names include table names, column names, etc. |
|
Query length |
None |
|
Depth of nesting subqueries |
None in FROM, WHERE, and HAVING clauses |
2 - Language elements
The following topics provide detailed descriptions of the language elements and conventions of Vertica SQL.
The following topics provide detailed descriptions of the language elements and conventions of Vertica SQL.
2.1 - Keywords
Keywords are words that have a specific meaning in the SQL language.
Keywords are words that have a specific meaning in the SQL language. Every SQL statement contains one or more keywords. Although SQL is not case-sensitive with respect to keywords, they are generally shown in uppercase letters throughout this documentation for readability purposes.
Note
If you use a keyword as the name of an identifier or an alias in your SQL statements, you may have to qualify the keyword with AS or double-quotes. Vertica requires AS or double-quotes for certain reserved and non-reserved words to prevent confusion with expression syntax, or where the use of a word would be ambiguous.
Reserved words and keywords
Many keywords are also reserved words.
Vertica recommends that you not use reserved words as names for objects, or as identifiers. Including reserved words can make your SQL statements confusing. Reserved words that are used as names for objects or identifiers must be enclosed in double-quotes.
Note
All reserved words are also keywords, but Vertica can add reserved words that are not keywords. A reserved word can simply be a word that is reserved for future use.
Non-reserved keywords
Non-reserved keywords have a special meaning in some contexts, but can be used as identifiers in others. You can use non-reserved keywords as aliases—for example, SOURCE:
=> SELECT my_node AS SOURCE FROM nodes;
Note
Vertica uses several non-reserved keywords in directed queries to specify special join types. You can use these keywords as table aliases only if they are double-quoted; otherwise, double-quotes can be omitted:
ANTINULLAWARESEMISEMIALLUNI
Viewing the list of reserved and non-reserved keywords
To view the current list of Vertica reserved and non-reserved words, query system table
KEYWORDS. Vertica lists keywords alphabetically and identifies them as reserved (R) or non-reserved (N).
For example, the following query gets all reserved keywords that begin with B:
=> SELECT * FROM keywords WHERE reserved = 'R' AND keyword ilike 'B%';
keyword | reserved
---------+----------
BETWEEN | R
BIGINT | R
BINARY | R
BIT | R
BOOLEAN | R
BOTH | R
(6 rows)
2.2 - Identifiers
Identifiers (names) of objects such as schema, table, projection, column names, and so on, can be up to 128 bytes in length.
Identifiers (names) of objects such as schema, table, projection, column names, and so on, can be up to 128 bytes in length.
Unquoted identifiers
Unquoted SQL identifiers must begin with one of the following:
Subsequent characters in an identifier can be any combination of the following:
-
Non-Unicode letters: A–Z or a-z
-
Underscore (_)
-
Digits(0–9)
-
Unicode letters (letters with diacriticals or not in the Latin alphabet), unsupported for model names
-
Dollar sign ($), unsupported for model names
Caution
The SQL standard does not support dollar sign in identifiers, so usage can cause application portability problems.
Quoted identifiers
Note
Quoted identifiers are not supported for model names
Identifiers enclosed in double quote (") characters can contain any character. If you want to include a double quote, you need a pair of them; for example """". You can use names that would otherwise be invalid—for example, names that include only numeric characters ("123") or contain space characters, punctuation marks, and SQL or Vertica-reserved keywords. For example:
CREATE SEQUENCE "my sequence!";
Double quotes are required for non-alphanumerics and SQL keywords such as "1time", "Next week" and "Select".
Case sensitivity
Identifiers are not case-sensitive. Thus, identifiers "ABC", "ABc", and "aBc" are synonymous, as are ABC, ABc, and aBc.
Non-ASCII characters
Vertica accepts non-ASCII UTF-8 Unicode characters for table names, column names, and other identifiers, extending the cases where upper/lower case distinctions are ignored (case-folded) to all alphabets, including Latin, Cyrillic, and Greek.
For example, the following CREATE TABLE statement uses the ß (German eszett) in the table name:
=> CREATE TABLE straße(x int, y int);
CREATE TABLE
Identifiers are stored as created
SQL identifiers, such as table and column names, are not converted to lowercase. They are stored as created, and references to them are resolved using case-insensitive compares. For example, the following statement creates table ALLCAPS.
=> CREATE TABLE ALLCAPS(c1 varchar(30));
=> INSERT INTO ALLCAPS values('upper case');
The following statements are variations of the same query:
=> SELECT * FROM ALLCAPS;
=> SELECT * FROM allcaps;
=> SELECT * FROM "allcaps";
The three queries all return the same result:
c1
------------
upper case
(1 row)
Note that Vertica returns an error if you try to create table AllCaps:
=> CREATE TABLE AllCaps(c1 varchar(30));
ROLLBACK: table "AllCaps" already exists
See QUOTE_IDENT for additional information.
2.3 - Literals
Literals are numbers or strings used in SQL as constants.
Literals are numbers or strings used in SQL as constants. Literals are included in the select-list, along with expressions and built-in functions and can also be constants.
Vertica provides support for number-type literals (integers and numerics), string literals, VARBINARY string literals, and date/time literals. The various string literal formats are discussed in this section.
2.3.1 - Number-type literals
Vertica supports three types of numbers: integers, numerics, and floats.
Vertica supports three types of numbers: integers, numerics, and floats.
-
Integers are whole numbers less than 2^63 and must be digits.
-
Numerics are whole numbers larger than 2^63 or that include a decimal point with a precision and a scale. Numerics can contain exponents. Numbers that begin with 0x are hexadecimal numerics.
Numeric-type values can also be generated using casts from character strings. This is a more general syntax. See the Examples section below, as well as Data type coercion operators (CAST).
Syntax
digits
digits.[digits] | [digits].digits
digits e[+-]digits | [digits].digits e[+-]digits | digits.[digits] e[+-]digits
Parameters
digits- One or more numeric characters, 0 through 9
e- Exponent marker
Notes
- At least one digit must follow the exponent marker (
e), if e is present.
- There cannot be any spaces or other characters embedded in the constant.
-
Leading plus (+) or minus (–) signs are not considered part of the constant; they are unary operators applied to the constant.
-
In most cases a numeric-type constant is automatically coerced to the most appropriate type depending on context. When necessary, you can force a numeric value to be interpreted as a specific data type by casting it as described in Data type coercion operators (CAST).
-
Floating point literals are not supported. If you specifically need to specify a float, you can cast as described in Data type coercion operators (CAST).
-
Vertica follows the IEEE specification for floating point, including NaN (not a number) and Infinity (Inf).
-
A NaN is not greater than and at the same time not less than anything, even itself. In other words, comparisons always return false whenever a NaN is involved.
-
Dividing INTEGERS (x / y) yields a NUMERIC result. You can use the // operator to truncate the result to a whole number.
Examples
The following are examples of number-type literals:
42
3.5
4.
.001
5e2
1.925e-3
Scientific notation:
=> SELECT NUMERIC '1e10';
?column?
-------------
10000000000
(1 row)
BINARY scaling:
=> SELECT NUMERIC '1p10';
?column?
----------
1024
(1 row)
=> SELECT FLOAT 'Infinity';
?column?
----------
Infinity
(1 row)
The following examples illustrated using the / and // operators to divide integers:
=> SELECT 40/25;
?column?
----------------------
1.600000000000000000
(1 row)
=> SELECT 40//25;
?column?
----------
1
(1 row)
See also
Data type coercion
2.3.2 - String literals
String literals are string values surrounded by single or double quotes.
String literals are string values surrounded by single or double quotes. Double-quoted strings are subject to the backslash, but single-quoted strings do not require a backslash, except for \' and \\.
You can embed single quotes and backslashes into single-quoted strings.
To include other backslash (escape) sequences, such as \t (tab), you must use the double-quoted form.
Precede single-quoted strings with a space between the string and its preceding word, since single quotes are allowed in identifiers.
See also
2.3.2.1 - Character string literals
Character string literals are a sequence of characters from a predefined character set, enclosed by single quotes.
Character string literals are a sequence of characters from a predefined character set, enclosed by single quotes.
Syntax
'character-seq'
Parameters
character-seq- Arbitrary sequence of characters
Embedded single quotes
If a character string literal includes a single quote, it must be doubled. For example:
=> SELECT 'Chester''s gorilla';
?column?
-------------------
Chester's gorilla
(1 row)
Vertica uses standard-conforming strings as specified in the SQL standard, so backslashes are treated as string literals and not escape characters.
Note
Earlier versions of Vertica did not use standard conforming strings, and backslashes were always considered escape sequences. To revert to this older behavior, set the configuration parameter
StandardConformingStrings to 0. You can also use the
EscapeStringWarning parameter to locate back slashes which have been incorporated into string literals, in order to remove them.
Examples
=> SELECT 'This is a string';
?column?
------------------
This is a string
(1 row)
=> SELECT 'This \is a string';
WARNING: nonstandard use of escape in a string literal at character 8
HINT: Use the escape string syntax for escapes, e.g., E'\r\n'.
?column?
------------------
This is a string
(1 row)
vmartdb=> SELECT E'This \is a string';
?column?
------------------
This is a string
=> SELECT E'This is a \n new line';
?column?
----------------------
This is a
new line
(1 row)
=> SELECT 'String''s characters';
?column?
--------------------
String's characters
(1 row)
See also
2.3.2.2 - Dollar-quoted string literals
Dollar-quoted string literals are rarely used, but are provided here for your convenience.
Dollar-quoted string literals are rarely used, but are provided here for your convenience.
The standard syntax for specifying string literals can be difficult to understand. To allow more readable queries in such situations, Vertica SQL provides dollar quoting. Dollar quoting is not part of the SQL standard, but it is often a more convenient way to write complicated string literals than the standard-compliant single quote syntax.
Syntax
$$characters$$
Parameters
characters- Arbitrary sequence of characters bounded by paired dollar signs (
$$)
Dollar-quoted string content is treated as a literal. Single quote, backslash, and dollar sign characters have no special meaning within a dollar-quoted string.
Notes
A dollar-quoted string that follows a keyword or identifier must be separated from the preceding word by whitespace; otherwise, the dollar-quoting delimiter is taken as part of the preceding identifier.
Examples
=> SELECT $$Fred's\n car$$;
?column?
-------------------
Fred's\n car
(1 row)
=> SELECT 'SELECT 'fact';';
ERROR: syntax error at or near "';'" at character 21
LINE 1: SELECT 'SELECT 'fact';';
=> SELECT 'SELECT $$fact';$$;
?column?
---------------
SELECT $$fact
(1 row)
=> SELECT 'SELECT ''fact'';';
?column?
----------------
SELECT 'fact';
(1 row)
2.3.2.3 - Unicode string literals
hexit is hexadecimal integer (0-9, a-f).
Syntax
U&'characters' [ UESCAPE '<Unicode escape character>' ]
Parameters
characters- Arbitrary sequence of UTF-8 characters bounded by single quotes (')
Unicode escape character- A single character from the source language character set other than a hexit, plus sign (+), quote ('), double quote (''), or white space
With StandardConformingStrings enabled, Vertica supports SQL standard Unicode character string literals (the character set is UTF-8 only).
Before you enter a Unicode character string literal, enable standard conforming strings in one of the following ways.
See also Extended String Literals.
Examples
To enter a Unicode character in hexadecimal, such as the Russian phrase for "thank you, use the following syntax:
=> SET STANDARD_CONFORMING_STRINGS TO ON;
=> SELECT U&'\0441\043F\0430\0441\0438\0431\043E' as 'thank you';
thank you
-----------
спасибо
(1 row)
To enter the German word mude (where u is really u-umlaut) in hexadecimal:
=> SELECT U&'m\00fcde';
?column?
----------
müde
(1 row)
=> SELECT 'ü';
?column?
----------
ü
(1 row)
To enter the LINEAR B IDEOGRAM B240 WHEELED CHARIOT in hexadecimal:
=> SELECT E'\xF0\x90\x83\x8C';
?column?
----------
(wheeled chariot character)
(1 row)
Note
Not all fonts support the wheeled chariot character.
See also
2.3.2.4 - VARBINARY string literals
VARBINARY string literals allow you to specify hexadecimal or binary digits in a string literal.
VARBINARY string literals allow you to specify hexadecimal or binary digits in a string literal.
Syntax
X''
B''
Parameters
X or x- Specifies hexadecimal digits. The <hexadecimal digits> string must be enclosed in single quotes (').
B or b- Specifies binary digits. The <binary digits> string must be enclosed in single quotes (').
Examples
=> SELECT X'abcd';
?column?
----------
\253\315
(1 row)
=> SELECT B'101100';
?column?
----------
,
(1 row)
2.3.2.5 - Extended string literals
Syntax
E'characters'
Parameters
characters- Arbitrary sequence of characters bounded by single quotes (')
You can use C-style backslash sequence in extended string literals, which are an extension to the SQL standard. You specify an extended string literal by writing the letter E as a prefix (before the opening single quote); for example:
E'extended character string\n'
Within an extended string, the backslash character (\) starts a C-style backslash sequence, in which the combination of backslash and following character or numbers represent a special byte value, as shown in the following list. Any other character following a backslash is taken literally; for example, to include a backslash character, write two backslashes (\\).
-
\\ is a backslash
-
\b is a backspace
-
\f is a form feed
-
\n is a newline
-
\r is a carriage return
-
\t is a tab
-
\x##,where ## is a 1 or 2-digit hexadecimal number; for example \x07 is a tab
-
\###, where ### is a 1, 2, or 3-digit octal number representing a byte with the corresponding code.
When an extended string literal is concatenated across lines, write only E before the first opening quote:
=> SELECT E'first part o'
'f a long line';
?column?
---------------------------
first part of a long line
(1 row)
Two adjacent single quotes are used as one single quote:
=> SELECT 'Aren''t string literals fun?';
?column?
-----------------------------
Aren't string literals fun?
(1 row)
When interpreting commands, such as those entered in vsql or in queries passed via JDBC or ODBC, Vertica uses standard conforming strings as specified in the SQL standard. In standard conforming strings, backslashes are treated as string literals (ordinary characters), not escape characters.
Note
Text read in from files or streams (such as the data inserted using the
COPY statement) are not treated as literal strings. The COPY command defines its own escape characters for the data it reads. See the
COPY statement documentation for details.
The following options are available, but Vertica recommends that you migrate your application to use standard conforming strings at your earliest convenience, after warnings have been addressed.
-
To treat back slashes as escape characters, set configuration parameter
StandardConformingStrings to 0.
-
To enable standard conforming strings permanently, set the StandardConformingStrings parameter to '1', as described below.
-
To enable standard conforming strings per session, use SET STANDARD_CONFORMING_STRING TO ON, which treats backslashes as escape characters for the current session only.
The following procedure can be used to identify nonstandard conforming strings in your application so that you can convert them into standard conforming strings:
-
Be sure the StandardConformingStrings parameter is off, as described in Internationalization parameters.
=> ALTER DATABASE DEFAULT SET StandardConformingStrings = 0;
Note
Vertica recommends that you migrate your application to use standard conforming strings .
-
If necessary, turn on the EscapeStringWarning parameter.
=> ALTER DATABASE DEFAULT SET EscapeStringWarning = 1;
Vertica now returns a warning each time it encounters an escape string within a string literal. For example, Vertica interprets the \n in the following example as a new line:
=> SELECT 'a\nb';
WARNING: nonstandard use of escape in a string literal at character 8
HINT: Use the escape string syntax for escapes, e.g., E'\r\n'.
?column?
----------
a
b
(1 row)
When StandardConformingStrings is ON, the string is interpreted as four characters: a \ n b.
Modify each string that Vertica flags by extending it as in the following example:
E'a\nb'
Or if the string has quoted single quotes, double them; for example, 'one'' double'.
-
Turn on the StandardConformingStrings parameter for all sessions:
=> ALTER DATABASE DEFAULT SET StandardConformingStrings = 1;
Doubled single quotes
This section discusses vsql inputs that are not passed on to the server.
Vertica recognizes two consecutive single quotes within a string literal as one single quote character. For example, the following inputs, 'You''re here!' ignored the second consecutive quote and returns the following:
=> SELECT 'You''re here!';
?column?
--------------
You're here!at
(1 row)
This is the SQL standard representation and is preferred over the form, 'You\'re here!', because backslashes are not parsed as before. You need to escape the backslash:
=> SELECT (E'You\'re here!');
?column?
--------------
You're here!
(1 row)
This behavior change introduces a potential incompatibility in the use of the vsql meta-command \set, which automatically concatenates its arguments. For example:
\set file '\'' 'pwd' '/file.txt' '\''\echo :file
vsql takes the four arguments and outputs the following:
'/home/vertica/file.txt'
Vertica parses the adjacent single quotes as follows:
\set file '\'''pwd''/file.txt''\''\echo :file
'/home/vertica/file.txt''
Note the extra single quote at the end. This is due to the pair of adjacent single quotes together with the backslash-quoted single quote.
The extra quote can be resolved either as in the first example above, or by combining the literals as follows:
\set file '\''`pwd`'/file.txt'''\echo :file
'/home/vertica/file.txt'
In either case the backslash-quoted single quotes should be changed to doubled single quotes as follows:
\set file '''' `pwd` '/file.txt'''
Additional examples
=> SELECT 'This \is a string';
?column?
------------------
This \is a string
(1 row)
=> SELECT E'This \is a string';
?column?
------------------
This is a string
=> SELECT E'This is a \n new line';
?column?
----------------------
This is a
new line
(1 row)
=> SELECT 'String''s characters';
?column?
--------------------
String's characters
(1 row)
2.3.3 - Date/time literals
Date or time literal input must be enclosed in single quotes.
Date or time literal input must be enclosed in single quotes. Input is accepted in almost any reasonable format, including ISO 8601, SQL-compatible, traditional POSTGRES, and others.
Vertica handles date/time input more flexibly than the SQL standard requires. The exact parsing rules of date/time input and for the recognized text fields including months, days of the week, and time zones are described in Date/time expressions.
2.3.3.1 - Time zone values
Vertica attempts to be compatible with the SQL standard definitions for time zones.
Vertica attempts to be compatible with the SQL standard definitions for time zones. However, the SQL standard has an odd mix of date and time types and capabilities. Obvious problems are:
-
Although the DATE type does not have an associated time zone, the TIME type can. Time zones in the real world have little meaning unless associated with a date as well as a time, since the offset can vary through the year with daylight-saving time boundaries.
-
Vertica assumes your local time zone for any data type containing only date or time.
-
The default time zone is specified as a constant numeric offset from UTC. It is therefore not possible to adapt to daylight-saving time when doing date/time arithmetic across DST boundaries.
To address these difficulties, OpenText recommends using Date/Time types that contain both date and time when you use time zones. OpenText recommends that you do not use the type TIME WITH TIME ZONE, even though it is supported it for legacy applications and for compliance with the SQL standard.
Time zones and time-zone conventions are influenced by political decisions, not just earth geometry. Time zones around the world became somewhat standardized during the 1900's, but continue to be prone to arbitrary changes, particularly with respect to daylight-savings rules.
Vertica currently supports daylight-savings rules over the time period 1902 through 2038, corresponding to the full range of conventional UNIX system time. Times outside that range are taken to be in "standard time" for the selected time zone, no matter what part of the year in which they occur.
|
Example |
Description |
PST |
Pacific Standard Time |
-8:00 |
ISO-8601 offset for PST |
-800 |
ISO-8601 offset for PST |
-8 |
ISO-8601 offset for PST |
zulu |
Military abbreviation for UTC |
z |
Short form of zulu |
2.3.3.2 - Day of the week names
The following tokens are recognized as names of days of the week:.
The following tokens are recognized as names of days of the week:
|
Day |
Abbreviations |
|
SUNDAY |
SUN |
|
MONDAY |
MON |
|
TUESDAY |
TUE, TUES |
|
WEDNESDAY |
WED, WEDS |
|
THURSDAY |
THU, THUR, THURS |
|
FRIDAY |
FRI |
|
SATURDAY |
SAT |
2.3.3.3 - Month names
The following tokens are recognized as names of months:.
The following tokens are recognized as names of months:
|
Month |
Abbreviations |
|
JANUARY |
JAN |
|
FEBRUARY |
FEB |
|
MARCH |
MAR |
|
APRIL |
APR |
|
MAY |
MAY |
|
JUNE |
JUN |
|
JULY |
JUL |
|
AUGUST |
AUG |
|
SEPTEMBER |
SEP, SEPT |
|
OCTOBER |
OCT |
|
NOVEMBER |
NOV |
|
DECEMBER |
DEC |
2.3.3.4 - Interval literal
A literal that represents a time span.
A literal that represents a time span.
Syntax
[ @ ] [-] { quantity subtype-unit }[...] [ AGO ]
Parameters
@- Ignored
- (minus)- Specifies a negative interval value.
quantity - Integer numeric constant
subtype-unit- See Interval subtype units for valid values. Subtype units must be specified for year-month intervals; they are optional for day-time intervals.
AGO- Specifies a negative interval value.
AGO and - (minus) are synonymous.
Notes
-
The amounts of different units are implicitly added up with appropriate sign accounting.
-
The boundaries of an interval constant are:
-
The range of an interval constant is
+/– 263 – 1 microseconds.
-
In Vertica, interval fields are additive and accept large floating-point numbers.
Examples
See Specifying interval input.
2.3.3.4.1 - Interval subtype units
The following tables lists subtype units that you can specify in an interval literal, divided into major categories:.
The following tables lists subtype units that you can specify in an interval literal, divided into major categories:
Year-month subtype units
|
Subtypes |
Units |
Notes |
|
Millennium |
mil, millennium, millennia, mils, millenniums |
|
|
Century |
c, cent, century, centuries |
|
|
Decade |
dec, decs, decade, decades |
|
|
Year |
a |
Julian year: 365.25 days |
|
|
ka |
Julian kilo-year: 365250 days |
|
|
y, yr, yrs, year, years |
Calendar year: 365 days |
|
Quarter |
q, qtr, qtrs, quarter, quarters |
|
|
Month |
m, mon, mons, months, month |
Vertica can interpret m as minute or month, depending on context. See Processing m Input below. |
|
Week |
w, wk, week, wks, weeks |
|
Day-time subtype units
|
Subtypes |
Units |
Notes |
|
Day |
d, day, days |
|
Hour |
h, hr, hrs, hour, hours |
|
|
Minute |
m, min, mins, minute, minutes |
Vertica can interpret input unit m as minute or month, depending on context. See Processing m Input below. |
|
Second |
s, sec, secs, second, seconds |
|
Millisecond |
ms, msec, msecs, msecond, mseconds, millisecond, milliseconds |
|
|
Microsecond |
us, usec, usecs, usecond, useconds, microseconds, microsecond |
|
Vertica uses context to interpret the input unit m as months or minutes. For example, the following command creates a one-column table with an interval value:
=> CREATE TABLE int_test(i INTERVAL YEAR TO MONTH);
Given the following INSERT statement, Vertica interprets the interval literal 1y 6m as 1 year 6 months:
=> INSERT INTO int_test VALUES('1y 6m');
OUTPUT
--------
1
(1 row)
=> COMMIT;
COMMIT
=> SET INTERVALSTYLE TO UNITS;
SET
=> SELECT * FROM int_test;
i
-----------------
1 year 6 months
(1 row)
The following ALTER TABLE statement adds a DAY TO MINUTE interval column to table int_test:
=> ALTER TABLE int_test ADD COLUMN x INTERVAL DAY TO MINUTE;
ALTER TABLE
The next INSERT statement sets the first and second columns to 3y 20m and 1y 6m, respectively. In this case, Vertica interprets the m input literals in two ways:
-
For column i, Vertica interprets the m input as months, and displays 4 years 8 months.
-
For column x, Vertica interprets the m input as minutes. Because the interval is defined as DAY TO MINUTE, it converts the inserted input value 1y 6m to 365 days 6 minutes:
=> INSERT INTO int_test VALUES ('3y 20m', '1y 6m');
OUTPUT
--------
1
(1 row)
=> SELECT * FROM int_test;
i | x
------------------+-----------------
1 year 6 months |
4 years 8 months | 365 days 6 mins
(2 rows)
2.3.3.4.2 - Interval qualifier
Specifies how to interpret and format an interval literal for output, and optionally sets precision.
Specifies how to interpret and format an interval literal for output, and optionally sets precision. Interval qualifiers are composed of one or two units:
unit [ TO unit ] [ (p) ]
where:
If an interval omits an interval qualifier, the default is DAY TO SECOND(6).
Interval qualifiers are divided into two categories:
Day-time interval qualifiers
|
Qualifier |
Description |
DAY |
Unconstrained |
DAY TO HOUR |
Span of days and hours |
DAY TO MINUTE |
Span of days and minutes |
DAY TO SECOND [(p)] |
Span of days, hours, minutes, seconds, and fractions of a second. |
HOUR |
Hours within days |
HOUR TO MINUTE |
Span of hours and minutes |
HOUR TO SECOND [(p)] |
Span of hours and seconds |
MINUTE |
Minutes within hours |
MINUTE TO SECOND [(p)] |
Span of minutes and seconds |
SECOND [(p)] |
Seconds within minutes |
Year-month interval qualifiers
YEAR- Unconstrained
MONTH- Months within year
YEAR TO MONTH- Span of years and months
Note
Vertica also supports INTERVALYM, which is an alias for INTERVAL YEAR TO MONTH. Thus, the following two statements are equivalent:
=> SELECT INTERVALYM '1 2';
?column?
----------
1-2
(1 row)
=> SELECT INTERVAL '1 2' YEAR TO MONTH;
?column?
----------
1-2
(1 row)
Examples
See Controlling interval format.
2.4 - Operators
Operators are logical, mathematical, and equality symbols used in SQL to evaluate, compare, or calculate values.
Operators are logical, mathematical, and equality symbols used in SQL to evaluate, compare, or calculate values.
2.4.1 - Bitwise operators
Bitwise operators perform bit manipulations on INTEGER and BINARY/VARBINARY data types:.
Bitwise operators perform bit manipulations on INTEGER and BINARY/VARBINARY data types:
|
Operator |
Description |
Example |
Result |
& |
AND |
12 & 4 |
4 |
| |
OR |
32 | 3 |
35 |
# |
XOR |
17 # 5 |
20 |
~ |
NOT |
~1 |
-2 |
<< † |
Bitwise shift left |
1 << 4 |
16 |
>> † |
Bitwise shift right |
8 >> 2 |
2 |
† Invalid for BINARY/VARBINARY data types
String argument handling
String arguments must be explicitly cast as BINARY or VARBINARY data types for all bitwise operators. For example:
=> SELECT 'xyz'::VARBINARY & 'zyx'::VARBINARY AS AND;
AND
-----
xyx
(1 row)
=> SELECT 'xyz'::VARBINARY | 'zyx'::VARBINARY AS OR;
OR
-----
zyz
(1 row)
Bitwise operators treats all string arguments as equal in length. If the arguments have different lengths, the operator function right-pads the smaller string with one or more zero bytes to equal the length of the larger string.
For example, the following statement ANDs unequal strings xyz and zy. Vertica right-pads string zy with one zero byte. The last character in the result is represented accordingly, as \000:
=> SELECT 'xyz'::VARBINARY & 'zy'::VARBINARY AS AND;
AND
--------
xy\000
(1 row)
2.4.2 - Logical operators
Vertica supports the logical operators AND, OR, and NOT:.
Vertica supports the logical operators AND, OR, and NOT:
-
AND evaluates to true when both of the conditions joined by AND are true.
-
OR evaluates to true when either condition is true.
-
NOT negates the result of any Boolean expression.
AND and OR are commutative—that is, you can switch left and right operands without affecting the result. However, the order of evaluation of sub-expressions is not defined. To force evaluation order, use a CASE construct.
Caution
Do not confuse Boolean operators with the
Boolean predicate or
Boolean data type, which can have only two values: true and false.
Logic
SQL uses a three-valued Boolean logic where NULL represents "unknown":
-
true AND NULL = NULL
-
true OR NULL = true
-
false AND NULL = false
-
false OR NULL = NULL
-
NULL AND NULL = NULL
-
NULL OR NULL = NULL
-
NOT NULL = NULL
2.4.3 - Comparison operators
Comparison operators are available for all data types where comparison makes sense.
Comparison operators are available for all data types where comparison makes sense. All comparison operators are binary operators that return values of true, false, or NULL (unknown).
|
Operator |
Description |
Binary function |
< |
less than |
binary_lt |
> |
greater than |
binary_gt |
<= |
less than or equal to |
binary_le |
>= |
greater than or equal to |
binary_ge |
=, <=> |
equal
Note
Do not use the negation operator (!) with the <=> operator. Instead, use != to test for inequality. !, except as part of !=, is the factorial operator.
|
binary_eq |
!=, <> |
not equal (unsupported for correlated subqueries) |
binary_ne |
NULL handling
Comparison operators return NULL (unknown) if either or both operands are null. One exception applies: <=> returns true if both operands are NULL, and false if one operand is NULL.
Collections
When comparing collections, null collections are ordered last. Otherwise, collections are compared element by element until there is a mismatch, and then they are ordered based on the non-matching elements. If all elements are equal up to the length of the shorter one, then the shorter one is ordered first.
2.4.4 - Data type coercion operators (CAST)
Data type coercion (casting) passes an expression value to an input conversion routine for a specified data type, resulting in a constant of the indicated type.
Data type coercion (casting) passes an expression value to an input conversion routine for a specified data type, resulting in a constant of the indicated type. In Vertica, data type coercion can be invoked by an explicit cast request that uses one of the following constructs:
Syntax
SELECT CAST ( expression AS data-type )
SELECT expression::data-type
SELECT data-type 'string'
Parameters
expression |
An expression of any type |
data-type |
An SQL data type that Vertica supports to convert expression. |
Truncation
If a binary value is cast (implicitly or explicitly) to a binary type with a smaller length, the value is silently truncated. For example:
=> SELECT 'abcd'::BINARY(2);
?column?
----------
ab
(1 row)
Similarly, if a character value is cast (implicitly or explicitly) to a character value with a smaller length, the value is silently truncated. For example:
=> SELECT 'abcd'::CHAR(3);
?column?
----------
abc
(1 row)
Binary casting and resizing
Vertica supports only casts and resize operations as follows:
-
BINARY to and from VARBINARY
-
VARBINARY to and from LONG VARBINARY
-
BINARY to and from LONG VARBINARY
On binary data that contains a value with fewer bytes than the target column, values are right-extended with the zero byte '\0' to the full width of the column. Trailing zeros on variable-length binary values are not right-extended:
=> SELECT 'ab'::BINARY(4), 'ab'::VARBINARY(4), 'ab'::LONG VARBINARY(4);
?column? | ?column? | ?column?
------------+----------+----------
ab\000\000 | ab | ab
(1 row)
Automatic coercion
The explicit type cast can be omitted if there is no ambiguity as to the type the constant must be. For example, when a constant is assigned directly to a column, it is automatically coerced to the column's data type.
Examples
=> SELECT CAST((2 + 2) AS VARCHAR);
?column?
----------
4
(1 row)
=> SELECT (2 + 2)::VARCHAR;
?column?
----------
4
(1 row)
=> SELECT INTEGER '123';
?column?
----------
123
(1 row)
=> SELECT (2 + 2)::LONG VARCHAR
?column?
----------
4
(1 row)
=> SELECT '2.2' + 2;
ERROR: invalid input syntax for integer: "2.2"
=> SELECT FLOAT '2.2' + 2;
?column?
----------
4.2
(1 row)
See also
2.4.4.1 - Cast failures
When you invoke data type coercion (casting) by an explicit cast and the cast fails, the result returns either an error or NULL.
When you invoke data type coercion (casting) by an explicit cast and the cast fails, the result returns either an error or NULL. Cast failures commonly occur when you try to cast conflicting conversions, such as coercing a VARCHAR expression that contains letters to an integer.
When a cast fails, the result returned depends on the data type.
|
Data type |
Cast failure default |
|
date, time |
NULL |
|
literals |
error |
|
all other types |
error |
Enabling strict time casts
You can enable all cast failures to result in an error, including those for date/time data types. Doing so lets you see the reason why some or all of the cast failed. To return an error instead of NULL, set the configuration parameter EnableStrictTimeCasts to 1:
ALTER SESSION SET EnableStrictTimeCasts=1;
By default, EnableStrictTimeCasts is set to 0. Thus, the following attempt to cast a VARCHAR to a TIME data type returns NULL:
==> SELECT current_value from configuration_parameters WHERE parameter_name ilike '%EnableStrictTimeCasts%';
current_value
---------------
0
(1 row)
=> CREATE TABLE mytable (a VARCHAR);
CREATE TABLE
=> INSERT INTO mytable VALUES('one');
OUTPUT
--------
1
(1 row)
=> INSERT INTO mytable VALUES('1');
OUTPUT
--------
1
(1 row)
=> COMMIT;
COMMIT
=> SELECT a::time FROM mytable;
a
---
(2 rows)
If EnableStrictTimeCasts is enabled, the cast failure returns an error:
=> ALTER SESSION SET EnableStrictTimeCasts=1;
ALTER SESSION
=> SELECT a::time FROM mytable;
ERROR 3679: Invalid input syntax for time: "1"
Returning all cast failures as NULL
To explicitly cast an expression to a requested data type, use the following construct:
SELECT expression::data-type
Using this command to cast any values to a conflicting data type returns the following error:
=> SELECT 'one'::time;
ERROR 3679: Invalid input syntax for time: "one"
Vertica also supports the use of the coercion operator ::!, which is useful when you want to return:
Returning all cast failures as NULL allows those expressions that succeed during the cast to appear in the result. Those expressions that fail during the cast, however, have a NULL value.
The following example queries mytable using the coercion operator ::!. The query returns NULL where column a contains the string one, and returns 1 where the column contains 1. Query results are identical no matter how EnableStrictTimeCasts is set:
=> SELECT current_value FROM configuration_parameters WHERE parameter_name ilike '%EnableStrictTimeCasts%';
current_value
---------------
0
(1 row)
=> SELECT a::!int FROM mytable;
a
---
1
(2 rows)
ALTER SESSION SET EnableStrictTimeCasts=1;
ALTER SESSION
=> SELECT a::!int FROM mytable;
a
---
1
(2 rows)
You can use ::! for casts of arrays and sets. The cast resolves each element individually, producing NULL for elements that cannot be cast.
Note that this functionality only applies to table data. It does not work on inline constant casts and in expressions automatically reduced to such. For example,
SELECT constant ::! FLOAT from (select 'some string' as constant) a;
results in ERROR 2826: Could not convert "some string" to a float8. However, the following returns cast failures as NULL as described:
SELECT string_field ::! float FROM (SELECT 'a string' as string_field UNION ALL SELECT 'another string' ) a;
2.4.5 - Date/time operators
Vertica supports usage of arithmetic operators on DATE/TIME operands:.
Vertica supports usage of arithmetic operators on DATE/TIME operands:
+ (addition)- (subtraction)* (multiplication)/ (division)
Examples
The operators described below that take TIME or TIMESTAMP input have two variants:
For brevity, these variants are not shown separately.
The + and * operators come in commutative pairs—for example, both DATE + INTEGER and INTEGER + DATE. Only one of each pair is shown.
|
Example |
Result Type |
Result |
DATE '2001-09-28' + INTEGER '7' |
DATE |
'2001-10-05' |
DATE '2001-09-28' + INTERVAL '1 HOUR' |
TIMESTAMP |
'2001-09-28 01:00:00' |
DATE '2001-09-28' + TIME
'03:00'
|
TIMESTAMP |
'2001-09-28 03:00:00' |
INTERVAL '1 DAY' + INTERVAL
'1 HOUR'
|
INTERVAL |
'1 DAY 01:00:00' |
TIMESTAMP '2001-09-28 01:00'
+ INTERVAL '23 HOURS'
|
TIMESTAMP |
'2001-09-29 00:00:00' |
TIME '01:00' + INTERVAL
'3 HOURS'
|
TIME |
'04:00:00' |
- INTERVAL '23 HOURS' |
INTERVAL |
'-23:00:00' |
DATE '2001-10-01' – DATE
'2001-09-28'
|
INTEGER |
'3' |
DATE '2001-10-01' – INTEGER '7' |
DATE |
'2001-09-24' |
DATE '2001-09-28' – INTERVAL
'1 HOUR'
|
TIMESTAMP |
'2001-09-27 23:00:00' |
TIME '05:00' – TIME '03:00' |
INTERVAL |
'02:00:00' |
TIME '05:00' INTERVAL
'2 HOURS'
|
TIME |
'03:00:00' |
TIMESTAMP '2001-09-28 23:00'
– INTERVAL '23 HOURS'
|
TIMESTAMP |
'2001-09-28 00:00:00' |
INTERVAL '1 DAY' – INTERVAL
'1 HOUR'
|
INTERVAL |
'1 DAY -01:00:00' |
TIMESTAMP '2001-09-29 03:00'
– TIMESTAMP '2001-09-27 12:00'
|
INTERVAL |
'1 DAY 15:00:00' |
900 * INTERVAL '1 SECOND' |
INTERVAL |
'00:15:00' |
21 * INTERVAL '1 DAY' |
INTERVAL |
'21 DAYS' |
DOUBLE PRECISION '3.5'
* INTERVAL '1 HOUR'
|
INTERVAL |
'03:30:00' |
INTERVAL '1 HOUR' /
DOUBLE PRECISION '1.5'
|
INTERVAL |
'00:40:00' |
2.4.6 - Mathematical operators
Mathematical operators are provided for many data types.
Mathematical operators are provided for many data types.
|
Operator |
Description |
Example |
Result |
! |
Factorial |
5 ! |
120 |
+ |
Addition |
2 + 3 |
5 |
– |
Subtraction |
2 – 3 |
–1 |
* |
Multiplication |
2 * 3 |
6 |
/ |
Division (integer division produces NUMERIC results). |
4 / 2 |
2.00... |
// |
With integer division, returns an INTEGER rather than a NUMERIC. |
117.32 // 2.5 |
46 |
% |
Modulo (remainder). For details, see
MOD. |
5 % 4 |
1 |
^ |
Exponentiation |
2.0 ^ 3.0 |
8 |
|/ |
Square root |
|/ 25.0 |
5 |
||/ |
Cube root |
||/ 27.0 |
3 |
!! |
Factorial (prefix operator) |
!! 5 |
120 |
@ |
Absolute value |
@ -5.0 |
5 |
Factorial operator support
Vertica supports use of factorial operators on positive and negative floating point (DOUBLE PRECISION) numbers and integers. For example:
=> SELECT 4.98!;
?column?
------------------
115.978600750905
(1 row)
Factorial is defined in terms of the gamma function, where (-1) = Infinity and the other negative integers are undefined. For example:
(–4)! = NaN
–(4!) = –24
Factorial is defined as follows for all complex numbers z:
z! = gamma(z+1)
For details, see Abramowitz and Stegun: Handbook of Mathematical Functions.
2.4.7 - NULL operators
To check whether a value is or is not NULL, use the following equivalent constructs:.
To check whether a value is or is not NULL, use the following equivalent constructs:
Standard:
[expression IS NULL | expression IS NOT NULL]
Non-standard:
[expression ISNULL | expression NOTNULL]
Do not write expression = NULL: NULL represents an unknown value, and two unknown values are not necessarily equal. This behavior conforms to the SQL standard.
Note
Some applications might expect that expression = NULL returns true if expression evaluates to NULL. In this case, modify the application to comply with the SQL standard.
2.4.8 - String concatenation operators
To concatenate two strings on a single line, use the concatenation operator (two consecutive vertical bars).
To concatenate two strings on a single line, use the concatenation operator (two consecutive vertical bars).
Syntax
string || string
Parameters
string |
Expression of type CHAR or VARCHAR |
Notes
- || is used to concatenate expressions and constants. The expressions are cast to
VARCHAR if possible, otherwise to VARBINARY, and must both be one or the other.
- Two consecutive strings within a single SQL statement on separate lines are automatically concatenated
Examples
The following example is a single string written on two lines:
=> SELECT E'xx'-> '\\';
?column?
----------
xx\
(1 row)
The following examples show two strings concatenated:
=> SELECT E'xx' ||-> '\\';
?column?
----------
xx\\
(1 row)
=> SELECT 'auto' || 'mobile';
?column?
----------
automobile
(1 row)
=> SELECT 'auto'-> 'mobile';
?column?
----------
automobile
(1 row)
=> SELECT 1 || 2;
?column?
----------
12
(1 row)
=> SELECT '1' || '2';
?column?
----------
12
(1 row)
=> SELECT '1'-> '2';
?column?
----------
12
(1 row)
2.5 - Expressions
SQL expressions are the components of a query that compare a value or values against other values.
SQL expressions are the components of a query that compare a value or values against other values. They can also perform calculations. An expression found inside a SQL statement is usually in the form of a conditional statement.
Some functions also use Lambda functions.
Operator precedence
The following table shows operator precedence in decreasing (high to low) order.
When an expression includes more than one operator, specify the order of operation using parentheses, rather than relying on operator precedence.
|
Operator/Element |
Associativity |
Description |
. |
left |
table/column name separator |
:: |
left |
typecast |
[ ] |
left |
array element selection |
- |
right |
unary minus |
^ |
left |
exponentiation |
* / % |
left |
multiplication, division, modulo |
+ - |
left |
addition, subtraction |
IS |
|
IS TRUE, IS FALSE, IS UNKNOWN, IS NULL |
IN |
|
set membership |
BETWEEN |
|
range containment |
OVERLAPS |
|
time interval overlap |
LIKE |
|
string pattern matching |
< > |
|
less than, greater than |
= |
right |
equality, assignment |
NOT |
right |
logical negation |
AND |
left |
logical conjunction |
OR |
left |
logical disjunction |
Expression evaluation rules
The order of evaluation of subexpressions is not defined. In particular, the inputs of an operator or function are not necessarily evaluated left-to-right or in any other fixed order. To force evaluation in a specific order, use a CASE construct. For example, this is an untrustworthy way of trying to avoid division by zero in a WHERE clause:
=> SELECT x, y WHERE x <> 0 AND y/x > 1.5; --- unsafe
But this is safe:
=> SELECT x, y
WHERE
CASE
WHEN x <> 0 THEN y/x > 1.5
ELSE false
END;
A CASE construct used in this fashion defeats optimization attempts, so use it only when necessary. (In this particular example, it would be best to avoid the issue by writing y > 1.5*x instead.)
Limits to SQL expressions
Expressions are limited by the available stack. Vertica requires at least 100KB of free stack. If this limit is exceeded then the error "The query contains an expression that is too complex to analyze" might be thrown. Adding physical memory and/or increasing the value of ulimit -s can increase the available stack and prevent the error.
Analytic expressions have a maximum recursion depth of 2000. If this limit is exceeded then the error "The query contains an expression that is too complex to analyze" might be thrown. This limit cannot be increased.
2.5.1 - Aggregate expressions
An aggregate expression applies an aggregate function across the rows or groups of rows selected by a query.
An aggregate expression applies an aggregate function across the rows or groups of rows selected by a query.
An aggregate expression only can appear in the select list or HAVING clause of a SELECT statement. It is invalid in other clauses such as WHERE, because those clauses are evaluated before the results of aggregates are formed.
Syntax
An aggregate expression has the following format:
aggregate-function ( [ * ] [ ALL | DISTINCT ] expression )
Parameters
|
aggregate-function |
A Vertica function that aggregates data over groups of rows from a query result set. |
ALL | DISTINCT |
Specifies which input rows to process:
-
ALL (default): Invokes aggregate-function across all input rows where expression evaluates to a non-null value.
-
DISTINCT: Invokes aggregate-function across all input rows where expression evaluates to a unique non-null value.
|
expression |
A value expression that does not itself contain an aggregate expression. |
Examples
The AVG aggregate function returns the average income from the customer_dimension table:
=> SELECT AVG(annual_income) FROM customer_dimension;
AVG
--------------
2104270.6485
(1 row)
The following example shows how to use the COUNT aggregate function with the DISTINCT keyword to return all distinct values of evaluating the expression x+y for all inventory_fact records.
=> SELECT COUNT (DISTINCT date_key + product_key) FROM inventory_fact;
COUNT
-------
21560
(1 row)
2.5.2 - CASE expressions
The CASE expression is a generic conditional expression that can be used wherever an expression is valid.
The CASE expression is a generic conditional expression that can be used wherever an expression is valid. It is similar to CASE and IF/THEN/ELSE statements in other languages.
CASE
WHEN condition THEN result
[ WHEN condition THEN result ]
...
[ ELSE result ]
END
Parameters
*condition |
An expression that returns a Boolean (true/false) result. If the result is false, subsequent WHEN clauses are evaluated in the same way. |
*result |
Specifies the value to return when the associated condition is true. |
ELSE result |
If no condition is true then the value of the CASE expression is the result in the ELSE clause. If the ELSE clause is omitted and no condition matches, the result is NULL. |
CASE expression
WHEN value THEN result
[ WHEN value THEN result ]
...
[ ELSE result ]
END
Parameters
*expression |
An expression that is evaluated and compared to all the value specifications in WHEN clauses until one is found that is equal. |
*value |
Specifies a value to compare to the expression. |
*result |
Specifies the value to return when the expression is equal to the specified value. |
ELSE result |
Specifies the value to return when the expression is not equal to any value; if no ELSE clause is specified, the value returned is null. |
Notes
The data types of all result expressions must be convertible to a single output type.
Examples
The following examples show two uses of the CASE statement.
=> SELECT * FROM test;
a
---
1
2
3
=> SELECT a,
CASE WHEN a=1 THEN 'one'
WHEN a=2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
=> SELECT a,
CASE a WHEN 1 THEN 'one'
WHEN 2 THEN 'two'
ELSE 'other'
END
FROM test;
a | case
---+-------
1 | one
2 | two
3 | other
Special example
A CASE expression does not evaluate subexpressions that are not needed to determine the result. You can use this behavior to avoid division-by-zero errors:
=> SELECT x FROM T1 WHERE
CASE WHEN x <> 0 THEN y/x > 1.5
ELSE false
END;
2.5.3 - Column references
A column reference cannot contain any spaces.
Syntax
[[[database.]schema.]table-name.]column-name
Parameters
schema |
Database and schema. The default schema is public. If you specify a database, it must be the current database. |
table-name |
One of the following:
|
column-name |
A column name that is unique among all queried tables. |
Restrictions
A column reference cannot contain any spaces.
2.5.4 - Comments
A comment is an arbitrary sequence of characters beginning with two consecutive hyphen characters and extending to the end of the line.
A comment is an arbitrary sequence of characters beginning with two consecutive hyphen characters and extending to the end of the line. For example:
-- This is a standard SQL comment
A comment is removed from the input stream before further syntax analysis and is effectively replaced by white space.
Alternatively, C-style block comments can be used where the comment begins with /* and extends to the matching occurrence of */.
/* multiline comment
* with nesting: /* nested block comment */
*/
These block comments nest, as specified in the SQL standard. Unlike C, you can comment out larger blocks of code that might contain existing block comments.
2.5.5 - Date/time expressions
Vertica uses an internal heuristic parser for all date/time input support.
Vertica uses an internal heuristic parser for all date/time input support. Dates and times are input as strings, and are broken up into distinct fields with a preliminary determination of what kind of information might be in the field. Each field is interpreted and either assigned a numeric value, ignored, or rejected. The parser contains internal lookup tables for all textual fields, including months, days of the week, and time zones.
Vertica parses date/time type inputs as follows:
-
Break the input string into tokens and categorize each token as a string, time, time zone, or number.
-
Numeric token contains:
-
colon (:) — Parse as a time string, include all subsequent digits and colons.
-
dash (-), slash (/), or two or more dots (.) — Parse as a date string which might have a text month.
-
Numeric only — Parse as a single field or an ISO 8601 concatenated date (19990113 for January 13, 1999) or time (141516 for 14:15:16).
-
Token starts with a plus (+) or minus (–): Parse as a time zone or a special field.
-
Token is a text string: match up with possible strings.
-
Perform a binary-search table lookup for the token as either a special string (for example, today), day (for example, Thursday), month (for example, January), or noise word (for example, at, on).
-
Set field values and bit mask for fields. For example, set year, month, day for today, and additionally hour, minute, second for now.
-
If not found, do a similar binary-search table lookup to match the token with a time zone.
-
If still not found, throw an error.
-
Token is a number or number field:
-
If eight or six digits, and if no other date fields were previously read, interpret as a "concatenated date" (19990118 or 990118). The interpretation is YYYYMMDD or YYMMDD.
-
If token is three digits and a year was already read, interpret as day of year.
-
If four or six digits and a year was already read, interpret as a time (HHMM or HHMMSS).
-
If three or more digits and no date fields were found yet, interpret as a year (this forces yy-mm-dd ordering of the remaining date fields).
-
Otherwise the date field ordering is assumed to follow the DateStyle setting: mm-dd-yy, dd-mm-yy, or yy-mm-dd. Throw an error if a month or day field is found to be out of range.
-
If BC is specified: negate the year and add one for internal storage. (In the Vertica implementation, 1 BC = year zero.)
-
If BC is not specified, and year field is two digits in length: adjust the year to four digits. If field is less than 70, add 2000, otherwise add 1900.
Tip
Gregorian years AD 1–99 can be entered as 4 digits with leading zeros— for example, 0099 = AD 99.
Month day year ordering
For some formats, ordering of month, day, and year in date input is ambiguous and there is support for specifying the expected ordering of these fields.
Special date/time values
Vertica supports several special date/time values for convenience, as shown below. All of these values need to be written in single quotes when used as constants in SQL statements.
The values INFINITY and -INFINITY are specially represented inside the system and are displayed the same way. The others are simply notational shorthands that are converted to ordinary date/time values when read. (In particular, NOW and related strings are converted to a specific time value as soon as they are read.)
|
String |
Valid Data Types |
Description |
epoch |
DATE, TIMESTAMP |
1970-01-01 00:00:00+00 (UNIX SYSTEM TIME ZERO) |
INFINITY |
TIMESTAMP |
Later than all other time stamps |
-INFINITY |
TIMESTAMP |
Earlier than all other time stamps |
NOW |
DATE, TIME, TIMESTAMP |
Current transaction's start time
Note: NOW is not the same as the NOW function.
|
TODAY |
DATE, TIMESTAMP |
Midnight today |
TOMORROW |
DATE, TIMESTAMP |
Midnight tomorrow |
YESTERDAY |
DATE, TIMESTAMP |
Midnight yesterday |
ALLBALLS |
TIME |
00:00:00.00 UTC |
The following SQL-compatible functions can also be used to obtain the current time value for the corresponding data type:
The latter four accept an optional precision specification. (See Date/time functions.) However, these functions are SQL functions and are not recognized as data input strings.
2.5.6 - NULL value
NULL is a reserved keyword used to indicate that a data value is unknown.
NULL is a reserved keyword used to indicate that a data value is unknown. It is the ASCII abbreviation for NULL characters (\0).
Usage in expressions
Vertica does not treat an empty string as a NULL value. An expression must specify NULL to indicate that a column value is unknown.
The following considerations apply to using NULL in expressions:
-
NULL is not greater than, less than, equal to, or not equal to any other expression. Use the Boolean to determine whether an expression value is NULL.
-
You can write queries with expressions that contain the <=> operator for NULL=NULL joins. See Equi-joins and non equi-joins.
-
Vertica accepts NULL characters ('\0') in constant strings and does not remove null characters from VARCHAR fields on input or output.
Projection ordering of NULL data
Vertica sorts NULL values in projection columns as follows:
See also
NULL-handling functions
2.6 - Lambda functions
Some SQL functions have arguments that are lambda functions.
Some SQL functions have arguments that are lambda functions. A lambda function is an unnamed inline function that is evaluated by the containing SQL function and returns a value.
Syntax
Lambda with one argument:
argument -> expression
Lambda with more than one argument:
(argument, ...) -> expression
Arguments
argument |
Name to use for an input value for the expression. The name cannot be a reserved keyword, the name of an argument to a parent or nested lambda, or a column name or alias. |
expression |
Expression that uses the input arguments and returns a result to the containing SQL function. See the documentation of individual SQL functions for restrictions on return values. For example, some functions require a Boolean result. |
Examples
The ARRAY_FIND function returns the first index that matches the element being searched for. Instead of a literal element, you can write a lambda function that returns a Boolean. The lambda function is applied to each element in the array until a match is found or all elements have been tested. In the following example, each person in the table has an array of email addresses, and the function locates fake addresses:
=> CREATE TABLE people (id INT, name VARCHAR, email ARRAY[VARCHAR,5]);
=> SELECT name, ARRAY_FIND(email, e -> REGEXP_LIKE(e,'example.com','i'))
AS 'example.com'
FROM people;
name | example.com
---------------+-------------
Alice Adams | 1
Bob Adams | 1
Carol Collins | 0
Dave Jones | 0
(4 rows)
The argument e represents the individual element, and the body of the lambda expression is the regular-expression comparison. The input table has four rows; in each row, the lambda function is called once per array element.
In the following example, a schedules table includes an array of events, where each event is a ROW with several fields:
=> CREATE TABLE schedules
(guest VARCHAR,
events ARRAY[ROW(e_date DATE, e_name VARCHAR, price NUMERIC(8,2))]);
You can use the CONTAINS function with a lambda expression to find people who have more than one event on the same day. The second argument, idx, is the index of the current element:
=> SELECT guest FROM schedules
WHERE CONTAINS(events, (e, idx) ->
(idx < ARRAY_LENGTH(events) - 1)
AND (e.e_date = events[idx + 1].e_date));
guest
-------------
Alice Adams
(1 row)
2.7 - Predicates
Predicates are truth-tests.
Predicates are truth-tests. If the predicate test is true, it returns a value. Each predicate is evaluated per row, so that when the predicate is part of an entire table SELECT statement, the statement can return multiple results.
Predicates consist of a set of parameters and arguments. For example, in the following WHERE clause:
WHERE name = 'Smith'
2.7.1 - ANY and ALL
ANY and ALL are logical operators that let you make comparisons on subqueries that return one or more rows.
ANY and ALL are logical operators that let you make comparisons on subqueries that return one or more rows. Both operators must be preceded by a comparison operator and followed by a subquery:
expression comparison-operator { ANY | ALL } (subquery)
- ANY returns true if the comparison between
expression and any value returned by subquery evaluates to true.
- ALL returns true only if the comparison between
expression and all values returned by subquery evaluates to true.
Equivalent operators
You can use the following operators instead of ANY or ALL:
|
This operator... |
Is equivalent to: |
|
SOME |
ANY |
|
IN |
= ANY |
|
NOT IN |
<> ALL |
NULL handling
Vertica supports multicolumn <> ALL subqueries where the columns are not marked NOT NULL. If any column contains a NULL value, Vertica returns a run-time error.
Vertica does not support ANY subqueries that are nested in another expression if any column values are NULL.
Examples
Examples below use the following tables and data:
=> SELECT * FROM t1 ORDER BY c1;
c1 | c2
----+-----
1 | cab
1 | abc
2 | fed
2 | def
3 | ihg
3 | ghi
4 | jkl
5 | mno
(8 rows)
=> SELECT * FROM t2 ORDER BY c1;
c1 | c2
----+-----
1 | abc
2 | fed
3 | jkl
3 | stu
3 | zzz
(5 rows)
ANY subqueries
Subqueries that use the ANY keyword return true when any value retrieved in the subquery matches the value of the left-hand expression.
ANY subquery within an expression:
=> SELECT c1, c2 FROM t1 WHERE COALESCE((t1.c1 > ANY (SELECT c1 FROM t2)));
c1 | c2
----+-----
2 | fed
2 | def
3 | ihg
3 | ghi
4 | jkl
5 | mno
(6 rows)
ANY noncorrelated subqueries without aggregates:
=> SELECT c1 FROM t1 WHERE c1 = ANY (SELECT c1 FROM t2) ORDER BY c1;
c1
----
1
1
2
2
3
3
(6 rows)
ANY noncorrelated subqueries with aggregates:
=> SELECT c1, c2 FROM t1 WHERE c1 <> ANY (SELECT MAX(c1) FROM t2) ORDER BY c1;
c1 | c2
----+-----
1 | cab
1 | abc
2 | fed
2 | def
4 | jkl
5 | mno
(6 rows)
=> SELECT c1 FROM t1 GROUP BY c1 HAVING c1 <> ANY (SELECT MAX(c1) FROM t2) ORDER BY c1;
c1
----
1
2
4
5
(4 rows)
ANY noncorrelated subqueries with aggregates and a GROUP BY clause:
=> SELECT c1, c2 FROM t1 WHERE c1 <> ANY (SELECT MAX(c1) FROM t2 GROUP BY c2) ORDER BY c1;
c1 | c2
----+-----
1 | cab
1 | abc
2 | fed
2 | def
3 | ihg
3 | ghi
4 | jkl
5 | mno
(8 rows)
ANY noncorrelated subqueries with a GROUP BY clause:
=> SELECT c1, c2 FROM t1 WHERE c1 <=> ANY (SELECT c1 FROM t2 GROUP BY c1) ORDER BY c1;
c1 | c2
----+-----
1 | cab
1 | abc
2 | fed
2 | def
3 | ihg
3 | ghi
(6 rows)
ANY correlated subqueries with no aggregates or GROUP BY clause:
=> SELECT c1, c2 FROM t1 WHERE c1 >= ANY (SELECT c1 FROM t2 WHERE t2.c2 = t1.c2) ORDER BY c1;
c1 | c2
----+-----
1 | abc
2 | fed
4 | jkl
(3 rows)
ALL subqueries
A subquery that uses the ALL keyword returns true when all values retrieved by the subquery match the left-hand expression, otherwise it returns false.
ALL noncorrelated subqueries without aggregates:
=> SELECT c1, c2 FROM t1 WHERE c1 >= ALL (SELECT c1 FROM t2) ORDER BY c1;
c1 | c2
----+-----
3 | ihg
3 | ghi
4 | jkl
5 | mno
(4 rows)
ALL noncorrelated subqueries with aggregates:
=> SELECT c1, c2 FROM t1 WHERE c1 = ALL (SELECT MAX(c1) FROM t2) ORDER BY c1;
c1 | c2
----+-----
3 | ihg
3 | ghi
(2 rows)
=> SELECT c1 FROM t1 GROUP BY c1 HAVING c1 <> ALL (SELECT MAX(c1) FROM t2) ORDER BY c1;
c1
----
1
2
4
5
(4 rows)
ALL noncorrelated subqueries with aggregates and a GROUP BY clause:
=> SELECT c1, c2 FROM t1 WHERE c1 <= ALL (SELECT MAX(c1) FROM t2 GROUP BY c2) ORDER BY c1;
c1 | c2
----+-----
1 | cab
1 | abc
(2 rows)
ALL noncorrelated subqueries with a GROUP BY clause:
=> SELECT c1, c2 FROM t1 WHERE c1 <> ALL (SELECT c1 FROM t2 GROUP BY c1) ORDER BY c1;
c1 | c2
----+-----
4 | jkl
5 | mno
(2 rows)
2.7.2 - BETWEEN
Checks whether an expression is within the range of two other expressions, inclusive.
Checks whether an expression is within the range of two other expressions, inclusive. All expressions must be of the same or compatible data types.
Syntax
WHERE a BETWEEN x AND y
Equivalent predicates
The following BETWEEN predicates can be rewritten in conventional SQL with logical operators AND and OR.
|
This BETWEEN predicate... |
Is equivalent to... |
WHERE aBETWEENxANDy |
WHERE a>=xANDa<=y |
WHERE aNOT BETWEENxANDy |
WHERE a<xORa>y |
Examples
The BETWEEN predicate can be especially useful for querying date ranges, as shown in the following examples:
=> SELECT NOW()::DATE;
NOW
------------
2022-12-15
(1 row)
=> CREATE TABLE t1 (a INT, b varchar(12), c DATE);
CREATE TABLE
=> INSERT INTO t1 VALUES
(0,'today',NOW()),
(1,'today+1',NOW()+1),
(2,'today+2',NOW()+2),
(3,'today+3',NOW()+3),
(4,'today+4',NOW()+4),
(5,'today+5',NOW()+5),
(6,'today+6',NOW()+6);
OUTPUT
--------
7
(1 row)
=> COMMIT;
COMMIT
=> SELECT * FROM t1;
a | b | c
---+---------+------------
0 | today | 2022-12-15
1 | today+1 | 2022-12-16
2 | today+2 | 2022-12-17
3 | today+3 | 2022-12-18
4 | today+4 | 2022-12-19
5 | today+5 | 2022-12-20
6 | today+6 | 2022-12-21
(7 rows)
=> SELECT * FROM t1 WHERE c BETWEEN '2022-12-17' AND '2022-12-20';
a | b | c
---+---------+------------
2 | today+2 | 2022-12-17
3 | today+3 | 2022-12-18
4 | today+4 | 2022-12-19
5 | today+5 | 2022-12-20
(4 rows)
Use the NOW and INTERVAL keywords to query a date range:
=> SELECT * FROM t1 WHERE c BETWEEN NOW()::DATE AND NOW()::DATE + INTERVAL '2 days';
a | b | c
---+---------+------------
0 | today | 2022-12-15
1 | today+1 | 2022-12-16
2 | today+2 | 2022-12-17
(3 rows)
2.7.3 - Boolean
Retrieves rows where the value of an expression is true, false, or unknown (NULL).
Retrieves rows where the value of an expression is true, false, or unknown (NULL).
Syntax
expression IS [NOT] TRUE
expression IS [NOT] FALSE
expression IS [NOT] UNKNOWN
Notes
- NULL input is treated as the value
UNKNOWN.
IS UNKNOWN and IS NOT UNKNOWN are effectively the same as the NULL predicate, except that the input expression does not have to be a single column value. To check a single column value for NULL, use the NULL predicate.- Do not confuse the Boolean predicate with Boolean operators or the Boolean data type, which can have only two values: true and false.
2.7.4 - EXISTS
EXISTS and NOT EXISTS predicates compare an expression against a subquery:.
EXISTS and NOT EXISTS predicates compare an expression against a subquery:
- EXISTS returns true if the subquery returns one or more rows.
- NOT EXISTS returns true if the subquery returns no rows.
Syntax
expression [ NOT ] EXISTS ( subquery )
Usage
EXISTS results only depend on whether any or no records are returned, and not on the contents of those records. Because the subquery output is usually of no interest, EXISTS tests are commonly written in one of the following ways:
EXISTS (SELECT 1 WHERE...)
EXISTS (SELECT * WHERE...)
In the first case, the subquery returns 1 for every record found by the subquery. For example, the following query retrieves a list of all customers whose store purchases were greater than 550 dollars:
=> SELECT customer_key, customer_name, customer_state
FROM public.customer_dimension WHERE EXISTS
(SELECT 1 FROM store.store_sales_fact
WHERE customer_key = public.customer_dimension.customer_key
AND sales_dollar_amount > 550)
AND customer_state = 'MA' ORDER BY customer_key;
customer_key | customer_name | customer_state
--------------+------------------------+----------------
2 | Anna G. Li | CA
4 | Daniel I. Fortin | TX
7 | David H. Greenwood | MA
8 | Wendy S. Young | IL
9 | Theodore X. Brown | MA
...
49902 | Amy Q. Pavlov | MA
49922 | Doug C. Carcetti | MA
49930 | Theodore G. McNulty | MA
49979 | Ben Z. Miller | MA
(1058 rows)
EXISTS versus IN
Whether you use EXISTS or IN subqueries depends on which predicates you select in outer and inner query blocks. For example, the following query gets a list of all the orders placed by all stores on January 2, 2007 for vendors with records in the vendor table:
=> SELECT store_key, order_number, date_ordered
FROM store.store_orders_fact WHERE EXISTS
(SELECT 1 FROM public.vendor_dimension vd JOIN store.store_orders_fact ord ON vd.vendor_key = ord.vendor_key)
AND date_ordered = '2007-01-02';
store_key | order_number | date_ordered
-----------+--------------+--------------
114 | 271071 | 2007-01-02
19 | 290888 | 2007-01-02
132 | 58942 | 2007-01-02
232 | 9286 | 2007-01-02
126 | 224474 | 2007-01-02
196 | 63482 | 2007-01-02
...
196 | 83327 | 2007-01-02
138 | 278373 | 2007-01-02
179 | 293586 | 2007-01-02
155 | 213413 | 2007-01-02
(506 rows)
The above query looks for existence of the vendor and date ordered. To return a particular value, rather than simple existence, the query looks for orders placed by the vendor who got the best deal on January 2, 2007:
=> SELECT store_key, order_number, date_ordered, vendor_name
FROM store.store_orders_fact ord JOIN public.vendor_dimension vd ON ord.vendor_key = vd.vendor_key
WHERE vd.deal_size IN (SELECT MAX(deal_size) FROM public.vendor_dimension) AND date_ordered = '2007-01-02';
store_key | order_number | date_ordered | vendor_name
-----------+--------------+--------------+----------------------
50 | 99234 | 2007-01-02 | Everything Wholesale
81 | 200802 | 2007-01-02 | Everything Wholesale
115 | 13793 | 2007-01-02 | Everything Wholesale
204 | 41842 | 2007-01-02 | Everything Wholesale
133 | 169025 | 2007-01-02 | Everything Wholesale
163 | 208580 | 2007-01-02 | Everything Wholesale
29 | 154972 | 2007-01-02 | Everything Wholesale
145 | 236790 | 2007-01-02 | Everything Wholesale
249 | 54838 | 2007-01-02 | Everything Wholesale
7 | 161536 | 2007-01-02 | Everything Wholesale
(10 rows)
See also
IN
2.7.5 - IN
Checks whether a single value is found (or not found) within a set of values.
Checks whether a single value is found (or not found) within a set of values.
Syntax
(column-list) [ NOT ] IN ( values-list )
Arguments
column-list- One or more comma-delimited columns in the queried tables.
values-list- Comma-delimited list of constant values to find in the
column-list columns. Each values-list value maps to a column-list column according to their order in values-list and column-list, respectively. Column/value pairs must have compatible data types.
You can specify multiple sets of values as follows:
( (values-list), (values-list)[,...] )
Null handling
Vertica supports multicolumn NOT IN subqueries where the columns are not marked NOT NULL. If one of the columns is found to contain a NULL value during query execution, Vertica returns a run-time error.
Similarly, IN subqueries nested within another expression are not supported if any column values are NULL. For example, if in the following statement column x from either table contains a NULL value, Vertica returns a run-time error:
=> SELECT * FROM t1 WHERE (x IN (SELECT x FROM t2)) IS FALSE;
ERROR: NULL value found in a column used by a subquery
EXISTS versus IN
Whether you use EXISTS or IN subqueries depends on which predicates you select in outer and inner query blocks. For example, the following query gets a list of all the orders placed by all stores on January 2, 2007 for vendors with records in the vendor table:
=> SELECT store_key, order_number, date_ordered
FROM store.store_orders_fact WHERE EXISTS
(SELECT 1 FROM public.vendor_dimension vd JOIN store.store_orders_fact ord ON vd.vendor_key = ord.vendor_key)
AND date_ordered = '2007-01-02';
store_key | order_number | date_ordered
-----------+--------------+--------------
114 | 271071 | 2007-01-02
19 | 290888 | 2007-01-02
132 | 58942 | 2007-01-02
232 | 9286 | 2007-01-02
126 | 224474 | 2007-01-02
196 | 63482 | 2007-01-02
...
196 | 83327 | 2007-01-02
138 | 278373 | 2007-01-02
179 | 293586 | 2007-01-02
155 | 213413 | 2007-01-02
(506 rows)
The above query looks for existence of the vendor and date ordered. To return a particular value, rather than simple existence, the query looks for orders placed by the vendor who got the best deal on January 2, 2007:
=> SELECT store_key, order_number, date_ordered, vendor_name
FROM store.store_orders_fact ord JOIN public.vendor_dimension vd ON ord.vendor_key = vd.vendor_key
WHERE vd.deal_size IN (SELECT MAX(deal_size) FROM public.vendor_dimension) AND date_ordered = '2007-01-02';
store_key | order_number | date_ordered | vendor_name
-----------+--------------+--------------+----------------------
50 | 99234 | 2007-01-02 | Everything Wholesale
81 | 200802 | 2007-01-02 | Everything Wholesale
115 | 13793 | 2007-01-02 | Everything Wholesale
204 | 41842 | 2007-01-02 | Everything Wholesale
133 | 169025 | 2007-01-02 | Everything Wholesale
163 | 208580 | 2007-01-02 | Everything Wholesale
29 | 154972 | 2007-01-02 | Everything Wholesale
145 | 236790 | 2007-01-02 | Everything Wholesale
249 | 54838 | 2007-01-02 | Everything Wholesale
7 | 161536 | 2007-01-02 | Everything Wholesale
(10 rows)
Examples
The following SELECT statement queries all data in table t11.
=> SELECT * FROM t11 ORDER BY pk;
pk | col1 | col2 | SKIP_ME_FLAG
----+------+------+--------------
1 | 2 | 3 | t
2 | 3 | 4 | t
3 | 4 | 5 | f
4 | 5 | 6 | f
5 | 6 | 7 | t
6 | | 8 | f
7 | 8 | | t
(7 rows)
The following query specifies an IN predicate, to find all rows in t11 where columns col1 and col2 contain values of (2,3) or (6,7):
=> SELECT * FROM t11 WHERE (col1, col2) IN ((2,3), (6,7)) ORDER BY pk;
pk | col1 | col2 | SKIP_ME_FLAG
----+------+------+--------------
1 | 2 | 3 | t
5 | 6 | 7 | t
(2 rows)
The following query uses the VMart schema to illustrate the use of outer expressions referring to different inner expressions:
=> SELECT product_description, product_price FROM product_dimension
WHERE (product_dimension.product_key, product_dimension.product_key) IN
(SELECT store.store_orders_fact.order_number,
store.store_orders_fact.quantity_ordered
FROM store.store_orders_fact);
product_description | product_price
-----------------------------+---------------
Brand #73 wheechair | 454
Brand #72 box of candy | 326
Brand #71 vanilla ice cream | 270
(3 rows)
2.7.6 - INTERPOLATE
Joins two using some ordered attribute.
Joins two event series using some ordered attribute. Event series joins let you compare values from two series directly, rather than having to normalize the series to the same measurement interval.
An event series join is an extension of a regular outer join. The difference between expressing a regular outer join and an event series join is the INTERPOLATE predicate, which is used in the ON clause (see Examples below). Instead of padding the non-preserved side with null values when there is no match, the event series join pads the non-preserved side with the previous/next values from the table.
Interpolated values come from the table that contains the null, not from the other table.Vertica does not guarantee that the output contains no null values. If there is no previous/next value for a mismatched row, that row is padded with nulls.
Syntax
expression1 INTERPOLATE { PREVIOUS | NEXT } VALUE expression2
Arguments
expression1,expression2 |
A column reference from one of the tables specified in the FROM clause.
The columns can be of any data type. Because event series are time-based, the type is typically DATE/TIMEor TIMESTAMP.
|
{ PREVIOUS | NEXT } VALUE |
Pads the non-preserved side with the previous/next values when there is no match. If previous is called on the first row (or next on the last row), will pad with null values.
Input rows are sorted in ascending logical order of the join column.
Note
An ORDER BY clause, if used, does not determine the input order but only determines query output order.
|
Notes
-
Data is logically partitioned on the table in which it resides, based on other ON clause equality predicates.
-
Event series join requires that the joined tables are both sorted on columns in equality predicates, in any order, followed by the INTERPOLATED column. If data is already sorted in this order, then an explicit sort is avoided, which can improve query performance. For example, given the following tables:
ask: exchange, stock, ts, pricebid: exchange,
stock, ts, price
In the query that follows:
-
ask is sorted on exchange, stock (or the reverse), ts
-
bid is sorted on exchange, stock (or the reverse), ts
SELECT ask.price - bid.price, ask.ts, ask.stock, ask.exchange
FROM ask FULL OUTER JOIN bid
ON ask.stock = bid.stock AND ask.exchange =
bid.exchange AND ask.ts INTERPOLATE PREVIOUS
VALUE bid.ts;
Restrictions
- Only one INTERPOLATE expression is allowed per join.
- INTERPOLATE expressions are used only with ANSI SQL-99 syntax (the ON clause), which is already true for full outer joins.
- INTERPOLATE can be used with equality predicates only.
- The AND operator is supported but not the OR and NOT operators.
- Expressions and implicit or explicit casts are not supported, but subqueries are allowed.
Semantics
When you write an event series join in place of normal join, values are evaluated as follows (using the schema in the examples below):
In the case of a full outer join, all values from both tables are preserved.
Examples
The examples that follow use this simple schema.
CREATE TABLE t(x TIME);
CREATE TABLE t1(y TIME);
INSERT INTO t VALUES('12:40:23');
INSERT INTO t VALUES('13:40:25');
INSERT INTO t VALUES('13:45:00');
INSERT INTO t VALUES('14:49:55');
INSERT INTO t1 VALUES('12:40:23');
INSERT INTO t1 VALUES('14:00:00');
COMMIT;
Normal full outer join
=> SELECT * FROM t FULL OUTER JOIN t1 ON t.x = t1.y;
Notice the null rows from the non-preserved table:
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 |
13:45:00 |
14:49:55 |
| 14:00:00
(5 rows)
Full outer join with interpolation
=> SELECT * FROM t FULL OUTER JOIN t1 ON t.x INTERPOLATE PREVIOUS VALUE t1.y;
In this case, the rows with no entry point are padded with values from the previous row.
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 | 12:40:23
13:45:00 | 12:40:23
14:49:55 | 12:40:23
13:40:25 | 14:00:00
(5 rows)
Likewise, interpolate next is also supported:
=> SELECT * FROM t FULL OUTER JOIN t1 ON t.x INTERPOLATE NEXT VALUE t1.y;
In this case, the rows with no entry point are padded with values from the next row.
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 | 14:00:00
13:45:00 | 14:00:00
14:49:55 |
14:49:55 | 14:00:00
(5 rows)
Normal left outer join
=> SELECT * FROM t LEFT OUTER JOIN t1 ON t.x = t1.y;
Again, there are nulls in the non-preserved table
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 |
13:45:00 |
14:49:55 |
(4 rows)
Left outer join with interpolation
=> SELECT * FROM t LEFT OUTER JOIN t1 ON t.x INTERPOLATE PREVIOUS VALUE t1.y;
Nulls have been padded with interpolated values.
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 | 12:40:23
13:45:00 | 12:40:23
14:49:55 | 14:00:00
(4 rows)
Likewise, interpolate next is also supported:
=> SELECT * FROM t LEFT OUTER JOIN t1 ON t.x INTERPOLATE NEXT VALUE t1.y;
Nulls have been padded with interpolated values here as well.
x | y
----------+----------
12:40:23 | 12:40:23
13:40:25 | 14:00:00
13:45:00 | 14:00:00
14:49:55 |
(4 rows)
Inner joins
For inner joins, there is no difference between a regular inner join and an event series inner join. Since null values are eliminated from the result set, there is nothing to interpolate.
A regular inner join returns only the single matching row at 12:40:23:
=> SELECT * FROM t INNER JOIN t1 ON t.x = t1.y;
x | y
----------+----------
12:40:23 | 12:40:23
(1 row)
An event series inner join finds the same single-matching row at 12:40:23:
=> SELECT * FROM t INNER JOIN t1 ON t.x INTERPOLATE PREVIOUS VALUE t1.y;
x | y
----------+----------
12:40:23 | 12:40:23
(1 row)
See also
Event series joins
2.7.6.1 - Join predicate
Specifies the columns on which records from two or more tables are joined.
Specifies the columns on which records from two or more tables are joined. You can connect multiple join predicates with logical operators AND, OR, and NOT.
Syntax
ON column-ref = column-ref [ {AND | OR | NOT } column-ref = column-ref ]...
Parameters
|
column-ref |
Specifies a column in a queried table. For best performance, do not join on LONG VARBINARY and LONG VARCHAR columns. |
See also
Joins
2.7.7 - LIKE
Retrieves rows where a string expression—typically a column—matches the specified pattern or, if qualified by ANY or ALL, set of patterns.
Retrieves rows where a string expression—typically a column—matches the specified pattern or, if qualified by ANY or ALL, set of patterns. Patterns can contain one or more wildcard characters.
If an ANY or ALL pattern is qualified with NOT, the negation is pushed down to each clause. NOT LIKE ANY (a, b) is equivalent to NOT LIKE a OR NOT LIKE b. See the examples.
Syntax
string-expression [ NOT ] { LIKE | ILIKE | LIKEB | ILIKEB }
{ pattern | { ANY | SOME | ALL } ( pattern,... ) } [ ESCAPE 'char' ]
Arguments
string-expression- String expression, typically a column, to test for instances of the specified pattern or patterns.
NOT- Returns true if the LIKE predicate returns false and vice-versa. When used with ANY or ALL, applies to each value individually.
LIKE | ILIKE | LIKEB | ILIKEB- Type of comparison:
LIKE: Complies with the SQL standard, case-sensitive, operates on UTF-8 character strings, exact behavior depends on collation parameters such as strength. LIKE is stable for character strings, but immutable for binary stringsILIKE: Same as LIKE but case-insensitive.LIKEB: Performs case-sensitive byte-at-a-time ASCII comparisons, immutable for character and binary strings.ILIKEB: Same as LIKEB but case-insensitive.
pattern- A pattern to test against the expression. Pattern strings can contain the following wildcard characters:
ANY | SOME | ALL- Apply a comma-delimited list of patterns, where:
-
ANY and SOME return true if any pattern matches, equivalent to logical OR. These options are synonyms.
-
ALL returns true only if all patterns match, equivalent to logical AND.
ESCAPE char- Escape character, by default backslash (
\), used to escape reserved characters: wildcard characters (underscore and percent), and the escape character itself.
This option is enforced only for non-default collations; it is currently unsupported with ANY/ALL pattern matching.
Note
Backslash is not valid for binary data type characters. To embed an escape character for binary data types, use ESCAPE to specify a valid binary character.
Substitute symbols
You can substitute the following symbols for LIKE and its variants:
Note
ESCAPE usage is not valid for these symbols.
|
Symbol |
Eqivalent to: |
~~ |
LIKE |
~# |
LIKEB |
~~* |
ILIKE |
~#* |
ILIKEB |
!~~ |
NOT LIKE |
!~# |
NOT LIKEB |
!~~* |
NOT ILIKE |
!~#* |
NOT ILIKEB |
Pattern matching
LIKE and its variants require that the entire string expression match the specified patterns. To match a sequence of characters anywhere within a string, the pattern must start and end with a percent sign.
LIKE does not ignore trailing white space characters. If the data values to match end with an indeterminate amount of white space, append the wildcard character % to pattern.
Locale dependencies
In the default locale, LIKE and ILIKE handle UTF-8 character-at-a-time, locale-insensitive comparisons. ILIKE handles language-independent case-folding.
In non-default locales, LIKE and ILIKE perform locale-sensitive string comparisons, including some automatic normalization, using the same algorithm as the = operator on VARCHAR types.
ESCAPE expressions evaluate to exactly one octet—or one UTF-8 character for non-default locales.
Examples
Basic pattern matching
The following query searches for names with a common prefix:
=> SELECT name FROM people WHERE name LIKE 'Ann%';
name
-----------
Ann
Ann Marie
Anna
(3 rows)
LIKE ANY/ALL
LIKE operators support the keywords ANY and ALL, which let you specify multiple patterns to test against a string expression. For example, the following query finds all names that begin or end with the letter 'A':
=> SELECT name FROM people WHERE name LIKE ANY ('A%', '%a');
name
-----------
Alice
Ann
Ann Marie
Anna
Roberta
(5 rows)
LIKE ANY usage is equivalent to individual LIKE conditions combined with OR:
=> SELECT name FROM people WHERE name LIKE 'A%' OR name LIKE '%a';
name
-----------
Alice
Ann
Ann Marie
Anna
Roberta
(5 rows)
Similarly, LIKE ALL is equivalent to individual LIKE conditions combined with AND.
NOT LIKE ANY/ALL
You can use NOT with LIKE ANY or LIKE ALL. NOT does not negate the LIKE expression; instead it negates each clause.
Consider a table with the following contents:
=> SELECT name FROM people;
name
-----------
Alice
Ann
Ann Marie
Anna
Richard
Rob
Robert
Roberta
(8 rows)
In the following query, NOT LIKE ANY ('A%', '%a') is equivalent to NOT LIKE 'A%' OR NOT LIKE '%a', so the only result that is eliminated is Anna, which matches both patterns:
=> SELECT name FROM people WHERE name NOT LIKE ANY ('A%', '%a');
name
-----------
Alice
Ann
Ann Marie
Richard
Rob
Robert
Roberta
(7 rows)
--- same results:
=> SELECT name FROM people WHERE name NOT LIKE 'A%' OR name NOT LIKE '%a';
NOT LIKE ALL eliminates results that satisfy any pattern:
=> SELECT name FROM people WHERE name NOT LIKE ALL ('A%', '%a');
name
---------
Richard
Rob
Robert
(3 rows)
--- same results:
=> SELECT name FROM people WHERE name NOT LIKE 'A%' AND name NOT LIKE '%a';
Pattern matching in locales
The following example illustrates pattern matching in locales.
=> \locale default
INFO 2567: Canonical locale: 'en_US'
Standard collation: 'LEN_KBINARY'
English (United States)
=> CREATE TABLE src(c1 VARCHAR(100));
=> INSERT INTO src VALUES (U&'\00DF'); --The sharp s (ß)
=> INSERT INTO src VALUES ('ss');
=> COMMIT;
Querying the src table in the default locale returns both ss and sharp s.
=> SELECT * FROM src;
c1
----
ß
ss
(2 rows)
The following query combines pattern-matching predicates to return the results from column c1:
=> SELECT c1, c1 = 'ss' AS equality, c1 LIKE 'ss'
AS LIKE, c1 ILIKE 'ss' AS ILIKE FROM src;
c1 | equality | LIKE | ILIKE
----+----------+------+-------
ß | f | f | f
ss | t | t | t
(2 rows)
The next query specifies unicode format for c1:
=> SELECT c1, c1 = U&'\00DF' AS equality,
c1 LIKE U&'\00DF' AS LIKE,
c1 ILIKE U&'\00DF' AS ILIKE from src;
c1 | equality | LIKE | ILIKE
----+----------+------+-------
ß | t | t | t
ss | f | f | f
(2 rows)
Now change the locale to German with a strength of 1 (ignore case and accents):
=> \locale LDE_S1
INFO 2567: Canonical locale: 'de'
Standard collation: 'LDE_S1'
German Deutsch
=> SELECT c1, c1 = 'ss' AS equality,
c1 LIKE 'ss' as LIKE, c1 ILIKE 'ss' AS ILIKE from src;
c1 | equality | LIKE | ILIKE
----+----------+------+-------
ß | t | t | t
ss | t | t | t
(2 rows)
This example illustrates binary data types with pattern-matching predicates:
=> CREATE TABLE t (c BINARY(1));
CREATE TABLE
=> INSERT INTO t VALUES (HEX_TO_BINARY('0x00')), (HEX_TO_BINARY('0xFF'));
OUTPUT
--------
2
(1 row)
=> COMMIT;
COMMIT
=> SELECT TO_HEX(c) FROM t;
TO_HEX
--------
00
ff
(2 rows)
=> SELECT * FROM t;
c
------
\000
\377
(2 rows)
=> SELECT c, c = '\000', c LIKE '\000', c ILIKE '\000' from t;
c | ?column? | ?column? | ?column?
------+----------+----------+----------
\000 | t | t | t
\377 | f | f | f
(2 rows)
=> SELECT c, c = '\377', c LIKE '\377', c ILIKE '\377' FROM t;
c | ?column? | ?column? | ?column?
------+----------+----------+----------
\000 | f | f | f
\377 | t | t | t
(2 rows)
2.7.8 - NULL
Tests for null values.
Tests for null values. The expression can be a column name, literal, or function.
Syntax
value-expression IS [ NOT ] NULL
Examples
Column name:
=> SELECT date_key FROM date_dimension WHERE date_key IS NOT NULL;
date_key
----------
1
366
1462
1097
2
3
6
7
8
...
Function:
=> SELECT MAX(household_id) IS NULL FROM customer_dimension;
?column?
----------
f
(1 row)
Literal:
=> SELECT 'a' IS NOT NULL;
?column?
----------
t
(1 row)
2.8 - Hints
Hints are directives that you embed within a query or.
Hints are directives that you embed within a query or directed query. They conform to the following syntax:
/*+hint-name[, hint-name]...*/
Hints are bracketed by comment characters /*+ and */, which can enclose multiple comma-delimited hints. For example:
SELECT /*+syntactic_join,verbatim*/
Restrictions
When embedding hints in a query, be aware of the following restrictions:
-
Do not embed spaces in the comment characters /* and */.
-
In general, spaces are allowed before and after the plus (+) character and hint-name; however, some third-party tools do not support spaces embedded inside /*+.
Supported hints
Vertica supports the following hints:
General hints
Eon Mode hints
Join hints
|
Hint |
Description |
|
SYNTACTIC_JOIN |
Enforces join order and enables other join hints. |
|
DISTRIB |
Sets the input operations for a distributed join to broadcast, resegment, local, or filter. |
|
GBYTYPE |
Specifies which algorithm—GROUPBY HASH or GROUPBY PIPELINED—the Vertica query optimizer should use to implement a GROUP BY clause. |
|
JTYPE |
Enforces the join type: merge or hash join. |
|
UTYPE |
Specifies how to combine UNION ALL input. |
Projection hints
|
Hint |
Description |
|
PROJS |
Specifies one or more projections to use for a queried table. |
|
SKIP_PROJS |
Specifies which projections to avoid using for a queried table. |
Directed query hints
The following hints are only supported by directed queries:
|
Hint |
Description |
|
:c |
Marks a query constant that must be included in an input query; otherwise, that input query is disqualified from using the directed query. |
|
:v |
Maps an input query constant to one or more annotated query constants. |
|
VERBATIM |
Enforces execution of an annotated query exactly as written. |
2.8.1 - :c
In a directed query, marks a query constant that must be included in an input query; otherwise, that input query is disqualified from using the directed query.
In a directed query, marks a query constant that must be included in an input query; otherwise, that input query is disqualified from using the directed query.
Syntax
/*+:c*/
Usage
By default, optimizer-generated directed queries set ignore constant (:v) hints on predicate constants. You can override this behavior by setting the :c hint on input query constants that must not be ignored. For example, the following statement creates a directed query that can be used only for input queries where the join predicate constant is the same as in the original input query—8:
=> CREATE DIRECTED QUERY OPTIMIZER simpleJoin_KeepPredicateConstant SELECT * FROM S JOIN T ON S.a = T.b WHERE S.a = 8 /*+:c*/;
CREATE DIRECTED QUERY
=> ACTIVATE DIRECTED QUERY simpleJoin_KeepPredicateConstant;
See also
Conserving Predicate Constants in Directed Queries
2.8.2 - :v
In a directed query, marks an input query constant that the optimizer ignores when it considers whether to use the directed query for a given query.
In a directed query, marks an input query constant that the optimizer ignores when it considers whether to use the directed query for a given query. Use this hint to create a directed query that can be used for multiple variants of an input query.
Vertica also supports IGNORECONST as an alias of :v . Optimizer-generated directed queries automatically mark predicate constants in input and annotated queries with :v hints.
For details, see Ignoring constants in directed queries.
Syntax
/*+:v(arg)*/
/*+IGNORECONST(arg)*/
arg- Integer argument that is used in the directed query to pair each input query
:v hint with one or more annotated query :v hints.
Examples
See Ignoring constants in directed queries.
2.8.3 - ALLNODES
Qualifies an EXPLAIN statement to request a query plan that assumes all nodes are active.
Qualifies an
EXPLAIN statement to request a query plan that assumes all nodes are active. If you omit this hint, the EXPLAIN statement produces a query plan that takes into account any nodes that are currently down.
Syntax
EXPLAIN /*+ALLNODES*/
Examples
In the following example, the ALLNODES hint requests a query plan that assumes all nodes are active.
QUERY PLAN DESCRIPTION:
------------------------------
Opt Vertica Options
--------------------
PLAN_ALL_NODES_ACTIVE
EXPLAIN /*+ALLNODES*/ select * from Emp_Dimension;
Access Path:
+-STORAGE ACCESS for Emp_Dimension [Cost: 125, Rows: 10K (NO STATISTICS)] (PATH ID: 1)
| Projection: public.Emp_Dimension_b0
| Materialize: Emp_Dimension.Employee_key, Emp_Dimension.Employee_gender, Emp_Dimension.Courtesy_title, Emp_Dimension.Employee_first_name, Emp_Dimension.Employee_middle_initial, Emp_Dimension.Employee_last_name, Emp_Dimension.Employee_age, Emp_Dimension.Employee_birthdate, Emp_Dimension.Employee_street, Emp_Dimension.Employee_city, Emp_Dimension.Employee_state, Emp_Dimension.Employee_region, Emp_Dimension.Employee_position
| Execute on: All Nodes
2.8.4 - DEPOT_FETCH
Specifies whether a query fetches data to the depot from communal storage when the depot lacks data for this query.
Eon Mode only
Specifies whether a query fetches data to the depot from communal storage when the depot lacks data for this query. This hint overrides configuration parameter DepotOperationsForQuery.
Syntax
SELECT /*+DEPOT_FETCH (option)*/
Arguments
*option*- Specifies behavior when the depot does not contain queried file data, one of the following:
-
ALL (default): Fetch file data from communal storage, if necessary displace existing files by evicting them from the depot.
-
FETCHES: Fetch file data from communal storage only if space is available; otherwise, read the queried data directly from communal storage.
-
NONE: Do not fetch file data to the depot, read the queried data directly from communal storage.
Examples
SELECT /*+DEPOT_FETCH(All)*/ count(*) FROM bar;
SELECT /*+DEPOT_FETCH(FETCHES)*/ count(*) FROM bar;
SELECT /*+DEPOT_FETCH(NONE)*/ count(*) FROM bar;
2.8.5 - DISTRIB
The DISTRIB hint specifies to the optimizer how to distribute join key data in order to implement a join.
The DISTRIB hint specifies to the optimizer how to distribute join key data in order to implement a join. If a specified distribution is not feasible, the optimizer ignores the hint and throws a warning.
The following requirements apply:
-
Queries that include the DISTRIB hint must also include the SYNTACTIC_JOIN hint. Otherwise, the optimizer ignores the DISTRIB hint and throws a warning.
-
Join syntax must conform with ANSI SQL-92 join conventions.
Syntax
JOIN /*+DISTRIB(outer-join, inner-join)*/
Arguments
- outer-join
inner-join
- Specifies how to distribute data on the outer and inner joins:
-
L (local): Inner and outer join keys are identically segmented on each node, join locally.
-
R (resegment): Inner and outer join keys are not identically segmented. Resegment join-key data before implementing the join.
-
B (broadcast): Inner and outer join keys are not identically segmented. Broadcast data of this join key to other nodes before implementing the join.
-
F (filter): Join table is unsegmented. Filter data as needed by the other join key before implementing the join.
-
A (any): Let the optimizer choose the distribution method that it considers to be most cost-effective.
Examples
In the following query, the join is qualified with a DISTRIB hint of /*+DISTRIB(L,R)*/. This hint tells the optimizer to resegment data of join key stores.store_key before joining it to the sales.store_key data:
SELECT /*+SYNTACTIC_JOIN*/ sales.store_key, stores.store_name, sales.product_description, sales.sales_quantity, sales.sale_date
FROM (store.storeSales AS sales JOIN /*+DISTRIB(L,R),JTYPE(H)*/ store.store_dimension AS stores ON (sales.store_key = stores.store_key))
WHERE (sales.sale_date = '2014-12-01'::date) ORDER BY sales.store_key, sales.sale_date;
2.8.6 - EARLY_MATERIALIZATION
Specifies early materialization of a table for the current query.
Specifies early materialization of a table for the current query. A query can include this hint for any number of tables. Typically, the query optimizer delays materialization until late in the query execution process. This hint overrides any choices that the optimizer otherwise would make.
This hint can be useful in cases where late materialization of join inputs precludes other optimizations—for example, pushing aggregation down the joins, or using live aggregate projections. In these cases, qualifying a join input with EARLY_MATERIALIZATION can enable the optimizations.
Syntax
table-name [ [AS] alias ] /*+EARLY_MATERIALIZATION*/
2.8.7 - ECSMODE
Sets the ECS strategy that the optimizer uses when it divides responsibility for processing shard data among subscriber nodes.
Eon Mode only
Sets the ECS strategy that the optimizer uses when it divides responsibility for processing shard data among subscriber nodes. This hint is applied only if the subcluster uses elastic crunch scaling (ECS).
Syntax
SELECT /*+ECSMODE(option)*/
Arguments
*option*- Specifies the strategy to use when dividing shard data among its subscribing nodes, one of the following:
-
AUTO: The optimizer chooses the strategy to use, useful only if ECS mode is set at the session level (see Setting the ECS Strategy for the Session or Database).
-
IO_OPTIMIZED: Use I/O-optimized strategy.
-
COMPUTE_OPTIMIZED: Use compute-optimized strategy.
-
NONE: Disable use of ECS for this query. Only participating nodes are involved in query execution; collaborating nodes are not.
Example
The following example shows the query plan for a simple single-table query that is forced to use the compute-optimized strategy:
=> EXPLAIN SELECT /*+ECSMode(COMPUTE_OPTIMIZED)*/ employee_last_name,
employee_first_name,employee_age
FROM employee_dimension
ORDER BY employee_age DESC;
QUERY PLAN
--------------------------------------------------------------------------------
------------------------------
QUERY PLAN DESCRIPTION:
The execution of this query involves non-participating nodes.
Crunch scaling strategy preserves data segmentation
------------------------------
. . .
2.8.8 - ENABLE_WITH_CLAUSE_MATERIALIZATION
Enables materialization of all queries in the current WITH clause. Otherwise, materialization is set by configuration parameter WithClauseMaterialization, by default set to 0 (disabled). If WithClauseMaterialization is disabled, materialization is automatically cleared when the primary query of the WITH clause returns. For details, see
Materialization of WITH clause.
Syntax
WITH /*+ENABLE_WITH_CLAUSE_MATERIALIZATION*/
2.8.9 - GBYTYPE
Specifies which algorithm—GROUPBY HASH or GROUPBY PIPELINED —the Vertica query optimizer should use to implement a GROUP BY clause.
Specifies which algorithm—GROUPBY HASH or GROUPBY PIPELINED —the Vertica query optimizer should use to implement a GROUP BY clause. If both algorithms are valid for this query, the query optimizer chooses the specified algorithm over the algorithm that the query optimizer might otherwise choose in its query plan.
Note
Vertica uses the GROUPBY PIPELINED algorithm only if the query and one of its projections comply with GROUPBY PIPELINED
requirements. Otherwise, Vertica issues a warning and uses GROUPBY HASH.
For more information about both algorithms, see GROUP BY implementation options.
Syntax
GROUP BY /*+GBYTYPE( HASH | PIPE )*/
Arguments
HASH- Use the GROUPBY HASH algorithm.
PIPE- Use the GROUPBY PIPELINED algorithm.
Examples
See Controlling GROUPBY Algorithm Choice.
2.8.10 - JFMT
Specifies how to size VARCHAR column data when joining tables on those columns, and buffer that data accordingly.
Specifies how to size VARCHAR column data when joining tables on those columns, and buffer that data accordingly. The JFMT hint overrides the default behavior that is set by configuration parameter JoinDefaultTupleFormat, which can be set at database and session levels.
For more information, see Joining variable length string data.
Syntax
JOIN /*+JFMT(format-type)*/
Arguments
format-type- Specifies how to format VARCHAR column data when joining tables on those columns, and buffers the data accordingly. Set to one of the following:
-
f (fixed): Use join column metadata to size column data to a fixed length, and buffer accordingly.
-
v (variable): Use the actual length of join column data, so buffer size varies for each join.
For example:
SELECT /*+SYNTACTIC_JOIN*/ s.store_region, SUM(e.vacation_days) TotalVacationDays
FROM public.employee_dimension e
JOIN /*+JFMT(f)*/ store.store_dimension s ON s.store_region=e.employee_region
GROUP BY s.store_region ORDER BY TotalVacationDays;
Requirements
-
Queries that include the JFMT hint must also include the SYNTACTIC_JOIN hint. Otherwise, the optimizer ignores the JFMT hint and throws a warning.
-
Join syntax must conform with ANSI SQL-92 join conventions.
2.8.11 - JTYPE
Specifies the join algorithm as hash or merge.
Specifies the join algorithm as hash or merge.
Use the JTYPE hint to specify the algorithm the optimizer uses to join table data. If the specified algorithm is not feasible, the optimizer ignores the hint and throws a warning.
Syntax
JOIN /*+JTYPE(join-type)*/
Arguments
join-type- One of the following:
-
H: Hash join
-
M: Merge join, valid only if both join inputs are already sorted on the join columns, otherwise Vertica ignores it and throws a warning. The optimizer relies upon the query or DDL to verify whether input data is sorted, rather than the actual runtime order of the data.
-
FM: Forced merge join. Before performing the merge, the optimizer re-sorts the join inputs. Join columns must be of the same type and precision or scale, except that string columns can have different lengths.
A value of FM is valid only for simple join conditions. For example:
=> SELECT /*+SYNTACTIC_JOIN*/ * FROM x JOIN /*+JTYPE(FM)*/ y ON x.c1 = y.c1;
Requirements
-
Queries that include the JTYPE hint must also include the SYNTACTIC_JOIN hint. Otherwise, the optimizer ignores the JTYPE hint and throws a warning.
-
Join syntax must conform with ANSI SQL-92 join conventions.
2.8.12 - LABEL
Assigns a label to a statement so it can easily be identified to evaluate performance and debug problems.
Assigns a label to a statement so it can easily be identified to evaluate performance and debug problems.
LABEL hints are valid in the following statements:
Syntax
statement-name /*+LABEL (label-string)*/
Arguments
label-string- A string that is up to 128 octets long. If enclosed with single quotes,
label-string can contain embedded spaces.
Examples
See Labeling statements.
2.8.13 - PROJS
Specifies one or more projections to use for a queried table.
Specifies one or more projections to use for a queried table.
The PROJS hint can specify multiple projections; the optimizer determines which ones are valid and uses the one that is most cost-effective for the queried table. If no hinted projection is valid, the query returns a warning and ignores projection hints.
Syntax
FROM `*`table-name`*` /*+PROJS( [[`*`database`*`.]`*`schema.`*`]`*`projection`*`[,...] )*/
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The projection to use. You can specify a list of comma-delimited projections.
Examples
The employee_dimension table has two projections: segmented superprojection public.employee_dimension, which includes all table columns; and the unsegmented projection public.employee_dimension_rep, which includes a subset of the columns:
=> SELECT export_objects('','employee_dimension');
export_objects
--------------------------------------------------------------------------------------------------------------------------
CREATE TABLE public.employee_dimension
(
employee_key int NOT NULL,
employee_gender varchar(8),
courtesy_title varchar(8),
employee_first_name varchar(64),
employee_middle_initial varchar(8),
employee_last_name varchar(64),
employee_age int,
hire_date date,
employee_street_address varchar(256),
employee_city varchar(64),
employee_state char(2),
employee_region char(32),
job_title varchar(64),
reports_to int,
salaried_flag int,
annual_salary int,
hourly_rate float,
vacation_days int,
CONSTRAINT C_PRIMARY PRIMARY KEY (employee_key) DISABLED
);
CREATE PROJECTION public.employee_dimension
...
AS
SELECT employee_dimension.employee_key,
employee_dimension.employee_gender,
employee_dimension.courtesy_title,
employee_dimension.employee_first_name,
employee_dimension.employee_middle_initial,
employee_dimension.employee_last_name,
employee_dimension.employee_age,
employee_dimension.hire_date,
employee_dimension.employee_street_address,
employee_dimension.employee_city,
employee_dimension.employee_state,
employee_dimension.employee_region,
employee_dimension.job_title,
employee_dimension.reports_to,
employee_dimension.salaried_flag,
employee_dimension.annual_salary,
employee_dimension.hourly_rate,
employee_dimension.vacation_days
FROM public.employee_dimension
ORDER BY employee_dimension.employee_key
SEGMENTED BY hash(employee_dimension.employee_key) ALL NODES KSAFE 1;
CREATE PROJECTION public.employee_dimension_rep
...
AS
SELECT employee_dimension.employee_key,
employee_dimension.employee_gender,
employee_dimension.employee_first_name,
employee_dimension.employee_middle_initial,
employee_dimension.employee_last_name,
employee_dimension.employee_age,
employee_dimension.employee_street_address,
employee_dimension.employee_city,
employee_dimension.employee_state,
employee_dimension.employee_region
FROM public.employee_dimension
ORDER BY employee_dimension.employee_key
UNSEGMENTED ALL NODES;
SELECT MARK_DESIGN_KSAFE(1);
(1 row)
The following query selects all table columns from employee_dimension and includes the PROJS hint, which specifies both projections. public.employee_dimension_rep does not include all columns in the queried table, so the optimizer cannot use it. The segmented projection includes all table columns so the optimizer uses it, as verified by the following query plan:
=> EXPLAIN SELECT * FROM employee_dimension /*+PROJS('public.employee_dimension_rep', 'public.employee_dimension')*/;
QUERY PLAN DESCRIPTION:
------------------------------
EXPLAIN SELECT * FROM employee_dimension /*+PROJS('public.employee_dimension_rep', 'public.employee_dimension')*/;
Access Path:
+-STORAGE ACCESS for employee_dimension [Cost: 177, Rows: 10K (NO STATISTICS)] (PATH ID: 1)
| Projection: public.employee_dimension_b0
2.8.14 - SKIP_PROJS
Specifies which projections to avoid using for a queried table.
Specifies which projections to avoid using for a queried table. If SKIP_PROJS excludes all available projections that are valid for the query, the optimizer issues a warning and ignores the projection hints.
Syntax
FROM table-name /*+SKIP_PROJS( [[database.]schema.]projection[,...] )*/
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- A projection to skip. You can specify a list of comma-delimited projections.
Examples
In this example, the EXPLAIN output shows that the optimizer uses the projection public.employee_dimension_b0 for a given query:
QUERY PLAN DESCRIPTION:
------------------------------
EXPLAIN SELECT employee_last_name, employee_first_name, employee_city, job_title FROM employee_dimension;
Access Path:
+-STORAGE ACCESS for employee_dimension [Cost: 59, Rows: 10K (NO STATISTICS)] (PATH ID: 1)
| Projection: public.employee_dimension_b0
| Materialize: employee_dimension.employee_first_name, employee_dimension.employee_last_name, employee_dimension.employee_city, employee_dimension.job_title
| Execute on: All Nodes
You can use the SKIP_PROJS hint to avoid using this projection. If another projection is available that is valid for this query, the optimizer uses it instead:
QUERY PLAN DESCRIPTION:
------------------------------
EXPLAIN SELECT employee_last_name, employee_first_name, employee_city, job_title FROM employee_dimension /*+SKIP_PROJS('public.employee_dimension')*/;
Access Path:
+-STORAGE ACCESS for employee_dimension [Cost: 156, Rows: 10K (NO STATISTICS)] (PATH ID: 1)
| Projection: public.employee_dimension_super
| Materialize: employee_dimension.employee_first_name, employee_dimension.employee_last_name, employee_dimension.emplo
yee_city, employee_dimension.job_title
| Execute on: Query Initiator
2.8.15 - SKIP_STATISTICS
Directs the optimizer to produce a query plan that incorporates only the minimal statistics that are collected by ANALYZE_ROW_COUNT.
Directs the optimizer to produce a query plan that incorporates only the minimal statistics that are collected by
ANALYZE_ROW_COUNT. The optimizer ignores other statistics that would otherwise be used, that are generated by
ANALYZE_STATISTICS and
ANALYZE_STATISTICS_PARTITION. This hint is especially useful when used in queries on small tables, where the amount of time required to collect full statistics is often greater than actual execution time.
Syntax
SELECT /*+SKIP_STAT[ISTIC]S*/
EXPLAIN output
EXPLAIN returns the following output for a query that includes SKIP_STATISTICS (using its shortened form SKIP_STATS):
=> EXPLAIN SELECT /*+ SKIP_STATS*/ customer_key, customer_name, customer_gender, customer_city||', '||customer_state, customer_age
FROM customer_dimension WHERE customer_region = 'East' AND customer_age > 60;
QUERY PLAN DESCRIPTION:
------------------------------
EXPLAIN SELECT /*+ SKIP_STATS*/ customer_key, customer_name, customer_gender, customer_city||', '||customer_state,
customer_age FROM customer_dimension WHERE customer_region = 'East' AND customer_age > 60;
Access Path:
+-STORAGE ACCESS for customer_dimension [Cost: 2K, Rows: 10K (STATISTICS SKIPPED)] (PATH ID: 1)
| Projection: public.customer_dimension_b0
| Materialize: public.customer_dimension.customer_age, public.customer_dimension.customer_key, public.customer_dimensi
on.customer_name, public.customer_dimension.customer_gender, public.customer_dimension.customer_city, public.customer_di
mension.customer_state
| Filter: (public.customer_dimension.customer_region = 'East')
| Filter: (public.customer_dimension.customer_age > 60)
| Execute on: All Nodes
...
2.8.16 - SYNTACTIC_JOIN
Enforces join order and enables other join hints.
Enforces join order and enables other join hints.
In order to achieve optimal performance, the optimizer often overrides a query's specified join order. By including the SYNTACTIC_JOIN hint, you can ensure that the optimizer enforces the query's join order exactly as specified. One requirement applies: the join syntax must conform with ANSI SQL-92 conventions.
The SYNTACTIC_JOIN hint must immediately follow SELECT. If the annotated query includes another hint that must also follow SELECT, such as VERBATIM, combine the two hints together. For example:
SELECT /*+ syntactic_join,verbatim*/
Syntax
SELECT /*+SYN[TACTIC]_JOIN*/
Examples
In the following examples, the optimizer produces different plans for two queries that differ only by including or excluding the SYNTACTIC_JOIN hint.
Excludes SYNTACTIC_JOIN:
EXPLAIN SELECT sales.store_key, stores.store_name, products.product_description, sales.sales_quantity, sales.sale_date
FROM (store.store_sales sales JOIN products ON sales.product_key=products.product_key)
JOIN store.store_dimension stores ON sales.store_key=stores.store_key
WHERE sales.sale_date='2014-12-01' order by sales.store_key, sales.sale_date;
Access Path:
+-SORT [Cost: 14K, Rows: 100K (NO STATISTICS)] (PATH ID: 1)
| Order: sales.store_key ASC, sales.sale_date ASC
| Execute on: All Nodes
| +---> JOIN HASH [Cost: 11K, Rows: 100K (NO STATISTICS)] (PATH ID: 2) Outer (RESEGMENT)(LOCAL ROUND ROBIN) Inner (RESEGMENT)
| | Join Cond: (sales.product_key = products.product_key)
| | Materialize at Input: sales.store_key, sales.product_key, sales.sale_date, sales.sales_quantity
| | Execute on: All Nodes
| | +-- Outer -> JOIN HASH [Cost: 1K, Rows: 100K (NO STATISTICS)] (PATH ID: 3)
| | | Join Cond: (sales.store_key = stores.store_key)
| | | Execute on: All Nodes
| | | +-- Outer -> STORAGE ACCESS for sales [Cost: 1K, Rows: 100K (NO STATISTICS)] (PATH ID: 4)
| | | | Projection: store.store_sales_b0
| | | | Materialize: sales.store_key
| | | | Filter: (sales.sale_date = '2014-12-01'::date)
| | | | Execute on: All Nodes
| | | | Runtime Filter: (SIP1(HashJoin): sales.store_key)
| | | +-- Inner -> STORAGE ACCESS for stores [Cost: 34, Rows: 250] (PATH ID: 5)
| | | | Projection: store.store_dimension_DBD_10_rep_VMartDesign_node0001
| | | | Materialize: stores.store_key, stores.store_name
| | | | Execute on: All Nodes
| | +-- Inner -> STORAGE ACCESS for products [Cost: 3K, Rows: 60K (NO STATISTICS)] (PATH ID: 6)
| | | Projection: public.products_b0
| | | Materialize: products.product_key, products.product_description
| | | Execute on: All Nodes
Includes SYNTACTIC_JOIN:
EXPLAIN SELECT /*+SYNTACTIC_JOIN*/ sales.store_key, stores.store_name, products.product_description, sales.sales_quantity, sales.sale_date
FROM (store.store_sales sales JOIN products ON sales.product_key=products.product_key)
JOIN store.store_dimension stores ON sales.store_key=stores.store_key
WHERE sales.sale_date='2014-12-01' order by sales.store_key, sales.sale_date;
Access Path:
+-SORT [Cost: 11K, Rows: 100K (NO STATISTICS)] (PATH ID: 1)
| Order: sales.store_key ASC, sales.sale_date ASC
| Execute on: All Nodes
| +---> JOIN HASH [Cost: 8K, Rows: 100K (NO STATISTICS)] (PATH ID: 2)
| | Join Cond: (sales.store_key = stores.store_key)
| | Execute on: All Nodes
| | +-- Outer -> JOIN HASH [Cost: 7K, Rows: 100K (NO STATISTICS)] (PATH ID: 3) Outer (BROADCAST)(LOCAL ROUND ROBIN)
| | | Join Cond: (sales.product_key = products.product_key)
| | | Execute on: All Nodes
| | | Runtime Filter: (SIP1(HashJoin): sales.store_key)
| | | +-- Outer -> STORAGE ACCESS for sales [Cost: 2K, Rows: 100K (NO STATISTICS)] (PATH ID: 4)
| | | | Projection: store.store_sales_b0
| | | | Materialize: sales.sale_date, sales.store_key, sales.product_key, sales.sales_quantity
| | | | Filter: (sales.sale_date = '2014-12-01'::date)
| | | | Execute on: All Nodes
| | | +-- Inner -> STORAGE ACCESS for products [Cost: 3K, Rows: 60K (NO STATISTICS)] (PATH ID: 5)
| | | | Projection: public.products_b0
| | | | Materialize: products.product_key, products.product_description
| | | | Execute on: All Nodes
| | +-- Inner -> STORAGE ACCESS for stores [Cost: 34, Rows: 250] (PATH ID: 6)
| | | Projection: store.store_dimension_DBD_10_rep_VMartDesign_node0001
| | | Materialize: stores.store_key, stores.store_name
| | | Execute on: All Nodes
2.8.17 - UTYPE
Specifies how to combine UNION ALL input.
Specifies how to combine UNION ALL input.
Syntax
UNION ALL /*+UTYPE(union-type)*/
Arguments
union-type- One of the following values:
-
U: Concatenates UNION ALL input (default).
-
M: Merges UNION ALL input in the same sort order as the source query results. This option requires all input from the source queries to use the same sort order; otherwise, Vertica throws a warning and concatenates the UNION ALL input.
Note
The optimizer relies upon the query or DDL to verify whether input data is sorted, rather than the actual runtime order of the data.
Requirements
Queries that include the UTYPE hint must also include the SYNTACTIC_JOIN hint. Otherwise, the optimizer ignores the UTYPE hint and throws a warning.
2.8.18 - VERBATIM
Enforces execution of an annotated query exactly as written.
Enforces execution of an annotated query exactly as written.
VERBATIM directs the optimizer to create a query plan that incorporates all hints in a annotated query. Furthermore, it directs the optimizer not to apply its own plan development processing on query plan components that pertain to those hints.
Usage of this hint varies between optimizer-generated and custom directed queries, as described below.
Syntax
SELECT /*+ VERBATIM*/
Requirements
The VERBATIM hint must immediately follow SELECT. If the annotated query includes another hint that must also follow SELECT, such as SYNTACTIC_JOIN, combine the two hints together. For example:
SELECT /*+ syntactic_join,verbatim*/
Optimizer-generated directed queries
The optimizer always includes the VERBATIM hint in the annotated queries that it generates for directed queries. For example, given the following CREATE DIRECTED QUERY OPTIMIZER statement:
=> CREATE DIRECTED QUERY OPTIMIZER getStoreSales SELECT sales.store_key, stores.store_name, sales.product_description, sales.sales_quantity, sales.sale_date FROM store.storesales sales JOIN store.store_dimension stores ON sales.store_key=stores.store_key WHERE sales.sale_date='2014-12-01' /*+IGNORECONST(1)*/ AND stores.store_name='Store1' /*+IGNORECONST(2)*/ ORDER BY sales.store_key, sales.sale_date;
CREATE DIRECTED QUERY
The optimizer generates an annotated query that includes the VERBATIM hint:
=> SELECT query_name, annotated_query FROM V_CATALOG.DIRECTED_QUERIES WHERE query_name = 'getStoreSales';
-[ RECORD 1 ]---+------
query_name | getStoreSales
annotated_query | SELECT /*+ syntactic_join,verbatim*/ sales.store_key AS store_key, stores.store_name AS store_name, sales.product_description AS product_description, sales.sales_quantity AS sales_quantity, sales.sale_date AS sale_date
FROM (store.storeSales AS sales/*+projs('store.storeSales')*/ JOIN /*+Distrib(L,L),JType(H)*/ store.store_dimension AS stores/*+projs('store.store_dimension_DBD_10_rep_VMartDesign')*/ ON (sales.store_key = stores.store_key))
WHERE (sales.sale_date = '2014-12-01'::date /*+IgnoreConst(1)*/) AND (stores.store_name = 'Store1'::varchar(6) /*+IgnoreConst(2)*/)
ORDER BY 1 ASC, 5 ASC
When the optimizer uses this directed query, it produces a query plan that is equivalent to the query plan that it used when it created the directed query:
=> ACTIVATE DIRECTED QUERY getStoreSales;
ACTIVATE DIRECTED QUERY
=> EXPLAIN SELECT sales.store_key, stores.store_name, sales.product_description, sales.sales_quantity, sales.sale_date FROM store.storesales sales JOIN store.store_dimension stores ON sales.store_key=stores.store_key WHERE sales.sale_date='2014-12-04' AND stores.store_name='Store14' ORDER BY sales.store_key, sales.sale_date;
QUERY PLAN DESCRIPTION:
------------------------------
EXPLAIN SELECT sales.store_key, stores.store_name, sales.product_description, sales.sales_quantity, sales.sale_date FROM store.storesales sales JOIN store.store_dimension stores ON sales.store_key=stores.store_key WHERE sales.sale_date='2014-12-04' AND stores.store_name='Store14' ORDER BY sales.store_key, sales.sale_date;
The following active directed query(query name: getStoreSales) is being executed:
SELECT /*+syntactic_join,verbatim*/ sales.store_key, stores.store_name, sales.product_description, sales.sales_quantity, sales.sale_date
FROM (store.storeSales sales/*+projs('store.storeSales')*/ JOIN /*+Distrib('L', 'L'), JType('H')*/store.store_dimension stores
/*+projs('store.store_dimension_DBD_10_rep_VMartDesign')*/ ON ((sales.store_key = stores.store_key))) WHERE ((sales.sale_date = '2014-12-04'::date)
AND (stores.store_name = 'Store14'::varchar(7))) ORDER BY sales.store_key, sales.sale_date
Access Path:
+-JOIN HASH [Cost: 463, Rows: 622 (NO STATISTICS)] (PATH ID: 2)
| Join Cond: (sales.store_key = stores.store_key)
| Materialize at Output: sales.sale_date, sales.sales_quantity, sales.product_description
| Execute on: All Nodes
| +-- Outer -> STORAGE ACCESS for sales [Cost: 150, Rows: 155K (NO STATISTICS)] (PATH ID: 3)
| | Projection: store.storeSales_b0
| | Materialize: sales.store_key
| | Filter: (sales.sale_date = '2014-12-04'::date)
| | Execute on: All Nodes
| | Runtime Filter: (SIP1(HashJoin): sales.store_key)
| +-- Inner -> STORAGE ACCESS for stores [Cost: 35, Rows: 2] (PATH ID: 4)
| | Projection: store.store_dimension_DBD_10_rep_VMartDesign_node0001
| | Materialize: stores.store_name, stores.store_key
| | Filter: (stores.store_name = 'Store14')
| | Execute on: All Nodes
Custom directed queries
The VERBATIM hint is included in a custom directed query only if you explicitly include it in the annotated query that you write for that directed query. When the optimizer uses that directed query, it respects the VERBATIM hint and creates a query plan accordingly.
If you omit the VERBATIM hint when you create a custom directed query, the hint is not stored with the annotated query. When the optimizer uses that directed query, it applies its own plan development processing on the annotated query before it generates a query plan. This query plan might not be equivalent to the query plan that the optimizer would have generated for the Vertica version in which the directed query was created.
2.9 - Window clauses
When used with an analytic function, window clauses specify how to partition and sort function input, as well as how to frame input with respect to the current row.
When used with an analytic function, window clauses specify how to partition and sort function input, as well as how to frame input with respect to the current row. When used with a single-phase transform function, the PARTITION ROW and PARTITION LEFT JOIN window clauses support single-row partitions for single-phase transform functions, rather than analytic functions.
2.9.1 - Window partition clause
When specified, a window partition clause divides the rows of the function input based on user-provided expressions.
When specified, a window partition clause divides the rows of the function input based on user-provided expressions. If no expression is provided, the partition clause can improve query performance by using parallelism. If you do not specify a window partition clause, all input rows are treated as a single partition.
Window partitioning is similar to the GROUP BY clause. However, PARTITION BEST and PARTITION NODES may only be used with analytic functions and return only one result per input row, while PARTITION ROW and PARTITION LEFT JOIN can be used for single-phase transform functions and return multiple values per input row.
When used with analytic functions, results are computed per partition and start over again (reset) at the beginning of each subsequent partition.
Syntax
{ PARTITION BY expression[,...]
| PARTITION BEST
| PARTITION NODES
| PARTITION ROW
| PARTITION LEFT JOIN }
Arguments
PARTITION BY expression- Expression on which to sort the partition, where
expression can be a column, constant, or an arbitrary expression formed on columns. Use PARTITION BY for functions with specific partitioning requirements.
PARTITION BEST- Use parallelism to improve performance for multi-threaded queries across multiple nodes.
OVER(PARTITION BEST) provides the best performance on multi-threaded queries across multiple nodes.
The following considerations apply to using PARTITION BEST:
-
Use PARTITION BEST for analytic functions that have no partitioning requirements and are thread safe—for example, a one-to-many transform.
-
Do not use PARTITION BEST on user-defined transform functions (UDTFs) that are not thread-safe. Doing so can produce an error or incorrect results. If a UDTF is not thread safe, use PARTITION NODES .
PARTITION NODES- Use parallelism to improve performance for single-threaded queries across multiple nodes.
OVER(PARTITION NODES) provides the best performance on single-threaded queries across multiple nodes.
PARTITION ROW, PARTITION LEFT JOIN- Use to feed input partitions of exactly one row. If used, any arbitrary expression may be used in the query target list alongside the UDTF. PARTITION LEFT JOIN returns a row of NULLs if an input row would otherwise produce no output.
May not be used for analytic functions or multi-phase transform functions. Note that only one PARTITION ROW transform function is allowed in the target list for each level of the query.
Examples
See Window partitioning.
2.9.2 - Window order clause
Specifies how to sort rows that are supplied to an analytic function.
Specifies how to sort rows that are supplied to an analytic function. If the OVER clause also includes a window partition clause, rows are sorted within each partition.
The window order clause only specifies order within a window result set. The query can have its own ORDER BY clause outside the OVER clause. This has precedence over the window order clause and orders the final result set.
A window order clause also creates a default window frame if none is explicitly specified.
Syntax
ORDER BY { expression [ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] ]
}[,...]
Arguments
expression- A column, constant, or arbitrary expression formed on columns on which to sort input rows.
ASC | DESC- Sort order: ascending (default) or descending.
NULLS {FIRST | LAST | AUTO}- How to position nulls.
NULLS AUTO means to choose the positioning that is most efficient for this query.
ASC defaults to NULLS LAST and DESC defaults to NULLS FIRST.
If you omit all sort qualifiers, Vertica uses ASC NULLS LAST.
For more information, see NULL sort order and Runtime sorting of NULL values in analytic functions.
Examples
See Window ordering.
2.9.3 - Window frame clause
Specifies a window frame, which comprises a set of rows relative to the row that is currently being evaluated by an analytic function.
Specifies a window frame, which comprises a set of rows relative to the row that is currently being evaluated by an analytic function. After the function processes that row and its window, Vertica advances the current row and adjusts the window boundaries accordingly. If the OVER clause also specifies a partition, Vertica also checks that window boundaries do not cross partition boundaries. This process repeats until the function evaluates the last row of the last partition.
Syntax
{ ROWS | RANGE } { BETWEEN start-point AND end-point } | start-point
start-point | end-point:
{ UNBOUNDED {PRECEDING | FOLLOWING}
| CURRENT ROW
| constant-value {PRECEDING | FOLLOWING}}
Arguments
ROWS | RANGE- Whether to interpret window frame dimensions as physical (
ROWS) or logical (RANGE) offsets from the current row. See ROWS versus RANGE below for details.
BETWEEN start-point AND end-point- First and last rows of the window, where
start-point and end-point can be one of the following:
-
UNBOUNDED {PRECEDING | FOLLOWING}: The current partition's first (PRECEDING) or last (FOLLOWING) row.
-
CURRENT ROW: The current row or value.
-
constant-value {PRECEDING | FOLLOWING}: A constant value or expression that evaluates to a constant value. This value is interpreted as either a physical or logical offset from the current row, depending on whether you use ROWS or RANGE. See ROWS versus RANGE for other restrictions.
start-point must resolve to a row or value that is less than or equal to end-point.
start-point- If
ROWS or RANGE specifies only a start point, Vertica uses the current row as the end point and creates the window frame accordingly. In this case, start-point must resolve to a row that is less than or equal to the current row.
Requirements
In order to specify a window frame, the OVER must also specify a window order (ORDER BY) clause. If the OVER clause omits specifying a window frame, the function creates a default window that extends from the current row to the first row in the current partition. This is equivalent to the following clause:
RANGE UNBOUNDED PRECEDING AND CURRENT ROW
ROWS versus RANGE
The window frame's offset from the current row can be physical or logical:
-
ROWS (physical): the start and end points are relative to the current row. If either is a constant value, it must evaluate to a positive integer.
-
RANGE (logical): the start and end points represent a logical offset, such as time. The range value must match the window order (ORDER BY) clause data type: NUMERIC, DATE/TIME, FLOAT or INTEGER.
When setting constant values for ROWS, the constant must evaluate to a positive INTEGER.
When setting constant values for RANGE, the following requirements apply:
-
The constant must evaluate to a positive numeric value or INTERVAL literal.
-
If the constant evaluates to a NUMERIC value, the ORDER BY column type must be a NUMERIC data type.
-
If the constant evaluates to an INTERVAL DAY TO SECOND subtype, the ORDER BY column type must be one of the following: TIMESTAMP, TIME, DATE, or INTERVAL DAY TO SECOND.
-
If the constant evaluates to an INTERVAL YEAR TO MONTH, the ORDER BY column type must be one of the following: TIMESTAMP, DATE, or INTERVAL YEAR TO MONTH.
-
The window order clause can specify only one expression.
Examples
See Window framing.
2.9.4 - Window name clause
Defines a named window that specifies window partition and order clauses for an analytic function.
Defines a named window that specifies window partition and order clauses for an analytic function. This window is specified in the function's OVER clause. Named windows can be useful when you write queries that invoke multiple analytic functions with similar OVER clauses, such as functions that use the same partition (PARTITION BY) clauses.
Syntax
WINDOW window-name AS ( window-partition-clause [window-order-clause] )
Arguments
WINDOW window-name- A window name that is unique within the same query.
-
window-partition-clause [window-order-clause]
-
Clauses to invoke when an OVER clause references this window.
If the window definition omits a window order clause, the OVER clause can specify its own order clause.
Requirements
-
A WINDOW clause cannot include a window frame clause.
-
Each WINDOW clause within the same query must have a unique name.
-
A WINDOW clause can reference another window that is already named. For example, the following query names window w1 before w2. Thus, the WINDOW clause that defines w2 can reference w1:
=> SELECT RANK() OVER(w1 ORDER BY sal DESC), RANK() OVER w2
FROM EMP WINDOW w1 AS (PARTITION BY deptno), w2 AS (w1 ORDER BY sal);
Examples
See Named windows.
See also
Analytic functions
3 - Data types
The following table summarizes the internal data types that Vertica supports.
The following table summarizes the internal data types that Vertica supports. It also shows the default placement of null values in projections. The Size column lists uncompressed bytes.
|
Data Type |
Size / bytes |
Description |
NULL Sorting |
|
Binary |
|
BINARY |
1 to 65,000 |
Fixed-length binary string |
NULLS LAST |
|
VARBINARY (synonyms: BYTEA, RAW) |
1 to 65,000 |
Variable-length binary string |
NULLS LAST |
|
LONG VARBINARY |
1 to 32,000,000 |
Long variable-length binary string |
NULLS LAST |
|
Boolean |
|
BOOLEAN |
1 |
True or False or NULL |
NULLS LAST |
|
Character / Long |
|
CHAR |
1 to 65,000 |
Fixed-length character string |
NULLS LAST |
|
VARCHAR |
1 to 65,000 |
Variable-length character string |
NULLS LAST |
|
LONG VARCHAR |
1 to 32,000,000 |
Long variable-length character string |
NULLS LAST |
|
Date/Time |
|
DATE |
8 |
A month, day, and year |
NULLS FIRST |
|
TIME |
8 |
A time of day without timezone |
NULLS FIRST |
|
TIME WITH TIMEZONE |
8 |
A time of day with timezone |
NULLS FIRST |
|
TIMESTAMP (synonyms: DATETIME, SMALLDATETIME) |
8 |
A date and time without timezone |
NULLS FIRST |
|
TIMESTAMP WITH TIMEZONE |
8 |
A date and time with timezone |
NULLS FIRST |
|
INTERVAL |
8 |
The difference between two points in time |
NULLS FIRST |
|
INTERVAL DAY TO SECOND |
8 |
An interval measured in days and seconds |
NULLS FIRST |
|
INTERVAL YEAR TO MONTH |
8 |
An interval measured in years and months |
NULLS FIRST |
|
Approximate Numeric |
|
DOUBLE PRECISION |
8 |
Signed 64-bit IEEE floating point number, requiring 8 bytes of storage |
NULLS LAST |
|
FLOAT |
8 |
Signed 64-bit IEEE floating point number, requiring 8 bytes of storage |
NULLS LAST |
|
FLOAT(n) |
8 |
Signed 64-bit IEEE floating point number, requiring 8 bytes of storage |
NULLS LAST |
|
FLOAT8 |
8 |
Signed 64-bit IEEE floating point number, requiring 8 bytes of storage |
NULLS LAST |
|
REAL |
8 |
Signed 64-bit IEEE floating point number, requiring 8 bytes of storage |
NULLS LAST |
|
Exact Numeric |
|
INTEGER |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
INT |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
BIGINT |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
INT8 |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
SMALLINT |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
TINYINT |
8 |
Signed 64-bit integer, requiring 8 bytes of storage |
NULLS FIRST |
|
DECIMAL |
8+ |
8 bytes for the first 18 digits of precision, plus 8 bytes for each additional 19 digits |
NULLS FIRST |
|
NUMERIC |
8+ |
8 bytes for the first 18 digits of precision, plus 8 bytes for each additional 19 digits |
NULLS FIRST |
|
NUMBER |
8+ |
8 bytes for the first 18 digits of precision, plus 8 bytes for each additional 19 digits |
NULLS FIRST |
|
MONEY |
8+ |
8 bytes for the first 18 digits of precision, plus 8 bytes for each additional 19 digits |
NULLS FIRST |
|
Spatial |
|
GEOMETRY |
1 to 10,000,000 |
Coordinates expressed as (x,y) pairs, defined in the Cartesian plane. |
NULLS LAST |
|
GEOGRAPHY |
1 to 10,000,000 |
Coordinates expressed in longitude/latitude angular values, measured in degrees |
NULLS LAST |
|
UUID |
|
UUID |
16 |
Stores universally unique identifiers (UUIDs). |
NULLS FIRST |
|
Complex |
|
ARRAY |
1 to 32,000,000 |
Collection of values of a primitive or complex type. |
Native array: same as the element type
Non-native array: cannot be used to order projections
|
|
ROW |
1 to 32,000,000 |
Structure of property-value pairs. |
Cannot be used to order projections |
|
SET |
1 to 32,000,000 |
Collection of unique values of a primitive type. |
Same as the primitive type |
3.1 - Binary data types (BINARY and VARBINARY)
Store raw-byte data, such as IP addresses, up to bytes.
Store raw-byte data, such as IP addresses, up to 65000 bytes. The BINARY and BINARY VARYING (VARBINARY) data types are collectively referred to as binary string types and the values of binary string types are referred to as binary strings. A binary string is a sequence of octets or bytes.
BYTEA and RAW are synonyms for VARBINARY.
Syntax
BINARY ( length )
{ VARBINARY | BINARY VARYING | BYTEA | RAW } ( max-length )
Arguments
length, max-length- The length of the string or column width, in bytes (octets).
BINARY and VARBINARY data types
BINARY and VARBINARY data types have the following attributes:
-
BINARY: A fixed-width string of length bytes, where the number of bytes is declared as an optional specifier to the type. If length is omitted, the default is 1. Where necessary, values are right-extended to the full width of the column with the zero byte. For example:
=> SELECT TO_HEX('ab'::BINARY(4));
to_hex
----------
61620000
-
VARBINARY: A variable-width string up to a length of max-length bytes, where the maximum number of bytes is declared as an optional specifier to the type. The default is the default attribute size, which is 80, and the maximum length is 65000 bytes. VARBINARY values are not extended to the full width of the column. For example:
=> SELECT TO_HEX('ab'::VARBINARY(4));
to_hex
--------
6162
You can use several formats when working with binary values. The hexadecimal format is generally the most straightforward and is emphasized in Vertica documentation.
Binary values can also be represented in octal format by prefixing the value with a backslash '\'.
Note
If you use vsql, you must use the escape character (\) when you insert another backslash on input; for example, input '\141' as '\\141'.
You can also input values represented by printable characters. For example, the hexadecimal value '0x61' can also be represented by the symbol a.
See Data load.
On input, strings are translated from:
Both functions take a VARCHAR argument and return a VARBINARY value.
Like the input format, the output format is a hybrid of octal codes and printable ASCII characters. A byte in the range of printable ASCII characters (the range [0x20, 0x7e]) is represented by the corresponding ASCII character, with the exception of the backslash ('\'), which is escaped as '\\'. All other byte values are represented by their corresponding octal values. For example, the bytes {97,92,98,99}, which in ASCII are {a,\,b,c}, are translated to text as 'a\\bc'.
Binary operators and functions
The binary operators &, ~, |, and # have special behavior for binary data types, as described in Bitwise operators.
The following aggregate functions are supported for binary data types:
BIT_AND, BIT_OR, and BIT_XOR are bit-wise operations that are applied to each non-null value in a group, while MAX and MIN are byte-wise comparisons of binary values.
Like their binary operator counterparts, if the values in a group vary in length, the aggregate functions treat the values as though they are all equal in length by extending shorter values with zero bytes to the full width of the column. For example, given a group containing the values 'ff', null, and 'f', a binary aggregate ignores the null value and treats the value 'f' as 'f0'. Also, like their binary operator counterparts, these aggregate functions operate on VARBINARY types explicitly and operate on BINARY types implicitly through casts. See Data type coercion operators (CAST).
Binary versus character data types
The BINARY and VARBINARY binary types are similar to the CHAR and VARCHAR character data types, respectively. They differ as follows:
-
Binary data types contain byte strings (a sequence of octets or bytes).
-
Character data types contain character strings (text).
-
The lengths of binary data types are measured in bytes, while character data types are measured in characters.
Examples
The following example shows HEX_TO_BINARY and TO_HEX usage.
Table t and its projection are created with binary columns:
=> CREATE TABLE t (c BINARY(1));
=> CREATE PROJECTION t_p (c) AS SELECT c FROM t;
Insert minimum byte and maximum byte values:
=> INSERT INTO t values(HEX_TO_BINARY('0x00'));
=> INSERT INTO t values(HEX_TO_BINARY('0xFF'));
Binary values can then be formatted in hex on output using the TO_HEX function:
=> SELECT TO_HEX(c) FROM t;
to_hex
--------
00
ff
(2 rows)
The BIT_AND, BIT_OR, and BIT_XOR functions are interesting when operating on a group of values. For example, create a sample table and projections with binary columns:
The example that follows uses table t with a single column of VARBINARY data type:
=> CREATE TABLE t ( c VARBINARY(2) );
=> INSERT INTO t values(HEX_TO_BINARY('0xFF00'));
=> INSERT INTO t values(HEX_TO_BINARY('0xFFFF'));
=> INSERT INTO t values(HEX_TO_BINARY('0xF00F'));
Query table t to see column c output:
=> SELECT TO_HEX(c) FROM t;
TO_HEX
--------
ff00
ffff
f00f
(3 rows)
Now issue the bitwise AND operation. Because these are aggregate functions, an implicit GROUP BY operation is performed on results using (ff00&(ffff)&f00f):
=> SELECT TO_HEX(BIT_AND(c)) FROM t;
TO_HEX
--------
f000
(1 row)
Issue the bitwise OR operation on (ff00|(ffff)|f00f):
=> SELECT TO_HEX(BIT_OR(c)) FROM t;
TO_HEX
--------
ffff
(1 row)
Issue the bitwise XOR operation on (ff00#(ffff)#f00f):
=> SELECT TO_HEX(BIT_XOR(c)) FROM t;
TO_HEX
--------
f0f0
(1 row)
3.2 - Boolean data type
Vertica provides the standard SQL type BOOLEAN, which has two states: true and false.
Vertica provides the standard SQL type BOOLEAN, which has two states: true and false. The third state in SQL boolean logic is unknown, which is represented by the NULL value.
Syntax
BOOLEAN
Parameters
Valid literal data values for input are:
TRUE |
't' |
'true' |
'y' |
'yes' |
'1' |
1 |
FALSE |
'f' |
'false' |
'n' |
'no' |
'0' |
0 |
Notes
-
Do not confuse the BOOLEAN data type with Logical operators or the Boolean.
-
The keywords TRUE and FALSE are preferred and are SQL-compliant.
-
A Boolean value of NULL appears last (largest) in ascending order.
-
All other values must be enclosed in single quotes.
-
Boolean values are output using the letters t and f.
See also
3.3 - Character data types (CHAR and VARCHAR)
Stores strings of letters, numbers, and symbols.
Stores strings of letters, numbers, and symbols. The CHARACTER (CHAR) and CHARACTER VARYING (VARCHAR) data types are collectively referred to as character string types, and the values of character string types are known as character strings.
Character data can be stored as fixed-length or variable-length strings. Fixed-length strings are right-extended with spaces on output; variable-length strings are not extended.
String literals in SQL statements must be enclosed in single quotes.
Syntax
{ CHAR | CHARACTER } [ (octet-length) ]
{ VARCHAR | CHARACTER VARYING ] } [ (octet-length) ]
Arguments
octet-length- Length of the string or column width, declared in bytes (octets).
This argument is optional.
CHAR versus VARCHAR data types
The following differences apply to CHAR and VARCHAR data:
-
CHAR is conceptually a fixed-length, blank-padded string. Trailing blanks (spaces) are removed on input and are restored on output. The default length is 1, and the maximum length is 65000 octets (bytes).
-
VARCHAR is a variable-length character data type. The default length is 80, and the maximum length is 65000 octets. For string values longer than 65000, use Long data types. Values can include trailing spaces.
Normally, you use VARCHAR for all of string data. Use CHAR when you need fixed-width string output. For example, you can use CHAR columns for data to be transferred to a legacy system that requires fixed-width strings.
Setting maximum length
When you define character columns, specify the maximum size of any string to be stored in a column. For example, to store strings up to 24 octets in length, use one of the following definitions:
CHAR(24) --- fixed-length
VARCHAR(24) --- variable-length
The maximum length parameter for VARCHAR and CHAR data types refers to the number of octets that can be stored in that field, not the number of characters (Unicode code points). When using multibyte UTF-8 characters, the fields must be sized to accommodate from 1 to 4 octets per character, depending on the data. If the data loaded into a VARCHAR or CHAR column exceeds the specified maximum size for that column, data is truncated on UTF-8 character boundaries to fit within the specified size. See COPY.
Note
Remember to include the extra octets required for multibyte characters in the column-width declaration, keeping in mind the 65000 octet column-width limit.
Due to compression in Vertica, the cost of overestimating the length of these fields is incurred primarily at load time and during sorts.
NULL versus NUL
NULL and NUL differ as follows:
-
NUL represents a character whose ASCII/Unicode code is 0, sometimes qualified "ASCII NUL".
-
NULL means no value, and is true of a field (column) or constant, not of a character.
CHAR, LONG VARCHAR, and VARCHAR string data types accept ASCII NUL values.
In ascending sorts, NULL appears last (largest).
For additional information about NULL ordering, see NULL sort order.
The following example casts the input string containing NUL values to VARCHAR:
=> SELECT 'vert\0ica'::CHARACTER VARYING AS VARCHAR;
VARCHAR
---------
vert\0ica
(1 row)
The result contains 9 characters:
=> SELECT LENGTH('vert\0ica'::CHARACTER VARYING);
length
--------
9
(1 row)
If you use an extended string literal, the length is 8 characters:
=> SELECT E'vert\0ica'::CHARACTER VARYING AS VARCHAR;
VARCHAR
---------
vertica
(1 row)
=> SELECT LENGTH(E'vert\0ica'::CHARACTER VARYING);
LENGTH
--------
8
(1 row)
3.4 - Date/time data types
Vertica supports the full set of SQL date and time data types.
Vertica supports the full set of SQL date and time data types.
The following rules apply to all date/time data types:
-
All have a size of 8 bytes.
-
A date/time value of NULL is smallest relative to all other date/time values,.
-
Vertica uses Julian dates for all date/time calculations, which can correctly predict and calculate any date more recent than 4713 BC to far into the future, based on the assumption that the average length of the year is 365.2425 days.
-
All the date/time data types accept the special literal value NOW to specify the current date and time. For example:
=> SELECT TIMESTAMP 'NOW';
?column?
---------------------------
2020-09-23 08:23:50.42325
(1 row)
-
By default, Vertica rounds with a maximum precision of six decimal places. You can substitute an integer between 0 and 6 for p to specify your preferred level of precision.
The following table lists specific attributes of date/time data types:
|
Name |
Description |
Low Value |
High Value |
Resolution |
DATE |
Dates only (no time of day) |
~ 25e+15 BC |
~ 25e+15 AD |
1 day |
TIME [(p)] |
Time of day only (no date) |
00:00:00.00 |
23:59:60.999999 |
1 μs |
TIMETZ [(p)] |
Time of day only, with time zone |
00:00:00.00+14 |
23:59:59.999999-14 |
1 μs |
TIMESTAMP [(p)] |
Both date and time, without time zone |
290279-12-22 19:59:05.224194 BC |
294277-01-09 04:00:54.775806 AD |
1 μs |
TIMESTAMPTZ [(p)]* |
Both date and time, with time zone |
290279-12-22 19:59:05.224194 BC UTC |
294277-01-09 04:00:54.775806 AD UTC |
1 μs |
INTERVAL DAY TO SECOND [(p)] |
Time intervals |
-106751991 days 04:00:54.775807 |
+-106751991 days 04:00:54.775807 |
1 μs |
INTERVAL YEAR TO MONTH |
Time intervals |
~ -768e15 yrs |
~ 768e15 yrs |
1 month |
Vertica recognizes the files in
/opt/vertica/share/timezonesets as date/time input values and defines the default list of strings accepted in the AT TIME ZONE zone parameter. The names are not necessarily used for date/time output—output is driven by the official time zone abbreviations associated with the currently selected time zone parameter setting.
3.4.1 - DATE
Consists of a month, day, and year.
Consists of a month, day, and year. The following limits apply:
See SET DATESTYLE for information about ordering.
Note
'0000-00-00' is not valid. If you try to insert that value into a DATE or TIMESTAMP field, an error occurs. If you copy '0000-00-00' into a DATE or TIMESTAMP field, Vertica converts the value to 0001-01-01 00:00:00 BC.
Syntax
DATE
Examples
|
Example |
Description |
January 8, 1999 |
Unambiguous in any datestyle input mode |
1999-01-08 |
ISO 8601; January 8 in any mode (recommended format) |
1/8/1999 |
January 8 in MDY mode; August 1 in DMY mode |
1/18/1999 |
January 18 in MDY mode; rejected in other modes |
01/02/03 |
January 2, 2003 in MDY mode
February 1, 2003 in DMY mode
February 3, 2001 in YMD mode |
1999-Jan-08 |
January 8 in any mode |
Jan-08-1999 |
January 8 in any mode |
08-Jan-1999 |
January 8 in any mode |
99-Jan-08 |
January 8 in YMD mode, else error |
08-Jan-99 |
January 8, except error in YMD mode |
Jan-08-99 |
January 8, except error in YMD mode |
19990108 |
ISO 8601; January 8, 1999 in any mode |
990108 |
ISO 8601; January 8, 1999 in any mode |
1999.008 |
Year and day of year |
J2451187 |
Julian day |
January 8, 99 BC |
Year 99 before the Common Era |
3.4.2 - DATETIME
DATETIME is an alias for TIMESTAMP.
DATETIME is an alias for TIMESTAMP/TIMESTAMPTZ.
3.4.3 - INTERVAL
Measures the difference between two points in time.
Measures the difference between two points in time. Intervals can be positive or negative. The INTERVAL data type is SQL:2008 compliant, and supports interval qualifiers that are divided into two major subtypes:
-
Year-month: Span of years and months
-
Day-time: Span of days, hours, minutes, seconds, and fractional seconds
Intervals are represented internally as some number of microseconds and printed as up to 60 seconds, 60 minutes, 24 hours, 30 days, 12 months, and as many years as necessary. You can control the output format of interval units with SET INTERVALSTYLE and SET DATESTYLE.
Syntax
INTERVAL 'interval-literal' [ interval-qualifier ] [ (p) ]
Parameters
-
interval-literal
- A character string that expresses an interval, conforming to this format:
[-] { quantity subtype-unit }[...] [ AGO ]
For details, see Interval literal.
-
interval-qualifier
- Optionally specifies how to interpret and format an interval literal for output, and, optionally, sets precision. If omitted, the default is
DAY TO SECOND(6). For details, see Interval qualifier.
p- Specifies precision of the seconds field, where
p is an integer between 0 - 6. For details, see Specifying interval precision.
Default: 6
Limits
|
Name |
Low Value |
High Value |
Resolution |
INTERVAL DAY TO SECOND [(p)] |
-106751991 days 04:00:54.775807 |
+/-106751991 days 04:00:54.775807 |
1 microsecond |
INTERVAL YEAR TO MONTH |
~/ -768e15 yrs |
~ 768e15 yrs |
1 month |
3.4.3.1 - Setting interval unit display
SET INTERVALSTYLE and SET DATESTYLE control the output format of interval units.
SET INTERVALSTYLE and SET DATESTYLE control the output format of interval units.
Important
DATESTYLE settings supersede INTERVALSTYLE. If DATESTYLE is set to SQL, interval unit display always conforms to the SQL:2008 standard, which omits interval unit display. If DATESTYLE is set to ISO, you can use
SET INTERVALSTYLE to omit or display interval unit display, as described below.
Omitting interval units
To omit interval units from the output, set INTERVALSTYLE to PLAIN. This is the default setting, which conforms with the SQL:2008 standard:
=> SET INTERVALSTYLE TO PLAIN;
SET
=> SELECT INTERVAL '3 2';
?column?
----------
3 02:00
When INTERVALSTYLE is set to PLAIN, units are omitted from the output, even if the query specifies input units:
=> SELECT INTERVAL '3 days 2 hours';
?column?
----------
3 02:00
If DATESTYLE is set to SQL, Vertica conforms with SQL:2008 standard and always omits interval units from output:
=> SET DATESTYLE TO SQL;
SET
=> SET INTERVALSTYLE TO UNITS;
SET
=> SELECT INTERVAL '3 2';
?column?
----------
3 02:00
Displaying interval units
To enable display of interval units, DATESTYLE must be set to ISO. You can then display interval units by setting INTERVALSTYLE to UNITS:
=> SET DATESTYLE TO ISO;
SET
=> SET INTERVALSTYLE TO UNITS;
SET
=> SELECT INTERVAL '3 2';
?column?
----------------
3 days 2 hours
Checking INTERVALSTYLE and DATESTYLE settings
Use
SHOW statements to check INTERVALSTYLE and DATESTYLE settings:
=> SHOW INTERVALSTYLE;
name | setting
---------------+---------
intervalstyle | units
=> SHOW DATESTYLE;
name | setting
-----------+----------
datestyle | ISO, MDY
3.4.3.2 - Specifying interval input
Interval values are expressed through interval literals.
Interval values are expressed through interval literals. An interval literal is composed of one or more interval fields, where each field represents a span of days and time, or years and months, as follows:
[-] { quantity subtype-unit }[...] [AGO]
Using subtype units
Subtype units are optional for day-time intervals; they must be specified for year-month intervals.
For example, the first statement below implicitly specifies days and time; the second statement explicitly identifies day and time units. Both statements return the same result:
=> SET INTERVALSTYLE TO UNITS;
=> SELECT INTERVAL '1 12:59:10:05';
?column?
--------------------
1 day 12:59:10.005
(1 row)
=> SELECT INTERVAL '1 day 12 hours 59 min 10 sec 5 milliseconds';
?column?
--------------------
1 day 12:59:10.005
(1 row)
The following two statements add 28 days and 4 weeks to the current date, respectively. The intervals in both cases are equal and the statements return the same result. However, in the first statement, the interval literal omits the subtype (implicitly days); in the second statement, the interval literal must include the subtype unit weeks:
=> SELECT CURRENT_DATE;
?column?
------------
2016-08-15
(1 row)
=> SELECT CURRENT_DATE + INTERVAL '28';
?column?
---------------------
2016-09-12 00:00:00
(1 row)
dbadmin=> SELECT CURRENT_DATE + INTERVAL '4 weeks';
?column?
---------------------
2016-09-12 00:00:00
(1 row)
An interval literal can include day-time and year-month fields. For example, the following statement adds an interval of 4 years, 4 weeks, 4 days and 14 hours to the current date. The years and weeks fields must include subtype units; the days and hours fields omit them:
> SELECT CURRENT_DATE + INTERVAL '4 years 4 weeks 4 14';
?column?
---------------------
2020-09-15 14:00:00
(1 row)
Omitting subtype units
You can specify quantities of days, hours, minutes, and seconds without specifying units. Vertica recognizes colons in interval literals as part of the timestamp:
=> SELECT INTERVAL '1 4 5 6';
?column?
------------
1 day 04:05:06
=> SELECT INTERVAL '1 4:5:6';
?column?
------------
1 day 04:05:06
=> SELECT INTERVAL '1 day 4 hour 5 min 6 sec';
?column?
------------
1 day 04:05:06
If Vertica cannot determine the units, it applies the quantity to any missing units based on the interval qualifier. In the next two examples, Vertica uses the default interval qualifier (DAY TO SECOND(6)) and assigns the trailing 1 to days, since it has already processed hours, minutes, and seconds in the output:
=> SELECT INTERVAL '4:5:6 1';
?column?
------------
1 day 04:05:06
=> SELECT INTERVAL '1 4:5:6';
?column?
------------
1 day 04:05:06
In the next two examples, Vertica recognizes 4:5 as hours:minutes. The remaining values in the interval literal are assigned to the missing units: 1 is assigned to days and 2 is assigned to seconds.
SELECT INTERVAL '4:5 1 2';
?column?
------------
1 day 04:05:02
=> SELECT INTERVAL '1 4:5 2';
?column?
------------
1 day 04:05:02
Specifying the interval qualifier can change how Vertica interprets 4:5:
=> SELECT INTERVAL '4:5' MINUTE TO SECOND;
?column?
------------
00:04:05
3.4.3.3 - Controlling interval format
Interval qualifiers specify a range of options that Vertica uses to interpret and format an interval literal.
Interval qualifiers specify a range of options that Vertica uses to interpret and format an interval literal. The interval qualifier can also specify precision. Each interval qualifier is composed of one or two units:
unit[p] [ TO unit[p] ]
where:
-
unit specifies a day-time or year-month subtype.
-
p specifies precision, an integer between 0 and 6. In general, precision only applies to SECOND units. The default precision for SECOND is 6. For details, see Specifying interval precision.
If an interval omits an interval qualifier, Vertica uses the default DAY TO SECOND(6).
Interval qualifier categories
Interval qualifiers belong to one of the following categories:
-
Year-month: Span of years and months
-
Day-time: Span of days, hours, minutes, seconds, and fractional seconds
Note
All examples below assume that
INTERVALSTYLE is set to plain.
Year-Month
Vertica supports two year-month subtypes: YEAR and MONTH.
In the following example, YEAR TO MONTH qualifies the interval literal 1 2 to indicate a span of 1 year and two months:
=> SELECT interval '1 2' YEAR TO MONTH;
?column?
----------
1-2
(1 row)
If you omit the qualifier, Vertica uses the default interval qualifier DAY TO SECOND and returns a different result:
=> SELECT interval '1 2';
?column?
----------
1 02:00
(1 row)
The following example uses the interval qualifier YEAR. In this case, Vertica extracts only the year from the interval literal 1y 10m :
=> SELECT INTERVAL '1y 10m' YEAR;
?column?
----------
1
(1 row)
In the next example, the interval qualifier MONTH converts the same interval literal to months:
=> SELECT INTERVAL '1y 10m' MONTH;
?column?
----------
22
(1 row)
Day-time
Vertica supports four day-time subtypes: DAY, HOUR, MINUTE, and SECOND.
In the following example, the interval qualifier DAY TO SECOND(4) qualifies the interval literal 1h 3m 6s 5msecs 57us. The qualifier also sets precision on seconds to 4:
=> SELECT INTERVAL '1h 3m 6s 5msecs 57us' DAY TO SECOND(4);
?column?
---------------
01:03:06.0051
(1 row)
If no interval qualifier is specified, Vertica uses the default subtype DAY TO SECOND(6), regardless of how you specify the interval literal. For example, as an extension to SQL:2008, both of the following commands return 910 days:
=> SELECT INTERVAL '2-6';
?column?
-----------------
910
=> SELECT INTERVAL '2 years 6 months';
?column?
-----------------
910
An interval qualifier can extract other values from the input parameters. For example, the following command extracts the HOUR value from the interval literal 3 days 2 hours:
=> SELECT INTERVAL '3 days 2 hours' HOUR;
?column?
----------
74
The primary day/time (DAY TO SECOND) and year/month (YEAR TO MONTH) subtype ranges can be restricted to more specific range of types by an interval qualifier. For example, HOUR TO MINUTE is a limited form of day/time interval, which can be used to express time zone offsets.
=> SELECT INTERVAL '1 3' HOUR to MINUTE;
?column?
---------------
01:03
hh:mm:ss and hh:mm formats are used only when at least two of the fields specified in the interval qualifier are non-zero and there are no more than 23 hours or 59 minutes:
=> SELECT INTERVAL '2 days 12 hours 15 mins' DAY TO MINUTE;
?column?
--------------
2 12:15
=> SELECT INTERVAL '15 mins 20 sec' MINUTE TO SECOND;
?column?
----------
15:20
=> SELECT INTERVAL '1 hour 15 mins 20 sec' MINUTE TO SECOND;
?column?
-----------------
75:20
3.4.3.4 - Specifying interval precision
In general, interval precision only applies to seconds.
In general, interval precision only applies to seconds. If no precision is explicitly specified, Vertica rounds precision to a maximum of six decimal places. For example:
=> SELECT INTERVAL '2 hours 4 minutes 3.709384766 seconds' DAY TO SECOND;
?column?
-----------------
02:04:03.709385
(1 row)
Vertica lets you specify interval precision in two ways:
For example, the following statements use both methods to set precision, and return identical results:
=> SELECT INTERVAL(4) '2 hours 4 minutes 3.709384766 seconds' DAY TO SECOND;
?column?
---------------
02:04:03.7094
(1 row)
=> SELECT INTERVAL '2 hours 4 minutes 3.709384766 seconds' DAY TO SECOND(4);
?column?
---------------
02:04:03.7094
(1 row)
If the same statement specifies precision more than once, Vertica uses the lesser precision. For example, the following statement specifies precision twice: the INTERVAL keyword specifies precision of 1, while the interval qualifier SECOND specifies precision of 2. Vertica uses the lesser precision of 1:
=> SELECT INTERVAL(1) '1.2467' SECOND(2);
?column?
----------
1.2 secs
Setting precision on interval table columns
If you create a table with an interval column, the following restrictions apply to the column definition:
-
You can set precision on the INTERVAL keyword only if you omit specifying an interval qualifier. If you try to set precision on the INTERVAL keyword and include an interval qualifier, Vertica returns an error.
-
You can set precision only on the last unit of an interval qualifier. For example:
CREATE TABLE public.testint2
(
i INTERVAL HOUR TO SECOND(3)
);
If you specify precision on another unit, Vertica discards it when it saves the table definition.
3.4.3.5 - Fractional seconds in interval units
Vertica supports intervals in milliseconds (hh:mm:ss:ms), where 01:02:03:25 represents 1 hour, 2 minutes, 3 seconds, and 025 milliseconds.
Vertica supports intervals in milliseconds (hh:mm:ss:ms), where 01:02:03:25 represents 1 hour, 2 minutes, 3 seconds, and 025 milliseconds. Milliseconds are converted to fractional seconds as in the following example, which returns 1 day, 2 hours, 3 minutes, 4 seconds, and 25.5 milliseconds:
=> SELECT INTERVAL '1 02:03:04:25.5';
?column?
------------
1 day 02:03:04.0255
Vertica allows fractional minutes. The fractional minutes are rounded into seconds:
=> SELECT INTERVAL '10.5 minutes';
?column?
------------
00:10:30
=> select interval '10.659 minutes';
?column?
-------------
00:10:39.54
=> select interval '10.3333333333333 minutes';
?column?
----------
00:10:20
Considerations
-
An INTERVAL can include only the subset of units that you need; however, year/month intervals represent calendar years and months with no fixed number of days, so year/month interval values cannot include days, hours, minutes. When year/month values are specified for day/time intervals, the intervals extension assumes 30 days per month and 365 days per year. Since the length of a given month or year varies, day/time intervals are never output as months or years, only as days, hours, minutes, and so on.
-
Day/time and year/month intervals are logically independent and cannot be combined with or compared to each other. In the following example, an interval-literal that contains DAYS cannot be combined with the YEAR TO MONTH type:
=> SELECT INTERVAL '1 2 3' YEAR TO MONTH;
ERROR 3679: Invalid input syntax for interval year to month: "1 2 3"
-
Vertica accepts intervals up to 2^63 – 1 microseconds or months (about 18 digits).
-
INTERVAL YEAR TO MONTH can be used in an analytic RANGE window when the ORDER BY column type is TIMESTAMP/TIMESTAMP WITH TIMEZONE, or DATE. Using TIME/TIME WITH TIMEZONE are not supported.
-
You can use INTERVAL DAY TO SECOND when the ORDER BY column type is TIMESTAMP/TIMESTAMP WITH TIMEZONE, DATE, and TIME/TIME WITH TIMEZONE.
Examples
Examples in this section assume that INTERVALSTYLE is set to PLAIN, so results omit subtype units. Interval values that omit an interval qualifier use the default to DAY TO SECOND(6).
=> SELECT INTERVAL '00:2500:00';
?column?
----------
1 17:40
(1 row)
=> SELECT INTERVAL '2500' MINUTE TO SECOND;
?column?
----------
2500
(1 row)
=> SELECT INTERVAL '2500' MINUTE;
?column?
----------
2500
(1 row)
=> SELECT INTERVAL '28 days 3 hours' HOUR TO SECOND;
?column?
----------
675:00
(1 row)
=> SELECT INTERVAL(3) '28 days 3 hours';
?column?
----------
28 03:00
(1 row)
=> SELECT INTERVAL(3) '28 days 3 hours 1.234567';
?column?
-----------------
28 03:01:14.074
(1 row)
=> SELECT INTERVAL(3) '28 days 3 hours 1.234567 sec';
?column?
-----------------
28 03:00:01.235
(1 row)
=> SELECT INTERVAL(3) '28 days 3.3 hours' HOUR TO SECOND;
?column?
----------
675:18
(1 row)
=> SELECT INTERVAL(3) '28 days 3.35 hours' HOUR TO SECOND;
?column?
----------
675:21
(1 row)
=> SELECT INTERVAL(3) '28 days 3.37 hours' HOUR TO SECOND;
?column?
-----------
675:22:12
(1 row)
=> SELECT INTERVAL '1.234567 days' HOUR TO SECOND;
?column?
---------------
29:37:46.5888
(1 row)
=> SELECT INTERVAL '1.23456789 days' HOUR TO SECOND;
?column?
-----------------
29:37:46.665696
(1 row)
=> SELECT INTERVAL(3) '1.23456789 days' HOUR TO SECOND;
?column?
--------------
29:37:46.666
(1 row)
=> SELECT INTERVAL(3) '1.23456789 days' HOUR TO SECOND(2);
?column?
-------------
29:37:46.67
(1 row)
=> SELECT INTERVAL(3) '01:00:01.234567' as "one hour+";
one hour+
--------------
01:00:01.235
(1 row)
=> SELECT INTERVAL(3) '01:00:01.234567' = INTERVAL(3) '01:00:01.234567';
?column?
----------
t
(1 row)
=> SELECT INTERVAL(3) '01:00:01.234567' = INTERVAL '01:00:01.234567';
?column?
----------
f
(1 row)
=> SELECT INTERVAL(3) '01:00:01.234567' = INTERVAL '01:00:01.234567'
HOUR TO SECOND(3);
?column?
----------
t
(1 row)
=> SELECT INTERVAL(3) '01:00:01.234567' = INTERVAL '01:00:01.234567'
MINUTE TO SECOND(3);
?column?
----------
t
(1 row)
=> SELECT INTERVAL '255 1.1111' MINUTE TO SECOND(3);
?column?
------------
255:01.111
(1 row)
=> SELECT INTERVAL '@ - 5 ago';
?column?
----------
5
(1 row)
=> SELECT INTERVAL '@ - 5 minutes ago';
?column?
----------
00:05
(1 row)
=> SELECT INTERVAL '@ 5 minutes ago';
?column?
----------
-00:05
(1 row)
=> SELECT INTERVAL '@ ago -5 minutes';
?column?
----------
00:05
(1 row)
=> SELECT DATE_PART('month', INTERVAL '2-3' YEAR TO MONTH);
DATE_PART
-----------
3
(1 row)
=> SELECT FLOOR((TIMESTAMP '2005-01-17 10:00'
- TIMESTAMP '2005-01-01')
/ INTERVAL '7');
FLOOR
-------
2
(1 row)
3.4.3.6 - Processing signed intervals
In the SQL:2008 standard, a minus sign before an interval-literal or as the first character of the interval-literal negates the entire literal, not just the first component.
In the SQL:2008 standard, a minus sign before an interval-literal or as the first character of the interval-literal negates the entire literal, not just the first component. In Vertica, a leading minus sign negates the entire interval, not just the first component. The following commands both return the same value:
=> SELECT INTERVAL '-1 month - 1 second';
?column?
----------
-29 days 23:59:59
=> SELECT INTERVAL -'1 month - 1 second';
?column?
----------
-29 days 23:59:59
Use one of the following commands instead to return the intended result:
=> SELECT INTERVAL -'1 month 1 second';
?column?
----------
-30 days 1 sec
=> SELECT INTERVAL -'30 00:00:01';
?column?
----------
-30 days 1 sec
Two negatives together return a positive:
=> SELECT INTERVAL -'-1 month - 1 second';
?column?
----------
29 days 23:59:59
=> SELECT INTERVAL -'-1 month 1 second';
?column?
----------
30 days 1 sec
You can use the year-month syntax with no spaces. Vertica allows the input of negative months but requires two negatives when paired with years.
=> SELECT INTERVAL '3-3' YEAR TO MONTH;
?column?
----------
3 years 3 months
=> SELECT INTERVAL '3--3' YEAR TO MONTH;
?column?
----------
2 years 9 months
When the interval-literal looks like a year/month type, but the type is day/second, or vice versa, Vertica reads the interval-literal from left to right, where number-number is years-months, and number <space> <signed number> is whatever the units specify. Vertica processes the following command as (–) 1 year 1 month = (–) 365 + 30 = –395 days:
=> SELECT INTERVAL '-1-1' DAY TO HOUR;
?column?
----------
-395 days
If you insert a space in the interval-literal, Vertica processes it based on the subtype DAY TO HOUR: (–) 1 day – 1 hour = (–) 24 – 1 = –23 hours:
=> SELECT INTERVAL '-1 -1' DAY TO HOUR;
?column?
----------
-23 hours
Two negatives together returns a positive, so Vertica processes the following command as (–) 1 year – 1 month = (–) 365 – 30 = –335 days:
=> SELECT INTERVAL '-1--1' DAY TO HOUR;
?column?
----------
-335 days
If you omit the value after the hyphen, Vertica assumes 0 months and processes the following command as 1 year 0 month –1 day = 365 + 0 – 1 = –364 days:
=> SELECT INTERVAL '1- -1' DAY TO HOUR;
?column?
----------
364 days
3.4.3.7 - Casting with intervals
You can use CAST to convert strings to intervals, and vice versa.
You can use CAST to convert strings to intervals, and vice versa.
String to interval
You cast a string to an interval as follows:
CAST( [ INTERVAL[(p)] ] [-] ] interval-literal AS INTERVAL[(p)] interval-qualifier )
For example:
=> SELECT CAST('3700 sec' AS INTERVAL);
?column?
----------
01:01:40
You can cast intervals within day-time or the year-month subtypes but not between them:
=> SELECT CAST(INTERVAL '4440' MINUTE as INTERVAL);
?column?
----------
3 days 2 hours
=> SELECT CAST(INTERVAL -'01:15' as INTERVAL MINUTE);
?column?
----------
-75 mins
Interval to string
You cast an interval to a string as follows:
CAST( (SELECT interval ) AS VARCHAR[(n)] )
For example:
=> SELECT CONCAT(
'Tomorrow at this time: ',
CAST((SELECT INTERVAL '24 hours') + CURRENT_TIMESTAMP(0) AS VARCHAR));
CONCAT
-----------------------------------------------
Tomorrow at this time: 2016-08-17 08:41:23-04
(1 row)
3.4.3.8 - Operations with intervals
If you divide an interval by an interval, you get a FLOAT:.
If you divide an interval by an interval, you get a FLOAT:
=> SELECT INTERVAL '28 days 3 hours' HOUR(4) / INTERVAL '27 days 3 hours' HOUR(4);
?column?
------------
1.036866359447
An INTERVAL divided by FLOAT returns an INTERVAL:
=> SELECT INTERVAL '3' MINUTE / 1.5;
?column?
------------
2 mins
INTERVAL MODULO (remainder) INTERVAL returns an INTERVAL:
=> SELECT INTERVAL '28 days 3 hours' HOUR % INTERVAL '27 days 3 hours' HOUR;
?column?
------------
24 hours
If you add INTERVAL and TIME, the result is TIME, modulo 24 hours:
=> SELECT INTERVAL '1' HOUR + TIME '1:30';
?column?
------------
02:30:00
3.4.4 - SMALLDATETIME
SMALLDATETIME is an alias for TIMESTAMP.
SMALLDATETIME is an alias for TIMESTAMP/TIMESTAMPTZ.
3.4.5 - TIME/TIMETZ
Stores the specified time of day.
Stores the specified time of day. TIMETZ is the same as TIME WITH TIME ZONE: both data types store the UTC offset of the specified time.
Syntax
TIME [ (p) ] [ { WITHOUT | WITH } TIME ZONE ] 'input-string' [ AT TIME ZONE zone ]
Parameters
p- Optional precision value that specifies the number of fractional digits retained in the seconds field, an integer value between 0 and 6. If you omit specifying precision, Vertica returns up to 6 fractional digits.
WITHOUT TIME ZONE- Ignore any time zone in the input string and use a value without a time zone (default).
WITH TIME ZONE- Convert the time to UTC. If the input string includes a time zone, use its UTC offset for the conversion. If the input string omits a time zone, Vertica uses the UTC offset of the time zone that is configured for your system.
input-string- See Input String below.
-
AT TIME ZONE zone
- See TIME AT TIME ZONE and TIMESTAMP AT TIME ZONE.
TIMETZ vs. TIMESTAMPTZ
TIMETZ and
TIMESTAMPTZ are not parallel SQL constructs. TIMESTAMPTZ records a time and date in GMT, converting from the specified TIME ZONE.TIMETZ records the specified time and the specified time zone, in minutes, from GMT.
Limits
|
Name |
Low Value |
High Value |
Resolution |
TIME [p] |
00:00:00.00 |
23:59:60.999999 |
1 µs |
TIME [p] WITH TIME ZONE |
00:00:00.00+14 |
23:59:59.999999-14 |
1 µs |
A TIME input string can be set to any of the formats shown below:
|
Example |
Description |
04:05:06.789 |
ISO 8601 |
04:05:06 |
ISO 8601 |
04:05 |
ISO 8601 |
040506 |
ISO 8601 |
04:05 AM |
Same as 04:05; AM does not affect value |
04:05 PM |
Same as 16:05 |
04:05:06.789-8 |
ISO 8601 |
04:05:06-08:00 |
ISO 8601 |
04:05-08:00 |
ISO 8601 |
040506-08 |
ISO 8601 |
04:05:06 PST |
Time zone specified by name |
Data type coercion
You can cast a TIME or TIMETZ interval to a TIMESTAMP. This returns the local date and time as follows:
=> SELECT (TIME '3:01am')::TIMESTAMP;
?column?
---------------------
2012-08-30 03:01:00
(1 row)
=> SELECT (TIMETZ '3:01am')::TIMESTAMP;
?column?
---------------------
2012-08-22 03:01:00
(1 row)
Casting the same TIME or TIMETZ interval to a TIMESTAMPTZ returns the local date and time, appended with the UTC offset—in this example, -05:
=> SELECT (TIME '3:01am')::TIMESTAMPTZ;
?column?
------------------------
2016-12-08 03:01:00-05
(1 row)
3.4.6 - TIME AT TIME ZONE
Converts the specified TIME to the time in another time zone.
Converts the specified TIME to the time in another time zone.
Syntax
TIME [WITH TIME ZONE] 'input-string' AT TIME ZONE 'zone'
Parameters
WITH TIME ZONE- Converts the input string to UTC, using the UTC offset for the specified time zone. If the input string omits a time zone, Vertica uses the UTC offset of the time zone that is configured for your system, and converts the input string accordingly
zone- Specifies the time zone to use in the conversion, either as a literal or interval that specifies UTC offset:
For details, see Specifying Time Zones below.
Note
Vertica treats literals TIME ZONE and TIMEZONE as synonyms.
Specifying time zones
You can specify time zones in two ways:
-
A string literal such as America/Chicago or PST
-
An interval that specifies a UTC offset—for example, INTERVAL '-08:00'
It is generally good practice to specify time zones with literals that indicate a geographic location. Vertica makes the necessary seasonal adjustments, and thereby avoids inconsistent results. For example, the following two queries are issued when daylight time is in effect. Because the local UTC offset during daylight time is -04, both queries return the same results:
=> SELECT CURRENT_TIME(0) "EDT";
EDT
-------------
12:34:35-04
(1 row)
=> SELECT CURRENT_TIME(0) AT TIME ZONE 'America/Denver' "Mountain Time";
Mountain Time
---------------
10:34:35-06
(1 row)
=> SELECT CURRENT_TIME(0) AT TIME ZONE INTERVAL '-06:00' "Mountain Time";
Mountain Time
---------------
10:34:35-06
(1 row)
If you issue a use the UTC offset in a similar query when standard time is in effect, you must adjust the UTC offset accordingly—for Denver time, to -07—otherwise, Vertica returns a different (and erroneous) result:
=> SELECT CURRENT_TIME(0) "EST";
EST
-------------
14:18:22-05
(1 row)
=> SELECT CURRENT_TIME(0) AT TIME ZONE INTERVAL '-06:00' "Mountain Time";
Mountain Time
---------------
13:18:22-06
(1 row)
You can show and set the session's time zone with
SHOW TIMEZONE and
SET TIME ZONE, respectively:
=> SHOW TIMEZONE;
name | setting
----------+------------------
timezone | America/New_York
(1 row)
=> SELECT CURRENT_TIME(0) "Eastern Daylight Time";
Eastern Daylight Time
-----------------------
12:18:24-04
(1 row)
=> SET TIMEZONE 'America/Los_Angeles';
SET
=> SELECT CURRENT_TIME(0) "Pacific Daylight Time";
Pacific Daylight Time
-----------------------
09:18:24-07
(1 row)
Time zone literals
To view the default list of valid literals, see the files in the following directory:
opt/vertica/share/timezonesets
For example:
$ cat Antarctica.txt
...
# src/timezone/tznames/Antarctica.txt
#
AWST 28800 # Australian Western Standard Time
# (Antarctica/Casey)
# (Australia/Perth)
...
NZST 43200 # New Zealand Standard Time
# (Antarctica/McMurdo)
# (Pacific/Auckland)
ROTT -10800 # Rothera Time
# (Antarctica/Rothera)
SYOT 10800 # Syowa Time
# (Antarctica/Syowa)
VOST 21600 # Vostok time
# (Antarctica/Vostok)
Examples
The following example assumes that local time is EST (Eastern Standard Time). The query converts the specified time to MST (mountain standard time):
=> SELECT CURRENT_TIME(0);
timezone
-------------
10:10:56-05
(1 row)
=> SELECT TIME '10:10:56' AT TIME ZONE 'America/Denver' "Denver Time";
Denver Time
-------------
08:10:56-07
(1 row)
The next example adds a time zone literal to the input string—in this case, Europe/Vilnius—and converts the time to MST:
=> SELECT TIME '09:56:13 Europe/Vilnius' AT TIME ZONE 'America/Denver';
Denver Time
-------------
00:56:13-07
(1 row)
See also
3.4.7 - TIMESTAMP/TIMESTAMPTZ
Stores the specified date and time.
Stores the specified date and time. TIMESTAMPTZ is the same as TIMESTAMP WITH TIME ZONE: both data types store the UTC offset of the specified time.
TIMESTAMP is an alias for DATETIME and SMALLDATETIME.
Syntax
TIMESTAMP [ (p) ] [ { WITHOUT | WITH } TIME ZONE ] 'input-string' [AT TIME ZONE zone ]
TIMESTAMPTZ [ (p) ] 'input-string' [ AT TIME ZONE zone ]
Parameters
p- Optional precision value that specifies the number of fractional digits retained in the seconds field, an integer value between 0 and 6. If you omit specifying precision, Vertica returns up to 6 fractional digits.
WITHOUT TIME ZONE
WITH TIME ZONESpecifies whether to include a time zone with the stored value:
-
WITHOUT TIME ZONE (default): Specifiesthat input-string does not include a time zone. If the input string contains a time zone, Vertica ignores this qualifier. Instead, it conforms to WITH TIME ZONE behavior.
-
WITH TIME ZONE: Specifies to convert input-string to UTC, using the UTC offset for the specified time zone. If the input string omits a time zone, Vertica uses the UTC offset of the time zone that is configured for your system.
input-string- See Input String below.
-
AT TIME ZONE zone
- See TIMESTAMP AT TIME ZONE.
Limits
In the following table, values are rounded. See Date/time data types for more detail.
|
Name |
Low Value |
High Value |
Resolution |
TIMESTAMP [ (p) ] [ WITHOUT TIME ZONE ] |
290279 BC |
294277 AD |
1 µs |
TIMESTAMP [ (p) ] WITH TIME ZONE |
290279 BC |
294277 AD |
1 µs |
The date/time input string concatenates a date and a time. The input string can include a time zone, specified as a literal such as America/Chicago, or as a UTC offset.
The following list represents typical date/time input variations:
Note
0000-00-00 is invalid input. If you try to insert that value into a DATE or TIMESTAMP field, an error occurs. If you copy 0000-00-00 into a DATE or TIMESTAMP field, Vertica converts the value to 0001-01-01 00:00:00 BC.
The input string can also specify the calendar era, either AD (default) or BC. If you omit the calendar era, Vertica assumes the current calendar era (AD). The calendar era typically follows the time zone; however, the input string can include it in various locations. For example, the following queries return the same results:
=> SELECT TIMESTAMP WITH TIME ZONE 'March 1, 44 12:00 CET BC ' "Caesar's Time of Death EST";
Caesar's Time of Death EST
----------------------------
0044-03-01 06:00:00-05 BC
(1 row)
=> SELECT TIMESTAMP WITH TIME ZONE 'March 1, 44 12:00 BC CET' "Caesar's Time of Death EST";
Caesar's Time of Death EST
----------------------------
0044-03-01 06:00:00-05 BC
(1 row)
Examples
=> SELECT (TIMESTAMP '2014-01-17 10:00' - TIMESTAMP '2014-01-01');
?column?
----------
16 10:00
(1 row)
=> SELECT (TIMESTAMP '2014-01-17 10:00' - TIMESTAMP '2014-01-01') / 7;
?column?
-------------------
2 08:17:08.571429
(1 row)
=> SELECT TIMESTAMP '2009-05-29 15:21:00.456789'-TIMESTAMP '2009-05-28';
?column?
-------------------
1 15:21:00.456789
(1 row)
=> SELECT (TIMESTAMP '2009-05-29 15:21:00.456789'-TIMESTAMP '2009-05-28')(3);
?column?
----------------
1 15:21:00.457
(1 row)
=> SELECT '2017-03-18 07:00'::TIMESTAMPTZ(0) + INTERVAL '1.5 day';
?column?
------------------------
2017-03-19 19:00:00-04
(1 row)
=> SELECT (TIMESTAMP '2014-01-17 10:00' - TIMESTAMP '2014-01-01') day;
?column?
----------
16
(1 row)
=> SELECT cast((TIMESTAMP '2014-01-17 10:00' - TIMESTAMP '2014-01-01')
day as integer) / 7;
?column?
----------------------
2.285714285714285714
(1 row)
=> SELECT floor((TIMESTAMP '2014-01-17 10:00' - TIMESTAMP '2014-01-01')
/ interval '7');
floor
-------
2
(1 row)
=> SELECT (TIMESTAMP '2009-05-29 15:21:00.456789'-TIMESTAMP '2009-05-28') second;
?column?
---------------
141660.456789
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01') year;
?column?
----------
3
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01') month;
?column?
----------
40
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01')
year to month;
?column?
----------
3-4
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01')
second(3);
?column?
---------------
107536860.457
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01') minute;
?column?
----------
1792281
(1 row)
=> SELECT (TIMESTAMP '2012-05-29 15:21:00.456789'-TIMESTAMP '2009-01-01')
minute to second(3);
?column?
----------------
1792281:00.457
(1 row)
=> SELECT TIMESTAMP 'infinity';
?column?
----------
infinity
(1 row)
3.4.8 - TIMESTAMP AT TIME ZONE
Converts the specified TIMESTAMP or TIMESTAMPTZ (TIMESTAMP WITH TIMEZONE) to another time zone.
Converts the specified TIMESTAMP or TIMESTAMPTZ (TIMESTAMP WITH TIMEZONE) to another time zone. Vertica executes AT TIME ZONE differently, depending on whether the date input is a TIMESTAMP or TIMESTAMPTZ. See TIMESTAMP versus TIMESTAMPTZ Behavior below.
Syntax
timestamp-clause AT TIME ZONE 'zone'
Parameters
- [timestamp-clause](/en/sql-reference/data-types/datetime-data-types/timestamptimestamptz/)
- Specifies the timestamp to convert, either
TIMESTAMP or TIMESTAMPTZ.
For details, see
TIMESTAMP/TIMESTAMPTZ.
AT TIME ZONE zone- Specifies the time zone to use in the timestamp conversion, where
zone is a literal or interval that specifies a UTC offset:
For details, see Specifying Time Zones below.
Note
Vertica treats literals TIME ZONE and TIMEZONE as synonyms.
TIMESTAMP versus TIMESTAMPTZ behavior
How Vertica interprets AT TIME ZONE depends on whether the date input is a TIMESTAMP or TIMESTAMPTZ:
|
Date input |
Action |
TIMESTAMP |
If the input string specifies no time zone, Vertica performs two actions:
-
Converts the input string to the time zone of the AT TIME ZONE argument.
-
Returns the time for the current session's time zone.
If the input string includes a time zone, Vertica implicitly casts it to a TIMESTAMPTZ and converts it accordingly (see TIMESTAMPTZ below).
For example, the following statement specifies a TIMESTAMP with no time zone. Vertica executes the statement as follows:
-
Converts the input string to PDT (Pacific Daylight Time).
-
Returns that time in the local time zone, which is three hours later:
=> SHOW TIMEZONE;
name | setting
----------+------------------
timezone | America/New_York
(1 row)
SELECT TIMESTAMP '2017-3-14 5:30' AT TIME ZONE 'PDT';
timezone
------------------------
2017-03-14 08:30:00-04
(1 row)
|
TIMESTAMPTZ |
Vertica converts the input string to the time zone of the AT TIME ZONE argument and returns that time.
For example, the following statement specifies a TIMESTAMPTZ data type. The input string omits any time zone expression, so Vertica assumes the input string to be in local time zone (America/New_York) and returns the time of the AT TIME ZONE argument:
=> SHOW TIMEZONE;
name | setting
----------+------------------
timezone | America/New_York
(1 row)
=> SELECT TIMESTAMP WITH TIME ZONE '2001-02-16 20:38:40' AT TIME ZONE 'America/Denver';
timezone
---------------------
2001-02-16 18:38:40
(1 row)
The input string in the next statement explicitly specifies a time zone, so Vertica coerces the TIMESTAMP to a TIMESTAMPTZ and returns the time of the AT TIME ZONE argument:
=> SELECT TIMESTAMP '2001-02-16 20:38:40 America/Mexico_City' AT TIME ZONE 'Asia/Tokyo';
timezone
---------------------
2001-02-17 11:38:40
(1 row)
|
Specifying time zones
You can specify time zones in two ways:
-
A string literal such as America/Chicago or PST
-
An interval that specifies a UTC offset—for example, INTERVAL '-08:00'
It is generally good practice to specify time zones with literals that indicate a geographic location. Vertica makes the necessary seasonal adjustments, and thereby avoids inconsistent results. For example, the following two queries are issued when daylight time is in effect. Because the local UTC offset during daylight time is -04, both queries return the same results:
=> SELECT TIMESTAMPTZ '2017-03-16 09:56:13' AT TIME ZONE 'America/Denver' "Denver Time";
Denver Time
---------------------
2017-03-16 07:56:13
(1 row)
=> SELECT TIMESTAMPTZ '2017-03-16 09:56:13' AT TIME ZONE INTERVAL '-06:00' "Denver Time";
Denver Time
---------------------
2017-03-16 07:56:13
(1 row)
If you issue a use the UTC offset in a similar query when standard time is in effect, you must adjust the UTC offset accordingly—for Denver time, to -07—otherwise, Vertica returns a different (and erroneous) result:
=> SELECT TIMESTAMPTZ '2017-01-16 09:56:13' AT TIME ZONE 'America/Denver' "Denver Time";
Denver Time
---------------------
2017-0-16 07:56:13
(1 row)
=> SELECT TIMESTAMPTZ '2017-01-16 09:56:13' AT TIME ZONE INTERVAL '-06:00' "Denver Time";
Denver Time
---------------------
2017-01-16 08:56:13
(1 row)
You can show and set the session's time zone with
SHOW TIMEZONE and
SET TIME ZONE, respectively:
=> SHOW TIMEZONE;
name | setting
----------+------------------
timezone | America/New_York
(1 row)
=> SELECT CURRENT_TIMESTAMP(0) "Eastern Daylight Time";
Eastern Daylight Time
------------------------
2017-03-20 12:18:24-04
(1 row)
=> SET TIMEZONE 'America/Los_Angeles';
SET
=> SELECT CURRENT_TIMESTAMP(0) "Pacific Daylight Time";
Pacific Daylight Time
------------------------
2017-03-20 09:18:24-07
(1 row)
Time zone literals
To view the default list of valid literals, see the files in the following directory:
opt/vertica/share/timezonesets
For example:
$ cat Antarctica.txt
...
# src/timezone/tznames/Antarctica.txt
#
AWST 28800 # Australian Western Standard Time
# (Antarctica/Casey)
# (Australia/Perth)
...
NZST 43200 # New Zealand Standard Time
# (Antarctica/McMurdo)
# (Pacific/Auckland)
ROTT -10800 # Rothera Time
# (Antarctica/Rothera)
SYOT 10800 # Syowa Time
# (Antarctica/Syowa)
VOST 21600 # Vostok time
# (Antarctica/Vostok)
See also
3.5 - Long data types
Store data up to 32000000 octets.
Store data up to 32000000 octets. Vertica supports two long data types:
-
LONG VARBINARY: Variable-length raw-byte data, such as spatial data. LONG VARBINARY values are not extended to the full width of the column.
-
LONG VARCHAR: Variable-length strings, such as log files and unstructured data. LONG VARCHAR values are not extended to the full width of the column.
Use LONG data types only when you need to store data greater than the maximum size of VARBINARY and VARCHAR data types (65 KB). Long data can include unstructured data, online comments or posts, or small log files.
Flex tables have a default LONG VARBINARY __raw__ column, with a NOT NULL constraint. For more information, see Flex tables.
Syntax
LONG VARBINARY [(max-length)]
LONG VARCHAR [(octet-length)]
Parameters
max-length- Length of the byte string or column width, declared in bytes (octets), up to 32000000.
Default: 1 MB
octet-length- Length of the string or column width, declared in bytes (octets), up to 32000000.
Default: 1 MB
For optimal performance of LONG data types, Vertica recommends that you:
-
Use the LONG data types as storage only containers; Vertica supports operations on the content of LONG data types, but does not support all the operations that VARCHAR and VARBINARY take.
-
Use VARBINARY and VARCHAR data types, instead of their LONG counterparts, whenever possible. VARBINARY and VARCHAR data types are more flexible and have a wider range of operations.
-
Do not sort, segment, or partition projections on LONG data type columns.
-
Do not add constraints, such as a primary key, to any LONG VARBINARY or LONG VARCHAR columns.
-
Do not join or aggregate any LONG data type columns.
Examples
The following example creates a table user_comments with a LONG VARCHAR column and inserts data into it:
=> CREATE TABLE user_comments
(id INTEGER,
username VARCHAR(200),
time_posted TIMESTAMP,
comment_text LONG VARCHAR(200000));
=> INSERT INTO user_comments VALUES
(1,
'User1',
TIMESTAMP '2013-06-25 12:47:32.62',
'The weather tomorrow will be cold and rainy and then
on the day after, the sun will come and the temperature
will rise dramatically.');
3.6 - Numeric data types
Numeric data types are numbers stored in database columns.
Numeric data types are numbers stored in database columns. These data types are typically grouped by:
-
Exact numeric types, values where the precision and scale need to be preserved. The exact numeric types are INTEGER, BIGINT, DECIMAL, NUMERIC, NUMBER, and MONEY.
-
Approximate numeric types, values where the precision needs to be preserved and the scale can be floating. The approximate numeric types are DOUBLE PRECISION, FLOAT, and REAL.
Implicit casts from INTEGER, FLOAT, and NUMERIC to VARCHAR are not supported. If you need that functionality, write an explicit cast using one of the following forms:
CAST(numeric-expression AS data-type)
numeric-expression::data-type
For example, you can cast a float to an integer as follows:
=> SELECT(FLOAT '123.5')::INT;
?column?
----------
124
(1 row)
String-to-numeric data type conversions accept formats of quoted constants for scientific notation, binary scaling, hexadecimal, and combinations of numeric-type literals:
-
Scientific notation:
=> SELECT FLOAT '1e10';
?column?
-------------
10000000000
(1 row)
-
BINARY scaling:
=> SELECT NUMERIC '1p10';
?column?
----------
1024
(1 row)
-
hexadecimal:
=> SELECT NUMERIC '0x0abc';
?column?
----------
2748
(1 row)
3.6.1 - DOUBLE PRECISION (FLOAT)
Vertica supports the numeric data type DOUBLE PRECISION, which is the IEEE-754 8-byte floating point type, along with most of the usual floating point operations.
Vertica supports the numeric data type DOUBLE PRECISION, which is the IEEE-754 8-byte floating point type, along with most of the usual floating point operations.
Syntax
[ DOUBLE PRECISION | FLOAT | FLOAT(n) | FLOAT8 | REAL ]
Parameters
Note
On a machine whose floating-point arithmetic does not follow IEEE-754, these values probably do not work as expected.
Double precision is an inexact, variable-precision numeric type. In other words, some values cannot be represented exactly and are stored as approximations. Thus, input and output operations involving double precision might show slight discrepancies.
-
All of the DOUBLE PRECISION data types are synonyms for 64-bit IEEE FLOAT.
-
The n in FLOAT(n) must be between 1 and 53, inclusive, but a 53-bit fraction is always used. See the IEEE-754 standard for details.
-
For exact numeric storage and calculations (money for example), use NUMERIC.
-
Floating point calculations depend on the behavior of the underlying processor, operating system, and compiler.
-
Comparing two floating-point values for equality might not work as expected.
-
While Vertica treats decimal values as FLOAT internally, if a column is defined as FLOAT then you cannot read decimal values from ORC and Parquet files. In those formats, FLOAT and DECIMAL are different types.
Values
COPY accepts floating-point data in the following format:
-
Optional leading white space
-
An optional plus ("+") or minus sign ("-")
-
A decimal number, a hexadecimal number, an infinity, a NAN, or a null value
Decimal Number
A decimal number consists of a non-empty sequence of decimal digits possibly containing a radix character (decimal point "."), optionally followed by a decimal exponent. A decimal exponent consists of an "E" or "e", followed by an optional plus or minus sign, followed by a non-empty sequence of decimal digits, and indicates multiplication by a power of 10.
Hexadecimal Number
A hexadecimal number consists of a "0x" or "0X" followed by a non-empty sequence of hexadecimal digits possibly containing a radix character, optionally followed by a binary exponent. A binary exponent consists of a "P" or "p", followed by an optional plus or minus sign, followed by a non-empty sequence of decimal digits, and indicates multiplication by a power of 2. At least one of radix character and binary exponent must be present.
Infinity
An infinity is either INF or INFINITY, disregarding case.
NaN (Not A Number)
A NaN is NAN (disregarding case) optionally followed by a sequence of characters enclosed in parentheses. The character string specifies the value of NAN in an implementation-dependent manner. (The Vertica internal representation of NAN is 0xfff8000000000000LL on x86 machines.)
When writing infinity or NAN values as constants in a SQL statement, enclose them in single quotes. For example:
=> UPDATE table SET x = 'Infinity'
Note
Vertica follows the IEEE definition of NaNs (IEEE 754). The SQL standards do not specify how floating point works in detail.
IEEE defines NaNs as a set of floating point values where each one is not equal to anything, even to itself. A NaN is not greater than and at the same time not less than anything, even itself. In other words, comparisons always return false whenever a NaN is involved.
However, for the purpose of sorting data, NaN values must be placed somewhere in the result. The value generated 'NaN' appears in the context of a floating point number matches the NaN value generated by the hardware. For example, Intel hardware generates (0xfff8000000000000LL), which is technically a Negative, Quiet, Non-signaling NaN.
Vertica uses a different NaN value to represent floating point NULL (0x7ffffffffffffffeLL). This is a Positive, Quiet, Non-signaling NaN and is reserved by Vertica
A NaN example follows.
=> SELECT CBRT('Nan'); -- cube root
CBRT
------
NaN
(1 row)
=> SELECT 'Nan' > 1.0;
?column?
----------
f
(1 row)
Null Value
The load file format of a null value is user defined, as described in the COPY command. The Vertica internal representation of a null value is 0x7fffffffffffffffLL. The interactive format is controlled by the vsql printing option null. For example:
\pset null '(null)'
The default option is not to print anything.
Rules
To search for NaN column values, use the following predicate:
... WHERE column != column
This is necessary because WHERE column = 'Nan' cannot be true by definition.
Sort order (ascending)
-
NaN
-
-Inf
-
numbers
-
+Inf
-
NULL
Notes
-
NULL appears last (largest) in ascending order.
-
All overflows in floats generate +/-infinity or NaN, per the IEEE floating point standard.
3.6.2 - INTEGER
A signed 8-byte (64-bit) data type.
A signed 8-byte (64-bit) data type.
Syntax
[ INTEGER | INT | BIGINT | INT8 | SMALLINT | TINYINT ]
Parameters
INT, INTEGER, INT8, SMALLINT, TINYINT, and BIGINT are all synonyms for the same signed 64-bit integer data type. Automatic compression techniques are used to conserve disk space in cases where the full 64 bits are not required.
Notes
-
The range of values is –2^63+1 to 2^63-1.
-
2^63 = 9,223,372,036,854,775,808 (19 digits).
-
The value –2^63 is reserved to represent NULL.
-
NULL appears first (smallest) in ascending order.
-
Vertica does not have an explicit 4-byte (32-bit integer) or smaller types. Vertica's encoding and compression automatically eliminate the storage overhead of values that fit in less than 64 bits.
Restrictions
-
The JDBC type INTEGER is 4 bytes and is not supported by Vertica. Use BIGINT instead.
-
Vertica does not support the SQL/JDBC types NUMERIC, SMALLINT, or TINYINT.
-
Vertica does not check for overflow (positive or negative) except in the aggregate function SUM(). If you encounter overflow when using SUM, use SUM_FLOAT(), which converts to floating point.
See also
Data Type Coercion Chart
3.6.3 - NUMERIC
Numeric data types store fixed-point numeric data.
Numeric data types store fixed-point numeric data. For example, a value of $123.45 can be stored in a NUMERIC(5,2) field. Note that the first number, the precision, specifies the total number of digits.
Syntax
numeric-type [ ( precision[, scale] ) ]
Parameters
numeric-type- One of the following:
-
NUMERIC
-
DECIMAL
-
NUMBER
-
MONEY
precision- An unsigned integer that specifies the total number of significant digits that the data type stores, where
precision is ≤ 1024. If omitted, the default precision depends on numeric type that you specify. If you assign a value that exceeds precision, Vertica returns an error.
If a data type's precision is ≤ 18, performance is equivalent to an INTEGER data type, regardless of scale. When possible, Vertica recommends using a precision ≤ 18.
scale- An unsigned integer that specifies the maximum number of digits to the right of the decimal point to store.
scale must be ≤ precision. If omitted, the default scale depends on numeric type that you specify. If you assign a value with more decimal digits than scale, the scale is rounded to scale digits.
When using ALTER to modify the data type of a numeric column, scale cannot be changed.
Default precision and scale
NUMERIC, DECIMAL, NUMBER, and MONEY differ in their default precision and scale values:
|
Type |
Precision |
Scale |
|
NUMERIC |
37 |
15 |
|
DECIMAL |
37 |
15 |
|
NUMBER |
38 |
0 |
|
MONEY |
18 |
4 |
Supported encoding
Vertica supports the following encoding for numeric data types:
-
Precision ≤ 18: AUTO, BLOCK_DICT, BLOCKDICT_COMP, COMMONDELTA_COMP, DELTAVAL, GCDDELTA, and RLE
-
Precision > 18: AUTO, BLOCK_DICT, BLOCKDICT_COMP, RLE
For details, see Encoding types.
Numeric versus integer and floating data types
Numeric data types are exact data types that store values of a specified precision and scale, expressed with a number of digits before and after a decimal point. This contrasts with the Vertica integer and floating data types:
-
DOUBLE PRECISION (FLOAT) supports ~15 digits, variable exponent, and represents numeric values approximately. It can be less precise than NUMERIC data types.
-
INTEGER supports ~18 digits, whole numbers only.
The NUMERIC data type is preferred for non-integer constants, because it is always exact. For example:
=> SELECT 1.1 + 2.2 = 3.3;
?column?
----------
t
(1 row)
=> SELECT 1.1::float + 2.2::float = 3.3::float;
?column?
----------
f
(1 row)
Numeric operations
Supported numeric operations include the following:
-
Basic math: +, -, *, /
-
Aggregation: SUM, MIN, MAX, COUNT
-
Comparison: <, <=, =, <=>, <>, >, >=
NUMERIC divide operates directly on numeric values, without converting to floating point. The result has at least 18 decimal places and is rounded.
NUMERIC mod (including %) operates directly on numeric values, without converting to floating point. The result has the same scale as the numerator and never needs rounding.
Some complex operations used with numeric data types result in an implicit cast to FLOAT. When using SQRT, STDDEV, transcendental functions such as LOG, and TO_CHAR/TO_NUMBER formatting, the result is always FLOAT.
Examples
The following series of commands creates a table that contains a numeric data type and then performs some mathematical operations on the data:
=> CREATE TABLE num1 (id INTEGER, amount NUMERIC(8,2));
Insert some values into the table:
=> INSERT INTO num1 VALUES (1, 123456.78);
Query the table:
=> SELECT * FROM num1;
id | amount
------+-----------
1 | 123456.78
(1 row)
The following example returns the NUMERIC column, amount, from table num1:
=> SELECT amount FROM num1;
amount
-----------
123456.78
(1 row)
The following syntax adds one (1) to the amount:
=> SELECT amount+1 AS 'amount' FROM num1;
amount
-----------
123457.78
(1 row)
The following syntax multiplies the amount column by 2:
=> SELECT amount*2 AS 'amount' FROM num1;
amount
-----------
246913.56
(1 row)
The following syntax returns a negative number for the amount column:
=> SELECT -amount FROM num1;
?column?
------------
-123456.78
(1 row)
The following syntax returns the absolute value of the amount argument:
=> SELECT ABS(amount) FROM num1;
ABS
-----------
123456.78
(1 row)
The following syntax casts the NUMERIC amount as a FLOAT data type:
=> SELECT amount::float FROM num1;
amount
-----------
123456.78
(1 row)
See also
Mathematical functions
3.6.4 - Numeric data type overflow
Vertica does not check for overflow (positive or negative) except in the aggregate function SUM().
Vertica does not check for overflow (positive or negative) except in the aggregate function SUM(). If you encounter overflow when using SUM, use SUM_FLOAT() which converts to floating point.
For a detailed discussion of how Vertica handles overflow when you use the functions SUM, SUM_FLOAT, and AVG with numeric data types, see Numeric data type overflow with SUM, SUM_FLOAT, and AVG. The discussion includes directives for turning off silent numeric overflow and setting precision for numeric data types.
Dividing by zero returns an error:
=> SELECT 0/0;
ERROR 3117: Division by zero
=> SELECT 0.0/0;
ERROR 3117: Division by zero
=> SELECT 0 // 0;
ERROR 3117: Division by zero
=> SELECT 200.0/0;
ERROR 3117: Division by zero
=> SELECT 116.43 // 0;
ERROR 3117: Division by zero
Dividing zero as a FLOAT by zero returns NaN:
=> SELECT 0.0::float/0;
?column?
----------
NaN
=> SELECT 0.0::float//0;
?column?
----------
NaN
Dividing a non-zero FLOAT by zero returns Infinity:
=> SELECT 2.0::float/0;
?column?
----------
Infinity
=> SELECT 200.0::float//0;
?column?
----------
Infinity
Add, subtract, and multiply operations ignore overflow. Sum and average operations use 128-bit arithmetic internally. SUM() reports an error if the final result overflows, suggesting the use of SUM_FLOAT(INT), which converts the 128-bit sum to a FLOAT. For example:
=> CREATE TEMP TABLE t (i INT);
=> INSERT INTO t VALUES (1<<62);
=> INSERT INTO t VALUES (1<<62);
=> INSERT INTO t VALUES (1<<62);
=> INSERT INTO t VALUES (1<<62);
=> INSERT INTO t VALUES (1<<62);
=> SELECT SUM(i) FROM t;
ERROR: sum() overflowed
HINT: try sum_float() instead
=> SELECT SUM_FLOAT(i) FROM t;
SUM_FLOAT
---------------------
2.30584300921369e+19
3.6.5 - Numeric data type overflow with SUM, SUM_FLOAT, and AVG
When you use the SUM, SUM_FLOAT, and AVG functions (aggregate and analytic) to query a numeric column, overflow can occur.
When you use the SUM, SUM_FLOAT, and AVG functions (aggregate and analytic) to query a numeric column, overflow can occur. How Vertica responds to that overflow depends on the settings of two configuration parameters:
- AllowNumericOverflow (Boolean, default 1) allows numeric overflow. Vertica does not implicitly extend precision of numeric data types.
- NumericSumExtraPrecisionDigits (integer, default 6) determines whether to return an overflow error if a result exceeds the specified precision. This parameter is ignored if AllowNumericOverflow is set to 1 (true).
Vertica also allows numeric overflow when you use SUM or SUM_FLOAT to query pre-aggregated data. See Impact on Pre-Aggregated Data Projections below.
Default overflow handling
With numeric columns, Vertica internally works with multiples of 18 digits. If specified precision is less than 18—for example, x(12,0)—Vertica allows overflow up to and including the first multiple of 18. In some situations, if you sum a column, you can exceed the number of digits Vertica internally reserves for the result. In this case, Vertica allows silent overflow.
Turning off silent numeric overflow
You can turn off silent numeric overflow by setting AllowNumericOverflow to 0. In this case, Vertica checks the value of configuration parameter NumericSumExtraPrecisionDigits. By default, this parameter is set to 6, which means that Vertica internally adds extra digit places beyond a column's DDL-specified precision. Adding extra precision digits enables Vertica to consistently return results that overflow the column's precision. However, crossing into the second multiple of 18 internally can adversely impact performance.
For example, if AllowNumericOverflow is set to 0 :
- Column
x is defined as x(12,0)and NumericSumExtraPrecisionDigits is set to 6: Vertica internally stays within the first multiple of 18 digits and no additional performance impact occurs (a).
- Column
x is defined as x(2,0)and NumericSumExtraPrecisionDigits is set to 20: Vertica internally crosses a threshold into the second multiple of 18. In this case, performance is significantly affected (2a). Performance beyond the second multiple of 18 continues to be 2a.
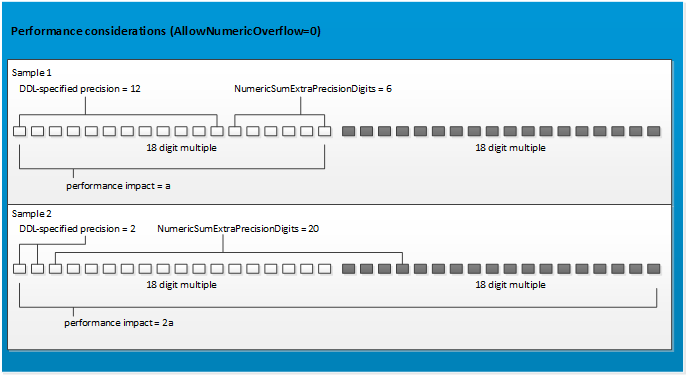
Tip
Vertica recommends that you turn off silent numeric overflow and set the parameter NumericSumExtraPrecisionDigits if you expect query results to exceed the precision specified in the DDL of numeric columns. Be aware of the following considerations:
- If you turn off AllowNumericOverflow and exceed the number of extra precision digits set by NumericSumExtraPrecisionDigits, Vertica returns an error.
- Be careful to set NumericSumExtraPrecisionDigits only as high as necessary to return the SUM of numeric columns.
Impact on pre-aggregated data projections
Vertica supports silent numeric overflow for queries that use SUM or SUM_FLOAT on projections with pre-aggregated data such as live aggregate or Top-K projections. To turn off silent numeric overflow for these queries:
-
Set AllowNumericOverflow to 0.
-
Set NumericSumExtraPrecisionDigits to the desired number of implicit digits. Alternatively, use the default setting of 6.
-
Drop and re-create the affected projections.
If you turn off silent numeric overflow, be aware that overflow can sometimes cause rollback or errors:
-
Overflow occurs during load operations, such as COPY, MERGE, or INSERT:
Vertica aggregates data before loading the projection with data. If overflow occurs while data is aggregated, , Vertica rolls back the load operation.
-
Overflow occurs after load, while Vertica sums existing data.
Vertica computes the sum of existing data separately from the computation that it does during data load. If the projection selects a column with SUM or SUM_FLOAT and overflow occurs, Vertica produces an error message. This response resembles the way Vertica produces an error for a query that uses SUM or SUM_FLOAT.
-
Overflow occurs during mergeout.
Vertica logs a message during mergeout if overflow occurs while Vertica computes a final sum during the mergeout operation. If an error occurs, Vertica marks the projection as out of date and disqualifies it from further mergeout operations.
3.7 - Spatial data types
The maximum amount of spatial data that a GEOMETRY or GEOGRAPHY column can store, up to 10 MB.
Vertica supports two spatial data types. These data types store two- and three-dimensional spatial objects in a table column:
The maximum size of a GEOMETRY or GEOGRAPHY data type is 10,000,000 bytes (10 MB). You cannot use either data type as a table's primary key.
Syntax
GEOMETRY [ (length) ]
GEOGRAPHY [ (length) ]
Parameters
length- The maximum amount of spatial data that a
GEOMETRY or GEOGRAPHY column can store, up to 10 MB.
Default: 1 MB
3.8 - UUID data type
Stores universally unique identifiers (UUIDs).
Stores universally unique identifiers (UUIDs). UUIDs are 16-byte (128-bit) numbers used to uniquely identify records. To generate UUIDs, Vertica provides the function
UUID_GENERATE, which returns UUIDs based on high-quality randomness from /dev/urandom.
Syntax
UUID
UUIDs support input of case-insensitive string literal formats, as specified by RFC 4122. In general, a UUID is written as a sequence of hexadecimal digits, in several groups optionally separated by hyphens, for a total of 32 digits representing 128 bits.
The following input formats are valid:
6bbf0744-74b4-46b9-bb05-53905d4538e7
{6bbf0744-74b4-46b9-bb05-53905d4538e7}
6BBF074474B446B9BB0553905D4538E7
6BBf-0744-74B4-46B9-BB05-5390-5D45-38E7
On output, Vertica always uses the following format:
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
For example, the following table defines column cust_id as a UUID:
=> CREATE TABLE public.Customers
(
cust_id uuid,
lname varchar(36),
fname varchar(24)
);
The following input for cust_id uses several valid formats:
=> COPY Customers FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {cede66b7-3d29-4da6-b700-871fc0ac57be}|Kearney|Thomas
>> 34462732ed5649838f3be735b0c32d50|Pham|Duc
>> 9fb0-1de0-1d63-4d09-9415-90e0-b4e9-3b9a|Steinberg|Jeremy
>> \.
On querying this table, Vertica formats all cust_id data in the same way:
=> SELECT cust_id, fname, lname FROM Customers;
cust_id | fname | lname
--------------------------------------+--------+-----------
9fb01de0-1d63-4d09-9415-90e0b4e93b9a | Jeremy | Steinberg
34462732-ed56-4983-8f3b-e735b0c32d50 | Duc | Pham
cede66b7-3d29-4da6-b700-871fc0ac57be | Thomas | Kearney
(3 rows)
Generating UUIDs
You can use the Vertica function
UUID_GENERATE to automatically generate UUIDs that uniquely identify table records. For example:
=> INSERT INTO Customers SELECT UUID_GENERATE(),'Rostova','Natasha';
OUTPUT
--------
1
(1 row)
=> COMMIT;
COMMIT
=> SELECT cust_id, fname, lname FROM Customers;
cust_id | fname | lname
--------------------------------------+---------+-----------
9fb01de0-1d63-4d09-9415-90e0b4e93b9a | Jeremy | Steinberg
34462732-ed56-4983-8f3b-e735b0c32d50 | Duc | Pham
cede66b7-3d29-4da6-b700-871fc0ac57be | Thomas | Kearney
9aad6757-fe1b-473a-a109-b89b7b358c69 | Natasha | Rostova
(4 rows)
The following string is reserved as NULL for UUID columns:
00000000-0000-0000-0000-000000000000
Vertica always renders NULL as blank.
The following COPY statements insert NULL values into the UUID column, explicitly and implicitly:
=> COPY Customers FROM STDIN NULL AS 'null';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> null|Doe|Jane
>> 00000000-0000-0000-0000-000000000000|Man|Nowhere
>> \.
=> COPY Customers FROM STDIN;
>> |Doe|John
>> \.
In all cases, Vertica renders NULL as blank:
=> SELECT cust_id, fname, lname FROM Customers WHERE cust_id IS NULL;
cust_id | fname | lname
---------+---------+-------
| Nowhere | Man
| Jane | Doe
| John | Doe
(3 rows)
Usage restrictions
UUID data types only support relational operators and functions that are also supported by CHAR and VARCHAR data types—for example,
MIN,
MAX, and
COUNT. UUID data types do not support mathematical operators or functions, such as
SUM and
AVG.
3.9 - Data type coercion
Vertica supports two types of data type casting:.
Vertica supports two types of data type casting:
Implicit casting
The ANSI SQL-92 standard supports implicit casting among similar data types:
-
Number types
-
CHAR, VARCHAR, LONG VARCHAR
-
BINARY, VARBINARY, LONG VARBINARY
Vertica supports two types of nonstandard implicit casts of scalar types:
-
From CHAR to FLOAT, to match the one from VARCHAR to FLOAT. The following example converts the CHAR '3' to a FLOAT so it can add the number 4.33 to the FLOAT result of the second expression:
=> SELECT '3'::CHAR + 4.33::FLOAT;
?column?
----------
7.33
(1 row)
-
Between DATE and TIMESTAMP. The following example DATE to a TIMESTAMP and calculates the time 6 hours, 6 minutes, and 6 seconds back from 12:00 AM:
=> SELECT DATE('now') - INTERVAL '6:6:6';
?column?
---------------------
2013-07-30 17:53:54
(1 row)
When there is no ambiguity about the data type of an expression value, it is implicitly coerced to match the expected data type. In the following statement, the quoted string constant '2' is implicitly coerced into an INTEGER value so that it can be the operand of an arithmetic operator (addition):
=> SELECT 2 + '2';
?column?
----------
4
(1 row)
A concatenate operation explicitly takes arguments of any data type. In the following example, the concatenate operation implicitly coerces the arithmetic expression 2 + 2 and the INTEGER constant 2 to VARCHAR values so that they can be concatenated.
=> SELECT 2 + 2 || 2;
?column?
----------
42
(1 row)
Another example is to first get today's date:
=> SELECT DATE 'now';
?column?
------------
2013-07-31
(1 row)
The following command converts DATE to a TIMESTAMP and adds a day and a half to the results by using INTERVAL:
=> SELECT DATE 'now' + INTERVAL '1 12:00:00';
?column?
---------------------
2013-07-31 12:00:00
(1 row)
Most implicit casts stay within their relational family and go in one direction, from less detailed to more detailed. For example:
-
DATE to TIMESTAMP/TZ
-
INTEGER to NUMERIC to FLOAT
-
CHAR to FLOAT
-
CHAR to VARCHAR
-
CHAR and/or VARCHAR to FLOAT
-
CHAR to LONG VARCHAR
-
VARCHAR to LONG VARCHAR
-
BINARY to VARBINARY
-
BINARY to LONG VARBINARY
-
VARBINARY to LONG VARBINARY
More specifically, data type coercion works in this manner in Vertica:
|
Conversion |
Notes |
|
INT8 > FLOAT8 |
Implicit, can lose significance |
|
FLOAT8 > INT8 |
Explicit, rounds |
|
VARCHAR <-> CHAR |
Implicit, adjusts trailing spaces |
|
VARBINARY <-> BINARY |
Implicit, adjusts trailing NULs |
|
VARCHAR > LONG VARCHAR |
Implicit, adjusts trailing spaces |
|
VARBINARY > LONG VARBINARY |
Implicit, adjusts trailing NULs |
No other types cast to or from LONGVARBINARY, VARBINARY, or BINARY. In the following list, <any> means one these types: INT8, FLOAT8, DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ, INTERVAL:
-
<any> -> VARCHAR—implicit
-
VARCHAR -> <any>—explicit, except that VARCHAR->FLOAT is implicit
-
<any> <-> CHAR—explicit
-
DATE -> TIMESTAMP/TZ—implicit
-
TIMESTAMP/TZ -> DATE—explicit, loses time-of-day
-
TIME -> TIMETZ—implicit, adds local timezone
-
TIMETZ -> TIME—explicit, loses timezone
-
TIME -> INTERVAL—implicit, day to second with days=0
-
INTERVAL -> TIME—explicit, truncates non-time parts
-
TIMESTAMP <-> TIMESTAMPTZ—implicit, adjusts to local timezone
-
TIMESTAMP/TZ -> TIME—explicit, truncates non-time parts
-
TIMESTAMPTZ -> TIMETZ—explicit
-
VARBINARY -> LONG VARBINARY—implicit
-
LONG VARBINARY -> VARBINARY—explicit
-
VARCHAR -> LONG VARCHAR—implicit
-
LONG VARCHAR -> VARCHAR—explicit
Important
Implicit casts from INTEGER, FLOAT, and NUMERIC to VARCHAR are not supported. If you need that functionality, write an explicit cast:
CAST(x AS data-type-name)
or
x::data-type-name
The following example casts a FLOAT to an INTEGER:
=> SELECT(FLOAT '123.5')::INT;
?column?
----------
124
(1 row)
String-to-numeric data type conversions accept formats of quoted constants for scientific notation, binary scaling, hexadecimal, and combinations of numeric-type literals:
-
Scientific notation:
=> SELECT FLOAT '1e10';
?column?
-------------
10000000000
(1 row)
-
BINARY scaling:
=> SELECT NUMERIC '1p10';
?column?
----------
1024
(1 row)
-
hexadecimal:
=> SELECT NUMERIC '0x0abc';
?column?
----------
2748
(1 row)
Complex types
Collections (arrays and sets) can be cast implicitly and explicitly. Casting a collection casts each element of the collection. You can, for example, cast an ARRAY[VARCHAR] to an ARRAY[INT] or a SET[DATE] to SET[TIMESTAMPTZ]. You can cast between arrays and sets.
When casting to a bounded native array, inputs that are too long are truncated. When casting to a non-native array (an array containing complex data types including other arrays), if the new bounds are too small for the data the cast fails
Rows (structs) can be cast implicitly and explicitly. Casting a ROW casts each field value. You can specify new field names in the cast or specify only the field types to use the existing field names.
Casting can increase the storage needed for a column. For example, if you cast an array of INT to an array of VARCHAR(50), each element takes more space and thus the array takes more space. If the difference is extreme or the array has many elements, this could mean that the array no longer fits within the space allotted for the column. In this case the operation reports an error and fails.
Examples
The following example casts three strings as NUMERICs:
=> SELECT NUMERIC '12.3e3', '12.3p10'::NUMERIC, CAST('0x12.3p-10e3' AS NUMERIC);
?column? | ?column? | ?column?
----------+----------+-------------------
12300 | 12595.2 | 17.76123046875000
(1 row)
This example casts a VARBINARY string into a LONG VARBINARY data type:
=> SELECT B'101111000'::LONG VARBINARY;
?column?
----------
\001x
(1 row)
The following example concatenates a CHAR with a LONG VARCHAR, resulting in a LONG VARCHAR:
=> \set s ''''`cat longfile.txt`''''
=> SELECT length ('a' || :s ::LONG VARCHAR);
length
----------
65002
(1 row)
The following example casts a combination of NUMERIC and INTEGER data into a NUMERIC result:
=> SELECT (18. + 3./16)/1024*1000;
?column?
-----------------------------------------
17.761230468750000000000000000000000000
(1 row)
Note
In SQL expressions, pure numbers between (–2^63–1) and (2^63–1) are INTEGERs. Numbers with decimal points are NUMERIC.
See also
3.10 - Data type coercion chart
The following table defines all possible type conversions that Vertica supports.
Conversion types
The following table defines all possible type conversions that Vertica supports. The data types in the first column of the table are the inputs to convert, and the remaining columns indicate the result for the different conversion types.
|
Source Data Type |
Implicit |
Explicit |
Assignment |
Assignment without numeric meaning |
Conversion without explicit casting |
|
BOOLEAN |
|
|
INTEGER, LONG VARCHAR, VARCHAR, CHAR |
|
|
|
INTEGER |
BOOLEAN, NUMERIC, FLOAT |
|
INTERVAL DAY/SECOND, INTERVAL YEAR/MONTH |
LONG VARCHAR, VARCHAR, CHAR |
|
|
NUMERIC |
FLOAT |
|
INTEGER |
LONG VARCHAR, VARCHAR, CHAR |
NUMERIC |
|
FLOAT |
|
|
INTEGER, NUMERIC |
LONG VARCHAR, VARCHAR, CHAR |
|
|
LONG VARCHAR |
FLOAT, CHAR |
BOOLEAN, INTEGER, NUMERIC, VARCHAR, TIMESTAMP, TIMESTAMPTZ, DATE, TIME, TIMETZ, INTERVAL DAY/SECOND, INTERVAL YEAR/MONTH, LONG VARBINARY |
|
|
LONG VARCHAR |
|
VARCHAR |
CHAR, FLOAT, LONG VARCHAR |
BOOLEAN, INTEGER, NUMERIC, TIMESTAMP, TIMESTAMPTZ, DATE, TIME, TIMETZ, UUID, BINARY, VARBINARY, INTERVAL DAY/SECOND, INTERVAL YEAR/MONTH |
|
|
VARCHAR |
|
CHAR |
FLOAT, LONG VARCHAR, VARCHAR |
BOOLEAN, INTEGER, NUMERIC, TIMESTAMP, TIMESTAMPTZ, DATE, TIME, TIMETZ, UUID (CHAR length ≥ 36), BINARY, VARBINARY, INTERVAL DAY/SECOND, INTERVAL YEAR/MONTH |
|
|
CHAR |
|
TIMESTAMP |
TIMESTAMPTZ |
|
LONG CHAR, VARCHAR, CHAR, DATE, TIME |
|
TIMESTAMP |
|
TIMESTAMPTZ |
TIMESTAMP |
|
LONG CHAR, VARCHAR, CHAR, DATE, TIME, TIMETZ |
|
TIMESTAMPTZ |
|
DATE |
TIMESTAMP |
|
LONG CHAR, VARCHAR, CHAR, TIMESTAMPTZ |
|
|
|
TIME |
TIMETZ |
TIMESTAMP, TIMESTAMPTZ, INTERVAL DAY/SECOND |
LONG CHAR, VARCHAR, CHAR |
|
TIME |
|
TIMETZ |
|
TIMESTAMP, TIMESTAMPTZ |
LONG CHAR, VARCHAR, CHAR, TIME |
|
TIMETZ |
|
INTERVAL DAY/SECOND |
|
TIME |
INTEGER, LONG CHAR, VARCHAR, CHAR |
|
INTERVAL DAY/SECOND |
|
INTERVAL YEAR/MONTH |
|
|
INTEGER, LONG CHAR, VARCHAR, CHAR |
|
INTERVAL YEAR/MONTH |
|
LONG VARBINARY |
|
VARBINARY |
|
|
LONG VARBINARY |
|
VARBINARY |
LONG VARBINARY, BINARY |
|
|
|
VARBINARY |
|
BINARY |
VARBINARY |
|
|
|
BINARY |
|
UUID |
|
CHAR(36), VARCHAR |
|
|
UUID |
Implicit and explicit conversion
Vertica supports data type conversion of values without explicit casting, such as NUMERIC(10,6) -> NUMERIC(18,4).Implicit data type conversion occurs automatically when converting values of different, but compatible, types to the target column's data type. For example, when adding values, (INTEGER + NUMERIC), the result is implicitly cast to a NUMERIC type to accommodate the prominent type in the statement. Depending on the input data types, different precision and scale can occur.
An explicit type conversion must occur when the source data cannot be cast implicitly to the target column's data type.
Assignment conversion
In data assignment conversion, coercion implicitly occurs when values are assigned to database columns in an INSERT or UPDATE...SET statement. For example, in a statement that includes INSERT...VALUES('2.5'), where the target column data type is NUMERIC(18,5), a cast from VARCHAR to the column data type is inferred.
In an assignment without numeric meaning, the value is subject to CHAR/VARCHAR/LONG VARCHAR comparisons.
See also
3.11 - Complex types
Complex types such as structures (also known as rows), arrays, and maps are composed of primitive types and sometimes other complex types.
Complex types such as structures (also known as rows), arrays, and maps are composed of primitive types and sometimes other complex types. Complex types can be used in the following ways:
-
Arrays and rows (in any combination) can be used as column data types in both native and external tables.
-
Sets of primitive element types can be used as column data types in native and external tables.
-
Arrays and rows, but not combinations of them, can be created as literals, for example to use in query expressions.
The MAP type is a legacy type. To represent maps, use ARRAY[ROW].
If a flex table has a real column that uses a complex type, the values from that column are not included in the __raw__ column. For more information, see Loading Data into Flex Table Real Columns.
3.11.1 - ARRAY
Represents array data.
Represents array data. There are two types of arrays in Vertica:
-
Native array: a one-dimensional array of a primitive type. Native arrays are tracked in the TYPES system table and used in native tables.
-
Non-native array: all other supported arrays, including arrays that contain other arrays (multi-dimensional arrays) or structs (ROWs). Non-native arrays have some usage restrictions. Non-native arrays are tracked in the COMPLEX_TYPES system table.
Both types of arrays operate in the same way, but they have different OIDs.
Arrays can be bounded, meaning they specify a maximum element count, or unbounded. Unbounded arrays have a maximum binary size, which can be set explicitly or defaulted. See Limits on Element Count and Collection Size.
Selected parsers support using COPY to load arrays. See the documentation of individual parsers for more information.
Syntax
In column definitions:
ARRAY[data_type, max_elements] |
ARRAY[data_type](max_size) |
ARRAY[data_type]
In literals:
ARRAY[value[, ...] ]
Restrictions
-
Native arrays support only data of primitive types, for example, int, UUID, and so on.
-
Array dimensionality is enforced. A column cannot contain arrays of varying dimensions. For example, a column that contains a three-dimensional array can only contain other three-dimensional arrays; it cannot simultaneously include a one-dimensional array. However, the arrays in a column can vary in size, where one array can contain four elements while another contains ten.
-
Array bounds, if specified, are enforced for all operations that load or alter data. Unbounded arrays may have as many elements as will fit in the allotted binary size.
-
An array has a maximum binary size. If this size is not set when the array is defined, a default value is used.
-
Arrays do not support LONG types (like LONG VARBINARY or LONG VARCHAR) or user-defined types (like Geometry).
Syntax for column definition
Arrays used in column definitions can be either bounded or unbounded. Bounded arrays must specify a maximum number of elements. Unbounded arrays can specify a maximum binary size (in bytes) for the array, or the value of DefaultArrayBinarySize is used. You can specify a bound or a binary size but not both. For more information about these values, see Limits on Element Count and Collection Size.
|
Type |
Syntax |
Semantics |
|
Bounded array |
ARRAY[data_type, max_elements]
Example:
ARRAY[VARCHAR(50),100]
|
Can contain no more than max_elements elements. Attempting to add more is an error.
Has a binary size of the size of the data type multiplied by the maximum number of elements (possibly rounded up).
|
|
Unbounded array with maximum binary size |
ARRAY[data_type](max_size)
Example:
ARRAY[VARCHAR(50)](32000)
|
Can contain as many elements as fit in max_size. Ignores the value of DefaultArrayBinarySize. |
|
Unbounded array with default binary size |
ARRAY[data_type]
Example:
ARRAY[VARCHAR(50)]
|
Can contain as many elements as fit in the default binary size.
Equivalent to:
ARRAY[data_type](DefaultArrayBinarySize)
|
The following example defines a table for customers using an unbounded array:
=> CREATE TABLE customers (id INT, name VARCHAR, email ARRAY[VARCHAR(50)]);
The following example uses a bounded array for customer email addresses and an unbounded array for order history:
=> CREATE TABLE customers (id INT, name VARCHAR, email ARRAY[VARCHAR(50),5], orders ARRAY[INT]);
The following example uses an array that has ROW elements:
=> CREATE TABLE orders(
orderid INT,
accountid INT,
shipments ARRAY[
ROW(
shipid INT,
address ROW(
street VARCHAR,
city VARCHAR,
zip INT
),
shipdate DATE
)
]
);
To declare a multi-dimensional array, use nesting. For example, ARRAY[ARRAY[int]] specifies a two-dimensional array.
Syntax for direct construction (literals)
Use the ARRAY keyword to construct an array value. The following example creates an array of integer values.
=> SELECT ARRAY[1,2,3];
array
-------
[1,2,3]
(1 row)
You can nest an array inside another array, as in the following example.
=> SELECT ARRAY[ARRAY[1],ARRAY[2]];
array
-----------
[[1],[2]]
(1 row)
If an array of arrays contains no null elements and no function calls, you can abbreviate the syntax:
=> SELECT ARRAY[[1,2],[3,4]];
array
---------------
[[1,2],[3,4]]
(1 row)
---not valid:
=> SELECT ARRAY[[1,2],null,[3,4]];
ERROR 4856: Syntax error at or near "null" at character 20
LINE 1: SELECT ARRAY[[1,2],null,[3,4]];
^
Array literals can contain elements of all scalar types, ROW, and ARRAY. ROW elements must all have the same set of fields:
=> SELECT ARRAY[ROW(1,2),ROW(1,3)];
array
-----------------------------------
[{"f0":1,"f1":2},{"f0":1,"f1":3}]
(1 row)
=> SELECT ARRAY[ROW(1,2),ROW(1,3,'abc')];
ERROR 3429: For 'ARRAY', types ROW(int,int) and ROW(int,int,unknown) are inconsistent
Because the elements are known at the time you directly construct an array, these arrays are implicitly bounded.
You can use ARRAY literals in comparisons, as in the following example:
=> SELECT id.name, id.num, GPA FROM students
WHERE major = ARRAY[ROW('Science','Physics')];
name | num | GPA
-------+-----+-----
bob | 121 | 3.3
carol | 123 | 3.4
(2 rows)
Queries of array columns return JSON format, with the values shown in comma-separated lists in brackets. The following example shows a query that includes array columns.
=> SELECT cust_custkey,cust_custstaddress,cust_custcity,cust_custstate from cust;
cust_custkey | cust_custstaddress | cust_custcity | cust_custstate
-------------+------- ----------------------------------------------+---------------------------------------------+----------------
342176 | ["668 SW New Lane","518 Main Ave","7040 Campfire Dr"] | ["Winchester","New Hyde Park","Massapequa"] | ["VA","NY","NY"]
342799 | ["2400 Hearst Avenue","3 Cypress Street"] | ["Berkeley","San Antonio"] | ["CA","TX"]
342845 | ["336 Boylston Street","180 Clarkhill Rd"] | ["Boston","Amherst"] | ["MA","MA"]
342321 | ["95 Fawn Drive"] | ["Allen Park"] | ["MI"]
342989 | ["5 Thompson St"] | ["Massillon"] | ["OH"]
(5 rows)
Note that JSON format escapes some characters that would not be escaped in native VARCHARs. For example, if you insert "c:\users\data" into an array, the JSON output for that value is "c:\\users\\data".
Element access
Arrays are 0-indexed. The first element's ordinal position is 0, second is 1, and so on.
You can access (dereference) elements from an array by index:
=> SELECT (ARRAY['a','b','c','d','e'])[1];
array
-------
b
(1 row)
To specify a range, use the format start:end. The end of the range is non-inclusive.
=> SELECT(ARRAY['a','b','c','d','e','f','g'])[1:4];
array
---------
["b","c","d"]
(1 row)
To dereference an element from a multi-dimensional array, put each index in brackets:
=> SELECT(ARRAY[ARRAY[1,2],ARRAY[3,4]])[0][0];
array
-------
1
(1 row)
Out-of-bound index references return NULL.
Limits on element count and collection size
When declaring a collection type for a table column, you can limit either the number of elements or the total binary size of the collection. During query processing, Vertica always reserves the maximum memory needed for the column, based on either the element count or the binary size. If this size is much larger than your data actually requires, setting one of these limits can improve query performance by reducing the amount of memory that must be reserved for the column.
You can change the bounds of a collection, including changing between bounded and unbounded collections, by casting. See Casting.
A bounded collection specifies a maximum element count. A value in a bounded collection column may contain fewer elements, but it may not contain more. Any attempt to insert more elements into a bounded collection than the declared maximum is an error. A bounded collection has a binary size that is the product of the data-type size and the maximum number of elements, possibly rounded up.
An unbounded collection specifies a binary size in bytes, explicitly or implicitly. It may contain as many elements as can fit in that binary size.
If a nested array specifies bounds for all dimensions, Vertica sets a single bound that is the product of the bounds. In the following example, the inner and outer arrays each have a bound of 10, but only a total element count of 100 is enforced.
ARRAY[ARRAY[INT,10],10]
If a nested array specifies a bound for only the outer collection, it is treated as the total bound. The previous example is equivalent to the following:
ARRAY[ARRAY[INT],100]
You must either specify bounds for all nested collections or specify a bound only for the outer one. For any other distribution of bounds, Vertica treats the collection as unbounded.
Instead of specifying a bound, you can specify a maximum binary size for an unbounded collection. The binary size acts as an absolute limit, regardless of how many elements the collection contains. Collections that do not specify a maximum binary size use the value of DefaultArrayBinarySize. This size is set at the time the collection is defined and is not affected by later changes to the value of DefaultArrayBinarySize.
You cannot set a maximum binary size for a bounded collection, only an unbounded one.
You can change the bounds or the binary size of an array column using ALTER TABLE as in the following example:
=> ALTER TABLE cust ALTER COLUMN orders SET DATA TYPE ARRAY[INTEGER](100);
If the change reduces the size of the collection and would result in data loss, the change fails.
Comparisons
All collections support equality (=), inequality (<>), and null-safe equality (<=>). 1D collections also support comparison operators (<, <=, >, >=) between collections of the same type (arrays or sets). Comparisons follow these rules:
-
A null collection is ordered last.
-
Non-null collections are compared element by element, using the ordering rules of the element's data type. The relative order of the first pair of non-equal elements determines the order of the two collections.
-
If all elements in both collections are equal up to the length of the shorter collection, the shorter collection is ordered before the longer one.
-
If all elements in both collections are equal and the collections are of equal length, the collections are equal.
Null-handling
Null semantics for collections are consistent with normal columns in most regards. See NULL sort order for more information on null-handling.
The null-safe equality operator (<=>) behaves differently from equality (=) when the collection is null rather than empty. Comparing a collection to NULL strictly returns null:
=> SELECT ARRAY[1,3] = NULL;
?column?
----------
(1 row)
=> SELECT ARRAY[1,3] <=> NULL;
?column?
----------
f
(1 row)
In the following example, the grants column in the table is null for employee 99:
=> SELECT grants = NULL FROM employees WHERE id=99;
?column?
----------
(1 row)
=> SELECT grants <=> NULL FROM employees WHERE id=99;
?column?
----------
t
(1 row)
Empty collections are not null and behave as expected:
=> SELECT ARRAY[]::ARRAY[INT] = ARRAY[]::ARRAY[INT];
?column?
----------
t
(1 row)
Collections are compared element by element. If a comparison depends on a null element, the result is unknown (null), not false. For example, ARRAY[1,2,null]=ARRAY[1,2,null] and ARRAY[1,2,null]=ARRAY[1,2,3] both return null, but ARRAY[1,2,null]=ARRAY[1,4,null] returns false because the second elements do not match.
Casting
Casting an array casts each element of the array. You can therefore cast between data types following the same rules as for casts of scalar values.
You can cast both literal arrays and array columns explicitly:
=> SELECT ARRAY['1','2','3']::ARRAY[INT];
array
---------
[1,2,3]
(1 row)
You can change the bound of an array or set by casting. When casting to a bounded native array, inputs that are too long are truncated. When casting to a non-native array (an array containing complex data types including other arrays), if the new bounds are too small for the data the cast fails:
=> SELECT ARRAY[1,2,3]::ARRAY[VARCHAR,2];
array
-----------
["1","2"]
(1 row)
=> SELECT ARRAY[ARRAY[1,2,3],ARRAY[4,5,6]]::ARRAY[ARRAY[VARCHAR,2],2];
ERROR 9227: Output array isn't big enough
DETAIL: Type limit is 4 elements, but value has 6 elements
If you cast to a bounded multi-dimensional array, you must specify the bounds at all levels:
=> SELECT ARRAY[ARRAY[1,2,3],ARRAY[4,5,6]]::ARRAY[ARRAY[VARCHAR,5],10];
array
-------------------------------
[["1","2","3"],["4","5","6"]]
(1 row)
=> SELECT ARRAY[ARRAY[1,2,3],ARRAY[4,5,6]]::ARRAY[ARRAY[VARCHAR,2]];
WARNING 9753: Collection type bound will not be used
DETAIL: A bound was provided for an inner dimension, but not for an outer dimension
array
-------------------------------
[["1","2","3"],["4","5","6"]]
(1 row)
Assignment casts and implicit casts work the same way as for scalars:
=> CREATE TABLE transactions (tid INT, prod_ids ARRAY[VARCHAR,100], quantities ARRAY[INT,100]);
CREATE TABLE
=> INSERT INTO transactions VALUES (12345, ARRAY['p1265', 'p4515'], ARRAY[15,2]);
OUTPUT
--------
1
(1 row)
=> CREATE TABLE txreport (prod_ids ARRAY[VARCHAR(12),100], quants ARRAY[VARCHAR(32),100]);
CREATE TABLE
=> INSERT INTO txreport SELECT prod_ids, quantities FROM transactions;
OUTPUT
--------
1
(1 row)
=> SELECT * FROM txreport;
prod_ids | quants
-------------------+------------
["p1265","p4515"] | ["15","2"]
(1 row)
You can perform explicit casts, but not implicit casts, between the ARRAY and SET types (native arrays only). If the collection is unbounded and the data type does not change, the binary size is preserved. For example, if you cast an ARRAY[INT] to a SET[INT], the set has the same binary size as the array.
If you cast from one element type to another, the resulting collection uses the default binary size. If this would cause the data not to fit, the cast fails.
You cannot cast from an array to an array with a different dimensionality, for example from a two-dimensional array to a one-dimensional array.
Functions and operators
See Collection functions for a comprehensive list of functions that can be used to manipulate arrays and sets.
Collections can be used in the following ways:
Collections cannot be used in the following ways:
-
As part of an IN or NOT IN expression.
-
As partition columns when creating tables.
-
With ANALYZE_STATISTICS or TopK projections.
-
Non-native arrays only: ORDER BY, PARTITION BY, DEFAULT, SET USING, or constraints.
3.11.2 - MAP
Represents map data in external tables in the Parquet, ORC, and Avro formats only.
Represents map data in external tables in the Parquet, ORC, and Avro formats only. A MAP must use only primitive types and may not contain other complex types. You can use the MAP type in a table definition to consume columns in the data, but you cannot query those columns.
A superior alternative to MAP is ARRAY[ROW]. An array of rows can use all supported complex types and can be queried. This is the representation that INFER_TABLE_DDL suggests. For Avro data, the ROW must have fields named key and value.
Within a single table you must define all map columns using the same approach, MAP or ARRAY[ROW].
Syntax
In column definitions:
MAP<key,value>
In a column definition in an external table, a MAP consists of a key-value pair, specified as types. The table in the following example defines a map of product IDs to names.
=> CREATE EXTERNAL TABLE store (storeID INT, inventory MAP<INT,VARCHAR(100)>)
AS COPY FROM '...' PARQUET;
3.11.3 - ROW
Represents structured data (structs).
Represents structured data (structs). A ROW can contain fields of any primitive or complex type supported by Vertica.
Syntax
In column definitions:
ROW([field] type[, ...])
If the field name is omitted, Vertica generates names starting with "f0".
In literals:
ROW(value [AS field] [, ...]) [AS name(field[, ...])]
Syntax for column definition
In a column definition, a ROW consists of one or more comma-separated pairs of field names and types. In the following example, the Parquet data file contains a struct for the address, which is read as a ROW in an external table:
=> CREATE EXTERNAL TABLE customers (name VARCHAR,
address ROW(street VARCHAR, city VARCHAR, zipcode INT))
AS COPY FROM '...' PARQUET;
ROWs can be nested; a field can have a type of ROW:
=> CREATE TABLE employees(
employeeID INT,
personal ROW(
name VARCHAR,
address ROW(street VARCHAR, city VARCHAR, zipcode INT),
taxID INT),
department VARCHAR);
ROWs can contain arrays:
=> CREATE TABLE customers(
name VARCHAR,
contact ROW(
street VARCHAR,
city VARCHAR,
zipcode INT,
email ARRAY[VARCHAR]
),
accountid INT );
When loading data, the primitive types in the table definition must match those in the data. The ROW structure must also match; a ROW must contain all and only the fields in the struct in the data.
Restrictions on ROW columns
ROW columns have several restrictions:
- Maximum nesting depth is 100.
- Vertica tables support up to 9800 columns and fields. The ROW itself is not counted, only its fields.
- ROW columns cannot use any constraints (such as NOT NULL) or defaults.
- ROW fields cannot be auto_increment or setof.
- ROW definition must include at least one field.
Row is a reserved keyword within a ROW definition, but is permitted as the name of a table or column.- Tables containing ROW columns cannot also contain IDENTITY, default, SET USING, or named sequence columns.
Syntax for direct construction (literals)
In a literal, such as a value in a comparison operation, a ROW consists of one or more values. If you omit field names in the ROW expression, Vertica generates them automatically. If you do not coerce types, Vertica infers the types from the data values.
=> SELECT ROW('Amy',2,false);
row
--------------------------------------------
{"f0":"Amy","f1":2,"f2":false}
(1 row)
You can use an AS clause to name the ROW and its fields:
=> SELECT ROW('Amy',2,false) AS student(name, id, current);
student
--------------------------------------------
{"name":"Amy","id":2,"current":false}
(1 row)
You can also name individual fields using AS. This query produces the same output as the previous one:
=> SELECT ROW('Amy' AS name, 2 AS id, false AS current) AS student;
You do not need to name all fields.
In an array of ROW elements, if you use AS to name fields and the names differ among the elements, Vertica uses the right-most names for all elements:
=> SELECT ARRAY[ROW('Amy' AS name, 2 AS id),ROW('Fred' AS first_name, 4 AS id)];
array
------------------------------------------------------------
[{"first_name":"Amy","id":2},{"first_name":"Fred","id":4}]
(1 row)
You can coerce types explicitly:
=> SELECT ROW('Amy',2.5::int,false::varchar);
row
------------------------------------------
{"f0":"Amy","f1":3,"f2":"f"}
(1 row)
Escape single quotes in literal inputs using single quotes, as in the following example:
=> SELECT ROW('Howard''s house',2,false);
row
---------------------------------------------------
{"f0":"Howard's house","f1":2,"f2":false}
(1 row)
You can use fields of all scalar types, ROW, and ARRAY, as in the following example:
=> SELECT id.name, major, GPA FROM students
WHERE id = ROW('alice',119, ARRAY['alice@example.com','ap16@cs.example.edu']);
name | major | GPA
-------+------------------------------------+-----
alice | [{"school":"Science","dept":"CS"}] | 3.8
(1 row)
ROW values are output in JSON format as in the following example.
=> CREATE EXTERNAL TABLE customers (name VARCHAR,
address ROW(street VARCHAR, city VARCHAR, zipcode INT))
AS COPY FROM '...' PARQUET;
=> SELECT address FROM customers WHERE address.city ='Pasadena';
address
--------------------------------------------------------------------
{"street":"100 Main St Apt 4B","city":"Pasadena","zipcode":91001}
{"street":"100 Main St Apt 4A","city":"Pasadena","zipcode":91001}
{"street":"23 Fifth Ave Apt 8C","city":"Pasadena","zipcode":91001}
{"street":"15 Raymond Dr","city":"Pasadena","zipcode":91003}
(4 rows)
The following table specifies the mappings from Vertica data types to JSON data types.
|
Vertica Type |
JSON Type |
|
Integer |
Integer |
|
Float |
Numeric |
|
Numeric |
Numeric |
|
Boolean |
Boolean |
|
All others |
String |
Comparisons
ROW supports equality (=), inequality (<>), and null-safe equality (<=>) between inputs that have the same set of fields. ROWs that contain only primitive types, including nested ROWs of primitive types, also support comparison operators (<, <=, >, >=).
Two ROWs are equal if and only if all fields are equal. Vertica compares fields in order until an inequality is found or all fields have been compared. The evaluation of the first non-equal field determines which ROW is greater:
=> SELECT ROW(1, 'joe') > ROW(2, 'bob');
?column?
----------
f
(1 row)
Comparisons between ROWs with different schemas fail:
=> SELECT ROW(1, 'joe') > ROW(2, 'bob', 123);
ERROR 5162: Unequal number of entries in row expressions
If the result of a comparison depends on a null field, the result is null:
=> select row(1, null, 3) = row(1, 2, 3);
?column?
----------
(1 row)
Null-handling
If a struct exists but a field value is null, Vertica assigns NULL as its value in the ROW. A struct where all fields are null is treated as a ROW with null fields. If the struct itself is null, Vertica reads the ROW as NULL.
Casting
Casting a ROW casts each field. You can therefore cast between data types following the same rules as for casts of scalar values.
The following example casts the contact ROW in the customers table, changing the zipcode field from INT to VARCHAR and adding a bound to the array:
=> SELECT contact::ROW(VARCHAR,VARCHAR,VARCHAR,ARRAY[VARCHAR,20]) FROM customers;
contact
--------------------------------------------------------------------------------
-----------------------------------------
{"street":"911 San Marcos St","city":"Austin","zipcode":"73344","email":["missy@mit.edu","mcooper@cern.gov"]}
{"street":"100 Main St Apt 4B","city":"Pasadena","zipcode":"91001","email":["shelly@meemaw.name","cooper@caltech.edu"]}
{"street":"100 Main St Apt 4A","city":"Pasadena","zipcode":"91001","email":["hofstadter@caltech.edu"]}
{"street":"23 Fifth Ave Apt 8C","city":"Pasadena","zipcode":"91001","email":[]}
{"street":null,"city":"Pasadena","zipcode":"91001","email":["raj@available.com"]}
(6 rows)
You can specify new field names to change them in the output:
=> SELECT contact::ROW(str VARCHAR, city VARCHAR, zip VARCHAR, email ARRAY[VARCHAR,
20]) FROM customers;
contact
--------------------------------------------------------------------------------
----------------------------------
{"str":"911 San Marcos St","city":"Austin","zip":"73344","email":["missy@mit.edu","mcooper@cern.gov"]}
{"str":"100 Main St Apt 4B","city":"Pasadena","zip":"91001","email":["shelly@meemaw.name","cooper@caltech.edu"]}
{"str":"100 Main St Apt 4A","city":"Pasadena","zip":"91001","email":["hofstadter@caltech.edu"]}
{"str":"23 Fifth Ave Apt 8C","city":"Pasadena","zip":"91001","email":[]}
{"str":null,"city":"Pasadena","zip":"91001","email":["raj@available.com"]}
(6 rows)
Supported operators and predicates
ROW values may be used in queries in the following ways:
-
INNER and OUTER JOIN
-
Comparisons, IN, BETWEEN (non-nullable filters only)
-
IS NULL, IS NOT NULL
-
CASE
-
GROUP BY, ORDER BY
-
SELECT DISTINCT
-
Arguments to user-defined scalar, transform, and analytic functions
The following operators and predicates are not supported for ROW values:
-
Math operators
-
Type coercion of whole rows (coercion of field values is supported)
-
BITWISE, LIKE
-
MLA (ROLLUP, CUBE, GROUPING SETS)
-
Aggregate functions including MAX, MIN, and SUM
-
Set operators including UNION, UNION ALL, MINUS, and INTERSECT
COUNT is not supported for ROWs returned from user-defined scalar functions, but is supported for ROW columns and literals.
In comparison operations (including implicit comparisons like ORDER BY), a ROW literal is treated as the sequence of its field values. For example, the following two statements are equivalent:
GROUP BY ROW(zipcode, city)
GROUP BY zipcode, city
Using rows in views and subqueries
You can use ROW columns to construct views and in subqueries. Consider employee and customer tables with the following definitions:
=> CREATE EXTERNAL TABLE customers(name VARCHAR,
address ROW(street VARCHAR, city VARCHAR, zipcode INT), accountID INT)
AS COPY FROM '...' PARQUET;
=> CREATE EXTERNAL TABLE employees(employeeID INT,
personal ROW(name VARCHAR,
address ROW(street VARCHAR, city VARCHAR, zipcode INT),
taxID INT), department VARCHAR)
AS COPY FROM '...' PARQUET;
The following example creates a view and queries it.
=> CREATE VIEW neighbors (num_neighbors, area(city, zipcode))
AS SELECT count(*), ROW(address.city, address.zipcode)
FROM customers GROUP BY address.city, address.zipcode;
CREATE VIEW
=> SELECT employees.personal.name, neighbors.area FROM neighbors, employees
WHERE employees.personal.address.zipcode=neighbors.area.zipcode AND neighbors.nu
m_neighbors > 1;
name | area
--------------------+-------------------------------------
Sheldon Cooper | {"city":"Pasadena","zipcode":91001}
Leonard Hofstadter | {"city":"Pasadena","zipcode":91001}
(2 rows)
3.11.4 - SET
Represents a collection of unordered, unique elements.
Represents a collection of unordered, unique elements. Sets may contain only primitive types. In sets, unlike in arrays, element position is not meaningful.
Sets do not support LONG types (like LONG VARBINARY or LONG VARCHAR) or user-defined types (like Geometry).
If you populate a set from an array, Vertica sorts the values and removes duplicate elements. If you do not care about element position and plan to run queries that check for the presence of specific elements (find, contains), using a set could improve query performance.
Sets can be bounded, meaning they specify a maximum element count, or unbounded. Unbounded sets have a maximum binary size, which can be set explicitly or defaulted. See Limits on Element Count and Collection Size.
Syntax
In column definitions:
SET[data_type, max_elements] |
SET[data_type](max_size) |
SET[data_type]
In literals:
SET[value[, ...] ]
Restrictions
-
Sets support only data of primitive (scalar) types.
-
Bounds, if specified, are enforced for all operations that load or alter data. Unbounded sets may have as many elements as will fit in the allotted binary size.
-
A set has a maximum binary size. If this size is not set when the set is defined, a default value is used.
Syntax for column definition
Sets used in column definitions can be either bounded or unbounded. Bounded sets must specify a maximum number of elements. Unbounded sets can specify a maximum binary size for the set, or the value of DefaultArrayBinarySize is used. You can specify a bound or a binary size but not both. For more information about these values, see Limits on Element Count and Collection Size.
|
Type |
Syntax |
Semantics |
|
Bounded set |
SET[data_type, max_elements]
Example:
SET[VARCHAR(50),100]
|
Can contain no more than max_elements elements. Attempting to add more is an error.
Has a binary size of the size of the data type multiplied by the maximum number of elements (possibly rounded up).
|
|
Unbounded set with maximum size |
SET[data_type](max_size)
Example:
SET[VARCHAR(50)](32000)
|
Can contain as many elements as fit in max_size. Ignores the value of DefaultArrayBinarySize. |
|
Unbounded set |
SET[data_type]
Example:
SET[VARCHAR(50)]
|
Can contain as many elements as fit in the default binary size.
Equivalent to:
SET[data_type](DefaultArrayBinarySize)
|
The following example defines a table with an unbounded set colum.
=> CREATE TABLE users
(
user_id INTEGER,
display_name VARCHAR,
email_addrs SET[VARCHAR]
);
When you load array data into a column defined as a set, the array data is automatically converted to a set.
Syntax for direct construction (literals)
Use the SET keyword to construct a set value. Literal set values are contained in brackets. For example, to create a set of INT, you would do the following:
=> SELECT SET[1,2,3];
set
-------
[1,2,3]
(1 row)
You can explicitly convert an array to a set by casting, as in the following example:
=> SELECT ARRAY[1, 5, 2, 6, 3, 0, 6, 4]::SET[INT];
set
-----------------
[0,1,2,3,4,5,6]
(1 row)
Notice that duplicate elements have been removed and the elements have been sorted.
Because the elements are known at the time you directly construct a set, these sets are implicitly bounded.
Sets are shown in a JSON-like format, with comma-separated elements contained in brackets (like arrays). In the following example, the email_addrs column is a set.
=> SELECT custkey,email_addrs FROM customers LIMIT 4;
custkey | email_addrs
---------+------------------------------------------------------------------------
342176 | ["joe.smith@example.com"]
342799 | ["bob@example,com","robert.jones@example.com"]
342845 | ["br92@cs.example.edu"]
342321 | ["789123@example-isp.com","sjohnson@eng.example.com","sara@johnson.example.name"]
Limits on element count and collection size
When declaring a collection type for a table column, you can limit either the number of elements or the total binary size of the collection. During query processing, Vertica always reserves the maximum memory needed for the column, based on either the element count or the binary size. If this size is much larger than your data actually requires, setting one of these limits can improve query performance by reducing the amount of memory that must be reserved for the column.
You can change the bounds of a collection, including changing between bounded and unbounded collections, by casting. See Casting.
A bounded collection specifies a maximum element count. A value in a bounded collection column may contain fewer elements, but it may not contain more. Any attempt to insert more elements into a bounded collection than the declared maximum is an error. A bounded collection has a binary size that is the product of the data-type size and the maximum number of elements, possibly rounded up.
An unbounded collection specifies a binary size in bytes, explicitly or implicitly. It may contain as many elements as can fit in that binary size.
Instead of specifying a bound, you can specify a maximum binary size for an unbounded collection. The binary size acts as an absolute limit, regardless of how many elements the collection contains. Collections that do not specify a maximum binary size use the value of DefaultArrayBinarySize. This size is set at the time the collection is defined and is not affected by later changes to the value of DefaultArrayBinarySize.
You cannot set a maximum binary size for a bounded collection, only an unbounded one.
Comparisons
All collections support equality (=), inequality (<>), and null-safe equality (<=>). 1D collections also support comparison operators (<, <=, >, >=) between collections of the same type (arrays or sets). Comparisons follow these rules:
-
A null collection is ordered last.
-
Non-null collections are compared element by element, using the ordering rules of the element's data type. The relative order of the first pair of non-equal elements determines the order of the two collections.
-
If all elements in both collections are equal up to the length of the shorter collection, the shorter collection is ordered before the longer one.
-
If all elements in both collections are equal and the collections are of equal length, the collections are equal.
Null handling
Null semantics for collections are consistent with normal columns in most regards. See NULL sort order for more information on null-handling.
The null-safe equality operator (<=>) behaves differently from equality (=) when the collection is null rather than empty. Comparing a collection to NULL strictly returns null:
=> SELECT ARRAY[1,3] = NULL;
?column?
----------
(1 row)
=> SELECT ARRAY[1,3] <=> NULL;
?column?
----------
f
(1 row)
In the following example, the grants column in the table is null for employee 99:
=> SELECT grants = NULL FROM employees WHERE id=99;
?column?
----------
(1 row)
=> SELECT grants <=> NULL FROM employees WHERE id=99;
?column?
----------
t
(1 row)
Empty collections are not null and behave as expected:
=> SELECT ARRAY[]::ARRAY[INT] = ARRAY[]::ARRAY[INT];
?column?
----------
t
(1 row)
Collections are compared element by element. If a comparison depends on a null element, the result is unknown (null), not false. For example, ARRAY[1,2,null]=ARRAY[1,2,null] and ARRAY[1,2,null]=ARRAY[1,2,3] both return null, but ARRAY[1,2,null]=ARRAY[1,4,null] returns false because the second elements do not match.
Casting
Casting a set casts each element of the set. You can therefore cast between data types following the same rules as for casts of scalar values.
You can cast both literal sets and set columns explicitly:
=> SELECT SET['1','2','3']::SET[INT];
set
---------
[1,2,3]
(1 row)
=> CREATE TABLE transactions (tid INT, prod_ids SET[VARCHAR], quantities SET[VARCHAR(32)]);
=> INSERT INTO transactions VALUES (12345, SET['p1265', 'p4515'], SET['15','2']);
=> SELECT quantities :: SET[INT] FROM transactions;
quantities
------------
[15,2]
(1 row)
Assignment casts and implicit casts work the same way as for scalars.
You can perform explicit casts, but not implicit casts, between ARRAY and SET types. If the collection is unbounded and the data type does not change, the binary size is preserved. For example, if you cast an ARRAY[INT] to a SET[INT], the set has the same binary size as the array.
When casting an array to a set, Vertica first casts each element and then sorts the set and removes duplicates. If two source values are cast to the same target value, one of them will be removed. For example, if you cast an array of FLOAT to a set of INT, two values in the array might be rounded to the same integer and then be treated as duplicates. This also happens if the array contains more than one value that is cast to NULL.
If you cast from one element type to another, the resulting collection uses the default binary size. If this would cause the data not to fit, the cast fails.
Functions and operators
See Collection functions for a comprehensive list of functions that can be used to manipulate arrays and sets.
Collections can be used in the following ways:
Collections cannot be used in the following ways:
-
As part of an IN or NOT IN expression.
-
As partition columns when creating tables.
-
With ANALYZE_STATISTICS or TopK projections.
-
Non-native arrays only: ORDER BY, PARTITION BY, DEFAULT, SET USING, or constraints.
3.12 - Data type mappings between Vertica and Oracle
Oracle uses proprietary data types for all main data types, such as VARCHAR, INTEGER, FLOAT, DATE.
Oracle uses proprietary data types for all main data types, such as VARCHAR, INTEGER, FLOAT, DATE. Before migrating a database from Oracle to Vertica, first convert the schema to minimize errors and time spent fixing erroneous data issues.
The following table compares the behavior of Oracle data types to Vertica data types.
|
Oracle |
Vertica |
Notes |
|
NUMBER
(no explicit precision)
|
INTEGER |
In Oracle, the NUMBER data type with no explicit precision stores each number N as an integer M, together with a scale S. The scale can range from -84 to 127, while the precision of M is limited to 38 digits. Thus:
N = M * 10^S
When precision is specified, precision/scale applies to all entries in the column. If omitted, the scale defaults to 0.
For the common case—Oracle NUMBER with no explicit precision used to store only integer values—the Vertica INTEGER data type is the most appropriate and the fastest equivalent data type. However, INTEGER is limited to a little less than 19 digits, with a scale of 0: [-9223372036854775807, +9223372036854775807].
|
|
NUMERIC |
If an Oracle column contains integer values outside of the range [-9223372036854775807, +9223372036854775807], then use the Vertica data type NUMERIC(p,0) where p is the maximum number of digits required to represent values of the source data.
If the data is exact with fractional places—for example dollar amounts—Vertica recommends NUMERIC(p,s) where p is the precision (total number of digits) and s is the maximum scale (number of decimal places).
Vertica conforms to standard SQL, which requires that p ≥ s and s ≥ 0. Vertica's NUMERIC data type is most effective for p=18, and increasingly expensive for p=37, 58, 67, etc., where p ≤ 1024.
Tip
Vertica recommends against using the data type NUMERIC(38,s) as a default "failsafe" mapping to guarantee no loss of precision. NUMERIC(18,s) is better, and INTEGER or FLOAT better yet, if one of these data types will do the job.
|
|
FLOAT |
Even though no explicit scale is specified for an Oracle NUMBER column, Oracle allows non-integer values, each with its own scale. If the data stored in the column is approximate, Vertica recommends using the Vertica data type FLOAT, which is standard IEEE floating point, like ORACLE BINARY_DOUBLE. |
|
NUMBER(P,0)
P ≤ 18
|
INTEGER |
For Oracle NUMBER data types with 0 scale and a precision less than or equal to 18, use the Vertica INTEGER data type. |
|
NUMBER(P,0)
P > 18
|
NUMERIC(p,0) |
In the rare case where a Oracle column specifies precision greater than 18, use the Vertica data type NUMERIC(p, 0), where p = P. |
|
NUMBER(P,S)
All cases other than above
|
NUMERIC(p,s) |
- When P ≥ S and S ≥ 0, use p = P and s = S, unless the data allows reducing P or using FLOAT as discussed above.
- If S > P, use p = S, s = S.
- If S < 0, use p = P – S, s = 0.
|
|
FLOAT |
|
NUMERIC(P,S) |
|
Rarely used in Oracle, see notes for Oracle NUMBER. |
|
DECIMAL(P,S) |
|
Synonym for Oracle NUMERIC. |
|
BINARY_FLOAT |
FLOAT |
Same as FLOAT(53) or DOUBLE PRECISION |
|
BINARY_DOUBLE |
FLOAT |
Same as FLOAT(53) or DOUBLE PRECISION |
|
RAW |
VARBINARY |
Maximum sizes compared:
|
|
LONG RAW |
LONG VARBINARY |
Maximum sizes compared:
Caution
Be careful to avoid truncation when migrating Oracle LONG RAW data to Vertica.
|
|
CHAR(n) |
CHAR(n) |
Maximum sizes compared:
|
|
NCHAR(n) |
CHAR(*n**3) |
Vertica supports national characters with CHAR(n) as variable-length UTF8-encoded UNICODE character string. UTF-8 represents ASCII in 1 byte, most European characters in 2 bytes, and most oriental and Middle Eastern characters in 3 bytes. |
|
VARCHAR2(n) |
VARCHAR(n) |
Maximum sizes compared:
Important
The Oracle VARCHAR2 and Vertica VARCHAR data types are semantically different:
- VARCHAR exhibits standard SQL behavior
- VARCHAR2 is inconsistent with standard SQL behavior in that it treats an empty string as NULL value, and uses non-padded comparison if one operand is VARCHAR2.
|
|
NVARCHAR2(n) |
VARCHAR(*n**3) |
See notes for NCHAR. |
|
DATE |
TIMESTAMP |
Oracle’s DATE is different from the SQL standard DATE data type implemented by Vertica. Oracle’s DATE includes the time (no fractional seconds), while Vertica DATE data types include only date as per the SQL standard. |
|
DATE |
|
TIMESTAMP |
TIMESTAMP |
TIMESTAMP defaults to six places—that is, to microseconds. |
|
TIMESTAMP WITH TIME ZONE |
TIMESTAMP WITH TIME ZONE |
TIME ZONE defaults to the currently SET or system time zone. |
|
INTERVAL YEAR TO MONTH |
INTERVAL YEAR TO MONTH |
As per the SQL standard, you can qualify Vertica INTERVAL data types with the YEAR TO MONTH subtype. |
|
INTERVAL DAY TO SECOND |
INTERVAL DAY TO SECOND |
The default subtype for Vertica INTERVAL data types is DAY TO SECOND. |
|
CLOB |
LONG VARCHAR |
You can store a CLOB (character large object) or BLOB (binary large object) value in a table or in an external location. The maximum size of a CLOB or BLOB is 128 TB.
You can store Vertica LONG data types only in LONG VARCHAR and LONG VARBINARY columns. The maximum size of LONG data types is 32M bytes.
|
|
BLOB |
LONG VARBINARY |
|
LONG |
LONG VARCHAR |
Oracle recommends using CLOB and BLOB data types instead of LONG and LONG RAW data types.
An Oracle table can contain only one LONG column, The maximum size of a LONG or LONG RAW data type is 2 GB.
|
|
LONG RAW |
LONG VARBINARY |
4 - Configuration parameters
Vertica supports a wide variety of configuration parameters that affect many facets of database behavior. These parameters can be set with the appropriate ALTER statements at one or more levels, listed here in descending order of precedence:
-
User (ALTER USER)
-
Session (ALTER SESSION)
-
Node (ALTER NODE)
-
Database (ALTER DATABASE)
Not all parameters can be set at all levels. Consult the documentation of individual parameters for restrictions.
You can query the CONFIGURATION_PARAMETERS system table to obtain the current settings for all user-accessible parameters. For example, the following query returns settings for partitioning parameters: their current and default values, which levels they can be set at, and whether changes require a database restart to take effect:
=> SELECT parameter_name, current_value, default_value, allowed_levels, change_requires_restart
FROM configuration_parameters WHERE parameter_name ILIKE '%partitioncount%';
parameter_name | current_value | default_value | allowed_levels | change_requires_restart
----------------------+---------------+---------------+----------------+-------------------------
MaxPartitionCount | 1024 | 1024 | NODE, DATABASE | f
ActivePartitionCount | 1 | 1 | NODE, DATABASE | f
(2 rows)
4.1 - General parameters
The following parameters configure basic database operations.
The following parameters configure basic database operations. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- ApplyEventsDuringSALCheck
- Boolean, specifies whether Vertica uses catalog events to filter out dropped corrupt partitions during node startup. Dropping corrupt partitions can speed node recovery.
When disabled (0), Vertica reports corrupt partitions, but takes no action. Leaving corrupt partitions in place can reset the current projection checkpoint epoch to the epoch before the corruption occurred.
This parameter has no effect on unpartitioned tables.
Default: 0
- ApportionedFileMinimumPortionSizeKB
- Specifies the minimum portion size (in kilobytes) for use with apportioned file loads. Vertica apportions a file load across multiple nodes only if:
See also EnableApportionLoad and EnableApportionedFileLoad.
Default: 1024
- BlockedSocketGracePeriod
- Sets how long a session socket remains blocked while awaiting client input or output for a given query. See Handling session socket blocking.
Default: None (Socket blocking can continue indefinitely.)
- CatalogCheckpointPercent
- Specifies the threshold at which a checkpoint is created for the database catalog.
By default, this parameter is set to 50 (percent), so when transaction logs reach 50% of the size of the last checkpoint, Vertica adds a checkpoint. Each checkpoint demarcates all changes to the catalog since the last checkpoint.
Default: 50 (percent)
- ClusterSequenceCacheMode
- Boolean, specifies whether the initiator node requests cache for other nodes in a cluster, and then sends cache to other nodes along with the execution plan, one of the following.
See Distributing sequences.
Default: 1 (enabled)
- CompressCatalogOnDisk
- Whether to compress the size of the catalog on disk, one of the following:
This parameter is most effective if the catalog disk partition is small (<50 GB) and the metadata is large (hundreds of tables, partitions, or nodes).
Default: 1
- CompressNetworkData
- Boolean, specifies whether to compress all data sent over the internal network when enabled (set to 1). This compression speeds up network traffic at the expense of added CPU load. If the network is throttling database performance, enable compression to correct the issue.
Default: 0
- CopyFaultTolerantExpressions
- Boolean, indicates whether to report record rejections during transformations and proceed (true) or abort COPY operations if a transformation fails.
Default: 0 (false)
- CopyFromVerticaWithIdentity
- Allows COPY FROM VERTICA and EXPORT TO VERTICA to load values into IDENTITY columns. The destination IDENTITY column is not incremented automatically. To disable the default behavior, set this parameter to 0 (zero).
Default: 1
- DatabaseHeartbeatInterval
- Determines the interval (in seconds) at which each node performs a health check and communicates a heartbeat. If a node does not receive a message within five times of the specified interval, the node is evicted from the cluster. Setting the interval to 0 disables the feature.
See Automatic eviction of unhealthy nodes.
Default: 120
- DataLoaderDefaultRetryLimit
- Default number of times a data loader retries failed loads. Changing this value changes the retry limit for existing data loaders that do not specify another limit.
Default: 3
- DefaultArrayBinarySize
- The maximum binary size, in bytes, for an unbounded collection, if a maximum size is not specified at creation time.
Default: 65000
- DefaultResourcePoolForUsers
- Resource pool that is assigned to the profile of a new user, whether created in Vertica or LDAP. This pool is also assigned to users when their assigned resource pool is dropped.
You can set DefaultResourcePoolForUsers only to a global resource pool; attempts to set it to a subcluster resource pool return with an error.
Note
If an LDAP user is merged with an existing Vertica user, the resource pool setting on the existing user remains unchanged.
For details, see User resource allocation.
Default: GENERAL
- DefaultTempTableLocal
- Boolean, specifies whether CREATE TEMPORARY TABLE creates a local or global temporary table, one of the following:
For details, see Creating temporary tables.
Default: 0
- DivideZeroByZeroThrowsError
- Boolean, specifies whether to return an error if a division by zero operation is requested:
-
0: Return 0.
-
1: Returns an error.
Default: 1
- EnableApportionedChunkingInDefaultLoadParser
- Boolean, specifies whether to enable the built-in parser for delimited files to take advantage of both apportioned load and cooperative parse for potentially better performance.
Default: 1 (enable)
- EnableApportionedFileLoad
- Boolean, specifies whether to enable automatic apportioning across nodes of file loads using COPY FROM VERTICA. Vertica attempts to apportion the load if:
-
This parameter and EnableApportionLoad are both enabled.
-
The parser supports apportioning.
-
The load is divisible into portion sizes of at least the value of ApportionedFileMinimumPortionSizeKB.
Setting this parameter does not guarantee that loads will be apportioned, but disabling it guarantees that they will not be.
See Distributing a load.
Default: 1 (enable)
- EnableApportionLoad
- Boolean, specifies whether to enable automatic apportioning across nodes of data loads using COPY...WITH SOURCE. Vertica attempts to apportion the load if:
Setting this parameter does not guarantee that loads will be apportioned, but disabling it guarantees that they will not be.
For details, see Distributing a load.
Default: 1 (enable)
- EnableBetterFlexTypeGuessing
- Boolean, specifies whether to enable more accurate type guessing when assigning data types to non-string keys in a flex table
__raw__ column with COMPUTE_FLEXTABLE_KEYS or COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW. If this parameter is disabled (0), Vertica uses a limited set of Vertica data type assignments.
Default: 1 (enable)
- EnableCooperativeParse
- Boolean, specifies whether to implement multi-threaded parsing capabilities on a node. You can use this parameter for both delimited and fixed-width loads.
Default: 1 (enable)
- EnableForceOuter
- Boolean, specifies whether Vertica uses a table's
force_outer value to implement a join. For more information, see Controlling join inputs.
Default: 0 (forced join inputs disabled)
- EnableMetadataMemoryTracking
- Boolean, specifies whether to enable Vertica to track memory used by database metadata in the METADATA resource pool.
Default: 1 (enable)
- EnableResourcePoolCPUAffinity
- Boolean, specifies whether Vertica aligns queries to the resource pool of the processing CPU. When disabled (0), queries run on any CPU, regardless of the
CPU_AFFINITY_SET of the resource pool.
Default: 1
- EnableStrictTimeCasts
- Specifies whether all cast failures result in an error.
Default: 0 (disable)
- EnableUniquenessOptimization
- Boolean, specifies whether to enable query optimization that is based on guaranteed uniqueness of column values. Columns that can be guaranteed to include unique values include:
Default: 1 (enable)
- EnableWithClauseMaterialization
- Superseded by WithClauseMaterialization.
- ExternalTablesExceptionsLimit
- Determines the maximum number of
COPY exceptions and rejections allowed when a SELECT statement references an external table. Set to -1 to remove any exceptions limit. See Querying external tables.
Default: 100
- FailoverToStandbyAfter
- Specifies the length of time that an active standby node waits before taking the place of a failed node.
This parameter is set to an interval literal.
Default: None
- FencedUDxMemoryLimitMB
- Sets the maximum amount of memory, in megabytes (MB), that a fenced-mode UDF can use. If a UDF attempts to allocate more memory than this limit, that attempt triggers an exception. For more information, see Fenced and unfenced modes.
Default: -1 (no limit)
- FlexTableDataTypeGuessMultiplier
- Specifies a multiplier that the COMPUTE_FLEXTABLE_KEYS and COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW functions use when assigning a data type and column width for the flex keys table. Both functions assign each key a data type, and multiply the longest key value by this factor to estimate column width. This value is not used to calculate the width of any real columns in a flex table.
Default: 2.0
- FlexTableRawSize
- Specifies the default column width for the
__raw__ column of new flex tables, a value between 1 and 32000000, inclusive.
Default: 130000
- ForceUDxFencedMode
- When enabled (1), forces all UDxs that support fenced mode to run in fenced mode even if their definitions specify NOT FENCED.
-
File exporters cannot be run in fenced mode.
Default: 0
- HTTPServerPortOffset
- Controls the offset for the HTTPS port. The default HTTPS port is 8443, the sum of the client port (5433) and default HTTPServerPortOffset (3010).
Caution
This parameter should not be changed without support guidance.
Default: 3010
- HTTPSlowRequestThreshold
- Threshold in milliseconds for logging HTTP requests in UDFS_STATISTICS. Requests that take longer than this value are logged; faster ones are not.
Default: 500
- IcebergPathMapping
- For external tables using Iceberg data, a map of URI prefixes used by Iceberg to prefixes accessible to Vertica. The value is a JSON object:
'{"source-prefix":"new-prefix"[,...]}'
Specify prefixes only (up through port number), not complete paths.
- IdleTimeoutInitializingConnectionsMs
- The length of time (in milliseconds) that the server waits before timing out, during each step in connection initialization. After connection initialization, the session is created.
Default: 10000
- JavaBinaryForUDx
- Sets the full path to the Java executable that Vertica uses to run Java UDxs. See Installing Java on Vertica hosts.
- JoinDefaultTupleFormat
- Specifies how to size VARCHAR column data when joining tables on those columns, and buffers accordingly, one of the following:
-
fixed: Use join column metadata to size column data to a fixed length, and buffer accordingly.
-
variable: Use the actual length of join column data, so buffer size varies for each join.
Default: fixed
- KeepAliveIdleTime
- Length (in seconds) of the idle period before the first TCP keepalive probe is sent to ensure that the client is still connected. If set to 0, Vertica uses the kernel's tcp_keepalive_time parameter setting.
Default: 0
- KeepAliveProbeCount
- Number of consecutive keepalive probes that must go unacknowledged by the client before the client connection is considered lost and closed. If set to 0, Vertica uses the kernel's tcp_keepalive_probes parameter setting.
Default: 0
- KeepAliveProbeInterval
- Time interval (in seconds) between keepalive probes. If set to 0, Vertica uses the kernel's tcp_keepalive_intvl parameter setting.
Default: 0
- LockTimeout
- Specifies in seconds how long a table waits to acquire a lock.
Default: 300
- LoadSourceStatisticsLimit
- Specifies the maximum number of sources per load operation that are profiled in the LOAD_SOURCES system table. Set it to 0 to disable profiling.
Default: 256
- MaxBundleableROSSizeKB
- Specifies the minimum size, in kilobytes, of an independent ROS file. Vertica bundles storage container ROS files below this size into a single file. Bundling improves the performance of any file-intensive operations, including backups, restores, and mergeouts.
If you set this parameter to a value of 0, Vertica bundles .fdb and .pidx files without bundling other storage container files.
Default: 1024
- MaxClientSessions
- Determines the maximum number of client sessions that can run on a single node of the database. The default value allows for five additional administrative logins. These logins prevent DBAs from being locked out of the system if non-dbadmin users reach the login limit.
Tip
Setting this parameter to 0 prevents new client sessions from being opened while you are shutting down the database. Restore the parameter to its original setting after you restart the database. For details, see
Managing Sessions.
Default: 50 user logins and 5 additional administrative logins
- ObjectStoreGlobStrategy
- For partitioned external tables in object stores, the strategy to use for expanding globs before pruning partitions:
-
Flat: COPY fetches a list of all full object names with a given prefix, which can incur latency if partitions are numerous or deeply nested.
-
Hierarchical: COPY fetches object names one partition layer at a time, allowing earlier pruning but possibly requiring more calls to the object store when queries are not selective or there are not many partittion directory levels.
For details, see Partitions on Object Stores.
Default: Flat
- ObjStoreUploadParallelism
- Integer (maximum 1000), size of the thread pool used when writing files to S3. Using more threads parallelizes uploads, but uses more memory. Each node has a single thread pool used for all file writes.
This configuration parameter can be set only at the database level.
Default: 0 (disabled)
- ParquetMetadataCacheSizeMB
- Size of the cache used for metadata when reading Parquet data. The cache uses local TEMP storage.
Default: 4096
- PatternMatchingUseJit
- Boolean, specifies whether to enables just-in-time compilation (to machine code) of regular expression pattern matching functions used in queries. Enabling this parameter can usually improve pattern matching performance on large tables. The Perl Compatible Regular Expressions (PCRE) pattern-match library evaluates regular expressions. Restart the database for this parameter to take effect.
See also Regular expression functions.
Default: 1 (enable)
- PatternMatchStackAllocator
- Boolean, specifies whether to override the stack memory allocator for the pattern-match library. The Perl Compatible Regular Expressions (PCRE) pattern-match library evaluates regular expressions. Restart the database for this parameter to take effect.
See also Regular expression functions.
Default: 1 (enable override)
- TerraceRoutingFactor
- Specifies whether to enable or disable terrace routing on any Enterprise Mode large cluster that implements rack-based fault groups.
- To enable, set as follows:
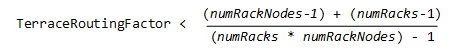 where: *
where: * numRackNodes: Number of nodes in a rack * numRacks: Number of racks in the cluster
- To disable, set to a value so large that terrace routing cannot be enabled for the largest clusters—for example, 1000.
For details, see Terrace routing.
Default: 2
- TransactionIsolationLevel
- Changes the isolation level for the database. After modification, Vertica uses the new transaction level for every new session. Existing sessions and their transactions continue to use the original isolation level.
See also Change transaction isolation levels.
Default: READ COMMITTED
- TransactionMode
- Whether transactions are in read/write or read-only modes. Read/write is the default. Existing sessions and their transactions continue to use the original isolation level.
Default: READ WRITE
- UDFSSlowRequestThreshold
- Threshold in milliseconds for logging events in UDFS_EVENTS. Requests that take longer than this value are logged; faster ones are not.
Default: 1000
- UDxFencedBlockTimeout
- Number of seconds to wait for output before aborting a UDx running in Fenced and unfenced modes. If the server aborts a UDx for this reason, it produces an error message similar to "ERROR 3399: Failure in UDx RPC call: timed out in receiving a UDx message". If you see this error frequently, you can increase this limit. UDxs running in fenced mode do not run in the server process, so increasing this value does not impede server performance.
Default: 60
- UseLocalTzForParquetTimestampConversion
- Boolean, specifies whether to do timezone conversion when reading Parquet files. Hive version 1.2.1 introduced an option to localize timezones when writing Parquet files. Previously it wrote them in UTC and Vertica adjusted the value when reading the files.
Set to 0 if Hive already adjusted the timezones.
Default: 1 (enable conversion)
- UseServerIdentityOverUserIdentity
- Boolean, specifies whether to ignore user-supplied credentials for non-Linux file systems and always use a USER storage location to govern access to data. See Creating a Storage Location for USER Access.
Default: 0 (disable)
- WithClauseMaterialization
- Boolean, specifies whether to enable materialization of WITH clause results. When materialization is enabled (1), Vertica evaluates each WITH clause once and stores results in a temporary table.
For WITH queries with complex types, temp relations are disabled.
Default: 0 (disable)
- WithClauseRecursionLimit
- Specifies the maximum number of times a WITH RECURSIVE clause iterates over the content of its own result set before it exits. For details, see WITH clause recursion.
Important
Be careful to set WithClauseRecursionLimit only as high as needed to traverse the deepest hierarchies. Vertica sets no limit on this parameter; however, a high value can incur considerable overhead that adversely affects performance and exhausts system resources.
If a high recursion count is required, then consider enabling materialization. For details, see WITH RECURSIVE Materialization.
Default: 8
4.2 - Azure parameters
Use the following parameters to configure reading from Azure blob storage.
Use the following parameters to configure reading from Azure blob storage. For more information about reading data from Azure, see Azure Blob Storage object store.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- AzureStorageCredentials
- Collection of JSON objects, each of which specifies connection credentials for one endpoint. This parameter takes precedence over Azure managed identities.
The collection must contain at least one object and may contain more. Each object must specify at least one of accountName or blobEndpoint, and at least one of accountKey or sharedAccessSignature.
accountName: If not specified, uses the label of blobEndpoint.blobEndpoint: Host name with optional port (host:port). If not specified, uses account.blob.core.windows.net.accountKey: Access key for the account or endpoint.sharedAccessSignature: Access token for finer-grained access control, if being used by the Azure endpoint.
- AzureStorageEndpointConfig
- Collection of JSON objects, each of which specifies configuration elements for one endpoint. Each object must specify at least one of
accountName or blobEndpoint.
accountName: If not specified, uses the label of blobEndpoint.blobEndpoint: Host name with optional port (host:port). If not specified, uses account.blob.core.windows.net.protocol: HTTPS (default) or HTTP.isMultiAccountEndpoint: true if the endpoint supports multiple accounts, false otherwise (default is false). To use multiple-account access, you must include the account name in the URI. If a URI path contains an account, this value is assumed to be true unless explicitly set to false.
4.3 - Constraints parameters
The following configuration parameters control how Vertica evaluates and enforces constraints.
The following configuration parameters control how Vertica evaluates and enforces constraints. All parameters are set at the database level through
ALTER DATABASE.
Three of these parameters—EnableNewCheckConstraintsByDefault, EnableNewPrimaryKeysByDefault, and EnableNewUniqueKeysByDefault—can be used to enforce CHECK, PRIMARY KEY, and UNIQUE constraints, respectively. For details, see Constraint enforcement.
- EnableNewCheckConstraintsByDefault
- Boolean parameter, set to 0 or 1:
- EnableNewPrimaryKeysByDefault
- Boolean parameter, set to 0 or 1:
-
0 (default): Disable enforcement of new PRIMARY KEY constraints except where the table DDL explicitly enables them.
-
1: Enforce new PRIMARY KEY constraints except where the table DDL explicitly disables them.
Note
Vertica recommends enforcing constraints PRIMARY KEY and UNIQUE together.
- EnableNewUniqueKeysByDefault
- Boolean parameter, set to 0 or 1:
- MaxConstraintChecksPerQuery
- Sets the maximum number of constraints that
ANALYZE_CONSTRAINTS can handle with a single query:
-
-1 (default): No maximum set, ANALYZE_CONSTRAINTS uses a single query to evaluate all constraints within the specified scope.
-
Integer > 0: The maximum number of constraints per query. If the number of constraints to evaluate exceeds this value, ANALYZE_CONSTRAINTS handles it with multiple queries.
For details, see Distributing Constraint Analysis.
4.4 - Database Designer parameters
The following table describes the parameters for configuring the Vertica Database Designer.
The following table describes the parameters for configuring the Vertica Database Designer.
DBDCorrelationSampleRowCount- Minimum number of table rows at which Database Designer discovers and records correlated columns.
Default: 4000
DBDLogInternalDesignProcess- Enables or disables Database Designer logging.
Default: 0 (False)
DBDUseOnlyDesignerResourcePool- Enables use of the DBD pool by the Vertica Database Designer.
When set to false, design processing is mostly contained by the user's resource pool, but might spill over into some system resource pools for less-intensive tasks
Default: 0 (False)
4.5 - Eon Mode parameters
The following parameters configure how the database operates when running in Eon Mode.
The following parameters configure how the database operates when running in Eon Mode. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- BackgroundDepotWarming
- Specifies background depot warming behavior:
-
1: The depot loads objects while it is warming, and continues to do so in the background after the node becomes active and starts executing queries.
-
0: Node activation is deferred until the depot fetches and loads all queued objects
For details, see Depot Warming.
Default: 1
- CatalogSyncInterval
- Specifies in minutes how often the transaction log sync service syncs metadata to communal storage. If you change this setting, Vertica restarts the interval count.
Default: 5
- DelayForDeletes
- Specifies in hours how long to wait before deleting a file from communal storage. Vertica first deletes a file from the depot. After the specified time interval, the delete also occurs in communal storage.
Default: 0. Deletes the file from communal storage as soon as it is not in use by shard subscribers.
- DepotOperationsForQuery
- Specifies behavior when the depot does not contain queried file data, one of the following:
-
ALL (default): Fetch file data from communal storage, if necessary displace existing files by evicting them from the depot.
-
FETCHES: Fetch file data from communal storage only if space is available; otherwise, read the queried data directly from communal storage.
-
NONE: Do not fetch file data to the depot, read the queried data directly from communal storage.
You can also specify query-level behavior with the hint
DEPOT_FETCH.
- ECSMode
- String parameter that sets the strategy Vertica uses when dividing the data in a shard among subscribing nodes during an ECS-enabled query, one of the following:
-
AUTO: Optimizer automatically determines the strategy to use.
-
COMPUTE_OPTIMIZED: Force use of the compute-optimized strategy.
-
IO_OPTIMIZED: Force use of the I/O-optimized strategy.
For details, see Manually choosing an ECS strategy.
Default: AUTO
- ElasticKSafety
- Boolean parameter that controls whether Vertica adjusts shard subscriptions due to the loss of a primary node:
- 1: When a primary node is lost, Vertica subscribes other primary nodes to the down node's shard subscriptions. This action helps reduce the chances of a database into going read-only mode due to loss of shard coverage.
- 0 : Vertica does not change shard subscriptions in reaction to the loss of a primary node.
Default: 1
For details, see Maintaining Shard Coverage.
- EnableDepotWarmingFromPeers
- Boolean parameter, specifies whether Vertica warms a node depot while the node is starting up and not ready to process queries:
For details, see Depot Warming.
Default: 0
- FileDeletionServiceInterval
- Specifies in seconds the interval between each execution of the reaper cleaner service task.
Default: 60 seconds
- MaxDepotSizePercent
- An integer value that specifies the maximum size of the depot as a percentage of disk size,
Default: 80
- PreFetchPinnedObjectsToDepotAtStartup
- If enabled (set to 1), a warming depot fetches objects that are pinned on its subcluster. For details, see Depot Warming.
Default: 0
- ReaperCleanUpTimeoutAtShutdown
- Specifies in seconds how long Vertica waits for the reaper to delete files from communal storage before shutting down. If set to a negative value, Vertica shuts down without waiting for the reaper.
Note
The reaper is a service task that deletes disk files.
Default: 300
- StorageMergeMaxTempCacheMB
- The size of temp space allocated per query to the StorageMerge operator for caching the data of S3 storage containers.
Note
The actual temp space that is allocated is the lesser of:
For details, see Local caching of storage containers.
- UseCommunalStorageForBatchDepotWarming
- Boolean parameter, specifies whether where a node retrieves data when warming its depot:
Note
The actual temp space that is allocated is the lesser of two settings:
Default: 1
Important
This parameter is for internal use only. Do not change it unless directed to do so by Vertica support.
- UseDepotForReads
- Boolean parameter, specifies whether Vertica accesses the depot to answer queries, or accesses only communal storage:
-
1: Vertica first searches the depot for the queried data; if not there, Vertica fetches the data from communal storage for this and future queries.
-
0: Vertica bypasses the depot and always obtains queried data from communal storage.
Note
Enable depot reads to improve query performance and support K-safety.
Default: 1
- UseDepotForWrites
- Boolean parameter, specifies whether Vertica writes loaded data to the depot and then uploads files to communal storage:
-
1: Write loaded data to the depot, upload files to communal storage.
-
0: Bypass the depot and always write directly to communal storage.
Default: 1
- UsePeerToPeerDataTransfer
- Boolean parameter, specifies whether Vertica pushes loaded data to other shard subscribers:
Note
Setting to 1 helps improve performance when a node is down.
Default: 0
Important
This parameter is for internal use only. Do not change it unless directed to do so by Vertica support.
4.6 - Epoch management parameters
The following table describes the epoch management parameters for configuring Vertica.
The following table describes the epoch management parameters for configuring Vertica.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- AdvanceAHMInterval
- Determines how frequently (in seconds) Vertica checks the history retention status.
AdvanceAHMInterval cannot be set to a value that is less than the EpochMapInterval.
Default: 180 (seconds)
- AHMBackupManagement
- Blocks the advancement of the Ancient History Mark (AHM). When this parameter is enabled, the AHM epoch cannot be later than the epoch of your latest full backup. If you advance the AHM to purge and delete data, do not enable this parameter.
Caution
Do not enable this parameter before taking full backups, as it would prevent the AHM from advancing.
Default: 0
- EpochMapInterval
- Determines the granularity of mapping between epochs and time available to historical queries. When a historical queries
AT TIME T request is issued, Vertica maps it to an epoch within a granularity of EpochMapInterval seconds. It similarly affects the time reported for Last Good Epoch during Failure recovery. Note that it does not affect internal precision of epochs themselves.
Tip
Decreasing this interval increases the number of epochs saved on disk. Therefore, consider reducing the HistoryRetentionTime parameter to limit the number of history epochs that Vertica retains.
Default: 180 (seconds)
- HistoryRetentionTime
- Determines how long deleted data is saved (in seconds) as an historical reference. When the specified time since the deletion has passed, you can purge the data. Use the -1 setting if you prefer to use
HistoryRetentionEpochs to determine which deleted data can be purged.
Note
The default setting of 0 effectively prevents the use of the
Administration tools 'Roll Back Database to Last Good Epoch' option because the
AHM remains close to the current epoch and a rollback is not permitted to an epoch prior to the AHM.
Tip
If you rely on the Roll Back option to remove recently loaded data, consider setting a day-wide window to remove loaded data. For example:
ALTER DATABASE DEFAULT SET HistoryRetentionTime = 86400;
Default: 0 (Data saved when nodes are down.)
- HistoryRetentionEpochs
- Specifies the number of historical epochs to save, and therefore, the amount of deleted data.
Unless you have a reason to limit the number of epochs, Vertica recommends that you specify the time over which deleted data is saved.
If you specify both History parameters, HistoryRetentionTime takes precedence. Setting both parameters to -1, preserves all historical data.
See Setting a purge policy.
Default: -1 (disabled)
4.7 - Google Cloud Storage parameters
Use the following parameters to configure reading from Google Cloud Storage (GCS) using COPY FROM.
Use the following parameters to configure reading from Google Cloud Storage (GCS) using COPY FROM. For more information about reading data from S3, see Specifying where to load data from.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- GCSAuth
- An ID and secret key to authenticate to GCS. You can set parameters globally and for the current session with ALTER DATABASE...SET PARAMETER and ALTER SESSION...SET PARAMETER, respectively. For extra security, do not store credentials in the database; instead, set it for the current session with ALTER SESSION. For example:
=> ALTER SESSION SET GCSAuth='ID:secret';
If you use a shared credential, set it in the database with ALTER DATABASE.
- GCSEnableHttps
- Specifies whether to use the HTTPS protocol when connecting to GCS, can be set only at the database level with ALTER DATABASE...SET PARAMETER.
Default: 1 (enabled)
- GCSEndpoint
- The connection endpoint address.
Default: storage.googleapis.com
4.8 - Hadoop parameters
The following table describes general parameters for configuring integration with Apache Hadoop.
The following table describes general parameters for configuring integration with Apache Hadoop. See Apache Hadoop integration for more information.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- EnableHDFSBlockInfoCache
- Boolean, whether to distribute block location metadata collected during planning on the initiator to all database nodes for execution. Distributing this metadata reduces name node accesses, and thus load, but can degrade database performance somewhat in deployments where the name node isn't contended. This performance effect is because the data must be serialized and distributed. Enable distribution if protecting the name node is more important than query performance; usually this applies to large HDFS clusters where name node contention is already an issue.
Default: 0 (disabled)
- HadoopConfDir
- Directory path containing the XML configuration files copied from Hadoop. The same path must be valid on every Vertica node. You can use the VERIFY_HADOOP_CONF_DIR meta-function to test that the value is set correctly. Setting this parameter is required to read data from HDFS.
For all Vertica users, the files are accessed by the Linux user under which the Vertica server process runs.
When you set this parameter, previously-cached configuration information is flushed.
You can set this parameter at the session level. Doing so overrides the database value; it does not append to it. For example:
=> ALTER SESSION SET HadoopConfDir='/test/conf:/hadoop/hcat/conf';
To append, get the current value and include it on the new path after your additions. Setting this parameter at the session level does not change how the files are accessed.
Default: obtained from environment if possible
- HadoopFSAuthentication
- How (or whether) to use Kerberos authentication with HDFS. By default, if KerberosKeytabFile is set, Vertica uses that credential for both Vertica and HDFS. Usually this is the desired behavior. However, if you are using a Kerberized Vertica cluster with a non-Kerberized HDFS cluster, set this parameter to "none" to indicate that Vertica should not use the Vertica Kerberos credential to access HDFS.
Default: "keytab" if KerberosKeytabFile is set, otherwise "none"
- HadoopFSBlockSizeBytes
- Block size to write to HDFS. Larger files are divided into blocks of this size.
Default: 64MB
- HadoopFSNNOperationRetryTimeout
- Number of seconds a metadata operation (such as list directory) waits for a response before failing. Accepts float values for millisecond precision.
Default: 6 seconds
- HadoopFSReadRetryTimeout
- Number of seconds a read operation waits before failing. Accepts float values for millisecond precision. If you are confident that your file system will fail more quickly, you can improve performance by lowering this value.
Default: 180 seconds
- HadoopFSReplication
- Number of replicas HDFS makes. This is independent of the replication that Vertica does to provide K-safety. Do not change this setting unless directed otherwise by Vertica support.
Default: 3
- HadoopFSRetryWaitInterval
- Initial number of seconds to wait before retrying read, write, and metadata operations. Accepts float values for millisecond precision. The retry interval increases exponentially with every retry.
Default: 3 seconds
- HadoopFSTokenRefreshFrequency
- How often, in seconds, to refresh the Hadoop tokens used to hold Kerberos tickets (see Token expiration).
Default: 0 (refresh when token expires)
- HadoopFSWriteRetryTimeout
- Number of seconds a write operation waits before failing. Accepts float values for millisecond precision. If you are confident that your file system will fail more quickly, you can improve performance by lowering this value.
Default: 180 seconds
- HadoopImpersonationConfig
- Session parameter specifying the delegation token or Hadoop user for HDFS access. See HadoopImpersonationConfig format for information about the value of this parameter and Proxy users and delegation tokens for more general context.
- HDFSUseWebHDFS
- Boolean, whether URLs in the
hdfs scheme use WebHDFS instead of LibHDFS++ to access data.
Deprecated
This parameter is deprecated because LibHDFS++ is deprecated. In the future, Vertica will use WebHDFS for all hdfs URLs.
Default: 1 (enabled)
- WebhdfsClientCertConf
- mTLS configurations for accessing one or more WebHDFS servers. The value is a JSON string; each member has the following properties:
nameservice and authority are mutually exclusive.
For example:
=> ALTER SESSION SET WebhdfsClientCertConf =
'[{"authority" : "my.authority.com:50070", "certName" : "myCert"},
{"nameservice" : "prod", "certName" : "prodCert"}]';
HCatalog Connector parameters
The following table describes the parameters for configuring the HCatalog Connector. See Using the HCatalog Connector for more information.
Note
You can override HCatalog configuration parameters when you create an HCatalog schema with
CREATE HCATALOG SCHEMA.
- EnableHCatImpersonation
- Boolean, whether the HCatalog Connector uses (impersonates) the current Vertica user when accessing Hive. If impersonation is enabled, the HCatalog Connector uses the Kerberos credentials of the logged-in Vertica user to access Hive data. Disable impersonation if you are using an authorization service to manage access without also granting users access to the underlying files. For more information, see Configuring security.
Default: 1 (enabled)
- HCatalogConnectorUseHiveServer2
- Boolean, whether Vertica internally uses HiveServer2 instead of WebHCat to get metadata from Hive.
Default: 1 (enabled)
- HCatalogConnectorUseLibHDFSPP
- Boolean, whether the HCatalog Connector should use the
hdfs scheme instead of webhdfs with the HCatalog Connector.
Deprecated
Vertica uses the hdfs scheme by default. To use webhdfs, set the HDFSUseWebHDFS parameter.
Default: 1 (enabled)
- HCatConnectionTimeout
- The number of seconds the HCatalog Connector waits for a successful connection to the HiveServer2 (or WebHCat) server before returning a timeout error.
Default: 0 (Wait indefinitely)
- HCatSlowTransferLimit
- Lowest transfer speed (in bytes per second) that the HCatalog Connector allows when retrieving data from the HiveServer2 (or WebHCat) server. In some cases, the data transfer rate from the server to Vertica is below this threshold. In such cases, after the number of seconds specified in the HCatSlowTransferTime parameter pass, the HCatalog Connector cancels the query and closes the connection.
Default: 65536
- HCatSlowTransferTime
- Number of seconds the HCatalog Connector waits before testing whether the data transfer from the server is too slow. See the HCatSlowTransferLimit parameter.
Default: 60
4.9 - Internationalization parameters
The following table describes internationalization parameters for configuring Vertica.
The following table describes internationalization parameters for configuring Vertica.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- DefaultIntervalStyle
- Sets the default interval style to use. If set to 0 (default), the interval is in PLAIN style (the SQL standard), no interval units on output. If set to 1, the interval is in UNITS on output. This parameter does not take effect until the database is restarted.
Default: 0
- DefaultSessionLocale
- Sets the default session startup locale for the database. This parameter does not take effect until the database is restarted.
Default: en_US@collation=binary
- EscapeStringWarning
- Issues a warning when backslashes are used in a string literal. This can help locate backslashes that are being treated as escape characters so they can be fixed to follow the SQL standard-conforming string syntax instead.
Default: 1
- StandardConformingStrings
- Determines whether character string literals treat backslashes () as string literals or escape characters. When set to -1, backslashes are treated as string literals; when set to 0, backslashes are treated as escape characters.
Tip
To treat backslashes as escape characters, use the Extended string syntax
(E'...');
Default: -1
4.10 - Kafka user-defined session parameters
Set Vertica user-defined session parameters to configure Kafka SSL when not using a scheduler, using ALTER SESSION SET UDPARAMETER.
Set Vertica user-defined session parameters to configure Kafka SSL when not using a scheduler, using ALTER SESSION SET UDPARAMETER. The kafka-prefixed parameters configure SSL authentication for Kafka. For details, see TLS/SSL encryption with Kafka.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- kafka_SSL_CA
- The contents of the certificate authority certificate. For example:
=> ALTER SESSION SET UDPARAMETER kafka_SSL_CA='MIIBOQIBAAJBAIOL';
Default: none
- kafka_SSL_Certificate
- The contents of the SSL certificate. For example:
=> ALTER SESSION SET UDPARAMETER kafka_SSL_Certificate='XrM07O4dV/nJ5g';
This parameter is optional when the Kafka server's parameter ssl.client.auth is set to none or requested.
Default: none
- kafka_SSL_PrivateKey_secret
- The private key used to encrypt the session. Vertica does not log this information. For example:
=> ALTER SESSION SET UDPARAMETER kafka_SSL_PrivateKey_secret='A60iThKtezaCk7F';
This parameter is optional when the Kafka server's parameter ssl.client.auth is set to none or requested.
Default: none
- kafka_SSL_PrivateKeyPassword_secret
- The password used to create the private key. Vertica does not log this information.
For example:
ALTER SESSION SET UDPARAMETER kafka_SSL_PrivateKeyPassword_secret='secret';
This parameter is optional when the Kafka server's parameter ssl.client.auth is set to none or requested.
Default: none
- kafka_Enable_SSL
- Enables SSL authentication for Vertica-Kafka integration. For example:
=> ALTER SESSION SET UDPARAMETER kafka_Enable_SSL=1;
Default: 0
- MaxSessionUDParameterSize
- Sets the maximum length of a value in a user-defined session parameter. For example:
=> ALTER SESSION SET MaxSessionUDParameterSize = 2000
Default: 1000
User-defined session parameters
4.11 - Kerberos parameters
The following parameters let you configure the Vertica principal for Kerberos authentication and specify the location of the Kerberos keytab file.
The following parameters let you configure the Vertica principal for Kerberos authentication and specify the location of the Kerberos keytab file.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- KerberosEnableKeytabPermissionCheck
- Whether the Vertica server verifies permissions on the keytab file. By default, the Vertica server verifies these permissions.
In a hybrid Kubernetes cluster, set this parameter to 0 so that there is no permissions check. Otherwise, Kerberos authentication fails because the keytab file is stored in a Secret, and the VerticaDB operator cannot verify permissions on a Secret.
Default: 1
- KerberosHostname
- Instance or host name portion of the Vertica Kerberos principal. For example:
vertica/host@EXAMPLE.COM
If you omit the optional KerberosHostname parameter, Vertica uses the return value from the function gethostname(). Assuming each cluster node has a different host name, those nodes will each have a different principal, which you must manage in that node's keytab file.
- KerberosKeytabFile
- Location of the
keytab file that contains credentials for the Vertica Kerberos principal. By default, this file is located in /etc. For example:
KerberosKeytabFile=/etc/krb5.keytab
Note
-
The principal must take the form KerberosServiceName/KerberosHostName@KerberosRealm
-
The keytab file must be readable by the file owner who is running the process (typically the Linux dbadmin user assigned file permissions 0600).
- KerberosRealm
- Realm portion of the Vertica Kerberos principal. A realm is the authentication administrative domain and is usually formed in uppercase letters. For example:
vertica/hostEXAMPLE.COM
- KerberosServiceName
- Service name portion of the Vertica Kerberos principal. By default, this parameter is
vertica. For example:
vertica/host@EXAMPLE.COM
Default: vertica
- KerberosTicketDuration
- Lifetime of the ticket retrieved from performing a kinit. The default is 0 (zero) which disables this parameter.
If you omit setting this parameter, the lifetime is determined by the default Kerberos configuration.
4.12 - Machine learning parameters
You use machine learning parameters to configure various aspects of machine learning functionality in Vertica.
You use machine learning parameters to configure various aspects of machine learning functionality in Vertica.
- MaxModelSizeKB
- Sets the maximum size of models that can be imported. The sum of the size of files specified in the metadata.json file determines the model size. The unit of this parameter is KBytes. The native Vertica model (category=VERTICA_MODELS) is exempted from this limit. If you can export the model from Vertica, and the model is not altered while outside Vertica, you can import it into Vertica again.
The MaxModelSizeKB parameter can be set only by a superuser and only at the database level. It is visible only to a superuser. Its default value is 4GB, and its valid range is between 1KB and 64GB (inclusive).
Examples:
To set this parameter to 3KB:
=> ALTER DATABASE DEFAULT SET MaxModelSizeKB = 3;
To set this parameter to 64GB (the maximum allowed):
=> ALTER DATABASE DEFAULT SET MaxModelSizeKB = 67108864;
To reset this parameter to the default value:
=> ALTER DATABASE DEFAULT CLEAR MaxModelSizeKB;
Default: 4GB
4.13 - Memory management parameters
The following table describes parameters for managing Vertica memory usage.
The following table describes parameters for managing Vertica memory usage.
Caution
Modify these parameters only under guidance from Vertica Support.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- MemoryPollerIntervalSec
- Specifies in seconds how often the Vertica memory poller checks whether Vertica memory usage is below the thresholds of several configuration parameters (see below):
-
MemoryPollerMallocBloatThreshold
-
MemoryPollerReportThreshold
-
MemoryPollerTrimThreshold
Important
To disable polling of all thresholds, set this parameter to 0. Doing so effectively disables automatic memory usage
reporting and
trimming.
Default: 2
- MemoryPollerMallocBloatThreshold
- Threshold of glibc memory bloat.
The memory poller calls glibc function malloc_info() to obtain the amount of free memory in malloc. It then compares MemoryPollerMallocBloatThreshold—by default, set to 0.3—with the following expression:
free-memory-in-malloc / RSS
If this expression evaluates to a value higher than MemoryPollerMallocBloatThreshold, the memory poller calls glibc function
malloc_trim(). This function reclaims free memory from malloc and returns it to the operating system. Details on calls to malloc_trim() are written to system table
MEMORY_EVENTS.
To disable polling of this threshold, set the parameter to 0.
Default: 0.3
- MemoryPollerReportThreshold
- Threshold of memory usage that determines whether the Vertica memory poller writes a report.
The memory poller compares MemoryPollerReportThreshold with the following expression:
RSS / available-memory
When this expression evaluates to a value higher than MemoryPollerReportThreshold—by default, set to 0.93, then the memory poller writes a report to MemoryReport.log, in the Vertica working directory. This report includes information about Vertica memory pools, how much memory is consumed by individual queries and session, and so on. The memory poller also logs the report as an event in system table
MEMORY_EVENTS, where it sets EVENT_TYPE to MEMORY_REPORT.
To disable polling of this threshold, set the parameter to 0.
Default: 0.93
- MemoryPollerTrimThreshold
- Threshold for the memory poller to start checking whether to trim glibc-allocated memory.
The memory poller compares MemoryPollerTrimThreshold—by default, set to 0.83— with the following expression:
RSS / available-memory
If this expression evaluates to a value higher than MemoryPollerTrimThreshold, then the memory poller starts checking the next threshold—set in MemoryPollerMallocBloatThreshold—for glibc memory bloat.
To disable polling of this threshold, set the parameter to 0. Doing so also disables polling of MemoryPollerMallocBloatThreshold.
Default: 0.83
4.14 - Monitoring parameters
The following table describes parameters that control options for monitoring the Vertica database.
The following parameters control options for monitoring the Vertica database.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- EnableDataCollector
- Enables the Data Collector, which is the Workload Analyzer's internal diagnostics utility. Affects all sessions on all nodes. To disable, set to 0.
Default: 1 (enabled)
- EnableLogRotate
- Enables and disables the timed LogRotate service.
Default: 1 (enabled)
- LogRotateInterval
- Interval literal, how often the LogRotate service runs.
Default: 8h (runs every 8 hours)
- LogRotateMaxAge
- Interval literal, the maximum age of rotated logs (
.gz) to keep. Rotated logs with an age greater than this value are rotated. For details, see Rotating log files.
Default: 7 days
- LogRotateMaxSize
- String, the maximum size of a log (
.log) file. The string has format integer{K|M|G|T}, where K is kibibytes, M is mebibytes, G is gibibytes, and T is tebibytes. Logs larger than this value are rotated. For details, see Rotating log files.
Default: 100M
- SnmpTrapDestinationsList
- Defines where Vertica sends traps for SNMP. See Configuring reporting for SNMP. For example:
=> ALTER DATABASE DEFAULT SET SnmpTrapDestinationsList = 'localhost 162 public';
Default: none
- SnmpTrapsEnabled
- Enables event trapping for SNMP. See Configuring reporting for SNMP.
Default: 0
- SnmpTrapEvents
- Defines which events Vertica traps through SNMP. See Configuring reporting for SNMP. For example:
=> ALTER DATABASE DEFAULT SET SnmpTrapEvents = 'Low Disk Space, Recovery Failure';
Default: Low Disk Space, Read Only File System, Loss of K Safety, Current Fault Tolerance at Critical Level, Too Many ROS Containers, Node State Change, Recovery Failure, Stale Checkpoint, and CRC Mismatch.
- SyslogEnabled
- Enables event trapping for syslog. See Configuring reporting for syslog.
Default: 0 (disabled)
- SyslogEvents
- Defines events that generate a syslog entry. See Configuring reporting for syslog. For example:
=> ALTER DATABASE DEFAULT SET SyslogEvents = 'Low Disk Space, Recovery Failure';
Default: none
- SyslogFacility
- Defines which SyslogFacility Vertica uses. See Configuring reporting for syslog.
Default: user
4.15 - Numeric precision parameters
The following configuration parameters let you configure numeric precision for numeric data types.
The following configuration parameters let you configure numeric precision for numeric data types. For more about using these parameters, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- AllowNumericOverflow
- Boolean, set to one of the following:
-
1 (true): Allows silent numeric overflow. Vertica does not implicitly extend precision of numeric data types. Vertica ignores the value of NumericSumExtraPrecisionDigits.
-
0 (false): Vertica produces an overflow error, if a result exceeds the precision set by NumericSumExtraPrecisionDigits.
Default: 1 (true)
- NumericSumExtraPrecisionDigits
- An integer between 0 and 20, inclusive. Vertica produces an overflow error if a result exceeds the specified precision. This parameter setting only applies if AllowNumericOverflow is set to 0 (false).
Default: 6 (places beyond the DDL-specified precision)
4.16 - Profiling parameters
The following table describes the profiling parameters for configuring Vertica.
The following table describes the profiling parameters for configuring Vertica. See Profiling database performance for more information on profiling queries.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- GlobalEEProfiling
- Enables profiling for query execution runs in all sessions on all nodes.
Default: 0
- GlobalQueryProfiling
- Enables query profiling for all sessions on all nodes.
Default: 0
- GlobalSessionProfiling
- Enables session profiling for all sessions on all nodes.
Default: 0
- SaveDCEEProfileThresholdUS
- Sets in microseconds the query duration threshold for saving profiling information to system tables QUERY_CONSUMPTION and EXECUTION_ENGINE_PROFILES. You can set this parameter to a maximum value of 2147483647 (231-1, or ~35.79 minutes).
Default: 60000000 (60 seconds)
4.17 - Projection parameters
The following configuration parameters help you manage projections.
The following configuration parameters help you manage projections.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- AnalyzeRowCountInterval
- Specifies how often Vertica checks the number of projection rows and whether the threshold set by
ARCCommitPercentage has been crossed.
For more information, see Collecting database statistics.
Default: 86400 seconds (24 hours)
- ARCCommitPercentage
- Sets the threshold percentage of difference between the last-recorded aggregate projection row count and current row count for a given table. When the difference exceeds this threshold, Vertica updates the catalog with the current row count.
Default: 3 (percent)
- ContainersPerProjectionLimit
- Specifies how many ROS containers Vertica creates per projection before ROS pushback occurs.
Caution
Increasing this parameter's value can cause serious degradation of database performance. Vertica strongly recommends that you not modify this parameter without first consulting with Customer Support professionals.
Default: 1024
- MaxAutoSegColumns
- Specifies the number of columns (0 –1024) to use in an auto-projection's hash segmentation clause. Set to
0 to use all columns.
Default: 8
- MaxAutoSortColumns
- Specifies the number of columns (0 –1024) to use in an auto-projection's sort expression. Set to
0 to use all columns.
Default: 8
- RebalanceQueryStorageContainers
- By default, prior to performing a rebalance, Vertica performs a system table query to compute the size of all projections involved in the rebalance task. This query enables Vertica to optimize the rebalance to most efficiently utilize available disk space. This query can, however, significantly increase the time required to perform the rebalance.
By disabling the system table query, you can reduce the time required to perform the rebalance. If your nodes are low on disk space, disabling the query increases the chance that a node runs out of disk space. In that situation, the rebalance fails.
Default: 1 (enable)
- RewriteQueryForLargeDim
- If enabled (1), Vertica rewrites a SET USING or DEFAULT USING query during a REFRESH_COLUMNS operation by reversing the inner and outer join between the target and source tables. Doing so can optimize refresh performance in cases where the source data is in a table that is larger than the target table.
Important
Enable this parameter only if the SET USING source data is in a table that is larger than the target table. If the source data is in a table smaller than the target table, then enabling RewriteQueryForLargeDim can adversely affect refresh performance.
Default: 0
- SegmentAutoProjection
- Determines whether auto-projections are segmented if the table definition omits a segmentation clause. You can set this parameter at database and session scopes.
Default: 1 (create segmented auto projections)
4.18 - S3 parameters
Use the following parameters to configure reading from S3 file systems and on-premises storage with S3-compatible APIs, using COPY.
Use the following parameters to configure reading from S3 file systems and on-premises storage with S3-compatible APIs. For more information about reading data from S3, see S3 Object Store.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- AWSAuth
- ID and secret key for authentication. For extra security, do not store credentials in the database; use ALTER SESSION...SET PARAMETER to set this value for the current session only. If you use a shared credential, you can set it in the database with ALTER DATABASE...SET PARAMETER. For example:
=> ALTER SESSION SET AWSAuth='ID:secret';
In AWS, these arguments are named AccessKeyID and SecretAccessKey.
To use admintools create_db or revive_db for Eon Mode on-premises, create a configuration file called auth_params.conf with these settings:
AWSAuth = key:secret
AWSEndpoint = IP:port
- AWSCAFile
File name of the TLS server certificate bundle to use. If set, this parameter overrides the Vertica default CA bundle path specified in the SystemCABundlePath parameter.
=> ALTER DATABASE DEFAULT SET AWSCAFile = '/etc/ssl/ca-bundle.pem';
Default: system-dependent
- AWSCAPath
Path Vertica uses to look up TLS server certificate bundles. If set, this parameter overrides the Vertica default CA bundle path specified in the SystemCABundlePath parameter.
=> ALTER DATABASE DEFAULT SET AWSCAPath = '/etc/ssl/';
Default: system-dependent
- AWSEnableHttps
Boolean, specifies whether to use the HTTPS protocol when connecting to S3, can be set only at the database level with ALTER DATABASE. If you choose not to use TLS, this parameter must be set to 0.
Default: 1 (enabled)
- AWSEndpoint
- Endpoint to use when interpreting S3 URLs, set as follows.
Important
Do not include http(s):// for AWS endpoints.
-
AWS: hostname_or_ip:port_number.
-
AWS with a FIPS-compliant S3 Endpoint: S3_hostname and enable virtual addressing:
Important
Do not include http(s)://
AWSEndpoint = s3-fips.dualstack.us-east-1.amazonaws.com
S3EnableVirtualAddressing = 1
-
On-premises/Pure: IP address of the Pure Storage server. If using admintools create_db or revive_db, create configuration file auth_params.conf and include these settings:
awsauth = key:secret
awsendpoint = IP:port
-
When AWSEndpoint is not set, the default behavior is to use virtual-hosted request URLs.
Default: s3.amazonaws.com
- AWSLogLevel
- Log level, one of the following:
-
OFF
-
FATAL
-
ERROR
-
WARN
-
INFO
-
DEBUG
-
TRACE
**Default:**ERROR
- AWSRegion
- AWS region containing the S3 bucket from which to read files. This parameter can only be configured with one region at a time. If you need to access buckets in multiple regions, change the parameter each time you change regions.
If you do not set the correct region, you might experience a delay before queries fail because Vertica retries several times before giving up.
Default: us-east-1
- AWSSessionToken
- Temporary security token generated by running the
get-session-token command, which generates temporary credentials you can use to configure multi-factor authentication.
Set this parameter in a user session using ALTER SESSION. You can set this parameter at the database level, but be aware that session tokens are temporary. When the token expires, any attempt to access AWS fails.
Note
If you use session tokens at the session level, you must set all parameters at the session level, even if some of them are set at the database level. Use
ALTER SESSION to set session parameters.
- AWSStreamingConnectionPercentage
- Controls the number of connections to the communal storage that Vertica uses for streaming reads. In a cloud environment, this setting helps prevent streaming data from communal storage using up all available file handles. It leaves some file handles available for other communal storage operations.
Due to the low latency of on-premises object stores, this option is unnecessary for an Eon Mode database that uses on-premises communal storage. In this case, disable the parameter by setting it to 0.
- S3BucketConfig
- A JSON array of objects specifying per-bucket configuration overrides. Each property other than the bucket name has a corresponding configuration parameter (shown in parentheses). If both the database-level parameter and its equivalent in S3BucketConfig are set, the value in S3BucketConfig takes precedence.
Properties:
-
bucket: Name of the bucket
-
region (AWSRegion): Name of the region
-
protocol (AWSEnableHttps): Connection protocol, either http or https
-
endpoint (AWSEndpoint): Endpoint URL or IP address
-
enableVirtualAddressing (S3EnableVirtualAddressing): Whether to rewrite the S3 URL to use a virtual hosted path
-
requesterPays (S3RequesterPays): Whether requester (instead of bucket owner) pays the cost of accessing data on the bucket
-
serverSideEncryption (S3ServerSideEncryption): Encryption algorithm if using SSE-S3 or SSE-KMS, one of AES256, aws:kms, or an empty string
-
sseCustomerAlgorithm (S3SseCustomerAlgorithm): Encryption algorithm if using SSE-C; must be AES256
-
sseCustomerKey (S3SseCustomerKey): Key if using SSE-C encryption, either 32-character plaintext or 44-character base64-encoded
-
sseKmsKeyId (S3SseKmsKeyId): Key ID if using SSE-KMS encryption
-
proxy (S3Proxy): HTTP(S) proxy string
The configuration properties for a given bucket might differ based on its type. For example, the following S3BucketConfig is for an AWS bucket AWSBucket and a Pure Storage bucket PureStorageBucket. AWSBucket doesn't specify an endpoint, so Vertica uses the value of AWSEndpoint, which defaults to s3.amazonaws.com:
ALTER DATABASE DEFAULT SET S3BucketConfig=
'[
{
"bucket": "AWSBucket",
"region": "us-east-2",
"protocol": "https",
"requesterPays": true
},
{
"bucket": "PureStorageBucket",
"endpoint": "pure.mycorp.net:1234",
"protocol": "http",
"enableVirtualAddressing": false
}
]';
- S3BucketCredentials
- Contains credentials for accessing an S3 bucket. Each property in S3BucketCredentials has an equivalent parameter (shown in parentheses). When set, S3BucketCredentials takes precedence over both AWSAuth and AWSSessionToken.
Providing credentials for more than one bucket authenticates to them simultaneously, allowing you to perform cross-endpoint joins, export from one bucket to another, etc.
Properties:
-
bucket: Name of the bucket
-
accessKey: Access key for the bucket (the ID in AWSAuth)
-
secretAccessKey: Secret access key for the bucket (the secret in AWSAuth)
-
sessionToken: Session token, only used when S3BucketCredentials is set at the session level (AWSSessionToken)
For example, the following S3BucketCredentials is for an AWS bucket AWSBucket and a Pure Storage bucket PureStorageBucket and sets all possible properties:
ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "AWSBucket",
"accessKey": "<AK0>",
"secretAccessKey": "<SAK0>",
"sessionToken": "1234567890"
},
{
"bucket": "PureStorageBucket",
"accessKey": "<AK1>",
"secretAccessKey": "<SAK1>"
}
]';
This parameter is only visible to the superuser. Users can set this parameter at the session level with ALTER SESSION.
- S3EnableVirtualAddressing
- Boolean, specifies whether to rewrite S3 URLs to use virtual-hosted paths. For example, if you use AWS, the S3 URLs change to
bucketname.s3.amazonaws.com instead of s3.amazonaws.com/bucketname. This configuration setting takes effect only when you have specified a value for AWSEndpoint.
If you set AWSEndpoint to a FIPS-compliant S3 Endpoint, you must enable S3EnableVirtualAddressing in auth_params.conf:
AWSEndpoint = s3-fips.dualstack.us-east-1.amazonaws.com
S3EnableVirtualAddressing = 1
The value of this parameter does not affect how you specify S3 paths.
Default: 0 (disabled)
Note
As of September 30, 2020, AWS requires virtual address paths for newly created buckets.
- S3Proxy
- HTTP(S) proxy settings, if needed, a string in the following format:
http[s]://[user:password@]host[:port]
Default: "" (empty string)
- S3RequesterPays
- Boolean, specifies whether requester (instead of bucket owner) pays the cost of accessing data on the bucket. When true, the bucket owner is only responsible for paying the cost of storing the data, rather than all costs associated with the bucket; must be set in order to access S3 buckets configured as Requester Pays buckets. By setting this property to true, you are accepting the charges for accessing data. If not specified, the default value is false.
- S3ServerSideEncryption
- String, encryption algorithm to use when reading or writing to S3. The value depends on which type of encryption at rest is configured for S3:
-
AES256: Use for SSE-S3 encryption
-
aws:kms: Use for SSE-KMS encryption
-
Empty string (""): No encryption
SSE-C encryption does not use this parameter. Instead, see S3SseCustomerAlgorithm.
For details on using SSE parameters, see S3 object store.
Default: "" (no encryption)
- S3SseCustomerAlgorithm
- String, the encryption algorithm to use when reading or writing to S3 using SSE-C encryption. The only supported values are
AES256 and "".
For SSE-S3 and SSE-KMS, instead use S3ServerSideEncryption.
Default: "" (no encryption)
- S3SseCustomerKey
- If using SSE-C encryption, the client key for S3 access.
- S3SseKmsKeyId
- If using SSE-KMS encryption, the key identifier (not the key) to pass to the Key Management Server. Vertica must have permission to use the key, which is managed through KMS.
4.19 - SNS parameters
The following parameters configure Amazon Simple Notification Service (SNS) notifiers.
The following parameters configure Amazon Simple Notification Service (SNS) notifiers. These parameters can only be set at the database level and some, if unset, fall back to their equivalent S3 parameters.
Notifiers must be disabled and then reenabled for these parameters to take effect:
=> ALTER NOTIFIER sns_notifier DISABLE;
=> ALTER NOTIFIER sns_notifier ENABLE;
- SNSAuth (falls back to AWSAuth)
- ID and secret key for authentication, equivalent to the AccessKeyID and SecretAccessKey in AWS. For example:
=> ALTER DATABASE DEFAULT SET SNSAuth='myID:mySecret';
Default: "" (empty string)
- SNSCAFile (falls back to AWSCAFile)
File name of the TLS server certificate bundle to use. If set, this parameter overrides the Vertica default CA bundle path specified in the SystemCABundlePath parameter.
=> ALTER DATABASE DEFAULT SET SNSCAFile = '/etc/ssl/ca-bundle.pem';
Default: "" (empty string)
- SNSCAPath (falls back to AWSCAPath)
Path Vertica uses to look up TLS server certificate bundles. If set, this parameter overrides the Vertica default CA bundle path specified in the SystemCABundlePath parameter.
=> ALTER DATABASE DEFAULT SET SNSCAPath = '/etc/ssl/';
Default: "" (empty string)
- SNSEnableHttps
Boolean, specifies whether to use the HTTPS protocol when connecting to S3, can be set only at the database level with ALTER DATABASE. If you choose not to use TLS, this parameter must be set to 0.
Default: 1 (enabled)
- SNSEndpoint
- URL of the SNS API endpoint. If this parameter is set to an empty string and the region is specified (either by SNSRegion or its fallback to AWSRegion), Vertica automatically infers the appropriate endpoint.
If you use FIPS, you must manually specify a FIPS-compliant endpoint.
Default: "" (empty string)
- SNSRegion (falls back to AWSRegion)
- AWS region for the SNSEndpoint. This parameter can only be configured with one region at a time.
Default: "" (empty string)
4.20 - SQS parameters
The following parameters configure Amazon Simple Queue Service (SQS) access.
The following parameters configure access to Amazon Simple Queue Service (SQS) queues. SQS is used with CREATE DATA LOADER to automatically load data from a queue into Vertica. These parameters can be set at the database or session level and some, if unset, fall back to their equivalent S3 parameters.
- SQSAuth (falls back to AWSAuth)
- ID and secret key for authentication, equivalent to the AccessKeyID and SecretAccessKey in AWS. For example:
=> ALTER DATABASE DEFAULT SET SQSAuth='myID:mySecret';
Default: "" (empty string)
- SQSQueueCredentials
- Per-queue credentials for accessing SQS queues, a JSON array. When set, these values take precedence over SQSAuth.
Properties:
-
accessKey: Access key for the queue (the ID in AWSAuth)
-
secretAccessKey: Secret access key for the queue (the secret in AWSAuth)
-
sessionToken: AWS session token, only used when SQSQueueCredentials is set at the session level
The following example sets credentials for two queues:
=> ALTER SESSION SET SQSQueueCredentials='[
{"queue":"queue0","accessKey":"<AK0>","secretAccessKey":"<SAK0>","sessionToken":"1234567890"},
{"queue":"queue1","accessKey":"foo","secretAccessKey":"bar"}]';
Default: "" (empty string)
- SQSSessionToken
- Temporary, session-level SQS access token. Set this parameter in a user session using ALTER SESSION.
If you set a session token at the session level, you must also set SQSAuth at the session level, even if it is already set at the database level.
In general, SQSSessionToken should be set only at the session level. While you can set this parameter at the database level, session tokens are ephemeral, so when the database-level token expires, you must set it again either at the session or database level.
4.21 - Security parameters
Use these client authentication configuration parameters and general security parameters to configure TLS.
Use these client authentication configuration parameters and general security parameters to configure TLS.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
Database parameters
- DataSSLParams
- This parameter has been deprecated. Use the data_channel TLS Configuration instead.
Enables encryption using SSL on the data channel. The value of this parameter is a comma-separated list of the following:
-
An SSL certificate (chainable)
-
The corresponding SSL private key
-
The SSL CA (Certificate Authority) certificate.
You should set EncryptSpreadComm before setting this parameter.
In the following example, the SSL Certificate contains two certificates, where the certificate for the non-root CA verifies the certificate for the cluster. This is called an SSL Certificate Chain.
=> ALTER DATABASE DEFAULT SET PARAMETER DataSSLParams =
'----BEGIN CERTIFICATE-----<certificate for Cluster>-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----<certificate for non-root CA>-----END CERTIFICATE-----,
-----BEGIN RSA PRIVATE KEY-----<private key for Cluster>-----END RSA PRIVATE KEY-----,
-----BEGIN CERTIFICATE-----<certificate for public CA>-----END CERTIFICATE-----';
- DefaultIdleSessionTimeout
- Indicates a default session timeout value for all users where
IDLESESSIONTIMEOUT is not set. For example:
=> ALTER DATABASE DEFAULT SET defaultidlesessiontimeout = '300 secs';
- DHParams
-
Deprecated
This parameter has been deprecated and will be removed in a future release.
String, a Diffie-Hellman group of at least 2048 bits in the form:
-----BEGIN DH PARAMETERS-----...-----END DH PARAMETERS-----
You can generate your own or use the pre-calculated Modular Exponential (MODP) Diffie-Hellman groups specified in RFC 3526.
Changes to this parameter do not take effect until you restart the database.
Default: RFC 3526 2048-bit MODP Group 14:
-----BEGIN DH PARAMETERS-----MIIBCAKCAQEA///////////
JD9qiIWjCNMTGYouA3BzRKQJOCIpnzHQCC76mOxObIlFKCHmONAT
d75UZs806QxswKwpt8l8UN0/hNW1tUcJF5IW1dmJefsb0TELppjf
tawv/XLb0Brft7jhr+1qJn6WunyQRfEsf5kkoZlHs5Fs9wgB8uKF
jvwWY2kg2HFXTmmkWP6j9JM9fg2VdI9yjrZYcYvNWIIVSu57VKQd
wlpZtZww1Tkq8mATxdGwIyhghfDKQXkYuNs474553LBgOhgObJ4O
i7Aeij7XFXfBvTFLJ3ivL9pVYFxg5lUl86pVq5RXSJhiY+gUQFXK
OWoqsqmj//////////wIBAg==-----END DH PARAMETERS-----
- DisableInheritedPrivileges
- Boolean, whether to disable privilege inheritance at the database level (enabled by default).
- DoUserSpecificFilteringInSysTables
- Boolean, specifies whether a non-superuser can view details of another user:
Default: 0
- EnableAllRolesOnLogin
- Boolean, specifies whether to automatically enable all roles granted to a user on login:
-
0: Do not automatically enable roles
-
1: Automatically enable roles. With this setting, users do not need to run SET ROLE.
Default: 0 (disable)
- EnabledCipherSuites
- Specifies which SSL cipher suites to use for secure client-server communication. Changes to this parameter apply only to new connections.
Default: Vertica uses the Microsoft Schannel default cipher suites. For more information, see the Schannel documentation.
- EnableConnectCredentialForwarding
- When using CONNECT TO VERTICA, whether to use the password of the current user to authenticate to a target database.
Default: 0 (disable)
- EnableOAuth2JITCleanup
- If enabled, users created by just-in-time OAuth provisioning are automatically dropped if the user does not log in after the number of days specified by OAuth2UserExpiredInterval.
To view provisioned users, see USERS.
Default: 0 (disable)
- EncryptSpreadComm
- Enables Spread encryption on the control channel, set to one of the following strings:
-
vertica: Specifies that Vertica generates the Spread encryption key for the database cluster.
-
aws-kms|key-name, where key-name is a named key in the iAWS Key Management Service (KMS). On database restart, Vertica fetches the named key from the KMS instead of generating its own.
If the parameter is empty, Spread communication is unencrypted. In general, you should enable this parameter before modifying other security parameters.
Enabling this parameter requires database restart.
- GlobalHeirUsername
- A string that specifies which user inherits objects after their owners are dropped. This setting ensures preservation of data that would otherwise be lost.
Set this parameter to one of the following string values:
-
Empty string: Objects of dropped users are removed from the database.
-
username: Reassigns objects of dropped users to username. If username does not exist, Vertica creates that user and sets GlobalHeirUsername to it.
-
<auto>: Reassigns objects of dropped LDAP or just-in-time-provisioned users to the dbadmin user. The brackets (< and >) are required for this option.
For more information about usage, see Examples.
Default: <auto>
- ImportExportTLSMode
- When using CONNECT TO VERTICA to connect to another Vertica cluster for import or export, specifies the degree of stringency for using TLS. Possible values are:
-
PREFER: Try TLS but fall back to plaintext if TLS fails.
-
REQUIRE: Use TLS and fail if the server does not support TLS.
-
VERIFY_CA: Require TLS (as with REQUIRE), and also validate the other server's certificate using the CA specified by the "server" TLS Configuration's CA certificates (in this case, "ca_cert" and "ica_cert"):
=> SELECT name, certificate, ca_certificate, mode FROM tls_configurations WHERE name = 'server';
name | certificate | ca_certificate | mode
--------+------------------+--------------------+-----------
server | server_cert | ca_cert,ica_cert | VERIFY_CA
(1 row)
-
VERIFY_FULL: Require TLS and validate the certificate (as with VERIFY_CA), and also validate the server certificate's hostname.
-
REQUIRE_FORCE, VERIFY_CA_FORCE, and VERIFY_FULL_FORCE: Same behavior as REQUIRE, VERIFY_CA, and VERIFY_FULL, respectively, and cannot be overridden by CONNECT TO VERTICA.
Default: PREFER
- InternodeTLSConfig
- The TLS Configuration to use for internode encryption.
For example:
=> ALTER DATABASE DEFAULT SET InternodeTLSConfig = my_tls_config;
Default: data_channel
- LDAPAuthTLSConfig
- The TLS Configuration to use for TLS with LDAP authentication.
For example:
=> ALTER DATABASE DEFAULT SET LDAPAuthTLSConfig = my_tls_config;
Default: ldapauth
- LDAPLinkTLSConfig
- The TLS Configuration to use for TLS for the LDAP Link service.
For example:
=> ALTER DATABASE DEFAULT SET LDAPLinkTLSConfig = my_tls_config;
Default: ldaplink
- OAuth2JITClient
-
Deprecated
This parameter is deprecated. Use the OAuth2JITRolesClaimName parameter instead.
The client/application name that contains Vertica roles in the Keycloak identity provider. The Vertica roles under resource_access.OAuth2JITClient.roles are automatically granted to and set as default roles for users created by just-in-time provisioning. Roles that do not exist in Vertica are ignored.
For details, see Just-in-time user provisioning.
Default:
vertica
- OAuth2JITRolesClaimName
- Specifies an IdP client with one or more roles that correspond to a Vertica database role. During just-in-time user provisioning, each client role that matches an existing Vertica role is automatically assigned to the user. Roles that do not exist in Vertica are ignored.
For authentication records that use JWT validation, Vertica retrieves the client roles from the access token.
To retrieve client roles for authentication records that use IdP validation, Vertica sends a request to either the introspect_url or the userinfo_url set in the authentication record. This parameter requires the full path to the roles claim in that request. For example, the full path to the roles claim in a Keycloak request uses the following format:
resource_access.clientName.roles
For details, see Just-in-time user provisioning.
Default: resource_access.vertica.roles
- OAuth2JITForbiddenRoles
- Vertica database roles that you do not want Vertica to automatically assign to users during just-in-time provisioning. This parameter accepts one or more roles as a comma-separated list.
- OAuth2JITGroupsClaimName
- The name of the IdP group whose name or role mappings correspond to Vertica database roles. During just-in-time user provisioning, each group name or group role mapping that matches an existing Vertica role is automatically assigned to the user. Roles that do not exist in Vertica are ignored.
For authentication records that use JWT validation, Vertica retrieves the JIT-provisioned user's groups from the access token.
To retrieve the JIT-provisioned user's groups for authentication records that use IdP validation, Vertica sends a request to either the introspect_url or the userinfo_url set in the authentication record.
Default:
groups
- OAuth2UserExpiredInterval
- If EnableOAuthJITCleanup is enabled, users created by just-in-time OAuth provisioning are automatically dropped after not logging in for the number of days specified by OAuth2UserExpiredInterval. The number of days the user has not logged in is calculated relative to the
LAST_LOGIN_TIME column in the USERS system table.
Note
The LAST_LOGIN_TIME as recorded by the USERS system table is not persistent; if the database is restarted, the LAST_LOGIN_TIME for users created by just-in-time user provisioning is set to the database start time (this appears as an empty value in LAST_LOGIN_TIME).
You can view the database start time by querying the DATABASES system table:
=> SELECT database_name, start_time FROM databases;
database_name | start_time
---------------+-------------------------------
VMart | 2023-02-06 14:26:50.630054-05
(1 row)
Default: 14
- PasswordLockTimeUnit
- The time units for which an account is locked by
PASSWORD_LOCK_TIME after FAILED_LOGIN_ATTEMPTS, one of the following:
-
'd': days (default)
-
'h': hours
-
'm': minutes
-
's': seconds
For example, to configure the default profile to lock user accounts for 30 minutes after three unsuccessful login attempts:
=> ALTER DATABASE DEFAULT SET PasswordLockTimeUnit = 'm'
=> ALTER PROFILE DEFAULT LIMIT PASSWORD_LOCK_TIME 30;
- RequireFIPS
- Boolean, specifies whether the FIPS mode is enabled:
On startup, Vertica automatically sets this parameter from the contents of the file crypto.fips_enabled. You cannot modify this parameter.
For details, see FIPS compliance for the Vertica server.
Default: 0
- SecurityAlgorithm
- Sets the algorithm for the function that hash authentication uses, one of the following:
For example:
=> ALTER DATABASE DEFAULT SET SecurityAlgorithm = 'SHA512';
Default: SHA512
- ServerTLSConfig
- The TLS Configuration to use for client-server TLS.
For example:
=> ALTER DATABASE DEFAULT SET ServerTLSConfig = my_tls_config;
Default: server
- SystemCABundlePath
- The absolute path to a certificate bundle of trusted CAs. This CA bundle is used when establishing TLS connections to external services such as AWS or Azure through their respective SDKs and libcurl. The CA bundle file must be in the same location on all nodes.
If this parameter is empty, Vertica searches the "standard" paths for the CA bundles, which differs between distributions:
- Red Hat-based:
/etc/pki/tls/certs/ca-bundle.crt
- Debian-based:
/etc/ssl/certs/ca-certificates.crt
- SUSE:
/var/lib/ca-certificates/ca-bundle.pem
Example:
=> ALTER DATABASE DEFAULT SET SystemCABundlePath = 'path/to/ca_bundle.pem';
Default: Empty
TLS parameters
To set your Vertica database's TLSMode, private key, server certificate, and CA certificate(s), see TLS configurations. In versions prior to 11.0.0, these parameters were known as EnableSSL, SSLPrivateKey, SSLCertificate, and SSLCA, respectively.
Examples
Set the database parameter GlobalHeirUsername:
=> \du
List of users
User name | Is Superuser
-----------+--------------
Joe | f
SuzyQ | f
dbadmin | t
(3 rows)
=> ALTER DATABASE DEFAULT SET PARAMETER GlobalHeirUsername='SuzyQ';
ALTER DATABASE
=> \c - Joe
You are now connected as user "Joe".
=> CREATE TABLE t1 (a int);
CREATE TABLE
=> \c
You are now connected as user "dbadmin".
=> \dt t1
List of tables
Schema | Name | Kind | Owner | Comment
--------+------+-------+-------+---------
public | t1 | table | Joe |
(1 row)
=> DROP USER Joe;
NOTICE 4927: The Table t1 depends on User Joe
ROLLBACK 3128: DROP failed due to dependencies
DETAIL: Cannot drop User Joe because other objects depend on it
HINT: Use DROP ... CASCADE to drop the dependent objects too
=> DROP USER Joe CASCADE;
DROP USER
=> \dt t1
List of tables
Schema | Name | Kind | Owner | Comment
--------+------+-------+-------+---------
public | t1 | table | SuzyQ |
(1 row)
4.22 - Stored procedure parameters
The following parameters configure the behavior of stored procedures and triggers.
The following parameters configure the behavior of stored procedures and triggers.
- EnableNestedStoredProcedures
- Boolean, whether to enable nested stored procedures.
Default: 0
- EnableStoredProcedureScheduler
- Boolean, whether to enable the scheduler. For details, see Scheduled execution.
Default: 1
- PLvSQLCoerceNull
- Boolean, whether to allow NULL-to-false type coercion to improve compatibility with PLpgSQL. For details, see PL/pgSQL to PL/vSQL migration guide.
Default: 0
4.23 - Text search parameters
You can configure Vertica for text search using the following parameter.
You can configure Vertica for text search using the following parameter.
- TextIndexMaxTokenLength
- Controls the maximum size of a token in a text index.
For example:
ALTER DATABASE database_name SET PARAMETER TextIndexMaxTokenLength=760;
If the parameter is set to a value greater than 65000 characters, then the tokenizer truncates the token at 65000 characters.
Caution
Avoid setting this parameter near its maximum value, 65000. Doing so can result in a significant decrease in performance. For optimal performance, set this parameter to the maximum token value of your tokenizer.
Default: 128 (characters)
4.24 - Tuple mover parameters
These parameters control how the operates.
These parameters control how the Tuple Mover operates.
Query the
CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
- ActivePartitionCount
- Sets the number of active partitions. The active partitions are those most recently created. For example:
=> ALTER DATABASE DEFAULT SET ActivePartitionCount = 2;
For information about how the Tuple Mover treats active and inactive partitions during a mergeout operation, see Partition mergeout.
Default: 1
- CancelTMTimeout
- When partition, copy table, and rebalance operations encounter a conflict with an internal Tuple Mover job, those operations attempt to cancel the conflicting Tuple Mover job. This parameter specifies the amount of time, in seconds, that the blocked operation waits for the Tuple Mover cancellation to take effect. If the operation is unable to cancel the Tuple Mover job within limit specified by this parameter, the operation displays an error and rolls back.
Default: 300
- EnableTMOnRecoveringNode
- Boolean, specifies whether Tuple Mover performs mergeout activities on nodes with a node state of RECOVERING. Enabling Tuple Mover reduces the number of ROS containers generated during recovery. Having fewer than 1024 ROS containers per projection allows Vertica to maintain optimal recovery performance.
Default: 1 (enabled)
- MaxMrgOutROSSizeMB
- Specifies in MB the maximum size of ROS containers that are candidates for mergeout operations. The Tuple Mover avoids merging ROS containers that are larger than this setting.
Note
After a
rebalance operation, Tuple Mover groups ROS containers in batches that are smaller than MaxMrgOutROSSizeMB. ROS containers that are larger than MaxMrgOutROSSizeMB are merged individually
Default: -1 (no maximum limit)
- MergeOutInterval
- Specifies in seconds how frequently the Tuple Mover checks the mergeout request queue for pending requests:
-
If the queue contains mergeout requests, the Tuple Mover does nothing and goes back to sleep.
-
If the queue is empty, the Tuple Mover:
It then goes back to sleep.
Default: 600
- PurgeMergeoutPercent
- Specifies as a percentage the threshold of deleted records in a ROS container that invokes an automatic mergeout operation, to purge those records. Vertica only counts the number of 'aged-out' delete vectors—that is, delete vectors that are as 'old' or older than the ancient history mark (AHM) epoch.
This threshold applies to all ROS containers for non-partitioned tables. It also applies to ROS containers of all inactive partitions. In both cases, aged-out delete vectors are permanently purged from the ROS container.
Note
This configuration parameter only applies to automatic mergeout operations. It does not apply to manual mergeout operations that are invoked by calling meta-functions
DO_TM_TASK('mergeout') and
PURGE.
Default: 20 (percent)
5 - File systems and object stores
Vertica supports access to several file systems and object stores in addition to the Linux file system.
Vertica supports access to several file systems and object stores in addition to the Linux file system. The reference pages in this section provide information on URI syntax, configuration parameters, and authentication.
Vertica accesses the file systems in this section in one of two ways:
-
If user-provided credentials are present, Vertica uses them to access the storage. Note that on HDFS, user credentials are always present because Vertica accesses HDFS using the Vertica user identity.
-
If user-provided credentials are not present, or if the UseServerIdentityOverUserIdentity configuration parameter is set, Vertica checks for a configured USER storage location. When access is managed through USER storage locations, Vertica uses the server credential to access the file system. For more information about USER storage locations, see CREATE LOCATION.
Not all file systems are supported in all contexts. See the documentation of specific features for the file systems those features support.
5.1 - Azure Blob Storage object store
Azure has several interfaces for accessing data.
Azure has several interfaces for accessing data. Vertica reads and always writes Block Blobs in Azure Storage. Vertica can read external data created using ADLS Gen2, and data that Vertica exports can be read using ADLS Gen2.
One of the following:
-
azb://account/container/path
-
azb://[account@]host[:port]/container/path
In the first version, a URI like 'azb://myaccount/mycontainer/path' treats the first token after the '//' as the account name. In the second version, you can specify account and must specify host explicitly.
The following rules apply to the second form:
- If
account is not specified, the first label of the host is used. For example, if the URI is 'azb://myaccount.blob.core.windows.net/mycontainer/my/object', then 'myaccount' is used for account.
- If
account is not specified and host has a single label and no port, the endpoint is host.blob.core.windows.net. Otherwise, the endpoint is the host and port specified in the URI.
The protocol (HTTP or HTTPS) is specified in the AzureStorageEndpointConfig configuration parameter.
Authentication
If you are using Azure managed identities, no further configuration in Vertica is needed. If your Azure storage uses multiple managed identities, you must tag the one to be used. Vertica looks for an Azure tag with a key of VerticaManagedIdentityClientId, the value of which must be the client_id attribute of the managed identity to be used. If you update the Azure tag, call AZURE_TOKEN_CACHE_CLEAR.
If you are not using managed identities, use the AzureStorageCredentials configuration parameter to provide credentials to Azure. If loading data, you can set the parameter at the session level. If using Eon Mode communal storage on Azure, you must set this configuration parameter at the database level.
In Azure you must also grant access to the containers for the identities used from Vertica.
Configuration parameters
The following database configuration parameters apply to the Azure blob file system. You can set parameters at different levels with the appropriate ALTER statement, such as ALTER SESSION...SET PARAMETER. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
- AzureStorageCredentials
- Collection of JSON objects, each of which specifies connection credentials for one endpoint. This parameter takes precedence over Azure managed identities.
The collection must contain at least one object and may contain more. Each object must specify at least one of accountName or blobEndpoint, and at least one of accountKey or sharedAccessSignature.
accountName: If not specified, uses the label of blobEndpoint.blobEndpoint: Host name with optional port (host:port). If not specified, uses account.blob.core.windows.net.accountKey: Access key for the account or endpoint.sharedAccessSignature: Access token for finer-grained access control, if being used by the Azure endpoint.
- AzureStorageEndpointConfig
- Collection of JSON objects, each of which specifies configuration elements for one endpoint. Each object must specify at least one of
accountName or blobEndpoint.
accountName: If not specified, uses the label of blobEndpoint.blobEndpoint: Host name with optional port (host:port). If not specified, uses account.blob.core.windows.net.protocol: HTTPS (default) or HTTP.isMultiAccountEndpoint: true if the endpoint supports multiple accounts, false otherwise (default is false). To use multiple-account access, you must include the account name in the URI. If a URI path contains an account, this value is assumed to be true unless explicitly set to false.
Examples
The following examples use these values for the configuration parameters. AzureStorageCredentials contains sensitive information and is set at the session level in this example.
=> ALTER SESSION SET AzureStorageCredentials =
'[{"accountName": "myaccount", "accountKey": "REAL_KEY"},
{"accountName": "myaccount", "blobEndpoint": "localhost:8080", "accountKey": "TEST_KEY"}]';
=> ALTER DATABASE default SET AzureStorageEndpointConfig =
'[{"accountName": "myaccount", "blobEndpoint": "localhost:8080", "protocol": "http"}]';
The following example creates an external table using data from Azure. The URI specifies an account name of "myaccount".
=> CREATE EXTERNAL TABLE users (id INT, name VARCHAR(20))
AS COPY FROM 'azb://myaccount/mycontainer/my/object/*';
Vertica uses AzureStorageEndpointConfig and the account name to produce the following location for the files:
https://myaccount.blob.core.windows.net/mycontainer/my/object/*
Data is accessed using the REAL_KEY credential.
If the URI in the COPY statement is instead azb://myaccount.blob.core.windows.net/mycontainer/my/object, then the resulting location is https://myaccount.blob.core.windows.net/mycontainer/my/object, again using the REAL_KEY credential.
However, if the URI in the COPY statement is azb://myaccount@localhost:8080/mycontainer/my/object, then the host and port specify a different endpoint: http://localhost:8080/myaccount/mycontainer/my/object. This endpoint is configured to use a different credential, TEST_KEY.
5.2 - Google Cloud Storage (GCS) object store
File system using the Google Cloud Storage platform.
File system using the Google Cloud Storage platform.
gs://bucket/path
Authentication
To access data in Google Cloud Storage (GCS) you must first do the following tasks:
-
Create a default project, obtain a developer key, and enable S3 interoperability mode as described in the GCS documentation.
-
Set the GCSAuth configuration parameter as in the following example.
=> ALTER SESSION SET GCSAuth='id:secret';
Configuration parameters
The following database configuration parameters apply to the GCS file system. You can set parameters at different levels with the appropriate ALTER statement, such as ALTER SESSION...SET PARAMETER. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter. For information about all parameters related to GCS, see Google Cloud Storage parameters.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
- GCSAuth
- An ID and secret key to authenticate to GCS. For extra security, do not store credentials in the database; instead, use ALTER SESSION...SET PARAMETER to set this value for the current session only.
- GCSEnableHttps
- Boolean, whether to use the HTTPS protocol when connecting to GCS, can be set only at the database level with ALTER DATABASE...SET PARAMETER.
Default: 1 (enabled)
- GCSEndpoint
- The connection endpoint address.
Default: storage.googleapis.com
Examples
The following example loads data from GCS:
=> ALTER SESSION SET GCSAuth='my_id:my_secret_key';
=> COPY t FROM 'gs://DataLake/clicks.parquet' PARQUET;
5.3 - HDFS file system
HDFS is the Hadoop Distributed File System.
HDFS is the Hadoop Distributed File System. You can use the webhdfs and swebhdfs schemes to access data through the WebHDFS service. Vertica also supports the hdfs scheme, which by default uses WebHDFS. To have hdfs URIs use the deprecated LibHDFS++ package, set the HDFSUseWebHDFS configuration parameter to 0 (disabled).
If you specify a webhdfs URI but the Hadoop HTTP policy (dfs.http.policy) is set to HTTPS_ONLY, Vertica automatically uses swebhdfs instead.
If you use LibHDFS++, the WebHDFS service must still be available because Vertica falls back to WebHDFS for operations not supported by LibHDFS++.
Deprecated
Support for LibHDFS++ is deprecated. In the future, HDFSUseWebHDFS will be enabled in all cases and hdfs URIs will be equivalent to webhdfs URIs.
URIs in the webhdfs, swebhdfs, and hdfs schemes all have two formats, depending on whether you specify a name service or the host and port of a name node:
-
[[s]web]hdfs://[nameservice]/path
-
[[s]web]hdfs://namenode-host:port/path
Characters may be URL-encoded (%NN where NN is a two-digit hexadecimal number) but are not required to be, except that the '%' character must be encoded.
To use the default name service specified in the HDFS configuration files, omit nameservice. Use this shorthand only for reading external data, not for creating a storage location.
Always specify a name service or host explicitly when using Vertica with more than one HDFS cluster. The name service or host name must be globally unique. Using [web]hdfs:/// could produce unexpected results because Vertica uses the first value of fs.defaultFS that it finds.
Authentication
Vertica can use Kerberos authentication with Cloudera or Hortonworks HDFS clusters. See Accessing kerberized HDFS data.
For loading and exporting data, Vertica can access HDFS clusters protected by mTLS through the swebhdfs scheme. You must create a certificate and key and set the WebhdfsClientCertConf configuration parameter.
You can use CREATE KEY and CREATE CERTIFICATE to create temporary, session-scoped values if you specify the TEMPORARY keyword. Temporary keys and certificates are stored in memory, not on disk.
The WebhdfsClientCertConf configuration parameter holds client credentials for one or more HDFS clusters. The value is a JSON string listing name services or authorities and their corresponding keys. You can set the configuration parameter at the session or database level. Setting the parameter at the database level has the following additional requirements:
The following example shows how to use mTLS. The key and certificate values themselves are not shown, just the beginning and end markers:
=> CREATE TEMPORARY KEY client_key TYPE 'RSA'
AS '-----BEGIN PRIVATE KEY-----...-----END PRIVATE KEY-----';
-> CREATE TEMPORARY CERTIFICATE client_cert
AS '-----BEGIN CERTIFICATE-----...-----END CERTIFICATE-----' key client_key;
=> ALTER SESSION SET WebhdfsClientCertConf =
'[{"authority": "my.hdfs.namenode1:50088", "certName": "client_cert"}]';
=> COPY people FROM 'swebhdfs://my.hdfs.namenode1:50088/path/to/file/1.txt';
Rows Loaded
-------------
1
(1 row)
To configure access to more than one HDFS cluster, define the keys and certificates and then include one object per cluster in the value of WebhdfsClientCertConf:
=> ALTER SESSION SET WebhdfsClientCertConf =
'[{"authority" : "my.authority.com:50070", "certName" : "myCert"},
{"nameservice" : "prod", "certName" : "prodCert"}]';
Configuration parameters
The following database configuration parameters apply to the HDFS file system. You can set parameters at different levels with the appropriate ALTER statement, such as ALTER SESSION...SET PARAMETER. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter. For information about all parameters related to Hadoop, see Hadoop parameters.
- EnableHDFSBlockInfoCache
- Boolean, whether to distribute block location metadata collected during planning on the initiator to all database nodes for execution, reducing name node contention. Disabled by default.
- HadoopConfDir
- Directory path containing the XML configuration files copied from Hadoop. The same path must be valid on every Vertica node. The files are accessed by the Linux user under which the Vertica server process runs.
- HadoopImpersonationConfig
- Session parameter specifying the delegation token or Hadoop user for HDFS access. See HadoopImpersonationConfig format for information about the value of this parameter and Proxy users and delegation tokens for more general context.
- HDFSUseWebHDFS
- Boolean. If true (the default), URIs in the
hdfs scheme are treated as if they were in the webhdfs scheme. If false, Vertica uses LibHDFS++ where possible, though some operations can still use WebHDFS if not supported by LibHDFS++.
- WebhdfsClientCertConf
- mTLS configurations for accessing one or more WebHDFS servers, a JSON string. Each object must specify either a
nameservice or authority field and a certName field. See Authentication.
Configuration files
The path specified in HadoopConfDir must include a directory containing the files listed in the following table. Vertica reads these files at database start time. If you do not set a value, Vertica looks for the files in /etc/hadoop/conf.
If a property is not defined, Vertica uses the defaults shown in the table. If no default is specified for a property, the configuration files must specify a value.
|
File |
Properties |
Default |
|
core-site.xml |
fs.defaultFS |
none |
|
|
(for doAs users:) hadoop.proxyuser.username.users |
none |
|
|
(for doAs users:) hadoop.proxyuser.username.hosts |
none |
|
hdfs-site.xml |
dfs.client.failover.max.attempts |
15 |
|
|
dfs.client.failover.sleep.base.millis |
500 |
|
|
dfs.client.failover.sleep.max.millis |
15000 |
|
|
(For HA NN:) dfs.nameservices |
none |
|
|
(WebHDFS:) dfs.namenode.http-address or dfs.namenode.https-address |
none |
|
|
(WebHDFS:) dfs.datanode.http.address or dfs.datanode.https.address |
none |
|
|
(WebHDFS:) dfs.http.policy |
HTTP_ONLY |
If using High Availability (HA) Name Nodes, the individual name nodes must also be defined in hdfs-site.xml.
Note
If you are using Eon Mode with communal storage on HDFS, then if you set dfs.encrypt.data.transfer you must use the swebhdfs scheme for communal storage.
To verify that Vertica can find configuration files in HadoopConfDir, use the VERIFY_HADOOP_CONF_DIR function.
To test access through the hdfs scheme, use the HDFS_CLUSTER_CONFIG_CHECK function.
For more information about testing your configuration, see Verifying HDFS configuration.
To reread the configuration files, use the CLEAR_HDFS_CACHES function.
Name nodes and name services
You can access HDFS data using the default name node by not specifying a name node or name service:
=> COPY users FROM 'webhdfs:///data/users.csv';
Vertica uses the fs.defaultFS Hadoop configuration parameter to find the name node. (It then uses that name node to locate the data.) You can instead specify a host and port explicitly using the following format:
webhdfs://nn-host:nn-port/
The specified host is the name node, not an individual data node. If you are using High Availability (HA) Name Nodes you should not use an explicit host because high availability is provided through name services instead.
If the HDFS cluster uses High Availability Name Nodes or defines name services, use the name service instead of the host and port, in the format webhdfs://nameservice/. The name service you specify must be defined in hdfs-site.xml.
The following example shows how you can use a name service, hadoopNS:
=> CREATE EXTERNAL TABLE users (id INT, name VARCHAR(20))
AS COPY FROM 'webhdfs://hadoopNS/data/users.csv';
If you are using Vertica to access data from more than one HDFS cluster, always use explicit name services or hosts in the URL. Using the /// shorthand could produce unexpected results because Vertica uses the first value of fs.defaultFS that it finds. To access multiple HDFS clusters, you must use host and service names that are globally unique. See Configuring HDFS access for more information.
5.4 - S3 object store
File systems using the S3 protocol, including AWS, Pure Storage, and MinIO.
File systems using the S3 protocol, including AWS, Pure Storage, and MinIO.
s3://bucket/path
For AWS, specify the region using the AWSRegion configuration parameter, not the URI. If the region is incorrect, you might experience a delay before the load fails because Vertica retries several times before giving up. The default region is us-east-1.
Authentication
For AWS:
-
To access S3 you must create an IAM role and grant that role permission to access your S3 resources.
-
By default, bucket access is restricted to the communal storage bucket. Use an AWS access key to load data from non-communal storage buckets.
-
Either set the AWSAuth configuration parameter to provide credentials or create a USER storage location for the S3 path (see CREATE LOCATION) and grant users access.
-
You can use AWS STS temporary session tokens to load data. Because they are session tokens, do not use them for access to storage locations.
-
You can configure S3 buckets individually with the per-bucket parameters S3BucketConfig and S3BucketCredentials. For details, see Per-bucket S3 configurations.
Configuration parameters
The following database configuration parameters apply to the S3 file system. You can set parameters at different levels with the appropriate ALTER statement, such as ALTER SESSION...SET PARAMETER. Query the CONFIGURATION_PARAMETERS system table to determine what levels (node, session, user, database) are valid for a given parameter.
You can configure individual buckets using the S3BucketConfig and S3BucketCredentials parameters instead of the global parameters.
For external tables using highly partitioned data in an object store, see the ObjectStoreGlobStrategy configuration parameter and Partitions on Object Stores.
The following descriptions are summaries. For details about all parameters specific to S3, see S3 parameters.
- AWSAuth
- An ID and secret key for authentication. AWS calls these AccessKeyID and SecretAccessKey. For extra security, do not store credentials in the database; use ALTER SESSION...SET PARAMETER to set this value for the current session only.
- AWSCAFile
- The file name of the TLS server certificate bundle to use. You must set a value when installing a CA certificate on a SUSE Linux Enterprise Server.
- AWSCAPath
- The path Vertica uses to look up TLS server certificates. You must set a value when installing a CA certificate on a SUSE Linux Enterprise Server.
- AWSEnableHttps
- Boolean, whether to use the HTTPS protocol when connecting to S3. Can be set only at the database level. You can set the prototol for individual buckets using S3BucketConfig.
Default: 1 (enabled)
- AWSEndpoint
- String, the endpoint host for all S3 URLs, set as follows:
-
AWS: hostname_or_IP:port. Do not include the scheme (http(s)).
-
AWS with a FIPS-compliant S3 Endpoint: Hostname of a FIPS-compliant S3 endpoint. You must also enable S3EnableVirtualAddressing.
-
On-premises/Pure: IP address of the Pure Storage server.
If not set, Vertica uses virtual-hosted request URLs.
Default: 's3.amazonaws.com'
- AWSLogLevel
- The log level, one of: OFF, FATAL, ERROR, WARN, INFO, DEBUG, or TRACE.
Default: ERROR
- AWSRegion
- The AWS region containing the S3 bucket from which to read files. This parameter can only be configured with one region at a time. Failure to set the correct region can lead to a delay before queries fail.
Default: 'us-east-1'
- AWSSessionToken
- A temporary security token generated by running the
get-session-token command, used to configure multi-factor authentication.
Note
If you use session tokens at the session level, you must set all parameters at the session level, even if some of them are set at the database level.
- AWSStreamingConnectionPercentage
- In Eon Mode, the number of connections to the communal storage to use for streaming reads. In a cloud environment, this setting helps prevent streaming data from using up all available file handles. This setting is unnecessary when using on-premises object stores because of their lower latency.
- S3BucketConfig
- A JSON array of objects specifying per-bucket configuration overrides. Each property other than the bucket name has a corresponding configuration parameter (shown in parentheses). If both the database-level parameter and its equivalent in S3BucketConfig are set, the value in S3BucketConfig takes precedence.
Properties:
-
bucket: Bucket name
-
region (AWSRegion)
-
protocol (AWSEnableHttp): Connection protocol, one of http or https
-
endpoint (AWSEndpoint)
-
enableVirtualAddressing (S3BucketCredentials): Boolean, whether to rewrite the S3 URL to use a virtual hosted path
-
requesterPays (S3RequesterPays)
-
serverSideEncryption (S3ServerSideEncryption)
-
sseCustomerAlgorithm (S3SseCustomerAlgorithm)
-
sseCustomerKey (S3SseCustomerKey)
-
sseKmsKeyId (S3SseKmsKeyId)
-
proxy (S3Proxy)
- S3BucketCredentials
- A JSON object specifying per-bucket credentials. Each property other than the bucket name has a corresponding configuration parameter. If both the database-level parameter and its equivalent in S3BucketCredentials are set, the value in S3BucketCredentials takes precedence.
Properties:
-
bucket: Bucket name
-
accessKey: Access key for the bucket (the ID in AWSAuth)
-
secretAccessKey: Secret access key for the bucket (the secret in AWSAuth)
-
sessionToken: Session token, only used when S3BucketCredentials is set at the session level (AWSSessionToken)
This parameter is only visible to superusers. Users can set this parameter at the session level with ALTER SESSION.
- S3EnableVirtualAddressing
- Boolean, whether to rewrite S3 URLs to use virtual-hosted paths (disabled by default). This configuration setting takes effect only when you have specified a value for AWSEndpoint.
If you set AWSEndpoint to a FIPS-compliant S3 endpoint, you must enable S3EnableVirtualAddressing.
The value of this parameter does not affect how you specify S3 paths.
- S3Proxy
- HTTP(S) proxy settings, if needed, a string in the following format:
http[s]://[user:password@]host[:port].
- S3RequesterPays
- Boolean, whether requester (instead of bucket owner) pays the cost of accessing data on the bucket.
- S3ServerSideEncryption
- String, encryption algorithm to use when reading or writing to S3. Supported values are
AES256 (for SSE-S3), aws:kms (for SSE-KMS), and an empty string (for no encryption). See Server-Side Encryption.
Default: "" (no encryption)
- S3SseCustomerAlgorithm
- String, the encryption algorithm to use when reading or writing to S3 using SSE-C encryption. The only supported values are
AES256 and "". For SSE-S3 and SSE-KMS, instead use S3ServerSideEncryption.
Default: "" (no encryption)
- S3SseCustomerKey
- If using SSE-C encryption, the client key for S3 access.
- S3SseKmsKeyId
- If using SSE-KMS encryption, the key identifier (not the key) to pass to the Key Management Service. Vertica must have permission to use the key, which is managed through KMS.
By default, Vertica performs writes using a single thread, but a single write usually includes multiple files or parts of files. For writes to S3, you can use a larger thread pool to perform writes in parallel. This thread pool is used for all file writes to S3, including file exports and writes to communal storage.
The size of the thread pool is controlled by the ObjStoreUploadParallelism configuration parameter. Each node has a single thread pool used for all file writes. In general, one or two threads per concurrent writer produces good results.
Server-side encryption
By default, Vertica reads and writes S3 data that is not encrypted. If the S3 bucket uses server-side encryption (SSE), you can configure Vertica to access it. S3 supports three types of server-side encryption: SSE-S3, SSE-KMS, and SSE-C.
Vertica must also have read or write permissions (depending on the operation) on the bucket.
SSE-S3
With SSE-S3, the S3 service manages encryption keys. Reads do not require additional configuration. To write to S3, the client (Vertica, in this case) must specify only the encryption algorithm.
If the S3 bucket is configured with the default encryption settings, Vertica can read and write data to them with no further changes. If the bucket does not use the default encryption settings, set the S3ServerSideEncryption configuration parameter or the serverSideEncryption field in S3BucketConfig to AES256.
SSE-KMS
With SSE-KMS, encryption keys are managed by the Key Management Service (KMS). The client must supply a KMS key identifier (not the actual key) when writing data. For all operations, the client must have permission to use the KMS key. These permissions are managed in KMS, not in Vertica.
To use SSE-KMS:
-
Set the S3ServerSideEncryption configuration parameter or the serverSideEncryption field in S3BucketConfig to aws:kms.
-
Set the S3SseKmsKeyId configuration parameter or the sseKmsKeyId field in S3BucketConfig to the key ID.
SSE-C
With SSE-C, the client manages encryption keys and provides them to S3 for each operation.
To use SSE-C:
-
Set the S3SseCustomerAlgorithm configuration parameter or the sseCustomerAlgorithm field in S3BucketConfig to AES256.
-
Set the S3SseCustomerKey configuration parameter or the sseCustomerKey field in S3BucketConfig to the access key. The value can be either a 32-character plaintext key or a 44-character base64-encoded key.
HTTP(S) logging (AWS)
When a request to AWS fails or is retried, or Vertica detects a performance degradation, Vertica logs the event in the UDFS_EVENTS system table. The event type for these records is HttpRequestAttempt, and the description is a JSON object with more details. For example:
=> SELECT filesystem, event, description FROM UDFS_EVENTS;
filesystem | event | description
------------+---------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------
S3 | HttpRequestAttempt | {"AttemptStartTimeGMT":"2024-01-18 16:45:52.663","RetryCount":0,"HttpMethod":"GET","URIString":"s3://mybucket/s3_2.dat","AmzRequestId":"79104EXAMPLEB723","AmzId2":"IOWQ4fDEXAMPLEQM+ey7N9WgVhSnQ6JEXAMPLEZb7hSQDASK+Jd1vEXAMPLEa3Km","HttpStatusCode":404,"HttpRequestLatency":2,"SdkExceptionMessage":"No response body."}
S3 | HttpRequestAttempt | {"AttemptStartTimeGMT":"2024-01-18 16:46:02.663","RetryCount":1,"HttpMethod":"GET","URIString":"s3://mybucket/s3_2.dat","AmzRequestId":"79104EXAMPLEB791","AmzId2":"JPXQ4fDEXAMPLEQM+ey7N9WgVhSnQ6JEXAMPLEZb7hSQDASK+Jd1vEXAMPLEa4Ln","HttpStatusCode":206,"HttpRequestLatency":1}
(2 rows)
To extract fields from this description, use the MAPJSONEXTRACTOR function:
=> SELECT filesystem, event,
(MapJSONExtractor(description))['RetryCount'] as RetryCount,
(MapJSONExtractor(description))['HttpStatusCode'] as HttpStatusCode
FROM UDFS_EVENTS;
filesystem | event | RetryCount | HttpStatusCode
------------+---------------------+------------+-----------------
S3 | HttpRequestAttempt | 0 | 404
S3 | HttpRequestAttempt | 1 | 206
(2 rows)
For details on AWS-specific fields such as AmzRequestId, see the AWS documentation.
The UDFS_STATISTICS system table records the accumulated duration for all HTTP requests in the TOTAL_REQUEST_DURATION_MS column. This table also provides computed values for average duration and throughput.
Examples
The following example sets a database-wide AWS region and credentials:
=> ALTER DATABASE DEFAULT SET AWSRegion='us-west-1';
=> ALTER DATABASE DEFAULT SET AWSAuth = 'myaccesskeyid123456:mysecretaccesskey123456789012345678901234';
The following example loads data from S3. You can use a glob if all files in the glob can be loaded together. In the following example, AWS_DataLake contains only ORC files.
=> COPY t FROM 's3://datalake/*' ORC;
You can specify a list of comma-separated S3 buckets as in the following example. All buckets must be in the same region. To load from more than one region, use separate COPY statements and change the value of AWSRegion between calls.
=> COPY t FROM 's3://AWS_Data_1/sales.parquet', 's3://AWS_Data_2/sales.parquet' PARQUET;
The following example creates a user storage location and a role, so that users without their own S3 credentials can read data from S3 using the server credential.
--- set database-level credential (once):
=> ALTER DATABASE DEFAULT SET AWSAuth = 'myaccesskeyid123456:mysecretaccesskey123456789012345678901234';
=> CREATE LOCATION 's3://datalake' SHARED USAGE 'USER' LABEL 's3user';
=> CREATE ROLE ExtUsers;
--- Assign users to this role using GRANT (Role).
=> GRANT READ ON LOCATION 's3://datalake' TO ExtUsers;
The configuration properties for a given bucket may differ based on its type. The following S3BucketConfig setting is for an AWS bucket (AWSBucket) and a Pure Storage bucket (PureStorageBucket). AWSBucket doesn't specify an endpoint, so Vertica uses the AWSEndpoint configuration parameter, which defaults to s3.amazonaws.com:
=> ALTER DATABASE DEFAULT SET S3BucketConfig=
'[
{
"bucket": "AWSBucket",
"region": "us-east-2",
"protocol": "https",
"requesterPays": true,
"serverSideEncryption": "aes256"
},
{
"bucket": "PureStorageBucket",
"endpoint": "pure.mycorp.net:1234",
"protocol": "http",
"enableVirtualAddressing": false
}
]';
The following example sets S3BucketCredentials for these two buckets:
=> ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "AWSBucket",
"accessKey": "<AK0>",
"secretAccessKey": "<SAK0>",
"sessionToken": "1234567890"
},
{
"bucket": "PureStorageBucket",
"accessKey": "<AK1>",
"secretAccessKey": "<SAK1>"
}
]';
The following example sets an STS temporary session token. Vertica uses the session token to access S3 with the specified credentials and bypasses checking for a USER storage location.
$ aws sts get-session-token
{
"Credentials": {
"AccessKeyId": "ASIAJZQNDVS727EHDHOQ",
"SecretAccessKey": "F+xnpkHbst6UPorlLGj/ilJhO5J2n3Yo7Mp4vYvd",
"SessionToken": "FQoDYXdzEKv//////////wEaDMWKxakEkCyuDH0UjyKsAe6/3REgW5VbWtpuYyVvSnEK1jzGPHi/jPOPNT7Kd+ftSnD3qdaQ7j28SUW9YYbD50lcXikz/HPlusPuX9sAJJb7w5oiwdg+ZasIS/+ejFgCzLeNE3kDAzLxKKsunvwuo7EhTTyqmlLkLtIWu9zFykzrR+3Tl76X7EUMOaoL31HOYsVEL5d9I9KInF0gE12ZB1yN16MsQVxpSCavOFHQsj/05zbxOQ4o0erY1gU=",
"Expiration": "2018-07-18T05:56:33Z"
}
}
$ vsql
=> ALTER SESSION SET AWSAuth = 'ASIAJZQNDVS727EHDHOQ:F+xnpkHbst6UPorlLGj/ilJhO5J2n3Yo7Mp4vYvd';
=> ALTER SESSION SET AWSSessionToken = 'FQoDYXdzEKv//////////wEaDMWKxakEkCyuDH0UjyKsAe6/3REgW5VbWtpuYyVvSnEK1jzGPHi/jPOPNT7Kd+ftSnD3qdaQ7j28SUW9YYbD50lcXikz/HPlusPuX9sAJJb7w5oiwdg+ZasIS/+ejFgCzLeNE3kDAzLxKKsunvwuo7EhTTyqmlLkLtIWu9zFykzrR+3Tl76X7EUMOaoL31HOYsVEL5d9I9KInF0gE12ZB1yN16MsQVxpSCavOFHQsj/05zbxOQ4o0erY1gU=';
See also
Per-Bucket S3 Configurations
5.4.1 - Per-bucket S3 configurations
You can manage configurations and credentials for individual buckets with the S3BucketConfig and S3BucketCredentials configuration parameters.
You can manage configurations and credentials for individual buckets with the S3BucketConfig and S3BucketCredentials configuration parameters. These parameters each take a JSON object, whose respective properties behave like the related S3 configuration parameters.
For example, you can create a different configuration for each of your S3 buckets by setting S3BucketConfig at the database level with ALTER DATABASE. The following S3BucketConfig specifies several common bucket properties:
=> ALTER DATABASE DEFAULT SET S3BucketConfig='
[
{
"bucket": "exampleAWS",
"region": "us-east-2",
"protocol": "https",
"requesterPays": true
},
{
"bucket": "examplePureStorage",
"endpoint": "pure.mycorp.net:1234",
"protocol": "http",
"enableVirtualAddressing": false
}
]';
Users can then access a bucket by setting S3BucketCredentials at the session level with ALTER SESSION. The following S3BucketCredentials specifies all properties and authenticates to both exampleAWS and examplePureStorage simultaneously:
=> ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "exampleAWS",
"accessKey": "<AK0>",
"secretAccessKey": "<SAK0>",
"sessionToken": "1234567890"
},
{
"bucket": "examplePureStorage",
"accessKey": "<AK1>",
"secretAccessKey": "<SAK1>",
}
]';
Recommended usage
The recommended usage is as follows:
-
Define in your S3 storage system one set of credentials per principal, per storage system.
-
It is often most convenient to set S3BucketConfig once at the database level and have users authenticate by setting S3BucketCredentials at the session level.
-
To access buckets outside those configured at the database level, set both S3BucketConfig and S3BucketCredentials at the session level.
If you cannot define credentials for your S3 storage, you can set S3BucketCredentials or AWSAuth at the database level with ALTER DATABASE, but this comes with certain drawbacks:
-
Storing credentials statically in another location (in this case, in the Vertica catalog) always incurs additional risk.
-
This increases overhead for the dbadmin, who needs to create user storage locations and grant access to each user or role.
-
Users share one set of credentials, increasing the potential impact if the credentials are compromised.
Note
If you set AWSEndpoint to a non-Amazon S3 storage system like Pure Storage or MinIO and you want to configure S3BucketConfig for real Amazon S3, the following requirements apply:
-
If your real Amazon S3 region is not us-east-1 (the default), you must specify the region.
-
Set endpoint to an empty string ("").
=> ALTER DATABASE DEFAULT SET S3BucketConfig='
[
{
"bucket": "additionalAWSBucket",
"region": "us-east-2",
"endpoint": ""
}
]';
Precedence of per-bucket and standard parameters
Vertica uses the following rules to determine the effective set of properties for an S3 connection:
-
If set, S3BucketCredentials takes priority over its standard parameters. S3BucketCredentials is checked first at the session level and then at the database level.
-
The level/source of the S3 credential parameters determines the source of the S3 configuration parameters:
-
If credentials come from the session level, then the configuration can come from either the session or database level (with the session level taking priority).
-
If your credentials come from the database level, then the configuration can only come from the database level.
-
If S3BucketConfig is set, it takes priority over its standard parameters. If an S3BucketConfig property isn't specified, Vertica falls back to the missing property's equivalent parameter. For example, if S3BucketConfig specifies every property except protocol, Vertica falls back to the standard parameter AWSEnableHttps.
Examples
Multiple buckets
This example configures a real Amazon S3 bucket AWSBucket and a Pure Storage bucket PureStorageBucket with S3BucketConfig.
AWSBucket does not specify an endpoint or protocol, so Vertica falls back to AWSEndpoint (defaults to s3.amazonaws.com) and AWSEnableHttps (defaults to 1).
In this example environment, access to the PureStorageBucket is over a secure network, so HTTPS is disabled:
=> ALTER DATABASE DEFAULT SET S3BucketConfig='
[
{
"bucket": "AWSBucket",
"region": "us-east-2"
},
{
"bucket": "PureStorageBucket",
"endpoint": "pure.mycorp.net:1234",
"protocol": "http",
"enableVirtualAddressing": false
}
]';
Bob can then set S3BucketCredentials at the session level to authenticate to AWSBucket:
=> ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "AWSBucket",
"accessKey": "<AK0>",
"secretAccessKey": "<SAK0>",
"sessionToken": "1234567890"
}
]';
Similarly, Alice can authenticate to PureStorageBucket:
=> ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "PureStorageBucket",
"accessKey": "<AK1>",
"secretAccessKey": "<SAK1>"
}
]';
Charlie provides credentials for both AWSBucket and PureStorageBucket and authenticates to them simultaneously. This allows him to perform cross-endpoint joins, export from one bucket to another, etc.
=> ALTER SESSION SET S3BucketCredentials='
[
{
"bucket": "AWSBucket",
"accessKey": "<AK0>",
"secretAccessKey": "<SAK0>",
"sessionToken": "1234567890"
},
{
"bucket": "PureStorageBucket",
"accessKey": "<AK1>",
"secretAccessKey": "<SAK1>"
}
]';
S3 server-side encryption
S3 has three types of server-side encryption: SSE-S3, SSE-KMS, and SSE-C. The following example configures access using SSE-KMS:
=> ALTER DATABASE DEFAULT SET S3BucketConfig='
[
{
"bucket": "AWSBucket",
"region": "us-east-2",
"serverSideEncryption": "aws:kms",
"sseKmsKeyId": "1234abcd-12ab-34cd-56ef-1234567890ab"
}
]';
For more information, see Server-Side Encryption.
Non-amazon S3 storage with AWSEndpoint and S3BucketConfig
If AWSEndpoint is set to a non-Amazon S3 bucket like Pure Storage or MinIO and you want to configure S3BucketConfig for a real Amazon S3 bucket, the following requirements apply:
-
If your real Amazon S3 region is not us-east-1 (the default), you must specify the region.
-
Set endpoint to an empty string ("").
In this example, AWSEndpoint is set to a Pure Storage bucket.
=> ALTER DATABASE DEFAULT SET AWSEndpoint='pure.mycorp.net:1234';
To configure S3BucketConfig for a real Amazon S3 bucket realAmazonS3Bucket in region "us-east-2":
=> ALTER DATABASE DEFAULT SET S3BucketConfig='
[
{
"bucket": "realAmazonS3Bucket",
"region": "us-east-2",
"endpoint": ""
},
]';
6 - Functions
Functions return information from the database.
Functions return information from the database. This section describes functions that Vertica supports. Except for meta-functions, you can use a function anywhere an expression is allowed.
Meta-functions usually access the internal state of Vertica. They can be used in a top-level SELECT statement only, and the statement cannot contain other clauses such as FROM or WHERE. Meta-functions are labeled on their reference pages.
The Behavior Type section on each reference page categorizes the function's return behavior as one or more of the following:
- Immutable (invariant): When run with a given set of arguments, immutable functions always produce the same result, regardless of environment or session settings such as locale.
- Stable: When run with a given set of arguments, stable functions produce the same result within a single query or scan operation. However, a stable function can produce different results when issued under different environments or at different times, such as change of locale and time zone—for example, SYSDATE.
- Volatile: Regardless of their arguments or environment, volatile functions can return a different result with each invocation—for example, UUID_GENERATE.
List of all functions
The following list contains all Vertica SQL functions.
-
ABS
- Returns the absolute value of the argument. [Mathematical functions]
-
ACOS
- Returns a DOUBLE PRECISION value representing the trigonometric inverse cosine of the argument. [Mathematical functions]
-
ACOSH
- Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic cosine of the function argument. [Mathematical functions]
-
ACTIVE_SCHEDULER_NODE
- Returns the active scheduler node. [Stored procedure functions]
-
ADD_MONTHS
- Adds the specified number of months to a date and returns the sum as a DATE. [Date/time functions]
-
ADVANCE_EPOCH
- Manually closes the current epoch and begins a new epoch. [Epoch functions]
-
AGE_IN_MONTHS
- Returns the difference in months between two dates, expressed as an integer. [Date/time functions]
-
AGE_IN_YEARS
- Returns the difference in years between two dates, expressed as an integer. [Date/time functions]
-
ALTER_LOCATION_LABEL
- Adds a label to a storage location, or changes or removes an existing label. [Storage functions]
-
ALTER_LOCATION_SIZE
- Resizes on one node, all nodes in a subcluster, or all nodes in the database. [Eon Mode functions]
-
ALTER_LOCATION_USE
- Alters the type of data that a storage location holds. [Storage functions]
-
ANALYZE_CONSTRAINTS
- Analyzes and reports on constraint violations within the specified scope. [Table functions]
-
ANALYZE_CORRELATIONS
- This function is deprecated and will be removed in a future release. [Table functions]
-
ANALYZE_EXTERNAL_ROW_COUNT
- Calculates the exact number of rows in an external table. [Statistics management functions]
-
ANALYZE_STATISTICS
- Collects and aggregates data samples and storage information from all nodes that store projections associated with the specified table. [Statistics management functions]
-
ANALYZE_STATISTICS_PARTITION
- Collects and aggregates data samples and storage information for a range of partitions in the specified table. [Statistics management functions]
-
ANALYZE_WORKLOAD
- Runs Workload Analyzer, a utility that analyzes system information held in system tables. [Workload management functions]
-
APPLY_AVG
- Returns the average of all elements in a with numeric values. [Collection functions]
-
APPLY_BISECTING_KMEANS
- Applies a trained bisecting k-means model to an input relation, and assigns each new data point to the closest matching cluster in the trained model. [Transformation functions]
-
APPLY_COUNT (ARRAY_COUNT)
- Returns the total number of non-null elements in a. [Collection functions]
-
APPLY_COUNT_ELEMENTS (ARRAY_LENGTH)
- Returns the total number of elements in a , including NULLs. [Collection functions]
-
APPLY_IFOREST
- Applies an isolation forest (iForest) model to an input relation. [Transformation functions]
-
APPLY_INVERSE_PCA
- Inverts the APPLY_PCA-generated transform back to the original coordinate system. [Transformation functions]
-
APPLY_INVERSE_SVD
- Transforms the data back to the original domain. [Transformation functions]
-
APPLY_KMEANS
- Assigns each row of an input relation to a cluster center from an existing k-means model. [Transformation functions]
-
APPLY_KPROTOTYPES
- Assigns each row of an input relation to a cluster center from an existing k-prototypes model. [Transformation functions]
-
APPLY_MAX
- Returns the largest non-null element in a. [Collection functions]
-
APPLY_MIN
- Returns the smallest non-null element in a. [Collection functions]
-
APPLY_NORMALIZE
- A UDTF function that applies the normalization parameters saved in a model to a set of specified input columns. [Transformation functions]
-
APPLY_ONE_HOT_ENCODER
- A user-defined transform function (UDTF) that loads the one hot encoder model and writes out a table that contains the encoded columns. [Transformation functions]
-
APPLY_PCA
- Transforms the data using a PCA model. [Transformation functions]
-
APPLY_SUM
- Computes the sum of all elements in a of numeric values (INTEGER, FLOAT, NUMERIC, or INTERVAL). [Collection functions]
-
APPLY_SVD
- Transforms the data using an SVD model. [Transformation functions]
-
APPROXIMATE_COUNT_DISTINCT
- Returns the number of distinct non-NULL values in a data set. [Aggregate functions]
-
APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS
- Calculates the number of distinct non-NULL values from the synopsis objects created by APPROXIMATE_COUNT_DISTINCT_SYNOPSIS. [Aggregate functions]
-
APPROXIMATE_COUNT_DISTINCT_SYNOPSIS
- Summarizes the information of distinct non-NULL values and materializes the result set in a VARBINARY or LONG VARBINARY synopsis object. [Aggregate functions]
-
APPROXIMATE_COUNT_DISTINCT_SYNOPSIS_MERGE
- Aggregates multiple synopses into one new synopsis. [Aggregate functions]
-
APPROXIMATE_MEDIAN [aggregate]
- Computes the approximate median of an expression over a group of rows. [Aggregate functions]
-
APPROXIMATE_PERCENTILE [aggregate]
- Computes the approximate percentile of an expression over a group of rows. [Aggregate functions]
-
APPROXIMATE_QUANTILES
- Computes an array of weighted, approximate percentiles of a column within some user-specified error. [Aggregate functions]
-
ARGMAX [analytic]
- This function is patterned after the mathematical function argmax(f(x)), which returns the value of x that maximizes f(x). [Analytic functions]
-
ARGMAX_AGG
- Takes two arguments target and arg, where both are columns or column expressions in the queried dataset. [Aggregate functions]
-
ARGMIN [analytic]
- This function is patterned after the mathematical function argmin(f(x)), which returns the value of x that minimizes f(x). [Analytic functions]
-
ARGMIN_AGG
- Takes two arguments target and arg, where both are columns or column expressions in the queried dataset. [Aggregate functions]
-
ARIMA
- Creates and trains an autoregressive integrated moving average (ARIMA) model from a time series with consistent timesteps. [Machine learning algorithms]
-
ARRAY_CAT
- Concatenates two arrays of the same element type and dimensionality. [Collection functions]
-
ARRAY_CONTAINS
- Returns true if the specified element is found in the array and false if not. [Collection functions]
-
ARRAY_DIMS
- Returns the dimensionality of the input array. [Collection functions]
-
ARRAY_FIND
- Returns the ordinal position of a specified element in an array, or -1 if not found. [Collection functions]
-
ASCII
- Converts the first character of a VARCHAR datatype to an INTEGER. [String functions]
-
ASIN
- Returns a DOUBLE PRECISION value representing the trigonometric inverse sine of the argument. [Mathematical functions]
-
ASINH
- Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic sine of the function argument. [Mathematical functions]
-
ATAN
- Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the argument. [Mathematical functions]
-
ATAN2
- Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the arithmetic dividend of the arguments. [Mathematical functions]
-
ATANH
- Returns a DOUBLE PRECISION value that represents the inverse hyperbolic tangent of the function argument. [Mathematical functions]
-
AUDIT
- Returns the raw data size (in bytes) of a database, schema, or table as it is counted in an audit of the database size. [License functions]
-
AUDIT_FLEX
- Returns the estimated ROS size of __raw__ columns, equivalent to the export size of the flex data in the audited objects. [License functions]
-
AUDIT_LICENSE_SIZE
- Triggers an immediate audit of the database size to determine if it is in compliance with the raw data storage allowance included in your Vertica licenses. [License functions]
-
AUDIT_LICENSE_TERM
- Triggers an immediate audit to determine if the Vertica license has expired. [License functions]
-
AUTOREGRESSOR
- Creates an autoregressive (AR) model from a stationary time series with consistent timesteps that can then be used for prediction via PREDICT_AR. [Machine learning algorithms]
-
AVG [aggregate]
- Computes the average (arithmetic mean) of an expression over a group of rows. [Aggregate functions]
-
AVG [analytic]
- Computes an average of an expression in a group within a. [Analytic functions]
-
AZURE_TOKEN_CACHE_CLEAR
- Clears the cached access token for Azure. [Cloud functions]
-
BACKGROUND_DEPOT_WARMING
- Vertica version 10.0.0 removes support for foreground depot warming. [Eon Mode functions]
-
BALANCE
- Returns a view with an equal distribution of the input data based on the response_column. [Data preparation]
-
BISECTING_KMEANS
- Executes the bisecting k-means algorithm on an input relation. [Machine learning algorithms]
-
BIT_AND
- Takes the bitwise AND of all non-null input values. [Aggregate functions]
-
BIT_LENGTH
- Returns the length of the string expression in bits (bytes * 8) as an INTEGER. [String functions]
-
BIT_OR
- Takes the bitwise OR of all non-null input values. [Aggregate functions]
-
BIT_XOR
- Takes the bitwise XOR of all non-null input values. [Aggregate functions]
-
BITCOUNT
- Returns the number of one-bits (sometimes referred to as set-bits) in the given VARBINARY value. [String functions]
-
BITSTRING_TO_BINARY
- Translates the given VARCHAR bitstring representation into a VARBINARY value. [String functions]
-
BOOL_AND [aggregate]
- Processes Boolean values and returns a Boolean value result. [Aggregate functions]
-
BOOL_AND [analytic]
- Returns the Boolean value of an expression within a. [Analytic functions]
-
BOOL_OR [aggregate]
- Processes Boolean values and returns a Boolean value result. [Aggregate functions]
-
BOOL_OR [analytic]
- Returns the Boolean value of an expression within a. [Analytic functions]
-
BOOL_XOR [aggregate]
- Processes Boolean values and returns a Boolean value result. [Aggregate functions]
-
BOOL_XOR [analytic]
- Returns the Boolean value of an expression within a. [Analytic functions]
-
BTRIM
- Removes the longest string consisting only of specified characters from the start and end of a string. [String functions]
-
BUILD_FLEXTABLE_VIEW
- Creates, or re-creates, a view for a default or user-defined keys table, ignoring any empty keys. [Flex data functions]
-
CALENDAR_HIERARCHY_DAY
- Groups DATE partition keys into a hierarchy of years, months, and days. [Partition functions]
-
CANCEL_DEPOT_WARMING
- Cancels depot warming on a node. [Eon Mode functions]
-
CANCEL_DRAIN_SUBCLUSTER
- Cancels the draining of a subcluster or subclusters. [Eon Mode functions]
-
CANCEL_REBALANCE_CLUSTER
- Stops any rebalance task that is currently in progress or is waiting to execute. [Cluster functions]
-
CANCEL_REFRESH
- Cancels refresh-related internal operations initiated by START_REFRESH and REFRESH. [Session functions]
-
CBRT
- Returns the cube root of the argument. [Mathematical functions]
-
CEILING
- Rounds up the returned value up to the next whole number. [Mathematical functions]
-
CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY
- Changes the run-time priority of an active query. [Workload management functions]
-
CHANGE_MODEL_STATUS
- Changes the status of a registered model. [Model management]
-
CHANGE_RUNTIME_PRIORITY
- Changes the run-time priority of a query that is actively running. [Workload management functions]
-
CHARACTER_LENGTH
- The CHARACTER_LENGTH() function:. [String functions]
-
CHI_SQUARED
- Computes the conditional chi-Square independence test on two categorical variables to find the likelihood that the two variables are independent. [Data preparation]
-
CHR
- Converts the first character of an INTEGER datatype to a VARCHAR. [String functions]
-
CLEAN_COMMUNAL_STORAGE
- Marks for deletion invalid data in communal storage, often data that leaked due to an event where Vertica cleanup mechanisms failed. [Eon Mode functions]
-
CLEAR_CACHES
- Clears the Vertica internal cache files. [Storage functions]
-
CLEAR_DATA_COLLECTOR
- Clears all memory and disk records from Data Collector tables and logs, and resets collection statistics in system table DATA_COLLECTOR. [Data Collector functions]
-
CLEAR_DATA_DEPOT
- Deletes the specified depot data. [Eon Mode functions]
-
CLEAR_DEPOT_ANTI_PIN_POLICY_PARTITION
- Removes an anti-pinning policy from the specified partition. [Eon Mode functions]
-
CLEAR_DEPOT_ANTI_PIN_POLICY_PROJECTION
- Removes an anti-pinning policy from the specified projection. [Eon Mode functions]
-
CLEAR_DEPOT_ANTI_PIN_POLICY_TABLE
- Removes an anti-pinning policy from the specified table. [Eon Mode functions]
-
CLEAR_DEPOT_PIN_POLICY_PARTITION
- Clears a depot pinning policy from the specified table or projection partitions. [Eon Mode functions]
-
CLEAR_DEPOT_PIN_POLICY_PROJECTION
- Clears a depot pinning policy from the specified projection. [Eon Mode functions]
-
CLEAR_DEPOT_PIN_POLICY_TABLE
- Clears a depot pinning policy from the specified table. [Eon Mode functions]
-
CLEAR_DIRECTED_QUERY_USAGE
- Resets the counter in the DIRECTED_QUERY_STATUS table. [Directed queries functions]
-
CLEAR_FETCH_QUEUE
- Removes all entries or entries for a specific transaction from the queue of fetch requests of data from the communal storage. [Eon Mode functions]
-
CLEAR_HDFS_CACHES
- Clears the configuration information copied from HDFS and any cached connections. [Hadoop functions]
-
CLEAR_OBJECT_STORAGE_POLICY
- Removes a user-defined storage policy from the specified database, schema or table. [Storage functions]
-
CLEAR_PROFILING
- Clears from memory data for the specified profiling type. [Profiling functions]
-
CLEAR_PROJECTION_REFRESHES
- Clears information projection refresh history from system table PROJECTION_REFRESHES. [Projection functions]
-
CLEAR_RESOURCE_REJECTIONS
- Clears the content of the RESOURCE_REJECTIONS and DISK_RESOURCE_REJECTIONS system tables. [Database functions]
-
CLOCK_TIMESTAMP
- Returns a value of type TIMESTAMP WITH TIMEZONE that represents the current system-clock time. [Date/time functions]
-
CLOSE_ALL_RESULTSETS
- Closes all result set sessions within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets. [Client connection functions]
-
CLOSE_ALL_SESSIONS
- Closes all external sessions except the one that issues this function. [Session functions]
-
CLOSE_RESULTSET
- Closes a specific result set within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets. [Client connection functions]
-
CLOSE_SESSION
- Interrupts the specified external session, rolls back the current transaction if any, and closes the socket. [Session functions]
-
CLOSE_USER_SESSIONS
- Stops the session for a user, rolls back any transaction currently running, and closes the connection. [Session functions]
-
COALESCE
- Returns the value of the first non-null expression in the list. [NULL-handling functions]
-
COLLATION
- Applies a collation to two or more strings. [String functions]
-
COMPACT_STORAGE
- Bundles existing data (.fdb) and index (.pidx) files into the .gt file format. [Database functions]
-
COMPUTE_FLEXTABLE_KEYS
- Computes the virtual columns (keys and values) from flex table VMap data. [Flex data functions]
-
COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW
- Combines the functionality of BUILD_FLEXTABLE_VIEW and COMPUTE_FLEXTABLE_KEYS to compute virtual columns (keys) from the VMap data of a flex table and construct a view. [Flex data functions]
-
CONCAT
- Concatenates two strings and returns a varchar data type. [String functions]
-
CONDITIONAL_CHANGE_EVENT [analytic]
- Assigns an event window number to each row, starting from 0, and increments by 1 when the result of evaluating the argument expression on the current row differs from that on the previous row. [Analytic functions]
-
CONDITIONAL_TRUE_EVENT [analytic]
- Assigns an event window number to each row, starting from 0, and increments the number by 1 when the result of the boolean argument expression evaluates true. [Analytic functions]
-
CONFUSION_MATRIX
- Computes the confusion matrix of a table with observed and predicted values of a response variable. [Model evaluation]
-
CONTAINS
- Returns true if the specified element is found in the collection and false if not. [Collection functions]
-
COPY_PARTITIONS_TO_TABLE
- Copies partitions from one table to another. [Partition functions]
-
COPY_TABLE
- Copies one table to another. [Table functions]
-
CORR
- Returns the DOUBLE PRECISION coefficient of correlation of a set of expression pairs, as per the Pearson correlation coefficient. [Aggregate functions]
-
CORR_MATRIX
- Takes an input relation with numeric columns, and calculates the Pearson Correlation Coefficient between each pair of its input columns. [Data preparation]
-
COS
- Returns a DOUBLE PRECISION value tat represents the trigonometric cosine of the passed parameter. [Mathematical functions]
-
COSH
- Returns a DOUBLE PRECISION value that represents the hyperbolic cosine of the passed parameter. [Mathematical functions]
-
COT
- Returns a DOUBLE PRECISION value representing the trigonometric cotangent of the argument. [Mathematical functions]
-
COUNT [aggregate]
- Returns as a BIGINT the number of rows in each group where the expression is not NULL. [Aggregate functions]
-
COUNT [analytic]
- Counts occurrences within a group within a. [Analytic functions]
-
COVAR_POP
- Returns the population covariance for a set of expression pairs. [Aggregate functions]
-
COVAR_SAMP
- Returns the sample covariance for a set of expression pairs. [Aggregate functions]
-
CROSS_VALIDATE
- Performs k-fold cross validation on a learning algorithm using an input relation, and grid search for hyper parameters. [Model evaluation]
-
CUME_DIST [analytic]
- Calculates the cumulative distribution, or relative rank, of the current row with regard to other rows in the same partition within a . [Analytic functions]
-
CURRENT_DATABASE
- Returns the name of the current database, equivalent to DBNAME. [System information functions]
-
CURRENT_DATE
- Returns the date (date-type value) on which the current transaction started. [Date/time functions]
-
CURRENT_LOAD_SOURCE
- When called within the scope of a COPY statement, returns the file name or path part used for the load. [System information functions]
-
CURRENT_SCHEMA
- Returns the name of the current schema. [System information functions]
-
CURRENT_SESSION
- Returns the ID of the current client session. [System information functions]
-
CURRENT_TIME
- Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction. [Date/time functions]
-
CURRENT_TIMESTAMP
- Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction. [Date/time functions]
-
CURRENT_TRANS_ID
- Returns the ID of the transaction currently in progress. [System information functions]
-
CURRENT_USER
- Returns a VARCHAR containing the name of the user who initiated the current database connection. [System information functions]
-
CURRVAL
- Returns the last value across all nodes that was set by NEXTVAL on this sequence in the current session. [Sequence functions]
-
DATA_COLLECTOR_HELP
- Returns online usage instructions about the Data Collector, the V_MONITOR.DATA_COLLECTOR system table, and the Data Collector control functions. [Data Collector functions]
-
DATE
- Converts the input value to a DATE data type. [Date/time functions]
-
DATE_PART
- Extracts a sub-field such as year or hour from a date/time expression, equivalent to the the SQL-standard function EXTRACT. [Date/time functions]
-
DATE_TRUNC
- Truncates date and time values to the specified precision. [Date/time functions]
-
DATEDIFF
- Returns the time span between two dates, in the intervals specified. [Date/time functions]
-
DAY
- Returns as an integer the day of the month from the input value. [Date/time functions]
-
DAYOFMONTH
- Returns the day of the month as an integer. [Date/time functions]
-
DAYOFWEEK
- Returns the day of the week as an integer, where Sunday is day 1. [Date/time functions]
-
DAYOFWEEK_ISO
- Returns the ISO 8061 day of the week as an integer, where Monday is day 1. [Date/time functions]
-
DAYOFYEAR
- Returns the day of the year as an integer, where January 1 is day 1. [Date/time functions]
-
DAYS
- Returns the integer value of the specified date, where 1 AD is 1. [Date/time functions]
-
DBNAME (function)
- Returns the name of the current database, equivalent to CURRENT_DATABASE. [System information functions]
-
DECODE
- Compares expression to each search value one by one. [String functions]
-
DEGREES
- Converts an expression from radians to fractional degrees, or from degrees, minutes, and seconds to fractional degrees. [Mathematical functions]
-
DELETE_TOKENIZER_CONFIG_FILE
- Deletes a tokenizer configuration file. [Text search functions]
-
DEMOTE_SUBCLUSTER_TO_SECONDARY
- Converts a to a . [Eon Mode functions]
-
DENSE_RANK [analytic]
- Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause. [Analytic functions]
-
DESCRIBE_LOAD_BALANCE_DECISION
- Evaluates if any load balancing routing rules apply to a given IP address and This function is useful when you are evaluating connection load balancing policies you have created, to ensure they work the way you expect them to. [Client connection functions]
-
DESIGNER_ADD_DESIGN_QUERIES
- Reads and evaluates queries from an input file, and adds the queries that it accepts to the specified design. [Database Designer functions]
-
DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS
- Executes the specified query and evaluates results in the following columns:. [Database Designer functions]
-
DESIGNER_ADD_DESIGN_QUERY
- Reads and parses the specified query, and if accepted, adds it to the design. [Database Designer functions]
-
DESIGNER_ADD_DESIGN_TABLES
- Adds the specified tables to a design. [Database Designer functions]
-
DESIGNER_CANCEL_POPULATE_DESIGN
- Cancels population or deployment operation for the specified design if it is currently running. [Database Designer functions]
-
DESIGNER_CREATE_DESIGN
- Creates a design with the specified name. [Database Designer functions]
-
DESIGNER_DESIGN_PROJECTION_ENCODINGS
- Analyzes encoding in the specified projections, creates a script to implement encoding recommendations, and optionally deploys the recommendations. [Database Designer functions]
-
DESIGNER_DROP_ALL_DESIGNS
- Removes all Database Designer-related schemas associated with the current user. [Database Designer functions]
-
DESIGNER_DROP_DESIGN
- Removes the schema associated with the specified design and all its contents. [Database Designer functions]
-
DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS
- Displays the DDL statements that define the design projections to standard output. [Database Designer functions]
-
DESIGNER_OUTPUT_DEPLOYMENT_SCRIPT
- Displays the deployment script for the specified design to standard output. [Database Designer functions]
-
DESIGNER_RESET_DESIGN
- Discards all run-specific information of the previous Database Designer build or deployment of the specified design but keeps its configuration. [Database Designer functions]
-
DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY
- Populates the design and creates the design and deployment scripts. [Database Designer functions]
-
DESIGNER_SET_DESIGN_KSAFETY
- Sets K-safety for a comprehensive design and stores the K-safety value in the DESIGNS table. [Database Designer functions]
-
DESIGNER_SET_DESIGN_TYPE
- Specifies whether Database Designer creates a comprehensive or incremental design. [Database Designer functions]
-
DESIGNER_SET_OPTIMIZATION_OBJECTIVE
- Valid only for comprehensive database designs, specifies the optimization objective Database Designer uses. [Database Designer functions]
-
DESIGNER_SET_PROPOSE_UNSEGMENTED_PROJECTIONS
- Specifies whether a design can include unsegmented projections. [Database Designer functions]
-
DESIGNER_SINGLE_RUN
- Evaluates all queries that completed execution within the specified timespan, and returns with a design that is ready for deployment. [Database Designer functions]
-
DESIGNER_WAIT_FOR_DESIGN
- Waits for completion of operations that are populating and deploying the design. [Database Designer functions]
-
DETECT_OUTLIERS
- Returns the outliers in a data set based on the outlier threshold. [Data preparation]
-
DISABLE_DUPLICATE_KEY_ERROR
- Disables error messaging when Vertica finds duplicate primary or unique key values at run time (for use with key constraints that are not automatically enabled). [Table functions]
-
DISABLE_LOCAL_SEGMENTS
- Disables local data segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes. [Cluster functions]
-
DISABLE_PROFILING
- Disables for the current session collection of profiling data of the specified type. [Profiling functions]
-
DISPLAY_LICENSE
- Returns the terms of your Vertica license. [License functions]
-
DISTANCE
- Returns the distance (in kilometers) between two points. [Mathematical functions]
-
DISTANCEV
- Returns the distance (in kilometers) between two points using the Vincenty formula. [Mathematical functions]
-
DO_LOGROTATE_LOCAL
- Rotates logs and removes rotated logs on the current node. [Database functions]
-
DO_TM_TASK
- Runs a (TM) operation and commits current transactions. [Storage functions]
-
DROP_EXTERNAL_ROW_COUNT
- Removes external table row count statistics compiled by ANALYZE_EXTERNAL_ROW_COUNT. [Statistics management functions]
-
DROP_LICENSE
- Drops a license key from the global catalog. [Catalog functions]
-
DROP_LOCATION
- Permanently removes a retired storage location. [Storage functions]
-
DROP_PARTITIONS
- Drops the specified table partition keys. [Partition functions]
-
DROP_STATISTICS
- Removes statistical data on database projections previously generated by ANALYZE_STATISTICS. [Statistics management functions]
-
DROP_STATISTICS_PARTITION
- Removes statistical data on database projections previously generated by ANALYZE_STATISTICS_PARTITION. [Statistics management functions]
-
DUMP_CATALOG
- Returns an internal representation of the Vertica catalog. [Catalog functions]
-
DUMP_LOCKTABLE
- Returns information about deadlocked clients and the resources they are waiting for. [Database functions]
-
DUMP_PARTITION_KEYS
- Dumps the partition keys of all projections in the system. [Database functions]
-
DUMP_PROJECTION_PARTITION_KEYS
- Dumps the partition keys of the specified projection. [Partition functions]
-
DUMP_TABLE_PARTITION_KEYS
- Dumps the partition keys of all projections for the specified table. [Partition functions]
-
EDIT_DISTANCE
- Calculates and returns the Levenshtein distance between two strings. [String functions]
-
EMPTYMAP
- Constructs a new VMap with one row but without keys or data. [Flex map functions]
-
ENABLE_ELASTIC_CLUSTER
- Enables elastic cluster scaling, which makes enlarging or reducing the size of your database cluster more efficient by segmenting a node's data into chunks that can be easily moved to other hosts. [Cluster functions]
-
ENABLE_LOCAL_SEGMENTS
- Enables local storage segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes. [Cluster functions]
-
ENABLE_PROFILING
- Enables collection of profiling data of the specified type for the current session. [Profiling functions]
-
ENABLE_SCHEDULE
- Enables or disables a schedule. [Stored procedure functions]
-
ENABLE_TRIGGER
- Enables or disables a trigger. [Stored procedure functions]
-
ENABLED_ROLE
- Checks whether a Vertica user role is enabled, and returns true or false. [Privileges and access functions]
-
ENFORCE_OBJECT_STORAGE_POLICY
- Applies storage policies of the specified object immediately. [Storage functions]
-
ERROR_RATE
- Using an input table, returns a table that calculates the rate of incorrect classifications and displays them as FLOAT values. [Model evaluation]
-
EVALUATE_DELETE_PERFORMANCE
- Evaluates projections for potential DELETE and UPDATE performance issues. [Projection functions]
-
EVENT_NAME
- Returns a VARCHAR value representing the name of the event that matched the row. [MATCH clause functions]
-
EXECUTE_TRIGGER
- Manually executes the stored procedure attached to a trigger. [Stored procedure functions]
-
EXP
- Returns the exponential function, e to the power of a number. [Mathematical functions]
-
EXPLODE
- Expands the elements of one or more collection columns (ARRAY or SET) into individual table rows, one row per element. [Collection functions]
-
EXPONENTIAL_MOVING_AVERAGE [analytic]
- Calculates the exponential moving average (EMA) of expression E with smoothing factor X. [Analytic functions]
-
EXPORT_CATALOG
- This function and EXPORT_OBJECTS return equivalent output. [Catalog functions]
-
EXPORT_DIRECTED_QUERIES
- Generates SQL for creating directed queries from a set of input queries. [Directed queries functions]
-
EXPORT_MODELS
- Exports machine learning models. [Model management]
-
EXPORT_OBJECTS
- This function and EXPORT_CATALOG return equivalent output. [Catalog functions]
-
EXPORT_STATISTICS
- Generates statistics in XML format from data previously collected by ANALYZE_STATISTICS. [Statistics management functions]
-
EXPORT_STATISTICS_PARTITION
- Generates partition-level statistics in XML format from data previously collected by ANALYZE_STATISTICS_PARTITION. [Statistics management functions]
-
EXPORT_TABLES
- Generates a SQL script that can be used to recreate a logical schema—schemas, tables, constraints, and views—on another cluster. [Catalog functions]
-
EXTERNAL_CONFIG_CHECK
- Tests the Hadoop configuration of a Vertica cluster. [Hadoop functions]
-
EXTRACT
- Retrieves sub-fields such as year or hour from date/time values and returns values of type NUMERIC. [Date/time functions]
-
FILTER
- Takes an input array and returns an array containing only elements that meet a specified condition. [Collection functions]
-
FINISH_FETCHING_FILES
- Fetches to the depot all files that are queued for download from communal storage. [Eon Mode functions]
-
FIRST_VALUE [analytic]
- Lets you select the first value of a table or partition (determined by the window-order-clause) without having to use a self join. [Analytic functions]
-
FLOOR
- Rounds down the returned value to the previous whole number. [Mathematical functions]
-
FLUSH_DATA_COLLECTOR
- Waits until memory logs are moved to disk and then flushes the Data Collector, synchronizing the log with disk storage. [Data Collector functions]
-
FLUSH_REAPER_QUEUE
- Deletes all data marked for deletion in the database. [Eon Mode functions]
-
GET_AHM_EPOCH
- Returns the number of the in which the is located. [Epoch functions]
-
GET_AHM_TIME
- Returns a TIMESTAMP value representing the. [Epoch functions]
-
GET_AUDIT_TIME
- Reports the time when the automatic audit of database size occurs. [License functions]
-
GET_CLIENT_LABEL
- Returns the client connection label for the current session. [Client connection functions]
-
GET_COMPLIANCE_STATUS
- Displays whether your database is in compliance with your Vertica license agreement. [License functions]
-
GET_CONFIG_PARAMETER
- Gets the value of a configuration parameter at the specified level. [Database functions]
-
GET_CURRENT_EPOCH
- Returns the number of the current epoch. [Epoch functions]
-
GET_DATA_COLLECTOR_NOTIFY_POLICY
- Lists any notification policies set on a component. [Notifier functions]
-
GET_DATA_COLLECTOR_POLICY
- Retrieves a brief statement about the retention policy for the specified component. [Data Collector functions]
-
GET_LAST_GOOD_EPOCH
- Returns the number. [Epoch functions]
-
GET_METADATA
- Returns the metadata of a Parquet file. [Hadoop functions]
-
GET_MODEL_ATTRIBUTE
- Extracts either a specific attribute from a model or all attributes from a model. [Model management]
-
GET_MODEL_SUMMARY
- Returns summary information of a model. [Model management]
-
GET_NUM_ACCEPTED_ROWS
- Returns the number of rows loaded into the database for the last completed load for the current session. [Session functions]
-
GET_NUM_REJECTED_ROWS
- Returns the number of rows that were rejected during the last completed load for the current session. [Session functions]
-
GET_PRIVILEGES_DESCRIPTION
- Returns the effective privileges the current user has on an object, including explicit, implicit, inherited, and role-based privileges. [Privileges and access functions]
-
GET_PROJECTION_SORT_ORDER
- Returns the order of columns in a projection's ORDER BY clause. [Projection functions]
-
GET_PROJECTION_STATUS
- Returns information relevant to the status of a :. [Projection functions]
-
GET_PROJECTIONS
- Returns contextual and projection information about projections of the specified anchor table. [Projection functions]
-
GET_TOKENIZER_PARAMETER
- Returns the configuration parameter for a given tokenizer. [Text search functions]
-
GETDATE
- Returns the current statement's start date and time as a TIMESTAMP value. [Date/time functions]
-
GETUTCDATE
- Returns the current statement's start date and time as a TIMESTAMP value. [Date/time functions]
-
GREATEST
- Returns the largest value in a list of expressions of any data type. [String functions]
-
GREATESTB
- Returns the largest value in a list of expressions of any data type, using binary ordering. [String functions]
-
GROUP_ID
- Uniquely identifies duplicate sets for GROUP BY queries that return duplicate grouping sets. [Aggregate functions]
-
GROUPING
- Disambiguates the use of NULL values when GROUP BY queries with multilevel aggregates generate NULL values to identify subtotals in grouping columns. [Aggregate functions]
-
GROUPING_ID
- Concatenates the set of Boolean values generated by the GROUPING function into a bit vector. [Aggregate functions]
-
HADOOP_IMPERSONATION_CONFIG_CHECK
- Reports the delegation tokens Vertica will use when accessing Kerberized data in HDFS. [Hadoop functions]
-
HAS_ROLE
- Checks whether a Vertica user role is granted to the specified user or role, and returns true or false. [Privileges and access functions]
-
HAS_TABLE_PRIVILEGE
- Returns true or false to verify whether a user has the specified privilege on a table. [System information functions]
-
HASH
- Calculates a hash value over the function arguments, producing a value in the range 0 <= x < 263. [Mathematical functions]
-
HASH_EXTERNAL_TOKEN
- Returns a hash of a string token, for use with HADOOP_IMPERSONATION_CONFIG_CHECK. [Hadoop functions]
-
HCATALOGCONNECTOR_CONFIG_CHECK
- Tests the configuration of a Vertica cluster that uses the HCatalog Connector to access Hive data. [Hadoop functions]
-
HDFS_CLUSTER_CONFIG_CHECK
- Tests the configuration of a Vertica cluster that uses HDFS. [Hadoop functions]
-
HEX_TO_BINARY
- Translates the given VARCHAR hexadecimal representation into a VARBINARY value. [String functions]
-
HEX_TO_INTEGER
- Translates the given VARCHAR hexadecimal representation into an INTEGER value. [String functions]
-
HOUR
- Returns the hour portion of the specified date as an integer, where 0 is 00:00 to 00:59. [Date/time functions]
-
IFNULL
- Returns the value of the first non-null expression in the list. [NULL-handling functions]
-
IFOREST
- Trains and returns an isolation forest (iForest) model. [Data preparation]
-
IMPLODE
- Takes a column of any scalar type and returns an unbounded array. [Collection functions]
-
IMPORT_DIRECTED_QUERIES
- Imports to the database catalog directed queries from a SQL file that was generated by EXPORT_DIRECTED_QUERIES. [Directed queries functions]
-
IMPORT_MODELS
- Imports models into Vertica, either Vertica models that were exported with EXPORT_MODELS, or models in Predictive Model Markup Language (PMML) or TensorFlow format. [Model management]
-
IMPORT_STATISTICS
- Imports statistics from the XML file that was generated by EXPORT_STATISTICS. [Statistics management functions]
-
IMPUTE
- Imputes missing values in a data set with either the mean or the mode, based on observed values for a variable in each column. [Data preparation]
-
INET_ATON
- Converts a string that contains a dotted-quad representation of an IPv4 network address to an INTEGER. [IP address functions]
-
INET_NTOA
- Converts an INTEGER value into a VARCHAR dotted-quad representation of an IPv4 network address. [IP address functions]
-
INFER_EXTERNAL_TABLE_DDL
- This function is deprecated and will be removed in a future release. [Table functions]
-
INFER_TABLE_DDL
- Inspects a file in Parquet, ORC, JSON, or Avro format and returns a CREATE TABLE or CREATE EXTERNAL TABLE statement based on its contents. [Table functions]
-
INITCAP
- Capitalizes first letter of each alphanumeric word and puts the rest in lowercase. [String functions]
-
INITCAPB
- Capitalizes first letter of each alphanumeric word and puts the rest in lowercase. [String functions]
-
INSERT
- Inserts a character string into a specified location in another character string. [String functions]
-
INSTALL_LICENSE
- Installs the license key in the global catalog. [Catalog functions]
-
INSTR
- Searches string for substring and returns an integer indicating the position of the character in string that is the first character of this occurrence. [String functions]
-
INSTRB
- Searches string for substring and returns an integer indicating the octet position within string that is the first occurrence. [String functions]
-
INTERRUPT_STATEMENT
- Interrupts the specified statement in a user session, rolls back the current transaction, and writes a success or failure message to the log file. [Session functions]
-
ISFINITE
- Tests for the special TIMESTAMP constant INFINITY and returns a value of type BOOLEAN. [Date/time functions]
-
ISNULL
- Returns the value of the first non-null expression in the list. [NULL-handling functions]
-
ISUTF8
- Tests whether a string is a valid UTF-8 string. [String functions]
-
JARO_DISTANCE
- Calculates and returns the Jaro similarity, an edit distance between two sequences. [String functions]
-
JARO_WINKLER_DISTANCE
- Calculates and returns the Jaro-Winkler similarity, an edit distance between two sequences. [String functions]
-
JULIAN_DAY
- Returns the integer value of the specified day according to the Julian calendar, where day 1 is the first day of the Julian period, January 1, 4713 BC (on the Gregorian calendar, November 24, 4714 BC). [Date/time functions]
-
KERBEROS_CONFIG_CHECK
- Tests the Kerberos configuration of a Vertica cluster. [Database functions]
-
KERBEROS_HDFS_CONFIG_CHECK
- This function is deprecated and will be removed in a future release. [Hadoop functions]
-
KMEANS
- Executes the k-means algorithm on an input relation. [Machine learning algorithms]
-
KPROTOTYPES
- Executes the k-prototypes algorithm on an input relation. [Machine learning algorithms]
-
LAG [analytic]
- Returns the value of the input expression at the given offset before the current row within a. [Analytic functions]
-
LAST_DAY
- Returns the last day of the month in the specified date. [Date/time functions]
-
LAST_INSERT_ID
- Returns the last value of an IDENTITY column. [Table functions]
-
LAST_VALUE [analytic]
- Lets you select the last value of a table or partition (determined by the window-order-clause) without having to use a self join. [Analytic functions]
-
LDAP_LINK_DRYRUN_CONNECT
- Takes a set of LDAP Link connection parameters as arguments and begins a dry run connection between the LDAP server and Vertica. [LDAP link functions]
-
LDAP_LINK_DRYRUN_SEARCH
- Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run search for users and groups that would get imported from the LDAP server. [LDAP link functions]
-
LDAP_LINK_DRYRUN_SYNC
- Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run synchronization between the database and the LDAP server, which maps and synchronizes the LDAP server's users and groups with their equivalents in Vertica. [LDAP link functions]
-
LDAP_LINK_SYNC_CANCEL
- Cancels in-progress LDAP Link synchronizations (including those started by LDAP_LINK_DRYRUN_SYNC) between the LDAP server and Vertica. [LDAP link functions]
-
LDAP_LINK_SYNC_START
- Begins the synchronization between the LDAP and Vertica servers immediately rather than waiting for the next scheduled run set by the parameters LDAPLinkInterval and LDAPLinkCron. [LDAP link functions]
-
LEAD [analytic]
- Returns values from the row after the current row within a , letting you access more than one row in a table at the same time. [Analytic functions]
-
LEAST
- Returns the smallest value in a list of expressions of any data type. [String functions]
-
LEASTB
- Returns the smallest value in a list of expressions of any data type, using binary ordering. [String functions]
-
LEFT
- Returns the specified characters from the left side of a string. [String functions]
-
LENGTH
- Returns the length of a string. [String functions]
-
LIFT_TABLE
- Returns a table that compares the predictive quality of a machine learning model. [Model evaluation]
-
LINEAR_REG
- Executes linear regression on an input relation, and returns a linear regression model. [Machine learning algorithms]
-
LIST_ENABLED_CIPHERS
- Returns a list of enabled cipher suites, which are sets of algorithms used to secure TLS/SSL connections. [System information functions]
-
LISTAGG
- Transforms non-null values from a group of rows into a list of values that are delimited by commas (default) or a configurable separator. [Aggregate functions]
-
LN
- Returns the natural logarithm of the argument. [Mathematical functions]
-
LOCALTIME
- Returns a value of type TIME that represents the start of the current transaction. [Date/time functions]
-
LOCALTIMESTAMP
- Returns a value of type TIMESTAMP/TIMESTAMPTZ that represents the start of the current transaction, and remains unchanged until the transaction is closed. [Date/time functions]
-
LOG
- Returns the logarithm to the specified base of the argument. [Mathematical functions]
-
LOG10
- Returns the base 10 logarithm of the argument, also known as the common logarithm. [Mathematical functions]
-
LOGISTIC_REG
- Executes logistic regression on an input relation. [Machine learning algorithms]
-
LOWER
- Takes a string value and returns a VARCHAR value converted to lowercase. [String functions]
-
LOWERB
- Returns a character string with each ASCII character converted to lowercase. [String functions]
-
LPAD
- Returns a VARCHAR value representing a string of a specific length filled on the left with specific characters. [String functions]
-
LTRIM
- Returns a VARCHAR value representing a string with leading blanks removed from the left side (beginning). [String functions]
-
MAKE_AHM_NOW
- Sets the (AHM) to the greatest allowable value. [Epoch functions]
-
MAKEUTF8
- Coerces a string to UTF-8 by removing or replacing non-UTF-8 characters. [String functions]
-
MAPAGGREGATE
- Returns a LONG VARBINARY VMap with key and value pairs supplied from two VARCHAR input columns. [Flex map functions]
-
MAPCONTAINSKEY
- Determines whether a VMap contains a virtual column (key). [Flex map functions]
-
MAPCONTAINSVALUE
- Determines whether a VMap contains a specific value. [Flex map functions]
-
MAPDELIMITEDEXTRACTOR
- Extracts data with a delimiter character and other optional arguments, returning a single VMap value. [Flex extractor functions]
-
MAPITEMS
- Returns information about items in a VMap. [Flex map functions]
-
MAPJSONEXTRACTOR
- Extracts content of repeated JSON data objects,, including nested maps, or data with an outer list of JSON elements. [Flex extractor functions]
-
MAPKEYS
- Returns the virtual columns (and values) present in any VMap data. [Flex map functions]
-
MAPKEYSINFO
- Returns virtual column information from a given map. [Flex map functions]
-
MAPLOOKUP
- Returns single-key values from VMAP data. [Flex map functions]
-
MAPPUT
- Accepts a VMap and one or more key/value pairs and returns a new VMap with the key/value pairs added. [Flex map functions]
-
MAPREGEXEXTRACTOR
- Extracts data with a regular expression and returns results as a VMap. [Flex extractor functions]
-
MAPSIZE
- Returns the number of virtual columns present in any VMap data. [Flex map functions]
-
MAPTOSTRING
- Recursively builds a string representation of VMap data, including nested JSON maps. [Flex map functions]
-
MAPVALUES
- Returns a string representation of the top-level values from a VMap. [Flex map functions]
-
MAPVERSION
- Returns the version or invalidity of any map data. [Flex map functions]
-
MARK_DESIGN_KSAFE
- Enables or disables high availability in your environment, in case of a failure. [Catalog functions]
-
MATCH_COLUMNS
- Specified as an element in a SELECT list, returns all columns in queried tables that match the specified pattern. [Regular expression functions]
-
MATCH_ID
- Returns a successful pattern match as an INTEGER value. [MATCH clause functions]
-
MATERIALIZE_FLEXTABLE_COLUMNS
- Materializes virtual columns listed as key_names in the flextable_keys table you compute using either COMPUTE_FLEXTABLE_KEYS or COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW. [Flex data functions]
-
MAX [aggregate]
- Returns the greatest value of an expression over a group of rows. [Aggregate functions]
-
MAX [analytic]
- Returns the maximum value of an expression within a. [Analytic functions]
-
MD5
- Calculates the MD5 hash of string, returning the result as a VARCHAR string in hexadecimal. [String functions]
-
MEASURE_LOCATION_PERFORMANCE
- Measures a storage location's disk performance. [Storage functions]
-
MEDIAN [analytic]
- For each row, returns the median value of a value set within each partition. [Analytic functions]
-
MEMORY_TRIM
- Calls glibc function malloc_trim() to reclaim free memory from malloc and return it to the operating system. [Database functions]
-
MICROSECOND
- Returns the microsecond portion of the specified date as an integer. [Date/time functions]
-
MIDNIGHT_SECONDS
- Within the specified date, returns the number of seconds between midnight and the date's time portion. [Date/time functions]
-
MIGRATE_ENTERPRISE_TO_EON
- Migrates an Enterprise database to an Eon Mode database. [Eon Mode functions]
-
MIN [aggregate]
- Returns the smallest value of an expression over a group of rows. [Aggregate functions]
-
MIN [analytic]
- Returns the minimum value of an expression within a. [Analytic functions]
-
MINUTE
- Returns the minute portion of the specified date as an integer. [Date/time functions]
-
MOD
- Returns the remainder of a division operation. [Mathematical functions]
-
MONTH
- Returns the month portion of the specified date as an integer. [Date/time functions]
-
MONTHS_BETWEEN
- Returns the number of months between two dates. [Date/time functions]
-
MOVE_PARTITIONS_TO_TABLE
- Moves partitions from one table to another. [Partition functions]
-
MOVE_RETIRED_LOCATION_DATA
- Moves all data from the specified retired storage location or from all retired storage locations in the database. [Storage functions]
-
MOVE_STATEMENT_TO_RESOURCE_POOL
- Attempts to move the specified query to the specified target pool. [Workload management functions]
-
MOVING_AVERAGE
- Creates a moving-average (MA) model from a stationary time series with consistent timesteps that can then be used for prediction via PREDICT_MOVING_AVERAGE. [Machine learning algorithms]
-
MSE
- Returns a table that displays the mean squared error of the prediction and response columns in a machine learning model. [Model evaluation]
-
NAIVE_BAYES
- Executes the Naive Bayes algorithm on an input relation and returns a Naive Bayes model. [Machine learning algorithms]
-
NEW_TIME
- Converts a timestamp value from one time zone to another and returns a TIMESTAMP. [Date/time functions]
-
NEXT_DAY
- Returns the date of the first instance of a particular day of the week that follows the specified date. [Date/time functions]
-
NEXTVAL
- Returns the next value in a sequence. [Sequence functions]
-
NORMALIZE
- Runs a normalization algorithm on an input relation. [Data preparation]
-
NORMALIZE_FIT
- This function differs from NORMALIZE, which directly outputs a view with normalized results, rather than storing normalization parameters into a model for later operation. [Data preparation]
-
NOTIFY
- Sends a specified message to a NOTIFIER. [Notifier functions]
-
NOW [date/time]
- Returns a value of type TIMESTAMP WITH TIME ZONE representing the start of the current transaction. [Date/time functions]
-
NTH_VALUE [analytic]
- Returns the value evaluated at the row that is the nth row of the window (counting from 1). [Analytic functions]
-
NTILE [analytic]
- Equally divides an ordered data set (partition) into a {value} number of subsets within a , where the subsets are numbered 1 through the value in parameter constant-value. [Analytic functions]
-
NULLIF
- Compares two expressions. [NULL-handling functions]
-
NULLIFZERO
- Evaluates to NULL if the value in the column is 0. [NULL-handling functions]
-
NVL
- Returns the value of the first non-null expression in the list. [NULL-handling functions]
-
NVL2
- Takes three arguments. [NULL-handling functions]
-
OCTET_LENGTH
- Takes one argument as an input and returns the string length in octets for all string types. [String functions]
-
ONE_HOT_ENCODER_FIT
- Generates a sorted list of each of the category levels for each feature to be encoded, and stores the model. [Data preparation]
-
OVERLAPS
- Evaluates two time periods and returns true when they overlap, false otherwise. [Date/time functions]
-
OVERLAY
- Replaces part of a string with another string and returns the new string value as a VARCHAR. [String functions]
-
OVERLAYB
- Replaces part of a string with another string and returns the new string as an octet value. [String functions]
-
PARTITION_PROJECTION
- Splits containers for a specified projection. [Partition functions]
-
PARTITION_TABLE
- Invokes the to reorganize ROS storage containers as needed to conform with the current partitioning policy. [Partition functions]
-
PATTERN_ID
- Returns an integer value that is a partition-wide unique identifier for the instance of the pattern that matched. [MATCH clause functions]
-
PCA
- Computes principal components from the input table/view. [Data preparation]
-
PERCENT_RANK [analytic]
- Calculates the relative rank of a row for a given row in a group within a by dividing that row’s rank less 1 by the number of rows in the partition, also less 1. [Analytic functions]
-
PERCENTILE_CONT [analytic]
- An inverse distribution function where, for each row, PERCENTILE_CONT returns the value that would fall into the specified percentile among a set of values in each partition within a. [Analytic functions]
-
PERCENTILE_DISC [analytic]
- An inverse distribution function where, for each row, PERCENTILE_DISC returns the value that would fall into the specified percentile among a set of values in each partition within a. [Analytic functions]
-
PI
- Returns the constant pi (P), the ratio of any circle's circumference to its diameter in Euclidean geometry The return type is DOUBLE PRECISION. [Mathematical functions]
-
PLS_REG
- Executes PLS regression on an input relation, and returns a PLS regression model. [Machine learning algorithms]
-
POISSON_REG
- Executes Poisson regression on an input relation, and returns a Poisson regression model. [Machine learning algorithms]
-
POSITION
- Returns an INTEGER value representing the character location of a specified substring with a string (counting from one). [String functions]
-
POSITIONB
- Returns an INTEGER value representing the octet location of a specified substring with a string (counting from one). [String functions]
-
POWER
- Returns a DOUBLE PRECISION value representing one number raised to the power of another number. [Mathematical functions]
-
PRC
- Returns a table that displays the points on a receiver precision recall (PR) curve. [Model evaluation]
-
PREDICT_ARIMA
- Applies an autoregressive integrated moving average (ARIMA) model to an input relation or makes predictions using the in-sample data. [Transformation functions]
-
PREDICT_AUTOREGRESSOR
- Applies an autoregressor (AR) model to an input relation. [Transformation functions]
-
PREDICT_LINEAR_REG
- Applies a linear regression model on an input relation and returns the predicted value as a FLOAT. [Transformation functions]
-
PREDICT_LOGISTIC_REG
- Applies a logistic regression model on an input relation. [Transformation functions]
-
PREDICT_MOVING_AVERAGE
- Applies a moving-average (MA) model, created by MOVING_AVERAGE, to an input relation. [Transformation functions]
-
PREDICT_NAIVE_BAYES
- Applies a Naive Bayes model on an input relation. [Transformation functions]
-
PREDICT_NAIVE_BAYES_CLASSES
- Applies a Naive Bayes model on an input relation and returns the probabilities of classes:. [Transformation functions]
-
PREDICT_PLS_REG
- Applies a PLS regression model on an input relation and returns the predicted values. [Transformation functions]
-
PREDICT_PMML
- Applies an imported PMML model on an input relation. [Transformation functions]
-
PREDICT_POISSON_REG
- Applies a Poisson regression model on an input relation and returns the predicted value as a FLOAT. [Transformation functions]
-
PREDICT_RF_CLASSIFIER
- Applies a random forest model on an input relation. [Transformation functions]
-
PREDICT_RF_CLASSIFIER_CLASSES
- Applies a random forest model on an input relation and returns the probabilities of classes:. [Transformation functions]
-
PREDICT_RF_REGRESSOR
- Applies a random forest model on an input relation, and returns with a FLOAT data type that specifies the predicted value of the random forest model—the average of the prediction of the trees in the forest. [Transformation functions]
-
PREDICT_SVM_CLASSIFIER
- Uses an SVM model to predict class labels for samples in an input relation, and returns the predicted value as a FLOAT data type. [Transformation functions]
-
PREDICT_SVM_REGRESSOR
- Uses an SVM model to perform regression on samples in an input relation, and returns the predicted value as a FLOAT data type. [Transformation functions]
-
PREDICT_TENSORFLOW
- Applies a TensorFlow model on an input relation, and returns with the result expected for the encoded model type. [Transformation functions]
-
PREDICT_TENSORFLOW_SCALAR
- Applies a TensorFlow model on an input relation, and returns with the result expected for the encoded model type. This function supports 1D complex types as input and output. [Transformation functions]
-
PREDICT_XGB_CLASSIFIER
- Applies an XGBoost classifier model on an input relation. [Transformation functions]
-
PREDICT_XGB_CLASSIFIER_CLASSES
- Applies an XGBoost classifier model on an input relation and returns the probabilities of classes:. [Transformation functions]
-
PREDICT_XGB_REGRESSOR
- Applies an XGBoost regressor model on an input relation. [Transformation functions]
-
PROMOTE_SUBCLUSTER_TO_PRIMARY
- Converts a secondary subcluster to a. [Eon Mode functions]
-
PURGE
- Permanently removes delete vectors from ROS storage containers so disk space can be reused. [Database functions]
-
PURGE_PARTITION
- Purges a table partition of deleted rows. [Partition functions]
-
PURGE_PROJECTION
- PURGE_PROJECTION can use significant disk space while purging the data. [Projection functions]
-
PURGE_TABLE
- This function was formerly named PURGE_TABLE_PROJECTIONS(). [Table functions]
-
QUARTER
- Returns calendar quarter of the specified date as an integer, where the January-March quarter is 1. [Date/time functions]
-
QUOTE_IDENT
- Returns the specified string argument in the format required to use the string as an identifier in an SQL statement. [String functions]
-
QUOTE_LITERAL
- Returns the given string suitably quoted for use as a string literal in a SQL statement string. [String functions]
-
QUOTE_NULLABLE
- Returns the given string suitably quoted for use as a string literal in an SQL statement string; or if the argument is null, returns the unquoted string NULL. [String functions]
-
RADIANS
- Returns a DOUBLE PRECISION value representing an angle expressed in radians. [Mathematical functions]
-
RANDOM
- Returns a uniformly-distributed random DOUBLE PRECISION value x, where 0 <= x < 1. [Mathematical functions]
-
RANDOMINT
- Accepts and returns an integer between 0 and the integer argument expression-1. [Mathematical functions]
-
RANDOMINT_CRYPTO
- Accepts and returns an INTEGER value from a set of values between 0 and the specified function argument -1. [Mathematical functions]
-
RANK [analytic]
- Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause. [Analytic functions]
-
READ_CONFIG_FILE
- Reads and returns the key-value pairs of all the parameters of a given tokenizer. [Text search functions]
-
READ_TREE
- Reads the contents of trees within the random forest or XGBoost model. [Model evaluation]
-
REALIGN_CONTROL_NODES
- Causes Vertica to re-evaluate which nodes in the cluster or subcluster are and which nodes are assigned to them as dependents when large cluster is enabled. [Cluster functions]
-
REBALANCE_CLUSTER
- Rebalances the database cluster synchronously as a session foreground task. [Cluster functions]
-
REBALANCE_SHARDS
- Rebalances shard assignments in a subcluster or across the entire cluster in Eon Mode. [Eon Mode functions]
-
REBALANCE_TABLE
- Synchronously rebalances data in the specified table. [Table functions]
-
REENABLE_DUPLICATE_KEY_ERROR
- Restores the default behavior of error reporting by reversing the effects of DISABLE_DUPLICATE_KEY_ERROR. [Table functions]
-
REFRESH
- Synchronously refreshes one or more table projections in the foreground, and updates the PROJECTION_REFRESHES system table. [Projection functions]
-
REFRESH_COLUMNS
- Refreshes table columns that are defined with the constraint SET USING or DEFAULT USING. [Projection functions]
-
REGEXP_COUNT
- Returns the number times a regular expression matches a string. [Regular expression functions]
-
REGEXP_ILIKE
- Returns true if the string contains a match for the regular expression. [Regular expression functions]
-
REGEXP_INSTR
- Returns the starting or ending position in a string where a regular expression matches. [Regular expression functions]
-
REGEXP_LIKE
- Returns true if the string matches the regular expression. [Regular expression functions]
-
REGEXP_NOT_ILIKE
- Returns true if the string does not match the case-insensitive regular expression. [Regular expression functions]
-
REGEXP_NOT_LIKE
- Returns true if the string does not contain a match for the regular expression. [Regular expression functions]
-
REGEXP_REPLACE
- Replaces all occurrences of a substring that match a regular expression with another substring. [Regular expression functions]
-
REGEXP_SUBSTR
- Returns the substring that matches a regular expression within a string. [Regular expression functions]
-
REGISTER_MODEL
- Registers a trained model and adds it to Model Versioning environment with a status of 'under_review'. [Model management]
-
REGR_AVGX
- Returns the DOUBLE PRECISION average of the independent expression in an expression pair. [Aggregate functions]
-
REGR_AVGY
- Returns the DOUBLE PRECISION average of the dependent expression in an expression pair. [Aggregate functions]
-
REGR_COUNT
- Returns the count of all rows in an expression pair. [Aggregate functions]
-
REGR_INTERCEPT
- Returns the y-intercept of the regression line determined by a set of expression pairs. [Aggregate functions]
-
REGR_R2
- Returns the square of the correlation coefficient of a set of expression pairs. [Aggregate functions]
-
REGR_SLOPE
- Returns the slope of the regression line, determined by a set of expression pairs. [Aggregate functions]
-
REGR_SXX
- Returns the sum of squares of the difference between the independent expression (expression2) and its average. [Aggregate functions]
-
REGR_SXY
- Returns the sum of products of the difference between the dependent expression (expression1) and its average and the difference between the independent expression (expression2) and its average. [Aggregate functions]
-
REGR_SYY
- Returns the sum of squares of the difference between the dependent expression (expression1) and its average. [Aggregate functions]
-
RELEASE_ALL_JVM_MEMORY
- Forces all sessions to release the memory consumed by their Java Virtual Machines (JVM). [Session functions]
-
RELEASE_JVM_MEMORY
- Terminates a Java Virtual Machine (JVM), making available the memory the JVM was using. [Session functions]
-
RELEASE_SYSTEM_TABLES_ACCESS
- Enables non-superuser access to all system tables. [Privileges and access functions]
-
RELOAD_ADMINTOOLS_CONF
- Updates the admintools.conf on each UP node in the cluster. [Catalog functions]
-
RELOAD_SPREAD
- Updates cluster changes to the catalog's Spread configuration file. [Cluster functions]
-
REPEAT
- Replicates a string the specified number of times and concatenates the replicated values as a single string. [String functions]
-
REPLACE
- Replaces all occurrences of characters in a string with another set of characters. [String functions]
-
RESERVE_SESSION_RESOURCE
- Reserves memory resources from the general resource pool for the exclusive use of the Vertica backup and restore process. [Session functions]
-
RESET_LOAD_BALANCE_POLICY
- Resets the counter each host in the cluster maintains, to track which host it will refer a client to when the native connection load balancing scheme is set to ROUNDROBIN. [Client connection functions]
-
RESET_SESSION
- Applies your default connection string configuration settings to your current session. [Session functions]
-
RESHARD_DATABASE
- Changes the number of shards in a database. [Eon Mode functions]
-
RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW
- Restores the keys table and the view. [Flex data functions]
-
RESTORE_LOCATION
- Restores a storage location that was previously retired with RETIRE_LOCATION. [Storage functions]
-
RESTRICT_SYSTEM_TABLES_ACCESS
- Checks system table SYSTEM_TABLES to determine which system tables non-superusers can access. [Privileges and access functions]
-
RETIRE_LOCATION
- Deactivates the specified storage location. [Storage functions]
-
REVERSE_NORMALIZE
- Reverses the normalization transformation on normalized data, thereby de-normalizing the normalized data. [Transformation functions]
-
RF_CLASSIFIER
- Trains a random forest model for classification on an input relation. [Machine learning algorithms]
-
RF_PREDICTOR_IMPORTANCE
- Measures the importance of the predictors in a random forest model using the Mean Decrease Impurity (MDI) approach. [Model evaluation]
-
RF_REGRESSOR
- Trains a random forest model for regression on an input relation. [Machine learning algorithms]
-
RIGHT
- Returns the specified characters from the right side of a string. [String functions]
-
ROC
- Returns a table that displays the points on a receiver operating characteristic curve. [Model evaluation]
-
ROUND
- Rounds the specified date or time. [Date/time functions]
-
ROUND
- Rounds a value to a specified number of decimal places, retaining the original precision and scale. [Mathematical functions]
-
ROW_NUMBER [analytic]
- Assigns a sequence of unique numbers to each row in a partition, starting with 1. [Analytic functions]
-
RPAD
- Returns a VARCHAR value representing a string of a specific length filled on the right with specific characters. [String functions]
-
RSQUARED
- Returns a table with the R-squared value of the predictions in a regression model. [Model evaluation]
-
RTRIM
- Returns a VARCHAR value representing a string with trailing blanks removed from the right side (end). [String functions]
-
RUN_INDEX_TOOL
- Runs the Index tool on a Vertica database to perform one of these tasks:. [Database functions]
-
SANDBOX_SUBCLUSTER
- Creates a sandbox for a secondary subcluster. [Eon Mode functions]
-
SAVE_PLANS
- Creates optimizer-generated directed queries from the most frequently executed queries, up to the maximum specified. [Directed queries functions]
-
SECOND
- Returns the seconds portion of the specified date as an integer. [Date/time functions]
-
SECURITY_CONFIG_CHECK
- Returns the status of various security-related parameters. [Database functions]
-
SESSION_USER
- Returns a VARCHAR containing the name of the user who initiated the current database session. [System information functions]
-
SET_AHM_EPOCH
- Sets the (AHM) to the specified epoch. [Epoch functions]
-
SET_AHM_TIME
- Sets the (AHM) to the epoch corresponding to the specified time on the initiator node. [Epoch functions]
-
SET_AUDIT_TIME
- Sets the time that Vertica performs automatic database size audit to determine if the size of the database is compliant with the raw data allowance in your Vertica license. [License functions]
-
SET_CLIENT_LABEL
- Assigns a label to a client connection for the current session. [Client connection functions]
-
SET_CONFIG_PARAMETER
- Sets or clears a configuration parameter at the specified level. [Database functions]
-
SET_CONTROL_SET_SIZE
- Sets the number of that participate in the spread service when large cluster is enabled. [Cluster functions]
-
SET_DATA_COLLECTOR_NOTIFY_POLICY
- Creates/enables notification policies for a component. [Notifier functions]
-
SET_DATA_COLLECTOR_POLICY
- Updates the following retention policy properties for the specified component:. [Data Collector functions]
-
SET_DATA_COLLECTOR_POLICY (using parameters)
- Updates selected retention policy properties for a component. [Data Collector functions]
-
SET_DATA_COLLECTOR_TIME_POLICY
- Updates the retention policy property INTERVAL_TIME for the specified component. [Data Collector functions]
-
SET_DEPOT_ANTI_PIN_POLICY_PARTITION
- Assigns the highest depot eviction priority to a partition. [Eon Mode functions]
-
SET_DEPOT_ANTI_PIN_POLICY_PROJECTION
- Assigns the highest depot eviction priority to a projection. [Eon Mode functions]
-
SET_DEPOT_ANTI_PIN_POLICY_TABLE
- Assigns the highest depot eviction priority to a table. [Eon Mode functions]
-
SET_DEPOT_PIN_POLICY_PARTITION
- Pins the specified partitions of a table or projection to a subcluster depot, or all database depots, to reduce exposure to depot eviction. [Eon Mode functions]
-
SET_DEPOT_PIN_POLICY_PROJECTION
- Pins a projection to a subcluster depot, or all database depots, to reduce its exposure to depot eviction. [Eon Mode functions]
-
SET_DEPOT_PIN_POLICY_TABLE
- Pins a table to a subcluster depot, or all database depots, to reduce its exposure to depot eviction. [Eon Mode functions]
-
SET_LOAD_BALANCE_POLICY
- Sets how native connection load balancing chooses a host to handle a client connection. [Client connection functions]
-
SET_LOCATION_PERFORMANCE
- Sets disk performance for a storage location. [Storage functions]
-
SET_OBJECT_STORAGE_POLICY
- Creates or changes the storage policy of a database object by assigning it a labeled storage location. [Storage functions]
-
SET_SCALING_FACTOR
- Sets the scaling factor that determines the number of storage containers used when rebalancing the database and when using local data segmentation is enabled. [Cluster functions]
-
SET_SPREAD_OPTION
- Changes daemon settings. [Database functions]
-
SET_TOKENIZER_PARAMETER
- Configures the tokenizer parameters. [Text search functions]
-
SET_UNION
- Returns a SET containing all elements of two input sets. [Collection functions]
-
SHA1
- Uses the US Secure Hash Algorithm 1 to calculate the SHA1 hash of string. [String functions]
-
SHA224
- Uses the US Secure Hash Algorithm 2 to calculate the SHA224 hash of string. [String functions]
-
SHA256
- Uses the US Secure Hash Algorithm 2 to calculate the SHA256 hash of string. [String functions]
-
SHA384
- Uses the US Secure Hash Algorithm 2 to calculate the SHA384 hash of string. [String functions]
-
SHA512
- Uses the US Secure Hash Algorithm 2 to calculate the SHA512 hash of string. [String functions]
-
SHOW_PROFILING_CONFIG
- Shows whether profiling is enabled. [Profiling functions]
-
SHUTDOWN
- Shuts down a Vertica database. [Database functions]
-
SHUTDOWN_SUBCLUSTER
- Shuts down a subcluster. [Eon Mode functions]
-
SHUTDOWN_WITH_DRAIN
- Gracefully shuts down a subcluster or subclusters. [Eon Mode functions]
-
SIGN
- Returns a DOUBLE PRECISION value of -1, 0, or 1 representing the arithmetic sign of the argument. [Mathematical functions]
-
SIN
- Returns a DOUBLE PRECISION value that represents the trigonometric sine of the passed parameter. [Mathematical functions]
-
SINH
- Returns a DOUBLE PRECISION value that represents the hyperbolic sine of the passed parameter. [Mathematical functions]
-
SLEEP
- Waits a specified number of seconds before executing another statement or command. [Workload management functions]
-
SOUNDEX
- Takes a VARCHAR argument and returns a four-character code that enables comparison of that argument with other SOUNDEX-encoded strings that are spelled differently in English, but are phonetically similar. [String functions]
-
SOUNDEX_MATCHES
- Compares the Soundex encodings of two strings. [String functions]
-
SPACE
- Returns the specified number of blank spaces, typically for insertion into a character string. [String functions]
-
SPLIT_PART
- Splits string on the delimiter and returns the string at the location of the beginning of the specified field (counting from 1). [String functions]
-
SPLIT_PARTB
- Divides an input string on a delimiter character and returns the Nth segment, counting from 1. [String functions]
-
SQRT
- Returns a DOUBLE PRECISION value representing the arithmetic square root of the argument. [Mathematical functions]
-
ST_Area
- Calculates the area of a spatial object. [Geospatial functions]
-
ST_AsBinary
- Creates the Well-Known Binary (WKB) representation of a spatial object. [Geospatial functions]
-
ST_AsText
- Creates the Well-Known Text (WKT) representation of a spatial object. [Geospatial functions]
-
ST_Boundary
- Calculates the boundary of the specified GEOMETRY object. [Geospatial functions]
-
ST_Buffer
- Creates a GEOMETRY object greater than or equal to a specified distance from the boundary of a spatial object. [Geospatial functions]
-
ST_Centroid
- Calculates the geometric center—the centroid—of a spatial object. [Geospatial functions]
-
ST_Contains
- Determines if a spatial object is entirely inside another spatial object without existing only on its boundary. [Geospatial functions]
-
ST_ConvexHull
- Calculates the smallest convex GEOMETRY object that contains a GEOMETRY object. [Geospatial functions]
-
ST_Crosses
- Determines if one GEOMETRY object spatially crosses another GEOMETRY object. [Geospatial functions]
-
ST_Difference
- Calculates the part of a spatial object that does not intersect with another spatial object. [Geospatial functions]
-
ST_Disjoint
- Determines if two GEOMETRY objects do not intersect or touch. [Geospatial functions]
-
ST_Distance
- Calculates the shortest distance between two spatial objects. [Geospatial functions]
-
ST_Envelope
- Calculates the minimum bounding rectangle that contains the specified GEOMETRY object. [Geospatial functions]
-
ST_Equals
- Determines if two spatial objects are spatially equivalent. [Geospatial functions]
-
ST_GeographyFromText
- Converts a Well-Known Text (WKT) string into its corresponding GEOGRAPHY object. [Geospatial functions]
-
ST_GeographyFromWKB
- Converts a Well-Known Binary (WKB) value into its corresponding GEOGRAPHY object. [Geospatial functions]
-
ST_GeoHash
- Returns a GeoHash in the shape of the specified geometry. [Geospatial functions]
-
ST_GeometryN
- Returns the n geometry within a geometry object. [Geospatial functions]
-
ST_GeometryType
- Determines the class of a spatial object. [Geospatial functions]
-
ST_GeomFromGeoHash
- Returns a polygon in the shape of the specified GeoHash. [Geospatial functions]
-
ST_GeomFromGeoJSON
- Converts the geometry portion of a GeoJSON record in the standard format into a GEOMETRY object. [Geospatial functions]
-
ST_GeomFromText
- Converts a Well-Known Text (WKT) string into its corresponding GEOMETRY object. [Geospatial functions]
-
ST_GeomFromWKB
- Converts the Well-Known Binary (WKB) value to its corresponding GEOMETRY object. [Geospatial functions]
-
ST_Intersection
- Calculates the set of points shared by two GEOMETRY objects. [Geospatial functions]
-
ST_Intersects
- Determines if two GEOMETRY or GEOGRAPHY objects intersect or touch at a single point. [Geospatial functions]
-
ST_IsEmpty
- Determines if a spatial object represents the empty set. [Geospatial functions]
-
ST_IsSimple
- Determines if a spatial object does not intersect itself or touch its own boundary at any point. [Geospatial functions]
-
ST_IsValid
- Determines if a spatial object is well formed or valid. [Geospatial functions]
-
ST_Length
- Calculates the length of a spatial object. [Geospatial functions]
-
ST_NumGeometries
- Returns the number of geometries contained within a spatial object. [Geospatial functions]
-
ST_NumPoints
- Calculates the number of vertices of a spatial object, empty objects return NULL. [Geospatial functions]
-
ST_Overlaps
- Determines if a GEOMETRY object shares space with another GEOMETRY object, but is not completely contained within that object. [Geospatial functions]
-
ST_PointFromGeoHash
- Returns the center point of the specified GeoHash. [Geospatial functions]
-
ST_PointN
- Finds the n point of a spatial object. [Geospatial functions]
-
ST_Relate
- Determines if a given GEOMETRY object is spatially related to another GEOMETRY object, based on the specified DE-9IM pattern matrix string. [Geospatial functions]
-
ST_SRID
- Identifies the spatial reference system identifier (SRID) stored with a spatial object. [Geospatial functions]
-
ST_SymDifference
- Calculates all the points in two GEOMETRY objects except for the points they have in common, but including the boundaries of both objects. [Geospatial functions]
-
ST_Touches
- Determines if two GEOMETRY objects touch at a single point or along a boundary, but do not have interiors that intersect. [Geospatial functions]
-
ST_Transform
- Returns a new GEOMETRY with its coordinates converted to the spatial reference system identifier (SRID) used by the srid argument. [Geospatial functions]
-
ST_Union
- Calculates the union of all points in two spatial objects. [Geospatial functions]
-
ST_Within
- If spatial object g1 is completely inside of spatial object g2, then ST_Within returns true. [Geospatial functions]
-
ST_X
- Determines the x- coordinate for a GEOMETRY point or the longitude value for a GEOGRAPHY point. [Geospatial functions]
-
ST_XMax
- Returns the maximum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object. [Geospatial functions]
-
ST_XMin
- Returns the minimum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object. [Geospatial functions]
-
ST_Y
- Determines the y-coordinate for a GEOMETRY point or the latitude value for a GEOGRAPHY point. [Geospatial functions]
-
ST_YMax
- Returns the maximum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object. [Geospatial functions]
-
ST_YMin
- Returns the minimum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object. [Geospatial functions]
-
START_DRAIN_SUBCLUSTER
- Drains a subcluster or subclusters. [Eon Mode functions]
-
START_REAPING_FILES
- Starts the disk file deletion in the background as an asynchronous function. [Eon Mode functions]
-
START_REBALANCE_CLUSTER
- Asynchronously rebalances the database cluster as a background task. [Cluster functions]
-
START_REFRESH
- Refreshes projections in the current schema with the latest data of their respective. [Projection functions]
-
STATEMENT_TIMESTAMP
- Similar to TRANSACTION_TIMESTAMP, returns a value of type TIMESTAMP WITH TIME ZONE that represents the start of the current statement. [Date/time functions]
-
STDDEV [aggregate]
- Evaluates the statistical sample standard deviation for each member of the group. [Aggregate functions]
-
STDDEV [analytic]
- Computes the statistical sample standard deviation of the current row with respect to the group within a. [Analytic functions]
-
STDDEV_POP [aggregate]
- Evaluates the statistical population standard deviation for each member of the group. [Aggregate functions]
-
STDDEV_POP [analytic]
- Evaluates the statistical population standard deviation for each member of the group. [Analytic functions]
-
STDDEV_SAMP [aggregate]
- Evaluates the statistical sample standard deviation for each member of the group. [Aggregate functions]
-
STDDEV_SAMP [analytic]
- Computes the statistical sample standard deviation of the current row with respect to the group within a. [Analytic functions]
-
STRING_TO_ARRAY
- Splits a string containing array values and returns a native one-dimensional array. [Collection functions]
-
STRPOS
- Returns an INTEGER value that represents the location of a specified substring within a string (counting from one). [String functions]
-
STRPOSB
- Returns an INTEGER value representing the location of a specified substring within a string, counting from one, where each octet in the string is counted (as opposed to characters). [String functions]
-
STV_AsGeoJSON
- Returns the geometry or geography argument as a Geometry Javascript Object Notation (GeoJSON) object. [Geospatial functions]
-
STV_Create_Index
- Creates a spatial index on a set of polygons to speed up spatial intersection with a set of points. [Geospatial functions]
-
STV_Describe_Index
- Retrieves information about an index that contains a set of polygons. [Geospatial functions]
-
STV_Drop_Index
- Deletes a spatial index. [Geospatial functions]
-
STV_DWithin
- Determines if the shortest distance from the boundary of one spatial object to the boundary of another object is within a specified distance. [Geospatial functions]
-
STV_Export2Shapefile
- Exports GEOGRAPHY or GEOMETRY data from a database table or a subquery to a shapefile. [Geospatial functions]
-
STV_Extent
- Returns a bounding box containing all of the input data. [Geospatial functions]
-
STV_ForceLHR
- Alters the order of the vertices of a spatial object to follow the left-hand-rule. [Geospatial functions]
-
STV_Geography
- Casts a GEOMETRY object into a GEOGRAPHY object. [Geospatial functions]
-
STV_GeographyPoint
- Returns a GEOGRAPHY point based on the input values. [Geospatial functions]
-
STV_Geometry
- Casts a GEOGRAPHY object into a GEOMETRY object. [Geospatial functions]
-
STV_GeometryPoint
- Returns a GEOMETRY point, based on the input values. [Geospatial functions]
-
STV_GetExportShapefileDirectory
- Returns the path of the export directory. [Geospatial functions]
-
STV_Intersect scalar function
- Spatially intersects a point or points with a set of polygons. [Geospatial functions]
-
STV_Intersect transform function
- Spatially intersects points and polygons. [Geospatial functions]
-
STV_IsValidReason
- Determines if a spatial object is well formed or valid. [Geospatial functions]
-
STV_LineStringPoint
- Retrieves the vertices of a linestring or multilinestring. [Geospatial functions]
-
STV_MemSize
- Returns the length of the spatial object in bytes as an INTEGER. [Geospatial functions]
-
STV_NN
- Calculates the distance of spatial objects from a reference object and returns (object, distance) pairs in ascending order by distance from the reference object. [Geospatial functions]
-
STV_PolygonPoint
- Retrieves the vertices of a polygon as individual points. [Geospatial functions]
-
STV_Refresh_Index
- Appends newly added or updated polygons and removes deleted polygons from an existing spatial index. [Geospatial functions]
-
STV_Rename_Index
- Renames a spatial index. [Geospatial functions]
-
STV_Reverse
- Reverses the order of the vertices of a spatial object. [Geospatial functions]
-
STV_SetExportShapefileDirectory
- Specifies the directory to export GEOMETRY or GEOGRAPHY data to a shapefile. [Geospatial functions]
-
STV_ShpCreateTable
- Returns a CREATE TABLE statement with the columns and types of the attributes found in the specified shapefile. [Geospatial functions]
-
STV_ShpSource and STV_ShpParser
- These two functions work with COPY to parse and load geometries and attributes from a shapefile into a Vertica table, and convert them to the appropriate GEOMETRY data type. [Geospatial functions]
-
SUBSTR
- Returns VARCHAR or VARBINARY value representing a substring of a specified string. [String functions]
-
SUBSTRB
- Returns an octet value representing the substring of a specified string. [String functions]
-
SUBSTRING
- Returns a value representing a substring of the specified string at the given position, given a value, a position, and an optional length. [String functions]
-
SUM [aggregate]
- Computes the sum of an expression over a group of rows. [Aggregate functions]
-
SUM [analytic]
- Computes the sum of an expression over a group of rows within a. [Analytic functions]
-
SUM_FLOAT [aggregate]
- Computes the sum of an expression over a group of rows and returns a DOUBLE PRECISION value. [Aggregate functions]
-
SUMMARIZE_CATCOL
- Returns a statistical summary of categorical data input, in three columns:. [Data preparation]
-
SUMMARIZE_NUMCOL
- Returns a statistical summary of columns in a Vertica table:. [Data preparation]
-
SVD
- Computes singular values (the diagonal of the S matrix) and right singular vectors (the V matrix) of an SVD decomposition of the input relation. [Data preparation]
-
SVM_CLASSIFIER
- Trains the SVM model on an input relation. [Machine learning algorithms]
-
SVM_REGRESSOR
- Trains the SVM model on an input relation. [Machine learning algorithms]
-
SWAP_PARTITIONS_BETWEEN_TABLES
- Swaps partitions between two tables. [Partition functions]
-
SYNC_CATALOG
- Synchronizes the catalog to communal storage to enable reviving the current catalog version in the case of an imminent crash. [Eon Mode functions]
-
SYNC_WITH_HCATALOG_SCHEMA
- Copies the structure of a Hive database schema available through the HCatalog Connector to a Vertica schema. [Hadoop functions]
-
SYNC_WITH_HCATALOG_SCHEMA_TABLE
- Copies the structure of a single table in a Hive database schema available through the HCatalog Connector to a Vertica table. [Hadoop functions]
-
SYSDATE
- Returns the current statement's start date and time as a TIMESTAMP value. [Date/time functions]
-
TAN
- Returns a DOUBLE PRECISION value that represents the trigonometric tangent of the passed parameter. [Mathematical functions]
-
TANH
- Returns a DOUBLE PRECISION value that represents the hyperbolic tangent of the passed parameter. [Mathematical functions]
-
Template patterns for date/time formatting
- In an output template string (for TO_CHAR), certain patterns are recognized and replaced with appropriately formatted data from the value to format. [Formatting functions]
-
Template patterns for numeric formatting
- A sign formatted using SG, PL, or MI is not anchored to the number. [Formatting functions]
-
THROW_ERROR
- Returns a user-defined error message. [Error-handling functions]
-
TIME_SLICE
- Aggregates data by different fixed-time intervals and returns a rounded-up input TIMESTAMP value to a value that corresponds with the start or end of the time slice interval. [Date/time functions]
-
TIMEOFDAY
- Returns the wall-clock time as a text string. [Date/time functions]
-
TIMESTAMP_ROUND
- Rounds the specified TIMESTAMP. [Date/time functions]
-
TIMESTAMP_TRUNC
- Truncates the specified TIMESTAMP. [Date/time functions]
-
TIMESTAMPADD
- Adds the specified number of intervals to a TIMESTAMP or TIMESTAMPTZ value and returns a result of the same data type. [Date/time functions]
-
TIMESTAMPDIFF
- Returns the time span between two TIMESTAMP or TIMESTAMPTZ values, in the intervals specified. [Date/time functions]
-
TO_BITSTRING
- This topic is shared in two locations: Formatting Functions and String Functions. [Formatting functions]
-
TO_CHAR
- Converts date/time and numeric values into text strings. [Formatting functions]
-
TO_DATE
- This topic shared in two places: Date/Time functions and Formatting Functions. [Formatting functions]
-
TO_HEX
- This topic is shared in two locations: Formatting Functions and String Functions. [Formatting functions]
-
TO_JSON
- Returns the JSON representation of a complex-type argument, including mixed and nested complex types. [Collection functions]
-
TO_NUMBER
- Converts a string value to DOUBLE PRECISION. [Formatting functions]
-
TO_TIMESTAMP
- Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP type. [Formatting functions]
-
TO_TIMESTAMP_TZ
- Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP WITH TIME ZONE type. [Formatting functions]
-
TRANSACTION_TIMESTAMP
- Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction. [Date/time functions]
-
TRANSLATE
- Replaces individual characters in string_to_replace with other characters. [String functions]
-
TRIM
- Combines the BTRIM, LTRIM, and RTRIM functions into a single function. [String functions]
-
TRUNC
- Truncates the specified date or time. [Date/time functions]
-
TRUNC
- Returns the expression value fully truncated (toward zero). [Mathematical functions]
-
TS_FIRST_VALUE
- Processes the data that belongs to each time slice. [Aggregate functions]
-
TS_LAST_VALUE
- Processes the data that belongs to each time slice. [Aggregate functions]
-
UNNEST
- Expands the elements of one or more collection columns (ARRAY or SET) into individual rows. [Collection functions]
-
UNSANDBOX_SUBCLUSTER
- Removes a subcluster from a sandbox. [Eon Mode functions]
-
UPGRADE_MODEL
- Upgrades a model from a previous Vertica version. [Model management]
-
UPPER
- Returns a VARCHAR value containing the argument converted to uppercase letters. [String functions]
-
UPPERB
- Returns a character string with each ASCII character converted to uppercase. [String functions]
-
URI_PERCENT_DECODE
- Decodes a percent-encoded Universal Resource Identifier (URI) according to the RFC 3986 standard. [URI functions]
-
URI_PERCENT_ENCODE
- Encodes a Universal Resource Identifier (URI) according to the RFC 3986 standard for percent encoding. [URI functions]
-
USER
- Returns a VARCHAR containing the name of the user who initiated the current database connection. [System information functions]
-
USERNAME
- Returns a VARCHAR containing the name of the user who initiated the current database connection. [System information functions]
-
UUID_GENERATE
- Returns a new universally unique identifier (UUID) that is generated based on high-quality randomness from /dev/urandom. [UUID functions]
-
V6_ATON
- Converts a string containing a colon-delimited IPv6 network address into a VARBINARY string. [IP address functions]
-
V6_NTOA
- Converts an IPv6 address represented as varbinary to a character string. [IP address functions]
-
V6_SUBNETA
- Returns a VARCHAR containing a subnet address in CIDR (Classless Inter-Domain Routing) format from a binary or alphanumeric IPv6 address. [IP address functions]
-
V6_SUBNETN
- Calculates a subnet address in CIDR (Classless Inter-Domain Routing) format from a varbinary or alphanumeric IPv6 address. [IP address functions]
-
V6_TYPE
- Returns an INTEGER value that classifies the type of the network address passed to it as defined in IETF RFC 4291 section 2.4. [IP address functions]
-
VALIDATE_STATISTICS
- Validates statistics in the XML file generated by EXPORT_STATISTICS. [Statistics management functions]
-
VAR_POP [aggregate]
- Evaluates the population variance for each member of the group. [Aggregate functions]
-
VAR_POP [analytic]
- Returns the statistical population variance of a non-null set of numbers (nulls are ignored) in a group within a. [Analytic functions]
-
VAR_SAMP [aggregate]
- Evaluates the sample variance for each row of the group. [Aggregate functions]
-
VAR_SAMP [analytic]
- Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a. [Analytic functions]
-
VARIANCE [aggregate]
- Evaluates the sample variance for each row of the group. [Aggregate functions]
-
VARIANCE [analytic]
- Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a. [Analytic functions]
-
VERIFY_HADOOP_CONF_DIR
- Verifies that the Hadoop configuration that is used to access HDFS is valid on all Vertica nodes. [Hadoop functions]
-
VERSION
- Returns a VARCHAR containing a Vertica node's version information. [System information functions]
-
WEEK
- Returns the week of the year for the specified date as an integer, where the first week begins on the first Sunday on or preceding January 1. [Date/time functions]
-
WEEK_ISO
- Returns the week of the year for the specified date as an integer, where the first week starts on Monday and contains January 4. [Date/time functions]
-
WIDTH_BUCKET
- Constructs equiwidth histograms, in which the histogram range is divided into intervals (buckets) of identical sizes. [Mathematical functions]
-
WITHIN GROUP ORDER BY clause
- Specifies how to sort rows that are grouped by aggregate functions, one of the following:. [Aggregate functions]
-
XGB_CLASSIFIER
- Trains an XGBoost model for classification on an input relation. [Machine learning algorithms]
-
XGB_PREDICTOR_IMPORTANCE
- Measures the importance of the predictors in an XGBoost model. [Model evaluation]
-
XGB_REGRESSOR
- Trains an XGBoost model for regression on an input relation. [Machine learning algorithms]
-
YEAR
- Returns an integer that represents the year portion of the specified date. [Date/time functions]
-
YEAR_ISO
- Returns an integer that represents the year portion of the specified date. [Date/time functions]
-
ZEROIFNULL
- Evaluates to 0 if the column is NULL. [NULL-handling functions]
6.1 - Aggregate functions
All functions in this section that have an analytic function counterpart are appended with [Aggregate] to avoid confusion between the two.
Aggregate functions summarize data over groups of rows from a query result set. The groups are specified using the GROUP BY clause. They are allowed only in the select list and in the HAVING and ORDER BY clauses of a SELECT statement (as described in Aggregate expressions).
Except for COUNT, these functions return a null value when no rows are selected. In particular, SUM of no rows returns NULL, not zero.
In some cases, you can replace an expression that includes multiple aggregates with a single aggregate of an expression. For example SUM(x) + SUM(y) can be expressed as as SUM(x+y) if neither argument is NULL.
Vertica does not support nested aggregate functions.
You can use some of the simple aggregate functions as analytic (window) functions. See Analytic functions for details. See also SQL analytics.
Some collection functions also behave as aggregate functions.
Note
All functions in this section that have an
analytic function counterpart are appended with [aggregate] to avoid confusion between the two.
6.1.1 - APPROXIMATE_COUNT_DISTINCT
Returns the number of distinct non-NULL values in a data set.
Returns the number of distinct non-NULL values in a data set.
Behavior type
Immutable
Syntax
APPROXIMATE_COUNT_DISTINCT ( expression[, error-tolerance ] )
Parameters
expression- Value to be evaluated using any data type that supports equality comparison.
error-tolerance Numeric value that represents the desired percentage of error tolerance, distributed around the value returned by this function. The smaller the error tolerance, the closer the approximation.
You can set error-tolerance to a minimum value of 0.88. Vertica imposes no maximum restriction, but any value greater than 5 is implemented with 5% error tolerance.
If you omit this argument, Vertica uses an error tolerance of 1.25(%).
Restrictions
APPROXIMATE_COUNT_DISTINCT and DISTINCT aggregates cannot be in the same query block.
Error tolerance
APPROXIMATE_COUNT_DISTINCT(x, error-tolerance) returns a value equal to COUNT(DISTINCT x), with an error that is lognormally distributed with standard deviation.
Parameter error-tolerance is optional. Supply this argument to specify the desired standard deviation. error-tolerance is defined as 2.17 standard deviations, which corresponds to a 97 percent confidence interval:
standard-deviation = error-tolerance / 2.17
For example:
-
error-tolerance = 1
Default setting, corresponds to a standard deviation
97 percent of the time, APPROXIMATE_COUNT_DISTINCT(x,5) returns a value between:
-
COUNT(DISTINCT x) * 0.99
-
COUNT(DISTINCT x) * 1.01
-
error-tolerance = 5
97 percent of the time, APPROXIMATE_COUNT_DISTINCT(x) returns a value between:
-
COUNT(DISTINCT x) * 0.95
-
COUNT(DISTINCT x) * 1.05
A 99 percent confidence interval corresponds to 2.58 standard deviations. To set error-tolerance confidence level corresponding to 99 (instead of a 97) percent , multiply error-tolerance by 2.17 / 2.58 = 0.841.
For example, if you specify error-tolerance as 5 * 0.841 = 4.2, APPROXIMATE_COUNT_DISTINCT(x,4.2) returns values 99 percent of the time between:
Examples
Count the total number of distinct values in column product_key from table store.store_sales_fact:
=> SELECT COUNT(DISTINCT product_key) FROM store.store_sales_fact;
COUNT
-------
19982
(1 row)
Count the approximate number of distinct values in product_key with various error tolerances. The smaller the error tolerance, the closer the approximation:
=> SELECT APPROXIMATE_COUNT_DISTINCT(product_key,5) AS five_pct_accuracy,
APPROXIMATE_COUNT_DISTINCT(product_key,1) AS one_pct_accuracy,
APPROXIMATE_COUNT_DISTINCT(product_key,.88) AS point_eighteight_pct_accuracy
FROM store.store_sales_fact;
five_pct_accuracy | one_pct_accuracy | point_eighteight_pct_accuracy
-------------------+------------------+-------------------------------
19431 | 19921 | 19921
(1 row)
See also
Approximate count distinct functions
6.1.2 - APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS
Calculates the number of distinct non-NULL values from the synopsis objects created by APPROXIMATE_COUNT_DISTINCT_SYNOPSIS.
Calculates the number of distinct non-NULL values from the synopsis objects created by APPROXIMATE_COUNT_DISTINCT_SYNOPSIS.
Behavior type
Immutable
Syntax
APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS ( synopsis-obj[, error-tolerance ] )
Parameters
synopsis-obj- A synopsis object created by APPROXIMATE_COUNT_DISTINCT_SYNOPSIS.
error-toleranceNumeric value that represents the desired percentage of error tolerance, distributed around the value returned by this function. The smaller the error tolerance, the closer the approximation.
You can set error-tolerance to a minimum value of 0.88. Vertica imposes no maximum restriction, but any value greater than 5 is implemented with 5% error tolerance.
If you omit this argument, Vertica uses an error tolerance of 1.25(%).
For more details, see APPROXIMATE_COUNT_DISTINCT.
Restrictions
APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS and DISTINCT aggregates cannot be in the same query block.
Examples
The following examples review and compare different ways to obtain a count of unique values in a table column:
Return an exact count of unique values in column product_key, from table store.store_sales_fact:
=> \timing
Timing is on.
=> SELECT COUNT(DISTINCT product_key) from store.store_sales_fact;
count
-------
19982
(1 row)
Time: First fetch (1 row): 553.033 ms. All rows formatted: 553.075 ms
Return an approximate count of unique values in column product_key:
=> SELECT APPROXIMATE_COUNT_DISTINCT(product_key) as unique_product_keys
FROM store.store_sales_fact;
unique_product_keys
---------------------
19921
(1 row)
Time: First fetch (1 row): 394.562 ms. All rows formatted: 394.600 ms
Create a synopsis object that represents a set of store.store_sales_fact data with unique product_key values, store the synopsis in the new table my_summary:
=> CREATE TABLE my_summary AS SELECT APPROXIMATE_COUNT_DISTINCT_SYNOPSIS (product_key) syn
FROM store.store_sales_fact;
CREATE TABLE
Time: First fetch (0 rows): 582.662 ms. All rows formatted: 582.682 ms
Return a count from the saved synopsis:
=> SELECT APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS(syn) FROM my_summary;
ApproxCountDistinctOfSynopsis
-------------------------------
19921
(1 row)
Time: First fetch (1 row): 105.295 ms. All rows formatted: 105.335 ms
See also
Approximate count distinct functions
6.1.3 - APPROXIMATE_COUNT_DISTINCT_SYNOPSIS
Summarizes the information of distinct non-NULL values and materializes the result set in a VARBINARY or LONG VARBINARY synopsis object.
Summarizes the information of distinct non-NULL values and materializes the result set in a VARBINARY or LONG VARBINARY synopsis object. The calculated result is within a specified range of error tolerance. You save the synopsis object in a Vertica table for use by APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS.
Behavior type
Immutable
Syntax
APPROXIMATE_COUNT_DISTINCT_SYNOPSIS ( expression[, error-tolerance] )
Parameters
expression- Value to evaluate using any data type that supports equality comparison.
error-toleranceNumeric value that represents the desired percentage of error tolerance, distributed around the value returned by this function. The smaller the error tolerance, the closer the approximation.
You can set error-tolerance to a minimum value of 0.88. Vertica imposes no maximum restriction, but any value greater than 5 is implemented with 5% error tolerance.
If you omit this argument, Vertica uses an error tolerance of 1.25(%).
For more details, see APPROXIMATE_COUNT_DISTINCT.
Restrictions
APPROXIMATE_COUNT_DISTINCT_SYNOPSIS and DISTINCT aggregates cannot be in the same query block.
Examples
See APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS.
See also
Approximate count distinct functions
6.1.4 - APPROXIMATE_COUNT_DISTINCT_SYNOPSIS_MERGE
Aggregates multiple synopses into one new synopsis.
Aggregates multiple synopses into one new synopsis. This function is similar to APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS but returns one synopsis instead of the count estimate. The benefit of this function is that it speeds up final estimation when calling APPROXIMATE_COUNT_DISTINCT_OF_SYNOPSIS.
For example, if you need to regularly estimate count distinct of users for a long period of time (such as several years) you can pre-accumulate synopses of days into one synopsis for a year.
Behavior type
Immutable
Syntax
APPROXIMATE_COUNT_DISTINCT_SYNOPSIS_MERGE ( synopsis-obj [, error-tolerance] )
Parameters
synopsis-obj- An expression that can be evaluated to one or more synopses. Typically a
synopsis-obj is generated as a binary string by either the APPROXIMATE_COUNT_DISTINCT or APPROXIMATE_COUNT_DISTINCT_SYNOPSIS_MERGE function and is stored in a table column of type VARBINARY or LONG VARBINARY.
error-toleranceNumeric value that represents the desired percentage of error tolerance, distributed around the value returned by this function. The smaller the error tolerance, the closer the approximation.
You can set error-tolerance to a minimum value of 0.88. Vertica imposes no maximum restriction, but any value greater than 5 is implemented with 5% error tolerance.
If you omit this argument, Vertica uses an error tolerance of 1.25(%).
For more details, see APPROXIMATE_COUNT_DISTINCT.
Examples
See Approximate count distinct functions.
6.1.5 - APPROXIMATE_MEDIAN [aggregate]
Computes the approximate median of an expression over a group of rows.
Computes the approximate median of an expression over a group of rows. The function returns a FLOAT value.
APPROXIMATE_MEDIAN is an alias of APPROXIMATE_PERCENTILE [aggregate] with a parameter of 0.5.
Note
Note: This function is best suited for large groups of data. If you have a small group of data, use the exact
MEDIAN [analytic] function.
Behavior type
Immutable
Syntax
APPROXIMATE_MEDIAN ( expression )
Parameters
expression- Any FLOAT or INTEGER data type. The function returns the approximate middle value or an interpolated value that would be the approximate middle value once the values are sorted. Null values are ignored in the calculation.
Examples
Tip
For optimal performance when using GROUP BY in your query, verify that your table is sorted on the GROUP BY column.
The following examples uses this table:
CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT) ORDER BY state;
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
Calculate the approximate median of all sales in this table:
=> SELECT APPROXIMATE_MEDIAN (sales) FROM allsales;
APROXIMATE_MEDIAN
--------------------
20
(1 row)
Modify the query to group sales by state, and obtain the approximate median for each one:
=> SELECT state, APPROXIMATE_MEDIAN(sales) FROM allsales GROUP BY state;
state | APPROXIMATE_MEDIAN
-------+--------------------
MA | 35
NY | 20
(2 rows)
See also
6.1.6 - APPROXIMATE_PERCENTILE [aggregate]
Computes the approximate percentile of an expression over a group of rows.
Computes the approximate percentile of an expression over a group of rows. This function returns a FLOAT value.
Note
Note: Use this function when many rows are aggregated into groups. If the number of aggregated rows is small, use the analytic function
PERCENTILE_CONT.
Behavior type
Immutable
Syntax
APPROXIMATE_PERCENTILE ( column-expression USING PARAMETERS percentiles='percentile-values' )
Arguments
column-expression- A column of FLOAT or INTEGER data types whose percentiles will be calculated. NULL values are ignored.
Parameters
percentiles- One or more (up to 1000) comma-separated
FLOAT constants ranging from 0 to 1 inclusive, specifying the percentile values to be calculated.
Note
Note: The deprecated parameter percentile, which takes only a single float, continues to be supported for backwards-compatibility.
Examples
Tip
For optimal performance when using GROUP BY in your query, verify that your table is sorted on the GROUP BY column.
The following examples use this table:
=> CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT) ORDER BY state;
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
=> SELECT * FROM allsales;
state | name | sales
-------+------+-------
MA | A | 60
NY | B | 20
NY | C | 15
NY | F | 40
MA | D | 20
MA | E | 50
MA | G | 10
(7 rows)
Calculate the approximate percentile for sales in each state:
=> SELECT state, APPROXIMATE_PERCENTILE(sales USING PARAMETERS percentiles='0.5') AS median
FROM allsales GROUP BY state;
state | median
-------+--------
MA | 35
NY | 20
(2 rows)
Calculate multiple approximate percentiles for sales in each state:
=> SELECT state, APPROXIMATE_PERCENTILE(sales USING PARAMETERS percentiles='0.5,1.0')
FROM allsales GROUP BY state;
state | APPROXIMATE_PERCENTILE
-------+--------
MA | [35.0,60.0]
NY | [20.0,40.0]
(2 rows)
Calculate multiple approximate percentiles for sales in each state and show results for each percentile in separate columns:
=> SELECT ps[0] as q0, ps[1] as q1, ps[2] as q2, ps[3] as q3, ps[4] as q4
FROM (SELECT APPROXIMATE_PERCENTILE(sales USING PARAMETERS percentiles='0, 0.25, 0.5, 0.75, 1')
AS ps FROM allsales GROUP BY state) as s1;
q0 | q1 | q2 | q3 | q4
------+------+------+------+------
10.0 | 17.5 | 35.0 | 52.5 | 60.0
15.0 | 17.5 | 20.0 | 30.0 | 40.0
(2 rows)
See also
6.1.7 - APPROXIMATE_QUANTILES
Computes an array of weighted, approximate percentiles of a column within some user-specified error.
Computes an array of weighted, approximate percentiles of a column within some user-specified error. This algorithm is similar to APPROXIMATE_PERCENTILE [aggregate], which instead returns a single percentile.
The performance of this function depends entirely on the specified epsilon and the size of the provided array.
The OVER clause for this function must be empty.
Behavior type
Immutable
Syntax
APPROXIMATE_QUANTILES ( column USING PARAMETERS [nquantiles=n], [epsilon=error] ) OVER() FROM table
Parameters
column- The
INTEGER or FLOAT column for which to calculate the percentiles. NULL values are ignored.
n- An integer that specifies the number of desired quantiles in the returned array.
Default: 11
error- The allowed error for any returned percentile. Specifically, for an array of size N, the specified error ε (epsilon) for the φ-quantile guarantees that the rank r of the return value with respect to the rank ⌊φN⌋ of the exact value is such that:
⌊(φ-ε)N⌋ ≤ r ≤ ⌊(φ+ε)N⌋
For n quantiles, if the error ε is specified such that ε > 1/n, this function will return non-deterministic results.
Default: 0.001
table- The table containing
column.
Examples
The following example uses this table:
=> CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT) ORDER BY state;
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
=> SELECT * FROM allsales;
state | name | sales
-------+------+-------
MA | A | 60
NY | B | 20
NY | C | 15
NY | F | 40
MA | D | 20
MA | E | 50
MA | G | 10
(7 rows)
This call to APPROXIMATE_QUANTILES returns a 6-element array of approximate percentiles, one for each quantile. Each quantile relates to the percentile by a factor of 100. For example, the second entry in the output indicates that 15 is the 0.2-quantile of the input column, so 15 is the 20th percentile of the input column.
=> SELECT APPROXIMATE_QUANTILES(sales USING PARAMETERS nquantiles=6) OVER() FROM allsales;
Quantile | Value
----------+-------
0 | 10
0.2 | 15
0.4 | 20
0.6 | 40
0.8 | 50
1 | 60
(6 rows)
6.1.8 - ARGMAX_AGG
Takes two arguments target and arg, where both are columns or column expressions in the queried dataset.
Takes two arguments target and arg, where both are columns or column expressions in the queried dataset. ARGMAX_AGG finds the row with the highest non-null value in target and returns the value of arg in that row. If multiple rows contain the highest target value, ARGMAX_AGG returns arg from the first row that it finds. Use the WITHIN GROUP ORDER BY clause to control which row ARGMAX_AGG finds first.
Behavior type
Immutable if the WITHIN GROUP ORDER BY clause specifies a column or set of columns that resolves to unique values within the group; otherwise Volatile.
Syntax
ARGMAX_AGG ( target, arg ) [ within-group-order-by-clause ]
Arguments
target, arg- Columns in the queried dataset.
Note
The
target argument cannot reference a
spatial data type column, GEOMETRY or GEOGRAPHY.
- [within-group-order-by-clause](/en/sql-reference/functions/aggregate-functions/within-group-order-by-clause/)
- Sorts target values within each group of rows:
WITHIN GROUP (ORDER BY { column-expression[ sort-qualifiers ] }[,...])
sort-qualifiers:
{ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] }
Use this clause to determine which row is returned when multiple rows contain the highest target value; otherwise, results are likely to vary with each iteration of the same query.
Tip
WITHIN GROUP ORDER BY can consume a large amount of memory per group. To minimize memory consumption, create projections that support
GROUPBY PIPELINED.
Examples
The following example calls ARGMAX_AGG in a WITH clause to find which employees in each region are at or near retirement age. If multiple employees within each region have the same age, ARGMAX_AGG chooses the employees with the highest salary level and returns with their IDs. The primary query returns with details on the employees selected from each region:
=> WITH r AS (SELECT employee_region, ARGMAX_AGG(employee_age, employee_key)
WITHIN GROUP (ORDER BY annual_salary DESC) emp_id
FROM employee_dim GROUP BY employee_region ORDER BY employee_region)
SELECT r.employee_region, ed.annual_salary AS highest_salary, employee_key,
ed.employee_first_name||' '||ed.employee_last_name AS employee_name, ed.employee_age
FROM r JOIN employee_dim ed ON r.emp_id = ed.employee_key ORDER BY ed.employee_region;
employee_region | highest_salary | employee_key | employee_name | employee_age
----------------------------------+----------------+--------------+------------------+--------------
East | 927335 | 70 | Sally Gauthier | 65
MidWest | 177716 | 869 | Rebecca McCabe | 65
NorthWest | 100300 | 7597 | Kim Jefferson | 65
South | 196454 | 275 | Alexandra Harris | 65
SouthWest | 198669 | 1043 | Seth Stein | 65
West | 197203 | 681 | Seth Jones | 65
(6 rows)
See also
ARGMIN_AGG
6.1.9 - ARGMIN_AGG
Takes two arguments target and arg, where both are columns or column expressions in the queried dataset.
Takes two arguments target and arg, where both are columns or column expressions in the queried dataset. ARGMIN_AGG finds the row with the lowest non-null value in target and returns the value of arg in that row. If multiple rows contain the lowest target value, ARGMIN_AGG returns arg from the first row that it finds. Use the WITHIN GROUP ORDER BY clause to control which row ARGMMIN_AGG finds first.
Behavior type
Immutable if the WITHIN GROUP ORDER BY clause specifies a column or set of columns that resolves to unique values within the group; otherwise Volatile.
Syntax
ARGMIN_AGG ( target, arg ) [ within-group-order-by-clause ]
Arguments
target, arg- Columns in the queried dataset.
Note
The
target argument cannot reference a
spatial data type column, GEOMETRY or GEOGRAPHY.
- [within-group-order-by-clause](/en/sql-reference/functions/aggregate-functions/within-group-order-by-clause/)
- Sorts target values within each group of rows:
WITHIN GROUP (ORDER BY { column-expression[ sort-qualifiers ] }[,...])
sort-qualifiers:
{ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] }
Use this clause to determine which row is returned when multiple rows contain the lowest target value; otherwise, results are likely to vary with each iteration of the same query.
Tip
WITHIN GROUP ORDER BY can consume a large amount of memory per group. To minimize memory consumption, create projections that support
GROUPBY PIPELINED.
Examples
The following example calls ARGMIN_AGG in a WITH clause to find the lowest salary among all employees in each region, and returns with the lowest-paid employee IDs. The primary query returns with the salary amounts and employee names:
=> WITH msr (employee_region, emp_id) AS
(SELECT employee_region, argmin_agg(annual_salary, employee_key) lowest_paid_employee FROM employee_dim GROUP BY employee_region)
SELECT msr.employee_region, ed.annual_salary AS lowest_salary, ed.employee_first_name||' '||ed.employee_last_name AS employee_name
FROM msr JOIN employee_dim ed ON msr.emp_id = ed.employee_key ORDER BY annual_salary DESC;
employee_region | lowest_salary | employee_name
----------------------------------+---------------+-----------------
NorthWest | 20913 | Raja Garnett
SouthWest | 20750 | Seth Moore
West | 20443 | Midori Taylor
South | 20363 | David Bauer
East | 20306 | Craig Jefferson
MidWest | 20264 | Dean Vu
(6 rows)
See also
ARGMAX_AGG
6.1.10 - AVG [aggregate]
Computes the average (arithmetic mean) of an expression over a group of rows.
Computes the average (arithmetic mean) of an expression over a group of rows. AVG always returns a DOUBLE PRECISION value.
The AVG aggregate function differs from the AVG analytic function, which computes the average of an expression over a group of rows within a window.
Behavior type
Immutable
Syntax
AVG ( [ ALL | DISTINCT ] expression )
Parameters
ALL- Invokes the aggregate function for all rows in the group (default).
DISTINCT- Invokes the aggregate function for all distinct non-null values of the expression found in the group.
expression- The value whose average is calculated over a set of rows, any expression that can have a DOUBLE PRECISION result.
Overflow handling
By default, Vertica allows silent numeric overflow when you call this function on numeric data types. For more information on this behavior and how to change it, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Examples
The following query returns the average income from the customer table:
=> SELECT AVG(annual_income) FROM customer_dimension;
AVG
--------------
2104270.6485
(1 row)
See also
6.1.11 - BIT_AND
Takes the bitwise AND of all non-null input values.
Takes the bitwise AND of all non-null input values. If the input parameter is NULL, the return value is also NULL.
Behavior type
Immutable
Syntax
BIT_AND ( expression )
Parameters
expression- The BINARY or VARBINARY input value to evaluate. BIT_AND operates on VARBINARY types explicitly and on BINARY types implicitly through casts.
Returns
BIT_AND returns:
If the columns are different lengths, the return values are treated as though they are all equal in length and are right-extended with zero bytes. For example, given a group containing hex values ff, null, and f, BIT_AND ignores the null value and extends the value f to f0.
Examples
The example that follows uses table t with a single column of VARBINARY data type:
=> CREATE TABLE t ( c VARBINARY(2) );
=> INSERT INTO t values(HEX_TO_BINARY('0xFF00'));
=> INSERT INTO t values(HEX_TO_BINARY('0xFFFF'));
=> INSERT INTO t values(HEX_TO_BINARY('0xF00F'));
Query table t to see column c output:
=> SELECT TO_HEX(c) FROM t;
TO_HEX
--------
ff00
ffff
f00f
(3 rows)
Query table t to get the AND value for column c:
=> SELECT TO_HEX(BIT_AND(c)) FROM t;
TO_HEX
--------
f000
(1 row)
The function is applied pairwise to all values in the group, resulting in f000, which is determined as follows:
-
ff00 (record 1) is compared with ffff (record 2), which results in ff00.
-
The result from the previous comparison is compared with f00f (record 3), which results in f000.
See also
Binary data types (BINARY and VARBINARY)
6.1.12 - BIT_OR
Takes the bitwise OR of all non-null input values.
Takes the bitwise OR of all non-null input values. If the input parameter is NULL, the return value is also NULL.
Behavior type
Immutable
Syntax
BIT_OR ( expression )
Parameters
expression- The BINARY or VARBINARY input value to evaluate. BIT_OR operates on VARBINARY types explicitly and on BINARY types implicitly through casts.
Returns
BIT_OR returns:
If the columns are different lengths, the return values are treated as though they are all equal in length and are right-extended with zero bytes. For example, given a group containing hex values ff, null, and f, the function ignores the null value and extends the value f to f0.
Examples
The example that follows uses table t with a single column of VARBINARY data type:
=> CREATE TABLE t ( c VARBINARY(2) );
=> INSERT INTO t values(HEX_TO_BINARY('0xFF00'));
=> INSERT INTO t values(HEX_TO_BINARY('0xFFFF'));
=> INSERT INTO t values(HEX_TO_BINARY('0xF00F'));
Query table t to see column c output:
=> SELECT TO_HEX(c) FROM t;
TO_HEX
--------
ff00
ffff
f00f
(3 rows)
Query table t to get the OR value for column c:
=> SELECT TO_HEX(BIT_OR(c)) FROM t;
TO_HEX
--------
ffff
(1 row)
The function is applied pairwise to all values in the group, resulting in ffff, which is determined as follows:
-
ff00 (record 1) is compared with ffff, which results in ffff.
-
The ff00 result from the previous comparison is compared with f00f (record 3), which results in ffff.
See also
Binary data types (BINARY and VARBINARY)
6.1.13 - BIT_XOR
Takes the bitwise XOR of all non-null input values.
Takes the bitwise XOR of all non-null input values. If the input parameter is NULL, the return value is also NULL.
Behavior type
Immutable
Syntax
BIT_XOR ( expression )
Parameters
expression- The
BINARY or VARBINARY input value to evaluate. BIT_XOR operates on VARBINARY types explicitly and on BINARY types implicitly through casts.
Returns
BIT_XOR returns:
-
The same value as the argument data type.
-
1 for each bit compared, if there are an odd number of arguments with set bits; otherwise 0.
If the columns are different lengths, the return values are treated as though they are all equal in length and are right-extended with zero bytes. For example, given a group containing hex values ff, null, and f, the function ignores the null value and extends the value f to f0.
Examples
First create a sample table and projections with binary columns:
The example that follows uses table t with a single column of VARBINARY data type:
=> CREATE TABLE t ( c VARBINARY(2) );
=> INSERT INTO t values(HEX_TO_BINARY('0xFF00'));
=> INSERT INTO t values(HEX_TO_BINARY('0xFFFF'));
=> INSERT INTO t values(HEX_TO_BINARY('0xF00F'));
Query table t to see column c output:
=> SELECT TO_HEX(c) FROM t;
TO_HEX
--------
ff00
ffff
f00f
(3 rows)
Query table t to get the XOR value for column c:
=> SELECT TO_HEX(BIT_XOR(c)) FROM t;
TO_HEX
--------
f0f0
(1 row)
See also
Binary data types (BINARY and VARBINARY)
6.1.14 - BOOL_AND [aggregate]
Processes Boolean values and returns a Boolean value result.
Processes Boolean values and returns a Boolean value result. If all input values are true, BOOL_AND returns t. Otherwise it returns f (false).
Behavior type
Immutable
Syntax
BOOL_AND ( expression )
Parameters
expression- A Boolean data type or any non-Boolean data type that can be implicitly coerced to a Boolean data type.
Examples
The following example shows how to use aggregate functions BOOL_AND, BOOL_OR, and BOOL_XOR. The sample table mixers includes columns for models and colors.
=> CREATE TABLE mixers(model VARCHAR(20), colors VARCHAR(20));
CREATE TABLE
Insert sample data into the table. The sample adds two color fields for each model.
=> INSERT INTO mixers
SELECT 'beginner', 'green'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'advanced', 'green'
UNION ALL
SELECT 'advanced', 'blue'
UNION ALL
SELECT 'professional', 'blue'
UNION ALL
SELECT 'professional', 'green'
UNION ALL
SELECT 'beginner', 'green';
OUTPUT
--------
8
(1 row)
Query the table. The result shows models that have two blue (BOOL_AND), one or two blue (BOOL_OR), and specifically not more than one blue (BOOL_XOR) mixer.
=> SELECT model,
BOOL_AND(colors= 'blue')AS two_blue,
BOOL_OR(colors= 'blue')AS one_or_two_blue,
BOOL_XOR(colors= 'blue')AS specifically_not_more_than_one_blue
FROM mixers
GROUP BY model;
model | two_blue | one_or_two_blue | specifically_not_more_than_one_blue
--------------+----------+-----------------+-------------------------------------
advanced | f | t | t
beginner | f | f | f
intermediate | t | t | f
professional | f | t | t
(4 rows)
See also
6.1.15 - BOOL_OR [aggregate]
Processes Boolean values and returns a Boolean value result.
Processes Boolean values and returns a Boolean value result. If at least one input value is true, BOOL_OR returns t. Otherwise, it returns f.
Behavior type
Immutable
Syntax
BOOL_OR ( expression )
Parameters
expression- A Boolean data type or any non-Boolean data type that can be implicitly coerced to a Boolean data type.
Examples
The following example shows how to use aggregate functions BOOL_AND, BOOL_OR, and BOOL_XOR. The sample table mixers includes columns for models and colors.
=> CREATE TABLE mixers(model VARCHAR(20), colors VARCHAR(20));
CREATE TABLE
Insert sample data into the table. The sample adds two color fields for each model.
=> INSERT INTO mixers
SELECT 'beginner', 'green'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'advanced', 'green'
UNION ALL
SELECT 'advanced', 'blue'
UNION ALL
SELECT 'professional', 'blue'
UNION ALL
SELECT 'professional', 'green'
UNION ALL
SELECT 'beginner', 'green';
OUTPUT
--------
8
(1 row)
Query the table. The result shows models that have two blue (BOOL_AND), one or two blue (BOOL_OR), and specifically not more than one blue (BOOL_XOR) mixer.
=> SELECT model,
BOOL_AND(colors= 'blue')AS two_blue,
BOOL_OR(colors= 'blue')AS one_or_two_blue,
BOOL_XOR(colors= 'blue')AS specifically_not_more_than_one_blue
FROM mixers
GROUP BY model;
model | two_blue | one_or_two_blue | specifically_not_more_than_one_blue
--------------+----------+-----------------+-------------------------------------
advanced | f | t | t
beginner | f | f | f
intermediate | t | t | f
professional | f | t | t
(4 rows)
See also
6.1.16 - BOOL_XOR [aggregate]
Processes Boolean values and returns a Boolean value result.
Processes Boolean values and returns a Boolean value result. If specifically only one input value is true, BOOL_XOR returns t. Otherwise, it returns f.
Behavior type
Immutable
Syntax
BOOL_XOR ( expression )
Parameters
expression- A Boolean data type or any non-Boolean data type that can be implicitly coerced to a Boolean data type.
Examples
The following example shows how to use aggregate functions BOOL_AND, BOOL_OR, and BOOL_XOR. The sample table mixers includes columns for models and colors.
=> CREATE TABLE mixers(model VARCHAR(20), colors VARCHAR(20));
CREATE TABLE
Insert sample data into the table. The sample adds two color fields for each model.
=> INSERT INTO mixers
SELECT 'beginner', 'green'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'intermediate', 'blue'
UNION ALL
SELECT 'advanced', 'green'
UNION ALL
SELECT 'advanced', 'blue'
UNION ALL
SELECT 'professional', 'blue'
UNION ALL
SELECT 'professional', 'green'
UNION ALL
SELECT 'beginner', 'green';
OUTPUT
--------
8
(1 row)
Query the table. The result shows models that have two blue (BOOL_AND), one or two blue (BOOL_OR), and specifically not more than one blue (BOOL_XOR) mixer.
=> SELECT model,
BOOL_AND(colors= 'blue')AS two_blue,
BOOL_OR(colors= 'blue')AS one_or_two_blue,
BOOL_XOR(colors= 'blue')AS specifically_not_more_than_one_blue
FROM mixers
GROUP BY model;
model | two_blue | one_or_two_blue | specifically_not_more_than_one_blue
--------------+----------+-----------------+-------------------------------------
advanced | f | t | t
beginner | f | f | f
intermediate | t | t | f
professional | f | t | t
(4 rows)
See also
6.1.17 - CORR
Returns the DOUBLE PRECISION coefficient of correlation of a set of expression pairs, as per the Pearson correlation coefficient.
Returns the DOUBLE PRECISION coefficient of correlation of a set of expression pairs, as per the Pearson correlation coefficient. CORR eliminates expression pairs where either expression in the pair is NULL. If no rows remain, the function returns NULL.
Syntax
CORR ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT CORR (Annual_salary, Employee_age) FROM employee_dimension;
CORR
----------------------
-0.00719153413192422
(1 row)
6.1.18 - COUNT [aggregate]
Returns as a BIGINT the number of rows in each group where the expression is not NULL.
Returns as a BIGINT the number of rows in each group where the expression is not NULL. If the query has no GROUP BY clause, COUNT returns the number of table rows.
The COUNT aggregate function differs from the COUNT analytic function, which returns the number over a group of rows within a window.
Behavior type
Immutable
Syntax
COUNT ( [ * ] [ ALL | DISTINCT ] expression )
Parameters
*- Specifies to count all rows in the specified table or each group.
ALL | DISTINCT- Specifies how to count rows where
expression has a non-null value:
expression- The column or expression whose non-null values are counted.
Examples
The following query returns the number of distinct values in a column:
=> SELECT COUNT (DISTINCT date_key) FROM date_dimension;
COUNT
-------
1826
(1 row)
This example returns the number of distinct return values from an expression:
=> SELECT COUNT (DISTINCT date_key + product_key) FROM inventory_fact;
COUNT
-------
21560
(1 row)
You can create an equivalent query using the LIMIT keyword to restrict the number of rows returned:
=> SELECT COUNT(date_key + product_key) FROM inventory_fact GROUP BY date_key LIMIT 10;
COUNT
-------
173
31
321
113
286
84
244
238
145
202
(10 rows)
The following query uses GROUP BY to count distinct values within groups:
=> SELECT product_key, COUNT (DISTINCT date_key) FROM inventory_fact
GROUP BY product_key LIMIT 10;
product_key | count
-------------+-------
1 | 12
2 | 18
3 | 13
4 | 17
5 | 11
6 | 14
7 | 13
8 | 17
9 | 15
10 | 12
(10 rows)
The following query returns the number of distinct products and the total inventory within each date key:
=> SELECT date_key, COUNT (DISTINCT product_key), SUM(qty_in_stock) FROM inventory_fact
GROUP BY date_key LIMIT 10;
date_key | count | sum
----------+-------+--------
1 | 173 | 88953
2 | 31 | 16315
3 | 318 | 156003
4 | 113 | 53341
5 | 285 | 148380
6 | 84 | 42421
7 | 241 | 119315
8 | 238 | 122380
9 | 142 | 70151
10 | 202 | 95274
(10 rows)
This query selects each distinct product_key value and then counts the number of distinct date_key values for all records with the specific product_key value. It also counts the number of distinct warehouse_key values in all records with the specific product_key value:
=> SELECT product_key, COUNT (DISTINCT date_key), COUNT (DISTINCT warehouse_key) FROM inventory_fact
GROUP BY product_key LIMIT 15;
product_key | count | count
-------------+-------+-------
1 | 12 | 12
2 | 18 | 18
3 | 13 | 12
4 | 17 | 18
5 | 11 | 9
6 | 14 | 13
7 | 13 | 13
8 | 17 | 15
9 | 15 | 14
10 | 12 | 12
11 | 11 | 11
12 | 13 | 12
13 | 9 | 7
14 | 13 | 13
15 | 18 | 17
(15 rows)
This query selects each distinct product_key value, counts the number of distinct date_key and warehouse_key values for all records with the specific product_key value, and then sums all qty_in_stock values in records with the specific product_key value. It then returns the number of product_version values in records with the specific product_key value:
=> SELECT product_key, COUNT (DISTINCT date_key),
COUNT (DISTINCT warehouse_key),
SUM (qty_in_stock),
COUNT (product_version)
FROM inventory_fact GROUP BY product_key LIMIT 15;
product_key | count | count | sum | count
-------------+-------+-------+-------+-------
1 | 12 | 12 | 5530 | 12
2 | 18 | 18 | 9605 | 18
3 | 13 | 12 | 8404 | 13
4 | 17 | 18 | 10006 | 18
5 | 11 | 9 | 4794 | 11
6 | 14 | 13 | 7359 | 14
7 | 13 | 13 | 7828 | 13
8 | 17 | 15 | 9074 | 17
9 | 15 | 14 | 7032 | 15
10 | 12 | 12 | 5359 | 12
11 | 11 | 11 | 6049 | 11
12 | 13 | 12 | 6075 | 13
13 | 9 | 7 | 3470 | 9
14 | 13 | 13 | 5125 | 13
15 | 18 | 17 | 9277 | 18
(15 rows)
See also
6.1.19 - COVAR_POP
Returns the population covariance for a set of expression pairs.
Returns the population covariance for a set of expression pairs. The return value is of type DOUBLE PRECISION. COVAR_POP eliminates expression pairs where either expression in the pair is NULL. If no rows remain, the function returns NULL.
Syntax
SELECT COVAR_POP ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT COVAR_POP (Annual_salary, Employee_age)
FROM employee_dimension;
COVAR_POP
-------------------
-9032.34810730019
(1 row)
6.1.20 - COVAR_SAMP
Returns the sample covariance for a set of expression pairs.
Returns the sample covariance for a set of expression pairs. The return value is of type DOUBLE PRECISION. COVAR_SAMP eliminates expression pairs where either expression in the pair is NULL. If no rows remain, the function returns NULL.
Syntax
SELECT COVAR_SAMP ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT COVAR_SAMP (Annual_salary, Employee_age)
FROM employee_dimension;
COVAR_SAMP
-------------------
-9033.25143244343
(1 row)
6.1.21 - GROUP_ID
Uniquely identifies duplicate sets for GROUP BY queries that return duplicate grouping sets.
Uniquely identifies duplicate sets for GROUP BY queries that return duplicate grouping sets. This function returns one or more integers, starting with zero (0), as identifiers.
For the number of duplicates n for a particular grouping, GROUP_ID returns a range of sequential numbers, 0 to n–1. For the first each unique group it encounters, GROUP_ID returns the value 0. If GROUP_ID finds the same grouping again, the function returns 1, then returns 2 for the next found grouping, and so on.
Behavior type
Immutable
Syntax
GROUP_ID ()
Examples
This example shows how GROUP_ID creates unique identifiers when a query produces duplicate groupings. For an expenses table, the following query groups the results by category of expense and year and rolls up the sum for those two columns. The results have duplicate groupings for category and NULL. The first grouping has a GROUP_ID of 0, and the second grouping has a GROUP_ID of 1.
=> SELECT Category, Year, SUM(Amount), GROUPING_ID(Category, Year),
GROUP_ID() FROM expenses GROUP BY Category, ROLLUP(Category,Year)
ORDER BY Category, Year, GROUPING_ID();
Category | Year | SUM | GROUPING_ID | GROUP_ID
-------------+------+--------+-------------+----------
Books | 2005 | 39.98 | 0 | 0
Books | 2007 | 29.99 | 0 | 0
Books | 2008 | 29.99 | 0 | 0
Books | | 99.96 | 1 | 0
Books | | 99.96 | 1 | 1
Electricity | 2005 | 109.99 | 0 | 0
Electricity | 2006 | 109.99 | 0 | 0
Electricity | 2007 | 229.98 | 0 | 0
Electricity | | 449.96 | 1 | 1
Electricity | | 449.96 | 1 | 0
See also
6.1.22 - GROUPING
Disambiguates the use of NULL values when GROUP BY queries with multilevel aggregates generate NULL values to identify subtotals in grouping columns.
Disambiguates the use of NULL values when GROUP BY queries with multilevel aggregates generate NULL values to identify subtotals in grouping columns. Such NULL values from the original data can also occur in rows. GROUPING returns 1, if the value of expression is:
-
NULL, representing an aggregated value
-
0 for any other value, including NULL values in rows
Behavior type
Immutable
Syntax
GROUPING ( expression )
Parameters
expression- An expression in the
GROUP BY clause
Examples
The following query uses the GROUPING function, taking one of the GROUP BY expressions as an argument. For each row, GROUPING returns one of the following:
The 1 in the GROUPING(Year) column for electricity and books indicates that these values are subtotals. The right-most column values for both GROUPING(Category) and GROUPING(Year) are 1. This value indicates that neither column contributed to the GROUP BY. The final row represents the total sales.
=> SELECT Category, Year, SUM(Amount),
GROUPING(Category), GROUPING(Year) FROM expenses
GROUP BY ROLLUP(Category, Year) ORDER BY Category, Year, GROUPING_ID();
Category | Year | SUM | GROUPING | GROUPING
-------------+------+--------+----------+----------
Books | 2005 | 39.98 | 0 | 0
Books | 2007 | 29.99 | 0 | 0
Books | 2008 | 29.99 | 0 | 0
Books | | 99.96 | 0 | 1
Electricity | 2005 | 109.99 | 0 | 0
Electricity | 2006 | 109.99 | 0 | 0
Electricity | 2007 | 229.98 | 0 | 0
Electricity | | 449.96 | 0 | 1
| | 549.92 | 1 | 1
See also
6.1.23 - GROUPING_ID
Concatenates the set of Boolean values generated by the GROUPING function into a bit vector.
Concatenates the set of Boolean values generated by the GROUPING function into a bit vector. GROUPING_ID treats the bit vector as a binary number and returns it as a base-10 value that identifies the grouping set combination.
By using GROUPING_ID you avoid the need for multiple, individual GROUPING functions. GROUPING_ID simplifies row-filtering conditions, because rows of interest are identified using a single return from GROUPING_ID = n. Use GROUPING_ID to identify grouping combinations.
Behavior type
Immutable
Syntax
GROUPING_ID ( [expression[,...] )
expression - An expression that matches one of the expressions in the
GROUP BY clause.
If the GROUP BY clause includes a list of expressions, GROUPING_ID returns a number corresponding to the GROUPING bit vector associated with a row.
Examples
This example shows how calling GROUPING_ID without an expression returns the GROUPING bit vector associated with a full set of multilevel aggregate expressions. The GROUPING_ID value is comparable to GROUPING_ID(a,b) because GROUPING_ID() includes all columns in the GROUP BY ROLLUP:
=> SELECT a,b,COUNT(*), GROUPING_ID() FROM T GROUP BY ROLLUP(a,b);
In the following query, the GROUPING(Category) and GROUPING(Year) columns have three combinations:
=> SELECT Category, Year, SUM(Amount),
GROUPING(Category), GROUPING(Year) FROM expenses
GROUP BY ROLLUP(Category, Year) ORDER BY Category, Year, GROUPING_ID();
Category | Year | SUM | GROUPING | GROUPING
-------------+------+--------+----------+----------
Books | 2005 | 39.98 | 0 | 0
Books | 2007 | 29.99 | 0 | 0
Books | 2008 | 29.99 | 0 | 0
Books | | 99.96 | 0 | 1
Electricity | 2005 | 109.99 | 0 | 0
Electricity | 2006 | 109.99 | 0 | 0
Electricity | 2007 | 229.98 | 0 | 0
Electricity | | 449.96 | 0 | 1
| | 549.92 | 1 | 1
GROUPING_ID converts these values as follows:
|
Binary Set Values |
Decimal Equivalents |
|
00 |
0 |
|
01 |
1 |
|
11 |
3 |
|
0 |
Category, Year |
The following query returns the single number for each GROUP BY level that appears in the gr_id column:
=> SELECT Category, Year, SUM(Amount),
GROUPING(Category),GROUPING(Year),GROUPING_ID(Category,Year) AS gr_id
FROM expenses GROUP BY ROLLUP(Category, Year);
Category | Year | SUM | GROUPING | GROUPING | gr_id
-------------+------+--------+----------+----------+-------
Books | 2008 | 29.99 | 0 | 0 | 0
Books | 2005 | 39.98 | 0 | 0 | 0
Electricity | 2007 | 229.98 | 0 | 0 | 0
Books | 2007 | 29.99 | 0 | 0 | 0
Electricity | 2005 | 109.99 | 0 | 0 | 0
Electricity | | 449.96 | 0 | 1 | 1
| | 549.92 | 1 | 1 | 3
Electricity | 2006 | 109.99 | 0 | 0 | 0
Books | | 99.96 | 0 | 1 | 1
The gr_id value determines the GROUP BY level for each row:
- GROUP BY Level
- GROUP BY Row Level
- 3
- Total sum
- 1
- Category
- 0
- Category, year
You can also use the DECODE function to give the values more meaning by comparing each search value individually:
=> SELECT Category, Year, SUM(AMOUNT), DECODE(GROUPING_ID(Category, Year),
3, 'Total',
1, 'Category',
0, 'Category,Year')
AS GROUP_NAME FROM expenses GROUP BY ROLLUP(Category, Year);
Category | Year | SUM | GROUP_NAME
-------------+------+--------+---------------
Electricity | 2006 | 109.99 | Category,Year
Books | | 99.96 | Category
Electricity | 2007 | 229.98 | Category,Year
Books | 2007 | 29.99 | Category,Year
Electricity | 2005 | 109.99 | Category,Year
Electricity | | 449.96 | Category
| | 549.92 | Total
Books | 2005 | 39.98 | Category,Year
Books | 2008 | 29.99 | Category,Year
See also
6.1.24 - LISTAGG
Transforms non-null values from a group of rows into a list of values that are delimited by commas (default) or a configurable separator.
Transforms non-null values from a group of rows into a list of values that are delimited by commas (default) or a configurable separator. LISTAGG can be used to denormalize rows into a string of concatenated values.
Behavior type
Immutable if the WITHIN GROUP ORDER BY clause specifies a column or set of columns that resolves to unique values within the aggregated list; otherwise Volatile.
Syntax
LISTAGG ( aggregate-expression [ USING PARAMETERS parameter=value][,...] ] ) [ within-group-order-by-clause ]
Arguments
aggregate-expression- Aggregation of one or more columns or column expressions to select from the source table or view.
LISTAGG does not support spatial data types directly. In order to pass column data of this type, convert the data to strings with the geospatial function ST_AsText.
Caution
Converted spatial data frequently contains commas. LISTAGG uses comma as the default separator character. To avoid ambiguous output, override this default by setting the function's separator parameter to another character.
- [within-group-order-by-clause](/en/sql-reference/functions/aggregate-functions/within-group-order-by-clause/)
- Sorts aggregated values within each group of rows, where
column-expression is typically a column in aggregate-expression:
WITHIN GROUP (ORDER BY { column-expression[ sort-qualifiers ] }[,...])
sort-qualifiers:
{ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] }
Tip
WITHIN GROUP ORDER BY can consume a large amount of memory per group. Including wide strings in the aggregate expression can also adversely affect performance. To minimize memory consumption, create projections that support
GROUPBY PIPELINED.
Parameters
|
Parameter name |
Set to... |
max_length |
An integer or integer expression that specifies in bytes the maximum length of the result, up to 32M.
Default: 1024
|
separator |
Separator string of length 0 to 80, inclusive. A length of 0 concatenates the output with no separators.
Default: comma (,)
|
on_overflow |
Specifies behavior when the result overflows the max_length setting, one of the following strings:
-
ERROR (default): Return an error when overflow occurs.
-
TRUNCATE: Remove any characters that exceed max_length setting from the query result, and return the truncated string.
|
Privileges
None
Examples
In the following query, the aggregated results in the CityState column use the string " | " as a separator. The outer GROUP BY clause groups the output rows according to their Region values. Within each group, the aggregated list items are sorted according to their city values, as per the WITHIN GROUP ORDER BY clause:
=> \x
Expanded display is on.
=> WITH cd AS (SELECT DISTINCT (customer_city) city, customer_state, customer_region FROM customer_dimension)
SELECT customer_region Region, LISTAGG(city||', '||customer_state USING PARAMETERS separator=' | ')
WITHIN GROUP (ORDER BY city) CityAndState FROM cd GROUP BY region ORDER BY region;
-[ RECORD 1 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | East
CityAndState | Alexandria, VA | Allentown, PA | Baltimore, MD | Boston, MA | Cambridge, MA | Charlotte, NC | Clarksville, TN | Columbia, SC | Elizabeth, NJ | Erie, PA | Fayetteville, NC | Hartford, CT | Lowell, MA | Manchester, NH | Memphis, TN | Nashville, TN | New Haven, CT | New York, NY | Philadelphia, PA | Portsmouth, VA | Stamford, CT | Sterling Heights, MI | Washington, DC | Waterbury, CT
-[ RECORD 2 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | MidWest
CityAndState | Ann Arbor, MI | Cedar Rapids, IA | Chicago, IL | Columbus, OH | Detroit, MI | Evansville, IN | Flint, MI | Gary, IN | Green Bay, WI | Indianapolis, IN | Joliet, IL | Lansing, MI | Livonia, MI | Milwaukee, WI | Naperville, IL | Peoria, IL | Sioux Falls, SD | South Bend, IN | Springfield, IL
-[ RECORD 3 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | NorthWest
CityAndState | Bellevue, WA | Portland, OR | Seattle, WA
-[ RECORD 4 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | South
CityAndState | Abilene, TX | Athens, GA | Austin, TX | Beaumont, TX | Cape Coral, FL | Carrollton, TX | Clearwater, FL | Coral Springs, FL | Dallas, TX | El Paso, TX | Fort Worth, TX | Grand Prairie, TX | Houston, TX | Independence, MS | Jacksonville, FL | Lafayette, LA | McAllen, TX | Mesquite, TX | San Antonio, TX | Savannah, GA | Waco, TX | Wichita Falls, TX
-[ RECORD 5 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | SouthWest
CityAndState | Arvada, CO | Denver, CO | Fort Collins, CO | Gilbert, AZ | Las Vegas, NV | North Las Vegas, NV | Peoria, AZ | Phoenix, AZ | Pueblo, CO | Topeka, KS | Westminster, CO
-[ RECORD 6 ]+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Region | West
CityAndState | Berkeley, CA | Burbank, CA | Concord, CA | Corona, CA | Costa Mesa, CA | Daly City, CA | Downey, CA | El Monte, CA | Escondido, CA | Fontana, CA | Fullerton, CA | Inglewood, CA | Lancaster, CA | Los Angeles, CA | Norwalk, CA | Orange, CA | Palmdale, CA | Pasadena, CA | Provo, UT | Rancho Cucamonga, CA | San Diego, CA | San Francisco, CA | San Jose, CA | Santa Clara, CA | Simi Valley, CA | Sunnyvale, CA | Thousand Oaks, CA | Vallejo, CA | Ventura, CA | West Covina, CA | West Valley City, UT
6.1.25 - MAX [aggregate]
Returns the greatest value of an expression over a group of rows.
Returns the greatest value of an expression over a group of rows. The return value has the same type as the expression data type.
The MAX analytic function function differs from the aggregate function, in that it returns the maximum value of an expression over a group of rows within a window.
Aggregate functions MIN and MAX can operate with Boolean values. MAX can act upon a Boolean data type or a value that can be implicitly converted to a Boolean. If at least one input value is true, MAX returns t (true). Otherwise, it returns f (false). In the same scenario, MIN returns t (true) if all input values are true. Otherwise it returns f.
Behavior type
Immutable
Syntax
MAX ( expression )
Parameters
expression- Any expression for which the maximum value is calculated, typically a column reference.
Examples
The following query returns the largest value in column sales_dollar_amount.
=> SELECT MAX(sales_dollar_amount) AS highest_sale FROM store.store_sales_fact;
highest_sale
--------------
600
(1 row)
The following example shows you the difference between the MIN and MAX aggregate functions when you use them with a Boolean value. The sample creates a table, adds two rows of data, and shows sample output for MIN and MAX.
=> CREATE TABLE min_max_functions (torf BOOL);
=> INSERT INTO min_max_functions VALUES (1);
=> INSERT INTO min_max_functions VALUES (0);
=> SELECT * FROM min_max_functions;
torf
------
t
f
(2 rows)
=> SELECT min(torf) FROM min_max_functions;
min
-----
f
(1 row)
=> SELECT max(torf) FROM min_max_functions;
max
-----
t
(1 row)
See also
Data aggregation
6.1.26 - MIN [aggregate]
Returns the smallest value of an expression over a group of rows.
Returns the smallest value of an expression over a group of rows. The return value has the same type as the expression data type.
The MIN analytic function differs from the aggregate function, in that it returns the minimum value of an expression over a group of rows within a window.
Aggregate functions MIN and MAX can operate with Boolean values. MAX can act upon a Boolean data type or a value that can be implicitly converted to a Boolean. If at least one input value is true, MAX returns t (true). Otherwise, it returns f (false). In the same scenario, MIN returns t (true) if all input values are true. Otherwise it returns f.
Behavior type
Immutable
Syntax
MIN ( expression )
Parameters
expression- Any expression for which the minimum value is calculated, typically a column reference.
Examples
The following query returns the lowest salary from the employee dimension table.
This example shows how you can query to return the lowest salary from the employee dimension table.
=> SELECT MIN(annual_salary) AS lowest_paid FROM employee_dimension;
lowest_paid
-------------
1200
(1 row)
The following example shows you the difference between the MIN and MAX aggregate functions when you use them with a Boolean value. The sample creates a table, adds two rows of data, and shows sample output for MIN and MAX.
=> CREATE TABLE min_max_functions (torf BOOL);
=> INSERT INTO min_max_functions VALUES (1);
=> INSERT INTO min_max_functions VALUES (0);
=> SELECT * FROM min_max_functions;
torf
------
t
f
(2 rows)
=> SELECT min(torf) FROM min_max_functions;
min
-----
f
(1 row)
=> SELECT max(torf) FROM min_max_functions;
max
-----
t
(1 row)
See also
Data aggregation
6.1.27 - REGR_AVGX
Returns the DOUBLE PRECISION average of the independent expression in an expression pair.
Returns the DOUBLE PRECISION average of the independent expression in an expression pair. REGR_AVGX eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_AVGX returns NULL.
Syntax
SELECT REGR_AVGX ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_AVGX (Annual_salary, Employee_age)
FROM employee_dimension;
REGR_AVGX
-----------
39.321
(1 row)
6.1.28 - REGR_AVGY
Returns the DOUBLE PRECISION average of the dependent expression in an expression pair.
Returns the DOUBLE PRECISION average of the dependent expression in an expression pair. The function eliminates expression pairs where either expression in the pair is NULL. If no rows remain, the function returns NULL.
Syntax
REGR_AVGY ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_AVGY (Annual_salary, Employee_age)
FROM employee_dimension;
REGR_AVGY
------------
58354.4913
(1 row)
6.1.29 - REGR_COUNT
Returns the count of all rows in an expression pair.
Returns the count of all rows in an expression pair. The function eliminates expression pairs where either expression in the pair is NULL. If no rows remain, the function returns 0.
Syntax
SELECT REGR_COUNT ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_COUNT (Annual_salary, Employee_age) FROM employee_dimension;
REGR_COUNT
------------
10000
(1 row)
6.1.30 - REGR_INTERCEPT
Returns the y-intercept of the regression line determined by a set of expression pairs.
Returns the y-intercept of the regression line determined by a set of expression pairs. The return value is of type DOUBLE PRECISION. REGR_INTERCEPT eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_INTERCEPT returns NULL.
Syntax
SELECT REGR_INTERCEPT ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_INTERCEPT (Annual_salary, Employee_age) FROM employee_dimension;
REGR_INTERCEPT
------------------
59929.5490163437
(1 row)
6.1.31 - REGR_R2
Returns the square of the correlation coefficient of a set of expression pairs.
Returns the square of the correlation coefficient of a set of expression pairs. The return value is of type DOUBLE PRECISION. REGR_R2 eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_R2 returns NULL.
Syntax
SELECT REGR_R2 ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_R2 (Annual_salary, Employee_age) FROM employee_dimension;
REGR_R2
----------------------
5.17181631706311e-05
(1 row)
6.1.32 - REGR_SLOPE
Returns the slope of the regression line, determined by a set of expression pairs.
Returns the slope of the regression line, determined by a set of expression pairs. The return value is of type DOUBLE PRECISION. REGR_SLOPE eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_SLOPE returns NULL.
Syntax
SELECT REGR_SLOPE ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_SLOPE (Annual_salary, Employee_age) FROM employee_dimension;
REGR_SLOPE
------------------
-40.056400303749
(1 row)
6.1.33 - REGR_SXX
Returns the sum of squares of the difference between the independent expression (expression2) and its average.
Returns the sum of squares of the difference between the independent expression (expression2) and its average.
That is, REGR_SXX returns: ∑[(expression2 - average(expression2)(expression2 - average(expression2)]
The return value is of type DOUBLE PRECISION. REGR_SXX eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_SXX returns NULL.
Syntax
SELECT REGR_SXX ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_SXX (Annual_salary, Employee_age) FROM employee_dimension;
REGR_SXX
------------
2254907.59
(1 row)
6.1.34 - REGR_SXY
Returns the sum of products of the difference between the dependent expression (expression1) and its average and the difference between the independent expression (expression2) and its average.
Returns the sum of products of the difference between the dependent expression (expression1) and its average and the difference between the independent expression (expression2) and its average.
That is, REGR_SXY returns: ∑[(expression1 - average(expression1)(expression2 - average(expression2))]
The return value is of type DOUBLE PRECISION. REGR_SXY eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_SXY returns NULL.
Syntax
SELECT REGR_SXY ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_SXY (Annual_salary, Employee_age) FROM employee_dimension;
REGR_SXY
-------------------
-90323481.0730019
(1 row)
6.1.35 - REGR_SYY
Returns the sum of squares of the difference between the dependent expression (expression1) and its average.
Returns the sum of squares of the difference between the dependent expression (expression1) and its average.
That is, REGR_SYY returns: ∑[(expression1 - average(expression1)(expression1 - average(expression1)]
The return value is of type DOUBLE PRECISION. REGR_SYY eliminates expression pairs where either expression in the pair is NULL. If no rows remain, REGR_SYY returns NULL.
Syntax
SELECT REGR_SYY ( expression1, expression2 )
Parameters
expression1- The dependent
DOUBLE PRECISION expression
expression2- The independent
DOUBLE PRECISION expression
Examples
=> SELECT REGR_SYY (Annual_salary, Employee_age) FROM employee_dimension;
REGR_SYY
------------------
69956728794707.2
(1 row)
6.1.36 - STDDEV [aggregate]
Evaluates the statistical sample standard deviation for each member of the group.
Evaluates the statistical sample standard deviation for each member of the group. The return value is the same as the square root of
VAR_SAMP:
STDDEV(expression) = SQRT(VAR_SAMP(expression))
Behavior type
Immutable
Syntax
STDDEV ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. STDDEV returns the same data type as expression.
-
Nonstandard function STDDEV is provided for compatibility with other databases. It is semantically identical to
STDDEV_SAMP.
-
This aggregate function differs from analytic function
STDDEV, which computes the statistical sample standard deviation of the current row with respect to the group of rows within a window.
-
When
VAR_SAMP returns NULL, STDDEV returns NULL.
Examples
The following example returns the statistical sample standard deviation for each household ID from the customer_dimension table of the VMart example database:
=> SELECT STDDEV(household_id) FROM customer_dimension;
STDDEV
-----------------
8651.5084240071
6.1.37 - STDDEV_POP [aggregate]
Evaluates the statistical population standard deviation for each member of the group.
Evaluates the statistical population standard deviation for each member of the group.
Behavior type
Immutable
Syntax
STDDEV_POP ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. STDDEV_POP returns the same data type as expression.
-
This function differs from the analytic function
STDDEV_POP, which evaluates the statistical population standard deviation for each member of the group of rows within a window.
-
STDDEV_POP returns the same value as the square root of
VAR_POP:
STDDEV_POP(expression) = SQRT(VAR_POP(expression))
-
When
VAR_SAMP returns NULL, this function returns NULL.
Examples
The following example returns the statistical population standard deviation for each household ID in the customer table.
=> SELECT STDDEV_POP(household_id) FROM customer_dimension;
STDDEV_POP
------------------
8651.41895973367
(1 row)
See also
6.1.38 - STDDEV_SAMP [aggregate]
Evaluates the statistical sample standard deviation for each member of the group.
Evaluates the statistical sample standard deviation for each member of the group. The return value is the same as the square root of
VAR_SAMP:
STDDEV_SAMP(expression) = SQRT(VAR_SAMP(expression))
Behavior type
Immutable
Syntax
STDDEV_SAMP ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. STDDEV_SAMP returns the same data type as expression.
-
STDDEV_SAMP is semantically identical to nonstandard function
STDDEV, which is provided for compatibility with other databases.
-
This aggregate function differs from analytic function
STDDEV_SAMP, which computes the statistical sample standard deviation of the current row with respect to the group of rows within a window.
-
When
VAR_SAMP returns NULL, STDDEV_SAMP returns NULL.
Examples
The following example returns the statistical sample standard deviation for each household ID from the customer dimension table.
=> SELECT STDDEV_SAMP(household_id) FROM customer_dimension;
stddev_samp
------------------
8651.50842400771
(1 row)
6.1.39 - SUM [aggregate]
Computes the sum of an expression over a group of rows.
Computes the sum of an expression over a group of rows. SUM returns a DOUBLE PRECISION value for a floating-point expression. Otherwise, the return value is the same as the expression data type.
The SUM aggregate function differs from the
SUM analytic function, which computes the sum of an expression over a group of rows within a window.
Behavior type
Immutable
Syntax
SUM ( [ ALL | DISTINCT ] expression )
Parameters
ALL- Invokes the aggregate function for all rows in the group (default)
DISTINCT- Invokes the aggregate function for all distinct non-null values of the expression found in the group
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
Overflow handling
If you encounter data overflow when using SUM(), use
SUM_FLOAT which converts the data to a floating point.
By default, Vertica allows silent numeric overflow when you call this function on numeric data types. For more information on this behavior and how to change it, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Examples
The following query returns the total sum of the product_cost column.
=> SELECT SUM(product_cost) AS cost FROM product_dimension;
cost
---------
9042850
(1 row)
See also
6.1.40 - SUM_FLOAT [aggregate]
Computes the sum of an expression over a group of rows and returns a DOUBLE PRECISION value.
Computes the sum of an expression over a group of rows and returns a DOUBLE PRECISION value.
Behavior type
Immutable
Syntax
SUM_FLOAT ( [ ALL | DISTINCT ] expression )
Parameters
ALL- Invokes the aggregate function for all rows in the group (default).
DISTINCT- Invokes the aggregate function for all distinct non-null values of the expression found in the group.
expression- Any expression whose result is type
DOUBLE PRECISION.
Overflow handling
By default, Vertica allows silent numeric overflow when you call this function on numeric data types. For more information on this behavior and how to change it, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Examples
The following query returns the floating-point sum of the average price from the product table:
=> SELECT SUM_FLOAT(average_competitor_price) AS cost FROM product_dimension;
cost
----------
18181102
(1 row)
6.1.41 - TS_FIRST_VALUE
Processes the data that belongs to each time slice.
Processes the data that belongs to each time slice. A time series aggregate (TSA) function, TS_FIRST_VALUE returns the value at the start of the time slice, where an interpolation scheme is applied if the timeslice is missing, in which case the value is determined by the values corresponding to the previous (and next) timeslices based on the interpolation scheme of const (linear).
TS_FIRST_VALUE returns one output row per time slice, or one output row per partition per time slice if partition expressions are specified
Behavior type
Immutable
Syntax
TS_FIRST_VALUE ( expression [ IGNORE NULLS ] [, { 'CONST' | 'LINEAR' } ] )
Parameters
expression- An
INTEGER or FLOAT expression on which to aggregate and interpolate.
IGNORE NULLS- The
IGNORE NULLS behavior changes depending on a CONST or LINEAR interpolation scheme. See When Time Series Data Contains Nulls in Analyzing Data for details.
'CONST' | 'LINEAR'- Specifies the interpolation value as constant or linear:
Requirements
You must use an ORDER BY clause with a TIMESTAMP column.
Multiple time series aggregate functions
The same query can call multiple time series aggregate functions. They share the same gap-filling policy as defined by the TIMESERIES clause; however, each time series aggregate function can specify its own interpolation policy. For example:
=> SELECT slice_time, symbol,
TS_FIRST_VALUE(bid, 'const') fv_c,
TS_FIRST_VALUE(bid, 'linear') fv_l,
TS_LAST_VALUE(bid, 'const') lv_c
FROM TickStore
TIMESERIES slice_time AS '3 seconds'
OVER(PARTITION BY symbol ORDER BY ts);
Examples
See Gap Filling and Interpolation in Analyzing Data.
See also
6.1.42 - TS_LAST_VALUE
Processes the data that belongs to each time slice.
Processes the data that belongs to each time slice. A time series aggregate (TSA) function, TS_LAST_VALUE returns the value at the end of the time slice, where an interpolation scheme is applied if the timeslice is missing. In this case the value is determined by the values corresponding to the previous (and next) timeslices based on the interpolation scheme of const (linear).
TS_LAST_VALUE returns one output row per time slice, or one output row per partition per time slice if partition expressions are specified.
Behavior type
Immutable
Syntax
TS_LAST_VALUE ( expression [ IGNORE NULLS ] [, { 'CONST' | 'LINEAR' } ] )
Parameters
expression- An
INTEGER or FLOAT expression on which to aggregate and interpolate.
IGNORE NULLS- The
IGNORE NULLS behavior changes depending on a CONST or LINEAR interpolation scheme. See When Time Series Data Contains Nulls in Analyzing Data for details.
'CONST' | 'LINEAR'- Specifies the interpolation value as constant or linear:
Requirements
You must use the ORDER BY clause with a TIMESTAMP column.
Multiple time series aggregate functions
The same query can call multiple time series aggregate functions. They share the same gap-filling policy as defined by the TIMESERIES clause; however, each time series aggregate function can specify its own interpolation policy. For example:
=> SELECT slice_time, symbol,
TS_FIRST_VALUE(bid, 'const') fv_c,
TS_FIRST_VALUE(bid, 'linear') fv_l,
TS_LAST_VALUE(bid, 'const') lv_c
FROM TickStore
TIMESERIES slice_time AS '3 seconds'
OVER(PARTITION BY symbol ORDER BY ts);
Examples
See Gap Filling and Interpolation in Analyzing Data.
See also
6.1.43 - VAR_POP [aggregate]
Evaluates the population variance for each member of the group.
Evaluates the population variance for each member of the group. This is defined as the sum of squares of the difference of *expression*from the mean of expression, divided by the number of remaining rows:
(SUM(expression*expression) - SUM(expression)*SUM(expression) / COUNT(expression)) / COUNT(expression)
Behavior type
Immutable
Syntax
VAR_POP ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. VAR_POP returns the same data type as expression.
This aggregate function differs from analytic function
VAR_POP, which computes the population variance of the current row with respect to the group of rows within a window.
Examples
The following example returns the population variance for each household ID in the customer table.
=> SELECT VAR_POP(household_id) FROM customer_dimension;
var_pop
------------------
74847050.0168393
(1 row)
6.1.44 - VAR_SAMP [aggregate]
Evaluates the sample variance for each row of the group.
Evaluates the sample variance for each row of the group. This is defined as the sum of squares of the difference of expression from the mean of expression divided by the number of remaining rows minus 1:
(SUM(expression*expression) - SUM(expression) *SUM(expression) / COUNT(expression)) / (COUNT(expression) -1)
Behavior type
Immutable
Syntax
VAR_SAMP ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. VAR_SAMP returns the same data type as expression.
-
VAR_SAMP is semantically identical to nonstandard function
VARIANCE, which is provided for compatibility with other databases.
-
This aggregate function differs from analytic function
VAR_SAMP, which computes the sample variance of the current row with respect to the group of rows within a window.
Examples
The following example returns the sample variance for each household ID in the customer table.
=> SELECT VAR_SAMP(household_id) FROM customer_dimension;
var_samp
------------------
74848598.0106764
(1 row)
See also
VARIANCE [aggregate]
6.1.45 - VARIANCE [aggregate]
Evaluates the sample variance for each row of the group.
Evaluates the sample variance for each row of the group. This is defined as the sum of squares of the difference of expression from the mean of expression divided by the number of remaining rows minus 1.
(SUM(expression*expression) - SUM(expression) *SUM(expression) /COUNT(expression)) / (COUNT(expression) -1)
Behavior type
Immutable
Syntax
VARIANCE ( expression )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. VARIANCE returns the same data type as expression.
The nonstandard function VARIANCE is provided for compatibility with other databases. It is semantically identical to
VAR_SAMP.
This aggregate function differs from analytic function
VARIANCE, which computes the sample variance of the current row with respect to the group of rows within a window.
Examples
The following example returns the sample variance for each household ID in the customer table.
=> SELECT VARIANCE(household_id) FROM customer_dimension;
variance
------------------
74848598.0106764
(1 row)
See also
6.1.46 - WITHIN GROUP ORDER BY clause
Specifies how to sort rows that are grouped by aggregate functions, one of the following:.
Specifies how to sort rows that are grouped by aggregate functions, one of the following:
This clause is also supported for user-defined aggregate functions.
The order clause only specifies order within the result set of each group. The query can have its own ORDER BY clause, which has precedence over order that is specified by WITHIN GROUP ORDER BY, and orders the final result set.
Syntax
WITHIN GROUP (ORDER BY
{ column-expression [ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] ]
}[,...])
Parameters
column-expression- A column, constant, or arbitrary expression formed on columns, on which to sort grouped rows.
ASC | DESC- Specifies the ordering sequence as ascending (default) or descending.
NULLS {FIRST | LAST | AUTO}- Specifies whether to position null values first or last. Default positioning depends on whether the sort order is ascending or descending:
If you specify NULLS AUTO, Vertica chooses the positioning that is most efficient for this query, either NULLS FIRST or NULLS LAST.
If you omit all sort qualifiers, Vertica uses ASC NULLS LAST.
Examples
For usage examples, see these functions:
6.2 - Analytic functions
All analytic functions in this section with an aggregate counterpart are appended with [Analytics] in the heading to avoid confusion between the two function types.
Note
All analytic functions in this section with an aggregate counterpart are appended with [Analytics] in the heading to avoid confusion between the two function types.
Vertica analytics are SQL functions based on the ANSI 99 standard. These functions handle complex analysis and reporting tasks—for example:
-
Rank the longest-standing customers in a particular state.
-
Calculate the moving average of retail volume over a specified time.
-
Find the highest score among all students in the same grade.
-
Compare the current sales bonus that salespersons received against their previous bonus.
Analytic functions return aggregate results but they do not group the result set. They return the group value multiple times, once per record. You can sort group values, or partitions, using a window ORDER BY clause, but the order affects only the function result set, not the entire query result set.
Syntax
General
analytic-function(arguments) OVER(
[ window-partition-clause ]
[ window-order-clause [ window-frame-clause ] ]
)
With named window
analytic-function(arguments) OVER(
[ named-window [ window-frame-clause ] ]
)
Parameters
analytic-function(arguments)- A Vertica analytic function and its arguments.
OVER- Specifies how to partition, sort, and window frame function input with respect to the current row. The input data is the result set that the query returns after it evaluates
FROM, WHERE, GROUP BY, and HAVING clauses.
An empty OVER clause provides the best performance for single threaded queries on a single node.
- window-partition-clause
- Groups input rows according to one or more columns or expressions.
If you omit this clause, no grouping occurs and the analytic function processes all input rows as a single partition.
- window-order-clause
- Optionally specifies how to sort rows that are supplied to the analytic function. If the
OVER clause also includes a partition clause, rows are sorted within each partition.
-
window-frame-clause
- Only valid for some analytic functions, specifies as input a set of rows relative to the row that is currently being evaluated by the analytic function. After the function processes that row and its window, Vertica advances the current row and adjusts the window boundaries accordingly.
named-window- The name of a window that you define in the same query with a window-name-clause. This definition encapsulates window partitioning and sorting. Named windows are useful when the query invokes multiple analytic functions with similar
OVER clauses.
A window name clause cannot specify a window frame clause. However, you can qualify the named window in an OVER clause with a window frame clause.
Requirements
The following requirements apply to analytic functions:
-
All require an OVER clause. Each function has its own OVER clause requirements. For example, you can supply an empty OVER clause for some analytic aggregate functions such as
SUM. For other functions, window frame and order clauses might be required, or might be invalid.
-
Analytic functions can be invoked only in a query's SELECT and ORDER BY clauses.
-
Analytic functions cannot be nested. For example, the following query is not allowed:
=> SELECT MEDIAN(RANK() OVER(ORDER BY sal) OVER()).
-
WHERE, GROUP BY and HAVING operators are technically not part of the analytic function. However, they determine input to that function.
See also
6.2.1 - ARGMAX [analytic]
This function is patterned after the mathematical function argmax(f(x)), which returns the value of x that maximizes f(x).
This function is patterned after the mathematical function argmax(f(x)), which returns the value of x that maximizes f(x). Similarly, ARGMAX takes two arguments target and arg, where both are columns or column expressions in the queried dataset. ARGMAX finds the row with the largest non-null value in target and returns the value of arg in that row. If multiple rows contain the largest target value, ARGMAX returns arg from the first row that it finds.
Behavior type
Immutable
Syntax
ARGMAX ( target, arg ) OVER ( [ PARTITION BY expression[,...] ] [ window-order-clause ] )
Arguments
target, arg- Columns in the queried dataset.
OVER()- Specifies the following window clauses:
-
PARTITION BY expression: Groups (partitions) input rows according to the values in expression, which resolves to one or more columns in the queried dataset. If you omit this clause, ARGMAX processes all input rows as a single partition.
-
window-order-clause: Specifies how to sort input rows. If the OVER clause also includes a partition clause, rows are sorted separately within each partition.
Important
To ensure consistent results when multiple rows contain the largest target value, include a window order clause that sorts on arg.
For details, see Analytic Functions.
Examples
Create and populate table service_info, which contains information on various services, their respective development groups, and their userbase. A NULL in the users column indicates that the service has not been released, and so it cannot have users.
=> CREATE TABLE service_info(dev_group VARCHAR(10), product_name VARCHAR(30), users INT);
=> COPY t FROM stdin NULL AS 'null';
>> iris|chat|48193
>> aspen|trading|3000
>> orchid|cloud|990322
>> iris|video call| 10203
>> daffodil|streaming|44123
>> hydrangea|password manager|null
>> hydrangea|totp|1837363
>> daffodil|clip share|3000
>> hydrangea|e2e sms|null
>> rose|crypto|null
>> iris|forum|48193
>> \.
ARGMAX returns the value in the product_name column that maximizes the value in the users column. In this case, ARGMAX returns totp, which indicates that the totp service has the largest user base:
=> SELECT dev_group, product_name, users, ARGMAX(users, product_name) OVER (ORDER BY dev_group ASC) FROM service_info;
dev_group | product_name | users | ARGMAX
-----------+------------------+---------+--------
aspen | trading | 3000 | totp
daffodil | clip share | 3000 | totp
daffodil | streaming | 44123 | totp
hydrangea | e2e sms | | totp
hydrangea | password manager | | totp
hydrangea | totp | 1837363 | totp
iris | chat | 48193 | totp
iris | forum | 48193 | totp
iris | video call | 10203 | totp
orchid | cloud | 990322 | totp
rose | crypto | | totp
(11 rows)
The next query partitions the data on dev_group to identify the most popular service created by each development group. ARGMAX returns NULL if the partition's users column contains only NULL values and breaks ties using the first value in product_name from the top of the partition.
=> SELECT dev_group, product_name, users, ARGMAX(users, product_name) OVER (PARTITION BY dev_group ORDER BY product_name ASC) FROM service_info;
dev_group | product_name | users | ARGMAX
-----------+------------------+---------+-----------
iris | chat | 48193 | chat
iris | forum | 48193 | chat
iris | video call | 10203 | chat
orchid | cloud | 990322 | cloud
aspen | trading | 3000 | trading
daffodil | clip share | 3000 | streaming
daffodil | streaming | 44123 | streaming
rose | crypto | |
hydrangea | e2e sms | | totp
hydrangea | password manager | | totp
hydrangea | totp | 1837363 | totp
(11 rows)
See also
ARGMIN [analytic]
6.2.2 - ARGMIN [analytic]
This function is patterned after the mathematical function argmin(f(x)), which returns the value of x that minimizes f(x).
This function is patterned after the mathematical function argmin(f(x)), which returns the value of x that minimizes f(x). Similarly, ARGMIN takes two arguments target and arg, where both are columns or column expressions in the queried dataset. ARGMIN finds the row with the smallest non-null value in target and returns the value of arg in that row. If multiple rows contain the smallest target value, ARGMIN returns arg from the first row that it finds.
Behavior type
Immutable
Syntax
ARGMIN ( target, arg ) OVER ( [ PARTITION BY expression[,...] ] [ window-order-clause ] )
Arguments
target, arg- Columns in the queried dataset.
OVER()- Specifies the following window clauses:
-
PARTITION BY expression: Groups (partitions) input rows according to the values in expression, which resolves to one or more columns in the queried dataset. If you omit this clause, ARGMIN processes all input rows as a single partition.
-
window-order-clause: Specifies how to sort input rows. If the OVER clause also includes a partition clause, rows are sorted separately within each partition.
Important
To ensure consistent results when multiple rows contain the smallest target value, include a window order clause that sorts on arg.
For details, see Analytic Functions.
Examples
Create and populate table service_info, which contains information on various services, their respective development groups, and their userbase. A NULL in the users column indicates that the service has not been released, and so it cannot have users.
=> CREATE TABLE service_info(dev_group VARCHAR(10), product_name VARCHAR(30), users INT);
=> COPY t FROM stdin NULL AS 'null';
>> iris|chat|48193
>> aspen|trading|3000
>> orchid|cloud|990322
>> iris|video call| 10203
>> daffodil|streaming|44123
>> hydrangea|password manager|null
>> hydrangea|totp|1837363
>> daffodil|clip share|3000
>> hydrangea|e2e sms|null
>> rose|crypto|null
>> iris|forum|48193
>> \.
ARGMIN returns the value in the product_name column that minimizes the value in the users column. In this case, ARGMIN returns totp, which indicates that the totp service has the smallest user base:
=> SELECT dev_group, product_name, users, ARGMIN(users, product_name) OVER (ORDER BY dev_group ASC) FROM service_info;
dev_group | product_name | users | ARGMIN
-----------+------------------+---------+---------
aspen | trading | 3000 | trading
daffodil | clip share | 3000 | trading
daffodil | streaming | 44123 | trading
hydrangea | e2e sms | | trading
hydrangea | password manager | | trading
hydrangea | totp | 1837363 | trading
iris | chat | 48193 | trading
iris | forum | 48193 | trading
iris | video call | 10203 | trading
orchid | cloud | 990322 | trading
rose | crypto | | trading
(11 rows)
The next query partitions the data on dev_group to identify the least popular service created by each development group. ARGMIN returns NULL if the partition's users column contains only NULL values and breaks ties using the first value in product_name from the top of the partition.
=> SELECT dev_group, product_name, users, ARGMIN(users, product_name) OVER (PARTITION BY dev_group ORDER BY product_name ASC) FROM service_info;
dev_group | product_name | users | ARGMIN
-----------+------------------+---------+------------
iris | chat | 48193 | video call
iris | forum | 48193 | video call
iris | video call | 10203 | video call
orchid | cloud | 990322 | cloud
aspen | trading | 3000 | trading
daffodil | clip share | 3000 | clip share
daffodil | streaming | 44123 | clip share
rose | crypto | |
hydrangea | e2e sms | | totp
hydrangea | password manager | | totp
hydrangea | totp | 1837363 | totp
(11 rows)
See also
ARGMAX [analytic]
6.2.3 - AVG [analytic]
Computes an average of an expression in a group within a.
Computes an average of an expression in a group within a window. AVG returns the same data type as the expression's numeric data type.
The AVG analytic function differs from the
AVG aggregate function, which computes the average of an expression over a group of rows.
Behavior type
Immutable
Syntax
AVG ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression - Any data that can be implicitly converted to a numeric data type.
OVER()- See Analytic Functions.
Overflow handling
By default, Vertica allows silent numeric overflow when you call this function on numeric data types. For more information on this behavior and how to change it, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Examples
The following query finds the sales for that calendar month and returns a running/cumulative average (sometimes called a moving average) using the default window of RANGE UNBOUNDED PRECEDING AND CURRENT ROW:
=> SELECT calendar_month_number_in_year Mo, SUM(product_price) Sales,
AVG(SUM(product_price)) OVER (ORDER BY calendar_month_number_in_year)::INTEGER Average
FROM product_dimension pd, date_dimension dm, inventory_fact if
WHERE dm.date_key = if.date_key AND pd.product_key = if.product_key GROUP BY Mo;
Mo | Sales | Average
----+----------+----------
1 | 23869547 | 23869547
2 | 19604661 | 21737104
3 | 22877913 | 22117374
4 | 22901263 | 22313346
5 | 23670676 | 22584812
6 | 22507600 | 22571943
7 | 21514089 | 22420821
8 | 24860684 | 22725804
9 | 21687795 | 22610470
10 | 23648921 | 22714315
11 | 21115910 | 22569005
12 | 24708317 | 22747281
(12 rows)
To return a moving average that is not a running (cumulative) average, the window can specify ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING:
=> SELECT calendar_month_number_in_year Mo, SUM(product_price) Sales,
AVG(SUM(product_price)) OVER (ORDER BY calendar_month_number_in_year
ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING)::INTEGER Average
FROM product_dimension pd, date_dimension dm, inventory_fact if
WHERE dm.date_key = if.date_key AND pd.product_key = if.product_key GROUP BY Mo;
Mo | Sales | Average
----+----------+----------
1 | 23869547 | 22117374
2 | 19604661 | 22313346
3 | 22877913 | 22584812
4 | 22901263 | 22312423
5 | 23670676 | 22694308
6 | 22507600 | 23090862
7 | 21514089 | 22848169
8 | 24860684 | 22843818
9 | 21687795 | 22565480
10 | 23648921 | 23204325
11 | 21115910 | 22790236
12 | 24708317 | 23157716
(12 rows)
See also
6.2.4 - BOOL_AND [analytic]
Returns the Boolean value of an expression within a.
Returns the Boolean value of an expression within a window. If all input values are true, BOOL_AND returns t. Otherwise, it returns f.
Behavior type
Immutable
Syntax
BOOL_AND ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- A Boolean data type or any non-Boolean data type that can be implicitly converted to a Boolean data type. The function returns a Boolean value.
OVER()- See Analytic Functions.
Examples
The following example illustrates how you can use the BOOL_AND, BOOL_OR, and BOOL_XOR analytic functions. The sample table, employee, includes a column for type of employee and years paid.
=> CREATE TABLE employee(emptype VARCHAR, yearspaid VARCHAR);
CREATE TABLE
Insert sample data into the table to show years paid. In more than one case, an employee could be paid more than once within one year.
=> INSERT INTO employee
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2015'
UNION ALL
SELECT 'contractor3', '2014'
UNION ALL
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2014'
UNION ALL
SELECT 'contractor3', '2015'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor5', '2015'
UNION ALL
SELECT 'contractor5', '2016';
OUTPUT
--------
10
(1 row)
Query the table. The result shows employees that were paid twice in 2014 (BOOL_AND), once or twice in 2014 (BOOL_OR), and specifically not more than once in 2014 (BOOL_XOR).
=> SELECT DISTINCT emptype,
BOOL_AND(yearspaid='2014') OVER (PARTITION BY emptype) AS paidtwicein2014,
BOOL_OR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidonceortwicein2014,
BOOL_XOR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidjustoncein2014
FROM employee;
emptype | paidtwicein2014 | paidonceortwicein2014 | paidjustoncein2014
-------------+-----------------+-----------------------+--------------------
contractor1 | t | t | f
contractor2 | f | t | t
contractor3 | f | t | t
contractor4 | t | t | f
contractor5 | f | f | f
(5 rows)
See also
6.2.5 - BOOL_OR [analytic]
Returns the Boolean value of an expression within a.
Returns the Boolean value of an expression within a window. If at least one input value is true, BOOL_OR returns t. Otherwise, it returns f.
Behavior type
Immutable
Syntax
BOOL_OR ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression - A Boolean data type or any non-Boolean data type that can be implicitly converted to a Boolean data type. The function returns a Boolean value.
OVER()- See Analytic Functions.
Examples
The following example illustrates how you can use the BOOL_AND, BOOL_OR, and BOOL_XOR analytic functions. The sample table, employee, includes a column for type of employee and years paid.
=> CREATE TABLE employee(emptype VARCHAR, yearspaid VARCHAR);
CREATE TABLE
Insert sample data into the table to show years paid. In more than one case, an employee could be paid more than once within one year.
=> INSERT INTO employee
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2015'
UNION ALL
SELECT 'contractor3', '2014'
UNION ALL
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2014'
UNION ALL
SELECT 'contractor3', '2015'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor5', '2015'
UNION ALL
SELECT 'contractor5', '2016';
OUTPUT
--------
10
(1 row)
Query the table. The result shows employees that were paid twice in 2014 (BOOL_AND), once or twice in 2014 (BOOL_OR), and specifically not more than once in 2014 (BOOL_XOR).
=> SELECT DISTINCT emptype,
BOOL_AND(yearspaid='2014') OVER (PARTITION BY emptype) AS paidtwicein2014,
BOOL_OR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidonceortwicein2014,
BOOL_XOR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidjustoncein2014
FROM employee;
emptype | paidtwicein2014 | paidonceortwicein2014 | paidjustoncein2014
-------------+-----------------+-----------------------+--------------------
contractor1 | t | t | f
contractor2 | f | t | t
contractor3 | f | t | t
contractor4 | t | t | f
contractor5 | f | f | f
(5 rows)
See also
6.2.6 - BOOL_XOR [analytic]
Returns the Boolean value of an expression within a.
Returns the Boolean value of an expression within a window. If only one input value is true, BOOL_XOR returns t. Otherwise, it returns f.
Behavior type
Immutable
Syntax
BOOL_XOR ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression - A Boolean data type or any non-Boolean data type that can be implicitly converted to a Boolean data type. The function returns a Boolean value.
OVER()- See Analytic Functions.
Examples
The following example illustrates how you can use the BOOL_AND, BOOL_OR, and BOOL_XOR analytic functions. The sample table, employee, includes a column for type of employee and years paid.
=> CREATE TABLE employee(emptype VARCHAR, yearspaid VARCHAR);
CREATE TABLE
Insert sample data into the table to show years paid. In more than one case, an employee could be paid more than once within one year.
=> INSERT INTO employee
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2015'
UNION ALL
SELECT 'contractor3', '2014'
UNION ALL
SELECT 'contractor1', '2014'
UNION ALL
SELECT 'contractor2', '2014'
UNION ALL
SELECT 'contractor3', '2015'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor4', '2014'
UNION ALL
SELECT 'contractor5', '2015'
UNION ALL
SELECT 'contractor5', '2016';
OUTPUT
--------
10
(1 row)
Query the table. The result shows employees that were paid twice in 2014 (BOOL_AND), once or twice in 2014 (BOOL_OR), and specifically not more than once in 2014 (BOOL_XOR).
=> SELECT DISTINCT emptype,
BOOL_AND(yearspaid='2014') OVER (PARTITION BY emptype) AS paidtwicein2014,
BOOL_OR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidonceortwicein2014,
BOOL_XOR(yearspaid='2014') OVER (PARTITION BY emptype) AS paidjustoncein2014
FROM employee;
emptype | paidtwicein2014 | paidonceortwicein2014 | paidjustoncein2014
-------------+-----------------+-----------------------+--------------------
contractor1 | t | t | f
contractor2 | f | t | t
contractor3 | f | t | t
contractor4 | t | t | f
contractor5 | f | f | f
(5 rows)
See also
6.2.7 - CONDITIONAL_CHANGE_EVENT [analytic]
Assigns an event window number to each row, starting from 0, and increments by 1 when the result of evaluating the argument expression on the current row differs from that on the previous row.
Assigns an event window number to each row, starting from 0, and increments by 1 when the result of evaluating the argument expression on the current row differs from that on the previous row.
Behavior type
Immutable
Syntax
CONDITIONAL_CHANGE_EVENT ( expression ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
expression- SQL scalar expression that is evaluated on an input record. The result of *
expression *can be of any data type.
OVER()- See Analytic Functions.
Notes
The analytic window-order-clause is required but the window-partition-clause is optional.
Examples
=> SELECT CONDITIONAL_CHANGE_EVENT(bid)
OVER (PARTITION BY symbol ORDER BY ts) AS cce
FROM TickStore;
The system returns an error when no ORDER BY clause is present:
=> SELECT CONDITIONAL_CHANGE_EVENT(bid)
OVER (PARTITION BY symbol) AS cce
FROM TickStore;
ERROR: conditional_change_event must contain an
ORDER BY clause within its analytic clause
For more examples, see Event-based windows.
See also
6.2.8 - CONDITIONAL_TRUE_EVENT [analytic]
Assigns an event window number to each row, starting from 0, and increments the number by 1 when the result of the boolean argument expression evaluates true.
Assigns an event window number to each row, starting from 0, and increments the number by 1 when the result of the boolean argument expression evaluates true. For example, given a sequence of values for column a, as follows:
( 1, 2, 3, 4, 5, 6 )
CONDITIONAL_TRUE_EVENT(a > 3) returns 0, 0, 0, 1, 2, 3.
Behavior type
Immutable
Syntax
CONDITIONAL_TRUE_EVENT ( boolean-expression ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
boolean-expression- SQL scalar expression that is evaluated on an input record, type BOOLEAN.
OVER()- See Analytic functions.
Notes
The analytic window-order-clause is required but the window-partition-clause is optional.
Examples
> SELECT CONDITIONAL_TRUE_EVENT(bid > 10.6)
OVER(PARTITION BY bid ORDER BY ts) AS cte
FROM Tickstore;
The system returns an error if the ORDER BY clause is omitted:
> SELECT CONDITIONAL_TRUE_EVENT(bid > 10.6)
OVER(PARTITION BY bid) AS cte
FROM Tickstore;
ERROR: conditional_true_event must contain an ORDER BY
clause within its analytic clause
For more examples, see Event-based windows.
See also
6.2.9 - COUNT [analytic]
Counts occurrences within a group within a.
Counts occurrences within a group within a window. If you specify * or some non-null constant, COUNT() counts all rows.
Behavior type
Immutable
Syntax
COUNT ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Returns the number of rows in each group for which the
expression is not null. Can be any expression resulting in BIGINT.
OVER()- See Analytic Functions.
Examples
Using the schema defined in Window framing, the following COUNT function omits window order and window frame clauses; otherwise Vertica would treat it as a window aggregate. Think of the window of reporting aggregates as RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
=> SELECT deptno, sal, empno, COUNT(sal)
OVER (PARTITION BY deptno) AS count FROM emp;
deptno | sal | empno | count
--------+-----+-------+-------
10 | 101 | 1 | 2
10 | 104 | 4 | 2
20 | 110 | 10 | 6
20 | 110 | 9 | 6
20 | 109 | 7 | 6
20 | 109 | 6 | 6
20 | 109 | 8 | 6
20 | 109 | 11 | 6
30 | 105 | 5 | 3
30 | 103 | 3 | 3
30 | 102 | 2 | 3
Using ORDER BY sal creates a moving window query with default window: RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW.
=> SELECT deptno, sal, empno, COUNT(sal)
OVER (PARTITION BY deptno ORDER BY sal) AS count
FROM emp;
deptno | sal | empno | count
--------+-----+-------+-------
10 | 101 | 1 | 1
10 | 104 | 4 | 2
20 | 100 | 11 | 1
20 | 109 | 7 | 4
20 | 109 | 6 | 4
20 | 109 | 8 | 4
20 | 110 | 10 | 6
20 | 110 | 9 | 6
30 | 102 | 2 | 1
30 | 103 | 3 | 2
30 | 105 | 5 | 3
Using the VMart schema, the following query finds the number of employees who make less than or equivalent to the hourly rate of the current employee. The query returns a running/cumulative average (sometimes called a moving average) using the default window of RANGE UNBOUNDED PRECEDING AND CURRENT ROW:
=> SELECT employee_last_name AS "last_name", hourly_rate, COUNT(*)
OVER (ORDER BY hourly_rate) AS moving_count from employee_dimension;
last_name | hourly_rate | moving_count
------------+-------------+--------------
Gauthier | 6 | 4
Taylor | 6 | 4
Jefferson | 6 | 4
Nielson | 6 | 4
McNulty | 6.01 | 11
Robinson | 6.01 | 11
Dobisz | 6.01 | 11
Williams | 6.01 | 11
Kramer | 6.01 | 11
Miller | 6.01 | 11
Wilson | 6.01 | 11
Vogel | 6.02 | 14
Moore | 6.02 | 14
Vogel | 6.02 | 14
Carcetti | 6.03 | 19
...
To return a moving average that is not also a running (cumulative) average, the window should specify ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING:
=> SELECT employee_last_name AS "last_name", hourly_rate, COUNT(*)
OVER (ORDER BY hourly_rate ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING)
AS moving_count from employee_dimension;
See also
6.2.10 - CUME_DIST [analytic]
Calculates the cumulative distribution, or relative rank, of the current row with regard to other rows in the same partition within a .
Calculates the cumulative distribution, or relative rank, of the current row with regard to other rows in the same partition within a window.
CUME_DIST() returns a number greater then 0 and less then or equal to 1, where the number represents the relative position of the specified row within a group of n rows. For a row x (assuming ASC ordering), the CUME_DIST of x is the number of rows with values lower than or equal to the value of x, divided by the number of rows in the partition. For example, in a group of three rows, the cumulative distribution values returned would be 1/3, 2/3, and 3/3.
Note
Because the result for a given row depends on the number of rows preceding that row in the same partition, you should always specify a window-order-clause when you call this function.
Behavior type
Immutable
Syntax
CUME_DIST ( ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
OVER()- See Analytic Functions.
Examples
The following example returns the cumulative distribution of sales for different transaction types within each month of the first quarter.
=> SELECT calendar_month_name AS month, tender_type, SUM(sales_quantity),
CUME_DIST()
OVER (PARTITION BY calendar_month_name ORDER BY SUM(sales_quantity)) AS
CUME_DIST
FROM store.store_sales_fact JOIN date_dimension
USING(date_key) WHERE calendar_month_name IN ('January','February','March')
AND tender_type NOT LIKE 'Other'
GROUP BY calendar_month_name, tender_type;
month | tender_type | SUM | CUME_DIST
----------+-------------+--------+-----------
March | Credit | 469858 | 0.25
March | Cash | 470449 | 0.5
March | Check | 473033 | 0.75
March | Debit | 475103 | 1
January | Cash | 441730 | 0.25
January | Debit | 443922 | 0.5
January | Check | 446297 | 0.75
January | Credit | 450994 | 1
February | Check | 425665 | 0.25
February | Debit | 426726 | 0.5
February | Credit | 430010 | 0.75
February | Cash | 430767 | 1
(12 rows)
See also
6.2.11 - DENSE_RANK [analytic]
Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause.
Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause. A DENSE_RANK function returns a sequence of ranking numbers without any gaps.
DENSE_RANK executes as follows:
-
Sorts partition rows as specified by the ORDER BY clause.
-
Compares the ORDER BY values of the preceding row and current row and ranks the current row as follows:
-
If ORDER BY values are the same, the current row gets the same ranking as the preceding row.
Note
Null values are considered equal. For detailed information on how null values are sorted, see
NULL sort order.
-
If the ORDER BY values are different, DENSE_RANK increments or decrements the current row's ranking by 1, depending whether sort order is ascending or descending.
DENSE_RANK always changes the ranking by 1, so no gaps appear in the ranking sequence. The largest rank value is the number of unique ORDER BY values returned by the query.
Behavior type
Immutable
Syntax
DENSE_RANK() OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
OVER()- See Analytic Functions.
See Analytic Functions
Compared with RANK
RANK leaves gaps in the ranking sequence, while DENSE_RANK does not. The example below compares the behavior of the two functions.
Examples
The following query invokes RANK and DENSE_RANK to rank customers by annual income. The two functions return different rankings, as follows:
-
If annual_salary contains duplicate values, RANK() inserts duplicate rankings and then skips one or more values—for example, from 4 to 6 and 7 to 9.
-
In the parallel column Dense Rank, DENSE_RANK() also inserts duplicate rankings, but leaves no gaps in the rankings sequence:
=> SELECT employee_region region, employee_key, annual_salary,
RANK() OVER (PARTITION BY employee_region ORDER BY annual_salary) Rank,
DENSE_RANK() OVER (PARTITION BY employee_region ORDER BY annual_salary) "Dense Rank"
FROM employee_dimension;
region | employee_key | annual_salary | Rank | Dense Rank
----------------------------------+--------------+---------------+------+------------
West | 5248 | 1200 | 1 | 1
West | 6880 | 1204 | 2 | 2
West | 5700 | 1214 | 3 | 3
West | 9857 | 1218 | 4 | 4
West | 6014 | 1218 | 4 | 4
West | 9221 | 1220 | 6 | 5
West | 7646 | 1222 | 7 | 6
West | 6621 | 1222 | 7 | 6
West | 6488 | 1224 | 9 | 7
West | 7659 | 1226 | 10 | 8
West | 7432 | 1226 | 10 | 8
West | 9905 | 1226 | 10 | 8
West | 9021 | 1228 | 13 | 9
...
West | 56 | 963104 | 2794 | 2152
West | 100 | 992363 | 2795 | 2153
East | 8353 | 1200 | 1 | 1
East | 9743 | 1202 | 2 | 2
East | 9975 | 1202 | 2 | 2
East | 9205 | 1204 | 4 | 3
East | 8894 | 1206 | 5 | 4
East | 7740 | 1206 | 5 | 4
East | 7324 | 1208 | 7 | 5
East | 6505 | 1208 | 7 | 5
East | 5404 | 1208 | 7 | 5
East | 5010 | 1208 | 7 | 5
East | 9114 | 1212 | 11 | 6
...
See also
SQL analytics
6.2.12 - EXPONENTIAL_MOVING_AVERAGE [analytic]
Calculates the exponential moving average (EMA) of expression E with smoothing factor X.
Calculates the exponential moving average (EMA) of expression E with smoothing factor X. An EMA differs from a simple moving average in that it provides a more stable picture of changes to data over time.
The EMA is calculated by adding the previous EMA value to the current data point scaled by the smoothing factor, as in the following formula:
EMA=EMA0 + (X * (E-EMA0))
where:
-
E is the current data point
-
EMA0 is the previous row's EMA value.
-
X is the smoothing factor.
This function also works at the row level. For example, EMA assumes the data in a given column is sampled at uniform intervals. If the users' data points are sampled at non-uniform intervals, they should run the time series gap filling and interpolation (GFI) operations before EMA()
Behavior type
Immutable
Syntax
EXPONENTIAL_MOVING_AVERAGE ( E, X ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
E- The value whose average is calculated over a set of rows. Can be
INTEGER, FLOAT or NUMERIC type and must be a constant.
X- A positive
FLOAT value between 0 and 1 that is used as the smoothing factor.
OVER()- See Analytic Functions.
Examples
The following example uses time series gap filling and interpolation (GFI) first in a subquery, and then performs an EXPONENTIAL_MOVING_AVERAGE operation on the subquery result.
Create a simple four-column table:
=> CREATE TABLE ticker(
time TIMESTAMP,
symbol VARCHAR(8),
bid1 FLOAT,
bid2 FLOAT );
Insert some data, including nulls, so GFI can do its interpolation and gap filling:
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:00', 'ABC', 60.45, 60.44);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:01', 'ABC', 60.49, 65.12);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:02', 'ABC', 57.78, 59.25);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:03', 'ABC', null, 65.12);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:04', 'ABC', 67.88, null);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:00', 'XYZ', 47.55, 40.15);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:01', 'XYZ', 44.35, 46.78);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:02', 'XYZ', 71.56, 75.78);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:03', 'XYZ', 85.55, 70.21);
=> INSERT INTO ticker VALUES ('2009-07-12 03:00:04', 'XYZ', 45.55, 58.65);
=> COMMIT;
Note
During gap filling and interpolation, Vertica takes the closest non null value on either side of the time slice and uses that value. For example, if you use a linear interpolation scheme and you do not specify
IGNORE NULLS, and your data has one real value and one null, the result is null. If the value on either side is null, the result is null. See
When Time Series Data Contains Nulls for details.
Query the table that you just created to you can see the output:
=> SELECT * FROM ticker;
time | symbol | bid1 | bid2
---------------------+--------+-------+-------
2009-07-12 03:00:00 | ABC | 60.45 | 60.44
2009-07-12 03:00:01 | ABC | 60.49 | 65.12
2009-07-12 03:00:02 | ABC | 57.78 | 59.25
2009-07-12 03:00:03 | ABC | | 65.12
2009-07-12 03:00:04 | ABC | 67.88 |
2009-07-12 03:00:00 | XYZ | 47.55 | 40.15
2009-07-12 03:00:01 | XYZ | 44.35 | 46.78
2009-07-12 03:00:02 | XYZ | 71.56 | 75.78
2009-07-12 03:00:03 | XYZ | 85.55 | 70.21
2009-07-12 03:00:04 | XYZ | 45.55 | 58.65
(10 rows)
The following query processes the first and last values that belong to each 2-second time slice in table trades' column a. The query then calculates the exponential moving average of expression fv and lv with a smoothing factor of 50%:
=> SELECT symbol, slice_time, fv, lv,
EXPONENTIAL_MOVING_AVERAGE(fv, 0.5)
OVER (PARTITION BY symbol ORDER BY slice_time) AS ema_first,
EXPONENTIAL_MOVING_AVERAGE(lv, 0.5)
OVER (PARTITION BY symbol ORDER BY slice_time) AS ema_last
FROM (
SELECT symbol, slice_time,
TS_FIRST_VALUE(bid1 IGNORE NULLS) as fv,
TS_LAST_VALUE(bid2 IGNORE NULLS) AS lv
FROM ticker TIMESERIES slice_time AS '2 seconds'
OVER (PARTITION BY symbol ORDER BY time) ) AS sq;
symbol | slice_time | fv | lv | ema_first | ema_last
--------+---------------------+-------+-------+-----------+----------
ABC | 2009-07-12 03:00:00 | 60.45 | 65.12 | 60.45 | 65.12
ABC | 2009-07-12 03:00:02 | 57.78 | 65.12 | 59.115 | 65.12
ABC | 2009-07-12 03:00:04 | 67.88 | 65.12 | 63.4975 | 65.12
XYZ | 2009-07-12 03:00:00 | 47.55 | 46.78 | 47.55 | 46.78
XYZ | 2009-07-12 03:00:02 | 71.56 | 70.21 | 59.555 | 58.495
XYZ | 2009-07-12 03:00:04 | 45.55 | 58.65 | 52.5525 | 58.5725
(6 rows)
See also
6.2.13 - FIRST_VALUE [analytic]
Lets you select the first value of a table or partition (determined by the window-order-clause) without having to use a self join.
Lets you select the first value of a table or partition (determined by the window-order-clause) without having to use a self join. This function is useful when you want to use the first value as a baseline in calculations.
Use FIRST_VALUE() with the window-order-clause to produce deterministic results. If no window is specified for the current row, the default window is UNBOUNDED PRECEDING AND CURRENT ROW.
Behavior type
Immutable
Syntax
FIRST_VALUE ( expression [ IGNORE NULLS ] ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Expression to evaluate—or example, a constant, column, nonanalytic function, function expression, or expressions involving any of these.
IGNORE NULLS- Specifies to return the first non-null value in the set, or
NULL if all values are NULL. If you omit this option and the first value in the set is null, the function returns NULL.
OVER()- See Analytic Functions.
Examples
The following query asks for the first value in the partitioned day of week, and illustrates the potential nondeterministic nature of FIRST_VALUE():
=> SELECT calendar_year, date_key, day_of_week, full_date_description,
FIRST_VALUE(full_date_description)
OVER(PARTITION BY calendar_month_number_in_year ORDER BY day_of_week)
AS "first_value"
FROM date_dimension
WHERE calendar_year=2003 AND calendar_month_number_in_year=1;
The first value returned is January 31, 2003; however, the next time the same query is run, the first value might be January 24 or January 3, or the 10th or 17th. This is because the analytic ORDER BY column day_of_week returns rows that contain ties (multiple Fridays). These repeated values make the ORDER BY evaluation result nondeterministic, because rows that contain ties can be ordered in any way, and any one of those rows qualifies as being the first value of day_of_week.
calendar_year | date_key | day_of_week | full_date_description | first_value
--------------+----------+-------------+-----------------------+------------------
2003 | 31 | Friday | January 31, 2003 | January 31, 2003
2003 | 24 | Friday | January 24, 2003 | January 31, 2003
2003 | 3 | Friday | January 3, 2003 | January 31, 2003
2003 | 10 | Friday | January 10, 2003 | January 31, 2003
2003 | 17 | Friday | January 17, 2003 | January 31, 2003
2003 | 6 | Monday | January 6, 2003 | January 31, 2003
2003 | 27 | Monday | January 27, 2003 | January 31, 2003
2003 | 13 | Monday | January 13, 2003 | January 31, 2003
2003 | 20 | Monday | January 20, 2003 | January 31, 2003
2003 | 11 | Saturday | January 11, 2003 | January 31, 2003
2003 | 18 | Saturday | January 18, 2003 | January 31, 2003
2003 | 25 | Saturday | January 25, 2003 | January 31, 2003
2003 | 4 | Saturday | January 4, 2003 | January 31, 2003
2003 | 12 | Sunday | January 12, 2003 | January 31, 2003
2003 | 26 | Sunday | January 26, 2003 | January 31, 2003
2003 | 5 | Sunday | January 5, 2003 | January 31, 2003
2003 | 19 | Sunday | January 19, 2003 | January 31, 2003
2003 | 23 | Thursday | January 23, 2003 | January 31, 2003
2003 | 2 | Thursday | January 2, 2003 | January 31, 2003
2003 | 9 | Thursday | January 9, 2003 | January 31, 2003
2003 | 16 | Thursday | January 16, 2003 | January 31, 2003
2003 | 30 | Thursday | January 30, 2003 | January 31, 2003
2003 | 21 | Tuesday | January 21, 2003 | January 31, 2003
2003 | 14 | Tuesday | January 14, 2003 | January 31, 2003
2003 | 7 | Tuesday | January 7, 2003 | January 31, 2003
2003 | 28 | Tuesday | January 28, 2003 | January 31, 2003
2003 | 22 | Wednesday | January 22, 2003 | January 31, 2003
2003 | 29 | Wednesday | January 29, 2003 | January 31, 2003
2003 | 15 | Wednesday | January 15, 2003 | January 31, 2003
2003 | 1 | Wednesday | January 1, 2003 | January 31, 2003
2003 | 8 | Wednesday | January 8, 2003 | January 31, 2003
(31 rows)
Note
The day_of_week results are returned in alphabetical order because of lexical rules. The fact that each day does not appear ordered by the 7-day week cycle (for example, starting with Sunday followed by Monday, Tuesday, and so on) has no affect on results.
To return deterministic results, modify the query so that it performs its analytic ORDER BY operations on a unique field, such as date_key:
=> SELECT calendar_year, date_key, day_of_week, full_date_description,
FIRST_VALUE(full_date_description) OVER
(PARTITION BY calendar_month_number_in_year ORDER BY date_key) AS "first_value"
FROM date_dimension WHERE calendar_year=2003;
FIRST_VALUE() returns a first value of January 1 for the January partition and the first value of February 1 for the February partition. Also, the full_date_description column contains no ties:
calendar_year | date_key | day_of_week | full_date_description | first_value
---------------+----------+-------------+-----------------------+------------
2003 | 1 | Wednesday | January 1, 2003 | January 1, 2003
2003 | 2 | Thursday | January 2, 2003 | January 1, 2003
2003 | 3 | Friday | January 3, 2003 | January 1, 2003
2003 | 4 | Saturday | January 4, 2003 | January 1, 2003
2003 | 5 | Sunday | January 5, 2003 | January 1, 2003
2003 | 6 | Monday | January 6, 2003 | January 1, 2003
2003 | 7 | Tuesday | January 7, 2003 | January 1, 2003
2003 | 8 | Wednesday | January 8, 2003 | January 1, 2003
2003 | 9 | Thursday | January 9, 2003 | January 1, 2003
2003 | 10 | Friday | January 10, 2003 | January 1, 2003
2003 | 11 | Saturday | January 11, 2003 | January 1, 2003
2003 | 12 | Sunday | January 12, 2003 | January 1, 2003
2003 | 13 | Monday | January 13, 2003 | January 1, 2003
2003 | 14 | Tuesday | January 14, 2003 | January 1, 2003
2003 | 15 | Wednesday | January 15, 2003 | January 1, 2003
2003 | 16 | Thursday | January 16, 2003 | January 1, 2003
2003 | 17 | Friday | January 17, 2003 | January 1, 2003
2003 | 18 | Saturday | January 18, 2003 | January 1, 2003
2003 | 19 | Sunday | January 19, 2003 | January 1, 2003
2003 | 20 | Monday | January 20, 2003 | January 1, 2003
2003 | 21 | Tuesday | January 21, 2003 | January 1, 2003
2003 | 22 | Wednesday | January 22, 2003 | January 1, 2003
2003 | 23 | Thursday | January 23, 2003 | January 1, 2003
2003 | 24 | Friday | January 24, 2003 | January 1, 2003
2003 | 25 | Saturday | January 25, 2003 | January 1, 2003
2003 | 26 | Sunday | January 26, 2003 | January 1, 2003
2003 | 27 | Monday | January 27, 2003 | January 1, 2003
2003 | 28 | Tuesday | January 28, 2003 | January 1, 2003
2003 | 29 | Wednesday | January 29, 2003 | January 1, 2003
2003 | 30 | Thursday | January 30, 2003 | January 1, 2003
2003 | 31 | Friday | January 31, 2003 | January 1, 2003
2003 | 32 | Saturday | February 1, 2003 | February 1, 2003
2003 | 33 | Sunday | February 2, 2003 | February 1,2003
...
(365 rows)
See also
6.2.14 - LAG [analytic]
Returns the value of the input expression at the given offset before the current row within a.
Returns the value of the input expression at the given offset before the current row within a window. This function lets you access more than one row in a table at the same time. This is useful for comparing values when the relative positions of rows can be reliably known. It also lets you avoid the more costly self join, which enhances query processing speed.
For information on getting the rows that follow, see LEAD.
Behavior type
Immutable
Syntax
LAG ( expression[, offset ] [, default ] ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
expression- The expression to evaluate—for example, a constant, column, non-analytic function, function expression, or expressions involving any of these.
offset- Indicates how great is the lag. The default value is 1 (the previous row). This parameter must evaluate to a constant positive integer.
default- The value returned if
offset falls outside the bounds of the table or partition. This value must be a constant value or an expression that can be evaluated to a constant; its data type is coercible to that of the first argument.
Examples
This example sums the current balance by date in a table and also sums the previous balance from the last day. Given the inputs that follow, the data satisfies the following conditions:
-
For each some_id, there is exactly 1 row for each date represented by month_date.
-
For each some_id, the set of dates is consecutive; that is, if there is a row for February 24 and a row for February 26, there would also be a row for February 25.
-
Each some_id has the same set of dates.
=> CREATE TABLE balances (
month_date DATE,
current_bal INT,
some_id INT);
=> INSERT INTO balances values ('2009-02-24', 10, 1);
=> INSERT INTO balances values ('2009-02-25', 10, 1);
=> INSERT INTO balances values ('2009-02-26', 10, 1);
=> INSERT INTO balances values ('2009-02-24', 20, 2);
=> INSERT INTO balances values ('2009-02-25', 20, 2);
=> INSERT INTO balances values ('2009-02-26', 20, 2);
=> INSERT INTO balances values ('2009-02-24', 30, 3);
=> INSERT INTO balances values ('2009-02-25', 20, 3);
=> INSERT INTO balances values ('2009-02-26', 30, 3);
Now run LAG to sum the current balance for each date and sum the previous balance from the last day:
=> SELECT month_date,
SUM(current_bal) as current_bal_sum,
SUM(previous_bal) as previous_bal_sum FROM
(SELECT month_date, current_bal,
LAG(current_bal, 1, 0) OVER
(PARTITION BY some_id ORDER BY month_date)
AS previous_bal FROM balances) AS subQ
GROUP BY month_date ORDER BY month_date;
month_date | current_bal_sum | previous_bal_sum
------------+-----------------+------------------
2009-02-24 | 60 | 0
2009-02-25 | 50 | 60
2009-02-26 | 60 | 50
(3 rows)
Using the same example data, the following query would not be allowed because LAG is nested inside an aggregate function:
=> SELECT month_date,
SUM(current_bal) as current_bal_sum,
SUM(LAG(current_bal, 1, 0) OVER
(PARTITION BY some_id ORDER BY month_date)) AS previous_bal_sum
FROM some_table GROUP BY month_date ORDER BY month_date;
The following example uses the VMart database. LAG first returns the annual income from the previous row, and then it calculates the difference between the income in the current row from the income in the previous row:
=> SELECT occupation, customer_key, customer_name, annual_income,
LAG(annual_income, 1, 0) OVER (PARTITION BY occupation
ORDER BY annual_income) AS prev_income, annual_income -
LAG(annual_income, 1, 0) OVER (PARTITION BY occupation
ORDER BY annual_income) AS difference
FROM customer_dimension ORDER BY occupation, customer_key LIMIT 20;
occupation | customer_key | customer_name | annual_income | prev_income | difference
------------+--------------+----------------------+---------------+-------------+------------
Accountant | 15 | Midori V. Peterson | 692610 | 692535 | 75
Accountant | 43 | Midori S. Rodriguez | 282359 | 280976 | 1383
Accountant | 93 | Robert P. Campbell | 471722 | 471355 | 367
Accountant | 102 | Sam T. McNulty | 901636 | 901561 | 75
Accountant | 134 | Martha B. Overstreet | 705146 | 704335 | 811
Accountant | 165 | James C. Kramer | 376841 | 376474 | 367
Accountant | 225 | Ben W. Farmer | 70574 | 70449 | 125
Accountant | 270 | Jessica S. Lang | 684204 | 682274 | 1930
Accountant | 273 | Mark X. Lampert | 723294 | 722737 | 557
Accountant | 295 | Sharon K. Gauthier | 29033 | 28412 | 621
Accountant | 338 | Anna S. Jackson | 816858 | 815557 | 1301
Accountant | 377 | William I. Jones | 915149 | 914872 | 277
Accountant | 438 | Joanna A. McCabe | 147396 | 144482 | 2914
Accountant | 452 | Kim P. Brown | 126023 | 124797 | 1226
Accountant | 467 | Meghan K. Carcetti | 810528 | 810284 | 244
Accountant | 478 | Tanya E. Greenwood | 639649 | 639029 | 620
Accountant | 511 | Midori P. Vogel | 187246 | 185539 | 1707
Accountant | 525 | Alexander K. Moore | 677433 | 677050 | 383
Accountant | 550 | Sam P. Reyes | 735691 | 735355 | 336
Accountant | 577 | Robert U. Vu | 616101 | 615439 | 662
(20 rows)
The next example uses LEAD and LAG to return the third row after the salary in the current row and fifth salary before the salary in the current row:
=> SELECT hire_date, employee_key, employee_last_name,
LEAD(hire_date, 1) OVER (ORDER BY hire_date) AS "next_hired" ,
LAG(hire_date, 1) OVER (ORDER BY hire_date) AS "last_hired"
FROM employee_dimension ORDER BY hire_date, employee_key;
hire_date | employee_key | employee_last_name | next_hired | last_hired
------------+--------------+--------------------+------------+------------
1956-04-11 | 2694 | Farmer | 1956-05-12 |
1956-05-12 | 5486 | Winkler | 1956-09-18 | 1956-04-11
1956-09-18 | 5525 | McCabe | 1957-01-15 | 1956-05-12
1957-01-15 | 560 | Greenwood | 1957-02-06 | 1956-09-18
1957-02-06 | 9781 | Bauer | 1957-05-25 | 1957-01-15
1957-05-25 | 9506 | Webber | 1957-07-04 | 1957-02-06
1957-07-04 | 6723 | Kramer | 1957-07-07 | 1957-05-25
1957-07-07 | 5827 | Garnett | 1957-11-11 | 1957-07-04
1957-11-11 | 373 | Reyes | 1957-11-21 | 1957-07-07
1957-11-21 | 3874 | Martin | 1958-02-06 | 1957-11-11
(10 rows)
See also
6.2.15 - LAST_VALUE [analytic]
Lets you select the last value of a table or partition (determined by the window-order-clause) without having to use a self join.
Lets you select the last value of a table or partition (determined by the window-order-clause) without having to use a self join. LAST_VALUE takes the last record from the partition after the window order clause. The function then computes the expression against the last record, and returns the results. This function is useful when you want to use the last value as a baseline in calculations.
Use LAST_VALUE() with the window-order-clause to produce deterministic results. If no window is specified for the current row, the default window is UNBOUNDED PRECEDING AND CURRENT ROW.
Tip
Due to default window semantics,
LAST_VALUE does not always return the last value of a partition. If you omit
window-frame-clause from the analytic clause,
LAST_VALUE operates on this default window. Although results can seem non-intuitive by not returning the bottom of the current partition, it returns the bottom of the window, which continues to change along with the current input row being processed. If you want to return the last value of a partition, use
UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING. See examples below.
Behavior type
Immutable
Syntax
LAST_VALUE ( expression [ IGNORE NULLS ] ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Expression to evaluate—for example, a constant, column, nonanalytic function, function expression, or expressions involving any of these.
IGNORE NULLS- Specifies to return the last non-null value in the set, or
NULL if all values are NULL. If you omit this option and the last value in the set is null, the function returns NULL.
OVER()- See Analytic Functions.
Examples
Using the schema defined in Window framing in Analyzing Data, the following query does not show the highest salary value by department; instead it shows the highest salary value by department by salary.
=> SELECT deptno, sal, empno, LAST_VALUE(sal)
OVER (PARTITION BY deptno ORDER BY sal) AS lv
FROM emp;
deptno | sal | empno | lv
--------+-----+-------+--------
10 | 101 | 1 | 101
10 | 104 | 4 | 104
20 | 100 | 11 | 100
20 | 109 | 7 | 109
20 | 109 | 6 | 109
20 | 109 | 8 | 109
20 | 110 | 10 | 110
20 | 110 | 9 | 110
30 | 102 | 2 | 102
30 | 103 | 3 | 103
30 | 105 | 5 | 105
If you include the window frame clause ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING, LAST_VALUE() returns the highest salary by department, an accurate representation of the information:
=> SELECT deptno, sal, empno, LAST_VALUE(sal)
OVER (PARTITION BY deptno ORDER BY sal
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv
FROM emp;
deptno | sal | empno | lv
--------+-----+-------+--------
10 | 101 | 1 | 104
10 | 104 | 4 | 104
20 | 100 | 11 | 110
20 | 109 | 7 | 110
20 | 109 | 6 | 110
20 | 109 | 8 | 110
20 | 110 | 10 | 110
20 | 110 | 9 | 110
30 | 102 | 2 | 105
30 | 103 | 3 | 105
30 | 105 | 5 | 105
For more examples, see FIRST_VALUE().
See also
6.2.16 - LEAD [analytic]
Returns values from the row after the current row within a , letting you access more than one row in a table at the same time.
Returns values from the row after the current row within a window, letting you access more than one row in a table at the same time. This is useful for comparing values when the relative positions of rows can be reliably known. It also lets you avoid the more costly self join, which enhances query processing speed.
Behavior type
Immutable
Syntax
LEAD ( expression[, offset ] [, default ] ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
expression- The expression to evaluate—for example, a constant, column, non-analytic function, function expression, or expressions involving any of these.
offset- Is an optional parameter that defaults to 1 (the next row). This parameter must evaluate to a constant positive integer.
default- The value returned if
offset falls outside the bounds of the table or partition. This value must be a constant value or an expression that can be evaluated to a constant; its data type is coercible to that of the first argument.
Examples
LEAD finds the hire date of the employee hired just after the current row:
=> SELECT employee_region, hire_date, employee_key, employee_last_name,
LEAD(hire_date, 1) OVER (PARTITION BY employee_region ORDER BY hire_date) AS "next_hired"
FROM employee_dimension ORDER BY employee_region, hire_date, employee_key;
employee_region | hire_date | employee_key | employee_last_name | next_hired
-------------------+------------+--------------+--------------------+------------
East | 1956-04-08 | 9218 | Harris | 1957-02-06
East | 1957-02-06 | 7799 | Stein | 1957-05-25
East | 1957-05-25 | 3687 | Farmer | 1957-06-26
East | 1957-06-26 | 9474 | Bauer | 1957-08-18
East | 1957-08-18 | 570 | Jefferson | 1957-08-24
East | 1957-08-24 | 4363 | Wilson | 1958-02-17
East | 1958-02-17 | 6457 | McCabe | 1958-06-26
East | 1958-06-26 | 6196 | Li | 1958-07-16
East | 1958-07-16 | 7749 | Harris | 1958-09-18
East | 1958-09-18 | 9678 | Sanchez | 1958-11-10
(10 rows)
The next example uses LEAD and LAG to return the third row after the salary in the current row and fifth salary before the salary in the current row.
=> SELECT hire_date, employee_key, employee_last_name,
LEAD(hire_date, 1) OVER (ORDER BY hire_date) AS "next_hired" ,
LAG(hire_date, 1) OVER (ORDER BY hire_date) AS "last_hired"
FROM employee_dimension ORDER BY hire_date, employee_key;
hire_date | employee_key | employee_last_name | next_hired | last_hired
------------+--------------+--------------------+------------+------------
1956-04-11 | 2694 | Farmer | 1956-05-12 |
1956-05-12 | 5486 | Winkler | 1956-09-18 | 1956-04-11
1956-09-18 | 5525 | McCabe | 1957-01-15 | 1956-05-12
1957-01-15 | 560 | Greenwood | 1957-02-06 | 1956-09-18
1957-02-06 | 9781 | Bauer | 1957-05-25 | 1957-01-15
1957-05-25 | 9506 | Webber | 1957-07-04 | 1957-02-06
1957-07-04 | 6723 | Kramer | 1957-07-07 | 1957-05-25
1957-07-07 | 5827 | Garnett | 1957-11-11 | 1957-07-04
1957-11-11 | 373 | Reyes | 1957-11-21 | 1957-07-07
1957-11-21 | 3874 | Martin | 1958-02-06 | 1957-11-11
(10 rows)
The following example returns employee name and salary, along with the next highest and lowest salaries.
=> SELECT employee_last_name, annual_salary,
NVL(LEAD(annual_salary) OVER (ORDER BY annual_salary),
MIN(annual_salary) OVER()) "Next Highest",
NVL(LAG(annual_salary) OVER (ORDER BY annual_salary),
MAX(annual_salary) OVER()) "Next Lowest"
FROM employee_dimension;
employee_last_name | annual_salary | Next Highest | Next Lowest
--------------------+---------------+--------------+-------------
Nielson | 1200 | 1200 | 995533
Lewis | 1200 | 1200 | 1200
Harris | 1200 | 1202 | 1200
Robinson | 1202 | 1202 | 1200
Garnett | 1202 | 1202 | 1202
Weaver | 1202 | 1202 | 1202
Nielson | 1202 | 1202 | 1202
McNulty | 1202 | 1204 | 1202
Farmer | 1204 | 1204 | 1202
Martin | 1204 | 1204 | 1204
(10 rows)
The next example returns, for each assistant director in the employees table, the hire date of the director hired just after the director on the current row. For example, Jackson was hired on 2016-12-28, and the next director hired was Bauer:
=> SELECT employee_last_name, hire_date,
LEAD(hire_date, 1) OVER (ORDER BY hire_date DESC) as "NextHired"
FROM employee_dimension WHERE job_title = 'Assistant Director';
employee_last_name | hire_date | NextHired
--------------------+------------+------------
Jackson | 2016-12-28 | 2016-12-26
Bauer | 2016-12-26 | 2016-12-11
Miller | 2016-12-11 | 2016-12-07
Fortin | 2016-12-07 | 2016-11-27
Harris | 2016-11-27 | 2016-11-15
Goldberg | 2016-11-15 |
(5 rows)
See also
6.2.17 - MAX [analytic]
Returns the maximum value of an expression within a.
Returns the maximum value of an expression within a window. The return value has the same type as the expression data type.
The analytic functions MIN() and MAX() can operate with Boolean values. The MAX() function acts upon a Boolean data type or a value that can be implicitly converted to a Boolean value. If at least one input value is true, MAX() returns t (true). Otherwise, it returns f (false). In the same scenario, the MIN() function returns t (true) if all input values are true. Otherwise, it returns f.
Behavior type
Immutable
Syntax
MAX ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any expression for which the maximum value is calculated, typically a column reference.
OVER()- See Analytic Functions.
Examples
The following query computes the deviation between the employees' annual salary and the maximum annual salary in Massachusetts:
=> SELECT employee_state, annual_salary,
MAX(annual_salary)
OVER(PARTITION BY employee_state ORDER BY employee_key) max,
annual_salary- MAX(annual_salary)
OVER(PARTITION BY employee_state ORDER BY employee_key) diff
FROM employee_dimension
WHERE employee_state = 'MA';
employee_state | annual_salary | max | diff
----------------+---------------+--------+---------
MA | 1918 | 995533 | -993615
MA | 2058 | 995533 | -993475
MA | 2586 | 995533 | -992947
MA | 2500 | 995533 | -993033
MA | 1318 | 995533 | -994215
MA | 2072 | 995533 | -993461
MA | 2656 | 995533 | -992877
MA | 2148 | 995533 | -993385
MA | 2366 | 995533 | -993167
MA | 2664 | 995533 | -992869
(10 rows)
The following example shows you the difference between the MIN and MAX analytic functions when you use them with a Boolean value. The sample creates a table with two columns, adds two rows of data, and shows sample output for MIN and MAX.
CREATE TABLE min_max_functions (emp VARCHAR, torf BOOL);
INSERT INTO min_max_functions VALUES ('emp1', 1);
INSERT INTO min_max_functions VALUES ('emp1', 0);
SELECT DISTINCT emp,
min(torf) OVER (PARTITION BY emp) AS worksasbooleanand,
Max(torf) OVER (PARTITION BY emp) AS worksasbooleanor
FROM min_max_functions;
emp | worksasbooleanand | worksasbooleanor
------+-------------------+------------------
emp1 | f | t
(1 row)
See also
6.2.18 - MEDIAN [analytic]
For each row, returns the median value of a value set within each partition.
For each row, returns the median value of a value set within each partition. MEDIAN determines the argument with the highest numeric precedence, implicitly converts the remaining arguments to that data type, and returns that data type.
MEDIAN is an alias of
PERCENTILE_CONT [analytic] with an argument of 0.5 (50%).
Behavior type
Immutable
Syntax
MEDIAN ( expression ) OVER ( [ window-partition-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the middle value or an interpolated value that would be the middle value once the values are sorted. Null values are ignored in the calculation.
OVER()- If the
OVER clause specifies window-partition-clause, MEDIAN groups input rows according to one or more columns or expressions. If this clause is omitted, no grouping occurs and MEDIAN processes all input rows as a single partition.
Examples
See Calculating a median value
See also
6.2.19 - MIN [analytic]
Returns the minimum value of an expression within a.
Returns the minimum value of an expression within a window. The return value has the same type as the expression data type.
The analytic functions MIN() and MAX() can operate with Boolean values. The MAX() function acts upon a Boolean data type or a value that can be implicitly converted to a Boolean value. If at least one input value is true, MAX() returns t (true). Otherwise, it returns f (false). In the same scenario, the MIN() function returns t (true) if all input values are true. Otherwise, it returns f.
Behavior type
Immutable
Syntax
MIN ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any expression for which the minimum value is calculated, typically a column reference.
OVER()- See Analytic Functions.
Examples
The following example shows how you can query to determine the deviation between the employees' annual salary and the minimum annual salary in Massachusetts:
=> SELECT employee_state, annual_salary,
MIN(annual_salary)
OVER(PARTITION BY employee_state ORDER BY employee_key) min,
annual_salary- MIN(annual_salary)
OVER(PARTITION BY employee_state ORDER BY employee_key) diff
FROM employee_dimension
WHERE employee_state = 'MA';
employee_state | annual_salary | min | diff
----------------+---------------+------+------
MA | 1918 | 1204 | 714
MA | 2058 | 1204 | 854
MA | 2586 | 1204 | 1382
MA | 2500 | 1204 | 1296
MA | 1318 | 1204 | 114
MA | 2072 | 1204 | 868
MA | 2656 | 1204 | 1452
MA | 2148 | 1204 | 944
MA | 2366 | 1204 | 1162
MA | 2664 | 1204 | 1460
(10 rows)
The following example shows you the difference between the MIN and MAX analytic functions when you use them with a Boolean value. The sample creates a table with two columns, adds two rows of data, and shows sample output for MIN and MAX.
CREATE TABLE min_max_functions (emp VARCHAR, torf BOOL);
INSERT INTO min_max_functions VALUES ('emp1', 1);
INSERT INTO min_max_functions VALUES ('emp1', 0);
SELECT DISTINCT emp,
min(torf) OVER (PARTITION BY emp) AS worksasbooleanand,
Max(torf) OVER (PARTITION BY emp) AS worksasbooleanor
FROM min_max_functions;
emp | worksasbooleanand | worksasbooleanor
------+-------------------+------------------
emp1 | f | t
(1 row)
See also
6.2.20 - NTH_VALUE [analytic]
Returns the value evaluated at the row that is the nth row of the window (counting from 1).
Returns the value evaluated at the row that is the *n*th row of the window (counting from 1). If the specified row does not exist, NTH_VALUE returns NULL.
Behavior type
Immutable
Syntax
NTH_VALUE ( expression, row-number [ IGNORE NULLS ] ) OVER (
[ window-frame-clause ]
[ window-order-clause ])
Parameters
expression- Expression to evaluate. The expression can be a constant, column name, nonanalytic function, function expression, or expressions that include any of these.
row-number- Specifies the row to evaluate, where
row-number evaluates to an integer ≥ 1.
IGNORE NULLS- Specifies to return the first non-
NULL value in the set, or NULL if all values are NULL.
OVER()- See Analytic Functions.
Examples
In the following example, for each tuple (current row) in table t1, the window frame clause defines the window as follows:
ORDER BY b ROWS BETWEEN 3 PRECEDING AND CURRENT ROW
For each window, n for *n*th value is a+1. a is the value of column a in the tuple.
NTH_VALUE returns the result of the expression b+1, where b is the value of column b in the *n*th row, which is the a+1 row within the window.
=> SELECT * FROM t1 ORDER BY a;
a | b
---+----
1 | 10
2 | 20
2 | 21
3 | 30
4 | 40
5 | 50
6 | 60
(7 rows)
=> SELECT NTH_VALUE(b+1, a+1) OVER
(ORDER BY b ROWS BETWEEN 3 PRECEDING AND CURRENT ROW) FROM t1;
?column?
----------
22
31
(7 rows)
6.2.21 - NTILE [analytic]
Equally divides an ordered data set (partition) into a {value} number of subsets within a , where the subsets are numbered 1 through the value in parameter constant-value.
Equally divides an ordered data set (partition) into a {value} number of subsets within a window, where the subsets are numbered 1 through the value in parameter constant-value. For example, if constant-value= 4 and the partition contains 20 rows, NTILE divides the partition rows into four equal subsets of five rows. NTILE assigns each row to a subset by giving row a number from 1 to 4. The rows in the first subset are assigned 1, the next five are assigned 2, and so on.
If the number of partition rows is not evenly divisible by the number of subsets, the rows are distributed so no subset is more than one row larger than any other subset, and the lowest subsets have extra rows. For example, if constant-value= 4 and the number of rows = 21, the first subset has six rows, the second subset has five rows, and so on.
If the number of subsets is greater than the number of rows, then a number of subsets equal to the number of rows is filled, and the remaining subsets are empty.
Behavior type
Immutable
Syntax
NTILE ( constant-value ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
constant-value- Specifies the number of subsets , where
constant-value must resolve to a positive constant for each partition.
OVER()- See Analytic Functions.
Examples
The following query assigns each month's sales total into one of four subsets:
=> SELECT calendar_month_name AS MONTH, SUM(sales_quantity),
NTILE(4) OVER (ORDER BY SUM(sales_quantity)) AS NTILE
FROM store.store_sales_fact JOIN date_dimension
USING(date_key)
GROUP BY calendar_month_name
ORDER BY NTILE;
MONTH | SUM | NTILE
-----------+---------+-------
November | 2040726 | 1
June | 2088528 | 1
February | 2134708 | 1
April | 2181767 | 2
January | 2229220 | 2
October | 2316363 | 2
September | 2323914 | 3
March | 2354409 | 3
August | 2387017 | 3
July | 2417239 | 4
May | 2492182 | 4
December | 2531842 | 4
(12 rows)
See also
6.2.22 - PERCENT_RANK [analytic]
Calculates the relative rank of a row for a given row in a group within a by dividing that row’s rank less 1 by the number of rows in the partition, also less 1.
Calculates the relative rank of a row for a given row in a group within a window by dividing that row’s rank less 1 by the number of rows in the partition, also less 1. PERCENT_RANK always returns values from 0 to 1 inclusive. The first row in any set has a PERCENT_RANK of 0. The return value is NUMBER.
( rank - 1 ) / ( [ rows ] - 1 )
In the preceding formula, rank is the rank position of a row in the group and rows is the total number of rows in the partition defined by the OVER() clause.
Behavior type
Immutable
Syntax
PERCENT_RANK ( ) OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
OVER()- See Analytic Functions
Examples
The following example finds the percent rank of gross profit for different states within each month of the first quarter:
=> SELECT calendar_month_name AS MONTH, store_state,
SUM(gross_profit_dollar_amount),
PERCENT_RANK() OVER (PARTITION BY calendar_month_name
ORDER BY SUM(gross_profit_dollar_amount)) AS PERCENT_RANK
FROM store.store_sales_fact JOIN date_dimension
USING(date_key)
JOIN store.store_dimension
USING (store_key)
WHERE calendar_month_name IN ('January','February','March')
AND store_state IN ('OR','IA','DC','NV','WI')
GROUP BY calendar_month_name, store_state
ORDER BY calendar_month_name, PERCENT_RANK;
MONTH | store_state | SUM | PERCENT_RANK
----------+-------------+--------+--------------
February | IA | 418490 | 0
February | OR | 460588 | 0.25
February | DC | 616553 | 0.5
February | WI | 619204 | 0.75
February | NV | 838039 | 1
January | OR | 446528 | 0
January | IA | 474501 | 0.25
January | DC | 628496 | 0.5
January | WI | 679382 | 0.75
January | NV | 871824 | 1
March | IA | 460282 | 0
March | OR | 481935 | 0.25
March | DC | 716063 | 0.5
March | WI | 771575 | 0.75
March | NV | 970878 | 1
(15 rows)
The following example calculates, for each employee, the percent rank of the employee's salary by their job title:
=> SELECT job_title, employee_last_name, annual_salary,
PERCENT_RANK()
OVER (PARTITION BY job_title ORDER BY annual_salary DESC) AS percent_rank
FROM employee_dimension
ORDER BY percent_rank, annual_salary;
job_title | employee_last_name | annual_salary | percent_rank
--------------------+--------------------+---------------+---------------------
Cashier | Fortin | 3196 | 0
Delivery Person | Garnett | 3196 | 0
Cashier | Vogel | 3196 | 0
Customer Service | Sanchez | 3198 | 0
Shelf Stocker | Jones | 3198 | 0
Custodian | Li | 3198 | 0
Customer Service | Kramer | 3198 | 0
Greeter | McNulty | 3198 | 0
Greeter | Greenwood | 3198 | 0
Shift Manager | Miller | 99817 | 0
Advertising | Vu | 99853 | 0
Branch Manager | Jackson | 99858 | 0
Marketing | Taylor | 99928 | 0
Assistant Director | King | 99973 | 0
Sales | Kramer | 99973 | 0
Head of PR | Goldberg | 199067 | 0
Regional Manager | Gauthier | 199744 | 0
Director of HR | Moore | 199896 | 0
Head of Marketing | Overstreet | 199955 | 0
VP of Advertising | Meyer | 199975 | 0
VP of Sales | Sanchez | 199992 | 0
Founder | Gauthier | 927335 | 0
CEO | Taylor | 953373 | 0
Investor | Garnett | 963104 | 0
Co-Founder | Vu | 977716 | 0
CFO | Vogel | 983634 | 0
President | Sanchez | 992363 | 0
Delivery Person | Li | 3194 | 0.00114155251141553
Delivery Person | Robinson | 3194 | 0.00114155251141553
Custodian | McCabe | 3192 | 0.00126582278481013
Shelf Stocker | Moore | 3196 | 0.00128040973111396
Branch Manager | Moore | 99716 | 0.00186567164179104
...
See also
6.2.23 - PERCENTILE_CONT [analytic]
An inverse distribution function where, for each row, PERCENTILE_CONT returns the value that would fall into the specified percentile among a set of values in each partition within a.
An inverse distribution function where, for each row, PERCENTILE_CONT returns the value that would fall into the specified percentile among a set of values in each partition within a window. For example, if the argument to the function is 0.5, the result of the function is the median of the data set (50th percentile). PERCENTILE_CONT assumes a continuous distribution data model. NULL values are ignored.
PERCENTILE_CONT computes the percentile by first computing the row number where the percentile row would exist. For example:
row-number = 1 + percentile-value * (num-partition-rows -1)
If row-number is a whole number (within an error of 0.00001), the percentile is the value of row row-number.
Otherwise, Vertica interpolates the percentile value between the value of the CEILING(row-number) row and the value of the FLOOR(row-number) row. In other words, the percentile is calculated as follows:
( CEILING( row-number) - row-number ) * ( value of FLOOR(row-number) row )
+ ( row-number - FLOOR(row-number) ) * ( value of CEILING(row-number) row)
Note
If the percentile value is 0.5, PERCENTILE_CONT returns the same result set as the function
MEDIAN.
Behavior type
Immutable
Syntax
PERCENTILE_CONT ( percentile ) WITHIN GROUP ( ORDER BY expression [ ASC | DESC ] ) OVER ( [ window-partition-clause ] )
Parameters
percentile- Percentile value, a FLOAT constant that ranges from 0 to 1 (inclusive).
WITHIN GROUP (ORDER BY expression)- Specifies how to sort data within each group. ORDER BY takes only one column/expression that must be INTEGER, FLOAT, INTERVAL, or NUMERIC data type. NULL values are discarded.
The WITHIN GROUP(ORDER BY) clause does not guarantee the order of the SQL result. To order the final result , use the SQL ORDER BY clause set.
ASC | DESC- Specifies the ordering sequence as ascending (default) or descending.
Specifying ASC or DESC in the WITHIN GROUP clause affects results as long as the percentile is not 0.5.
OVER()- See Analytic Functions
Examples
This query computes the median annual income per group for the first 300 customers in Wisconsin and the District of Columbia.
=> SELECT customer_state, customer_key, annual_income, PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY annual_income)
OVER (PARTITION BY customer_state) AS PERCENTILE_CONT
FROM customer_dimension WHERE customer_state IN ('DC','WI') AND customer_key < 300
ORDER BY customer_state, customer_key;
customer_state | customer_key | annual_income | PERCENTILE_CONT
----------------+--------------+---------------+-----------------
DC | 52 | 168312 | 483266.5
DC | 118 | 798221 | 483266.5
WI | 62 | 283043 | 377691
WI | 139 | 472339 | 377691
(4 rows)
This query computes the median annual income per group for all customers in Wisconsin and the District of Columbia.
=> SELECT customer_state, customer_key, annual_income, PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY annual_income)
OVER (PARTITION BY customer_state) AS PERCENTILE_CONT
FROM customer_dimension WHERE customer_state IN ('DC','WI') ORDER BY customer_state, customer_key;
customer_state | customer_key | annual_income | PERCENTILE_CONT
----------------+--------------+---------------+-----------------
DC | 52 | 168312 | 483266.5
DC | 118 | 798221 | 483266.5
DC | 622 | 220782 | 555088
DC | 951 | 178453 | 555088
DC | 972 | 961582 | 555088
DC | 1286 | 760445 | 555088
DC | 1434 | 44836 | 555088
...
WI | 62 | 283043 | 377691
WI | 139 | 472339 | 377691
WI | 359 | 42242 | 517717
WI | 364 | 867543 | 517717
WI | 403 | 509031 | 517717
WI | 455 | 32000 | 517717
WI | 485 | 373129 | 517717
...
(1353 rows)
See also
6.2.24 - PERCENTILE_DISC [analytic]
An inverse distribution function where, for each row, PERCENTILE_DISC returns the value that would fall into the specified percentile among a set of values in each partition within a.
An inverse distribution function where, for each row, PERCENTILE_DISC returns the value that would fall into the specified percentile among a set of values in each partition within a window. PERCENTILE_DISC() assumes a discrete distribution data model. NULL values are ignored.
PERCENTILE_DISC examines the cumulative distribution values in each group until it finds one that is greater than or equal to the specified percentile. Vertica computes the percentile where, for each row, PERCENTILE_DISC outputs the first value of the WITHIN GROUP(ORDER BY) column whose CUME_DIST (cumulative distribution) value is >= the argument FLOAT value—for example, 0.4:
PERCENTILE_DIST(0.4) WITHIN GROUP (ORDER BY salary) OVER(PARTITION BY deptno)...
Given the following query:
SELECT CUME_DIST() OVER(ORDER BY salary) FROM table-name;
The smallest CUME_DIST value that is greater than 0.4 is also the PERCENTILE_DISC.
Behavior type
Immutable
Syntax
PERCENTILE_DISC ( percentile ) WITHIN GROUP (
ORDER BY expression [ ASC | DESC ] ) OVER (
[ window-partition-clause ] )
Parameters
percentile- Percentile value, a
FLOAT constant that ranges from 0 to 1 (inclusive).
WITHIN GROUP(ORDER BY expression)- Specifies how to sort data within each group.
ORDER BY takes only one column/expression that must be INTEGER, FLOAT, INTERVAL, or NUMERIC data type. NULL values are discarded.
The WITHIN GROUP(ORDER BY) clause does not guarantee the order of the SQL result. To order the final result , use the SQL
ORDER BY clause set.
ASC | DESC- Specifies the ordering sequence as ascending (default) or descending.
OVER()- See Analytic Functions
Examples
This query computes the 20th percentile annual income by group for first 300 customers in Wisconsin and the District of Columbia.
=> SELECT customer_state, customer_key, annual_income,
PERCENTILE_DISC(.2) WITHIN GROUP(ORDER BY annual_income)
OVER (PARTITION BY customer_state) AS PERCENTILE_DISC
FROM customer_dimension
WHERE customer_state IN ('DC','WI')
AND customer_key < 300
ORDER BY customer_state, customer_key;
customer_state | customer_key | annual_income | PERCENTILE_DISC
----------------+--------------+---------------+-----------------
DC | 104 | 658383 | 417092
DC | 168 | 417092 | 417092
DC | 245 | 670205 | 417092
WI | 106 | 227279 | 227279
WI | 127 | 703889 | 227279
WI | 209 | 458607 | 227279
(6 rows)
See also
6.2.25 - RANK [analytic]
Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause.
Within each window partition, ranks all rows in the query results set according to the order specified by the window's ORDER BY clause.
RANK executes as follows:
-
Sorts partition rows as specified by the ORDER BY clause.
-
Compares the ORDER BY values of the preceding row and current row and ranks the current row as follows:
-
If ORDER BY values are the same, the current row gets the same ranking as the preceding row.
Note
Null values are considered equal. For detailed information on how null values are sorted, see
NULL sort order.
-
If the ORDER BY values are different, DENSE_RANK increments or decrements the current row's ranking by 1, plus the number of consecutive duplicate values in the rows that precede it.
The largest rank value is the equal to the total number of rows returned by the query.
Behavior type
Immutable
Syntax
RANK() OVER (
[ window-partition-clause ]
window-order-clause )
Parameters
OVER()- See Analytic Functions
Compared with DENSE_RANK
RANK can leave gaps in the ranking sequence, while
DENSE_RANK does not.
Examples
The following query ranks by state all company customers that have been customers since 2007. In rows where the customer_since dates are the same, RANK assigns the rows equal ranking. When the customer_since date changes, RANK skips one or more rankings—for example, within CA, from 12 to 14, and from 17 to 19.
=> SELECT customer_state, customer_name, customer_since,
RANK() OVER (PARTITION BY customer_state ORDER BY customer_since) AS rank
FROM customer_dimension WHERE customer_type='Company' AND customer_since > '01/01/2007'
ORDER BY customer_state;
customer_state | customer_name | customer_since | rank
----------------+---------------+----------------+------
AZ | Foodshop | 2007-01-20 | 1
AZ | Goldstar | 2007-08-11 | 2
CA | Metahope | 2007-01-05 | 1
CA | Foodgen | 2007-02-05 | 2
CA | Infohope | 2007-02-09 | 3
CA | Foodcom | 2007-02-19 | 4
CA | Amerihope | 2007-02-22 | 5
CA | Infostar | 2007-03-05 | 6
CA | Intracare | 2007-03-14 | 7
CA | Infocare | 2007-04-07 | 8
...
CO | Goldtech | 2007-02-19 | 1
CT | Foodmedia | 2007-02-11 | 1
CT | Metatech | 2007-02-20 | 2
CT | Infocorp | 2007-04-10 | 3
...
See also
SQL analytics
6.2.26 - ROW_NUMBER [analytic]
Assigns a sequence of unique numbers to each row in a partition, starting with 1.
Assigns a sequence of unique numbers to each row in a window partition, starting with 1. ROW_NUMBER and RANK are generally interchangeable, with the following differences:
-
ROW_NUMBER assigns a unique ordinal number to each row in the ordered set, starting with 1.
-
ROW_NUMBER() is a Vertica extension, while RANK conforms to the SQL-99 standard.
Behavior type
Immutable
Syntax
ROW_NUMBER () OVER (
[ window-partition-clause ]
[ window-order-clause ] )
Parameters
OVER()- See Analytic Functions
Examples
The following ROW_NUMBER query partitions customers in the VMart table customer_dimension by customer_region. Within each partition, the function ranks those customers in order of seniority, as specified by its window order clause:
=> SELECT * FROM
(SELECT ROW_NUMBER() OVER (PARTITION BY customer_region ORDER BY customer_since) AS most_senior,
customer_region, customer_name, customer_since FROM public.customer_dimension WHERE customer_type = 'Individual') sq
WHERE most_senior <= 5;
most_senior | customer_region | customer_name | customer_since
-------------+-----------------+----------------------+----------------
1 | West | Jack Y. Perkins | 1965-01-01
2 | West | Linda Q. Winkler | 1965-01-02
3 | West | Marcus K. Li | 1965-01-03
4 | West | Carla R. Jones | 1965-01-07
5 | West | Seth P. Young | 1965-01-09
1 | East | Kim O. Vu | 1965-01-01
2 | East | Alexandra L. Weaver | 1965-01-02
3 | East | Steve L. Webber | 1965-01-04
4 | East | Thom Y. Li | 1965-01-05
5 | East | Martha B. Farmer | 1965-01-07
1 | SouthWest | Martha V. Gauthier | 1965-01-01
2 | SouthWest | Jessica U. Goldberg | 1965-01-07
3 | SouthWest | Robert O. Stein | 1965-01-07
4 | SouthWest | Emily I. McCabe | 1965-01-18
5 | SouthWest | Jack E. Miller | 1965-01-25
1 | NorthWest | Julie O. Greenwood | 1965-01-08
2 | NorthWest | Amy X. McNulty | 1965-01-25
3 | NorthWest | Kevin S. Carcetti | 1965-02-09
4 | NorthWest | Sam K. Carcetti | 1965-03-16
5 | NorthWest | Alexandra X. Winkler | 1965-04-05
1 | MidWest | Michael Y. Meyer | 1965-01-01
2 | MidWest | Joanna W. Bauer | 1965-01-06
3 | MidWest | Amy E. Harris | 1965-01-08
4 | MidWest | Julie W. McCabe | 1965-01-09
5 | MidWest | William . Peterson | 1965-01-09
1 | South | Dean . Martin | 1965-01-01
2 | South | Ruth U. Williams | 1965-01-02
3 | South | Steve Y. Farmer | 1965-01-03
4 | South | Mark V. King | 1965-01-08
5 | South | Lucas Y. Young | 1965-01-10
(30 rows)
See also
6.2.27 - STDDEV [analytic]
Computes the statistical sample standard deviation of the current row with respect to the group within a.
Computes the statistical sample standard deviation of the current row with respect to the group within a window. STDDEV_SAMP returns the same value as the square root of the variance defined for the
VAR_SAMP function:
STDDEV( expression ) = SQRT(VAR_SAMP( expression ))
When VAR_SAMP returns NULL, this function returns NULL.
Note
The nonstandard function
STDDEV is provided for compatibility with other databases. It is semantically identical to
STDDEV_SAMP.
Behavior type
Immutable
Syntax
STDDEV ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
OVER()- See Analytic Functions
Examples
The following example returns the standard deviations of salaries in the employee dimension table by job title Assistant Director:
=> SELECT employee_last_name, annual_salary,
STDDEV(annual_salary) OVER (ORDER BY hire_date) as "stddev"
FROM employee_dimension
WHERE job_title = 'Assistant Director';
employee_last_name | annual_salary | stddev
--------------------+---------------+------------------
Bauer | 85003 | NaN
Reyes | 91051 | 4276.58181261624
Overstreet | 53296 | 20278.6923394976
Gauthier | 97216 | 19543.7184537642
Jones | 82320 | 16928.0764028285
Fortin | 56166 | 18400.2738421652
Carcetti | 71135 | 16968.9453554483
Weaver | 74419 | 15729.0709901852
Stein | 85689 | 15040.5909495309
McNulty | 69423 | 14401.1524291943
Webber | 99091 | 15256.3160166536
Meyer | 74774 | 14588.6126417355
Garnett | 82169 | 14008.7223268494
Roy | 76974 | 13466.1270356647
Dobisz | 83486 | 13040.4887828347
Martin | 99702 | 13637.6804131055
Martin | 73589 | 13299.2838158566
...
See also
6.2.28 - STDDEV_POP [analytic]
Evaluates the statistical population standard deviation for each member of the group.
Computes the statistical population standard deviation and returns the square root of the population variance within a window. The STDDEV_POP() return value is the same as the square root of the VAR_POP() function:
STDDEV_POP( expression ) = SQRT(VAR_POP( expression ))
When VAR_POP returns null, STDDEV_POP returns null.
Behavior type
Immutable
Syntax
STDDEV_POP ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
OVER()- See Analytic Functions.
Examples
The following example returns the population standard deviations of salaries in the employee dimension table by job title Assistant Director:
=> SELECT employee_last_name, annual_salary,
STDDEV_POP(annual_salary) OVER (ORDER BY hire_date) as "stddev_pop"
FROM employee_dimension WHERE job_title = 'Assistant Director';
employee_last_name | annual_salary | stddev_pop
--------------------+---------------+------------------
Goldberg | 61859 | 0
Miller | 79582 | 8861.5
Goldberg | 74236 | 7422.74712548456
Campbell | 66426 | 6850.22125098891
Moore | 66630 | 6322.08223926257
Nguyen | 53530 | 8356.55480080699
Harris | 74115 | 8122.72288970008
Lang | 59981 | 8053.54776538731
Farmer | 60597 | 7858.70140687825
Nguyen | 78941 | 8360.63150784682
See also
6.2.29 - STDDEV_SAMP [analytic]
Computes the statistical sample standard deviation of the current row with respect to the group within a.
Computes the statistical sample standard deviation of the current row with respect to the group within a window. STDDEV_SAM's return value is the same as the square root of the variance defined for the VAR_SAMP function:
STDDEV( expression ) = SQRT(VAR_SAMP( expression ))
When VAR_SAMP returns NULL, STDDEV_SAMP returns NULL.
Note
STDDEV_SAMP() is semantically identical to the nonstandard function,
STDDEV().
Behavior type
Immutable
Syntax
STDDEV_SAMP ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument..
OVER()- See Analytic Functions
Examples
The following example returns the sample standard deviations of salaries in the employee dimension table by job title Assistant Director:
=> SELECT employee_last_name, annual_salary,
STDDEV(annual_salary) OVER (ORDER BY hire_date) as "stddev_samp"
FROM employee_dimension WHERE job_title = 'Assistant Director';
employee_last_name | annual_salary | stddev_samp
--------------------+---------------+------------------
Bauer | 85003 | NaN
Reyes | 91051 | 4276.58181261624
Overstreet | 53296 | 20278.6923394976
Gauthier | 97216 | 19543.7184537642
Jones | 82320 | 16928.0764028285
Fortin | 56166 | 18400.2738421652
Carcetti | 71135 | 16968.9453554483
Weaver | 74419 | 15729.0709901852
Stein | 85689 | 15040.5909495309
McNulty | 69423 | 14401.1524291943
Webber | 99091 | 15256.3160166536
Meyer | 74774 | 14588.6126417355
Garnett | 82169 | 14008.7223268494
Roy | 76974 | 13466.1270356647
Dobisz | 83486 | 13040.4887828347
...
See also
6.2.30 - SUM [analytic]
Computes the sum of an expression over a group of rows within a.
Computes the sum of an expression over a group of rows within a window. It returns a DOUBLE PRECISION value for a floating-point expression. Otherwise, the return value is the same as the expression data type.
Behavior type
Immutable
Syntax
SUM ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
OVER()- See Analytic Functions
Overflow handling
If you encounter data overflow when using SUM, use
SUM_FLOAT which converts data to a floating point.
By default, Vertica allows silent numeric overflow when you call this function on numeric data types. For more information on this behavior and how to change it, seeNumeric data type overflow with SUM, SUM_FLOAT, and AVG.
Examples
The following query returns the cumulative sum all of the returns made to stores in January:
=> SELECT calendar_month_name AS month, transaction_type, sales_quantity,
SUM(sales_quantity)
OVER (PARTITION BY calendar_month_name ORDER BY date_dimension.date_key) AS SUM
FROM store.store_sales_fact JOIN date_dimension
USING(date_key) WHERE calendar_month_name IN ('January')
AND transaction_type= 'return';
month | transaction_type | sales_quantity | SUM
---------+------------------+----------------+------
January | return | 7 | 651
January | return | 3 | 651
January | return | 7 | 651
January | return | 7 | 651
January | return | 7 | 651
January | return | 3 | 651
January | return | 7 | 651
January | return | 5 | 651
January | return | 1 | 651
January | return | 6 | 651
January | return | 6 | 651
January | return | 3 | 651
January | return | 9 | 651
January | return | 7 | 651
January | return | 6 | 651
January | return | 8 | 651
January | return | 7 | 651
January | return | 2 | 651
January | return | 4 | 651
January | return | 5 | 651
January | return | 7 | 651
January | return | 8 | 651
January | return | 4 | 651
January | return | 10 | 651
January | return | 6 | 651
...
See also
6.2.31 - VAR_POP [analytic]
Returns the statistical population variance of a non-null set of numbers (nulls are ignored) in a group within a.
Returns the statistical population variance of a non-null set of numbers (nulls are ignored) in a group within a window. Results are calculated by the sum of squares of the difference of expression from the mean of expression, divided by the number of rows remaining:
(SUM( expression * expression ) - SUM( expression ) * SUM( expression ) / COUNT( expression )) / COUNT( expression )
Behavior type
Immutable
Syntax
VAR_POP ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument
OVER()- See Analytic Functions
Examples
The following example calculates the cumulative population in the store orders fact table of sales in January 2007:
=> SELECT date_ordered,
VAR_POP(SUM(total_order_cost))
OVER (ORDER BY date_ordered) "var_pop"
FROM store.store_orders_fact s
WHERE date_ordered BETWEEN '2007-01-01' AND '2007-01-31'
GROUP BY s.date_ordered;
date_ordered | var_pop
--------------+------------------
2007-01-01 | 0
2007-01-02 | 89870400
2007-01-03 | 3470302472
2007-01-04 | 4466755450.6875
2007-01-05 | 3816904780.80078
2007-01-06 | 25438212385.25
2007-01-07 | 22168747513.1016
2007-01-08 | 23445191012.7344
2007-01-09 | 39292879603.1113
2007-01-10 | 48080574326.9609
(10 rows)
See also
6.2.32 - VAR_SAMP [analytic]
Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a.
Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a window. Results are calculated as follows:
(SUM( expression * expression ) - SUM( expression ) * SUM( expression ) / COUNT( expression ) )
/ (COUNT( expression ) - 1 )
This function and
VARIANCE differ in one way: given an input set of one element, VARIANCE returns 0 and VAR_SAMP returns NULL.
Behavior type
Immutable
Syntax
VAR_SAMP ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any
NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument
OVER()- See Analytic Functions
Null handling
-
VAR_SAMP returns the sample variance of a set of numbers after it discards the NULL values in the set.
-
If the function is applied to an empty set, then it returns NULL.
Examples
The following example calculates the sample variance in the store orders fact table of sales in December 2007:
=> SELECT date_ordered,
VAR_SAMP(SUM(total_order_cost))
OVER (ORDER BY date_ordered) "var_samp"
FROM store.store_orders_fact s
WHERE date_ordered BETWEEN '2007-12-01' AND '2007-12-31'
GROUP BY s.date_ordered;
date_ordered | var_samp
--------------+------------------
2007-12-01 | NaN
2007-12-02 | 90642601088
2007-12-03 | 48030548449.3359
2007-12-04 | 32740062504.2461
2007-12-05 | 32100319112.6992
2007-12-06 | 26274166814.668
2007-12-07 | 23017490251.9062
2007-12-08 | 21099374085.1406
2007-12-09 | 27462205977.9453
2007-12-10 | 26288687564.1758
(10 rows)
See also
6.2.33 - VARIANCE [analytic]
Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a.
Returns the sample variance of a non-NULL set of numbers (NULL values in the set are ignored) for each row of the group within a window. Results are calculated as follows:
( SUM( expression * expression ) - SUM( expression ) * SUM( expression ) / COUNT( expression )) / (COUNT( expression ) - 1 )
VARIANCE returns the variance of expression, which is calculated as follows:
Note
The nonstandard function
VARIANCE is provided for compatibility with other databases. It is semantically identical to
VAR_SAMP.
Behavior type
Immutable
Syntax
VAR_SAMP ( expression ) OVER (
[ window-partition-clause ]
[ window-order-clause ]
[ window-frame-clause ] )
Parameters
expression- Any NUMERIC data type or any non-numeric data type that can be implicitly converted to a numeric data type. The function returns the same data type as the numeric data type of the argument.
OVER()- See Analytic Functions
Examples
The following example calculates the cumulative variance in the store orders fact table of sales in December 2007:
=> SELECT date_ordered,
VARIANCE(SUM(total_order_cost))
OVER (ORDER BY date_ordered) "variance"
FROM store.store_orders_fact s
WHERE date_ordered BETWEEN '2007-12-01' AND '2007-12-31'
GROUP BY s.date_ordered;
date_ordered | variance
--------------+------------------
2007-12-01 | NaN
2007-12-02 | 2259129762
2007-12-03 | 1809012182.33301
2007-12-04 | 35138165568.25
2007-12-05 | 26644110029.3003
2007-12-06 | 25943125234
2007-12-07 | 23178202223.9048
2007-12-08 | 21940268901.1431
2007-12-09 | 21487676799.6108
2007-12-10 | 21521358853.4331
(10 rows)
See also
6.3 - Client connection functions
This section contains client connection management functions specific to Vertica.
This section contains client connection management functions specific to Vertica.
6.3.1 - CLOSE_ALL_RESULTSETS
Closes all result set sessions within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets.
Closes all result set sessions within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SELECT CLOSE_ALL_RESULTSETS ('session_id')
Parameters
session_id- A string that specifies the Multiple Active Result Sets session.
Privileges
None; however, without superuser privileges, you can only close your own session's results.
Examples
This example shows how you can view a MARS result set, then close the result set, and then confirm that the result set has been closed.
Query the MARS storage table. One session ID is open and three result sets appear in the output.
=> SELECT * FROM SESSION_MARS_STORE;
node_name | session_id | user_name | resultset_id | row_count | remaining_row_count | bytes_used
------------------+-----------------------------------+-----------+--------------+-----------+---------------------+------------
v_vmart_node0001 | server1.company.-83046:1y28gu9 | dbadmin | 7 | 777460 | 776460 | 89692848
v_vmart_node0001 | server1.company.-83046:1y28gu9 | dbadmin | 8 | 324349 | 323349 | 81862010
v_vmart_node0001 | server1.company.-83046:1y28gu9 | dbadmin | 9 | 277947 | 276947 | 32978280
(1 row)
Close all result sets for session server1.company.-83046:1y28gu9:
=> SELECT CLOSE_ALL_RESULTSETS('server1.company.-83046:1y28gu9');
close_all_resultsets
-------------------------------------------------------------
Closing all result sets from server1.company.-83046:1y28gu9
(1 row)
Query the MARS storage table again for the current status. You can see that the session and result sets have been closed:
=> SELECT * FROM SESSION_MARS_STORE;
node_name | session_id | user_name | resultset_id | row_count | remaining_row_count | bytes_used
------------------+-----------------------------------+-----------+--------------+-----------+---------------------+------------
(0 rows)
6.3.2 - CLOSE_RESULTSET
Closes a specific result set within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets.
Closes a specific result set within Multiple Active Result Sets (MARS) and frees the MARS storage for other result sets.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SELECT CLOSE_RESULTSET ('session_id', ResultSetID)
Parameters
session_id- A string that specifies the Multiple Active Result Sets session containing the ResultSetID to close.
ResultSetID- An integer that specifies which result set to close.
Privileges
None; however, without superuser privileges, you can only close your own session's results.
Examples
This example shows a MARS storage table opened. One session_id is currently open, and one result set appears in the output.
=> SELECT * FROM SESSION_MARS_STORE;
node_name | session_id | user_name | resultset_id | row_count | remaining_row_count | bytes_used
------------------+-----------------------------------+-----------+--------------+-----------+---------------------+------------
v_vmart_node0001 | server1.company.-83046:1y28gu9 | dbadmin | 1 | 318718 | 312718 | 80441904
(1 row)
Close user session server1.company.-83046:1y28gu9 and result set 1:
=> SELECT CLOSE_RESULTSET('server1.company.-83046:1y28gu9', 1);
close_resultset
-------------------------------------------------------------
Closing result set 1 from server1.company.-83046:1y28gu9
(1 row)
Query the MARS storage table again for current status. You can see that result set 1 is now closed:
SELECT * FROM SESSION_MARS_STORE;
node_name | session_id | user_name | resultset_id | row_count | remaining_row_count | bytes_used
------------------+-----------------------------------+-----------+--------------+-----------+---------------------+------------
(0 rows)
6.3.3 - DESCRIBE_LOAD_BALANCE_DECISION
Evaluates if any load balancing routing rules apply to a given IP address and This function is useful when you are evaluating connection load balancing policies you have created, to ensure they work the way you expect them to.
Evaluates if any load balancing routing rules apply to a given IP address and describes how the client connection would be handled. This function is useful when you are evaluating connection load balancing policies you have created, to ensure they work the way you expect them to.
You pass this function an IP address of a client connection, and it uses the load balancing routing rules to determine how the connection will be handled. The logic this function uses is the same logic used when Vertica load balances client connections, including determining which nodes are available to handle the client connection.
This function assumes the client connection has opted into being load balanced. If actual clients have not opted into load balancing, the connections will not be redirected. See Load balancing in ADO.NET, Load balancing in JDBC, and Load balancing, for information on enabling load balancing on the client. For vsql, use the -C command-line option to enable load balancing.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESCRIBE_LOAD_BALANCE_DECISION('ip_address')
Arguments
'ip_address'- An IP address of a client connection to be tested against the load balancing rules. This can be either an IPv4 or IPv6 address.
Return value
A step-by-step description of how the load balancing rules are being evaluated, including the final decision of which node in the database has been chosen to service the connection.
Privileges
None.
Examples
The following example demonstrates calling DESCRIBE_LOAD_BALANCE_DECISION with three different IP addresses, two of which are handled by different routing rules, and one which is not handled by any rule.
=> SELECT describe_load_balance_decision('192.168.1.25');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [192.168.1.25]
Load balance cache internal version id (node-local): [2]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address matches this rule
Matched to load balance group [group_1] the group has policy [ROUNDROBIN]
number of addresses [2]
(0) LB Address: [10.20.100.247]:5433
(1) LB Address: [10.20.100.248]:5433
Chose address at position [1]
Routing table decision: Success. Load balance redirect to: [10.20.100.248] port [5433]
(1 row)
=> SELECT describe_load_balance_decision('192.168.2.25');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [192.168.2.25]
Load balance cache internal version id (node-local): [2]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address does not match source ip filter for this rule.
Considered rule [subnet_192] source ip filter [192.0.0.0/8]... input address
matches this rule
Matched to load balance group [group_all] the group has policy [ROUNDROBIN]
number of addresses [3]
(0) LB Address: [10.20.100.247]:5433
(1) LB Address: [10.20.100.248]:5433
(2) LB Address: [10.20.100.249]:5433
Chose address at position [1]
Routing table decision: Success. Load balance redirect to: [10.20.100.248] port [5433]
(1 row)
=> SELECT describe_load_balance_decision('1.2.3.4');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [1.2.3.4]
Load balance cache internal version id (node-local): [2]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address does not match source ip filter for this rule.
Considered rule [subnet_192] source ip filter [192.0.0.0/8]... input address
does not match source ip filter for this rule.
Routing table decision: No matching routing rules: input address does not match
any routing rule source filters. Details: [Tried some rules but no matching]
No rules matched. Falling back to classic load balancing.
Classic load balance decision: Classic load balancing considered, but either
the policy was NONE or no target was available. Details: [NONE or invalid]
(1 row)
The following example demonstrates calling DESCRIBE_LOAD_BALANCE_DECISION repeatedly with the same IP address. You can see that the load balance group's ROUNDROBIN load balance policy has it switch between the two nodes in the load balance group:
=> SELECT describe_load_balance_decision('192.168.1.25');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [192.168.1.25]
Load balance cache internal version id (node-local): [1]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address matches this rule
Matched to load balance group [group_1] the group has policy [ROUNDROBIN]
number of addresses [2]
(0) LB Address: [10.20.100.247]:5433
(1) LB Address: [10.20.100.248]:5433
Chose address at position [1]
Routing table decision: Success. Load balance redirect to: [10.20.100.248]
port [5433]
(1 row)
=> SELECT describe_load_balance_decision('192.168.1.25');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [192.168.1.25]
Load balance cache internal version id (node-local): [1]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address matches this rule
Matched to load balance group [group_1] the group has policy [ROUNDROBIN]
number of addresses [2]
(0) LB Address: [10.20.100.247]:5433
(1) LB Address: [10.20.100.248]:5433
Chose address at position [0]
Routing table decision: Success. Load balance redirect to: [10.20.100.247]
port [5433]
(1 row)
=> SELECT describe_load_balance_decision('192.168.1.25');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [192.168.1.25]
Load balance cache internal version id (node-local): [1]
Considered rule [etl_rule] source ip filter [10.20.100.0/24]... input address
does not match source ip filter for this rule.
Considered rule [internal_clients] source ip filter [192.168.1.0/24]... input
address matches this rule
Matched to load balance group [group_1] the group has policy [ROUNDROBIN]
number of addresses [2]
(0) LB Address: [10.20.100.247]:5433
(1) LB Address: [10.20.100.248]:5433
Chose address at position [1]
Routing table decision: Success. Load balance redirect to: [10.20.100.248]
port [5433]
(1 row)
See also
6.3.4 - GET_CLIENT_LABEL
Returns the client connection label for the current session.
Returns the client connection label for the current session.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_CLIENT_LABEL()
Privileges
None
Examples
Return the current client connection label:
=> SELECT GET_CLIENT_LABEL();
GET_CLIENT_LABEL
-----------------------
data_load_application
(1 row)
See also
Setting a client connection label
6.3.5 - RESET_LOAD_BALANCE_POLICY
Resets the counter each host in the cluster maintains, to track which host it will refer a client to when the native connection load balancing scheme is set to ROUNDROBIN.
Resets the counter each host in the cluster maintains, to track which host it will refer a client to when the native connection load balancing scheme is set to ROUNDROBIN. To reset the counter, run this function on all cluster nodes.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESET_LOAD_BALANCE_POLICY()
Privileges
Superuser
Examples
=> SELECT RESET_LOAD_BALANCE_POLICY();
RESET_LOAD_BALANCE_POLICY
-------------------------------------------------------------------------
Successfully reset stateful client load balance policies: "roundrobin".
(1 row)
6.3.6 - SET_CLIENT_LABEL
Assigns a label to a client connection for the current session.
Assigns a label to a client connection for the current session. You can use this label to distinguish client connections.
Labels appear in the SESSIONS system table. However, only certain Data collector tables show new client labels set by SET_CLIENT_LABEL. For example, DC_REQUESTS_ISSUED reflects changes by SET_CLIENT_LABEL, while DC_SESSION_STARTS, which collects login data before SET_CLIENT_LABEL can be run, does not.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_CLIENT_LABEL('label-name')
Parameters
label-name- VARCHAR name assigned to the client connection label.
Privileges
None
Examples
Assign label data_load_application to the current client connection:
=> SELECT SET_CLIENT_LABEL('data_load_application');
SET_CLIENT_LABEL
-------------------------------------------
client_label set to data_load_application
(1 row)
See also
Setting a client connection label
6.3.7 - SET_LOAD_BALANCE_POLICY
Sets how native connection load balancing chooses a host to handle a client connection.
Sets how native connection load balancing chooses a host to handle a client connection.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_LOAD_BALANCE_POLICY('policy')
Parameters
policy - The name of the load balancing policy to use, one of the following:
-
NONE (default): Disables native connection load balancing.
-
ROUNDROBIN: Chooses the next host from a circular list of hosts in the cluster that are up—for example, in a three-node cluster, iterates over node1, node2, and node3, then wraps back to node1. Each host in the cluster maintains its own pointer to the next host in the circular list, rather than there being a single cluster-wide state.
-
RANDOM: Randomly chooses a host from among all hosts in the cluster that are up.
Note
Even if the load balancing policy is set on the server to something other than NONE, clients must indicate they want their connections to be load balanced by setting a connection property.
Privileges
Superuser
Examples
The following example demonstrates enabling native connection load balancing on the server by setting the load balancing scheme to ROUNDROBIN:
=> SELECT SET_LOAD_BALANCE_POLICY('ROUNDROBIN');
SET_LOAD_BALANCE_POLICY
--------------------------------------------------------------------------------
Successfully changed the client initiator load balancing policy to: roundrobin
(1 row)
See also
About native connection load balancing
6.4 - Data-type-specific functions
Vertica provides functions for use with specific data types, described in this section.
Vertica provides functions for use with specific data types, described in this section.
6.4.1 - Collection functions
The functions in this section apply to collection types (arrays and sets).
The functions in this section apply to collection types (arrays and sets).
Some functions apply aggregation operations (such as sum) to collections. These function names all begin with APPLY.
Other functions in this section operate specifically on arrays or sets, as indicated on the individual reference pages. Array functions operate on both native array values and array values in external tables.
Notes
-
Arrays are 0-indexed. The first element's ordinal position in 0, second is 1, and so on. Indexes are not meaningful for sets.
-
Unless otherwise stated, functions operate on one-dimensional (1D) collections only. To use multidimensional arrays, you must first dereference to a 1D array type. Sets can only be one-dimensional.
6.4.1.1 - APPLY_AVG
Returns the average of all elements in a with numeric values.
Returns the average of all elements in a collection (array or set) with numeric values.
Behavior type
Immutable
Syntax
APPLY_AVG(collection)
Arguments
collection- Target collection
Null-handling
The following cases return NULL:
-
if the input collection is NULL
-
if the input collection contains only null values
-
if the input collection is empty
If the input collection contains a mix of null and non-null elements, only the non-null values are considered in the calculation of the average.
Examples
=> SELECT apply_avg(ARRAY[1,2.4,5,6]);
apply_avg
-----------
3.6
(1 row)
See also
6.4.1.2 - APPLY_COUNT (ARRAY_COUNT)
Returns the total number of non-null elements in a.
Returns the total number of non-null elements in a collection (array or set). To count all elements including nulls, use APPLY_COUNT_ELEMENTS (ARRAY_LENGTH).
Behavior type
Immutable
Syntax
APPLY_COUNT(collection)
ARRAY_COUNT is a synonym of APPLY_COUNT.
Arguments
collection- Target collection
Null-handling
Null values are not included in the count.
Examples
The array in this example contains six elements, one of which is null:
=> SELECT apply_count(ARRAY[1,NULL,3,7,8,5]);
apply_count
-------------
5
(1 row)
6.4.1.3 - APPLY_COUNT_ELEMENTS (ARRAY_LENGTH)
Returns the total number of elements in a , including NULLs.
Returns the total number of elements in a collection (array or set), including NULLs. To count only non-null values, use APPLY_COUNT (ARRAY_COUNT).
Behavior type
Immutable
Syntax
APPLY_COUNT_ELEMENTS(collection)
ARRAY_LENGTH is a synonym of APPLY_COUNT_ELEMENTS.
Arguments
collection- Target collection
Null-handling
This function counts all members, including nulls.
An empty collection (ARRAY[] or SET[]) has a length of 0. A collection containing a single null (ARRAY[null] or SET[null]) has a length of 1.
Examples
The following array has six elements including one null:
=> SELECT apply_count_elements(ARRAY[1,NULL,3,7,8,5]);
apply_count_elements
---------------------
6
(1 row)
As the previous example shows, a null element is an element. Thus, an array containing only a null element has one element:
=> SELECT apply_count_elements(ARRAY[null]);
apply_count_elements
---------------------
1
(1 row)
A set does not contain duplicates. If you construct a set and pass it directly to this function, the result could differ from the number of inputs:
=> SELECT apply_count_elements(SET[1,1,3]);
apply_count_elements
---------------------
2
(1 row)
6.4.1.4 - APPLY_MAX
Returns the largest non-null element in a.
Returns the largest non-null element in a collection (array or set). This function is similar to the MAX [aggregate] function; APPLY_MAX operates on elements of a collection and MAX operates on an expression such as a column selection.
Behavior type
Immutable
Syntax
APPLY_MAX(collection)
Arguments
collection- Target collection
Null-handling
This function ignores null elements. If all elements are null or the collection is empty, this function returns null.
Examples
=> SELECT apply_max(ARRAY[1,3.4,15]);
apply_max
-----------
15.0
(1 row)
6.4.1.5 - APPLY_MIN
Returns the smallest non-null element in a.
Returns the smallest non-null element in a collection (array or set). This function is similar to the MIN [aggregate] function; APPLY_MIN operates on elements of a collection and MIN operates on an expression such as a column selection.
Behavior type
Immutable
Syntax
APPLY_MIN(collection)
Arguments
collection- Target collection
Null-handling
This function ignores null elements. If all elements are null or the collection is empty, this function returns null.
Examples
=> SELECT apply_min(ARRAY[1,3.4,15]);
apply_min
-----------
1.0
(1 row)
6.4.1.6 - APPLY_SUM
Computes the sum of all elements in a of numeric values (INTEGER, FLOAT, NUMERIC, or INTERVAL).
Computes the sum of all elements in a collection (array or set) of numeric values (INTEGER, FLOAT, NUMERIC, or INTERVAL).
Behavior type
Immutable
Syntax
APPLY_SUM(collection)
Arguments
collection- Target collection
Null-handling
The following cases return NULL:
-
if the input collection is NULL
-
if the input collection contains only null values
-
if the input collection is empty
Examples
=> SELECT apply_sum(ARRAY[12.5,3,4,1]);
apply_sum
-----------
20.5
(1 row)
See also
6.4.1.7 - ARRAY_CAT
Concatenates two arrays of the same element type and dimensionality.
Concatenates two arrays of the same element type and dimensionality. For example, ROW elements must have the same fields.
If the inputs are both bounded, the bound for the result is the sum of the bounds of the inputs.
If any input is unbounded, the result is unbounded with a binary size that is the sum of the sizes of the inputs.
Behavior type
Immutable
Syntax
ARRAY_CAT(array1,array2)
Arguments
array1, array2- Arrays of matching dimensionality and element type
Null-handling
If either input is NULL, the function returns NULL.
Examples
Types are coerced if necessary, as shown in the second example.
=> SELECT array_cat(ARRAY[1,2], ARRAY[3,4,5]);
array_cat
-----------------------
[1,2,3,4,5]
(1 row)
=> SELECT array_cat(ARRAY[1,2], ARRAY[3,4,5.0]);
array_cat
-----------------------
["1.0","2.0","3.0","4.0","5.0"]
(1 row)
6.4.1.8 - ARRAY_CONTAINS
Returns true if the specified element is found in the array and false if not.
Returns true if the specified element is found in the array and false if not. Both arguments must be non-null, but the array may be empty.
Deprecated
This function has been renamed to
CONTAINS.
6.4.1.9 - ARRAY_DIMS
Returns the dimensionality of the input array.
Returns the dimensionality of the input array.
Behavior type
Immutable
Syntax
ARRAY_DIMS(array)
Arguments
array- Target array
Examples
=> SELECT array_dims(ARRAY[[1,2],[2,3]]);
array_dims
------------
2
(1 row)
6.4.1.10 - ARRAY_FIND
Returns the ordinal position of a specified element in an array, or -1 if not found.
Returns the ordinal position of a specified element in an array, or -1 if not found. This function uses null-safe equality checks when testing elements.
Behavior type
Immutable
Syntax
ARRAY_FIND(array, { value | lambda-expression })
Arguments
array- Target array.
value- Value to search for; type must match or be coercible to the element type of the array.
lambda-expressionLambda function to apply to each element. The function must return a Boolean value. The first argument to the function is the element, and the optional second element is the index of the element.
Examples
The function returns the first occurrence of the specified element. However, nothing ensures that value is unique in the array:
=> SELECT array_find(ARRAY[1,2,7,5,7],7);
array_find
------------
2
(1 row)
The function returns -1 if the specified element is not found:
=> SELECT array_find(ARRAY[1,3,5,7],4);
array_find
------------
-1
(1 row)
You can search for complex element types:
=> SELECT ARRAY_FIND(ARRAY[ARRAY[1,2,3],ARRAY[1,null,4]],
ARRAY[1,2,3]);
ARRAY_FIND
------------
0
(1 row)
=> SELECT ARRAY_FIND(ARRAY[ARRAY[1,2,3],ARRAY[1,null,4]],
ARRAY[1,null,4]);
ARRAY_FIND
------------
1
(1 row)
The second example, comparing arrays with null elements, finds a match because ARRAY_FIND uses a null-safe equality check when evaluating elements.
Lambdas
Consider a table of departments where each department has an array of ROW elements representing employees. The following example searches for a specific employee name in those records. The results show that Alice works (or has worked) for two departments:
=> SELECT deptID, ARRAY_FIND(employees, e -> e.name = 'Alice Adams') AS 'has_alice'
FROM departments;
deptID | has_alice
--------+-----------
1 | 0
2 | -1
3 | 0
(3 rows)
In the following example, each person in the table has an array of email addresses, and the function locates fake addresses. The function takes one argument, the array element to test, and calls a regular-expression function that returns a Boolean:
=> SELECT name, ARRAY_FIND(email, e -> REGEXP_LIKE(e,'example.com','i'))
AS 'example.com'
FROM people;
name | example.com
----------------+-------------
Elaine Jackson | -1
Frank Adams | 0
Lee Jones | -1
M Smith | 0
(4 rows)
See also
6.4.1.11 - CONTAINS
Returns true if the specified element is found in the collection and false if not.
Returns true if the specified element is found in the collection and false if not. This function uses null-safe equality checks when testing elements.
Behavior type
Immutable
Syntax
CONTAINS(collection, { value | lambda-expression })
Arguments
collection- Target collection (ARRAY or SET).
value- Value to search for; type must match or be coercible to the element type of the collection.
lambda-expressionLambda function to apply to each element. The function must return a Boolean value. The first argument to the function is the element, and the optional second element is the index of the element.
Examples
=> SELECT CONTAINS(SET[1,2,3,4],2);
contains
----------
t
(1 row)
You can search for NULL as an element value:
=> SELECT CONTAINS(ARRAY[1,null,2],null);
contains
----------
t
(1 row)
You can search for complex element types:
=> SELECT CONTAINS(ARRAY[ARRAY[1,2,3],ARRAY[1,null,4]],
ARRAY[1,2,3]);
CONTAINS
----------
t
(1 row)
=> SELECT CONTAINS(ARRAY[ARRAY[1,2,3],ARRAY[1,null,4]],
ARRAY[1,null,4]);
CONTAINS
----------
t
(1 row)
The second example, comparing arrays with null elements, returns true because CONTAINS uses a null-safe equality check when evaluating elements.
In the following example, the orders table has the following definition:
=> CREATE EXTERNAL TABLE orders(
orderid int,
accountid int,
shipments Array[
ROW(
shipid int,
address ROW(
street varchar,
city varchar,
zip int
),
shipdate date
)
]
) AS COPY FROM '...' PARQUET;
The following query tests for a specific order. When passing a ROW literal as the second argument, cast any ambiguous fields to ensure type matches:
=> SELECT CONTAINS(shipments,
ROW(1,ROW('911 San Marcos St'::VARCHAR,
'Austin'::VARCHAR, 73344),
'2020-11-05'::DATE))
FROM orders;
CONTAINS
----------
t
f
f
(3 rows)
Lambdas
Consider a table of departments where each department has an array of ROW elements representing employees. The following query finds departments with early hires (low employee IDs):
=> SELECT deptID FROM departments
WHERE CONTAINS(employees, e -> e.id < 20);
deptID
--------
1
3
(2 rows)
In the following example, a schedules table includes an array of events, where each event is a ROW with several fields:
=> CREATE TABLE schedules
(guest VARCHAR,
events ARRAY[ROW(e_date DATE, e_name VARCHAR, price NUMERIC(8,2))]);
You can use the CONTAINS function with a lambda expression to find people who have more than one event on the same day. The second argument, idx, is the index of the current element:
=> SELECT guest FROM schedules
WHERE CONTAINS(events, (e, idx) ->
(idx < ARRAY_LENGTH(events) - 1)
AND (e.e_date = events[idx + 1].e_date));
guest
-------------
Alice Adams
(1 row)
See also
6.4.1.12 - EXPLODE
Expands the elements of one or more collection columns (ARRAY or SET) into individual table rows, one row per element.
Expands the elements of one or more collection columns (ARRAY or SET) into individual table rows, one row per element. For each exploded collection, the results include two columns, one for the element index, and one for the value at that position. If the function explodes a single collection, these columns are named position and value by default. If the function explodes two or more collections, the columns for each collection are named pos_column-name and val_column-name. You can use an AS clause in the SELECT to change these column names.
EXPLODE and UNNEST both expand collections. They have the following differences:
-
By default, EXPLODE expands only the first collection it is passed and UNNEST expands all of them. See the explode_count and explode_all parameters.
-
By default, EXPLODE returns element positions in an index column and UNNEST does not. See the with_offsets parameter.
-
By default, EXPLODE requires an OVER clause and UNNEST ignores an OVER clause if present. See the skip_partitioning parameter.
Behavior type
Immutable
Syntax
EXPLODE (column[,...] [USING PARAMETERS param=value])
[ OVER ( [window-partition-clause] ) ]
Arguments
column- Column in the table being queried. Unless
explode_all is true, you must specify at least as many collection columns as the value of the explode_count parameter. Columns that are not collections are passed through without modification.
Passthrough columns are not needed if skip_partitioning is true.
OVER(...)- How to partition and sort input data. The input data is the result set that the query returns after it evaluates FROM, WHERE, GROUP BY, and HAVING clauses. For EXPLODE, use OVER() or OVER(PARTITION BEST).
This clause is ignored if skip_partitioning is true.
Parameters
explode_all (BOOLEAN)- If true, explode all collection columns. When
explode_all is true, passthrough columns are not permitted.
Default: false
explode_count (INT)- The number of collection columns to explode. The function checks each column, up to this value, and either explodes it if is a collection or passes it through if it is not a collection or if this limit has been reached. If the value of
explode_count is greater than the number of collection columns specified, the function returns an error.
If explode_all is true, you cannot specify explode_count.
Default: 1
skip_partitioning (BOOLEAN)- Whether to skip partitioning and ignore the OVER clause if present. EXPLODE translates a single row of input into multiple rows of output, one per collection element. There is, therefore, usually no benefit to partitioning the input first. Skipping partitioning can help a query avoid an expensive sort or merge operation. Even so, setting this parameter can negatively affect performance in rare cases.
Default: false
with_offset (BOOLEAN)- Whether to return the index of each element.
Default: true
Null-handling
This function expands each element in a collection into a row, including null elements. If the input column is NULL or an empty collection, the function produces no rows for that column:
=> SELECT EXPLODE(ARRAY[1,2,null,4]) OVER();
position | value
----------+-------
0 | 1
1 | 2
2 |
3 | 4
(4 rows)
=> SELECT EXPLODE(ARRAY[]::ARRAY[INT]) OVER();
position | value
----------+-------
(0 rows)
=> SELECT EXPLODE(NULL::ARRAY[INT]) OVER();
position | value
----------+-------
(0 rows)
Joining on results
To use JOIN with this function you must set the skip_partitioning parameter, either in the function call or as a session parameter.
You can use the output of this function as if it were a relation by using CROSS JOIN or LEFT JOIN LATERAL in a query. Other JOIN types are not supported.
Consider the following table of students and exam scores:
=> SELECT * FROM tests;
student | scores | questions
---------+---------------+-----------------
Bob | [92,78,79] | [20,20,100]
Lee | |
Pat | [] | []
Sam | [97,98,85] | [20,20,100]
Tom | [68,75,82,91] | [20,20,100,100]
(5 rows)
The following query finds the best test scores across all students who have scores:
=> ALTER SESSION SET UDPARAMETER FOR ComplexTypesLib skip_partitioning = true;
=> SELECT student, score FROM tests
CROSS JOIN EXPLODE(scores) AS t (pos, score)
ORDER BY score DESC;
student | score
---------+-------
Sam | 98
Sam | 97
Bob | 92
Tom | 91
Sam | 85
Tom | 82
Bob | 79
Bob | 78
Tom | 75
Tom | 68
(10 rows)
The following query returns maximum and average per-question scores, considering both the exam score and the number of questions:
=> SELECT student, MAX(score/qcount), AVG(score/qcount) FROM tests
CROSS JOIN EXPLODE(scores, questions USING PARAMETERS explode_count=2)
AS t(pos_s, score, pos_q, qcount)
GROUP BY student;
student | MAX | AVG
---------+----------------------+------------------
Bob | 4.600000000000000000 | 3.04333333333333
Sam | 4.900000000000000000 | 3.42222222222222
Tom | 4.550000000000000000 | 2.37
(3 rows)
These queries produce results for three of the five students. One student has a null value for scores and another has an empty array. These rows are not included in the function's output.
To include null and empty arrays in output, use LEFT JOIN LATERAL instead of CROSS JOIN:
=> SELECT student, MIN(score), AVG(score) FROM tests
LEFT JOIN LATERAL EXPLODE(scores) AS t (pos, score)
GROUP BY student;
student | MIN | AVG
---------+-----+------------------
Bob | 78 | 83
Lee | |
Pat | |
Sam | 85 | 93.3333333333333
Tom | 68 | 79
(5 rows)
The LATERAL keyword is required with LEFT JOIN. It is optional for CROSS JOIN.
Examples
Consider an orders table with the following contents:
=> SELECT orderkey, custkey, prodkey, orderprices, email_addrs
FROM orders LIMIT 5;
orderkey | custkey | prodkey | orderprices | email_addrs
------------+---------+-----------------------------------------------+-----------------------------------+----------------------------------------------------------------------------------------------------------------
113-341987 | 342799 | ["MG-7190 ","VA-4028 ","EH-1247 ","MS-7018 "] | ["60.00","67.00","22.00","14.99"] | ["bob@example,com","robert.jones@example.com"]
111-952000 | 342845 | ["ID-2586 ","IC-9010 ","MH-2401 ","JC-1905 "] | ["22.00","35.00",null,"12.00"] | ["br92@cs.example.edu"]
111-345634 | 342536 | ["RS-0731 ","SJ-2021 "] | ["50.00",null] | [null]
113-965086 | 342176 | ["GW-1808 "] | ["108.00"] | ["joe.smith@example.com"]
111-335121 | 342321 | ["TF-3556 "] | ["50.00"] | ["789123@example-isp.com","alexjohnson@example.com","monica@eng.example.com","sara@johnson.example.name",null]
(5 rows)
The following query explodes the order prices for a single customer. The other two columns are passed through and are repeated for each returned row:
=> SELECT EXPLODE(orderprices, custkey, email_addrs
USING PARAMETERS skip_partitioning=true)
AS (position, orderprices, custkey, email_addrs)
FROM orders WHERE custkey='342845' ORDER BY orderprices;
position | orderprices | custkey | email_addrs
----------+-------------+---------+------------------------------
2 | | 342845 | ["br92@cs.example.edu",null]
3 | 12.00 | 342845 | ["br92@cs.example.edu",null]
0 | 22.00 | 342845 | ["br92@cs.example.edu",null]
1 | 35.00 | 342845 | ["br92@cs.example.edu",null]
(4 rows)
The previous example uses the skip_partitioning parameter. Instead of setting it for each call to EXPLODE, you can set it as a session parameter. EXPLODE is part of the ComplexTypesLib UDx library. The following example returns the same results:
=> ALTER SESSION SET UDPARAMETER FOR ComplexTypesLib skip_partitioning=true;
=> SELECT EXPLODE(orderprices, custkey, email_addrs)
AS (position, orderprices, custkey, email_addrs)
FROM orders WHERE custkey='342845' ORDER BY orderprices;
You can explode more than one column by specifying the explode_count parameter:
=> SELECT EXPLODE(orderkey, prodkey, orderprices
USING PARAMETERS explode_count=2, skip_partitioning=true)
AS (orderkey,pk_idx,pk_val,ord_idx,ord_val)
FROM orders
WHERE orderkey='113-341987';
orderkey | pk_idx | pk_val | ord_idx | ord_val
------------+--------+----------+---------+---------
113-341987 | 0 | MG-7190 | 0 | 60.00
113-341987 | 0 | MG-7190 | 1 | 67.00
113-341987 | 0 | MG-7190 | 2 | 22.00
113-341987 | 0 | MG-7190 | 3 | 14.99
113-341987 | 1 | VA-4028 | 0 | 60.00
113-341987 | 1 | VA-4028 | 1 | 67.00
113-341987 | 1 | VA-4028 | 2 | 22.00
113-341987 | 1 | VA-4028 | 3 | 14.99
113-341987 | 2 | EH-1247 | 0 | 60.00
113-341987 | 2 | EH-1247 | 1 | 67.00
113-341987 | 2 | EH-1247 | 2 | 22.00
113-341987 | 2 | EH-1247 | 3 | 14.99
113-341987 | 3 | MS-7018 | 0 | 60.00
113-341987 | 3 | MS-7018 | 1 | 67.00
113-341987 | 3 | MS-7018 | 2 | 22.00
113-341987 | 3 | MS-7018 | 3 | 14.99
(16 rows)
The following example uses a multi-dimensional array:
=> SELECT name, pingtimes FROM network_tests;
name | pingtimes
------+-------------------------------------------------------
eng1 | [[24.24,25.27,27.16,24.97],[23.97,25.01,28.12,29.5]]
eng2 | [[27.12,27.91,28.11,26.95],[29.01,28.99,30.11,31.56]]
qa1 | [[23.15,25.11,24.63,23.91],[22.85,22.86,23.91,31.52]]
(3 rows)
=> SELECT EXPLODE(name, pingtimes USING PARAMETERS explode_count=1) OVER()
FROM network_tests;
name | position | value
------+----------+---------------------------
eng1 | 0 | [24.24,25.27,27.16,24.97]
eng1 | 1 | [23.97,25.01,28.12,29.5]
eng2 | 0 | [27.12,27.91,28.11,26.95]
eng2 | 1 | [29.01,28.99,30.11,31.56]
qa1 | 0 | [23.15,25.11,24.63,23.91]
qa1 | 1 | [22.85,22.86,23.91,31.52]
(6 rows)
You can rewrite the previous query as follows to produce the same results:
=> SELECT name, EXPLODE(pingtimes USING PARAMETERS skip_partitioning=true)
FROM network_tests;
6.4.1.13 - FILTER
Takes an input array and returns an array containing only elements that meet a specified condition.
Takes an input array and returns an array containing only elements that meet a specified condition. This function uses null-safe equality checks when testing elements.
Behavior type
Immutable
Syntax
FILTER(array, lambda-expression )
Arguments
array- Input array.
lambda-expressionLambda function to apply to each element. The function must return a Boolean value. The first argument to the function is the element, and the optional second element is the index of the element.
Examples
Given a table that contains names and arrays of email addresses, the following query filters out fake email addresses and returns the rest:
=> SELECT name, FILTER(email, e -> NOT REGEXP_LIKE(e,'example.com','i')) AS 'real_email'
FROM people;
name | real_email
----------------+-------------------------------------------------
Elaine Jackson | ["ejackson@somewhere.org","elaine@jackson.com"]
Frank Adams | []
Lee Jones | ["lee.jones@somewhere.org"]
M Smith | ["ms@msmith.com"]
(4 rows)
You can use the results in a WHERE clause to exclude rows that no longer contain any email addresses:
=> SELECT name, FILTER(email, e -> NOT REGEXP_LIKE(e,'example.com','i')) AS 'real_email'
FROM people
WHERE ARRAY_LENGTH(real_email) > 0;
name | real_email
----------------+-------------------------------------------------
Elaine Jackson | ["ejackson@somewhere.org","elaine@jackson.com"]
Lee Jones | ["lee.jones@somewhere.org"]
M Smith | ["ms@msmith.com"]
(3 rows)
See also
6.4.1.14 - IMPLODE
Takes a column of any scalar type and returns an unbounded array.
Takes a column of any scalar type and returns an unbounded array. Combined with GROUP BY, this function can be used to reverse an EXPLODE operation.
Behavior type
-
Immutable if the WITHIN GROUP ORDER BY clause specifies a column or set of columns that resolves to unique element values within each output array group.
-
Volatile otherwise because results are non-commutative.
Syntax
IMPLODE (input-column [ USING PARAMETERS param=value[,...] ] )
[ within-group-order-by-clause ]
Arguments
input-column- Column of any scalar type from which to create the array.
- [within-group-order-by-clause](/en/sql-reference/functions/aggregate-functions/within-group-order-by-clause/)
- Sorts elements within each output array group:
WITHIN GROUP (ORDER BY { column-expression[ sort-qualifiers ] }[,...])
sort-qualifiers: { ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] }
Tip
WITHIN GROUP ORDER BY can consume a large amount of memory per group. To minimize memory consumption, create projections that support
GROUPBY PIPELINED.
Parameters
allow_truncate- Boolean, if true truncates results when output length exceeds column size. If false (the default), the function returns an error if the output array is too large.
Even if this parameter is set to true, IMPLODE returns an error if any single array element is too large. Truncation removes elements from the output array but does not alter individual elements.
max_binary_size- The maximum binary size in bytes for the returned array. If you omit this parameter, IMPLODE uses the value of the configuration parameter DefaultArrayBinarySize.
Examples
Consider a table with the following contents:
=> SELECT * FROM filtered;
position | itemprice | itemkey
----------+-----------+---------
0 | 14.99 | 345
0 | 27.99 | 567
1 | 18.99 | 567
1 | 35.99 | 345
2 | 14.99 | 123
(5 rows)
The following query calls IMPLODE to assemble prices into arrays (grouped by keys):
=> SELECT itemkey AS key, IMPLODE(itemprice) AS prices
FROM filtered GROUP BY itemkey ORDER BY itemkey;
key | prices
-----+-------------------
123 | ["14.99"]
345 | ["35.99","14.99"]
567 | ["27.99","18.99"]
(3 rows)
You can modify this query by including a WITHIN GROUP ORDER BY clause, which specifies how to sort array elements within each group:
=> SELECT itemkey AS key, IMPLODE(itemprice) WITHIN GROUP (ORDER BY itemprice) AS prices
FROM filtered GROUP BY itemkey ORDER BY itemkey;
key | prices
-----+-------------------
123 | ["14.99"]
345 | ["14.99","35.99"]
567 | ["18.99","27.99"]
(3 rows)
See Arrays and sets (collections) for a fuller example.
6.4.1.15 - SET_UNION
Returns a SET containing all elements of two input sets.
Returns a SET containing all elements of two input sets.
If the inputs are both bounded, the bound for the result is the sum of the bounds of the inputs.
If any input is unbounded, the result is unbounded with a binary size that is the sum of the sizes of the inputs.
Behavior type
Immutable
Syntax
SET_UNION(set1,set2)
Arguments
set1, set2- Sets of matching element type
Null-handling
-
Null arguments are ignored. If one of the inputs is null, the function returns the non-null input. In other words, an argument of NULL is equivalent to SET[].
-
If both inputs are null, the function returns null.
Examples
=> SELECT SET_UNION(SET[1,2,4], SET[2,3,4,5.9]);
set_union
-----------------------
["1.0","2.0","3.0","4.0","5.9"]
(1 row)
6.4.1.16 - STRING_TO_ARRAY
Splits a string containing array values and returns a native one-dimensional array.
Splits a string containing array values and returns a native one-dimensional array. The output does not include the "ARRAY" keyword. This function does not support nested (multi-dimensional) arrays.
This function returns array elements as strings by default. You can cast to other types, as in the following example:
=> SELECT STRING_TO_ARRAY('[1,2,3]')::ARRAY[INT];
Behavior
Immutable
Syntax
STRING_TO_ARRAY(string [USING PARAMETERS param=value[,...]])
The following syntax is deprecated:
STRING_TO_ARRAY(string, delimiter)
Arguments
string- String representation of a one-dimensional array; can be a VARCHAR or LONG VARCHAR column, a literal string, or the string output of an expression.
Spaces in the string are removed unless elements are individually quoted. For example, ' a,b,c' is equivalent to 'a,b,c'. To preserve the space, use '" a","b","c"'.
Parameters
These parameters behave the same way as the corresponding options when loading delimited data (see DELIMITED).
No parameter may have the same value as any other parameter.
collection_delimiter- The character or character sequence used to separate array elements (VARCHAR(8)). You can use any ASCII values in the range E'\000' to E'\177', inclusive.
Default: Comma (',').
collection_open, collection_close- The characters that mark the beginning and end of the array (VARCHAR(8)). It is an error to use these characters elsewhere within the list of elements without escaping them. These characters can be omitted from the input string.
Default: Square brackets ('[' and ']').
collection_null_element- The string representing a null element value (VARCHAR(65000)). You can specify a null value using any ASCII values in the range E'\001' to E'\177' inclusive (any ASCII value except NULL: E'\000').
Default: 'null'
collection_enclose- An optional quote character within which to enclose individual elements, allowing delimiter characters to be embedded in string values. You can choose any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII character except NULL: E'\000'). Elements do not need to be enclosed by this value.
Default: double quote ('"')
Examples
The function uses comma as the default delimiter. You can specify a different value:
=> SELECT STRING_TO_ARRAY('[1,3,5]');
STRING_TO_ARRAY
-----------------
["1","3","5"]
(1 row)
=> SELECT STRING_TO_ARRAY('[t|t|f|t]' USING PARAMETERS collection_delimiter = '|');
STRING_TO_ARRAY
-------------------
["t","t","f","t"]
(1 row)
The bounding brackets are optional:
=> SELECT STRING_TO_ARRAY('t|t|f|t' USING PARAMETERS collection_delimiter = '|');
STRING_TO_ARRAY
-------------------
["t","t","f","t"]
(1 row)
The input can use other characters for open and close:
=> SELECT STRING_TO_ARRAY('{NASA-1683,NASA-7867,SPX-76}' USING PARAMETERS collection_open = '{', collection_close = '}');
STRING_TO_ARRAY
------------------------------------
["NASA-1683","NASA-7867","SPX-76"]
(1 row)
By default the string 'null' in input is treated as a null value:
=> SELECT STRING_TO_ARRAY('{"us-1672",null,"darpa-1963"}' USING PARAMETERS collection_open = '{', collection_close = '}');
STRING_TO_ARRAY
-------------------------------
["us-1672",null,"darpa-1963"]
(1 row)
In the following example, the input comes from a column:
=> SELECT STRING_TO_ARRAY(name USING PARAMETERS collection_delimiter=' ') FROM employees;
STRING_TO_ARRAY
-----------------------
["Howard","Wolowitz"]
["Sheldon","Cooper"]
(2 rows)
6.4.1.17 - TO_JSON
Returns the JSON representation of a complex-type argument, including mixed and nested complex types.
Returns the JSON representation of a complex-type argument, including mixed and nested complex types. This is the same format that queries of complex-type columns return.
Behavior
Immutable
Syntax
TO_JSON(value)
Arguments
value- Column or literal of a complex type
Examples
These examples query the following table:
=> SELECT name, contact FROM customers;
name | contact
--------------------+-----------------------------------------------------------------------------------------------------------------------
Missy Cooper | {"street":"911 San Marcos St","city":"Austin","zipcode":73344,"email":["missy@mit.edu","mcooper@cern.gov"]}
Sheldon Cooper | {"street":"100 Main St Apt 4B","city":"Pasadena","zipcode":91001,"email":["shelly@meemaw.name","cooper@caltech.edu"]}
Leonard Hofstadter | {"street":"100 Main St Apt 4A","city":"Pasadena","zipcode":91001,"email":["hofstadter@caltech.edu"]}
Leslie Winkle | {"street":"23 Fifth Ave Apt 8C","city":"Pasadena","zipcode":91001,"email":[]}
Raj Koothrappali | {"street":null,"city":"Pasadena","zipcode":91001,"email":["raj@available.com"]}
Stuart Bloom |
(6 rows)
You can call TO_JSON on a column or on specific fields or array elements:
=> SELECT TO_JSON(contact) FROM customers;
to_json
-----------------------------------------------------------------------------------------------------------------------
{"street":"911 San Marcos St","city":"Austin","zipcode":73344,"email":["missy@mit.edu","mcooper@cern.gov"]}
{"street":"100 Main St Apt 4B","city":"Pasadena","zipcode":91001,"email":["shelly@meemaw.name","cooper@caltech.edu"]}
{"street":"100 Main St Apt 4A","city":"Pasadena","zipcode":91001,"email":["hofstadter@caltech.edu"]}
{"street":"23 Fifth Ave Apt 8C","city":"Pasadena","zipcode":91001,"email":[]}
{"street":null,"city":"Pasadena","zipcode":91001,"email":["raj@available.com"]}
(6 rows)
=> SELECT TO_JSON(contact.email) FROM customers;
to_json
---------------------------------------------
["missy@mit.edu","mcooper@cern.gov"]
["shelly@meemaw.name","cooper@caltech.edu"]
["hofstadter@caltech.edu"]
[]
["raj@available.com"]
(6 rows)
When calling TO_JSON with a SET, note that duplicates are removed and elements can be reordered:
=> SELECT TO_JSON(SET[1683,7867,76,76]);
TO_JSON
----------------
[76,1683,7867]
(1 row)
6.4.1.18 - UNNEST
Expands the elements of one or more collection columns (ARRAY or SET) into individual rows.
Expands the elements of one or more collection columns (ARRAY or SET) into individual rows. If called with a single array, UNNEST returns the elements in a column named value. If called with two or more arrays, it returns columns named val_column-name. You can use an AS clause in the SELECT to change these names.
UNNEST and EXPLODE both expand collections. They have the following differences:
-
By default, UNNEST expands all passed collections and EXPLODE expands only the first. See the explode_count and explode_all parameters.
-
By default, UNNEST returns only the elements and EXPLODE also returns their positions in an index column. See the with_offsets parameter.
-
By default, UNNEST does not partition its input and ignores an OVER() clause if present. See the skip_partitioning parameter.
Behavior type
Immutable
Syntax
UNNEST (column[,...])
[USING PARAMETERS param=value])
[ OVER ( [window-partition-clause
Arguments
column- Column in the table being queried. If
explode_all is false, you must specify at least as many collection columns as the value of the explode_count parameter. Columns that are not collections are passed through without modification.
Passthrough columns are not needed if skip_partitioning is true.
OVER(...)- How to partition and sort input data. The input data is the result set that the query returns after it evaluates FROM, WHERE, GROUP BY, and HAVING clauses.
This clause only applies if skip_partitioning is false.
Parameters
explode_all (BOOLEAN)- If true, explode all collection columns. When
explode_all is true, passthrough columns are not permitted.
Default: true
explode_count (INT)- The number of collection columns to explode. The function checks each column, up to this value, and either explodes it if is a collection or passes it through if it is not a collection or if this limit has been reached. If the value of
explode_count is greater than the number of collection columns specified, the function returns an error.
If explode_all is true, you cannot specify explode_count.
Default: 1
skip_partitioning (BOOLEAN)- Whether to skip partitioning and ignore the OVER clause if present. UNNEST translates a single row of input into multiple rows of output, one per collection element. There is, therefore, usually no benefit to partitioning the input first. Skipping partitioning can help a query avoid an expensive sort or merge operation.
Default: true
with_offset (BOOLEAN)- Whether to return the index of each element as an additional column.
Default: false
Null-handling
This function expands each element in a collection into a row, including null elements. If the input column is NULL or an empty collection, the function produces no rows for that column:
=> SELECT UNNEST(ARRAY[1,2,null,4]) OVER();
value
-------
1
2
4
(4 rows)
=> SELECT UNNEST(ARRAY[]::ARRAY[INT]) OVER();
value
-------
(0 rows)
=> SELECT UNNEST(NULL::ARRAY[INT]) OVER();
value
-------
(0 rows)
Joining on results
You can use the output of this function as if it were a relation by using CROSS JOIN or LEFT JOIN LATERAL in a query. Other JOIN types are not supported.
Consider the following table of students and exam scores:
=> SELECT * FROM tests;
student | scores | questions
---------+---------------+-----------------
Bob | [92,78,79] | [20,20,100]
Lee | |
Pat | [] | []
Sam | [97,98,85] | [20,20,100]
Tom | [68,75,82,91] | [20,20,100,100]
(5 rows)
The following query finds the best test scores across all students who have scores:
=> SELECT student, score FROM tests
CROSS JOIN UNNEST(scores) AS t (score)
ORDER BY score DESC;
student | score
---------+-------
Sam | 98
Sam | 97
Bob | 92
Tom | 91
Sam | 85
Tom | 82
Bob | 79
Bob | 78
Tom | 75
Tom | 68
(10 rows)
The following query returns maximum and average per-question scores, considering both the exam score and the number of questions:
=> SELECT student, MAX(score/qcount), AVG(score/qcount) FROM tests
CROSS JOIN UNNEST(scores, questions) AS t(score, qcount)
GROUP BY student;
student | MAX | AVG
---------+----------------------+------------------
Bob | 4.600000000000000000 | 3.04333333333333
Sam | 4.900000000000000000 | 3.42222222222222
Tom | 4.550000000000000000 | 2.37
(3 rows)
These queries produce results for three of the five students. One student has a null value for scores and another has an empty array. These rows are not included in the function's output.
To include null and empty arrays in output, use LEFT JOIN LATERAL instead of CROSS JOIN:
=> SELECT student, MIN(score), AVG(score) FROM tests
LEFT JOIN LATERAL UNNEST(scores) AS t (score)
GROUP BY student;
student | MIN | AVG
---------+-----+------------------
Bob | 78 | 83
Lee | |
Pat | |
Sam | 85 | 93.3333333333333
Tom | 68 | 79
(5 rows)
The LATERAL keyword is required with LEFT JOIN. It is optional for CROSS JOIN.
Examples
Consider a table with the following definition:
=> CREATE TABLE orders (
orderkey VARCHAR, custkey INT,
prodkey ARRAY[VARCHAR], orderprices ARRAY[DECIMAL(12,2)],
email_addrs ARRAY[VARCHAR]);
The following query expands one of the array columns. One of the elements is null:
=> SELECT UNNEST(orderprices) AS price, custkey, email_addrs
FROM orders WHERE custkey='342845' ORDER BY price;
price | custkey | email_addrs
-------+---------+-------------------------
| 342845 | ["br92@cs.example.edu"]
12.00 | 342845 | ["br92@cs.example.edu"]
22.00 | 342845 | ["br92@cs.example.edu"]
35.00 | 342845 | ["br92@cs.example.edu"]
(4 rows)
UNNEST can expand more than one column:
=> SELECT orderkey, UNNEST(prodkey, orderprices)
FROM orders WHERE orderkey='113-341987';
orderkey | val_prodkey | val_orderprices
------------+-------------+-----------------
113-341987 | MG-7190 | 60.00
113-341987 | MG-7190 | 67.00
113-341987 | MG-7190 | 22.00
113-341987 | MG-7190 | 14.99
113-341987 | VA-4028 | 60.00
113-341987 | VA-4028 | 67.00
113-341987 | VA-4028 | 22.00
113-341987 | VA-4028 | 14.99
113-341987 | EH-1247 | 60.00
113-341987 | EH-1247 | 67.00
113-341987 | EH-1247 | 22.00
113-341987 | EH-1247 | 14.99
113-341987 | MS-7018 | 60.00
113-341987 | MS-7018 | 67.00
113-341987 | MS-7018 | 22.00
113-341987 | MS-7018 | 14.99
(16 rows)
6.4.2 - Date/time functions
Date and time functions perform conversion, extraction, or manipulation operations on date and time data types and can return date and time information.
Date and time functions perform conversion, extraction, or manipulation operations on date and time data types and can return date and time information.
Usage
Functions that take TIME or TIMESTAMP inputs come in two variants:
For brevity, these variants are not shown separately.
The + and * operators come in commutative pairs; for example, both DATE + INTEGER and INTEGER + DATE. We show only one of each such pair.
Daylight savings time considerations
When adding an INTERVAL value to (or subtracting an INTERVAL value from) a TIMESTAMP WITH TIME ZONE value, the days component advances (or decrements) the date of the TIMESTAMP WITH TIME ZONE by the indicated number of days. Across daylight saving time changes (with the session time zone set to a time zone that recognizes DST), this means INTERVAL '1 day' does not necessarily equal INTERVAL '24 hours'.
For example, with the session time zone set to CST7CDT:
TIMESTAMP WITH TIME ZONE '2014-04-02 12:00-07' + INTERVAL '1 day'
produces
TIMESTAMP WITH TIME ZONE '2014-04-03 12:00-06'
Adding INTERVAL '24 hours' to the same initial TIMESTAMP WITH TIME ZONE produces
TIMESTAMP WITH TIME ZONE '2014-04-03 13:00-06',
This result occurs because there is a change in daylight saving time at 2014-04-03 02:00 in time zone CST7CDT.
Date/time functions in transactions
Certain date/time functions such as
CURRENT_TIMESTAMP and
NOW return the start time of the current transaction; for the duration of that transaction, they return the same value. Other date/time functions such as
TIMEOFDAY always return the current time.
See also
Template patterns for date/time formatting
6.4.2.1 - ADD_MONTHS
Adds the specified number of months to a date and returns the sum as a DATE.
Adds the specified number of months to a date and returns the sum as a DATE. In general, ADD_MONTHS returns a date with the same day component as the start date. For example:
=> SELECT ADD_MONTHS ('2015-09-15'::date, -2) "2 Months Ago";
2 Months Ago
--------------
2015-07-15
(1 row)
Two exceptions apply:
-
If the start date's day component is greater than the last day of the result month, ADD_MONTHS returns the last day of the result month. For example:
=> SELECT ADD_MONTHS ('31-Jan-2016'::TIMESTAMP, 1) "Leap Month";
Leap Month
------------
2016-02-29
(1 row)
-
If the start date's day component is the last day of that month, and the result month has more days than the start date month, ADD_MONTHS returns the last day of the result month. For example:
=> SELECT ADD_MONTHS ('2015-09-30'::date,-1) "1 Month Ago";
1 Month Ago
-------------
2015-08-31
(1 row)
Behavior type
Syntax
ADD_MONTHS ( start-date, num-months );
Parameters
start-date- The date to process, an expression that evaluates to one of the following data types:
-
DATE
-
TIMESTAMP
-
TIMESTAMPTZ
num-months- An integer expression that specifies the number of months to add to or subtract from
start-date.
Examples
Add one month to the current date:
=> SELECT CURRENT_DATE Today;
Today
------------
2016-05-05
(1 row)
VMart=> SELECT ADD_MONTHS(CURRENT_TIMESTAMP,1);
ADD_MONTHS
------------
2016-06-05
(1 row)
Subtract four months from the current date:
=> SELECT ADD_MONTHS(CURRENT_TIMESTAMP, -4);
ADD_MONTHS
------------
2016-01-05
(1 row)
Add one month to January 31 2016:
=> SELECT ADD_MONTHS('31-Jan-2016'::TIMESTAMP, 1) "Leap Month";
Leap Month
------------
2016-02-29
(1 row)
The following example sets the timezone to EST; it then adds 24 months to a TIMESTAMPTZ that specifies a PST time zone, so ADD_MONTHS takes into account the time change:
=> SET TIME ZONE 'America/New_York';
SET
VMart=> SELECT ADD_MONTHS('2008-02-29 23:30 PST'::TIMESTAMPTZ, 24);
ADD_MONTHS
------------
2010-03-01
(1 row)
6.4.2.2 - AGE_IN_MONTHS
Returns the difference in months between two dates, expressed as an integer.
Returns the difference in months between two dates, expressed as an integer.
Behavior type
Syntax
AGE_IN_MONTHS ( [ date1,] date2 )
Parameters
date1
date2- Specify the boundaries of the period to measure. If you supply only one argument, Vertica sets
date2 to the current date. Both parameters must evaluate to one of the following data types:
-
DATE
-
TIMESTAMP
-
TIMESTAMPTZ
If date1 < date2, AGE_IN_MONTHS returns a negative value.
Examples
Get the age in months of someone born March 2 1972, as of June 21 1990:
=> SELECT AGE_IN_MONTHS('1990-06-21'::TIMESTAMP, '1972-03-02'::TIMESTAMP);
AGE_IN_MONTHS
---------------
219
(1 row)
If the first date is less than the second date, AGE_IN_MONTHS returns a negative value
=> SELECT AGE_IN_MONTHS('1972-03-02'::TIMESTAMP, '1990-06-21'::TIMESTAMP);
AGE_IN_MONTHS
---------------
-220
(1 row)
Get the age in months of someone who was born November 21 1939, as of today:
=> SELECT AGE_IN_MONTHS ('1939-11-21'::DATE);
AGE_IN_MONTHS
---------------
930
(1 row)
6.4.2.3 - AGE_IN_YEARS
Returns the difference in years between two dates, expressed as an integer.
Returns the difference in years between two dates, expressed as an integer.
Behavior type
Syntax
AGE_IN_YEARS( [ date1,] date2 )
Parameters
date1
date2- Specify the boundaries of the period to measure. If you supply only one argument, Vertica sets
date1 to the current date. Both parameters must evaluate to one of the following data types:
-
DATE
-
TIMESTAMP
-
TIMESTAMPTZ
If date1 < date2, AGE_IN_YEARS returns a negative value.
Examples
Get the age of someone born March 2 1972, as of June 21 1990:
=> SELECT AGE_IN_YEARS('1990-06-21'::TIMESTAMP, '1972-03-02'::TIMESTAMP);
AGE_IN_YEARS
--------------
18
(1 row)
If the first date is earlier than the second date, AGE_IN_YEARS returns a negative number:
=> SELECT AGE_IN_YEARS('1972-03-02'::TIMESTAMP, '1990-06-21'::TIMESTAMP);
AGE_IN_YEARS
--------------
-19
(1 row)
Get the age of someone who was born November 21 1939, as of today:
=> SELECT AGE_IN_YEARS('1939-11-21'::DATE);
AGE_IN_YEARS
--------------
77
(1 row)
6.4.2.4 - CLOCK_TIMESTAMP
Returns a value of type TIMESTAMP WITH TIMEZONE that represents the current system-clock time.
Returns a value of type TIMESTAMP WITH TIMEZONE that represents the current system-clock time.
CLOCK_TIMESTAMP uses the date and time supplied by the operating system on the server to which you are connected, which should be the same across all servers. The value changes each time you call it.
Behavior type
Volatile
Syntax
CLOCK_TIMESTAMP()
Examples
The following command returns the current time on your system:
SELECT CLOCK_TIMESTAMP() "Current Time";
Current Time
------------------------------
2010-09-23 11:41:23.33772-04
(1 row)
Each time you call the function, you get a different result. The difference in this example is in microseconds:
SELECT CLOCK_TIMESTAMP() "Time 1", CLOCK_TIMESTAMP() "Time 2";
Time 1 | Time 2
-------------------------------+-------------------------------
2010-09-23 11:41:55.369201-04 | 2010-09-23 11:41:55.369202-04
(1 row)
See also
6.4.2.5 - CURRENT_DATE
Returns the date (date-type value) on which the current transaction started.
Returns the date (date-type value) on which the current transaction started.
Behavior type
Stable
Syntax
CURRENT_DATE()
Note
You can call this function without parentheses.
Examples
SELECT CURRENT_DATE;
?column?
------------
2010-09-23
(1 row)
6.4.2.6 - CURRENT_TIME
Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction.
Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction.
The return value does not change during the transaction. Thus, multiple calls to CURRENT_TIME within the same transaction return the same timestamp.
Behavior type
Stable
Syntax
CURRENT_TIME [ ( precision ) ]
Note
If you specify a column label without precision, you must also omit parentheses.
Parameters
precision- An integer value between 0-6, specifies to round the seconds fraction field result to the specified number of digits.
Examples
=> SELECT CURRENT_TIME(1) AS Time;
Time
---------------
06:51:45.2-07
(1 row)
=> SELECT CURRENT_TIME(5) AS Time;
Time
-------------------
06:51:45.18435-07
(1 row)
6.4.2.7 - CURRENT_TIMESTAMP
Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction.
Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction.
The return value does not change during the transaction. Thus, multiple calls to CURRENT_TIMESTAMP within the same transaction return the same timestamp.
Behavior type
Stable
Syntax
CURRENT_TIMESTAMP ( precision )
Parameters
precision- An integer value between 0-6, specifies to round the seconds fraction field result to the specified number of digits.
Examples
=> SELECT CURRENT_TIMESTAMP(1) AS time;
time
--------------------------
2017-03-27 06:50:49.7-07
(1 row)
=> SELECT CURRENT_TIMESTAMP(5) AS time;
time
------------------------------
2017-03-27 06:50:49.69967-07
(1 row)
6.4.2.8 - DATE
Converts the input value to a DATE data type.
Converts the input value to a
DATE data type.
Behavior type
-
Immutable if the input value is a TIMESTAMP, DATE, VARCHAR, or integer
-
Stable if the input value is a TIMESTAMPTZ
Syntax
DATE ( value )
Parameters
value- The value to convert, one of the following:
-
TIMESTAMP, TIMESTAMPTZ, VARCHAR, or another DATE.
-
Integer: Vertica treats the integer as the number of days since 01/01/0001 and returns the date.
Examples
=> SELECT DATE (1);
DATE
------------
0001-01-01
(1 row)
=> SELECT DATE (734260);
DATE
------------
2011-05-03
(1 row)
=> SELECT DATE('TODAY');
DATE
------------
2016-12-07
(1 row)
See also
6.4.2.9 - DATE_PART
Extracts a sub-field such as year or hour from a date/time expression, equivalent to the the SQL-standard function EXTRACT.
Extracts a sub-field such as year or hour from a date/time expression, equivalent to the the SQL-standard function
EXTRACT.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or INTERVAL
-
Stable if the specified date is a TIMESTAMPTZ
Syntax
DATE_PART ( 'field', date )
Parameters
field- A constant value that specifies the sub-field to extract from
date (see Field Values below).
date- The date to process, an expression that evaluates to one of the following data types:
Field values
CENTURY- The century number.
The first century starts at 0001-01-01 00:00:00 AD. This definition applies to all Gregorian calendar countries. There is no century number 0, you go from –1 to 1.
DAY- The day (of the month) field (1–31).
DECADE- The year field divided by 10.
DOQ- The day within the current quarter. DOQ recognizes leap year days.
DOW- Zero-based day of the week, where Sunday=0.
Note
EXTRACT's day of week numbering differs from the function
TO_CHAR .
DOY- The day of the year (1–365/366)
EPOCH- Specifies to return one of the following:
-
For DATE and TIMESTAMP values: the number of seconds before or since 1970-01-01 00:00:00-00 (if before, a negative number).
-
For INTERVAL values, the total number of seconds in the interval.
HOUR- The hour field (0–23).
ISODOW- The ISO day of the week, an integer between 1 and 7 where Monday is 1.
ISOWEEK- The ISO week of the year, an integer between 1 and 53.
ISOYEAR- The ISO year.
MICROSECONDS- The seconds field, including fractional parts, multiplied by 1,000,000. This includes full seconds.
MILLENNIUM- The millennium number, where the first millennium is 1 and each millenium starts on
01-01-y001. For example, millennium 2 starts on 01-01-1001.
MILLISECONDS- The seconds field, including fractional parts, multiplied by 1000. This includes full seconds.
MINUTE- The minutes field (0 - 59).
MONTH- For
TIMESTAMP values, the number of the month within the year (1 - 12) ; for interval values the number of months, modulo 12 (0 - 11).
QUARTER- The calendar quarter of the specified date as an integer, where the January-March quarter is 1, valid only for
TIMESTAMP values.
SECOND- The seconds field, including fractional parts, 0–59, or 0-60 if the operating system implements leap seconds.
TIME ZONE- The time zone offset from UTC, in seconds. Positive values correspond to time zones east of UTC, negative values to zones west of UTC.
TIMEZONE_HOUR- The hour component of the time zone offset.
TIMEZONE_MINUTE- The minute component of the time zone offset.
WEEK- The number of the week of the calendar year that the day is in.
YEAR- The year field. There is no
0 AD, so subtract BC years from AD years accordingly.
Notes
According to the ISO-8601 standard, the week starts on Monday, and the first week of a year contains January 4. Thus, an early January date can sometimes be in the week 52 or 53 of the previous calendar year. For example:
=> SELECT YEAR_ISO('01-01-2016'::DATE), WEEK_ISO('01-01-2016'), DAYOFWEEK_ISO('01-01-2016');
YEAR_ISO | WEEK_ISO | DAYOFWEEK_ISO
----------+----------+---------------
2015 | 53 | 5
(1 row)
Examples
Extract the day value:
SELECT DATE_PART('DAY', TIMESTAMP '2009-02-24 20:38:40') "Day";
Day
-----
24
(1 row)
Extract the month value:
SELECT DATE_PART('MONTH', '2009-02-24 20:38:40'::TIMESTAMP) "Month";
Month
-------
2
(1 row)
Extract the year value:
SELECT DATE_PART('YEAR', '2009-02-24 20:38:40'::TIMESTAMP) "Year";
Year
------
2009
(1 row)
Extract the hours:
SELECT DATE_PART('HOUR', '2009-02-24 20:38:40'::TIMESTAMP) "Hour";
Hour
------
20
(1 row)
Extract the minutes:
SELECT DATE_PART('MINUTES', '2009-02-24 20:38:40'::TIMESTAMP) "Minutes";
Minutes
---------
38
(1 row)
Extract the day of quarter (DOQ):
SELECT DATE_PART('DOQ', '2009-02-24 20:38:40'::TIMESTAMP) "DOQ";
DOQ
-----
55
(1 row)
See also
TO_CHAR
6.4.2.10 - DATE_TRUNC
Truncates date and time values to the specified precision.
Truncates date and time values to the specified precision. The return value is the same data type as the input value. All fields that are less than the specified precision are set to 0, or to 1 for day and month.
Behavior type
Stable
Syntax
DATE_TRUNC( precision, trunc-target )
Parameters
precision- A string constant that specifies precision for the truncated value. See Precision Field Values below. The precision must be valid for the
trunc-target date or time.
trunc-target- Valid date/time expression.
Precision field values
MILLENNIUM- The millennium number.
CENTURY- The century number.
The first century starts at 0001-01-01 00:00:00 AD. This definition applies to all Gregorian calendar countries.
DECADE- The year field divided by 10.
YEAR- The year field. Keep in mind there is no
0 AD, so subtract BC years from AD years with care.
QUARTER- The calendar quarter of the specified date as an integer, where the January-March quarter is 1.
MONTH- For
timestamp values, the number of the month within the year (1–12) ; for interval values the number of months, modulo 12 (0–11).
WEEK- The number of the week of the year that the day is in.
According to the ISO-8601 standard, the week starts on Monday, and the first week of a year contains January 4. Thus, an early January date can sometimes be in the week 52 or 53 of the previous calendar year. For example:
=> SELECT YEAR_ISO('01-01-2016'::DATE), WEEK_ISO('01-01-2016'), DAYOFWEEK_ISO('01-01-2016');
YEAR_ISO | WEEK_ISO | DAYOFWEEK_ISO
----------+----------+---------------
2015 | 53 | 5
(1 row)
DAY- The day (of the month) field (1–31).
HOUR- The hour field (0–23).
MINUTE- The minutes field (0–59).
SECOND- The seconds field, including fractional parts (0–59) (60 if leap seconds are implemented by the operating system).
MILLISECONDS- The seconds field, including fractional parts, multiplied by 1000. Note that this includes full seconds.
MICROSECONDS- The seconds field, including fractional parts, multiplied by 1,000,000. This includes full seconds.
Examples
The following example sets the field value as hour and returns the hour, truncating the minutes and seconds:
=> SELECT DATE_TRUNC('HOUR', TIMESTAMP '2012-02-24 13:38:40') AS HOUR;
HOUR
---------------------
2012-02-24 13:00:00
(1 row)
The following example returns the year from the input timestamptz '2012-02-24 13:38:40'. The function also defaults the month and day to January 1, truncates the hour:minute:second of the timestamp, and appends the time zone (-05):
=> SELECT DATE_TRUNC('YEAR', TIMESTAMPTZ '2012-02-24 13:38:40') AS YEAR;
YEAR
------------------------
2012-01-01 00:00:00-05
(1 row)
The following example returns the year and month and defaults day of month to 1, truncating the rest of the string:
=> SELECT DATE_TRUNC('MONTH', TIMESTAMP '2012-02-24 13:38:40') AS MONTH;
MONTH
---------------------
2012-02-01 00:00:00
(1 row)
6.4.2.11 - DATEDIFF
Returns the time span between two dates, in the intervals specified.
Returns the time span between two dates, in the intervals specified. DATEDIFF excludes the start date in its calculation.
Behavior type
-
Immutable if start and end dates are TIMESTAMP , DATE, TIME, or INTERVAL
-
Stable if start and end dates are TIMESTAMPTZ
Syntax
DATEDIFF ( datepart, start, end );
Parameters
datepart- Specifies the type of date or time intervals that
DATEDIFF returns. If datepart is an expression, it must be enclosed in parentheses:
DATEDIFF((expression), start, end);
datepart must evaluate to one of the following string literals, either quoted or unquoted:
start, end- Specify the start and end dates, where
start and end evaluate to one of the following data types:
If end < start, DATEDIFF returns a negative value.
Note
TIME and INTERVAL data types are invalid for start and end dates if datepart is set to year, quarter, or month.
Compatible start and end date data types
The following table shows which data types can be matched as start and end dates:
|
|
DATE |
TIMESTAMP |
TIMESTAMPTZ |
TIME |
INTERVAL |
DATE |
• |
• |
• |
|
|
TIMESTAMP |
• |
• |
• |
|
|
TIMESTAMPTZ |
• |
• |
• |
|
|
TIME |
|
|
|
• |
|
INTERVAL |
|
|
|
|
• |
For example, if you set the start date to an INTERVAL data type, the end date must also be an INTERVAL, otherwise Vertica returns an error:
SELECT DATEDIFF(day, INTERVAL '26 days', INTERVAL '1 month ');
datediff
----------
4
(1 row)
Date part intervals
DATEDIFF uses the datepart argument to calculate the number of intervals between two dates, rather than the actual amount of time between them. DATEDIFF uses the following cutoff points to calculate those intervals:
-
year: January 1
-
quarter: January 1, April 1, July 1, October 1
-
month: the first day of the month
-
week: Sunday at midnight (24:00)
For example, if datepart is set to year, DATEDIFF uses January 01 to calculate the number of years between two dates. The following DATEDIFF statement sets datepart to year, and specifies a time span 01/01/2005 - 06/15/2008:
SELECT DATEDIFF(year, '01-01-2005'::date, '12-31-2008'::date);
datediff
----------
3
(1 row)
DATEDIFF always excludes the start date when it calculates intervals—in this case, 01/01//2005. DATEDIFF considers only calendar year starts in its calculation, so in this case it only counts years 2006, 2007, and 2008. The function returns 3, although the actual time span is nearly four years.
If you change the start and end dates to 12/31/2004 and 01/01/2009, respectively, DATEDIFF also counts years 2005 and 2009. This time, it returns 5, although the actual time span is just over four years:
=> SELECT DATEDIFF(year, '12-31-2004'::date, '01-01-2009'::date);
datediff
----------
5
(1 row)
Similarly, DATEDIFF uses month start dates when it calculates the number of months between two dates. Thus, given the following statement, DATEDIFF counts months February through September and returns 8:
=> SELECT DATEDIFF(month, '01-31-2005'::date, '09-30-2005'::date);
datediff
----------
8
(1 row)
See also
TIMESTAMPDIFF
6.4.2.12 - DAY
Returns as an integer the day of the month from the input value.
Returns as an integer the day of the month from the input value.
Behavior type
-
Immutable if the input value is a TIMESTAMP, DATE, VARCHAR, or INTEGER
-
Stable if the specified date is a TIMESTAMPTZ
Syntax
DAY ( value )
Parameters
value- The value to convert, one of the following:
TIMESTAMP, TIMESTAMPTZ, INTERVAL, VARCHAR, or INTEGER.
Examples
=> SELECT DAY (6);
DAY
-----
6
(1 row)
=> SELECT DAY(TIMESTAMP 'sep 22, 2011 12:34');
DAY
-----
22
(1 row)
=> SELECT DAY('sep 22, 2011 12:34');
DAY
-----
22
(1 row)
=> SELECT DAY(INTERVAL '35 12:34');
DAY
-----
35
(1 row)
6.4.2.13 - DAYOFMONTH
Returns the day of the month as an integer.
Returns the day of the month as an integer.
Behavior type
-
Immutable if thetarget date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the target date is aTIMESTAMPTZ
Syntax
DAYOFMONTH ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT DAYOFMONTH (TIMESTAMP 'sep 22, 2011 12:34');
DAYOFMONTH
------------
22
(1 row)
6.4.2.14 - DAYOFWEEK
Returns the day of the week as an integer, where Sunday is day 1.
Returns the day of the week as an integer, where Sunday is day 1.
Behavior type
-
Immutable if thetarget date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the target date is aTIMESTAMPTZ
Syntax
DAYOFWEEK ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT DAYOFWEEK (TIMESTAMP 'sep 17, 2011 12:34');
DAYOFWEEK
-----------
7
(1 row)
6.4.2.15 - DAYOFWEEK_ISO
Returns the ISO 8061 day of the week as an integer, where Monday is day 1.
Returns the ISO 8061 day of the week as an integer, where Monday is day 1.
Behavior type
-
Immutable if thetarget date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the target date is aTIMESTAMPTZ
Syntax
DAYOFWEEK_ISO ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT DAYOFWEEK_ISO(TIMESTAMP 'Sep 22, 2011 12:34');
DAYOFWEEK_ISO
---------------
4
(1 row)
The following example shows how to combine the DAYOFWEEK_ISO, WEEK_ISO, and YEAR_ISO functions to find the ISO day of the week, week, and year:
=> SELECT DAYOFWEEK_ISO('Jan 1, 2000'), WEEK_ISO('Jan 1, 2000'),YEAR_ISO('Jan1,2000');
DAYOFWEEK_ISO | WEEK_ISO | YEAR_ISO
---------------+----------+----------
6 | 52 | 1999
(1 row)
See also
6.4.2.16 - DAYOFYEAR
Returns the day of the year as an integer, where January 1 is day 1.
Returns the day of the year as an integer, where January 1 is day 1.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
DAYOFYEAR ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT DAYOFYEAR (TIMESTAMP 'SEPT 22,2011 12:34');
DAYOFYEAR
-----------
265
(1 row)
6.4.2.17 - DAYS
Returns the integer value of the specified date, where 1 AD is 1.
Returns the integer value of the specified date, where 1 AD is 1. If the date precedes 1 AD, DAYS returns a negative integer.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
DAYS ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT DAYS (DATE '2011-01-22');
DAYS
--------
734159
(1 row)
=> SELECT DAYS (DATE 'March 15, 0044 BC');
DAYS
--------
-15997
(1 row)
6.4.2.18 - EXTRACT
Retrieves sub-fields such as year or hour from date/time values and returns values of type NUMERIC.
Retrieves sub-fields such as year or hour from date/time values and returns values of type
NUMERIC. EXTRACT is intended for computational processing, rather than for formatting date/time values for display.
Behavior type
-
Immutable if the specified date is a TIMESTAMP, DATE, or INTERVAL
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
EXTRACT ( field FROM date )
Parameters
field- A constant value that specifies the sub-field to extract from
date (see Field Values below).
date- The date to process, an expression that evaluates to one of the following data types:
Field values
CENTURY- The century number.
The first century starts at 0001-01-01 00:00:00 AD. This definition applies to all Gregorian calendar countries. There is no century number 0, you go from –1 to 1.
DAY- The day (of the month) field (1–31).
DECADE- The year field divided by 10.
DOQ- The day within the current quarter. DOQ recognizes leap year days.
DOW- Zero-based day of the week, where Sunday=0.
Note
EXTRACT's day of week numbering differs from the function
TO_CHAR .
DOY- The day of the year (1–365/366)
EPOCH- Specifies to return one of the following:
-
For DATE and TIMESTAMP values: the number of seconds before or since 1970-01-01 00:00:00-00 (if before, a negative number).
-
For INTERVAL values, the total number of seconds in the interval.
HOUR- The hour field (0–23).
ISODOW- The ISO day of the week, an integer between 1 and 7 where Monday is 1.
ISOWEEK- The ISO week of the year, an integer between 1 and 53.
ISOYEAR- The ISO year.
MICROSECONDS- The seconds field, including fractional parts, multiplied by 1,000,000. This includes full seconds.
MILLENNIUM- The millennium number, where the first millennium is 1 and each millenium starts on
01-01-y001. For example, millennium 2 starts on 01-01-1001.
MILLISECONDS- The seconds field, including fractional parts, multiplied by 1000. This includes full seconds.
MINUTE- The minutes field (0 - 59).
MONTH- For
TIMESTAMP values, the number of the month within the year (1 - 12) ; for interval values the number of months, modulo 12 (0 - 11).
QUARTER- The calendar quarter of the specified date as an integer, where the January-March quarter is 1, valid only for
TIMESTAMP values.
SECOND- The seconds field, including fractional parts, 0–59, or 0-60 if the operating system implements leap seconds.
TIME ZONE- The time zone offset from UTC, in seconds. Positive values correspond to time zones east of UTC, negative values to zones west of UTC.
TIMEZONE_HOUR- The hour component of the time zone offset.
TIMEZONE_MINUTE- The minute component of the time zone offset.
WEEK- The number of the week of the calendar year that the day is in.
YEAR- The year field. There is no
0 AD, so subtract BC years from AD years accordingly.
Examples
Extract the day of the week and day in quarter from the current TIMESTAMP:
=> SELECT CURRENT_TIMESTAMP AS NOW;
NOW
-------------------------------
2016-05-03 11:36:08.829004-04
(1 row)
=> SELECT EXTRACT (DAY FROM CURRENT_TIMESTAMP);
date_part
-----------
3
(1 row)
=> SELECT EXTRACT (DOQ FROM CURRENT_TIMESTAMP);
date_part
-----------
33
(1 row)
Extract the timezone hour from the current time:
=> SELECT CURRENT_TIMESTAMP;
?column?
-------------------------------
2016-05-03 11:36:08.829004-04
(1 row)
=> SELECT EXTRACT(TIMEZONE_HOUR FROM CURRENT_TIMESTAMP);
date_part
-----------
-4
(1 row)
Extract the number of seconds since 01-01-1970 00:00:
=> SELECT EXTRACT(EPOCH FROM '2001-02-16 20:38:40-08'::TIMESTAMPTZ);
date_part
------------------
982384720.000000
(1 row)
Extract the number of seconds between 01-01-1970 00:00 and 5 days 3 hours before:
=> SELECT EXTRACT(EPOCH FROM -'5 days 3 hours'::INTERVAL);
date_part
----------------
-442800.000000
(1 row)
Convert the results from the last example to a TIMESTAMP:
=> SELECT 'EPOCH'::TIMESTAMPTZ -442800 * '1 second'::INTERVAL;
?column?
------------------------
1969-12-26 16:00:00-05
(1 row)
6.4.2.19 - GETDATE
Returns the current statement's start date and time as a TIMESTAMP value.
Returns the current statement's start date and time as a TIMESTAMP value. This function is identical to
SYSDATE.
GETDATE uses the date and time supplied by the operating system on the server to which you are connected, which is the same across all servers. Internally, GETDATE converts
STATEMENT_TIMESTAMP from TIMESTAMPTZ to TIMESTAMP.
Behavior type
Stable
Syntax
GETDATE()
Examples
=> SELECT GETDATE();
GETDATE
----------------------------
2011-03-07 13:21:29.497742
(1 row)
See also
Date/time expressions
6.4.2.20 - GETUTCDATE
Returns the current statement's start date and time as a TIMESTAMP value.
Returns the current statement's start date and time as a TIMESTAMP value.
GETUTCDATE uses the date and time supplied by the operating system on the server to which you are connected, which is the same across all servers. Internally, GETUTCDATE converts
STATEMENT_TIMESTAMP at TIME ZONE 'UTC'.
Behavior type
Stable
Syntax
GETUTCDATE()
Examples
=> SELECT GETUTCDATE();
GETUTCDATE
----------------------------
2011-03-07 20:20:26.193052
(1 row)
See also
6.4.2.21 - HOUR
Returns the hour portion of the specified date as an integer, where 0 is 00:00 to 00:59.
Returns the hour portion of the specified date as an integer, where 0 is 00:00 to 00:59.
Behavior type
Syntax
HOUR( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT HOUR (TIMESTAMP 'sep 22, 2011 12:34');
HOUR
------
12
(1 row)
=> SELECT HOUR (INTERVAL '35 12:34');
HOUR
------
12
(1 row)
=> SELECT HOUR ('12:34');
HOUR
------
12
(1 row)
6.4.2.22 - ISFINITE
Tests for the special TIMESTAMP constant INFINITY and returns a value of type BOOLEAN.
Tests for the special TIMESTAMP constant INFINITY and returns a value of type BOOLEAN.
Behavior type
Immutable
Syntax
ISFINITE ( timestamp )
Parameters
timestamp- Expression of type TIMESTAMP
Examples
SELECT ISFINITE(TIMESTAMP '2009-02-16 21:28:30');
ISFINITE
----------
t
(1 row)
SELECT ISFINITE(TIMESTAMP 'INFINITY');
ISFINITE
----------
f
(1 row)
6.4.2.23 - JULIAN_DAY
Returns the integer value of the specified day according to the Julian calendar, where day 1 is the first day of the Julian period, January 1, 4713 BC (on the Gregorian calendar, November 24, 4714 BC).
Returns the integer value of the specified day according to the Julian calendar, where day 1 is the first day of the Julian period, January 1, 4713 BC (on the Gregorian calendar, November 24, 4714 BC).
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
JULIAN_DAY ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT JULIAN_DAY (DATE 'MARCH 15, 0044 BC');
JULIAN_DAY
------------
1705428
(1 row)
=> SELECT JULIAN_DAY (DATE '2001-01-01');
JULIAN_DAY
------------
2451911
(1 row)
6.4.2.24 - LAST_DAY
Returns the last day of the month in the specified date.
Returns the last day of the month in the specified date.
Behavior type
Syntax
LAST_DAY ( date )
Parameters
date- The date to process, one of the following data types:
Calculating first day of month
SQL does not support any function that returns the first day in the month of a given date. You must use other functions to work around this limitation. For example:
=> SELECT DATE ('2022/07/04') - DAYOFMONTH ('2022/07/04') +1;
?column?
------------
2022-07-01
(1 row)
=> SELECT LAST_DAY('1929/06/06') - (SELECT DAY(LAST_DAY('1929/06/06'))-1);
?column?
------------
1929-06-01
(1 row)
Examples
The following example returns the last day of February as 29 because 2016 is a leap year:
=> SELECT LAST_DAY('2016-02-28 23:30 PST') "Last Day";
Last Day
------------
2016-02-29
(1 row)
The following example returns the last day of February in a non-leap year:
> SELECT LAST_DAY('2017/02/03') "Last";
Last
------------
2017-02-28
(1 row)
The following example returns the last day of March, after converting the string value to the specified DATE type:
=> SELECT LAST_DAY('2003/03/15') "Last";
Last
------------
2012-03-31
(1 row)
6.4.2.25 - LOCALTIME
Returns a value of type TIME that represents the start of the current transaction.
Returns a value of type TIME that represents the start of the current transaction.
The return value does not change during the transaction. Thus, multiple calls to LOCALTIME within the same transaction return the same timestamp.
Behavior type
Stable
Syntax
LOCALTIME [ ( precision ) ]
Parameters
precision- Rounds the result to the specified number of fractional digits in the seconds field.
Examples
=> CREATE TABLE t1 (a int, b int);
CREATE TABLE
=> INSERT INTO t1 VALUES (1,2);
OUTPUT
--------
1
(1 row)
=> SELECT LOCALTIME time;
time
-----------------
15:03:14.595296
(1 row)
=> INSERT INTO t1 VALUES (3,4);
OUTPUT
--------
1
(1 row)
=> SELECT LOCALTIME;
time
-----------------
15:03:14.595296
(1 row)
=> COMMIT;
COMMIT
=> SELECT LOCALTIME;
time
-----------------
15:03:49.738032
(1 row)
6.4.2.26 - LOCALTIMESTAMP
Returns a value of type TIMESTAMP/TIMESTAMPTZ that represents the start of the current transaction, and remains unchanged until the transaction is closed.
Returns a value of type TIMESTAMP/TIMESTAMPTZ that represents the start of the current transaction, and remains unchanged until the transaction is closed. Thus, multiple calls to LOCALTIMESTAMP within a given transaction return the same timestamp.
Behavior type
Stable
Syntax
LOCALTIMESTAMP [ ( precision ) ]
Parameters
precision- Rounds the result to the specified number of fractional digits in the seconds field.
Examples
=> CREATE TABLE t1 (a int, b int);
CREATE TABLE
=> INSERT INTO t1 VALUES (1,2);
OUTPUT
--------
1
(1 row)
=> SELECT LOCALTIMESTAMP(2) AS 'local timestamp';
local timestamp
------------------------
2021-03-05 10:48:58.26
(1 row)
=> INSERT INTO t1 VALUES (3,4);
OUTPUT
--------
1
(1 row)
=> SELECT LOCALTIMESTAMP(2) AS 'local timestamp';
local timestamp
------------------------
2021-03-05 10:48:58.26
(1 row)
=> COMMIT;
COMMIT
=> SELECT LOCALTIMESTAMP(2) AS 'local timestamp';
local timestamp
------------------------
2021-03-05 10:50:08.99
(1 row)
6.4.2.27 - MICROSECOND
Returns the microsecond portion of the specified date as an integer.
Returns the microsecond portion of the specified date as an integer.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, INTERVAL, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
MICROSECOND ( date )
Parameters
date- The date to process, one of the following data types:
Examples
=> SELECT MICROSECOND (TIMESTAMP 'Sep 22, 2011 12:34:01.123456');
MICROSECOND
-------------
123456
(1 row)
6.4.2.28 - MIDNIGHT_SECONDS
Within the specified date, returns the number of seconds between midnight and the date's time portion.
Within the specified date, returns the number of seconds between midnight and the date's time portion.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
MIDNIGHT_SECONDS ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
Get the number of seconds since midnight:
=> SELECT MIDNIGHT_SECONDS(CURRENT_TIMESTAMP);
MIDNIGHT_SECONDS
------------------
36480
(1 row)
Get the number of seconds between midnight and noon on March 3 2016:
=> SELECT MIDNIGHT_SECONDS('3-3-2016 12:00'::TIMESTAMP);
MIDNIGHT_SECONDS
------------------
43200
(1 row)
6.4.2.29 - MINUTE
Returns the minute portion of the specified date as an integer.
Returns the minute portion of the specified date as an integer.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, VARCHAR or INTERVAL
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
MINUTE ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT MINUTE('12:34:03.456789');
MINUTE
--------
34
(1 row)
=>SELECT MINUTE (TIMESTAMP 'sep 22, 2011 12:34');
MINUTE
--------
34
(1 row)
=> SELECT MINUTE(INTERVAL '35 12:34:03.456789');
MINUTE
--------
34
(1 row)
6.4.2.30 - MONTH
Returns the month portion of the specified date as an integer.
Returns the month portion of the specified date as an integer.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, VARCHAR or INTERVAL
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
MONTH ( date )
Parameters
dateThe date to process, one of the following data types:
Examples
In the following examples, Vertica returns the month portion of the specified string. For example, '6-9' represent September 6.
=> SELECT MONTH('6-9');
MONTH
-------
9
(1 row)
=> SELECT MONTH (TIMESTAMP 'sep 22, 2011 12:34');
MONTH
-------
9
(1 row)
=> SELECT MONTH(INTERVAL '2-35' year to month);
MONTH
-------
11
(1 row)
6.4.2.31 - MONTHS_BETWEEN
Returns the number of months between two dates.
Returns the number of months between two dates. MONTHS_BETWEEN can return an integer or a FLOAT:
-
Integer: The day portions of date1 and date2 are the same, and neither date is the last day of the month. MONTHS_BETWEEN also returns an integer if both dates in date1 and date2 are the last days of their respective months. For example, MONTHS_BETWEEN calculates the difference between April 30 and March 31 as 1 month.
-
FLOAT: The day portions of date1 and date2 are different and one or both dates are not the last day of their respective months. For example, the difference between April 2 and March 1 is 1.03225806451613. To calculate month fractions, MONTHS_BETWEEN assumes all months contain 31 days.
MONTHS_BETWEEN disregards timestamp time portions.
Behavior type
Syntax
MONTHS_BETWEEN ( date1 , date2 );
Parameters
date1
date2- Specify the dates to evaluate where
date1 and date2 evaluate to one of the following data types:
-
DATE
-
TIMESTAMP
-
TIMESTAMPTZ
If date1 < date2, MONTHS_BETWEEN returns a negative value.
Examples
Return the number of months between April 7 2016 and January 7 2015:
=> SELECT MONTHS_BETWEEN ('04-07-16'::TIMESTAMP, '01-07-15'::TIMESTAMP);
MONTHS_BETWEEN
----------------
15
(1 row)
Return the number of months between March 31 2016 and February 28 2016 (MONTHS_BETWEEN assumes both months contain 31 days):
=> SELECT MONTHS_BETWEEN ('03-31-16'::TIMESTAMP, '02-28-16'::TIMESTAMP);
MONTHS_BETWEEN
------------------
1.09677419354839
(1 row)
Return the number of months between March 31 2016 and February 29 2016:
=> SELECT MONTHS_BETWEEN ('03-31-16'::TIMESTAMP, '02-29-16'::TIMESTAMP);
MONTHS_BETWEEN
----------------
1
(1 row)
6.4.2.32 - NEW_TIME
Converts a timestamp value from one time zone to another and returns a TIMESTAMP.
Converts a timestamp value from one time zone to another and returns a TIMESTAMP.
Behavior type
Immutable
Syntax
NEW_TIME( 'timestamp' , 'timezone1' , 'timezone2')
Parameters
timestamp- The timestamp to convert, conforms to one of the following formats:
- timezone1
*`timezone2`*
- Specify the source and target timezones, one of the strings defined in
/opt/vertica/share/timezonesets. For example:
-
GMT: Greenwich Mean Time
-
AST / ADT: Atlantic Standard/Daylight Time
-
EST / EDT: Eastern Standard/Daylight Time
-
CST / CDT: Central Standard/Daylight Time
-
MST / MDT: Mountain Standard/Daylight Time
-
PST / PDT: Pacific Standard/Daylight Time
Examples
Convert the specified time from Eastern Standard Time (EST) to Pacific Standard Time (PST):
=> SELECT NEW_TIME('05-24-12 13:48:00', 'EST', 'PST');
NEW_TIME
---------------------
2012-05-24 10:48:00
(1 row)
Convert 1:00 AM January 2012 from EST to PST:
=> SELECT NEW_TIME('01-01-12 01:00:00', 'EST', 'PST');
NEW_TIME
---------------------
2011-12-31 22:00:00
(1 row)
Convert the current time EST to PST:
=> SELECT NOW();
NOW
-------------------------------
2016-12-09 10:30:36.727307-05
(1 row)
=> SELECT NEW_TIME('NOW', 'EDT', 'CDT');
NEW_TIME
----------------------------
2016-12-09 09:30:36.727307
(1 row)
The following example returns the year 45 before the Common Era in Greenwich Mean Time and converts it to Newfoundland Standard Time:
=> SELECT NEW_TIME('April 1, 45 BC', 'GMT', 'NST')::DATE;
NEW_TIME
---------------
0045-03-31 BC
(1 row)
6.4.2.33 - NEXT_DAY
Returns the date of the first instance of a particular day of the week that follows the specified date.
Returns the date of the first instance of a particular day of the week that follows the specified date.
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Syntax
NEXT_DAY( 'date', 'day-string')
Parameters
dateThe date to process, one of the following data types:
day-string- The day of the week to process, a CHAR or VARCHAR string or character constant. Supply the full English name such as Tuesday, or any conventional abbreviation, such as Tue or Tues.
day-string is not case sensitive and trailing spaces are ignored.
Examples
Get the date of the first Monday that follows April 29 2016:
=> SELECT NEXT_DAY('4-29-2016'::TIMESTAMP,'Monday') "NEXT DAY" ;
NEXT DAY
------------
2016-05-02
(1 row)
Get the first Tuesday that follows today:
SELECT NEXT_DAY(CURRENT_TIMESTAMP,'tues') "NEXT DAY" ;
NEXT DAY
------------
2016-05-03
(1 row)
6.4.2.34 - NOW [date/time]
Returns a value of type TIMESTAMP WITH TIME ZONE representing the start of the current transaction.
Returns a value of type TIMESTAMP WITH TIME ZONE representing the start of the current transaction. NOW is equivalent to
CURRENT_TIMESTAMP except that it does not accept a precision parameter.
The return value does not change during the transaction. Thus, multiple calls to CURRENT_TIMESTAMP within the same transaction return the same timestamp.
Behavior type
Stable
Syntax
NOW()
Examples
=> CREATE TABLE t1 (a int, b int);
CREATE TABLE
=> INSERT INTO t1 VALUES (1,2);
OUTPUT
--------
1
(1 row)
=> SELECT NOW();
NOW
------------------------------
2016-12-09 13:00:08.74685-05
(1 row)
=> INSERT INTO t1 VALUES (3,4);
OUTPUT
--------
1
(1 row)
=> SELECT NOW();
NOW
------------------------------
2016-12-09 13:00:08.74685-05
(1 row)
=> COMMIT;
COMMIT
dbadmin=> SELECT NOW();
NOW
-------------------------------
2016-12-09 13:01:31.420624-05
(1 row)
6.4.2.35 - OVERLAPS
Evaluates two time periods and returns true when they overlap, false otherwise.
Evaluates two time periods and returns true when they overlap, false otherwise.
Behavior type
Syntax
( start, end ) OVERLAPS ( start, end )
( start, interval) OVERLAPS ( start, interval )
Parameters
startDATE, TIME, or TIMESTAMP/TIMESTAMPTZ value that specifies the beginning of a time period.endDATE, TIME, or TIMESTAMP/TIMESTAMPTZ value that specifies the end of a time period.interval- Value that specifies the length of the time period.
Examples
Evaluate whether date ranges Feb 16 - Dec 21, 2016 and Oct 10 2008 - Oct 3 2016 overlap:
=> SELECT (DATE '2016-02-16', DATE '2016-12-21') OVERLAPS (DATE '2008-10-30', DATE '2016-10-30');
overlaps
----------
t
(1 row)
Evaluate whether date ranges Feb 16 - Dec 21, 2016 and Jan 01 - Oct 30 2008 - Oct 3, 2016 overlap:
=> SELECT (DATE '2016-02-16', DATE '2016-12-21') OVERLAPS (DATE '2008-01-30', DATE '2008-10-30');
overlaps
----------
f
(1 row)
Evaluate whether date range Feb 02 2016 + 1 week overlaps with date range Oct 16 2016 - 8 months:
=> SELECT (DATE '2016-02-16', INTERVAL '1 week') OVERLAPS (DATE '2016-10-16', INTERVAL '-8 months');
overlaps
----------
t
(1 row)
6.4.2.36 - QUARTER
Returns calendar quarter of the specified date as an integer, where the January-March quarter is 1.
Returns calendar quarter of the specified date as an integer, where the January-March quarter is 1.
Syntax
QUARTER ( date )
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR.
-
Stable if the specified date is aTIMESTAMPTZ
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT QUARTER (TIMESTAMP 'sep 22, 2011 12:34');
QUARTER
---------
3
(1 row)
6.4.2.37 - ROUND
Rounds the specified date or time.
Rounds the specified date or time. If you omit the precision argument, ROUND rounds to day (DD) precision.
Behavior type
Syntax
ROUND( rounding-target[, 'precision'] )
Parameters
*rounding-target*- An expression that evaluates to one of the following data types:
precision- A string constant that specifies precision for the rounded value, one of the following:
-
Century: CC | SCC
-
Year: SYYY | YYYY | YEAR | YYY | YY | Y
-
ISO Year: IYYY | IYY | IY | I
-
Quarter: Q
-
Month: MONTH | MON | MM | RM
-
Same weekday as first day of year: WW
-
Same weekday as first day of ISO year: IW
-
Same weekday as first day of month: W
-
Day (default): DDD | DD | J
-
First weekday: DAY | DY | D
-
Hour: HH | HH12 | HH24
-
Minute: MI
-
Second: SS
Note
Hour, minute, and second rounding is not supported by DATE expressions.
Examples
Round to the nearest hour:
=> SELECT ROUND(CURRENT_TIMESTAMP, 'HH');
ROUND
---------------------
2016-04-28 15:00:00
(1 row)
Round to the nearest month:
=> SELECT ROUND('9-22-2011 12:34:00'::TIMESTAMP, 'MM');
ROUND
---------------------
2011-10-01 00:00:00
(1 row)
See also
TIMESTAMP_ROUND
6.4.2.38 - SECOND
Returns the seconds portion of the specified date as an integer.
Returns the seconds portion of the specified date as an integer.
Syntax
SECOND ( date )
Behavior type
Immutable, except for TIMESTAMPTZ arguments where it is stable.
Parameters
date- The date to process, one of the following data types:
Examples
=> SELECT SECOND ('23:34:03.456789');
SECOND
--------
3
(1 row)
=> SELECT SECOND (TIMESTAMP 'sep 22, 2011 12:34');
SECOND
--------
0
(1 row)
=> SELECT SECOND (INTERVAL '35 12:34:03.456789');
SECOND
--------
3
(1 row)
6.4.2.39 - STATEMENT_TIMESTAMP
Similar to TRANSACTION_TIMESTAMP, returns a value of type TIMESTAMP WITH TIME ZONE that represents the start of the current statement.
Similar to
TRANSACTION_TIMESTAMP, returns a value of type TIMESTAMP WITH TIME ZONE that represents the start of the current statement.
The return value does not change during statement execution. Thus, different stages of statement execution always have the same timestamp.
Behavior type
Stable
Syntax
STATEMENT_TIMESTAMP()
Examples
=> SELECT foo, bar FROM (SELECT STATEMENT_TIMESTAMP() AS foo)foo, (SELECT STATEMENT_TIMESTAMP() as bar)bar;
foo | bar
-------------------------------+-------------------------------
2016-12-07 14:55:51.543988-05 | 2016-12-07 14:55:51.543988-05
(1 row)
See also
6.4.2.40 - SYSDATE
Returns the current statement's start date and time as a TIMESTAMP value.
Returns the current statement's start date and time as a TIMESTAMP value. This function is identical to
GETDATE.
SYSDATE uses the date and time supplied by the operating system on the server to which you are connected, which is the same across all servers. Internally, GETDATE converts
STATEMENT_TIMESTAMP from TIMESTAMPTZ to TIMESTAMP.
Behavior type
Stable
Syntax
SYSDATE()
Note
You can call this function with no parentheses.
Examples
=> SELECT SYSDATE;
sysdate
----------------------------
2016-12-12 06:11:10.699642
(1 row)
See also
Date/time expressions
6.4.2.41 - TIME_SLICE
Aggregates data by different fixed-time intervals and returns a rounded-up input TIMESTAMP value to a value that corresponds with the start or end of the time slice interval.
Aggregates data by different fixed-time intervals and returns a rounded-up input TIMESTAMP value to a value that corresponds with the start or end of the time slice interval.
Given an input TIMESTAMP value such as 2000-10-28 00:00:01, the start time of a 3-second time slice interval is 2000-10-28 00:00:00, and the end time of the same time slice is 2000-10-28 00:00:03.
Behavior type
Immutable
Syntax
TIME_SLICE( expression, slice-length [, 'time-unit' [, 'start-or-end' ] ] )
Parameters
expression- One of the following:
Vertica evaluates expression on each row.
slice-length- A positive integer that specifies the slice length.
time-unit- Time unit of the slice, one of the following:
-
HOUR
-
MINUTE
-
SECOND (default)
-
MILLISECOND
-
MICROSECOND
start-or-end - Specifies whether the returned value corresponds to the start or end time with one of the following strings:
Note
This parameter can be included only if you also supply a non-null time-unit argument.
Null argument handling
TIME_SLICE handles null arguments as follows:
-
TIME_SLICE returns an error when any one of slice-length, time-unit, or start-or-end parameters is null.
-
If expression is null and *slice-length*, *time-unit*, or *start-or-end* contain legal values, TIME_SLICE returns a NULL value instead of an error.
Usage
The following command returns the (default) start time of a 3-second time slice:
=> SELECT TIME_SLICE('2009-09-19 00:00:01', 3);
TIME_SLICE
---------------------
2009-09-19 00:00:00
(1 row)
The following command returns the end time of a 3-second time slice:
=> SELECT TIME_SLICE('2009-09-19 00:00:01', 3, 'SECOND', 'END');
TIME_SLICE
---------------------
2009-09-19 00:00:03
(1 row)
This command returns results in milliseconds, using a 3-second time slice:
=> SELECT TIME_SLICE('2009-09-19 00:00:01', 3, 'ms');
TIME_SLICE
-------------------------
2009-09-19 00:00:00.999
(1 row)
This command returns results in microseconds, using a 9-second time slice:
=> SELECT TIME_SLICE('2009-09-19 00:00:01', 3, 'us');
TIME_SLICE
----------------------------
2009-09-19 00:00:00.999999
(1 row)
The next example uses a 3-second interval with an input value of '00:00:01'. To focus specifically on seconds, the example omits date, though all values are implied as being part of the timestamp with a given input of '00:00:01':
-
'00:00:00' is the start of the 3-second time slice
-
'00:00:03' is the end of the 3-second time slice.
-
'00:00:03' is also the start of the second 3-second time slice. In time slice boundaries, the end value of a time slice does not belong to that time slice; it starts the next one.
When the time slice interval is not a factor of 60 seconds, such as a given slice length of 9 in the following example, the slice does not always start or end on 00 seconds:
=> SELECT TIME_SLICE('2009-02-14 20:13:01', 9);
TIME_SLICE
---------------------
2009-02-14 20:12:54
(1 row)
This is expected behavior, as the following properties are true for all time slices:
To force the above example ('2009-02-14 20:13:01') to start at '2009-02-14 20:13:00', adjust the output timestamp values so that the remainder of 54 counts up to 60:
=> SELECT TIME_SLICE('2009-02-14 20:13:01', 9 )+'6 seconds'::INTERVAL AS time;
time
---------------------
2009-02-14 20:13:00
(1 row)
Alternatively, you could use a different slice length, which is divisible by 60, such as 5:
=> SELECT TIME_SLICE('2009-02-14 20:13:01', 5);
TIME_SLICE
---------------------
2009-02-14 20:13:00
(1 row)
A TIMESTAMPTZ value is implicitly cast to TIMESTAMP. For example, the following two statements have the same effect.
=> SELECT TIME_SLICE('2009-09-23 11:12:01'::timestamptz, 3);
TIME_SLICE
---------------------
2009-09-23 11:12:00
(1 row)
=> SELECT TIME_SLICE('2009-09-23 11:12:01'::timestamptz::timestamp, 3);
TIME_SLICE
---------------------
2009-09-23 11:12:00
(1 row)
Examples
You can use the SQL analytic functions
FIRST_VALUE and
LAST_VALUE to find the first/last price within each time slice group (set of rows belonging to the same time slice). This structure can be useful if you want to sample input data by choosing one row from each time slice group.
=> SELECT date_key, transaction_time, sales_dollar_amount,TIME_SLICE(DATE '2000-01-01' + date_key + transaction_time, 3),
FIRST_VALUE(sales_dollar_amount)
OVER (PARTITION BY TIME_SLICE(DATE '2000-01-01' + date_key + transaction_time, 3)
ORDER BY DATE '2000-01-01' + date_key + transaction_time) AS first_value
FROM store.store_sales_fact
LIMIT 20;
date_key | transaction_time | sales_dollar_amount | time_slice | first_value
----------+------------------+---------------------+---------------------+-------------
1 | 00:41:16 | 164 | 2000-01-02 00:41:15 | 164
1 | 00:41:33 | 310 | 2000-01-02 00:41:33 | 310
1 | 15:32:51 | 271 | 2000-01-02 15:32:51 | 271
1 | 15:33:15 | 419 | 2000-01-02 15:33:15 | 419
1 | 15:33:44 | 193 | 2000-01-02 15:33:42 | 193
1 | 16:36:29 | 466 | 2000-01-02 16:36:27 | 466
1 | 16:36:44 | 250 | 2000-01-02 16:36:42 | 250
2 | 03:11:28 | 39 | 2000-01-03 03:11:27 | 39
3 | 03:55:15 | 375 | 2000-01-04 03:55:15 | 375
3 | 11:58:05 | 369 | 2000-01-04 11:58:03 | 369
3 | 11:58:24 | 174 | 2000-01-04 11:58:24 | 174
3 | 11:58:52 | 449 | 2000-01-04 11:58:51 | 449
3 | 19:01:21 | 201 | 2000-01-04 19:01:21 | 201
3 | 22:15:05 | 156 | 2000-01-04 22:15:03 | 156
4 | 13:36:57 | -125 | 2000-01-05 13:36:57 | -125
4 | 13:37:24 | -251 | 2000-01-05 13:37:24 | -251
4 | 13:37:54 | 353 | 2000-01-05 13:37:54 | 353
4 | 13:38:04 | 426 | 2000-01-05 13:38:03 | 426
4 | 13:38:31 | 209 | 2000-01-05 13:38:30 | 209
5 | 10:21:24 | 488 | 2000-01-06 10:21:24 | 488
(20 rows)
TIME_SLICE rounds the transaction time to the 3-second slice length.
The following example uses the analytic (window) OVER clause to return the last trading price (the last row ordered by TickTime) in each 3-second time slice partition:
=> SELECT DISTINCT TIME_SLICE(TickTime, 3), LAST_VALUE(price)OVER (PARTITION BY TIME_SLICE(TickTime, 3)
ORDER BY TickTime ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING);
Note
If you omit the windowing clause from an analytic clause,
LAST_VALUE defaults to
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. Results can seem non-intuitive, because instead of returning the value from the bottom of the current partition, the function returns the bottom of the
window, which continues to change along with the current input row that is being processed. For more information, see
Time series analytics and
SQL analytics.
In the next example, FIRST_VALUE is evaluated once for each input record and the data is sorted by ascending values. Use SELECT DISTINCT to remove the duplicates and return only one output record per TIME_SLICE:
=> SELECT DISTINCT TIME_SLICE(TickTime, 3), FIRST_VALUE(price)OVER (PARTITION BY TIME_SLICE(TickTime, 3)
ORDER BY TickTime ASC)
FROM tick_store;
TIME_SLICE | ?column?
---------------------+----------
2009-09-21 00:00:06 | 20.00
2009-09-21 00:00:09 | 30.00
2009-09-21 00:00:00 | 10.00
(3 rows)
The information output by the above query can also return MIN, MAX, and AVG of the trading prices within each time slice.
=> SELECT DISTINCT TIME_SLICE(TickTime, 3),FIRST_VALUE(Price) OVER (PARTITION BY TIME_SLICE(TickTime, 3)
ORDER BY TickTime ASC),
MIN(price) OVER (PARTITION BY TIME_SLICE(TickTime, 3)),
MAX(price) OVER (PARTITION BY TIME_SLICE(TickTime, 3)),
AVG(price) OVER (PARTITION BY TIME_SLICE(TickTime, 3))
FROM tick_store;
See also
6.4.2.42 - TIMEOFDAY
Returns the wall-clock time as a text string.
Returns the wall-clock time as a text string. Function results advance during transactions.
Behavior type
Volatile
Syntax
TIMEOFDAY()
Examples
=> SELECT TIMEOFDAY();
TIMEOFDAY
-------------------------------------
Mon Dec 12 08:18:01.022710 2016 EST
(1 row)
6.4.2.43 - TIMESTAMP_ROUND
Rounds the specified TIMESTAMP.
Rounds the specified TIMESTAMP. If you omit the precision argument, TIMESTAMP_ROUND rounds to day (DD) precision.
Behavior type
Syntax
TIMESTAMP_ROUND ( rounding-target[, 'precision'] )
Parameters
rounding-target- An expression that evaluates to one of the following data types:
precision- A string constant that specifies precision for the rounded value, one of the following:
-
Century: CC | SCC
-
Year: SYYY | YYYY | YEAR | YYY | YY | Y
-
ISO Year: IYYY | IYY | IY | I
-
Quarter: Q
-
Month: MONTH | MON | MM | RM
-
Same weekday as first day of year: WW
-
Same weekday as first day of ISO year: IW
-
Same weekday as first day of month: W
-
Day (default): DDD | DD | J
-
First weekday: DAY | DY | D
-
Hour: HH | HH12 | HH24
-
Minute: MI
-
Second: SS
Note
Hour, minute, and second rounding is not supported by DATE expressions.
Examples
Round to the nearest hour:
=> SELECT TIMESTAMP_ROUND(CURRENT_TIMESTAMP, 'HH');
ROUND
---------------------
2016-04-28 15:00:00
(1 row)
Round to the nearest month:
=> SELECT TIMESTAMP_ROUND('9-22-2011 12:34:00'::TIMESTAMP, 'MM');
ROUND
---------------------
2011-10-01 00:00:00
(1 row)
See also
ROUND
6.4.2.44 - TIMESTAMP_TRUNC
Truncates the specified TIMESTAMP.
Truncates the specified TIMESTAMP. If you omit the precision argument, TIMESTAMP_TRUNC truncates to day (DD) precision.
Behavior type
Syntax
TIMESTAMP_TRUNC( trunc-target[, 'precision'] )
Parameters
trunc-target- An expression that evaluates to one of the following data types:
precision- A string constant that specifies precision for the truncated value, one of the following:
-
Century: CC | SCC
-
Year: SYYY | YYYY | YEAR | YYY | YY | Y
-
ISO Year: IYYY | IYY | IY | I
-
Quarter: Q
-
Month: MONTH | MON | MM | RM
-
Same weekday as first day of year: WW
-
Same weekday as first day of ISO year: IW
-
Same weekday as first day of month: W
-
Day: DDD | DD | J
-
First weekday: DAY | DY | D
-
Hour: HH | HH12 | HH24
-
Minute: MI
-
Second: SS
Note
Hour, minute, and second truncating is not supported by DATE expressions.
Examples
Truncate to the current hour:
=> SELECT TIMESTAMP_TRUNC(CURRENT_TIMESTAMP, 'HH');
TIMESTAMP_TRUNC
---------------------
2016-04-29 08:00:00
(1 row)
Truncate to the month:
=> SELECT TIMESTAMP_TRUNC('9-22-2011 12:34:00'::TIMESTAMP, 'MM');
TIMESTAMP_TRUNC
---------------------
2011-09-01 00:00:00
(1 row)
See also
TRUNC
6.4.2.45 - TIMESTAMPADD
Adds the specified number of intervals to a TIMESTAMP or TIMESTAMPTZ value and returns a result of the same data type.
Adds the specified number of intervals to a TIMESTAMP or TIMESTAMPTZ value and returns a result of the same data type.
Behavior type
Syntax
TIMESTAMPADD ( datepart, count, start-date );
Parameters
datepart- Specifies the type of time intervals that
TIMESTAMPADD adds to the specified start date. If datepart is an expression, it must be enclosed in parentheses:
TIMESTAMPADD((expression), interval, start;
datepart must evaluate to one of the following string literals, either quoted or unquoted:
count- Integer or integer expression that specifies the number of
datepart intervals to add to start-date.
start-date- TIMESTAMP or TIMESTAMPTZ value.
Examples
Add two months to the current date:
=> SELECT CURRENT_TIMESTAMP AS Today;
Today
-------------------------------
2016-05-02 06:56:57.923045-04
(1 row)
=> SELECT TIMESTAMPADD (MONTH, 2, (CURRENT_TIMESTAMP)) AS TodayPlusTwoMonths;;
TodayPlusTwoMonths
-------------------------------
2016-07-02 06:56:57.923045-04
(1 row)
Add 14 days to the beginning of the current month:
=> SELECT TIMESTAMPADD (DD, 14, (SELECT TRUNC((CURRENT_TIMESTAMP), 'MM')));
timestampadd
---------------------
2016-05-15 00:00:00
(1 row)
6.4.2.46 - TIMESTAMPDIFF
Returns the time span between two TIMESTAMP or TIMESTAMPTZ values, in the intervals specified.
Returns the time span between two TIMESTAMP or TIMESTAMPTZ values, in the intervals specified. TIMESTAMPDIFF excludes the start date in its calculation.
Behavior type
Syntax
TIMESTAMPDIFF ( datepart, start, end );
Parameters
datepart- Specifies the type of date or time intervals that
TIMESTAMPDIFF returns. If datepart is an expression, it must be enclosed in parentheses:
TIMESTAMPDIFF((expression), start, end );
datepart must evaluate to one of the following string literals, either quoted or unquoted:
start, end- Specify the start and end dates, where
start and end evaluate to one of the following data types:
If end < start, TIMESTAMPDIFF returns a negative value.
Date part intervals
TIMESTAMPDIFF uses the datepart argument to calculate the number of intervals between two dates, rather than the actual amount of time between them. For detailed information, see
DATEDIFF.
Examples
=> SELECT TIMESTAMPDIFF (YEAR,'1-1-2006 12:34:00', '1-1-2008 12:34:00');
timestampdiff
---------------
2
(1 row)
See also
DATEDIFF
6.4.2.47 - TRANSACTION_TIMESTAMP
Returns a value of type TIME WITH TIMEZONE that represents the start of the current transaction.
Returns a value of type
`TIME WITH TIMEZONE` that represents the start of the current transaction.
The return value does not change during the transaction. Thus, multiple calls to TRANSACTION_TIMESTAMP within the same transaction return the same timestamp.
TRANSACTION_TIMESTAMP is equivalent to
CURRENT_TIMESTAMP, except it does not accept a precision parameter.
Behavior type
Stable
Syntax
TRANSACTION_TIMESTAMP()
Examples
=> SELECT foo, bar FROM (SELECT TRANSACTION_TIMESTAMP() AS foo)foo, (SELECT TRANSACTION_TIMESTAMP() as bar)bar;
foo | bar
-------------------------------+-------------------------------
2016-12-12 08:18:00.988528-05 | 2016-12-12 08:18:00.988528-05
(1 row)
See also
6.4.2.48 - TRUNC
Truncates the specified date or time.
Truncates the specified date or time. If you omit the precision argument, TRUNC truncates to day (DD) precision.
Behavior type
Syntax
TRUNC( trunc-target[, 'precision'] )
Parameters
*trunc-target*- An expression that evaluates to one of the following data types:
precision- A string constant that specifies precision for the truncated value, one of the following:
-
Century: CC | SCC
-
Year: SYYY | YYYY | YEAR | YYY | YY | Y
-
ISO Year: IYYY | IYY | IY | I
-
Quarter: Q
-
Month: MONTH | MON | MM | RM
-
Same weekday as first day of year: WW
-
Same weekday as first day of ISO year: IW
-
Same weekday as first day of month: W
-
Day (default): DDD | DD | J
-
First weekday: DAY | DY | D
-
Hour: HH | HH12 | HH24
-
Minute: MI
-
Second: SS
Note
Hour, minute, and second truncating is not supported by DATE expressions.
Examples
Truncate to the current hour:
=> => SELECT TRUNC(CURRENT_TIMESTAMP, 'HH');
TRUNC
---------------------
2016-04-29 10:00:00
(1 row)
Truncate to the month:
=> SELECT TRUNC('9-22-2011 12:34:00'::TIMESTAMP, 'MM');
TIMESTAMP_TRUNC
---------------------
2011-09-01 00:00:00
(1 row)
See also
TIMESTAMP_TRUNC
6.4.2.49 - WEEK
Returns the week of the year for the specified date as an integer, where the first week begins on the first Sunday on or preceding January 1.
Returns the week of the year for the specified date as an integer, where the first week begins on the first Sunday on or preceding January 1.
Syntax
WEEK ( date )
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Parameters
dateThe date to process, one of the following data types:
Examples
January 2 is on Saturday, so WEEK returns 1:
=> SELECT WEEK ('1-2-2016'::DATE);
WEEK
------
1
(1 row)
January 3 is the second Sunday in 2016, so WEEK returns 2:
=> SELECT WEEK ('1-3-2016'::DATE);
WEEK
------
2
(1 row)
6.4.2.50 - WEEK_ISO
Returns the week of the year for the specified date as an integer, where the first week starts on Monday and contains January 4.
Returns the week of the year for the specified date as an integer, where the first week starts on Monday and contains January 4. This function conforms with the ISO 8061 standard.
Syntax
WEEK_ISO ( date )
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Parameters
dateThe date to process, one of the following data types:
Examples
The first week of 2016 begins on Monday January 4:
=> SELECT WEEK_ISO ('1-4-2016'::DATE);
WEEK_ISO
----------
1
(1 row)
January 3 2016 returns week 53 of the previous year (2015):
=> SELECT WEEK_ISO ('1-3-2016'::DATE);
WEEK_ISO
----------
53
(1 row)
In 2015, January 4 is on Sunday, so the first week of 2015 begins on the preceding Monday (December 29 2014):
=> SELECT WEEK_ISO ('12-29-2014'::DATE);
WEEK_ISO
----------
1
(1 row)
6.4.2.51 - YEAR
Returns an integer that represents the year portion of the specified date.
Returns an integer that represents the year portion of the specified date.
Syntax
YEAR( date )
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, VARCHAR, or INTERVAL
-
Stable if the specified date is aTIMESTAMPTZ
Parameters
dateThe date to process, one of the following data types:
Examples
=> SELECT YEAR(CURRENT_DATE::DATE);
YEAR
------
2016
(1 row)
See also
YEAR_ISO
6.4.2.52 - YEAR_ISO
Returns an integer that represents the year portion of the specified date.
Returns an integer that represents the year portion of the specified date. The return value is based on the ISO 8061 standard.
The first week of the ISO year is the week that contains January 4.
Syntax
YEAR_ISO ( date )
Behavior type
-
Immutable if thespecified date is a TIMESTAMP, DATE, or VARCHAR
-
Stable if the specified date is aTIMESTAMPTZ
Parameters
dateThe date to process, one of the following data types:
Examples
> SELECT YEAR_ISO(CURRENT_DATE::DATE);
YEAR_ISO
----------
2016
(1 row)
See also
YEAR
6.4.3 - IP address functions
IP functions perform conversion, calculation, and manipulation operations on IP, network, and subnet addresses.
IP functions perform conversion, calculation, and manipulation operations on IP, network, and subnet addresses.
6.4.3.1 - INET_ATON
Converts a string that contains a dotted-quad representation of an IPv4 network address to an INTEGER.
Converts a string that contains a dotted-quad representation of an IPv4 network address to an INTEGER. It trims any surrounding white space from the string. This function returns NULL if the string is NULL or contains anything other than a quad dotted IPv4 address.
Behavior type
Immutable
Syntax
INET_ATON ( expression )
Arguments
expression- the string to convert.
Examples
=> SELECT INET_ATON('209.207.224.40');
inet_aton
------------
3520061480
(1 row)
=> SELECT INET_ATON('1.2.3.4');
inet_aton
-----------
16909060
(1 row)
=> SELECT TO_HEX(INET_ATON('1.2.3.4'));
to_hex
---------
1020304
(1 row)
See also
6.4.3.2 - INET_NTOA
Converts an INTEGER value into a VARCHAR dotted-quad representation of an IPv4 network address.
Converts an INTEGER value into a VARCHAR dotted-quad representation of an IPv4 network address. INET_NTOA returns NULL if the integer value is NULL, negative, or is greater than 232 (4294967295).
Behavior type
Immutable
Syntax
INET_NTOA ( expression )
Arguments
expression- The integer network address to convert.
Examples
=> SELECT INET_NTOA(16909060);
inet_ntoa
-----------
1.2.3.4
(1 row)
=> SELECT INET_NTOA(03021962);
inet_ntoa
-------------
0.46.28.138
(1 row)
See also
6.4.3.3 - V6_ATON
Converts a string containing a colon-delimited IPv6 network address into a VARBINARY string.
Converts a string containing a colon-delimited IPv6 network address into a VARBINARY string. Any spaces around the IPv6 address are trimmed. This function returns NULL if the input value is NULL or it cannot be parsed as an IPv6 address. This function relies on the Linux function inet_pton.
Behavior type
Immutable
Syntax
V6_ATON ( expression )
Arguments
expression- (VARCHAR) the string containing an IPv6 address to convert.
Examples
=> SELECT V6_ATON('2001:DB8::8:800:200C:417A');
v6_aton
------------------------------------------------------
\001\015\270\000\000\000\000\000\010\010\000 \014Az
(1 row)
=> SELECT V6_ATON('1.2.3.4');
v6_aton
------------------------------------------------------------------
\000\000\000\000\000\000\000\000\000\000\377\377\001\002\003\004
(1 row)
SELECT TO_HEX(V6_ATON('2001:DB8::8:800:200C:417A'));
to_hex
----------------------------------
20010db80000000000080800200c417a
(1 row)
=> SELECT V6_ATON('::1.2.3.4');
v6_aton
------------------------------------------------------------------
\000\000\000\000\000\000\000\000\000\000\000\000\001\002\003\004
(1 row)
See also
6.4.3.4 - V6_NTOA
Converts an IPv6 address represented as varbinary to a character string.
Converts an IPv6 address represented as varbinary to a character string.
Behavior type
Immutable
Syntax
V6_NTOA ( expression )
Arguments
expression- (
VARBINARY) is the binary string to convert.
Notes
The following syntax converts an IPv6 address represented as VARBINARY B to a string A.
V6_NTOA right-pads B to 16 bytes with zeros, if necessary, and calls the Linux function inet_ntop.
=> V6_NTOA(VARBINARY B) -> VARCHAR A
If B is NULL or longer than 16 bytes, the result is NULL.
Vertica automatically converts the form '::ffff:1.2.3.4' to '1.2.3.4'.
Examples
=> SELECT V6_NTOA(' \001\015\270\000\000\000\000\000\010\010\000 \014Az');
v6_ntoa
---------------------------
2001:db8::8:800:200c:417a
(1 row)
=> SELECT V6_NTOA(V6_ATON('1.2.3.4'));
v6_ntoa
---------
1.2.3.4
(1 row)
=> SELECT V6_NTOA(V6_ATON('::1.2.3.4'));
v6_ntoa
-----------
::1.2.3.4
(1 row)
See also
6.4.3.5 - V6_SUBNETA
Returns a VARCHAR containing a subnet address in CIDR (Classless Inter-Domain Routing) format from a binary or alphanumeric IPv6 address.
Returns a VARCHAR containing a subnet address in CIDR (Classless Inter-Domain Routing) format from a binary or alphanumeric IPv6 address. Returns NULL if either parameter is NULL, the address cannot be parsed as an IPv6 address, or the subnet value is outside the range of 0 to 128.
Behavior type
Immutable
Syntax
V6_SUBNETA ( address, subnet)
Arguments
address- VARBINARY or VARCHAR containing the IPv6 address.
subnet- The size of the subnet in bits as an INTEGER. This value must be greater than zero and less than or equal to 128.
Examples
=> SELECT V6_SUBNETA(V6_ATON('2001:db8::8:800:200c:417a'), 28);
v6_subneta
---------------
2001:db0::/28
(1 row)
See also
6.4.3.6 - V6_SUBNETN
Calculates a subnet address in CIDR (Classless Inter-Domain Routing) format from a varbinary or alphanumeric IPv6 address.
Calculates a subnet address in CIDR (Classless Inter-Domain Routing) format from a varbinary or alphanumeric IPv6 address.
Behavior type
Immutable
Syntax
V6_SUBNETN ( address, subnet-size)
Arguments
address- The IPv6 address as a VARBINARY or VARCHAR. The format you pass in determines the date type of the output. If you pass in a VARBINARY address, V6_SUBNETN returns a VARBINARY value. If you pass in a VARCHAR value, it returns a VARCHAR.
subnet-size- The size of the subnet as an INTEGER.
Notes
The following syntax masks a BINARY IPv6 address B so that the N left-most bits of S form a subnet address, while the remaining right-most bits are cleared.
V6_SUBNETN right-pads B to 16 bytes with zeros, if necessary and masks B, preserving its N-bit subnet prefix.
=> V6_SUBNETN(VARBINARY B, INT8 N) -> VARBINARY(16) S
If B is NULL or longer than 16 bytes, or if N is not between 0 and 128 inclusive, the result is NULL.
S = [B]/N in Classless Inter-Domain Routing notation (CIDR notation).
The following syntax masks an alphanumeric IPv6 address A so that the N leftmost bits form a subnet address, while the remaining rightmost bits are cleared.
=> V6_SUBNETN(VARCHAR A, INT8 N) -> V6_SUBNETN(V6_ATON(A), N) -> VARBINARY(16) S
Examples
This example returns VARBINARY, after using V6_ATON to convert the VARCHAR string to VARBINARY:
=> SELECT V6_SUBNETN(V6_ATON('2001:db8::8:800:200c:417a'), 28);
v6_subnetn
---------------------------------------------------------------
\001\015\260\000\000\000\000\000\000\000\000\000\000\000\000
See also
6.4.3.7 - V6_TYPE
Returns an INTEGER value that classifies the type of the network address passed to it as defined in IETF RFC 4291 section 2.4.
Returns an INTEGER value that classifies the type of the network address passed to it as defined in IETF RFC 4291 section 2.4. For example, If you pass this function the string 127.0.0.1, it returns 2 which indicates the address is a loopback address. This function accepts both IPv4 and IPv6 addresses.
Behavior type
Immutable
Syntax
V6_TYPE ( address)
Arguments
address- A VARBINARY or VARCHAR containing an IPv6 or IPv4 address to describe.
Returns
The values returned by this function are:
|
Return Value |
Address Type |
Description |
|
0 |
GLOBAL |
Global unicast addresses |
|
1 |
LINKLOCAL |
Link-Local unicast (and private-use) addresses |
|
2 |
LOOPBACK |
Loopback addresses |
|
3 |
UNSPECIFIED |
Unspecifiedaddresses |
|
4 |
MULTICAST |
Multicastaddresses |
The return value is based on the following table of IP address ranges:
|
Address Family |
CIDR |
Type |
|
IPv4 |
0.0.0.0/8 |
UNSPECIFIED |
|
10.0.0.0/8 |
LINKLOCAL |
|
127.0.0.0/8 |
LOOPBACK |
|
169.254.0.0/16 |
LINKLOCAL |
|
172.16.0.0/12 |
LINKLOCAL |
|
192.168.0.0/16 |
LINKLOCAL |
|
224.0.0.0/4 |
MULTICAST |
|
All other addresses |
GLOBAL |
|
IPv6 |
::0/128 |
UNSPECIFIED |
|
::1/128 |
LOOPBACK |
|
fe80::/10 |
LINKLOCAL |
|
ff00::/8 |
MULTICAST |
|
All other addresses |
GLOBAL |
This function returns NULL if you pass it a NULL value or an invalid address.
Examples
=> SELECT V6_TYPE(V6_ATON('192.168.2.10'));
v6_type
---------
1
(1 row)
=> SELECT V6_TYPE(V6_ATON('2001:db8::8:800:200c:417a'));
v6_type
---------
0
(1 row)
See also
6.4.4 - Sequence functions
The sequence functions provide simple, multiuser-safe methods for obtaining successive sequence values from sequence objects.
The sequence functions provide simple, multiuser-safe methods for obtaining successive sequence values from sequence objects.
6.4.4.1 - CURRVAL
Returns the last value across all nodes that was set by NEXTVAL on this sequence in the current session.
Returns the last value across all nodes that was set by NEXTVAL on this sequence in the current session. If NEXTVAL was never called on this sequence since its creation, Vertica returns an error.
Syntax
CURRVAL ('[[database.]schema.]sequence-name')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence-name - The target sequence
Privileges
Restrictions
You cannot invoke CURRVAL in a SELECT statement, in the following contexts:
-
WHERE clause
-
GROUP BY clause
-
ORDER BY clause
-
DISTINCT clause
-
UNION
-
Subquery
You also cannot invoke CURRVAL to act on a sequence in:
Examples
See Creating and using named sequences.
See also
NEXTVAL
6.4.4.2 - NEXTVAL
Returns the next value in a sequence.
Returns the next value in a sequence. Call NEXTVAL after creating a sequence to initialize the sequence with its default value. Thereafter, call NEXTVAL to increment the sequence value for ascending sequences, or decrement its value for descending sequences.
Syntax
NEXTVAL ('[[database.]schema.]sequence')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence- Identifies the target sequence.
Privileges
Restrictions
You cannot invoke NEXTVAL in a SELECT statement, in the following contexts:
-
WHERE clause
-
GROUP BY clause
-
ORDER BY clause
-
DISTINCT clause
-
UNION
-
Subquery
You also cannot invoke NEXTVAL to act on a sequence in:
You can use subqueries to work around some of these restrictions. For example, to use sequences with a DISTINCT clause:
=> SELECT t.col1, shift_allocation_seq.NEXTVAL FROM (
SELECT DISTINCT col1 FROM av_temp1) t;
Examples
See Creating and using named sequences.
See also
CURRVAL
6.4.5 - String functions
String functions perform conversion, extraction, or manipulation operations on strings, or return information about strings.
String functions perform conversion, extraction, or manipulation operations on strings, or return information about strings.
This section describes functions and operators for examining and manipulating string values. Strings in this context include values of the types CHAR, VARCHAR, BINARY, and VARBINARY.
Unless otherwise noted, all of the functions listed in this section work on all four data types. As opposed to some other SQL implementations, Vertica keeps CHAR strings unpadded internally, padding them only on final output. So converting a CHAR(3) 'ab' to VARCHAR(5) results in a VARCHAR of length 2, not one with length 3 including a trailing space.
Some of the functions described here also work on data of non-string types by converting that data to a string representation first. Some functions work only on character strings, while others work only on binary strings. Many work for both. BINARY and VARBINARY functions ignore multibyte UTF-8 character boundaries.
Non-binary character string functions handle normalized multibyte UTF-8 characters, as specified by the Unicode Consortium. Unless otherwise specified, those character string functions for which it matters can optionally specify whether VARCHAR arguments should be interpreted as octet (byte) sequences, or as (locale-aware) sequences of UTF-8 characters. This is accomplished by adding "USING OCTETS" or "USING CHARACTERS" (default) as a parameter to the function.
Some character string functions are stable because in general UTF-8 case-conversion, searching and sorting can be locale dependent. Thus, LOWER is stable, while LOWERB is immutable. The USING OCTETS clause converts these functions into their "B" forms, so they become immutable. If the locale is set to collation=binary, which is the default, all string functions—except CHAR_LENGTH/CHARACTER_LENGTH, LENGTH, SUBSTR, and OVERLAY—are converted to their "B" forms and so are immutable.
BINARY implicitly converts to VARBINARY, so functions that take VARBINARY arguments work with BINARY.
For other functions that operate on strings (but not VARBINARY), see Regular expression functions.
6.4.5.1 - ASCII
Converts the first character of a VARCHAR datatype to an INTEGER.
Converts the first character of a VARCHAR datatype to an INTEGER. This function is the opposite of the CHR function.
ASCII operates on UTF-8 characters and single-byte ASCII characters. It returns the same results for the ASCII subset of UTF-8.
Behavior type
Immutable
Syntax
ASCII ( expression )
Arguments
expression- VARCHAR (string) to convert.
Examples
This example returns employee last names that begin with L. The ASCII equivalent of L is 76:
=> SELECT employee_last_name FROM employee_dimension
WHERE ASCII(SUBSTR(employee_last_name, 1, 1)) = 76
LIMIT 5;
employee_last_name
--------------------
Lewis
Lewis
Lampert
Lampert
Li
(5 rows)
6.4.5.2 - BIT_LENGTH
Returns the length of the string expression in bits (bytes * 8) as an INTEGER.
Returns the length of the string expression in bits (bytes * 8) as an INTEGER. BIT_LENGTH applies to the contents of VARCHAR and VARBINARY fields.
Behavior type
Immutable
Syntax
BIT_LENGTH ( expression )
Arguments
expression- (CHAR or VARCHAR or BINARY or VARBINARY) is the string to convert.
Examples
|
Expression |
Result |
SELECT BIT_LENGTH('abc'::varbinary); |
24 |
SELECT BIT_LENGTH('abc'::binary); |
8 |
SELECT BIT_LENGTH(''::varbinary); |
0 |
SELECT BIT_LENGTH(''::binary); |
8 |
SELECT BIT_LENGTH(null::varbinary); |
|
SELECT BIT_LENGTH(null::binary); |
|
SELECT BIT_LENGTH(VARCHAR 'abc'); |
24 |
SELECT BIT_LENGTH(CHAR 'abc'); |
24 |
SELECT BIT_LENGTH(CHAR(6) 'abc'); |
48 |
SELECT BIT_LENGTH(VARCHAR(6) 'abc'); |
24 |
SELECT BIT_LENGTH(BINARY(6) 'abc'); |
48 |
SELECT BIT_LENGTH(BINARY 'abc'); |
24 |
SELECT BIT_LENGTH(VARBINARY 'abc'); |
24 |
SELECT BIT_LENGTH(VARBINARY(6) 'abc'); |
24 |
See also
6.4.5.3 - BITCOUNT
Returns the number of one-bits (sometimes referred to as set-bits) in the given VARBINARY value.
Returns the number of one-bits (sometimes referred to as set-bits) in the given VARBINARY value. This is also referred to as the population count.
Behavior type
Immutable
Syntax
BITCOUNT ( expression )
Arguments
expression- (BINARY or VARBINARY) is the string to return.
Examples
=> SELECT BITCOUNT(HEX_TO_BINARY('0x10'));
BITCOUNT
----------
1
(1 row)
=> SELECT BITCOUNT(HEX_TO_BINARY('0xF0'));
BITCOUNT
----------
4
(1 row)
=> SELECT BITCOUNT(HEX_TO_BINARY('0xAB'));
BITCOUNT
----------
5
(1 row)
6.4.5.4 - BITSTRING_TO_BINARY
Translates the given VARCHAR bitstring representation into a VARBINARY value.
Translates the given VARCHAR bitstring representation into a VARBINARY value. This function is the inverse of
TO_BITSTRING.
Behavior type
Immutable
Syntax
BITSTRING_TO_BINARY ( expression )
Arguments
expression- The VARCHAR string to process.
Examples
If there are an odd number of characters in the hex value, the first character is treated as the low nibble of the first (furthest to the left) byte.
=> SELECT BITSTRING_TO_BINARY('0110000101100010');
BITSTRING_TO_BINARY
---------------------
ab
(1 row)
6.4.5.5 - BTRIM
Removes the longest string consisting only of specified characters from the start and end of a string.
Removes the longest string consisting only of specified characters from the start and end of a string.
Behavior type
Immutable
Syntax
BTRIM ( expression [ , characters-to-remove ] )
Arguments
expression- (CHAR or VARCHAR) is the string to modify
characters-to-remove- (CHAR or VARCHAR) specifies the characters to remove. The default is the space character.
Examples
=> SELECT BTRIM('xyxtrimyyx', 'xy');
BTRIM
-------
trim
(1 row)
See also
6.4.5.6 - CHARACTER_LENGTH
The CHARACTER_LENGTH() function:.
The CHARACTER_LENGTH() function:
-
Returns the string length in UTF-8 characters for CHAR and VARCHAR columns
-
Returns the string length in bytes (octets) for BINARY and VARBINARY columns
-
Strips the padding from CHAR expressions but not from VARCHAR expressions
-
Is identical to LENGTH() for CHAR and VARCHAR. For binary types, CHARACTER_LENGTH() is identical to OCTET_LENGTH().
Behavior type
Immutable if USING OCTETS, stable otherwise.
Syntax
[ CHAR_LENGTH | CHARACTER_LENGTH ] ( expression ... [ USING { CHARACTERS | OCTETS } ] )
Arguments
expression- (CHAR or VARCHAR) is the string to measure
USING CHARACTERS | OCTETS- Determines whether the character length is expressed in characters (the default) or octets.
Examples
=> SELECT CHAR_LENGTH('1234 '::CHAR(10) USING OCTETS);
octet_length
--------------
4
(1 row)
=> SELECT CHAR_LENGTH('1234 '::VARCHAR(10));
char_length
-------------
6
(1 row)
=> SELECT CHAR_LENGTH(NULL::CHAR(10)) IS NULL;
?column?
----------
t
(1 row)
See also
6.4.5.7 - CHR
Converts the first character of an INTEGER datatype to a VARCHAR.
Converts the first character of an INTEGER datatype to a VARCHAR.
Behavior type
Immutable
Syntax
CHR ( expression )
Arguments
expression- (INTEGER) is the string to convert and is masked to a single character.
Notes
-
CHR is the opposite of the ASCII function.
-
CHR operates on UTF-8 characters, not only on single-byte ASCII characters. It continues to get the same results for the ASCII subset of UTF-8.
Examples
This example returns the VARCHAR datatype of the CHR expressions 65 and 97 from the employee table:
=> SELECT CHR(65), CHR(97) FROM employee;
CHR | CHR
-----+-----
A | a
A | a
A | a
A | a
A | a
A | a
A | a
A | a
A | a
A | a
A | a
A | a
(12 rows)
6.4.5.8 - COLLATION
Applies a collation to two or more strings.
Applies a collation to two or more strings. Use COLLATION with ORDER BY, GROUP BY, and equality clauses.
Syntax
COLLATION ( 'expression' [ , 'locale_or_collation_name' ] )
Arguments
'expression'- Any expression that evaluates to a column name or to two or more values of type
CHAR or VARCHAR.
'locale_or_collation_name'- The ICU (International Components for Unicode) locale or collation name to use when collating the string. If you omit this parameter,
COLLATION uses the collation associated with the session locale.
To determine the current session locale, enter the vsql meta-command \locale:
=> \locale
en_US@collation=binary
To set the locale and collation, use \locale as follows:
=> \locale en_US@collation=binary
INFO 2567: Canonical locale: 'en_US'
Standard collation: 'LEN_KBINARY'
English (United States)
Locales
The locale used for COLLATION can be one of the following:
For a list of valid ICU locales, go to Locale Explorer (ICU).
Binary and non-binary collations
The Vertica default locale is en_US@collation=binary, which uses binary collation. Binary collation compares binary representations of strings. Binary collation is fast, but it can result in a sort order where K precedes c because the binary representation of K is lower than c.
For non-binary collation, Vertica transforms the data according to the rules of the locale or the specified collation, and then applies the sorting rules. Suppose the locale collation is non-binary and you request a GROUP BY on string data. In this case,Vertica calls COLLATION, whether or not you specify the function in your query.
For information about collation naming, see Collator Naming Scheme.
Examples
Collating GROUP BY results
The following examples are based on a Premium_Customer table that contains the following data:
=> SELECT * FROM Premium_Customer;
ID | LName | FName
----+--------+---------
1 | Mc Coy | Bob
2 | Mc Coy | Janice
3 | McCoy | Jody
4 | McCoy | Peter
5 | McCoy | Brendon
6 | Mccoy | Cameron
7 | Mccoy | Lisa
The first statement shows how COLLATION applies the collation for the EN_US locale to the LName column for the locale EN_US. Vertica sorts the GROUP BY output as follows:
=> SELECT * FROM Premium_Customer ORDER BY COLLATION(LName, 'EN_US'), FName;
ID | LName | FName
----+--------+---------
1 | Mc Coy | Bob
2 | Mc Coy | Janice
6 | Mccoy | Cameron
7 | Mccoy | Lisa
5 | McCoy | Brendon
3 | McCoy | Jody
4 | McCoy | Peter
The next statement shows how COLLATION collates the LName column for the locale LEN_AS:
In the results, the last names in which "coy" starts with a lowercase letter precede the last names where "Coy" starts with an uppercase letter.
=> SELECT * FROM Premium_Customer ORDER BY COLLATION(LName, 'LEN_AS'), FName;
ID | LName | FName
----+--------+---------
6 | Mccoy | Cameron
7 | Mccoy | Lisa
1 | Mc Coy | Bob
5 | McCoy | Brendon
2 | Mc Coy | Janice
3 | McCoy | Jody
4 | McCoy | Peter
Comparing strings with an equality clause
In the following query, COLLATION removes spaces and punctuation when comparing two strings in English. It then determines whether the two strings still have the same value after the punctuation has been removed:
=> SELECT COLLATION ('U.S.A', 'LEN_AS') = COLLATION('USA', 'LEN_AS');
?column?
----------
t
Sorting strings in non-english languages
The following table contains data that uses the German character eszett, ß:
=> SELECT * FROM t1;
a | b | c
------------+---+----
ßstringß | 1 | 10
SSstringSS | 2 | 20
random1 | 3 | 30
random1 | 4 | 40
random2 | 5 | 50
When you specify the collation LDE_S1:
The query returns the data in the following order:
=> SELECT a FROM t1 ORDER BY COLLATION(a, 'LDE_S1'));
a
------------
random1
random1
random2
SSstringSS
ßstringß
6.4.5.9 - CONCAT
Concatenates two strings and returns a varchar data type.
Concatenates two strings and returns a varchar data type. If either argument is null, concat returns null.
Syntax
CONCAT ('string-expression1, string-expression2)
Behavior type
Immutable
Arguments
string-expression1, string-expression2- The values to concatenate, any data type that can be cast to a string value.
Examples
The following examples use a sample table named alphabet with two varchar columns:
=> CREATE TABLE alphabet (letter1 varchar(2), letter2 varchar(2));
CREATE TABLE
=> COPY alphabet FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> A|B
>> C|D
>> \.
=> SELECT * FROM alphabet;
letter1 | letter2
---------+---------
C | D
A | B
(2 rows)
Concatenate the contents of the first column with a character string:
=> SELECT CONCAT(letter1, ' is a letter') FROM alphabet;
CONCAT
---------------
A is a letter
C is a letter
(2 rows)
Concatenate the output of two nested CONCAT functions:
=> SELECT CONCAT(CONCAT(letter1, ' and '), CONCAT(letter2, ' are both letters')) FROM alphabet;
CONCAT
--------------------------
C and D are both letters
A and B are both letters
(2 rows)
Concatenate a date and string:
=> SELECT current_date today;
today
------------
2021-12-10
(1 row)
=> SELECT CONCAT('2021-12-31'::date - current_date, ' days until end of year 2021');
CONCAT
--------------------------------
21 days until end of year 2021
(1 row)
6.4.5.10 - DECODE
Compares expression to each search value one by one.
Compares *expression *to each search value one by one. If *expression *is equal to a search, the function returns the corresponding result. If no match is found, the function returns default. If default is omitted, the function returns null.
DECODE is similar to the IF-THEN-ELSE and CASE expressions:
CASE expression
[WHEN search THEN result]
[WHEN search THEN result]
...
[ELSE default];
The arguments can have any data type supported by Vertica. The result types of individual results are promoted to the least common type that can be used to represent all of them. This leads to a character string type, an exact numeric type, an approximate numeric type, or a DATETIME type, where all the various result arguments must be of the same type grouping.
Behavior type
Immutable
Syntax
DECODE ( expression, search, result [ , search, result ]...[, default ] )
Arguments
expression - The value to compare.
search - The value compared against
expression.
result - The value returned, if *
expression *is equal to search.
default - Optional. If no matches are found, DECODE returns default. If default is omitted, then DECODE returns NULL (if no matches are found).
Examples
The following example converts numeric values in the weight column from the product_dimension table to descriptive values in the output.
=> SELECT product_description, DECODE(weight,
2, 'Light',
50, 'Medium',
71, 'Heavy',
99, 'Call for help',
'N/A')
FROM product_dimension
WHERE category_description = 'Food'
AND department_description = 'Canned Goods'
AND sku_number BETWEEN 'SKU-#49750' AND 'SKU-#49999'
LIMIT 15;
product_description | case
-----------------------------------+---------------
Brand #499 canned corn | N/A
Brand #49900 fruit cocktail | Medium
Brand #49837 canned tomatoes | Heavy
Brand #49782 canned peaches | N/A
Brand #49805 chicken noodle soup | N/A
Brand #49944 canned chicken broth | N/A
Brand #49819 canned chili | N/A
Brand #49848 baked beans | N/A
Brand #49989 minestrone soup | N/A
Brand #49778 canned peaches | N/A
Brand #49770 canned peaches | N/A
Brand #4977 fruit cocktail | N/A
Brand #49933 canned olives | N/A
Brand #49750 canned olives | Call for help
Brand #49777 canned tomatoes | N/A
(15 rows)
6.4.5.11 - EDIT_DISTANCE
Calculates and returns the Levenshtein distance between two strings.
Calculates and returns the Levenshtein distance between two strings. The return value indicates the minimum number of single-character edits—insertions, deletions, or substitutions—that are required to change one string into the other. Compare to Jaro distance and Jaro-Winkler distance.
Behavior type
Immutable
Syntax
EDIT_DISTANCE ( string-expression1, string-expression2 )
Arguments
string-expression1, string-expression2- The two VARCHAR expressions to compare.
Examples
The Levenshtein distance between kitten and knitting is 3:
=> SELECT EDIT_DISTANCE ('kitten', 'knitting');
EDIT_DISTANCE
---------------
3
(1 row)
EDIT_DISTANCE calculates that no fewer than three changes are required to transform kitten to knitting:
-
kitten → knitten (insert n after k)
-
knitten → knittin (substitute i for e)
-
knittin → knitting (append g)
6.4.5.12 - GREATEST
Returns the largest value in a list of expressions of any data type.
Returns the largest value in a list of expressions of any data type. All data types in the list must be the same or compatible. A NULL value in any one of the expressions returns NULL. Results can vary, depending on the locale's collation setting.
Behavior type
Stable
Syntax
GREATEST ( { * | expression[,...] } )
Arguments
* | expression[,...]- The expressions to evaluate, one of the following:
Examples
GREATEST returns 10 as the largest value in the list:
=> SELECT GREATEST(7,5,10);
GREATEST
----------
10
(1 row)
If you put quotes around the integer expressions, GREATEST compares the values as strings and returns '7' as the greatest value:
=> SELECT GREATEST('7', '5', '10');
GREATEST
----------
7
(1 row)
The next example returns FLOAT 1.5 as the greatest because the integer is implicitly cast to float:
=> SELECT GREATEST(1, 1.5);
GREATEST
----------
1.5
(1 row)
GREATEST queries all columns in a view based on the VMart table product_dimension, and returns the largest value in each row:
=> CREATE VIEW query1 AS SELECT shelf_width, shelf_height, shelf_depth FROM product_dimension;
CREATE VIEW
=> SELECT shelf_width, shelf_height, shelf_depth, greatest(*) FROM query1 WHERE shelf_width = 1;
shelf_width | shelf_height | shelf_depth | greatest
-------------+--------------+-------------+----------
1 | 3 | 1 | 3
1 | 3 | 3 | 3
1 | 5 | 4 | 5
1 | 2 | 2 | 2
1 | 1 | 3 | 3
1 | 2 | 2 | 2
1 | 2 | 3 | 3
1 | 1 | 5 | 5
1 | 1 | 4 | 4
1 | 5 | 3 | 5
1 | 4 | 2 | 4
1 | 4 | 5 | 5
1 | 5 | 3 | 5
1 | 2 | 5 | 5
1 | 4 | 2 | 4
1 | 4 | 4 | 4
1 | 1 | 2 | 2
1 | 4 | 3 | 4
...
See also
LEAST
6.4.5.13 - GREATESTB
Returns the largest value in a list of expressions of any data type, using binary ordering.
Returns the largest value in a list of expressions of any data type, using binary ordering. All data types in the list must be the same or compatible. A NULL value in any one of the expressions returns NULL. Results can vary, depending on the locale's collation setting.
Behavior type
Immutable
Syntax
GREATEST ( { * | expression[,...] } )
Arguments
* | expression[,...]- The expressions to evaluate, one of the following:
Examples
The following command selects straße as the greatest in the series of inputs:
=> SELECT GREATESTB('straße', 'strasse');
GREATESTB
-----------
straße
(1 row)
GREATESTB returns 10 as the largest value in the list:
=> SELECT GREATESTB(7,5,10);
GREATESTB
-----------
10
(1 row)
If you put quotes around the integer expressions, GREATESTB compares the values as strings and returns '7' as the greatest value:
=> SELECT GREATESTB('7', '5', '10');
GREATESTB
-----------
7
(1 row)
The next example returns FLOAT 1.5 as the greatest because the integer is implicitly cast to float:
=> SELECT GREATESTB(1, 1.5);
GREATESTB
-----------
1.5
(1 row)
GREATESTB queries all columns in a view based on the VMart table product_dimension, and returns the largest value in each row:
=> CREATE VIEW query1 AS SELECT shelf_width, shelf_height, shelf_depth FROM product_dimension;
CREATE VIEW
=> SELECT shelf_width, shelf_height, shelf_depth, greatestb(*) FROM query1 WHERE shelf_width = 1;
shelf_width | shelf_height | shelf_depth | greatestb
-------------+--------------+-------------+-----------
1 | 3 | 1 | 3
1 | 3 | 3 | 3
1 | 5 | 4 | 5
1 | 2 | 2 | 2
1 | 1 | 3 | 3
1 | 2 | 2 | 2
1 | 2 | 3 | 3
1 | 1 | 5 | 5
1 | 1 | 4 | 4
1 | 5 | 3 | 5
1 | 4 | 2 | 4
1 | 4 | 5 | 5
1 | 5 | 3 | 5
1 | 2 | 5 | 5
1 | 4 | 2 | 4
...
See also
LEASTB
6.4.5.14 - HEX_TO_BINARY
Translates the given VARCHAR hexadecimal representation into a VARBINARY value.
Translates the given VARCHAR hexadecimal representation into a VARBINARY value.
Behavior type
Immutable
Syntax
HEX_TO_BINARY ( [ 0x ] expression )
Arguments
expression- (BINARY or VARBINARY) String to translate.
0x- Optional prefix.
Notes
VARBINARY HEX_TO_BINARY(VARCHAR) converts data from character type in hexadecimal format to binary type. This function is the inverse of TO_HEX.
HEX_TO_BINARY(TO_HEX(x)) = x)
TO_HEX(HEX_TO_BINARY(x)) = x)
If there are an odd number of characters in the hexadecimal value, the first character is treated as the low nibble of the first (furthest to the left) byte.
Examples
If the given string begins with "0x" the prefix is ignored. For example:
=> SELECT HEX_TO_BINARY('0x6162') AS hex1, HEX_TO_BINARY('6162') AS hex2;
hex1 | hex2
------+------
ab | ab
(1 row)
If an invalid hex value is given, Vertica returns an “invalid binary representation" error; for example:
=> SELECT HEX_TO_BINARY('0xffgf');
ERROR: invalid hex string "0xffgf"
See also
6.4.5.15 - HEX_TO_INTEGER
Translates the given VARCHAR hexadecimal representation into an INTEGER value.
Translates the given VARCHAR hexadecimal representation into an INTEGER value.
Vertica completes this conversion as follows:
-
Adds the 0x prefix if it is not specified in the input
-
Casts the VARCHAR string to a NUMERIC
-
Casts the NUMERIC to an INTEGER
Behavior type
Immutable
Syntax
HEX_TO_INTEGER ( [ 0x ] expression )
Arguments
expression- VARCHAR is the string to translate.
0x- Is the optional prefix.
Examples
You can enter the string with or without the Ox prefix. For example:
=> SELECT HEX_TO_INTEGER ('0aedc')
AS hex1,HEX_TO_INTEGER ('aedc') AS hex2;
hex1 | hex2
-------+-------
44764 | 44764
(1 row)
If you pass the function an invalid hex value, Vertica returns an invalid input syntax error; for example:
=> SELECT HEX_TO_INTEGER ('0xffgf');
ERROR 3691: Invalid input syntax for numeric: "0xffgf"
See also
6.4.5.16 - INITCAP
Capitalizes first letter of each alphanumeric word and puts the rest in lowercase.
Capitalizes first letter of each alphanumeric word and puts the rest in lowercase.
Behavior type
Immutable
Syntax
INITCAP ( expression )
Arguments
expression- (VARCHAR) is the string to format.
Notes
-
Depends on collation setting of the locale.
-
INITCAP is restricted to 32750 octet inputs, since it is possible for the UTF-8 representation of result to double in size.
Examples
|
Expression |
Result |
SELECT INITCAP('high speed database'); |
High Speed Database |
SELECT INITCAP('LINUX TUTORIAL'); |
Linux Tutorial |
SELECT INITCAP('abc DEF 123aVC 124Btd,lAsT'); |
Abc Def 123Avc 124Btd,Last |
SELECT INITCAP(''); |
|
SELECT INITCAP(null); |
|
6.4.5.17 - INITCAPB
Capitalizes first letter of each alphanumeric word and puts the rest in lowercase.
Capitalizes first letter of each alphanumeric word and puts the rest in lowercase. Multibyte characters are not converted and are skipped.
Behavior type
Immutable
Syntax
INITCAPB ( expression )
Arguments
expression- (VARCHAR) is the string to format.
Notes
Depends on collation setting of the locale.
Examples
|
Expression |
Result |
SELECT INITCAPB('étudiant'); |
éTudiant |
SELECT INITCAPB('high speed database'); |
High Speed Database |
SELECT INITCAPB('LINUX TUTORIAL'); |
Linux Tutorial |
SELECT INITCAPB('abc DEF 123aVC 124Btd,lAsT'); |
Abc Def 123Avc 124Btd,Last |
SELECT INITCAPB(''); |
|
SELECT INITCAPB(null); |
|
6.4.5.18 - INSERT
Inserts a character string into a specified location in another character string.
Inserts a character string into a specified location in another character string.
Syntax
INSERT( 'string1', n, m, 'string2' )
Behavior type
Immutable
Arguments
string1- (VARCHAR) Is the string in which to insert the new string.
n- A character of type INTEGER that represents the starting point for the insertion within*
string1*. You specify the number of characters from the first character in string1 as the starting point for the insertion. For example, to insert characters before "c", in the string "abcdef," enter 3.
m- A character of type INTEGER that represents the number of characters in*
string1(if any) *that should be replaced by the insertion. For example,if you want the insertion to replace the letters "cd" in the string "abcdef, " enter 2.
string2- (VARCHAR) Is the string to be inserted.
Examples
The following example changes the string Warehouse to Storehouse using the INSERT function:
=> SELECT INSERT ('Warehouse',1,3,'Stor');
INSERT
------------
Storehouse
(1 row)
6.4.5.19 - INSTR
Searches string for substring and returns an integer indicating the position of the character in string that is the first character of this occurrence.
Searches *string *for *substring *and returns an integer indicating the position of the character in *string *that is the first character of this occurrence. The return value is based on the character position of the identified character.
Behavior type
Immutable
Syntax
INSTR ( string , substring [, position [, occurrence ] ] )
Arguments
string - (CHAR or VARCHAR, or BINARY or VARBINARY) Text expression to search.
substring - (CHAR or VARCHAR, or BINARY or VARBINARY) String to search for.
position - Nonzero integer indicating the character of string where Vertica begins the search. If position is negative, then Vertica counts backward from the end of string and then searches backward from the resulting position. The first character of string occupies the default position 1, and position cannot be 0.
occurrence - Integer indicating which occurrence of string Vertica searches. The value of occurrence must be positive (greater than 0), and the default is 1.
Notes
Both position and occurrence must be of types that can resolve to an integer. The default values of both parameters are 1, meaning Vertica begins searching at the first character of string for the first occurrence of substring. The return value is relative to the beginning of string, regardless of the value of position, and is expressed in characters.
If the search is unsuccessful (that is, if substring does not appear *occurrence *times after the position character of string, the return value is 0.
Examples
The first example searches forward in string ‘abc’ for substring ‘b’. The search returns the position in ‘abc’ where ‘b’ occurs, or position 2. Because no position parameters are given, the default search starts at ‘a’, position 1.
=> SELECT INSTR('abc', 'b');
INSTR
-------
2
(1 row)
The following three examples use character position to search backward to find the position of a substring.
Note
Although it might seem intuitive that the function returns a negative integer, the position of n occurrence is read left to right in the sting, even though the search happens in reverse (from the end—or right side—of the string).
In the first example, the function counts backward one character from the end of the string, starting with character ‘c’. The function then searches backward for the first occurrence of ‘a’, which it finds it in the first position in the search string.
=> SELECT INSTR('abc', 'a', -1);
INSTR
-------
1
(1 row)
In the second example, the function counts backward one byte from the end of the string, starting with character ‘c’. The function then searches backward for the first occurrence of ‘a’, which it finds it in the first position in the search string.
=> SELECT INSTR(VARBINARY 'abc', VARBINARY 'a', -1);
INSTR
-------
1
(1 row)
In the third example, the function counts backward one character from the end of the string, starting with character ‘b’, and searches backward for substring ‘bc’, which it finds in the second position of the search string.
=> SELECT INSTR('abcb', 'bc', -1);
INSTR
-------
2
(1 row)
In the fourth example, the function counts backward one character from the end of the string, starting with character ‘b’, and searches backward for substring ‘bcef’, which it does not find. The result is 0.
=> SELECT INSTR('abcb', 'bcef', -1);
INSTR
-------
0
(1 row)
In the fifth example, the function counts backward one byte from the end of the string, starting with character ‘b’, and searches backward for substring ‘bcef’, which it does not find. The result is 0.
=> SELECT INSTR(VARBINARY 'abcb', VARBINARY 'bcef', -1);
INSTR
-------
0
(1 row)
Multibyte characters are treated as a single character:
=> SELECT INSTR('aébc', 'b');
INSTR
-------
3
(1 row)
Use INSTRB to treat multibyte characters as binary:
=> SELECT INSTRB('aébc', 'b');
INSTRB
--------
4
(1 row)
6.4.5.20 - INSTRB
Searches string for substring and returns an integer indicating the octet position within string that is the first occurrence.
Searches string for substring and returns an integer indicating the octet position within string that is the first occurrence. The return value is based on the octet position of the identified byte.
Behavior type
Immutable
Syntax
INSTRB ( string , substring [, position [, occurrence ] ] )
Arguments
string - Is the text expression to search.
substring - Is the string to search for.
position - Is a nonzero integer indicating the character of string where Vertica begins the search. If position is negative, then Vertica counts backward from the end of string and then searches backward from the resulting position. The first byte of string occupies the default position 1, and position cannot be 0.
occurrence - Is an integer indicating which occurrence of string Vertica searches. The value of occurrence must be positive (greater than 0), and the default is 1.
Notes
Both position and occurrence must be of types that can resolve to an integer. The default values of both parameters are 1, meaning Vertica begins searching at the first byte of string for the first occurrence of substring. The return value is relative to the beginning of string, regardless of the value of position, and is expressed in octets.
If the search is unsuccessful (that is, if substring does not appear *occurrence *times after the *position *character of *string, *then the return value is 0.
Examples
=> SELECT INSTRB('straße', 'ß');
INSTRB
--------
5
(1 row)
See also
6.4.5.21 - ISUTF8
Tests whether a string is a valid UTF-8 string.
Tests whether a string is a valid UTF-8 string. Returns true if the string conforms to UTF-8 standards, and false otherwise. This function is useful to test strings for UTF-8 compliance before passing them to one of the regular expression functions, such as REGEXP_LIKE, which expect UTF-8 characters by default.
ISUTF8 checks for invalid UTF8 byte sequences, according to UTF-8 rules:
The presence of an invalid UTF-8 byte sequence results in a return value of false.
To coerce a string to UTF-8, use MAKEUTF8.
Syntax
ISUTF8( string );
Arguments
string- The string to test for UTF-8 compliance.
Examples
=> SELECT ISUTF8(E'\xC2\xBF'); -- UTF-8 INVERTED QUESTION MARK ISUTF8
--------
t
(1 row)
=> SELECT ISUTF8(E'\xC2\xC0'); -- UNDEFINED UTF-8 CHARACTER
ISUTF8
--------
f
(1 row)
6.4.5.22 - JARO_DISTANCE
Calculates and returns the Jaro similarity, an edit distance between two sequences.
Calculates and returns the Jaro similarity, an edit distance between two sequences. It is useful for queries designed for short strings, such as finding similar names. Also see Jaro-Winkler distance, which adds a prefix scale favoring strings that match in the beginning, and edit distance, which returns the Levenshtein distance between two strings.
Behavior type
Immutable
Syntax
JARO_DISTANCE (string-expression1, string-expression2)
Arguments
string-expression1, string-expression2 - The two VARCHAR expressions to compare. Neither can be NULL.
Example
Return only the names with a Jaro distance from 'rode' that is greater than 0.6:
=> SELECT name FROM names WHERE JARO_DISTANCE('rode', name) > 0.6;
name
---------
fred
frieda
rodgers
rogers
(4 rows)
6.4.5.23 - JARO_WINKLER_DISTANCE
Calculates and returns the Jaro-Winkler similarity, an edit distance between two sequences.
Calculates and returns the Jaro-Winkler similarity, an edit distance between two sequences. It is useful for queries designed for short strings, such as finding similar names. It is a variant of the Jaro distance metric, to which it adds a prefix scale giving more favorable ratings for strings that match from the beginning. See also edit distance, which returns the Levenshtein distance between two strings.
Behavior type
Immutable
Syntax
JARO_WINKLER_DISTANCE (string-expression1 , string-expression2 [ USING PARAMETERS prefix_scale=scale, prefix_length=length])
Arguments
string-expression1, string-expression2 - The two VARCHAR expressions to compare. Neither can be NULL.
Parameters
scale- A FLOAT specifying the scale value by which to weight the importance of matching prefixes. Optional.
default = 0.1
length- An non-negative INT representing the maximum matching prefix length. Optional.
default = 4
Examples
Return only the names with a Jaro-Winkler distance from 'rode' that is greater than 0.6:
=> SELECT name FROM names WHERE JARO_WINKLER_DISTANCE('rode', name) > 0.6;
name
---------
fred
frieda
rodgers
rogers
(4 rows)
The Jaro-Winkler distance between 'help' and 'hello' given a prefix_scale of 0.1 and prefix_length of 0 is 0.783333333333333:
=> select JARO_WINKLER_DISTANCE('help', 'hello' USING PARAMETERS prefix_scale=0.1, prefix_length=0);
jaro_winkler_distance
-----------------------
0.783333333333333
(1 row)
6.4.5.24 - LEAST
Returns the smallest value in a list of expressions of any data type.
Returns the smallest value in a list of expressions of any data type. All data types in the list must be the same or compatible. A NULL value in any one of the expressions returns NULL. Results can vary, depending on the locale's collation setting.
Behavior type
Stable
Syntax
LEAST ( { * | expression[,...] } )
Arguments
* | expression[,...]- The expressions to evaluate, one of the following:
Examples
LEASTB returns 5 as the smallest value in the list:
=> SELECT LEASTB(7, 5, 10);
LEASTB
--------
5
(1 row)
If you put quotes around the integer expressions, LEASTB compares the values as strings and returns '10' as the smallest value:
=> SELECT LEASTB('7', '5', '10');
LEASTB
--------
10
(1 row)
LEAST returns 1.5, as INTEGER 2 is implicitly cast to FLOAT:
=> SELECT LEAST(2, 1.5);
LEAST
-------
1.5
(1 row)
LEAST queries all columns in a view based on the VMart table product_dimension, and returns the smallest value in each row:
=> CREATE VIEW query1 AS SELECT shelf_width, shelf_height, shelf_depth FROM product_dimension;
CREATE VIEW
=> SELECT shelf_height, shelf_width, shelf_depth, least(*) FROM query1 WHERE shelf_height = 5;
shelf_height | shelf_width | shelf_depth | least
--------------+-------------+-------------+-------
5 | 3 | 4 | 3
5 | 4 | 3 | 3
5 | 1 | 4 | 1
5 | 4 | 1 | 1
5 | 2 | 4 | 2
5 | 2 | 3 | 2
5 | 1 | 3 | 1
5 | 1 | 3 | 1
5 | 5 | 1 | 1
5 | 2 | 4 | 2
5 | 4 | 5 | 4
5 | 2 | 4 | 2
5 | 4 | 4 | 4
5 | 3 | 4 | 3
...
See also
GREATEST
6.4.5.25 - LEASTB
Returns the smallest value in a list of expressions of any data type, using binary ordering.
Returns the smallest value in a list of expressions of any data type, using binary ordering. All data types in the list must be the same or compatible. A NULL value in any one of the expressions returns NULL. Results can vary, depending on the locale's collation setting.
Behavior type
Immutable
Syntax
LEASTB ( { * | expression[,...] } )
Arguments
* | expression[,...]- The expressions to evaluate, one of the following:
Examples
The following command selects strasse as the smallest value in the list:
=> SELECT LEASTB('straße', 'strasse');
LEASTB
---------
strasse
(1 row)
LEASTB returns 5 as the smallest value in the list:
=> SELECT LEAST(7, 5, 10);
LEAST
-------
5
(1 row)
If you put quotes around the integer expressions, LEAST compares the values as strings and returns '10' as the smallest value:
=> SELECT LEASTB('7', '5', '10');
LEAST
-------
10
(1 row)
The next example returns 1.5, as INTEGER 2 is implicitly cast to FLOAT:
=> SELECT LEASTB(2, 1.5);
LEASTB
--------
1.5
(1 row)
LEASTB queries all columns in a view based on the VMart table product_dimension, and returns the smallest value in each row:
=> CREATE VIEW query1 AS SELECT shelf_width, shelf_height, shelf_depth FROM product_dimension;
CREATE VIEW
=> SELECT shelf_height, shelf_width, shelf_depth, leastb(*) FROM query1 WHERE shelf_height = 5;
shelf_height | shelf_width | shelf_depth | leastb
--------------+-------------+-------------+--------
5 | 3 | 4 | 3
5 | 4 | 3 | 3
5 | 1 | 4 | 1
5 | 4 | 1 | 1
5 | 2 | 4 | 2
5 | 2 | 3 | 2
5 | 1 | 3 | 1
5 | 1 | 3 | 1
5 | 5 | 1 | 1
5 | 2 | 4 | 2
5 | 4 | 5 | 4
5 | 2 | 4 | 2
5 | 4 | 4 | 4
5 | 3 | 4 | 3
5 | 5 | 4 | 4
5 | 5 | 1 | 1
5 | 3 | 1 | 1
...
See also
GREATESTB
6.4.5.26 - LEFT
Returns the specified characters from the left side of a string.
Returns the specified characters from the left side of a string.
Behavior type
Immutable
Syntax
LEFT ( string-expr, length )
Arguments
string-expr- The string expression to return.
length- An integer value that specifies how many characters to return.
Examples
=> SELECT LEFT('vertica', 3);
LEFT
------
ver
(1 row)
SELECT DISTINCT(
LEFT (customer_name, 4)) FnameTruncated
FROM customer_dimension ORDER BY FnameTruncated LIMIT 10;
FnameTruncated
----------------
Alex
Amer
Amy
Anna
Barb
Ben
Bett
Bria
Carl
Crai
(10 rows)
See also
SUBSTR
6.4.5.27 - LENGTH
Returns the length of a string.
Returns the length of a string. The behavior of LENGTH varies according to the input data type:
-
CHAR and VARCHAR: Identical to
CHARACTER_LENGTH, returns the string length in UTF-8 characters, .
-
CHAR: Strips padding.
-
BINARY and VARBINARY: Identical to
OCTET_LENGTH, returns the string length in bytes (octets).
Behavior type
Immutable
Syntax
LENGTH ( expression )
Arguments
expression- String to evaluate, one of the following: CHAR, VARCHAR, BINARY or VARBINARY.
Examples
|
Statement |
Returns |
SELECT LENGTH('1234 '::CHAR(10)); |
4 |
SELECT LENGTH('1234 '::VARCHAR(10)); |
6 |
SELECT LENGTH('1234 '::BINARY(10)); |
10 |
SELECT LENGTH('1234 '::VARBINARY(10)); |
6 |
SELECT LENGTH(NULL::CHAR(10)) IS NULL; |
t |
See also
BIT_LENGTH
6.4.5.28 - LOWER
Takes a string value and returns a VARCHAR value converted to lowercase.
Takes a string value and returns a VARCHAR value converted to lowercase.
Behavior type
stable
Syntax
LOWER ( expression )
Arguments
expression- CHAR or VARCHAR string to convert, where the string width is ≤ 65000 octets.
Important
In practice, expression should not exceed 32,500 octets. LOWER does not use the locale's collation setting—for example, collation=binary—to identify its encoding; rather, it treats the input argument as a UTF-8 encoded string. The UTF-8 representation of the input value might be double its original width. As a result, LOWER returns an error if the input value exceeds 32,500 octets.
Note also that if expression is a table column, LOWER calculates its size from the column's defined width, and not from the column data. If the column width is greater than VARCHAR(32500), Vertica returns an error.
Examples
=> SELECT LOWER('AbCdEfG');
LOWER
---------
abcdefg
(1 row)
=> SELECT LOWER('The Bat In The Hat');
LOWER
--------------------
the bat in the hat
(1 row)
=> SELECT LOWER('ÉTUDIANT');
LOWER
----------
étudiant
(1 row)
6.4.5.29 - LOWERB
Returns a character string with each ASCII character converted to lowercase.
Returns a character string with each ASCII character converted to lowercase. Multi-byte characters are skipped and not converted.
Behavior type
Immutable
Syntax
LOWERB ( expression )
Arguments
expression- CHAR or VARCHAR string to convert
Examples
In the following example, the multi-byte UTF-8 character É is not converted to lowercase:
=> SELECT LOWERB('ÉTUDIANT');
LOWERB
----------
Étudiant
(1 row)
=> SELECT LOWER('ÉTUDIANT');
LOWER
----------
étudiant
(1 row)
=> SELECT LOWERB('AbCdEfG');
LOWERB
---------
abcdefg
(1 row)
=> SELECT LOWERB('The Vertica Database');
LOWERB
----------------------
the vertica database
(1 row)
6.4.5.30 - LPAD
Returns a VARCHAR value representing a string of a specific length filled on the left with specific characters.
Returns a VARCHAR value representing a string of a specific length filled on the left with specific characters.
Behavior type
Immutable
Syntax
LPAD ( expression , length [ , fill ] )
Arguments
expression- (CHAR OR VARCHAR) specifies the string to fill
length- (INTEGER) specifies the number of characters to return
fill- (CHAR OR VARCHAR) specifies the repeating string of characters with which to fill the output string. The default is the space character.
Examples
=> SELECT LPAD('database', 15, 'xzy');
LPAD
-----------------
xzyxzyxdatabase
(1 row)
If the string is already longer than the specified length it is truncated on the right:
=> SELECT LPAD('establishment', 10, 'abc');
LPAD
------------
establishm
(1 row)
6.4.5.31 - LTRIM
Returns a VARCHAR value representing a string with leading blanks removed from the left side (beginning).
Returns a VARCHAR value representing a string with leading blanks removed from the left side (beginning).
Behavior type
Immutable
Syntax
LTRIM ( expression [ , characters ] )
Arguments
expression- (CHAR or VARCHAR) is the string to trim
characters- (CHAR or VARCHAR) specifies the characters to remove from the left side of
expression. The default is the space character.
Examples
=> SELECT LTRIM('zzzyyyyyyxxxxxxxxtrim', 'xyz');
LTRIM
-------
trim
(1 row)
See also
6.4.5.32 - MAKEUTF8
Coerces a string to UTF-8 by removing or replacing non-UTF-8 characters.
Coerces a string to UTF-8 by removing or replacing non-UTF-8 characters.
MAKEUTF8 flags invalid UTF-8 characters byte by byte. For example, the byte sequence 0xE0 0x7F 0x80 is an invalid three-byte UTF-8 sequence, but the middle byte, 0x7F, is a valid one-byte UTF-8 character. In this example, 0x7F is preserved and the other two bytes are removed or replaced.
Syntax
MAKEUTF8( string-expression [USING PARAMETERS param=value] );
Arguments
string-expression- The string expression to evaluate for non-UTF-8 characters
Parameters
replacement_string- Specifies the VARCHAR(16) string that MAKEUTF8 uses to replace each non-UTF-8 character that it finds in
string-expression. If this parameter is omitted, non-UTF-8 characters are removed. For example, the following SQL specifies to replace all non-UTF characters in the name column with the string ^:
=> SELECT MAKEUTF8(name USING PARAMETERS replacement_string='^') FROM people;
6.4.5.33 - MD5
Calculates the MD5 hash of string, returning the result as a VARCHAR string in hexadecimal.
Calculates the MD5 hash of string, returning the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
MD5 ( string )
Arguments
string- Is the argument string.
Examples
=> SELECT MD5('123');
MD5
----------------------------------
202cb962ac59075b964b07152d234b70
(1 row)
=> SELECT MD5('Vertica'::bytea);
MD5
----------------------------------
fc45b815747d8236f9f6fdb9c2c3f676
(1 row)
See also
6.4.5.34 - OCTET_LENGTH
Takes one argument as an input and returns the string length in octets for all string types.
Takes one argument as an input and returns the string length in octets for all string types.
Behavior type
Immutable
Syntax
OCTET_LENGTH ( expression )
Arguments
expression- (CHAR or VARCHAR or BINARY or VARBINARY) is the string to measure.
Notes
-
If the data type of expression is a CHAR, VARCHAR or VARBINARY, the result is the same as the actual length of expression in octets. For CHAR, the length does not include any trailing spaces.
-
If the data type of expression is BINARY, the result is the same as the fixed-length of expression.
-
If the value of expression is NULL, the result is NULL.
Examples
|
Expression |
Result |
SELECT OCTET_LENGTH(CHAR(10) '1234 '); |
4 |
SELECT OCTET_LENGTH(CHAR(10) '1234'); |
4 |
SELECT OCTET_LENGTH(CHAR(10) ' 1234'); |
6 |
SELECT OCTET_LENGTH(VARCHAR(10) '1234 '); |
6 |
SELECT OCTET_LENGTH(VARCHAR(10) '1234 '); |
5 |
SELECT OCTET_LENGTH(VARCHAR(10) '1234'); |
4 |
SELECT OCTET_LENGTH(VARCHAR(10) ' 1234'); |
7 |
SELECT OCTET_LENGTH('abc'::VARBINARY); |
3 |
SELECT OCTET_LENGTH(VARBINARY 'abc'); |
3 |
SELECT OCTET_LENGTH(VARBINARY 'abc '); |
5 |
SELECT OCTET_LENGTH(BINARY(6) 'abc'); |
6 |
SELECT OCTET_LENGTH(VARBINARY ''); |
0 |
SELECT OCTET_LENGTH(''::BINARY); |
1 |
SELECT OCTET_LENGTH(null::VARBINARY); |
|
SELECT OCTET_LENGTH(null::BINARY); |
|
See also
6.4.5.35 - OVERLAY
Replaces part of a string with another string and returns the new string value as a VARCHAR.
Replaces part of a string with another string and returns the new string value as a VARCHAR.
Behavior type
Immutable if using OCTETS, Stable otherwise
Syntax
OVERLAY ( input-string PLACING replace-string FROM position [ FOR extent ] [ USING { CHARACTERS | OCTETS } ] )
Arguments
input-string- The string to process, of type CHAR or VARCHAR.
replace-string- The string to replace the specified substring of
input-string, of type CHAR or VARCHAR.
position - Integer ≥1 that specifies the first character or octet of
input-string to overlay replace-string.
extent- Integer that specifies how many characters or octets of
input-string to overlay with replace-string. If omitted, OVERLAY uses the length of replace-string.
For example, compare the following calls to OVERLAY:
-
OVERLAY omits FOR clause. The number of characters replaced in the input string equals the number of characters in replacement string ABC:
dbadmin=> SELECT OVERLAY ('123456789' PLACING 'ABC' FROM 5);
overlay
-----------
1234ABC89
(1 row)
-
OVERLAY includes a FOR clause that specifies to replace four characters in the input string with the replacement string. The replacement string is three characters long, so OVERLAY returns a string that is one character shorter than the input string:
=> SELECT OVERLAY ('123456789' PLACING 'ABC' FROM 5 FOR 4);
overlay
----------
1234ABC9
(1 row)
-
OVERLAY includes a FOR clause that specifies to replace -2 characters in the input string with the replacement string. The function returns a string that is two characters longer than the input string:
=> SELECT OVERLAY ('123456789' PLACING 'ABC' FROM 5 FOR -2);
overlay
----------------
1234ABC3456789
(1 row)
USING CHARACTERS | OCTETS- Specifies whether OVERLAY uses characters (default) or octets.
Note
If you specify
USING OCTETS, Vertica calls the
OVERLAYB function.
Examples
=> SELECT OVERLAY('123456789' PLACING 'xxx' FROM 2);
overlay
-----------
1xxx56789
(1 row)
=> SELECT OVERLAY('123456789' PLACING 'XXX' FROM 2 USING OCTETS);
overlayb
-----------
1XXX56789
(1 row)
=> SELECT OVERLAY('123456789' PLACING 'xxx' FROM 2 FOR 4);
overlay
----------
1xxx6789
(1 row)
=> SELECT OVERLAY('123456789' PLACING 'xxx' FROM 2 FOR 5);
overlay
---------
1xxx789
(1 row)
=> SELECT OVERLAY('123456789' PLACING 'xxx' FROM 2 FOR 6);
overlay
---------
1xxx89
(1 row)
6.4.5.36 - OVERLAYB
Replaces part of a string with another string and returns the new string as an octet value.
Replaces part of a string with another string and returns the new string as an octet value.
The OVERLAYB function treats the multibyte character string as a string of octets (bytes) and use octet numbers as incoming and outgoing position specifiers and lengths. The strings themselves are type VARCHAR, but they treated as if each byte was a separate character.
Behavior type
Immutable
Syntax
OVERLAYB ( input-string, replace-string, position [, extent ] )
Arguments
input-string- The string to process, of type CHAR or VARCHAR.
replace-string- The string to replace the specified substring of
input-string, of type CHAR or VARCHAR.
position - Integer ≥1 that specifies the first octet of*
input-string* to overlay replace-string.
extent- Integer that specifies how many octets of
input-string to overlay with replace-string. If omitted, OVERLAY uses the length of replace-string.
Examples
=> SELECT OVERLAYB('123456789', 'ééé', 2);
OVERLAYB
----------
1ééé89
(1 row)
=> SELECT OVERLAYB('123456789', 'ßßß', 2);
OVERLAYB
----------
1ßßß89
(1 row)
=> SELECT OVERLAYB('123456789', 'xxx', 2);
OVERLAYB
-----------
1xxx56789
(1 row)
=> SELECT OVERLAYB('123456789', 'xxx', 2, 4);
OVERLAYB
----------
1xxx6789
(1 row)
=> SELECT OVERLAYB('123456789', 'xxx', 2, 5);
OVERLAYB
----------
1xxx789
(1 row)
=> SELECT OVERLAYB('123456789', 'xxx', 2, 6);
OVERLAYB
----------
1xxx89
(1 row)
6.4.5.37 - POSITION
Returns an INTEGER value representing the character location of a specified substring with a string (counting from one).
Returns an INTEGER value representing the character location of a specified substring with a string (counting from one).
Behavior type
Immutable
Syntax 1
POSITION ( substring IN string [ USING { CHARACTERS | OCTETS } ] )
Arguments
substring- (CHAR or VARCHAR) is the substring to locate
string- (CHAR or VARCHAR) is the string in which to locate the substring
USING CHARACTERS | OCTETS- Determines whether the position is reported by using characters (the default) or octets.
Syntax 2
POSITION ( substring IN string )
Arguments
substring- (VARBINARY) is the substring to locate
string- (VARBINARY) is the string in which to locate the substring
Notes
-
When the string and substring are CHAR or VARCHAR, the return value is based on either the character or octet position of the substring.
-
When the string and substring are VARBINARY, the return value is always based on the octet position of the substring.
-
The string and substring must be consistent. Do not mix VARBINARY with CHAR or VARCHAR.
-
POSITION is similar to STRPOS although POSITION allows finding by characters and by octet.
-
If the string is not found, the return value is zero.
Examples
=> SELECT POSITION('é' IN 'étudiant' USING CHARACTERS);
position
----------
1
(1 row)
=> SELECT POSITION('ß' IN 'straße' USING OCTETS);
positionb
-----------
5
(1 row)
=> SELECT POSITION('c' IN 'abcd' USING CHARACTERS);
position
----------
3
(1 row)
=> SELECT POSITION(VARBINARY '456' IN VARBINARY '123456789');
position
----------
4
(1 row)
SELECT POSITION('n' in 'León') as 'default',
POSITIONB('León', 'n') as 'POSITIONB',
POSITION('n' in 'León' USING CHARACTERS) as 'pos_chars',
POSITION('n' in 'León' USING OCTETS) as 'pos_oct',INSTR('León','n'),
INSTRB('León','n'), REGEXP_INSTR('León','n');
default | POSITIONB | pos_chars | pos_oct | INSTR | INSTRB | REGEXP_INSTR
---------+-----------+-----------+---------+-------+--------+--------------
4 | 5 | 4 | 5 | 4 | 5 | 4
(1 row)
6.4.5.38 - POSITIONB
Returns an INTEGER value representing the octet location of a specified substring with a string (counting from one).
Returns an INTEGER value representing the octet location of a specified substring with a string (counting from one).
Behavior type
Immutable
Syntax
POSITIONB ( string, substring )
Arguments
string- (CHAR or VARCHAR) is the string in which to locate the substring
substring- (CHAR or VARCHAR) is the substring to locate
Examples
=> SELECT POSITIONB('straße', 'ße');
POSITIONB
-----------
5
(1 row)
=> SELECT POSITIONB('étudiant', 'é');
POSITIONB
-----------
1
(1 row)
6.4.5.39 - QUOTE_IDENT
Returns the specified string argument in the format required to use the string as an identifier in an SQL statement.
Returns the specified string argument in the format required to use the string as an identifier in an SQL statement. Quotes are added as needed—for example, if the string contains non-identifier characters or is an SQL or Vertica-reserved keyword:
Embedded double quotes are doubled.
Note
-
SQL identifiers such as table and column names are stored as created, and references to them are resolved using case-insensitive compares. Thus, you do not need to double-quote mixed-case identifiers.
-
Vertica quotes all reserved keywords, even if unused.
Behavior type
Immutable
Syntax
QUOTE_IDENT( 'string' )
Arguments
string- String to quote
Examples
Quoted identifiers are case-insensitive, and Vertica does not supply the quotes:
=> SELECT QUOTE_IDENT('VErtIcA');
QUOTE_IDENT
-------------
VErtIcA
(1 row)
=> SELECT QUOTE_IDENT('Vertica database');
QUOTE_IDENT
--------------------
"Vertica database"
(1 row)
Embedded double quotes are doubled:
=> SELECT QUOTE_IDENT('Vertica "!" database');
QUOTE_IDENT
--------------------------
"Vertica ""!"" database"
(1 row)
The following example uses the SQL keyword SELECT, so results are double quoted:
=> SELECT QUOTE_IDENT('select');
QUOTE_IDENT
-------------
"select"
(1 row)
See also
6.4.5.40 - QUOTE_LITERAL
Returns the given string suitably quoted for use as a string literal in a SQL statement string.
Returns the given string suitably quoted for use as a string literal in a SQL statement string. Embedded single quotes and backslashes are doubled. As per the SQL standard, the function recognizes two consecutive single quotes within a string literal as a single quote character.
Behavior type
Immutable
Syntax
QUOTE_LITERAL ( string )
Arguments
string-expression- Argument that resolves to one or more strings to format as string literals.
Examples
In the following example, the first query returns no first name for Cher or Sting; the second query uses QUOTE_LITERAL, which sets off string values with single quotes, including empty strings. In this case, fname for Sting is set to an empty string (''), while fname for Cher is empty, indicating that it is set to null value:
=> SELECT * FROM lead_vocalists ORDER BY lname ASC;
fname | lname | band
--------+---------+-------------------------------------------------
| Cher | ["Sonny and Cher"]
Mick | Jagger | ["Rolling Stones"]
Diana | Ross | ["Supremes"]
Grace | Slick | ["Jefferson Airplane","Jefferson Starship"]
| Sting | ["Police"]
Stevie | Winwood | ["Spencer Davis Group","Traffic","Blind Faith"]
(6 rows)
=> SELECT QUOTE_LITERAL (fname) "First Name", QUOTE_NULLABLE (lname) "Last Name", band FROM lead_vocalists ORDER BY lname ASC;
First Name | Last Name | band
------------+-----------+-------------------------------------------------
| 'Cher' | ["Sonny and Cher"]
'Mick' | 'Jagger' | ["Rolling Stones"]
'Diana' | 'Ross' | ["Supremes"]
'Grace' | 'Slick' | ["Jefferson Airplane","Jefferson Starship"]
'' | 'Sting' | ["Police"]
'Stevie' | 'Winwood' | ["Spencer Davis Group","Traffic","Blind Faith"]
(6 rows)
See also
6.4.5.41 - QUOTE_NULLABLE
Returns the given string suitably quoted for use as a string literal in an SQL statement string; or if the argument is null, returns the unquoted string NULL.
Returns the given string suitably quoted for use as a string literal in an SQL statement string; or if the argument is null, returns the unquoted string NULL. Embedded single-quotes and backslashes are properly doubled.
Behavior type
Immutable
Syntax
QUOTE_NULLABLE ( string-expression )
Arguments
string-expression- Argument that resolves to one or more strings to format as string literals. If
string-expression resolves to null value, QUOTE_NULLABLE returns NULL.
Examples
The following examples use the table lead_vocalists, where the first names (fname) for Cher and Sting are set to NULL and an empty string, respectively
=> SELECT * from lead_vocalists ORDER BY lname DESC;
fname | lname | band
--------+---------+-------------------------------------------------
Stevie | Winwood | ["Spencer Davis Group","Traffic","Blind Faith"]
| Sting | ["Police"]
Grace | Slick | ["Jefferson Airplane","Jefferson Starship"]
Diana | Ross | ["Supremes"]
Mick | Jagger | ["Rolling Stones"]
| Cher | ["Sonny and Cher"]
(6 rows)
=> SELECT * FROM lead_vocalists WHERE fname IS NULL;
fname | lname | band
-------+-------+--------------------
| Cher | ["Sonny and Cher"]
(1 row)
=> SELECT * FROM lead_vocalists WHERE fname = '';
fname | lname | band
-------+-------+------------
| Sting | ["Police"]
(1 row)
The following query uses QUOTE_NULLABLE. Like QUOTE_LITERAL, QUOTE_NULLABLE sets off string values with single quotes, including empty strings. Unlike QUOTE_LITERAL, QUOTE_NULLABLE outputs NULL for null values:
=> SELECT QUOTE_NULLABLE (fname) "First Name", QUOTE_NULLABLE (lname) "Last Name", band FROM lead_vocalists ORDER BY fname DESC;
First Name | Last Name | band
------------+-----------+-------------------------------------------------
NULL | 'Cher' | ["Sonny and Cher"]
'Stevie' | 'Winwood' | ["Spencer Davis Group","Traffic","Blind Faith"]
'Mick' | 'Jagger' | ["Rolling Stones"]
'Grace' | 'Slick' | ["Jefferson Airplane","Jefferson Starship"]
'Diana' | 'Ross' | ["Supremes"]
'' | 'Sting' | ["Police"]
(6 rows)
See also
Character string literals
6.4.5.42 - REPEAT
Replicates a string the specified number of times and concatenates the replicated values as a single string.
Replicates a string the specified number of times and concatenates the replicated values as a single string. The return value takes on the data type of the string argument. Return values for non-LONG data types and LONG data types can be up to 65000 and 32000000 bytes in length, respectively. If the length of string*count exceeds these limits, Vertica silently truncates the results.
Behavior type
Immutable
Syntax
REPEAT ( 'string', count )
Arguments
string- The string to repeat, one of the following:
-
CHAR
-
VARCHAR
-
BINARY
-
VARBINARY
-
LONG VARCHAR
-
LONG VARBINARY
count- An integer expression that specifies how many times to repeat
string.
Examples
The following example repeats vmart three times:
=> SELECT REPEAT ('vmart', 3);
REPEAT
-----------------
vmartvmartvmart
(1 row)
6.4.5.43 - REPLACE
Replaces all occurrences of characters in a string with another set of characters.
Replaces all occurrences of characters in a string with another set of characters.
Behavior type
Immutable
Syntax
REPLACE ('string', 'target', 'replacement' )
Arguments
string- The string to modify.
target- The characters in
string to replace.
replacement- The characters to replace
target.
Examples
=> SELECT REPLACE('Documentation%20Library', '%20', ' ');
REPLACE
-----------------------
Documentation Library
(1 row)
=> SELECT REPLACE('This & That', '&', 'and');
REPLACE
---------------
This and That
(1 row)
=> SELECT REPLACE('straße', 'ß', 'ss');
REPLACE
---------
strasse
(1 row)
6.4.5.44 - RIGHT
Returns the specified characters from the right side of a string.
Returns the specified characters from the right side of a string.
Behavior type
Immutable
Syntax
RIGHT ( string-expr, length )
Arguments
string-expr- The string expression to return.
length- An integer value that specifies how many characters to return.
Examples
The following query returns the last three characters of the string 'vertica':
=> SELECT RIGHT('vertica', 3);
RIGHT
-------
ica
(1 row)
The following query queries date column date_ordered from table store.store_orders_fact. It coerces the dates to strings and extracts the last five characters from each string. It then returns all distinct strings:
SELECT DISTINCT(
RIGHT(date_ordered::varchar, 5)) MonthDays
FROM store.store_orders_fact ORDER BY MonthDays;
MonthDays
-----------
01-01
01-02
01-03
01-04
01-05
01-06
01-07
01-08
01-09
01-10
02-01
02-02
02-03
...
11-08
11-09
11-10
12-01
12-02
12-03
12-04
12-05
12-06
12-07
12-08
12-09
12-10
(120 rows)
See also
SUBSTR
6.4.5.45 - RPAD
Returns a VARCHAR value representing a string of a specific length filled on the right with specific characters.
Returns a VARCHAR value representing a string of a specific length filled on the right with specific characters.
Behavior type
Immutable
Syntax
RPAD ( expression , length [ , fill ] )
Arguments
expression- (CHAR OR VARCHAR) specifies the string to fill
length- (INTEGER) specifies the number of characters to return
fill- (CHAR OR VARCHAR) specifies the repeating string of characters with which to fill the output string. The default is the space character.
Examples
=> SELECT RPAD('database', 15, 'xzy');
RPAD
-----------------
databasexzyxzyx
(1 row)
If the string is already longer than the specified length it is truncated on the right:
=> SELECT RPAD('database', 6, 'xzy');
RPAD
--------
databa
(1 row)
6.4.5.46 - RTRIM
Returns a VARCHAR value representing a string with trailing blanks removed from the right side (end).
Returns a VARCHAR value representing a string with trailing blanks removed from the right side (end).
Behavior type
Immutable
Syntax
RTRIM ( expression [ , characters ] )
Arguments
expression- (CHAR or VARCHAR) is the string to trim
characters- (CHAR or VARCHAR) specifies the characters to remove from the right side of
expression. The default is the space character.
Examples
=> SELECT RTRIM('trimzzzyyyyyyxxxxxxxx', 'xyz');
RTRIM
-------
trim
(1 row)
See also
6.4.5.47 - SHA1
Uses the US Secure Hash Algorithm 1 to calculate the SHA1 hash of string.
Uses the US Secure Hash Algorithm 1 to calculate the SHA1 hash of string. Returns the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
SHA1 ( string )
Arguments
string- The
VARCHAR or VARBINARY string to be calculated.
Examples
The following examples calculate the SHA1 hash of the provided strings:
=> SELECT SHA1('123');
SHA1
------------------------------------------
40bd001563085fc35165329ea1ff5c5ecbdbbeef
(1 row)
=> SELECT SHA1('Vertica'::bytea);
SHA1
------------------------------------------
ee2cff8d3444995c6c301546c4fc5ee152d77c11
(1 row)
See also
6.4.5.48 - SHA224
Uses the US Secure Hash Algorithm 2 to calculate the SHA224 hash of string.
Uses the US Secure Hash Algorithm 2 to calculate the SHA224 hash of string. Returns the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
SHA224 ( string )
Arguments
string- The
VARCHAR or VARBINARY string to be calculated.
Examples
The following examples calculate the SHA224 hash of the provided strings:
=> SELECT SHA224('abc');
SHA224
----------------------------------------------------------
78d8045d684abd2eece923758f3cd781489df3a48e1278982466017f
(1 row)
=> SELECT SHA224('Vertica'::bytea);
SHA224
----------------------------------------------------------
135ac268f64ff3124aeeebc3cc0af0a29fd600a3be8e29ed97e45e25
(1 row)
=> SELECT sha224(''::varbinary) = 'd14a028c2a3a2bc9476102bb288234c415a2b01f828ea62ac5b3e42f' AS "TRUE";
TRUE
------
t
(1 row)
See also
6.4.5.49 - SHA256
Uses the US Secure Hash Algorithm 2 to calculate the SHA256 hash of string.
Uses the US Secure Hash Algorithm 2 to calculate the SHA256 hash of string. Returns the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
SHA256 ( string )
Arguments
string- The
VARCHAR or VARBINARY string to be calculated.
Examples
The following examples calculate the SHA256 hash of the provided strings:
=> SELECT SHA256('abc');
SHA256
------------------------------------------------------------------
a665a45920422f9d417e4867efdc4fb8a04a1f3fff1fa07e998e86f7f7a27ae3
(1 row)
=> SELECT SHA256('Vertica'::bytea);
SHA256
------------------------------------------------------------------
9981b0b7df9f5be06e9e1a7f4ae2336a7868d9ab522b9a6ca6a87cd9ed95ba53
(1 row)
=> SELECT sha256('') = 'e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855' AS "TRUE";
TRUE
------
t
(1 row)
See also
6.4.5.50 - SHA384
Uses the US Secure Hash Algorithm 2 to calculate the SHA384 hash of string.
Uses the US Secure Hash Algorithm 2 to calculate the SHA384 hash of string. Returns the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
SHA384 ( string )
Arguments
string- The
VARCHAR or VARBINARY string to be calculated.
Examples
The following examples calculate the SHA384 hash of the provided strings:
=> SELECT SHA384('123');
SHA384
--------------------------------------------------------------------------------------------------
9a0a82f0c0cf31470d7affede3406cc9aa8410671520b727044eda15b4c25532a9b5cd8aaf9cec4919d76255b6bfb00f
(1 row)
=> SELECT SHA384('Vertica'::bytea);
SHA384
--------------------------------------------------------------------------------------------------
3431a717dc3289862bbd636a064d26980b47ebe4684b800cff4756f0c24985866ef97763eafd548fedb0ce28722c96bb
(1 row)
See also
6.4.5.51 - SHA512
Uses the US Secure Hash Algorithm 2 to calculate the SHA512 hash of string.
Uses the US Secure Hash Algorithm 2 to calculate the SHA512 hash of string. Returns the result as a VARCHAR string in hexadecimal.
Behavior type
Immutable
Syntax
SHA512 ( string )
Arguments
string- The
VARCHAR or VARBINARY string to be calculated.
Examples
The following examples calculate the SHA512 hash of the provided strings:
=> SELECT SHA512('123');
SHA512
----------------------------------------------------------------------------------------------------------------------------------
3c9909afec25354d551dae21590bb26e38d53f2173b8d3dc3eee4c047e7ab1c1eb8b85103e3be7ba613b31bb5c9c36214dc9f14a42fd7a2fdb84856bca5c44c2
(1 row)
=> SELECT SHA512('Vertica'::bytea);
SHA512
----------------------------------------------------------------------------------------------------------------------------------
c4ee2b2d17759226a3897c9c30d7c6df1145c4582849bb5191ee140bce05b83d3d869890cc3619b534fea6f97ff28a739d8b568a5ade66e756b3243ef97d3f00
(1 row)
See also
6.4.5.52 - SOUNDEX
Takes a VARCHAR argument and returns a four-character code that enables comparison of that argument with other SOUNDEX-encoded strings that are spelled differently in English, but are phonetically similar.
Takes a VARCHAR argument and returns a four-character code that enables comparison of that argument with other SOUNDEX-encoded strings that are spelled differently in English, but are phonetically similar. SOUNDEX implements an algorithm that was developed by Robert C. Russell and Margaret King Odell, and is described in The Art of Computer Programming, Vol. 3.
Behavior type
Immutable
Syntax
SOUNDEX ( string-expression )
Arguments
string-expression- The VARCHAR expression to encode.
Soundex encoding algorithm
Vertica uses the following Soundex encoding algorithm, which complies with most SQL implementations:
-
Save the first letter. Map all occurrences of a, e, i, o, u, y, h, w to zero (0).
-
Replace all consonants (include the first letter) with digits:
-
b, f, p, v → 1
-
c, g, j, k, q, s, x, z → 2
-
d, t → 3
-
l → 4
-
m, n → 5
-
r → 6
-
Replace all adjacent same digits with one digit, and then remove all zero (0) digits
-
If the saved letter's digit is the same as the resulting first digit, remove the digit (keep the letter).
-
Append 3 zeros if result contains less than 3 digits. Remove all except first letter and 3 digits after it.
Note
Encoding ignores all non-alphabetic characters—for example, the apostrophe in O'Connor.
Examples
Find last names in the employee_dimension table that are phonetically similar to Lee:
SELECT employee_last_name, employee_first_name, employee_state
FROM public.employee_dimension
WHERE SOUNDEX(employee_last_name) = SOUNDEX('Lee')
ORDER BY employee_state, employee_last_name, employee_first_name;
Lea | James | AZ
Li | Sam | AZ
Lee | Darlene | CA
Lee | Juanita | CA
Li | Amy | CA
Li | Barbara | CA
Li | Ben | CA
...
See also
SOUNDEX_MATCHES
6.4.5.53 - SOUNDEX_MATCHES
Compares the Soundex encodings of two strings.
Compares the Soundex encodings of two strings. The function then returns an integer that indicates the number of matching characters, in the same order. The return value is 0 to 4 inclusive, where 0 indicates no match, and 4 an exact match.
For details on how Vertica implements Soundex encoding, see Soundex Encoding Algorithm.
Behavior type
Immutable
Syntax
SOUNDEX_MATCHES ( string-expression1, string-expression2 )
Arguments
string-expression1, string-expression2- The two VARCHAR expressions to encode and compare.
Examples
Find how well the Soundex encodings of two strings match:
-
Compare the Soundex encodings of Lewis and Li:
> SELECT SOUNDEX_MATCHES('Lewis', 'Li');
SOUNDEX_MATCHES
-----------------
3
(1 row)
-
Compare the Soundex encodings of Lee and Li:
=> SELECT SOUNDEX_MATCHES('Lee', 'Li');
SOUNDEX_MATCHES
-----------------
4
(1 row)
Find last names in the employee_dimension table whose Soundex encodings match at least 3 characters in the encoding for Lewis:
=> SELECT DISTINCT(employee_last_name)
FROM public.employee_dimension
WHERE SOUNDEX_MATCHES (employee_last_name, 'Lewis' ) >= 3 ORDER BY employee_last_name;
employee_last_name
--------------------
Lea
Lee
Leigh
Lewis
Li
Reyes
(6 rows)
See also
SOUNDEX
6.4.5.54 - SPACE
Returns the specified number of blank spaces, typically for insertion into a character string.
Returns the specified number of blank spaces, typically for insertion into a character string.
Behavior type
Immutable
Syntax
SPACE(n)
Arguments
n- An integer argument that specifies how many spaces to insert.
Examples
The following example concatenates strings x and y with 10 spaces inserted between them:
=> SELECT 'x' || SPACE(10) || 'y' AS Ten_spaces;
Ten_spaces
--------------
x y
(1 row)
6.4.5.55 - SPLIT_PART
Splits string on the delimiter and returns the string at the location of the beginning of the specified field (counting from 1).
Splits string on the delimiter and returns the string at the location of the beginning of the specified field (counting from 1).
Behavior type
Immutable
Syntax
SPLIT_PART ( string , delimiter , field )
Arguments
string- Argument string
delimiter- Delimiter
field- (INTEGER) Number of the part to return
Notes
Use this with the character form of the subfield.
Examples
The specified integer of 2 returns the second string, or def.
=> SELECT SPLIT_PART('abc~@~def~@~ghi', '~@~', 2);
SPLIT_PART
------------
def
(1 row)
In the next example, specify 3, which returns the third string, or 789.
=> SELECT SPLIT_PART('123~|~456~|~789', '~|~', 3);
SPLIT_PART
------------
789
(1 row)
The tildes are for readability only. Omitting them returns the same results:
=> SELECT SPLIT_PART('123|456|789', '|', 3);
SPLIT_PART
------------
789
(1 row)
See what happens if you specify an integer that exceeds the number of strings: The result is not null, it is an empty string.
=> SELECT SPLIT_PART('123|456|789', '|', 4);
SPLIT_PART
------------
(1 row)
=> SELECT SPLIT_PART('123|456|789', '|', 4) IS NULL;
?column?
----------
f
(1 row)
If SPLIT_PART had returned NULL, LENGTH would have returned 0.
=> SELECT LENGTH (SPLIT_PART('123|456|789', '|', 4));
LENGTH
--------
0
(1 row)
If the locale of your database is BINARY, SPLIT_PART calls SPLIT_PARTB:
=> SHOW LOCALE;
name | setting
--------+--------------------------------------
locale | en_US@collation=binary (LEN_KBINARY)
(1 row)
=> SELECT SPLIT_PART('123456789', '5', 1);
split_partb
-------------
1234
(1 row)
=> SET LOCALE TO 'en_US@collation=standard';
INFO 2567: Canonical locale: 'en_US@collation=standard'
Standard collation: 'LEN'
English (United States, collation=standard)
SET
=> SELECT SPLIT_PART('123456789', '5', 1);
split_part
------------
1234
(1 row)
See also
6.4.5.56 - SPLIT_PARTB
Divides an input string on a delimiter character and returns the Nth segment, counting from 1.
Divides an input string on a delimiter character and returns the Nth segment, counting from 1. The VARCHAR arguments are treated as octets rather than UTF-8 characters.
Behavior type
Immutable
Syntax
SPLIT_PARTB ( string, delimiter, part-number)
Arguments
string- VARCHAR, the string to split.
delimiter- VARCHAR, the delimiter between segments.
part-number- INTEGER, the part number to return. The first part is 1, not 0.
Examples
The following example returns the third part of its input:
=> SELECT SPLIT_PARTB('straße~@~café~@~soupçon', '~@~', 3);
SPLIT_PARTB
-------------
soupçon
(1 row)
The tildes are for readability only. Omitting them returns the same results:
=> SELECT SPLIT_PARTB('straße @ café @ soupçon', '@', 3);
SPLIT_PARTB
-------------
soupçon
(1 row)
If the requested part number is greater than the number of parts, the function returns an empty string:
=> SELECT SPLIT_PARTB('straße @ café @ soupçon', '@', 4);
SPLIT_PARTB
-------------
(1 row)
=> SELECT SPLIT_PARTB('straße @ café @ soupçon', '@', 4) IS NULL;
?column?
----------
f
(1 row)
If the locale of your database is BINARY, SPLIT_PART calls SPLIT_PARTB:
=> SHOW LOCALE;
name | setting
--------+--------------------------------------
locale | en_US@collation=binary (LEN_KBINARY)
(1 row)
=> SELECT SPLIT_PART('123456789', '5', 1);
split_partb
-------------
1234
(1 row)
=> SET LOCALE TO 'en_US@collation=standard';
INFO 2567: Canonical locale: 'en_US@collation=standard'
Standard collation: 'LEN'
English (United States, collation=standard)
SET
=> SELECT SPLIT_PART('123456789', '5', 1);
split_part
------------
1234
(1 row)
See also
6.4.5.57 - STRPOS
Returns an INTEGER value that represents the location of a specified substring within a string (counting from one).
Returns an INTEGER value that represents the location of a specified substring within a string (counting from one). If the substring is not found, STRPOS returns 0.
STRPOS is similar to POSITION; however, POSITION allows finding by characters and by octet.
Behavior type
Immutable
Syntax
STRPOS ( string-expression , substring )
Arguments
string-expression - The string in which to locate
substring
substring- The substring to locate in
string-expression
Examples
=> SELECT ship_type, shipping_key, strpos (ship_type, 'DAY') FROM shipping_dimension WHERE strpos > 0 ORDER BY ship_type, shipping_key;
ship_type | shipping_key | strpos
--------------------------------+--------------+--------
NEXT DAY | 1 | 6
NEXT DAY | 13 | 6
NEXT DAY | 19 | 6
NEXT DAY | 22 | 6
NEXT DAY | 26 | 6
NEXT DAY | 30 | 6
NEXT DAY | 34 | 6
NEXT DAY | 38 | 6
NEXT DAY | 45 | 6
NEXT DAY | 51 | 6
NEXT DAY | 67 | 6
NEXT DAY | 69 | 6
NEXT DAY | 80 | 6
NEXT DAY | 90 | 6
NEXT DAY | 96 | 6
NEXT DAY | 98 | 6
TWO DAY | 9 | 5
TWO DAY | 21 | 5
TWO DAY | 28 | 5
TWO DAY | 32 | 5
TWO DAY | 40 | 5
TWO DAY | 43 | 5
TWO DAY | 49 | 5
TWO DAY | 50 | 5
TWO DAY | 52 | 5
TWO DAY | 53 | 5
TWO DAY | 61 | 5
TWO DAY | 73 | 5
TWO DAY | 81 | 5
TWO DAY | 83 | 5
TWO DAY | 84 | 5
TWO DAY | 85 | 5
TWO DAY | 94 | 5
TWO DAY | 100 | 5
(34 rows)
6.4.5.58 - STRPOSB
Returns an INTEGER value representing the location of a specified substring within a string, counting from one, where each octet in the string is counted (as opposed to characters).
Returns an INTEGER value representing the location of a specified substring within a string, counting from one, where each octet in the string is counted (as opposed to characters).
Behavior type
Immutable
Syntax
STRPOSB ( string , substring )
Arguments
string- (CHAR or VARCHAR) is the string in which to locate the substring
substring- (CHAR or VARCHAR) is the substring to locate
Notes
STRPOSB is identical to POSITIONB except for the order of the arguments.
Examples
=> SELECT STRPOSB('straße', 'e');
STRPOSB
---------
7
(1 row)
=> SELECT STRPOSB('étudiant', 'tud');
STRPOSB
---------
3
(1 row)
6.4.5.59 - SUBSTR
Returns VARCHAR or VARBINARY value representing a substring of a specified string.
Returns VARCHAR or VARBINARY value representing a substring of a specified string.
Behavior type
Immutable
Syntax
SUBSTR ( string , position [ , extent ] )
Arguments
string- (CHAR/VARCHAR or BINARY/VARBINARY) is the string from which to extract a substring. If null, Vertica returns no results.
position- (INTEGER or DOUBLE PRECISION) is the starting position of the substring (counting from one by characters). If 0 or negative, Vertica returns no results.
extent- (INTEGER or DOUBLE PRECISION) is the length of the substring to extract (in characters). The default is the end of the string.
Notes
SUBSTR truncates DOUBLE PRECISION input values.
Examples
=> SELECT SUBSTR('abc'::binary(3),1);
substr
--------
abc
(1 row)
=> SELECT SUBSTR('123456789', 3, 2);
substr
--------
34
(1 row)
=> SELECT SUBSTR('123456789', 3);
substr
---------
3456789
(1 row)
=> SELECT SUBSTR(TO_BITSTRING(HEX_TO_BINARY('0x10')), 2, 2);
substr
--------
00
(1 row)
=> SELECT SUBSTR(TO_HEX(10010), 2, 2);
substr
--------
71
(1 row)
6.4.5.60 - SUBSTRB
Returns an octet value representing the substring of a specified string.
Returns an octet value representing the substring of a specified string.
Behavior type
Immutable
Syntax
SUBSTRB ( string , position [ , extent ] )
Arguments
string- (CHAR/VARCHAR) is the string from which to extract a substring.
position- (INTEGER or DOUBLE PRECISION) is the starting position of the substring (counting from one in octets).
extent- (INTEGER or DOUBLE PRECISION) is the length of the substring to extract (in octets). The default is the end of the string
Notes
-
This function treats the multibyte character string as a string of octets (bytes) and uses octet numbers as incoming and outgoing position specifiers and lengths. The strings themselves are type VARCHAR, but they treated as if each octet were a separate character.
-
SUBSTRB truncates DOUBLE PRECISION input values.
Examples
=> SELECT SUBSTRB('soupçon', 5);
SUBSTRB
---------
çon
(1 row)
=> SELECT SUBSTRB('soupçon', 5, 2);
SUBSTRB
---------
ç
(1 row)
Vertica returns the following error message if you use BINARY/VARBINARY:
=>SELECT SUBSTRB('abc'::binary(3),1);
ERROR: function substrb(binary, int) does not exist, or permission is denied for substrb(binary, int)
HINT: No function matches the given name and argument types. You may need to add explicit type casts.
6.4.5.61 - SUBSTRING
Returns a value representing a substring of the specified string at the given position, given a value, a position, and an optional length.
Returns a value representing a substring of the specified string at the given position, given a value, a position, and an optional length. SUBSTRING truncates DOUBLE PRECISION input values.
Behavior type
Immutable if USING OCTETS, stable otherwise.
Syntax
SUBSTRING ( string, position[, length ]
[USING {CHARACTERS | OCTETS } ] )
SUBSTRING ( string FROM position [ FOR length ]
[USING { CHARACTERS | OCTETS } ] )
Arguments
string- (CHAR/VARCHAR or BINARY/VARBINARY) is the string from which to extract a substring
position- (INTEGER or DOUBLE PRECISION) is the starting position of the substring (counting from one by either characters or octets). (The default is characters.) If position is greater than the length of the given value, an empty value is returned.
length- (INTEGER or DOUBLE PRECISION) is the length of the substring to extract in either characters or octets. (The default is characters.) The default is the end of the string.If a length is given the result is at most that many bytes. The maximum length is the length of the given value less the given position. If no length is given or if the given length is greater than the maximum length then the length is set to the maximum length.
USING CHARACTERS | OCTETS- Determines whether the value is expressed in characters (the default) or octets.
Examples
=> SELECT SUBSTRING('abc'::binary(3),1);
substring
-----------
abc
(1 row)
=> SELECT SUBSTRING('soupçon', 5, 2 USING CHARACTERS);
substring
-----------
ço
(1 row)
=> SELECT SUBSTRING('soupçon', 5, 2 USING OCTETS);
substring
-----------
ç
(1 row)
If you use a negative position, then the functions starts at a non-existent position. In this example, that means counting eight characters starting at position -4. So the function starts at the empty position -4 and counts five characters, including a position for zero which is also empty. This returns three characters.
=> SELECT SUBSTRING('1234567890', -4, 8);
substring
-----------
123
(1 row)
6.4.5.62 - TRANSLATE
Replaces individual characters in string_to_replace with other characters.
Replaces individual characters in string_to_replace with other characters.
Behavior type
Immutable
Syntax
TRANSLATE ( string_to_replace , from_string , to_string );
Arguments
string_to_replace- String to be translated.
from_string- Contains characters that should be replaced in string_to_replace.
to_string- Any character in string_to_replace that matches a character in from_string is replaced by the corresponding character in to_string.
Examples
=> SELECT TRANSLATE('straße', 'ß', 'ss');
TRANSLATE
-----------
strase
(1 row)
6.4.5.63 - TRIM
Combines the BTRIM, LTRIM, and RTRIM functions into a single function.
Combines the BTRIM, LTRIM, and RTRIM functions into a single function.
Behavior type
Immutable
Syntax
TRIM ( [ [ LEADING | TRAILING | BOTH ] [ characters ] FROM ] expression )
Arguments
LEADING- Removes the specified characters from the left side of the string
TRAILING- Removes the specified characters from the right side of the string
BOTH- Removes the specified characters from both sides of the string (default)
characters- (CHAR or VARCHAR) specifies the characters to remove from
expression. The default is the space character.
expression- (CHAR or VARCHAR) is the string to trim
Examples
=> SELECT '-' || TRIM(LEADING 'x' FROM 'xxdatabasexx') || '-';
?column?
--------------
-databasexx-
(1 row)
=> SELECT '-' || TRIM(TRAILING 'x' FROM 'xxdatabasexx') || '-';
?column?
--------------
-xxdatabase-
(1 row)
=> SELECT '-' || TRIM(BOTH 'x' FROM 'xxdatabasexx') || '-';
?column?
------------
-database-
(1 row)
=> SELECT '-' || TRIM('x' FROM 'xxdatabasexx') || '-';
?column?
------------
-database-
(1 row)
=> SELECT '-' || TRIM(LEADING FROM ' database ') || '-';
?column?
--------------
-database -
(1 row)
=> SELECT '-' || TRIM(' database ') || '-'; ?column?
------------
-database-
(1 row)
See also
6.4.5.64 - UPPER
Returns a VARCHAR value containing the argument converted to uppercase letters.
Returns a VARCHAR value containing the argument converted to uppercase letters.
Starting in Release 5.1, this function treats the string argument as a UTF-8 encoded string, rather than depending on the collation setting of the locale (for example, collation=binary) to identify the encoding.
Behavior type
stable
Syntax
UPPER ( expression )
Arguments
expression- CHAR or VARCHAR containing the string to convert
Notes
UPPER is restricted to 32500 octet inputs, since it is possible for the UTF-8 representation of result to double in size.
Examples
=> SELECT UPPER('AbCdEfG');
UPPER
----------
ABCDEFG
(1 row)
=> SELECT UPPER('étudiant');
UPPER
----------
ÉTUDIANT
(1 row)
6.4.5.65 - UPPERB
Returns a character string with each ASCII character converted to uppercase.
Returns a character string with each ASCII character converted to uppercase. Multibyte characters are not converted and are skipped.
Behavior type
Immutable
Syntax
UPPERB ( expression )
Arguments
expression- (CHAR or VARCHAR) is the string to convert
Examples
In the following example, the multibyte UTF-8 character é is not converted to uppercase:
=> SELECT UPPERB('étudiant');
UPPERB
----------
éTUDIANT
(1 row)
=> SELECT UPPERB('AbCdEfG');
UPPERB
---------
ABCDEFG
(1 row)
=> SELECT UPPERB('The Vertica Database');
UPPERB
----------------------
THE VERTICA DATABASE
(1 row)
6.4.6 - URI functions
The functions in this section follow the RFC 3986 standard for percent-encoding a Universal Resource Identifier (URI).
The functions in this section follow the RFC 3986 standard for percent-encoding a Universal Resource Identifier (URI).
6.4.6.1 - URI_PERCENT_DECODE
Decodes a percent-encoded Universal Resource Identifier (URI) according to the RFC 3986 standard.
Decodes a percent-encoded Universal Resource Identifier (URI) according to the RFC 3986 standard.
Syntax
URI_PERCENT_DECODE (expression)
Behavior type
Immutable
Parameters
expression- (VARCHAR) is the string to convert.
Examples
The following example invokes uri_percent_decode on the Websites column of the URI table and returns a decoded URI:
=> SELECT URI_PERCENT_DECODE(Websites) from URI;
URI_PERCENT_DECODE
-----------------------------------------------
http://www.faqs.org/rfcs/rfc3986.html x xj%a%
(1 row)
The following example returns the original URI in the Websites column and its decoded version:
=> SELECT Websites, URI_PERCENT_DECODE (Websites) from URI;
Websites | URI_PERCENT_DECODE
---------------------------------------------------+---------------------------------------------
http://www.faqs.org/rfcs/rfc3986.html+x%20x%6a%a% | http://www.faqs.org/rfcs/rfc3986.html x xj%a%
(1 row)
6.4.6.2 - URI_PERCENT_ENCODE
Encodes a Universal Resource Identifier (URI) according to the RFC 3986 standard for percent encoding.
Encodes a Universal Resource Identifier (URI) according to the RFC 3986 standard for percent encoding. For compatibility with older encoders, this function converts + to space; space is converted to %20.
Syntax
URI_PERCENT_ENCODE (expression)
Behavior type
Immutable
Parameters
expression- (VARCHAR) is the string to convert.
Examples
The following example shows how the uri_percent_encode function is invoked on a the Websites column of the URI table and returns an encoded URI:
=> SELECT URI_PERCENT_ENCODE(Websites) from URI;
URI_PERCENT_ENCODE
------------------------------------------
http%3A%2F%2Fexample.com%2F%3F%3D11%2F15
(1 row)
The following example returns the original URI in the Websites column and it's encoded form:
=> SELECT Websites, URI_PERCENT_ENCODE(Websites) from URI; Websites | URI_PERCENT_ENCODE
----------------------------+------------------------------------------
http://example.com/?=11/15 | http%3A%2F%2Fexample.com%2F%3F%3D11%2F15
(1 row)
6.4.7 - UUID functions
Currently, Vertica provides one function to support UUID data types, UUID_GENERATE.
Currently, Vertica provides one function to support UUID data types,
UUID_GENERATE.
6.4.7.1 - UUID_GENERATE
Returns a new universally unique identifier (UUID) that is generated based on high-quality randomness from /dev/urandom.
Returns a new universally unique identifier (UUID) that is generated based on high-quality randomness from /dev/urandom.
Behavior type
Volatile
Syntax
UUID_GENERATE()
Examples
=> CREATE TABLE Customers(
cust_id UUID DEFAULT UUID_GENERATE(),
lname VARCHAR(36),
fname VARCHAR(24));
CREATE TABLE
=> INSERT INTO Customers VALUES (DEFAULT, 'Kearney', 'Thomas');
OUTPUT
--------
1
(1 row)
=> COPY Customers (lname, fname) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Pham|Duc
>> Garcia|Mary
>> \.
=> SELECT * FROM Customers;
cust_id | lname | fname
--------------------------------------+---------+--------
03fe0794-ac5d-42d4-8246-54f7ec81ed0c | Pham | Duc
6950313d-c77e-4c11-a86e-0a54aa3ec114 | Kearney | Thomas
9c9653ce-c2e4-4441-b0f7-0137b54cc28c | Garcia | Mary
(3 rows)
6.5 - Database Designer functions
Database Designer functions perform the following operations, generally performed in the following order:
-
Create a design.
-
Set design properties.
-
Populate a design.
-
Create design and deployment scripts.
-
Get design data.
-
Clean up.
Important
You can also use meta-function
DESIGNER_SINGLE_RUN, which encapsulates all of these steps with a single call. The meta-function iterates over all queries within a specified timespan, and returns with a design ready for deployment.
For detailed information, see Workflow for running Database Designer programmatically. For information on required privileges, see Privileges for running Database Designer functions
Caution
Before running Database Designer functions on an existing schema, back up the current design by calling
EXPORT_CATALOG.
Create a design
DESIGNER_CREATE_DESIGN directs Database Designer to create a design.
Set design properties
The following functions let you specify design properties:
Populate a design
The following functions let you add tables and queries to your Database Designer design:
Create design and deployment scripts
The following functions populate the Database Designer workspace and create design and deployment scripts. You can also analyze statistics, deploy the design automatically, and drop the workspace after the deployment:
Reset a design
DESIGNER_RESET_DESIGN discards all the run-specific information of the previous Database Designer build or deployment of the specified design but retains its configuration.
Get design data
The following functions display information about projections and scripts that the Database Designer created:
Cleanup
The following functions cancel any running Database Designer operation or drop a Database Designer design and all its contents:
6.5.1 - DESIGNER_ADD_DESIGN_QUERIES
Reads and evaluates queries from an input file, and adds the queries that it accepts to the specified design.
Reads and evaluates queries from an input file, and adds the queries that it accepts to the specified design. All accepted queries are assigned a weight of 1.
The following requirements apply:
-
All queried tables must previously be added to the design with DESIGNER_ADD_DESIGN_TABLES.
-
If the design type is incremental, the Database Designer reads only the first 100 queries in the input file, and ignores all queries beyond that number.
All accepted queries are added to the system table DESIGN_QUERIES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_ADD_DESIGN_QUERIES ( 'design-name', 'queries-file' [, return-results] )
Parameters
design-name- Name of the target design.
queries-file- Absolute path and name of the file that contains the queries to evaluate, on the local file system of the node where the session is connected, or another file system or object store that Vertica supports.
return-results- Boolean, optionally specifies whether to return results of the add operation to standard output. If set to true, Database Designer returns the following results:
-
Number of accepted queries
-
Number of queries referencing non-design tables
-
Number of unsupported queries
-
Number of illegal queries
Privileges
Non-superuser: design creator with all privileges required to execute the queries in input-file.
Errors
Database Designer returns an error in the following cases:
-
The query contains illegal syntax.
-
The query references:
-
DELETE or UPDATE query has one or more subqueries.
-
INSERT query does not include a SELECT clause.
-
Database Designer cannot optimize the query.
Examples
The following example adds queries from vmart_queries.sql to the VMART_DESIGN design. This file contains nine queries. The statement includes a third argument of true, so Database Designer returns results of the add operation:
=> SELECT DESIGNER_ADD_DESIGN_QUERIES ('VMART_DESIGN', '/tmp/examples/vmart_queries.sql', 'true');
...
DESIGNER_ADD_DESIGN_QUERIES
----------------------------------------------------
Number of accepted queries =9
Number of queries referencing non-design tables =0
Number of unsupported queries =0
Number of illegal queries =0
(1 row)
See also
Running Database Designer programmatically
6.5.2 - DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS
Executes the specified query and evaluates results in the following columns:.
Executes the specified query and evaluates results in the following columns:
-
QUERY_TEXT (required): Text of potential design queries.
-
QUERY_WEIGHT (optional): The weight assigned to each query that indicates its importance relative to other queries, a real number >0 and ≤ 1. Database Designer uses this setting when creating the design to prioritize the query. If DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS returns any results that omit this value, Database Designer sets their weight to 1.
After evaluating the queries in QUERY_TEXT, DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS adds all accepted queries to the design. An unlimited number of queries can be added to the design.
Before you add queries to a design, you must add the queried tables with
DESIGNER_ADD_DESIGN_TABLES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS ( 'design-name', 'query' )
Parameters
design-name- Name of the target design.
query- A valid SQL query whose results contain columns named
QUERY_TEXT and, optionally, QUERY_WEIGHT.
Privileges
Non-superuser: design creator with all privileges required to execute the specified query, and all queries returned by this function
Errors
Database Designer returns an error in the following cases:
-
The query contains illegal syntax.
-
The query references:
-
DELETE or UPDATE query has one or more subqueries.
-
INSERT query does not include a SELECT clause.
-
Database Designer cannot optimize the query.
Examples
The following example queries the system table
QUERY_REQUESTS for all long-running queries (> 1 million microseconds) and adds them to the VMART_DESIGN design. The query returns no information on query weights, so all queries are assigned a weight of 1:
=> SELECT DESIGNER_ADD_DESIGN_QUERIES_FROM_RESULTS ('VMART_DESIGN',
'SELECT request as query_text FROM query_requests where request_duration_ms > 1000000 AND request_type =
''QUERY'';');
See also
Running Database Designer programmatically
6.5.3 - DESIGNER_ADD_DESIGN_QUERY
Reads and parses the specified query, and if accepted, adds it to the design.
Reads and parses the specified query, and if accepted, adds it to the design. Before you add queries to a design, you must add the queried tables with
DESIGNER_ADD_DESIGN_TABLES.
All accepted queries are added to the system table
DESIGN_QUERIES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_ADD_DESIGN_QUERY ( 'design-name', 'design-query' [, query-weight] )
Parameters
design-name- Name of the target design.
design-query- Executable SQL query.
query-weight- Optionally assigns a weight to each query that indicates its importance relative to other queries, a real number >0 and ≤ 1. Database Designer uses this setting to prioritize queries in the design .
If you omit this parameter, Database Designer assigns a weight of 1.
Privileges
Non-superuser: design creator with all privileges required to execute the specified query
Errors
Database Designer returns an error in the following cases:
-
The query contains illegal syntax.
-
The query references:
-
DELETE or UPDATE query has one or more subqueries.
-
INSERT query does not include a SELECT clause.
-
Database Designer cannot optimize the query.
Examples
The following example adds the specified query to the VMART_DESIGN design and assigns that query a weight of 0.5:
=> SELECT DESIGNER_ADD_DESIGN_QUERY (
'VMART_DESIGN',
'SELECT customer_name, customer_type FROM customer_dimension ORDER BY customer_name ASC;', 0.5
);
See also
Running Database Designer programmatically
6.5.4 - DESIGNER_ADD_DESIGN_TABLES
Adds the specified tables to a design.
Adds the specified tables to a design. You must run DESIGNER_ADD_DESIGN_TABLES before adding design queries to the design. If no tables are added to the design, Vertica does not accept design queries.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_ADD_DESIGN_TABLES ( 'design-name', '[ table-spec[,...] ]' [, 'analyze-statistics'] )
Parameters
design-name- Name of the Database Designer design.
table-spec[,...]- One or more comma-delimited arguments that specify which tables to add to the design, where each
table-spec argument can specify tables as follows:
If set to an empty string, Vertica adds all tables in the database to which the user has access.
analyze-statistics- Boolean that optionally specifies whether to run
ANALYZE_STATISTICS after adding the specified tables to the design, by default set to false.
Accurate statistics help Database Designer optimize compression and query performance. Updating statistics takes time and resources.
Privileges
Non-superuser: design creator with USAGE privilege on the design table schema and owner of the design table
Examples
The following example adds to design VMART_DESIGN all tables from schemas online_sales and store, and analyzes statistics for those tables:
=> SELECT DESIGNER_ADD_DESIGN_TABLES('VMART_DESIGN', 'online_sales.*, store.*','true');
DESIGNER_ADD_DESIGN_TABLES
----------------------------
7
(1 row)
See also
Running Database Designer programmatically
6.5.5 - DESIGNER_CANCEL_POPULATE_DESIGN
Cancels population or deployment operation for the specified design if it is currently running.
Cancels population or deployment operation for the specified design if it is currently running. When you cancel a deployment, the Database Designer cancels the projection refresh operation. It does not roll back projections that it already deployed and refreshed.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_CANCEL_POPULATE_DESIGN ( 'design-name' )
Parameters
design-name- Name of the design operation to cancel.
Privileges
Non-superuser: design creator
Examples
The following example cancels a currently running design for VMART_DESIGN and then drops the design:
=> SELECT DESIGNER_CANCEL_POPULATE_DESIGN ('VMART_DESIGN');
=> SELECT DESIGNER_DROP_DESIGN ('VMART_DESIGN', 'true');
See also
Running Database Designer programmatically
6.5.6 - DESIGNER_CREATE_DESIGN
Creates a design with the specified name.
Creates a design with the specified name.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_CREATE_DESIGN ( 'design-name' )
Parameters
design-name- Name of the design to create, can contain only alphanumeric and underscore (_) characters.
Two users cannot have designs with the same name at the same time.
Privileges
Database Designer system views
If any of the following
V_MONITOR tables do not already exist from previous designs, DESIGNER_CREATE_DESIGN creates them:
Examples
The following example creates the design VMART_DESIGN:
=> SELECT DESIGNER_CREATE_DESIGN('VMART_DESIGN');
DESIGNER_CREATE_DESIGN
------------------------
0
(1 row)
See also
Running Database Designer programmatically
6.5.7 - DESIGNER_DESIGN_PROJECTION_ENCODINGS
Analyzes encoding in the specified projections, creates a script to implement encoding recommendations, and optionally deploys the recommendations.
Analyzes encoding in the specified projections, creates a script to implement encoding recommendations, and optionally deploys the recommendations.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_DESIGN_PROJECTION_ENCODINGS ( '[ proj-spec[,... ] ]', '[destination]' [, 'deploy'] [, 'reanalyze-encodings'] )
Parameters
proj-spec[,...]- One or more comma-delimited projections to add to the design. Each projection can be specified in one of the following ways:
-
[[schema.]table.]projection
Specifies to analyze projection.
-
schema.*
Specifies to analyze all projections in the named schema.
-
[schema.]table
Specifiesto analyze all projections of the named table.
If set to an empty string, Vertica analyzes all projections in the database to which the user has access.
For example, the following statement specifies to analyze all projections in schema private, and send the results to the file encodings.sql:
=> SELECT DESIGNER_DESIGN_PROJECTION_ENCODINGS ('mydb.private.*','encodings.sql');
destination- Specifies where to send output, one of the following:
-
Empty string ('') writes the script to standard output.
-
Pathname of a SQL output file. If you specify a file that does not exist, the function creates one. If you specify only a file name, Vertica creates it in the catalog directory. If the file already exists, the function silently overwrites its contents.
deploy- Boolean that specifies whether to deploy encoding changes.
Default: false
reanalyze-encodings- Boolean that specifies whether
DESIGNER_DESIGN_PROJECTION_ENCODINGS analyzes encodings in a projection where all columns are already encoded:
Default: false
Privileges
Superuser, or DBDUSER with the following privileges:
Examples
The following example requests that Database Designer analyze encodings of the table online_sales.call_center_dimension:
-
The second parameter destination is set to an empty string, so the script is sent to standard output (shown truncated below).
-
The last two parameters deploy and reanalyze-encodings are omitted, so Database Designer does not execute the script or reanalyze existing encodings:
=> SELECT DESIGNER_DESIGN_PROJECTION_ENCODINGS ('online_sales.call_center_dimension','');
DESIGNER_DESIGN_PROJECTION_ENCODINGS
----------------------------------------------------------------
CREATE PROJECTION call_center_dimension_DBD_1_seg_EncodingDesign /*+createtype(D)*/
(
call_center_key ENCODING COMMONDELTA_COMP,
cc_closed_date,
cc_open_date,
cc_name ENCODING ZSTD_HIGH_COMP,
cc_class ENCODING ZSTD_HIGH_COMP,
cc_employees,
cc_hours ENCODING ZSTD_HIGH_COMP,
cc_manager ENCODING ZSTD_HIGH_COMP,
cc_address ENCODING ZSTD_HIGH_COMP,
cc_city ENCODING ZSTD_COMP,
cc_state ENCODING ZSTD_FAST_COMP,
cc_region ENCODING ZSTD_HIGH_COMP
)
AS
SELECT call_center_dimension.call_center_key,
call_center_dimension.cc_closed_date,
call_center_dimension.cc_open_date,
call_center_dimension.cc_name,
call_center_dimension.cc_class,
call_center_dimension.cc_employees,
call_center_dimension.cc_hours,
call_center_dimension.cc_manager,
call_center_dimension.cc_address,
call_center_dimension.cc_city,
call_center_dimension.cc_state,
call_center_dimension.cc_region
FROM online_sales.call_center_dimension
ORDER BY call_center_dimension.call_center_key
SEGMENTED BY hash(call_center_dimension.call_center_key) ALL NODES KSAFE 1;
select refresh('online_sales.call_center_dimension');
select make_ahm_now();
DROP PROJECTION online_sales.call_center_dimension CASCADE;
ALTER PROJECTION online_sales.call_center_dimension_DBD_1_seg_EncodingDesign RENAME TO call_center_dimension;
(1 row)
See also
Running Database Designer programmatically
6.5.8 - DESIGNER_DROP_ALL_DESIGNS
Removes all Database Designer-related schemas associated with the current user.
Removes all Database Designer-related schemas associated with the current user. Use this function to remove database objects after one or more Database Designer sessions complete execution.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_DROP_ALL_DESIGNS()
Parameters
None.
Privileges
Non-superuser: design creator
Examples
The following example removes all schema and their contents associated with the current user. DESIGNER_DROP_ALL_DESIGNS returns the number of designs dropped:
=> SELECT DESIGNER_DROP_ALL_DESIGNS();
DESIGNER_DROP_ALL_DESIGNS
---------------------------
2
(1 row)
See also
6.5.9 - DESIGNER_DROP_DESIGN
Removes the schema associated with the specified design and all its contents.
Removes the schema associated with the specified design and all its contents. Use DESIGNER_DROP_DESIGN after a Database Designer design or deployment completes successfully. You must also use it to drop a design before creating another one under the same name.
To drop all designs that you created, use
DESIGNER_DROP_ALL_DESIGNS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_DROP_DESIGN ( 'design-name' [, force-drop ] )
Parameters
design-name- Name of the design to drop.
force-drop- Boolean that overrides any dependencies that otherwise prevent Vertica from executing this function—for example, the design is in use or is currently being deployed. If you omit this parameter, Vertica sets it to
false.
Privileges
Non-superuser: design creator
Examples
The following example deletes the Database Designer design VMART_DESIGN and all its contents:
=> SELECT DESIGNER_DROP_DESIGN ('VMART_DESIGN');
See also
Running Database Designer programmatically
6.5.10 - DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS
Displays the DDL statements that define the design projections to standard output.
Displays the DDL statements that define the design projections to standard output.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS ( 'design-name' )
Parameters
design-name- Name of the target design.
Privileges
Superuseror DBDUSER
Examples
The following example returns the design projection DDL statements for vmart_design:
=> SELECT DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS('vmart_design');
CREATE PROJECTION customer_dimension_DBD_1_rep_VMART_DESIGN /*+createtype(D)*/
(
customer_key ENCODING DELTAVAL,
customer_type ENCODING AUTO,
customer_name ENCODING AUTO,
customer_gender ENCODING REL,
title ENCODING AUTO,
household_id ENCODING DELTAVAL,
customer_address ENCODING AUTO,
customer_city ENCODING AUTO,
customer_state ENCODING AUTO,
customer_region ENCODING AUTO,
marital_status ENCODING AUTO,
customer_age ENCODING DELTAVAL,
number_of_children ENCODING BLOCKDICT_COMP,
annual_income ENCODING DELTARANGE_COMP,
occupation ENCODING AUTO,
largest_bill_amount ENCODING DELTAVAL,
store_membership_card ENCODING BLOCKDICT_COMP,
customer_since ENCODING DELTAVAL,
deal_stage ENCODING AUTO,
deal_size ENCODING DELTARANGE_COMP,
last_deal_update ENCODING DELTARANGE_COMP
)
AS
SELECT customer_key,
customer_type,
customer_name,
customer_gender,
title,
household_id,
customer_address,
customer_city,
customer_state,
customer_region,
marital_status,
customer_age,
number_of_children,
annual_income,
occupation,
largest_bill_amount,
store_membership_card,
customer_since,
deal_stage,
deal_size,
last_deal_update
FROM public.customer_dimension
ORDER BY customer_gender,
annual_income
UNSEGMENTED ALL NODES;
CREATE PROJECTION product_dimension_DBD_2_rep_VMART_DESIGN /*+createtype(D)*/
(
...
See also
DESIGNER_OUTPUT_DEPLOYMENT_SCRIPT
6.5.11 - DESIGNER_OUTPUT_DEPLOYMENT_SCRIPT
Displays the deployment script for the specified design to standard output.
Displays the deployment script for the specified design to standard output. If the design is already deployed, Vertica ignores this function.
To output only the CREATE PROJECTION commands in a design script, use
DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_OUTPUT_DEPLOYMENT_SCRIPT ( 'design-name' )
Parameters
design-name- Name of the target design.
Privileges
Non-superuser: design creator
Examples
The following example displays the deployment script for VMART_DESIGN:
=> SELECT DESIGNER_OUTPUT_DEPLOYMENT_SCRIPT('VMART_DESIGN');
CREATE PROJECTION customer_dimension_DBD_1_rep_VMART_DESIGN /*+createtype(D)*/
...
CREATE PROJECTION product_dimension_DBD_2_rep_VMART_DESIGN /*+createtype(D)*/
...
select refresh('public.customer_dimension,
public.product_dimension,
public.promotion.dimension,
public.date_dimension');
select make_ahm_now();
DROP PROJECTION public.customer_dimension_super CASCADE;
DROP PROJECTION public.product_dimension_super CASCADE;
...
See also
DESIGNER_OUTPUT_ALL_DESIGN_PROJECTIONS
6.5.12 - DESIGNER_RESET_DESIGN
Discards all run-specific information of the previous Database Designer build or deployment of the specified design but keeps its configuration.
Discards all run-specific information of the previous Database Designer build or deployment of the specified design but keeps its configuration. You can make changes to the design as needed, for example, by changing parameters or adding additional tables and/or queries, before running the design again.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_RESET_DESIGN ( 'design-name' )
Parameters
design-name- Name of the design to reset.
Privileges
Non-superuser: design creator
Examples
The following example resets the Database Designer design VMART_DESIGN:
=> SELECT DESIGNER_RESET_DESIGN ('VMART_DESIGN');
6.5.13 - DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY
Populates the design and creates the design and deployment scripts.
Populates the design and creates the design and deployment scripts. DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY can also analyze statistics, deploy the design, and drop the workspace after the deployment.
The files output by this function have the permissions 666 or rw-rw-rw-, which allows any Linux user on the node to read or write to them. It is highly recommended that you keep the files in a secure directory.
Caution
DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY does not create a backup copy of the current design before deploying the new design. Before running this function, back up the existing schema design with
EXPORT_CATALOG.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY (
'design-name',
'output-design-file',
'output-deployment-file'
[ , 'analyze-statistics']
[ , 'deploy']
[ , 'drop-design-workspace']
[ , 'continue-after-error']
)
Parameters
design-name- Name of the design to populate and deploy.
output-design-filename- Absolute path and name of the file to contain DDL statements that create design projections, on the local file system of the node where the session is connected, or another file system or object store that Vertica supports.
output-deployment-filename- Absolute path and name of the file to contain the deployment script, on the local file system of the node where the session is connected, or another file system or object store that Vertica supports.
analyze-statistics- Specifies whether to collect or refresh statistics for the tables before populating the design. If set to true, Vertica Invokes ANALYZE_STATISTICS. Accurate statistics help Database Designer optimize compression and query performance. However, updating statistics requires time and resources.
Default: false
- deploy
- Specifies whether to deploy the Database Designer design using the deployment script created by this function.
Default: true
drop-design-workspace- Specifies whether to drop the design workspace after the design is deployed.
Default: true
continue-after-error- Specifies whether DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY continues to run after an error occurs. By default, an error causes this function to terminate.
Default: false
Privileges
Non-superuser: design creator with WRITE privileges on storage locations of design and deployment scripts
Requirements
Before calling this function, you must:
-
Create a design, a logical schema with tables.
-
Associate tables with the design.
-
Load queries to the design.
-
Set design properties (K-safety level, mode, and policy).
Examples
The following example creates projections for and deploys the VMART_DESIGN design, and analyzes statistics about the design tables.
=> SELECT DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY (
'VMART_DESIGN',
'/tmp/examples/vmart_design_files/design_projections.sql',
'/tmp/examples/vmart_design_files/design_deploy.sql',
'true',
'true',
'false',
'false'
);
See also
Running Database Designer programmatically
6.5.14 - DESIGNER_SET_DESIGN_KSAFETY
Sets K-safety for a comprehensive design and stores the K-safety value in the DESIGNS table.
Sets K-safety for a comprehensive design and stores the K-safety value in the
DESIGNS table. Database Designer ignores this function for incremental designs.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_SET_DESIGN_KSAFETY ( 'design-name' [, k-level ] )
Parameters
design-name- Name of the design for which you want to set the K-safety value, type VARCHAR.
k-level- An integer between 0 and 2 that specifies the level of K-safety for the target design. This value must be compatible with the number of nodes in the database cluster:
-
k-level = 0: ≥ 1 nodes
-
k-level = 1: ≥ 3 nodes
-
k-level = 2: ≥ 5 nodes
If you omit this parameter, Vertica sets K-safety for this design to 0 or 1, according to the number of nodes: 1 if the cluster contains ≥ 3 nodes, otherwise 0.
If you are a DBADMIN user and k-level differs from system K-safety, Vertica changes system K-safety as follows:
-
If k-level is less than system K-safety, Vertica changes system K-safety to the lower level after the design is deployed.
-
If k-level is greater than system K-safety and is valid for the database cluster, Vertica creates the required number of buddy projections for the tables in this design. If the design applies to all database tables, or all tables in the database have the required number of buddy projections, Database Designer changes system K-safety to k-level.
If the design excludes some database tables and the number of their buddy projections is less than k-level, Database Designer leaves system K-safety unchanged. Instead, it returns a warning and indicates which tables need new buddy projections in order to adjust system K-safety.
If you are a DBDUSER, Vertica ignores this parameter.
Privileges
Non-superuser: design creator
Examples
The following example set K-safety for the VMART_DESIGN design to 1:
=> SELECT DESIGNER_SET_DESIGN_KSAFETY('VMART_DESIGN', 1);
See also
Running Database Designer programmatically
6.5.15 - DESIGNER_SET_DESIGN_TYPE
Specifies whether Database Designer creates a comprehensive or incremental design.
Specifies whether Database Designer creates a comprehensive or incremental design. DESIGNER_SET_DESIGN_TYPE stores the design mode in the
DESIGNS table.
Important
If you do not explicitly set a design mode with this function, Database Designer creates a comprehensive design.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_SET_DESIGN_TYPE ( 'design-name', 'mode' )
Parameters
design-name- Name of the target design.
mode- Name of the mode that Database Designer should use when designing the database, one of the following:
-
COMPREHENSIVE: Creates an initial or replacement design for all tables in the specified schemas. You typically create a comprehensive design for a new database.
-
INCREMENTAL: Modifies an existing design with additional projection that are optimized for new or modified queries.
Note
Incremental designs always inherit the K-safety value of the database.
For more information, see Design Types.
Privileges
Non-superuser: design creator
Examples
The following examples show the two design mode options for the VMART_DESIGN design:
=> SELECT DESIGNER_SET_DESIGN_TYPE(
'VMART_DESIGN',
'COMPREHENSIVE');
DESIGNER_SET_DESIGN_TYPE
--------------------------
0
(1 row)
=> SELECT DESIGNER_SET_DESIGN_TYPE(
'VMART_DESIGN',
'INCREMENTAL');
DESIGNER_SET_DESIGN_TYPE
--------------------------
0
(1 row)
See also
Running Database Designer programmatically
6.5.16 - DESIGNER_SET_OPTIMIZATION_OBJECTIVE
Valid only for comprehensive database designs, specifies the optimization objective Database Designer uses.
Valid only for comprehensive database designs, specifies the optimization objective Database Designer uses. Database Designer ignores this function for incremental designs.
DESIGNER_SET_OPTIMIZATION_OBJECTIVE stores the optimization objective in the
DESIGNS table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_SET_OPTIMIZATION_OBJECTIVE ( 'design-name', 'policy' )
Parameters
design-name- Name of the target design.
policy- Specifies the design's optimization policy, one of the following:
-
QUERY: Optimize for query performance. This can result in a larger database storage footprint because additional projections might be created.
-
LOAD: Optimize for load performance so database size is minimized. This can result in slower query performance.
-
BALANCED: Balance the design between query performance and database size.
Privileges
Non-superuser: design creator
Examples
The following example sets the optimization objective option for the VMART_DESIGN design: to QUERY:
=> SELECT DESIGNER_SET_OPTIMIZATION_OBJECTIVE( 'VMART_DESIGN', 'QUERY');
DESIGNER_SET_OPTIMIZATION_OBJECTIVE
------------------------------------
0
(1 row)
See also
Running Database Designer programmatically
6.5.17 - DESIGNER_SET_PROPOSE_UNSEGMENTED_PROJECTIONS
Specifies whether a design can include unsegmented projections.
Specifies whether a design can include unsegmented projections. Vertica ignores this function on a one-node cluster, where all projections must be unsegmented.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_SET_PROPOSE_UNSEGMENTED_PROJECTIONS ( 'design-name', unsegmented )
Parameters
design-name- Name of the target design.
unsegmented - Boolean that specifies whether Database Designer can propose unsegmented projections for tables in this design. When you create a design, the
propose_unsegmented_projections value in system table
DESIGNS for this design is set to true. If DESIGNER_SET_PROPOSE_UNSEGMENTED_PROJECTIONS sets this value to false, Database Designer proposes only segmented projections.
Privileges
Non-superuser: design creator
Examples
The following example specifies that Database Designer can propose only segmented projections for tables in the design VMART_DESIGN:
=> SELECT DESIGNER_SET_PROPOSE_UNSEGMENTED_PROJECTIONS('VMART_DESIGN', false);
See also
Running Database Designer programmatically
6.5.18 - DESIGNER_SINGLE_RUN
Evaluates all queries that completed execution within the specified timespan, and returns with a design that is ready for deployment.
Evaluates all queries that completed execution within the specified timespan, and returns with a design that is ready for deployment. This design includes projections that are recommended for optimizing the evaluated queries. Unless you redirect output, DESIGNER_SINGLE_RUN returns the design to stdout.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_SINGLE_RUN ('interval')
interval- Specifies an interval of time that precedes the meta-function call. Database Designer evaluates all queries that ran to completion over the specified interval.
Privileges
Superuser or DBUSER
Examples
-----------------------------------------------------------------------
-- SSBM dataset test
-----------------------------------------------------------------------
-- create ssbm schema
\! $TARGET/bin/vsql -f 'sql/SSBM/SSBM_schema.sql' > /dev/null 2>&1
\! $TARGET/bin/vsql -f 'sql/SSBM/SSBM_constraints.sql' > /dev/null 2>&1
\! $TARGET/bin/vsql -f 'sql/SSBM/SSBM_funcdeps.sql' > /dev/null 2>&1
-- run these queries
\! $TARGET/bin/vsql -f 'sql/SSBM/SSBM_queries.sql' > /dev/null 2>&1
-- Run single API
select designer_single_run('1 minute');
...
designer_single_run
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
CREATE PROJECTION public.part_DBD_1_rep_SingleDesign /*+createtype(D)*/
(
p_partkey ENCODING AUTO,
p_name ENCODING AUTO,
p_mfgr ENCODING AUTO,
p_category ENCODING AUTO,
p_brand1 ENCODING AUTO,
p_color ENCODING AUTO,
p_type ENCODING AUTO,
p_size ENCODING AUTO,
p_container ENCODING AUTO
)
AS
SELECT p_partkey,
p_name,
p_mfgr,
p_category,
p_brand1,
p_color,
p_type,
p_size,
p_container
FROM public.part
ORDER BY p_partkey
UNSEGMENTED ALL NODES;
CREATE PROJECTION public.supplier_DBD_2_rep_SingleDesign /*+createtype(D)*/
(
s_suppkey ENCODING AUTO,
s_name ENCODING AUTO,
s_address ENCODING AUTO,
s_city ENCODING AUTO,
s_nation ENCODING AUTO,
s_region ENCODING AUTO,
s_phone ENCODING AUTO
)
AS
SELECT s_suppkey,
s_name,
s_address,
s_city,
s_nation,
s_region,
s_phone
FROM public.supplier
ORDER BY s_suppkey
UNSEGMENTED ALL NODES;
CREATE PROJECTION public.customer_DBD_3_rep_SingleDesign /*+createtype(D)*/
(
c_custkey ENCODING AUTO,
c_name ENCODING AUTO,
c_address ENCODING AUTO,
c_city ENCODING AUTO,
c_nation ENCODING AUTO,
c_region ENCODING AUTO,
c_phone ENCODING AUTO,
c_mktsegment ENCODING AUTO
)
AS
SELECT c_custkey,
c_name,
c_address,
c_city,
c_nation,
c_region,
c_phone,
c_mktsegment
FROM public.customer
ORDER BY c_custkey
UNSEGMENTED ALL NODES;
CREATE PROJECTION public.dwdate_DBD_4_rep_SingleDesign /*+createtype(D)*/
(
d_datekey ENCODING AUTO,
d_date ENCODING AUTO,
d_dayofweek ENCODING AUTO,
d_month ENCODING AUTO,
d_year ENCODING AUTO,
d_yearmonthnum ENCODING AUTO,
d_yearmonth ENCODING AUTO,
d_daynuminweek ENCODING AUTO,
d_daynuminmonth ENCODING AUTO,
d_daynuminyear ENCODING AUTO,
d_monthnuminyear ENCODING AUTO,
d_weeknuminyear ENCODING AUTO,
d_sellingseason ENCODING AUTO,
d_lastdayinweekfl ENCODING AUTO,
d_lastdayinmonthfl ENCODING AUTO,
d_holidayfl ENCODING AUTO,
d_weekdayfl ENCODING AUTO
)
AS
SELECT d_datekey,
d_date,
d_dayofweek,
d_month,
d_year,
d_yearmonthnum,
d_yearmonth,
d_daynuminweek,
d_daynuminmonth,
d_daynuminyear,
d_monthnuminyear,
d_weeknuminyear,
d_sellingseason,
d_lastdayinweekfl,
d_lastdayinmonthfl,
d_holidayfl,
d_weekdayfl
FROM public.dwdate
ORDER BY d_datekey
UNSEGMENTED ALL NODES;
CREATE PROJECTION public.lineorder_DBD_5_rep_SingleDesign /*+createtype(D)*/
(
lo_orderkey ENCODING AUTO,
lo_linenumber ENCODING AUTO,
lo_custkey ENCODING AUTO,
lo_partkey ENCODING AUTO,
lo_suppkey ENCODING AUTO,
lo_orderdate ENCODING AUTO,
lo_orderpriority ENCODING AUTO,
lo_shippriority ENCODING AUTO,
lo_quantity ENCODING AUTO,
lo_extendedprice ENCODING AUTO,
lo_ordertotalprice ENCODING AUTO,
lo_discount ENCODING AUTO,
lo_revenue ENCODING AUTO,
lo_supplycost ENCODING AUTO,
lo_tax ENCODING AUTO,
lo_commitdate ENCODING AUTO,
lo_shipmode ENCODING AUTO
)
AS
SELECT lo_orderkey,
lo_linenumber,
lo_custkey,
lo_partkey,
lo_suppkey,
lo_orderdate,
lo_orderpriority,
lo_shippriority,
lo_quantity,
lo_extendedprice,
lo_ordertotalprice,
lo_discount,
lo_revenue,
lo_supplycost,
lo_tax,
lo_commitdate,
lo_shipmode
FROM public.lineorder
ORDER BY lo_suppkey
UNSEGMENTED ALL NODES;
(1 row)
6.5.19 - DESIGNER_WAIT_FOR_DESIGN
Waits for completion of operations that are populating and deploying the design.
Waits for completion of operations that are populating and deploying the design. Ctrl+C cancels this operation and returns control to the user.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DESIGNER_WAIT_FOR_DESIGN ( 'design-name' )
Parameters
design-name- Name of the running design.
Privileges
Superuser, or DBDUSER with USAGE privilege on the design schema
Examples
The following example requests to wait for the currently running design of VMART_DESIGN to complete:
=> SELECT DESIGNER_WAIT_FOR_DESIGN ('VMART_DESIGN');
See also
6.6 - Directed queries functions
The following meta-functions let you batch export query plans as directed queries from one Vertica database, and import those directed queries to another database.
The following meta-functions let you batch export query plans as directed queries from one Vertica database, and import those directed queries to another database.
6.6.1 - CLEAR_DIRECTED_QUERY_USAGE
Resets the counter in the DIRECTED_QUERY_STATUS table.
Resets the counter in the DIRECTED_QUERY_STATUS table for a single query or for all queries.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DIRECTED_QUERY_USAGE( [ 'query-name' ] )
Arguments
query-name- The name of the directed query to reset. If omitted, the function resets counters for all queries.
Privileges
Superuser
Examples
In the following example, three directed queries have been used:
=> SELECT query_name, sum(hits) FROM DIRECTED_QUERY_STATUS GROUP BY 1;
query_name | sum
-------------------------------+-----
findEmployeesCityJobTitle_OPT | 5
save_plans_nolabel_3_3 | 2
save_plans_nolabel_6_3 | 3
(3 rows)
After calling the function for one of the queries, its counter is reset to 0:
=> SELECT CLEAR_DIRECTED_QUERY_USAGE('findEmployeesCityJobTitle_OPT');
CLEAR_DIRECTED_QUERY_USAGE
----------------------------
Usage cleared.
(1 row)
=> SELECT query_name, sum(hits) FROM DIRECTED_QUERY_STATUS GROUP BY 1;
query_name | sum
-------------------------------+-----
findEmployeesCityJobTitle_OPT | 0
save_plans_nolabel_3_3 | 2
save_plans_nolabel_6_3 | 3
(3 rows)
6.6.2 - EXPORT_DIRECTED_QUERIES
Generates SQL for creating directed queries from a set of input queries.
Generates SQL for creating directed queries from a set of input queries.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXPORT_DIRECTED_QUERIES('input-file', '[output-file]')
Arguments
input-file- A SQL file that contains one or more input queries. See Input Format below for details on format requirements.
output-file- Specifies where to write the generated SQL for creating directed queries. If
output-file already exists, EXPORT_DIRECTED_QUERIES returns with an error. If you supply an empty string, Vertica writes the SQL to standard output. See Output Format below for details.
Privileges
Superuser
The input file that you supply to EXPORT_DIRECTED_QUERIES contains one or more input queries. For each input query, you can optionally specify two fields that are used in the generated directed query:
-
DirQueryName provides the directed query's unique identifier, a string that conforms to conventions described in Identifiers.
-
DirQueryComment specifies a quote-delimited string, up to 128 characters.
You format each input query as follows:
--DirQueryName=query-name
--DirQueryComment='comment'
input-query
EXPORT_DIRECTED_QUERIES generates SQL for creating directed queries, and writes the SQL to the specified file or to standard output. In both cases, output conforms to the following format:
/* Query: directed-query-name */
/* Comment: directed-query-comment */
SAVE QUERY input-query;
CREATE DIRECTED QUERY CUSTOM 'directed-query-name'
COMMENT 'directed-query-comment'
OPTVER 'vertica-release-num'
PSDATE 'timestamp'
annotated-query
If a given input query omits DirQueryName and DirQueryComment fields, EXPORT_DIRECTED_QUERIES automatically generates the following output:
-
/* Query: Autoname:timestamp.n */, where n is a zero-based integer index that ensures uniqueness among auto-generated names with the same timestamp.
-
/* Comment: Optimizer-generated directed query */
Error handling
If any errors or warnings occur during EXPORT_DIRECTED_QUERIES execution, it returns with a message like this one:
1 queries successfully exported.
1 warning message was generated.
Queries exported to /home/dbadmin/outputQueries.
See error report, /home/dbadmin/outputQueries.err for details.
EXPORT_DIRECTED_QUERIES writes all errors and warnings to a file that it creates on the same path as the output file, and uses the output file's base name.
For example:
---------------------------------------------------------------------------------------------------
WARNING: Name field not supplied. Using auto-generated name: 'Autoname:2016-04-25 15:03:32.115317.0'
Input Query: SELECT employee_dimension.employee_first_name, employee_dimension.employee_last_name, employee_dimension.job_title FROM public.employee_dimension WHERE (employee_dimension.employee_city = 'Boston'::varchar(6)) ORDER BY employee_dimension.job_title;
END WARNING
Examples
See Exporting directed queries.
See also
6.6.3 - IMPORT_DIRECTED_QUERIES
Imports to the database catalog directed queries from a SQL file that was generated by EXPORT_DIRECTED_QUERIES.
Imports to the database catalog directed queries from a SQL file that was generated by EXPORT_DIRECTED_QUERIES. If no directed queries are specified, Vertica lists all directed queries in the SQL file.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
IMPORT_DIRECTED_QUERIES( 'export-file'[, 'directed-query-name'[,...] ] )
Arguments
export-file- A SQL file generated by
EXPORT_DIRECTED_QUERIES. When you run this file, Vertica creates the specified directed queries in the current database catalog.
directed-query-name- The name of a directed query that is defined in
export-file. You can specify multiple comma-delimited directed query names.
If you omit this parameter, Vertica lists the names of all directed queries in export-file.
Privileges
Superuser
Examples
See Importing directed queries.
See also
Batch query plan export
6.6.4 - SAVE_PLANS
Creates optimizer-generated directed queries from the most frequently executed queries, up to the maximum specified.
Creates optimizer-generated directed queries from the most frequently executed queries, up to the maximum specified. You can also limit the scope of SAVE_PLANS to queries only issued after a specified date.
As SAVE_PLANS iterates over past queries, it tests them against various restrictions. In general, directed queries support only SELECT statements as input. Within this broad requirement, input queries are subject to other restrictions. After qualifying all candidate input queries, SAVE_PLANS operates as follows:
- Calls CREATE DIRECTED QUERY OPTIMIZER on all qualified input queries, which creates a directed query for each unique input query.
- Saves metadata on the new set of directed queries to the system table DIRECTED_QUERIES, where all directed queries of that set share the same integer identifier.
All directed queries created by SAVE_PLANS are initially inactive. You can activate them individually; you can also use SAVE_PLANS_VERSION identifiers to activate, deactivate, and drop one or more sets of directed queries.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SAVE_PLANS( query-budget [, since-date] [, drop-old-plans[, 'comment']] )
Arguments
query-budget- Maximum number of input queries to save as directed queries, an integer between 1 and 100, inclusive.
since-date- The earliest timestamp of input queries to save as directed queries.
drop-old-plans- Boolean, specifies whether to drop all directed queries generated by earlier SAVE_PLANS invocations. Only directed queries that were generated by the current Vertica version are dropped; directed queries generated by earlier Vertica versions are untouched. To drop older directed queries, use DROP DIRECTED QUERY.
comment- String comment that is attached to all plans saved with this function call.
Privileges
Superuser
For each set of directed queries that SAVE_PLANS creates, Vertica updates the system table DIRECTED_QUERIES with metadata on each directed query in the set:
|
Column name |
SAVE_PLANS-generated data |
|
QUERY_NAME |
Concatenated from the following strings:
save_plans_query-label_query-number_save-plans-version
where:
query-label is a LABEL hint embedded in the input query associated with this directed query. If theinput query contains no label, then this string is set to nolabel.query-number is an integer in a continuous sequence between 0 and budget-query, which uniquely identifies this directed query from others in the same SAVE_PLANS-generated set.- [save-plans-version](/en/sql-reference/system-tables/v-catalog-schema/directed-queries/#SAVE_PLANS_VERSION) identifies the set of directed queries to which this directed query belongs.
|
|
SAVE_PLANS_VERSION |
Identifies a set of directed queries that were generated by the same call to SAVE_PLANS. All directed queries of the set share the same SAVE_PLANS_VERSION integer, which increments by 1 the previous highest SAVE_PLANS_VERSION setting. Use this identifier to activate, deactivate, and drop a set of directed queries. |
|
USERNAME |
User who invoked SAVE_PLANS to create this set of directed queries. |
|
SINCE_DATE |
The since-date timestamp supplied to SAVE_PLANS, which specified the earliest timestamp of input queries to evaluate as directed query candidates. |
|
DIGEST |
Hash of saved query plan data, used by the optimizer to map identical input queries to the same active directed query. |
Examples
See Bulk-Creation of Directed Queries.
6.7 - Error-handling functions
Error-handling functions take a string and return the string when the query is executed.
Error-handling functions take a string and return the string when the query is executed.
6.7.1 - THROW_ERROR
Returns a user-defined error message.
Returns a user-defined error message.
In a multi-node cluster, race conditions might cause the order of error messages to differ.
Behavior type
Immutable
Syntax
THROW_ERROR ( message )
Parameters
message- The VARCHAR string to return.
Examples
Return an error message when a CASE statement is met:
=> CREATE TABLE pitcher_err (some_text varchar);
CREATE TABLE
=> COPY pitcher_err FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> big foo value
>> bigger foo other value
>> bar another foo value
>> \.
=> SELECT (CASE WHEN true THEN THROW_ERROR('Failure!!!') ELSE some_text END) FROM pitcher_err;
ERROR 7137: USER GENERATED ERROR: Failure!!!
Return an error message when a CASE statement using REGEXP_LIKE is met:
=> SELECT (CASE WHEN REGEXP_LIKE(some_text, 'other') THEN THROW_ERROR('Failure at "' || some_text || '"') END) FROM pitcher_err;
ERROR 4566: USER GENERATED ERROR: Failure at "bar another foo value"
6.8 - Flex functions
This section contains helper functions for use in working with flex tables and flexible columns for complex types.
This section contains helper functions for use in working with flex tables and flexible columns for complex types. You can use these functions with flex tables, their associated flex_table_keys tables and flex_table_view views, and flexible columns in external tables. These functions do not apply to other tables.
For more information about flex tables, see Flex tables. For more information about flexible columns for complex types, see Flexible complex types.
Flex functions allow you to manage and query flex tables. You can also use the map functions to query flexible complex-type columns in non-flex tables.
6.8.1 - Flex data functions
The flex table data helper functions supply information you need to directly query data in flex tables.
The flex table data helper functions supply information you need to directly query data in flex tables. After you compute keys and create views from the raw data, you can use field names directly in queries instead of using map functions to extract data. The fata functions are:
Flex table dependencies
Each flex table has two dependent objects, a keys table and a view. While both objects are dependent on their parent table, you can drop either object independently. Dropping the parent table removes both dependents, without a CASCADE option.
Associating flex tables and views
The helper functions automatically use the dependent table and view if they are internally linked with the parent table. You create both when you create the flex table. You can drop either the keys table or the view and re-create objects of the same name. However, if you do so, the new objects are not internally linked with the parent flex table.
In this case, you can restore the internal links of these objects to the parent table. To do so, drop the keys table and the view before calling the RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW function. Calling this function re-creates the keys table and view.
The remaining helper functions perform the tasks described in this section.
6.8.1.1 - BUILD_FLEXTABLE_VIEW
Creates, or re-creates, a view for a default or user-defined keys table, ignoring any empty keys.
Creates, or re-creates, a view for a default or user-defined keys table, ignoring any empty keys.
Note
If the length of a key exceeds 65,000, Vertica truncates the key.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
BUILD_FLEXTABLE_VIEW ('[[database.]schema.]flex-table'
[ [,'view-name'] [,'user-keys-table'] ])
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
flex-table- The flex table name. By default, this function builds or rebuilds a view for the input table with the current contents of the associated
flex_table_keys table.
view-name- A custom view name. Use this option to build a new view for
flex-table with the name you specify.
user-keys-table- Name of a keys table from which to create the view. Use this option if you created a custom keys table from the flex table map data, rather than from the default
flex_table_keys table. The function builds a view from the keys in user_keys, rather than from flex_table_keys.
Examples
The following examples show how to call BUILD_FLEXTABLE_VIEW with 1, 2, or 3 arguments.
To create, or re-create, a default view:
-
Call the function with an input flex table:
=> SELECT BUILD_FLEXTABLE_VIEW('darkdata');
build_flextable_view
-----------------------------------------------------
The view public.darkdata_view is ready for querying
(1 row)
The function creates a view with the default name (darkdata_view) from the darkdata_keys table.
-
Query a key name from the new or updated view:
=> SELECT "user.id" FROM darkdata_view;
user.id
-----------
340857907
727774963
390498773
288187825
164464905
125434448
601328899
352494946
(12 rows)
To create, or re-create, a view with a custom name:
-
Call the function with two arguments, an input flex table, darkdata, and the name of the view to create, dd_view:
=> SELECT BUILD_FLEXTABLE_VIEW('darkdata', 'dd_view');
build_flextable_view
-----------------------------------------------
The view public.dd_view is ready for querying
(1 row)
-
Query a key name (user.lang) from the new or updated view (dd_view):
=> SELECT "user.lang" FROM dd_view;
user.lang
-----------
tr
en
es
en
en
it
es
en
(12 rows)
To create a view from a custom keys table with BUILD_FLEXTABLE_VIEW, the custom table must have the same schema and table definition as the default table (darkdata_keys). Create a custom keys table, using any of these three approaches:
-
Create a columnar table with all keys from the default keys table for a flex table (darkdata_keys):
=> CREATE TABLE new_darkdata_keys AS SELECT * FROMdarkdata_keys;
CREATE TABLE
-
Create a columnar table without content (LIMIT 0) from the default keys table for a flex table (darkdata_keys):
=> CREATE TABLE new_darkdata_keys AS SELECT * FROM darkdata_keys LIMIT 0;
CREATE TABLE
kdb=> SELECT * FROM new_darkdata_keys;
key_name | frequency | data_type_guess
----------+-----------+-----------------
(0 rows)
-
Create a columnar table without content (LIMIT 0) from the default keys table, and insert two values ('user.lang', 'user.name') into the key_name column:
=> CREATE TABLE dd_keys AS SELECT * FROM darkdata_keys limit 0;
CREATE TABLE
=> INSERT INTO dd_keys (key_name) values ('user.lang');
OUTPUT
--------
1
(1 row)
=> INSERT INTO dd_keys (key_name) values ('user.name');
OUTPUT
--------
1
(1 row)
=> SELECT * FROM dd_keys;
key_name | frequency | data_type_guess
-----------+-----------+-----------------
user.lang | |
user.name | |
(2 rows)
After creating a custom keys table, call BUILD_FLEXTABLE_VIEW with all arguments (an input flex table, the new view name, the custom keys table):
=> SELECT BUILD_FLEXTABLE_VIEW('darkdata', 'dd_view', 'dd_keys');
build_flextable_view
-----------------------------------------------
The view public.dd_view is ready for querying
(1 row)
Query the new view:
=> SELECT * FROM dd_view;
See also
6.8.1.2 - COMPUTE_FLEXTABLE_KEYS
Computes the virtual columns (keys and values) from flex table VMap data.
Computes the virtual columns (keys and values) from flex table VMap data. Use this function to compute keys without creating an associated table view. To also build a view, use COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
COMPUTE_FLEXTABLE_KEYS ('[[database.]schema.]flex-table')
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
flex-table- Name of the flex table.
Output
The function stores its results in a table named flex-table_keys. The table has the following columns:
|
Column |
Description |
|
KEY_NAME |
The name of the virtual column (key). Keys larger than 65,000 bytes are truncated. |
|
FREQUENCY |
The number of times the key occurs in the VMap. |
|
DATA_TYPE_GUESS |
Estimate of the data type for the key based on the non-null values found in the VMap. The function determines the type of each non-string value, depending on the length of the key, and whether the key includes nested maps. If the EnableBetterFlexTypeGuessing configuration parameter is 0 (OFF), this function instead treats all flex table keys as string types ([LONG] VARCHAR or [LONG] VARBINARY). |
COMPUTE_FLEXTABLE_KEYS sets the column width for keys to the length of the largest value for each key multiplied by the FlexTableDataTypeGuessMultiplier factor.
Examples
In the following example, JSON data with consistent fields has been loaded into a flex table. Had the data been more varied, you would see different numbers of occurrences in the keys table:
=> SELECT COMPUTE_FLEXTABLE_KEYS('reviews_flex');
COMPUTE_FLEXTABLE_KEYS
-------------------------------------------------
Please see public.reviews_flex_keys for updated keys
(1 row)
SELECT * FROM reviews_flex_keys;
key_name | frequency | data_type_guess
-------------+-----------+-----------------
user_id | 1000 | Varchar(44)
useful | 1000 | Integer
text | 1000 | Varchar(9878)
stars | 1000 | Numeric(5,2)
review_id | 1000 | Varchar(44)
funny | 1000 | Integer
date | 1000 | Timestamp
cool | 1000 | Integer
business_id | 1000 | Varchar(44)
(9 rows)
See also
6.8.1.3 - COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW
Combines the functionality of BUILD_FLEXTABLE_VIEW and COMPUTE_FLEXTABLE_KEYS to compute virtual columns (keys) from the VMap data of a flex table and construct a view.
Combines the functionality of BUILD_FLEXTABLE_VIEW and COMPUTE_FLEXTABLE_KEYS to compute virtual columns (keys) from the VMap data of a flex table and construct a view. Creating a view with this function ignores empty keys. If you do not need to perform both operations together, use one of the single-operation functions instead.
Note
If the length of a key exceeds 65,000, Vertica truncates the key.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW ('flex-table')
Arguments
flex-table- Name of a flex table
Examples
This example shows how to call the function for the darkdata flex table.
=> SELECT COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW('darkdata');
compute_flextable_keys_and_build_view
-----------------------------------------------------------------------
Please see public.darkdata_keys for updated keys
The view public.darkdata_view is ready for querying
(1 row)
See also
6.8.1.4 - MATERIALIZE_FLEXTABLE_COLUMNS
Materializes virtual columns listed as key_names in the flextable_keys table you compute using either COMPUTE_FLEXTABLE_KEYS or COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW.
Materializes virtual columns listed as key_names in the flextable_keys table you compute using either COMPUTE_FLEXTABLE_KEYS or COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW.
Note
Each column that you materialize with this function counts against the data storage limit of your license. To check your Vertica license compliance, call the AUDIT() or AUDIT_FLEX() functions.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MATERIALIZE_FLEXTABLE_COLUMNS ('[[database.]schema.]flex-table' [, n-columns [, keys-table-name] ])
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
flex-table- The name of the flex table with columns to materialize. The function:
n-columns- The number of columns to materialize, up to 9800. The function attempts to materialize the number of columns from the keys table, skipping any columns already materialized. It orders the materialized results by frequency, descending. If not specified, the default is a maximum of 50 columns.
keys-table-name- The name of a keys from which to materialize columns. The function:
-
Materializes n-columns columns from the keys table
-
Skips any columns already materialized
-
Orders the materialized results by frequency, descending
Examples
The following example shows how to call MATERIALIZE_FLEXTABLE_COLUMNS to materialize columns. First, load a sample file of tweets (tweets_10000.json) into the flex table twitter_r. After loading data and computing keys for the sample flex table, call MATERIALIZE_FLEXTABLE_COLUMNS to materialize the first four columns:
=> COPY twitter_r FROM '/home/release/KData/tweets_10000.json' parser fjsonparser();
Rows Loaded
-------------
10000
(1 row)
=> SELECT compute_flextable_keys ('twitter_r');
compute_flextable_keys
---------------------------------------------------
Please see public.twitter_r_keys for updated keys
(1 row)
=> SELECT MATERIALIZE_FLEXTABLE_COLUMNS('twitter_r', 4);
MATERIALIZE_FLEXTABLE_COLUMNS
-------------------------------------------------------------------------------
The following columns were added to the table public.twitter_r:
contributors
entities.hashtags
entities.urls
For more details, run the following query:
SELECT * FROM v_catalog.materialize_flextable_columns_results WHERE table_schema = 'public' and table_name = 'twitter_r';
(1 row)
The last message in the example recommends querying the MATERIALIZE_FLEXTABLE_COLUMNS_RESULTS system table for the results of materializing the columns, as shown:
=> SELECT * FROM v_catalog.materialize_flextable_columns_results WHERE table_schema = 'public' and table_name = 'twitter_r';
table_id | table_schema | table_name | creation_time | key_name | status | message
-------------------+--------------+------------+------------------------------+-------------------+--------+---------------------
45035996273733172 | public | twitter_r | 2013-11-20 17:00:27.945484-05| contributors | ADDED | Added successfully
45035996273733172 | public | twitter_r | 2013-11-20 17:00:27.94551-05 | entities.hashtags | ADDED | Added successfully
45035996273733172 | public | twitter_r | 2013-11-20 17:00:27.945519-05| entities.urls | ADDED | Added successfully
45035996273733172 | public | twitter_r | 2013-11-20 17:00:27.945532-05| created_at | EXISTS | Column of same name already
(4 rows)
See also
6.8.1.5 - RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW
Restores the keys table and the view.
Restores the keys table and the view. The function also links the keys table with its associated flex table, in cases where either table is dropped. The function also indicates whether it restored one or both objects.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW ('flex-table')
Arguments
flex-table- Name of a flex table
Examples
This example shows how to invoke this function with an existing flex table, restoring both the keys table and view:
=> SELECT RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW('darkdata');
RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW
----------------------------------------------------------------------------------
The keys table public.darkdata_keys was restored successfully.
The view public.darkdata_view was restored successfully.
(1 row)
This example illustrates that the function restored darkdata_view, but that darkdata_keys did not need restoring:
=> SELECT RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW('darkdata');
RESTORE_FLEXTABLE_DEFAULT_KEYS_TABLE_AND_VIEW
------------------------------------------------------------------------------------
The keys table public.darkdata_keys already exists and is linked to darkdata.
The view public.darkdata_view was restored successfully.
(1 row)
After restoring the keys table, there is no content. To populate the flex keys, call the COMPUTE_FLEXTABLE_KEYS function.
=> SELECT * FROM darkdata_keys;
key_name | frequency | data_type_guess
----------+-----------+-----------------
(0 rows)
See also
6.8.2 - Flex extractor functions
The flex extractor scalar functions process polystructured data.
The flex extractor scalar functions process polystructured data. Each function accepts input data that is any of:
These functions do not parse data from an external file source. All functions return a single VMap value. The extractor functions can return data with NULL-specified columns.
6.8.2.1 - MAPDELIMITEDEXTRACTOR
Extracts data with a delimiter character and other optional arguments, returning a single VMap value.
Extracts data with a delimiter character and other optional arguments, returning a single VMap value.
Syntax
MAPDELIMITEDEXTRACTOR (record-value [ USING PARAMETERS param=value[,...] ])
Arguments
record-value- String containing a JSON or delimited format record on which to apply the expression.
Parameters
delimiter- Single delimiter character.
Default: |
header_names- Delimiter-separated list of column header names.
Default: ucoln, where n is the column offset number, starting with 0 for the first column.
trim- Boolean, trim white space from header names and field values.
Default: true
treat_empty_val_as_null- Boolean, set empty fields to
NULL rather than an empty string ('').
Default: true
Examples
These examples use a short set of delimited data:
Name|CITY|New city|State|zip
Tom|BOSTON|boston|MA|01
Eric|Burlington|BURLINGTON|MA|02
Jamie|cambridge|CAMBRIDGE|MA|08
To begin, save this data as delim.dat.
-
Create a flex table, dflex:
=> CREATE FLEX TABLE dflex();
CREATE TABLE
-
Use COPY to load the delim.dat file. Use the flex tables fdelimitedparser with the header='false' option:
=> COPY dflex FROM '/home/release/kmm/flextables/delim.dat' parser fdelimitedparser(header='false');
Rows Loaded
-------------
4
(1 row)
-
Create a columnar table, dtab, with an identity id column, a delim column, and a vmap column to hold a VMap:
=> CREATE TABLE dtab (id IDENTITY(1,1), delim varchar(128), vmap long varbinary(512));
CREATE TABLE
-
Use COPY to load the delim.dat file into the dtab table. MAPDELIMITEDEXTRACTOR uses the header_names parameter to specify a header row for the sample data, along with delimiter '!' :
=> COPY dtab(delim, vmap AS MAPDELIMITEDEXTRACTOR (delim
USING PARAMETERS header_names='Name|CITY|New City|State|Zip')) FROM '/home/dbadmin/data/delim.dat'
DELIMITER '!';
Rows Loaded
-------------
4
(1 row)
-
Use MAPTOSTRING for the flex table dflex to view the __raw__ column contents. Notice the default header names in use (ucol0 – ucol4), since you specified header='false' when you loaded the flex table:
=> SELECT MAPTOSTRING(__raw__) FROM dflex limit 10;
maptostring
-------------------------------------------------------------------------------------
{
"ucol0" : "Jamie",
"ucol1" : "cambridge",
"ucol2" : "CAMBRIDGE",
"ucol3" : "MA",
"ucol4" : "08"
}
{
"ucol0" : "Name",
"ucol1" : "CITY",
"ucol2" : "New city",
"ucol3" : "State",
"ucol4" : "zip"
}
{
"ucol0" : "Tom",
"ucol1" : "BOSTON",
"ucol2" : "boston",
"ucol3" : "MA",
"ucol4" : "01"
}
{
"ucol0" : "Eric",
"ucol1" : "Burlington",
"ucol2" : "BURLINGTON",
"ucol3" : "MA",
"ucol4" : "02"
}
(4 rows)
-
Use MAPTOSTRING again, this time with the dtab table's vmap column. Compare the results of this output to those for the flex table. Note that MAPTOSTRING returns the header_name parameter values you specified when you loaded the data:
=> SELECT MAPTOSTRING(vmap) FROM dtab;
maptostring
------------------------------------------------------------------------------------------------------------------------
{
"CITY" : "CITY",
"Name" : "Name",
"New City" : "New city",
"State" : "State",
"Zip" : "zip"
}
{
"CITY" : "BOSTON",
"Name" : "Tom",
"New City" : "boston",
"State" : "MA",
"Zip" : "02121"
}
{
"CITY" : "Burlington",
"Name" : "Eric",
"New City" : "BURLINGTON",
"State" : "MA",
"Zip" : "02482"
}
{
"CITY" : "cambridge",
"Name" : "Jamie",
"New City" : "CAMBRIDGE",
"State" : "MA",
"Zip" : "02811"
}
(4 rows)
-
Query the delim column to view the contents differently:
=> SELECT delim FROM dtab;
delim
-------------------------------------
Name|CITY|New city|State|zip
Tom|BOSTON|boston|MA|02121
Eric|Burlington|BURLINGTON|MA|02482
Jamie|cambridge|CAMBRIDGE|MA|02811
(4 rows)
See also
6.8.2.2 - MAPJSONEXTRACTOR
Extracts content of repeated JSON data objects,, including nested maps, or data with an outer list of JSON elements.
Extracts content of repeated JSON data objects,, including nested maps, or data with an outer list of JSON elements. You can set one or more optional parameters to control the extraction process.
Note
Empty input does not generate warnings or errors.
Syntax
MAPJSONEXTRACTOR (record-value [ USING PARAMETERS param=value[,...] ])
Arguments
record-value- String containing a JSON or delimited format record on which to apply the expression.
Parameters
flatten_maps- Boolean, flatten sub-maps within the JSON data, separating map levels with a period (
.).
Default: true
flatten_arrays- Boolean, convert lists to sub-maps with integer keys. Lists are not flattened by default.
Default value: false
reject_on_duplicate- Boolean, ignore duplicate records (
false), or reject duplicates (true). In either case, loading is unaffected.
Default: false
reject_on_empty_key- Boolean, reject any row that contains a key without a value.
Default: false
omit_empty_keys- Boolean, omit any key from the load data without a value.
Default: false
start_point- Name of a key in the JSON load data at which to begin parsing. The parser ignores all data before the
start_point value. The parser processes data after the first instance, and up to the second, ignoring any remaining data.
Default: none
Examples
These examples use the following sample JSON data:
{ "id": "5001", "type": "None" }
{ "id": "5002", "type": "Glazed" }
{ "id": "5005", "type": "Sugar" }
{ "id": "5007", "type": "Powdered Sugar" }
{ "id": "5004", "type": "Maple" }
Save this example data as bake_single.json, and load that file.
-
Create a flex table, flexjson:
=> CREATE FLEX TABLE flexjson();
CREATE TABLE
-
Use COPY to load the bake_single.json file with the fjsonparser parser:
=> COPY flexjson FROM '/home/dbadmin/data/bake_single.json' parser fjsonparser();
Rows Loaded
-------------
5
(1 row)
-
Create a columnar table, coljson, with an IDENTITY column (id), a json column, and a column to hold a VMap, called vmap:
=> CREATE TABLE coljson(id IDENTITY(1,1), json varchar(128), vmap long varbinary(10000));
CREATE TABLE
-
Use COPY to load the bake_single.json file into the coljson table, using MAPJSONEXTRACTOR:
=> COPY coljson (json, vmap AS MapJSONExtractor(json)) FROM '/home/dbadmin/data/bake_single.json';
Rows Loaded
-------------
5
(1 row)
-
Use the MAPTOSTRING function for the flex table flexjson to output the __raw__ column contents as strings:
=> SELECT MAPTOSTRING(__raw__) FROM flexjson limit 5;
maptostring
-----------------------------------------------------
{
"id" : "5001",
"type" : "None"
}
{
"id" : "5002",
"type" : "Glazed"
}
{
"id" : "5005",
"type" : "Sugar"
}
{
"id" : "5007",
"type" : "Powdered Sugar"
}
{
"id" : "5004",
"type" : "Maple"
}
(5 rows)
-
Use MAPTOSTRING again, this time with the coljson table's vmap column and compare the results. The element order differs:
=> SELECT MAPTOSTRING(vmap) FROM coljson limit 5;
maptostring
-----------------------------------------------------
{
"id" : "5001",
"type" : "None"
}
{
"id" : "5002",
"type" : "Glazed"
}
{
"id" : "5004",
"type" : "Maple"
}
{
"id" : "5005",
"type" : "Sugar"
}
{
"id" : "5007",
"type" : "Powdered Sugar"
}
(5 rows)
See also
6.8.2.3 - MAPREGEXEXTRACTOR
Extracts data with a regular expression and returns results as a VMap.
Extracts data with a regular expression and returns results as a VMap.
Syntax
MAPREGEXEXTRACTOR (record-value [ USING PARAMETERS param=value[,...] ])
Arguments
record-value- String containing a JSON or delimited format record on which to apply the regular expression.
Parameters
pattern- Regular expression used to extract the desired data.
Default: Empty string ('')
use_jit- Boolean, use just-in-time compiling when parsing the regular expression.
Default: false
record_terminator- Character used to separate input records.
Default: \n
logline_column- Destination column containing the full string that the regular expression matched.
Default: Empty string ('')
Examples
These examples use the following regular expression, which searches for information that includes the timestamp, date, thread_name, and thread_id strings.
Caution
For display purposes, this sample regular expression adds new line characters to split long lines of text. To use this expression in a query, first copy and edit the example to remove any new line characters.
This example expression loads any thread_id hex value, regardless of whether it has a 0x prefix, (<thread_id>(?:0x)?[0-9a-f]+).
'^(?<time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d\.\d+)
(?<thread_name>[A-Za-z ]+):(?<thread_id>(?:0x)?[0-9a-f]+)
-?(?<transaction_id>[0-9a-f])?(?:[(?<component>\w+)]
\<(?<level>\w+)\> )?(?:<(?<elevel>\w+)> @[?(?<enode>\w+)]?: )
?(?<text>.*)'
The following examples may include newline characters for display purposes.
-
Create a flex table, flogs:
=> CREATE FLEX TABLE flogs();
CREATE TABLE
-
Use COPY to load a sample log file (vertica.log), using the flex table fregexparser. Note that this example includes added line characters for displaying long text lines.
=> COPY flogs FROM '/home/dbadmin/tempdat/vertica.log' PARSER FREGEXPARSER(pattern='
^(?<time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d\.\d+) (?<thread_name>[A-Za-z ]+):
(?<thread_id>(?:0x)?[0-9a-f])-?(?<transaction_id>[0-9a-f])?(?:[(?<component>\w+)]
\<(?<level>\w+)\> )?(?:<(?<elevel>\w+)> @[?(?<enode>\w+)]?: )?(?<text>.*)');
Rows Loaded
-------------
81399
(1 row)
-
Use to return the results from calling MAPREGEXEXTRACTOR with a regular expression. The output returns the results of the function in string format.
=> SELECT MAPTOSTRING(MapregexExtractor(E'2014-04-02 04:02:51.011
TM Moveout:0x2aab9000f860-a0000000002067 [Txn] <INFO>
Begin Txn: a0000000002067 \'Moveout: Tuple Mover\'' using PARAMETERS
pattern='^(?<time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d\.\d+)
(?<thread_name>[A-Za-z ]+):(?<thread_id>(?:0x)?[0-9a-f]+)
-?(?<transaction_id>[0-9a-f])?(?:[(?<component>\w+)]
\<(?<level>\w+)\> )?(?:<(?<elevel>\w+)> @[?(?<enode>\w+)]?: )
?(?<text>.*)'
)) FROM flogs where __identity__=13;
maptostring
--------------------------------------------------------------------------------------------------
{
"component" : "Txn",
"level" : "INFO",
"text" : "Begin Txn: a0000000002067 'Moveout: Tuple Mover'",
"thread_id" : "0x2aab9000f860",
"thread_name" : "TM Moveout",
"time" : "2014-04-02 04:02:51.011",
"transaction_id" : "a0000000002067"
}
(1 row)
See also
6.8.3 - Flex map functions
The flex map functions let you extract and manipulate nested map data.
The flex map functions let you extract and manipulate nested map data.
The first argument of all flex map functions (except EMPTYMAP and MAPAGGREGATE) takes a VMap. The VMap can originate from the __raw__ column in a flex table or be returned from a map or extraction function.
All map functions (except EMPTYMAP and MAPAGGREGATE) accept either a LONG VARBINARY or a LONG VARCHAR map argument.
In the following example, the outer MAPLOOKUP function operates on the VMap data returned from the inner MAPLOOKUP function:
=> MAPLOOKUP(MAPLOOKUP(ret_map, 'batch'), 'scripts')
You can use flex map functions exclusively with:
6.8.3.1 - EMPTYMAP
Constructs a new VMap with one row but without keys or data.
Constructs a new VMap with one row but without keys or data. Use this transform function to populate a map without using a flex parser. Instead, you use either from SQL queries or from map data present elsewhere in the database.
Syntax
EMPTYMAP()
Examples
Create an Empty Map
=> SELECT EMPTYMAP();
emptymap
------------------------------------------------------------------
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
(1 row)
Create an Empty Map from an Existing Flex Table
If you create an empty map from an existing flex table, the new map has the same number of rows as the table from which it was created.
This example shows the result if you create an empty map from the darkdata table, which has 12 rows of JSON data:
=> SELECT EMPTYMAP() FROM darkdata;
emptymap
------------------------------------------------------------------
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
\001\000\000\000\004\000\000\000\000\000\000\000\000\000\000\000
(12 rows)
See also
6.8.3.2 - MAPAGGREGATE
Returns a LONG VARBINARY VMap with key and value pairs supplied from two VARCHAR input columns.
Returns a LONG VARBINARY VMap with key and value pairs supplied from two VARCHAR input columns. This function requires an OVER clause.
Syntax
MAPAGGREGATE (keys-column1, values-column2 [USING PARAMETERS param=value[,...]])
Arguments
keys-column- Table column with the keys for the key/value pairs of the returned
VMap data. Keys with a NULL value are excluded. If there are duplicate keys, the duplicate key and value that appear first in the query result are used, while the other duplicates are omitted.
values-column- Table column with the values for the key/value pairs of the returned
VMap data.
Parameters
max_vmap_length- Maximum length in bytes for the VMap result, an integer between 1-32000000 inclusive.
Default: 130000
on_overflow- Overflow behavior for cases when the VMap result is larger than the
max_vmap_length. The value must be one of the following strings:
- 'ERROR': Returns an error when overflow occurs.
- 'TRUNCATE': Stops aggregating key/value pairs if the result exceeds
max_vmap_length. The query executes, but the resulting VMap does not have all key/value pairs. When the provided max_vmap_length is not large enough to store an empty VMap, the result returned is NULL. Note that you need to specify order criteria in the OVER clause to get consistent results.
- 'RETURN_NULL': Return NULL if overflow occurs.
Default: 'ERROR'
Examples
The following examples use this input table:
=> SELECT * FROM inventory;
product | stock
--------------+--------
Planes | 100
Trains | 50
Automobiles | 200
(3 rows)
Call MAPAGGREGATE as follows to return the raw_map data of the resulting VMap:
=> SELECT raw_map FROM (SELECT MAPAGGREGATE(product, stock) OVER(ORDER BY product) FROM inventory) inventory;
raw_map
------------------------------------------------------------------------------------------------------------
\001\000\000\000\030\000\000\000\003\000\000\000\020\000\000\000\023\000\000\000\026\000\000\00020010050\003
\000\000\000\020\000\000\000\033\000\000\000!\000\000\000AutomobilesPlanesTrains
(1 row)
To transform the returned raw_map data into string representation, use MAPAGGREGATE with MAPTOSTRING:
=> SELECT MAPTOSTRING(raw_map) FROM (SELECT MAPAGGREGATE(product, stock) OVER(ORDER BY product) FROM
inventory) inventory;
MAPTOSTRING
--------------------------------------------------------------
{
"Automobiles": "200",
"Planes": "100",
"Trains": "50"
}
(1 row)
If you run the above query with on_overflow left as default and a max_vmap_length less than the returned VMap size, the function returns with an error message indicating the need to increase VMap length:
=> SELECT MAPTOSTRING(raw_map) FROM (SELECT MAPAGGREGATE(product, stock USING PARAMETERS max_vmap_length=60)
OVER(ORDER BY product) FROM inventory) inventory;
----------------------------------------------------------------------------------------------------------
ERROR 5861: Error calling processPartition() in User Function MapAggregate at [/data/jenkins/workspace
/RE-PrimaryBuilds/RE-Build-Master_2/server/udx/supported/flextable/Dict.cpp:1324], error code: 0, message:
Exception while finalizing map aggregation: Output VMap length is too small [60]. HINT: Set the parameter
max_vmap_length=71 and retry your query
Switching the value of on_overflow allows you to alter how MAPAGGREGATE behaves in the case of overflow. For example, changing on_overflow to 'RETURN_NULL' causes the above query to execute and return NULL:
SELECT raw_map IS NULL FROM (SELECT MAPAGGREGATE(product, stock USING PARAMETERS max_vmap_length=60,
on_overflow='RETURN_NULL') OVER(ORDER BY product) FROM inventory) inventory;
?column?
----------
t
(1 row)
If on_overflow is set to 'TRUNCATE', the resulting VMap has enough space for two of the key/value pairs, but must cut the third:
SELECT raw_map IS NULL FROM (SELECT MAPAGGREGATE(product, stock USING PARAMETERS max_vmap_length=60,
on_overflow='TRUNCATE') OVER(ORDER BY product) FROM inventory) inventory;
MAPTOSTRING
---------------------------------------------
{
"Automobiles": "200",
"Planes": "100"
}
(1 row)
See also
6.8.3.3 - MAPCONTAINSKEY
Determines whether a VMap contains a virtual column (key).
Determines whether a VMap contains a virtual column (key). This scalar function returns true (t), if the virtual column exists, or false (f) if it does not. Determining that a key exists before calling maplookup() lets you distinguish between NULL returns. The maplookup() function uses for both a non-existent key and an existing key with a NULL value.
Syntax
MAPCONTAINSKEY (VMap-data, 'virtual-column-name')
Arguments
VMap-dataAny VMap data. The VMap can exist as:
virtual-column-name- Name of the key to check.
Examples
This example shows how to use the mapcontainskey() functions with maplookup(). View the results returned from both functions. Check whether the empty fields that maplookup() returns indicate a NULL value for the row (t) or no value (f):
You can use mapcontainskey( ) to determine that a key exists before calling maplookup(). The maplookup() function uses both NULL returns and existing keys with NULL values to indicate a non-existent key.
=> SELECT MAPLOOKUP(__raw__, 'user.location'), MAPCONTAINSKEY(__raw__, 'user.location')
FROM darkdata ORDER BY 1;
maplookup | mapcontainskey
-----------+----------------
| t
| t
| t
| t
Chile | t
Narnia | t
Uptown.. | t
chicago | t
| f
| f
| f
| f
(12 rows)
See also
6.8.3.4 - MAPCONTAINSVALUE
Determines whether a VMap contains a specific value.
Determines whether a VMap contains a specific value. Use this scalar function to return true (t) if the value exists, or false (f) if it does not.
Syntax
MAPCONTAINSVALUE (VMap-data, 'virtual-column-value')
Arguments
VMap-dataAny VMap data. The VMap can exist as:
virtual-column-value- Value to confirm.
Examples
This example shows how to use mapcontainsvalue() to determine whether or not a virtual column contains a particular value. Create a flex table (ftest), and populate it with some virtual columns and values. Name both virtual columns one:
=> CREATE FLEX TABLE ftest();
CREATE TABLE
=> copy ftest from stdin parser fjsonparser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {"one":1, "two":2}
>> {"one":"one","2":"2"}
>> \.
Call mapcontainsvalue() on the ftest map data. The query returns false (f) for the first virtual column, and true (t) for the second , which contains the value one:
=> SELECT MAPCONTAINSVALUE(__raw__, 'one') FROM ftest;
mapcontainsvalue
------------------
f
t
(2 rows)
See also
6.8.3.5 - MAPITEMS
Returns information about items in a VMap.
Returns information about items in a VMap. Use this transform function with one or more optional arguments to access polystructured values within the VMap data. This function requires an over()` clause.
Syntax
MAPITEMS (VMap-data [, passthrough-arg[,...] ])
Arguments
VMap-dataAny VMap data. The VMap can exist as:
max_key_length- In a
__raw__ column, determines the maximum length of keys that the function can return. Keys that are longer than max_key_length cause the query to fail. Defaults to the smaller of VMap column length and 65K.
max_value_length- In a
__raw__ column, determines the maximum length of values the function can return. Values that are larger than max_value_length cause the query to fail. Defaults to the smaller of VMap column length and 65K.
passthrough-arg- One or more arguments indicating keys within the map data in
VMap-data.
Examples
The following examples illustrate using MAPITEMS()with the over(PARTITION BEST) clause.
This example determines the number of virtual columns in the map data using a flex table, labeled darkmountain. Query using the count() function to return the number of virtual columns in the map data:
=> SELECT COUNT(keys) FROM (SELECT MAPITEMS(darkmountain.__raw__) OVER(PARTITION BEST) FROM
darkmountain) AS a;
count
-------
19
(1 row)
The next example determines what items exist in the map data:
=> SELECT * FROM (SELECT MAPITEMS(darkmountain.__raw__) OVER(PARTITION BEST) FROM darkmountain) AS a;
keys | values
-------------+---------------
hike_safety | 50.6
name | Mt Washington
type | mountain
height | 17000
hike_safety | 12.2
name | Denali
type | mountain
height | 29029
hike_safety | 34.1
name | Everest
type | mountain
height | 14000
hike_safety | 22.8
name | Kilimanjaro
type | mountain
height | 29029
hike_safety | 15.4
name | Mt St Helens
type | volcano
(19 rows)
The following example shows how to restrict the length of returned values to 100000:
=> SELECT LENGTH(keys), LENGTH(values) FROM (SELECT MAPITEMS(__raw__ USING PARAMETERS max_value_length=100000) OVER() FROM t1) x;
LENGTH | LENGTH
--------+--------
9 | 98899
(1 row)
Directly Query a Key Value in a VMap
Review the following JSON input file, simple.json. In particular, notice the array called three_Array, and its four values:
{
"one": "one",
"two": 2,
"three_Array":
[
"three_One",
"three_Two",
3,
"three_Four"
],
"four": 4,
"five_Map":
{
"five_One": 51,
"five_Two": "Fifty-two",
"five_Three": "fifty three",
"five_Four": 54,
"five_Five": "5 x 5"
},
"six": 6
}
-
Create a flex table, mapper:
=> CREATE FLEX TABLE mapper();
CREATE TABLE
Load simple.json into the flex table mapper:
=> COPY mapper FROM '/home/dbadmin/data/simple.json' parser fjsonparser (flatten_arrays=false,
flatten_maps=false);
Rows Loaded
-------------
1
(1 row)
Call MAPKEYS on the flex table's __raw__ column to see the flex table's keys, but not the key submaps. The return values indicate three_Array as one of the virtual columns:
=> SELECT MAPKEYS(__raw__) OVER() FROM mapper;
keys
-------------
five_Map
four
one
six
three_Array
two
(6 rows)
Call mapitems on flex table mapper with three_Array as a pass-through argument to the function. The call returns these array values:
=> SELECT __identity__, MAPITEMS(three_Array) OVER(PARTITION BY __identity__) FROM mapper;
__identity__ | keys | values
--------------+------+------------
1 | 0 | three_One
1 | 1 | three_Two
1 | 2 | 3
1 | 3 | three_Four
(4 rows)
See also
6.8.3.6 - MAPKEYS
Returns the virtual columns (and values) present in any VMap data.
Returns the virtual columns (and values) present in any VMap data. This transform function requires an OVER(PARTITION BEST) clause.
Syntax
MAPKEYS (VMap-data)
Arguments
VMap-dataAny VMap data. The VMap can exist as:
max_key_length- In a
__raw__ column, specifies the maximum length of keys that the function can return. Keys that are longer than max_key_length cause the query to fail. Defaults to the smaller of VMap column length and 65K.
Examples
Determine Number of Virtual Columns in Map Data
This example shows how to create a query, using an over(PARTITION BEST) clause with a flex table, darkdata to find the number of virtual column in the map data. The table is populated with JSON tweet data.
=> SELECT COUNT(keys) FROM (SELECT MAPKEYS(darkdata.__raw__) OVER(PARTITION BEST) FROM darkdata) AS a;
count
-------
550
(1 row)
Query Ordered List of All Virtual Columns in the Map
This example shows a snippet of the return data when you query an ordered list of all virtual columns in the map data:
=> SELECT * FROM (SELECT MAPKEYS(darkdata.__raw__) OVER(PARTITION BEST) FROM darkdata) AS a;
keys
-------------------------------------
contributors
coordinates
created_ at
delete.status.id
delete.status.id_str
delete.status.user_id
delete.status.user_id_str
entities.hashtags
entities.media
entities.urls
entities.user_mentions
favorited
geo
id
.
.
.
user.statuses_count
user.time_zone
user.url
user.utc_offset
user.verified
(125 rows)
Specify the Maximum Length of Keys that MAPKEYS Can Return
=> SELECT MAPKEYS(__raw__ USING PARAMETERS max_key_length=100000) OVER() FROM mapper;
keys
-------------
five_Map
four
one
six
three_Array
two
(6 rows)
See also
6.8.3.7 - MAPKEYSINFO
Returns virtual column information from a given map.
Returns virtual column information from a given map. This transform function requires an OVER(PARTITION BEST) clause.
Syntax
MAPKEYSINFO (VMap-data)
Arguments
VMap-dataAny VMap data. The VMap can exist as:
max_key_length- In a
__raw__ column, determines the maximum length of keys that the function can return. Keys that are longer than max_key_length cause the query to fail. Defaults to the smaller of VMap column length and 65K.
Returns
This function is a superset of the MAPKEYS() function. It returns the following information about each virtual column:
|
Column |
Description |
keys |
The virtual column names in the raw data. |
length |
The data length of the key name, which can differ from the actual string length. |
type_oid |
The OID type into which the value should be converted. Currently, the type is always 116 for a LONG VARCHAR, or 199 for a nested map that is stored as a LONG VARBINARY. |
row_num |
The number of rows in which the key was found. |
field_num |
The field number in which the key exists. |
Examples
This example shows a snippet of the return data you receive if you query an ordered list of all virtual columns in the map data:
=> SELECT * FROM (SELECT MAPKEYSINFO(darkdata.__raw__) OVER(PARTITION BEST) FROM darkdata) AS a;
keys | length | type_oid | row_num | field_num
----------------------------------------------------------+--------+----------+---------+-----------
contributors | 0 | 116 | 1 | 0
coordinates | 0 | 116 | 1 | 1
created_at | 30 | 116 | 1 | 2
entities.hashtags | 93 | 199 | 1 | 3
entities.media | 772 | 199 | 1 | 4
entities.urls | 16 | 199 | 1 | 5
entities.user_mentions | 16 | 199 | 1 | 6
favorited | 1 | 116 | 1 | 7
geo | 0 | 116 | 1 | 8
id | 18 | 116 | 1 | 9
id_str | 18 | 116 | 1 | 10
.
.
.
delete.status.id | 18 | 116 | 11 | 0
delete.status.id_str | 18 | 116 | 11 | 1
delete.status.user_id | 9 | 116 | 11 | 2
delete.status.user_id_str | 9 | 116 | 11 | 3
delete.status.id | 18 | 116 | 12 | 0
delete.status.id_str | 18 | 116 | 12 | 1
delete.status.user_id | 9 | 116 | 12 | 2
delete.status.user_id_str | 9 | 116 | 12 | 3
(550 rows)
Specify the Maximum Length of Keys that MAPKEYSINFO Can Return
=> SELECT MAPKEYSINFO(__raw__ USING PARAMETERS max_key_length=100000) OVER() FROM mapper;
keys
-------------
five_Map
four
one
six
three_Array
two
(6 rows)
See also
6.8.3.8 - MAPLOOKUP
Returns single-key values from VMAP data.
Returns single-key values from VMAP data. This scalar function returns a LONG VARCHAR, with values, or NULL if the virtual column does not have a value.
Using maplookup is case insensitive to virtual column names. To avoid loading same-name values, set the fjsonparser parser reject_on_duplicate parameter to true when data loading.
You can control the behavior for non-scalar values in a VMAP (like arrays), when loading data with the fjsonparser or favroparser parsers and its flatten-arrays argument. See JSON data and the FJSONPARSER reference.
For information about using maplookup() to access nested JSON data, see Querying nested data.
Syntax
MAPLOOKUP (VMap-data, 'virtual-column-name' [USING PARAMETERS [case_sensitive={false | true}] [, buffer_size=n] ] )
Parameters
VMap-dataAny VMap data. The VMap can exist as:
virtual-column-name- The name of the virtual column whose values this function returns.
buffer_size- [Optional parameter] Specifies the maximum length (in bytes) of each value returned for
virtual-column-name. To return all values for virtual-column-name, specify a buffer_size equal to or greater than (=>) the number of bytes for any returned value. Any returned values greater in length than buffer_size are rejected.
Default: 0 (No limit on buffer_size)
case_sensitive- [Optional parameter]
Specifies whether to return values for virtual-column-name if keys with different cases exist.
Example:
(... USING PARAMETERS case_sensitive=true)
Default: false
Examples
This example returns the values of one virtual column, user.location:
=> SELECT MAPLOOKUP(__raw__, 'user.location') FROM darkdata ORDER BY 1;
maplookup
-----------
Chile
Nesnia
Uptown
.
.
chicago
(12 rows)
Using maplookup buffer_size
Use the buffer_size= parameter to indicate the maximum length of any value that maplookup returns for the virtual column you specify. If none of the returned key values can be greater than n bytes, use this parameter to allocate n bytes as the buffer_size.
For the next example, save this JSON data to a file, simple_name.json:
{
"name": "sierra",
"age": "63",
"eyes": "brown",
"weapon": "doggie"
}
{
"name": "janis",
"age": "10",
"eyes": "blue",
"weapon": "humor"
}
{
"name": "ben",
"age": "43",
"eyes": "blue",
"weapon": "sword"
}
{
"name": "jen",
"age": "38",
"eyes": "green",
"weapon": "shopping"
}
-
Create a flex table, logs.
-
Load the simple_name.json data into logs, using the fjsonparser. Specify the flatten_arrays option as True:
=> COPY logs FROM '/home/dbadmin/data/simple_name.json'
PARSER fjsonparser(flatten_arrays=True);
-
Use maplookup with buffer_size=0 for the logs table name key. This query returns all of the values:
=> SELECT MAPLOOKUP(__raw__, 'name' USING PARAMETERS buffer_size=0) FROM logs;
MapLookup
-----------
sierra
ben
janis
jen
(4 rows)
-
Next, call maplookup() three times, specifying the buffer_size parameter as 3, 5, and 6, respectively. Now, maplookup() returns values with a byte length less than or equal to (<=) buffer_size:
=> SELECT MAPLOOKUP(__raw__, 'name' USING PARAMETERS buffer_size=3) FROM logs;
MapLookup
-----------
ben
jen
(4 rows)
=> SELECT MAPLOOKUP(__raw__, 'name' USING PARAMETERS buffer_size=5) FROM logs;
MapLookup
-----------
janis
jen
ben
(4 rows)
=> SELECT MAPLOOKUP(__raw__, 'name' USING PARAMETERS buffer_size=6) FROM logs;
MapLookup
-----------
sierra
janis
jen
ben
(4 rows)
Disambiguate Empty Output Rows
This example shows how to interpret empty rows. Using maplookup without first checking whether a key exists can be ambiguous. When you review the following output, 12 empty rows, you cannot determine whether a user.location key has:
-
A non-NULL value
-
A NULL value
-
No value
=> SELECT MAPLOOKUP(__raw__, 'user.location') FROM darkdata;
maplookup
-----------
(12 rows)
To disambiguate empty output rows, use the mapcontainskey() function in conjunction with maplookup(). When maplookup returns an empty field, the corresponding value from mapcontainskey indicates t for a NULL or other value, or ffor no value.
The following example output using both functions lists rows with NULL or a name value as t, and rows with no value as f:
=> SELECT MAPLOOKUP(__raw__, 'user.location'), MAPCONTAINSKEY(__raw__, 'user.location')
FROM darkdata ORDER BY 1;
maplookup | mapcontainskey
-----------+----------------
| t
| t
| t
| t
Chile | t
Nesnia | t
Uptown | t
chicago | t
| f >>>>>>>>>>No value
| f >>>>>>>>>>No value
| f >>>>>>>>>>No value
| f >>>>>>>>>>No value
(12 rows)
Check for Case-Sensitive Virtual Columns
You can use maplookup() with the case_sensitive parameter to return results when key names with different cases exist.
-
Save the following sample content as a JSON file. This example saves the file as repeated_key_name.json:
{
"test": "lower1"
}
{
"TEST": "upper1"
}
{
"TEst": "half1"
}
{
"test": "lower2",
"TEst": "half2"
}
{
"TEST": "upper2",
"TEst": "half3"
}
{
"test": "lower3",
"TEST": "upper3"
}
{
"TEst": "half4",
"test": "lower4",
"TEST": "upper4"
}
{
"TesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttest
TesttestTesttestTesttestTesttest":"1",
"TesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttestTesttest
TesttestTesttestTesttestTesttestTest12345":"2"
}
-
Create a flex table, dupe, and load the JSON file:
=> CREATE FLEX TABLE dupe();
CREATE TABLE
dbt=> COPY dupe FROM '/home/release/KData/repeated_key_name.json' parser fjsonparser();
Rows Loaded
-------------
8
(1 row)
See also
6.8.3.9 - MAPPUT
Accepts a VMap and one or more key/value pairs and returns a new VMap with the key/value pairs added.
Accepts a VMap and one or more key/value pairs and returns a new VMap with the key/value pairs added. Keys must be set using the auxiliary function SetMapKeys(), and can only be constant strings. If the VMap has any of the new input keys, then the original values are replaced by the new ones.
Syntax
MAPPUT (VMap-data, value[,...] USING PARAMETERS keys=SetMapKeys('key'[,...])
Arguments
VMap-data- Any VMap data. The VMap can exist as:
value[,...]- One or more values to add to the VMap specified in
VMap-data.
Parameters
keys- The result of
SetMapKeys(). SetMapKeys() takes one or more constant string arguments.
The following example shows how to create a flex table and use COPY to enter some basic JSON data. After creating a second flex table, insert the new VMap results from mapput(), with additional key/value pairs.
-
Create sample table:
=> CREATE FLEX TABLE vmapdata1();
CREATE TABLE
-
Load sample JSON data from STDIN:
=> COPY vmapdata1 FROM stdin parser fjsonparser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {"aaa": 1, "bbb": 2, "ccc": 3}
>> \.
-
Create another flex table and use the function to insert data into it: => CREATE FLEX TABLE vmapdata2(); => INSERT INTO vmapdata2 SELECT MAPPUT(__raw__, '7','8','9' using parameters keys=SetMapKeys('xxx','yyy','zzz')) from vmapdata1;
-
View the difference between the original and the new flex tables:
=> SELECT MAPTOSTRING(__raw__) FROM vmapdata1;
maptostring
-----------------------------------------------------
{
"aaa" : "1",
"bbb" : "2",
"ccc" : "3"
}
(1 row)
=> SELECT MAPTOSTRING(__raw__) from vmapdata2;
maptostring
-------------------------------------------------------
{
"mapput" : {
"aaa" : "1",
"bbb" : "2",
"ccc" : "3",
"xxx" : "7",
"yyy" : "8",
"zzz" : "9"
}
}
See also
6.8.3.10 - MAPSIZE
Returns the number of virtual columns present in any VMap data.
Returns the number of virtual columns present in any VMap data. Use this scalar function to determine the size of keys.
Syntax
MAPSIZE (VMap-data)
Arguments
VMap-dataAny VMap data. The VMap can exist as:
Examples
This example shows the returned sizes from the number of keys in the flex table darkmountain:
=> SELECT MAPSIZE(__raw__) FROM darkmountain;
mapsize
---------
3
4
4
4
4
(5 rows)
See also
6.8.3.11 - MAPTOSTRING
Recursively builds a string representation of VMap data, including nested JSON maps.
Recursively builds a string representation of VMap data, including nested JSON maps. Use this transform function to display the VMap contents in a LONG VARCHAR format. You can use MAPTOSTRING to see how map data is nested before querying virtual columns with MAPVALUES.
Syntax
MAPTOSTRING ( VMap-data [ USING PARAMETERS param=value ] )
Arguments
VMap-dataAny VMap data. The VMap can exist as:
Parameters
canonical_json- Boolean, whether to produce canonical JSON format, using the first instance of any duplicate keys in the map data. If false, the function returns duplicate keys and their values.
Default: true
Examples
The following example uses this table definition and sample data:
=> CREATE FLEX TABLE darkdata();
CREATE TABLE
=> COPY darkdata FROM stdin parser fjsonparser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {"aaa": 1, "aaa": 2, "AAA": 3, "bbb": "aaa\"bbb"}
>> \.
Calling MAPTOSTRING with the default value of canonical_json returns only the first instance of the duplicate key:
=> SELECT MAPTOSTRING (__raw__) FROM darkdata;
maptostring
------------------------------------------------------------
{
"AAA" : "3",
"aaa" : "1",
"bbb" : "aaa\"bbb"
}
(1 row)
With canonical_json set to false, the function returns all of the keys, including duplicates:
=> SELECT MAPTOSTRING(__raw__ using parameters canonical_json=false) FROM darkdata;
maptostring
---------------------------------------------------------------
{
"aaa": "1",
"aaa": "2",
"AAA": "3",
"bbb": "aaa"bbb"
}
(1 row)
See also
6.8.3.12 - MAPVALUES
Returns a string representation of the top-level values from a VMap.
Returns a string representation of the top-level values from a VMap. This transform function requires an OVER() clause.
Syntax
MAPVALUES (VMap-data)
Arguments
VMap-dataAny VMap data. The VMap can exist as:
max_value_length- In a
__raw__ column, specifies the maximum length of values the function can return. Values that are larger than max_value_length cause the query to fail. Defaults to the smaller of VMap column length and 65K.
Examples
The following example shows how to query a darkmountain flex table, using an over() clause (in this case, the over(PARTITION BEST) clause) with mapvalues().
=> SELECT * FROM (SELECT MAPVALUES(darkmountain.__raw__) OVER(PARTITION BEST) FROM darkmountain) AS a;
values
---------------
29029
34.1
Everest
mountain
29029
15.4
Mt St Helens
volcano
17000
12.2
Denali
mountain
14000
22.8
Kilimanjaro
mountain
50.6
Mt Washington
mountain
(19 rows)
Specify the Maximum Length of Values that MAPVALUES Can Return
=> SELECT MAPVALUES(__raw__ USING PARAMETERS max_value_length=100000) OVER() FROM mapper;
keys
-------------
five_Map
four
one
six
three_Array
two
(6 rows)
See also
6.8.3.13 - MAPVERSION
Returns the version or invalidity of any map data.
Returns the version or invalidity of any map data. This scalar function returns the map version (such as 1) or -1, if the map data is invalid.
Syntax
MAPVERSION (VMap-data)
Arguments
VMap-dataAny VMap data. The VMap can exist as:
Examples
The following example shows how to use mapversion() with the darkmountainflex table, returning mapversion 1 for the flex table map data:
=> SELECT MAPVERSION(__raw__) FROM darkmountain;
mapversion
------------
1
1
1
1
1
(5 rows)
See also
6.9 - Formatting functions
Formatting functions provide a powerful tool set for converting various data types (DATE/TIME, INTEGER, FLOATING POINT) to formatted strings and for converting from formatted strings to specific data types.
Formatting functions provide a powerful tool set for converting various data types (DATE/TIME, INTEGER, FLOATING POINT) to formatted strings and for converting from formatted strings to specific data types.
6.9.1 - Template patterns for date/time formatting
In an output template string (for TO_CHAR), certain patterns are recognized and replaced with appropriately formatted data from the value to format.
In an output template string (for TO_CHAR), certain patterns are recognized and replaced with appropriately formatted data from the value to format. Any text that is not a template pattern is copied verbatim. Similarly, in an input template string (for anything other than TO_CHAR), template patterns identify the parts of the input data string to look at and the values to find there.
Note
Vertica uses the ISO 8601:2004 style for date/time fields in Vertica log files. For example:
2020-03-25 05:04:22.372 Init Session:0x7f8fcefec700-a000000013dcd4 [Txn] <INFO> Begin Txn: a000000013dcd4 'read role info'
|
Pattern |
Description |
HH |
Hour of day (00-23) |
HH12 |
Hour of day (01-12) |
HH24 |
Hour of day (00-23) |
MI |
Minute (00-59) |
SS |
Second (00-59) |
MS |
Millisecond (000-999) |
US |
Microsecond (000000-999999) |
SSSS |
Seconds past midnight (0-86399) |
AM A.M. PM P.M. |
Meridian indicator (uppercase) |
am a.m. pm p.m. |
Meridian indicator (lowercase) |
Y YYY |
Year (4 and more digits) with comma |
YYYY |
Year (4 and more digits) |
YYY |
Last 3 digits of year |
YY |
Last 2 digits of year |
Y |
Last digit of year |
IYYY |
ISO year (4 and more digits) |
IYY |
Last 3 digits of ISO year |
IY |
Last 2 digits of ISO year |
I |
Last digits of ISO year |
BC B.C. AD A.D. |
Era indicator (uppercase) |
bc b.c. ad a.d. |
Era indicator (lowercase) |
MONTH |
Full uppercase month name (blank-padded to 9 chars) |
Month |
Full mixed-case month name (blank-padded to 9 chars) |
month |
Full lowercase month name (blank-padded to 9 chars) |
MON |
Abbreviated uppercase month name (3 chars) |
Mon |
Abbreviated mixed-case month name (3 chars) |
mon |
Abbreviated lowercase month name (3 chars) |
MM |
Month number (01-12) |
DAY |
Full uppercase day name (blank-padded to 9 chars) |
Day |
Full mixed-case day name (blank-padded to 9 chars) |
day |
full lowercase day name (blank-padded to 9 chars) |
DY |
Abbreviated uppercase day name (3 chars) |
Dy |
Abbreviated mixed-case day name (3 chars) |
dy |
Abbreviated lowercase day name (3 chars) |
DDD |
Day of year (001-366) |
DD |
Day of month (01-31) for TIMESTAMP
Note
For INTERVAL, DD is day of year (001-366) because day of month is undefined.
|
D |
Day of week (1-7; Sunday is 1) |
W |
Week of month (1-5) (The first week starts on the first day of the month.) |
WW |
Week number of year (1-53) (The first week starts on the first day of the year.) |
IW |
ISO week number of year (The first Thursday of the new year is in week 1.) |
CC |
Century (2 digits) |
J |
Julian Day (days since January 1, 4712 BC) |
Q |
Quarter |
RM |
Month in Roman numerals (I-XII; I=January) (uppercase) |
rm |
Month in Roman numerals (i-xii; i=January) (lowercase) |
TZ |
Time-zone name (uppercase) |
tz |
Time-zone name (lowercase) |
Template pattern modifiers
Certain modifiers can be applied to any date/time template pattern to alter its behavior. For example, FMMonth is the Month pattern with the FM modifier.
|
Modifier |
Description |
AM |
Time is before 12:00 |
AT |
Ignored |
JULIAN, JD, J |
Next field is Julian Day |
FM prefix |
Fill mode (suppress padding blanks and zeros)
For example: FMMonth
Note: The FM modifier suppresses leading zeros and trailing blanks that would otherwise be added to make the output of a pattern fixed width.
|
FX prefix |
Fixed format global option
For example: FX Month DD Day
|
ON |
Ignored |
PM |
Time is on or after 12:00 |
T |
Next field is time |
TH suffix |
Uppercase ordinal number suffix
For example: DDTH
|
th suffix |
Lowercase ordinal number suffix
For example: DDth
|
TM prefix |
Translation mode (print localized day and month names based on lc_messages). For example: TMMonth |
Examples
Use TO_TIMESTAMP to convert an expression using the pattern 'YYY MON':
=> SELECT TO_TIMESTAMP('2017 JUN', 'YYYY MON');
TO_TIMESTAMP
---------------------
2017-06-01 00:00:00
(1 row)
Use TO_DATE to convert an expression using the pattern 'YYY-MMDD':
=> SELECT TO_DATE('2017-1231', 'YYYY-MMDD');
TO_DATE
------------
2017-12-31
(1 row)
6.9.2 - Template patterns for numeric formatting
A sign formatted using SG, PL, or MI is not anchored to the number.
|
Pattern |
Description |
9 |
Value with the specified number of digits |
0 |
Value with leading zeros |
. |
Decimal point |
, |
Group (thousand) separator |
PR |
Negative value in angle brackets |
S |
Sign anchored to number (uses locale) |
L |
Currency symbol (uses locale) |
D |
Decimal point (uses locale) |
G |
Group separator (uses locale) |
MI |
Minus sign in specified position (if number < 0) |
PL |
Plus sign in specified position (if number > 0) |
SG |
Plus/minus sign in specified position |
RN |
Roman numeral (input between 1 and 3999) |
TH/th |
Ordinal number suffix |
V |
Shift specified number of digits |
EEEE |
Scientific notation (not implemented yet) |
Usage
-
A sign formatted using SG, PL, or MI is not anchored to the number. For example:
=> SELECT to_char(-12, 'S9999'), to_char(-12, 'MI9999');
to_char | to_char
---------+---------
-12 | - 12
(1 row)
-
TO_CHAR(-12, 'S9999') produces ' -12'
-
TO_CHAR(-12, 'MI9999') produces '- 12'
-
9 results in a value with the same number of digits as there are 9s. If a digit is not available it outputs a space.
-
TH does not convert values less than zero and does not convert fractional numbers.
-
V effectively multiplies the input values by 10^n, where n is the number of digits following V. TO_CHAR does not support the use of V combined with a decimal point—for example: 99.9V99.
6.9.3 - TO_BITSTRING
This topic is shared in two locations: Formatting Functions and String Functions.
Returns a VARCHAR that represents the given VARBINARY value in bitstring format. This function is the inverse of
BITSTRING_TO_BINARY.
Behavior type
Immutable
Syntax
TO_BITSTRING ( expression )
Arguments
expression- The VARCHAR string to process.
Examples
=> SELECT TO_BITSTRING('ab'::BINARY(2));
to_bitstring
------------------
0110000101100010
(1 row)
=> SELECT TO_BITSTRING(HEX_TO_BINARY('0x10'));
to_bitstring
--------------
00010000
(1 row)
=> SELECT TO_BITSTRING(HEX_TO_BINARY('0xF0'));
to_bitstring
--------------
11110000
(1 row)
See also
BITCOUNT
6.9.4 - TO_CHAR
Converts date/time and numeric values into text strings.
Converts date/time and numeric values into text strings.
Behavior type
Stable
Syntax
TO_CHAR ( expression [, pattern ] )
Parameters
expression- Specifies the value to convert, one of the following data types:
The following restrictions apply:
-
TO_CHAR does not support binary data types BINARY and VARBINARY
-
TO_CHAR does not support the use of V combined with a decimal point—for example, 99.9V99
pattern- A CHAR or VARCHAR that specifies an output pattern string. See Template patterns for date/time formatting.
Notes
-
Vertica pads TO_CHAR output with a leading space, so positive and negative values have the same length. To suppress padding, use the FM prefix.
-
TO_CHAR accepts TIME and TIMETZ data types as inputs if you explicitly cast TIME to TIMESTAMP and TIMETZ to TIMESTAMPTZ.
=> SELECT TO_CHAR(TIME '14:34:06.4','HH12:MI am'), TO_CHAR(TIMETZ '14:34:06.4+6','HH12:MI am');
TO_CHAR | TO_CHAR
----------+----------
02:34 pm | 04:34 am
(1 row)
-
You can extract the timezone hour from TIMETZ:
=> SELECT EXTRACT(timezone_hour FROM TIMETZ '10:30+13:30');
date_part
-----------
13
(1 row)
-
Ordinary text is allowed in TO_CHAR templates and is output literally. You can put a substring in double quotes to force it to be interpreted as literal text even if it contains pattern key words. In the following example, YYYY is replaced by the year data, but the Y in Year is not:
=> SELECT to_char(CURRENT_TIMESTAMP, '"Hello Year " YYYY');
to_char
------------------
Hello Year 2021
(1 row)
-
TO_CHAR uses different day-of-the-week numbering (see the D template pattern) than EXTRACT.
-
Given an INTERVAL type, TO_CHAR formats HH and HH12 as hours in a single day, while HH24 can output hours exceeding a single day—for example, >24.
-
To include a double quote (") character in output, precede it with a double backslash (\\). This is necessary because the backslash already has a special meaning in a string constant. For example: '\\"YYYY Month\\"'
-
When rounding, the last digit of the rounded representation is selected to be even if the number is exactly half way between the two.
Examples
|
TO_CHAR expression and pattern argument |
Output |
CURRENT_TIMESTAMP, 'Day, DD HH12:MI:SS' |
Tuesday , 06 05:39:18 |
CURRENT_TIMESTAMP, 'FMDay, FMDD HH12:MI:SS' |
Tuesday, 6 05:39:18 |
TIMETZ '14:34:06.4+6','HH12:MI am' |
04:34 am |
-0.1, '99.99' |
-.10 |
-0.1, 'FM9.99' |
-.1 |
0.1, '0.9' |
0.1 |
12, '9990999.9' |
`0012.0`
|
12, 'FM9990999.9' |
0012. |
485, '999' |
485 |
-485, '999' |
-485 |
485, '9 9 9' |
4 8 5 |
1485, '9,999' |
1,485 |
1485, '9G999' |
1 485 |
148.5, '999.999' |
148.500 |
148.5, 'FM999.999' |
148.5 |
148.5, 'FM999.990' |
148.500 |
148.5, '999D999' |
148,500 |
3148.5, '9G999D999' |
3 148,500 |
-485, '999S' |
485- |
-485, '999MI' |
485- |
485, '999MI' |
485 |
485, 'FM999MI' |
485 |
485, 'PL999' |
+485 |
485, 'SG999' |
+485 |
-485, 'SG999' |
-485 |
-485, '9SG99' |
4-85 |
-485, '999PR' |
<485> |
485, 'L999' |
DM 485 |
485, 'RN' |
`CDLXXXV`
|
485, 'FMRN' |
CDLXXXV |
5.2, 'FMRN' |
V |
482, '999th' |
482nd |
485, '"Good number:"999' |
Good number: 485 |
485.8, '"Pre:"999" Post:" .999' |
Pre: 485 Post: .800 |
12, '99V999' |
12000 |
12.4, '99V999' |
12400 |
12.45, '99V9' |
125 |
-1234.567 |
-1234.567 |
'1999-12-25'::DATE |
1999-12-25 |
'1999-12-25 11:31'::TIMESTAMP |
1999-12-25 11:31:00 |
'1999-12-25 11:31 EST'::TIMESTAMPTZ |
1999-12-25 11:31:00-05 |
'3 days 1000.333 secs'::INTERVAL |
3 days 00:16:40.333 |
See also
DATE_PART
6.9.5 - TO_DATE
This topic shared in two places: Date/Time functions and Formatting Functions.
Converts a string value to a DATE type.
Behavior type
Stable
Syntax
TO_DATE ( expression , pattern )
Parameters
expression- Specifies the string value to convert, either
CHAR or VARCHAR.
pattern- A
CHAR or VARCHAR that specifies an output pattern string. See:
TO_DATE requires a CHAR or VARCHAR expression. For other input types, use
TO_CHAR to perform an explicit cast to a CHAR or VARCHAR before using this function.
Notes
- To use a double quote character in the output, precede it with a double backslash. This is necessary because the backslash already has a special meaning in a string constant. For example:
'\\"YYYY Month\\"'
-
TO_TIMESTAMP, TO_TIMESTAMP_TZ, and TO_DATE skip multiple blank spaces in the input string if the FX option is not used. FX must be specified as the first item in the template. For example:
-
TO_TIMESTAMP('2000 JUN', 'YYYY MON') is correct.
-
TO_TIMESTAMP('2000 JUN', 'FXYYYY MON') returns an error, because TO_TIMESTAMP expects one space only.
-
The YYYY conversion from string to TIMESTAMP or DATE has a restriction if you use a year with more than four digits. You must use a non-digit character or template after YYYY, otherwise the year is always interpreted as four digits. For example, given the following arguments, TO_DATE interprets the five-digit year 20000 as a four-digit year:
=> SELECT TO_DATE('200001131','YYYYMMDD');
TO_DATE
------------
2000-01-13
(1 row)
Instead, use a non-digit separator after the year. For example:
=> SELECT TO_DATE('20000-1131', 'YYYY-MMDD');
TO_DATE
-------------
20000-12-01
(1 row)
-
In conversions from string to TIMESTAMP or DATE, the CC field is ignored if there is a YYY, YYYY or Y,YYY field. If CC is used with YY or Y, then the year is computed as (CC–1)*100+YY.
Examples
=> SELECT TO_DATE('13 Feb 2000', 'DD Mon YYYY');
to_date
------------
2000-02-13
(1 row)
See also
Date/time functions
6.9.6 - TO_HEX
This topic is shared in two locations: Formatting Functions and String Functions.
Returns a VARCHAR or VARBINARY representing the hexadecimal equivalent of a number. This function is the inverse of HEX_TO_BINARY.
Behavior type
Immutable
Syntax
TO_HEX ( number )
Arguments
number- An INTEGER or VARBINARY value to convert to hexadecimal. If you supply a VARBINARY argument, the function's return value is not preceded by
0x.
Examples
=> SELECT TO_HEX(123456789);
TO_HEX
---------
75bcd15
(1 row)
For VARBINARY inputs, the returned value is not preceded by 0x. For example:
=> SELECT TO_HEX('ab'::binary(2));
TO_HEX
--------
6162
(1 row)
6.9.7 - TO_NUMBER
Converts a string value to DOUBLE PRECISION.
Converts a string value to DOUBLE PRECISION.
Behavior type
Stable
Syntax
TO_NUMBER ( expression, [ pattern ] )
Parameters
expression- Specifies the string value to convert, either CHAR or VARCHAR.
pattern- A string value, either CHAR or VARCHAR, that specifies an output pattern string using one of the supported Template patterns for numeric formatting. If you omit this parameter,
TO_NUMBER returns a floating point.
Notes
To use a double quote character in the output, precede it with a double backslash. This is necessary because the backslash already has a special meaning in a string constant. For example: '\\"YYYY Month\\"'
Examples
=> SELECT TO_NUMBER('MCML', 'rn');
TO_NUMBER
-----------
1950
(1 row)
It the pattern parameter is omitted, the function returns a floating point. For example:
=> SELECT TO_NUMBER('-123.456e-01');
TO_NUMBER
-----------
-12.3456
6.9.8 - TO_TIMESTAMP
Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP type.
Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP type.
Behavior type
Stable
Syntax
TO_TIMESTAMP ( { expression, pattern } | unix-epoch )
Parameters
expression- Specifies the string value to convert, of type CHAR or VARCHAR.
pattern- A CHAR or VARCHAR that specifies an output pattern string. See:
unix-epoch- DOUBLE PRECISION value that specifies some number of seconds elapsed since midnight UTC of January 1, 1970, excluding leap seconds. INTEGER values are implicitly cast to DOUBLE PRECISION.
Notes
-
Millisecond (MS) and microsecond (US) values in a conversion from string to TIMESTAMP are used as part of the seconds after the decimal point. For example TO_TIMESTAMP('12:3', 'SS:MS') is not 3 milliseconds, but 300, because the conversion counts it as 12 + 0.3 seconds. This means for the format SS:MS, the input values 12:3, 12:30, and 12:300 specify the same number of milliseconds. To get three milliseconds, use 12:003, which the conversion counts as 12 + 0.003 = 12.003 seconds.
Here is a more complex example: TO_TIMESTAMP('15:12:02.020.001230', 'HH:MI:SS.MS.US') is 15 hours, 12 minutes, and 2 seconds + 20 milliseconds + 1230 microseconds = 2.021230 seconds.
-
To use a double quote character in the output, precede it with a double backslash. This is necessary because the backslash already has a special meaning in a string constant. For example: '\\"YYYY Month\\"'
-
TO_TIMESTAMP, TO_TIMESTAMP_TZ, and TO_DATE skip multiple blank spaces in the input string if the FX option is not used. FX must be specified as the first item in the template. For example:
-
TO_TIMESTAMP('2000 JUN', 'YYYY MON') is correct.
-
TO_TIMESTAMP('2000 JUN', 'FXYYYY MON') returns an error, because TO_TIMESTAMP expects one space only.
-
The YYYY conversion from string to TIMESTAMP or DATE has a restriction if you use a year with more than four digits. You must use a non-digit character or template after YYYY, otherwise the year is always interpreted as four digits. For example, given the following arguments, TO_DATE interprets the five-digit year 20000 as a four-digit year:
=> SELECT TO_DATE('200001131','YYYYMMDD');
TO_DATE
------------
2000-01-13
(1 row)
Instead, use a non-digit separator after the year. For example:
=> SELECT TO_DATE('20000-1131', 'YYYY-MMDD');
TO_DATE
-------------
20000-12-01
(1 row)
-
In conversions from string to TIMESTAMP or DATE, the CC field is ignored if there is a YYY, YYYY or Y,YYY field. If CC is used with YY or Y, then the year is computed as (CC–1)*100+YY.
Examples
=> SELECT TO_TIMESTAMP('13 Feb 2009', 'DD Mon YYYY');
TO_TIMESTAMP
---------------------
1200-02-13 00:00:00
(1 row)
=> SELECT TO_TIMESTAMP(200120400);
TO_TIMESTAMP
---------------------
1976-05-05 01:00:00
(1 row)
See also
Date/time functions
6.9.9 - TO_TIMESTAMP_TZ
Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP WITH TIME ZONE type.
Converts a string value or a UNIX/POSIX epoch value to a TIMESTAMP WITH TIME ZONE type.
Behavior type
Immutable if single argument form, Stable otherwise.
Syntax
TO_TIMESTAMP_TZ ( { expression, pattern } | unix-epoch )
Parameters
expression- Specifies the string value to convert, of type CHAR or VARCHAR.
pattern- A CHAR or VARCHAR that specifies an output pattern string. See:
unix-epoch- A DOUBLE PRECISION value that specifies some number of seconds elapsed since midnight UTC of January 1, 1970, excluding leap seconds. INTEGER values are implicitly cast to DOUBLE PRECISION.
Notes
-
Millisecond (MS) and microsecond (US) values in a conversion from string to TIMESTAMP are used as part of the seconds after the decimal point. For example TO_TIMESTAMP('12:3', 'SS:MS') is not 3 milliseconds, but 300, because the conversion counts it as 12 + 0.3 seconds. This means for the format SS:MS, the input values 12:3, 12:30, and 12:300 specify the same number of milliseconds. To get three milliseconds, use 12:003, which the conversion counts as 12 + 0.003 = 12.003 seconds.
Here is a more complex example: TO_TIMESTAMP('15:12:02.020.001230', 'HH:MI:SS.MS.US') is 15 hours, 12 minutes, and 2 seconds + 20 milliseconds + 1230 microseconds = 2.021230 seconds.
-
To use a double quote character in the output, precede it with a double backslash. This is necessary because the backslash already has a special meaning in a string constant. For example: '\\"YYYY Month\\"'
-
TO_TIMESTAMP, TO_TIMESTAMP_TZ, and TO_DATE skip multiple blank spaces in the input string if the FX option is not used. FX must be specified as the first item in the template. For example:
-
TO_TIMESTAMP('2000 JUN', 'YYYY MON') is correct.
-
TO_TIMESTAMP('2000 JUN', 'FXYYYY MON') returns an error, because TO_TIMESTAMP expects one space only.
-
The YYYY conversion from string to TIMESTAMP or DATE has a restriction if you use a year with more than four digits. You must use a non-digit character or template after YYYY, otherwise the year is always interpreted as four digits. For example, given the following arguments, TO_DATE interprets the five-digit year 20000 as a four-digit year:
=> SELECT TO_DATE('200001131','YYYYMMDD');
TO_DATE
------------
2000-01-13
(1 row)
Instead, use a non-digit separator after the year. For example:
=> SELECT TO_DATE('20000-1131', 'YYYY-MMDD');
TO_DATE
-------------
20000-12-01
(1 row)
-
In conversions from string to TIMESTAMP or DATE, the CC field is ignored if there is a YYY, YYYY or Y,YYY field. If CC is used with YY or Y, then the year is computed as (CC–1)*100+YY.
Examples
=> SELECT TO_TIMESTAMP_TZ('13 Feb 2009', 'DD Mon YYY');
TO_TIMESTAMP_TZ
------------------------
1200-02-13 00:00:00-05
(1 row)
=> SELECT TO_TIMESTAMP_TZ(200120400);
TO_TIMESTAMP_TZ
------------------------
1976-05-05 01:00:00-04
(1 row)
See also
Date/time functions
6.10 - Geospatial functions
Geospatial functions manipulate complex two-dimensional spatial objects and store them in a database according to the Open Geospatial Consortium (OGC) standards.
Geospatial functions manipulate complex two-dimensional spatial objects and store them in a database according to the Open Geospatial Consortium (OGC) standards.
Function naming conventions
The geospatial functions use the following naming conventions:
-
Most ST_function-name functions are compliant with the latest OGC standard OGC SFA-SQL version 1.2.1 (reference. number is OGC 06-104r4, date: 2010-08-04). Currently, some ST_function-name functions may not support all data types. Each function page contains details about the supported data types.
Note
Some functions, such as ST_GeomFromText, are based on previous versions of the standard.
-
The STV_function-name functions are unique to Vertica and not compliant with OGC standards. Each function page explains its functionality in detail.
Verifying spatial objects validity
Many spatial functions do not validate their parameters. If you pass an invalid spatial object to an ST_ or STV_ function, the function might return an error or produce incorrect results.
To avoid this issue, Vertica recommends that you first run ST_IsValid on all spatial objects to validate the parameters. If your object is not valid, run STV_IsValidReason to get information about the location of the invalidity.
6.10.1 - ST_Area
Calculates the area of a spatial object.
Calculates the area of a spatial object.
The units are:
Behavior type
Immutable
Syntax
ST_Area( g )
Arguments
g- Spatial object for which you want to calculate the area, type GEOMETRY or GEOGRAPHY
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_Area.
Calculate the area of a polygon:
=> SELECT ST_Area(ST_GeomFromText('POLYGON((0 0,1 0,1 1,0 1,0 0))'));
ST_Area
---------
1
(1 row)
Calculate the area of a multipolygon:
=> SELECT ST_Area(ST_GeomFromText('MultiPolygon(((0 0,1 0,1 1,0 1,0 0)),
((2 2,2 3,4 6,3 3,2 2)))'));
ST_Area
---------
3
(1 row)
Suppose the polygon has a hole, as in the following figure.

Calculate the area, excluding the area of the hole:
=> SELECT ST_Area(ST_GeomFromText('POLYGON((2 2,5 5,8 2,2 2),
(4 3,5 4,6 3,4 3))'));
ST_Area
---------
8
(1 row)
Calculate the area of a geometry collection:
=> SELECT ST_Area(ST_GeomFromText('GEOMETRYCOLLECTION(POLYGON((20.5 20.45,
20.51 20.52,20.69 20.32,20.5 20.45)),POLYGON((10 20,30 40,25 50,10 20)))'));
ST_Area
----------
150.0073
(1 row)
Calculate the area of a geography object:
=> SELECT ST_Area(ST_GeographyFromText('POLYGON((20.5 20.45,20.51 20.52,
20.69 20.32,20.5 20.45))'));
ST_Area
------------------
84627437.116037
(1 row)
6.10.2 - ST_AsBinary
Creates the Well-Known Binary (WKB) representation of a spatial object.
Creates the Well-Known Binary (WKB) representation of a spatial object. Use this function when you need to convert an object to binary form for porting spatial data to or from other applications.
The Open Geospatial Consortium (OGC) defines the format of a WKB representation in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_AsBinary( g )
Arguments
g- Spatial object for which you want the WKB, type GEOMETRY or GEOGRAPHY
Returns
LONG VARBINARY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following example shows how to use ST_AsBinary.
Retrieve WKB and WKT representations:
=> CREATE TABLE locations (id INTEGER, name VARCHAR(100), geom1 GEOMETRY(800), geom2 GEOGRAPHY);
CREATE TABLE
=> COPY locations
(id, geom1x FILLER LONG VARCHAR(800), geom1 AS ST_GeomFromText(geom1x), geom2x FILLER LONG VARCHAR (800),
geom2 AS ST_GeographyFromText(geom2x))
FROM stdin;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POINT(2 3)|
>> 2|LINESTRING(2 4,1 5)|
>> 3||POLYGON((-70.96 43.27,-70.67 42.95,-66.90 44.74,-67.81 46.08,-67.81 47.20,-69.22 47.43,-71.09 45.25,-70.96 43.27))
>> \.
=> SELECT id, ST_AsText(geom1),ST_AsText(geom2) FROM locations ORDER BY id ASC;
id | ST_AsText | ST_AsText
----+-----------------------+---------------------------------------------
1 | POINT (2 3) |
2 | LINESTRING (2 4, 1 5) |
3 | | POLYGON ((-70.96 43.27, -70.67 42.95, -66.9 44.74, -67.81 46.08, -67.81 47.2, -69.22 47.43, -71.09 45.25, -70.96 43.27))
=> SELECT id, ST_AsBinary(geom1),ST_AsBinary(geom2) FROM locations ORDER BY id ASC;
.
.
.
(3 rows)
Calculate the length of a WKB using the Vertica SQL function LENGTH:
=> SELECT LENGTH(ST_AsBinary(St_GeomFromText('POLYGON ((-1 2, 0 3, 1 2,
0 1, -1 2))')));
LENGTH
--------
93
(1 row)
See also
ST_AsText
6.10.3 - ST_AsText
Creates the Well-Known Text (WKT) representation of a spatial object.
Creates the Well-Known Text (WKT) representation of a spatial object. Use this function when you need to specify a spatial object in ASCII form.
The Open Geospatial Consortium (OGC) defines the format of a WKT string in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_AsText( g )
Arguments
g- Spatial object for which you want the WKT string, type GEOMETRY or GEOGRAPHY
Returns
LONG VARCHAR
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following example shows how to use ST_AsText.
Retrieve WKB and WKT representations:
=> CREATE TABLE locations (id INTEGER, name VARCHAR(100), geom1 GEOMETRY(800),
geom2 GEOGRAPHY);
CREATE TABLE
=> COPY locations
(id, geom1x FILLER LONG VARCHAR(800), geom1 AS ST_GeomFromText(geom1x), geom2x FILLER LONG VARCHAR (800),
geom2 AS ST_GeographyFromText(geom2x))
FROM stdin;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POINT(2 3)|
>> 2|LINESTRING(2 4,1 5)|
>> 3||POLYGON((-70.96 43.27,-70.67 42.95,-66.90 44.74,-67.81 46.08,-67.81 47.20,-69.22 47.43,-71.09 45.25,-70.96 43.27))
>> \.
=> SELECT id, ST_AsText(geom1),ST_AsText(geom2) FROM locations ORDER BY id ASC;
id | ST_AsText | ST_AsText
----+-----------------------+---------------------------------------------
1 | POINT (2 3) |
2 | LINESTRING (2 4, 1 5) |
3 | | POLYGON ((-70.96 43.27, -70.67 42.95, -66.9 44.74, -67.81 46.08, -67.81 47.2, -69.22 47.43, -71.09 45.25, -70.96 43.27))
(3 rows)
Calculate the length of a WKT using the Vertica SQL function LENGTH:
=> SELECT LENGTH(ST_AsText(St_GeomFromText('POLYGON ((-1 2, 0 3, 1 2,
0 1, -1 2))')));
LENGTH
--------
37
(1 row)
See also
6.10.4 - ST_Boundary
Calculates the boundary of the specified GEOMETRY object.
Calculates the boundary of the specified GEOMETRY object. An object's boundary is the set of points that define the limit of the object.
For a linestring, the boundary is the start and end points. For a polygon, the boundary is a linestring that begins and ends at the same point.
Behavior type
Immutable
Syntax
ST_Boundary( g )
Arguments
g- Spatial object for which you want the boundary, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
No |
Examples
The following examples show how to use ST_Boundary.
Returns a linestring that represents the boundary:
=> SELECT ST_AsText(ST_Boundary(ST_GeomFromText('POLYGON((-1 -1,2 2,
0 1,-1 -1))')));
ST_AsText
--------------
LINESTRING(-1 -1, 2 2, 0 1, -1 -1)
(1 row)
Returns a multilinestring that contains the boundaries of both polygons:
=> SELECT ST_AsText(ST_Boundary(ST_GeomFromText('POLYGON((2 2,5 5,8 2,2 2),
(4 3,5 4,6 3,4 3))')));
ST_AsText
------------------------------------------------------------------
MULTILINESTRING ((2 2, 5 5, 8 2, 2 2), (4 3, 5 4, 6 3, 4 3))
(1 row)
The boundary of a linestring is its start and end points:
=> SELECT ST_AsText(ST_Boundary(ST_GeomFromText(
'LINESTRING(1 1,2 2,3 3,4 4)')));
ST_AsText
-----------------------
MULTIPOINT (1 1, 4 4)
(1 row)
A closed linestring has no boundary because it has no start and end points:
=> SELECT ST_AsText(ST_Boundary(ST_GeomFromText(
'LINESTRING(1 1,2 2,3 3,4 4,1 1)')));
ST_AsText
------------------
MULTIPOINT EMPTY
(1 row)
6.10.5 - ST_Buffer
Creates a GEOMETRY object greater than or equal to a specified distance from the boundary of a spatial object.
Creates a GEOMETRY object greater than or equal to a specified distance from the boundary of a spatial object. The distance is measured in Cartesian coordinate units. ST_Buffer does not accept a distance size greater than +1e15 or less than –1e15.
Behavior type
Immutable
Syntax
ST_Buffer( g, d )
Arguments
g- Spatial object for which you want to calculate the buffer, type GEOMETRY
d- Distance from the object in Cartesian coordinate units, type FLOAT
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Usage tips
-
If you specify a positive distance, ST_Buffer returns a polygon that represents the points within or equal to the distance outside the object. If you specify a negative distance, ST_Buffer returns a polygon that represents the points within or equal to the distance inside the object.
-
For points, multipoints, linestrings, and multilinestrings, if you specify a negative distance, ST_Buffer returns an empty polygon.
-
The Vertica Place version of ST_Buffer returns the buffer as a polygon, so the buffer object has corners at its vertices. It does not contain rounded corners.
Examples
The following example shows how to use ST_Buffer.
Returns a GEOMETRY object:
=> SELECT ST_AsText(ST_Buffer(ST_GeomFromText('POLYGON((0 1,1 4,4 3,0 1))'),1));
ST_AsText
------------------------------------------------------------------------------
POLYGON ((-0.188847498856 -0.159920845081, -1.12155598386 0.649012935089, 0.290814745534 4.76344136152,
0.814758063466 5.02541302048, 4.95372324225 3.68665254814, 5.04124517538 2.45512549204, -0.188847498856 -0.159920845081))
(1 row)
6.10.6 - ST_Centroid
Calculates the geometric center—the centroid—of a spatial object.
Calculates the geometric center—the centroid—of a spatial object. If points or linestrings or both are present in a geometry with polygons, only the polygons contribute to the calculation of the centroid. Similarly, if points are present with linestrings, the points do not contribute to the calculation of the centroid.
To calculate the centroid of a GEOGRAPHY object, see the examples for STV_Geometry and STV_Geography.
Behavior type
Immutable
Syntax
ST_Centroid( g )
Arguments
g- Spatial object for which you want to calculate the centroid, type GEOMETRY
Returns
GEOMETRY (POINT only)
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_Centroid.
Calculate the centroid for a polygon:
=> SELECT ST_AsText(ST_Centroid(ST_GeomFromText('POLYGON((-1 -1,2 2,-1 2,
-1 -1))')));
ST_AsText
------------
POINT (-0 1)
(1 row)
Calculate the centroid for a multipolygon:
=> SELECT ST_AsText(ST_Centroid(ST_GeomFromText('MULTIPOLYGON(((1 0,2 1,2 0,
1 0)),((-1 -1,2 2,-1 2,-1 -1)))')));
ST_AsText
--------------------------------------
POINT (0.166666666667 0.933333333333)
(1 row)
This figure shows the centroid for the multipolygon.
6.10.7 - ST_Contains
Determines if a spatial object is entirely inside another spatial object without existing only on its boundary.
Determines if a spatial object is entirely inside another spatial object without existing only on its boundary. Both arguments must be the same spatial data type. Either specify two GEOMETRY objects or two GEOGRAPHY objects.
If an object such as a point or linestring only exists along a spatial object's boundary, then ST_Contains returns false. The interior of a linestring is all the points on the linestring except the start and end points.
ST_Contains(g1, g2) is functionally equivalent to ST_Within(g2, g1).
GEOGRAPHY Polygons with a vertex or border on the International Date Line (IDL) or the North or South pole are not supported.
Behavior type
Immutable
Syntax
ST_Contains( g1, g2
[USING PARAMETERS spheroid={true | false}] )
Arguments
g1- Spatial object, type GEOMETRY or GEOGRAPHY
g2- Spatial object, type GEOMETRY or GEOGRAPHY
Parameters
spheroid = {true | false}(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
No |
No |
|
Linestring |
Yes |
Yes |
No |
|
Multilinestring |
Yes |
No |
No |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
No |
|
GeometryCollection |
Yes |
No |
No |
Compatible GEOGRAPHY pairs:
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point-Point |
Yes |
No |
|
Linestring-Point |
Yes |
No |
|
Polygon-Point |
Yes |
Yes |
|
Multipolygon-Point |
Yes |
No |
Examples
The following examples show how to use ST_Contains.
The first polygon does not completely contain the second polygon:
=> SELECT ST_Contains(ST_GeomFromText('POLYGON((0 2,1 1,0 -1,0 2))'),
ST_GeomFromText('POLYGON((-1 3,2 1,0 -3,-1 3))'));
ST_Contains
-------------
f
(1 row)

If a point is on a linestring, but not on an end point:
=> SELECT ST_Contains(ST_GeomFromText('LINESTRING(20 20,30 30)'),
ST_GeomFromText('POINT(25 25)'));
ST_Contains
--------------
t
(1 row)
If a point is on the boundary of a polygon:
=> SELECT ST_Contains(ST_GeographyFromText('POLYGON((20 20,30 30,30 25,20 20))'),
ST_GeographyFromText('POINT(20 20)'));
ST_Contains
--------------
f
(1 row)
Two spatially equivalent polygons:
=> SELECT ST_Contains (ST_GeomFromText('POLYGON((-1 2, 0 3, 0 1, -1 2))'),
ST_GeomFromText('POLYGON((0 3, -1 2, 0 1, 0 3))'));
ST_Contains
--------------
t
(1 row)

See also
6.10.8 - ST_ConvexHull
Calculates the smallest convex GEOMETRY object that contains a GEOMETRY object.
Calculates the smallest convex GEOMETRY object that contains a GEOMETRY object.
Behavior type
Immutable
Syntax
ST_ConvexHull( g )
Arguments
g- Spatial object for which you want the convex hull, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_ConvexHull.
For a pair of points in a geometry collection:
=> SELECT ST_AsText(ST_ConvexHull(ST_GeomFromText('GEOMETRYCOLLECTION(
POINT(1 1),POINT(0 0))')));
ST_AsText
-----------------------
LINESTRING (1 1, 0 0)
(1 row)
For a geometry collection:
=> SELECT ST_AsText(ST_ConvexHull(ST_GeomFromText('GEOMETRYCOLLECTION(
LINESTRING(2.5 3,-2 1.5), POLYGON((0 1,1 3,1 -2,0 1)))')));
ST_AsText
---------------------------------------------
POLYGON ((1 -2, -2 1.5, 1 3, 2.5 3, 1 -2))
(1 row)
The solid lines represent the original geometry collection and the dashed lines represent the convex hull.

6.10.9 - ST_Crosses
Determines if one GEOMETRY object spatially crosses another GEOMETRY object.
Determines if one GEOMETRY object spatially crosses another GEOMETRY object. If two objects touch only at a border, ST_Crosses returns FALSE.
Two objects spatially cross when both of the following are true:
-
The two objects have some, but not all, interior points in common.
-
The dimension of the result of their intersection is less than the maximum dimension of the two objects.
Behavior type
Immutable
Syntax
ST_Crosses( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_Crosses.
=> SELECT ST_Crosses(ST_GeomFromText('LINESTRING(-1 3,1 4)'),
ST_GeomFromText('LINESTRING(-1 4,1 3)'));
ST_Crosses
------------
t
(1 row)
=> SELECT ST_Crosses(ST_GeomFromText('LINESTRING(-1 1,1 2)'),
ST_GeomFromText('POLYGON((1 1,0 -1,3 -1,2 1,1 1))'));
ST_Crosses
------------
f
(1 row)
=> SELECT ST_Crosses(ST_GeomFromText('POINT(-1 4)'),
ST_GeomFromText('LINESTRING(-1 4,1 3)'));
ST_ Crosses
------------
f
(1 row)
6.10.10 - ST_Difference
Calculates the part of a spatial object that does not intersect with another spatial object.
Calculates the part of a spatial object that does not intersect with another spatial object.
Behavior type
Immutable
Syntax
ST_Difference( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_Difference.
Two overlapping linestrings:
=> SELECT ST_AsText(ST_Difference(ST_GeomFromText('LINESTRING(0 0,0 2)'),
ST_GeomFromText('LINESTRING(0 1,0 2)')));
ST_AsText
-----------------------
LINESTRING (0 0, 0 1)
(1 row)
=> SELECT ST_AsText(ST_Difference(ST_GeomFromText('LINESTRING(0 0,0 3)'),
ST_GeomFromText('LINESTRING(0 1,0 2)')));
ST_AsText
------------------------------------------
MULTILINESTRING ((0 0, 0 1), (0 2, 0 3))
(1 row)
Two overlapping polygons:
=> SELECT ST_AsText(ST_Difference(ST_GeomFromText('POLYGON((0 1,0 3,2 3,2 1,0 1))'),
ST_GeomFromText('POLYGON((0 0,0 2,2 2,2 0,0 0))')));
ST_AsText
-------------------------------------
POLYGON ((0 2, 0 3, 2 3, 2 2, 0 2))
(1 row)
Two non-intersecting polygons:
=> SELECT ST_AsText(ST_Difference(ST_GeomFromText('POLYGON((1 1,1 3,3 3,3 1,
1 1))'),ST_GeomFromText('POLYGON((1 5,1 7,-1 7,-1 5,1 5))')));
ST_AsText
-------------------------------------
POLYGON ((1 1, 1 3, 3 3, 3 1, 1 1))
(1 row)
6.10.11 - ST_Disjoint
Determines if two GEOMETRY objects do not intersect or touch.
Determines if two GEOMETRY objects do not intersect or touch.
If ST_Disjoint returns TRUE for a pair of GEOMETRY objects, ST_Intersects returns FALSE for the same two objects.
GEOGRAPHY Polygons with a vertex or border on the International Date Line (IDL) or the North or South pole are not supported.
Behavior type
Immutable
Syntax
ST_Disjoint( g1, g2
[USING PARAMETERS spheroid={true | false}] )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Parameters
spheroid = {true | false}(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
No |
|
Linestring |
Yes |
No |
|
Multilinestring |
Yes |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
Yes |
No |
Compatible GEOGRAPHY pairs:
- Data Type
- GEOGRAPHY (WGS84)
- Point-Point
- No
- Linestring-Point
- No
- Polygon-Point
- Yes
- Multipolygon-Point
- No
Examples
The following examples show how to use ST_Disjoint.
Two non-intersecting or touching polygons:
=> SELECT ST_Disjoint (ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((1 0, 1 1, 2 2, 1 0))'));
ST_Disjoint
-------------
t
(1 row)
Two intersecting linestrings:
=> SELECT ST_Disjoint(ST_GeomFromText('LINESTRING(-1 2,0 3)'),
ST_GeomFromText('LINESTRING(0 2,-1 3)'));
ST_Disjoint
-------------
f
(1 row)
Two polygons touching at a single point:
=> SELECT ST_Disjoint (ST_GeomFromText('POLYGON((-1 2, 0 3, 0 1, -1 2))'),
ST_GeomFromText('POLYGON((0 2, 1 1, 1 2, 0 2))'));
ST_Disjoint
--------------
f
(1 row)
See also
6.10.12 - ST_Distance
Calculates the shortest distance between two spatial objects.
Calculates the shortest distance between two spatial objects. For GEOMETRY objects, the distance is measured in Cartesian coordinate units. For GEOGRAPHY objects, the distance is measured in meters.
Parameters g1 and g2 must be both GEOMETRY objects or both GEOGRAPHY objects.
Behavior type
Immutable
Syntax
ST_Distance( g1, g2
[USING PARAMETERS spheroid={ true | false } ] )
Arguments
g1- Spatial object, type GEOMETRY or GEOGRAPHY
g2- Spatial object, type GEOMETRY or GEOGRAPHY
Parameters
spheroid = { true | false }(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
No |
|
Multipolygon |
Yes |
Yes |
No |
|
GeometryCollection |
Yes |
No |
No |
Compatible GEOGRAPHY pairs:
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point-Point |
Yes |
Yes |
|
Linestring-Point |
Yes |
Yes |
|
Multilinestring-Point |
Yes |
Yes |
|
Polygon-Point |
Yes |
No |
|
Multipoint-Point |
Yes |
Yes |
|
Multipoint-Multilinestring |
Yes |
No |
|
Multipolygon-Point |
Yes |
No |
Recommendations
Vertica recommends pruning invalid data before using ST_Distance. Invalid geography values could return non-guaranteed results.
Examples
The following examples show how to use ST_Distance.
Distance between two polygons:
=> SELECT ST_Distance(ST_GeomFromText('POLYGON((-1 -1,2 2,0 1,-1 -1))'),
ST_GeomFromText('POLYGON((5 2,7 4,5 5,5 2))'));
ST_Distance
-------------
3
(1 row)
Distance between a point and a linestring in meters:
=> SELECT ST_Distance(ST_GeographyFromText('POINT(31.75 31.25)'),
ST_GeographyFromText('LINESTRING(32 32,32 35,40.5 35,32 35,32 32)'));
ST_Distance
------------------
86690.3950562969
(1 row)
6.10.13 - ST_Envelope
Calculates the minimum bounding rectangle that contains the specified GEOMETRY object.
Calculates the minimum bounding rectangle that contains the specified GEOMETRY object.
Behavior type
Immutable
Syntax
ST_Envelope( g )
Arguments
g- Spatial object for which you want to find the minimum bounding rectangle, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following example shows how to use ST_Envelope.
Returns the minimum bounding rectangle:
=> SELECT ST_AsText(ST_Envelope(ST_GeomFromText('POLYGON((0 0,1 1,1 2,2 2,
2 1,3 0,1.5 -1.5,0 0))')));
ST_AsText
-------------------------------------------
POLYGON ((0 -1.5, 3 -1.5, 3 2, 0 2, 0 -1.5))
(1 row)

6.10.14 - ST_Equals
Determines if two spatial objects are spatially equivalent.
Determines if two spatial objects are spatially equivalent. The coordinates of the two objects and their WKT/WKB representations must match exactly for ST_Equals to return TRUE.
The order of the points do not matter in determining spatial equivalence:
-
LINESTRING(1 2, 4 3) equals LINESTRING(4 3, 1 2).
-
POLYGON ((0 0, 1 1, 1 2, 2 2, 2 1, 3 0, 1.5 -1.5, 0 0)) equals POLYGON((1 1 , 1 2, 2 2, 2 1, 3 0, 1.5 -1.5, 0 0, 1 1)).
-
MULTILINESTRING((1 2, 4 3),(0 0, -1 -4)) equals MULTILINESTRING((0 0, -1 -4),(1 2, 4 3)).
Coordinates are stored as FLOAT types. Thus, rounding errors are expected when importing Well-Known Text (WKT) values because the limitations of floating-point number representation.
g1 and g2 must both be GEOMETRY objects or both be GEOGRAPHY objects. Also, g1 and g2 cannot both be of type GeometryCollection.
Behavior type
Immutable
Syntax
ST_Equals( g1, g2 )
Arguments
g1- Spatial object to compare to
g2, type GEOMETRY or GEOGRAPHY
g2- Spatial object to compare to
g1, type GEOMETRY or GEOGRAPHY
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_Equals.
Two linestrings:
=> SELECT ST_Equals (ST_GeomFromText('LINESTRING(-1 2, 0 3)'),
ST_GeomFromText('LINESTRING(0 3, -1 2)'));
ST_Equals
--------------
t
(1 row)
Two polygons:
=> SELECT ST_Equals (ST_GeographyFromText('POLYGON((43.22 42.21,40.3 39.88,
42.1 50.03,43.22 42.21))'),ST_GeographyFromText('POLYGON((43.22 42.21,
40.3 39.88,42.1 50.31,43.22 42.21))'));
ST_Equals
--------------
f
(1 row)
6.10.15 - ST_GeographyFromText
Converts a Well-Known Text (WKT) string into its corresponding GEOGRAPHY object.
Converts a Well-Known Text (WKT) string into its corresponding GEOGRAPHY object. Use this function to convert a WKT string into the format expected by the Vertica Place functions.
A GEOGRAPHY object is a spatial object with coordinates (longitude, latitude) defined on the surface of the earth. Coordinates are expressed in degrees (longitude, latitude) from reference planes dividing the earth.
The maximum size of a GEOGRAPHY object is 10 MB. If you pass a WKT to ST_GeographyFromText, the result is a spatial object whose size is greater than 10 MB, ST_GeographyFromText returns an error.
The Open Geospatial Consortium (OGC) defines the format of a WKT string in Section 7 in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_GeographyFromText( wkt [ USING PARAMETERS ignore_errors={'y'|'n'} ] )
Arguments
wkt- Well-Known Text (WKT) string of a GEOGRAPHY object, type LONG VARCHAR
ignore_errors- (Optional) ST_GeographyFromText returns the following, based on the parameters supplied:
Returns
GEOGRAPHY
Supported data types
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
No |
No |
Examples
The following example shows how to use ST_GeographyFromText.
Convert WKT into a GEOGRAPHY object:
=> CREATE TABLE wkt_ex (g GEOGRAPHY);
CREATE TABLE
=> INSERT INTO wkt_ex VALUES(ST_GeographyFromText('POLYGON((1 2,3 4,2 3,1 2))'));
OUTPUT
--------
1
(1 row)
6.10.16 - ST_GeographyFromWKB
Converts a Well-Known Binary (WKB) value into its corresponding GEOGRAPHY object.
Converts a Well-Known Binary (WKB) value into its corresponding GEOGRAPHY object. Use this function to convert a WKB into the format expected by Vertica Place functions.
A GEOGRAPHY object is a spatial object defined on the surface of the earth. Coordinates are expressed in degrees (longitude, latitude) from reference planes dividing the earth. All calculations are in meters.
The maximum size of a GEOGRAPHY object is 10 MB. If you pass a WKB to ST_GeographyFromWKB that results in a spatial object whose size is greater than 10 MB, ST_GeographyFromWKB returns an error.
The Open Geospatial Consortium (OGC) defines the format of a WKB representation in Section 8 in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_GeographyFromWKB( wkb [ USING PARAMETERS ignore_errors={'y'|'n'} ] )
Arguments
wkb- Well-Known Binary (WKB) value of a GEOGRAPHY object, type LONG VARBINARY
ignore_errors- (Optional) ST_GeographyFromWKB returns the following, based on the parameters supplied:
Returns
GEOGRAPHY
Supported data types
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
No |
No |
Examples
The following example shows how to use ST_GeographyFromWKB.
Convert WKB into a GEOGRAPHY object:
=> CREATE TABLE wkb_ex (g GEOGRAPHY);
CREATE TABLE
=> INSERT INTO wkb_ex VALUES(ST_GeographyFromWKB(X'0103000000010000000 ... );
OUTPUT
--------
1
(1 row)
6.10.17 - ST_GeoHash
Returns a GeoHash in the shape of the specified geometry.
Returns a GeoHash in the shape of the specified geometry.
Behavior type
Immutable
Syntax
ST_GeoHash( SpatialObject [ USING PARAMETERS numchars=n] )
Arguments
Spatial object- A GEOMETRY or GEOGRAPHY spatial object. Inputs must be in polar coordinates (-180 <= x <= 180 and -90 <= y <= 90) for all points inside the given geometry.
n- Specifies the length, in characters, of the returned GeoHash.
Returns
GEOHASH
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following examples show how to use ST_PointFromGeoHash.
Generate a full precision GeoHash for the specified geometry:
=> SELECT ST_GeoHash(ST_GeographyFromText('POINT(3.14 -1.34)'));
ST_GeoHash
----------------------
kpf0rkn3zmcswks75010
(1 row)
Generate a GeoHash based on the first five characters of the specified geometry:
=> select ST_GeoHash(ST_GeographyFromText('POINT(3.14 -1.34)')USING PARAMETERS numchars=5);
ST_GeoHash
------------
kpf0r
(1 row)
6.10.18 - ST_GeometryN
Returns the n geometry within a geometry object.
Returns the nth geometry within a geometry object.
If n is out of range of the index, then NULL is returned.
Behavior type
Immutable
Syntax
ST_GeometryN( g , n )
Arguments
g - Spatial object of type GEOMETRY.
n - The geometry's index number, 1-based.
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_GeometryN.
Return the second geometry in a multipolygon:
=> CREATE TABLE multipolygon_geom (gid int, geom GEOMETRY(1000));
CREATE TABLE
=> COPY multipolygon_geom(gid, gx FILLER LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>>9|MULTIPOLYGON(((2 6, 2 9, 6 9, 7 7, 4 6, 2 6)),((0 0, 0 5, 1 0, 0 0)),((0 2, 2 5, 4 5, 0 2)))
>>\.
=> SELECT gid, ST_AsText(ST_GeometryN(geom, 2)) FROM multipolygon_geom;
gid | ST_AsText
-----+--------------------------------
9 | POLYGON ((0 0, 0 5, 1 0, 0 0))
(1 row)
Return all the geometries within a multipolygon:
=> CREATE TABLE multipolygon_geom (gid int, geom GEOMETRY(1000));
CREATE TABLE
=> COPY multipolygon_geom(gid, gx FILLER LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>>9|MULTIPOLYGON(((2 6, 2 9, 6 9, 7 7, 4 6, 2 6)),((0 0, 0 5, 1 0, 0 0)),((0 2, 2 5, 4 5, 0 2)))
>>\.
=> CREATE TABLE series_numbers (numbs int);
CREATE TABLE
=> COPY series_numbers FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1
>> 2
>> 3
>> 4
>> 5
>> \.
=> SELECT numbs, ST_AsText(ST_GeometryN(geom, numbs))
FROM multipolygon_geom, series_numbers
WHERE ST_AsText(ST_GeometryN(geom, numbs)) IS NOT NULL
ORDER BY numbs ASC;
numbs | ST_AsText
-------+------------------------------------------
1 | POLYGON ((2 6, 2 9, 6 9, 7 7, 4 6, 2 6))
2 | POLYGON ((0 0, 0 5, 1 0, 0 0))
3 | POLYGON ((0 2, 2 5, 4 5, 0 2))
(3 rows)
See also
ST_NumGeometries
6.10.19 - ST_GeometryType
Determines the class of a spatial object.
Determines the class of a spatial object.
Behavior type
Immutable
Syntax
ST_GeometryType( g )
Arguments
g- Spatial object for which you want the class, type GEOMETRY or GEOGRAPHY
Returns
VARCHAR
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following example shows how to use ST_GeometryType.
Returns spatial class:
=> SELECT ST_GeometryType(ST_GeomFromText('GEOMETRYCOLLECTION(LINESTRING(1 1,
2 2), POLYGON((1 3,4 5,2 2,1 3)))'));
ST_GeometryType
-----------------------
ST_GeometryCollection
(1 row)
6.10.20 - ST_GeomFromGeoHash
Returns a polygon in the shape of the specified GeoHash.
Returns a polygon in the shape of the specified GeoHash.
Behavior type
Immutable
Syntax
ST_GeomFromGeoHash(GeoHash)
Arguments
GeoHash- A valid GeoHash string of arbitrary length.
Returns
GEOGRAPHY
Examples
The following examples show how to use ST_GeomFromGeoHash.
Converts a GeoHash string to a Geography object and back to a GeoHash
=> SELECT ST_GeoHash(ST_GeomFromGeoHash(‘vert1c9’));
ST_GeoHash
--------------------
vert1c9
(1 row)
Returns a polygon of the specified GeoHash and uses ST_AsText to convert the polygon, rectangle map tile, into Well-Known Text:
=> SELECT ST_AsText(ST_GeomFromGeoHash('drt3jj9n4dpcbcdef'));
ST_AsText
------------------------------------------------------------------------------------------------------------------------------------------------------------------
POLYGON ((-71.1459699298 42.3945346513, -71.1459699297 42.3945346513, -71.1459699297 42.3945346513, -71.1459699298 42.3945346513, -71.1459699298 42.3945346513))
(1 row)
Returns multiple polygons and their areas for the specified GeoHashes. The polygon for the high level GeoHash (1234) has a significant area, while the low level GeoHash (1234567890bcdefhjkmn) has an area of zero.
=> SELECT ST_Area(short) short_area, ST_AsText(short) short_WKT, ST_Area(long) long_area, ST_AsText(long) long_WKT from (SELECT ST_GeomFromGeoHash('1234') short, ST_GeomFromGeoHash('1234567890bcdefhjkmn') long) as foo;
-[ RECORD 1 ]---------------------------------------------------------------------------------------------------------------------------------------------------------------------
short_area | 24609762.8991076
short_WKT | POLYGON ((-122.34375 -88.2421875, -121.9921875 -88.2421875, -121.9921875 -88.06640625, -122.34375 -88.06640625, -122.34375 -88.2421875))
long_area | 0
long_WKT | POLYGON ((-122.196077187 -88.2297377551, -122.196077187 -88.2297377551, -122.196077187 -88.2297377551, -122.196077187 -88.2297377551, -122.196077187 -88.2297377551))
6.10.21 - ST_GeomFromGeoJSON
Converts the geometry portion of a GeoJSON record in the standard format into a GEOMETRY object.
Converts the geometry portion of a GeoJSON record in the standard format into a GEOMETRY object. This function returns an error when you provide a GeoJSON Feature or FeatureCollection object.
Behavior type
Immutable
Syntax
ST_GeomFromGeoJSON( geojson [, srid] [ USING PARAMETERS param=value[,...] ] );
Arguments
geojson- String containing a GeoJSON GEOMETRY object, type LONG VARCHAR.
Vertica accepts the following GeoJSON key values:
-
type
-
coordinates
-
geometries
Other key values are ignored.
sridSpatial reference system identifier (SRID) of the GEOMETRY object, type INTEGER.
The SRID is stored in the GEOMETRY object, but does not influence the results of spatial computations.
This argument is optional when not performing operations.
Parameters
ignore_3d- (Optional) Boolean, whether to silently remove 3D and higher-dimensional data from the returned GEOMETRY object or return an error, based on the following values:
ignore_errors- (Optional) Boolean, whether to ignore errors on invalid GeoJSON objects or return an error, based on the following values:
Note
The ignore_errors setting takes precedence over the ignore_3d setting. For example, if ignore_errors is set to true and ignore_3d is set to false, the function returns NULL if a GeoJSON object contains 3D and higher-dimensional data.
Returns
GEOMETRY
Supported data types
-
Point
-
Multipoint
-
Linestring
-
Multilinestring
-
Polygon
-
Multipolygon
-
GeometryCollection
Examples
The following example shows how to use ST_GeomFromGeoJSON.
Validating a single record
The following example validates a ST_GeomFromGeoJSON statement with ST_IsValid. The statement includes the SRID 4326 to indicate that the point data type represents latitude and longitude coordinates, and sets ignore_3d to true to ignore the last value that represents the altitude:
=> SELECT ST_IsValid(ST_GeomFromGeoJSON('{"type":"Point","coordinates":[35.3606, 138.7274, 29032]}', 4326 USING PARAMETERS ignore_3d=true));
ST_IsValid
------------
t
(1 row)
Loading data into a table
The following example processes GeoJSON types from STDIN and stores them in a GEOMETRY data type table column:
-
Create a table named polygons that stores GEOMETRY spatial types:
=> CREATE TABLE polygons(geom GEOMETRY(1000));
CREATE TABLE
-
Use COPY to read supported GEOMETRY data types from STDIN and store them in an object named geom:
=> COPY polygons(geojson filler VARCHAR(1000), geom as ST_GeomFromGeoJSON(geojson)) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> { "type": "Polygon", "coordinates": [ [ [100.0, 0.0], [101.0, 0.0], [101.0, 1.0], [100.0, 1.0], [100.0, 0.0] ] ] }
>> { "type": "Point", "coordinates": [1, 2] }
>> { "type": "Polygon", "coordinates": [ [ [1, 3], [3, 2], [1, 1], [3, 0], [1, 0], [1, 3] ] ] }
>> \.
-
Query the polygons table. The following example uses ST_AsText to return the geom object in its Well-known text (WKT) representation, and uses ST_IsValid to validate each object:
=> SELECT ST_AsText(geom), ST_IsValid(geom) FROM polygons;
ST_AsText | ST_IsValid
-----------------------------------------------+------------
POINT (1 2) | t
POLYGON ((1 3, 3 2, 1 1, 3 0, 1 0, 1 3)) | f
POLYGON ((100 0, 101 0, 101 1, 100 1, 100 0)) | t
(3 rows)
6.10.22 - ST_GeomFromText
Converts a Well-Known Text (WKT) string into its corresponding GEOMETRY object.
Converts a Well-Known Text (WKT) string into its corresponding GEOMETRY object. Use this function to convert a WKT string into the format expected by the Vertica Place functions.
A GEOMETRY object is a spatial object defined by the coordinates of a plane. Coordinates are expressed as points on a Cartesian plane (x,y). SRID values of 0 to 232-1 are valid. SRID values outside of this range will generate an error.
The maximum size of a GEOMETRY object is 10 MB. If you pass a WKT to ST_GeomFromText and the result is a spatial object whose size is greater than 10 MB, ST_GeomFromText returns an error.
The Open Geospatial Consortium (OGC) defines the format of a WKT representation. See section 7 in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_GeomFromText( wkt [, srid] [ USING PARAMETERS ignore_errors={'y'|'n'} ])
Arguments
wkt- Well-Known Text (WKT) string of a GEOMETRY object, type LONG VARCHAR.
srid- (Optional when not performing operations)
Spatial reference system identifier (SRID) of the GEOMETRY object, type INTEGER.
The SRID is stored in the GEOMETRY object, but does not influence the results of spatial computations.
ignore_errors- (Optional) ST_GeomFromText returns the following, based on parameters supplied:
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
No |
Examples
The following example shows how to use ST_GeomFromText.
Convert WKT into a GEOMETRY object:
=> SELECT ST_Area(ST_GeomFromText('POLYGON((1 1,2 3,3 5,0 5,1 -2,0 0,1 1))'));
ST_Area
---------
6
(1 row)
6.10.23 - ST_GeomFromWKB
Converts the Well-Known Binary (WKB) value to its corresponding GEOMETRY object.
Converts the Well-Known Binary (WKB) value to its corresponding GEOMETRY object. Use this function to convert a WKB into the format expected by many of the Vertica Place functions.
A GEOMETRY object is a spatial object with coordinates (x,y) defined in the Cartesian plane.
The maximum size of a GEOMETRY object is 10 MB. If you pass a WKB to ST_GeomFromWKB and the result is a spatial object whose size is greater than 10 MB, ST_GeomFromWKB returns an error.
The Open Geospatial Consortium (OGC) defines the format of a WKB representation in section 8 in the Simple Feature Access Part 1 - Common Architecture specification.
Behavior type
Immutable
Syntax
ST_GeomFromWKB( wkb[, srid] [ USING PARAMETERS ignore_errors={'y'|'n'} ])
Arguments
wkb- Well-Known Binary (WKB) value of a GEOMETRY object, type LONG VARBINARY
srid- (Optional) Spatial reference system identifier (SRID) of the GEOMETRY object, type INTEGER.
The SRID is stored in the GEOMETRY object, but does not influence the results of spatial computations.
ignore_errors- (Optional)
ST_GeomFromWKB returns the following, based on the parameters supplied:
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following example shows how to use ST_GeomFromWKB.
Convert GEOMETRY into WKT:
=> CREATE TABLE t(g GEOMETRY);
CREATE TABLE
=> INSERT INTO t VALUES(
ST_GeomFromWKB(X'0103000000010000000400000000000000000000000000000000000000000000000000f
03f0000000000000000f64ae1c7022db544000000000000f03f00000000000000000000000000000000'));
OUTPUT
--------
1
(1 row)
=> SELECT ST_AsText(g) from t;
ST_AsText
------------------------------------
POLYGON ((0 0, 1 0, 1e+23 1, 0 0))
(1 row)
6.10.24 - ST_Intersection
Calculates the set of points shared by two GEOMETRY objects.
Calculates the set of points shared by two GEOMETRY objects.
Behavior type
Immutable
Syntax
ST_Intersection( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_Intersection.
Two polygons intersect at a single point:
=> SELECT ST_AsText(ST_Intersection(ST_GeomFromText('POLYGON((0 2,1 1,0 -1,
0 2))'),ST_GeomFromText('POLYGON((-1 2,0 0,-2 0,-1 2))')));
ST_AsText
-----------------
POINT(0 0)
(1 row)
Two polygons:
=> SELECT ST_AsText(ST_Intersection(ST_GeomFromText('POLYGON((1 2,1 5,4 5,
4 2,1 2))'), ST_GeomFromText('POLYGON((3 1,3 3,5 3,5 1,3 1))')));
ST_AsText
------------------
POLYGON ((4 3, 4 2, 3 2, 3 3, 4 3))
(1 row)
Two non-intersecting linestrings:

=> SELECT ST_AsText(ST_Intersection(ST_GeomFromText('LINESTRING(1 1,1 3,3 3)'),
ST_GeomFromText('LINESTRING(1 5,1 7,-1 7)')));
ST_AsText
--------------------------
GEOMETRYCOLLECTION EMPTY
(1 row)
6.10.25 - ST_Intersects
Determines if two GEOMETRY or GEOGRAPHY objects intersect or touch at a single point.
Determines if two GEOMETRY or GEOGRAPHY objects intersect or touch at a single point. If ST_Disjoint returns TRUE, ST_Intersects returns FALSE for the same GEOMETRY or GEOGRAPHY objects.
GEOGRAPHY Polygons with a vertex or border on the International Date Line (IDL) or the North or South pole are not supported.
Behavior type
Immutable
Syntax
ST_Intersects( g1, g2
[USING PARAMETERS bbox={true | false}, spheroid={true | false}])
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Parameters
bbox = {true | false}- Boolean. Intersects the bounding box of
g1 and g2.
Default: False
spheroid = {true | false}(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
No |
|
Linestring |
Yes |
No |
|
Multilinestring |
Yes |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
Yes |
No |
Compatible GEOGRAPHY pairs:
|
Data Type |
GEOGRAPHY (WGS84) |
|
Point-Point |
No |
|
Linestring-Point |
No |
|
Polygon-Point |
Yes |
|
Multipolygon-Point |
No |
Examples
The following examples show how to use ST_Intersects.
Two polygons do not intersect or touch:

=> SELECT ST_Intersects (ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((1 0,1 1,2 2,1 0))'));
ST_Intersects
--------------
f
(1 row)
Two polygons touch at a single point:
=> SELECT ST_Intersects (ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((1 0,1 1,0 1,1 0))'));
ST_Intersects
--------------
t
(1 row)
Two polygons intersect:
=> SELECT ST_Intersects (ST_GeomFromText('POLYGON((-1 2, 0 3, 0 1, -1 2))'),
ST_GeomFromText('POLYGON((0 2, -1 3, -2 0, 0 2))'));
ST_Intersects
--------------
t
(1 row)
See also
ST_Disjoint
6.10.26 - ST_IsEmpty
Determines if a spatial object represents the empty set.
Determines if a spatial object represents the empty set. An empty object has no dimension.
Behavior type
Immutable
Syntax
ST_IsEmpty( g )
Arguments
g- Spatial object, type GEOMETRY or GEOGRAPHY
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following example shows how to use ST_IsEmpty.
An empty polygon:
=> SELECT ST_IsEmpty(ST_GeomFromText('GeometryCollection EMPTY'));
ST_IsEmpty
------------
t
(1 row)
6.10.27 - ST_IsSimple
Determines if a spatial object does not intersect itself or touch its own boundary at any point.
Determines if a spatial object does not intersect itself or touch its own boundary at any point.
Behavior type
Immutable
Syntax
ST_IsSimple( g )
Arguments
g- Spatial object, type GEOMETRY or GEOGRAPHY
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
No |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
No |
No |
Examples
The following examples show how to use ST_IsSimple.
Polygon does not intersect itself:
=> SELECT ST_IsSimple(ST_GeomFromText('POLYGON((-1 2,0 3,1 2,1 -2,-1 2))'));
ST_IsSimple
--------------
t
(1 row)
Linestring intersects itself.:
=> SELECT ST_IsSimple(ST_GeographyFromText('LINESTRING(10 10,25 25,26 34.5,
10 30,10 20,20 10)'));
St_IsSimple
-------------
f
(1 row)
Linestring touches its interior at one or more locations:
=> SELECT ST_IsSimple(ST_GeomFromText('LINESTRING(0 0,0 1,1 0,2 1,2 0,0 0)'));
ST_IsSimple
-------------
f
(1 row)
6.10.28 - ST_IsValid
Determines if a spatial object is well formed or valid.
Determines if a spatial object is well formed or valid. If the object is valid, ST_IsValid returns TRUE; otherwise, it returns FALSE. Use STV_IsValidReason to identify the location of the invalidity.
Spatial validity applies only to polygons and multipolygons. A polygon or multipolygon is valid if all of the following are true:
-
The polygon is closed; its start point is the same as its end point.
-
Its boundary is a set of linestrings.
-
The boundary does not touch or cross itself.
-
Any polygons in the interior do not touch the boundary of the exterior polygon except at a vertex.
The Open Geospatial Consortium (OGC) defines the validity of a polygon in section 6.1.11.1 of the Simple Feature Access Part 1 - Common Architecture specification.
If you are not sure if a polygon is valid, run ST_IsValid first. If you pass an invalid spatial object to a Vertica Place function, the function fails or returns incorrect results.
Behavior type
Immutable
Syntax
ST_IsValid( g )
Arguments
g- Geospatial object to test for validity, value of type GEOMETRY or GEOGRAPHY (WGS84).
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
No |
No |
|
Multipoint |
Yes |
No |
No |
|
Linestring |
Yes |
No |
No |
|
Multilinestring |
Yes |
No |
No |
|
Polygon |
Yes |
No |
Yes |
|
Multipolygon |
Yes |
No |
No |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following examples show how to use ST_IsValid.
Valid polygon:

=> SELECT ST_IsValid(ST_GeomFromText('POLYGON((1 1,1 3,3 3,3 1,1 1))'));
ST_IsValid
------------
t
(1 row)
Invalid polygon:

=> SELECT ST_IsValid(ST_GeomFromText('POLYGON((1 3,3 2,1 1,3 0,1 0,1 3))'));
ST_IsValid
------------
f
(1 row)
Invalid polygon:

=> SELECT ST_IsValid(ST_GeomFromText('POLYGON((0 0,2 2,0 2,2 0,0 0))'));
ST_IsValid
------------
f
(1 row)
Invalid multipolygon:.

=> SELECT ST_IsValid(ST_GeomFromText('MULTIPOLYGON(((0 0, 0 1, 1 1, 0 0)),
((0.5 0.5, 0.7 0.5, 0.7 0.7, 0.5 0.7, 0.5 0.5)))'));
ST_IsValid
------------
f
(1 row)
Valid polygon with hole:
=> SELECT ST_IsValid(ST_GeomFromText('POLYGON((1 1,3 3,6 -1,0.5 -1,1 1),
(1 1,3 1,2 0,1 1))'));
ST_IsValid
------------
t
(1 row)
Invalid polygon with hole:
=> SELECT ST_IsValid(ST_GeomFromText('POLYGON((1 1,3 3,6 -1,0.5 -1,1 1),
(1 1,4.5 1,2 0,1 1))'));
ST_IsValid
------------
f
(1 row)
6.10.29 - ST_Length
Calculates the length of a spatial object.
Calculates the length of a spatial object. For GEOMETRY objects, the length is measured in Cartesian coordinate units. For GEOGRAPHY objects, the length is measured in meters.
Calculates the length as follows:
-
The length of a point or multipoint object is 0.
-
The length of a linestring is the sum of the lengths of each line segment The length of a line segment is the distance from the start point to the end point.
-
The length of a polygon is the sum of the lengths of the exterior boundary and any interior boundaries.
-
The length of a multilinestring, multipolygon, or geometrycollection is the sum of the lengths of all the objects it contains.
Note
ST_Length does not calculate the length of WKTs or WKBs. To calculate the lengths of those objects, use the Vertica
LENGTH SQL function with ST_AsBinary or ST_AsText.
Behavior type
Immutable
Syntax
ST_Length( g )
Arguments
g- Spatial object for which you want to calculate the length, type GEOMETRY or GEOGRAPHY
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_Length.
Returns length in Cartesian coordinate units:
=> SELECT ST_Length(ST_GeomFromText('LINESTRING(-1 -1,2 2,4 5,6 7)'));
ST_Length
------------------
10.6766190873295
(1 row)
Returns length in meters:
=> SELECT ST_Length(ST_GeographyFromText('LINESTRING(-56.12 38.26,-57.51 39.78,
-56.37 45.24)'));
ST_Length
------------------
821580.025733461
(1 row)
6.10.30 - ST_NumGeometries
Returns the number of geometries contained within a spatial object.
Returns the number of geometries contained within a spatial object. Single GEOMETRY or GEOGRAPHY objects return 1 and empty objects return NULL.
Behavior type
Immutable
Syntax
ST_NumGeometries( g )
Arguments
gSpatial object of type GEOMETRY or GEOGRAPHY
Returns
INTEGER
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following example shows how to use ST_NumGeometries.
Return the number of geometries:
=> SELECT ST_NumGeometries(ST_GeomFromText('MULTILINESTRING ((1 5, 2 4, 5 3, 6 6), (3 5, 3 7))'));
ST_NumGeometries
------------------
2
(1 row)
See also
ST_GeometryN
6.10.31 - ST_NumPoints
Calculates the number of vertices of a spatial object, empty objects return NULL.
Calculates the number of vertices of a spatial object, empty objects return NULL.
The first and last vertex of polygons and multipolygons are counted separately.
Behavior type
Immutable
Syntax
ST_NumPoints( g )
Arguments
g- Spatial object for which you want to count the vertices, type GEOMETRY or GEOGRAPHY
Returns
INTEGER
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_NumPoints.
Returns the number of vertices in a linestring:
=> SELECT ST_NumPoints(ST_GeomFromText('LINESTRING(1.33 1.56,2.31 3.4,2.78 5.82,
3.76 3.9,4.11 3.27,5.85 4.34,6.9 4.231,7.61 5.77)'));
ST_NumPoints
--------------
8
(1 row)
Use ST_Boundary and ST_NumPoints to return the number of vertices of a polygon:
=> SELECT ST_NumPoints(ST_Boundary(ST_GeomFromText('POLYGON((1 2,1 4,
2 5,3 6,4 6,5 5,4 4,3 3,1 2))')));
ST_NumPoints
--------------
9
(1 row)
6.10.32 - ST_Overlaps
Determines if a GEOMETRY object shares space with another GEOMETRY object, but is not completely contained within that object.
Determines if a GEOMETRY object shares space with another GEOMETRY object, but is not completely contained within that object. They must overlap at their interiors. If two objects touch at a single point or intersect only along a boundary, they do not overlap. Both parameters must have the same dimension; otherwise, ST_Overlaps returns FALSE.
Behavior type
Immutable
Syntax
ST_Overlaps ( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
BOOLEAN
Supported data types
- Data Type
- GEOMETRY
- Point
- Yes
- Multipoint
- Yes
- Linestring
- Yes
- Multilinestring
- Yes
- Polygon
- Yes
- Multipolygon
- Yes
- GeometryCollection
- Yes
Examples
The following examples show how to use ST_Overlaps.
Polygon_1 overlaps but does not completely contain Polygon_2:
=> SELECT ST_Overlaps(ST_GeomFromText('POLYGON((0 0, 0 1, 1 1, 0 0))'),
ST_GeomFromText('POLYGON((0.5 0.5, 0.7 0.5, 0.7 0.7, 0.5 0.7, 0.5 0.5))'));
ST_Overlaps
-------------
t
(1 row)
Two objects with different dimensions:
=> SELECT ST_Overlaps(ST_GeomFromText('LINESTRING(2 2,4 4)'),
ST_GeomFromText('POINT(3 3)'));
ST_Overlaps
-------------
f
(1 row)
6.10.33 - ST_PointFromGeoHash
Returns the center point of the specified GeoHash.
Returns the center point of the specified GeoHash.
Behavior type
Immutable
Syntax
ST_PointFromGeoHash(GeoHash)
Arguments
GeoHash- A valid GeoHash string of arbitrary length.
Returns
GEOGRAPHY POINT
Examples
The following examples show how to use ST_PointFromGeoHash.
Returns the geography point of a high-level GeoHash and uses ST_AsText to convert that point into Well-Known Text:
=> SELECT ST_AsText(ST_PointFromGeoHash('dr'));
ST_AsText
-------------------------
POINT (-73.125 42.1875)
(1 row)
Returns the geography point of a detailed GeoHash and uses ST_AsText to convert that point into Well-Known Text:
=> SELECT ST_AsText(ST_PointFromGeoHash('1234567890bcdefhjkmn'));
ST_AsText
---------------------------------------
POINT (-122.196077187 -88.2297377551)
(1 row)
6.10.34 - ST_PointN
Finds the n point of a spatial object.
Finds the nth point of a spatial object. If you pass a negative number, zero, or a number larger than the total number of points on the linestring, ST_PointN returns NULL.
The vertex order is based on the Well-Known Text (WKT) representation of the spatial object.
Behavior type
Immutable
Syntax
ST_PointN( g, n )
Arguments
g- Spatial object to search, type GEOMETRY or GEOGRAPHY
n- Point in the spatial object to be returned. The index is one-based, type INTEGER
Returns
GEOMETRY or GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_PointN.
Returns the fifth point:
=> SELECT ST_AsText(ST_PointN(ST_GeomFromText('
POLYGON(( 2 6, 2 9, 6 9, 7 7, 4 6, 2 6))'), 5));
ST_AsText
-------------
POINT (4 6)
(1 row)
Returns the second point:
=> SELECT ST_AsText(ST_PointN(ST_GeographyFromText('
LINESTRING(23.41 24.93,34.2 32.98,40.7 41.19)'), 2));
ST_AsText
--------------------
POINT (34.2 32.98)
(1 row)
6.10.35 - ST_Relate
Determines if a given GEOMETRY object is spatially related to another GEOMETRY object, based on the specified DE-9IM pattern matrix string.
Determines if a given GEOMETRY object is spatially related to another GEOMETRY object, based on the specified DE-9IM pattern matrix string.
The DE-9IM standard identifies how two objects are spatially related to each other.
Behavior type
Immutable
Syntax
ST_Relate( g1, g2, matrix )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
matrix- DE-9IM pattern matrix string, type CHAR(9). This string represents a 3 x 3 matrix of restrictions on the dimensions of the respective intersections of the interior, boundary, and exterior of the two geometries. Must contain exactly 9 of the following characters:
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_Relate.
The DE-9IM pattern for "equals" is 'T*F**FFF2':
=> SELECT ST_Relate(ST_GeomFromText('LINESTRING(0 1,2 2)'),
ST_GeomFromText('LINESTRING(2 2,0 1)'), 'T*F**FFF2');
ST_Relate
--------------
t
(1 row)
The DE-9IM pattern for "overlaps" is 'T*T***T**':
=> SELECT ST_Relate(ST_GeomFromText('POLYGON((-1 -1,0 1,2 2,-1 -1))'),
ST_GeomFromText('POLYGON((0 1,1 -1,1 1,0 1))'), 'T*T***T**');
ST_Relate
-----------
t
(1 row)
6.10.36 - ST_SRID
Identifies the spatial reference system identifier (SRID) stored with a spatial object.
Identifies the spatial reference system identifier (SRID) stored with a spatial object.
The SRID of a GEOMETRY object can only be determined when passing an SRID to either ST_GeomFromText or ST_GeomFromWKB. ST_SRID returns this stored value. SRID values of 0 to 232-1 are valid.
Behavior type
Immutable
Syntax
ST_SRID( g )
Arguments
g- Spatial object for which you want the SRID, type GEOMETRY or GEOGRAPHY
Returns
INTEGER
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following examples show how to use ST_SRID.
The default SRID of a GEOMETRY object is 0:
=> SELECT ST_SRID(ST_GeomFromText(
'POLYGON((-1 -1,2 2,0 1,-1 -1))'));
ST_SRID
---------
0
(1 row)
The default SRID of a GEOGRAPHY object is 4326:
=> SELECT ST_SRID(ST_GeographyFromText(
'POLYGON((22 35,24 35,26 32,22 35))'));
ST_SRID
---------
4326
(1 row)
6.10.37 - ST_SymDifference
Calculates all the points in two GEOMETRY objects except for the points they have in common, but including the boundaries of both objects.
Calculates all the points in two GEOMETRY objects except for the points they have in common, but including the boundaries of both objects.
This result is called the symmetric difference and is represented mathematically as: Closure (g1 – g2) È Closure (g2 – g1)
Behavior type
Immutable
Syntax
ST_SymDifference( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how to use ST_SymDifference.
Returns the two linestrings:
=> SELECT ST_AsText(ST_SymDifference(ST_GeomFromText('LINESTRING(30 40,
30 55)'),ST_GeomFromText('LINESTRING(30 32.5,30 47.5)')));
ST_AsText
-----------------
MULTILINESTRING ((30 47.5, 30 55),(30 32.5,30 40))
(1 row)
Returns four squares:

=> SELECT ST_AsText(ST_SymDifference(ST_GeomFromText('POLYGON((2 1,2 4,3 4,
3 1,2 1))'),ST_GeomFromText('POLYGON((1 2,1 3,4 3,4 2,1 2))')));
ST_AsText
-------------------------------------------------------------------------
MULTIPOLYGON (((2 1, 2 2, 3 2, 3 1, 2 1)), ((1 2, 1 3, 2 3, 2 2, 1 2)),
((2 3, 2 4, 3 4, 3 3, 2 3)), ((3 2, 3 3, 4 3, 4 2, 3 2)))
(1 row)
6.10.38 - ST_Touches
Determines if two GEOMETRY objects touch at a single point or along a boundary, but do not have interiors that intersect.
Determines if two GEOMETRY objects touch at a single point or along a boundary, but do not have interiors that intersect.
GEOGRAPHY Polygons with a vertex or border on the International Date Line (IDL) or the North or South pole are not supported.
Behavior type
Immutable
Syntax
ST_Touches( g1, g2
[USING PARAMETERS spheroid={true | false}] )
Arguments
g1- Spatial object, value of type GEOMETRY
g2- Spatial object, value of type GEOMETRY
Parameters
spheroid = {true | false}(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
No |
|
Linestring |
Yes |
No |
|
Multilinestring |
Yes |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
Yes |
No |
Compatible GEOGRAPHY pairs:
|
Data Type |
GEOGRAPHY (WGS84) |
|
Point-Point |
No |
|
Linestring-Point |
No |
|
Polygon-Point |
Yes |
|
Multipolygon-Point |
No |
Examples
The following examples show how to use ST_Touches.
Two polygons touch at a single point:
=> SELECT ST_Touches(ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((1 3,0 3,1 2,1 3))'));
ST_Touches
------------
t
(1 row)
Two polygons touch only along part of the boundary:
=> SELECT ST_Touches(ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((1 2,0 3,0 1,1 2))'));
ST_Touches
------------
t
(1 row)
Two polygons do not touch at any point:
=> SELECT ST_Touches(ST_GeomFromText('POLYGON((-1 2,0 3,0 1,-1 2))'),
ST_GeomFromText('POLYGON((0 2,-1 3,-2 0,0 2))'));
ST_Touches
------------
f
(1 row)
6.10.39 - ST_Transform
Returns a new GEOMETRY with its coordinates converted to the spatial reference system identifier (SRID) used by the srid argument.
Returns a new GEOMETRY with its coordinates converted to the spatial reference system identifier (SRID) used by the srid argument.
This function supports the following transformations:
For EPSG 4326 (WGS84), unless the coordinates fall within the following ranges, conversion results in failure:
- Longitude limits: -572 to +572
- Latitude limits: -89.9999999 to +89.9999999
Behavior type
Immutable
Syntax
ST_Transform( g1, srid )
Arguments
g1- Spatial object of type GEOMETRY.
srid - Spatial reference system identifier (SRID) to which you want to convert your spatial object, of type INTEGER.
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
No |
No |
|
Multipoint |
Yes |
No |
No |
|
Linestring |
Yes |
No |
No |
|
Multilinestring |
Yes |
No |
No |
|
Polygon |
Yes |
No |
No |
|
Multipolygon |
Yes |
No |
No |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following example shows how you can transform data from Web Mercator (3857) to WGS84 (4326):
=> SELECT ST_AsText(ST_Transform(STV_GeometryPoint(7910240.56433, 5215074.23966, 3857), 4326));
ST_AsText
-------------------------
POINT (71.0589 42.3601)
(1 row)
The following example shows how you can transform linestring data in a table from WGS84 (4326) to Web Mercator (3857):
=> CREATE TABLE transform_line_example (g GEOMETRY);
CREATE TABLE
=> COPY transform_line_example (gx FILLER LONG VARCHAR, g AS ST_GeomFromText(gx, 4326)) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> LINESTRING(0 0, 1 1, 2 2, 3 4)
>> \.
=> SELECT ST_AsText(ST_Transform(g, 3857)) FROM transform_line_example;
ST_AsText
-------------------------------------------------------------------------------------------------------------------------
LINESTRING (0 -7.08115455161e-10, 111319.490793 111325.142866, 222638.981587 222684.208506, 333958.47238 445640.109656)
(1 row)
The following example shows how you can transform point data in a table from WGS84 (4326) to Web Mercator (3857):
=> CREATE TABLE transform_example (x FLOAT, y FLOAT, srid INT);
CREATE TABLE
=> COPY transform_example FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 42.3601|71.0589|4326
>> 122.4194|37.7749|4326
>> 94.5786|39.0997|4326
>> \.
=> SELECT ST_AsText(ST_Transform(STV_GeometryPoint(x, y, srid), 3857)) FROM transform_example;
ST_AsText
-------------------------------------
POINT (4715504.76195 11422441.5961)
POINT (13627665.2712 4547675.35434)
POINT (10528441.5919 4735962.8206)
(3 rows)
6.10.40 - ST_Union
Calculates the union of all points in two spatial objects.
Calculates the union of all points in two spatial objects.
This result is represented mathematically by: g1 È g2
Behavior type
Immutable
Syntax
ST_Union( g1, g2 )
Arguments
g1- Spatial object, type GEOMETRY
g2- Spatial object, type GEOMETRY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following example shows how to use ST_Union.
Returns a polygon that represents all the points contained in these two polygons:

=> SELECT ST_AsText(ST_Union(ST_GeomFromText('POLYGON((0 2,1 1,0 -1,-1 1,0 2))'),
ST_GeomFromText('POLYGON((-1 2, 0 0, -2 0, -1 2))')));
ST_AsText
------------------------------------------------------------------------------
POLYGON ((0 2, 1 1, 0 -1, -0.5 0, -2 0, -1 2, -0.666666666667 1.33333333333, 0 2))
(1 row)
6.10.41 - ST_Within
If spatial object g1 is completely inside of spatial object g2, then ST_Within returns true.
If spatial object g1 is completely inside of spatial object g2, then ST_Within returns true. Both parameters must be the same spatial data type. Either specify two GEOMETRY objects or two GEOGRAPHY objects.
If an object such as a point or linestring only exists along a polygon's boundary, then ST_Within returns false. The interior of a linestring is all the points along the linestring except the start and end points.
ST_Within(g``g is functionally equivalent to ST_Contains(g``g.
GEOGRAPHY Polygons with a vertex or border on the International Date Line (IDL) or the North or South pole are not supported.
Behavior type
Immutable
Syntax
ST_Within( g1, g2
[USING PARAMETERS spheroid={true | false}] )
Arguments
g1- Spatial object, type GEOMETRY or GEOGRAPHY
g2- Spatial object, type GEOMETRY or GEOGRAPHY
Parameters
spheroid = {true | false}(Optional) BOOLEAN that specifies whether to use a perfect sphere or WGS84.
Default: False
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
No |
No |
|
Linestring |
Yes |
Yes |
No |
|
Multilinestring |
Yes |
No |
No |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
No |
|
GeometryCollection |
Yes |
No |
No |
Compatible GEOGRAPHY pairs:
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point-Point |
Yes |
No |
|
Point-Linestring |
Yes |
No |
|
Point-Polygon |
Yes |
Yes |
|
Point-Multipolygon |
Yes |
No |
Examples
The following examples show how to use ST_Within.
The first polygon is completely contained within the second polygon:
=> SELECT ST_Within(ST_GeomFromText('POLYGON((0 2,1 1,0 -1,0 2))'),
ST_GeomFromText('POLYGON((-1 3,2 1,0 -3,-1 3))'));
ST_Within
-----------
t
(1 row)
The point is on a vertex of the polygon, but not in its interior:
=> SELECT ST_Within (ST_GeographyFromText('POINT(30 25)'),
ST_GeographyFromText('POLYGON((25 25,25 35,32.2 35,30 25,25 25))'));
ST_Within
-----------
f
(1 row)
Two polygons are spatially equivalent:
=> SELECT ST_Within (ST_GeomFromText('POLYGON((-1 2, 0 3, 0 1, -1 2))'),
ST_GeomFromText('POLYGON((0 3, -1 2, 0 1, 0 3))'));
ST_Within
-----------
t
(1 row)
See also
6.10.42 - ST_X
Determines the x- coordinate for a GEOMETRY point or the longitude value for a GEOGRAPHY point.
Determines the x- coordinate for a GEOMETRY point or the longitude value for a GEOGRAPHY point.
Behavior type
Immutable
Syntax
ST_X( g )
Arguments
g- Point of type GEOMETRY or GEOGRAPHY
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
No |
No |
No |
|
Linestring |
No |
No |
No |
|
Multilinestring |
No |
No |
No |
|
Polygon |
No |
No |
No |
|
Multipolygon |
No |
No |
No |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_X.
Returns the x-coordinate:
=> SELECT ST_X(ST_GeomFromText('POINT(3.4 1.25)'));
ST_X
-----
3.4
(1 row)
Returns the longitude value:
=> SELECT ST_X(ST_GeographyFromText('POINT(25.34 45.67)'));
ST_X
-------
25.34
(1 row)
6.10.43 - ST_XMax
Returns the maximum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
Returns the maximum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
For GEOGRAPHY types, Vertica Place computes maximum coordinates by calculating the maximum longitude of the great circle arc from (MAX(longitude), ST_YMin(GEOGRAPHY)) to (MAX(longitude), ST_YMax(GEOGRAPHY)). In this case, MAX(longitude) is the maximum longitude value of the geography object.
If either latitude or longitude is out of range, ST_XMax returns the maximum plain value of the geography object.
Behavior type
Immutable
Syntax
ST_XMax( g )
Arguments
g- Spatial object for which you want to find the maximum
x-coordinate, type GEOMETRY or GEOGRAPHY.
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_XMax.
Returns the maximum x-coordinate within a rectangle:
=> SELECT ST_XMax(ST_GeomFromText('POLYGON((0 1,0 2,1 2,1 1,0 1))'));
ST_XMax
-----------
1
(1 row)
Returns the maximum longitude value within a rectangle:
=> SELECT ST_XMax(ST_GeographyFromText(
'POLYGON((-71.50 42.35, -71.00 42.35, -71.00 42.38, -71.50 42.38, -71.50 42.35))'));
ST_XMax
---------
-71
(1 row)
6.10.44 - ST_XMin
Returns the minimum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
Returns the minimum x-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
For GEOGRAPHY types, Vertica Place computes minimum coordinates by calculating the minimum longitude of the great circle arc from (MIN(longitude), ST_YMin(GEOGRAPHY)) to (MIN(longitude), ST_YMax(GEOGRAPHY)). In this case, MIN(latitude) represents the minimum longitude value of the geography object
If either latitude or longitude is out of range, ST_XMin returns the minimum plain value of the geography object.
Behavior type
Immutable
Syntax
ST_XMin( g )
Arguments
g- Spatial object for which you want to find the minimum
x-coordinate, type GEOMETRY or GEOGRAPHY.
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_XMin.
Returns the minimum x-coordinate within a rectangle:
=> SELECT ST_XMin(ST_GeomFromText('POLYGON((0 1,0 2,1 2,1 1,0 1))'));
ST_XMin
----------
0
(1 row)
Returns the minimum longitude value within a rectangle:
=> SELECT ST_XMin(ST_GeographyFromText(
'POLYGON((-71.50 42.35, -71.00 42.35, -71.00 42.38, -71.50 42.38, -71.50 42.35))'));
ST_XMin
----------
-71.5
(1 row)
6.10.45 - ST_Y
Determines the y-coordinate for a GEOMETRY point or the latitude value for a GEOGRAPHY point.
Determines the y-coordinate for a GEOMETRY point or the latitude value for a GEOGRAPHY point.
Behavior type
Immutable
Syntax
ST_Y( g )
Arguments
g- Point of type GEOMETRY or GEOGRAPHY
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
No |
No |
No |
|
Linestring |
No |
No |
No |
|
Multilinestring |
No |
No |
No |
|
Polygon |
No |
No |
No |
|
Multipolygon |
No |
No |
No |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use ST_Y.
Returns the y-coordinate:
=> SELECT ST_Y(ST_GeomFromText('POINT(3 5.25)'));
ST_Y
------
5.25
(1 row)
Returns the latitude value:
=> SELECT ST_Y(ST_GeographyFromText('POINT(35.44 51.04)'));
ST_Y
-------
51.04
(1 row)
6.10.46 - ST_YMax
Returns the maximum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
Returns the maximum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
For GEOGRAPHY types, Vertica Place computes maximum coordinates by calculating the maximum latitude of the great circle arc from (ST_XMin(GEOGRAPHY), MAX(latitude)) to (ST_XMax(GEOGRAPHY), MAX(latitude)). In this case, MAX(latitude) is the maximum latitude value of the geography object.
If either latitude or longitude is out of range, ST_YMax returns the maximum plain value of the geography object.
Behavior type
Immutable
Syntax
ST_YMax( g )
Arguments
g- Spatial object for which you want to find the maximum
y-coordinate, type GEOMETRY or GEOGRAPHY.
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_YMax.
Returns the maximum y-coordinate within a rectangle:
=> SELECT ST_YMax(ST_GeomFromText('POLYGON((0 1,0 4,1 4,1 1,0 1))'));
ST_YMax
-----------
4
(1 row)
Returns the maximum latitude value within a rectangle:
=> SELECT ST_YMax(ST_GeographyFromText(
'POLYGON((-71.50 42.35, -71.00 42.35, -71.00 42.38, -71.50 42.38, -71.50 42.35))'));
ST_YMax
------------------
42.3802715689979
(1 row)
6.10.47 - ST_YMin
Returns the minimum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
Returns the minimum y-coordinate of the minimum bounding rectangle of the GEOMETRY or GEOGRAPHY object.
For GEOGRAPHY types, Vertica Place computes minimum coordinates by calculating the minimum latitude of the great circle arc from (ST_XMin(GEOGRAPHY), MIN(latitude)) to (ST_XMax(GEOGRAPHY), MIN(latitude)). In this case, MIN(latitude) represents the minimum latitude value of the geography object.
If either latitude or longitude is out of range, ST_YMin returns the minimum plain value of the geography object.
Behavior type
Immutable
Syntax
ST_YMin( g )
Arguments
g- Spatial object for which you want to find the minimum
y-coordinate, type GEOMETRY or GEOGRAPHY.
Returns
FLOAT
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following examples show how to use ST_YMin.
Returns the minimum y-coordinate within a rectangle:
=> SELECT ST_YMin(ST_GeomFromText('POLYGON((0 1,0 4,1 4,1 1,0 1))'));
ST_YMin
-----------
1
(1 row)
Returns the minimum latitude value within a rectangle:
=> SELECT ST_YMin(ST_GeographyFromText(
'POLYGON((-71.50 42.35, -71.00 42.35, -71.00 42.38, -71.50 42.38, -71.50 42.35))'));
ST_YMin
------------------
42.35
(1 row)
6.10.48 - STV_AsGeoJSON
Returns the geometry or geography argument as a Geometry Javascript Object Notation (GeoJSON) object.
Returns the geometry or geography argument as a Geometry Javascript Object Notation (GeoJSON) object.
Behavior type
Immutable
Syntax
STV_AsGeoJSON( g, [USING PARAMETERS maxdecimals=[dec_value]])
Arguments
gSpatial object of type GEOMETRY or GEOGRAPHY
maxdecimals = dec_value - (Optional) Integer value. Determines the maximum number of digits to output after the decimal of floating point coordinates.
Valid values**:** Between 0 and 15.
Default** value****:** 6
Returns
LONG VARCHAR
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how you can use STV_AsGeoJSON.
Convert a geometry polygon to GeoJSON:
=> SELECT STV_AsGeoJSON(ST_GeomFromText('POLYGON((3 2, 4 3, 5 1, 3 2), (3.5 2, 4 2.5, 4.5 1.5, 3.5 2))'));
STV_AsGeoJSON
--------------------------------------------------------------------------------------------------
{"type":"Polygon","coordinates":[[[3,2],[4,3],[5,1],[3,2]],[[3.5,2],[4,2.5],[4.5,1.5],[3.5,2]]]}
(1 row)
Convert a geography point to GeoJSON:
=> SELECT STV_AsGeoJSON(ST_GeographyFromText('POINT(42.36011 71.05899)') USING PARAMETERS maxdecimals=4);
STV_AsGeoJSON
-------------------------------------------------
{"type":"Point","coordinates":[42.3601,71.059]}
(1 row)
6.10.49 - STV_Create_Index
Creates a spatial index on a set of polygons to speed up spatial intersection with a set of points.
Creates a spatial index on a set of polygons to speed up spatial intersection with a set of points.
A spatial index is created from an input polygon set, which can be the result of a query. Spatial indexes are created in a global name space. Vertica uses a distributed plan whenever the input table or projection is segmented across nodes of the cluster.
The OVER() clause must be empty.
Important
You cannot access spatial indexes on newly added nodes without rebalancing your cluster. For more information, see
REBALANCE_CLUSTER.
Behavior type
Immutable
Note
Indexes are not connected to any specific table. Subsequent DML commands on the underlying table or tables of the input data source do not modify the index.
Syntax
STV_Create_Index( gid, g
USING PARAMETERS index='index_name'
[, overwrite={ true | false } ]
[, max_mem_mb=maxmem_value]
[, skip_nonindexable_polygons={true | false } ] )
OVER()
[ AS (polygons, srid, min_x, min_y, max_x, max_y, info) ]
Arguments
gid- Name of an integer column that uniquely identifies the polygon. The gid cannot be NULL.
g- Name of a geometry or geography (WGS84) column or expression that contains polygons and multipolygons. Only polygon and multipolygon can be indexed. Other shape types are excluded from the index.
Parameters
index = 'index_name'- Name of the index, type VARCHAR. Index names cannot exceed 110 characters. The slash, backslash, and tab characters are not allowed in index names.
overwrite = [ true | false ]Boolean, whether to overwrite the index, if an index exists. This parameter cannot be NULL.
Default: False
max_mem_mb = maxmem_value- A positive integer that assigns a limit to the amount of memory in megabytes that
STV_Create_Index can allocate during index construction. On a multi-node database this is the memory limit per node. The default value is 256. Do not assign a value higher than the amount of memory in the GENERAL resource pool. For more information about this pool, see Monitoring resource pools.
Setting a value for max_mem_mb that is at or near the maximum memory available on the node can negatively affect your system's performance. For example, it could cause other queries to time out waiting for memory resources during index construction.
skip_nonindexable_polygons = [ true | false ](Optional) BOOLEAN
In rare cases, intricate polygons (for instance, with too high resolution or anomalous spikes) cannot be indexed. These polygons are considered non-indexable. When set to False, non-indexable polygons cause the index creation to fail. When set to True, index creation can succeed by excluding non-indexable polygons from the index.
To review the polygons that were not able to be indexed, use STV_Describe_Index with the parameter list_polygon.
Default: False
Returns
polygons - Number of polygons indexed.
SRID - Spatial reference system identifier.
min_x, min_y, max_x, max_y - Coordinates of the minimum bounding rectangle (MBR) of the indexed geometries. (
min_x, min_y) are the south-west coordinates, and (max_x, max_y) are the north-east coordinates.
info - Lists the number of excluded spatial objects as well as their type that were excluded from the index.
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
|
Multipoint |
No |
No |
|
Linestring |
No |
No |
|
Multilinestring |
No |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
No |
No |
Privileges
Any user with access to the STV_*_Index functions can describe, rename, or drop indexes created by any other user.
Recommendations
-
Segment large polygon tables across multiple nodes. Table segmentation causes index creation to run in parallel, leveraging the Massively Parallel Processing (MPP) architecture in Vertica. This significantly reduces execution time on large tables.
Vertica recommends that you segment the table from which you are building the index when the total number of polygons is large.
-
STV_Create_Index can consume large amounts of processing time and memory.
Vertica recommends that when indexing new data for the first time, you monitor memory usage to be sure it stays within safe limits. Memory usage depends on number of polygons, number of vertices, and the amount of overlap among polygons.
-
STV_Create_Index tries to allocate memory before it starts creating the index. If it cannot allocate enough memory, the function fails. If not enough memory is available, try the following:
-
Create the index at a time of less load on the system.
-
Avoid concurrent index creation.
-
Try segmenting the input table across the nodes of the cluster.
-
Ensure that all of the polygons you plan to index are valid polygons. STV_Create_Index and STV_Refresh_Index do not check polygon validity when building an index.
For more information, see Ensuring polygon validity before creating or refreshing an index.
Limitations
-
Any indexes created prior to 24.2.x need to re-created.
-
Index creation fails if there are WGS84 polygons with vertices on the International Date Line (IDL) or the North and South Poles.
-
The backslash or tab characters are not allowed in index names.
-
Indexes cannot have names greater than 110 characters.
-
The following geometries are excluded from the index:
-
The following geographies are excluded from the index:
- Polygons with holes
- Polygons crossing the International Date Line
- Polygons covering the north or south pole
- Antipodal polygons
Usage tips
-
To cancel an STV_Create_Index run, use Ctrl + C.
-
If there are no valid polygons in the geom column, STV_Create_Index reports an error in vertica.log and stops index creation.
-
If index creation uses a large amount of memory, consider segmenting your data to utilize parallel index creation.
Examples
The following examples show how to use STV_Create_Index.
Create an index with a single literal argument:
=> SELECT STV_Create_Index(1, ST_GeomFromText('POLYGON((0 0,0 15.2,3.9 15.2,3.9 0,0 0))')
USING PARAMETERS index='my_polygon') OVER();
polygons | SRID | min_x | min_y | max_x | max_y | info
----------+------+-------+-------+-------+-------+------
1 | 0 | 0 | 0 | 3.9 | 15.2 |
(1 row)
Create an index from a table:
=> CREATE TABLE pols (gid INT, geom GEOMETRY(1000));
CREATE TABLE
=> COPY pols(gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POLYGON((-31 74,8 70,8 50,-36 53,-31 74))
>> 2|POLYGON((-38 50,4 13,11 45,0 65,-38 50))
>> 3|POLYGON((10 20,15 60,20 45,46 15,10 20))
>> 4|POLYGON((5 20,9 30,20 45,36 35,5 20))
>> 5|POLYGON((12 23,9 30,20 45,36 35,37 67,45 80,50 20,12 23))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons_1', overwrite=true,
max_mem_mb=256) OVER() FROM pols;
polygons | SRID | min_x | min_y | max_x | max_y | info
----------+------+-------+-------+-------+-------+------
5 | 0 | -38 | 13 | 50 | 80 |
(1 row)
Create an index in parallel from a partitioned table:
=> CREATE TABLE pols (p INT, gid INT, geom GEOMETRY(1000)) SEGMENTED BY HASH(p) ALL NODES;
CREATE TABLE
=> COPY pols (p, gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|10|POLYGON((-31 74,8 70,8 50,-36 53,-31 74))
>> 1|11|POLYGON((-38 50,4 13,11 45,0 65,-38 50))
>> 3|12|POLYGON((-12 42,-12 42,27 48,14 26,-12 42))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons', overwrite=true,
max_mem_mb=256) OVER() FROM pols;
polygons | SRID | min_x | min_y | max_x | max_y | info
----------+------+-------+-------+-------+-------+------
3 | 0 | -38 | 13 | 27 | 74 |
(1 row)
See also
6.10.50 - STV_Describe_Index
Retrieves information about an index that contains a set of polygons.
Retrieves information about an index that contains a set of polygons. If you do not pass any parameters, STV_Describe_Index returns all of the defined indexes.
The OVER() clause must be empty.
Behavior type
Immutable
Syntax
STV_Describe_Index ( [ USING PARAMETERS [index='index_name']
[, list_polygons={true | false } ]] ) OVER ()
Arguments
index = 'index_name'- Name of the index, type VARCHAR. Index names cannot exceed 110 characters. The slash, backslash, and tab characters are not allowed in index names.
list_polygon- (Optional) BOOLEAN that specifies whether to list the polygons in the index. The index argument must be used with this argument.
Returns
polygons- Number of polygons indexed.
SRID- Spatial reference system identifier.
min_x, min_y, max_x, max_y- Coordinates of the minimum bounding rectangle (MBR) of the indexed geometries. (
min_x, min_y) are the south-west coordinates, and (max_x, max_y) are the north-east coordinates.
name- The name of the spatial index(es).
gid- Name of an integer column that uniquely identifies the polygon. The gid cannot be NULL.
state- The spatial object's state in the index. Possible values are:
-
INDEXED - The spatial object was successfully indexed.
-
SELF_INTERSECT - (WGS84 Only) The spatial object was not indexed because one of its edges intersects with another of its edges.
-
EDGE_CROSS_IDL - (WGS84 Only) The spatial object was not indexed because one of its edges crosses the International Date Line.
-
EDGE_HALF_CIRCLE - (WGS84 Only) The spatial object was not indexed because it contains two adjacent vertices that are antipodal.
-
NON_INDEXABLE - The spatial object was not able to be indexed.
geographyThe Well-Known Binary (WKB) representation of the spatial object.
geometryThe Well-Known Binary (WKB) representation of the spatial object.
Privileges
Any user with access to the STV_*_Index functions can describe, rename, or drop indexes created by any other user.
Limitations
Some functionality will require the index to be rebuilt if the index was created with 24.2.x or earlier.
Examples
The following examples show how to use STV_Describe_Index.
Retrieve information about the index:
=> SELECT STV_Describe_Index (USING PARAMETERS index='my_polygons') OVER ();
type | polygons | SRID | min_x | min_y | max_x | max_y
----------+----------+------+-------+-------+-------+-------
GEOMETRY | 4 | 0 | -1 | -1 | 12 | 12
(1 row)
Return the names of all the defined indexes:
=> SELECT STV_Describe_Index() OVER ();
name
------------------
MA_counties_index
my_polygons
NY_counties_index
US_States_Index
(4 rows)
Return the polygons included in an index:
=> SELECT STV_Describe_Index(USING PARAMETERS index='my_polygons', list_polygons=TRUE) OVER ();
gid | state | geometry
-----+---------------+----------------------------------
12 | INDEXED | \260\000\000\000\000\000\000\ ...
14 | INDEXED | \200\000\000\000\000\000\000\ ...
10 | NON_INDEXABLE | \274\000\000\000\000\000\000\ ...
11 | INDEXED | \260\000\000\000\000\000\000\ ...
(4 rows)
See also
6.10.51 - STV_Drop_Index
Deletes a spatial index.
Deletes a spatial index. If STV_Drop_Index cannot find the specified spatial index, it returns an error.
The OVER clause must be empty.
Behavior type
Immutable
Syntax
STV_Drop_Index( USING PARAMETERS index = 'index_name' ) OVER ()
Arguments
index = 'index_name'- Name of the index, type VARCHAR. Index names cannot exceed 110 characters. The slash, backslash, and tab characters are not allowed in index names.
Examples
The following example shows how to use STV_Drop_Index.
Drop an index:
=> SELECT STV_Drop_Index(USING PARAMETERS index ='my_polygons') OVER ();
drop_index
------------
Index dropped
(1 row)
See also
6.10.52 - STV_DWithin
Determines if the shortest distance from the boundary of one spatial object to the boundary of another object is within a specified distance.
Determines if the shortest distance from the boundary of one spatial object to the boundary of another object is within a specified distance.
Parameters g1 and g2 must be both GEOMETRY objects or both GEOGRAPHY objects.
Behavior type
Immutable
Syntax
STV_DWithin( g1, g2, d )
Arguments
g1Spatial object of type GEOMETRY or GEOGRAPHY
g2Spatial object of type GEOMETRY or GEOGRAPHY
d- Value of type FLOAT indicating a distance. For GEOMETRY objects, the distance is measured in Cartesian coordinate units. For GEOGRAPHY objects, the distance is measured in meters.
Returns
BOOLEAN
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Compatible GEOGRAPHY pairs:
- Data Type
- GEOGRAPHY (Perfect Sphere)
- Point-Point
- Yes
- Point-Linestring
- Yes
- Point-Polygon
- Yes
- Point-Multilinestring
- Yes
- Point-Multipolygon
- Yes
Examples
The following examples show how to use STV_DWithin.
Two geometries are one Cartesian coordinate unit from each other at their closest points:
=> SELECT STV_DWithin(ST_GeomFromText('POLYGON((-1 -1,2 2,0 1,-1 -1))'),
ST_GeomFromText('POLYGON((4 3,2 3,4 5,4 3))'),1);
STV_DWithin
-------------
t
(1 row)
If you reduce the distance to 0.99 units:
=> SELECT STV_DWithin(ST_GeomFromText('POLYGON((-1 -1,2 2,0 1,-1 -1))'),
ST_GeomFromText('POLYGON((4 3,2 3,4 5,4 3))'),0.99);
STV_DWithin
-------------
f
(1 row)
The first polygon touches the second polygon:
=> SELECT STV_DWithin(ST_GeomFromText('POLYGON((-1 -1,2 2,0 1,-1 -1))'),
ST_GeomFromText('POLYGON((1 1,2 3,4 5,1 1))'),0.00001);
STV_DWithin
-------------
t
(1 row)
The first polygon is not within 1000 meters from the second polygon:
=> SELECT STV_DWithin(ST_GeomFromText('POLYGON((45.2 40,50.65 51.29,
55.67 47.6,50 47.6,45.2 40))'),ST_GeomFromText('POLYGON((25 25,25 30,
30 30,30 25,25 25))'), 1000);
STV_DWithin
--------------
t
(1 row)
6.10.53 - STV_Export2Shapefile
Exports GEOGRAPHY or GEOMETRY data from a database table or a subquery to a shapefile.
Exports GEOGRAPHY or GEOMETRY data from a database table or a subquery to a shapefile. Output is written to the directory set with STV_SetExportShapefileDirectory.
Behavior type
Immutable
Syntax
STV_Export2Shapefile( columns USING PARAMETERS shapefile = 'filename'
[, overwrite = boolean ]
[, shape = 'spatial-class'] )
OVER()
Arguments
columns- The columns to export to the shapefile.
A value of asterisk (*) is the equivalent to listing all columns of the FROM clause.
Parameters
shapefile- Prefix of the component names of the shapefile. The following requirements apply:
To save the shapefile to a subdirectory, concatenate the subdirectory to shapefile-name—for example, visualizations/city-data.shp. The subdirectory must exist; this function does not create it.
overwriteBoolean, whether to overwrite the index, if an index exists. This parameter cannot be NULL.
Default: False
shape- One of the following spatial classes:
-
Point
-
Polygon
-
Linestring
-
Multipoint
-
Multipolygon
-
Multilinestring
Polygons and multipolygons always have a clockwise orientation.
Default: Polygon
Returns
Three files in the shapefile export directory with the extensions .shp, .shx, and .dbf.
Limitations
-
If a multipolygon, multilinestring, or multipoint contains only one element, then it is written as a polygon, line, or point, respectively.
-
Column names longer than 10 characters are truncated.
-
Empty POINTS cannot be exported.
-
All rows with NULL geometry or geography data are skipped.
-
Unsupported or invalid dates are replaced with NULLs.
-
Numeric values may lose precision when they are exported. This loss occurs because the target field in the .dbf file is a 64-bit FLOAT column, which can only represent about 15 significant digits.
-
Shapefiles cannot exceed 4GB in size. If your shapefile is too large, try splitting the data and exporting to multiple shapefiles.
Examples
The following example shows how you can use STV_Export2Shapefile to export all columns from the table geo_data to a shapefile named city-data.shp:
=> SELECT STV_Export2Shapefile(*
USING PARAMETERS shapefile = 'visualizations/city-data.shp',
overwrite = true, shape = 'Point')
OVER()
FROM geo_data
WHERE REVENUE > 25000;
Rows Exported | File Path
---------------+--------------------------------------------------------------
6442892 | v_geo-db_node0001: /home/geo/temp/visualizations/city-data.shp
(1 row)
6.10.54 - STV_Extent
Returns a bounding box containing all of the input data.
Returns a bounding box containing all of the input data.
Use STV_Extent inside of a nested query for best results. The OVER clause must be empty.
Important
STV_Extent does not return a valid polygon when the input is a single point.
Behavior type
Immutable
Syntax
STV_Extent( g )
Arguments
g- Spatial object, type GEOMETRY.
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
Yes |
Examples
The following examples show how you can use STV_Extent.
Return the bounding box of a linestring, and verify that it is a valid polygon:
=> SELECT ST_AsText(geom) AS bounding_box, ST_IsValid(geom)
FROM (SELECT STV_Extent(ST_GeomFromText('LineString(0 0, 1 1)')) OVER() AS geom) AS g;
bounding_box | ST_IsValid
-------------------------------------+------------
POLYGON ((0 0, 1 0, 1 1, 0 1, 0 0)) | t
(1 row)
Return the bounding box of spatial objects in a table:
=> CREATE TABLE misc_geo_shapes (id IDENTITY, geom GEOMETRY);
CREATE TABLE
=> COPY misc_geo_shapes (gx FILLER LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> POINT(-71.03 42.37)
>> LINESTRING(-71.058849 42.367501, -71.062240 42.371276, -71.067938 42.371246)
>> POLYGON((-71.066030 42.380617, -71.055827 42.376734, -71.060811 42.376011, -71.066030 42.380617))
>> \.
=> SELECT ST_AsText(geom_col) AS bounding_box
FROM (SELECT STV_Extent(geom) OVER() AS geom_col FROM misc_geo_shapes) AS g;
bounding_box
------------------------------------------------------------------------------------------------------------------
POLYGON ((-71.067938 42.367501, -71.03 42.367501, -71.03 42.380617, -71.067938 42.380617, -71.067938 42.367501))
(1 row)
6.10.55 - STV_ForceLHR
Alters the order of the vertices of a spatial object to follow the left-hand-rule.
Alters the order of the vertices of a spatial object to follow the left-hand-rule.
Behavior type
Immutable
Syntax
STV_ForceLHR( g, [USING PARAMETERS skip_nonreorientable_polygons={true | false} ])
Arguments
g- Spatial object, type GEOGRAPHY.
skip_nonreorientable_polygons = { true | false }(Optional) Boolean
When set to False, non-orientable polygons generate an error. For example, if you use STV_ForceLHR or STV_Reverse with skip_nonorientable_polygons set to False, a geography polygon containing a hole generates an error. When set to True, the result returned is the polygon, as passed to the API, without alteration.
This argument can help you when you are creating an index from a table containing polygons that cannot be re-oriented.
Vertica Place considers these polygons non-orientable:
Default value: False
Returns
GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
No |
|
Multipoint |
No |
No |
No |
|
Linestring |
No |
No |
No |
|
Multilinestring |
No |
No |
No |
|
Polygon |
No |
Yes |
Yes |
|
Multipolygon |
No |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following example shows how you can use STV_ForceLHR.
Re-orient a geography polygon to left-hand orientation:
=> SELECT ST_AsText(STV_ForceLHR(ST_GeographyFromText('Polygon((1 1, 3 1, 2 2, 1 1))')));
ST_AsText
--------------------------------
POLYGON ((1 1, 3 1, 2 2, 1 1))
(1 row)
Reverse the orientation of a geography polygon by forcing left-hand orientation:
=> SELECT ST_AsText(STV_ForceLHR(ST_GeographyFromText('Polygon((1 1, 2 2, 3 1, 1 1))')));
ST_AsText
--------------------------------
POLYGON ((1 1, 3 1, 2 2, 1 1))
(1 row)
See also
STV_Reverse
6.10.56 - STV_Geography
Casts a GEOMETRY object into a GEOGRAPHY object.
Casts a GEOMETRY object into a GEOGRAPHY object. The SRID value does not affect the results of Vertica Place queries.
When STV_Geography converts a GEOMETRY object to a GEOGRAPHY object, it sets its SRID to 4326.
Behavior type
Immutable
Syntax
STV_Geography( geom )
Arguments
geom- Spatial object that you want to cast into a GEOGRAPHY object, type GEOMETRY
Returns
GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
|
Point |
Yes |
|
Multipoint |
Yes |
|
Linestring |
Yes |
|
Multilinestring |
Yes |
|
Polygon |
Yes |
|
Multipolygon |
Yes |
|
GeometryCollection |
No |
Examples
The following example shows how to use STV_Geography.
To calculate the centroid of the GEOGRAPHY object, convert it to a GEOMETRY object, then convert it back to a GEOGRAPHY object:
=> CREATE TABLE geogs(g GEOGRAPHY);
CREATE TABLE
=> COPY geogs(gx filler LONG VARCHAR, geog AS ST_GeographyFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> MULTIPOINT(-108.619726 45.000284,-107.866813 45.00107,-106.363711 44.994223,-70.847746 41.205814)
>> \.
=> SELECT ST_AsText(STV_Geography(ST_Centroid(STV_Geometry(g)))) FROM geogs;
ST_AsText
--------------------------------
POINT (-98.424499 44.05034775)
(1 row)
6.10.57 - STV_GeographyPoint
Returns a GEOGRAPHY point based on the input values.
Returns a GEOGRAPHY point based on the input values.
This is the optimal way to convert raw coordinates to GEOGRAPHY points.
Behavior type
Immutable
Syntax
STV_GeographyPoint( x, y )
Arguments
x- x-coordinate or longitude, FLOAT.
y- y-coordinate or latitude, FLOAT.
Returns
GEOGRAPHY
Examples
The following examples show how to use STV_GeographyPoint.
Return a GEOGRAPHY point:
=> SELECT ST_AsText(STV_GeographyPoint(-114.101588, 47.909677));
ST_AsText
-------------------------------
POINT (-114.101588 47.909677)
(1 row)
Return GEOGRAPHY points using two columns:
=> CREATE TABLE geog_data (id IDENTITY, x FLOAT, y FLOAT);
CREATE TABLE
=> COPY geog_data FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> -114.101588|47.909677
>> -111.532377|46.430753
>> \.
=> SELECT id, ST_AsText(STV_GeographyPoint(x, y)) FROM geog_data;
id | ST_AsText
----+-------------------------------
1 | POINT (-114.101588 47.909677)
2 | POINT (-111.532377 46.430753)
(2 rows)
Create GEOGRAPHY points by manipulating data source columns during load:
=> CREATE TABLE geog_data_load (id IDENTITY, geog GEOGRAPHY);
CREATE TABLE
=> COPY geog_data_load (lon FILLER FLOAT,
lat FILLER FLOAT,
geog AS STV_GeographyPoint(lon, lat))
FROM 'test_coords.csv' DELIMITER ',';
Rows Loaded
-------------
2
(1 row)
=> SELECT id, ST_AsText(geog) FROM geog_data_load;
id | ST_AsText
----+------------------------------------
1 | POINT (-75.101654451 43.363830536)
2 | POINT (-75.106444487 43.367093798)
(2 rows)
See also
STV_GeometryPoint
6.10.58 - STV_Geometry
Casts a GEOGRAPHY object into a GEOMETRY object.
Casts a GEOGRAPHY object into a GEOMETRY object.
The SRID value does not affect the results of Vertica Place queries.
Behavior type
Immutable
Syntax
STV_Geometry( geog )
Arguments
geog- Spatial object that you want to cast into a GEOMETRY object, type GEOGRAPHY
Returns
GEOMETRY
Supported data types
|
Data Type |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
No |
No |
Examples
The following example shows how to use STV_Geometry.
Convert the GEOGRAPHY values to GEOMETRY values, then convert the result back to a GEOGRAPHY type:
=> CREATE TABLE geogs(g GEOGRAPHY);
CREATE TABLE
=> COPY geogs(gx filler LONG VARCHAR, geog AS ST_GeographyFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> MULTIPOINT(-108.619726 45.000284,-107.866813 45.00107,-106.363711 44.994223,-70.847746 41.205814)
>> \.
=> SELECT ST_AsText(STV_Geography(ST_Centroid(STV_Geometry(g)))) FROM geogs;
ST_AsText
--------------------------------
POINT (-98.424499 44.05034775)
6.10.59 - STV_GeometryPoint
Returns a GEOMETRY point, based on the input values.
Returns a GEOMETRY point, based on the input values.
This approach is the most-optimal way to convert raw coordinates to GEOMETRY points.
Behavior type
Immutable
Syntax
STV_GeometryPoint( x, y [, srid] )
Arguments
x- x-coordinate or longitude, FLOAT.
y- y-coordinate or latitude, FLOAT.
srid- (Optional) Spatial Reference Identifier (SRID) assigned to the point, INTEGER.
Returns
GEOMETRY
Examples
The following examples show how to use STV_GeometryPoint.
Return a GEOMETRY point with an SRID:
=> SELECT ST_AsText(STV_GeometryPoint(71.148562, 42.989374, 4326));
ST_AsText
-----------------------------
POINT (-71.148562 42.989374)
(1 row)
Return GEOMETRY points using two columns:
=> CREATE TABLE geom_data (id IDENTITY, x FLOAT, y FLOAT, SRID int);
CREATE TABLE
=> COPY geom_data FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 42.36383053600048|-71.10165445099966|4326
>> 42.3670937980005|-71.10644448699964|4326
>> \.
=> SELECT id, ST_AsText(STV_GeometryPoint(x, y, SRID)) FROM geom_data;
id | ST_AsText
----+------------------------------------
1 | POINT (-71.101654451 42.363830536)
2 | POINT (-71.106444487 42.367093798)
(2 rows)
Create GEOMETRY points by manipulating data source columns during load:
=> CREATE TABLE geom_data_load (id IDENTITY, geom GEOMETRY);
CREATE TABLE
=> COPY geom_data_load (lon FILLER FLOAT,
lat FILLER FLOAT,
geom AS STV_GeometryPoint(lon, lat))
FROM 'test_coords.csv' DELIMITER ',';
Rows Loaded
-------------
2
(1 row)
=> SELECT id, ST_AsText(geom) FROM geom_data_load;
id | ST_AsText
----+------------------------------------
1 | POINT (-75.101654451 43.363830536)
2 | POINT (-75.106444487 43.367093798)
(2 rows)
See also
STV_GeographyPoint
6.10.60 - STV_GetExportShapefileDirectory
Returns the path of the export directory.
Returns the path of the export directory.
Behavior type
Immutable
Syntax
STV_GetExportShapefileDirectory( )
Returns
The path of the shapefile export directory.
Examples
The following example shows how you can use STV_GetExportShapefileDirectory to query the path of the shapefile export directory:
=> SELECT STV_GetExportShapefileDirectory();
STV_GetExportShapefileDirectory
-----------------------------------------------
Shapefile export directory: [/home/user/temp]
(1 row)
6.10.61 - STV_Intersect scalar function
Spatially intersects a point or points with a set of polygons.
Spatially intersects a point or points with a set of polygons. The STV_Intersect scalar function returns the identifier associated with an intersecting polygon.
Behavior type
Immutable
Syntax
STV_Intersect( { g | x , y }
USING PARAMETERS index= 'index_name')
Arguments
g- A geometry or geography (WGS84) column that contains points. The g column can contain only point geometries or geographies. If the column contains a different geometry or geography type, STV_Intersect terminates with an error.
x- x-coordinate or longitude, FLOAT.
y- y-coordinate or latitude, FLOAT.
Parameters
index = 'index_name'- Name of the spatial index, of type VARCHAR.
Returns
The identifier of a matching polygon. If the point does not intersect any of the index's polygons, then the STV_Intersect scalar function returns NULL.
Examples
The following examples show how you can use STV_Intersect scalar.
Using two floats, return the gid of a matching polygon or NULL:
=> CREATE TABLE pols (gid INT, geom GEOMETRY(1000));
CREATE TABLE
=> COPY pols(gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POLYGON((31 74,8 70,8 50,36 53,31 74))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons_1', overwrite=true,
max_mem_mb=256) OVER() FROM pols;
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 1 | 0 | 8 | 50 | 36 | 74 |
(1 row)
=> SELECT STV_Intersect(12.5683, 55.6761 USING PARAMETERS index = 'my_polygons_1');
STV_Intersect
---------------
1
(1 row)
Using a GEOMETRY column, return the gid of a matching polygon or NULL:
=> CREATE TABLE polygons (gid INT, geom GEOMETRY(700));
CREATE TABLE
=> COPY polygons (gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POLYGON((-31 74,8 70,8 50,-36 53,-31 74))
>> 2|POLYGON((-38 50,4 13,11 45,0 65,-38 50))
>> 3|POLYGON((-18 42,-10 65,27 48,14 26,-18 42))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons', overwrite=true,
max_mem_mb=256) OVER() FROM polygons;
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 3 | 0 | -38 | 13 | 27 | 74 |
(1 row)
=> CREATE TABLE points (gid INT, geom GEOMETRY(700));
CREATE TABLE
=> COPY points (gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 100|POINT(-1 52)
>> 101|POINT(-20 0)
>> 102|POINT(-8 25)
>> 103|POINT(0 0)
>> 104|POINT(1 5)
>> 105|POINT(20 45)
>> 106|POINT(-20 5)
>> 107|POINT(-20 1)
>> \.
=> SELECT gid AS pt_gid, STV_Intersect(geom USING PARAMETERS index='my_polygons') AS pol_gid
FROM points ORDER BY pt_gid;
pt_gid | pol_gid
--------+---------
100 | 1
101 |
102 | 2
103 |
104 |
105 | 3
106 |
107 |
(8 rows)
See also
6.10.62 - STV_Intersect transform function
Spatially intersects points and polygons.
Spatially intersects points and polygons. The STV_Intersect transform function returns a tuple with matching point/polygon pairs. For every point, Vertica returns either one or many matching polygons.
You can improve performance when you parallelize the computation of the STV_Intersect transform function over multiple nodes. To parallelize the computation, use an OVER(PARTITION BEST) clause.
Behavior type
Immutable
Syntax
STV_Intersect ( { gid | i }, { g | x , y }
USING PARAMETERS index='index_name')
OVER() AS (pt_gid, pol_gid)
Arguments
gid | i- An integer column or integer that uniquely identifies the spatial object(s) of
g or x and y.
g- A geometry or geography (WGS84) column that contains points. The g column can contain only point geometries or geographies. If the column contains a different geometry or geography type, STV_Intersect terminates with an error.
x- x-coordinate or longitude, FLOAT.
y- y-coordinate or latitude, FLOAT.
Parameters
index = 'index_name'- Name of the spatial index, of type VARCHAR.
Returns
pt_gid- Unique identifier of the point geometry or geography, of type INTEGER.
pol_gid- Unique identifier of the polygon geometry or geography, of type INTEGER.
Examples
The following examples show how you can use STV_Intersect transform.
Using two floats, return the matching point-polygon pairs.
=> CREATE TABLE pols (gid INT, geom GEOMETRY(1000));
CREATE TABLE
=> COPY pols(gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POLYGON((31 74,8 70,8 50,36 53,31 74))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons_1', overwrite=true,
max_mem_mb=256) OVER() FROM pols;
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 1 | 0 | 8 | 50 | 36 | 74 |
(1 row)
=> SELECT STV_Intersect(56, 12.5683, 55.6761 USING PARAMETERS index = 'my_polygons_1') OVER();
pt_gid | pol_gid
--------+---------
56 | 1
(1 row)
Using a GEOMETRY column, return the matching point-polygon pairs.
=> CREATE TABLE polygons (gid int, geom GEOMETRY(700));
CREATE TABLE
=> COPY polygons (gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 10|POLYGON((5 5, 5 10, 10 10, 10 5, 5 5))
>> 11|POLYGON((0 0, 0 2, 2 2, 2 0, 0 0))
>> 12|POLYGON((1 1, 1 3, 3 3, 3 1, 1 1))
>> 14|POLYGON((-1 -1, -1 12, 12 12, 12 -1, -1 -1))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons', overwrite=true, max_mem_mb=256)
OVER() FROM polygons;
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 4 | 0 | -1 | -1 | 12 | 12 |
(1 row)
=> CREATE TABLE points (gid INT, geom GEOMETRY(700));
CREATE TABLE
=> COPY points (gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POINT(9 9)
>> 2|POINT(0 1)
>> 3|POINT(2.5 2.5)
>> 4|POINT(0 0)
>> 5|POINT(1 5)
>> 6|POINT(1.5 1.5)
>> \.
=> SELECT STV_Intersect(gid, geom USING PARAMETERS index='my_polygons') OVER (PARTITION BEST)
AS (point_id, polygon_gid)
FROM points;
point_id | polygon_gid
----------+-------------
5 | 14
1 | 14
1 | 10
4 | 14
4 | 11
6 | 12
6 | 14
6 | 11
2 | 14
2 | 11
3 | 12
3 | 14
(12 rows)
You can improve query performance by using the STV_Intersect transform function in a WHERE clause. Performance improves because this syntax eliminates all points that do not intersect polygons in the index.
Return the count of points that intersect with the polygon, where gid = 14:
=> SELECT COUNT(pt_id) FROM
(SELECT STV_Intersect(gid, geom USING PARAMETERS index='my_polygons')
OVER (PARTITION BEST) AS (pt_id, pol_id) FROM points)
AS T WHERE pol_id = 14;
COUNT
-------
6
(1 row)
See also
6.10.63 - STV_IsValidReason
Determines if a spatial object is well formed or valid.
Determines if a spatial object is well formed or valid. If the object is not valid, STV_IsValidReason returns a string that explains where the invalidity occurs.
A polygon or multipolygon is valid if all of the following are true:
-
The polygon is closed; its start point is the same as its end point.
-
Its boundary is a set of linestrings.
-
The boundary does not touch or cross itself.
-
Any polygons in the interior that do not have more than one point touching the boundary of the exterior polygon.
If you pass an invalid object to a Vertica Place function, the function fails or returns incorrect results. To determine if a polygon is valid, first run ST_IsValid. ST_IsValid returns TRUE if the polygon is valid, FALSE otherwise.
Note
If you pass a valid polygon to STV_IsValidReason, it returns NULL.
Behavior type
Immutable
Syntax
STV_IsValidReason( g )
Arguments
g- Geospatial object to test for validity, value of type GEOMETRY or GEOGRAPHY (WGS84).
Returns
LONG VARCHAR
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
Yes |
No |
No |
|
Multipoint |
Yes |
No |
No |
|
Linestring |
Yes |
No |
No |
|
Multilinestring |
Yes |
No |
No |
|
Polygon |
Yes |
No |
Yes |
|
Multipolygon |
Yes |
No |
No |
|
GeometryCollection |
Yes |
No |
No |
Examples
The following example shows how to use STV_IsValidReason.
Returns a string describing where the polygon is invalid:
=> SELECT STV_IsValidReason(ST_GeomFromText('POLYGON((1 3,3 2,1 1,
3 0,1 0,1 3))'));
STV_IsValidReason
-----------------------------------------------
Ring Self-intersection at or near POINT (1 1)
(1 row)
See also
ST_IsValid
6.10.64 - STV_LineStringPoint
Retrieves the vertices of a linestring or multilinestring.
Retrieves the vertices of a linestring or multilinestring. The values returned are points of either GEOMETRY or GEOGRAPHY type depending on the input object's type. GEOMETRY points inherit the SRID of the input object.
STV_LineStringPoint is an analytic function. For more information, see Analytic functions.
Behavior type
Immutable
Syntax
STV_LineStringPoint( g )
OVER( [PARTITION NODES] ) AS
Arguments
g- Linestring or multilinestring, value of type GEOMETRY or GEOGRAPHY
Returns
GEOMETRY or GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
No |
|
Multipoint |
No |
No |
No |
|
Linestring |
Yes |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
Yes |
|
Polygon |
No |
No |
No |
|
Multipolygon |
No |
No |
No |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use STV_LineStringPoint.
Returns the vertices of the geometry linestring and their SRID:
=> SELECT ST_AsText(Point), ST_SRID(Point)
FROM (SELECT STV_LineStringPoint(
ST_GeomFromText('MULTILINESTRING((1 2, 2 3, 3 1, 4 2),
(10 20, 20 30, 30 10, 40 20))', 4269)) OVER () AS Point) AS foo;
ST_AsText | ST_SRID
---------------+---------
POINT (1 2) | 4269
POINT (2 3) | 4269
POINT (3 1) | 4269
POINT (4 2) | 4269
POINT (10 20) | 4269
POINT (20 30) | 4269
POINT (30 10) | 4269
POINT (40 20) | 4269
(8 rows)
Returns the vertices of the geography linestring:
=> SELECT ST_AsText(g)
FROM (SELECT STV_LineStringPoint(
ST_GeographyFromText('MULTILINESTRING ((42.1 71.0, 41.4 70.0, 41.3 72.9),
(42.99 71.46, 44.47 73.21)', 4269)) OVER () AS g) AS line_geog_points;
ST_AsText
---------------------
POINT (42.1 71.0)
POINT (41.4 70.0)
POINT (41.3 72.9)
POINT (42.99 71.46)
POINT (44.47 73.21)
(5 rows)
See also
STV_PolygonPoint
6.10.65 - STV_MemSize
Returns the length of the spatial object in bytes as an INTEGER.
Returns the length of the spatial object in bytes as an INTEGER.
Use this function to determine the optimal column width for your spatial data.
Behavior type
Immutable
Syntax
STV_MemSize( g )
Arguments
g- Spatial object, value of type GEOMETRY or GEOGRAPHY
Returns
INTEGER
Examples
The following example shows how you can optimize your table by sizing the GEOMETRY or GEOGRAPHY column to the maximum value returned by STV_MemSize:
=> CREATE TABLE mem_size_table (id int, geom geometry(800));
CREATE TABLE
=> COPY mem_size_table (id, gx filler LONG VARCHAR, geom as ST_GeomFromText(gx)) FROM STDIN DELIMITER '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>>1|POINT(3 5)
>>2|MULTILINESTRING((1 5, 2 4, 5 3, 6 6),(3 5, 3 7))
>>3|MULTIPOLYGON(((2 6, 2 9, 6 9, 7 7, 4 6, 2 6)),((0 0, 0 5, 1 0, 0 0)),((0 2, 2 5, 4 5, 0 2)))
>>\.
=> SELECT max(STV_MemSize(geom)) FROM mem_size_table;
max
-----
336
(1 row)
=> CREATE TABLE production_table(id int, geom geometry(336));
CREATE TABLE
=> INSERT INTO production_table SELECT * FROM mem_size_table;
OUTPUT
--------
3
(1 row)
=> DROP mem_size_table;
DROP TABLE
6.10.66 - STV_NN
Calculates the distance of spatial objects from a reference object and returns (object, distance) pairs in ascending order by distance from the reference object.
Calculates the distance of spatial objects from a reference object and returns (object, distance) pairs in ascending order by distance from the reference object.
Parameters g1 and g2 must be both GEOMETRY objects or both GEOGRAPHY objects.
STV_NN is an analytic function. For more information, see Analytic functions.
Behavior type
Immutable
Syntax
STV_NN( g, ref_obj, k ) OVER()
Arguments
g- Spatial object, value of type GEOMETRY or GEOGRAPHY
ref_obj- Reference object, type GEOMETRY or GEOGRAPHY
k- Number of rows to return, type INTEGER
Returns
(Object, distance) pairs, in ascending order by distance. If a parameter is EMPTY or NULL, then 0 rows are returned.
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
|
Point |
Yes |
Yes |
|
Multipoint |
Yes |
Yes |
|
Linestring |
Yes |
Yes |
|
Multilinestring |
Yes |
Yes |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
|
GeometryCollection |
Yes |
No |
Examples
The following example shows how to use STV_NN.
Create a table and insert nine GEOGRAPHY points:
=> CREATE TABLE points (g geography);
CREATE TABLE
=> COPY points (gx filler LONG VARCHAR, g AS ST_GeographyFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> POINT (21.5 18.4)
>> POINT (21.5 19.2)
>> POINT (21.5 20.7)
>> POINT (22.5 16.4)
>> POINT (22.5 17.15)
>> POINT (22.5 18.33)
>> POINT (23.5 13.68)
>> POINT (23.5 15.9)
>> POINT (23.5 18.4)
>> \.
Calculate the distances (in meters) of objects in table points from the GEOGRAPHY point (23.5, 20).
Returns the five objects that are closest to that point:
=> SELECT ST_AsText(nn), dist FROM (SELECT STV_NN(g,
ST_GeographyFromText('POINT(23.5 20)'),5) OVER() AS (nn,dist) FROM points) AS example;
ST_AsText | dist
--------------------+------------------
POINT (23.5 18.4) | 177912.12757541
POINT (22.5 18.33) | 213339.210738322
POINT (21.5 20.7) | 222561.43679943
POINT (21.5 19.2) | 227604.371833335
POINT (21.5 18.4) | 275239.416790128
(5 rows)
6.10.67 - STV_PolygonPoint
Retrieves the vertices of a polygon as individual points.
Retrieves the vertices of a polygon as individual points. The values returned are points of either GEOMETRY or GEOGRAPHY type depending on the input object's type. GEOMETRY points inherit the SRID of the input object.
STV_PolygonPoint is an analytic function. For more information, see Analytic functions.
Behavior type
Immutable
Syntax
STV_PolygonPoint( g )
OVER( [PARTITION NODES] ) AS
Arguments
g- Polygon, value of type GEOMETRY or GEOGRAPHY
Returns
GEOMETRY or GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
No |
|
Multipoint |
No |
No |
No |
|
Linestring |
No |
No |
No |
|
Multilinestring |
No |
No |
No |
|
Polygon |
Yes |
Yes |
Yes |
|
Multipolygon |
Yes |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how to use STV_PolygonPoint.
Returns the vertices of the geometry polygon:
=> SELECT ST_AsText(g) FROM (SELECT STV_PolygonPoint(ST_GeomFromText('POLYGON((1 2, 2 3, 3 1, 1 2))'))
OVER (PARTITION NODES) AS g) AS poly_points;
ST_AsText
-------------
POINT (1 2)
POINT (2 3)
POINT (3 1)
POINT (1 2)
(4 rows)
Returns the vertices of the geography polygon:
=> SELECT ST_AsText(g) FROM (SELECT STV_PolygonPoint(ST_GeographyFromText('
POLYGON((25.5 28.76, 28.83 29.13, 27.2 30.99, 25.5 28.76))'))
OVER (PARTITION NODES) AS g) AS poly_points;
ST_AsText
---------------------
POINT (25.5 28.76)
POINT (28.83 29.13)
POINT (27.2 30.99)
POINT (25.5 28.76)
(4 rows)
See also
STV_LineStringPoint
6.10.68 - STV_Refresh_Index
Appends newly added or updated polygons and removes deleted polygons from an existing spatial index.
Appends newly added or updated polygons and removes deleted polygons from an existing spatial index.
The OVER() clause must be empty.
Behavior type
Mutable
Syntax
STV_Refresh_Index( gid, g
USING PARAMETERS index='index_name'
[, skip_nonindexable_polygons={ true | false } ] )
OVER()
[ AS (type, polygons, srid, min_x, min_y, max_x, max_y, info,
indexed, appended, updated, deleted) ]
Arguments
gid- Name of an integer column that uniquely identifies the polygon. The gid cannot be NULL.
g- Name of a geometry or geography (WGS84) column or expression that contains polygons and multipolygons. Only polygon and multipolygon can be indexed. Other shape types are excluded from the index.
Parameters
index = 'index_name'- Name of the index, type VARCHAR. Index names cannot exceed 110 characters. The slash, backslash, and tab characters are not allowed in index names.
skip_nonindexable_polygons = { true | false }(Optional) BOOLEAN
In rare cases, intricate polygons (for instance, with too high resolution or anomalous spikes) cannot be indexed. These polygons are considered non-indexable. When set to False, non-indexable polygons cause the index creation to fail. When set to True, index creation can succeed by excluding non-indexable polygons from the index.
To review the polygons that were not able to be indexed, use STV_Describe_Index with the parameter list_polygon.
Default: False
Returns
type- Spatial object type of the index.
polygons- Number of polygons indexed.
SRID- Spatial reference system identifier.
min_x, min_y, max_x, max_y- Coordinates of the minimum bounding rectangle (MBR) of the indexed geometries. (
min_x, min_y) are the south-west coordinates, and (max_x, max_y) are the north-east coordinates.
info- Lists the number of excluded spatial objects as well as their type that were excluded from the index.
indexed- Number of polygons indexed during the operation.
appended- Number of appended polygons.
updated- Number of updated polygons.
deleted- Number of deleted polygons.
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
|
Multipoint |
No |
No |
|
Linestring |
No |
No |
|
Multilinestring |
No |
No |
|
Polygon |
Yes |
Yes |
|
Multipolygon |
Yes |
No |
|
GeometryCollection |
No |
No |
Privileges
Any user with access to the STV_*_Index functions can describe, rename, or drop indexes created by any other user.
Limitations
-
In rare cases, intricate polygons (such as those with too-high a resolution or anomalous spikes) cannot be indexed. See the parameter skip_nonindexable_polygons.
-
If you replace a valid polygon in the source table with an invalid polygon, STV_Refresh_Index ignores the invalid polygon. As a result, the polygon originally indexed persists in the index.
-
The following geometries cannot be indexed:
-
Non-polygons
-
NULL gid
-
NULL (multi) polygon
-
EMPTY (multi) polygon
-
Invalid (multi) polygon
-
The following geographies are excluded from the index:
- Polygons with holes
- Polygons crossing the International Date Line
- Polygons covering the north or south pole
- Antipodal polygons
Usage tips
-
To cancel an STV_Refresh_Index run, use Ctrl + C.
-
If you use source data not previously associated with the index, then the index will be overwritten.
-
If STV_Refresh_Index has insufficient memory to process the query, then rebuild the index using STV_Create_Index.
-
If there are no valid polygons in the geom column, STV_Refresh_Index reports an error in vertica.log and stops the index refresh.
-
Ensure that all of the polygons you plan to index are valid polygons. STV_Create_Index and STV_Refresh_Index do not check polygon validity when building an index.
For more information, see Ensuring polygon validity before creating or refreshing an index.
Examples
The following examples show how to use STV_Refresh_Index.
Refresh an index with a single literal argument:
=> SELECT STV_Create_Index(1, ST_GeomFromText('POLYGON((0 0,0 15.2,3.9 15.2,3.9 0,0 0))')
USING PARAMETERS index='my_polygon') OVER();
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 1 | 0 | 0 | 0 | 3.9 | 15.2 |
(1 row)
=> SELECT STV_Refresh_Index(2, ST_GeomFromText('POLYGON((0 0,0 13.2,3.9 18.2,3.9 0,0 0))')
USING PARAMETERS index='my_polygon') OVER();
type | polygons | SRID | min_x | min_y | max_x | max_y | info | indexed | appended | updated | deleted
----------+----------+------+-------+-------+-------+-------+------+---------+----------+---------+---------
GEOMETRY | 1 | 0 | 0 | 0 | 3.9 | 18.2 | | 1 | 1 | 0 | 1
(1 row)
Refresh an index from a table:
=> CREATE TABLE pols (gid INT, geom GEOMETRY);
CREATE TABLE
=> COPY pols(gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|POLYGON((-31 74,8 70,8 50,-36 53,-31 74))
>> 2|POLYGON((5 20,9 30,20 45,36 35,5 20))
>> 3|POLYGON((12 23,9 30,20 45,36 35,37 67,45 80,50 20,12 23))
>> \.
=> SELECT STV_Create_Index(gid, geom USING PARAMETERS index='my_polygons_1', overwrite=true)
OVER() FROM pols;
type | polygons | SRID | min_x | min_y | max_x | max_y | info
----------+----------+------+-------+-------+-------+-------+------
GEOMETRY | 3 | 0 | -36 | 20 | 50 | 80 |
(1 row)
=> COPY pols(gid, gx filler LONG VARCHAR, geom AS ST_GeomFromText(gx)) FROM stdin delimiter '|';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 6|POLYGON((-32 74,8 70,8 50,-36 53,-32 74))
>> \.
=> SELECT STV_Refresh_Index(gid, geom USING PARAMETERS index='my_polygons_1') OVER() FROM pols;
type | polygons | SRID | min_x | min_y | max_x | max_y | info | indexed | appended | updated | deleted
----------+----------+------+-------+-------+-------+-------+------+---------+----------+---------+---------
GEOMETRY | 4 | 0 | -36 | 20 | 50 | 80 | | 1 | 1 | 0 | 0
(1 row)
See also
6.10.69 - STV_Rename_Index
Renames a spatial index.
Renames a spatial index. If the index format is out of date, you cannot rename the index.
A spatial index is created from an input polygon set, which can be the result of a query. Spatial indexes are created in a global name space. Vertica uses a distributed plan whenever the input table or projection is segmented across nodes of the cluster.
The OVER() clause must be empty.
Behavior type
Immutable
Syntax
STV_Rename_Index( USING PARAMETERS
source = 'old_index_name',
dest = 'new_index_name',
overwrite = [ 'true' | 'false' ]
)
OVER ()
Arguments
source = 'old_index_name'- Current name of the spatial index, type VARCHAR.
dest = 'new_index_name'- New name of the spatial index, type VARCHAR.
overwrite = [ 'true' | 'false' ]Boolean, whether to overwrite the index, if an index exists. This parameter cannot be NULL.
Default: False
Privileges
Any user with access to the STV_*_Index functions can describe, rename, or drop indexes created by any other user.
Limitations
Examples
The following example shows how to use STV_Rename_Index.
Rename an index:
=> SELECT STV_Rename_Index (
USING PARAMETERS
source = 'my_polygons',
dest = 'US_states',
overwrite = 'false'
)
OVER ();
rename_index
---------------
Index renamed
(1 Row)
6.10.70 - STV_Reverse
Reverses the order of the vertices of a spatial object.
Reverses the order of the vertices of a spatial object.
Behavior type
Immutable
Syntax
STV_Reverse( g, [USING PARAMETERS skip_nonreorientable_polygons={true | false} ])
Arguments
g- Spatial object, type GEOGRAPHY.
skip_nonreorientable_polygons = { true | false }(Optional) Boolean
When set to False, non-orientable polygons generate an error. For example, if you use STV_ForceLHR or STV_Reverse with skip_nonorientable_polygons set to False, a geography polygon containing a hole generates an error. When set to True, the result returned is the polygon, as passed to the API, without alteration.
This argument can help you when you are creating an index from a table containing polygons that cannot be re-oriented.
Vertica Place considers these polygons non-orientable:
Default value: False
Returns
GEOGRAPHY
Supported data types
|
Data Type |
GEOMETRY |
GEOGRAPHY (Perfect Sphere) |
GEOGRAPHY (WGS84) |
|
Point |
No |
No |
No |
|
Multipoint |
No |
No |
No |
|
Linestring |
No |
No |
No |
|
Multilinestring |
No |
No |
No |
|
Polygon |
No |
Yes |
Yes |
|
Multipolygon |
No |
Yes |
Yes |
|
GeometryCollection |
No |
No |
No |
Examples
The following examples show how you can use STV_Reverse.
Reverse vertices of a geography polygon:
=> SELECT ST_AsText(STV_Reverse(ST_GeographyFromText('Polygon((1 1, 3 1, 2 2, 1 1))')));
ST_AsText
--------------------------------
POLYGON ((1 1, 2 2, 3 1, 1 1))
(1 row)
Force the polygon to reverse orientation:
=> SELECT ST_AsText(STV_Reverse(ST_GeographyFromText('Polygon((1 1, 2 2, 3 1, 1 1))')));
ST_AsText
--------------------------------
POLYGON ((1 1, 3 1, 2 2, 1 1))
(1 row)
See also
STV_ForceLHR
6.10.71 - STV_SetExportShapefileDirectory
Specifies the directory to export GEOMETRY or GEOGRAPHY data to a shapefile.
Specifies the directory to export GEOMETRY or GEOGRAPHY data to a shapefile. The validity of the path is not checked, and the path cannot be empty.
Behavior type
Immutable
Syntax
STV_SetExportShapefileDirectory( USING PARAMETERS path='path' )
Parameters
path- Destination path for the exported shapefile. The path can be on any shared file system or object store.
Returns
The path of the shapefile export directory.
Privileges
Only a superuser can use this function.
Examples
The following example shows how you can use STV_SetExportShapefileDirectory to set the shapefile export directory to /home/user/temp:
=> SELECT STV_SetExportShapefileDirectory(USING PARAMETERS path = '/home/user/temp');
STV_SetExportShapefileDirectory
------------------------------------------------------------
SUCCESS. Set shapefile export directory: [/home/user/temp]
(1 row)
6.10.72 - STV_ShpCreateTable
Returns a CREATE TABLE statement with the columns and types of the attributes found in the specified shapefile.
Returns a CREATE TABLE statement with the columns and types of the attributes found in the specified shapefile.
The column types are sized according to the shapefile metadata. The size of the column is based on the largest geometry found in the shapefile. The first column in the table is named gid, which is an IDENTITY primary key column. The cache value is set to 64 by default. The last column is a GEOMETRY data type for storing the actual geometry data.
Behavior type
Immutable
Syntax
STV_ShpCreateTable (USING PARAMETERS file='filename') OVER()
Parameters
file- Fully qualified path of the
.dbf, .shp, or .shx file. The path can be on any shared file system or object store.
Returns
CREATE TABLE statement that matches the specified shapefile
Usage tips
-
STV_ShpCreateTable returns a CREATE TABLE statement; but it does not create the table. Modify the CREATE TABLE statement as needed, and then create the table before loading the shapefile into the table.
-
To create a table with characters other than alphanumeric and underscore (_) characters, you must specify the table name enclosed in double quotes, such as "counties%NY".
-
The name of the table is the same as the name of the shapefile, without the directory name or extension.
-
The shapefile must be accessible from the initiator node.
-
If the .shp and .shx files are corrupt, STV_ShpCreateTable returns an error. If the .shp and .shx files are valid, but the .dbf file is corrupt, STV_ShpCreateTable ignores the .dbf file and does not create columns for that data.
-
All the mandatory files (.dbf, .shp, .shx) must be in the same directory. If not, STV_ShpCreateTable returns an error.
-
If the .dbf component of a shapefile contains a Numeric attribute, this field's values may lose precision when the Vertica shapefile loader loads it into a table. The target field is a 64-bit FLOAT column, which can only represent about 15 significant digits. In a .dbf file, numeric fields can be up to 30 digits.
Vertica records all instances of shapefile values that are too long in the vertica.log file.
Examples
The following example shows how to use STV_ShpCreateTable.
Returns a CREATE TABLE statement:
=> SELECT STV_ShpCreateTable
(USING PARAMETERS file='/shapefiles/tl_2010_us_state10.shp')
OVER() as create_table_states;
create_table_states
----------------------------------
CREATE TABLE tl_2010_us_state10(
gid IDENTITY(64) PRIMARY KEY,
REGION10 VARCHAR(2),
DIVISION10 VARCHAR(2),
STATEFP10 VARCHAR(2),
STATENS10 VARCHAR(8),
GEOID10 VARCHAR(2),
STUSPS10 VARCHAR(2),
NAME10 VARCHAR(100),
LSAD10 VARCHAR(2),
MTFCC10 VARCHAR(5),
FUNCSTAT10 VARCHAR(1),
ALAND10 INT8,
AWATER10 INT8,
INTPTLAT10 VARCHAR(11),
INTPTLON10 VARCHAR(12),
geom GEOMETRY(940845)
);
(18 rows)
See also
6.10.73 - STV_ShpSource and STV_ShpParser
These two functions work with COPY to parse and load geometries and attributes from a shapefile into a Vertica table, and convert them to the appropriate GEOMETRY data type.
These two functions work with COPY to parse and load geometries and attributes from a shapefile into a Vertica table, and convert them to the appropriate GEOMETRY data type. You must use these two functions together.
The following restrictions apply:
-
An empty multipoint or an invalid multipolygon can not be loaded from a shapefile.
-
If the .dbf component of a shapefile contains a numeric attribute, this field's values might lose precision when the Vertica Place shapefile loader loads it into a table. The target field is a 64-bit FLOAT column, which can only represent about 15 significant digits; in a .dbf file, Numeric fields can be up to 30 digits.
Rejected records are saved to CopyErrorLogs subdirectory, under the Vertica catalog directory.
Behavior type
Immutable
Syntax
COPY table( columnslist )
WITH SOURCE STV_ShpSource
( file = 'path'[[, SRID=spatial-reference-identifier] [, flatten_2d={true | false }] ] )
PARSER STV_ShpParser()
Arguments
table- Name of the table in which to load the geometry data.
columnslist- Comma-delimited list of column names in the table that match fields in the external file. Run the CREATE TABLE command that STV_ShpCreateTable creates. When you do so, these columns correspond to the second through the second-to-last columns.
Parameters
file- Fully qualified path of a
.dbf, .shp, or .shx file. The path can be on any shared file system or object store.
SRID- Specifies an integer spatial reference identifier (SRID) associated with the shape file.
flatten_2d- Specifies a BOOLEAN argument that excludes 3D or 4D coordinates during COPY commands:
Default: false
Privileges
COPY errors
The COPY command fails under one of the following conditions:
-
The shapefile cannot be located or opened.
-
The number of columns or the data types of the columns that STV_ShpParser creates do not match the columns in the destination table. Use STV_ShpCreateTable to generate the appropriate CREATE TABLE command.
-
One of the mandatory files is missing or cannot be opened. When opening a shapefile, you must have three files: .dbf, .shp, and .shx.
STV_ShpSource file corruption handling
-
If the .shp and .shx files are corrupt, STV_ShpSource returns an error.
-
If the .shp and .shx files are valid, but the .dbf file is corrupt, STV_ShpSource ignores the .dbf file and does not create columns for that data.
Examples
=> COPY tl_2010_us_state10 WITH SOURCE
STV_ShpSource(file='/shapefiles/tl_2010_us_state10.shp', SRID=4269) PARSER STV_ShpParser();
Rows loaded
-------------
52
6.11 - Hadoop functions
This section contains functions to manage interactions with Hadoop.
This section contains functions to manage interactions with Hadoop.
6.11.1 - CLEAR_HDFS_CACHES
Clears the configuration information copied from HDFS and any cached connections.
Clears the configuration information copied from HDFS and any cached connections.
This function affects reads using the hdfs scheme in the following ways:
-
This function flushes information loaded from configuration files copied from Hadoop (such as core-site.xml). These files are found on the path set by the HadoopConfDir configuration parameter.
-
This function flushes information about which NameNode is active in a High Availability (HA) Hadoop cluster. Therefore, the first request to Hadoop after calling this function is slower than expected.
Vertica maintains a cache of open connections to NameNodes to reduce latency. This function flushes that cache.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_HDFS_CACHES ( )
Privileges
Superuser
Examples
The following example clears the Hadoop configuration information:
=> SELECT CLEAR_HDFS_CACHES();
CLEAR_HDFS_CACHES
--------------
Cleared
(1 row)
See also
Hadoop parameters
6.11.2 - EXTERNAL_CONFIG_CHECK
Tests the Hadoop configuration of a Vertica cluster.
Tests the Hadoop configuration of a Vertica cluster. This function tests HDFS configuration files, HCatalog Connector configuration, and Kerberos configuration.
This function calls the following functions:
If you call this function with an argument, it passes the argument to functions it calls that also take an argument.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXTERNAL_CONFIG_CHECK( ['what_to_test' ] )
Arguments
what_to_test- A string specifying the authorities, nameservices, and/or HCatalog schemas to test. The format is a comma-separated list of "key=value" pairs, where keys are "authority", "nameservice", and "schema". The value is passed to all of the sub-functions; see those reference pages for details on how values are interpreted.
Privileges
This function does not require privileges.
Examples
The following example tests the configuration of only the nameservice named "ns1". Output has been omitted due to length.
=> SELECT EXTERNAL_CONFIG_CHECK('nameservice=ns1');
6.11.3 - GET_METADATA
Returns the metadata of a Parquet file.
Returns the metadata of a Parquet file. Metadata includes the number and sizes of row groups, column names, and information about chunks and compression. Metadata is returned as JSON.
This function inspects one file. Parquet data usually spans many files in a single directory; choose one. The function does not accept a directory name as an argument.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_METADATA( 'filename' )
Arguments
filename - The name of a Parquet file. Any path that is valid for COPY is valid for this function. This function does not operate on files in other formats.
Privileges
Superuser, or non-superuser with READ privileges on the USER-accessible storage location (see GRANT (storage location)).
Examples
You must call this function with a single file, not a directory or glob:
=> SELECT GET_METADATA('/data/emp-row.parquet');
GET_METADATA
----------------------------------------------------------------------------------------------------
schema:
required group field_id=-1 spark_schema {
optional int32 field_id=-1 employeeID;
optional group field_id=-1 personal {
optional binary field_id=-1 name (String);
optional group field_id=-1 address {
optional binary field_id=-1 street (String);
optional binary field_id=-1 city (String);
optional int32 field_id=-1 zipcode;
}
optional int32 field_id=-1 taxID;
}
optional binary field_id=-1 department (String);
}
data page version:
data page v1
metadata:
{
"FileName": "/data/emp-row.parquet",
"FileFormat": "Parquet",
"Version": "1.0",
"CreatedBy": "parquet-mr version 1.10.1 (build a89df8f9932b6ef6633d06069e50c9b7970bebd1)",
"TotalRows": "4",
"NumberOfRowGroups": "1",
"NumberOfRealColumns": "3",
"NumberOfColumns": "7",
"Columns": [
{ "Id": "0", "Name": "employeeID", "PhysicalType": "INT32", "ConvertedType": "NONE", "LogicalType": {"Type": "None"} },
{ "Id": "1", "Name": "personal.name", "PhysicalType": "BYTE_ARRAY", "ConvertedType": "UTF8", "LogicalType": {"Type": "String"} },
{ "Id": "2", "Name": "personal.address.street", "PhysicalType": "BYTE_ARRAY", "ConvertedType": "UTF8", "LogicalType": {"Type": "String"} },
{ "Id": "3", "Name": "personal.address.city", "PhysicalType": "BYTE_ARRAY", "ConvertedType": "UTF8", "LogicalType": {"Type": "String"} },
{ "Id": "4", "Name": "personal.address.zipcode", "PhysicalType": "INT32", "ConvertedType": "NONE", "LogicalType": {"Type": "None"} },
{ "Id": "5", "Name": "personal.taxID", "PhysicalType": "INT32", "ConvertedType": "NONE", "LogicalType": {"Type": "None"} },
{ "Id": "6", "Name": "department", "PhysicalType": "BYTE_ARRAY", "ConvertedType": "UTF8", "LogicalType": {"Type": "String"} }
],
"RowGroups": [
{
"Id": "0", "TotalBytes": "642", "TotalCompressedBytes": "0", "Rows": "4",
"ColumnChunks": [
{"Id": "0", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "51513", "Min": "17103" },
"Compression": "SNAPPY", "Encodings": "PLAIN RLE BIT_PACKED ", "UncompressedSize": "67", "CompressedSize": "69" },
{"Id": "1", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "Sheldon Cooper", "Min": "Howard Wolowitz" },
"Compression": "SNAPPY", "Encodings": "PLAIN RLE BIT_PACKED ", "UncompressedSize": "142", "CompressedSize": "145" },
{"Id": "2", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "52 Broad St", "Min": "100 Main St Apt 4A" },
"Compression": "SNAPPY", "Encodings": "PLAIN RLE BIT_PACKED ", "UncompressedSize": "139", "CompressedSize": "123" },
{"Id": "3", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "Pasadena", "Min": "Pasadena" },
"Compression": "SNAPPY", "Encodings": "RLE PLAIN_DICTIONARY BIT_PACKED ", "UncompressedSize": "95", "CompressedSize": "99" },
{"Id": "4", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "91021", "Min": "91001" },
"Compression": "SNAPPY", "Encodings": "PLAIN RLE BIT_PACKED ", "UncompressedSize": "68", "CompressedSize": "70" },
{"Id": "5", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "4", "DistinctValues": "0", "Max": "0", "Min": "0" },
"Compression": "SNAPPY", "Encodings": "PLAIN RLE BIT_PACKED ", "UncompressedSize": "28", "CompressedSize": "30" },
{"Id": "6", "Values": "4", "StatsSet": "True", "Stats": {"NumNulls": "0", "DistinctValues": "0", "Max": "Physics", "Min": "Astronomy" },
"Compression": "SNAPPY", "Encodings": "RLE PLAIN_DICTIONARY BIT_PACKED ", "UncompressedSize": "103", "CompressedSize": "107" }
]
}
]
}
(1 row)
6.11.4 - HADOOP_IMPERSONATION_CONFIG_CHECK
Reports the delegation tokens Vertica will use when accessing Kerberized data in HDFS.
Reports the delegation tokens Vertica will use when accessing Kerberized data in HDFS. The HadoopImpersonationConfig configuration parameter specifies one or more authorities, nameservices, and HCatalog schemas and their associated tokens. For each tested value, the function reports what doAs user or delegation token Vertica will use for access. Use this function to confirm that you have defined your delegation tokens as you intended.
You can call this function with an argument to specify the authority, nameservice, or HCatalog schema to test, or without arguments to test all configured values.
This function does not check that you can use these delegation tokens to access HDFS.
See Proxy users and delegation tokens for more about impersonation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
HADOOP_IMPERSONATION_CONFIG_CHECK( ['what_to_test' ] )
Arguments
what_to_test- A string specifying the authorities, nameservices, and/or HCatalog schemas to test. For example, a value of 'nameservice=ns1' means the function tests only access to the nameservice "ns1" and ignores any other authorities and schemas. A value of 'nameservice=ns1, schema=hcat1' means the function tests one nameservice and one HCatalog schema.
If you do not specify this argument, the function tests all authorities, nameservices, and schemas defined in HadoopImpersonationConfig .
Privileges
This function does not require privileges.
Examples
Consider the following definition of HadoopImpersonationConfig:
[{
"nameservice": "ns1",
"token": "RANDOM-TOKEN-STRING"
},
{
"nameservice": "*",
"doAs": "Paul"
},
{
"schema": "hcat1",
"doAs": "Fred"
}
]
The following query tests only the "ns1" name service:
=> SELECT HADOOP_IMPERSONATION_CONFIG_CHECK('nameservice=ns1');
-- hadoop_impersonation_config_check --
Connections to nameservice [ns1] will use a delegation token with hash [b3dd9e71cd695d91]
This function returns a hash of the token for security reasons. You can call HASH_EXTERNAL_TOKEN with the expected value and compare that hash to the one in this function's output.
A query with no argument tests all values:
=> SELECT HADOOP_IMPERSONATION_CONFIG_CHECK();
-- hadoop_impersonation_config_check --
Connections to nameservice [ns1] will use a delegation token with hash [b3dd9e71cd695d91]
JDBC connections for HCatalog schema [hcat1] will doAs [Fred]
[!] hadoop_impersonation_config_check : [PASS]
6.11.5 - HASH_EXTERNAL_TOKEN
Returns a hash of a string token, for use with HADOOP_IMPERSONATION_CONFIG_CHECK.
Returns a hash of a string token, for use with HADOOP_IMPERSONATION_CONFIG_CHECK. Call HASH_EXTERNAL_TOKEN with the delegation token you expect Vertica to use and compare it to the hash in the output of HADOOP_IMPERSONATION_CONFIG_CHECK.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
HASH_EXTERNAL_TOKEN( 'token' )
Arguments
token- A string specifying the token to hash. The token is configured in the HadoopImpersonationConfig parameter.
Privileges
This function does not require privileges.
Examples
The following query tests the expected value shown in the example on the HADOOP_IMPERSONATION_CONFIG_CHECK reference page.
=> SELECT HASH_EXTERNAL_TOKEN('RANDOM-TOKEN-STRING');
hash_external_token
---------------------
b3dd9e71cd695d91
(1 row)
6.11.6 - HCATALOGCONNECTOR_CONFIG_CHECK
Tests the configuration of a Vertica cluster that uses the HCatalog Connector to access Hive data.
Tests the configuration of a Vertica cluster that uses the HCatalog Connector to access Hive data. The function first verifies that the HCatalog Connector is properly installed and reports on the values of several related configuration parameters. It then tests the connection using HiveServer2. This function does not support the WebHCat server.
If you specify an HCatalog schema, and if you have defined a delegation token for that schema, this function uses the delegation token. Otherwise, the function uses the default endpoint without a delegation token.
See Proxy users and delegation tokens for more about delegation tokens.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
HCATALOGCONNECTOR_CONFIG_CHECK( ['what_to_test' ] )
Arguments
what_to_test- A string specifying the HCatalog schemas to test. For example, a value of 'schema=hcat1' means the function tests only the "hcat1" schema and ignores any others that are found.
Privileges
This function does not require privileges.
Examples
The following query tests with the default endpoint and no delegation token.
=> SELECT HCATALOGCONNECTOR_CONFIG_CHECK();
-- hcatalogconnector_config_check --
HCatalogConnectorUseHiveServer2 : [1]
EnableHCatImpersonation : [1]
HCatalogConnectorUseORCReader : [1]
HCatalogConnectorUseParquetReader : [1]
HCatalogConnectorUseTxtReader : [0]
[INFO] Vertica is not configured to use its internal parsers for delimited files.
[INFO] This is off by default, but will be changed in a future release.
HCatalogConnectorUseLibHDFSPP : [1]
[OK] HCatalog connector library is properly installed.
[INFO] Creating JDBC connection as session user.
[OK] Successful JDBC connection to HiveServer2 as user [USER].
[!] hcatalogconnector_config_check : [PASS]
To test with the configured delegation token, pass the schema as an argument:
=> SELECT HCATALOGCONNECTOR_CONFIG_CHECK('schema=hcat1');
6.11.7 - HDFS_CLUSTER_CONFIG_CHECK
Tests the configuration of a Vertica cluster that uses HDFS.
Tests the configuration of a Vertica cluster that uses HDFS. The function scans the Hadoop configuration files found in HadoopConfDir and performs configuration checks on each cluster it finds. If you have more than one cluster configured, you can specify which one to test instead of testing all of them.
For each Hadoop cluster, it reports properties including:
It then tests connections using http(s), hdfs, and webhdfs URL schemes. It tests the latter two using both the Vertica and session user.
See Configuring HDFS access for information about configuration files and HadoopConfDir.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
HDFS_CLUSTER_CONFIG_CHECK( ['what_to_test' ] )
Arguments
what_to_test- A string specifying the authorities or nameservices to test. For example, a value of 'nameservice=ns1' means the function tests only "ns1" cluster. If you specify both an authority and a nameservice, the authority must be a NameNode in the specified nameservice for the check to pass.
If you do not specify this argument, the function tests all cluster configurations found in HadoopConfDir.
Privileges
This function does not require privileges.
Examples
The following example tests all clusters.
=> SELECT HDFS_CLUSTER_CONFIG_CHECK();
-- hdfs_cluster_config_check --
Hadoop Conf Path : [/conf/hadoop_conf]
[OK] HadoopConfDir verified on all nodes
Connection Timeout (seconds) : [60]
Token Refresh Frequency (seconds) : [0]
HadoopFSBlockSizeBytes (MiB) : [64]
[OK] Found [1] hadoop cluster configurations
------------- Cluster 1 -------------
Is DefaultFS : [true]
Nameservice : [vmns]
Namenodes : [node1.example.com:8020, node2.example.com:8020]
High Availability : [true]
RPC Encryption : [false]
Kerberos Authentication : [true]
HTTPS Only : [false]
[INFO] Checking connections to [hdfs:///]
vertica : [OK]
dbuser : [OK]
[INFO] Checking connections to [http://node1.example.com:50070]
[INFO] Node is in standby
[INFO] Checking connections to [http://node2.example.com:50070]
[OK] Can make authenticated external curl connection
[INFO] Checking webhdfs
vertica : [OK]
USER : [OK]
[!] hdfs_cluster_config_check : [PASS]
6.11.8 - KERBEROS_HDFS_CONFIG_CHECK
This function is deprecated and will be removed in a future release.
Deprecated
This function is deprecated and will be removed in a future release. Instead, use
EXTERNAL_CONFIG_CHECK.
Tests the Kerberos configuration of a Vertica cluster that uses HDFS. The function succeeds if it can use both the Vertica keytab file and the session user to access HDFS, and reports errors otherwise. This function is a more specific version of KERBEROS_CONFIG_CHECK.
If the current session is not Kerberized, this function will not be able to use secured HDFS connections and will fail.
You can call this function with arguments to specify an HDFS configuration to test, or without arguments. If you call it with no arguments, this function reads the HDFS configuration files and fails if it does not find them. See Configuring HDFS access. If it finds configuration files, it tests all configured nameservices.
The function performs the following tests, in order:
-
Are Kerberos services available?
-
Does a keytab file exist and are the Kerberos and HDFS configuration parameters set in the database?
-
Can Vertica read and invoke kinit with the keys to authenticate to HDFS and obtain the database Kerberos ticket?
-
Can Vertica perform hdfs and webhdfs operations using both the database Kerberos ticket and user-forwardable tickets for the current session?
-
Can Vertica connect to HiveServer2? (This function does not support WebHCat.)
If any test fails, the function returns a descriptive error message.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
KERBEROS_HDFS_CONFIG_CHECK( ['hdfsHost:hdfsPort',
'webhdfsHost:webhdfsPort', 'webhcatHost' ] )
Arguments
hdfsHost, hdfsPort- The hostname or IP address and port of the HDFS NameNode. Vertica uses this server to access data that is specified with
hdfs URLs. If the value is ' ', the function skips this part of the check.
webhdfsHost, webhdfsPort- The hostname or IP address and port of the WebHDFS server. Vertica uses this server to access data that is specified with
webhdfs URLs. If the value is ' ', the function skips this part of the check.
webhcatHost- Pass any value in this position. WebHCat is deprecated and this value is ignored but must be present.
Privileges
This function does not require privileges.
6.11.9 - SYNC_WITH_HCATALOG_SCHEMA
Copies the structure of a Hive database schema available through the HCatalog Connector to a Vertica schema.
Copies the structure of a Hive database schema available through the HCatalog Connector to a Vertica schema. If the HCatalog schema and the target Vertica schema have matching table names, SYNC_WITH_HCATALOG_SCHEMA overwrites the Vertica tables.
This function can synchronize the HCatalog schema directly. In this case, call it with the same schema name for the vertica_schema and hcatalog_schema parameters. The function can also synchronize a different schema to the HCatalog schema.
If you change the settings of HCatalog Connector configuration parameters, you must call this function again.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SYNC_WITH_HCATALOG_SCHEMA( vertica_schema, hcatalog_schema, [drop_non_existent] )
Parameters
vertica_schema- The target Vertica schema to store the copied HCatalog schema's metadata. This can be the same schema as
hcatalog_schema, or it can be a separate one created with CREATE SCHEMA.
Caution
Do not use the Vertica schema to store other data.
hcatalog_schema- The HCatalog schema to copy, created with CREATE HCATALOG SCHEMA
drop_non_existent- If
true, drop any tables in vertica_schema that do not correspond to a table in hcatalog_schema
Privileges
Non-superuser: CREATE privileges on vertica_schema.
Users also require access to Hive data, one of the following:
-
USAGE permissions on hcat_schema, if Hive does not use an authorization service to manage access.
-
Permission through an authorization service (Sentry or Ranger), and access to the underlying files in HDFS. (Sentry can provide that access through ACL synchronization.)
-
dbadmin user privileges, with or without an authorization service.
Data type matching
Hive STRING and BINARY data types are matched, in Vertica, to the VARCHAR(65000) and VARBINARY(65000) types. Adjust the data types with ALTER TABLE as needed after creating the schema. The maximum size of a VARCHAR or VARBINARY in Vertica is 65000, but you can use LONG VARCHAR and LONG VARBINARY to specify larger values.
Hive and Vertica define string length in different ways. In Hive the length is the number of characters; in Vertica it is the number of bytes. Thus, a character encoding that uses more than one byte, such as Unicode, can cause mismatches between the two. To avoid data truncation, set values in Vertica based on bytes, not characters.
If data size exceeds the column size, Vertica logs an event at read time in the QUERY_EVENTS system table.
Examples
The following example uses SYNC_WITH_HCATALOG_SCHEMA to synchronize an HCatalog schema named hcat:
=> CREATE HCATALOG SCHEMA hcat WITH hostname='hcathost' HCATALOG_SCHEMA='default'
HCATALOG_USER='hcatuser';
CREATE SCHEMA
=> SELECT sync_with_hcatalog_schema('hcat', 'hcat');
sync_with_hcatalog_schema
----------------------------------------
Schema hcat synchronized with hcat
tables in hcat = 56
tables altered in hcat = 0
tables created in hcat = 56
stale tables in hcat = 0
table changes erred in hcat = 0
(1 row)
=> -- Use vsql's \d command to describe a table in the synced schema
=> \d hcat.messages
List of Fields by Tables
Schema | Table | Column | Type | Size | Default | Not Null | Primary Key | Foreign Key
-----------+----------+---------+----------------+-------+---------+----------+-------------+-------------
hcat | messages | id | int | 8 | | f | f |
hcat | messages | userid | varchar(65000) | 65000 | | f | f |
hcat | messages | "time" | varchar(65000) | 65000 | | f | f |
hcat | messages | message | varchar(65000) | 65000 | | f | f |
(4 rows)
The following example uses SYNC_WITH_HCATALOG_SCHEMA followed by ALTER TABLE to adjust a column value:
=> CREATE HCATALOG SCHEMA hcat WITH hostname='hcathost' HCATALOG_SCHEMA='default'
-> HCATALOG_USER='hcatuser';
CREATE SCHEMA
=> SELECT sync_with_hcatalog_schema('hcat', 'hcat');
...
=> ALTER TABLE hcat.t ALTER COLUMN a1 SET DATA TYPE long varchar(1000000);
=> ALTER TABLE hcat.t ALTER COLUMN a2 SET DATA TYPE long varbinary(1000000);
The following example uses SYNC_WITH_HCATALOG_SCHEMA with a local (non-HCatalog) schema:
=> CREATE HCATALOG SCHEMA hcat WITH hostname='hcathost' HCATALOG_SCHEMA='default'
-> HCATALOG_USER='hcatuser';
CREATE SCHEMA
=> CREATE SCHEMA hcat_local;
CREATE SCHEMA
=> SELECT sync_with_hcatalog_schema('hcat_local', 'hcat');
6.11.10 - SYNC_WITH_HCATALOG_SCHEMA_TABLE
Copies the structure of a single table in a Hive database schema available through the HCatalog Connector to a Vertica table.
Copies the structure of a single table in a Hive database schema available through the HCatalog Connector to a Vertica table.
This function can synchronize the HCatalog schema directly. In this case, call it with the same schema name for the vertica_schema and hcatalog_schema parameters. The function can also synchronize a different schema to the HCatalog schema.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SYNC_WITH_HCATALOG_SCHEMA_TABLE( vertica_schema, hcatalog_schema, table_name )
Parameters
vertica_schema- The existing Vertica schema to store the copied HCatalog schema's metadata. This can be the same schema as
hcatalog_schema, or it can be a separate one created with CREATE SCHEMA.
hcatalog_schema- The HCatalog schema to copy, created with CREATE HCATALOG SCHEMA.
table_name- The table in
hcatalog_schema to copy. If table_name already exists in vertica_schema, the function overwrites it.
Privileges
Non-superuser: CREATE privileges on vertica_schema.
Users also require access to Hive data, one of the following:
-
USAGE permissions on hcat_schema, if Hive does not use an authorization service to manage access.
-
Permission through an authorization service (Sentry or Ranger), and access to the underlying files in HDFS. (Sentry can provide that access through ACL synchronization.)
-
dbadmin user privileges, with or without an authorization service.
Data type matching
Hive STRING and BINARY data types are matched, in Vertica, to the VARCHAR(65000) and VARBINARY(65000) types. Adjust the data types with ALTER TABLE as needed after creating the schema. The maximum size of a VARCHAR or VARBINARY in Vertica is 65000, but you can use LONG VARCHAR and LONG VARBINARY to specify larger values.
Hive and Vertica define string length in different ways. In Hive the length is the number of characters; in Vertica it is the number of bytes. Thus, a character encoding that uses more than one byte, such as Unicode, can cause mismatches between the two. To avoid data truncation, set values in Vertica based on bytes, not characters.
If data size exceeds the column size, Vertica logs an event at read time in the QUERY_EVENTS system table.
Examples
The following example uses SYNC_WITH_HCATALOG_SCHEMA_TABLE to synchronize the "nation" table:
=> CREATE SCHEMA 'hcat_local';
CREATE SCHEMA
=> CREATE HCATALOG SCHEMA hcat WITH hostname='hcathost' HCATALOG_SCHEMA='hcat'
HCATALOG_USER='hcatuser';
CREATE SCHEMA
=> SELECT sync_with_hcatalog_schema_table('hcat_local', 'hcat', 'nation');
sync_with_hcatalog_schema_table
-----------------------------------------------------------------------------
Schema hcat_local synchronized with hcat for table nation
table nation is created in schema hcat_local
(1 row)
The following example shows the behavior if the "nation" table already exists in the local schema:
=> SELECT sync_with_hcatalog_schema_table('hcat_local','hcat','nation');
sync_with_hcatalog_schema_table
-----------------------------------------------------------------------------
Schema hcat_local synchronized with hcat for table nation
table nation is altered in schema hcat_local
(1 row)
6.11.11 - VERIFY_HADOOP_CONF_DIR
Verifies that the Hadoop configuration that is used to access HDFS is valid on all Vertica nodes.
Verifies that the Hadoop configuration that is used to access HDFS is valid on all Vertica nodes. The configuration is valid if:
This function does not attempt to validate the settings of those properties; it only verifies that they have values.
It is possible for Hadoop configuration to be valid on some nodes and invalid on others. The function reports a validation failure if the value is invalid on any node; the rest of the output reports the details.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
VERIFY_HADOOP_CONF_DIR( )
Parameters
This function has no parameters.
Privileges
This function does not require privileges.
Examples
The following example shows the results when the Hadoop configuration is valid.
=> SELECT VERIFY_HADOOP_CONF_DIR();
verify_hadoop_conf_dir
-------------------------------------------------------------------
Validation Success
v_vmart_node0001: HadoopConfDir [PG_TESTOUT/config] is valid
v_vmart_node0002: HadoopConfDir [PG_TESTOUT/config] is valid
v_vmart_node0003: HadoopConfDir [PG_TESTOUT/config] is valid
v_vmart_node0004: HadoopConfDir [PG_TESTOUT/config] is valid
(1 row)
In the following example, the Hadoop configuration is valid on one node, but on other nodes a needed value is missing.
=> SELECT VERIFY_HADOOP_CONF_DIR();
verify_hadoop_conf_dir
-------------------------------------------------------------------
Validation Failure
v_vmart_node0001: HadoopConfDir [PG_TESTOUT/test_configs/config] is valid
v_vmart_node0002: No fs.defaultFS parameter found in config files in [PG_TESTOUT/config]
v_vmart_node0003: No fs.defaultFS parameter found in config files in [PG_TESTOUT/config]
v_vmart_node0004: No fs.defaultFS parameter found in config files in [PG_TESTOUT/config]
(1 row)
6.12 - Machine learning functions
Machine learning functions let you work with your data set in different stages of the data analysis process:.
Machine learning functions let you work with your data set in different stages of the data analysis process:
-
Preparing models
-
Training models
-
Evaluating models
-
Applying models
-
Managing models
Some Vertica machine learning functions are implemented as Vertica UDx functions, while others are implemented as meta-functions:
-
A UDx function accepts an input relation name from a FROM clause. The SELECT statement that calls the functions is composable—it can be used as a sub-query in another SELECT statement.
-
A meta-function accepts the input relation name as a single-quoted string passed to it as an argument or a named parameter. The data that the SELECT statement returns cannot be used in a sub-query. Machine learning meta-functions do not support temporary tables.
All machine learning functions automatically cast NUMERIC arguments to FLOAT.
Important
Before using a machine learning function, be aware that any open transaction on the current session might be committed.
6.12.1 - Data preparation
Vertica supports machine learning functions that prepare data as needed before subjecting it to analysis.
Vertica supports machine learning functions that prepare data as needed before subjecting it to analysis.
6.12.1.1 - BALANCE
Returns a view with an equal distribution of the input data based on the response_column.
Returns a view with an equal distribution of the input data based on the response_column.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
BALANCE ( 'output-view', 'input-relation', 'response-column', 'balance-method'
[ USING PARAMETERS sampling_ratio=ratio ] )
Arguments
output-view- The name of the view where Vertica saves the balanced data from the input relation.
Note
Note: The view that results from this function employs a random function. Its content can differ each time it is used in a query. To make the operations on the view predictable, store it in a regular table.
input-relation- The table or view that contains the data the function uses to create a more balanced data set. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- Name of the input column that represents the dependent variable, of type VARCHAR or INTEGER.
balance-method- Specifies a method to select data from the minority and majority classes, one of the following.
-
hybrid_sampling: Performs over-sampling and under-sampling on different classes so each class is equally represented.
-
over_sampling: Over-samples on all classes, with the exception of the most majority class, towards the most majority class's cardinality.
-
under_sampling: Under-samples on all classes, with the exception of the most minority class, towards the most minority class's cardinality.
-
weighted_sampling: An alias of under_sampling.
Parameters
ratio- The desired ratio between the majority class and the minority class. This value has no effect when used with balance method
hybrid_sampling.
Default: 1.0
Privileges
Non-superusers:
Examples
=> CREATE TABLE backyard_bugs (id identity, bug_type int, finder varchar(20));
CREATE TABLE
=> COPY backyard_bugs FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 1|Ants
>> 1|Beetles
>> 3|Ladybugs
>> 3|Ants
>> 3|Beetles
>> 3|Caterpillars
>> 2|Ladybugs
>> 3|Ants
>> 3|Beetles
>> 1|Ladybugs
>> 3|Ladybugs
>> \.
=> SELECT bug_type, COUNT(bug_type) FROM backyard_bugs GROUP BY bug_type;
bug_type | COUNT
----------+-------
2 | 1
1 | 3
3 | 7
(3 rows)
=> SELECT BALANCE('backyard_bugs_balanced', 'backyard_bugs', 'bug_type', 'under_sampling');
BALANCE
--------------------------
Finished in 1 iteration
(1 row)
=> SELECT bug_type, COUNT(bug_type) FROM backyard_bugs_balanced GROUP BY bug_type;
----------+-------
2 | 1
1 | 2
3 | 1
(3 rows)
See also
6.12.1.2 - CHI_SQUARED
Computes the conditional chi-Square independence test on two categorical variables to find the likelihood that the two variables are independent.
Computes the conditional chi-square independence test on two categorical variables to find the likelihood that the two variables are independent. To condition the independence test on another set of variables, you can partition the data on these variables using a PARTITION BY clause.
Tip
If a categorical column is not of a
numeric data type, you can use the
HASH function to convert it into a column of type INT, where each category is mapped to a unique integer. However, note that NULL values are hashed to zero, so they will be included in the test instead of skipped by the function.
This function is a multi-phase transform function.
Syntax
CHI_SQUARED( 'x-column', 'y-column'
[ USING PARAMETERS param=value[,...] ] )
Arguments
x-column, y-column- Columns in the input relation to be tested for dependency with each other. These columns must contain categorical data in numeric format.
Parameters
x_cardinality- Integer in the range [1, 20], the cardinality of x-column. If the cardinality of x-column is less than the default value of 20, setting this parameter can decrease the amount memory used by the function.
Default: 20
y_cardinality- Integer in the range [1, 20], the cardinality of y-column. If the cardinality of y-column is less than the default value of 20, setting this parameter can decrease the amount memory used by the function.
Default: 20
alpha- Float in the range (0.0, 1.0), the significance level. If the returned
pvalue is less than this value, the null hypothesis, which assumes the variables are independent, is rejected.
Default: 0.05
Returns
The function returns two values:
pvalue (float): the confidence that the two variables are independent. If this value is greater than the alpha parameter value, the null hypothesis is accepted and the variables are considered independent.independent (boolean): true if the variables are independent; otherwise, false.
Privileges
SELECT privileges on the input relation
Examples
The following examples use the titanic dataset from the machine learning example data. If you have not downloaded these datasets, see Download the machine learning example data for instructions.
The titanic_training table contains data related to passengers on the Titanic, including:
pclass: the ticket class of the passenger, ranging from 1st class to 3rd classsurvived: whether the passenger survived, where 1 is yes and 0 is nogender: gender of the passengersibling_and_spouse_count: number of siblings aboard the Titanicembarkation_point: port of embarkation
To test whether the survival of a passenger is dependent on their ticket class, run the following chi-square test:
=> SELECT CHI_SQUARED(pclass, survived USING PARAMETERS x_cardinality=3, y_cardinality=2, alpha=0.05) OVER() FROM titanic_training;
pvalue | independent
--------+-------------
0 | f
(1 row)
With a returned pvalue of zero, the null hypothesis is rejected and you can conclude that the survived and pclass variables are dependent. To test whether this outcome is conditional on the gender of the passenger, partition by the gender column in the OVER clause:
=> SELECT CHI_SQUARED(pclass, survived USING PARAMETERS x_cardinality=3, y_cardinality=2) OVER(PARTITION BY gender) FROM titanic;
pvalue | independent
--------+-------------
0 | f
(1 row)
As the pvalue is still zero, it is clear that the dependence of the pclass and survived variables is not conditional on the gender of the passenger.
If one of the categorical columns that you want to test is not a numeric type, use the HASH function to convert it into type INT:
=> SELECT CHI_SQUARED(sibling_and_spouse_count, HASH(embarkation_point) USING PARAMETERS alpha=0.05) OVER() FROM titanic_training;
pvalue | independent
--------------------+-------------
0.0753039994044853 | t
(1 row)
The returned pvalue is greater than alpha, meaning the null hypothesis is accepted and the sibling_and_spouse_count and embarkation_point are independent.
6.12.1.3 - CORR_MATRIX
Takes an input relation with numeric columns, and calculates the Pearson Correlation Coefficient between each pair of its input columns.
Takes an input relation with numeric columns, and calculates the Pearson Correlation Coefficient between each pair of its input columns. The function is implemented as a Multi-Phase Transform function.
Syntax
CORR_MATRIX ( input-columns ) OVER()
Arguments
input-columns- A comma-separated list of the columns in the input table. The input columns can be of any numeric type or BOOL, but they will be converted internally to FLOAT. The number of input columns must be more than 1 and not more than 1600.
Returns
CORR_MATRIX returns the correlation matrix in triplet format. That is, each pair-wise correlation is identified by three returned columns: name of the first variable, name of the second variable, and the correlation value of the pair. The function also returns two extra columns: number_of_ignored_input_rows and number_of_processed_input_rows. The value of the fourth/fifth column indicates the number of rows from the input which are ignored/used to calculate the corresponding correlation value. Any input pair with NULL, Inf, or NaN is ignored.
The correlation matrix is symmetric with a value of 1 on all diagonal elements; therefore, it can return only the value of elements above the diagonals—that is, the upper triangle. Nevertheless, the function returns the entire matrix to simplify any later operations. Then, the number of output rows is:
(#input-columns)^2
The first two output columns are of type VARCHAR(128), the third one is of type FLOAT, and the last two are of type INT.
Notes
-
The contents of the OVER clause must be empty.
-
The function returns no rows when the input table is empty.
-
When any of X_i and Y_i is NULL, Inf, or NaN, the pair will not be included in the calculation of CORR(X, Y). That is, any input pair with NULL, Inf, or NaN is ignored.
-
For the pair of (X,X), regardless of the contents of X: CORR(X,X) = 1, number_of_ignored_input_rows = 0, and number_of_processed_input_rows = #input_rows.
-
When (NSUMX2 == SUMXSUMX) or (NSUMY2 == SUMYSUMY) then value of CORR(X, Y) will be NULL. In theory it can happen in case of a column with constant values; nevertheless, it may not be always observed because of rounding error.
-
In the special case where all pair values of (X_i,Y_i) contain NULL, inf, or NaN, and X != Y: CORR(X,Y)=NULL.
Examples
The following example uses the iris dataset.*
SELECT CORR_MATRIX("Sepal.Length", "Sepal.Width", "Petal.Length", "Petal.Width") OVER() FROM iris;
variable_name_1 | variable_name_2 | corr_value | number_of_ignored_input_rows | number_of_processed_input_rows
----------------+-----------------+-------------------+------------------------------+--------------------------------
Sepal.Length | Sepal.Width |-0.117569784133002 | 0 | 150
Sepal.Width | Sepal.Length |-0.117569784133002 | 0 | 150
Sepal.Length | Petal.Length |0.871753775886583 | 0 | 150
Petal.Length | Sepal.Length |0.871753775886583 | 0 | 150
Sepal.Length | Petal.Width |0.817941126271577 | 0 | 150
Petal.Width | Sepal.Length |0.817941126271577 | 0 | 150
Sepal.Width | Petal.Length |-0.42844010433054 | 0 | 150
Petal.Length | Sepal.Width |-0.42844010433054 | 0 | 150
Sepal.Width | Petal.Width |-0.366125932536439 | 0 | 150
Petal.Width | Sepal.Width |-0.366125932536439 | 0 | 150
Petal.Length | Petal.Width |0.962865431402796 | 0 | 150
Petal.Width | Petal.Length |0.962865431402796 | 0 | 150
Sepal.Length | Sepal.Length |1 | 0 | 150
Sepal.Width | Sepal.Width |1 | 0 | 150
Petal.Length | Petal.Length |1 | 0 | 150
Petal.Width | Petal.Width |1 | 0 | 150
(16 rows)
|
6.12.1.4 - DETECT_OUTLIERS
Returns the outliers in a data set based on the outlier threshold.
Returns the outliers in a data set based on the outlier threshold. The output is a table that contains the outliers. DETECT_OUTLIERS uses the detection method robust_szcore to normalize each input column. The function then identifies as outliers all rows that contain a normalized value greater than the default or specified threshold.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DETECT_OUTLIERS ( 'output-table', 'input-relation','input-columns', 'detection-method'
[ USING PARAMETERS
[outlier_threshold = threshold]
[, exclude_columns = 'excluded-columns']
[, partition_columns = 'partition-columns'] ] )
Arguments
output-table- The name of the table where Vertica saves rows that are outliers along the chosen
input_columns. All columns are present in this table.
input-relation- The table or view that contains outlier data. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be of type numeric.
detection-method- The outlier detection method to use, set to
robust_zscore.
Parameters
outlier_threshold- The minimum normalized value in a row that is used to identify that row as an outlier.
Default: 3.0
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
partition_columns- Comma-separated list of column names from the input table or view that defines the partitions.
DETECT_OUTLIERS detects outliers among each partition separately.
Default: empty list
Privileges
Non-superusers:
Examples
The following example shows how to use DETECT_OUTLIERS:
=> CREATE TABLE baseball_roster (id identity, last_name varchar(30), hr int, avg float);
CREATE TABLE
=> COPY baseball_roster FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Polo|7|.233
>> Gloss|45|.170
>> Gus|12|.345
>> Gee|1|.125
>> Laus|3|.095
>> Hilltop|16|.222
>> Wicker|78|.333
>> Scooter|0|.121
>> Hank|999999|.8888
>> Popup|35|.378
>> \.
=> SELECT * FROM baseball_roster;
id | last_name | hr | avg
----+-----------+--------+--------
3 | Gus | 12 | 0.345
4 | Gee | 1 | 0.125
6 | Hilltop | 16 | 0.222
10 | Popup | 35 | 0.378
1 | Polo | 7 | 0.233
7 | Wicker | 78 | 0.333
9 | Hank | 999999 | 0.8888
2 | Gloss | 45 | 0.17
5 | Laus | 3 | 0.095
8 | Scooter | 0 | 0.121
(10 rows)
=> SELECT DETECT_OUTLIERS('baseball_outliers', 'baseball_roster', 'id, hr, avg', 'robust_zscore' USING PARAMETERS
outlier_threshold=3.0);
DETECT_OUTLIERS
--------------------------
Detected 2 outliers
(1 row)
=> SELECT * FROM baseball_outliers;
id | last_name | hr | avg
----+-----------+------------+-------------
7 | Wicker | 78 | 0.333
9 | Hank | 999999 | 0.8888
(2 rows)
6.12.1.5 - IFOREST
Trains and returns an isolation forest (iForest) model.
Trains and returns an isolation forest (iForest) model. After you train the model, you can use the APPLY_IFOREST function to predict outliers in an input relation.
For more information about how the iForest algorithm works, see Isolation Forest.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
IFOREST( 'model-name', 'input-relation', 'input-columns' [ USING PARAMETERS param=value[,...] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the input data for IFOREST.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Columns must be of types CHAR, VARCHAR, BOOL, INT, or FLOAT.
Columns of types CHAR, VARCHAR, and BOOL are treated as categorical features; all others are treated as numeric features.
Parameters
exclude_columns- Comma-separated list of column names from
input-columns to exclude from processing.
Default: Empty string ('')
ntree- Integer in the range [1, 1000], specifies the number of trees in the forest.
Default: 100
sampling_size- Float in the range (0.0, 1.0], specifies the portion of the input data set that is randomly picked, without replacement, for training each tree.
Default: 0.632
col_sample_by_tree- Float in the range (0.0, 1.0], specifies the fraction of columns that are randomly picked for training each tree.
Default: 1.0
max_depth- Integer in the range [1, 100], specifies the maximum depth for growing each tree.
Default: 10
nbins- Integer in the range [2, 1000], specifies the number of bins used to discretize continuous features.
Default: 32
Model Attributes
details- Details about the function's predictor columns, including:
tree_count- Number of trees in the model.
rejected_row_count- Number of rows in
input-relation that were skipped because they contained an invalid value.
accepted_row_count- Total number of rows in
input-relation minus rejected_row_count.
call_string- Value of all input arguments that were specified at the time the function was called.
Privileges
Non-superusers:
Examples
In the following example, the input data to the function contains columns of type INT, VARCHAR, and FLOAT:
=> SELECT IFOREST('baseball_anomalies','baseball','team, hr, hits, avg, salary' USING PARAMETERS ntree=75, sampling_size=0.7,
max_depth=15);
IFOREST
----------
Finished
(1 row)
You can verify that all the input columns were read in correctly by calling GET_MODEL_SUMMARY and checking the details section:
=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='baseball_anomalies');
GET_MODEL_SUMMARY
-------------------------------------------------------------------------------------------------------------------------------------
===========
call_string
===========
SELECT iforest('public.baseball_anomalies', 'baseball', 'team, hr, hits, avg, salary' USING PARAMETERS exclude_columns='', ntree=75,
sampling_size=0.7, col_sample_by_tree=1, max_depth=15, nbins=32);
=======
details
=======
predictor| type
---------+----------------
team |char or varchar
hr | int
hits | int
avg |float or numeric
salary |float or numeric
===============
Additional Info
===============
Name |Value
------------------+-----
tree_count | 75
rejected_row_count| 0
accepted_row_count|1000
(1 row)
See also
6.12.1.6 - IMPUTE
Imputes missing values in a data set with either the mean or the mode, based on observed values for a variable in each column.
Imputes missing values in a data set with either the mean or the mode, based on observed values for a variable in each column. This function supports numeric and categorical data types.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
IMPUTE( 'output-view', 'input-relation', 'input-columns', 'method'
[ USING PARAMETERS [exclude_columns = 'excluded-columns'] [, partition_columns = 'partition-columns'] ] )
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Arguments
output-view- Name of the view that shows the input table with imputed values in place of missing values. In this view, rows without missing values are kept intact while the rows with missing values are modified according to the specified method.
input-relation- The table or view that contains the data for missing-value imputation. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of input columns where missing values will be replaced, or asterisk (*) to specify all columns. All columns must be of type numeric or BOOLEAN.
method- The method to compute the missing value replacements, one of the following:
-
mean: The missing values in each column will be replaced by the mean of that column. This method can be used for numeric data only.
-
mode: The missing values in each column will be replaced by the most frequent value in that column. This method can be used for categorical data only.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
partition_columns- Comma-separated list of column names from the input relation that defines the partitions.
Privileges
Non-superusers:
Examples
Execute IMPUTE on the small_input_impute table, specifying the mean method:
=> SELECT impute('output_view','small_input_impute', 'pid, x1,x2,x3,x4','mean'
USING PARAMETERS exclude_columns='pid');
impute
--------------------------
Finished in 1 iteration
(1 row)
Execute IMPUTE, specifying the mode method:
=> SELECT impute('output_view3','small_input_impute', 'pid, x5,x6','mode' USING PARAMETERS exclude_columns='pid');
impute
--------------------------
Finished in 1 iteration
(1 row)
See also
Imputing missing values
6.12.1.7 - NORMALIZE
Runs a normalization algorithm on an input relation.
Runs a normalization algorithm on an input relation. The output is a view with the normalized data.
Note
Note: This function differs from NORMALIZE_FIT, which creates and stores a model rather than creating a view definition. This can lead to different performance characteristics between the two functions.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
NORMALIZE ( 'output-view', 'input-relation', 'input-columns', 'normalization-method'
[ USING PARAMETERS exclude_columns = 'excluded-columns' ] )
Arguments
output-view- The name of the view showing the input relation with normalized data replacing the specified input columns. .
input-relation- The table or view that contains the data to normalize. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of numeric input columns that contain the values to normalize, or asterisk (*) to select all columns.
normalization-method- The normalization method to use, one of the following:
-
minmax
-
zscore
-
robust_zscore
If infinity values appear in the table, the method ignores those values.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
Privileges
Non-superusers:
Examples
These examples show how you can use the NORMALIZE function on the wt and hp columns in the mtcars table.
Execute the NORMALIZE function, and specify the minmax method:
=> SELECT NORMALIZE('mtcars_norm', 'mtcars',
'wt, hp', 'minmax');
NORMALIZE
--------------------------
Finished in 1 iteration
(1 row)
Execute the NORMALIZE function, and specify the zscore method:
=> SELECT NORMALIZE('mtcars_normz','mtcars',
'wt, hp', 'zscore');
NORMALIZE
--------------------------
Finished in 1 iteration
(1 row)
Execute the NORMALIZE function, and specify the robust_zscore method:
=> SELECT NORMALIZE('mtcars_normz', 'mtcars',
'wt, hp', 'robust_zscore');
NORMALIZE
--------------------------
Finished in 1 iteration
(1 row)
See also
Normalizing data
6.12.1.8 - NORMALIZE_FIT
This function differs from NORMALIZE, which directly outputs a view with normalized results, rather than storing normalization parameters into a model for later operation.
Note
This function differs from
NORMALIZE, which directly outputs a view with normalized results, rather than storing normalization parameters into a model for later operation.
NORMALIZE_FIT computes normalization parameters for each of the specified columns in an input relation. The resulting model stores the normalization parameters. For example, for MinMax normalization, the minimum and maximum value of each column are stored in the model. The generated model serves as input to functions APPLY_NORMALIZE and REVERSE_NORMALIZE.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
NORMALIZE_FIT ( 'model-name', 'input-relation', 'input-columns', 'normalization-method'
[ USING PARAMETERS [exclude_columns = 'excluded-columns'] [, output_view = 'output-view'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the data to normalize. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be of data type numeric.
normalization-method- The normalization method to use, one of the following:
-
minmax
-
zscore
-
robust_zscore
If you specify robust_zscore, NORMALIZE_FIT uses the function APPROXIMATE_MEDIAN [aggregate].
All normalization methods ignore infinity, negative infinity, or NULL values in the input relation.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
output_view- Name of the view that contains all columns from the input relation, with the specified input columns normalized.
Model attributes
data- Normalization method set to
minmax:
-
colNames: Model column names
-
mins: Minimum value of each column
-
maxes: Maximum value of each column
Privileges
Non-superusers:
-
CREATE privileges on the schema where the model is created
-
SELECT privileges on the input relation
-
CREATE privileges on the output view schema
Examples
The following example creates a model with NORMALIZE_FIT using the wt and hp columns in table mtcars , and then uses this model in successive calls to APPLY_NORMALIZE and REVERSE_NORMALIZE.
=> SELECT NORMALIZE_FIT('mtcars_normfit', 'mtcars', 'wt,hp', 'minmax');
NORMALIZE_FIT
---------------
Success
(1 row)
The following call to APPLY_NORMALIZE specifies the hp and cyl columns in table mtcars, where hp is in the normalization model and cyl is not in the normalization model:
=> CREATE TABLE mtcars_normalized AS SELECT APPLY_NORMALIZE (hp, cyl USING PARAMETERS model_name = 'mtcars_normfit') FROM mtcars;
CREATE TABLE
=> SELECT * FROM mtcars_normalized;
hp | cyl
--------------------+-----
0.434628975265018 | 8
0.681978798586572 | 8
0.434628975265018 | 6
1 | 8
0.540636042402827 | 8
0 | 4
0.681978798586572 | 8
0.0459363957597173 | 4
0.434628975265018 | 8
0.204946996466431 | 6
0.250883392226148 | 6
0.049469964664311 | 4
0.204946996466431 | 6
0.201413427561837 | 4
0.204946996466431 | 6
0.250883392226148 | 6
0.049469964664311 | 4
0.215547703180212 | 4
0.0353356890459364 | 4
0.187279151943463 | 6
0.452296819787986 | 8
0.628975265017668 | 8
0.346289752650177 | 8
0.137809187279152 | 4
0.749116607773852 | 8
0.144876325088339 | 4
0.151943462897526 | 4
0.452296819787986 | 8
0.452296819787986 | 8
0.575971731448763 | 8
0.159010600706714 | 4
0.346289752650177 | 8
(32 rows)
=> SELECT REVERSE_NORMALIZE (hp, cyl USING PARAMETERS model_name='mtcars_normfit') FROM mtcars_normalized;
hp | cyl
-----+-----
175 | 8
245 | 8
175 | 6
335 | 8
205 | 8
52 | 4
245 | 8
65 | 4
175 | 8
110 | 6
123 | 6
66 | 4
110 | 6
109 | 4
110 | 6
123 | 6
66 | 4
113 | 4
62 | 4
105 | 6
180 | 8
230 | 8
150 | 8
91 | 4
264 | 8
93 | 4
95 | 4
180 | 8
180 | 8
215 | 8
97 | 4
150 | 8
(32 rows)
The following call to REVERSE_NORMALIZE also specifies the hp and cyl columns in table mtcars, where hp is in normalization model mtcars_normfit, and cyl is not in the normalization model.
=> SELECT REVERSE_NORMALIZE (hp, cyl USING PARAMETERS model_name='mtcars_normfit') FROM mtcars_normalized;
hp | cyl
-----------------+-----
205.000005722046 | 8
150.000000357628 | 8
150.000000357628 | 8
93.0000016987324 | 4
174.99999666214 | 8
94.9999992102385 | 4
214.999997496605 | 8
97.0000009387732 | 4
245.000006556511 | 8
174.99999666214 | 6
335 | 8
245.000006556511 | 8
62.0000002086163 | 4
174.99999666214 | 8
230.000002026558 | 8
52 | 4
263.999997675419 | 8
109.999999523163 | 6
123.000002324581 | 6
64.9999996386468 | 4
66.0000005029142 | 4
112.999997898936 | 4
109.999999523163 | 6
180.000000983477 | 8
180.000000983477 | 8
108.999998658895 | 4
109.999999523163 | 6
104.999999418855 | 6
123.000002324581 | 6
180.000000983477 | 8
66.0000005029142 | 4
90.9999999701977 | 4
(32 rows)
See also
Normalizing data
6.12.1.9 - ONE_HOT_ENCODER_FIT
Generates a sorted list of each of the category levels for each feature to be encoded, and stores the model.
Generates a sorted list of each of the category levels for each feature to be encoded, and stores the model.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ONE_HOT_ENCODER_FIT ( 'model-name', 'input-relation','input-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, output_view = 'output-view']
[, extra_levels = 'category-levels'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the data for one hot encoding. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be INTEGER, BOOLEAN, VARCHAR, or dates.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
output_view- The name of the view that stores the input relation and the one hot encodings. Columns are returned in the order they appear in the input relation, with the one-hot encoded columns appended after the original columns.
extra_levels- Additional levels in each category that are not in the input relation. This parameter should be passed as a string that conforms with the JSON standard, with category names as keys, and lists of extra levels in each category as values.
Model attributes
call_string- The value of all input arguments that were specified at the time the function was called.
-
varchar_categories integer_categories boolean_categories date_categories
- Settings for all:
-
category_name: Column name
-
category_level: Levels of the category, sorted for each category
-
category_level_index: Index of this categorical level in the sorted list of levels for the category.
Privileges
Non-superusers:
-
CREATE privileges on the schema where the model is created
-
SELECT privileges on the input relation
-
CREATE privileges on the output view schema
Examples
=> SELECT ONE_HOT_ENCODER_FIT ('one_hot_encoder_model','mtcars','*'
USING PARAMETERS exclude_columns='mpg,disp,drat,wt,qsec,vs,am');
ONE_HOT_ENCODER_FIT
--------------------
Success
(1 row)
See also
6.12.1.10 - PCA
Computes principal components from the input table/view.
Computes principal components from the input table/view. The results are saved in a PCA model. Internally, PCA finds the components by using SVD on the co-variance matrix built from the input date. The singular values of this decomposition are also saved as part of the PCA model. The signs of all elements of a principal component could be flipped all together on different runs.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PCA ( 'model-name', 'input-relation', 'input-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, num_components = num-components]
[, scale = is-scaled]
[, method = 'method'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the input data for PCA.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. All input columns must be a numeric data type.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
num_components- The number of components to keep in the model. If this value is not provided, all components are kept. The maximum number of components is the number of non-zero singular values returned by the internal call to SVD. This number is less than or equal to SVD (number of columns, number of rows).
scale- A Boolean value that specifies whether to standardize the columns during the preparation step:
method- The method used to calculate PCA, can be set to
LAPACK.
Model attributes
columns- The information about columns from the input relation used for creating the PCA model:
singular_values- The information about singular values found. They are sorted in descending order:
-
index
-
value
-
explained_variance : percentage of the variance in data that can be attributed to this singular value
-
accumulated_explained_variance : percentage of the variance in data that can be retained if we drop all singular values after this current one
principal_components- The principal components corresponding to the singular values mentioned above:
counters- The information collected during training the model, stored as name-value pairs:
-
counter_name
-
accepted_row_count: number of valid rows in the data
-
rejected_row_count: number of invalid rows (having NULL, INF or NaN) in the data
-
iteration_count: number of iterations, always 1 for the current implementation of PCA
-
counter_value
call_string- The function call that created the model.
Privileges
Non-superusers:
Examples
=> SELECT PCA ('pcamodel', 'world','country,HDI,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,
em1978,em1979,em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,
em1993,em1994,em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,
em2008,em2009,em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,
gdp1981,gdp1982,gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,
gdp1994,gdp1995,gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,
gdp2007,gdp2008,gdp2009,gdp2010' USING PARAMETERS exclude_columns='HDI,country');
PCA
---------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 96 Rejected Rows: 0
(1 row)
=> CREATE TABLE worldPCA AS SELECT
APPLY_PCA (HDI,country,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,em1978,em1979,
em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,em1993,em1994,
em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,em2008,em2009,
em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,gdp1981,gdp1982,
gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,gdp1994,gdp1995,
gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,gdp2007,gdp2008,
gdp2009,gdp2010 USING PARAMETERS model_name='pcamodel', exclude_columns='HDI, country', key_columns='HDI,
country',cutoff=.3)OVER () FROM world;
CREATE TABLE
=> SELECT * FROM worldPCA;
HDI | country | col1
------+---------------------+-------------------
0.886 | Belgium | 79002.2946705704
0.699 | Belize | -25631.6670012556
0.427 | Benin | -40373.4104598122
0.805 | Chile | -16805.7940082156
0.687 | China | -37279.2893141103
0.744 | Costa Rica | -19505.5631231635
0.4 | Cote d'Ivoire | -38058.2060339272
0.776 | Cuba | -23724.5779612041
0.895 | Denmark | 117325.594028813
0.644 | Egypt | -34609.9941604549
...
(96 rows)
=> SELECT APPLY_INVERSE_PCA (HDI, country, col1
USING PARAMETERS model_name = 'pcamodel', exclude_columns='HDI,country',
key_columns = 'HDI, country') OVER () FROM worldPCA;
HDI | country | em1970 | em1971 | em1972 | em1973 |
em1974 | em1975 | em1976| em1977 | em1978 | em1979
| em1980 | em1981 | em1982 | em1983 | em1984 |em1985
| em1986 | em1987 | em1988 | em1989 | em1990 | em1991
| em1992 | em1993| em1994 | em1995 | em1996 | em1997
| em1998 | em1999 | em2000 | em2001 |em2002 |
em2003 | em2004 | em2005 | em2006 | em2007 | em2008
| em2009 | em2010 | gdp1970 | gdp1971 | gdp1972 | gdp1973
| gdp1974 | gdp1975 | gdp1976 | gdp1977 |gdp1978 | gdp1979
| gdp1980 | gdp1981 | gdp1982 | gdp1983 | gdp1984 | gdp1985
| gdp1986| gdp1987 | gdp1988 | gdp1989 | gdp1990 | gdp1991
| gdp1992 | gdp1993 | gdp1994 | gdp1995 | gdp1996 |
gdp1997 | gdp1998 | gdp1999 | gdp2000 | gdp2001 | gdp2002
| gdp2003 |gdp2004 | gdp2005 | gdp2006 | gdp2007 | gdp2008
| gdp2009 | gdp2010
-------+---------------------+-------------------+-------------------+------------------+------------------
+------------------+-------------------+------------------+------------------+-------------------+---------
----------+-------------------+------------------+-------------------+-------------------+-----------------
--+------------------+-------------------+-------------------+-------------------+------------------+-------
-----------+------------------+-------------------+-------------------+------------------+------------------
-+-------------------+------------------+-------------------+-------------------+-------------------+-------
------------+--------------------+------------------+-------------------+------------------+----------------
---+-------------------+-------------------+------------------+-------------------+------------------+------
------------+------------------+------------------+------------------+------------------+------------------+
------------------+------------------+------------------+------------------+------------------+-------------
-----+------------------+------------------+------------------+------------------+------------------+-------
-----------+------------------+------------------+------------------+------------------+------------------+-
-----------------+------------------+------------------+------------------+------------------+--------------
----+------------------+------------------+------------------+------------------+------------------+--------
----------+------------------+------------------+------------------+------------------+------------------
0.886 | Belgium | 18585.6613572407 | -16145.6374560074 | 26938.956253415 | 8094.30475779595 |
12073.5461203817 | -11069.0567600181 | 19133.8584911727| 5500.312894949 | -4227.94863799987 | 6265.77925410752
| -10884.749295608 | 30929.4669575201 | -7831.49439429977 | 3235.81760508742 | -22765.9285442662 | 27200
.6767714485 | -10554.9550160917 | 1169.4144482273 | -16783.7961289161 | 27932.2660829329 | 17227.9083196848
| 13956.0524012749 | -40175.6286481088 | -10889.4785920499 | 22703.6576872859 | -14635.5832197402 |
2857.12270512168 | 20473.5044214494 | -52199.4895696423 | -11038.7346460738 | 18466.7298633088 | -17410.4225137703 |
-3475.63826305462 | 29305.6753822341 | 1242.5724942049 | 17491.0096310849 | -12609.9984515902 | -17909.3603476248
| 6276.58431412381 | 21851.9475485178 | -2614.33738160397 | 3777.74134131349 | 4522.08854282736 | 4251.90446379366
| 4512.15101396876 | 4265.49424538129 | 5190.06845330997 | 4543.80444817989 | 5639.81122679089 | 4420.44705213467
| 5658.8820279283 | 5172.69025294376 | 5019.63640408663 | 5938.84979495903 | 4976.57073629812 | 4710.49525137591
| 6523.65700286465 | 5067.82520773578 | 6789.13070219317 | 5525.94643553563 | 6894.68336419297 | 5961.58442474331
| 5661.21093840818 | 7721.56088518218 | 5959.7301109143 | 6453.43604137202 | 6739.39384033096 | 7517.97645468455
| 6907.49136910647 | 7049.03921764209 | 7726.49091035527 | 8552.65909911844 | 7963.94487647115 | 7187.45827585515
| 7994.02955410523 | 9532.89844418041 | 7962.25713582666 | 7846.68238907624 | 10230.9878908643 | 8642.76044946519
| 8886.79860331866 | 8718.3731386891
...
(96 rows)
See also
6.12.1.11 - SUMMARIZE_CATCOL
Returns a statistical summary of categorical data input, in three columns:.
Returns a statistical summary of categorical data input, in three columns:
-
CATEGORY: Categorical levels, of the same SQL data type as the summarized column
-
COUNT: The number of category levels, of type INTEGER
-
PERCENT: Represents category percentage, of type FLOAT
Syntax
SUMMARIZE_CATCOL (target-column
[ USING PARAMETERS TOPK = topk-value [, WITH_TOTALCOUNT = show-total] ] )
OVER()
Arguments
target-column- The name of the input column to summarize, one of the following data types:
-
BOOLEAN
-
FLOAT
-
INTEGER
-
DATE
-
CHAR/VARCHAR
Parameters
TOPK- Integer, specifies how many of the most frequent rows to include in the output.
WITH_TOTALCOUNT- A Boolean value that specifies whether the table contains a heading row that displays the total number of rows displayed in the target column, and a percent equal to 100.
Default:true
Examples
This example shows the categorical summary for the current_salary column in the salary_data table. The output of the query shows the column category, count, and percent. The first column gives the categorical levels, with the same SQL data type as the input column, the second column gives a count of that value, and the third column gives a percentage.
=> SELECT SUMMARIZE_CATCOL (current_salary USING PARAMETERS TOPK = 5) OVER() FROM salary_data;
CATEGORY | COUNT | PERCENT
---------+-------+---------
| 1000 | 100
39004 | 2 | 0.2
35321 | 1 | 0.1
36313 | 1 | 0.1
36538 | 1 | 0.1
36562 | 1 | 0.1
(6 rows)
6.12.1.12 - SUMMARIZE_NUMCOL
Returns a statistical summary of columns in a Vertica table:.
Returns a statistical summary of columns in a Vertica table:
-
Count
-
Mean
-
Standard deviation
-
Min/max values
-
Approximate percentile
-
Median
All summary values are FLOAT data types, except INTEGER for count.
Syntax
SUMMARIZE_NUMCOL (input-columns [ USING PARAMETERS exclude_columns = 'excluded-columns'] ) OVER()
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. All columns must be a numeric data type. If you select all columns,
SUMMARIZE_NUMCOL normalizes all columns in the model
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
Examples
Show the statistical summary for the age and salary columns in the employee table:
=> SELECT SUMMARIZE_NUMCOL(* USING PARAMETERS exclude_columns='id,name,gender,title') OVER() FROM employee;
COLUMN | COUNT | MEAN | STDDEV | MIN | PERC25 | MEDIAN | PERC75 | MAX
---------------+-------+------------+------------------+---------+---------+---------+-----------+--------
age | 5 | 63.4 | 19.3209730603818 | 44 | 45 | 67 | 71 | 90
salary | 5 | 3456.76 | 1756.78754300285 | 1234.56 | 2345.67 | 3456.78 | 4567.89 | 5678.9
(2 rows)
6.12.1.13 - SVD
Computes singular values (the diagonal of the S matrix) and right singular vectors (the V matrix) of an SVD decomposition of the input relation.
Computes singular values (the diagonal of the S matrix) and right singular vectors (the V matrix) of an SVD decomposition of the input relation. The results are saved as an SVD model. The signs of all elements of a singular vector in SVD could be flipped all together on different runs.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SVD ( 'model-name', 'input-relation', 'input-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, num_components = num-components]
[, method = 'method'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the input data for SVD.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be a numeric data type.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
num_components- The number of components to keep in the model. The maximum number of components is the number of non-zero singular values computed, which is less than or equal to min (number of columns, number of rows). If you omit this parameter, all components are kept.
method- The method used to calculate SVD, can be set to
LAPACK.
Model attributes
columns- The information about columns from the input relation used for creating the SVD model:
singular_values- The information about singular values found. They are sorted in descending order:
-
index
-
value
-
explained_variance : percentage of the variance in data that can be attributed to this singular value
-
accumulated_explained_variance : percentage of the variance in data that can be retained if we drop all singular values after this current one
right_singular_vectors- The right singular vectors corresponding to the singular values mentioned above:
counters- The information collected during training the model, stored as name-value pairs:
-
counter_name
-
accepted_row_count: number of valid rows in the data
-
rejected_row_count: number of invalid rows (having NULL, INF or NaN) in the data
-
iteration_count: number of iterations, always 1 for the current implementation of SVD
-
counter_value
call_string- The function call that created the model.
Privileges
Non-superusers:
Examples
=> SELECT SVD ('svdmodel', 'small_svd', 'x1,x2,x3,x4');
SVD
--------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 8 Rejected Rows: 0
(1 row)
=> CREATE TABLE transform_svd AS SELECT
APPLY_SVD (id, x1, x2, x3, x4 USING PARAMETERS model_name='svdmodel', exclude_columns='id', key_columns='id')
OVER () FROM small_svd;
CREATE TABLE
=> SELECT * FROM transform_svd;
id | col1 | col2 | col3 | col4
----+-------------------+---------------------+---------------------+--------------------
4 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
6 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
1 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
2 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
3 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
5 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
8 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
7 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
(8 rows)
=> SELECT APPLY_INVERSE_SVD (* USING PARAMETERS model_name='svdmodel', exclude_columns='id',
key_columns='id') OVER () FROM transform_svd;
id | x1 | x2 | x3 | x4
----+------------------+------------------+------------------+------------------
4 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
6 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
7 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
1 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
2 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
3 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
5 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
8 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
(8 rows)
See also
6.12.2 - Machine learning algorithms
Vertica supports a full range of machine learning functions that train a model on a set of data, and return a model that can be saved for later execution.
Vertica supports a full range of machine learning functions that train a model on a set of data, and return a model that can be saved for later execution.
These functions require the following privileges for non-superusers:
Note
Machine learning algorithms contain a subset of four classification functions:
6.12.2.1 - ARIMA
Creates and trains an autoregressive integrated moving average (ARIMA) model from a time series with consistent timesteps.
Creates and trains an autoregressive integrated moving average (ARIMA) model from a time series with consistent timesteps. ARIMA models combine the abilities of AUTOREGRESSOR and MOVING_AVERAGE models by making future predictions based on both preceding time series values and errors of previous predictions. ARIMA models also provide the option to apply a differencing operation to the input data, which can turn a non-stationary time series into a stationary time series. After the model is trained, you can make predictions with the PREDICT_ARIMA function.
In Vertica, ARIMA is implemented using a Kalman Filter state-space approach, similar to Gardner, G., et al. This approach updates the state-space model with each element in the training data in order to calculate a loss score over the training data. A BFGS optimizer is then used to adjust the coefficients, and the state-space estimation is rerun until convergence. Because of this repeated estimation process, ARIMA consumes large amounts of memory when called with high values of p and q.
Given that the input data must be sorted by timestamp, this algorithm is single-threaded.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Immutable
Syntax
ARIMA( 'model-name', 'input-relation', 'timeseries-column', 'timestamp-column'
USING PARAMETERS param=value[,...] )
Arguments
model-name- Model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- Name of the table or view containing
timeseries-column and timestamp-column.
timeseries-column- Name of a NUMERIC column in
input-relation that contains the dependent variable or outcome.
timestamp-column- Name of an INTEGER, FLOAT, or TIMESTAMP column in
input-relation that represents the timestamp variable. The timestep between consecutive entries should be consistent throughout the timestamp-column.
Tip
If your
timestamp-column has varying timesteps, consider standardizing the step size with the
TIME_SLICE function.
Parameters
p- Integer in the range [0, 1000], the number of lags to include in the autoregressive component of the computation. If
q is unspecified or set to zero, p must be set to a nonzero value. In some cases, using a large p value can result in a memory overload error.
Note
The
AUTOREGRESSOR and
ARIMA models use different training techniques that produce distinct models when trained with matching parameter values on the same data. For example, if you train an autoregressor model using the same data and
p value as an ARIMA model trained with
d and
q parameters set to zero, those two models will not be identical.
Default: 0
d- Integer in the range [0, 10], the difference order of the model.
If the timeseries-column is a non-stationary time series, whose statistical properties change over time, you can specify a non-zero d value to difference the input data. This operation can remove or reduce trends in the time series data.
Differencing computes the differences between consecutive time series values and then trains the model on these values. The difference order d, where 0 implies no differencing, determines how many times to repeat the differencing operation. For example, second-order differencing takes the results of the first-order operation and differences these values again to obtain the second-order values. For an example that trains an ARIMA model that uses differencing, see ARIMA model example.
Default: 0
q- Integer in the range [0, 1000], the number of lags to include in the moving average component of the computation. If
p is unspecified or set to zero, q must be set to a nonzero value. In some cases, using a large q value can result in a memory overload error.
Note
The
MOVING_AVERAGE and
ARIMA models use different training techniques that produce distinct models when trained with matching parameter values on the same data. For example, if you train a moving-average model using the same data and
q value as an ARIMA model trained with
p and
d parameters set to zero, those two models will not be identical.
Default: 0
missing- Method for handling missing values, one of the following strings:
-
'drop': Missing values are ignored.
-
'raise': Missing values raise an error.
-
'zero': Missing values are set to zero.
-
'linear_interpolation': Missing values are replaced by a linearly interpolated value based on the nearest valid entries before and after the missing value. In cases where the first or last values in a dataset are missing, the function errors.
Default: 'linear_interpolation'
init_method- Initialization method, one of the following strings:
Default: 'Zero'
epsilon- Float in the range (0.0, 1.0), controls the convergence criteria of the optimization algorithm.
Default: 1e-6
max_iterations- Integer in the range [1, 1000000), the maximum number of training iterations. If you set this value too low, the algorithm might not converge.
Default: 100
Model attributes
coefficients- Coefficients of the model:
-
phi: parameters for the autoregressive component of the computation. The number of returned phi values is equal to the value of p.
-
theta: parameters for the moving average component of the computation. The number of returned theta values is equal to the value of q.
p, q, d- ARIMA component values:
-
p: number of lags included in the autoregressive component of the computation
-
d: difference order of the model
-
q: number of lags included in the moving average component of the computation
mean- The model mean, average of the accepted sample values from
timeseries-column
regularization- Type of regularization used when training the model
lambda- Regularization parameter. Higher values indicates stronger regularization.
mean_squared_error- Mean squared error of the model on the training set
rejected_row_count- Number of samples rejected during training
accepted_row_count- Number of samples accepted for training from the data set
timeseries_name- Name of the
timeseries-column used to train the model
timestamp_name- Name of the
timestamp-column used to train the model
missing_method- Method used for handling missing values
call_string- SQL statement used to train the model
Examples
The function requires that at least one of the p and q parameters be a positive, nonzero integer. The following example trains a model where both of these parameters are set to two:
=> SELECT ARIMA('arima_temp', 'temp_data', 'temperature', 'time' USING PARAMETERS p=2, q=2);
ARIMA
-------------------------------------
Finished in 24 iterations.
3650 elements accepted, 0 elements rejected.
(1 row)
To see a summary of the model, including all model coefficients and parameter values, call GET_MODEL_SUMMARY:
=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='arima_temp');
GET_MODEL_SUMMARY
------------------------------------------------------------
============
coefficients
============
parameter| value
---------+--------
phi_1 | 1.23639
phi_2 |-0.24201
theta_1 |-0.64535
theta_2 |-0.23046
==============
regularization
==============
none
===============
timeseries_name
===============
temperature
==============
timestamp_name
==============
time
==============
missing_method
==============
linear_interpolation
===========
call_string
===========
ARIMA('public.arima_temp', 'temp_data', 'temperature', 'time' USING PARAMETERS p=2, d=0, q=2, missing='linear_interpolation', init_method='Zero', epsilon=1e-06, max_iterations=100);
===============
Additional Info
===============
Name | Value
------------------+--------
p | 2
q | 2
d | 0
mean |11.17775
lambda | 1.00000
mean_squared_error| 5.80628
rejected_row_count| 0
accepted_row_count| 3650
(1 row)
For an in-depth example that trains and makes predictions with ARIMA models, see ARIMA model example.
See also
6.12.2.2 - AUTOREGRESSOR
Creates an autoregressive (AR) model from a stationary time series with consistent timesteps that can then be used for prediction via PREDICT_AR.
Creates and trains an autoregression (AR) or vector autoregression (VAR) model, depending on the number of provided value columns:
- One value column: the function executes autoregression and returns a trained AR model. AR is a univariate autoregressive time series algorithm that predicts a variable's future values based on its preceding values. The user specifies the number of lagged timesteps taken into account during computation, and the model then predicts future values as a linear combination of the values at each lag.
- Multiple value columns: the function executes vector autoregression and returns a trained VAR model. VAR is a multivariate autoregressive time series algorithm that captures the relationship between multiple time series variables over time. Unlike AR, which only considers a single variable, VAR models incorporate feedback between different variables in the model, enabling the model to analyze how variables interact across lagged time steps. For example, with two variables—atmospheric pressure and rain accumulation—a VAR model could determine whether a drop in pressure tends to result in rain at a future date.
To make predictions with a VAR or AR model, use the PREDICT_AUTOREGRESSOR function.
Because the input data must be sorted by timestamp, this function is single-threaded.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AUTOREGRESSOR ('model-name', 'input-relation', 'value-columns', 'timestamp-column'
[ USING PARAMETERS param=value[,...] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view containing
timestamp-column and value-columns.
This algorithm expects a stationary time series as input; using a time series with a mean that shifts over time may lead to weaker results.
value-columns- Comma-separated list of one or more NUMERIC input columns that contain the dependent variables or outcomes.
The number of value columns determines whether the function performs the autoregression (AR) or vector autoregression (VAR) algorithm. If only one input column is provided, the function executes autoregression. For multiple input columns, the function performs the VAR algorithm.
timestamp-column- Name of an INTEGER, FLOAT, or TIMESTAMP column in
input-relation that represents the timestamp variable. The timestep between consecutive entries must be consistent throughout the timestamp-column.
Tip
If your
timestamp-column has varying timesteps, consider standardizing the step size with the
TIME_SLICE function.
Parameters
p- INTEGER in the range [1, 1999], the number of lags to consider in the computation. Larger values for
p weaken the correlation.
Note
The
AUTOREGRESSOR and
ARIMA models use different training techniques that produce distinct models when trained with matching parameter values on the same data. For example, if you train an autoregressor model using the same data and
p value as an ARIMA model trained with
d and
q parameters set to zero, those two models will not be identical.
Default: 3
method- One of the following algorithms for training the model:
missing- One of the following methods for handling missing values:
-
'drop': Missing values are ignored.
-
'error': Missing values raise an error.
-
'zero': Missing values are replaced with 0.
-
'linear_interpolation': Missing values are replaced by linearly-interpolated values based on the nearest valid entries before and after the missing value. This means that in cases where the first or last values in a dataset are missing, they will simply be dropped. The VAR algorithm does not support linear interpolation.
The default method depends on the model type:
- AR: 'linear_interpolation'
- VAR: 'error'
regularization- For the OLS training method only, one of the following regularization methods used when fitting the data:
Default: None
lambda- For the OLS training method only, FLOAT in the range [0, 100000], the regularization value, lambda.
Default: 1.0
compute_mse- BOOLEAN, whether to calculate and output the mean squared error (MSE).
Default: False
subtract_mean- BOOLEAN, whether the mean of each column in
value-columns is subtracted from its column values before calculating the model coefficients. This parameter only applies if method is set to 'Yule-Walker'. If set to False, the model saves the column means as zero.
Default: False
Examples
The following example creates and trains an autoregression model using the Yule-Walker training algorithm and a lag of 3:
=> SELECT AUTOREGRESSOR('AR_temperature_yw', 'temp_data', 'Temperature', 'time' USING PARAMETERS p=3, method='yule-walker');
AUTOREGRESSOR
---------------------------------------------------------
Finished. 3650 elements accepted, 0 elements rejected.
(1 row)
The following example creates and trains a VAR model with a lag of 2:
=> SELECT AUTOREGRESSOR('VAR_temperature', 'temp_data_VAR', 'temp_location1, temp_location2', 'time' USING PARAMETERS p=2);
WARNING 0: Only the Yule Walker method is currently supported for Vector Autoregression, setting method to Yule Walker
AUTOREGRESSOR
---------------------------------------------------------
Finished. 3650 elements accepted, 0 elements rejected.
(1 row)
See Autoregressive model example and VAR model example for extended examples that train and make predictions with AR and VAR models.
See also
6.12.2.3 - BISECTING_KMEANS
Executes the bisecting k-means algorithm on an input relation.
Executes the bisecting k-means algorithm on an input relation. The result is a trained model with a hierarchy of cluster centers, with a range of k values, each of which can be used for prediction.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
BISECTING_KMEANS('model-name', 'input-relation', 'input-columns', 'num-clusters'
[ USING PARAMETERS
[exclude_columns = 'exclude-columns']
[, bisection_iterations = bisection-iterations]
[, split_method = 'split-method']
[, min_divisible_cluster_size = min-cluster-size]
[, kmeans_max_iterations = kmeans-max-iterations]
[, kmeans_epsilon = kmeans-epsilon]
[, kmeans_center_init_method = 'kmeans-init-method']
[, distance_method = 'distance-method']
[, output_view = 'output-view']
[, key_columns = 'key-columns'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- Table or view that contains the input data for k-means. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be of data type numeric.
num-clusters- Number of clusters to create, an integer ≤ 10,000. This argument represents the
k in k-means.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
bisection_iterations- Integer between 1 - 1MM inclusive, specifies number of iterations the bisecting k-means algorithm performs for each bisection step. This corresponds to how many times a standalone k-means algorithm runs in each bisection step.
A setting >1 allows the algorithm to run and choose the best k-means run within each bisection step. If you use kmeanspp, the value of bisection_iterations is always 1, because kmeanspp is more costly to run but also better than the alternatives, so it does not require multiple runs.
Default: 1
split_method- The method used to choose a cluster to bisect/split, one of:
Default: sum_squares
min_divisible_cluster_size- Integer ≥ 2, specifies minimum number of points of a divisible cluster.
Default: 2
kmeans_max_iterations- Integer between 1 and 1MM inclusive, specifies the maximum number of iterations the k-means algorithm performs. If you set this value to a number lower than the number of iterations needed for convergence, the algorithm might not converge.
Default: 10
kmeans_epsilon- Integer between 1 and 1MM inclusive, determines whether the k-means algorithm has converged. The algorithm is considered converged after no center has moved more than a distance of
epsilon from the previous iteration.
Default: 1e-4
kmeans_center_init_method- The method used to find the initial cluster centers in k-means, one of:
-
kmeanspp (default): kmeans++ algorithm
-
pseudo: Uses "pseudo center" approach used by Spark, bisects given center without iterating over points
distance_method- The measure for distance between two data points. Only Euclidean distance is supported at this time.
Default: euclidean
output_view- Name of the view where you save the assignment of each point to its cluster. You must have CREATE privileges on the view schema.
key_columns- Comma-separated list of column names that identify the output rows. Columns must be in the
input-columns argument list. To exclude these and other input columns from being used by the algorithm, list them in parameter exclude_columns.
Model attributes
centers- A list of centers of the K centroids.
hierarchy- The hierarchy of K clusters, including:
-
ParentCluster: Parent cluster centroid of each centroid—that is, the centroid of the cluster from which a cluster is obtained by bisection.
-
LeftChildCluster: Left child cluster centroid of each centroid—that is, the centroid of the first sub-cluster obtained by bisecting a cluster.
-
RightChildCluster: the right child cluster centroid of each centroid—that is, the centroid of the second sub-cluster obtained by bisecting a cluster.
-
BisectionLevel: Specifies which bisection step a cluster is obtained from.
-
WithinSS: Within-cluster sum of squares for the current cluster
-
TotalWithinSS: Total within-cluster sum of squares of leaf clusters thus far obtained.
metrics- Several metrics related to the quality of the clustering, including
-
Total sum of squares
-
Total within-cluster sum of squares
-
Between-cluster sum of squares
-
Between-cluster sum of squares / Total sum of squares
-
Sum of squares for cluster x, center_id y[...]
Examples
SELECT BISECTING_KMEANS('myModel', 'iris1', '*', '5'
USING PARAMETERS exclude_columns = 'Species,id', split_method ='sum_squares', output_view = 'myBKmeansView');
See also
6.12.2.4 - KMEANS
Executes the k-means algorithm on an input relation.
Executes the k-means algorithm on an input relation. The result is a model with a list of cluster centers.
You can export the resulting k-means model in VERTICA_MODELS or PMML format to apply it on data outside Vertica. You can also train a k-means model elsewhere, then import it to Vertica in PMML format to predict on data in Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
KMEANS ( 'model-name', 'input-relation', 'input-columns', 'num-clusters'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, max_iterations = max-iterations]
[, epsilon = epsilon-value]
[, { init_method = 'init-method' } | { initial_centers_table = 'init-table' } ]
[, output_view = 'output-view']
[, key_columns = 'key-columns'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the input data for k-means. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be of data type numeric.
num-clusters- The number of clusters to create, an integer ≤ 10,000. This argument represents the
k in k-means.
Parameters
Important
Parameters init_method and initial_centers_table are mutually exclusive. If you set both, the function returns an error.
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
max_iterations- The maximum number of iterations the algorithm performs. If you set this value to a number lower than the number of iterations needed for convergence, the algorithm may not converge.
Default: 10
epsilon- Determines whether the algorithm has converged. The algorithm is considered converged after no center has moved more than a distance of
'epsilon' from the previous iteration.
Default: 1e-4
init_method- The method used to find the initial cluster centers, one of the following:
-
random
-
kmeanspp (default): kmeans++ algorithm
This value can be memory intensive for high k. If the function returns an error that not enough memory is available, decrease the value of k or use the random method.
initial_centers_table- The table with the initial cluster centers to use. Supply this value if you know the initial centers to use and do not want Vertica to find the initial cluster centers for you.
output_view- The name of the view where you save the assignments of each point to its cluster. You must have CREATE privileges on the schema where the view is saved.
key_columns- Comma-separated list of column names from
input-columns that will appear as the columns of output_view. These columns should be picked such that their contents identify each input data point. This parameter is only used if output_view is specified. Columns listed in input-columns that are only meant to be used as key_columns and not for training should be listed in exclude_columns.
Model attributes
centers- A list that contains the center of each cluster.
metrics- A string summary of several metrics related to the quality of the clustering.
Examples
The following example creates k-means model myKmeansModel and applies it to input table iris1. The call to APPLY_KMEANS mixes column names and constants. When a constant is passed in place of a column name, the constant is substituted for the value of the column in all rows:
=> SELECT KMEANS('myKmeansModel', 'iris1', '*', 5
USING PARAMETERS max_iterations=20, output_view='myKmeansView', key_columns='id', exclude_columns='Species, id');
KMEANS
----------------------------
Finished in 12 iterations
(1 row)
=> SELECT id, APPLY_KMEANS(Sepal_Length, 2.2, 1.3, Petal_Width
USING PARAMETERS model_name='myKmeansModel', match_by_pos='true') FROM iris2;
id | APPLY_KMEANS
-----+--------------
5 | 1
10 | 1
14 | 1
15 | 1
21 | 1
22 | 1
24 | 1
25 | 1
32 | 1
33 | 1
34 | 1
35 | 1
38 | 1
39 | 1
42 | 1
...
(60 rows)
See also
6.12.2.5 - KPROTOTYPES
Executes the k-prototypes algorithm on an input relation.
Executes the k-prototypes algorithm on an input relation. The result is a model with a list of cluster centers.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Syntax
SELECT KPROTOTYPES ('`*`model-name`*`', '`*`input-relation`*`', '`*`input-columns`*`', `*`num-clusters`*`
[USING PARAMETERS [exclude_columns = '`*`exclude-columns`*`']
[, max_iterations = '`*`max-iterations`*`']
[, epsilon = `*`epsilon`*`]
[, {[init_method = '`*`init-method`*`'] } | { initial_centers_table = '`*`init-table`*`' } ]
[, gamma = '`*`gamma`*`']
[, output_view = '`*`output-view`*`']
[, key_columns = '`*`key-columns`*`']]);
Behavior type
Volatile
Arguments
model-name- Name of the model resulting from the training.
input-relation- Name of the table or view containing the training samples.
input-columns- String containing a comma-separated list of columns to use from the input-relation, or asterisk (*) to select all columns.
num-clusters- Integer ≤ 10,000 representing the number of clusters to create. This argument represents the k in k-prototypes.
Parameters
exclude-columns- String containing a comma-separated list of column names from input-columns to exclude from processing.
Default: (empty)
max_iterations- Integer ≤ 1M representing the maximum number of iterations the algorithm performs.
Default: Integer ≤ 1M
epsilon- Integer which determines whether the algorithm has converged.
Default: 1e-4
init_method- String specifying the method used to find the initial k-prototypes cluster centers.
Default: "random"
initial_centers_table- The table with the initial cluster centers to use.
gamma- Float between 0 and 10000 specifying the weighing factor for categorical columns. It can determine relative importance of numerical and categorical attributes
Default: Inferred from data.
output_view- The name of the view where you save the assignments of each point to its cluster
key_columns- Comma-separated list of column names that identify the output rows. Columns must be in the input-columns argument list
Examples
The following example creates k-prototypes model small_model and applies it to input table small_test_mixed:
=> SELECT KPROTOTYPES('small_model_initcenters', 'small_test_mixed', 'x0, country', 3 USING PARAMETERS initial_centers_table='small_test_mixed_centers', key_columns='pid');
KPROTOTYPES
---------------------------
Finished in 2 iterations
(1 row)
=> SELECT country, x0, APPLY_KPROTOTYPES(country, x0
USING PARAMETERS model_name='small_model')
FROM small_test_mixed;
country | x0 | apply_kprototypes
------------+-----+-------------------
'China' | 20 | 0
'US' | 85 | 2
'Russia' | 80 | 1
'Brazil' | 78 | 1
'US' | 23 | 0
'US' | 50 | 0
'Canada' | 24 | 0
'Canada' | 18 | 0
'Russia' | 90 | 2
'Russia' | 98 | 2
'Brazil' | 89 | 2
...
(45 rows)
See also
6.12.2.6 - LINEAR_REG
Executes linear regression on an input relation, and returns a linear regression model.
Executes linear regression on an input relation, and returns a linear regression model.
You can export the resulting linear regression model in VERTICA_MODELS or PMML format to apply it on data outside Vertica. You can also train a linear regression model elsewhere, then import it to Vertica in PMML format to model on data inside Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LINEAR_REG ( 'model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, optimizer = 'optimizer-method']
[, regularization = 'regularization-method']
[, epsilon = epsilon-value]
[, max_iterations = iterations]
[, lambda = lamda-value]
[, alpha = alpha-value]
[, fit_intercept = boolean-value] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- Table or view that contains the training data for building the model. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- Name of the input column that represents the dependent variable or outcome. All values in this column must be numeric, otherwise the model is invalid.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
optimizer- Optimizer method used to train the model, one of the following:
Default: CGD if regularization-method is set to L1 or ENet, otherwise Newton.
regularization- Method of regularization, one of the following:
-
None (default)
-
L1
-
L2
-
ENet
epsilonFLOAT in the range (0.0, 1.0), the error value at which to stop training. Training stops if either the difference between the actual and predicted values is less than or equal to epsilon or if the number of iterations exceeds max_iterations.
Default: 1e-6
max_iterationsINTEGER in the range (0, 1000000), the maximum number of training iterations. Training stops if either the number of iterations exceeds max_iterations or if the difference between the actual and predicted values is less than or equal to epsilon.
Default: 100
lambda- Integer ≥ 0, specifies the value of the
regularization parameter.
Default: 1
alpha- Integer ≥ 0, specifies the value of the ENET
regularization parameter, which defines how much L1 versus L2 regularization to provide. A value of 1 is equivalent to L1 and a value of 0 is equivalent to L2.
Value range: [0,1]
Default: 0.5
fit_intercept- Boolean, specifies whether the model includes an intercept. By setting to false, no intercept will be used in training the model. Note that setting
fit_intercept to false does not work well with the BFGS optimizer.
Default: True
Model attributes
data- The data for the function, including:
-
coeffNames: Name of the coefficients. This starts with intercept and then follows with the names of the predictors in the same order specified in the call.
-
coeff: Vector of estimated coefficients, with the same order as coeffNames
-
stdErr: Vector of the standard error of the coefficients, with the same order as coeffNames
-
zValue (for logistic regression): Vector of z-values of the coefficients, in the same order as coeffNames
-
tValue (for linear regression): Vector of t-values of the coefficients, in the same order as coeffNames
-
pValue: Vector of p-values of the coefficients, in the same order as coeffNames
regularization- Type of regularization to use when training the model.
lambda- Regularization parameter. Higher values enforce stronger regularization. This value must be nonnegative.
alpha- Elastic net mixture parameter.
iterations- Number of iterations that actually occur for the convergence before exceeding
max_iterations.
skippedRows- Number of rows of the input relation that were skipped because they contained an invalid value.
processedRows- Total number of input relation rows minus
skippedRows.
callStr- Value of all input arguments specified when the function was called.
Examples
=> SELECT LINEAR_REG('myLinearRegModel', 'faithful', 'eruptions', 'waiting'
USING PARAMETERS optimizer='BFGS', fit_intercept=true);
LINEAR_REG
----------------------------
Finished in 10 iterations
(1 row)
See also
6.12.2.7 - LOGISTIC_REG
Executes logistic regression on an input relation.
Executes logistic regression on an input relation. The result is a logistic regression model.
You can export the resulting logistic regression model in VERTICA_MODELS or PMML format to apply it on data outside Vertica. You can also train a logistic regression model elsewhere, then import it to Vertica in PMML format to predict on data in Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LOGISTIC_REG ( 'model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS [exclude_columns = 'excluded-columns']
[, optimizer = 'optimizer-method']
[, regularization = 'regularization-method']
[, epsilon = epsilon-value]
[, max_iterations = iterations]
[, lambda = lamda-value]
[, alpha = alpha-value]
[, fit_intercept = boolean-value] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training data for building the model. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- The input column that represents the dependent variable or outcome. The column value must be 0 or 1, and of type numeric or BOOLEAN. The function automatically skips all other values.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
optimizer- The optimizer method used to train the model, one of the following:
Default: CGD if regularization-method is set to L1 or ENet, otherwise Newton.
regularization- The method of regularization, one of the following:
-
None (default)
-
L1
-
L2
-
ENet
epsilonFLOAT in the range (0.0, 1.0), the error value at which to stop training. Training stops if either the difference between the actual and predicted values is less than or equal to epsilon or if the number of iterations exceeds max_iterations.
Default: 1e-6
max_iterationsINTEGER in the range (0, 1000000), the maximum number of training iterations. Training stops if either the number of iterations exceeds max_iterations or if the difference between the actual and predicted values is less than or equal to epsilon.
Default: 100
lambda- Integer ≥ 0, specifies the value of the
regularization parameter.
Default: 1
alpha- Integer ≥ 0, specifies the value of the ENET
regularization parameter, which defines how much L1 versus L2 regularization to provide. A value of 1 is equivalent to L1 and a value of 0 is equivalent to L2.
Value range: [0,1]
Default: 0.5
fit_intercept- Boolean, specifies whether the model includes an intercept. By setting to false, no intercept will be used in training the model. Note that setting
fit_intercept to false does not work well with the BFGS optimizer.
Default: True
Model attributes
data- The data for the function, including:
-
coeffNames: Name of the coefficients. This starts with intercept and then follows with the names of the predictors in the same order specified in the call.
-
coeff: Vector of estimated coefficients, with the same order as coeffNames
-
stdErr: Vector of the standard error of the coefficients, with the same order as coeffNames
-
zValue (for logistic regression): Vector of z-values of the coefficients, in the same order as coeffNames
-
tValue (for linear regression): Vector of t-values of the coefficients, in the same order as coeffNames
-
pValue: Vector of p-values of the coefficients, in the same order as coeffNames
regularization- Type of regularization to use when training the model.
lambda- Regularization parameter. Higher values enforce stronger regularization. This value must be nonnegative.
alpha- Elastic net mixture parameter.
iterations- Number of iterations that actually occur for the convergence before exceeding
max_iterations.
skippedRows- Number of rows of the input relation that were skipped because they contained an invalid value.
processedRows- Total number of input relation rows minus
skippedRows.
callStr- Value of all input arguments specified when the function was called.
Privileges
Superuser, or SELECT privileges on the input relation
Examples
=> SELECT LOGISTIC_REG('myLogisticRegModel', 'mtcars', 'am',
'mpg, cyl, disp, hp, drat, wt, qsec, vs, gear, carb'
USING PARAMETERS exclude_columns='hp', optimizer='BFGS', fit_intercept=true);
LOGISTIC_REG
----------------------------
Finished in 20 iterations
(1 row)
See also
6.12.2.8 - MOVING_AVERAGE
Creates a moving-average (MA) model from a stationary time series with consistent timesteps that can then be used for prediction via PREDICT_MOVING_AVERAGE.
Creates a moving-average (MA) model from a stationary time series with consistent timesteps that can then be used for prediction via PREDICT_MOVING_AVERAGE.
Moving average models use the errors of previous predictions to make future predictions. More specifically, the user-specified lag determines how many previous predictions and errors it takes into account during computation.
Since its input data must be sorted by timestamp, this algorithm is single-threaded.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MOVING_AVERAGE ('model-name', 'input-relation', 'data-column', 'timestamp-column'
[ USING PARAMETERS
[ q = lags ]
[, missing = "imputation-method" ]
[, regularization = "regularization-method" ]
[, lambda = regularization-value ]
[, compute_mse = boolean ]
] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view containing the
timestamp-column.
This algorithm expects a stationary time series as input; using a time series with a mean that shifts over time may lead to weaker results.
data-column- An input column of type NUMERIC that contains the dependent variables or outcomes.
timestamp-column- One INTEGER, FLOAT, or TIMESTAMP column that represent the timestamp variable. Timesteps must be consistent.
Parameters
q- INTEGER in the range [1, 67), the number of lags to consider in the computation.
Note
The
MOVING_AVERAGE and
ARIMA models use different training techniques that produce distinct models when trained with matching parameter values on the same data. For example, if you train a moving-average model using the same data and
q value as an ARIMA model trained with
p and
d parameters set to zero, those two models will not be identical.
Default: 1
missing- One of the following methods for handling missing values:
-
drop: Missing values are ignored.
-
error: Missing values raise an error.
-
zero: Missing values are replaced with 0.
-
linear_interpolation: Missing values are replaced by linearly interpolated values based on the nearest valid entries before and after the missing value. This means that in cases where the first or last values in a dataset are missing, they will simply be dropped.
Default: linear_interpolation
regularization- One of the following regularization methods used when fitting the data:
Default: None
lambda- FLOAT in the range [0, 100000], the regularization value, lambda.
Default: 1.0
compute_mse- BOOLEAN, whether to calculate and output the mean squared error (MSE).
This parameter only accepts "true" or "false" rather than the standard literal equivalents for BOOLEANs like 1 or 0.
Default: False
Examples
See Moving-average model example.
See also
6.12.2.9 - NAIVE_BAYES
Executes the Naive Bayes algorithm on an input relation and returns a Naive Bayes model.
Executes the Naive Bayes algorithm on an input relation and returns a Naive Bayes model.
Columns are treated according to data type:
-
FLOAT: Values are assumed to follow some Gaussian distribution.
-
INTEGER: Values are assumed to belong to one multinomial distribution.
-
CHAR/VARCHAR: Values are assumed to follow some categorical distribution. The string values stored in these columns must not be greater than 128 characters.
-
BOOLEAN: Values are treated as categorical with two values.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
NAIVE_BAYES ( 'model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS [exclude_columns = 'excluded-columns'] [, alpha = alpha-value] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training data for building the model. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- Name of the input column that represents the dependent variable, or outcome. This column must contain discrete labels that represent different class labels.
The response column must be of type numeric, CHAR/VARCHAR, or BOOLEAN; otherwise the model is invalid.
Note
Vertica automatically casts
numeric response column values to VARCHAR.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric, CHAR/VARCHAR, or BOOLEAN; otherwise the model is invalid. BOOLEAN column values are converted to FLOAT values before training: 0 for false, 1 for true.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
alpha- Float, specifies use of Laplace smoothing if the event model is categorical, multinomial, or Bernoulli.
Default: 1.0
Model attributes
colsInfo- The information from the response and predictor columns used in training:
-
index: The index (starting at 0) of the column as provided in training. Index 0 is used for the response column.
-
name: The column name.
-
type: The label used for response with a value of Gaussian, Multinominal, Categorical, or Bernoulli.
alpha- The smooth parameter value.
prior- The percentage of each class among all training samples:
nRowsTotal- The number of samples accepted for training from the data set.
nRowsRejected- The number of samples rejected for training.
callStr- The SQL statement used to replicate the training.
Gaussian- The Gaussian model conditioned on the class indicated by the class_name:
-
index: The index of the predictor column.
-
mu: The mean value of the model.
-
sigmaSq: The squared standard deviation of the model.
Multinominal- The Multinomial model conditioned on the class indicated by the class_name:
Bernoulli- The Bernoulli model conditioned on the class indicated by the class_name:
Categorical- The Gaussian model conditioned on the class indicated by the class_name:
Privileges
Superuser, or SELECT privileges on the input relation.
Examples
=> SELECT NAIVE_BAYES('naive_house84_model', 'house84_train', 'party', '*'
USING PARAMETERS exclude_columns='party, id');
NAIVE_BAYES
--------------------------------------------------
Finished. Accepted Rows: 324 Rejected Rows: 0
(1 row)
See also
6.12.2.10 - PLS_REG
Executes PLS regression on an input relation, and returns a PLS regression model.
Executes the Partial Least Squares (PLS) regression algorithm on an input relation, and returns a PLS regression model.
Combining aspects of PCA (principal component analysis) and linear regression, the PLS regression algorithm extracts a set of latent components that explain as much covariance as possible between the predictor and response variables, and then performs a regression that predicts response values using the extracted components.
This technique is particularly useful when the number of predictor variables is greater than the number of observations or the predictor variables are highly collinear. If either of these conditions is true of the input relation, ordinary linear regression fails to converge to an accurate model.
The PLS_REG function supports PLS regression with only one response column, often referred to as PLS1. PLS regression with multiple response columns, known as PLS2, is not currently supported.
To make predictions with a PLS model, use the PREDICT_PLS_REG function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Syntax
PLS_REG ( 'model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS param=value[,...] ] )
Arguments
model-name- Model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- Table or view that contains the training data.
response-column- Name of the input column that represents the dependent variable or outcome. All values in this column must be numeric.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
num_components- Number of components in the model. The value must be an integer in the range [1, min(N, P)], where N is the number of rows in
input-relation and P is the number of columns in predictor-columns.
Default: 2
scale- Boolean, whether to standardize the response and predictor columns.
Default: True
Model attributes
details- Information about the model coefficients, including:
coeffNames: Name of the coefficients, starting with the intercept and following with the names of the predictors in the same order specified in the call.coeff: Vector of estimated coefficients, with the same order as coeffNames.
responses- Name of the response column.
call_string- SQL statement used to train the model.
Additional Info- Additional information about the model, including:
is_scaled: Whether the input columns were scaled before model training.n_components: Number of components in the model.rejected_row_count: Number of rows in input-relation that were rejected because they contained an invalid value.accepted_row_count: Number of rows in input-relation accepted for training the model.
Privileges
Non-superusers:
Examples
The following example trains a PLS regression model with the default number of components:
=> CREATE TABLE pls_data (y float, x1 float, x2 float, x3 float, x4 float, x5 float);
=> COPY pls_data FROM STDIN;
1|2|3|0|2|5
2|3|4|0|4|4
3|4|5|0|8|3
\.
=> SELECT PLS_REG('pls_model', 'pls_data', 'y', 'x1,x2');
WARNING 0: There are not more than 1 meaningful component(s)
PLS_REG
------------------------------------------------------------
Number of components 1.
Accepted Rows: 3 Rejected Rows: 0
(1 row)
For an in-depth example that trains and makes predictions with a PLS model, see PLS regression.
See also
6.12.2.11 - POISSON_REG
Executes Poisson regression on an input relation, and returns a Poisson regression model.
Executes Poisson regression on an input relation, and returns a Poisson regression model.
You can export the resulting Poisson regression model in VERTICA_MODELS or PMML format to apply it on data outside Vertica. You can also train a Poisson regression model elsewhere, then import it to Vertica in PMML format to apply it on data inside Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
POISSON_REG ( 'model-name', 'input-table', 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, optimizer = 'optimizer-method']
[, regularization = 'regularization-method']
[, epsilon = epsilon-value]
[, max_iterations = iterations]
[, lambda = lamda-value]
[, fit_intercept = boolean-value] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-table- Table or view that contains the training data for building the model. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- Name of input column that represents the dependent variable or outcome. All values in this column must be numeric, otherwise the model is invalid.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
optimizer- Optimizer method used to train the model. The currently supported method is
Newton.
regularization- Method of regularization, one of the following:
epsilon- FLOAT in the range (0.0, 1.0), the error value at which to stop training. Training stops if either the relative change in Poisson deviance is less than or equal to epsilon or if the number of iterations exceeds
max_iterations.
Default: 1e-6
max_iterations- INTEGER in the range (0, 1000000), the maximum number of training iterations. Training stops if either the number of iterations exceeds
max_iterations or the relative change in Poisson deviance is less than or equal to epsilon.
lambda- FLOAT ≥ 0, specifies the
regularization strength.
Default: 1.0
fit_intercept- Boolean, specifies whether the model includes an intercept. By setting to false, no intercept will be used in training the model.”
Default: True
Model attributes
data- Data for the function, including:
-
coeffNames: Name of the coefficients. This starts with intercept and then follows with the names of the predictors in the same order specified in the call.
-
coeff: Vector of estimated coefficients, with the same order as coeffNames
-
stdErr: Vector of the standard error of the coefficients, with the same order as coeffNames
-
zValue: (for logistic and Poisson regression): Vector of z-values of the coefficients, in the same order as coeffNames
-
tValue (for linear regression): Vector of t-values of the coefficients, in the same order as coeffNames
-
pValue: Vector of p-values of the coefficients, in the same order as coeffNames
regularization- Type of regularization to use when training the model.
lambda- Regularization parameter. Higher values enforce stronger regularization. This value must be nonnegative.
iterations- Number of iterations that actually occur for the convergence before exceeding
max_iterations.
skippedRows- Number of rows of the input relation that were skipped because they contained an invalid value.
processedRows- Total number of input relation rows minus
skippedRows.
callStr- Value of all input arguments specified when the function was called.
Examples
=> SELECT POISSON_REG('myModel', 'numericFaithful', 'eruptions', 'waiting' USING PARAMETERS epsilon=1e-8);
poisson_reg
---------------------------
Finished in 7 iterations
(1 row)
See also
6.12.2.12 - RF_CLASSIFIER
Trains a random forest model for classification on an input relation.
Trains a random forest model for classification on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RF_CLASSIFIER ( 'model-name', input-relation, 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, ntree = num-trees]
[, mtry = num-features]
[, sampling_size = sampling-size]
[, max_depth = depth]
[, max_breadth = breadth]
[, min_leaf_size = leaf-size]
[, min_info_gain = threshold]
[, nbins = num-bins] ] )
Arguments
model-name- Identifies the model stored as a result of the training, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training samples. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- An input column of type numeric, CHAR/VARCHAR, or BOOLEAN that represents the dependent variable.
Note
Vertica automatically casts
numeric response column values to VARCHAR.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric, CHAR/VARCHAR, or BOOLEAN; otherwise the model is invalid.
Vertica XGBoost and Random Forest algorithms offer native support for categorical columns (BOOL/VARCHAR). Simply pass the categorical columns as predictors to the models and the algorithm will automatically treat the columns as categorical and will not attempt to split them into bins in the same manner as numerical columns; Vertica treats these columns as true categorical values and does not simply cast them to continuous values under-the-hood.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
ntreeInteger in the range [1, 1000], the number of trees in the forest.
Default: 20
mtry- Integer in the range [1,
number-predictors], the number of randomly chosen features from which to pick the best feature to split on a given tree node.
Default: Square root of the total number of predictors
sampling_sizeFloat in the range (0.0, 1.0], the portion of the input data set that is randomly picked for training each tree.
Default: 0.632
max_depthInteger in the range [1, 100], the maximum depth for growing each tree. For example, a max_depth of 0 represents a tree with only a root node, and a max_depth of 2 represents a tree with four leaf nodes.
Default: 5
max_breadthInteger in the range [1, 1e9], the maximum number of leaf nodes a tree can have.
Default: 32
min_leaf_sizeInteger in the range [1, 1e6], the minimum number of samples each branch must have after splitting a node. A split that results in fewer remaining samples in its left or right branch is be discarded, and the node is treated as a leaf node.
Default: 1
min_info_gainFloat in the range [0.0, 1.0), the minimum threshold for including a split. A split with information gain less than this threshold is discarded.
Default: 0.0
nbinsInteger in the range [2, 1000], the number of bins to use for discretizing continuous features.
Default: 32
Model attributes
data- Data for the function, including:
ntree- Number of trees in the model.
skippedRows- Number of rows in
input_relation that were skipped because they contained an invalid value.
processedRows- Total number of rows in
input_relation minus skippedRows.
callStr- Value of all input arguments that were specified at the time the function was called.
Examples
=> SELECT RF_CLASSIFIER ('myRFModel', 'iris', 'Species', 'Sepal_Length, Sepal_Width,
Petal_Length, Petal_Width' USING PARAMETERS ntree=100, sampling_size=0.3);
RF_CLASSIFIER
--------------------------------------------------
Finished training
(1 row)
See also
6.12.2.13 - RF_REGRESSOR
Trains a random forest model for regression on an input relation.
Trains a random forest model for regression on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RF_REGRESSOR ( 'model-name', input-relation, 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, ntree = num-trees]
[, mtry = num-features]
[, sampling_size = sampling-size]
[, max_depth = depth]
[, max_breadth = breadth]
[, min_leaf_size = leaf-size]
[, min_info_gain = threshold]
[, nbins = num-bins] ] )
Arguments
model-name- The model that is stored as a result of training, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training samples. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- A numeric input column that represents the dependent variable.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric, CHAR/VARCHAR, or BOOLEAN; otherwise the model is invalid.
Vertica XGBoost and Random Forest algorithms offer native support for categorical columns (BOOL/VARCHAR). Simply pass the categorical columns as predictors to the models and the algorithm will automatically treat the columns as categorical and will not attempt to split them into bins in the same manner as numerical columns; Vertica treats these columns as true categorical values and does not simply cast them to continuous values under-the-hood.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
ntreeInteger in the range [1, 1000], the number of trees in the forest.
Default: 20
mtry- Integer in the range [1,
number-predictors], the number of features to consider at the split of a tree node.
Default: One-third the total number of predictors
sampling_sizeFloat in the range (0.0, 1.0], the portion of the input data set that is randomly picked for training each tree.
Default: 0.632
max_depthInteger in the range [1, 100], the maximum depth for growing each tree. For example, a max_depth of 0 represents a tree with only a root node, and a max_depth of 2 represents a tree with four leaf nodes.
Default: 5
max_breadthInteger in the range [1, 1e9], the maximum number of leaf nodes a tree can have.
Default: 32
min_leaf_size- Integer in the range [1, 1e6], the minimum number of samples each branch must have after splitting a node. A split that results in fewer remaining samples in its left or right branch is be discarded, and the node is treated as a leaf node.
The default value of this parameter differs from that of analogous parameters in libraries like sklearn and will therefore yield a model with predicted values that differ from the original response values.
Default: 5
min_info_gainFloat in the range [0.0, 1.0), the minimum threshold for including a split. A split with information gain less than this threshold is discarded.
Default: 0.0
nbinsInteger in the range [2, 1000], the number of bins to use for discretizing continuous features.
Default: 32
Model attributes
data- Data for the function, including:
ntree- Number of trees in the model.
skippedRows- Number of rows in
input_relation that were skipped because they contained an invalid value.
processedRows- Total number of rows in
input_relation minus skippedRows.
callStr- Value of all input arguments that were specified at the time the function was called.
Examples
=> SELECT RF_REGRESSOR ('myRFRegressorModel', 'mtcars', 'carb', 'mpg, cyl, hp, drat, wt' USING PARAMETERS
ntree=100, sampling_size=0.3);
RF_REGRESSOR
--------------
Finished
(1 row)
See also
6.12.2.14 - SVM_CLASSIFIER
Trains the SVM model on an input relation.
Trains the SVM model on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SVM_CLASSIFIER ( 'model-name', input-relation, 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, C = 'cost']
[, epsilon = 'epsilon-value']
[, max_iterations = 'max-iterations']
[, class_weights = 'weight']
[, intercept_mode = 'intercept-mode']
[, intercept_scaling = 'scale'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training data. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- The input column that represents the dependent variable or outcome. The column value must be 0 or 1, and of type numeric or BOOLEAN, otherwise the function returns with an error.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
C- Weight for misclassification cost. The algorithm minimizes the regularization cost and the misclassification cost.
Default: 1.0
epsilon- Used to control accuracy.
Default: 1e-3
max_iterations- Maximum number of iterations that the algorithm performs.
Default: 100
class_weights- Specifies how to determine weights of the two classes, one of the following:
-
None (default): No weights are used
-
value0, value1: Two comma-delimited strings that specify two positive FLOAT values, where value0 assigns a weight to class 0, and value1 assigns a weight to class 1.
-
auto: Weights each class according to the number of samples.
intercept_mode- Specifies how to treat the intercept, one of the following:
intercept_scaling- Float value that serves as the value of a dummy feature whose coefficient Vertica uses to calculate the model intercept. Because the dummy feature is not in the training data, its values are set to a constant, by default 1.
Model attributes
coeff- Coefficients in the model:
nAccepted- Number of samples accepted for training from the data set
nRejected- Number of samples rejected when training
nIteration- Number of iterations used in training
callStr- SQL statement used to replicate the training
Examples
The following example uses SVM_CLASSIFIER on the mtcars table:
=> SELECT SVM_CLASSIFIER(
'mySvmClassModel', 'mtcars', 'am', 'mpg,cyl,disp,hp,drat,wt,qsec,vs,gear,carb'
USING PARAMETERS exclude_columns = 'hp,drat');
SVM_CLASSIFIER
----------------------------------------------------------------
Finished in 15 iterations.
Accepted Rows: 32 Rejected Rows: 0
(1 row)
See also
6.12.2.15 - SVM_REGRESSOR
Trains the SVM model on an input relation.
Trains the SVM model on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SVM_REGRESSOR ( 'model-name', input-relation, 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, error_tolerance = error-tolerance]
[, C = cost]
[, epsilon = epsilon-value]
[, max_iterations = max-iterations]
[, intercept_mode = 'mode']
[, intercept_scaling = 'scale'] ] )
Arguments
model-name- Identifies the model to create, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
input-relation- The table or view that contains the training data. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- An input column that represents the dependent variable or outcome. The column must be a numeric data type.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
All predictor columns must be of type numeric or BOOLEAN; otherwise the model is invalid.
Note
All BOOLEAN predictor values are converted to FLOAT values before training: 0 for false, 1 for true. No type checking occurs during prediction, so you can use a BOOLEAN predictor column in training, and during prediction provide a FLOAT column of the same name. In this case, all FLOAT values must be either 0 or 1.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
error_tolerance- Defines the acceptable error margin. Any data points outside this region add a penalty to the cost function.
Default: 0.1
C- The weight for misclassification cost. The algorithm minimizes the regularization cost and the misclassification cost.
Default: 1.0
epsilon- Used to control accuracy.
Default: 1e-3
max_iterations- The maximum number of iterations that the algorithm performs.
Default: 100
intercept_mode- A string that specifies how to treat the intercept, one of the following
intercept_scaling- A FLOAT value, serves as the value of a dummy feature whose coefficient Vertica uses to calculate the model intercept. Because the dummy feature is not in the training data, its values are set to a constant, by default set to 1.
Model attributes
coeff- Coefficients in the model:
nAccepted- Number of samples accepted for training from the data set
nRejected- Number of samples rejected when training
nIteration- Number of iterations used in training
callStr- SQL statement used to replicate the training
Examples
=> SELECT SVM_REGRESSOR('mySvmRegModel', 'faithful', 'eruptions', 'waiting'
USING PARAMETERS error_tolerance=0.1, max_iterations=100);
SVM_REGRESSOR
----------------------------------------------------------------
Finished in 5 iterations.
Accepted Rows: 272 Rejected Rows: 0
(1 row)
See also
6.12.2.16 - XGB_CLASSIFIER
Trains an XGBoost model for classification on an input relation.
Trains an XGBoost model for classification on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
XGB_CLASSIFIER ('model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS param=value[,...] ] )
Arguments
model-nameName of the model (case-insensitive).
input-relation- The table or view that contains the training samples. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- An input column of type CHAR or VARCHAR that represents the dependent variable or outcome.
predictor-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Columns must be of data types CHAR, VARCHAR, BOOL, INT, or FLOAT.
Columns of type CHAR, VARCHAR, and BOOL are treated as categorical features; all others are treated as numeric features.
Vertica XGBoost and Random Forest algorithms offer native support for categorical columns (BOOL/VARCHAR). Simply pass the categorical columns as predictors to the models and the algorithm will automatically treat the columns as categorical and will not attempt to split them into bins in the same manner as numerical columns; Vertica treats these columns as true categorical values and does not simply cast them to continuous values under-the-hood.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
max_ntree- Integer in the range [1,1000] that sets the maximum number of trees to create.
Default: 10
max_depth- Integer in the range [1,40] that specifies the maximum depth of each tree.
Default: 6
objective- The objective/loss function used to iteratively improve the model. 'crossentropy' is the only option.
Default: 'crossentropy'
split_proposal_method- The splitting strategy for the feature columns. 'global' is the only option. This method calculates the split for each feature column only at the beginning of the algorithm. The feature columns are split into the number of bins specified by
nbins.
Default: 'global'
learning_rate- Float in the range (0,1] that specifies the weight for each tree's prediction. Setting this parameter can reduce each tree's impact and thereby prevent earlier trees from monopolizing improvements at the expense of contributions from later trees.
Default: 0.3
min_split_loss- Float in the range [0,1000] that specifies the minimum amount of improvement each split must achieve on the model's objective function value to avoid being pruned.
If set to 0 or omitted, no minimum is set. In this case, trees are pruned according to positive or negative objective function values.
Default: 0.0 (disable)
weight_reg- Float in the range [0,1000] that specifies the regularization term applied to the weights of classification tree leaves. The higher the setting, the sparser or smoother the weights are, which can help prevent over-fitting.
Default: 1.0
nbins- Integer in the range (1,1000] that specifies the number of bins to use for finding splits in each column. More bins leads to longer runtime but more fine-grained and possibly better splits.
Default: 32
sampling_size- Float in the range (0,1] that specifies the fraction of rows to use in each training iteration.
A value of 1 indicates that all rows are used.
Default: 1.0
col_sample_by_tree- Float in the range (0,1] that specifies the fraction of columns (features), chosen at random, to use when building each tree.
A value of 1 indicates that all columns are used.
col_sample_by parameters "stack" on top of each other if several are specified. That is, given a set of 24 columns, for col_sample_by_tree=0.5 andcol_sample_by_node=0.5,col_sample_by_tree samples 12 columns, reducing the available, unsampled column pool to 12. col_sample_by_node then samples half of the remaining pool, so each node samples 6 columns.
This algorithm will always sample at least one column.
Default: 1
col_sample_by_node- Float in the range (0,1] that specifies the fraction of columns (features), chosen at random, to use when evaluating each split.
A value of 1 indicates that all columns are used.
col_sample_by parameters "stack" on top of each other if several are specified. That is, given a set of 24 columns, for col_sample_by_tree=0.5 andcol_sample_by_node=0.5,col_sample_by_tree samples 12 columns, reducing the available, unsampled column pool to 12. col_sample_by_node then samples half of the remaining pool, so each node samples 6 columns.
This algorithm will always sample at least one column.
Default: 1
Examples
See XGBoost for classification.
6.12.2.17 - XGB_REGRESSOR
Trains an XGBoost model for regression on an input relation.
Trains an XGBoost model for regression on an input relation.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
XGB_REGRESSOR ('model-name', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS param=value[,...] ] )
Arguments
model-nameName of the model (case-insensitive).
input-relation- The table or view that contains the training samples. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- An input column of type INTEGER or FLOAT that represents the dependent variable or outcome.
predictor-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Columns must be of data types CHAR, VARCHAR, BOOL, INT, or FLOAT.
Columns of type CHAR, VARCHAR, and BOOL are treated as categorical features; all others are treated as numeric features.
Vertica XGBoost and Random Forest algorithms offer native support for categorical columns (BOOL/VARCHAR). Simply pass the categorical columns as predictors to the models and the algorithm will automatically treat the columns as categorical and will not attempt to split them into bins in the same manner as numerical columns; Vertica treats these columns as true categorical values and does not simply cast them to continuous values under-the-hood.
Parameters
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
max_ntree- Integer in the range [1,1000] that sets the maximum number of trees to create.
Default: 10
max_depth- Integer in the range [1,40] that specifies the maximum depth of each tree.
Default: 6
objective- The objective/loss function used to iteratively improve the model. 'squarederror' is the only option.
Default: 'squarederror'
split_proposal_method- The splitting strategy for the feature columns. 'global' is the only option. This method calculates the split for each feature column only at the beginning of the algorithm. The feature columns are split into the number of bins specified by
nbins.
Default: 'global'
learning_rate- Float in the range (0,1] that specifies the weight for each tree's prediction. Setting this parameter can reduce each tree's impact and thereby prevent earlier trees from monopolizing improvements at the expense of contributions from later trees.
Default: 0.3
min_split_loss- Float in the range [0,1000] that specifies the minimum amount of improvement each split must achieve on the model's objective function value to avoid being pruned.
If set to 0 or omitted, no minimum is set. In this case, trees are pruned according to positive or negative objective function values.
Default: 0.0 (disable)
weight_reg- Float in the range [0,1000] that specifies the regularization term applied to the weights of classification tree leaves. The higher the setting, the sparser or smoother the weights are, which can help prevent over-fitting.
Default: 1.0
nbins- Integer in the range (1,1000] that specifies the number of bins to use for finding splits in each column. More bins leads to longer runtime but more fine-grained and possibly better splits.
Default: 32
sampling_size- Float in the range (0,1] that specifies the fraction of rows to use in each training iteration.
A value of 1 indicates that all rows are used.
Default: 1.0
col_sample_by_tree- Float in the range (0,1] that specifies the fraction of columns (features), chosen at random, to use when building each tree.
A value of 1 indicates that all columns are used.
col_sample_by parameters "stack" on top of each other if several are specified. That is, given a set of 24 columns, for col_sample_by_tree=0.5 andcol_sample_by_node=0.5,col_sample_by_tree samples 12 columns, reducing the available, unsampled column pool to 12. col_sample_by_node then samples half of the remaining pool, so each node samples 6 columns.
This algorithm will always sample at least one column.
Default: 1
col_sample_by_node- Float in the range (0,1] that specifies the fraction of columns (features), chosen at random, to use when evaluating each split.
A value of 1 indicates that all columns are used.
col_sample_by parameters "stack" on top of each other if several are specified. That is, given a set of 24 columns, for col_sample_by_tree=0.5 andcol_sample_by_node=0.5,col_sample_by_tree samples 12 columns, reducing the available, unsampled column pool to 12. col_sample_by_node then samples half of the remaining pool, so each node samples 6 columns.
This algorithm will always sample at least one column.
Default: 1
Examples
See XGBoost for regression.
6.12.3 - Model evaluation
A set of Vertica machine learning functions evaluate the prediction data that is generated by trained models, or return information about the models themselves.
A set of Vertica machine learning functions evaluate the prediction data that is generated by trained models, or return information about the models themselves.
6.12.3.1 - CONFUSION_MATRIX
Computes the confusion matrix of a table with observed and predicted values of a response variable.
Computes the confusion matrix of a table with observed and predicted values of a response variable. CONFUSION_MATRIX produces a table with the following dimensions:
Syntax
CONFUSION_MATRIX ( targets, predictions [ USING PARAMETERS num_classes = num-classes ] OVER()
Arguments
targets- An input column that contains the true values of the response variable.
predictions- An input column that contains the predicted class labels.
Arguments targets and predictions must be set to input columns of the same data type, one of the following: INTEGER, BOOLEAN, or CHAR/VARCHAR. Depending on their data type, these columns identify classes as follows:
-
INTEGER: Zero-based consecutive integers between 0 and (num-classes-1) inclusive, where num-classes is the number of classes. For example, given the following input column values— {0, 1, 2, 3, 4}—Vertica assumes five classes.
Note
If input column values are not consecutive, Vertica interpolates the missing values. Thus, given the following input values— {0, 1, 3, 5, 6,}— Vertica assumes seven classes.
-
BOOLEAN: Yes or No
-
CHAR/VARCHAR: Class names. If the input columns are of type CHAR/VARCHAR columns, you must also set parameter num_classes to the number of classes.
Note
Vertica computes the number of classes as the union of values in both input columns. For example, given the following sets of values in the targets and predictions input columns, Vertica counts four classes:
{'milk', 'soy milk', 'cream'}
{'soy milk', 'almond milk'}
Parameters
num_classesAn integer > 1, specifies the number of classes to pass to the function.
You must set this parameter if the specified input columns are of type CHAR/VARCHAR. Otherwise, the function processes this parameter according to the column data types:
-
INTEGER: By default set to 2, you must set this parameter correctly if the number of classes is any other value.
-
BOOLEAN: By default set to 2, cannot be set to any other value.
Examples
This example computes the confusion matrix for a logistic regression model that classifies cars in the mtcars data set as automatic or manual transmission. Observed values are in input column obs, while predicted values are in input column pred. Because this is a binary classification problem, all values are either 0 or 1.
In the table returned, all 19 cars with a value of 0 in column am are correctly predicted by PREDICT_LOGISTIC_REGRESSION as having a value of 0. Of the 13 cars with a value of 1 in column am, 12 are correctly predicted to have a value of 1, while 1 car is incorrectly classified as having a value of 0:
=> SELECT CONFUSION_MATRIX(obs::int, pred::int USING PARAMETERS num_classes=2) OVER()
FROM (SELECT am AS obs, PREDICT_LOGISTIC_REG(mpg, cyl, disp,drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel')AS PRED
FROM mtcars) AS prediction_output;
actual_class | predicted_0 | predicted_1 | comment
-------------+-------------+-------------+------------------------------------------
0 | 19 | 0 |
1 | 0 | 13 | Of 32 rows, 32 were used and 0 were ignored
(2 rows)
6.12.3.2 - CROSS_VALIDATE
Performs k-fold cross validation on a learning algorithm using an input relation, and grid search for hyper parameters.
Performs k-fold cross validation on a learning algorithm using an input relation, and grid search for hyper parameters. The output is an average performance indicator of the selected algorithm. This function supports SVM classification, naive bayes, and logistic regression.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CROSS_VALIDATE ( 'algorithm', 'input-relation', 'response-column', 'predictor-columns'
[ USING PARAMETERS
[exclude_columns = 'excluded-columns']
[, cv_model_name = 'model']
[, cv_metrics = 'metrics']
[, cv_fold_count = num-folds]
[, cv_hyperparams = 'hyperparams']
[, cv_prediction_cutoff = prediction-cutoff] ] )
Arguments
algorithm- Name of the algorithm training function, one of the following:
input-relation- The table or view that contains data used for training and testing. If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the hcatalog schema, and then run the machine learning function.
response-column- Name of the input column that contains the response.
predictor-columnsComma-separated list of columns in the input relation that represent independent variables for the model, or asterisk (*) to select all columns. If you select all columns, the argument list for parameter exclude_columns must include response-column, and any columns that are invalid as predictor columns.
Parameters
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
cv_model_name- The name of a model that lets you retrieve results of the cross validation process. If you omit this parameter, results are displayed but not saved. If you set this parameter to a model name, you can retrieve the results with summary functions
GET_MODEL_ATTRIBUTE and
GET_MODEL_SUMMARY
-
cv_metrics
- The metrics used to assess the algorithm, specified either as a comma-separated list of metric names or in a JSON array. In both cases, you specify one or more of the following metric names:
-
accuracy (default)
-
error_rate
-
TP: True positive, the number of cases of class 1 predicted as class 1
-
FP: False positive, the number of cases of class 0 predicted as class 1
-
TN: True negative, the number of cases of class 0 predicted as class 0
-
FN: False negative, the number of cases of class 1 predicted as class 0
-
TPR or recall: True positive rate, the correct predictions among class 1
-
FPR: False positive rate, the wrong predictions among class 0
-
TNR: True negative rate, the correct predictions among class 0
-
FNR: False negative rate, the wrong predictions among class 1
-
PPV or precision: The positive predictive value, the correct predictions among cases predicted as class 1
-
NPV: Negative predictive value, the correct predictions among cases predicted as class 0
-
MSE: Mean squared error
-
MAE: Mean absolute error
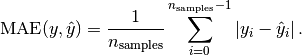
-
rsquared: coefficient of determination
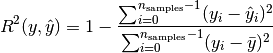
-
explained_variance
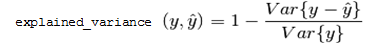
-
fscore
(1 + beta˄2) * precison * recall / (beta˄2 * precision + recall)
beta equals 1 by default
-
auc_roc: AUC of ROC using the specified number of bins, by default 100
-
auc_prc: AUC of PRC using the specified number of bins, by default 100
-
counts: Shortcut that resolves to four other metrics: TP, FP, TN, and FN
-
count: Valid only in JSON syntax, counts the number of cases labeled by one class (case-class-label) but predicted as another class (predicted-class-label):
cv_metrics='[{"count":[case-class-label, predicted-class-label]}]'
cv_fold_count- The number of folds to split the data.
Default: 5
cv_hyperparams- A JSON string that describes the combination of parameters for use in grid search of hyper parameters. The JSON string contains pairs of the hyper parameter name. The value of each hyper parameter can be specified as an array or sequence. For example:
{"param1":[value1,value2,...], "param2":{"first":first_value, "step":step_size, "count":number_of_values} }
Hyper parameter names and string values should be quoted using the JSON standard. These parameters are passed to the training function.
cv_prediction_cutoff- The cutoff threshold that is passed to the prediction stage of logistic regression, a FLOAT between 0 and 1, exclusive
Default: 0.5
Model attributes
call_string- The value of all input arguments that were specified at the time
CROSS_VALIDATE was called.
run_average- The average across all folds of all metrics specified in parameter
cv_metrics, if specified; otherwise, average accuracy.
fold_info- The number of rows in each fold:
counters- All counters for the function, including:
-
accepted_row_count: The total number of rows in the input_relation, minus the number of rejected rows.
-
rejected_row_count: The number of rows of the input_relation that were skipped because they contained an invalid value.
-
feature_count: The number of features input to the machine learning model.
run_details- Information about each run, where a run means training a single model, and then testing that model on the one held-out fold:
-
fold_id: The index of the fold held out for testing.
-
iteration_count: The number of iterations used in model training on non-held-out folds.
-
accuracy: All metrics specified in parameter cv_metrics, or accuracy if cv_metrics is not provided.
-
error_rate: All metrics specified in parameter cv_metrics, or accuracy if the parameter is omitted.
Privileges
Non-superusers:
-
SELECT privileges on the input relation
-
CREATE and USAGE privileges on the default schema where machine learning algorithms generate models. If cv_model_name is provided, the cross validation results are saved as a model in the same schema.
Specifying metrics in JSON
Parameter cv_metrics can specify metrics as an array of JSON objects, where each object specifies a metric name . For example, the following expression sets cv_metrics to two metrics specified as JSON objects, accuracy and error_rate:
cv_metrics='["accuracy", "error_rate"]'
In the next example, cv_metrics is set to two metrics, accuracy and TPR (true positive rate). Here, the TPR metric is specified as a JSON object that takes an array of two class label arguments, 2 and 3:
cv_metrics='[ "accuracy", {"TPR":[2,3] } ]'
Metrics specified as JSON objects can accept parameters. In the following example, the fscore metric specifies parameter beta, which is set to 0.5:
cv_metrics='[ {"fscore":{"beta":0.5} } ]'
Parameter support can be especially useful for certain metrics. For example, metrics auc_roc and auc_prc build a curve, and then compute the area under that curve. For ROC, the curve is formed by plotting metrics TPR against FPR; for PRC, PPV (precision) against TPR (recall). The accuracy of such curves can be increased by setting parameter num_bins to a value greater than the default value of 100. For example, the following expression computes AUC for an ROC curve built with 1000 bins:
cv_metrics='[{"auc_roc":{"num_bins":1000}}]'
Using metrics with Multi-class classifier functions
All supported metrics are defined for binary classifier functions
LOGISTIC_REG and
SVM_CLASSIFIER. For multi-class classifier functions such as
NAIVE_BAYES, these metrics can be calculated for each one-versus-the-rest binary classifier. Use arguments to request the metrics for each classifier. For example, if training data has integer class labels, you can set cv_metrics with the precision (PPV) metric as follows:
cv_metrics='[{"precision":[0,4]}]'
This setting specifies to return two columns with precision computed for two classifiers:
If you omit class label arguments, the class with index 1 is used. Instead of computing metrics for individual one-versus-the-rest classifiers, the average is computed in one of the following styles: macro, micro, or weighted (default). For example, the following cv_metrics setting returns the average weighted by class sizes:
cv_metrics='[{"precision":{"avg":"weighted"}}]'
AUC-type metrics can be similarly defined for multi-class classifiers. For example, the following cv_metrics setting computes the area under the ROC curve for each one-versus-the-rest classifier, and then returns the average weighted by class sizes.
cv_metrics='[{"auc_roc":{"avg":"weighted", "num_bins":1000}}]'
Examples
=> SELECT CROSS_VALIDATE('svm_classifier', 'mtcars', 'am', 'mpg'
USING PARAMETERS cv_fold_count= 6,
cv_hyperparams='{"C":[1,5]}',
cv_model_name='cv_svm',
cv_metrics='accuracy, error_rate');
CROSS_VALIDATE
----------------------------
Finished
===========
run_average
===========
C |accuracy |error_rate
---+--------------+----------
1 | 0.75556 | 0.24444
5 | 0.78333 | 0.21667
(1 row)
6.12.3.3 - ERROR_RATE
Using an input table, returns a table that calculates the rate of incorrect classifications and displays them as FLOAT values.
Using an input table, returns a table that calculates the rate of incorrect classifications and displays them as FLOAT values. ERROR_RATE returns a table with the following dimensions:
Syntax
ERROR_RATE ( targets, predictions [ USING PARAMETERS num_classes = num-classes ] ) OVER()
Arguments
targets- An input column that contains the true values of the response variable.
predictions- An input column that contains the predicted class labels.
Arguments targets and predictions must be set to input columns of the same data type, one of the following: INTEGER, BOOLEAN, or CHAR/VARCHAR. Depending on their data type, these columns identify classes as follows:
-
INTEGER: Zero-based consecutive integers between 0 and (num-classes-1) inclusive, where num-classes is the number of classes. For example, given the following input column values— {0, 1, 2, 3, 4}—Vertica assumes five classes.
Note
If input column values are not consecutive, Vertica interpolates the missing values. Thus, given the following input values— {0, 1, 3, 5, 6,}— Vertica assumes seven classes.
-
BOOLEAN: Yes or No
-
CHAR/VARCHAR: Class names. If the input columns are of type CHAR/VARCHAR columns, you must also set parameter num_classes to the number of classes.
Note
Vertica computes the number of classes as the union of values in both input columns. For example, given the following sets of values in the targets and predictions input columns, Vertica counts four classes:
{'milk', 'soy milk', 'cream'}
{'soy milk', 'almond milk'}
Parameters
num_classesAn integer > 1, specifies the number of classes to pass to the function.
You must set this parameter if the specified input columns are of type CHAR/VARCHAR. Otherwise, the function processes this parameter according to the column data types:
-
INTEGER: By default set to 2, you must set this parameter correctly if the number of classes is any other value.
-
BOOLEAN: By default set to 2, cannot be set to any other value.
Privileges
Non-superusers: model owner, or USAGE privileges on the model
Examples
This example shows how to execute the ERROR_RATE function on an input table named mtcars. The response variables appear in the column obs, while the prediction variables appear in the column pred. Because this example is a classification problem, all response variable values and prediction variable values are either 0 or 1, indicating binary classification.
In the table returned by the function, the first column displays the class id column. The second column displays the corresponding error rate for the class id. The third column indicates how many rows were successfully used by the function and whether any rows were ignored.
=> SELECT ERROR_RATE(obs::int, pred::int USING PARAMETERS num_classes=2) OVER()
FROM (SELECT am AS obs, PREDICT_LOGISTIC_REG (mpg, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel', type='response') AS pred
FROM mtcars) AS prediction_output;
class | error_rate | comment
-------+--------------------+---------------------------------------------
0 | 0 |
1 | 0.0769230797886848 |
| 0.03125 | Of 32 rows, 32 were used and 0 were ignored
(3 rows)
6.12.3.4 - LIFT_TABLE
Returns a table that compares the predictive quality of a machine learning model.
Returns a table that compares the predictive quality of a machine learning model. This function is also known as a lift chart.
Syntax
LIFT_TABLE ( targets, probabilities
[ USING PARAMETERS [num_bins = num-bins] [, main_class = class-name ] ] )
OVER()
Arguments
targets- An input column that contains the true values of the response variable, one of the following data types: INTEGER, BOOLEAN, or CHAR/VARCHAR. Depending on the column data type, the function processes column data as follows:
-
INTEGER: Uses the input column as containing the true value of the response variable.
-
BOOLEAN: Resolves Yes to 1, 0 to No.
-
CHAR/VARCHAR: Resolves the value specified by parameter main_class to 1, all other values to 0.
Note
If the input column is of data type INTEGER or BOOLEAN, the function ignores parameter main_class.
probabilities- A FLOAT input column that contains the predicted probability of response being the main class, set to 1 if
targets is of type INTEGER.
Parameters
num_binsAn integer value that determines the number of decision boundaries. Decision boundaries are set at equally spaced intervals between 0 and 1, inclusive. The function computes the table at each num-bin + 1 point.
Default: 100
main_classUsed only if targets is of type CHAR/VARCHAR, specifies the class to associate with the probabilities argument.
Examples
Execute LIFT_TABLE on an input table mtcars.
=> SELECT LIFT_TABLE(obs::int, prob::float USING PARAMETERS num_bins=2) OVER()
FROM (SELECT am AS obs, PREDICT_LOGISTIC_REG(mpg, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel',
type='probability') AS prob
FROM mtcars) AS prediction_output;
decision_boundary | positive_prediction_ratio | lift | comment
-------------------+---------------------------+------------------+---------------------------------------------
1 | 0 | NaN |
0.5 | 0.40625 | 2.46153846153846 |
0 | 1 | 1 | Of 32 rows, 32 were used and 0 were ignored
(3 rows)
The first column, decision_boundary, indicates the cut-off point for whether to classify a response as 0 or 1. For instance, for each row, if prob is greater than or equal to decision_boundary, the response is classified as 1. If prob is less than decision_boundary, the response is classified as 0.
The second column, positive_prediction_ratio, shows the percentage of samples in class 1 that the function classified correctly using the corresponding decision_boundary value.
For the third column, lift, the function divides the positive_prediction_ratio by the percentage of rows correctly or incorrectly classified as class 1.
6.12.3.5 - MSE
Returns a table that displays the mean squared error of the prediction and response columns in a machine learning model.
Returns a table that displays the mean squared error of the prediction and response columns in a machine learning model.
Syntax
MSE ( targets, predictions ) OVER()
Arguments
targets- The model response variable, of type FLOAT.
predictions- A FLOAT input column that contains predicted values for the response variable.
Examples
Execute the MSE function on input table faithful_testing. The response variables appear in the column obs, while the prediction variables appear in the column prediction.
=> SELECT MSE(obs, prediction) OVER()
FROM (SELECT eruptions AS obs,
PREDICT_LINEAR_REG (waiting USING PARAMETERS model_name='myLinearRegModel') AS prediction
FROM faithful_testing) AS prediction_output;
mse | Comments
-------------------+-----------------------------------------------
0.252925741352641 | Of 110 rows, 110 were used and 0 were ignored
(1 row)
6.12.3.6 - PRC
Returns a table that displays the points on a receiver precision recall (PR) curve.
Returns a table that displays the points on a receiver precision recall (PR) curve.
Syntax
PRC ( targets, probabilities
[ USING PARAMETERS
[num_bins = num-bins]
[, f1_score = return-score ]
[, main_class = class-name ] )
OVER()
Arguments
targets- An input column that contains the true values of the response variable, one of the following data types: INTEGER, BOOLEAN, or CHAR/VARCHAR. Depending on the column data type, the function processes column data as follows:
-
INTEGER: Uses the input column as containing the true value of the response variable.
-
BOOLEAN: Resolves Yes to 1, 0 to No.
-
CHAR/VARCHAR: Resolves the value specified by parameter main_class to 1, all other values to 0.
Note
If the input column is of data type INTEGER or BOOLEAN, the function ignores parameter main_class.
probabilities- A FLOAT input column that contains the predicted probability of response being the main class, set to 1 if
targets is of type INTEGER.
Parameters
num_binsAn integer value that determines the number of decision boundaries. Decision boundaries are set at equally spaced intervals between 0 and 1, inclusive. The function computes the table at each num-bin + 1 point.
Default: 100
f1_score- A Boolean that specifies whether to return a column that contains the f1 score—the harmonic average of the precision and recall measures, where an F1 score reaches its best value at 1 (perfect precision and recall) and worst at 0.
Default: false
main_classUsed only if targets is of type CHAR/VARCHAR, specifies the class to associate with the probabilities argument.
Examples
Execute the PRC function on an input table named mtcars. The response variables appear in the column obs, while the prediction variables appear in column pred.
=> SELECT PRC(obs::int, prob::float USING PARAMETERS num_bins=2, f1_score=true) OVER()
FROM (SELECT am AS obs,
PREDICT_LOGISTIC_REG (mpg, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel',
type='probability') AS prob
FROM mtcars) AS prediction_output;
decision_boundary | recall | precision | f1_score | comment
------------------+--------+-----------+-------------------+--------------------------------------------
0 | 1 | 0.40625 | 0.577777777777778 |
0.5 | 1 | 1 | 1 | Of 32 rows, 32 were used and 0 were ignored
(2 rows)
The first column, decision_boundary, indicates the cut-off point for whether to classify a response as 0 or 1. For example, in each row, if the probability is equal to or greater than decision_boundary, the response is classified as 1. If the probability is less than decision_boundary, the response is classified as 0.
6.12.3.7 - READ_TREE
Reads the contents of trees within the random forest or XGBoost model.
Reads the contents of trees within the random forest or XGBoost model.
Syntax
READ_TREE ( USING PARAMETERS model_name = 'model-name' [, tree_id = tree-id] [, format = 'format'] )
Parameters
model_name- Identifies the model that is stored as a result of training, where
model-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
tree_id- The tree identifier, an integer between 0 and
n-1, where n is the number of trees in the random forest or XGBoost model. If you omit this parameter, all trees are returned.
format- Output format of the returned tree, one of the following:
Privileges
Non-superusers: USAGE privileges on the model
Examples
Get tabular output from READ_TREE for a random forest model:
=> SELECT READ_TREE ( USING PARAMETERS model_name='myRFModel', tree_id=1 ,
format= 'tabular') LIMIT 2;
-[ RECORD 1 ]-------------+-------------------
tree_id | 1
node_id | 1
node_depth | 0
is_leaf | f
is_categorical_split | f
split_predictor | petal_length
split_value | 1.921875
weighted_information_gain | 0.111242236024845
left_child_id | 2
right_child_id | 3
prediction |
probability/variance |
-[ RECORD 2 ]-------------+-------------------
tree_id | 1
node_id | 2
node_depth | 1
is_leaf | t
is_categorical_split |
split_predictor |
split_value |
weighted_information_gain |
left_child_id |
right_child_id |
prediction | setosa
probability/variance | 1
Get graphviz-formatted output from READ_TREE:
=> SELECT READ_TREE ( USING PARAMETERS model_name='myRFModel', tree_id=1 ,
format= 'graphviz')LIMIT 1;
-[ RECORD 1 ]+-------------------------------------------------------------------
---------------------------------------------------------------------------------
tree_id | 1
tree_digraph | digraph Tree{
1 [label="petal_length < 1.921875 ?", color="blue"];
1 -> 2 [label="yes", color="black"];
1 -> 3 [label="no", color="black"];
2 [label="prediction: setosa, probability: 1", color="red"];
3 [label="petal_length < 4.871875 ?", color="blue"];
3 -> 6 [label="yes", color="black"];
3 -> 7 [label="no", color="black"];
6 [label="prediction: versicolor, probability: 1", color="red"];
7 [label="prediction: virginica, probability: 1", color="red"];
}
This renders as follows:
See also
6.12.3.8 - RF_PREDICTOR_IMPORTANCE
Measures the importance of the predictors in a random forest model using the Mean Decrease Impurity (MDI) approach.
Measures the importance of the predictors in a random forest model using the Mean Decrease Impurity (MDI) approach. The importance vector is normalized to sum to 1.
Syntax
RF_PREDICTOR_IMPORTANCE ( USING PARAMETERS model_name = 'model-name' [, tree_id = tree-id] )
Parameters
model_name- Identifies the model that is stored as a result of the training, where
model-name must be of type rf_classifier or rf_regressor.
tree_id- Identifies the tree to process, an integer between 0 and
n-1, where n is the number of trees in the forest. If you omit this parameter, the function uses all trees to measure importance values.
Privileges
Non-superusers: USAGE privileges on the model
Examples
This example shows how you can use the RF_PREDICTOR_IMPORTANCE function.
=> SELECT RF_PREDICTOR_IMPORTANCE ( USING PARAMETERS model_name = 'myRFModel');
predictor_index | predictor_name | importance_value
-----------------+----------------+--------------------
0 | sepal.length | 0.106763318092655
1 | sepal.width | 0.0279536658041994
2 | petal.length | 0.499198722346586
3 | petal.width | 0.366084293756561
(4 rows)
See also
6.12.3.9 - ROC
Returns a table that displays the points on a receiver operating characteristic curve.
Returns a table that displays the points on a receiver operating characteristic curve. The ROC function tells you the accuracy of a classification model as you raise the discrimination threshold for the model.
Syntax
ROC ( targets, probabilities
[ USING PARAMETERS
[num_bins = num-bins]
[, AUC = output]
[, main_class = class-name ] ) ] )
OVER()
Arguments
targets- An input column that contains the true values of the response variable, one of the following data types: INTEGER, BOOLEAN, or CHAR/VARCHAR. Depending on the column data type, the function processes column data as follows:
-
INTEGER: Uses the input column as containing the true value of the response variable.
-
BOOLEAN: Resolves Yes to 1, 0 to No.
-
CHAR/VARCHAR: Resolves the value specified by parameter main_class to 1, all other values to 0.
Note
If the input column is of data type INTEGER or BOOLEAN, the function ignores parameter main_class.
probabilities- A FLOAT input column that contains the predicted probability of response being the main class, set to 1 if
targets is of type INTEGER.
Parameters
num_binsAn integer value that determines the number of decision boundaries. Decision boundaries are set at equally spaced intervals between 0 and 1, inclusive. The function computes the table at each num-bin + 1 point.
Default: 100
Greater values result in more precise approximations of the AUC.
AUC- A Boolean value that specifies whether to output the area under the curve (AUC) value.
Default: True
main_classUsed only if targets is of type CHAR/VARCHAR, specifies the class to associate with the probabilities argument.
Examples
Execute ROC on input table mtcars. Observed class labels are in column obs, predicted class labels are in column prob:
=> SELECT ROC(obs::int, prob::float USING PARAMETERS num_bins=5, AUC = True) OVER()
FROM (SELECT am AS obs,
PREDICT_LOGISTIC_REG (mpg, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS
model_name='myLogisticRegModel', type='probability') AS prob
FROM mtcars) AS prediction_output;
decision_boundary | false_positive_rate | true_positive_rate | AUC |comment
-------------------+---------------------+--------------------+-----+-----------------------------------
0 | 1 | 1 | |
0.5 | 0 | 1 | |
1 | 0 | 0 | 1 | Of 32 rows,32 were used and 0 were ignoreded
(3 rows)
The function returns a table with the following results:
-
decision_boundary indicates the cut-off point for whether to classify a response as 0 or 1. In each row, if prob is equal to or greater than decision_boundary, the response is classified as 1. If prob is less than decision_boundary, the response is classified as 0.
-
false_positive_rate shows the percentage of false positives (when 0 is classified as 1) in the corresponding decision_boundary.
-
true_positive_rate shows the percentage of rows that were classified as 1 and also belong to class 1.
6.12.3.10 - RSQUARED
Returns a table with the R-squared value of the predictions in a regression model.
Returns a table with the R-squared value of the predictions in a regression model.
Syntax
RSQUARED ( targets, predictions ) OVER()
Important
The OVER() clause must be empty.
Arguments
targets- A FLOAT response variable for the model.
predictions- A FLOAT input column that contains the predicted values for the response variable.
Examples
This example shows how to execute the RSQUARED function on an input table named faithful_testing. The observed values of the response variable appear in the column, obs, while the predicted values of the response variable appear in the column, pred.
=> SELECT RSQUARED(obs, prediction) OVER()
FROM (SELECT eruptions AS obs,
PREDICT_LINEAR_REG (waiting
USING PARAMETERS model_name='myLinearRegModel') AS prediction
FROM faithful_testing) AS prediction_output;
rsq | comment
-------------------+-----------------------------------------------
0.801392981147911 | Of 110 rows, 110 were used and 0 were ignored
(1 row)
6.12.3.11 - XGB_PREDICTOR_IMPORTANCE
Measures the importance of the predictors in an XGBoost model.
Measures the importance of the predictors in an XGBoost model. The function outputs three measures of importance for each predictor:
-
frequency: relative number of times the model uses a predictor to split the data.
-
total_gain: relative contribution of a predictor to the model based on the total information gain across a predictor's splits. A higher value means more predictive importance.
-
avg_gain: relative contribution of a predictor to the model based on the average information gain across a predictor's splits.
The sum of each importance measure is normalized to one across all predictors.
Syntax
XGB_PREDICTOR_IMPORTANCE ( USING PARAMETERS param=value[,...] )
Parameters
model_name- Name of the model, which must be of type
xgb_classifier or xgb_regressor.
tree_id- Integer in the range [0,
n-1], where n is the number of trees in model_name, that specifies the tree to process. If you omit this parameter, the function uses all trees in the model to measure predictor importance values.
Privileges
Non-superusers: USAGE privileges on the model
Examples
The following example measures the importance of the predictors in the model 'xgb_iris', an XGBoost classifier model, across all trees:
=> SELECT XGB_PREDICTOR_IMPORTANCE( USING PARAMETERS model_name = 'xgb_iris' );
predictor_index | predictor_name | frequency | total_gain | avg_gain
-----------------+----------------+-------------------+--------------------+--------------------
0 | sepal_length | 0.15384615957737 | 0.0183021749937 | 0.0370849960701401
1 | sepal_width | 0.215384617447853 | 0.0154729501420881 | 0.0223944615251752
2 | petal_length | 0.369230777025223 | 0.607349886817728 | 0.512770753876444
3 | petal_width | 0.261538475751877 | 0.358874988046484 | 0.427749788528241
(4 rows)
To sort the predictors by importance values, you can use a nested query with an ORDER BY clause. The following sorts the model predictors by descending avg_gain:
=> SELECT * FROM (SELECT XGB_PREDICTOR_IMPORTANCE( USING PARAMETERS model_name = 'xgb_iris' )) AS importances ORDER BY avg_gain DESC;
predictor_index | predictor_name | frequency | total_gain | avg_gain
-----------------+----------------+-------------------+--------------------+--------------------
2 | petal_length | 0.369230777025223 | 0.607349886817728 | 0.512770753876444
3 | petal_width | 0.261538475751877 | 0.358874988046484 | 0.427749788528241
0 | sepal_length | 0.15384615957737 | 0.0183021749937 | 0.0370849960701401
1 | sepal_width | 0.215384617447853 | 0.0154729501420881 | 0.0223944615251752
(4 rows)
See also
6.12.4 - Model management
Vertica provides several functions for managing models.
Vertica provides several functions for managing models.
6.12.4.1 - CHANGE_MODEL_STATUS
Changes the status of a registered model.
Changes the status of a registered model. Only dbadmin and users with the MLSUPERVISOR role can call this function.
The following diagram depicts the valid status transitions:

This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
CHANGE_MODEL_STATUS( 'registered_name', registered_version, 'new_status' )
Arguments
registered_name- Identifies the abstract name to which the model is registered. This
registered_name can represent a group of models for a higher-level application, where each model in the group has a unique version number.
registered_version- Unique version number of the model under the specified
registered_name.
If there is no registered model with the given registered_name and registered_version, the function errors.
new_status- New status of the registered model. Must be one of the following strings and adhere to the valid status transitions depicted in the above diagram:
-
under_review: Status assigned to newly registered models.
-
staging: Model is targeted for A/B testing against the model currently in production.
-
production: Model is in production for its specified application. Only one model can be in production for a given registered_name at one time.
-
archived: Status of models that were previously in production. Archived models can be returned to production at any time.
-
declined: Model is no longer in consideration for production.
-
unregistered: Model is removed from the versioning environment. The model does not appear in the REGISTERED_MODELS system table.
If you change the status of a model to 'production' and there is already a model in production under the given registered_name, the status of the model in production is set to 'archived' and the status of the new model is set to 'production'.
Privileges
One of the following:
Examples
In the following example, the linear_reg_spark1 model, which is uniquely identified by the registered_name 'linear_reg_app' and the registered_version of two, is set to 'production' status:
=> SELECT * FROM REGISTERED_MODELS;
registered_name | registered_version | status | registered_time | model_id | schema_name | model_name | model_type | category
------------------+--------------------+--------------+-------------------------------+-------------------+-------------+-------------------+-----------------------+----------------
linear_reg_app | 2 | STAGING | 2023-01-29 05:49:00.082166-04 | 45035996273714020 | public | linear_reg_spark1 | PMML_REGRESSION_MODEL | PMML
linear_reg_app | 1 | PRODUCTION | 2023-01-24 09:19:04.553102-05 | 45035996273850350 | public | native_linear_reg | LINEAR_REGRESSION | VERTICA_MODELS
logistic_reg_app | 1 | DECLINED | 2023-01-11 02:47:25.990626-02 | 45035996273853740 | public | log_reg_bfgs | LOGISTIC_REGRESSION | VERTICA_MODELS
(3 rows)
=> SELECT CHANGE_MODEL_STATUS('linear_reg_app', 2, 'production');
CHANGE_MODEL_STATUS
-----------------------------------------------------------------------------
The status of model [linear_reg_app] - version [2] is changed to [production]
(1 row)
You can query the REGISTERED_MODELS system table to confirm that the linear_reg_spark1 model is now in 'production' and the native_linear_reg model, which was currently in 'production', is moved to 'archived':
=> SELECT * FROM REGISTERED_MODELS;
registered_name | registered_version | status | registered_time | model_id | schema_name | model_name | model_type | category
------------------+--------------------+--------------+-------------------------------+-------------------+-------------+-------------------+-----------------------+----------------
linear_reg_app | 2 | PRODUCTION | 2023-01-29 05:49:00.082166-04 | 45035996273714020 | public | linear_reg_spark1 | PMML_REGRESSION_MODEL | PMML
linear_reg_app | 1 | ARCHIVED | 2023-01-24 09:19:04.553102-05 | 45035996273850350 | public | native_linear_reg | LINEAR_REGRESSION | VERTICA_MODELS
logistic_reg_app | 1 | DECLINED | 2023-01-11 02:47:25.990626-02 | 45035996273853740 | public | log_reg_bfgs | LOGISTIC_REGRESSION | VERTICA_MODELS
(2 rows)
If you change a model's status to 'unregistered', the model is removed from the model versioning environment and no longer appears in the REGISTERED_MODELS system table:
=> SELECT CHANGE_MODEL_STATUS('logistic_reg_app', 1, 'unregistered');
CHANGE_MODEL_STATUS
----------------------------------------------------------------------------------
The status of model [logistic_reg_app] - version [1] is changed to [unregistered]
(1 row)
=> SELECT * FROM REGISTERED_MODELS;
registered_name | registered_version | status | registered_time | model_id | schema_name | model_name | model_type | category
------------------+--------------------+--------------+-------------------------------+-------------------+-------------+-------------------+-----------------------+----------------
linear_reg_app | 2 | STAGING | 2023-01-29 05:49:00.082166-04 | 45035996273714020 | public | linear_reg_spark1 | PMML_REGRESSION_MODEL | PMML
linear_reg_app | 1 | PRODUCTION | 2023-01-24 09:19:04.553102-05 | 45035996273850350 | public | native_linear_reg | LINEAR_REGRESSION | VERTICA_MODELS
(2 rows)
See also
6.12.4.2 - EXPORT_MODELS
Exports machine learning models.
Exports machine learning models. Vertica supports three model formats:
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXPORT_MODELS ( 'output-dir', 'export-target' [ USING PARAMETERS category = 'model-category' ] )
Arguments
output-dir- Absolute path of an output directory to store the exported models, either an absolute path on the initiator node file system or a URI for a supported file system or object store.
export-target- Models to export:
[schema.]{model-name | * }
schema specifies the schema from which models are exported. If omitted, EXPORT_MODELS uses the default schema. Supply * (asterisk) to batch export all models from the schema.
If a model in a batch fails to export, the function issues a warning and then continues to export any remaining models in the batch. Details about any failed model exports are available in the log file generated at the output-dir location.
Parameters
category- The category of models to export, one of the following:
-
VERTICA_MODELS
-
PMML
-
TENSORFLOW
EXPORT_MODELS exports models of the specified category according to the scope of the export operation—that is, whether it applies to a single model, or to all models within a schema. See Export Scope and Category Processing below.
Exported Files below describes the files that EXPORT_MODELS exports for each category.
If you omit this parameter, EXPORT_MODELS exports the model, or models in the specified schema, according to their model type.
Privileges
Superuser or MLSUPERVISOR
Export scope and category processing
EXPORT_MODELS executes according to the following parameter settings:
-
Scope of the export operation: single model, or all models within a given schema
-
Category specified or omitted
The following table shows how these two parameters control the export process:
|
Export scope |
If category specified... |
If category omitted... |
|
Single model |
Convert the model to the specified category, provided the model and category are compatible; otherwise, return with a mismatch error. |
Export the model according to model type. |
|
All models in schema |
Export only models that are compatible with the specified category and issue mismatch warnings on all other models in the schema. |
Export all models in the schema according to model type. |
Exported files
EXPORT_MODELS exports the following files for each model category:
VERTICA_MODELS
-
Multiple binary files (exact number dependent on model type)
-
metadata.json: Metadata file with model information, including model name, category, type, and Vertica version on export.
-
crc.json: Used on import to validate other files of this model.
PMML
-
XML file with the same name as the model and complying with PMML standard.
-
metadata.json: Metadata file with model information, including model name, category, type, and Vertica version on export.
-
crc.json: Used on import to validate other files of this model.
TENSORFLOW
-
model-name.pb: Contains the TensorFlow model, saved in 'frozen graph' format.
-
metadata.json: Metadata file with model information, including model name, category, type, and Vertica version on export.
-
tf_model_desc.json: Summary model description.
-
model.json: Verbose model description.
-
crc.json: Used on import to validate other files of this model.
Categories and compatible models
If EXPORT_MODELS specifies a single model and also sets the category parameter, the function succeeds if the model type and category are compatible; otherwise, it returns with an error. The following model types are compatible with the listed categories:
PMMLPMMLTensorFlowTENSORFLOWVERTICA_MODELSPMML
VERTICA_MODELS
If EXPORT_MODELS specifies to export all models from a schema and sets a category, it issues a warning message on each model that is incompatible with that category. The function then continues to process remaining models in that schema.
EXPORT_MODELS logs all errors and warnings in output-dir/export_log.json.
Examples
Export models without changing their category
Export model myschema.mykmeansmodel without changing its category:
=> SELECT EXPORT_MODELS ('/home/dbadmin', 'myschema.mykmeansmodel');
EXPORT_MODELS
----------------
Success
(1 row)
Export all models in schema myschema without changing their categories:
=> SELECT EXPORT_MODELS ('/home/dbadmin', 'myschema.*');
EXPORT_MODELS
----------------
Success
(1 row)
Export all the models in schema models to an S3 bucket without changing the model categories:
SELECT export_models('s3://vertica/ml_models', 'models.*');
EXPORT_MODELS
---------------
Success
(1 row)
Export models that are compatible with the specified category
Note
When you import a model of category VERTICA_MODELS trained in a different version of Vertica, Vertica automatically upgrades the model version to match that of the database. If this fails, you must run UPGRADE_MODEL.
If both methods fail, the model cannot be used for in-database scoring and cannot be exported as a PMML model.
The category is set to PMML. Models of type PMML and VERTICA_MODELS are compatible with the PMML category, so the export operation succeeds if my_keans is of either type:
=> SELECT EXPORT_MODELS ('/tmp/', 'my_kmeans' USING PARAMETERS category='PMML');
The category is set to VERTICA_MODELS. Only models of type VERTICA_MODELS are compatible with the VERTICA_MODELS category, so the export operation succeeds only if my_keans is of that type:
=> SELECT EXPORT_MODELS ('/tmp/', 'public.my_kmeans' USING PARAMETERS category='VERTICA_MODELS');
The category is set to TENSORFLOW. Only models of type TensorFlow are compatible with the TENSORFLOW category, so the model tf_mnist_keras must be of type TensorFlow:
=> SELECT EXPORT_MODELS ('/tmp/', 'tf_mnist_keras', USING PARAMETERS category='TENSORFLOW');
export_models
---------------
Success
(1 row)
After exporting the TensorFlow model tf_mnist_keras, list the exported files:
$ ls tf_mnist_keras/
crc.json metadata.json mnist_keras.pb model.json tf_model_desc.json
See also
IMPORT_MODELS
6.12.4.3 - GET_MODEL_ATTRIBUTE
Extracts either a specific attribute from a model or all attributes from a model.
Extracts either a specific attribute from a model or all attributes from a model. Use this function to view a list of attributes and row counts or view detailed information about a single attribute. The output of GET_MODEL_ATTRIBUTE is a table format where users can select particular columns or rows.
Syntax
GET_MODEL_ATTRIBUTE ( USING PARAMETERS model_name = 'model-name' [, attr_name = 'attribute' ] )
Parameters
model_nameName of the model (case-insensitive).
attr_name- Name of the model attribute to extract. If omitted, the function shows all available attributes. Attribute names are case-sensitive.
Privileges
Non-superusers: model owner, or USAGE privileges on the model
Examples
This example returns a summary of all model attributes.
=> SELECT GET_MODEL_ATTRIBUTE ( USING PARAMETERS model_name='myLinearRegModel');
attr_name | attr_fields | #_of_rows
-------------------+---------------------------------------------------+-----------
details | predictor, coefficient, std_err, t_value, p_value | 2
regularization | type, lambda | 1
iteration_count | iteration_count | 1
rejected_row_count | rejected_row_count | 1
accepted_row_count | accepted_row_count | 1
call_string | call_string | 1
(6 rows)
This example extracts the details attribute from the myLinearRegModel model.
=> SELECT GET_MODEL_ATTRIBUTE ( USING PARAMETERS model_name='myLinearRegModel', attr_name='details');
coeffNames | coeff | stdErr | zValue | pValue
-----------+--------------------+---------------------+-------------------+-----------------------
Intercept | -1.87401598641074 | 0.160143331525544 | -11.7021169008952 | 7.3592939615234e-26
waiting | 0.0756279479518627 | 0.00221854185633525 | 34.0890336307608 | 8.13028381124448e-100
(2 rows)
6.12.4.4 - GET_MODEL_SUMMARY
Returns summary information of a model.
Returns summary information of a model.
Syntax
GET_MODEL_SUMMARY ( USING PARAMETERS model_name = 'model-name' )
Parameters
- model_name
Name of the model (case-insensitive).
Privileges
Non-superusers: model owner, or USAGE privileges on the model
Examples
This example shows how you can view the summary of a linear regression model.
=> SELECT GET_MODEL_SUMMARY( USING PARAMETERS model_name='myLinearRegModel');
--------------------------------------------------------------------------------
=======
details
=======
predictor|coefficient|std_err |t_value |p_value
---------+-----------+--------+--------+--------
Intercept| -2.06795 | 0.21063|-9.81782| 0.00000
waiting | 0.07876 | 0.00292|26.96925| 0.00000
==============
regularization
==============
type| lambda
----+--------
none| 1.00000
===========
call_string
===========
linear_reg('public.linear_reg_faithful', 'faithful_training', '"eruptions"', 'waiting'
USING PARAMETERS optimizer='bfgs', epsilon=1e-06, max_iterations=100,
regularization='none', lambda=1)
===============
Additional Info
===============
Name |Value
------------------+-----
iteration_count | 3
rejected_row_count| 0
accepted_row_count| 162
(1 row)
6.12.4.5 - IMPORT_MODELS
Imports models into Vertica, either Vertica models that were exported with EXPORT_MODELS, or models in Predictive Model Markup Language (PMML) or TensorFlow format.
Imports models into Vertica, either Vertica models that were exported with EXPORT_MODELS, or models in Predictive Model Markup Language (PMML) or TensorFlow format. You can use this function to move models between Vertica clusters, or to import PMML and TensorFlow models trained elsewhere.
Other Vertica model management operations such as GET_MODEL_SUMMARY and GET_MODEL_ATTRIBUTE support imported models.
Caution
Changing the exported model files causes the import functionality to fail on attempted re-import.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
IMPORT_MODELS ( 'source'
[ USING PARAMETERS [ new_schema = 'schema-name' ] [, category = 'model-category' ] ] )
Arguments
source- Path from which to import models, either an absolute path on the initiator node file system or a URI for a supported file system or object store. The path format depends on whether you are importing a single model or a batch of models:
-
To import a single model, provide the path to the model's directory:
path/model-directory
-
To import a batch of models, provide the path to a parent directory that contains the model directories for each model in the batch:
parent-dir-path/*
If a model in a batch fails to import, the function issues a warning and then continues to import any remaining models in the batch. Details about any failed model import are available in the log file generated at the source location.
Parameters
new_schema- An existing schema where the machine learning models are imported. If omitted, models are imported to the default schema.
IMPORT_MODELS extracts the name of the imported model from its metadata.json file, if it exists. Otherwise, the function uses the name of the model directory.
category- Specifies the category of the model to import, one of the following:
-
VERTICA_MODELS
-
PMML
-
TENSORFLOW
This parameter is required if the model directory has no metadata.json file. IMPORT_MODELS returns with an error if one of the following cases is true:
Note
If the category is TENSORFLOW, IMPORT_MODELS only imports the following files from the model directory:
Privileges
Superuser or MLSUPERVISOR
Requirements and restrictions
The following requirements and restrictions apply:
-
If you export a model, then import it again, the export and import model directory names must match. If naming conflicts occur, import the model to a different schema by using the new_schema parameter, and then rename the model.
-
The machine learning configuration parameter MaxModelSizeKB sets the maximum size of a model that can be imported into Vertica.
-
Some PMML features and attributes are not currently supported. See PMML features and attributes for details.
-
If you import a PMML model with both metadata.json and crc.json files, the CRC file must contain the metadata file's CRC value. Otherwise, the import operation returns with an error.
Examples
If no model category is specified, IMPORT_MODELS uses the model's metadata.json file to determine its category.
Import a single model mykmeansmodel into the newschema schema:
=> SELECT IMPORT_MODELS ('/home/dbadmin/myschema/mykmeansmodel' USING PARAMETERS new_schema='newschema')
IMPORT_MODELS
----------------
Success
(1 row)
Import all models in the myschema directory into the newschema schema:
=> SELECT IMPORT_MODELS ('/home/dbadmin/myschema/*' USING PARAMETERS new_schema='newschema')
IMPORT_MODELS
----------------
Success
(1 row)
Import the model tf_mnsit_estimator from an S3 bucket into the ml_models schema:
=> SELECT IMPORT_MODELS ('s3://ml-models/tensorflow/mnist' USING PARAMETERS new_schema='ml_models')
IMPORT MODELS
---------------
Success
(1 row)
When you set the category parameter, the specified category must match the model type of the imported models; otherwise, the function returns an error.
Import kmeans_pmml as a PMML model:
SELECT IMPORT_MODELS ('/root/user/kmeans_pmml' USING PARAMETERS category='PMML')
import_models
---------------
Success
(1 row)
Attempt to import kmeans_pmml, a PMML model, as a TENSORFLOW model:
SELECT IMPORT_MODELS ('/root/user/kmeans_pmml' USING PARAMETERS category='TENSORFLOW')
import_models
-------------------------------------------------
Has failure. Please check import_log.json file
(1 row)
Import tf_mnist_estimator as a TensorFlow model:
=> SELECT IMPORT_MODELS ( '/path/tf_models/tf_mnist_estimator' USING PARAMETERS category='TENSORFLOW');
import_models
---------------
Success
(1 row)
Import all TensorFlow models from the specified directory:
=> SELECT IMPORT_MODELS ( '/path/tf_models/*' USING PARAMETERS category='TENSORFLOW');
import_models
---------------
Success
(1 row)
See also
EXPORT_MODELS
6.12.4.6 - REGISTER_MODEL
Registers a trained model and adds it to Model Versioning environment with a status of 'under_review'.
Registers a trained model and adds it to Model versioning environment with a status of 'under_review'. The model must be registered by the owner of the model, dbadmin, or MLSUPERVISOR.
After a model is registered, the model owner is automatically changed to Superuser and the previous owner is given USAGE privileges. Users with the MLSUPERVISOR role or dbamin can call the CHANGE_MODEL_STATUS function to alter the status of registered models.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
REGISTER_MODEL( 'model_name', 'registered_name' )
Arguments
model_name- Identifies the model to register. If the model has already been registered, the function throws an error.
registered_name- Identifies an abstract name to which the model is registered. This
registered_name can represent a group of models for a higher-level application, where each model in the group has a unique version number.
If a model is the first to be registered to a given registered_name, the model is assigned a registered_version of one. Otherwise, newly registered models are assigned an incremented registered_version of n + 1, where n is the number of models already registered to the given registered_name. Each registered model can be uniquely identified by the combination of registered_name and registered_version.
Privileges
Non-superusers: model owner
Examples
In the following example, the model log_reg_bfgs is registered to the logistic_reg_app application:
=> SELECT REGISTER_MODEL('log_reg_bfgs', 'logistic_reg_app');
REGISTER_MODEL
----------------------------------------------------------------------
Model [log_reg_bfgs] is registered as [logistic_reg_app], version [1]
(1 row)
You can query the REGISTERED_MODELS system table to view details about the newly registered model:
=> SELECT * FROM REGISTERED_MODELS;
registered_name | registered_version | status | registered_time | model_id | schema_name | model_name | model_type | category
------------------+--------------------+--------------+-------------------------------+-------------------+-------------+-------------------+-----------------------+----------------
logistic_reg_app | 1 | UNDER_REVIEW | 2023-01-22 09:49:25.990626-02 | 45035996273853740 | public | log_reg_bfgs | LOGISTIC_REGRESSION | VERTICA_MODELS
(1 row)
See also
6.12.4.7 - UPGRADE_MODEL
Upgrades a model from a previous Vertica version.
Upgrades a model from a previous Vertica version. Vertica automatically runs this function during a database upgrade and if you run the IMPORT_MODELS function. Manually call this function to upgrade models after a backup or restore.
If UPGRADE_MODEL fails to upgrade the model and the model is of category VERTICA_MODELS, it cannot be used for in-database scoring and cannot be exported as a PMML model.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
UPGRADE_MODEL ( [ USING PARAMETERS [model_name = 'model-name'] ] )
Parameters
model_name- Name of the model to upgrade. If you omit this parameter, Vertica upgrades all models on which you have privileges.
Privileges
Non-superuser: Upgrades only models that the user owns.
Examples
Upgrade model myLogisticRegModel:
=> SELECT UPGRADE_MODEL( USING PARAMETERS model_name = 'myLogisticRegModel');
UPGRADE_MODEL
----------------------------
1 model(s) upgrade
(1 row)
Upgrade all models that the user owns:
=> SELECT UPGRADE_MODEL();
UPGRADE_MODEL
----------------------------
20 model(s) upgrade
(1 row)
6.12.5 - Transformation functions
The machine learning API includes a set of UDx functions that transform the columns of each input row to one or more corresponding output columns.
The machine learning API includes a set of UDx functions that transform the columns of each input row to one or more corresponding output columns. These transformations follow rules that are defined in models that were created earlier. For example,
APPLY_SVD uses an SVD model to transform input data.
Unless otherwise indicated, these functions require the following privileges for non-superusers:
In general, given an invalid input row, the return value for these functions is NULL.
6.12.5.1 - APPLY_BISECTING_KMEANS
Applies a trained bisecting k-means model to an input relation, and assigns each new data point to the closest matching cluster in the trained model.
Applies a trained bisecting k-means model to an input relation, and assigns each new data point to the closest matching cluster in the trained model.
Note
If the input relation is defined in Hive, use
SYNC_WITH_HCATALOG_SCHEMA to sync the
hcatalog schema, and then run the machine learning function.
Syntax
SELECT APPLY_BISECTING_KMEANS( 'input-columns'
USING PARAMETERS model_name = 'model-name'
[, num_clusters = 'num-clusters']
[, match_by_pos = match-by-position] ] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Input columns must be of data type numeric.
Parameters
model_nameName of the model (case-insensitive).
num_clusters- Integer between 1 and
k inclusive, where k is the number of centers in the model, specifies the number of clusters to use for prediction.
Default: Value that the model specifies for k
match_by_posBoolean value that specifies how input columns are matched to model features:
Privileges
Non-superusers: model owner, or USAGE privileges on the model
6.12.5.2 - APPLY_IFOREST
Applies an isolation forest (iForest) model to an input relation.
Applies an isolation forest (iForest) model to an input relation. For each input row, the function returns an output row with two fields:
anomaly_score: A float value that represents the average path length across all trees in the model normalized by the training sample size.is_anomaly: A Boolean value that indicates whether the input row is an anomaly. This value is true when anomaly_score is equal to or larger than a given threshold; otherwise, it's false.
Syntax
APPLY_IFOREST( input-columns USING PARAMETERS param=value[,...] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. Column types must match the types of the predictors in
model_name.
Parameters
model_nameName of the model (case-insensitive).
threshold- Optional. Float in the range (0.0, 1.0), specifies the threshold that determines if a data point is an anomaly. If the
anomaly_score for a data point is equal to or larger than the value of threshold, the data point is marked as an outlier.
Alternatively, you can specify a contamination value that sets a threshold where the percentage of training data points labeled as outliers is approximately equal to the value of contamination. You cannot set both contamination and threshold in the same function call.
Default: 0.7
match_by_pos- Optional. Boolean value that specifies how input columns are matched to model columns:
Default: false
contamination- Optional. Float in the range (0.0, 1.0), the approximate ratio of data points in the training data that are labeled as outliers. The function calculates a threshold based on this
contamination value. If you do not set this parameter, the function marks outliers using the specified or default threshold value.
You cannot set both contamination and threshold in the same function call.
Privileges
Non-superusers:
Examples
The following example demonstrates how different threshold values can affect outlier detection on an input relation:
=> SELECT * FROM (SELECT first_name, last_name, APPLY_IFOREST(team, hr, hits, avg, salary USING PARAMETERS model_name='baseball_anomalies',
threshold=0.75) AS predictions FROM baseball) AS outliers WHERE predictions.is_anomaly IS true;
first_name | last_name | predictions
------------+-----------+-------------------------------------------------------
Jacqueline | Richards | {"anomaly_score":0.777757463074347,"is_anomaly":true}
(1 row)
=> SELECT * FROM (SELECT first_name, last_name, APPLY_IFOREST(team, hr, hits, avg, salary USING PARAMETERS model_name='baseball_anomalies',
threshold=0.55) AS predictions FROM baseball) AS outliers WHERE predictions.is_anomaly IS true;
first_name | last_name | predictions
------------+-----------+--------------------------------------------------------
Jacqueline | Richards | {"anomaly_score":0.777757463074347,"is_anomaly":true}
Debra | Hall | {"anomaly_score":0.5714649698133808,"is_anomaly":true}
Gerald | Fuller | {"anomaly_score":0.5980549926114661,"is_anomaly":true}
(3 rows)
You can also use different contamination values to alter the outlier threshold:
=> SELECT * FROM (SELECT first_name, last_name, APPLY_IFOREST(team, hr, hits, avg, salary USING PARAMETERS model_name='baseball_anomalies',
contamination = 0.1) AS predictions FROM baseball) AS outliers WHERE predictions.is_anomaly IS true;
first_name | last_name | predictions
------------+-----------+--------------------------------------------------------
Marie | Fields | {"anomaly_score":0.5307715717521868,"is_anomaly":true}
Jacqueline | Richards | {"anomaly_score":0.777757463074347,"is_anomaly":true}
Debra | Hall | {"anomaly_score":0.5714649698133808,"is_anomaly":true}
Gerald | Fuller | {"anomaly_score":0.5980549926114661,"is_anomaly":true}
(4 rows)
=> SELECT * FROM (SELECT first_name, last_name, APPLY_IFOREST(team, hr, hits, avg, salary USING PARAMETERS model_name='baseball_anomalies',
contamination = 0.01) AS predictions FROM baseball) AS outliers WHERE predictions.is_anomaly IS true;
first_name | last_name | predictions
------------+-----------+--------------------------------------------------------
Jacqueline | Richards | {"anomaly_score":0.777757463074347,"is_anomaly":true}
Debra | Hall | {"anomaly_score":0.5714649698133808,"is_anomaly":true}
Gerald | Fuller | {"anomaly_score":0.5980549926114661,"is_anomaly":true}
(3 rows)
See also
6.12.5.3 - APPLY_INVERSE_PCA
Inverts the APPLY_PCA-generated transform back to the original coordinate system.
Inverts the APPLY_PCA-generated transform back to the original coordinate system.
Syntax
APPLY_INVERSE_PCA ( input-columns
USING PARAMETERS model_name = 'model-name'
[, exclude_columns = 'excluded-columns']
[, key_columns = 'key-columns'] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. The following requirements apply:
Parameters
model_nameName of the model (case-insensitive).
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
key_columns- Comma-separated list of column names from
input-columns that identify its data rows. These columns are included in the output table.
Examples
The following example shows how to use the APPLY_INVERSE_PCA function. It shows the output for the first record.
=> SELECT PCA ('pcamodel', 'world','country,HDI,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,
em1978,em1979,em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,
em1993,em1994,em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,
em2008,em2009,em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,
gdp1981,gdp1982,gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,
gdp1994,gdp1995,gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,
gdp2007,gdp2008,gdp2009,gdp2010' USING PARAMETERS exclude_columns='HDI,country');
PCA
---------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 96 Rejected Rows: 0
(1 row)
=> CREATE TABLE worldPCA AS SELECT
APPLY_PCA (HDI,country,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,em1978,em1979,
em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,em1993,em1994,
em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,em2008,em2009,
em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,gdp1981,gdp1982,
gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,gdp1994,gdp1995,
gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,gdp2007,gdp2008,
gdp2009,gdp2010 USING PARAMETERS model_name='pcamodel', exclude_columns='HDI, country', key_columns='HDI,
country',cutoff=.3)OVER () FROM world;
CREATE TABLE
=> SELECT * FROM worldPCA;
HDI | country | col1
------+---------------------+-------------------
0.886 | Belgium | 79002.2946705704
0.699 | Belize | -25631.6670012556
0.427 | Benin | -40373.4104598122
0.805 | Chile | -16805.7940082156
0.687 | China | -37279.2893141103
0.744 | Costa Rica | -19505.5631231635
0.4 | Cote d'Ivoire | -38058.2060339272
0.776 | Cuba | -23724.5779612041
0.895 | Denmark | 117325.594028813
0.644 | Egypt | -34609.9941604549
...
(96 rows)
=> SELECT APPLY_INVERSE_PCA (HDI, country, col1
USING PARAMETERS model_name = 'pcamodel', exclude_columns='HDI,country',
key_columns = 'HDI, country') OVER () FROM worldPCA;
HDI | country | em1970 | em1971 | em1972 | em1973 |
em1974 | em1975 | em1976| em1977 | em1978 | em1979
| em1980 | em1981 | em1982 | em1983 | em1984 |em1985
| em1986 | em1987 | em1988 | em1989 | em1990 | em1991
| em1992 | em1993| em1994 | em1995 | em1996 | em1997
| em1998 | em1999 | em2000 | em2001 |em2002 |
em2003 | em2004 | em2005 | em2006 | em2007 | em2008
| em2009 | em2010 | gdp1970 | gdp1971 | gdp1972 | gdp1973
| gdp1974 | gdp1975 | gdp1976 | gdp1977 |gdp1978 | gdp1979
| gdp1980 | gdp1981 | gdp1982 | gdp1983 | gdp1984 | gdp1985
| gdp1986| gdp1987 | gdp1988 | gdp1989 | gdp1990 | gdp1991
| gdp1992 | gdp1993 | gdp1994 | gdp1995 | gdp1996 |
gdp1997 | gdp1998 | gdp1999 | gdp2000 | gdp2001 | gdp2002
| gdp2003 |gdp2004 | gdp2005 | gdp2006 | gdp2007 | gdp2008
| gdp2009 | gdp2010
-------+---------------------+-------------------+-------------------+------------------+------------------
+------------------+-------------------+------------------+------------------+-------------------+---------
----------+-------------------+------------------+-------------------+-------------------+-----------------
--+------------------+-------------------+-------------------+-------------------+------------------+-------
-----------+------------------+-------------------+-------------------+------------------+------------------
-+-------------------+------------------+-------------------+-------------------+-------------------+-------
------------+--------------------+------------------+-------------------+------------------+----------------
---+-------------------+-------------------+------------------+-------------------+------------------+------
------------+------------------+------------------+------------------+------------------+------------------+
------------------+------------------+------------------+------------------+------------------+-------------
-----+------------------+------------------+------------------+------------------+------------------+-------
-----------+------------------+------------------+------------------+------------------+------------------+-
-----------------+------------------+------------------+------------------+------------------+--------------
----+------------------+------------------+------------------+------------------+------------------+--------
----------+------------------+------------------+------------------+------------------+------------------
0.886 | Belgium | 18585.6613572407 | -16145.6374560074 | 26938.956253415 | 8094.30475779595 |
12073.5461203817 | -11069.0567600181 | 19133.8584911727| 5500.312894949 | -4227.94863799987 | 6265.77925410752
| -10884.749295608 | 30929.4669575201 | -7831.49439429977 | 3235.81760508742 | -22765.9285442662 | 27200
.6767714485 | -10554.9550160917 | 1169.4144482273 | -16783.7961289161 | 27932.2660829329 | 17227.9083196848
| 13956.0524012749 | -40175.6286481088 | -10889.4785920499 | 22703.6576872859 | -14635.5832197402 |
2857.12270512168 | 20473.5044214494 | -52199.4895696423 | -11038.7346460738 | 18466.7298633088 | -17410.4225137703 |
-3475.63826305462 | 29305.6753822341 | 1242.5724942049 | 17491.0096310849 | -12609.9984515902 | -17909.3603476248
| 6276.58431412381 | 21851.9475485178 | -2614.33738160397 | 3777.74134131349 | 4522.08854282736 | 4251.90446379366
| 4512.15101396876 | 4265.49424538129 | 5190.06845330997 | 4543.80444817989 | 5639.81122679089 | 4420.44705213467
| 5658.8820279283 | 5172.69025294376 | 5019.63640408663 | 5938.84979495903 | 4976.57073629812 | 4710.49525137591
| 6523.65700286465 | 5067.82520773578 | 6789.13070219317 | 5525.94643553563 | 6894.68336419297 | 5961.58442474331
| 5661.21093840818 | 7721.56088518218 | 5959.7301109143 | 6453.43604137202 | 6739.39384033096 | 7517.97645468455
| 6907.49136910647 | 7049.03921764209 | 7726.49091035527 | 8552.65909911844 | 7963.94487647115 | 7187.45827585515
| 7994.02955410523 | 9532.89844418041 | 7962.25713582666 | 7846.68238907624 | 10230.9878908643 | 8642.76044946519
| 8886.79860331866 | 8718.3731386891
...
(96 rows)
See also
6.12.5.4 - APPLY_INVERSE_SVD
Transforms the data back to the original domain.
Transforms the data back to the original domain. This essentially computes the approximated version of the original data by multiplying three matrices: matrix U (input to this function), matrices S and V (stored in the model).
Syntax
APPLY_INVERSE_SVD ( 'input-columns'
USING PARAMETERS model_name = 'model-name'
[, exclude_columns = 'excluded-columns']
[, key_columns = 'key-columns'] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. The following requirements apply:
Parameters
model_nameName of the model (case-insensitive).
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
key_columns- Comma-separated list of column names from
input-columns that identify its data rows. These columns are included in the output table.
Examples
=> SELECT SVD ('svdmodel', 'small_svd', 'x1,x2,x3,x4');
SVD
--------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 8 Rejected Rows: 0
(1 row)
=> CREATE TABLE transform_svd AS SELECT
APPLY_SVD (id, x1, x2, x3, x4 USING PARAMETERS model_name='svdmodel', exclude_columns='id', key_columns='id')
OVER () FROM small_svd;
CREATE TABLE
=> SELECT * FROM transform_svd;
id | col1 | col2 | col3 | col4
----+-------------------+---------------------+---------------------+--------------------
4 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
6 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
1 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
2 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
3 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
5 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
8 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
7 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
(8 rows)
=> SELECT APPLY_INVERSE_SVD (* USING PARAMETERS model_name='svdmodel', exclude_columns='id',
key_columns='id') OVER () FROM transform_svd;
id | x1 | x2 | x3 | x4
----+------------------+------------------+------------------+------------------
4 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
6 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
7 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
1 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
2 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
3 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
5 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
8 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
(8 rows)
See also
6.12.5.5 - APPLY_KMEANS
Assigns each row of an input relation to a cluster center from an existing k-means model.
Assigns each row of an input relation to a cluster center from an existing k-means model.
Syntax
APPLY_KMEANS ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Privileges
Non-superusers: model owner, or USAGE privileges on the model
Examples
The following example creates k-means model myKmeansModel and applies it to input table iris1. The call to APPLY_KMEANS mixes column names and constants. When a constant is passed in place of a column name, the constant is substituted for the value of the column in all rows:
=> SELECT KMEANS('myKmeansModel', 'iris1', '*', 5
USING PARAMETERS max_iterations=20, output_view='myKmeansView', key_columns='id', exclude_columns='Species, id');
KMEANS
----------------------------
Finished in 12 iterations
(1 row)
=> SELECT id, APPLY_KMEANS(Sepal_Length, 2.2, 1.3, Petal_Width
USING PARAMETERS model_name='myKmeansModel', match_by_pos='true') FROM iris2;
id | APPLY_KMEANS
-----+--------------
5 | 1
10 | 1
14 | 1
15 | 1
21 | 1
22 | 1
24 | 1
25 | 1
32 | 1
33 | 1
34 | 1
35 | 1
38 | 1
39 | 1
42 | 1
...
(60 rows)
See also
6.12.5.6 - APPLY_KPROTOTYPES
Assigns each row of an input relation to a cluster center from an existing k-prototypes model.
Assigns each row of an input relation to a cluster center from an existing k-prototypes model.
Syntax
APPLY_KPROTOTYPES ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Privileges
Non-superusers: model owner, or USAGE privileges on the model
Examples
The following example creates k-prototypes model small_model and applies it to input table small_test_mixed:
=> SELECT KPROTOTYPES('small_model_initcenters', 'small_test_mixed', 'x0, country', 3 USING PARAMETERS initial_centers_table='small_test_mixed_centers', key_columns='pid');
KPROTOTYPES
---------------------------
Finished in 2 iterations
(1 row)
=> SELECT country, x0, APPLY_KPROTOTYPES(country, x0
USING PARAMETERS model_name='small_model')
FROM small_test_mixed;
country | x0 | apply_kprototypes
------------+-----+-------------------
'China' | 20 | 0
'US' | 85 | 2
'Russia' | 80 | 1
'Brazil' | 78 | 1
'US' | 23 | 0
'US' | 50 | 0
'Canada' | 24 | 0
'Canada' | 18 | 0
'Russia' | 90 | 2
'Russia' | 98 | 2
'Brazil' | 89 | 2
...
(45 rows)
See also
6.12.5.7 - APPLY_NORMALIZE
A UDTF function that applies the normalization parameters saved in a model to a set of specified input columns.
A UDTF function that applies the normalization parameters saved in a model to a set of specified input columns. If any column specified in the function is not in the model, its data passes through unchanged to APPLY_NORMALIZE.
Note
Note: If a column contains only one distinct value, APPLY_NORMALIZE returns NaN for values in that column.
Syntax
APPLY_NORMALIZE ( input-columns USING PARAMETERS model_name = 'model-name');
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns. If you supply an asterisk,
APPLY_NORMALIZE normalizes all columns in the model.
Parameters
model_nameName of the model (case-insensitive).
Examples
The following example creates a model with NORMALIZE_FIT using the wt and hp columns in table mtcars , and then uses this model in successive calls to APPLY_NORMALIZE and REVERSE_NORMALIZE.
=> SELECT NORMALIZE_FIT('mtcars_normfit', 'mtcars', 'wt,hp', 'minmax');
NORMALIZE_FIT
---------------
Success
(1 row)
The following call to APPLY_NORMALIZE specifies the hp and cyl columns in table mtcars, where hp is in the normalization model and cyl is not in the normalization model:
=> CREATE TABLE mtcars_normalized AS SELECT APPLY_NORMALIZE (hp, cyl USING PARAMETERS model_name = 'mtcars_normfit') FROM mtcars;
CREATE TABLE
=> SELECT * FROM mtcars_normalized;
hp | cyl
--------------------+-----
0.434628975265018 | 8
0.681978798586572 | 8
0.434628975265018 | 6
1 | 8
0.540636042402827 | 8
0 | 4
0.681978798586572 | 8
0.0459363957597173 | 4
0.434628975265018 | 8
0.204946996466431 | 6
0.250883392226148 | 6
0.049469964664311 | 4
0.204946996466431 | 6
0.201413427561837 | 4
0.204946996466431 | 6
0.250883392226148 | 6
0.049469964664311 | 4
0.215547703180212 | 4
0.0353356890459364 | 4
0.187279151943463 | 6
0.452296819787986 | 8
0.628975265017668 | 8
0.346289752650177 | 8
0.137809187279152 | 4
0.749116607773852 | 8
0.144876325088339 | 4
0.151943462897526 | 4
0.452296819787986 | 8
0.452296819787986 | 8
0.575971731448763 | 8
0.159010600706714 | 4
0.346289752650177 | 8
(32 rows)
=> SELECT REVERSE_NORMALIZE (hp, cyl USING PARAMETERS model_name='mtcars_normfit') FROM mtcars_normalized;
hp | cyl
-----+-----
175 | 8
245 | 8
175 | 6
335 | 8
205 | 8
52 | 4
245 | 8
65 | 4
175 | 8
110 | 6
123 | 6
66 | 4
110 | 6
109 | 4
110 | 6
123 | 6
66 | 4
113 | 4
62 | 4
105 | 6
180 | 8
230 | 8
150 | 8
91 | 4
264 | 8
93 | 4
95 | 4
180 | 8
180 | 8
215 | 8
97 | 4
150 | 8
(32 rows)
The following call to REVERSE_NORMALIZE also specifies the hp and cyl columns in table mtcars, where hp is in normalization model mtcars_normfit, and cyl is not in the normalization model.
=> SELECT REVERSE_NORMALIZE (hp, cyl USING PARAMETERS model_name='mtcars_normfit') FROM mtcars_normalized;
hp | cyl
-----------------+-----
205.000005722046 | 8
150.000000357628 | 8
150.000000357628 | 8
93.0000016987324 | 4
174.99999666214 | 8
94.9999992102385 | 4
214.999997496605 | 8
97.0000009387732 | 4
245.000006556511 | 8
174.99999666214 | 6
335 | 8
245.000006556511 | 8
62.0000002086163 | 4
174.99999666214 | 8
230.000002026558 | 8
52 | 4
263.999997675419 | 8
109.999999523163 | 6
123.000002324581 | 6
64.9999996386468 | 4
66.0000005029142 | 4
112.999997898936 | 4
109.999999523163 | 6
180.000000983477 | 8
180.000000983477 | 8
108.999998658895 | 4
109.999999523163 | 6
104.999999418855 | 6
123.000002324581 | 6
180.000000983477 | 8
66.0000005029142 | 4
90.9999999701977 | 4
(32 rows)
See also
6.12.5.8 - APPLY_ONE_HOT_ENCODER
A user-defined transform function (UDTF) that loads the one hot encoder model and writes out a table that contains the encoded columns.
A user-defined transform function (UDTF) that loads the one hot encoder model and writes out a table that contains the encoded columns.
Syntax
APPLY_ONE_HOT_ENCODER( input-columns
USING PARAMETERS model_name = 'model-name'
[, drop_first = 'is-first']
[, ignore_null = 'ignore']
[, separator = 'separator-character']
[, column_naming = 'name-output']
[, null_column_name = 'null-column-name'] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
, stores the categories and their corresponding levels.drop_first- Boolean value, one of the following:
ignore_null- Boolean value, one of the following:
separator- The character that separates the input variable name and the indicator variable level in the output table.To avoid using any separator, set this parameter to null value.
Default: Underscore (_)
column_naming- Appends categorical levels to column names according to the specified method:
-
indices (default): Uses integer indices to represent categorical levels.
-
values/values_relaxed: Both methods use categorical level names. If duplicate column names occur, the function attempts to disambiguate them by appending _n, where n is a zero-based integer index (_0, _1,...).
If the function cannot produce unique column names , it handles this according to the chosen method:
Important
The following column naming rules apply if column_naming is set to values or values_relaxed:
-
Input column names with more than 128 characters are truncated.
-
Column names can contain special characters.
-
If parameter ignore_null is set to true, APPLY_ONE_HOT_ENCODER constructs the column name from the value set in parameter null_column_name. If this parameter is omitted, the string null is used.
null_column_name- The string used in naming the indicator column for null values, used only if
ignore_null is set to false and column_naming is set to values or values_relaxed.
Default:null
Note
Note: If an input row contains a level not stored in the model, the output row columns corresponding to that categorical level are returned as null values.
Examples
=> SELECT APPLY_ONE_HOT_ENCODER(cyl USING PARAMETERS model_name='one_hot_encoder_model',
drop_first='true', ignore_null='false') FROM mtcars;
cyl | cyl_1 | cyl_2
----+-------+-------
8 | 0 | 1
4 | 0 | 0
4 | 0 | 0
8 | 0 | 1
8 | 0 | 1
8 | 0 | 1
4 | 0 | 0
8 | 0 | 1
8 | 0 | 1
4 | 0 | 0
8 | 0 | 1
6 | 1 | 0
4 | 0 | 0
4 | 0 | 0
6 | 1 | 0
6 | 1 | 0
8 | 0 | 1
8 | 0 | 1
4 | 0 | 0
4 | 0 | 0
6 | 1 | 0
8 | 0 | 1
8 | 0 | 1
6 | 1 | 0
4 | 0 | 0
8 | 0 | 1
8 | 0 | 1
8 | 0 | 1
6 | 1 | 0
6 | 1 | 0
4 | 0 | 0
4 | 0 | 0
(32 rows)
See also
6.12.5.9 - APPLY_PCA
Transforms the data using a PCA model.
Transforms the data using a PCA model. This returns new coordinates of each data point.
Syntax
APPLY_PCA ( input-columns
USING PARAMETERS model_name = 'model-name'
[, num_components = num-components]
[, cutoff = cutoff-value]
[, match_by_pos = match-by-position]
[, exclude_columns = 'excluded-columns']
[, key_columns = 'key-columns'] )
Arguments
input-columns- Comma-separated list of columns that contain the data matrix, or asterisk (*) to select all columns. The following requirements apply:
Parameters
model_nameName of the model (case-insensitive).
num_components- The number of components to keep in the model. This is the number of output columns that will be generated. If you omit this parameter and the
cutoff parameter, all model components are kept.
cutoff- Set to 1, specifies the minimum accumulated explained variance. Components are taken until the accumulated explained variance reaches this value.
match_by_posBoolean value that specifies how input columns are matched to model features:
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
key_columns- Comma-separated list of column names from
input-columns that identify its data rows. These columns are included in the output table.
Examples
=> SELECT PCA ('pcamodel', 'world','country,HDI,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,
em1978,em1979,em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,
em1993,em1994,em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,
em2008,em2009,em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,
gdp1981,gdp1982,gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,
gdp1994,gdp1995,gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,
gdp2007,gdp2008,gdp2009,gdp2010' USING PARAMETERS exclude_columns='HDI,country');
PCA
---------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 96 Rejected Rows: 0
(1 row)
=> CREATE TABLE worldPCA AS SELECT
APPLY_PCA (HDI,country,em1970,em1971,em1972,em1973,em1974,em1975,em1976,em1977,em1978,em1979,
em1980,em1981,em1982,em1983,em1984 ,em1985,em1986,em1987,em1988,em1989,em1990,em1991,em1992,em1993,em1994,
em1995,em1996,em1997,em1998,em1999,em2000,em2001,em2002,em2003,em2004,em2005,em2006,em2007,em2008,em2009,
em2010,gdp1970,gdp1971,gdp1972,gdp1973,gdp1974,gdp1975,gdp1976,gdp1977,gdp1978,gdp1979,gdp1980,gdp1981,gdp1982,
gdp1983,gdp1984,gdp1985,gdp1986,gdp1987,gdp1988,gdp1989,gdp1990,gdp1991,gdp1992,gdp1993,gdp1994,gdp1995,
gdp1996,gdp1997,gdp1998,gdp1999,gdp2000,gdp2001,gdp2002,gdp2003,gdp2004,gdp2005,gdp2006,gdp2007,gdp2008,
gdp2009,gdp2010 USING PARAMETERS model_name='pcamodel', exclude_columns='HDI, country', key_columns='HDI,
country',cutoff=.3)OVER () FROM world;
CREATE TABLE
=> SELECT * FROM worldPCA;
HDI | country | col1
------+---------------------+-------------------
0.886 | Belgium | 79002.2946705704
0.699 | Belize | -25631.6670012556
0.427 | Benin | -40373.4104598122
0.805 | Chile | -16805.7940082156
0.687 | China | -37279.2893141103
0.744 | Costa Rica | -19505.5631231635
0.4 | Cote d'Ivoire | -38058.2060339272
0.776 | Cuba | -23724.5779612041
0.895 | Denmark | 117325.594028813
0.644 | Egypt | -34609.9941604549
...
(96 rows)
=> SELECT APPLY_INVERSE_PCA (HDI, country, col1
USING PARAMETERS model_name = 'pcamodel', exclude_columns='HDI,country',
key_columns = 'HDI, country') OVER () FROM worldPCA;
HDI | country | em1970 | em1971 | em1972 | em1973 |
em1974 | em1975 | em1976| em1977 | em1978 | em1979
| em1980 | em1981 | em1982 | em1983 | em1984 |em1985
| em1986 | em1987 | em1988 | em1989 | em1990 | em1991
| em1992 | em1993| em1994 | em1995 | em1996 | em1997
| em1998 | em1999 | em2000 | em2001 |em2002 |
em2003 | em2004 | em2005 | em2006 | em2007 | em2008
| em2009 | em2010 | gdp1970 | gdp1971 | gdp1972 | gdp1973
| gdp1974 | gdp1975 | gdp1976 | gdp1977 |gdp1978 | gdp1979
| gdp1980 | gdp1981 | gdp1982 | gdp1983 | gdp1984 | gdp1985
| gdp1986| gdp1987 | gdp1988 | gdp1989 | gdp1990 | gdp1991
| gdp1992 | gdp1993 | gdp1994 | gdp1995 | gdp1996 |
gdp1997 | gdp1998 | gdp1999 | gdp2000 | gdp2001 | gdp2002
| gdp2003 |gdp2004 | gdp2005 | gdp2006 | gdp2007 | gdp2008
| gdp2009 | gdp2010
-------+---------------------+-------------------+-------------------+------------------+------------------
+------------------+-------------------+------------------+------------------+-------------------+---------
----------+-------------------+------------------+-------------------+-------------------+-----------------
--+------------------+-------------------+-------------------+-------------------+------------------+-------
-----------+------------------+-------------------+-------------------+------------------+------------------
-+-------------------+------------------+-------------------+-------------------+-------------------+-------
------------+--------------------+------------------+-------------------+------------------+----------------
---+-------------------+-------------------+------------------+-------------------+------------------+------
------------+------------------+------------------+------------------+------------------+------------------+
------------------+------------------+------------------+------------------+------------------+-------------
-----+------------------+------------------+------------------+------------------+------------------+-------
-----------+------------------+------------------+------------------+------------------+------------------+-
-----------------+------------------+------------------+------------------+------------------+--------------
----+------------------+------------------+------------------+------------------+------------------+--------
----------+------------------+------------------+------------------+------------------+------------------
0.886 | Belgium | 18585.6613572407 | -16145.6374560074 | 26938.956253415 | 8094.30475779595 |
12073.5461203817 | -11069.0567600181 | 19133.8584911727| 5500.312894949 | -4227.94863799987 | 6265.77925410752
| -10884.749295608 | 30929.4669575201 | -7831.49439429977 | 3235.81760508742 | -22765.9285442662 | 27200
.6767714485 | -10554.9550160917 | 1169.4144482273 | -16783.7961289161 | 27932.2660829329 | 17227.9083196848
| 13956.0524012749 | -40175.6286481088 | -10889.4785920499 | 22703.6576872859 | -14635.5832197402 |
2857.12270512168 | 20473.5044214494 | -52199.4895696423 | -11038.7346460738 | 18466.7298633088 | -17410.4225137703 |
-3475.63826305462 | 29305.6753822341 | 1242.5724942049 | 17491.0096310849 | -12609.9984515902 | -17909.3603476248
| 6276.58431412381 | 21851.9475485178 | -2614.33738160397 | 3777.74134131349 | 4522.08854282736 | 4251.90446379366
| 4512.15101396876 | 4265.49424538129 | 5190.06845330997 | 4543.80444817989 | 5639.81122679089 | 4420.44705213467
| 5658.8820279283 | 5172.69025294376 | 5019.63640408663 | 5938.84979495903 | 4976.57073629812 | 4710.49525137591
| 6523.65700286465 | 5067.82520773578 | 6789.13070219317 | 5525.94643553563 | 6894.68336419297 | 5961.58442474331
| 5661.21093840818 | 7721.56088518218 | 5959.7301109143 | 6453.43604137202 | 6739.39384033096 | 7517.97645468455
| 6907.49136910647 | 7049.03921764209 | 7726.49091035527 | 8552.65909911844 | 7963.94487647115 | 7187.45827585515
| 7994.02955410523 | 9532.89844418041 | 7962.25713582666 | 7846.68238907624 | 10230.9878908643 | 8642.76044946519
| 8886.79860331866 | 8718.3731386891
...
(96 rows)
See also
6.12.5.10 - APPLY_SVD
Transforms the data using an SVD model.
Transforms the data using an SVD model. This computes the matrix U of the SVD decomposition.
Syntax
APPLY_SVD ( input-columns
USING PARAMETERS model_name = 'model-name'
[, num_components = num-components]
[, cutoff = cutoff-value]
[, match_by_pos = match-by-position]
[, exclude_columns = 'excluded-columns']
[, key_columns = 'key-columns'] )
Arguments
input-columns- Comma-separated list of columns that contain the data matrix, or asterisk (*) to select all columns. The following requirements apply:
Parameters
model_nameName of the model (case-insensitive).
num_components- The number of components to keep in the model. This is the number of output columns that will be generated. If neither this parameter nor the
cutoff parameter is provided, all components from the model are kept.
cutoff- Set to 1, specifies the minimum accumulated explained variance. Components are taken until the accumulated explained variance reaches this value. If you omit this parameter and the
num_components parameter, all model components are kept.
match_by_pos- Boolean value that specifies how input columns are matched to model columns:
exclude_columnsComma-separated list of column names from input-columns to exclude from processing.
key_columns- Comma-separated list of column names from
input-columns that identify its data rows. These columns are included in the output table.
Examples
=> SELECT SVD ('svdmodel', 'small_svd', 'x1,x2,x3,x4');
SVD
--------------------------------------------------------------
Finished in 1 iterations.
Accepted Rows: 8 Rejected Rows: 0
(1 row)
=> CREATE TABLE transform_svd AS SELECT
APPLY_SVD (id, x1, x2, x3, x4 USING PARAMETERS model_name='svdmodel', exclude_columns='id', key_columns='id')
OVER () FROM small_svd;
CREATE TABLE
=> SELECT * FROM transform_svd;
id | col1 | col2 | col3 | col4
----+-------------------+---------------------+---------------------+--------------------
4 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
6 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
1 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
2 | 0.17652411036246 | -0.0753183783382909 | -0.678196192333598 | 0.0567124770173372
3 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
5 | 0.494871802886819 | 0.161721379259287 | 0.0712816417153664 | -0.473145877877408
8 | 0.44849499240202 | -0.347260956311326 | 0.186958376368345 | 0.378561270493651
7 | 0.150974762654569 | 0.589561842046029 | 0.00392654610109522 | 0.360011163271921
(8 rows)
=> SELECT APPLY_INVERSE_SVD (* USING PARAMETERS model_name='svdmodel', exclude_columns='id',
key_columns='id') OVER () FROM transform_svd;
id | x1 | x2 | x3 | x4
----+------------------+------------------+------------------+------------------
4 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
6 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
7 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
1 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
2 | 20.6468626294368 | 9.30974906868751 | 8.71006863405534 | 6.5855928603967
3 | 31.2494347777156 | 20.6336519003026 | 27.5668287751507 | 5.84427645886865
5 | 107.93376580719 | 51.6980548011917 | 97.9665796560552 | 40.4918236881051
8 | 91.4056627665577 | 44.7629617207482 | 83.1704961993117 | 38.9274292265543
(8 rows)
See also
6.12.5.11 - PREDICT_ARIMA
Applies an autoregressive integrated moving average (ARIMA) model to an input relation or makes predictions using the in-sample data.
Applies an autoregressive integrated moving average (ARIMA) model to an input relation or makes predictions using the in-sample data. ARIMA models make predictions based on preceding time series values and errors of previous predictions. The function, by default, returns the predicted values plus the mean of the model.
Behavior type
Immutable
Syntax
Apply to an input relation:
PREDICT_ARIMA ( timeseries-column
USING PARAMETERS param=value[,...] )
OVER (ORDER BY timestamp-column)
FROM input-relation
Make predictions using the in-sample data:
PREDICT_ARIMA ( USING PARAMETERS model_name = 'ARIMA-model'
[, start = prediction-start ]
[, npredictions = num-predictions ]
[, output_standard_errors = boolean ] )
OVER ()
Arguments
timeseries-column- Name of a NUMERIC column in
input-relation used to make predictions.
timestamp-column- Name of an INTEGER, FLOAT, or TIMESTAMP column in
input-relation that represents the timestamp variable. The timestep between consecutive entries should be consistent throughout the timestamp-column.
input-relation- Input relation containing
timeseries-column and timestamp-column.
Parameters
model_name- Name of a trained ARIMA model.
start- The behavior of the
start parameter and its range of accepted values depends on whether you provide a timeseries-column:
- No provided
timeseries-column: start must be an integer ≥0, where zero indicates to start prediction at the end of the in-sample data. If start is a positive value, the function predicts the values between the end of the in-sample data and the start index, and then uses the predicted values as time series inputs for the subsequent npredictions.
timeseries-column provided: start must be an integer ≥1 and identifies the index (row) of the timeseries-column at which to begin prediction. If the start index is greater than the number of rows, N, in the input data, the function predicts the values between N and start and uses the predicted values as time series inputs for the subsequent npredictions.
Default:
npredictions- Integer ≥1, the number of predicted timesteps.
Default: 10
missing- Methods for handling missing values, one of the following strings:
-
'drop': Missing values are ignored.
-
'error': Missing values raise an error.
-
'zero': Missing values are replaced with 0.
-
'linear_interpolation': Missing values are replaced by linearly-interpolated values based on the nearest valid entries before and after the missing value. If all values before or after a missing value in the prediction range are missing or invalid, interpolation is impossible and the function errors.
Default: Method used when training the model
add_mean- Boolean, whether to add the model mean to the predicted value.
Default: True
output_standard_errors- Boolean, whether to return estimates of the standard error of each prediction.
Default: False
Examples
The following example makes predictions using the in-sample data that the arima_temp model was trained on:
=> SELECT PREDICT_ARIMA(USING PARAMETERS model_name='arima_temp', npredictions=10) OVER();
index | prediction
-------+------------------
1 | 12.9794640462952
2 | 13.3759980774506
3 | 13.4596213753292
4 | 13.4670492239575
5 | 13.4559956810351
6 | 13.4405315951159
7 | 13.424086943584
8 | 13.4074973032696
9 | 13.3909657020137
10 | 13.374540947803
(10 rows)
You can also apply the model to an input relation:
=> SELECT PREDICT_ARIMA(temperature USING PARAMETERS model_name='arima_temp', start=100, npredictions=10) OVER(ORDER BY time) FROM temp_data;
index | prediction
-------+------------------
1 | 15.0373821404594
2 | 13.4707358943239
3 | 10.5714574755414
4 | 13.1957213344543
5 | 13.5606204019976
6 | 13.1604413418938
7 | 13.3998222399722
8 | 12.6110939669533
9 | 12.9015211253485
10 | 13.2382768006631
(10 rows)
For an in-depth example that trains and makes predictions with an ARIMA model, see ARIMA model example.
See also
6.12.5.12 - PREDICT_AUTOREGRESSOR
Applies an autoregressor (AR) model to an input relation.
Applies an autoregressor (AR) or vector autoregression (VAR) model to an input relation. The function returns predictions for each value column specified during model creation.
AR and VAR models use previous values to make predictions. During model training, the user specifies the number of lagged timesteps taken into account during computation. The model predicts future values as a linear combination of the timeseries values at each lag.
Syntax
PREDICT_AUTOREGRESSOR ( timeseries-columns
USING PARAMETERS model_name = 'model-name' [, param=value[,...] ] )
OVER (ORDER BY timestamp-column)
FROM input-relation
Note
The following argument, as written, is required and cannot be omitted nor substituted with another type of clause.
OVER (ORDER BY timestamp-column)
Arguments
timeseries-columns- The timeseries columns used to make predictions. The number of
timeseries-columns must be the same as the number of value columns provided during model training.
For each prediction, the model only considers the previous P values of each column, where P is the lag set during model creation.
timestamp-column- The timestamp column, with consistent timesteps, used to make the prediction.
input-relation- The input relation containing the
timeseries-columns and timestamp-column.
The input-relation cannot have missing values in any of the P rows preceding start, where P is the lag set during model creation. To handle missing values, see IMPUTE or Linear interpolation.
Parameters
model_nameName of the model (case-insensitive).
start- INTEGER >p or ≤0, the index (row) of the
input-relation at which to start the prediction. If omitted, the prediction starts at the end of the input-relation.
If the start index is greater than the number of rows N in timeseries-columns, then the values between N and start are predicted and used for the prediction.
If negative, the start index is identified by counting backwards from the end of the input-relation.
For an input-relation of N rows, negative values have a lower limit of either -1000 or -(N-p), whichever is greater.
Default: the end of input-relation
npredictions- INTEGER ≥1, the number of predicted timesteps.
Default: 10
missing- One of the following methods for handling missing values:
-
drop: Missing values are ignored.
-
error: Missing values raise an error.
-
zero: Missing values are replaced with 0.
-
linear_interpolation: Missing values are replaced by linearly-interpolated values based on the nearest valid entries before and after the missing value. If all values before or after a missing value in the prediction range are missing or invalid, interpolation is impossible and the function errors. VAR models do not support linear interpolation.
Default: Method used when training the model
Examples
The following example makes predictions using an AR model for 10 timesteps after the end of the input relation:
=> SELECT PREDICT_AUTOREGRESSOR(Temperature USING PARAMETERS model_name='AR_temperature', npredictions=10)
OVER(ORDER BY time) FROM temp_data;
index | prediction
-------+------------------
1 | 12.6235419917807
2 | 12.9387860506032
3 | 12.6683380680058
4 | 12.3886937385419
5 | 12.2689506237424
6 | 12.1503023330142
7 | 12.0211734746741
8 | 11.9150531529328
9 | 11.825870404008
10 | 11.7451846722395
(10 rows)
The following example makes predictions using a VAR model for 10 timesteps after the end of the input relation:
=> SELECT PREDICT_AUTOREGRESSOR(temp_location1, temp_location2 USING PARAMETERS
model_name='VAR_temperature', npredictions=10) OVER(ORDER BY time) FROM temp_data_VAR;
index | temp_location1 | temp_location2
-------+------------------+------------------
1 | 11.7583950082813 | 12.7193948948294
2 | 11.8492948294829 | 12.2400294852222
3 | 11.9917382847772 | 13.8385038582000
4 | 11.2302988673747 | 13.1174827497563
5 | 11.8920481717273 | 13.1948776593788
6 | 12.1737583757385 | 12.7362846366622
7 | 12.0397364321183 | 12.9274628462844
8 | 12.0395726450372 | 12.1749275028444
9 | 11.8249947849488 | 12.3274926927433
10 | 11.1129497288422 | 12.1749274927493
(10 rows)
See Autoregressive model example and VAR model example for extended examples.
See also
6.12.5.13 - PREDICT_LINEAR_REG
Applies a linear regression model on an input relation and returns the predicted value as a FLOAT.
Applies a linear regression model on an input relation and returns the predicted value as a FLOAT.
Syntax
PREDICT_LINEAR_REG ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT PREDICT_LINEAR_REG(waiting USING PARAMETERS model_name='myLinearRegModel')FROM
faithful ORDER BY id;
PREDICT_LINEAR_REG
--------------------
4.15403481386324
2.18505296804024
3.76023844469864
2.8151271587036
4.62659045686076
2.26381224187316
4.86286827835952
4.62659045686076
1.94877514654148
4.62659045686076
2.18505296804024
...
(272 rows)
The following example shows how to use the PREDICT_LINEAR_REG function on an input table, using the match_by_pos parameter. Note that you can replace the column argument with a constant that does not match an input column:
=> SELECT PREDICT_LINEAR_REG(55 USING PARAMETERS model_name='linear_reg_faithful',
match_by_pos='true')FROM faithful ORDER BY id;
PREDICT_LINEAR_REG
--------------------
2.28552115094171
2.28552115094171
2.28552115094171
2.28552115094171
2.28552115094171
2.28552115094171
2.28552115094171
...
(272 rows)
6.12.5.14 - PREDICT_LOGISTIC_REG
Applies a logistic regression model on an input relation.
Applies a logistic regression model on an input relation.
PREDICT_LOGISTIC_REG returns as a FLOAT the predicted class or the probability of the predicted class, depending on how the type parameter is set. You can cast the return value to INTEGER or another numeric type when the return is in the probability of the predicted class.
Syntax
PREDICT_LOGISTIC_REG ( input-columns
USING PARAMETERS model_name = 'model-name'
[, type = 'prediction-type']
[, cutoff = probability-cutoff]
[, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
type- Type of prediction for logistic regression, one of the following:
cutoff- Used in conjunction with the
type parameter, a FLOAT between 0 and 1, exclusive. When type is set to response, the returned value of prediction is 1 if its corresponding probability is greater than or equal to the value of cutoff; otherwise, it is 0.
Default: 0.5
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT car_model,
PREDICT_LOGISTIC_REG(mpg, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel')
FROM mtcars;
car_model | PREDICT_LOGISTIC_REG
---------------------+----------------------
Camaro Z28 | 0
Fiat 128 | 1
Fiat X1-9 | 1
Ford Pantera L | 1
Merc 450SE | 0
Merc 450SL | 0
Toyota Corona | 0
AMC Javelin | 0
Cadillac Fleetwood | 0
Datsun 710 | 1
Dodge Challenger | 0
Hornet 4 Drive | 0
Lotus Europa | 1
Merc 230 | 0
Merc 280 | 0
Merc 280C | 0
Merc 450SLC | 0
Pontiac Firebird | 0
Porsche 914-2 | 1
Toyota Corolla | 1
Valiant | 0
Chrysler Imperial | 0
Duster 360 | 0
Ferrari Dino | 1
Honda Civic | 1
Hornet Sportabout | 0
Lincoln Continental | 0
Maserati Bora | 1
Mazda RX4 | 1
Mazda RX4 Wag | 1
Merc 240D | 0
Volvo 142E | 1
(32 rows)
The following example shows how to use PREDICT_LOGISTIC_REG on an input table, using the match_by_pos parameter. Note that you can replace any of the column inputs with a constant that does not match an input column. In this example, column mpg was replaced with the constant 20:
=> SELECT car_model,
PREDICT_LOGISTIC_REG(20, cyl, disp, drat, wt, qsec, vs, gear, carb
USING PARAMETERS model_name='myLogisticRegModel', match_by_pos='true')
FROM mtcars;
car_model | PREDICT_LOGISTIC_REG
--------------------+----------------------
AMC Javelin | 0
Cadillac Fleetwood | 0
Camaro Z28 | 0
Chrysler Imperial | 0
Datsun 710 | 1
Dodge Challenger | 0
Duster 360 | 0
Ferrari Dino | 1
Fiat 128 | 1
Fiat X1-9 | 1
Ford Pantera L | 1
Honda Civic | 1
Hornet 4 Drive | 0
Hornet Sportabout | 0
Lincoln Continental | 0
Lotus Europa | 1
Maserati Bora | 1
Mazda RX4 | 1
Mazda RX4 Wag | 1
Merc 230 | 0
Merc 240D | 0
Merc 280 | 0
Merc 280C | 0
Merc 450SE | 0
Merc 450SL | 0
Merc 450SLC | 0
Pontiac Firebird | 0
Porsche 914-2 | 1
Toyota Corolla | 1
Toyota Corona | 0
Valiant | 0
Volvo 142E | 1
(32 rows)
6.12.5.15 - PREDICT_MOVING_AVERAGE
Applies a moving-average (MA) model, created by MOVING_AVERAGE, to an input relation.
Applies a moving-average (MA) model, created by MOVING_AVERAGE, to an input relation.
Moving average models use the errors of previous predictions to make future predictions. More specifically, the user-specified "lag" determines how many previous predictions and errors it takes into account during computation.
Syntax
PREDICT_MOVING_AVERAGE ( timeseries-column
USING PARAMETERS
model_name = 'model-name'
[, start = starting-index]
[, npredictions = npredictions]
[, missing = "imputation-method" ] )
OVER (ORDER BY timestamp-column)
FROM input-relation
Note
The following argument, as written, is required and cannot be omitted nor substituted with another type of clause.
OVER (ORDER BY timestamp-column)
Arguments
timeseries-column- The timeseries column used to make the prediction (only the last
q values, specified during model creation, are used).
timestamp-column- The timestamp column, with consistent timesteps, used to make the prediction.
input-relation- The input relation containing the
timeseries-column and timestamp-column.
Note that input-relation cannot have missing values in any of the q (set during training) rows preceding start. To handle missing values, see IMPUTE or Linear interpolation.
Parameters
model_nameName of the model (case-insensitive).
start- INTEGER >q or ≤0, the index (row) of the
input-relation at which to start the prediction. If omitted, the prediction starts at the end of the input-relation.
If the start index is greater than the number of rows N in timeseries-column, then the values between N and start are predicted and used for the prediction.
If negative, the start index is identified by counting backwards from the end of the input-relation.
For an input-relation of N rows, negative values have a lower limit of either -1000 or -(N-q), whichever is greater.
Default: the end of input-relation
npredictions- INTEGER ≥1, the number of predicted timesteps.
Default: 10
missing- One of the following methods for handling missing values:
-
drop: Missing values are ignored.
-
error: Missing values raise an error.
-
zero: Missing values are replaced with 0.
-
linear_interpolation: Missing values are replaced by linearly-interpolated values based on the nearest valid entries before and after the missing value. If all values before or after a missing value in the prediction range are missing or invalid, interpolation is impossible and the function errors.
Default: Method used when training the model
Examples
See Moving-average model example.
See also
6.12.5.16 - PREDICT_NAIVE_BAYES
Applies a Naive Bayes model on an input relation.
Applies a Naive Bayes model on an input relation.
Depending on how the type parameter is set, PREDICT_NAIVE_BAYES returns a VARCHAR that specifies either the predicted class or probability of the predicted class. If the function returns probability, you can cast the return value to an INTEGER or another numeric data type.
Syntax
PREDICT_NAIVE_BAYES ( input-columns
USING PARAMETERS model_name = 'model-name'
[, type = ' return-type ']
[, class = 'user-input-class']
[, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
type- One of the following:
-
response (default): Returns the class with the highest probability.
-
probability: Valid only if class parameter is set, returns the probability of belonging to the specified class argument.
class- Required if
type parameter is set to probability. If you omit this parameter, PREDICT_NAIVE_BAYES returns the class that it predicts as having the highest probability.
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT party, PREDICT_NAIVE_BAYES (vote1, vote2, vote3
USING PARAMETERS model_name='naive_house84_model',
type='response')
AS Predicted_Party
FROM house84_test;
party | Predicted_Party
------------+-----------------
democrat | democrat
democrat | democrat
democrat | democrat
republican | republican
democrat | democrat
democrat | democrat
democrat | democrat
democrat | democrat
democrat | democrat
republican | republican
democrat | democrat
democrat | democrat
democrat | democrat
democrat | republican
republican | republican
democrat | democrat
republican | republican
...
(99 rows)
See also
6.12.5.17 - PREDICT_NAIVE_BAYES_CLASSES
Applies a Naive Bayes model on an input relation and returns the probabilities of classes:.
Applies a Naive Bayes model on an input relation and returns the probabilities of classes:
-
VARCHAR predicted column contains the class label with the highest probability.
-
Multiple FLOAT columns, where the first probability column contains the probability for the class specified in the predicted column. Other columns contain the probability of belonging to each class specified in the classes parameter.
Syntax
PREDICT_NAIVE_BAYES_CLASSES ( predictor-columns
USING PARAMETERS model_name = 'model-name'
[, key_columns = 'key-columns']
[, exclude_columns = 'excluded-columns]
[, classes = 'classes']
[, match_by_pos = match-by-position] )
OVER( [window-partition-clause] )
Arguments
predictor-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
key_columnsComma-separated list of predictor column names that identify the output rows. To exclude these and other predictor columns from being used for prediction, include them in the argument list for parameter exclude_columns.
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
classes- Comma-separated list of class labels in the model. The probability of belonging to this given class as predicted by the classifier. The values are case sensitive.
match_by_pos- Boolean value that specifies how predictor columns are matched to model features:
Examples
=> SELECT PREDICT_NAIVE_BAYES_CLASSES (id, vote1, vote2 USING PARAMETERS
model_name='naive_house84_model',key_columns='id',exclude_columns='id',
classes='democrat, republican', match_by_pos='false')
OVER() FROM house84_test;
id | Predicted | Probability | democrat | republican
-----+------------+-------------------+-------------------+-------------------
21 | democrat | 0.775473383353576 | 0.775473383353576 | 0.224526616646424
28 | democrat | 0.775473383353576 | 0.775473383353576 | 0.224526616646424
83 | republican | 0.592510497724379 | 0.407489502275621 | 0.592510497724379
102 | democrat | 0.779889432167111 | 0.779889432167111 | 0.220110567832889
107 | republican | 0.598662714551597 | 0.401337285448403 | 0.598662714551597
125 | republican | 0.598662714551597 | 0.401337285448403 | 0.598662714551597
132 | republican | 0.592510497724379 | 0.407489502275621 | 0.592510497724379
136 | republican | 0.592510497724379 | 0.407489502275621 | 0.592510497724379
155 | republican | 0.598662714551597 | 0.401337285448403 | 0.598662714551597
174 | republican | 0.592510497724379 | 0.407489502275621 | 0.592510497724379
...
(1 row)
See also
6.12.5.18 - PREDICT_PLS_REG
Applies a PLS regression model on an input relation and returns the predicted values.
Applies a PLS_REG model to an input relation and returns a predicted FLOAT value for each row in the input relation.
Syntax
PREDICT_PLS_REG ( input-columns
USING PARAMETERS param=value[,...] )
Arguments
input-columns- Comma-separated list of predictor columns to use from the input relation or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
The following example uses the monarch_pls model to make predictions on the monarch_test input relation:
=> SELECT PREDICT_PLS_REG (* USING PARAMETERS model_name='monarch_pls') FROM monarch_test;
PREDICT_PLS_REG
------------------
2.88462577469318
2.86535009598611
2.84138719904564
2.7222022770597
3.96163608455087
3.30690898656628
2.99904802221049
(7 rows)
For an in-depth example, see PLS regression.
See also
6.12.5.19 - PREDICT_PMML
Applies an imported PMML model on an input relation.
Applies an imported PMML model on an input relation. The function returns the result that would be expected for the model type encoded in the PMML model.
PREDICT_PMML returns NULL in the following cases:
Note
PREDICT_PMML returns values of complex type ROW for models that use the Output tag. Currently, Vertica does not support directly inserting this data into a table.
You can work around this limitation by changing the output to JSON with TO_JSON before inserting it into a table:
=> CREATE TABLE predicted_output AS SELECT TO_JSON(PREDICT_PMML(X1,X2,X3
USING PARAMETERS model_name='pmml_imported_model'))
AS predicted_value
FROM input_table;
Syntax
PREDICT_PMML ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_name- Name of the model (case-insensitive). For a list of supported PMML model types and tags, see PMML features and attributes.
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
In this example, the function call uses all the columns from the table as predictors and predicts the value using the 'my_kmeans' model in PMML format:
SELECT PREDICT_PMML(* USING PARAMETERS model_name='my_kmeans') AS predicted_label FROM table;
In this example, the function call takes only columns col1, col2 as predictors, and predicts the value for each row using the 'my_kmeans' model from schema 'my_schema':
SELECT PREDICT_PMML(col1, col2 USING PARAMETERS model_name='my_schema.my_kmeans') AS predicted_label FROM table;
In this example, the function call returns an error as neither schema nor model-name can accept * as a value:
SELECT PREDICT_PMML(* USING PARAMETERS model_name='*.*') AS predicted_label FROM table;
SELECT PREDICT_PMML(* USING PARAMETERS model_name='*') AS predicted_label FROM table;
SELECT PREDICT_PMML(* USING PARAMETERS model_name='models.*') AS predicted_label FROM table;
See also
6.12.5.20 - PREDICT_POISSON_REG
Applies a Poisson regression model on an input relation and returns the predicted value as a FLOAT.
Applies a Poisson regression model on an input relation and returns the predicted value as a FLOAT.
Syntax
PREDICT_POISSON_REG ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT PREDICT_POISSON_REG(waiting USING PARAMETERS model_name='MYModel')::numeric(20,10) FROM lin.faithful ORDER BY id;
predict_poisson_reg
---------------------
4.0230080811
2.2284857176
3.5747254723
2.6921731651
4.6357580051
2.2817680621
4.9762900161
4.6357580051
2.0759884314
(9 rows)
6.12.5.21 - PREDICT_RF_CLASSIFIER
Applies a random forest model on an input relation.
Applies a random forest model on an input relation. PREDICT_RF_CLASSIFIER returns a VARCHAR data type that specifies one of the following, as determined by how the type parameter is set:
Note
The predicted class is selected only based on the popular vote of the decision trees in the forest. Therefore, in special cases the calculated probability of the predicted class may not be the highest.
Syntax
PREDICT_RF_CLASSIFIER ( input-columns
USING PARAMETERS model_name = 'model-name'
[, type = 'prediction-type']
[, class = 'user-input-class']
[, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
type- Type of prediction to return, one of the following:
-
response (default): The class with the highest probability among all possible classes.
-
probability: Valid only if the class parameter is set, returns the probability of the specified class.
class- Class to use when the
type parameter is set to probability. If you omit this parameter, the function uses the predicted class—the one with the popular vote. Thus, the predict function returns the probability that the input instance belongs to its predicted class.
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT PREDICT_RF_CLASSIFIER (Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='myRFModel') FROM iris;
PREDICT_RF_CLASSIFIER
-----------------------
setosa
setosa
setosa
...
versicolor
versicolor
versicolor
...
virginica
virginica
virginica
...
(150 rows)
This example shows how you can use the PREDICT_RF_CLASSIFIER function, using the match_by_pos parameter:
=> SELECT PREDICT_RF_CLASSIFIER (Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='myRFModel', match_by_pos='true') FROM iris;
PREDICT_RF_CLASSIFIER
-----------------------
setosa
setosa
setosa
...
versicolor
versicolor
versicolor
...
virginica
virginica
virginica
...
(150 rows)
See also
6.12.5.22 - PREDICT_RF_CLASSIFIER_CLASSES
Applies a random forest model on an input relation and returns the probabilities of classes:.
Applies a random forest model on an input relation and returns the probabilities of classes:
-
VARCHAR predicted column contains the class label with the highest vote (popular vote).
-
Multiple FLOAT columns, where the first probability column contains the probability for the class reported in the predicted column. Other columns contain the probability of each class specified in the classes parameter.
-
Key columns with the same value and data type as matching input columns specified in parameter key_columns.
Note
Selection of the predicted class is based on the popular vote of decision trees in the forest. Thus, in special cases the calculated probability of the predicted class might not be the highest.
Syntax
PREDICT_RF_CLASSIFIER_CLASSES ( predictor-columns
USING PARAMETERS model_name = 'model-name'
[, key_columns = 'key-columns']
[, exclude_columns = 'excluded-columns']
[, classes = 'classes']
[, match_by_pos = match-by-position] )
OVER( [window-partition-clause] )
Arguments
predictor-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
key_columnsComma-separated list of predictor column names that identify the output rows. To exclude these and other predictor columns from being used for prediction, include them in the argument list for parameter exclude_columns.
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
classes- Comma-separated list of class labels in the model. The probability of belonging to this given class is predicted by the classifier. Values are case sensitive.
match_by_pos- Boolean value that specifies how predictor columns are matched to model features:
Examples
=> SELECT PREDICT_RF_CLASSIFIER_CLASSES(Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='myRFModel') OVER () FROM iris;
predicted | probability
-----------+-------------------
setosa | 1
setosa | 0.99
setosa | 1
setosa | 1
setosa | 1
setosa | 0.97
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 0.99
...
(150 rows)
This example shows how to use function PREDICT_RF_CLASSIFIER_CLASSES, using the match_by_pos parameter:
=> SELECT PREDICT_RF_CLASSIFIER_CLASSES(Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='myRFModel', match_by_pos='true') OVER () FROM iris;
predicted | probability
-----------+-------------------
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
setosa | 1
...
(150 rows)s
See also
6.12.5.23 - PREDICT_RF_REGRESSOR
Applies a random forest model on an input relation, and returns with a FLOAT data type that specifies the predicted value of the random forest model—the average of the prediction of the trees in the forest.
Applies a random forest model on an input relation, and returns with a FLOAT data type that specifies the predicted value of the random forest model—the average of the prediction of the trees in the forest.
Syntax
PREDICT_RF_REGRESSOR ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT PREDICT_RF_REGRESSOR (mpg,cyl,hp,drat,wt
USING PARAMETERS model_name='myRFRegressorModel')FROM mtcars;
PREDICT_RF_REGRESSOR
----------------------
2.94774203574204
2.6954087024087
2.6954087024087
2.89906346431346
2.97688489288489
2.97688489288489
2.7086587024087
2.92078965478965
2.97688489288489
2.7086587024087
2.95621822621823
2.82255155955156
2.7086587024087
2.7086587024087
2.85650394050394
2.85650394050394
2.97688489288489
2.95621822621823
2.6954087024087
2.6954087024087
2.84493251193251
2.97688489288489
2.97688489288489
2.8856467976468
2.6954087024087
2.92078965478965
2.97688489288489
2.97688489288489
2.7934087024087
2.7934087024087
2.7086587024087
2.72469441669442
(32 rows)
See also
6.12.5.24 - PREDICT_SVM_CLASSIFIER
Uses an SVM model to predict class labels for samples in an input relation, and returns the predicted value as a FLOAT data type.
Uses an SVM model to predict class labels for samples in an input relation, and returns the predicted value as a FLOAT data type.
Syntax
PREDICT_SVM_CLASSIFIER (input-columns
USING PARAMETERS model_name = 'model-name'
[, match_by_pos = match-by-position]
[, type = 'return-type']
[, cutoff = 'cutoff-value'] ] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
type- A string that specifies the output to return for each input row, one of the following:
-
response: Outputs the predicted class of 0 or 1.
-
probability: Outputs a value in the range (0,1), the prediction score transformed using the logistic function.
cutoff- Valid only if the
type parameter is set to probability, a FLOAT value that is compared to the transformed prediction score to determine the predicted class.
Default: 0
Examples
=> SELECT PREDICT_SVM_CLASSIFIER (mpg,cyl,disp,wt,qsec,vs,gear,carb
USING PARAMETERS model_name='mySvmClassModel') FROM mtcars;
PREDICT_SVM_CLASSIFIER
------------------------
0
0
1
0
0
1
1
1
1
0
0
1
0
0
1
0
0
0
0
0
0
1
1
0
0
1
1
1
1
0
0
0
(32 rows)
This example shows how to use PREDICT_SVM_CLASSIFIER on the mtcars table, using the match_by_pos parameter. In this example, column mpg was replaced with the constant 40:
=> SELECT PREDICT_SVM_CLASSIFIER (40,cyl,disp,wt,qsec,vs,gear,carb
USING PARAMETERS model_name='mySvmClassModel', match_by_pos ='true') FROM mtcars;
PREDICT_SVM_CLASSIFIER
------------------------
0
0
0
0
1
0
0
1
1
1
1
1
0
0
0
1
1
1
1
0
0
0
0
0
0
0
0
1
1
0
0
1
(32 rows)
See also
6.12.5.25 - PREDICT_SVM_REGRESSOR
Uses an SVM model to perform regression on samples in an input relation, and returns the predicted value as a FLOAT data type.
Uses an SVM model to perform regression on samples in an input relation, and returns the predicted value as a FLOAT data type.
Syntax
PREDICT_SVM_REGRESSOR(input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
=> SELECT PREDICT_SVM_REGRESSOR(waiting USING PARAMETERS model_name='mySvmRegModel')
FROM faithful ORDER BY id;
PREDICT_SVM_REGRESSOR
--------------------
4.06488248694445
2.30392277646291
3.71269054484815
2.867429883817
4.48751281746003
2.37436116488217
4.69882798271781
4.48751281746003
2.09260761120512
...
(272 rows)
This example shows how you can use the PREDICT_SVM_REGRESSOR function on the faithful table, using the match_by_pos parameter. In this example, the waiting column was replaced with the constant 40:
=> SELECT PREDICT_SVM_REGRESSOR(40 USING PARAMETERS model_name='mySvmRegModel', match_by_pos='true')
FROM faithful ORDER BY id;
PREDICT_SVM_REGRESSOR
--------------------
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
1.31778533859324
...
(272 rows)
See also
6.12.5.26 - PREDICT_TENSORFLOW
Applies a TensorFlow model on an input relation, and returns with the result expected for the encoded model type.
Applies a TensorFlow model on an input relation, and returns with the result expected for the encoded model type.
Syntax
PREDICT_TENSORFLOW ( input-columns
USING PARAMETERS model_name = 'model-name' [, num_passthru_cols = 'n-first-columns-to-ignore'] )
OVER( [window-partition-clause] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
num_passthru_cols- Integer that specifies the number of input columns to skip.
Examples
Use PREDICT_TENSORFLOW with the num_passthru_cols parameter to skip the first two input columns:
=> SELECT PREDICT_TENSORFLOW ( pid,label,x1,x2
USING PARAMETERS model_name='spiral_demo', num_passthru_cols=2 )
OVER(PARTITION BEST) as predicted_class FROM points;
--example output, the skipped columns are displayed as the first columns of the output
pid | label | col0 | col1
-------+-------+----------------------+----------------------
0 | 0 | 0.990638732910156 | 0.00936129689216614
1 | 0 | 0.999036073684692 | 0.000963933940511197
2 | 1 | 0.0103802494704723 | 0.989619791507721
See also
6.12.5.27 - PREDICT_TENSORFLOW_SCALAR
Applies a TensorFlow model on an input relation, and returns with the result expected for the encoded model type. This function supports 1D complex types as input and output.
Applies an imported TensorFlow model on an input relation. This function, unlike PREDICT_TENSORFLOW, accepts one input column of type ROW, where each field corresponds to an input tensor, and returns one output column of type ROW, where each field corresponds to an output tensor.
For details about importing TensorFlow models into Vertica, see TensorFlow integration and directory structure.
Syntax
PREDICT_TENSORFLOW_SCALAR ( inputs
USING PARAMETERS model_name = 'model-name' )
Arguments
inputs- Input column of type ROW with fields of 1D ARRAYs that represent input tensors. These tensors can represent outputs for various input operations.
Parameters
model_nameName of the model (case-insensitive).
Examples
This function can simplify the process for making predictions on data with many input features.
For instance, the MNIST handwritten digit classification dataset contains 784 input features for each input row, one feature for each pixel in the images of handwritten digits. The PREDICT_TENSORFLOW function requires that each of these input features are contained in a separate input column. By encapsulating these features into a single ARRAY, the PREDICT_TENSORFLOW_SCALAR function only needs a single input column of type ROW, where the pixel values are the array elements for an input field:
--Each array for the "image" field has 784 elements.
=> SELECT * FROM mnist_train;
id | inputs
---+---------------------------------------------
1 | {"image":[0, 0, 0,..., 244, 222, 210,...]}
2 | {"image":[0, 0, 0,..., 185, 84, 223,...]}
3 | {"image":[0, 0, 0,..., 133, 254, 78,...]}
...
In this case, the function output consists of a single opeartion with one tensor. The value of this field is an array of ten elements, which are all zero except for the element whose index is the predicted digit:
=> SELECT id, PREDICT_TENSORFLOW_SCALAR(inputs USING PARAMETERS model_name='tf_mnist_ct') FROM mnist_test;
id | PREDICT_TENSORFLOW_SCALAR
----+-------------------------------------------------------------------
1 | {"prediction:0":["0", "0", "0", "0", "1", "0", "0", "0", "0", "0"]}
2 | {"prediction:0":["0", "1", "0", "0", "0", "0", "0", "0", "0", "0"]}
3 | {"prediction:0":["0", "0", "0", "0", "0", "0", "0", "1", "0", "0"]}
...
To view the expected input and output tensors for an imported TensorFlow model, call GET_MODEL_SUMMARY:
=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='tf_mnist_ct');
GET_MODEL_SUMMARY
---------------------------------------------------------------------------
=============
input_tensors
=============
name |type |dimensions
-------+-----+----------
image |int32| [-1,784]
==============
output_tensors
==============
name | type |dimensions
--------------+------+----------
prediction:0 |int32 | [-1,10]
(1 row)
See also
6.12.5.28 - PREDICT_XGB_CLASSIFIER
Applies an XGBoost classifier model on an input relation.
Applies an XGBoost classifier model on an input relation. PREDICT_XGB_CLASSIFIER returns a VARCHAR data type that specifies one of the following, as determined by how the type parameter is set:
Syntax
PREDICT_XGB_CLASSIFIER ( input-columns
USING PARAMETERS model_name = 'model-name'
[, type = 'prediction-type' ]
[, class = 'user-input-class' ]
[, match_by_pos = 'match-by-position' ]
[, probability_normalization = 'prob-normalization' ] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
type- Type of prediction to return, one of the following:
-
response (default): The class with the highest probability among all possible classes.
-
probability: Valid only if the class parameter is set, returns for each input instance the probability of the specified class or predicted class.
class- Class to use when the
type parameter is set to probability. If you omit this parameter, the function uses the predicted class—the one with the highest probability score. Thus, the predict function returns the probability that the input instance belongs to the specified or predicted class.
match_by_posBoolean value that specifies how input columns are matched to model features:
probability_normalizationThe classifier's normalization method, either softmax (multi-class classifier) or logit (binary classifier). If unspecified, the default logit function is used for normalization.
Examples
Use
PREDICT_XGB_CLASSIFIER to apply the classifier to the test data:
=> SELECT PREDICT_XGB_CLASSIFIER (Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='xgb_iris', probability_normalization='logit') FROM iris1;
PREDICT_XGB_CLASSIFIER
------------------------
setosa
setosa
setosa
.
.
.
versicolor
versicolor
versicolor
.
.
.
virginica
virginica
virginica
.
.
.
(90 rows)
See XGBoost for classification for more examples.
6.12.5.29 - PREDICT_XGB_CLASSIFIER_CLASSES
Applies an XGBoost classifier model on an input relation and returns the probabilities of classes:.
Applies an XGBoost classifier model on an input relation and returns the probabilities of classes:
-
VARCHAR predicted column contains the class label with the highest probability.
-
Multiple FLOAT columns, where the first probability column contains the probability for the class reported in the predicted column. Other columns contain the probability of each class specified in the classes parameter.
-
Key columns with the same value and data type as matching input columns specified in parameter key_columns.
All trees contribute to a predicted probability for each response class, and the highest probability class is chosen.
Syntax
PREDICT_XGB_CLASSIFIER_CLASSES ( predictor-columns)
USING PARAMETERS model_name = 'model-name'
[, key_columns = 'key-columns']
[, exclude_columns = 'excluded-columns']
[, classes = 'classes']
[, match_by_pos = match-by-position]
[, probability_normalization = 'prob-normalization' ] )
OVER( [window-partition-clause] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
key_columnsComma-separated list of predictor column names that identify the output rows. To exclude these and other predictor columns from being used for prediction, include them in the argument list for parameter exclude_columns.
exclude_columns- Comma-separated list of columns from
predictor-columns to exclude from processing.
classes- Comma-separated list of class labels in the model. The probability of belonging to each given class is predicted by the classifier. Values are case sensitive.
match_by_pos- Boolean value that specifies how predictor columns are matched to model features:
probability_normalizationThe classifier's normalization method, either softmax (multi-class classifier) or logit (binary classifier). If unspecified, the default logit function is used for normalization.
Examples
After creating an XGBoost classifier model with
XGB_CLASSIFIER, you can use PREDICT_XGB_CLASSIFIER_CLASSES to view the probability of each classification. In this example, the XGBoost classifier model "xgb_iris" is used to predict the probability that a given flower belongs to a species of iris:
=> SELECT PREDICT_XGB_CLASSIFIER_CLASSES(Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='xgb_iris') OVER (PARTITION BEST) FROM iris1;
predicted | probability
------------+-------------------
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.999911552783011
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
setosa | 0.9999650465368
versicolor | 0.99991871763563
.
.
.
(90 rows)
You can also specify additional classes. In this example, PREDICT_XGB_CLASSIFIER_CLASSES makes the same prediction as the previous example, but also returns the probability that a flower belongs to the specified classes "virginica" and "versicolor":
=> SELECT PREDICT_XGB_CLASSIFIER_CLASSES(Sepal_Length, Sepal_Width, Petal_Length, Petal_Width
USING PARAMETERS model_name='xgb_iris', classes='virginica,versicolor', probability_normalization='logit') OVER (PARTITION BEST) FROM iris1;
predicted | probability | virginica | versicolor
------------+-------------------+----------------------+----------------------
setosa | 0.9999650465368 | 1.16160301545536e-05 | 2.33374330460065e-05
setosa | 0.9999650465368 | 1.16160301545536e-05 | 2.33374330460065e-05
setosa | 0.9999650465368 | 1.16160301545536e-05 | 2.33374330460065e-05
.
.
.
versicolor | 0.99991871763563 | 6.45697562080953e-05 | 0.99991871763563
versicolor | 0.999967282051702 | 1.60052775404199e-05 | 0.999967282051702
versicolor | 0.999648819964864 | 0.00028366342010669 | 0.999648819964864
.
.
.
virginica | 0.999977039257386 | 0.999977039257386 | 1.13305901169304e-05
virginica | 0.999977085131063 | 0.999977085131063 | 1.12847163501674e-05
virginica | 0.999977039257386 | 0.999977039257386 | 1.13305901169304e-05
(90 rows)
6.12.5.30 - PREDICT_XGB_REGRESSOR
Applies an XGBoost regressor model on an input relation.
Applies an XGBoost regressor model on an input relation. PREDICT_XGB_REGRESSOR returns a FLOAT data type that specifies the predicted value by the XGBoost model: a weighted sum of contributions by each tree in the model.
Syntax
PREDICT_XGB_REGRESSOR ( input-columns
USING PARAMETERS model_name = 'model-name' [, match_by_pos = match-by-position] )
Arguments
input-columns- Comma-separated list of columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
match_by_posBoolean value that specifies how input columns are matched to model features:
Examples
See XGBoost for regression.
6.12.5.31 - REVERSE_NORMALIZE
Reverses the normalization transformation on normalized data, thereby de-normalizing the normalized data.
Reverses the normalization transformation on normalized data, thereby de-normalizing the normalized data. If you specify a column that is not in the specified model, REVERSE_NORMALIZE returns that column unchanged.
Syntax
REVERSE_NORMALIZE ( input-columns USING PARAMETERS model_name = 'model-name' );
Arguments
input-columns- The columns to use from the input relation, or asterisk (*) to select all columns.
Parameters
model_nameName of the model (case-insensitive).
Examples
Use REVERSE_NORMALIZE on the hp and cyl columns in table mtcars, where hp is in normalization model mtcars_normfit, and cyl is not in the normalization model.
=> SELECT REVERSE_NORMALIZE (hp, cyl USING PARAMETERS model_name='mtcars_normfit') FROM mtcars;
hp | cyl
------+-----
42502 | 8
58067 | 8
26371 | 4
42502 | 8
31182 | 6
32031 | 4
26937 | 4
34861 | 6
34861 | 6
50992 | 8
50992 | 8
49577 | 8
25805 | 4
18447 | 4
29767 | 6
65142 | 8
69387 | 8
14768 | 4
49577 | 8
60897 | 8
94857 | 8
31182 | 6
31182 | 6
30899 | 4
69387 | 8
49577 | 6
18730 | 4
18730 | 4
74764 | 8
17598 | 4
50992 | 8
27503 | 4
(32 rows)
See also
6.13 - Management functions
Vertica has functions to manage various aspects of database operation, such as sessions, privileges, projections, and the catalog.
Vertica has functions to manage various aspects of database operation, such as sessions, privileges, projections, and the catalog.
6.13.1 - Catalog functions
This section contains catalog management functions specific to Vertica.
This section contains catalog management functions specific to Vertica.
6.13.1.1 - DROP_LICENSE
Drops a license key from the global catalog.
Drops a license key from the global catalog. Dropping expired keys is optional. Vertica automatically ignores expired license keys if a valid, alternative license key is installed.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_LICENSE( 'license-name' )
Parameters
license-name- The name of the license to drop. Use the name (or long license key) in the
NAME column of system table
LICENSES.
Privileges
Superuser
Examples
=> SELECT DROP_LICENSE('9b2d81e2-aab1-4cfb-bc07-fa9a696e8f5e');
See also
Managing licenses
6.13.1.2 - DUMP_CATALOG
Returns an internal representation of the Vertica catalog.
Returns an internal representation of the Vertica catalog. This function is used for diagnostic purposes.
DUMP_CATALOG returns only the objects that are visible to the user.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DUMP_CATALOG()
Privileges
None
Examples
The following query obtains an internal representation of the Vertica catalog:
=> SELECT DUMP_CATALOG();
The output is written to the specified file:
\o /tmp/catalog.txt
SELECT DUMP_CATALOG();
\o
6.13.1.3 - EXPORT_CATALOG
This function and EXPORT_OBJECTS return equivalent output.
Generates a SQL script you can use to recreate a physical schema design on another cluster.
If you omit all arguments, this function exports to standard output all objects to which you have access.
The SQL script:
-
Only includes objects to which the user has access.
-
Orders CREATE statements based on object dependencies so they can be recreated in the correct sequence. For example, if a table is in a non-public schema, the required CREATE SCHEMA statement precedes the CREATE TABLE statement. Similarly, a table's CREATE ACCESS POLICY statement follows the table's CREATE TABLE statement.
-
If possible, creates projections with a KSAFE clause, if any, otherwise with an OFFSET clause.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXPORT_CATALOG ( [ '[destination]' [, 'scope'] ] )
Arguments
destination- Where to send output. To write the script to standard output, use an empty string (
''). A superusers can specify a file path. If you specify only a file name, Vertica creates it in the catalog directory. If the file already exists, the function silently overwrites its contents.
scope- What to export. Within the specified scope, EXPORT_CATALOG exports all the objects to which you have access:
-
DESIGN: Exports all catalog objects, including schemas, tables, constraints, views, access policies, projections, SQL macros, and stored procedures.
-
DESIGN_ALL: Deprecated.
-
TABLES: Exports all tables and their access policies. See also EXPORT_TABLES.
-
DIRECTED_QUERIES: Exports all directed queries that are stored in the database. For details, see Managing directed queries.
Default: DESIGN
Privileges
None
Examples
Export all design elements in order of their dependencies:
=> SELECT EXPORT_CATALOG(
'/home/dbadmin/xtest/sql_cat_design.sql',
'DESIGN' );
EXPORT_CATALOG
-------------------------------------
Catalog data exported successfully
(1 row)
Export only tables and their dependencies:
=> SELECT EXPORT_CATALOG (
'/home/dbadmin/xtest/sql_cat_tables.sql',
'TABLES');
EXPORT_CATALOG
-------------------------------------
Catalog data exported successfully
(1 row)
See also
6.13.1.4 - EXPORT_OBJECTS
This function and EXPORT_CATALOG return equivalent output.
Generates a SQL script you can use to recreate non-virtual catalog objects on another cluster.
If you omit all arguments, this function exports to standard output all objects to which you have access.
The SQL script:
-
Only includes objects to which the user has access.
-
Orders CREATE statements based on object dependencies so they can be recreated in the correct sequence. For example, if a table is in a non-public schema, the required CREATE SCHEMA statement precedes the CREATE TABLE statement. Similarly, a table's CREATE ACCESS POLICY statement follows the table's CREATE TABLE statement.
-
If possible, creates projections with a KSAFE clause, if any, otherwise with an OFFSET clause.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXPORT_OBJECTS( ['[destination]' [, '[scope]'] [, 'mark-ksafe']] )
Arguments
destination- Where to send output. To write the script to standard output, use an empty string (
''). A superusers can specify a file path. If you specify only a file name, Vertica creates it in the catalog directory. If the file already exists, the function silently overwrites its contents.
scope- The objects to export, a comma-delimited list, or an empty string to export all objects to which the user has access. If you specify a schema, the function exports all accessible objects in that schema.
For stored procedures with the same name but different formal parameters, you can export all implementations by exporting the parent schema, or specify the types or types and names of the formal parameters to identify the implementation to export.
mark-ksafe- Boolean, whether the generated script calls the MARK_DESIGN_KSAFE function. If true (default), MARK_DESIGN_KSAFE uses the correct K-safe argument for the current database.
Privileges
None
Examples
The following query exports all accessible objects to a named file:
=> SELECT EXPORT_OBJECTS(
'/home/dbadmin/xtest/sql_objects_all.sql',
'',
'true');
EXPORT_OBJECTS
-------------------------------------
Catalog data exported successfully
(1 row)
To export a particular implementation of a stored procedure, specify either the types or both the names and types of the procedure's formal parameters. The following example specifies the types:
=> SELECT EXPORT_OBJECTS('','raiseXY(int, int)');
EXPORT_OBJECTS
----------------------
CREATE PROCEDURE public.raiseXY(x int, y int)
LANGUAGE 'PL/vSQL'
SECURITY INVOKER
AS '
BEGIN
RAISE NOTICE ''x = %'', x;
RAISE NOTICE ''y = %'', y;
-- some processing statements
END
';
SELECT MARK_DESIGN_KSAFE(0);
(1 row)
To export all implementations of an overloaded stored procedure, export its parent schema:
=> SELECT EXPORT_OBJECTS('','public');
EXPORT_OBJECTS
----------------------
...
CREATE PROCEDURE public.raiseXY(x int, y varchar)
LANGUAGE 'PL/vSQL'
SECURITY INVOKER
AS '
BEGIN
RAISE NOTICE ''x = %'', x;
RAISE NOTICE ''y = %'', y;
-- some processing statements
END
';
CREATE PROCEDURE public.raiseXY(x int, y int)
LANGUAGE 'PL/vSQL'
SECURITY INVOKER
AS '
BEGIN
RAISE NOTICE ''x = %'', x;
RAISE NOTICE ''y = %'', y;
-- some processing statements
END
';
SELECT MARK_DESIGN_KSAFE(0);
(1 row)
See also
6.13.1.5 - EXPORT_TABLES
Generates a SQL script that can be used to recreate a logical schema—schemas, tables, constraints, and views—on another cluster.
Generates a SQL script that can be used to recreate a logical schema—schemas, tables, constraints, and views—on another cluster. EXPORT_TABLES only exports objects to which the user has access.
The SQL script conforms to the following requirements:
-
Only includes objects to which the user has access.
-
Orders CREATE statements according to object dependencies so they can be recreated in the correct sequence. For example, if a table references a named sequence, a CREATE SEQUENCE statement precedes the CREATE TABLE statement. Similarly, a table's CREATE ACCESS POLICY statement follows the table's CREATE TABLE statement.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXPORT_TABLES( ['[destination]' [, '[scope]']] )
Note
If you omit all parameters, EXPORT_CATALOG exports to standard output all tables to which you have access.
Parameters
destination- Specifies where to send output, one of the following:
-
An empty string ('') writes the script to standard output.
-
The path and name of a SQL output file. This option is valid only for superusers. If you specify a file that does not exist, the function creates one. If you specify only a file name, Vertica creates it in the catalog directory. If the file already exists, the function silently overwrites its contents.
scope- Specifies one or more tables to export, as follows:
[database.]schema[.table][,...]
- If set to an empty string, Vertica exports all non-virtual table objects to which you have access, including table schemas, sequences, and constraints.
- If you specify a schema, Vertica exports all non-virtual table objects in that schema.
- If you specify a database, it must be the current database.
Privileges
None
Examples
See Exporting tables.
See also
6.13.1.6 - INSTALL_LICENSE
Installs the license key in the global catalog.
Installs the license key in the global catalog.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
INSTALL_LICENSE( 'filename' )
Parameters
filename- The absolute path name of a valid license file.
Privileges
Superuser
Examples
=> SELECT INSTALL_LICENSE('/tmp/vlicense.dat');
See also
Managing licenses
6.13.1.7 - MARK_DESIGN_KSAFE
Enables or disables high availability in your environment, in case of a failure.
Enables or disables high availability in your environment, in case of a failure. Before enabling recovery, MARK_DESIGN_KSAFE queries the catalog to determine whether a cluster's physical schema design meets the following requirements:
-
Small, unsegmented tables are replicated on all nodes.
-
Large table superprojections are segmented with each segment on a different node.
-
Each large table projection has at least one buddy projection for K-safety=1 (or two buddy projections for K-safety=2).
Buddy projections are also segmented across database nodes, but the distribution is modified so segments that contain the same data are distributed to different nodes. See High availability with projections.
MARK_DESIGN_KSAFE does not change the physical schema.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MARK_DESIGN_KSAFE ( k )
Parameters
k- Specifies the level of K-safety, one of the following:
-
2: Enables high availability if the schema design meets requirements for K-safety=2
-
1: Enables high availability if the schema design meets requirements for K-safety=1
-
0: Disables high availability
Privileges
Superuser
Return messages
If you specify a k value of 1 or 2, Vertica returns one of the following messages.
Success:
Marked design n-safe
Failure:
The schema does not meet requirements for K=n.
Fact table projection projection-name
has insufficient "buddy" projections.
where n is a K-safety setting.
Notes
-
The database's internal recovery state persists across database restarts but it is not checked at startup time.
-
When one node fails on a system marked K-safe=1, the remaining nodes are available for DML operations.
Examples
=> SELECT MARK_DESIGN_KSAFE(1);
mark_design_ksafe
----------------------
Marked design 1-safe
(1 row)
If the physical schema design is not K-safe, messages indicate which projections do not have a buddy:
=> SELECT MARK_DESIGN_KSAFE(1);
The given K value is not correct;
the schema is 0-safe
Projection pp1 has 0 buddies,
which is smaller that the given K of 1
Projection pp2 has 0 buddies,
which is smaller that the given K of 1
.
.
.
(1 row)
See also
6.13.1.8 - RELOAD_ADMINTOOLS_CONF
Updates the admintools.conf on each UP node in the cluster.
Updates the admintools.conf on each UP node in the cluster. Updates include:
This function provides a manual method to instruct the server to update admintools.conf on all UP nodes. For example, if you restart a node, call this function to confirm its admintools.conf file is accurate.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RELOAD_ADMINTOOLS_CONF()
Privileges
Superuser
Examples
Update admintools.conf on each UP node in the cluster:
=> SELECT RELOAD_ADMINTOOLS_CONF();
RELOAD_ADMINTOOLS_CONF
--------------------------
admintools.conf reloaded
(1 row)
6.13.2 - Cloud functions
This section contains functions for managing cloud integrations.
This section contains functions for managing cloud integrations. See also Hadoop functions for HDFS.
6.13.2.1 - AZURE_TOKEN_CACHE_CLEAR
Clears the cached access token for Azure.
Clears the cached access token for Azure. Call this function after changing the configuration of Azure managed identities.
An Azure object store can support and manage multiple identities. If multiple identities are in use, Vertica looks for an Azure tag with a key of VerticaManagedIdentityClientId, the value of which must be the client_id attribute of the managed identity to be used. If the Azure configuration changes, use this function to clear the cache.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AZURE_TOKEN_CACHE_CLEAR ( )
Privileges
Superuser
6.13.3 - Cluster functions
This section contains functions that manage deployment on large, distributed database clusters and functions that control how the cluster organizes data for rebalancing.
This section contains functions that manage spread deployment on large, distributed database clusters and functions that control how the cluster organizes data for rebalancing.
6.13.3.1 - CANCEL_REBALANCE_CLUSTER
Stops any rebalance task that is currently in progress or is waiting to execute.
Stops any rebalance task that is currently in progress or is waiting to execute.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CANCEL_REBALANCE_CLUSTER()
Privileges
Superuser
Examples
=> SELECT CANCEL_REBALANCE_CLUSTER();
CANCEL_REBALANCE_CLUSTER
--------------------------
CANCELED
(1 row)
See also
6.13.3.2 - DISABLE_LOCAL_SEGMENTS
Disables local data segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes.
Disables local data segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes. See Local data segmentation for details.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DISABLE_LOCAL_SEGMENTS()
Privileges
Superuser
Examples
=> SELECT DISABLE_LOCAL_SEGMENTS();
DISABLE_LOCAL_SEGMENTS
------------------------
DISABLED
(1 row)
6.13.3.3 - ENABLE_ELASTIC_CLUSTER
Enables elastic cluster scaling, which makes enlarging or reducing the size of your database cluster more efficient by segmenting a node's data into chunks that can be easily moved to other hosts.
Enables elastic cluster scaling, which makes enlarging or reducing the size of your database cluster more efficient by segmenting a node's data into chunks that can be easily moved to other hosts.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLE_ELASTIC_CLUSTER()
Privileges
Superuser
Examples
=> SELECT ENABLE_ELASTIC_CLUSTER();
ENABLE_ELASTIC_CLUSTER
------------------------
ENABLED
(1 row)
6.13.3.4 - ENABLE_LOCAL_SEGMENTS
Enables local storage segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes.
Enables local storage segmentation, which breaks projections segments on nodes into containers that can be easily moved to other nodes. See Local data segmentation for more information.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLE_LOCAL_SEGMENTS()
Privileges
Superuser
Examples
=> SELECT ENABLE_LOCAL_SEGMENTS();
ENABLE_LOCAL_SEGMENTS
-----------------------
ENABLED
(1 row)
6.13.3.5 - REALIGN_CONTROL_NODES
Causes Vertica to re-evaluate which nodes in the cluster or subcluster are and which nodes are assigned to them as dependents when large cluster is enabled.
Causes Vertica to re-evaluate which nodes in the cluster or subcluster are control nodes and which nodes are assigned to them as dependents when large cluster is enabled. Call this function after altering fault groups in an Enterprise Mode database, or changing the number of control nodes in either database mode. After calling this function, query the
V_CATALOG.CLUSTER_LAYOUT system table to see the proposed new layout for nodes in the cluster. You must also take additional steps before the new control node assignments take effect. See Changing the number of control nodes and realigning for details.
Note
In Vertica versions prior to 10.0.1, control node assignments weren't restricted to be within the same Eon Mode subcluster. If you attempt to realign control nodes in a subcluster whose control nodes have dependents in other subclusters, this function returns an error. In this case, you must realign the control nodes in those other subclusters first. Realigning the other subclusters fixes the cross-subcluster dependencies, allowing you to realign the control nodes in the original subcluster you attempted to realign.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
In Enterprise Mode:
REALIGN_CONTROL_NODES()
In Eon Mode:
REALIGN_CONTROL_NODES('subcluster_name')
Parameters
subcluster_name- The name of the subcluster where you want to realign control nodes. Only the nodes in this subcluster are affected. Other subclusters are unaffected. Only allowed when the database is running in Eon Mode.
Privileges
Superuser
Examples
In an Enterprise Mode database, choose control nodes from all nodes and assign the remaining nodes to a control node:
=> SELECT REALIGN_CONTROL_NODES();
In an Eon Mode database, re-evaluate the control node assignments in the subcluster named analytics:
=> SELECT REALIGN_CONTROL_NODES('analytics');
See also
6.13.3.6 - REBALANCE_CLUSTER
Rebalances the database cluster synchronously as a session foreground task.
Rebalances the database cluster synchronously as a session foreground task. REBALANCE_CLUSTER returns only after the rebalance operation is complete. If the current session ends, the operation immediately aborts. To rebalance the cluster as a background task, call START_REBALANCE_CLUSTER.
On large cluster arrangements, you typically call REBALANCE_CLUSTER in a flow (see Changing the number of control nodes and realigning). After you change the number and distribution of control nodes (spread hosts), run REBALANCE_CLUSTER to achieve fault tolerance.
For detailed information about rebalancing tasks, see Rebalancing data across nodes.
Tip
By default, before performing a rebalance, Vertica queries system tables to compute the size of all projections involved in the rebalance task. This query can add significant overhead to the rebalance operation. To disable this query, set projection configuration parameter
RebalanceQueryStorageContainers to 0.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REBALANCE_CLUSTER()
Privileges
Superuser
Examples
=> SELECT REBALANCE_CLUSTER();
REBALANCE_CLUSTER
-------------------
REBALANCED
(1 row)
6.13.3.7 - RELOAD_SPREAD
Updates cluster changes to the catalog's Spread configuration file.
Updates cluster changes to the catalog's Spread configuration file. These changes include:
-
New or realigned control nodes
-
New Spread hosts or fault group
-
New or dropped cluster nodes
This function is often used in a multi-step process for large and elastic cluster arrangements. Calling it might require you to restart the database. You must then rebalance the cluster to realize fault tolerance. For details, see Defining and Realigning Control Nodes.
Caution
In an Eon Mode database, using this function could result in the database becoming read-only. Nodes may become disconnected after you call this function. If the database no longer has
primary shard coverage without these nodes, it goes into read-only mode to maintain data integrity. Once the nodes rejoin the cluster, the database will resume normal operation. See
Maintaining Shard Coverage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RELOAD_SPREAD( true )
Parameters
true- Updates cluster changes related to control message responsibilities to the Spread configuration file.
Privileges
Superuser
Examples
Update the cluster with changes to control messaging:
=> SELECT reload_spread(true);
reload_spread
---------------
reloaded
(1 row)
See also
REBALANCE_CLUSTER
6.13.3.8 - SET_CONTROL_SET_SIZE
Sets the number of that participate in the spread service when large cluster is enabled.
Sets the number of control nodes that participate in the spread service when large cluster is enabled. If the database is running in Enterprise Mode, this function sets the number of control nodes for the entire database cluster. If the database is running in Eon Mode, this function sets the number of control nodes in the subcluster you specify. See Large cluster for more information.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
In Enterprise Mode:
SET_CONTROL_SET_SIZE( control_nodes )
In Eon Mode:
SET_CONTROL_SET_SIZE('subcluster_name', control_nodes )
Parameters
subcluster_name- The name of the subcluster where you want to set the number of control nodes. Only allowed when the database is running in Eon Mode.
control_nodes- The number of control nodes to assign to the cluster (when in Enterprise Mode) or subcluster (when in Eon Mode). Value can be one of the following:
-
Positive integer value: Vertica assigns the number of control nodes you specify to the cluster or subcluster. This value can be larger than the current node count. This value cannot be larger than 120 (the maximum number of control nodes for a database). In Eon Mode, the total of this value plus the number of control nodes set for all other subclusters cannot be more than 120.
-
-1: Makes every node in the cluster or subcluster into control nodes. This value effectively disables large cluster for the cluster or subcluster.
Privileges
Superuser
Examples
In an Enterprise Mode database, set the number of control nodes for the entire cluster to 5:
=> SELECT set_control_set_size(5);
SET_CONTROL_SET_SIZE
----------------------
Control size set
(1 row)
See also
6.13.3.9 - SET_SCALING_FACTOR
Sets the scaling factor that determines the number of storage containers used when rebalancing the database and when using local data segmentation is enabled.
Sets the scaling factor that determines the number of storage containers used when rebalancing the database and when using local data segmentation is enabled. See Cluster Scaling for details.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_SCALING_FACTOR( factor )
Parameters
factor- An integer value between 1 and 32. Vertica uses this value to calculate the number of storage containers each projection is broken into when rebalancing or when local data segmentation is enabled.
Privileges
Superuser
Best practices
The scaling factor determines the number of storage containers that Vertica uses to store each projection across the database during rebalancing when local segmentation is enabled. When setting the scaling factor, follow these guidelines:
-
The number of storage containers should be greater than or equal to the number of partitions multiplied by the number of local segments:
num-storage-containers>= (num-partitions*num-local-segments )
-
Set the scaling factor high enough so rebalance can transfer local segments to satisfy the skew threshold, but small enough so the number of storage containers does not result in too many ROS containers, and cause ROS pushback. The maximum number of ROS containers (by default 1024) is set by configuration parameter ContainersPerProjectionLimit.
Examples
=> SELECT SET_SCALING_FACTOR(12);
SET_SCALING_FACTOR
--------------------
SET
(1 row)
6.13.3.10 - START_REBALANCE_CLUSTER
Asynchronously rebalances the database cluster as a background task.
Asynchronously rebalances the database cluster as a background task. This function returns immediately after the rebalancing operation is complete. Rebalancing persists until the operation is complete, even if you close the current session or the database shuts down. In the case of shutdown, rebalancing resumes after the cluster restarts. To stop the rebalance operation, call
CANCEL_REBALANCE_CLUSTER.
For detailed information about rebalancing tasks, see Rebalancing data across nodes.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
START_REBALANCE_CLUSTER()
Privileges
Superuser
Examples
=> SELECT START_REBALANCE_CLUSTER();
START_REBALANCE_CLUSTER
-------------------------
REBALANCING
(1 row)
See also
REBALANCE_CLUSTER
6.13.4 - Data Collector functions
The Vertica Data Collector is a utility that extends system table functionality by providing a framework for recording events.
The Vertica Data Collector is a utility that extends system table functionality by providing a framework for recording events. It gathers and retains monitoring information about your database cluster and makes that information available in system tables with negligble performance impact.
Collected data is stored on disk in the DataCollector directory under the Vertica /catalog path. You can use the information the Data Collector retains in the following ways:
-
Query the past state of system tables and extract aggregate information
-
See what actions users have taken
-
Locate performance bottlenecks
-
Identify potential improvements to Vertica configuration
Data Collector works in conjunction with an advisor tool called Workload Analyzer, which intelligently monitors the performance of SQL queries and workloads and recommends tuning actions based on observations of the actual workload history.
By default, Data Collector is enabled and retains information for all sessions. If performance issues arise, a superuser can disable Data Collector by setting the EnableDataCollector configuration parameter to 0.
6.13.4.1 - CLEAR_DATA_COLLECTOR
Clears all memory and disk records from Data Collector tables and logs, and resets collection statistics in system table DATA_COLLECTOR.
Clears all memory and disk records from Data Collector tables and logs, and resets collection statistics in the DATA_COLLECTOR system table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DATA_COLLECTOR( [ 'component' ] )
Arguments
component- Component to clear. If not specified, the function clears memory and disk records for all components.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
Privileges
Superuser
Examples
By default, the function clears data collection for all components:
=> SELECT CLEAR_DATA_COLLECTOR();
CLEAR_DATA_COLLECTOR
----------------------
CLEAR
(1 row)
To clear memory and disk records for only one component, specify the component:
=> SELECT CLEAR_DATA_COLLECTOR('ResourceAcquisitions');
CLEAR_DATA_COLLECTOR
----------------------
CLEAR
(1 row)
See also
Data Collector utility
6.13.4.2 - DATA_COLLECTOR_HELP
Returns online usage instructions about the Data Collector, the V_MONITOR.DATA_COLLECTOR system table, and the Data Collector control functions.
Returns online usage instructions about the Data Collector, the
DATA_COLLECTOR system table, and the Data Collector control functions.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DATA_COLLECTOR_HELP()
Privileges
None
Returns
The function returns information like the following (exact contents might differ from this example):
=> SELECT DATA_COLLECTOR_HELP();
-----------------------------------------------------------------------------
Usage Data Collector
The data collector retains history of important system activities.
This data can be used as a reference of what actions have been taken
by users, but it can also be used to locate performance bottlenecks,
or identify potential improvements to the Vertica configuration.
This data is queryable via Vertica system tables.
Acccess a list of data collector components, and some statistics, by running:
SELECT * FROM v_monitor.data_collector;
The amount of data retained by size and time can be controlled with several
functions.
To just set the size amount:
set_data_collector_policy(<component>,
<memory retention (KB)>,
<disk retention (KB)>);
To set both the size and time amounts (the smaller one will dominate):
set_data_collector_policy(<component>,
<memory retention (KB)>,
<disk retention (KB)>,
<interval>);
To set just the time amount:
set_data_collector_time_policy(<component>,
<interval>);
To set the time amount for all tables:
set_data_collector_time_policy(<interval>);
The current retention policy for a component can be queried with:
get_data_collector_policy(<component>);
Data on disk is kept in the "DataCollector" directory under the Vertica
\catalog path. This directory also contains instructions on how to load
the monitoring data into another Vertica database.
To move the data collector logs and instructions to other storage locations,
create labeled storage locations using add_location and then use:
set_data_collector_storage_location(<storage_label>);
Additional commands can be used to configure the data collection logs.
The log can be cleared with:
clear_data_collector([<optional component>]);
The log can be synchronized with the disk storage using:
flush_data_collector([<optional component>]);
See also
6.13.4.3 - FLUSH_DATA_COLLECTOR
Waits until memory logs are moved to disk and then flushes the Data Collector, synchronizing the log with disk storage.
Waits until memory logs are moved to disk and then flushes the Data Collector, synchronizing the log with disk storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
FLUSH_DATA_COLLECTOR( [ 'component' ] )
Arguments
component- Component to flush. If not specified, the function flushes data for all components.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
Privileges
Superuser
Examples
By default, the function flushes the Data Collector for all components:
=> SELECT FLUSH_DATA_COLLECTOR();
FLUSH_DATA_COLLECTOR
----------------------
FLUSH
(1 row)
To flush only one component, specify it:
=> SELECT FLUSH_DATA_COLLECTOR('ResourceAcquisitions');
FLUSH_DATA_COLLECTOR
----------------------
FLUSH
(1 row)
See also
Data Collector utility
6.13.4.4 - GET_DATA_COLLECTOR_POLICY
Retrieves a brief statement about the retention policy for the specified component.
Returns a brief statement about the retention policy for the specified component.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_DATA_COLLECTOR_POLICY( 'component' )
Arguments
component- Component to query.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
Privileges
None
Examples
=> SELECT GET_DATA_COLLECTOR_POLICY('ResourceAcquisitions');
GET_DATA_COLLECTOR_POLICY
----------------------------------------------
1000KB kept in memory, 10000KB kept on disk. Synchronous logging disabled. Time based retention disabled.
(1 row)
See also
6.13.4.5 - SET_DATA_COLLECTOR_POLICY
Updates the following retention policy properties for the specified component:.
Updates selected retention policy properties for a specified component. SET_DATA_COLLECTOR_POLICY (using parameters) is another version of this function that uses named parameters instead of positional arguments.
Before you change a retention policy, you can view its current settings by querying the DATA_COLLECTOR table or by calling the GET_DATA_COLLECTOR_POLICY function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DATA_COLLECTOR_POLICY('component', 'memory-buffer-size', 'disk-size' [,'interval-time'] )
Arguments
component- The retention policy to update.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
memory-buffer-size- Maximum amount of data, in kilobytes, that is buffered in memory before moving it to disk. The retention policy property MEMORY_BUFFER_SIZE_KB is set from this value. This value must be positive and greater than 0.
Consider setting this parameter to a high value in the following cases:
-
Unusually high levels of data collection. If the value is too low, the Data Collector might be unable to flush buffered data to disk quickly enough to keep up with the activity level, which can lead to loss of in-memory data.
-
Very large data collector records—for example, records with very long query strings. The Data Collector uses double-buffering, so it cannot retain in-memory records that are more than half the size of the memory buffer.
disk-size- Maximum disk space, in kilobytes, allocated for this component's Data Collector table. The retention policy property DISK_SIZE_KB is set from this value. If set to 0, the Data Collector retains only as much component data as it can buffer in memory, as specified by
memory-buffer-size.
interval-timeHow long to retain data in the component's Data Collector table, an INTERVAL. The INTERVAL_TIME retention policy property is set from this value. If the value is positive, it also sets the INTERVAL_SET policy property to true.
For example, if you specify the TupleMoverEvents component and set this value to two days ('2 days'::interval), the DC_TUPLE_MOVER_EVENTS Data Collector table retains records over the last 48 hours. Older Tuple Mover data is automatically dropped from this table.
Setting a component's policy's INTERVAL_TIME property has no effect on how much data storage the Data Collector retains on disk for that component. Maximum disk storage capacity is determined by the DISK_SIZE_KB property. Setting the INTERVAL_TIME property only affects how long data is retained by the component's Data Collector table. For details, see Configuring data retention policies.
To disable the INTERVAL_TIME policy property, set this value to a negative integer. Doing so reverts two retention policy properties to their default settings:
-
INTERVAL_SET: false
-
INTERVAL_TIME: 0
With these two properties thus set, the component's Data Collector table retains data on all component events until it reaches its maximum limit, as set by the DISK_SIZE_KB retention policy property.
Privileges
Superuser
Examples
=> SELECT SET_DATA_COLLECTOR_POLICY('ResourceAcquisitions', '1500', '25000');
SET_DATA_COLLECTOR_POLICY
---------------------------
SET
(1 row)
See also
6.13.4.6 - SET_DATA_COLLECTOR_POLICY (using parameters)
Updates selected retention policy properties for a component.
Updates selected retention policy properties for a specified component. SET_DATA_COLLECTOR_POLICY is another version of this function that uses positional arguments instead of named parameters.
Before you change a retention policy, you can view its current settings by querying the DATA_COLLECTOR table or by calling the GET_DATA_COLLECTOR_POLICY function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DATA_COLLECTOR_POLICY('component' USING PARAMETERS param=value[,...] )
Arguments
component- The retention policy to update.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
Parameters
memKB (INTEGER)- Maximum amount of data, in kilobytes, that is buffered in memory before moving it to disk. The retention policy property MEMORY_BUFFER_SIZE_KB is set from this value. This value must be positive and greater than 0.
Consider setting this parameter to a high value in the following cases:
-
Unusually high levels of data collection. If the value is too low, the Data Collector might be unable to flush buffered data to disk quickly enough to keep up with the activity level, which can lead to loss of in-memory data.
-
Very large data collector records—for example, records with very long query strings. The Data Collector uses double-buffering, so it cannot retain in-memory records that are more than half the size of the memory buffer.
diskKB (INTEGER)- Maximum disk space, in kilobytes, allocated for this component's Data Collector table. The retention policy property DISK_SIZE_KB is set from this value. If set to 0, the Data Collector retains only as much component data as it can buffer in memory, as specified by
memory-buffer-size.
synchronous (BOOLEAN)- Whether to ensure that no data is lost by performing synchronous writes. By default, if the Data Collector cannot keep up with the activity level, it can drop data buffered in memory before writing it to disk. If it is important to retain all activity records, set this parameter to true.
retention (INTERVAL)How long to retain data in the component's Data Collector table, an INTERVAL. The INTERVAL_TIME retention policy property is set from this value. If the value is positive, it also sets the INTERVAL_SET policy property to true.
For example, if you specify the TupleMoverEvents component and set this value to two days ('2 days'::interval), the DC_TUPLE_MOVER_EVENTS Data Collector table retains records over the last 48 hours. Older Tuple Mover data is automatically dropped from this table.
Setting a component's policy's INTERVAL_TIME property has no effect on how much data storage the Data Collector retains on disk for that component. Maximum disk storage capacity is determined by the DISK_SIZE_KB property. Setting the INTERVAL_TIME property only affects how long data is retained by the component's Data Collector table. For details, see Configuring data retention policies.
To disable the INTERVAL_TIME policy property, set this value to a negative integer. Doing so reverts two retention policy properties to their default settings:
-
INTERVAL_SET: false
-
INTERVAL_TIME: 0
With these two properties thus set, the component's Data Collector table retains data on all component events until it reaches its maximum limit, as set by the DISK_SIZE_KB retention policy property.
Privileges
Superuser
Examples
=> SELECT SET_DATA_COLLECTOR_POLICY('ResourceAcquisitions'
USING PARAMETERS synchronous=TRUE, memKB=100, diskKB=50000);
set_data_collector_policy
---------------------------
SET
(1 row)
6.13.4.7 - SET_DATA_COLLECTOR_TIME_POLICY
Updates the retention policy property INTERVAL_TIME for the specified component.
Updates the INTERVAL_TIME retention policy property for a specified component or globally. Calling this function has no effect on other properties of the same component.
You can also set the retention policy using SET_DATA_COLLECTOR_POLICY (using parameters).
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DATA_COLLECTOR_TIME_POLICY( ['component',] 'interval-time' )
Arguments
component- Component to update. If not specified, the function updates the retention policy of all Data Collector components.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
interval-timeHow long to retain data in the component's Data Collector table, an INTERVAL. The INTERVAL_TIME retention policy property is set from this value. If the value is positive, it also sets the INTERVAL_SET policy property to true.
For example, if you specify the TupleMoverEvents component and set this value to two days ('2 days'::interval), the DC_TUPLE_MOVER_EVENTS Data Collector table retains records over the last 48 hours. Older Tuple Mover data is automatically dropped from this table.
Setting a component's policy's INTERVAL_TIME property has no effect on how much data storage the Data Collector retains on disk for that component. Maximum disk storage capacity is determined by the DISK_SIZE_KB property. Setting the INTERVAL_TIME property only affects how long data is retained by the component's Data Collector table. For details, see Configuring data retention policies.
To disable the INTERVAL_TIME policy property, set this value to a negative integer. Doing so reverts two retention policy properties to their default settings:
-
INTERVAL_SET: false
-
INTERVAL_TIME: 0
With these two properties thus set, the component's Data Collector table retains data on all component events until it reaches its maximum limit, as set by the DISK_SIZE_KB retention policy property.
Privileges
Superuser
Examples
The following example sets a retention time for a single component. Other components are unaffected:
=> SELECT SET_DATA_COLLECTOR_TIME_POLICY('TupleMoverEvents ', '30 minutes'::INTERVAL);
SET_DATA_COLLECTOR_TIME_POLICY
--------------------------------
SET
(1 row)
To set a retention time for all components, omit the first argument:
=> SELECT SET_DATA_COLLECTOR_TIME_POLICY('1 day'::INTERVAL);
SET_DATA_COLLECTOR_TIME_POLICY
--------------------------------
SET
(1 row)
6.13.5 - Database functions
This section contains the database management functions specific to Vertica.
This section contains the database management functions specific to Vertica.
6.13.5.1 - CLEAR_RESOURCE_REJECTIONS
Clears the content of the RESOURCE_REJECTIONS and DISK_RESOURCE_REJECTIONS system tables.
Clears the content of the RESOURCE_REJECTIONS and DISK_RESOURCE_REJECTIONS system tables. Normally, these tables are only cleared during a node restart. This function lets you clear the tables whenever you need. For example, you might want to clear the system tables after you resolved a disk space issue that was causing disk resource rejections.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Immutable
Syntax
CLEAR_RESOURCE_REJECTIONS();
Privileges
Superuser
Examples
The following command clears the content of the RESOURCE_REJECTIONS and DISK_RESOURCE_REJECTIONS system tables:
=> SELECT clear_resource_rejections();
clear_resource_rejections
---------------------------
OK
(1 row)
See also
6.13.5.2 - COMPACT_STORAGE
Bundles existing data (.fdb) and index (.pidx) files into the .gt file format.
Bundles existing data (.fdb) and index (.pidx) files into the .gt file format. The .gt format is enabled by default for data files created version 7.2 or later. If you upgrade a database from an earlier version, use COMPACT_STORAGE to bundle storage files into the .gt format. Your database can continue to operate with a mix of file storage formats.
If the settings you specify for COMPACT_STORAGE vary from the limit specified in configuration parameter MaxBundleableROSSizeKB, Vertica does not change the size of the automatically created bundles.
Note
Run this function during periods of low demand.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SELECT COMPACT_STORAGE ('[[[database.]schema.]object-name]', min-ros-filesize-kb, 'small-or-all-files', 'simulate');
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Specifies the table or projection to bundle. If set to an empty string, COMPACT_STORAGE evaluates the data of all projections in the database for bundling.
min-ros-filesize-kb- Integer ≥ 1, specifies in kilobytes the minimum size of an independent ROS file. COMPACT_STORAGE bundles storage container ROS files below this size into a single file.
small-or-all-files- One of the following:
-
small: Bundles only files smaller than the limit specified in min-ros-filesize-kb
-
all: Bundles files smaller than the limit specified in min-ros-filesize-kb and bundles the .fdb and .pidx files for larger storage containers.
simulate- Specifies whether to simulate the storage settings and produce a report describing the impact of those settings.
Privileges
Superuser
Bundling reduces the number of files in your file system by at least fifty percent and improves the performance of file-intensive operations. Improved operations include backups, restores, and mergeout.
Vertica creates small files for the following reasons:
-
Tables contain hundreds of columns.
-
Partition ranges are small (partition by minute).
-
Local segmentation is enabled and your factor is set to a high value.
Examples
The following example describes the impact of bundling the table EMPLOYEES:
=> SELECT COMPACT_STORAGE('employees', 1024,'small','true');
Task: compact_storage
On node v_vmart_node0001:
Projection Name :public.employees_b0 | selected_storage_containers :0 |
selected_files_to_compact :0 | files_after_compact : 0 | modified_storage_KB :0
On node v_vmart_node0002:
Projection Name :public.employees_b0 | selected_storage_containers :1 |
selected_files_to_compact :6 | files_after_compact : 1 | modified_storage_KB :0
On node v_vmart_node0003:
Projection Name :public.employees_b0 | selected_storage_containers :2 |
selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node v_vmart_node0001:
Projection Name :public.employees_b1 | selected_storage_containers :2 |
selected_files_to_compact :12 | files_after_compact : 2 | modified_storage_KB :0
On node v_vmart_node0002:
Projection Name :public.employees_b1 | selected_storage_containers :0 |
selected_files_to_compact :0 | files_after_compact : 0 | modified_storage_KB :0
On node v_vmart_node0003:
Projection Name :public.employees_b1 | selected_storage_containers :1 |
selected_files_to_compact :6 | files_after_compact : 1 | modified_storage_KB :0
Success
(1 row)
6.13.5.3 - DO_LOGROTATE_LOCAL
Rotates logs and removes rotated logs on the current node.
If the following files exceed the specified maximum size, they are rotated:
vertica.logUDxFencedProcesses.logMemoryReport.logeditor.logdbLog
Rotated files are compressed and marked with a timestamp in the same location as the original log file: path/to/logfile.logtimestamp.gz. For example, /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log is rotated to /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-08-14-09-02-381909-05.gz.
If a log file was rotated, the previously rotated logs (.gz) in that directory are checked against the specified maximum age. Rotated logs older than the maximum age are deleted.
To view previous rotation events, see LOG_ROTATE_EVENTS
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DO_LOGROTATE_LOCAL('[ max_size=log_size{K|M|G|T};max_age=log_age;force=force_value ]')
Parameters
max_size=log_size{K|M|G|T}- String, the maximum size of logs (
.log) to keep, where K is kibibytes, M is mebibytes, G is gibibytes, and T is tebibytes. This overrides the LogRotateMaxSize parameter.
Default: The default (not current) value of LogRotateMaxSize
max_age=log_age- Interval literal of rotated logs (
.gz) to keep. This overrides the LogRotateMaxAge configuration parameter. If the unit is not specified, the unit is assumed to be days.
Default: The default (not current) value of LogRotateMaxAge
force=force_value- Boolean, whether to force rotation, ignoring the maximum size. You can also specify
true by specifying force without the boolean value.
Default: false
Privileges
Superuser
Examples
To rotate logs that are larger than 1 kilobyte, and then remove rotated logs that are older than 1 day:
=> SELECT do_logrotate_local('max_size=1K;max_age=1 day');
do_logrotate_local
-----------------------------------------------------------------------------------------------------------
Doing Logrotate
Considering file /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
File size: 35753 Bytes
Force rotate? no
Renaming to /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-08-13-55-51-651129-05
Opening new log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
Compressing /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-08-13-55-51-651129-05 to /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-08-13-55-51-651129-05.gz
Done with /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
Considering file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
File size: 68 Bytes
Force rotate? no
Rotation not required for file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
Done with /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
(1 row)
To force rotation and then remove all logs older than 4 days (default value of LogRotateMaxAge):
=> SELECT do_logrotate_local('force;max_age=4 days');
do_logrotate_local
-----------------------------------------------------------------------------------------------------------
Doing Logrotate
Considering file /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
File size: 4310245 Bytes
Force rotate? yes
Renaming to /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-10-13-45-15-53837-05
Opening new log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
Compressing /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-10-13-45-15-53837-05 to /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log.2023-11-10-13-45-15-53837-05.gz
Done with /scratch_b/qa/VMart/v_vmart_node0001_catalog/vertica.log
Considering file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
File size: 68 Bytes
Force rotate? yes
Remove old log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-06-13-18-27-23141-05.gz
Remove old log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-07-13-18-30-059008-05.gz
Remove old log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-08-13-47-11-707903-05.gz
Remove old log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-09-14-09-02-386402-05.gz
Renaming to /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-10-13-45-15-647762-05
Opening new log file /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
Compressing /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-10-13-45-15-647762-05 to /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-11-10-13-45-15-647762-05.gz
Done with /scratch_b/qa/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
(1 row)
6.13.5.4 - DUMP_LOCKTABLE
Returns information about deadlocked clients and the resources they are waiting for.
Returns information about deadlocked clients and the resources they are waiting for.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DUMP_LOCKTABLE()
Privileges
None
Notes
Use DUMP_LOCKTABLE if Vertica becomes unresponsive:
-
Open an additional vsql connection.
-
Execute the query:
=> SELECT DUMP_LOCKTABLE();
The output is written to vsql. See Monitoring the Log Files.
You can also see who is connected using the following command:
=> SELECT * FROM SESSIONS;
Close all sessions using the following command:
=> SELECT CLOSE_ALL_SESSIONS();
Close a single session using the following command:
=> SELECT CLOSE_SESSION('session_id');
You get the session_id value from the V_MONITOR.SESSIONS system table.
See also
6.13.5.5 - DUMP_PARTITION_KEYS
Dumps the partition keys of all projections in the system.
Dumps the partition keys of all projections in the system.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DUMP_PARTITION_KEYS( )
Note
The
ROS objects of partitioned tables without partition keys are ignored by the tuple mover and are not merged during automatic tuple mover operations.
Privileges
User must have select privileges on the table or usage privileges on the schema.
Examples
=> SELECT DUMP_PARTITION_KEYS( );
Partition keys on node v_vmart_node0001
Projection 'states_b0'
Storage [ROS container]
No of partition keys: 1
Partition keys: NH
Storage [ROS container]
No of partition keys: 1
Partition keys: MA
Projection 'states_b1'
Storage [ROS container]
No of partition keys: 1
Partition keys: VT
Storage [ROS container]
No of partition keys: 1
Partition keys: ME
Storage [ROS container]
No of partition keys: 1
Partition keys: CT
See also
6.13.5.6 - GET_CONFIG_PARAMETER
Gets the value of a configuration parameter at the specified level.
Gets the value of a configuration parameter at the specified level. If no value is set at that level, the function returns an empty row.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_CONFIG_PARAMETER( 'parameter-name' [, 'level' | NULL] )
Parameters
parameter-name- Name of the configuration parameter value to get.
level- Level at which to get
parameter-name's setting, one of the following string values:
If level is omitted or set to NULL, GET_CONFIG_PARAMETER returns the database setting.
Privileges
None
Examples
Get the AnalyzeRowCountInterval parameter at the database level:
=> SELECT GET_CONFIG_PARAMETER ('AnalyzeRowCountInterval');
GET_CONFIG_PARAMETER
----------------------
3600
Get the MaxSessionUDParameterSize parameter at the session level:
=> SELECT GET_CONFIG_PARAMETER ('MaxSessionUDParameterSize','session');
GET_CONFIG_PARAMETER
----------------------
2000
(1 row)
Get the UseDepotForReads parameter at the user level:
=> SELECT GET_CONFIG_PARAMETER ('UseDepotForReads', 'user');
GET_CONFIG_PARAMETER
----------------------
1
(1 row)
See also
6.13.5.7 - KERBEROS_CONFIG_CHECK
Tests the Kerberos configuration of a Vertica cluster.
Tests the Kerberos configuration of a Vertica cluster. The function succeeds if it can kinit with both the keytab file and the current user's credential, and reports errors otherwise.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
KERBEROS_CONFIG_CHECK( )
Parameters
This function has no parameters.
Privileges
This function does not require privileges.
Examples
The following example shows the results when the Kerberos configuration is valid.
=> SELECT KERBEROS_CONFIG_CHECK();
kerberos_config_check
-----------------------------------------------------------------------------
ok: krb5 exists at [/etc/krb5.conf]
ok: Vertica Keytab file is set to [/etc/vertica.keytab]
ok: Vertica Keytab file exists at [/etc/vertica.keytab]
[INFO] KerberosCredentialCache [/tmp/vertica_D4/vertica450676899262134963.cc]
Kerberos configuration parameters set in the database
KerberosServiceName : [vertica]
KerberosHostname : [data.hadoop.com]
KerberosRealm : [EXAMPLE.COM]
KerberosKeytabFile : [/etc/vertica.keytab]
Vertica Principal: [vertica/data.hadoop.com@EXAMPLE.COM]
[OK] Vertica can kinit using keytab file
[OK] User [bob] has valid client authentication for kerberos principal [bob@EXAMPLE.COM]]
(1 row)
6.13.5.8 - MEMORY_TRIM
Calls glibc function malloc_trim() to reclaim free memory from malloc and return it to the operating system.
Calls glibc function
malloc_trim() to reclaim free memory from malloc and return it to the operating system. Details on the trim operation are written to system table
MEMORY_EVENTS.
Unless you turn off memory polling, Vertica automatically detects when glibc accumulates an excessive amount of free memory in its allocation arena. When this occurs, Vertica consolidates much of this memory and returns it to the operating system. Call this function if you disable memory polling and wish to reduce glibc-allocated memory manually.
For more information, see Memory trimming.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MEMORY_TRIM()
Privileges
Superuser
Examples
=> SELECT memory_trim();
memory_trim
-----------------------------------------------------------------
Pre-RSS: [378822656] Post-RSS: [372129792] Benefit: [0.0176675]
(1 row)
6.13.5.9 - PURGE
Permanently removes delete vectors from ROS storage containers so disk space can be reused.
Permanently removes delete vectors from ROS storage containers so disk space can be reused. PURGE removes all historical data up to and including the Ancient History Mark epoch.
PURGE does not delete temporary tables.
Caution
PURGE can temporarily use significant disk space.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SELECT PURGE()
Privileges
Examples
After you delete data from a Vertica table, that data is marked for deletion. To see the data that is marked for deletion, query system table
DELETE_VECTORS.
Run PURGE to remove the delete vectors from ROS containers.
=> SELECT * FROM test1;
number
--------
3
12
33
87
43
99
(6 rows)
=> DELETE FROM test1 WHERE number > 50;
OUTPUT
--------
2
(1 row)
=> SELECT * FROM test1;
number
--------
43
3
12
33
(4 rows)
=> SELECT node_name, projection_name, deleted_row_count FROM DELETE_VECTORS;
node_name | projection_name | deleted_row_count
------------------+-----------------+-------------------
v_vmart_node0002 | test1_b1 | 1
v_vmart_node0001 | test1_b1 | 1
v_vmart_node0001 | test1_b0 | 1
v_vmart_node0003 | test1_b0 | 1
(4 rows)
=> SELECT PURGE();
...
(Table: public.test1) (Projection: public.test1_b0)
(Table: public.test1) (Projection: public.test1_b1)
...
(4 rows)
After the ancient history mark (AHM) advances:
=> SELECT * FROM DELETE_VECTORS;
(No rows)
See also
6.13.5.10 - RUN_INDEX_TOOL
Runs the Index tool on a Vertica database to perform one of these tasks:.
Runs the Index tool on a Vertica database to perform one of these tasks:
The function writes summary information about its operation to standard output; detailed information on results is logged in vertica.log on the current node. For more about evaluating tool output, see:
You can also run the Index tool on a database that is down, from the Linux command line. For details, see CRC and sort order check.
Caution
Use this function only under guidance from Vertica Support.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RUN_INDEX_TOOL ( 'taskType', global, '[projFilter]' [, numThreads ] );
Parameters
taskType- Specifies the operation to run, one of the following:
-
checkcrc: Run a cyclic redundancy check (CRC) on each block of existing data storage to check the data integrity of ROS data blocks.
-
checksort: Evaluate each ROS row to determine whether it is sorted correctly. If ROS data is not sorted correctly in the projection's order, query results that rely on sorted data will be incorrect.
global- Boolean, specifies whether to run the specified task on all nodes (true), or the current one (false).
projFilter- Specifies the scope of the operation:
numThreads- An unsigned (positive) or signed (negative) integer that specifies the number of threads used to run this operation:
-
n: Number of threads, ≥ 1
-
-n: Negative integer, denotes a fraction of all CPU cores as follows:
num-cores / n
Thus, -1 specifies all cores, -2, half the cores, -3, a third of all cores, and so on.
Default: 1
Privileges
Superuser
You can optimize meta-function performance by setting two parameters:
6.13.5.11 - SECURITY_CONFIG_CHECK
Returns the status of various security-related parameters.
Returns the status of various security-related parameters. Use this function to verify completeness of your TLS configuration.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SECURITY_CONFIG_CHECK( 'db-component' )
Parameters
db-component- The component to check. Currently,
NETWORK is the only supported component.
NETWORK: Returns the status and parameters for spread encryption, internode TLS, and client-server TLS.
Examples
In this example, SECURITY_CONFIG_CHECK shows that spread encryption and data channel TLS are disabled because EncryptSpreadComm is disabled and the data_channel TLS Configuration is not configured.
Similarly, client-server TLS is disabled because the TLS Configuration "server" has a server certificate, but its TLSMODE is disabled. Setting TLSMODE to 'Enable' enables server mode client-server TLS. See TLS protocol for details.
=> SELECT SECURITY_CONFIG_CHECK('NETWORK');
SECURITY_CONFIG_CHECK
----------------------------------------------------------------------------------------------------------------------
Spread security details:
* EncryptSpreadComm = []
Spread encryption is disabled
It is NOT safe to set/change other security config parameters while spread is not encrypted!
Please set EncryptSpreadComm to enable spread encryption first
Data Channel security details:
TLS Configuration 'data_channel' TLSMODE is DISABLE
TLS on the data channel is disabled
Please set EncryptSpreadComm and configure TLS Configuration 'data_channel' to enable TLS on the data channel
Client-Server network security details:
* TLS Configuration 'server' TLSMODE is DISABLE
* TLS Configuration 'server' has a certificate set
Client-Server TLS is disabled
To enable Client-Server TLS set a certificate on TLS Configuration 'server' and/or set the tlsmode to 'ENABLE' or higher
(1 row)
See also
6.13.5.12 - SET_CONFIG_PARAMETER
Sets or clears a configuration parameter at the specified level.
Sets or clears a configuration parameter at the specified level.
Important
You can only use this function to set configuration parameters with string or integer values. To set configuration parameters that accept other data types, use the
appropriate ALTER statement.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_CONFIG_PARAMETER( 'param-name', { param-value | NULL}, ['level'| NULL])
Arguments
param-name- Name of the configuration parameter to set.
param-value- Value to set for
param-name, either a string or integer. If a string, enclose in single quotes; if an integer, single quotes are optional.
To clear param-name at the specified level, set to NULL.
level- Level at which to set
param-name, one of the following string values:
-
user: Current user.
-
session: Current session, overrides the database setting.
-
node-name: Name of database node, overrides session and database settings.
If level is omitted or set to NULL, param-name is set at the database level.
Note
Some parameters require restart for the value to take effect.
Privileges
Superuser
Examples
Set the AnalyzeRowCountInterval parameter to 3600 at the database level:
=> SELECT SET_CONFIG_PARAMETER('AnalyzeRowCountInterval',3600);
SET_CONFIG_PARAMETER
----------------------------
Parameter set successfully
(1 row)
Note
You can achieve the same result with ALTER DATABASE:
ALTER DATABASE DEFAULT SET PARAMETER AnalyzeRowCountInterval = 3600;
Set the MaxSessionUDParameterSize parameter to 2000 at the session level.
=> SELECT SET_CONFIG_PARAMETER('MaxSessionUDParameterSize',2000,'SESSION');
SET_CONFIG_PARAMETER
----------------------------
Parameter set successfully
(1 row)
See also
6.13.5.13 - SET_SPREAD_OPTION
Changes daemon settings.
Changes spread daemon settings. This function is mainly used to set the timeout before spread assumes a node has gone down.
Note
Changing Spread settings with SET_SPREAD_OPTION has minor impact on your cluster as it pauses while the new settings are propagated across the cluster. Because of this delay, changes to the Spread timeout are not immediately visible in system table SPREAD_STATE.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_SPREAD_OPTION( option-name, option-value )
Parameters
option-name- String containing the spread daemon setting to change.
Currently, this function supports only one option: TokenTimeout. This setting controls how long spread waits for a node to respond to a message before assuming it is lost. See Adjusting Spread Daemon timeouts for virtual environments for more information.
option-value- The new setting for
option-name.
Examples
=> SELECT SET_SPREAD_OPTION( 'TokenTimeout', '35000');
NOTICE 9003: Spread has been notified about the change
SET_SPREAD_OPTION
--------------------------------------------------------
Spread option 'TokenTimeout' has been set to '35000'.
(1 row)
=> SELECT * FROM V_MONITOR.SPREAD_STATE;
node_name | token_timeout
------------------+---------------
v_vmart_node0001 | 35000
v_vmart_node0002 | 35000
v_vmart_node0003 | 35000
(3 rows);
See also
6.13.5.14 - SHUTDOWN
Shuts down a Vertica database.
Shuts down a Vertica database. By default, the shutdown fails if any users are connected. You can check the status of the shutdown operation in the
vertica.log file.
In Eon Mode, you can call SHUTDOWN_WITH_DRAIN to perform a graceful shutdown that drains client connections and then shuts down the database.
Tip
Before calling SHUTDOWN, you can close all current user connections and prevent further connection attempts as follows:
-
Temporarily set configuration parameter MaxClientSessions to 0.
-
Call CLOSE_ALL_SESSIONS to close all non-dbamin connections.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SHUTDOWN ( [ 'false' | 'true' ] )
Parameters
false- Default, returns a message if users are connected and aborts the shutdown.
true- Forces the database to shut down, disallowing further connections.
Privileges
Superuser
Examples
The following command attempts to shut down the database. Because users are connected, the command fails:
=> SELECT SHUTDOWN('false');
NOTICE: Cannot shut down while users are connected
SHUTDOWN
-----------------------------
Shutdown: aborting shutdown
(1 row)
See also
SESSIONS
6.13.6 - Eon Mode functions
The following functions are meant to be used in Eon Mode.
The following functions are meant to be used in Eon Mode.
6.13.6.1 - ALTER_LOCATION_SIZE
Resizes on one node, all nodes in a subcluster, or all nodes in the database.
Eon Mode only
Resizes the depot on one node, all nodes in a subcluster, or all nodes in the database.
Important
Reducing the size of the depot is liable to increase contention over depot usage and require frequent
evictions. This behavior can increase the number of queries and load operations that are routed to communal storage for processing, which can incur slower performance and increased access charges.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Immutable
Syntax
ALTER_LOCATION_SIZE( 'location', '[target]', 'size')
Parameters
location- Specifies the location to resize, one of the following:
-
depot: Resizes the node's current depot.
-
The depot's absolute path in the Linux filesystem. If you change the depot size on multiple nodes and specify a path, the path must be identical on all affected nodes . By default, this is not the case, as the node's name is typically this path. For example, the default depot path for node 1 in the verticadb database is /vertica/data/verticadb/v_verticadb_node0001_depot.
target- The node or nodes on which to change the depot, one of the following:
-
Node name: Resize the specified node.
-
Subcluster name: Resize depots of all nodes in the specified subcluster.
-
Empty string: Resize all depots in the database.
sizeValid only if the storage location usage type is set to DEPOT, specifies the maximum amount of disk space that the depot can allocate from the storage location's file system.
You can specify size in two ways:
-
integer%: Percentage of storage location disk size.
-
integer{K|M|G|T}: Amount of storage location disk size in kilobytes, megabytes, gigabytes, or terabytes.
Important
The depot size cannot exceed 80 percent of the file system disk space where the depot is stored. If you specify a value that is too large, Vertica issues a warning and automatically changes the value to 80 percent of the file system size.
Privileges
Superuser
Examples
Increase depot size on all nodes to 80 percent of file system:
=> SELECT node_name, location_label, location_path, max_size, disk_percent FROM storage_locations WHERE location_usage = 'DEPOT' ORDER BY node_name;
node_name | location_label | location_path | max_size | disk_percent
------------------+-----------------+-------------------------+-------------+--------------
v_vmart_node0001 | auto-data-depot | /home/dbadmin/verticadb | 36060108800 | 70%
v_vmart_node0002 | auto-data-depot | /home/dbadmin/verticadb | 36059377664 | 70%
v_vmart_node0003 | auto-data-depot | /home/dbadmin/verticadb | 36060108800 | 70%
(3 rows)
=> SELECT alter_location_size('depot', '','80%');
alter_location_size
---------------------
depotSize changed.
(1 row)
=> SELECT node_name, location_label, location_path, max_size, disk_percent FROM storage_locations WHERE location_usage = 'DEPOT' ORDER BY node_name;
node_name | location_label | location_path | max_size | disk_percent
------------------+-----------------+-------------------------+-------------+--------------
v_vmart_node0001 | auto-data-depot | /home/dbadmin/verticadb | 41211552768 | 80%
v_vmart_node0002 | auto-data-depot | /home/dbadmin/verticadb | 41210717184 | 80%
v_vmart_node0003 | auto-data-depot | /home/dbadmin/verticadb | 41211552768 | 80%
(3 rows)
Change the depot size to 75% of the filesystem size for all nodes in the analytics subcluster:
=> SELECT subcluster_name, subclusters.node_name, storage_locations.max_size, storage_locations.disk_percent FROM subclusters INNER JOIN storage_locations ON subclusters.node_name = storage_locations.node_name WHERE storage_locations.location_usage='DEPOT';
subcluster_name | node_name | max_size | disk_percent
--------------------+----------------------+----------------------------
default_subcluster | v_verticadb_node0001 | 25264737485 | 60%
default_subcluster | v_verticadb_node0002 | 25264737485 | 60%
default_subcluster | v_verticadb_node0003 | 25264737485 | 60%
analytics | v_verticadb_node0004 | 25264737485 | 60%
analytics | v_verticadb_node0005 | 25264737485 | 60%
analytics | v_verticadb_node0006 | 25264737485 | 60%
analytics | v_verticadb_node0007 | 25264737485 | 60%
analytics | v_verticadb_node0008 | 25264737485 | 60%
analytics | v_verticadb_node0009 | 25264737485 | 60%
(9 rows)
=> SELECT ALTER_LOCATION_SIZE('depot','analytics','75%');
ALTER_LOCATION_SIZE
---------------------
depotSize changed.
(1 row)
=> SELECT subcluster_name, subclusters.node_name, storage_locations.max_size, storage_locations.disk_percent FROM subclusters INNER JOIN storage_locations ON subclusters.node_name = storage_locations.node_name WHERE storage_locations.location_usage='DEPOT';
subcluster_name | node_name | max_size | disk_percent
--------------------+----------------------+----------------------------
default_subcluster | v_verticadb_node0001 | 25264737485 | 60%
default_subcluster | v_verticadb_node0002 | 25264737485 | 60%
default_subcluster | v_verticadb_node0003 | 25264737485 | 60%
analytics | v_verticadb_node0004 | 31580921856 | 75%
analytics | v_verticadb_node0005 | 31580921856 | 75%
analytics | v_verticadb_node0006 | 31580921856 | 75%
analytics | v_verticadb_node0007 | 31580921856 | 75%
analytics | v_verticadb_node0008 | 31580921856 | 75%
analytics | v_verticadb_node0009 | 31580921856 | 75%
(9 rows)
See also
Eon Mode architecture
6.13.6.2 - BACKGROUND_DEPOT_WARMING
Vertica version 10.0.0 removes support for foreground depot warming.
Eon Mode only
Deprecated
Vertica version 10.0.0 removes support for foreground depot warming. When enabled, depot warming always happens in the background. Because foreground depot warming no longer exists, this function serves no purpose and has been deprecated. Calling it has no effect.
Forces a node that is warming its depot to start processing queries while continuing to warm its depot in the background. Depot warming only occurs when a node is joining the database and is activating its subscriptions. This function only has an effect if:
-
The database is running in Eon Mode.
-
The node is currently warming its depot.
-
The node is warming its depot from communal storage. This is the case when the UseCommunalStorageForBatchDepotWarming configuration parameter is set to the default value of 1. See Eon Mode parameters for more information about this parameter.
After calling this function, the node warms its depot in the background while taking part in queries.
This function has no effect on a node that is not warming its depot.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
BACKGROUND_DEPOT_WARMING('node-name' [, 'subscription-name'])
Arguments
node-name- The name of the node that you want to warm its depot in the background.
subscription-name- The name of a shard that the node subscribes to that you want the node to warm in the background. You can find the names of the shards a node subscribes to in the SHARD_NAME column of the NODE_SUBSCRIPTIONS system table.
Note
When you supply the name of a specific shard subscription to warm in the background, the node may not immediately begin processing queries. It continues to warm any other shard subscriptions in the foreground if they are not yet warm. The node does not begin taking part in queries until it finishes warming the other subscriptions.
Return value
A message indicating that the node's warming will continue in the background.
Privileges
The user must be a
superuser .
Examples
The following example demonstrates having node 6 of the verticadb database warm its depot in the background:
=> SELECT BACKGROUND_DEPOT_WARMING('v_verticadb_node0006');
BACKGROUND_DEPOT_WARMING
----------------------------------------------------------------------------
Depot warming running in background. Check monitoring tables for progress.
(1 row)
See also
6.13.6.3 - CANCEL_DEPOT_WARMING
Cancels depot warming on a node.
Eon Mode only
Cancels depot warming on a node. Depot warming only occurs when a node is joining the database and is activating its subscriptions. You can choose to cancel all warming on the node, or cancel the warming of a specific shard's subscription. The node finishes whatever data transfers it is currently carrying out to warm its depot and removes pending warming-related transfers from its queue. It keeps any data it has already loaded into its depot. If you cancel warming for a specific subscription, it stops warming its depot if all of its other subscriptions are warmed. If they aren't warmed, the node continues to warm those other subscriptions.
This function only has an effect if:
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CANCEL_DEPOT_WARMING('node-name' [, 'subscription-name'])
Arguments
'node-name'- The name of the node whose depot warming you want canceled.
'subscription-name'- The name of a shard that the node subscribes to that you want the node to stop warming. You can find the names of the shards a node subscribes to in the SHARD_NAME column of the NODE_SUBSCRIPTIONS system table.
Return value
Returns a message indicating warming has been canceled.
Privileges
The user must be a
superuser.
Usage considerations
Canceling depot warming can negatively impact the performance of your queries. A node with a cold depot may have to retrieve much of its data from communal storage, which is slower than accessing the depot.
Examples
The following demonstrates canceling the depot warming taking place on node 7:
=> SELECT CANCEL_DEPOT_WARMING('v_verticadb_node0007');
CANCEL_DEPOT_WARMING
--------------------------
Depot warming cancelled.
(1 row)
See also
6.13.6.4 - CANCEL_DRAIN_SUBCLUSTER
Cancels the draining of a subcluster or subclusters.
Eon Mode only
Cancels the draining of a subcluster or subclusters. This function can cancel draining operations that were started by either START_DRAIN_SUBCLUSTER or the draining portion of the SHUTDOWN_WITH_DRAIN function. CANCEL_DRAIN_SUBCLUSTER marks all nodes in the designated subclusters as not draining. The previously draining nodes again accept new client connections and connections redirected from load-balancing.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CANCEL_DRAIN_SUBCLUSTER( 'subcluster-name' )
Arguments
subcluster-name- Name of the subcluster whose draining operation to cancel. Enter an empty string to cancel the draining operation on all subclusters.
Privileges
Superuser
Examples
The following example demonstrates how to cancel a draining operation on a subcluster.
First, you can query the DRAINING_STATUS system table to view which subclusters are currently draining:
=> SELECT node_name, subcluster_name, is_draining FROM draining_status ORDER BY 1;
node_name | subcluster_name | is_draining
-------------------+--------------------+-------
verticadb_node0001 | default_subcluster | f
verticadb_node0002 | default_subcluster | f
verticadb_node0003 | default_subcluster | f
verticadb_node0004 | analytics | t
verticadb_node0005 | analytics | t
verticadb_node0006 | analytics | t
The following function call cancels the draining of the analytics subcluster:
=> SELECT CANCEL_DRAIN_SUBCLUSTER('analytics');
CANCEL_DRAIN_SUBCLUSTER
--------------------------------------------------------
Targeted subcluster: 'analytics'
Action: CANCEL DRAIN
(1 row)
To confirm that the subcluster is no longer draining, you can again query the DRAINING_STATUS system table:
=> SELECT node_name, subcluster_name, is_draining FROM draining_status ORDER BY 1;
node_name | subcluster_name | is_draining
-------------------+--------------------+-------
verticadb_node0001 | default_subcluster | f
verticadb_node0002 | default_subcluster | f
verticadb_node0003 | default_subcluster | f
verticadb_node0004 | analytics | f
verticadb_node0005 | analytics | f
verticadb_node0006 | analytics | f
(6 rows)
See also
6.13.6.5 - CLEAN_COMMUNAL_STORAGE
Marks for deletion invalid data in communal storage, often data that leaked due to an event where Vertica cleanup mechanisms failed.
Eon Mode only
Marks for deletion invalid data in communal storage, often data that leaked due to an event where Vertica cleanup mechanisms failed. Events that require calling this function include:
Tip
It is generally good practice to call CLEAN_COMMUNAL_STORAGE soon after completing an
Enterprise-to-Eon migration, and reviving the migrated Eon database.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAN_COMMUNAL_STORAGE ( ['actually-delete'] )
Parameters
actually-delete- BOOLEAN, specifies whether to queue data files for deletion:
-
true (default): Add files to the reaper queue and return immediately. The queued files are removed automatically by the reaper service, or can be removed manually by calling FLUSH_REAPER_QUEUE.
-
false: Report information about extra files but do not queue them for deletion.
Privileges
Superuser
Examples
=> SELECT CLEAN_COMMUNAL_STORAGE('true')
CLEAN_COMMUNAL_STORAGE
------------------------------------------------------------------
CLEAN COMMUNAL STORAGE
Task was canceled.
Total leaked files: 9265
Total size: 4236501526
Files have been queued for deletion.
Check communal_cleanup_records for more information.
(1 row)
6.13.6.6 - CLEAR_DATA_DEPOT
Deletes the specified depot data.
Eon Mode only
Deletes the specified depot data. You can clear depot data of a single table or all tables, from one subcluster, a single node, or the entire database cluster. Clearing depot data can incur extra processing time for any subsequent queries that require that data and must now fetch it from communal storage. Clearing depot data has no effect on communal storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DATA_DEPOT( [ '[table-name]' [, '[target-depots]'] ] )
Arguments
To clear all depot data from the database cluster, call this function with no arguments.
table-name- Name of the table to delete from the target depots. If you omit a table name or supply an empty string, data of all tables is deleted from the target depots.
target-depots- The depots to clear, one of the following:
subcluster-name: Name of the depot subcluster, default_subcluster to specify the default database subcluster.node-name: Clears depot data from the specified node. Depot data on other nodes in the same subcluster are unaffected.
This argument optionally qualifies the argument for table-name. If you omit this argument or supply an empty string, Vertica clears all depot data from the database cluster.
Privileges
Superuser
Examples
Clear the cached data of one table from the specified subcluster depot:
=> SELECT CLEAR_DATA_DEPOT('t1', 'subcluster_1');
clear_data_depot
------------------
Depot cleared
(1 row)
Clear all depot data that is cached on the specified subcluster:.
=> SELECT CLEAR_DATA_DEPOT('', 'subcluster_1');
clear_data_depot
------------------
Depot cleared
(1 row)
Clear all depot data that is cached on the specified node:
=> select clear_data_depot('','v_vmart_node0001');
clear_data_depot
------------------
Depot cleared
(1 row)
Clear all data of the specified table from the depots of all cluster nodes:
=> SELECT CLEAR_DATA_DEPOT('t1');
clear_data_depot
------------------
Depot cleared
(1 row)
Clear all depot data from the database cluster:
=> SELECT CLEAR_DATA_DEPOT();
clear_data_depot
------------------
Depot cleared
(1 row)
See also
Managing depot caching
6.13.6.7 - CLEAR_DEPOT_ANTI_PIN_POLICY_PARTITION
Removes an anti-pinning policy from the specified partition.
Eon Mode only
Removes an anti-pinning policy from the specified partition.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_ANTI_PIN_POLICY_PARTITION( '[[database.]schema.]object-name', 'min-range-value', 'max-range-value' [, 'subcluster'] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Table or projection with a partition anti-pinning policy to clear.
min-range-value, max-range-value- Range of partition keys in
table from which to clear an anti-pinning policy, where min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.8 - CLEAR_DEPOT_ANTI_PIN_POLICY_PROJECTION
Removes an anti-pinning policy from the specified projection.
Eon Mode only
Removes an anti-pinning policy from the specified projection.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_ANTI_PIN_POLICY_PROJECTION( '[[database.]schema.]projection' [, 'subcluster' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- Projection with the anti-pinning policy to clear.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.9 - CLEAR_DEPOT_ANTI_PIN_POLICY_TABLE
Removes an anti-pinning policy from the specified table.
Eon Mode only
Removes an anti-pinning policy from the specified table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_PIN_POLICY_TABLE( '[[database.]schema.]table' [, 'subcluster' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table with the anti-pinning policy to clear.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.10 - CLEAR_DEPOT_PIN_POLICY_PARTITION
Clears a depot pinning policy from the specified table or projection partitions.
Eon Mode only
Clears a depot pinning policy from the specified table or projection partitions. After the object is unpinned, it can be evicted from the depot by any unpinned or pinned object.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_PIN_POLICY_PARTITION( '[[database.]schema.]object-name', 'min-range-value', 'max-range-value' [, subcluster ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Table or projection with a partition pinning policy to clear.
min-range-value, max-range-value- Range of partition keys in
table from which to clear a pinning policy, where min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.11 - CLEAR_DEPOT_PIN_POLICY_PROJECTION
Clears a depot pinning policy from the specified projection.
Eon Mode only
Clears a depot pinning policy from the specified projection. After the object is unpinned, it can be evicted from the depot by any unpinned or pinned object.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_PIN_POLICY_PROJECTION( '[[database.]schema.]projection' [, 'subcluster' ] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- Projection with a pinning policy to clear.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.12 - CLEAR_DEPOT_PIN_POLICY_TABLE
Clears a depot pinning policy from the specified table.
Eon Mode only
Clears a depot pinning policy from the specified table. After the object is unpinned, it can be evicted from the depot by any unpinned or pinned object.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_DEPOT_PIN_POLICY_TABLE( '[[database.]schema.]table' [, 'subcluster' ] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table with a pinning policy to clear.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.13 - CLEAR_FETCH_QUEUE
Removes all entries or entries for a specific transaction from the queue of fetch requests of data from the communal storage.
Eon Mode only
Removes all entries or entries for a specific transaction from the queue of fetch requests of data from the communal storage. You can view the fetch queue by querying the DEPOT_FETCH_QUEUE system table. This function removes all of the queued requests synchronously. It returns after all the fetches have been removed from the queue.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_FETCH_QUEUE([transaction_id])
Parameters
*transaction_id*- The id of the transaction whose fetches will be cleared from the queue. If this value is not specified, all fetches are removed from the fetch queue.
Examples
This example clears all of the queued fetches for all transactions.
=> SELECT CLEAR_FETCH_QUEUE();
CLEAR_FETCH_QUEUE
--------------------------
Cleared the fetch queue.
(1 row)
This example clears the fetch queue for a specific transaction.
=> SELECT node_name,transaction_id FROM depot_fetch_queue;
node_name | transaction_id
----------------------+-------------------
v_verticadb_node0001 | 45035996273719510
v_verticadb_node0003 | 45035996273719510
v_verticadb_node0002 | 45035996273719510
v_verticadb_node0001 | 45035996273719777
v_verticadb_node0003 | 45035996273719777
v_verticadb_node0002 | 45035996273719777
(6 rows)
=> SELECT clear_fetch_queue(45035996273719510);
clear_fetch_queue
--------------------------
Cleared the fetch queue.
(1 row)
=> SELECT node_name,transaction_id from depot_fetch_queue;
node_name | transaction_id
----------------------+-------------------
v_verticadb_node0001 | 45035996273719777
v_verticadb_node0003 | 45035996273719777
v_verticadb_node0002 | 45035996273719777
(3 rows)
6.13.6.14 - DEMOTE_SUBCLUSTER_TO_SECONDARY
Converts a to a .
Eon Mode only
Converts a primary subcluster to a secondary subcluster.
Vertica will not allow you to demote a primary subcluster if any of the following are true:
-
The subcluster contains a critical node.
-
The subcluster is the only primary subcluster in the database. You must have at least one primary subcluster.
-
The initiator node is a member of the subcluster you are trying to demote. You must call DEMOTE_SUBCLUSTER_TO_SECONDARY from another subcluster.
Important
This function call can take a long time to complete because all the nodes in the subcluster you are promoting or demoting take a global catalog lock, write a checkpoint, and then commit. This global catalog lock can cause other database tasks to fail with errors.
Schedule calls to this function when other database activity is low.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DEMOTE_SUBCLUSTER_TO_SECONDARY('subcluster-name')
Parameters
subcluster-name- The name of the primary subcluster to demote to a secondary subcluster.
Privileges
Superuser
Examples
The following example demotes the subcluster analytics_cluster to a secondary subcluster:
=> SELECT DISTINCT subcluster_name, is_primary from subclusters;
subcluster_name | is_primary
-------------------+------------
analytics_cluster | t
load_subcluster | t
(2 rows)
=> SELECT DEMOTE_SUBCLUSTER_TO_SECONDARY('analytics_cluster');
DEMOTE_SUBCLUSTER_TO_SECONDARY
--------------------------------
DEMOTE SUBCLUSTER TO SECONDARY
(1 row)
=> SELECT DISTINCT subcluster_name, is_primary from subclusters;
subcluster_name | is_primary
-------------------+------------
analytics_cluster | f
load_subcluster | t
(2 rows)
Attempting to demote the subcluster that contains the initiator node results in an error:
=> SELECT node_name FROM sessions WHERE user_name = 'dbadmin'
AND client_type = 'vsql';
node_name
----------------------
v_verticadb_node0004
(1 row)
=> SELECT node_name, is_primary FROM subclusters WHERE subcluster_name = 'analytics';
node_name | is_primary
----------------------+------------
v_verticadb_node0004 | t
v_verticadb_node0005 | t
v_verticadb_node0006 | t
(3 rows)
=> SELECT DEMOTE_SUBCLUSTER_TO_SECONDARY('analytics');
ERROR 9204: Cannot promote or demote subcluster including the initiator node
HINT: Run this command on another subcluster
See also
6.13.6.15 - FINISH_FETCHING_FILES
Fetches to the depot all files that are queued for download from communal storage.
Eon Mode only
Fetches to the depot all files that are queued for download from communal storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
FINISH_FETCHING_FILES()
Privileges
Superuser
Examples
Get all files queued for download:
=> SELECT FINISH_FETCHING_FILES();
FINISH_FETCHING_FILES
---------------------------------
Finished fetching all the files
(1 row)
See also
Eon Mode concepts
6.13.6.16 - FLUSH_REAPER_QUEUE
Deletes all data marked for deletion in the database.
Eon Mode only
Deletes all data marked for deletion in the database. Use this function to remove all data marked for deletion before the reaper service deletes disk files.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
FLUSH_REAPER_QUEUE( [sync-catalog] )
Parameters
*sync-catalog*- Specifies to sync metadata in the database catalog on all nodes before the function executes:
Privileges
Superuser
Examples
Remove all files that are marked for deletion:
=> SELECT FLUSH_REAPER_QUEUE();
FLUSH_REAPER_QUEUE
-----------------------------------------------------
Sync'd catalog and deleted all files in the reaper queue.
(1 row)
See also
CLEAN_COMMUNAL_STORAGE
6.13.6.17 - MIGRATE_ENTERPRISE_TO_EON
Migrates an Enterprise database to an Eon Mode database.
Enterprise Mode only
Migrates an Enterprise database to an Eon Mode database. MIGRATE_ENTERPRISE_TO_EON runs in the foreground; until it returns—either with success or an error—it blocks all operations in the same session on the source Enterprise database. If successful, MIGRATE_ENTERPRISE_TO_EON returns with a list of nodes in the migrated database.
If migration is interrupted before the meta-function returns—for example, the client disconnects, or a network outage occurs—the migration returns an error. In this case, call MIGRATE_ENTERPRISE_TO_EON again to restart migration. For details, see Handling Interrupted Migration.
You can repeat migration multiple times to the same communal storage location—for example, to capture changes that occurred in the source database during the previous migration. For details, see Repeating Migration.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MIGRATE_ENTERPRISE_TO_EON ( 'communal-storage-location', 'depot-location' [, is-dry-run] )
communal-storage-location- URI of communal storage location. For URI syntax examples for each supported schema, see File systems and object stores.
depot-location- Path of Eon depot location, typically:
/vertica/depot
Important
Management Console requires this convention to enable access to depot data and activity.
is-dry-run- Boolean. If set to true, MIGRATE_ENTERPRISE_TO_EON only checks whether the Enterprise source database complies with all migration prerequisites. If the meta-function discovers any compliance issues, it writes these to the migration error log
migrate_enterprise_to_eon_error.log in the database directory.
Default: false
Privileges
Superuser
Examples
Migrate an Enterprise database to Eon Mode on AWS:
=> SELECT MIGRATE_ENTERPRISE_TO_EON ('s3://verticadbbucket', '/vertica/depot');
migrate_enterprise_to_eon
---------------------------------------------------------------------
v_vmart_node0001,v_vmart_node0002,v_vmart_node0003,v_vmart_node0004
(1 row)
See also
Migrating an enterprise database to Eon Mode
6.13.6.18 - PROMOTE_SUBCLUSTER_TO_PRIMARY
Converts a secondary subcluster to a.
Eon Mode only
Converts a secondary subcluster to a primary subcluster. You cannot use this function to promote the subcluster that contains the initiator node. You must call it while connected to a node in another subcluster.
Important
This function call can take a long time to complete because all the nodes in the subcluster you are promoting or demoting take a global catalog lock, write a checkpoint, and then commit. This global catalog lock can cause other database tasks to fail with errors.
Schedule calls to this function when other database activity is low.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PROMOTE_SUBCLUSTER_TO_PRIMARY('subcluster-name')
Parameters
subcluster-name- The name of the secondary cluster to promote to a primary subcluster.
Privileges
Superuser
Examples
The following example promotes the subcluster named analytics_cluster to a primary cluster:
=> SELECT DISTINCT subcluster_name, is_primary from subclusters;
subcluster_name | is_primary
-------------------+------------
analytics_cluster | f
load_subcluster | t
(2 rows)
=> SELECT PROMOTE_SUBCLUSTER_TO_PRIMARY('analytics_cluster');
PROMOTE_SUBCLUSTER_TO_PRIMARY
-------------------------------
PROMOTE SUBCLUSTER TO PRIMARY
(1 row)
=> SELECT DISTINCT subcluster_name, is_primary from subclusters;
subcluster_name | is_primary
-------------------+------------
analytics_cluster | t
load_subcluster | t
(2 rows)
See also
6.13.6.19 - REBALANCE_SHARDS
Rebalances shard assignments in a subcluster or across the entire cluster in Eon Mode.
Eon Mode only
Rebalances shard assignments in a subcluster or across the entire cluster in Eon Mode. If the current session ends, the operation immediately aborts. The amount of time required to rebalance shards scales in a roughly linear fashion based on the number of objects in your database.
Important
If your database has multiple
namespaces, REBALANCE_SHARDS rebalances the shards across all namespaces.
Run REBALANCE_SHARDS after you modify your cluster using ALTER NODE or when you add nodes to a subcluster.
Note
Vertica rebalances shards in a subcluster automatically when you:
After you rebalance shards, you will no longer be able to restore objects from a backup taken before the rebalancing. (Full backups are always possible.) After you rebalance, make another full backup so you will be able to restore objects from it in the future.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REBALANCE_SHARDS(['subcluster-name'])
Parameters
subcluster-name- The name of the subcluster where shards will be rebalanced. If you do not supply this parameter, all subclusters in the database rebalance their shards.
Privileges
Superuser
Examples
The following shows that the nodes in the in the newly-added analytics_subcluster do not yet have shard subscriptions:
=> SELECT subcluster_name, n.node_name, shard_name, subscription_state FROM
v_catalog.nodes n LEFT JOIN v_catalog.node_subscriptions ns ON (n.node_name
= ns.node_name) ORDER BY 1,2,3;
subcluster_name | node_name | shard_name | subscription_state
----------------------+----------------------+-------------+--------------------
analytics_subcluster | v_verticadb_node0004 | |
analytics_subcluster | v_verticadb_node0005 | |
analytics_subcluster | v_verticadb_node0006 | |
default_subcluster | v_verticadb_node0001 | replica | ACTIVE
default_subcluster | v_verticadb_node0001 | segment0001 | ACTIVE
default_subcluster | v_verticadb_node0001 | segment0003 | ACTIVE
default_subcluster | v_verticadb_node0002 | replica | ACTIVE
default_subcluster | v_verticadb_node0002 | segment0001 | ACTIVE
default_subcluster | v_verticadb_node0002 | segment0002 | ACTIVE
default_subcluster | v_verticadb_node0003 | replica | ACTIVE
default_subcluster | v_verticadb_node0003 | segment0002 | ACTIVE
default_subcluster | v_verticadb_node0003 | segment0003 | ACTIVE
(12 rows)
Rebalance the shards to analytics_subcluster, then confirm the rebalance was successful by querying the NODES system table:
=> SELECT REBALANCE_SHARDS('analytics_subcluster');
REBALANCE_SHARDS
-------------------
REBALANCED SHARDS
(1 row)
=> SELECT subcluster_name, n.node_name, shard_name, subscription_state FROM
v_catalog.nodes n LEFT JOIN v_catalog.node_subscriptions ns ON (n.node_name
= ns.node_name) ORDER BY 1,2,3;
subcluster_name | node_name | shard_name | subscription_state
----------------------+----------------------+-------------+--------------------
analytics_subcluster | v_verticadb_node0004 | replica | ACTIVE
analytics_subcluster | v_verticadb_node0004 | segment0001 | ACTIVE
analytics_subcluster | v_verticadb_node0004 | segment0003 | ACTIVE
analytics_subcluster | v_verticadb_node0005 | replica | ACTIVE
analytics_subcluster | v_verticadb_node0005 | segment0001 | ACTIVE
analytics_subcluster | v_verticadb_node0005 | segment0002 | ACTIVE
analytics_subcluster | v_verticadb_node0006 | replica | ACTIVE
analytics_subcluster | v_verticadb_node0006 | segment0002 | ACTIVE
analytics_subcluster | v_verticadb_node0006 | segment0003 | ACTIVE
default_subcluster | v_verticadb_node0001 | replica | ACTIVE
default_subcluster | v_verticadb_node0001 | segment0001 | ACTIVE
default_subcluster | v_verticadb_node0001 | segment0003 | ACTIVE
default_subcluster | v_verticadb_node0002 | replica | ACTIVE
default_subcluster | v_verticadb_node0002 | segment0001 | ACTIVE
default_subcluster | v_verticadb_node0002 | segment0002 | ACTIVE
default_subcluster | v_verticadb_node0003 | replica | ACTIVE
default_subcluster | v_verticadb_node0003 | segment0002 | ACTIVE
default_subcluster | v_verticadb_node0003 | segment0003 | ACTIVE
(18 rows)
If your database has multiple namespaces, you can run the following query to confirm the rebalance was successful across all namespaces:
=> SELECT nodes.subcluster_name AS subcluster_name, vs_namespaces.name AS namespace_name, vs_shards.shardname, vs_nodes.name AS nodename, vs_node_subscriptions.type, vs_node_subscriptions.state
FROM vs_node_subscriptions
INNER JOIN vs_shards
ON vs_node_subscriptions.shardoid=vs_shards.oid
INNER JOIN vs_shard_groups ON vs_shard_groups.oid=vs_shards.shardgroupoid
INNER JOIN vs_nodes ON vs_nodes.oid=vs_node_subscriptions.nodeoid
INNER JOIN nodes ON nodes.node_id=vs_nodes.oid
INNER JOIN vs_namespaces ON vs_namespaces.oid=vs_shard_groups.namespaceoid;
subcluster_name | namespace_name | shardname | nodename | type | state
-----------------------+--------------------+-------------+----------------------+-----------+--------
default_subcluster | default_namespace | replica | v_verticadb_node0002 | SECONDARY | ACTIVE
default_subcluster | default_namespace | replica | v_verticadb_node0003 | SECONDARY | ACTIVE
default_subcluster | default_namespace | replica | v_verticadb_node0001 | PRIMARY | ACTIVE
default_subcluster | default_namespace | segment0001 | v_verticadb_node0002 | SECONDARY | ACTIVE
default_subcluster | default_namespace | segment0001 | v_verticadb_node0001 | PRIMARY | ACTIVE
default_subcluster | default_namespace | segment0002 | v_verticadb_node0002 | PRIMARY | ACTIVE
default_subcluster | default_namespace | segment0002 | v_verticadb_node0003 | SECONDARY | ACTIVE
default_subcluster | default_namespace | segment0003 | v_verticadb_node0003 | SECONDARY | ACTIVE
default_subcluster | default_namespace | segment0003 | v_verticadb_node0001 | PRIMARY | ACTIVE
default_subcluster | ns1 | replica | v_verticadb_node0002 | SECONDARY | ACTIVE
default_subcluster | ns1 | replica | v_verticadb_node0003 | SECONDARY | ACTIVE
default_subcluster | ns1 | replica | v_verticadb_node0001 | PRIMARY | ACTIVE
default_subcluster | ns1 | segment0001 | v_verticadb_node0002 | SECONDARY | ACTIVE
default_subcluster | ns1 | segment0001 | v_verticadb_node0001 | PRIMARY | ACTIVE
default_subcluster | ns1 | segment0002 | v_verticadb_node0002 | PRIMARY | ACTIVE
default_subcluster | ns1 | segment0002 | v_verticadb_node0003 | SECONDARY | ACTIVE
default_subcluster | ns1 | segment0003 | v_verticadb_node0003 | PRIMARY | ACTIVE
default_subcluster | ns1 | segment0003 | v_verticadb_node0001 | SECONDARY | ACTIVE
default_subcluster | ns1 | segment0004 | v_verticadb_node0002 | SECONDARY | ACTIVE
default_subcluster | ns1 | segment0004 | v_verticadb_node0001 | PRIMARY | ACTIVE
analytics_subcluster | default_namespace | replica | v_verticadb_node0005 | SECONDARY | ACTIVE
analytics_subcluster | default_namespace | replica | v_verticadb_node0006 | SECONDARY | ACTIVE
analytics_subcluster | default_namespace | replica | v_verticadb_node0004 | PRIMARY | ACTIVE
analytics_subcluster | default_namespace | segment0001 | v_verticadb_node0005 | SECONDARY | ACTIVE
analytics_subcluster | default_namespace | segment0001 | v_verticadb_node0004 | PRIMARY | ACTIVE
analytics_subcluster | default_namespace | segment0002 | v_verticadb_node0005 | PRIMARY | ACTIVE
analytics_subcluster | default_namespace | segment0002 | v_verticadb_node0006 | SECONDARY | ACTIVE
analytics_subcluster | default_namespace | segment0003 | v_verticadb_node0006 | SECONDARY | ACTIVE
analytics_subcluster | default_namespace | segment0003 | v_verticadb_node0004 | PRIMARY | ACTIVE
analytics_subcluster | ns1 | replica | v_verticadb_node0005 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | replica | v_verticadb_node0006 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | replica | v_verticadb_node0004 | PRIMARY | ACTIVE
analytics_subcluster | ns1 | segment0001 | v_verticadb_node0005 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | segment0001 | v_verticadb_node0004 | PRIMARY | ACTIVE
analytics_subcluster | ns1 | segment0002 | v_verticadb_node0006 | PRIMARY | ACTIVE
analytics_subcluster | ns1 | segment0002 | v_verticadb_node0006 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | segment0003 | v_verticadb_node0006 | PRIMARY | ACTIVE
analytics_subcluster | ns1 | segment0003 | v_verticadb_node0004 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | segment0004 | v_verticadb_node0005 | SECONDARY | ACTIVE
analytics_subcluster | ns1 | segment0004 | v_verticadb_node0004 | PRIMARY | ACTIVE
(40 rows)
See also
6.13.6.20 - RESHARD_DATABASE
Changes the number of shards in a database.
Eon Mode only
Changes the number of shards in the default_namespace. You can only change the number of shards in the default_namespace if it is the only namespace in your database. If your database contains any non-default namespaces, running RESHARD_DATABASE results in an error.
RESHARD_DATABASE does not immediately affect the storage containers in communal storage. After re-sharding, the new shards still point to the existing containers. If you increase the number of shards in the namespace, multiple shards will point to the same storage containers. Eventually, the Tuple Mover (TM) mergeout tasks will realign the storage containers with the new shard segmentation bounds. If you want the TM to immediately realign storage containers, call DO_TM_TASK to run a 'RESHARDMERGEOUT' task.
This function requires a global catalog lock (GCLX) during runtime. The runtime depends on the size of your catalog. The function does not disrupt most queries. However, the global catalog lock might affect data loads and DDL statements.
Important
RESHARD_DATABASE might be rolled back if you call
REBALANCE_SHARDS during runtime. In some cases, rollback is caused by down nodes or nodes that fail during the re-shard process.
Syntax
RESHARD_DATABASE(shard-count)
Arguments
shard-count- A positive integer, the number of shards in the re-sharded
default_namespace. For information about choosing a suitable shard-count, see Choosing the initial node and shard counts.
Privileges
Superuser
Examples
See Reshard the default namespace.
See also
6.13.6.21 - SANDBOX_SUBCLUSTER
Creates a sandbox for a secondary subcluster.
Creates a sandbox for a secondary subcluster.
Note
Vertica recommends using the admintools sandbox_subcluster command to create sandboxes. This command includes additional sanity checks and validates that the sandboxed nodes are UP after sandbox creation. However, you must use the SANDBOX_SUBCLUSTER function to add additional subclusters to an existing sandbox.
If sandboxing the first subcluster in a sandbox, the nodes in the specified subcluster create a checkpoint of the catalog at function runtime. When these nodes auto-restart in the sandbox cluster, they form a primary subcluster that uses the data and catalog checkpoint from the main cluster. After the nodes successfully restart, the sandbox cluster and the main cluster are mutually isolated and can diverge.
While the nodes in the main cluster sync their metadata to /path-to-communal-storage/metadata/db_name, the nodes in the sandbox sync to /path-to-communal-storage/metadata/sandbox_name.
You can perform standard database operations and queries, such as loading data or creating new tables, in either cluster without affecting the other cluster. For example, dropping a table in the sandbox cluster does not drop the table in the main cluster, and vice versa.
Because both clusters reference the same data files, neither cluster can delete files that existed at the time of sandbox creation. However, files that are created in the sandbox can be removed. Files in the main cluster can be queued for removal, but they are not processed until all active sandboxes are removed.
You cannot nest sandboxes, but you can have more than one subcluster in a sandbox and multiple sandboxes active at the same time. To add an additional secondary subcluster to an existing sandbox, you must first call SANDBOX_SUBCLUSTER in the sandbox cluster and then in the main cluster. For details, see Adding subclusters to existing sandboxes.
This is a meta-function. You must call-meta-functions in a top-level SELECT statement. The function also requires a global catalog lock (GCLX) during runtime.
Behavior type
Volatile
Syntax
SANDBOX_SUBCLUSTER( 'sandbox-name', 'subcluster-name', 'options' )
Arguments
sandbox-name- Name of the sandbox. The name must conform to the following rules:
-
Consist of at most 30 characters, all of which must have an ASCII code between 36 and 126
-
Begin with a letter
-
Unique among all existing databases and sandboxes
subcluster-name- Name of the secondary subcluster to sandbox. Attempting to sandbox a primary subcluster or a subcluster that is already sandboxed results in an error. The nodes in the subcluster must all have a status of UP and provide full subscription coverage for all shards.
options- Currently, there are no options for this function.
Privileges
Superuser
Examples
The following example sandboxes the sc02 secondary subcluster into a sandbox named sand:
=> SELECT SANDBOX_SUBCLUSTER('sand', 'sc_02', '');
SANDBOX_SUBCLUSTER
-----------------------------------------------------------------------------------------------
Subcluster 'sc_02' has been sandboxed to 'sand'. It is going to auto-restart and re-form.
(1 row)
If you query the NODES system table from the main cluster, you can see that the nodes of sc_02 have a status of UNKNOWN and are listed as member of the sand sandbox:
=> SELECT node_name, subcluster_name, node_state, sandbox FROM NODES;
node_name | subcluster_name | node_state | sandbox
----------------------+--------------------+------------+---------
v_verticadb_node0001 | default_subcluster | UP |
v_verticadb_node0002 | default_subcluster | UP |
v_verticadb_node0003 | default_subcluster | UP |
v_verticadb_node0004 | sc_02 | UNKNOWN | sand
v_verticadb_node0005 | sc_02 | UNKNOWN | sand
v_verticadb_node0006 | sc_02 | UNKNOWN | sand
(6 rows)
When you issue the same query on one of the sandboxed nodes, the table shows that the sandboxed nodes are UP and the nodes from the main cluster are UNKNOWN, confirming that the cluster is successfully sandboxed:
=> SELECT node_name, subcluster_name, node_state, sandbox FROM NODES;
node_name | subcluster_name | node_state | sandbox
----------------------+--------------------+------------+---------
v_verticadb_node0001 | default_subcluster | UNKNOWN |
v_verticadb_node0002 | default_subcluster | UNKNOWN |
v_verticadb_node0003 | default_subcluster | UNKNOWN |
v_verticadb_node0004 | sc_02 | UP | sand
v_verticadb_node0005 | sc_02 | UP | sand
v_verticadb_node0006 | sc_02 | UP | sand
(6 rows)
You can now perform standard database operations in either cluster without impacting the other cluster. For instance, if you create a machine learning dataset named train_data in the sandboxed subcluster, the new table does not propagate to the main cluster:
--In the sandboxed subcluster
=> CREATE TABLE train_data(time timestamp, Temperature float);
CREATE TABLE
=> COPY train_data FROM LOCAL 'daily-min-temperatures.csv' DELIMITER ',';
Rows Loaded
-------------
3650
(1 row)
=> SELECT * FROM train_data LIMIT 5;
time | Temperature
---------------------+-------------
1981-01-27 00:00:00 | 19.4
1981-02-20 00:00:00 | 15.7
1981-02-27 00:00:00 | 17.5
1981-03-04 00:00:00 | 16
1981-04-24 00:00:00 | 11.5
(5 rows)
--In the main cluster
=> SELECT * FROM train_data LIMIT 5;
ERROR 4566: Relation "train_data" does not exist
See also
6.13.6.22 - SET_DEPOT_ANTI_PIN_POLICY_PARTITION
Assigns the highest depot eviction priority to a partition.
Eon Mode only
Assigns the highest depot eviction priority to a partition.
Among other depot-cached objects, objects with an anti-pinning policy are the most susceptible to eviction from the depot. After eviction, the object must be read directly from communal storage the next time it is needed.
If the table has another partition-level eviction policy already set on it, then Vertica combines the policies based on policy type.
If you alter or remove table partitioning, Vertica automatically clears all eviction policies previously set on partitions of that table. The table's eviction policy, if any, is unaffected.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_ANTI_PIN_POLICY_PARTITION (
'[[database.]schema.]object-name', 'min-range-value', 'max-range-value' [, 'subcluster' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Target of this policy.
min-range-value, max-range-value- Minimum and maximum value of partition keys in
object-name to anti-pin, where min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
If the new policy's partition key range overlaps the range of an existing partition-level eviction policy, Vertica gives precedence to the new policy, as described in Overlapping Policies.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.23 - SET_DEPOT_ANTI_PIN_POLICY_PROJECTION
Assigns the highest depot eviction priority to a projection.
Eon Mode only
Assigns the highest depot eviction priority to a projection.
Among other depot-cached objects, objects with an anti-pinning policy are the most susceptible to eviction from the depot. After eviction, the object must be read directly from communal storage the next time it is needed.
If the projection has another eviction policy already set on it, the new policy supersedes it.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_ANTI_PIN_POLICY_PROJECTION ( '[[database.]schema.]projection' [, 'subcluster' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- Target of this policy.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.24 - SET_DEPOT_ANTI_PIN_POLICY_TABLE
Assigns the highest depot eviction priority to a table.
Eon Mode only
Assigns the highest depot eviction priority to a table.
Among other depot-cached objects, objects with an anti-pinning policy are the most susceptible to eviction from the depot. After eviction, the object must be read directly from communal storage the next time it is needed.
If the table has another eviction policy already set on it, the new policy supersedes it.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_ANTI_PIN_POLICY_TABLE ( '[[database.]schema.]table' [, 'subcluster' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Target of this policy.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
Privileges
Superuser
See also
6.13.6.25 - SET_DEPOT_PIN_POLICY_PARTITION
Pins the specified partitions of a table or projection to a subcluster depot, or all database depots, to reduce exposure to depot eviction.
Eon Mode only
Pins the specified partitions of a table or projection to a subcluster depot, or all database depots, to reduce exposure to depot eviction.
If the table has another partition-level eviction policy already set on it, then Vertica combines the policies based on policy type.
If you alter or remove table partitioning, Vertica automatically clears all eviction policies previously set on partitions of that table. The table's eviction policy, if any, is unaffected.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_PIN_POLICY_PARTITION (
'[[database.]schema.]object-name', 'min-range-value', 'max-range-value' [, 'subcluster' ] [, 'download' ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Table or projection to pin. If you specify a projection, it must store the partition keys.
min-range-value, max-range-value- Minimum and maximum value of partition keys in
object-name to pin, where min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
If the new policy's partition key range overlaps the range of an existing partition-level eviction policy, Vertica gives precedence to the new policy, as described in Overlapping Policies below.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
download- Boolean, if true, SET_DEPOT_PIN_POLICY_PARTITION immediately queues the specified partitions for download from communal storage.
Default: false
Privileges
Superuser
Overlapping policies
If a new partition pinning policy overlaps the partition key range of an existing eviction policy, Vertica determines how to apply the policy based on the type of the new and existing policies.
Both policies are pinning policies
If both the new and existing policies are pining policies, then Vertica collates the two ranges. For example, if you create two partition pinning policies with key ranges of 1-3 and 2-10, Vertica creates a single policy with a key range of 1-10.
Partition pinning policy overlaps anti-pinning policy
If the new partition pinning policy overlaps an anti-pinning policy, then Vertica issues a warning and informational message that it reassigned the range of overlapping keys from the anti-pinning policy to the new pinning policy.
For example, if you create an anti-partition pinning policy and then a pinning policy with key ranges of 1-10 and 5-20, respectively, Vertica truncates the earlier anti-pinning policy's key range:
|
policy_type |
min_value |
max_value |
|
PIN |
5 |
20 |
|
ANTI_PIN |
1 |
4 |
If the new pinning policy's partition range falls inside the range of an older anti-pinning policy, Vertica splits the anti-pinning policy. So, given an existing partition anti-pinning policy with a key range of 1-20, a new partition pinning policy with a key range of 5-10 splits the anti-pinning policy:
|
policy_type |
min_value |
max_value |
|
ANTI_PIN |
1 |
4 |
|
PIN |
5 |
10 |
|
ANTI_PIN |
11 |
20 |
Precedence of pinning policies
In general, partition management functions that involve two partitioned tables give precedence to the target table's pinning policy, as follows:
-
COPY_PARTITIONS_TO_TABLE: Partition-level pinning is reliable if the source and target tables have pinning policies on the same partition keys. If the two tables have different pinning policies, then the partition pinning policies of the target table apply.
-
MOVE_PARTITIONS_TO_TABLE: Partition-level pinning policies of the target table apply.
-
SWAP_PARTITIONS_BETWEEN_TABLES: Partition-level pinning policies of the target table apply.
For example, the following statement copies partitions from table t1 to table t2:
=> SELECT COPY_PARTITIONS_TO_TABLE('t1', '1', '5', 't2');
In this case, the following logic applies:
-
If the two tables have different partition pinning policies, then the pinning policy of target table t2 for partition keys 1-5 applies.
-
If table t2 does not exist, then Vertica creates it from table t1, and copies t1's policy on partition keys 1-5. Subsequently, if you clear the partition pinning policy from either table, it is also cleared from the other.
See also
6.13.6.26 - SET_DEPOT_PIN_POLICY_PROJECTION
Pins a projection to a subcluster depot, or all database depots, to reduce its exposure to depot eviction.
Eon Mode only
Pins a projection to a subcluster depot, or all database depots, to reduce its exposure to depot eviction. For details on pinning policies and usage guidelines, see Pinning Policies.
If the projection has another eviction policy already set on it, the new policy supersedes it.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_PIN_POLICY_PROJECTION ( '[[database.]schema.]projection' [, 'subcluster' ] [, download ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- Projection to pin.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
download- Boolean, if true SET_DEPOT_PIN_POLICY_PROJECTION immediately queues the specified projection for download from communal storage.
Default: false
Privileges
Superuser
See also
6.13.6.27 - SET_DEPOT_PIN_POLICY_TABLE
Pins a table to a subcluster depot, or all database depots, to reduce its exposure to depot eviction.
Eon Mode only
Pins a table to a subcluster depot, or all database depots, to reduce its exposure to depot eviction.
If the table has another eviction policy already set on it, the new policy supersedes it. After you pin a table to a subcluster depot, you cannot subsequently pin any of its partitions and projections in that depot.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DEPOT_PIN_POLICY_TABLE ( '[[database.]schema.]table' [, 'subcluster' ] [, download ] )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table to pin.
subclusterName of a depot subcluster, default_subcluster to specify the default database subcluster. If this argument is omitted, all database depots are targeted.
download- Boolean, if true, SET_DEPOT_PIN_POLICY_TABLE immediately queues the specified table for download from communal storage.
Default: false
Privileges
Superuser
See also
6.13.6.28 - SHUTDOWN_SUBCLUSTER
Shuts down a subcluster.
Eon Mode only
Shuts down a subcluster. This function shuts down the subcluster synchronously, returning when shutdown is complete with the message Subcluster shutdown. If the subcluster is already down, the function returns with no error.
Stopping a subcluster does not warn you if there are active user sessions connected to the subcluster. This behavior is the same as stopping an individual node. Before stopping a subcluster, verify that no users are connected to it.
If you want to drain client connections before shutting down a subcluster, you can gracefully shutdown the subcluster using SHUTDOWN_WITH_DRAIN.
Caution
This function does not test whether the target subcluster is critical (a subcluster whose loss would cause the database to shut down). Using this function to shut down a critical subcluster results in the database shutting down. Always verify that the subcluster you want to shut down is not critical by querying the
CRITICAL_SUBCLUSTERS system table before calling this function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SHUTDOWN_SUBCLUSTER('subcluster-name')
Arguments
subcluster-name- Name of the subcluster to shut down.
Privileges
Superuser
Examples
The following example demonstrates shutting down the subcluster analytics:
=> SELECT subcluster_name, node_name, node_state FROM nodes order by 1,2;
subcluster_name | node_name | node_state
--------------------+----------------------+------------
analytics | v_verticadb_node0004 | UP
analytics | v_verticadb_node0005 | UP
analytics | v_verticadb_node0006 | UP
default_subcluster | v_verticadb_node0001 | UP
default_subcluster | v_verticadb_node0002 | UP
default_subcluster | v_verticadb_node0003 | UP
(6 rows)
=> SELECT SHUTDOWN_SUBCLUSTER('analytics');
WARNING 4539: Received no response from v_verticadb_node0004 in stop subcluster
WARNING 4539: Received no response from v_verticadb_node0005 in stop subcluster
WARNING 4539: Received no response from v_verticadb_node0006 in stop subcluster
SHUTDOWN_SUBCLUSTER
---------------------
Subcluster shutdown
(1 row)
=> SELECT subcluster_name, node_name, node_state FROM nodes order by 1,2;
subcluster_name | node_name | node_state
--------------------+----------------------+------------
analytics | v_verticadb_node0004 | DOWN
analytics | v_verticadb_node0005 | DOWN
analytics | v_verticadb_node0006 | DOWN
default_subcluster | v_verticadb_node0001 | UP
default_subcluster | v_verticadb_node0002 | UP
default_subcluster | v_verticadb_node0003 | UP
(6 rows)
Note
The "WARNING 4539" messages after calling SHUTDOWN_SUBCLUSTER occur because the nodes are in the process of shutting down. They are expected.
See also
6.13.6.29 - SHUTDOWN_WITH_DRAIN
Gracefully shuts down a subcluster or subclusters.
Eon Mode only
Gracefully shuts down a subcluster or subclusters. The function drains client connections on the subcluster's nodes and then shuts down the subcluster. This is synchronous function that returns when the shutdown message has been sent to the subcluster.
Work from existing user sessions continues on draining nodes, but the nodes refuse new client connections and are excluded from load-balancing operations. dbadmin can still connect to draining nodes.
The nodes drain until either the existing connections complete their work and close or the user-specified timeout is reached. When one of these conditions is met, the function proceeds to shut down the subcluster.
For more information about the graceful shutdown process, see Graceful Shutdown.
Caution
This function does not test whether the target subcluster is critical (a subcluster whose loss would cause the database to shut down). Using this function to shut down a critical subcluster results in the database shutting down. Always verify that the subcluster you want to shut down is not critical by querying the
CRITICAL_SUBCLUSTERS system table before calling this function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SHUTDOWN_WITH_DRAIN( 'subcluster-name', timeout-seconds )
Arguments
subcluster-name- Name of the subcluster to shutdown. Enter an empty string to shutdown all subclusters in a database.
timeout-seconds- Number of seconds to wait before forcefully closing
subcluster-name's client connections and shutting down. The behavior depends on the sign of timeout-seconds:
- Positive integer: The function waits until either the runtime reaches
timeout-seconds or the client connections finish their work and close. As soon as one of these conditions is met, the function immediately proceeds to shut down the subcluster.
- Zero: The function immediately closes any open client connections and shuts down the subcluster.
- Negative integer: The function marks the subcluster as draining and waits indefinitely to shut down the subcluster until all active user sessions disconnect.
Privileges
Superuser
Examples
In the following example, the function marks the subcluster named analytics as draining and then shuts it down as soon as either the existing client connections close or 300 seconds pass:
=> SELECT SHUTDOWN_WITH_DRAIN('analytics', 120);
NOTICE 0: Draining has started on subcluster (analytics)
NOTICE 0: Begin shutdown of subcluster (analytics)
SHUTDOWN_WITH_DRAIN
--------------------------------------------------------------------------------------------------------------------
Set subcluster (analytics) to draining state
Waited for 3 nodes to drain
Shutdown message sent to subcluster (analytics)
(1 row)
You can query the DC_DRAINING_EVENTS table to see more information about draining and shutdown events, such as whether any user sessions were forcibly closed. This subcluster had one active user session when the shutdown began, but it closed before the timeout was reached:
=> SELECT event_type, event_type_name, event_description, event_result, event_result_name FROM dc_draining_events;
event_type | event_type_name | event_description | event_result | event_result_name
------------+------------------------------+---------------------------------------------------------------------+--------------+-------------------
0 | START_DRAIN_SUBCLUSTER | START_DRAIN for SHUTDOWN of subcluster (analytics) | 0 | SUCCESS
2 | START_WAIT_FOR_NODE_DRAIN | Wait timeout is 120 seconds | 4 | INFORMATIONAL
4 | INTERVAL_WAIT_FOR_NODE_DRAIN | 1 sessions remain after 0 seconds | 4 | INFORMATIONAL
4 | INTERVAL_WAIT_FOR_NODE_DRAIN | 1 sessions remain after 30 seconds | 4 | INFORMATIONAL
3 | END_WAIT_FOR_NODE_DRAIN | Wait for drain ended with 0 sessions remaining | 0 | SUCCESS
5 | BEGIN_SHUTDOWN_AFTER_DRAIN | Starting shutdown of subcluster (analytics) following drain | 4 | INFORMATIONAL
(6 rows)
See also
6.13.6.30 - START_DRAIN_SUBCLUSTER
Drains a subcluster or subclusters.
Eon Mode only
Drains a subcluster or subclusters. The function marks all nodes in the designated subcluster as draining. Work from existing user sessions continues on draining nodes, but the nodes refuse new client connections and are excluded from load balancing operations. dbadmin can still connect to draining nodes.
To drain connections on a subcluster as part of a graceful shutdown process, you can call SHUTDOWN_WITH_DRAIN. For details, see Graceful Shutdown.
To cancel a draining operation on a subcluster, call CANCEL_DRAIN_SUBCLUSTER. If all draining nodes in a subcluster are stopped, they are marked as not draining upon restart.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
START_DRAIN_SUBCLUSTER( 'subcluster-name' )
Arguments
subcluster-name- Name of the subcluster to drain. Enter an empty string to drain all subclusters in the database.
Privileges
Superuser
Examples
The following example demonstrates how to drain a subcluster named analytics:
=> SELECT subcluster_name, node_name, node_state FROM nodes;
subcluster_name | node_name | node_state
-------------------+--------------------+------------
default_subcluster | verticadb_node0001 | UP
default_subcluster | verticadb_node0002 | UP
default_subcluster | verticadb_node0003 | UP
analytics | verticadb_node0004 | UP
analytics | verticadb_node0005 | UP
analytics | verticadb_node0006 | UP
(6 rows)
=> SELECT START_DRAIN_SUBCLUSTER('analytics');
START_DRAIN_SUBCLUSTER
-------------------------------------------------------
Targeted subcluster: 'analytics'
Action: START DRAIN
(1 row)
You can confirm that the subcluster is draining by querying the DRAINING_STATUS system table:
=> SELECT node_name, subcluster_name, is_draining FROM draining_status ORDER BY 1;
node_name | subcluster_name | is_draining
-------------------+--------------------+-------
verticadb_node0001 | default_subcluster | f
verticadb_node0002 | default_subcluster | f
verticadb_node0003 | default_subcluster | f
verticadb_node0004 | analytics | t
verticadb_node0005 | analytics | t
verticadb_node0006 | analytics | t
See also
6.13.6.31 - START_REAPING_FILES
Starts the disk file deletion in the background as an asynchronous function.
Eon Mode only
Starts the disk file deletion in the background as an asynchronous function. By default, this meta-function syncs the catalog before beginning deletion. Disk file deletion is handled in the foreground by FLUSH_REAPER_QUEUE.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
START_REAPING_FILES( [sync-catalog] )
Parameters
*sync-catalog*- Specifies to sync metadata in the database catalog on all nodes before the function executes:
Privileges
Superuser
Examples
Start the reaper service:
=> SELECT START_REAPING_FILES();
Start the reaper service and skip the initial catalog sync:
=> SELECT START_REAPING_FILES(false);
6.13.6.32 - SYNC_CATALOG
Synchronizes the catalog to communal storage to enable reviving the current catalog version in the case of an imminent crash.
Eon Mode only
Synchronizes the catalog to communal storage to enable reviving the current catalog version in the case of an imminent crash. Vertica synchronizes all pending checkpoint and transaction logs to communal storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SYNC_CATALOG( [ 'node-name' ] )
Parameters
node-name- The node to synchronize. If you omit this argument, Vertica synchronizes the catalog on all nodes.
Privileges
Superuser
Examples
Synchronize the catalog on all nodes:
=> SELECT SYNC_CATALOG();
Synchronize the catalog on one node:
=> SELECT SYNC_CATALOG( 'node001' );
6.13.6.33 - UNSANDBOX_SUBCLUSTER
Removes a subcluster from a sandbox.
Removes a subcluster from a sandbox.
Note
Vertica recommends using the admintools unsandbox_subcluster command to remove the sandbox's primary subcluster. This command automatically stops the sandboxed nodes, wipes the node's catalog subdirectories, and restarts the nodes. If you use the UNSANDBOX_SUBCLUSTER function, these steps must be completed manually.
After stopping the nodes in the sandboxed subcluster, you must run this function in the main cluster from which the sandboxed subcluster was spun-off. The function changes the metadata in the main cluster that designates the specified subcluster as sandboxed, but does not restart the subcluster and rejoin it to the main cluster.
If you are unsandboxing a secondary subcluster from the sandbox, Vertica recommends that you also call the UNSANDBOX_SUBCLUSTER function in the sandbox cluster. This makes sure that both clusters are aware of the state of the subcluster and that relevant system tables accurately reflect the subcluster's status.
To rejoin the subcluster to the main cluster and return the nodes to their normal state, you must complete the following tasks:
-
Wipe the catalog subdirectory from the sandboxed nodes. The main cluster provides the current catalog information on node restart.
-
Restart the nodes. On successful restart, the nodes should rejoin the main cluster.
-
If unsandboxing the last subcluster in a sandbox, remove the sandbox metadata prefix from the shared communal storage location. This helps avoid problems that might arise form reusing the same sandbox name.
Note
If you upgraded the Vertica version of the sandboxed subcluster, you must downgrade the version of the subcluster before rejoining it to the main cluster.
If there are no more active sandboxes, you can run CLEAN_COMMUNAL_STORAGE to remove any data created in the sandbox. The main cluster can also resume processing data queued for deletion.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
UNSANDBOX_SUBCLUSTER( 'subcluster-name', 'options' )
Arguments
subcluster-name- Identifies the subcluster to unsandbox. This must be a currently sandboxed subcluster.
options- Currently, there are no options for this function.
Privileges
Superuser
Examples
In the following example, the function unsandboxes the sc_02 secondary subcluster from the sand sandbox. After stopping the nodes in the subcluster, you can unsandbox the subcluster by calling the UNSANDBOX_SUBCLUSTER function from the main cluster:
=> SELECT UNSANDBOX_SUBCLUSTER('sc_02', '');
UNSANDBOX_SUBCLUSTER
---------------------------------------------------------------------------------------------------------------
Subcluster 'sc_02' has been unsandboxed. If wiped out and restarted, it should be able to rejoin the cluster.
(1 row)
To rejoin the nodes to the main cluster, you must wipe the local catalog from each of the previously sandboxed nodes—whose catalog location can be found by querying NODES—and then restart the nodes:
$ rm -rf paths-to-node-catalogs
$ admintools -t restart_node -s list-of-nodes -p password
After the nodes restart, you can query the NODES system table to confirm that the previously sandboxed nodes are UP and are no longer a member of sand:
=> SELECT node_name, subcluster_name, node_state, sandbox FROM NODES;
node_name | subcluster_name | node_state | sandbox
----------------------+--------------------+------------+---------
v_verticadb_node0001 | default_subcluster | UP |
v_verticadb_node0002 | default_subcluster | UP |
v_verticadb_node0003 | default_subcluster | UP |
v_verticadb_node0004 | sc_01 | UNKNOWN | sand
v_verticadb_node0005 | sc_01 | UNKNOWN | sand
v_verticadb_node0006 | sc_01 | UNKNOWN | sand
v_verticadb_node0007 | sc_02 | UP |
v_verticadb_node0008 | sc_02 | UP |
v_verticadb_node0009 | sc_02 | UP |
(9 rows)
Because sc_02 was a secondary subcluster in the sandbox, you should also call the UNSANDBOX_SUBCLUSTER function in the sandbox cluster. This makes sure that both clusters are aware of the state of the subcluster and that relevant system tables accurately reflect the subcluster's status:
=> SELECT UNSANDBOX_SUBCLUSTER('sc_02', '');
UNSANDBOX_SUBCLUSTER
-------------------------------------------------------------------------------------------------------------------
Subcluster 'sc_02' has been unsandboxed from 'sand'. This command should be executed in the main cluster as well.
(1 row)
If there are no more active sandboxes, you can run the CLEAN_COMMUNAL_STORAGE function to remove any data created in the sandbox. You should also remove the sandbox's metadata from the shared communal storage location, which can be found at /path-to-communal-storage/metadata/sandbox_name.
The following example removes the sandbox's metadata from an S3 bucket and then calls CLEAN_COMMUNAL_STORAGE to cleanup any data from the sandbox:
$ aws s3 rm /path-to-communal/metadata/sandbox_name
=> SELECT CLEAN_COMMUNAL_STORAGE('true');
CLEAN_COMMUNAL_STORAGE
-----------------------------------------------------------------
CLEAN COMMUNAL STORAGE
Total leaked files: 143
Files have been queued for deletion.
Check communal_cleanup_records for more information.
(1 row)
See also
6.13.7 - Epoch functions
This section contains the epoch management functions specific to Vertica.
This section contains the epoch management functions specific to Vertica.
6.13.7.1 - ADVANCE_EPOCH
Manually closes the current epoch and begins a new epoch.
Manually closes the current epoch and begins a new epoch.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ADVANCE_EPOCH ( [ integer ] )
Parameters
integer- Specifies the number of epochs to advance.
Privileges
Superuser
Notes
This function is primarily maintained for backward compatibility with earlier versions of Vertica.
Examples
The following command increments the epoch number by 1:
=> SELECT ADVANCE_EPOCH(1);
6.13.7.2 - GET_AHM_EPOCH
Returns the number of the in which the is located.
Returns the number of the epoch in which the Ancient History Mark is located. Data deleted up to and including the AHM epoch can be purged from physical storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_AHM_EPOCH()
Note
The AHM epoch is 0 (zero) by default (purge is disabled).
Privileges
None
Examples
=> SELECT GET_AHM_EPOCH();
GET_AHM_EPOCH
----------------------
Current AHM epoch: 0
(1 row)
6.13.7.3 - GET_AHM_TIME
Returns a TIMESTAMP value representing the.
Returns a TIMESTAMP value representing the Ancient History Mark. Data deleted up to and including the AHM epoch can be purged from physical storage.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_AHM_TIME()
Privileges
None
Examples
=> SELECT GET_AHM_TIME();
GET_AHM_TIME
-------------------------------------------------
Current AHM Time: 2010-05-13 12:48:10.532332-04
(1 row)
6.13.7.4 - GET_CURRENT_EPOCH
Returns the number of the current epoch.
The epoch into which data (COPY, INSERT, UPDATE, and DELETE operations) is currently being written.
Returns the number of the current epoch.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_CURRENT_EPOCH()
Privileges
None
Examples
=> SELECT GET_CURRENT_EPOCH();
GET_CURRENT_EPOCH
-------------------
683
(1 row)
6.13.7.5 - GET_LAST_GOOD_EPOCH
Returns the number.
Returns the last good epoch number. If the database has no projections, the function returns an error.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_LAST_GOOD_EPOCH()
Privileges
None
Examples
=> SELECT GET_LAST_GOOD_EPOCH();
GET_LAST_GOOD_EPOCH
---------------------
682
(1 row)
6.13.7.6 - MAKE_AHM_NOW
Sets the (AHM) to the greatest allowable value.
Sets the Ancient History Mark (AHM) to the greatest allowable value. This lets you purge all deleted data.
Caution
After running this function, you cannot query historical data that precedes the current epoch. Only database administrators should use this function.
MAKE_AHM_NOW performs the following operations:
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MAKE_AHM_NOW ( [ true ] )
Parameters
true - Allows AHM to advance when one of the following conditions is true:
In both cases , you must supply this argument to MAKE_AHM_NOW, otherwise Vertica returns an error. If you execute MAKE_AHM_NOW(true) during retentive refresh, Vertica rolls back the refresh operation and advances the AHM.
Caution
If the function advances AHM beyond the last good epoch of the down nodes, those nodes must recover all data from scratch.
Privileges
Superuser
Setting AHM when nodes are down
If any node in the cluster is down, you must call MAKE_AHM_NOW with an argument of true; otherwise, the function returns an error.
Note
This requirement applies only to Enterprise mode; in Eon mode, it is ignored.
In the following example, MAKE_AHM_NOW advances the AHM even though a node is down:
=> SELECT MAKE_AHM_NOW(true);
WARNING: Received no response from v_vmartdb_node0002 in get cluster LGE
WARNING: Received no response from v_vmartdb_node0002 in get cluster LGE
WARNING: Received no response from v_vmartdb_node0002 in set AHM
MAKE_AHM_NOW
------------------------------
AHM set (New AHM Epoch: 684)
(1 row)
See also
6.13.7.7 - SET_AHM_EPOCH
Sets the (AHM) to the specified epoch.
Sets the Ancient History Mark (AHM) to the specified epoch. This function allows deleted data up to and including the AHM epoch to be purged from physical storage.
SET_AHM_EPOCH is normally used for testing purposes. Instead, consider using
SET_AHM_TIME which is easier to use.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_AHM_EPOCH ( epoch, [ true ] )
Parameters
epoch - Specifies one of the following:
Important
The number of the specified epoch must be:
Query the SYSTEM table to view current epoch values relative to the AHM.
true - Allows the AHM to advance when nodes are down.
Caution
If you advance AHM beyond the
last good epoch of the down nodes, those nodes must recover all data from scratch.
Privileges
Superuser
Setting AHM when nodes are down
If any node in the cluster is down, you must call SET_AHM_EPOCH with an argument of true; otherwise, the function returns an error.
Note
This requirement applies only to Enterprise mode; in Eon mode, it is ignored.
Examples
The following command sets the AHM to a specified epoch of 12:
=> SELECT SET_AHM_EPOCH(12);
The following command sets the AHM to a specified epoch of 2 and allows the AHM to advance despite a failed node:
=> SELECT SET_AHM_EPOCH(2, true);
See also
6.13.7.8 - SET_AHM_TIME
Sets the (AHM) to the epoch corresponding to the specified time on the initiator node.
Sets the Ancient History Mark (AHM) to the epoch corresponding to the specified time on the initiator node. This function allows historical data up to and including the AHM epoch to be purged from physical storage. SET_AHM_TIME returns a TIMESTAMPTZ that represents the end point of the AHM epoch.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_AHM_TIME ( time, [ true ] )
Parameters
time- A TIMESTAMP/TIMESTAMPTZ value that is automatically converted to the appropriate epoch number.
true- Allows the AHM to advance when nodes are down.
Caution
If you advance AHM beyond the
last good epoch of the down nodes, those nodes must recover all data from scratch.
Privileges
Superuser
Setting AHM when nodes are down
If any node in the cluster is down, you must call SET_AHM_TIME with an argument of true; otherwise, the function returns an error.
Note
This requirement applies only to Enterprise mode; in Eon mode, it is ignored.
Examples
Epochs depend on a configured epoch advancement interval. If an epoch includes a three-minute range of time, the purge operation is accurate only to within minus three minutes of the specified timestamp:
=> SELECT SET_AHM_TIME('2008-02-27 18:13');
set_ahm_time
------------------------------------
AHM set to '2008-02-27 18:11:50-05'
(1 row)
Note
The –05 part of the output string is a time zone value, an offset in hours from UTC (Universal Coordinated Time, traditionally known as Greenwich Mean Time, or GMT).
In the previous example, the actual AHM epoch ends at 18:11:50, roughly one minute before the specified timestamp. This is because SET_AHM_TIME selects the epoch that ends at or before the specified timestamp. It does not select the epoch that ends after the specified timestamp because that would purge data deleted as much as three minutes after the AHM.
For example, using only hours and minutes, suppose that epoch 9000 runs from 08:50 to 11:50 and epoch 9001 runs from 11:50 to 15:50. SET_AHM_TIME('11:51') chooses epoch 9000 because it ends roughly one minute before the specified timestamp.
In the next example, suppose that a node went down at 11:00:00 AM on January 1st 2017. At noon, you want to advance the AHM to 11:15:00, but the node is still down.
Suppose you try to set the AHM using this command:
=> SELECT SET_AHM_TIME('2017-01-01 11:15:00');
Then you will receive an error message. Vertica prevents you from moving the AHM past the point where a node went down. Vertica returns this error to prevent the AHM from advancing past the down node's last good epoch. You can force the AHM to advance by supplying the optional second parameter:
=> SELECT SET_AHM_TIME('2017-01-01 11:15:00', true);
However, if you force the AHM past the last good epoch, the failed node will have to recover from scratch.
See also
6.13.8 - LDAP link functions
This section contains the functions associated with the Vertica LDAP Link service.
This section contains the functions associated with the Vertica LDAP Link service.
6.13.8.1 - LDAP_LINK_DRYRUN_CONNECT
Takes a set of LDAP Link connection parameters as arguments and begins a dry run connection between the LDAP server and Vertica.
Takes a set of LDAP Link connection parameters as arguments and begins a dry run connection between the LDAP server and Vertica.
By providing an empty string for the LDAPLinkBindPswd argument, you can also perform an anonymous bind if your LDAP server allows unauthenticated binds.
The dryrun and LDAP_LINK_SYNC_START functions must be run from the clerk node. To determine the clerk node, query NODE_RESOURCES:
=> SELECT node_name, dbclerk FROM node_resources WHERE dbclerk='t';
node_name | dbclerk
------------------+---------
v_vmart_node0001 | t
(1 row)
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LDAP_LINK_DRYRUN_CONNECT (
'LDAPLinkURL',
'LDAPLinkBindDN',
'LDAPLinkBindPswd'
)
Privileges
Superuser
Examples
This tests the connection to an LDAP server at ldap://example.dc.com with the DN CN=amir,OU=QA,DC=dc,DC=com.
=> SELECT LDAP_LINK_DRYRUN_CONNECT('ldap://example.dc.com','CN=amir,OU=QA,DC=dc,DC=com','password');
ldap_link_dryrun_connect
---------------------------------------------------------------------------------
Dry Run Connect Completed. Query v_monitor.ldap_link_dryrun_events for results.
To check the results of the bind, query the system table LDAP_LINK_DRYRUN_EVENTS.
=> SELECT event_timestamp, event_type, entry_name, role_name, link_scope, search_base from LDAP_LINK_DRYRUN_EVENTS;
event_timestamp | event_type | entry_name | link_scope | search_base
------------------------------+-----------------------+----------------------+------------+-------------
2019-12-09 15:41:43.589398-05 | BIND_STARTED | -------------------- | ---------- | -----------
2019-12-09 15:41:43.590504-05 | BIND_FINISHED | -------------------- | ---------- | -----------
See also
6.13.8.2 - LDAP_LINK_DRYRUN_SEARCH
Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run search for users and groups that would get imported from the LDAP server.
Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run search for users and groups that would get imported from the LDAP server.
By providing an empty string for the LDAPLinkBindPswd argument, you can also perform an anonymous search if your LDAP server's Access Control List (ACL) is configured to allow unauthenticated searches. The settings for allowing anonymous binds are different from the ACL settings for allowing anonymous searches.
The dryrun and LDAP_LINK_SYNC_START functions must be run from the clerk node. To determine the clerk node, query NODE_RESOURCES:
=> SELECT node_name, dbclerk FROM node_resources WHERE dbclerk='t';
node_name | dbclerk
------------------+---------
v_vmart_node0001 | t
(1 row)
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LDAP_LINK_DRYRUN_SEARCH (
'LDAPLinkURL',
'LDAPLinkBindDN',
'LDAPLinkBindPswd',
'LDAPLinkSearchBase',
'LDAPLinkScope',
'LDAPLinkFilterUser',
'LDAPLinkFilterGroup',
'LDAPLinkUserName',
'LDAPLinkGroupName',
'LDAPLinkGroupMembers',
[LDAPLinkSearchTimeout],
['LDAPLinkJoinAttr']
)
Privileges
Superuser
Examples
This searches for users and groups in the LDAP server. In this case, the LDAPLinkSearchBase parameter specifies the dc.com domain and a sub scope, which replicates the entire subtree under the DN.
To further filter results, the function checks for users and groups with the person and group objectClass attributes. It then searches the group attribute cn, identifying members of that group with the member attribute, and then identifying those individual users with the attribute uid.
=> SELECT LDAP_LINK_DRYRUN_SEARCH('ldap://example.dc.com','CN=amir,OU=QA,DC=dc,DC=com','$vertica$','dc=DC,dc=com','sub',
'(objectClass=person)','(objectClass=group)','uid','cn','member',10,'dn');
ldap_link_dryrun_search
--------------------------------------------------------------------------------
Dry Run Search Completed. Query v_monitor.ldap_link_dryrun_events for results.
To check the results of the search, query the system table LDAP_LINK_DRYRUN_EVENTS.
=> SELECT event_timestamp, event_type, entry_name, ldapurihash, link_scope, search_base from LDAP_LINK_DRYRUN_EVENTS;
event_timestamp | event_type | entry_name | ldapurihash | link_scope | search_base
---------------------------------+------------------+------------------------+-------------+------------+--------------
2020-01-03 21:03:26.411753+05:30 | BIND_STARTED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:26.422188+05:30 | BIND_FINISHED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:26.422223+05:30 | SYNC_STARTED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:26.422229+05:30 | SEARCH_STARTED | ********** | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:32.043107+05:30 | LDAP_GROUP_FOUND | Account Operators | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:32.04312+05:30 | LDAP_GROUP_FOUND | Administrators | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:32.043182+05:30 | LDAP_USER_FOUND | user1 | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:32.043186+05:30 | LDAP_USER_FOUND | user2 | 0 | sub | dc=DC,dc=com
2020-01-03 21:03:32.04319+05:30 | SEARCH_FINISHED | ********** | 0 | sub | dc=DC,dc=com
See also
6.13.8.3 - LDAP_LINK_DRYRUN_SYNC
Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run synchronization between the database and the LDAP server, which maps and synchronizes the LDAP server's users and groups with their equivalents in Vertica.
Takes a set of LDAP Link connection and search parameters as arguments and begins a dry run synchronization between the database and the LDAP server, which maps and synchronizes the LDAP server's users and groups with their equivalents in Vertica. This meta-function also dry runs the creation and orphaning of users and roles in Vertica.
The dryrun and LDAP_LINK_SYNC_START functions must be run from the clerk node. To determine the clerk node, query NODE_RESOURCES:
=> SELECT node_name, dbclerk FROM node_resources WHERE dbclerk='t';
node_name | dbclerk
------------------+---------
v_vmart_node0001 | t
(1 row)
You can view the results of the dry run in the system table LDAP_LINK_DRYRUN_EVENTS.
To cancel an in-progress synchronization, use LDAP_LINK_SYNC_CANCEL.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LDAP_LINK_DRYRUN_SYNC (
'LDAPLinkURL',
'LDAPLinkBindDN',
'LDAPLinkBindPswd',
'LDAPLinkSearchBase',
'LDAPLinkScope',
'LDAPLinkFilterUser',
'LDAPLinkFilterGroup',
'LDAPLinkUserName',
'LDAPLinkGroupName',
'LDAPLinkGroupMembers',
[LDAPLinkSearchTimeout],
['LDAPLinkJoinAttr']
)
Privileges
Superuser
Examples
To perform a dry run to map the users and groups returned from LDAP_LINK_DRYRUN_SEARCH, pass the same parameters as arguments to LDAP_LINK_DRYRUN_SYNC.
=> SELECT LDAP_LINK_DRYRUN_SYNC('ldap://example.dc.com','CN=amir,OU=QA,DC=dc,DC=com','$vertica$','dc=DC,dc=com','sub',
'(objectClass=person)','(objectClass=group)','uid','cn','member',10,'dn');
LDAP_LINK_DRYRUN_SYNC
------------------------------------------------------------------------------------------
Dry Run Connect and Sync Completed. Query v_monitor.ldap_link_dryrun_events for results.
To check the results of the sync, query the system table LDAP_LINK_DRYRUN_EVENTS.
=> SELECT event_timestamp, event_type, entry_name, ldapurihash, link_scope, search_base from LDAP_LINK_DRYRUN_EVENTS;
event_timestamp | event_type | entry_name | ldapurihash | link_scope | search_base
---------------------------------+---------------------+------------------------+-------------+------------+--------------
2020-01-03 21:08:30.883783+05:30 | BIND_STARTED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:30.890574+05:30 | BIND_FINISHED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:30.890602+05:30 | SYNC_STARTED | ---------------------- | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:30.890605+05:30 | SEARCH_STARTED | ********** | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939369+05:30 | LDAP_GROUP_FOUND | Account Operators | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939395+05:30 | LDAP_GROUP_FOUND | Administrators | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939461+05:30 | LDAP_USER_FOUND | user1 | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939463+05:30 | LDAP_USER_FOUND | user2 | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939468+05:30 | SEARCH_FINISHED | ********** | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939718+05:30 | PROCESSING_STARTED | ********** | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939887+05:30 | USER_CREATED | user1 | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939895+05:30 | USER_CREATED | user2 | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939949+05:30 | ROLE_CREATED | Account Operators | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.939959+05:30 | ROLE_CREATED | Administrators | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.940603+05:30 | PROCESSING_FINISHED | ********** | 0 | sub | dc=DC,dc=com
2020-01-03 21:08:31.940613+05:30 | SYNC_FINISHED | ---------------------- | 0 | sub | dc=DC,dc=com
See also
6.13.8.4 - LDAP_LINK_SYNC_CANCEL
Cancels in-progress LDAP Link synchronizations (including those started by LDAP_LINK_DRYRUN_SYNC) between the LDAP server and Vertica.
Cancels in-progress LDAP Link synchronizations (including those started by LDAP_LINK_DRYRUN_SYNC) between the LDAP server and Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ldap_link_sync_cancel()
Privileges
Superuser
Examples
=> SELECT ldap_link_sync_cancel();
See also
6.13.8.5 - LDAP_LINK_SYNC_START
Begins the synchronization between the LDAP and Vertica servers immediately rather than waiting for the next scheduled run set by the parameters LDAPLinkInterval and LDAPLinkCron.
Begins the synchronization between the LDAP server and Vertica immediately rather than waiting for the next scheduled run set by the parameters LDAPLinkInterval and LDAPLinkCron.
The dryrun and LDAP_LINK_SYNC_START functions must be run from the clerk node. To determine the clerk node, query NODE_RESOURCES:
=> SELECT node_name, dbclerk FROM node_resources WHERE dbclerk='t';
node_name | dbclerk
------------------+---------
v_vmart_node0001 | t
(1 row)
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ldap_link_sync_start()
Privileges
Superuser
Examples
=> SELECT ldap_link_sync_start();
See also
LDAP link parameters
6.13.9 - License functions
This section contains functions that monitor Vertica license status and compliance.
This section contains functions that monitor Vertica license status and compliance.
6.13.9.1 - AUDIT
Returns the raw data size (in bytes) of a database, schema, or table as it is counted in an audit of the database size.
Returns the raw data size (in bytes) of a database, schema, or table as it is counted in an audit of the database size. Unless you specify zero error tolerance and 100 percent confidence level, AUDIT returns only approximate results that can vary over multiple iterations.
Important
The data size returned by
AUDIT should not be compared with the compressed data size of objects reported in the
USED_BYTES column of system tables like
STORAGE_CONTAINERS and
PROJECTION_STORAGE.
AUDIT estimates the size for data in Vertica tables using the same data sampling method that Vertica uses to determine if a database complies with the licensed database size allowance. Vertica does not use these results to determine whether the size of the database complies with the Vertica license's data allowance. For details, see Auditing database size.
For data stored in external tables based on ORC or Parquet format, AUDIT uses the total size of the data files. This value is never estimated—it is read from the file system storing the ORC or Parquet files (either the Vertica node's local file system, S3, or HDFS).
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AUDIT('[[[database.]schema.]scope ]'[, 'granularity'] [, error-tolerance[, confidence-level]] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
scope- Specifies the extent of the audit:
The schema or table to audit. To audit the database, set this parameter to an empty string.
granularity- The level at which the audit reports its results, one of the following strings:
The level of granularity must be equal to or less than the granularity of scope. If you omit this parameter, granularity is set to the same level as scope. Thus, if online_sales is a schema, the following statements are identical:
AUDIT('online_sales', 'schema');
AUDIT('online_sales');
If AUDIT sets granularity to a level lower than the target object, it returns with a message that refers you to system table
USER_AUDITS. For details, see Querying V_CATALOG.USER_AUDITS, below.
error-tolerance- Specifies the percentage margin of error allowed in the audit estimate. Enter the tolerance value as a decimal number, between 0 and 100. The default value is 5, for a 5% margin of error.
This argument has no effect on audits of external tables based on ORC or Parquet files. Audits of these tables always returns the actual size of the underlying data files.
Setting this value to 0 results in a full database audit, which is very resource intensive, as AUDIT analyzes the entire database. A full database audit significantly impacts performance, so Vertica does not recommend it for a production database.
Caution
Due to the iterative sampling that the auditing process uses, setting the error tolerance to a small fraction of a percent (for example, 0.00001) can cause AUDIT to run for a longer period than a full database audit. The lower you specify this value, the more resources the audit uses, as it performs more data sampling.
confidence-level- Specifies the statistical confidence level percentage of the estimate. Enter the confidence value as a decimal number, between 0 and 100. The default value is 99, indicating a confidence level of 99%.
This argument has no effect on audits of external tables based on ORC or Parquet files. Audits of these tables always returns the actual size of the underlying data files.
The higher the confidence value, the more resources the function uses, as it performs more data sampling. Setting this value to 100 results in a full audit of the database, which is very resource intensive, as the function analyzes all of the database. A full database audit significantly impacts performance, so Vertica does not recommend it for a production database.
Privileges
Superuser, or the following privileges:
Note
If you audit a schema or the database, Vertica only returns the size of all objects that you have privileges to access within the audited object, as described above.
Querying V_CATALOG.USER_AUDITS
If AUDIT sets granularity to a level lower than the target object, it returns with a message that refers you to system table
USER_AUDITS. To obtain audit data on objects of the specified granularity, query this table. For example, the following query seeks to audit all tables in the store schema:
=> SELECT AUDIT('store', 'table');
AUDIT
-----------------------------------------------------------
See table sizes in v_catalog.user_audits for schema store
(1 row)
The next query queries USER_AUDITS and obtains the latest audits on those tables:
=> SELECT object_name, AVG(size_bytes)::int size_bytes, MAX(audit_start_timestamp::date) audit_start
FROM user_audits WHERE object_schema='store'
GROUP BY rollup(object_name) HAVING GROUPING_ID(object_name) < 1 ORDER BY GROUPING_ID();
object_name | size_bytes | audit_start
-------------------+------------+-------------
store_dimension | 22067 | 2017-10-26
store_orders_fact | 27201312 | 2017-10-26
store_sales_fact | 301260170 | 2017-10-26
(3 rows)
Examples
See Auditing database size.
6.13.9.2 - AUDIT_FLEX
Returns the estimated ROS size of raw columns, equivalent to the export size of the flex data in the audited objects.
Returns the estimated ROS size of __raw__ columns, equivalent to the export size of the flex data in the audited objects. You can audit all flex data in the database, or narrow the audit scope to a specific flex table, projection, or schema. Vertica stores the audit results in system table
USER_AUDITS.
The audit excludes the following:
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AUDIT_FLEX ('[scope]')
Parameters
scope- Specifies the extent of the audit:
-
Empty string ('') audits all flexible tables in the database.
-
The name of a schema, projection, or flex table.
Privileges
Superuser, or the following privileges:
Note
If you audit a schema or the database, Vertica only returns the size of all objects that you have privileges to access within the audited object, as described above.
Examples
Audit all flex tables in the current database:
dbs=> select audit_flex('');
audit_flex
------------
8567679
(1 row)
Audit the flex tables in schema public:
dbs=> select audit_flex('public');
audit_flex
------------
8567679
(1 row)
Audit the flex data in projection bakery_b0:
dbs=> select audit_flex('bakery_b0');
audit_flex
------------
8566723
(1 row)
Audit flex table bakery:
dbs=> select audit_flex('bakery');
audit_flex
------------
8566723
(1 row)
To report the results of all audits saved in the USER_AUDITS, the following shows part of an extended display from the system table showing an audit run on a schema called test, and the entire database, dbs:
dbs=> \x
Expanded display is on.
dbs=> select * from user_audits;
-[ RECORD 1 ]-------------------------+------------------------------
size_bytes | 0
user_id | 45035996273704962
user_name | release
object_id | 45035996273736664
object_type | SCHEMA
object_schema |
object_name | test
audit_start_timestamp | 2014-02-04 14:52:15.126592-05
audit_end_timestamp | 2014-02-04 14:52:15.139475-05
confidence_level_percent | 99
error_tolerance_percent | 5
used_sampling | f
confidence_interval_lower_bound_bytes | 0
confidence_interval_upper_bound_bytes | 0
sample_count | 0
cell_count | 0
-[ RECORD 2 ]-------------------------+------------------------------
size_bytes | 38051
user_id | 45035996273704962
user_name | release
object_id | 45035996273704974
object_type | DATABASE
object_schema |
object_name | dbs
audit_start_timestamp | 2014-02-05 13:44:41.11926-05
audit_end_timestamp | 2014-02-05 13:44:41.227035-05
confidence_level_percent | 99
error_tolerance_percent | 5
used_sampling | f
confidence_interval_lower_bound_bytes | 38051
confidence_interval_upper_bound_bytes | 38051
sample_count | 0
cell_count | 0
-[ RECORD 3 ]-------------------------+------------------------------
...
6.13.9.3 - AUDIT_LICENSE_SIZE
Triggers an immediate audit of the database size to determine if it is in compliance with the raw data storage allowance included in your Vertica licenses.
Triggers an immediate audit of the database size to determine if it is in compliance with the raw data storage allowance included in your Vertica licenses.
If you use ORC or Parquet data stored in HDFS, results are only accurate if you run this function as a user who has access to all HDFS data. Either run the query with a principal that has read access to all such data, or use a Hadoop delegation token that grants this access. For more information about using delegation tokens, see Accessing kerberized HDFS data.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AUDIT_LICENSE_SIZE()
Privileges
Superuser
Examples
=> SELECT audit_license_size();
audit_license_size
--------------------
Raw Data Size: 0.00TB +/- 0.00TB
License Size : 10.00TB
Utilization : 0%
Audit Time : 2015-09-24 12:19:15.425486-04
Compliance Status : The database is in compliance with respect to raw data size.
License End Date: 2015-11-23 00:00:00 Days Remaining: 60.53
(1 row)
6.13.9.4 - AUDIT_LICENSE_TERM
Triggers an immediate audit to determine if the Vertica license has expired.
Triggers an immediate audit to determine if the Vertica license has expired.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
AUDIT_LICENSE_TERM()
Privileges
Superuser
Examples
=> SELECT audit_license_term();
audit_license_term
--------------------
Raw Data Size: 0.00TB +/- 0.00TB
License Size : 10.00TB
Utilization : 0%
Audit Time : 2015-09-24 12:19:15.425486-04
Compliance Status : The database is in compliance with respect to raw data size.
License End Date: 2015-11-23 00:00:00 Days Remaining: 60.53
(1 row)
6.13.9.5 - DISPLAY_LICENSE
Returns the terms of your Vertica license.
Returns the terms of your Vertica license. The information this function displays is:
-
The start and end dates for which the license is valid (or "Perpetual" if the license has no expiration).
-
The number of days you are allowed to use Vertica after your license term expires (the grace period)
-
The amount of data your database can store, if your license includes a data allowance.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DISPLAY_LICENSE()
Privileges
None
Examples
=> SELECT DISPLAY_LICENSE();
DISPLAY_LICENSE
---------------------------------------------------
Vertica Systems, Inc.
2007-08-03
Perpetual
500GB
(1 row)
6.13.9.6 - GET_AUDIT_TIME
Reports the time when the automatic audit of database size occurs.
Reports the time when the automatic audit of database size occurs. Vertica performs this audit if your Vertica license includes a data size allowance. For details of this audit, see Managing licenses in the Administrator's Guide. To change the time the audit runs, use the SET_AUDIT_TIME function.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_AUDIT_TIME()
Privileges
None
Examples
=> SELECT get_audit_time();
get_audit_time
-----------------------------------------------------
The audit is scheduled to run at 11:59 PM each day.
(1 row)
6.13.9.7 - GET_COMPLIANCE_STATUS
Displays whether your database is in compliance with your Vertica license agreement.
Displays whether your database is in compliance with your Vertica license agreement. This information includes the results of Vertica's most recent audit of the database size (if your license has a data allowance as part of its terms), the license term (if your license has an end date), and the number of nodes (if your license has a node limit).
GET_COMPLIANCE_STATUS measures data allowance by TBs (where a TB equals 10244 bytes).
The information displayed by GET_COMPLIANCE_STATUS includes:
-
The estimated size of the database (see Auditing database size for an explanation of the size estimate).
-
The raw data size allowed by your Vertica license.
-
The percentage of your allowance that your database is currently using.
-
The number of nodes and license limit.
-
The date and time of the last audit.
-
Whether your database complies with the data allowance terms of your license agreement.
-
The end date of your license.
-
How many days remain until your license expires.
Note
If your license does not have a data allowance, end date, or node limit, some of the values might not appear in the output for GET_COMPLIANCE_STATUS.
If the audit shows your license is not in compliance with your data allowance, you should either delete data to bring the size of the database under the licensed amount, or upgrade your license. If your license term has expired, you should contact Vertica immediately to renew your license. See Managing licenses for further details.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_COMPLIANCE_STATUS()
Privileges
None
Examples
=> SELECT GET_COMPLIANCE_STATUS();
get_compliance_status
--------------------
Raw Data Size: 0.00TB +/- 0.00TB
License Size : 10.00TB
Utilization : 0%
Audit Time : 2015-09-24 12:19:15.425486-04
Compliance Status : The database is in compliance with respect to raw data size.
License End Date: 2015-11-23 00:00:00 Days Remaining: 60.53
(1 row)
The following example shows output for a Vertica for SQL on Apache Hadoop cluster.
=> SELECT GET_COMPLIANCE_STATUS();
get_compliance_status
--------------------
Node count : 4
License Node limit : 5
No size-compliance concerns for an Unlimited license
No expiration date for a Perpetual license
(1 row)
6.13.9.8 - SET_AUDIT_TIME
Sets the time that Vertica performs automatic database size audit to determine if the size of the database is compliant with the raw data allowance in your Vertica license.
Sets the time that Vertica performs automatic database size audit to determine if the size of the database is compliant with the raw data allowance in your Vertica license. Use this function if the audits are currently scheduled to occur during your database's peak activity time. This is normally not a concern, since the automatic audit has little impact on database performance.
Audits are scheduled by the preceding audit, so changing the audit time does not affect the next scheduled audit. For example, if your next audit is scheduled to take place at 11:59PM and you use SET_AUDIT_TIME to change the audit schedule 3AM, the previously scheduled 11:59PM audit still runs. As that audit finishes, it schedules the next audit to occur at 3AM.
Vertica always performs the next scheduled audit even where you have changed the audit time using SET_AUDIT_TIME and then triggered an automatic audit by issuing the statement, SELECT AUDIT_LICENSE_SIZE. Only after the next scheduled audit does Vertica begin auditing at the new time you set using SET_AUDIT_TIME. Thereafter, Vertica audits at the new time.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_AUDIT_TIME(time)
time- A string containing the time in
'HH:MM AM/PM' format (for example, '1:00 AM') when the audit should run daily.
Privileges
Superuser
Examples
=> SELECT SET_AUDIT_TIME('3:00 AM');
SET_AUDIT_TIME
-----------------------------------------------------------------------
The scheduled audit time will be set to 3:00 AM after the next audit.
(1 row)
6.13.10 - Notifier functions
This section contains functions for using and managing the notifier.
This section contains functions for using and managing the notifier.
6.13.10.1 - GET_DATA_COLLECTOR_NOTIFY_POLICY
Lists any notification policies set on a component.
Lists any notification policies set on a Data collector component.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_DATA_COLLECTOR_NOTIFY_POLICY('component')
component- Name of the Data Collector component to check for notification policies.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
Examples
=> SELECT GET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures');
GET_DATA_COLLECTOR_NOTIFY_POLICY
----------------------------------------------------------------------
Notifiable; Notifier: vertica_stats; Channel: vertica_notifications
(1 row)
The following example shows the output from the function when there is no notification policy for the component:
=> SELECT GET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures');
GET_DATA_COLLECTOR_NOTIFY_POLICY
----------------------------------
Not notifiable;
(1 row)
See also
6.13.10.2 - NOTIFY
Sends a specified message to a NOTIFIER.
Sends a specified message to a NOTIFIER.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
NOTIFY ( 'message', 'notifier', 'target-topic' )
Parameters
message- The message to send to the endpoint.
notifier- The name of the NOTIFIER.
target-topic- String that specifies one of the following based on the
notifier type:
Privileges
Superuser
Examples
Send a message to confirm that an ETL job is complete:
=> SELECT NOTIFY('ETL Done!', 'my_notifier', 'DB_activity_topic');
6.13.10.3 - SET_DATA_COLLECTOR_NOTIFY_POLICY
Creates/enables notification policies for a component.
Creates/enables notification policies for a Data collector component. Notification policies automatically send messages to the specified NOTIFIER when certain events occur.
To view existing notification policies on a Data Collector component, see GET_DATA_COLLECTOR_NOTIFY_POLICY.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_DATA_COLLECTOR_NOTIFY_POLICY('component','notifier', 'topic', enabled)
component- Name of the component whose change will be reported via the notifier.
Query DATA_COLLECTOR to get a list of components:
=> SELECT DISTINCT component, description FROM DATA_COLLECTOR
WHERE component ILIKE '%Depot%' ORDER BY component;
component | description
----------------+-------------------------------
DepotEvictions | Files evicted from the Depot
DepotFetches | Files fetched to the Depot
DepotUploads | Files Uploaded from the Depot
(3 rows)
notifier- Name of the notifier that will send the message.
topic- One of the following:
enabled- Boolean value that specifies whether this policy is enabled. Set to TRUE to enable reporting component changes. Set to FALSE to disable the notifier.
Examples
SNS notifier
The following example creates an SNS topic, subscribes to it with an SQS queue, and then configures an SNS notifier for the DC component LoginFailures:
-
Create an SNS topic.
-
Create an SQS queue.
-
Subscribe the SQS queue to the SNS topic.
-
Set SNSAuth with your AWS credentials:
=> ALTER DATABASE DEFAULT SET SNSAuth='VNDDNVOPIUQF917O5PDB:+mcnVONVIbjOnf1ekNis7nm3mE83u9fjdwmlq36Z';
-
Set SNSRegion:
=> ALTER DATABASE DEFAULT SET SNSRegion='us-east-1'
-
Enable HTTPS:
=> ALTER DATABASE DEFAULT SET SNSEnableHttps=1;
-
Create an SNS notifier:
=> CREATE NOTIFIER v_sns_notifier ACTION 'sns' MAXPAYLOAD '256K' MAXMEMORYSIZE '10M' CHECK COMMITTED;
-
Verify that the SNS notifier, SNS topic, and SQS queue are properly configured:
-
Manually send a message from the notifier to the SNS topic with NOTIFY:
=> SELECT NOTIFY('test message', 'v_sns_notifier', 'arn:aws:sns:us-east-1:123456789012:MyTopic')
-
Poll the SQS queue for your message.
-
Attach the SNS notifier to the LoginFailures component with SET_DATA_COLLECTOR_NOTIFY_POLICY:
=> SELECT SET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures', 'v_sns_notifier', 'Login failed!', true)
Kafka notifier
To be notified of failed login attempts, you can create a notifier that sends a notification when the DC component LoginFailures updates. The TLSMODE 'verify-ca' verifies that the server's certificate is signed by a trusted CA.
=> CREATE NOTIFIER vertica_stats ACTION 'kafka://kafka01.example.com:9092' MAXMEMORYSIZE '10M' TLSMODE 'verify-ca';
CREATE NOTIFIER
=> SELECT SET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures','vertica_stats', 'vertica_notifications', true);
SET_DATA_COLLECTOR_NOTIFY_POLICY
----------------------------------
SET
(1 row)
The following example shows how to disable the policy created in the previous example:
=> SELECT SET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures','vertica_stats', 'vertica_notifications', false);
SET_DATA_COLLECTOR_NOTIFY_POLICY
----------------------------------
SET
(1 row)
=> SELECT GET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures');
GET_DATA_COLLECTOR_NOTIFY_POLICY
----------------------------------
Not notifiable;
(1 row)
Syslog notifier
The following example creates a notifier that writes a message to syslog when the Data collector (DC) component LoginFailures updates:
-
Enable syslog notifiers for the current database:
=> ALTER DATABASE DEFAULT SET SyslogEnabled = 1;
-
Create and enable a syslog notifier v_syslog_notifier:
=> CREATE NOTIFIER v_syslog_notifier ACTION 'syslog'
ENABLE
MAXMEMORYSIZE '10M'
IDENTIFIED BY 'f8b0278a-3282-4e1a-9c86-e0f3f042a971'
PARAMETERS 'eventSeverity = 5';
-
Configure the syslog notifier v_syslog_notifier for updates to the LoginFailures DC component with SET_DATA_COLLECTOR_NOTIFY_POLICY:
=> SELECT SET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures','v_syslog_notifier', 'Login failed!', true);
This notifier writes the following message to syslog (default location: /var/log/messages) when a user fails to authenticate as the user Bob:
Apr 25 16:04:58
vertica_host_01
vertica:
Event Posted:
Event Code:21
Event Id:0
Event Severity: Notice [5]
PostedTimestamp: 2022-04-25 16:04:58.083063
ExpirationTimestamp: 2022-04-25 16:04:58.083063
EventCodeDescription: Notifier
ProblemDescription: (Login failed!)
{
"_db":"VMart",
"_schema":"v_internal",
"_table":"dc_login_failures",
"_uuid":"f8b0278a-3282-4e1a-9c86-e0f3f042a971",
"authentication_method":"Reject",
"client_authentication_name":"default: Reject",
"client_hostname":"::1",
"client_label":"",
"client_os_user_name":"dbadmin",
"client_pid":523418,
"client_version":"",
"database_name":"dbadmin",
"effective_protocol":"3.8",
"node_name":"v_vmart_node0001",
"reason":"REJECT",
"requested_protocol":"3.8",
"ssl_client_fingerprint":"",
"ssl_client_subject":"",
"time":"2022-04-25 16:04:58.082568-05",
"user_name":"Bob"
}#012
DatabaseName: VMart
Hostname: vertica_host_01
See also
6.13.11 - Partition functions
This section contains partition management functions specific to Vertica.
This section contains partition management functions specific to Vertica.
6.13.11.1 - CALENDAR_HIERARCHY_DAY
Groups DATE partition keys into a hierarchy of years, months, and days.
Groups DATE partition keys into a hierarchy of years, months, and days. The Tuple Mover regularly evaluates partition keys against the current date, and merges partitions as needed into the appropriate year and month partition groups.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CALENDAR_HIERARCHY_DAY( partition-expression[, active-months[, active-years] ] )
Arguments
partition-expression- The DATE expression on which to group partition keys, which must be identical to the table's
PARTITION BY expression.
active-months- How many months preceding the current month to store unique partition keys in separate partitions, a positive integer.
A value of 1 means only partition keys of the current month are stored in separate partitions.
A value of 0 means all partition keys of the current month are merged into a partition group for that month.
For details, see Hierarchical partitioning.
Default: 2
active-years- How many years preceding the current year to partition group keys by month in separate partitions, a positive integer.
A value of 1 means only partition keys of the current year are stored in month partition groups.
A value of 0 means all partition keys of the current and previous years are merged into year partition groups.
For details, see Hierarchical partitioning.
Default: 2
Important
The CALENDAR_HIERARCHY_DAY algorithm assumes that most table activity is focused on recent dates. Setting active-years and active-months to a low number ≥ 2 serves to isolate most merge activity to date-specific containers, and incurs minimal overhead. Vertica recommends that you use the default setting of 2 for active-years and active-months. For most users, these settings achieve an optimal balance between ROS storage and performance.
As a best practice, never set active-years and active-months to 0.
Usage
Use this function in the GROUP BY expression of a table partition clause:
PARTITION BY partition-expression
GROUP BY CALENDAR_HIERARCHY_DAY(
group-expression [, active-months[, active-years] ] )
For example:
=> CREATE TABLE public.store_orders
(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date
);
...
=> ALTER TABLE public.store_orders
PARTITION BY order_date::DATE
GROUP BY CALENDAR_HIERARCHY_DAY(order_date::DATE, 3, 2) REORGANIZE;
Examples
See Hierarchical partitioning.
6.13.11.2 - COPY_PARTITIONS_TO_TABLE
Copies partitions from one table to another.
Copies partitions from one table to another. This lightweight partition copy increases performance by initially sharing the same storage between two tables. After the copy operation is complete, the tables are independent of each other. Users can perform operations on one table without impacting the other. These operations can increase the overall storage required for both tables.
Note
Although they share storage space, Vertica considers the partitions as discrete objects for license capacity purposes. For example, copying a one TB partition would only consume one TB of space. Your Vertica license, however, considers them as separate objects consuming two TB of space.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
COPY_PARTITIONS_TO_TABLE (
'[[{namespace. | database. }]schema.]source-table',
'min-range-value',
'max-range-value',
'[[{namespace. | database. }]schema.]target-table'
[, 'force-split']
)
Arguments
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
For Eon Mode databases, the namespaces of staging-table and target-table must have the same shard count.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
source-table- The source table of the partitions to copy.
min-range-value, max-range-value- The minimum and maximum value of partition keys to copy, where
min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
target-table- The target table of the partitions to copy. If the table does not exist, Vertica creates a table from the source table's definition, by calling
CREATE TABLE with LIKE and INCLUDING PROJECTIONS clause. The new table inherits ownership from the source table. For details, see Replicating a table.
force-splitOptional Boolean argument, specifies whether to split ROS containers if the range of partition keys spans multiple containers or part of a single container:
Privileges
Non-superuser, one of the following:
-
Owner of source and target tables
-
TRUNCATE (if force-split is true) and SELECT on the source table, INSERT on the target table
If the target table does not exist, you must also have CREATE privileges on the target schema to enable table creation.
Table attribute requirements
The following attributes of both tables must be identical:
-
Column definitions, including NULL/NOT NULL constraints
-
Segmentation
-
Partition clause
-
Number of projections
-
Shard count (Eon Mode only)
-
Projection sort order
-
Primary and unique key constraints. However, the key constraints do not have to be identically enabled. For more information on constraints, see Constraints.
Note
If the target table has primary or unique key constraints enabled and copying or moving the partitions will insert duplicate key values into the target table, Vertica rolls back the operation.
-
Check constraints. For MOVE_PARTITIONS_TO_TABLE and COPY_PARTITIONS_TO_TABLE, Vertica enforces enabled check constraints on the target table only. For SWAP_PARTITIONS_BETWEEN_TABLES, Vertica enforces enabled check constraints on both tables. If there is a violation of an enabled check constraint, Vertica rolls back the operation.
-
Number and definitions of text indices.
Additionally, If access policies exist on the source table, the following must be true:
Table restrictions
The following restrictions apply to the source and target tables:
-
If the source and target partitions are in different storage tiers, Vertica returns a warning but the operation proceeds. The partitions remain in their existing storage tier.
-
The target table cannot be immutable.
-
The following tables cannot be used as sources or targets:
-
Temporary tables
-
Virtual tables
-
System tables
-
External tables
Examples
If you call COPY_PARTITIONS_TO_TABLE and the target table does not exist, the function creates the table automatically. In the following example, the target table partn_backup.tradfes_200801 does not exist. COPY_PARTITIONS_TO_TABLE creates the table and replicates the partition. Vertica also copies all the constraints associated with the source table except foreign key constraints.
=> SELECT COPY_PARTITIONS_TO_TABLE (
'prod_trades',
'200801',
'200801',
'partn_backup.trades_200801');
COPY_PARTITIONS_TO_TABLE
-------------------------------------------------
1 distinct partition values copied at epoch 15.
(1 row)
See also
Archiving partitions
6.13.11.3 - DROP_PARTITIONS
Drops the specified table partition keys.
Note
This function supersedes meta-function DROP_PARTITION, which was deprecated in Vertica 9.0.
Drops the specified table partition keys.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_PARTITIONS (
'[[database.]schema.]table-name',
'min-range-value',
'max-range-value'
[, 'force-split']
)
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name- The target table. The table cannot be used as a dimension table in a pre-join projection and cannot have out-of-date (unrefreshed) projections.
min-range-value, max-range-value- The minimum and maximum value of partition keys to drop, where
min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
force-splitOptional Boolean argument, specifies whether to split ROS containers if the range of partition keys spans multiple containers or part of a single container:
Note
In rare cases, DROP_PARTITIONS executes at the same time as a
mergeout operation on the same ROS container. As a result, the function cannot split the container as specified and returns with an error. When this happens, call DROP_PARTITIONS again.
Privileges
One of the following:
Examples
See Dropping partitions.
See also
PARTITION_TABLE
6.13.11.4 - DUMP_PROJECTION_PARTITION_KEYS
Dumps the partition keys of the specified projection.
Dumps the partition keys of the specified projection.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DUMP_PROJECTION_PARTITION_KEYS( '[[database.]schema.]projection-name')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection-name- Projection name
Privileges
Non-superuser: TRUNCATE on anchor table
Examples
The following statements create the table and projection online_sales.online_sales_fact and online_sales.online_sales_fact_rep, respectively, and partitions table data by the column call_center_key:
=> CREATE TABLE online_sales.online_sales_fact
(
sale_date_key int NOT NULL,
ship_date_key int NOT NULL,
product_key int NOT NULL,
product_version int NOT NULL,
customer_key int NOT NULL,
call_center_key int NOT NULL,
online_page_key int NOT NULL,
shipping_key int NOT NULL,
warehouse_key int NOT NULL,
promotion_key int NOT NULL,
pos_transaction_number int NOT NULL,
sales_quantity int,
sales_dollar_amount float,
ship_dollar_amount float,
net_dollar_amount float,
cost_dollar_amount float,
gross_profit_dollar_amount float,
transaction_type varchar(16)
)
PARTITION BY (online_sales_fact.call_center_key);
=> CREATE PROJECTION online_sales.online_sales_fact_rep AS SELECT * from online_sales.online_sales_fact unsegmented all nodes;
The following DUMP_PROJECTION_PARTITION_KEYS statement dumps the partition key from the projection online_sales.online_sales_fact_rep:
=> SELECT DUMP_PROJECTION_PARTITION_KEYS('online_sales.online_sales_fact_rep');
Partition keys on node v_vmart_node0001
Projection 'online_sales_fact_rep'
Storage [ROS container]
No of partition keys: 1
Partition keys: 200
Storage [ROS container]
No of partition keys: 1
Partition keys: 199
...
Storage [ROS container]
No of partition keys: 1
Partition keys: 2
Storage [ROS container]
No of partition keys: 1
Partition keys: 1
Partition keys on node v_vmart_node0002
Projection 'online_sales_fact_rep'
Storage [ROS container]
No of partition keys: 1
Partition keys: 200
Storage [ROS container]
No of partition keys: 1
Partition keys: 199
...
(1 row)
See also
6.13.11.5 - DUMP_TABLE_PARTITION_KEYS
Dumps the partition keys of all projections for the specified table.
Dumps the partition keys of all projections for the specified table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DUMP_TABLE_PARTITION_KEYS ( '[[database.]schema.]table-name' )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name- Name of the table
Privileges
Non-superuser: TRUNCATE on table
Examples
The following example creates a simple table called states and partitions the data by state:
=> CREATE TABLE states (year INTEGER NOT NULL,
state VARCHAR NOT NULL)
PARTITION BY state;
=> CREATE PROJECTION states_p (state, year) AS
SELECT * FROM states
ORDER BY state, year UNSEGMENTED ALL NODES;
Now dump the partition keys of all projections anchored on table states:
=> SELECT DUMP_TABLE_PARTITION_KEYS( 'states' );
DUMP_TABLE_PARTITION_KEYS --------------------------------------------------------------------------------------------
Partition keys on node v_vmart_node0001
Projection 'states_p'
Storage [ROS container]
No of partition keys: 1
Partition keys: VT
Storage [ROS container]
No of partition keys: 1
Partition keys: PA
Storage [ROS container]
No of partition keys: 1
Partition keys: NY
Storage [ROS container]
No of partition keys: 1
Partition keys: MA
Partition keys on node v_vmart_node0002
...
(1 row)
See also
6.13.11.6 - MOVE_PARTITIONS_TO_TABLE
Moves partitions from one table to another.
Moves partitions from one table to another.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MOVE_PARTITIONS_TO_TABLE (
'[[{namespace. | database. }]schema.]source-table',
'min-range-value',
'max-range-value',
'[[{namespace. | database. }]schema.]target-table'
[, force-split]
)
Arguments
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
For Eon Mode databases, the namespaces of staging-table and target-table must have the same shard count.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
source-table- The source table of the partitions to move.
min-range-value, max-range-value- The minimum and maximum value of partition keys to move, where
min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
target-table- The target table of the partitions to move. If the table does not exist, Vertica creates a table from the source table's definition, by calling
CREATE TABLE with LIKE and INCLUDING PROJECTIONS clause. The new table inherits ownership from the source table. For details, see Replicating a table.
force-splitOptional Boolean argument, specifies whether to split ROS containers if the range of partition keys spans multiple containers or part of a single container:
Privileges
Non-superuser, one of the following:
-
Owner of source and target tables
-
SELECT, TRUNCATE on the source table, INSERT on the target table
If the target table does not exist, you must also have CREATE privileges on the target schema to enable table creation.
Table attribute requirements
The following attributes of both tables must be identical:
-
Column definitions, including NULL/NOT NULL constraints
-
Segmentation
-
Partition clause
-
Number of projections
-
Shard count (Eon Mode only)
-
Projection sort order
-
Primary and unique key constraints. However, the key constraints do not have to be identically enabled. For more information on constraints, see Constraints.
Note
If the target table has primary or unique key constraints enabled and copying or moving the partitions will insert duplicate key values into the target table, Vertica rolls back the operation.
-
Check constraints. For MOVE_PARTITIONS_TO_TABLE and COPY_PARTITIONS_TO_TABLE, Vertica enforces enabled check constraints on the target table only. For SWAP_PARTITIONS_BETWEEN_TABLES, Vertica enforces enabled check constraints on both tables. If there is a violation of an enabled check constraint, Vertica rolls back the operation.
-
Number and definitions of text indices.
Additionally, If access policies exist on the source table, the following must be true:
Table restrictions
The following restrictions apply to the source and target tables:
-
If the source and target partitions are in different storage tiers, Vertica returns a warning but the operation proceeds. The partitions remain in their existing storage tier.
-
The target table cannot be immutable.
-
The following tables cannot be used as sources or targets:
-
Temporary tables
-
Virtual tables
-
System tables
-
External tables
Examples
See Archiving partitions.
See also
6.13.11.7 - PARTITION_PROJECTION
Splits containers for a specified projection.
Splits ROS containers for a specified projection. PARTITION_PROJECTION also purges data while partitioning ROS containers if deletes were applied before the AHM epoch.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PARTITION_PROJECTION ( '[[database.]schema.]projection')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection``- The projection to partition.
Privileges
Examples
In this example, PARTITION_PROJECTION forces a split of ROS containers on the states_p projection:
=> SELECT PARTITION_PROJECTION ('states_p');
PARTITION_PROJECTION
------------------------
Projection partitioned
(1 row)
See also
6.13.11.8 - PARTITION_TABLE
Invokes the to reorganize ROS storage containers as needed to conform with the current partitioning policy.
Invokes the Tuple Mover to reorganize ROS storage containers as needed to conform with the current partitioning policy.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PARTITION_TABLE ( '[schema.]table-name')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name - The table to partition.
Privileges
Restrictions
-
You cannot run PARTITION_TABLE on a table that is an anchor table for a live aggregate projection or a Top-K projection.
-
To reorganize storage to conform to a new policy, run PARTITION_TABLE after changing the partition GROUP BY expression.
See also
6.13.11.9 - PURGE_PARTITION
Purges a table partition of deleted rows.
Purges a table partition of deleted rows. Similar to PURGE and PURGE_PROJECTION, this function removes deleted data from physical storage so you can reuse the disk space. PURGE_PARTITION removes data only from the AHM epoch and earlier.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PURGE_PARTITION ( '[[database.]schema.]table', partition-key )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The partitioned table to purge.
partition-key - The key of the partition to purge.
Privileges
Examples
The following example lists the count of deleted rows for each partition in a table, then calls PURGE_PARTITION() to purge the deleted rows from the data.
=> SELECT partition_key,table_schema,projection_name,sum(deleted_row_count)
AS deleted_row_count FROM partitions
GROUP BY partition_key,table_schema,projection_name
ORDER BY partition_key;
partition_key | table_schema | projection_name | deleted_row_count
---------------+--------------+-----------------+-------------------
0 | public | t_super | 2
1 | public | t_super | 2
2 | public | t_super | 2
3 | public | t_super | 2
4 | public | t_super | 2
5 | public | t_super | 2
6 | public | t_super | 2
7 | public | t_super | 2
8 | public | t_super | 2
9 | public | t_super | 1
(10 rows)
=> SELECT PURGE_PARTITION('t',5); -- Purge partition with key 5.
purge_partition
------------------------------------------------------------------------
Task: merge partitions
(Table: public.t) (Projection: public.t_super)
(1 row)
=> SELECT partition_key,table_schema,projection_name,sum(deleted_row_count)
AS deleted_row_count FROM partitions
GROUP BY partition_key,table_schema,projection_name
ORDER BY partition_key;
partition_key | table_schema | projection_name | deleted_row_count
---------------+--------------+-----------------+-------------------
0 | public | t_super | 2
1 | public | t_super | 2
2 | public | t_super | 2
3 | public | t_super | 2
4 | public | t_super | 2
5 | public | t_super | 0
6 | public | t_super | 2
7 | public | t_super | 2
8 | public | t_super | 2
9 | public | t_super | 1
(10 rows)
See also
6.13.11.10 - SWAP_PARTITIONS_BETWEEN_TABLES
Swaps partitions between two tables.
Swaps partitions between two tables.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SWAP_PARTITIONS_BETWEEN_TABLES (
'[[{namespace. | database. }]schema.]staging-table',
'min-range-value',
'max-range-value',
'[[{namespace. | database. }]schema.]target-table'
[, force-split]
)
Arguments
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
For Eon Mode databases, the namespaces of staging-table and target-table must have the same shard count.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
staging-table- The staging table from which to swap partitions.
min-range-value, max-range-value- The minimum and maximum value of partition keys to swap, where
min‑range‑value must be ≤ max‑range‑value. To specify a single partition key, min‑range‑value and max‑range‑value must be equal.
target-table- The table to which the partitions are to be swapped. The target table cannot be the same as the staging table.
force-splitOptional Boolean argument, specifies whether to split ROS containers if the range of partition keys spans multiple containers or part of a single container:
Privileges
Non-superuser, one of the following:
-
Owner of source and target tables
-
Target and source tables: TRUNCATE, INSERT, SELECT
Requirements
The following attributes of both tables must be identical:
-
Column definitions, including NULL/NOT NULL constraints
-
Segmentation
-
Partition clause
-
Number of projections
-
Shard count (Eon Mode only)
-
Projection sort order
-
Primary and unique key constraints. However, the key constraints do not have to be identically enabled. For more information on constraints, see Constraints.
Note
If the target table has primary or unique key constraints enabled and copying or moving the partitions will insert duplicate key values into the target table, Vertica rolls back the operation.
-
Check constraints. For MOVE_PARTITIONS_TO_TABLE and COPY_PARTITIONS_TO_TABLE, Vertica enforces enabled check constraints on the target table only. For SWAP_PARTITIONS_BETWEEN_TABLES, Vertica enforces enabled check constraints on both tables. If there is a violation of an enabled check constraint, Vertica rolls back the operation.
-
Number and definitions of text indices.
Additionally, If access policies exist on the source table, the following must be true:
Restrictions
The following restrictions apply to the source and target tables:
-
If the source and target partitions are in different storage tiers, Vertica returns a warning but the operation proceeds. The partitions remain in their existing storage tier.
-
The target table cannot be immutable.
-
The following tables cannot be used as sources or targets:
-
Temporary tables
-
Virtual tables
-
System tables
-
External tables
Examples
See Swapping partitions.
6.13.12 - Privileges and access functions
This section contains functions for managing user and role privileges, and access policies.
This section contains functions for managing user and role privileges, and access policies.
6.13.12.1 - ENABLED_ROLE
Checks whether a Vertica user role is enabled, and returns true or false.
Checks whether a Vertica user role is enabled, and returns true or false. This function is typically used when you create access policies on database roles.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLED_ROLE ( 'role' )
Parameters
role- The role to evaluate.
Privileges
None
Examples
See:
See also
CREATE ACCESS POLICY
6.13.12.2 - GET_PRIVILEGES_DESCRIPTION
Returns the effective privileges the current user has on an object, including explicit, implicit, inherited, and role-based privileges.
Returns the effective privileges the current user has on an object, including explicit, implicit, inherited, and role-based privileges.
Because this meta-function only returns effective privileges, GET_PRIVILEGES_DESCRIPTION only returns privileges with fully-satisfied prerequisites. For a list of prerequisites for common operations, see Privileges required for common database operations.
For example, a user must have the following privileges to query a table:
-
Schema: USAGE
-
Table: SELECT
If user Brooke has SELECT privileges on table s1.t1 but lacks USAGE privileges on schema s1, Brooke cannot query the table, and GET_PRIVILEGES_DESCRIPTION does not return SELECT as a privilege for the table.
Note
Inherited privileges are not displayed if privilege inheritance is disabled at the database level with
DisableInheritedPrivileges.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_PRIVILEGES_DESCRIPTION( 'type', '[[database.]schema.]name' );
Parameters
type- Specifies an object type, one of the following:
-
database
-
table
-
schema
-
view
-
sequence
-
model
-
library
-
resource pool
[database.]schema- Specifies a database and schema, by default the current database and
public, respectively.
name- Name of the target object
Privileges
None
Examples
In the following example, user Glenn has set the REPORTER role and wants to check his effective privileges on schema s1 and table s1.articles.
-
Table s1.articles inherits privileges from its schema (s1).
-
The REPORTER role has the following privileges:
-
User Glenn has the following privileges:
GET_PRIVILEGES_DESCRIPTION returns the following effective privileges for Glenn on schema s1:
=> SELECT GET_PRIVILEGES_DESCRIPTION('schema', 's1');
GET_PRIVILEGES_DESCRIPTION
--------------------------------
SELECT, UPDATE, USAGE
(1 row)
GET_PRIVILEGES_DESCRIPTION returns the following effective privileges for Glenn on table s1.articles:
=> SELECT GET_PRIVILEGES_DESCRIPTION('table', 's1.articles');
GET_PRIVILEGES_DESCRIPTION
--------------------------------
INSERT*, SELECT, UPDATE, DELETE
(1 row)
See also
6.13.12.3 - HAS_ROLE
Checks whether a Vertica user role is granted to the specified user or role, and returns true or false.
Checks whether a Vertica user role is granted to the specified user or role, and returns true or false.
You can also query system tables ROLES, GRANTS, and USERS to obtain information on users and their role assignments. For details, see Viewing user roles.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
HAS_ROLE( [ 'grantee' ,] 'verify-role' );
Parameters
grantee- Valid only for superusers, specifies the name of a user or role to look up. If this argument is omitted, the function uses the current user name (
CURRENT_USER). If you specify a role, Vertica checks whether this role is granted to the role specified in verify-role.
Important
If a non-superuser supplies this argument, Vertica returns an error.
verify-role- Name of the role to verify for
grantee.
Privileges
None
Examples
In the following example, a dbadmin user checks whether user MikeL is assigned the admnistrator role:
=> \c
You are now connected as user "dbadmin".
=> SELECT HAS_ROLE('MikeL', 'administrator');
HAS_ROLE
----------
t
(1 row)
User MikeL checks whether he has the regional_manager role:
=> \c - MikeL
You are now connected as user "MikeL".
=> SELECT HAS_ROLE('regional_manager');
HAS_ROLE
----------
f
(1 row)
The dbadmin grants the regional_manager role to the administrator role. On checking again, MikeL verifies that he now has the regional_manager role:
dbadmin=> \c
You are now connected as user "dbadmin".
dbadmin=> GRANT regional_manager to administrator;
GRANT ROLE
dbadmin=> \c - MikeL
You are now connected as user "MikeL".
dbadmin=> SELECT HAS_ROLE('regional_manager');
HAS_ROLE
----------
t
(1 row)
See also
6.13.12.4 - RELEASE_SYSTEM_TABLES_ACCESS
Enables non-superuser access to all system tables.
Allows non-superusers to access all non-SUPERUSER_ONLY system tables. After you call this function, Vertica ignores the IS_ACCESSIBLE_DURING_LOCKDOWN setting in table SYSTEM_TABLES. To restrict non-superusers access to system tables, call RESTRICT_SYSTEM_TABLES_ACCESS.
By default, the database behaves as though RELEASE_SYSTEM_TABLES_ACCESS() was called. That is, non-superusers have access to all non-SUPERUSER_ONLY system tables.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RELEASE_SYSTEM_TABLES_ACCESS()
Privileges
Superuser
Examples
By default, non-superuser Alice has access to client_auth and disk_storage. She also has access to replication_status because she was granted the privilege by the dbadmin:
=> SELECT table_name, is_superuser_only, is_accessible_during_lockdown FROM system_tables WHERE table_name='disk_storage' OR table_name='database_backups' OR table_name='replication_status' OR table_name='client_auth';
table_name | is_superuser_only | is_accessible_during_lockdown
--------------------+-------------------+-------------------------------
client_auth | f | t
disk_storage | f | f
database_backups | t | f
replication_status | t | t
(4 rows)
The dbadmin calls RESTRICT_SYSTEM_TABLES_ACCESS:
=> SELECT RESTRICT_SYSTEM_TABLES_ACCESS();
RESTRICT_SYSTEM_TABLES_ACCESS
----------------------------------------------------------------------------
Dropped grants to public on non-accessible during lockdown system tables.
(1 row)
Alice loses access to disk_storage, but she retains access to client_auth and replication_status because their IS_ACCESSIBLE_DURING_LOCKDOWN fields are true:
=> SELECT storage_status FROM disk_storage;
ERROR 4367: Permission denied for relation disk_storage
The dbadmin calls RELEASE_SYSTEM_TABLES_ACCESS(), restoring Alice's access to disk_storage:
=> SELECT RELEASE_SYSTEM_TABLES_ACCESS();
RELEASE_SYSTEM_TABLES_ACCESS
--------------------------------------------------------
Granted SELECT privileges on system tables to public.
(1 row)
6.13.12.5 - RESTRICT_SYSTEM_TABLES_ACCESS
Checks system table SYSTEM_TABLES to determine which system tables non-superusers can access.
Prevents non-superusers from accessing tables that have the IS_ACCESSIBLE_DURING_LOCKDOWN flag set to false.
To enable non-superuser access to system tables restricted by this function, call RELEASE_SYSTEM_TABLES_ACCESS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESTRICT_SYSTEM_TABLES_ACCESS()
Privileges
Superuser
Examples
By default, client_auth and disk_storage tables are accessible to all users, but only the former is accessible after RESTRICT_SYSTEM_TABLES_ACCESS() is called. Non-superusers never have access to database_backups and replication_status unless explicitly granted the privilege by the dbadmin:
=> SELECT table_name, is_superuser_only, is_accessible_during_lockdown FROM system_tables WHERE table_name='disk_storage' OR table_name='database_backups' OR table_name='replication_status' OR table_name='client_auth';
table_name | is_superuser_only | is_accessible_during_lockdown
--------------------+-------------------+-------------------------------
client_auth | f | t
disk_storage | f | f
database_backups | t | f
replication_status | t | t
(4 rows)
The dbadmin then calls RESTRICT_SYSTEM_TABLES_ACCESS():
=> SELECT RESTRICT_SYSTEM_TABLES_ACCESS();
RESTRICT_SYSTEM_TABLES_ACCESS
----------------------------------------------------------------------------
Dropped grants to public on non-accessible during lockdown system tables.
(1 row)
Bob loses access to disk_storage, but retains access to client_auth because its IS_ACCESSIBLE_DURING_LOCKDOWN field is true:
=> SELECT storage_status FROM disk_storage;
ERROR 4367: Permission denied for relation disk_storage
=> SELECT auth_oid FROM client_auth;
auth_oid
-------------------
45035996273705106
45035996273705110
45035996273705114
(3 rows)
6.13.13 - Projection functions
This section contains projection management functions specific to Vertica.
This section contains projection management functions specific to Vertica.
See also
6.13.13.1 - CLEAR_PROJECTION_REFRESHES
Clears information projection refresh history from system table PROJECTION_REFRESHES.
Clears projection refresh history from the PROJECTION_REFRESHES system table. PROJECTION_REFRESHES records information about successful and unsuccessful refresh operations.
CLEAR_PROJECTION_REFRESHES removes information only for refresh operations that are complete, as indicated by the IS_EXECUTING column in PROJECTION_REFRESHES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_PROJECTION_REFRESHES()
Privileges
Superuser
Examples
=> SELECT CLEAR_PROJECTION_REFRESHES();
CLEAR_PROJECTION_REFRESHES
----------------------------
CLEAR
(1 row)
See also
6.13.13.2 - EVALUATE_DELETE_PERFORMANCE
Evaluates projections for potential DELETE and UPDATE performance issues.
Evaluates projections for potential DELETE and UPDATE performance issues. If Vertica finds any issues, it issues a warning message. When evaluating multiple projections, EVALUATE_DELETE_PERFORMANCE returns up to ten projections with issues, and the name of a table that lists all issues that it found.
Note
EVALUATE_DELETE_PERFORMANCE returns messages that specifically reference delete performance. Keep in mind, however, that delete and update operations benefit equally from the same optimizations.
For information on resolving delete and update performance issues, see Optimizing DELETE and UPDATE.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EVALUATE_DELETE_PERFORMANCE ( ['[[database.]schema.]scope'] )
Parameters
-
`[database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
scope- Specifies the projections to evaluate, one of the following:
-
[table.]projection
Evaluate projection. For example:
SELECT EVALUATE_DELETE_PERFORMANCE('store.store_orders_fact.store_orders_fact_b1');
-
table
Specifies to evaluate all projections of table. For example:
SELECT EVALUATE_DELETE_PERFORMANCE('store.store_orders_fact');
If you supply no arguments, EVALUATE_DELETE_PERFORMANCE evaluates all projections that you can access. Depending on the size of your database, this can incur considerable overhead.
Privileges
Non-superuser: SELECT privilege on the anchor table
Examples
EVALUATE_DELETE_PERFORMANCE evaluates all projections of table example for potential DELETE and UPDATE performance issues.
=> create table example (A int, B int,C int);
CREATE TABLE
=> create projection one_sort (A,B,C) as (select A,B,C from example) order by A;
CREATE PROJECTION
=> create projection two_sort (A,B,C) as (select A,B,C from example) order by A,B;
CREATE PROJECTION
=> select evaluate_delete_performance('example');
evaluate_delete_performance
---------------------------------------------------
No projection delete performance concerns found.
(1 row)
The previous example show that the two projections one_sort and two_sort have no inherent structural issues that might cause poor DELETE performance. However, the data contained within the projection can create potential delete issues if the sorted columns do not uniquely identify a row or small number of rows.
In the following example, Perl is used to populate the table with data using a nested series of loops:
-
The inner loop populates column C.
-
The middle loop populates column B.
-
The outer loop populates column A.
The result is column A contains only three distinct values (0, 1, and 2), while column B slowly varies between 20 and 0 and column C changes in each row:
=> \! perl -e 'for ($i=0; $i<3; $i++) { for ($j=0; $j<21; $j++) { for ($k=0; $k<19; $k++) { printf "%d,%d,%d\n", $i,$j,$k;}}}' | /opt/vertica/bin/vsql -c "copy example from stdin delimiter ',' direct;"
Password:
=> select * from example;
A | B | C
---+----+----
0 | 20 | 18
0 | 20 | 17
0 | 20 | 16
0 | 20 | 15
0 | 20 | 14
0 | 20 | 13
0 | 20 | 12
0 | 20 | 11
0 | 20 | 10
0 | 20 | 9
0 | 20 | 8
0 | 20 | 7
0 | 20 | 6
0 | 20 | 5
0 | 20 | 4
0 | 20 | 3
0 | 20 | 2
0 | 20 | 1
0 | 20 | 0
0 | 19 | 18
...
2 | 1 | 0
2 | 0 | 18
2 | 0 | 17
2 | 0 | 16
2 | 0 | 15
2 | 0 | 14
2 | 0 | 13
2 | 0 | 12
2 | 0 | 11
2 | 0 | 10
2 | 0 | 9
2 | 0 | 8
2 | 0 | 7
2 | 0 | 6
2 | 0 | 5
2 | 0 | 4
2 | 0 | 3
2 | 0 | 2
2 | 0 | 1
2 | 0 | 0
=> SELECT COUNT (*) FROM example;
COUNT
-------
1197
(1 row)
=> SELECT COUNT (DISTINCT A) FROM example;
COUNT
-------
3
(1 row)
EVALUATE_DELETE_PERFORMANCE is run against the projections again to determine whether the data within the projections causes any potential DELETE performance issues. Projection one_sort has potential delete issues as it only sorts on column A which has few distinct values. Each value in the sort column corresponds to many rows in the projection, which can adversely impact DELETE performance. In contrast, projection two_sort is sorted on columns A and B, where each combination of values in the two sort columns identifies just a few rows, so deletes can be performed faster:
=> select evaluate_delete_performance('example');
evaluate_delete_performance
---------------------------------------------------
The following projections exhibit delete performance concerns:
"public"."one_sort_b1"
"public"."one_sort_b0"
See v_catalog.projection_delete_concerns for more details.
=> \x
Expanded display is on.
dbadmin=> select * from projection_delete_concerns;
-[ RECORD 1 ]------+------------------------------------------------------------------------------------------------------------------------------------------------------------
projection_id | 45035996273878562
projection_schema | public
projection_name | one_sort_b1
creation_time | 2019-06-17 13:59:03.777085-04
last_modified_time | 2019-06-17 14:00:27.702223-04
comment | The squared number of rows matching each sort key is about 159201 on average.
-[ RECORD 2 ]------+------------------------------------------------------------------------------------------------------------------------------------------------------------
projection_id | 45035996273878548
projection_schema | public
projection_name | one_sort_b0
creation_time | 2019-06-17 13:59:03.777279-04
last_modified_time | 2019-06-17 13:59:03.777279-04
comment | The squared number of rows matching each sort key is about 159201 on average.
If you omit supplying an argument to EVALUATE_DELETE_PERFORMANCE, it evaluates all projections that you can access:
=> select evaluate_delete_performance();
evaluate_delete_performance
---------------------------------------------------------------------------
The following projections exhibit delete performance concerns:
"public"."one_sort_b0"
"public"."one_sort_b1"
See v_catalog.projection_delete_concerns for more details.
(1 row)
6.13.13.3 - GET_PROJECTION_SORT_ORDER
Returns the order of columns in a projection's ORDER BY clause.
Returns the order of columns in a projection's ORDER BY clause.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_PROJECTION_SORT_ORDER( '[[database.]schema.]projection' );
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The target projection.
Privileges
Non-superuser: SELECT privilege on the anchor table
Examples
=> SELECT get_projection_sort_order ('store_orders_super');
get_projection_sort_order
--------------------------------------------------------------------------------------------
public.store_orders_super [Sort Cols: "order_no", "order_date", "shipper", "ship_date"]
(1 row)
6.13.13.4 - GET_PROJECTION_STATUS
Returns information relevant to the status of a :.
Returns information relevant to the status of a projection:
-
The current K-safety status of the database
-
The number of nodes in the database
-
Whether the projection is segmented
-
The number and names of buddy projections
-
Whether the projection is safe
-
Whether the projection is up to date
-
Whether statistics have been computed for the projection
Use
GET_PROJECTION_STATUS to monitor the progress of a projection data refresh.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_PROJECTION_STATUS ( '[[database.]schema.]projection' );
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The projection for which to display status.
Examples
=> SELECT GET_PROJECTION_STATUS('public.customer_dimension_site01');
GET_PROJECTION_STATUS
-----------------------------------------------------------------------------------------------
Current system K is 1.
# of Nodes: 4.
public.customer_dimension_site01 [Segmented: No] [Seg Cols: ] [K: 3] [public.customer_dimension_site04, public.customer_dimension_site03,
public.customer_dimension_site02]
[Safe: Yes] [UptoDate: Yes][Stats: Yes]
6.13.13.5 - GET_PROJECTIONS
Returns contextual and projection information about projections of the specified anchor table.
Returns contextual and projection information about projections of the specified anchor table.
- Contextual information
-
- Projection data
- For each projection, specifies:
You can also use GET_PROJECTIONS to monitor the progress of a projection data refresh.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_PROJECTIONS ( '[[database.]schema-name.]table' )
Parameters
-
`[database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
table- Anchor table of the projections to list.
Privileges
None
Examples
The following example gets information about projections for VMart table store.store_dimension:
=> SELECT GET_PROJECTIONS('store.store_dimension');
-[ RECORD 1 ]---+
GET_PROJECTIONS | Current system K is 1.
# of Nodes: 3.
Table store.store_dimension has 2 projections.
Projection Name: [Segmented] [Seg Cols] [# of Buddies] [Buddy Projections] [Safe] [UptoDate] [Stats]
----------------------------------------------------------------------------------------------------
store.store_dimension_b1 [Segmented: Yes] [Seg Cols: "store.store_dimension.store_key"] [K: 1] [store.store_dimension_b0] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
store.store_dimension_b0 [Segmented: Yes] [Seg Cols: "store.store_dimension.store_key"] [K: 1] [store.store_dimension_b1] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
6.13.13.6 - PURGE_PROJECTION
PURGE_PROJECTION can use significant disk space while purging the data.
Permanently removes deleted data from physical storage so disk space can be reused. You can purge historical data up to and including the Ancient History Mark epoch.
Caution
PURGE_PROJECTION can use significant disk space while purging the data.
See
PURGE for details about purge operations.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PURGE_PROJECTION ( '[[database.]schema.]projection' )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The projection to purge.
Privileges
Examples
The following example purges all historical data in projection tbl_p that precedes the Ancient History Mark epoch.
=> CREATE TABLE tbl (x int, y int);
CREATE TABLE
=> INSERT INTO tbl VALUES(1,2);
OUTPUT
--------
1
(1 row)
=> INSERT INTO tbl VALUES(3,4);
OUTPUT
--------
1
(1 row)
dbadmin=> COMMIT;
COMMIT
=> CREATE PROJECTION tbl_p AS SELECT x FROM tbl UNSEGMENTED ALL NODES;
WARNING 4468: Projection <public.tbl_p> is not available for query processing.
Execute the select start_refresh() function to copy data into this projection.
The projection must have a sufficient number of buddy projections and all nodes must be up before starting a refresh
CREATE PROJECTION
=> SELECT START_REFRESH();
START_REFRESH
----------------------------------------
Starting refresh background process.
=> DELETE FROM tbl WHERE x=1;
OUTPUT
--------
1
(1 row)
=> COMMIT;
COMMIT
=> SELECT MAKE_AHM_NOW();
MAKE_AHM_NOW
-------------------------------
AHM set (New AHM Epoch: 9066)
(1 row)
=> SELECT PURGE_PROJECTION ('tbl_p');
PURGE_PROJECTION
-------------------
Projection purged
(1 row)
See also
6.13.13.7 - REFRESH
Synchronously refreshes one or more table projections in the foreground, and updates the PROJECTION_REFRESHES system table.
Synchronously refreshes one or more table projections in the foreground, and updates the PROJECTION_REFRESHES system table. If you run REFRESH with no arguments, it refreshes all projections that contain stale data.
To understand projection refreshing in detail, see Refreshing projections.
If a refresh would violate a table or schema disk quota, the operation fails. For more information, see Disk quotas.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REFRESH ( [ '[[database.]schema.]table[,...]' ] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The anchor table of the projections to refresh. If you specify multiple tables, REFRESH attempts to refresh them in parallel. Such calls are part of the Database Designer deployment (and deployment script).
Returns
Note
If REFRESH does not refresh any projections, it returns a header string with no results.
|
Column |
Returns |
Projection Name |
The projection targeted for refresh. |
Anchor Table |
The projection's associated anchor table. |
Status |
Projections' refresh status:
-
queued: Queued for refresh.
-
refreshing: Refresh is in process.
-
refreshed: Refresh successfully completed.
-
failed: Refresh did not successfully complete.
|
Refresh Method |
Method used to refresh the projection. |
Error Count |
Number of times a refresh failed for the projection. |
Duration (sec) |
How long (in seconds) the projection refresh ran. |
Privileges
Refresh methods
Vertica can refresh a projection from one of its buddies, if one is available. In this case, the target projection gets the source buddy's historical data. Otherwise, the projection is refreshed from scratch with data of the latest epoch at the time of the refresh operation. In this case, the projection cannot participate in historical queries on any epoch that precedes the refresh operation.
Vertica can perform incremental refreshes when the following conditions are met:
-
The table being refreshed is partitioned.
-
The table does not contain any unpartitioned data.
-
The operation is a full projection refresh (not a partition range projection refresh).
In an incremental refresh, the refresh operation first loads data from the partition with the highest range of keys. After refreshing this partition, Vertica begins to refresh the partition with next highest partition range. This process continues until all projection partitions are refreshed. While the refresh operation is in progress, projection partitions that have completed the refresh process become available to process query requests.
The method used to refresh a given projection is recorded in the REFRESH_METHOD column of the PROJECTION_REFRESHES system table.
Examples
The following example refreshes the projections in two tables:
=> SELECT REFRESH('t1, t2');
REFRESH
----------------------------------------------------------------------------------------
Refresh completed with the following outcomes:
Projection Name: [Anchor Table] [Status] [Refresh Method] [Error Count] [Duration (sec)]
----------------------------------------------------------------------------------------
"public"."t1_p": [t1] [refreshed] [scratch] [0] [0]"public"."t2_p": [t2] [refreshed] [scratch] [0] [0]
In the following example, only the projection on one table was refreshed:
=> SELECT REFRESH('allow, public.deny, t');
REFRESH
----------------------------------------------------------------------------------------
Refresh completed with the following outcomes:
Projection Name: [Anchor Table] [Status] [Refresh Method] [Error Count] [Duration (sec)]
----------------------------------------------------------------------------------------
"n/a"."n/a": [n/a] [failed: insufficient permissions on table "allow"] [] [1] [0]
"n/a"."n/a": [n/a] [failed: insufficient permissions on table "public.deny"] [] [1] [0]
"public"."t_p1": [t] [refreshed] [scratch] [0] [0]
See also
6.13.13.8 - REFRESH_COLUMNS
Refreshes table columns that are defined with the constraint SET USING or DEFAULT USING.
Refreshes table columns that are defined with the constraint SET USING or DEFAULT USING. All refresh operations associated with a call to REFRESH_COLUMNS belong to the same transaction. Thus, all tables and columns specified by REFRESH_COLUMNS must be refreshed; otherwise, the entire operation is rolled back.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REFRESH_COLUMNS ( 'table-list', '[column-list]'
[, '[refresh-mode]' [, min-partition-key, max-partition-key [, force-split] ]
)
Arguments
table-list- A comma-delimited list of the tables to refresh:
[[database.]schema.]table[,...]
If you specify multiple tables, refresh-mode must be set to REBUILD.
column-list- A comma-delimited list of columns to refresh:
[[[database.]schema.]table.]column[,...] or [[database.]schema.]table.*, where asterisk (*) means to refresh all SET USING/DEFAULT USING columns in the table. For example:
SELECT REFRESH_COLUMNS ('t1, t2', 't1.*, t2.b', 'REBUILD');
If column-list is set to an empty string (''), REFRESH_COLUMNS refreshes all SET USING/DEFAULT USING columns in the specified tables.
The following requirements apply:
-
All specified columns must have a SET USING or DEFAULT USING constraint.
-
If REFRESH_COLUMNS specifies multiple tables, all column names must be qualified by their table names. If the target tables span multiple schemas, all column names must be fully qualified by their schema and table names. For example:
SELECT REFRESH_COLUMNS ('t1, t2', 't1.a, t2.b', 'REBUILD');
If you specify a database, it must be the current database.
refresh-mode- Specifies how to refresh SET USING columns:
-
UPDATE (default): Marks original rows as deleted and replaces them with new rows. In order to save these updates, you must issue a COMMIT statement.
-
REBUILD: Replaces all data in the specified columns. The rebuild operation is auto-committed.
If you specify multiple tables, you must explicitly specify REBUILD mode.
In both cases, REFRESH_COLUMNS returns an error if any SET USING column is defined as a primary or unique key in a table that enforces those constraints.
See REBUILD Mode Restrictions for limitations on using the REBUILD option.
min-partition-key, max-partition-key- Qualifies REBUILD mode, limiting the rebuild operation to one or more partitions. To specify a range of partitions,
max-partition-key must be greater than min-partition-key. To update one partition, the two arguments must be equal.
The following requirements apply:
You can use these arguments to refresh columns with recently loaded data—that is, data in the latest partitions. Using this option regularly can significantly minimize the overhead otherwise incurred by rebuilding entire columns in a large table.
See Partition-based REBUILD below for details.
force-split- Boolean, whether to split ROS containers if the range of partition keys spans multiple containers or part of a single container:
Privileges
UPDATE versus REBUILD modes
In general, UPDATE mode is a better choice when changes to SET USING column data are confined to a relatively small number of rows. Use REBUILD mode when a significant amount of SET USING column data is stale and must be updated. It is generally good practice to call REFRESH_COLUMNS with REBUILD on any new SET USING column—for example, to populate a SET USING column after adding it with ALTER TABLE...ADD COLUMN.
REBUILD mode restrictions
If you call REFRESH_COLUMNS on a SET USING column and specify the refresh mode as REBUILD, Vertica returns an error if the column is specified in any of the following:
Partition-based REBUILD operations
If a flattened table is partitioned, you can reduce the overhead of calling REFRESH_COLUMNS in REBUILD mode, by specifying one or more partition keys. Doing so limits the rebuild operation to the specified partitions. For example, table public.orderFact is defined with SET USING column cust_name. This table is partitioned on column order_date, where the partition clause invokes Vertica function CALENDAR_HIERARCHY_DAY. Thus, you can call REFRESH_COLUMNS on specific time-delimited partitions of this table—in this case, on orders over the last two months:
=> SELECT REFRESH_COLUMNS ('public.orderFact',
'cust_name',
'REBUILD',
TO_CHAR(ADD_MONTHS(current_date, -2),'YYYY-MM')||'-01',
TO_CHAR(LAST_DAY(ADD_MONTHS(current_date, -1))));
REFRESH_COLUMNS
---------------------------
refresh_columns completed
(1 row)
Rewriting SET USING queries
When you call REFRESH_COLUMNS on a flattened table's SET USING (or DEFAULT USING) column, it executes the SET USING query by joining the target and source tables. By default, the source table is always the inner table of the join. In most cases, cardinality of the source table is less than the target table, so REFRESH_COLUMNS executes the join efficiently.
Occasionally—notably, when you call REFRESH_COLUMNS on a partitioned table—the source table can be larger than the target table. In this case, performance of the join operation can be suboptimal.
You can address this issue by enabling configuration parameter RewriteQueryForLargeDim. When enabled (1), Vertica rewrites the query, by reversing the inner and outer join between the target and source tables.
Important
Enable this parameter only if the SET USING source data is in a table that is larger than the target table. If the source data is in a table smaller than the target table, then enabling RewriteQueryForLargeDim can adversely affect refresh performance.
Examples
See Flattened table example and DEFAULT versus SET USING.
6.13.13.9 - START_REFRESH
Refreshes projections in the current schema with the latest data of their respective.
Refreshes projections in the current schema with the latest data of their respective anchor tables. START_REFRESH runs asynchronously in the background, and updates the PROJECTION_REFRESHES system table. This function has no effect if a refresh is already running.
To refresh only projections of a specific table, use REFRESH. When you deploy a design through Database Designer, it automatically refreshes its projections.
If a refresh would violate a table or schema disk quota, the operation fails. For more information, see Disk quotas.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
START_REFRESH()
Privileges
None
Requirements
All nodes must be up.
Refresh methods
Vertica can refresh a projection from one of its buddies, if one is available. In this case, the target projection gets the source buddy's historical data. Otherwise, the projection is refreshed from scratch with data of the latest epoch at the time of the refresh operation. In this case, the projection cannot participate in historical queries on any epoch that precedes the refresh operation.
Vertica can perform incremental refreshes when the following conditions are met:
-
The table being refreshed is partitioned.
-
The table does not contain any unpartitioned data.
-
The operation is a full projection refresh (not a partition range projection refresh).
In an incremental refresh, the refresh operation first loads data from the partition with the highest range of keys. After refreshing this partition, Vertica begins to refresh the partition with next highest partition range. This process continues until all projection partitions are refreshed. While the refresh operation is in progress, projection partitions that have completed the refresh process become available to process query requests.
The method used to refresh a given projection is recorded in the REFRESH_METHOD column of the PROJECTION_REFRESHES system table.
Examples
=> SELECT START_REFRESH();
START_REFRESH
----------------------------------------
Starting refresh background process.
(1 row)
See also
6.13.14 - Session functions
This section contains session management functions specific to Vertica.
This section contains session management functions specific to Vertica.
See also the SQL system table V_MONITOR.SESSIONS.
6.13.14.1 - CANCEL_REFRESH
Cancels refresh-related internal operations initiated by START_REFRESH and REFRESH.
Cancels refresh-related internal operations initiated by START_REFRESH and REFRESH.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CANCEL_REFRESH()
Privileges
None
Notes
-
Refresh tasks run in a background thread in an internal session, so you cannot use INTERRUPT_STATEMENT to cancel those statements. Instead, use CANCEL_REFRESH to cancel statements that are run by refresh-related internal sessions.
-
Run CANCEL_REFRESH() on the same node on which START_REFRESH() was initiated.
-
CANCEL_REFRESH() cancels the refresh operation running on a node, waits for the cancelation to complete, and returns SUCCESS.
-
Only one set of refresh operations runs on a node at any time.
Examples
Cancel a refresh operation executing in the background.
=> SELECT START_REFRESH();
START_REFRESH
----------------------------------------
Starting refresh background process.
(1 row)
=> SELECT CANCEL_REFRESH();
CANCEL_REFRESH
----------------------------------------
Stopping background refresh process.
(1 row)
See also
6.13.14.2 - CLOSE_ALL_SESSIONS
Closes all external sessions except the one that issues this function.
Closes all external sessions except the one that issues this function. Call this function before shutting down the Vertica database.
Vertica closes sessions asynchronously, so another session can open before this function returns. In this case, reissue this function. To view the status of all open sessions, query system table
SESSIONS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLOSE_ALL_SESSIONS()
Privileges
Non-superuser: None to close your own session
Examples
Two user sessions are open on separate nodes:
=> SELECT * FROM sessions;
-[ RECORD 1 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (select * from sessions;)
statement_start | 2011-01-03 15:36:13.896288
statement_id | 10
last_statement_duration_us | 14978
current_statement | select * from sessions;
ssl_state | None
authentication_method | Trust
-[ RECORD 2 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0002
user_name | dbadmin
client_hostname | 127.0.0.1:57174
client_pid | 30117
login_timestamp | 2011-01-03 15:33:00.842021-05
session_id | stress05-27944:0xc1a
client_label |
transaction_start | 2011-01-03 15:34:46.538102
transaction_id | -1
transaction_description | user dbadmin (COPY Mart_Fact FROM '/data/mart_Fact.tbl'
DELIMITER '|' NULL '\\n';)
statement_start | 2011-01-03 15:34:46.538862
statement_id |
last_statement_duration_us | 26250
current_statement | COPY Mart_Fact FROM '/data/Mart_Fact.tbl' DELIMITER '|'
NULL '\\n';
ssl_state | None
authentication_method | Trust
-[ RECORD 3 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0003
user_name | dbadmin
client_hostname | 127.0.0.1:56367
client_pid | 1191
login_timestamp | 2011-01-03 15:31:44.939302-05
session_id | stress06-25663:0xbec
client_label |
transaction_start | 2011-01-03 15:34:51.05939
transaction_id | 54043195528458775
transaction_description | user dbadmin (COPY Mart_Fact FROM '/data/Mart_Fact.tbl'
DELIMITER '|' NULL '\\n' DIRECT;)
statement_start | 2011-01-03 15:35:46.436748
statement_id |
last_statement_duration_us | 1591403
current_statement | COPY Mart_Fact FROM '/data/Mart_Fact.tbl' DELIMITER '|'
NULL '\\n' DIRECT;
ssl_state | None
authentication_method | Trust
Close all sessions:
=> \x
Expanded display is off.
=> SELECT CLOSE_ALL_SESSIONS();
CLOSE_ALL_SESSIONS
-------------------------------------------------------------------------
Close all sessions command sent. Check v_monitor.sessions for progress.
(1 row)
Session contents after issuing CLOSE_ALL_SESSIONS:
=> SELECT * FROM SESSIONS;
-[ RECORD 1 ]--------------+----------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (SELECT * FROM sessions;)
statement_start | 2011-01-03 16:19:56.720071
statement_id | 25
last_statement_duration_us | 15605
current_statement | SELECT * FROM SESSIONS;
ssl_state | None
authentication_method | Trust
See also
6.13.14.3 - CLOSE_SESSION
Interrupts the specified external session, rolls back the current transaction if any, and closes the socket.
Interrupts the specified external session, rolls back the current transaction if any, and closes the socket. You can only close your own session.
It might take some time before a session is closed. To view the status of all open sessions, query the system table
SESSIONS.
For detailed information about session management options, see Managing sessions.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLOSE_SESSION ( 'sessionid')
Parameters
sessionid - A string that specifies the session to close. This identifier is unique within the cluster at any point in time but can be reused when the session closes.
Privileges
None
Examples
User session opened. Record 2 shows the user session running a COPY DIRECT statement.
=> SELECT * FROM sessions;
-[ RECORD 1 ]--------------+-----------------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (SELECT * FROM sessions;)
statement_start | 2011-01-03 15:36:13.896288
statement_id | 10
last_statement_duration_us | 14978
current_statement | select * from sessions;
ssl_state | None
authentication_method | Trust
-[ RECORD 2 ]--------------+-----------------------------------------------
node_name | v_vmartdb_node0002
user_name | dbadmin
client_hostname | 127.0.0.1:57174
client_pid | 30117
login_timestamp | 2011-01-03 15:33:00.842021-05
session_id | stress05-27944:0xc1a
client_label |
transaction_start | 2011-01-03 15:34:46.538102
transaction_id | -1
transaction_description | user dbadmin (COPY ClickStream_Fact FROM
'/data/clickstream/1g/ClickStream_Fact.tbl'
DELIMITER '|' NULL '\\n' DIRECT;)
statement_start | 2011-01-03 15:34:46.538862
statement_id |
last_statement_duration_us | 26250
current_statement | COPY ClickStream_Fact FROM '/data/clickstream
/1g/ClickStream_Fact.tbl' DELIMITER '|' NULL
'\\n' DIRECT;
ssl_state | None
authentication_method | Trust
Close user session stress05-27944:0xc1a
=> \x
Expanded display is off.
=> SELECT CLOSE_SESSION('stress05-27944:0xc1a');
CLOSE_SESSION
--------------------------------------------------------------------
Session close command sent. Check v_monitor.sessions for progress.
(1 row)
Query the sessions table again for current status, and you can see that the second session has been closed:
=> SELECT * FROM SESSIONS;
-[ RECORD 1 ]--------------+--------------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (select * from SESSIONS;)
statement_start | 2011-01-03 16:12:07.841298
statement_id | 20
last_statement_duration_us | 2099
current_statement | SELECT * FROM SESSIONS;
ssl_state | None
authentication_method | Trust
See also
6.13.14.4 - CLOSE_USER_SESSIONS
Stops the session for a user, rolls back any transaction currently running, and closes the connection.
Stops the session for a user, rolls back any transaction currently running, and closes the connection. To determine the status of the sessions to close, query the
SESSIONS table.
Note
Running this function on your own sessions leaves one session running.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLOSE_USER_SESSIONS ( 'user-name' )
Parameters
user-name- Specifies the user whose sessions are to be closed. If you specify your own user name, Vertica closes all sessions except the one in which you issue this function.
Privileges
DBADMIN
Examples
This example closes all active session for user u1:
=> SELECT close_user_sessions('u1');
See also
6.13.14.5 - GET_NUM_ACCEPTED_ROWS
Returns the number of rows loaded into the database for the last completed load for the current session.
Returns the number of rows loaded into the database for the last completed load for the current session. GET_NUM_ACCEPTED_ROWS is a meta-function. Do not use it as a value in an INSERT query.
The number of accepted rows is not available for a load that is currently in process. Check the LOAD_STREAMS system table for its status.
This meta-function supports loads from STDIN, COPY LOCAL from a Vertica client, or a single file on the initiator. You cannot use GET_NUM_ACCEPTED_ROWS for multi-node loads.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_NUM_ACCEPTED_ROWS();
Privileges
None
Note
The data regarding accepted rows from the last load during the current session does not persist, and is lost when you initiate a new load.
Examples
This examples shows the number of accepted rows from the vmart_load_data.sql meta-command.
=> \i vmart_load_data.sql;
=> SELECT GET_NUM_ACCEPTED_ROWS ();
GET_NUM_ACCEPTED_ROWS
-----------------------
300000
(1 row)
See also
6.13.14.6 - GET_NUM_REJECTED_ROWS
Returns the number of rows that were rejected during the last completed load for the current session.
Returns the number of rows that were rejected during the last completed load for the current session. GET_NUM_REJECTED_ROWS is a meta-function. Do not use it as a value in an INSERT query.
Rejected row information is unavailable for a load that is currently running. The number of rejected rows is not available for a load that is currently in process. Check the LOAD_STREAMS system table for its status.
This meta-function supports loads from STDIN, COPY LOCAL from a Vertica client, or a single file on the initiator. You cannot use GET_NUM_REJECTED_ROWS for multi-node loads.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
GET_NUM_REJECTED_ROWS();
Privileges
None
Note
The data regarding rejected rows from the last load during the current session does not persist, and is dropped when you initiate a new load.
Examples
This example shows the number of rejected rows from the vmart_load_data.sql meta-command.
=> \i vmart_load_data.sql
=> SELECT GET_NUM_REJECTED_ROWS ();
GET_NUM_REJECTED_ROWS
-----------------------
0
(1 row)
See also
6.13.14.7 - INTERRUPT_STATEMENT
Interrupts the specified statement in a user session, rolls back the current transaction, and writes a success or failure message to the log file.
Interrupts the specified statement in a user session, rolls back the current transaction, and writes a success or failure message to the log file.
Sessions can be interrupted during statement execution. Only statements run by user sessions can be interrupted.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
INTERRUPT_STATEMENT( 'session-id', statement-id)
Parameters
session-id- Identifies the session to interrupt. This identifier is unique within the cluster at any point in time.
statement-id- Identifies the statement to interrupt. If the
*statement-id* is valid, the statement can be interrupted and INTERRUPT_STATEMENT returns a success message. Otherwise the system returns an error.
Privileges
Superuser
Messages
The following list describes messages you might encounter:
|
Message |
Meaning |
Statement interrupt sent. Check SESSIONS for progress. |
This message indicates success. |
Session <id> could not be successfully interrupted: session not found. |
The session ID argument to the interrupt command does not match a running session. |
Session <id> could not be successfully interrupted: statement not found. |
The statement ID does not match (or no longer matches) the ID of a running statement (if any). |
No interruptible statement running |
The statement is DDL or otherwise non-interruptible. |
Internal (system) sessions cannot be interrupted. |
The session is internal, and only statements run by external sessions can be interrupted. |
Examples
Two user sessions are open. RECORD 1 shows user session running SELECT FROM SESSION, and RECORD 2 shows user session running COPY DIRECT:
=> SELECT * FROM SESSIONS;
-[ RECORD 1 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (select * from sessions;)
statement_start | 2011-01-03 15:36:13.896288
statement_id | 10
last_statement_duration_us | 14978
current_statement | select * from sessions;
ssl_state | None
authentication_method | Trust
-[ RECORD 2 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0003
user_name | dbadmin
client_hostname | 127.0.0.1:56367
client_pid | 1191
login_timestamp | 2011-01-03 15:31:44.939302-05
session_id | stress06-25663:0xbec
client_label |
transaction_start | 2011-01-03 15:34:51.05939
transaction_id | 54043195528458775
transaction_description | user dbadmin (COPY Mart_Fact FROM '/data/Mart_Fact.tbl'
DELIMITER '|' NULL '\\n' DIRECT;)
statement_start | 2011-01-03 15:35:46.436748
statement_id | 5
last_statement_duration_us | 1591403
current_statement | COPY Mart_Fact FROM '/data/Mart_Fact.tbl' DELIMITER '|'
NULL '\\n' DIRECT;
ssl_state | None
authentication_method | Trust
Interrupt the COPY DIRECT statement running in session stress06-25663:0xbec:
=> \x
Expanded display is off.
=> SELECT INTERRUPT_STATEMENT('stress06-25663:0x1537', 5);
interrupt_statement
------------------------------------------------------------------
Statement interrupt sent. Check v_monitor.sessions for progress.
(1 row)
Verify that the interrupted statement is no longer active by looking at the current_statement column in the SESSIONS system table. This column becomes blank when the statement is interrupted:
=> SELECT * FROM SESSIONS;
-[ RECORD 1 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0001
user_name | dbadmin
client_hostname | 127.0.0.1:52110
client_pid | 4554
login_timestamp | 2011-01-03 14:05:40.252625-05
session_id | stress04-4325:0x14
client_label |
transaction_start | 2011-01-03 14:05:44.325781
transaction_id | 45035996273728326
transaction_description | user dbadmin (select * from sessions;)
statement_start | 2011-01-03 15:36:13.896288
statement_id | 10
last_statement_duration_us | 14978
current_statement | select * from sessions;
ssl_state | None
authentication_method | Trust
-[ RECORD 2 ]--------------+----------------------------------------------------
node_name | v_vmartdb_node0003
user_name | dbadmin
client_hostname | 127.0.0.1:56367
client_pid | 1191
login_timestamp | 2011-01-03 15:31:44.939302-05
session_id | stress06-25663:0xbec
client_label |
transaction_start | 2011-01-03 15:34:51.05939
transaction_id | 54043195528458775
transaction_description | user dbadmin (COPY Mart_Fact FROM '/data/Mart_Fact.tbl'
DELIMITER '|' NULL '\\n' DIRECT;)
statement_start | 2011-01-03 15:35:46.436748
statement_id | 5
last_statement_duration_us | 1591403
current_statement |
ssl_state | None
authentication_method | Trust
See also
6.13.14.8 - RELEASE_ALL_JVM_MEMORY
Forces all sessions to release the memory consumed by their Java Virtual Machines (JVM).
Forces all sessions to release the memory consumed by their Java Virtual Machines (JVM).
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RELEASE_ALL_JVM_MEMORY();
Privileges
Must be a superuser.
Examples
The following example demonstrates viewing the JVM memory use in all open sessions, then calling RELEASE_ALL_JVM_MEMORY() to release the memory:
=> select user_name,external_memory_kb FROM V_MONITOR.SESSIONS;
user_name | external_memory_kb
-----------+---------------
dbadmin | 79705
(1 row)
=> SELECT RELEASE_ALL_JVM_MEMORY();
RELEASE_ALL_JVM_MEMORY
-----------------------------------------------------------------------------
Close all JVM sessions command sent. Check v_monitor.sessions for progress.
(1 row)
=> SELECT user_name,external_memory_kb FROM V_MONITOR.SESSIONS;
user_name | external_memory_kb
-----------+---------------
dbadmin | 0
(1 row)
See also
6.13.14.9 - RELEASE_JVM_MEMORY
Terminates a Java Virtual Machine (JVM), making available the memory the JVM was using.
Terminates a Java Virtual Machine (JVM), making available the memory the JVM was using.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RELEASE_JVM_MEMORY();
Privileges
None.
Examples
User session opened. RECORD 2 shows the user session running COPY DIRECT statement.
=> SELECT RELEASE_JVM_MEMORY();
release_jvm_memory
-----------------------------------------
Java process killed and memory released
(1 row)
See also
6.13.14.10 - RESERVE_SESSION_RESOURCE
Reserves memory resources from the general resource pool for the exclusive use of the Vertica backup and restore process.
Reserves memory resources from the general resource pool for the exclusive use of the Vertica backup and restore process. No other Vertica process can access reserved resources. If insufficient resources are available, Vertica queues the reservation request.
This meta-function is a session level reservation. When a session ends Vertica automatically releases any resources reserved in that session. Because the meta-function operates at the session level, the resource name does not need to be unique across multiple sessions.
You can view reserved resources by querying the SESSIONS table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESERVE_SESSION_RESOURCE ( 'name', memory)
Parameters
name- The name of the resource to reserve.
memory- The amount of memory in kilobytes to allocate to the resource.
Privileges
None
Examples
Reserve 1024 kilobytes of memory for the backup and restore process:
=> SELECT reserve_session_resource('VBR_RESERVE',1024);
-[ RECORD 1 ]------------+----------------
reserve_session_resource | Grant succeed
6.13.14.11 - RESET_SESSION
Applies your default connection string configuration settings to your current session.
Applies your default connection string configuration settings to your current session.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESET_SESSION()
Examples
The following example shows how you use RESET_SESSION.
Resets the current client connection string to the default connection string settings:
=> SELECT RESET_SESSION();
RESET_SESSION
----------------------
Reset session: done.
(1 row)
6.13.15 - Storage functions
This section contains storage management functions specific to Vertica.
This section contains storage management functions specific to Vertica.
6.13.15.1 - ALTER_LOCATION_LABEL
Adds a label to a storage location, or changes or removes an existing label.
Adds a label to a storage location, or changes or removes an existing label. You can change a location label if it is not specified by any storage policy.
Caution
If you label a storage location that contains data, Vertica moves the data to an unlabeled location, if one exists. To prevent data movement between storage locations, labels should be applied either to all storage locations or none.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ALTER_LOCATION_LABEL ( 'path' , '[node]' , '[location-label]' )
Parameters
path- The storage location path.
node- The node where the label change is applied. If you supply an empty string, Vertica applies the change across all cluster nodes.
location-label- The label to assign to the specified storage location.
If you supply an empty string, Vertica removes that storage location's label.
You can remove a location label only if the following conditions are both true:
Privileges
Superuser
Examples
The following ALTER_LOCATION_LABEL statement applies across all cluster nodes the label SSD to the storage location /home/dbadmin/SSD/tables:
=> SELECT ALTER_LOCATION_LABEL('/home/dbadmin/SSD/tables','', 'SSD');
ALTER_LOCATION_LABEL
---------------------------------------
/home/dbadmin/SSD/tables label changed.
(1 row)
See also
6.13.15.2 - ALTER_LOCATION_USE
Alters the type of data that a storage location holds.
Alters the type of data that a storage location holds.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ALTER_LOCATION_USE ( 'path' , '[node]' , 'usage' )
Arguments
path- Where the storage location is mounted.
node- The Vertica node on which to alter the storage location. To alter the location on all cluster nodes in a single transaction, use an empty string (
''). If the usage is SHARED TEMP or SHARED USER, you must alter it on all nodes.
usage- One of the following:
-
DATA: The storage location stores only data files.
-
TEMP: The location stores only temporary files that are created during loads or queries.
-
DATA,TEMP: The location can store both types of files.
Privileges
Superuser
Restrictions
You cannot change a storage location from a USER usage type if you created the location that way, or to a USER type if you did not. You can change a USER storage location to specify DATA (storing TEMP files is not supported). However, doing so does not affect the primary objective of a USER storage location, to be accessible by non-dbadmin users with assigned privileges.
You cannot change a storage location from SHARED TEMP or SHARED USER to SHARED DATA or the reverse.
Monitoring storage locations
For information about the disk storage used on each node, query the
DISK_STORAGE system table.
Examples
The following example alters a storage location across all cluster nodes to store only data:
=> SELECT ALTER_LOCATION_USE ('/thirdSL/' , '' , 'DATA');
See also
6.13.15.3 - CLEAR_CACHES
Clears the Vertica internal cache files.
Clears the Vertica internal cache files.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_CACHES ( )
Privileges
Superuser
Notes
If you want to run benchmark tests for your queries, in addition to clearing the internal Vertica cache files, clear the Linux file system cache. The kernel uses unallocated memory as a cache to hold clean disk blocks. If you are running version 2.6.16 or later of Linux and you have root access, you can clear the kernel file system cache as follows:
-
Make sure that all data in the cache is written to disk:
# sync
-
Writing to the drop_caches file causes the kernel to drop clean caches, entries, and inodes from memory, causing that memory to become free, as follows:
-
To clear the page cache:
# echo 1 > /proc/sys/vm/drop_caches
-
To clear the entries and inodes:
# echo 2 > /proc/sys/vm/drop_caches
-
To clear the page cache, entries, and inodes:
# echo 3 > /proc/sys/vm/drop_caches
Examples
The following example clears the Vertica internal cache files:
=> SELECT CLEAR_CACHES();
CLEAR_CACHES
--------------
Cleared
(1 row)
6.13.15.4 - CLEAR_OBJECT_STORAGE_POLICY
Removes a user-defined storage policy from the specified database, schema or table.
Removes a user-defined storage policy from the specified database, schema or table. Storage containers at the previous policy's labeled location are moved to the default location. By default, this move occurs after all pending mergeout tasks return.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_OBJECT_STORAGE_POLICY ( 'object-name' [,'key-min', 'key-max'] [, 'enforce-storage-move' ] )
Parameters
object-name- The object to clear, one of the following:
-
database: Clears database of its storage policy.
-
[database.]schema: Clears schema of its storage policy.
-
[[database.]schema.]table: Clears table of its storage policy. If table is in any schema other than public, you must supply the schema name.
In all cases, database must be the name of the current database.
key-min
key-max- Valid only if
object-name is a table, specifies the range of table partition key values stored at the labeled location.
enforce-storage-move- Specifies when the Tuple Mover moves all existing storage containers for the specified object to its default storage location:
Privileges
Superuser
Examples
This following statement clears the storage policy for table store.store_orders_fact. The true argument specifies to implement the move immediately:
=> SELECT CLEAR_OBJECT_STORAGE_POLICY ('store.store_orders_fact', 'true');
CLEAR_OBJECT_STORAGE_POLICY
-----------------------------------------------------------------------------
Object storage policy cleared.
Task: moving storages
(Table: store.store_orders_fact) (Projection: store.store_orders_fact_b0)
(Table: store.store_orders_fact) (Projection: store.store_orders_fact_b1)
(1 row)
See also
6.13.15.5 - DO_TM_TASK
Runs a (TM) operation and commits current transactions.
Runs a Tuple Mover (TM) operation and commits current transactions. You can limit this operation to a specific table or projection. When started using this function, the TM uses the GENERAL resource pool instead of the TM resource pool.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DO_TM_TASK('task'[, '[[database.]schema.]{ table | projection}]' )
Parameters
task- Specifies one of the following tuple mover operations:
-
mergeout: Consolidates ROS containers and purges deleted records. For details, seeMergeout.
-
reshardmergeout: Realigns storage containers to the shard definitions created by a RESHARD_DATABASE call. Specify a table or projection and a range of partition values to limit the scope of the reshardmergeout operations.
-
analyze_row_count: Collects a minimal set of statistics and aggregate row counts for the specified projections, and saves it in the database catalog. Collects the number of rows in the specified projection. If you specify a table name, DO_TM_TASK returns the row counts for all projections of that table. For details, see Analyzing row counts.
-
update_storage_catalog (recommended only for Eon Mode): Updates the catalog with metadata on bundled table data. For details, see Writing bundle metadata to the catalog.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table|projection- Applies
task to the specified table or projection. If you specify a projection and it is not found, DO_TM_TASK looks for a table with that name and, if found, applies the task to it and all projections associated with it.
If you specify no table or projection, the task is applied to all database tables and their projections.
Privileges
Examples
The following example performs a mergeout on all projections in a table:
=> SELECT DO_TM_TASK('mergeout', 't1');
You can perform a re-shard mergeout task on a range of partitions of a table:
=> SELECT DO_TM_TASK('reshardmergeout', 'store_orders', '2001', '2005');
6.13.15.6 - DROP_LOCATION
Permanently removes a retired storage location.
Permanently removes a retired storage location. This operation cannot be undone. You must first retire a storage location with RETIRE_LOCATION before dropping it; you cannot drop a storage location that is in use.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_LOCATION ( 'path', 'node' )
Arguments
path- Where the storage location to drop is mounted.
node- The Vertica node on which to drop the location. To perform this operation on all nodes, use an empty string (
''). If the storage location is SHARED, you must perform this operation on all nodes.
Privileges
Superuser
Storage locations with temp and data files
If you use a storage location to store data and then alter it to store only temp files, the location can still contain data files. Vertica does not let you drop a storage location containing data files. You can use the MOVE_RETIRED_LOCATION_DATA function to manually merge out the data files from the storage location, or you can drop partitions. Deleting data files does not work.
Examples
The following example shows how to drop a previously retired storage location on v_vmart_node0003:
=> SELECT DROP_LOCATION('/data', 'v_vmart_node0003');
See also
6.13.15.7 - ENFORCE_OBJECT_STORAGE_POLICY
Applies storage policies of the specified object immediately.
Enterprise Mode only
Applies storage policies of the specified object immediately. By default, the Tuple Mover enforces object storage policies after all pending mergeout operations are complete. Calling this function is equivalent to setting the enforce argument when using RETIRE_LOCATION. You typically use this function as the last step before dropping a storage location.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENFORCE_OBJECT_STORAGE_POLICY ( 'object-name' [,'key-min', 'key-max'] )
Arguments
object-name- The database object whose storage policies are to be applied, one of the following:
-
database: Applies database storage policies.
-
[database.]schema: Applies schema storage policies.
-
[[database.]schema.]table: Applies table storage policies. If table is in any schema other than public, you must supply the schema name.
In all cases, database must be the name of the current database.
key-min, key-max- Valid only if
object-name is a table, specifies the range of table partition key values on which to perform the move.
Privileges
One of the following:
Examples
Apply storage policy updates to the test table:
=> SELECT ENFORCE_OBJECT_STORAGE_POLICY ('test');
See also
6.13.15.8 - MEASURE_LOCATION_PERFORMANCE
Measures a storage location's disk performance.
Measures a storage location's disk performance.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MEASURE_LOCATION_PERFORMANCE ( 'path', 'node' )
Parameters
path- Specifies where the storage location to measure is mounted.
node- The Vertica node where the location to be measured is available. To obtain a list of all node names on the cluster, query system table DISK_STORAGE.
Privileges
Superuser
Notes
-
If you intend to create a tiered disk architecture in which projections, columns, and partitions are stored on different disks based on predicted or measured access patterns, you need to measure storage location performance for each location in which data is stored. You do not need to measure storage location performance for temp data storage locations because temporary files are stored based on available space.
-
The method of measuring storage location performance applies only to configured clusters. If you want to measure a disk before configuring a cluster see Measuring storage performance.
-
Storage location performance equates to the amount of time it takes to read and write 1MB of data from the disk. This time equates to:
IO-time = (time-to-read-write-1MB + time-to-seek) = (1/throughput + 1/latency)
Throughput is the average throughput of sequential reads/writes (units in MB per second).
Latency is for random reads only in seeks (units in seeks per second)
Note
The IO time of a faster storage location is less than a slower storage location.
Examples
The following example measures the performance of a storage location on v_vmartdb_node0004:
=> SELECT MEASURE_LOCATION_PERFORMANCE('/secondVerticaStorageLocation/' , 'v_vmartdb_node0004');
WARNING: measure_location_performance can take a long time. Please check logs for progress
measure_location_performance
--------------------------------------------------
Throughput : 122 MB/sec. Latency : 140 seeks/sec
See also
6.13.15.9 - MOVE_RETIRED_LOCATION_DATA
Moves all data from the specified retired storage location or from all retired storage locations in the database.
Moves all data from the specified retired storage location or from all retired storage locations in the database. MOVE_RETIRED_LOCATION_DATA migrates the data to non-retired storage locations according to the storage policies of the objects whose data is stored in the location. This function returns only after it completes migration of all affected storage location data.
Note
The Tuple Mover migrates data of retired storage locations when it consolidates data into larger
ROS containers.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MOVE_RETIRED_LOCATION_DATA( ['location-path'] [, 'node'] )
Arguments
location-path- The path of the storage location as specified in the
LOCATION_PATH column of system table
STORAGE_LOCATIONS. This storage location must be marked as retired.
If you omit this argument, MOVE_RETIRED_LOCATION_DATA moves data from all retired storage locations.
node- The node on which to move data of the retired storage location. If
location-path is undefined on node, this function returns an error.
If you omit this argument, MOVE_RETIRED_LOCATION_DATA moves data from*location-path* on all nodes.
Privileges
Superuser
Examples
-
Query system table STORAGE_LOCATIONS to show which storage locations are retired:
=> SELECT node_name, location_path, location_label, is_retired FROM STORAGE_LOCATIONS
WHERE is_retired = 't';
node_name | location_path | location_label | is_retired
------------------+----------------------+----------------+------------
v_vmart_node0001 | /home/dbadmin/SSDLoc | ssd | t
v_vmart_node0002 | /home/dbadmin/SSDLoc | ssd | t
v_vmart_node0003 | /home/dbadmin/SSDLoc | ssd | t
(3 rows)
-
Query system table STORAGE_LOCATIONS for the location of the messages table, which is currently stored in retired storage location ssd:
=> SELECT node_name, total_row_count, location_label FROM STORAGE_CONTAINERS
WHERE projection_name ILIKE 'messages%';
node_name | total_row_count | location_label
------------------+-----------------+----------------
v_vmart_node0001 | 333514 | ssd
v_vmart_node0001 | 333255 | ssd
v_vmart_node0002 | 333255 | ssd
v_vmart_node0002 | 333231 | ssd
v_vmart_node0003 | 333231 | ssd
v_vmart_node0003 | 333514 | ssd
(6 rows)
-
Call MOVE_RETIRED_LOCATION_DATA to move the data off the ssd storage location.
=> SELECT MOVE_RETIRED_LOCATION_DATA('/home/dbadmin/SSDLoc');
MOVE_RETIRED_LOCATION_DATA
-----------------------------------------------
Move data off retired storage locations done
(1 row)
-
Repeat the previous query to verify the storage location of the messages table:
=> SELECT node_name, total_row_count, storage_type, location_label FROM storage_containers
WHERE projection_name ILIKE 'messages%';
node_name | total_row_count | location_label
------------------+-----------------+----------------
v_vmart_node0001 | 333255 | base
v_vmart_node0001 | 333514 | base
v_vmart_node0003 | 333514 | base
v_vmart_node0003 | 333231 | base
v_vmart_node0002 | 333231 | base
v_vmart_node0002 | 333255 | base
(6 rows)
See also
6.13.15.10 - RESTORE_LOCATION
Restores a storage location that was previously retired with RETIRE_LOCATION.
Restores a storage location that was previously retired with RETIRE_LOCATION.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RESTORE_LOCATION ( 'path', 'node' )
Arguments
path- Where to mount the retired storage location.
node- The Vertica node on which to restore the location. To perform this operation on all nodes, use an empty string (
''). If the storage location is SHARED, you must perform this operation on all nodes.
The operation fails if you dropped any locations.
Privileges
Superuser
Effects of restoring a previously retired location
After restoring a storage location, Vertica re-ranks all of the cluster storage locations. It uses the newly restored location to process queries as determined by its rank.
Monitoring storage locations
For information about the disk storage used on each node, query the
DISK_STORAGE system table.
Examples
Restore a retired storage location on node4:
=> SELECT RESTORE_LOCATION ('/thirdSL/' , 'v_vmartdb_node0004');
See also
6.13.15.11 - RETIRE_LOCATION
Deactivates the specified storage location.
Deactivates the specified storage location. To obtain a list of all existing storage locations, query the STORAGE_LOCATIONS system table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
RETIRE_LOCATION ( 'path', 'node' [, enforce ] )
Arguments
path- Where the storage location to retire is mounted.
node- The Vertica node on which to retire the location. To perform this operation on all nodes, use an empty string (
''). If the storage location is SHARED, you must perform this operation on all nodes.
enforce- If
true, the location label is set to an empty string and the data is moved elsewhere. The location can then be dropped without errors or warnings. Use this argument to expedite dropping a location.
Privileges
Superuser
Effects of retiring a storage location
RETIRE_LOCATION checks that the location is not the only storage for data and temp files. At least one location must exist on each node to store data and temp files. However, you can store both sorts of files in either the same location or separate locations.
If a location is the last available storage for its associated objects, you can retire it only if you set enforce to true.
When you retire a storage location:
-
No new data is stored at the retired location, unless you first restore it using RESTORE_LOCATION.
-
By default, if the storage location being retired contains stored data, the data is not moved. Thus, you cannot drop the storage location. Instead, Vertica removes the stored data through one or more mergeouts. To drop the location immediately after retiring it, set enforce to true.
-
If the storage location being retired is used only for temp files or you use enforce, you can drop the location. See Dropping storage locations and DROP_LOCATION.
Monitoring storage locations
For information about the disk storage used on each node, query the
DISK_STORAGE system table.
Examples
The following examples show two approaches to retiring a storage location.
You can retire a storage location and its data will be moved out automatically at a future time:
=> SELECT RETIRE_LOCATION ('/data' , 'v_vmartdb_node0004');
You can specify that data in the storage location be moved immediately, so that you can then drop the location without waiting:
=> SELECT RETIRE_LOCATION ('/data' , 'v_vmartdb_node0004', true);
See also
6.13.15.12 - SET_LOCATION_PERFORMANCE
Sets disk performance for a storage location.
Sets disk performance for a storage location.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_LOCATION_PERFORMANCE ( 'path', 'node' , 'throughput', 'average-latency')
Parameters
path- Specifies where the storage location to set is mounted.
node- Specifies the Vertica node where the location to set is available.
throughput - Specifies the throughput for the location, set to a value ≥1.
average-latency - Specifies the average latency for the location, set to a value ≥1.
Privileges
Superuser
Examples
The following example sets the performance of a storage location on node2 to a throughput of 122 megabytes per second and a latency of 140 seeks per second.
=> SELECT SET_LOCATION_PERFORMANCE('/secondVerticaStorageLocation/','node2','122','140');
See also
6.13.15.13 - SET_OBJECT_STORAGE_POLICY
Creates or changes the storage policy of a database object by assigning it a labeled storage location.
Creates or changes the storage policy of a database object by assigning it a labeled storage location. The Tuple Mover uses this location to store new and existing data for this object. If the object already has an active storage policy, calling SET_OBJECT_STORAGE_POLICY sets this object's default storage to the new labeled location. Existing data for the object is moved to the new location.
Note
You cannot create a storage policy on a USER type storage location.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SET_OBJECT_STORAGE_POLICY (
'[[database.]schema.]object-name', 'location-label'
[,'key-min', 'key-max'] [, 'enforce-storage-move' ] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object-name- Identifies the database object assigned to a labeled storage location. The
object-name can resolve to a database, schema, or table.
location-label- The label of
object-name's storage location.
key-min
key-max- Valid only if
object-name is a table, specifies the range of table partition key values to store at the labeled location.
enforce-storage-move- Specifies when the Tuple Mover moves all existing storage containers for
object-name to the labeled storage location:
Privileges
One of the following:
Examples
See Clearing storage policies
See also
6.13.16 - Table functions
This section contains functions for managing tables and constraints.
This section contains functions for managing tables and constraints.
See also the V_CATALOG.TABLE_CONSTRAINTS system table.
6.13.16.1 - ANALYZE_CONSTRAINTS
Analyzes and reports on constraint violations within the specified scope.
Analyzes and reports on constraint violations within the specified scope
You can enable automatic enforcement of primary key, unique key, and check constraints when INSERT, UPDATE, MERGE, or COPY statements execute. Alternatively, you can use ANALYZE_CONSTRAINTS to validate constraints after issuing these statements. Refer to Constraint enforcement for more information.
ANALYZE_CONSTRAINTS performs a lock in the same way that SELECT * FROM t1 holds a lock on table t1. See
LOCKS for additional information.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ANALYZE_CONSTRAINTS ('[[[database.]schema.]table ]' [, 'column[,...]'] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Identifies the table to analyze. If you omit specifying a schema, Vertica uses the current schema search path. If set to an empty string, Vertica analyzes all tables in the current schema.
column- The column in
table to analyze. You can specify multiple comma-delimited columns. Vertica narrows the scope of the analysis to the specified columns. If you omit specifying a column, Vertica analyzes all columns in table.
Privileges
-
Schema: USAGE
-
Table: SELECT
Detecting constraint violations during a load process
Vertica checks for constraint violations when queries are run, not when data is loaded. To detect constraint violations as part of the load process, use a COPY statement with the NO COMMIT option. By loading data without committing it, you can run a post-load check of your data using the ANALYZE_CONSTRAINTS function. If the function finds constraint violations, you can roll back the load because you have not committed it.
If ANALYZE_CONSTRAINTS finds violations, such as when you insert a duplicate value into a primary key, you can correct errors using the following functions. Effects last until the end of the session only:
Important
If a check constraint SQL expression evaluates to an unknown for a given row because a column within the expression contains a null, the row passes the constraint condition.
Return values
ANALYZE_CONSTRAINTS returns results in a structured set (see table below) that lists the schema name, table name, column name, constraint name, constraint type, and the column values that caused the violation.
If the result set is empty, then no constraint violations exist; for example:
> SELECT ANALYZE_CONSTRAINTS ('public.product_dimension', 'product_key');
Schema Name | Table Name | Column Names | Constraint Name | Constraint Type | Column Values
-------------+------------+--------------+-----------------+-----------------+---------------
(0 rows)
The following result set shows a primary key violation, along with the value that caused the violation ('10'):
=> SELECT ANALYZE_CONSTRAINTS ('');
Schema Name | Table Name | Column Names | Constraint Name | Constraint Type | Column Values
-------------+------------+--------------+-----------------+-----------------+---------------
store t1 c1 pk_t1 PRIMARY ('10')
(1 row)
The result set columns are described in further detail in the following table:
|
Column Name |
Data Type |
Description |
Schema Name |
VARCHAR |
The name of the schema. |
Table Name |
VARCHAR |
The name of the table, if specified. |
Column Names |
VARCHAR |
A list of comma-delimited columns that contain constraints. |
Constraint Name |
VARCHAR |
The given name of the primary key, foreign key, unique, check, or not null constraint, if specified. |
Constraint Type |
VARCHAR |
Identified by one of the following strings:
-
PRIMARY KEY
-
FOREIGN KEY
-
UNIQUE
-
CHECK
-
NOT NULL
|
Column Values |
VARCHAR |
Value of the constraint column, in the same order in which Column Names contains the value of that column in the violating row.
When interpreted as SQL, the value of this column forms a list of values of the same type as the columns in Column Names; for example:
('1'), ('1', 'z')
|
Examples
See Detecting constraint violations.
6.13.16.2 - ANALYZE_CORRELATIONS
This function is deprecated and will be removed in a future release.
Deprecated
This function is deprecated and will be removed in a future release.
Analyzes the specified tables for pairs of columns that are strongly correlated. ANALYZE_CORRELATIONS stores the 20 pairs with the strongest correlation. ANALYZE_CORRELATIONS also analyzes statistics.
ANALYZE_CORRELATIONS analyzes only pairwise single-column correlations.
For example, state name and country name columns are strongly correlated because the city name usually, but perhaps not always, identifies the state name. The city of Conshohoken is uniquely associated with Pennsylvania, while the city of Boston exists in Georgia, Indiana, Kentucky, New York, Virginia, and Massachusetts. In this case, city name is strongly correlated with state name.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
ANALYZE_CORRELATIONS ('[[[database.]schema.]table ]' [, 'recalculate'] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name- Identifies the table to analyze. If you omit specifying a schema, Vertica uses the current schema search path. If set to an empty string, Vertica analyzes all tables in the current schema.
recalculate- Boolean that specifies whether to analyze correlated columns that were previously analyzed.
Note
Column correlation analysis typically needs to be done only once.
Default:false
Privileges
One of the following:
Examples
In the following example, ANALYZE_CORRELATIONS analyzes column correlations for all tables in the public schema, even if they currently exist:
=> SELECT ANALYZE_CORRELATIONS ('public.*', 'true');
ANALYZE_CORRELATIONS
----------------------
0
(1 row)
6.13.16.3 - COPY_TABLE
Copies one table to another.
Copies one table to another. This lightweight, in-memory function copies the DDL and all user-created projections from the source table. Projection statistics for the source table are also copied. Thus, the source and target tables initially have identical definitions and share the same storage.
Note
Although they share storage space, Vertica regards the tables as discrete objects for license capacity purposes. For example, a single-terabyte table and its copy initially consume only one TB of space. However, your Vertica license regards them as separate objects that consume two TB of space.
After the copy operation is complete, the source and copy tables are independent of each other, so you can perform DML operations on one table without impacting the other. These operations can increase the overall storage required for both tables.
Caution
If you create multiple copies of the same table concurrently, one or more of the copy operations is liable to fail. Instead, copy tables sequentially.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
COPY_TABLE (
'[[{namespace. | database. }]schema.]source-table',
'[[{namespace. | database. }]schema.]target-table'
)
Parameters
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
For Eon Mode databases, the namespaces of staging-table and target-table must have the same shard count.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
source-table- The source table to copy. Vertica copies all data from this table to the target table.
target-table- The target table of the source table. If the target table already exists, Vertica appends the source to the existing table.
If the table does not exist, Vertica creates a table from the source table's definition, by calling
CREATE TABLE with LIKE and INCLUDING PROJECTIONS clause. The new table inherits ownership from the source table. For details, see Replicating a table.
Privileges
Non-superuser:
Table attribute requirements
The following attributes of both tables must be identical:
-
Column definitions, including NULL/NOT NULL constraints
-
Segmentation
-
Partitioning expression
-
Number of projections
-
Projection sort order
-
Primary and unique key constraints. However, the key constraints do not have to be identically enabled.
Note
If the target table has primary or unique key constraints enabled and moving the partitions will insert duplicate key values into the target table, Vertica rolls back the operation. Enforcing constraints requires disk reads and can slow the copy process.
-
Number and definitions of text indices.
-
If the destination table already exists, the source and destination tables must have identical access policies.
Additionally, If access policies exist on the source table, the following must be true:
Table restrictions
The following restrictions apply to the source and target tables:
- If the source and target partitions are in different storage tiers, Vertica returns a warning but the operation proceeds. The partitions remain in their existing storage tier.
- If the source table contains a sequence, Vertica converts the sequence to an integer before copying it to the target table. If the target table contains IDENTITY or named sequence columns, Vertica cancels the copy and displays an error message.
- The following tables cannot be used as sources or targets:
-
Temporary tables
-
Virtual tables
-
System tables
-
External tables
Examples
If you call COPY_TABLE and the target table does not exist, the function creates the table automatically. In the following example, COPY_TABLE creates the target table public.newtable. Vertica also copies all the constraints associated with the source table public.product_dimension except foreign key constraints:
=> SELECT COPY_TABLE ( 'public.product_dimension', 'public.newtable');
-[ RECORD 1 ]--------------------------------------------------
copy_table | Created table public.newtable.
Copied table public.product_dimension to public.newtable
See also
Creating a table from other tables
6.13.16.4 - DISABLE_DUPLICATE_KEY_ERROR
Disables error messaging when Vertica finds duplicate primary or unique key values at run time (for use with key constraints that are not automatically enabled).
Disables error messaging when Vertica finds duplicate primary or unique key values at run time (for use with key constraints that are not automatically enabled). Queries execute as though no constraints are defined on the schema. Effects are session scoped.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DISABLE_DUPLICATE_KEY_ERROR();
Privileges
Superuser
Examples
When you call DISABLE_DUPLICATE_KEY_ERROR, Vertica issues warnings letting you know that duplicate values will be ignored, and incorrect results are possible. DISABLE_DUPLICATE_KEY_ERROR is for use only for key constraints that are not automatically enabled.
=> select DISABLE_DUPLICATE_KEY_ERROR();
WARNING 3152: Duplicate values in columns marked as UNIQUE will now be ignored for the remainder of your session or until reenable_duplicate_key_error() is called
WARNING 3539: Incorrect results are possible. Please contact Vertica Support if unsure
disable_duplicate_key_error
------------------------------
Duplicate key error disabled
(1 row)
See also
ANALYZE_CONSTRAINTS
6.13.16.5 - INFER_EXTERNAL_TABLE_DDL
This function is deprecated and will be removed in a future release.
Deprecated
This function is deprecated and will be removed in a future release. Instead, use
INFER_TABLE_DDL.
Inspects a file in Parquet, ORC, or Avro format and returns a CREATE EXTERNAL TABLE AS COPY statement that can be used to read the file. This statement might be incomplete. It could also contain more columns or columns with longer names than what Vertica supports; this function does not enforce Vertica system limits. Always inspect the output and address any issues before using it to create a table.
This function supports partition columns for the Parquet, ORC, and Avro formats, inferred from the input path. Because partitioning is done through the directory structure, there might not be enough information to infer the type of partition columns. In this case, this function shows these columns with a data type of UNKNOWN and emits a warning.
The function handles most data types, including complex types. If an input type is not supported in Vertica, the function emits a warning.
By default, the function uses strong typing for complex types. You can instead treat the column as a flexible complex type by setting the vertica_type_for_complex_type parameter to LONG VARBINARY.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
INFER_EXTERNAL_TABLE_DDL( path USING PARAMETERS param=value[,...] )
Arguments
path- Path to a file or directory. Any path that is valid for COPY and uses a file format supported by this function is valid.
Parameters
format- Input format (string), one of 'Parquet', 'ORC', or 'Avro'. This parameter is required.
table_name- The name of the external table to create. This parameter is required.
Do not include a schema name as part of the table name; use the table_schema parameter.
table_schema- The schema in which to create the external table. If omitted, the function does not include a schema in the output.
vertica_type_for_complex_type- Type used to represent all columns of complex types, if you do not want to expand them fully. The only supported value is LONG VARBINARY. For more information, see Flexible complex types.
Privileges
Non-superuser: READ privileges on the USER-accessible storage location.
Examples
In the following example, the input file contains data for a table with two integer columns. The table definition can be fully inferred, and you can use the returned SQL statement as-is.
=> SELECT INFER_EXTERNAL_TABLE_DDL('/data/orders/*.orc'
USING PARAMETERS format = 'orc', table_name = 'orders');
INFER_EXTERNAL_TABLE_DDL
--------------------------------------------------------------------------------------------------
create external table "orders" (
"id" int,
"quantity" int
) as copy from '/data/orders/*.orc' orc;
(1 row)
To create a table in a schema, use the table_schema parameter. Do not add it to the table name; the function treats it as a name with a period in it, not a schema.
The following example shows output with complex types. You can use the definition as-is or modify the VARCHAR sizes:
=> SELECT INFER_EXTERNAL_TABLE_DDL('/data/people/*.parquet'
USING PARAMETERS format = 'parquet', table_name = 'employees');
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
INFER_EXTERNAL_TABLE_DDL
-------------------------------------------------------------------------
create external table "employees"(
"employeeID" int,
"personal" Row(
"name" varchar,
"address" Row(
"street" varchar,
"city" varchar,
"zipcode" int
),
"taxID" int
),
"department" varchar
) as copy from '/data/people/*.parquet' parquet;
(1 row)
In the following example, the input file contains a map in the "prods" column. You can read a map as an array of rows:
=> SELECT INFER_EXTERNAL_TABLE_DDL('/data/orders.parquet'
USING PARAMETERS format='parquet', table_name='orders');
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
INFER_EXTERNAL_TABLE_DDL
------------------------------------------------------------------------
create external table "orders"(
"orderkey" int,
"custkey" int,
"prods" Array[Row(
"key" varchar,
"value" numeric(12,2)
)],
"orderdate" date
) as copy from '/data/orders.parquet' parquet;
(1 row)
In the following example, the data is partitioned by region. The function was not able to infer the data type and reports UNKNOWN:
=> SELECT INFER_EXTERNAL_TABLE_DDL('/data/sales/*/*
USING PARAMETERS format = 'parquet', table_name = 'sales');
WARNING 9262: This generated statement is incomplete because of one or more unknown column types.
Fix these data types before creating the table
INFER_EXTERNAL_TABLE_DDL
------------------------------------------------------------------------
create external table "sales"(
"tx_id" int,
"date" date,
"region" UNKNOWN
) as copy from '/data/sales/*/*' PARTITION COLUMNS region parquet;
(1 row)
For VARCHAR and VARBINARY columns, this function does not specify a length. The Vertica default length for these types is 80 bytes. If the data values are longer, using this table definition unmodified could cause data to be truncated. Always review VARCHAR and VARBINARY columns to determine if you need to specify a length. This function emits a warning if the input file contains columns of these types:
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
6.13.16.6 - INFER_TABLE_DDL
Inspects a file in Parquet, ORC, JSON, or Avro format and returns a CREATE TABLE or CREATE EXTERNAL TABLE statement based on its contents.
Inspects a file in Parquet, ORC, JSON, or Avro format and returns a CREATE TABLE or CREATE EXTERNAL TABLE statement based on its contents.
The returned statement might be incomplete if the input data contains ambiguous or unknown data types. It could also contain more columns or columns with longer names than what Vertica supports; this function does not enforce Vertica system limits. Always inspect the output and address any issues before using it to create a table.
This function supports partition columns, inferred from the input path. Because partitioning is done through the directory structure, there might not be enough information to infer the type of partition columns. In this case, this function shows these columns with a data type of UNKNOWN and emits a warning.
The function handles most data types, including complex types. If an input type is not supported in Vertica, the function emits a warning.
For VARCHAR and VARBINARY columns, this function does not specify a length. The Vertica default length for these types is 80 bytes. If the data values are longer, using the returned table definition unmodified could cause data to be truncated. Always review VARCHAR and VARBINARY columns to determine if you need to specify a length. This function emits a warning if the input file contains columns of these types:
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
INFER_TABLE_DDL( path USING PARAMETERS param=value[,...] )
Arguments
path- Path to a file or glob. Any path that is valid for COPY and uses a file format supported by this function is valid. For all formats except JSON, if a glob specifies more than one file, this function reads a single, arbitrarily-chosen file. For JSON, the function might read more than one file. See JSON.
Parameters
format- Input format (string), one of 'Parquet', 'ORC', 'Avro', or 'JSON'. This parameter is required.
table_name- The name of the table to create. This parameter is required.
Do not include a schema name as part of the table name; use the table_schema parameter.
table_schema- The schema in which to create the table. If omitted, the function does not include a schema in the output.
table_type- The type of table to create, either 'native' or 'external'.
Default: 'native'
with_copy_statement- For native tables, whether to include a COPY statement in addition to the CREATE TABLE statement.
Default: false
one_line_result- Whether to return the DDL as a single line instead of pretty-printing. The single-line format might be easier to copy into SQL scripts.
Default: false (pretty-print)
max_files- (JSON only.) Maximum number of files in
path to inspect, if path is a glob. Use this parameter to increase the amount of data the function considers, for example if you suspect variation among files. Files are chosen arbitrarily from the glob. For details, see JSON.
Default: 1
max_candidates- (JSON only.) Number of candidate table definitions to show. The function generates only one candidate per file, so if you increase
max_candidates, also increase max_files. For details, see JSON.
Default: 1
Privileges
Non-superuser: READ privileges on the USER-accessible storage location.
JSON
JSON, unlike the other supported formats, does not embed a schema in data files. This function infers JSON table DDL by instead inspecting the raw data. Because raw data can be ambiguous or inconsistent, the function takes a different approach for this format.
For each input file, the function iterates through records to develop a candidate table definition. A top-level field that appears in any record is included as a column, even if not all records use it. If the same field appears in the file with different types, the function chooses a type that is consistent with all observed occurrences.
Consider a file with data about restaurants:
{
"name" : "Pizza House",
"cuisine" : "Italian",
"location_city" : [],
"chain" : true,
"hours" : [],
"menu" : [{"item" : "cheese pizza", "price" : 7.99},
{"item" : "spinach pizza", "price" : 8.99},
{"item" : "garlic bread", "price" : 4.99}]
}
{
"name" : "Sushi World",
"cuisine" : "Asian",
"location_city" : ["Pittsburgh"],
"chain" : false,
"menu" : [{"item" : "maki platter", "price" : "21.95"},
{"item" : "tuna roll", "price" : "4.95"}]
}
The first record contains two empty arrays, so there is not enough information to determine the element types. The second record has a string value for one of them, so the function can infer a type of VARCHAR for it. The other array element type remains unknown.
In the first record menu prices are numbers, but in the second they are strings. Both FLOAT and the string can be coerced to NUMERIC, so the function returns NUMERIC:
=> SELECT INFER_TABLE_DDL ('/data/restaurants.json'
USING PARAMETERS table_name='restaurants', format='json');
WARNING 0: This generated statement contains one or more varchar/varbinary types which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
Candidate matched 1 out of 1 total files:
create table "restaurants"(
"chain" bool,
"cuisine" varchar,
"hours" Array[UNKNWON],
"location_city" Array[varchar],
"menu" Array[Row(
"item" varchar,
"price" numeric
)],
"name" varchar
);
(1 row)
All scalar types can be coerced to VARCHAR, so if a conflict cannot be resolved more specifically (as in the NUMERIC example), the function can still return a type. Complex types, however, cannot always be resolved in this way. In the following example, records in a file have conflicting definitions of the hours field:
{
"name" : "Sushi World",
"cuisine" : "Asian",
"location_city" : ["Pittsburgh"],
"chain" : false,
"hours" : {"open" : "11:00", "close" : "22:00" }
}
{
"name" : "Greasy Spoon",
"cuisine" : "American",
"location_city" : [],
"chain" : "false",
"hours" : {"open" : ["11:00","12:00"], "close" : ["21:00","22:00"] },
}
In the first record the value is a ROW with two TIME fields. In the second record the value is a ROW with two ARRAY[TIME] fields (representing weekday and weekend hours). These types are incompatible, so the function suggests a flexible complex type by using LONG VARBINARY:
=> SELECT INFER_TABLE_DDL ('/data/restaurants.json'
USING PARAMETERS table_name='restaurants', format='json');
WARNING 0: This generated statement contains one or more varchar/varbinary types which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
Candidate matched 1 out of 1 total files:
create table "restaurants"(
"chain" bool,
"cuisine" varchar,
"hours" long varbinary,
"location_city" Array[varchar],
"name" varchar
);
(1 row)
If you call the function with a glob, by default it reads one file. Set max_files to a higher number to inspect more data. The function calculates one candidate table definition per file and returns the definition that covers the largest number of files.
Increasing the number of files does not, by itself, increase the number of candidates the function returns. With more files the function can consider more candidates, but by default it returns the single candidate that represents the largest number of files. To see more than one possible table definition, also set max_candidates. There is no benefit to setting max_candidates to a larger number than max_files.
In the following example, the glob contains two files that differ in the structure of the menu column. In the first file, the menu field has two fields:
{
"name" : "Bob's pizzeria",
"cuisine" : "Italian",
"location_city" : ["Cambridge", "Pittsburgh"],
"menu" : [{"item" : "cheese pizza", "price" : 8.25},
{"item" : "spinach pizza", "price" : 10.50}]
}
In the second file, the menu has different offerings at different times of day:
{
"name" : "Greasy Spoon",
"cuisine" : "American",
"location_city" : [],
"menu" : [{"time" : "breakfast",
"items" :
[{"item" : "scrambled eggs", "price" : "3.99"}]
},
{"time" : "lunch",
"items" :
[{"item" : "grilled cheese", "price" : "3.95"},
{"item" : "tuna melt", "price" : "5.95"},
{"item" : "french fries", "price" : "1.99"}]}]
}
To see both candidates, raise both max_files and max_candidates:
=> SELECT INFER_TABLE_DDL ('/data/*.json'
USING PARAMETERS table_name='restaurants', format='json',
max_files=3, max_candidates=3);
WARNING 0: This generated statement contains one or more float types which might lose precision
WARNING 0: This generated statement contains one or more varchar/varbinary types which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
Candidate matched 1 out of 2 total files:
create table "restaurants"(
"cuisine" varchar,
"location_city" Array[varchar],
"menu" Array[Row(
"item" varchar,
"price" float
)],
"name" varchar
);
Candidate matched 1 out of 2 total files:
create table "restaurants"(
"cuisine" varchar,
"location_city" Array[varchar],
"menu" Array[Row(
"items" Array[Row(
"item" varchar,
"price" numeric
)],
"time" varchar
)],
"name" varchar
);
(1 row)
Examples
In the following example, the input path contains data for a table with two integer columns. The external table definition can be fully inferred, and you can use the returned SQL statement as-is. The function reads one file from the input path:
=> SELECT INFER_TABLE_DDL('/data/orders/*.orc'
USING PARAMETERS format = 'orc', table_name = 'orders', table_type = 'external');
INFER_TABLE_DDL
------------------------------------------------------------------------
create external table "orders" (
"id" int,
"quantity" int
) as copy from '/data/orders/*.orc' orc;
(1 row)
To create a table in a schema, use the table_schema parameter. Do not add it to the table name; the function treats it as a name with a period in it, not a schema.
The following example shows output with complex types. You can use the definition as-is or modify the VARCHAR sizes:
=> SELECT INFER_TABLE_DDL('/data/people/*.parquet'
USING PARAMETERS format = 'parquet', table_name = 'employees');
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
create table "employees"(
"employeeID" int,
"personal" Row(
"name" varchar,
"address" Row(
"street" varchar,
"city" varchar,
"zipcode" int
),
"taxID" int
),
"department" varchar
);
(1 row)
In the following example, the input file contains a map in the "prods" column. You can read a map as an array of rows:
=> SELECT INFER_TABLE_DDL('/data/orders.parquet'
USING PARAMETERS format='parquet', table_name='orders');
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
create table "orders"(
"orderkey" int,
"custkey" int,
"prods" Array[Row(
"key" varchar,
"value" numeric(12,2)
)],
"orderdate" date
);
(1 row)
The following example returns the definition of a native table and the COPY statement, putting the table definition on a single line to simplify cutting and pasting into a script:
=> SELECT INFER_TABLE_DDL('/data/orders/*.orc'
USING PARAMETERS format = 'orc', table_name = 'orders',
table_type = 'native', with_copy_statement = true, one_line_result=true);
INFER_TABLE_DDL
-----------------------------------------------------------------------
create table "orders" ("id" int, "quantity" int);
copy "orders" from '/data/orders/*.orc' orc;
(1 row)
In the following example, the data is partitioned by region. The function was not able to infer the data type and reports UNKNOWN:
=> SELECT INFER_TABLE_DDL('/data/sales/*/*
USING PARAMETERS format = 'orc', table_name = 'sales', table_type = 'external');
WARNING 9262: This generated statement is incomplete because of one or more unknown column types. Fix these data types before creating the table
WARNING 9311: This generated statement contains one or more varchar/varbinary columns which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
create external table "sales"(
"orderkey" int,
"custkey" int,
"prodkey" Array[varchar],
"orderprices" Array[numeric(12,2)],
"orderdate" date,
"region" UNKNOWN
) as copy from '/data/sales/*/*' PARTITION COLUMNS region orc;
(1 row)
In the following example, the function reads multiple JSON files and they differ in how they represent the menu column:
=> SELECT INFER_TABLE_DDL ('/data/*.json'
USING PARAMETERS table_name='restaurants', format='json',
max_files=3, max_candidates=3);
WARNING 0: This generated statement contains one or more float types which might lose precision
WARNING 0: This generated statement contains one or more varchar/varbinary types which default to length 80
INFER_TABLE_DDL
------------------------------------------------------------------------
Candidate matched 1 out of 2 total files:
create table "restaurants"(
"cuisine" varchar,
"location_city" Array[varchar],
"menu" Array[Row(
"item" varchar,
"price" float
)],
"name" varchar
);
Candidate matched 1 out of 2 total files:
create table "restaurants"(
"cuisine" varchar,
"location_city" Array[varchar],
"menu" Array[Row(
"items" Array[Row(
"item" varchar,
"price" numeric
)],
"time" varchar
)],
"name" varchar
);
(1 row)
6.13.16.7 - LAST_INSERT_ID
Returns the last value of an IDENTITY column.
Returns the last value of an IDENTITY column. If multiple sessions concurrently load the same table with an IDENTITY column, the function returns the last value generated for that column.
Note
This function works only with IDENTITY columns. It does not work with
named sequences.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
LAST_INSERT_ID()
Privileges
Examples
See IDENTITY sequences.
6.13.16.8 - PURGE_TABLE
This function was formerly named PURGE_TABLE_PROJECTIONS().
Note
This function was formerly named PURGE_TABLE_PROJECTIONS(). Vertica still supports the former function name.
Permanently removes deleted data from physical storage so disk space can be reused. You can purge historical data up to and including the Ancient History Mark epoch.
Purges all projections of the specified table. You cannot use this function to purge temporary tables.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
PURGE_TABLE ( '[[database.]schema.]table' )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The table to purge.
Privileges
Caution
PURGE_TABLE could temporarily take up significant disk space while the data is being purged.
Examples
The following example purges all projections for the store sales fact table located in the Vmart schema:
=> SELECT PURGE_TABLE('store.store_sales_fact');
See also
6.13.16.9 - REBALANCE_TABLE
Synchronously rebalances data in the specified table.
Synchronously rebalances data in the specified table.
A rebalance operation performs the following tasks:
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REBALANCE_TABLE('[[database.]schema.]table-name')
Parameters
schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name- The table to rebalance.
Privileges
Superuser
When to rebalance
Rebalancing is useful or even necessary after you perform the following tasks:
-
Mark one or more nodes as ephemeral in preparation of removing them from the cluster.
-
Add one or more nodes to the cluster so that Vertica can populate the empty nodes with data.
-
Change the scaling factor of an elastic cluster, which determines the number of storage containers used to store a projection across the database.
-
Set the control node size or realign control nodes on a large cluster layout
-
Add nodes to or remove nodes from a fault group.
Tip
By default, before performing a rebalance, Vertica queries system tables to compute the size of all projections involved in the rebalance task. This query can add significant overhead to the rebalance operation. To disable this query, set projection configuration parameter
RebalanceQueryStorageContainers to 0.
Examples
The following command shows how to rebalance data on the specified table.
=> SELECT REBALANCE_TABLE('online_sales.online_sales_fact');
REBALANCE_TABLE
-------------------
REBALANCED
(1 row)
See also
6.13.16.10 - REENABLE_DUPLICATE_KEY_ERROR
Restores the default behavior of error reporting by reversing the effects of DISABLE_DUPLICATE_KEY_ERROR.
Restores the default behavior of error reporting by reversing the effects of
DISABLE_DUPLICATE_KEY_ERROR. Effects are session-scoped.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
REENABLE_DUPLICATE_KEY_ERROR();
Privileges
Superuser
Examples
=> SELECT REENABLE_DUPLICATE_KEY_ERROR();
REENABLE_DUPLICATE_KEY_ERROR
------------------------------
Duplicate key error enabled
(1 row)
See also
ANALYZE_CONSTRAINTS
6.14 - Match and search functions
This section contains functions for text search and regular expressions, and functions used in the MATCH clause.
This section contains functions for text search and regular expressions, and functions used in the MATCH clause.
6.14.1 - MATCH clause functions
Used with the MATCH clause, the functions in this section return additional data about the patterns found or returned.
Used with the MATCH clause, the functions in this section return additional data about the patterns found or returned. For example, you can use these functions to return values representing the name of the event or pattern that matched the input row, the sequential number of the match, or a partition-wide unique identifier for the instance of the pattern that matched.
Pattern matching is particularly useful for clickstream analysis where you might want to identify users' actions based on their Web browsing behavior (page clicks). A typical online clickstream funnel is:
Company home page -> product home page -> search -> results -> purchase online
Using the above clickstream funnel, you can search for a match on the user's sequence of web clicks and identify that the user:
-
Landed on the company home page.
-
Navigated to the product page.
-
Ran a search.
-
Clicked a link from the search results.
-
Made a purchase.
For examples that use this clickstream model, see Event series pattern matching.
Note
GROUP BY and PARTITION BY expressions do not support window functions.
6.14.1.1 - EVENT_NAME
Returns a VARCHAR value representing the name of the event that matched the row.
Returns a VARCHAR value representing the name of the event that matched the row.
Syntax
EVENT_NAME()
Notes
Pattern matching functions must be used in MATCH clause syntax; for example, if you call EVENT_NAME() on its own, Vertica returns the following error message:
=> SELECT event_name();
ERROR: query with pattern matching function event_name must include a MATCH clause
Examples
The following statement analyzes users' browsing history on website2.com and identifies patterns where the user landed on website2.com from another Web site (Entry) and browsed to any number of other pages (Onsite) before making a purchase (Purchase). The query also outputs the values for EVENT_NAME(), which is the name of the event that matched the row.
SELECT uid,
sid,
ts,
refurl,
pageurl,
action,
event_name()
FROM clickstream_log
MATCH
(PARTITION BY uid, sid ORDER BY ts
DEFINE
Entry AS RefURL NOT ILIKE '%website2.com%' AND PageURL ILIKE '%website2.com%',
Onsite AS PageURL ILIKE '%website2.com%' AND Action='V',
Purchase AS PageURL ILIKE '%website2.com%' AND Action = 'P'
PATTERN
P AS (Entry Onsite* Purchase)
ROWS MATCH FIRST EVENT);
uid | sid | ts | refurl | pageurl | action | event_name
-----+-----+----------+----------------------+----------------------+--------+------------
1 | 100 | 12:00:00 | website1.com | website2.com/home | V | Entry
1 | 100 | 12:01:00 | website2.com/home | website2.com/floby | V | Onsite
1 | 100 | 12:02:00 | website2.com/floby | website2.com/shamwow | V | Onsite
1 | 100 | 12:03:00 | website2.com/shamwow | website2.com/buy | P | Purchase
2 | 100 | 12:10:00 | website1.com | website2.com/home | V | Entry
2 | 100 | 12:11:00 | website2.com/home | website2.com/forks | V | Onsite
2 | 100 | 12:13:00 | website2.com/forks | website2.com/buy | P | Purchase
(7 rows)
See also
6.14.1.2 - MATCH_ID
Returns a successful pattern match as an INTEGER value.
Returns a successful pattern match as an INTEGER value. The returned value is the ordinal position of a match within a partition.
Syntax
MATCH_ID()
Notes
Pattern matching functions must be used in MATCH clause syntax; for example, if you call MATCH_ID() on its own, Vertica returns the following error message:
=> SELECT match_id();
ERROR: query with pattern matching function match_id must include a MATCH clause
Examples
The following statement analyzes users' browsing history on a site called website2.com and identifies patterns where the user reached website2.com from another Web site (Entry in the MATCH clause) and browsed to any number of other pages (Onsite) before making a purchase (Purchase). The query also outputs values for the MATCH_ID(), which represents a sequential number of the match.
SELECT uid,
sid,
ts,
refurl,
pageurl,
action,
match_id()
FROM clickstream_log
MATCH
(PARTITION BY uid, sid ORDER BY ts
DEFINE
Entry AS RefURL NOT ILIKE '%website2.com%' AND PageURL ILIKE '%website2.com%',
Onsite AS PageURL ILIKE '%website2.com%' AND Action='V',
Purchase AS PageURL ILIKE '%website2.com%' AND Action = 'P'
PATTERN
P AS (Entry Onsite* Purchase)
ROWS MATCH FIRST EVENT);
uid | sid | ts | refurl | pageurl | action | match_id
----+-----+----------+----------------------+----------------------+--------+------------
1 | 100 | 12:00:00 | website1.com | website2.com/home | V | 1
1 | 100 | 12:01:00 | website2.com/home | website2.com/floby | V | 2
1 | 100 | 12:02:00 | website2.com/floby | website2.com/shamwow | V | 3
1 | 100 | 12:03:00 | website2.com/shamwow | website2.com/buy | P | 4
2 | 100 | 12:10:00 | website1.com | website2.com/home | V | 1
2 | 100 | 12:11:00 | website2.com/home | website2.com/forks | V | 2
2 | 100 | 12:13:00 | website2.com/forks | website2.com/buy | P | 3
(7 rows)
See also
6.14.1.3 - PATTERN_ID
Returns an integer value that is a partition-wide unique identifier for the instance of the pattern that matched.
Returns an integer value that is a partition-wide unique identifier for the instance of the pattern that matched.
Syntax
PATTERN_ID()
Notes
Pattern matching functions must be used in MATCH clause syntax; for example, if call PATTERN_ID() on its own, Vertica returns the following error message:
=> SELECT pattern_id();
ERROR: query with pattern matching function pattern_id must include a MATCH clause
Examples
The following statement analyzes users' browsing history on website2.com and identifies patterns where the user landed on website2.com from another Web site (Entry) and browsed to any number of other pages (Onsite) before making a purchase (Purchase). The query also outputs values for PATTERN_ID(), which represents the partition-wide identifier for the instance of the pattern that matched.
SELECT uid,
sid,
ts,
refurl,
pageurl,
action,
pattern_id()
FROM clickstream_log
MATCH
(PARTITION BY uid, sid ORDER BY ts
DEFINE
Entry AS RefURL NOT ILIKE '%website2.com%' AND PageURL ILIKE '%website2.com%',
Onsite AS PageURL ILIKE '%website2.com%' AND Action='V',
Purchase AS PageURL ILIKE '%website2.com%' AND Action = 'P'
PATTERN
P AS (Entry Onsite* Purchase)
ROWS MATCH FIRST EVENT);
uid | sid | ts | refurl | pageurl | action | pattern_id
----+-----+----------+----------------------+----------------------+--------+------------
1 | 100 | 12:00:00 | website1.com | website2.com/home | V | 1
1 | 100 | 12:01:00 | website2.com/home | website2.com/floby | V | 1
1 | 100 | 12:02:00 | website2.com/floby | website2.com/shamwow | V | 1
1 | 100 | 12:03:00 | website2.com/shamwow | website2.com/buy | P | 1
2 | 100 | 12:10:00 | website1.com | website2.com/home | V | 1
2 | 100 | 12:11:00 | website2.com/home | website2.com/forks | V | 1
2 | 100 | 12:13:00 | website2.com/forks | website2.com/buy | P | 1
(7 rows)
See also
6.14.2 - Regular expression functions
A regular expression lets you perform pattern matching on strings of characters.
A regular expression lets you perform pattern matching on strings of characters. The regular expression syntax allows you to precisely define the pattern used to match strings, giving you much greater control than wildcard matching used in the LIKE predicate. The Vertica regular expression functions let you perform tasks such as determining if a string value matches a pattern, extracting a portion of a string that matches a pattern, or counting the number of times a pattern occurs within a string.
Vertica uses the Perl Compatible Regular Expression (PCRE) library to evaluate regular expressions. As its name implies, PCRE's regular expression syntax is compatible with the syntax used by the Perl 5 programming language. You can read PCRE's documentation about its library. However, if you are unfamiliar with using regular expressions, the Perl Regular Expressions Documentation is a good introduction.
Note
The regular expression functions only operate on valid UTF-8 strings. If you try using a regular expression function on a string that is not valid UTF-8, the query fails with an error. To prevent an error from occurring, use the
ISUTF8 function as an initial clause to ensure the strings you pass to the regular expression functions are valid UTF-8 strings. Alternatively, or you can use the 'b' argument to treat the strings as binary octets, rather than UTF-8 encoded strings.
6.14.2.1 - MATCH_COLUMNS
Specified as an element in a SELECT list, returns all columns in queried tables that match the specified pattern.
Specified as an element in a SELECT list, returns all columns in queried tables that match the specified pattern. For example:
=> SELECT MATCH_COLUMNS ('%order%') FROM store.store_orders_fact LIMIT 3;
order_number | date_ordered | quantity_ordered | total_order_cost | reorder_level
--------------+--------------+------------------+------------------+---------------
191119 | 2003-03-09 | 15 | 4021 | 23
89985 | 2003-05-04 | 19 | 2692 | 23
246962 | 2007-06-01 | 77 | 4419 | 42
(3 rows)
Syntax
MATCH_COLUMNS ('pattern')
Arguments
pattern- The pattern to match against all column names in the queried tables, where
pattern typically contains one or both of the following wildcard characters:
The pattern can also include backslash (\) characters to escape reserved characters that are embedded in column names: _(underscore), % (percent sign), and backlash (\) itself.
Privileges
None
DDL usage
You can use MATCH_COLUMNS to define database objects—for example, specify it in CREATE PROJECTION to identify projection columns, or in CREATE TABLE...AS to identify columns in the new table. In all cases, Vertica expands the MATCH_COLUMNS output before it stores the object DDL. Subsequent changes to the original source table have no effect on the derived object definitions.
Restrictions
In general, MATCH_COLUMNS is specified as an element in a SELECT list. For example, CREATE PROJECTION can call MATCH_COLUMNS to specify the columns to include in a projection. However, attempts to specify columns in the projection's segmentation clause return with an error:
=> CREATE PROJECTION p_store_orders AS SELECT
MATCH_COLUMNS('%product%'),
MATCH_COLUMNS('%store%'),
order_number FROM store.store_orders_fact SEGMENTED BY MATCH_COLUMNS('products%') ALL NODES;
ERROR 0: MATCH_COLUMNS() function can only be specified as an element in a SELECT list
=> CREATE PROJECTION p_store_orders AS SELECT
MATCH_COLUMNS('%product%'),
MATCH_COLUMNS('%store%'),
order_number FROM store.store_orders_fact;
WARNING 4468: Projection <store.p_store_orders_b0> is not available for query processing. Execute the select start_refresh() function to copy data into this projection.
The projection must have a sufficient number of buddy projections and all nodes must be up before starting a refresh
WARNING 4468: Projection <store.p_store_orders_b1> is not available for query processing. Execute the select start_refresh() function to copy data into this projection.
The projection must have a sufficient number of buddy projections and all nodes must be up before starting a refresh
CREATE PROJECTION
If you call MATCH_COLUMNS from a function that supports a fixed number of arguments, Vertica returns an error. For example, the UPPER function supports only one argument; so calling MATCH_COLUMNS from UPPER as follows returns an error:
=> SELECT MATCH_COLUMNS('emp%') FROM employee_dimension LIMIT 1;
-[ RECORD 1 ]-----------+---------------------------------
employee_key | 1
employee_gender | Male
employee_first_name | Craig
employee_middle_initial | F
employee_last_name | Robinson
employee_age | 22
employee_street_address | 5 Bakers St
employee_city | Thousand Oaks
employee_state | CA
employee_region | West
=> SELECT UPPER (MATCH_COLUMNS('emp%')) FROM employee_dimension;
ERROR 10465: MATCH_COLUMNS() function can only be specified as an element in a SELECT list
In contrast, the HASH function accepts an unlimited number of arguments, so calling MATCH_COLUMNS as an argument succeeds:
=> select HASH(MATCH_COLUMNS('emp%')) FROM employee_dimension LIMIT 10;
HASH
---------------------
2047284364908178817
1421997332260827278
7981613309330877388
792898558199431621
5275639269069980417
7892790768178152349
184601038712735208
3020263228621856381
7056305566297085916
3328422577712931057
(10 rows)
Other constraints
The following usages of MATCH_COLUMNS are invalid and return with an error:
-
Including MATCH_COLUMNS in the non-recursive (base) term query of a RECURSIVE WITH clause
-
Concatenating the results of MATCH_COLUMNS calls:
=> SELECT MATCH_COLUMNS ('%store%')||MATCH_COLUMNS('%store%') FROM store.store_orders_fact;
ERROR 0: MATCH_COLUMNS() function can only be specified as an element in a SELECT list
-
Setting an alias on MATCH_COLUMNS
Examples
The following CREATE PROJECTION statement uses MATCH_COLUMNS to specify table columns in the new projection:
=> CREATE PROJECTION p_store_orders AS SELECT
MATCH_COLUMNS('%product%'),
MATCH_COLUMNS('%store%'),
order_number FROM store.store_orders_fact;
WARNING 4468: Projection <store.p_store_orders_b0> is not available for query processing. Execute the select start_refresh() function to copy data into this projection.
The projection must have a sufficient number of buddy projections and all nodes must be up before starting a refresh
WARNING 4468: Projection <store.p_store_orders_b1> is not available for query processing. Execute the select start_refresh() function to copy data into this projection.
The projection must have a sufficient number of buddy projections and all nodes must be up before starting a refresh
CREATE PROJECTION
=> SELECT export_objects('', 'store.p_store_orders_b0');
...
CREATE PROJECTION store.p_store_orders_b0 /*+basename(p_store_orders)*/
(
product_key,
product_version,
store_key,
order_number
)
AS
SELECT store_orders_fact.product_key,
store_orders_fact.product_version,
store_orders_fact.store_key,
store_orders_fact.order_number
FROM store.store_orders_fact
ORDER BY store_orders_fact.product_key,
store_orders_fact.product_version,
store_orders_fact.store_key,
store_orders_fact.order_number
SEGMENTED BY hash(store_orders_fact.product_key, store_orders_fact.product_version, store_orders_fact.store_key, store_orders_fact.order_number) ALL NODES OFFSET 0;
SELECT MARK_DESIGN_KSAFE(1);
(1 row)
As shown in the EXPORT_OBJECTS output, Vertica stores the result sets of the two MATCH_COLUMNS calls in the new projection's DDL. Later changes in the anchor table DDL have no effect on this projection.
6.14.2.2 - REGEXP_COUNT
Returns the number times a regular expression matches a string.
Returns the number times a regular expression matches a string.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_COUNT ( string-expession, pattern [, position [, regexp-modifier ]... ] )
Parameters
string-expressionThe VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
patternThe regular expression to match against string-expression. The regular expression must conform with Perl regular expression syntax.
position- The number of characters from the start of the string where the function should start searching for matches. By default, the function begins searching for a match at the first (leftmost) character. Setting this parameter to a value greater than 1 begins searching for a match at the *
n*th character you specify.
Default: 1
regexp-modifierOne or more single-character flags that modify how the regular expression pattern is matched to string-expression:
-
b: Treat strings as binary octets, rather than UTF-8 characters.
-
c (default): Force the match to be case sensitive.
-
i: Force the match to be case insensitive.
-
m: Treat the string to match as multiple lines. Using this modifier, the start of line (^) and end of line ($) regular expression operators match line breaks (\n) within the string. Without the m modifier, the start and end of line operators match only the start and end of the string.
-
n: Match the regular expression operator (.) to a newline (\n). By default, the . operator matches any character except a newline.
-
x: Add comments to regular expressions. The x modifier causes the function to ignore all un-escaped space characters and comments in the regular expression. Comments start with hash (#) and end with a newline (\n). All spaces in the regular expression to be matched in strings must be escaped with a backslash (\).
Examples
Count the number of occurrences of the substring an in the specified string (a man, a plan, a canal: Panama):
=> SELECT REGEXP_COUNT('a man, a plan, a canal: Panama', 'an');
REGEXP_COUNT
--------------
4
(1 row)
Find the number of occurrences of the substring an, starting with the fifth character.
=> SELECT REGEXP_COUNT('a man, a plan, a canal: Panama', 'an',5);
REGEXP_COUNT
--------------
3
(1 row)
Find the number of occurrences of a substring containing a lower-case character followed by an:
=> SELECT REGEXP_COUNT('a man, a plan, a canal: Panama', '[a-z]an');
REGEXP_COUNT
--------------
3
(1 row
REGEXP_COUNT specifies the i modifier, so it ignores case:
=> SELECT REGEXP_COUNT('a man, a plan, a canal: Panama', '[a-z]an', 1, 'i');
REGEXP_COUNT
--------------
4
6.14.2.3 - REGEXP_ILIKE
Returns true if the string contains a match for the regular expression.
Returns true if the string contains a match for the regular expression. REGEXP_ILIKE is similar to the LIKE, except that it uses a case insensitive regular expression, rather than simple wildcard character matching.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_ILIKE ( string-expression, pattern )
Parameters
string-expression``- The
VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
pattern``- The regular expression to match against
string-expression. The regular expression must conform with Perl regular expression syntax.
Examples
This example creates a table containing several strings to demonstrate regular expressions.
-
Create table longvc with a single, long varchar column body, and insert data with distinct characters:
=> CREATE table longvc(body long varchar (1048576));
CREATE TABLE
=> insert into longvc values ('На берегу пустынных волн');
=> insert into longvc values ('Voin syödä lasia, se ei vahingoita minua');
=> insert into longvc values ('私はガラスを食べられます。それは私を傷つけません。');
=> insert into longvc values ('Je peux manger du verre, ça ne me fait pas mal.');
=> insert into longvc values ('zésbaésbaa');
=> insert into longvc values ('Out of the frying pan, he landed immediately in the fire');
=> SELECT * FROM longvc;
body
------------------------------------------------
На берегу пустынных волн
Voin syödä lasia, se ei vahingoita minua
私はガラスを食べられます。それは私を傷つけません。
Je peux manger du verre, ça ne me fait pas mal.
zésbaésbaa
Out of the frying pan, he landed immediately in the fire
(6 rows)
-
Pattern match table rows containing the character ç:
=> SELECT * FROM longvc where regexp_ilike(body, 'ç');
body
-------------------------------------------------
Je peux manger du verre, ça ne me fait pas mal.
(1 row)
-
Select all rows that contain the characters A/a:
=> SELECT * FROM longvc where regexp_ilike(body, 'A');
body
-------------------------------------------------
Je peux manger du verre, ça ne me fait pas mal.
Voin syödä lasia, se ei vahingoita minua
zésbaésbaa
(3 rows)
-
Select all rows that contain the characters O/o:
=> SELECT * FROM longvc where regexp_ilike(body, 'O');
body
----------------------------------------------------------
Voin syödä lasia, se ei vahingoita minua
Out of the frying pan, he landed immediately in the fire
(2 rows)
6.14.2.4 - REGEXP_INSTR
Returns the starting or ending position in a string where a regular expression matches.
Returns the starting or ending position in a string where a regular expression matches. REGEXP_INSTR returns 0 if no match for the regular expression is found in the string.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_INSTR ( string-expression, pattern
[, position [, occurrence [, return-position [, regexp-modifier ]... [, captured-subexp ]]]] )
Parameters
string-expressionThe VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
patternThe regular expression to match against string-expression. The regular expression must conform with Perl regular expression syntax.
position- The number of characters from the start of the string where the function should start searching for matches. By default, the function begins searching for a match at the first (leftmost) character. Setting this parameter to a value greater than 1 begins searching for a match at the *
n*th character you specify.
Default: 1
occurrence- Controls which occurrence of a pattern match in the string to return. By default, the function returns the position of the first matching substring. Use this parameter to find the position of subsequent matching substrings. For example, setting this parameter to 3 returns the position of the third substring that matches the pattern.
Default: 1
return-position- Sets the position within the string to return. Using the default position (0), the function returns the string position of the first character of the substring that matches the pattern. If you set
return-position to 1, the function returns the position of the first character after the end of the matching substring.
Default: 0
regexp-modifierOne or more single-character flags that modify how the regular expression pattern is matched to string-expression:
-
b: Treat strings as binary octets, rather than UTF-8 characters.
-
c (default): Force the match to be case sensitive.
-
i: Force the match to be case insensitive.
-
m: Treat the string to match as multiple lines. Using this modifier, the start of line (^) and end of line ($) regular expression operators match line breaks (\n) within the string. Without the m modifier, the start and end of line operators match only the start and end of the string.
-
n: Match the regular expression operator (.) to a newline (\n). By default, the . operator matches any character except a newline.
-
x: Add comments to regular expressions. The x modifier causes the function to ignore all un-escaped space characters and comments in the regular expression. Comments start with hash (#) and end with a newline (\n). All spaces in the regular expression to be matched in strings must be escaped with a backslash (\).
captured-subexp- The captured subexpression whose position to return. By default, the function returns the position of the first character in
string that matches the regular expression. If you set this value from 1 – 9, the function returns the subexpression captured by the corresponding set of parentheses in the regular expression. For example, setting this value to 3 returns the substring captured by the third set of parentheses in the regular expression.
Default: 0
Note
The subexpressions are numbered left to right, based on the appearance of opening parenthesis, so nested regular expressions . For example, in the regular expression \s*(\w+\s+(\w+)), subexpression 1 is the one that captures everything but any leading whitespaces.
Examples
Find the first occurrence of a sequence of letters starting with the letter e and ending with the letter y in the specified string (easy come, easy go).
=> SELECT REGEXP_INSTR('easy come, easy go','e\w*y');
REGEXP_INSTR
--------------
1
(1 row)
Starting at the second character (2), find the first sequence of letters starting with the letter e and ending with the letter y:
=> SELECT REGEXP_INSTR('easy come, easy go','e\w*y',2);
REGEXP_INSTR
--------------
12
(1 row)
Starting at the first character (1), find the second sequence of letters starting with the letter e and ending with the letter y:
=> SELECT REGEXP_INSTR('easy come, easy go','e\w*y',1,2);
REGEXP_INSTR
--------------
12
(1 row)
Find the position of the first character after the first whitespace:
=> SELECT REGEXP_INSTR('easy come, easy go','\s',1,1,1);
REGEXP_INSTR
--------------
6
(1 row)
Find the position of the start of the third word in a string by capturing each word as a subexpression, and returning the third subexpression's start position.
=> SELECT REGEXP_INSTR('one two three','(\w+)\s+(\w+)\s+(\w+)', 1,1,0,'',3);
REGEXP_INSTR
--------------
9
(1 row)
6.14.2.5 - REGEXP_LIKE
Returns true if the string matches the regular expression.
Returns true if the string matches the regular expression. REGEXP_LIKE is similar to the LIKE, except that it uses regular expressions rather than simple wildcard character matching.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_LIKE ( string-expression, pattern [, regexp-modifier ]... )
Parameters
string-expressionThe VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
patternThe regular expression to match against string-expression. The regular expression must conform with Perl regular expression syntax.
regexp-modifierOne or more single-character flags that modify how the regular expression pattern is matched to string-expression:
-
b: Treat strings as binary octets, rather than UTF-8 characters.
-
c (default): Force the match to be case sensitive.
-
i: Force the match to be case insensitive.
-
m: Treat the string to match as multiple lines. Using this modifier, the start of line (^) and end of line ($) regular expression operators match line breaks (\n) within the string. Without the m modifier, the start and end of line operators match only the start and end of the string.
-
n: Match the regular expression operator (.) to a newline (\n). By default, the . operator matches any character except a newline.
-
x: Add comments to regular expressions. The x modifier causes the function to ignore all un-escaped space characters and comments in the regular expression. Comments start with hash (#) and end with a newline (\n). All spaces in the regular expression to be matched in strings must be escaped with a backslash (\).
Examples
Create a table that contains several strings:
=> CREATE TABLE t (v VARCHAR);
CREATE TABLE
=> CREATE PROJECTION t1 AS SELECT * FROM t;
CREATE PROJECTION
=> COPY t FROM stdin;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> aaa
>> Aaa
>> abc
>> abc1
>> 123
>> \.
=> SELECT * FROM t;
v
-------
aaa
Aaa
abc
abc1
123
(5 rows)
Select all records from table t that contain the letter a:
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'a');
v
------
Aaa
aaa
abc
abc1
(4 rows)
Select all rows from table t that start with the letter a:
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'^a');
v
------
aaa
abc
abc1
(3 rows)
Select all rows that contain the substring aa:
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'aa');
v
-----
Aaa
aaa
(2 rows)
Select all rows that contain a digit.
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'\d');
v
------
123
abc1
(2 rows)
Select all rows that contain the substring aaa.
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'aaa');
v
-----
aaa
(1 row)
Select all rows that contain the substring aaa using case-insensitive matching.
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'aaa', 'i');
v
-----
Aaa
aaa
(2 rows)
Select rows that contain the substring a b c.
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'a b c');
v
---
(0 rows)
Select rows that contain the substring a b c, ignoring space within the regular expression.
=> SELECT v FROM t WHERE REGEXP_LIKE(v,'a b c','x');
v
------
abc
abc1
(2 rows)
Add multi-line rows to table t:
=> COPY t FROM stdin RECORD TERMINATOR '!';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Record 1 line 1
>> Record 1 line 2
>> Record 1 line 3!
>> Record 2 line 1
>> Record 2 line 2
>> Record 2 line 3!
>> \.
Select rows from table t that start with the substring Record and end with the substring line 2.
=> SELECT v from t WHERE REGEXP_LIKE(v,'^Record.*line 2$');
v
---
(0 rows)
Select rows that start with the substring Record and end with the substring line 2, treating multiple lines as separate strings.
=> SELECT v from t WHERE REGEXP_LIKE(v,'^Record.*line 2$','m');
v
--------------------------------------------------
Record 2 line 1
Record 2 line 2
Record 2 line 3
Record 1 line 1
Record 1 line 2
Record 1 line 3
(2 rows)
6.14.2.6 - REGEXP_NOT_ILIKE
Returns true if the string does not match the case-insensitive regular expression.
Returns true if the string does not match the case-insensitive regular expression.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_NOT_ILIKE ( string-expression, pattern )
Parameters
string-expression``- The
VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
pattern``- The regular expression to match against
string-expression. The regular expression must conform with Perl regular expression syntax.
Examples
-
Create a table (longvc) with a single, long varchar column (body). Then, insert data with some distinct characters, and query the table contents:
=> CREATE table longvc(body long varchar (1048576));
CREATE TABLE
=> insert into longvc values ('На берегу пустынных волн');
=> insert into longvc values ('Voin syödä lasia, se ei vahingoita minua');
=> insert into longvc values ('私はガラスを食べられます。それは私を傷つけません。');
=> insert into longvc values ('Je peux manger du verre, ça ne me fait pas mal.');
=> insert into longvc values ('zésbaésbaa');
=> SELECT * FROM longvc;
body
------------------------------------------------
На берегу пустынных волн
Voin syödä lasia, se ei vahingoita minua
私はガラスを食べられます。それは私を傷つけません。
Je peux manger du verre, ça ne me fait pas mal.
zésbaésbaa
(5 rows)
-
Find all rows that do not contain the character ç:
=> SELECT * FROM longvc where regexp_not_ilike(body, 'ç');
body
----------------------------------------------------
Voin syödä lasia, se ei vahingoita minua
zésbaésbaa
На берегу пустынных волн
私はガラスを食べられます。それは私を傷つけません。
(4 rows)
-
Find all rows that do not contain the substring a:
=> SELECT * FROM longvc where regexp_not_ilike(body, 'a');
body
----------------------------------------------------
На берегу пустынных волн
私はガラスを食べられます。それは私を傷つけません。
(2 rows)
6.14.2.7 - REGEXP_NOT_LIKE
Returns true if the string does not contain a match for the regular expression.
Returns true if the string does not contain a match for the regular expression. REGEXP_NOT_LIKE is a case sensitive regular expression.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_NOT_LIKE ( string-expression, pattern )
Parameters
string-expression``- The
VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
pattern``- The regular expression to match against
string-expression. The regular expression must conform with Perl regular expression syntax.
Examples
-
Create a table (longvc) with the LONG VARCHAR column body. Then, insert data with some distinct characters and query the table contents:
=> CREATE table longvc(body long varchar (1048576));
CREATE TABLE
=> insert into longvc values ('На берегу пустынных волн');
=> insert into longvc values ('Voin syödä lasia, se ei vahingoita minua');
=> insert into longvc values ('私はガラスを食べられます。それは私を傷つけません。');
=> insert into longvc values ('Je peux manger du verre, ça ne me fait pas mal.');
=> insert into longvc values ('zésbaésbaa');
=> SELECT * FROM longvc;
body
------------------------------------------------
На берегу пустынных волн
Voin syödä lasia, se ei vahingoita minua
私はガラスを食べられます。それは私を傷つけません。
Je peux manger du verre, ça ne me fait pas mal.
zésbaésbaa
(5 rows)
-
Use REGEXP_NOT_LIKE to return rows that do not contain the character ç:
=> SELECT * FROM longvc where regexp_not_like(body, 'ç');
body
----------------------------------------------------
Voin syödä lasia, se ei vahingoita minua
zésbaésbaa
На берегу пустынных волн
私はガラスを食べられます。それは私を傷つけません。
(4 rows)
-
Return all rows that do not contain the characters *ö and *ä:
=> SELECT * FROM longvc where regexp_not_like(body, '.*ö.*ä');
body
----------------------------------------------------
Je peux manger du verre, ça ne me fait pas mal.
zésbaésbaa
На берегу пустынных волн
私はガラスを食べられます。それは私を傷つけません。
(4 rows)
-
Pattern match all rows that do not contain the characters z and *ésbaa:
=> SELECT * FROM longvc where regexp_not_like(body, 'z.*ésbaa');
body
----------------------------------------------------
Je peux manger du verre, ça ne me fait pas mal.
Voin syödä lasia, se ei vahingoita minua
zésbaésbaa
На берегу пустынных волн
私はガラスを食べられます。それは私を傷つけません。
(5 rows)
6.14.2.8 - REGEXP_REPLACE
Replaces all occurrences of a substring that match a regular expression with another substring.
Replaces all occurrences of a substring that match a regular expression with another substring. REGEXP_REPLACE is similar to the REPLACE function, except it uses a regular expression to select the substring to be replaced.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_REPLACE ( string-expression, target
[, replacement [, position [, occurrence[...] [, regexp-modifier]]]] )
Parameters
string-expressionThe VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
patternThe regular expression to match against string-expression. The regular expression must conform with Perl regular expression syntax.
replacement- The string to replace matched substrings. If you do not supply a
replacement, the function deletes matched substrings. The replacement string can contain backreferences for substrings captured by the regular expression. The first captured substring is inserted into the replacement string using \1, the second \2, and so on.
position- The number of characters from the start of the string where the function should start searching for matches. By default, the function begins searching for a match at the first (leftmost) character. Setting this parameter to a value greater than 1 begins searching for a match at the
n-th character you specify.
Default: 1
occurrence- Controls which occurrence of a pattern match in the string to replace. By default, the function replaces all matching substrings. For example, setting this parameter to 3 replaces the third matching instance.
Default: 1
regexp-modifierOne or more single-character flags that modify how the regular expression pattern is matched to string-expression:
-
b: Treat strings as binary octets, rather than UTF-8 characters.
-
c (default): Force the match to be case sensitive.
-
i: Force the match to be case insensitive.
-
m: Treat the string to match as multiple lines. Using this modifier, the start of line (^) and end of line ($) regular expression operators match line breaks (\n) within the string. Without the m modifier, the start and end of line operators match only the start and end of the string.
-
n: Match the regular expression operator (.) to a newline (\n). By default, the . operator matches any character except a newline.
-
x: Add comments to regular expressions. The x modifier causes the function to ignore all un-escaped space characters and comments in the regular expression. Comments start with hash (#) and end with a newline (\n). All spaces in the regular expression to be matched in strings must be escaped with a backslash (\).
How Oracle handles subexpressions
Unlike Oracle, Vertica can handle an unlimited number of captured subexpressions, while Oracle is limited to nine.
In Vertica, you can use \10 in the replacement pattern to access the substring captured by the tenth set of parentheses in the regular expression. In Oracle, \10 is treated as the substring captured by the first set of parentheses, followed by a zero. To force this Oracle behavior in Vertica, use the \g back reference and enclose the number of the captured subexpression in curly braces. For example, \g{1}0 is the substring captured by the first set of parentheses followed by a zero.
You can also name captured subexpressions to make your regular expressions less ambiguous. See the PCRE documentation for details.
Examples
Find groups of word characters—letters, numbers and underscore—that end with thy in the string healthy, wealthy, and wise, and replace them with nothing.
=> SELECT REGEXP_REPLACE('healthy, wealthy, and wise','\w+thy');
REGEXP_REPLACE
----------------
, , and wise
(1 row)
Find groups of word characters ending with thy and replace with the string something.
=> SELECT REGEXP_REPLACE('healthy, wealthy, and wise','\w+thy', 'something');
REGEXP_REPLACE
--------------------------------
something, something, and wise
(1 row)
Find groups of word characters ending with thy and replace with the string something starting at the third character in the string.
=> SELECT REGEXP_REPLACE('healthy, wealthy, and wise','\w+thy', 'something', 3);
REGEXP_REPLACE
----------------------------------
hesomething, something, and wise
(1 row)
Replace the second group of word characters ending with thy with the string something.
=> SELECT REGEXP_REPLACE('healthy, wealthy, and wise','\w+thy', 'something', 1, 2);
REGEXP_REPLACE
------------------------------
healthy, something, and wise
(1 row)
Find groups of word characters ending with thy capturing the letters before the thy, and replace with the captured letters plus the letters ish.
=> SELECT REGEXP_REPLACE('healthy, wealthy, and wise','(\w+)thy', '\1ish');
REGEXP_REPLACE
----------------------------
healish, wealish, and wise
(1 row)
Create a table to demonstrate replacing strings in a query.
=> CREATE TABLE customers (name varchar(50), phone varchar(11));
CREATE TABLE
=> CREATE PROJECTION customers1 AS SELECT * FROM customers;
CREATE PROJECTION
=> COPY customers FROM stdin;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Able, Adam|17815551234
>> Baker,Bob|18005551111
>> Chu,Cindy|16175559876
>> Dodd,Dinara|15083452121
>> \.
Query the customers, using REGEXP_REPLACE to format phone numbers.
=> SELECT name, REGEXP_REPLACE(phone, '(\d)(\d{3})(\d{3})(\d{4})',
'\1-(\2) \3-\4') as phone FROM customers;
name | phone
-------------+------------------
Able, Adam | 1-(781) 555-1234
Baker,Bob | 1-(800) 555-1111
Chu,Cindy | 1-(617) 555-9876
Dodd,Dinara | 1-(508) 345-2121
(4 rows)
6.14.2.9 - REGEXP_SUBSTR
Returns the substring that matches a regular expression within a string.
Returns the substring that matches a regular expression within a string. If no matches are found, REGEXP_SUBSTR returns NULL. This is different from an empty string, which the function can return if the regular expression matches a zero-length string.
This function operates on UTF-8 strings using the default locale, even if the locale is set otherwise.
Important
If you port a regular expression query from an Oracle database, remember that Oracle considers a zero-length string to be equivalent to NULL, while Vertica does not.
Syntax
REGEXP_SUBSTR ( string-expression, pattern
[, position [, occurrence [, regexp-modifier [, captured-subexp ]]... ]] )
Parameters
string-expressionThe VARCHAR or LONG VARCHAR expression to evaluate for matches with the regular expression specified in pattern. If string-expression is in the __raw__ column of a flex or columnar table, cast the string to a LONG VARCHAR before searching for pattern.
patternThe regular expression to match against string-expression. The regular expression must conform with Perl regular expression syntax.
position- The number of characters from the start of the string where the function should start searching for matches. By default, the function begins searching for a match at the first (leftmost) character. Setting this parameter to a value greater than 1 begins searching for a match at the
n-th character you specify.
Default: 1
occurrence- Controls which occurrence of a pattern match in the string to return. By default, the function returns the first matching substring. For example, setting this parameter to 3 returns the third matching instance.
Default: 1
regexp-modifierOne or more single-character flags that modify how the regular expression pattern is matched to string-expression:
-
b: Treat strings as binary octets, rather than UTF-8 characters.
-
c (default): Force the match to be case sensitive.
-
i: Force the match to be case insensitive.
-
m: Treat the string to match as multiple lines. Using this modifier, the start of line (^) and end of line ($) regular expression operators match line breaks (\n) within the string. Without the m modifier, the start and end of line operators match only the start and end of the string.
-
n: Match the regular expression operator (.) to a newline (\n). By default, the . operator matches any character except a newline.
-
x: Add comments to regular expressions. The x modifier causes the function to ignore all un-escaped space characters and comments in the regular expression. Comments start with hash (#) and end with a newline (\n). All spaces in the regular expression to be matched in strings must be escaped with a backslash (\).
captured-subexp- The group to return. By default, the function returns all matching groups. For example, setting this value to 3 returns the substring captured by the third set of parentheses in the regular expression.
Default: 0
Note
The subexpressions are numbered left to right, based on the appearance of opening parenthesis, so nested regular expressions . For example, in the regular expression \s*(\w+\s+(\w+)), subexpression 1 is the one that captures everything but any leading whitespaces.
Examples
Select the first substring of letters that end with thy.
=> SELECT REGEXP_SUBSTR('healthy, wealthy, and wise','\w+thy');
REGEXP_SUBSTR
---------------
healthy
(1 row)
Select the first substring of letters that ends with thy starting at the second character in the string.
=> SELECT REGEXP_SUBSTR('healthy, wealthy, and wise','\w+thy',2);
REGEXP_SUBSTR
---------------
ealthy
(1 row)
Select the second substring of letters that ends with thy.
=> SELECT REGEXP_SUBSTR('healthy, wealthy, and wise','\w+thy',1,2);
REGEXP_SUBSTR
---------------
wealthy
(1 row)
Return the contents of the third captured subexpression, which captures the third word in the string.
=> SELECT REGEXP_SUBSTR('one two three', '(\w+)\s+(\w+)\s+(\w+)', 1, 1, '', 3);
REGEXP_SUBSTR
---------------
three
(1 row)
6.14.3 - Text search functions
This section contains text search functions specific to Vertica.
This section contains text search functions specific to Vertica.
6.14.3.1 - DELETE_TOKENIZER_CONFIG_FILE
Deletes a tokenizer configuration file.
Deletes a tokenizer configuration file.
Syntax
SELECT v_txtindex.DELETE_TOKENIZER_CONFIG_FILE (USING PARAMETERS proc_oid='proc_oid', confirm={true | false });
Parameters
confirm = [true | false]- Boolean flag. Indicates that the configuration file should be removed even if the tokenizer is still in use.
True — Force deletion of the tokenizer when the used parameter value is True.
False — Delete tokenizer if the used parameter value is False.
Default:False
proc_oid- A unique identifier assigned to a tokenizer when it is created. Users must query the system table vs_procedures to get the proc_oid for a given tokenizer name. See Configuring a tokenizer for more information.
Examples
The following example shows how you can use DELETE_TOKENIZER_CONFIG_FILE to delete the tokenizer configuration file:
=> SELECT v_txtindex.DELETE_TOKENIZER_CONFIG_FILE (USING PARAMETERS proc_oid='45035996274126984');
DELETE_TOKENIZER_CONFIG_FILE
------------------------------
t
(1 row)
6.14.3.2 - GET_TOKENIZER_PARAMETER
Returns the configuration parameter for a given tokenizer.
Returns the configuration parameter for a given tokenizer.
Syntax
SELECT v_txtindex.GET_TOKENIZER_PARAMETER(parameter_name USING PARAMETERS proc_oid='proc_oid');
Parameters
parameter_name- Name of the parameter to be returned.
One of the following:
-
stopWordsCaseInsensitive
-
minorSeparators
-
majorSeparators
-
minLength
-
maxLength
-
ngramsSize
-
used
proc_oid- A unique identifier assigned to a tokenizer when it is created. Users must query the system table vs_procedures to get the proc_oid for a given tokenizer name. See Configuring a tokenizer for more information.
Examples
The following examples show how you can use GET_TOKENIZER_PARAMETER.
Return the stop words used in a tokenizer:
=> SELECT v_txtindex.GET_TOKENIZER_PARAMETER('stopwordscaseinsensitive' USING PARAMETERS proc_oid='45035996274126984');
getTokenizerParameter
-----------------------
devil,TODAY,the,fox
(1 row)
Return the major separators used in a tokenizer:
=> SELECT v_txtindex.GET_TOKENIZER_PARAMETER('majorseparators' USING PARAMETERS proc_oid='45035996274126984');
getTokenizerParameter
-----------------------
{}()&[]
(1 row)
6.14.3.3 - READ_CONFIG_FILE
Reads and returns the key-value pairs of all the parameters of a given tokenizer.
Reads and returns the key-value pairs of all the parameters of a given tokenizer.
You must use the OVER() clause with this function.
Syntax
SELECT v_txtindex.READ_CONFIG_FILE(USING PARAMETERS proc_oid='proc_oid') OVER ()
Parameters
proc_oid- A unique identifier assigned to a tokenizer when it is created. Users must query the system table vs_procedures to get the proc_oid for a given tokenizer name. See Configuring a tokenizer for more information.
Examples
The following example shows how you can use READ_CONFIG_FILE to return the parameters associated with a tokenizer:
=> SELECT v_txtindex.READ_CONFIG_FILE(USING PARAMETERS proc_oid='45035996274126984') OVER();
config_key | config_value
--------------------------+---------------------
majorseparators | {}()&[]
stopwordscaseinsensitive | devil,TODAY,the,fox
(2 rows)
6.14.3.4 - SET_TOKENIZER_PARAMETER
Configures the tokenizer parameters.
Configures the tokenizer parameters.
Important
\n, \t,\r must be entered as Unicode using Vertica notation, U&’\000D’, or using Vertica escaping notation, E’\r’. Otherwise, they are taken literally as two separate characters. For example, "\" & "r".
Syntax
SELECT v_txtindex.SET_TOKENIZER_PARAMETER (parameter_name, parameter_value USING PARAMETERS proc_oid='proc_oid')
Parameters
parameter_name- Name of the parameter to be configured.
Use one of the following:
-
stopwordsCaseInsensitive: List of stop words. All the tokens that belong to the list are ignored. Vertica supports separators and stop words up to the first 256 Unicode characters.
If you want to define a stop word that contains a comma or a backslash, then it needs to be escaped.
For example: "Dear Jack\," "Dear Jack\\"
Default: '' (empty list)
-
majorSeparators:List of major separators. Enclose in quotes with no spaces between.
Default: E' []<>(){}|!;,''"*&?+\r\n\t'
-
minorSeparators: List of minor separators. Enclose in quotes with no spaces between.
Default: E'/:=@.-$#%\\_'
-
minLength — Minimum length a token can have, type Integer. Must be greater than 0.
Default: '2'
-
maxLength: Maximum length a token can be. Type Integer. Cannot be greater than 1024 bytes. For information about increasing the token size, see Text search parameters.
Default: '128'
-
ngramsSize: Integer value greater than zero. Use only with ngram tokenizers.
Default: '3'
-
used: Indicates when a tokenizer configuration cannot be changed. Type Boolean. After you set used to True, any calls to setTokenizerParameter fail.
You must set the parameter used to True before using the configured tokenizer. Doing so prevents the configuration from being modified after being used to create a text index.
Default: False
parameter_value- The value of a configuration parameter.
If you want to disable minorSeperators or stopWordsCaseInsensitive, then set their values to ''.
proc_oid- A unique identifier assigned to a tokenizer when it is created. Users must query the system table vs_procedures to get the proc_oid for a given tokenizer name. See Configuring a tokenizer for more information.
Examples
The following examples show how you can use SET_TOKENIZER_PARAMETER to configure stop words and separators.
Configure the stop words of a tokenizer:
=> SELECT v_txtindex.SET_TOKENIZER_PARAMETER('stopwordsCaseInsensitive', 'devil,TODAY,the,fox' USING PARAMETERS proc_oid='45035996274126984');
SET_TOKENIZER_PARAMETER
-------------------------
t
(1 row)
Configure the major separators of a tokenizer:
=> SELECT v_txtindex.SET_TOKENIZER_PARAMETER('majorSeparators',E'{}()&[]' USING PARAMETERS proc_oid='45035996274126984');
SET_TOKENIZER_PARAMETER
-------------------------
t
(1 row)
6.15 - Mathematical functions
Some of these functions are provided in multiple forms with different argument types.
Some of these functions are provided in multiple forms with different argument types. Except where noted, any given form of a function returns the same data type as its argument. The functions working with DOUBLE PRECISION data could vary in accuracy and behavior in boundary cases depending on the host system.
6.15.1 - ABS
Returns the absolute value of the argument.
Returns the absolute value of the argument. The return value has the same data type as the argument..
Behavior type
Immutable
Syntax
ABS ( expression )
Arguments
expression- Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
SELECT ABS(-28.7);
abs
------
28.7
(1 row)
6.15.2 - ACOS
Returns a DOUBLE PRECISION value representing the trigonometric inverse cosine of the argument.
Returns a DOUBLE PRECISION value representing the trigonometric inverse cosine of the argument.
Behavior type
Immutable
Syntax
ACOS ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT ACOS (1);
acos
------
0
(1 row)
6.15.3 - ACOSH
Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic cosine of the function argument.
Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic cosine of the function argument.
Behavior type
Immutable
Syntax
ACOSH ( expression )
Arguments
expression - Resolves to a value of type INTEGER or DOUBLE PRECISION ≥ 1.0, otherwise returns NaN.
Examples
=> SELECT acosh(4);
acosh
------------------
2.06343706889556
(1 row)
6.15.4 - ASIN
Returns a DOUBLE PRECISION value representing the trigonometric inverse sine of the argument.
Returns a DOUBLE PRECISION value representing the trigonometric inverse sine of the argument.
Behavior type
Immutable
Syntax
ASIN ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT ASIN(1);
asin
-----------------
1.5707963267949
(1 row)
6.15.5 - ASINH
Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic sine of the function argument.
Returns a DOUBLE PRECISION value that represents the inverse (arc) hyperbolic sine of the function argument.
Behavior type
Immutable
Syntax
ASINH ( expression )
Arguments
expression - Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
=> SELECT asinh(2.85);
asinh
------------------
1.76991385902105
(1 row)
6.15.6 - ATAN
Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the argument.
Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the argument.
Behavior type
Immutable
Syntax
ATAN ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT ATAN(1);
atan
-------------------
0.785398163397448
(1 row)
6.15.7 - ATAN2
Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the arithmetic dividend of the arguments.
Returns a DOUBLE PRECISION value representing the trigonometric inverse tangent of the arithmetic dividend of the arguments.
Behavior type
Immutable
Syntax
ATAN2 ( quotient, divisor )
Arguments
quotient- Resolves to a value of type DOUBLE PRECISION representing the quotient.
divisor- Resolves to a value of type DOUBLE PRECISION representing the divisor.
Examples
SELECT ATAN2(2,1);
ATAN2
------------------
1.10714871779409
(1 row)
6.15.8 - ATANH
Returns a DOUBLE PRECISION value that represents the inverse hyperbolic tangent of the function argument.
Returns a DOUBLE PRECISION value that represents the inverse hyperbolic tangent of the function argument.
Behavior type
Immutable
Syntax
ATANH ( expression )
Arguments
expression - Resolves to a value of type INTEGER or DOUBLE PRECISION between -1.0 and +1.0, inclusive, otherwise returns NaN.
Examples
=> SELECT atanh(-0.875);
atanh
-------------------
-1.35402510055111
(1 row)
6.15.9 - CBRT
Returns the cube root of the argument.
Returns the cube root of the argument. The return value has the type DOUBLE PRECISION.
Behavior type
Immutable
Syntax
CBRT ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT CBRT(27.0);
cbrt
------
3
(1 row)
6.15.10 - CEILING
Rounds up the returned value up to the next whole number.
Rounds up the returned value up to the next whole number. For example, given arguments of 5.01 and 5.99, CEILING returns 6. CEILING is the opposite of FLOOR, which rounds down the returned value.
Behavior type
Immutable
Syntax
CEIL[ING] ( expression )
Arguments
expression- Resolves to an INTEGER or DOUBLE PRECISION value.
Examples
=> SELECT CEIL(-42.8);
CEIL
------
-42
(1 row)
SELECT CEIL(48.01);
CEIL
------
49
(1 row)
6.15.11 - COS
Returns a DOUBLE PRECISION value tat represents the trigonometric cosine of the passed parameter.
Returns a DOUBLE PRECISION value tat represents the trigonometric cosine of the passed parameter.
Behavior type
Immutable
Syntax
COS ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT COS(-1);
COS
------------------
0.54030230586814
(1 row)
6.15.12 - COSH
Returns a DOUBLE PRECISION value that represents the hyperbolic cosine of the passed parameter.
Returns a DOUBLE PRECISION value that represents the hyperbolic cosine of the passed parameter.
Behavior type
Immutable
Syntax
COSH ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
=> SELECT COSH(-1);
COSH
------------------
1.54308063481524
6.15.13 - COT
Returns a DOUBLE PRECISION value representing the trigonometric cotangent of the argument.
Returns a DOUBLE PRECISION value representing the trigonometric cotangent of the argument.
Behavior type
Immutable
Syntax
COT ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT COT(1);
cot
-------------------
0.642092615934331
(1 row)
6.15.14 - DEGREES
Converts an expression from radians to fractional degrees, or from degrees, minutes, and seconds to fractional degrees.
Converts an expression from radians to fractional degrees, or from degrees, minutes, and seconds to fractional degrees. The return value has the type DOUBLE PRECISION.
Behavior type
Immutable
Syntax
DEGREES ( { radians | degrees, minutes, seconds } )
Arguments
radians- Unit of angular measure. 2*
π* radians is equal to a full rotation.
degrees- Unit of angular measure, equal to 1/360 of a full rotation.
minutes- Unit of angular measurement, representing 1/60 of a degree.
seconds- Unit of angular measurement, representing 1/60 of a minute.
Examples
SELECT DEGREES(0.5);
DEGREES
------------------
28.6478897565412
(1 row)
SELECT DEGREES(1,2,3);
DEGREES
------------------
1.03416666666667
(1 row)
6.15.15 - DISTANCE
Returns the distance (in kilometers) between two points.
Returns the distance (in kilometers) between two points. You specify the latitude and longitude of the starting point and the ending point. You can also specify the radius of curvature for greater accuracy when using an ellipsoidal model.
Behavior type
Immutable
Syntax
DISTANCE ( lat0, lon0, lat1, lon1 [, radius-of-curvature ] )
Arguments
lat0- Starting point latitude.
lon0- Starting point longitude.
lat1- Ending point latitude
lon1- Ending point longitude.
radius-of-curvature- Radius of the earth's curvature at the midpoint between the starting and ending points. This argument allows for greater accuracy when using an ellipsoidal earth model. If you omit this argument, DISTANCE uses the WGS-84 average r1 radius, about 6371.009 km.
Examples
This example finds the distance in kilometers for 1 degree of longitude at latitude 45 degrees, assuming earth is spherical.
SELECT DISTANCE(45,0,45,1);
DISTANCE
----------------------
78.6262959272162
(1 row)
6.15.16 - DISTANCEV
Returns the distance (in kilometers) between two points using the Vincenty formula.
Returns the distance (in kilometers) between two points using the Vincenty formula. Because the Vincenty formula includes the parameters of the WGS-84 ellipsoid model, you need not specify a radius of curvature. You specify the latitude and longitude of both the starting point and the ending point. This function is more accurate, but will be slower, than the DISTANCE function.
Behavior type
Immutable
Syntax
DISTANCEV (lat0, lon0, lat1, lon1);
Arguments
lat0- Specifies the latitude of the starting point.
lon0- Specifies the longitude of the starting point.
lat1- Specifies the latitude of the ending point.
lon1- Specifies the longitude of the ending point.
Examples
This example finds the distance in kilometers for 1 degree of longitude at latitude 45 degrees, assuming earth is ellipsoidal.
SELECT DISTANCEV(45,0, 45,1);
distanceV
------------------
78.8463347095916
(1 row)
6.15.17 - EXP
Returns the exponential function, e to the power of a number.
Returns the exponential function, e to the power of a number. The return value has the same data type as the argument.
Behavior type
Immutable
Syntax
EXP ( exponent )
Arguments
exponent- Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
SELECT EXP(1.0);
exp
------------------
2.71828182845905
(1 row)
6.15.18 - FLOOR
Rounds down the returned value to the previous whole number.
Rounds down the returned value to the previous whole number. For example, given arguments of 5.01 and 5.99, FLOOR returns 5. FLOOR is the opposite of CEILING, which rounds up the returned value.
Behavior type
Immutable
Syntax
FLOOR ( expression )
Arguments
expression- Resolves to an INTEGER or DOUBLE PRECISION value.
Examples
=> SELECT FLOOR((TIMESTAMP '2005-01-17 10:00' - TIMESTAMP '2005-01-01') / INTERVAL '7');
FLOOR
-------
2
(1 row)
=> SELECT FLOOR(-42.8);
FLOOR
-------
-43
(1 row)
=> SELECT FLOOR(42.8);
FLOOR
-------
42
(1 row)
Although the following example looks like an INTEGER, the number on the left is 2^49 as an INTEGER, while the number on the right is a FLOAT:
=> SELECT 1<<49, FLOOR(1 << 49);
?column? | floor
-----------------+-----------------
562949953421312 | 562949953421312
(1 row)
Compare the previous example to:
=> SELECT 1<<50, FLOOR(1 << 50);
?column? | floor
------------------+----------------------
1125899906842624 | 1.12589990684262e+15
(1 row)
6.15.19 - HASH
Calculates a hash value over the function arguments, producing a value in the range 0 <= x < 263.
Calculates a hash value over the function arguments, producing a value in the range
0 <= x < 263.
The HASH function is typically used to segment a projection over a set of cluster nodes. The function selects a specific node for each row based on the values of the row columns. The HASH function distributes data evenly across the cluster, which facilitates optimal query execution.
Behavior type
Immutable
Syntax
HASH ( { * | expression[,...] } )
Arguments
* | expression[,...]- One of the following:
-
* (asterisk)
Specifies to hash all columns in the queried table.
-
expression
An expression of any data type. Functions that are included in expression must be deterministic. If specified in a projection's hash segmentation clause, each expression typically resolves to a column reference.
Examples
=> SELECT HASH(product_price, product_cost) FROM product_dimension
WHERE product_price = '11';
hash
---------------------
4157497907121511878
1799398249227328285
3250220637492749639
(3 rows)
See also
Hash segmentation clause
6.15.20 - LN
Returns the natural logarithm of the argument.
Returns the natural logarithm of the argument. The return data type is the same as the argument.
Behavior type
Immutable
Syntax
LN ( expression )
Arguments
expression- Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
SELECT LN(2);
ln
-------------------
0.693147180559945
(1 row)
6.15.21 - LOG
Returns the logarithm to the specified base of the argument.
Returns the logarithm to the specified base of the argument. The data type of the return value is the same data type as the passed parameter.
Behavior type
Immutable
Syntax
LOG ( [ base, ] expression )
Arguments
base- Specifies the base (default is base 10)
expression- Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
=> SELECT LOG(2.0, 64);
LOG
-----
6
(1 row)
SELECT LOG(100);
LOG
-----
2
(1 row)
6.15.22 - LOG10
Returns the base 10 logarithm of the argument, also known as the common logarithm.
Returns the base 10 logarithm of the argument, also known as the common logarithm. The data type of the return value is the same as the data type of the passed parameter.
Behavior type
Immutable
Syntax
LOG10 ( expression )
Arguments
expression- Resolves to a value of type INTEGER or DOUBLE PRECISION.
Examples
=> SELECT LOG10(30);
LOG10
------------------
1.47712125471966
(1 row)
6.15.23 - MOD
Returns the remainder of a division operation.
Returns the remainder of a division operation.
Behavior type
Immutable
Syntax
MOD( expression1, expression2 )
Arguments
expression1- Resolves to a numeric data type that specifies the dividend.
expression2- Resolves to a numeric data type that specifies the divisor.
Computation rules
When computing MOD(expression1, expression2), the following rules apply:
-
If either expression1 or expression2 is the null value, then the result is the null value.
-
If expression2 is zero, then an exception condition is raised: data exception — division by zero.
-
Otherwise, the result is the unique exact numeric value R with scale 0 (zero) such that all of the following are true:
-
R has the same sign as expression2.
-
The absolute value of R is less than the absolute value of expression1.
-
expression2 = expression1 * K + R for some exact numeric value K with scale 0 (zero).
Examples
SELECT MOD(9,4);
mod
-----
1
(1 row)
SELECT MOD(10,3);
mod
-----
1
(1 row)
SELECT MOD(-10,3);
mod
-----
-1
(1 row)
SELECT MOD(-10,-3);
mod
-----
-1
(1 row)
SELECT MOD(10,-3);
mod
-----
1
(1 row)
=> SELECT MOD(6.2,0);
ERROR 3117: Division by zero
6.15.24 - PI
Returns the constant pi (P), the ratio of any circle's circumference to its diameter in Euclidean geometry The return type is DOUBLE PRECISION.
Returns the constant pi (P), the ratio of any circle's circumference to its diameter in Euclidean geometry The return type is DOUBLE PRECISION.
Behavior type
Immutable
Syntax
PI()
Examples
SELECT PI();
pi
------------------
3.14159265358979
(1 row)
6.15.25 - POWER
Returns a DOUBLE PRECISION value representing one number raised to the power of another number.
Returns a DOUBLE PRECISION value representing one number raised to the power of another number.
Behavior type
Immutable
Syntax
POW[ER] ( expression1, expression2 )
Arguments
expression1- Resolves to a DOUBLE PRECISION value that represents the base.
expression2- Resolves to a DOUBLE PRECISION value that represents the exponent.
Examples
SELECT POWER(9.0, 3.0);
power
-------
729
(1 row)
6.15.26 - RADIANS
Returns a DOUBLE PRECISION value representing an angle expressed in radians.
Returns a DOUBLE PRECISION value representing an angle expressed in radians. You can express the input angle in DEGREES, and optionally include minutes and seconds.
Behavior type
Immutable
Syntax
RADIANS (degrees [, minutes, seconds])
Arguments
degrees- Unit of angular measurement, representing 1/360 of a full rotation.
minutes- Unit of angular measurement, representing 1/60 of a degree.
seconds- Unit of angular measurement, representing 1/60 of a minute.
Examples
SELECT RADIANS(45);
RADIANS
-------------------
0.785398163397448
(1 row)
SELECT RADIANS (1,2,3);
RADIANS
-------------------
0.018049613347708
(1 row)
6.15.27 - RANDOM
Returns a uniformly-distributed random DOUBLE PRECISION value x, where 0 <= x < 1.
Returns a uniformly-distributed random DOUBLE PRECISION value x, where 0 <= x < 1.
Typical pseudo-random generators accept a seed, which is set to generate a reproducible pseudo-random sequence. Vertica, however, distributes SQL processing over a cluster of nodes, where each node generates its own independent random sequence.
Results depending on RANDOM are not reproducible because the work might be divided differently across nodes. Therefore, Vertica automatically generates truly random seeds for each node each time a request is executed and does not provide a mechanism for forcing a specific seed.
Behavior type
Volatile
Syntax
RANDOM()
Examples
In the following example, RANDOM returns a float ≥ 0 and < 1.0:
SELECT RANDOM();
random
-------------------
0.211625560652465
(1 row)
6.15.28 - RANDOMINT
Accepts and returns an integer between 0 and the integer argument expression-1.
Accepts and returns an integer between 0 and the integer argument expression-1.
Typical pseudo-random generators accept a seed, which is set to generate a reproducible pseudo-random sequence. Vertica, however, distributes SQL processing over a cluster of nodes, where each node generates its own independent random sequence.
Results depending on RANDOM are not reproducible because the work might be divided differently across nodes. Therefore, Vertica automatically generates truly random seeds for each node each time a request is executed and does not provide a mechanism for forcing a specific seed.
Behavior type
Volatile
Syntax
RANDOMINT ( expression )
Arguments
expression- Resolves to a positive INTEGER between 1 and 263 − 1, inclusive. If you supply a negative value or
expression > 1, Vertica returns an error.
Examples
In the following example, the result is an INTEGER ≥ 0 and < expression, randomly chosen from the set {0,1,2,3,4}.
=> SELECT RANDOMINT(5);
RANDOMINT
----------
3
(1 row)
6.15.29 - RANDOMINT_CRYPTO
Accepts and returns an INTEGER value from a set of values between 0 and the specified function argument -1.
Accepts and returns an INTEGER value from a set of values between 0 and the specified function argument -1. For this cryptographic random number generator, Vertica uses RAND_bytes to provide the random value.
Behavior type
Volatile
Syntax
RANDOMINT_CRYPTO ( expression )
Arguments
expression- Resolves to a positive integer between 1 and 263 − 1, inclusive.
Examples
In the following example, RANDOMINT_CRYPTO returns an INTEGER >= 0 and less than the specified argument 5, randomly chosen from the set {0,1,2,3,4}.
=> SELECT RANDOMINT_crypto(5);
RANDOMINT_crypto
----------------
3
(1 row)
6.15.30 - ROUND
Rounds a value to a specified number of decimal places, retaining the original precision and scale.
Rounds a value to a specified number of decimal places, retaining the original precision and scale. Fractions greater than or equal to .5 are rounded up. Fractions less than .5 are rounded down (truncated).
Behavior type
Immutable
Syntax
ROUND ( expression [, places ] )
Arguments
expression- Resolves to a value of type
NUMERIC or DOUBLE PRECISION (FLOAT).
places- An INTEGER value. When
places is a positive integer, Vertica rounds the value to the right of the decimal point using the specified number of places. When places is a negative integer, Vertica rounds the value on the left side of the decimal point using the specified number of places.
Notes
Using ROUND with a NUMERIC datatype returns NUMERIC, retaining the original precision and scale.
=> SELECT ROUND(3.5);
ROUND
-------
4.0
(1 row)
Examples
=> SELECT ROUND(2.0, 1.0) FROM dual;
ROUND
-------
2.0
(1 row)
=> SELECT ROUND(12.345, 2.0);
ROUND
--------
12.350
(1 row)
=> SELECT ROUND(3.444444444444444);
ROUND
-------------------
3.000000000000000
(1 row)
=> SELECT ROUND(3.14159, 3);
ROUND
---------
3.14200
(1 row)
=> SELECT ROUND(1234567, -3);
ROUND
---------
1235000
(1 row)
=> SELECT ROUND(3.4999, -1);
ROUND
--------
0.0000
(1 row)
The following example creates a table with two columns, adds one row of values, and shows sample rounding to the left and right of a decimal point.
=> CREATE TABLE sampleround (roundcol1 NUMERIC, roundcol2 NUMERIC);
CREATE TABLE
=> INSERT INTO sampleround VALUES (1234567, .1234567);
OUTPUT
--------
1
(1 row)
=> SELECT ROUND(roundcol1,-3) AS pn3, ROUND(roundcol1,-4) AS pn4, ROUND(roundcol1,-5) AS pn5 FROM sampleround;
pn3 | pn4 | pn5
-------------------------+-------------------------+-------------------------
1235000.000000000000000 | 1230000.000000000000000 | 1200000.000000000000000
(1 row)
=> SELECT ROUND(roundcol2,3) AS p3, ROUND(roundcol2,4) AS p4, ROUND(roundcol2,5) AS p5 FROM sampleround;
p3 | p4 | p5
-------------------+-------------------+-------------------
0.123000000000000 | 0.123500000000000 | 0.123460000000000
(1 row)
6.15.31 - SIGN
Returns a DOUBLE PRECISION value of -1, 0, or 1 representing the arithmetic sign of the argument.
Returns a DOUBLE PRECISION value of -1, 0, or 1 representing the arithmetic sign of the argument.
Behavior type
Immutable
Syntax
SIGN ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT SIGN(-8.4);
sign
------
-1
(1 row)
6.15.32 - SIN
Returns a DOUBLE PRECISION value that represents the trigonometric sine of the passed parameter.
Returns a DOUBLE PRECISION value that represents the trigonometric sine of the passed parameter.
Behavior type
Immutable
Syntax
SIN ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT SIN(30 * 2 * 3.14159 / 360);
SIN
-------------------
0.499999616987256
(1 row)
6.15.33 - SINH
Returns a DOUBLE PRECISION value that represents the hyperbolic sine of the passed parameter.
Returns a DOUBLE PRECISION value that represents the hyperbolic sine of the passed parameter.
Behavior type
Immutable
Syntax
SINH ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
=> SELECT SINH(30 * 2 * 3.14159 / 360);
SINH
-------------------
0.547852969600632
6.15.34 - SQRT
Returns a DOUBLE PRECISION value representing the arithmetic square root of the argument.
Returns a DOUBLE PRECISION value representing the arithmetic square root of the argument.
Behavior type
Immutable
Syntax
SQRT ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
SELECT SQRT(2);
sqrt
-----------------
1.4142135623731
(1 row)
6.15.35 - TAN
Returns a DOUBLE PRECISION value that represents the trigonometric tangent of the passed parameter.
Returns a DOUBLE PRECISION value that represents the trigonometric tangent of the passed parameter.
Behavior type
Immutable
Syntax
TAN ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
=> SELECT TAN(30);
TAN
-------------------
-6.40533119664628
(1 row)
6.15.36 - TANH
Returns a DOUBLE PRECISION value that represents the hyperbolic tangent of the passed parameter.
Returns a DOUBLE PRECISION value that represents the hyperbolic tangent of the passed parameter.
Behavior type
Immutable
Syntax
TANH ( expression )
Arguments
expression- Resolves to a value of type DOUBLE PRECISION.
Examples
=> SELECT TANH(-1);
TANH
-------------------
-0.761594155955765
6.15.37 - TRUNC
Returns the expression value fully truncated (toward zero).
Returns the expression value fully truncated (toward zero). Supplying a places argument truncates the expression to the number of decimal places you indicate.
Behavior type
Immutable
Syntax
TRUNC ( expression [, places ] )
Arguments
expression- Resolves to a value of type
NUMERIC or DOUBLE PRECISION (FLOAT).
places- INTEGER value:
- Positive: Vertica truncates the value to the right of the decimal point.
- Negative: Vertica truncates the value on the left side of the decimal point.
Notes
Using TRUNC with a NUMERIC datatype returns NUMERIC, retaining the original precision and scale.
=> SELECT TRUNC(3.5);
TRUNC
-------
3.0
(1 row)
Examples
=> SELECT TRUNC(42.8);
TRUNC
-------
42.0
(1 row)
=> SELECT TRUNC(42.4382, 2);
TRUNC
---------
42.4300
(1 row)
The following example creates a table with two columns, adds one row of values, and shows sample truncating to the left and right of a decimal point.
=> CREATE TABLE sampletrunc (truncol1 NUMERIC, truncol2 NUMERIC);
CREATE TABLE
=> INSERT INTO sampletrunc VALUES (1234567, .1234567);
OUTPUT
--------
1
(1 row)
=> SELECT TRUNC(truncol1,-3) AS p3, TRUNC(truncol1,-4) AS p4, TRUNC(truncol1,-5) AS p5 FROM sampletrunc;
p3 | p4 | p5
-------------------------+-------------------------+-------------------------
1234000.000000000000000 | 1230000.000000000000000 | 1200000.000000000000000
(1 row)
=> SELECT TRUNC(truncol2,3) AS p3, TRUNC(truncol2,4) AS p4, TRUNC(truncol2,5) AS p5 FROM sampletrunc;
p3 | p4 | p5
-------------------+-------------------+-------------------
0.123000000000000 | 0.123400000000000 | 0.123450000000000
(1 row)
6.15.38 - WIDTH_BUCKET
Constructs equiwidth histograms, in which the histogram range is divided into intervals (buckets) of identical sizes.
Constructs equiwidth histograms, in which the histogram range is divided into intervals (buckets) of identical sizes. In addition, values below the low bucket return 0, and values above the high bucket return bucket-count +1. Returns an integer value.
Behavior type
Immutable
Syntax
WIDTH_BUCKET ( expression, hist-min, hist-max, bucket-count )
Arguments
expression- The expression for which the histogram is created. This expression must resolve to a numeric or datetime value or a value that can be implicitly converted to a numeric or datetime value. If *
expression *evaluates to null, then the *expression *returns null.
hist-min- Resolves to the low boundary of
bucket-count, a non-null numeric or datetime value.
hist-max- Resolves to the high boundary of
bucket-count, a non-null numeric or datetime value.
bucket-count- Resolves to an INTEGER constant that indicates the number of buckets.
Notes
-
WIDTH_BUCKET divides a data set into buckets of equal width. For example, Age = 0–20, 20–40, 40–60, 60–80. This is known as an equiwidth histogram.
-
When using WIDTH_BUCKET pay attention to the minimum and maximum boundary values. Each bucket contains values equal to or greater than the base value of that bucket, so that age ranges of 0–20, 20–40, and so on, are actually 0–19.99 and 20–39.999.
-
WIDTH_BUCKET accepts the following data types: (FLOAT and/or INTEGER), (TIMESTAMP and/or DATE and/or TIMESTAMPTZ), or (INTERVAL and/or TIME).
Examples
The following example returns five possible values and has three buckets: 0 [Up to 100), 1 [100–300), 2 [300–500), 3 [500–700), and 4 [700 and up):
SELECT product_description, product_cost, WIDTH_BUCKET(product_cost, 100, 700, 3);
The following example creates a nine-bucket histogram on the annual_income column for customers in Connecticut who are female doctors. The results return the bucket number to an Income column, divided into eleven buckets, including an underflow and an overflow. Note that if customers had annual incomes greater than the maximum value, they would be assigned to an overflow bucket, 10:
SELECT customer_name, annual_income, WIDTH_BUCKET (annual_income, 100000, 1000000, 9) AS "Income"
FROM public.customer_dimension WHERE customer_state='CT'
AND title='Dr.' AND customer_gender='Female' AND household_id < '1000'
ORDER BY "Income";
In the following result set, the reason there is a bucket 0 is because buckets are numbered from 1 to bucket_count. Anything less than the given value of hist_min goes in bucket 0, and anything greater than the given value of hist_max goes in the bucket bucket_count+1. In this example, bucket 9 is empty, and there is no overflow. The value 12,283 is less than 100,000, so it goes into the underflow bucket.
customer_name | annual_income | Income
--------------------+---------------+--------
Joanna A. Nguyen | 12283 | 0
Amy I. Nguyen | 109806 | 1
Juanita L. Taylor | 219002 | 2
Carla E. Brown | 240872 | 2
Kim U. Overstreet | 284011 | 2
Tiffany N. Reyes | 323213 | 3
Rebecca V. Martin | 324493 | 3
Betty . Roy | 476055 | 4
Midori B. Young | 462587 | 4
Martha T. Brown | 687810 | 6
Julie D. Miller | 616509 | 6
Julie Y. Nielson | 894910 | 8
Sarah B. Weaver | 896260 | 8
Jessica C. Nielson | 861066 | 8
(14 rows)
See also
6.16 - NULL-handling functions
NULL-handling functions take arguments of any type, and their return type is based on their argument types.
NULL-handling functions take arguments of any type, and their return type is based on their argument types.
6.16.1 - COALESCE
Returns the value of the first non-null expression in the list.
Returns the value of the first non-null expression in the list. If all expressions evaluate to null, then COALESCE returns null.
COALESCE conforms to the ANSI SQL-92 standard.
Behavior type
Immutable
Syntax
COALESCE ( { * | expression[,...] } )
Arguments
* | expression[,...]- One of the following:
Examples
COALESCE returns the first non-null value in each row that is queried from table lead_vocalists. Note that in the first row, COALESCE returns an empty string.
=> SELECT quote_nullable(fname)fname, quote_nullable(lname)lname,
quote_nullable(coalesce (fname, lname)) "1st non-null value" FROM lead_vocalists ORDER BY fname;
fname | lname | 1st non-null value
---------+-----------+--------------------
'' | 'Sting' | ''
'Diana' | 'Ross' | 'Diana'
'Grace' | 'Slick' | 'Grace'
'Mick' | 'Jagger' | 'Mick'
'Steve' | 'Winwood' | 'Steve'
NULL | 'Cher' | 'Cher'
(6 rows)
See also
6.16.2 - IFNULL
Returns the value of the first non-null expression in the list.
Returns the value of the first non-null expression in the list.
IFNULL is an alias of NVL.
Behavior type
Immutable
Syntax
IFNULL ( expression1 , expression2 );
Parameters
-
If *expression1 *is null, then IFNULL returns expression2.
-
If *expression1 *is not null, then IFNULL returns expression1.
Notes
-
COALESCE is the more standard, more general function.
-
IFNULL is equivalent to ISNULL.
-
IFNULL is equivalent to COALESCE except that IFNULL is called with only two arguments.
-
ISNULL(a,b) is different from x IS NULL.
-
The arguments can have any data type supported by Vertica.
-
Implementation is equivalent to the CASE expression. For example:
CASE WHEN expression1 IS NULL THEN expression2
ELSE expression1 END;
-
The following statement returns the value 140:
SELECT IFNULL(NULL, 140) FROM employee_dimension;
-
The following statement returns the value 60:
SELECT IFNULL(60, 90) FROM employee_dimension;
Examples
=> SELECT IFNULL (SCORE, 0.0) FROM TESTING;
IFNULL
--------
100.0
87.0
.0
.0
.0
(5 rows)
See also
6.16.3 - ISNULL
Returns the value of the first non-null expression in the list.
Returns the value of the first non-null expression in the list.
ISNULL is an alias of NVL.
Behavior type
Immutable
Syntax
ISNULL ( expression1 , expression2 );
Parameters
-
If *expression1 *is null, then ISNULL returns expression2.
-
If *expression1 *is not null, then ISNULL returns expression1.
Notes
-
COALESCE is the more standard, more general function.
-
ISNULL is equivalent to COALESCE except that ISNULL is called with only two arguments.
-
ISNULL(a,b) is different from x IS NULL.
-
The arguments can have any data type supported by Vertica.
-
Implementation is equivalent to the CASE expression. For example:
CASE WHEN expression1 IS NULL THEN expression2
ELSE expression1 END;
-
The following statement returns the value 140:
SELECT ISNULL(NULL, 140) FROM employee_dimension;
-
The following statement returns the value 60:
SELECT ISNULL(60, 90) FROM employee_dimension;
Examples
SELECT product_description, product_price,
ISNULL(product_cost, 0.0) AS cost
FROM product_dimension;
product_description | product_price | cost
--------------------------------+---------------+------
Brand #59957 wheat bread | 405 | 207
Brand #59052 blueberry muffins | 211 | 140
Brand #59004 english muffins | 399 | 240
Brand #53222 wheat bread | 323 | 94
Brand #52951 croissants | 367 | 121
Brand #50658 croissants | 100 | 94
Brand #49398 white bread | 318 | 25
Brand #46099 wheat bread | 242 | 3
Brand #45283 wheat bread | 111 | 105
Brand #43503 jelly donuts | 259 | 19
(10 rows)
See also
6.16.4 - NULLIF
Compares two expressions.
Compares two expressions. If the expressions are not equal, the function returns the first expression (expression1). If the expressions are equal, the function returns null.
Behavior type
Immutable
Syntax
NULLIF( expression1, expression2 )
Parameters
expression1- Is a value of any data type.
expression2- Must have the same data type as *
expr1 *or a type that can be implicitly cast to match expression1. The result has the same type as expression1.
Examples
The following series of statements illustrates one simple use of the NULLIF function.
Creates a single-column table t and insert some values:
CREATE TABLE t (x TIMESTAMPTZ);
INSERT INTO t VALUES('2009-09-04 09:14:00-04');
INSERT INTO t VALUES('2010-09-04 09:14:00-04');
Issue a select statement:
SELECT x, NULLIF(x, '2009-09-04 09:14:00 EDT') FROM t;
x | nullif
------------------------+------------------------
2009-09-04 09:14:00-04 |
2010-09-04 09:14:00-04 | 2010-09-04 09:14:00-04
SELECT NULLIF(1, 2);
NULLIF
--------
1
(1 row)
SELECT NULLIF(1, 1);
NULLIF
--------
(1 row)
SELECT NULLIF(20.45, 50.80);
NULLIF
--------
20.45
(1 row)
6.16.5 - NULLIFZERO
Evaluates to NULL if the value in the column is 0.
Evaluates to NULL if the value in the column is 0.
Syntax
NULLIFZERO(expression)
Parameters
expression- (INTEGER, DOUBLE PRECISION, INTERVAL, or NUMERIC) Is the string to evaluate for 0 values.
Examples
The TESTING table below shows the test scores for 5 students. Note that test scores are missing for S. Robinson and K. Johnson (NULL values appear in the Score column.)
=> SELECT * FROM TESTING;
Name | Score
-------------+-------
J. Doe | 100
R. Smith | 87
L. White | 0
S. Robinson |
K. Johnson |
(5 rows)
The SELECT statement below specifies that Vertica should return any 0 values in the Score column as Null. In the results, you can see that Vertica returns L. White's 0 score as Null.
=> SELECT Name, NULLIFZERO(Score) FROM TESTING;
Name | NULLIFZERO
-------------+------------
J. Doe | 100
R. Smith | 87
L. White |
S. Robinson |
K. Johnson |
(5 rows)
6.16.6 - NVL
Returns the value of the first non-null expression in the list.
Returns the value of the first non-null expression in the list.
Behavior type
Immutable
Syntax
NVL ( expression1 , expression2 );
Parameters
-
If *expression1 *is null, then NVL returns expression2.
-
If *expression1 *is not null, then NVL returns expression1.
Notes
-
COALESCE is the more standard, more general function.
-
NVL is equivalent to COALESCE except that NVL is called with only two arguments.
-
The arguments can have any data type supported by Vertica.
-
Implementation is equivalent to the CASE expression:
CASE WHEN expression1 IS NULL THEN expression2
ELSE expression1 END;
Examples
expression1 is not null, so NVL returns expression1:
SELECT NVL('fast', 'database');
nvl
------
fast
(1 row)
expression1 is null, so NVL returns expression2:
SELECT NVL(null, 'database');
nvl
----------
database
(1 row)
expression2 is null, so NVL returns expression1:
SELECT NVL('fast', null);
nvl
------
fast
(1 row)
In the following example, expression1 (title) contains nulls, so NVL returns expression2 and substitutes 'Withheld' for the unknown values:
SELECT customer_name, NVL(title, 'Withheld') as title
FROM customer_dimension
ORDER BY title;
customer_name | title
------------------------+-------
Alexander I. Lang | Dr.
Steve S. Harris | Dr.
Daniel R. King | Dr.
Luigi I. Sanchez | Dr.
Duncan U. Carcetti | Dr.
Meghan K. Li | Dr.
Laura B. Perkins | Dr.
Samantha V. Robinson | Dr.
Joseph P. Wilson | Mr.
Kevin R. Miller | Mr.
Lauren D. Nguyen | Mrs.
Emily E. Goldberg | Mrs.
Darlene K. Harris | Ms.
Meghan J. Farmer | Ms.
Bettercare | Withheld
Ameristar | Withheld
Initech | Withheld
(17 rows)
See also
6.16.7 - NVL2
Takes three arguments.
Takes three arguments. If the first argument is not NULL, it returns the second argument, otherwise it returns the third argument. The data types of the second and third arguments are implicitly cast to a common type if they don't agree, similar to COALESCE.
Behavior type
Immutable
Syntax
NVL2 ( expression1 , expression2 , expression3 );
Parameters
-
If expression1 is not null, then NVL2 returns expression2.
-
If expression1 is null, then NVL2 returns expression3.
Notes
Arguments two and three can have any data type supported by Vertica.
Implementation is equivalent to the CASE expression:
CASE WHEN expression1 IS NOT NULL THEN expression2 ELSE expression3 END;
Examples
In this example, expression1 is not null, so NVL2 returns expression2:
SELECT NVL2('very', 'fast', 'database');
nvl2
------
fast
(1 row)
In this example, expression1 is null, so NVL2 returns expression3:
SELECT NVL2(null, 'fast', 'database');
nvl2
----------
database
(1 row)
In the following example, expression1 (title) contains nulls, so NVL2 returns expression3 ('Withheld') and also substitutes the non-null values with the expression 'Known':
SELECT customer_name, NVL2(title, 'Known', 'Withheld')
as title
FROM customer_dimension
ORDER BY title;
customer_name | title
------------------------+-------
Alexander I. Lang | Known
Steve S. Harris | Known
Daniel R. King | Known
Luigi I. Sanchez | Known
Duncan U. Carcetti | Known
Meghan K. Li | Known
Laura B. Perkins | Known
Samantha V. Robinson | Known
Joseph P. Wilson | Known
Kevin R. Miller | Known
Lauren D. Nguyen | Known
Emily E. Goldberg | Known
Darlene K. Harris | Known
Meghan J. Farmer | Known
Bettercare | Withheld
Ameristar | Withheld
Initech | Withheld
(17 rows)
See also
6.16.8 - ZEROIFNULL
Evaluates to 0 if the column is NULL.
Evaluates to 0 if the column is NULL.
Syntax
ZEROIFNULL(expression)
Parameters
expression- String to evaluate for NULL values, one of the following data types:
-
INTEGER
-
DOUBLE PRECISION
-
INTERVAL
-
NUMERIC
Examples
The following query returns scores for five students from table test_results, where Score is set to 0 for L. White, and null for S. Robinson and K. Johnson:
=> SELECT Name, Score FROM test_results;
Name | Score
-------------+-------
J. Doe | 100
R. Smith | 87
L. White | 0
S. Robinson |
K. Johnson |
(5 rows)
The next query invokes ZEROIFNULL on column Score, so Vertica returns 0 for for S. Robinson and K. Johnson:
=> SELECT Name, ZEROIFNULL (Score) FROM test_results;
Name | ZEROIFNULL
-------------+------------
J. Doe | 100
R. Smith | 87
L. White | 0
S. Robinson | 0
K. Johnson | 0
(5 rows)
You can also use ZEROIFNULL in PARTITION BY expressions, which must always resolve to a non-null value. For example:
CREATE TABLE t1 (a int, b int) PARTITION BY (ZEROIFNULL(a));
CREATE TABLE
Vertica invokes this function when it partitions table t1, typically during a load operation. During the load, the function checks the data of the PARTITION BY expression—in this case, column a—for null values. If encounters a null value in a given row, it sets the partition key to 0, instead of returning with an error.
6.17 - Performance analysis functions
The functions in this section support profiling and analyzing database and query performance.
The functions in this section support profiling and analyzing database and query performance.
6.17.1 - Profiling functions
This section contains profiling functions specific to Vertica.
This section contains profiling functions specific to Vertica.
6.17.1.1 - CLEAR_PROFILING
Clears from memory data for the specified profiling type.
Clears from memory data for the specified profiling type.
Note
Vertica stores profiled data in memory, so profiling can be memory intensive depending on how much data you collect.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CLEAR_PROFILING( 'profiling-type' [, 'scope'] )
Parameters
profiling-type- The type of profiling data to clear:
-
session: Clear profiling for basic session parameters and lock time out data.
-
query: Clear profiling for general information about queries that ran, such as the query strings used and the duration of queries.
-
ee: Clear profiling for information about the execution run of each query.
scope- Specifies at what scope to clear profiling on the specified data, one of the following:
Examples
The following statement clears profiled data for queries:
=> SELECT CLEAR_PROFILING('query');
See also
6.17.1.2 - DISABLE_PROFILING
Disables for the current session collection of profiling data of the specified type.
Disables for the current session collection of profiling data of the specified type. For detailed information, see Enabling profiling.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DISABLE_PROFILING( 'profiling-type' )
Parameters
profiling-type- The type of profiling data to disable:
-
session: Disables profiling for basic session parameters and lock time out data.
-
query: Disables profiling for general information about queries that ran, such as the query strings used and the duration of queries.
-
ee: Disables profiling for information about the execution run of each query.
Examples
The following statement disables profiling on query execution runs:
=> SELECT DISABLE_PROFILING('ee');
DISABLE_PROFILING
-----------------------
EE Profiling Disabled
(1 row)
See also
6.17.1.3 - ENABLE_PROFILING
Enables collection of profiling data of the specified type for the current session.
Enables collection of profiling data of the specified type for the current session. For detailed information, see Enabling profiling.
Note
Vertica stores session and query profiling data in memory, so profiling can be memory intensive, depending on how much data you collect.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLE_PROFILING( 'profiling-type' )
Parameters
profiling-type- The type of profiling data to enable:
-
session: Enable profiling for basic session parameters and lock time out data.
-
query: Enable profiling for general information about queries that ran, such as the query strings used and the duration of queries.
-
ee: Enable profiling for information about the execution run of each query.
Examples
The following statement enables profiling on query execution runs:
=> SELECT ENABLE_PROFILING('ee');
ENABLE_PROFILING
----------------------
EE Profiling Enabled
(1 row)
See also
6.17.1.4 - SHOW_PROFILING_CONFIG
Shows whether profiling is enabled.
Shows whether profiling is enabled.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
SHOW_PROFILING_CONFIG ()
Examples
The following statement shows that profiling is enabled globally for all profiling types (session, execution engine, and query):
=> SELECT SHOW_PROFILING_CONFIG();
SHOW_PROFILING_CONFIG
------------------------------------------
Session Profiling: Session off, Global on
EE Profiling: Session off, Global on
Query Profiling: Session off, Global on
(1 row)
See also
6.17.2 - Statistics management functions
This section contains Vertica functions for collecting and managing table data statistics.
This section contains Vertica functions for collecting and managing table data statistics.
6.17.2.1 - ANALYZE_EXTERNAL_ROW_COUNT
Calculates the exact number of rows in an external table.
Calculates the exact number of rows in an external table. ANALYZE_EXTERNAL_ROW_COUNT runs in the background.
Note
You cannot calculate row counts on external tables with
DO_TM_TASK.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ANALYZE_EXTERNAL_ROW_COUNT ('[[[database.]schema.]table-name ]')
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name - Specifies the name of the external table for which to calculate the exact row count. If you supply an empty string, Vertica calculate the exact number of rows for all external tables.
Privileges
Any INSERT/UPDATE/DELETE privilege on the external table
Examples
Calculate the exact row count for all external tables:
=> SELECT ANALYZE_EXTERNAL_ROW_COUNT('');
Calculate the exact row count for table loader_rejects:
=> SELECT ANALYZE_EXTERNAL_ROW_COUNT('loader_rejects');
See also
6.17.2.2 - ANALYZE_STATISTICS
Collects and aggregates data samples and storage information from all nodes that store projections associated with the specified table.
Collects and aggregates data samples and storage information from all nodes that store projections associated with the specified table. The function skips columns of complex data types. You can set the scope of the collection at several levels:
-
Database
-
Table
-
Table column
By default, Vertica analyzes multiple columns in a single-query execution plan, depending on resource limits. This multi-column analysis reduces plan execution latency and speeds up analysis of relatively small tables with many columns.
Vertica writes statistics to the database catalog. The query optimizer uses this collected data to create query plans. Without this data, the query optimizer assumes uniform distribution of data values and equal storage usage for all projections.
You can cancel statistics collection with CTRL+C or by calling INTERRUPT_STATEMENT.
ANALYZE_STATISTICS is an alias of the function ANALYZE_HISTOGRAM, which is no longer documented.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ANALYZE_STATISTICS ('[[[database.]schema.]table]' [, 'column-list' [, percent ]] )
Returns
0—Success
If an error occurs, refer to
vertica.log for details.
Arguments
[[database.]schema].table- Table on which to collect data. If set to an empty string, Vertica collects statistics for all database tables and their projections. The default schema is
public. If you specify a database, it must be the current database.
column-list- Comma-delimited list of columns in
table, typically predicate columns. Vertica narrows the scope of the data collection to the specified columns. Columns of complex types are not supported.
If you alter a table to add a column and populate its contents with either default or other values, call ANALYZE_STATISTICS on this column to get the most current statistics.
percent- Percentage of data to read from disk (not the amount to analyze), a float between 0 and 100. The default value is 10.
Analyzing a higher percentage takes proportionally longer to process, but produces a higher level of sampling accuracy.
Privileges
Non-superuser:
Restrictions
-
Vertica supports ANALYZE_STATISTICS on local and global temporary tables. In both cases, you can obtain statistics only on tables that are created with the option ON COMMIT PRESERVE ROWS. Otherwise, Vertica deletes table content when committing the current transaction, so no table data is available for analysis.
-
Vertica collects no statistics from the following projections:
- Live aggregate and Top-K projections
- Projections that are defined to include a SQL function within an expression
-
Vertica collects no statistics on columns of ARRAY, SET, or ROW types.
Examples
See Collecting table statistics.
See also
ANALYZE_STATISTICS_PARTITION
6.17.2.3 - ANALYZE_STATISTICS_PARTITION
Collects and aggregates data samples and storage information for a range of partitions in the specified table.
Collects and aggregates data samples and storage information for a range of partitions in the specified table. Vertica writes the collected statistics to the database catalog.
You can cancel statistics collection with CTRL+C or meta-function INTERRUPT_STATEMENT.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ANALYZE_STATISTICS_PARTITION ('[[database.]schema.]table', 'min-range-value','max-range-value' [, 'column-list' [, percent ]] )
Returns
0: Success
If an error occurs, refer to
vertica.log for details.
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table on which to collect data.
min-range-value
max-range-value- Minimum and maximum value of partition keys to analyze, where
min-range-value must be ≤ max-range-value. To analyze one partition, min-range-value and max-range-value must be equal.
column-list- Comma-delimited list of columns in
table, typically a predicate column. Vertica narrows the scope of the data collection to the specified columns.
percent- Float value between 0 and 100 that specifies what percentage of data to read from disk (not the amount of data to analyze). If you omit this argument, Vertica sets the percentage to 10.
Analyzing more than 10 percent disk space takes proportionally longer to process, but produces a higher level of sampling accuracy.
Privileges
Non-superuser:
Requirements and restrictions
The following requirements and restrictions apply to ANALYZE_STATISTICS_PARTITION:
-
The table must be partitioned and cannot contain unpartitioned data.
-
The table partition expression must specify a single column. The following expressions are supported:
-
Expressions that specify only the column—that is, partition on all column values. For example:
PARTITION BY ship_date GROUP BY CALENDAR_HIERARCHY_DAY(ship_date, 2, 2)
-
If the column is a DATE or TIMESTAMP/TIMESTAMPTZ, the partition expression can specify a supported date/time function that returns that column or any portion of it, such as month or year. For example, the following partition expression specifies to partition on the year portion of column order_date:
PARTITION BY YEAR(order_date)
-
Expressions that perform addition or subtraction on the column. For example:
PARTITION BY YEAR(order_date) -1
-
The table partition expression cannot coerce the specified column to another data type.
-
Vertica collects no statistics from the following projections:
Examples
See Collecting partition statistics.
6.17.2.4 - DROP_EXTERNAL_ROW_COUNT
Removes external table row count statistics compiled by ANALYZE_EXTERNAL_ROW_COUNT.
Removes external table row count statistics compiled by
ANALYZE_EXTERNAL_ROW_COUNT. DROP_EXTERNAL_ROW_COUNT runs in the background.
Caution
Statistics can be time consuming to regenerate.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_EXTERNAL_ROW_COUNT ('[[[database.]schema.]table-name ]');
Parameters
schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table-name- The external table for which to remove the exact row count. If you specify an empty string, Vertica drops the exact row count statistic for all external tables.
Privileges
Examples
Drop row count statistics for external table loader_rejects:
=> SELECT DROP_EXTERNAL_ROW_COUNT('loader_rejects');
See also
Collecting database statistics
6.17.2.5 - DROP_STATISTICS
Removes statistical data on database projections previously generated by ANALYZE_STATISTICS.
Removes statistical data on database projections previously generated by
ANALYZE_STATISTICS. When you drop this data, the Vertica optimizer creates query plans using default statistics.
Caution
Regenerating statistics can incur significant overhead.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_STATISTICS ('[[[database.]schema.]table]' [, 'category' [, '[column-list]'] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table on which to drop statistics. If set to an empty string, Vertica drops statistics for all database tables and their projections.
category- Category of statistics to drop, one of the following:
-
ALL (default): Drop all statistics, including histograms and row counts.
-
HISTOGRAMS: Drop only histograms. Row count statistics remain.
column-list - Comma-delimited list of columns in
table, typically predicate columns. Vertica narrows the scope of dropped statistics to the specified columns. If you omit this parameter or supply an empty string, Vertica drops statistics on all columns.
Privileges
Non-superuser:
Examples
Drop all base statistics for the table store.store_sales_fact:
=> SELECT DROP_STATISTICS('store.store_sales_fact');
DROP_STATISTICS
-----------------
0
(1 row)
Drop statistics for all table projections:
=> SELECT DROP_STATISTICS ('');
DROP_STATISTICS
-----------------
0
(1 row)
See also
DROP_STATISTICS_PARTITION
6.17.2.6 - DROP_STATISTICS_PARTITION
Removes statistical data on database projections previously generated by ANALYZE_STATISTICS_PARTITION.
Removes statistical data on database projections previously generated by
ANALYZE_STATISTICS_PARTITION. When you drop this data, the Vertica optimizer creates query plans using table-level statistics, if available, or default statistics.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
DROP_STATISTICS_PARTITION ('[[database.]schema.]table', '[min-range-value]', '[max-range-value]' [, category [, '[column-list]'] )
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Table on which to drop statistics.
-
min-range-value max-range-value
- The minimum and maximum value of partition keys on which to drop statistics, where
min-range-value must be ≤ max-range-value. If you supply empty strings for both parameters, Vertica drops all partition-level statistics for this table or the specified columns.
Important
The range of keys to drop must be equal to, or a superset of, the full range of partitions previously analyzed by ANALYZE_STATISTICS_PARTITION. If the range omits any analyzed partition, DROP_STATISTICS_PARTITION drops no statistics.
category - The category of statistics to drop, one of the following:
-
BASE (default): Drop histograms and row counts (min/max column values, histogram).
-
HISTOGRAMS: Drop only histograms. Row count statistics remain.
-
ALL: Drop all statistics.
column-list - A comma-delimited list of columns in
table, typically predicate columns. Vertica narrows the scope of dropped statistics to the specified columns. If you omit this parameter or supply an empty string, Vertica drops statistics on all columns.
Privileges
Non-superuser:
See also
DROP_STATISTICS
6.17.2.7 - EXPORT_STATISTICS
Generates statistics in XML format from data previously collected by ANALYZE_STATISTICS.
Generates statistics in XML format from data previously collected by ANALYZE_STATISTICS. Before you export statistics, collect the latest data by calling ANALYZE_STATISTICS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
EXPORT_STATISTICS ('[ filename ]' [,'table-spec' [,'column[,...]']])
Arguments
filename- Specifies where to write the generated XML. If
filename already exists, EXPORT_STATISTICS overwrites it. If you supply an empty string, EXPORT_STATISTICS writes the XML to standard output.
table-spec- Specifies the table on which to export projection statistics:
[[database.]schema.]table
The default schema is public. If you specify a database, it must be the current database.
If table-spec is omitted or set to an empty string, Vertica exports all statistics for the database.
column - The name of a column in
table-spec, typically a predicate column. You can specify multiple comma-delimited columns. Vertica narrows the scope of exported statistics to the specified columns.
Privileges
Superuser
Restrictions
EXPORT_STATISTICS does not export statistics for LONG data type columns.
Examples
The following statement exports statistics on the VMart example database to a file:
=> SELECT EXPORT_STATISTICS('/opt/vertica/examples/VMart_Schema/vmart_stats.xml');
EXPORT_STATISTICS
-----------------------------------
Statistics exported successfully
(1 row)
The next statement exports statistics on a single column (price) from a table named food:
=> SELECT EXPORT_STATISTICS('/opt/vertica/examples/VMart_Schema/price.xml', 'food.price');
EXPORT_STATISTICS
-----------------------------------
Statistics exported successfully
(1 row)
See also
6.17.2.8 - EXPORT_STATISTICS_PARTITION
Generates partition-level statistics in XML format from data previously collected by ANALYZE_STATISTICS_PARTITION.
Generates partition-level statistics in XML format from data previously collected by ANALYZE_STATISTICS_PARTITION.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
EXPORT_STATISTICS_PARTITION ('[ filename ]', 'table-spec', 'min-range-value','max-range-value' [, 'column[,...]' )
Arguments
filename- Specifies where to write the generated XML. If
filename already exists, EXPORT_STATISTICS_PARTITION overwrites it. If you supply an empty string, the function writes to standard output.
table-spec- Specifies the table on which to export partition statistics:
[[database.]schema.]table
The default schema is public. If you specify a database, it must be the current database.
min-range-value, max-range-value- The minimum and maximum value of partition keys on which to export statistics, where
min-range-value must be ≤ max-range-value.
Important
The range of keys to export must be equal to, or a superset of, the full range of partitions previously analyzed by ANALYZE_STATISTICS_PARTITION. If the range omits any analyzed partition, EXPORT_STATISTICS_PARTITION exports no statistics.
column - The name of a column in
table, typically a predicate column. You can specify multiple comma-delimited columns. Vertica narrows the scope of exported statistics to the specified columns.
Privileges
Superuser
Restrictions
EXPORT_STATISTICS_PARTITION does not export statistics for LONG data type columns.
See also
EXPORT_STATISTICS
6.17.2.9 - IMPORT_STATISTICS
Imports statistics from the XML file that was generated by EXPORT_STATISTICS.
Imports statistics from the XML file that was generated by
EXPORT_STATISTICS. Imported statistics override existing statistics for the projections that are referenced in the XML file.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
IMPORT_STATISTICS ( 'filename' )
Parameters
filename- The path and name of an XML input file that was generated by
EXPORT_STATISTICS.
Privileges
Superuser
Restrictions
-
IMPORT_STATISTICS imports only valid statistics. If the source XML file has invalid statistics for a specific column, those statistics are not imported and Vertica throws a warning. If the statistics file has an invalid structure, the import operation fails. To check a statistics file for validity, run
VALIDATE_STATISTICS.
-
IMPORT_STATISTICS returns warnings for LONG data type columns, as the source XML file generated by EXPORT_STATISTICS contains no statistics for columns of that type.
Examples
Import the statistics for the VMart database from an XML file previously created by EXPORT_STATISTICS:
=> SELECT IMPORT_STATISTICS('/opt/vertica/examples/VMart_Schema/vmart_stats.xml');
IMPORT_STATISTICS
----------------------------------------------------------------------------
Importing statistics for projection date_dimension_super column date_key failure (stats did not contain row counts)
Importing statistics for projection date_dimension_super column date failure (stats did not contain row counts)
Importing statistics for projection date_dimension_super column full_date_description failure (stats did not contain row counts)
...
(1 row)
See also
6.17.2.10 - VALIDATE_STATISTICS
Validates statistics in the XML file generated by EXPORT_STATISTICS.
Validates statistics in the XML file generated by
EXPORT_STATISTICS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
VALIDATE_STATISTICS ( 'XML-file' )
Parameters
XML-file- the path and name of the XML file that contains the statistics to validate.
Privileges
Superuser
Reporting valid statistics
The following example shows the results when the statistics are valid:
=> SELECT EXPORT_STATISTICS('cust_dim_stats.xml','customer_dimension');
EXPORT_STATISTICS
-----------------------------------
Statistics exported successfully
(1 row)
=> SELECT VALIDATE_STATISTICS('cust_dim_stats.xml');
VALIDATE_STATISTICS
---------------------
(1 row)
Identifying invalid statistics
If VALIDATE_STATISTICS is unable to read a document's XML, it throws this error:
=> SELECT VALIDATE_STATISTICS('/home/dbadmin/stats.xml');
VALIDATE_STATISTICS
----------------------------------------------------------------------------
Error validating statistics file: At line 1:1. Invalid document structure
(1 row)
If some table statistics are invalid, VALIDATE_STATISTICS returns a report that identifies them. In the following example, the function reports that attributes distinct, buckets, rows, count, and distinctCount cannot be negative numbers.
=> SELECT VALIDATE_STATISTICS('/stats.xml');
WARNING 0: Invalid value '-1' for attribute 'distinct' under column 'public.t.x'.
Please use a positive value.
WARNING 0: Invalid value '-1' for attribute 'buckets' under column 'public.t.x'.
Please use a positive value.
WARNING 0: Invalid value '-1' for attribute 'rows' under column 'public.t.x'.
Please use a positive value.
WARNING 0: Invalid value '-1' for attribute 'count' under bound '1', column 'public.t.x'.
Please use a positive value.
WARNING 0: Invalid value '-1' for attribute 'distinctCount' under bound '1', column 'public.t.x'.
Please use a positive value.
VALIDATE_STATISTICS
---------------------
(1 row)
In this case, run
ANALYZE_STATISTICS on the table again to create valid statistics.
See also
6.17.3 - Workload management functions
This section contains workload management functions specific to Vertica.
This section contains workload management functions specific to Vertica.
6.17.3.1 - ANALYZE_WORKLOAD
Runs Workload Analyzer, a utility that analyzes system information held in system tables.
Runs Workload Analyzer, a utility that analyzes system information held in system tables.
Workload Analyzer intelligently monitors the performance of SQL queries and workload history, resources, and configurations to identify the root causes for poor query performance. ANALYZE_WORKLOAD returns tuning recommendations for all events within the scope and time that you specify, from system table
TUNING_RECOMMENDATIONS.
Tuning recommendations are based on a combination of statistics, system and data collector events, and database-table-projection design. Workload Analyzer recommendations can help you quickly and easily tune query performance.
See Workload analyzer recommendations for the common triggering conditions and recommendations.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ANALYZE_WORKLOAD ( '[ scope ]' [, 'since-time' | save-data ] );
Parameters
scope- Specifies the catalog objects to analyze, as follows:
[[database.]schema.]table
If set to an empty string, Vertica returns recommendations for all database objects.
If you specify a database, it must be the current database.
since-time - Specifies the start time for the analysis time span, which continues up to the current system status, inclusive. If you omit this parameter,
ANALYZE_WORKLOAD returns recommendations on events since the last time you called this function.
Note
You must explicitly cast strings to TIMESTAMP or TIMESTAMPTZ. For example:
SELECT ANALYZE_WORKLOAD('T1', '2010-10-04 11:18:15'::TIMESTAMPTZ);
SELECT ANALYZE_WORKLOAD('T1', TIMESTAMPTZ '2010-10-04 11:18:15');
save-data- Specifies whether to save returned values from
ANALYZE_WORKLOAD:
-
false (default): Results are discarded.
-
true: Saves the results returned by ANALYZE_WORKLOAD. Subsequent calls to ANALYZE_WORKLOAD return results that start from the last invocation when results were saved. Object events preceding that invocation are ignored.
Return values
Returns aggregated tuning recommendations from
TUNING_RECOMMENDATIONS.
Privileges
Superuser
Examples
See Getting tuning recommendations.
See also
6.17.3.2 - CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY
Changes the run-time priority of an active query.
Changes the run-time priority of an active query.
Note
This function replaces deprecated function CHANGE_RUNTIME_PRIORITY.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY(transaction-id, 'value')
Parameters
transaction-id- Identifies the transaction, obtained from the system table
SESSIONS.
value- The
RUNTIMEPRIORITY value: HIGH, MEDIUM, or LOW.
Privileges
Examples
See Changing runtime priority of a running query.
6.17.3.3 - CHANGE_RUNTIME_PRIORITY
Changes the run-time priority of a query that is actively running.
Changes the run-time priority of a query that is actively running. Note that, while this function is still valid, you should instead use CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY to change run-time priority. CHANGE_RUNTIME_PRIORITY will be deprecated in a future release of Vertica.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
CHANGE_RUNTIME_PRIORITY(TRANSACTION_ID,STATEMENT_ID, 'value')
Parameters
TRANSACTION_ID- An identifier for the transaction within the session.
TRANSACTION_ID cannot be NULL.
You can find the transaction ID in the Sessions table.
STATEMENT_ID- A unique numeric ID assigned by the Vertica catalog, which identifies the currently executing statement.
You can find the statement ID in the Sessions table.
You can specify NULL to change the run-time priority of the currently running query within the transaction.
'value'- The
RUNTIMEPRIORITY value. Can be HIGH, MEDIUM, or LOW.
Privileges
No special privileges required. However, non-superusers can change the run-time priority of their own queries only. In addition, non-superusers can never raise the run-time priority of a query to a level higher than that of the resource pool.
Examples
=> SELECT CHANGE_RUNTIME_PRIORITY(45035996273705748, NULL, 'low');
6.17.3.4 - MOVE_STATEMENT_TO_RESOURCE_POOL
Attempts to move the specified query to the specified target pool.
Attempts to move the specified query to the specified target pool.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
MOVE_STATEMENT_TO_RESOURCE_POOL (session_id , transaction_id, statement_id, target_resource_pool_name)
Parameters
session_id- Identifier for the session where the query you want to move is currently executing.
transaction_id- Identifier for the transaction within the session.
statement_id- Unique numeric ID for the statement you want to move.
target_resource_pool_name- Name of the existing resource pool to which you want to move the specified query.
Outputs
The function may return the following results:
|
MOV_REPLAN: Target pool does not have sufficient resources. See v_monitor.resource_pool_move for details. Vertica will attempt to replan the statement on target pool. |
|
MOV_REPLAN: Target pool has priority HOLD. Vertica will attempt to replan the statement on target pool. |
|
MOV_FAILED: Statement not found. |
|
MOV_NO_OP: Statement already on target pool. |
|
MOV_REPLAN: Statement is in queue. Vertica will attempt to replan the statement on target pool. |
|
MOV_SUCC: Statement successfully moved to target pool. |
Privileges
Superuser
Examples
The following example shows how you can move a specific statement to a resource pool called my_target_pool:
=> SELECT MOVE_STATEMENT_TO_RESOURCE_POOL ('v_vmart_node0001.example.-31427:0x82fbm', 45035996273711993, 1, 'my_target_pool');
See also:
6.17.3.5 - SLEEP
Waits a specified number of seconds before executing another statement or command.
Waits a specified number of seconds before executing another statement or command.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
SLEEP( seconds )
Parameters
seconds- The wait time, specified in one or more seconds (0 or higher) expressed as a positive integer. Single quotes are optional; for example,
SLEEP(3) is the same as SLEEP('3').
Notes
-
This function returns value 0 when successful; otherwise it returns an error message due to syntax errors.
-
You cannot cancel a sleep operation.
-
Be cautious when using SLEEP() in an environment with shared resources, such as in combination with transactions that take exclusive locks.
Examples
The following command suspends execution for 100 seconds:
=> SELECT SLEEP(100);
sleep
-------
0
(1 row)
6.18 - Stored procedure functions
This section contains functions for managing stored procedures.
This section contains functions for managing stored procedures.
6.18.1 - ACTIVE_SCHEDULER_NODE
Returns the active scheduler node.
Returns the active scheduler node. A schedule must be associated with a trigger to be enabled.
To view existing schedules, see USER_SCHEDULES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ACTIVE_SCHEDULER_NODE()
Privileges
Superuser
Examples
To return the active scheduler node:
=> SELECT active_scheduler_node();
active_scheduler_node
-----------------------
initiator
(1 row)
6.18.2 - ENABLE_SCHEDULE
Enables or disables a schedule.
Enables or disables a schedule. A schedule can only be enabled if a trigger is attached to it.
To view existing schedules, see USER_SCHEDULES.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLE_SCHEDULE ( '[[database.]schema.]schedule', enabled )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
schedule- The schedule to enable or disable.
enabled- Boolean, whether to enable the trigger.
Privileges
Superuser
Examples
To enable a schedule:
=> SELECT enable_schedule('vmart.management.daily_1am', true);
To disable a schedule:
=> SELECT enable_schedule('vmart.management.daily_1am', false);
If you leave the database and schema empty, the default is current_database.public:
=> SELECT enable_schedule('biannual_22_noon_gmt', true);
6.18.3 - ENABLE_TRIGGER
Enables or disables a trigger.
Enables or disables a trigger.
To view existing triggers, see STORED_PROC_TRIGGERS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
ENABLE_TRIGGER ( '[[database.]schema.]trigger', enabled )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
trigger- The trigger to enable or disable.
enabled- Boolean, whether to enable the trigger.
Privileges
Superuser
Examples
To enable a trigger:
=> SELECT enable_trigger('vmart.management.log_user_actions', true);
To disable a trigger:
=> SELECT enable_trigger('vmart.management.log_user_actions', false);
If you leave the database and schema empty, the default is current_database.public:
=> SELECT enable_trigger('revoke_log_privileges', true);
6.18.4 - EXECUTE_TRIGGER
Manually executes the stored procedure attached to a trigger.
Manually executes the stored procedure attached to a trigger. This is generally used for testing the trigger.
To view existing triggers, see STORED_PROC_TRIGGERS.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Syntax
EXECUTE_TRIGGER ( '[[database.]schema.]trigger' )
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
trigger- The trigger to execute.
Privileges
Superuser
Examples
To execute a trigger:
=> SELECT execute_trigger('vmart.management.log_user_actions');
If you leave the database and schema empty, the default is current_database.public:
=> SELECT execute_trigger('revoke_log_privileges');
6.19 - System information functions
These functions provide information about the current system state.
These functions provide information about the current system state. A superuser has unrestricted access to all system information, but users can view only information about their own, current sessions.
6.19.1 - CURRENT_DATABASE
Returns the name of the current database, equivalent to DBNAME.
Returns the name of the current database, equivalent to
DBNAME.
Behavior type
Stable
Syntax
Note
Parentheses are optional.
CURRENT_DATABASE()
Examples
=> SELECT CURRENT_DATABASE;
CURRENT_DATABASE
------------------
VMart
(1 row)
6.19.2 - CURRENT_LOAD_SOURCE
When called within the scope of a COPY statement, returns the file name or path part used for the load.
When called within the scope of a COPY statement, returns the file name used for the load. With an optional integer argument, it returns the Nth /-delimited path part.
If the function is called outside of the context of a COPY statement, it returns NULL.
If the current load uses a UDSource function that does not set the URI, CURRENT_LOAD_SOURCE returns the string UNKNOWN. You cannot call CURRENT_LOAD_SOURCE(INT) when using a UDSource.
Behavior type
Stable
Syntax
CURRENT_LOAD_SOURCE( [ position ])
Arguments
position (positive INTEGER)- Path element to return instead of returning the full path. Elements are separated by slashes (
/) and the first element is position 1. If the value is greater than the number of elements, the function returns an error. You cannot use this argument with a UDSource function.
Examples
The following load statement populates a column with the name of the file the row was loaded from:
=> CREATE TABLE t (c1 integer, c2 varchar(50), c3 varchar(200));
CREATE TABLE
=> COPY t (c1, c2, c3 AS CURRENT_LOAD_SOURCE())
FROM '/home/load_file_1' ON exampledb_node02,
'/home/load_file_2' ON exampledb_node03 DELIMITER ',';
Rows Loaded
-------------
5
(1 row)
=> SELECT * FROM t;
c1 | c2 | c3
----+--------------+-----------------------
2 | dogs | /home/load_file_1
1 | cats | /home/load_file_1
4 | superheroes | /home/load_file_2
3 | birds | /home/load_file_1
5 | whales | /home/load_file_2
(5 rows)
The following example reads year and month columns out of a path:
=> COPY reviews
(review_id, stars,
year AS CURRENT_LOAD_SOURCE(3)::INT,
month AS CURRENT_LOAD_SOURCE(4)::INT)
FROM '/data/reviews/*/*/*.json' PARSER FJSONPARSER();
6.19.3 - CURRENT_SCHEMA
Returns the name of the current schema.
Returns the name of the current schema.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Stable
Syntax
CURRENT_SCHEMA()
Note
You can call this function without parentheses.
Privileges
None
Examples
The following command returns the name of the current schema:
=> SELECT CURRENT_SCHEMA();
current_schema
----------------
public
(1 row)
The following command returns the same results without the parentheses:
=> SELECT CURRENT_SCHEMA;
current_schema
----------------
public
(1 row)
The following command shows the current schema, listed after the current user, in the search path:
=> SHOW SEARCH_PATH;
name | setting
-------------+---------------------------------------------------
search_path | "$user", public, v_catalog, v_monitor, v_internal
(1 row)
See also
6.19.4 - CURRENT_SESSION
Returns the ID of the current client session.
Returns the ID of the current client session.
Many system tables have a SESSION_ID column. You can use the CURRENT_SESSION function in queries of these tables.
Behavior type
Stable
Syntax
CURRENT_SESSION()
Examples
Each new session has a new session ID:
$ vsql
Welcome to vsql, the Vertica Analytic Database interactive terminal.
=> SELECT CURRENT_SESSION();
CURRENT_SESSION
-----------------------
initiator-24897:0x1f7
(1 row)
=> \q
$ vsql
Welcome to vsql, the Vertica Analytic Database interactive terminal.
=> SELECT CURRENT_SESSION();
CURRENT_SESSION
-----------------------
initiator-24897:0x200
(1 row)
6.19.5 - CURRENT_TRANS_ID
Returns the ID of the transaction currently in progress.
Returns the ID of the transaction currently in progress.
Many system tables have a TRANSACTION_ID column. You can use the CURRENT_TRANS_ID function in queries of these tables.
Behavior type
Stable
Syntax
CURRENT_TRANS_ID()
Examples
Even a new session has a transaction ID:
$ vsql
Welcome to vsql, the Vertica Analytic Database interactive terminal.
=> SELECT CURRENT_TRANS_ID();
current_trans_id
-------------------
45035996273705927
(1 row)
This function can be used in queries of certain system tables. In the following example, a load operation is in progress:
=> SELECT key, SUM(num_instances) FROM v_monitor.UDX_EVENTS
WHERE event_type = 'UNMATCHED_KEY'
AND transaction_id=CURRENT_TRANS_ID()
GROUP BY key;
key | SUM
------------------------+-----
chain | 1
menu.elements.calories | 7
(2 rows)
6.19.6 - CURRENT_USER
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Behavior type
Stable
Syntax
CURRENT_USER()
Notes
-
The CURRENT_USER function does not require parentheses.
-
This function is useful for permission checking.
-
CURRENT_USER is equivalent to SESSION_USER, USER, and USERNAME.
Examples
=> SELECT CURRENT_USER();
CURRENT_USER
--------------
dbadmin
(1 row)
The following command returns the same results without the parentheses:
=> SELECT CURRENT_USER;
CURRENT_USER
--------------
dbadmin
(1 row)
6.19.7 - DBNAME (function)
Returns the name of the current database, equivalent to CURRENT_DATABASE.
Returns the name of the current database, equivalent to
CURRENT_DATABASE.
Behavior type
Immutable
Syntax
DBNAME()
Examples
=> SELECT DBNAME();
dbname
------------------
VMart
(1 row)
6.19.8 - HAS_TABLE_PRIVILEGE
Returns true or false to verify whether a user has the specified privilege on a table.
Returns true or false to verify whether a user has the specified privilege on a table.
This is a meta-function. You must call meta-functions in a top-level SELECT statement.
Behavior type
Volatile
Behavior type
Stable
Syntax
HAS_TABLE_PRIVILEGE ( [ user, ] '[[database.]schema.]table', 'privilege' )
Parameters
user- Name or OID of a database user. If omitted, Vertica checks privileges for the current user.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- Name or OID of the table to check.
privilege- A table privilege, one of the following:
-
SELECT: Query tables. SELECT privileges are granted by default to the PUBLIC role.
-
INSERT: Insert table rows with INSERT, and load data with
COPY.
Note
COPY FROM STDIN is allowed for users with INSERT privileges, while COPY FROM file requires admin privileges.
-
UPDATE: Update table rows.
-
DELETE: Delete table rows.
-
REFERENCES: Create foreign key constraints on this table. This privilege must be set on both referencing and referenced tables.
-
TRUNCATE: Truncate table contents. Non-owners of tables can also execute the following partition operations on them:
-
ALTER: Modify a table's DDL with
ALTER TABLE.
-
DROP: Drop a table.
Privileges
Non-superuser, one of the following:
Examples
=> SELECT HAS_TABLE_PRIVILEGE('store.store_dimension', 'SELECT');
HAS_TABLE_PRIVILEGE
---------------------
t
(1 row)
=> SELECT HAS_TABLE_PRIVILEGE('release', 'store.store_dimension', 'INSERT');
HAS_TABLE_PRIVILEGE
---------------------
t
(1 row)
=> SELECT HAS_TABLE_PRIVILEGE(45035996273711159, 45035996273711160, 'select');
HAS_TABLE_PRIVILEGE
---------------------
t
(1 row)
6.19.9 - LIST_ENABLED_CIPHERS
Returns a list of enabled cipher suites, which are sets of algorithms used to secure TLS/SSL connections.
Returns a list of enabled cipher suites, which are sets of algorithms used to secure TLS/SSL connections.
By default, Vertica uses OpenSSL's default cipher suites. For more information, see the OpenSSL man page.
Syntax
LIST_ENABLED_CIPHERS()
Examples
=> SELECT LIST_ENABLED_CIPHERS();
SSL_RSA_WITH_RC4_128_MD5
SSL_RSA_WITH_RC4_128_SHA
TLS_RSA_WITH_AES_128_CBC_SHA
See also
6.19.10 - SESSION_USER
Returns a VARCHAR containing the name of the user who initiated the current database session.
Returns a VARCHAR containing the name of the user who initiated the current database session.
Behavior type
Stable
Syntax
SESSION_USER()
Notes
Examples
=> SELECT SESSION_USER();
session_user
--------------
dbadmin
(1 row)
The following command returns the same results without the parentheses:
=> SELECT SESSION_USER;
session_user
--------------
dbadmin
(1 row)
6.19.11 - USER
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Behavior type
Stable
Syntax
USER()
Notes
Examples
=> SELECT USER();
current_user
--------------
dbadmin
(1 row)
The following command returns the same results without the parentheses:
=> SELECT USER;
current_user
--------------
dbadmin
(1 row)
6.19.12 - USERNAME
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Returns a VARCHAR containing the name of the user who initiated the current database connection.
Behavior type
Stable
Syntax
USERNAME()
Notes
Examples
=> SELECT USERNAME();
username
--------------
dbadmin
(1 row)
6.19.13 - VERSION
Returns a VARCHAR containing a Vertica node's version information.
Returns a VARCHAR containing a Vertica node's version information.
Behavior type
Stable
Syntax
VERSION()
Note
The parentheses are required.
Examples
=> SELECT VERSION();
VERSION
-------------------------------------------
Vertica Analytic Database v10.0.0-0
(1 row)
7 - Statements
The primary structure of a SQL query is its statement.
The primary structure of a SQL query is its statement. Whether a statement stands on its own, or is part of a multi-statement query, each statement must end with a semicolon. The following example contains four common SQL statements—CREATE TABLE, INSERT, SELECT, and COMMIT:
=> CREATE TABLE comments (id INT, comment VARCHAR);
CREATE TABLE
=> INSERT INTO comments VALUES (1, 'Hello World');
OUTPUT
--------
1
(1 row)
=> SELECT * FROM comments;
id | comment
----+-------------
1 | Hello World
(1 row)
=> COMMIT;
COMMIT
=>
7.1 - ACTIVATE DIRECTED QUERY
Activates a directed query and makes it available to the query optimizer across all sessions.
Activates a directed query and makes it available to the query optimizer across all sessions.
Syntax
ACTIVATE DIRECTED QUERY { query-name | where-clause }
Arguments
query-name- Name of the directed query to activate, as stored in the DIRECTED_QUERIES column
query_name. You can also use GET DIRECTED QUERY to obtain names of all directed queries that map to an input query.
where-clause- Resolves to one or more directed queries that are filtered from system table DIRECTED_QUERIES. For example, the following statement activates all directed queries with the same
save_plans_version identifier:
=> ACTIVATE DIRECTED QUERY WHERE save_plans_version = 21;
Privileges
Superuser
Activation life cycle
After you activate a directed query, it remains active until it is explicitly deactivated by DEACTIVATE DIRECTED QUERY or removed from storage by DROP DIRECTED QUERY. If a directed query is active at the time of database shutdown, Vertica automatically reactivates it when you restart the database.
Examples
See Managing directed queries.
7.2 - ALTER statements
ALTER statements let you change existing database objects.
ALTER statements let you change existing database objects.
7.2.1 - ALTER ACCESS POLICY
Performs one of the following actions on existing access policies:.
Performs one of the following actions on existing access policies:
-
Modify an access policy by changing its expression, and by enabling/disabling the policy.
-
Copy an access policy from one table to another.
Syntax
Modify policy:
ALTER ACCESS POLICY ON [[database.]schema.]table
{ FOR COLUMN column [ expression ] | FOR ROWS [ WHERE expression ] } { GRANT TRUSTED } { ENABLE | DISABLE }
Copy policy:
ALTER ACCESS POLICY ON [[database.]schema.]table
{ FOR COLUMN column | FOR ROWS } COPY TO TABLE table;
Parameters
-
`[database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
table- The name of the table that contains the access policy you want to enable, disable, or copy.
FOR COLUMN column [expression]- Replaces the access policy expression that was previously set for this column. Omit
expression from the FOR COLUMN clause in order to enable or disable this policy only, or copy it to another table.
FOR ROWS [WHERE expression]- Replaces the row access policy expression that was previously set for this table. Omit
WHERE expression from the FOR ROWS clause in order to enable or disable this policy only, or copy it to another table.
GRANT TRUSTEDSpecifies that GRANT statements take precedence over the access policy in determining whether users can perform DML operations on the target table. If omitted, users can only modify table data if the access policy allows them to see the stored data in its original, unaltered state. For more information, see Access policies and DML operations.
Important
GRANT TRUSTED only affects DML operations and does not enable users to see data that the access policy would otherwise mask. Specifying this option may allow users with certain grants to update data that they cannot see.
ENABLE | DISABLE- Indicates whether to enable or disable the access policy at the table level.
COPY TO TABLE tablename- Copies the existing access policy to the specified table. The copied access policy includes its enabled/disabled and GRANT TRUSTED statuses.
The following requirements apply:
Privileges
Modify access policy
Non-superuser: Ownership of the table
Copy access policy
Non-superuser: Ownership of the source and destination tables
Examples
See Managing access policies
See also
CREATE ACCESS POLICY
7.2.2 - ALTER AUTHENTICATION
Modifies the settings for a specified authentication method.
Modifies the settings for a specified authentication method.
Syntax
ALTER AUTHENTICATION auth_record {
| { ENABLE | DISABLE }
| { LOCAL | HOST [ { TLS | NO TLS } ] host_ip_address }
| RENAME TO new_auth_record_name
| METHOD value
| SET param=value[,...]
| PRIORITY value
| [ [ NO ] FALLTHROUGH ]
}
Parameters
|
Parameter Name |
Description |
auth_record |
Name of the authentication method to alter.
Type: VARCHAR
|
ENABLE | DISABLE |
Enable or disable the specified authentication method.
Default: Enabled
When you perform an upgrade and use Kerberos authentication, you must manually set the authentication to ENABLE as it is disabled by default.
|
LOCAL | HOST [ { TLS | NO TLS } host_ip_address |
Specify that the authentication method applies to local or remote (HOST) connections.
For authentication methods that use LDAP, specify whether or not LDAP uses Transport Layer Security (TLS).
For remote (HOST) connections, you must specify the IP address of the host from which the user or application is connecting, VARCHAR.
Vertica supports IPv4 and IPv6 addresses.
|
RENAME TO new_auth_record_name |
Rename the authentication record.
Type: VARCHAR
|
METHOD value |
The authentication method you are altering. |
SET param=value |
Set a parameter name and value for the authentication method that you are creating. This is required for LDAP, Ident, and OAuth authentication methods. |
PRIORITY value |
If the user is associated with multiple authentication methods, the priority value specifies which authentication method Vertica tries first.
Default: 0
Type: INTEGER
Greater values indicate higher priorities. For example, a priority of 10 is higher than a priority of 5; priority 0 is the lowest possible value.
For details, see Authentication record priority.
|
[ [ NO ] FALLTHROUGH ] |
Specifies whether to enable authentication fallthrough. For details, see Client authentication. |
Privileges
Superuser
Examples
Enabling and Disabling Authentication Methods
This example uses ALTER AUTHENTICATION to disable the v_ldap authentication method and then enable it again:
=> ALTER AUTHENTICATION v_ldap DISABLE;
=> ALTER AUTHENTICATION v_ldap ENABLE;
Renaming Authentication Methods
This example renames the v_kerberos authentication method to K5. All users who have been granted the v_kerberos authentication method now have the K5 method granted instead.
=> ALTER AUTHENTICATION v_kerberos RENAME TO K5;
Modifying Authentication Parameters
This example sets the system user for ident1 authentication to user1:
=> CREATE AUTHENTICATION ident1 METHOD 'ident' LOCAL;
=> ALTER AUTHENTICATION ident1 SET system_users='user1';
When you set or modify LDAP or Ident parameters using ALTER AUTHENTICATION, Vertica validates them.
This example changes the IP address and specifies the parameters for an LDAP authentication method named Ldap1. Specify the bind parameters for the LDAP server. Vertica connects to the LDAP server, which authenticates the database client. If authentication succeeds, Vertica authenticates any users who have been associated with (granted) the Ldap1 authentication method on the designated LDAP server:
=> CREATE AUTHENTICATION Ldap1 METHOD 'ldap' HOST '172.16.65.196';
=> ALTER AUTHENTICATION Ldap1 SET host='ldap://172.16.65.177',
binddn_prefix='cn=', binddn_suffix=',dc=qa_domain,dc=com';
The next example specifies the parameters for an LDAP authentication method named Ldap2. Specify the LDAP search and bind parameters. Sometimes, Vertica does not have enough information to create the distinguished name (DN) for a user attempting to authenticate. In such cases, you must specify to use LDAP search and bind:
=> CREATE AUTHENTICATION Ldap2 METHOD 'ldap' HOST '172.16.65.196';
=> ALTER AUTHENTICATION Ldap2 SET basedn='dc=qa_domain,dc=com',
binddn='cn=Manager,dc=qa_domain,
dc=com',search_attribute='cn',bind_password='secret';
Changing the Authentication Method
This example changes the localpwd authentication from hash to trust:
=> CREATE AUTHENTICATION localpwd METHOD 'hash' LOCAL;
=> ALTER AUTHENTICATION localpwd METHOD 'trust';
Set Multiple Realms
This example sets another realm for the authentication method krb_local:
=> ALTER AUTHENTICATION krb_local set realm = 'COMPANY.COM';
See also
7.2.3 - ALTER CA BUNDLE
Adds and removes certificates from or changes the owner of a certificate authority (CA) bundle.
Deprecated
CA bundles are only usable with certain deprecated parameters in
Kafka notifiers. You should prefer using
TLS configurations and the TLS CONFIGURATION parameter for notifiers instead.
Adds and removes certificates from or changes the owner of a certificate authority (CA) bundle.
Syntax
ALTER CA BUNDLE name
[ADD CERTIFICATES ca_cert[, ca_cert[, ...]]
[REMOVE CERTIFICATES ca_cert[, ca_cert[, ...]]
[OWNER TO user]
Parameters
name- The name of the CA bundle.
ca_cert- The name of the CA certificate to add or remove from the bundle.
user- The name of a database user.
Privileges
Ownership of the CA bundle.
Examples
See Managing CA bundles.
See also
7.2.4 - ALTER DATA LOADER
Changes the properties of a data loader.
Changes the properties of a data loader created with CREATE DATA LOADER.
You cannot use ALTER DATA LOADER to add, remove, or modify a trigger.
Syntax
ALTER DATA LOADER [schema.]name {
SET TO copy-statement
| RETRY LIMIT { NONE | DEFAULT | limit }
| RETENTION INTERVAL monitoring-retention
| RENAME TO new-name
| OWNER TO user
| ENABLE | DISABLE
}
Arguments
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader to alter.
SET TO copy-statement- The new COPY statement that the loader executes. The FROM clause typically uses a glob.
RETRY LIMIT { NONE | DEFAULT | limit }- Maximum number of times to retry a failing file. Each time the data loader is executed, it attempts to load all files that have not yet been successfully loaded, up to this per-file limit. If set to DEFAULT, at load time the loader uses the value of the DataLoaderDefaultRetryLimit configuration parameter.
Default: DEFAULT
RETENTION INTERVAL monitoring-retention- How long to keep records in the events table. DATA_LOADER_EVENTS records events for all data loaders, but each data loader has its own retention interval.
Default: 14 days
RENAME TO new-name- New name for the data loader.
OWNER TO user- New owner for the data loader.
ENABLE | DISABLE- Whether the data loader can be executed. Calling EXECUTE DATA LOADER on a disabled data loader returns an error. When created, data loaders with triggers are disabled by default; all others are enabled by default. If a data loader has a trigger, you must disable it before dropping it.
Privileges
Non-superuser:
- USAGE on the schema.
- Owner or ALTER privilege on the data loader.
See also
7.2.5 - ALTER DATABASE
Use ALTER DATABASE to perform the following tasks:.
Use ALTER DATABASE to perform the following tasks:
To see the current value of a parameter, query system table CONFIGURATION_PARAMETERS or use SHOW DATABASE.
Syntax
ALTER DATABASE db-spec {
DROP ALL FAULT GROUP
| EXPORT ON { subnet-name | DEFAULT }
| RESET STANDBY
| SET [PARAMETER] parameter=value [,...]
| CLEAR [PARAMETER] parameter[,...]
}
Parameters
db-spec- Specifies the database to alter, one of the following:
DROP ALL FAULT GROUP- Drops all fault groups defined on the specified database.
EXPORT ON- Specifies the network to use for importing and exporting data, one of the following:
For details, see Identify the database or nodes used for import/export, and Changing node export addresses.
RESET STANDBY- Enterprise Mode only, restores all down nodes and reverts their replacement nodes to standby status. If any replaced nodes cannot resume activity, Vertica leaves their standby nodes in place.
SET [PARAMETER]- Sets the specified parameters.
CLEAR [PARAMETER]- Resets the specified parameters to their default values.
Privileges
Superuser
7.2.6 - ALTER FAULT GROUP
Modifies an existing fault group.
Modifies an existing fault group. ALTER FAULT GROUP can perform the following tasks:
Syntax
ALTER FAULT GROUP fault-group-name {
| ADD NODE node-name
| DROP NODE node-name
| ADD FAULT GROUP child-fault-group-name
| DROP FAULT GROUP child-fault-group-name
| RENAME TO new-fault-group-name }
Parameters
fault-group-name- The existing fault group name you want to modify.
Tip
For a list of all fault groups defined in the cluster, query the
FAULT_GROUPS system table.
node-name- The node name you want to add to or drop from the existing (parent) fault group.
child-fault-group-name- The name of the child fault group you want to add to or remove from an existing parent fault group.
new-fault-group-name- The new name for the fault group you want to rename.
Privileges
Superuser
Examples
This example shows how to rename the parent0 fault group to parent100:
=> ALTER FAULT GROUP parent0 RENAME TO parent100;
ALTER FAULT GROUP
Verify the change by querying the FAULT_GROUPS system table:
=> SELECT member_name FROM fault_groups;
member_name
----------------------
v_exampledb_node0003
parent100
mygroup
(3 rows)
See also
7.2.7 - ALTER FUNCTION statements
Vertica provides ALTER statements for each type of user-defined extension.
Vertica provides ALTER statements for each type of user-defined extension. Each ALTER statement modifies the metadata of a user-defined function in the Vertica catalog:
Vertica also provides ALTER FUNCTION (SQL), which modifies the metadata of a user-defined SQL function.
7.2.7.1 - ALTER AGGREGATE FUNCTION
Alters a user-defined aggregate function.
Alters a user-defined aggregate function.
Syntax
ALTER AGGREGATE FUNCTION [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET SCHEMA new-schema
}
Parameters
[db-name.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function-name``- Name of the SQL function to alter.
arg-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
For these operations... |
Schema privileges required... |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
CREATE: destination schema
USAGE: current schema |
See also
CREATE AGGREGATE FUNCTION
7.2.7.2 - ALTER ANALYTIC FUNCTION
Alters a user-defined analytic function.
Alters a user-defined analytic function.
Syntax
ALTER ANALYTIC FUNCTION [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED boolean-expr
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
See also
CREATE ANALYTIC FUNCTION
7.2.7.3 - ALTER FILTER
Alters a user-defined filter.
Alters a user-defined filter.
Syntax
ALTER FILTER [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED boolean-expr
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
See also
CREATE FILTER
7.2.7.4 - ALTER FUNCTION (scalar)
Alters a user-defined scalar function.
Alters a user-defined scalar function.
Syntax
ALTER FUNCTION [[db-name.]schema.]function-name( [ parameter-list] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED boolean-expr
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
Examples
Rename function UDF_one to UDF_two:
=> ALTER FUNCTION UDF_one (int, int) RENAME TO UDF_two;
Move function UDF_two to schema macros:
=> ALTER FUNCTION UDF_two (int, int) SET SCHEMA macros;
Disable fenced mode for function UDF_two:
=> ALTER FUNCTION UDF_two (int, int) SET FENCED false;
See also
CREATE FUNCTION (scalar)
7.2.7.5 - ALTER FUNCTION (SQL)
Alters a user-defined SQL function.
Alters a user-defined SQL function.
Syntax
ALTER FUNCTION [[db-name.]schema.]function-name( [arg-list] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET SCHEMA new-schema
}
Parameters
[db-name.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function-name- The name of the SQL function to alter.
arg-list- A comma-delimited list of function argument names. If none, specify an empty list.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
For these operations... |
Schema privileges required... |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
CREATE: destination schema
USAGE: current schema |
Examples
Rename function SQL_one to SQL_two:
=> ALTER FUNCTION SQL_one (int, int) RENAME TO SQL_two;
Move function SQL_two to schema macros:
=> ALTER FUNCTION SQL_two (int, int) SET SCHEMA macros;
Reassign ownership of SQL_two:
=> ALTER FUNCTION SQL_two (int, int) OWNER TO user1;
See also
7.2.7.6 - ALTER PARSER
Alters a user-defined parser.
Alters a user-defined parser.
Syntax
ALTER PARSER [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED boolean-expr
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
See also
CREATE PARSER
7.2.7.7 - ALTER SOURCE
Alters a user-defined load source function.
Alters a user-defined load source function.
Syntax
ALTER SOURCE [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED boolean-expr
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
See also
CREATE SOURCE
7.2.7.8 - ALTER TRANSFORM FUNCTION
Alters a user-defined transform function.
Alters a user-defined transform function.
Syntax
ALTER TRANSFORM FUNCTION [[db-name.]schema.]function-name( [ parameter-list ] ) {
OWNER TO new-owner
| RENAME TO new-name
| SET FENCED { true | false }
| SET SCHEMA new-schema
}
Parameters
[db-name.]schema- Database and schema. The default schema is
public. If you specify a database, it must be the current database.
function-name- Name of the function to alter.
parameter-list- Comma-delimited list of parameters that are defined for this function. If none, specify an empty list.
Note
Vertica supports function overloading, and uses the parameter list to identify the function to alter.
OWNER TO new-owner- Transfers function ownership to another user.
RENAME TO new-name- Renames this function.
SET FENCED { true | false }- Specifies whether to enable fenced mode for this function.
SET SCHEMA new-schema- Moves the function to another schema.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must also have the following schema privileges:
|
Operation |
Schema privileges required |
|
RENAME TO (rename function) |
CREATE, USAGE |
|
SET SCHEMA (move function to another schema) |
|
See also
CREATE TRANSFORM FUNCTION
7.2.8 - ALTER HCATALOG SCHEMA
Alters parameter values on a schema that was created with CREATE HCATALOG SCHEMA.
Alters parameter values on a schema that was created with CREATE HCATALOG SCHEMA. HCatalog schemas are used by the HCatalog Connector to access data stored in a Hive data warehouse. For more information, see Using the HCatalog Connector.
Some parameters cannot be altered after creation. If you need to change one of those values, delete and recreate the schema instead. You can use ALTER HCATALOG SCHEMA to change the following parameters:
-
HOSTNAME
-
PORT
-
HIVESERVER2_HOSTNAME
-
WEBSERVICE_HOSTNAME
-
WEBSERVICE_PORT
-
WEBHDFS_ADDRESS
-
HCATALOG_CONNECTION_TIMEOUT
-
HCATALOG_SLOW_TRANSFER_LIMIT
-
HCATALOG_SLOW_TRANSFER_TIME
-
SSL_CONFIG
-
CUSTOM_PARTITIONS
Syntax
ALTER HCATALOG SCHEMA schema-name SET [param=value]+;
Parameters
|
Parameter |
Description |
schema-name |
The name of the schema in the Vertica catalog to alter. The tables in the Hive database are available through this schema. |
param |
The name of the parameter to alter. |
value |
The new value for the parameter. You must specify a value; this statement does not read default values from configuration files like CREATE HCATALOG SCHEMA. |
Privileges
One of the following:
Examples
The following example shows how to change the Hive metastore hostname and port for the "hcat" schema. In this example, Hive uses High Availability metastore.
=> ALTER HCATALOG SCHEMA hcat SET HOSTNAME='thrift://ms1.example.com:9083,thrift://ms2.example.com:9083';
The following example shows the error you receive if you try to set an unalterable parameter.
=> ALTER HCATALOG SCHEMA hcat SET HCATALOG_USER='admin';
ERROR 4856: Syntax error at or near "HCATALOG_USER" at character 39
7.2.9 - ALTER LIBRARY
Replaces the library file that is currently associated with a UDx library in the Vertica catalog.
Replaces the library file that is currently associated with a UDx library in the Vertica catalog. Vertica automatically distributes copies of the updated file to all cluster nodes. UDxs defined in the catalog that reference the updated library automatically start using the updated library file. A UDx is considered to be the same if its name and signature match.
The current and replacement libraries must be written in the same language.
Caution
If a UDx function that is present in the original library is not present in the updated library, it is automatically dropped. This can result in loss of data if that function is in use, for example if a table depends on it to populate a column.
Syntax
ALTER LIBRARY [[database.]schema.]name [DEPENDS 'depends-path'] AS 'path';
Arguments
schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
name- The name of an existing library created with CREATE LIBRARY.
DEPENDS 'depends-path'Files or libraries on which this library depends, one or more files or directories on the initiator node file system or other supported file systems or object stores. For a directory, end the path entry with a slash (/), optionally followed by a wildcard (*). To specify more than one file, separate entries with colons (:).
If any path entry contain colons, such as a URI, place brackets around the entire DEPENDS path and use double quotes for the individual path elements, as in the following example:
DEPENDS '["s3://mybucket/gson-2.3.1.jar"]'
To specify libraries with multiple directory levels, see Multi-level Library Dependencies.
DEPENDS has no effect for libraries written in R. R packages must be installed locally on each node, including external dependencies.
Important
The performance of CREATE LIBRARY can degrade in Eon Mode, in proportion to the number and depth of dependencies specified by the DEPENDS clause.
AS path- The absolute path on the initiator node file system of the replacement library file.
Privileges
Superuser, or UDXDEVELOPER and CREATE on the schema. Non-superusers must explicitly enable the UDXDEVELOPER role. See CREATE LIBRARY for examples.
Multi-level library dependencies
If a DEPENDS clause specifies a library with multiple directory levels, Vertica follows the library path to include all subdirectories of that library. For example, the following CREATE LIBRARY statement enables the UDx library mylib to import all Python packages and modules that it finds in subdirectories of site-packages:
=> CREATE LIBRARY mylib AS '/path/to/python_udx' DEPENDS '/path/to/python/site-packages' LANGUAGE 'Python';
Important
DEPENDS can specify Java library dependencies that are up to 100 levels deep.
Examples
This example shows how to update an already-defined library named myFunctions with a new file.
=> ALTER LIBRARY myFunctions AS '/home/dbadmin/my_new_functions.so';
See also
Developing user-defined extensions (UDxs)
7.2.10 - ALTER LOAD BALANCE GROUP
Changes the configuration of a load balance group.
Changes the configuration of a load balance group.
Syntax
ALTER LOAD BALANCE GROUP group-name {
RENAME TO new-name |
SET FILTER TO 'ip-cidr-addr' |
SET POLICY TO 'policy' |
ADD {ADDRESS | FAULT GROUP | SUBCLUSTER} add-list |
DROP {ADDRESS | FAULT GROUP | SUBCLUSTER} drop-list
}
Parameters
group-name- Name of an existing load balance group to change.
RENAME TO new-name- Renames the group to new-name.
SET FILTER TO 'ip-cidr-addr'- An IPv4 or IPv6 CIDR to replace the existing IP address filter that selects which members of a fault group or subcluster to include in the load balance group. This setting is only valid if the load balance group contains fault groups or subclusters.
SET POLICY TO 'policy'- Changes the policy the load balance group uses to select the target node for the incoming connection. One of:
See CREATE LOAD BALANCE GROUP for details.
ADD {ADDRESS | FAULT GROUP | SUBCLUSTER }- Adds objects of the specified type to the load balance group. Load balance groups can only contain one type of object. For example, if you created the load balance group using a list of addresses, you can only add additional addresses, not fault groups or subclusters.
add-list- A comma-delimited list of objects (addresses, fault groups, or subclusters) to add to the fault group.
DROP {ADDRESS | FAULT GROUP | SUBCLUSTER}- Removes objects of the specified type from the load balance group (addresses, fault groups, or subclusters). The object type must match the type of the objects already in the load balance group.
drop-list- The list of objects to remove from the load balance group.
Privileges
Superuser
Examples
Remove an address from the load balance group named group_2.
=> SELECT * FROM LOAD_BALANCE_GROUPS;
name | policy | filter | type | object_name
---------+------------+--------+-----------------------+-------------
group_1 | ROUNDROBIN | | Network Address Group | node01
group_1 | ROUNDROBIN | | Network Address Group | node02
group_2 | ROUNDROBIN | | Network Address Group | node03
(3 rows)
=> ALTER LOAD BALANCE GROUP group_2 DROP ADDRESS node03;
ALTER LOAD BALANCE GROUP
=> SELECT * FROM LOAD_BALANCE_GROUPS;
name | policy | filter | type | object_name
---------+------------+--------+-----------------------+-------------
group_1 | ROUNDROBIN | | Network Address Group | node01
group_1 | ROUNDROBIN | | Network Address Group | node02
group_2 | ROUNDROBIN | | Empty Group |
(3 rows)
The following example adds three network addresses to the group named group_2:
=> ALTER LOAD BALANCE GROUP group_2 ADD ADDRESS node01,node02,node03;
ALTER LOAD BALANCE GROUP
=> SELECT * FROM load_balance_groups WHERE name = 'group_2';
-[ RECORD 1 ]----------------------
name | group_2
policy | ROUNDROBIN
filter |
type | Network Address Group
object_name | node01
-[ RECORD 2 ]----------------------
name | group_2
policy | ROUNDROBIN
filter |
type | Network Address Group
object_name | node02
-[ RECORD 3 ]----------------------
name | group_2
policy | ROUNDROBIN
filter |
type | Network Address Group
object_name | node03
See also
7.2.11 - ALTER MODEL
Allows users to rename an existing model, change ownership, or move it to a another schema.
Allows users to rename an existing model, change ownership, or move it to a another schema.
Syntax
ALTER MODEL [[database.]schema.]model
{ OWNER TO owner
| RENAME TO new-name
| SET SCHEMA schema
| { INCLUDE | EXCLUDE | MATERIALIZE } [ SCHEMA ] PRIVILEGES }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
model- Identifies the model to alter.
OWNER TO owner- Reassigns ownership of this model to
owner. If a non-superuser, you must be the current owner.
RENAME TO- Renames the mode, where
new-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
SET SCHEMA schema- Moves the model from one schema to another. If privilege inheritance is enabled with INCLUDE SCHEMA PRIVILEGES, the model inherits the privileges of its new parent schema.
[ { INCLUDE | EXCLUDE | MATERIALIZE } [ SCHEMA ] PRIVILEGES ]- The INCLUDE and EXCLUDE parameters determine whether the model inherits the privileges of its parent schema, overriding the schema-level setting:
-
INCLUDE SCHEMA PRIVILEGES: The model inherits the privileges of its parent schema. This parameter has no effect while privilege inheritance is disabled at the database level with DisableInheritedPrivileges.
-
EXCLUDE SCHEMA PRIVILEGES: The model does not inherit the privileges of its parent schema.
The MATERIALIZE parameter converts inherited privileges into explicit grants on the model. If privilege inheritance is disabled at the database level with DisableInheritedPrivileges, MATERIALIZE converts the set of inherited privileges that would be on the model if privilege inheritance was enabled.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must have the following schema privileges:
|
Schema privileges required... |
For these operations... |
|
CREATE, USAGE |
Rename model |
|
CREATE: destination schema
USAGE: current schema
|
Move model to another schema |
Examples
To move a model to another schema:
=> ALTER MODEL my_kmeans_model SET SCHEMA clustering_models;
ALTER MODEL
To rename a model:
=> ALTER MODEL my_kmeans_model RENAME TO kmeans_model;
To change the owner of the model:
=> ALTER MODEL kmeans_model OWNER TO analytics_user;
7.2.12 - ALTER NETWORK ADDRESS
Changes the configuration of an existing network address.
Changes the configuration of an existing network address.
Syntax
ALTER NETWORK ADDRESS name {
RENAME TO new-name
| SET TO 'ip-addr' [PORT port-number]
| { ENABLE | DISABLE }
}
Parameters
name- Name of an existing network address to change.
RENAME TO new-name- Renames the network address to
new-name. This name change has no effect on the network address's membership in load balance groups.
SET TO 'ip-addr'- Changes the IP address assigned to the network address.
PORT port-number- Sets the port number for the network address. You must supply a network address when altering the port number.
ENABLE | DISABLE- Enables or disables the network address.
Examples
Rename the network address from test_addr to alt_node1, then change its IP address to 192.168.1.200 with port number 4000:
=> ALTER NETWORK ADDRESS test_addr RENAME TO alt_node1;
ALTER NETWORK ADDRESS
=> ALTER NETWORK ADDRESS alt_node1 SET TO '192.168.1.200' PORT 4000;
ALTER NETWORK ADDRESS
See also
7.2.13 - ALTER NETWORK INTERFACE
This statement has been deprecated.
Renames a network interface.
Syntax
ALTER NETWORK INTERFACE network-interface-name RENAME TO new-network-interface-name
Parameters
network-interface-name- The name of the existing network interface.
new-network-interface-name- The new name for the network interface.
Privileges
Superuser
Examples
Rename a network interface:
=> ALTER NETWORK INTERFACE myNetwork RENAME TO myNewNetwork;
7.2.14 - ALTER NODE
Sets and clears node-level configuration parameters on the specified node.
Sets and clears node-level configuration parameters on the specified node. ALTER NODE also performs the following management tasks:
For information about removing a node, see
Syntax
ALTER NODE node-name {
EXPORT ON { network-interface | DEFAULT }
| [IS] node-type
| REPLACE [ WITH standby-node ]
| RESET
| SET [PARAMETER] parameter=value[,...]
| CLEAR [PARAMETER] parameter[,...]
}
Parameters
node-name - The name of the node to alter.
[IS] node-type- Changes the node type, where
node-type is one of the following:
-
PERMANENT: (default): A node that stores data.
-
EPHEMERAL: A node that is in transition from one type to another—typically, from PERMANENT to either STANDBY or EXECUTE.
-
STANDBY: A node that is reserved to replace any node when it goes down. A standby node stores no segments or data until it is called to replace a down node. When used as a replacement node, Vertica changes its type to PERMANENT. For more information, see Active standby nodes.
-
EXECUTE: A node that is reserved for computation purposes only. An execute node contains no segments or data.
Note
STANDBY and EXECUTE node types are supported only in Enterprise Mode.
EXPORT ON- Specifies the network to use for importing and exporting data, one of the following:
-
network-interface: The name of a network interface of the public network.
-
DEFAULT: Use the default network interface of the public network, as specified by ALTER DATABASE.
REPLACE [WITH standby-node]- Enterprise Mode only, replaces the specified node with an available active standby node. If you omit the
WITH clause, Vertica tries to find a replacement node from the same fault group as the down node.
If you specify a node that is not down, Vertica ignores this statement.
RESET- Enterprise Mode only, restores the specified down node and returns its replacement to standby status. If the down node cannot resume activity, Vertica ignores this statement and leaves the standby node in place.
SET [PARAMETER]- Sets one or more configuration parameters to the specified value at the node level.
CLEAR [PARAMETER]- Clears one or more specified configuration parameters.
Privileges
Superuser
Examples
Specify to use the default network interface of public network on v_vmart_node0001 for import/export operations:
=> ALTER NODE v_vmart_node0001 EXPORT ON DEFAULT;
Replace down node v_vmart_node0001 with an active standby node, then restore it:
=> ALTER NODE v_vmart_node0001 REPLACE WITH standby1;
...
=> ALTER NODE v_vmart_node0001 RESET;
Set and clear configuration parameter MaxClientSessions:
=> ALTER NODE v_vmart_node0001 SET MaxClientSessions = 0;
...
=> ALTER NODE v_vmart_node0001 CLEAR MaxClientSessions;
Set the node type as EPHEMERAL:
=> ALTER NODE v_vmart_node0001 IS EPHEMERAL;
7.2.15 - ALTER NOTIFIER
Updates an existing notifier.
Updates an existing notifier.
Note
To change the action URL associated with an existing identifier,
drop the notifier and recreate it.
Syntax
ALTER NOTIFIER notifier-name
[ ENABLE | DISABLE ]
[ MAXPAYLOAD 'max-payload-size' ]
[ MAXMEMORYSIZE 'max-memory-size' ]
[ TLS CONFIGURATION tls-configuration ]
[ TLSMODE 'tls-mode' ]
[ CA BUNDLE bundle-name [ CERTIFICATE certificate-name ] ]
[ IDENTIFIED BY 'uuid' ]
[ [NO] CHECK COMMITTED ]
[ PARAMETERS 'adapter-params' ]
Parameters
notifier-name- Specifies the notifier to update.
[NO] CHECK COMMITTED- Specifies to wait for delivery confirmation before sending the next message in the queue. Not all messaging systems support delivery confirmation.
ENABLE | DISABLE- Specifies whether to enable or disable the notifier.
MAXPAYLOAD- The maximum size of the message, up to 2 TB, specified in kilobytes, megabytes, gigabytes, or terabytes as follows:
MAXPAYLOAD integer{K|M|G|T}
The default setting is adapter-specific—for example, 1 M for Kafka.
Changes to this parameter take effect either after the notifier is disabled and reenabled or after the database restarts.
MAXMEMORYSIZE- The maximum size of the internal notifier, up to 2 TB, specified in kilobytes, megabytes, gigabytes, or terabytes as follows:
MAXMEMORYSIZE integer{K|M|G|T}
If the queue exceeds this size, the notifier drops excess messages.
- TLS CONFIGURATION
tls-configuration
The TLS CONFIGURATION to use for TLS.
Notifiers support the following TLS modes:
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
TLSMODE 'tls-mode'-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies the type of connection between the notifier and an endpoint, one of the following:
-
disable (default): Plaintext connection.
-
verify-ca: Encrypted connection, and the server's certificate is verified as being signed by a trusted CA.
If you set this parameter to verify-ca, the generated TLS Configuration will be set to TRY_VERIFY, which has the same behavior as VERIFY_CA.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
CA BUNDLE bundle-name-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies a CA bundle. The certificates inside the bundle are used to validate the Kafka server's certificate if the TLSMODE requires it.
If a CA bundle is specified for a notifier that currently uses disable, which doesn't validate the Kafka server's certificate, the bundle will go unused when connecting to the Kafka server. This behavior persists unless the TLSMODE is changed to one that validates server certificates.
Changes to contents of the CA bundle take effect either after the notifier is disabled and re-enabled or after the database restarts. However, changes to which CA bundle the notifier uses takes effect immediately.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
CERTIFICATE certificate-name-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies a client certificate for validation by the endpoint.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
IDENTIFIED BY 'uuid'- Specifies the notifier's unique identifier. If set, all the messages published by this notifier have this attribute.
PARAMETERS 'adapter-params'- Specifies one or more optional adapter parameters that are passed as a string to the adapter. Adapter parameters apply only to the adapter associated with the notifier.
Changes to this parameter take effect either after the notifier is disabled and reenabled or after the database restarts.
For Kafka notifiers, refer to Kafka and Vertica configuration settings.
Privileges
Superuser
Encrypted notifiers for SASL_SSL Kafka configurations
Follow this procedure to create or alter notifiers for Kafka endpoints that use SASL_SSL. Note that you must repeat this procedure whenever you change the TLSMODE, certificates, or CA bundle for a given notifier.
-
Create a TLS Configuration with the desired TLS mode, certificate, and CA certificates.
-
Use CREATE or ALTER to disable the notifier and set the TLS Configuration:
=> ALTER NOTIFIER encrypted_notifier
DISABLE
TLS CONFIGURATION kafka_tls_config;
-
ALTER the notifier and set the proper rdkafka adapter parameters for SASL_SSL:
=> ALTER NOTIFIER encrypted_notifier PARAMETERS
'sasl.username=user;sasl.password=password;sasl.mechanism=PLAIN;security.protocol=SASL_SSL';
-
Enable the notifier:
=> ALTER NOTIFIER encrypted_notifier ENABLE;
Examples
Update the settings on an existing notifier:
=> ALTER NOTIFIER my_dc_notifier
ENABLE
MAXMEMORYSIZE '2G'
IDENTIFIED BY 'f8b0278a-3282-4e1a-9c86-e0f3f042a971'
CHECK COMMITTED;
Add a TLS Configuration to a notifier. To create a custom TLS Configuration, see TLS configurations:
=> ALTER NOTIFIER my_notifier TLS CONFIGURATION notifier_tls_config
See also
7.2.16 - ALTER PROCEDURE (stored)
Alters a stored procedure, retaining any existing grants.
Alters a stored procedure, retaining any existing grants.
Syntax
ALTER PROCEDURE procedure ( [ [ parameter_mode ] [ parameter ] parameter_type [, ...] ] )
[ SECURITY { INVOKER | DEFINER }
| RENAME TO new_procedure_name
| OWNER TO new_owner
| SET SCHEMA new_schema
| SOURCE TO new_source
]
Parameters
procedure- The procedure to alter.
parameter_mode- The IN and INOUT parameters of the stored procedure.
parameter- The name of the parameter.
parameter_type- The type of the parameter.
SECURITY { INVOKER | DEFINER }- Specifies whether to execute the procedure with the privileges of the invoker or its definer (owner).
For details, see Executing stored procedures.
RENAME TO new_procedure_name- The new name for the procedure.
OWNER TO new_owner- The new owner (definer) of the procedure.
SET SCHEMA new_schema- The new schema of the procedure.
SOURCE TO new_source- The new procedure source code. For details, see Scope and structure.
Privileges
OWNER TO
Superuser
RENAME and SCHEMA TO
Non-superuser:
Other operations
Non-superuser: Ownership of the procedure
Examples
See Altering stored procedures.
7.2.17 - ALTER PROFILE
Changes a profile.
Changes a profile. All parameters that are not set in a profile inherit their setting from the default profile. You can use ALTER PROFILE to change the default profile.
Syntax
ALTER PROFILE name LIMIT [
PASSWORD_LIFE_TIME setting
PASSWORD_MIN_LIFE_TIME setting
PASSWORD_GRACE_TIME setting
FAILED_LOGIN_ATTEMPTS setting
PASSWORD_LOCK_TIME setting
PASSWORD_REUSE_MAX setting
PASSWORD_REUSE_TIME setting
PASSWORD_MAX_LENGTH setting
PASSWORD_MIN_LENGTH setting
PASSWORD_MIN_LETTERS setting
PASSWORD_MIN_UPPERCASE_LETTERS setting
PASSWORD_MIN_LOWERCASE_LETTERS setting
PASSWORD_MIN_DIGITS setting
PASSWORD_MIN_SYMBOLS setting
PASSWORD_MIN_CHAR_CHANGE setting ]
Parameters
Note
To reset a parameter to inherit from the default profile, set its value to default.
|
Name |
Description |
name |
The name of the profile to create, where *name*conforms to conventions described in Identifiers.
To modify the default profile, set name to default. For example:
ALTER PROFILE DEFAULT LIMIT PASSWORD_MIN_SYMBOLS 1;
|
PASSWORD_LIFE_TIME |
Set to an integer value, one of the following:
After your password's lifetime and grace period expire, you must change your password on your next login, if you have not done so already.
|
PASSWORD_MIN_LIFE_TIME |
Set to an integer value, one of the following:
|
PASSWORD_GRACE_TIME |
Set to an integer value, one of the following:
|
FAILED_LOGIN_ATTEMPTS |
Set to an integer value, one of the following:
|
PASSWORD_LOCK_TIME |
-
≥ 1: The number of days (units configurable with PasswordLockTimeUnit) a user's account is locked after FAILED_LOGIN_ATTEMPTS number of login attempts. The account is automatically unlocked when the lock time elapses.
-
UNLIMITED: Account remains indefinitely inaccessible until a superuser manually unlocks it.
|
PASSWORD_REUSE_MAX |
Set to an integer value, one of the following:
|
PASSWORD_REUSE_TIME |
Set to an integer value, one of the following:
|
PASSWORD_MAX_LENGTH |
The maximum number of characters allowed in a password, one of the following:
- Integer between 8 and 512, inclusive
|
PASSWORD_MIN_LENGTH |
The minimum number of characters required in a password, one of the following:
|
PASSWORD_MIN_LETTERS |
Minimum number of letters (a-z and A-Z) that must be in a password, one of the following:
|
PASSWORD_MIN_UPPERCASE_LETTERS |
Minimum number of uppercase letters (A-Z) that must be in a password, one of the following:
|
PASSWORD_MIN_LOWERCASE_LETTERS |
Minimum number of lowercase letters (a-z) that must be in a password, one of the following:
|
PASSWORD_MIN_DIGITS |
Minimum number of digits (0-9) that must be in a password, one of the following:
|
PASSWORD_MIN_SYMBOLS |
Minimum number of symbols—printable non-letter and non-digit characters such as $, #, @—that must be in a password, one of the following:
|
PASSWORD_MIN_CHAR_CHANGE |
Minimum number of characters that must be different from the previous password:
|
Privileges
Superuser
Profile settings and client authentication
The following profile settings affect client authentication methods, such as LDAP or GSS:
-
FAILED_LOGIN_ATTEMPTS
-
PASSWORD_LOCK_TIME
All other profile settings are used only by Vertica to manage its passwords.
Examples
ALTER PROFILE sample_profile LIMIT FAILED_LOGIN_ATTEMPTS 3;
See also
7.2.18 - ALTER PROFILE RENAME
Rename an existing profile.
Rename an existing profile.
Syntax
ALTER PROFILE name RENAME TO new-name;
Parameters
name- The current name of the profile.
new-name- The new name for the profile.
Privileges
Superuser
Examples
This example shows how to rename an existing profile.
ALTER PROFILE sample_profile RENAME TO new_sample_profile;
See also
7.2.19 - ALTER PROJECTION
Changes the DDL of the specified projection.
Changes the DDL of the specified projection.
Syntax
ALTER PROJECTION [[database.]schema.]projection
{ RENAME TO new-name | ON PARTITION RANGE BETWEEN min-val AND max-val | { ENABLE | DISABLE } }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The projection to change, where
projection can be one of the following:
-
Projection base name: Rename all projections that share this base name.
-
Projection name: Rename the specified projection and its base name. If the projection is segmented, its buddies are unaffected by this change.
See Projection naming for projection name conventions.
RENAME TOnew-name- The new projection name.
ON PARTITION RANGE-
Note
Valid only for projections that were created with a partition range.
Limits projection data to a range of partition keys. The minimum value must be less than or equal to the maximum value.
Values can be NULL. A null minimum value indicates no lower bound and a null maximum value indicates no upper bound. If both are NULL, this statement drops the projection endpoints, producing a regular projection instead of a range projection.
If the new range of keys is outside the previous range, Vertica throws a warning that the projection is out of date and must be refreshed before it can be used.
For other requirements and usage details, see Partition range projections.
- ENABLE | DISABLE
- Specifies whether to mark this projection as unavailable for queries on its anchor table. If a projection is the queried table's only superprojection, attempts to disable it return with a rollback message. ENABLE restores the projection's availability to query planning. You can also mark a projection as unavailable for individual queries using the hint SKIP_PROJS.
Default: ENABLE
Privileges
Non-superuser, CREATE and USAGE on the schema and one of the following anchor table privileges:
Syntactic sugar
The statement
=> ALTER PROJECTION foo REMOVE PARTITION RANGE;
has the same effect as
=> ALTER PROJECTION foo ON PARTITION RANGE BETWEEN NULL AND NULL;
Examples
=> SELECT export_tables('','public.store_orders');
export_tables
---------------------------------------------
CREATE TABLE public.store_orders
(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date NOT NULL
);
(1 row)
=> CREATE PROJECTION store_orders_p AS SELECT * from store_orders;
CREATE PROJECTION
=> ALTER PROJECTION store_orders_p RENAME to store_orders_new;
ALTER PROJECTION
=> ALTER PROJECTION store_orders_new DISABLE;
=> SELECT * FROM store_orders_new;
ERROR 3586: Insufficient projections to answer query
DETAIL: No projections eligible to answer query
HINT: Projection store_orders_new not used in the plan because the projection is disabled.
=> ALTER PROJECTION store_orders_new ENABLE;
See also
CREATE PROJECTION
7.2.20 - ALTER RESOURCE POOL
Modifies an existing resource pool by setting one or more parameters.
Modifies an existing resource pool by setting one or more parameters.
You can use ALTER RESOURCE POOL to modify some parameters in Vertica built-in resource pools. For details on default settings and restrictions, see Built-in resource pools configuration.
Important
Changes to parameters of the built-in
GENERAL resource pool take effect only when the database restarts.
Syntax
ALTER RESOURCE POOL pool-name [ FOR subcluster ] parameter-name setting[...]
Arguments
pool-name- Name of the resource pool to modify.
FOR subclusterEon Mode only, the subcluster to associate with this resource pool, where subcluster is one of the following:
SUBCLUSTER subcluster-name: Resource pool for an existing subcluster. You cannot be connected to this subcluster, otherwise Vertica returns an error.CURRENT SUBCLUSTER: Resource pool for the subcluster that you are connected to.
Important
You cannot use ALTER RESOURCE POOL to convert a global resource pool to a subcluster-level resource pool.
parameter-name setting- A resource pool parameter and its new setting. To reset this parameter to its default value, specify
DEFAULT.
If you specify a subcluster, you can alter only the MAXMEMORYSIZE, MAXQUERYMEMORYSIZE, and MEMORYSIZE parameters for built-in pools.
Parameters
-
CASCADE TO
Secondary resource pool for executing queries that exceed the
RUNTIMECAP setting of their assigned resource pool:
CASCADE TO secondary-pool
-
CPUAFFINITYMODE
Specifies whether the resource pool has exclusive or shared use of the CPUs specified in
CPUAFFINITYSET:
CPUAFFINITYMODE { SHARED | EXCLUSIVE | ANY }
SHARED: Queries that run in this resource pool share its CPUAFFINITYSET CPUs with other Vertica resource pools.EXCLUSIVE: Dedicates CPUAFFINITYSET CPUs to this resource pool only, and excludes other Vertica resource pools. If CPUAFFINITYSET is set as a percentage, then that percentage of CPU resources available to Vertica is assigned solely for this resource pool.ANY: Queries in this resource pool can run on any CPU, invalid if CPUAFFINITYSET designates CPU resources.
Default: ANY
-
CPUAFFINITYSET
CPUs available to this resource pool. All cluster nodes must have the same number of CPUs. The CPU resources assigned to this set are unavailable to general resource pools.
CPUAFFINITYSET {
'cpu-index[,...]'
| 'cpu-indexi-cpu-indexn'
| 'integer%'
| NONE
}
cpu-index[,...]: Dedicates one or more comma-delimited CPUs to this resource pool.cpu-indexi-cpu-indexn: Dedicates a range of contiguous CPU indexes i through n to this resource pool.integer%: Percentage of all available CPUs to use for this resource pool. Vertica rounds this percentage down to include whole CPU units.NONE (empty string): No affinity set is assigned to this resource pool. Queries associated with this pool are executed on any CPU.
Default: NONE
Important
CPUAFFINITYSET and CPUAFFINITYMODE must be set together in the same statement.
-
EXECUTIONPARALLELISM
Number of threads used to process any single query issued in this resource pool.
EXECUTIONPARALLELISM { limit | AUTO }
limit: An integer value between 1 and the number of cores. Setting this parameter to a reduced value increases throughput of short queries issued in the resource pool, especially if queries are executed concurrently.AUTO or 0: Vertica calculates the setting from the number of cores, available memory, and amount of data in the system. Unless memory is limited, or the amount of data is very small, Vertica sets this parameter to the number of cores on the node.
Default: AUTO
-
MAXCONCURRENCY
Maximum number of concurrent execution slots available to the resource pool across the cluster:
MAXCONCURRENCY { integer | NONE }
NONE (empty string): Unlimited number of concurrent execution slots.
Default: NONE
-
MAXMEMORYSIZE
Maximum size per node the resource pool can grow by borrowing memory from the
GENERAL pool:
MAXMEMORYSIZE {
'integer%'
|'integer{K|M|G|T}'
NONE
}
integer%: Percentage of total memoryinteger{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytesNONE (empty string): Unlimited, resource pool can borrow any amount of available memory from the GENERAL pool.
Default: NONE
MAXQUERYMEMORYSIZEMaximum amount of memory this resource pool can allocate at runtime to process a query. If the query requires more memory than this setting, Vertica stops execution and returns an error.
Set this parameter as follows:
MAXQUERYMEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
| NONE
}
integer%: Percentage of
MAXMEMORYSIZE for this resource pool.integer{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes, up to the value of
MAXMEMORYSIZE.NONE (empty string): Unlimited; resource pool can borrow any amount of available memory from the GENERAL pool, within the limits set by
MAXMEMORYSIZE.
Default: NONE
Important
Changes to MAXQUERYMEMORYSIZE are applied retroactively to queries that are currently executing. If you reduce this setting, queries that were budgeted with the previous memory size are liable to fail if they try to allocate more memory than the new setting allows.
-
MEMORYSIZE
Total per-node memory available to the Vertica resource manager that is allocated to this resource pool:
MEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
}
integer%: Percentage of total memoryinteger{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes
Default: 0%. No memory allocated, the resource pool borrows memory from the
GENERAL pool.
-
PLANNEDCONCURRENCY
Preferred number of queries to execute concurrently in the resource pool. This setting applies to the entire cluster:
PLANNEDCONCURRENCY { num-queries | AUTO }
-
num-queries: Integer value ≥ 1, the preferred number of queries to execute concurrently in the resource pool. When possible, query resource budgets are limited to allow this level of concurrent execution.
-
AUTO: Value is calculated automatically at query runtime. Vertica sets this parameter to the lower of these two calculations, but never less than 4:
-
Number of logical cores
-
Memory divided by 2GB
If the number of logical cores on each node is different, AUTO is calculated differently for each node. Distributed queries run like the minimal effective planned concurrency. Single node queries run with the planned concurrency of the initiator.
Default: AUTO
Tip
Change this parameter only after evaluating performance over a period of time.
-
PRIORITY
Priority of queries in this resource pool when they compete for resources in the
GENERAL pool:
PRIORITY { integer | HOLD }
-
integer: Negative or positive integer value, where higher numbers denote higher priority:
-
User-defined resource pool: -100 to 100
-
Built-in resource pools
SYSQUERY,
RECOVERY, and
TM: -110 to 110
-
HOLD: Sets priority to -999. Queries in this resource pool are queued until
QUEUETIMEOUT is reached.
Default: 0
-
QUEUETIMEOUT
Maximum time a request can wait for pool resources before it is rejected, not more than one year:
QUEUETIMEOUT { integer | 'interval' | 'NONE' }
-
integer: Maximum wait time in seconds
-
[interval](/en/sql-reference/language-elements/literals/datetime-literals/interval-literal/): Maximum wait time expressed in the following format:
num year num months num [days] HH:MM:SS.ms
-
NONE (empty string): No maximum wait time, request can be queued indefinitely, up to one year.
If the value that you specify resolves to more than one year, Vertica returns with a warning and sets the parameter to 365 days:
=> ALTER RESOURCE POOL user_0 QUEUETIMEOUT '11 months 50 days 08:32';
WARNING 5693: Using 1 year for QUEUETIMEOUT
ALTER RESOURCE POOL
=> SELECT QUEUETIMEOUT FROM resource_pools WHERE name = 'user_0';
QUEUETIMEOUT
--------------
365
(1 row)
Default: 00:05 (5 minutes)
-
RUNTIMECAP
Maximum execution time allowed to queries in this resource pool, not more than one year, otherwise Vertica returns with an error. If a query exceeds this setting, it tries to cascade to a secondary pool:
RUNTIMECAP { 'interval' | NONE }
-
interval: Maximum wait time expressed in the following format:
num year num month num [day] HH:MM:SS.ms
-
NONE (empty string): No maximum wait time, request can be queued indefinitely, up to one year.
If the user or session also has a RUNTIMECAP, the shorter limit applies.
-
RUNTIMEPRIORITY
Determines how the resource manager should prioritize dedication of run-time resources (CPU, I/O bandwidth) to queries already running in this resource pool:
RUNTIMEPRIORITY { HIGH | MEDIUM | LOW }
Default: MEDIUM
-
RUNTIMEPRIORITYTHRESHOLD
Maximum time (in seconds) in which query processing must complete before the resource manager assigns to it the resource pool's RUNTIMEPRIORITY. All queries begin execution with a priority of HIGH.
RUNTIMEPRIORITYTHRESHOLD seconds
Default: 2
SINGLEINITIATORSet to false for backward compatibility. Do not change this setting.
Privileges
Superuser
Examples
Set resource pool PRIORITY to 5:
=> ALTER RESOURCE POOL ceo_pool PRIORITY 5;
Designate a secondary resource pool:
=> CREATE RESOURCE POOL second_pool;
=> ALTER RESOURCE POOL ceo_pool CASCADE TO second_pool;
Decrease to 0% the MAXMEMORYSIZE and MEMORYSIZE settings on the dashboard subcluster's built-in TM resource pool. Changing these settings to 0 prevents the subcluster from running mergeout operations:
=> ALTER RESOURCE POOL TM FOR SUBCLUSTER dashboard MEMORYSIZE '0%'
MAXMEMORYSIZE '0%';
See Tuning tuple mover pool settings for more information.
See also
7.2.21 - ALTER ROLE
Renames an existing role.
Renames an existing role.
Note
You cannot use ALTER ROLE to rename a role that was added to the Vertica database with the LDAPLink service.
Syntax
ALTER ROLE name RENAME TO new-name
Parameters
name- The role to rename.
new-name- The role's new name.
Privileges
Superuser
Examples
=> ALTER ROLE applicationadministrator RENAME TO appadmin;
ALTER ROLE
See also
7.2.22 - ALTER ROUTING RULE
Changes an existing load balancing policy routing rule.
Changes an existing load balancing policy routing rule.
Syntax
ALTER ROUTING RULE { rule_name | FOR WORKLOAD workload_name } {
RENAME TO new_name |
SET ROUTE TO 'cidr_range'|
SET GROUP TO group_name |
SET WORKLOAD TO workload_name |
SET SUBCLUSTER TO subcluster_name [,...] |
SET PRIORITY TO priority |
{ ADD | REMOVE } SUBCLUSTER subcluster_name [,...]
}
Parameters
rule_name- The name of the existing routing rule to change.
FOR WORKLOAD workload_name- The name of a workload.
RENAME TO new_name- The new name of the routing rule.
SET ROUTE TO 'cidr_range'- An IPv4 or IPv6 address range in CIDR format. Changes the address range of client connections this rule applies to.
SET GROUP TO group_name- The load balancing group that handles the connections that match this rule.
SET WORKLOAD TO workload_name- The name of the workload.
SET SUBCLUSTER TO subcluster_name- One or more subclusters to route clients to.
SET PRIORITY TO priority- Sets the priority for the routing rule, where
priority is a non-negative INTEGER. The greater the value, the greater the priority. If a user or their role is granted multiple routing rules, the one with the greatest priority applies. You can set the priority for a routing rule only when applying a routing rule to a workload.
{ADD | REMOVE} SUBCLUSTER subcluster_name- Add or remove one or more subclusters from the routing rule.
Examples
This example changes the routing rule named etl_rule so it uses the load balancing group named etl_rule to handle incoming connections in the IP address range of 10.20.100.0 to 10.20.100.255.
=> ALTER ROUTING RULE etl_rule SET GROUP TO etl_group;
ALTER ROUTING RULE
=> ALTER ROUTING RULE etl_rule SET ROUTE TO '10.20.100.0/24';
ALTER ROUTING RULE
=> \x
Expanded display is on.
=> SELECT * FROM routing_rules WHERE NAME = 'etl_rule';
-[ RECORD 1 ]----+---------------
name | etl_rule
source_address | 10.20.100.0/24
destination_name | etl_group
This example routes analytics workloads to the sc_analytics_2 subcluster:
=> ALTER ROUTING RULE FOR WORKLOAD analytics SET SUBCLUSTER TO `sc_analytics_2`;
This example changes the workload rule to handle reporting instead of analytics workloads:
=> ALTER ROUTING RULE FOR WORKLOAD analytics SET WORKLOAD TO reporting;
This example changes the priority of the workload rule for reporting workloads:
=> ALTER ROUTING RULE FOR WORKLOAD reporting SET PRIORITY TO 5;
This example adds a subcluster to the routing rule:
=> ALTER ROUTING RULE FOR WORKLOAD analytics ADD SUBCLUSTER sc_01, sc_02;
This example removes a subcluster from the routing rule:
=> ALTER ROUTING RULE FOR WORKLOAD analytics REMOVE SUBCLUSTER sc_01, sc_02;
See also
7.2.23 - ALTER SCHEDULE
Modifies a schedule.
Modifies a schedule.
Syntax
ALTER SCHEDULE [[database.]schema.]schedule {
OWNER TO new_owner
| SET SCHEMA new_schema
| RENAME TO new_schedule
| USING CRON new_cron_expression
| USING DATETIMES new_timestamp_list
}
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
schedule- The schedule to modify.
new_owner- The new owner of the schedule.
new_schema- The new schema of the schedule.
new_schedule- The new name for the schedule.
new_cron_expression- A
cron expression. You should use this for recurring tasks. Value separators are not currently supported.
new_timestamp_list- A comma-separated list of timestamps. You should use this to schedule non-recurring events at arbitrary times.
Privileges
Superuser
Examples
To change the cron expression for a schedule:
=> ALTER SCHEDULE daily_schedule USING CRON '0 8 * * *';
To change a schedule that uses a cron expression to use a timestamp list instead:
=> ALTER SCHEDULE my_schedule USING DATETIMES('2023-10-01 12:30:00', '2022-11-01 12:30:00');
To rename a schedule:
=> ALTER SCHEDULE daily_schedule RENAME TO daily_8am_gmt;
7.2.24 - ALTER SCHEMA
Changes one or more schemas in one of the following ways:.
Changes one or more schemas in one of the following ways:
-
Enable or disable inheritance of schema privileges by tables created in the schemas.
-
Reassign schema ownership to another user.
-
Change schema disk quota.
-
Rename one or more schemas.
Syntax
ALTER SCHEMA [{ namespace. | database. }]schema
DEFAULT {INCLUDE | EXCLUDE} SCHEMA PRIVILEGES
| OWNER TO user-name [CASCADE]
| DISK_QUOTA { value | SET NULL }
You can rename more than one schema in a single operation:
ALTER SCHEMA [{ namespace. | database. }]schema[,...] RENAME TO [namespace.]new-schema-name[,...]
Parameters
namespace- For Eon Mode databases, namespace of the schema to alter. If no namespace is specified, the namespace of the schema is assumed to be
default_namespace.
database- For Enterprise Mode databases, name of the database containing the schema. If specified, it must be the current database.
schema- Name of the schema to modify.
DEFAULT {INCLUDE | EXCLUDE} SCHEMA PRIVILEGESSpecifies whether to enable or disable default inheritance of privileges for new tables in the specified schema:
-
EXCLUDE SCHEMA PRIVILEGES (default): Disables inheritance of schema privileges.
-
INCLUDE SCHEMA PRIVILEGES: Specifies to grant tables in the specified schema the same privileges granted to that schema. This option has no effect on existing tables in the schema.
See also Enabling schema inheritance.
OWNER TO- Reassigns schema ownership to the specified user:
OWNER TO user-name [CASCADE]
By default, ownership of objects in the reassigned schema remain unchanged. To reassign ownership of schema objects to the new schema owner, qualify the OWNER TO clause with CASCADE. For details, see Cascading Schema Ownership below.
DISK_QUOTA- One of the following:
-
A string, an integer followed by a supported unit: K, M, G, or T. If the new value is smaller than the current usage, the operation succeeds but no further disk space can be used until usage is reduced below the new quota.
-
SET NULL to remove a quota.
For more information, see Disk quotas.
RENAME TO- Renames one or more schemas:
RENAME TO [namespace.]new-schema-name[,...]
The following requirements apply:
-
The new schema name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, models, and schemas in the namespace.
-
If you specify multiple schemas to rename, the source and target lists must have the same number of names.
-
If you specified the namespace of the schema to alter, you must provide the same namespace for the new-schema-name. You cannot rename a schema to a different namespace.
Caution
Renaming a schema referenced by a view causes the view to fail unless another schema is created to replace it.
Privileges
One of the following:
Cascading schema ownership
By default, ALTER SCHEMA...OWNER TO does not affect ownership of objects in the target schema or the privileges granted on them. If you qualify the OWNER TO clause with CASCADE, Vertica acts as follows on objects in the target schema:
If issued by non-superusers, ALTER SCHEMA...OWNER TO CASCADE ignores all objects that belong to other users, and returns with notices on the objects that it cannot change. For example:
-
Schema ms is owned by user mayday, and contains two tables: ms.t1 owned by mayday, and ms.t2 owned by user joe:
=> \dt
List of tables
Schema | Name | Kind | Owner | Comment
----------------+-----------------------+-------+---------+---------
ms | t1 | table | mayday |
ms | t2 | table | joe |
-
User mayday transfers ownership of schema ms to user dbadmin, using CASCADE. On return, ALTER SCHEMA reports that it cannot transfer ownership of table ms.t2 and its projections, which are owned by user joe:
=> \c - mayday
You are now connected as user "mayday".
=> ALTER SCHEMA ms OWNER TO dbadmin CASCADE;
NOTICE 3583: Insufficient privileges on ms.t2
NOTICE 3583: Insufficient privileges on ms.t2_b0
NOTICE 3583: Insufficient privileges on ms.t2_b1
ALTER SCHEMA
=> \c
You are now connected as user "dbadmin".
=> \dt
List of tables
Schema | Name | Kind | Owner | Comment
----------------+-----------------------+-------+---------+---------
ms | t1 | table | dbadmin |
ms | t2 | table | joe |
-
User dbadmin transfers ownership of schema ms to user pat, again using CASCADE. This time, because dbadmin is a superuser, ALTER SCHEMA transfers ownership of all ms tables to user pat
=> ALTER SCHEMA ms OWNER TO pat CASCADE;
ALTER SCHEMA
=> \dt
List of tables
Schema | Name | Kind | Owner | Comment
----------------+-----------------------+-------+---------+---------
ms | t1 | table | pat |
ms | t2 | table | pat |
Swapping schemas
Renaming schemas is useful for swapping schemas without actually moving data. To facilitate the swap, enter a non-existent, temporary placeholder schema. For example, the following ALTER SCHEMA statement uses the temporary schema temps to facilitate swapping schema S1 with schema S2. In this example, S1 is renamed to temps. Then S2 is renamed to S1. Finally, temps is renamed to S2.
=> ALTER SCHEMA S1, S2, temps RENAME TO temps, S1, S2;
Examples
The following example renames schemas S1 and S2 to S3 and S4, respectively:
=> ALTER SCHEMA S1, S2 RENAME TO S3, S4;
This example sets the default behavior for new table t2 to automatically inherit the schema's privileges:
=> ALTER SCHEMA s1 DEFAULT INCLUDE SCHEMA PRIVILEGES;
=> CREATE TABLE s1.t2 (i, int);
This example sets the default for new tables to not automatically inherit privileges from the schema:
=> ALTER SCHEMA s1 DEFAULT EXCLUDE SCHEMA PRIVILEGES;
In an Eon Mode database, the following statement renames the train schema to ferry in the transit namespace:
=> ALTER SCHEMA transit.train RENAME TO transit.ferry;
See also
7.2.25 - ALTER SEQUENCE
Changes a sequence in two ways:.
Changes a sequence in two ways:
- Changes values that control sequence behavior—for example, its start value and range of minimum and maximum values. These changes take effect only when you start a new database session.
- Changes sequence name, schema, or ownership. These changes take effect immediately.
Syntax
Change sequence behavior:
ALTER SEQUENCE [[database.]schema.]sequence
[ INCREMENT [ BY ] integer ]
[ MINVALUE integer | NO MINVALUE ]
[ MAXVALUE integer | NO MAXVALUE ]
[ RESTART [ WITH ] integer ]
[ CACHE integer | NO CACHE ]
[ CYCLE | NO CYCLE ]
Change sequence name, schema, or ownership:
ALTER SEQUENCE [schema.]sequence-name {
RENAME TO name
| SET SCHEMA schema]
| OWNER TO owner
}
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence- Name of the sequence to alter.
In the case of IDENTITY table columns, Vertica generates the sequence name using the following convention:
table-name_col-name_seq
To obtain this name, query the SEQUENCES system table.
INCREMENT integerPositive or negative minimum value change on each call to NEXTVAL. The default is 1.
This value is a minimum increment size. The sequence can increment by more than this value unless you also specify NO CACHE.
MINVALUE integer | NO MINVALUE- Minimum value the sequence can generate. If this change would invalidate the current sequence position, the operation fails.
MAXVALUE integer | NO MAXVALUE- Maximum value the sequence can generate. If this change would invalidate the current sequence position, the operation fails.
RESTART integer- New start value of the sequence. The next call to NEXTVAL returns the new start value.
Caution
Using ALTER SEQUENCE to set a sequence start value below its
current value can result in duplicate keys.
CACHE | NO CACHEHow many unique sequence numbers to pre-allocate and store in memory on each node for faster access. Vertica sets up caching for each session and distributes it across all nodes. A value of 0 or 1 is equivalent to NO CACHE.
Caution
If sequence caching is set to a low number, nodes might request a new set of cache values more frequently. While it supplies a new cache, Vertica must lock the catalog. Until Vertica releases the lock, other database activities such as table inserts are blocked, which can adversely affect overall performance.
By default, the sequence cache is set to 250,000.
For details, see Distributing sequences.
CYCLE | NO CYCLE- How to handle reaching the end of the sequence. The default is
NO CYCLE, meaning that a call to NEXTVAL returns an error after the sequence reaches its upper or lower limit. CYCLE instead wraps, as follows:
- Ascending sequence: wraps to the minimum value.
- Descending sequence: wraps to the maximum value.
RENAME TO name- New name in the current schema for the sequence. Supported only for named sequences.
SET SCHEMA schema- Moves the sequence to a new schema. Supported only for named sequences.
OWNER TO owner- Reassigns sequence ownership to another user.
Privileges
For named sequences, USAGE on the schema and one of the following:
-
Sequence owner
-
ALTER privilege on the sequence
-
For certain operations, non-superusers must have the following schema privileges:
- To rename a sequence: CREATE, USAGE
- To move a sequence to another schema: CREATE on the destination, USAGE on the source
For IDENTITY column sequences, USAGE on the table schema and one of the following:
-
Table owner
-
ALTER privileges
Non-superusers must also have SELECT privileges to enable or disable constraint enforcement, or remove partitioning.
Examples
See Altering sequences.
See also
CREATE SEQUENCE
7.2.26 - ALTER SESSION
ALTER SESSION sets and clears session-level configuration parameter values for the current session.
ALTER SESSION sets and clears session-level configuration parameter values for the current session. To identify session-level parameters, query the CONFIGURATION_PARAMETERS system table.
Syntax
ALTER SESSION {
SET [PARAMETER] parameter=value[,...]
| CLEAR { [PARAMETER] parameter[,...] | PARAMETER ALL }
| SET UDPARAMETER [ FOR libname ] ud-parameter=value[,...]
| CLEAR UDPARAMETER { [ FOR libname ] ud-parameter[,...] | ALL }
}
Arguments
SET [PARAMETER] parameter=value- Sets one or more configuration parameters to the specified value.
CLEAR { [PARAMETER] parameter | PARAMETER ALL }- Clears the specified configuration parameters, or all parameters, of changes that were set in the current session.
SET UDPARAMETER [ FOR libname ] ud-parameter=value[,...]- Sets one or more user-defined session parameters to be used with UDxs. The maximum length of a parameter name when set with ALTER SESSION is 128 characters.
If you specify a library, then only that library can access the parameter's value. Use this restriction to protect parameters that hold sensitive data, such as credentials.
CLEAR UDPARAMETER { [ FOR libname ] ud-parameter[,...] | ALL }- Clears the specified user-defined parameters, or all of them, of changes that were set in the current session.
Privileges
None
Examples
Set a configuration parameter:
=> ALTER SESSION SET ForceUDxFencedMode = 1;
ALTER SESSION
=> SELECT parameter_name, current_value, default_value
FROM CONFIGURATION_PARAMETERS
WHERE parameter_name = 'ForceUDxFencedMode';
parameter_name | current_value | default_value
--------------------+---------------+---------------
ForceUDxFencedMode | 1 | 0
(1 row)
Clear all session-level settings for configuration parameters:
=> ALTER SESSION CLEAR PARAMETER ALL;
ALTER SESSION
Set a UDx parameter in a single library:
=> ALTER SESSION SET UDPARAMETER FOR MyLibrary RowCount = 25;
ALTER SESSION
7.2.27 - ALTER SUBCLUSTER
Changes the configuration of a subcluster.
Changes the configuration of a subcluster. You can use this statement to rename a subcluster or make it the default subcluster.
Syntax
ALTER SUBCLUSTER subcluster-name {
RENAME TO new-name |
SET DEFAULT
}
Parameters
subcluster-name- The name of the subcluster to alter.
RENAME TO new-name- Changes the name of the subcluster to
new-name.
SET DEFAULT- Makes the subcluster the default subcluster. When you add new nodes to the database and do not specify a subcluster to contain them, Vertica adds them to the default subcluster. There can be only one default subcluster at a time. The subcluster that was previously the default subcluster becomes a non-default subcluster.
Privileges
Superuser
Examples
This example makes the analytics_cluster the default subcluster:
=> SELECT DISTINCT subcluster_name FROM SUBCLUSTERS WHERE is_default = true;
subcluster_name
--------------------
default_subcluster
(1 row)
=> ALTER SUBCLUSTER analytics_cluster SET DEFAULT;
ALTER SUBCLUSTER
=> SELECT DISTINCT subcluster_name FROM SUBCLUSTERS WHERE is_default = true;
subcluster_name
-------------------
analytics_cluster
(1 row)
This example renames default_subcluster to load_subcluster:
=> ALTER SUBCLUSTER default_subcluster RENAME TO load_subcluster;
ALTER SUBCLUSTER
=> SELECT DISTINCT subcluster_name FROM subclusters;
subcluster_name
-------------------
load_subcluster
analytics_cluster
(2 rows)
See also
7.2.28 - ALTER SUBNET
Renames an existing subnet.
Renames an existing subnet.
Syntax
ALTER SUBNET subnet-name RENAME TO new-subnet-name
Parameters
subnet-name- The name of the existing subnet.
new-subnet-name- The new name for the subnet.
Privileges
Superuser
Examples
=> ALTER SUBNET mysubnet RENAME TO myNewSubnet;
7.2.29 - ALTER TABLE
Modifies the metadata of an existing table.
Modifies the metadata of an existing table. All changes are auto-committed.
Syntax
ALTER TABLE [[{ namespace. | database. } ]schema.]table {
ADD COLUMN [ IF NOT EXISTS ] column datatype
[ column‑constraint ]
[ ENCODING encoding-type ]
[ PROJECTIONS (projections-list) | ALL PROJECTIONS ]
[, ...]
| ADD table-constraint
| ALTER COLUMN column {
ENCODING encoding-type PROJECTIONS (projection-list)
| { SET | DROP } expression }
| ALTER CONSTRAINT constraint-name { ENABLED | DISABLED }
| DISK_QUOTA { value | SET NULL }
| DROP CONSTRAINT constraint-name [ CASCADE | RESTRICT ]
| DROP [ COLUMN ] [ IF EXISTS ] column [ CASCADE | RESTRICT ]
| FORCE OUTER integer
| { INCLUDE | EXCLUDE | MATERIALIZE } [ SCHEMA ] PRIVILEGES
| OWNER TO owner
| partition-clause [ REORGANIZE ]
| REMOVE PARTITIONING
| RENAME [ COLUMN ] name TO new‑name
| RENAME TO new-table-name[,...]
| REORGANIZE
| SET {
ActivePartitionCount { count | DEFAULT }
| IMMUTABLE ROWS
| MERGEOUT { 1 | 0 }
| SCHEMA [namespace.]schema }
}
Note
Several ALTER TABLE clauses cannot be specified with other clauses in the same statement (see Exclusive ALTER TABLE Clauses below). Otherwise, ALTER TABLE supports multiple comma-delimited clauses. For example, the following ALTER TABLE statement changes the my_table table in two ways: reassigns ownership to Joe, and sets a UNIQUE constraint on the b column:
=> ALTER TABLE my_table OWNER TO Joe,
ADD CONSTRAINT unique_b UNIQUE (b) ENABLED;
Arguments
namespace- For Eon Mode databases, namespace that contains the table to alter. If no namespace is specified, the namespace of the table is assumed to be
default_namespace.
database- For Enterprise Mode databases, name of the database containing the table. If specified, it must be the current database.
schema- Name of the schema that contains the table to alter.
table- The table to alter.
-
ADD COLUMN
- Adds one or more columns to the table and to the specified projections (or all projections, if not specified).
Adding a column with the same name as one that already exists is an error unless you use IF NOT EXISTS.
Restrictions on columns of complex types also apply to columns that you add using ADD COLUMN.
You can qualify the new column definition with one or more of these options:
-
A column constraint:
[ CONSTRAINT constraint-name ]
{ [NOT] NULL
| DEFAULT expression
| SET USING expression
| DEFAULT USING expression }
Columns that use DEFAULT with static values can be added in a single ALTER TABLE statement. Columns that use non-static DEFAULT values must be added in separate ALTER TABLE statements. For more information, see Column-constraint.
-
ENCODING: the column encoding type, by default AUTO.
-
PROJECTIONS: a comma-separated list of base names of existing projections to add the column to. Vertica adds the column to all buddies of each projection. The projection list cannot include projections with pre-aggregated data such as live aggregate projections. Instead of specifying projections, you can use ALL PROJECTIONS to add the column to all projections, excluding those with pre-aggregated data.
-
ADD table‑constraint
- Adds a constraint to a table that does not have any associated projections.
-
ALTER COLUMN
- You can alter an existing column in one of two ways:
-
Set encoding on a column for one or more projections of this table:
ENCODING encoding-type PROJECTIONS (projections-list)
where projections-list is a comma-delimited list of projections to update with the new encoding. You can specify each projection in two ways:
-
Projection base name: Update all projections that share this base name.
-
Projection name: Update the specified projection. If the projection is segmented, the change is propagated to all buddies.
If one of the projections does not contain the target column, Vertica returns with a rollback error.
For details, see Projection Column Encoding.
-
Set or drop a setting for a column of scalar data, including primitive arrays:
SET { DEFAULT expression
| USING expression
| DEFAULT USING expression
| NOT NULL
| DATA TYPE datatype
}
DROP { DEFAULT
| SET USING
| DEFAULT USING
| NOT NULL
}
You cannot change the data type of a column of any complex type that is neither a scalar type nor an array of scalar types. One exception applies: in external tables, you can change a primitive column type to a complex type.
Setting a DEFAULT or SET USING expression has no effect on existing column values. To refresh the column with its DEFAULT or SET USING expression, update it as follows
-
SET USING column: Call REFRESH_COLUMNS on the table.
-
DEFAULT column: update the column as follows:
UPDATE table-name SET column-name=DEFAULT;
Altering a column with DEFAULT or SET USING can increase disk usage, which can cause the operation to fail if it would violate the table or schema disk quota.
-
ALTER CONSTRAINT
- Specifies whether to enforce primary key, unique key, and check constraints:
ALTER CONSTRAINT constraint-name {ENABLED | DISABLED}
DISK_QUOTA- One of the following:
-
A string, an integer followed by a supported unit: K, M, G, or T. If the new value is smaller than the current usage, the operation succeeds but no further disk space can be used until usage is reduced below the new quota.
-
SET NULL to remove a quota.
For more information, see Disk quotas.
-
DROP CONSTRAINT
- Drops the specified table constraint from the table:
DROP CONSTRAINT constraint-name [CASCADE | RESTRICT]
You can qualify DROP CONSTRAINT with one of these options:
Dropping a table constraint has no effect on views that reference the table.
-
DROP [COLUMN]
- Drops the specified column from the table and that column's ROS containers:
DROP [COLUMN] [IF EXISTS] column [CASCADE | RESTRICT]
You can qualify DROP COLUMN with one of these options:
-
IF EXISTS generates an informational message if the column does not exist. If you omit this option and the column does not exist, Vertica generates a ROLLBACK error message.
-
CASCADE is required if the column has dependencies.
-
RESTRICT drops the column only from the given table.
The column's table cannot be immutable.
See Dropping table columns.
FORCE OUTER integer- Specifies whether a table is joined to another as an inner or outer input. For details, see Controlling join inputs.
{INCLUDE | EXCLUDE | MATERIALIZE} [SCHEMA] PRIVILEGES- Specifies default inheritance of schema privileges for this table:
-
EXCLUDE PRIVILEGES (default) disables inheritance of privileges from the schema.
-
INCLUDE PRIVILEGES grants the table the same privileges granted to its schema.
-
MATERIALIZE PRIVILEGES copies grants to the table and creates a GRANT object on the table. This disables the inherited privileges flag on the table, so you can:
-
Grant more specific privileges at the table level.
-
Use schema-level privileges as a template.
-
Move the table to a different schema.
-
Change schema privileges without affecting the table.
See also Setting privilege inheritance on tables and views.
OWNER TO owner- Changes the table owner.
-
partition-clause [REORGANIZE]
- Invalid for external tables, logically divides table data storage through a PARTITION BY clause:
PARTITION BY expression
[ GROUP BY expression ]
[ SET ACTIVEPARTITIONCOUNT integer ]
For details, see Partition clause.
If you qualify the partition clause with REORGANIZE and the table previously specified no partitioning, the Vertica Tuple Mover immediately implements the partition clause. If the table previously specified partitioning, the Tuple Mover evaluates ROS storage containers and reorganizes them as needed to conform with the new partition clause.
REMOVE PARTITIONING- Specifies to remove partitioning from a table definition. The Tuple Mover subsequently removes existing partitions from ROS containers.
-
RENAME [COLUMN]
- Renames the specified column within the table. The column's table cannot be immutable.
-
RENAME TO
- Renames one or more tables:
RENAME TO new-table-name[,...]
The following requirements apply:
-
The renamed table must be in the same schema as the original table.
-
The new table name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
-
If you specify multiple tables to rename, the source and target lists must have the same number of names.
-
REORGANIZE
- Valid only for partitioned tables, invokes the Tuple Mover to reorganize ROS storage containers as needed to conform with the table's current partition clause. ALTER TABLE...REORGANIZE and Vertica meta-function PARTITION_TABLE operate identically.
REORGANIZE can also qualify a new partition clause.
SET- Changes a table setting, one of the following:
-
ActivePartitionCount { count | DEFAULT }, valid only for partitioned tables, specifies how many partitions are active for this table, one of the following:
-
count: Unsigned integer, supersedes configuration parameter ActivePartitionCount.
-
DEFAULT: Removes the table-level active partition count. The table obtains its active partition count from the configuration parameter ActivePartitionCount.
For details on usage, see Active and inactive partitions.
-
IMMUTABLE ROWS prevents changes to table row values by blocking DML operations such as UPDATE and DELETE. Once set, table immutability cannot be reverted.
You cannot set a flattened table to be immutable. For details on all immutable table restrictions, see Immutable tables.
-
MERGEOUT { 1 | 0 } specifies whether to enable or disable mergeout to ROS containers that consolidate projection data of this table. By default, mergeout is enabled (1) on all tables.
-
SCHEMA [namespace.]schema-name moves the table from its current schema to [namespace.]schema-name. For Eon Mode databases, the new schema must be in the same namespace as the old schema. When no namespace is provided, the namespace is set to default_namespace.
Vertica automatically moves all projections that are anchored to the source table to the destination schema. It also moves all IDENTITY columns to the destination schema. For details, see Moving tables to another schema
Privileges
Non-superuser: USAGE on the schema and one of the following:
-
Table owner
-
ALTER privileges
Non-superusers must also have SELECT privileges to enable or disable constraint enforcement, or remove partitioning.
For certain operations, non-superusers must have the following schema privileges:
-
To rename a table: CREATE, USAGE
-
To move a table to another schema: USAGE on the source schema, CREATE on the destination schema
Restrictions for complex types
Complex types used in native tables have some restrictions, in addition to the restrictions for individual types listed on their reference pages:
-
A native table must have at least one column that is a primitive type or a native array (one-dimensional array of a primitive type). If a flex table has real columns, it must also have at least one column satisfying this restriction.
-
Complex type columns cannot be used in ORDER BY or PARTITION BY clauses nor as FILLER columns.
-
Complex type columns cannot have constraints.
-
Complex type columns cannot use DEFAULT or SET USING.
-
Expressions returning complex types cannot be used as projection columns, and projections cannot be segmented or ordered by columns of complex types.
Exclusive ALTER TABLE clauses
The following ALTER TABLE clauses cannot be combined with another ALTER TABLE clause:
-
ADD COLUMN
-
DROP COLUMN
-
RENAME COLUMN
-
SET SCHEMA
-
RENAME [TO]
Node down limitations
Enterprise Mode only
The following ALTER TABLE operations are not supported when one or more database cluster nodes are down:
-
ALTER COLUMN ... ADD table-constraint
-
ALTER COLUMN ... SET DATA TYPE
-
ALTER COLUMN ... { SET DEFAULT | DROP DEFAULT }
-
ALTER COLUMN ... { SET USING | DROP SET USING }
-
ALTER CONSTRAINT
-
DROP COLUMN
-
DROP CONSTRAINT
Pre-aggregated projection restrictions
You cannot modify the metadata of anchor table columns that are included in live aggregate or Top-K projections. You also cannot drop these columns. To make these changes, you must first drop all live aggregate and Top-K projections that are associated with it.
External table restrictions
Not all ALTER TABLE options pertain to external tables. For instance, you cannot add a column to an external table, but you can rename the table:
=> ALTER TABLE mytable RENAME TO mytable2;
ALTER TABLE
Locked tables
If the operation cannot obtain an O lock on the target table, Vertica tries to close any internal Tuple Mover sessions that are running on that table. If successful, the operation can proceed. Explicit Tuple Mover operations that are running in user sessions do not close. If an explicit Tuple Mover operation is running on the table, the operation proceeds only when the operation is complete.
Examples
In an Eon Mode database, the following statement alters the schema of the flights table from schema airline1 in namespace airport to schema airline2 in namespace airport:
=> ALTER TABLE airport.airline1.flights SET SCHEMA airport.airline2.flights;
See also
7.2.29.1 - Projection column encoding
After you create a table and its projections, you can call ALTER TABLE...ALTER COLUMN to set or change the encoding type of an existing column in one or more projections.
After you create a table and its projections, you can call ALTER TABLE...ALTER COLUMN to set or change the encoding type of an existing column in one or more projections. For example:
ALTER TABLE store.store_dimension ALTER COLUMN store_region
ENCODING rle PROJECTIONS (store.store_dimension_p1_b0, store.store_dimension_p2);
In this example, the ALTER TABLE statement specifies to set RLE encoding on column store_region for two projections: store_dimension_p1_b0 and store_dimension_p2. The PROJECTIONS list references the two projections by their projection name and base name, respectively. You can reference a projection either way; in both cases, the change is propagated to all buddies of the projection and stored in its DDL accordingly:
=> select export_objects('','store.store_dimension');
export_objects
------------------------------------------------------------------
CREATE TABLE store.store_dimension
(
store_key int NOT NULL,
store_name varchar(64),
store_number int,
store_address varchar(256),
store_city varchar(64),
store_state char(2),
store_region varchar(64)
);
CREATE PROJECTION store.store_dimension_p1
(
store_key,
store_name,
store_number,
store_address,
store_city,
store_state,
store_region ENCODING RLE
)
AS
SELECT store_dimension.store_key,
store_dimension.store_name,
store_dimension.store_number,
store_dimension.store_address,
store_dimension.store_city,
store_dimension.store_state,
store_dimension.store_region
FROM store.store_dimension
ORDER BY store_dimension.store_key
SEGMENTED BY hash(store_dimension.store_key) ALL NODES KSAFE 1;
CREATE PROJECTION store.store_dimension_p2
(
store_key,
store_name,
store_number,
store_address,
store_city,
store_state,
store_region ENCODING RLE
)
AS
SELECT ...
Important
When you add or change a column's encoding type, it has no immediate effect on existing projection data. Vertica applies the encoding only to newly loaded data, and to existing data on
mergeout.
7.2.30 - ALTER TLS CONFIGURATION
Alters a specified TLS Configuration object.
Alters a specified TLS Configuration object. For information on existing TLS Configuration objects, query TLS_CONFIGURATIONS.
Syntax
ALTER TLS CONFIGURATION tls_config_name {
[ CERTIFICATE { NULL | cert_name } ]
[ ADD CA CERTIFICATES ca_cert_name [,...] ]
[ REMOVE CA CERTIFICATES ca_cert_name [,...] ]
[ CIPHER SUITES { '' | 'openssl_cipher [,...]' } ]
[ TLSMODE 'tlsmode' ]
[ OWNER TO user_name ]
}
Parameters
tls_config_name- The TLS Configuration object to alter.
NULL- Removes the non-CA certificate from the TLS Configuration.
cert_name- A certificate created with CREATE CERTIFICATE.
You must have USAGE privileges on the certificate (either from ownership of the certificate or USAGE on its key, if any) to add it to a TLS Configuration.
ca_cert_name- A CA certificate created with CREATE CERTIFICATE.
You must have USAGE privileges on the certificate (either from ownership of the certificate or USAGE on its key, if any) to add it to a TLS Configuration.
openssl_cipher- A comma-separated list of cipher suites to use instead of the default set of cipher suites. Providing an empty string for this parameter clears the alternate cipher suite list and instructs the specified TLS Configuration to use the default set of cipher suites.
To view enabled cipher suites, use LIST_ENABLED_CIPHERS.
tlsmode- How Vertica establishes TLS connections and handles certificates, one of the following, in order of ascending security:
-
DISABLE: Disables TLS. All other options for this parameter enable TLS.
-
ENABLE: Enables TLS. Vertica does not check client certificates.
-
TRY_VERIFY: Establishes a TLS connection if one of the following is true:
If the other host presents an invalid certificate, the connection will use plaintext.
-
VERIFY_CA: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA. If the other host does not present a certificate, the connection uses plaintext.
-
VERIFY_FULL: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA and the certificate's cn (Common Name) or subjectAltName attribute matches the hostname or IP address of the other host.
Note that for client certificates, cn is used for the username, so subjectAltName must match the hostname or IP address of the other host.
VERIFY_FULL is unsupported for client-server TLS (the connection type handled by ServerTLSConfig) and behaves like VERIFY_CA.
Note
Whether Vertica or the other party acts as the client or server depends on the type of connection. For connections between the Vertica database and an LDAP server for LDAP Link or LDAP authentication, the Vertica database is the client and the LDAP server is the server:
For all other connection types, Vertica is the server and the other party is the client:
Privileges
Non-superuser: ALTER privileges on the TLS Configuration.
Examples
To remove all certificates and CA certificates from the LDAPLink TLS Configuration:
=> SELECT * FROM tls_configurations WHERE name='LDAPLink';
name | owner | certificate | ca_certificate | cipher_suites | mode
----------+---------+-------------+----------------+---------------+---------
LDAPLink | dbadmin | server_cert | ca | | DISABLE
LDAPLink | dbadmin | server_cert | ica | | DISABLE
(2 rows)
=> ALTER TLS CONFIGURATION LDAPLink CERTIFICATE NULL REMOVE CA CERTIFICATES ca, ica;
ALTER TLS CONFIGURATION
=> SELECT * FROM tls_configurations WHERE name='LDAPLink';
name | owner | certificate | ca_certificate | cipher_suites | mode
----------+---------+-------------+----------------+---------------+---------
LDAPLink | dbadmin | | | | DISABLE
(3 rows)
To use an alternate set of cipher suites for client-server TLS:
=> ALTER TLS CONFIGURATION server CIPHER SUITES
'DHE-PSK-AES256-CBC-SHA384,
DHE-PSK-AES128-GCM-SHA256,
PSK-AES128-CBC-SHA256';
ALTER TLS CONFIGURATION
=> SELECT name, cipher_suites FROM tls_configurations WHERE name='server';
name | cipher_suites
server | DHE-PSK-AES256-CBC-SHA384,DHE-PSK-AES128-GCM-SHA256,PSK-AES128-CBC-SHA256
(1 row)
For other examples, see:
7.2.31 - ALTER TRIGGER
Modifies a trigger.
Modifies a trigger.
Syntax
ALTER TRIGGER [[database.]schema.]trigger {
OWNER TO new_owner
| SET SCHEMA new_schema
| RENAME TO new_trigger
| PROCEDURE TO new_procedure
}
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
trigger- The trigger to modify.
new_owner- The new owner and definer of the trigger. This affects the behavior of AS DEFINER.
new_schema- The new schema of the trigger.
new_trigger- The new name for the trigger.
new_procedure- The function signature of the stored procedure.
Privileges
Superuser
Examples
To attach a different procedure to the trigger:
=> ALTER TRIGGER daily_1am PROCEDURE TO log_user_actions(10, 20);
To rename a trigger:
=> ALTER TRIGGER daily_1am RENAME TO daily_1am_gmt;
To move the trigger to a different schema:
=> ALTER TRIGGER daily_1am_gmt
7.2.32 - ALTER USER
Changes user account parameters and user-level configuration parameters.
Changes user account parameters and user-level configuration parameters.
Syntax
ALTER USER user-name {
account-parameter value[,...]
| SET [PARAMETER] cfg-parameter=value[,...]
| CLEAR [PARAMETER] cfg-parameter[,...]
}
Parameters
user-name - Name of the user. Names that contain special characters must be double-quoted. To enforce case-sensitivity, use double-quotes.
For details on name requirements, see Creating a database name and password.
account-parameter value- Specifies user account settings (see below).
Note
Changes to a user account apply only to the current session and to all later sessions launched by this user.
SET [PARAMETER]- Sets the specified configuration parameters. The new setting applies only to the current session, and to all later sessions launched by this user. Concurrent user sessions are unaffected by new settings unless they call meta-function RESET_SESSION.
CLEAR [PARAMETER]- Resets the specified configuration parameters to their default values.
User account parameters
Specify one or more user-account parameters and their settings as a comma-delimited list:
account-parameter value[,...]
Important
The following user-account parameters are invalid for a user who is added to the Vertica database with the LDAPLink service:
-
IDENTIFIED BY
-
PROFILE
-
SECURITY ALGORITHM
|
Parameter |
Setting |
ACCOUNT |
Locks or unlocks user access to the database, one of the following:
Tip
To automate account locking, set a maximum number of failed login attempts with CREATE PROFILE.
|
DEFAULT ROLE |
Specifies what roles are the default roles for this user, set to one of the following:
-
NONE (default): Removes all default roles.
-
role[,...]: Comma-delimited list of roles.
-
ALL: Sets as default all user roles.
-
ALL EXCEPT role[,...]: Comma-delimited list of roles to exclude as default roles.
Default roles are automatically activated when a user logs in. The roles specified by this parameter supersede any roles assigned earlier.
Note
DEFAULT ROLE cannot be specified in combination with other ALTER USER parameters.
|
GRACEPERIOD |
Specifies how long a user query can block on any session socket, one of the following:
-
NONE (default): Removes any grace period previously set on session queries.
-
'interval': Specifies as an interval the maximum grace period for current session queries, up to 20 days.
For details, see Handling session socket blocking.
|
IDENTIFIED BY |
Changes the user's password:
IDENTIFIED BY '[new-password]'
| ['hashed-password' SALT 'hash-salt']
[REPLACE 'current-password']
-
new-password: ASCII password that Vertica then hashes for internal storage. An empty string enables this user to access the database with no password.
-
hashed-password: A pre-hashed password and its associated hex string hash-salt. Setting a password this way bypasses all password complexity requirements.
-
REPLACE: Required for non-superusers, who must supply their current password. Non-superusers can only change their own passwords.
For details, see Password guidelines and Creating a database name and password.
|
IDLESESSIONTIMEOUT |
The length of time the system waits before disconnecting an idle session, one of the following:
-
NONE (default): No limit set for this user. If you omit this parameter, no limit is set for this user.
-
'interval': An interval value, up to one year.
For details, see Managing client connections.
|
MAXCONNECTIONS |
Sets the maximum number of connections the user can have to the server, one of the following:
-
NONE (default): No limit set. If you omit this parameter, the user can have an unlimited number of connections across the database cluster.
-
integer ON DATABASE: Sets to integer the maximum number of connections across the database cluster.
-
integer ON NODE: Sets to integer the maximum number of connections to each node.
For details, see Managing client connections.
|
MEMORYCAP |
Sets how much memory can be allocated to user requests, one of the following:
|
PASSWORD EXPIRE |
Forces immediate expiration of the user's password. The user must change the password on the next login.
Note
PASSWORD EXPIRE has no effect when using external password authentication methods such as LDAP or Kerberos.
|
PROFILE |
Assigns a profile that controls password requirements for this user, one of the following:
|
RENAME TO |
Assigns the user a new user name. All privileges assigned to the user remain unchanged.
Note
RENAME TO cannot be specified in combination with other ALTER USER parameters.
|
RESOURCE POOL pool-name [FOR SUBCLUSTER sc-name] |
Assigns a resource pool to this user. The user must also be granted privileges to this pool, unless privileges to the pool are set to PUBLIC.
The FOR SUBCLUSTER clause assigns a subcluster-specific resource pool to the user. You can assign only one subcluster-specific resource pool to each user.
|
RUNTIMECAP |
Sets how long this user's queries can execute, one of the following:
-
NONE (default): No limit set for this user. If you omit this parameter, no limit is set for this user.
-
'interval': An interval value, up to one year.
A query's runtime limit can be set at three levels: the user's runtime limit, the user's resource pool, and the session setting. For more information, see Setting a runtime limit for queries.
|
SEARCH_PATH |
Specifies the user's default search path, that tells Vertica which schemas to search for unqualified references to tables and UDFs, one of the following:
-
DEFAULT (default): Sets the search path as follows:
"$user", public, v_catalog, v_monitor, v_internal
-
Comma-delimited list of schemas.
For details, see Setting Search Paths.
|
SECURITY_ALGORITHM 'algorithm' |
Sets the user-level security algorithm for hash authentication, where algorithm is one of the following:
The user's password expires when you change the SECURITY_ALGORITHM value and must be reset.
|
TEMPSPACECAP |
Sets how much temporary file storage is available for user requests, one of the following:
|
Privileges
Non-superusers can change the following options on their own user accounts:
-
IDENTIFIED BY
-
RESOURCE POOL
-
SEARCH_PATH
-
SECURITY_ALGORITHM
When changing a another user's resource pool to one outside of the PUBLIC schema, the user must have USAGE privileges on the resource pool from at least one of the following:
Setting user-level configuration parameters
SET | CLEAR PARAMETER can specify only user-level configuration parameters, otherwise Vertica returns an error. Only superusers can set and clear user-level parameters, unless they are also supported at the session level.
To get the names of user-level parameters, query system table CONFIGURATION_PARAMETERS. For example:
=> SELECT parameter_name, allowed_levels FROM configuration_parameters
WHERE allowed_levels ilike '%USER%' AND parameter_name ilike '%depot%' ORDER BY parameter_name;
parameter_name | allowed_levels
-----------------------------+-------------------------
BackgroundDepotWarming | SESSION, USER, DATABASE
DepotOperationsForQuery | SESSION, USER, DATABASE
EnableDepotWarmingFromPeers | SESSION, USER, DATABASE
UseDepotForReads | SESSION, USER, DATABASE
UseDepotForWrites | SESSION, USER, DATABASE
(5 rows)
The following example sets the user-level configuration parameter UseDepotForWrites for two users, Yvonne and Ahmed:
=> SHOW USER Yvonne PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Yvonne | DepotOperationsForQuery | Fetches
(1 row)
=> ALTER USER Yvonne SET PARAMETER UseDepotForWrites = 0;
ALTER USER
=> SHOW USER Yvonne PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Yvonne | DepotOperationsForQuery | Fetches
Yvonne | UseDepotForWrites | 0
(2 rows)
=> ALTER USER Ahmed SET PARAMETER DepotOperationsForQuery = 'Fetches';
ALTER USER
=> SHOW USER ALL PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Ahmed | DepotOperationsForQuery | Fetches
Yvonne | DepotOperationsForQuery | Fetches
Yvonne | UseDepotForWrites | 0
(3 rows)
Examples
Set a user's password
=> CREATE USER user1;
=> ALTER USER user1 IDENTIFIED BY 'newpassword';
Set user's security algorithm and password
This example sets a user's security algorithm and password to SHA-512 and newpassword, respectively. When you execute the ALTER USER statement, Vertica hashes the password with the SHA-512 algorithm and saves the hash:
=> CREATE USER user1;
=> ALTER USER user1 SECURITY_ALGORITHM 'SHA512' IDENTIFIED BY 'newpassword'
Assign default roles to a user
This example make a user's assigned roles their default roles. Default roles are automatically set (enabled) when a user logs in:
=> CREATE USER user1;
CREATE USER
=> GRANT role1, role2, role3 to user1;
=> ALTER USER user1 DEFAULT ROLE ALL;
You can pair ALL with EXCEPT to exclude certain roles:
=> CREATE USER user2;
CREATE USER
=> GRANT role1, role2, role3 to user2;
=> ALTER USER user2 DEFAULT ROLE ALL EXCEPT role1;
See also
7.2.33 - ALTER VIEW
Modifies the metadata of an existing.
Modifies the metadata of an existing view. The changes are auto-committed.
Syntax
General usage:
ALTER VIEW [[database.]schema.]view {
| OWNER TO owner
| SET SCHEMA schema
| { INCLUDE | EXCLUDE | MATERIALIZE } [ SCHEMA ] PRIVILEGES
}
Rename view:
ALTER VIEW [[database.]schema.]view[,...] RENAME TO new-view-name[,...]
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- The view to alter.
SET SCHEMA schema``- Moves the view from one schema to another.
OWNER TO owner- Changes the view owner.
Important
The new view owner should also have SELECT privileges on the objects that the view references; otherwise the view is inaccessible to that user.
-
{ INCLUDE | EXCLUDE | MATERIALIZE } [SCHEMA] PRIVILEGES
- Specifies default inheritance of schema privileges for this view:
-
EXCLUDE [SCHEMA] PRIVILEGES (default) disables inheritance of privileges from the schema.
-
INCLUDE [SCHEMA] PRIVILEGES grants the view the same privileges granted to its schema.
-
MATERIALIZE: Copies grants to the view and creates a GRANT object on the view. This disables the inherited privileges flag on the view, so you can:
-
Grant more specific privileges at the view level
-
Use schema-level privileges as a template
-
Move the view to a different schema
-
Change schema privileges without affecting the view
See also Setting privilege inheritance on tables and views.
RENAME TO- Renames one or more views:
RENAME TO new-view-name[,...]
The following requirements apply:
-
The new view name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
-
If you specify multiple views to rename, the source and target lists must have the same number of names.
-
Renaming a view requires USAGE and CREATE privileges on the schema that contains the view.
Privileges
Non-superuser: USAGE on the schema and one of the following:
For certain operations, non-superusers must have the following schema privileges:
|
Schema privileges required... |
For these operations... |
|
CREATE, USAGE |
Rename view |
CREATE: destination schema
USAGE: current schema |
Move view to another schema |
Examples
Rename view view1 to view2:
=> CREATE VIEW view1 AS SELECT * FROM t;
CREATE VIEW
=> ALTER VIEW view1 RENAME TO view2;
ALTER VIEW
7.3 - BEGIN
Starts a transaction block.
Starts a transaction block.
Syntax
BEGIN [ WORK | TRANSACTION ] [ isolation-level ] [ READ [ONLY] | WRITE ]
Parameters
WORK | TRANSACTION- Optional keywords for readability only.
isolation-level- Specifies the transaction's isolation level, which determines what data the transaction can access when other transactions are running concurrently, one of the following:
For details, see Transactions.
READ [ONLY] | WRITE- Specifies the transaction mode, one of the following:
Setting the transaction session mode to read-only disallows the following SQL statements, but does not prevent all disk write operations:
-
INSERT, UPDATE, DELETE, and COPY if the target table is not a temporary table
-
All CREATE, ALTER, and DROP commands
-
GRANT, REVOKE, and EXPLAIN if the SQL to run is one of the statements cited above.
Privileges
None
Examples
Create a transaction with the isolation level set to READ COMMITTED and the transaction mode to READ WRITE:
=> BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED READ WRITE;
BEGIN
=> CREATE TABLE sample_table (a INT);
CREATE TABLE
=> INSERT INTO sample_table (a) VALUES (1);
OUTPUT
--------
1
(1 row)
=> END;
COMMIT
See also
7.4 - CALL
Invokes a stored procedure created with CREATE PROCEDURE (Stored).
Invokes a stored procedure created with CREATE PROCEDURE (stored).
Syntax
CALL [[database.]schema.]procedure( [ argument-list] );
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
procedure- The name of the stored procedure, where
procedure conforms to conventions described in Identifiers.
argument-list- A comma-delimited list of arguments to pass to the stored procedure, whose types correspond to the types of the argument's IN parameters.
Privileges
Non-superuser: EXECUTE on the procedure
Examples
See Executing stored procedures and Stored procedures: use cases and examples.
See also
7.5 - COMMENT ON statements
COMMENT ON statements let you create comments on database objects, such as schemas, tables, and libraries.
COMMENT ON statements let you create comments on database objects, such as schemas, tables, and libraries. Each object can have one comment. Comments are stored in the system table
COMMENTS.
7.5.1 - COMMENT ON AGGREGATE FUNCTION
Adds, revises, or removes a comment on an aggregate function.
Adds, revises, or removes a comment on an aggregate function. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON AGGREGATE FUNCTION [[database.]schema.]function (function-args) IS { 'comment' | NULL };
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- The name of the aggregate function with which to associate the comment.
function-args- The function arguments.
comment- Specifies the comment text to add. If a comment already exists for this function, this overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the APPROXIMATE_MEDIAN(x FLOAT) function:
=> COMMENT ON AGGREGATE FUNCTION APPROXIMATE_MEDIAN(x FLOAT) IS 'alias of APPROXIMATE_PERCENTILE with 0.5 as its parameter';
The following example removes a comment from the APPROXIMATE_MEDIAN(x FLOAT) function:
=> COMMENT ON AGGREGATE FUNCTION APPROXIMATE_MEDIAN(x FLOAT) IS NULL;
7.5.2 - COMMENT ON ANALYTIC FUNCTION
Adds, revises, or removes a comment on an analytic function.
Adds, revises, or removes a comment on an analytic function. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON ANALYTIC FUNCTION [[database.]schema.]function (function-args) IS { 'comment' | NULL };
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- The name of the analytic function with which to associate the comment.
function-args- The function arguments.
comment- Specifies the comment text to add. If a comment already exists for this function, this overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the user-defined an_rank() function:
=> COMMENT ON ANALYTIC FUNCTION an_rank() IS 'built from the AnalyticFunctions library';
The following example removes a comment from the user-defined an_rank() function:
=> COMMENT ON ANALYTIC FUNCTION an_rank() IS NULL;
7.5.3 - COMMENT ON COLUMN
Adds, revises, or removes a comment on a column in a table or projection.
Adds, revises, or removes a comment on a column in a table or projection. Each object can have one comment. Comments are stored in the COMMENTS system table.
Syntax
COMMENT ON COLUMN [[database.]schema.]object.column IS {'comment' | NULL}
Arguments
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
object- Name of the table or projection containing the column.
column- Name of the column to which the comment applies.
comment | NULL- Comment text to add, or NULL to remove an existing comment. The new value replaces any existing comment for this column.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment for a table column:
=> COMMENT ON COLUMN store.store_sales_fact.transaction_time IS 'GMT';
You can also add comments to columns in projections:
=> COMMENT ON COLUMN customer_dimension_vmart_node01.customer_name IS 'Last name only';
To remove a comment, specify NULL:
=> COMMENT ON COLUMN store.store_sales_fact.transaction_time IS NULL;
7.5.4 - COMMENT ON CONSTRAINT
Adds, revises, or removes a comment on a constraint.
Adds, revises, or removes a comment on a constraint. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON CONSTRAINT constraint ON [[database.]schema.]table IS ... {'comment' | NULL };
Parameters
constraint- The name of the constraint associated with the comment.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The name of the table constraint with which to associate a comment.
comment- Specifies the comment text to add. If a comment already exists for this constraint, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the constraint_x constraint on the promotion_dimension table:
=> COMMENT ON CONSTRAINT constraint_x ON promotion_dimension IS 'Primary key';
The following example removes a comment from the constraint_x constraint on the promotion_dimension table:
=> COMMENT ON CONSTRAINT constraint_x ON promotion_dimension IS NULL;
7.5.5 - COMMENT ON FUNCTION
Adds, revises, or removes a comment on a function.
Adds, revises, or removes a comment on a function. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON FUNCTION [[database.]schema.]function (function-args) IS { 'comment' | NULL };
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- The name of the function with which to associate the comment.
function-args- The function arguments.
comment- Specifies the comment text to add. If a comment already exists for this function, this overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the macros.zerowhennull (x INT) function:
=> COMMENT ON FUNCTION macros.zerowhennull(x INT) IS 'Returns a 0 if not NULL';
The following example removes a comment from the macros.zerowhennull (x INT) function:
=> COMMENT ON FUNCTION macros.zerowhennull(x INT) IS NULL;
7.5.6 - COMMENT ON LIBRARY
Adds, revises, or removes a comment on a library.
Adds, revises, or removes a comment on a library . Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON LIBRARY [[database.]schema.]library IS {'comment' | NULL}
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
library- The name of the library associated with the comment.
comment- Specifies the comment text to add. If a comment already exists for this library, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the library MyFunctions:
=> COMMENT ON LIBRARY MyFunctions IS 'In development';
The following example removes a comment from the library MyFunctions:
=> COMMENT ON LIBRARY MyFunctions IS NULL;
See also
7.5.7 - COMMENT ON NODE
Adds, revises, or removes a comment on a node.
Adds, revises, or removes a comment on a node. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Dropping an object drops all comments associated with the object.
Syntax
COMMENT ON NODE node-name IS { 'comment' | NULL }
Parameters
node-name- The name of the node associated with the comment.
comment- Specifies the comment text to add. If a comment already exists for this node, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment for the initiator node:
=> COMMENT ON NODE initiator IS 'Initiator node';
The following example removes a comment from the initiator node:
=> COMMENT ON NODE initiator IS NULL;
See also
COMMENTS
7.5.8 - COMMENT ON PROJECTION
Adds, revises, or removes a comment on a projection.
Adds, revises, or removes a comment on a projection. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Dropping an object drops all comments associated with the object.
Syntax
COMMENT ON PROJECTION [[database.]schema.]projection IS { 'comment' | NULL }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- The name of the projection associated with the comment.
comment- Specifies the text of the comment to add. If a comment already exists for this projection, the comment you enter here overwrites the previous comment.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the customer_dimension_vmart_node01 projection:
=> COMMENT ON PROJECTION customer_dimension_vmart_node01 IS 'Test data';
The following example removes a comment from the customer_dimension_vmart_node01 projection:
=> COMMENT ON PROJECTION customer_dimension_vmart_node01 IS NULL;
See also
COMMENTS
7.5.9 - COMMENT ON SCHEMA
Adds, revises, or removes a comment on a schema.
Adds, revises, or removes a comment on a schema. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON SCHEMA schema-name IS {'comment' | NULL}
Parameters
schema-name- The schema associated with the comment.
comment- Text of the comment to add. If a comment already exists for this schema, the comment you enter here overwrites the previous comment.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the public schema:
=> COMMENT ON SCHEMA public IS 'All users can access this schema';
The following example removes a comment from the public schema.
=> COMMENT ON SCHEMA public IS NULL;
7.5.10 - COMMENT ON SEQUENCE
Adds, revises, or removes a comment on a sequence.
Adds, revises, or removes a comment on a sequence. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON SEQUENCE [[database.]schema.]sequence IS { 'comment' | NULL }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence- The name of the sequence associated with the comment.
comment- Specifies the text of the comment to add. If a comment already exists for this sequence, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the sequence called prom_seq.
=> COMMENT ON SEQUENCE prom_seq IS 'Promotion codes';
The following example removes a comment from the prom_seq sequence.
=> COMMENT ON SEQUENCE prom_seq IS NULL;
7.5.11 - COMMENT ON TABLE
Adds, revises, or removes a comment on a table.
Adds, revises, or removes a comment on a table. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON TABLE [[database.]schema.]table IS { 'comment' | NULL }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The name of the table with which to associate the comment.
comment- Specifies the text of the comment to add. Enclose the text of the comment within single-quotes. If a comment already exists for this table, the comment you enter here overwrites the previous comment.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes a previously added comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the promotion_dimension table:
=> COMMENT ON TABLE promotion_dimension IS '2011 Promotions';
The following example removes a comment from the promotion_dimension table:
=> COMMENT ON TABLE promotion_dimension IS NULL;
7.5.12 - COMMENT ON TRANSFORM FUNCTION
Adds, revises, or removes a comment on a user-defined transform function.
Adds, revises, or removes a comment on a user-defined transform function. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON TRANSFORM FUNCTION [[database.]schema.]tfunction
...( [ tfunction-arg-name tfunction-arg-type ][,...] ) IS {'comment' | NULL}
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
tfunction- The name of the transform function with which to associate the comment.
-
tfunction-arg-name tfunction-arg-type
- The names and data types of one or more transform function arguments. If you supply argument names and types, each type must match the type specified in the library used to create the original transform function.
comment- Specifies the comment text to add. If a comment already exists for this transform function, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment to the macros.zerowhennull (x INT) UTF function:
=> COMMENT ON TRANSFORM FUNCTION macros.zerowhennull(x INT) IS 'Returns a 0 if not NULL';
The following example removes a comment from the acros.zerowhennull (x INT) function by using the NULL option:
=> COMMENT ON TRANSFORM FUNCTION macros.zerowhennull(x INT) IS NULL;
7.5.13 - COMMENT ON VIEW
Adds, revises, or removes a comment on a view.
Adds, revises, or removes a comment on a view. Each object can have one comment. Comments are stored in the system table
COMMENTS.
Syntax
COMMENT ON VIEW [[database.]schema.]view IS { 'comment' | NULL }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- The name of the view with which to associate the comment.
comment- Specifies the text of the comment to add. If a comment already exists for this view, this comment overwrites the previous one.
Comments can be up to 8192 characters in length. If a comment exceeds that limitation, Vertica truncates the comment and emits a message.
NULL- Removes an existing comment.
Privileges
Non-superuser: object owner
Examples
The following example adds a comment from the curr_month_ship view:
=> COMMENT ON VIEW curr_month_ship IS 'Shipping data for the current month';
The following example removes a comment from the curr_month_ship view:
=> COMMENT ON VIEW curr_month_ship IS NULL;
7.6 - COMMIT
Ends the current transaction and makes all changes that occurred during the transaction permanent and visible to other users.
Ends the current transaction and makes all changes that occurred during the transaction permanent and visible to other users.
COMMIT is a synonym for
END
Syntax
COMMIT [ WORK | TRANSACTION ]
Parameters
-
WORK TRANSACTION
- Optional keywords for readability only.
Privileges
None
Examples
This example shows how to commit an insert.
=> CREATE TABLE sample_table (a INT);
=> INSERT INTO sample_table (a) VALUES (1);
OUTPUT
--------
1
=> COMMIT;
See also
7.7 - CONNECT TO VERTICA
Connects to another Vertica database to enable importing and exporting data across Vertica databases, with COPY FROM VERTICA and EXPORT TO VERTICA, respectively.
Connects to another Vertica database to enable importing and exporting data across Vertica databases, with
COPY FROM VERTICA and
EXPORT TO VERTICA, respectively.
After you establish a connection to another database, the connection remains open in the current session until you explicitly close it with
DISCONNECT. You can have only one connection to another database at a time. However, you can establish successive connections to different databases in the same session.
By default, invoking CONNECT TO VERTICA occurs over the Vertica private network. For information about creating a connection over a public network, see Using public and private IP networks.
Important
Copy and export operations can fail if either side of the connection is a single-node cluster installed on localhost.
Syntax
CONNECT TO VERTICA db-spec
[ USER username ]
[ PASSWORD 'password' ] ON 'host', port
[ TLS CONFIGURATION tls_configuration ]
[ TLSMODE PREFER ]
Parameters
db-spec- The target database, either the database name or
DEFAULT.
username- The username to use when connecting to the other database. If omitted, the current user's username is used.
password- The password of the user on the target database. If omitted, you can use credential forwarding or mutual TLS to authenticate to the target database. For details, see Passwordless authentication
host- The host name of one of the nodes in the other database.
port- The port number of the other database.
tls_configuration- The TLS Configuration to use for TLS. The TLS Configuration is ignored if
ImportExportTLSMode is set to any of the following:
-
REQUIRE_FORCE
-
VERIFY_CA_FORCE
-
VERIFY_FULL_FORCE
The effective TLS mode of CONNECT TO VERTICA changes depending on the TLSMODE of the TLS Configuration and the value of ImportExportTLSMode (for non-FORCE values). For details, see Effective TLSMode.
If the target database is configured for mutual TLS and the user on the target database can authenticate with TLS, you can use tls_configuration to authenticate instead of password.
- TLSMODE PREFER
-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. TLSMODE PREFER only takes effect if TLS CONFIGURATION is not set.
Overrides the value of configuration parameter
ImportExportTLSMode for this connection to PREFER. If TLS CONFIGURATION is set or ImportExportTLSMode is set to REQUIRE_FORCE, VERIFY_CA_FORCE, or VERIFY_FULL_FORCE, then TLSMODE PREFER has no effect.
If TLSMODE PREFER and ImportExportTLSMode are both not set, CONNECT TO VERTICA uses ENABLE.
Effective TLS mode
The effective TLS mode of CONNECT TO VERTICA is determined by the TLSMODE of the TLS Configuration and the value of ImportExportTLSMode. The following table summarizes this interaction for non-FORCE values of ImportExportTLSMode:
|
TLS Configuration |
ImportExportTLSMode |
Effective TLS mode |
|
ENABLE |
PREFER |
PREFER |
|
ENABLE |
Anything except PREFER |
REQUIRE |
|
TRY_VERIFY, VERIFY_CA |
Anything |
VERIFY_CA |
|
VERIFY_FULL |
Anything |
VERIFY_FULL |
Privileges
None
Security requirements
When importing from or exporting to a Vertica database, you can connect only to a database that uses trusted (username only) or password-based authentication, as described in Security and authentication. OAuth and Kerberos authentication methods are not supported.
If configured with a certificate, Vertica encrypts data during transmission using TLS and attempts to encrypt plan metadata. You can set configuration parameter
ImportExportTLSMode to require encryption for plan metadata.
Passwordless authentication
If you omit the password in the call to CONNECT TO VERTICA, you can authenticate to the target database in the following ways:
- Credential forwarding
- TLS authentication
For brevity, in this and later sections, "caller" refers to the user that runs CONNECT TO VERTICA from the source database to connect to the target database.
Credential forwarding
Credential forwarding lets you authenticate as the current user on the target database by forwarding your hash or password, depending on the caller's authentication method on the target database. To do this, the following requirements must be met:
For an example, see Examples.
TLS authentication
TLS authentication lets you use the certificates and keys in the specified tls_configuration parameter to authenticate instead of a password. To do this, the following requirements must be met:
- The caller exists in both databases.
- In the source database:
- A custom TLS configurations contains a CA certificate, a client certificate, and client key that can be used to authenticate to the target database with TLS authentication.
- The caller has USAGE privileges on the TLS Configuration.
- In the target database:
For an example, see Examples.
Examples
Password authentication
The following example authenticates as the dbadmin to ExampleDB on the host VerticaHost01 on port 5433:
=> CONNECT TO VERTICA ExampleDB USER dbadmin PASSWORD 'Password123' ON 'VerticaHost01',5433;
CONNECT
Credential forwarding
In the following example, Penny wants to run CONNECT TO VERTICA from db_1 to connect to db_2:
Note
In general, the
LDAP link service should be used instead to synchronize users between databases. For demonstration purposes, the example below manually configures the user
penny on both databases. You can skip these steps if you use LDAP Link.
-
On db_1, create the user penny:
=> CREATE USER penny IDENTIFIED BY 'my_password';
-
On db_2, create the user penny with the same hash, salt, and security (hashing) algorithm:
- On
db_1, retrieve the hash (from the password column) and salt from PASSWORDS:
=> SELECT user_name, password, salt FROM passwords WHERE user_name='penny';
-[ RECORD 1 ]-------------------------------------------------------------------------------------------------------------------------------------
user_name | penny
password | sha512b2e0911954a79d9d419b7b42774d36d17dd8a663c966bf0dd8f4cd6aad00d3c7ee7ba74b9bf0e56071cd995ae04aeaae537b35903e97255ed5fe286b6ff0d00a
salt | eac4ad840264e8c590120b31b815318f
- On
db_1, retrieve the effective security algorithm from PASSWORD_AUDITOR:
=> SELECT user_name, effective_security_algorithm FROM password_auditor WHERE user_name='penny';
user_name | effective_security_algorithm
-----------+------------------------------
penny | SHA512
(1 row)
- On
db_2, create the user penny:
- On
db_2, use ALTER USER to set the security algorithm to the value in db_1. For details, see Password hashing algorithm:
=> ALTER USER penny SECURITY_ALGORITHM 'SHA512';
- On
db_2, set penny's password using the hash and salt from db_1:
=> ALTER USER penny IDENTIFIED BY
'sha512b2e0911954a79d9d419b7b42774d36d17dd8a663c966bf0dd8f4cd6aad00d3c7ee7ba74b9bf0e56071cd995ae04aeaae537b35903e97255ed5fe286b6ff0d00a'
SALT 'eac4ad840264e8c590120b31b815318f';
-
On db_1, enable credential forwarding for penny by setting EnableConnectCredentialForwarding (disabled by default):
=> ALTER USER penny SET EnableConnectCredentialForwarding=1;
-
On db_2, create an authentication record with the hash method:
Note
This example authentication record lets its grantees authenticate to Vertica without TLS. In general, you should also configure client-server TLS and then specify
HOST TLS so the hashed password is forwarded to the target database over a secure connection. For example:
=> CREATE AUTHENTICATION v_hash_auth METHOD 'hash' HOST TLS '0.0.0.0/0';
=> CREATE AUTHENTICATION v_hash_auth METHOD 'hash' HOST '0.0.0.0/0';
-
Grant the authentication record to penny:
=> GRANT AUTHENTICATION v_hash_auth TO penny;
-
On db_1, run CONNECT TO VERTICA to connect to db_2, omitting the password. This example uses the default port:
=> CONNECT TO VERTICA db_2 ON 'example.com', 5433;
TLS authentication
In the following example, Penny wants to run CONNECT TO VERTICA from db_1 to connect to db_2 without specifying her password:
-
Create the user penny on both databases.
=> CREATE USER penny IDENTIFIED BY 'my_password';
-
On db_1, create or import a CA certificate, server certificate, and client certificate.
-- Create a CA certificate
=> CREATE KEY root_key TYPE 'RSA' LENGTH 2048;
=> CREATE CA CERTIFICATE mtls_root_cert
SUBJECT '/C=US/ST=Massachusetts/L=Burlington/O=OpenText/OU=Vertica/CN=Vertica Root CA'
VALID FOR 3650
EXTENSIONS 'authorityKeyIdentifier' = 'keyid:always,issuer', 'nsComment' = 'Vertica generated root CA cert'
KEY mtls_root_key;
-- Create a client certificate, signing it with the CA certificate
=> CREATE KEY client_key TYPE 'RSA' LENGTH 2048;
=> CREATE CERTIFICATE mtls_client_cert
SUBJECT '/C=US/ST=Massachusetts/L=Burlington/O=OpenText/OU=Vertica/CN=penny'
SIGNED BY mtls_root_cert
EXTENSIONS 'nsComment' = 'Vertica client cert', 'extendedKeyUsage' = 'clientAuth'
KEY mtls_client_key;
-- Create a server certificate, signing it with the CA certificate
CREATE KEY mtls_server_key TYPE 'RSA' LENGTH 2048;
CREATE CERTIFICATE mtls_server_cert
SUBJECT '/C=US/ST=Massachusetts/L=Burlington/O=OpenText/OU=Vertica/CN=*.example.com'
SIGNED BY mtls_root_cert
EXTENSIONS 'extendedKeyUsage' = 'serverAuth'
KEY mtls_server_key;
-
On db_1, create a custom TLS configuration to use with CONNECT TO VERTICA, adding the mtls_client_cert and mtls_root_cert as the certificates and setting TLSMODE to ENABLE or higher:
=> CREATE TLS CONFIGURATION mtls;
=> ALTER TLS CONFIGURATION mtls CERTIFICATE mtls_client_cert ADD CA CERTIFICATES mtls_root_cert TLSMODE 'ENABLE';
-
On db_2, import the CA certificate, server certificate, and server key from db_1. You can retrieve the contents of a certificate and key from the CERTIFICATES and CRYPTOGRAPHIC_KEYS system tables:
=> CREATE CA CERTIFICATE mtls_root_cert AS '-----BEGIN CERTIFICATE-----certificate_text-----END CERTIFICATE-----';
=> CREATE CERTIFICATE mtls_server_key AS '-----BEGIN PRIVATE KEY-----key-----END PRIVATE KEY-----'
=> CREATE CERTIFICATE mtls_server_cert AS '-----BEGIN CERTIFICATE-----certificate_text-----END CERTIFICATE-----';
-
On db_2, configure mutual mode client-server TLS using mtls_root_cert and mtls_server_cert and setting the TLSMODE to TRY_VERIFY or higher:
=> ALTER TLS CONFIGURATION server CERTIFICATE mtls_server_cert ADD CA CERTIFICATES mtls_root_cert TLSMODE 'TRY_VERIFY';
-
On db_2, create an authentication record for TLS authentication.
=> CREATE AUTHENTICATION mtls_auth METHOD 'tls' HOST TLS '0.0.0.0/0';
-
On db_2, grant mtls_auth to penny:
=> GRANT AUTHENTICATION mtls_auth TO penny;
-
On db_1, run CONNECT TO VERTICA to connect to db_2, specifying the mtls TLS Configuration. This example uses the default port:
=> CONNECT TO VERTICA vmart USER penny ON 'example.com', 5433 TLS CONFIGURATION mtls;
7.8 - COPY
COPY; Load data;.
COPY bulk-loads data into a Vertica database. By default, COPY automatically commits itself and any current transaction except when loading temporary tables. If COPY is terminated or interrupted, Vertica rolls it back.
COPY reads data as UTF-8 encoding.
For information on loading one or more files or pipes on a cluster host or on a client system, see COPY LOCAL.
To define a data pipeline to automatically load new files, see Automatic load.
Syntax
COPY [ /*+ LABEL (label-string)*/ ] [[{namespace. | database. }]schema.]target-table
[ ( { column-as-expression | column }
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ FILLER datatype]
[ FORMAT 'format' ]
[ NULL [ AS ] 'string' ]
[ TRIM 'byte' ]
[,...] ) ]
[ COLUMN OPTION (column
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ FORMAT 'format' ]
[ NULL [ AS ] 'string' ]
[ TRIM 'byte' ]
[,...] ) ]
FROM {
[ LOCAL ] STDIN [ compression ]
| { 'path-to-data'
[ ON { nodename | (nodeset) | ANY NODE | EACH NODE } ] [ compression ] }[,...]
[ PARTITION COLUMNS column[,...] ]
| LOCAL 'path-to-data' [ compression ] [,...]
| VERTICA {source-namespace. | source-database. }[source-schema.]source-table[( source-column[,...] ) ]
}
[ NATIVE
| FIXEDWIDTH COLSIZES {( integer )[,...]}
| NATIVE VARCHAR
| ORC
| PARQUET
]
| [ WITH ] UDL-clause[...]
}
[ ABORT ON ERROR ]
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char'
[ ENFORCELENGTH ]
[ ERROR TOLERANCE ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ EXCEPTIONS 'path' [ ON nodename] [,...]
[ NULL [ AS ] 'string' ]
[ RECORD TERMINATOR 'string' ]
[ REJECTED DATA {'path' [ ON nodename] [,...] | AS TABLE reject-table} ]
[ REJECTMAX integer ]
[ SKIP integer ]
[ SKIP BYTES integer ]
[ STREAM NAME 'streamName']
[ TRAILING NULLCOLS ]
[ TRIM 'byte' ]
[ [ WITH ] PARSER parser ([ arg=value[,...] ]) ] ]
[ NO COMMIT ]
Parameters
See Parameters.
Restrictions
See Restrictions.
Privileges
Superusers have full COPY privileges. The following requirements apply to non-superusers:
-
INSERT privilege on table
-
USAGE privilege on schema
-
USER-accessible storage location
-
Applicable READ or WRITE privileges granted to the storage location where files are read or written
COPY can specify a path to store rejected data and exceptions. If the path resolves to a storage location, the following privileges apply to non-superusers:
7.8.1 - Parameters
COPY parameters and their descriptions are divided into the following sections:.
COPY parameters and their descriptions are divided into the following sections:
Target options
The following options apply to the target tables and their columns:
-
LABEL
Assigns a label to a statement to identify it for profiling and debugging.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
Note
COPY ignores schema when used in CREATE EXTERNAL TABLE or CREATE FLEX EXTERNAL TABLE statements.
target-table- The target columnar or flexible table for loading new data. Vertica loads the data into all projections that include columns from the schema table.
column-as-expression- An expression used to compute values for the target column, which must not be of a complex type. For example:
=> COPY t(year AS TO_CHAR(k, 'YYYY')) FROM 'myfile.dat'
Use this option to transform data when it is loaded into the target database.
For details, see Transforming data during loads.
column- Restricts the load to one or more specified columns in the table. If you omit specifying columns, COPY loads all columns by default.
Table columns that you omit from the column list are assigned their DEFAULT or SET USING values, if any; otherwise, COPY inserts NULL.
If you leave the column parameter blank to load all columns in the table, you can use the optional parameter COLUMN OPTION to specify parsing options for specific columns.
The data file must contain the same number of columns as the COPY command's column list.
COLUMN OPTION- Specifies load metadata for one or more columns declared in the table column list. For example, you can specify that a column has its own DELIMITER, ENCLOSED BY, or NULL AS expression, and so on. You do not have to specify every column name explicitly in the COLUMN OPTION list, but each column you specify must correspond to a column in the table column list.
Column options
Depending on how they are specified, the following COPY options can qualify specific columns or all columns. Some parser-specific options can also apply to either specific columns or all columns. See Global and column-specific options For details about these two modes.
ENFORCELENGTH- If specified, COPY rejects data rows of type CHAR, VARCHAR, BINARY, and VARBINARY, or elements of those types in collections, if they are larger than the declared size.
By default, COPY truncates offending rows of these data types and elements of these types in collections, but does not reject the rows. For more details, see Handling Messy Data.
If a collection does not fit with all of its elements, COPY rejects the row without truncating. It does not reduce the number of elements. This can happen if each element is individually within limits but the number of elements causes the collection to exceed the maximum size for the column.
FILLER datatype- Reads but does not copy the data of an input column. Use filler columns to ignore input columns that do not have columns in the table. You can also use filler columns to transform data (see Examples and Transforming data during loads). Filler columns cannot be of complex types.
If a filler column has the same name as a column in the table, you must explicitly scope other uses of the name in the COPY statement. To refer to an ambiguous filler column, prefix the name with "*FILLER*".:
=> COPY names(first FILLER VARCHAR, last,
full AS "*FILLER*".first||' '||last) FROM ...;
FORMAT 'format'- Input format, one of the following:
See Binary (native) data to learn more about these formats.
When loading date/time columns, using FORMAT significantly improves load performance. COPY supports the same formats as the TO_DATE function. See Template patterns for date/time formatting.
If you specify invalid format strings, the COPY operation returns an error.
NULL [AS]- The string representing a null value. The default is an empty string (
''). You can specify a null value as any ASCII value in the range E'\000' to E'\177' inclusive. You cannot use the same character for both the DELIMITER and NULL options. For details, see Delimited data.
The following options are available for specifying source data:
LOCAL- Loads data files (up to 4,294,967,295 files) on a client system, rather than on a cluster host. LOCAL can qualify the STDIN and path-to-data arguments. For details, see COPY LOCAL.
Restrictions: Invalid for CREATE EXTERNAL TABLE AS COPY
STDIN- Reads from the client a standard input instead of a file. STDIN takes one input source only. To load multiple input sources, use path-to-data.
User must have INSERT privileges on the table and USAGE privileges on its schema.
Restrictions: Invalid for CREATE EXTERNAL TABLE AS COPY
path-to-data- Specifies the absolute path of the file (or files) containing the data, which can be from multiple input sources.
-
If the file is stored in HDFS, path-to-data is a URI in the webhdfs scheme, typically [[s]web]hdfs://[nameservice]/path. See HDFS file system.
-
If the file is stored in an S3 bucket, path-to-data is a URI in the format s3://bucket/path. See S3 object store.
-
If the file is stored in Google Cloud Storage, path-to-data is a URI in the format gs://bucket/path. See Google Cloud Storage (GCS) object store.
-
If the file is stored in Azure Blob Storage, path-to-data is a URI in the format azb://account/container/path. See Azure Blob Storage object store.
-
If the file is on the local Linux file system or an NFS mount, path-to-data is a local absolute file path.
path-to-data can optionally contain wildcards to match more than one file. The file or files must be accessible to the local client or the host on which the COPY statement runs. COPY skips empty files in the file list. A file list that includes directories causes the query to fail. See Specifying where to load data from. The supported patterns for wildcards are specified in the Linux Manual Page for Glob (7), and for ADO.net platforms, through the .NET Directory.getFiles method.
You can use variables to construct the pathname as described in Using load scripts.
If path-to-data resolves to a storage location on a local file system, and the user invoking COPY is not a superuser, the following requirements apply:
Further, if a user has privileges but is not a superuser, and invokes COPY from that storage location, Vertica ensures that symbolic links do not result in unauthorized access.
PARTITION COLUMNS column[,...]- Columns whose values are specified in the directory structure and not in the data itself.
- For Hive-style partitioning, paths contain directory names of the form
form
colname=value, and COPY parses values for the specified partition columns. If a value is missing or cannot be coerced to the column data type, the source path is rejected.
- For other partition schemes, column expressions specify how to extract values using the CURRENT_LOAD_SOURCE function. If the expression cannot be evaluated, the source path is rejected.
For more information, see Partitioned data.
ON nodename- Specifies the node on which the data to copy resides and the node that should parse the load file. If you omit
nodename, the location of the input file defaults to the initiator node. Use nodename to copy and parse a load file from a node other than the COPY initiator node.
Note
nodename is invalid with STDIN and LOCAL.
ON (nodeset)- Specifies a set of nodes on which to perform the load. The same data must be available for load on all named nodes.
nodeset is a comma-separated list of node names in parentheses. For example:
=> COPY t FROM 'file1.txt' ON (v_vmart_node0001, v_vmart_node0002);
Vertica apportions the load among all of the specified nodes. If you also specify ERROR TOLERANCE or REJECTMAX, Vertica instead chooses a single node on which to perform the load.
If the data is available on all nodes, you usually use ON ANY NODE, which is the default for loads from HDFS and cloud object stores. However, you can use ON nodeset to do manual load-balancing among concurrent loads.
-
ON ANY NODE
- Specifies that the data to load is available on all nodes, so COPY opens the path and parses it from any node in the cluster. For an Eon Mode database, COPY uses nodes within the same subcluster as the initiator.
Caution
The data must be the same on all nodes. If the data differs on two nodes, an incorrect or incomplete result is returned, with no error or warning.
Vertica attempts to apportion the load among several nodes if a file is large enough to benefit from apportioning. It chooses a single node if ERROR TOLERANCE or REJECTMAX is specified.
You can use a wildcard or glob (such as *.dat) to load multiple input files, combined with the ON ANY NODE clause. If you use a glob, COPY distributes the list of files to all cluster nodes and spreads the workload.
ON ANY NODE is invalid with STDIN and LOCAL. STDIN can only use the client host, and LOCAL indicates a client node.
ON ANY NODE is the default for loads from all paths other than Linux (HDFS and cloud object stores).
ON EACH NODE- Loads data from the specified path on each node. Use this option when the path exists on all nodes but the data files it contains are different on each node. If the path is not valid on all nodes, COPY loads the valid paths and produces a warning. If the path is a shared location, COPY loads it only once as for ON ANY NODE.
-
compression
- The input compression type, one of the following:
-
UNCOMPRESSED (default)
-
BZIP
-
GZIP
-
LZO
-
ZSTD
Input files can be of any format. If you use wildcards, all qualifying input files must be in the same format. To load different file formats, specify the format types specifically.
The following requirements and restrictions apply:
-
When using concatenated BZIP or GZIP files, verify that all source files terminate with a record terminator before concatenating them.
-
Concatenated BZIP and GZIP files are not supported for NATIVE (binary) and NATIVE VARCHAR formats.
-
LZO files are assumed to be compressed with lzop. Vertica supports the following lzop arguments:
-
BZIP, GZIP, ZSTD, and LZO compression cannot be used with ORC format.
VERTICA- See COPY FROM VERTICA.
[WITH] UDL-clause[...]- Specifies one or more user-defined load functions—one source, and optionally one or more filters and one parser, as follows:
SOURCE source( [arg=value[,...] ]
[ FILTER filter( [arg=value[,...] ] ) ]...
[ PARSER parser( [arg=value[,...] ] ) ]
To use a flex table parser for column tables, use the PARSER parameter followed by a flex table parser argument. For supported flex table parsers, see Bulk loading data into flex tables.
Handling options
The following options control how COPY handles different contingencies:
ABORT ON ERROR- Specifies that COPY stops if any row is rejected. The statement is rolled back and no data is loaded.
COLSIZES (integer[,...])- Specifies column widths when loading fixed-width data. COPY requires that you specify COLSIZES when using the FIXEDWIDTH parser. COLSIZES and the list of integers must correspond to the columns listed in the table column list. For details, see Fixed-width format data.
ERROR TOLERANCE- Specifies that COPY treats each source during execution independently when loading data. The statement is not rolled back if a single source is invalid. The invalid source is skipped and the load continues.
Using this parameter disables apportioned load.
Restrictions: Invalid for ORC or Parquet data
EXCEPTIONS { 'path' [ ON nodename ] [,...]- Exceptions, used in combination with
REJECTED DATA, describe why each rejected row was rejected. Each exception row corresponds to a rejection row.
This option specifies the file name or absolute path of the output file for exceptions. If the file already exists, it is overwritten.
Files are written on the node or nodes executing the load or, if ON is used, on the designated node. You cannot specify a path on a shared file system or qualify the path with ON ANY NODE. For more information, see Saving load exceptions (EXCEPTIONS).
To collect exceptions together with the rejected rows, use REJECTED DATA AS TABLE. You cannot use EXCEPTIONS with REJECTED DATA AS TABLE.
If you use this option with COPY...ON ANY NODE, you must still specify the individual nodes for the exception files, as in the following example:
EXCEPTIONS '/home/ex01.txt' on v_db_node0001,'/home/ex02.txt'
on v_db_node0002,'/home/ex03.txt' on v_db_node0003
If path resolves to a storage location, non-superusers have the following requirements:
-
The storage location must be created with the USER option (see CREATE LOCATION).
-
The user must have READ access to the storage location where the files exist, as described in GRANT (storage location).
REJECTED DATA { 'path' [ ON nodename ] [,...] | AS TABLE reject-table- Specifies where to write each row that failed to load. If this option is specified, records that failed due to parsing errors are always written. Records that failed due to an error during a transformation are written only if the CopyFaultTolerantExpressions configuration parameter is set.
Vertica can write rejected data to the local file system or to a table:
-
Local file system: Vertica writes rejected row data to the specified path on the node or nodes executing the load or, if ON is used, on the designated node. You cannot specify a path on a shared file system or qualify the path with ON ANY NODE. To make rejected data available on all nodes, write rejections to a table.
The value of path can be a directory or a file prefix. If there are multiple load sources, path is always treated as a directory. If there are not multiple load sources but path ends with '/', or if a directory of that name already exists, it is also treated as a directory. Otherwise, path is treated as a file prefix.
If the output file already exists, it is overwritten.
When REJECTED DATA with a path is used with LOCAL, the output is written to the client.
-
Table: Vertica writes rejected row data and exceptions to a table. You cannot use this option with EXCEPTIONS.
Writing rejections to a table is generally the better option, because they can then be queried from any node. If rejected data needs to be available from outside of Vertica, you can write it to a table and then export that table to a shared file system.
For more information about both options, see Handling messy data.
REJECTMAX integer- The maximum number of logical records that can be rejected before a load fails. For details, see Handling messy data.
REJECTMAX disables apportioned load.
SKIP integer- The number of records to skip in a load file. For example, you can use the SKIP option to omit table header information.
Restrictions: Invalid for ORC or Parquet data
STREAM NAME- Supplies a COPY load stream identifier. Using a stream name helps to quickly identify a particular load. The STREAM NAME value that you supply in the load statement appears in the STREAM_NAME column of system tables LOAD_STREAMS and LOAD_SOURCES.
A valid stream name can contain any combination of alphanumeric or special characters up to 128 bytes in length.
For example:
=> COPY mytable FROM myfile
DELIMITER '|' STREAM NAME 'My stream name';
-
WITH parser
- Specifies the parser to use when bulk loading columnar tables, one of the following:
By default, COPY uses the DELIMITER parser for UTF-8 format, delimited text input data. You do not specify the DELIMITER parser directly; absence of a specific parser indicates the default.
To use a flex table parser for column tables, use the PARSER parameter followed by a flex table parser argument. For supported flex table parsers, see Bulk loading data into flex tables.
When loading into flex tables, you must use a compatible parser. For supported flex table parsers, see Bulk loading data into flex tables.
COPY LOCAL does not support the NATIVE, NATIVE VARCHAR, ORC, and PARQUET parsers.
For parser support for complex data types, see the documentation of the specific parser.
For parser details, see Data formats in Data load.
-
NO COMMIT
- Prevents the COPY statement from committing its transaction automatically when it finishes copying data. This option must be the last COPY statement parameter. For details, see Using transactions to stage a load.
This option is ignored by CREATE EXTERNAL TABLE AS COPY.
Parser-specific options
The following options apply only when using specific parsers.
DELIMITED parser
DELIMITERIndicates the single ASCII character used to separate columns within each record of a file. You can use any ASCII value in the range E'\000' to E'\177', inclusive. You cannot use the same character for both the DELIMITER and NULL parameters. For more information, see Delimited data.
Default: Vertical bar ('|').
ENCLOSED [BY]Sets the quote character within which to enclose data, allowing delimiter characters to be embedded in string values. You can choose any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII character except NULL: E'\000'). By default, ENCLOSED BY has no value, meaning data is not enclosed by any sort of quote character.
ESCAPE [AS]Sets the escape character. Once set, the character following the escape character is interpreted literally, rather than as a special character. You can define an escape character using any ASCII value in the range E'\001' to E'\177', inclusive (any ASCII character except NULL: E'\000').
The COPY statement does not interpret the data it reads in as String literals. It also does not follow the same escape rules as other SQL statements (including the COPY parameters). When reading data, COPY interprets only the characters defined by these options as special values:
-
ESCAPE [AS]
-
DELIMITER
-
ENCLOSED [BY]
-
RECORD TERMINATOR
-
All COLLECTION options
Default: Backslash ('\').
NO ESCAPEEliminates escape-character handling. Use this option if you do not need any escape character and you want to prevent characters in your data from being interpreted as escape sequences.
RECORD TERMINATOR- Specifies the literal character string indicating the end of a data file record. For more information about using this parameter, see Delimited data.
TRAILING NULLCOLS- Specifies that if Vertica encounters a record with insufficient data to match the columns in the table column list, COPY inserts the missing columns with NULL values. For other information and examples, see Fixed-width format data.
COLLECTIONDELIMITERFor columns of collection types, indicates the single ASCII character used to separate elements within each collection. You can use any ASCII value in the range E'\000' to E'\177', inclusive. No COLLECTION option may have the same value as any other COLLECTION option. For more information, see Delimited data.
Default: Comma (',').
COLLECTIONOPEN, COLLECTIONCLOSEFor columns of collection types, these options indicate the characters that mark the beginning and end of the collection. It is an error to use these characters elsewhere within the list of elements without escaping them. No COLLECTION option may have the same value as any other COLLECTION option.
Default: Square brackets ('[' and ']').
COLLECTIONNULLELEMENTThe string representing a null element value in a collection. You can specify a null value as any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII value except NULL: E'\000'). No COLLECTION option may have the same value as any other COLLECTION option. For more information, see Delimited data.
Default: 'null'
COLLECTIONENCLOSEFor columns of collection types, sets the quote character within which to enclose individual elements, allowing delimiter characters to be embedded in string values. You can choose any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII character except NULL: E'\000').
No COLLECTION option may have the same value as any other COLLECTION option.
Default: double quote ('"')
FIXEDWIDTH parser
SKIP BYTES integer- The total number of bytes in a record to skip.
TRIM- Trims the number of bytes you specify from a column. This option is only available when loading fixed-width data. You can set TRIM at the table level for a column, or as part of the COLUMN OPTION parameter.
7.8.2 - Restrictions
COPY has the following restrictions:.
COPY has the following restrictions:
Invalid data
COPY considers the following data invalid:
-
Missing columns (an input line has fewer columns than the recipient table).
-
Extra columns (an input line has more columns than the recipient table).
-
Empty columns for an INTEGER or DATE/TIME data type. If a column is empty for either of these types, COPY does not use the default value that was defined by CREATE TABLE. However, if you do not supply a column option as part of the COPY statement, the default value is used.
-
Incorrect representation of a data type. For example, trying to load a non-numeric value into an INTEGER column is invalid.
Constraint violations
If primary key, unique key, or check constraints are enabled for automatic enforcement in the target table, Vertica enforces those constraints when you load new data. If a violation occurs, Vertica rolls back the operation and returns an error.
Empty line handling
When COPY encounters an empty line while loading data, the line is neither inserted nor rejected, but COPY increments the line record number. Consider this behavior when evaluating rejected records. If you return a list of rejected records and COPY encountered an empty row while loading data, the position of rejected records is not incremented by one, as demonstrated in the following example.
The example first loads values into a table that defines the first column as INT. Note the errors on rows 3, 4, and 8:
=> \! cat -n /home/dbadmin/test.txt
1 1|A|2
2 2|B|4
3 A|D|7
4 A|E|7
5
6
7 6|A|3
8 B|A|3
The empty rows (5 and 6) shift the reporting of the error on row 8:
=> SELECT row_number, rejected_data, rejected_reason FROM test_bad;
row_number | rejected_data | rejected_reason
------------+---------------+----------------------------------------------
3 | A|D|7 | Invalid integer format 'A' for column 1 (c1)
4 | A|E|7 | Invalid integer format 'A' for column 1 (c1)
6 | B|A|3 | Invalid integer format 'B' for column 1 (c1)
(3 rows)
Compressed file errors
When loading compressed files, COPY might abort and report an error, if the file seems to be corrupted. For example, this behavior can occur if reading the header block fails.
Disk quota
Tables and schemas can have disk quotas. If a load would violate either quota, the operation fails. For more information, see Disk quotas.
7.8.3 - Parsers
Vertica supports several parsers to load different types of data.
Vertica supports several parsers to load different types of data. Some parsers are for use only with flex tables, as noted.
7.8.3.1 - DELIMITED
Use the DELIMITED parser, which is the default, to load delimited text data using COPY.
Use the DELIMITED parser, which is the default, to load delimited text data using COPY. You can specify the delimiter, escape characters, how to handle null values, and other parameters.
The DELIMITED parser supports both apportioned load and cooperative parse.
COPY options
The following options are specific to this parser. See Parameters for other applicable options.
DELIMITERIndicates the single ASCII character used to separate columns within each record of a file. You can use any ASCII value in the range E'\000' to E'\177', inclusive. You cannot use the same character for both the DELIMITER and NULL parameters. For more information, see Delimited data.
Default: Vertical bar ('|').
ENCLOSED [BY]Sets the quote character within which to enclose data, allowing delimiter characters to be embedded in string values. You can choose any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII character except NULL: E'\000'). By default, ENCLOSED BY has no value, meaning data is not enclosed by any sort of quote character.
ESCAPE [AS]Sets the escape character. Once set, the character following the escape character is interpreted literally, rather than as a special character. You can define an escape character using any ASCII value in the range E'\001' to E'\177', inclusive (any ASCII character except NULL: E'\000').
The COPY statement does not interpret the data it reads in as String literals. It also does not follow the same escape rules as other SQL statements (including the COPY parameters). When reading data, COPY interprets only the characters defined by these options as special values:
-
ESCAPE [AS]
-
DELIMITER
-
ENCLOSED [BY]
-
RECORD TERMINATOR
-
All COLLECTION options
Default: Backslash ('\').
NO ESCAPEEliminates escape-character handling. Use this option if you do not need any escape character and you want to prevent characters in your data from being interpreted as escape sequences.
RECORD TERMINATOR- Specifies the literal character string indicating the end of a data file record. For more information about using this parameter, see Delimited data.
TRAILING NULLCOLS- Specifies that if Vertica encounters a record with insufficient data to match the columns in the table column list, COPY inserts the missing columns with NULL values. For other information and examples, see Fixed-width format data.
COLLECTIONDELIMITERFor columns of collection types, indicates the single ASCII character used to separate elements within each collection. You can use any ASCII value in the range E'\000' to E'\177', inclusive. No COLLECTION option may have the same value as any other COLLECTION option. For more information, see Delimited data.
Default: Comma (',').
COLLECTIONOPEN, COLLECTIONCLOSEFor columns of collection types, these options indicate the characters that mark the beginning and end of the collection. It is an error to use these characters elsewhere within the list of elements without escaping them. No COLLECTION option may have the same value as any other COLLECTION option.
Default: Square brackets ('[' and ']').
COLLECTIONNULLELEMENTThe string representing a null element value in a collection. You can specify a null value as any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII value except NULL: E'\000'). No COLLECTION option may have the same value as any other COLLECTION option. For more information, see Delimited data.
Default: 'null'
COLLECTIONENCLOSEFor columns of collection types, sets the quote character within which to enclose individual elements, allowing delimiter characters to be embedded in string values. You can choose any ASCII value in the range E'\001' to E'\177' inclusive (any ASCII character except NULL: E'\000').
No COLLECTION option may have the same value as any other COLLECTION option.
Default: double quote ('"')
Data types
The DELIMITED parser supports reading one-dimensional collections (arrays or sets) of scalar types.
If the total size of an array exceeds the size defined by the target table, the parser rejects the row.
Examples
The following example shows the default behavior, in which the delimiter character is '|'
=> CREATE TABLE employees (id INT, name VARCHAR(50), department VARCHAR(50));
CREATE TABLE
=> COPY employees FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 42|Sheldon Cooper|Physics
>> 17|Howard Wolowitz|Astronomy
>> \.
=> SELECT * FROM employees;
id | name | department
----+-----------------+--------------
17 | Howard Wolowitz | Astrophysics
42 | Sheldon Cooper | Physics
(2 rows)
The following example shows loading array values with the default options.
=> CREATE TABLE researchers (id INT, name VARCHAR, grants ARRAY[VARCHAR], values ARRAY[INT]);
CREATE TABLE
=> COPY researchers FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 42|Sheldon Cooper|[US-7376,DARPA-1567]|[65000,135000]
>> 17|Howard Wolowitz|[NASA-1683,NASA-7867,SPX-76]|[16700,85000,45000]
>> \.
=> SELECT * FROM researchers;
id | name | grants | values
----+-----------------+------------------------------------+---------------------
17 | Howard Wolowitz | ["NASA-1683","NASA-7867","SPX-76"] | [16700,85000,45000]
42 | Sheldon Cooper | ["US-7376","DARPA-1567"] | [65000,135000]
(2 rows)
In the following example, collections are enclosed in braces and delimited by periods, and the arrays contain null values.
=> COPY researchers FROM STDIN COLLECTIONOPEN '{' COLLECTIONCLOSE '}' COLLECTIONDELIMITER '.';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 19|Leonard|{"us-1672".null."darpa-1963"}|{16200.null.16700}
>> \.
=> SELECT * FROM researchers;
id | name | grants | values
----+-----------------+------------------------------------+---------------------
17 | Howard Wolowitz | ["NASA-1683","NASA-7867","SPX-76"] | [16700,85000,45000]
42 | Sheldon Cooper | ["US-7376","DARPA-1567"] | [65000,135000]
19 | Leonard | ["us-1672",null,"darpa-1963"] | [16200,null,16700]
(3 rows)
7.8.3.2 - FAVROPARSER
Parses data from an Avro file.
Parses data from an Avro file. The following requirements apply:
-
Avro files must be encoded in the Avro binary serialization encoding format, described in the Apache Avro standard. The parser also supports Snappy and deflate compression.
-
FAVROPARSER does not support Avro files with separate schema files. The Avro file must include the schema.
You can load complex types in the Avro source (arrays, structs, or combinations) with strong typing or as flexible complex types. A flexible complex type is loaded into a VMap column, as in flex tables. To load complex types as VMap columns, specify a column type of LONG VARBINARY. To preserve the indexing in complex types, set flatten_maps to false.
This parser can notify you if it finds keys in the data that are not part of the table definition. See Unmatched Keys.
When loading into a flex table, Vertica loads all data into the __raw__ (VMap) column, including complex types found in the data.
This parser does not support apportioned load or cooperative parse.
Syntax
FAVROPARSER ( [parameter=value[,...]] )
Parameters
flatten_maps- Boolean, whether to flatten all Avro maps. Key names are concatenated with nested levels. This value is recursive and affects all data in the load.
This parameter applies only to flex tables or VMap columns and is ignored when loading strongly-typed complex types.
Default: true
flatten_arrays- Boolean, whether to flatten all Avro arrays. Key names are concatenated with nested levels. This value is recursive and affects all data in the load.
This parameter applies only to flex tables or VMap columns and is ignored when loading strongly-typed complex types.
Default: false
flatten_records- Boolean, whether to flatten all Avro records. Key names are concatenated with nested levels. This value is recursive and affects all data in the load.
This parameter applies only to flex tables or VMap columns and is ignored when loading strongly-typed complex types.
Default: true
reject_on_materialized_type_errorBoolean, whether to reject a data row that contains a materialized column value that cannot be coerced into a compatible data type. If the value is false and the type cannot be coerced, the parser sets the value in that column to NULL.
If the column is an array and the data to be loaded is too large, then false sets the column value to NULL and true rejects the row.
If the column is a strongly-typed complex type, as opposed to a flexible complex type, then a type mismatch anywhere in the complex type causes the entire column to be treated as a mismatch. The parser does not partially load complex types.
Default: false
suppress_warnings- String, which warnings to suppress:
-
unmatched_key (see Unmatched Keys)
-
true or t (suppress all warnings)
-
false or f (do not suppress warnings)
Default: false
Primitive data types
FAVROPARSER supports the following primitive data types, including as element types and field values in complex types.
Note
Vertica does not have an explicit 4-byte (32-bit integer) or smaller types. Instead, Vertica encoding and compression automatically eliminate the storage overhead of values that require less than 64 bits.
Avro logical types
FAVROPARSER supports the following Avro logical types. The target column must use a Vertica data type that supports the logical type. When you attempt to load data using an invalid logical type, the logical type is ignored and the underlying Avro type is used.
|
AVRO Logical Type |
Base Avro Type |
Supported Vertica Data Types |
|
decimal
0 < precision ≤ 1024
0 ≤ scale ≤ precision
|
bytes or fixed |
NUMERIC, Character
Vertica rejects the value if:
-
The Avro precision setting is greater than the precision setting for the target column.
-
For fixed types, the precision value is greater than what is allowed by the size attribute.
If the data type for the target column uses the default precision setting, the precision setting in the Avro schema overrides the default.
|
date |
integer |
DATE, Character |
time-micros |
long |
TIME/TIMETZ, Character
The time logical type does not provide a time zone value. For target columns that use the TIMETZ data type, Vertica uses UTC as the default.
|
time-millis |
int |
timestamp-micros |
long |
TIMESTAMP/TIMESTAMPTZ, TIME/TIMETZ
For timestamp-millis only, the timezone is included and is represented as an offset to UTC. Additionally, the millisecond values are right-extended with padded zeros.
|
timestamp-millis |
long |
duration |
fixed |
INTERVAL, Character |
Avro complex data types
The Avro format supports several complex data types. When loading into strongly-typed columns, you can use the ROW and ARRAY types to represent them. For example, Avro Record and Enums are structs (ROWs); see the Avro specification.
You can use ARRAY[ROW] to match an Avro map. You must name the ROW fields key and value. These are the names that the Avro format uses for those fields in the data, and the parser relies on field names to match data to table columns.
If the total size of an array exceeds the size defined by the target table, the parser sets the value to null.
When loading into flex tables or using flexible complex types, this parser handles Avro complex types as follows:
Record
The name of each field is used as a virtual column name. If flatten_records is true and several nesting levels are present, Vertica concatenates the record names to create the key name.
Map
The value of each map key is used as a virtual column name. If flatten_maps is true and several nesting levels are present, Vertica concatenates the key names to create the key name.
Enum
Vertica treats Avro Enums like records, with the name of the Enum as the key and the value as the value.
Array
Vertica treats Avro Arrays as key/value pairs. By default, the index of each element is the key. In the following example, product_detail is a Record with a field, product_category, that is an Array:
=> CREATE FLEX TABLE products;
CREATE TABLE
=> COPY products FROM :datafile WITH PARSER FAVROPARSER();
Rows Loaded
-------------
2
(1 row)
=> SELECT MAPTOSTRING(__raw__) FROM products ORDER BY __identity__;
maptostring
--------------------------------------------------------------------------------
{
"__name__": "Order",
"customer_id": "111222",
"order_details": {
"0.__name__": "OrderDetail",
"0.product_detail.__name__": "Product",
"0.product_detail.price": "46.21",
"0.product_detail.product_category": {
"0": "electronics",
"1": "printers",
"2": "computers"
},
"0.product_detail.product_description": "hp printer X11ew description :\
P",
"0.product_detail.product_hash": "\u0000\u0001\u0002\u0003\u0004",
"0.product_detail.product_id": "999012",
"0.product_detail.product_map.one": "1.1",
"0.product_detail.product_map.two": "1.1",
"0.product_detail.product_name": "hp printer X11ew",
"0.product_detail.product_status": "ONLY_FEW_LEFT",
"0.quantity": "3",
"0.total": "354.34"
},
"order_id": "2389646",
"total": "132.43"
}
...
If flatten_arrays is true and several nesting levels are present, Vertica concatenates the indices to create the key name.
=> COPY products FROM :datafile WITH PARSER FAVROPARSER(flatten_arrays=true);
Rows Loaded
-------------
2
(1 row)
=> SELECT MAPTOSTRING(__raw__) FROM products ORDER BY __identity__;
maptostring
--------------------------------------------------------------------------------
{
"__name__": "Order",
"customer_id": "111222",
"order_details.0.__name__": "OrderDetail",
"order_details.0.product_detail.__name__": "Product",
"order_details.0.product_detail.price": "46.21",
"order_details.0.product_detail.product_category.0": "electronics",
"order_details.0.product_detail.product_category.1": "printers",
"order_details.0.product_detail.product_category.2": "computers",
"order_details.0.product_detail.product_description": "hp printer X11ew des\
cription :P",
"order_details.0.product_detail.product_hash": "\u0000\u0001\u0002\u0003\u0\
004",
"order_details.0.product_detail.product_id": "999012",
"order_details.0.product_detail.product_map.one": "1.1",
"order_details.0.product_detail.product_map.two": "1.1",
"order_details.0.product_detail.product_name": "hp printer X11ew",
"order_details.0.product_detail.product_status": "ONLY_FEW_LEFT",
"order_details.0.quantity": "3",
"order_details.0.total": "354.34",
"order_id": "2389646",
"total": "132.43"
}
...
Union
Vertica treats Avro Unions as arrays.
Unmatched keys
Data being loaded can contain keys that are not part of the table definition. If you are loading into a flex table (or a flexible complex type column), no data is lost. For a table with strongly-defined columns, however, new keys cannot be loaded because the table does not have a place to put them.
This parser emits warnings if it finds new keys and if both of the following are true:
New keys are logged in the UDX_EVENTS system table. If a new key is a complex type with nested keys, only the top-level key is logged. When you see a warning about unmatched keys, you can query this table and then use ALTER TABLE to modify your table definition for future loads.
Querying an external table loads data and thus can trigger these warnings. To prevent them, set the suppress_warnings parameter to 'unmatched_keys' or 'true':
=> CREATE EXTERNAL TABLE restaurants(
name VARCHAR(50),
menu ARRAY[ROW(item VARCHAR(50), price NUMERIC(8,2)),100])
AS COPY FROM '/data/rest.json'
PARSER FAVROPARSER(suppress_warnings='unmatched_key');
Examples
This example shows how to create and load a flex table with Avro data using favroparser. After loading the data, you can query virtual columns:
=> CREATE FLEX TABLE avro_basic();
CREATE TABLE
=> COPY avro_basic FROM '/home/dbadmin/data/weather.avro' PARSER FAVROPARSER();
Rows Loaded
-------------
5
(1 row)
=> SELECT station, temp, time FROM avro_basic;
station | temp | time
---------+------+---------------
mohali | 0 | -619524000000
lucknow | 22 | -619506000000
norwich | -11 | -619484400000
ams | 111 | -655531200000
baddi | 78 | -655509600000
(5 rows)
For more information, see Avro data.
7.8.3.3 - FCEFPARSER
Parses ArcSight Common Event Format (CEF) log files.
Parses ArcSight Common Event Format (CEF) log files. This parser loads values directly into any table column with a column name that matches a source data key. The parser stores the data loaded into a flex table in a single VMap.
This parser is for use in Flex tables only. All flex parsers store the data as a single VMap in the LONG VARBINAR_raw__ column. If a data row is too large to fit in the column, it is rejected. Vertica supports null values for loading data with NULL-specified columns.
Syntax
FCEFPARSER ( [parameter-name='value'[,...]] )
Parameters
delimiter- Single-character delimiter.
Default: ' '
record_terminator- Single-character record terminator.
**Default ****value: **newline
trim- Boolean, specifies whether to trim white space from header names and key values.
Default: true
reject_on_unescaped_delimiter- Boolean, specifies whether to reject rows containing unescaped delimiters. The CEF standard does not permit them.
Default: false
Examples
The following example illustrates creating a sample flex table for CEF data, with two real columns, eventId and priority.
-
Create a flex table cefdata:
=> create flex table cefdata();
CREATE TABLE
-
Load some basic CEF data, using the flex parser fcefparser:
=> copy cefdata from stdin parser fcefparser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> CEF:0|ArcSight|ArcSight|2.4.1|machine:20|New alert|High|
>> \.
-
Use the maptostring() function to view the contents of your cefdata flex table:
=> select maptostring(__raw__) from cefdata;
maptostring
-------------------------------------------------------------
{
"deviceproduct" : "ArcSight",
"devicevendor" : "ArcSight",
"deviceversion" : "2.4.1",
"name" : "New alert",
"severity" : "High",
"signatureid" : "machine:20",
"version" : "0"
}
(1 row)
-
Select some virtual columns from the cefdata flex table:
= select deviceproduct, severity, deviceversion from cefdata;
deviceproduct | severity | deviceversion
---------------+----------+---------------
ArcSight | High | 2.4.1
(1 row)
For more information, see Common event format (CEF) data
See also
7.8.3.4 - FCSVPARSER
Parses CSV format (comma-separated values) data.
Parses CSV format (comma-separated values) data. Use this parser to load CSV data into columnar, flex, and hybrid tables. All data must be encoded in Unicode UTF-8 format. The fcsvparser parser supports the RFC 4180 standard for CSV data, and other options, to accommodate variations in CSV file format definitions. Invalid records are rejected. For more information about data formats, see Handling Non-UTF-8 input.
This parser is for use in Flex tables only. All flex parsers store the data as a single VMap in the LONG VARBINAR_raw__ column. If a data row is too large to fit in the column, it is rejected. Vertica supports null values for loading data with NULL-specified columns.
Syntax
FCSVPARSER ( [parameter='value'[,...]] )
Parameters
type- The default parameter values for the parser, one of the following strings:
You do not have to use the type parameter when loading data that conforms to the RFC 4180 standard (such as MS Excel files). See Loading CSV data for the RFC4180 default parameters, and other options you can specify for traditional CSV files.
Default: RFC4180
delimiter- A single-character value used to separate fields in the CSV data.
Default: , (for rfc4180 and traditional)
escape- A single-character value used as an escape character to interpret the next character in the data literally.
Default:
-
rfc4180: "
-
traditional: \
enclosed_by- A single-character value. Use
enclosed_by to include a value that is identical to the delimiter, but should be interpreted literally. For example, if the data delimiter is a comma (,), and you want to use a comma within the data ("my name is jane, and his is jim").
Default: "
record_terminator- A single-character value used to specify the end of a record.
Default:
-
rfc4180: \n
-
traditional: \r\n
header- Boolean, specifies whether to use the first row of data as a header column. When
header=true (default), and no header exists, fcsvparser uses a default column heading. The default header consists of ucoln, where n is the column offset number, starting with 0 for the first column. You can specify custom column heading names using the header_names parameter, described next.
If you specify header=false, the fcsvparser parses the first row of input as data, rather than as column headers.
Default: true
header_names- A list of column header names, delimited by the character defined by the parser's delimiter parameter. Use this parameter to specify header names in a CSV file without a header row, or to override the column names present in the CSV source. To override one or more existing column names, specify the header names to use. This parameter overrides any header row in the data.
trim- Boolean, specifies whether to trim white space from header names and key values.
Default: true
omit_empty_keys- Boolean, specifies how the parser handles header keys without values. If true, keys with an empty value in the
header row are not loaded.
Default: false
reject_on_duplicate- Boolean, specifies whether to ignore duplicate records (false), or to reject duplicates (true). In either case, the load continues.
Default: false
reject_on_empty_key- Boolean, specifies whether to reject any row containing a key without a value.
Default: false
reject_on_materialized_type_error- Boolean, specifies whether to reject any materialized column value that the parser cannot coerce into a compatible data type. See Loading CSV data.
Default: false
Examples
The following example loads data that complies with RFC 4180:
=> CREATE TABLE sample(a INT, b VARCHAR, c INT);
CREATE TABLE
=> COPY sample FROM stdin PARSER FCSVPARSER(header='false');
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 10,10,20
>> 10,"10",30
>> 10,"20""5",90
>> \.
=> SELECT * FROM sample;
a | b | c
----+------+----
10 | 10 | 20
10 | 10 | 30
10 | 20"5 | 90
(3 rows)
Note the value 20"5, which came from the input "20""5". Per RFC 4180, to include a double-quote character in a string, you must double-quote the entire string and then escape the double-quote with another double-quote.
For more information and examples using other parameters of this parser, see Loading CSV data.
See also
7.8.3.5 - FDELIMITEDPAIRPARSER
Parses delimited data files.
Parses delimited data files. This parser provides a subset of the functionality in the parser fdelimitedparser. Use the fdelimitedpairparser when the data you are loading specifies pairs of column names with data in each row.
This parser is for use in Flex tables only. All flex parsers store the data as a single VMap in the LONG VARBINAR_raw__ column. If a data row is too large to fit in the column, it is rejected. Vertica supports null values for loading data with NULL-specified columns.
Syntax
FDELIMITEDPAIRPARSER ( [parameter-name='value'[,...]] )
Parameters
delimiter- Specifies a single-character delimiter.
Default: ' '
record_terminator- Specifies a single-character record terminator.
Default: newline
trim- Boolean specifies whether to trim white space from header names and key values.
Default: true
Examples
The following example illustrates creating a sample flex table for simple delimited data, with two real columns, eventId and priority.
-
Create a table:
=> create flex table CEFData(eventId int default(eventId::int), priority int default(priority::int) );
CREATE TABLE
-
Load a sample delimited OpenText ArcSight log file into the CEFData table, using the fcefparser:
=> copy CEFData from '/home/release/kmm/flextables/sampleArcSight.txt' parser fdelimitedpairparser();
Rows Loaded | 200
-
After loading the sample data file, use maptostring() to display the virtual columns in the __raw__ column of CEFData:
=> select maptostring(__raw__) from CEFData limit 1; maptostring
-----------------------------------------------------------
"agentassetid" : "4-WwHuD0BABCCQDVAeX21vg==",
"agentzone" : "3083",
"agt" : "265723237",
"ahost" : "svsvm0176",
"aid" : "3tGoHuD0BABCCMDVAeX21vg==",
"art" : "1099267576901",
"assetcriticality" : "0",
"at" : "snort_db",
"atz" : "America/Los_Angeles",
"av" : "5.3.0.19524.0",
"cat" : "attempted-recon",
"categorybehavior" : "/Communicate/Query",
"categorydevicegroup" : "/IDS/Network",
"categoryobject" : "/Host",
"categoryoutcome" : "/Attempt",
"categorysignificance" : "/Recon",
"categorytechnique" : "/Scan",
"categorytupledescription" : "An IDS observed a scan of a host.",
"cnt" : "1",
"cs2" : "3",
"destinationgeocountrycode" : "US",
"destinationgeolocationinfo" : "Richardson",
"destinationgeopostalcode" : "75082",
"destinationgeoregioncode" : "TX",
"destinationzone" : "3133",
"device product" : "Snort",
"device vendor" : "Snort",
"device version" : "1.8",
"deviceseverity" : "2",
"dhost" : "198.198.121.200",
"dlat" : "329913940429",
"dlong" : "-966644973754",
"dst" : "3334896072",
"dtz" : "America/Los_Angeles",
"dvchost" : "unknown:eth1",
"end" : "1364676323451",
"eventid" : "1219383333",
"fdevice product" : "Snort",
"fdevice vendor" : "Snort",
"fdevice version" : "1.8",
"fdtz" : "America/Los_Angeles",
"fdvchost" : "unknown:eth1",
"lblstring2label" : "sig_rev",
"locality" : "0",
"modelconfidence" : "0",
"mrt" : "1364675789222",
"name" : "ICMP PING NMAP",
"oagentassetid" : "4-WwHuD0BABCCQDVAeX21vg==",
"oagentzone" : "3083",
"oagt" : "265723237",
"oahost" : "svsvm0176",
"oaid" : "3tGoHuD0BABCCMDVAeX21vg==",
"oat" : "snort_db",
"oatz" : "America/Los_Angeles",
"oav" : "5.3.0.19524.0",
"originator" : "0",
"priority" : "8",
"proto" : "ICMP",
"relevance" : "10",
"rt" : "1099267573000",
"severity" : "8",
"shost" : "198.198.104.10",
"signature id" : "[1:469]",
"slat" : "329913940429",
"slong" : "-966644973754",
"sourcegeocountrycode" : "US",
"sourcegeolocationinfo" : "Richardson",
"sourcegeopostalcode" : "75082",
"sourcegeoregioncode" : "TX",
"sourcezone" : "3133",
"src" : "3334891530",
"start" : "1364676323451",
"type" : "0"
}
(1 row)
-
Select the eventID and priority real columns, along with two virtual columns, atz and destinationgeoregioncode:
=> select eventID, priority, atz, destinationgeoregioncode from CEFData limit 10;
eventID | priority | atz | destinationgeoregioncode
------------+----------+---------------------+--------------------------
1218325417 | 5 | America/Los_Angeles |
1219383333 | 8 | America/Los_Angeles | TX
1219533691 | 9 | America/Los_Angeles | TX
1220034458 | 5 | America/Los_Angeles | TX
1220034578 | 9 | America/Los_Angeles |
1220067119 | 5 | America/Los_Angeles | TX
1220106960 | 5 | America/Los_Angeles | TX
1220142122 | 5 | America/Los_Angeles | TX
1220312009 | 5 | America/Los_Angeles | TX
1220321355 | 5 | America/Los_Angeles | CA
(10 rows)
See also
7.8.3.6 - FDELIMITEDPARSER
Parses data using a delimiter character to separate values.
Parses data using a delimiter character to separate values. The fdelimitedparser loads delimited data, storing it in a single-value VMap.
This parser is for use in Flex tables only. All flex parsers store the data as a single VMap in the LONG VARBINAR_raw__ column. If a data row is too large to fit in the column, it is rejected. Vertica supports null values for loading data with NULL-specified columns.
Note
By default, fdelimitedparser treats empty fields as NULL, rather than as an empty string (''). This behavior makes casting easier. Casting a NULL to an integer (NULL::int) is valid, while casting an empty string to an integer (''::int) is not. If required, use the treat_empty_val_as_null parameter to change the default behavior of fdelimitedparser.
Syntax
FDLIMITEDPARSER ( [parameter-name='value'[,...]] )
Parameters
delimiter- Single character delimiter.
Default:|
record_terminator- Single-character record terminator.
Default:\n
trim- Boolean, specifies whether to trim white space from header names and key values.
Default: true
header- Boolean, specifies that a header column exists. The parser uses
col### for the column names if you use this parameter but no header exists.
Default:true
omit_empty_keys- Boolean, specifies how the parser handles header keys without values. If
omit_empty_keys=true, keys with an empty value in the headerrow are not loaded.
Default: false
reject_on_duplicate- Boolean, specifies whether to ignore duplicate records (
false), or to reject duplicates (true). In either case, the load continues.
Default:false
reject_on_empty_key- Boolean, specifies whether to reject any row containing a key without a value.
Default:false
reject_on_materialized_type_error- Boolean, specifies whether to reject any row value for a materialized column that the parser cannot coerce into a compatible data type. See Using flex table parsers.
Default:false
treat_empty_val_as_null- Boolean, specifies that empty fields become
NULLs, rather than empty strings ('').
Default: true
Examples
-
Create a flex table for delimited data:
t=> CREATE FLEX TABLE delim_flex ();
CREATE TABLE
-
Use the fdelimitedparser to load some delimited data from STDIN, specifying a comma (,) column delimiter:
=> COPY delim_flex FROM STDIN parser fdelimitedparser (delimiter=',');
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> deviceproduct, severity, deviceversion
>> ArcSight, High, 2.4.1
>> \.
You can now query virtual columns in the delim_flex flex table:
=> SELECT deviceproduct, severity, deviceversion from delim_flex;
deviceproduct | severity | deviceversion
---------------+----------+---------------
ArcSight | High | 2.4.1
(1 row)
See also
7.8.3.7 - FJSONPARSER
Parses and loads a JSON file.
Parses and loads a JSON file. This file can contain either repeated JSON data objects (including nested maps), or an outer list of JSON elements.
When loading into a flex or hybrid table, the parser stores the JSON data in a single-value VMap. When loading into a hybrid or columnar table, the parser loads data directly into any table column with a column name that matches a key in the JSON source data.
You can load complex types in the JSON source (arrays, structs, or combinations) with strong typing or as flexible complex types. A flexible complex type is loaded into a VMap column, as in flex tables. To load complex types as VMap columns, specify a column type of LONG VARBINARY. To preserve the indexing in complex types, set flatten_maps to false.
This parser can notify you if it finds keys in the data that are not part of the table definition. See Unmatched Keys.
FJSONPARSER supports cooperative parse only if record_terminator is specified. It does not support apportioned load.
Syntax
FJSONPARSER ( [parameter=value[,...]] )
Parameters
flatten_maps- Boolean, whether to flatten sub-maps within the JSON data, separating map levels with a period (
.). This value affects all data in the load, including nested maps.
This parameter applies only to flex tables or VMap columns and is ignored when loading strongly-typed complex types.
Default: true
flatten_arrays- Boolean, whether to convert lists to sub-maps with integer keys. When lists are flattened, key names are concatenated as for maps. Lists are not flattened by default. This value affects all data in the load, including nested lists.
This parameter applies only to flex tables or VMap columns and is ignored when loading strongly-typed complex types.
Default: false
reject_on_duplicate- Boolean, whether to ignore duplicate records (false), or to reject duplicates (true). In either case, the load continues.
Default: false
reject_on_empty_key- Boolean, whether to reject any row containing a field key without a value.
Default: false
omit_empty_keys- Boolean, whether to omit any field key from the data that does not have a value. Other fields in the same record are loaded.
Default: false
record_terminator- When set, any invalid JSON records are skipped and parsing continues with the next record. Records must be terminated uniformly. For example, if your input file has JSON records terminated by newline characters, set this parameter to
E'\n'). If any invalid JSON records exist, parsing continues after the next record_terminator.
Even if the data does not contain invalid records, specifying an explicit record terminator can improve load performance by allowing cooperative parse and apportioned load to operate more efficiently.
When you omit this parameter, parsing ends at the first invalid JSON record.
reject_on_materialized_type_errorBoolean, whether to reject a data row that contains a materialized column value that cannot be coerced into a compatible data type. If the value is false and the type cannot be coerced, the parser sets the value in that column to NULL.
If the column is an array and the data to be loaded is too large, then false sets the column value to NULL and true rejects the row.
If the column is a strongly-typed complex type, as opposed to a flexible complex type, then a type mismatch anywhere in the complex type causes the entire column to be treated as a mismatch. The parser does not partially load complex types.
Default: false
start_point- String, the name of a key in the JSON load data at which to begin parsing. The parser ignores all data before the
start_point value. The value is loaded for each object in the file. The parser processes data after the first instance, and up to the second, ignoring any remaining data.
start_point_occurrence- Integer, the nth occurrence of the value you specify with
start_point. Use in conjunction with start_point when the data has multiple start values and you know the occurrence at which to begin parsing.
Default: 1
suppress_nonalphanumeric_key_chars- Boolean, whether to suppress non-alphanumeric characters in JSON key values. The parser replaces these characters with an underscore (
_) when this parameter is true.
Default: false
key_separator- Character for the parser to use when concatenating key names.
Default: period (.)
suppress_warnings- String, which warnings to suppress:
-
unmatched_key (see Unmatched Keys)
-
true or t (suppress all warnings)
-
false or f (do not suppress warnings)
Default: false
Data types
If the total size of an array exceeds the size defined by the target table, the parser sets the value to null.
Unmatched keys
Data being loaded can contain keys that are not part of the table definition. If you are loading into a flex table (or a flexible complex type column), no data is lost. For a table with strongly-defined columns, however, new keys cannot be loaded because the table does not have a place to put them.
This parser emits warnings if it finds new keys and if both of the following are true:
New keys are logged in the UDX_EVENTS system table. If a new key is a complex type with nested keys, only the top-level key is logged. When you see a warning about unmatched keys, you can query this table and then use ALTER TABLE to modify your table definition for future loads.
Querying an external table loads data and thus can trigger these warnings. To prevent them, set the suppress_warnings parameter to 'unmatched_keys' or 'true':
=> CREATE EXTERNAL TABLE restaurants(
name VARCHAR(50),
menu ARRAY[ROW(item VARCHAR(50), price NUMERIC(8,2)),100])
AS COPY FROM '/data/rest.json'
PARSER FJSONPARSER(suppress_warnings='unmatched_key');
Examples
The following example loads JSON data from STDIN using the default parameters:
=> CREATE TABLE people(age INT, name VARCHAR);
CREATE TABLE
=> COPY people FROM STDIN PARSER FJSONPARSER();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {"age": 5, "name": "Tim"}
>> {"age": 3}
>> {"name": "Fred"}
>> {"name": "Bob", "age": 10}
>> \.
=> SELECT * FROM people;
age | name
-----+------
| Fred
10 | Bob
5 | Tim
3 |
(4 rows)
The following example uses the reject_on_duplicate parameter to reject duplicate values:
=> CREATE FLEX TABLE json_dupes();
CREATE TABLE
=> COPY json_dupes FROM stdin PARSER fjsonparser(reject_on_duplicate=true)
exceptions '/home/dbadmin/load_errors/json_e.out'
rejected data '/home/dbadmin/load_errors/json_r.out';
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> {"a":"1","a":"2","b":"3"}
>> \.
=> \!cat /home/dbadmin/load_errors/json_e.out
COPY: Input record 1 has been rejected (Rejected by user-defined parser).
Please see /home/dbadmin/load_errors/json_r.out, record 1 for the rejected record.
COPY: Loaded 0 rows, rejected 1 rows.
The following example loads array data:
$ cat addrs.json
{"number": 301, "street": "Grant", "attributes": [1, 2, 3, 4]}
=> CREATE EXTERNAL TABLE customers(number INT, street VARCHAR, attributes ARRAY[INT])
AS COPY FROM 'addrs.json' PARSER fjsonparser();
=> SELECT number, street, attributes FROM customers;
num | street| attributes
-----+-----------+---------------
301 | Grant | [1,2,3,4]
(1 row)
The following example loads a flexible complex type, rejecting rows that have empty keys within the nested records. Notice that while the data has two restaurants, one has a key name that is an empty string. This one is rejected:
$ cat rest1.json
{
"name" : "Bob's pizzeria",
"cuisine" : "Italian",
"location_city" : ["Cambridge", "Pittsburgh"],
"menu" : [{"item" : "cheese pizza", "" : "$8.25"},
{"item" : "spinach pizza", "price" : "$10.50"}]
}
{
"name" : "Bakersfield Tacos",
"cuisine" : "Mexican",
"location_city" : ["Pittsburgh"],
"menu" : [{"item" : "veggie taco", "price" : "$9.95"},
{"item" : "steak taco", "price" : "$10.95"}]
}
=> CREATE TABLE rest (name VARCHAR, cuisine VARCHAR, location_city LONG VARBINARY, menu LONG VARBINARY);
=> COPY rest FROM '/data/rest1.json'
PARSER fjsonparser(flatten_maps=false, reject_on_empty_key=true);
Rows Loaded
------------
1
(1 row)
=> SELECT maptostring(location_city), maptostring(menu) FROM rest;
maptostring | maptostring
---------------------------+-------------------------------------------------------
{
"0": "Pittsburgh"
} | {
"0": {
"item": "veggie taco",
"price": "$9.95"
},
"1": {
"item": "steak taco",
"price": "$10.95"
}
}
(1 row)
To instead load partial data, use omit_empty_keys to bypass the missing keys while loading everything else:
=> COPY rest FROM '/data/rest1.json'
PARSER fjsonparser(flatten_maps=false, omit_empty_keys=true);
Rows Loaded
-------------
2
(1 row)
=> SELECT maptostring(location_city), maptostring(menu) from rest;
maptostring | maptostring
-------------------------------------------------+---------------------------------
{
"0": "Pittsburgh"
} | {
"0": {
"item": "veggie taco",
"price": "$9.95"
},
"1": {
"item": "steak taco",
"price": "$10.95"
}
}
{
"0": "Cambridge",
"1": "Pittsburgh"
} | {
"0": {
"item": "cheese pizza"
},
"1": {
"item": "spinach pizza",
"price": "$10.50"
}
}
(2 rows)
To instead load this data with strong typing, define the complex types in the table:
=> CREATE EXTERNAL TABLE restaurants
(name VARCHAR, cuisine VARCHAR,
location_city ARRAY[VARCHAR(80)],
menu ARRAY[ ROW(item VARCHAR(80), price FLOAT) ]
)
AS COPY FROM '/data/rest.json' PARSER fjsonparser();
=> SELECT * FROM restaurants;
name | cuisine | location_city | \
menu
-------------------+---------+----------------------------+--------------------\
--------------------------------------------------------
Bob's pizzeria | Italian | ["Cambridge","Pittsburgh"] | [{"item":"cheese pi\
zza","price":0.0},{"item":"spinach pizza","price":0.0}]
Bakersfield Tacos | Mexican | ["Pittsburgh"] | [{"item":"veggie ta\
co","price":0.0},{"item":"steak taco","price":0.0}]
(2 rows)
In the following example, the data contains two new fields. One is a top-level field (a new column), and the other is a new field on an existing struct. The new fields are recorded in the UDX_EVENTS system table:
=> COPY rest FROM '/data/rest2.json' PARSER FJSONPARSER();
WARNING 10596: Warning in UDx call in user-defined object [FJSONParser], code: 0, message:
Data source contained keys which did not match table schema
HINT: SELECT key, sum(num_instances) FROM v_monitor.udx_events WHERE event_type = 'UNMATCHED_KEY' GROUP BY key
Rows Loaded
-------------
2
(1 row)
=> SELECT key, SUM(num_instances) FROM v_monitor.UDX_EVENTS
WHERE event_type = 'UNMATCHED_KEY' GROUP BY key;
key | SUM
------------------------+-----
chain | 1
menu.elements.calories | 7
(2 rows)
For other examples, see JSON data.
7.8.3.8 - FREGEXPARSER
Parses a regular expression, matching columns to the contents of the named regular expression groups.
Parses a regular expression, matching columns to the contents of the named regular expression groups.
This parser is for use in Flex tables only. All flex parsers store the data as a single VMap in the LONG VARBINAR_raw__ column. If a data row is too large to fit in the column, it is rejected. Vertica supports null values for loading data with NULL-specified columns.
Syntax
FREGEXPARSER ( pattern=[parameter-name='value'[,...]] )
Parameters
pattern- Specifies the regular expression of data to match.
Default: Empty string ("")
use_jit- Boolean, specifies whether to use just-in-time compiling when parsing the regular expression.
Default: false
record_terminator- Specifies the character used to separate input records.
Default: \n
logline_column- A string that captures the destination column containing the full string that the regular expression matched.
Default: Empty string ("")
Example
These examples use the following regular expression, which searches for information that includes the timestamp, date, thread_name, and thread_id strings.
Caution
For display purposes, this sample regular expression adds new line characters to split long lines of text. To use this expression in a query, first copy and edit the example to remove any new line characters.
This example expression loads any thread_id hex value, regardless of whether it has a 0x prefix, (<thread_id>(?:0x)?[0-9a-f]+).
'^(?<time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d\.\d+)
(?<thread_name>[A-Za-z ]+):(?<thread_id>(?:0x)?[0-9a-f]+)
-?(?<transaction_id>[0-9a-f])?(?:[(?<component>\w+)]
\<(?<level>\w+)\> )?(?:<(?<elevel>\w+)> @[?(?<enode>\w+)]?: )
?(?<text>.*)'
-
Create a flex table (vlog) to contain the results of a Vertica log file. For this example, we made a copy of a log file in the directory /home/dbadmin/data/vertica.log:
=> CREATE FLEX TABLE vlog1();
CREATE TABLE
-
Use the fregexparser with the sample regular expression to load data from the log file. Be sure to remove any line characters before using this expression shown here:
=> COPY vlog1 FROM '/home/dbadmin/tempdat/KMvertica.log'
PARSER FREGEXPARSER(pattern='^(?<time>\d\d\d\d-\d\d-\d\d \d\d:\d\d:\d\d\.\d+)
(?<thread_name>[A-Za-z ]+):(?<thread_id>(?:0x)?[0-9a-f]+)
-?(?<transaction_id>[0-9a-f])?(?:[(?<component>\w+)]
\<(?<level>\w+)\> )?(?:<(?<elevel>\w+)> @[?(?<enode>\w+)]?: )
?(?<text>.*)'
);
Rows Loaded
-------------
31049
(1 row)
-
After successfully loading data, use the MAPTOSTRING() function with the table's __raw__ column. The four rows (limt 4) that the query returns are regular expression results of the KMvertica.log file, parsed with fregexparser. The output shows thread_id values with a preceding 0x or without:
=> SELECT maptostring(__raw__) FROM vlog1 LIMIT 4;
maptostring
-------------------------------------------------------------------------------------
{
"text" : " [Init] <INFO> Log /home/dbadmin/VMart/v_vmart_node0001_catalog/vertica.log
opened; #2",
"thread_id" : "0x7f2157e287c0",
"thread_name" : "Main",
"time" : "2017-03-21 23:30:01.704"
}
{
"text" : " [Init] <INFO> Processing command line: /opt/vertica/bin/vertica -D
/home/dbadmin/VMart/v_vmart_node0001_catalog -C VMart -n v_vmart_node0001 -h
10.20.100.247 -p 5433 -P 4803 -Y ipv4",
"thread_id" : "0x7f2157e287c0",
"thread_name" : "Main",
"time" : "2017-03-21 23:30:01.704"
}
{
"text" : " [Init] <INFO> Starting up Vertica Analytic Database v8.1.1-20170321",
"thread_id" : "7f2157e287c0",
"thread_name" : "Main",
"time" : "2017-03-21 23:30:01.704"
}
{
"text" : " [Init] <INFO> Compiler Version: 4.8.2 20140120 (Red Hat 4.8.2-15)",
"thread_id" : "7f2157e287c0",
"thread_name" : "Main",
"time" : "2017-03-21 23:30:01.704"
}
(4 rows)
See also
7.8.3.9 - ORC
Use the ORC clause with the COPY FROM statement to load data in the ORC format.
Use the ORC clause with the COPY statement to load data in the ORC format. When loading data into Vertica, you can read all primitive types, UUIDs, and complex types.
By default, the ORC parser uses strong schema matching, meaning that columns in the data must exactly match the columns in the table using the data. You can optionally use Loose (soft) Schema Matching.
If the table definition includes columns of primitive types and those columns are not in the data, the parser fills those columns with NULL. If the table definition includes columns of complex types, those columns must be present in the data.
This parser does not support apportioned load or cooperative parse.
Syntax
ORC ( [ parameter=value[,...] ] )
Parameters
All parameters are optional.
hive_partition_cols- Comma-separated list of columns that are partition columns in the data.
Deprecated
Instead, use COPY PARTITION COLUMNS. See
Partitioned data. If you use both this parameter and PARTITION COLUMNS, COPY ignores the parameter.
allow_no_match- Whether to accept a path containing a glob with no matching files and report zero rows in query results. If this parameter is not set, Vertica returns an error if the path in the FROM clause does not match at least one file.
do_soft_schema_match_by_name- Whether to enable loose schema matching (true) instead of the strict matching based on column order in the table definition and ORC file (false, default). See Loose Schema Matching for more information.
Default: false.
reject_on_materialized_type_error- Boolean, applies only if
do_soft_schema_match_by_name is true. Specifies what to do when loose schema matching is being used and a value cannot be coerced from the data to the target column type. A value of true means to reject the row; a value of false means to use NULL for the value or, for strings that are too long, truncate. See the table of type coercions for coercible type mappings.
Default: true.
Loose schema matching
By default, the ORC parser uses strong schema matching. This means that all columns in the ORC data must be loaded, and they must be loaded in the same order as in the data. However, there are times when you only want to pull certain columns, or you want to be able to accommodate future changes in the ORC schema. This is called loose (or soft) schema matching.
Use the do_soft_schema_match_by_name parameter to enable loose schema matching. This setting has the following effects:
-
Columns in the data are matched to columns in the table by their names. Names must exactly match but are case-insensitive.
-
Columns that exist in the ORC data but are not part of the table definition are ignored.
-
Columns that exist in the table definition but not the ORC data are filled with NULL.
-
If the same case-insensitive column name occurs more than once in the ORC data, the parser uses the last one. (This situation can arise when using data written by tools that are case-sensitive.)
-
Column types do not need to exactly match, so long as the data type in the ORC file can be coerced to the type used by the table.
While the Parquet parser applies loose schema matching to both column and field names, the ORC parser applies it only to column names.
Data types
This parser can read all primitive types, UUIDs, and complex types.
If the total size of an array exceeds the size defined by the target table, the parser rejects the row.
The following mappings are supported with type coercion and loose schema matching:
|
ORC Physical Type |
Coercible to Vertica Data Type |
|
BOOLEAN |
BOOLEAN |
|
BYTE, SHORT, INT, LONG |
INT |
|
FLOAT, DOUBLE |
FLOAT |
|
DECIMAL |
NUMERIC |
|
DATE |
DATE |
|
TIMESTAMP |
TIMESTAMP, TIMESTAMPTZ |
|
STRING, CHAR, VARCHAR |
CHAR, VARCHAR, LONG VARCHAR |
|
BINARY |
BINARY, VARBINARY, LONG VARBINARY |
Examples
The ORC clause does not use the PARSER option:
=> CREATE EXTERNAL TABLE orders (...)
AS COPY FROM 's3://DataLake/orders.orc' ORC;
You can read a map column as an array of rows, as in the following example:
=> CREATE EXTERNAL TABLE orders
(orderkey INT,
custkey INT,
prods ARRAY[ROW(key VARCHAR(10), value DECIMAL(12,2))],
orderdate DATE
) AS COPY FROM '...' ORC;
7.8.3.10 - PARQUET
Use the PARQUET parser with the COPY FROM statement to load data in the Parquet format.
Use the PARQUET parser with the COPY statement to load data in the Parquet format. When loading data into Vertica you can read all primitive types, UUIDs, and complex types.
By default, the Parquet parser uses strong schema matching, meaning that columns in the data must exactly match the columns in the table using the data. You can optionally use Loose Schema Matching.
When loading Parquet data, Vertica caches the Parquet metadata to improve efficiency. This cache uses local TEMP storage and is not used if TEMP is remote. See the ParquetMetadataCacheSizeMB configuration parameter to change the size of the cache.
This parser does not support apportioned load or cooperative parse.
Syntax
PARQUET ( [ parameter=value[,...] ] )
Parameters
All parameters are optional.
hive_partition_cols- Comma-separated list of columns that are partition columns in the data.
Deprecated
Instead, use COPY PARTITION COLUMNS. See
Partitioned data. If you use both this parameter and PARTITION COLUMNS, COPY ignores the parameter.
allow_no_match- Boolean. Whether to accept a path containing a glob with no matching files and report zero rows in query results. If this parameter is not set, Vertica returns an error if the path in the FROM clause does not match at least one file.
allow_long_varbinary_match_complex_type- Boolean. Whether to enable flexible column types (see Flexible complex types). If true, the Parquet parser allows a complex type in the data to match a table column defined as LONG VARBINARY. If false, the Parquet parser requires strong typing of complex types. With the parameter set you can still use strong typing. Set this parameter to false if you want use of flexible columns to be treated as an error.
do_soft_schema_match_by_name- Whether to enable loose schema matching (true) instead of the strict matching based on column order in the table definition and parquet file (false, default). See Loose Schema Matching for more information.
Default: false.
reject_on_materialized_type_error- Boolean, applies only if
do_soft_schema_match_by_name is true. Specifies what to do when loose schema matching is being used and a value cannot be coerced from the data to the target column type. A value of true means to reject the row; a value of false means to use NULL for the value or, for strings that are too long, truncate. See the table of type coercions for coercible type mappings.
Default: true.
Loose schema matching
By default, the Parquet parser uses strong schema matching. This means that all columns and struct fields in the Parquet data must be loaded, and they must be loaded in the same order as in the data. However, there are times when you only want to pull certain columns or fields, or you want to be able to accommodate future changes in the Parquet schema. This is called loose (or soft) schema matching.
Use the do_soft_schema_match_by_name parameter to enable loose schema matching. This setting has the following effects:
-
Columns or struct fields in the data are matched to columns or fields in the table by their names. Names must exactly match but are case-insensitive.
-
Columns or fields that exist in the Parquet data but are not part of the table definition are ignored.
-
Columns or fields that exist in the table definition but not the Parquet data are filled with NULL. The parser logs an UNMATCHED_TABLE_COLUMNS_PARQUETPARSER event in QUERY_EVENTS.
-
If the same case-insensitive column name occurs more than once in the Parquet data, the parser uses the last one. (This situation can arise when using data written by tools that are case-sensitive.)
-
Column and field types do not need to exactly match, so long as the data type in the Parquet file can be coerced to the type used by the table. If a type cannot be coerced, the parser logs a TYPE_MISMATCH_COLUMNS_PARQUETPARSER event in QUERY_EVENTS. If reject_on_materialized_type_error is true then the parser rejects the row. If it is false, the parser uses NULL or, for string values that are too long, truncates the value.
Data types
The Parquet parser maps Parquet data types to Vertica data types as follows.
|
Parquet Logical Type |
Vertica Data Type |
|
StringLogicalType |
VARCHAR |
|
MapLogicalType |
ARRAY[ROW] |
|
ListLogicalType |
ARRAY/SET |
|
IntLogicalType |
INT/NUMERIC |
|
DecimalLogicalType |
NUMERIC |
|
DateLogicalType |
DATE |
|
TimeLogicalType |
TIME |
|
TimestampLogicalType |
TIMESTAMP |
|
UUIDLogicalType |
UUID |
If the total size of an array exceeds the size defined by the target table, the parser rejects the row.
The following logical types are not supported:
- EnumLogicalType
- IntervalLogicalType
- JSONLogicalType
- BSONLogicalType
- UnknownLogicalType
The Parquet parser supports the following mappings of physical types:
|
Parquet Physical Type |
Vertica Data Type |
|
BOOLEAN |
BOOLEAN |
|
INT32/INT64 |
INT |
|
INT96 |
Supported only for TIMESTAMP |
|
FLOAT |
DOUBLE |
|
DOUBLE |
DOUBLE |
|
BYTE_ARRAY |
VARBINARY |
|
FIXED_LEN_BYTE_ARRAY |
BINARY |
The following mappings are supported with type coercion and loose schema matching.
|
Parquet Physical Type |
Coercible to Vertica Data Type |
|
BOOLEAN |
BOOLEAN |
|
INT32, INT64, BOOLEAN |
INT |
|
FLOAT, DOUBLE |
DOUBLE |
|
INT32, INT96 |
DATE |
|
INT64, INT96 |
TIMESTAMP, TIMESTAMPTZ |
|
INT64
If precision > 0: INT32, BYTE_ARRAY, FIXED_LEN_BYTE_ARRAY
|
Numeric |
|
BYTE_ARRAY |
CHAR, VARCHAR, LONG VARCHAR, BINARY, VARBINARY, LONG VARBINARY |
|
FIXED_LEN_BYTE_ARRAY |
UUID |
Vertica supports only 3-level-encoded arrays, not 2-level-encoded.
Examples
The PARQUET clause does not use the PARSER option:
=> COPY sales FROM 's3://DataLake/sales.parquet' PARQUET;
In the following example, the data directory contains no files:
=> CREATE EXTERNAL TABLE customers (...)
AS COPY FROM 'webhdfs:///data/*.parquet' PARQUET;
=> SELECT COUNT(*) FROM customers;
ERROR 7869: No files match when expanding glob: [webhdfs:///data/*.parquet]
To read zero rows instead of producing an error, use the allow_no_match parameter:
=> CREATE EXTERNAL TABLE customers (...)
AS COPY FROM 'webhdfs:///data/*.parquet'
PARQUET(allow_no_match='true');
=> SELECT COUNT(*) FROM customers;
count
-------
0
(1 row)
To allow reading a complex type (menu, in this example) as a flexible column type, use the allow_long_varbinary_match_complex_type parameter:
=> CREATE EXTERNAL TABLE restaurants
(name VARCHAR, cuisine VARCHAR, location_city ARRAY[VARCHAR], menu LONG VARBINARY)
AS COPY FROM '/data/rest*.parquet'
PARQUET(allow_long_varbinary_match_complex_type='True');
To read only some columns from the restaurant data, use loose schema matching:
=> CREATE EXTERNAL TABLE restaurants(name VARCHAR, cuisine VARCHAR)
AS COPY FROM '/data/rest*.parquet'
PARQUET(allow_long_varbinary_match_complex_type='True',
do_soft_schema_match_by_name='True');
=> SELECT * from restaurant;
name | cuisine
-------------------+----------
Bob's pizzeria | Italian
Bakersfield Tacos | Mexican
(2 rows)
7.8.4 - Examples
For additional COPY examples, see the reference pages for specific parsers, including: DELIMITED (Parser), ORC (Parser), PARQUET (Parser), FJSONPARSER (Parser), and FAVROPARSER (Parser).
For additional COPY examples, see the reference pages for specific parsers, including: DELIMITED, ORC, PARQUET, FJSONPARSER, and FAVROPARSER.
Specifying string options
Use COPY with FORMAT, DELIMITER, NULL, and ENCLOSED BY options:
=> COPY public.customer_dimension (customer_since FORMAT 'YYYY')
FROM STDIN
DELIMITER ','
NULL AS 'null'
ENCLOSED BY '"';
This example sets and references a vsql variable for the input file:
=> \set input_file ../myCopyFromLocal/large_table.gzip
=> COPY store.store_dimension
FROM :input_file
DELIMITER '|'
NULL ''
RECORD TERMINATOR E'\f';
Including multiple source files
Create a table and then copy multiple source files to it:
=> CREATE TABLE sampletab (a int);
CREATE TABLE
=> COPY sampletab FROM '/home/dbadmin/one.dat', 'home/dbadmin/two.dat';
Rows Loaded
-------------
2
(1 row)
Use wildcards to indicate a group of files:
=> COPY myTable FROM 'webhdfs:///mydirectory/ofmanyfiles/*.dat';
Wildcards can include regular expressions:
=> COPY myTable FROM 'webhdfs:///mydirectory/*_[0-9]';
Specify multiple paths in a single COPY statement:
=> COPY myTable FROM 'webhdfs:///data/sales/01/*.dat', 'webhdfs:///data/sales/02/*.dat',
'webhdfs:///data/sales/historical.dat';
Distributing a load
Load data that is shared across all nodes. Vertica distributes the load across all nodes, if possible:
=> COPY sampletab FROM '/data/file.dat' ON ANY NODE;
Load data from two files. Because the first load file does not specify nodes (or ON ANY NODE), the initiator performs the load. Loading the second file is distributed across all nodes:
=> COPY sampletab FROM '/data/file1.dat', '/data/file2.dat' ON ANY NODE;
Specify different nodes for each load file:
=> COPY sampletab FROM '/data/file1.dat' ON (v_vmart_node0001, v_vmart_node0002),
'/data/file2.dat' ON (v_vmart_node0003, v_vmart_node0004);
Loading data from shared storage
To load data from shared storage, use URLs in the corresponding schemes:
-
HDFS: [[s]web]hdfs://[nameservice]/path
-
S3: s3://bucket/path
-
Google Cloud: gs://bucket/path
-
Azure: azb://account/container/path
Note
Loads from HDFS, S3, GCS, and Azure default to ON ANY NODE; you do not need to specify it.
Load a file stored in HDFS using the default name node or name service:
=> COPY t FROM 'webhdfs:///opt/data/file1.dat';
Load data from a particular HDFS name service (testNS). You specify a name service if your database is configured to read from more than one HDFS cluster:
=> COPY t FROM 'webhdfs://testNS/opt/data/file2.csv';
Load data from an S3 bucket:
=> COPY t FROM 's3://AWS_DataLake/*' ORC;
Partitioned data
Data files can be partitioned using the directory structure, such as:
path/created=2016-11-01/region=northeast/*
path/created=2016-11-01/region=central/*
path/created=2016-11-01/region=southeast/*
path/created=2016-11-01/...
path/created=2016-11-02/region=northeast/*
path/created=2016-11-02/region=central/*
path/created=2016-11-02/region=southeast/*
path/created=2016-11-02/...
path/created=2016-11-03/...
path/...
Load partition columns using the PARTITION COLUMNS option:
=> CREATE EXTERNAL TABLE records (id int, name varchar(50), created date, region varchar(50))
AS COPY FROM 'webhdfs:///path/*/*/*'
PARTITION COLUMNS created, region;
Using filler columns
In the following example, the table has columns for first name, last name, and full name, but the data being loaded contains columns for first, middle, and last names. The COPY statement reads all of the source data but only loads the source columns for first and last names. It constructs the data for the full name by concatenating each of the source data columns, including the middle name. The middle name is read as a FILLER column so it can be used in the concatenation, but is ignored otherwise. (There is no table column for middle name.)
=> CREATE TABLE names(first VARCHAR(20), last VARCHAR(20), full VARCHAR(60));
CREATE TABLE
=> COPY names(first,
middle FILLER VARCHAR(20),
last,
full AS first||' '||middle||' '||last)
FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Marc|Gregory|Smith
>> Sue|Lucia|Temp
>> Jon|Pete|Hamilton
>> \.
=> SELECT * from names;
first | last | full
-------+----------+--------------------
Jon | Hamilton | Jon Pete Hamilton
Marc | Smith | Marc Gregory Smith
Sue | Temp | Sue Lucia Temp
(3 rows)
In the following example, JSON data contains an unencrypted password. The JSON data and the table definition use the same name for the field. Instead of loading the value directly, the COPY statement uses a filler column and a (hypothetical) function to encrypt the value. Both the table column (users.password) and the filler column ("*FILLER*".password) are fully qualified:
=> CREATE TABLE users(user VARCHAR(32), password VARCHAR(32));
=> COPY users(user, password FILLER VARCHAR(32),
users.password AS encrypt("*FILLER*".password))
FROM ... PARSER FJSONPARSER();
Setting defaults for null values
When creating a table, you can specify a default value for a column. When loading data, Vertica uses the default if the column value is not present. However, defaults do not override null values.
To intercept null values and apply defaults, you can first stage the load with COPY NO COMMIT and then update the values:
=> CREATE TABLE sales (id INT, shipped TIMESTAMP(6) DEFAULT now());
=> COPY sales FROM ... NO COMMIT;
=> UPDATE sales SET shipped = DEFAULT WHERE epoch IS NULL;
=> COMMIT;
All Vertica tables have an implicit epoch column, which records when the data was committed. For data that is not yet committed, this value is null. You can use this column to identify the just-loaded data and update it before committing.
Loading data into a flex table
Create a Flex table and copy JSON data into it:
=> CREATE FLEX TABLE darkdata();
CREATE TABLE
=> COPY tweets FROM '/myTest/Flexible/DATA/tweets_12.json' PARSER FJSONPARSER();
Rows Loaded
-------------
12
(1 row)
Using named pipes
COPY supports named pipes that follow the same naming conventions as file names on the given file system. Permissions are open, write, and close.
Create a named pipe and set two vsql variables:
=> \! mkfifo pipe1
=> \set dir `pwd`/
=> \set file '''':dir'pipe1'''
Copy an uncompressed file from the named pipe:
=> \! cat pf1.dat > pipe1 &
=> COPY large_tbl FROM :file delimiter '|';
=> SELECT * FROM large_tbl;
=> COMMIT;
Loading compressed data
Copy a GZIP file from a named pipe and uncompress it:
=> \! gzip pf1.dat
=> \! cat pf1.dat.gz > pipe1 &
=> COPY large_tbl FROM :file ON site01 GZIP delimiter '|';
=> SELECT * FROM large_tbl;
=> COMMIT;
=> \!gunzip pf1.dat.gz
7.9 - COPY FROM VERTICA
Imports data from another Vertica database.
Imports data from another Vertica database. COPY FROM VERTICA is similar to COPY, but supports only a subset of its parameters.
Important
The source database must be no more than one major release behind the target database.
Syntax
COPY [[{namespace. | database. }]schema.]target-table
[( target-columns )]
FROM VERTICA {source-namespace. | source-database. }[source-schema.]source-table
[( source-columns )]
[STREAM NAME 'stream name']
[NO COMMIT]
Parameters
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
-
target-table
- The target table for the imported data. Vertica loads the data into all projections that include columns from the schema table.
target-columns- A comma-delimited list of columns in
target-table to store the copied data.See Mapping Between Target and Source Columns below.
You cannot use FILLER columns or columns of complex types, except native arrays, as part of the column definition.
{ source-database. | [source-namespace.] }- The source of the data to import, which depends on the mode of your database:
- Eon Mode: specify the namespace in the source database that contains the data to import, by default
default_namespace.
- Enterprise Mode: specify the source database name.
A connection to the source database must already exist in the current session before starting the copy operation; otherwise Vertica returns an error. For details, see
CONNECT TO VERTICA.
[source-schema.]source-table- The table that is the source of the imported data. If
schema is any schema other than public or if you specified a source-namespace, you must supply the schema name.
source-columns- A comma-delimited list of the columns in the source table to import. If omitted, all columns are exported.Columns cannot be of complex types. See Mapping Between Target and Source Columns below.
STREAM NAME- A COPY load stream identifier. Using a stream name helps to quickly identify a particular load. The STREAM NAME value that you specify in the load statement appears in the
stream column of the LOAD_STREAMS system table.
NO COMMIT- Prevents
COPY from committing its transaction automatically when it finishes copying data. For details, see Using transactions to stage a load.
Privileges
Mapping between target and source columns
If you copy all table data from one database to another, COPY FROM VERTICA can omit specifying column lists if column definitions in both tables comply with the following conditions:
-
Same number of columns
-
Identical column names
-
Same sequence of columns
-
Matching or compatible column data types
-
No complex data types (ARRAY, SET, or ROW), except for native arrays
If any of these conditions is not true, the COPY FROM VERTICA statement must include column lists that explicitly map target and source columns to each other, as follows:
-
Contain the same number of columns.
-
List source and target columns in the same order.
-
Pair columns with the same (or compatible) data types.
Node failure during COPY
See Handling node failure during copy/export.
Examples
The following example copies the contents of an entire table from the vmart database to an identically-defined table in the current database:
=> CONNECT TO VERTICA vmart USER dbadmin PASSWORD 'myPassword' ON 'VertTest01',5433;
CONNECT
=> COPY customer_dimension FROM VERTICA vmart.customer_dimension;
Rows Loaded
-------------
500000
(1 row)
=> DISCONNECT vmart;
DISCONNECT
For more examples, see Copying data from another Vertica database.
See also
EXPORT TO VERTICA
7.10 - COPY LOCAL
Using the COPY statement with its LOCAL option lets you load a data file on a client system, rather than on a cluster host.
Using the COPY statement with its LOCAL option lets you load data files (up to 4,294,967,295 files) on a client system, rather than on a cluster host. COPY LOCAL supports the STDIN and 'pathToData' parameters, but not the [ON nodename] clause. COPY LOCAL does not support multiple file batches in NATIVE or NATIVE VARCHAR formats. COPY LOCAL does not support reading ORC or Parquet files; use ON NODE instead. COPY LOCAL does not support CURRENT_LOAD_SOURCE().
The COPY LOCAL option is platform-independent. The statement works in the same way across all supported Vertica platforms and drivers. For more details about supported drivers, see Client drivers.
COPY LOCAL does not automatically create files detailing exceptions and rejections, even if exceptions occur.
COPY LOCAL is subject to the following restrictions when used with vsql and the client libraries:
- COPY LOCAL must be the first statement in any multi-statement query.
- COPY LOCAL cannot be used multiple times in the same query.
Note
On Windows clients, the path you supply for the COPY LOCAL file is limited to 216 characters due to limitations in the Windows API.
Privileges
User must have INSERT privilege on the table and USAGE privilege on the schema.
How COPY LOCAL works
COPY LOCAL loads data in a platform-neutral way. The COPY LOCAL statement loads all files from a local client system to the Vertica host, where the server processes the files. You can copy files in various formats: uncompressed, compressed, fixed-width format, in bzip or gzip format, or specified as a bash glob. Files of a single format (such as all bzip, or gzip) can be comma-separated in the list of input files. You can also use any of the applicable COPY statement options (as long as the data format supports the option). For instance, you can define a specific delimiter character, or how to handle NULLs, and so forth.
For more information about using the COPY LOCAL option to load data, see COPY for syntactical descriptions, and Specifying where to load data from for detailed examples.
The Vertica host uncompresses and processes the files as necessary, regardless of file format or the client platform from which you load the files. Once the server has the copied files, Vertica maintains performance by distributing file parsing tasks, such as encoding, compressing, uncompressing, across nodes.
Viewing copy local operations in a query plan
When you use the COPY LOCAL option, the GraphViz query plan includes a label for Load-Client-File, rather than Load-File. Following is a section from a sample query plan:
-----------------------------------------------
PLAN: BASE BULKLOAD PLAN (GraphViz Format)
-----------------------------------------------
digraph G {
graph [rankdir=BT, label = " BASE BULKLOAD PLAN \nAll Nodes Vector:
\n\n node[0]=initiator (initiator) Up\n", labelloc=t, labeljust=l ordering=out]
.
.
.
10[label = "Load-Client-File(/tmp/diff) \nOutBlk=[UncTuple]",
color = "green", shape = "ellipse"];
Examples
The following example shows a load from a local file.
$ cat > t.dat
12
17
9
^C
=> CREATE TABLE numbers (value INT);
CREATE TABLE
=> COPY numbers FROM LOCAL 't.dat';
Rows Loaded
-------------
3
(1 row)
=> SELECT * FROM numbers;
value
-------
12
17
9
(3 rows)
7.11 - CREATE statements
CREATE statements let you create new database objects such as tables and users.
CREATE statements let you create new database objects such as tables and users.
7.11.1 - CREATE ACCESS POLICY
Creates an access policy that filters access to table data to users and roles.
Creates an access policy that filters access to table data to users and roles. You can create access policies for table rows and columns. Vertica applies the access policy filters with each query and returns only the data that is permissible for the current user or role.
You cannot set access policies on columns of complex data types other than native arrays. If the table contains complex-type columns, you can still set row access policies and column access policies on other columns.
Syntax
CREATE ACCESS POLICY ON [[database.]schema.]table
{ FOR COLUMN column | FOR ROWS WHERE } expression [GRANT TRUSTED] { ENABLE | DISABLE }
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- The table with the target column or rows.
FOR COLUMN column- The column on which to apply this access policy. The column can be a native array, but other complex types are not supported. (See Complex types.)
FOR ROWS WHERE- The rows on which to apply this access policy.
expression- A SQL expression that specifies conditions for accessing row or column data:
-
Row access policies limit access to specific rows in a table, as specified by the policy's WHERE expression. Only rows that satisfy this expression are fetched from the table. For details and sample usage, see Creating row access policies.
-
Column access policies limit access to specific table columns. The access policy expression can also specify how to render column data to specific users and roles. For details and sample usage, see Creating column access policies.
GRANT TRUSTEDSpecifies that GRANT statements take precedence over the access policy in determining whether users can perform DML operations on the target table. If omitted, users can only modify table data if the access policy allows them to see the stored data in its original, unaltered state. For more information, see Access policies and DML operations.
Important
GRANT TRUSTED only affects DML operations and does not enable users to see data that the access policy would otherwise mask. Specifying this option may allow users with certain grants to update data that they cannot see.
ENABLE | DISABLE- Whether to enable the access policy. You can enable and disable existing access policies with ALTER ACCESS POLICY.
Privileges
Non-superuser: Ownership of the table
Restrictions
The following limitations apply to access policies:
-
A column can have only one access policy.
-
Column access policies cannot be set on columns of complex types other than native arrays.
-
Column access policies cannot be set for materialized columns on flex tables. While it is possible to set an access policy for the __raw__ column, doing so restricts access to the whole table.
-
Row access policies are invalid on temporary tables and tables with aggregate projections.
-
Access policy expressions cannot contain:
-
If the query optimizer cannot replace a deterministic expression that involves only constants with their computed values, it blocks all DML operations such as INSERT.
See also
7.11.2 - CREATE AUTHENTICATION
Creates and enables an authentication record associated with users or roles.
Creates and enables an authentication record associated with users or roles. Authentication records are automatically enabled after creation.
Syntax
CREATE AUTHENTICATION auth-record-name
METHOD 'auth-method'
access-method
[ FALLTHROUGH ]
Parameters
|
Name |
Description |
auth-record-name |
Name of the authentication record, where auth-record-name conforms to conventions described in Identifiers. |
auth-method |
The authentication method, one of the following:
-
trust: Users can authenticate with a valid username (that is, without a password).
-
reject: Rejects the connection attempt.
-
hash: Users must provide a valid username and password. For details, see Hash authentication.
-
gss: Authorizes clients that connect to Vertica with an MIT Kerberos implementation. The Key Distribution Center (KDC) must support Kerberos 5 using the GSS-API. Non-MIT Kerberos implementations must use the GSS-API. For details, see Kerberos authentication.
-
ident: Authenticates the client against a username on an Ident server. For details, see Ident authentication.
-
ldap: Authenticates a client and their username and password with an LDAP or Active Directory server. For details, see LDAP authentication.
-
tls: Authenticates clients that provide a certificate with a Common Name (CN) that specifies a valid database username. Vertica must be configured for mutual mode TLS to use this method. For details, see TLS authentication
-
oauth: Authenticates a client with an access token. For details, see OAuth 2.0 authentication.
For details, see Supported Client Authentication Methods.
|
access-method |
The access method the client uses to connect, specified in one of the following ways:
-
LOCAL: Matches connection attempts made using local domain sockets.
-
HOST [ TLS | NO TLS ] 'host-ip-address': Matches connection attempts made using TCP/IP, where host-ip-address can be an IPv4 or IPv6 address. You can qualify HOST with one of the following options:
|
|
[ FALLTHROUGH ] |
Whether to enable fallthrough authentication for this record. To disable fallthrough, see ALTER AUTHENTICATION.
Fallthrough cannot be enabled for authentication records that use the following authentication methods:
|
Privileges
DBADMIN
Examples
See Creating authentication records.
See also
7.11.3 - CREATE CA BUNDLE
Creates a certificate authority (CA) bundle.
Deprecated
CA bundles are only usable with certain deprecated parameters in
Kafka notifiers. You should prefer using
TLS configurations and the TLS CONFIGURATION parameter for notifiers instead.
Creates a certificate authority (CA) bundle. These contain root CA certificates.
Syntax
CREATE CA BUNDLE name [CERTIFICATES ca_cert[, ca_cert[, ...]]
Parameters
name- The name of the CA bundle.
ca_cert- The name of the CA certificate. If no certificates are specified, the bundle will be empty.
Privileges
Ownership of the CA certificates in the CA bundle.
Examples
See Managing CA bundles.
See also
7.11.4 - CREATE CERTIFICATE
Creates or imports a certificate, Certificate Authority (CA), or intermediate CA.
Creates or imports a certificate, Certificate Authority (CA), or intermediate CA. These certificates can be used with ALTER TLS CONFIGURATION to set up client-server TLS, LDAPLink TLS, LDAPAuth TLS, and internode TLS.
CREATE CERTIFICATE generates x509v3 certificates.
Syntax
CREATE [TEMP[ORARY]] [CA] CERTIFICATE certificate_name
{AS cert [KEY key_name]
| SUBJECT subject
[ SIGNED BY ca_cert ]
[ VALID FOR days ]
[ EXTENSIONS ext = val[,...] ]
[ KEY private_key ]}
Parameters
TEMPORARY- Create with session scope. The key is stored in memory and is valid only for the current session.
CA- Designates the certificate as a CA or intermediate certificate. If omitted, the operation creates a normal certificate.
certificate_name- The name of the certificate.
AS cert- The imported certificate (string).
This parameter should include the entire chain of certificates, excluding the CA certificate.
KEY key_name- The name of the key.
This parameter only needs to be set for client/server certificates and CA certificates that you intend to sign other certificates with in Vertica. If your imported CA certificate will only be used for validating other certificates, you do not need to specify a key.
SUBJECT subject- The entity to issue the certificate to (string).
SIGNED BY ca_cert- The name of the CA that signed the certificate.
When adding a CA certificate, this parameter is optional. Specifying it will create an intermediate CA that cannot be used to sign other CA certificates.
When creating a certificate, this parameter is required.
VALID FOR days- The number of days that the certificate is valid.
EXTENSIONS ext=val- Strings specifying certificate extensions. For a full list of extensions, see the OpenSSL documentation.
KEY private_key- The name of the certificate's private key.
When importing a certificate, this parameter is required.
Privileges
Superuser
Default extensions
CREATE CERTIFICATE generates x509v3 certificates and includes several extensions by default. These differ based on the type of certificate you create:
CA Certificate:
-
'basicConstraints' = 'critical, CA:true'
-
'keyUsage' = 'critical, digitalSignature, keyCertSign'
-
'nsComment' = Vertica generated [CA] certificate'
-
'subjectKeyIdentifier' = 'hash'
Certificate:
-
'basicConstraints' = 'CA:false'
-
'keyUsage' = 'critical, digitalSignature, keyEncipherment'
Examples
See Generating TLS certificates and keys.
See also
7.11.5 - CREATE DATA LOADER
CREATE DATA LOADER creates an automatic data loader that executes a COPY statement when new data files appear in a specified location. The loader records which files have already been successfully loaded and skips them.
CREATE DATA LOADER creates an automatic data loader that executes a COPY statement when new data files appear in a specified path. The loader records which files have already been successfully loaded and skips them. These events are recorded in the DATA_LOADER_EVENTS system table.
You can execute a data loader in the following ways:
Executing the loader automatically commits the transaction.
The DATA_LOADERS system table shows all defined loaders. The DATA_LOADER_EVENTS system table records paths that were attempted and their outcomes. To prevent unbounded growth, records in DATA_LOADER_EVENTS are purged after a specified retention interval. If previously-loaded files are still in the source path after this purge, the data loader sees them as new files and loads them again.
Syntax
CREATE [ OR REPLACE ] DATA LOADER [ IF NOT EXISTS ]
[schema.]name
[ RETRY LIMIT { NONE | DEFAULT | limit } ]
[ RETENTION INTERVAL monitoring-retention ]
[ TRIGGERED BY integration-json ]
AS copy-statement
Arguments
OR REPLACE- If a data loader with the same name in the same schema exists, replace it. The original data loader's monitoring table is dropped.
This option cannot be used with IF NOT EXISTS.
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
This option cannot be used with OR REPLACE.
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader.
RETRY LIMIT { NONE | DEFAULT | limit }- Maximum number of times to retry a failing file. Each time the data loader is executed, it attempts to load all files that have not yet been successfully loaded, up to this per-file limit. If set to DEFAULT, at load time the loader uses the value of the DataLoaderDefaultRetryLimit configuration parameter.
Default: DEFAULT
RETENTION INTERVAL monitoring-retention- How long to keep records in the events table. DATA_LOADER_EVENTS records events for all data loaders, but each data loader has its own retention interval.
Default: 14 days
TRIGGERED BY integration-json- Information about an external input for the data loader, a JSON object with the following keys:
provider: name of the provider; the only supported value is "AWS-SQS"resourceUrl: endpoint for the integration
If a data loader has a trigger, the loader is initially disabled. When you are ready to use it, use ALTER DATA LOADER with the ENABLE option. When the loader is enabled, Vertica executes it automatically when the trigger produces notifications for new files. For details, see Triggers.
AS copy-statement- The COPY statement that the loader executes. The FROM clause typically uses a glob.
Privileges
Non-superuser: CREATE privileges on the schema.
Restrictions
- COPY NO COMMIT is not supported.
- Data loaders are executed with COPY ABORT ON ERROR.
- The COPY statement must specify file paths. You cannot use COPY FROM VERTICA.
Triggers (AWS SQS only)
If the data to be loaded is stored on AWS and you have configured an SQS queue, then instead of executing a data loader explicitly using EXECUTE DATA LOADER, you can define the loader to respond to S3 events. When files are added to the AWS bucket, a service running on AWS adds a message to the SQS queue. Vertica reads from this queue, executes the data loader, and, if the load was successful, removes the message from the queue. After the initial setup, this process is automatic.
To configure the data loader with a trigger, use the TRIGGERED BY option with a JSON object following this template:
{
"provider" : "AWS-SQS",
"resourceUrl" : "https://sqs.region.amazonaws.com/account_number/queue_name"
}
Use the following SQS parameters to authenticate to SQS:
SQSAuth, to set an ID and key for all queue access.SQSQueueCredentials, to set per-queue access. Queue-specific values take precedence over SQSAuth.
A data loader with a trigger is initially disabled. Use ALTER DATA LOADER with the ENABLE option when you are ready to begin processing events. To pause execution, call ALTER DATA LOADER with the DISABLE option.
If a data loader has a trigger, you must disable it before dropping it.
File systems
The source path can be any shared file system or object store that all database nodes can access. To use an HDFS or Linux file system safely, you must prevent the loader from reading a partially-written file. One way to achieve this is to only execute the loader when files are not being written to the loader's path. Another way to achieve this is to write new files in a temporary location and move them to the loader's path only when they are complete.
Examples
=> CREATE DATA LOADER s.dl1 RETRY LIMIT NONE
AS COPY s.local FROM 's3://b/data/*.dat';
=> SELECT name, schemaname, copystmt, retrylimit FROM data_loaders;
name | schemaname | copystmt | retrylimit
------+------------+---------------------------------------+------------
dl1 | s | COPY s.local FROM 's3://b/data/*.dat' | -1
(1 row)
See Automatic load for an extended example.
See also
7.11.6 - CREATE DIRECTED QUERY
Saves an association between an input query and a query that is annotated with optimizer hints.
Saves an association between an input query and a query that is annotated with optimizer hints.
CREATE DIRECTED QUERY has two variants:
- CREATE DIRECTED QUERY OPTIMIZER directs the query optimizer to generate annotated SQL from the specified input query. The annotated query contains hints that the optimizer can use to recreate its current query plan for that input query.
- CREATE DIRECTED QUERY CUSTOM specifies an annotated query supplied by the user. Vertica associates the annotated query with the input query specified by the last SAVE QUERY statement.
In both cases, Vertica associates the annotated query and input query, and registers their association in the system table DIRECTED_QUERIES under query_name.
Syntax
Optimizer-generated
CREATE DIRECTED QUERY OPT[IMIZER] query-name [COMMENT 'comments'] input-query
User-defined (custom)
CREATE DIRECTED QUERY CUSTOM query-name [COMMENT 'comments'] annotated-query
Parameters
OPT[IMIZER]- Directs the query optimizer to generate an annotated query from
input-query, and associate both in the new directed query.
CUSTOM- Specifies to associate
annotated-query with the query previously specified by SAVE QUERY.
query-name- A unique identifier for the directed query, a string that conforms to conventions described in Identifiers.
COMMENT 'comments'- Comment about the directed query, up to 128 characters. Comments can be useful for future reference—for example, to explain why a given directed query was created.
If you omit this argument, Vertica inserts one of the following comments:
input-query- The input query to associate with an optimizer-generated directed query. The input query supports only one optimizer hint,
:v (alias IGNORECONST).
annotated-query- A query with embedded optimizer hints to associate with the input query most recently saved with SAVE QUERY.
Privileges
Superuser
See also
Creating directed queries
7.11.7 - CREATE EXTERNAL TABLE AS COPY
CREATE EXTERNAL TABLE AS COPY creates a table definition for data external to your Vertica database.
CREATE EXTERNAL TABLE AS COPY creates a table definition for data external to your Vertica database. This statement is a combination of the CREATE TABLE and COPY statements, supporting a subset of each statement's parameters.
Canceling a CREATE EXTERNAL TABLE AS COPY statement can cause unpredictable results. If you need to make a change, allow the statement to complete, drop the table, and then retry.
You can use ALTER TABLE to change the data types of columns instead of dropping and recreating the table.
You can use CREATE EXTERNAL TABLE AS COPY with any types except types from the Place package.
Vertica also supports external tables backed by Iceberg data. See CREATE EXTERNAL TABLE ICEBERG.
Note
Vertica does not create superprojections for external tables, since external tables are not stored in the database.
Syntax
CREATE EXTERNAL TABLE [ IF NOT EXISTS ] [[{namespace. | database. }]schema.]table-name
( column-definition[,...] )
[{INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGES]
AS COPY
[ ( { column-as-expression | column }
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ FILLER datatype ]
[ FORMAT 'format' ]
[ NULL [ AS ] 'string' ]
[ TRIM 'byte' ]
[,...] ) ]
[ COLUMN OPTION ( column
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ FORMAT 'format' ]
[ NULL [ AS ] 'string' ]
[ TRIM 'byte' ]
[,...] ) ]
FROM {
{ 'path-to-data'
[ ON { nodename | (nodeset) | ANY NODE | EACH NODE } ] [ compression ] }[,...]
[ PARTITION COLUMNS column[,...] ]
| LOCAL 'path-to-data' [ compression ] [,...]
| VERTICA {source-namespace. | source-database. }[source-schema.]source-table[( source-column[,...] ) ]
}
[ NATIVE
| FIXEDWIDTH COLSIZES {( integer )[,...]}
| NATIVE VARCHAR
| ORC
| PARQUET
]
[ ABORT ON ERROR ]
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ERROR TOLERANCE ]
[ ESCAPE AS 'char' | NO ESCAPE ]
[ EXCEPTIONS 'path' [ ON nodename ] [,...] ]
[ [ WITH ] FILTER filter( [ arg=value[,...] ] ) ]
[ NULL [ AS ] 'string' ]
[ [ WITH ] PARSER parser([arg=value [,...] ]) ]
[ RECORD TERMINATOR 'string' ]
[ REJECTED DATA 'path' [ ON nodename ] [,...] ]
[ REJECTMAX integer ]
[ SKIP integer ]
[ SKIP BYTES integer ]
[ TRAILING NULLCOLS ]
[ TRIM 'byte' ]
Parameters
For all supported parameters, see the CREATE TABLE and COPY statements. For information on using this statement with UDLs, see User-defined load (UDL).
For additional guidance on using COPY parameters, see Specifying where to load data from.
Privileges
Superuser, or non-superuser with the following privileges:
Partitioned data
Data can be partitioned using its directory structure and Vertica can take advantage of that partitioning to improve query performance for external tables. For details, seePartitioned data.
If you see unexpected results when reading data, verify that globs in your file paths correctly align with the partition structure. See Troubleshooting external tables.
ORC and Parquet data
When using the ORC and Parquet formats, Vertica supports some additional options in the COPY statement and data structures for columns. See ORC and PARQUET.
Examples
The following example defines an external table for delimited data stored in HDFS:
=> CREATE EXTERNAL TABLE sales (itemID INT, date DATE, price FLOAT)
AS COPY FROM 'hdfs:///data/ext1.csv' DELIMITER ',';
The following example uses data in the ORC format that is stored in S3. The data has two partition columns. For more information about partitions, see Partitioned data.
=> CREATE EXTERNAL TABLE records (id int, name varchar(50), created date, region varchar(50))
AS COPY FROM 's3://datalake/sales/*/*/*'
PARTITION COLUMNS created, region;
The following example shows how you can read from all Parquet files in a local directory, with no partitions and no globs:
=> CREATE EXTERNAL TABLE sales (itemID INT, date DATE, price FLOAT)
AS COPY FROM '/data/sales/*.parquet' PARQUET;
The following example creates an external table for data containing arrays:
=> CREATE EXTERNAL TABLE cust (cust_custkey int,
cust_custname varchar(50),
cust_custstaddress ARRAY[varchar(100)],
cust_custaddressln2 ARRAY[varchar(100)],
cust_custcity ARRAY[varchar(50)],
cust_custstate ARRAY[char(2)],
cust_custzip ARRAY[int],
cust_email varchar(50), cust_phone varchar(30))
AS COPY FROM 'webhdfs://data/*.parquet' PARQUET;
To allow users without superuser access to use external tables with data on the local file system, S3, or GCS, create a location for 'user' usage and grant access to it. This example shows granting access to a user named Bob to any external table whose data is located under /tmp (including in subdirectories to any depth):
=> CREATE LOCATION '/tmp' ALL NODES USAGE 'user';
=> GRANT ALL ON LOCATION '/tmp' to Bob;
The following example shows CREATE EXTERNAL TABLE using a user-defined source:
=> CREATE SOURCE curl AS LANGUAGE 'C++' NAME 'CurlSourceFactory' LIBRARY curllib;
=> CREATE EXTERNAL TABLE curl_table1 as COPY SOURCE CurlSourceFactory;
See also
Creating external tables
7.11.8 - CREATE EXTERNAL TABLE ICEBERG
Creates an external table for data stored by Apache Iceberg.
Creates an external table for data stored by Apache Iceberg. An Iceberg table consists of data files and metadata describing the schema. Unlike other external tables, an Iceberg external table need not specify column definitions (DDL). The information is read from Iceberg metadata at query time. For certain data types you can adjust column definitions, for example to specify VARCHAR sizes.
A single Iceberg table can have more than one metadata file, each describing a different version of the table. Iceberg supports two types of tables based on how their metadata files are stored:
- File System Tables - In this type, the writer is responsible for naming and organizing the metadata files. For file system tables, you can create an external table using either the base location of the table or a specific metadata file.
- Metastore Tables - In this type, a separate metastore handles metadata management. Vertica supports the AWS Glue metastore and all metastores that comply with the Iceberg Standard Rest Open API, such as Project Nessie and others.
- AWS Glue tables - You can create an external table by specifying the Glue database location and using the
glue-db and glue-table parameters.
- Rest Open API tables - You can create an external table by specifying the HTTP or HTTPs endpoint location and using the
rest-auth parameter.
If a metadata file specifies columns or struct fields that are not present in the data, Vertica treats the missing values as NULL.
All Iceberg files, both data and metadata, must be accessible to all database nodes.
Iceberg can store data in several file formats. Vertica can read Iceberg data in the Parquet format only and with either version 1 or version 2 metadata. If the Parquet files encode field IDs, Vertica uses them directly. Otherwise, Vertica uses Iceberg fallback name mapping to read field IDs from the metadata (the schema.name-mapping.default property). If the metadata does not contain a mapping for a field, Vertica sets the column values to NULL.
Syntax
CREATE EXTERNAL TABLE [[{namespace. | database. }]schema.]table
STORED BY ICEBERG LOCATION { path | metadata-file | glue-path | rest-endpoint }
[GLUE_DB glue-db]
[GLUE_TABLE glue-table]
[REST_AUTH rest-auth]
[COLUMN TYPES (column-name type[,...])] ;
Arguments
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table- Name of the table to create, which must be unique among names of all sequences, tables, projections, views, and models within the schema.
glue-db- Name of the AWS Glue database. If specified
glue-table must also be specified.
glue-table- Name of the AWS Glue table. If specified
glue-db must also be specified.
rest-auth- A JSON parameter for authentication credentials to access an Iceberg table through a REST OpenAPI endpoint. It can include either a
bearerToken (used for stateless authentication) or OAuth2 fields to acquire its own tokens.
- oauthTokenUri: The URL used to obtain the OAuth2 token.
- oauthClientId: The client ID used for OAuth2 authentication.
- oauthClientSecret: The secret associated with the client ID.
- oauthAllowedScopes: A list of scopes determining the access granted.
STORED BY ICEBERG LOCATION { path|metadata-file|glue-path|rest-endpoint }- Location of Iceberg data, one of:
-
Base location of an Iceberg File System table. Vertica uses the latest metadata file.
-
Path to a metadata file with a name ending in .metadata.json. Vertica uses this metadata file even if it is not the latest.
-
AWS Glue database path (glue-path): An S3 path where the specified Glue database (glue-db) is located, or the S3 bucket containing this path.
-
HTTP or HTTPS endpoint (rest-endpoint) of a table managed by an Iceberg metastore that follows Iceberg's REST OpenAPI specification.
If the paths embedded in the Iceberg data are not accessible to Vertica, use the IcebergPathMapping configuration parameter to provide mappings. See Path Prefixes.
COLUMN TYPES (column-name type[,...])- Column names and types for VARCHAR, VARBINARY, or ARRAY columns or ROW fields only. You can specify types only to set lengths or array bounds, not type coercion. See Data Types. If you do not specify a type, the table uses the Vertica defaults.
You cannot specify any other column properties, such as defaults or constraints.
Columns that are specified but not found in the Iceberg schema are ignored.
Privileges
Superuser, or non-superuser with the following privileges:
Path prefixes
Iceberg tables store file paths in the metadata as absolute URIs (host and port). Sometimes this URI differs from the URI that Vertica can use to access the data. This can particularly be an issue for files stored on HDFS, where the metadata can use a different URI scheme and port number than what Vertica expects.
To change the URIs, set the IcebergPathMapping configuration parameter. The value is a list of one or more pairs of Iceberg URI prefixes and corresponding Vertica prefixes:
=> ALTER SESSION SET IcebergPathMapping=
'{"hdfs://node-196.example.com:9000":"webhdfs://node-196.example.com:9870"}';
Include only the URI prefix (up through the port), not complete paths. If IcebergPathMapping contains more than one mapping that could apply, Vertica uses the longest entry that matches.
You can set IcebergPathMapping at the database, session, or user level.
Data types
The following table shows the mappings of Iceberg data types to Vertica data types. For types that allow it, you can use the COLUMN TYPES clause to override these defaults.
|
Iceberg Type |
Vertica Type |
Allows Override? |
|
boolean |
BOOLEAN |
No |
|
int (32-bit) |
INT |
No |
|
long (64-bit) |
INT |
No |
|
float (32-bit) |
FLOAT |
No |
|
double (64-bit) |
FLOAT |
No |
|
decimal(precision, scale) |
NUMERIC with same precision and scale |
No |
|
date |
DATE |
No |
|
time |
TIME |
No |
|
timestamp |
TIMESTAMP |
No |
|
timestamptz |
TIMESTAMP WITH TIMEZONE |
No |
|
string |
VARCHAR(80) |
VARCHAR or LONG VARCHAR with custom length |
|
uuid |
UUID |
No |
|
fixed(length) |
BINARY(length) if length <= 65000
LONG VARBINARY(length) otherwise
|
No |
|
binary (variable length) |
VARBINARY(80) |
VARBINARY or LONG VARBINARY with custom length |
|
struct |
ROW |
No, but you can override individual fields if their types permit |
|
list |
ARRAY (default bound) |
ARRAY with custom bound |
|
map<key, value> |
ARRAY[ROW(key, value)] (default bound) |
ARRAY[ROW(key, value)] with custom bound |
Restrictions
The following restrictions apply to external tables backed by Iceberg:
-
Data files must be in Parquet format.
-
Metadata files must use version 1 or version 2 format.
-
Iceberg column defaults are not supported.
-
Iceberg delete files are not supported.
-
Malformed data is an error that aborts the load. You cannot reject bad data and continue.
-
VARCHAR values are not truncated. If a string is too long, it is treated as an error.
The following restrictions apply to queries of Iceberg tables:
-
You cannot use a column in an Iceberg table as a DEFAULT or SET USING option in another table. The following example is an error:
=> CREATE TABLE t(
id INT DEFAULT (SELECT COUNT(*) FROM iceberg_table));
ERROR 0: Default and set using expressions cannot refer to external iceberg tables
-
Errors in Iceberg data or metadata, such as missing files or type mismatches, can manifest as query errors such as the following:
=> SELECT * FROM iceberg_table;
ERROR 0: Problem reading metadata for table iceberg_table. Detail: Could not determine type of column a. User specified type: int. Iceberg type: boolean
Examples
The following example creates a table based on the Parquet data files with no overrides:
=> CREATE EXTERNAL TABLE sales
STORED BY ICEBERG LOCATION 's3:/sales/*';
In the following example, the data uses a struct for the shipping address, with fields for street address (string), city (string), and zip code (integer). The following table definition overrides the default VARCHAR lengths. Note that the zip code is not included in COLUMN TYPES overrides. The ROW column contains only the fields being changed, but all fields including the zip code are part of the table definition and are included in query results:
=> CREATE EXTERNAL TABLE sales
STORED BY ICEBERG LOCATION 's3:/sales/*'
COLUMN TYPES (address ROW(street VARCHAR(50), city VARCHAR(50)));
The following example creates an external table named users_glue for the Iceberg table users in the Glue database testdb. The metadata is stored at s3://vertica-fleeting/my-iceberg:
=> CREATE EXTERNAL TABLE users_glue
STORED BY ICEBERG LOCATION 's3://vertica-fleeting/my-iceberg'
GLUE_DB 'testdb'
GLUE_TABLE 'users';
The following example creates an external table named rest_t1 for the Iceberg table my_t1, managed by an Iceberg metastore through a REST OpenAPI endpoint. Authentication is provided using a bearerToken:
=> CREATE EXTERNAL TABLE rest_t1
STORED BY ICEBERG LOCATION 'https://myhost:19120/iceberg/v1/main/namespaces/my_ice_db/tables/my_t1'
REST_AUTH '{"bearerToken": "eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICIzWFRweHB"}';
The following example creates an external table named rest_t2 for the Iceberg table my_t2, managed by an Iceberg metastore through a REST OpenAPI endpoint. Authentication is provided using OAuth2 fields:
=> CREATE EXTERNAL TABLE rest_t2
STORED BY ICEBERG LOCATION 'https://myhost:19120/iceberg/v1/main/namespaces/my_ice_db/tables/my_t2'
REST_AUTH '{"oauthTokenUri": "http://myhost:8080/realms/iceberg/protocol/openid-connect/token",
"oauthClientId": "client1",
"oauthClientSecret": "s3cr3t",
"oauthAllowedScopes": ["profile", "catalog"]}';
See also
EXTERNAL_DATA_FILES_PRUNED event in QUERY_EVENTS.
7.11.9 - CREATE FAULT GROUP
Creates a fault group, which can contain the following:.
Enterprise Mode only
Creates a fault group, which can contain the following:
CREATE FAULT GROUP creates an empty fault group. Use ALTER FAULT GROUP to add nodes or other fault groups to an existing fault group.
Syntax
CREATE FAULT GROUP name
Parameters
name- The name of the fault group to create, unique among all fault groups, where
name conforms to conventions described in Identifiers.
Privileges
Superuser
Examples
The following command creates a fault group called parent0:
=> CREATE FAULT GROUP parent0;
CREATE FAULT GROUP
See also
7.11.10 - CREATE FLEXIBLE EXTERNAL TABLE AS COPY
CREATE FLEXIBLE EXTERNAL TABLE AS COPY creates a flexible external table.
CREATE FLEXIBLE EXTERNAL TABLE AS COPY creates a flexible external table. This statement combines statements CREATE FLEXIBLE TABLE and COPY statements, supporting a subset of each statement's parameters.
You can also use user-defined load functions (UDLs) to create external flex tables. For details about creating and using flex tables, see Using Flex Tables.
Note
Vertica does not create a superprojection for an external table when you create it.
For details about creating and using flex tables, see Creating flex tables in Using Flex Tables.
Caution
Canceling a
CREATE FLEX EXTERNAL TABLE AS COPY statement can cause unpredictable results. Vertica recommends that you allow the statement to finish, then use
DROP TABLE after the table exists.
Syntax
CREATE FLEX[IBLE] EXTERNAL TABLE [ IF NOT EXISTS ] [[database.]schema.]table-name
( [ column-definition[,...] ] )
[ INCLUDE | EXCLUDE [SCHEMA] PRIVILEGES ]
AS COPY [ ( { column-as-expression | column } [ FILLER datatype ] ]
FROM {
'path-to-data' [ ON nodename | ON ANY NODE | ON (nodeset) ] input-format [,...]
| [ WITH ] UDL-clause[...]
}
[ ABORT ON ERROR ]
[ DELIMITER [ AS ] 'char' ]
[ ENCLOSED [ BY ] 'char' ]
[ ENFORCELENGTH ]
[ ESCAPE [ AS ] 'char' | NO ESCAPE ]
[ EXCEPTIONS 'path' [ ON nodename ] [,...] ]
[ NULL [ AS ] 'string' ]
[ RECORD TERMINATOR 'string' ]
[ REJECTED DATA 'path' [ ON nodename ][,...] ]
[ REJECTMAX integer ]
[ SKIP integer ]
[ SKIP BYTES integer ]
[ TRAILING NULLCOLS ]
[ TRIM 'byte' ]
Parameters
For parameter descriptions, see CREATE TABLE and Parameters.
Note
CREATE FLEXIBLE EXTERNAL TABLE AS COPY supports only a subset of CREATE TABLE and COPY parameters.
Privileges
Superuser, or non-superuser with the following privileges:
Examples
To create an external flex table:
=> CREATE flex external table mountains() AS COPY FROM 'home/release/KData/kmm_ountains.json' PARSER fjsonparser();
CREATE TABLE
As with other flex tables, creating an external flex table produces two regular tables: the named table and its associated _keys table. The keys table is not an external table:
=> \dt mountains
List of tables
Schema | Name | Kind | Owner | Comment
--------+-----------+-------+---------+---------
public | mountains | table | release |
(1 row)
You can use the helper function, COMPUTE_FLEXTABLE_KEYS_AND_BUILD_VIEW, to compute keys and create a view for the external table:
=> SELECT compute_flextable_keys_and_build_view ('appLog');
compute_flextable_keys_and_build_view
--------------------------------------------------------------------------------------------------
Please see public.appLog_keys for updated keys
The view public.appLog_view is ready for querying
(1 row)
Check the keys from the _keys table for the results of running the helper application:
=> SELECT * FROM appLog_keys;
key_name | frequency | data_type_guess
----------------------------------------------------------+-----------+------------------
contributors | 8 | varchar(20)
coordinates | 8 | varchar(20)
created_at | 8 | varchar(60)
entities.hashtags | 8 | long varbinary(186)
.
.
.
retweeted_status.user.time_zone | 1 | varchar(20)
retweeted_status.user.url | 1 | varchar(68)
retweeted_status.user.utc_offset | 1 | varchar(20)
retweeted_status.user.verified | 1 | varchar(20)
(125 rows)
You can query the view:
=> SELECT "user.lang" FROM appLog_view;
user.lang
-----------
it
en
es
en
en
es
tr
en
(12 rows)
See also
7.11.11 - CREATE FLEXIBLE TABLE
Creates a flexible (flex) table in the logical schema.
Creates a flexible (flex) table in the logical schema.
When you create a flex table, Vertica automatically creates two dependent objects:
The flex table requires the keys table and view. Neither of these objects can exist independently of the flex table.
Syntax
Create with column definitions:
CREATE [[ scope ] TEMP[ORARY]] FLEX[IBLE] TABLE [ IF NOT EXISTS ]
[[database.]schema.]table-name
( [ column-definition[,...] [, table-constraint ][,...] ] )
[ ORDER BY column[,...] ]
[ segmentation-spec ]
[ KSAFE [k-num] ]
[ partition-clause]
[ {INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGES ]
[ DISK_QUOTA quota ]
Create from another table:
CREATE FLEX[IBLE] TABLE [[database.]schema.] table-name
[ ( column-name-list ) ]
[ {INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGES ]
AS query [ ENCODED BY column-ref-list ]
[ DISK_QUOTA quota ]
Parameters
For general parameter descriptions, see CREATE TABLE; for parameters specific to temporary flex tables, see CREATE TEMPORARY TABLE and Creating flex tables.
You cannot partition a flex table on any virtual column (key).
Privileges
Non-superuser: CREATE privilege on table schema
Default columns
The CREATE statement can omit specifying any column definitions. CREATE FLEXIBLE TABLE always creates two columns automatically:
__raw__- LONG VARBINARY type column to store unstructured data that you load. By default, this column has a
NOT NULL constraint.
__identity__- IDENTITY column that is used for segmentation and sorting when no other column is defined.
Default projections
Vertica automatically creates superprojections for both the flex table and keys tables when you create them.
If you create a flex table with one or more of the ORDER BY, ENCODED BY, SEGMENTED BY, or KSAFE clauses, the clause information is used to create projections. If no clauses are in use, Vertica uses the following defaults:
|
Table |
Sort order |
Encoding |
Segmentation |
K-safety |
|
Flexible table |
ORDER BY *.__identity__ |
none |
SEGMENTED BY hash *.__identity__ ALL NODES OFFSET 0 |
1 |
|
Keys table |
ORDER BY *._keys_frequency |
none |
UNSEGMENTED ALL NODES |
1 |
Note
When you build a view for a flex table (see
BUILD_FLEXTABLE_VIEW), the view is ordered by
frequency,
desc, and
key_name.
Examples
The following example creates a flex table named darkdata without specifying any column information. Vertica creates a default superprojection and buddy projection as part of creating the table:
=> CREATE FLEXIBLE TABLE darkdata();
CREATE TABLE
=> \dj darkdata1*
List of projections
Schema | Name | Owner | Node | Comment
--------+----------------------+---------+------------------+---------
public | darkdata1_b0 | dbadmin | |
public | darkdata1_b1 | dbadmin | |
public | darkdata1_keys_super | dbadmin | v_vmart_node0001 |
public | darkdata1_keys_super | dbadmin | v_vmart_node0002 |
public | darkdata1_keys_super | dbadmin | v_vmart_node0003 |
(5 rows)
=> SELECT export_objects('','darkdata1_b0');
CREATE PROJECTION public.darkdata1_b0 /*+basename(darkdata1),createtype(P)*/
(
__identity__,
__raw__
)
AS
SELECT darkdata1.__identity__,
darkdata1.__raw__
FROM public.darkdata1
ORDER BY darkdata1.__identity__
SEGMENTED BY hash(darkdata1.__identity__) ALL NODES OFFSET 0;
SELECT MARK_DESIGN_KSAFE(1);
(1 row)
=> select export_objects('','darkdata1_keys_super');
CREATE PROJECTION public.darkdata1_keys_super /*+basename(darkdata1_keys),createtype(P)*/
(
key_name,
frequency,
data_type_guess
)
AS
SELECT darkdata1_keys.key_name,
darkdata1_keys.frequency,
darkdata1_keys.data_type_guess
FROM public.darkdata1_keys
ORDER BY darkdata1_keys.frequency
UNSEGMENTED ALL NODES;
SELECT MARK_DESIGN_KSAFE(1);
(1 row)
The following example creates a table called darkdata1 with one column definition (date_col). The statement specifies the partition by clause to partition the data by year. Vertica creates a default superprojection and buddy projections as part of creating the table:
=> CREATE FLEX TABLE darkdata1 (date_col date NOT NULL) partition by
extract('year' from date_col);
CREATE TABLE
See also
7.11.12 - CREATE FUNCTION statements
Vertica provides CREATE statements for each type of user-defined extension.
Vertica provides CREATE statements for each type of user-defined extension. Each CREATE statement adds a user-defined function to the Vertica catalog:
Vertica also provides CREATE FUNCTION (SQL), which stores SQL expressions as functions that you can invoke in a query.
7.11.12.1 - CREATE AGGREGATE FUNCTION
Adds a user-defined aggregate function (UDAF) to the catalog.
Adds a user-defined aggregate function (UDAF) to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
CREATE AGGREGATE FUNCTION automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading aggregate functions. When you call the SQL function, Vertica passes the input table to the function to process.
User-defined aggregate functions run in unfenced mode only.
Syntax
CREATE [ OR REPLACE ] AGGREGATE FUNCTION [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ NOT FENCED ];
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- The language used to develop this function, currently
C++ only (the default).
NAME 'factory'- Name of the factory class that generates the function instance.
LIBRARY library- Name of the shared library that contains the function. This library must have already been loaded by CREATE LIBRARY.
NOT FENCED- Indicates that the function runs in unfenced mode. Aggregate functions cannot be run in fenced mode.
Privileges
Non-superuser:
Examples
The following example demonstrates loading a library named AggregateFunctions and then defining functions named ag_avg and ag_cat. The functions are mapped to the AverageFactory and ConcatenateFactory classes in the library:
=> CREATE LIBRARY AggregateFunctions AS '/opt/vertica/sdk/examples/build/AggregateFunctions.so';
CREATE LIBRARY
=> CREATE AGGREGATE FUNCTION ag_avg AS LANGUAGE 'C++' NAME 'AverageFactory'
library AggregateFunctions;
CREATE AGGREGATE FUNCTION
=> CREATE AGGREGATE FUNCTION ag_cat AS LANGUAGE 'C++' NAME 'ConcatenateFactory'
library AggregateFunctions;
CREATE AGGREGATE FUNCTION
=> \x
Expanded display is on.
select * from user_functions;
-[ RECORD 1 ]----------+------------------------------------------------------------------
schema_name | public
function_name | ag_avg
procedure_type | User Defined Aggregate
function_return_type | Numeric
function_argument_type | Numeric
function_definition | Class 'AverageFactory' in Library 'public.AggregateFunctions'
volatility |
is_strict | f
is_fenced | f
comment |
-[ RECORD 2 ]----------+------------------------------------------------------------------
schema_name | public
function_name | ag_cat
procedure_type | User Defined Aggregate
function_return_type | Varchar
function_argument_type | Varchar
function_definition | Class 'ConcatenateFactory' in Library 'public.AggregateFunctions'
volatility |
is_strict | f
is_fenced | f
comment |
See also
7.11.12.2 - CREATE ANALYTIC FUNCTION
Adds a user-defined analytic function (UDAnF) to the catalog.
Adds a user-defined analytic function (UDAnF) to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
CREATE ANALYTIC FUNCTION automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading analytic functions. When you call the SQL function, Vertica passes the input table to the function in the library to process.
Syntax
CREATE [ OR REPLACE ] ANALYTIC FUNCTION [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- Language used to develop this function, one of the following:
NAME 'factory'- Name of the factory class that generates the function instance.
LIBRARY library- Name of the library that contains the function. This library must already be loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function.
Default: FENCED
Privileges
Non-superuser:
Examples
This example creates an analytic function named an_rank based on the factory class named RankFactory in the AnalyticFunctions library:
=> CREATE ANALYTIC FUNCTION an_rank AS LANGUAGE 'C++'
NAME 'RankFactory' LIBRARY AnalyticFunctions;
See also
Analytic functions (UDAnFs)
7.11.12.3 - CREATE FILTER
Adds a user-defined load filter function to the catalog.
Adds a user-defined load filter function to the catalog. The library containing the filter function must have been previously added using CREATE LIBRARY.
CREATE FILTER automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading load filter functions. When you call the SQL function, Vertica passes the input table to the function in the library to process.
Important
Installing an untrusted UDL function can compromise the security of the server. UDxs can contain arbitrary code. In particular, user-defined parser functions can read data from any arbitrary location. It is up to the developer of the function to enforce proper security limitations. Superusers must not grant access to UDxs to untrusted users.
Syntax
CREATE [ OR REPLACE ] FILTER [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory' LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- The language used to develop this function, one of the following:
-
C++ (default)
-
Java
-
Python
NAME 'factory'- Name of the factory class that generates the function instance. This is the same name used by the RegisterFactory class.
LIBRARY library- Name of the C++ library shared object file, Python file, or Java Jar file. This library must already have been loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function.
Default: FENCED
Privileges
Superuser
Examples
The following example demonstrates loading a library named iConverterLib, then defining a filter function named Iconverter that is mapped to the iConverterFactory factory class in the library:
=> CREATE LIBRARY iConverterLib as '/opt/vertica/sdk/examples/build/IconverterLib.so';
CREATE LIBRARY
=> CREATE FILTER Iconverter AS LANGUAGE 'C++' NAME 'IconverterFactory' LIBRARY IconverterLib;
CREATE FILTER FUNCTION
=> \x
Expanded display is on.
=> SELECT * FROM user_functions;
-[ RECORD 1 ]----------+--------------------
schema_name | public
function_name | Iconverter
procedure_type | User Defined Filter
function_return_type |
function_argument_type |
function_definition |
volatility |
is_strict | f
is_fenced | f
comment |
See also
7.11.12.4 - CREATE FUNCTION (scalar)
Adds a user-defined scalar function (UDSF) to the catalog.
Adds a user-defined scalar function (UDSF) to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
A UDSF takes in a single row of data and returns a single value. These functions can be used anywhere a native Vertica function or statement can be used, except CREATE TABLE with its PARTITION BY or any segmentation clause.
CREATE FUNCTION automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading UDxs. When you call the function, Vertica passes the parameters to the function in the library to process.
Syntax
CREATE [ OR REPLACE ] FUNCTION [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- Language used to develop this function, one of the following:
-
C++ (default)
-
Python
-
Java
-
R
NAME 'factory'- Name of the factory class that generates the function instance.
LIBRARY library- Name of the C++ shared object file, Python file, Java Jar file, or R functions file. This library must already have been loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function. Functions written in Java and R always run in fenced mode.
Default: FENCED
Privileges
Examples
The following example loads a library named ScalarFunctions and then defines a function named Add2ints that is mapped to the Add2intsInfo factory class in the library:
=> CREATE LIBRARY ScalarFunctions AS '/opt/vertica/sdk/examples/build/ScalarFunctions.so';
CREATE LIBRARY
=> CREATE FUNCTION Add2Ints AS LANGUAGE 'C++' NAME 'Add2IntsFactory' LIBRARY ScalarFunctions;
CREATE FUNCTION
=> \x
Expanded display is on.
=> SELECT * FROM USER_FUNCTIONS;
-[ RECORD 1 ]----------+----------------------------------------------------
schema_name | public
function_name | Add2Ints
procedure_type | User Defined Function
function_return_type | Integer
function_argument_type | Integer, Integer
function_definition | Class 'Add2IntsFactory' in Library 'public.ScalarFunctions'
volatility | volatile
is_strict | f
is_fenced | t
comment |
=> \x
Expanded display is off.
=> -- Try a simple call to the function
=> SELECT Add2Ints(23,19);
Add2Ints
----------
42
(1 row)
The following example uses a scalar function that returns a ROW:
=> CREATE FUNCTION div_with_rem AS LANGUAGE 'C++' NAME 'DivFactory' LIBRARY ScalarFunctions;
=> SELECT div_with_rem(18,5);
div_with_rem
------------------------------
{"quotient":3,"remainder":3}
(1 row)
See also
Developing user-defined extensions (UDxs)
7.11.12.5 - CREATE FUNCTION (SQL)
Stores SQL expressions as functions for use in queries.
Stores SQL expressions as functions for use in queries. User-defined SQL functions are useful for executing complex queries and combining Vertica built-in functions. You can call the function in a given query. If multiple SQL functions with the same name and argument types are in the search path, Vertica calls the first match that it finds.
SQL functions do not support complex types for arguments or return values.
SQL functions are flattened in all cases, including DDL.
Syntax
CREATE [ OR REPLACE ] FUNCTION [ IF NOT EXISTS ]
[[database.]schema.]function( [ argname argtype[,...] ] )
RETURN return_type
AS
BEGIN
RETURN expression;
END;
Arguments
OR REPLACE- If a function of the same name and arguments exists, replace it. If you only change the function arguments, Vertica ignores this option and maintains both functions under the same name.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- Name of the function to create, which must conform to the conventions described in Identifiers.
argname argtype[,...]- A comma-delimited list of argument names and their data types. Complex types are not supported.
return_type- The data type that this function returns. Complex types are not supported.
RETURN expression- The SQL function body, which can contain built-in functions, operators, and argument names specified in the CREATE FUNCTION statement. The expression must end with a semicolon.
Note
CREATE FUNCTION allows only one RETURN expression. Return expressions do not support the following:
-
FROM, WHERE, GROUP BY, ORDER BY, and LIMIT clauses
-
Aggregation, analytics, and meta-functions
Privileges
Non-superuser:
Strictness and volatility
Vertica infers the strictness and volatility (stable, immutable, or volatile) of a SQL function from its definition. Vertica then determines the correctness of usage, such as where an immutable function is expected but a volatile function is provided.
SQL functions and views
You can create views on the queries that use SQL functions and then query the views. When you create a view, a SQL function replaces a call to the user-defined function with the function body in a view definition. Therefore, when the body of the user-defined function is replaced, the view should also be replaced.
Examples
See Creating user-defined SQL functions.
See also
7.11.12.6 - CREATE PARSER
Adds a user-defined load parser function to the catalog.
Adds a user-defined load parser function to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
CREATE PARSER automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading load parser functions. When you call the SQL function, Vertica passes the input table to the function in the library to process.
Important
Installing an untrusted UDL function can compromise the security of the server. UDxs can contain arbitrary code. In particular, user-defined parser functions can read data from any arbitrary location. It is up to the developer of the function to enforce proper security limitations. Superusers must not grant access to UDxs to untrusted users.
Syntax
CREATE [ OR REPLACE ] PARSER [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- The language used to develop this function, one of the following:
-
C++ (default)
-
Java
-
Python
NAME 'factory'- Name of the factory class that generates the function instance. This is the same name used by the RegisterFactory class.
LIBRARY library- Name of the C++ library shared object file, Python file, or Java Jar file. This library must already have been loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function.
Default: FENCED
Privileges
Superuser
Examples
The following example demonstrates loading a library named BasicIntegrerParserLib, then defining a parser function named BasicIntegerParser that is mapped to the BasicIntegerParserFactory factory class in the library:
=> CREATE LIBRARY BasicIntegerParserLib as '/opt/vertica/sdk/examples/build/BasicIntegerParser.so';
CREATE LIBRARY
=> CREATE PARSER BasicIntegerParser AS LANGUAGE 'C++' NAME 'BasicIntegerParserFactory' LIBRARY BasicIntegerParserLib;
CREATE PARSER FUNCTION
=> \x
Expanded display is on.
=> SELECT * FROM user_functions;
-[ RECORD 1 ]----------+--------------------
schema_name | public
function_name | BasicIntegerParser
procedure_type | User Defined Parser
function_return_type |
function_argument_type |
function_definition |
volatility |
is_strict | f
is_fenced | f
comment |
See also
7.11.12.7 - CREATE SOURCE
Adds a user-defined load source function to the catalog.
Adds a user-defined load source function to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
CREATE SOURCE automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading load source functions. When you call the SQL function, Vertica passes the input table to the function in the library to process.
Important
Installing an untrusted UDL function can compromise the security of the server. UDxs can contain arbitrary code. In particular, user-defined parser functions can read data from any arbitrary location. It is up to the developer of the function to enforce proper security limitations. Superusers must not grant access to UDxs to untrusted users.
Syntax
CREATE [ OR REPLACE ] SOURCE [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- Language used to develop this function, one of the following:
NAME 'factory'- Name of the factory class that generates the function instance. This is the same name used by the RegisterFactory class.
LIBRARY library- Name of the C++ library shared object file or Java Jar file. This library must already have been loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function.
Default: FENCED
Privileges
Superuser
Examples
The following example demonstrates loading a library named curllib, then defining a source function named curl that is mapped to the CurlSourceFactory factory class in the library:
=> CREATE LIBRARY curllib as '/opt/vertica/sdk/examples/build/cURLLib.so';
CREATE LIBRARY
=> CREATE SOURCE curl AS LANGUAGE 'C++' NAME 'CurlSourceFactory' LIBRARY curllib;
CREATE SOURCE
=> \x
Expanded display is on.
=> SELECT * FROM user_functions;
-[ RECORD 1 ]----------+--------------------
schema_name | public
function_name | curl
procedure_type | User Defined Source
function_return_type |
function_argument_type |
function_definition |
volatility |
is_strict | f
is_fenced | f
comment |
See also
7.11.12.8 - CREATE TRANSFORM FUNCTION
Adds a user-defined transform function (UDTF) to the catalog.
Adds a user-defined transform function (UDTF) to the catalog. The library containing the function must have been previously added using CREATE LIBRARY.
CREATE TRANSFORM FUNCTION automatically determines the function parameters and return value from data supplied by the factory class. Vertica supports overloading transform functions. When you call the SQL function, Vertica passes the input table to the transform function in the library to process.
Syntax
CREATE [ OR REPLACE ] TRANSFORM FUNCTION [ IF NOT EXISTS ]
[[database.]schema.]function AS
[ LANGUAGE 'language' ]
NAME 'factory'
LIBRARY library
[ FENCED | NOT FENCED ]
Arguments
OR REPLACEIf a function with the same name and arguments exists, replace it. You can use this to change between fenced and unfenced modes, for example. If you do not use this directive and the function already exists, the CREATE statement returns with a rollback error.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
IF NOT EXISTSIf a function with the same name and arguments exists, return without creating the function.
OR REPLACE and IF NOT EXISTS are mutually exclusive.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
functionName of the function to create. This is the name used in SQL invocations of the function. It does not need to match the name of the factory, but it is less confusing if they are the same or similar.
The function name must conform to the restrictions on Identifiers.
LANGUAGE 'language'- The language used to develop this function, one of the following:
-
C++ (default)
-
Java
-
R
-
Python
NAME 'factory'- Name of the factory class that generates the function instance.
LIBRARY library- Name of the C++ shared object file, Python file, Java Jar file, or R functions file. This library must already have been loaded by CREATE LIBRARY.
FENCED | NOT FENCED- Enables or disables fenced mode for this function. Functions written in Java and R always run in fenced mode.
Default: FENCED
Privileges
Non-superuser:
Restrictions
A query that includes a UDTF cannot:
-
Include statements other than the SELECT statement that calls the UDTF and a PARTITION BY expression unless the UDTF is marked as a one-to-many UDTF
-
Call an analytic function
-
Call another UDTF
-
Include one of the following clauses:
Examples
The following example loads a library named TransformFunctions and then defines a function named tokenize that is mapped to the TokenFactory factory class in the library:
=> CREATE LIBRARY TransformFunctions AS
'/home/dbadmin/TransformFunctions.so';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION tokenize
AS LANGUAGE 'C++' NAME 'TokenFactory' LIBRARY TransformFunctions;
CREATE TRANSFORM FUNCTION
See also
7.11.13 - CREATE HCATALOG SCHEMA
Define a schema for data stored in a Hive data warehouse using the HCatalog Connector.
Define a schema for data stored in a Hive data warehouse using the HCatalog Connector. For more information, see Using the HCatalog Connector.
Most of the optional parameters are read out of Hadoop configuration files if available. If you copied the Hadoop configuration files as described in Configuring Vertica for HCatalog, you can omit most parameters. By default this statement uses the values specified in those configuration files. If the configuration files are complete, the following is a valid statement:
=> CREATE HCATALOG SCHEMA hcat;
If a value is not specified in the configuration files and a default is shown in the parameter list, then that default value is used.
Some parameters apply only if you are using HiveServer2 (the default). Others apply only if you are using WebHCat, a legacy Hadoop service. When using HiveServer2, use HIVESERVER2_HOSTNAME to specify the server host. When using WebHCat, use WEBSERVICE_HOSTNAME to specify the server host.
If you need to use WebHCat you must also set the HCatalogConnectorUseHiveServer2 configuration parameter to 0. See Hadoop parameters.
After creating the schema, you can change many (but not all) parameters using ALTER HCATALOG SCHEMA.
Syntax
CREATE HCATALOG SCHEMA [IF NOT EXISTS] schemaName
[AUTHORIZATION user-id]
[WITH [param=value [,...] ] ]
Arguments
|
Argument |
Description |
[IF NOT EXISTS] |
If given, the statement exits without an error when the schema named in schemaName already exists. |
schemaName |
The name of the schema to create in the Vertica catalog. The tables in the Hive database will be available through this schema. |
AUTHORIZATION user-id |
The name of a Vertica account to own the schema being created. This parameter is ignored if Kerberos authentication is being used; in that case the current vsql user is used. |
Parameters
|
Parameter |
Description |
HOSTNAME |
The hostname, IP address, or URI of the database server that stores the Hive data warehouse's metastore information.
If you specify this parameter and do not also specify PORT, then this value must be in the URI format used for hive.metastore.uris in hive-site.xml.
If the Hive metastore supports High Availability, you can specify a comma-separated list of URIs for this value.
If this value is not specified, hive-site.xml must be available.
|
PORT |
The port number on which the metastore database is running. If you specify this parameter, you must also specify HOSTNAME and it must be a name or IP address (not a URI). |
HIVESERVER2_HOSTNAME |
The hostname or IP address of the HiveServer2 service. This parameter is optional if in hive-site.xml you set one of the following properties:
This parameter is ignored if you are using WebHCat.
|
WEBSERVICE_HOSTNAME |
The hostname or IP address of the WebHCat service, if using WebHCat instead of HiveServer2. If this value is not specified, webhcat-site.xml must be available. |
WEBSERVICE_PORT |
The port number on which the WebHCat service is running, if using WebHCat instead of HiveServer2. If this value is not specified, webhcat-site.xml must be available. |
WEBHDFS_ADDRESS |
The host and port ("host:port") for the WebHDFS service. This parameter is used only for reading ORC and Parquet files. If this value is not set, hdfs-site.xml must be available to read these file types through the HCatalog Connector. |
HCATALOG_SCHEMA |
The name of the Hive schema or database that the Vertica schema is being mapped to. The default is schemaName. |
CUSTOM_PARTITIONS |
Whether the Hive schema uses custom partition locations ('YES' or 'NO'). If the schema uses custom partition locations, then Vertica queries Hive to get those locations when executing queries. These additional Hive queries can be expensive, so use this parameter only if you need to. The default is 'NO' (disabled). For more information, see Using Partitioned Data. |
HCATALOG_USER |
The username of the HCatalog user to use when making calls to the HiveServer2 or WebHCat server. The default is the current database user. |
HCATALOG_CONNECTION_TIMEOUT |
The number of seconds the HCatalog Connector waits for a successful connection to the HiveServer or WebHCat server. A value of 0 means wait indefinitely. |
HCATALOG_SLOW_TRANSFER_LIMIT |
The lowest data transfer rate (in bytes per second) from the HiveServer2 or WebHCat server that the HCatalog Connector accepts. See HCATALOG_SLOW_TRANSFER_TIME for details. |
HCATALOG_SLOW_TRANSFER_TIME |
The number of seconds the HCatalog Connector waits before enforcing the data transfer rate lower limit. After this time has passed, the HCatalog Connector tests whether the data transfer rate is at least as fast as the value set in HCATALOG_SLOW_TRANSFER_LIMIT. If it is not, then the HCatalog Connector breaks the connection and terminates the query. |
SSL_CONFIG |
The path of the Hadoop ssl-client.xml configuration file. This parameter is required if you are using HiveServer2 and it uses SSL wire encryption. This parameter is ignored if you are using WebHCat. |
The default values for HCATALOG_CONNECTOR_TIMEOUT, HCATALOG_SLOW_TRANSFER_LIMIT, and HCATALOG_SLOW_TRANSFER_TIME are set by the database configuration parameters HCatConnectionTimeout, HCatSlowTransferLimit, and HCatSlowTransferTime. See Hadoop parameters for more information.
Configuration files
The HCatalog Connector uses the following values from the Hadoop configuration files if you do not override them when creating the schema.
|
File |
Properties |
hive-site.xml |
hive.server2.thrift.bind.host (used for HIVESERVER2_HOSTNAME) |
|
hive.server2.thrift.port |
|
hive.server2.transport.mode |
|
hive.server2.authentication |
|
hive.server2.authentication.kerberos.principal |
|
hive.server2.support.dynamic.service.discovery |
|
hive.zookeeper.quorum (used as HIVESERVER2_HOSTNAME if dynamic service discovery is enabled) |
|
hive.zookeeper.client.port |
|
hive.server2.zookeeper.namespace |
|
hive.metastore.uris (used for HOSTNAME and PORT) |
ssl-client.xml |
ssl.client.truststore.location |
|
ssl.client.truststore.password |
Privileges
The user must be a superuser or be granted all permissions on the database to use this statement.
The user also requires access to Hive data in one of the following ways:
-
Have USAGE permissions on hcatalog_schema, if Hive does not use an authorization service (Sentry or Ranger) to manage access.
-
Have permission through an authorization service, if Hive uses it to manage access. In this case you must either set EnableHCatImpersonation to 0, to access data as the Vertica principal, or grant users access to the HDFS data. For Sentry, you can use ACL synchronization to manage HDFS access.
-
Be the dbadmin user, with or without an authorization service.
Examples
The following example shows how to use CREATE HCATALOG SCHEMA to define a new schema for tables stored in a Hive database and then query the system tables that contain information about those tables:
=> CREATE HCATALOG SCHEMA hcat WITH HOSTNAME='hcathost' PORT=9083
HCATALOG_SCHEMA='default' HIVESERVER2_HOSTNAME='hs.example.com'
SSL_CONFIG='/etc/hadoop/conf/ssl-client.xml' HCATALOG_USER='admin';
CREATE SCHEMA
=> \x
Expanded display is on.
=> SELECT * FROM v_catalog.hcatalog_schemata;
-[ RECORD 1 ]----------------+-------------------------------------------
schema_id | 45035996273748224
schema_name | hcat
schema_owner_id | 45035996273704962
schema_owner | admin
create_time | 2017-12-05 14:43:03.353404-05
hostname | hcathost
port | -1
hiveserver2_hostname | hs.example.com
webservice_hostname |
webservice_port | 50111
webhdfs_address | hs.example.com:50070
hcatalog_schema_name | default
ssl_config | /etc/hadoop/conf/ssl-client.xml
hcatalog_user_name | admin
hcatalog_connection_timeout | -1
hcatalog_slow_transfer_limit | -1
hcatalog_slow_transfer_time | -1
custom_partitions | f
=> SELECT * FROM v_catalog.hcatalog_table_list;
-[ RECORD 1 ]------+------------------
table_schema_id | 45035996273748224
table_schema | hcat
hcatalog_schema | default
table_name | nation
hcatalog_user_name | admin
-[ RECORD 2 ]------+------------------
table_schema_id | 45035996273748224
table_schema | hcat
hcatalog_schema | default
table_name | raw
hcatalog_user_name | admin
-[ RECORD 3 ]------+------------------
table_schema_id | 45035996273748224
table_schema | hcat
hcatalog_schema | default
table_name | raw_rcfile
hcatalog_user_name | admin
-[ RECORD 4 ]------+------------------
table_schema_id | 45035996273748224
table_schema | hcat
hcatalog_schema | default
table_name | raw_sequence
hcatalog_user_name | admin
The following example shows how to specify more than one metastore host.
=> CREATE HCATALOG SCHEMA hcat
WITH HOSTNAME='thrift://node1.example.com:9083,thrift://node2.example.com:9083';
The following example shows how to include custom partition locations:
=> CREATE HCATALOG SCHEMA hcat WITH HCATALOG_SCHEMA='default'
HIVESERVER2_HOSTNAME='hs.example.com'
CUSTOM_PARTITIONS='yes';
7.11.14 - CREATE KEY
Creates a private key.
Creates a private key.
Syntax
CREATE [TEMP[ORARY]] KEY name
{ 'AES' [ PASSWORD 'password' ] | 'RSA' }
{LENGTH length | AS key_text}
Parameters
TEMPORARY- Create with session scope. The key is stored in memory and is valid only for the current session.
name- The name of the key.
password- Password for the key.
length- Size of the key in bits.
Example: 2048
key_text- The contents of the key to import.
Example:
-----BEGIN RSA PRIVATE KEY-----...ABCD1234...-----END RSA PRIVATE KEY-----
Privileges
Superuser
Examples
See Generating TLS certificates and keys.
See also
7.11.15 - CREATE LIBRARY
Loads a library containing user-defined extensions (UDxs) into the Vertica catalog.
Loads a library containing user-defined extensions (UDxs) into the Vertica catalog. Vertica automatically distributes copies of the library file and supporting libraries to all cluster nodes.
Because libraries are added to the database catalog, they persist across database restarts.
After loading a library in the catalog, you can use statements such as CREATE FUNCTION to define the extensions contained in the library. See Developing user-defined extensions (UDxs) for details.
Syntax
CREATE [OR REPLACE] LIBRARY
[[database.]schema.]name
AS 'path'
[ DEPENDS 'depends-path' ]
[ LANGUAGE 'language' ]
Arguments
OR REPLACE- If a library with the same name exists, replace it. UDxs defined in the catalog that reference the updated library automatically start using the new library file.
If you do not use this directive and the library already exists, the CREATE statement returns with an error.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
name- Name of the library to create. This is the name used when creating functions in the library (see Creating UDx Functions). While not required, it is good practice to match the file name.
AS path- Path of the library to load, either an absolute path on the initiator node file system or a URI for another supported file system or object store.
DEPENDS 'depends-path'Files or libraries on which this library depends, one or more files or directories on the initiator node file system or other supported file systems or object stores. For a directory, end the path entry with a slash (/), optionally followed by a wildcard (*). To specify more than one file, separate entries with colons (:).
If any path entry contain colons, such as a URI, place brackets around the entire DEPENDS path and use double quotes for the individual path elements, as in the following example:
DEPENDS '["s3://mybucket/gson-2.3.1.jar"]'
To specify libraries with multiple directory levels, see Multi-level Library Dependencies.
DEPENDS has no effect for libraries written in R. R packages must be installed locally on each node, including external dependencies.
Important
The performance of CREATE LIBRARY can degrade in Eon Mode, in proportion to the number and depth of dependencies specified by the DEPENDS clause.
If a Java library depends on native libraries (SO files), use DEPENDS to specify the path and call System.loadLibrary() in your UDx to load the native libraries from that path.
LANGUAGE 'language'- The programming language of the functions in the library, one of:
-
C++ (default)
-
Python
-
Java
-
R
Privileges
Superuser, or UDXDEVELOPER and CREATE on the schema. Non-superusers must explicitly enable the UDXDEVELOPER role, as in the following example:
=> SET ROLE UDXDEVELOPER;
SET
-- Not required, but you can confirm the role as follows:
=> SHOW ENABLED ROLES;
name | setting
---------------+--------------
enabled roles | udxdeveloper
(1 row)
=> CREATE LIBRARY MyLib AS '/home/dbadmin/my_lib.so';
CREATE LIBRARY
-- Create functions...
-- UDXDEVELOPER also grants DROP (replace):
=> CREATE OR REPLACE LIBRARY MyLib AS '/home/dbadmin/my_lib.so';
Requirements
-
Vertica makes its own copies of the library files. Later modification or deletion of the original files specified in the statement does not affect the library defined in the catalog. To update the library, use ALTER LIBRARY.
-
Loading a library does not guarantee that it functions correctly. CREATE LIBRARY performs some basic checks on the library file to verify it is compatible with Vertica. The statement fails if it detects that the library was not correctly compiled or it finds other basic incompatibilities. However, CREATE LIBRARY cannot detect many other issues in shared libraries.
Multi-level library dependencies
If a DEPENDS clause specifies a library with multiple directory levels, Vertica follows the library path to include all subdirectories of that library. For example, the following CREATE LIBRARY statement enables the UDx library mylib to import all Python packages and modules that it finds in subdirectories of site-packages:
=> CREATE LIBRARY mylib AS '/path/to/python_udx' DEPENDS '/path/to/python/site-packages' LANGUAGE 'Python';
Important
DEPENDS can specify Java library dependencies that are up to 100 levels deep.
Examples
Load a library in the home directory of the dbadmin account:
=> CREATE LIBRARY MyFunctions AS '/home/dbadmin/my_functions.so';
Load a library located in the directory where you started vsql:
=> \set libfile '\''`pwd`'/MyOtherFunctions.so\'';
=> CREATE LIBRARY MyOtherFunctions AS :libfile;
Load a library from the cloud:
=> CREATE LIBRARY SomeFunctions AS 'S3://mybucket/extensions.so';
Load a library that depends on multiple JAR files in the same directory:
=> CREATE LIBRARY DeleteVowelsLib AS '/home/dbadmin/JavaLib.jar'
DEPENDS '/home/dbadmin/mylibs/*' LANGUAGE 'Java';
Load a library with multiple explicit dependencies:
=> CREATE LIBRARY mylib AS '/path/to/java_udx'
DEPENDS '/path/to/jars/this.jar:/path/to/jars/that.jar' LANGUAGE 'Java';
Load a library with dependencies in the cloud:
=> CREATE LIBRARY s3lib AS 's3://mybucket/UdlLib.jar'
DEPENDS '["s3://mybucket/gson-2.3.1.jar"]' LANGUAGE 'Java';
7.11.16 - CREATE LOAD BALANCE GROUP
Creates a group of network addresses that can be targeted by a load balancing routing rule.
Creates a group of network addresses that can be targeted by a load balancing routing rule. You create a group either using a list of network addresses, or basing it on one or more fault groups or subclusters.
Note
You cannot add multiple network addresses for one node to the same load balancing group.
Syntax
CREATE LOAD BALANCE GROUP group_name WITH {
ADDRESS address[,...]
| FAULT GROUP fault_group[,...] FILTER 'IP_range'
| SUBCLUSTER subcluster[,...] FILTER 'IP_range'
}
[ POLICY 'policy_setting' ]
Parameters
group_name- Name of the group to create. You use this name later when defining load balancing rules.
address[,...]- Comma-delimited list of network addresses you created earlier.
fault_group[,...]- Comma-delimited list of fault groups to use as the basis of the load balance group.
Note
Before you create your load balance group from a fault group, you must create network addresses on the nodes you want in your load balance group. Load balance groups only work with the network addresses you define on nodes, rather than IP addresses. See
CREATE NETWORK ADDRESS.
subcluster[,...]- Comma-delimited list of subclusters to use as the basis of the load balance group.
Note
As with fault groups, you must create network addresses on the nodes in the subcluster you want to be part of the load balance group.
IP_range- Range of IP addresses in CIDR notation to include in the load balance group from the fault groups or subclusters. This range can be either IPv4 or IPv6. Only nodes that have a network address with an IP address that falls within this range are added to the load balancing group.
policy_setting- Determines how the initially-contacted node chooses a target from the group, one of the following:
-
ROUNDROBIN (default) rotates among the available members of the load balancing group. The initially-contacted node keeps track of which node it chose last time, and chooses the next one in the cluster.
Note
Each node in the cluster maintains its own round-robin pointer that indicates which node it should pick next for each load-balancing group. Therefore, if clients connect to different initial nodes, they may be redirected to the same node.
-
RANDOM chooses an available node from the group randomly.
-
NONE disables load balancing.
Privileges
Superuser
Examples
The following statement demonstrates creating a load balance group that contains several network addresses:
=> CREATE NETWORK ADDRESS addr01 ON v_vmart_node0001 WITH '10.20.110.21';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS addr02 ON v_vmart_node0002 WITH '10.20.110.22';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS addr03 on v_vmart_node0003 WITH '10.20.110.23';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS addr04 on v_vmart_node0004 WITH '10.20.110.24';
CREATE NETWORK ADDRESS
=> CREATE LOAD BALANCE GROUP group_1 WITH ADDRESS addr01, addr02;
CREATE LOAD BALANCE GROUP
=> CREATE LOAD BALANCE GROUP group_2 WITH ADDRESS addr03, addr04;
CREATE LOAD BALANCE GROUP
=> SELECT * FROM LOAD_BALANCE_GROUPS;
name | policy | filter | type | object_name
------------+------------+-----------------+-----------------------+-------------
group_1 | ROUNDROBIN | | Network Address Group | addr01
group_1 | ROUNDROBIN | | Network Address Group | addr02
group_2 | ROUNDROBIN | | Network Address Group | addr03
group_2 | ROUNDROBIN | | Network Address Group | addr04
(4 rows)
This example demonstrates creating a load balancing group using a fault group:
=> CREATE FAULT GROUP fault_1;
CREATE FAULT GROUP
=> ALTER FAULT GROUP fault_1 ADD NODE v_vmart_node0001;
ALTER FAULT GROUP
=> ALTER FAULT GROUP fault_1 ADD NODE v_vmart_node0002;
ALTER FAULT GROUP
=> ALTER FAULT GROUP fault_1 ADD NODE v_vmart_node0003;
ALTER FAULT GROUP
=> ALTER FAULT GROUP fault_1 ADD NODE v_vmart_node0004;
ALTER FAULT GROUP
=> SELECT node_name,node_address,node_address_family,export_address
FROM v_catalog.nodes;
node_name | node_address | node_address_family | export_address
------------------+--------------+---------------------+----------------
v_vmart_node0001 | 10.20.110.21 | ipv4 | 10.20.110.21
v_vmart_node0002 | 10.20.110.22 | ipv4 | 10.20.110.22
v_vmart_node0003 | 10.20.110.23 | ipv4 | 10.20.110.23
v_vmart_node0004 | 10.20.110.24 | ipv4 | 10.20.110.24
(4 rows)
=> CREATE LOAD BALANCE GROUP group_all WITH FAULT GROUP fault_1 FILTER
'0.0.0.0/0';
CREATE LOAD BALANCE GROUP
=> CREATE LOAD BALANCE GROUP group_some WITH FAULT GROUP fault_1 FILTER
'10.20.110.21/30';
CREATE LOAD BALANCE GROUP
=> SELECT * FROM LOAD_BALANCE_GROUPS;
name | policy | filter | type | object_name
----------------+------------+-----------------+-----------------------+-------------
group_all | ROUNDROBIN | 0.0.0.0/0 | Fault Group | fault_1
group_some | ROUNDROBIN | 10.20.110.21/30 | Fault Group | fault_1
(2 rows)
See also
7.11.17 - CREATE LOCAL TEMPORARY VIEW
Creates or replaces a local temporary view.
Creates or replaces a local temporary view. Views are read only, so they do not support insert, update, delete, or copy operations. Local temporary views are session-scoped, so they are visible only to their creator in the current session. Vertica drops the view when the session ends.
Note
Vertica does not support global temporary views.
Syntax
CREATE [OR REPLACE] LOCAL TEMP[ORARY] VIEW view [ (column[,...] ) ] AS query
Parameters
OR REPLACE- Specifies to overwrite the existing view
view-name. If you omit this option and view-name already exists, CREATE VIEW returns an error.
view- Identifies the view to create, where
view conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
column[,...]- List of up to 9800 names to use as view column names. Vertica maps view column names to query columns according to the order of their respective lists. By default, the view uses column names as they are specified in the query.
AS query - A
SELECT statement that the temporary view executes. The SELECT statement can reference tables, temporary tables, and other views.
Privileges
See Creating views.
Examples
The following CREATE LOCAL TEMPORARY VIEW statement creates the temporary view myview. This view sums all individual incomes of customers listed in the store.store_sales_fact table, and groups results by state:
=> CREATE LOCAL TEMP VIEW myview AS
SELECT SUM(annual_income), customer_state FROM public.customer_dimension
WHERE customer_key IN (SELECT customer_key FROM store.store_sales_fact)
GROUP BY customer_state
ORDER BY customer_state ASC;
The following example uses the temporary view myview with a WHERE clause that limits the results to combined salaries greater than $2 billion:
=> SELECT * FROM myview WHERE SUM > 2000000000;
SUM | customer_state
-------------+----------------
2723441590 | AZ
29253817091 | CA
4907216137 | CO
3769455689 | CT
3330524215 | FL
4581840709 | IL
3310667307 | IN
2793284639 | MA
5225333668 | MI
2128169759 | NV
2806150503 | PA
2832710696 | TN
14215397659 | TX
2642551509 | UT
(14 rows)
See also
7.11.18 - CREATE LOCATION
Creates a storage location where Vertica can store data.
Creates a storage location where Vertica can store data. After you create the location, you create storage policies that assign the storage location to the database objects that will store data in the location.
Caution
While no technical issue prevents you from using CREATE LOCATION to add one or more Network File System (NFS) storage locations, Vertica does not support NFS data or catalog storage except for MapR mount points. You will be unable to run queries against any other NFS data. When creating locations on MapR file systems, you must specify ALL NODES SHARED.
If you use HDFS storage locations, the HDFS data must be available when you start Vertica. Your HDFS cluster must be operational, and the ROS files must be present. If you moved data files, or they are corrupted, or your HDFS cluster is not responsive, Vertica cannot start.
Syntax
CREATE LOCATION 'path'
[NODE 'node' | ALL NODES]
[SHARED]
[USAGE 'usage']
[LABEL 'label']
[LIMIT 'size']
Arguments
path- Where to store this location's data. The type of file system on which the location is based determines the
path format:
HDFS storage locations have additional requirements.
Important
Vertica performs no validation on storage location paths. Confirm that the path value points to a valid location.
ALL NODES | NODE 'node'- The node or nodes on which the storage location is defined, one of the following:
ALL NODES (default): Create the storage location on each node that is currently part of the cluster. If you later add nodes, you must also create the location on those nodes. If SHARED is also specified, create the storage location once for use by all nodes.NODE 'node': Create the storage location on a single node, where node is the name of the node in the NODES system table. You cannot use this option with SHARED.
SHARED- Indicates the location set by
path is shared (used by all nodes) rather than local to each node. You cannot specify individual nodes with SHARED; you must use ALL NODES.
Most remote file systems such as HDFS and S3 are shared. For these file systems, the path argument represents a single location in the remote file system where all nodes store data. If using a remote file system, you must specify SHARED, even for one-node clusters.
If path is set to S3 communal storage, SHARED is always implied and can be omitted.
Deprecated
SHARED DATA and SHARED DATA,TEMP storage locations are deprecated.
-
USAGE 'usage'
- The type of data the storage location can hold, where
usage is one of the following:
-
DATA,TEMP (default): The storage location can store persistent and temporary DML-generated data, and data for temporary tables.
-
TEMP: A path-specified location to store DML-generated temporary data. If path is set to S3, then this location is used only when the RemoteStorageForTemp configuration parameter is set to 1, and TEMP must be qualified with ALL NODES SHARED. For details, see S3 Storage of Temporary Data.
-
DATA: The storage location can only store persistent data.
-
USER: Users with READ and WRITE privileges can access data and external tables of this storage location.
-
DEPOT: The storage location is used in Eon Mode to store the depot. Only create DEPOT storage locations on local Linux file systems.
Vertica allows a single DEPOT storage location per node. If you want to move your depot to different location (on a different file system, for example) you must first drop the old depot storage location, then create the new location.
LABEL 'label'- A label for the storage location, used when assigning the storage location to data objects. You use this name later when assigning the storage location to data objects.
Important
You must supply a label for depot storage locations.
LIMIT 'size'Valid only if the storage location usage type is set to DEPOT, specifies the maximum amount of disk space that the depot can allocate from the storage location's file system.
You can specify size in two ways:
-
integer%: Percentage of storage location disk size.
-
integer{K|M|G|T}: Amount of storage location disk size in kilobytes, megabytes, gigabytes, or terabytes.
Important
The depot size cannot exceed 80 percent of the file system disk space where the depot is stored. If you specify a value that is too large, Vertica issues a warning and automatically changes the value to 80 percent of the file system size.
If you do not specify a limit, it is set to 60 percent.
Privileges
Superuser
File system access
The Vertica process must have read and write permissions to the location where data is to be stored. Each file system has its own requirements:
|
File system |
Requirements |
|
Linux |
Database superuser account (usually named dbadmin) must have full read and write access to the directory in the path argument. |
|
HDFS without Kerberos |
A Hadoop user whose username matches the Vertica database administrator username (usually dbadmin) must have read and write access to the HDFS directory specified in the path argument. The UseServerIdentityOverUserIdentity configuration parameter must be set to true in the user session; otherwise Vertica tries to use the identity associated with the logged-in user. |
|
HDFS with Kerberos |
A Hadoop user whose username matches the principal in the keytab file on each Vertica node must have read and write access to the HDFS directory stored in the path argument. This is not the same as the database administrator username. The UseServerIdentityOverUserIdentity configuration parameter must be set to true in the user session; otherwise Vertica tries to use the Kerberos principal associated with the logged-in user. |
|
Object stores (S3, GCS, Azure) |
Database-level credentials must be specified and provide full read and write access to the location in the path argument. If session-level credentials are specified they are used, directly overriding the use of the storage location. |
Examples
Create a storage location in the local Linux file system for temporary data storage:
=> CREATE LOCATION '/home/dbadmin/testloc' USAGE 'TEMP' LABEL 'tempfiles';
Create a storage location on HDFS. The HDFS cluster does not use Kerberos:
=> CREATE LOCATION 'hdfs://hadoopNS/vertica/colddata' ALL NODES SHARED
USAGE 'data' LABEL 'coldstorage';
Create the same storage location, but on a Hadoop cluster that uses Kerberos. Note the output that reports the principal being used:
=> CREATE LOCATION 'hdfs://hadoopNS/vertica/colddata' ALL NODES SHARED
USAGE 'data' LABEL 'coldstorage';
NOTICE 0: Performing HDFS operations using kerberos principal [vertica/hadoop.example.com]
CREATE LOCATION
Create a location for user data, grant access to it, and use it to create an external table:
=> CREATE LOCATION '/tmp' ALL NODES USAGE 'user';
CREATE LOCATION
=> GRANT ALL ON LOCATION '/tmp' to Bob;
GRANT PRIVILEGE
=> CREATE EXTERNAL TABLE ext1 (x integer) AS COPY FROM '/tmp/data/ext1.dat' DELIMITER ',';
CREATE TABLE
Create a user storage location on S3 and a role, so that users without their own S3 credentials can read data from S3 using the server credential:
--- set database-level credential (once):
=> ALTER DATABASE DEFAULT SET AWSAuth = 'myaccesskeyid123456:mysecretaccesskey123456789012345678901234';
=> CREATE LOCATION 's3://datalake' SHARED USAGE 'USER' LABEL 's3user';
=> CREATE ROLE ExtUsers;
--- Assign users to this role using GRANT (Role).
=> GRANT READ ON LOCATION 's3://datalake' TO ExtUsers;
See also
7.11.19 - CREATE NAMESPACE
Eon Mode only
Creates a namespace for an Eon Mode database.
Important
If you create a non-default namespace, you cannot reshard the default_namespace or save an in-database restore point.
When you create a database, a default_namespace is created with the shard count defined during database creation. This function lets you create additional namespaces. Each namespace has a distinct shard count that determines the segmentation of its member objects. For more information, see Managing namespaces and Namespaces and shards.
Every schema and table in an Eon Mode database belongs to a namespace. When you create a table or schema, you optionally specify the namespace under which to create the object. If no namespace is specified, the table or schema is created under the default_namespace.
Syntax
CREATE NAMESPACE namespace-name [ SHARD COUNT shards ]
Arguments
namespace-name- Name of the namespace.
SHARD COUNT shards- Shard count of the namespace. If unspecified, the shard count is set to that of the
default_namespace.
Privileges
Superuser
Examples
Create the analytics namespace with a shard count of 12:
=> CREATE NAMESPACE analytics SHARD COUNT 12;
CREATE NAMESPACE
You can view all namespaces in your database by querying the NAMESPACES system table:
=> SELECT namespace_name, is_default, default_shard_count FROM NAMESPACES;
namespace_name | is_default | default_shard_count
-------------------+------------+---------------------
default_namespace | t | 6
analytics | f | 12
(2 rows)
For a more in-depth example, see Managing namespaces.
See also
7.11.20 - CREATE NETWORK ADDRESS
Creates a network address that can be used as part of a connection load balancing policy.
Creates a network address that can be used as part of a connection load balancing policy. A network address creates a name in the Vertica catalog for an IP address and port number associated with a node. Nodes can have multiple network addresses, up to one for each IP address they have on the network.
Syntax
CREATE NETWORK ADDRESS name ON node WITH 'ip-address' [PORT port-number] [ENABLED | DISABLED]
Parameters
name- The name of the new network address. Use this name when creating connection load balancing groups.
node- The name of the node on which to create the network address. This should be name of the node as it appears in the
node_name column of system table NODES.
ip-address- The IPv4 or and IPv6 address on the node to associate with the network address.
Note
Vertica does not verify that the IP address you supply in this parameter is actually associated with the specified node. Be sure that the IP address actually belongs to the node. Otherwise, your load balancing policy is liable to send a client connection to the wrong node, or a non-Vertica host. Vertica rejects IP address that are invalid for a node. For example, it checks whether the IP address falls in the loopback address range of 127.0.0.0/8. If it finds that the IP address is invalid, CREATE NETWORK ADDRESS returns an error.
PORT port-number- Sets the port number for the network address. You must supply a network address when altering the port number.
ENABLED | DISABLED- Enables or disables the network address.
Privileges
Superuser
Examples
Create three network addresses, one for each node in a three-node cluster:
=> SELECT node_name,export_address from v_catalog.nodes;
node_name | export_address
---------------------+----------------
v_vmart_br_node0001 | 10.20.100.62
v_vmart_br_node0002 | 10.20.100.63
v_vmart_br_node0003 | 10.20.100.64
(3 rows)
=> CREATE NETWORK ADDRESS node01 ON v_vmart_br_node0001 WITH '10.20.100.62';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS node02 ON v_vmart_br_node0002 WITH '10.20.100.63';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS node03 ON v_vmart_br_node0003 WITH '10.20.100.64';
See also
7.11.21 - CREATE NETWORK INTERFACE
Identifies a network interface to which a node belongs.
Identifies a network interface to which a node belongs.
Use this statement when you want to configure import/export operations from individual nodes to other Vertica clusters. By default, when you install Vertica, it creates interfaces for all connected networks. You would only need CREATE NETWORK INTERFACE in situations where the network topology has changed since you installed Vertica.
Syntax
CREATE NETWORK INTERFACE network-interface-name ON node-name [WITH] 'node-IP-address' [PORT port-number] [ENABLED | DISABLED]
network-interface-name- The name you assign to the network interface, where
network-interface-name conforms to conventions described in Identifiers.
node-name- The name of the node.
node-IP-address- The node's IP address, either a public or private IP address. For more information, see Using Public and Private IP Networks.
- PORT
port-number
- Sets the port number for the network interface. You must supply a network interface when altering the port number.
- [ENABLED | DISABLED]
- Enables or disables the network interface.
Privileges
Superuser
Examples
Create a network interface:
=> CREATE NETWORK INTERFACE mynetwork ON v_vmart_node0001 WITH '123.4.5.6' PORT 456 ENABLED;
7.11.22 - CREATE NOTIFIER
Creates a push-based notifier to send event notifications and messages out of Vertica.
Creates a push-based notifier to send event notifications and messages out of Vertica.
Syntax
CREATE NOTIFIER [ IF NOT EXISTS ] notifier-name ACTION 'notifier-type'
[ ENABLE | DISABLE ]
[ MAXPAYLOAD 'integer{K|M}' ]
MAXMEMORYSIZE 'integer{K|M|G|T}'
[ TLS CONFIGURATION tls-configuration ]
[ TLSMODE 'tls-mode' ]
[ CA BUNDLE bundle-name [ CERTIFICATE certificate-name ] ]
[ IDENTIFIED BY 'uuid' ]
[ [NO] CHECK COMMITTED ]
[ PARAMETERS 'adapter-params' ]
Parameters
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
notifier-name- This notifier's unique identifier.
ACTION 'notifier-type'- String, the type of notifier, one of the following:
-
URL, with the following format, that identifies one or more target Kafka servers:
kafka://kafka-server-ip-address:port-number
To enable failover when a Kafka server is unavailable, specify additional hosts in a comma-delimited list. For example:
kafka://192.0.2.0:9092,192.0.2.1:9092,192.0.2.2:9092
-
syslog: Notifications are sent to syslog. To use notifiers of this type, you must set the SyslogEnabled parameter:
=> ALTER DATABASE DEFAULT SET SyslogEnabled = 1
Events monitored by this notifier type are not logged to MONITORING_EVENTS nor vertica.log.
-
sns: Notifications are sent to a Simple Notification Service (SNS) endpoint.
ENABLE | DISABLE- Specifies whether to enable or disable the notifier.
Default: ENABLE.
MAXPAYLOAD 'integer{K|M}'- The maximum size of the message, up to 10^9 bytes, specified in kilobytes or megabytes.
The following restrictions apply:
-
MAXPAYLOAD cannot be greater than MAXMEMORYSIZE.
-
If you configure syslog to send messages to a remote destination, ensure that MaxMessageSize (in /etc/rsyslog for rsyslog) is greater than or equal to MAXPAYLOAD.
-
The MAXPAYLOAD for SNS notifiers cannot exceed 256KB.
Defaults:
-
Kafka: 1M
-
syslog: 1M
-
SNS: 256K
MAXMEMORYSIZE 'integer{K|M|G|T}'- The maximum size of the internal notifier, up to 2 TB, specified in kilobytes, megabytes, gigabytes, or terabytes.
MAXMEMORYSIZE must be greater than MAXPAYLOAD.
If the size of the message queue exceeds MAXMEMORYSIZE, the notifier drops excess messages.
- TLS CONFIGURATION
tls-configuration
The TLS CONFIGURATION to use for TLS.
Notifiers support the following TLS modes:
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
TLSMODE 'tls-mode'-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies the type of connection between the notifier and an endpoint, one of the following:
-
disable (default): Plaintext connection.
-
verify-ca: Encrypted connection, and the server's certificate is verified as being signed by a trusted CA.
If you set this parameter to verify-ca, the generated TLS Configuration will be set to TRY_VERIFY, which has the same behavior as VERIFY_CA.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
CA BUNDLE bundle-name-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies a CA bundle. The certificates inside the bundle are used to validate the Kafka server's certificate if the TLSMODE requires it.
If a CA bundle is specified for a notifier that currently uses disable, which doesn't validate the Kafka server's certificate, the bundle will go unused when connecting to the Kafka server. This behavior persists unless the TLSMODE is changed to one that validates server certificates.
Changes to contents of the CA bundle take effect either after the notifier is disabled and re-enabled or after the database restarts. However, changes to which CA bundle the notifier uses takes effect immediately.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
CERTIFICATE certificate-name-
Deprecated
This parameter has been superseded by the TLS CONFIGURATION parameter. If you use this parameter while the TLS CONFIGURATION parameter is not set, Vertica automatically creates a new TLS Configuration for the notifier uses the same values as the deprecated parameter.
Specifies a client certificate for validation by the endpoint.
If the notifier ACTION is 'syslog' or 'sns', this parameter has no effect.
To encrypt messages sent to syslog, you must configure syslog for TLS.
To encrypt messages sent to an SNS endpoint, you must set the following configuration parameters:
-
SNSCAFile or AWSCAFile
-
SNSCAPath or AWSCAPath
-
SNSEnableHttps
IDENTIFIED BY uuid- Specifies the notifier's unique identifier. If set, all the messages published by this notifier have this attribute.
[NO] CHECK COMMITTED- Specifies to wait for delivery confirmation before sending the next message in the queue.
Some messaging systems, like syslog, do not support delivery confirmation.
For SNS notifiers, CHECK COMMITTED must be specified, and NO CHECK COMMITTED behaves like CHECK COMMITTED.
PARAMETERS 'adapter-params'- Specifies one or more optional adapter parameters that are passed as a string to the adapter. Adapter parameters apply only to the adapter associated with the notifier.
For Kafka notifiers, refer to Kafka and Vertica configuration settings.
For syslog notifiers, specify the severity of the event with eventSeverity=severity, where severity is one of the following:
-
0: Emergency
-
1: Alert
-
2: Critical
-
3: Error
-
4: Warning
-
5: Notice
-
6: Informational
-
7: Debug
Most syslog implementations, by default, do not log events with a severity level of 7. You must configure syslog to record these types of events.
Parameters cannot be set for SNS notifiers.
Privileges
Superuser
Encrypted notifiers for SASL_SSL Kafka configurations
Follow this procedure to create or alter notifiers for Kafka endpoints that use SASL_SSL. Note that you must repeat this procedure whenever you change the TLSMODE, certificates, or CA bundle for a given notifier.
-
Create a TLS Configuration with the desired TLS mode, certificate, and CA certificates.
-
Use CREATE or ALTER to disable the notifier and set the TLS Configuration:
=> ALTER NOTIFIER encrypted_notifier
DISABLE
TLS CONFIGURATION kafka_tls_config;
-
ALTER the notifier and set the proper rdkafka adapter parameters for SASL_SSL:
=> ALTER NOTIFIER encrypted_notifier PARAMETERS
'sasl.username=user;sasl.password=password;sasl.mechanism=PLAIN;security.protocol=SASL_SSL';
-
Enable the notifier:
=> ALTER NOTIFIER encrypted_notifier ENABLE;
Examples
Kafka notifiers
Create a Kafka notifier:
=> CREATE NOTIFIER my_dc_notifier
ACTION 'kafka://172.16.20.10:9092'
MAXMEMORYSIZE '1G'
IDENTIFIED BY 'f8b0278a-3282-4e1a-9c86-e0f3f042a971'
NO CHECK COMMITTED;
Create a notifier with an adapter-specific parameter:
=> CREATE NOTIFIER my_notifier
ACTION 'kafka://127.0.0.1:9092'
MAXMEMORYSIZE '10M'
PARAMETERS 'queue.buffering.max.ms=1000';
Create a notifier that uses an encrypted connection and verifies the Kafka server's certificate with the CA certificates in the notifier_tls_config object:
=> CREATE NOTIFIER encrypted_notifier
ACTION 'kafka://127.0.0.1:9092'
MAXMEMORYSIZE '10M'
TLS CONFIGURATION 'notifier_tls_config'
Syslog notifiers
The following example creates a notifier that writes a message to syslog when the Data collector (DC) component LoginFailures updates:
-
Enable syslog notifiers for the current database:
=> ALTER DATABASE DEFAULT SET SyslogEnabled = 1;
-
Create and enable a syslog notifier v_syslog_notifier:
=> CREATE NOTIFIER v_syslog_notifier ACTION 'syslog'
ENABLE
MAXMEMORYSIZE '10M'
IDENTIFIED BY 'f8b0278a-3282-4e1a-9c86-e0f3f042a971'
PARAMETERS 'eventSeverity = 5';
-
Configure the syslog notifier v_syslog_notifier for updates to the LoginFailures DC component with SET_DATA_COLLECTOR_NOTIFY_POLICY:
=> SELECT SET_DATA_COLLECTOR_NOTIFY_POLICY('LoginFailures','v_syslog_notifier', 'Login failed!', true);
This notifier writes the following message to syslog (default location: /var/log/messages) when a user fails to authenticate as the user Bob:
Apr 25 16:04:58
vertica_host_01
vertica:
Event Posted:
Event Code:21
Event Id:0
Event Severity: Notice [5]
PostedTimestamp: 2022-04-25 16:04:58.083063
ExpirationTimestamp: 2022-04-25 16:04:58.083063
EventCodeDescription: Notifier
ProblemDescription: (Login failed!)
{
"_db":"VMart",
"_schema":"v_internal",
"_table":"dc_login_failures",
"_uuid":"f8b0278a-3282-4e1a-9c86-e0f3f042a971",
"authentication_method":"Reject",
"client_authentication_name":"default: Reject",
"client_hostname":"::1",
"client_label":"",
"client_os_user_name":"dbadmin",
"client_pid":523418,
"client_version":"",
"database_name":"dbadmin",
"effective_protocol":"3.8",
"node_name":"v_vmart_node0001",
"reason":"REJECT",
"requested_protocol":"3.8",
"ssl_client_fingerprint":"",
"ssl_client_subject":"",
"time":"2022-04-25 16:04:58.082568-05",
"user_name":"Bob"
}#012
DatabaseName: VMart
Hostname: vertica_host_01
For details on syslog notifiers, see Configuring reporting for syslog.
See also
7.11.23 - CREATE PROCEDURE (external)
Adds an external procedure to Vertica.
Enterprise Mode only
Adds an external procedure to Vertica. See External procedures for more information.
Syntax
CREATE PROCEDURE [ IF NOT EXISTS ]
[[database.]schema.]procedure( [ argument-list ] )
AS executable
LANGUAGE 'EXTERNAL'
USER OS-user
Parameters
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
This option cannot be used with OR REPLACE.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
procedure- Specifies a name for the external procedure, where
procedure-name conforms to conventions described in Identifiers.
argument-list- A comma-delimited list of procedure arguments, where each argument is specified as follows:
[ argname ] argtype
executable- The name of the executable program in the procedures directory, a string.
OS-user- The owner of the file, a string. The owner:
Privileges
Superuser
System security
-
The procedure file must be owned by the database administrator (OS account) or by a user in the same group as the administrator. The procedure file must also have the set UID attribute enabled, and allow read and execute permission for the group.
-
External procedures that you create with CREATE PROCEDURE (external) are always run with Linux dbadmin privileges. If a dbadmin or pseudosuperuser grants a non-dbadmin permission to run a procedure using GRANT (procedure), be aware that the non-dbadmin user runs the procedure with full Linux dbadmin privileges.
Examples
The following example shows how to create a procedure named helloplanet for the procedure file helloplanet.sh. This file accepts one VARCHAR argument.
Create the file:
#!/bin/bash
echo "hello planet argument: $1" >> /tmp/myprocedure.log
Create the procedure with the following SQL:
=> CREATE PROCEDURE helloplanet(arg1 varchar) AS 'helloplanet.sh' LANGUAGE 'external' USER 'dbadmin';
See also
7.11.24 - CREATE PROCEDURE (stored)
Creates a stored procedure.
Creates a stored procedure.
Syntax
CREATE [ OR REPLACE ] PROCEDURE [ IF NOT EXISTS ]
[[{namespace. | database. }]schema.]procedure( [ parameter-list ] )
[ LANGUAGE 'language-name' ]
[ SECURITY { DEFINER | INVOKER } ]
AS $$ source $$;
Parameters
OR REPLACE- If a procedure with the same name already exists, replace it. Users and roles with privileges on the original procedure retain these privileges on the new procedure.
This option cannot be used with IF NOT EXISTS.
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
This option cannot be used with OR REPLACE.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
procedure- The name of the stored procedure, where *
procedure-name*conforms to conventions described in Identifiers.
parameter-list- A comma-delimited list of formal parameters, each specified as follows:
[ parameter-mode ] parameter-name parameter-type
-
parameter-name: the name of the parameter.
-
parameter-type: Any SQL data type, with the following exceptions:
-
DECIMAL
-
NUMERIC
-
NUMBER
-
MONEY
-
UUID
-
GEOGRAPHY
-
GEOMETRY
-
Complex types
language-name- Specifies the language of the procedure
source, one of the following (both options refer to PLvSQL; PLpgSQL is included to maintain compatibility with existing scripts):
Default: PLvSQL
SECURITY { DEFINER | INVOKER }- Determines whose privileges to use when the procedure is called and executes it as if the user is one of the following:
A procedure with SECURITY DEFINER effectively executes the procedure as that user, so changes to the database appear to be performed by the procedure's definer rather than its caller.
Caution
Improper use of SECURITY DEFINER can lead to the
confused deputy problem and introduce vulnerabilities into your system like SQL injection.
For more information, see Executing stored procedures.
source- The procedure source code. For details, see Scope and structure.
Privileges
Non-superuser: CREATE on the procedure's schema
Examples
For more complex examples, see Stored procedures: use cases and examples
The following procedure echoes its inputs as a result set:
=> CREATE PROCEDURE echo_int_varchar(INOUT x INT, INOUT y VARCHAR) LANGUAGE PLvSQL AS $$
BEGIN
RAISE NOTICE 'This procedure outputs a result set of its inputs:';
END
$$;
=> CALL echo_int_varchar(3, 'a string');
NOTICE 2005: This procedure outputs a result set of its inputs:
x | y
---+----------
3 | a string
(1 row)
The example uses a set of procedures that convert a given Fahrenheit temperature to Celsius and Kelvin and returns them all as a result set. The procedure f_to_c_and_k() calls the helper procedures f_to_c() and f_to_k() to convert to Celsius and Kelvin, respectively. The f_to_k() procedure uses the output of f_to_c() for part of the conversion:
=> CREATE PROCEDURE f_to_c_and_k(IN f_temp DOUBLE PRECISION, OUT c_temp DOUBLE PRECISION, OUT k_temp DOUBLE PRECISION) AS $$
BEGIN
c_temp := CALL f_to_c(f_temp);
k_temp := CALL f_to_k(f_temp);
END;
$$;
=> CREATE PROCEDURE f_to_c(INOUT temp DOUBLE PRECISION) AS $$
BEGIN
temp := (temp - 32) * 5/9;
END;
$$;
=> CREATE PROCEDURE f_to_k(INOUT temp DOUBLE PRECISION) AS $$
BEGIN
temp := CALL f_to_c(temp);
temp := temp + 273.15;
END;
$$;
=> CALL f_to_c_and_k(80);
c_temp | k_temp
------------------+------------------
26.6666666666667 | 299.816666666667
(1 row)
See also
7.11.25 - CREATE PROFILE
Creates a profile that controls password requirements for users.
Creates a profile that controls password requirements for users.
Syntax
CREATE PROFILE profile-name LIMIT [
PASSWORD_LIFE_TIME setting
PASSWORD_MIN_LIFE_TIME setting
PASSWORD_GRACE_TIME setting
FAILED_LOGIN_ATTEMPTS setting
PASSWORD_LOCK_TIME setting
PASSWORD_REUSE_MAX setting
PASSWORD_REUSE_TIME setting
PASSWORD_MAX_LENGTH setting
PASSWORD_MIN_LENGTH setting
PASSWORD_MIN_LETTERS setting
PASSWORD_MIN_UPPERCASE_LETTERS setting
PASSWORD_MIN_LOWERCASE_LETTERS setting
PASSWORD_MIN_DIGITS setting
PASSWORD_MIN_SYMBOLS setting
PASSWORD_MIN_CHAR_CHANGE setting ]
Parameters
Note
All parameters that are not explicitly set in a new profile are set to default, and inherit their settings from the default profile.
|
Name |
Description |
name |
The name of the profile to create, where *name*conforms to conventions described in Identifiers.
To modify the default profile, set name to default. For example:
ALTER PROFILE DEFAULT LIMIT PASSWORD_MIN_SYMBOLS 1;
|
PASSWORD_LIFE_TIME |
Set to an integer value, one of the following:
After your password's lifetime and grace period expire, you must change your password on your next login, if you have not done so already.
|
PASSWORD_MIN_LIFE_TIME |
Set to an integer value, one of the following:
|
PASSWORD_GRACE_TIME |
Set to an integer value, one of the following:
|
FAILED_LOGIN_ATTEMPTS |
Set to an integer value, one of the following:
|
PASSWORD_LOCK_TIME |
-
≥ 1: The number of days (units configurable with PasswordLockTimeUnit) a user's account is locked after FAILED_LOGIN_ATTEMPTS number of login attempts. The account is automatically unlocked when the lock time elapses.
-
UNLIMITED: Account remains indefinitely inaccessible until a superuser manually unlocks it.
|
PASSWORD_REUSE_MAX |
Set to an integer value, one of the following:
|
PASSWORD_REUSE_TIME |
Set to an integer value, one of the following:
|
PASSWORD_MAX_LENGTH |
The maximum number of characters allowed in a password, one of the following:
- Integer between 8 and 512, inclusive
|
PASSWORD_MIN_LENGTH |
The minimum number of characters required in a password, one of the following:
|
PASSWORD_MIN_LETTERS |
Minimum number of letters (a-z and A-Z) that must be in a password, one of the following:
|
PASSWORD_MIN_UPPERCASE_LETTERS |
Minimum number of uppercase letters (A-Z) that must be in a password, one of the following:
|
PASSWORD_MIN_LOWERCASE_LETTERS |
Minimum number of lowercase letters (a-z) that must be in a password, one of the following:
|
PASSWORD_MIN_DIGITS |
Minimum number of digits (0-9) that must be in a password, one of the following:
|
PASSWORD_MIN_SYMBOLS |
Minimum number of symbols—printable non-letter and non-digit characters such as $, #, @—that must be in a password, one of the following:
|
PASSWORD_MIN_CHAR_CHANGE |
Minimum number of characters that must be different from the previous password:
|
Privileges
Superuser
Profile settings and client authentication
The following profile settings affect client authentication methods, such as LDAP or GSS:
-
FAILED_LOGIN_ATTEMPTS
-
PASSWORD_LOCK_TIME
All other profile settings are used only by Vertica to manage its passwords.
Examples
=> CREATE PROFILE sample_profile LIMIT PASSWORD_MAX_LENGTH 20;
See also
7.11.26 - CREATE PROJECTION
Creates metadata for a in the Vertica catalog.
Creates metadata for a projection in the Vertica catalog. Vertica supports four types of projections:
-
Standard projection: Stores a collection of table data in a format that optimizes execution of certain queries on that table.
-
Live aggregate projection: Stores the grouped results of queries that invoke aggregate functions (such as SUM) on table columns.
-
Top-K projection: Stores the top k rows from partitions of selected rows.
-
UDTF projection: Stores newly-loaded data after it is transformed and/or aggregated by user-defined transformation functions (UDTFs).
Complex data types have additional restrictions when used within a projection:
-
Each projection must include at least one column that is a primitive type or native array.
-
An AS SELECT clause can use a complex-type column, but any other expression must be of a scalar type or native array.
-
The ORDER BY, PARTITION BY, and GROUP BY clauses cannot use complex types.
-
If a projection does not include an ORDER BY or segmentation clause, Vertica uses only the primitive columns from the select list to order or segment data.
-
Projection columns cannot be complex types returned from functions such as ARRAY_CAT.
-
TopK and UDTF projections do not support complex types.
7.11.26.1 - Encoding types
Vertica supports various encoding and compression types, specified by the following ENCODING parameter arguments:.
Vertica supports various encoding and compression types, specified by the following ENCODING parameter arguments:
Note
Vertica supports the following encoding for numeric data types:
-
Precision ≤ 18: AUTO, BLOCK_DICT, BLOCKDICT_COMP, COMMONDELTA_COMP, DELTAVAL, GCDDELTA, and RLE
-
Precision > 18: AUTO, BLOCK_DICT, BLOCKDICT_COMP, RLE
You can set encoding types on a projection column when you create the projection. You can also change the encoding of one or more projection columns for a given table with ALTER TABLE...ALTER COLUMN.
AUTO (default)
AUTO encoding is ideal for sorted, many-valued columns such as primary keys. It is also suitable for general purpose applications for which no other encoding or compression scheme is applicable. Therefore, it serves as the default if no encoding/compression is specified.
|
Column data type |
Default encoding type |
BINARY/VARBINARY
BOOLEAN
CHAR/VARCHAR
FLOAT |
Lempel-Ziv-Oberhumer-based (LZO) compression |
DATE/TIME/TIMESTAMP
INTEGER
INTERVAL |
Compression scheme based on the delta between consecutive column values. |
The CPU requirements for this type are relatively small. In the worst case, data might expand by eight percent (8%) for LZO and twenty percent (20%) for integer data.
BLOCK_DICT
For each block of storage, Vertica compiles distinct column values into a dictionary and then stores the dictionary and a list of indexes to represent the data block.
BLOCK_DICT is ideal for few-valued, unsorted columns where saving space is more important than encoding speed. Certain kinds of data, such as stock prices, are typically few-valued within a localized area after the data is sorted, such as by stock symbol and timestamp, and are good candidates for BLOCK_DICT. By contrast, long CHAR/VARCHAR columns are not good candidates for BLOCK_DICT encoding.
CHAR and VARCHAR columns that contain 0x00 or 0xFF characters should not be encoded with BLOCK_DICT. Also, BINARY/VARBINARY columns do not support BLOCK_DICT encoding.
BLOCK_DICT encoding requires significantly higher CPU usage than default encoding schemes. The maximum data expansion is eight percent (8%).
BLOCKDICT_COMP
This encoding type is similar to BLOCK_DICT except dictionary indexes are entropy coded. This encoding type requires significantly more CPU time to encode and decode and has a poorer worst-case performance. However, if the distribution of values is extremely skewed, using BLOCK_DICT_COMP encoding can lead to space savings.
BZIP_COMP
BZIP_COMP encoding uses the bzip2 compression algorithm on the block contents. See bzip web site for more information. This algorithm results in higher compression than the automatic LZO and gzip encoding; however, it requires more CPU time to compress. This algorithm is best used on large string columns such as VARCHAR, VARBINARY, CHAR, and BINARY. Choose this encoding type when you are willing to trade slower load speeds for higher data compression.
COMMONDELTA_COMP
This compression scheme builds a dictionary of all deltas in the block and then stores indexes into the delta dictionary using entropy coding.
This scheme is ideal for sorted FLOAT and INTEGER-based (DATE/TIME/TIMESTAMP/INTERVAL) data columns with predictable sequences and only occasional sequence breaks, such as timestamps recorded at periodic intervals or primary keys. For example, the following sequence compresses well: 300, 600, 900, 1200, 1500, 600, 1200, 1800, 2400. The following sequence does not compress well: 1, 3, 6, 10, 15, 21, 28, 36, 45, 55.
If delta distribution is excellent, columns can be stored in less than one bit per row. However, this scheme is very CPU intensive. If you use this scheme on data with arbitrary deltas, it can cause significant data expansion.
DELTARANGE_COMP
This compression scheme is primarily used for floating-point data; it stores each value as a delta from the previous one.
This scheme is ideal for many-valued FLOAT columns that are sorted or confined to a range. Do not use this scheme for unsorted columns that contain NULL values, as the storage cost for representing a NULL value is high. This scheme has a high cost for both compression and decompression.
To determine if DELTARANGE_COMP is suitable for a particular set of data, compare it to other schemes. Be sure to use the same sort order as the projection, and select sample data that will be stored consecutively in the database.
DELTAVAL
For INTEGER and DATE/TIME/TIMESTAMP/INTERVAL columns, data is recorded as a difference from the smallest value in the data block. This encoding has no effect on other data types.
DELTAVAL is best used for many-valued, unsorted integer or integer-based columns. CPU requirements for this encoding type are minimal, and data never expands.
GCDDELTA
For INTEGER and DATE/TIME/TIMESTAMP/INTERVAL columns, and NUMERIC columns with 18 or fewer digits, data is recorded as the difference from the smallest value in the data block divided by the greatest common divisor (GCD) of all entries in the block. This encoding has no effect on other data types.
ENCODING GCDDELTA is best used for many-valued, unsorted, integer columns or integer-based columns, when the values are a multiple of a common factor. For example, timestamps are stored internally in microseconds, so data that is only precise to the millisecond are all multiples of 1000. The CPU requirements for decoding GCDDELTA encoding are minimal, and the data never expands, but GCDDELTA may take more encoding time than DELTAVAL.
GZIP_COMP
This encoding type uses the gzip compression algorithm. See gzip web site for more information. This algorithm results in better compression than the automatic LZO compression, but lower compression than BZIP_COMP. It requires more CPU time to compress than LZO but less CPU time than BZIP_COMP. This algorithm is best used on large string columns such as VARCHAR, VARBINARY, CHAR, and BINARY. Use this encoding when you want a better compression than LZO, but at less CPU time than bzip2.
RLE
RLE (run length encoding) replaces sequences (runs) of identical values with a single pair that contains the value and number of occurrences. Therefore, it is best used for low cardinality columns that are present in the ORDER BY clause of a projection.
The Vertica execution engine processes RLE encoding run-by-run and the Vertica optimizer gives it preference. Use it only when run length is large, such as when low-cardinality columns are sorted.
Zstandard compression
Vertica supports three ZSTD compression types:
-
ZSTD_COMP provides high compression ratios. This encoding type has a higher compression than gzip. Use this when you want a better compression than gzip. For general use cases, use this or the ZSTD_FAST_COMP encoding type.
-
ZSTD_FAST_COMP uses the fastest compression level that the zstd library provides. It is the fastest encoding type of the zstd library, but takes up more space than the other two encoding types. For general use cases, use this or the ZSTD_COMP encoding type.
-
ZSTD_HIGH_COMP offers the best compression in the zstd library. It is slower than the other two encoding types. Use this type when you need the best compression, with slower CPU time.
7.11.26.2 - GROUPED clause
Groups two or more columns into a single disk file.
Enterprise Mode only
Groups two or more columns into a single disk file. Doing so minimizes file I/O for the following tasks:
-
Read a large percentage of the columns in a table.
-
Perform single row look-ups.
-
Query against many small columns.
-
Frequently update data in these columns.
You can improve query performance by grouping columns that are always accessed together and are not used in predicates. Once columns are grouped, queries can no longer retrieve from disk records for one column independently of the others.
Note
RLE encoding is reduced when an RLE column is grouped with one or more non-RLE columns.
You can group columns in several ways:
-
Group some of the columns:
(a, GROUPED(b, c), d)
-
Group all of the columns:
(GROUPED(a, b, c, d))
-
Create multiple groupings in the same projection:
(GROUPED(a, b), GROUPED(c, d))
Note
Vertica performs dynamic column grouping. For example, to provide better read and write efficiency for small loads, Vertica ignores any projection-defined column grouping (or lack thereof) and groups all columns together by default.
Grouping columns
The following example shows how to group columns bid and ask. The stock column is stored separately.
=> CREATE TABLE trades (stock CHAR(5), bid INT, ask INT);
=> CREATE PROJECTION tradeproj (stock ENCODING RLE,
GROUPED(bid ENCODING DELTAVAL, ask))
AS (SELECT * FROM trades) KSAFE 1;
The following example show how to create a projection that uses expressions in the column definition. The projection contains two integer columns a and b, and a third column product_value that stores the product of a and b:
=> CREATE TABLE values (a INT, b INT);
=> CREATE PROJECTION product (a, b, product_value) AS
SELECT a, b, a*b FROM values ORDER BY a KSAFE;
7.11.26.3 - Hash segmentation clause
A general SQL expression.
Specifies how to segment projection data for distribution across all cluster nodes. You can specify segmentation for a table and a projection. If a table definition specifies segmentation, Vertica uses it for that table's auto-projections.
It is strongly recommended that you use Vertica's built-in
HASH function, which distributes data evenly across the cluster, and facilitates optimal query execution.
Syntax
SEGMENTED BY expression ALL NODES [ OFFSET offset ]
Parameters
SEGMENTED BY expression- A general SQL expression. Hash segmentation is the preferred method of segmentation. Vertica recommends using its built-in
HASH function, whose arguments resolve to table columns. If you use an expression other than HASH, Vertica issues a warning.
The segmentation expression should specify columns with a large number of unique data values and acceptable skew in their data distribution. In general, primary key columns that meet these criteria are good candidates for hash segmentation.
For details, see Expression Requirements below.
ALL NODES- Automatically distributes data evenly across all nodes when the projection is created. Node ordering is fixed.
OFFSET offset- A zero-based offset that indicates on which node to start segmentation distribution.
This option is not valid for
CREATE TABLE and
CREATE TEMPORARY TABLE.
Important
If you create a projection for a table with the OFFSET option, be sure to create enough copies of each projection segment to satisfy system K-safety; otherwise, Vertica regards the projection as unsafe and cannot use it to query the table.
You can ensure K-safety compliance when you create projections by combining OFFSET and
KSAFE options in the CREATE PROJECTION statement. On executing this statement, Vertica automatically creates the necessary number of projection copies.
Expression requirements
A segmentation expression must specify table columns as they are defined in the source table. Projection column names are not supported.
The following restrictions apply to segmentation expressions:
-
All leaf expressions must be constants or column references to a column in the CREATE PROJECTION 's SELECT list.
-
The expression must return the same value over the life of the database.
-
Aggregate functions are not allowed.
-
The expression must return non-negative INTEGER values in the range
0 <= x < 263, and values are generally distributed uniformly over that range.
Note
If the expression produces a value outside the expected range—for example, a negative value—no error occurs, and the row is added to the projection's first segment.
Examples
The following CREATE PROJECTION statement creates projection public.employee_dimension_super. It specifies to include all columns in table public.employee_dimension. The hash segmentation clause invokes the Vertica HASH function to segment projection data on the column employee_key; it also includes the ALL NODES clause, which specifies to distribute projection data evenly across all nodes in the cluster:
=> CREATE PROJECTION public.employee_dimension_super
AS SELECT * FROM public.employee_dimension
ORDER BY employee_key
SEGMENTED BY hash(employee_key) ALL NODES;
7.11.26.4 - Live aggregate projection
Stores the grouped results of queries that invoke aggregate functions (such as SUM) on table columns.
Stores the grouped results of queries that invoke aggregate functions (such as SUM) on table columns. For details, see Live aggregate projections.
Vertica does not regard live aggregate projections as superprojections, even those that include all table columns. For other requirements and restrictions, see Creating live aggregate projections.
Syntax
CREATE PROJECTION [ IF NOT EXISTS ] [[database.]schema.]projection
[ (
{ projection-column | grouped-clause
[ ENCODING encoding-type ]
[ ACCESSRANK integer ] }[,...]
) ]
AS SELECT { table-column | expr-with-table-columns }[,...] FROM [[database.]schema.]table [ [AS] alias]
GROUP BY column-expr[,...]
[ KSAFE [ k-num ] ]
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaSchema for this projection and its anchor table. The value must be the same for both. If you specify a database, it must be the current database.
projectionName of the projection to create, which must conform to Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
projection-columnThe name of a projection column. The list of projection columns must match the SELECT list columns and expressions in number, type, and sequence.
If projection column names are omitted, Vertica uses the anchor table column names specified in the SELECT list.
grouped-clause- See GROUPED clause.
ENCODING encoding-typeThe column encoding type, by default set to AUTO.
ACCESSRANK integerOverrides the default access rank for a column. Use this parameter to increase or decrease the speed at which Vertica accesses a column. For more information, see Overriding Default Column Ranking.
AS SELECTSpecifies the table data to query:
{table-column | expr-with-table-columns } [ [AS] alias] }[,...]
You can optionally assign an alias to each column expression and reference that alias elsewhere in the SELECT statement.
If you specify projection column names, the two lists of projection columns and table columns/expressions must exactly match in number and order.
GROUP BY column-expr[,...]- One or more column expressions from the SELECT list. The first expression must be the first column expression in the SELECT list, the second expression must be the second column expression in the SELECT list, and so on.
Privileges
Non-superusers:
Examples
See Live aggregate projection example.
7.11.26.5 - Standard projection
Stores a collection of table data in a format that optimizes execution of certain queries on that table.
Stores a collection of table data in a format that optimizes execution of certain queries on that table. For details, see Projections .
Syntax
CREATE PROJECTION [ IF NOT EXISTS ] [[database.]schema.]projection
[ (
{ projection-column | grouped-clause
[ ENCODING encoding-type ]
[ ACCESSRANK integer ] }[,...]
) ]
AS SELECT { * | { MATCH_COLUMNS('pattern') | expression [ [AS] alias ] }[,...] }
FROM [[database.]schema.]table [ [AS] alias]
[ ORDER BY column[,...] ]
[ SEGMENTED BY expression ALL NODES [ OFFSET offset ] | UNSEGMENTED ALL NODES ]
[ KSAFE [ k-num ]
[ ON PARTITION RANGE BETWEEN min-val AND max-val ] ]
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaSchema for this projection and its anchor table. The value must be the same for both. If you specify a database, it must be the current database.
projectionName of the projection to create, which must conform to Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
projection-columnThe name of a projection column. The list of projection columns must match the SELECT list columns and expressions in number, type, and sequence.
If projection column names are omitted, Vertica uses the anchor table column names specified in the SELECT list.
grouped-clause- See GROUPED clause.
ENCODING encoding-typeThe column encoding type, by default set to AUTO.
ACCESSRANK integerOverrides the default access rank for a column. Use this parameter to increase or decrease the speed at which Vertica accesses a column. For more information, see Overriding Default Column Ranking.
AS SELECT- Columns or column expressions to select from the specified table:
-
* (asterisk): Returns all columns in the queried tables.
-
MATCH_COLUMNS('pattern'): Returns the names of all columns in the queried anchor table that match pattern.
-
expression[[AS]alias]: Resolves to column data from the queried anchor table. You can optionally assign an alias to each column expression and reference that alias elsewhere in the SELECT statement—for example, in the ORDER BY or segmentation clause.
If you specify projection column names, the two lists of projection columns and table columns/expressions must exactly match in number and order.
ORDER BY column- Columns from the SELECT list on which to sort the projection. The ORDER BY clause can only be set to ASC (the default). Vertica always stores projection data in ascending sort order.
If you order by a column with a collection data type (ARRAY or SET), queries that use that column in an ORDER BY clause perform the sort again. This is because projections and queries perform the ordering differently.
If you omit the ORDER BY clause, Vertica uses the SELECT list to sort the projection.
SEGMENTED BY expression ALL NODES [ OFFSET offset ] | UNSEGMENTED ALL NODES-
How to distribute projection data:
If neither the anchor table nor the projection specifies segmentation, Vertica uses hash segmentation using all columns:
SEGMENTED BY HASH(column[,...]) ALL NODES OFFSET 0;
Tip
Vertica recommends segmenting large tables.
KSAFE k-numSpecifies K-safety for the projection. The value must be equal to or greater than database K-safety. Vertica ignores this option if set for unsegmented projections.
If you omit this clause, Vertica uses database K-safety.
For general information, see K-safety in an Enterprise Mode database.
ON PARTITION RANGE BETWEEN min-val AND max-valLimits projection data to a range of partition keys. The minimum value must be less than or equal to the maximum value.
Values can be NULL. A null minimum value indicates no lower bound and a null maximum value indicates no upper bound. If both are NULL, this statement drops the projection endpoints, producing a regular projection instead of a range projection.
For other requirements and usage details, see Partition range projections.
Privileges
Non-superusers:
Examples
See:
7.11.26.6 - Top-k projection
Stores the top k rows from partitions of selected rows.
Stores the top k rows from partitions of selected rows. For details, see Top-k projections.
Vertica does not regard Top-K projections as superprojections, even those that include all table columns. For other requirements and restrictions, see Creating top-k projections.
Syntax
CREATE PROJECTION [ IF NOT EXISTS ] [[database.]schema.]projection
[ (
{ projection-column | grouped-clause
[ ENCODING encoding-type ]
[ ACCESSRANK integer ] }[,...]
) ]
AS SELECT { table-column | expr-with-table-columns }[,...] FROM [[database.]schema.]table [ [AS] alias]
LIMIT num-rows OVER ( window-partition-clause window-order-clause )
[ KSAFE [ k-num ] ]
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaSchema for this projection and its anchor table. The value must be the same for both. If you specify a database, it must be the current database.
projectionName of the projection to create, which must conform to Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
projection-columnThe name of a projection column. The list of projection columns must match the SELECT list columns and expressions in number, type, and sequence.
If projection column names are omitted, Vertica uses the anchor table column names specified in the SELECT list.
grouped-clause- See GROUPED clause.
ENCODING encoding-typeThe column encoding type, by default set to AUTO.
ACCESSRANK integerOverrides the default access rank for a column. Use this parameter to increase or decrease the speed at which Vertica accesses a column. For more information, see Overriding Default Column Ranking.
AS SELECTSpecifies the table data to query:
{table-column | expr-with-table-columns } [ [AS] alias] }[,...]
You can optionally assign an alias to each column expression and reference that alias elsewhere in the SELECT statement.
If you specify projection column names, the two lists of projection columns and table columns/expressions must exactly match in number and order.
LIMIT num-rows- The number of rows to return from the specified partition.
OVER (window-partition-clause window-order-clause)- Specifies window partitioning by one or more comma-delimited column expressions from the SELECT list. The first partition expression must be the first SELECT list item, the second partition expression the second SELECT list item, and so on.
The order clause is required, and specifies the order in which the top k rows are returned. The default is ascending (ASC) order. All column expressions must be from the SELECT list, where the first window order expression must be the first SELECT list item not specified in the window partition clause.
Top-K projections support ORDER BY NULLS FIRST/LAST.
Privileges
Non-superusers:
Examples
See Top-k projection examples.
7.11.26.7 - UDTF projection
Stores newly-loaded data after it is transformed and/or aggregated by user-defined transformation functions (UDTFs).
Stores newly-loaded data after it is transformed and/or aggregated by user-defined transformation functions (UDTFs). For details and examples, see Pre-aggregating UDTF results.
Syntax
CREATE PROJECTION [ IF NOT EXISTS ] [[database.]schema.]projection
[ (
{ projection-column | grouped-clause
[ ENCODING encoding-type ]
[ ACCESSRANK integer ] }[,...]
) ]
AS { batch-query FROM { prepass-query sq-ref | table [[AS] alias] }
| prepass-query }
batch-query:
SELECT { table-column | expr-with-table-columns }[,...], batch-udtf(batch-args)
OVER (PARTITION BATCH BY partition-column-expr[,...])
[ AS (output-columns) ]
prepass-query:
SELECT { table-column | expr-with-table-columns }[,...], prepass-udtf(prepass-args)
OVER (PARTITION PREPASS BY partition-column-expr[,...])
[ AS (output-columns) ] FROM table
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaSchema for this projection and its anchor table. The value must be the same for both. If you specify a database, it must be the current database.
projectionName of the projection to create, which must conform to Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
projection-columnThe name of a projection column. The list of projection columns must match the SELECT list columns and expressions in number, type, and sequence.
If projection column names are omitted, Vertica uses the anchor table column names specified in the SELECT list.
grouped-clause- See GROUPED clause.
ENCODING encoding-typeThe column encoding type, by default set to AUTO.
ACCESSRANK integerOverrides the default access rank for a column. Use this parameter to increase or decrease the speed at which Vertica accesses a column. For more information, see Overriding Default Column Ranking.
SELECTSpecifies the table data to query:
{table-column | expr-with-table-columns } [ [AS] alias] }[,...]
You can optionally assign an alias to each column expression and reference that alias elsewhere in the SELECT statement.
If you specify projection column names, the two lists of projection columns and table columns/expressions must exactly match in number and order.
batch-udtf(batch-args)- The batch UDTF to invoke each time the following events occur:
Important
If the projection definition includes a pre-pass subquery, batch-args must exactly match the pre-pass UDTF output columns, in name and order.
prepass-udtf(prepass-args)- The pre-pass UDTF to invoke on each load operation such as COPY or INSERT.
If specified in a subquery, the pre-pass UDTF returns transformed data to the batch query for further processing. Otherwise, the pre-pass query results are added to projection data storage.
OVER (PARTITION { BATCH | PREPASS } BY partition-column-expr[,...])- Specifies the UDTF type and how to partition the data it returns:
In both cases, the OVER clause specifies partitioning with one or more column expressions from the SELECT list. The first expression is the first column expression in the SELECT list, the second expression is the second column expression in the SELECT list, and so on.
Note
The projection is implicitly segmented and ordered on PARTITION BY columns.
AS output-columns- Optionally names columns that are returned by the UDTF.
If a pre-pass subquery omits this clause, the outer batch query UDTF arguments (batch-args) must reference the column names as they are defined in the pre-pass UDTF.
table[[AS]alias]- The projection's anchor table, optionally qualified by an alias.
sq-results- Subquery result set that is returned to the outer batch UDTF.
Privileges
Non-superusers:
Examples
See Pre-aggregating UDTF results.
7.11.26.8 - Unsegmented clause
Specifies to distribute identical copies of table or projection data on all nodes across the cluster.
Specifies to distribute identical copies of table or projection data on all nodes across the cluster. Use this clause to facilitate distributed query execution on tables and projections that are too small to benefit from segmentation.
Vertica uses the same name to identify all instances of an unsegmented projection. For more information about projection name conventions, see Projection naming.
Syntax
UNSEGMENTED ALL NODES
Examples
This example creates an unsegmented projection for table store.store_dimension:
=> CREATE PROJECTION store.store_dimension_proj (storekey, name, city, state)
AS SELECT store_key, store_name, store_city, store_state
FROM store.store_dimension
UNSEGMENTED ALL NODES;
CREATE PROJECTION
=> SELECT anchor_table_name anchor_table, projection_name, node_name
FROM PROJECTIONS WHERE projection_basename='store_dimension_proj';
anchor_table | projection_name | node_name
-----------------+----------------------+------------------
store_dimension | store_dimension_proj | v_vmart_node0001
store_dimension | store_dimension_proj | v_vmart_node0002
store_dimension | store_dimension_proj | v_vmart_node0003
(3 rows)
7.11.27 - CREATE RESOURCE POOL
Creates a user-defined resource pool.
Creates a user-defined resource pool.
Syntax
CREATE RESOURCE POOL pool-name [ FOR subcluster ] [ parameter-name setting ]...
Arguments
pool-name- Name of the resource pool. If you specify a resource pool name with uppercase letters, Vertica converts them to lowercase letters.
The following naming requirements apply:
-
Built-in pool names cannot be used for user-defined pools.
-
All user-defined global resource pools must have unique names.
-
Names of global and subcluster-assigned resource pools cannot be the same. However, the same name can be shared by resource pools of different subclusters.
FOR subclusterEon Mode only, the subcluster to associate with this resource pool, where subcluster is one of the following:
SUBCLUSTER subcluster-name: Resource pool for an existing subcluster. You cannot be connected to this subcluster, otherwise Vertica returns an error.CURRENT SUBCLUSTER: Resource pool for the subcluster that you are connected to.
If omitted, the resource pool is created globally.
parameter-name setting- A resource pool parameter and its initial value. If you omit this argument, Vertica sets this resource pool's parameters to their default values (see Parameters).
Parameters
Default values specified here pertain only to user-defined resource pools. For built-in pool default values, see Built-in resource pools configuration, or query system table RESOURCE_POOL_DEFAULTS.
-
CASCADE TO
Secondary resource pool for executing queries that exceed the
RUNTIMECAP setting of their assigned resource pool:
CASCADE TO secondary-pool
-
CPUAFFINITYMODE
Specifies whether the resource pool has exclusive or shared use of the CPUs specified in
CPUAFFINITYSET:
CPUAFFINITYMODE { SHARED | EXCLUSIVE | ANY }
SHARED: Queries that run in this resource pool share its CPUAFFINITYSET CPUs with other Vertica resource pools.EXCLUSIVE: Dedicates CPUAFFINITYSET CPUs to this resource pool only, and excludes other Vertica resource pools. If CPUAFFINITYSET is set as a percentage, then that percentage of CPU resources available to Vertica is assigned solely for this resource pool.ANY: Queries in this resource pool can run on any CPU, invalid if CPUAFFINITYSET designates CPU resources.
Default: ANY
-
CPUAFFINITYSET
CPUs available to this resource pool. All cluster nodes must have the same number of CPUs. The CPU resources assigned to this set are unavailable to general resource pools.
CPUAFFINITYSET {
'cpu-index[,...]'
| 'cpu-indexi-cpu-indexn'
| 'integer%'
| NONE
}
cpu-index[,...]: Dedicates one or more comma-delimited CPUs to this resource pool.cpu-indexi-cpu-indexn: Dedicates a range of contiguous CPU indexes i through n to this resource pool.integer%: Percentage of all available CPUs to use for this resource pool. Vertica rounds this percentage down to include whole CPU units.NONE (empty string): No affinity set is assigned to this resource pool. Queries associated with this pool are executed on any CPU.
Default: NONE
Important
CPUAFFINITYSET and CPUAFFINITYMODE must be set together in the same statement.
-
EXECUTIONPARALLELISM
Number of threads used to process any single query issued in this resource pool.
EXECUTIONPARALLELISM { limit | AUTO }
limit: An integer value between 1 and the number of cores. Setting this parameter to a reduced value increases throughput of short queries issued in the resource pool, especially if queries are executed concurrently.AUTO or 0: Vertica calculates the setting from the number of cores, available memory, and amount of data in the system. Unless memory is limited, or the amount of data is very small, Vertica sets this parameter to the number of cores on the node.
Default: AUTO
-
MAXCONCURRENCY
Maximum number of concurrent execution slots available to the resource pool across the cluster:
MAXCONCURRENCY { integer | NONE }
NONE (empty string): Unlimited number of concurrent execution slots.
Default: NONE
-
MAXMEMORYSIZE
Maximum size per node the resource pool can grow by borrowing memory from the
GENERAL pool:
MAXMEMORYSIZE {
'integer%'
|'integer{K|M|G|T}'
NONE
}
integer%: Percentage of total memoryinteger{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytesNONE (empty string): Unlimited, resource pool can borrow any amount of available memory from the GENERAL pool.
Default: NONE
MAXQUERYMEMORYSIZEMaximum amount of memory this resource pool can allocate at runtime to process a query. If the query requires more memory than this setting, Vertica stops execution and returns an error.
Set this parameter as follows:
MAXQUERYMEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
| NONE
}
integer%: Percentage of
MAXMEMORYSIZE for this resource pool.integer{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes, up to the value of
MAXMEMORYSIZE.NONE (empty string): Unlimited; resource pool can borrow any amount of available memory from the GENERAL pool, within the limits set by
MAXMEMORYSIZE.
Default: NONE
-
MEMORYSIZE
Total per-node memory available to the Vertica resource manager that is allocated to this resource pool:
MEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
}
integer%: Percentage of total memoryinteger{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes
Default: 0%. No memory allocated, the resource pool borrows memory from the
GENERAL pool.
-
PLANNEDCONCURRENCY
Preferred number of queries to execute concurrently in the resource pool. This setting applies to the entire cluster:
PLANNEDCONCURRENCY { num-queries | AUTO }
-
num-queries: Integer value ≥ 1, the preferred number of queries to execute concurrently in the resource pool. When possible, query resource budgets are limited to allow this level of concurrent execution.
-
AUTO: Value is calculated automatically at query runtime. Vertica sets this parameter to the lower of these two calculations, but never less than 4:
-
Number of logical cores
-
Memory divided by 2GB
If the number of logical cores on each node is different, AUTO is calculated differently for each node. Distributed queries run like the minimal effective planned concurrency. Single node queries run with the planned concurrency of the initiator.
Default: AUTO
Tip
Change this parameter only after evaluating performance over a period of time.
-
PRIORITY
Priority of queries in this resource pool when they compete for resources in the
GENERAL pool:
PRIORITY { integer | HOLD }
-
integer: Negative or positive integer value, where higher numbers denote higher priority:
-
User-defined resource pool: -100 to 100
-
Built-in resource pools
SYSQUERY,
RECOVERY, and
TM: -110 to 110
-
HOLD: Sets priority to -999. Queries in this resource pool are queued until
QUEUETIMEOUT is reached.
Default: 0
-
QUEUETIMEOUT
Maximum time a request can wait for pool resources before it is rejected, not more than one year:
QUEUETIMEOUT { integer | 'interval' | 'NONE' }
-
integer: Maximum wait time in seconds
-
[interval](/en/sql-reference/language-elements/literals/datetime-literals/interval-literal/): Maximum wait time expressed in the following format:
num year num months num [days] HH:MM:SS.ms
-
NONE (empty string): No maximum wait time, request can be queued indefinitely, up to one year.
If the value that you specify resolves to more than one year, Vertica returns with a warning and sets the parameter to 365 days:
=> ALTER RESOURCE POOL user_0 QUEUETIMEOUT '11 months 50 days 08:32';
WARNING 5693: Using 1 year for QUEUETIMEOUT
ALTER RESOURCE POOL
=> SELECT QUEUETIMEOUT FROM resource_pools WHERE name = 'user_0';
QUEUETIMEOUT
--------------
365
(1 row)
Default: 00:05 (5 minutes)
RUNTIMECAPMaximum execution time allowed to queries in this resource pool, not more than one year, otherwise Vertica returns with an error. If a query exceeds this setting, it tries to cascade to a secondary pool:
RUNTIMECAP { 'interval' | NONE }
-
interval: Maximum wait time expressed in the following format:
num year num month num [day] HH:MM:SS.ms
-
NONE (empty string): No maximum wait time, request can be queued indefinitely, up to one year.
If the user or session also has a RUNTIMECAP, the shorter limit applies.
-
RUNTIMEPRIORITY
Determines how the resource manager should prioritize dedication of run-time resources (CPU, I/O bandwidth) to queries already running in this resource pool:
RUNTIMEPRIORITY { HIGH | MEDIUM | LOW }
Default: MEDIUM
-
RUNTIMEPRIORITYTHRESHOLD
Maximum time (in seconds) in which query processing must complete before the resource manager assigns to it the resource pool's RUNTIMEPRIORITY. All queries begin execution with a priority of HIGH.
RUNTIMEPRIORITYTHRESHOLD seconds
Default: 2
SINGLEINITIATORSet to false for backward compatibility. Do not change this setting.
Privileges
Superuser
Examples
This example shows how to create a resource pool with MEMORYSIZE of 1800 MB.
=> CREATE RESOURCE POOL ceo_pool MEMORYSIZE '1800M' PRIORITY 10;
CREATE RESOURCE POOL
Assuming the CEO report user already exists, associate this user with the preceding resource pool using ALTER USER statement.
=> GRANT USAGE ON RESOURCE POOL ceo_pool to ceo_user;
GRANT PRIVILEGE
=> ALTER USER ceo_user RESOURCE POOL ceo_pool;
ALTER USER
Issue the following command to confirm that the ceo_user is associated with the ceo_pool:
=> SELECT * FROM users WHERE user_name ='ceo_user';
-[ RECORD 1 ]-----+--------------------------------------------------
user_id | 45035996273733402
user_name | ceo_user
is_super_user | f
profile_name | default
is_locked | f
lock_time |
resource_pool | ceo_pool
memory_cap_kb | unlimited
temp_space_cap_kb | unlimited
run_time_cap | unlimited
all_roles |
default_roles |
search_path | "$user", public, v_catalog, v_monitor, v_internal
This exampleshows how to create and designate secondary resource pools.
=> CREATE RESOURCE POOL rp3 RUNTIMECAP '5 minutes';
=> CREATE RESOURCE POOL rp2 RUNTIMECAP '3 minutes' CASCADE TO rp3;
=> CREATE RESOURCE POOL rp1 RUNTIMECAP '1 minute' CASCADE TO rp2;
=> SET SESSION RESOURCE_POOL = rp1;
This Eon Mode example confirms the current subcluster name, then creates a resource pool for the current subcluster:
=> SELECT CURRENT_SUBCLUSTER_NAME();
CURRENT_SUBCLUSTER_NAME
-------------------------
analytics_1
(1 row)
=> CREATE RESOURCE POOL dashboard FOR SUBCLUSTER analytics_1;
CREATE RESOURCE POOL
See also
7.11.27.1 - Built-in pools
Vertica is preconfigured with built-in pools for various system tasks:.
Vertica is preconfigured with built-in pools for various system tasks:
For details on resource pool settings, see ALTER RESOURCE POOL.
GENERAL
Catch-all pool used to answer requests that have no specific resource pool associated with them. Any memory left over after memory has been allocated to all other pools is automatically allocated to the GENERAL pool. The MEMORYSIZE parameter of the GENERAL pool is undefined (variable), however, the GENERAL pool must be at least 1GB in size and cannot be smaller than 25% of the memory in the system.
The MAXMEMORYSIZE parameter of the GENERAL pool has special meaning; when set as a % value it represents the percent of total physical RAM on the machine that the Resource manager can use for queries. By default, it is set to 95%. MAXMEMORYSIZE governs the total amount of RAM that the Resource Manager can use for queries, regardless of whether it is set to a percent or to a specific value (for example, '10GB').
User-defined pools can borrow memory from the GENERAL pool to satisfy requests that need extra memory until the MAXMEMORYSIZE parameter of that pool is reached. If the pool is configured to have MEMORYSIZE equal to MAXMEMORYSIZE, it cannot borrow any memory from the GENERAL pool. When multiple pools request memory from the GENERAL pool, they are granted access to general pool memory according to their priority setting. In this manner, the GENERAL pool provides some elasticity to account for point-in-time deviations from normal usage of individual resource pools.
Vertica recommends reducing the GENERAL pool MAXMEMORYSIZE if your catalog uses over 5 percent of overall memory. You can calculate what percentage of GENERAL pool memory the catalog uses as follows:
=> WITH memory_use_metadata AS (SELECT node_name, memory_size_kb FROM resource_pool_status WHERE pool_name='metadata'),
memory_use_general AS (SELECT node_name, memory_size_kb FROM resource_pool_status WHERE pool_name='general')
SELECT m.node_name, ((m.memory_size_kb/g.memory_size_kb) * 100)::NUMERIC(4,2) pct_catalog_usage
FROM memory_use_metadata m JOIN memory_use_general g ON m.node_name = g.node_name;
node_name | pct_catalog_usage
------------------+-------------------
v_vmart_node0001 | 0.41
v_vmart_node0002 | 0.37
v_vmart_node0003 | 0.36
(3 rows)
BLOBDATA
Controls resource usage for in-memory blobs. In-memory blobs are objects used by a number of the machine learning SQL functions. You should adjust this pool if you plan on processing large machine learning workloads. For information about tuning the pool, see Tuning for machine learning.
If a query using the BLOBDATA pool exceeds its query planning budget, then it spills to disk. For more information about tuning your query budget, see Query budgeting.
DBD
Controls resource usage for Database Designer processing. Use of this pool is enabled by configuration parameter DBDUseOnlyDesignerResourcePool, by default set to false.
By default, QUEUETIMEOUT is set to 0 for this pool. When resources are under pressure, this setting causes the DBD to time out immediately, and not be queued to run later. Database Designer then requests the user to run the designer later, when resources are more available.
Important
Do not change QUEUETIMEOUT or any DBD resource pool parameters.
JVM
Controls Java Virtual Machine resources used by Java User Defined Extensions. When a Java UDx starts the JVM, it draws resources from the those specified in the JVM resource pool. Vertica does not reserve memory in advance for the JVM pool. When needed, the pool can expand to 10% of physical memory or 2 GB of memory, whichever is smaller. If you are buffering large amounts of data, you may need to increase the size of the JVM resource pool.
You can adjust the size of your JVM resource pool by changing its configuration settings. Unlike other resource pools, the JVM resource pool does not release resources until a session is closed.
Tracks memory allocated for catalog data and storage data structures. This pool increases in size as Vertica metadata consumes additional resources. Memory assigned to the METADATA pool is subtracted from the GENERAL pool, enabling the Vertica resource manager to make more effective use of available resources. If the METADATA resource pool reaches 75% of the GENERAL pool, Vertica stops updating METADATA memory size and displays a warning message in vertica.log. You can enable or disable the METADATA pool with configuration parameter EnableMetadataMemoryTracking.
If you created a "dummy" or "swap" resource pool to protect resources for use by your operating system, you can replace that pool with the METADATA pool.
Users cannot change the parameters of the METADATA resource pool.
RECOVERY
Used by queries issued when recovering another node of the database. The MAXCONCURRENCY parameter is used to determine how many concurrent recovery threads to use. You can use the PLANNEDCONCURRENCY parameter (by default, set to twice the MAXCONCURRENCY) to tune how to apportion memory to recovery queries.
See Tuning for recovery.
REFRESH
Used by queries issued by
PROJECTION_REFRESHES operations. Refresh does not currently use multiple concurrent threads; thus, changes to the MAXCONCURRENCY values have no effect.
See Scenario: Tuning for Refresh.
SYSQUERY
Runs queries against all system monitoring and catalog tables. The SYSQUERY pool reserves resources for system table queries so that they are never blocked by contention for available resources.
TM
The Tuple Mover (TM) pool. You can set the MAXCONCURRENCY parameter for the TM pool to allow concurrent TM operations.
See Tuning tuple mover pool settings.
7.11.27.2 - Built-in resource pools configuration
To view the current and default configuration for built-in resource pools, query the system tables RESOURCE_POOLS and RESOURCE_POOL_DEFAULTS, respectively.
To view the current and default configuration for built-in resource pools, query the system tables RESOURCE_POOLS and RESOURCE_POOL_DEFAULTS, respectively. The sections below provide this information, and also indicate which built-in pool parameters can be modified with ALTER RESOURCE POOL:
GENERAL
Important
Changes to GENERAL resource pool parameters take effect only when the database restarts.
|
Parameter |
Settings |
|
MEMORYSIZE |
Empty / cannot be set |
|
MAXMEMORYSIZE |
The maximum memory to use for all resource pools, one of the following:
MAXMEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
}
integer%: Percentage of total system RAM, must be ≥ 25%
Caution
Setting this parameter to 100% generates a warning of potential swapping.
integer{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes, must be ≥ 1GB
For example, if your node has 64GB of memory, setting MAXMEMORYSIZE to 50% allocates half of available memory. Thus, the maximum amount of memory available to all resource pools is 32GB.
Default: 95%
|
|
MAXQUERYMEMORYSIZE |
The maximum amount of memory allocated by this pool to process any query:
MAXQUERYMEMORYSIZE {
'integer%'
| 'integer{K|M|G|T}'
}
-
integer%: Percentage of MAXMEMORYSIZE for this pool.
-
integer{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytes
|
|
EXECUTIONPARALLELISM |
Default: AUTO |
|
PRIORITY |
Default: 0 |
|
RUNTIMEPRIORITY |
Default: Medium |
|
RUNTIMEPRIORITYTHRESHOLD |
Default: 2 |
|
QUEUETIMEOUT |
Default: 00:05 (minutes) |
|
RUNTIMECAP |
Prevents runaway queries by setting the maximum time a query in the pool can execute. If a query exceeds this setting, it tries to cascade to a secondary pool:
RUNTIMECAP { 'interval' | NONE }
|
|
PLANNEDCONCURRENCY |
The number of concurrent queries you expect to run against the resource pool, an integer ≥ 4. If set to AUTO (default), Vertica automatically sets PLANNEDCONCURRENCY at query runtime, choosing the lower of these two values:
-
Number of cores
-
Memory/2GB
Important
In systems with a large number of cores, the default AUTO setting of PLANNEDCONCURRENCY is liable to be too low. In this case, set the parameter to the actual number of cores:
ALTER RESOURCE POOL general PLANNEDCONCURRENCY #cores;
Default: AUTO
|
|
MAXCONCURRENCY |
Caution
Must be set ≥ 1, otherwise Vertica generates a warning that system queries might be unable to execute.
Default: Empty
|
|
SINGLEINITIATOR |
Important
Included for backwards compatibility. Do not change.
Default: False |
|
CPUAFFINITYSET |
Default: Empty |
|
CPUAFFINITYMODE |
Default: ANY |
|
CASCADETO |
Default: Empty |
BLOBDATA
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
10 |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
|
PRIORITY |
|
RUNTIMEPRIORITY |
|
RUNTIMEPRIORITYTHRESHOLD |
|
QUEUETIMEOUT |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
|
MAXCONCURRENCY |
Empty / cannot be set |
|
SINGLEINITIATOR |
|
CPUAFFINITYSET |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
DBD
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
Unlimited |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
0 |
|
RUNTIMEPRIORITY |
MEDIUM |
|
RUNTIMEPRIORITYTHRESHOLD |
0 |
|
QUEUETIMEOUT |
0 |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
MAXCONCURRENCY |
NONE |
|
SINGLEINITIATOR |
True
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
JVM
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
10% of memory or 2 GB, whichever is smaller |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
0 |
|
RUNTIMEPRIORITY |
MEDIUM |
|
RUNTIMEPRIORITYTHRESHOLD |
2 |
|
QUEUETIMEOUT |
00:05 (minutes) |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
|
MAXCONCURRENCY |
Empty / cannot be set |
|
SINGLEINITIATOR |
FALSE
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
Unlimited |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
108 |
|
RUNTIMEPRIORITY |
HIGH |
|
RUNTIMEPRIORITYTHRESHOLD |
0 |
|
QUEUETIMEOUT |
0 |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
|
MAXCONCURRENCY |
0 |
|
SINGLEINITIATOR |
FALSE.
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
RECOVERY
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
Maximum size per node the resource pool can grow by borrowing memory from the
GENERAL pool:
MAXMEMORYSIZE {
'integer%'
|'integer{K|M|G|T}'
NONE
}
integer%: Percentage of total memoryinteger{K|M|G|T}: Amount of memory in kilobytes, megabytes, gigabytes, or terabytesNONE (empty string): Unlimited, resource pool can borrow any amount of available memory from the GENERAL pool.
Default: NONE
Caution
Setting must resolve to ≥ 25%. Otherwise, Vertica generates a warning that system queries might be unable to execute.
|
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
One of the following:
-
Enterprise Mode: 107
-
Eon Mode: 110
Caution
Change these settings only under guidance from Vertica technical support.
|
|
RUNTIMEPRIORITY |
MEDIUM |
|
RUNTIMEPRIORITYTHRESHOLD |
60 |
|
QUEUETIMEOUT |
00:05 (minutes) |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
|
MAXCONCURRENCY |
By default, set as follows:
(numberCores / 2) + 1
Thus, given a system with four cores, MAXCONCURRENCY has a default setting of 3.
Note
0 or NONE (unlimited) are invalid settings.
|
|
SINGLEINITIATOR |
True.
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
REFRESH
|
Parameter |
Default Setting |
|
MEMORYSIZE |
0% |
|
MAXMEMORYSIZE |
NONE (unlimited) |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
-10 |
|
RUNTIMEPRIORITY |
MEDIUM |
|
RUNTIMEPRIORITYTHRESHOLD |
60 |
|
QUEUETIMEOUT |
00:05 (minutes) |
|
RUNTIMECAP |
NONE (unlimited) |
|
PLANNEDCONCURRENCY |
AUTO (4) |
|
MAXCONCURRENCY |
3
This parameter must be set ≥ 1.
|
|
SINGLEINITIATOR |
True.
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
SYSQUERY
|
Parameter |
Default Setting |
|
MEMORYSIZE |
1G
Caution
Setting must resolve to ≥ 20M, otherwise Vertica generates a warning that system queries might be unable to execute, and diagnosing problems might be difficult.
|
|
MAXMEMORYSIZE |
Empty (unlimited) |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
110 |
|
RUNTIMEPRIORITY |
HIGH |
|
RUNTIMEPRIORITYTHRESHOLD |
0 |
|
QUEUETIMEOUT |
00:05 (minutes) |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
AUTO |
|
MAXCONCURRENCY |
Empty
Caution
Must be set ≥ 1, otherwise Vertica generates a warning that system queries might be unable to execute.
|
|
SINGLEINITIATOR |
False.
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
|
CASCADETO |
TM
|
Parameter |
Default Setting |
|
MEMORYSIZE |
5% (of the GENERAL pool's MAXMEMORYSIZE setting) + 2GB
Important
You can estimate the optimal amount of RAM for the TM resource pool as follows:
GbRAM/ (6 *#table-cols) > 10
where #table-cols is the number of columns in the largest database table. For example, given a 100-column table, MEMORYSIZE needs least 6GB of RAM:
6144MB / (6 * 100) = 10.24
|
|
MAXMEMORYSIZE |
Unlimited |
|
MAXQUERYMEMORYSIZE |
Empty / cannot be set |
|
EXECUTIONPARALLELISM |
AUTO |
|
PRIORITY |
105 |
|
RUNTIMEPRIORITY |
MEDIUM |
|
RUNTIMEPRIORITYTHRESHOLD |
60 |
|
QUEUETIMEOUT |
00:05 (minutes) |
|
RUNTIMECAP |
NONE |
|
PLANNEDCONCURRENCY |
7 |
|
MAXCONCURRENCY |
Sets across all nodes the maximum number of concurrent execution slots available to TM pool. In databases created in Vertica releases ≥9.3, the default value is 7. In databases created in earlier versions, the default is 3.This setting specifies the maximum number of merges that can occur simultaneously on multiple threads.
Note
0 or NONE (unlimited) are invalid settings.
|
|
SINGLEINITIATOR |
True
Important
Included for backwards compatibility. Do not change.
|
|
CPUAFFINITYSET |
Empty / cannot be set |
|
CPUAFFINITYMODE |
ANY / cannot be set |
|
CASCADETO |
Empty / cannot be set |
7.11.28 - CREATE ROLE
Creates a.
Creates a role. After creating a role, use GRANT statements to specify role permissions.
Syntax
CREATE ROLE role
Parameters
role- The name for the new role, where
role conforms to conventions described in Identifiers.
Privileges
Superuser
Examples
This example shows to create an empty role called roleA.
=> CREATE ROLE roleA;
CREATE ROLE
See also
7.11.29 - CREATE ROUTING RULE
Creates a load balancing routing rule that directs incoming client connections from an IP address range to a group of Vertica nodes.
Creates one of the following rules:
- A load balancing routing rule that directs incoming client connections from an IP address range to a group of Vertica nodes. This group of Vertica nodes is defined by a load balance group. Once you create a routing rule, any client connection originating from the rule's IP address range is redirected to one of the nodes in the load balance group if the client opts into load balancing.
- A workload routing rule that routes incoming client connections to the specified subcluster. To view existing workload routing rules, see WORKLOAD_ROUTING_RULES.
Syntax
CREATE ROUTING RULE
{
rule_name ROUTE 'address_range' TO group_name |
ROUTE WORKLOAD workload_name TO SUBCLUSTER subcluster_name [,...] [ PRIORITY priority]
}
Arguments
rule_name- A name for the load balancing routing rule.
address_range- An IPv4 or IPv6 address range in CIDR format, the address range of client connections that this rule applies to.
group_name- The name of the load balance group to handle the client connections from the address range. You create this group with CREATE LOAD BALANCE GROUP.
workload_name- The name of the workload.
subcluster_name- A list of subclusters to route client connections to.
priority- A non-negative INTEGER, the priority of the workload (default: 0). The greater the value, the greater the priority. If a user or their role is granted multiple routing rules, the one with the greatest priority applies.
Privileges
Superuser
Examples
The following example creates a routing rule that routes all client connections from 192.168.1.0 to 192.168.1.255 to a load balance group named internal_clients:
=> CREATE ROUTING RULE internal_clients ROUTE '192.168.1.0/24' TO internal_clients;
CREATE ROUTING RULE
The following example creates a routing rule that routes analytics workloads to subclusters sc_analytics and sc_analytics_2 with a priority of 5. For details, see Workload routing:
=> CREATE ROUTING RULE ROUTE WORKLOAD analytics TO SUBCLUSTER sc_analytics, sc_analytics_2 PRIORITY 5;
See also
7.11.30 - CREATE SCHEDULE
Creates a schedule.
Creates a schedule. For details, see Scheduled execution.
To view existing schedules, query USER_SCHEDULES.
Syntax
CREATE SCHEDULE [ IF NOT EXISTS ] [[database.]schema.]schedule
{ USING CRON 'cron_expression' | USING DATETIMES timestamp_list }
Arguments
- IF NOT EXISTS
If an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
schedule- The name of the schedule.
cron_expression- A
cron expression. You should use this for recurring tasks. Value separators are not currently supported.
timestamp_list- A comma-separated list of timestamps. You should use this to schedule non-recurring events at arbitrary times.
Privileges
Superuser
Examples
To create a schedule for October 2, 2022 and November 2, 2022:
=> CREATE SCHEDULE oct_nov_2 USING DATETIMES('2022-10-02 12:00:00', '2022-11-02 12:00:00');
To create a schedule for January 1 at 12:00 PM:
=> CREATE SCHEDULE annual_schedule USING CRON '0 12 1 1 *';
To create a schedule for the first of every month:
=> CREATE SCHEDULE monthly_schedule USING CRON '0 0 1 * *';
To create a schedule for Sunday at 12:00 AM:
=> CREATE SCHEDULE weekly_schedule USING CRON '0 0 * * 0';
To create a schedule for every day at 1:00 PM:
=> CREATE SCHEDULE daily_schedule USING CRON '0 13 * * *';
To create a schedule for every five minutes:
=> CREATE SCHEDULE every_5_minutes USING CRON '*/5 * * * *';
To create a schedule for every hour from 9:00 AM to 4:59 PM:
=> CREATE SCHEDULE 9_to_5 USING CRON '0 9-16 * * *';
7.11.31 - CREATE SCHEMA
Defines a schema.
Defines a schema.
Syntax
CREATE SCHEMA [ IF NOT EXISTS ] [{ namespace. | database. }]schema
[ AUTHORIZATION username]
[ DEFAULT { INCLUDE | EXCLUDE } [ SCHEMA ] PRIVILEGES ]
[ DISK_QUOTA quota ]
Parameters
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
namespace- For Eon Mode databases, namespace under which to create the schema. If unspecified, the schema is created under the
default_namespace.
database- For Enterprise Mode databases, name of the database. If specified, it must be the current database.
schema- Name of the schema to create, with the following requirements:
-
Must be unique among all other schema names in the namespace under which the schema is created.
-
Must comply with keyword restrictions and rules for Identifiers.
-
Cannot begin with v_; this prefix is reserved for Vertica system tables.
AUTHORIZATION username- Valid only for superusers, assigns ownership of the schema to another user. By default, the user who creates a schema is also assigned ownership.
After you create a schema, you can reassign ownership to another user with
ALTER SCHEMA.
DEFAULT {INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGESSpecifies whether to enable or disable default inheritance of privileges for new tables in the specified schema:
-
EXCLUDE SCHEMA PRIVILEGES (default): Disables inheritance of schema privileges.
-
INCLUDE SCHEMA PRIVILEGES: Specifies to grant tables in the specified schema the same privileges granted to that schema. This option has no effect on existing tables in the schema.
If you omit INCLUDE PRIVILEGES, you must explicitly grant schema privileges on the desired tables.
For more information see Enabling schema inheritance.
DISK_QUOTA quota- String, an integer followed by a supported unit: K, M, G, or T. Data-load, DML, and ILM operations that increase the schema's usage beyond the set quota fail. For details, see Disk quotas.
If not specified, the schema has no quota.
Privileges
Supported sub-statements
CREATE SCHEMA can include one or more sub-statements—for example, to create tables or projections within the new schema. Supported sub-statements include:
CREATE SCHEMA statement and all sub-statements are treated as a single transaction. If any statement fails, Vertica rolls back the entire transaction. The owner of the new schema is assigned ownership of all objects that are created within this transaction.
For example, the following CREATE SCHEMA statement also grants privileges on the new schema, and creates a table and view of that table:
=> \c - Joan
You are now connected as user "Joan".
=> CREATE SCHEMA s1
GRANT USAGE, CREATE ON SCHEMA s1 TO public
CREATE TABLE s1.t1 (a varchar)
CREATE VIEW s1.t1v AS SELECT * FROM s1.t1;
CREATE SCHEMA
=> \dtv s1.*
List of tables
Schema | Name | Kind | Owner | Comment
--------+------+-------+-------+---------
s1 | t1 | table | Joan |
s1 | t1v | view | Joan |
(2 rows)
Examples
Create schema s1:
Create schema s2 if it does not already exist:
=> CREATE SCHEMA IF NOT EXISTS s2;
In an Eon Mode database, create schema s3 in namespace n1:
=> CREATE SCHEMA n1.s3;
CREATE SCHEMA
In an Eon Mode database, create schema s3 in the default_namespace:
=> CREATE SCHEMA s3;
CREATE SCHEMA
If the schema already exists, Vertica returns a rollback message:
=> CREATE SCHEMA IF NOT EXISTS s2;
NOTICE 4214: Object "s2" already exists; nothing was done
Create table t1 in schema s1, then grant users Fred and Aniket access to all existing tables and all privileges on table t1:
=> CREATE TABLE s1.t1 (c INT);
CREATE TABLE
=> GRANT USAGE ON SCHEMA s1 TO Fred, Aniket;
GRANT PRIVILEGE
=> GRANT ALL PRIVILEGES ON TABLE s1.t1 TO Fred, Aniket;
GRANT PRIVILEGE
Enable inheritance on new schema s3 so all tables created in it automatically inherit its privileges. In this case, new table s3.t2 inherits USAGE, CREATE, and SELECT privileges, which are automatically granted to all database users:
=> CREATE SCHEMA s3 DEFAULT INCLUDE SCHEMA PRIVILEGES;
CREATE SCHEMA
=> GRANT USAGE, CREATE, SELECT, INSERT ON SCHEMA S3 TO PUBLIC;
GRANT PRIVILEGE
=> CREATE TABLE s3.t2(i int);
WARNING 6978: Table "t2" will include privileges from schema "s3"
CREATE TABLE
See also
7.11.32 - CREATE SEQUENCE
Defines a named sequence number generator object.
Defines a named sequence number generator. Named sequences let you set the default values of primary key columns. Sequences guarantee uniqueness and avoid constraint enforcement issues.
A sequence has minimum and maximum values, a starting position, and an increment. The increment can be positive (ascending) or negative (descending). By default, an ascending sequence starts at 1, its minimum value, and a descending sequence starts at -1, its maximum value. You can specify minimum, maximum, increment, and start values for a new sequence, so long as the values are mathematically consistent.
For more information about sequence types and usage, see Sequences.
Syntax
CREATE SEQUENCE [ IF NOT EXISTS ] [[database.]schema.]sequence
[ INCREMENT [ BY ] integer ]
[ MINVALUE integer | NO MINVALUE ]
[ MAXVALUE integer | NO MAXVALUE ]
[ START [ WITH ] integer ]
[ CACHE integer | NO CACHE ]
[ CYCLE | NO CYCLE ]
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence- Name of the sequence to create, where the name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
INCREMENT integerPositive or negative minimum value change on each call to NEXTVAL. The default is 1.
This value is a minimum increment size. The sequence can increment by more than this value unless you also specify NO CACHE.
MINVALUE integer | NO MINVALUE- Minimum value the sequence can generate. The default depends on the direction of the sequence:
MAXVALUE integer | NO MAXVALUE- Maximum value the sequence can generate. The default depends on the direction of the sequence:
-
Ascending sequence: 263
-
Descending sequence: -1
START [WITH] integer- Initial value of the sequence. The next call to NEXTVAL returns this start value. By default, an ascending sequence begins with the minimum value and a descending sequence begins with the maximum value.
CACHE integer | NO CACHEHow many unique sequence numbers to pre-allocate and store in memory on each node for faster access. Vertica sets up caching for each session and distributes it across all nodes. A value of 0 or 1 is equivalent to NO CACHE.
Caution
If sequence caching is set to a low number, nodes might request a new set of cache values more frequently. While it supplies a new cache, Vertica must lock the catalog. Until Vertica releases the lock, other database activities such as table inserts are blocked, which can adversely affect overall performance.
By default, the sequence cache is set to 250,000.
For details, see Distributing sequences.
CYCLE | NO CYCLE- How to handle reaching the end of the sequence. The default is
NO CYCLE, meaning that a call to NEXTVAL returns an error after the sequence reaches its upper or lower limit. CYCLE instead wraps, as follows:
- Ascending sequence: wraps to the minimum value.
- Descending sequence: wraps to the maximum value.
Privileges
Non-superusers: CREATE privilege on the schema
Examples
See Creating and using named sequences.
See also
7.11.33 - CREATE SUBNET
Identifies the subnet to which the nodes of a Vertica database belong.
Identifies the subnet to which the nodes of a Vertica database belong. Use this statement to configure import/export from a database to other Vertica clusters.
Syntax
CREATE SUBNET subnet-name WITH 'subnet-prefix'
Parameters
subnet-name- A name you assign to the subnet, where
subnet-name conforms to conventions described in Identifiers.
subnet-prefix- The subnet prefix in either a dotted-quad number format for IPv4 addresses, or four colon-delimited four-digit hexadecimal numbers for IPv6 addresses. Refer to system table
NETWORK_INTERFACES to get the prefix of all available IP networks.
You can then configure the database to use the subnet for import/export. For details, see Identify the database or nodes used for import/export.
Privileges
Superuser
Examples
=> CREATE SUBNET mySubnet WITH '123.4.5.6';
=> CREATE SUBNET mysubnet WITH 'fd9b:1fcc:1dc4:78d3::';
7.11.34 - CREATE TABLE
Creates a table in the logical schema.
Creates a table in the logical schema. You can specify the column definitions directly, or you can base a table on an existing table using AS or LIKE.
Syntax
Create with column definitions
CREATE TABLE [ IF NOT EXISTS ] [[ { namespace. | database. } ]schema.]table
( column-definition[,...] [, table-constraint [,...]] )
[ ORDER BY column[,...] ]
[ segmentation-spec ]
[ KSAFE [safety] ]
[ partition-clause]
[ { INCLUDE | EXCLUDE } [SCHEMA] PRIVILEGES ]
[ DISK_QUOTA quota ]
Create from another table
CREATE TABLE [ IF NOT EXISTS ] [[{ namespace. | database. } ]schema.]table
{ AS-clause | LIKE-clause }
[ DISK_QUOTA quota ]
AS-clause:
[ ( column-name-list ) ]
[ {INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGES ]
AS [ /*+ LABEL */ ] [ AT epoch ] query [ ENCODED BY column-ref-list ] [ segmentation-spec ]
LIKE-clause:
LIKE [[{ namespace. | database. } ]schema.]existing-table
[ { INCLUDING | EXCLUDING } PROJECTIONS ]
[ { INCLUDE | EXCLUDE } [SCHEMA] PRIVILEGES ]
Arguments
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
namespace- For Eon Mode databases, name of the namespace under which to create the table. If unspecified, the table is created under the
default_namespace.
database- For Enterprise Mode databases, name of the database. If specified, it must be the current database.
schema- Name of the schema under which to create the table. If no schema is specified, the table is created in the
public schema.
table- Name of the table to create, which must be unique among names of all sequences, tables, projections, views, and models within the schema.
- column-definition
- Column name, data type, and optional constraints. A table can have up to 9800 columns. At least one column in the table must be of a scalar type or native array.
- table-constraint
- Table-level constraint, as opposed to column constraints.
ORDER BY column[,...]Invalid for external tables, specifies columns from the SELECT list on which to sort the superprojection that is automatically created for this table. The ORDER BY clause cannot include qualifiers ASC or DESC. Vertica always stores projection data in ascending sort order.
If you omit the
`ORDER BY` clause, Vertica uses the SELECT list order as the projection sort order.
segmentation-specInvalid for external tables, specifies how to distribute data for auto-projections of this table. Supply one of the following clauses:
If this clause is omitted, Vertica generates auto-projections with default hash segmentation.
KSAFE [ safety ]Invalid for external tables, specifies K-safety of auto-projections created for this table, where k-num must be equal to or greater than system K-safety. If you omit this option, the projection uses the system K-safety level.
- partition-clause
- Invalid for external tables, logically divides table data storage through a PARTITION BY clause:
PARTITION BY partition-expression
[ GROUP BY group-expression ] [ ACTIVEPARTITIONCOUNT integer ]
- column-name-list
Valid only when creating a table from a query (AS query), defines column names that map to the query output. If you omit this list, Vertica uses the query output column names.
This clause and the ENCODED BY clause are mutually exclusive. Column name lists are invalid for external tables.
The names in column-name-list and queried columns must be the same in number.
For example:
CREATE TABLE customer_occupations (name, profession)
AS SELECT customer_name, occupation FROM customer_dimension;
{INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGESDefault inheritance of schema privileges for this table:
-
INCLUDE PRIVILEGES specifies that the table inherits privileges that are set on its schema. This is the default behavior if privileges inheritance is enabled for the schema.
-
EXCLUDE PRIVILEGES disables inheritance of privileges from the schema.
For details, see Inherited privileges.
AS queryCreates and loads a table from the results of a query, specified as follows:
AS [ /*+ LABEL */ ] [ AT ] epoch query
The query cannot include complex type columns.
ENCODED BY column-ref-listA comma-delimited list of columns from the source table, where each column is qualified by one or both of the following encoding options:
-
ACCESSRANK integer: Overrides the default access rank for a column, useful for prioritizing access to a column. See Prioritizing column access speed.
-
ENCODING encoding-type: Specifies the type of encoding to use on the column. The default encoding type is AUTO.
This option and *column-name-list *are mutually exclusive. This option is invalid for external tables.
LIKE existing-table- Creates the table by replicating an existing table. The user issuing the CREATE TABLE LIKE statement owns the new table, not the original owner.
You can qualify the LIKE clause with one of the following options:
-
EXCLUDING PROJECTIONS (default): Do not copy projections from the source table.
-
INCLUDING PROJECTIONS: Copy current projections from the source table for the new table.
-
{INCLUDE|EXCLUDE} [SCHEMA] PRIVILEGES: See description above).
DISK_QUOTA quota- String, an integer followed by a supported unit: K, M, G, or T. Data-load, DML, and ILM operations that increase the table's usage beyond the set quota fail. For details, see Disk quotas.
If not specified, the table has no quota.
Privileges
Superuser to set disk quota.
Non-superuser:
Restrictions for complex types
Complex types used in native tables have some restrictions, in addition to the restrictions for individual types listed on their reference pages:
-
A native table must have at least one column that is a primitive type or a native array (one-dimensional array of a primitive type). If a flex table has real columns, it must also have at least one column satisfying this restriction.
-
Complex type columns cannot be used in ORDER BY or PARTITION BY clauses nor as FILLER columns.
-
Complex type columns cannot have constraints.
-
Complex type columns cannot use DEFAULT or SET USING.
-
Expressions returning complex types cannot be used as projection columns, and projections cannot be segmented or ordered by columns of complex types.
Examples
The following example creates a table in the public schema:
CREATE TABLE public.Premium_Customer
(
ID IDENTITY ,
lname varchar(25),
fname varchar(25),
store_membership_card int
);
In an Eon Mode database, the following example creates the same table from the previous example, but in the store schema of the company namespace:
CREATE TABLE company.store.Premium_Customer
(
ID IDENTITY ,
lname varchar(25),
fname varchar(25),
store_membership_card int
);
The following example uses LIKE to create a new table from the Premium_Customer table:
=> CREATE TABLE All_Customers LIKE Premium_Customer;
CREATE TABLE
The following example selects columns from one table to use in a new table, using an AS clause:
=> CREATE TABLE cust_basic_profile AS SELECT
customer_key, customer_gender, customer_age, marital_status, annual_income, occupation
FROM customer_dimension WHERE customer_age>18 AND customer_gender !='';
CREATE TABLE
=> SELECT customer_age, annual_income, occupation FROM cust_basic_profile
WHERE customer_age > 23 ORDER BY customer_age;
customer_age | annual_income | occupation
--------------+---------------+--------------------
24 | 469210 | Hairdresser
24 | 140833 | Butler
24 | 558867 | Lumberjack
24 | 529117 | Mechanic
24 | 322062 | Acrobat
24 | 213734 | Writer
...
The following example creates a table using array columns:
=> CREATE TABLE orders(
orderkey INT,
custkey INT,
prodkey ARRAY[VARCHAR(10)],
orderprices ARRAY[DECIMAL(12,2)],
orderdate DATE
);
The following example uses a ROW complex type:
=> CREATE TABLE inventory
(store INT, products ROW(name VARCHAR, code VARCHAR));
The following example uses quotas:
=> CREATE SCHEMA internal DISK_QUOTA '10T';
CREATE SCHEMA
=> CREATE TABLE internal.sales (...) DISK_QUOTA '5T';
CREATE TABLE
=> CREATE TABLE internal.leads (...) DISK_QUOTA '12T';
WARNING 0: Table leads has disk quota greater than its schema internal
The following statement creates a flights table in the airline schema under the airport namespace:
=> CREATE TABLE airport.airline.flights(
flight_number INT,
leaving_from VARCHAR,
arriving_at VARCHAR,
expected_departure DATE,
gate VARCHAR
);
See also
7.11.34.1 - Column-constraint
Adds a constraint to a column's metadata.
Adds a constraint to a column's metadata.
Syntax
[ { AUTO_INCREMENT | IDENTITY } [ (args) ] ]
[ CONSTRAINT constraint-name ] {
[ CHECK (expression) [ ENABLED | DISABLED ] ]
[ [ DEFAULT expression ] [ SET USING expression } | DEFAULT USING expression ]
[ NULL | NOT NULL ]
[ { PRIMARY KEY [ ENABLED | DISABLED ] REFERENCES table [( column )] } ]
[ UNIQUE [ ENABLED | DISABLED ] ]
}
Arguments
You can specify enforcement of several constraints by qualifying them with the keywords ENABLED or DISABLED. See Enforcing Constraints below.
{ AUTO_INCREMENT | IDENTITY } [ (args) ]- Creates a table column whose values are automatically generated by and managed by the database. You cannot change or load values in this column. You can set this constraint on only one table column. You cannot set this constraint in a temporary table.
AUTO_INCREMENT and IDENTITY are synonyms.
The following arguments can be added:
( { cache-size | start }, increment, [ cache-size ] )
-
start: First value to set for this column (default 1).
-
increment: How much to change the value for each new row insertion, a positive or negative value (default 1).
-
cache-size: How many unique values each node caches per session, or 0 or 1 to disable (default 250,000).
For more information about these arguments, see IDENTITY sequences.
CONSTRAINT constraint-name- Assigns a name to the constraint, valid for the following constraints:
-
PRIMARY KEY
-
REFERENCES (foreign key)
-
CHECK
-
UNIQUE
If you omit assigning a name to these constraints, Vertica assigns its own name. For details, see Naming constraints.
Vertica recommends that you name all constraints.
CHECK (expression)- Sets a Boolean condition to check.
DEFAULT default-expr- Sets this column's default value. Vertica evaluates the expression and sets the column on load operations, if the operation omits a value for the column. For details about valid expressions, see Defining column values.
SET USING using-expr- Sets column values from an expression. Vertica evaluates the expression and refreshes column values only when REFRESH_COLUMNS is invoked. For details about valid expressions, see Defining column values.
DEFAULT USING expression- Defines the column with
DEFAULT and SET USING constraints, specifying the same expression for both. DEFAULT USING columns support the same expressions as SET USING columns, and are subject to the same restrictions.
NULL | NOT NULL- Whether the column allows null values.
-
NULL: Allows null values in the column. If you set this constraint on a primary key column, Vertica ignores it and sets it to NOT NULL.
-
NOT NULL: Requires the column to be set to a value during insert and update operations. If the column has no default value and no value is provided, INSERT or UPDATE returns an error.
The default is NULL for all columns except primary key columns, which Vertica always sets to NOT NULL.
For an external table, data violating a NOT NULL constraint can produce unexpected results when the table is queried. Use NOT NULL for an external table column only if you are sure that the data does not contain nulls.
PRIMARY KEY- Identifies this column as the table's primary key.
REFERENCES table [ ( column ) ]- Identifies this column as a foreign key to a column in another table. If you omit the column, Vertica uses the table's primary key.
UNIQUE- Requires column data to be unique with respect to all table rows.
Privileges
Table owner or user WITH GRANT OPTION is grantor.
Enforcing constraints
The following constraints can be qualified with the keyword ENABLED or DISABLED:
If you omit ENABLED or DISABLED, Vertica determines whether to enable the constraint automatically by checking the appropriate constraints configuration parameter:
-
EnableNewPrimaryKeysByDefault
-
EnableNewUniqueKeysByDefault
-
EnableNewCheckConstraintsByDefault
See also
7.11.34.2 - Column-definition
Specifies the name, data type, and constraints to be applied to a column.
Specifies the name, data type, and constraints to be applied to a column.
Syntax
column-name data-type
[ column-constraint ][...]
[ ENCODING encoding-type ]
[ ACCESSRANK integer ]
Parameters
column-name- The name of a column to be created or added.
data-type- A Vertica-supported data type.
Tip
When specifying the maximum column width in a CREATE TABLE statement, use the width in bytes (octets) for any of the string types. Each UTF-8 character might require four bytes, but European languages generally require a little over one byte per character, while Oriental languages generally require a little under three bytes per character.
-
column-constraint
- A constraint type that Vertica supports—for example, NOT NULL or UNIQUE. For general information, see Constraints.
-
ENCODING encoding-type
The column encoding type, by default set to AUTO.
ACCESSRANK integerOverrides the default access rank for a column. Use this parameter to increase or decrease the speed at which Vertica accesses a column. For more information, see Overriding Default Column Ranking.
Examples
The following example creates a table named Employee_Dimension and its associated superprojection in the public schema. The Employee_key column is designated as a primary key, and RLE encoding is specified for the Employee_gender column definition:
=> CREATE TABLE public.Employee_Dimension (
Employee_key integer PRIMARY KEY NOT NULL,
Employee_gender varchar(8) ENCODING RLE,
Courtesy_title varchar(8),
Employee_first_name varchar(64),
Employee_middle_initial varchar(8),
Employee_last_name varchar(64)
);
7.11.34.3 - Column-name-list
Used to rename columns when creating a table or temporary table from a query; also used to specify the column's encoding type and .
Used to rename columns when creating a table or temporary table from a query; also used to specify the column's encoding type and access rank .
Syntax
column-name-list
[ ENCODING encoding-type ]
[ ACCESSRANK integer ]
[ GROUPED ( column-reference[,...] ) ]
Parameters
column-name- Specifies the new name for the column.
ENCODING [encoding-type](/en/sql-reference/statements/create-statements/create-projection/encoding-types/)- Specifies the type of encoding to use on the column. The default encoding type is
AUTO.
ACCESSRANK integer- Overrides the default access rank for a column, useful for prioritizing access to a column. See Prioritizing column access speed.
GROUPED- Groups two or more columns . For detailed information, see GROUPED clause.
Requirements
-
A column in the list can not specify the column's data type or any constraint. These are derived from the queried table.
-
If the query output has expressions other than simple columns (for example, constants or functions) then an alias must be specified for that expression, or the column name list must include all queried columns.
-
CREATE TABLE can specify encoding types and access ranks in the column name list or the query's ENCODED BY clause, but not in both. For example, the following CREATE TABLE statement sets encoding and access rank on two columns in the column name list:
=> CREATE TABLE promo1 (state ENCODING RLE ACCESSRANK 1, zip ENCODING RLE,...)
AS SELECT * FROM customer_dimension ORDER BY customer_state;
The next statement specifies the same encoding and access rank in the query's ENCODED BY clause.
=> CREATE TABLE promo2
AS SELECT * FROM customer_dimension ORDER BY customer_state
ENCODED BY customer_state ENCODING RLE ACCESSRANK 1, customer_zip ENCODING RLE;
7.11.34.4 - Partition clause
Specifies partitioning of table data, through a PARTITION BY clause in the table definition:.
Specifies partitioning of table data, through a PARTITION BY clause in the table definition:
PARTITION BY partition-expression [ GROUP BY group-expression ] [ active-partition-count-expr ]
PARTITION BY partition-expression- For each table row, resolves to a partition key that is derived from one or more table columns.
Caution
Avoid partitioning tables on LONG VARBINARY and LONG VARCHAR columns. Doing so can adversely impact performance.
GROUP BY group-expression- For each table row, resolves to a partition group key that is derived from the partition key. Vertica uses group keys to merge partitions into separate partition groups. GROUP BY must use the same expression as PARTITION BY. For example:
...PARTITION BY (i+j) GROUP BY (
CASE WHEN (i+j) < 5 THEN 1
WHEN (i+j) < 10 THEN 2
ELSE 3);
For details on partitioning table data by groups, see Partition grouping and Hierarchical partitioning.
active-partition-count-expr- Specifies how many partitions are active for this table, specified as follows:
-
In partition clause of CREATE TABLE:
ACTIVEPARTITIONCOUNT integer
-
In partition clause of ALTER TABLE:
SET ACTIVEPARTITIONCOUNT integer
This setting supersedes configuration parameter ActivePartitionCount. For details on usage, see Active and inactive partitions.
Partitioning requirements and restrictions
PARTITION BY expressions can specify leaf expressions, functions, and operators. The following requirements and restrictions apply:
- All table projections must include all columns referenced in the expression; otherwise, Vertica cannot resolve the expression.
- The expression can reference multiple columns, but it must resolve to a single non-null value for each row.
Note
You can avoid null-related errors with the function
ZEROIFNULL. This function can check a PARTITION BY expression for null values and evaluate them to 0. For example:
CREATE TABLE t1 (a int, b int) PARTITION BY (ZEROIFNULL(a)); CREATE TABLE
- All leaf expressions must be constants or table columns.
- All other expressions must be functions and operators. The following restrictions apply to functions: * They must be immutable—that is, they return the same value regardless of time and locale and other session- or environment-specific conditions. * They cannot be aggregate functions. * They cannot be Vertica meta-functions.
- The expression cannot include queries.
- The expression cannot include user-defined data types such as Geometry.
GROUP BY expressions do not support modulo (%) operations.
Examples
The following statements create the store_orders table and load data into it. The CREATE TABLE statement includes a simple partition clause that specifies to partition data by year:
=> CREATE TABLE public.store_orders
(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date
)
UNSEGMENTED ALL NODES
PARTITION BY YEAR(order_date);
CREATE TABLE
=> COPY store_orders FROM '/home/dbadmin/export_store_orders_data.txt';
41834
As COPY loads the new table data into ROS storage, the Tuple Mover executes the table's partition clause by dividing orders for each year into separate partitions, and consolidating these partitions in ROS containers.
In this case, the Tuple Mover creates four partition keys for the loaded data—2017, 2016, 2015, and 2014—and divides the data into separate ROS containers accordingly:
=> SELECT dump_table_partition_keys('store_orders');
... Partition keys on node v_vmart_node0001
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 1
Partition keys: 2017
Storage [ROS container]
No of partition keys: 1
Partition keys: 2016
Storage [ROS container]
No of partition keys: 1
Partition keys: 2015
Storage [ROS container]
No of partition keys: 1
Partition keys: 2014
Partition keys on node v_vmart_node0002
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 1
Partition keys: 2017
...
(1 row)
As new data is loaded into store_orders, the Tuple Mover merges it into the appropriate partitions, creating partition keys as needed for new years.
See also
Partitioning tables
7.11.34.5 - Table-constraint
Adds a constraint to table metadata. You can specify table constraints with
CREATE TABLE,
or add a constraint to an existing table with ALTER TABLE. For details, see Setting constraints.
Adding a constraint to a table that is referenced in a view does not affect the view.
Syntax
[ CONSTRAINT constraint-name ]
{
... PRIMARY KEY (column[,... ]) [ ENABLED | DISABLED ]
... | FOREIGN KEY (column[,... ] ) REFERENCES table [ (column[,...]) ]
... | UNIQUE (column[,...]) [ ENABLED | DISABLED ]
... | CHECK (expression) [ ENABLED | DISABLED ]
}
Parameters
CONSTRAINT constraint‑name- Assigns a name to the constraint. Vertica recommends that you name all constraints.
PRIMARY KEY- Defines one or more
NOT NULL columns as the primary key as follows:
PRIMARY KEY (column[,...]) [ ENABLED | DISABLED]
You can qualify this constraint with the keyword ENABLED or DISABLED. See Enforcing Constraints below.
If you do not name a primary key constraint, Vertica assigns the name C_PRIMARY.
FOREIGN KEY- Adds a referential integrity constraint defining one or more columns as foreign keys as follows:
FOREIGN KEY (column[,... ]) REFERENCES table [(column[,... ])]
If you omit column, Vertica references the primary key in table.
If you do not name a foreign key constraint, Vertica assigns the name C_FOREIGN.
Important
Adding a foreign key constraint requires the following privileges (in addition to privileges also required by ALTER TABLE):
UNIQUE- Specifies that the data in a column or group of columns is unique with respect to all table rows, as follows:
UNIQUE (column[,...]) [ENABLED | DISABLED]
You can qualify this constraint with the keyword ENABLED or DISABLED. See Enforcing Constraints below.
If you do not name a unique constraint, Vertica assigns the name C_UNIQUE.
CHECK- Specifies a check condition as an expression that returns a Boolean value, as follows:
CHECK (expression) [ENABLED | DISABLED]
You can qualify this constraint with the keyword ENABLED or DISABLED. See Enforcing Constraints below.
If you do not name a check constraint, Vertica assigns the name C_CHECK.
Privileges
Non-superusers: table owner, or the following privileges:
Enforcing constraints
A table can specify whether Vertica automatically enforces a primary key, unique key or check constraint with the keyword ENABLED or DISABLED. If you omit ENABLED or DISABLED, Vertica determines whether to enable the constraint automatically by checking the appropriate configuration parameter:
-
EnableNewPrimaryKeysByDefault
-
EnableNewUniqueKeysByDefault
-
EnableNewCheckConstraintsByDefault
For details, see Constraint enforcement.
Examples
The following example creates a table (t01) with a primary key constraint.
CREATE TABLE t01 (id int CONSTRAINT sampleconstraint PRIMARY KEY);
CREATE TABLE
This example creates the same table without the constraint, and then adds the constraint with ALTER TABLE ADD CONSTRAINT
CREATE TABLE t01 (id int);
CREATE TABLE
ALTER TABLE t01 ADD CONSTRAINT sampleconstraint PRIMARY KEY(id);
WARNING 2623: Column "id" definition changed to NOT NULL
ALTER TABLE
The following example creates a table (addapk) with two columns, adds a third column to the table, and then adds a primary key constraint on the third column.
=> CREATE TABLE addapk (col1 INT, col2 INT);
CREATE TABLE
=> ALTER TABLE addapk ADD COLUMN col3 INT;
ALTER TABLE
=> ALTER TABLE addapk ADD CONSTRAINT col3constraint PRIMARY KEY (col3) ENABLED;
WARNING 2623: Column "col3" definition changed to NOT NULL
ALTER TABLE
Using the sample table addapk, check that the primary key constraint is enabled (is_enabled is t).
=> SELECT constraint_name, column_name, constraint_type, is_enabled FROM PRIMARY_KEYS WHERE table_name IN ('addapk');
constraint_name | column_name | constraint_type | is_enabled
-----------------+-------------+-----------------+------------
col3constraint | col3 | p | t
(1 row)
This example disables the constraint using ALTER TABLE ALTER CONSTRAINT.
=> ALTER TABLE addapk ALTER CONSTRAINT col3constraint DISABLED;
Check that the primary key is now disabled (is_enabled is f).
=> SELECT constraint_name, column_name, constraint_type, is_enabled FROM PRIMARY_KEYS WHERE table_name IN ('addapk');
constraint_name | column_name | constraint_type | is_enabled
-----------------+-------------+-----------------+------------
col3constraint | col3 | p | f
(1 row)
For a general discussion of constraints, see Constraints. For additional examples of creating and naming constraints, see Naming constraints.
7.11.35 - CREATE TEMPORARY TABLE
Creates a table whose data persists only during the current session.
Creates a table whose data persists only during the current session. By default, temporary table data is not visible to other sessions.
Syntax
Create with column definitions:
CREATE [ scope ] TEMP[ORARY] TABLE [ IF NOT EXISTS ] [[{namespace. | database. }]schema.]table-name
( column-definition[,...] )
[ table-constraint ]
[ ON COMMIT { DELETE | PRESERVE } ROWS ]
[ NO PROJECTION ]
[ ORDER BY table-column[,...] ]
[ segmentation-spec ]
[ KSAFE [safety-level] ]
[ {INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGES ]
[ DISK_QUOTA quota ]
Create from another table:
CREATE TEMP[ORARY] TABLE [ IF NOT EXISTS ] [[{namespace. | database. }]schema.]table-name
[ ( column-name-list ) ]
[ ON COMMIT { DELETE | PRESERVE } ROWS ]
AS [ /*+ LABEL */ ] [ AT epoch ] query [ ENCODED BY column-ref-list ]
[ DISK_QUOTA quota ]
Parameters
scope- Visibility of the table definition:
-
GLOBAL: The table definition is visible to all sessions, and persists until you explicitly drop the table.
-
LOCAL: the table definition is visible only to the session in which it is created, and is dropped when the session ends.
If no scope is specified, Vertica uses the default that is set by the DefaultTempTableLocal configuration parameter.
Regardless of this setting, retention of temporary table data is set by the keywords ON COMMIT DELETE and ON COMMIT PRESERVE (see below).
For more information, see Creating temporary tables.
IF NOT EXISTSIf an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
{ namespace. | database. }- Qualifies the
schema name with one of the following names, depending on the mode of the database:
- Eon Mode: name of the namespace to which the schema belongs. If unspecified, the namespace is assumed to be
default_namespace. If scope is set to LOCAL, the namespace must be default_namespace.
- Enterprise Mode: name of the database. If specified, it must be the current database.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must specify the schema name, even if the schema is public.
table-name- Name of the table to create, where
table-name conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
-
column-definition
- Column names and types. A table can have up to 9800 columns.
-
table-constraint
- Adds a constraint to table metadata.
ON COMMIT- Whether data is transaction- or session-scoped:
ON COMMIT {PRESERVE | DELETE} ROWS
-
DELETE (default) marks the temporary table for transaction-scoped data. Vertica removes all table data after each commit.
-
PRESERVE marks the temporary table for session-scoped data, which is preserved beyond the lifetime of a single transaction. Vertica removes all table data when the session ends.
NO PROJECTION- Prevents Vertica from creating auto-projections for this table. A superprojection is created only when data is explicitly loaded into this table.
NO PROJECTION is invalid with the following clauses:
{INCLUDE | EXCLUDE} [SCHEMA] PRIVILEGESDefault inheritance of schema privileges for this table:
-
INCLUDE PRIVILEGES specifies that the table inherits privileges that are set on its schema. This is the default behavior if privileges inheritance is enabled for the schema.
-
EXCLUDE PRIVILEGES disables inheritance of privileges from the schema.
For details, see Inherited privileges.
ORDER BY table-column[,...]Invalid for external tables, specifies columns from the SELECT list on which to sort the superprojection that is automatically created for this table. The ORDER BY clause cannot include qualifiers ASC or DESC. Vertica always stores projection data in ascending sort order.
If you omit the
`ORDER BY` clause, Vertica uses the SELECT list order as the projection sort order.
segmentation-specInvalid for external tables, specifies how to distribute data for auto-projections of this table. Supply one of the following clauses:
If this clause is omitted, Vertica generates auto-projections with default hash segmentation.
KSAFE [safety-level]Invalid for external tables, specifies K-safety of auto-projections created for this table, where k-num must be equal to or greater than system K-safety. If you omit this option, the projection uses the system K-safety level.
Eon Mode: K-safety of temporary tables is always set to 0, regardless of system K-safety. If a CREATE TEMPORARY TABLE statement sets k-num greater than 0, Vertica returns an warning.
- column-name-list
Valid only when creating a table from a query (AS query), defines column names that map to the query output. If you omit this list, Vertica uses the query output column names.
This clause and the ENCODED BY clause are mutually exclusive. Column name lists are invalid for external tables.
The names in column-name-list and queried columns must be the same in number.
For example:
CREATE TEMP TABLE customer_occupations (name, profession)
AS SELECT customer_name, occupation FROM customer_dimension;
AS queryCreates and loads a table from the results of a query, specified as follows:
AS [ /*+ LABEL */ ] [ AT ] epoch query
The query cannot include complex type columns.
ENCODED BY column-ref-listA comma-delimited list of columns from the source table, where each column is qualified by one or both of the following encoding options:
-
ACCESSRANK integer: Overrides the default access rank for a column, useful for prioritizing access to a column. See Prioritizing column access speed.
-
ENCODING encoding-type: Specifies the type of encoding to use on the column. The default encoding type is AUTO.
This option and *column-name-list *are mutually exclusive. This option is invalid for external tables.
DISK_QUOTA quota- String, an integer followed by a supported unit: K, M, G, or T. If the schema has a quota, this value must be smaller than the schema quota. Data-load and ILM operations that increase the table's usage beyond the set quota fail. For details, see Disk quotas.
If not specified, the table has no quota.
Disk quota is valid for global temporary tables but not local ones.
Privileges
The following privileges are required:
Restrictions
-
Queries on temporary tables are subject to the same restrictions on SQL support as persistent tables.
-
You cannot add projections to non-empty, global temporary tables (ON COMMIT PRESERVE ROWS). Make sure that projections exist before you load data. See Auto-projections.
-
While you can add projections for temporary tables that are defined with ON COMMIT DELETE ROWS specified, be aware that you might lose all data.
-
Mergeout operations cannot be used on session-scoped temporary data.
-
In general, session-scoped temporary table data is not visible using system (virtual) tables.
-
Temporary tables do not recover. If a node fails, queries that use the temporary table also fail. Restart the session and populate the temporary table.
-
Local temporary tables cannot have disk quotas.
Examples
See Creating temporary tables.
See also
7.11.36 - CREATE TEXT INDEX
Creates a text index used to perform text searches.
Creates a text index used to perform text searches. If data within a table is partitioned, then an extra column appears in the text index, showing the partition.
Syntax
CREATE TEXT INDEX [[database.]schema.]txtindex-name
ON [schema.]source-table (unique-id, text-field [, column-name,...])
[STEMMER {stemmer-name(stemmer-input-data-type)| NONE}]
[TOKENIZER tokenizer-name(tokenizer-input-data-type)];
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
If you do not specify a schema, the table is created in the default schema.
txtindex-name- The text index name.
source-table- The source table to index.
unique-id- The name of the column in the source table that contains a unique identifier. Any data type is permissible. The column must be the primary key in the source table.
text-field- The name of the column in the source table that contains the text field. Valid data types are:
-
CHAR
-
VARCHAR
-
LONG VARCHAR
-
VARBINARY
-
LONG VARBINARY
Nulls are allowed.
column-name- The name of a column or columns to be included as additional columns.
stemmer-name- The name of the stemmer.
stemmer-input-data-type- The input data type of the
stemmer-name function.
tokenizer-name- Specifies the name of the tokenizer.
tokenizer-input-data-type- This value is the input data type of the
tokenizer-name function. It can accept any number of arguments.
If a Vertica tokenizers is used, then this parameter can be omitted.
Privileges
The index automatically inherits the query permissions of its parent table. The table owner and dbadmin will be allowed to create and/or modify the indices.
Important
Do not alter the contents or definitions of the text index. If the contents or definitions of the text index are altered, then the results will not appropriately match the source table.
Requirements
-
Requires there be a column with a unique identifier set as the primary key.
-
The source table must have an associated projection, and must be both sorted and segmented by the primary key.
Examples
The following example shows how to create a text index with an additional unindexed column on the table t_log using the CREATE TEXT INDEX statement:
=> CREATE TEXT INDEX t_log_index ON t_log (id, text, day_of_week);
CREATE INDEX
=> SELECT * FROM t_log_index;
token | doc_id | day_of_week
-----------------------+--------+-------------
'catalog | 1 | Monday
'dbadmin' | 2 | Monday
2014-06-04 | 1 | Monday
2014-06-04 | 2 | Monday
2014-06-04 | 3 | Monday
2014-06-04 | 4 | Monday
2014-06-04 | 5 | Monday
2014-06-04 | 6 | Monday
2014-06-04 | 7 | Monday
2014-06-04 | 8 | Monday
45035996273704966 | 3 | Tuesday
45035996273704968 | 4 | Tuesday
<INFO> | 1 | Tuesday
<INFO> | 6 | Tuesday
<INFO> | 7 | Tuesday
<INFO> | 8 | Tuesday
<WARNING> | 2 | Tuesday
<WARNING> | 3 | Tuesday
<WARNING> | 4 | Tuesday
<WARNING> | 5 | Tuesday
...
(97 rows)
The following example shows a text index, tpart_index, created from a partitioned source table:
=> SELECT * FROM tpart_index;
token | doc_id | partition
------------------------+--------+-----------
0 | 4 | 2014
0 | 5 | 2014
11:00:49.568 | 4 | 2014
11:00:49.568 | 5 | 2014
11:00:49.569 | 6 | 2014
<INFO> | 6 | 2014
<WARNING> | 4 | 2014
<WARNING> | 5 | 2014
Database | 6 | 2014
Execute: | 6 | 2014
Object | 4 | 2014
Object | 5 | 2014
[Catalog] | 4 | 2014
[Catalog] | 5 | 2014
'catalog | 1 | 2013
'dbadmin' | 2 | 2013
0 | 3 | 2013
11:00:49.568 | 1 | 2013
11:00:49.568 | 2 | 2013
11:00:49.568 | 3 | 2013
11:00:49.570 | 7 | 2013
11:00:49.571 | 8 | 2013
45035996273704966 | 3 | 2013
...
(89 rows)
See also
7.11.37 - CREATE TLS CONFIGURATION
Creates a TLS Configuration object.
Creates a TLS Configuration object. For information on existing TLS Configuration objects, query TLS_CONFIGURATIONS.
To modify an existing TLS Configuration object, see ALTER TLS CONFIGURATION.
Syntax
CREATE TLS CONFIGURATION tls_config_name {
[ CERTIFICATE { NULL | cert_name } ]
[ CA CERTIFICATES ca_cert_name [,...] ]
[ CIPHER SUITES { '' | 'openssl_cipher [,...]' } ]
[ TLSMODE 'tlsmode' ]
}
Parameters
tls_config_name- The name of the TLS Configuration object.
cert_name- A certificate created with CREATE CERTIFICATE.
ca_cert_name- A CA certificate created with CREATE CERTIFICATE.
openssl_cipher- A comma-separated list of cipher suites to use instead of the default set of cipher suites. Providing an empty string for this parameter clears the alternate cipher suite list and instructs the specified TLS Configuration to use the default set of cipher suites.
To view enabled cipher suites, use LIST_ENABLED_CIPHERS.
tlsmode- How Vertica establishes TLS connections and handles client certificates, one of the following, in order of ascending security:
-
DISABLE: Disables TLS. All other options for this parameter enable TLS.
-
ENABLE: Enables TLS. Vertica does not check client certificates.
-
TRY_VERIFY: Establishes a TLS connection if one of the following is true:
If the other host presents an invalid certificate, the connection will use plaintext.
-
VERIFY_CA: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA. If the other host does not present a certificate, the connection uses plaintext.
-
VERIFY_FULL: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA and the certificate's cn (Common Name) or subjectAltName attribute matches the hostname or IP address of the other host.
Note that for client certificates, cn is used for the username, so subjectAltName must match the hostname or IP address of the other host.
VERIFY_FULL is unsupported for client-server TLS (the server TLS Configuration context) and behaves as VERIFY_CA.
7.11.38 - CREATE TRIGGER
Creates a trigger.
Creates a trigger. For details, see Triggers.
Syntax
CREATE TRIGGER [ IF NOT EXISTS ] [[database.]schema.]trigger
ON SCHEDULE [[database.]schema.]schedule
EXECUTE PROCEDURE procedure AS DEFINER
Parameters
- IF NOT EXISTS
If an object with the same name exists, return without creating the object. If you do not use this directive and the object already exists, Vertica returns with an error message.
The IF NOT EXISTS clause is useful for SQL scripts where you might not know if the object already exists. The ON ERROR STOP directive can be helpful in scripts.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
trigger- The name of the trigger.
schedule- The schedule with which to associate the trigger.
procedure- The function signature of the stored procedure.
- AS DEFINER
- The user to execute the stored procedure as. Currently, the only option is DEFINER, which executes the stored procedure as the definer of the trigger.
Privileges
Superuser
Examples
CREATE TRIGGER requires a schedule and stored procedure:
=> CREATE PROCEDURE revoke_all_on_table(table_name VARCHAR, user_name VARCHAR)
LANGUAGE PLvSQL
AS $$
BEGIN
EXECUTE 'REVOKE ALL ON ' || QUOTE_IDENT(table_name) || ' FROM ' || QUOTE_IDENT(user_name);
END;
$$;
=> CREATE SCHEDULE 24_hours_later USING DATETIMES('2022-12-16 12:00:00');
To create the trigger with schedule 24_hours_later and stored procedure revoke_all_on_table() with arguments customer_dimension and Bob:
=> CREATE TRIGGER revoke_trigger ON SCHEDULE 24_hours_later EXECUTE PROCEDURE revoke_all_on_table('customer_dimension', 'Bob') AS DEFINER;;
7.11.39 - CREATE USER
Adds a name to the list of authorized database users.
Adds a name to the list of authorized database users.
Syntax
CREATE USER user-name [ parameter value[,...] ]
Arguments
user-name- Name of the new user, where the value conforms to conventions described in Identifiers.
parameter value- One or more user account parameter settings (see below). Note that the parameter name and value are separated by a space, not
=.
Parameters
ACCOUNTLocks or unlocks user access to the database, one of the following:
Tip
To automate account locking, set a maximum number of failed login attempts with
CREATE PROFILE.
GRACEPERIODSpecifies how long a user query can block on any session socket, one of the following:
-
NONE (default): Removes any grace period previously set on session queries.
-
'interval': Specifies as an interval the maximum grace period for current session queries, up to 20 days.
For details, see Handling session socket blocking.
IDENTIFIED BY { 'password' | 'hashed-password' SALT 'hash-salt' }- Sets the user's password. Options are:
-
password: ASCII password that Vertica then hashes for internal storage. An empty string enables this user to access the database with no password.
-
hashed-password: A pre-hashed password and its associated hex string hash-salt. Setting a password this way bypasses all password complexity requirements.
Important
If you omit this parameter, this user can access the database with no password.
For details, see Password guidelines and Creating a database name and password.
IDLESESSIONTIMEOUTThe length of time the system waits before disconnecting an idle session, one of the following:
-
NONE (default): No limit set for this user. If you omit this parameter, no limit is set for this user.
-
'interval': An interval value, up to one year.
For details, see Managing client connections.
MAXCONNECTIONSSets the maximum number of connections the user can have to the server, one of the following:
-
NONE (default): No limit set. If you omit this parameter, the user can have an unlimited number of connections across the database cluster.
-
integer ON DATABASE: Sets to integer the maximum number of connections across the database cluster.
-
integer ON NODE: Sets to integer the maximum number of connections to each node.
For details, see Managing client connections.
MEMORYCAPSets how much memory can be allocated to user requests, one of the following:
PASSWORD EXPIREForces immediate expiration of the user's password. The user must change the password on the next login.
Note
PASSWORD EXPIRE has no effect when using external password authentication methods such as LDAP or Kerberos.
PROFILEAssigns a profile that controls password requirements for this user, one of the following:
If you omit this parameter, the user is assigned the default profile.
RESOURCE POOL pool-name [FOR SUBCLUSTER sc-name]Assigns a resource pool to this user. The user must also be granted privileges to this pool, unless privileges to the pool are set to PUBLIC.
The FOR SUBCLUSTER clause assigns a subcluster-specific resource pool to the user. You can assign only one subcluster-specific resource pool to each user.
RUNTIMECAPSets how long this user's queries can execute, one of the following:
-
NONE (default): No limit set for this user. If you omit this parameter, no limit is set for this user.
-
'interval': An interval value, up to one year.
A query's runtime limit can be set at three levels: the user's runtime limit, the user's resource pool, and the session setting. For more information, see Setting a runtime limit for queries.
SEARCH_PATHSpecifies the user's default search path, that tells Vertica which schemas to search for unqualified references to tables and UDFs, one of the following:
-
DEFAULT (default): Sets the search path as follows:
"$user", public, v_catalog, v_monitor, v_internal
-
Comma-delimited list of schemas.
For details, see Setting Search Paths.
TEMPSPACECAPSets how much temporary file storage is available for user requests, one of the following:
Privileges
Superuser
User name best practices
Vertica database user names are logically separate from user names of the operating system in which the server runs. If all the users of a particular server also have accounts on the server's machine, it makes sense to assign database user names that match their operating system user names. However, a server that accepts remote connections might many database users with no local operating system account. In this case, there is no need to connect database and system user names.
Examples
=> CREATE USER Fred IDENTIFIED BY 'Mxyzptlk';
=> GRANT USAGE ON SCHEMA PUBLIC to Fred;
See also
7.11.40 - CREATE VIEW
Defines a.
Defines a view. Views are read only, so they do not support insert, update, delete, or copy operations.
Syntax
CREATE [ OR REPLACE ] VIEW [[database.]schema.]view [ (column[,...]) ]
[ {INCLUDE|EXCLUDE} [SCHEMA] PRIVILEGES ] AS query
Parameters
OR REPLACE- Specifies to overwrite the existing view
view-name. If you omit this option and view-name already exists, CREATE VIEW returns an error.
Any grants assigned to the view before you execute a CREATE OR REPLACE remain on the updated view. See GRANT (view).
[database]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- Identifies the view to create, where
view conforms to conventions described in Identifiers. It must also be unique among all names of sequences, tables, projections, views, and models within the same schema.
column[,...]- List of up to 9800 names to use as view column names. Vertica maps view column names to query columns according to the order of their respective lists. By default, the view uses column names as they are specified in the query.
query - A
SELECT statement that the temporary view executes. The SELECT statement can reference tables, temporary tables, and other views.
{INCLUDE|EXCLUDE}[SCHEMA] PRIVILEGES- Specifies whether this view inherits schema privileges:
-
INCLUDE PRIVILEGES specifies that the view inherits privileges that are set on its schema. This is the default behavior if privileges inheritance is enabled for the schema.
-
EXCLUDE PRIVILEGES disables inheritance of privileges from the schema.
For details, see Inherited privileges.
Privileges
See Creating views.
Examples
The following example shows how to create a view that contains data from multiple tables.
=> CREATE VIEW temp_t0 AS SELECT * from t0_p1 UNION ALL
SELECT * from t0_p2 UNION ALL
SELECT * from t0_p3 UNION ALL
SELECT * from t0_p4 UNION ALL
SELECT * from t0_p5;
See also
7.12 - DEACTIVATE DIRECTED QUERY
Deactivates one or more directed queries previously activated by ACTIVATE DIRECTED QUERY.
Deactivates one or more directed queries previously activated by ACTIVATE DIRECTED QUERY.
Syntax
DEACTIVATE DIRECTED QUERY { query-name | input-query | where-clause }
Arguments
query-name- Name of the directed query to deactivate, as stored in the DIRECTED_QUERIES column
query_name.
input-query- The input query of the directed queries to deactivate. Use this argument to deactivate multiple direct queries that map to the same input query.
where-clause- Resolves to one or more directed queries that are filtered from system table DIRECTED_QUERIES. For example, the following statement specifies to deactivate all directed queries with the same
save_plans_version identifier:
=> DEACTIVATE DIRECTED QUERY WHERE save_plans_version = 21;
Privileges
Superuser
Examples
See Managing directed queries.
7.13 - DELETE
Removes the specified rows from a table and returns a count of the deleted rows.
Removes the specified rows from a table and returns a count of the deleted rows. A count of 0 is not an error, but indicates that no rows matched the condition. An unqualified DELETE statement (one that omits a WHERE clause) removes all rows but leaves intact table columns, projections, and constraints.
DELETE supports subqueries and joins, so you can delete values in a table based on values in other tables.
Important
The Vertica implementation of DELETE differs from traditional databases: it does not delete data from disk storage, but instead marks rows as deleted so they are available for historical queries. Deleted data remains on disk, and counts against disk quota, until purged.
Syntax
DELETE [ /*+LABEL (label-string)*/ ] FROM [[{namespace. | database. }]schema.]table [ where-clause ]
Arguments
-
LABEL
Assigns a label to a statement to identify it for profiling and debugging.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table- Any table, including temporary tables.
- where-clause
- Which rows to mark for deletion. If you omit this clause, DELETE behavior varies depending on whether the table is persistent or temporary. See below for details.
Privileges
Table owner or user with GRANT OPTION is grantor.
-
DELETE privilege on table
-
USAGE privilege on the schema of the target table
-
SELECT privilege on a table when the DELETE statement includes a WHERE or SET clause that specifies columns from that table.
Restrictions
You cannot execute DELETE on an immutable table.
Committing successive table changes
Vertica follows the SQL-92 transaction model, so successive INSERT, UPDATE, and DELETE statements are included in the same transaction. You do not need to explicitly start this transaction; however, you must explicitly end it with COMMIT, or implicitly end it with COPY. Otherwise, Vertica discards all changes that were made within the transaction.
Persistent and temporary tables
When deleting from a persistent table, DELETE removes data directly from the ROS.
DELETE execution on temporary tables varies, depending on whether the table was created with ON COMMIT DELETE ROWS (default) or ON COMMIT PRESERVE ROWS:
-
If DELETE contains a WHERE clause that specifies which rows to remove, behavior is identical: DELETE marks the rows for deletion. In both cases, you cannot roll back to an earlier savepoint.
-
If DELETE omits a WHERE clause and the table was created with ON COMMIT PRESERVE ROWS, Vertica marks all table rows for deletion. If the table was created with ON COMMIT DELETE ROWS, DELETE behaves like TRUNCATE TABLE and removes all rows from storage.
Note
If you issue an unqualified DELETE statement on a temporary table created with ON COMMIT DELETE ROWS, Vertica removes all rows from storage but does not end the transaction.
Examples
The following statement removes all rows from a temporary table:
=> DELETE FROM temp1;
The following statement deletes all records from a schema-qualified table where a condition is satisfied:
=> DELETE FROM retail.customer WHERE state IN ('MA', 'NH');
For examples that show how to nest a subquery within a DELETE statement, see Subqueries in UPDATE and DELETE.
See also
7.14 - DISCONNECT
Closes a connection to another Vertica database that was opened in the same session with CONNECT TO VERTICA.
Closes a connection to another Vertica database that was opened in the same session with
CONNECT TO VERTICA.
Note
Closing your session also closes the database connection. However, it is a good practice to explicitly close the connection to the other database, both to free up resources and to prevent issues with other SQL scripts that might be running in your session. Always closing the connection prevents potential errors if you run a script in the same session that attempts to open a connection to the same database, since each session can only have one connection to a given database at a time.
Syntax
DISCONNECT db-spec
Parameters
db-spec- Specifies the target database, either the database name or
DEFAULT.
Privileges
None
Examples
=> DISCONNECT DEFAULT;
DISCONNECT
7.15 - DO
Executes an anonymous (unnamed) stored procedure without saving it.
Executes an anonymous (unnamed) stored procedure without saving it.
Syntax
DO [ LANGUAGE 'language-name' ] $$
source
$$;
Parameters
language-name- Specifies the language of the procedure
source, one of the following (both options refer to PLvSQL; PLpgSQL is included to maintain compatibility with existing scripts):
Default: PLvSQL
source- The source code of the procedure.
Privileges
None
Examples
For more complex examples, see Stored procedures: use cases and examples
This procedure prints the variables in the DECLARE block:
DO LANGUAGE PLvSQL $$
DECLARE
x int := 3;
y varchar := 'some string';
BEGIN
RAISE NOTICE 'x = %', x;
RAISE NOTICE 'y = %', y;
END;
$$;
NOTICE 2005: x = 3
NOTICE 2005: y = some string
For more information on RAISE NOTICE, see Errors and diagnostics.
See also
7.16 - DROP statements
DROP statements let you delete database objects such as schemas, tables, and users.
DROP statements let you delete database objects such as schemas, tables, and users.
7.16.1 - DROP ACCESS POLICY
Removes an access policy from a column or row.
Removes an access policy from a column or row.
Syntax
DROP ACCESS POLICY ON table FOR { COLUMN column | ROWS}
Parameters
table- Name of the table that contains the column access policy to remove
column- Name of the column that contains the access policy to remove
Privileges
Non-superuser: Ownership of the table
Examples
These examples show various cases where you can drop an access policy.
Drop column access policy:
=> DROP ACCESS POLICY ON customer FOR COLUMN Customer_Number;
Drop row access policy on a table:
=> DROP ACCESS POLICY ON customer_info FOR ROWS;
7.16.2 - DROP AGGREGATE FUNCTION
Drops a user-defined aggregate function (UDAnF) from the Vertica catalog.
Drops a user-defined aggregate function (UDAnF) from the Vertica catalog.
Syntax
DROP AGGREGATE FUNCTION [ IF EXISTS ] [[database.]schema.]function( [ arglist ] )
Parameters
IF EXISTS- Specifies not to report an error if the function to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- Specifies a name of the SQL function to drop. If the function name is schema-qualified, the function is dropped from the specified schema (as noted above).
arglist- A comma delimited list of argument names and data types that are passed to the function, formatted as follows:
{ [argname] argtype }[,...]
-
argname optionally specifies the argument name, typically a column name.
-
argtype specifies the argument's data type, where argtype matches a Vertica data type.
Privileges
Non-superuser: Owner
Requirements
-
To drop a function, you must specify the argument types because several functions might share the same name with different parameters.
-
Vertica does not check for dependencies, so if you drop a SQL function where other objects reference it (such as views or other SQL functions), Vertica returns an error when those objects are used and not when the function is dropped.
Examples
The following command drops the ag_avg function:
=> DROP AGGREGATE FUNCTION ag_avg(numeric);
DROP AGGREGATE FUNCTION
See also
Aggregate functions (UDAFs)
7.16.3 - DROP ANALYTIC FUNCTION
Drops a user-defined analytic function from the Vertica catalog.
Drops a user-defined analytic function from the Vertica catalog.
Syntax
DROP ANALYTIC FUNCTION [ IF EXISTS ] [[database.]schema.]function( [ arglist ] )
Parameters
IF EXISTS- Specifies not to report an error if the function to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- Specifies a name of the SQL function to drop. If the function name is schema-qualified, the function is dropped from the specified schema (as noted above).
arglist- A comma delimited list of argument names and data types that are passed to the function, formatted as follows:
{ [argname] argtype }[,...]
-
argname optionally specifies the argument name, typically a column name.
-
argtype specifies the argument's data type, where argtype matches a Vertica data type.
Privileges
Non-superuser: Owner
Requirements
-
To drop a function, you must specify the argument types because several functions might share the same name with different parameters.
-
Vertica does not check for dependencies, so if you drop a SQL function where other objects reference it (such as views or other SQL functions), Vertica returns an error when those objects are used and not when the function is dropped.
Examples
The following command drops the analytic_avg function:
=> DROP ANALYTIC FUNCTION analytic_avg(numeric);
DROP ANALYTIC FUNCTION
See also
Analytic functions (UDAnFs)
7.16.4 - DROP AUTHENTICATION
Drops an authentication method.
Drops an authentication method.
Syntax
DROP AUTHENTICATION [ IF EXISTS ] auth-method-name [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the authentication method to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
auth-method-name- Name of the authentication method to drop.
CASCADE- Required if the authentication method to drop is granted to users. In this case, omission of this option causes the drop operation to fail.
Privileges
Superuser
Examples
Delete authentication method md5_auth:
=> DROP AUTHENTICATION md5_auth;
Use CASCADE to drop authentication method that was granted to a user:
=> CREATE AUTHENTICATION localpwd METHOD 'password' LOCAL;
=> GRANT AUTHENTICATION localpwd TO jsmith;
=> DROP AUTHENTICATION localpwd CASCADE;
See also
7.16.5 - DROP CA BUNDLE
Drops a certificate authority (CA) bundle.
Deprecated
CA bundles are only usable with certain deprecated parameters in
Kafka notifiers. You should prefer using
TLS configurations and the TLS CONFIGURATION parameter for notifiers instead.
Drops a certificate authority (CA) bundle.
Syntax
DROP CA BUNDLE [ IF EXISTS ] name [,...] [ CASCADE ]
Parameters
IF EXISTS- Vertica does not report an error if the CA bundle to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
name- The name of the CA bundle.
CASCADE- Drops dependent objects before dropping the CA bundle.
Privileges
Ownership of the CA bundle
Examples
See Managing CA bundles.
See also
7.16.6 - DROP CERTIFICATE
Drops a TLS certificate from the database.
Drops a TLS certificate from the database.
To view existing certificates, query CERTIFICATES.
Syntax
DROP CERTIFICATE [ IF EXISTS ] certificate-name [,...] [ CASCADE ]
Parameters
IF EXISTS- Vertica does not report an error if the certificate to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
certificate-name- The name of the certificate to drop.
CASCADE- Drops dependent objects before dropping the certificate.
Predefined TLS Configurations and TLS Configurations that manage a connection type cannot be dropped, nor can the keys and certificates referenced by such TLS Configurations. For details, see TLS configurations.
Privileges
Non-superuser, one of the following:
Examples
Drop server_cert, if it exists:
=> DROP CERTIFICATE server_cert;
DROP CERTIFICATE;
Drop a CA certificate and its dependencies (typically the certificates that it has signed):
=> DROP CERTIFICATE ca_cert CASCADE;
DROP CERTIFICATE;
See also
7.16.7 - DROP DATA LOADER
DROP DATA LOADER drops a data loader and its associated monitoring table.
DROP DATA LOADER drops a data loader created with CREATE DATA LOADER. It also drops the associated monitoring table.
If the data loader was created with a trigger, you must disable it before dropping it. Call ALTER DATA LOADER with the DISABLE option.
Syntax
DROP DATA LOADER [ IF EXISTS ] [schema.]name
Arguments
IF EXISTS- Do not report an error if the data loader does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader.
Privileges
Non-superuser: owner or DROP privilege on the data loader.
See also
7.16.8 - DROP DIRECTED QUERY
Removes a directed query from the database.
Removes a directed query from the database. If the directed query is active, Vertica deactivates it before removal.
Syntax
DROP DIRECTED QUERY { query-name | where-clause }
Arguments
query-name- Name of the directed query to remove from the database, as stored in the DIRECTED_QUERIES column
query_name. You can also use GET DIRECTED QUERY to obtain names of all directed queries that map to an input query.
where-clause- Resolves to one or more directed queries that are filtered from system table DIRECTED_QUERIES. For example, the following statement specifies to drop all directed queries with the same
save_plans_version identifier:
=> DROP DIRECTED QUERY WHERE save_plans_version = 21;
Privileges
Superuser
Examples
See Managing directed queries.
7.16.9 - DROP FAULT GROUP
Removes the specified fault group and its child fault groups, placing all nodes under the parent of the dropped fault group.
Removes the specified fault group and its child fault groups, placing all nodes under the parent of the dropped fault group.
To drop all fault groups, use ALTER DATABASE..DROP ALL FAULT GROUP.
To add an orphaned node back to a fault group, you must manually reassign it to a new or existing fault group with CREATE FAULT GROUP and ALTER FAULT GROUP...ADD NODE.
Tip
For a list of all fault groups defined in the cluster, query system table
FAULT_GROUPS .
Syntax
DROP FAULT GROUP [ IF EXISTS ] fault-group
Parameters
IF EXISTS- Specifies not to report an error if
fault-group does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
fault-group- Specifies the name of the fault group to drop.
Privileges
Superuser
Examples
=> DROP FAULT GROUP group2;
DROP FAULT GROUP
See also
7.16.10 - DROP FILTER
Drops a User Defined Load Filter function from the Vertica catalog.
Drops a User Defined Load Filter function from the Vertica catalog.
Syntax
DROP FILTER [[database.]schema.]filter()
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
filter()- Specifies the filter function to drop. You must append empty parentheses to the function name.
Privileges
Non-superuser:
Examples
The following command drops the Iconverter filter function::
=> drop filter Iconverter();
DROP FILTER
See also
7.16.11 - DROP FUNCTION
Drops an SQL function or user-defined functions (UDFs) from the Vertica catalog.
Drops an SQL function or user-defined functions (UDFs) from the Vertica catalog.
Syntax
DROP FUNCTION [ IF EXISTS ] [[database.]schema.]function[,...] ( [ arg-list ] )
Parameters
IF EXISTS- Specifies not to report an error if the function to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- The SQL or user-defined function (UDF) to drop, where UDFs can be one of the following types:
arg-listA comma-delimited list of arguments as defined for this function when it was created, specified as follows:
[arg-name] arg-type[,...]
where arg-name optionally qualifies arg-type:
Privileges
Non-superuser, one of the following:
Requirements
-
To drop a function, you must specify the argument types because several functions might share the same name with different parameters.
-
Vertica does not check for dependencies when you drop a SQL function, so if other objects reference it (such as views or other SQL functions), Vertica returns an error only when those objects are used.
Examples
The following command drops the zerowhennull function in the macros schema:
=> DROP FUNCTION macros.zerowhennull(x INT);
DROP FUNCTION
See also
7.16.12 - DROP KEY
Drops a cryptographic key and its certificate, if any, from the database.
Drops a cryptographic key and its certificate, if any, from the database.
To view existing cryptographic keys, query CRYPTOGRAPHIC_KEYS.
Syntax
DROP KEY [ IF EXISTS ] key-name [,...] [ CASCADE ]
Parameters
IF EXISTS- Vertica does not report an error if the key to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
key-name- The name of the cryptographic key to drop.
CASCADE- Drops dependent objects before dropping the key.
Predefined TLS Configurations and TLS Configurations that manage a connection type cannot be dropped, nor can the keys and certificates referenced by such TLS Configurations. For details, see TLS configurations.
Privileges
Non-superuser, one of the following:
-
Ownership of the key
-
DROP privileges
Examples
Drop k_ca, if it exists:
=> DROP KEY k_ca IF EXISTS;
DROP KEY;
Drop k_client and its dependencies (the certificate it's associated with):
=> DROP KEY k_client CASCADE;
DROP KEY;
See also
7.16.13 - DROP LIBRARY
Removes a UDx library from the database.
Removes a UDx library from the database. The library file is deleted from managed directories on the Vertica nodes. The user-defined functions (UDFs) in the library are no longer available. See Developing user-defined extensions (UDxs) for details.
Syntax
DROP LIBRARY [ IF EXISTS ] [[database.]schema.]library [ CASCADE]
Arguments
IF EXISTS- Execute this command only if the library exists. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
library- The name of the library to drop, the same name used in CREATE LIBRARY to load the library.
CASCADE- Also drop any functions that were defined using the library. DROP LIBRARY fails if CASCADE is omitted and one or more UDxs use the target library.
Privileges
One of:
Examples
A superuser can drop any library:
=> DROP LIBRARY ml.MyLib CASCADE;
Users with the UDXDEVELOPER role can drop libraries that they created:
=> GRANT UDXDEVELOPER TO alice, bob;
GRANT ROLE
=> \c - alice;
You are now connected as user "alice".
-- Must enable the role before using:
=> SET ROLE UDXDEVELOPER;
SET
-- Create and use ml.mylib...
-- Drop library and dependencies:
DROP LIBRARY ml.mylib CASCADE;
DROP LIBRARY
A user can be granted explicit permission to drop a library:
=> \c - alice
You are now connected as user "alice".
=> GRANT DROP ON LIBRARY ml.mylib to bob;
GRANT PRIVILEGE
=> \c - bob
You are now connected as user "bob".
=> SET ROLE UDXDEVELOPER;
SET
=> DROP LIBRARY ml.mylib cascade;
DROP LIBRARY
7.16.14 - DROP LOAD BALANCE GROUP
Deletes a load balancing group.
Deletes a load balancing group.
Syntax
DROP LOAD BALANCE GROUP [ IF EXISTS ] group_name [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the load balance group to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
-
group_name
- The name of the group to drop.
[CASCADE]- Also drops all load balancing routing rules that target this group. If you do not supply this keyword and one or more routing rules target
group_name, this statement fails with an error message.
Privileges
Superuser
Examples
The following statement demonstrates the error you get if the load balancing group has a dependent routing rule, and the use of the CASCADE keyword:
=> DROP LOAD BALANCE GROUP group_all;
NOTICE 4927: The RoutingRule catch_all depends on LoadBalanceGroup group_all
ROLLBACK 3128: DROP failed due to dependencies
DETAIL: Cannot drop LoadBalanceGroup group_all because other objects depend on it
HINT: Use DROP ... CASCADE to drop the dependent objects too
=> DROP LOAD BALANCE GROUP group_all CASCADE;
DROP LOAD BALANCE GROUP
See also
7.16.15 - DROP MODEL
Removes one or more models from the Vertica database.
Removes one or more models from the Vertica database.
Syntax
DROP MODEL [ IF EXISTS ] [[database.]schema.]model[,...]
Parameters
IF EXISTS- Specifies not to report an error if the models to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
- [
database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
model- The model to drop.
Privileges
One of the following:
Examples
See Dropping models.
7.16.16 - DROP NAMESPACE
Eon Mode only
Drops a namespace from an Eon Mode database. The statement errors if there are any schemata or tables in the namespace.
Syntax
DROP NAMESPACE [ IF EXISTS ] name
Arguments
IF EXISTS- Do not report an error if the namespace does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
name- Name of the namespace to drop. You cannot drop the
default_namespace.
Privileges
Superuser
Examples
Drop the analytics namespace:
=> DROP NAMESAPCE `analytics`;
DROP NAMESPACE
See also
7.16.17 - DROP NETWORK ADDRESS
Deletes a network address from the catalog.
Deletes a network address from the catalog. A network address is a name for a IP address and port on a node for use in connection load balancing policies.
Syntax
DROP NETWORK ADDRESS [ IF EXISTS ] address-name [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the network address to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
address-name- Name of the network address to drop.
CASCADE- Removes the network address from any load balancing groups that target it. If you do not supply this keyword and one or more load balance groups include this address, this statement fails with an error message.
Privileges
Superuser
Examples
The following statement demonstrates the error you get if the network address has a dependent load balance group, and the use of the CASCADE keyword:
=> DROP NETWORK ADDRESS node01;
NOTICE 4927: The LoadBalanceGroup group_1 depends on NetworkInterface node01
NOTICE 4927: The LoadBalanceGroup group_random depends on NetworkInterface node01
ROLLBACK 3128: DROP failed due to dependencies
DETAIL: Cannot drop NetworkInterface node01 because other objects depend on it
HINT: Use DROP ... CASCADE to drop the dependent objects too
=> DROP NETWORK ADDRESS node01 CASCADE;
DROP NETWORK ADDRESS
7.16.18 - DROP NETWORK INTERFACE
Removes a network interface from Vertica.
Removes a network interface from Vertica. You can use the CASCADE option to also remove the network interface from any node definition. (See Identify the database or nodes used for import/export for more information.)
Syntax
DROP NETWORK INTERFACE [ IF EXISTS ] network-interface-name [ CASCADE ]
Parameters
The parameters are defined as follows:
IF EXISTS- Specifies not to report an error if the network interface to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
network-interface-name- The network interface to remove.
CASCADE- Removes the network interface from all node definitions.
Privileges
Superuser
Examples
=> DROP NETWORK INTERFACE myNetwork;
7.16.19 - DROP NOTIFIER
Drops a push-based notifier created by CREATE NOTIFIER.
Drops a push-based notifier created by
CREATE NOTIFIER.
Syntax
DROP NOTIFIER [ IF EXISTS ] notifier-name [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if notifier to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
notifier-name- The notifier's unique identifier.
CASCADE- Removes the notifier from any data collector (DC) table policies before dropping the notifier. If the notifier is set for a DC table and CASCADE is not specified, the DROP command fails.
To manually remove the notifier from DC table policies, use the SET_DATA_COLLECTOR_NOTIFY_POLICY function.
Examples
Drop the requests_issued notifier, specifying CASCADE to remove it from any DC table policies:
DROP NOTIFIER requests_issued CASCADE;
7.16.20 - DROP PARSER
Drops a User Defined Load Parser function from the Vertica catalog.
Drops a User Defined Load Parser function from the Vertica catalog.
Syntax
DROP PARSER[[database.]schema.]parser()
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
parser()- The name of the parser function to drop. You must append empty parentheses to the function name.
Privileges
Non-superuser:
Examples
=> DROP PARSER BasicIntegerParser();
DROP PARSER
See also
7.16.21 - DROP PROCEDURE (external)
Removes an external procedure from Vertica.
Enterprise Mode only
Removes an external procedure from Vertica. Only the reference to the procedure inside Vertica is removed. The external file remains in the database/procedures directory of each database node.
Syntax
DROP PROCEDURE [ IF EXISTS ] [[database.]schema.]procedure( [ parameter-list ] )
Parameters
IF EXISTS- Specifies not to report an error if the procedure to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
procedure- Specifies the procedure to drop.
parameter-list- A comma-delimited list of formal parameters defined for this procedure, specified as follows:
[parameter-name] parameter-type[,...]
where parameter-name optionally qualifies parameter-type.
Privileges
Non-superuser:
Examples
=> DROP PROCEDURE helloplanet(arg1 varchar);
See also
CREATE PROCEDURE (external)
7.16.22 - DROP PROCEDURE (stored)
Drops a stored procedure.
Drops a stored procedure.
Syntax
DROP PROCEDURE [ IF EXISTS ] [[database.]schema.]procedure( [ parameter-type-list] ) [ CASCADE ];
Parameters
IF EXISTS- Specifies not to report an error if the procedure to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
procedure- The name of the stored procedure, where
procedure conforms to conventions described in Identifiers.
parameter-type-list- A comma-delimited list of the IN and INOUT parameters' types.
- CASCADE
- Drops the trigger that references the stored procedure, if any.
Privileges
Non-superuser:
Examples
Given the following procedure:
=> CREATE PROCEDURE raiseXY(IN x INT, y VARCHAR) LANGUAGE PLvSQL AS $$
BEGIN
RAISE NOTICE 'x = %', x;
RAISE NOTICE 'y = %', y;
-- some processing statements
END;
$$;
CALL raiseXY(3, 'some string');
NOTICE 2005: x = 3
NOTICE 2005: y = some string
You can drop it with:
=> DROP PROCEDURE raiseXY(INT, VARCHAR);
DROP PROCEDURE
For details on RAISE NOTICE, see Errors and diagnostics.
See also
7.16.23 - DROP PROFILE
Removes a user-defined profile (created by CREATE PROFILE) from the database.
Removes a user-defined profile (created by
CREATE PROFILE) from the database. You cannot drop the DEFAULT profile.
Syntax
DROP PROFILE [ IF EXISTS ] profile-name[,...] [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the profile to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
profile-name- The profile to drop.
CASCADE- Moves all users assigned to the dropped profiles to the DEFAULT profile. If you omit this option and a targeted profile has users assigned to it, Vertica returns an error.
Privileges
Superuser
Examples
=> DROP PROFILE sample_profile;
7.16.24 - DROP PROJECTION
Marks a to drop from the catalog so it is unavailable to user queries.
Marks a projection to drop from the catalog so it is unavailable to user queries.
Syntax
DROP PROJECTION [ IF EXISTS ] { [[database.]schema.]projection[,...] } [ RESTRICT | CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the projection to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
projection- Specifies a projection to drop:
-
If the projection is unsegmented, all projection replicas in the database cluster are dropped.
-
If the projection is segmented, drop all buddy projections by specifying the projection base name. You can also specify the name of a specific buddy projection as long as dropping it so does not violate system K-safety.
See Projection naming for projection name conventions.
RESTRICT | CASCADE- Specifies whether to drop the projection when it contains objects:
Privileges
Non-superuser: owner of the anchor table
Restrictions
The following restrictions apply to dropping a projection:
-
The projection cannot be the anchor table's superprojection.
-
You cannot drop a buddy projection if doing so violates system K-safety.
-
Another projection must be available to enforce the same primary or unique key constraint.
See also
7.16.25 - DROP RESOURCE POOL
Drops a user-created resource pool.
Drops a user-created resource pool. All memory allocated to the pool is returned to the GENERAL pool.
Syntax
DROP RESOURCE POOL resource-pool [ FOR { SUBCLUSTER subcluster | CURRENT SUBCLUSTER } ]
Parameters
resource-pool- Name of the resource pool to drop.
FOR {SUBCLUSTER subcluster | CURRENT SUBCLUSTER}- Eon Mode only, drops
resource-pool from the specified subcluster, one of the following:
SUBCLUSTER subcluster: Drops resource-pool from the named subcluster . You cannot be connected to this subcluster, otherwise Vertica returns an error.CURRENT SUBCLUSTER: Drops resource-pool from the subcluster you are connected to.
If you omit this parameter, the resource pool is dropped from all subclusters. If a resource pool was created for an individual subcluster, you must explicitly drop it from that subcluster with this parameter; otherwise, Vertica returns an error.
Privileges
Superuser
Resource pool transfers
Requests that are queued against the dropped pool are transferred to the GENERAL pool according to the priority of the pool compared to the GENERAL pool. If the pool’s priority is higher than the GENERAL pool, the requests are placed at the head of the queue; otherwise, transferred requests are placed at the end of the queue.
Users who are assigned to the dropped pool are reassigned to the default user resource pool as set by DefaultResourcePoolForUser. The DROP request returns with a notice like this:
NOTICE: Switched the following users to the <name> pool: <username>
If any user lacks permission to use the default user resource pool, Vertica rolls back the drop operation.
Existing sessions are transferred to the GENERAL pool regardless of whether the session user has privileges to use that pool. This can result in additional user privileges if access to the dropped pool is more restrictive than the GENERAL pool. In this case, you can prevent giving users additional privileges as follows:
-
Revoke permissions on the target resource pool from all users.
-
Close any sessions that had permissions on the resource pool.
-
Drop the resource pool.
Restrictions
-
If you try to drop a resource pool that is the secondary pool for another resource pool, Vertica returns an error. The error lists the resource pools that depend on the secondary pool you tried to drop. To drop a secondary resource pool, first set the CASCADE TO parameter to DEFAULT on the primary resource pool, and then drop the secondary pool.
For example, you can drop resource pool rp2, which is a secondary pool for rp1, as follows:
=> ALTER RESOURCE POOL rp1 CASCADE TO DEFAULT;
=> DROP RESOURCE POOL rp2;
-
You cannot drop a resource pool that is configured as the default user resource pool by the DefaultResourcePoolForUsers parameter.
Examples
Drop a user-defined resource pool:
=> DROP RESOURCE POOL ceo_pool;
Get the name of the current subcluster for an Eon Mode database, then drop its resource pool:
=> SELECT CURRENT_SUBCLUSTER_NAME();
CURRENT_SUBCLUSTER_NAME
-------------------------
analytics_1
(1 row)
=> DROP RESOURCE POOL dashboard FOR CURRENT SUBCLUSTER;
DROP RESOURCE POOL
See also
7.16.26 - DROP ROLE
Removes a role from the database.
Removes a role from the database.
Note
You cannot use DROP ROLE on a role added to the Vertica database with the LDAPLink service.
Syntax
DROP ROLE [ IF EXISTS ] role-name[,...] [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if the roles to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
role-name- The name of the role to drop
CASCADE- Revoke the role from users and other roles before dropping the role
Privileges
Superuser
Examples
=> DROP ROLE appadmin;
NOTICE: User bob depends on Role appadmin
ROLLBACK: DROP ROLE failed due to dependencies
DETAIL: Cannot drop Role appadmin because other objects depend on it
HINT: Use DROP ROLE ... CASCADE to remove granted roles from the dependent users/roles
=> DROP ROLE appadmin CASCADE;
DROP ROLE
See also
7.16.27 - DROP ROUTING RULE
Deletes a routing rule from the catalog.
Deletes a routing rule from the catalog.
Syntax
DROP ROUTING RULE [ IF EXISTS ] { rule_name | FOR WORKLOAD workload_name }
Parameters
IF EXISTS- Specifies not to report an error if the routing rule to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
rule_name- Name of the rule to drop.
workload_name- The name of a workload.
Privileges
Superuser
Examples
To drop a routing rule:
=> DROP ROUTING RULE internal_clients;
DROP ROUTING RULE
To drop a rule for a workload:
=> DROP ROUTING RULE FOR WORKLOAD analytics;
See also
7.16.28 - DROP SCHEDULE
Drops schedules.
Drops schedules.
Syntax
DROP SCHEDULE [[database.]schema.]schedule[,...] [ CASCADE ]
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
schedule- The schedule to drop.
- CASCADE
- Drops triggers that use this schedule, if any.
Privileges
Superuser
Examples
=> DROP SCHEDULE monthly_schedule;
7.16.29 - DROP SCHEMA
Permanently removes a schema from the database.
Permanently removes a schema from the database. Be sure that you want to remove the schema before you drop it, because DROP SCHEMA is an irreversible process. Use the CASCADE parameter to drop a schema containing one or more objects.
Syntax
DROP SCHEMA [ IF EXISTS ] [{namespace. | database. }]schema[,...] [ CASCADE | RESTRICT ]
Parameters
IF EXISTS- Specifies not to report an error if the schemas to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
{ namespace. | database. }- Name of the database or namespace that contains
schema:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public.
CASCADE- Specifies to drop the schema and all objects in it, regardless of who owns those objects.
Caution
Objects in other schemas that depend on objects in the dropped schema—for example, user-defined functions—also are silently dropped.
RESTRICT- Drops the schema only if it is empty (default).
Privileges
Non-superuser: schema owner
Restrictions
-
You cannot drop the PUBLIC schema.
-
If a user is accessing an object within a schema that is in the process of being dropped, the schema is not deleted until the transaction completes.
-
Canceling a DROP SCHEMA statement can cause unpredictable results.
Examples
The following example drops schema S1 only if it doesn't contain any objects:
=> DROP SCHEMA S1;
The following example drops schema S1 whether or not it contains objects:
=> DROP SCHEMA S1 CASCADE;
7.16.30 - DROP SEQUENCE
Removes the specified named sequence number generator.
Removes the specified named sequence number generator.
Syntax
DROP SEQUENCE [ IF EXISTS ] [[database.]schema.]sequence[,...]
Parameters
IF EXISTS- Specifies not to report an error if the sequences to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
sequence- Name of the sequence to drop.
Privileges
Non-superusers: sequence or schema owner
Restrictions
-
For sequences specified in a table's default expression, the default expression fails the next time you try to load data. Vertica does not check for these instances.
-
DROP SEQUENCE does not support the CASCADE keyword. Sequences used in a default expression of a column cannot be dropped until all references to the sequence are removed from the default expression.
Examples
The following command drops the sequence named sequential.
=> DROP SEQUENCE sequential;
See also
7.16.31 - DROP SOURCE
Drops a User Defined Load Source function from the Vertica catalog.
Drops a User Defined Load Source function from the Vertica catalog.
Syntax
DROP SOURCE [[database.]schema.]source()
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
source()- Specifies the source function to drop. You must append empty parentheses to the function name.
Privileges
Non-superuser:
Examples
The following command drops the curl source function:
=> DROP SOURCE curl();
DROP SOURCE
See also
7.16.32 - DROP SUBNET
Removes a subnet from Vertica.
Removes a subnet from Vertica.
Syntax
DROP SUBNET [ IF EXISTS ] subnet-name[,...] [ CASCADE ]
Parameters
The parameters are defined as follows:
IF EXISTS- Specifies not to report an error if the subnets to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
subnet-name- A subnet to remove.
CASCADE- Removes the specified subnets from all database definitions.
Privileges
Superuser
Examples
=> DROP SUBNET mySubnet;
See also
Identify the database or nodes used for import/export
7.16.33 - DROP TABLE
DROP TABLE;delete table;.
Removes one or more tables and their projections. When you run DROP TABLE, the change is auto-committed.
Syntax
DROP TABLE [ IF EXISTS ] [[{namespace. | database. }]schema.]table[,...] [ CASCADE ]
Parameters
IF EXISTS- Specifies not to report an error if one or more of the tables to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table- The table to drop.
CASCADE- Specifies to drop all projections of the target tables.
CASCADE is optional if the target tables have only auto-projections. If you omit this option and any of the tables has non-superprojections, Vertica returns an error and rolls back the entire drop operation.
This option is not valid for external tables.
Privileges
Non-superuser:
Requirements
-
Do not cancel an executing DROP TABLE. Doing so can leave the database in an inconsistent state.
-
Check that the target table is not in use, either directly or indirectly—for example, in a view.
-
If you drop and restore a table that is referenced by a view, the new table must have the same name and column definitions.
Examples
See Dropping tables
See also
7.16.34 - DROP TEXT INDEX
Drops a text index used to perform text searches.
Drops a text index used to perform text searches.
Note
When a source table is dropped that has a text index associated with it, the text index is also dropped.
Syntax
DROP TEXT INDEX [ IF EXISTS ] [[database.]schema.]idx-table
Parameters
IF EXISTS- Specifies not to report an error if the text index to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
idx-table- Specifies the text index name. When using more than one schema, specify the schema that contains the index in the
DROP TEXT INDEX statement.
Privileges
Examples
=> DROP TEXT INDEX t_text_index;
DROP INDEX
See also
7.16.35 - DROP TLS CONFIGURATION
Drops an existing TLS Configuration.
Drops an existing TLS Configuration.
You cannot drop a TLS Configuration if it set as a configuration parameter. For details, see TLS configurations.
Syntax
DROP TLS CONFIGURATION tls_config_name
Parameters
tls_config_name- The name of the TLS Configuration object to drop.
Privileges
Non-superuser, one of the following:
7.16.36 - DROP TRANSFORM FUNCTION
Drops a user-defined transform function (UDTF) from the Vertica catalog.
Drops a user-defined transform function (UDTF) from the Vertica catalog.
Syntax
DROP TRANSFORM FUNCTION [ IF EXISTS ] [[database.]schema.]function( [ arg-list ] )
Parameters
IF EXISTS- Specifies not to report an error if the function to drop does not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- Specifies the transform function to drop.
arg-listA comma-delimited list of arguments as defined for this function when it was created, specified as follows:
[arg-name] arg-type[,...]
where arg-name optionally qualifies arg-type:
Note
You can omit arg-list when dropping a polymorphic function.
Privileges
One of the following:
Examples
The following command drops the tokenize UDTF in the macros schema:
=> DROP TRANSFORM FUNCTION macros.tokenize(varchar);
DROP TRANSFORM FUNCTION
The following command drops the Pagerank polymorphic function in the online schema:
=> DROP TRANSFORM FUNCTION online.Pagerank();
DROP TRANSFORM FUNCTION
See also
CREATE TRANSFORM FUNCTION
7.16.37 - DROP TRIGGER
Drops triggers.
Drops triggers. Dropping a trigger disables its associated schedule, if any.
Syntax
DROP TRIGGER [[database.]schema.]trigger[,...]
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
trigger- The trigger to drop.
Privileges
Superuser
Examples
To drop a trigger:
=> DROP TRIGGER revoke_trigger;
7.16.38 - DROP USER
Removes a name from the list of authorized database users.
Removes a name from the list of authorized database users.
Note
DROP USER can not remove a user that was added to the Vertica database with the LDAPLink service.
Syntax
DROP USER [ IF EXISTS ] user-name[,...] [ CASCADE ]
Parameters
IF EXISTS- Do not report an error if the users to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
user-name- Name of a user to drop.
CASCADE- Drop all user-defined objects created by
user-name, including schemas, tables and all views that reference the table, and projections of that table.
Caution
Tables owned by the dropped user cannot be recovered after you issue DROP USER CASCADE.
Privileges
Superuser
Examples
DROP USER succeeds if no user-defined objects exist:
=> CREATE USER user2;
CREATE USER
=> DROP USER IF EXISTS user2;
DROP USER
DROP USER fails if objects that the user created still exist:
=> DROP USER IF EXISTS user1;
NOTICE: Table T_tbd1 depends on User user1
ROLLBACK: DROP failed due to dependencies
DETAIL: Cannot drop User user1 because other objects depend on it
HINT: Use DROP ... CASCADE to drop the dependent objects too
DROP USER CASCADE succeeds regardless of any existing user-defined objects. The statement forcibly drops all user-defined objects, such as schemas, tables and their associated projections:
=> DROP USER IF EXISTS user1 CASCADE;
DROP USER
See also
7.16.39 - DROP VIEW
Removes the specified view.
Removes the specified view. Vertica does not check for dependencies on the dropped view. After dropping a view, other views that reference it fail.
If you drop a view and replace it with another view or table with the same name and column names, other views that reference that name use the new view. If you change the column data type in the new view, the server coerces the old data type to the new one if possible; otherwise, it returns an error.
Syntax
DROP VIEW [ IF EXISTS ] [[database.]schema.]view[,...]
Parameters
IF EXISTS- Specifies not to report an error if the views to drop do not exist. Use this clause in SQL scripts to avoid errors on dropping non-existent objects before attempting to create them.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- Name of a view to drop.
Privileges
One of the following
Examples
=> DROP VIEW myview;
7.17 - END
Ends the current transaction and makes all changes that occurred during the transaction permanent and visible to other users.
Ends the current transaction and makes all changes that occurred during the transaction permanent and visible to other users.
Note
COMMIT is a synonym for END.
Syntax
END [ WORK | TRANSACTION ]
Parameters
WORK | TRANSACTION- Optional keywords that have no effect, for readability only.
Privileges
None
Examples
=> BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED READ WRITE;
BEGIN
=> CREATE TABLE sample_table (a INT);
CREATE TABLE
=> INSERT INTO sample_table (a) VALUES (1);
OUTPUT
--------
1
(1 row)
=> END;
COMMIT
See also
7.18 - EXECUTE DATA LOADER
EXECUTE DATA LOADER runs a data loader to load new files from a specified path.
EXECUTE DATA LOADER executes a data loader created with CREATE DATA LOADER. It attempts to load all files in the specifed location that have not already been loaded and that have not reached the retry limit. By default, executing the loader commits the transaction.
Data loaders are excuted with COPY ABORT ON ERROR.
EXECUTE DATA LOADER records events in the DATA_LOADER_EVENTS system table.
EXECUTE DATA LOADER runs the data loader once. To execute it periodically, you can use a scheduled stored procedure. To suspend execution, call ALTER DATA LOADER with the DISABLE option.
Syntax
EXECUTE DATA LOADER [schema.]name
[ WITH FILES file [{ EXACT_PATH | EXPAND_GLOB }][,...] ]
[ FORCE RETRY ]
[ BATCH_SIZE { 'size{K|M|G|T}' | '0' | 'UNLIMITED' } ]
[ NO COMMIT ]
Arguments
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader.
WITH FILES file- Load only the specified files from the data loader's COPY path. Files that do not also match the COPY path are ignored. Files that have already been loaded are not reloaded. Both of these events are recorded in the loader's associated monitoring table.
EXACT_PATH | EXPAND_GLOB- How to match the named file:
-
EXACT_PATH (default): file names must match exactly. Any special characters in the file name are treated as literal parts of the name. For example, sales*.parquet specifies a single file whose name includes the * character.
-
EXPAND_GLOB: glob characters in file names are interpreted as globs. For example, sales*.parquet specifies one or more Parquet files begainning with sales.
FORCE RETRY- Ignore the retry limit.
BATCH_SIZE { 'size{K|M|G|T}' | '0' | 'UNLIMITED' }- When dividing a load for parallel execution, override the Vertica default and set the target total size of files to include in one batch. This value is a hint and batches could be larger, depending on the sizes of individual files.
If this option is omitted, Vertica chooses a size based on the total data volume and the number of executor nodes. The maximum batch size that Vertica automatically chooses is 10GB on each node, but you can specify a larger value with this option.
To set a target size, specify an integer with a unit of measure, such as '100M' or '2G'. To disable batch loads and load files one at a time, specify '0'. To load all files in a single batch, specify 'UNLIMITED'.
NO COMMIT- Do not commit the transaction after execution. Use when execution is part of an operation that must be atomic. SQS triggers use this option so that execution and queue management are part of the same transaction.
Privileges
Read privileges to the source location.
Non-superuser:
- Owner or EXECUTE privilege on the data loader.
- Write privilege on the table.
Examples
Execute a data loader once:
=> EXECUTE DATA LOADER sales_dl;
Rows Loaded
-------------
5
(1 row)
Schedule a recurring execution:
=> CREATE SCHEDULE daily_load USING CRON '0 13 * * *';
--- statement must be quoted:
=> CREATE PROCEDURE dl_runner() as $$ begin EXECUTE 'EXECUTE DATA LOADER sales_dl'; end; $$;
=> CREATE TRIGGER t_load ON SCHEDULE daily_load EXECUTE PROCEDURE dl_runner() AS DEFINER;
Load specific files with globbing:
--- no file named '09*.dat' so nothing loaded by default:
=> EXECUTE DATA LOADER sales_dl
WITH FILES 's3://MyBucket/sales/2023/09*.dat';
Rows Loaded
-------------
0
(1 row)
--- loads '09-01.dat', '09-02.dat', etc:
=> EXECUTE DATA LOADER sales_dl
WITH FILES 's3://MyBucket/sales/2023/09*.dat' EXPAND_GLOB;
Rows Loaded
-------------
20
(1 row)
--- loads one glob and one specific file:
=> EXECUTE DATA LOADER sales_dl
WITH FILES 's3://MyBucket/sales/2023/09*.dat' EXPAND_GLOB,
's3://MyBucket/sales/2023/specials.dat' EXACT_PATH;
Rows Loaded
-------------
32
(1 row)
See Automatic load for an extended example.
See also
7.19 - EXPLAIN
Returns a formatted description of the Vertica optimizer's plan for executing the specified statement.
Returns a formatted description of the Vertica optimizer's plan for executing the specified statement.
Syntax
EXPLAIN [/*+ ALLNODES */] [explain-options] sql-statement
Parameters
-
/*+ALLNODES*/
- Specifies to create a query plan that assumes all nodes are active, not valid with
LOCAL option.
explain-options- One or more
EXPLAIN options, specified in the order shown:
[ LOCAL ] [ VERBOSE ] [ JSON ] [ ANNOTATED ]
-
LOCAL: On a multi-node database, shows the local query plans assigned to each node, which together comprise the total (global) query plan. If you omit this option, Vertica shows only the global query plan. Local query plans are shown only in DOT language source, which can be rendered in Graphviz.
This option is incompatible with the hint /*+ALLNODES*/. If you specify both, EXPLAIN returns with an error.
-
VERBOSE: Increases the level of detail in the rendered query plan.
-
JSON: Renders the query plan in JSON format. This option is compatible only with VERBOSE.
-
ANNOTATED: Embeds optimizer hints that encapsulate the query plan for this query. This option is compatible with LOCAL and VERBOSE.
sql-statement- A query or DML statement—for example, SELECT, INSERT, UPDATE, COPY, and MERGE.
Privileges
The same privileges required by the specified statement.
Requirements
The following requirements apply to EXPLAIN's ability to produce useful information:
- Reasonably representative statistics of your data must be available. See Collecting Statistics for details.
- EXPLAIN produces useful output only if projections are available for the queried tables.
- Qualifier options must be specified in the order shown earlier, otherwise EXPLAIN returns with an error. If an option is incompatible with any preceding options, EXPLAIN ignores them.
Examples
See Viewing query plans.
7.20 - EXPORT TO DELIMITED
Exports a table, columns from a table, or query results to delimited files.
Exports a table, columns from a table, or query results to delimited files. The files can be read back in using DELIMITED. Several exporter parameters have corresponding parser parameters, allowing you to change delimiters, null indicators, and other formatting.
There are some limitations on the queries you can use in an export statement. See Query Restrictions.
You can export data stored in Vertica in ROS format and data from external tables.
File exporters are UDxs that cannot be run in fenced mode. If the ForceUDxFencedMode configuration parameter is set to true to support other UDxs, you can set it to false at the session level before performing the export.
This statement returns the number of rows written and logs information about exported files in a system table. See Monitoring exports.
During an export to HDFS or an NFS mount point, Vertica writes files to a temporary directory in the same location as the destination and renames the directory when the export is complete. Do not attempt to use the files in the temporary directory. During an export to S3, GCS, or Azure, Vertica writes files directly to the destination path, so you must wait for the export to finish before reading the files. For more information, see Exporting to object stores.
Syntax
EXPORT [ /*+LABEL (label-string)*/ ] TO DELIMITED
( directory='path'[, param=value[,...] ] )
[ OVER (over-clause ) ] AS SELECT query-expression
Arguments
-
LABEL
- Assigns a label to a statement to identify it for profiling and debugging.
over-clause- Specifies how to partition table data using PARTITION BY. Within partitions you can sort using ORDER BY. See SQL analytics. This clause may contain column references but not expressions.
If you partition data, Vertica creates a partition directory structure, transforming column names to lowercase. See Partitioned data for a description of the directory structure. If you use the fileName parameter, you cannot use partitioning.
If you omit this clause, Vertica optimizes for maximum parallelism.
query-expression- Specifies the data to export. See Query Restrictions for important limitations.
Parameters
directoryThe destination directory for the output files. The current user must have permission to write it. The destination can be on any of the following file systems:
See also: ifDirExists.
ifDirExistsWhat to do if directory already exists, one of:
-
fail (default)
-
overwrite: replace the entire directory
-
append: export new files into the existing directory with a prepended hash that identifies all files in the exported batch
-
appendNoHash: export new files into the existing directory without a prepended hash; with this option, Vertica cannot clean up partial exports
If you specify overwrite for an export to an object store, the existing directory is deleted recursively at the beginning of the operation and is not restored if the operation fails. Be careful not to export to a directory containing data you want to keep. For an export to a Linux file system or HDFS, the directory is only overwritten if the export succeeds.
Do not do concurrent exports to the same directory. In particular, if you do so with a value of overwrite, all operations appear to succeed, but the results are incorrect.
When using append, be careful to use the same table schema. Otherwise, queries of external tables using this data path could fail.
filenameIf specified, all output is written to a single file of this name in the location specified by directory. While the query can be processed by multiple nodes, only a single node generates the output data. The fileSizeMB parameter is ignored, and the query cannot use partitioning in the OVER() clause.
filePrefixPrefix to use for exported files instead of the default hash. If used with ifDirExists=appendNoHash, choose a unique prefix to avoid overwriting existing files.
addHeader- If true, add a header row to the beginning of each file.
Default: false
delimiter- Column delimiter character. To produce CSV in accordance with RFC 4180, set the delimiter character to
, (comma).
Default: | (vertical bar)
escapeDelimitersInsideEnclosures- If true, delimiter characters are escaped within values that are enclosed by
enclosedBy. This parameter is most relevant when enclosedBy and escapeAs have the same value. A value of false only applies when enclosedBy has a value (is not an empty string).
Default: true
recordTerminator- Character that marks the record end.
Default: \n
enclosedBy- Character to use to enclose string and date/time data. If you omit this parameter, no character encloses these data types.
Default: '' (empty string, no enclosing character)
escapeAs- Character to use to escape values in exported data that must be escaped, including the
enclosedBy value.
Default: \ (backslash)
nullAs- String to represent null values in the data. If this parameter is included, the exporter exports all null values as this value. Otherwise, the exporter exports null values as zero-length strings.
binaryTypesFormat- Format for exported binary data type (BINARY, VARBINARY, and LONG VARBINARY) values, one of the following:
-
Default: Printable ASCII characters where possible and escaped octal representations of the non-printable bytes. The DELIMITED parser reads this format.
-
Hex: Base 16 (hexadecimal) representation; value is preceded by '0x' and bytes are not escaped.
-
Octal: Base 8 (octal) representation, without escaping.
-
Bitstring: Binary representation, without escaping.
For example, the value a\000b\001c can be exported as follows:
compression- Compression type, one of:
Default: Uncompressed
fileExtension- Output file extension. If using compression, a compression-specific extension such as
.bz2 is appended.
Default: csv
fileSizeMBThe maximum file size of a single output file. This value is a hint, not a hard limit. A value of 0 specifies no limit. If filename is also specified, fileSizeMB is ignored.
This value affects the size of individual output files, not the total output size. For smaller values, Vertica divides the output into more files; all data is still exported.
Default: 10GB
fileModeFor writes to HDFS only, permission to apply to all exported files. You can specify the value in Unix octal format (such as 665) or user-group-other format—for example, rwxr-xr-x. The value must be formatted as a string even if using the octal format.
Valid octal values range between 0 and 1777, inclusive. See HDFS Permissions in the Apache Hadoop documentation.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 660, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
dirModeFor writes to HDFS only, permission to apply to all exported directories. Values follow the same rules as those for fileMode. Further, you must give the Vertica HDFS user full permission, at least rwx------ or 700.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 755, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
Privileges
Non-superusers:
Query restrictions
You must provide an alias column label for selected column targets that are expressions.
If you partition the output, you cannot specify schema and table names in the SELECT statement. Specify only the column name.
The query can contain only a single outer SELECT statement. For example, you cannot use UNION:
=> EXPORT TO DELIMITED(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash;
ERROR 8975: Only a single outer SELECT statement is supported
HINT: Please use a subquery for multiple outer SELECT statements
Instead, rewrite the query to use a subquery:
=> EXPORT TO DELIMITED(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT
account_id,
json
FROM
(
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash
) a;
Rows Exported
---------------
2
(1 row)
To use composite statements such as UNION, INTERSECT, and EXCEPT, rewrite them as subqueries.
Data types
EXPORT TO DELIMITED does not support ARRAY, ROW, and SET types.
This operation exports raw Flex columns as binary data.
Output
The export operation always creates (or appends to) an output directory, even if all output is written to a single file or the query produces zero rows.
By default, output file names follow the pattern: prefix-nodename-threadId[-sequenceNumber].extension. prefix is typically an 8-character hash, but can be longer if the export appended to an existing directory. A sequence number is added if an export needs to be broken into pieces to satisfy fileSizeMB. You can change the prefix using the filePrefix parameter or, for appends, by setting ifDirExists=appendNoHash. You can write all output to a single named file using the filename parameter.
Column names in partition directories are lowercase.
Files exported to a local file system by any Vertica user are owned by the Vertica superuser. Files exported to HDFS or object stores are owned by the Vertica user who exported the data.
Making concurrent exports to the same output destination is an error and can produce incorrect results.
Exports to the local file system can be to an NFS mount (shared) or to the Linux file system on each node (non-shared). For details, see Exporting to the Linux file system. Exports to non-shared local file systems have the following restrictions:
-
The output directory must not exist on any node.
-
You must have a USER storage location or superuser privileges.
-
You cannot override the permissions mode of 700 for directories and 600 for files.
Exports to object-store file systems are not atomic. Be careful to wait for the export to finish before using the data. For details, see Exporting to object stores.
Examples
The following example exports uncompressed comma-separated values (CSV) with a header row in each file:
=> EXPORT TO DELIMITED(directory='webhdfs:///user1/data', delimiter=',', addHeader='true')
AS SELECT * FROM public.sales;
7.21 - EXPORT TO JSON
Exports a table, columns from a table, or query results to JSON files.
Exports a table, columns from a table, or query results to JSON files. The files can be read back into Vertica using FJSONPARSER.
There are some limitations on the queries you can use in an export statement. See Query Restrictions.
You can export data stored in Vertica in ROS format and data from external tables.
File exporters are UDxs that cannot be run in fenced mode. If the ForceUDxFencedMode configuration parameter is set to true to support other UDxs, you can set it to false at the session level before performing the export.
This statement returns the number of rows written and logs information about exported files in a system table. See Monitoring exports.
During an export to HDFS or an NFS mount point, Vertica writes files to a temporary directory in the same location as the destination and renames the directory when the export is complete. Do not attempt to use the files in the temporary directory. During an export to S3, GCS, or Azure, Vertica writes files directly to the destination path, so you must wait for the export to finish before reading the files. For more information, see Exporting to object stores.
Syntax
EXPORT [ /*+LABEL (label)*/ ] TO JSON
( directory='path'[, param=value[,...] ] )
[ OVER (over-clause ) ] AS SELECT query-expression
Arguments
-
LABEL
- Assigns a label to a statement to identify it for profiling and debugging.
over-clause- Specifies how to partition table data using PARTITION BY. Within partitions you can sort using ORDER BY. See SQL analytics. This clause may contain column references but not expressions.
If you partition data, Vertica creates a partition directory structure, transforming column names to lowercase. See Partitioned data for a description of the directory structure. If you use the fileName parameter, you cannot use partitioning.
If you omit this clause, Vertica optimizes for maximum parallelism.
query-expression- Specifies the data to export. See Query Restrictions for important limitations.
Parameters
directoryThe destination directory for the output files. The current user must have permission to write it. The destination can be on any of the following file systems:
See also: ifDirExists.
ifDirExistsWhat to do if directory already exists, one of:
-
fail (default)
-
overwrite: replace the entire directory
-
append: export new files into the existing directory with a prepended hash that identifies all files in the exported batch
-
appendNoHash: export new files into the existing directory without a prepended hash; with this option, Vertica cannot clean up partial exports
If you specify overwrite for an export to an object store, the existing directory is deleted recursively at the beginning of the operation and is not restored if the operation fails. Be careful not to export to a directory containing data you want to keep. For an export to a Linux file system or HDFS, the directory is only overwritten if the export succeeds.
Do not do concurrent exports to the same directory. In particular, if you do so with a value of overwrite, all operations appear to succeed, but the results are incorrect.
When using append, be careful to use the same table schema. Otherwise, queries of external tables using this data path could fail.
filenameIf specified, all output is written to a single file of this name in the location specified by directory. While the query can be processed by multiple nodes, only a single node generates the output data. The fileSizeMB parameter is ignored, and the query cannot use partitioning in the OVER() clause.
filePrefixPrefix to use for exported files instead of the default hash. If used with ifDirExists=appendNoHash, choose a unique prefix to avoid overwriting existing files.
omitNullFields- Boolean, whether to omit ROW fields with null values.
Default: false
compression- Compression type, one of:
Default: Uncompressed
fileSizeMBThe maximum file size of a single output file. This value is a hint, not a hard limit. A value of 0 specifies no limit. If filename is also specified, fileSizeMB is ignored.
This value affects the size of individual output files, not the total output size. For smaller values, Vertica divides the output into more files; all data is still exported.
Default: 10GB
fileModeFor writes to HDFS only, permission to apply to all exported files. You can specify the value in Unix octal format (such as 665) or user-group-other format—for example, rwxr-xr-x. The value must be formatted as a string even if using the octal format.
Valid octal values range between 0 and 1777, inclusive. See HDFS Permissions in the Apache Hadoop documentation.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 660, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
dirModeFor writes to HDFS only, permission to apply to all exported directories. Values follow the same rules as those for fileMode. Further, you must give the Vertica HDFS user full permission, at least rwx------ or 700.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 755, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
Privileges
Non-superusers:
Query restrictions
You must provide an alias column label for selected column targets that are expressions.
If you partition the output, you cannot specify schema and table names in the SELECT statement. Specify only the column name.
The query can contain only a single outer SELECT statement. For example, you cannot use UNION:
=> EXPORT TO JSON(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash;
ERROR 8975: Only a single outer SELECT statement is supported
HINT: Please use a subquery for multiple outer SELECT statements
Instead, rewrite the query to use a subquery:
=> EXPORT TO JSON(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT
account_id,
json
FROM
(
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash
) a;
Rows Exported
---------------
2
(1 row)
To use composite statements such as UNION, INTERSECT, and EXCEPT, rewrite them as subqueries.
Data types
EXPORT TO JSON can export ARRAY and ROW types in any combination.
EXPORT TO JSON does not support binary output (VARBINARY).
Output
The export operation always creates (or appends to) an output directory, even if all output is written to a single file or the query produces zero rows.
By default, output file names follow the pattern: prefix-nodename-threadId[-sequenceNumber].extension. prefix is typically an 8-character hash, but can be longer if the export appended to an existing directory. A sequence number is added if an export needs to be broken into pieces to satisfy fileSizeMB. You can change the prefix using the filePrefix parameter or, for appends, by setting ifDirExists=appendNoHash. You can write all output to a single named file using the filename parameter.
Column names in partition directories are lowercase.
Files exported to a local file system by any Vertica user are owned by the Vertica superuser. Files exported to HDFS or object stores are owned by the Vertica user who exported the data.
Making concurrent exports to the same output destination is an error and can produce incorrect results.
Exports to the local file system can be to an NFS mount (shared) or to the Linux file system on each node (non-shared). For details, see Exporting to the Linux file system. Exports to non-shared local file systems have the following restrictions:
-
The output directory must not exist on any node.
-
You must have a USER storage location or superuser privileges.
-
You cannot override the permissions mode of 700 for directories and 600 for files.
Exports to object-store file systems are not atomic. Be careful to wait for the export to finish before using the data. For details, see Exporting to object stores.
Examples
In the following example, one of the ROW elements has a null value, which is omitted in the output. EXPORT TO JSON writes each JSON record on one line; line breaks have been inserted into the following output for readability:
=> SELECT name, menu FROM restaurants;
name | menu
-------------------+------------------------------------------------------------
------------------
Bob's pizzeria | [{"item":"cheese pizza","price":null},{"item":"spinach pizza","price":10.5}]
Bakersfield Tacos | [{"item":"veggie taco","price":9.95},{"item":"steak taco","price":10.95}]
(2 rows)
=> EXPORT TO JSON (directory='/output/json', omitNullFields=true)
AS SELECT * FROM restaurants;
Rows Exported
---------------
2
(1 row)
=> \! cat /output/json/*.json
{"name":"Bob's pizzeria","cuisine":"Italian","location_city":["Cambridge","Pittsburgh"],
"menu":[{"item":"cheese pizza"},{"item":"spinach pizza","price":10.5}]}
{"name":"Bakersfield Tacos","cuisine":"Mexican","location_city":["Pittsburgh"],
"menu":[{"item":"veggie taco","price":9.95},{"item":"steak taco","price":10.95}]}
7.22 - EXPORT TO ORC
Exports a table, columns from a table, or query results to files in the ORC format.
Exports a table, columns from a table, or query results to files in the ORC format.
You can use an OVER() clause to partition the data before export. You can partition data instead of or in addition to exporting the column data. Partitioning data can improve query performance by enabling partition pruning. See Partitioned data.
There are some limitations on the queries you can use in an export statement. See Query Restrictions.
You can export data stored in Vertica in ROS format and data from external tables.
File exporters are UDxs that cannot be run in fenced mode. If the ForceUDxFencedMode configuration parameter is set to true to support other UDxs, you can set it to false at the session level before performing the export.
This statement returns the number of rows written and logs information about exported files in a system table. See Monitoring exports.
During an export to HDFS or an NFS mount point, Vertica writes files to a temporary directory in the same location as the destination and renames the directory when the export is complete. Do not attempt to use the files in the temporary directory. During an export to S3, GCS, or Azure, Vertica writes files directly to the destination path, so you must wait for the export to finish before reading the files. For more information, see Exporting to object stores.
Syntax
EXPORT [ /*+LABEL (label-string)*/ ] TO ORC
( directory='path'[, param=value[,...] ] )
[ OVER (over-clause ) ] AS SELECT query-expression
Arguments
-
LABEL
- Assigns a label to a statement to identify it for profiling and debugging.
over-clause- Specifies how to partition table data using PARTITION BY. Within partitions you can sort using ORDER BY. See SQL analytics. This clause may contain column references but not expressions.
If you partition data, Vertica creates a partition directory structure, transforming column names to lowercase. See Partitioned data for a description of the directory structure. If you use the fileName parameter, you cannot use partitioning.
If you omit this clause, Vertica optimizes for maximum parallelism.
query-expression- Specifies the data to export. See Query Restrictions for important limitations.
Parameters
directoryThe destination directory for the output files. The current user must have permission to write it. The destination can be on any of the following file systems:
See also: ifDirExists.
ifDirExistsWhat to do if directory already exists, one of:
-
fail (default)
-
overwrite: replace the entire directory
-
append: export new files into the existing directory with a prepended hash that identifies all files in the exported batch
-
appendNoHash: export new files into the existing directory without a prepended hash; with this option, Vertica cannot clean up partial exports
If you specify overwrite for an export to an object store, the existing directory is deleted recursively at the beginning of the operation and is not restored if the operation fails. Be careful not to export to a directory containing data you want to keep. For an export to a Linux file system or HDFS, the directory is only overwritten if the export succeeds.
Do not do concurrent exports to the same directory. In particular, if you do so with a value of overwrite, all operations appear to succeed, but the results are incorrect.
When using append, be careful to use the same table schema. Otherwise, queries of external tables using this data path could fail.
filenameIf specified, all output is written to a single file of this name in the location specified by directory. While the query can be processed by multiple nodes, only a single node generates the output data. The fileSizeMB parameter is ignored, and the query cannot use partitioning in the OVER() clause.
filePrefixPrefix to use for exported files instead of the default hash. If used with ifDirExists=appendNoHash, choose a unique prefix to avoid overwriting existing files.
compression- Column compression type, one of:
Default: Zlib
stripeSizeMB- The uncompressed size of exported stripes in MB, an integer value between 1 and 1024, inclusive.
Default: 250
rowIndexStride- Integer that specifies how frequently the exporter builds indexing statistics in the output, between 1 and 1000000 (1 million), inclusive. A value of 0 disables indexing. The exporter builds statistics after every
rowIndexStride rows in each stripe, or once for stripes < rowIndexStride.
Default: 1000
fileSizeMBThe maximum file size of a single output file. This value is a hint, not a hard limit. A value of 0 specifies no limit. If filename is also specified, fileSizeMB is ignored.
This value affects the size of individual output files, not the total output size. For smaller values, Vertica divides the output into more files; all data is still exported.
Default: 10GB
fileModeFor writes to HDFS only, permission to apply to all exported files. You can specify the value in Unix octal format (such as 665) or user-group-other format—for example, rwxr-xr-x. The value must be formatted as a string even if using the octal format.
Valid octal values range between 0 and 1777, inclusive. See HDFS Permissions in the Apache Hadoop documentation.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 660, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
dirModeFor writes to HDFS only, permission to apply to all exported directories. Values follow the same rules as those for fileMode. Further, you must give the Vertica HDFS user full permission, at least rwx------ or 700.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 755, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
Privileges
Non-superusers:
Query restrictions
You must provide an alias column label for selected column targets that are expressions.
If you partition the output, you cannot specify schema and table names in the SELECT statement. Specify only the column name.
The query can contain only a single outer SELECT statement. For example, you cannot use UNION:
=> EXPORT TO ORC(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash;
ERROR 8975: Only a single outer SELECT statement is supported
HINT: Please use a subquery for multiple outer SELECT statements
Instead, rewrite the query to use a subquery:
=> EXPORT TO ORC(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT
account_id,
json
FROM
(
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash
) a;
Rows Exported
---------------
2
(1 row)
To use composite statements such as UNION, INTERSECT, and EXCEPT, rewrite them as subqueries.
Data types
EXPORT TO ORC converts Vertica data types to Hive data types as shown in the following table.
|
Vertica Data Type |
Hive Data Type |
|
INTEGER, BIGINT |
BIGINT |
|
FLOAT, DECIMAL, SMALLINT, TINYINT, CHAR, BOOLEAN |
Corresponding Hive type |
|
VARCHAR, LONG VARCHAR |
VARCHAR (max 64KB) or STRING (can be read as either) |
|
BINARY, VARBINARY, LONG VARBINARY |
BINARY |
|
DATE |
DATE if supported by your version of Hive, otherwise INT96 (can be read as TIMESTAMP) |
|
TIMESTAMP, TIMESTAMPTZ |
TIMESTAMP. Vertica does not convert TIMESTAMP values to UTC. To avoid problems arising from time zones, use TIMESTAMPTZ instead of TIMESTAMP. |
|
TIME, TIMEZ, INTERVAL, UUID |
Not supported |
|
ARRAY, SET |
Not supported |
|
ROW |
Not supported |
Decimal precision must be <= 38.
The exported Hive types might not be identical to the Vertica types. For example, a Vertica INT is exported as a Hive BIGINT. When defining Hive external tables to read exported data, you might have to adjust column definitions.
This operation exports raw Flex columns as binary data.
Output
The export operation always creates (or appends to) an output directory, even if all output is written to a single file or the query produces zero rows.
By default, output file names follow the pattern: prefix-nodename-threadId[-sequenceNumber].extension. prefix is typically an 8-character hash, but can be longer if the export appended to an existing directory. A sequence number is added if an export needs to be broken into pieces to satisfy fileSizeMB. You can change the prefix using the filePrefix parameter or, for appends, by setting ifDirExists=appendNoHash. You can write all output to a single named file using the filename parameter.
Column names in partition directories are lowercase.
Files exported to a local file system by any Vertica user are owned by the Vertica superuser. Files exported to HDFS or object stores are owned by the Vertica user who exported the data.
Making concurrent exports to the same output destination is an error and can produce incorrect results.
Exports to the local file system can be to an NFS mount (shared) or to the Linux file system on each node (non-shared). For details, see Exporting to the Linux file system. Exports to non-shared local file systems have the following restrictions:
-
The output directory must not exist on any node.
-
You must have a USER storage location or superuser privileges.
-
You cannot override the permissions mode of 700 for directories and 600 for files.
Exports to object-store file systems are not atomic. Be careful to wait for the export to finish before using the data. For details, see Exporting to object stores.
Examples
The following example demonstrates partitioning and exporting data. EXPORT TO ORC first partitions the data on region and then, within each partition, sorts by store.
=> EXPORT TO ORC(directory='gs://DataLake/user2/data')
OVER(PARTITION BY store.region ORDER BY store.ID)
AS SELECT sale.price, sale.date, store.ID
FROM public.sales sale
JOIN public.vendor store ON sale.distribID = store.ID;
For more examples, see EXPORT TO PARQUET, which (aside from a few parameters) behaves the same as EXPORT TO ORC.
7.23 - EXPORT TO PARQUET
Exports a table, columns from a table, or query results to files in the Parquet format.
Exports a table, columns from a table, or query results to files in the Parquet format.
You can use an OVER() clause to partition the data before export. You can partition data instead of or in addition to exporting the column data. Partitioning data can improve query performance by enabling partition pruning. See Partitioned data.
There are some limitations on the queries you can use in an export statement. See Query Restrictions.
You can export data stored in Vertica in ROS format and data from external tables.
File exporters are UDxs that cannot be run in fenced mode. If the ForceUDxFencedMode configuration parameter is set to true to support other UDxs, you can set it to false at the session level before performing the export.
This statement returns the number of rows written and logs information about exported files in a system table. See Monitoring exports.
During an export to HDFS or an NFS mount point, Vertica writes files to a temporary directory in the same location as the destination and renames the directory when the export is complete. Do not attempt to use the files in the temporary directory. During an export to S3, GCS, or Azure, Vertica writes files directly to the destination path, so you must wait for the export to finish before reading the files. For more information, see Exporting to object stores.
After you export data, you can use the GET_METADATA function to inspect the results.
Syntax
EXPORT [ /*+LABEL (label-string)*/ ] TO PARQUET
( directory='path'[, param=value[,...] ] )
[ OVER (over-clause ) ] AS SELECT query-expression
Arguments
-
LABEL
- Assigns a label to a statement to identify it for profiling and debugging.
over-clause- Specifies how to partition table data using PARTITION BY. Within partitions you can sort using ORDER BY. See SQL analytics. This clause may contain column references but not expressions.
If you partition data, Vertica creates a partition directory structure, transforming column names to lowercase. See Partitioned data for a description of the directory structure. If you use the fileName parameter, you cannot use partitioning.
If you omit this clause, Vertica optimizes for maximum parallelism.
query-expression- Specifies the data to export. See Query Restrictions for important limitations.
Parameters
directoryThe destination directory for the output files. The current user must have permission to write it. The destination can be on any of the following file systems:
See also: ifDirExists.
ifDirExistsWhat to do if directory already exists, one of:
-
fail (default)
-
overwrite: replace the entire directory
-
append: export new files into the existing directory with a prepended hash that identifies all files in the exported batch
-
appendNoHash: export new files into the existing directory without a prepended hash; with this option, Vertica cannot clean up partial exports
If you specify overwrite for an export to an object store, the existing directory is deleted recursively at the beginning of the operation and is not restored if the operation fails. Be careful not to export to a directory containing data you want to keep. For an export to a Linux file system or HDFS, the directory is only overwritten if the export succeeds.
Do not do concurrent exports to the same directory. In particular, if you do so with a value of overwrite, all operations appear to succeed, but the results are incorrect.
When using append, be careful to use the same table schema. Otherwise, queries of external tables using this data path could fail.
filenameIf specified, all output is written to a single file of this name in the location specified by directory. While the query can be processed by multiple nodes, only a single node generates the output data. The fileSizeMB parameter is ignored, and the query cannot use partitioning in the OVER() clause.
filePrefixPrefix to use for exported files instead of the default hash. If used with ifDirExists=appendNoHash, choose a unique prefix to avoid overwriting existing files.
compression- Column compression type, one of:
-
Snappy
-
GZIP
-
Brotli
-
ZSTD
-
Uncompressed
Default: Snappy
rowGroupSizeMB- The uncompressed size of exported row groups, in MB, an integer value between 1 and
fileSizeMB , inclusive, or unlimited if fileSizeMB is 0.
The row groups in the exported files are smaller than this value because Parquet files are compressed on write. For best performance when exporting to HDFS, set size to be smaller than the HDFS block size.
Row-group size affects memory consumption during export. An export thread consumes at least double the row-group size. The default value of 512MB is a compromise between writing larger row groups and allowing enough free memory for other Vertica operations. If you perform exports when the database is not otherwise under heavy load, you can improve read performance on the exported data by increasing row-group size on export. However, row groups that span multiple blocks on HDFS decrease read performance by requiring more I/O, so do not set the row-group size to be larger than your HDFS block size.
Default: 512
fileSizeMBThe maximum file size of a single output file. This value is a hint, not a hard limit. A value of 0 specifies no limit. If filename is also specified, fileSizeMB is ignored.
This value affects the size of individual output files, not the total output size. For smaller values, Vertica divides the output into more files; all data is still exported.
Default: 10GB
fileModeFor writes to HDFS only, permission to apply to all exported files. You can specify the value in Unix octal format (such as 665) or user-group-other format—for example, rwxr-xr-x. The value must be formatted as a string even if using the octal format.
Valid octal values range between 0 and 1777, inclusive. See HDFS Permissions in the Apache Hadoop documentation.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 660, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
dirModeFor writes to HDFS only, permission to apply to all exported directories. Values follow the same rules as those for fileMode. Further, you must give the Vertica HDFS user full permission, at least rwx------ or 700.
When writing files to any destination other than HDFS, this parameter has no effect.
Default: 755, regardless of the value of fs.permissions.umask-mode in hdfs-site.xml.
int96AsTimestamp- Boolean, specifies whether to export timestamps as int96 physical type (true) or int64 physical type (false).
Default: true
Privileges
Non-superusers:
Query restrictions
You must provide an alias column label for selected column targets that are expressions.
If you partition the output, you cannot specify schema and table names in the SELECT statement. Specify only the column name.
The query can contain only a single outer SELECT statement. For example, you cannot use UNION:
=> EXPORT TO PARQUET(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash;
ERROR 8975: Only a single outer SELECT statement is supported
HINT: Please use a subquery for multiple outer SELECT statements
Instead, rewrite the query to use a subquery:
=> EXPORT TO PARQUET(directory = '/mnt/shared_nfs/accounts/rm')
OVER(PARTITION BY hash)
AS
SELECT
account_id,
json
FROM
(
SELECT 1 as account_id, '{}' as json, 0 hash
UNION ALL
SELECT 2 as account_id, '{}' as json, 1 hash
) a;
Rows Exported
---------------
2
(1 row)
To use composite statements such as UNION, INTERSECT, and EXCEPT, rewrite them as subqueries.
Data types
EXPORT TO PARQUET converts Vertica data types to Hive data types as shown in the following table.
|
Vertica Data Type |
Hive Data Type |
|
INTEGER, BIGINT |
BIGINT |
|
FLOAT, DECIMAL, SMALLINT, TINYINT, CHAR, BOOLEAN |
Corresponding Hive type |
|
VARCHAR, LONG VARCHAR |
VARCHAR (max 64KB) or STRING (can be read as either) |
|
BINARY, VARBINARY, LONG VARBINARY |
BINARY |
|
DATE |
DATE if supported by your version of Hive, otherwise INT96 (can be read as TIMESTAMP) |
|
TIMESTAMP, TIMESTAMPTZ |
TIMESTAMP. Vertica does not convert TIMESTAMP values to UTC. To avoid problems arising from time zones, use TIMESTAMPTZ instead of TIMESTAMP. |
|
TIME, TIMEZ, INTERVAL |
Not supported |
|
ARRAY |
ARRAY |
|
SET |
Not supported |
|
ROW |
STRUCT |
Decimal precision must be <= 38.
The exported Hive types might not be identical to the Vertica types. For example, a Vertica INT is exported as a Hive BIGINT. When defining Hive external tables to read exported data, you might have to adjust column definitions.
This operation exports raw Flex columns as binary data.
Output
The export operation always creates (or appends to) an output directory, even if all output is written to a single file or the query produces zero rows.
By default, output file names follow the pattern: prefix-nodename-threadId[-sequenceNumber].extension. prefix is typically an 8-character hash, but can be longer if the export appended to an existing directory. A sequence number is added if an export needs to be broken into pieces to satisfy fileSizeMB. You can change the prefix using the filePrefix parameter or, for appends, by setting ifDirExists=appendNoHash. You can write all output to a single named file using the filename parameter.
Column names in partition directories are lowercase.
Files exported to a local file system by any Vertica user are owned by the Vertica superuser. Files exported to HDFS or object stores are owned by the Vertica user who exported the data.
Making concurrent exports to the same output destination is an error and can produce incorrect results.
Exports to the local file system can be to an NFS mount (shared) or to the Linux file system on each node (non-shared). For details, see Exporting to the Linux file system. Exports to non-shared local file systems have the following restrictions:
-
The output directory must not exist on any node.
-
You must have a USER storage location or superuser privileges.
-
You cannot override the permissions mode of 700 for directories and 600 for files.
Exports to object-store file systems are not atomic. Be careful to wait for the export to finish before using the data. For details, see Exporting to object stores.
Examples
The following example demonstrates exporting all columns from theT1 table in the public schema, using GZIP compression.
=> EXPORT TO PARQUET(directory='webhdfs:///user1/data', compression='gzip')
AS SELECT * FROM public.T1;
The following example demonstrates exporting the results of a query using more than one table.
=> EXPORT TO PARQUET(directory='s3://DataLake/sales_by_region')
AS SELECT sale.price, sale.date, store.region
FROM public.sales sale
JOIN public.vendor store ON sale.distribID = store.ID;
The following example demonstrates partitioning and exporting data. EXPORT TO PARQUET first partitions the data on region and then, within each partition, sorts by store.
=> EXPORT TO PARQUET(directory='gs://DataLake/user2/data')
OVER(PARTITION BY store.region ORDER BY store.ID)
AS SELECT sale.price, sale.date, store.ID
FROM public.sales sale
JOIN public.vendor store ON sale.distribID = store.ID;
The following example uses an alias column label for a selected column target that is an expression.
=> EXPORT TO PARQUET(directory='webhdfs:///user3/data')
OVER(ORDER BY col1) AS SELECT col1 + col1 AS A, col2
FROM public.T3;
The following example sets permissions for the output.
=> EXPORT TO PARQUET(directory='webhdfs:///user1/data',
fileMode='432', dirMode='rwxrw-r-x')
AS SELECT * FROM public.T1;
7.24 - EXPORT TO VERTICA
Exports table data from one Vertica database to another.
Exports table data from one Vertica database to another. A connection to the target database must exist in the current session before starting the copy operation. Otherwise, Vertica returns an error. For details, see CONNECT TO VERTICA.
Important
The source database must be no more than one major release behind the target database.
Syntax
EXPORT [ /*+LABEL (label-string)*/ ] TO VERTICA
{ database. | [namespace.] }[schema.]target-table [ ( target-columns ) ]
{ AS SELECT query-expression | FROM [schema.]source-table[ ( source-columns ) ] }
Arguments
-
LABEL
Assigns a label to a statement to identify it for profiling and debugging.
namespace- For Eon Mode databases, namespace in the target database to which data is exported. If unspecified, the target namespace is set to
default_namespace.
database- For Enterprise Mode databases, the target database to which data is exported. A connection to this database must already exist in the current session before starting the copy operation; otherwise Vertica returns an error. For details, see CONNECT TO VERTICA.
target-table- The table in the target database to store the exported data. The table cannot have columns of complex data types other than native arrays.
target-columns- A comma-delimited list of columns in
target-table in which to store the exported data.See Mapping Between Source and Target Columns, below.
query-expression- The data to export.
[namespace.][schema.]source-table- The table in the source database that contains the data to export. The namespace option only applies to Eon Mode databases. If no namespace is specified, Vertica assumes the table belongs to the
default_namespace.
source-columns- A comma-delimited list of the columns in the source table to export. The table cannot have columns of complex data types.See Mapping Between Source and Target Columns, below.
Privileges
Non-superusers:
Mapping between source and target columns
If you export all table data from one database to another, EXPORT TO VERTICA can omit specifying column lists if column definitions in both tables comply with the following conditions:
-
Same number of columns
-
Identical column names
-
Same sequence of columns
-
Matching or compatible column data types
-
No complex data types (ARRAY, SET, or ROW), except for native arrays
If any of these conditions is not true, the EXPORT TO VERTICA statement must include column lists that explicitly map source and target columns to each other, as follows:
-
Contain the same number of columns.
-
List source and target columns in the same order.
-
Pair columns with the same (or compatible) data types.
Examples
See Exporting data to another database.
See also
7.25 - GET DIRECTED QUERY
Queries system table DIRECTED_QUERIES on the specified input query, and returns details of all directed queries that map to the input query.
Queries the DIRECTED_QUERIES system table on the specified input query, and returns details of all directed queries that map to the input query. For details about output, see Managing directed queries.
Syntax
GET DIRECTED QUERY input-query
Arguments
input-query- An input query that is associated with one or more directed queries.
Privileges
None
Examples
See Managing directed queries.
7.26 - GRANT statements
GRANT statements grant privileges on database objects to users and roles.
GRANT statements grant privileges on database objects to users and roles.
Important
In a database with trust authentication, GRANT statements appear to work as expected but have no real effect on database security.
7.26.1 - GRANT (authentication)
Associates an authentication record to one or more users and roles.
Associates an authentication record to one or more users and roles.
Syntax
GRANT AUTHENTICATION auth-method-name TO grantee[,...]
Parameters
auth-method-name- Name of the authentication method to associate with one or more users or roles.
grantee- Specifies who is associated with the authentication method, one of the following:
Privileges
Superuser
Examples
-
Associate v_ldap authentication with user jsmith:
=> GRANT AUTHENTICATION v_ldap TO jsmith;
-
Associate v_gss authentication to the role DBprogrammer:
=> CREATE ROLE DBprogrammer;
=> GRANT AUTHENTICATION v_gss TO DBprogrammer;
-
Associate client authentication method v_localpwd with role PUBLIC, which is assigned by default to all users:
=> GRANT AUTHENTICATION v_localpwd TO PUBLIC;
See also
7.26.2 - GRANT (data loader)
Grants data-loader privileges to users and roles.
Grants privileges on automatic data loaders to users and roles. By default, only superusers and the owner can execute or alter a data loader.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] }
ON DATA LOADER [schema.]name
TO grantee[,...]
[ WITH GRANT OPTION ]
Arguments
privilege- One of the following privileges:
ALL [PRIVILEGES]- Grants all privileges. Inherited privileges must be granted explicitly.
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers, one of the following:
See also
7.26.3 - GRANT (database)
Grants database privileges to users and roles.
Grants database privileges to users and roles.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] }
ON DATABASE db-spec
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- The following privileges are valid for a database:
ALL [PRIVILEGES]- Grants all database privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
db-specSpecifies the current database, set to the database name or DEFAULT.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser: Privileges grantee given the option (WITH GRANT OPTION) of granting privileges to other users or roles.
Examples
The following example grants user Fred the right to create schemas in the current database.
=> GRANT CREATE ON DATABASE DEFAULT TO Fred;
See also
7.26.4 - GRANT (key)
Grants privileges on a cryptographic key to a user or role.
Grants privileges on a cryptographic key to a user or role.
Important
Because certificates depend on their underlying key, DROP privileges on a key effectively act as DROP privileges on its associated certificate when used with
DROP KEY...CASCADE.
To revoke granted privileges, see REVOKE (key).
Superusers have limited access to cryptographic objects that they do not own. For details, see Database object privileges.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] } ON KEY
key_name[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilegeA privilege, one of the following:
-
USAGE: Allows a user to perform the following actions:
USAGE on the key also gives implicit USAGE privileges on a certificate that uses it as its private key. Users can also get these privileges from ownership of the key or certificate. USAGE privileges on a certificate allow a user to perform the following actions:
-
View the contents of the certificate.
-
Add (with CREATE or ALTER) the certificate to a TLS Configuration.
-
Reuse the CA certificate when importing certificates signed by it. For example, if a user imports a chain of certificates A > B > C and have USAGE on B, the database reuses B (as opposed to creating a duplicate of B).
-
Specify that the CA certificate signed an imported certificate. For example, if certificate B signed certificate C, USAGE on B allows a user to import C and specify that it was SIGNED BY B.
-
DROP
-
ALTER: Allows a user to see the key and its associated certificates in their respective system tables, but not their contents.
key_name- The target key.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser:
Examples
The following example grants USAGE privileges on a private key to a user, which then allows the user to add the self-signed CA certificate to the server TLS Configuration:
=> CREATE KEY new_ca_key TYPE 'RSA' LENGTH 2048;
=> CREATE CA CERTIFICATE new_ca_cert
SUBJECT '/C=US/ST=Massachusetts/L=Cambridge/O=Micro Focus/OU=Vertica/CN=Vertica example CA'
VALID FOR 3650
EXTENSIONS 'authorityKeyIdentifier' = 'keyid:always,issuer', 'nsComment' = 'new CA'
KEY new_ca_key;
=> CREATE USER u1;
=> GRANT USAGE ON KEY new_ca_key TO u1;
=> GRANT ALTER ON TLS CONFIGURATION data_channel TO u1;
=> \c - u1
=> ALTER TLS CONFIGURATION data_channel ADD CA CERTIFICATES new_ca_cert;
-- clean up:
=> \c
=> ALTER TLS CONFIGURATION data_channel REMOVE CA CERTIFICATES new_ca_cert;
=> DROP KEY new_ca_key CASCADE;
=> DROP USER u1;
7.26.5 - GRANT (library)
Grants privileges on one or more libraries to users and roles.
Grants privileges on one or more libraries to users and roles.
For example, when working with the Connector Framework Service, you might need to grant a user usage privileges to a library to be able to set UDSession parameters. For more information see Implementing CFS.
Syntax
GRANT privilege
ON LIBRARY [[database.]schema.]library[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Arguments
privilege- Privilege to grant, one of:
-
USAGE: Grants access to functions in the specified libraries.
-
DROP: Grants permission to drop libraries that the grantee created.
-
ALL [PRIVILEGES] [EXTEND]: Grants all library privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include DROP privileges. An unqualified ALL excludes this privilege. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
Important
To execute functions inside the library, users must also have separate EXECUTE privileges on them, and USAGE privileges on their respective schemas.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
library- The target library.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
Grant USAGE privileges on the MyFunctions library to Fred:
=> GRANT USAGE ON LIBRARY MyFunctions TO Fred;
See also
7.26.6 - GRANT (model)
Grants usage privileges on a model to users and roles.
Grants usage privileges on a model to users and roles.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON MODEL [[database.]schema.]model-name[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- The following privileges are valid for models:
ALL [PRIVILEGES][EXTEND]- Grants all model privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
model-name- The model on which to grant the privilege.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
This example grants USAGE privileges on the mySvmClassModel model to user1:
=> GRANT USAGE ON MODEL mySvmClassModel TO user1;
See also
7.26.7 - GRANT (procedure)
Grants privileges on a stored procedure or external procedure to a user or role.
Grants privileges on a stored procedure or external procedure to a user or role.
Important
External procedures that you create with
CREATE PROCEDURE (external) are always run with Linux dbadmin privileges. If a dbadmin or pseudosuperuser grants a non-dbadmin permission to run a procedure using
GRANT (procedure), be aware that the non-dbadmin user runs the procedure with full Linux dbadmin privileges.
Syntax
GRANT { EXECUTE | ALL [ PRIVILEGES ] }
ON PROCEDURE [[database.]schema.]procedure( [arg-list] )[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
EXECUTE- Enables grantees to run the specified
procedure.
ALL [PRIVILEGES]- Grants all procedure privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
procedure- The target procedure.
arg-list- A comma-delimited list of procedure arguments, where each argument is specified as follows:
[ argname ] argtype
If the procedure is defined with no arguments, supply an empty argument list.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser, one of the following:
Examples
Grant EXECUTE privileges on the tokenize procedure to users Bob and Jules, and to the role Operator:
=> GRANT EXECUTE ON PROCEDURE tokenize(varchar) TO Bob, Jules, Operator;
See also
7.26.8 - GRANT (Resource pool)
Grants USAGE privileges on resource pools to users and roles.
Grants USAGE privileges on resource pools to users and roles. Users can access their resource pools with ALTER USER or SET SESSION RESOURCE POOL.
Syntax
GRANT USAGE
ON RESOURCE POOL resource-pool[,...]
[FOR SUBCLUSTER subcluster | FOR CURRENT SUBCLUSTER]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
USAGE- Enables grantees to acess the specified resource pools.
ALL [PRIVILEGES]- Grants all resource pool privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
resource-pool- A resource pool on which to grant the specified privileges.
subcluster- The subcluster for the resource pool.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser, one of the following:
Examples
Grant user Joe USAGE privileges on resource pool Joe_pool.
=> CREATE USER Joe;
CREATE USER
=> CREATE RESOURCE POOL Joe_pool;
CREATE RESOURCE POOL
=> GRANT USAGE ON RESOURCE POOL Joe_pool TO Joe;
GRANT PRIVILEGE
Grant user Joe USAGE privileges on resource pool Joe_pool for subcluster sub1.
=> GRANT USAGE on RESOURCE POOL Joe_pool FOR SUBCLUSTER sub1 TO Joe;
GRANT PRIVILEGE
See also
7.26.9 - GRANT (Role)
Assigns roles to users or other roles.
Assigns roles to users or other roles.
Note
Granting a role does not activate the role automatically; you must
enable it with the
SET ROLE statement or specify it as a default role to enable it automatically.
Syntax
GRANT role[,...] TO grantee[,...] [ WITH ADMIN OPTION ]
Arguments
role- A role to grant
grantee- User or role to be granted the specified roles, one of the following:
WITH ADMIN OPTION- Gives
grantee the privilege to grant the specified roles to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser: If WITH GRANT OPTION is used, can grant the same roles to other users or roles.
Examples
See Granting database roles.
See also
REVOKE (Role)
7.26.10 - GRANT (schema)
Grants schema privileges to users and roles.
Grants schema privileges to users and roles. By default, only superusers and the schema owner have the following schema privileges:
Note
By default, new users cannot access schema PUBLIC. You must explicitly grant all new users USAGE privileges on the PUBLIC schema.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON SCHEMA [{namespace. | database. }]schema[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- One of the following privileges:
-
USAGE: Enables access to objects in the specified schemas. Grantees can then be granted privileges on individual objects in these schemas in order to access them, for example, with GRANT TABLE and GRANT VIEW.
-
CREATE: Create and rename objects in the specified schemas, and move objects from other schemas.
You can also grant the following privileges on a schema, to be inherited by tables and their projections, and by views of that schema. If inheritance is enabled for the database and schema, these privileges are automatically granted to those objects on creation:
-
SELECT: Query tables and views. SELECT privileges are granted by default to the PUBLIC role.
-
INSERT: Insert rows, or and load data into tables with
COPY.
Note
COPY FROM STDIN is allowed for users with INSERT privileges, while COPY FROM file requires admin privileges.
-
UPDATE: Update table rows.
-
DELETE: Delete table rows.
-
REFERENCES: Create foreign key constraints on this table. This privilege must be set on both referencing and referenced tables.
-
TRUNCATE: Truncate table contents. Non-owners of tables can also execute the following partition operations on them:
-
ALTER: Modify the DDL of tables and views with
ALTER TABLE and
ALTER VIEW, respectively.
-
DROP: Drop tables and views.
ALL [PRIVILEGES][EXTEND]- Grants USAGE AND CREATE privileges. Inherited privileges must be granted explicitly.
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
{ namespace. | database. }- Name of the database or namespace that contains
schema:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers, one of the following:
Examples
Grant user Joe USAGE privilege on schema online_sales.
=> CREATE USER Joe;
CREATE USER
=> GRANT USAGE ON SCHEMA online_sales TO Joe;
GRANT PRIVILEGE
See also
7.26.11 - GRANT (sequence)
Grants sequence privileges to users and roles.
Grants sequence privileges to users and roles.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON {
SEQUENCE [[database.]schema.]sequence[,...]
| ALL SEQUENCES IN SCHEMA [database.]schema[,...] }
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- The following privileges are valid for sequences:
ALL [PRIVILEGES][EXTEND]- Grants all sequence privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
SEQUENCE sequence- Specifies the sequence on which to grant privileges.
ALL SEQUENCES IN SCHEMA schema - Grants the specified privileges on all sequences in schema
schema.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
This example shows how to grant user Joe all privileges on sequence my_seq.
=> CREATE SEQUENCE my_seq START 100;
CREATE SEQUENCE
=> GRANT ALL PRIVILEGES ON SEQUENCE my_seq TO Joe;
GRANT PRIVILEGE
See also
7.26.12 - GRANT (storage location)
Grants privileges to users and roles on a USER-defined storage location.
Grants privileges to users and roles on a USER-defined storage location. For details, see Creating storage locations.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] }
ON LOCATION 'path' [ ON node ]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- The following privileges are valid for storage locations:
-
READ: Copy data from files in the storage location into a table.
-
WRITE: Export data from the database to the storage location. With WRITE privileges, grantees can also save COPY statement rejected data and exceptions files to the storage location.
ALL [PRIVILEGES]- Grants all storage location privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
ON LOCATION 'path' [ ON node]- Specifies the path name mount point of the storage location. If qualified by
ON NODE, Vertica grants access to the storage location residing on node.
If no node is specified, the grant operation applies to all nodes on the specified path. All nodes must be on the specified path; otherwise, the entire grant operation rolls back.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser, one of the following:
Note
Only a superuser can add, alter, retire, drop, and restore a location.
Examples
Create a storage location:
=> CREATE LOCATION '/home/dbadmin/UserStorage/BobStore' NODE 'v_mcdb_node0007' USAGE 'USER';
CREATE LOCATION
Grant user Bob all available privileges to the /BobStore location:
=> GRANT ALL ON LOCATION '/home/dbadmin/UserStorage/BobStore' TO Bob;
GRANT PRIVILEGE
Revoke all storage location privileges from Bob:
=> REVOKE ALL ON LOCATION '/home/dbadmin/UserStorage/BobStore' FROM Bob;
REVOKE PRIVILEGE
Grant privileges to Bob on the BobStore location again, specifying a node:
=> GRANT ALL ON LOCATION '/home/dbadmin/UserStorage/BobStore' ON v_mcdb_node0007 TO Bob;
GRANT PRIVILEGE
Revoke all storage location privileges from Bob:
=> REVOKE ALL ON LOCATION '/home/dbadmin/UserStorage/BobStore' ON v_mcdb_node0007 FROM Bob;
REVOKE PRIVILEGE
See also
7.26.13 - GRANT (table)
Grants table privileges to users and roles.
Grants table privileges to users and roles. Users must also be granted USAGE on the table schema.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON {
[ TABLE ] [[{namespace. | database. }]schema.]table[,...]
| ALL TABLES IN SCHEMA [{namespace. | database. }]schema[,...] }
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege- The following privileges are valid for tables:
Important
Only SELECT privileges are valid for system tables.
-
SELECT: Query tables. SELECT privileges are granted by default to the PUBLIC role.
-
INSERT: Insert table rows with INSERT, and load data with
COPY.
Note
COPY FROM STDIN is allowed for users with INSERT privileges, while COPY FROM file requires admin privileges.
-
UPDATE: Update table rows.
-
DELETE: Delete table rows.
-
REFERENCES: Create foreign key constraints on this table. This privilege must be set on both referencing and referenced tables.
-
TRUNCATE: Truncate table contents. Non-owners of tables can also execute the following partition operations on them:
-
ALTER: Modify a table's DDL with
ALTER TABLE.
-
DROP: Drop a table.
ALL [PRIVILEGES][EXTEND]- Invalid for system tables, grants all table privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
TABLE table- Specifies the table on which to grant privileges.
ON ALL TABLES IN SCHEMA schema - Grants the specified privileges on all tables and views in schema
schema.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
Grant user Joe all privileges on table customer_dimension:
=> CREATE USER Joe;
CREATE USER
=> GRANT ALL PRIVILEGES ON TABLE customer_dimension TO Joe;
GRANT PRIVILEGE
Grant user Joe SELECT privileges on all system tables:
=> GRANT SELECT on all tables in schema V_MONITOR, V_CATALOG TO Joe;
GRANT PRIVILEGE
See also
7.26.14 - GRANT (TLS configuration)
Grants privileges on a TLS Configuration to a user or role.
Grants privileges on a TLS Configuration to a user or role.
To revoke granted privileges, see REVOKE (TLS configuration).
Superusers have limited access to cryptographic objects that they do not own. For details, see Database object privileges.
Syntax
GRANT { privilege[,...] } ON TLS CONFIGURATION
tls_configuration[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilegeA privilege, one of the following:
tls_configuration- The target TLS Configuration.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superuser:
Examples
You can grant ALTER on a TLS Configuration to a user or role to delegate management of that TLS context, which includes adding and removing certificates, setting the TLSMODE, etc. For example, the following statement grants ALTER privileges on the TLS CONFIGURATION server to the role client_server_tls_manager:
=> GRANT ALTER ON TLS CONFIGURATION server TO client_server_tls_manager;
7.26.15 - GRANT (user defined extension)
Grants privileges on a user-defined extensions (UDx) to users and roles.
Grants privileges on a user-defined extensions (UDx) to users and roles.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON {
UDx-type [[database.]schema.]function( [arg-list] )[,...]
| ALL FUNCTIONS IN SCHEMA schema[,...] }
TO grantee[,...]
[ WITH GRANT OPTION ]
Arguments
privilege- The following privileges are valid for user-defined extensions:
Note
Users can only call a UDx function on which they have EXECUTE privilege, and USAGE privilege on its schema.
ALL [PRIVILEGES] [EXTEND]- Grants all function privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
ON UDx-type- Type of the user-defined extension (UDx), one of the following:
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function- Name of the user-defined function on which to grant privileges.
ON ALL FUNCTIONS IN SCHEMAschema- Grants privileges on all functions in the specified schema.
arg-list- Required for all polymorphic functions, a comma-delimited list of function arguments, where each argument is specified as follows:
[ argname ] argtype
If the procedure is defined with no arguments, supply an empty argument list.
granteeWho is granted privileges, one of the following:
Note
Grantees must have USAGE privileges on the schema.
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
Grant EXECUTE privileges on the myzeroifnull SQL function to users Bob and Jules, and to the role Operator. The function takes one integer argument:
=> GRANT EXECUTE ON FUNCTION myzeroifnull (x INT) TO Bob, Jules, Operator;
Grant EXECUTE privileges on all functions in the zero-schema schema to user Bob:
=> GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA zero-schema TO Bob;
Grant EXECUTE privileges on the tokenize transform function to user Bob and the role Operator:
=> GRANT EXECUTE ON TRANSFORM FUNCTION tokenize(VARCHAR) TO Bob, Operator;
Grant EXECUTE privileges on the ExampleSource() source to user Alice:
=> CREATE USER Alice;
=> GRANT USAGE ON SCHEMA hdfs TO Alice;
=> GRANT EXECUTE ON SOURCE ExampleSource() TO Alice;
Grant all privileges on the ExampleSource() source to user Alice:
=> GRANT ALL ON SOURCE ExampleSource() TO Alice;
Grant all privileges on polymorphic function Pagerank to the dbadmin role:
=> GRANT ALL ON TRANSFORM FUNCTION Pagerank(z varchar) to dbadmin;
See also
7.26.16 - GRANT (view)
Grants view privileges to users and roles.
Grants view privileges to users and roles.
Syntax
GRANT { privilege[,...] | ALL [ PRIVILEGES ] [ EXTEND ] }
ON [[database.]schema.]view[,...]
TO grantee[,...]
[ WITH GRANT OPTION ]
Parameters
privilege``- The following privileges are valid for views:
ALL [PRIVILEGES][EXTEND]- Grants all view privileges that also belong to the grantor. Grantors cannot grant privileges that they themselves lack.
You can qualify ALL with two optional keywords:
-
PRIVILEGES conforms with the SQL standard.
-
EXTEND extends the semantics of ALL to include ALTER and DROP privileges. An unqualified ALL excludes these two privileges. This option enables backward compatibility with GRANT ALL usage in pre-9.2.1 Vertica releases.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- The target view.
granteeWho is granted privileges, one of the following:
WITH GRANT OPTIONAllows the grantee to grant and revoke the same privileges to other users or roles. For details, see Granting privileges.
Privileges
Non-superusers require USAGE on the schema and one of the following:
Note
As view owner, you can grant other users SELECT privilege on the view only if one of the following is true:
Examples
Grant user Joe all privileges on view ship.
=> CREATE VIEW ship AS SELECT * FROM public.shipping_dimension;
CREATE VIEW
=> GRANT ALL PRIVILEGES ON ship TO Joe;
GRANT PRIVILEGE
See also
REVOKE (view)
7.26.17 - GRANT (workload)
Grants privileges to a role to use a workload, routing queries to its associated subclusters.
Grants privileges to a user or role to use a workload, routing its queries to its associated subclusters.
Syntax
GRANT USAGE ON WORKLOAD workload TO {role | user}
Parameters
workload- A workload defined by a routing rule. For details, see Workload routing.
user | role- The user or role permitted to use the workload.
Privileges
Superuser
Examples
The following example grants the USAGE privilege on the analytics workload to users with the analytics_role role:
=> GRANT USAGE ON WORKLOAD analytics TO analytics_role;
Similarly, this example grants the USAGE privilege on the analytics workload to the user jacob:
=> GRANT USAGE ON WORKLOAD analytics TO jacob;
For more examples, see Workload routing.
7.27 - INSERT
Inserts values into all projections of the specified table.
Inserts values into all projections of the specified table. You must insert one complete tuple at a time. If no projections are associated with the target table, Vertica creates a superprojection to store the inserted values.
INSERT works for flex tables as well as regular native tables. If the table has real columns, inserted data of scalar types and native arrays of scalar types is added to both the real column and the __raw__ column. For data of complex types, the values are not added to the __raw__ column.
Syntax
INSERT [ /*+LABEL (label-string)*/ ] INTO [[{namespace. | database. }]schema.]table-name
[ ( column-list ) ]
{ DEFAULT VALUES | VALUES ( values-list )[,...] | SELECT query-expression }
Arguments
-
LABEL
Assigns a label to a statement to identify it for profiling and debugging.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table-name- The target table. You cannot invoke INSERT on a projection.
column-list- A comma-delimited list of one or more target columns in this table, listed in any order. VALUES clause values are mapped to columns in the same order. If you omit this list, Vertica maps VALUES clause values to columns according to column order in the table definition.
A list of target columns is invalid with DEFAULT VALUES.
DEFAULT VALUES- Fills all columns with their default values as specified in the table definition. If no default value is specified for a column, Vertica inserts a NULL value.
You cannot specify a list of target columns with this option.
VALUES (values-list)- A comma-delimited list of one or more values to insert in the target columns, where each value is one of the following:
-
expression resolves to a value to insert in the target column. The expression must not nest other expressions, include Vertica meta-functions, or use mixed complex types. Values may include native array or ROW types if Vertica can coerce the element or field types.
-
DEFAULT inserts the default value as specified in the table definition.
If no value is supplied for a column, Vertica implicitly adds a DEFAULT value, if defined. Otherwise Vertica inserts a NULL value. If the column is defined as NOT NULL, INSERT returns an error.
You can use INSERT to insert multiple rows in the target table, by specifying multiple comma-delimited VALUES lists:
INSERT INTO table-name
VALUES ( values-list ), ( values-list )[,...]
For details, see Multi-Row INSERT below.
SELECT query-expression- A query that returns the rows to insert. Isolation level applies only to the SELECT clauses and works like any query. Restrictions on use of complex types apply as in other queries.
Privileges
-
Table owner or user with GRANT OPTION is grantor
-
INSERT privilege on table
-
USAGE privilege on schema that contains the table
Committing successive table changes
Vertica follows the SQL-92 transaction model, so successive INSERT, UPDATE, and DELETE statements are included in the same transaction. You do not need to explicitly start this transaction; however, you must explicitly end it with COMMIT, or implicitly end it with COPY. Otherwise, Vertica discards all changes that were made within the transaction.
Multi-row INSERT
You can use INSERT to insert multiple rows in the target table, by specifying multiple comma-delimited VALUES lists. For example:
=> CREATE TABLE public.t1(a int, b int, c varchar(16));
CREATE TABLE
=> INSERT INTO t1 VALUES (1,2, 'un, deux'), (3,4, 'trois, quatre');
OUTPUT
--------
2
(1 row)
=> COMMIT;
COMMIT
=> SELECT * FROM t1;
a | b | c
---+---+---------------
1 | 2 | un, deux
3 | 4 | trois, quatre
(4 rows)
Restrictions
-
Vertica does not support subqueries as the target of an INSERT statement.
-
Restrictions on the use of complex types in SELECT statements apply equally to INSERT. Using complex values that cannot be coerced to the column type results in an error.
-
If primary key, unique key, or check constraints are enabled for automatic enforcement in the target table, Vertica enforces those constraints when you load new data. If a violation occurs, Vertica rolls back the operation and returns an error.
-
If an insert would violate a table or schema disk quota, the operation fails. For more information, see Disk quotas.
Examples
=> INSERT INTO t1 VALUES (101, 102, 103, 104);
=> INSERT INTO customer VALUES (10, 'male', 'DPR', 'MA', 35);
=> INSERT INTO start_time VALUES (12, 'film','05:10:00:01');
=> INSERT INTO retail.t1 (C0, C1) VALUES (1, 1001);
=> INSERT INTO films SELECT * FROM tmp_films WHERE date_prod < '2004-05-07';
Vertica does not support subqueries or nested expressions as the target of an INSERT statement. For example, the following query returns an error message:
=> INSERT INTO t1 (col1, col2) VALUES ('abc', (SELECT mycolumn FROM mytable));
ERROR 4821: Subqueries not allowed in target of insert
You can rewrite the above query as follows:
=> INSERT INTO t1 (col1, col2) (SELECT 'abc', mycolumn FROM mytable);
OUTPUT
--------
0
(1 row)
The following example shows how to use INSERT...VALUES with flex tables:
=> CREATE FLEX TABLE flex1();
CREATE TABLE
=> INSERT INTO flex1(a,b) VALUES (1, 'x');
OUTPUT
--------
1
(1 row)
=> SELECT MapToString(__raw__) FROM flex1;
MapToString
---------------------------------
{
"a" : "1",
"b" : "x"
}
(1 row)
The following example shows how to use INSERT...SELECT with flex tables:
=> CREATE FLEX TABLE flex2();
CREATE TABLE
=> INSERT INTO flex2(a, b) SELECT a, b, '2016-08-10 11:10' c, 'Hello' d, 3.1415 e, f from flex1;
OUTPUT
--------
1
(1 row)
=> SELECT MapToString(__raw__) FROM flex2;
MapToString
---------------------------------
{
"a" : "1",
"b" : "x",
"c" : "2016-08-10",
"d" : "Hello",
"e" : 3.1415,
"f" : null
}
(1 row)
The following examples use complex types:
=> CREATE TABLE inventory(storeID INT, product ROW(name VARCHAR, code VARCHAR));
CREATE TABLE
--- LookUpProducts() returns a row(varchar, int), which is cast to row(varchar, varchar):
=> INSERT INTO inventory(product) SELECT LookUpProducts();
OUTPUT
--------
5
(1 row)
--- Cannot use with select...values:
=> INSERT INTO inventory(product) VALUES(LookUpProducts());
ERROR 2631: Column "product" is of type "row(varchar,varchar)" but expression is of type "row(varchar,int)"
--- Literal values are supported:
=> INSERT INTO inventory(product) VALUES(ROW('xbox',165));
OUTPUT
--------
1
(1 row)
=> SELECT product FROM inventory;
product
------------------------------
{"name":"xbox","code":"125"}
(1 row)
7.28 - LOCK TABLE
Locks a table, giving the caller's session exclusive access to certain operations.
Locks a table, giving the caller's session exclusive access to certain operations. Tables are automatically unlocked after the current transaction ends—that is, after COMMIT or ROLLBACK. LOCK TABLE can be useful for preventing deadlocks.
To view existing locks, see LOCKS.
Note
READ COMMITTED isolation (default) and SERIALIZABLE isolation automatically handle locks for you, and the vast majority of users can rely on them exclusively; LOCK TABLE is only for advanced users who need granular control over locks for more complex workloads.
To implement pessimistic concurrency without manually locking tables, you can use SELECT...FOR UPDATE to acquire an EXCLUSIVE (X) lock on the table.
Syntax
LOCK [ TABLE ] [[{namespace. | database. }]schema.]table [,...]
IN { lock_type } MODE
[ NOWAIT ]
Parameters
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table- The table to lock.
lock-type- The type of lock, one of the following:
-
SHARE
-
INSERT
-
INSERT VALIDATE
-
SHARE INSERT
-
EXCLUSIVE
-
NOT DELETE
-
USAGE
-
OWNER
Note
LOCK TABLE does not currently support D (drop partition) locks.
NOWAIT- If specified, LOCK TABLE returns and reports an error immediately if it cannot acquire the lock. Otherwise, LOCK TABLE waits for incompatible locks to be released by their respective sessions, returning an error if the lock is not released after a certain amount of time, as defined by LockTimeout.
Privileges
Required privileges depend on the type of lock requested:
|
Lock |
Privileges |
|
SHARED (S) |
SELECT |
|
INSERT (I) |
INSERT |
|
SHARE INSERT |
SELECT, INSERT |
|
INSERT VALIDATE (IV) |
SELECT, INSERT |
|
EXCLUSIVE (X) |
UPDATE, DELETE |
|
NOT DELETE (T) |
SELECT |
|
USAGE |
All privileges |
|
Owner |
All privileges |
Examples
See Lock examples.
7.29 - MERGE
Performs update and insert operations on a target table based on the results of a join with another data set, such as a table or view.
Performs update and insert operations on a target table based on the results of a join with another data set, such as a table or view. The join can match a source row with only one target row; otherwise, Vertica returns an error.
If a merge would violate a table or schema disk quota, the operation fails. For more information, see Disk quotas.
The target table cannot have columns of complex data types. The source table can, so long as those columns are not included in the merge operation.
Syntax
MERGE [ /*+LABEL (label-string)*/ ]
INTO [[{namespace. | database. }]schema.]target-table [ [AS] alias ]
USING source-dataset
ON join-condition matching-clause[ matching-clause ]
Returns
Number of target table rows updated or inserted
Arguments
-
LABEL
Assigns a label to a statement to identify it for profiling and debugging.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
target-table- The table on which to perform update and insert operations. MERGE takes an X (exclusive) lock on the target table during the operation. The table must not contain columns of complex types.
Important
The total number of target table columns cannot exceed 831.
source-dataset- The data to join to
target-table, one of the following:
The specified data set typically supplies the data used to update the target table and populate new rows. You can specify an external table.
ON join-condition- The conditions on which to join the target table and source data set.
Tip
The Vertica query optimizer can create an optimized query plan for a
MERGE statement only if the target table join column has a unique or primary key constraint. For details, see
MERGE optimization.
matching-clause- One of the following clauses:
MERGE supports one instance of each clause, and must include at least one.
-
WHEN MATCHED THEN UPDATE
- For each
target-table row that is joined (matched) to source-dataset, specifies to update one or more columns:
WHEN MATCHED [ AND update-filter ] THEN UPDATE
SET { column = expression }[,...]
update-filter optionally filters the set of matching rows. The update filter can specify any number of conditions. Vertica evaluates each matching row against this filter, and updates only the rows that evaluate to true. For details, see Update and insert filters.
Note
Vertica also supports Oracle syntax for specifying update filters:
WHEN MATCHED THEN UPDATE
SET { column = expression }[,...]
[ WHERE update-filter ]
The following requirements apply:
For details, see Merging table data.
-
WHEN NOT MATCHED THEN INSERT
- For each
source-dataset row that is not joined (not matched) to target-table, specifies to:
WHEN NOT MATCHED [ AND insert-filter ] THEN INSERT
[ ( column-list ) ] VALUES ( values-list )
column-list is a comma-delimited list of one or more target columns in the target table, listed in any order. MERGE maps column-list columns to values-list values in the same order, and each column-value pair must be compatible. If you omit column-list, Vertica maps values-list values to columns according to column order in the table definition.
insert-filter optionally filters the set of non-matching rows. The insert filter can specify any number of conditions. Vertica evaluates each non-matching source row against this filter. For each row that evaluates to true, Vertica inserts a new row in the target table. For details, see Update and insert filters.
Note
Vertica also supports Oracle syntax for specifying insert filters:
WHEN NOT MATCHED THEN INSERT
[ ( column-list ) ] VALUES ( values-list )
[ WHERE insert-filter ]
The following requirements apply:
-
A MERGE statement can contain only one WHEN NOT MATCHED clause.
-
*column-list* can only specify column names in the target table. It cannot be qualified with a table name.
-
Insert filter conditions can only reference the source data. If any condition references the target table, Vertica returns an error.
For details, see Merging table data.
Privileges
MERGE requires the following privileges:
-
SELECT permissions on the source data and INSERT, UPDATE, and DELETE permissions on the target table.
-
Automatic constraint enforcement requires SELECT permissions on the table containing the constraint.
-
SELECT permissions on the target table if the condition in the syntax reads data from the target table.
For example, the following GRANT statement grants user1 access to the t2 table. This allows user1 to run the MERGE statement that follows:
=> GRANT SELECT, INSERT, UPDATE, DELETE ON TABLE t2 to user1;
GRANT PRIVILEGE
=>\c - user1
You are now connected as user "user1".
=> MERGE INTO t2 USING t1 ON t1.a = t2.a
WHEN MATCHED THEN UPDATE SET b = t1.b
WHEN NOT MATCHED THEN INSERT (a, b) VALUES (t1.a, t1.b);
You can improve MERGE performance in several ways:
For details, see MERGE optimization.
Constraint enforcement
If primary key, unique key, or check constraints are enabled for automatic enforcement in the target table, Vertica enforces those constraints when you load new data. If a violation occurs, Vertica rolls back the operation and returns an error.
Caution
If you run MERGE multiple times using the same target and source table, each iteration is liable to introduce duplicate values into the target columns and return with an error.
Columns prohibited from merge
The following columns cannot be specified in a merge operation; attempts to do so return with an error:
-
IDENTITY columns, or columns whose default value is set to a named sequence.
-
Vmap columns such as __raw__ in flex tables.
-
Columns of complex types ARRAY, SET, or ROW.
Examples
See:
See also
7.30 - PROFILE
Profiles a single SQL statement.
Profiles a single SQL statement.
Syntax
PROFILE { sql-statement }
Parameters
sql-statement- A query (
SELECT) statement or DML statement--for example, you can profile
INSERT,
UPDATE,
COPY, and
MERGE.
Output
Writes profile summary to stderr, saves details to system catalog
V_MONITOR.EXECUTION_ENGINE_PROFILES.
Privileges
The same privileges required to run the profiled statement
Description
PROFILE generates detailed information about how the target statement executes, and saves that information in the system catalog
V_MONITOR.EXECUTION_ENGINE_PROFILES. Query output is preceded by a profile summary: profile identifiers transaction_id and statement_id, initiator memory for the query, and total memory required. For example:
=> PROFILE SELECT customer_name, annual_income FROM public.customer_dimension WHERE (customer_gender, annual_income) IN (SELECT customer_gender, MAX(annual_income) FROM public.customer_dimension GROUP BY customer_gender);
NOTICE 4788: Statement is being profiled
HINT: Select * from v_monitor.execution_engine_profiles where transaction_id=45035996274683334 and statement_id=7;
NOTICE 3557: Initiator memory for query: [on pool general: 708421 KB, minimum: 554324 KB]
NOTICE 5077: Total memory required by query: [708421 KB]
customer_name | annual_income
------------------+---------------
Emily G. Vogel | 999998
James M. McNulty | 999979
(2 rows)
Use profile identifiers to query the table for profile information on a given query.
See also
Profiling single statements
7.31 - RELEASE SAVEPOINT
Destroys a savepoint without undoing the effects of commands executed after the savepoint was established.
Destroys a savepoint without undoing the effects of commands executed after the savepoint was established.
Syntax
RELEASE [ SAVEPOINT ] savepoint_name
Parameters
savepoint_name- Specifies the name of the savepoint to destroy.
Privileges
None
Notes
Once destroyed, the savepoint is unavailable as a rollback point.
Examples
The following example establishes and then destroys a savepoint called my_savepoint. The values 101 and 102 are both inserted at commit.
=> INSERT INTO product_key VALUES (101);
=> SAVEPOINT my_savepoint;
=> INSERT INTO product_key VALUES (102);
=> RELEASE SAVEPOINT my_savepoint;
=> COMMIT;
See also
7.32 - REPLICATE
Copies data directly from one Eon Mode database's communal store to another.
Eon Mode only
Copies table or schema data directly from one Eon Mode database's communal storage to another. REPLICATE copies all table data and metadata. Each REPLICATE call can only replicate tables and schemas to a single namespace in the target database. When called multiple times, this statement only copies data that has changed in the source database since the last call. The tables do not have to exist in the target database before replication. If the table does exist in the target, it is overwritten.
Caution
Replication overwrites any data in the target table. You do not receive any notification that the data in the target database will be overwritten, even if the target table's design does not match the source table. Verify that the tables you want to replicate either do not exist in the target database or do not contain data that you need. Be especially cautious when replicating entire schemas to prevent overwriting data in the target database.
Similarly, changes to a replicated table in the target database are overwritten each time you replicate the table. When performing scheduled replications, only grant read access to replicated tables in the target database. Limiting these tables to read-only access will help prevent confusion if a user makes changes to a replicated table.
Syntax
REPLICATE { table | schema | "[.namespace.]schema.table"
| INCLUDE "inc_pattern" [ EXCLUDE "ex_pattern" ] }
{ FROM | TO } database_name
[ TARGET_NAMESPACE namespace-name ]
Arguments
table | schema | "[.namespace.]schema.table"- The name of a single table or schema to replicate. If specified, the namespace name must be front-qualified with a period. For example, to specify table
t in schema s in namespace n, you would write ".n.s.t". If you do not specify a namespace, the object is assumed to be in the default_namespace.
inc_pattern- A string containing a wildcard pattern of the schemas and/or tables to include in the replication. Namespace names must be front-qualified with a period.
ex_pattern- A string containing a wildcard pattern of the schemas and/or tables to exclude from the set of tables matched by the include pattern. Namespace names must be front-qualified with a period.
Note
When using wildcard patterns, be sure to anchor the patterns with a period to indicate the separation between the schema and the table name and between the namespace and schema. For example, suppose you wanted to replicate all tables in the public schema in the n1 namespace that started with the letter t, except the table public.t3. This pattern statement does not work because the exclude wildcard only applies to schemas:
=> REPLICATE INCLUDE ".n1.public.t*" EXCLUDE "*3" FROM verticadb;
The following statement does work because the periods in the EXCLUDE wildcard force the wildcard to apply to the table:
=> REPLICATE INCLUDE ".n1.public.t*" EXCLUDE ".n1.*.*3" FROM verticadb;
database_name- The name of the database from or to which data is replicated. The replication steps depend on whether the call is initiated from the source or target database:
- Target-inititated replication: use the CONNECT TO VERTICA statement to create a connection to the source database, and specify the source database in the REPLICATE statement using a
FROM source_db clause.
- Source-inititated replication: use the CONNECT TO VERTICA statement to connect to the target database, and specify the target database in the REPLICATE statement using a
TO target_db clause.
Both of these methods copy the shard data directly from the source communal storage location to the target communal storage location.
TARGET_NAMESPACE namespace-name- Namespace in the target cluster to which objects are replicated. The target namespace must have the same shard count as the source namespace in the source cluster.
If you do not specify a target namespace, objects are replicated to a namespace with the same name as the source namespace. If no such namespace exists in the target cluster, it is created with the same name and shard count as the source namespace. You can only replicate tables in the public schema to the default_namespace in the target cluster.
Privileges
Superuser
Examples
Connect to the source database from the target database and then replicate the source database's customers table to the target database:
=> CONNECT TO VERTICA source_db USER dbadmin
PASSWORD 'mypassword' ON 'vertica_node01', 5433;
CONNECT
=> REPLICATE customers FROM source_db;
REPLICATE
The following example performs the same data replication as the previous example, but the following replication is initiated from the source database instead of the target database:
=> CONNECT TO VERTICA target_db USER dbadmin
PASSWORD 'mypassword' ON 'vertica_node01', 5433;
CONNECT
=> REPLICATE customers TO target_db;
REPLICATE
Replicate all tables in the public schema that start with the letter t:
=> REPLICATE INCLUDE "public.t*" FROM source_db;
Replicate all tables in the public schema except those that start with the string customer_:
=> REPLICATE INCLUDE "public.*" EXCLUDE '*.customer_*' FROM source_db;
Replicate the flights table in the airline schema of the airport namespace to the airport2 namespace in the target cluster:
=> REPLICATE ".airport.airline.flights" FROM source_db TARGET_NAMESPACE airport2;
Replicate all schemas and tables in the default_namespace of the source database to the default_namespace in the target database:
=> REPLICATE INCLUDE ".default_namespace.*.*" FROM source_db;
See also
7.33 - REVOKE statements
REVOKE statements let you revoke privileges on database objects from users and roles.
REVOKE statements let you revoke privileges on database objects from users and roles.
Important
In a database with trust authentication, REVOKE statements appear to work as expected but have no real effect on database security.
7.33.1 - REVOKE (authentication)
Revokes privileges on an authentication method from users and roles.
Revokes privileges on an authentication method from users and roles.
Syntax
REVOKE AUTHENTICATION auth-method-name FROM grantee[,...]
Parameters
auth-method-name- Name of the target authentication method.
granteeWhose privileges are revoked, one of the following:
Privileges
Superuser
Examples
-
Revoke v_ldap authentication from user jsmith:
=> REVOKE AUTHENTICATION v_ldap FROM jsmith;
-
Revoke v_gss authentication from the role DBprogrammer:
=> REVOKE AUTHENTICATION v_gss FROM DBprogrammer;
-
Revoke localpwd as the default client authentication method:
=> REVOKE AUTHENTICATION localpwd FROM PUBLIC;
See also
7.33.2 - REVOKE (data loader)
Revokes data-loader privileges from users and roles.
Revokes privileges on automatic data loaders from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON DATA LOADER [schema.]name
FROM grantee[,...]
[ CASCADE ]
Arguments
privilege- One of the following privileges:
ALL [PRIVILEGES]- Revokes all privileges.
schema- Schema containing the data loader. The default schema is
public.
name- Name of the data loader.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
See also
7.33.3 - REVOKE (database)
Revokes database privileges from users and roles.
Revokes database privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON DATABASE db-spec
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- The database privilege to revoke, one of the following:
ALL [PRIVILEGES]- Revokes all database privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES is supported to comply with the SQL standard.
ON DATABASE db-specSpecifies the current database, set to the database name or DEFAULT.
*`grantee`*Whose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Fred's privilege to create schemas in the current database:
=> REVOKE CREATE ON DATABASE DEFAULT FROM Fred;
Revoke user Fred's privilege to create temporary tables in the current database:
=> REVOKE TEMP ON DATABASE DEFAULT FROM Fred;
See also
7.33.4 - REVOKE (key)
Revokes privileges on a cryptographic key from a user or role.
Revokes privileges on a cryptographic key from a user or role.
Important
Because certificates depend on their underlying key, DROP privileges on a key effectively act as DROP privileges on its associated certificate when used with
DROP KEY...CASCADE.
To grant privileges on a key, see GRANT (key).
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] } ON KEY
key_name[,...]
FROM user[,...]
Parameters
-
`GRANT OPTION FOR`
Revokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilegeA privilege, one of the following:
-
USAGE: Allows a user to perform the following actions:
USAGE on the key also gives implicit USAGE privileges on a certificate that uses it as its private key. Users can also get these privileges from ownership of the key or certificate. USAGE privileges on a certificate allow a user to perform the following actions:
-
View the contents of the certificate.
-
Add (with CREATE or ALTER) the certificate to a TLS Configuration.
-
Reuse the CA certificate when importing certificates signed by it. For example, if a user imports a chain of certificates A > B > C and have USAGE on B, the database reuses B (as opposed to creating a duplicate of B).
-
Specify that the CA certificate signed an imported certificate. For example, if certificate B signed certificate C, USAGE on B allows a user to import C and specify that it was SIGNED BY B.
-
DROP
-
ALTER: Allows a user to see the key and its associated certificates in their respective system tables, but not their contents.
key_name- The target key.
userWho is granted privileges, one of the following:
Privileges
Non-superuser:
Examples
The following example revokes DROP privileges on a key (and, by extension, its associated certificate) from a user:
=> REVOKE USAGE ON KEY new_key FROM u1;
REVOKE PRIVILEGE
7.33.5 - REVOKE (library)
Revokes library privileges from users and roles.
Revokes library privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { USAGE | ALL [ PRIVILEGES ] }
ON LIBRARY [[database.]schema.]library[,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
USAGE- Revokes access to the specified libraries.
Important
Privileges on functions in these libraries must be separately revoked.
ALL [PRIVILEGES]- Revokes all library privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack. The optional keyword
PRIVILEGES conforms with the SQL standard.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
library- The target library.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Examples
These commands show how to create a new library, and then grant and revoke user Fred's USAGE privilege on that library.
=> CREATE LIBRARY MyFunctions AS 'home/dbadmin/my_functions.so';
=> GRANT USAGE ON LIBRARY MyFunctions TO Fred;
=> REVOKE USAGE ON LIBRARY MyFunctions FROM Fred;
See also
7.33.6 - REVOKE (model)
Revokes model privileges from users and roles.
Revokes model privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON MODEL [[database.]schema.]model-name [,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
USAGE- One of the following privileges:
ALL [PRIVILEGES]- Revokes all model privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
model-name- Name of the target model.
-
grantee
Whose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Fred's USAGE privilege on model mySvmClassModel:
=> REVOKE USAGE ON mySvmClassModel FROM Fred;
See also
7.33.7 - REVOKE (procedure)
Revokes procedure privileges from users and roles.
Revokes procedure privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { EXECUTE | ALL PRIVILEGES }
ON PROCEDURE [[database.]schema.]procedure( [argument-list] )[,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
EXECUTE- Revokes grantees ability to run the specified procedures.
ALL [PRIVILEGES]- Revokes all procedure privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
- [database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
-
procedure
- The target procedure.
argument-list- A comma-delimited list of procedure arguments, where each argument is specified as follows:
[argname] argtype
If the procedure is defined with no arguments, supply an empty argument list.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
This example revokes user Bob's execute privilege on the tokenize procedure.
=> REVOKE EXECUTE ON PROCEDURE tokenize(varchar) FROM Bob;
See also
7.33.8 - REVOKE (Resource pool)
Revokes resource pool access privileges from users and roles.
Revokes resource pool access privileges from users and roles.
Vertica checks resource pool privileges at runtime. Revoking a user's privileges for a resource pool can have an immediate effect on the user's current session. For example, a user query might require USAGE privileges on a resource pool. If you revoke those privileges from that user, subsequent attempts by the user to execute that query fail and return with an error message.
Syntax
REVOKE [ GRANT OPTION FOR ] { USAGE | ALL PRIVILEGES }
ON RESOURCE POOL resource-pool[,...]
[FOR SUBCLUSTER subcluster | FOR CURRENT SUBCLUSTER]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
USAGE- Revokes grantee's access to the specified resource pool.
ALL PRIVILEGES- Revokes all resource pool privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
resource-pool- The target resource pool.
subcluster- The subcluster for the resource pool.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Joe's USAGE privileges on resource pool Joe_pool.
=> REVOKE USAGE ON RESOURCE POOL Joe_pool FROM Joe;
REVOKE PRIVILEGE
Revoke user Joe's USAGE privileges on resource pool Joe_pool for subcluster sub1.
=> REVOKE USAGE ON RESOURCE POOL Joe_pool FOR SUBCLUSTER sub1 FROM Joe;
REVOKE PRIVILEGE
See also
7.33.9 - REVOKE (Role)
Revokes a role from users and roles.
Revokes a role from users and roles.
Syntax
REVOKE [ ADMIN OPTION FOR ] role[,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
ADMIN OPTION FOR- Revokes from the grantees the authority to assign the specified roles to other users or roles. Current roles for grantees remain unaffected. If you omit this clause, Vertica revokes role assignment privileges and the current roles .
role- Role to revoke.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
One of the following:
Examples
This example shows the revocation of the pseudosuperuser role from the dbadmin user:
=> REVOKE pseudosuperuser from dbadmin;
This example shows the revocation of administration access from the dbadmin user for the pseudosuperuser role. The ADMIN OPTION command does not remove the pseudosuperuser role.
=> REVOKE ADMIN OPTION FOR pseudosuperuser FROM dbadmin;
Notes
If the role you are trying to revoke was not already granted to the user, Vertica returns a NOTICE:
=> REVOKE commentor FROM Sue;
NOTICE 2022: Role "commentor" was not already granted to user "Sue"
REVOKE ROLE
See also
7.33.10 - REVOKE (schema)
Revokes schema privileges from users and roles.
Revokes schema privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON SCHEMA [{namespace. | database. }]schema[,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- The schema privilege to revoke, one of the following:
You can also revoke privileges from tables and views that they inherited on creation from this schema. When you revoke inherited privileges at the schema level, Vertica automatically applies the revocation to all tables and views that inherited these privileges.
-
SELECT: Query tables and views. SELECT privileges are granted by default to the PUBLIC role.
-
INSERT: Insert rows, or and load data into tables with
COPY.
Note
COPY FROM STDIN is allowed for users with INSERT privileges, while COPY FROM file requires admin privileges.
-
UPDATE: Update table rows.
-
DELETE: Delete table rows.
-
REFERENCES: Create foreign key constraints on this table. This privilege must be set on both referencing and referenced tables.
-
TRUNCATE: Truncate table contents. Non-owners of tables can also execute the following partition operations on them:
-
ALTER: Modify the DDL of tables and views with
ALTER TABLE and
ALTER VIEW, respectively.
-
DROP: Drop tables and views.
ALL [PRIVILEGES]- Revokes USAGE AND CREATE privileges. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
Important
Inherited privileges must be explicitly revoked.
{ namespace. | database. }- Name of the database or namespace that contains
schema:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Joe's USAGE privilege on schema online_sales.
=> REVOKE USAGE ON SCHEMA online_sales FROM Joe;
REVOKE PRIVILEGE
See also
7.33.11 - REVOKE (sequence)
Revokes sequence privileges from users and roles.
Revokes sequence privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON {
SEQUENCE [[database.]schema.]sequence[,...]
| ALL SEQUENCES IN SCHEMA [database.]schema[,...] }
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- One of the following privileges:
ALL [PRIVILEGES]- Revokes all sequence privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES is supported to comply with the SQL standard.
-
[database.]schema
Database and schema. The default schema is public. If you specify a database, it must be the current database.
SEQUENCE sequence- Specifies the sequence on which to revoke privileges.
-
ALL SEQUENCES IN SCHEMA schema
- Revokes the specified privileges on all sequences in schema
schema.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Joe's privileges on sequence my_seq.
=> REVOKE ALL PRIVILEGES ON SEQUENCE my_seq FROM Joe;
REVOKE PRIVILEGE
See also
7.33.12 - REVOKE (storage location)
Revokes privileges on a USER-defined storage location from users and roles.
Revokes privileges on a USER-defined storage location from users and roles. For more information, see Creating storage locations.
Note
If the storage location is
dropped, Vertica automatically revokes all privileges on it.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON LOCATION 'path' [ ON node ]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- One of the following privileges:
-
READ: Copy data from files in the storage location into a table.
-
WRITE: Export data from the database to the storage location. With WRITE privileges, grantees can also save COPY statement rejected data and exceptions files to the storage location.
ALL [PRIVILEGES]- Revokes all storage location privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES is supported to comply with the SQL standard.
ON LOCATION 'path' [ ON node ]- Specifies the path name mount point of the storage location. If qualified by
ON NODE, Vertica revokes access to the storage location residing on node.
If no node is specified, the revoke operation applies to all nodes on the specified path. All nodes must be on the specified path; otherwise, the entire revoke operation rolls back.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
See GRANT (storage location).
See also
Granting and revoking privileges
7.33.13 - REVOKE (table)
Revokes table privileges from users and roles.
Revokes table privileges from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON {
[ TABLE ] [[{namespace. | database. }]schema.]table[,...]
| ALL TABLES IN SCHEMA [database.]schema[,...] }
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- One of the following privileges:
-
SELECT: Query tables. SELECT privileges are granted by default to the PUBLIC role.
-
INSERT: Insert table rows with INSERT, and load data with
COPY.
Note
COPY FROM STDIN is allowed for users with INSERT privileges, while COPY FROM file requires admin privileges.
-
UPDATE: Update table rows.
-
DELETE: Delete table rows.
-
REFERENCES: Create foreign key constraints on this table. This privilege must be set on both referencing and referenced tables.
-
TRUNCATE: Truncate table contents. Non-owners of tables can also execute the following partition operations on them:
-
ALTER: Modify a table's DDL with
ALTER TABLE.
-
DROP: Drop a table.
ALL [PRIVILEGES]- Revokes all table privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES is supported to comply with the SQL standard.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
TABLE table- Specifies the table on which to revoke privileges.
ON ALL TABLES IN SCHEMA schema - Revokes the specified privileges on all tables and views in schema
schema.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke user Joe's privileges on table customer_dimension.
=> REVOKE ALL PRIVILEGES ON TABLE customer_dimension FROM Joe;
REVOKE PRIVILEGE
See also
7.33.14 - REVOKE (TLS configuration)
Revokes privileges granted on one or more TLS Configurations from users and roles.
Revokes privileges granted on one or more TLS Configurations from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ]
{ ALL | [ privilege[,...] ]}
ON TLS CONFIGURATION tls_configuration[,...]
FROM grantee [,...]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilegeA privilege, one of the following:
tls_configuration- The TLS Configuration on which to revoke privileges.
granteeWho is granted privileges, one of the following:
Privileges
Non-superusers require USAGE on the schema and one of the following:
Examples
To revoke ALTER privileges on the TLS Configuration server from the role client_server_tls_manager:
=> REVOKE ALTER ON TLS CONFIGURATION server FROM client_server_tls_manager;
7.33.15 - REVOKE (user defined extension)
Revokes privileges on one or more user-defined extensions from users and roles.
Revokes privileges on one or more user-defined extensions from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { EXECUTE | ALL PRIVILEGES }
ON {
UDx-type [[database.]schema.]function-name( [argument-list] )[,...]
| ALL FUNCTIONS IN SCHEMA schema[,...] }
FROM grantee[,...]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
EXECUTE- Revokes grantees ability to run the specified functions.
ALL [PRIVILEGES]- Revokes all function privileges that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
-
ON UDx-type
- Specifies the function's user-defined extension (UDx) type, where
UDx-type is one of the following:
-
FUNCTION
-
AGGREGATE FUNCTION
-
ANALYTIC FUNCTION
-
TRANSFORM FUNCTION
-
FILTER
-
PARSER
-
SOURCE
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
function-name- The name of the user-defined function on which to revoke privileges.
ON ALL FUNCTIONS IN SCHEMA schema- Revokes privileges on all functions in the specified schema.
argument-list- Required for all polymorphic functions, a comma-delimited list of function arguments, where each argument is specified as follows:
[argname] argtype
If the procedure is defined with no arguments, supply an empty argument list.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Privileges
Non-superuser, one of the following:
Examples
Revoke EXECUTE privileges from user Bob on function myzeroifnull:
=> REVOKE EXECUTE ON FUNCTION myzeroifnull (x INT) FROM Bob;
Revoke all privileges from user Doug on function Pagerank:
=> REVOKE ALL ON TRANSFORM FUNCTION Pagerank (t float) FROM Doug;
Revoke EXECUTE privileges on all functions in the zero-schema schema from user Bob:
=> REVOKE EXECUTE ON ALL FUNCTIONS IN SCHEMA zero-schema FROM Bob;
Revoke EXECUTE privileges from user Bob on the tokenize function:
=> REVOKE EXECUTE ON TRANSFORM FUNCTION tokenize(VARCHAR) FROM Bob;
Revoke all privileges on the ExampleSource() source from user Alice:
=> REVOKE ALL ON SOURCE ExampleSource() FROM Alice;
See also
7.33.16 - REVOKE (view)
Revokes privileges on a view from users and roles.
Revokes privileges on a view from users and roles.
Syntax
REVOKE [ GRANT OPTION FOR ] { privilege[,...] | ALL [ PRIVILEGES ] }
ON [[database.]schema.]view[,...]
FROM grantee[,...]
[ CASCADE ]
Parameters
GRANT OPTION FORRevokes the grant option for the specified privileges. Current privileges for grantees remain unaffected. If you omit this clause, Vertica revokes both the grant option and current privileges.
privilege- One of the following:
-
SELECT: Query the specified views.
-
ALTER: Modify a view's DDL with ALTER VIEW
-
DROP: Drop this view with DROP VIEW.
ALL PRIVILEGES- Revokes all privileges that pertain to views that also belong to the revoker. Users cannot revoke privileges that they themselves lack.
The optional keyword PRIVILEGES conforms with the SQL standard.
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
view- The view on which to revoke privileges.
granteeWhose privileges are revoked, one of the following:
CASCADERevoke privileges from users who received them from the grantee through WITH GRANT OPTION.
Examples
Revoke SELECT privileges from user Joe on view test_view.
=> REVOKE SELECT ON test_view FROM Joe;
REVOKE PRIVILEGE
See also
7.33.17 - REVOKE (workload)
Revokes privileges from a role to use a workload.
Revokes privileges from a user or role to use a workload
Syntax
REVOKE USAGE ON WORKLOAD workload FROM {user | role}
Parameters
workload- A workload defined by a routing rule. For details, see Workload routing.
user | role- The user or role to revoke privileges from.
Privileges
Superuser
Examples
The following example revokes the USAGE privilege on the analytics workload from users with the analytics_role role:
=> REVOKE USAGE ON WORKLOAD analytics FROM analytics_role;
Similarly, this example revokes the USAGE privilege on the analytics workload from the user jacob:
=> REVOKE USAGE ON WORKLOAD analytics FROM jacob;
For more examples, see Workload routing.
7.34 - ROLLBACK
Ends the current transaction and discards all changes that occurred during the transaction.
Ends the current transaction and discards all changes that occurred during the transaction.
Syntax
ROLLBACK [ WORK | TRANSACTION ]
Parameters
WORK | TRANSACTION - Have no effect; they are optional keywords for readability.
Privileges
None
Notes
When an operation is rolled back, any locks that are acquired by the operation are also rolled back.
ABORT is a synonym for ROLLBACK.
Examples
This example shows how to roll back from a DELETE transaction.
=> SELECT * FROM sample_table;
a
---
1
(1 row)
=> DELETE FROM sample_table WHERE a = 1;
=> SELECT * FROM sample_table;
a
---
(0 rows)
=> ROLLBACK;
=> SELECT * FROM sample_table;
a
---
1
(1 row)
This example shows how to roll back the changes you made since the BEGIN statement.
=> BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED READ ONLY;
BEGIN
=> ROLLBACK TRANSACTION;
ROLLBACK
See also
7.35 - ROLLBACK TO SAVEPOINT
Rolls back all commands that have been entered within the transaction since the given savepoint was established.
Rolls back all commands that have been entered within the transaction since the given savepoint was established.
Syntax
ROLLBACK TO [SAVEPOINT] savepoint_name
Parameters
savepoint_name- Specifies the name of the savepoint to roll back to.
Privileges
None
Notes
-
The savepoint remains valid and can be rolled back to again later if needed.
-
When an operation is rolled back, any locks that are acquired by the operation are also rolled back.
-
ROLLBACK TO SAVEPOINT implicitly destroys all savepoints that were established after the named savepoint.
Examples
The following example rolls back the values 102 and 103 that were entered after the savepoint, my_savepoint, was established. Only the values 101 and 104 are inserted at commit.
=> INSERT INTO product_key VALUES (101);
=> SAVEPOINT my_savepoint;
=> INSERT INTO product_key VALUES (102);
=> INSERT INTO product_key VALUES (103);
=> ROLLBACK TO SAVEPOINT my_savepoint;
=> INSERT INTO product_key VALUES (104);
=> COMMIT;
See also
7.36 - SAVE QUERY
Saves an input query to associate with a custom directed query.
Saves an input query to associate with a custom directed query.
Syntax
SAVE QUERY input-query
Arguments
input-query- The input query to associate with a custom directed query. The input query supports only one optimizer hint,
:v.
Privileges
Superuser
Usage
SAVE QUERY saves the specified input query for use by the next invocation of CREATE DIRECTED QUERY CUSTOM. CREATE DIRECTED QUERY CUSTOM pairs the saved query with its annotated query argument to create a directed query. Both statements must be issued in the same user session.
The saved query remains available until the one of the following events occurs:
-
The next invocation of CREATE DIRECTED QUERY, whether invoked with CUSTOM or OPTIMIZER.
-
Another invocation of SAVE QUERY.
-
The session ends.
Caution
Vertica associates a saved query with a directed query without checking whether the input and annotated queries are compatible. Be careful to sequence SAVE QUERY and CREATE DIRECTED QUERY CUSTOM so the saved and directed queries are correctly matched.
Examples
See Custom directed queries.
7.37 - SAVEPOINT
SAVEPOINT is a transaction control command that.
Creates a special mark, called a savepoint, inside a transaction. A savepoint allows all commands that are executed after it was established to be rolled back, restoring the transaction to the state it was in at the point in which the savepoint was established.
Tip
Savepoints are useful when creating nested transactions. For example, a savepoint could be created at the beginning of a subroutine. That way, the result of the subroutine could be rolled back if necessary.
Syntax
SAVEPOINT savepoint_name
Parameters
savepoint_name- Specifies the name of the savepoint to create.
Privileges
None
Notes
-
Savepoints are local to a transaction and can only be established when inside a transaction block.
-
Multiple savepoints can be defined within a transaction.
-
If a savepoint with the same name already exists, it is replaced with the new savepoint.
Examples
The following example illustrates how a savepoint determines which values within a transaction can be rolled back. The values 102 and 103 that were entered after the savepoint, my_savepoint, was established are rolled back. Only the values 101 and 104 are inserted at commit.
=> INSERT INTO T1 (product_key) VALUES (101);
=> SAVEPOINT my_savepoint;
=> INSERT INTO T1 (product_key) VALUES (102);
=> INSERT INTO T1 (product_key) VALUES (103);
=> ROLLBACK TO SAVEPOINT my_savepoint;
=> INSERT INTO T1 (product_key) VALUES (104);
=> COMMIT;
=> SELECT product_key FROM T1;
.
.
.
101
104
(2 rows)
See also
7.38 - SELECT
Returns a result set from one or more data sources—tables, views, joined tables, and named subqueries.
Returns a result set from one or more data sources—tables, views, joined tables, and named subqueries.
Syntax
[ AT epoch ] [ WITH-clause ] SELECT [ ALL | DISTINCT ]
{ * | { MATCH_COLUMNS('pattern') | expression [ [AS] alias ] }[,...] }
[ into-table-clause ]
[ from-clause ]
[ where-clause ]
[ time-series-clause ]
[ group-by-clause[,...] ]
[ having-clause[,...] ]
[ match-clause ]
[ union-clause ]
[ intersect-clause ]
[ except-clause ]
[ order-by-clause [ offset-clause ]]
[ limit-clause ]
[ FOR UPDATE [ OF table-name[,...] ] ]
Note
SELECT statements can also embed various directives, or hints, that let you control how a given query is handled—for example, join hints such as JTYPE, which enforces the join type (merge or hash join).
For details on using Vertica hints, see Hints.
Parameters
AT epoch- Returns data from the specified epoch, where
epoch is one of the following:
-
EPOCH LATEST: Return data up to but not including the current epoch. The result set includes data from the latest committed DML transaction.
-
EPOCH integer: Return data up to and including the integer-specified epoch.
-
TIME 'timestamp': Return data from the timestamp-specified epoch.
Note
These options are ignored if used to query temporary or external tables.
See Epochs for additional information about how Vertica uses epochs.
For details, see Historical queries.
ALL | DISTINCT-
The
ALL or DISTINCT qualifier must immediately follow the SELECT keyword. Only one instance of this keyword can appear in the select list.
*- Lists all columns in the queried tables.
Caution
Selecting all columns from the queried tables can produce a very large wide set, which can adversely affect performance.
-
MATCH_COLUMNS('pattern')
- Returns all columns in the queried tables that match
pattern.
expression [[AS] alias]- An expression that typically resolves to column data from the queried tables—for example, names of columns that are specified in the FROM clause; also:
You can optionally assign a temporary alias to each column expression and reference that alias elsewhere in the SELECT statement—for example, in the query predicate or ORDER BY clause. Vertica uses the alias as the column heading in query output.
FOR UPDATE- Specifies to obtain an X lock on all tables specified in the query, most often used from
READ COMMITTED isolation.
FOR UPDATE requires update/delete permissions on the queried tables and cannot be issued from a read-only transaction.
Privileges
Non-superusers:
Note
As view owner, you can grant other users SELECT privilege on the view only if one of the following is true:
Examples
When multiple clients run transactions as in the following example query, deadlocks can occur if FOR UPDATE is not used. Two transactions acquire an S lock, and when both attempt to upgrade to an X lock, they encounter deadlocks:
=> SELECT balance FROM accounts WHERE account_id=3476 FOR UPDATE;
...
=> UPDATE accounts SET balance = balance+10 WHERE account_id=3476;
=> COMMIT;
See also
7.38.1 - EXCEPT clause
Combines two or more SELECT queries.
Combines two or more SELECT queries. EXCEPT returns distinct results of the left-hand query that are not also found in the right-hand query.
Note
MINUS is an alias for EXCEPT.
Syntax
SELECT
EXCEPT except-query[...]
[ ORDER BY { column-name | ordinal-number } [ ASC | DESC ] [,...] ]
[ LIMIT { integer | ALL } ]
[ OFFSET integer ]
Notes
-
Use the EXCEPT clause to filter out specific results from a SELECT statement. The EXCEPT query operates on the results of two or more SELECT queries. It returns only those rows in the left-hand query that are not also present in the right-hand query.
-
Vertica evaluates multiple EXCEPT clauses in the same SELECT query from left to right, unless parentheses indicate otherwise.
-
You cannot use the ALL keyword with an EXCEPT query.
-
The results of each SELECT statement must be union compatible. Each statement must return the same number of columns, and the corresponding columns must have compatible data types. For example, you cannot use the EXCEPT clause on a column of type INTEGER and a column of type VARCHAR. If statements do not meet these criteria, Vertica returns an error.
Note
The
Data type coercion chart lists the data types that can be cast to other data types. If one data type can be cast to the other, those two data types are compatible.
-
You can use EXCEPT in FROM, WHERE, and HAVING clauses.
-
You can order the results of an EXCEPT operation by including an ORDER BY operation in the statement. When you write the ORDER BY list, specify the column names from the leftmost SELECT statement, or specify integers that indicate the position of the columns by which to sort.
-
The rightmost ORDER BY, LIMIT, or OFFSET clauses in an EXCEPT query do not need to be enclosed in parentheses, because the rightmost query specifies that Vertica perform the operation on the results of the EXCEPT operation. Any ORDER BY, LIMIT, or OFFSET clauses contained in SELECT queries that appear earlier in the EXCEPT query must be enclosed in parentheses.
-
Vertica supports EXCEPT noncorrelated subquery predicates. For example:
=> SELECT * FROM T1
WHERE T1.x IN
(SELECT MAX(c1) FROM T2
EXCEPT
SELECT MAX(cc1) FROM T3
EXCEPT
SELECT MAX(d1) FROM T4);
Examples
Consider the following three tables:
Company_A
Id | emp_lname | dept | sales
------+-----------+----------------+-------
1234 | Stephen | auto parts | 1000
5678 | Alice | auto parts | 2500
9012 | Katherine | floral | 500
3214 | Smithson | sporting goods | 1500
(4 rows)
Company_B
Id | emp_lname | dept | sales
------+-----------+-------------+-------
4321 | Marvin | home goods | 250
8765 | Bob | electronics | 20000
9012 | Katherine | home goods | 500
3214 | Smithson | home goods | 1500
(4 rows)
Company_C
Id | emp_lname | dept | sales
------+-----------+----------------+-------
3214 | Smithson | sporting goods | 1500
5432 | Madison | sporting goods | 400
7865 | Cleveland | outdoor | 1500
1234 | Stephen | floral | 1000
(4 rows)
The following query returns the IDs and last names of employees that exist in Company_A, but not in Company_B:
=> SELECT id, emp_lname FROM Company_A
EXCEPT
SELECT id, emp_lname FROM Company_B;
id | emp_lname
------+-----------
1234 | Stephen
5678 | Alice
(2 rows)
The following query sorts the results of the previous query by employee last name:
=> SELECT id, emp_lname FROM Company_A
EXCEPT
SELECT id, emp_lname FROM Company_B
ORDER BY emp_lname ASC;
id | emp_lname
------+-----------
5678 | Alice
1234 | Stephen
(2 rows)
If you order by the column position, the query returns the same results:
=> SELECT id, emp_lname FROM Company_A
EXCEPT
SELECT id, emp_lname FROM Company_B
ORDER BY 2 ASC;
id | emp_lname
------+-----------
5678 | Alice
1234 | Stephen
(2 rows)
The following query returns the IDs and last names of employees that exist in Company_A, but not in Company_B or Company_C:
=> SELECT id, emp_lname FROM Company_A
EXCEPT
SELECT id, emp_lname FROM Company_B
EXCEPT
SELECT id, emp_lname FROM Company_C;
id | emp_lname
------+-----------
5678 | Alice
(1 row)
The following query shows the results of mismatched data types:
=> SELECT id, emp_lname FROM Company_A
EXCEPT
SELECT emp_lname, id FROM Company_B;
ERROR 3429: For 'EXCEPT', types int and varchar are inconsistent
DETAIL: Columns: id and emp_lname
Using the VMart example database, the following query returns information about all Connecticut-based customers who bought items through stores and whose purchases amounted to more than $500, except for those customers who paid cash:
=> SELECT customer_key, customer_name FROM public.customer_dimension
WHERE customer_key IN (SELECT customer_key FROM store.store_sales_fact
WHERE sales_dollar_amount > 500
EXCEPT
SELECT customer_key FROM store.store_sales_fact
WHERE tender_type = 'Cash')
AND customer_state = 'CT';
customer_key | customer_name
--------------+----------------------
15084 | Doug V. Lampert
21730 | Juanita F. Peterson
24412 | Mary U. Garnett
25840 | Ben Z. Taylor
29940 | Brian B. Dobisz
32225 | Ruth T. McNulty
33127 | Darlene Y. Rodriguez
40000 | Steve L. Lewis
44383 | Amy G. Jones
46495 | Kevin H. Taylor
(10 rows)
See also
7.38.2 - FROM clause
A comma-separated list of data sources to query.
A comma-separated list of data sources to query.
Syntax
FROM dataset[,...] [ TABLESAMPLE(percent) ]
Parameters
dataset``- A set of data to query, one of the following:
-
`TABLESAMPLE(percent)`
- Specifies to return a random sampling of records, where
percent specifies the approximate sampling size. The percent value must be between 0 and 100, exclusive, and can include decimal values. The number of records returned is not guaranteed to be the exact percentage specified.
All rows of the data have equal opportunities to be selected. Vertica performs sampling before applying other query filters.
Examples
Count all records in customer_dimension table:
=> SELECT COUNT(*) FROM customer_dimension;
COUNT
-------
50000
(1 row)
Return a small sampling of rows in table customer_dimension:
=> SELECT customer_name, customer_state FROM customer_dimension TABLESAMPLE(0.5) WHERE customer_state='IL';
customer_name | customer_state
---------------------+----------------
Amy Y. McNulty | IL
Daniel C. Nguyen | IL
Midori O. Greenwood | IL
Meghan U. Lampert | IL
Tiffany Y. Lang | IL
Laura S. King | IL
Steve T. Nguyen | IL
Craig S. Webber | IL
Luigi A. Lewis | IL
Mark W. Williams | IL
(10 rows)
7.38.2.1 - Joined-table
Specifies how to join tables.
Specifies how to join tables.
Syntax
table-reference [ join-type ] JOIN table-reference [ TABLESAMPLE(percent) ] [ ON join-predicate ]
Arguments
table-reference- A table name, optionally qualified.
join-type- One of the following:
TABLESAMPLE(percent)- Use simple random sampling to return an approximate percentage of records. The percentage value must be greater than 0 and less than 100. All rows in the total potential return set are equally eligible to be included in the sampling. Vertica performs this sampling before other filters in the query are applied. The number of records returned is not guaranteed to be exactly
percent.
The TABLESAMPLE option is valid only with user-defined tables and Data Collector (DC) tables. Views and system tables are not supported.
ON join-predicate- Specifies the columns to join on.
Invalid for
NATURAL and CROSS joins, required for all other join types.
Alternative JOIN syntax options
Vertica supports two older join syntax conventions:
For details, see Join Syntax.
Examples
The following SELECT statement qualifies its JOIN clause with the TABLESAMPLE option:
=> SELECT user_id.id, user_name.name FROM user_name TABLESAMPLE(50)
JOIN user_id TABLESAMPLE(50) ON user_name.id = user_id.id;
id | name
------+--------
489 | Markus
2234 | Cato
763 | Pompey
(3 rows)
7.38.2.2 - Table-reference
A temporary name used for references to table.
Syntax
[[database.]schema.]table[ [AS] alias]
Parameters
[database.]schemaDatabase and schema. The default schema is public. If you specify a database, it must be the current database.
table- A table in the logical schema.
[AS] alias- A temporary name used for references to
table.
7.38.3 - GROUP BY clause
Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records.
Use the GROUP BY clause with aggregate functions in a SELECT statement to collect data across multiple records. Vertica groups the results into one or more sets of rows that match an expression.
The GROUP BY clause without aggregates is similar to using SELECT DISTINCT.
ROLLUP is an extension to the GROUP BY clause. ROLLUP performs subtotal aggregations.
Syntax
GROUP BY [/*+GBYTYPE(algorithm)*/] { expression | aggregate-expression }[,...]
Arguments
-
/*+GBYTYPE(algorithm)*/
- Specifies which algorithm has precedence for implementing this
GROUP BY clause, over the algorithm the Vertica query optimizer might otherwise choose. You can set algorithm to one of the following values:
For more information about both algorithms, see GROUP BY implementation options.
expression- Any expression, including constants and column references in the tables specified in the FROM clause. For example:
column,... column, (expression)
aggregate-expression- An ordered list of columns, expressions,
CUBE, GROUPING SETS, or ROLLUP aggregates.
You can include CUBE and ROLLUP aggregates within a GROUPING SETS aggregate. CUBE and ROLLUP aggregates can result in a large amount of output. In that case, use GROUPING SETS to return only certain results.
You cannot include any aggregates within a CUBE or ROLLUP expression.
You can append multiple GROUPING SETS, CUBE, or ROLLUP aggregates in the same query. For example:
GROUP BY a,b,c,d, ROLLUP(a,b)
GROUP BY a,b,c,d, CUBE((a,b),c,d)
GROUP BY a,b,c,d, CUBE(a,b), ROLLUP (c,d)
GROUP BY ROLLUP(a), CUBE(b), GROUPING SETS(c)
GROUP BY a,b,c,d, GROUPING SETS ((a,d),(b,c),CUBE(a,b))
GROUP BY a,b,c,d, GROUPING SETS ((a,d),(b,c),(a,b),(a),(b),())
Usage considerations
-
expression cannot include aggregate functions. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group.
-
When you create a GROUP BY clause, you must include all non-aggregated columns that appear in the SELECT list.
-
If the GROUP BY clause includes a WHERE clause, Vertica ignores all rows that do not satisfy the WHERE clause.
Examples
This example shows how to use the WHERE clause with GROUP BY. In this case, the example retrieves all employees whose last name begins with S, and ignores all rows that do not meet this criteria. The GROUP BY clause uses the ILIKE function to retrieve only last names beginning with S. The aggregate function SUM computes the total vacation days for each group.
=> SELECT employee_last_name, SUM(vacation_days)
FROM employee_dimension
WHERE employee_last_name ILIKE 'S%'
GROUP BY employee_last_name;
employee_last_name | SUM
--------------------+------
Sanchez | 2892
Smith | 2672
Stein | 2660
(3 rows)
The GROUP BY clause in the following example groups results by vendor region, and vendor region's biggest deal:
=> SELECT vendor_region, MAX(deal_size) AS "Biggest Deal"
FROM vendor_dimension
GROUP BY vendor_region;
vendor_region | Biggest Deal
---------------+--------------
East | 990889
MidWest | 699163
NorthWest | 76101
South | 854136
SouthWest | 609807
West | 964005
(6 rows)
The following query modifies the previous one with a HAVING clause, which specifies to return only groups whose maximum deal size exceeds $900,000:
=> SELECT vendor_region, MAX(deal_size) as "Biggest Deal"
FROM vendor_dimension
GROUP BY vendor_region
HAVING MAX(deal_size) > 900000;
vendor_region | Biggest Deal
---------------+--------------
East | 990889
West | 964005
(2 rows)
You can use the GROUP BY clause with one-dimensional arrays of scalar types. In the following example, grants is an ARRAY[VARCHAR] and grant_values is an ARRAY[INT].
=> SELECT department, grants, SUM(apply_sum(grant_values))
FROM employees
GROUP BY grants, department;
department | grants | SUM
------------+--------------------------+--------
Physics | ["US-7376","DARPA-1567"] | 235000
Astronomy | ["US-7376","DARPA-1567"] | 9000
Physics | ["US-7376"] | 30000
(3 rows)
The GROUP BY clause without aggregates is similar to using SELECT DISTINCT. For example, the following two queries return the same results:
=> SELECT DISTINCT household_id FROM customer_dimension;
=> SELECT household_id FROM customer_dimension GROUP BY household_id;
See also
7.38.3.1 - CUBE aggregate
Automatically performs all possible aggregations of the specified columns, as an extension to the GROUP BY clause.
Automatically performs all possible aggregations of the specified columns, as an extension to the GROUP BY clause.
You can use the ROLLUP clause with three grouping functions:
Syntax
GROUP BY group-expression[,...]
Parameters
group-expression``- One or both of the following:
-
An expression that is not an aggregate or a grouping function that includes constants and column references in FROM-specified tables. For example:
column1, (column2+1), column3+column4
-
A multilevel expression, one of the following:
-
ROLLUP
-
CUBE
-
GROUPING SETS
Restrictions
- GROUP BY CUBE does not order data. If you want to sort data, use the ORDER BY clause. The ORDER BY clause must come after the GROUP BY clause.
- You can use CUBE inside a GROUPING SETS expression, but not inside a ROLLUP expression or another CUBE expression.
Levels of CUBE aggregation
If n is the number of grouping columns, CUBE creates 2n levels of aggregations. For example:
CUBE (A, B, C) creates all possible groupings, resulting in eight groups:
- (A, B, C)
- (A, B)
- (A, C)
- (B, C)
- (A)
- (B)
- (C)
- ()
If you increase the number of CUBE columns, the number of CUBE groupings increases exponentially. The CUBE query may be resource intensive and produce combinations that are not of interest. In that case, consider using theGROUPING SETS aggregate, which allows you to choose specific groupings.
Examples
Using CUBE to return all groupings
Suppose you have a table that contains information about family expenses for books and electricity:
=> SELECT * FROM expenses ORDER BY Category, Year;
Year | Category | Amount
------+-------------+--------
2005 | Books | 39.98
2007 | Books | 29.99
2008 | Books | 29.99
2005 | Electricity | 109.99
2006 | Electricity | 109.99
2007 | Electricity | 229.98
To aggregate the data by both Category and Year using the CUBE aggregate:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY CUBE(Category, Year) ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
-------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Books | | 99.96
Electricity | 2005 | 109.99
Electricity | 2006 | 109.99
Electricity | 2007 | 229.98
Electricity | | 449.96
| 2005 | 149.97
| 2006 | 109.99
| 2007 | 259.97
| 2008 | 29.99
| | 549.92
The results include subtotals for each category and year, and a grand total ($549.92).
Using CUBE with the HAVING clause
This example shows how you can restrict the GROUP BY results, use the HAVING clause with the CUBE aggregate. This query returns only the category totals and the full total:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY CUBE(Category,Year) HAVING GROUPING(Year)=1;
Category | Year | SUM
-------------+------+--------
Books | | 99.96
Electricity | | 449.96
| | 549.92
The next query returns only the aggregations for the two categories for each year. The GROUPING ID function specifies to omit the grand total ($549.92):
=> SELECT Category, Year, SUM (Amount) FROM expenses
GROUP BY CUBE(Category,Year) HAVING GROUPING_ID(Category,Year)<2
ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Books | | 99.96
Electrical | 2005 | 109.99
Electrical | 2006 | 109.99
Electrical | 2007 | 229.98
Electrical | | 449.96
See also
7.38.3.2 - GROUPING SETS aggregate
The GROUPING SETS aggregate is an extension to the GROUP BY clause that automatically performs subtotal aggregations on groupings that you specify.
The GROUPING SETS aggregate is an extension to the
GROUP BY clause that automatically performs subtotal aggregations on groupings that you specify.
You can use the GROUPING SETS clause with three grouping functions:
To sort data, use the
ORDER BY clause. The ORDER BY clause must follow the GROUP BY clause.
Syntax
GROUP BY group-expression[,...]
Parameters
group-expression``- One or both of the following:
-
An expression that is not an aggregate or a grouping function that includes constants and column references in FROM-specified tables. For example:
column1, (column2+1), column3+column4
-
A multilevel expression, one of the following:
-
ROLLUP
-
CUBE
-
GROUPING SETS
Defining the groupings
GROUPING SETS allows you to specify exactly which groupings you want in the results. You can also concatenate the groupings as follows:
The following example clauses result in the groupings shown.
|
This clause... |
Defines groupings... |
...GROUP BY GROUPING SETS(A,B,C,D)... |
(A), (B), (C), (D) |
...GROUP BY GROUPING SETS((A),(B),(C),(D))... |
(A), (B), (C), (D) |
...GROUP BY GROUPING SETS((A,B,C,D))... |
(A, B, C, D) |
...GROUP BY GROUPING SETS(A,B),GROUPING SETS(C,D)... |
(A, C), (B, C), (A, D), (B, C) |
...GROUP BY GROUPING SETS((A,B)),GROUPING SETS(C,D)... |
(A, B, C), (A, B, D) |
...GROUP BY GROUPING SETS(A,B),GROUPING SETS(ROLLUP(C,D))... |
(A,B), (A,B,C), (A,B,C,D) |
...GROUP BY A,B,C,GROUPING SETS(ROLLUP(C, D))... |
(A, B, C, D), (A, B, C), (A, B, C)
The clause contains two groups (A, B, C). In the HAVING clause, use the GROUP_ID function as a predicate, to eliminate the second grouping.
|
Example: selecting groupings
This example shows how to select only those groupings you want. Suppose you want to aggregate on columns only, and you do not need the grand total. The first query omits the total. In the second query, you add () to the GROUPING SETS list to get the total. Use the ORDER BY clause to sort the results by grouping:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY GROUPING SETS((Category, Year), (Year))
ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Electrical | 2005 | 109.99
Electrical | 2006 | 109.99
Electrical | 2007 | 229.98
| 2005 | 149.97
| 2006 | 109.99
| 2007 | 259.97
| 2008 | 29.99
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY GROUPING SETS((Category, Year), (Year), ())
ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Electrical | 2005 | 109.99
Electrical | 2006 | 109.99
Electrical | 2007 | 229.98
| 2005 | 149.97
| 2006 | 109.99
| 2007 | 259.97
| 2008 | 29.99
| | 549.92
See also
7.38.3.3 - ROLLUP aggregate
Automatically performs subtotal aggregations as an extension to the GROUP BY clause.
Automatically performs subtotal aggregations as an extension to the GROUP BY clause. ROLLUP performs these aggregations across multiple dimensions, at different levels, within a single SQL query.
You can use the ROLLUP clause with three grouping functions:
Syntax
ROLLUP grouping-expression[,...]
Parameters
group-expression- One or both of the following:
-
An expression that is not an aggregate or a grouping function that includes constants and column references in FROM-specified tables. For example:
column1, (column2+1), column3+column4
-
A multilevel expression, one of the following:
-
ROLLUP
-
CUBE
-
GROUPING SETS
Restrictions
GROUP BY ROLLUP does not sort results. To sort data, an ORDER BY clause must follow the GROUP BY clause.
Levels of aggregation
If n is the number of grouping columns, ROLLUP creates n+1 levels of subtotals and grand total. Because ROLLUP removes the right-most column at each step, specify column order carefully.
Suppose that ROLLUP(A, B, C) creates four groups:
Because ROLLUP removes the right-most column at each step, there are no groups for (A, C) and (B, C).
If you enclose two or more columns in parentheses, GROUP BY treats them as a single entity. For example:
-
ROLLUP(A, B, C) creates four groups:
(A, B, C)
(A, B)
(A)
()
-
ROLLUP((A, B), C) treats (A, B) as a single entity and creates three groups:
(A, B, C)
(A, B)
()
Example: aggregating the full data set
The following example shows how to use the GROUP BY clause to determine family expenses for electricity and books over several years. The SUM aggregate function computes the total amount of money spent in each category per year.
Suppose you have a table that contains information about family expenses for books and electricity:
=> SELECT * FROM expenses ORDER BY Category, Year;
Year | Category | Amount
------+-------------+--------
2005 | Books | 39.98
2007 | Books | 29.99
2008 | Books | 29.99
2005 | Electricity | 109.99
2006 | Electricity | 109.99
2007 | Electricity | 229.98
For the expenses table, ROLLUP computes the subtotals in each category between 2005–2007:
-
Books: $99.96
-
Electricity: $449.96
-
Grand total: $549.92.
Use the ORDER BY clause to sort the results:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY ROLLUP(Category, Year) ORDER BY 1,2, GROUPING_ID();
Category | Year | SUM
-------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Books | | 99.96
Electricity | 2005 | 109.99
Electricity | 2006 | 109.99
Electricity | 2007 | 229.98
Electricity | | 449.96
| | 549.92
Example: using ROLLUP with the HAVING clause
This example shows how to use the HAVING clause with ROLLUP to restrict the GROUP BY results. The following query produces only those ROLLUP categories where year is subtotaled, based on the expression in the GROUPING function:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY ROLLUP(Category,Year) HAVING GROUPING(Year)=1
ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
-------------+------+--------
Books | | 99.96
Electricity | | 449.96
| | 549.92
The next example rolls up on (Category, Year), but not on the full results. The GROUPING_ID function specifies to aggregate less than three levels:
=> SELECT Category, Year, SUM(Amount) FROM expenses
GROUP BY ROLLUP(Category,Year) HAVING GROUPING_ID(Category,Year)<3
ORDER BY 1, 2, GROUPING_ID();
Category | Year | SUM
-------------+------+--------
Books | 2005 | 39.98
Books | 2007 | 29.99
Books | 2008 | 29.99
Books | | 99.96
Electricity | 2005 | 109.99
Electricity | 2006 | 109.99
Electricity | 2007 | 229.98
Electricity | | 449.96
See also
7.38.4 - HAVING clause
Filters the results of a GROUP BY clause.
Filters the results of a GROUP BY clause. Semantically, the HAVING clause occurs after the GROUP BY operation. It was added to the SQL standard because a WHERE clause cannot specify aggregate functions.
Syntax
HAVING condition[,...]
Parameters
condition- Unambiguously references a grouping column, unless the reference appears in an aggregate function.
Examples
The following example returns the employees with salaries greater than $800,000:
=> SELECT employee_last_name, MAX(annual_salary) as highest_salary FROM employee_dimension
GROUP BY employee_last_name HAVING MAX(annual_salary) > 800000 ORDER BY highest_salary DESC;
employee_last_name | highest_salary
--------------------+----------------
Sanchez | 992363
Vogel | 983634
Vu | 977716
Lewis | 957949
Taylor | 953373
King | 937765
Gauthier | 927335
Garnett | 903104
Bauer | 901181
Jones | 885395
Rodriguez | 861647
Young | 846657
Greenwood | 837543
Overstreet | 831317
Garcia | 811231
(15 rows)
7.38.5 - INTERSECT clause
Calculates the intersection of the results of two or more SELECT queries.
Calculates the intersection of the results of two or more SELECT queries. INTERSECT returns distinct values by both the query on the left and right sides of the INTERSECT operand.
Syntax
select-stmt
INTERSECT query[...]
[ order-by-clause [ offset-clause ]]
[ limit-clause ]
Notes
-
Use the INTERSECT clause to return all elements that are common to the results of all the SELECT queries. The INTERSECT query operates on the results of two or more SELECT queries. INTERSECT returns only the rows that are returned by all the specified queries.
-
You cannot use the ALL keyword with an INTERSECT query.
-
The results of each SELECT query must be union compatible; they must return the same number of columns, and the corresponding columns must have compatible data types. For example, you cannot use the INTERSECT clause on a column of type INTEGER and a column of type VARCHAR. If the SELECT queries do not meet these criteria, Vertica returns an error.
Note
The
Data type coercion chart lists the data types that can be cast to other data types. If one data type can be cast to the other, those two data types are compatible.
-
Order the results of an INTERSECT operation by using an ORDER BY clause. In the ORDER BY list, specify the column names from the leftmost SELECT statement or specify integers that indicate the position of the columns by which to sort.
-
You can use INTERSECT in FROM, WHERE, and HAVING clauses.
-
The rightmost ORDER BY, LIMIT, or OFFSET clauses in an INTERSECT query do not need to be enclosed in parentheses because the rightmost query specifies that Vertica perform the operation on the results of the INTERSECT operation. Any ORDER BY, LIMIT, or OFFSET clauses contained in SELECT queries that appear earlier in the INTERSECT query must be enclosed in parentheses.
-
The order by column names is from the first select.
-
Vertica supports INTERSECT noncorrelated subquery predicates. For example:
=> SELECT * FROM T1
WHERE T1.x IN
(SELECT MAX(c1) FROM T2
INTERSECT
SELECT MAX(cc1) FROM T3
INTERSECT
SELECT MAX(d1) FROM T4);
Examples
Consider the following three tables:
Company_A
id emp_lname dept sales
------+------------+----------------+-------
1234 | Stephen | auto parts | 1000
5678 | Alice | auto parts | 2500
9012 | Katherine | floral | 500
3214 | Smithson | sporting goods | 1500
Company_B
id emp_lname dept sales
------+------------+-------------+-------
4321 | Marvin | home goods | 250
9012 | Katherine | home goods | 500
8765 | Bob | electronics | 20000
3214 | Smithson | home goods | 1500
Company_C
id | emp_lname | dept | sales
------+-----------+----------------+-------
3214 | Smithson | sporting goods | 1500
5432 | Madison | sporting goods | 400
7865 | Cleveland | outdoor | 1500
1234 | Stephen | floral | 1000
The following query returns the IDs and last names of employees that exist in both Company_A and Company_B:
=> SELECT id, emp_lname FROM Company_A
INTERSECT
SELECT id, emp_lname FROM Company_B;
id | emp_lname
------+-----------
3214 | Smithson
9012 | Katherine
(2 rows)
The following query returns the same two employees in descending order of sales:
=> SELECT id, emp_lname, sales FROM Company_A
INTERSECT
SELECT id, emp_lname, sales FROM Company_B
ORDER BY sales DESC;
id | emp_lname | sales
------+-----------+-------
3214 | Smithson | 1500
9012 | Katherine | 500
(2 rows)
The following query returns the employee who works for both companies whose sales in Company_B are greater than 1000:
=> SELECT id, emp_lname, sales FROM Company_A
INTERSECT
(SELECT id, emp_lname, sales FROM company_B WHERE sales > 1000)
ORDER BY sales DESC;
id | emp_lname | sales
------+-----------+-------
3214 | Smithson | 1500
(1 row)
In the following query returns the ID and last name of the employee who works for all three companies:
=> SELECT id, emp_lname FROM Company_A
INTERSECT
SELECT id, emp_lname FROM Company_B
INTERSECT
SELECT id, emp_lname FROM Company_C;
id | emp_lname
------+-----------
3214 | Smithson
(1 row)
The following query shows the results of a mismatched data types; these two queries are not union compatible:
=> SELECT id, emp_lname FROM Company_A
INTERSECT
SELECT emp_lname, id FROM Company_B;
ERROR 3429: For 'INTERSECT', types int and varchar are inconsistent
DETAIL: Columns: id and emp_lname
Using the VMart example database, the following query returns information about all Connecticut-based customers who bought items online and whose purchase amounts were between $400 and $500:
=> SELECT customer_key, customer_name from public.customer_dimension
WHERE customer_key IN (SELECT customer_key
FROM online_sales.online_sales_fact
WHERE sales_dollar_amount > 400
INTERSECT
SELECT customer_key FROM online_sales.online_sales_fact
WHERE sales_dollar_amount > 500)
AND customer_state = 'CT' ORDER BY customer_key;
customer_key | customer_name
--------------+------------------------
39 | Sarah S. Winkler
44 | Meghan H. Overstreet
70 | Jack X. Cleveland
103 | Alexandra I. Vu
110 | Matt . Farmer
173 | Mary R. Reyes
188 | Steve G. Williams
233 | Theodore V. McNulty
250 | Marcus E. Williams
294 | Samantha V. Young
313 | Meghan P. Pavlov
375 | Sally N. Vu
384 | Emily R. Smith
387 | Emily L. Garcia
...
The previous query and the next one are equivalent, and return the same results:
=> SELECT customer_key,customer_name FROM public.customer_dimension
WHERE customer_key IN (SELECT customer_key
FROM online_sales.online_sales_fact
WHERE sales_dollar_amount > 400
AND sales_dollar_amount < 500)
AND customer_state = 'CT' ORDER BY customer_key;
See also
7.38.6 - INTO TABLE clause
Creates a table from a query result set.
Creates a table from a query result set.
Syntax
Permanent table:
INTO [TABLE] [[{namespace. | database. }]schema.]table
Temporary table:
INTO [scope] TEMP[ORARY] [TABLE] [[database.]schema.]table
[ ON COMMIT { DELETE | PRESERVE } ROWS ]
Parameters
scope- Specifies visibility of a temporary table definition:
-
GLOBAL (default): The table definition is visible to all sessions, and persists until you explicitly drop the table.
-
LOCAL: The table definition is visible only to the session in which it is created, and is dropped when the session ends.
Regardless of this setting, retention of temporary table data is set by the keywords ON COMMIT DELETE ROWS and ON COMMIT PRESERVE ROWS (see below).
For more information, see Creating temporary tables.
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table- The name of the table to create.
-
ON COMMIT { DELETE | PRESERVE } ROWS
- Specifies whether data is transaction- or session-scoped:
-
DELETE (default) marks the temporary table for transaction-scoped data. Vertica removes all table data after each commit.
-
PRESERVE marks the temporary table for session-scoped data, which is preserved beyond the lifetime of a single transaction. Vertica removes all table data when the session ends.
Examples
The following SELECT statement has an INTO TABLE clause that creates table newTable from customer_dimension:
=> SELECT * INTO TABLE newTable FROM customer_dimension;
The following SELECT statement creates temporary table newTempTable. By default, temporary tables are created at a global scope, so its definition is visible to other sessions and persists until it is explicitly dropped. No customer_dimension data is copied into the new table, and Vertica issues a warning accordingly:
=> SELECT * INTO TEMP TABLE newTempTable FROM customer_dimension;
WARNING 4102: No rows are inserted into table "public"."newTempTable" because
ON COMMIT DELETE ROWS is the default for create temporary table
HINT: Use "ON COMMIT PRESERVE ROWS" to preserve the data in temporary table
CREATE TABLE
The following SELECT statement creates local temporary table newTempTableLocal. This table is visible only to the session in which it was created, and is automatically dropped when the session ends. The INTO TABLE clause includes ON COMMIT PRESERVE ROWS, so Vertica copies all selection data into the new table:
=> SELECT * INTO LOCAL TEMP TABLE newTempTableLocal ON COMMIT PRESERVE ROWS
FROM customer_dimension;
CREATE TABLE
7.38.7 - LIMIT clause
Specifies the maximum number of result set rows to return, either from the entire result set, or from windows of a partitioned result set.
Specifies the maximum number of result set rows to return, either from the entire result set, or from windows of a partitioned result set.
LIMIT { num-rows OVER ( PARTITION BY partition-expr[,...] ORDER BY order-expr[,...] ) }
| ALL }
Arguments
num-rows- The maximum number of rows to return.
OVER()- Specifies how to partition and sort input data with respect to the current row. The input data is the result set that the query returns after it evaluates FROM, WHERE, GROUP BY, and HAVING clauses.
For details, see Using LIMIT with Window Partitioning below.
partition-expr- Column or expression returning a column to partition results by.
order-expr [ ASC | DESC ] [ NULLS { FIRST | LAST } ]- Column or expression returning the column to order results by. Each column can be sorted in ascending (default) or descending order, with nulls first or last.
ALL- Returns all rows, valid only when LIMIT is applied to the entire result set.
Limiting returned rows
LIMIT returns the specified number of rows from the queried dataset. Row precedence is determined by the query's ORDER BY clause. If you do not use an ORDER BY clause, the query returns an undefined subset of the result set.
When a SELECT statement specifies both LIMIT and OFFSET, Vertica first processes the OFFSET, and then applies LIMIT to the remaining rows.
The following query returns the first 10 rows of data, as ordered first by region and then by number of employees:
=> SELECT store_region, store_city||', '||store_state location, store_name, number_of_employees
FROM store.store_dimension WHERE number_of_employees <= 12
ORDER BY store_region, number_of_employees LIMIT 10;
store_region | location | store_name | number_of_employees
--------------+----------------+------------+---------------------
East | Stamford, CT | Store219 | 12
East | New Haven, CT | Store66 | 12
East | New York, NY | Store122 | 12
MidWest | South Bend, IN | Store134 | 10
MidWest | Evansville, IN | Store30 | 11
MidWest | Green Bay, WI | Store27 | 12
South | Mesquite, TX | Store124 | 10
South | Cape Coral, FL | Store18 | 11
South | Beaumont, TX | Store226 | 11
South | Houston, TX | Store33 | 11
(10 rows)
Using LIMIT with window partitioning
You can use LIMIT to apply window partitioning on query results and limit the number of rows that are returned in each window.
For example, the following query specifies window partitioning on the result set. LIMIT is set to 2, so each window partition can return no more than two rows. The OVER clause partitions the result set by store_region, so in each region the query returns the two stores with the smallest number of employees:
=> SELECT store_region, store_city||', '||store_state location, store_name, number_of_employees
FROM store.store_dimension
LIMIT 2
OVER (PARTITION BY store_region ORDER BY number_of_employees ASC);
store_region | location | store_name | number_of_employees
--------------+---------------------+------------+---------------------
West | Norwalk, CA | Store43 | 10
West | Lancaster, CA | Store95 | 11
East | Stamford, CT | Store219 | 12
East | New York, NY | Store122 | 12
SouthWest | North Las Vegas, NV | Store170 | 10
SouthWest | Phoenix, AZ | Store228 | 11
NorthWest | Bellevue, WA | Store200 | 19
NorthWest | Portland, OR | Store39 | 22
MidWest | South Bend, IN | Store134 | 10
MidWest | Evansville, IN | Store30 | 11
South | Mesquite, TX | Store124 | 10
South | Beaumont, TX | Store226 | 11
(12 rows)
7.38.8 - MATCH clause
A SQL extension that lets you screen large amounts of historical data in search of event patterns, the MATCH clause provides subclasses for analytic partitioning and ordering and matches rows from the result table based on a pattern you define.
A SQL extension that lets you screen large amounts of historical data in search of event patterns, the MATCH clause provides subclasses for analytic partitioning and ordering and matches rows from the result table based on a pattern you define.
You specify a pattern as a regular expression, which is composed of event types defined in the DEFINE subclause, where each event corresponds to a row in the input table. Then you can search for the pattern within a sequence of input events. Pattern matching returns the contiguous sequence of rows that conforms to PATTERN subclause. For example, pattern P (A B* C) consist of three event types: A, B, and C. When Vertica finds a match in the input table, the associated pattern instance must be an event of type A followed by 0 or more events of type B, and an event of type C.
Pattern matching is particularly useful for clickstream analysis where you might want to identify users' actions based on their Web browsing behavior (page clicks). For details, see Event series pattern matching.
Syntax
MATCH ( [ PARTITION BY table-column ] ORDER BY table-column
DEFINE event-name AS boolean-expr [,...]
PATTERN pattern-name AS ( regexp)
[ rows-match-clause ] )
Arguments
PARTITION BY- Defines the window data scope in which the pattern, defined in the PATTERN subclause, is matched. The partition clause partitions the data by matched patterns defined in the PATTERN subclause. For each partition, data is sorted by the ORDER BY clause. If the partition clause is omitted, the entire data set is considered a single partition.
ORDER BY- Defines the window data scope in which the pattern, defined in the PATTERN subclause, is matched. For each partition, the order clause specifies how the input data is ordered for pattern matching.
Note
The ORDER BY clause is mandatory.
DEFINE- Defines the boolean expressions that make up the event types in the regular expressions. For example:
DEFINE
Entry AS RefURL NOT ILIKE '%website2.com%' AND PageURL ILIKE
'%website2.com%',
Onsite AS PageURL ILIKE '%website2.com%' AND Action='V',
Purchase AS PageURL ILIKE '%website2.com%' AND Action='P'
The DEFINE subclause accepts a maximum of 52 events. See Event series pattern matching for examples.
event-name- Name of the event to evaluate for each row—in the earlier example,
Entry, Onsite, Purchase.
Note
Event names are case insensitive and follow the same naming conventions as those used for tables and columns.
boolean-expr- Expression that returns true or false. boolean_expr can include Logical operators and relational (comparison) operators. For example:
Purchase AS PageURL ILIKE '%website2.com%' AND Action = 'P'
PATTERN pattern-name- Name of the pattern defined in the PATTERN subclause; for example, P is the pattern name defined below:
PATTERN P AS (...)
A PATTERN is a search pattern that is comprised of a name and a regular expression.
Note
Vertica supports one pattern per query.
regexp- A regular expression comprised of event types defined in the
DEFINE subclause and one or more quantifiers below. When Vertica evaluates the MATCH clause, the regular expression identifies the rows that meet the expression criteria.
-
*: Match 0 or more times
-
*?: Match 0 or more times, not greedily
-
+: Match 1 or more times
-
+?: Match 1 or more times, not greedily
-
?: Match 0 or 1 time
-
??: Match 0 or 1 time, not greedily
-
*+: Match 0 or more times, possessive
-
++: Match 1 or more times, possessive
-
?+: Match 0 or 1 time, possessive
-
|: Alternation. Matches expression before or after the vertical bar. Similar to a Boolean OR.
rows-match-clause- Specifies how to resolve more than one event evaluating to true for a single row, one of the following:
-
ROWS MATCH ALL EVENTS: If more than one event evaluates to true for a single row, Vertica returns this error :
ERROR: pattern events must be mutually exclusive
HINT: try using ROWS MATCH FIRST EVENT
-
ROWS MATCH FIRST EVENT: If more than one event evaluates to true for a given row, Vertica uses the first event in the SQL statement for that row.
Pattern semantic evaluation
-
The semantic evaluating ordering of the SQL clauses is: FROM -> WHERE -> PATTERN MATCH -> SELECT.
-
Data is partitioned as specified in the PARTITION BY clause. If the partition clause is omitted, the entire data set is considered a single partition.
-
For each partition, the order clause specifies how the input data is ordered for pattern matching.
-
Events are evaluated for each row. A row could have 0, 1, or N events evaluate to true. If more than one event evaluates to true for the same row, Vertica returns a run-time error unless you specify ROWS MATCH FIRST EVENT. If you specify ROWS MATCH FIRST EVENT and more than one event evaluates to TRUE for a single row, Vertica chooses the event that was defined first in the SQL statement to be the event it uses for the row.
-
Vertica performs pattern matching by finding the contiguous sequence of rows that conforms to the pattern defined in the PATTERN subclause.
For each match, Vertica outputs the rows that contribute to the match. Rows not part of the match (do not satisfy one or more predicates) are not output.
-
Vertica reports only non-overlapping matches. If an overlap occurs, Vertica chooses the first match found in the input stream. After finding the match, Vertica looks for the next match, starting at the end of the previous match.
-
Vertica reports the longest possible match, not a subset of a match. For example, consider pattern: AB with input: AAAB. Because A uses the greedy regular expression quantifier (), Vertica reports all A inputs (AAAB), not AAB, AB, or B.
Notes and restrictions
-
DISTINCT and GROUP BY/HAVING clauses are not allowed in pattern match queries.
-
The following expressions are not allowed in the DEFINE subclause:
-
Subqueries, such as DEFINE X AS c IN ELECT c FROM table
-
Analytic functions, such as DEFINE X AS c < LEA1) OVER (ORDER BY 1)
-
Aggregate functions, such as DEFINE X AS c < MA1)
-
You cannot use the same pattern name to define a different event; for example, the following is not allowed for X:
DEFINE X AS c1 < 3
X AS c1 >= 3
-
Used with MATCH clause, Vertica MATCH clause functions provide additional data about the patterns it finds. For example, you can use the functions to return values representing the name of the event that matched the input row, the sequential number of the match, or a partition-wide unique identifier for the instance of the pattern that matched.
Examples
For examples, see Event series pattern matching.
See also
7.38.8.1 - Event series pattern matching
The SQL MATCH clause syntax lets you screen large amounts of historical data in search of event patterns.
The SQL MATCH clause syntax lets you screen large amounts of historical data in search of event patterns. You specify a pattern as a regular expression and can then search for the pattern within a sequence of input events. MATCH provides subclauses for analytic data partitioning and ordering, and the pattern matching occurs on a contiguous set of rows.
Pattern matching is particularly useful for clickstream analysis where you might want to identify users' actions based on their Web browsing behavior (page clicks). A typical online clickstream funnel is:
Company home page -> product home page -> search -> results -> purchase online
Using this clickstream funnel, you can search for a match on the user's sequence of web clicks and identify that user:
-
Landed on the company home page
-
Navigated to the product page
-
Ran a search
-
Clicked a link from the search results
-
Made a purchase
Clickstream funnel schema
The examples in this topic use this clickstream funnel and the following clickstream_log table schema:
=> CREATE TABLE clickstream_log (
uid INT, --user ID
sid INT, --browsing session ID, produced by previous sessionization computation
ts TIME, --timestamp that occurred during the user's page visit
refURL VARCHAR(20), --URL of the page referencing PageURL
pageURL VARCHAR(20), --URL of the page being visited
action CHAR(1) --action the user took after visiting the page ('P' = Purchase, 'V' = View)
);
INSERT INTO clickstream_log VALUES (1,100,'12:00','website1.com','website2.com/home', 'V');
INSERT INTO clickstream_log VALUES (1,100,'12:01','website2.com/home','website2.com/floby', 'V');
INSERT INTO clickstream_log VALUES (1,100,'12:02','website2.com/floby','website2.com/shamwow', 'V');
INSERT INTO clickstream_log values (1,100,'12:03','website2.com/shamwow','website2.com/buy', 'P');
INSERT INTO clickstream_log values (2,100,'12:10','website1.com','website2.com/home', 'V');
INSERT INTO clickstream_log values (2,100,'12:11','website2.com/home','website2.com/forks', 'V');
INSERT INTO clickstream_log values (2,100,'12:13','website2.com/forks','website2.com/buy', 'P');
COMMIT;
Here's the clickstream_log table's output:
=> SELECT * FROM clickstream_log;
uid | sid | ts | refURL | pageURL | action
-----+-----+----------+----------------------+----------------------+--------
1 | 100 | 12:00:00 | website1.com | website2.com/home | V
1 | 100 | 12:01:00 | website2.com/home | website2.com/floby | V
1 | 100 | 12:02:00 | website2.com/floby | website2.com/shamwow | V
1 | 100 | 12:03:00 | website2.com/shamwow | website2.com/buy | P
2 | 100 | 12:10:00 | website1.com | website2.com/home | V
2 | 100 | 12:11:00 | website2.com/home | website2.com/forks | V
2 | 100 | 12:13:00 | website2.com/forks | website2.com/buy | P
(7 rows)
Examples
This example includes the Vertica MATCH clause functions to analyze users' browsing history over website2.com. It identifies patterns where the user performed the following tasks:
-
Landed on website2.com from another web site (Entry)
-
Browsed to any number of other pages (Onsite)
-
Made a purchase (Purchase)
In the following statement, pattern P (Entry Onsite* Purchase) consist of three event types: Entry, Onsite, and Purchase. When Vertica finds a match in the input table, the associated pattern instance must be an event of type Entry followed by 0 or more events of type Onsite, and an event of type Purchase
=> SELECT uid,
sid,
ts,
refurl,
pageurl,
action,
event_name(),
pattern_id(),
match_id()
FROM clickstream_log
MATCH
(PARTITION BY uid, sid ORDER BY ts
DEFINE
Entry AS RefURL NOT ILIKE '%website2.com%' AND PageURL ILIKE '%website2.com%',
Onsite AS PageURL ILIKE '%website2.com%' AND Action='V',
Purchase AS PageURL ILIKE '%website2.com%' AND Action = 'P'
PATTERN
P AS (Entry Onsite* Purchase)
ROWS MATCH FIRST EVENT);
In the output below, the first four rows represent the pattern for user 1's browsing activity, while the following three rows show user 2's browsing habits.
uid | sid | ts | refurl | pageurl | action | event_name | pattern_id | match_id
-----+-----+----------+----------------------+----------------------+--------+------------+------------+----------
1 | 100 | 12:00:00 | website1.com | website2.com/home | V | Entry | 1 | 1
1 | 100 | 12:01:00 | website2.com/home | website2.com/floby | V | Onsite | 1 | 2
1 | 100 | 12:02:00 | website2.com/floby | website2.com/shamwow | V | Onsite | 1 | 3
1 | 100 | 12:03:00 | website2.com/shamwow | website2.com/buy | P | Purchase | 1 | 4
2 | 100 | 12:10:00 | website1.com | website2.com/home | V | Entry | 1 | 1
2 | 100 | 12:11:00 | website2.com/home | website2.com/forks | V | Onsite | 1 | 2
2 | 100 | 12:13:00 | website2.com/forks | website2.com/buy | P | Purchase | 1 | 3
(7 rows)
See also
7.38.9 - MINUS clause
MINUS is an alias for EXCEPT.
MINUS is an alias for EXCEPT.
7.38.10 - OFFSET clause
Omits a specified number of rows from the beginning of the result set.
Omits a specified number of rows from the beginning of the result set.
Syntax
OFFSET rows
Parameters
start-row- Specifies the first row to include in the result set. All preceding rows are omitted.
Dependencies
-
Use an ORDER BY clause with OFFSET. Otherwise, the query returns an undefined subset of the result set.
-
OFFSET must follow the ORDER BY clause in a SELECT statement or UNION clause.
-
When a SELECT statement or UNION clause specifies both LIMIT and OFFSET, Vertica first processes the OFFSET statement, and then applies the LIMIT statement to the remaining rows.
Examples
The following query returns 14 rows from the customer_dimension table:
=> SELECT customer_name, customer_gender FROM customer_dimension
WHERE occupation='Dancer' AND customer_city = 'San Francisco' ORDER BY customer_name;
customer_name | customer_gender
----------------------+-----------------
Amy X. Lang | Female
Anna H. Li | Female
Brian O. Weaver | Male
Craig O. Pavlov | Male
Doug Z. Goldberg | Male
Harold S. Jones | Male
Jack E. Perkins | Male
Joseph W. Overstreet | Male
Kevin . Campbell | Male
Raja Y. Wilson | Male
Samantha O. Brown | Female
Steve H. Gauthier | Male
William . Nielson | Male
William Z. Roy | Male
(14 rows)
If you modify the previous query to specify an offset of 8 (OFFSET 8), Vertica skips the first eight rows of the previous result set. The query returns the following results:
=> SELECT customer_name, customer_gender FROM customer_dimension
WHERE occupation='Dancer' AND customer_city = 'San Francisco' ORDER BY customer_name OFFSET 8;
customer_name | customer_gender
-------------------+-----------------
Kevin . Campbell | Male
Raja Y. Wilson | Male
Samantha O. Brown | Female
Steve H. Gauthier | Male
William . Nielson | Male
William Z. Roy | Male
(6 rows)
7.38.11 - ORDER BY clause
Sorts a query result set on one or more columns or column expressions.
Sorts a query result set on one or more columns or column expressions. Vertica uses the current locale and collation sequence to compare and sort string values.
Note
Vertica projection data is always stored sorted by the ASCII (binary) collating sequence.
Syntax
ORDER BY expression [ ASC | DESC ] [,...]
Parameters
expression - One of the following:
-
Name or ordinal number of a SELECT list item. The ordinal number refers to the position of the result column, counting from the left beginning at one. Use them to order by a column whose name is not unique. Ordinal numbers are invalid for an ORDER BY clause of an analytic function's OVER clause.
-
Arbitrary expression formed from columns that do not appear in the SELECT list
-
CASE expression.
Note
You cannot use DISTINCT on a collection column if it is also included in the sort order.
- ASC | DESC
- Specifies whether to sort values in ascending or descending order. NULL values are either first or last in the sort order, depending on data type:
-
INTEGER, INT, DATE/TIME: NULL has the smallest value.
-
FLOAT, BOOLEAN, CHAR, VARCHAR, ARRAY, SET: NULL has the largest value
Examples
The follow example returns all the city and deal size for customer Metamedia, sorted by deal size in descending order.
=> SELECT customer_city, deal_siz FROM customer_dimension WHERE customer_name = 'Metamedia'
ORDER BY deal_size DESC;
customer_city | deal_size
------------------+-----------
El Monte | 4479561
Athens | 3815416
Ventura | 3792937
Peoria | 3227765
Arvada | 2671849
Coral Springs | 2643674
Fontana | 2374465
Rancho Cucamonga | 2214002
Wichita Falls | 2117962
Beaumont | 1898295
Arvada | 1321897
Waco | 1026854
Joliet | 945404
Hartford | 445795
(14 rows)
The following example uses a transform function. It returns an error because the ORDER BY column is not in the window partition.
=> CREATE TABLE t(geom geometry(200), geog geography(200));
=> SELECT PolygonPoint(geom) OVER(PARTITION BY geom)
AS SEL_0 FROM t ORDER BY geog;
ERROR 2521: Cannot specify anything other than user defined transforms and partitioning expressions in the ORDER BY list
The following example, using the same table, corrects this error.
=> SELECT PolygonPoint(geom) OVER(PARTITION BY geom)
AS SEL_0 FROM t ORDER BY geom;
The following example uses an array in the ORDER BY clause.
=> SELECT * FROM employees
ORDER BY grant_values;
id | department | grants | grant_values
----+------------+--------------------------+----------------
36 | Astronomy | ["US-7376","DARPA-1567"] | [5000,4000]
36 | Physics | ["US-7376","DARPA-1567"] | [10000,25000]
33 | Physics | ["US-7376"] | [30000]
42 | Physics | ["US-7376","DARPA-1567"] | [65000,135000]
(4 rows)
7.38.12 - TIMESERIES clause
Provides gap-filling and interpolation (GFI) computation, an important component of time series analytics computation.
Provides gap-filling and interpolation (GFI) computation, an important component of time series analytics computation. See Time series analytics for details and examples.
Syntax
TIMESERIES slice-time AS 'length-and-time-unit-expr' OVER (
[ PARTITION BY column-expr[,...] ] ORDER BY time-expr ) [ ORDER BY table-column[,...] ]
Parameters
slice-time- A time column produced by the
TIMESERIES clause, which stores the time slice start times generated from gap filling.
Note: This parameter is an alias, so you can use any name that an alias would take.
length-and-time-unit-expr- An
INTERVAL DAY TO SECOND literal that specifies the length of time unit of time slice computation. For example:
`TIMESERIES slice_time AS '3 seconds' ...
OVER()- Specifies partitioning and ordering for the function.
OVER() also specifies that the time series function operates on a query result set—that is, the rows that are returned after the FROM, WHERE, GROUP BY, and HAVING clauses are evaluated.
-
PARTITION BY (column-expr`[,...] )`
- Partitions the data by the specified column expressions. Gap filling and interpolation is performed on each partition separately.
ORDER BY time-expr- Sorts the data by the
TIMESTAMP expression time-expr, which computes the time information of the time series data.
Note
The TIMESERIES clause requires an ORDER BY operation on the timestamp column.
Notes
If the window-partition-clause is not specified in TIMESERIES OVER(), for each defined time slice, exactly one output record is produced; otherwise, one output record is produced per partition per time slice. Interpolation is computed there.
Given a query block that contains a TIMESERIES clause, the following are the semantic phases of execution (after evaluating the FROM and the optional WHERE clauses):
-
Compute time-expression.
-
Perform the same computation as the TIME_SLICE() function on each input record based on the result of time-exp and 'length-and-time-unit-expr'.
-
Perform gap filling to generate time slices missing from the input.
-
Name the result of this computation as slice_time, which represents the generated "time series" column (alias) after gap filling.
-
Partition the data by expression, slice-time. For each partition, do step 4.
-
Sort the data by time-expr. Interpolation is computed here.
There is semantic overlap between the TIMESERIES clause and the TIME_SLICE function with the following key differences:
-
TIMESERIES only supports the interval qualifier DAY TO SECOND; it does not allow YEAR TO MONTH.
-
Unlike TIME_SLICE, the time slice length and time unit expressed in *length-and-time-unit-expr *must be constants so gaps in the time slices are well-defined.
-
TIMESERIES performs gap filling; the TIME_SLICE function does not.
-
TIME_SLICE can return the start or end time of a time slice, depending on the value of its fourth input parameter (start-or-end). TIMESERIES, on the other hand, always returns the start time of each time slice. To output the end time of each time slice, write a SELECT statement like the following:
=> SELECT slice_time + <slice_length>;
Restrictions
-
When the TIMESERIES clause occurs in a SQL query block, only the following clauses can be used in the same query block:
-
SELECT
-
FROM
-
WHERE
-
ORDER BY
GROUP BY and HAVING clauses are not allowed. If a GROUP BY operation is needed before or after gap-filling and interpolation (GFI), use a subquery and place the GROUP BY In the outer query. For example:
=> SELECT symbol, AVG(first_bid) as avg_bid FROM (
SELECT symbol, slice_time, TS_FIRST_VALUE(bid1) AS first_bid
FROM Tickstore
WHERE symbol IN ('MSFT', 'IBM')
TIMESERIES slice_time AS '5 seconds' OVER (PARTITION BY symbol ORDER BY ts)
) AS resultOfGFI
GROUP BY symbol;
-
When the TIMESERIES clause is present in the SQL query block, the SELECT list can include only the following:
For example, the following two queries return a syntax error because bid1 is not a PARTITION BY or GROUP BY column:
=> SELECT bid, symbol, TS_FIRST_VALUE(bid) FROM Tickstore
TIMESERIES slice_time AS '5 seconds' OVER (PARTITION BY symbol ORDER BY ts);
ERROR: column "Tickstore.bid" must appear in the PARTITION BY list of Timeseries clause or be used in a Timeseries Output function
=> SELECT bid, symbol, AVG(bid) FROM Tickstore
GROUP BY symbol;
ERROR: column "Tickstore.bid" must appear in the GROUP BY clause or be used in an aggregate function
Examples
For examples, see Gap filling and interpolation (GFI).
See also
7.38.13 - UNION clause
Combines the results of multiple SELECT statements.
Combines the results of multiple SELECT statements. You can include UNION in FROM, WHERE, and HAVING clauses.
Syntax
select { UNION [ ALL | DISTINCT ] select }[...]
[ order-by-clause [ offset-clause ]]
[ limit-clause ]
Arguments
select- A SELECT statement that returns one or more rows, depending on whether you specify keywords DISTINCT or ALL.
The first SELECT statement can include the LABEL hint. Vertica ignores LABEL hints in subsequent SELECT statements.
Each SELECT statement can specify its own ORDER BY, LIMIT, and OFFSET clauses. A SELECT statement with one or more of these clauses must be enclosed by parentheses. See also: ORDER BY, LIMIT, and OFFSET Clauses in UNION.
DISTINCT, ALL- How to return duplicate rows:
-
DISTINCT (default) returns only unique rows.
-
ALL concatenates all rows, including duplicates. For best performance, use UNION ALL.
UNION ALL supports columns of complex types; UNION DISTINCT does not.
Requirements
-
Each row of the UNION result set must be in the result set of at least one of its SELECT statements.
-
Each SELECT statement must specify the same number of columns.
-
Data types of corresponding SELECT statement columns must be compatible, otherwise Vertica returns an error.
ORDER BY, LIMIT, and OFFSET clauses in UNION
A UNION statement can specify its own ORDER BY, LIMIT, and OFFSET clauses, as in the following example:
=> SELECT id, emp_name FROM company_a UNION ALL SELECT id, emp_name FROM company_b ORDER BY emp_name LIMIT 2;
id | emp_name
------+----------
5678 | Alice
8765 | Bob
(2 rows)
Each SELECT statement in a UNION clause can specify its own ORDER BY, LIMIT, and OFFSET clauses. Vertica processes the SELECT statement clauses before it processes the UNION clauses. In the following example, Vertica processes the individual queries and then concatenates the two result sets:
=> (SELECT id, emp_name FROM company_a ORDER BY emp_name LIMIT 2)
UNION ALL
(SELECT id, emp_name FROM company_b ORDER BY emp_name LIMIT 2);
id | emp_name
------+-----------
5678 | Alice
9012 | Katherine
8765 | Bob
9012 | Katherine
(4 rows)
The following requirements and restrictions determine how Vertica processes a UNION clause that contains ORDER BY, LIMIT, and OFFSET clauses:
-
A UNION's ORDER BY clause must specify columns from the first (leftmost) SELECT statement.
-
ORDER BY must precede LIMIT and OFFSET.
-
When a SELECT or UNION statement specifies both LIMIT and OFFSET, Vertica first processes the OFFSET statement, and then applies the LIMIT statement to the remaining rows.
Vertica supports UNION in noncorrelated subquery predicates. For example:
=> SELECT DISTINCT customer_key, customer_name FROM public.customer_dimension
WHERE customer_key IN
(SELECT customer_key FROM store.store_sales_fact WHERE sales_dollar_amount > 500
UNION ALL
SELECT customer_key FROM online_sales.online_sales_fact WHERE sales_dollar_amount > 500)
AND customer_state = 'CT';
customer_key | customer_name
--------------+------------------------
7021 | Luigi T. Dobisz
1971 | Betty V. Dobisz
46284 | Ben C. Gauthier
33885 | Tanya Y. Taylor
5449 | Sarah O. Robinson
29059 | Sally Z. Fortin
11200 | Foodhope
15582 | John J. McNulty
24638 | Alexandra F. Jones
...
UNION ALL with complex types
You can use UNION ALL with complex types. Consider a table with the following definition:
=> CREATE TABLE restaurants(
name VARCHAR, cuisine VARCHAR,
locations ARRAY[ROW(city VARCHAR(50), state VARCHAR(2)),50],
menu ARRAY[ROW(item VARCHAR(50), price FLOAT),100] );
Suppose you are in a new city looking for a place to eat. The database has information about the following restaurants:
=> SELECT name, cuisine FROM restaurants
WHERE CONTAINS(locations,ROW('Pittsburgh', 'PA'));
name | cuisine
-------------------+----------
Bakersfield Tacos | Mexican
Bob's pizzeria | Italian
Succulent Steaks | American
Sushi House | Asian
Villa Milano | Italian
(5 rows)
Suppose you are hungry for Italian food. If you cannot have Italian, you want something inexpensive. The following query uses two SELECT clauses from the same table, one finding menu items for Italian restaurants and one finding menu items under $10:
=> WITH menu_entries AS
(SELECT name, cuisine,
EXPLODE(menu USING PARAMETERS skip_partitioning=true) AS (idx, menu_entry)
FROM restaurants WHERE CONTAINS(locations,ROW('Pittsburgh', 'PA')))
SELECT name, cuisine, menu_entry FROM menu_entries WHERE cuisine = 'Italian'
UNION ALL
SELECT name, cuisine, menu_entry FROM menu_entries WHERE menu_entry.price <= 10;
name | cuisine | menu_entry
-------------------+---------+--------------------------------------------
Bob's pizzeria | Italian | {"item":"cheese pizza","price":8.25}
Bob's pizzeria | Italian | {"item":"spinach pizza","price":10.5}
Villa Milano | Italian | {"item":"pasta carbonara","price":24.99}
Villa Milano | Italian | {"item":"eggplant parmesan","price":23.49}
Villa Milano | Italian | {"item":"herbed salmon","price":28.99}
Bakersfield Tacos | Mexican | {"item":"veggie taco","price":9.95}
Bob's pizzeria | Italian | {"item":"cheese pizza","price":8.25}
(7 rows)
You cannot use LIMIT OVER with UNION ALL if the selected columns are of complex types. In this case, the statement returns an error like "Multi-value expressions are not supported in this context". You can still use LIMIT OVER in a single SELECT statement by using parentheses to make the scoping explicit.
Examples
The examples that follow use these two tables:
=> SELECT * FROM company_a;
ID emp_name dept sales
------+------------+-------------+-------
1234 | Stephen | auto parts | 1000
5678 | Alice | auto parts | 2500
9012 | Katherine | floral | 500
=> SELECT * FROM company_b;
ID emp_name dept sales
------+------------+-------------+-------
4321 | Marvin | home goods | 250
9012 | Katherine | home goods | 500
8765 | Bob | electronics | 20000
The following query finds all employee IDs and names from the two tables. The UNION statement uses DISTINCT to combine unique IDs and last names of employees. Katherine works for both companies, so she appears only once in the result set. DISTINCT is the default and can be omitted:
=> SELECT id, emp_name FROM company_a
UNION DISTINCT SELECT id, emp_name FROM company_b ORDER BY id;
id | emp_name
------+-----------
1234 | Stephen
4321 | Marvin
5678 | Alice
8765 | Bob
9012 | Katherine
(5 rows)
If the UNION statement instead uses ALL, the query returns two records for Katherine:
=> SELECT id, emp_name FROM company_a
UNION ALL SELECT id, emp_name FROM company_b ORDER BY id;
id | emp_name
------+-----------
1234 | Stephen
5678 | Alice
9012 | Katherine
4321 | Marvin
9012 | Katherine
8765 | Bob
(6 rows)
The following query returns the top two salespeople in each company. Each SELECT statement specifies its own ORDER BY and LIMIT clauses, and the UNION statement concatenates the result sets as returned by each query:
=> (SELECT id, emp_name, sales FROM company_a ORDER BY sales DESC LIMIT 2)
UNION ALL
(SELECT id, emp_name, sales FROM company_b ORDER BY sales DESC LIMIT 2);
id | emp_name | sales
------+-----------+-------
8765 | Bob | 20000
5678 | Alice | 2500
1234 | Stephen | 1000
9012 | Katherine | 500
(4 rows)
The following query returns all employees in both companies with an overall ordering. The ORDER BY clause is part of the UNION statement:
=> SELECT id, emp_name, sales FROM company_a
UNION
SELECT id, emp_name, sales FROM company_b
ORDER BY sales;
id | emp_name | sales
------+-----------+-------
4321 | Marvin | 250
9012 | Katherine | 500
1234 | Stephen | 1000
5678 | Alice | 2500
8765 | Bob | 20000
(5 rows)
The following query groups total sales by department within each company. Each SELECT statement has its own GROUP BY clause. UNION combines the aggregate results from each query:
=> (SELECT 'Company A' as company, dept, SUM(sales) FROM company_a
GROUP BY dept)
UNION
(SELECT 'Company B' as company, dept, SUM(sales) FROM company_b
GROUP BY dept)
ORDER BY 1;
company | dept | sum
-----------+-------------+-------
Company A | auto parts | 3500
Company A | floral | 500
Company B | electronics | 20000
Company B | home goods | 750
(4 rows)
See also
7.38.14 - WHERE clause
Specifies which rows to include in a query's result set.
Specifies which rows to include in a query's result set.
Syntax
WHERE boolean-expression [ subquery ]...
Arguments
boolean-expression- An expression that returns true or false. The result set only includes rows that evaluate to true. The expression can include boolean operators and the following predicate elements:
Use parentheses to group expressions, predicates, and boolean operators. For example:
... WHERE NOT (A=1 AND B=2) OR C=3;
Examples
The following example returns the names of all customers in the Eastern region whose name starts with the string Amer:
=> SELECT DISTINCT customer_name
FROM customer_dimension
WHERE customer_region = 'East'
AND customer_name ILIKE 'Amer%';
customer_name
---------------
Americare
Americom
Americore
Americorp
Ameridata
Amerigen
Amerihope
Amerimedia
Amerishop
Ameristar
Ameritech
(11 rows)
7.38.15 - WITH clause
A WITH clause defines one or more named common table expressions (CTEs), where each CTE encapsulates a result set that can be referenced by another CTE in the same WITH clause, or by the primary query.
A WITH clause defines one or more named common table expressions (CTEs), where each CTE encapsulates a result set that can be referenced by another CTE in the same WITH clause, or by the primary query. Vertica can evaluate WITH clauses in two ways:
- Inline expansion (default): Vertica evaluates each WITH clause every time it is referenced by the primary query.
- Materialization: Vertica evaluates each WITH clause once, stores results in a temporary table, and references this table as often as the query requires.
In both cases, WITH clauses can help simplify complicated queries and avoid statement repetition.
Syntax
WITH [ /*+ENABLE_WITH_CLAUSE_MATERIALIZATION */ ] [ RECURSIVE ] {
cte-identifier [ ( column-aliases ) ] AS (
[ subordinate-WITH-clause ]
query-expression )
} [,...]
Arguments
/*+ENABLE_WITH_CLAUSE_MATERIALIZATION*/- Enables materialization of all queries in the current WITH clause. Otherwise, materialization is set by configuration parameter WithClauseMaterialization, by default set to 0 (disabled). If WithClauseMaterialization is disabled, materialization is automatically cleared when the primary query of the WITH clause returns. For details, see Materialization of WITH clause.
RECURSIVE- Specifies to iterate over the WITH clause's own result set, through repeated execution of an embedded UNION or UNION ALL statement. For details, see WITH clause recursion.
cte-identifier- Identifies a common table expression (CTE) within a WITH clause. This identifier is available to CTEs of the same WITH clause, and of parent and child WITH clauses (if any). CTE identifiers of the outermost (primary) WITH clause are also available to the primary query.
All CTE identifiers of the same WITH clause must be unique. For example, the following WITH clause defines two CTEs, so they require unique identifiers: regional_sales and top_regions:
WITH
-- query sale amounts for each region
regional_sales AS (SELECT ... ),
top_regions AS ( SELECT ... )
)
column-aliases- A comma-delimited list of result set column aliases. The list of aliases must map to all column expressions in the CTE query. If omitted, result set columns can only be referenced by the names used in the query.
In the following example, the revenue CTE specifies two column aliases: vkey and total_revenue. These map to column vendor_key and aggregate expression SUM(total_order_cost), respectively. The primary query references these aliases:
WITH revenue ( vkey, total_revenue ) AS (
SELECT vendor_key, SUM(total_order_cost)
FROM store.store_orders_fact
GROUP BY vendor_key ORDER BY vendor_key)
SELECT v.vendor_name, v.vendor_address, v.vendor_city, r.total_revenue
FROM vendor_dimension v JOIN revenue r ON v.vendor_key = r.vkey
WHERE r.total_revenue = (SELECT MAX(total_revenue) FROM revenue )
ORDER BY vendor_name;
subordinate-WITH-clause- A WITH clause that is nested within the current one. CTEs of this WITH clause can only reference CTEs of the same clause, and of parent and child WITH clauses.
Important
The primary query can only reference CTEs in the outermost WITH clause. It cannot reference the CTEs of any nested WITH clause.
query-expression- The query of a given CTE.
Restrictions
WITH clauses only support SELECT and INSERT statements. They do not support UPDATE or DELETE statements.
Examples
Single WITH clause with single CTE
The following SQL defines a WITH clause with one CTE, revenue, which aggregates data in table store.store_orders_fact. The primary query references the WITH clause result set twice: in its JOIN clause and predicate:
-- define WITH clause
WITH revenue ( vkey, total_revenue ) AS (
SELECT vendor_key, SUM(total_order_cost)
FROM store.store_orders_fact
GROUP BY vendor_key ORDER BY 1)
-- End WITH clause
-- primary query
SELECT v.vendor_name, v.vendor_address, v.vendor_city, r.total_revenue
FROM vendor_dimension v JOIN revenue r ON v.vendor_key = r.vkey
WHERE r.total_revenue = (SELECT MAX(total_revenue) FROM revenue )
ORDER BY vendor_name;
vendor_name | vendor_address | vendor_city | total_revenue
------------------+----------------+-------------+---------------
Frozen Suppliers | 471 Mission St | Peoria | 49877044
(1 row)
Single WITH clause and multiple CTEs
In the following example, the WITH clause contains two CTEs:
The primary query aggregates sales by region and departments in the top_regions result set:
WITH
-- query sale amounts for each region
regional_sales (region, total_sales) AS (
SELECT sd.store_region, SUM(of.total_order_cost) AS total_sales
FROM store.store_dimension sd JOIN store.store_orders_fact of ON sd.store_key = of.store_key
GROUP BY store_region ),
-- query previous result set
top_regions AS (
SELECT region, total_sales
FROM regional_sales ORDER BY total_sales DESC LIMIT 3
)
-- primary query
-- aggregate sales in top_regions result set
SELECT sd.store_region AS region, pd.department_description AS department, SUM(of.total_order_cost) AS product_sales
FROM store.store_orders_fact of
JOIN store.store_dimension sd ON sd.store_key = of.store_key
JOIN public.product_dimension pd ON of.product_key = pd.product_key
WHERE sd.store_region IN (SELECT region FROM top_regions)
GROUP BY ROLLUP (region, department) ORDER BY region, product_sales DESC, GROUPING_ID();
region | department | product_sales
---------+----------------------------------+---------------
East | | 1716917786
East | Meat | 189837962
East | Produce | 170607880
East | Photography | 162271618
East | Frozen Goods | 141077867
East | Gifts | 137604397
East | Bakery | 136497842
East | Liquor | 130410463
East | Canned Goods | 128683257
East | Cleaning supplies | 118996326
East | Dairy | 118866901
East | Seafood | 109986665
East | Medical | 100404891
East | Pharmacy | 71671717
MidWest | | 1287550770
MidWest | Meat | 141446607
MidWest | Produce | 125156100
MidWest | Photography | 122666753
MidWest | Frozen Goods | 105893534
MidWest | Gifts | 103088595
MidWest | Bakery | 102844467
MidWest | Canned Goods | 97647270
MidWest | Liquor | 97306898
MidWest | Cleaning supplies | 90775242
MidWest | Dairy | 89065443
MidWest | Seafood | 82541528
MidWest | Medical | 76674814
MidWest | Pharmacy | 52443519
West | | 2159765937
West | Meat | 235841506
West | Produce | 215277204
West | Photography | 205949467
West | Frozen Goods | 178311593
West | Bakery | 172824555
West | Gifts | 172134780
West | Liquor | 164798022
West | Canned Goods | 163330813
West | Cleaning supplies | 148776443
West | Dairy | 145244575
West | Seafood | 139464407
West | Medical | 126184049
West | Pharmacy | 91628523
| | 5164234493
(43 rows)
INSERT statement that includes WITH clause
The following SQL uses a WITH clause to insert data from a JOIN query into table total_store_sales:
CREATE TABLE total_store_sales (store_key int, region VARCHAR(20), store_sales numeric (12,2));
INSERT INTO total_store_sales
WITH store_sales AS (
SELECT sd.store_key, sd.store_region::VARCHAR(20), SUM (of.total_order_cost)
FROM store.store_dimension sd JOIN store.store_orders_fact of ON sd.store_key = of.store_key
GROUP BY sd.store_region, sd.store_key ORDER BY sd.store_region, sd.store_key)
SELECT * FROM store_sales;
=> SELECT * FROM total_store_sales ORDER BY region, store_key;
store_key | region | store_sales
-----------+-----------+-------------
2 | East | 47668303.00
6 | East | 48136354.00
12 | East | 46673113.00
22 | East | 48711211.00
24 | East | 48603836.00
31 | East | 46836469.00
36 | East | 48461449.00
37 | East | 48018279.00
41 | East | 48713084.00
44 | East | 47808362.00
49 | East | 46990023.00
50 | East | 47643329.00
9 | MidWest | 46851087.00
15 | MidWest | 48787354.00
27 | MidWest | 48497620.00
29 | MidWest | 47639234.00
30 | MidWest | 49013483.00
38 | MidWest | 48856012.00
42 | MidWest | 47297912.00
45 | MidWest | 48544521.00
46 | MidWest | 48887255.00
4 | NorthWest | 47580215.00
39 | NorthWest | 47136892.00
47 | NorthWest | 48477574.00
8 | South | 48131455.00
13 | South | 47605422.00
17 | South | 46054367.00
...
(50 rows)
7.38.15.1 - Inline expansion of WITH clause
By default, Vertica uses inline expansion to evaluate WITH clauses.
By default, Vertica uses inline expansion to evaluate WITH clauses. Vertica evaluates each WITH clause every time it is referenced by the primary query. Inline expansion often works best if the query does not reference the same WITH clause multiple times, or if some local optimizations are possible after inline expansion.
Example
The following example shows a WITH clause that is a good candidate for inline expansion. The WITH clause is used in a query that obtains order information for all 2007 orders shipped between December 01-07:
-- Begin WITH
WITH store_orders_fact_new AS(
SELECT * FROM store.store_orders_fact WHERE date_shipped between '2007-12-01' and '2007-12-07')
-- End WITH
-- Begin primary query
SELECT store_key, product_key, product_version, SUM(quantity_ordered*unit_price) AS total_price
FROM store_orders_fact_new
GROUP BY store_key, product_key, product_version
ORDER BY total_price DESC;
store_key | product_key | product_version | total_price
-----------+-------------+-----------------+-------------
232 | 1855 | 2 | 29008
125 | 8500 | 4 | 28812
139 | 3707 | 2 | 28812
212 | 3203 | 1 | 28000
236 | 8023 | 4 | 27548
123 | 10598 | 2 | 27146
34 | 8888 | 4 | 27100
203 | 2243 | 1 | 27027
117 | 13932 | 2 | 27000
84 | 768 | 1 | 26936
123 | 1038 | 1 | 26885
106 | 18932 | 1 | 26864
93 | 10395 | 3 | 26790
162 | 13073 | 1 | 26754
15 | 3679 | 1 | 26675
52 | 5957 | 5 | 26656
190 | 8114 | 3 | 26611
5 | 7772 | 1 | 26588
139 | 6953 | 3 | 26572
202 | 14735 | 1 | 26404
133 | 2740 | 1 | 26312
198 | 8545 | 3 | 26287
221 | 7582 | 2 | 26280
127 | 9468 | 3 | 26224
63 | 8115 | 4 | 25960
171 | 2088 | 1 | 25650
250 | 11210 | 3 | 25608
...
Vertica processes the query as follows:
-
Expands the WITH clause reference to store_orders_fact_new within the primary query.
-
After expanding the WITH clause, evaluates the primary query.
7.38.15.2 - Materialization of WITH clause
When materialization is enabled, Vertica evaluates each WITH clause once, stores results in a temporary table, and references this table as often as the query requires.
When materialization is enabled, Vertica evaluates each WITH clause once, stores results in a temporary table, and references this table as often as the query requires. Vertica drops the temporary table after primary query execution completes.
Note
If the primary query returns with an error, temporary tables might be dropped only after the client’s session ends.
Materialization can facilitate better performance when WITH clauses are complex—for example, when the WITH clauses contain JOIN and GROUP BY clauses, and are referenced multiple times in the primary query.
If materialization is enabled, WITH statements perform an auto-commit of the user transaction. This occurs even when using EXPLAIN with the WITH statement.
Enabling WITH clause materialization
WITH materialization is set by configuration parameter WithClauseMaterialization, by default set to 0 (disabled). You can enable and disable materialization by setting WithClauseMaterialization at database and session levels, with ALTER DATABASE and ALTER SESSION, respectively:
-
Database:
=> ALTER DATABASE db-spec SET PARAMETER WithClauseMaterialization={ 0 | 1 };
=> ALTER DATABASE db-spec CLEAR PARAMETER WithClauseMaterialization;
-
Session: Parameter setting remains in effect until you explicitly clear it, or the session ends.
=> ALTER SESSION SET PARAMETER WithClauseMaterialization={ 0 | 1 };
=> ALTER SESSION CLEAR PARAMETER WithClauseMaterialization;
You can also enable WITH materialization for individual queries with the hint ENABLE_WITH_CLAUSE_MATERIALIZATION. Materialization is automatically cleared when the query returns. For example:
=> WITH /*+ENABLE_WITH_CLAUSE_MATERIALIZATION */ revenue AS (
SELECT vendor_key, SUM(total_order_cost) AS total_revenue
FROM store.store_orders_fact
GROUP BY vendor_key ORDER BY 1)
...
Processing WITH clauses using EE5 temp relations
By default, when WITH clause queries are reused, Vertica saves those WITH clause query outputs in EE5 temp relations. However, this option can be changed. EE5 temp relation support is set by configuration parameter EnableWITHTempRelReuseLimit, which can be set in the following ways:
-
0: Disables this feature.
-
1: Force-saves all WITH clause queries into EE5 temp relations, whether or not they are reused.
-
2 (default): Saves only reused WITH clause queries into EE5 temp relations.
-
3 or more: Saves WITH clause queries into EE5 temp relations only when they are used at least this number of times.
EnableWITHTempRelReuseLimit can be set at database and session levels, with ALTER DATABASE and ALTER SESSION, respectively. When WithClauseMaterialization is set to 1, that setting overrides any EnableWITHTempRelReuseLimit settings.
Note that for WITH queries with complex types, temp relations are disabled.
Example
The following example shows a WITH clause that is a good candidate for materialization. The query obtains data for the vendor who has the highest combined order cost for all orders:
-- Enable materialization
=> ALTER SESSION SET PARAMETER WithClauseMaterialization=1;
-- Define WITH clause
=> WITH revenue AS (
SELECT vendor_key, SUM(total_order_cost) AS total_revenue
FROM store.store_orders_fact
GROUP BY vendor_key ORDER BY 1)
-- End WITH clause
-- Primary query
=> SELECT vendor_name, vendor_address, vendor_city, total_revenue
FROM vendor_dimension v, revenue r
WHERE v.vendor_key = r.vendor_key AND total_revenue = (SELECT MAX(total_revenue) FROM revenue )
ORDER BY vendor_name;
vendor_name | vendor_address | vendor_city | total_revenue
------------------+----------------+-------------+---------------
Frozen Suppliers | 471 Mission St | Peoria | 49877044
(1 row)
Vertica processes this query as follows:
-
WITH clause revenue evaluates its SELECT statement from table store.store_orders_fact.
-
Results of the revenue clause are stored in a local temporary table.
-
Whenever the revenue clause statement is referenced, the results stored in the table are used.
-
The temporary table is dropped when query execution is complete.
7.38.15.3 - WITH clause recursion
A WITH clause that includes the RECURSIVE option iterates over its own output through repeated execution of a UNION or UNION ALL query.
A WITH clause that includes the RECURSIVE option iterates over its own output through repeated execution of a UNION or UNION ALL query. Recursive queries are useful when working with self-referential data—hierarchies such as manager-subordinate relationships, or tree-structured data such as taxonomies.
The configuration parameter WithClauseRecursionLimit—by default set to 8—sets the maximum depth of recursion. You can set this parameter at database and session scopes with ALTER DATABASE and ALTER SESSION, respectively. Recursion continues until it reaches the configured maximum depth, or until the last iteration returns with no data.
You specify a recursive WITH clause as follows:
WITH [ /*+ENABLE_WITH_CLAUSE_MATERIALIZATION*/ ] RECURSIVE
cte-identifier [ ( column-aliases ) ] AS (
non-recursive-term
UNION [ ALL ]
recursive-term
)
Non-recursive and recursive terms are separated by UNION or UNION ALL:
-
The non-recursive-term query sets its result set in cte-identifier, which is subject to recursion in recursive-term.
-
The UNION statement's recursive-term recursively iterates over its own output. When recursion is complete, the results of all iterations are compiled and set in cte-identifier.
For example:
=> ALTER SESSION SET PARAMETER WithClauseRecursionLimit=4; -- maximum recursion depth = 4
=> WITH RECURSIVE nums (n) AS (
SELECT 1 -- non-recursive (base) term
UNION ALL
SELECT n+1 FROM nums -- recursive term
)
SELECT n FROM nums; -- primary query
This simple query executes as follows:
-
Executes the WITH RECURSIVE clause:
-
Evaluates the non-recursive term SELECT 1, and places the result set—1—in nums.
-
Iterates over the UNION ALL query (SELECT n+1) until the number of iterations is greater than the configuration parameter WithClauseRecursionLimit.
-
Combines the results of all UNION queries and sets the result set in nums, and then exits to the primary query.
-
Executes the primary query SELECT n FROM nums:
n
---
1
2
3
4
5
(5 rows)
In this case , WITH RECURSIVE clause exits after four iterations as per WithClauseRecursionLimit. If you restore WithClauseRecursionLimit to its default value of 8, then the clause exits after eight iterations:
=> ALTER SESSION CLEAR PARAMETER WithClauseRecursionLimit;
=> WITH RECURSIVE nums (n) AS (
SELECT 1
UNION ALL
SELECT n+1 FROM nums
)
SELECT n FROM nums;
n
---
1
2
3
4
5
6
7
8
9
(9 rows)
Important
Be careful to set WithClauseRecursionLimit only as high as needed to traverse the deepest hierarchies. Vertica sets no limit on this parameter; however, a high value can incur considerable overhead that adversely affects performance and exhausts system resources.
If a high recursion count is required, then consider enabling materialization. For details, see WITH RECURSIVE Materialization.
Restrictions
The following restrictions apply:
-
The SELECT list of a non-recursive term cannot include the wildcard * (asterisk) or the function MATCH_COLUMNS.
-
A recursive term can reference the target CTE only once.
-
Recursive reference cannot appear within an outer join.
-
Recursive reference cannot appear within a subquery.
-
WITH clauses do not support UNION options ORDER BY, LIMIT, and OFFSET.
Examples
A small software company maintains the following data on employees and their managers:
=> SELECT * FROM personnel.employees ORDER BY emp_id;
emp_id | fname | lname | section_id | section_name | section_leader | leader_id
--------+-----------+-----------+------------+---------------------+------------------+-----------
0 | Stephen | Mulligan | 0 | | |
1 | Michael | North | 201 | Development | Zoe Black | 3
2 | Megan | Berry | 202 | QA | Richard Chan | 18
3 | Zoe | Black | 101 | Product Development | Renuka Patil | 24
4 | Tim | James | 203 | IT | Ebuka Udechukwu | 17
5 | Bella | Tucker | 201 | Development | Zoe Black | 3
6 | Alexandra | Climo | 202 | QA | Richard Chan | 18
7 | Leonard | Gray | 203 | IT | Ebuka Udechukwu | 17
8 | Carolyn | Henderson | 201 | Development | Zoe Black | 3
9 | Ryan | Henderson | 201 | Development | Zoe Black | 3
10 | Frank | Tucker | 205 | Sales | Benjamin Glover | 29
11 | Nathan | Ferguson | 102 | Sales Marketing | Eric Redfield | 28
12 | Kevin | Rampling | 101 | Product Development | Renuka Patil | 24
13 | Tuy Kim | Duong | 201 | Development | Zoe Black | 3
14 | Dwipendra | Sing | 204 | Tech Support | Sarah Feldman | 26
15 | Dylan | Wijman | 206 | Documentation | Kevin Rampling | 12
16 | Tamar | Sasson | 207 | Marketing | Nathan Ferguson | 11
17 | Ebuka | Udechukwu | 101 | Product Development | Renuka Patil | 24
18 | Richard | Chan | 101 | Product Development | Renuka Patil | 24
19 | Maria | del Rio | 201 | Development | Zoe Black | 3
20 | Hua | Song | 204 | Tech Support | Sarah Feldman | 26
21 | Carmen | Lopez | 204 | Tech Support | Sarah Feldman | 26
22 | Edgar | Mejia | 206 | Documentation | Kevin Rampling | 12
23 | Riad | Salim | 201 | Development | Zoe Black | 3
24 | Renuka | Patil | 100 | Executive Office | Stephen Mulligan | 0
25 | Rina | Dsouza | 202 | QA | Richard Chan | 18
26 | Sarah | Feldman | 101 | Product Development | Renuka Patil | 24
27 | Max | Mills | 102 | Sales Marketing | Eric Redfield | 28
28 | Eric | Redfield | 100 | Executive Office | Stephen Mulligan | 0
29 | Benjamin | Glover | 102 | Sales Marketing | Eric Redfield | 28
30 | Dominic | King | 205 | Sales | Benjamin Glover | 29
32 | Ryan | Metcalfe | 206 | Documentation | Kevin Rampling | 12
33 | Piers | Paige | 201 | Development | Zoe Black | 3
34 | Nicola | Kelly | 207 | Marketing | Nathan Ferguson | 11
(34 rows)
You can query this data for employee-manager relationships through WITH RECURSIVE. For example, the following query's WITH RECURSIVE clause gets employee-manager relationships for employee Eric Redfield, including all employees who report directly and indirectly to him:
WITH RECURSIVE managers (employeeID, employeeName, sectionID, section, lead, leadID)
AS (SELECT emp_id, fname||' '||lname, section_id, section_name, section_leader, leader_id
FROM personnel.employees WHERE fname||' '||lname = 'Eric Redfield'
UNION
SELECT emp_id, fname||' '||lname AS employee_name, section_id, section_name, section_leader, leader_id FROM personnel.employees e
JOIN managers m ON m.employeeID = e.leader_id)
SELECT employeeID, employeeName, lead AS 'Reports to', section, leadID from managers ORDER BY sectionID, employeeName;
The WITH RECURSIVE clause defines the CTE managers, and then executes in two phases:
-
The non-recursive term populates managers with data that it queries from personnel.employees.
-
The recursive term's UNION query iterates over its own output until, on the fourth cycle, it finds no more data. The results of all iterations are then compiled and set in managers, and the WITH CLAUSE exits to the primary query.
The primary query returns three levels of data from managers—one for each recursive iteration:
Similarly, the following query iterates over the same data to get all employee-manager relationships for employee Richard Chan, who is one level lower in the company chain of command:
WITH RECURSIVE managers (employeeID, employeeName, sectionID, section, lead, leadID)
AS (SELECT emp_id, fname||' '||lname, section_id, section_name, section_leader, leader_id
FROM personnel.employees WHERE fname||' '||lname = 'Richard Chan'
UNION
SELECT emp_id, fname||' '||lname AS employee_name, section_id, section_name, section_leader, leader_id FROM personnel.employees e
JOIN managers m ON m.employeeID = e.leader_id)
SELECT employeeID, employeeName, lead AS 'Reports to', section, leadID from managers ORDER BY sectionID, employeeName;
The WITH RECURSIVE clause executes as before, except this time it finds no more data after two iterations and exits. Accordingly, the primary query returns two levels of data from managers:

WITH RECURSIVE materialization
By default, materialization is disabled. In this case, Vertica rewrites the WITH RECURSIVE query into subqueries, as many as necessary for the required level of recursion.
If recursion is very deep, the high number of query rewrites is liable to incur considerable overhead that adversely affects performance and exhausts system resources. In this case, consider enabling materialization, either with the configuration parameter WithClauseMaterialization, or the hint ENABLE_WITH_CLAUSE_MATERIALIZATION. In either case, intermediate result sets from all recursion levels are written to local temporary tables. When recursion is complete, the intermediate results in all temporary tables are compiled and passed on to the primary query.
Note
If materialization is not possible, you can improve throughput on a resource pool that handles recursive queries by setting its
EXECUTIONPARALLELISM parameter to 1.
7.39 - SET statements
SET statements let you change how the database operates, such as changing the autocommit settings or the resource pool your session uses.
SET statements let you change how the database operates, such as changing the autocommit settings or the resource pool your session uses.
7.39.1 - SET DATESTYLE
Specifies how to format date/time output for the current session.
Specifies how to format date/time output for the current session. Use
SHOW DATESTYLE to verify the current output settings.
Syntax
SET DATESTYLE TO { arg | 'arg' }[, arg | 'arg' ]
Parameters
SET DATESTYLE has a single parameter, which can be set to one or two arguments that specify date ordering and style. Each argument can be specified singly or in combination with the other; if combined, they can be specified in any order.
The following table describes each style and the date ordering arguments it supports:
|
Date style arguments |
Order arguments |
Example |
ISO
(ISO 8601/SQL standard) |
n/a |
2016-03-16 00:00:00 |
GERMAN |
n/a |
16.03.2016 00:00:00 |
SQL |
MDY |
03/16/2016 00:00:00 |
DMY (default) |
16/03/2016 00:00:00 |
POSTGRES |
MDY (default) |
Wed Mar 16 00:00:00 2016 |
DMY |
Wed 16 Mar 00:00:00 2016 |
Vertica ignores the order argument for date styles ISO and GERMAN. If the date style is SQL or POSTGRES, the order setting determines whether dates are output in MDY or DMY order. Neither SQL nor POSTGRES support YMD order. If you specify YMD for SQL or POSTGRES, Vertica ignores it and uses their default MDY order.
Date styles and ordering can also affect how Vertica interprets input values. For more information, see Date/time literals.
Privileges
None
In some cases, input format can determine output, regardless of date style and order settings:
-
Vertica ISO output for DATESTYLE is ISO long form, but several input styles are accepted. If the year appears first in the input, YMD is used for input and output, regardless of the DATESTYLE value.
-
INTERVAL input and output share the same format, with the following exceptions:
If the date style is set to ISO, output follows this format:
[ quantity unit [...] ] [ days ] [ hours:minutes:seconds ]
Examples
=> CREATE TABLE t(a DATETIME);
CREATE TABLE
=> INSERT INTO t values ('3/16/2016');
OUTPUT
--------
1
(1 row)
=> SHOW DATESTYLE;
name | setting
-----------+----------
datestyle | ISO, MDY
(1 row)
=> SELECT * FROM t;
a
---------------------
2016-03-16 00:00:00
(1 row)
=> SET DATESTYLE TO German;
SET
=> SHOW DATESTYLE;
name | setting
-----------+-------------
datestyle | German, DMY
(1 row)
=> SELECT * FROM t;
a
---------------------
16.03.2016 00:00:00
(1 row)
=> SET DATESTYLE TO SQL;
SET
=> SHOW DATESTYLE;
name | setting
-----------+----------
datestyle | SQL, DMY
(1 row)
=> SELECT * FROM t;
a
---------------------
16/03/2016 00:00:00
(1 row)
=> SET DATESTYLE TO Postgres, MDY;
SET
=> SHOW DATESTYLE;
name | setting
-----------+---------------
datestyle | Postgres, MDY
(1 row)
=> SELECT * FROM t;
a
--------------------------
Wed Mar 16 00:00:00 2016
(1 row)
7.39.2 - SET ESCAPE_STRING_WARNING
Issues a warning when a backslash is used in a string literal during the current .
Issues a warning when a backslash is used in a string literal during the current session.
Syntax
SET ESCAPE_STRING_WARNING TO { ON | OFF }
Parameters
ON- [Default] Issues a warning when a back slash is used in a string literal.
Tip: Organizations that have upgraded from earlier versions of Vertica can use this as a debugging tool for locating backslashes that used to be treated as escape characters, but are now treated as literals.
OFF- Ignores back slashes within string literals.
Privileges
None
Notes
Examples
The following example shows how to turn OFF escape string warnings for the session.
=> SET ESCAPE_STRING_WARNING TO OFF;
See also
7.39.3 - SET INTERVALSTYLE
Specifies whether to include units in interval output for the current .
Specifies whether to include units in interval output for the current session.
Syntax
SET INTERVALSTYLE TO [ plain | units ]
Parameters
- plain
- (default) Sets the default interval output to omit units.
- units
- Enables interval output to include subtype unit identifiers. When
INTERVALSTYLE is set to units, the DATESTYLE parameter controls output. If you enable units and they do not display in the output, check the DATESTYLE parameter value, which must be set to ISO or POSTGRES for interval units to display.
Privileges
None
Examples
See Setting interval unit display.
7.39.4 - SET LOCALE
Specifies locale for the current.
Specifies locale for the current session.
You can also set the current locale with the vsql command
\locale.
Syntax
SET LOCALE TO ICU-locale-identifier
Parameters
locale-identifier - Specifies the ICU locale identifier to use, by default set to:
en_US@collation=binary
If set to an empty string, Vertica sets locale to en_US_POSIX.
The following requirements apply:
Privileges
None
Commonly used locales
For details on identifier options, see About locale. For a complete list of locale identifiers, see the ICU Project.
de_DE- German (Germany)
en_GB- English (Great Britain)
es_ES- Spanish (Spain)
fr_FR- French (France)
pt_BR- Portuguese (Brazil)
pt_PT- Portuguese (Portugal)
ru_RU- Russian (Russia)
ja_JP- Japanese (Japan)
zh_CN- Chinese (China, simplified Han)
zh_Hant_TW- Chinese (Taiwan, traditional Han)
Examples
Set session locale to en_GB:
=> SET LOCALE TO en_GB;
INFO 2567: Canonical locale: 'en_GB'
Standard collation: 'LEN'
English (United Kingdom)
SET
Use the short form of a locale:
=> SET LOCALE TO LEN;
INFO 2567: Canonical locale: 'en'
Standard collation: 'LEN'
English
SET
Specify collation:
=> SET LOCALE TO 'tr_tr@collation=standard';
INFO 2567: Canonical locale: 'tr_TR@collation=standard'
Standard collation: 'LTR'
Turkish (Turkey, collation=standard) Türkçe (Türkiye, Sıralama=standard)
SET
See also
7.39.5 - SET ROLE
Enables a role for the user's current session.
Enables a role for the user's current session. The user can access privileges that have been granted to the role. Enabling a role has no effect on roles that are currently enabled.
Syntax
SET ROLE roles-expression
Parameters
-
roles-expression
- Specifies what roles are the default roles for this user, with one of the following expressions:
-
NONE (default): Disables all roles.
-
roles-list: A comma-delimited list of roles to enable. You can only set roles that are currently granted to you.
-
ALL [EXCEPT roles-list]: Enables all roles currently granted to this user, excluding any comma-delimited roles specified in the optional EXCEPT clause.
-
DEFAULT: Enables all default roles. Default roles are, by definition, enabled automatically, but this option might be useful for re-enabling them if they are disabled with SET ROLE NONE.
Privileges
None
Examples
This example shows the following:
-
SHOW AVAILABLE_ROLES; lists the roles available to the user, but not enabled.
-
SET ROLE applogs; enables the applogs role for the user.
-
SHOW ENABLED_ROLES; lists the applogs role as enabled (SET) for the user.
-
SET ROLE appuser; enables the appuser role for the user.
-
SHOW ENABLED_ROLES now lists both applogs and appuser as enabled roles for the user.
-
SET ROLE NONE disables all the users' enabled roles .
-
SHOW ENABLED_ROLES shows that no roles are enabled for the user.
=> SHOW AVAILABLE_ROLES;
name | setting
-----------------+----------------------------
available roles | applogs, appadmin, appuser
(1 row)
=> SET ROLE applogs;
SET
=> SHOW ENABLED_ROLES;
name | setting
---------------+---------
enabled roles | applogs
(1 row)
=> SET ROLE appuser;
SET
=> SHOW ENABLED_ROLES;
name | setting
---------------+------------------
enabled roles | applogs, appuser
(1 row)
=> SET ROLE NONE;
SET
=> SHOW ENABLED_ROLES;
name | setting
---------------+---------
enabled roles |
(1 row)
Set User Default Roles
Though the DBADMIN user is normally responsible for setting a user's default roles, as a user you can set your own role. For example, if you run SET ROLE NONE all of your enabled roles are disabled. Then it was determined you need access to role1 as a default role. The DBADMIN uses ALTER USER to assign you a default role:
=> ALTER USER user1 default role role1;
This example sets role1 as user1's default role because the DBADMIN assigned this default role using ALTER USER.
user1 => SET ROLE default;
user1 => SHOW ENABLED_ROLES;
name | setting
-----------------------
enabled roles | role1
(1 row)
Set All Roles as Default
This example makes all roles granted to user1 default roles:
user1 => SET ROLE all;
user1 => show enabled roles;
name | setting
----------------------------------
enabled roles | role1, role2, role3
(1 row)
Set All Roles as Default With EXCEPT
This example makes all the roles granted to the user default roles with the exception of role1.
user1 => set role all except role1;
user1 => SHOW ENABLED_ROLES
name | setting
----------------------------
enabled roles | role2, role3
(1 row)
7.39.6 - SET SEARCH_PATH
Specifies the order in which Vertica searches schemas when a SQL statement specifies a table name that is unqualified by a schema name.
Specifies the order in which Vertica searches schemas when a SQL statement specifies a table name that is unqualified by a schema name. SET SEARCH_PATH overrides the current session's search path, which is initially set from the user profile. This search path remains in effect until the next SET SEARCH_PATH statement, or the session ends. For details, see Setting search paths.
To view the current search path, use
SHOW SEARCH_PATH.
Syntax
SET SEARCH_PATH { TO | = } { schema-list | DEFAULT }
Parameters
schema-list- A comma-delimited list of schemas that indicates the order in which Vertica searches schemas for a table whose name is unqualified by a schema name.
If the search path includes a schema that does not exist, or for which the user lacks access privileges, Vertica silently skips over that schema.
DEFAULT- Sets the search path to the database default:
"$user", public, v_catalog, v_monitor, v_internal
Privileges
None
Examples
Show the current search path:
=> SHOW SEARCH_PATH;
name | setting
-------------+---------------------------------------------------
search_path | "$user", public, v_catalog, v_monitor, v_internal
(1 row)
Reset the search path to schemas store and public:
=> SET SEARCH_PATH TO store, public;
=> SHOW SEARCH_PATH;
name | setting
-------------+-------------------------------------------------
search_path | store, public, v_catalog, v_monitor, v_internal
(1 row)
Reset the search path to the database default settings:
=> SET SEARCH_PATH TO DEFAULT;
SET
=> SHOW SEARCH_PATH;
name | setting
-------------+---------------------------------------------------
search_path | "$user", public, v_catalog, v_monitor, v_internal
(1 row)
7.39.7 - SET SESSION AUTHORIZATION
Sets the current and session user for the current database connection. You can change session authorization to execute queries as another user for testing or debugging purposes, or to limit query access.
Syntax
SET SESSION AUTHORIZATION { username | DEFAULT }
Parameters
username- The name of the user that you want to authorize for the current SQL session.
DEFAULT- Sets session authorization to the dbadmin user.
Privileges
Superuser
Examples
In the following example, the dbadmin gives the debuguser user session authorization, and then changes the session authorization back to the dbadmin user.
-
Verify the current user and session user:
=> SELECT CURRENT_USER(), SESSION_USER();
current_user | session_user
--------------+--------------
dbadmin | dbadmin
(1 row)
-
Set authorization for the current session to debuguser, and verify the changes:
=> SET SESSION AUTHORIZATION debuguser;
SET
=> SELECT CURRENT_USER(), SESSION_USER();
current_user | session_user
--------------+--------------
debuguser | debuguser
(1 row)
-
After you complete debugging tasks, set the session authorization to DEFAULT to set the current and session user back to dbadmin user, and verify the changes:
=> SET SESSION AUTHORIZATION DEFAULT;
SET
=> SELECT CURRENT_USER(), SESSION_USER();
current_user | session_user
--------------+--------------
dbadmin | dbadmin
(1 row)
7.39.8 - SET SESSION AUTOCOMMIT
Sets whether statements automatically commit their transactions on completion.
Sets whether statements automatically commit their transactions on completion. This statement is primarily used by the client drivers to enable and disable autocommit, you should never have to directly call it.
Syntax
SET SESSION AUTOCOMMIT TO { ON | OFF }
Parameters
ON- Enable autocommit. Statements automatically commit their transactions when they complete. This is the default setting for connections made using the Vertica client libraries.
OFF- Disable autocommit. Transactions are not automatically committed. This is the default for interactive sessions (connections made through vsql).
Privileges
None
Examples
This examples show how to set AUTOCOMMIT to 'on' and then to 'off'.
=> SET SESSION AUTOCOMMIT TO on;
SET
=> SET SESSION AUTOCOMMIT TO off;
SET
See also
7.39.9 - SET SESSION CHARACTERISTICS AS TRANSACTION
Sets the isolation level and access mode of all transactions that start after this statement is issued.
Sets the isolation level and access mode of all transactions that start after this statement is issued.
A transaction retains its isolation level until it completes, even if the session's isolation level changes during the transaction. Vertica internal processes (such as the Tuple Mover and refresh operations) and DDL operations always run at the SERIALIZABLE isolation level to ensure consistency.
Syntax
SET SESSION CHARACTERISTICS AS TRANSACTION settings
settings- One or both of the following:
ISOLATION LEVEL argument
ISOLATION LEVEL arguments
The ISOLATION LEVEL clause determines what data the transaction can access when other transactions run concurrently. You cannot change the isolation level after the first query (SELECT) or DML statement (INSERT, DELETE, UPDATE) if a transaction has run.
Set ISOLATION LEVEL to one of the following arguments:
SERIALIZABLE- Sets the strictest level of SQL transaction isolation. This level emulates transactions serially, rather than concurrently. It holds locks and blocks write operations until the transaction completes.
Applications that use SERIALIZABLE must be prepared to retry transactions in the event of serialization failures. This isolation level is not recommended for normal query operations.
Setting the transaction isolation level to SERIALIZABLE does not apply to temporary tables. Temporary tables are isolated by their transaction scope.
REPEATABLE READ- Automatically converted to
SERIALIZABLE.
READ COMMITTED- Default, allows concurrent transactions.
READ UNCOMMITTED- Automatically converted to
READ COMMITTED.
READ WRITE/READ ONLY
You can set the transaction access mode with one of the following:
READ WRITE- Default, allows read/write access to SQL statements.
READ ONLY- Disallows SQL statements that require write access:
-
INSERT, UPDATE, DELETE, and COPY operations on any non-temporary table.
-
CREATE, ALTER, and DROP
-
GRANT, REVOKE
-
EXPLAIN if the SQL statement to explain requires write access.
Note
Setting the transaction session mode to read-only does not prevent all write operations.
Privileges
None
Viewing session transaction characteristics
SHOW TRANSACTION_ISOLATION and SHOW TRANSACTION_READ_ONLY show the transaction settings for the current session:
=> SHOW TRANSACTION_ISOLATION;
name | setting
-----------------------+--------------
transaction_isolation | SERIALIZABLE
(1 row)
=> SHOW TRANSACTION_READ_ONLY;
name | setting
-----------------------+---------
transaction_read_only | true
(1 row)
7.39.10 - SET SESSION GRACEPERIOD
Sets how long a session socket remains blocked while awaiting client input or output for a given query.
Sets how long a session socket remains blocked while awaiting client input or output for a given query. If the socket is blocked for a continuous period that exceeds the grace period setting, the server shuts down the socket and throws a fatal error. The session is then terminated. If no grace period is set, the query can maintain its block on the socket indefinitely.
Vertica applies a session's grace period and
RUNTIMECAP settings independently. If no grace period is set, a query can continue to block indefinitely on a session socket, regardless of the query's RUNTIMECAP setting.
Syntax
SET SESSION GRACEPERIOD duration
Parameters
duration- Specifies how long a query can block on any session socket, one of the following:
-
'interval': Specifies as an interval the maximum grace period for current session queries, up to 20 days.
-
=DEFAULT: Sets the grace period for queries in this session to the user's GRACEPERIOD value. A new session is initially set to this value.
-
NONE: Valid only for superusers, removes any grace period previously set on session queries.
Privileges
-
Superusers can increase session grace period to any value, regardless of database or node settings.
-
Non-superusers can only set the session grace period to a value equal to or lower than their own user setting. If no grace period is explicitly set for a user, the grace period for that user is inherited from the node or database settings.
Examples
See Handling session socket blocking in the Administrator's Guide.
7.39.11 - SET SESSION IDLESESSIONTIMEOUT
Sets the maximum amount of time that a session can remain idle before it exits.
Sets the maximum amount of time that a session can remain idle before it exits.
Note
An idle session has no queries running.
Syntax
SET SESSION IDLESESSIONTIMEOUT duration
Parameters
duration- Specifies the amount of time a session can remain idle before it exits:
-
NONE (default): No idle timeout set on the session.
-
'interval': Specifies as an interval the maximum amount of time a session can remain idle.
-
=DEFAULT: Sets the idle timeout period for this session to the user's IDLESESSIONTIMEOUT value.
Privileges
-
Superusers can increase the time a session can remain idle to any value, regardless of database or node settings.
-
Non-superusers can only set the session idle time to a value equal to or lower than their own user setting. If no session idle time is explicitly set for a user, the session idle time for that user is inherited from the node or database settings.
Examples
See Managing client connections in the Administrator's Guide.
7.39.12 - SET SESSION MEMORYCAP
Limits how much memory can be allocated to any request in the current.
Limits how much memory can be allocated to any request in the current session. This limit only applies to the current session; it does not limit the total amount of memory used by multiple sessions.
Syntax
SET SESSION MEMORYCAP limit
Parameters
limit- One of the following:
-
'max-expression': A string value that specifies the memory limit, one of the following:
-
int% — Expresses the maximum as a percentage of total memory available to the Resource manager, where int is an integer value between 0 and 100.For example:
MEMORYCAP '40%'
-
int{K|M|G|T} — Expresses memory allocation in kilobytes, megabytes, gigabytes, or terabytes. For example:
MEMORYCAP '10G'
-
=DEFAULT: Sets the memory cap for queries in this session to the user's MEMORYCAP value.A new session is initially set to this value.
-
NONE: Removes the memory cap for this session.
Privileges
Examples
Set the session memory cap to 2 gigabytes:
=> SET SESSION MEMORYCAP '2G';
SET
=> SHOW MEMORYCAP;
name | setting
-----------+---------
memorycap | 2097152
(1 row)
Revert the memory cap to the default setting as specified in the user profile:
=> SET MEMORYCAP=DEFAULT;
SET
=> SHOW MEMORYCAP;
name | setting
-----------+---------
memorycap | 2013336
(1 row)
See also
Managing workloads
7.39.13 - SET SESSION MULTIPLEACTIVERESULTSETS
Enables or disable the execution of multiple active result sets (MARS) on a single JDBC connection.
Enables or disable the execution of multiple active result sets (MARS) on a single JDBC connection. Using this option requires an active JDBC connection.
Syntax
SET SESSION MULTIPLEACTIVERESULTSETS TO { ON | OFF }
Parameters
ON- Enable MultipleActiveResultSets.Allows you to execute multiple result sets on a single connection.
OFF- Disable MultipleActiveResultSets. Allows only one active result set per connection.(Default value.)
Privileges
None
Examples
This example shows how you can set MultipleActiveResultSets to on and then to off:
=> SET SESSION MULTIPLEACTIVERESULTSETS TO on;
SET
=> SET SESSION MULTIPLEACTIVERESULTSETS TO off;
SET
7.39.14 - SET SESSION RESOURCE_POOL
Associates the user with the specified resource pool.
Associates the user session with the specified resource pool.
Syntax
SET SESSION RESOURCE_POOL = { pool-name | DEFAULT }
Parameters
pool-name - The name of an existing resource pool to associate with the current session. Non-superusers must have USAGE privileges on the specified resource pool.
DEFAULT- Sets the session's resource pool to the resource pool assigned to this user.
Privileges
None
Examples
This example sets ceo_pool as the session resource pool:
=> SET SESSION RESOURCE_POOL = ceo_pool;
SET
See also
7.39.15 - SET SESSION RUNTIMECAP
Sets the maximum amount of time queries and stored procedures can run in a given session.
Sets the maximum amount of time queries and stored procedures can run in a given session. If a query or stored procedure exceeds its session's RUNTIMECAP, Vertica terminates it and returns an error. You cannot increase the RUNTIMECAP beyond the limit that is set in your user profile.
Note
Vertica does not strictly enforce session RUNTIMECAP settings. If you time a query or stored procedure, you might discover that it runs longer than the RUNTIMECAP setting.
Syntax
SET SESSION RUNTIMECAP duration
Parameters
duration- Specifies how long a given query can run in the current session, one of the following:
-
NONE (default): Removes a runtime limit for all current session queries.
-
'interval': Specifies as an interval the maximum runtime for current session queries, up to one year—for example, 1 minute or 100 seconds.
-
=DEFAULT: Sets maximum runtime for queries in this session to the user's RUNTIMECAP value.
Privileges
Examples
Set the maximum query runtime for the current session to 10 minutes:
=> SET SESSION RUNTIMECAP '10 minutes';
Revert the session RUNTIMECAP to your user default setting:
=> SET SESSION RUNTIMECAP =DEFAULT;
SET
=> SHOW RUNTIMECAP;
name | setting
------------+-----------
runtimecap | UNLIMITED
(1 row)
Set the RUNTIMECAP to 1 SECOND and run an anonymous procedure with an infinite loop:
=> SET SESSION RUNTIMECAP '1 SECOND';
SET
=> DO $$
BEGIN
LOOP
END LOOP;
END;
$$;
ERROR 0: Query exceeded maximum runtime
HINT: Change the maximum runtime using SET SESSION RUNTIMECAP
See also
7.39.16 - SET SESSION TEMPSPACECAP
Sets the maximum amount of temporary file storage that any request issued by the can consume.
Sets the maximum amount of temporary file storage that any request issued by the session can consume. If a query's execution plan requires more storage space than the session TEMPSPACECAP, it returns an error.
Syntax
SET SESSION TEMPSPACECAP limit
Arguments
limit - The maximum amount of temporary file storage to allocate to the current session, one of the following:
-
NONE (default): Unlimited temporary storage
-
= DEFAULT: Session TEMPSPACECAP is set to the user's TEMPSPACECAP value.
-
String that specifies the storage limit, one of the following:
-
int% expresses the maximum as a percentage of total temporary storage available to the Resource Manager, where int is an integer value between 0 and 100. For example:
SET SESSION TEMPSPACECAP '40%';
-
int{K|M|G|T} expresses storage allocation in kilobytes, megabytes, gigabytes, or terabytes. For example:
SET SESSION TEMPSPACECAP '10G';
Privileges
Non-superusers:
Examples
Set the session TEMPSPACECAP to 20 gigabytes:
=> SET SESSION TEMPSPACECAP '20G';
SET
=> SHOW TEMPSPACECAP;
name | setting
--------------+----------
tempspacecap | 20971520
(1 row)
Note
SHOW displays the TEMPSPACECAP in kilobytes.
Set the session TEMPSPACECAP to unlimited:
=> SET SESSION TEMPSPACECAP NONE;
SET
=> SHOW TEMPSPACECAP;
name | setting
--------------+-----------
tempspacecap | UNLIMITED
(1 row)
See also
7.39.17 - SET SESSION WORKLOAD
Sets the workload for the session.
Sets the workload for the current session.
For details on this and other session parameters, see SHOW:
Syntax
SET SESSION WORKLOAD TO { workload_name | DEFAULT | NONE }
Parameters
workload_name- The workload to use for the current session. The specified workload must be associated with a workload routing rule.
DEFAULT- Sets the workload to the workload granted to the current user or their roles. If they have more than one workload, the one with the highest priority is used.
NONE- Removes the workload for the current session.
Privileges
None
Examples
The following example sets analytics as the workload for the current session:
=> CREATE ROUTING RULE analytic_rule ROUTE WORKLOAD analytics TO SUBCLUSTER my_subcluster;
=> SET SESSION WORKLOAD analytics;
7.39.18 - SET STANDARD_CONFORMING_STRINGS
Specifies whether to treat backslashes as escape characters for the current session.
Specifies whether to treat backslashes as escape characters for the current session. By default, Vertica conforms to the SQL standard and supports SQL:2008 string literals within Unicode escapes.
Syntax
SET STANDARD_CONFORMING_STRINGS TO { ON | OFF }
Parameters
ON- (Default) Treat ordinary string literals ('...') as backslashes () literally. This means that backslashes are treated as string literals and not as escape characters.
OFF- Treat backslashes as escape characters.
Privileges
None
Requirements
Examples
Turn off conforming strings for the session:
=> SET STANDARD_CONFORMING_STRINGS TO OFF;
Verify the current setting:
=> SHOW STANDARD_CONFORMING_STRINGS;
name | setting
-----------------------------+---------
standard_conforming_strings | off
(1 row)
Turn on conforming strings for the session:
=> SET STANDARD_CONFORMING_STRINGS TO ON;
See also
7.39.19 - SET TIME ZONE
Changes the TIME ZONE run-time parameter for the current.
Changes the TIME ZONE run-time parameter for the current session. Use
SHOW TIMEZONE to show the session's current time zone.
If you set the timezone using POSIX format, the timezone abbreviation you use overrides the default timezone abbreviation. If the date style is set to POSTGRES, the timezone abbreviation you use is also used when converting a timestamp to a string.
Syntax
SET TIME ZONE [TO] { value | 'value' }
Note
Vertica treats literals TIME ZONE and TIMEZONE as synonyms.
Parameters
value- One of the following:
-
A time zone literal supported by Vertica. To view the default list of valid literals, see the files in the following directory:
/opt/vertica/share/timezonesets
-
A signed integer representing an offset from UTC in hours
-
A time zone literal with a signed integer offset. For example:
=> SET TIME ZONE TO 'America/New York -3'; -- equivalent to Pacific time
Note
Only valid timezone+offset combinations are meaningful as arguments to SET TIME ZONE. However, Vertica does not return an error for meaningless combinations—for example, America/NewYork + 150.
-
An interval value
-
Constants LOCAL and DEFAULT, which respectively set the time zone to the one specified in environment variable TZ, or if TZ is undefined, to the operating system time zone.
Only valid (timezone+offset) combination are acceptable as parameter for this function.
Privileges
None
Examples
=> SET TIME ZONE TO DEFAULT;
=> SET TIME ZONE TO 'PST8PDT'; -- Berkeley, California
=> SET TIME ZONE TO 'Europe/Rome'; -- Italy
=> SET TIME ZONE TO '-7'; -- UDT offset equivalent to PDT
=> SET TIME ZONE TO INTERVAL '-08:00 HOURS';
See also
Using time zones with Vertica
7.39.19.1 - Time zone names for setting TIME ZONE
The time zone names listed below are recognized by Vertica as valid settings for the SQL time zone (the TIME ZONE run-time parameter).
The time zone names listed below are valid settings for the SQL time zone (the TIME ZONE run-time parameter).
These names are not the same as the names shown in
/opt/vertica/share/timezonesets, which are recognized by Vertica in date/time input values. The TIME ZONE names listed below imply a local Daylight Saving Time rule, where date/time input names represent a fixed offset from UTC.
In many cases, the same zone has several names. These are grouped together. The list is sorted primarily by commonly used zone names.
In addition to the names in the list, Vertica accepts time zone names as one of the following:
where STD is a zone abbreviation, offset is a numeric offset in hours west from UTC, and DST is an optional Daylight Saving Time zone abbreviation, assumed to stand for one hour ahead of the given offset.
For example, if EST5EDT were not already a recognized zone name, Vertica accepts it as functionally equivalent to USA East Coast time. When a Daylight Saving Time zone name is present, Vertica assumes it uses USA time zone rules, so this feature is of limited use outside North America.
Caution
Be aware that this provision can lead to silently accepting invalid input, as there is no check on the reasonableness of the zone abbreviations. For example, SET TIME ZONE TO FOOBANKO works, leaving the system effectively using a rather peculiar abbreviation for GMT.
Time zones
- Africa:
- Africa/Abidjan
- Africa/Accra
- Africa/Addis_Ababa
- Africa/Algiers
- Africa/Asmera
- Africa/Bamako
- Africa/Bangui
- Africa/Banjul
- Africa/Bissau
- Africa/Blantyre
- Africa/Brazzaville
- Africa/Bujumbura
- Africa/Cairo Egypt
- Africa/Casablanca
- Africa/Ceuta
- Africa/Conakry
- Africa/Dakar
- Africa/Dar_es_Salaam
- Africa/Djibouti
- Africa/Douala
- Africa/El_Aaiun
- Africa/Freetown
- Africa/Gaborone
- Africa/Harare
- Africa/Johannesburg
- Africa/Kampala
- Africa/Khartoum
- Africa/Kigali
- Africa/Kinshasa
- Africa/Lagos
- Africa/Libreville
- Africa/Lome
- Africa/Luanda
- Africa/Lubumbashi
- Africa/Lusaka
- Africa/Malabo
- Africa/Maputo
- Africa/Maseru
- Africa/Mbabane
- Africa/Mogadishu
- Africa/Monrovia
- Africa/Nairobi
- Africa/Ndjamena
- Africa/Niamey
- Africa/Nouakchott
- Africa/Ouagadougou
- Africa/Porto-Novo
- Africa/Sao_Tome
- Africa/Timbuktu
- Africa/Tripoli Libya
- Africa/Tunis
- Africa/Windhoek
- America
- America/Adak America/Atka US/Aleutian
- America/Anchorage SystemV/YST9YDT US/Alaska
- America/Anguilla
- America/Antigua
- America/Araguaina
- America/Aruba
- America/Asuncion
- America/Bahia
- America/Barbados
- America/Belem
- America/Belize
- America/Boa_Vista
- America/Bogota
- America/Boise
- America/Buenos_Aires
- America/Cambridge_Bay
- America/Campo_Grande
- America/Cancun
- America/Caracas
- America/Catamarca
- America/Cayenne
- America/Cayman
- America/Chicago CST6CDT SystemV/CST6CDT US/Central
- America/Chihuahua
- America/Cordoba America/Rosario
- America/Costa_Rica
- America/Cuiaba
- America/Curacao
- America/Danmarkshavn
- America/Dawson
- America/Dawson_Creek
- America/Denver MST7MDT SystemV/MST7MDT US/Mountain America/Shiprock Navajo
- America/Detroit US/Michigan
- America/Dominica
- America/Edmonton Canada/Mountain
- America/Eirunepe
- America/El_Salvador
- America/Ensenada America/Tijuana Mexico/BajaNorte
- America/Fortaleza
- America/Glace_Bay
- America/Godthab
- America/Goose_Bay
- America/Grand_Turk
- America/Grenada
- America/Guadeloupe
- America/Guatemala
- America/Guayaquil
- America/Guyana
- America/Halifax Canada/Atlantic SystemV/AST4ADT
- America/Havana Cuba
- America/Hermosillo
- America/Indiana/Indianapolis
- America/Indianapolis
- America/Fort_Wayne EST SystemV/EST5 US/East-Indiana
- America/Indiana/Knox America/Knox_IN US/Indiana-Starke
- America/Indiana/Marengo
- America/Indiana/Vevay
- America/Inuvik
- America/Iqaluit
- America/Jamaica Jamaica
- America/Jujuy
- America/Juneau
- America/Kentucky/Louisville America/Louisville
- America/Kentucky/Monticello
- America/La_Paz
- America/Lima
- America/Los_Angeles PST8PDT SystemV/PST8PDT US/Pacific US/Pacific- New
- America/Maceio
- America/Managua
- America/Manaus Brazil/West
- America/Martinique
- America/Mazatlan Mexico/BajaSur
- America/Mendoza
- America/Menominee
- America/Merida
- America/Mexico_City Mexico/General
- America/Miquelon
- America/Monterrey
- America/Montevideo
- America/Montreal
- America/Montserrat
- America/Nassau
- America/New_York EST5EDT SystemV/EST5EDT US/Eastern
- America/Nipigon
- America/Nome
- America/Noronha Brazil/DeNoronha
- America/North_Dakota/Center
- America/Panama
- America/Pangnirtung
- America/Paramaribo
- America/Phoenix MST SystemV/MST7 US/Arizona
- America/Port-au-Prince
- America/Port_of_Spain
- America/Porto_Acre America/Rio_Branco Brazil/Acre
- America/Porto_Velho
- America/Puerto_Rico SystemV/AST4
- America/Rainy_River
- America/Rankin_Inlet
- America/Recife
- America/Regina Canada/East-Saskatchewan Canada/Saskatchewan SystemV/CST6
- America/Santiago Chile/Continental
- America/Santo_Domingo
- America/Sao_Paulo Brazil/East
- America/Scoresbysund
- America/St_Johns Canada/Newfoundland
- America/St_Kitts
- America/St_Lucia
- America/St_Thomas America/Virgin
- America/St_Vincent
- America/Swift_Current
- America/Tegucigalpa
- America/Thule
- America/Thunder_Bay
- America/Toronto Canada/Eastern
- America/Tortola
- America/Vancouver Canada/Pacific
- America/Whitehorse Canada/Yukon
- America/Winnipeg Canada/Central
- America/Yakutat
- America/Yellowknife
- Antarctica
- Antarctica/Casey
- Antarctica/Davis
- Antarctica/DumontDUrville
- Antarctica/Mawson
- Antarctica/McMurdo
- Antarctica/South_Pole
- Antarctica/Palmer
- Antarctica/Rothera
- Antarctica/Syowa
- Antarctica/Vostok
- Asia
- Asia/Aden
- Asia/Almaty
- Asia/Amman
- Asia/Anadyr
- Asia/Aqtau
- Asia/Aqtobe
- Asia/Ashgabat Asia/Ashkhabad
- Asia/Baghdad
- Asia/Bahrain
- Asia/Baku
- Asia/Bangkok
- Asia/Beirut
- Asia/Bishkek
- Asia/Brunei
- Asia/Calcutta
- Asia/Choibalsan
- Asia/Chongqing Asia/Chungking
- Asia/Colombo
- Asia/Dacca Asia/Dhaka
- Asia/Damascus
- Asia/Dili
- Asia/Dubai
- Asia/Dushanbe
- Asia/Gaza
- Asia/Harbin
- Asia/Hong_Kong Hongkong
- Asia/Hovd
- Asia/Irkutsk
- Asia/Jakarta
- Asia/Jayapura
- Asia/Jerusalem Asia/Tel_Aviv Israel
- Asia/Kabul
- Asia/Kamchatka
- Asia/Karachi
- Asia/Kashgar
- Asia/Katmandu
- Asia/Krasnoyarsk
- Asia/Kuala_Lumpur
- Asia/Kuching
- Asia/Kuwait
- Asia/Macao Asia/Macau
- Asia/Magadan
- Asia/Makassar Asia/Ujung_Pandang
- Asia/Manila
- Asia/Muscat
- Asia/Nicosia Europe/Nicosia
- Asia/Novosibirsk
- Asia/Omsk
- Asia/Oral
- Asia/Phnom_Penh
- Asia/Pontianak
- Asia/Pyongyang
- Asia/Qatar
- Asia/Qyzylorda
- Asia/Rangoon
- Asia/Riyadh
- Asia/Riyadh87 Mideast/Riyadh87
- Asia/Riyadh88 Mideast/Riyadh88
- Asia/Riyadh89 Mideast/Riyadh89
- Asia/Saigon
- Asia/Sakhalin
- Asia/Samarkand
- Asia/Seoul ROK
- Asia/Shanghai PRC
- Asia/Singapore Singapore
- Asia/Taipei ROC
- Asia/Tashkent
- Asia/Tbilisi
- Asia/Tehran Iran
- Asia/Thimbu Asia/Thimphu
- Asia/Tokyo Japan
- Asia/Ulaanbaatar Asia/Ulan_Bator
- Asia/Urumqi
- Asia/Vientiane
- Asia/Vladivostok
- Asia/Yakutsk
- Asia/Yekaterinburg
- Asia/Yerevan
- Atlantic
- Atlantic/Azores
- Atlantic/Bermuda
- Atlantic/Canary
- Atlantic/Cape_Verde
- Atlantic/Faeroe
- Atlantic/Madeira
- Atlantic/Reykjavik Iceland
- Atlantic/South_Georgia
- Atlantic/St_Helena
- Atlantic/Stanley
- Australia
- Australia/ACT
- Australia/Canberra
- Australia/NSW
- Australia/Sydney
- Australia/Adelaide
- Australia/South
- Australia/Brisbane
- Australia/Queensland
- Australia/Broken_Hill
- Australia/Yancowinna
- Australia/Darwin
- Australia/North
- Australia/Hobart
- Australia/Tasmania
- Australia/LHI
- Australia/Lord_Howe
- Australia/Lindeman
- Australia/Melbourne
- Australia/Victoria
- Australia/Perth Australia/West
- CET
- EET
- Etc/GMT
- GMT
- GMT+0
- GMT-0
- GMT0
- Greenwich
- Etc/Greenwich
- Etc/GMT+0...Etc/GMT+12
- Etc/GMT-0...Etc/GMT-14
- Europe
- Europe/Amsterdam
- Europe/Andorra
- Europe/Athens
- Europe/Belfast
- Europe/Belgrade
- Europe/Ljubljana
- Europe/Sarajevo
- Europe/Skopje
- Europe/Zagreb
- Europe/Berlin
- Europe/Brussels
- Europe/Bucharest
- Europe/Budapest
- Europe/Chisinau Europe/Tiraspol
- Europe/Copenhagen
- Europe/Dublin Eire
- Europe/Gibraltar
- Europe/Helsinki
- Europe/Istanbul Asia/Istanbul Turkey
- Europe/Kaliningrad
- Europe/Kiev
- Europe/Lisbon Portugal
- Europe/London GB GB-Eire
- Europe/Luxembourg
- Europe/Madrid
- Europe/Malta
- Europe/Minsk
- Europe/Monaco
- Europe/Moscow W-SU
- Europe/Oslo
- Arctic/Longyearbyen
- Atlantic/Jan_Mayen
- Europe/Paris
- Europe/Prague Europe/Bratislava
- Europe/Riga
- Europe/Rome Europe/San_Marino Europe/Vatican
- Europe/Samara
- Europe/Simferopol
- Europe/Sofia
- Europe/Stockholm
- Europe/Tallinn
- Europe/Tirane
- Europe/Uzhgorod
- Europe/Vaduz
- Europe/Vienna
- Europe/Vilnius
- Europe/Warsaw Poland
- Europe/Zaporozhye
- Europe/Zurich
- Factory
- Indian
- Indian/Antananarivo
- Indian/Chagos
- Indian/Christmas
- Indian/Cocos
- Indian/Comoro
- Indian/Kerguelen
- Indian/Mahe
- Indian/Maldives
- Indian/Mauritius
- Indian/Mayotte
- Indian/Reunion
- MET
- Pacific
- Pacific/Apia
- Pacific/Auckland NZ
- Pacific/Chatham NZ-CHAT
- Pacific/Easter
- Chile/EasterIsland
- Pacific/Efate
- Pacific/Enderbury
- Pacific/Fakaofo
- Pacific/Fiji
- Pacific/Funafuti
- Pacific/Galapagos
- Pacific/Gambier SystemV/YST9
- Pacific/Guadalcanal
- Pacific/Guam
- Pacific/Honolulu HST SystemV/HST10 US/Hawaii
- Pacific/Johnston
- Pacific/Kiritimati
- Pacific/Kosrae
- Pacific/Kwajalein Kwajalein
- Pacific/Majuro
- Pacific/Marquesas
- Pacific/Midway
- Pacific/Nauru
- Pacific/Niue
- Pacific/Norfolk
- Pacific/Noumea
- Pacific/Pago_Pago
- Pacific/Samoa US/Samoa
- Pacific/Palau
- Pacific/Pitcairn SystemV/PST8
- Pacific/Ponape
- Pacific/Port_Moresby
- Pacific/Rarotonga
- Pacific/Saipan
- Pacific/Tahiti
- Pacific/Tarawa
- Pacific/Tongatapu
- Pacific/Truk
- Pacific/Wake
- Pacific/Wallis
- Pacific/Yap
- UCT Etc
- UCT
- UTC
- Universal Zulu
- Etc/UTC
- Etc/Universal
- Etc/Zulu
- WET
7.40 - SHOW
Shows run-time parameters for the current session.
Shows run-time parameters for the current session.
Syntax
SHOW { parameter | ALL }
Parameters
ALL- Shows all run-time settings.
AUTOCOMMIT- Returns on/off to indicate whether statements automatically commit their transactions when they complete.
-
AVAILABLE ROLES
- Lists all roles available to the user.
AVAILABLE WORKLOADS- Returns the workloads available to the user and their enabled roles.
DATESTYLE- Shows the current style of date values. See SET DATESTYLE.
-
ENABLED ROLES
- Shows the roles enabled for the current session. See SET ROLE.
ESCAPE_STRING_WARNING- Returns on/off to indicate whether warnings are issued when backslash escapes are found in strings. See SET ESCAPE_STRING_WARNING.
GRACEPERIOD- Shows the session GRACEPERIOD set by SET SESSION GRACEPERIOD.
IDLESESSIONTIMEOUT- Shows how long the session can remain idle before it times out.
INTERVALSTYLE- Shows whether units are output when printing intervals. See SET INTERVALSTYLE.
LOCALE- Shows the current locale. See SET LOCALE.
MEMORYCAP- Shows the maximum amount of memory that any request use. See SET MEMORYCAP.
MULTIPLEACTIVERESULTSETS- Returns on/off to indicate whether multiple active result sets on one connection are allowed. See SET SESSION MULTIPLEACTIVERESULTSETS.
RESOURCE POOL- Shows the resource pool that the session is using. See SET RESOURCE POOL.
RUNTIMECAP- Shows the maximum amount of time that queries can run in the session. See SET RUNTIMECAP.
SEARCH_PATH- Shows the order in which Vertica searches schemas. See SET SEARCH_PATH. For example:
=> SHOW SEARCH_PATH;
name | setting
-------------+---------------------------------------------------
search_path | "$user", public, v_catalog, v_monitor, v_internal
(1 row)
STANDARD_CONFORMING_STRINGS- Shows whether backslash escapes are enabled for the session. See SET STANDARD_CONFORMING_STRINGS.
TEMPSPACECAP- Shows the maximum amount of temporary file space that queries can use in the session. See SET TEMPSPACECAP.
TIMEZONE- Shows the timezone set in the current session. See SET TIMEZONE.
-
TRANSACTION_ISOLATION
- Shows the current transaction isolation setting, as described in SET SESSION CHARACTERISTICS AS TRANSACTION. For example:
=> SHOW TRANSACTION_ISOLATION;
name | setting
-----------------------+----------------
transaction_isolation | READ COMMITTED
(1 row)
-
TRANSACTION_READ_ONLY
- Returns true/false to indicate the current read-only setting, as described in SET SESSION CHARACTERISTICS AS TRANSACTION. For example:
=> SHOW TRANSACTION_READ_ONLY;
name | setting
-----------------------+---------
transaction_read_only | false
(1 row)
WORKLOAD- Shows the workloads associated with the current session.
Privileges
None
Examples
Display all current runtime parameter settings:
=> SHOW ALL;
name | setting
-----------------------------+-----------------------------------------------------------
locale | en_US@collation=binary (LEN_KBINARY)
autocommit | off
standard_conforming_strings | on
escape_string_warning | on
multipleactiveresultsets | off
datestyle | ISO, MDY
intervalstyle | plain
timezone | America/New_York
search_path | "$user", public, v_catalog, v_monitor, v_internal, v_func
transaction_isolation | READ COMMITTED
transaction_read_only | false
resource_pool | general
memorycap | UNLIMITED
tempspacecap | UNLIMITED
runtimecap | UNLIMITED
idlesessiontimeout | UNLIMITED
graceperiod | UNLIMITED
enabled roles | dbduser*, dbadmin*, pseudosuperuser*
available roles | dbduser*, dbadmin*, pseudosuperuser*
tcp_keepalive | idle_time: [7200], probe_interval: [75], probe_count: [9]
workload | analytics
(21 rows)
7.41 - SHOW CURRENT
Displays active configuration parameter values that are set at all levels.
Displays active configuration parameter values that are set at all levels. Vertica first checks values set at the session level. If a value is not set for a configuration parameter at the session level, Vertica next checks if the value is set for the node where you are logged in, and then checks the database level. If no values are set, SHOW CURRENT shows the default value for the configuration parameter. If the configuration parameter requires a restart to take effect, the active values shown might differ from the set values.
Syntax
SHOW CURRENT { parameter-name[,...] | ALL }
Parameters
parameter-name- Names of configuration parameters to show.
ALL- Shows all configuration parameters set at all levels.
Privileges
Non-superuser: SHOW CURRENT ALL returns masked parameter settings. Attempts to view specific parameter settings return an error.
Examples
Show configuration parameters and their settings at all levels.
=> SHOW CURRENT ALL;
level | name |setting
---------+---------------------------+---------
DEFAULT | ActivePartitionCount | 1
DEFAULT | AdvanceAHMInterval | 180
DEFAULT | AHMBackupManagement | 0
DATABASE | AnalyzeRowCountInterval | 3600
SESSION | ForceUDxFencedMode | 1
NODE | MaxClientSessions | 0
...
7.42 - SHOW DATABASE
Displays configuration parameter values that are set for the database.
Displays configuration parameter values that are set for the database.
Important
You can also get detailed information on configuration parameters, including their current and default values, by querying system table
CONFIGURATION_PARAMETERS.
Note
If the configuration parameter is set but requires a database restart to take effect, the value shown might differ from the active value.
Syntax
SHOW DATABASE db-spec { parameter-name[,...] | ALL }
Parameters
db-specSpecifies the current database, set to the database name or DEFAULT.
parameter-name- Names of one or more configuration parameters to show.Non-superusers can only specify parameters whose settings are not masked by
SHOW DATABASE...ALL, otherwise Vertica returns an error.
If you specify a single parameter that is not set, SHOW DATABASE returns an empty row for that parameter.
To obtain the names of database-level parameters, query system table
CONFIGURATION_PARAMETERS.
ALL- Shows all configuration parameters set at the database level.For non-superusers, Vertica masks settings of security parameters, which only superusers can access.
Privileges
-
Superuser: Shows all database parameter settings.
-
Non-superuser: Masks all security parameter settings, which only superusers can access. To determine which parameters require superuser privileges, query system table
CONFIGURATION_PARAMETERS.
Examples
Show to a non-superuser all configuration parameters that are set on the database:
=> SHOW DATABASE DEFAULT ALL;
name | setting
--------------------------------+----------
AllowNumericOverflow | 1
CopyFaultTolerantExpressions | 1
GlobalHeirUsername | ********
MaxClientSessions | 50
NumericSumExtraPrecisionDigits | 0
(6 rows)
Show settings for two configuration parameters:
=> SHOW DATABASE DEFAULT AllowNumericOverflow, NumericSumExtraPrecisionDigits;
name | setting
--------------------------------+---------
AllowNumericOverflow | 1
NumericSumExtraPrecisionDigits | 0
(2 rows)
7.43 - SHOW NODE
Displays configuration parameter values that are set for a node.
Displays configuration parameter values that are set for a node. If you specify a parameter that is not set, SHOW NODE returns an empty row for that parameter.
Note
If the configuration parameter is set but requires a database restart to take effect, the value shown might differ from the active value.
Syntax
SHOW NODE node-name { parameter-name [,...] | ALL }
Parameters
node-name- Name of the target node.
parameter-name- Names of one or more node-level configuration parameters. To obtain the names of node-level parameters, query system table
CONFIGURATION_PARAMETERS.
ALL- Shows all configuration parameters set at the node level.
Privileges
None
Examples
View all configuration parameters and their settings for node v_vmart_node0001:
=> SHOW NODE v_vmart_node0001 ALL;
name | setting
---------------------------+---------
DefaultIdleSessionTimeout | 5 hour
MaxClientSessions | 20
7.44 - SHOW SESSION
Displays configuration parameter values that are set for the current session.
Displays configuration parameter values that are set for the current session. If you specify a parameter that is not set, SHOW SESSION returns an empty row for that parameter.
Note
If the configuration parameter is set but requires a database restart to take effect, the value shown might differ from the active value.
Syntax
SHOW SESSION { ALL | UDPARAMETER ALL }
Parameters
ALL- Shows all Vertica configuration parameters set at the session level.
UDPARAMETER ALL- Shows all parameters defined by user-defined extensions. These parameters are not shown in the CONFIGURATION_PARAMETERS table.
Privileges
None
Examples
View all Vertica configuration parameters and their settings for the current session. User-defined parameters are not included:
=> SHOW SESSION ALL;
name | setting
----------------------------+---------------------------------------------------
locale | en_US@collation=binary (LEN_KBINARY)
autocommit | off
standard_conforming_strings | on
escape_string_warning | on
datestyle | ISO, MDY
intervalstyle | plain
timezone | America/New_York
search_path | "$user", public, v_catalog, v_monitor, v_internal
transaction_isolation | READ COMMITTED
transaction_read_only | false
resource_pool | general
memorycap | UNLIMITED
tempspacecap | UNLIMITED
runtimecap | UNLIMITED
enabled roles | dbduser*, dbadmin*, pseudosuperuser*
available roles | dbduser*, dbadmin*, pseudosuperuser*
ForceUDxFencedMode | 1
(17 rows)
7.45 - SHOW USER
Displays configuration parameter settings for database users.
Displays configuration parameter settings for database users. To get the names of user-level parameters, query system table CONFIGURATION_PARAMETERS:
SELECT parameter_name, allowed_levels FROM configuration_parameters
WHERE allowed_levels ilike '%USER%' AND parameter_name ilike '%depot%';
parameter_name | allowed_levels
-------------------------+-------------------------
UseDepotForWrites | SESSION, USER, DATABASE
DepotOperationsForQuery | SESSION, USER, DATABASE
UseDepotForReads | SESSION, USER, DATABASE
(3 rows)
Syntax
SHOW USER { user-name | ALL } [PARAMETER] { cfg-parameter [,...] | ALL }
Parameters
user-name | ALL- Show parameter settings for the specified user, or for all users.
[PARAMETER] parameter-list- A comma-delimited list of user-level configuration parameters.
PARAMETER ALL- Show all configuration parameters that are set for the specified users.
Privileges
Non-superusers: Can view only their own configuration parameter settings.
Examples
The following example shows configuration parameter settings for two users, Yvonne and Ahmed:
=> SELECT user_name FROM v_catalog.users WHERE user_name != 'dbadmin';
user_name
-----------
Ahmed
Yvonne
(2 rows)
=> SHOW USER Yvonne PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Yvonne | DepotOperationsForQuery | Fetches
(1 row)
=> ALTER USER Yvonne SET PARAMETER UseDepotForWrites = 0;
ALTER USER
=> SHOW USER Yvonne PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Yvonne | DepotOperationsForQuery | Fetches
Yvonne | UseDepotForWrites | 0
(2 rows)
=> ALTER USER Ahmed SET PARAMETER DepotOperationsForQuery = 'Fetches';
ALTER USER
=> SHOW USER ALL PARAMETER ALL;
user | parameter | setting
--------+-------------------------+---------
Ahmed | DepotOperationsForQuery | Fetches
Yvonne | DepotOperationsForQuery | Fetches
Yvonne | UseDepotForWrites | 0
(3 rows)
See also
ALTER USER
7.46 - START TRANSACTION
Starts a transaction block.
Starts a transaction block.
Syntax
START TRANSACTION [ isolation_level ]
where isolation_level is one of:
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }READ { ONLY | WRITE }
Parameters
Isolation level, described in the following table, determines what data the transaction can access when other transactions are running concurrently. The isolation level cannot be changed after the first query (SELECT) or DML statement (INSERT, DELETE, UPDATE) has run. A transaction retains its isolation level until it completes, even if the session's isolation level changes during the transaction. Vertica internal processes (such as the Tuple Mover and refresh operations) and DDL operations always run at the SERIALIZABLE isolation level to ensure consistency.
WORK | TRANSACTION- Have no effect; they are optional keywords for readability.
ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
- SERIALIZABLE: Sets the strictest level of SQL transaction isolation. This level emulates transactions serially, rather than concurrently. It holds locks and blocks write operations until the transaction completes. Not recommended for normal query operations.
- REPEATABLE READ: Automatically converted to SERIALIZABLE by Vertica.
- READ COMMITTED (Default): Allows concurrent transactions. Use READ COMMITTED isolation for normal query operations, but be aware that there is a subtle difference between them. SeeTransactionsfor more information.
- READ UNCOMMITTED: Automatically converted to READ COMMITTED by Vertica.
READ {WRITE | ONLY}- Determines whether the transaction is read/write or read-only. Read/write is the default.
Setting the transaction session mode to read-only disallows the following SQL commands, but does not prevent all disk write operations:
- INSERT, UPDATE, DELETE, and COPY if the table they would write to is not a temporary table
- All CREATE, ALTER, and DROP commands
- GRANT, REVOKE, and EXPLAIN if the command it would run is among those listed.
Privileges
None
Notes
BEGIN performs the same function as START TRANSACTION.
Examples
This example shows how to start a transaction.
= > START TRANSACTION ISOLATION LEVEL READ COMMITTED READ WRITE;
START TRANSACTION
=> CREATE TABLE sample_table (a INT);
CREATE TABLE
=> INSERT INTO sample_table (a) VALUES (1);
OUTPUT
--------
1
(1 row)
See also
7.47 - TRUNCATE TABLE
Removes all storage associated with a table, while leaving the table definition intact.
Removes all storage associated with a table, while leaving the table definition intact. TRUNCATE TABLE auto-commits the current transaction after statement execution and cannot be rolled back.
TRUNCATE TABLE also performs the following actions:
-
Removes all table history preceding the current epoch. After TRUNCATE TABLE returns, AT EPOCH queries on the truncated table return nothing.
-
Drops all table- and partition-level statistics.
Syntax
TRUNCATE TABLE [[{namespace. | database. }]schema.]table-name
Parameters
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table-name - The name of the anchor table or temporary table to truncate. You cannot truncate an external table.
Privileges
Non-superuser:
Examples
See Truncating tables.
See also
7.48 - UPDATE
Replaces the values of the specified columns in all rows for which a specified condition is true.
Replaces the values of the specified columns in all rows for which a specified condition is true. All other columns and rows in the table are unchanged. If successful, UPDATE returns the number of rows updated. A count of 0 indicates no rows matched the condition.
Important
The Vertica implementation of UPDATE differs from traditional databases. It does not delete data from disk storage; it writes two rows, one with new data and one marked for deletion. Rows marked for deletion remain available for historical queries.
Syntax
UPDATE [[{namespace. | database. }]schema.]table-reference [AS] alias
SET set-expression [,...]
[ FROM from-list ]
[ where-clause ]
Note
UPDATE statements can also embed the following hints:
Parameters
{ namespace. | database. }- Name of the database or namespace that contains
table:
- Database name: If specified, it must be the current database. In Eon Mode databases, the database name is valid only if the object is in the default namespace.
- Namespace name (Eon Mode only): You must specify the namespace of objects in non-default namespaces. If no namespace is provided, Vertica assumes the object is in the default namespace.
You cannot specify both a database and namespace name.
schema- Name of the schema, by default
public. If you specify the namespace or database name, you must provide the schema name, even if the schema is public.
table-reference- A table, one of the following:
You cannot update a projection.
alias- A temporary name used to reference the table.
SET set-expression- The columns to update from one or more set expressions. Each SET clause expression specifies a target column and its new value as follows:
column-name = { expression | DEFAULT }
where:
-
*column-name* is any column that does not have primary key or foreign key referential integrity constraints and is not of a complex type. Native arrays are permitted.
-
expression specifies a value to assign to the column. The expression can use the current values of this and other table columns. For example:
=> UPDATE T1 SET C1 = C1+1
-
DEFAULT sets column-name to its default value, or is ignored if no default value is defined for this column.
UPDATE only modifies the columns specified by the SET clause. Unspecified columns remain unchanged.
FROM from-list- A list of table expressions, allowing columns from other tables to appear in the WHERE condition and the UPDATE expressions. This is similar to the list of tables that can be specified in the FROM clause of a SELECT command.
The FROM clause can reference the target table as follows:
FROM DEFAULT [join-type] JOIN table-reference [ ON join-predicate ]
DEFAULT specifies the table to update. This keyword can be used only once in the FROM clause, and it cannot be used elsewhere in the UPDATE statement.
Privileges
Table owner or user with GRANT OPTION is grantor.
-
UPDATE privilege on table
-
USAGE privilege on schema that contains the table
-
SELECT privilege on the table when executing an UPDATE statement that references table column values in a WHERE or SET clause
Subqueries and joins
UPDATE supports subqueries and joins, which is useful for updating values in a table based on values that are stored in other tables. For details, see Subqueries in UPDATE and DELETE statements.
Committing successive table changes
Vertica follows the SQL-92 transaction model, so successive INSERT, UPDATE, and DELETE statements are included in the same transaction. You do not need to explicitly start this transaction; however, you must explicitly end it with COMMIT, or implicitly end it with COPY. Otherwise, Vertica discards all changes that were made within the transaction.
Restrictions
-
You cannot update an immutable table.
-
You cannot update columns of complex types except for native arrays.
-
If the joins specified in the FROM clause or WHERE predicate produce more than one copy of the row in the target table, the new value of the row in the table is chosen arbitrarily.
-
If primary key, unique key, or check constraints are enabled for automatic enforcement in the target table, Vertica enforces those constraints when you load new data. If a violation occurs, Vertica rolls back the operation and returns an error.
-
If an update would violate a table or schema disk quota, the operation fails. For more information, see Disk quotas.
Examples
In the fact table, modify the price column value for all rows where the cost column value is greater than 100:
=> UPDATE fact SET price = price - cost * 80 WHERE cost > 100;
In the retail.customer table, set the state column to NH when the CID column value is greater than 100:
=> UPDATE retail.customer SET state = 'NH' WHERE CID > 100;
To use table aliases in UPDATE queries, consider the following two tables:
=> SELECT * FROM result_table;
cust_id | address
---------+--------------------
20 | Lincoln Street
30 | Beach Avenue
30 | Booth Hill Road
40 | Mt. Vernon Street
50 | Hillside Avenue
(5 rows)
=> SELECT * FROM new_addresses;
new_cust_id | new_address
-------------+---------------
20 | Infinite Loop
30 | Loop Infinite
60 | New Addresses
(3 rows)
The following query and subquery use table aliases to update the address column in result_table (alias r) with the new address from the corresponding column in the new_addresses table (alias n):
=> UPDATE result_table r
SET address=n.new_address
FROM new_addresses n
WHERE r.cust_id = n.new_cust_id;
result_table shows the address field updates made for customer IDs 20 and 30:
=> SELECT * FROM result_table ORDER BY cust_id;
cust_id | address
---------+------------------
20 | Infinite Loop
30 | Loop Infinite
30 | Loop Infinite
40 | Mt. Vernon Street
50 | Hillside Avenue
(5 rows)
You cannot use UPDATE to update individual elements of native arrays. Instead, replace the entire array value. The following example uses ARRAY_CAT to add an element to an array column:
=> SELECT * FROM singers;
lname | fname | bands
--------+-------+---------------------------------------------
Cher | | ["Sonny and Cher"]
Jagger | Mick | ["Rolling Stones"]
Slick | Grace | ["Jefferson Airplane","Jefferson Starship"]
(3 rows)
=> UPDATE singers SET bands=ARRAY_CAT(bands,ARRAY['something new'])
WHERE lname='Cher';
OUTPUT
--------
1
(1 row)
=> SELECT * FROM singers;
lname | fname | bands
--------+-------+---------------------------------------------
Jagger | Mick | ["Rolling Stones"]
Slick | Grace | ["Jefferson Airplane","Jefferson Starship"]
Cher | | ["Sonny and Cher","something new"]
(3 rows)
8 - Vertica system tables
Vertica provides system tables that let you monitor your database and evaluate settings of its objects.
Vertica provides system tables that let you monitor your database and evaluate settings of its objects. You can query these tables just as you do other tables, depending on privilege requirements.
See also
8.1 - V_CATALOG schema
The system tables in this section reside in the v_catalog schema.
The system tables in this section reside in the v_catalog schema. These tables provide information (metadata) about the objects in a database; for example, tables, constraints, users, projections, and so on.
8.1.1 - ACCESS_POLICY
Provides information about existing access policies.
Provides information about existing access policies.
|
Column Name |
Data Type |
Description |
|
ACCESS_POLICY_OID |
INTEGER |
The unique identifier for the access policy. |
|
TABLE_NAME |
VARCHAR |
Name of the table specified in the access policy. |
|
IS_POLICY_ENABLED |
BOOLEAN |
Whether the access policy is enabled. |
|
POLICY_TYPE |
VARCHAR |
The type of access policy assigned to the table:
|
|
EXPRESSION |
VARCHAR |
The expression used when creating the access policy. |
|
COLUMN_NAME |
VARCHAR |
The column to which the access policy is assigned. Row policies apply to all columns in the table. |
|
TRUST_GRANTS |
BOOLEAN |
If true, GRANT statements override the access policy when determining whether a user can perform DML operations on the column or row. |
Privileges
By default, only the superuser can view this table. Superusers can grant non-superusers access to this table with the following statement. Non-superusers can only see rows for tables that they own:
=> GRANT SELECT ON access_policy TO PUBLIC
Examples
The following query returns all access policies on table public.customer_dimension:
=> \x
=> SELECT policy_type, is_policy_enabled, table_name, column_name, expression FROM access_policy WHERE table_name = 'public.customer_dimension';
-[ RECORD 1 ]-----+----------------------------------------------------------------------------------------
policy_type | Column Policy
is_policy_enabled | Enabled
table_name | public.customer_dimension
column_name | customer_address
expression | CASE WHEN enabled_role('administrator') THEN customer_address ELSE '**************' END
8.1.2 - ALL_TABLES
Provides summary information about tables in a Vertica database.
Provides summary information about tables in a Vertica database.
|
Column Name |
Data Type |
Description |
SCHEMA_NAME |
VARCHAR |
The name of the schema that contains the table. |
TABLE_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the table. |
TABLE_NAME |
VARCHAR |
The table name. |
TABLE_TYPE |
VARCHAR |
The type of table, which can be one of the following:
-
TABLE
-
SYSTEM TABLE
-
VIEW
-
GLOBAL TEMPORARY
-
LOCAL TEMPORARY
|
REMARKS |
VARCHAR |
A brief comment about the table. You define this field by using the COMMENT ON TABLE and COMMENT ON VIEW commands. |
Examples
onenode=> SELECT DISTINCT table_name, table_type FROM all_tables
WHERE table_name ILIKE 't%';
table_name | table_type
------------------------+--------------
types | SYSTEM TABLE
trades | TABLE
tuple_mover_operations | SYSTEM TABLE
tables | SYSTEM TABLE
tuning_recommendations | SYSTEM TABLE
testid | TABLE
table_constraints | SYSTEM TABLE
transactions | SYSTEM TABLE
(8 rows)
onenode=> SELECT table_name, table_type FROM all_tables
WHERE table_name ILIKE 'my%';
table_name | table_type
------------+------------
mystocks | VIEW
(1 row)
=> SELECT * FROM all_tables LIMIT 4;
-[ RECORD 1 ]-------------------------------------------
schema_name | v_catalog
table_id | 10206
table_name | all_tables
table_type | SYSTEM TABLE
remarks | A complete listing of all tables and views
-[ RECORD 2 ]-------------------------------------------
schema_name | v_catalog
table_id | 10000
table_name | columns
table_type | SYSTEM TABLE
remarks | Table column information
-[ RECORD 3 ]-------------------------------------------
schema_name | v_catalog
table_id | 10054
table_name | comments
table_type | SYSTEM TABLE
remarks | User comments on catalog objects
-[ RECORD 4 ]-------------------------------------------
schema_name | v_catalog
table_id | 10134
table_name | constraint_columns
table_type | SYSTEM TABLE
remarks | Table column constraint information
8.1.3 - AUDIT_MANAGING_USERS_PRIVILEGES
Provides summary information about privileges, creating, modifying, and deleting users, and authentication changes.
Provides summary information about privileges, creating, modifying, and deleting users, and authentication changes. This table is a join of LOG_PARAMS, LOG_QUERIES, and LOG_TABLES filtered on the Managing_Users_Privileges category.
|
Column Name |
Data Type |
Description |
|
ISSUED_TIME |
VARCHAR |
The time at which the query was executed. |
|
USER_NAME |
VARCHAR |
Name of the user who issued the query at the time Vertica recorded the session. |
|
USER_ID |
INTEGER |
Numeric representation of the user who ran the query. |
|
HOSTNAME |
VARCHAR |
The hostname, IP address, or URL of the database server. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
AUDIT_TYPE |
VARCHAR |
The type of operation for the audit:
|
|
AUDIT_TAG_NAME |
VARCHAR |
The tag name for the specific parameter, query, or table. |
|
REQUEST_TYPE |
VARCHAR |
The type of query request. Examples include, but are not limited to:
-
QUERY
-
DDL
-
LOAD
-
UTILITY
-
TRANSACTION
-
PREPARE
-
EXECUTE
-
SET
-
SHOW
|
|
REQUEST_ID |
INTEGER |
The ID of the privilege request. |
|
SUBJECT |
VARCHAR |
The name of the table or parameter that was queried or the subject of a query. |
|
REQUEST |
VARCHAR |
Lists the privilege request. |
|
SUCCESS |
VARCHAR |
Indicates whether or not the operation was successful. |
|
CATEGORY |
VARCHAR |
The audit parent category, Managing_Users_Privileges. |
8.1.4 - CA_BUNDLES
Stores certificate authority (CA) bundles created by CREATE CA BUNDLE.
Stores certificate authority (CA) bundles created by CREATE CA BUNDLE.
|
Column Name |
Data Type |
Description |
|
OID |
INTEGER |
The object identifier. |
|
NAME |
VARCHAR |
The name of the CA bundle. |
|
OWNER |
INTEGER |
The OID of the owner of the CA bundle. |
|
CERTIFICATES |
INTEGER |
The OIDs of the CA certificates inside the CA bundle. |
Privileges
-
See CA bundle OID, name, and owner: Superuser or owner of the CA bundle.
-
See CA bundle contents: Owner of the bundle
Joining with CERTIFICATES
CA_BUNDLES only stores OIDs. Since operations on CA bundles require certificate and owner names, you can use the following query to map bundles to certificate and owner names:
=> SELECT user_name AS owner_name,
owner AS owner_oid,
b.name AS bundle_name,
c.name AS cert_name
FROM (SELECT name,
STRING_TO_ARRAY(certificates) :: array[INT] AS certs
FROM ca_bundles) b
LEFT JOIN certificates c
ON CONTAINS(b.certs, c.oid)
LEFT JOIN users
ON user_id = owner
ORDER BY 1;
owner_name | owner_oid | bundle_name | cert_name
------------+-------------------+--------------+-----------
dbadmin | 45035996273704962 | ca_bundle | root_ca
dbadmin | 45035996273704962 | ca_bundle | ca_cert
(2 rows)
See also
8.1.5 - CATALOG_SUBSCRIPTION_CHANGES
Lists the changes made to catalog subscriptions.
Lists the changes made to catalog subscriptions.
|
Column Name |
Data Type |
Description |
EVENT_TIMESTAMP |
TIMESTAMP |
The time a catalog subscription changed. |
SESSION_ID |
VARCHAR |
A unique numeric ID assigned by the Vertica catalog, which identifies the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
USER_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the user. |
USER_NAME |
VARCHAR |
The user who made changes to the subscriptions. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
SHARD_NAME |
VARCHAR |
The name of the shard. |
SHARD_OID |
INTEGER |
The OID of the shard. |
SUBSCRIBER_NODE_NAME |
VARCHAR |
The node name or names subscribed to the shard. |
SUBSCRIBER_NODE_OID |
INTEGER |
The OID of the subscribing node or nodes. |
OLD_STATE |
VARCHAR |
The previous state of the node subscription. |
NEW_STATE |
VARCHAR |
The current state of the node subscription. |
WAS_PRIMARY |
BOOLEAN |
Defines whether the node was the primary subscriber. |
IS_PRIMARY |
BOOLEAN |
Defines whether the node is currently the primary subscriber. |
CATALOG_VERSION |
INTEGER |
The version of the catalog at the time of the subscription change. |
8.1.6 - CATALOG_SYNC_STATE
Shows when an Eon Mode database node synchronized its catalog to communal storage.
Shows when an Eon Mode database node synchronized its catalog to communal storage.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
|
SYNC_CATALOG_VERSION |
INTEGER |
The version number of the catalog being synchronized. |
|
EARLIEST_CHECKPOINT_VERSION |
INTEGER |
The earliest checkpoint that is maintained in communal storage. |
|
SYNC_TRAILING_INTERVAL |
INTEGER |
The difference between the global catalog version and the synchronized catalog version for a node. |
|
LAST_SYNC_AT |
TIMESTAMPTZ |
The date and time the last time the catalog was synchronized. |
8.1.7 - CATALOG_TRUNCATION_STATUS
Indicates how up to date the catalog is on communal storage.
Indicates how up to date the catalog is on communal storage. It is completely up to date when the current catalog version is the same as the catalog truncation version.
The catalog truncation version (CTV) is the version that Vertica cluster uses when it revives after a crash, shutdown, or hibernation. A cluster has only one CTV for all nodes in a cluster.
|
Column Name |
Data Type |
Description |
|
CURRENT_CATALOG_VERSION |
INTEGER |
The version number of the catalog currently on the cluster. |
|
TRUNCATION_CATALOG_VERSION |
INTEGER |
The version number as of the last time the catalog was synced on communal storage. |
8.1.8 - CERTIFICATES
Stores certificates created by CREATE CERTIFICATE.
Stores certificates created by CREATE CERTIFICATE.
|
Column Name |
Data Type |
Description |
|
OID |
INTEGER |
The object identifier. |
|
NAME |
VARCHAR |
The name of the certificate. |
|
OWNER |
INTEGER |
The owner of the object. |
|
SIGNED_BY |
INTEGER |
The OID of the signing certificate. |
|
PRIVATE_KEY |
INTEGER |
The OID of the certificate's private key. |
|
START_DATE |
TIMESTAMPTZ |
When the certificate becomes valid. |
|
EXPIRATION_DATE |
TIMESTAMPTZ |
When the certificate expires. |
|
ISSUER |
VARCHAR |
The signing CA. |
|
SUBJECT |
VARCHAR |
The entity for which the certificate is issued. |
|
SERIAL |
VARCHAR |
The certificate's serial number. |
|
x509v3_EXTENSIONS |
VARCHAR |
Lists additional attributes specified during the certificate's creation.
For more information on extensions, see the OpenSSL documentation.
|
|
CERTIFICATE_TEXT |
VARCHAR |
The contents of the certificate. |
Examples
See Generating TLS certificates and keys.
8.1.9 - CLIENT_AUTH
Provides information about client authentication methods.
Provides information about client authentication methods.
Higher values indicate higher priorities. Vertica tries to authenticate a user with an authentication method in order of priority from highest to lowest. For example:
|
Column Name |
Data Type |
Description |
|
AUTH_OID |
INTEGER |
Unique identifier for the authentication method. |
|
AUTH_NAME |
VARCHAR |
User-given name of the authentication method. |
|
IS_AUTH_ENABLED |
BOOLEAN |
Indicates if the authentication method is enabled. |
|
AUTH_HOST_TYPE |
VARCHAR |
The authentication host type, one of the following:
-
LOCAL
-
HOST
-
HOSTSSL
-
HOSTNOSSL
|
|
AUTH_HOST_ADDRESS |
VARCHAR |
If AUTH_HOST_TYPE is HOST, AUTH_HOST_ADDRESS is the IP address (or address range) of the remote host. |
|
AUTH_METHOD |
VARCHAR |
Authentication method to be used.
Valid values:
-
IDENT
-
GSS
-
HASH
-
LDAP
-
REJECT
-
TLS
-
TRUST
|
|
AUTH_PARAMETERS |
VARCHAR |
The parameter names and values assigned to the authentication method. |
|
AUTH_PRIORITY |
INTEGER |
The priority specified for the authentication. Authentications with higher values are used first. |
|
METHOD_PRIORITY |
INTEGER |
The priority of this authentication based on the AUTH_METHOD.
Vertica only considers METHOD_PRIORITY when deciding between multiple authentication methods of equal AUTH_PRIORITY.
|
|
ADDRESS_PRIORITY |
INTEGER |
The priority of this authentication based on the specificity of the AUTH_HOST_ADDRESS, if any. More specific IP addresses (fewer zeros) are used first.
Vertica only considers ADDRESS_PRIORITY when deciding between multiple authentication methods of equal AUTH_PRIORITY and METHOD_PRIORITY.
|
|
IS_FALLTHROUGH_ENABLED |
Boolean |
Whether authentication fallthrough is enabled. |
Examples
This example shows how to get information about each client authentication method that you created:
=> SELECT * FROM client_auth;
auth_oid | auth_name | is_auth_enabled | auth_host_type | auth_host_address | auth_method | auth_parameters | auth_priority | method_priority | address_priority
-------------------+-------------+-----------------+----------------+-------------------+-------------+-----------------+---------------+-----------------+------------------
45035996274059694 | v_gss | True | HOST | 0.0.0.0/0 | GSS | | 0 | 5 | 96
45035996274059696 | v_trust | True | LOCAL | | TRUST | | 0 | 0 | 0
45035996274059698 | v_ldap | True | HOST | 10.19.133.123/ | LDAP | | 0 | 5 | 128
45035996274059700 | RejectNoSSL | True | HOSTNOSSL | 0.0.0.0/0 | REJECT | | 0 | 10 | 96
45035996274059702 | v_hash | True | LOCAL | | HASH | | 0 | 2 | 0
45035996274059704 | v_tls | True | HOSTSSL | 1.1.1.1/0 | TLS | | 0 | 5 | 96
(6 rows)
See also
8.1.10 - CLIENT_AUTH_PARAMS
Provides information about client authentication methods that have parameter values assigned.
Provides information about client authentication methods that have parameter values assigned.
|
Column Name |
Data Type |
Description |
|
AUTH_OID |
INTEGER |
A unique identifier for the authentication method. |
|
AUTH_NAME |
VARCHAR |
Name that you defined for the authentication method. |
|
AUTH_PARAMETER_NAME |
VARCHAR |
Parameter name required by the authentication method. Some examples are:
-
system_users
-
binddn_prefix
-
host
|
|
AUTH_PARAMETER_VALUE |
VARCHAR |
Value of the specified parameter. |
Examples
This example shows how to retrieve parameter names and values for all authentication methods that you created. The authentication methods that have parameters are:
=> SELECT * FROM CLIENT_AUTH_PARAMS;
auth_oid | auth_name | auth_parameter_name | auth_parameter_value
-------------------+---------------+---------------------+------------------------------
45035996273741304 | v_ident | system_users | root
45035996273741332 | v_gss | |
45035996273741350 | v_password | |
45035996273741368 | v_trust | |
45035996273741388 | v_ldap | host | ldap://172.16.65.177
45035996273741388 | v_ldap | binddn_prefix | cn=
45035996273741388 | v_ldap | binddn_suffix | ,dc=qa_domain,dc=com
45035996273741406 | RejectNoSSL | |
45035996273741424 | RejectWithSSL | |
45035996273741450 | v_md5 | |
45035996273904044 | l_tls | |
45035996273906566 | v_hash | |
45035996273910432 | v_ldap1 | host | ldap://172.16.65.177
45035996273910432 | v_ldap1 | basedn | dc=qa_domain,dc=com
45035996273910432 | v_ldap1 | binddn | cn=Manager,dc=qa_domain,dc=com
45035996273910432 | v_ldap1 | bind_password | secret
45035996273910432 | v_ldap1 | search_attribute | cn
(17 rows)
8.1.11 - CLUSTER_LAYOUT
Shows the relative position of the actual arrangement of the nodes participating in the cluster and the fault groups (in an Enterprise Mode database) or subclusters (in an Eon Mode database) that affect them.
Shows the relative position of the actual arrangement of the nodes participating in the cluster and the fault groups (in an Enterprise Mode database) or subclusters (in an Eon Mode database) that affect them. Ephemeral nodes are not shown in the cluster layout ring because they hold no resident data.
|
Column Name |
Data Type |
Description |
|
CLUSTER_POSITION |
INTEGER |
Position of the node in the cluster ring, counting forward from 0.
Note
An output value of 0 has no special meaning other than there are no nodes in position before the node assigned 0.
|
|
NODE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the node. |
|
NODE_NAME |
VARCHAR |
The name of the node in the cluster ring. Only permanent nodes participating in database activity appear in the cluster layout. Ephemeral nodes are not shown in the output. |
|
FAULT_GROUP_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the fault group. This column can only have a value in an Enterprise Mode database.
Note
This value matches the FAULT_GROUP.MEMBER_ID value, but only if this node is in a fault group; otherwise the value is NULL.
|
|
FAULT_GROUP_NAME |
VARCHAR |
The name of the fault group for the node.
This column can only have a value in an Enterprise Mode database. |
|
FAULT_GROUP_TIER |
INTEGER |
The node's depth in the fault group tree hierarchy. For example if the node:
-
Is not in a fault group, output is null
-
Is in the top level fault group, output is 0
-
Is in a fault group's child, output is 1
-
Is a fault group's grandchild, output is 2
This column can only have a value in an Enterprise Mode database.
|
|
SUBCLUSTER_ID |
INTEGER |
Unique identifier for the subcluster. This column only has a value in an Eon Mode database. |
|
SUBCLUSTER_NAME |
VARCHAR |
The name of the subcluster containing the node. This column only has a value in an Eon Mode database. |
See also
Large cluster
8.1.12 - COLUMNS
Provides table column information.
Provides table column information. For columns of Iceberg external tables, see ICEBERG_COLUMNS.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the table. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the table. |
TABLE_SCHEMA |
VARCHAR |
Name of the table's schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_NAME |
VARCHAR |
Name of the table containing the column. |
IS_SYSTEM_TABLE |
BOOLEAN |
Whether the table is a system table. |
COLUMN_ID |
VARCHAR |
Catalog-assigned VARCHAR value that uniquely identifies a table column. |
COLUMN_NAME |
VARCHAR |
Name of the column. |
DATA_TYPE |
VARCHAR |
Column data type.
Arrays of primitive types show the name ARRAY[type]. Other complex types show the inline name of the type, which matches the type_name value in the COMPLEX_TYPES table. For example: _ct_45035996273833610.
|
DATA_TYPE_ID |
INTEGER |
Catalog-assigned unique numeric ID of the data type. |
DATA_TYPE_LENGTH |
INTEGER |
Maximum allowable length of the data type. |
CHARACTER_MAXIMUM_LENGTH |
VARCHAR |
Maximum allowable length of a VARCHAR column. |
NUMERIC_PRECISION |
INTEGER |
Number of significant decimal digits for a NUMERIC column. |
NUMERIC_SCALE |
INTEGER |
Number of fractional digits for a NUMERIC column. |
DATETIME_PRECISION |
INTEGER |
Declared precision for a TIMESTAMP column, or NULL if no precision was declared. |
INTERVAL_PRECISION |
INTEGER |
Number of fractional digits retained in the seconds field of an INTERVAL column. |
ORDINAL_POSITION |
INTEGER |
Column position respective to other columns in the table. |
IS_NULLABLE |
BOOLEAN |
Whether the column can contain NULL values. |
COLUMN_DEFAULT |
VARCHAR |
Expression set on a column with the DEFAULT constraint. |
COLUMN_SET_USING |
VARCHAR |
Expression set on a column with the SET USING constraint. |
IS_IDENTITY |
BOOLEAN |
Whether the column is an IDENTITY column. |
Examples
=> SELECT table_schema, table_name, column_name, data_type, is_nullable
FROM columns WHERE table_schema = 'store'
AND data_type = 'Date';
table_schema | table_name | column_name | data_type | is_nullable
--------------+-------------------+------------------------+-----------+-------------
store | store_dimension | first_open_date | Date | f
store | store_dimension | last_remodel_date | Date | f
store | store_orders_fact | date_ordered | Date | f
store | store_orders_fact | date_shipped | Date | f
store | store_orders_fact | expected_delivery_date | Date | f
store | store_orders_fact | date_delivered | Date | f
6 rows)
In the following query, datetime_precision is NULL because the table definition declares no precision:
=> CREATE TABLE c (c TIMESTAMP);
CREATE TABLE
=> SELECT table_name, column_name, datetime_precision FROM columns
WHERE table_name = 'c';
table_name | column_name | datetime_precision
------------+-------------+--------------------
c | c |
(1 row)
In the following example, timestamp precision is set:
=> DROP TABLE c;
=> CREATE TABLE c (c TIMESTAMP(4));
CREATE TABLE
=> SELECT table_name, column_name, datetime_precision FROM columns
WHERE table_name = 'c';
table_name | column_name | datetime_precision
------------+-------------+--------------------
c | c | 4
An IDENTITY column sequence is defined in a table's DDL. Column values automatically increment as new rows are added. The following query returns identity columns:
=> CREATE TABLE employees (employeeID IDENTITY, fname varchar(36), lname varchar(36));
CREATE TABLE
=> SELECT table_name, column_name, is_identity FROM columns WHERE is_identity = 't';
table_name | column_name | is_identity
------------+-------------+-------------
employees | employeeID | t
(1 row)
You can query the SEQUENCES table to get detailed information about an IDENTITY column sequence:
=> SELECT sequence_schema, sequence_name, identity_table_name, sequence_id FROM sequences WHERE identity_table_name ='employees';
sequence_schema | sequence_name | identity_table_name | sequence_id
-----------------+--------------------------+---------------------+-------------------
public | employees_employeeID_seq | employees | 45035996273848816
(1 row)
For details about sequences and IDENTITY columns, see Sequences.
8.1.13 - COMMENTS
Returns information about comments associated with objects in the database.
Returns information about comments associated with objects in the database.
Note
Queries on this table can be slow because it fetches data at query time from other Vertica catalog tables.
|
Column Name |
Data Type |
Description |
|
COMMENT_ID |
INTEGER |
Comment's internal ID number |
|
OBJECT_ID |
INTEGER |
Internal ID number of the object associated with the comment. |
|
OBJECT_TYPE |
VARCHAR |
Type of object associated with the comment, one of the following:
-
COLUMN
-
CONSTRAINT
-
FUNCTION
-
LIBRARY
-
NODE
-
PROJECTION
-
SCHEMA
-
SEQUENCE
-
TABLE
-
VIEW
|
|
OBJECT_SCHEMA |
VARCHAR |
Name of the schema containing the object. |
|
OBJECT_NAME |
VARCHAR |
Name of the top-level object associated with the comment, such as a table or projection. |
|
CHILD_OBJECT |
VARCHAR |
Name of the specific object associated with the comment, such as a table column. If the comment is associated with a top-level object, this value is NULL. |
|
OWNER_ID |
VARCHAR |
Internal ID of the object's owner. |
|
OWNER_NAME |
VARCHAR |
Object owner's name. |
|
CREATION_TIME |
TIMESTAMPTZ |
When the comment was created. |
|
LAST_MODIFIED_TIME |
TIMESTAMPTZ |
When the comment was last modified. |
|
COMMENT |
VARCHAR |
Comment text. |
Examples
=> COMMENT ON COLUMN public.t.x1 IS 'Column comment';
=> SELECT * FROM COMMENTS;
-[ RECORD 1 ]------+------------------------------
comment_id | 45035996273838776
object_id | 45035996273838760
object_type | COLUMN
object_schema | public
object_name | t
child_object | x1
owner_id | 45035996273704962
owner_name | dbadmin
creation_time | 2023-02-01 10:47:13.028663+08
last_modified_time | 2023-02-01 10:47:13.028663+08
comment | Column comment
8.1.14 - COMPLEX_TYPES
Contains information about inlined complex types.
Contains information about inlined complex types.
Each complex type in each external table has a unique type internally, even if the types are structurally the same (like two different ROW(int,int) cases). This inlined type is created when the table using it is created and is automatically dropped when the table is dropped. Inlined complex types cannot be shared or reused in other tables.
Each row in the COMPLEX_TYPES table represents one component (field) in one complex type. A ROW produces one row per field, an ARRAY produces one, and a MAP produces two.
Arrays of primitive types used in native (ROS) tables are not included in the COMPLEX_TYPES table. They are included instead in the TYPES table.
This table does not include complex types in Iceberg tables.
|
Column Name |
Data Type |
Description |
TYPE_ID |
INTEGER |
A unique identifier for the inlined complex type. |
TYPE_KIND |
VARCHAR |
The specific kind of complex type: row, array, or map. |
TYPE_NAME |
VARCHAR |
The generated name of this type. All names begin with _ct_ followed by a number. |
FIELD_ID |
INTEGER |
A unique identifier for the field. |
FIELD_NAME |
VARCHAR |
The name of the field, if specified in the table definition, or a generated name beginning with "f". |
FIELD_TYPE_NAME |
VARCHAR |
The type of the field's value. |
FIELD_POSITION |
INTEGER |
The field's position in its containing complex type (0-based). |
FIELD_LENGTH |
INTEGER |
Number of bytes in the field value, or -1 if the value is not a scalar type. |
CHARACTER_MAXIMUM_LENGTH |
INTEGER |
Maximum allowable length of the column. |
NUMERIC_PRECISION |
INTEGER |
Number of significant decimal digits. |
NUMERIC_SCALE |
INTEGER |
Number of fractional digits. |
DATETIME_PRECISION |
INTEGER |
For TIMESTAMP data type, returns the declared precision; returns NULL if no precision was declared. |
INTERVAL_PRECISION |
INTEGER |
Number of fractional digits retained in the seconds field. |
Examples
The following example shows the type and field values after defining a single external table.
=> CREATE EXTERNAL TABLE warehouse(
name VARCHAR, id_map MAP<INT,VARCHAR>,
data row(record INT, total FLOAT, description VARCHAR(100)),
prices ARRAY[INT], comment VARCHAR(200), sales_total FLOAT, storeID INT)
AS COPY FROM ... PARQUET;
=> SELECT type_id,type_kind,type_name,field_id,field_name,field_type_name,field_position
FROM COMPLEX_TYPES ORDER BY type_id,field_name;
type_id | type_kind | type_name | field_id | field_name | field_type_name | field_position
-------------------+-----------+-----------------------+----------+-------------+-----------------+----------------
45035996274278280 | Map | _ct_45035996274278280 | 6 | key | int | 0
45035996274278280 | Map | _ct_45035996274278280 | 9 | value | varchar(80) | 1
45035996274278282 | Row | _ct_45035996274278282 | 9 | description | varchar(80) | 2
45035996274278282 | Row | _ct_45035996274278282 | 6 | record | int | 0
45035996274278282 | Row | _ct_45035996274278282 | 7 | total | float | 1
45035996274278284 | Array | _ct_45035996274278284 | 6 | | int | 0
(6 rows)
8.1.15 - CONSTRAINT_COLUMNS
Records information about table column constraints.
Records information about table column constraints.
|
Column Name |
Data Type |
Description |
CONSTRAINT_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog that identifies the constraint. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the table. |
TABLE_SCHEMA |
VARCHAR |
Name of the schema that contains this table.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog that identifies the table. |
TABLE_NAME |
VARCHAR |
Name of the table in which the column resides. |
COLUMN_NAME |
VARCHAR |
Name of the column that is constrained. For check constraints, if more than one column is referenced, each appears as a separate row. |
CONSTRAINT_NAME |
VARCHAR |
Constraint name for which information is listed. |
CONSTRAINT_TYPE |
CHAR |
The constraint type, one of the following:
-
c: check
-
f: foreign
-
n: not null
-
p: primary
-
u: unique
|
IS_ENABLED |
BOOLEAN |
Indicates whether a constraint for a primary key, unique key, or check constraint is currently enabled. |
REFERENCE_TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies the referenced table |
REFERENCE_TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, references the TABLE_NAMESPACE column in the PRIMARY_KEYS table. |
REFERENCE_TABLE_SCHEMA |
VARCHAR |
Schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
REFERENCE_TABLE_NAME |
VARCHAR |
References the TABLE_NAME column in the PRIMARY_KEYS table. |
REFERENCE_COLUMN_NAME |
VARCHAR |
References the COLUMN_NAME column in the PRIMARY_KEYS table. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.1.16 - CRYPTOGRAPHIC_KEYS
Stores private keys created by CREATE KEY.
Stores private keys created by CREATE KEY.
|
Column Name |
Data Type |
Description |
|
OID |
INTEGER |
The object identifier. |
|
NAME |
VARCHAR |
Name of the key. |
|
OWNER |
INTEGER |
The owner of the object. |
|
TYPE |
INTEGER |
The type of key.
|
|
LENGTH |
INTEGER |
The size of the key in bits. |
|
HAS_PASSWORD |
BOOLEAN |
Whether the key has a password. |
|
KEY |
VARCHAR |
The private key. |
Examples
See Generating TLS certificates and keys.
8.1.17 - DATABASES
Provides information about the databases in this Vertica installation.
Provides information about the databases in this Vertica installation.
|
Column Name |
Data Type |
Description |
DATABASE_ID |
INTEGER |
The database's internal ID number |
DATABASE_NAME |
VARCHAR |
The database's name |
OWNER_ID |
INTEGER |
The database owner's ID |
OWNER_NAME |
INTEGER |
The database owner's name |
START_TIME |
TIMESTAMPTZ |
The date and time the database last started |
COMPLIANCE_MESSAGE |
VARCHAR |
Message describing the current state of the database's license compliance |
EXPORT_SUBNET |
VARCHAR |
Can be either of the following:
|
LOAD_BALANCE_POLICY |
VARCHAR |
The current native connection load balance policy, which controls whether client connection requests are redirected to other hosts in the database. See About native connection load balancing. |
|
BACKEND_ADDRESS_FAMILY |
VARCHAR |
The Internet Protocol (IP) addressing standard used for internode communications. This value is either ipv4 or ipv6. |
|
BRANCH_NAME |
VARCHAR |
This column is no longer used. |
Examples
This example queries the databases table from a master database.
=> SELECT * FROM DATABASES;
-[ RECORD 1 ]----------+-------------------------------------------------------------
database_id | 45035996273704976
database_name | VMart
owner_id | 45035996273704962
owner_name | dbadmin
start_time | 2017-10-22 05:16:22.066961-04
compliance_message | The database is in compliance with respect to raw data size.
export_subnet | 0
load_balance_policy | none
backend_address_family | ipv4
branch_name |
8.1.18 - DIRECTED_QUERIES
Returns information about directed queries.
Returns information about directed queries.
|
Column Name |
Data Type |
Description |
|
QUERY_NAME |
VARCHAR |
Directed query's unique identifier, used by statements such as ACTIVATE DIRECTED QUERY. How this identifier is set depends on how it was created:
-
Direct call to CREATE DIRECTED QUERY: Set by the user-supplied query-name argument.
-
Call to SAVE_PLANS: Concatenated from the following strings:
save_plans_query-label_query-number_save-plans-version
where:
query-label is a LABEL hint embedded in the input query associated with this directed query. If theinput query contains no label, then this string is set to nolabel.query-number is an integer in a continuous sequence between 0 and budget-query, which uniquely identifies this directed query from others in the same SAVE_PLANS-generated set.- [save-plans-version](/en/sql-reference/system-tables/v-catalog-schema/directed-queries/#SAVE_PLANS_VERSION) identifies the set of directed queries to which this directed query belongs.
|
|
IS_ACTIVE |
BOOLEAN |
Whether the directed query is active |
|
VERTICA_VERSION |
VARCHAR |
Vertica version installed when this directed query was created. |
|
COMMENT |
VARCHAR |
User-supplied or optimizer-generated comment on a directed query, up to 128 characters. |
|
SAVE_PLANS_VERSION |
INTEGER |
One of the following:
- 0: Generated by a direct call to CREATE DIRECTED QUERY.
- >0: Identifies a set of directed queries that were generated by the same call to SAVE_PLANS. All directed queries of the set share the same
SAVE_PLANS_VERSION integer, which increments by 1 the previous highest SAVE_PLANS_VERSION setting. Use this identifier to activate, deactivate, and drop a set of directed queries.
|
|
USERNAME |
VARCHAR |
User that created this directed query. |
|
CREATION_DATE |
VARCHAR |
When the directed query was created. |
|
SINCE_DATE |
VARCHAR |
Populated by SAVE_PLANS-generated directed queries, the earliest timestamp of input queries eligible to be saved as directed queries. |
|
INPUT_QUERY |
VARCHAR |
Input query associated with this directed query. Multiple directed queries can map to the same input query. |
|
ANNOTATED_QUERY |
VARCHAR |
Query with embedded hints that was paired with the input query of this directed query, where the hints encapsulated the query plan saved with CREATE DIRECTED QUERY. |
|
DIGEST |
INTEGER |
Hash of saved query plan data, used by the optimizer to map identical input queries to the same active directed query. |
Privileges
Superuser
Truncated query results
Query results for the fields INPUT_QUERY and ANNOTATED_QUERY are truncated after ~32K characters. You can get the full content of both fields in two ways:
8.1.19 - DUAL
DUAL is a single-column "dummy" table with one record whose value is X; for example:.
DUAL is a single-column "dummy" table with one record whose value is X; for example:
=> SELECT * FROM DUAL;
dummy
-------
X
(1 row)
You can write the following types of queries:
=> SELECT 1 FROM dual;
?column?
----------
1
(1 row)
=> SELECT current_timestamp, current_user FROM dual;
?column? | current_user
-------------------------------+--------------
2010-03-08 12:57:32.065841-05 | release
(1 row)
=> CREATE TABLE t1(col1 VARCHAR(20), col2 VARCHAR(2));
=> INSERT INTO T1(SELECT 'hello' AS col1, 1 AS col2 FROM dual);)
=> SELECT * FROM t1;
col1 | col2
-------+------
hello | 1
(1 row
Restrictions
You cannot create projections for DUAL.
8.1.20 - ELASTIC_CLUSTER
Returns information about cluster elasticity, such as whether Elastic Cluster is running.
Returns information about cluster elasticity, such as whether Elastic cluster is running.
|
Column Name |
Data Type |
Description |
SCALING_FACTOR |
INTEGER |
This value is only meaningful when you enable local segments. SCALING_FACTOR influences the number of local segments on each node. Initially—before a rebalance runs—there are scaling_factor number of local segments per node. A large SCALING_FACTOR is good for rebalancing a potentially wide range of cluster configurations quickly. However, too large a value might lead to ROS pushback, particularly in a database with a table with a large number of partitions. See SET_SCALING_FACTOR for more details. |
MAXIMUM_SKEW_PERCENT |
INTEGER |
This value is only meaningful when you enable local segments. MAXIMUM_SKEW_PERCENT is the maximum amount of skew a rebalance operation tolerates, which preferentially redistributes local segments; however, if after doing so the segment ranges of any two nodes differs by more than this amount, rebalance will separate and distribute storage to even the distribution. |
SEGMENT_LAYOUT |
VARCHAR |
Current, offset=0, segment layout. New segmented projections will be created with this layout, with segments rotated by the corresponding offset. Existing segmented projections will be rebalanced into an offset of this layout. |
LOCAL_SEGMENT_LAYOUT |
VARCHAR |
Similar to SEGMENT_LAYOUT but includes details that indicate the number of local segments, their relative size and node assignment. |
VERSION |
INTEGER |
Number that gets incremented each time the cluster topology changes (nodes added, marked ephemeral, marked permanent, etc). Useful for monitoring active and past rebalance operations. |
IS_ENABLED |
BOOLEAN |
True if Elastic Cluster is enabled, otherwise false. |
IS_LOCAL_SEGMENT_ENABLED |
BOOLEAN |
True if local segments are enabled, otherwise false. |
IS_REBALANCE_RUNNING |
BOOLEAN |
True if rebalance is currently running, otherwise false. |
Privileges
Superuser
See also
8.1.21 - EPOCHS
For the most recently closed epochs, lists the date and time of the close and the corresponding epoch number of the closed epoch.
For the most recently closed epochs, lists the date and time of the close and the corresponding epoch number of the closed epoch. The EPOCHS table may return a varying number of rows depending on current commit activities.
|
Column Name |
Data Type |
Description |
EPOCH_CLOSE_TIME |
DATETIME |
The date and time that the epoch closed. |
EPOCH_NUMBER |
INTEGER |
The epoch number of the closed epoch. |
Examples
=> SELECT * FROM EPOCHS;
epoch_close_time | epoch_number
-------------------------------+--------------
2018-11-12 16:05:15.552571-05 | 16
(1 row)
Querying for historical data
If you need historical data about epochs and corresponding date information, query the DC_TRANSACTION_ENDS table.
=> select dc.end_epoch,min(dc.time),max(dc.time) from dc_transaction_ends dc group by end_epoch;
end_epoch | min | max
-----------+-------------------------------+-------------------------------
214 | 2018-10-12 08:05:47.02075-04 | 2018-10-15 10:22:24.015292-04
215 | 2018-10-15 10:22:47.015172-04 | 2018-10-15 13:00:44.888984-04
...
226 | 2018-10-15 15:03:47.015235-04 | 2018-10-15 20:37:34.346667-04
227 | 2018-10-15 20:37:47.008137-04 | 2018-10-16 07:39:00.29917-04
228 | 2018-10-16 07:39:47.012411-04 | 2018-10-16 08:16:01.470232-04
229 | 2018-10-16 08:16:47.018899-04 | 2018-10-16 08:21:13.854348-04
230 | 2018-10-16 08:21:47.013767-04 | 2018-10-17 12:21:09.224094-04
231 | 2018-10-17 12:21:09.23193-04 | 2018-10-17 15:11:59.338777-04
See also
8.1.22 - FAULT_GROUPS
View the fault groups and their hierarchy in the cluster.
View the fault groups and their hierarchy in the cluster.
|
Column Name |
Data Type |
Description |
MEMBER_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the fault group. |
MEMBER_TYPE |
VARCHAR |
The type of fault group. Values can be either NODE or FAULT GROUP. |
MEMBER_NAME |
VARCHAR |
Name associated with this fault group. Values will be the node name or the fault group name. |
PARENT_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the parent fault group. The parent fault group can contain:
|
PARENT_TYPE |
VARCHAR |
The type of parent fault group, where the default/root parent is the DATABASE object. Can be one of the following objects:
|
PARENT_NAME |
VARCHAR |
The name of the fault group that contains nodes or other fault groups or both nodes and fault groups. |
IS_AUTOMATICALLY_GENERATED |
BOOLEAN |
If true, denotes whether Vertica Analytic Database created fault groups for you to manage the fault tolerance of control nodes in large cluster configurations. If false, denotes that you created fault groups manually. See Fault Groups for more information |
Examples
Show the current hierarchy of fault groups in the cluster:
vmartdb=> SELECT member_type, member_name, parent_type, CASE
WHEN parent_type = 'DATABASE' THEN ''
ELSE parent_name END FROM fault_groups
ORDER BY member_name;
member_type | member_name | parent_type | parent_name
-------------+-----------------------+-------------+-------------
NODE | v_vmart_node0001 | FAULT GROUP | two
NODE | v_vmart_node0002 | FAULT GROUP | two
NODE | v_vmart_node0003 | FAULT GROUP | three
FAULT GROUP | one | DATABASE |
FAULT GROUP | three | DATABASE |
FAULT GROUP | two | FAULT GROUP | one
View the distribution of the segment layout:
vmartdb=> SELECT segment_layout from elastic_cluster;
segment_layout
-------------------------------------------------------------------------
v_vmart_node0001[33.3%] v_vmart_node0003[33.3%] v_vmart_node0004[33.3%]
(1 row)
See also
8.1.23 - FOREIGN_KEYS
Provides foreign key information.
Provides foreign key information.
|
Column Name |
Data Type |
Description |
CONSTRAINT_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the constraint. |
CONSTRAINT_NAME |
VARCHAR |
The constraint name for which information is listed. |
COLUMN_NAME |
VARCHAR |
The name of the column that is constrained. |
ORDINAL_POSITION |
VARCHAR |
The position of the column within the key. The numbering of columns starts at 1. |
TABLE_NAME |
VARCHAR |
The table name for which information is listed. |
REFERENCE_TABLE_NAME |
VARCHAR |
References the TABLE_NAME column in the PRIMARY_KEYS table. |
CONSTRAINT_TYPE |
VARCHAR |
The constraint type, f, for foreign key. |
REFERENCE_COLUMN_NAME |
VARCHAR |
References the COLUMN_NAME column in the PRIMARY_KEY table. |
TABLE_NAMESPACE_ID |
VARCHAR |
Unique numeric identifier for the table namespace. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace that contains the table for which information is listed. |
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
REFERENCE_TABLE_NAMESPACE_ID |
VARCHAR |
For Eon Mode databases, references the TABLE_NAMESPACE_ID column in the PRIMARY_KEYS table. |
REFERENCE_TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, references the TABLE_NAMESPACE column in the PRIMARY_KEYS table. |
REFERENCE_TABLE_SCHEMA |
VARCHAR |
References the TABLE_SCHEMA column in the PRIMARY_KEYS table.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
Examples
mydb=> SELECT
constraint_name,
table_name,
ordinal_position,
reference_table_name
FROM foreign_keys ORDER BY 3;
constraint_name | table_name | ordinal_position | reference_table_name
---------------------------+-------------------+------------------+-----------------------
fk_store_sales_date | store_sales_fact | 1 | date_dimension
fk_online_sales_saledate | online_sales_fact | 1 | date_dimension
fk_store_orders_product | store_orders_fact | 1 | product_dimension
fk_inventory_date | inventory_fact | 1 | date_dimension
fk_inventory_product | inventory_fact | 2 | product_dimension
fk_store_sales_product | store_sales_fact | 2 | product_dimension
fk_online_sales_shipdate | online_sales_fact | 2 | date_dimension
fk_store_orders_product | store_orders_fact | 2 | product_dimension
fk_inventory_product | inventory_fact | 3 | product_dimension
fk_store_sales_product | store_sales_fact | 3 | product_dimension
fk_online_sales_product | online_sales_fact | 3 | product_dimension
fk_store_orders_store | store_orders_fact | 3 | store_dimension
fk_online_sales_product | online_sales_fact | 4 | product_dimension
fk_inventory_warehouse | inventory_fact | 4 | warehouse_dimension
fk_store_orders_vendor | store_orders_fact | 4 | vendor_dimension
fk_store_sales_store | store_sales_fact | 4 | store_dimension
fk_store_orders_employee | store_orders_fact | 5 | employee_dimension
fk_store_sales_promotion | store_sales_fact | 5 | promotion_dimension
fk_online_sales_customer | online_sales_fact | 5 | customer_dimension
fk_store_sales_customer | store_sales_fact | 6 | customer_dimension
fk_online_sales_cc | online_sales_fact | 6 | call_center_dimension
fk_store_sales_employee | store_sales_fact | 7 | employee_dimension
fk_online_sales_op | online_sales_fact | 7 | online_page_dimension
fk_online_sales_shipping | online_sales_fact | 8 | shipping_dimension
fk_online_sales_warehouse | online_sales_fact | 9 | warehouse_dimension
fk_online_sales_promotion | online_sales_fact | 10 | promotion_dimension
(26 rows)
8.1.24 - GRANTS
Returns information about privileges that are explicitly granted on database objects.
Returns information about privileges that are explicitly granted on database objects. Information about inherited privileges is not included.
Note
While an ADMIN OPTION granted to users through roles is not viewable directly from this table, you can view it and a summary of privileges data with vsql meta-commands
\z and
\dp.
|
Column Name |
Data Type |
Description |
|
GRANTEE |
VARCHAR |
The user being granted permission. |
|
GRANTEE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theuser granted permissions. |
|
GRANT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thegrant operation. |
|
GRANTOR |
VARCHAR |
The user granting the permission. |
|
GRANTOR_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theuser who performed the grant operation. |
|
OBJECT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theobject granted. |
|
OBJECT_NAME |
VARCHAR |
The name of the object that is being granted privileges. Note that for schema privileges, the schema name appears in the OBJECT_NAME column instead of the OBJECT_SCHEMA column. |
|
OBJECT_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace of the object that is being granted privileges. |
|
OBJECT_SCHEMA |
VARCHAR |
Schema of the object that is being granted privileges.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
OBJECT_TYPE |
VARCHAR |
The object type on which the grant was applied—for example, ROLE, SCHEMA, DATABASE, RESOURCEPOOL. |
|
PRIVILEGES_DESCRIPTION |
VARCHAR |
Lists the privileges granted on an object—for example INSERT, SELECT. An asterisk in PRIVILEGES_DESCRIPTION output shows that the privilege grant included WITH GRANT OPTION. |
Examples
The following query shows the privileges that are granted to user Rob or role R1. An asterisk (*) appended to a privilege indicates that the user can grant the privilege to other users:
=> SELECT grantor,privileges_description,object_name,object_type,grantee FROM grants WHERE grantee='Rob' OR grantee='R1';
grantor | privileges_description | object_name | object_type | grantee
--------+---------------------------+-------------+--------------+---------
dbadmin | USAGE | general | RESOURCEPOOL | Rob
dbadmin | USAGE, CREATE | s1 | SCHEMA | Rob
dbadmin | INSERT*, SELECT*, UPDATE* | t1 | TABLE | Rob
dbadmin | SELECT | t1 | TABLE | R1
dbadmin | USAGE | s1 | SCHEMA | R1
dbadmin | | R1 | ROLE | Rob
(6 rows)
See also
8.1.25 - HCATALOG_COLUMNS
Describes the columns of all tables available through the HCatalog Connector.
Describes the columns of all tables available through the HCatalog Connector. Each row in this table corresponds to to a column in a table accessible through the HCatalog Connector. See Using the HCatalog Connector for more information.
|
Column Name |
Data Type |
Description |
TABLE_SCHEMA |
VARCHAR(128) |
The name of the Vertica Analytic Database schema that contains the table containing this column |
HCATALOG_SCHEMA |
VARCHAR(128) |
The name of the Hive schema or database that contains the table containing this column |
TABLE_NAME |
VARCHAR(128) |
The name of the table that contains the column |
IS_PARTITION_COLUMN |
BOOLEAN |
Whether the table is partitioned on this column |
COLUMN_NAME |
VARCHAR(128) |
The name of the column |
HCATALOG_DATA_TYPE |
VARCHAR(128) |
The Hive data type of this column |
DATA_TYPE |
VARCHAR(128) |
The Vertica Analytic Database data type of this column |
DATA_TYPE_ID |
INTEGER |
Numeric ID of the column's Vertica Analytic Database data type |
DATA_TYPE_LENGTH |
INTEGER |
The number of bytes used to store this data type |
CHARACTER_MAXIMUM_LENGTH |
INTEGER |
For string data types, the maximum number of characters it can hold |
NUMERIC_PRECISION |
INTEGER |
For numeric types, the precision of the values in the column |
NUMERIC_SCALE |
INTEGER |
For numeric data types, the scale of the values in the column |
DATETIME_PRECISION |
INTEGER |
For datetime data types, the precision of the values in the column |
INTERVAL_PRECISION |
INTEGER |
For interval data types, the precision of the values in the column |
ORDINAL_POSITION |
INTEGER |
The position of the column within the table |
Privileges
No explicit permissions are required; however, users see only the records that correspond to schemas they have permissions to access.
Notes
If you are using WebHCat instead of HiveServer2, querying this table results in one web service call to the WebHCat server for each table in each HCatalog schema. If you need to perform multiple queries on this table in a short period of time, consider creating a copy of the table using a CREATE TABLE AS statement to improve performance. The copy does not reflect any changes made to the schema of the Hive tables after it was created, but it is much faster to query.
Examples
The following example demonstrates finding the column information for a specific table:
=> SELECT * FROM HCATALOG_COLUMNS WHERE table_name = 'hcatalogtypes'
-> ORDER BY ordinal_position;
-[ RECORD 1 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | intcol
hcatalog_data_type | int
data_type | int
data_type_id | 6
data_type_length | 8
character_maximum_length |
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 1
-[ RECORD 2 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | floatcol
hcatalog_data_type | float
data_type | float
data_type_id | 7
data_type_length | 8
character_maximum_length |
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 2
-[ RECORD 3 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | doublecol
hcatalog_data_type | double
data_type | float
data_type_id | 7
data_type_length | 8
character_maximum_length |
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 3
-[ RECORD 4 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | charcol
hcatalog_data_type | string
data_type | varchar(65000)
data_type_id | 9
data_type_length | 65000
character_maximum_length | 65000
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 4
-[ RECORD 5 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | varcharcol
hcatalog_data_type | string
data_type | varchar(65000)
data_type_id | 9
data_type_length | 65000
character_maximum_length | 65000
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 5
-[ RECORD 6 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | boolcol
hcatalog_data_type | boolean
data_type | boolean
data_type_id | 5
data_type_length | 1
character_maximum_length |
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 6
-[ RECORD 7 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | timestampcol
hcatalog_data_type | string
data_type | varchar(65000)
data_type_id | 9
data_type_length | 65000
character_maximum_length | 65000
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 7
-[ RECORD 8 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | varbincol
hcatalog_data_type | binary
data_type | varbinary(65000)
data_type_id | 17
data_type_length | 65000
character_maximum_length | 65000
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 8
-[ RECORD 9 ]------------+-----------------
table_schema | hcat
hcatalog_schema | default
table_name | hcatalogtypes
is_partition_column | f
column_name | bincol
hcatalog_data_type | binary
data_type | varbinary(65000)
data_type_id | 17
data_type_length | 65000
character_maximum_length | 65000
numeric_precision |
numeric_scale |
datetime_precision |
interval_precision |
ordinal_position | 9
See also
8.1.26 - HCATALOG_SCHEMATA
Lists all of the schemas defined using the HCatalog Connector.
Lists all of the schemas defined using the HCatalog Connector. See Using the HCatalog Connector.
Unlike other HCatalog Connector-related system tables, this table makes no calls to Hive, so querying incurs very little overhead.
|
Column Name |
Data Type |
Description |
SCHEMA_ID |
INTEGER |
The Vertica Analytic Database ID number for the schema |
SCHEMA_NAME |
VARCHAR(128) |
The name of the schema defined in the Vertica Analytic Database catalog |
SCHEMA_OWNER_ID |
INTEGER |
The ID number of the user who owns the Vertica Analytic Database schema |
SCHEMA_OWNER |
VARCHAR(128) |
The username of the Vertica Analytic Database schema's owner |
CREATE_TIME |
TIMESTAMPTZ |
The date and time the schema as created |
HOSTNAME |
VARCHAR(128) |
The host name or IP address of the database server that holds the Hive metadata |
PORT |
INTEGER |
The port number on which the metastore database listens for connections |
HIVESERVER2_HOSTNAME |
VARCHAR(128) |
The host name or IP address of the HiveServer2 server for the Hive database |
WEBSERVICE_HOSTNAME |
VARCHAR(128) |
The host name or IP address of the WebHCat server for the Hive database, if used |
WEBSERVICE_PORT |
INTEGER |
The port number on which the WebHCat server listens for connections |
WEBHDFS_ADDRESS |
VARCHAR (128) |
The host and port ("host:port") for the WebHDFS service, used for reading ORC and Parquet files |
HCATALOG_SCHEMA_NAME |
VARCHAR(128) |
The name of the schema or database in Hive to which the Vertica Analytic Database schema is mapped/ |
HCATALOG_USER_NAME |
VARCHAR(128) |
The username the HCatalog Connector uses to authenticate itself to the Hive database. |
HCATALOG_CONNECTION_TIMEOUT |
INTEGER |
The number of seconds the HCatalog Connector waits for a successful connection to the HiveServer or WebHCat server. A value of 0 means wait indefinitely. |
HCATALOG_SLOW_TRANSFER_LIMIT |
INTEGER |
The lowest data transfer rate (in bytes per second) from the HiveServer2 or WebHCat server that the HCatalog Connector accepts. |
HCATALOG_SLOW_TRANSFER_TIME |
INTEGER |
The number of seconds the HCatalog Connector waits before enforcing the data transfer rate lower limit by breaking the connection and terminating the query. |
SSL_CONFIG |
VARCHAR(128) |
The path of the Hadoop ssl-client.xml configuration file, if using HiveServer2 with SSL wire encryption. |
CUSTOM_PARTITIONS |
BOOLEAN |
Whether the Hive schema uses custom partition locations. |
Privileges
No explicit permissions are required; however, users see only the records that correspond to schemas they have permissions to access.
See also
8.1.27 - HCATALOG_TABLE_LIST
A concise list of all tables contained in all Hive schemas and databases available through the HCatalog Connector.
A concise list of all tables contained in all Hive schemas and databases available through the HCatalog Connector. See Using the HCatalog Connector.
|
Column Name |
Data Type |
Description |
|
TABLE_SCHEMA_ID |
INTEGER |
Internal ID number for the schema containing the table |
|
TABLE_SCHEMA |
VARCHAR(128) |
Name of the Vertica Analytic Database schema through which the table is available |
|
HCATALOG_SCHEMA |
VARCHAR(128) |
Name of the Hive schema or database containing the table |
|
TABLE_NAME |
VARCHAR(128) |
The name of the table |
|
HCATALOG_USER_NAME |
VARCHAR(128) |
Name of Hive user used to access the table |
Privileges
No explicit permissions are required; however, users see only the records that correspond to schemas they have permissions to access.
Notes
-
Querying this table results in one call to HiveServer2 for each Hive schema defined using the HCatalog Connector. This means that the query usually takes longer than querying other system tables.
-
Querying this table is faster than querying HCATALOG_TABLES. Querying HCATALOG_TABLE_LIST only makes one HiveServer2 call per HCatalog schema versus one call per table for HCATALOG_TABLES.
Examples
The following example demonstrates defining a new HCatalog schema then querying HCATALOG_TABLE_LIST. Note that one table defined in a different HCatalog schema also appears. HCATALOG_TABLE_LIST lists all of the tables available in any of the HCatalog schemas:
=> CREATE HCATALOG SCHEMA hcat WITH hostname='hcathost'
-> HCATALOG_SCHEMA='default' HCATALOG_DB='default' HCATALOG_USER='hcatuser';
CREATE SCHEMA
=> \x
Expanded display is on.
=> SELECT * FROM v_catalog.hcatalog_table_list;
-[ RECORD 1 ]------+------------------
table_schema_id | 45035996273748980
table_schema | hcat
hcatalog_schema | default
table_name | weblogs
hcatalog_user_name | hcatuser
-[ RECORD 2 ]------+------------------
table_schema_id | 45035996273748980
table_schema | hcat
hcatalog_schema | default
table_name | tweets
hcatalog_user_name | hcatuser
-[ RECORD 3 ]------+------------------
table_schema_id | 45035996273748980
table_schema | hcat
hcatalog_schema | default
table_name | messages
hcatalog_user_name | hcatuser
-[ RECORD 4 ]------+------------------
table_schema_id | 45035996273864948
table_schema | hiveschema
hcatalog_schema | default
table_name | weblogs
hcatalog_user_name | hcatuser
See also
8.1.28 - HCATALOG_TABLES
Returns a detailed list of all tables made available through the HCatalog Connector.
Returns a detailed list of all tables made available through the HCatalog Connector. See Using the HCatalog Connector.
|
Column Name |
Data Type |
Description |
TABLE_SCHEMA_ID |
INTEGER |
ID number of the schema |
TABLE_SCHEMA |
VARCHAR(128) |
The name of the Vertica Analytic Database schema through which the table is available |
HCATALOG_SCHEMA |
VARCHAR(128) |
The name of the Hive schema or database that contains the table |
TABLE_NAME |
VARCHAR(128) |
The name of the table |
HCATALOG_USER_NAME |
VARCHAR(128) |
The name of the HCatalog user whose credentials are used to access the table's data |
MIN_FILE_SIZE_BYTES |
INTEGER |
The file size of the table's smallest data file, if using WebHCat; null if using HiveServer2 |
TOTAL_NUMBER_FILES |
INTEGER |
The number of files used to store this table's data in HDFS |
LOCATION |
VARCHAR(8192) |
The URI for the directory containing this table's data, normally an HDFS URI |
LAST_UPDATE_TIME |
TIMESTAMPTZ |
The last time data in this table was updated, if using WebHCat; null if using HiveServer2 |
OUTPUT_FORMAT |
VARCHAR(128) |
The Hive SerDe class used to output data from this table |
LAST_ACCESS_TIME |
TIMESTAMPTZ |
The last time data in this table was accessed, if using WebHCat; null if using HiveServer2 |
MAX_FILE_SIZE_BYTES |
INTEGER |
The size of the largest data file for this table, if using WebHCat; null if using HiveServer2 |
IS_PARTITIONED |
BOOLEAN |
Whether this table is partitioned |
PARTITION_EXPRESSION |
VARCHAR(128) |
The expression used to partition this table |
TABLE_OWNER |
VARCHAR(128) |
The Hive user that owns this table in the Hive database, if using WebHCat; null if using HiveServer2 |
INPUT_FORMAT |
VARCHAR(128) |
The SerDe class used to read the data from this table |
TOTAL_FILE_SIZE_BYTES |
INTEGER |
Total number of bytes used by all of this table's data files |
HCATALOG_GROUP |
VARCHAR(128) |
The permission group assigned to this table, if using WebHCat; null if using HiveServer2 |
PERMISSION |
VARCHAR(128) |
The Unix file permissions for this group, as shown by the ls -l command, if using WebHCat; null if using HiveServer2 |
Privileges
No explicit permissions are required; however, users see only the records that correspond to schemas they have permissions to access.
See also
8.1.29 - ICEBERG_COLUMNS
Provides column information for Iceberg external tables.
Provides column information for Iceberg external tables. The information in this table is drawn from the Iceberg metadata files at query time.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the table. |
TABLE_SCHEMA |
VARCHAR |
Name of the table's schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_NAME |
VARCHAR |
Name of the table containing the column. |
COLUMN_ID |
VARCHAR |
Catalog-assigned VARCHAR value that uniquely identifies a table column. |
COLUMN_NAME |
VARCHAR |
Name of the column. |
DATA_TYPE |
VARCHAR |
Column data type. |
DATA_TYPE_ID |
INTEGER |
Catalog-assigned unique numeric ID of the data type. |
DATA_TYPE_LENGTH |
INTEGER |
Maximum allowable length of the data type. |
CHARACTER_MAXIMUM_LENGTH |
VARCHAR |
Maximum allowable length of a VARCHAR column. |
NUMERIC_PRECISION |
INTEGER |
Number of significant decimal digits for a NUMERIC column. |
NUMERIC_SCALE |
INTEGER |
Number of fractional digits for a NUMERIC column. |
DATETIME_PRECISION |
INTEGER |
Declared precision for a TIMESTAMP column, or NULL if no precision was declared. |
INTERVAL_PRECISION |
INTEGER |
Number of fractional digits retained in the seconds field of an INTERVAL column. |
IS_NULLABLE |
BOOLEAN |
Whether the column can contain NULL values. |
WRITE_DEFAULT |
VARCHAR |
Field value for any records written after the field was added to the schema, if the writer does not supply the field’s value. |
INITIAL_DEFAULT |
VARCHAR |
Field value for all records that were written before the field was added to the schema. |
8.1.30 - INHERITED_PRIVILEGES
Provides summary information about privileges inherited by objects from GRANT statements on parent schemas, excluding inherited grant options.
Provides summary information about privileges inherited by objects from GRANT statements on parent schemas, excluding inherited grant options.
For information about explicitly granted permissions, see system table GRANTS.
Note
Inherited privileges are not displayed if privilege inheritance is disabled at the database level with
DisableInheritedPrivileges.
|
Column Name |
Data Type |
Description |
|
OBJECT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theobject inheriting the privileges. |
|
SCHEMA_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theparent schema. |
|
OBJECT_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace of the table or view. |
|
OBJECT_SCHEMA |
VARCHAR |
Name of the parent schema of a table or view.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
OBJECT_NAME |
VARCHAR |
Name of the table or view. |
|
OBJECT_TYPE |
VARCHAR |
The object type, one of the following:
|
|
PRIVILEGES_DESCRIPTION |
VARCHAR |
Lists the privileges inherited on an object. An asterisk (*) appended to a privilege indicates that the user can grant the privilege to other users by granting the privilege on the parent schema. |
|
PRINCIPAL |
VARCHAR |
Name of the role or user inheriting the privileges in the row. |
|
PRINCIPAL_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theuser inheriting the privileges. |
|
GRANTOR |
VARCHAR |
User that granted the privileges on the parent schema to the principal. |
|
GRANTOR_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theuser who performed the grant operation. |
|
GRANT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thegrant operation. |
Examples
The following query returns the privileges that the tables and views inherit from their parent schema, customers.
=> SELECT object_schema,object_name,object_type,privileges_description,principal,grantor FROM inherited_privileges WHERE object_schema='customers';
object_schema | object_name | object_type | privileges_description | principal | grantor
--------------+-----------------+-------------+---------------------------------------------------------------------------+-----------+---------
customers | cust_info | Table | INSERT, SELECT, UPDATE, DELETE, ALTER, REFERENCES, DROP, TRUNCATE | dbadmin | dbadmin
customers | shipping_info | Table | INSERT, SELECT, UPDATE, DELETE, ALTER, REFERENCES, DROP, TRUNCATE | dbadmin | dbadmin
customers | cust_set | View | SELECT, ALTER, DROP | dbadmin | dbadmin
customers | cust_info | Table | SELECT | Val | dbadmin
customers | shipping_info | Table | SELECT | Val | dbadmin
customers | cust_set | View | SELECT | Val | dbadmin
customers | sales_model | Model | USAGE, ALTER, DROP | Pooja | dbadmin
customers | shipping_info | Table | INSERT | Pooja | dbadmin
(8 rows)
See also
8.1.31 - INHERITING_OBJECTS
Provides information about the objects (table, view, or model) that inherit privileges from their parent schemas.
Provides information about the objects (table, view, or model) that inherit privileges from their parent schemas.
For information about the particular privileges inherited from schemas and their associated GRANT statements, see the INHERITED_PRIVILEGES table.
|
Column Name |
Data Type |
Description |
|
OBJECT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theobject inheriting the privileges. |
|
SCHEMA_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theparent schema. |
|
OBJECT_SCHEMA |
VARCHAR |
Name of the parent schema. |
|
OBJECT_NAME |
VARCHAR |
Name of the object. |
|
OBJECT_TYPE |
VARCHAR |
The object type, one of the following:
|
Examples
The following query returns the tables and views that inherit their privileges from their parent schema, customers.
=> SELECT * FROM inheriting_objects WHERE object_schema='customers';
object_id | schema_id | object_schema | object_name | object_type
------------------+-------------------+---------------+-------------------+-------------
45035996273980908 | 45035996273980902 | customers | cust_info | table
45035996273980984 | 45035996273980902 | customers | shipping_info | table
45035996273980980 | 45035996273980902 | customers | cust_set | view
45035996273980983 | 45035996273980901 | ml_models | clustering_model | model
(3 rows)
See also
8.1.32 - KEYWORDS
Identifies Vertica reserved and non-reserved keywords.
Identifies Vertica reserved and non-reserved keywords.
|
Column Name |
Data Type |
Description |
KEYWORD |
VARCHAR |
Vertica-reserved or non-reserved keyword. |
RESERVED |
VARCHAR |
Indicates whether a keyword is reserved or non-reserved:
-
R: reserved
-
N: non-reserved
|
Examples
The following query gets all reserved keywords that begin with B:
=> SELECT * FROM keywords WHERE reserved = 'R' AND keyword ilike 'B%';
keyword | reserved
---------+----------
BETWEEN | R
BIGINT | R
BINARY | R
BIT | R
BOOLEAN | R
BOTH | R
(6 rows)
See also
Keywords
8.1.33 - LARGE_CLUSTER_CONFIGURATION_STATUS
Shows the current cluster nodes and control node (spread hosts) designations in the Catalog so you can see if they match.
Shows the current cluster nodes and control node (spread hosts) designations in the Catalog so you can see if they match.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node in the cluster. |
SPREAD_HOST_NAME |
VARCHAR |
The host name of the control node (the host that manages control message responsibilities) |
CONTROL_NODE_NAME |
VARCHAR |
The name of the control node |
See also
Large Cluster
8.1.34 - LICENSE_AUDITS
Lists the results of Vertica's license automatic compliance audits.
Lists the results of Vertica's license automatic compliance audits. See How Vertica Calculates Database Size.
|
Column Name |
Data Type |
Description |
DATABASE_SIZE_BYTES |
INTEGER |
The estimated raw data size of the database |
LICENSE_SIZE_BYTES |
INTEGER |
The licensed data allowance |
USAGE_PERCENT |
FLOAT |
Percentage of the licensed allowance used |
AUDIT_START_TIMESTAMP |
TIMESTAMPTZ |
When the audit started |
AUDIT_END_TIMESTAMP |
TIMESTAMPTZ |
When the audit finished |
CONFIDENCE_LEVEL_PERCENT |
FLOAT |
The confidence level of the size estimate |
ERROR_TOLERANCE_PERCENT |
FLOAT |
The error tolerance used for the size estimate |
USED_SAMPLING |
BOOLEAN |
Whether data was randomly sampled (if false, all of the data was analyzed) |
CONFIDENCE_INTERVAL_LOWER_BOUND_BYTES |
INTEGER |
The lower bound of the data size estimate within the confidence level |
CONFIDENCE_INTERVAL_UPPER_BOUND_BYTES |
INTEGER |
The upper bound of the data size estimate within the confidence level |
SAMPLE_COUNT |
INTEGER |
The number of data samples used to generate the estimate |
CELL_COUNT |
INTEGER |
The number of cells in the database |
AUDITED_DATA |
VARCHAR |
The type of data audited, which includes regular (non-flex), flex, external, and total data |
8.1.35 - LICENSES
For all licenses, provides information on license types, the dates for which licenses are valid, and the limits the licenses impose.
For all licenses, provides information on license types, the dates for which licenses are valid, and the limits the licenses impose.
|
Column Name |
Data Type |
Description |
LICENSE_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the license. |
NAME |
VARCHAR |
The license’s name. (The license name in this column could be represented by a long license key.) |
LICENSEE |
VARCHAR |
The entity to which the product is licensed. |
START_DATE |
VARCHAR |
The start date for which the license is valid. |
END_DATE |
VARCHAR |
The end date until which the license is valid (or "Perpetual" if the license has no expiration). |
LICENSETYPE |
VARCHAR |
The type of the license (for example, Premium Edition). |
PARENT |
VARCHAR |
The parent license (field is blank if there is no parent). |
SIZE |
VARCHAR |
The size limit for data on the license. |
IS_SIZE_LIMIT_ENFORCED |
BOOLEAN |
Indicates whether the license includes enforcement of data and node limits, where t is true and f is false. |
NODE_RESTRICTION |
VARCHAR |
The node limit the license imposes. |
CONFIGURED_ID |
INTEGER |
A long license key. |
8.1.36 - LOAD_BALANCE_GROUPS
Lists the objects contained by all load balance groups.
Lists the objects contained by all load balance groups. Each row in this table represents a single object that is a member of a load balance group. If a load balance group does not contain any objects, it appears once in this table with its type column set to 'Empty Group.'
|
Column Name |
Data Type |
Description |
|
NAME |
VARCHAR |
The name of the load balance group |
|
POLICY |
VARCHAR |
The policy that sets how the group chooses the node for a connection. Contains one of the following:
|
|
FILTER |
VARCHAR |
The IP address range in CIDR format to select the members of a fault group that are included in the load balance group. This column only has a value if the TYPE column is 'Fault Group' or 'Subcluster.' |
|
TYPE |
VARCHAR |
The type of object contained in the load balance group. Contains one of:
-
Fault Group
-
Subcluster
-
Network Address Group
-
Empty Group
|
|
OBJECT_NAME |
VARCHAR |
The name of the fault group or network address included in the load balance group. This column is NULL if the group contains no objects. |
Examples
=> SELECT * FROM LOAD_BALANCE_GROUPS;
name | policy | filter | type | object_name
---------------+------------+-----------+-----------------------+-------------
group_1 | ROUNDROBIN | | Network Address Group | node01
group_1 | ROUNDROBIN | | Network Address Group | node02
group_2 | ROUNDROBIN | | Empty Group |
group_all | ROUNDROBIN | | Network Address Group | node01
group_all | ROUNDROBIN | | Network Address Group | node02
group_all | ROUNDROBIN | | Network Address Group | node03
group_fault_1 | RANDOM | 0.0.0.0/0 | Fault Group | fault_1
(7 rows)
See also
8.1.37 - LOG_PARAMS
Provides summary information about changes to configuration parameters related to authentication and security run in your database.
Provides summary information about changes to configuration parameters related to authentication and security run in your database.
|
Column Name |
Data Type |
Description |
|
ISSUED_TIME |
VARCHAR |
The time at which the query was executed. |
|
USER_NAME |
VARCHAR |
Name of the user who issued the query at the time Vertica recorded the session. |
|
USER_ID |
INTEGER |
Numeric representation of the user who ran the query. |
|
HOSTNAME |
VARCHAR |
The hostname, IP address, or URL of the database server. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
AUDIT_TYPE |
VARCHAR |
The type of operation for the audit, in this case, Parameter. |
|
AUDIT_TAG_NAME |
VARCHAR |
The tag for the specific parameter. |
|
REQUEST_TYPE |
VARCHAR |
The type of query request. |
|
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
|
SUBJECT |
VARCHAR |
The new value of the parameter. |
|
REQUEST |
VARCHAR |
Lists the query request. |
|
SUCCESS |
VARCHAR |
Indicates whether or not the operation was successful. |
|
CATEGORY |
VARCHAR |
The audit parent category, such as Authentication. |
Examples
The following example queries the LOG_PARAMS system table and shows only the most recent configuration parameter for this user under the Authentication category:
=> SELECT * FROM log_params limit 1;
--------------------------------------------------------------------------------------------------------
issued_time | 2018-02-12 13:41:20.837452-05
user_name | dbadmin
user_id | 45035996273704962
hostname | ::1:50690
session_id | v_vmart_node0001-341751:0x13878
audit_type | Param
audit_tag_name| SecurityAlgorithm
request_type | UTILITY
request_id | 8
subject | MD5
request | select set_config_parameter('SecurityAlgorithm','MD5',null);
success | t
category | Authentication
(1 row)
8.1.38 - LOG_QUERIES
Provides summary information about some queries related to authentication and security run in your database.
Provides summary information about some queries related to authentication and security run in your database.
|
Column Name |
Data Type |
Description |
|
ISSUED_TIME |
VARCHAR |
The time at which the query was executed. |
|
USER_NAME |
VARCHAR |
Name of the user who issued the query at the time Vertica recorded the session. |
|
USER_ID |
INTEGER |
Numeric representation of the user who ran the query. |
|
HOSTNAME |
VARCHAR |
The hostname, IP address, or URL of the database server. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
AUDIT_TYPE |
VARCHAR |
The type of operation for the audit, in this case, Query. |
|
AUDIT_TAG_NAME |
VARCHAR |
The tag for the specific query. |
|
REQUEST_TYPE |
VARCHAR |
The type of query request. Examples include, but are not limited to:
-
QUERY
-
DDL
-
LOAD
-
UTILITY
-
TRANSACTION
-
PREPARE
-
EXECUTE
-
SET
-
SHOW
|
|
REQUEST_ID |
INTEGER |
The ID of the query request. |
|
SUBJECT |
VARCHAR |
The subject of the query. |
|
REQUEST |
VARCHAR |
Lists the query request. |
|
SUCCESS |
VARCHAR |
Indicates whether or not the operation was successful. |
|
CATEGORY |
VARCHAR |
The audit parent category, such as Managing_Users_Privileges. |
Examples
The following example queries the LOG_QUERIES system table and shows only the most recent query for this user under the Managing_Users_Privileges category:
=> SELECT * FROM log_queries limit 1;
---------------------------------------------------------------------------
issued_time | 2018-01-22 10:36:55.634349-05
user_name | dbadmin
user_id | 45035996273704962
hostname |
session_id | v_vmart_node0001-237210:0x37e1d
audit_type | Query
audit_tag_name| REVOKE ROLE
request_type | DDL
request_id | 2
subject |
request | revoke all privileges from Joe;
success | f
category | Managing_Users_Privileges
(1 row)
8.1.39 - LOG_TABLES
Provides summary information about queries on system tables.
Provides summary information about queries on system tables.
|
Column Name |
Data Type |
Description |
|
ISSUED_TIME |
VARCHAR |
Time of query execution. |
|
USER_NAME |
VARCHAR |
Name of user who issued the query at the time Vertica recorded the session. |
|
USER_ID |
INTEGER |
Numeric representation of the user who ran the query. |
|
HOSTNAME |
VARCHAR |
The hostname, IP address, or URL of the database server. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
AUDIT_TYPE |
VARCHAR |
The type of operation for the audit, in this case, Table. |
|
AUDIT_TAG_NAME |
VARCHAR |
The tag for the specific table. |
|
REQUEST_TYPE |
VARCHAR |
The type of query request. In this case, QUERY. |
|
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
|
SUBJECT |
VARCHAR |
The name of the table that was queried. |
|
REQUEST |
VARCHAR |
Lists the query request. |
|
SUCCESS |
VARCHAR |
Indicates whether or not the operation was successful. |
|
CATEGORY |
VARCHAR |
The audit parent category—for example, Views, Security, and Managing_Users_Privileges. |
Examples
The following example shows recent queries on configuration parameters:
dbadmin=> SELECT issued_time, audit_type, request_type, subject, request, category FROM log_tables
WHERE category ilike '%Managing_Config_Parameters%' ORDER BY issued_time DESC LIMIT 4;
-[ RECORD 1 ]+-------------------------------------------------------------------------------------
issued_time | 2020-05-14 14:14:53.453552-04
audit_type | Table
request_type | QUERY
subject | vs_nodes
request | SELECT * from vs_nodes order by name limit 1;
category | Managing_Config_Parameters
-[ RECORD 2 ]+-------------------------------------------------------------------------------------
issued_time | 2020-05-14 14:14:27.546474-04
audit_type | Table
request_type | QUERY
subject | vs_nodes
request | SELECT * from vs_nodes order by name ;
category | Managing_Config_Parameters
-[ RECORD 3 ]+-------------------------------------------------------------------------------------
issued_time | 2020-05-14 08:54:32.86881-04
audit_type | Table
request_type | QUERY
subject | vs_parameters_mismatch
request | select * from configuration_parameters where parameter_name = 'MaxDepotSizePercent';
category | Managing_Config_Parameters
-[ RECORD 4 ]+-------------------------------------------------------------------------------------
issued_time | 2020-05-14 08:54:32.86881-04
audit_type | Table
request_type | QUERY
subject | vs_nodes
request | select * from configuration_parameters where parameter_name = 'MaxDepotSizePercent';
category | Managing_Config_Parameters
8.1.40 - MATERIALIZE_FLEXTABLE_COLUMNS_RESULTS
Contains the results of running the MATERIALIZE_FLEXTABLE_COLUMNS function.
Contains the results of running the MATERIALIZE_FLEXTABLE_COLUMNS function. The table contains information about keys that the function evaluated. It does not contain information about all keys.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the table. |
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed. |
TABLE_NAME |
VARCHAR |
The table name for which information is listed. |
CREATION_TIME |
VARCHAR |
Timestamp when the key was materialized. |
KEY_NAME |
VARCHAR |
Name of the key from the VMap column that was materialized. |
STATUS |
VARCHAR |
Status of the materialized column, one of the following:
|
MESSAGE |
BOOLEAN |
Message associated with the status in the previous column, one of the following:
|
Examples
=> \x
Expanded display is on.
=> SELECT table_id, table_schema, table_name, key_name, status, message FROM MATERIALIZE_FLEXTABLE_COLUMNS_RESULTS
WHERE table_name = 'mountains_hybrid';
-[ RECORD 1 ]+-------------------------------------------------------
table_id | 45035996273708192
table_schema | public
table_name | mountains_hybrid
key_name | type
status | ADDED
message | Added successfully
-[ RECORD 2 ]+-------------------------------------------------------
table_id | 45035996273708192
table_schema | public
table_name | mountains_hybrid
key_name | height
status | ADDED
message | Added successfully
-[ RECORD 3 ]+-------------------------------------------------------
table_id | 45035996273708192
table_schema | public
table_name | mountains_hybrid
key_name | name
status | EXISTS
message | Column of same name already exists in table definition
8.1.41 - MODELS
Lists details about the machine-learning models in the database.
Lists details about the machine-learning models in the database.
|
Column Name |
Data Type |
Description |
MODEL_ID |
INTEGER |
The model's internal ID. |
MODEL_NAME |
VARCHAR(128) |
The name of the model. |
SCHEMA_ID |
INTEGER |
The schema's internal ID. |
SCHEMA_NAME |
VARCHAR(128) |
The name of the schema. |
OWNER_ID |
INTEGER |
The model owner's ID. |
OWNER_NAME |
VARCHAR(128) |
The user who created the model. |
CATEGORY |
VARCHAR(128) |
The type of model. By default, models created in Vertica are assigned to the Vertica_Models category. |
MODEL_TYPE |
VARCHAR(128) |
The type of algorithm used to create the model. |
IS_COMPLETE |
VARCHAR(128) |
Denotes whether the model is complete and ready for use in machine learning functions. This field is usually false when the model is being trained. Once the training is complete, the field is set to true. |
CREATE_TIME |
TIMESTAMPTZ |
The time the model was created. |
SIZE |
INTEGER |
The size of the model in bytes. |
IS_INHERIT_PRIVILEGES |
BOOLEAN |
Whether the model inherits the privileges of its parent schema. |
Examples
=> SELECT * FROM models;
-[ RECORD 1 ]---------+------------------------------
model_id | 45035996273850350
model_name | xgb_iris
schema_id | 45035996273704984
schema_name | public
owner_id | 45035996273704962
owner_name | dbadmin
category | VERTICA_MODELS
model_type | XGB_CLASSIFIER
is_complete | t
create_time | 2022-11-29 13:38:59.259531-05
size | 11018
is_inherit_privileges | f
-[ RECORD 2 ]---------+------------------------------
model_id | 45035996273866816
model_name | arima_weather
schema_id | 45035996273704984
schema_name | public
owner_id | 45035996273704962
owner_name | dbadmin
category | VERTICA_MODELS
model_type | ARIMA
is_complete | t
create_time | 2023-03-31 13:13:06.342661-05
size | 2770
is_inherit_privileges | f
8.1.42 - NAMESPACES
Lists details about the namespaces in an Eon Mode database.
Lists details about the namespaces in an Eon Mode database.
|
Column Name |
Data Type |
Description |
|
NAMESPACE_OID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the namesapce. |
|
NAMESPACE_NAME |
VARCHAR |
Name of the namespace |
|
IS_DEFAULT |
BOOLEAN |
Whether the namespace is the default namespace of the database. |
|
DEFAULT_SHARD_COUNT |
VARCHAR |
Shard count of the namespace. |
Example
List the details of all namespaces in your database:
=> SELECT * FROM NAMESPACES;
namespace_oid | namespace_name | is_default | default_shard_count
-------------------+-------------------+------------+---------------------
45035996273704988 | default_namespace | t | 9
32582959204859183 | analytics | f | 12
(2 rows)
8.1.43 - NETWORK_ADDRESSES
Lists information about the network addresses defined in your database using the CREATE NETWORK ADDRESS statement.
Lists information about the network addresses defined in your database using the CREATE NETWORK ADDRESS statement.
|
Column Name |
Data Type |
Description |
|
NAME |
VARCHAR |
The name of the network address. |
|
NODE |
VARCHAR |
The name of the node that owns the network address. |
|
ADDRESS |
VARCHAR |
The network address's IP address. This address can be either in IPv4 or IPv6 format. |
|
PORT |
INT |
The network address's port number. |
|
ADDRESS_FAMILY |
VARCHAR |
The format of the network address's IP address. This values is either 'ipv4' or 'ipv6'. |
|
IS_ENABLED |
BOOLEAN |
Whether the network address is enabled. You can disable network addresses to prevent their use. If the address is disabled, the value in this column is False. |
|
IS_AUTO_DETECTED |
BOOLEAN |
Whether Vertica created the network address automatically. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM v_catalog.network_addresses;
-[ RECORD 1 ]----+-----------------
name | node01
node | v_vmart_node0001
address | 10.20.100.247
port | 5433
address_family | ipv4
is_enabled | t
is_auto_detected | f
-[ RECORD 2 ]----+-----------------
name | node02
node | v_vmart_node0002
address | 10.20.100.248
port | 5433
address_family | ipv4
is_enabled | t
is_auto_detected | f
-[ RECORD 3 ]----+-----------------
name | node03
node | v_vmart_node0003
address | 10.20.100.249
port | 5433
address_family | ipv4
is_enabled | t
is_auto_detected | f
See also
8.1.44 - NODE_SUBSCRIPTION_CHANGE_PHASES
In an Eon Mode database, stores information about changes to node's shard subscriptions.
In an Eon Mode database, stores information about changes to node's shard subscriptions.
|
Column Name |
Data Type |
Description |
|
node_name |
VARCHAR |
Name of the node |
|
subscription_change_type |
VARCHAR |
The change being made to the subscription |
|
session_id |
INTEGER |
ID of the session in which the change was initiated |
|
transaction_id |
INTEGER |
ID of the transaction in which the change was initiated |
|
user_id |
INTEGER |
ID of user that initiated the change |
|
user_name |
VARCHAR |
Name of user that initiated the change |
|
subscription_oid |
INTEGER |
Session object ID |
|
subscriber_node_oid |
INTEGER |
Object ID of node that requested the subscription |
|
subscriber_node_name |
VARCHAR |
Name of the node that requested the subscription |
|
shard_oid |
INTEGER |
Object ID of the shard to which the node is subscribed |
|
shard_name |
VARCHAR |
Name of the shard to which the node is subscribed |
|
min_time |
TIMESTAMPTZ |
Start time of the subscription change |
|
max_time |
TIMESTAMPTZ |
Completion time of the subscription change |
|
source_node_oid |
INTEGER |
Object ID of the node from which catalog objects were fetched |
|
source_node_name |
VARCHAR |
Name of the node from which catalog objects were fetched |
|
num_objs_affected |
INTEGER |
Number of catalog objects affected by the subscription change |
|
action |
VARCHAR |
Description of the action taken |
|
new_content_size |
INTEGER |
Total size of the catalog objects that were fetched for the subscription change |
|
phase_limit_reached |
BOOLEAN |
Reached maximum number of retries? |
|
START_TIME |
TIMESTAMPTZ |
When the subscription change started |
|
END_TIME |
TIMESTAMPTZ |
When the subscription change was finished |
|
retried |
BOOLEAN |
Retry of subscription phase? |
|
phase_result |
VARCHAR |
Outcome of the subscription change, one of the following:
|
Examples
=> SELECT NODE_NAME, SUBSCRIPTION_CHANGE_TYPE, SHARD_NAME,
ACTION FROM node_subscription_change_phases
ORDER BY start_time ASC LIMIT 10;
NODE_NAME | SUBSCRIPTION_CHANGE_TYPE | SHARD_NAME | ACTION
----------------------+--------------------------+-------------+------------------------
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0007 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0010 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0004 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0005 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | replica | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0005 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0006 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0008 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0011 | COLLECT SHARD METADATA
v_verticadb_node0001 | CREATE SUBSCRIPTION | segment0002 | COLLECT SHARD METADATA
8.1.45 - NODE_SUBSCRIPTIONS
Lists information about database node subscriptions to shards.
Eon Mode only
Lists information about database node subscriptions to shards.
|
Column Name |
Data Type |
Description |
|
SUBSCRIPTION_OID |
INTEGER |
Subscription OID |
|
NODE_OID |
INTEGER |
Subscribed node OID |
|
NODE_NAME |
VARCHAR |
Name of the node |
|
SHARD_OID |
INTEGER |
OID of the shard to which the node is subscribed |
|
SHARD_NAME |
VARCHAR |
Name of the shard to which the node is subscribed |
|
SUBSCRIPTION_STATE |
VARCHAR |
Node's current subscription state |
|
FROM _VERSION |
INTEGER |
Deprecated |
|
IS_PRIMARY |
BOOLEAN |
Specifies whether the node is currently the primary subscriber. |
|
IS_RESUBSCRIBING |
BOOLEAN |
Indicates whether a subscription is resubscribing to a node:
-
t (true): A subscription is resubscribing, only applies to PENDING subscriptions created during the cluster or node startup.
-
f (false): A subscription is not resubscribing, applies to PENDING subscriptions created with REBALANCE_SHARDS that transitioned to an ACTIVE state.
|
|
CREATOR_TID |
INTEGER |
ID of transaction that created this subscription |
|
SUBSCRIBED_TO_METADATA_AT |
INTEGER |
Deprecated |
|
IS_PARTICIPATING_PRIMARY |
BOOLEAN |
Whether this node is the participating primary subscriber for the shard. If true, the node listed in NODE_NAME is the only one that reads from and writes to communal storage for this shard in the subcluster. Other nodes in the subcluster that subscribe to the same shard receive data from this node via peer-to-peer transfers. |
Examples
The following example queries the NODE_SUBSCRIPTIONS table in a database with two three-node subclusters (a primary and a secondary) in a 12-shard database.
=> SELECT node_name, shard_name, subscription_state, is_primary,
is_participating_primary AS is_p_primary
FROM NODE_SUBSCRIPTIONS ORDER BY node_name, shard_name;
node_name | shard_name | subscription_state | is_primary | is_p_primary
----------------------+-------------+--------------------+------------+--------------
v_verticadb_node0001 | replica | ACTIVE | t | t
v_verticadb_node0001 | segment0001 | ACTIVE | t | t
v_verticadb_node0001 | segment0003 | ACTIVE | f | f
v_verticadb_node0001 | segment0004 | ACTIVE | t | t
v_verticadb_node0001 | segment0006 | ACTIVE | f | f
v_verticadb_node0001 | segment0007 | ACTIVE | t | t
v_verticadb_node0001 | segment0009 | ACTIVE | f | f
v_verticadb_node0001 | segment0010 | ACTIVE | t | t
v_verticadb_node0001 | segment0012 | ACTIVE | f | f
v_verticadb_node0002 | replica | ACTIVE | f | t
v_verticadb_node0002 | segment0001 | ACTIVE | f | f
v_verticadb_node0002 | segment0002 | ACTIVE | t | t
v_verticadb_node0002 | segment0004 | ACTIVE | f | f
v_verticadb_node0002 | segment0005 | ACTIVE | t | t
v_verticadb_node0002 | segment0007 | ACTIVE | f | f
v_verticadb_node0002 | segment0008 | ACTIVE | t | t
v_verticadb_node0002 | segment0010 | ACTIVE | f | f
v_verticadb_node0002 | segment0011 | ACTIVE | t | t
v_verticadb_node0003 | replica | ACTIVE | f | t
v_verticadb_node0003 | segment0002 | ACTIVE | f | f
v_verticadb_node0003 | segment0003 | ACTIVE | t | t
v_verticadb_node0003 | segment0005 | ACTIVE | f | f
v_verticadb_node0003 | segment0006 | ACTIVE | t | t
v_verticadb_node0003 | segment0008 | ACTIVE | f | f
v_verticadb_node0003 | segment0009 | ACTIVE | t | t
v_verticadb_node0003 | segment0011 | ACTIVE | f | f
v_verticadb_node0003 | segment0012 | ACTIVE | t | t
v_verticadb_node0004 | replica | ACTIVE | f | t
v_verticadb_node0004 | segment0001 | ACTIVE | f | t
v_verticadb_node0004 | segment0003 | ACTIVE | f | f
v_verticadb_node0004 | segment0004 | ACTIVE | f | t
v_verticadb_node0004 | segment0006 | ACTIVE | f | f
v_verticadb_node0004 | segment0007 | ACTIVE | f | t
v_verticadb_node0004 | segment0009 | ACTIVE | f | f
v_verticadb_node0004 | segment0010 | ACTIVE | f | t
v_verticadb_node0004 | segment0012 | ACTIVE | f | f
v_verticadb_node0005 | replica | ACTIVE | f | t
v_verticadb_node0005 | segment0001 | ACTIVE | f | f
v_verticadb_node0005 | segment0002 | ACTIVE | f | t
v_verticadb_node0005 | segment0004 | ACTIVE | f | f
v_verticadb_node0005 | segment0005 | ACTIVE | f | t
v_verticadb_node0005 | segment0007 | ACTIVE | f | f
v_verticadb_node0005 | segment0008 | ACTIVE | f | t
v_verticadb_node0005 | segment0010 | ACTIVE | f | f
v_verticadb_node0005 | segment0011 | ACTIVE | f | t
v_verticadb_node0006 | replica | ACTIVE | f | t
v_verticadb_node0006 | segment0002 | ACTIVE | f | f
v_verticadb_node0006 | segment0003 | ACTIVE | f | t
v_verticadb_node0006 | segment0005 | ACTIVE | f | f
v_verticadb_node0006 | segment0006 | ACTIVE | f | t
v_verticadb_node0006 | segment0008 | ACTIVE | f | f
v_verticadb_node0006 | segment0009 | ACTIVE | f | t
v_verticadb_node0006 | segment0011 | ACTIVE | f | f
v_verticadb_node0006 | segment0012 | ACTIVE | f | t
(54 rows)
8.1.46 - NODES
Lists details about the nodes in the database.
Lists details about the nodes in the database.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR(128) |
The name of the node. |
|
NODE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies the node. |
|
NODE_STATE |
VARCHAR(128) |
The node's current state, one of the following:
-
UP
-
DOWN
-
READY
-
UNSAFE
-
SHUTDOWN
-
SHUTDOWN_ERROR
-
RECOVERING
-
RECOVER_ERROR
-
RECOVERED
-
INITIALIZING
-
STANDBY
-
NEEDS_CATCHUP
|
|
IS_PRIMARY |
BOOLEAN |
Whether the node is a primary or secondary node. Primary nodes are the only ones Vertica considers when determining the K-Safety of an Eon Mode database. The node inherits this property from the subcluster that contains it. |
|
IS_READONLY |
BOOLEAN |
Whether the node is in read-only mode or not. This column is TRUE if the Eon Mode database is read-only due to the loss of quorum or primary shard coverage. See Database Read-Only Mode. |
|
NODE_ADDRESS |
VARCHAR(80) |
The host address of the node. |
|
NODE_ADDRESS_FAMILY |
VARCHAR(10) |
The IP Version of the node_address. For example, ipv4. |
|
EXPORT_ADDRESS |
VARCHAR(8192) |
The IP address of the node (on the public network) used for import/export operations and native load-balancing. |
|
EXPORT_ADDRESS_FAMILY |
VARCHAR(10) |
The IP Version of the export_address. For example, ipv4. |
|
CATALOG_PATH |
VARCHAR(8192) |
The absolute path to the catalog on the node. |
|
NODE_TYPE |
VARCHAR(9) |
The type of the node. For more information on the types of nodes, refer to Setting node type. |
|
IS_EPHEMERAL |
BOOLEAN |
(Deprecated) True if this node has been marked as ephemeral. (in preparation for removing it from the cluster). |
|
STANDING_IN_FOR |
VARCHAR(128) |
The name of the node that this node is currently replacing. |
|
SUBCLUSTER_NAME |
VARCHAR(128) |
In an Eon Mode database, the name of the subcluster that contains the node. Nodes belong to exactly one subcluster. |
|
SANDBOX |
VARCHAR(128) |
In an Eon Mode database, the name, if any, of the sandbox to which the node belongs. NULL if the node is not a member of an active sandbox. |
|
LAST_MSG_FROM_NODE_AT |
TIMESTAMPTZ |
The date and time the last message was received from this node. |
|
NODE_DOWN_SINCE |
TIMESTAMPTZ |
The amount of time that the replaced node has been unavailable. |
|
BUILD_INFO |
VARCHAR(128) |
The version of the Vertica server binary the node is running. |
Example
=> SELECT NODE_NAME, NODE_STATE, IS_PRIMARY, IS_READONLY, NODE_TYPE,
SUBCLUSTER_NAME FROM NODES ORDER BY NODE_NAME ASC;
NODE_NAME | NODE_STATE | IS_PRIMARY | IS_READONLY | NODE_TYPE | SUBCLUSTER_NAME
----------------------+------------+------------+-------------+-----------+--------------------
v_verticadb_node0001 | UP | t | f | PERMANENT | default_subcluster
v_verticadb_node0002 | UP | t | f | PERMANENT | default_subcluster
v_verticadb_node0003 | UP | t | f | PERMANENT | default_subcluster
v_verticadb_node0004 | UP | f | f | PERMANENT | analytics
v_verticadb_node0005 | UP | f | f | PERMANENT | analytics
v_verticadb_node0006 | UP | f | f | PERMANENT | analytics
(6 rows)
8.1.47 - ODBC_COLUMNS
Provides table column information.
Provides table column information. The format is defined by the ODBC standard for the ODBC SQLColumns metadata. Details on the ODBC SQLColumns format are available in the ODBC specification: http://msdn.microsoft.com/en-us/library/windows/desktop/ms711683%28v=vs.85%29.aspx.
|
Column Name |
Data Type |
Description |
SCHEMA_NAME |
VARCHAR |
Name of the schema in which the column resides. If the column does not reside in a schema, this field is empty. |
TABLE_NAME |
VARCHAR |
Name of the table in which the column resides. |
COLUMN_NAME |
VARCHAR |
Name of the column. |
DATA_TYPE |
INTEGER |
Data type of the column. This can be an ODBC SQL data type or a driver-specific SQL data type. This column corresponds to the ODBC_TYPE column in the TYPES table. |
DATA_TYPE_NAME |
VARCHAR |
Driver-specific data type name. |
COLUMN_SIZE |
INTEGER |
ODBC-defined data size of the column. |
BUFFER_LENGTH |
INTEGER |
Transfer octet length of a column is the maximum number of bytes returned to the application when data is transferred to its default C data type. See http://msdn.microsoft.com/en-us/library/windows/desktop/ms713979%28v=vs.85%29.aspx |
DECIMAL_DIGITS |
INTEGER |
Total number of significant digits to the right of the decimal point. This value has no meaning for non-decimal data types. |
NUM_PREC_RADIX |
INTEGER |
Radix Vertica reports decimal_digits and columns_size as. This value is always 10, because it refers to a number of decimal digits, rather than a number of bits. |
NULLABLE |
BOOLEAN |
Whether the column can contain null values. |
REMARKS |
VARCHAR |
Textual remarks for the column. |
COLUMN_DEFAULT |
VARCHAR |
Default value of the column. |
SQL_TYPE_ID |
INTEGER |
SQL data type of the column. |
SQL_DATETIME_SUB |
VARCHAR |
Subtype for a datetime data type. This value has no meaning for non-datetime data types. |
CHAR_OCTET_LENGTH |
INTEGER |
Maximum length of a string or binary data column. |
ORDINAL_POSITION |
INTEGER |
Position of the column in the table definition. |
IS_NULLABLE |
VARCHAR |
Values can be YES or NO, determined by the value of the NULLABLE column. |
IS_IDENTITY |
BOOLEAN |
Whether the column is an IDENTITY column. |
8.1.48 - PASSWORD_AUDITOR
Stores information about user accounts, account expirations, and password hashing algorithms.
Stores information about user accounts, account expirations, and password hashing algorithms.
|
Column Name |
Data Type |
Description |
|
USER_ID |
INTEGER |
Unique ID for the user. |
|
USER_NAME |
VARCHAR |
Name of the user. |
|
ACCTEXPIRED |
BOOLEAN |
Indicates if the user's password expires. 'f' indicates that it does not expire. 't' indicates that it does expire. |
|
SECURITY_ALGORITHM |
VARCHAR |
User-level security algorithm for hash authentication.
Valid values:
|
|
SYSTEM_SECURITY_ALGORITHM |
VARCHAR |
System-level security algorithm for hash authentication.
Valid values:
|
|
EFFECTIVE_SECURITY_ALGORITHM |
VARCHAR |
The resulting security algorithm, depending on the values of SECURTY_ALGORITHM and SYSTEM_SECURITY_ALGORITHM.
For details, see Password hashing algorithm.
|
|
CURRENT_SECURITY_ALGORITHM |
VARCHAR |
The security algorithm used to hash the user's current password. This can differ from the EFFECTIVE_SECURITY_ALGORITHM if a user hasn't reset their password since a change in the EFFECTIVE_SECURITY_ALGORITHM.
Valid values:
|
8.1.49 - PASSWORDS
Contains information on current user passwords.
Contains information on current user passwords. This table also includes information on past passwords if any Profiles have PASSWORD_REUSE_TIME or PASSWORD_REUSE_MAX parameters set. See CREATE PROFILE for details.
|
Column Name |
Data Type |
Description |
|
USER_ID |
INTEGER |
The ID of the user who owns the password. |
|
USER_NAME |
VARCHAR |
The name of the user who owns the password. |
|
PASSWORD |
VARCHAR |
The hashed password. |
|
PASSWORD_CREATE_TIME |
DATETIME |
The date and time when the password was created. |
|
IS_CURRENT_PASSWORD |
BOOLEAN |
Denotes whether this is the user's current password. Non-current passwords are retained to enforce password reuse limitations. |
|
PROFILE_ID |
INTEGER |
The ID number of the profile to which the user is assigned. |
|
PROFILE_NAME |
VARCHAR |
The name of the profile to which the user is assigned. |
|
PASSWORD_REUSE_MAX |
VARCHAR |
The number password changes that must take place before an old password can be reused. |
|
PASSWORD_REUSE_TIME |
VARCHAR |
The amount of time that must pass before an old password can be reused. |
|
SALT |
VARCHAR |
A hex string used to hash the password. |
Examples
The following query returns the SHA-512 hashed password and salt of user 'u1'.
=> SELECT user_name, password, salt FROM passwords WHERE user_name='u1';
user_name | password | salt
-----------+--------------------------------------------------------+----------------------------------
u1 | sha512f3f802f1c56e2530cd9c3164cc7b8002ba444c0834160f10 | f05e9d859fb441f9f612f8a787bfc872
(1 row)
8.1.50 - PRIMARY_KEYS
Provides primary key information.
Provides primary key information.
|
Column Name |
Data Type |
Description |
CONSTRAINT_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the constraint. |
CONSTRAINT_NAME |
VARCHAR |
The constraint name for which information is listed. |
COLUMN_NAME |
VARCHAR |
The column name for which information is listed. |
ORDINAL_POSITION |
VARCHAR |
The position of the column within the key. The numbering of columns starts at 1. |
TABLE_NAME |
VARCHAR |
The table name for which information is listed. |
CONSTRAINT_TYPE |
VARCHAR |
The constraint type, p, for primary key. |
|
IS_ENABLED` |
BOOLEAN |
Indicates if a table column constraint for a PRIMARY KEY is enabled by default. Can be t (True) or f (False). |
TABLE_NAMESPACE_ID |
VARCHAR |
For Eon Mode databases, unique numeric identifier of the namespace that contains the table. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the table. |
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
8.1.51 - PROFILE_PARAMETERS
Defines what information is stored in profiles.
Defines what information is stored in profiles.
|
Column Name |
Data Type |
Description |
PROFILE_ID |
INTEGER |
The ID of the profile to which this parameter belongs. |
PROFILE_NAME |
VARCHAR |
The name of the profile to which this parameter belongs. |
PARAMETER_TYPE |
VARCHAR |
The policy type of this parameter (password_complexity, password_security, etc.) |
PARAMETER_NAME |
VARCHAR |
The name of the parameter. |
PARAMETER_LIMIT |
VARCHAR |
The parameter's value. |
8.1.52 - PROFILES
Provides information about password policies that you set using the CREATE PROFILE statement.
Provides information about password policies that you set using the CREATE PROFILE statement.
|
Column Name |
Data Type |
Description |
PROFILE_ID |
INTEGER |
Unique identifier for the profile. |
PROFILE_NAME |
VARCHAR |
Profile name. |
PASSWORD_LIFE_TIME |
VARCHAR |
Number of days before the user's password expires. After expiration, the user is forced to change passwords during login or warned that their password has expired if password_grace_time is set to a value other than zero or unlimited. |
PASSWORD_MIN_LIFE_TIME |
VARCHAR |
The number of days a password must be set before it can be reset. |
PASSWORD_MIN_CHAR_CHANGE |
VARCHAR |
The minimum number of characters that must be different from the previous password when performing a password reset. |
PASSWORD_GRACE_TIME |
VARCHAR |
Number of days users are allowed to log in after their passwords expire. During the grace time, users are warned about their expired passwords when they log in. After the grace period, the user is forced to change passwords if he or she hasn't already. |
PASSWORD_REUSE_MAX |
VARCHAR |
Number of password changes that must occur before the current password can be reused. |
PASSWORD_REUSE_TIME |
VARCHAR |
Number of days that must pass after setting a password before it can be used again. |
FAILED_LOGIN_ATTEMPTS |
VARCHAR |
Number of consecutive failed login attempts that triggers Vertica to lock the account. |
PASSWORD_LOCK_TIME |
VARCHAR |
Number of days an account is locked after being locked due to too many failed login attempts. |
PASSWORD_MAX_LENGTH |
VARCHAR |
Maximum number of characters allowed in a password. |
PASSWORD_MIN_LENGTH |
VARCHAR |
Minimum number of characters required in a password. |
PASSWORD_MIN_LETTERS |
VARCHAR |
The minimum number of letters (either uppercase or lowercase) required in a password. |
PASSWORD_MIN_LOWERCASE_LETTERS |
VARCHAR |
The minimum number of lowercase. |
PASSWORD_MIN_UPPERCASE_LETTERS |
VARCHAR |
The minimum number of uppercase letters required in a password. |
PASSWORD_MIN_DIGITS |
VARCHAR |
The minimum number of digits required in a password. |
PASSWORD_MIN_SYMBOLS |
VARCHAR |
The minimum of symbols (for example, !, #, $, etc.) required in a password. |
Notes
Non-superusers querying this table see only the information for the profile to which they are assigned.
See also
8.1.53 - PROJECTION_CHECKPOINT_EPOCHS
Provides details on checkpoint epochs, applies only to Enterprise Mode.
Provides details on checkpoint epochs, applies only to Enterprise Mode.
|
Column Name |
Data Type |
Description |
|
NODE_ID |
INTEGER |
Unique numeric identifier of this projection's node. |
|
NODE_NAME |
VARCHAR |
Name of this projection's node. |
|
PROJECTION_SCHEMA_ID |
INTEGER |
Unique numeric identifier of the projection schema. |
|
PROJECTION_SCHEMA |
VARCHAR |
Name of the projection schema. |
|
PROJECTION_ID |
INTEGER |
Unique numeric identifier of this projection. |
|
PROJECTION_NAME |
VARCHAR |
Name of this projection. |
|
IS_UP_TO_DATE |
BOOLEAN |
Specifies whether the projection is up to date and available to participate in query execution. |
|
CHECKPOINT_EPOCH |
INTEGER |
Checkpoint epoch of the projection on the corresponding node. Data up to and including this epoch is in persistent storage, and can be recovered in the event of node failure. |
|
WOULD_RECOVER |
BOOLEAN |
Determines whether data up to and including CHECKPOINT_EPOCH can be used to recover from an unclean shutdown:
-
t: CHECKPOINT_EPOCH is less than the cluster's Last Good Epoch, so data up to and including this epoch can be used during recovery.
-
f: Vertica must use Last Good Epoch to recover data for this projection.
See also: GET_LAST_GOOD_EPOCH
|
|
IS_BEHIND_AHM |
BOOLEAN |
Specifies whether CHECKPOINT_EPOCH is less than the AHM (ancient history mark). If set to t (true), data for this projection cannot rolled back.
See also: GET_AHM_EPOCH
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
=> SELECT node_name, projection_schema, projection_name, is_up_to_date, checkpoint_epoch FROM projection_checkpoint_epochs
WHERE projection_name ilike 't1_b%' ORDER BY projection_name, node_name;
node_name | projection_schema | projection_name | is_up_to_date | checkpoint_epoch
------------------+-------------------+-----------------+---------------+------------------
v_vmart_node0001 | public | t1_b1 | t | 965
v_vmart_node0002 | public | t1_b1 | t | 965
v_vmart_node0003 | public | t1_b1 | t | 965
v_vmart_node0001 | public | t1_b0 | t | 965
v_vmart_node0002 | public | t1_b0 | t | 965
v_vmart_node0003 | public | t1_b0 | t | 965
(6 rows)
dbadmin=> INSERT INTO t1 VALUES (100, 101, 102);
OUTPUT
--------
1
(1 row)
dbadmin=> COMMIT;
COMMIT
dbadmin=> SELECT node_name, projection_schema, projection_name, is_up_to_date, checkpoint_epoch FROM projection_checkpoint_epochs
WHERE projection_name ILIKE 't1_b%' ORDER BY projection_name, node_name;
node_name | projection_schema | projection_name | is_up_to_date | checkpoint_epoch
------------------+-------------------+-----------------+---------------+------------------
v_vmart_node0001 | public | t1_b1 | t | 966
v_vmart_node0002 | public | t1_b1 | t | 966
v_vmart_node0003 | public | t1_b1 | t | 966
v_vmart_node0001 | public | t1_b0 | t | 966
v_vmart_node0002 | public | t1_b0 | t | 966
v_vmart_node0003 | public | t1_b0 | t | 966
(6 rows)
8.1.54 - PROJECTION_COLUMNS
Provides information about projection columns, such as encoding type, sort order, type of statistics, and the time at which columns statistics were last updated.
Provides information about projection columns, such as encoding type, sort order, type of statistics, and the time at which columns statistics were last updated.
|
Column Name |
Data Type |
Description |
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed. |
PROJECTION_COLUMN_NAME |
VARCHAR |
The projection column name. |
COLUMN_POSITION |
INTEGER |
The ordinal position of a projection's column used in the CREATE PROJECTION statement. |
SORT_POSITION |
INTEGER |
The projection's column sort specification, as specified in CREATE PROJECTION .. ORDER BY clause. If the column is not included in the projection's sort order, SORT_POSITION output is NULL. |
COLUMN_ID |
INTEGER |
A unique numeric object ID (OID) that identifies the associated projection column object and is assigned by the Vertica catalog. This field is helpful as a key to other system tables. |
DATA_TYPE |
VARCHAR |
Matches the corresponding table column data type (see V_CATALOG.COLUMNS). DATA_TYPE is provided as a complement to ENCODING_TYPE. |
ENCODING_TYPE |
VARCHAR |
The encoding type defined on the projection column. |
ACCESS_RANK |
INTEGER |
The access rank of the projection column. See the ACCESSRANK parameter in the CREATE PROJECTION statement for more information. |
GROUP_ID |
INTEGER |
A unique numeric ID (OID) that identifies the group and is assigned by the Vertica catalog. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the projection. |
TABLE_SCHEMA |
VARCHAR |
The name of the schema in which the projection is stored.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the table. |
TABLE_NAME |
VARCHAR |
The table name that contains the projection. |
TABLE_COLUMN_ID |
VARCHAR |
Catalog-assigned VARCHAR value that uniquely identifies a table column. |
TABLE_COLUMN_NAME |
VARCHAR |
The projection's corresponding table column name. |
STATISTICS_TYPE |
VARCHAR |
The type of statistics the column contains:
|
STATISTICS_UPDATED_TIMESTAMP |
TIMESTAMPTZ |
The time at which the columns statistics were last updated by ANALYZE_STATISTICS. By querying this column, along with STATISTICS_TYPE and PROJECTION_COLUMN_NAME, you can identify projection columns whose statistics need updating. See also system table PROJECTIONS. |
IS_EXPRESSION |
BOOLEAN |
Indicates whether this projection column is calculated with an expression. For aggregate columns, IS_EXPRESSION is always true. |
IS_AGGREGATE |
BOOLEAN |
Indicates whether the column is an aggregated column in a live aggregate projection. IS_AGGREGATE is always false for Top-K projection columns. |
PARTITION_BY_POSITION |
INTEGER |
Position of that column in the PARTITION BY and GROUP BY clauses, if applicable. |
ORDER_BY_POSITION |
INTEGER |
Set only for Top-K projections, specifies the column's position in the ORDER BY clause, as defined in the projection definition's window partition clause. If the column is omitted from the ORDER BY clause, ORDER_BY_POSITION output is NULL. |
ORDER_BY_TYPE |
INTEGER |
Type of sort order:
-
ASC NULLS FIRST
-
ASC NULLS LAST
-
DESC NULLS FIRST
-
DESC NULLS LAST
|
COLUMN_EXPRESSION |
VARCHAR |
Expression that calculates the column value. |
Examples
See Statistics Data in PROJECTION_COLUMNS
See also
8.1.55 - PROJECTION_DELETE_CONCERNS
Lists projections whose design are liable to cause performance issues when deleting data.
Lists projections whose design are liable to cause performance issues when deleting data. This table is generated by calling the EVALUATE_DELETE_PERFORMANCE function. See Optimizing DELETE and UPDATE for more information.
|
Column Name |
Data Type |
Description |
PROJECTION_ID |
INTEGER |
The ID number of the projection |
PROJECTION_SCHEMA |
VARCHAR |
The schema containing the projection |
PROJECTION_NAME |
VARCHAR |
The projection's name |
CREATION_TIME |
TIMESTAMPTZ |
When the projection was created |
LAST_MODIFIED_TIME |
TIMESTAMPTZ |
When the projection was last modified |
COMMENT |
VARCHAR |
A comment describing the potential delete performance issue. |
8.1.56 - PROJECTIONS
Provides information about projections.
Provides information about projections.
|
Column Name |
Data Type |
Description |
|
PROJECTION_SCHEMA_ID |
INTEGER |
A unique numeric ID that identifies the specific schema that contains the projection and is assigned by the Vertica catalog. |
|
PROJECTION_SCHEMA |
VARCHAR |
The name of the schema that contains the projection.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
PROJECTION_NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the projection. |
|
PROJECTION_ID |
INTEGER |
A unique numeric ID that identifies the projection and is assigned by the Vertica catalog. |
|
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed. |
|
PROJECTION_BASENAME |
VARCHAR |
The base name used for other projections:
-
For auto-created projections, identical to ANCHOR_TABLE_NAME.
-
For a manually-created projection, the name specified in the CREATE PROJECTION statement.
|
|
OWNER_ID |
INTEGER |
A unique numeric ID that identifies the projection owner and is assigned by the Vertica catalog. |
|
OWNER_NAME |
VARCHAR |
The name of the projection's owner. |
|
ANCHOR_TABLE_ID |
INTEGER |
The unique numeric identification (OID) of the projection's anchor table. |
|
ANCHOR_TABLE_NAME |
VARCHAR |
The name of the projection's anchor table. |
|
NODE_ID |
INTEGER |
A unique numeric ID (OID) for any nodes that contain any unsegmented projections. |
|
NODE_NAME |
VARCHAR |
The names of any nodes that contain the projection. This column returns information for unsegmented projections only. |
|
IS_PREJOIN |
BOOLEAN |
Deprecated, always set to f (false). |
|
CREATED_EPOCH |
INTEGER |
The epoch in which the projection was created. |
|
CREATE_TYPE |
VARCHAR |
The method in which the projection was created:
-
CREATE PROJECTION: A custom projection created using CREATE PROJECTION.
-
CREATE TABLE: A superprojection that was automatically created when its associated table was created using CREATE TABLE.
-
ALTER TABLE: The system automatically created the key projection in response to a non-empty table.
-
CREATE TABLE WITH PROJ CLAUSE: A superprojection that was automatically created using CREATE TABLE.
-
DELAYED_CREATION: A superprojection that was automatically created when data was loaded for the first time into a new table.
-
DESIGNER: A projection created by Database Designer.
-
SYSTEM TABLE: A projection that was automatically created for a system table.
Rebalancing does not change the CREATE_TYPE value for a projection.
|
|
VERIFIED_FAULT_TOLERANCE |
INTEGER |
The projection K-safe value. This value can be greater than the database K-safety value (if more replications of a projection exist than are required to meet the database K-safety). This value cannot be less than the database K-safe setting. |
|
IS_UP_TO_DATE |
BOOLEAN |
Specifies whether projection data is up to date. Only up-to-date projections are available to participate in query execution. |
|
HAS_STATISTICS |
BOOLEAN |
Specifies whether there are statistics for any column in the projection. HAS_STATISTICS returns true only when all non-epoch columns for a table or table partition have full statistics. For details, see Collecting table statistics and Collecting partition statistics.
Note
Projections that have no data never have full statistics. Query system table PROJECTION_STORAGE to determine whether your projection contains data.
|
|
IS_SEGMENTED |
BOOLEAN |
Specifies whether the projection is segmented. |
|
SEGMENT_EXRESSION |
VARCHAR |
The segmentation expression used for the projection. In the following example for the clicks_agg projection, the following values:
hash(clicks.user_id, (clicks.click_time)::date)
indicate that the projection was created with the following expression:
SEGMENTED BY HASH(clicks.user_id, (clicks.click_time)::date)
|
|
SEGMENT_RANGE |
VARCHAR |
The percentage of projection data stored on each node, according to the segmentation expression. For example, segmenting a projection by the HASH function on all nodes results in a SEGMENT_RANGE value such as the following:
implicit range: node01[33.3%] node02[33.3%] node03[33.3%]
|
|
IS_SUPER_PROJECTION |
BOOLEAN |
Specifies whether a projection is a superprojection. |
|
IS_KEY_CONSTRAINT_PROJECTION |
BOOLEAN |
Indicates whether a projection is a key constraint projection:
-
t: A key constraint projection that validates a key constraint. Vertica uses the projection to efficiently enforce at least one enabled key constraint.
-
f: Not a projection that validates a key constraint.
|
|
HAS_EXPRESSIONS |
BOOLEAN |
Specifies whether this projection has expressions that define the column values. HAS_EXPRESSIONS is always true for live aggregate projections. |
|
IS_AGGREGATE_PROJECTION |
BOOLEAN |
Specifies whether this projection is a live aggregate projection. |
|
AGGREGATE_TYPE |
VARCHAR |
Specifies the type of live aggregate projection:
|
|
IS_SHARED |
BOOLEAN |
Indicates whether the projection is located on shared storage. |
|
PARTITION_RANGE_MIN |
VARCHAR |
Populated only if a projection specifies a partition range, the lowest and highest partition keys of the range. |
|
PARTITION_RANGE_MAX |
|
PARTITION_RANGE_MIN_EXPRESSION |
VARCHAR |
Populated only if a projection specifies partition range, the minimum and maximum range expressions as defined in the projection DDL. |
|
PARTITION_RANGE_MAX_EXPRESSION |
Examples
The following projection defines a range of orders placed since the first of the current year:
=> CREATE PROJECTION ytd_orders AS SELECT * FROM store_orders ORDER BY order_date
ON PARTITION RANGE BETWEEN date_trunc('year',now())::date AND NULL;
Given that range, the PARTITION_RANGE_MIN and PARTITION_RANGE_MAX columns in the PROJECTIONS table contain the following values:
=> SELECT projection_name partition_range_min, partition_range_min, partition_range_max
FROM projections WHERE projection_name ILIKE 'ytd_orders%';
partition_range_min | partition_range_min | partition_range_max
---------------------+---------------------+---------------------
ytd_orders_b1 | 2024-01-01 | infinity
ytd_orders_b0 | 2024-01-01 | infinity
(2 rows)
The following projection defines a range of orders placed since the third quarter of last year:
=> CREATE PROJECTION q3_td AS SELECT * FROM store_orders ORDER BY order_date
ON PARTITION RANGE BETWEEN add_months(date_trunc('year',now()), -3)::date AND NULL;
Given that definition, the PARTITION_RANGE_MIN_EXPRESSION and PARTITION_RANGE_MAX_EXPRESSION columns in the PROJECTIONS table contain the following values:
=> SELECT projection_name, partition_range_min_expression, partition_range_max_expression
FROM projections WHERE projection_name ILIKE 'Q3_td%';
projection_name | partition_range_min_expression | partition_range_max_expression
-----------------+---------------------------------------------+--------------------------------
q3_td_b1 | add_months(date_trunc('year', now()), (-3)) | NULL
q3_td_b0 | add_months(date_trunc('year', now()), (-3)) | NULL
See also
PROJECTION_COLUMNS
8.1.57 - REGISTERED_MODELS
Lists details about registered machine learning models in the database.
Lists details about registered machine learning models in the database. The table lists only registered models for which the caller has USAGE privileges.
For a table that lists all models, registered and unregistered, see MODELS.
|
Column Name |
Data Type |
Description |
REGISTERED_NAME |
VARCHAR |
The abstract name to which the model is registered. This REGISTERED_NAME can represent a group of models for a higher-level application, where each model in the group has a unique version number. |
REGISTERED_VERSION |
INTEGER |
The unique version number of the model under its specified REGISTERED_NAME. |
STATUS |
INTEGER |
The status of the registered model, one of the following:
-
under_review: Status assigned to newly registered models.
-
staging: Model is targeted for A/B testing against the model currently in production.
-
production: Model is in production for its specified application. Only one model can be in production for a given registered_name at one time.
-
archived: Status of models that were previously in production. Archived models can be returned to production at any time.
-
declined: Model is no longer in consideration for production.
-
unregistered: Model is removed from the versioning environment. The model does not appear in the REGISTERED_MODELS system table.
|
REGISTERED_TIME |
VARCHAR |
The time at which the model was registered. |
MODEL_ID |
INTEGER |
The model's internal ID. |
SCHEMA_NAME |
VARCHAR |
The name of the schema that contains the model. |
MODEL_NAME |
VARCHAR |
The name of the model. [schema_name.]model_name can be used to uniquely identify a model, as can the combination of its REGISTERED_NAME and REGISTERED_VERSION. |
MODEL_TYPE |
VARCHAR |
The type of algorithm used to create the model. |
CATEGORY |
VARCHAR |
The category of the model, one of the following:
-
VERTICA_MODELS
-
PMML
-
TENSORFLOW
By default, models created in Vertica are assigned to the VERTICA_MODELS category.
|
Example
If a user with the MLSUPERVISOR role queries REGISTERED_MODELS, all registered models are listed:
=> SELECT * FROM REGISTERED_MODELS;
registered_name | registered_version | status | registered_time | model_id | schema_name | model_name | model_type | category
------------------+--------------------+--------------+-------------------------------+-------------------+-------------+-------------------+-----------------------+----------------
linear_reg_app | 2 | UNDER_REVIEW | 2023-01-29 09:09:00.082166-04 | 45035996273714020 | public | linear_reg_spark1 | PMML_REGRESSION_MODEL | PMML
linear_reg_app | 1 | PRODUCTION | 2023-01-24 06:19:04.553102-05 | 45035996273850350 | public | native_linear_reg | LINEAR_REGRESSION | VERTICA_MODELS
logistic_reg_app | 2 | PRODUCTION | 2023-01-25 08:45:11.279013-02 | 45035996273855542 | public | log_reg_cgd | LOGISTIC_REGRESSION | VERTICA_MODELS
logistic_reg_app | 1 | ARCHIVED | 2023-01-22 04:29:25.990626-02 | 45035996273853740 | public | log_reg_bfgs | LOGISTIC_REGRESSION | VERTICA_MODELS
(4 rows)
See also
8.1.58 - RESOURCE_POOL_DEFAULTS
Returns default parameter settings for built-in and user-defined resource pools.
Returns default parameter settings for built-in and user-defined resource pools. Use
ALTER RESOURCE POOL to restore resource pool parameters to their default settings.
For information about valid parameters for built-in resource pools and their default settings, see Built-in resource pools configuration.
To obtain a resource pool's current settings, query system table
RESOURCE_POOLS.
Privileges
None
8.1.59 - RESOURCE_POOLS
Displays settings for built-in and user-defined resource pools.
Displays settings for built-in and user-defined resource pools. For information about defining resource pools, see
CREATE RESOURCE POOL and
ALTER RESOURCE POOL.
|
Column Name |
Data Type |
Description |
POOL_ID |
INTEGER |
Unique identifier for the resource pool |
NAME |
VARCHAR |
The name of the resource pool. |
SUBCLUSTER_OID |
INTEGER |
Unique identifier for a subcluster-specific resource pool. For global resource pools, 0 is returned. |
SUBCLUSTER_NAME |
VARCHAR |
Specifies the subcluster that the subcluster-specific resource pool belongs to.If there are subcluster-specific resource pools with the same name on separate subclusters, multiple entries are returned. For global resource pools, this column is blank. |
IS_INTERNAL |
BOOLEAN |
Specifies whether this pool is a built-in pool. |
MEMORYSIZE |
VARCHAR |
The amount of memory allocated to this resource pool. |
MAXMEMORYSIZE |
VARCHAR |
Value assigned as the maximum size this resource pool can grow by borrowing memory from the GENERAL pool. |
MAXQUERYMEMORYSIZE |
VARCHAR |
The maximum amount of memory allocated by this pool to process any query. |
EXECUTIONPARALLELISM |
INTEGER |
Limits the number of threads used to process any single query issued in this resource pool. |
PRIORITY |
INTEGER |
Specifies priority of queries in this pool when they compete for resources in the GENERAL pool. |
RUNTIMEPRIORITY |
VARCHAR |
The run-time priority defined for this pool, indicates how many run-time resources (CPU, I/O bandwidth) the Resource Manager should dedicate to running queries in the resource pool. Valid values are:
-
HIGH
-
MEDIUM (default)
-
LOW
These values are relative to each other. Queries with a HIGH run-time priority are given more CPU and I/O resources than those with a MEDIUM or LOW run-time priority.
|
RUNTIMEPRIORITYTHRESHOLD |
INTEGER |
Limits in seconds how soon a query must finish before the Resource Manager assigns to it the resource pool's RUNTIMEPRIORITY setting. |
QUEUETIMEOUT |
INTEGER INTERVAL |
The maximum length of time requests can wait for resources to become available before being rejected, specified in seconds or as an interval. This value is set by the pool's QUEUETIMEOUT parameter. |
PLANNEDCONCURRENCY |
INTEGER |
The preferred number of queries that execute concurrently in this resource pool, specified by the pool's PLANNEDCONCURRENCY parameter. |
MAXCONCURRENCY |
INTEGER |
The maximum number of concurrent execution slots available to the resource pool, specified by the poolMAXCONCURRENCY parameter. |
RUNTIMECAP |
INTERVAL |
The maximum time a query in the pool can execute. |
SINGLEINITIATOR |
BOOLEAN |
Set for backward compatibility. |
CPUAFFINITYSET |
VARCHAR |
The set of CPUs on which queries associated with this pool are executed. For example:
-
0, 2-4 : Specifies CPUs 0, 2, 3, and 4
-
25%: A percentage of available CPUs, rounded down to whole CPUs.
|
CPUAFFINITYMODE |
VARCHAR |
Specifies whether to share usage of the CPUs assigned to this resource pool by CPUAFFINITYSET, one of the following:
-
SHARED: Queries that run in this pool share its CPUAFFINITYSET CPUs with other Vertica resource pools.
-
EXCLUSIVE: Dedicates CPUAFFINITYSET CPUs to this resource pool only, and excludes other Vertica resource pools. If CPUAFFINITYSET is set as a percentage, then that percentage of CPU resources available to Vertica is assigned solely for this resource pool.
-
ANY: Queries in this resource pool can run on any CPU.
|
CASCADETO |
VARCHAR |
A secondary resource pool for executing queries that exceed the RUNTIMECAP setting of this resource pool. |
CASCADETOSUBCLUSTERPOOL |
BOOLEAN |
Specifies whether this resource pool cascades to a subcluster-level resource pool. |
8.1.60 - ROLES
Contains the names of all roles the user can access, along with any roles that have been assigned to those roles.
Contains the names of all roles the user can access, along with any roles that have been assigned to those roles.
Tip
You can also use the function
HAS_ROLE to see if a role is available to a user.
|
Column Name |
Data Type |
Description |
ASSIGNED_ROLES |
VARCHAR |
The names of any roles that have been granted to this role. By enabling the role, the user also has access to the privileges of these additional roles.
Note
An asterisk (*) appended to a role in this column indicates that the user can grant the role to other users.
|
NAME |
VARCHAR |
The name of a role that the user can access. |
ROLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies therole. |
LDAP_DN |
VARCHAR |
Indicates whether or not the Vertica Analytic Database role maps to an LDAP Link group. When the column is set to dn, the Vertica role maps to LDAP Link. |
LDAP_URI_HASH |
VARCHAR |
The URI hash number for the LDAP role. |
IS_ORPHANED_FROM_LDAP |
VARCHAR |
Indicates if the role is disconnected (orphaned) from LDAP, valid values are:
t - role is orphaned
f - role is not orphaned
For more information see Troubleshooting LDAP link issues
|
See also
8.1.61 - ROUTING_RULES
Lists the routing rules that map incoming IP addresses to a load balancing group.
Lists the routing rules that map incoming IP addresses to a load balancing group.
|
Column Name |
Data Type |
Description |
|
NAME |
VARCHAR |
The name of the routing rule. |
|
SOURCE_ADDRESS |
VARCHAR |
The IP address range in CIDR format that this rule applies to. |
|
DESTINATION_NAME |
VARCHAR |
The load balance group that handles connections for this rule. |
Examples
=> SELECT * FROM routing_rules;
-[ RECORD 1 ]----+-----------------
name | internal_clients
source_address | 192.168.1.0/24
destination_name | group_1
-[ RECORD 2 ]----+-----------------
name | etl_rule
source_address | 10.20.100.0/24
destination_name | group_2
-[ RECORD 3 ]----+-----------------
name | subnet_192
source_address | 192.0.0.0/8
destination_name | group_all
-[ RECORD 4 ]----+--------------
name | all_ipv6
source_address | 0::0/0
destination_name | default_ipv6
See also
8.1.62 - SCHEDULER_TIME_TABLE
Contains information about scheduled tasks.
Contains information about scheduled tasks.
This table is local to the active scheduler node (ASN) and is only populated when queried from that node. To get the ASN, use ACTIVE_SCHEDULER_NODE:
=> SELECT active_scheduler_node();
active_scheduler_node
-----------------------
initiator
(1 row)
|
Column Name |
Data Type |
Description |
|
SCHEDULE_NAME |
VARCHAR |
The name of the schedule. |
|
SCHEMA_NAME |
VARCHAR |
The schedule's schema. |
|
OWNER |
VARCHAR |
The owner of the schedule. |
|
ATTACHED_TRIGGER |
VARCHAR |
The trigger attached to the schedule. For details, see Scheduled execution. |
|
ENABLED |
BOOLEAN |
Whether the schedule is enabled. |
|
DATE_TIME_TYPE |
VARCHAR |
The format for the scheduled event, one of the following:
|
|
DATE_TIME_STRING |
VARCHAR |
The string used to schedule the event, one of the following:
|
Examples
To view scheduled tasks, execute the following statement on the ASN:
=> SELECT * FROM scheduler_time_table;
schedule_name | attached_trigger | scheduled_execution_time
----------------+--------------------------------+--------------------------
daily_1am | log_user_actions | 2022-06-01 01:00:00-00
logging_2022 | refresh_logs | 2022-06-01 12:00:00-00
8.1.63 - SCHEMATA
Provides information about schemas in the database.
Provides information about schemas in the database.
|
Column Name |
Data Type |
Description |
SCHEMA_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the specific schema. |
SCHEMA_NAME |
VARCHAR |
Schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
SCHEMA_NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the schema. |
SCHEMA_OWNER_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the owner who created the schema. |
SCHEMA_OWNER |
VARCHAR |
Name of the owner who created the schema. |
SYSTEM_SCHEMA_CREATOR |
VARCHAR |
Creator information for system schema or NULL for non-system schema |
CREATE_TIME |
TIMESTAMPTZ |
Time when the schema was created. |
IS_SYSTEM_SCHEMA |
BOOLEAN |
Indicates whether the schema was created for system use, where t is true and f is false. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.1.64 - SEQUENCES
Displays information about sequences.
Displays information about sequences.
|
Column Name |
Data Type |
Description |
SEQUENCE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the sequence. |
SEQUENCE_SCHEMA |
VARCHAR |
The name of the schema that contains the sequence.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
SEQUENCE_NAME |
VARCHAR |
One of the following:
|
OWNER_NAME |
VARCHAR |
One of the following:
|
IDENTITY_TABLE_NAME |
VARCHAR |
Set only for IDENTITY column sequences, name of the column table. |
SESSION_CACHE_COUNT |
INTEGER |
Count of values cached in a session. |
ALLOW_CYCLE |
BOOLEAN |
Whether values cycle when a sequence reaches its minimum or maximum value, as set by CREATE SEQUENCE parameter CYCLE|NO CYCLE. |
OUTPUT_ORDERED |
BOOLEAN |
Values guaranteed to be ordered, always false. |
INCREMENT_BY |
INTEGER |
Value by which sequences are incremented or decremented. |
MINIMUM |
INTEGER |
Minimum value the sequence can generate. |
MAXIMUM |
INTEGER |
Maximum value the sequence can generate. |
CURRENT_VALUE |
INTEGER |
How many sequence numbers are distributed among all cluster nodes. |
SEQUENCE_SCHEMA_ID |
INTEGER |
Unique numeric catalog ID of the sequence schema. |
SEQUENCE_ID |
INTEGER |
Unique numeric catalog ID of the sequence. |
OWNER_ID |
INTEGER |
Unique numeric catalog ID of the user who created the sequence. |
IDENTITY_TABLE_ID |
INTEGER |
Set only for IDENTITY column sequences, unique numeric catalog ID of the column table. |
Examples
Create a sequence:
=> CREATE SEQUENCE my_seq MAXVALUE 5000 START 150;
CREATE SEQUENCE
Return information about this sequence:
=> SELECT sequence_schema, sequence_name, owner_name, session_cache_count, increment_by, current_value FROM sequences;
sequence_schema | sequence_name | owner_name | session_cache_count | increment_by | current_value
-----------------+--------------------------+------------+---------------------+--------------+--------------
public | my_seq | dbadmin | 250000 | 1 | 149
(2 rows)
IDENTITY columns are sequences that are defined in a table's DDL. IDENTITY column values automatically increment as new rows are added. To identify IDENTITY columns and their tables, query the system table
COLUMNS:
=> CREATE TABLE employees (employeeID IDENTITY, fname varchar(36), lname varchar(36));
CREATE TABLE
=> SELECT table_name, column_name, is_identity FROM columns WHERE is_identity = 't';
table_name | column_name | is_identity
------------+-------------+-------------
employees | employeeID | t
(1 row)
Query SEQUENCES to get detailed information about the IDENTITY column sequence in employees:
=> SELECT sequence_schema, sequence_name, identity_table_name, sequence_id FROM sequences
WHERE identity_table_name ='employees';
sequence_schema | sequence_name | identity_table_name | sequence_id
-----------------+--------------------------+---------------------+-------------------
public | employees_employeeID_seq | employees | 45035996273848816
(1 row)
Use the vsql command \ds to list all named and IDENTITY column sequences. The following results show the two sequences created previously:
=> \ds
List of Sequences
Schema | Sequence | CurrentValue | IncrementBy | Minimum | Maximum | AllowCycle | Comment
--------+--------------------------+--------------+-------------+---------+---------------------+------------+---------
public | employees_employeeID_seq | 0 | 1 | 1 | 9223372036854775807 | f |
public | my_seq | 149 | 1 | 1 | 5000 | f |
(2 rows)
Note
The CurrentValue of both sequences is one less than its start number—0 and 149 for the IDENTITY column employeeID and named sequence my_seq, respectively:
employeeID 's start number—by default set to 1 because the table DDL did not specify otherwise—is set to 0 because no rows have yet been added to the employees table.my_seq is set to 149 because NEXTVAL has not yet been called on it.
8.1.65 - SESSION_SUBSCRIPTIONS
In an Eon Mode database, lists the shard subscriptions for all nodes, and whether the subscriptions are used to resolve queries for the current session.
In an Eon Mode database, lists the shard subscriptions for all nodes, and whether the subscriptions are used to resolve queries for the current session. Nodes that will participate in resolving queries in this session have TRUE in their IS_PARTICIPATING column.
|
Column Name |
Data Type |
Description |
|
NODE_OID |
INTEGER |
The OID of the subscribing node. |
|
NODE_NAME |
VARCHAR |
The name of the subscribing node. |
|
SHARD_OID |
INTEGER |
The OID of the shard the node subscribes to. |
|
SHARD_NAME |
VARCHAR |
The name of the shard the node subscribes to. |
|
IS_PARTICIPATING |
BOOLEAN |
Whether this subscription is used when resolving queries in this session. |
|
IS_COLLABORATING |
BOOLEAN |
Whether this subscription is used to collaborate with a participating node when executing queries . This value is only true when queries are using elastic crunch scaling. |
Examples
The following example demonstrates listing the subscriptions that are either participating or collaborating in the current session:
=> SELECT node_name, shard_name, is_collaborating, is_participating
FROM V_CATALOG.SESSION_SUBSCRIPTIONS
WHERE is_participating = TRUE OR is_collaborating = TRUE
ORDER BY shard_name, node_name;
node_name | shard_name | is_collaborating | is_participating
----------------------+-------------+------------------+------------------
v_verticadb_node0004 | replica | f | t
v_verticadb_node0005 | replica | f | t
v_verticadb_node0006 | replica | t | f
v_verticadb_node0007 | replica | f | t
v_verticadb_node0008 | replica | t | f
v_verticadb_node0009 | replica | t | f
v_verticadb_node0007 | segment0001 | f | t
v_verticadb_node0008 | segment0001 | t | f
v_verticadb_node0005 | segment0002 | f | t
v_verticadb_node0009 | segment0002 | t | f
v_verticadb_node0004 | segment0003 | f | t
v_verticadb_node0006 | segment0003 | t | f
(12 rows)
8.1.66 - SHARDS
Lists the shards in your database.
Lists the shards in your database.
|
Column Name |
Data Type |
Description |
SHARD_OID |
INTEGER |
The OID of the shard. |
SHARD_NAME |
VARCHAR |
The name of the shard. |
SHARD_TYPE |
VARCHAR |
The type of the shard. |
LOWER_HASH_BOUND |
VARCHAR |
The lower hash bound of the shard. |
UPPER_HASH_BOUND |
VARCHAR |
The upper hash bound of the shard. |
IS_REPLICATED |
BOOLEAN |
Defines if the shard is replicated. |
HAS_OBJECTS |
BOOLEAN |
Defines if the shard contains objects. |
Examples
=> SELECT * FROM SHARDS;
-[ RECORD 1 ]----+------------------
shard_oid | 45035996273704980
shard_name | replica
shard_type | Replica
lower_hash_bound |
upper_hash_bound |
is_replicated | t
has_objects | t
...
8.1.67 - STORAGE_LOCATIONS
Provides information about storage locations, including IDs, labels, and status.
Provides information about storage locations, including IDs, labels, and status.
|
Column Name |
Data Type |
Description |
|
LOCATION_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thestorage location. |
|
NODE_NAME |
VARCHAR |
The node name on which the storage location exists. |
|
LOCATION_PATH |
VARCHAR |
The path where the storage location is mounted. |
|
LOCATION_USAGE |
VARCHAR |
The type of information stored in the location:
-
DATA: Only data is stored in the location.
-
TEMP: Only temporary files that are created during loads or queries are stored in the location.
-
DATA,TEMP: Both types of files are stored in the location.
-
USER: The storage location can be used by users without their own credentials or dbadmin access. Users gain access to data by being granted access to the user storage location.
-
CATALOG: The area is used for the Vertica catalog. This usage is set internally and cannot be removed or changed.
|
|
SHARING_TYPE |
VARCHAR |
How this location is shared among database nodes, if it is:
-
SHARED: The path used by the storage location is used by all nodes. See the SHARED parameter to CREATE LOCATION.
-
COMMUNAL: the location is used for communal storage in Eon Mode.
-
NONE: The location is not shared among nodes.
|
|
IS_RETIRED |
BOOLEAN |
Whether the storage location has been retired. This column has a value of t (true) if the location is retired, or f (false) if it is not. |
|
LOCATION_LABEL |
VARCHAR |
The label associated with a specific storage location, added with the ALTER_LOCATION_LABEL function. |
|
RANK |
INTEGER |
The Access rank value either assigned or supplied to the storage location, as described in Prioritizing column access speed. |
|
THROUGHPUT |
INTEGER |
The throughput performance of the storage location, measured in MB/sec. You can get location performance values using MEASURE_LOCATION_PERFORMANCE, and set them with the SET_LOCATION_PERFORMANCE function. |
|
LATENCY |
INTEGER |
The measured latency of the storage location as number of data seeks per second. You can get location performance values using MEASURE_LOCATION_PERFORMANCE, and set them with the SET_LOCATION_PERFORMANCE function. |
|
MAX_SIZE |
INTEGER |
Maximum size of the storage location in bytes. |
|
DISK_PERCENT |
VARCHAR |
Maximum percentage of available node disk space that this storage location can use, set only if depot size is defined as a percentage, otherwise blank. |
Privileges
Superuser
See also
8.1.68 - STORED_PROC_TRIGGERS
Contains information about Triggers.
Contains information about Triggers.
|
Column Name |
Data Type |
Description |
|
TRIGGER_NAME |
VARCHAR |
The name of the trigger. |
|
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, the trigger's namespace. |
|
SCHEMA_NAME |
VARCHAR |
The trigger's schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
OWNER |
VARCHAR |
The owner of the trigger. |
|
PROCEDURE_NAME |
VARCHAR |
The name of the stored procedure. |
|
PROCEDURE_ARGS |
INTEGER |
The number of formal parameters in the stored procedure. |
|
ENABLED |
BOOLEAN |
Whether the trigger is enabled. |
Examples
To view triggers:
=> SELECT * FROM stored_proc_triggers;
trigger_name | schema_name | owner | procedure_name | procedure_args | enabled
----------------+-------------+---------+----------------+----------------+---------
raise_trigger | public | dbadmin | raiseXY | 2 | t
8.1.69 - SUBCLUSTER_RESOURCE_POOL_OVERRIDES
Displays subcluster-level overrides of settings for built-in global resource pools.
Displays subcluster-level overrides of settings for built-in global resource pools.
|
Column Name |
Data Type |
Description |
POOL_OID |
INTEGER |
Unique identifier for the resource pool with settings overrides. |
NAME |
VARCHAR |
The name of the built-in resource pool. |
SUBCLUSTER_OID |
INTEGER |
Unique identifier for the subcluster with settings that override the global resource pool settings. |
SUBCLUSTER_NAME |
VARCHAR |
The name of the subcluster with settings that overrides the global resource pool settings. |
MEMORYSIZE |
VARCHAR |
The amount of memory allocated to the global resource pool. |
MAXMEMORYSIZE |
VARCHAR |
Value assigned as the maximum size this resource pool can grow by borrowing memory from the GENERAL pool. |
MAXQUERYMEMORYSIZE |
VARCHAR |
The maximum amount of memory allocated by this pool to process any query. |
8.1.70 - SUBCLUSTERS
This table lists all of the subclusters defined in the database.
This table lists all of the subclusters defined in the database. It contains an entry for each node in the database listing which subcluster it belongs to. Any subcluster that does not contain a node has a single entry in this table with empty NODE_NAME and NODE_OID columns. This table is only populated if the database is running in Eon Mode.
|
Column Name |
Data Type |
Description |
|
SUBCLUSTER_OID |
INTEGER |
Unique identifier for the subcluster. |
|
SUBCLUSTER_NAME |
VARCHAR |
The name of the subcluster. |
|
NODE_OID |
INTEGER |
The catalog-assigned ID of the node. |
|
NODE_NAME |
VARCHAR |
The name of the node. |
|
PARENT_OID |
INTEGER |
The unique ID of the parent of the node (the database). |
|
PARENT_NAME |
VARCHAR |
The name of the parent of the node (the database name). |
|
IS_DEFAULT |
BOOLEAN |
Whether the subcluster is the default cluster. |
|
IS_PRIMARY |
BOOLEAN |
Whether the subcluster is a primary subcluster. |
|
CONTROL_SET_SIZE |
INTEGER |
The number of control nodes defined for this subcluster. This value is -1 when the large cluster feature is not enabled, or when every node in the subcluster must be a control node. See Large cluster for more information. |
Examples
=> \x
Expanded display is on.
dbadmin=> SELECT * FROM SUBCLUSTERS;
-[ RECORD 1 ]----+---------------------
subcluster_oid | 45035996273704978
subcluster_name | default_subcluster
node_oid | 45035996273704982
node_name | v_verticadb_node0001
parent_oid | 45035996273704976
parent_name | verticadb
is_default | t
is_primary | t
control_set_size | -1
-[ RECORD 2 ]----+---------------------
subcluster_oid | 45035996273704978
subcluster_name | default_subcluster
node_oid | 45035996273840970
node_name | v_verticadb_node0002
parent_oid | 45035996273704976
parent_name | verticadb
is_default | t
is_primary | t
control_set_size | -1
-[ RECORD 3 ]----+---------------------
subcluster_oid | 45035996273704978
subcluster_name | default_subcluster
node_oid | 45035996273840974
node_name | v_verticadb_node0003
parent_oid | 45035996273704976
parent_name | verticadb
is_default | t
is_primary | t
control_set_size | -1
See also
8.1.71 - SYSTEM_COLUMNS
Provides table column information for SYSTEM_TABLES.
Provides table column information for SYSTEM_TABLES.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the table. |
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed. |
TABLE_NAME |
VARCHAR |
The table name for which information is listed. |
IS_SYSTEM_TABLE |
BOOLEAN |
Indicates whether the table is a system table, where t is true and f is false. |
COLUMN_ID |
VARCHAR |
Catalog-assigned VARCHAR value that uniquely identifies a table column. |
COLUMN_NAME |
VARCHAR |
The column name for which information is listed in the database. |
DATA_TYPE |
VARCHAR |
The data type assigned to the column; for example VARCHAR(16). |
DATA_TYPE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the data type. |
DATA_TYPE_LENGTH |
INTEGER |
The maximum allowable length of the data type. |
CHARACTER_MAXIMUM_LENGTH |
INTEGER |
The maximum allowable length of the column. |
NUMERIC_PRECISION |
INTEGER |
The number of significant decimal digits. |
NUMERIC_SCALE |
INTEGER |
The number of fractional digits. |
DATETIME_PRECISION |
INTEGER |
For TIMESTAMP data type, returns the declared precision; returns null if no precision was declared. |
INTERVAL_PRECISION |
INTEGER |
The number of fractional digits retained in the seconds field. |
ORDINAL_POSITION |
INTEGER |
The position of the column respective to other columns in the table. |
IS_NULLABLE |
BOOLEAN |
Indicates whether the column can contain null values, where t is true and f is false. |
COLUMN_DEFAULT |
VARCHAR |
The default value of a column, such as empty or expression. |
8.1.72 - SYSTEM_TABLES
Returns a list of all system table names.
Returns a list of all system table names.
|
Column Name |
Data Type |
Description |
TABLE_SCHEMA_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theschema. |
TABLE_SCHEMA |
VARCHAR |
The schema name in which the system table resides, one of the following:
|
TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thetable. |
TABLE_NAME |
VARCHAR |
The name of the system table. |
TABLE_DESCRIPTION |
VARCHAR |
A description of the system table's purpose. |
IS_SUPERUSER_ONLY |
BOOLEAN |
Specifies whether the table is accessible only by superusers by default. If false, then the PUBLIC role has the privileges to access the system table. |
IS_MONITORABLE |
BOOLEAN |
Specifies whether the table is accessible by a user with the SYSMONITOR role enabled. |
IS_ACCESSIBLE_DURING_LOCKDOWN |
BOOLEAN |
Specifies whether RESTRICT_SYSTEM_TABLES_ACCESS revokes privileges from PUBLIC on the system table. These privileges can be restored with RELEASE_SYSTEM_TABLES_ACCESS.
In general, this field is set to t (true) for system tables that contain information that is typically needed by most users, such as TYPES. Conversely, this field is set to f (false) for tables with data that should be restricted during lockdown, such as database settings and user information.
|
8.1.73 - TABLE_CONSTRAINTS
Provides information about table constraints.
Provides information about table constraints.
|
Column Name |
Data Type |
Description |
CONSTRAINT_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theconstraint. |
CONSTRAINT_NAME |
VARCHAR |
The name of the constraint, if specified as UNIQUE, FOREIGN KEY, NOT NULL, PRIMARY KEY, or CHECK. |
CONSTRAINT_SCHEMA_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theschema containing the constraint. |
CONSTRAINT_KEY_COUNT |
INTEGER |
The number of constraint keys. |
FOREIGN_KEY_COUNT |
INTEGER |
The number of foreign keys. |
TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thetable. |
TABLE_NAME |
VARCHAR |
The name of the table that contains the UNIQUE, FOREIGN KEY, NOT NULL, or PRIMARY KEY constraint |
FOREIGN_TABLE_ID |
INTEGER |
The unique object ID of the foreign table referenced in a foreign key constraint (zero if not a foreign key constraint). |
CONSTRAINT_TYPE |
CHAR |
Indicates the constraint type.
Valid Values:
-
c — check
-
f — foreign
-
p — primary
-
u — unique
|
|
IS_ENABLED` |
BOOLEAN |
Indicates if a constraint for a primary key, unique key, or check constraint is currently enabled. Can be t (True) or f (False). |
PREDICATE |
VARCHAR |
For check constraints, the SQL expression. |
See also
ANALYZE_CONSTRAINTS
8.1.74 - TABLES
Provides information about all tables in the database.
Provides information about all tables in the database.
The TABLE_SCHEMA and TABLE_NAME columns are case-sensitive. To restrict a query based on those columns, use the case-insensitive ILIKE predicate. For example:
=> SELECT table_schema, table_name FROM v_catalog.tables
WHERE table_schema ILIKE 'Store%';
|
Column Name |
Data Type |
Description |
|
TABLE_SCHEMA_ID |
INTEGER |
A unique numeric ID that identifies the schema and is assigned by the Vertica catalog. |
|
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed. |
|
TABLE_NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace to which the table belongs. |
|
TABLE_ID |
INTEGER |
A unique numeric ID that identifies the table and is assigned by the Vertica catalog. |
|
TABLE_NAME |
VARCHAR |
The table name for which information is listed. |
|
OWNER_ID |
INTEGER |
A unique numeric ID that identifies the owner and is assigned by the Vertica catalog. |
|
OWNER_NAME |
VARCHAR |
The name of the user who created the table. |
|
IS_TEMP_TABLE |
BOOLEAN |
Whether this table is a temporary table. |
|
IS_SYSTEM_TABLE |
BOOLEAN |
Whether this table is a system table. |
|
FORCE_OUTER |
INTEGER |
Whether this table is joined to another as an inner or outer input. For details, see Controlling join inputs. |
|
IS_FLEXTABLE |
BOOLEAN |
Whether the table is a Flex table. |
|
IS_SHARED |
BOOLEAN |
Whether the table is located on shared storage. Not used for temporary tables in Eon Mode. |
|
HAS_AGGREGATE_PROJECTION |
BOOLEAN |
Whether the table has live aggregate projections. |
|
SYSTEM_TABLE_CREATOR |
VARCHAR |
The name of the process that created the table, such as Designer. |
|
PARTITION_EXPRESSION |
VARCHAR |
The table's partition expression. |
|
CREATE_TIME |
TIMESTAMP |
When the table was created. |
|
TABLE_DEFINITION |
VARCHAR |
For external tables, the COPY FROM portion of the table definition. |
|
RECOVER_PRIORITY |
INTEGER |
The priority rank for the table for a Recovery By Table. |
|
STORAGE_MODE |
INTEGER |
Deprecated, always set to DIRECT. |
|
PARTITION_GROUP_EXPRESSION |
VARCHAR |
The expression of a GROUP BY clause that qualifies a table's partition clause. |
|
ACTIVE_PARTITION_COUNT |
INTEGER |
The table's active partition count as set by CREATE TABLE or ALTER TABLE. If null, the table gets its active partition count from the ActivePartitionCount configuration parameter. For details, see Active and inactive partitions. |
|
IS_MERGEOUT_ENABLED |
BOOLEAN |
Whether mergeout is enabled (t) or disabled (f) on ROS containers that consolidate projection data of this table. By default, mergeout is enabled on all tables. You can disable mergeout on a table with ALTER TABLE. For details, see Disabling mergeout on specific tables. |
|
IMMUTABLE_ROWS_SINCE_TIMESTAMP |
TIMESTAMPTZ |
Set only for immutable tables, the server system time when immutability was applied to this table. This value can help with long-term timestamp retrieval and efficient comparison. |
|
IMMUTABLE_ROWS_SINCE_EPOCH |
INTEGER |
Set only for immutable tables, the epoch that was current when immutability was applied. This setting can help protect the table from attempts to pre-insert records with a future timestamp, so that row's epoch is less than the table's immutability epoch. |
|
IS_EXTERNAL_ICEBERG_TABLE |
BOOLEAN |
Whether this table is an Iceberg table. |
Examples
Find when tables were created:
=> SELECT table_schema, table_name, create_time FROM tables;
table_schema | table_name | create_time
--------------+-----------------------+-------------------------------
public | customer_dimension | 2011-08-15 11:18:25.784203-04
public | product_dimension | 2011-08-15 11:18:25.815653-04
public | promotion_dimension | 2011-08-15 11:18:25.850592-04
public | date_dimension | 2011-08-15 11:18:25.892347-04
public | vendor_dimension | 2011-08-15 11:18:25.942805-04
public | employee_dimension | 2011-08-15 11:18:25.966985-04
public | shipping_dimension | 2011-08-15 11:18:25.999394-04
public | warehouse_dimension | 2011-08-15 11:18:26.461297-04
public | inventory_fact | 2011-08-15 11:18:26.513525-04
store | store_dimension | 2011-08-15 11:18:26.657409-04
store | store_sales_fact | 2011-08-15 11:18:26.737535-04
store | store_orders_fact | 2011-08-15 11:18:26.825801-04
online_sales | online_page_dimension | 2011-08-15 11:18:27.007329-04
online_sales | call_center_dimension | 2011-08-15 11:18:27.476844-04
online_sales | online_sales_fact | 2011-08-15 11:18:27.49749-04
(15 rows)
Find out whether certain tables are temporary and flex tables:
=> SELECT distinct table_name, table_schema, is_temp_table, is_flextable FROM v_catalog.tables
WHERE table_name ILIKE 't%';
table_name | table_schema | is_temp_table | is_flextable
--------------+--------------+---------------+-----------------
t2_temp | public | t | t
tt_keys | public | f | f
t2_temp_keys | public | f | f
t3 | public | t | f
t1 | public | f | f
t9_keys | public | f | f
t2_keys | public | f | t
t6 | public | t | f
t5 | public | f | f
t2 | public | f | t
t8 | public | f | f
t7 | public | t | f
tt | public | t | t
t2_keys_keys | public | f | f
t9 | public | t | t
(15 rows)
8.1.75 - TEXT_INDICES
Provides summary information about the text indices in Vertica.
Provides summary information about the text indices in Vertica.
|
Column Name |
Data Type |
Description |
INDEX_ID |
INTEGER |
A unique numeric ID that identifies the index and is assigned by the Vertica catalog. |
INDEX_NAME |
VARCHAR |
The name of the text index. |
INDEX_SCHEMA_NAME |
VARCHAR |
The schema name of the text index. |
SOURCE_TABLE_ID |
INTEGER |
A unique numeric ID that identifies the table and is assigned by the Vertica catalog. |
SOURCE_TABLE_NAME |
VARCHAR |
The name of the source table used to build the index. |
SOURCE_TABLE_SCHEMA_NAME |
VARCHAR |
The schema name of the source table. |
TOKENIZER_ID |
INTEGER |
A unique numeric ID that identifies the tokenizer and is assigned by the Vertica catalog. |
TOKENIZER_NAME |
VARCHAR |
The name of the tokenizer used when building the index. |
TOKENIZER_SCHEMA_NAME |
VARCHAR |
The schema name of the tokenizer. |
STEMMER_ID |
INTEGER |
A unique numeric ID that identifies the stemmer and is assigned by the Vertica catalog. |
STEMMER_NAME |
VARCHAR |
The name of the stemmer used when building the index. |
STEMMER_SCHEMA_NAME |
VARCHAR |
The schema name of the stemmer. |
TEXT_COL |
VARCHAR |
The text column used to build the index. |
8.1.76 - TYPES
Provides information about supported data types.
Provides information about supported data types. This table does not include inlined complex types; see COMPLEX_TYPES instead. This table does include arrays and sets of primitive types.
|
Column Name |
Data Type |
Description |
TYPE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the specific data type. |
ODBC_TYPE |
INTEGER |
The numerical ODBC type. |
ODBC_SUBTYPE |
INTEGER |
The numerical ODBC subtype, used to differentiate types such as time and interval that have multiple subtypes. |
JDBC_TYPE |
INTEGER |
The numerical JDBC type. |
JDBC_SUBTYPE |
INTEGER |
The numerical JDBC subtype, used to differentiate types such as time and interval that have multiple subtypes. |
MIN_SCALE |
INTEGER |
The minimum number of digits supported to the right of the decimal point for the data type. |
MAX_SCALE |
INTEGER |
The maximum number of digits supported to the right of the decimal point for the data type. A value of 0 is used for types that do not use decimal points. |
COLUMN_SIZE |
INTEGER |
The number of characters required to display the type. See: http://msdn.microsoft.com/en-us/library/windows/desktop/ms711786%28v=VS.85%29.aspx for the details on COLUMN_SIZE for each type. |
INTERVAL_MASK |
INTEGER |
For data types that are intervals, the bitmask to determine the range of the interval from the Vertica TYPE_ID. Details are available in the Vertica SDK. |
TYPE_NAME |
VARCHAR |
The data type name associated with a particular data type ID. |
CREATION_PARAMETERS |
VARCHAR |
A list of keywords, separated by commas, corresponding to each parameter that the application may specify in parentheses when using the name that is returned in the TYPE_NAME field. The keywords in the list can be any of the following: length, precision, or scale. They appear in the order that the syntax requires them to be used. |
8.1.77 - USER_AUDITS
Lists the results of database and object size audits generated by users calling the AUDIT function.
Lists the results of database and object size audits generated by users calling the AUDIT function. See Monitoring database size for license compliance for more information.
|
Column Name |
Data Type |
Description |
SIZE_BYTES |
INTEGER |
The estimated raw data size of the database |
USER_ID |
INTEGER |
The ID of the user who generated the audit |
USER_NAME |
VARCHAR |
The name of the user who generated the audit |
OBJECT_ID |
INTEGER |
The ID of the object being audited |
OBJECT_TYPE |
VARCHAR |
The type of object being audited (table, schema, etc.) |
OBJECT_SCHEMA |
VARCHAR |
The schema containing the object being audited |
OBJECT_NAME |
VARCHAR |
The name of the object being audited |
AUDITED_SCHEMA_NAME |
VARCHAR |
The name of the schema on which you want to query HISTORICAL data.
After running audit on a table, you can drop the table. In this case, object_schema becomes NULL.
|
AUDITED_OBJECT_NAME |
VARCHAR |
The name of the object on which you want to query HISTORICAL data.
After running audit on a table, you can drop the table. In this case, object_name becomes NULL.
|
LICENSE_NAME |
VARCHAR |
The name of the license. After running a compliance audit, the value for this column is always vertica. |
AUDIT_START_TIMESTAMP |
TIMESTAMPTZ |
When the audit started |
AUDIT_END_TIMESTAMP |
TIMESTAMPTZ |
When the audit finished |
CONFIDENCE_LEVEL_PERCENT |
FLOAT |
The confidence level of the size estimate |
ERROR_TOLERANCE_PERCENT |
FLOAT |
The error tolerance used for the size estimate |
USED_SAMPLING |
BOOLEAN |
Whether data was randomly sampled (if false, all of the data was analyzed) |
CONFIDENCE_INTERVAL_LOWER_BOUND_BYTES |
INTEGER |
The lower bound of the data size estimate within the confidence level |
CONFIDENCE_INTERVAL_UPPER_BOUND_BYTES |
INTEGER |
The upper bound of the data size estimate within the confidence level |
SAMPLE_COUNT |
INTEGER |
The number of data samples used to generate the estimate |
CELL_COUNT |
INTEGER |
The number of cells in the database |
8.1.78 - USER_CLIENT_AUTH
Provides information about the client authentication methods that are associated with database users.
Provides information about the client authentication methods that are associated with database users. You associate an authentication method with a user using GRANT (Authentication).
|
Column Name |
Data Type |
Description |
USER_OID |
INTEGER |
A unique identifier for that user. |
USER_NAME |
VARCHAR |
Name of the user. |
AUTH_OID |
INTEGER |
A unique identifier for the authentication method you are using. |
AUTH_NAME |
VARCHAR |
Name that you gave to the authentication method. |
GRANTED_TO |
BOOLEAN |
Name of the user with whom you have associated the authentication method using GRANT (Authentication). |
8.1.79 - USER_CONFIGURATION_PARAMETERS
Provides information about user-level configuration parameters that are in effect for database users.
Provides information about user-level configuration parameters that are in effect for database users.
|
Column Name |
Data Type |
Description |
|
USER_NAME |
VARCHAR |
Name of a database user with user-level settings. |
|
PARAMETER_NAME |
VARCHAR |
The configuration parameter name. |
|
CURRENT_ VALUE |
VARCHAR |
The parameter's current setting for this user. |
|
DEFAULT_VALUE |
VARCHAR |
The parameter's default value. |
Privileges
Superuser only
Examples
=> SELECT * FROM user_configuration_parameters;
user_name | parameter_name | current_value | default_value
-----------+---------------------------+---------------+---------------
Yvonne | LoadSourceStatisticsLimit | 512 | 256
(1 row)
=> ALTER USER Ahmed SET DepotOperationsForQuery='FETCHES';
ALTER USER
=> ALTER USER Yvonne SET DepotOperationsForQuery='FETCHES';
ALTER USER
=> SELECT * FROM user_configuration_parameters;
user_name | parameter_name | current_value | default_value
-----------+---------------------------+---------------+---------------
Ahmed | DepotOperationsForQuery | FETCHES | ALL
Yvonne | DepotOperationsForQuery | FETCHES | ALL
Yvonne | LoadSourceStatisticsLimit | 512 | 256
(3 rows)
8.1.80 - USER_FUNCTION_PARAMETERS
Provides information about the parameters of a C++ user-defined function (UDx).
Provides information about the parameters of a C++ user-defined function (UDx). You can only view parameters that have the Properties.visible parameter set to TRUE.
|
Column Name |
Data Type |
Description |
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the function. |
SCHEMA_NAME |
VARCHAR(128) |
The schema to which the function belongs.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
FUNCTION_NAME |
VARCHAR(128) |
The name assigned by the user to the user-defined function. |
FUNCTION_TYPE |
VARCHAR(128) |
The type of user-defined function. For example, 'User Defined Function'. |
FUNCTION_ARGUMENT_TYPE |
VARCHAR(8192) |
The number and data types of input arguments for the function. |
PARAMETER_NAME |
VARCHAR(128) |
The name of the parameter for the user-defined function. |
DATA_TYPE |
VARCHAR(128) |
The data type of the parameter. |
DATA_TYPE_ID |
INTEGER |
A number specifying the ID for the parameter's data type. |
DATA_TYPE_LENGTH |
INTEGER |
The maximum length of the parameter's data type. |
IS_REQUIRED |
BOOLEAN |
Indicates whether the parameter is required or not.
If set to TRUE, and you don't provide the parameter, Vertica throws an error.
|
CAN_BE_NULL |
BOOLEAN |
Indicates whether the parameter can be passed as a NULL value.
If set to FALSE, you pass the parameter with a NULL value, Vertica throws an error.
|
COMMENT |
VARCHAR(128) |
A user-supplied description of the parameter. |
Privileges
Any user can query the USER_FUNCTION_PARAMETERS table. However, users can only see table information about those UDx functions which the user has permission to use.
See also
8.1.81 - USER_FUNCTIONS
Returns metadata about user-defined SQL functions (which store commonly used SQL expressions as a function in the Vertica catalog) and user-defined functions.
Returns metadata about user-defined SQL functions (which store commonly used SQL expressions as a function in the Vertica catalog) and user-defined functions.
|
Column Name |
Data Type |
Description |
SCHEMA_NAME |
VARCHAR |
The name of the schema in which this function exists. |
FUNCTION_NAME |
VARCHAR |
The name assigned by the user to the SQL function or user-defined function. |
PROCEDURE_TYPE |
VARCHAR |
The type of user-defined function. For example, 'User Defined Function'. |
FUNCTION_RETURN_TYPE |
VARCHAR |
The data type name that the SQL function returns. |
FUNCTION_ARGUMENT_TYPE |
VARCHAR |
The number and data types of parameters for the function. |
FUNCTION_DEFINITION |
VARCHAR |
The SQL expression that the user defined in the SQL function's function body. |
VOLATILITY |
VARCHAR |
The SQL function's volatility (whether a function returns the same output given the same input). Can be immutable, volatile, or stable. |
IS_STRICT |
BOOLEAN |
Indicates whether the SQL function is strict, where t is true and f is false. |
IS_FENCED |
BOOLEAN |
Indicates whether the function runs in Fenced and unfenced modes or not. |
COMMENT |
VARCHAR |
A comment about this function provided by the function creator. |
Notes
-
The volatility and strictness of a SQL function are automatically inferred from the function definition in order that Vertica determine the correctness of usage, such as where an immutable function is expected but a volatile function is provided.
-
The volatility and strictness of a UDx is defined by the UDx's developer.
Examples
Create a SQL function called myzeroifnull in the public schema:
=> CREATE FUNCTION myzeroifnull(x INT) RETURN INT
AS BEGIN
RETURN (CASE WHEN (x IS NOT NULL) THEN x ELSE 0 END);
END;
Now query the USER_FUNCTIONS table. The query returns just the myzeroifnull macro because it is the only one created in this schema:
=> SELECT * FROM user_functions;
-[ RECORD 1 ]----------+---------------------------------------------------
schema_name | public
function_name | myzeroifnull
procedure_type | User Defined Function
function_return_type | Integer
function_argument_type | x Integer
function_definition | RETURN CASE WHEN (x IS NOT NULL) THEN x ELSE 0 END
volatility | immutable
is_strict | f
is_fenced | f
comment |
See also
8.1.82 - USER_PROCEDURES
Provides information about stored procedures and external procedures.
Provides information about stored procedures and external procedures. Users can only view procedures that they can execute.
|
Column Name |
Data Type |
Description |
PROCEDURE_NAME |
VARCHAR |
The name of the procedure. |
OWNER |
VARCHAR |
The owner (definer) of the procedure. |
LANGUAGE |
VARCHAR |
The language in which the procedure is defined.
For external procedures, this will be EXTERNAL.
For stored procedures, this will be one of the supported languages.
|
SECURITY |
VARCHAR |
The privileges to use when executing the procedure, one of the following:
For details, see Executing stored procedures.
|
PROCEDURE_ARGUMENTS |
VARCHAR |
The arguments of the procedure. |
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the procedure. |
SCHEMA_NAME |
VARCHAR |
The schema in which the procedure was defined.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
Privileges
Non-superusers can only view information on a procedure if they have:
Examples
=> SELECT * FROM user_procedures;
procedure_name | owner | language | security | procedure_arguments | schema_name
--------------------+---------+----------+----------+-----------------------------------------------------------------------------------+-------------
accurate_auc | dbadmin | PL/vSQL | INVOKER | relation varchar, observation_col varchar, probability_col varchar, epsilon float | public
conditionalTable | dbadmin | PL/vSQL | INVOKER | b boolean | public
update_salary | dbadmin | PL/vSQL | INVOKER | x int, y varchar | public
(3 rows)
8.1.83 - USER_SCHEDULES
Contains information about schedules.
Contains information about schedules.
|
Column Name |
Data Type |
Description |
|
SCHEDULE_NAME |
VARCHAR |
The name of the schedule. |
|
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, the schedule's namespace. |
|
SCHEMA_NAME |
VARCHAR |
The schedule's schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
OWNER |
VARCHAR |
The owner of the schedule. |
|
ATTACHED_TRIGGER |
VARCHAR |
The trigger attached to the schedule, if any. |
|
ATTACHED_TRIGGER |
BOOLEAN |
Whether the schedule is enabled. |
|
DATE_TIME_TYPE |
VARCHAR |
The format for the scheduled event, one of the following:
|
|
DATE_TIME_STRING |
VARCHAR |
The string used to schedule the event, one of the following:
|
Examples
To view schedules:
=> SELECT * FROM user_schedules;
schedule_name | schema_name | owner | attached_trigger | enabled | date_time_type | date_time_string
-----------------------+-------------+---------+--------------------------------+---------+----------------+------------------------------------------------
daily_1am | management | dbadmin | log_user_actions | t | CRON | 0 1 * * *
biannual_22_noon_gmt | public | dbadmin | refresh_logs | t | DATE_TIME_LIST | 2022-01-01 12:00:00-00, 2022-06-01 12:00:00-00
8.1.84 - USER_TRANSFORMS
Lists the currently-defined user-defined transform functions (UDTFs).
Lists the currently-defined user-defined transform functions (UDTFs).
|
Column Name |
Data Type |
Description |
SCHEMA_NAME |
VARCHAR(128) |
The name of the schema containing the UDTF. |
FUNCTION_NAME |
VARCHAR(128) |
The SQL function name assigned by the user. |
FUNCTION_RETURN_TYPE |
VARCHAR(128) |
The data types of the columns the UDTF returns. |
FUNCTION_ARGUMENT_TYPE |
VARCHAR(8192) |
The data types of the columns that make up the input row. |
FUNCTION_DEFINITION |
VARCHAR(128) |
A string containing the name of the factory class for the UDTF, and the name of the library that contains it. |
IS_FENCED |
BOOLEAN |
Whether the UDTF runs in fenced mode. |
Privileges
No explicit permissions are required; however, users see only UDTFs contained in schemas to which they have read access.
See also
8.1.85 - USERS
Provides information about all users in the database.
Provides information about all users in the database.
Tip
To see if a role has been assigned to a user, call the function
HAS_ROLE.
|
Column Name |
Data Type |
Description |
USER_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the user. |
USER_NAME |
VARCHAR |
The user name for which information is listed. |
IS_SUPER_USER |
BOOLEAN |
A system flag, where t (true) identifies the superuser created at the time of installation. All other users are denoted by f (false). |
PROFILE_NAME |
VARCHAR |
The name of the profile to which the user is assigned. The profile controls the user's password policy. |
IS_LOCKED |
BOOLEAN |
Whether the user's account is locked. A locked user cannot log into the system. |
LOCK_TIME |
TIMESTAMPTZ |
When the user's account was locked. Used to determine when to automatically unlock the account, if the user's profile has a PASSWORD_LOCK_TIME parameter set. |
RESOURCE_POOL |
VARCHAR |
The resource pool to which the user is assigned. |
MANAGED_BY_OAUTH2_AUTH_ID |
INTEGER |
The ID of the OAuth authentication record used to authenticate and provision the user, if any. |
LAST_LOGIN_TIME |
TIMESTAMPTZ |
The last time the user logged in.
Note
The LAST_LOGIN_TIME as recorded by the USERS system table is not persistent; if the database is restarted, the LAST_LOGIN_TIME for users created by just-in-time user provisioning is set to the database start time (this appears as an empty value in LAST_LOGIN_TIME).
You can view the database start time by querying the DATABASES system table:
=> SELECT database_name, start_time FROM databases;
database_name | start_time
---------------+-------------------------------
VMart | 2023-02-06 14:26:50.630054-05
(1 row)
|
MEMORY_CAP_KB |
VARCHAR |
The maximum amount of memory a query run by the user can consume, in kilobytes. |
TEMP_SPACE_CAP_KB |
VARCHAR |
The maximum amount of temporary disk space a query run by the user can consume, in kilobytes. |
RUN_TIME_CAP |
VARCHAR |
The maximum amount of time any of the user's queries are allowed to run. |
MAX_CONNECTIONS |
VARCHAR |
The maximum number of connections allowed for this user. |
CONNECTION_LIMIT_MODE |
VARCHAR |
Indicates whether the user sets connection limits through the node or in database mode. |
IDLE_SESSION_TIMEOUT |
VARCHAR |
How the user handles idle session timeout limits, one of the following:
unlimited: There is no idle session time limit for the user.default: The user's idle session time limit is the value of the DefaultIdleSessionTimeout database parameter, or if that parameter is not set or the user is a superuser, there is no timeout limit. To view the value of DefaultIdleSessionTimeout parameter, use the SHOW DATABASE statement:
=> SHOW DATABASE DEFAULT DEFAULTIDLESESSIONTIMEOUT;
- Interval literal: Interval after which the user's idle session is disconnected.
|
GRACE_PERIOD |
VARCHAR |
Specifies how long a user query can block on any session socket, while awaiting client input or output. If the socket is blocked for a continuous period that exceeds the grace period setting, the server shuts down the socket and throws a fatal error. The session is then terminated. |
ALL_ROLES |
VARCHAR |
Roles assigned to the user. An asterisk in ALL_ROLES output means role granted WITH ADMIN OPTION. See Database Roles. |
DEFAULT_ROLES |
VARCHAR |
Default roles assigned to the user. An asterisk in DEFAULT_ROLES output means role granted WITH ADMIN OPTION. See Enabling roles automatically. |
SEARCH_PATH |
VARCHAR |
Sets the default schema search path for the user. See Setting search paths. |
LDAP_DN |
VARCHAR |
Indicates whether or not the Vertica Analytic Database user maps to an LDAP Link user. When the column is set to dn, the Vertica user maps to LDAP Link.. |
LDAP_URI_HASH |
INTEGER |
The URI hash number for the LDAP user. |
IS_ORPHANED_FROM_LDAP |
BOOLEAN |
Indicates if the user is disconnected (orphaned) from LDAP, set to one of the following:
-
t: User is orphaned
-
f : User is not orphaned
For more information see Troubleshooting LDAP link issues
|
See also
8.1.86 - VIEW_COLUMNS
Provides view attribute information.
Provides view attribute information.
Note
If you drop a table that is referenced by a view, Vertica does not drop the view. However, attempts to access information about it from VIEW_COLUMNS return an error that the view is invalid.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies this view. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the view. |
TABLE_SCHEMA |
VARCHAR |
The name of this view's schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_NAME |
VARCHAR |
The view name. |
COLUMN_ID |
VARCHAR |
A unique VARCHAR ID, assigned by the Vertica catalog, that identifies a column in this view. |
COLUMN_NAME |
VARCHAR |
The name of a column in this view. |
DATA_TYPE |
VARCHAR |
The data type of a view column. |
DATA_TYPE_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies a view column's data type. |
DATA_TYPE_LENGTH |
INTEGER |
The data type's maximum length. |
CHARACTER_MAXIMUM_LENGTH |
INTEGER |
The column's maximum length, valid only for character types. |
NUMERIC_PRECISION |
INTEGER |
The column's number of significant decimal digits. |
NUMERIC_SCALE |
INTEGER |
The column's number of fractional digits. |
DATETIME_PRECISION |
INTEGER |
For TIMESTAMP data type, returns the declared precision; returns null if no precision was declared. |
INTERVAL_PRECISION |
INTEGER |
The number of fractional digits retained in the seconds field. |
ORDINAL_POSITION |
INTEGER |
The position of the column relative to other columns in the view. |
See also
VIEWS
8.1.87 - VIEW_TABLES
Shows details about view-related dependencies, including the table that reference a view, its schema, and owner.
Shows details about view-related dependencies, including the table that reference a view, its schema, and owner.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theview. |
TABLE_SCHEMA |
VARCHAR |
Name of the view schema. |
TABLE_NAME |
VARCHAR |
Name of the view. |
REFERENCE_TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theview's source table. |
REFERENCE_TABLE_SCHEMA |
VARCHAR |
Name of the view's source table schema. |
REFERENCE_TABLE_NAME |
VARCHAR |
Name of the view's source table. |
REFERENCE_TABLE_OWNER_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theview owner. |
8.1.88 - VIEWS
Provides information about all within the system.
Provides information about all views within the system. See Views for more information.
|
Column Name |
Data Type |
Description |
TABLE_SCHEMA_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theview schema. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace that contains the view. |
TABLE_SCHEMA |
VARCHAR |
The name of the view schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies the view. |
TABLE_NAME |
VARCHAR |
The view name. |
OWNER_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theview owner. |
OWNER_NAME |
VARCHAR |
View owner's user name |
VIEW_DEFINITION |
VARCHAR |
The query that defines the view. |
IS_SYSTEM_VIEW |
BOOLEAN |
Indicates whether the view is a system view. |
SYSTEM_VIEW_CREATOR |
VARCHAR |
View creator's user name. |
CREATE_TIME |
TIMESTAMP |
Specifies when this view was created. |
IS_LOCAL_TEMP_VIEW |
BOOLEAN |
Indicates whether this view is a temporary view stored locally. |
INHERIT_PRIVILEGES |
BOOLEAN |
Indicates whether inherited privileges are enabled for this view. For details, see Setting privilege inheritance on tables and views. |
See also
VIEW_COLUMNS
8.1.89 - WORKLOAD_ROUTING_RULES
Lists the routing rules that map workloads to a subcluster.
Lists the routing rules that map workloads to subclusters.
|
Column Name |
Data Type |
Description |
OID |
INTEGER |
The object identifier for the routing rule. |
WORKLOAD |
VARCHAR |
The name of the workload. When specified by a client (either as a connection property or as a session parameter with SET SESSION WORKLOAD), the client's queries are executed by the subcluster specified by the workload routing rule. |
SUBCLUSTER_OID |
INTEGER |
The object identifier for the Subcluster. |
SUBCLUSTER_NAME |
VARCHAR |
The subcluster that contains the Execution node that executes client queries for its associated workload. |
PRIORITY |
INTEGER |
A non-negative INTEGER, the priority of the workload. The greater the value, the greater the priority. If a user or their role is granted multiple routing rules, the one with the greatest priority applies. |
Privileges
Superuser
Examples
The following query shows two rules that define the following behavior:
- Clients with workload
reporting are routed to subcluster default_subcluster.
- Clients with workload
analytics are randomly routed to sc_01 or sc_02.
=> SELECT * FROM v_catalog.workload_routing_rules;
oid | workload | subcluster_oid | subcluster_name | priority
-------------------+-----------+-------------------+--------------------+----------
45035996273850122 | reporting | 45035996273704962 | default_subcluster | 5
45035996273849658 | analytics | 45035996273849568 | sc_01 | 4
45035996273849658 | analytics | 45035996273849568 | sc_02 | 0
See also
8.2 - V_MONITOR schema
The system tables in this section reside in the v_monitor schema.
The system tables in this section reside in the v_monitor schema. These tables provide information about the health of the Vertica database.
8.2.1 - ACTIVE_EVENTS
Returns all active events in the cluster.
Returns all active events in the cluster. See Monitoring events.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name where the event occurred. |
EVENT_CODE |
INTEGER |
A numeric ID that indicates the type of event. See Event Types for a list of event type codes. |
EVENT_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the specific event. |
EVENT_SEVERITY |
VARCHAR |
The severity of the event from highest to lowest. These events are based on standard syslog severity types.
-
0—Emergency
-
1—Alert
-
2—Critical
-
3—Error
-
4—Warning
-
5—Notice
-
6—Informational
-
7—Debug
|
EVENT_POSTED_TIMESTAMP |
TIMESTAMP |
The year, month, day, and time the event was reported. The time is posted in military time. |
EVENT_EXPIRATION |
VARCHAR |
The year, month, day, and time the event expire. The time is posted in military time. If the cause of the event is still active, the event is posted again. |
EVENT_CODE_DESCRIPTION |
VARCHAR |
A brief description of the event and details pertinent to the specific situation. |
EVENT_PROBLEM_DESCRIPTION |
VARCHAR |
A generic description of the event. |
REPORTING_NODE |
VARCHAR |
The name of the node within the cluster that reported the event. |
EVENT_SENT_TO_CHANNELS |
VARCHAR |
The event logging mechanisms that are configured for Vertica. These can include
vertica.log, (configured by default) syslog, and SNMP. |
EVENT_POSTED_COUNT |
INTEGER |
Tracks the number of times an event occurs. Rather than posting the same event multiple times, Vertica posts the event once and then counts the number of additional instances in which the event occurs. |
8.2.2 - ALLOCATOR_USAGE
Provides real-time information on the allocation and reuse of memory pools for a Vertica node.
Provides real-time information on the allocation and reuse of memory pools for a Vertica node.
There are two memory pools in Vertica, global and SAL. The global memory pool is related to Vertica catalog objects. The SAL memory pool is related to the system storage layer. These memory pools are physical structures from which Vertica allocates and reuses portions of memory.
Within the memory pools, there are two allocation types. Both global and SAL memory pools include chunk and object memory allocation types.
-
Chunk allocations are from tiered storage, and are grouped into sizes, in bytes, that are powers of 2.
-
Object allocations are object types, for example, a table or projection. Each object assumes a set size.
The table provides detailed information on these memory pool allocations.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node from which Vertica has collected this allocator information. |
POOL_NAME |
VARCHAR |
One of two memory pools:
|
ALLOCATION_TYPE |
VARCHAR |
One of two memory allocation types:
|
UNIT_SIZE |
INTEGER |
The size, in bytes, of the memory allocation.
For example, if the allocation type is a table (an object type), then Vertica allots 8 bytes.
|
FREE_COUNT |
INTEGER |
Indicates the count of blocks of freed memory that Vertica has reserved for future memory needs.
For example, if you delete a table, Vertica reserves the 8 bytes originally allotted for the table. The 8 bytes freed become 1 unit of memory that Vertica adds to this column.
|
FREE_BYTES |
INTEGER |
Indicates the number of freed memory bytes.
For example, with a table deletion, Vertica adds 8 bytes to this column.
Note
Vertica does not release memory after originally allocating it, unless the node or database is restarted.
|
USED_COUNT |
INTEGER |
Indicates the count of in-use blocks for this allocation.
For example, if your database includes two table objects, Vertica adds 2 to this column.
|
USED_BYTES |
INTEGER |
The number of bytes of in-use blocks of memory.
For example, if your database includes two table objects, each of which assume 8 bytes, Vertica adds 16 to this column.
|
TOTAL_SIZE |
INTEGER |
Indicates the number of bytes that is the sum of all free and used memory. |
CAPTURE_TIME |
TIMESTAMPTZ |
Indicates the current timestamp for when Vertica collected the for this table. |
ALLOCATION_NAME |
VARCHAR |
Provides the name of the allocation type.
-
If the allocation is an object type, provides the name of the object. For example, CAT::Schema. Object types can also have the name internal, meaning that the object is an internal data structure.
Those object types that are not internal are prefaced with either CAT or SAL. Those prefaced with CAT indicate memory from the global memory pool. SAL indicates memory from the system storage memory pool.
-
If the allocation type is chunk, indicates a power of 2 in this field to represent the number of bytes assumed by the chunk. For example, 2^5.
|
Sample: how memory pool memory is allotted, retained, and freed
The following table shows sample column values based upon a hypothetical example. The sample illustrates how column values change based upon addition or deletion of a table object.
-
When you add a table object (t1), Vertica assumes a UNIT_SIZE of 8 bytes, with a USED_COUNT of 1.
-
When you add a second table object (t2), the USED_COUNT increases to 2. Since each object assumes 8 bytes, USED_BYTES increases to 16.
-
When you delete one of the two table objects, Vertica USED_COUNT decreases to 1, and USED_BYTES decreases to 8. Since Vertica retains the memory for future use, FREE_BYTES increases to 8, and FREE_COUNT increases to 1.
-
Finally, when you create a new table object (t3), Vertica frees the memory for reuse. FREE_COUNT and FREE_BYTES return to 0.
|
Column Names |
Add One Table Object (t1) |
Add a Second Table Object (t2) |
Delete a Table Object (t2) |
Create a New Table Object (t3) |
NODE_NAME |
v_vmart_node0001 |
v_vmart_node0001 |
v_vmart_node0001 |
v_vmart_node0001 |
POOL_NAME |
global |
global |
global |
global |
ALLOCATION_TYPE |
object |
object |
object |
object |
UNIT_SIZE |
8 |
8 |
8 |
8 |
FREE_COUNT |
0 |
0 |
1 |
0 |
FREE_BYTES |
0 |
0 |
8 |
0 |
USED_COUNT |
1 |
2 |
1 |
2 |
USED_BYTES |
8 |
16 |
8 |
16 |
TOTAL_SIZE |
8 |
16 |
16 |
16 |
CAPTURE_TIME |
2017-05-24 13:28:07.83855-04 |
2017-05-24 14:16:04.480953-04 |
2017-05-24 14:16:32.077322-04 |
2017-05-24 14:17:07.320745-04 |
ALLOCATION_NAME |
CAT::Table |
CAT::Table |
CAT::Table |
CAT::Table |
Examples
The following example shows one sample record for a chunk allocation type, and one for an object type.
=> \x
Expanded display is on.
=> select * from allocator_usage;
-[ RECORD 1 ]---+-----------------------------
node_name | v_vmart_node0004
pool_name | global
allocation_type | chunk
unit_size | 8
free_count | 1069
free_bytes | 8552
used_count | 7327
used_bytes | 58616
total_size | 67168
capture_time | 2017-05-24 13:28:07.83855-04
allocation_name | 2^3
.
.
.
-[ RECORD 105 ]-+------------------------------
node_name | v_vmart_node0004
pool_name | SAL
allocation_type | object
unit_size | 128
free_count | 0
free_bytes | 0
used_count | 2
used_bytes | 256
total_size | 256
capture_time | 2017-05-24 14:44:30.153892-04
allocation_name | SAL::WOSAlloc
.
.
.
8.2.3 - COLUMN_STORAGE
Returns the amount of disk storage used by each column of each projection on each node.
Returns the amount of disk storage used by each column of each projection on each node.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
|
COLUMN_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thecolumn. |
|
COLUMN_NAME |
VARCHAR |
The column name for which information is listed. |
|
ROW_COUNT |
INTEGER |
The number of rows in the column. |
|
USED_BYTES |
INTEGER |
The disk storage allocation of the column in bytes. |
|
ENCODINGS |
VARCHAR |
The encoding type for the column. |
|
COMPRESSION |
VARCHAR |
The compression type for the column. You can compare ENCODINGS and COMPRESSION columns to see how different encoding types affect column storage when optimizing for compression. |
|
ROS_COUNT |
INTEGER |
The number of ROS containers. |
|
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
|
PROJECTION_NAME |
VARCHAR |
The associated projection name for the column. |
|
PROJECTION_SCHEMA |
VARCHAR |
The name of the schema associated with the projection. |
|
ANCHOR_TABLE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theanchor table. |
|
ANCHOR_TABLE_NAME |
VARCHAR |
The associated table name. |
|
ANCHOR_TABLE_SCHEMA |
VARCHAR |
The associated table's schema name.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
ANCHOR_TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the table. |
|
ANCHOR_TABLE_COLUMN_ID |
VARCHAR |
Catalog-assigned VARCHAR value that uniquely identifies a table column. |
|
ANCHOR_TABLE_COLUMN_NAME |
VARCHAR |
The name of the anchor table. |
8.2.4 - COMMUNAL_CLEANUP_RECORDS
This system table lists files that Vertica considers leaked on an Eon Mode communal storage.
Eon Mode only
This system table lists files that Vertica considers leaked on an Eon Mode communal storage. Leaked files are files that are detected as needing deletion but were missed by the normal cleanup mechanisms. This information helps you determine how much space on the communal storage you can reclaim or have reclaimed by cleaning up the leaked files.
|
Column Name |
Data Type |
Description |
|
detection_timestamp |
TIMESTAMPTZ |
Timestamp at which the file was detected as leaked. |
|
location_path |
VARCHAR |
The path of communal storage location. |
|
file_name |
VARCHAR |
The name of the leaked file. |
|
size_in_bytes |
INTEGER |
The size of the leaked file in bytes. |
|
queued_for_delete |
BOOLEAN |
Specifies whether the file was queued for deletion. Files queued for deletion might not be deleted right away. Also, a subsequent call to clean_communal_storage reports these files as leaked if the files hadn't already been deleted. |
Examples
=> SELECT clean_communal_storage('true');
clean_communal_storage
----------------------------------------------------------------------------------------------------------------------------------------------
CLEAN COMMUNAL STORAGE
Total leaked files: 10
Total size: 217088
Files have been queued for deletion.
Check communal_cleanup_records for more information.
(1 row)
=> SELECT * FROM communal_cleanup_records;
detection_timestamp | location_path | file_name | size_in_bytes | queued_for_delete
-------------------------------+-------------------+-------------------------------------------------------+---------------+-------------------
2018-05-01 17:01:34.045955-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000003_0.gt | 28672 | t
2018-05-01 17:01:34.045966-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000006_0.gt | 28672 | t
2018-05-01 17:01:34.045952-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000001_0.gt | 36864 | t
2018-05-01 17:01:34.045974-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000008_0.gt | 36864 | t
2018-05-01 17:01:34.045981-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000002_0.gt | 12288 | t
2018-05-01 17:01:34.045986-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000007_0.gt | 8192 | t
2018-05-01 17:01:34.045991-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000010_0.gt | 16384 | t
2018-05-01 17:01:34.046001-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000005_0.gt | 24576 | t
2018-05-01 17:01:34.046026-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000009_0.gt | 4096 | t
2018-05-01 17:01:34.046033-04 | s3://chumbucket/ | 020000000000000000000000000000000000000000000004_0.gt | 20480 | t
(10 rows)
See also
CLEAN_COMMUNAL_STORAGE
8.2.5 - COMMUNAL_TRUNCATION_STATUS
Stores information on the state of the cluster in the case of a catalog truncation event.
Eon Mode only
Stores information on the state of the cluster in the case of a catalog truncation event.
|
Column Name |
Data Type |
Description |
CURRENT_CATALOG_VERSION |
VARCHAR |
Current value of the catalog truncation version (CTV). |
CLUSTER_TRUNCATION_VERSION |
VARCHAR |
The value of the CTV from the cluster_config.json file. |
Examples
=> SELECT * FROM COMMUNAL_TRUNCATION_STATUS;
current_catalog_version | cluster_truncation_version
-------------------------+----------------------------
35 | 35
8.2.6 - CONFIGURATION_CHANGES
Records the change history of system configuration parameters.
Records the change history of system configuration parameters. This information is useful for identifying:
-
Who changed the configuration parameter value
-
When the configuration parameter was changed
-
Whether nonstandard settings were in effect in the past
|
Column Name |
Data Type |
Description |
EVENT_TIMESTAMP |
TIMESTAMPTZ |
Time when the row was recorded. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_ID |
INTEGER |
Identifier of the user who changed configuration parameters. |
USER_NAME |
VARCHAR |
Name of the user who changed configuration parameters at the time Vertica recorded the session. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
PARAMETER |
VARCHAR |
Name of the changed parameter. See Configuration parameter management for a detailed list of supported parameters. |
VALUE |
VARCHAR |
New value of the configuration parameter. |
Privileges
Superuser
8.2.7 - CONFIGURATION_PARAMETERS
Provides information about all configuration parameters that are currently in use by the system.
Provides information about all configuration parameters that are currently in use by the system.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Node names of the database cluster.
ALL indicates that all nodes have the same value.
|
|
PARAMETER_NAME |
VARCHAR |
The parameter name. |
|
CURRENT_VALUE |
VARCHAR |
The parameter's current setting. |
|
RESTART_VALUE |
VARCHAR |
The parameter's value after the next restart. |
|
DATABASE_VALUE |
VARCHAR |
The value that is set at the database level. If no database-level value is set, the value reflects the default value. |
|
DEFAULT_VALUE |
VARCHAR |
The parameter's default value. |
|
CURRENT_LEVEL |
VARCHAR |
Level at which CURRENT_VALUE is set, one of the following:
-
NODE
-
DATABASE
-
SESSION
-
DEFAULT
|
|
RESTART_LEVEL |
VARCHAR |
Level at which the parameter will be set after the next restart, one of the following:
|
|
IS_MISMATCH |
BOOLEAN |
Whether CURRENT_VALUE and RESTART_VALUE match. |
|
GROUPS |
VARCHAR |
A group to which the parameter belongs—for example, OptVOptions.
Note
Most configuration parameters do not belong to any group.
|
|
ALLOWED_LEVELS |
VARCHAR |
Levels at which the specified parameter can be set, a comma-delimited list of any of the following values:
-
DATABASE
-
NODE
-
SESSION
-
USER
|
|
SUPERUSER_VISIBLE_ONLY |
BOOLEAN |
Whether non-superusers can view all parameter settings. If true, the following columns are masked to non-superusers:
-
CURRENT_VALUE
-
RESTART_VALUE
-
DATABASE_VALUE
-
DEFAULT_VALUE
|
|
CHANGE_UNDER_SUPPORT_GUIDANCE |
BOOLEAN |
Whether the parameter is intended for use only under guidance from Vertica technical support. |
|
CHANGE_REQUIRES_RESTART |
BOOLEAN |
Whether the configuration change requires a restart. |
|
DESCRIPTION |
VARCHAR |
Describes the parameter's usage. |
Examples
The following example shows a case where the parameter requires a restart for the new setting to take effect:
=> SELECT * FROM CONFIGURATION_PARAMETERS WHERE parameter_name = 'RequireFIPS';
-[ RECORD 1 ]-----------------+----------------------
node_name | ALL
parameter_name | RequireFIPS
current_value | 0
restart_value | 0
database_value | 0
default_value | 0
current_level | DEFAULT
restart_level | DEFAULT
is_mismatch | f
groups |
allowed_levels | DATABASE
superuser_visible_only | f
change_under_support_guidance | f
change_requires_restart | t
description | Execute in FIPS mode
The following example shows a case where a non-superuser is viewing a parameter with restricted visibility:
=> \c VMart nonSuperuser
You are now connected to database "VMart" as user "nonSuperuser".
=> SELECT * FROM CONFIGURATION_PARAMETERS WHERE superuser_visible_only = 't';
-[ RECORD 1 ]-----------------+-------------------------------------------------------
node_name | ALL
parameter_name | S3BucketCredentials
current_value | ********
restart_value | ********
database_value | ********
default_value | ********
current_level | DEFAULT
restart_level | DEFAULT
is_mismatch | f
groups |
allowed_levels | SESSION, DATABASE
superuser_visible_only | t
change_under_support_guidance | f
change_requires_restart | f
description | JSON list mapping S3 buckets to specific credentials.
See also
Configuration parameter management
8.2.8 - CPU_USAGE
Records CPU usage history on the system.
Records CPU usage history on the system.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
START_TIME |
TIMESTAMP |
Beginning of history interval. |
END_TIME |
TIMESTAMP |
End of history interval. |
AVERAGE_CPU_USAGE_PERCENT |
FLOAT |
Average CPU usage in percent of total CPU time (0-100) during history interval. |
PHYSICAL_CORES |
INTEGER |
Number of physical cores used by the node. |
Privileges
Superuser
8.2.9 - CRITICAL_HOSTS
Lists the critical hosts whose failure would cause the database to become unsafe and force a shutdown.
Lists the critical hosts whose failure would cause the database to become unsafe and force a shutdown.
|
Column Name |
Data Type |
Description |
HOST_NAME |
VARCHAR |
Name of a critical host |
Privileges
None
8.2.10 - CRITICAL_NODES
Lists the whose failure would cause the database to become unsafe and force a shutdown.
Lists the critical nodes whose failure would cause the database to become unsafe and force a shutdown.
|
Column Name |
Data Type |
Description |
NODE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thenode. |
NODE_NAME |
VARCHAR |
Name of a critical node. |
8.2.11 - CRITICAL_SUBCLUSTERS
Lists the primary subclusters whose loss would cause the database to become unsafe and force it to shutdown.
Lists the primary subclusters whose loss would cause the database to become unsafe and force it to shutdown. Vertica checks this table before stopping a subcluster to ensure it will not trigger a database shutdown. If you attempt to stop or remove a subcluster in this table, Vertica returns an error message. See Starting and stopping subclusters for more information.
This table only has contents when the database is in Eon Mode and when one or more subclusters are critical.
|
Column Name |
Data Type |
Description |
|
SUBCLUSTER_OID |
INTEGER |
Unique identifier for the subcluster. |
|
SUBCLUSTER_NAME |
VARCHAR |
The name of the subcluster in a critical state. |
Examples
=> SELECT * FROM critical_subclusters;
subcluster_oid | subcluster_name
-------------------+--------------------
45035996273704996 | default_subcluster
(1 row)
See also
8.2.12 - CURRENT_SESSION
Returns information about the current active session.
Returns information about the current active session. Use this table to find out the current session's sessionID and get the duration of the previously-run query.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node for which information is listed |
USER_NAME |
VARCHAR |
Name used to log into the database, NULL if the session is internal |
CLIENT_OS_HOSTNAME |
VARCHAR |
The hostname of the client as reported by their operating system. |
CLIENT_HOSTNAME |
VARCHAR |
The IP address and port of the TCP socket from which the client connection was made; NULL if the session is internal.
Vertica accepts either IPv4 or IPv6 connections from a client machine. If the client machine contains mappings for both IPv4 and IPv6, the server randomly chooses one IP address family to make a connection. This can cause the CLIENT_HOSTNAME column to display either IPv4 or IPv6 values, based on which address family the server chooses.
|
TYPE |
INTEGER |
Identifies the session type, one of the following integer values:
-
1: Client
-
2: DBD
-
3: Merge out
-
4: Move out
-
5: Rebalance cluster
-
6: Recovery
-
7: Refresh
-
8: Shutdown
-
9: License audit
-
10: Timer service
-
11: Connection
-
12: VSpread
-
13: Sub-session
-
14: Repartition table
|
CLIENT_PID |
INTEGER |
Process identifier of the client process that issued this connection. This process might be on a different machine than the server. |
LOGIN_TIMESTAMP |
TIMESTAMP |
When the user logged into the database or the internal session was created. This column can help identify open sessions that are idle. |
SESSION_ID |
VARCHAR |
Identifier required to close or interrupt a session. This identifier is unique within the cluster at any point in time, but can be reused when the session closes. |
CLIENT_LABEL |
VARCHAR |
User-specified label for the client connection that can be set when using ODBC. See Label in ODBC DSN connection properties. |
TRANSACTION_START |
TIMESTAMP |
When the current transaction started, NULL if no transaction is running |
TRANSACTION_ID |
VARCHAR |
Hexadecimal identifier of the current transaction, NULL if no transaction is in progress |
TRANSACTION_DESCRIPTION |
VARCHAR |
Description of the current transaction |
STATEMENT_START |
TIMESTAMP |
When the current statement started execution, NULL if no statement is running |
STATEMENT_ID |
VARCHAR |
Unique numeric ID for the currently-running statement, NULL if no statement is being processed. Combined, TRANSACTION_ID and STATEMENT_ID uniquely identify a statement within a session. |
LAST_STATEMENT_DURATION_US |
INTEGER |
Duration in microseconds of the last completed statement |
CURRENT_STATEMENT |
VARCHAR |
The currently-running statement, if any. NULL indicates that no statement is currently being processed. |
LAST_STATEMENT |
VARCHAR |
NULL if the user has just logged in, otherwise the currently running statement or most recently completed statement. |
EXECUTION_ENGINE_PROFILING_CONFIGURATION |
VARCHAR |
See Profiling Settings below. |
QUERY_PROFILING_CONFIGURATION |
VARCHAR |
See Profiling Settings below. |
SESSION_PROFILING_CONFIGURATION |
VARCHAR |
See Profiling Settings below. |
CLIENT_TYPE |
VARCHAR |
Type of client from which the connection was made, one of the following:
-
ADO.NET Driver
-
ODBC Driver
-
JDBC Driver
-
vsql
|
CLIENT_VERSION |
VARCHAR |
Client version |
CLIENT_OS |
VARCHAR |
Client operating system |
CLIENT_OS_USER_NAME |
VARCHAR |
Identifies the user that logged into the database, also set for unsuccessful login attempts. |
REQUESTED_PROTOCOL |
VARCHAR |
Communication protocol version that the ODBC client driver sends to Vertica server, used to support backward compatibility with earlier server versions. |
EFFECTIVE_PROTOCOL |
VARCHAR |
Minimum protocol version supported by client and driver. |
Profiling settings
The following columns show settings for different profiling categories:
-
EXECUTION_ENGINE_PROFILING_CONFIGURATION
-
QUERY_PROFILING_CONFIGURATION
-
SESSION_PROFILING_CONFIGURATION
These can have the following values:
-
Empty: No profiling is set
-
Session: On for current session.
-
Global: On by default for all sessions.
-
>Session, Global: On by default for all sessions, including current session.
For information about controlling profiling settings, see Enabling profiling.
8.2.13 - DATA_COLLECTOR
Shows settings for all components: their current retention policy properties and other data collection statistics.
Shows settings for all Data collector components: their current retention policy properties and other data collection statistics.
Data Collector is on by default. To turn it off, set configuration parameter EnableDataCollector to 0.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Node name on which data is stored. |
|
COMPONENT |
VARCHAR |
Name of the component. |
|
TABLE_NAME |
VARCHAR |
The data collector table name for which information is listed. |
|
DESCRIPTION |
VARCHAR |
Short description about the component. |
|
ACCESS_RESTRICTED |
BOOLEAN |
Indicates whether access to the table is restricted to the DBADMIN, PSEUDOSUPERUSER, or SYSMONITOR roles. |
|
MEMORY_BUFFER_SIZE_KB |
INTEGER |
Specifies in kilobytes the maximum amount of data that is buffered in memory before moving it to disk. You can modify this value with SET_DATA_COLLECTOR_POLICY. |
|
DISK_SIZE_KB |
INTEGER |
Specifies in kilobytes the maximum disk space allocated for this component's Data Collector table. If set to 0, the Data Collector retains only as much component data as it can buffer in memory, as specified by MEMORY_BUFFER_SIZE_KB. You can modify this value with SET_DATA_COLLECTOR_POLICY. |
|
INTERVAL_SET |
BOOLEAN |
Boolean, specifies whether time-based retention is enabled (INTERVAL_TIME is ≥ 0). |
|
INTERVAL_TIME |
INTERVAL |
INTERVAL data type that specifies how long data of a given component is retained in that component's Data Collector table. You can modify this value with SET_DATA_COLLECTOR_POLICY or SET_DATA_COLLECTOR_TIME_POLICY.
For example, if you specify component TupleMoverEvents and set interval-time to an interval of two days ('2 days'::interval), the Data Collector table dc_tuple_mover_events retains records of Tuple Mover activity over the last 48 hours. Older Tuple Mover data are automatically dropped from this table.
Note
Setting a component's policy's interval_time property has no effect on how much data storage the Data Collector retains on disk for that component. Maximum disk storage capacity is determined by the disk_size_kb property. Setting the interval_time property only affects how long data is retained by the component's Data Collector table. For details, see Configuring data retention policies.
|
|
RECORD_TOO_BIG_ERRORS |
INTEGER |
Integer that increments by one each time an error is thrown because data did not fit in memory (based on the data collector retention policy). |
|
LOST_BUFFERS |
INTEGER |
Number of buffers lost. |
|
LOST_RECORDS |
INTEGER |
Number of records lost. |
|
RETIRED_FILES |
INTEGER |
Number of retired files. |
|
RETIRED_RECORDS |
INTEGER |
Number of retired records. |
|
CURRENT_MEMORY_RECORDS |
INTEGER |
The current number of rows in memory. |
|
CURRENT_DISK_RECORDS |
INTEGER |
The current number of rows stored on disk. |
|
CURRENT_MEMORY_BYTES |
INTEGER |
Total current memory used in kilobytes. |
|
CURRENT_DISK_BYTES |
INTEGER |
Total current disk space used in kilobytes. |
|
FIRST_TIME |
TIMESTAMP |
Timestamp of the first record. |
|
LAST_TIME |
TIMESTAMP |
Timestamp of the last record |
|
KB_PER_DAY |
FLOAT |
Total kilobytes used per day. |
Examples
Get the current status of resource pools:
=> SELECT * FROM data_collector WHERE component = 'ResourcePoolStatus' ORDER BY node_name;
-[ RECORD 1 ]----------+---------------------------------
node_name | v_vmart_node0001
component | ResourcePoolStatus
table_name | dc_resource_pool_status
description | Resource Pool status information
access_restricted | t
memory_buffer_size_kb | 64
disk_size_kb | 25600
interval_set | f
interval_time | 0
record_too_big_errors | 0
lost_buffers | 0
lost_records | 0
retired_files | 385
retired_records | 3492335
current_memory_records | 0
current_disk_records | 30365
current_memory_bytes | 0
current_disk_bytes | 21936993
first_time | 2020-08-14 11:03:28.007894-04
last_time | 2020-08-14 11:59:41.005675-04
kb_per_day | 548726.098227313
-[ RECORD 2 ]----------+---------------------------------
node_name | v_vmart_node0002
component | ResourcePoolStatus
table_name | dc_resource_pool_status
description | Resource Pool status information
access_restricted | t
memory_buffer_size_kb | 64
disk_size_kb | 25600
interval_set | f
interval_time | 0
record_too_big_errors | 0
lost_buffers | 0
lost_records | 0
retired_files | 385
retired_records | 3492335
current_memory_records | 0
current_disk_records | 28346
current_memory_bytes | 0
current_disk_bytes | 20478345
first_time | 2020-08-14 11:07:12.006484-04
last_time | 2020-08-14 11:59:41.004825-04
kb_per_day | 548675.811828872
-[ RECORD 3 ]----------+---------------------------------
node_name | v_vmart_node0003
component | ResourcePoolStatus
table_name | dc_resource_pool_status
description | Resource Pool status information
access_restricted | t
memory_buffer_size_kb | 64
disk_size_kb | 25600
interval_set | f
interval_time | 0
record_too_big_errors | 0
lost_buffers | 0
lost_records | 0
retired_files | 385
retired_records | 3492335
current_memory_records | 0
current_disk_records | 28337
current_memory_bytes | 0
current_disk_bytes | 20471843
first_time | 2020-08-14 11:07:13.008246-04
last_time | 2020-08-14 11:59:41.006729-04
kb_per_day | 548675.63541403
See also
8.2.14 - DATA_LOADER_EVENTS
Lists events from all data loaders.
Lists events from all data loaders, including the file path, whether the load succeeded, and how many times it has been retried. You must own or have any privilege (EXECUTE, ALTER, or DROP) on a data loader to see its events in this table.
To prevent unbounded growth, records in this table are purged periodically. You can set the purge frequency for individual data loaders when creating or altering the loader. See CREATE DATA LOADER and ALTER DATA LOADER. The default is 14 days.
|
Column Name |
Column Type |
Description |
DATA_LOADER_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace of the data loader that performed this load. |
DATA_LOADER_SCHEMA |
VARCHAR |
Schema for the data loader that performed this load.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
DATA_LOADER_NAME |
VARCHAR |
Name of the data loader that performed this load. |
TIME_STAMP |
TIMESTAMPTZ |
Time when Vertica recorded the event. |
FILE_NAME |
VARCHAR |
Path that was loaded (or attempted). |
TRANSACTION_ID |
VARCHAR |
Unique identifier for the transaction in which the load occurred. |
LOAD_STATUS |
VARCHAR |
OK if the load succeeded or FAIL if it did not. |
ROWS_LOADED |
INTEGER |
If a single file was loaded, the number of rows. If more than one file was loaded in a single batch, this value is null. For batch loads, FILE_SIZE_BYTES can be helpful in place of row counts. |
FAILURE_REASON |
VARCHAR |
If the load failed, an explanatory message. |
RETRY_ATTEMPT |
INTEGER |
0 if this was the first attempt to load the file, otherwise the number of retries including this one. |
FILE_SIZE_BYTES |
INTEGER |
File size in bytes when the data loader was executed. |
BATCH_ID |
INTEGER |
Identifier, unique within the transaction, for the batch this file was part of. If a file was loaded individually, this value is null. |
8.2.15 - DATA_LOADERS
Lists all defined data loaders.
Lists all defined data loaders.
|
Column Name |
Column Type |
Description |
NAME |
VARCHAR |
Loader name. |
NAMESPACENAME |
VARCHAR |
For Eon Mode databases, namespace in which the loader is defined. |
SCHEMANAME |
VARCHAR |
Schema in which the loader is defined.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
OWNER |
VARCHAR |
Vertica user who created the loader. |
COPYSTMT |
VARCHAR |
COPY statement used by this loader. |
RETRYLIMIT |
INT |
Number of times to retry a failed file load. For loaders that do not specify an explicit value, this value is updated if the value of the DataLoaderDefaultRetryLimit configuration parameter changes. |
HISTORYRETENTIONINTERVAL |
INTERVAL |
How long to wait before purging rows in the loader's monitoring table. See CREATE DATA LOADER. |
ENABLED |
BOOLEAN |
Whether the data loader is enabled. EXECUTE DATA LOADER does not run a disabled data loader. |
TRIGGER |
VARCHAR |
External trigger for this data loader, if any. |
Examples
=> SELECT * FROM DATA_LOADERS;
name | schemaname | owner | copystmt | retrylimit | historyretentioninterval | enabled | trigger
------+------------+---------+-----------------------------------+------------+---------------------------|--------+---------
dl | public | dbadmin | copy sales from 's3://data/*.dat' | 3 | 14 days | t |
(1 row)
8.2.16 - DATA_READS
Lists each storage location that a query reads in Eon Mode.
Eon Mode only
Lists each storage location that a query reads in Eon Mode. If the query fetches data from multiple locations, this table provides a row for each location per node that read data. For example, a query might run on three nodes and fetch data from the depot and communal storage. In this case, the table displays six rows for the query: three rows for each node's depot read, and three for each node's communal storage read.
Note
This table is only populated in Eon Mode.
|
Column Name |
Column Type |
Description |
START_TIME |
TIMESTAMP |
When Vertica started reading data from the location. |
NODE_NAME |
VARCHAR |
Name of the node that fetched the data |
SESSION_ID |
VARCHAR |
Unique numeric ID assigned by the Vertica catalog, which identifies the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
USER_ID |
INT |
Unique numeric ID assigned by the Vertica catalog, which identifies the user. |
USER_NAME |
VARCHAR |
Name of the user running the query. |
TRANSACTION_ID |
INT |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
STATEMENT_ID |
INT |
Unique numeric ID for the statement that read the data. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a statement within a session; these columns are useful for creating joins with other system tables. |
REQUEST_ID |
INT |
ID of the data request. |
LOCATION_ID |
INT |
ID of the storage location read. |
LOCATION_PATH |
VARCHAR |
Path of the storage container read by the query. |
BYTES_READ |
INT |
Number of bytes read by the query from this location. |
Examples
=> SELECT * FROM V_MONITOR.DATA_READS WHERE TRANSACTION_ID = 45035996273707457;
-[ RECORD 1 ]--+---------------------------------------------------
start_time | 2019-02-13 19:43:43.840836+00
node_name | v_verticadb_node0001
session_id | v_verticadb_node0001-11828:0x6f3
user_id | 45035996273704962
user_name | dbadmin
transaction_id | 45035996273707457
statement_id | 1
request_id | 230
location_id | 45035996273835000
location_path | /vertica/data/verticadb/v_verticadb_node0001_depot
bytes_read | 329460142
-[ RECORD 2 ]--+---------------------------------------------------
start_time | 2019-02-13 19:43:43.8421+00
node_name | v_verticadb_node0002
session_id | v_verticadb_node0001-11828:0x6f3
user_id | 45035996273704962
user_name | dbadmin
transaction_id | 45035996273707457
statement_id | 1
request_id | 0
location_id | 45035996273835002
location_path | /vertica/data/verticadb/v_verticadb_node0002_depot
bytes_read | 329473033
-[ RECORD 3 ]--+---------------------------------------------------
start_time | 2019-02-13 19:43:43.841845+00
node_name | v_verticadb_node0003
session_id | v_verticadb_node0001-11828:0x6f3
user_id | 45035996273704962
user_name | dbadmin
transaction_id | 45035996273707457
statement_id | 1
request_id | 0
location_id | 45035996273835004
location_path | /vertica/data/verticadb/v_verticadb_node0003_depot
bytes_read | 329677294
8.2.17 - DATABASE_BACKUPS
Lists historical information for each backup that successfully completed after running the vbr utility.
Lists historical information for each backup that successfully completed after running the vbr utility. This information is useful for determining whether to create a new backup before you advance the AHM. Because this system table displays historical information, its contents do not always reflect the current state of a backup repository. For example, if you delete a backup from a repository, the DATABASE_BACKUPS system table continues to display information about it.
To list existing backups, run vbr as described in Viewing backups.
|
Column Name |
Data Type |
Description |
BACKUP_TIMESTAMP |
TIMESTAMP |
The timestamp of the backup. |
NODE_NAME |
VARCHAR |
The name of the initiator node that performed the backup. |
SNAPSHOT_NAME |
VARCHAR |
The name of the backup, as specified in the snapshotName parameter of the vbr configuration file. |
BACKUP_EPOCH |
INTEGER |
The database epoch at which the backup was saved. |
NODE_COUNT |
INTEGER |
The number of nodes backed up in the completed backup, and as listed in the [Mappingn] sections of the configuration file. |
OBJECTS |
VARCHAR |
The name of the object(s) contained in an object-level backup. This column is empty if the record is for a full cluster backup. |
FILE_SYSTEM_TYPE |
VARCHAR |
The type of file system, such as Linux. |
Privileges
Superuser
8.2.18 - DATABASE_CONNECTIONS
Lists the connections to other databases for importing and exporting data.
Lists the connections to other databases for importing and exporting data. See Moving Data Between Vertica Databases.
|
Column Name |
Data Type |
Description |
DATABASE |
VARCHAR |
The name of the connected database |
USERNAME |
VARCHAR |
The username used to create the connection |
HOST |
VARCHAR |
The host name used to create the connection |
PORT |
VARCHAR |
The port number used to create the connection |
ISVALID |
BOOLEAN |
Whether the connection is still open and usable or not |
Examples
=> CONNECT TO VERTICA vmart USER dbadmin PASSWORD '' ON '10.10.20.150',5433;
CONNECT
=> SELECT * FROM DATABASE_CONNECTIONS;
database | username | host | port | isvalid
----------+----------+--------------+------+---------
vmart | dbadmin | 10.10.20.150 | 5433 | t
(1 row)
8.2.19 - DATABASE_MIGRATION_STATUS
Provides real-time and historical data on Enterprise-to- database migration attempts.
Provides real-time and historical data on Enterprise-to-Eon database migration attempts.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of a node in the source Enterprise database. |
|
TRANSACTION_ID |
VARCHAR |
Hexadecimal identifier of the migration process transaction. |
|
PHASE |
VARCHAR |
A stage of database migration on a given node, one of the following, listed in order of execution:
- Catalog Conversion: Conversion of enterprise-mode catalog to Eon-compatible catalog.
Note
No data is transferred during this phase, so BYTES_TO_TRANSFER and BYTES_TRANSFERED are always set to 0.
|
|
STATUS |
VARCHAR |
Specifies status of a given phase, one of the following:
ABORT indicates a given migration phase was unable to complete—for example, the client disconnected, or a network outage occurred—and the migration returned with an error. In this case, call MIGRATE_ENTERPRISE_TO_EON again to restart migration. For details, see Handling Interrupted Migration.
|
|
BYTES_TO_TRANSFER |
INTEGER |
For each migration phase, the size of data to transfer to communal storage, set when phase status is RUNNING:
|
|
BYTES_TRANSFERRED |
INTEGER |
For each migration phase, the size of data transfered to communal storage. This value is updated while phase status is RUNNING, and set to the total number of bytes transferred when status is COMPLETED:
|
|
COMMUNAL_STORAGE_LOCATION |
VARCHAR |
URL of targeted communal storage location |
START_TIME
|
TIMESTAMP |
Demarcate the start and end of each PHASE-specified migration operation. |
|
END_TIME |
Privileges
Superuser
Examples
The following example shows data of a migration that is in progress:
=> SELECT node_name, phase, status, bytes_to_transfer, bytes_transferred, communal_storage_location FROM database_migration_status ORDER BY node_name, start_time;
node_name | phase | status | bytes_to_transfer | bytes_transferred | communal_storage_location
------------------+--------------------+-----------+-------------------+------------------+---------------------------
v_vmart_node0001 | Catalog Conversion | COMPLETED | 0 | 0 | s3://verticadbbucket/
v_vmart_node0001 | Data Transfer | COMPLETED | 1134 | 1134 | s3://verticadbbucket/
v_vmart_node0001 | Catalog Transfer | COMPLETED | 3765 | 3765 | s3://verticadbbucket/
v_vmart_node0002 | Catalog Conversion | COMPLETED | 0 | 0 | s3://verticadbbucket/
v_vmart_node0002 | Data Transfer | COMPLETED | 1140 | 1140 | s3://verticadbbucket/
v_vmart_node0002 | Catalog Transfer | COMPLETED | 3766 | 3766 | s3://verticadbbucket/
v_vmart_node0003 | Catalog Conversion | COMPLETED | 0 | 0 | s3://verticadbbucket/
v_vmart_node0003 | Data Transfer | RUNNING | 5272616 | 183955 | s3://verticadbbucket/
8.2.20 - DELETE_VECTORS
Holds information on deleted rows to speed up the delete process.
Holds information on deleted rows to speed up the delete process.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The name of the node storing the deleted rows. |
|
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, namespace where the deleted rows are located. |
|
SCHEMA_NAME |
VARCHAR |
The name of the schema where the deleted rows are located.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
PROJECTION_NAME |
VARCHAR |
The name of the projection where the deleted rows are located. |
|
DV_OID |
INTEGER |
The unique numeric ID (OID) that identifies this delete vector. |
|
STORAGE_OID |
INTEGER |
The unique numeric ID (OID) that identifies the storage container that holds the delete vector. |
|
SAL_STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
DELETED_ROW_COUNT |
INTEGER |
The number of rows deleted. |
|
USED_BYTES |
INTEGER |
The number of bytes used to store the deletion. |
|
START_EPOCH |
INTEGER |
The start epoch of the data in the delete vector. |
|
END_EPOCH |
INTEGER |
The end epoch of the data in the delete vector. |
Examples
After you delete data from a Vertica table, that data is marked for deletion. To see the data that is marked for deletion, query the DELETE_VECTORS system table.
Run PURGE to remove the delete vectors from ROS containers.
=> SELECT * FROM test1;
number
--------
3
12
33
87
43
99
(6 rows)
=> DELETE FROM test1 WHERE number > 50;
OUTPUT
--------
2
(1 row)
=> SELECT * FROM test1;
number
--------
43
3
12
33
(4 rows)
=> SELECT node_name, projection_name, deleted_row_count FROM DELETE_VECTORS;
node_name | projection_name | deleted_row_count
------------------+-----------------+-------------------
v_vmart_node0002 | test1_b1 | 1
v_vmart_node0001 | test1_b1 | 1
v_vmart_node0001 | test1_b0 | 1
v_vmart_node0003 | test1_b0 | 1
(4 rows)
=> SELECT PURGE();
...
(Table: public.test1) (Projection: public.test1_b0)
(Table: public.test1) (Projection: public.test1_b1)
...
(4 rows)
After the ancient history mark (AHM) advances:
=> SELECT * FROM DELETE_VECTORS;
(No rows)
See also
8.2.21 - DEPLOY_STATUS
Records the history of deployed Database Designer designs and their deployment steps.
Records the history of deployed Database Designer designs and their deployment steps.
|
Column Name |
Data Type |
Description |
EVENT_TIME |
TIMESTAMP |
Time when the row recorded the event. |
USER_NAME |
VARCHAR |
Name of the user who deployed a design at the time Vertica recorded the session. |
DEPLOY_NAME |
VARCHAR |
Name the deployment, same as the user-specified design name. |
DEPLOY_STEP |
VARCHAR |
Steps in the design deployment. |
DEPLOY_STEP_STATUS |
VARCHAR |
Textual status description of the current step in the deploy process. |
DEPLOY_STEP_COMPLETE_PERCENT |
FLOAT |
Progress of current step in percentage (0–100). |
DEPLOY_COMPLETE_PERCENT |
FLOAT |
Progress of overall deployment in percentage (0–100). |
ERROR_MESSAGE |
VARCHAR |
Error or warning message during deployment. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.22 - DEPLOYMENT_PROJECTION_STATEMENTS
Contains information about CREATE PROJECTION statements used to deploy a database design.
Contains information about
CREATE PROJECTION statements used to deploy a database design. Each row contains information about a different CREATE PROJECTION statement. The function
DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY populates this table.
|
Column Name |
Column Type |
Description |
DEPLOYMENT_ID |
INTEGER |
Unique ID that Database Designer assigned to the deployment. |
DESIGN_NAME |
VARCHAR |
Unique name that the user assigned to the design. |
DEPLOYMENT_PROJECTION_ID |
INTEGER |
Unique ID assigned to the output projection by Database Designer. |
STATEMENT_ID |
INTEGER |
Unique ID assigned to the statement type that creates the projection. |
STATEMENT |
VARCHAR |
Text for the statement that creates the projection. |
8.2.23 - DEPLOYMENT_PROJECTIONS
Contains information about projections created and dropped during the design.
Contains information about projections created and dropped during the design. Each row contains information about a different projection. Database Designer populates this table after the design is deployed.
|
Column Name |
Column Type |
Description |
deployment_id |
INTEGER |
Unique ID that Database Designer assigned to the deployment. |
deployment_projection_id |
INTEGER |
Unique ID that Database Designer assigned to the output projection. |
design_name |
VARCHAR |
Name of the design being deployed. |
deployment_projection_name |
VARCHAR |
Name that Database Designer assigned to the projection. |
anchor_table_schema |
VARCHAR |
Name of the schema that contains the table the projection is based on.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
anchor_table_name |
VARCHAR |
Name of the table the projection is based on. |
deployment_operation |
VARCHAR |
Action being taken on the projection, for example, add or drop. |
deployment_projection_type |
VARCHAR |
Indicates whether Database Designer has proposed new projections for this design (DBD) or is using the existing catalog design (CATALOG). The REENCODED suffix indicates that the projection sort order and segmentation are the same, but the projection columns have new encodings:
-
DBD
-
CATALOG
-
DBD_REENCODED
-
CATALOG_REENCODED
|
deploy_weight |
INTEGER |
Weight of this projection in creating the design. This field is always 0 for projections that have been dropped. |
estimated_size_on_disk |
INTEGER |
Approximate size of the projection on disk, in MB. |
8.2.24 - DEPOT_EVICTIONS
Records data on eviction of objects from the depot.
Eon Mode only
Records data on eviction of objects from the depot.
|
Column Name |
Data Type |
Description |
|
START_TIME |
TIMESTAMP |
Demarcate the start and end of each depot eviction operation. |
|
END_TIME |
|
NODE_NAME |
VARCHAR |
Name of a node where the eviction occurred. |
|
SESSION_ID |
VARCHAR |
Unique numeric ID assigned by the Vertica catalog, which identifies the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
USER_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the user. |
|
USER_NAME |
VARCHAR |
The user who made changes to the depot. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
|
STATEMENT_ID |
INTEGER |
Unique numeric ID for the statement that caused the eviction. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a statement within a session; these columns are useful for creating joins with other system tables. |
|
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
|
STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
STORAGE_OID |
INTEGER |
Numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
FILE_SIZE_BYTES |
INTEGER |
The size of the file in bytes that was evicted. |
|
NUMBER_HITS |
INTEGER |
The number of times the file was accessed. |
|
LAST_ACCESS_TIME |
TIMESTAMP |
The last time the file was read. |
|
REASON |
VARCHAR |
The reason the file was evicted, one of the following:
-
CLEAR DEPOT
-
DEPOT FILL AT STARTUP
-
DEPOT SIZE CHANGE
-
DROP OBJECT
-
DROP SUBSCRIPTION
-
EVICTION DUE TO NEW
-
LOAD
-
PEER TO PEER FILL
-
QUERY
|
|
IS_PINNED |
BOOLEAN |
Whether the object has a pinning policy. |
|
IS_ANTI_PINNED |
BOOLEAN |
Whether the object has an anti-pinning policy. |
Examples
=> SELECT * FROM V_MONITOR.DEPOT_EVICTIONS LIMIT 2;
-[ RECORD 1 ]----+-------------------------------------------------
start_time | 2019-02-20 15:32:26.765937+00
end_time | 2019-02-20 15:32:26.766019+00
node_name | v_verticadb_node0001
session_id | v_verticadb_node0001-8997:0x3e
user_id | 45035996273704962
user_name | dbadmin
transaction_id | 45035996273705450
statement_id | 1
request_id | 406
storage_id | 0000000000000000000000000000000000a000000001fbf6
storage_oid | 45035996273842065
file_size_bytes | 61
number_hits | 1
last_access_time | 2019-02-20 15:32:26.668094+00
reason | DROP OBJECT
is_pinned | f
-[ RECORD 2 ]----+-------------------------------------------------
start_time | 2019-02-20 15:32:26.812803+00
end_time | 2019-02-20 15:32:26.812866+00
node_name | v_verticadb_node0001
session_id | v_verticadb_node0001-8997:0x3e
user_id | 45035996273704962
user_name | dbadmin
transaction_id | 45035996273705453
statement_id | 1
request_id | 409
storage_id | 0000000000000000000000000000000000a000000001fbf6
storage_oid | 45035996273842079
file_size_bytes | 91
number_hits | 1
last_access_time | 2019-02-20 15:32:26.770807+00
reason | DROP OBJECT
is_pinned | f
8.2.25 - DEPOT_FETCH_QUEUE
Lists all pending depot requests for queried file data to fetch from communal storage.
Eon Mode only
Lists all pending depot requests for queried file data to fetch from communal storage.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node that requested the fetch. |
|
SAL_STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
TRANSACTION_ID |
INTEGER |
Identifies the transaction that contains the fetch-triggering query. |
|
SOURCE_FILE_NAME |
VARCHAR |
Full path in communal storage of the file to fetch. |
|
DESTINATION_FILE_NAME |
VARCHAR |
Destination path of the file to fetch. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM depot_fetch_queue;
-[ RECORD 1 ]----------+-------------------------------------------------------------
node_name | v_example_db_node0002
sal_storage_id | 029b6fac864e1982531dcde47d00edc500d000000001d5e7
transaction_id | 45035996273705983
source_file_name | s3://mydata/mydb/14a/029b6fac864e1982531dcde47d00edc500d000
000001d5e7_0.gt
destination_file_name | /vertica/example_db/v_example_db_node0002_depot/747/029b6fac
864e1982531dcde47d00edc500d000000001d5eb_0.gt
-[ RECORD 2 ]----------+-------------------------------------------------------------
node_name | v_example_db_node0003
sal_storage_id | 026635d69719c45e8d2d86f5a4d62c7b00b000000001d5e7
transaction_id | 45035996273705983
source_file_name | s3://mydata/mydb/4a5/029b6fac864e1982531dcde47d00edc500d0000
00001d5eb_0.gt
destination_file_name | /vertica/example_db/v_example_db_node0002_depot/751/026635d6
9719c45e8d2d86f5a4d62c7b00b000000001d5e7_0.gt
8.2.26 - DEPOT_FETCHES
Records data of depot fetch requests.
Eon Mode only
Records data of depot fetch requests.
Note
Vertica reports all fetches to this table, including failed fetch attempts and their causes.
|
Column Name |
Data Type |
Description |
|
START_TIME |
TIMESTAMP |
Demarcate the start and end of each depot fetch operation. |
|
END_TIME |
|
NODE_NAME |
VARCHAR |
Identifies the node that initiated fetch request. |
|
TRANSACTION_ID |
INTEGER |
Uniquely identifies the transaction of the query that required the fetched file. |
|
STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, to identify the storage. |
|
STORAGE_OID |
INTEGER |
Numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
FILE_SIZE_BYTES |
INTEGER |
Fetch size in bytes. |
|
SOURCE_FILE |
VARCHAR |
Source file path used, set to null if the file was fetched from a peer. |
|
DESTINATION_FILE |
VARCHAR |
Destination file path |
|
SOURCE_NODE |
VARCHAR |
Source node from which the file was fetched, set to one of the following:
|
|
IS_SUCCESSFUL |
BOOLEAN |
Boolean, specifies whether this fetch succeeded. |
|
REASON |
VARCHAR |
Reason why the fetch failed, null if IS_SUCCESSFUL is true. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM DEPOT_FETCHES LIMIT 2;
-[ RECORD 1 ]----+-------------------------------------------------------------
start_time | 2019-08-30 15:16:15.125962+00
end_time | 2019-08-30 15:16:15.126791+00
node_name | v_verticadb_node0001
transaction_id | 45035996273706225
storage_id | 0239ef74126e70db410b301610f1e5b500b0000000020d65
storage_oid | 45035996273842065
file_size_bytes | 53033
source_file |
destination_file | /vertica/data/verticadb/v_verticadb_node0001_depot/957/0239e
f74126e70db410b301610f1e5b500b0000000020d65_0.gt
source_node | v_verticadb_node0002
is_successful | t
reason |
-[ RECORD 2 ]----+-------------------------------------------------------------
start_time | 2019-08-30 15:16:15.285208+00
end_time | 2019-08-30 15:16:15.285949+00
node_name | v_verticadb_node0001
transaction_id | 45035996273706234
storage_id | 0239ef74126e70db410b301610f1e5b500b0000000020dc7
storage_oid | 45035996273842075
file_size_bytes | 69640
source_file |
destination_file | /vertica/data/verticadb/v_verticadb_node0001_depot/055/0239e
f74126e70db410b301610f1e5b500b0000000020dc7_0.gt
source_node | v_verticadb_node0002
is_successful | t
reason |
=> select node_name,transaction_id,storage_id,is_successful,reason FROM
depot_fetches WHERE is_successful = 'f' LIMIT 3;
-[ RECORD 1 ]--+-------------------------------------------------
node_name | v_verticadb_node0001
transaction_id | 45035996273721070
storage_id | 0289281ac4c1f6580b95096fab25290800b0000000027d09
is_successful | f
reason | Could not create space in the depot
-[ RECORD 2 ]--+-------------------------------------------------
node_name | v_verticadb_node0001
transaction_id | 45035996273721070
storage_id | 0289281ac4c1f6580b95096fab25290800b0000000027d15
is_successful | f
reason | Could not create space in the depot
-[ RECORD 3 ]--+-------------------------------------------------
node_name | v_verticadb_node0002
transaction_id | 45035996273721070
storage_id | 02693f1c68266e38461084a840ee42aa00c0000000027d09
is_successful | f
reason | Could not create space in the depot
8.2.27 - DEPOT_FILES
Lists objects that are currently cached in the database depots.
Eon Mode only
Lists objects that are currently cached in the database depots.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the depot node. |
|
SAL_STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
STORAGE_OID |
INTEGER |
Numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
COMMUNAL_FILE_PATH |
VARCHAR |
Communal storage path to the file. On AWS, this is an S3 URI. |
|
DEPOT_FILE_PATH |
VARCHAR |
Depot path to the file. |
|
SHARD_NAME |
VARCHAR |
Name of the shard this file is a part of. |
|
STORAGE_TYPE |
VARCHAR |
Type of system storing this file. |
|
NUMBER_OF_ACCESSES |
INTEGER |
Number of times this file has been accessed. |
|
FILE_SIZE_BYTES |
INTEGER |
How large the file is in bytes. |
|
LAST_ACCESS_TIME |
TIMESTAMPTZ |
When the file was last accessed. |
|
ARRIVAL_TIME |
TIMESTAMPTZ |
When Vertica loaded the file into the depot. |
|
SOURCE |
VARCHAR |
How the data came to be cached, one of the following:
-
LOAD
-
QUERY
-
PEER TO PEER FILL
-
DEPOT FILL AT STARTUP
|
|
IS_PINNED |
BOOLEAN |
Whether a pinning policy is set on the cached data. |
|
IS_ANTI_PINNED |
BOOLEAN |
Whether an anti-pinning policy is set on the cached data. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM depot_files LIMIT 2;
-[ RECORD 1 ]------+---------------------------------------------------------------
node_name | v_verticadb_node0001
sal_storage_id | 0275d4a7c99795d22948605e5940758900a000000001d1b1
storage_oid | 45035996273842075
communal_file_path | s3://mybucket/myfolder/mydb/475/0275d4a7c99795d22948605e5940758900a000000001d1
b1/0275d4a7c99795d22948605e5940758900a000000001d1b1_
depot_file_path | /vertica/data/verticadb/v_verticadb_node0001_depot/177/0275d4a7c99795d229486
05e5940758900a000000001d1b1/0275d4a7c99795d22948605e
shard_name | replica
storage_type | DFS
number_of_accesses | 0
file_size_bytes | 456465645
last_access_time | 2018-09-05 17:34:30.417274+00
arrival_time | 2018-09-05 17:34:30.417274+00
source | DEPOT FILL AT STARTUP
is_pinned | f
-[ RECORD 2 ]------+---------------------------------------------------------------
node_name | v_verticadb_node0001
sal_storage_id | 0275d4a7c99795d22948605e5940758900a000000001d187
storage_oid | 45035996273842079
communal_file_path | s3://mybucket/myfolder/mydb/664/0275d4a7c99795d22948605e5940758900a000000001d1
87/0275d4a7c99795d22948605e5940758900a000000001d187_
depot_file_path | /vertica/data/verticadb/v_verticadb_node0001_depot/135/0275d4a7c99795d229486
05e5940758900a000000001d187/0275d4a7c99795d22948605e
shard_name | replica
storage_type | DFS
number_of_accesses | 0
file_size_bytes | 40
last_access_time | 2018-09-05 17:34:30.417244+00
arrival_time | 2018-09-05 17:34:30.417244+00
source | DEPOT FILL AT STARTUP
is_pinned | f
8.2.28 - DEPOT_PIN_POLICIES
Lists all objects —tables, projections, and table partitions—with depot eviction policies.
Eon Mode only
Lists all objects —tables, projections, and table partitions—with depot eviction policies.
|
Column Name |
Data Type |
Description |
|
NAMPESPACE_NAME |
VARCHAR |
For Eon Mode databases, object namespace. |
|
SCHEMA_NAME |
VARCHAR |
Object schema.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
OBJECT_NAME |
VARCHAR |
Object name. |
|
SUBCLUSTER_NAME |
VARCHAR |
Name of the subcluster where the pinning policy is set, null if the policy is set on all database depots. |
|
POLICY_DETAILS |
VARCHAR |
Object type, one of the following:
-
Table
-
Projection
-
Partition
|
|
MIN_VAL |
VARCHAR |
If POLICY_DETAILS is set to Partition, the range of contiguous partition keys specified by this policy. |
|
MAX_VAL |
|
LOCATION_LABEL |
VARCHAR |
Depot's storage location label. |
|
POLICY_TYPE |
VARCHAR |
Policy type set on this object (PIN or ANTI-PIN), if any. |
8.2.29 - DEPOT_SIZES
Reports depot caching capacity on Vertica nodes.
Eon Mode only
Reports depot caching capacity on Vertica nodes.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node containing the depot. |
LOCATION_OID |
INTEGER |
Catalog-assigned integer value that uniquely identifies the storage location storing the depot. |
LOCATION_PATH |
VARCHAR |
The path where the depot is stored. |
LOCATION_LABEL |
VARCHAR |
The label associated with the depot's storage location. |
MAX_SIZE_BYTES |
INTEGER |
The maximum size the depot can contain, in bytes. |
CURRENT_USAGE_BYTES |
INTEGER |
The current size of the depot, in bytes. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM Depot_Sizes;
-[ RECORD 1 ]-------+---------------------------------------------------
node_name | v_verticadb_node0003
location_oid | 45035996273823200
location_path | /vertica/data/verticadb/v_verticadb_node0003_depot
location_label | auto-data-depot
max_size_bytes | 0
current_usage_bytes | 0
-[ RECORD 2 ]-------+---------------------------------------------------
node_name | v_verticadb_node0001
location_oid | 45035996273823196
location_path | /vertica/data/verticadb/v_verticadb_node0001_depot
location_label | auto-data-depot
max_size_bytes | 33686316032
current_usage_bytes | 206801871
-[ RECORD 3 ]-------+---------------------------------------------------
node_name | v_verticadb_node0002
location_oid | 45035996273823198
location_path | /vertica/data/verticadb/v_verticadb_node0002_depot
location_label | auto-data-depot
max_size_bytes | 0
current_usage_bytes | 0
8.2.30 - DEPOT_UPLOADS
Lists details about depot uploads to communal storage.
Eon Mode only
Lists details about depot uploads to communal storage.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node on which the depot resides. |
PLAN_ID |
VARCHAR |
A unique node-specific numeric ID for each plan run by the Optimizer. |
SUBMIT_TIME |
TIMESTAMP |
The time the task was submitted to the uploader. |
START_TIME |
TIMESTAMP |
The time the upload started. |
END_TIME |
TIMESTAMP |
The time the upload ended. |
SOURCE_FILE |
VARCHAR |
The source file path used. |
DESTINATION_FILE |
VARCHAR |
The destination file path. |
FILE_SIZE_BYTES |
INTEGER |
The size of the uploaded file, in bytes. |
MEMORY_USED_KB |
INTEGER |
The size of the uploader file buffer for the task.
Valid for a task with a RUNNING or COMPLETED status. For a RUNNING status, this shows the current file buffer size, (whatever the uploader is using, which may grow over time for large uploads).
For a COMPLETED status, this shows the largest size used in case the buffer grew during the upload.
|
STATUS |
VARCHAR |
The status of the task, valid values are:
COMPLETED - the task has completed
QUEUED - the task is still in the queue, but haven't been picked up by the uploader.
RUNNING - the task is currently running and the corresponding file is uploading.
|
8.2.31 - DESIGN_QUERIES
Contains info about design queries for a given design.
Contains info about design queries for a given design. The following functions populate this table:
|
Column Name |
Column Type |
Description |
DESIGN_ID |
INTEGER |
Unique id that Database Designer assigned to the design. |
DESIGN_NAME |
VARCHAR |
Name that you specified for the design. |
DESIGN_QUERY_ID |
INTEGER |
Unique id that Database Designer assigned to the design query. |
DESIGN_QUERY_ID_INDEX |
INTEGER |
Database Designer chunks the query text if it exceeds the maximum attribute size before storing it in this table. Database Designer stored all chunks stored under the same value of DESIGN_QUERY_ID. DESIGN_QUERY_ID_INDEX keeps track of the order of the chunks, starting with 0 and ending in n, the index of the final chunk. |
QUERY_TEXT |
VARCHAR |
Text of the query chunk, or the entire query text if it does not exceed the maximum attribute size. |
WEIGHT |
FLOAT |
A value from 0 to 1 that indicates the importance of that query in creating the design. Assign a higher weight to queries that you run frequently so that Database Designer prioritizes those queries in creating the design. Default: 1. |
DESIGN_QUERY_SEARCH_PATH |
VARCHAR |
The search path with which the query is to be parsed. |
DESIGN_QUERY_SIGNATURE |
INTEGER |
Categorizes queries that affect the design that Database Designer creates in the same way. Database Designer assigns a signature to each query, weights one query for each signature group, depending on how many queries there are with that signature, and Database Designer considers that query when creating the design. |
Example
Add queries to VMART_DESIGN and query the DESIGN_QUERIES table:
=> SELECT DESIGNER_ADD_DESIGN_QUERIES('VMART_DESIGN', '/tmp/examples/vmart_queries.sql','true');
DESIGNER_ADD_DESIGN_QUERIES
-----------------------------
Number of accepted queries =9
Number of queries referencing non-design tables =0
Number of unsupported queries =0
Number of illegal queries =0
=> \x
Expanded display is on.
=> SELECT * FROM V_MONITOR.DESIGN.QUERIES
-[ RECORD 1 ]------------+-------------------
design_id | 45035996273705090
design_name | vmart_design
design_query_id | 1
design_query_id_index | 0
query_text | SELECT fat_content
FROM (
SELECT DISTINCT fat_content
FROM product_dimension
WHERE department_description
IN ('Dairy') ) AS food
ORDER BY fat_content
LIMIT 5;
weight | 1
design_query_search_path | v_dbd_vmart_design_vmart_design_ltt, "$user", public, v_catalog, v_monitor, v_internal
design_query_signature | 45035996273724651
-[ RECORD 2]-------------+-------------------
design_query_id | 2
design_query_id_index | 0
query_text | SELECT order_number, date_ordered
FROM store.store_orders_fact orders
WHERE orders.store_key IN (
SELECT store_key
FROM store.store_dimension
WHERE store_state = 'MA')
AND orders.vendor_key NOT IN (
SELECT vendor_key
FROM public.vendor_dimension
WHERE vendor_state = 'MA')
AND date_ordered < '2012-03-01';
weight | 1
design_query_search_path | v_dbd_vmart_design_vmart_design_ltt, "$user", public, v_catalog, v_monitor, v_internal
design_query_signature | 45035996273724508
-[ RECORD 3]-------------+-------------------
...
8.2.32 - DESIGN_STATUS
Records the progress of a running Database Designer design or history of the last Database Designer design executed by the current user.
Records the progress of a running Database Designer design or history of the last Database Designer design executed by the current user.
|
Column Name |
Data Type |
Description |
EVENT_TIME |
TIMESTAMP |
Time when the row recorded the event. |
USER_NAME |
VARCHAR |
Name of the user who ran a design at the time Vertica recorded the session. |
DESIGN_NAME |
VARCHAR |
Name of the user-specified design. |
DESIGN_PHASE |
VARCHAR |
Phase of the design. |
PHASE_STEP |
VARCHAR |
Substep in each design phase |
PHASE_STEP_COMPLETE_PERCENT |
FLOAT |
Progress of current substep in percentage (0–100). |
PHASE_COMPLETE_PERCENT |
FLOAT |
Progress of current design phase in percentage (0–100). |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
The following example shows the content of the DESIGN_STATUS table of a complete Database Designer run:
=> SELECT event_time, design_name, design_phase, phase_complete_percent
FROM v_monitor.design_status;
event_time | design_name | design_phase | phase_complete_percent
--------------------+-------------+------------------------------------------------+------------------------
2012-02-14 10:31:20 | design1 | Design started |
2012-02-14 10:31:21 | design1 | Design in progress: Analyze statistics phase |
2012-02-14 10:31:21 | design1 | Analyzing data statistics | 33.33
2012-02-14 10:31:22 | design1 | Analyzing data statistics | 66.67
2012-02-14 10:31:24 | design1 | Analyzing data statistics | 100
2012-02-14 10:31:25 | design1 | Design in progress: Query optimization phase |
2012-02-14 10:31:25 | design1 | Optimizing query performance | 37.5
2012-02-14 10:31:31 | design1 | Optimizing query performance | 62.5
2012-02-14 10:31:36 | design1 | Optimizing query performance | 75
2012-02-14 10:31:39 | design1 | Optimizing query performance | 87.5
2012-02-14 10:31:41 | design1 | Optimizing query performance | 87.5
2012-02-14 10:31:42 | design1 | Design in progress: Storage optimization phase |
2012-02-14 10:31:44 | design1 | Optimizing storage footprint | 4.17
2012-02-14 10:31:44 | design1 | Optimizing storage footprint | 16.67
2012-02-14 10:32:04 | design1 | Optimizing storage footprint | 29.17
2012-02-14 10:32:04 | design1 | Optimizing storage footprint | 31.25
2012-02-14 10:32:05 | design1 | Optimizing storage footprint | 33.33
2012-02-14 10:32:05 | design1 | Optimizing storage footprint | 35.42
2012-02-14 10:32:05 | design1 | Optimizing storage footprint | 37.5
2012-02-14 10:32:05 | design1 | Optimizing storage footprint | 62.5
2012-02-14 10:32:39 | design1 | Optimizing storage footprint | 87.5
2012-02-14 10:32:39 | design1 | Optimizing storage footprint | 87.5
2012-02-14 10:32:41 | design1 | Optimizing storage footprint | 100
2012-02-14 10:33:12 | design1 | Design completed successfully |
(24 rows)
8.2.33 - DESIGN_TABLES
Contains information about all the design tables for all the designs for which you are the owner.
Contains information about all the design tables for all the designs for which you are the owner. Each row contains information about a different design table. Vertica creates this table when you run
DESIGNER_CREATE_DESIGN.
|
Column Name |
Column Type |
Description |
DESIGN_NAME |
VARCHAR |
Unique name that the user specified for the design. |
DESIGN_TABLE_ID |
INTEGER |
Unique ID that Database Designer assigned to the design table. |
TABLE_SCHEMA |
VARCHAR |
Name of the schema that contains the design table.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_ID |
INTEGER |
System object identifier (OID) assigned to the design table. |
TABLE_NAME |
VARCHAR |
Name of the design table. |
Example
Add all the tables from the VMart database to the design VMART_DESIGN. This operation populates the DESIGN_TABLES table:
=> SELECT DESIGNER_ADD_DESIGN_TABLES('VMART_DESIGN','online_sales.*');
DESIGNER_ADD_DESIGN_TABLES
----------------------------
3
(1 row)
=> SELECT DESIGNER_ADD_DESIGN_TABLES('VMART_DESIGN','public.*');
DESIGNER_ADD_DESIGN_TABLES
----------------------------
9
(1 row)
=> SELECT DESIGNER_ADD_DESIGN_TABLES('VMART_DESIGN','store.*');
DESIGNER_ADD_DESIGN_TABLES
----------------------------
3
(1 row)
=> SELECT * FROM DESIGN_TABLES;
design_name | design_table_id | table_schema | table_id | table_name
-------------+-----------------+--------------+-------------------+-----------------------
VMART_DESIGN | 1 | online_sales | 45035996373718754 | online_page_dimension
VMART_DESIGN | 2 | online_sales | 45035996373718758 | call_center_dimension
VMART_DESIGN | 3 | online_sales | 45035996373718762 | online_sales_fact
VMART_DESIGN | 4 | public | 45035996373718766 | customer_dimension
VMART_DESIGN | 5 | public | 45035996373718770 | product_dimension
VMART_DESIGN | 6 | public | 45035996373718774 | promotion_dimension
VMART_DESIGN | 7 | public | 45035996373718778 | date_dimension
VMART_DESIGN | 8 | public | 45035996373718782 | vendor_dimension
VMART_DESIGN | 9 | public | 45035996373718786 | employee_dimension
VMART_DESIGN | 10 | public | 45035996373718822 | shipping_dimension
VMART_DESIGN | 11 | public | 45035996373718826 | warehouse_dimension
VMART_DESIGN | 12 | public | 45035996373718830 | inventory_face
VMART_DESIGN | 13 | store | 45035996373718794 | store_dimension
VMART_DESIGN | 14 | store | 45035996373718798 | store_sales_fact
VMART_DESIGN | 15 | store | 45035996373718812 | store_orders_fact
(15 rows)
8.2.34 - DESIGNS
Contains information about a Database Designer design.
Contains information about a Database Designer design. After you create a design and specify certain parameters for Database Designer,
DESIGNER_CREATE_DESIGN creates this table in the V_MONITOR schema.
|
Column Name |
Column Type |
Description |
DESIGN_ID |
INTEGER |
Unique ID that Database Designer assigns to this design. |
DESIGN_NAME |
VARCHAR |
Name that the user specifies for the design. |
KSAFETY_LEVEL |
INTEGER |
K-safety level for the design. Database Designer assigns a K-safety value of 0 for clusters with 1 or 2 nodes, and assigns a value of 1 for clusters with 3 or more nodes. |
OPTIMIZATION_OBJECTIVE |
VARCHAR |
Name of the optimization objective for the design. Valid values are:
-
QUERY
-
LOAD
-
BALANCED (default)
|
DESIGN_TYPE |
VARCHAR |
Name of the design type. Valid values are:
-
COMPREHENSIVE (default)
-
INCREMENTAL
|
PROPOSE_SUPER_FIRST |
BOOLEAN |
Specifies to propose superprojections before projections, by default f. If DESIGN_MODE is COMPREHENSIVE, this field has no impact. |
DESIGN_AVAILABLE |
BOOLEAN |
t if the design is currently available, otherwise, f (default). |
COLLECTED_STATISTICS |
BOOLEAN |
t if statistics are to be collected when creating the design, otherwise, f (default). |
POPULATE_DESIGN_TABLES_FROM_QUERIES |
BOOLEAN |
t if you want to populate the design tables from the design queries, otherwise, f (default). |
ENCODING_DESIGN |
BOOLEAN |
t if the design is an encoding optimization design on pre-existing projections, otherwise, f (default). |
DEPLOYMENT_PARALLELISM |
INTEGER |
Number of tables to be deployed in parallel when the design is complete. Default: 0 |
UNSEGMENTED_PROJECTIONS |
BOOLEAN |
t if you specify unsegmented projections, otherwise, f (default). |
ANALYZE_CORRELATIONS_MODE |
INTEGER |
Specifies how Database Designer should handle existing column correlations in a design and whether or not Database Designer should reanalyze existing column correlations.
-
0: (default) Ignore column correlations when creating the design.
-
1: Consider the existing correlations in the tables when creating the design.
-
2: Analyze column correlations if not previously performed, and consider the column correlations when creating the design.
-
3: Analyze all column correlations in the tables and consider them when creating the design, even if they have been analyzed previously.
|
8.2.35 - DIRECTED_QUERY_STATUS
Returns information about execution of directed queries.
Returns information about executions of directed queries.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Node on which the directed query ran. |
|
OID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the specific directed query. |
|
QUERY_NAME |
VARCHAR |
Directed query's unique identifier, used by statements such as ACTIVATE DIRECTED QUERY. |
|
DIGEST |
INTEGER |
Hash of the saved query plan data, used by the optimizer to map identical input queries to the same active directed query. |
|
HITS |
INTEGER |
Number of times this query has been executed since the last reset. Use CLEAR_DIRECTED_QUERY_USAGE to reset this counter to 0. |
Privileges
Superuser
8.2.36 - DISK_QUOTA_USAGES
Provides information about schemas and tables that have disk quotas.
Provides information about schemas and tables that have disk quotas. Schemas and tables without quotas are not included.
|
Column Name |
Data Type |
Description |
|
OBJECT_OID |
INTEGER |
Unique identifier for a schema or table. |
|
OBJECT_NAME |
VARCHAR |
Name of the schema or table. Table names include the schema prefix. |
|
IS_SCHEMA |
BOOLEAN |
Whether the object is a schema. If false, the object is a table. |
TOTAL_DISK_USAGE_IN_BYTES
|
INTEGER |
Current usage of the object. For information about what is counted, see Disk quotas. |
|
DISK_QUOTA_IN_BYTES |
INTEGER |
Current quota for the object. |
Examples
=> SELECT * FROM DISK_QUOTA_USAGES;
object_oid | object_name | is_schema | total_disk_usage_in_bytes | disk_quota_in_bytes
-------------------+-------------+-----------+---------------------+---------------------
45035996273705100 | s | t | 307 | 10240
45035996273705104 | public.t | f | 614 | 1024
45035996273705108 | s.t | f | 307 | 2048
(3 rows)
8.2.37 - DISK_RESOURCE_REJECTIONS
Returns requests for resources that are rejected due to disk space shortages.
Returns requests for resources that are rejected due to disk space shortages. Output is aggregated by both RESOURCE_TYPE and REJECTED_REASON to provide more comprehensive information.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
RESOURCE_TYPE |
VARCHAR |
The resource request requester (example: Temp files). |
REJECTED_REASON |
VARCHAR |
One of the following:
-
Insufficient disk space
-
Failed volume
|
REJECTED_COUNT |
INTEGER |
Number of times this REJECTED_REASON has been given for this RESOURCE_TYPE. |
FIRST_REJECTED_TIMESTAMP |
TIMESTAMP |
The time of the first rejection for this REJECTED_REASON and RESOURCE_TYPE. |
LAST_REJECTED_TIMESTAMP |
TIMESTAMP |
The time of the most recent rejection for this REJECTED_REASON and RESOURCE_TYPE. |
LAST_REJECTED_VALUE |
INTEGER |
The value of the most recent rejection for this REJECTED_REASON and RESOURCE_TYPE. |
See also
8.2.38 - DISK_STORAGE
Returns the amount of disk storage used by the database on each node.
Returns the amount of disk storage used by the database on each node. Each node can have one or more storage locations, and the locations can be on different disks with separate properties, such as free space, used space, and block size. The information in this system table is useful in determining where data files reside.
All returned values for this system table are in the context of the file system of the host operating system, and are not specific to Vertica-specific space.
The storage usage annotation called CATALOG indicates that the location is used to store the catalog. Each CATALOG location is specified only when creating a new database. You cannot add a CATALOG location annotation using CREATE LOCATION, nor remove an existing CATALOG annotation.
The performance of a storage location is measured with two values:
-
Throughput in MB/sec
-
Latency in seeks/sec
These two values are converted to a single number (Speed) with the following formula:
read-time = (1/throughput) + (1/latency)
-
read-time: Time to read 1MB of data
-
1/throughput: Time to read 1MB of data
-
1/latency: Time to seek to the data.
A disk is faster than another disk if its read-time is less.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
|
STORAGE_PATH |
VARCHAR |
Path where the storage location is mounted. |
|
STORAGE_USAGE |
VARCHAR |
Type of information stored in the location, one of the following:
-
DATA: Only data is stored in the location.
-
TEMP: Only temporary files that are created during loads or queries are stored in the location.
-
DATA,TEMP: Both types of files are stored in the location.
-
USER: The storage location can be used by non-dbadmin users, who are granted access to the storage location
-
CATALOG: The area is used for the Vertica catalog. This usage is set internally and cannot be removed or changed.
|
|
RANK |
INTEGER |
Integer rank assigned to the storage location based on its performance. Ranks are used to create a storage locations on which projections, columns, and partitions are stored on different disks based on predicted or measured access patterns. See Managing storage locations. |
|
THROUGHPUT |
INTEGER |
Integer that measures a storage location's performance in MB/sec. 1/throughput is the time taken to read 1MB of data. |
|
LATENCY |
INTEGER |
Integer that measures a storage location's performance in seeks/sec. 1/latency is the time taken to seek to the data. |
|
STORAGE_STATUS |
VARCHAR |
Status of the storage location, one of the following:
|
|
DISK_BLOCK_SIZE_BYTES |
INTEGER |
Block size of the disk in bytes |
|
DISK_SPACE_USED_BLOCKS |
INTEGER |
Number of disk blocks in use |
|
DISK_SPACE_USED_MB |
INTEGER |
Number of megabytes of disk storage in use |
|
DISK_SPACE_FREE_BLOCKS |
INTEGER |
Number of free disk blocks available |
|
DISK_SPACE_FREE_MB |
INTEGER |
Number of megabytes of free storage available |
|
DISK_SPACE_FREE_PERCENT |
VARCHAR |
Percentage of free disk space remaining |
8.2.39 - DRAINING_STATUS
Returns the draining status of each node in a database.
Returns the draining status of each node in a database. The table also provides aggregate user session counts and information about the oldest user session connected to each node. For more information about the user sessions connected to a database, see SESSIONS.
Note
If you aren't a superuser, the OLDEST_SESSION columns contain only information about sessions for which you have privileges. Unprivileged users do not see session details, but they do see the node draining status and the user session aggregate count.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node for which information is listed. |
SUBCLUSTER_NAME |
VARCHAR |
Name of the subcluster that contains the node. |
IS_DRAINING |
BOOLEAN |
True if the node is draining; otherwise, false. |
COUNT_CLIENT_USER_SESSIONS |
INTEGER |
Number of user client sessions connected to the node. |
OLDEST_SESSION_USER |
VARCHAR |
Name of the user with the oldest live session connected to the node. NULL if no users are connected. |
OLDEST_SESSION_ID |
VARCHAR |
Identifier associated with OLDEST_SESSION_USER. This is required to close or interrupt a session. NULL if no users are connected. |
OLDEST_SESSION_LOGIN_TIMESTAMP |
TIMESTAMP |
Date and time the OLDEST_SESSION_USER logged into the database. NULL if no users are connected. |
8.2.40 - ERROR_MESSAGES
Lists system error messages and warnings Vertica encounters while processing queries.
Lists system error messages and warnings Vertica encounters while processing queries. Some errors occur when no transaction is in progress, so the transaction identifier or statement identifier columns might return NULL.
|
Column Name |
Data Type |
Description |
EVENT_TIMESTAMP |
TIMESTAMPTZ |
Time when the row recorded the event |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information |
USER_ID |
INTEGER |
Identifier of the user who received the error message |
USER_NAME |
VARCHAR |
Name of the user who received the error message when Vertica recorded the session |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identifies a statement within a session. |
ERROR_LEVEL |
VARCHAR |
Severity of the error, one of the following:
-
LOG
-
INFO
-
NOTICE
-
WARNING
-
ERROR
-
ROLLBACK
-
INTERNAL
-
FATAL
-
PANIC
|
ERROR_CODE |
INTEGER |
Error code that Vertica reports |
MESSAGE |
VARCHAR |
Textual output of the error message |
DETAIL |
VARCHAR |
Additional information about the error message, in greater detail |
HINT |
VARCHAR |
Actionable hint about the error. For example:
HINT: Set the locale in this session to en_US@collation=binary using the command "\locale en_US@collation=binary"
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.41 - EVENT_CONFIGURATIONS
Monitors the configuration of events.
Monitors the configuration of events.
|
Column Name |
Data Type |
Description |
EVENT_ID |
VARCHAR |
The name of the event. |
EVENT_DELIVERY_CHANNELS |
VARCHAR |
The delivery channel on which the event occurred. |
8.2.42 - EXECUTION_ENGINE_PROFILES
Provides profiling information about runtime query execution.
Provides profiling information about runtime query execution. The hierarchy of IDs, from highest level to actual execution, is:
-
PATH_ID
-
BASEPLAN_ID
-
LOCALPLAN_ID
-
OPERATOR_ID
Counters (output from the COUNTER_NAME column) are collected for each actual Execution Engine (EE) operator instance.
The following columns combine to form a unique key:
-
TRANSACTION_ID
-
STATEMENT_ID
-
NODE_NAME
-
OPERATOR_ID
-
COUNTER_NAME
-
COUNTER_TAG
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
USER_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the user. |
USER_NAME |
VARCHAR |
User name for which query profile information is listed. |
SESSION_ID |
VARCHAR |
Identifier of the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session if any; otherwise NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. |
OPERATOR_NAME |
VARCHAR |
Name of the Execution Engine (EE) component; for example, NetworkSend. |
OPERATOR_ID |
INTEGER |
Identifier assigned by the EE operator instance that performs the work. OPERATOR_ID is different from LOCALPLAN_ID because each logical operator, such as Scan, may be executed by multiple threads concurrently. Each thread operates on a different operator instance, which has its own ID. |
BASEPLAN_ID |
INTEGER |
Assigned by the optimizer on the initiator to EE operators in the original base (EXPLAIN) plan. Each EE operator in the base plan gets a unique ID. |
PATH_ID |
INTEGER |
Identifier that Vertica assigns to a query operation or path; for example to a logical grouping operation that might be performed by multiple execution engine operators.
For each path, the same PATH ID is shared between the query plan (using EXPLAIN output) and in error messages that refer to joins.
|
LOCALPLAN_ID |
INTEGER |
Identifier assigned by each local executor while preparing for plan execution (local planning). Some operators in the base plan, such as the Root operator, which is connected to the client, do not run on all nodes. Similarly, certain operators, such as ExprEval, are added and removed during local planning due to implementation details. |
ACTIVITY_ID |
INTEGER |
Identifier of the plan activity. |
RESOURCE_ID |
INTEGER |
Identifier of the plan resource. |
COUNTER_NAME |
VARCHAR |
Name of the counter (see Counter Names below). The counter counts events for one statement. |
COUNTER_TAG |
VARCHAR |
String that uniquely identifies the counter for operators that might need to distinguish between different instances. For example, COUNTER_TAG is used to identify to which of the node bytes are being sent to or received from the NetworkSend operator. |
COUNTER_VALUE |
INTEGER |
Value of the counter. |
IS_EXECUTING |
BOOLEAN |
Indicates whether the profile is active or completed. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Counter names
The value of COUNTER_NAME can be any of the following:
active threads- A counter of the LoadUnion operator, indicates the number of input threads (Load operators) that are currently processing input.
blocks analyzed by SIPs expression- Number of data blocks (for scan operations) or files (for load operations) analyzed by SIPS expression.
blocks filtered by SIPs expression- Number of data blocks (for scan operations) or files (for load operations) filtered by SIPS expression.
blocks filtered by SIPs value lists- Number of data blocks (for scan operations) or files (for load operations) filtered by SIPS sorted value lists.
buffers spilled[NetworkSend] Buffers spilled to disk by NetworkSend.bytes read from disk[Scan] Amount of data read (locally or remotely) from ROS containers on disk.bytes read from disk cache[Scan] Amount of data read from cache.bytes received- Number of bytes received over the network for query execution.
bytes sent[NetworkSend] Size of data after encoding and compression sent over the network (actual network bytes).bytes spilled[NetworkSend] Bytes spilled to disk by NetworkSend.bytes total[SendFiles] (recover-by-container plan): Total number of bytes to send/receive.cached storages cumulative size (bytes)[StorageMerge] Total amount of temp space used by operator for caching.cached storages current size (bytes)[StorageMerge] Current amount of temp space used for caching.cached storages peak size (bytes)[StorageMerge] Peak amount of temp space an operator used for caching.clock time (µs)- Real-time clock time spent processing the query, in microseconds.
clock time (µs) of UDChunker- Real-time clock time spent in the UDChunker phase of a load operation, in microseconds. Use the COUNTER_TAG column to distinguish among load sources.
clock time (µs) of UDFilter(s)- Real-time clock time spent in all UDFilter phases of a load operation, in microseconds. Use the COUNTER_TAG column to distinguish among load sources.
clock time (µs) of UDParser- Real-time clock time spent in the UDParser phase of a load operation, in microseconds. Use the COUNTER_TAG column to distinguish among load sources.
clock time (µs) of UDSource- Real-time clock time spent in the UDSource phase of a load operation, in microseconds. Use the COUNTER_TAG column to distinguish among load sources.
completed merge phases- Number of merge phases already completed by an
LSort or DataTarget operator. Compare to the total merge phases. Variants on this value include join inner completed merge phases.
cumulative size of raw temp data (bytes)- Total amount of temporary data the operator has written to files. Compare to
cumulative size of temp files (bytes) to understand impact of encoding and compression in an externalizing operator. Variants on this value include join inner cumulative size of raw temp files (bytes).
cumulative size of temp files (bytes)- For externalizing operators only, the total number of encoded and compressed temp data the operator has written to files. A sort operator might go through multiple merge phases, where at each pass sorted chunks of data are merged into fewer chunks. This counter remembers the cumulative size of all temp files past and present. Variants on this value include
join inner cumulative size of temp files (bytes).
current allocated rid memory (bytes)- Per-rid memory tracking: current allocation amount under this rid.
current file handles- Number of files open.
current memory allocations (count)- Number of actual allocator calls made.
current memory capacity (bytes)- Amount of system memory held, which includes chunks that are only partially consumed.
current memory overhead (bytes)- Memory consumed, for example, by debug headers. (Normally no overhead.)
current memory padding (bytes)- Memory padding for free list tiers (2^n bytes).
current memory requested (bytes)- Memory actually requested by the caller.
current size of temp files (bytes)- For externalizing operators only, the current size of the encoded and compressed temp data that the operator has written to files. Variants on this value
include join inner current size of temp files (bytes).
current threads- Unused.
current unbalanced memory allocations (count)current unbalanced memory capacity (bytes)current unbalanced memory overhead (bytes)current unbalanced memory requested (bytes)- Pooled version of "current memory XXX" counters.
distinct value estimation time (µs)[Analyze Statistics] Time (in microcseconds) spent to estimate number of distinct values from the sample after data is read off disk and into the statistical sample.encoded bytes received[NetworkRecv] Size of received data after decompressed (but still encoded) received over the network.encoded bytes sent[NetworkSend] Size of data sent over the network after encoding.end time- Time (timestamp) when Vertica stopped processing the operation
estimated rows produced- Number of rows that the optimizer estimated would be produced. See
rows produced for the actual number of rows that are produced.
exceptions cumulative size of raw temp data (bytes)exceptions rows cumulative size of temp files (bytes)exceptions rows current size of temp files (bytes)- Counters that store the total or current size of exception data.
execution time (µs)- CPU clock time spent processing the query, in microseconds.
fast aggregated rows- Number of rows being processed by fast aggregations in the hash groupby operator (no group/aggregation).
files completed- Relevant only to
SendFiles/RecvFiles operators (that is, recover-by-container plan) number of files sent/received.
files total- Relevant only to
SendFiles/RecvFiles operators (that is, recover-by-container plan) total number of files to send/receive.
Hadoop FS bytes read through native libhdfs++ client[Scan, Load] Number of bytes read from an hdfs source (using libhdfs++).Hadoop FS bytes read through webhdfs[Scan, Load] Number of bytes read from a webhdfs source.Hadoop FS bytes written through webhdfs[DataTarget] Number of bytes written to webhdfs storage.Hadoop FS hdfs:// operations that used native libhdfs++ calls[Scan, Load, DataTarget] Number of times Vertica opened a file with an hdfs:// URL and used the native hdfs protocolHadoop FS hdfs:// operations that used webhdfs calls[Scan, Load, DataTarget] Number of times Vertica opened a file with an hdfs:// URL and used the webhdfs protocolHadoop FS read operations through native libhdfs++ client failure count[Scan, Load] Number of times a native libhdfs++ source encountered an error and gave upHadoop FS read operations through native libhdfs++ client retry count[Scan, Load] Number of times a native libhdfs++ source encountered an error and retriedHadoop FS read operations through webhdfs failure count[Scan, Load] Number of times a webhdfs source encountered an error and gave upHadoop FS read operations through webhdfs retry count[Scan, Load] Number of times a webhdfs source encountered an error and retriedHadoop FS write operations through webhdfs failure count[DataTarget] Number of times a webhdfs write encountered an error and gave upHadoop FS write operations through webhdfs retry count[DataTarget] Number of times a webhdfs write encountered an error and retriedhistogram creation time(µs)[Analyze Statistics] Time spent estimating the number of distinct values from the sample after data is read off disk and into the statistical sample.initialization time (µs)- Time in microseconds spent initializing an operator during the CompilePlan step of query processing. For example, initialization time could include the time spent compiling expressions and gathering resources.
input queue wait (µs)- Time in microseconds that an operator spends waiting for upstream operators.
input rows- Actual number of rows that were read into the operator.
input size (bytes)- Total number of bytes of the
Load operator's input source, where NULL is unknown (read from FIFO).
inputs processed- Number of sources processed by a Load operator.
intermediate rows to process- Number of rows to process in a phase as determined by a sort or
GROUP BY (HASH).
join inner clock time (µs)- Real clock time spent on processing the inner input of the join operator.
join inner completed mergephasesjoin inner cumulative size of raw temp data (bytes)join inner cumulative size of temp files (bytes)join inner current size of temp files (bytes)- See the
completed merge phases counter.
join inner execution time (µs)- The CPU clock time spent on processing the inner input of the join operator.
join inner hash table building time (µs)- Time spent for building the hash table for the inner input of the join operator.
join inner hash table collisions- Number of hash table collisions that occurred when building the hash table for the inner input of the join operator.
join inner hash table entries- Number of hash table entries for the inner input of the join operator.
join inner total merge phases- See the
completed merge phases counter.
join outer clock time (µs)- Real clock time spent on processing the outer input of the join operator (including doing the join).
join outer execution time (µs)- CPU clock time spent on processing the outer input of the join operator (including doing the join).
max sample size (rows)[Analyze Statistics] Maximum number of rows that will be stored in the statistical sample.memory reserved (bytes)- Memory reserved by this operator. Deprecated.
network wait (µs)[NetworkSend, NetworkRecv] Time in microseconds spent waiting on the network.number of bytes read from persistent storage- Estimated number of bytes read from persistent storage to process this query.
number of bytes read from depot storage- Estimated number of bytes read from the depot to process this query.
number of cancel requests received- Number of cancel requests received (per operator) when cancelling a call to the execution engine.
number of invocations- Number of times a UDSF function was invoked.
number of storage containers opened[Scan] Number of containers opened by the operator, at least 1. If the scan operator switches containers, this counter increases accordingly. See Local caching of storage containers for details.output queue wait (µs)- Time in microseconds that an operator spends waiting for the output buffer to be consumed by a downstream operator.
peak allocated rid memory (bytes)- Per-rid memory tracking: peak allocation amount under this rid.
peak cooperating threads- Peak number of threads which parsed (in parallel) a single load source, using "cooperative parse."
counter_tag indicates the source when joining with dc_load_events.
peak file handlespeak memory allocations (count)peak memory capacity (bytes)peak memory overhead (bytes)peak memory padding (bytes)peak memory requested (bytes)peak temp spacepeak threadspeak unbalanced memory allocations (count)peak unbalanced memory capacity (bytes)peak unbalanced memory overhead (bytes)peak unbalanced memory padding (bytes)peak unbalanced memory requested (bytes)- Peak value of the corresponding "current XXX" counters.
portion offset- Offset value of a portion descriptor in an apportioned load.
counter_tag indicates the source when joining with dc_load_events.
portion size- Size value of a portion descriptor in an apportioned load.
counter_tag indicates the source when joining with dc_load_events.
producer stall (µs)[NetworkSend] Time in microseconds spent by NetworkSend when stalled waiting for network buffers to clear.producer wait (µs)[NetworkSend] Time in microseconds spent by the input operator making rows to send.read (bytes)- Number of bytes read from the input source by the
Load operator.
receive time (µs)- Time in microseconds that a
Recv operator spends reading data from its socket.
rejected data cumulative size of raw temp data (bytes)rejected data cumulative size of temp files (bytes)rejected data current sizeof temp files (bytes)rejected rows cumulative size of raw temp data (bytes)rejected rows cumulative size of temp files (bytes)rejected rows current size of temp files (bytes)- Counters that store total or current size of rejected row numbers. Are variants of:
cumulative size of raw temp data (bytes)
cumulative size of temp files (bytes)
current size of temp files (bytes)
reserved rid memory (bytes)- Per-rid memory tracking: total memory reservation under this rid.
rle rows produced- Number of physical tuples produced by an operator. Complements the
rows produced counter, which shows the number of logical rows produced by an operator. For example, if a value occurs 1000 rows consecutively and is RLE encoded, it counts as 1000 rows produced not only 1 rle rows produced.
ROS blocks bounded[DataTarget] Number of ROS blocks created, due to boundary alignment with RLE prefix columns, when an EE DataTarget operator is writing to ROS containers.ROS blocks encoded[DataTarget] Number of ROS blocks created when an EE DataTarget operator is writing to ROS containers.ROS bytes written[DataTarget] Number of bytes written to disk when an EE DataTarget operator is writing to ROS containers.rows added by predicate analysis- Number of rows in the query results that were added without individual evaluation, based on the predicate and range of possible results in a block.
rows filtered by SIPs expression- Number of rows filtered by the SIPS expression from the Scan operator.
rows filtered by query predicate- Number of rows excluded from query results because they failed a condition (predicate), for example in a WHERE clause.
rows in sample[Analyze Statistics] Actual number of rows that will be stored in the statistical sample.rows output by sort[DataTarget] Number of rows sorted when an EE DataTarget operator is writing to ROS containers.rows processed[DataSource] Number of rows processed when an EE DataSource operator is reading from ROS containers.rows processed by SIPs expression- Number of rows processed by the SIPS expression in the Scan operator.
rows produced- Number of logical rows produced by an operator. See also the
rle rows produced counter.
rows pruned by query predicates- Number of rows discarded from query results because, based on predicates and value ranges, no row in the block could satisfy the predicate.
rows pruned by valindex[DataSource] Number of rows it skips direct scanning with help of valindex when an EE DataSource operator is writing to ROS containers. This counter's value is not greater than "rows processed" counter.rows read in sort- See the counter
total rows read in sort.
rows received[NetworkRecv] Number of received sent over the network.rows rejected- Number of rows rejected by the
Load operator.
rows sent[NetworkSend] Number of rows sent over the network.rows to process- Total number of rows to be processed in a phase, based upon the number of table accesses. Compare to the counter,
rows processed. Divide the rows processed value by the rows to process value for percent completion.
rows written in join sort- Total number of rows being read out of the sort facility in Join.
rows written in sort- Number of rows read out of the sort by the SortManager. This counter and the counter total rows read from sort are typically equal.
send time (µs)- Time in microseconds that a
Send operator spends writing data to its socket.
start time- Time (timestamp) when Vertica started to process the operation.
total merge phases- Number of merge phases an
LSort or DataTarget operator must complete to finish sorting its data. NULL until the operator can compute this value (all data must first be ingested by the operator). Variants on this value include join inner total merge phases.
total rows read in join sort- Total number of rows being put into the sort facility in Join.
total rows read in sort total- Total number of rows ingested into the sort by the SortManager. This counter and the counter rows written in sort are typically equal.
total rows written in sort- See the counter,
rows written in sort.
total sources- Total number of distinct input sources processed in a load.
unpacked (bytes)- Number of bytes produced by a compressed source in a load (for example, for a gzip file, the size of the file when decompressed).
wait clock time (µs)- StorageUnion wait time in microseconds.
written rows[DataTarget] Number of rows written when an EE DataTarget operator writes to ROS containers
Examples
The two queries below show the contents of the EXECUTION_ENGINE_PROFILES table:
=> SELECT operator_name, operator_id, counter_name, counter_value
FROM EXECUTION_ENGINE_PROFILES WHERE operator_name = 'Scan'
ORDER BY counter_value DESC;
operator_name | operator_id | counter_name | counter_value
---------------+-------------+--------------+------------------
Scan | 20 | end time | 1559929719983785
Scan | 20 | start time | 1559929719983737
Scan | 18 | end time | 1559929719983358
Scan | 18 | start time | 1559929718069860
Scan | 16 | end time | 1559929718069319
Scan | 16 | start time | 1559929718069188
Scan | 14 | end time | 1559929718068611
Scan | 18 | end time | 1559929717579145
Scan | 18 | start time | 1559929717579083
Scan | 16 | end time | 1559929717578509
Scan | 18 | end time | 1559929717379346
Scan | 18 | start time | 1559929717379307
Scan | 16 | end time | 1559929717378879
Scan | 16 | start time | 1559929716894312
Scan | 14 | end time | 1559929716893599
Scan | 14 | start time | 1559929716893501
Scan | 12 | end time | 1559929716892721
Scan | 16 | start time | 1559929716666110
...
=> SELECT DISTINCT counter_name FROM execution_engine_profiles;
counter_name
-----------------------------------------------------
reserved rid memory (bytes)
rows filtered by SIPs expression
rows output by sort
chunk rows scanned squared
join inner execution time (us)
current unbalanced memory requested (bytes)
clock time (us)
join outer clock time (us)
exception handling execution time (us)
peak memory capacity (bytes)
bytes received
peak memory requested (bytes)
send time (us)
ROS blocks encoded
current size of temp files (bytes)
peak memory allocations (count)
current unbalanced memory overhead (bytes)
rows segmented
...
The following query includes the path_id column, which links the path that the query optimizer takes (via the EXPLAIN command's textual output) with join error messages.
=> SELECT operator_name, path_id, counter_name, counter_value FROM execution_engine_profiles where operator_name = 'Join';
operator_name | path_id | counter_name | counter_value
---------------+---------+-----------------------------------------------------+------------------
Join | 64 | current memory allocations (count) | 0
Join | 64 | peak memory allocations (count) | 57
Join | 64 | current memory requested (bytes) | 0
Join | 64 | peak memory requested (bytes) | 1698240
Join | 64 | current memory overhead (bytes) | 0
Join | 64 | peak memory overhead (bytes) | 0
Join | 64 | current memory padding (bytes) | 0
Join | 64 | peak memory padding (bytes) | 249840
Join | 64 | current memory capacity (bytes) | 0
Join | 64 | peak memory capacity (bytes) | 294912
Join | 64 | current unbalanced memory allocations (count) | 145
Join | 64 | peak unbalanced memory allocations (count) | 146
Join | 64 | current unbalanced memory requested (bytes) | 116506
Join | 64 | peak unbalanced memory requested (bytes) | 1059111
Join | 64 | current unbalanced memory overhead (bytes) | 3120
Join | 64 | peak unbalanced memory overhead (bytes) | 3120
...
See also
8.2.43 - EXTERNAL_TABLE_DETAILS
Returns the amount of disk storage used by the source files backing external tables in the database.
Returns the amount of disk storage used by the source files backing external tables in the database. The information in this system table is useful in determining Hadoop license compliance.
When computing the size of an external table, Vertica counts all data found in the location specified by the COPY FROM clause. If you have a directory that contains ORC and delimited files, for example, and you define your external table with "COPY FROM *" instead of "COPY FROM *.orc", this table includes the size of the delimited files. (You would probably also encounter errors when querying that external table.) When you query this system table Vertica does not validate your table definition; it just uses the path to find files to report.
Restrict your queries to filter by schema, table, or format to avoid expensive queries. Vertica calculates the values in this table at query time, so "SELECT *" accesses every input file contributing to every external table.
Predicates in queries may use only the TABLE_SCHEMA, TABLE_NAME, and SOURCE_FORMAT columns. Values are case-sensitive.
This table includes TEMP external tables.
This table reports only data that the current user can read. To include all the data backing external tables, either query this table as a user that has access to all HDFS data or use a session delegation token that grants this access. For more information about using delegation tokens, see Accessing kerberized HDFS data.
|
Column Name |
Data Type |
Description |
SCHEMA_OID |
INTEGER |
The unique identification number of the schema in which the external table resides. |
TABLE_NAMESPACE |
VARCHAR |
For Eon Mode databases, namespace that contains the external table. |
TABLE_SCHEMA |
VARCHAR |
The name of the schema in which the external table resides.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
TABLE_OID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the table. |
TABLE_NAME |
VARCHAR |
The table name. |
SOURCE_FORMAT |
VARCHAR |
The data format the source file used, one of ORC, PARQUET, DELIMITED, USER DEFINED, or NULL if another format. |
TOTAL_FILE_COUNT |
INTEGER |
The number of files used to store this table's data, expanding globs and partitions. |
TOTAL_FILE_SIZE_BYTES |
INTEGER |
Total number of bytes used by all of this table's data files. |
SOURCE_STATEMENT |
VARCHAR |
The load statement used to copy data from the source files. |
FILE_ACCESS_ERROR |
VARCHAR |
The access error returned during the source statement. NULL, if there was no access error during the source statement. |
8.2.44 - HIVE_CUSTOM_PARTITIONS_ACCESSED
This table provides information about all custom locations for Hive partition data that Vertica has accessed.
This table provides information about all custom locations for Hive partition data that Vertica has accessed. It applies when Hive uses a non-default location for partition data, the HCatalog Connector is used to access that data, and the CREATE HCATALOG SCHEMA statement for the schema sets the CUSTOM_PARTITIONS parameter.
|
Column Name |
Data Type |
Description |
ACCESS_TIME |
TIMESTAMPTZ |
Time when Vertica accessed the partition data. |
ACCESS_NODE |
VARCHAR(128) |
Name of the node that performed the access. |
TRANSACTION_ID |
INTEGER |
Identifier for the query that produced the access. |
FILESYSTEM |
VARCHAR(128) |
File system of the partition data. This value is the scheme portion of the URL. |
AUTHORITY |
VARCHAR(128) |
If the file system is HDFS, this value is the nameservice. If the file system is S3, it is the name of the bucket. |
URL |
VARCHAR(6400) |
Full path to the partition. |
Privileges
No explicit permissions are required; however, users see only the records that correspond to schemas they have permissions to access.
8.2.45 - HOST_RESOURCES
Provides a snapshot of the node.
Provides a snapshot of the node. This is useful for regularly polling the node with automated tools or scripts.
|
Column Name |
Data Type |
Description |
HOST_NAME |
VARCHAR |
The host name for which information is listed. |
OPEN_FILES_LIMIT |
INTEGER |
The maximum number of files that can be open at one time on the node. |
THREADS_LIMIT |
INTEGER |
The maximum number of threads that can coexist on the node. |
CORE_FILE_LIMIT_MAX_SIZE_BYTES |
INTEGER |
The maximum core file size allowed on the node. |
PROCESSOR_COUNT |
INTEGER |
The number of system processors. |
PROCESSOR_CORE_COUNT |
INTEGER |
The number of processor cores in the system. |
PROCESSOR_DESCRIPTION |
VARCHAR |
A description of the processor. For example: Inter(R) Core(TM)2 Duo CPU T8100 @2.10GHz (1 row) |
OPENED_FILE_COUNT |
INTEGER |
The total number of open files on the node. |
OPENED_SOCKET_COUNT |
INTEGER |
The total number of open sockets on the node. |
OPENED_NONFILE_NONSOCKET_COUNT |
INTEGER |
The total number of other file descriptions open in which 'other' could be a directory or FIFO. It is not an open file or socket. |
TOTAL_MEMORY_BYTES |
INTEGER |
The total amount of physical RAM, in bytes, available on the system. |
TOTAL_MEMORY_FREE_BYTES |
INTEGER |
The amount of physical RAM, in bytes, left unused by the system. |
TOTAL_BUFFER_MEMORY_BYTES |
INTEGER |
The amount of physical RAM, in bytes, used for file buffers on the system |
TOTAL_MEMORY_CACHE_BYTES |
INTEGER |
The amount of physical RAM, in bytes, used as cache memory on the system. |
TOTAL_SWAP_MEMORY_BYTES |
INTEGER |
The total amount of swap memory available, in bytes, on the system. |
TOTAL_SWAP_MEMORY_FREE_BYTES |
INTEGER |
The total amount of swap memory free, in bytes, on the system. |
DISK_SPACE_FREE_MB |
INTEGER |
The free disk space available, in megabytes, for all storage location file systems (data directories). |
DISK_SPACE_USED_MB |
INTEGER |
The disk space used, in megabytes, for all storage location file systems. |
DISK_SPACE_TOTAL_MB |
INTEGER |
The total free disk space available, in megabytes, for all storage location file systems. |
Examples
=> SELECT * FROM HOST_RESOURCES;
-[ RECORD 1 ]------------------+------------------------------------------
host_name | 10.20.100.247
open_files_limit | 65536
threads_limit | 3833
core_file_limit_max_size_bytes | 0
processor_count | 2
processor_core_count | 2
processor_description | Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
opened_file_count | 8
opened_socket_count | 15
opened_nonfile_nonsocket_count | 7
total_memory_bytes | 4018823168
total_memory_free_bytes | 126550016
total_buffer_memory_bytes | 191803392
total_memory_cache_bytes | 2418753536
total_swap_memory_bytes | 2147479552
total_swap_memory_free_bytes | 2145771520
disk_space_free_mb | 18238
disk_space_used_mb | 30013
disk_space_total_mb | 48251
-[ RECORD 2 ]------------------+------------------------------------------
host_name | 10.20.100.248
open_files_limit | 65536
threads_limit | 3833
core_file_limit_max_size_bytes | 0
processor_count | 2
processor_core_count | 2
processor_description | Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
opened_file_count | 8
opened_socket_count | 9
opened_nonfile_nonsocket_count | 7
total_memory_bytes | 4018823168
total_memory_free_bytes | 356466688
total_buffer_memory_bytes | 327278592
total_memory_cache_bytes | 2744279040
total_swap_memory_bytes | 2147479552
total_swap_memory_free_bytes | 2147479552
disk_space_free_mb | 37102
disk_space_used_mb | 11149
disk_space_total_mb | 48251
-[ RECORD 3 ]------------------+------------------------------------------
host_name | 10.20.100.249
open_files_limit | 65536
threads_limit | 3833
core_file_limit_max_size_bytes | 0
processor_count | 2
processor_core_count | 2
processor_description | Intel(R) Xeon(R) CPU E5-2695 v2 @ 2.40GHz
opened_file_count | 8
opened_socket_count | 9
opened_nonfile_nonsocket_count | 7
total_memory_bytes | 4018823168
total_memory_free_bytes | 241610752
total_buffer_memory_bytes | 309395456
total_memory_cache_bytes | 2881675264
total_swap_memory_bytes | 2147479552
total_swap_memory_free_bytes | 2147479552
disk_space_free_mb | 37430
disk_space_used_mb | 10821
disk_space_total_mb | 48251
8.2.46 - IO_USAGE
Provides disk I/O bandwidth usage history for the system.
Provides disk I/O bandwidth usage history for the system.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
START_TIME |
TIMESTAMP |
Beginning of history interval. |
END_TIME |
TIMESTAMP |
End of history interval. |
READ_KBYTES_PER_SEC |
FLOAT |
Counter history of the number of bytes read measured in kilobytes per second. |
WRITTEN_KBYTES_PER_SEC |
FLOAT |
Counter history of the number of bytes written measured in kilobytes per second. |
Privileges
Superuser
8.2.47 - LDAP_LINK_DRYRUN_EVENTS
Collects the results from LDAP dry run meta-functions:.
Collects the results from LDAP dry run meta-functions:
For detailed instructions on using these meta-functions, see Configuring LDAP link with dry runs.
|
Column Name |
Data Type |
Description |
|
EVENT_TIMESTAMP |
TIMESTAMP |
The date and time of an LDAP server and Vertica LDAP Link interaction. |
|
NODE_NAME |
VARCHAR |
The clerk node. |
|
SESSION_ID |
VARCHAR |
The identification number of the LDAP Link session. |
|
USER_ID |
INTEGER |
The unique, system-generated user identification number. |
|
USER_NAME |
VARCHAR |
The name of the user for which the information is listed. |
|
TRANSACTION_ID |
INTEGER |
The system-generated transaction identification number. Is NULL if a transaction id does not exist. |
|
EVENT_TYPE |
VARCHAR |
The result of a dry run. |
|
ENTRY_NAME |
VARCHAR |
The name of the object on which the event occurred, if applicable. For example, the event SYNC-STARTED does not use an object. |
|
ROLE_NAME |
VARCHAR |
The name of a role. |
|
LDAPURIHASH |
INTEGER |
The URI hash number for the LDAP user. |
|
LDAP_URI |
VARCHAR |
The URI for the LDAP server. |
|
BIND_DN |
VARCHAR |
The Distinguished Name used for the dry run bind. |
|
FILTER_GROUP |
VARCHAR |
The group attribute passed to the dry run meta-functions as LDAPLinkFilterGroup. |
|
FILTER_USER |
VARCHAR |
The user attribute passed to the dry run meta-functions as LDAPLinkFilterUser. |
|
LINK_SCOPE |
VARCHAR |
The DN level to replicate, passed to the dry run meta-functions as LDAPLinkScope. |
|
SEARCH_BASE |
VARCHAR |
The DN level from which LDAP Link begins the search, passed to the dry run meta-functions as LDAPLinkSearchBase. |
|
GROUP_MEMBER |
VARCHAR |
Identifies the members of an LDAP group, passed to the dry run meta-functions as LDAPLinkGroupMembers. |
|
GROUP_NAME |
VARCHAR |
The LDAP field to use when creating a role name in Vertica, passed to the dry run meta-functions as LDAPLinkGroupName. |
|
LDAP_USER_NAME |
VARCHAR |
The attribute that identifies individual users, passed to the dry run meta-functions as LDAPLinkUserName. |
|
TLS_REC_CERT |
VARCHAR |
The connection policy used for the dry run connection for certificate management. This connection policy is set through the LDAPLink TLS Configuration. |
|
TLS_CA_CERT |
VARCHAR |
The CA certificate used for the dry run connection specified by the LDAPLink TLS Configuration. |
8.2.48 - LDAP_LINK_EVENTS
Monitors events that occurred during an LDAP Link synchronization.
Monitors events that occurred during an LDAP Link synchronization.
|
Column Name |
Data Type |
Description |
EVENT_TIMESTAMP |
TIMESTAMP |
The time the event occurred. |
NODE_NAME |
VARCHAR |
The name of the node or nodes for which the information is listed. |
SESSION_ID |
VARCHAR |
The identification number of the LDAP Link session. |
USER_ID |
INTEGER |
The unique, system-generated user identification number. |
USER_NAME |
VARCHAR |
The name of the user for which the information is listed. |
TRANSACTION_ID |
INTEGER |
The system-generated transaction identification number. Is NULL if a transaction id does not exist. |
EVENT_TYPE |
VARCHAR |
The type of event being logged, for example USER_CREATED and PROCESSING_STARTED. |
ENTRY_NAME |
VARCHAR |
The name of the object on which the event occurred, if applicable. For example, the event SYNC-STARTED does not use an object. |
ENTRY_OID |
INTEGER |
The unique identification number for the object on which the event occurred, if applicable. |
LDAPURIHASH |
INTEGER |
The URI hash number for the LDAP user. |
8.2.49 - LOAD_SOURCES
Like LOAD_STREAMS, monitors active and historical load metrics on each node.
Like LOAD_STREAMS, monitors active and historical load metrics on each node. The LOAD_SOURCES table breaks information down by source and portion. Rows appear in this table only for COPY operations that are profiled or run for more than one second. LOAD_SOURCES does not record information about loads from ORC or Parquet files or COPY LOCAL.
A row is added to this table when the loading of a source or portion begins. Column values related to the progress of the load are updated during the load operation.
Columns that uniquely identify the load source (the various ID and name columns) and column IS_EXECUTING always have non-NULL values.
|
Column Name |
Data Type |
Description |
|
SESSION_ID |
VARCHAR |
Identifier of the session for which Vertica captures load stream information. This identifier is unique within the cluster for the current session but can be reused in a subsequent session. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within a session. If a session is active, but no transaction has begun, this value is NULL. |
|
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID uniquely identifies a statement within a session. |
|
STREAM_NAME |
VARCHAR |
Load stream identifier. If the user does not supply a specific name, the STREAM_NAME default value is tablename-ID, where:
This system table includes stream names for every COPY statement that takes more than 1 second to run. The 1-second duration includes the time to plan and execute the statement.
|
|
SCHEMA_NAME |
VARCHAR |
Schema name for which load information is listed. Lets you identify two streams that are targeted at tables with the same name in different schemas. NULL, if selecting from an external table. |
|
TABLE_OID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog that identifies the table. NULL, if selecting from an external table. |
|
TABLE_NAME |
VARCHAR |
Name of the table being loaded. NULL, if selecting from an external table. |
|
NODE_NAME |
VARCHAR |
Name of the node loading the source. |
|
SOURCE_NAME |
VARCHAR |
-
Full file path if copying from a file.
-
Value returned by getUri() if the source is a user-defined source.
-
STDIN if loading from standard input.
|
|
PORTION_OFFSET |
INTEGER |
Offset of the source portion, or NULL if not apportioned. |
|
PORTION_SIZE |
INTEGER |
Size of the source portion, or NULL if not apportioned. |
|
IS_EXECUTING |
BOOLEAN |
Whether this source is currently being parsed, where t is true and f is false. |
|
READ_BYTES |
INTEGER |
Number of bytes read from the input file. |
|
ROWS_PRODUCED |
INTEGER |
Number of rows produced from parsing the source. |
|
ROWS_REJECTED |
INTEGER |
Number of rows rejected from parsing the source. If CopyFaultTolerantExpressions is true, also includes rows rejected during expression evaluation. |
|
INPUT_SIZE |
INTEGER |
Size of the input source in bytes, or NULL for unsized sources. For UDSources, this value is the value returned by getSize(). |
|
PARSE_COMPLETE_PERCENT |
INTEGER |
Percent of rows from the input file that have been parsed. |
|
FAILURE_REASON |
VARCHAR |
Indicates cause for failure, one of the following:
- Load source aborted, error message indicates cause. For example:
COPY: Could not open file [filename] for reading; Permission denied
- Load canceled, displays error message:
Statement interrupted
In all other cases, set to NULL.
|
|
PEAK_COOPERATING_THREADS |
INTEGER |
The peak number of threads parsing this source in parallel. |
|
CLOCK_TIME_SOURCE |
INTEGER |
Displays in real-time how many microseconds (µs) have been consumed by the UDSource phase of a load operation. |
|
CLOCK_TIME_FILTERS |
INTEGER |
Displays in real-time how many microseconds (µs) have been consumed by all UDFilter phases of a load operation. |
|
CLOCK_TIME_CHUNKER |
INTEGER |
Displays in real-time how many microseconds (µs) have been consumed by the UDChunker phase of a load operation. |
|
CLOCK_TIME_PARSER |
INTEGER |
Displays in real-time how many microseconds (µs) have been consumed by the UDParser phase of a load operation. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.50 - LOAD_STREAMS
Monitors active and historical load metrics for load streams.
Monitors active and historical load metrics for load streams. This is useful for obtaining statistics about how many records got loaded and rejected from the previous load. Vertica maintains system table metrics until they reach a designated size quota (in kilobytes). This quota is set through internal processes, which you cannot set or view directly.
|
Column Name |
Data Type |
Description |
SESSION_ID |
VARCHAR |
Identifier of the session for which Vertica captures load stream information. This identifier is unique within the cluster for the current session, but can be reused in a subsequent session. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within a session. If a session is active but no transaction has begun, this is NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID uniquely identifies a statement within a session. |
STREAM_NAME |
VARCHAR |
Load stream identifier. If the user does not supply a specific name, the STREAM_NAME default value is:
tablename-ID
where tablename is the table into which data is being loaded, and ID is an integer value, guaranteed to be unique with the current session on a node.
This system table includes stream names for every COPY statement that takes more than 1-second to run. The 1-second duration includes the time to plan and execute the statement.
|
SCHEMA_NAME |
VARCHAR |
Schema name for which load stream information is listed. Lets you identify two streams that are targeted at tables with the same name in different schemas |
TABLE_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the table. |
TABLE_NAME |
VARCHAR |
Name of the table being loaded. |
LOAD_START |
VARCHAR |
Linux system time when the load started. |
LOAD_DURATION_MS |
NUMERIC(54,0) |
Duration of the load stream in milliseconds. |
IS_EXECUTING |
BOOLEAN |
Indicates whether the load is executing, where t is true and f is false. |
ACCEPTED_ROW_COUNT |
INTEGER |
Number of rows loaded. |
REJECTED_ROW_COUNT |
INTEGER |
Number of rows rejected. |
READ_BYTES |
INTEGER |
Number of bytes read from the input file. |
INPUT_FILE_SIZE_BYTES |
INTEGER |
Size of the input file in bytes.
Note: When using STDIN as input, the input file size is zero (0).
|
PARSE_COMPLETE_PERCENT |
INTEGER |
Percent of rows from the input file that have been parsed. |
UNSORTED_ROW_COUNT |
INTEGER |
Cumulative number rows not sorted across all projections.
Note: UNSORTED_ROW_COUNT could be greater than ACCEPTED_ROW_COUNT because data is copied and sorted for every projection in the target table.
|
SORTED_ROW_COUNT |
INTEGER |
Cumulative number of rows sorted across all projections. |
SORT_COMPLETE_PERCENT |
INTEGER |
Percent of rows from the input file that have been sorted. |
Privileges
If you have the SYSMONITOR role or are the dbadmin user, this table shows all loads. Otherwise it shows only your loads.
8.2.51 - LOCK_USAGE
Provides aggregate information about lock requests, releases, and attempts, such as wait time/count and hold time/count.
Provides aggregate information about lock requests, releases, and attempts, such as wait time/count and hold time/count. Vertica records:
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information on which lock interaction occurs. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
OBJECT_NAME |
VARCHAR |
Name of object being locked; can be a table or an internal structure (projection, global catalog, or local catalog). |
MODE |
VARCHAR |
Intended operations of the transaction. Otherwise, this value is NONE. For a list of lock modes and compatibility, see Lock modes. |
AVG_HOLD_TIME |
INTERVAL |
Average time (measured in intervals) that Vertica holds a lock. |
MAX_HOLD_TIME |
INTERVAL |
Maximum time (measured in intervals) that Vertica holds a lock. |
HOLD_COUNT |
INTEGER |
Total number of times the lock was granted in the given mode. |
AVG_WAIT_TIME |
INTERVAL |
Average time (measured in intervals) that Vertica waits on the lock. |
MAX_WAIT_TIME |
INTERVAL |
Maximum time (measured in intervals) that Vertica waits on a lock. |
WAIT_COUNT |
INTEGER |
Total number of times lock was unavailable at the time it was first requested. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
8.2.52 - LOCKS
Monitors lock grants and requests for all nodes.
Monitors lock grants and requests for all nodes. If no locks are active, a query on LOCKS returns no rows.
|
Column Name |
Data Type |
Description |
NODE_NAMES |
VARCHAR |
Comma-separated list of nodes where lock interaction occurs.
A transaction can have the same lock in the same mode in the same scope on multiple nodes. However, the transaction gets only one line in the table.
|
OBJECT_NAME |
VARCHAR |
Name of object to lock, either a table or an internal structure: projection, global catalog, or local catalog. |
OBJECT_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog that identifies the object to lock. |
TRANSACTION_ID |
VARCHAR |
Identifier of transaction within the session, if any; otherwise NULL. Transaction IDs can be used to join other system tables. |
TRANSACTION_DESCRIPTION |
VARCHAR |
Identifier of transaction and associated description. Typically, this query caused the transaction's creation. |
LOCK_MODE |
VARCHAR |
Transaction's lock type. |
LOCK_SCOPE |
VARCHAR |
Expected duration of the lock after it is granted. Before the lock is granted, Vertica lists the scope as REQUESTED.
After a lock is granted, its scope is set to one of the following:
-
STATEMENT_LOCALPLAN
-
STATEMENT_COMPILE
-
STATEMENT_EXECUTE
-
TRANSACTION_POSTCOMMIT
-
TRANSACTION
All scopes other than TRANSACTION are transient and used only as part of normal query processing.
|
REQUEST_TIMESTAMP |
TIMESTAMP |
Time when the transaction began waiting on the lock. |
GRANT_TIMESTAMP |
TIMESTAMP |
Time the transaction acquired or upgraded the lock:
-
Return values are NULL until the grant occurs.
-
If the grant occurs immediately, values might be the same as REQUEST_TIMESTAMP.
|
See also
8.2.53 - LOG_ROTATE_EVENTS
Lists the rotation events from do_logrotate_local.
Lists the rotation events from DO_LOGROTATE_LOCAL.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node from which logs were rotated. |
SUCCESS |
BOOLEAN |
Whether the call to DO_LOGROTATE_LOCAL succeeded. |
MAX_SIZE |
INTEGER |
The size, in bytes, set for LogRotateMaxSize. |
MAX_AGE |
INTEGER |
The age, in days, set for LogRotateMaxAge. |
LOG_FILE |
VARCHAR |
The path of the original log file. |
NEED_ROTATION |
BOOLEAN |
Whether the LOG_FILE needed to be rotated. |
MESSAGE |
VARCHAR |
The actions performed by DO_LOGROTATE_LOCAL for LOG_FILE. |
Example
To view all successful rotation events:
=> SELECT * FROM log_rotate_events WHERE need_rotation='t' AND success='t';
-[ RECORD 1 ]-+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------
node_name | v_vmart_node0001
success | t
max_size | 104857600
max_age | 7
log_file | /scratch_b/VMart/v_vmart_node0001_catalog/vertica.log
need_rotation | t
message | /scratch_b/VMart/v_vmart_node0001_catalog/vertica.log was rotated to /scratch_b/VMart/v_vmart_node0001_catalog/vertica.log.2023-12-08-15-18-26-965729-05.gz due to force rotation
-[ RECORD 2 ]-+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------------
node_name | v_vmart_node0001
success | t
max_size | 104857600
max_age | 7
log_file | /scratch_b/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log
need_rotation | t
message | /scratch_b/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log was rotated to /scratch_b/VMart/v_vmart_node0001_catalog/UDxLogs/UDxFencedProcesses.log.2023-12-15-13-18-27-23141-05.gz due to force rotation
8.2.54 - LOGIN_FAILURES
This system table lists failures for each failed login attempt.
This system table lists failures for each failed login attempt. This information helps you determine if a user is having difficulty getting into the database or identify a possible intrusion attempt.
|
Column Name |
Data Type |
Description |
LOGIN_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica recorded the login. |
DATABASE_NAME |
VARCHAR |
The name of the database for the login attempt. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_NAME |
VARCHAR |
Name of the user whose login failed at the time Vertica recorded the session. |
CLIENT_HOSTNAME |
VARCHAR |
Host name and port of the TCP socket from which the client connection was made. NULL if the session is internal. |
CLIENT_PID |
INTEGER |
Identifier of the client process that issued this connection.
In some cases, the client process is on a different machine from the server.
|
CLIENT_VERSION |
VARCHAR |
Unused. |
CLIENT_OS_USER_NAME |
VARCHAR |
The name of the user that logged into, or attempted to log into, the database. This is logged even when the login attempt is unsuccessful. |
AUTHENTICATION_METHOD |
VARCHAR |
Name of the authentication method used to validate the client application or user who is trying to connect to the server using the database user name provided
Valid values:
-
Trust
-
Reject
-
GSS
-
LDAP
-
Ident
-
Hash
-
TLS
See Configuring client authentication for further information.
|
CLIENT_AUTHENTICATION_NAME |
VARCHAR |
Locally created name of the client authentication method. |
REASON |
VARCHAR |
Description of login failure reason.
Valid values:
-
INVALID USER
-
ACCOUNT LOCKED
-
REJECT
-
FAILED
-
INVALID AUTH METHOD
-
INVALID DATABASE
|
Privileges
Superuser
8.2.55 - MEMORY_EVENTS
Records events related to Vertica memory usage.
Records events related to Vertica memory usage.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Node where the event occurred |
EVENT_TIME |
TIMESTAMPTZ |
Event start time |
EVENT_TYPE |
VARCHAR |
Type of event, one of the following:
-
MEMORY_REPORT: The Vertica memory poller created a report on memory usage, for the reason specified in EVENT_REASON. For details, see Memory usage reporting.
-
MALLOC_TRIM: Vertica ran the glibc function malloc_trim() to reclaim glibc-allocated memory. For details, see Memory trimming.
|
EVENT_REASON |
VARCHAR |
Reason for the event—for example, trim threshold was greater than RSS / available-memory. |
EVENT_DETAILS |
VARCHAR |
Additional information about the event—for example, how much memory malloc_trim() reclaimed. |
DURATION_US |
INTEGER |
Duration of the event in microseconds (µs). |
Privileges
None
Examples
=> SELECT * FROM MEMORY_EVENTS;
-[ RECORD 1 ]-+-----------------------------------------------------------------
event_time | 2019-05-02 13:17:20.700892-04
node_name | v_vmart_node0001
event_type | MALLOC_TRIM
event_reason | memory_trim()
event_details | pre-trim RSS 378822656 post-trim RSS 372129792 benefit 0.0176675
duration_us | 7724
8.2.56 - MEMORY_USAGE
Records system resource history for memory usage.
Records system resource history for memory usage. This is useful for comparing memory that Vertica uses versus memory in use by the entire system.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
START_TIME |
TIMESTAMP |
Beginning of history interval. |
END_TIME |
TIMESTAMP |
End of history interval. |
AVERAGE_MEMORY_USAGE_PERCENT |
FLOAT |
Records the average memory usage in percent of total memory (0-100) during the history interval. |
Privileges
Superuser
8.2.57 - MERGEOUT_PROFILES
Returns information about and status of automatic mergeout operations.
Returns information about and status of automatic mergeout operations.
This table excludes operations with a REQUEST_TYPE of NO_WORK. It also excludes the operations of user-invoked mergeout functions, such as DO_TM_TASK.
|
Column Name |
Data Type |
Description |
|
START_TIME |
TIMESTAMP |
When the Tuple Mover began processing storage location mergeout requests. |
|
END_TIME |
TIMESTAMP |
When the mergeout finished. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session. |
|
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
|
SCHEMA_NAME |
VARCHAR |
The schema for which information is listed. |
|
TABLE_NAME |
VARCHAR |
The table for which information is listed. |
|
PROJECTION_NAME |
VARCHAR |
The projection for which information is listed. |
|
PROJECTION_OID |
INTEGER |
Projection's unique catalog identifier. |
|
REQUEST_TYPE |
VARCHAR |
Identifies the type of operation performed by the tuple mover. Possible values:
-
PURGE
-
MERGEOUT
-
DVMERGEOUT
|
|
EVENT_TYPE |
VARCHAR |
Displays the status of the mergeout operation. Possible values:
-
ERROR
-
RETRY
-
REQUEST_QUEUED
-
REQUEST_COMPLETED
|
|
THREAD_ID |
INTEGER |
The ID of the thread that performed the mergeout. |
|
STRATA_NO |
INTEGER |
The ID of the strata the ROS container belongs to. |
|
PARTITION_KEY |
INTEGER |
The key of the partition. |
|
CONTAINER_COUNT |
INTEGER |
The number of ROS containers in the mergeout operation. |
|
TOTAL_SIZE_IN_BYTES |
INTEGER |
Size in bytes of all ROS containers in the mergeout operation. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
To following statement returns failed mergeout operations for table public.store_orders.
=> SELECT node_name, schema_name, table_name, request_type, event_type FROM mergeout_profiles WHERE event_type='ERROR';
node_name | schema_name | table_name | request_type | event_type
------------------+-------------+--------------+--------------+------------
v_vmart_node0002 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0002 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0001 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0001 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0003 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0003 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0003 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0002 | public | store_orders | MERGEOUT | ERROR
v_vmart_node0001 | public | store_orders | MERGEOUT | ERROR
(9 rows)
See also
8.2.58 - MODEL_STATUS_HISTORY
Lists the status history of registered machine learning models in the database, including models that have been unregistered or dropped.
Lists the status history of registered machine learning models in the database, including models that have been unregistered or dropped. Only superusers or users to whom superusers have granted sufficient privileges can query the table. Vertica recommends granting access to the MLSUPERVISOR role.
|
Column Name |
Data Type |
Description |
REGISTERED_NAME |
VARCHAR |
Abstract name to which the model, identified by MODEL_ID, was registered at the time of the status change. This REGISTERED_NAME can represent a group of models for a higher-level application, where each model in the group has a unique version number. |
REGISTERED_VERSION |
INTEGER |
Unique version number of the registered model under its specified REGISTERED_NAME. |
NEW_STATUS |
VARCHAR |
New status of the registered model. |
OLD_STATUS |
VARCHAR |
Old status of the registered model. |
STATUS_CHANGE_TIME |
TIMESTAMPTZ |
Time at which the model status was changed. |
OPERATOR_ID |
INTEGER |
Internal ID of the user who performed the status change. |
OPERATOR_NAME |
VARCHAR |
Name of the user who performed the status change. |
MODEL_ID |
INTEGER |
Internal ID of the model for which information is listed. |
SCHEMA_NAME |
VARCHAR |
Name of the schema that contains the model. This value is NULL if the model has been dropped. |
MODEL_NAME |
VARCHAR |
Name of the model. This value is NULL if the model has been dropped.
Each existing model can be uniquely identified by either its [schema_name.]model_name or the combination of its REGISTERED_NAME and REGISTERED_VERSION.
|
Example
If a superuser grants SELECT access of the table to the MLSUPERVISOR role, users with that role can then query the MODEL_STATUS_HISTORY table:
-- as superuser
=> GRANT SELECT ON TABLE v_monitor.model_status_history TO MLSUPERVISOR;
WARNING 8555: You are granting privilege on a system table used by superuser only. Revoke the grant if you are unsure
GRANT PRIVILEGE
-- as user with MLSUPERVISOR role
=> SELECT * FROM MODEL_STATUS_HISTORY;
registered_name | registered_version | new_status | old_status | status_change_time | operator_id | operator_name | model_id | schema_name | model_name
-----------------+--------------------+--------------+------------- +-------------------------------+-------------+---------------+------------+-------------+-------------------
app1 | 1 | UNDER_REVIEW | UNREGISTERED | 2023-01-29 09:09:00.082166-05 | 1224567790 | u1 | 0113756739 | public | native_linear_reg
app1 | 1 | STAGING | UNDER_REVIEW | 2023-01-29 11:33:02.052464-05 | 2341679901 | supervisor1 | 0113756739 | public | native_linear_reg
app1 | 1 | PRODUCTION | STAGING | 2023-01-30 04:12:30.481136-05 | 2341679901 | supervisor1 | 0113756739 | public | native_linear_reg
(3 rows)
See also
8.2.59 - MONITORING_EVENTS
Reports significant events that can affect database performance and functionality if you do not address their root causes.
Reports significant events that can affect database performance and functionality if you do not address their root causes.
See Monitoring events for details.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
EVENT_CODE |
INTEGER |
Numeric identifier that indicates the type of event. See Event Types in Monitoring events for a list of event type codes. |
EVENT_ID |
INTEGER |
Unique numeric ID that identifies the specific event. |
EVENT_SEVERITY |
VARCHAR |
Severity of the event from highest to lowest. These events are based on standard syslog severity types:
0 – Emergency
1 – Alert
2 – Critical
3 – Error
4 – Warning
5 – Notice
6 – Info
7 – Debug
|
EVENT_POSTED_TIMESTAMP |
TIMESTAMPTZ |
When this event was posted. |
EVENT_CLEARED_TIMESTAMP |
TIMESTAMPTZ |
When this event was cleared.
Note: You can also query the ACTIVE_EVENTS system table to see events that have not been cleared.
|
EVENT_EXPIRATION |
TIMESTAMPTZ |
Time at which this event expires. If the same event is posted again prior to its expiration time, this field gets updated to a new expiration time. |
EVENT_CODE_DESCRIPTION |
VARCHAR |
Brief description of the event and details pertinent to the specific situation. |
EVENT_PROBLEM_DESCRIPTION |
VARCHAR |
Generic description of the event. |
Privileges
Superuser
See also
ACTIVE_EVENTS
8.2.60 - NETWORK_INTERFACES
Provides information about network interfaces on all Vertica nodes.
Provides information about network interfaces on all Vertica nodes.
|
Column Name |
Data Type |
Description |
|
NODE_ID |
INTEGER |
Unique identifier for the node that recorded the row. |
|
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
|
INTERFACE |
VARCHAR |
Network interface name. |
|
IP_ADDRESS_FAMILY |
VARCHAR |
Network address family (either 'ipv4' or 'ipv6'). |
|
IP_ADDRESS |
VARCHAR |
IP address for this interface. |
|
SUBNET |
VARCHAR |
IP subnet for this interface. |
|
MASK |
VARCHAR |
IP network mask for this interface. |
|
BROADCAST_ADDRESS |
VARCHAR |
IP broadcast address for this interface. |
Privileges
None
Examples
=> \x
Expanded display is on.
=> SELECT * FROM network_interfaces ORDER BY node_name ASC LIMIT 14;
-[ RECORD 1 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | lo
ip_address_family | ipv6
ip_address | ::1
subnet | ::1
mask | ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff
broadcast_address |
-[ RECORD 2 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | ens192
ip_address_family | ipv6
ip_address | fd9b:1fcc:1dc4:78d3::31
subnet | fd9b:1fcc:1dc4:78d3::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
-[ RECORD 3 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | lo
ip_address_family | ipv4
ip_address | 127.0.0.1
subnet | 127.0.0.0
mask | 255.0.0.0
broadcast_address | 127.0.0.1
-[ RECORD 4 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | ens192
ip_address_family | ipv4
ip_address | 192.168.111.31
subnet | 192.168.111.0
mask | 255.255.255.0
broadcast_address | 192.168.111.255
-[ RECORD 5 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | ens32
ip_address_family | ipv4
ip_address | 10.20.110.21
subnet | 10.20.110.0
mask | 255.255.255.0
broadcast_address | 10.20.110.255
-[ RECORD 6 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | ens32
ip_address_family | ipv6
ip_address | fe80::250:56ff:fe8e:61d3
subnet | fe80::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
-[ RECORD 7 ]-----+----------------------------------------
node_id | 45035996273704982
node_name | v_verticadb_node0001
interface | ens192
ip_address_family | ipv6
ip_address | fe80::250:56ff:fe8e:2721
subnet | fe80::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
-[ RECORD 8 ]-----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | lo
ip_address_family | ipv6
ip_address | ::1
subnet | ::1
mask | ffff:ffff:ffff:ffff:ffff:ffff:ffff:ffff
broadcast_address |
-[ RECORD 9 ]-----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | ens192
ip_address_family | ipv6
ip_address | fd9b:1fcc:1dc4:78d3::32
subnet | fd9b:1fcc:1dc4:78d3::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
-[ RECORD 10 ]----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | lo
ip_address_family | ipv4
ip_address | 127.0.0.1
subnet | 127.0.0.0
mask | 255.0.0.0
broadcast_address | 127.0.0.1
-[ RECORD 11 ]----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | ens192
ip_address_family | ipv4
ip_address | 192.168.111.32
subnet | 192.168.111.0
mask | 255.255.255.0
broadcast_address | 192.168.111.255
-[ RECORD 12 ]----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | ens32
ip_address_family | ipv4
ip_address | 10.20.110.22
subnet | 10.20.110.0
mask | 255.255.255.0
broadcast_address | 10.20.110.255
-[ RECORD 13 ]----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | ens32
ip_address_family | ipv6
ip_address | fe80::250:56ff:fe8e:1787
subnet | fe80::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
-[ RECORD 14 ]----+----------------------------------------
node_id | 45035996273841968
node_name | v_verticadb_node0002
interface | ens192
ip_address_family | ipv6
ip_address | fe80::250:56ff:fe8e:2c9c
subnet | fe80::
mask | ffff:ffff:ffff:ffff::
broadcast_address |
8.2.61 - NETWORK_USAGE
Provides network bandwidth usage history on the system.
Provides network bandwidth usage history on the system. This is useful for determining if Vertica is using a large percentage of its available network bandwidth.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
START_TIME |
TIMESTAMP |
Beginning of history interval. |
END_TIME |
TIMESTAMP |
End of history interval. |
TX_KBYTES_PER_SEC |
FLOAT |
Counter history of outgoing (transmitting) usage in kilobytes per second. |
RX_KBYTES_PER_SEC |
FLOAT |
Counter history of incoming (receiving) usage in kilobytes per second. |
Privileges
Superuser
8.2.62 - NODE_EVICTIONS
Monitors node evictions on the system.
Monitors node evictions on the system.
|
Column Name |
Data Type |
Description |
EVICTION_TIMESTAMP |
TIMESTAMPTZ |
Timestamp when the eviction request was made. |
NODE_NAME |
VARCHAR |
The node name logging the information. |
EVICTED_NODE_NAME |
VARCHAR |
The node name of the evicted node. |
EVICTED_NODE_ID |
INTEGER |
The evicted node ID. |
NODE_STATE_BEFORE_EVICTION |
VARCHAR |
The previous node state at the time of eviction. |
8.2.63 - NODE_RESOURCES
Provides a snapshot of the node.
Provides a snapshot of the node. This is useful for regularly polling the node with automated tools or scripts.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
|
HOST_NAME |
VARCHAR |
The hostname associated with a particular node. |
|
NODE_IDENTIFIER |
VARCHAR |
A unique identifier for the node. |
|
PROCESS_SIZE_BYTES |
INTEGER |
The total size of the program. |
|
PROCESS_RESIDENT_SET_SIZE_BYTES |
INTEGER |
The total number of bytes that the process has in memory. |
|
PROCESS_SHARED_MEMORY_SIZE_BYTES |
INTEGER |
The amount of shared memory used. |
|
PROCESS_TEXT_MEMORY_SIZE_BYTES |
INTEGER |
The total number of text bytes that the process has in physical memory. This does not include any shared libraries. |
|
PROCESS_DATA_MEMORY_SIZE_BYTES |
INTEGER |
The amount of physical memory, in bytes, used for performing processes. This does not include the executable code. |
|
PROCESS_LIBRARY_MEMORY_SIZE_BYTES |
INTEGER |
The total number of library bytes that the process has in physical memory. |
|
PROCESS_DIRTY_MEMORY_SIZE_BYTES |
INTEGER |
The number of bytes that have been modified since they were last written to disk. |
|
SPREAD_HOST |
VARCHAR |
The node name of the spread host. |
|
NODE_PORT |
VARCHAR |
The port used for intra-cluster communication. |
|
DATA_PORT |
VARCHAR |
The port used by the Vertica client. |
|
DBCLERK |
BOOLEAN |
Whether this node is the DB clerk. The DB clerk is responsible for coordinating some administrative tasks in the database. |
8.2.64 - NODE_STATES
Monitors node recovery state-change history on the system.
Monitors node recovery state-change history on the system. Vertica returns information only on nodes whose state is currently UP. To determine which nodes are not up, query the NODES table.
|
Column Name |
Data Type |
Description |
EVENT_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica recorded the event. |
NODE_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies thenode. |
NODE_NAME |
VARCHAR |
Name of the node. |
NODE_STATE |
VARCHAR |
The node's state, one of the following:
-
UP
-
DOWN
-
READY
-
UNSAFE
-
SHUTDOWN
-
SHUTDOWN_ERROR
-
RECOVERING
-
RECOVER_ERROR
-
RECOVERED
-
INITIALIZING
-
STANDBY
-
NEEDS_CATCHUP
|
The following flow chart details different node states:
Privileges
None
8.2.65 - NOTIFIER_ERRORS
Reports errors encountered by notifiers.
Reports errors encountered by notifiers.
|
Column Name |
Data Type |
Description |
ERROR_TIME |
TIMESTAMPTZ |
The time that the error occurred. |
NODE_NAME |
VARCHAR |
Name of the node that encountered the error. |
NOTIFIER_NAME |
VARCHAR |
Name of the notifier that triggered the error. |
DESCRIPTION |
VARCHAR |
A description of the error. |
Privileges
Superuser
8.2.66 - OUTPUT_DEPLOYMENT_STATUS
Contains information about the deployment status of all the projections in your design.
Contains information about the deployment status of all the projections in your design. Each row contains information about a different projection. Vertica populates this table when you deploy the database design by running the function
DESIGNER_RUN_POPULATE_DESIGN_AND_DEPLOY.
|
Column Name |
Column Type |
Description |
deployment_id |
INTEGER |
Unique ID that Database Designer assigned to the deployment. |
design_name |
VARCHAR |
Unique name that the user assigned to the design. |
deployment_projection_id |
INTEGER |
Unique ID that Database Designer assigned to the output projection. |
deployment_projection_name |
VARCHAR |
Name that Database Designer assigned to the output projection or the name of the projection to be dropped. |
deployment_status |
VARCHAR |
Status of the deployment:
-
pending
-
complete
-
needs_refresh
-
in_progress
-
error
|
error_message |
VARCHAR |
Text of any error that occurred when creating or refreshing the specified projection. |
8.2.67 - OUTPUT_EVENT_HISTORY
Contains information about each stage that Database Designer performs to design and optimize your database design.
Contains information about each stage that Database Designer performs to design and optimize your database design.
|
Column Name |
Data Type |
Description |
|
TIME_STAMP |
TIMESTAMP |
Date and time of the specified stage. |
|
DESIGN_ID |
INTEGER |
Unique id that Database Designer assigned to the design. |
|
DESIGN_NAME |
VARCHAR |
Unique name that the user assigned to the design. |
|
STAGE_TYPE |
VARCHAR |
Design stage that Database Designer was working on at the time indicated by the TIME_STAMP field. Possible values include:
-
Design in progress
-
Analyzing data statistics
-
Optimizing query performance
-
Optimizing storage footprint
-
All done
-
Deployment in progress
|
|
ITERATION_NUMBER |
INTEGER |
Iteration number for the Optimizing query performance stage. |
|
TOTAL_QUERY_COUNT |
INTEGER |
Total number of design queries in the design. |
|
REMAINING_QUERY_COUNT |
INTEGER |
Number of design queries remaining for Database Designer to process. |
|
MAX_STEP_NUMBER |
INTEGER |
Number of steps in the current stage. |
|
CURRENT_STEP_NUMBER |
INTEGER |
Step in the current stage being processed at the time indicated by the TIME_STAMP field. |
|
CURRENT_STEP_DESCRIPTION |
VARCHAR |
Name of the step that Database Designer is performing at that time indicated in the TIME_STAMP field. Possible values include:
-
Design with deployment started
-
Design in progress: Analyze statistics phase
-
design_table_name
-
projection_name
-
Design in progress: Query optimization phase
-
Extracting interesting columns
-
Enumerating sort orders
-
Setting up projection candidates
-
Assessing projection candidates
-
Choosing best projections
-
Calculating estimated benefit of best projections
-
Complete
-
Design in progress: Storage optimization phase
-
Design completed successfully
-
Setting up deployment metadata
-
Identifying projections to be dropped
-
Running deployment
-
Deployment completed successfully
|
|
TABLE_ID |
INTEGER |
Unique id that Database Designer assigned to the design table. |
Examples
The following example shows the steps that Database Designer performs while optimizing the VMart example database:
=> SELECT DESIGNER_CREATE_DESIGN('VMART_DESIGN');
=> SELECT DESIGNER_ADD_DESIGN_TABLES('VMART_DESIGN','public.*');
=> SELECT DESIGNER_ADD_DESIGN_QUERIES('VMART_DESIGN','/tmp/examples/vmart_queries.sql',);
...
=> \x
Expanded display is on.
=> SELECT * FROM OUTPUT_EVENT_HISTORY;
-[ RECORD 1 ] -----------+----------------------------
time_stamp | 2013-06-05 11:44:41.588
design_id | 45035996273705090
design_name | VMART_DESIGN
stage_type | Design in progress
iteration_number |
total_query_count |
remaining_query_count |
max_step_number |
current_step_number |
current_step_description | Design with deployment started
table id |
-[ RECORD 2 ] -----------+----------------------------
time_stamp | 2013-06-05 11:44:41.611
design_id | 45035996273705090
design_name | VMART_DESIGN
stage_type | Design in progress
iteration_number |
total_query_count |
remaining_query_count |
max_step_number |
current_step_number |
current_step_description | Design in progress: Analyze statistics phase
table id |
-[ RECORD 3 ] -----------+----------------------------
time_stamp | 2013-06-05 11:44:42.011
design_id | 45035996273705090
design_name | VMART_DESIGN
stage_type | Analyzing statistics
iteration_number |
total_query_count |
remaining_query_count |
max_step_number | 15
current_step_number | 1
current_step_description | public.customer_dimension
table id |
...
-[ RECORD 20 ] ----------+----------------------------
time_stamp | 2013-06-05 11:44:49.324
design_id | 45035996273705090
design_name | VMART_DESIGN
stage_type | Optimizing query performance
iteration_number | 1
total_query_count | 9
remaining_query_count | 9
max_step_number | 7
current_step_number | 1
current_step_description | Extracting interesting columns
table id |
...
-[ RECORD 62 ] ----------+----------------------------
time_stamp | 2013-06-05 11:51:23.790
design_id | 45035996273705090
design_name | VMART_DESIGN
stage_type | Deployment in progress
iteration_number |
total_query_count |
remaining_query_count |
max_step_number |
current_step_number |
current_step_description | Deployment completed successfully
table id |
8.2.68 - PARTITION_COLUMNS
For each projection of a partitioned table, shows the following information:.
For each projection of a partitioned table, shows the following information:
Disk usage
The column DISK_SPACE_BYTES shows how much disk space the partitioned data uses, including deleted data. So, if you delete rows but do not purge them, the DELETED_ROW_COUNT column changes to show the number of deleted rows in each column; however, DISK_SPACE_BYTES remains unchanged. After deleted rows are purged, Vertica,reclaims the disk space: DISK_SPACE_BYTES changes accordingly, and DELETED_ROW_COUNT is reset to 0.
For grouped partitions, PARTITION_COLUMNS shows the cumulative disk space used for each column per grouped partition. The column GROUPED_PARTITION_KEY, if not null, identifies the partition in which a given column is grouped.
Statistics
STATISTICS_TYPE always shows the most complete type of statistics that are available on a given column, irrespective of timestamp. For example, if you collect statistics for a table on all levels—table, partition, and row, STATISTICS_TYPE is set to FULL (table-level), even if partition- and row-level statistics were collected more recently.
|
Column Name |
Data Type |
Description |
|
COLUMN_NAME |
VARCHAR |
Identifies a named column within the partitioned table. |
|
COLUMN_ID |
INTEGER |
Unique numeric ID assigned by the Vertica, which identifies the column. |
|
TABLE_NAME |
VARCHAR |
Name of the partitioned table. |
|
PROJECTION_NAME |
VARCHAR |
Projection name for which information is listed. |
|
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by Vertica, which identifies the projection. |
|
NODE_NAME |
VARCHAR |
Node that hosts partitioned data. |
|
PARTITION_KEY |
VARCHAR |
Identifies the table partition. |
|
GROUPED_PARTITION_KEY |
VARCHAR |
Identifies the grouped partition to which a given column belongs. |
|
ROW_COUNT |
INTEGER |
The total number of partitioned data rows for each column, including deleted rows. |
|
DELETED_ROW_COUNT |
INTEGER |
Number of deleted partitioned data rows in each column. |
|
DISK_SPACE_BYTES |
INTEGER |
Amount of space used by partitioned data. |
|
STATISTICS_TYPE |
VARCHAR |
Specifies what sort of statistics are used for this column, one of the following listed in order of precedence:
-
FULL: Table-level statistics
-
PARTITION: Partition-level statistics
-
ROWCOUNT: Minimal set of statistics and aggregate row counts
|
|
STATISTICS_UPDATED_TIMESTAMP |
TIMESTAMPTZ |
Specifies when statistics of the type specified in STATISTICS_TYPE were collected for this column. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
Given the following table definition:
=> CREATE TABLE messages
(
time_interval timestamp NOT NULL,
thread_id varchar(32) NOT NULL,
unique_id varchar(53) NOT NULL,
msg_id varchar(65),
...
)
PARTITION BY ((messages.time_interval)::date);
a query on partition_columns might return the following (truncated) results:
=> SELECT * FROM partition_columns order by table_name, column_name;
column_name | column_id | table_name | projection_name | projection_id | node_name | partition_key | grouped_partition_key | row_count | deleted_row_count | disk_space_bytes
---------------------------+----------+----------------+-------------------+------------------+---------------+------------------------+-----------+-------------------+------------------
msg_id | 45035996273743190 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-03 | | 6147 | 0 | 41145
msg_id | 45035996273743190 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-15 | | 178 | 0 | 65
msg_id | 45035996273743190 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-03 | | 6782 | 0 | 45107
msg_id | 45035996273743190 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-04 | | 866 | 0 | 5883
...
thread_id | 45035996273743186 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-03 | | 6147 | 0 | 70565
thread_id | 45035996273743186 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-15 | | 178 | 0 | 2429
thread_id | 45035996273743186 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-03 | | 6782 | 0 | 77730
thread_id | 45035996273743186 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-04 | | 866 | 0 | 10317
...
time_interval | 45035996273743184 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-03 | | 6147 | 0 | 6320
time_interval | 45035996273743184 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-15 | | 178 | 0 | 265
time_interval | 45035996273743184 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-03 | | 6782 | 0 | 6967
time_interval | 45035996273743184 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-04 | | 866 | 0 | 892
...
unique_id | 45035996273743188 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-03 | | 6147 | 0 | 70747
unique_id | 45035996273743188 | messages | messages_super | 45035996273743182 | v_vmart_node0002 | 2010-07-15 | | 178 | 0 | 2460
unique_id | 45035996273743188 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-03 | | 6782 | 0 | 77959
unique_id | 45035996273743188 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-04 | | 866 | 0 | 10332
unique_id | 45035996273743188 | messages | messages_super | 45035996273743182 | v_vmart_node0003 | 2010-07-15 | | 184 | 0 | 2549
...
(11747 rows)
8.2.69 - PARTITION_REORGANIZE_ERRORS
new column projection_id.
Monitors all background partitioning tasks, and if Vertica encounters an error, creates an entry in this table with the appropriate information. Does not log repartitioning tasks that complete successfully.
|
Column Name |
Data Type |
Description |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
USER_NAME |
VARCHAR |
Name of the user who received the error at the time Vertica recorded the session. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
TABLE_NAME |
VARCHAR |
Name of the partitioned table. |
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
PROJECTION_NAME |
VARCHAR |
Projection name for which information is listed. |
MESSAGE |
VARCHAR |
Textual output of the error message. |
HINT |
VARCHAR |
Actionable hint about the error. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.70 - PARTITION_STATUS
For each projection of each partitioned table, shows the fraction of its data that is actually partitioned according to the current partition expression.
For each projection of each partitioned table, shows the fraction of its data that is actually partitioned according to the current partition expression. When the partitioning of a table is altered, the value in PARTITION_REORGANIZE_PERCENT for each of its projections drops to zero and goes back up to 100 when all the data is repartitioned.
|
Column Name |
Data Type |
Description |
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
TABLE_SCHEMA |
VARCHAR |
Name of the schema that contains the partitioned table. |
TABLE_NAME |
VARCHAR |
Table name that is partitioned. |
TABLE_ID |
INTEGER |
Unique numeric ID assigned by the Vertica, which identifies the table. |
PROJECTION_SCHEMA |
VARCHAR |
Schema containing the projection. |
PROJECTION_NAME |
VARCHAR |
Projection name for which information is listed. |
PARTITION_REORGANIZE_PERCENT |
INTEGER |
For each projection, drops to zero and goes back up to 100 when all the data is repartitioned after the partitioning of a table has been altered. Ideally all rows will show 100 (%). |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.71 - PARTITIONS
Displays partition metadata, one row per partition key, per ROS container.
Displays partition metadata, one row per partition key, per ROS container.
|
Column Name |
Data Type |
Description |
PARTITION_KEY |
VARCHAR |
The partition value(s). |
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
TABLE_SCHEMA |
VARCHAR |
The schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed. |
ROS_ID |
VARCHAR |
A unique numeric ID assigned by the Vertica catalog, which identifies the ROS container. |
ROS_SIZE_BYTES |
INTEGER |
The ROS container size in bytes. |
ROS_ROW_COUNT |
INTEGER |
Number of rows in the ROS container. |
NODE_NAME |
VARCHAR |
Node where the ROS container resides. |
DELETED_ROW_COUNT |
INTEGER |
The number of deleted rows in the partition. |
LOCATION_LABEL |
VARCHAR |
The location label of the default storage location. |
Notes
-
A many-to-many relationship exists between partitions and ROS containers. PARTITIONS displays information in a denormalized fashion.
-
To find the number of ROS containers having data of a specific partition, aggregate PARTITIONS over the partition_key column.
-
To find the number of partitions stored in a ROS container, aggregate PARTITIONS over the ros_id column.
Examples
See Viewing partition storage data.
8.2.72 - PROCESS_SIGNALS
Returns a history of signals that were received and handled by the Vertica process.
Returns a history of signals that were received and handled by the Vertica process. For details about signals, see the Linux documentation.
|
Column Name |
Data Type |
Description |
SIGNAL_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica recorded the signal. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
SIGNAL_NUMBER |
INTEGER |
Signal number, refers to POSIX SIGNAL_NUMBER |
SIGNAL_CODE |
INTEGER |
Signal code. |
SIGNAL_PID |
INTEGER |
Linux process identifier of the signal. |
SIGNAL_UID |
INTEGER |
Process ID of sending process. |
SIGNAL_ADDRESS |
INTEGER |
Address at which fault occurred. |
Privileges
Superuser
8.2.73 - PROJECTION_RECOVERIES
Retains history about projection recoveries.
Retains history about projection recoveries. Because Vertica adds an entry per recovery plan, a projection/node pair might appear multiple times in the output.
Note
You cannot query this or other system tables during cluster recovery; the cluster must be UP to accept connections.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is recovering or has recovered the corresponding projection. |
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
PROJECTION_NAME |
VARCHAR |
Name of the projection that is being or has been recovered on the corresponding node. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any. TRANSACTION_ID initializes as NO_TRANSACTION with a value of 0. Vertica will ignore the recovery query and keep (0) if there's no action to take (no data in the table, etc). When no recovery transaction starts, ignored value appears in this table's STATUS column. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID uniquely identifies a statement within a session. |
METHOD |
VARCHAR |
Recovery method that Vertica chooses. Possible values are:
|
STATUS |
VARCHAR |
Current projection-recovery status on the corresponding node. STATUS can be "queued," which indicates a brief period between the time the query is prepared and when it runs. Possible values are:
-
queued
-
running
-
finished
-
ignored
-
error-retry
-
error-fatal
|
PROGRESS |
INTEGER |
An estimate (value in the range [0,100]) of percent complete for the recovery task described by this information.
Note: The actual amount of time it takes to complete a recovery task depends on a number of factors, including concurrent workloads and characteristics of the data; therefore, accuracy of this estimate can vary.
The PROGRESS column value is NULL after the task completes.
|
DETAIL |
VARCHAR |
More detailed information about PROGRESS. The values returned for this column depend on the type of recovery plan:
-
General recovery plans – value displays the estimated progress, as a percent, of the three primary parts of the plan: Scan, Sort, and Write.
-
Recovery-by-container plans – value begins with CopyStorage: and is followed by the number of bytes copied over the total number of bytes to copy.
-
Replay delete plans – value begins with Delete: and is followed by the number of deletes replayed over an estimate of the total number of deletes to replay.
The DETAIL column value becomes NULL after the recovery plan completes.
|
START_TIME |
TIMESTAMPTZ |
Time the recovery task described by this information started. |
END_TIME |
TIMESTAMPTZ |
Time the recovery task described by this information ended. |
RUNTIME_PRIORITY |
VARCHAR |
Determines the amount of runtime resources (CPU, I/O bandwidth) the Resource Manager should dedicate to running queries in the resource pool. Valid values are:
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
RECOVERY_STATUS
8.2.74 - PROJECTION_REFRESHES
Records information about successful and unsuccessful refresh operations. PROJECTION_REFRESHES retains projection refresh data until one of the following events occurs:
-
Another refresh operation starts on a given projection.
-
CLEAR_PROJECTION_REFRESHES is called and clears data on all projections.
-
The table's storage quota is exceeded.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Node where the refresh was initiated. |
|
PROJECTION_SCHEMA |
VARCHAR |
Name of the projection schema. |
|
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
|
PROJECTION_NAME |
VARCHAR |
Name of the refreshed projection. |
|
ANCHOR_TABLE_NAME |
VARCHAR |
Name of the projection's anchor table. |
|
REFRESH_STATUS |
VARCHAR |
Status of refresh operations for this projection, one of the following:
-
Queued : Projection is queued for refresh.
-
Refreshing: Projection refresh is in progress.
-
Refreshed: Projection refresh is complete.
-
Failed: Projection refresh failed.
|
|
PERCENT_COMPLETE |
VARCHAR |
Shows the current percentage of completion for the refresh operation. When the refresh is complete, the column is set to NULL. |
|
REFRESH_PHASE |
VARCHAR |
Indicates how far the refresh has progressed:
-
Historical: Refresh reached the first phase and is refreshing data from historical data. This refresh phase requires the most amount of time.
-
Current: Refresh reached the final phase and is attempting to refresh data from the current epoch. To complete this phase, refresh must obtain a lock on the table. If the table is locked by another transaction, refresh is blocked until that transaction completes.
The LOCKS system table is useful for determining if a refresh is blocked on a table lock. To determine if a refresh has been blocked, locate the term "refresh" in the transaction description. A refresh has been blocked when the scope for the refresh is REQUESTED and other transactions acquired a lock on the table.
This field is NULL until the projection starts to refresh and is NULL after the refresh completes.
|
|
REFRESH_METHOD |
VARCHAR |
Method used to refresh the projection:
-
Buddy: Projection refreshed from the contents of a buddy projection. This method maintains historical data, so the projection can be used for historical queries.
-
Scratch: Projection refreshed without using a buddy projection. This method does not generate historical data, so the projection cannot participate in historical queries on data that precedes the refresh.
-
Rebalance: If the projection is segmented, it is refreshed from scratch; if unsegmented, it is refreshed from a buddy projection.
-
Incremental: Projections of a partitioned table were refreshed one partition at a time. For details, see Refreshing projections.
|
|
REFRESH_FAILURE_COUNT |
INTEGER |
Number of times a refresh failed for the projection. REFRESH_FAILURE_COUNT does not indicate whether the projection was eventually refreshed. See REFRESH_STATUS to determine whether the refresh operation is progressing. |
|
SESSION_ID |
VARCHAR |
Unique numeric ID assigned by the Vertica catalog, which identifies the refresh session. |
|
REFRESH_START |
TIMESTAMPTZ |
Time the projection refresh started. |
|
REFRESH_DURATION_SEC |
INTERVAL SECOND (0) |
How many seconds the projection refresh ran. |
|
IS_EXECUTING |
BOOLEAN |
Differentiates active and completed refresh operations. |
|
RUNTIME_PRIORITY |
VARCHAR |
Determines how many run-time resources (CPU, I/O bandwidth) the Resource Manager should dedicate to running queries in the resource pool, one of the following:
|
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL.
Note
The transaction_id is correlated with the execution plan only when refreshing from scratch. When refreshing from a buddy, multiple sub-transactions are created
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.75 - PROJECTION_STORAGE
Monitors the amount of disk storage used by each projection on each node.
Monitors the amount of disk storage used by each projection on each node.
Note
Projections that have no data never have full statistics. Querying this system table lets you see if your projection contains data.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
|
PROJECTION_ID |
VARCHAR |
Catalog-assigned numeric value that uniquely identifies the projection. |
|
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed. |
|
PROJECTION_SCHEMA |
VARCHAR |
The name of the schema associated with the projection. |
|
PROJECTION_COLUMN_COUNT |
INTEGER |
The number of columns in the projection. |
|
ROW_COUNT |
INTEGER |
The number of rows in the table's projections, including any rows marked for deletion. |
|
USED_BYTES |
INTEGER |
Number of bytes in disk storage used to store the compressed projection data. This value should not be compared to the output of the AUDIT function, which returns the raw data size of database objects. |
|
ROS_COUNT |
INTEGER |
The number of ROS containers in the projection. |
|
ANCHOR_TABLE_NAME |
VARCHAR |
The associated table name for which information is listed. |
|
ANCHOR_TABLE_SCHEMA |
VARCHAR |
The associated table schema for which information is listed. |
|
ANCHOR_TABLE_ID |
INTEGER |
A unique numeric ID, assigned by the Vertica catalog, which identifies the anchor table. |
See also
8.2.76 - PROJECTION_USAGE
Records information about projections Vertica used in each processed query.
Records information about projections Vertica used in each processed query.
|
Column Name |
Data Type |
Description |
QUERY_START_TIMESTAMP |
TIMESTAMPTZ |
Value of query at beginning of history interval. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_NAME |
VARCHAR |
Name of the user at the time Vertica recorded the session. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identifies a statement within a session. |
IO_TYPE |
VARCHAR |
Input/output. |
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
PROJECTION_NAME |
VARCHAR |
Projection name for which information is listed. |
ANCHOR_TABLE_ID |
INTEGER |
Unique numeric ID assigned by the Vertica, which identifies the anchor table. |
ANCHOR_TABLE_SCHEMA |
VARCHAR |
Name of the schema that contains the anchor table. |
ANCHOR_TABLE_NAME |
VARCHAR |
Name of the projection's associated anchor table. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.77 - QUERY_CONSUMPTION
Summarizes execution of individual queries.
Summarizes execution of individual queries. Columns STATEMENT_ID and TRANSACTION_ID combine as unique keys to these queries. One exception applies: a query with multiple plans has as many records.
|
Column Name |
Data Type |
Description |
START_TIME END_TIME |
TIMESTAMP |
Demarcate the start and end of query execution, whether successful or not. |
SESSION_ID |
VARCHAR |
Identifies the session where profiling information was captured. This identifier is unique within the cluster at any point in time, but can be reused when the session closes. |
USER_ID |
INTEGER |
Unique numeric user identifier assigned by the Vertica catalog. |
USER_NAME |
VARCHAR |
User name specified by this query profile. |
TRANSACTION_ID |
INTEGER |
Identifies the transaction in which the query ran. |
STATEMENT_ID |
INTEGER |
Numeric identifier of this query, unique within the query transaction. |
CPU_CYCLES_US |
INTEGER |
Sum, in microseconds, of CPU cycles spent by all threads to process this query. |
NETWORK_BYTES_SENT NETWORK_BYTES_RECEIVED |
INTEGER |
Total amount of data sent/received over the network by execution engine operators. |
DATA_BYTES_READ DATA_BYTES_WRITTEN |
INTEGER |
Total amount of data read/written by storage operators from and to disk, includes all locations: local, HDFS, S3. |
DATA_BYTES_LOADED |
INTEGER |
Total amount of data loaded from external sources: COPY, external tables, and data load. |
BYTES_SPILLED |
INTEGER |
Total amount of data spilled to disk—for example, by SortManager, Join, and NetworkSend operators. |
INPUT_ROWS |
INTEGER |
Number of unfiltered input rows from DataSource and Load operators. INPUT_ROWS shows the number of input rows that the query plan worked with, but excludes intermediate processing. For example, INPUT_ROWS excludes how many times SortManager spilled and read the same row. |
INPUT_ROWS_PROCESSED |
INTEGER |
Value of INPUT_ROWS minus what was filtered by applying query predicates (valindex) and SIPs, and rows rejected by COPY. |
PEAK_MEMORY_KB |
INTEGER |
Peak memory reserved by the resource manager for this query. |
THREAD_COUNT |
INTEGER |
Maximum number of threads opened to process this query. |
DURATION_MS |
INTEGER |
Total wall clock time, in milliseconds, spent to process this query. |
RESOURCE_POOL |
VARCHAR |
Name of the resource pool where the query was executed. |
OUTPUT_ROWS |
INTEGER |
Number of rows output to the client. |
REQUEST_TYPE |
VARCHAR |
Type of query—for example, QUERY or DDL. |
LABEL |
VARCHAR |
Label included as a LABEL hint in this query. |
IS_RETRY |
BOOLEAN |
This query was tried earlier. |
SUCCESS |
BOOLEAN |
This query executed successfully. |
8.2.78 - QUERY_EVENTS
Returns information about query planning, optimization, and execution events.
Returns information about query planning, optimization, and execution events.
|
Column Name |
Data Type |
Description |
|
EVENT_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica recorded the event. |
|
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
|
USER_ID |
INTEGER |
Identifier of the user for the query event. |
|
USER_NAME |
VARCHAR |
Name of the user for which Vertica lists query information at the time it recorded the session. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
REQUEST_ID* |
INTEGER |
Unique identifier of the query request in the user session. |
|
TRANSACTION_ID* |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL. |
|
STATEMENT_ID* |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. |
|
EVENT_CATEGORY |
VARCHAR |
Category of event: OPTIMIZATION or EXECUTION. |
|
EVENT_TYPE |
VARCHAR |
Type of event. For details on each type, see the following sections:
|
|
EVENT_DESCRIPTION |
VARCHAR |
Generic description of the event. |
|
OPERATOR_NAME |
VARCHAR |
Name of the Execution Engine component that generated the event, if applicable; for example, NetworkSend. Values from the OPERATOR_NAME and PATH_ID columns let you tie a query event back to a particular operator in the query plan. If the event did not come from a specific operator, the OPERATOR_NAME column is NULL. |
|
PATH_ID |
INTEGER |
Unique identifier that Vertica assigns to a query operation or path in a query plan, NULL if the event did not come from a specific operaton.
For more information, see EXECUTION_ENGINE_PROFILES.
|
|
OBJECT_ID |
INTEGER |
Object identifier such as projection or table to which the event refers. |
|
EVENT_DETAILS |
VARCHAR |
Free-form text describing the specific event. |
|
EVENT_SEVERITY |
VARCHAR |
Indicates severity of the event with one of the following values:
-
Informational: No action required
-
Warning: Remedial action recommended as specified in SUGGESTED_ACTION
-
Critical: Remedial action required, as specified by SUGGESTED_ACTION
|
|
SUGGESTED_ACTION |
VARCHAR |
Specifies remedial action, recommended or required as indicated by EVENT_SEVERITY. |
- CSE ANALYSIS
- The optimizer performed Common subexpressions analysis
- CSE ANALYSIS STATS
- Time spent on Common subexpressions analysis (msec)
- EXPRESSION_EVAL_ERROR
- An exception occurred during evaluation of an expression
- EXTERNAL_DATA_FILES_PRUNED
- Vertica skipped external data files (for example, Iceberg files) that could not satisfy predicates in the query. The event details include the number and paths of pruned files.
- EXTERNAL_PREDICATE_PUSHDOWN_NOT_SUPPORTED
- Predicate pushdown for older Hive versions may not be supported. For more information, see Querying external tables.
- FLATTENED SUBQUERIES
- Subqueries flattened in FROM clause
- GROUP_BY_PREPASS_FALLBACK
- Vertica could not run an optimization. In-memory prepass is disabled. The projection may not be optimal.
- GROUPBY PUSHDOWN
- Internal to Vertica
- LibHDFS++ FAILOVER RETRY
- Vertica attempted to contact a NameNode on an HDFS cluster that uses High Availability NameNode and did not receive a response. Vertica retried with a different NameNode.
- LibHDFS++ MANUAL FALLBACK
- Vertica accessed HDFS using the hdfs URL scheme but HDFSUseWebHDFS is set. Vertica fell back to WebHDFS.
- LibHDFS++ UNSUPPORTED OPERATION
- Vertica accessed HDFS using the hdfs URL scheme, but the HDFS cluster uses an unsupported feature such as wire encryption or HTTPS_ONLY or the Vertica session uses delegation tokens. Vertica fell back to WebHDFS.
- MERGE_CONVERTED_TO_UNION
- Vertica has converted a merge operator to a union operator due to the sort order of the multi-threaded storage access stream.
- NO GROUPBY PUSHDOWN
- Internal to Vertica
- NODE PRUNING
- Vertica performed node pruning, which is similar to partition pruning, but at the node level.
- ORC_FILE_INFO
- A query of ORC files encountered missing information (such as time zone) or an unrecognized ORC version. For missing information, Vertica uses a default value (such as the local time zone).
- ORC_SOURCE_PRUNED
- An entire ORC file was pruned during predicate pushdown.
- ORC_STRIPES_PRUNED
- The identified stripes were pruned during predicate pushdown. If an entire ORC file was pruned, it is instead recorded with an ORC_SOURCE_PRUNED event.
- OUTER OVERRIDE NOT USED
- Vertica found swapping inner/outer tables in a join unnecessary because the inner/outer tables were in good order. (For example, a smaller table was used in an inner join.)
- OUTER OVERRIDE USED
- For efficiency and optimization, Vertica has swapped the inner/outer tables in a join. Vertica used the smaller table as the inner table.
- PARQUET_ROWGROUPS_PRUNED
- The identified row groups were pruned during predicate pushdown.
- PARTITION_PATH_PRUNED
- A path (reported in event details) was pruned.
- PARTITION_PATH_REJECTED
- Could not evaluate partition column predicate on a path from source list. Path will be rejected.
- PARTITION_PRUNING
- COPY pruned partitions. The event reports how many paths were pruned, and PARTITION_PATH_PRUNED events record more details.
- PREDICATES_DISCARDED_FROM_SCAN
- Some predicates have been discarded from this scan because expression analysis shows they are not needed.
- REJECT_ROWNUMS_HIT_BUFFER_LIMIT
- Buffering row numbers during rejection hit buffer limit
- SEQUENCE CACHE REFILLED
- Vertica has refilled sequence cache.
- SIP_FALLBACK
- This optimization did not apply to this query type.
- SMALL_MERGE_REPLACED
- Vertica has chosen a more efficient way to access the data by replacing a merge.
- STORAGE_CONTAINERS_ELIMINATED
- Vertica has performed partition pruning for the purpose of optimization.
- TRANSITIVE PREDICATE
- Vertica has optimized by adding predicates to joins where it makes logical sense to do so.
For example, for the statement, SELECT * FROM A, B WHERE A.a = B.a AND A.a = 1;Vertica may add a predicate B a = 1 as a filter for better storage access of table B.
- TYPE_MISMATCH_COLUMNS_PARQUETPARSER
- The Parquet parser used loose schema matching to load data, and could not coerce values in the Parquet data to the types defined for the table. By default the parser rejects the row. For more information, see PARQUET.
- UNMATCHED_TABLE_COLUMNS_PARQUETPARSER
- The Parquet parser used loose schema matching to load data, and columns in the table had no corresponding columns in the data. The columns were given values of NULL.
- VALUE_TRUNCATED
- A character value is too long.
- WEBHDFS FAILOVER RETRY
- Vertica attempted to contact a NameNode on an HDFS cluster that uses High Availability NameNode and did not receive a response. Vertica retried with a different NameNode.
Warning event types
- AUTO_PROJECTION_USED
- The optimizer used an auto-projection to process this query.
Recommendation: Create a projection that is appropriate for this query and others like it; consider using Database Designer to generate query-specific projections.
- GROUP_BY_SPILLED
- This event type is typically related to a specific type of query, which you might need to adjust.
Recommendation: Identify the type of query and make adjustments accordingly. You might need to adjust resource pools, projections, or the amount of RAM available. Try running the query on a cluster with no additional workload.
- INVALID COST
- When creating a query plan, the optimizer calculated an invalid cost for a path: not-a-number (NaN) value, infinity value, or negative value. The path cost was set to its default value.
No action available to users.
- PATTERN_MATCH_NMEE
- More than one pattern event is true for a single row
Recommendation: Modify event expressions to ensure that only one event can be true for any row. Alternatively, modify the query using a MATCH clause with ROWS MATCH FIRST EVENT.
- PREDICATE OUTSIDE HISTOGRAM
- A predicate value you are trying to match does not exist in a set of possible values for a specific column. For example, you try to match a VARCHAR value WHERE mystring = "ABC<newline>". In this case, the newline character throws off the predicate matching optimizations.
Recommendation: Run ANALYZE_STATISTICS on the column.
- RESEGMENTED_MANY_ROWS
- This event type is typically related to a specific type of query, which you might need to adjust.
Recommendation: Do projections need to be segmented in a different way to allow for join locality? Can you rewrite the query to filter out more rows at storage access time? (Typically, Vertica does so automatically through predicate pushdown.) Review your explain plan.
- RLE_OVERRIDDEN
- The average run counts are not large enough for Run Length Encoding (RLE). This event occurs with queries where the filtered results for certain columns do not work with RLE because cardinality is less than 10.
Recommendation: Review and rewrite your query, if necessary.
Critical event types
- DELETE WITH NON OPTIMIZED PROJECTION
- One or more projections do not have your delete filter column in their sort order, causing Vertica difficulty identifying ros to mark as deleted.
To resolve: Add the delete filter column to the end of every projection sort order for your target delete table.
- JOIN_SPILLED
- Vertica has spilled a join to disk. A join spill event slows down the subject query and all other queries as it consumes resources while using disk as virtual memory.
To resolve: Try the following:
-
Review the explain plan. The query might be too ambitious, for example, cross joining two large tables.
-
Consider adding the query to a lower priority pool to reduce impact on other queries.
-
Create projections that allow for a merge join instead of a hash join.
-
Adjust the PLANNEDCONCURRENCYresource pool so that queries have more memory to execute.
- MEMORY LIMIT HIT
- Indicates query complexity or, possibly, lack of available system memory.
To resolve: Consider adjusting the MAXMEMORYSIZE and PLANNEDCONCURRENCY resource pools so that the optimizer has sufficient memory. On a heavily used system, this event may occur more frequently.
- NO HISTOGRAM
- Indicates a table does not have an updated column histogram.
To resolve: Running the function ANALYZE_STATISTICS most often corrects this issue.
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
8.2.79 - QUERY_METRICS
Monitors the sessions and queries running on each node.
Monitors the sessions and queries running on each node.
Note
Totals in this table are reset each time the database restarts.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
ACTIVE_USER_SESSION_COUNT |
INTEGER |
The number of active user sessions (connections). |
ACTIVE_SYSTEM_SESSION_COUNT |
INTEGER |
The number of active system sessions. |
TOTAL_USER_SESSION_COUNT |
INTEGER |
The total number of user sessions. |
TOTAL_SYSTEM_SESSION_COUNT |
INTEGER |
The total number of system sessions. |
TOTAL_ACTIVE_SESSION_COUNT |
INTEGER |
The total number of active user and system sessions. |
TOTAL_SESSION_COUNT |
INTEGER |
The total number of user and system sessions. |
RUNNING_QUERY_COUNT |
INTEGER |
The number of queries currently running. |
EXECUTED_QUERY_COUNT |
INTEGER |
The total number of queries that ran. |
8.2.80 - QUERY_PLAN_PROFILES
Provides detailed execution status for queries that are currently running in the system.
Provides detailed execution status for queries that are currently running in the system. Output from the table shows the real-time flow of data and the time and resources consumed for each path in each query plan.
|
Column Name |
Data Type |
Description |
TRANSACTION_ID |
INTEGER |
An identifier for the transaction within the session if any; otherwise NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a statement within a session; these columns are useful for creating joins with other system tables. |
PATH_ID |
INTEGER |
Unique identifier that Vertica assigns to a query operation or path in a query plan. Textual representation for this path is output in the PATH_LINE column. |
PATH_LINE_INDEX |
INTEGER |
Each plan path in QUERY_PLAN_PROFILES could be represented with multiple rows. PATH_LINE_INDEX returns the relative line order. You should include the PATH_LINE_INDEX column in the QUERY_PLAN_PROFILES ... ORDER BY clause so rows in the result set appear as they do in EXPLAIN-generated query plans. |
PATH_IS_EXECUTING |
BOOLEAN |
Status of a path in the query plan. True (t) if the path has started running, otherwise false. |
PATH_IS_COMPLETE |
BOOLEAN |
Status of a path in the query plan. True (t) if the path has finished running, otherwise false. |
IS_EXECUTING |
BOOLEAN |
Status of a running query. True if the query is currently active (t), otherwise false (f). |
RUNNING_TIME |
INTERVAL |
The amount of elapsed time the query path took to execute. |
MEMORY_ALLOCATED_BYTES |
INTEGER |
The amount of memory the path used, in bytes. |
READ_FROM_DISK_BYTES |
INTEGER |
The number of bytes the path read from disk (or the disk cache). |
RECEIVED_BYTES |
INTEGER |
The number of bytes received over the network. |
SENT_BYTES |
INTEGER |
Size of data sent over the network by the path. |
PATH_LINE |
VARCHAR |
The query plan text string for the path, associated with the PATH ID and PATH_LINE_INDEX columns. |
Privileges
Non-superusers see only the records of tables they have permissions to view.
Best practices
Table results can be very wide. For best results when you query QUERY_PLAN_PROFILES, sort on these columns:
-
TRANSACTION_ID
-
STATEMENT_ID
-
PATH_ID
-
PATH_LINE_INDEX
For example:
=> SELECT ... FROM query_plan_profiles
WHERE ...
ORDER BY transaction_id, statement_id, path_id, path_line_index;
Examples
See Profiling query plans
See also
8.2.81 - QUERY_PROFILES
Provides information about executed queries.
Provides information about executed queries.
|
Column Name |
Data Type |
Description |
SESSION_ID |
VARCHAR |
The identification of the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
TRANSACTION_ID |
INTEGER |
An identifier for the transaction within the session if any; otherwise NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID uniquely identifies a statement within a session. |
IDENTIFIER |
VARCHAR |
A string to identify the query in system tables.
Note: You can query the IDENTIFIER column to quickly identify queries you have labeled for profiling and debugging. See Labeling statements for details.
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
QUERY |
VARCHAR |
The query string used for the query. |
QUERY_SEARCH_PATH |
VARCHAR |
A list of schemas in which to look for tables. |
SCHEMA_NAME |
VARCHAR |
The schema name in which the query is being profiled, set only for load operations. |
TABLE_NAME |
VARCHAR |
The table name in the query being profiled, set only for load operations. |
QUERY_DURATION_US |
NUMERIC(18,0) |
The duration of the query in microseconds. |
QUERY_START_EPOCH |
INTEGER |
The epoch number at the start of the given query. |
QUERY_START |
VARCHAR |
The Linux system time of query execution in a format that can be used as a DATE/TIME expression. |
QUERY_TYPE |
VARCHAR |
Is one of INSERT, SELECT, UPDATE, DELETE, UTILITY, or UNKNOWN. |
ERROR_CODE |
INTEGER |
The return error code for the query. |
USER_NAME |
VARCHAR |
The name of the user who ran the query. |
PROCESSED_ROW_COUNT |
INTEGER |
The number of rows returned by the query. |
RESERVED_EXTRA_MEMORY_B |
INTEGER |
Shows how much unused memory (in bytes) remains that is reserved for a given query but is unassigned to a specific operator. This is the memory from which unbounded operators pull first.
The MEMORY_INUSE_KB column in system table
RESOURCE_ACQUISITIONS shows how much total memory was acquired for each query.
If operators acquire all memory acquired for the query, the plan must request more memory from the Vertica resource manager.
|
IS_EXECUTING |
BOOLEAN |
Displays information about actively running queries, regardless of whether profiling is enabled. |
8.2.82 - QUERY_REQUESTS
Returns information about user-issued query requests.
Returns information about user-issued query requests. A statement can include more than one query request; for example, adding data to a table could include a constraint check in addition to a load or insert request.
For a consolidated view with one row per statement, see STATEMENT_OUTCOMES.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node that reported the requested information. |
|
USER_NAME |
VARCHAR |
Name of the user who issued the query at the time Vertica recorded the session. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused after the session ends. |
|
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any, otherwise NULL. |
|
STATEMENT_ID |
INTEGER |
Unique identifier for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identifies a statement within a session. |
|
REQUEST_TYPE |
VARCHAR |
Type of the query request. Examples include, but are not limited to:
- QUERY
- DDL
- LOAD
- UTILITY
- TRANSACTION
- PREPARE
- EXECUTE
- SET
- SHOW
|
|
REQUEST |
VARCHAR |
Query statement. |
|
REQUEST_LABEL |
VARCHAR |
Label of the query, if any. |
|
SEARCH_PATH |
VARCHAR |
Contents of the search path. |
|
MEMORY_ACQUIRED_MB |
FLOAT |
Memory acquired by this query request in megabytes. |
|
SUCCESS |
BOOLEAN |
Whether the query request succeeded. |
|
ERROR_COUNT |
INTEGER |
Number of errors encountered in this query request (logged in ERROR_MESSAGES). |
|
START_TIMESTAMP |
TIMESTAMPTZ |
Beginning of history interval. |
|
END_TIMESTAMP |
TIMESTAMPTZ |
End of history interval. |
|
REQUEST_DURATION |
TIMESTAMPTZ |
Query request execution time in days, hours, minutes, seconds, and milliseconds. |
|
REQUEST_DURATION_MS |
INTEGER |
Query request execution time in milliseconds. |
|
IS_EXECUTING |
BOOLEAN |
Whether the query request is currently running. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
QUERY_PROFILES
8.2.83 - REBALANCE_OPERATIONS
Contains information on historic and ongoing rebalance operations.
Contains information on historic and ongoing rebalance operations.
|
Column Name |
Data Type |
Description |
|
OBJECT_TYPE |
VARCHAR |
The type of the rebalanced object:
|
|
OBJECT_ID |
INTEGER |
The ID of the rebalanced object. |
|
OBJECT_NAME |
VARCHAR |
The name of the rebalanced object. Objects can be tables, projections, or other Vertica objects. |
|
PATH_NAME |
VARCHAR |
The DFS path for unstructured data being rebalanced. |
|
TABLE_NAME |
VARCHAR |
The name of the rebalanced table. This value is NULL for DFS files. |
|
TABLE_SCHEMA |
VARCHAR |
The schema of the rebalanced table. This value is NULL for DFS files.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
TRANSACTION_ID |
INTEGER |
The identifier for the transaction within the session. |
|
STATEMENT_ID |
INTEGER |
The unique numeric ID for the currently-running statement. |
|
NODE_NAME |
VARCHAR |
Name of the rebalancing node. |
|
OPERATION_NAME |
VARCHAR |
Identifies the specific rebalance operation being performed, one of:
-
Refresh projection, update temporary projection name and ID to master projection name
-
Drop unsegmented replicas
-
Replicate DFS File
-
Refresh projection
-
Drop replaced or replacement projection, rename temporary projection name to original projection name
-
Update temp table segments
-
Prepare : separate
-
Move storage containers
|
|
OPERATION_STATUS |
VARCHAR |
Specifies status of the rebalance operation, one of the followin:
|
|
IS_EXECUTING |
BOOLEAN |
TRUE: the operation is currently running. |
|
REBALANCE_METHOD |
VARCHAR |
The method that Vertica is using to perform the rebalance, one of the following:
-
REFRESH: New projections are created according to the new segmentation definition. Data is copied via a refresh plan from projections with the previous segmentation to the new segments. This method is used only if START_REFRESH is called, a configuration parameter is set, or K-safety changes.
-
REPLICATE: Unsegmented projection data is copied to new nodes and removed from ephemeral nodes.
-
ELASTIC_CLUSTER: The segmentation of existing segmented projections is altered to adjust to a new cluster topology and data is redistributed accordingly.
|
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
OPERATION_START_TIMESTAMP |
TIMESTAMPTZ |
The time that the rebalance began. |
|
OPERATION_END_TIMESTAMP |
TIMESTAMPTZ |
The time that the rebalance ended. If the rebalance is ongoing, this value is NULL. |
|
ELASTIC_CLUSTER_VERSION |
INTEGER |
The Elastic Cluster has a version. Each time the cluster topology changes, this version increments. |
|
IS_LATEST |
BOOLEAN |
True if this row pertains to the most recent rebalance activity. |
Privileges
Superuser
8.2.84 - REBALANCE_PROJECTION_STATUS
Maintain history on rebalance progress for relevant projections.
Maintain history on rebalance progress for relevant projections.
|
Column Name |
Data Type |
Description |
PROJECTION_ID |
INTEGER |
Identifier of the projection to rebalance. |
PROJECTION_SCHEMA |
VARCHAR |
Schema of the projection to rebalance.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
PROJECTION_NAME |
VARCHAR |
Name of the projection to rebalance. |
ANCHOR_TABLE_ID |
INTEGER |
Anchor table identifier of the projection to rebalance. |
ANCHOR_TABLE_NAME |
VARCHAR |
Anchor table name of the projection to rebalance. |
REBALANCE_METHOD |
VARCHAR |
Method used to rebalance the projection, one of the following:
-
REFRESH: New projections are created according to the new segmentation definition. Data is copied via a refresh plan from projections with the previous segmentation to the new segments. This method is used only if START_REFRESH is called, a configuration parameter is set, or K-safety changes.
-
REPLICATE: Unsegmented projection data is copied to new nodes and removed from ephemeral nodes.
-
ELASTIC_CLUSTER: The segmentation of existing segmented projections is altered to adjust to a new cluster topology and data is redistributed accordingly.
|
DURATION_SEC |
INTERVAL SEC |
Deprecated, set to NULL. |
SEPARATED_PERCENT |
NUMERIC(5,2) |
Percent of storage that has been separated for this projection. |
TRANSFERRED_PERCENT |
NUMERIC(5,2) |
Percent of storage that has been transferred, for this projection. |
SEPARATED_BYTES |
INTEGER |
Number of bytes, separated by the corresponding rebalance operation, for this projection. |
TO_SEPARATE_BYTES |
INTEGER |
Number of bytes that remain to be separated by the corresponding rebalance operation for this projection. |
TRANSFERRED_BYTES |
INTEGER |
Number of bytes transferred by the corresponding rebalance operation for this projection. |
TO_TRANSFER_BYTES |
INTEGER |
Number of bytes that remain to be transferred by the corresponding rebalance operation for this projection. |
IS_LATEST |
BOOLEAN |
True if this row pertains to the most recent rebalance activity, where elastic_cluster_version = (SELECT version FROM v_catalog.elastic_cluster); |
ELASTIC_CLUSTER_VERSION |
INTEGER |
The elastic cluster has a version, and each time the cluster topology changes, this version is incremented. This column reflects the version to which this row of information pertains. The TO_* fields (TO_SEPARATE_* and TO_TRANSFER_*) are only valid for the current version.
To view only rows from the current, latest or upcoming rebalance operation, use:
WHERE elastic_cluster_version = (SELECT version FROM v_catalog.elastic_cluster);
|
Privileges
Superuser
See also
8.2.85 - REBALANCE_TABLE_STATUS
Maintain history on rebalance progress for relevant tables.
Maintain history on rebalance progress for relevant tables.
|
Column Name |
Data Type |
Description |
TABLE_ID |
INTEGER |
Identifier of the table that will be, was, or is being rebalanced. |
TABLE_SCHEMA |
VARCHAR |
Schema of the table that will be, was, or is being rebalanced. |
TABLE_NAME |
VARCHAR |
Name of the table that will be, was, or is being rebalanced. |
REBALANCE_METHOD |
VARCHAR |
Method that will be, is, or was used to rebalance the projections of this table. Possible values are:
-
REFRESH
-
REPLICATE
-
ELASTIC_CLUSTER
|
DURATION_SEC |
INTERVAL SEC |
Deprecated - populated by NULL.
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS.
|
SEPARATED_PERCENT |
NUMERIC(5,2) |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
TRANSFERRED_PERCENT |
NUMERIC(5,2) |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
SEPARATED_BYTES |
INTEGER |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
TO_SEPARATE_BYTES |
INTEGER |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
TRANSFERRED_BYTES |
INTEGER |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
TO_TRANSFER_BYTES |
INTEGER |
Aggregate, by table_id, rebalance_method, and elastic_cluster_version, of the same in REBALANCE_PROJECTION_STATUS. |
IS_LATEST |
BOOLEAN |
True if this row pertains to the most recent rebalance activity, where elastic_cluster_version = (SELECT version FROM v_catalog.elastic_cluster;) |
ELASTIC_CLUSTER_VERSION |
INTEGER |
The Elastic Cluster has a version, and each time the cluster topology changes, this version is incremented. This column reflects the version to which this row of information pertains. The TO_* fields (TO_SEPARATE_* and TO_TRANSFER_*) are only valid for the current version.
To view only rows from the current, latest or upcoming rebalance operation, use:
WHERE elastic_cluster_version = (SELECT version FROM v_catalog.elastic_cluster;)
|
start_timestamp |
TIMESTAMPTZ |
The time that the rebalance began. |
end_timestamp |
TIMESTAMPTZ |
The time that the rebalance ended. |
Privileges
Superuser
See also
8.2.86 - RECOVERY_STATUS
Provides the status of recovery operations, returning one row for each node.
Provides the status of recovery operations, returning one row for each node.
Note
You cannot query this or other system tables table during cluster recovery; the cluster must be UP to accept connections.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
RECOVER_EPOCH |
INTEGER |
Epoch the recovery operation is trying to catch up to. |
RECOVERY_PHASE |
VARCHAR |
Current stage in the recovery process. Can be one of the following:
|
SPLITS_COMPLETED |
INTEGER |
Number of independent recovery SPLITS queries that have run and need to run. |
SPLITS_TOTAL |
INTEGER |
Total number of SPLITS queries that ran. Each query corresponds to one row in the PROJECTION_RECOVERIES table. If SPLITS_TOTAL = 2, then there should be 2 rows added to PROJECTION_RECOVERIES, showing query details. |
HISTORICAL_COMPLETED |
INTEGER |
Number of independent recovery HISTORICAL queries that have run and need to run. |
HISTORICAL_TOTAL |
INTEGER |
Total number of HISTORICAL queries that ran. Each query corresponds to one row in the PROJECTION_RECOVERIES table. If HISTORICAL_TOTAL = 2, then there should be 2 rows added to PROJECTION_RECOVERIES, showing query details. |
CURRENT_COMPLETED |
INTEGER |
Number of independent recovery CURRENT queries that have run and need to run. |
CURRENT_TOTAL |
INTEGER |
Total number of CURRENT queries that ran. Each query corresponds to one row in the PROJECTION_RECOVERIES table. If CURRENT_TOTAL = 2, then there should be 2 rows added to PROJECTION_RECOVERIES, showing query details. |
IS_RUNNING |
BOOLEAN |
True (t) if the node is still running recovery; otherwise false (f). |
Privileges
None
See also
PROJECTION_RECOVERIES
8.2.87 - REMOTE_REPLICATION_STATUS
Provides the status of replication tasks to alternate clusters.
Provides the status of replication tasks to alternate clusters.
|
Column Name |
Data Type |
Description |
|
CURRENT_EPOCH |
INTEGER |
|
|
EPOCH |
INTEGER |
|
|
LAST_REPLICATED_TIME |
TIMESTAMPTZ |
|
|
OBJECTS |
VARCHAR |
|
|
REPLICATED_EPOCH |
INTEGER |
|
|
REPLICATION_POINT |
VARCHAR |
|
|
SNAPSHOT_NAME |
VARCHAR |
|
Privileges
None
8.2.88 - REPARENTED_ON_DROP
Lists re-parenting events of objects that were dropped from their original owner but still remain in Vertica.
Lists re-parenting events of objects that were dropped from their original owner but still remain in Vertica. For example, a user may leave the organization and need to be removed from the database. When the database administrator drops the user from the database, that user's objects are re-parented to another user.
In some cases, a Vertica user's objects are reassigned based on the GlobalHeirUsername parameter. In this case, a user's objects are re-parented to the user indicated by this parameter.
|
Column Name |
Data Type |
Description |
REPARENT_TIMESTAMP |
TIMESTAMP |
The time the re-parenting event occurred. |
NODE_NAME |
VARCHAR |
The name of the node or nodes on which the re-parenting occurred. |
SESSION_ID |
VARCHAR |
The identification number of the re-parenting event. |
USER_ID |
INTEGER |
The unique, system-generated user identification number. |
USER_NAME |
VARCHAR |
The name of the user that caused the re-parenting event. For example, a dbadmin user may have dropped a user thus re-parenting that user's objects. |
TRANSACTION_ID |
INTEGER |
The system-generated transaction identification number. Is NULL if a transaction id does not exist. |
OLD_OWNER_NAME |
VARCHAR |
The the name of the dropped user who used to own the re-parented object. |
OLD_OWNER_OID |
INTEGER |
The unique identification number of the user who used to own the re-parented object. |
NEW_OWNER_NAME |
VARCHAR |
The name of the user who now owns the re-parented objects. |
NEW_OWNER_OID |
INTEGER |
The unique identification number of the user who now owns the re-parented objects. |
OBJ_NAME |
VARCHAR |
The name of the object being re-parented. |
OBJ_OID |
INTEGER |
The unique identification number of the object being re-parented. |
SCHEMA_NAME |
VARCHAR |
The name of the schema in which the object resides. |
SCHEMA_OID |
INTEGER |
The unique identification number of the schema in which the re-parented object resides. |
8.2.89 - REPLICATION_STATUS
Monitors the status of server-based data replication.
Shows the status of current and past server-based replication of data from another Eon Mode database to this database. Each row records node-specific information about a given replication. For more information about server-based replication, see Server-based replication.
Note
If you replicate data between the main cluster and a
sandboxed cluster, the
SENT_BYTES and
TOTAL_BYTES_TO_SEND columns will both have a value of zero. Because the clusters use the same communal storage location, no data is actually copied between the two clusters.
|
Column name |
Data type |
Description |
|
NODE_NAME |
VARCHAR(128) |
The name of the node participating in the replication. |
|
TRANSACTION_ID |
INT |
The transaction in which the replication took place. |
|
STATUS |
VARCHAR(8192) |
The state of the replication. Values include:
abort: The replication did not complete successfully.completed: The replication has completed.data transferring: the node is actively copying shards from the source database's communal storage.
|
|
SENT_BYTES |
INT |
The number of bytes that the node has retrieved from the source database's communal storage. |
|
TOTAL_BYTES_TO_SEND |
INT |
The total number of bytes the node has to retrieve from the source database's communal storage for this replication. |
|
START_TIME |
TIMESTAMPTZ |
The start time of the replication. |
|
END_TIME |
TIMESTAMPTZ |
The time at which the node finished transferring data for the replication. |
Example
=> SELECT node_name, status, transaction_id FROM REPLICATION_STATUS
ORDER BY start_time ASC;
node_name | status | transaction_id
-----------------------+-------------------+-------------------
v_target_db_node0001 | completed | 45035996273706044
v_target_db_node0002 | completed | 45035996273706044
v_target_db_node0003 | completed | 45035996273706044
v_target_db_node0001 | completed | 45035996273706070
v_target_db_node0002 | completed | 45035996273706070
v_target_db_node0003 | completed | 45035996273706070
v_target_db_node0002 | data transferring | 45035996273706136
v_target_db_node0003 | data transferring | 45035996273706136
v_target_db_node0001 | data transferring | 45035996273706136
(9 rows)
8.2.90 - RESHARDING_EVENTS
Monitors historic and ongoing resharding operations.
Monitors historic and ongoing resharding operations.
|
Column Name |
Data Type |
Description |
|
EVENT_TIME_STAMP |
TIMESTAMP |
Date and time of the resharding event. |
|
NODE_NAME |
VARCHAR |
Node name for which resharding information is listed. |
|
SESSION_ID |
VARCHAR |
Unique numeric ID assigned by the Vertica catalog that identifies the session for which resharding information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
USER_ID |
INTEGER |
Numeric ID of the user who ran the resharding operation. |
|
USER_NAME |
VARCHAR |
Name of the user who ran the resharding operation. |
|
TRANSACTION_ID |
INTEGER |
Numeric ID of the specified rehsarding transaction within the session. |
|
RUNNING_STATUS |
VARCHAR |
Current status of the resharding operation, one of the following strings:
-
START: The resharding operation has begun on all nodes.
-
RUNNING: The shard named OLD_SHARD_NAME is currently being resharded on the node.
-
RESHARDED: The resharding operation on the node is complete for the shard named OLD_SHARD_NAME.
-
ABORT: The resharding operation was aborted on all nodes.
-
COMPLETE: The resharding operation has completed for all nodes in the database.
Note
Only the RESHARDED and RUNNING statuses are logged for each node. All other statuses are logged only on the initiator node.
|
|
OLD_SHARD_NAME |
VARCHAR |
Name of the shard to which the node was subscribed previous to the resharding operation. You can query the SHARDS system table for information about the new shard configuration. |
|
OLD_SHARD_OID |
INTEGER |
Numeric ID of the shard to which the node was subscribed previous to the resharding operation. |
|
OLD_SHARD_LOWER_BOUND |
INTEGER |
Lower bound of the shard to which the node was subscribed prior to the resharding operation. This value is set only if the resharding operation is complete for the shard specified by OLD_SHARD_OID. |
|
OLD_SHARD_UPPER_BOUND |
INTEGER |
Upper bound of the shard to which the node was subscribed prior to the resharding operation. This value is set only if the resharding operation is complete for the shard specified by OLD_SHARD_OID. |
|
CATALOG_SIZE |
INTEGER |
Catalog size (in bytes) on the node for the shard specified by OLD_SHARD_NAME. This value is provided only when the RUNNING_STATUS of the node is RUNNING or RESHARDED. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
8.2.91 - RESOURCE_ACQUISITIONS
Retains information about resources (memory, open file handles, threads) acquired by each running request.
Retains information about resources (memory, open file handles, threads) acquired by each running request. Each request is uniquely identified by its transaction and statement IDs within a given session.
Important
If a request cascades to one or more resource pools beyond the original pool, this table contains multiple records for the same request—one record for each resource pool. The following values are specific to each resource pool:
You can trace the history of cascade events by querying system table
RESOURCE_POOL_MOVE.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
TRANSACTION_ID |
INTEGER |
Transaction identifier for this request. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for each statement within a transaction. NULL indicates that no statement is currently being processed. |
REQUEST_TYPE |
VARCHAR |
Type of request issued to a resource pool. End users always see this column set to Reserve, to indicate that the request is query-specific. |
POOL_ID /
POOL_NAME |
INTEGER /
VARCHAR |
Each resource pool that participated in handling this request:
|
THREAD_COUNT |
INTEGER |
Number of threads in use by this request. |
OPEN_FILE_HANDLE_COUNT |
INTEGER |
Number of open file handles in use by this request. |
MEMORY_INUSE_KB |
INTEGER |
Total amount of memory in kilobytes acquired by this query.
Column RESERVED_EXTRA_MEMORY_B in system table
QUERY_PROFILES shows how much unused memory (in bytes) remains that is reserved for a given query but is unassigned to a specific operator.
If operators for a query acquire all memory specified by MEMORY_INUSE_KB, the plan must request more memory from the Vertica Resource Manager.
|
QUEUE_ENTRY_TIMESTAMP |
TIMESTAMPTZ |
Timestamp when the request was queued in this resource pool. |
ACQUISITION_TIMESTAMP |
TIMESTAMPTZ |
Timestamp when the request was admitted to run. |
RELEASE_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica released this resource acquisition. |
DURATION_MS |
INTEGER |
Duration in milliseconds of request execution. If the request cascaded across multiple resource pools, DURATION_MS applies only to this resource pool. |
IS_EXECUTING |
BOOLEAN |
Set to true if the resource pool is still executing this request. A value of false can indicate one of the following:
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Queue wait time
You can calculate how long a resource pool queues a given request before it begins execution by subtracting QUEUE_ENTRY_TIMESTAMP from ACQUISITION_TIMESTAMP. For example:
=> SELECT pool_name, queue_entry_timestamp, acquisition_timestamp,
(acquisition_timestamp-queue_entry_timestamp) AS 'queue wait'
FROM V_MONITOR.RESOURCE_ACQUISITIONS WHERE node_name ILIKE '%node0001';
See also
8.2.92 - RESOURCE_POOL_MOVE
Displays the cascade event information on each node.
Displays the cascade event information on each node.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
MOVE_TIMESTAMP |
TIMESTAMPTZ |
Time when the query attempted to move to the target pool. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
USER_ID |
INTEGER |
Identifies the query event user. |
USER_NAME |
VARCHAR |
Name of the user for which Vertica lists query information at the time it records the session. |
TRANSACTION_ID |
INTEGER |
Transaction identifier for the request. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the statement. |
SOURCE_POOL_NAME |
VARCHAR |
Name of the resource pool where the query was executing when Vertica attempted the move. |
TARGET_POOL_NAME |
VARCHAR |
Name of resource pool where the query attempted to move. |
MOVE_CAUSE |
VARCHAR |
Denotes why the query attempted to move.
Valid values:
|
SOURCE_CAP |
INTEGER |
Effective RUNTIMECAP value for the source pool. The value represents the lowest of these three values:
-
session RUNTIMECAP
-
user RUNTIMECAP
-
source pool RUNTIMECAP
|
TARGET_CAP |
INTEGER |
Effective RUNTIMECAP value for the target pool. The value represents the lowest of these three values:
-
session RUNTIMECAP
-
user RUNTIMECAP
-
target pool RUNTIMECAP
|
SUCCESS |
BOOLEAN |
True, if the query successfully moved to the target pool. |
RESULT_REASON |
VARCHAR |
States reason for success or failure of the move. |
See also
8.2.93 - RESOURCE_POOL_STATUS
Provides current state of built-in and user-defined resource pools on each node.
Provides current state of built-in and user-defined resource pools on each node. Information includes:
For general information about resource pools, see Resource pool architecture.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node for which information is provided. |
|
POOL_OID |
INTEGER |
Unique numeric ID that identifies the pool and is assigned by the Vertica catalog. |
|
POOL_NAME |
VARCHAR |
Name of the resource pool. |
|
IS_INTERNAL |
BOOLEAN |
Denotes whether a pool is built-in. |
|
MEMORY_SIZE_KB |
INTEGER |
Value of MEMORYSIZE setting of the pool in kilobytes. |
|
MEMORY_SIZE_ACTUAL_KB |
INTEGER |
Current amount of memory, in kilobytes, allocated to the pool by the resource manager. The actual size can be less than specified in the DDL, if both the following conditions exist:
|
|
MEMORY_INUSE_KB |
INTEGER |
Amount of memory, in kilobytes, acquired by requests running against this pool. |
|
GENERAL_MEMORY_BORROWED_KB |
INTEGER |
Amount of memory, in kilobytes, borrowed from the GENERAL pool by requests running against this pool. The sum of MEMORY_INUSE_KB and GENERAL_MEMORY_BORROWED_KB should be less than MAX_MEMORY_SIZE_KB. |
|
QUEUEING_THRESHOLD_KB |
INTEGER |
Calculated as MAX_MEMORY_SIZE_KB * 0.95. When the amount of memory used by all requests against this resource pool exceeds the QUEUEING_THRESHOLD_KB, new requests against the pool are queued until memory becomes available. |
|
MAX_MEMORY_SIZE_KB |
INTEGER |
Value, in kilobytes, of the MAXMEMORYSIZE parameter as defined for the pool. After this threshold is reached, new requests against this pool are rejected or queued until memory becomes available.
Note
MAX_MEMORY_SIZE_KB might not reflect the set MAXMEMORYSIZE parameter value if the specified value cannot be reached. For example, if MAXMEMORYSIZE = 10G but less than 2G is available, MAX_MEMORY_SIZE_KB will not reflect the original value in KB. Instead, it will display only 2G in KB, as that is the highest value available to it.
|
|
MAX_QUERY_MEMORY_SIZE_KB |
INTEGER |
Value, in kilobytes, of the MAXQUERYMEMORYSIZE parameter as defined for the pool. The resource pool limits this amount of memory to all queries that execute in it. |
|
RUNNING_QUERY_COUNT |
INTEGER |
Number of queries currently executing in this pool. |
|
PLANNED_CONCURRENCY |
INTEGER |
Value of PLANNEDCONCURRENCY parameter as defined for the pool. |
|
MAX_CONCURRENCY |
INTEGER |
Value of MAXCONCURRENCY parameter as defined for the pool. |
|
IS_STANDALONE |
BOOLEAN |
If the pool is configured to have MEMORYSIZE equal to MAXMEMORYSIZE, the pool is considered standalone because it does not borrow any memory from the General pool. |
|
QUEUE_TIMEOUT |
INTERVAL |
The interval that the request waits for resources to become available before being rejected. If you set this value to NONE, Vertica displays it as NULL. |
|
QUEUE_TIMEOUT_IN_SECONDS |
INTEGER |
Value of QUEUETIMEOUT parameter as defined for the pool. If QUEUETIMEOUT is set to NONE, Vertica displays this value as NULL. |
|
EXECUTION_PARALLELISM |
INTEGER |
Limits the number of threads used to process any single query issued in this resource pool. |
|
PRIORITY |
INTEGER |
Value of PRIORITY parameter as defined for the pool.
When set to HOLD, Vertica sets a pool's priority to -999 so the query remains queued until QUEUETIMEOUT is reached.
|
|
RUNTIMECAP_IN_SECONDS |
INTEGER |
Defined for this pool by parameter RUNTIMECAP, specifies in seconds the maximum time a query in the pool can execute. If a query exceeds this setting, it tries to cascade to a secondary pool. |
|
RUNTIME_PRIORITY |
VARCHAR |
Defined for this pool by parameter RUNTIMEPRIORITY, determines how the resource manager should prioritize dedication of run-time resources (CPU, I/O bandwidth) to queries already running in this resource pool. |
|
RUNTIME_PRIORITY_THRESHOLD |
INTEGER |
Defined for this pool by parameter RUNTIMEPRIORITYTHRESHOLD, specifies in seconds a time limit in which a query must finish before the resource manager assigns to it the resource pool's RUNTIME_PRIORITY setting. |
|
SINGLE_INITIATOR |
BOOLEAN |
Set for backward compatibility. |
|
QUERY_BUDGET_KB |
INTEGER |
The current amount of memory that queries are tuned to use. The calculation that Vertica uses to determine this value is described inQuery budgeting.
Note
The calculated value can change when one or more running queries needs more than the budgeted amount to run.
For a detailed example of query budget calculations, see Do You Need to Put Your Query on a Budget? in the Vertica User Community.
|
|
CPU_AFFINITY_SET |
VARCHAR |
The set of CPUs on which queries associated with this pool are executed. Can be:
-
A percentage of CPUs on the system
-
A zero-based list of CPUs (a four-CPU system c of CPUs 0, 1, 2, and 3).
|
|
CPU_AFFINITY_MASK |
VARCHAR |
The bit mask of CPUs available for use in this pool, read from right to left. See Examples below. |
|
CPU_AFFINITY_MODE |
VARCHAR |
The mode for the CPU affinity, one of the following:
|
Examples
The following query returns bit masks that show CPU assignments for three user-defined resource pools. Resource pool bigqueries runs queries on CPU 0, ceo_pool on CPU 1, and testrp on CPUs 0 and 1:
=> SELECT pool_name, node_name, cpu_affinity_set, cpu_affinity_mode,
TO_BITSTRING(CPU_AFFINITY_MASK::VARBINARY) "CPU Affinity Mask"
FROM resource_pool_status WHERE IS_INTERNAL = 'false' order by pool_name, node_name;
pool_name | node_name | cpu_affinity_set | cpu_affinity_mode | CPU Affinity Mask
------------+------------------+------------------+-------------------+-------------------
bigqueries | v_vmart_node0001 | 0 | SHARED | 00110001
bigqueries | v_vmart_node0002 | 0 | SHARED | 00110001
bigqueries | v_vmart_node0003 | 0 | SHARED | 00110001
ceo_pool | v_vmart_node0001 | 1 | SHARED | 00110010
ceo_pool | v_vmart_node0002 | 1 | SHARED | 00110010
ceo_pool | v_vmart_node0003 | 1 | SHARED | 00110010
testrp | v_vmart_node0001 | 0-1 | SHARED | 00110011
testrp | v_vmart_node0002 | 0-1 | SHARED | 00110011
testrp | v_vmart_node0003 | 0-1 | SHARED | 00110011
(9 rows)
See also
8.2.94 - RESOURCE_QUEUES
Provides information about requests pending for various resource pools.
Provides information about requests pending for various resource pools.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The name of the node for which information is listed. |
TRANSACTION_ID |
INTEGER |
Transaction identifier for this request |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID uniquely identifies a statement within a session. |
POOL_NAME |
VARCHAR |
The name of the resource pool |
MEMORY_REQUESTED_KB |
INTEGER |
Amount of memory in kilobytes requested by this request |
PRIORITY |
INTEGER |
Value of PRIORITY parameter specified when defining the pool. |
POSITION_IN_QUEUE |
INTEGER |
Position of this request within the pool’s queue |
QUEUE_ENTRY_TIMESTAMP |
TIMESTAMP |
Timestamp when the request was queued |
See also
8.2.95 - RESOURCE_REJECTION_DETAILS
Records an entry for each resource request that Vertica denies.
Records an entry for each resource request that Vertica denies. This is useful for determining if there are resource space issues, as well as which users/pools encounter problems.
|
Column Name |
Data Type |
Description |
REJECTED_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica rejected the resource. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_NAME |
VARCHAR |
Name of the user at the time Vertica recorded the session. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
REQUEST_ID |
INTEGER |
Unique identifier of the query request in the user session. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL. |
STATEMENT_ID |
INTEGER |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identifies a statement within a session. |
POOL_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theresource pool. |
POOL_NAME |
VARCHAR |
Name of the resource pool |
REASON |
VARCHAR |
Reason for rejecting this request; for example:
-
Usage of single request exceeds high limit
-
Timed out waiting for resource reservation
-
Canceled waiting for resource reservation
|
RESOURCE_TYPE |
VARCHAR |
Memory, threads, file handles or execution slots.
The following list shows the resources that are limited by the resource manager. A query might need some amount of each resource, and if the amount needed is not available, the query is queued and could eventually time out of the queue and be rejected.
-
Number of running plans
-
Number of running plans on initiator node (local)
-
Number of requested threads
-
Number of requested file handles
-
Number of requested KB of memory
-
Number of requested KB of address space
Note: Execution slots are determined by MAXCONCURRENCY parameter.
|
REJECTED_VALUE |
INTEGER |
Amount of the specific resource requested by the last rejection |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
RESOURCE_REJECTIONS
8.2.96 - RESOURCE_REJECTIONS
Monitors requests for resources that are rejected by the.
Monitors requests for resources that are rejected by the Resource manager. Information is valid only as long as the node is up and the counters reset to 0 upon node restart.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
POOL_ID |
INTEGER |
Catalog-assigned integer value that uniquely identifies theresource pool. |
POOL_NAME |
VARCHAR |
Name of the resource pool. |
REASON |
VARCHAR |
Reason for rejecting this request, for example:
-
Usage of single request exceeds high limit
-
Timed out waiting for resource reservation
-
Canceled waiting for resource reservation
|
RESOURCE_TYPE |
VARCHAR |
Memory, threads, file handles or execution slots.
The following list shows the resources that are limited by the resource manager. A query might need some amount of each resource, and if the amount needed is not available, the query is queued and could eventually time out of the queue and be rejected.
-
Number of running plans
-
Number of running plans on initiator node (local)
-
Number of requested threads
-
Number of requested file handles
-
Number of requested KB of memory
-
Number of requested KB of address space
Note
Execution slots are determined by MAXCONCURRENCY parameter.
|
REJECTION_COUNT |
INTEGER |
Number of requests rejected due to specified reason and RESOURCE_TYPE. |
FIRST_REJECTED_TIMESTAMP |
TIMESTAMPTZ |
Time of the first rejection for this pool. |
LAST_REJECTED_TIMESTAMP |
TIMESTAMPTZ |
Time of the last rejection for this pool. |
LAST_REJECTED_VALUE |
INTEGER |
Amount of the specific resource requested by the last rejection. |
Examples
=> SELECT node_name, pool_name, reason, resource_type, rejection_count AS count, last_rejected_value AS value FROM resource_rejections;
node_name | pool_name | reason | resource_type | count | value
------------------+-----------+-----------------------------+---------------+-------+---------
v_vmart_node0001 | sysquery | Request exceeded high limit | Memory(KB) | 1 | 8248449
(1 row)
See also
8.2.97 - RESOURCE_USAGE
Monitors system resource management on each node.
Monitors system resource management on each node.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
|
REQUEST_COUNT |
INTEGER |
The cumulative number of requests for threads, file handles, and memory (in kilobytes). |
|
LOCAL_REQUEST_COUNT |
INTEGER |
The cumulative number of local requests. |
|
REQUEST_QUEUE_DEPTH |
INTEGER |
The current request queue depth. |
|
ACTIVE_THREAD_COUNT |
INTEGER |
The current number of active threads. |
|
OPEN_FILE_HANDLE_COUNT |
INTEGER |
The current number of open file handles. |
|
MEMORY_REQUESTED_KB |
INTEGER |
The memory requested in kilobytes. |
|
ADDRESS_SPACE_REQUESTED_KB |
INTEGER |
The address space requested in kilobytes. |
|
ROS_USED_BYTES |
INTEGER |
The size of the ROS in bytes. |
|
ROS_ROW_COUNT |
INTEGER |
The number of rows in the ROS. |
|
RESOURCE_REQUEST_REJECT_COUNT |
INTEGER |
The number of rejected plan requests. |
|
RESOURCE_REQUEST_TIMEOUT_COUNT |
INTEGER |
The number of resource request timeouts. |
|
RESOURCE_REQUEST_CANCEL_COUNT |
INTEGER |
The number of resource request cancelations. |
|
DISK_SPACE_REQUEST_REJECT_COUNT |
INTEGER |
The number of rejected disk write requests. |
|
FAILED_VOLUME_REJECT_COUNT |
INTEGER |
The number of rejections due to a failed volume. |
|
TOKENS_USED |
INTEGER |
For internal use only. |
|
TOKENS_AVAILABLE |
INTEGER |
For internal use only. |
8.2.98 - SESSION_MARS_STORE
Shows Multiple Active Result Sets (MARS) storage information.
Shows Multiple Active Result Sets (MARS) storage information.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
SESSION_ID |
VARCHAR |
Identifier of the Vertica session. This identifier is unique within the cluster for the current session but can be reused in a subsequent session. |
USER_NAME |
VARCHAR |
The username used to create the connection. |
RESULTSET_ID |
INTEGER |
Identifier assigned to the result set. |
ROW_COUNT |
INTEGER |
Number of rows requested by the query. |
REMAINING_ROW_COUNT |
INTEGER |
Number of rows that still need to be returned. |
BYTES_USED |
INTEGER |
The number of bytes requested. |
8.2.99 - SESSION_PARAMETERS
Provides information about user-defined parameters (UDPARAMETERS) set for the current session.
Provides information about user-defined parameters (UDPARAMETERS) set for the current session.
|
Column Name |
Data Type |
Description |
SESSION_ID |
VARCHAR |
The unique identifier for the session. |
SCHEMA_NAME |
VARCHAR |
The name of the schema on which the session is running. |
LIB_NAME |
VARCHAR |
The name of the user library running the UDx, if necessary. |
LIB_OID |
VARCHAR |
The object ID of the library containing the function, if one is running. |
PARAMETER_NAME |
VARCHAR |
The name of the session parameter. |
CURRENT_VALUE |
VARCHAR |
The value of the session parameter. |
See also
8.2.100 - SESSION_PROFILES
Provides basic session parameters and lock time out data.
Provides basic session parameters and lock time out data. To obtain information about sessions, see Profiling database performance.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
USER_NAME |
VARCHAR |
The name used to log in to the database or NULL if the session is internal. |
CLIENT_HOSTNAME |
VARCHAR |
The host name and port of the TCP socket from which the client connection was made; NULL if the session is internal. |
LOGIN_TIMESTAMP |
TIMESTAMP |
The date and time the user logged into the database or when the internal session was created. This field is useful for identifying sessions that have been left open for a period of time and could be idle. |
LOGOUT_TIMESTAMP |
TIMESTAMP |
The date and time the user logged out of the database or when the internal session was closed. |
SESSION_ID |
VARCHAR |
A unique numeric ID assigned by the Vertica catalog, which identifies the session for which profiling information is captured. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
EXECUTED_STATEMENT_SUCCESS_COUNT |
INTEGER |
The number of successfully run statements. |
EXECUTED_STATEMENT_FAILURE_COUNT |
INTEGER |
The number of unsuccessfully run statements. |
LOCK_GRANT_COUNT |
INTEGER |
The number of locks granted during the session. |
DEADLOCK_COUNT |
INTEGER |
The number of deadlocks encountered during the session. |
LOCK_TIMEOUT_COUNT |
INTEGER |
The number of times a lock timed out during the session. |
LOCK_CANCELLATION_COUNT |
INTEGER |
The number of times a lock was canceled during the session. |
LOCK_REJECTION_COUNT |
INTEGER |
The number of times a lock was rejected during a session. |
LOCK_ERROR_COUNT |
INTEGER |
The number of lock errors encountered during the session. |
CLIENT_TYPE |
VARCHAR |
The type of client from which the connection was made. Possible client type values:
-
ADO.NET Driver
-
ODBC Driver
-
JDBC Driver
-
vsql
|
CLIENT_VERSION |
VARCHAR |
Returns the client version. |
CLIENT_OS |
VARCHAR |
Returns the client operating system. |
CLIENT_OS_USER_NAME |
VARCHAR |
The name of the user that logged into, or attempted to log into, the database. This is logged even when the login attempt is unsuccessful. |
See also
LOCKS
8.2.101 - SESSIONS
Monitors external sessions.
Monitors external sessions. Use this table to perform the following tasks:
-
Identify users who are running lengthy queries.
-
Identify users who hold locks because of an idle but uncommitted transaction.
-
Determine the details of the database security used for a particular session, either Secure Socket Layer (SSL) or client authentication.
-
Identify client-specific information, such as client version.
Note
During session initialization and termination, you might see sessions running only on nodes other than the node on which you ran the virtual table query. This is a temporary situation that corrects itself when session initialization and termination complete.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
USER_NAME |
VARCHAR |
The name used to log in to the database or NULL if the session is internal. |
CLIENT_OS_HOSTNAME |
VARCHAR |
The hostname of the client as reported by their operating system. |
CLIENT_HOSTNAME |
VARCHAR |
The IP address and port of the TCP socket from which the client connection was made; NULL if the session is internal.
Vertica accepts either IPv4 or IPv6 connections from a client machine. If the client machine contains mappings for both IPv4 and IPv6, the server randomly chooses one IP address family to make a connection. This can cause the CLIENT_HOSTNAME column to display either IPv4 or IPv6 values, based on which address family the server chooses.
|
CLIENT_PID |
INTEGER |
The process identifier of the client process that issued this connection. Remember that the client process could be on a different machine than the server. |
LOGIN_TIMESTAMP |
TIMESTAMP |
The date and time the user logged into the database or when the internal session was created. This field can help you identify sessions that have been left open for a period of time and could be idle. |
SESSION_ID |
VARCHAR |
The identifier required to close or interrupt a session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
IDLE_SESSION_TIMEOUT |
VARCHAR |
Specifies how long this session can remain idle before timing out, set by
SET SESSION IDLESESSIONTIMEOUT. |
GRACE_PERIOD |
VARCHAR |
Specifies how long a session socket remains blocked while awaiting client input or output for a given query, set by
SET SESSION GRACEPERIOD. If the socket is blocked for a continuous period that exceeds the grace period setting, the server shuts down the socket and throws a fatal error. The session is then terminated. |
CLIENT_LABEL |
VARCHAR |
A user-specified label for the client connection that can be set when using ODBC. See Label in ODBC DSN connection properties. An MC output value means there are is a client connection to an MC-managed database for that USER_NAME |
TRANSACTION_START |
DATE |
The date/time the current transaction started or NULL if no transaction is running. |
TRANSACTION_ID |
INTEGER |
A string containing the hexadecimal representation of the transaction ID, if any; otherwise, NULL. |
TRANSACTION _DESCRIPTION |
VARCHAR |
Description of the current transaction. |
STATEMENT_START |
TIMESTAMP |
The timestamp the current statement started execution, or NULL if no statement is running. |
STATEMENT_ID |
INTEGER |
A unique numeric ID assigned by the Vertica catalog, which identifies the currently-executing statement.
A value of NULL indicates that no statement is currently being processed.
|
LAST_STATEMENT_DURATION_US |
INTEGER |
The duration of the last completed statement in microseconds. |
RUNTIME_PRIORITY |
VARCHAR |
Specifies how many run-time resources (CPU, I/O bandwidth) are allocated to queries that are running in the resource pool. |
CURRENT_STATEMENT |
VARCHAR |
The currently executing statement, if any. NULL indicates that no statement is currently being processed. |
LAST_STATEMENT |
VARCHAR |
NULL if the user has just logged in; otherwise the currently running statement or the most recently completed statement. |
SSL_STATE |
VARCHAR |
Indicates if Vertica used Secure Socket Layer (SSL) for a particular session. Possible values are:
-
None—Vertica did not use SSL.
-
Server—Server authentication was used, so the client could authenticate the server.
-
Mutual—Both the server and the client authenticated one another through mutual authentication.
See Security and authentication and TLS protocol.
|
AUTHENTICATION_ METHOD |
VARCHAR |
The type of client authentication used for a particular session, if known. Possible values are:
-
Unknown
-
Trust
-
Reject
-
Hash
-
Ident
-
LDAP
-
GSS
-
TLS
See Security and authentication and Configuring client authentication.
|
CLIENT_TYPE |
VARCHAR |
The type of client from which the connection was made. Possible client type values:
-
ADO.NET Driver
-
ODBC Driver
-
JDBC Driver
-
vsql
|
CLIENT_VERSION |
VARCHAR |
Client version. |
CLIENT_OS |
VARCHAR |
Client operating system. |
CLIENT_OS_USER _NAME |
VARCHAR |
The name of the user that logged into, or attempted to log into, the database. This is logged even when the login attempt is unsuccessful. |
CLIENT_AUTHENTICATION_NAME |
VARCHAR |
User-assigned name of the authentication method. |
CLIENT_ AUTHENTICATION |
INTEGER |
Object identifier of the client authentication method. |
REQUESTED_PROTOCOL |
INTEGER |
The requested Vertica client server protocol to be used when connecting. |
EFFECTIVE_PROTOCOL |
INTEGER |
The requested Vertica client server protocol used when connecting. |
EXTERNAL_MEMORY_KB |
INTEGER |
Amount of memory consumed by the Java Virtual Machines associated with the session. |
Privileges
A superuser has unrestricted access to all session information. Users can view information only about their own, current sessions.
See also
8.2.102 - SPREAD_STATE
Lists daemon settings for all nodes in the cluster.
Lists Spread daemon settings for all nodes in the cluster.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Which node the settings are for. |
|
TOKEN_TIMEOUT |
INTEGER |
The timeout period in milliseconds before spread considers a node to be down due to lack of response to a message. |
Examples
=> SELECT * FROM V_MONITOR.SPREAD_STATE;
node_name | token_timeout
------------------+---------------
v_vmart_node0003 | 8000
v_vmart_node0001 | 8000
v_vmart_node0002 | 8000
(3 rows)
See also
8.2.103 - STATEMENT_OUTCOMES
...
Records consolidated information about session-level statements, which can consist of more than one operation and might include retries. For example, inserting into a table with a column constraint includes an INSERT query and a constraint check. STATEMENT_OUTCOMES has one row for the statement, and the related QUERY_REQUESTS table has two rows.
This table tracks only statements that are executed within transactions. Many meta-functions do not automatically open transactions.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node that reported the requested information. |
|
USER_NAME |
VARCHAR |
Name of the user who issued the query at the time Vertica recorded the session. |
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused after the session ends. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session. Statements that are not executed within transactions are not recorded in this table. |
|
STATEMENT_ID |
INTEGER |
Unique identifier for the statement. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a user query within a session. |
|
REQUEST_TYPE |
VARCHAR |
Type of the query request. Examples include, but are not limited to:
- QUERY
- DDL
- LOAD
- UTILITY
- TRANSACTION
- PREPARE
- EXECUTE
- SET
- SHOW
|
|
REQUEST |
VARCHAR |
Query statement. |
|
REQUEST_LABEL |
VARCHAR |
Label of the query, if any. |
|
SEARCH_PATH |
VARCHAR |
Contents of the search path. |
|
SUCCESS |
BOOLEAN |
Whether the statement succeeded. |
|
ERROR |
VARCHAR |
If the statement did not succeed, the error message. |
|
START_TIMESTAMP |
TIMESTAMPTZ |
Beginning of history interval. |
|
END_TIMESTAMP |
TIMESTAMPTZ |
End of history interval. |
|
REQUEST_DURATION |
TIMESTAMPTZ |
Statement execution time in days, hours, minutes, seconds, and milliseconds. This time includes all operations that make up the statement, including any retries. |
|
REQUEST_DURATION_MS |
INTEGER |
Statement execution time in milliseconds. This time includes all operations that make up the statement, including any retries. |
|
IS_EXECUTING |
BOOLEAN |
Whether the statement is currently running. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
QUERY_PROFILES
8.2.104 - STORAGE_BUNDLE_INFO_STATISTICS
Indicates which projections have storage containers with invalid bundle metadata in the database catalog.
Indicates which projections have storage containers with invalid bundle metadata in the database catalog. If any ROS or DV container has invalid bundle metadata fields, Vertica increments the corresponding column (ros_without_bundle_info_count or dv_ros_without_bundle_info_count) by one.
To update the catalog with valid bundle metadata, call UPDATE_STORAGE_CATALOG, as an argument to Vertica meta-function
DO_TM_TASK. For details, see Writing bundle metadata to the catalog.
|
Column Name |
Data Type |
Description |
node_name |
VARCHAR |
Name of this projection's node |
projection_oid |
INTEGER |
Projection's unique catalog identifier |
projection_name |
VARCHAR |
Projection name |
projection_schema |
VARCHAR |
Projection schema name |
total_ros_count |
INTEGER |
Total number of ROS containers for this projection |
ros_without_bundle_info_count |
INTEGER |
Number of ROS containers for this projection with invalid bundle metadata |
total_dv_ros_count |
INTEGER |
Total number of DV (delete vector) containers for this projection |
dv_ros_without_bundle_info_count |
INTEGER |
Number of DV containers for this projection with invalid bundle metadata |
8.2.105 - STORAGE_CONTAINERS
Monitors information about Vertica storage containers.
Monitors information about Vertica storage containers.
|
Column Name |
Data Type |
Description |
|
NODE_NAME* |
VARCHAR |
Node name for which information is listed. |
|
NAMESPACE_NAME* |
VARCHAR |
For Eon Mode databases, namespace for which information is listed. |
|
SCHEMA_NAME* |
VARCHAR |
Schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
PROJECTION_ID* |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
|
PROJECTION_NAME* |
VARCHAR |
Projection name for which information is listed on that node. |
|
STORAGE_OID* |
INTEGER |
Numeric ID assigned by the Vertica catalog, which identifies the storage. The same OID can appear on more than one node. |
|
SAL_STORAGE_ID |
VARCHAR |
Unique hexadecimal numeric ID assigned by the Vertica catalog, which identifies the storage. |
|
TOTAL_ROW_COUNT* |
VARCHAR |
Total rows in the storage container listed for that projection.
If the database has been re-sharded, this value will be inaccurate until the Tuple mover realigns the storage containers to the new shard layout.
|
|
DELETED_ROW_COUNT* |
INTEGER |
Total rows in the storage container deleted for that projection.
If the database has been re-sharded, this value will be inaccurate until the Tuple mover realigns the storage containers to the new shard layout.
|
|
USED_BYTES* |
INTEGER |
Number of bytes in the storage container used to store the compressed projection data. This value should not be compared to the output of the AUDIT function, which returns the raw data size of database objects.
If the database has been re-sharded, this value will be inaccurate until the Tuple mover realigns the storage containers to the new shard layout.
|
|
START_EPOCH* |
INTEGER |
Number of the start epoch in the storage container for which information is listed. |
|
END_EPOCH* |
INTEGER |
Number of the end epoch in the storage container for which information is listed. |
|
GROUPING |
VARCHAR |
The group by which columns are stored:
-
ALL: All columns are grouped
-
PROJECTION: Columns grouped according to projection definition
-
NONE: No columns grouped, despite grouping in the projection definition
-
OTHER: Some grouping but neither all nor according to projection (e.g., results from add column)
|
|
SEGMENT_LOWER_BOUND |
INTEGER |
Lower bound of the segment range spanned by the storage container or NULL if the corresponding projection is not elastic. |
|
SEGMENT_UPPER_BOUND |
INTEGER |
Upper bound of the segment range spanned by the storage container or NULL if the corresponding projection is not elastic. |
|
LOCATION_LABEL |
VARCHAR (128) |
The location label (if any) for the storage container is stored. |
|
DELETE_VECTOR_COUNT |
INTEGER |
The number of delete vectors in the storage container.
If the database has been re-sharded, this value will be inaccurate until the Tuple mover realigns the storage containers to the new shard layout.
|
|
SHARD_ID |
INTEGER |
Set only for an Eon Mode database, ID of the shard that this container belongs to. |
|
SHARD_NAME |
VARCHAR(128) |
Set only for an Eon Mode database, name of the shard that this container belongs to. |
|
ORIGINAL_SEGMENT_LOWER_BOUND |
INTEGER |
The lower bound of a storage container before database re-sharding. This value is set only if the database has been re-sharded and the storage containers have not been realigned with current shard definitions. For details, see RESHARD_DATABASE. |
|
ORIGINAL_SEGMENT_UPPER_BOUND |
INTEGER |
The upper bound of a storage container before database re-sharding. This value is set only if the database has been re-sharded and the storage container has not been realigned with current shard definitions. For details, see RESHARD_DATABASE. |
* Column values cached for faster query performance
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
The following query identifies any storage containers that have not yet been realigned to the new shard segmentation bounds after running RESHARD_DATABASE:
=> SELECT COUNT(*) FROM storage_containers WHERE original_segment_lower_bound IS NOT NULL AND original_segment_upper_bound IS NOT NULL;
8.2.106 - STORAGE_POLICIES
Monitors the current storage policies in effect for one or more database objects.
Monitors the current storage policies in effect for one or more database objects.
|
Column Name |
Data Type |
Description |
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, namespace for which information is listed. |
SCHEMA_NAME |
VARCHAR |
Schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
OBJECT_NAME |
VARCHAR |
The name of the database object associated through the storage policy. |
POLICY_DETAILS |
VARCHAR |
The object type of the storage policy. |
LOCATION_LABEL |
VARCHAR (128) |
The label for this storage location. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
8.2.107 - STORAGE_TIERS
Provides information about all storage locations with the same label across all cluster nodes.
Provides information about all storage locations with the same label across all cluster nodes. This table lists data totals for all same-name labeled locations.
The system table shows what labeled locations exist on the cluster, as well as other cluster-wide data about the locations.
|
Column Name |
Data Type |
Description |
LOCATION_LABEL |
VARCHAR |
The label associated with a specific storage location. The storage_tiers system table includes data totals for unlabeled locations, which are considered labeled with empty strings (''). |
NODE_COUNT |
INTEGER |
The total number of nodes that include a storage location named location_label. |
LOCATION_COUNT |
INTEGER |
The total number of storage locations named location_label.
This value can differ from node_count if you create labeled locations with the same name at different paths on different nodes. For example:
v_vmart_node0001: Create one labeled location, FAST
V_vmart_node0002: Create two labeled locations, FAST, at different directory paths
In this case, node_count value = 2, while location_count value = 3.
|
ROS_CONTAINER_COUNT |
INTEGER |
The total number of ROS containers stored across all cluster nodes for location_label. |
TOTAL_OCCUPIED_SIZE |
INTEGER |
The total number of bytes that all ROS containers for location_label occupy across all cluster nodes. |
Privileges
None
See also
8.2.108 - STORAGE_USAGE
Provides information about file system storage usage.
Provides information about file system storage usage. This is useful for determining disk space usage trends.
|
Column Name |
Data Type |
Description |
POLL_TIMESTAMP |
TIMESTAMPTZ |
Time when Vertica recorded the row. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
PATH |
VARCHAR |
Path where the storage location is mounted. |
DEVICE |
VARCHAR |
Device on which the storage location is mounted. |
FILESYSTEM |
VARCHAR |
File system on which the storage location is mounted. |
USED_BYTES |
INTEGER |
Counter history of number of used bytes. |
FREE_BYTES |
INTEGER |
Counter history of number of free bytes. |
USAGE_PERCENT |
FLOAT |
Percent of storage in use. |
Privileges
Superuser
See also
8.2.109 - STRATA
Contains internal details of how the combines ROS containers in each projection, broken down by stratum and classifies the ROS containers by size and partition.
Contains internal details of how the Tuple Mover combines ROS containers in each projection, broken down by stratum and classifies the ROS containers by size and partition. The related
STRATA_STRUCTURES table provides a summary of the strata values.
Mergeout describes how the Tuple Mover combines ROS containers.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
SCHEMA_NAME |
VARCHAR |
The schema name for which information is listed.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed on that node. |
STRATUM_KEY |
VARCHAR |
References the partition or partition group for which information is listed. |
STRATA_COUNT |
INTEGER |
The total number of strata for this projection partition. |
MERGING_STRATA_COUNT |
INTEGER |
The number of strata the Tuple Mover can merge out. |
STRATUM_CAPACITY |
INTEGER |
The maximum number of ROS containers for the stratum before they must be merged. |
STRATUM_HEIGHT |
FLOAT |
The size ratio between the smallest and largest ROS container in this stratum. |
STRATUM_NO |
INTEGER |
The stratum number. Strata are numbered starting at 0, for the stratum containing the smallest ROS containers. |
STRATUM_LOWER_SIZE |
VARCHAR |
The smallest ROS container size allowed in this stratum. |
STRATUM_UPPER_SIZE |
VARCHAR |
The largest ROS container size allowed in this stratum. |
ROS_CONTAINER_COUNT |
INTEGER |
The current number of ROS containers in the projection partition. |
8.2.110 - STRATA_STRUCTURES
This table provides an overview of internal details.
This table provides an overview of Tuple Mover internal details. It summarizes how the ROS containers are classified by size. A more detailed view can be found in the STRATA virtual table.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
The node name for which information is listed. |
SCHEMA_NAME |
VARCHAR |
The schema name for which information is listed. |
PROJECTION_NAME |
VARCHAR |
The projection name for which information is listed on that node. |
PROJECTION_ID |
INTEGER |
Catalog-assigned numeric value that uniquely identifies the projection. |
STRATUM_KEY |
VARCHAR |
References the partition or partition group for which information is listed. |
STRATA_COUNT |
INTEGER |
The total number of strata for this projection partition. |
MERGING_STRATA_COUNT |
INTEGER |
In certain hardware configurations, a high strata could contain more ROS containers than the Tuple Mover can merge out; output from this column denotes the number of strata the Tuple Mover can merge out. |
STRATUM_CAPACITY |
INTEGER |
The maximum number of ROS containers that the strata can contained before it must merge them. |
STRATUM_HEIGHT |
FLOAT |
The size ratio between the smallest and largest ROS container in a stratum. |
ACTIVE_STRATA_COUNT |
INTEGER |
The total number of strata that have ROS containers in them. |
Examples
=> \pset expanded
Expanded display is on.
=> SELECT node_name, schema_name, projection_name, strata_count,
stratum_capacity, stratum_height, active_strata_count
FROM strata_structures WHERE stratum_capacity > 60;
-[ RECORD 1 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0001
schema_name | public
projection_name | shipping_dimension_DBD_22_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 2 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0001
schema_name | public
projection_name | shipping_dimension_DBD_23_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 3 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0002
schema_name | public
projection_name | shipping_dimension_DBD_22_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 4 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0002
schema_name | public
projection_name | shipping_dimension_DBD_23_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 5 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0003
schema_name | public
projection_name | shipping_dimension_DBD_22_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 6 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0003
schema_name | public
projection_name | shipping_dimension_DBD_23_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 7 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0004
schema_name | public
projection_name | shipping_dimension_DBD_22_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
-[ RECORD 8 ]-------+--------------------------------------------------------
node_name | v_vmartdb_node0004
schema_name | public
projection_name | shipping_dimension_DBD_23_seg_vmart_design_vmart_design
strata_count | 4
stratum_capacity | 62
stratum_height | 25.6511590887058
active_strata_count | 1
8.2.111 - SYSTEM
Monitors the overall state of the database.
Monitors the overall state of the database.
|
Column Name |
Data Type |
Description |
CURRENT_EPOCH |
INTEGER |
The current epoch number. |
AHM_EPOCH |
INTEGER |
The AHM epoch number. |
LAST_GOOD_EPOCH |
INTEGER |
The smallest (min) of all the
checkpoint epochs on the cluster. |
REFRESH_EPOCH |
INTEGER |
Deprecated, always set to -1. |
DESIGNED_FAULT_TOLERANCE |
INTEGER |
The designed or intended K-safety level. |
NODE_COUNT |
INTEGER |
The number of nodes in the cluster. |
NODE_DOWN_COUNT |
INTEGER |
The number of nodes in the cluster that are currently down. |
CURRENT_FAULT_TOLERANCE |
INTEGER |
The number of node failures the cluster can tolerate before it shuts down automatically.
This is the current K-safety level.
|
CATALOG_REVISION_NUMBER |
INTEGER |
The catalog version number. |
ROS_USED_BYTES |
INTEGER |
The ROS size in bytes (cluster-wide). |
ROS_ROW_COUNT |
INTEGER |
The number of rows in ROS (cluster-wide). |
TOTAL_USED_BYTES |
INTEGER |
The total storage in bytes across the database cluster. |
TOTAL_ROW_COUNT |
INTEGER |
The total number of rows across the database cluster. |
8.2.112 - SYSTEM_RESOURCE_USAGE
Provides history about system resources, such as memory, CPU, network, disk, I/O.
Provides history about system resources, such as memory, CPU, network, disk, I/O.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
END_TIME |
TIMESTAMP |
End time of the history interval. |
AVERAGE_MEMORY_USAGE_PERCENT |
FLOAT |
Average memory usage in percent of total memory (0-100) during the history interval. |
AVERAGE_CPU_USAGE_PERCENT |
FLOAT |
Average CPU usage in percent of total CPU time (0-100) during the history interval. |
NET_RX_KBYTES_PER_SECOND |
FLOAT |
Average number of kilobytes received from network (incoming) per second during the history interval. |
NET_TX_KBYTES_PER_SECOND |
FLOAT |
Average number of kilobytes transmitting to network (outgoing) per second during the history interval. |
IO_READ_KBYTES_PER_SECOND |
FLOAT |
Disk I/O average number of kilobytes read from disk per second during the history interval. |
IO_WRITTEN_KBYTES_PER_SECOND |
FLOAT |
Average number of kilobytes written to disk per second during the history interval. |
Privileges
Superuser
8.2.113 - SYSTEM_SERVICES
Provides information about background system services that Workload Analyzer monitors.
Provides information about background system services that Workload Analyzer monitors.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
SERVICE_TYPE |
VARCHAR |
Type of service; can be one of:
|
SERVICE_GROUP |
VARCHAR |
Group name, if there are multiple services of the same type. |
SERVICE_NAME |
VARCHAR |
Name of the service. |
SERVICE_INTERVAL_SEC |
INTEGER |
How often the service is executed (in seconds) during the history interval. |
IS_ENABLED |
BOOLEAN |
Denotes if the service is enabled. |
LAST_RUN_START |
TIMESTAMPTZ |
Denotes when the service was started last time. |
LAST_RUN_END |
TIMESTAMPTZ |
Denotes when the service was completed last time. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
8.2.114 - SYSTEM_SESSIONS
Provides information about system internal session history by system task.
Provides information about system internal session history by system task.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_NAME |
VARCHAR |
Name of the user at the time Vertica recorded the session. |
SESSION_ID |
INTEGER |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
STATEMENT_ID |
VARCHAR |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a statement within a session. |
SESSION_TYPE |
VARCHAR |
Session type, one of:
-
CLIENT
-
DBD
-
MERGEOUT
-
REBALANCE_CLUSTER
-
RECOVERY
-
REFRESH
-
TIMER_SERVICE
-
CONNECTION
-
SUBSESSION
-
REPARTITION_TABLE
-
LICENSE_AUDIT
-
STARTUP
-
SHUTDOWN
-
VSPREAD
|
RUNTIME_PRIORITY |
VARCHAR |
Specifies how many run-time resources (CPU, I/O bandwidth) are allocated to queries that are running in the resource pool. |
DESCRIPTION |
VARCHAR |
Transaction description in this session. |
SESSION_START_TIMESTAMP |
TIMESTAMPTZ |
Value of session at beginning of history interval. |
SESSION_END_TIMESTAMP |
TIMESTAMPTZ |
Value of session at end of history interval. |
IS_ACTIVE |
BOOLEAN |
Denotes if the session is still running. |
SESSION_DURATION_MS |
INTEGER |
Duration of the session in milliseconds. |
CLIENT_TYPE |
VARCHAR |
Columns not used in SYSTEM_SESSIONS system table. To view values for these columns, see the V_MONITOR schema system tables SESSIONS, USER_SESSIONS, CURRENT_SESSION, and SESSION_PROFILES. |
CLIENT_VERSION |
VARCHAR |
CLIENT_OS |
VARCHAR |
CLIENT_OS_USER_NAME |
VARCHAR |
The name of the user that logged into, or attempted to log into, the database. This is logged even when the login attempt is unsuccessful. |
Privileges
Superuser
8.2.115 - TABLE_RECOVERIES
Provides detailed information about recovered and recovering tables during a recovery by table.
Provides detailed information about recovered and recovering tables during a recovery by table.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is performing the recovery. |
TABLE_NAME |
VARCHAR |
The name of the table being recovered. |
TABLE_OID |
INTEGER |
The object ID of the table being recovered. |
STATUS |
VARCHAR |
The status of the table. Tables can have the following status:
-
recovered: The table is fully recovered
-
recovering: The table is in the process of recovery
-
error_retry: Vertica has attempted to recover the table, but the recovery failed.
Tables that have not yet begun the recovery process do not have a status.
|
PHASE |
VARCHAR |
The phase of the recovery. |
THREAD_ID |
VARCHAR |
The ID of the thread that performed the recovery. |
START_TIME |
TIMESTAMPTZ |
The date and time that the table began recovery. |
END_TIME |
TIMESTAMPTZ |
The date and time that the table completed recovery. |
RECOVER_PRIORITY |
INTEGER |
The recovery priority of the table being recovered. |
RECOVER_ERROR |
VARCHAR |
Error that caused the recovery to fail. |
IS_HISTORICAL |
BOOLEAN |
If f, the record contains recovery information for the current process. |
Privileges
None
Examples
=> SELECT * FROM TABLE_RECOVERIES;
-[RECORD 1]----------------------------------
node_name | node04
table_oid | 45035996273708000
table_name | public.t
status | recovered
phase | current replay delete
thread_id | 7f7a817fd700
start_time | 2017-12-13 08:47:28.825085-05
end_time | 2017-12-13 08:47:29.216571-05
recover_priority | -9223372036854775807
recover_error | Event apply failed
is_historical | t
-[RECORD 2]--------------------------------------
node_name | v_test_parquet_ha_node0011
table_oid | 45035996273937680
table_name | public.t2_impala230_uncompre_multi_file_libhdfs_1
status | error-retry
phase | historical
thread_id | 7f89a574f700
start_time | 2018-02-24 11:30:59.008831-05
end_time | 2018-02-24 11:33:09.780798-05
recover_priority | -9223372036854775807
recover_error | Could not stop all dirty transactions[txnId = 45035996273718426; ]
is_historical | t
8.2.116 - TABLE_RECOVERY_STATUS
Provides node recovery information during a Recovery By Table.
Provides node recovery information during a Recovery By Table.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is performing the recovery. |
NODE_RECOVERY_START_TIME |
TIMESTAMPTZ |
The timestamp for when the node began recovering. |
RECOVER_EPOCH |
INTEGER |
The epoch that the recovery operation is trying to recover to. |
RECOVERING_TABLE_NAME |
VARCHAR |
The name of the table currently recovering. |
TABLES_REMAIN |
INTEGER |
The total number of tables on the node. |
IS_RUNNING |
BOOLEAN |
Indicates if the recovery process is still running. |
Privileges
None
Examples
=> SELECT * FROM TABLE_RECOVERY_STATUS;
-[ RECORD 1 ]------------+-----------------
node_name | v_vmart_node0001
node_recovery_start_time |
recover_epoch |
recovering_table_name |
tables_remain | 0
is_running | f
-[ RECORD 2 ]------------+-----------------
node_name | v_vmart_node0002
node_recovery_start_time |
recover_epoch |
recovering_table_name |
tables_remain | 0
is_running | f
-[ RECORD 3 ]------------+-----------------
node_name | v_vmart_node0003
node_recovery_start_time | 2017-12-13 08:47:28.282377-05
recover_epoch | 23
recovering_table_name | user_table
tables_remain | 5
is_running | y
8.2.117 - TABLE_STATISTICS
Displays statistics that have been collected for tables and their respective partitions.
Displays statistics that have been collected for tables and their respective partitions.
|
Column Name |
Data Type |
Description |
|
LOGICAL_STATS_OID |
INTEGER |
Uniquely identifies a collection of statistics for a given table. |
|
TABLE_NAME |
VARCHAR |
Name of an existing database table. |
MIN_PARTITION_KEY,
MAX_PARTITION_KEY
|
VARCHAR |
Statistics for a range of partition keys collected by ANALYZE_STATISTICS_PARTITION, empty if statistics were collected by ANALYZE_STATISTICS. |
|
ROW_COUNT |
INTEGER |
The number of rows analyzed for each statistics collection. |
|
STAT_COLLECTION_TIME |
TIMESTAMPTZ |
The timestamp of each statistics collection. |
8.2.118 - TLS_CONFIGURATIONS
Lists settings for TLS Configuration objects for the server, LDAP, etc.
Lists settings for TLS Configuration objects for the server, LDAP, etc.
|
Column Name |
Data Type |
Description |
|
NAME |
VARCHAR |
Name of the TLS Configuration. Vertica includes the following TLS Configurations by default:
-
server
-
LDAPLink
-
LDAPAuth
-
data_channel
|
|
OWNER |
VARCHAR |
Owner of the TLS Configuration object. |
|
CERTIFICATE |
VARCHAR |
The certificate associated with the TLS Configuration object. |
|
CA_CERTIFICATES |
VARCHAR |
The CA certificate(s) used to verify client certificates.
In cases where a TLS Configuration uses more than one CA, each CA will have its own row in the table.
|
|
CIPHER_SUITES |
VARCHAR |
The cipher suites to used to secure the connection. |
|
MODE |
VARCHAR |
How Vertica establishes TLS connections with another host, one of the following, in order of ascending security:
-
DISABLE: Disables TLS. All other options for this parameter enable TLS.
-
ENABLE: Enables TLS. Vertica does not check client certificates.
-
TRY_VERIFY: Establishes a TLS connection if one of the following is true:
If the other host presents an invalid certificate, the connection will use plaintext.
-
VERIFY_CA: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA. If the other host does not present a certificate, the connection uses plaintext.
-
VERIFY_FULL: Connection succeeds if Vertica verifies that the other host's certificate is from a trusted CA and the certificate's cn (Common Name) or subjectAltName attribute matches the hostname or IP address of the other host.
Note that for client certificates, cn is used for the username, so subjectAltName must match the hostname or IP address of the other host.
VERIFY_FULL is unsupported for client-server TLS (the connection type handled by ServerTLSConfig) and behaves as VERIFY_CA.
|
Examples
In this example, the LDAPAuth TLS Configuration uses two CA certificates:
=> SELECT * FROM tls_configurations WHERE name='LDAPAuth';
name | owner | certificate | ca_certificate | cipher_suites | mode
----------+---------+-------------+----------------+---------------+---------
LDAPAuth | dbadmin | server_cert | ca | | DISABLE
LDAPAuth | dbadmin | server_cert | ica | | DISABLE
(2 rows)
To make more clear the relationship between a TLS Configuration and its CA certificates, you can format the query with LISTAGG:
=> SELECT name, owner, certificate, LISTAGG(ca_certificate) AS ca_certificates, cipher_suites, mode
FROM tls_configurations
WHERE name='LDAPAuth'
GROUP BY name, owner, certificate, cipher_suites, mode
ORDER BY 1;
name | owner | certificate | ca_certificates | cipher_suites | mode
----------+---------+-------------+-----------------+---------------+---------
LDAPAuth | dbadmin | server_cert | ca,ica | | DISABLE
(1 row)
8.2.119 - TRANSACTIONS
Records the details of each transaction.
Records the details of each transaction.
|
Column Name |
Data Type |
Description |
START_TIMESTAMP |
TIMESTAMPTZ |
Beginning of history interval. |
END_TIMESTAMP |
TIMESTAMPTZ |
End of history interval. |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the user. |
USER_NAME |
VARCHAR |
Name of the user for which transaction information is listed. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL. |
DESCRIPTION |
VARCHAR |
Textual description of the transaction. |
START_EPOCH |
INTEGER |
Number of the start epoch for the transaction. |
END_EPOCH |
INTEGER |
Number of the end epoch for the transaction |
NUMBER_OF_STATEMENTS |
INTEGER |
Number of query statements executed in this transaction. |
ISOLATION |
VARCHAR |
Denotes the transaction mode as "READ COMMITTED" or "SERIALIZABLE". |
IS_READ_ONLY |
BOOLEAN |
Denotes "READ ONLY" transaction mode. |
IS_COMMITTED |
BOOLEAN |
Determines if the transaction was committed. False means ROLLBACK. |
IS_LOCAL |
BOOLEAN |
Denotes transaction is local (non-distributed). |
IS_INITIATOR |
BOOLEAN |
Denotes if the transaction occurred on this node (t). |
IS_DDL |
BOOLEAN |
Distinguishes between a DDL transaction (t) and non-DDL transaction (f). |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also
Transactions
8.2.120 - TRUNCATED_SCHEMATA
Lists the original names of restored schemas that were truncated due to name lengths exceeding 128 characters.
Lists the original names of restored schemas that were truncated due to name lengths exceeding 128 characters.
|
Column Name |
Data Type |
Description |
RESTORE_TIME |
TIMESTAMPTZ |
The time that the table was restored. |
SESSION_ID |
VARCHAR |
Identifier for the restoring session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
USER_ID |
INTEGER |
Identifier of the user for the restore event. |
USER_NAME |
VARCHAR |
Name of the user for which Vertica lists restore information at the time it recorded the session. |
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any; otherwise NULL. |
ORIGINAL_SCHEMA_NAME |
VARCHAR |
The original name of the schema prior to the restore. |
NEW_SCHEMA_NAME |
VARCHAR |
The name of the schema after it was truncated. |
Privileges
None
8.2.121 - TUNING_RECOMMENDATIONS
Returns tuning recommendation results from the last call to ANALYZE_WORKLOAD.
Returns tuning recommendation results from the last call to
ANALYZE_WORKLOAD. This information is useful for building filters on the Workload Analyzer result set.
|
Column Name |
Data Type |
Description |
|
OBSERVATION_COUNT |
INTEGER |
Integer for the total number of events observed for this tuning recommendation. For example, if you see a return value of 1, Workload Analyzer is making its first tuning recommendation for the event in 'scope'. |
|
FIRST_OBSERVATION_TIME |
TIMESTAMPTZ |
Timestamp when the event first occurred. If this column returns a null value, the tuning recommendation is from the current status of the system instead of from any prior event. |
|
LAST_OBSERVATION_TIME |
TIMESTAMPTZ |
Timestamp when the event last occurred. If this column returns a null value, the tuning recommendation is from the current status of the system instead of from any prior event. |
|
TUNING_PARAMETER |
VARCHAR |
Objects on which to perform a tuning action. For example, a return value of:
|
|
TUNING_DESCRIPTION |
VARCHAR |
Textual description of the tuning recommendation to perform on the tuning_parameter object. For example:
-
Run database designer on table schema.table
-
Create replicated projection for table schema.table
-
Consider incremental design on query
-
Re-segment projection projection-name on high-cardinality column(s)
-
Drop the projection projection-name
-
Alter a table's partition expression
-
Reorganize data in partitioned table
-
Decrease the MoveOutInterval configuration parameter setting
|
|
TUNING_COMMAND |
VARCHAR |
Command string if tuning action is a SQL command. For example:
Update statistics on a particular schema's table.column:
SELECT ANALYZE_STATISTICS('public.table.column');
Resolve mismatched configuration parameter
LockTimeout:
SELECT * FROM CONFIGURATION_PARAMETERS WHERE parameter_name = 'LockTimeout';
Set the password for user bsmith:
ALTER USER (bsmith) IDENTIFIED BY ('new_password');
|
|
TUNING_COST |
VARCHAR |
Cost is based on the type of tuning recommendation and is one of:
-
LOW: minimal impact on resources from running the tuning command
-
MEDIUM: moderate impact on resources from running the tuning command
-
HIGH: maximum impact on resources from running the tuning command
Depending on the size of your database or table, consider running high-cost operations after hours instead of during peak load times.
|
Privileges
Superuser
Examples
See
ANALYZE_WORKLOAD.
See also
8.2.122 - TUPLE_MOVER_OPERATIONS
Monitors the status of operations on each node.
Monitors the status of Tuple Mover operations on each node.
|
Column Name |
Data Type |
Description |
|
OPERATION_START_TIMESTAMP |
TIMESTAMP |
Start time of a Tuple Mover operation. |
|
NODE_NAME |
VARCHAR |
Node name for which information is listed. |
|
OPERATION_NAME |
VARCHAR |
One of the following:
-
Analyze Statistics
-
DVMergeout
-
Mergeout
-
Partitioning
-
Rebalance
-
Recovery Replay Delete
|
|
OPERATION_STATUS |
VARCHAR |
Returns the status of each operation, one of the following:
|
|
TABLE_SCHEMA |
VARCHAR |
Schema name for the specified projection.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
|
TABLE_NAME |
VARCHAR |
Table name for the specified projection. |
|
PROJECTION_NAME |
VARCHAR |
Name of the projection being processed. |
|
PROJECTION_ID |
INTEGER |
Unique numeric ID assigned by the Vertica catalog, which identifies the projection. |
|
COLUMN_ID |
INTEGER |
Identifier for the column for the associated projection being processed. |
|
EARLIEST_CONTAINER_START_EPOCH |
INTEGER |
Populated for mergeout and purge operations only. For an automatically-invoked mergeout, for example, the returned value represents the lowest epoch of containers involved in the mergeout. |
|
LATEST_CONTAINER_END_EPOCH |
INTEGER |
Populated for mergeout and purge_partitions operations. For an automatically-invoked mergeout, for example, the returned value represents the highest epoch of containers involved in the mergeout. |
|
ROS_COUNT |
INTEGER |
Number of ROS containers. |
|
TOTAL_ROS_USED_BYTES |
INTEGER |
Size in bytes of all ROS containers in the mergeout operation. (Not applicable for other operations.) |
|
PLAN_TYPE |
VARCHAR |
One of the following:
-
Analyze Statistics
-
DVMergeout
-
Mergeout
-
Partitioning
-
Rebalance
-
Recovery Replay Delete
-
Replay Delete
|
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
|
TRANSACTION_ID |
INTEGER |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
|
IS_EXECUTING |
BOOLEAN |
Distinguishes between actively-running (t) and completed (f) tuple mover operations. |
|
RUNTIME_PRIORITY |
VARCHAR |
Determines how many run-time resources (CPU, I/O bandwidth) the Resource Manager should dedicate to running queries in the resource pool, one of the following:
|
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
Examples
=> SELECT node_name, operation_status, projection_name, plan_type
FROM TUPLE_MOVER_OPERATIONS;
node_name | operation_status | projection_name | plan_type
-------------------+------------------+------------------+-----------
v_vmart_node0001 | Running | p1_b2 | Mergeout
v_vmart_node0002 | Running | p1 | Mergeout
v_vmart_node0001 | Running | p1_b2 | Replay Delete
v_vmart_node0001 | Running | p1_b2 | Mergeout
v_vmart_node0002 | Running | p1_b2 | Mergeout
v_vmart_node0001 | Running | p1_b2 | Replay Delete
v_vmart_node0002 | Running | p1 | Mergeout
v_vmart_node0003 | Running | p1_b2 | Replay Delete
v_vmart_node0001 | Running | p1 | Mergeout
v_vmart_node0002 | Running | p1_b1 | Mergeout
See also
8.2.123 - UDFS_EVENTS
Records information about events involving the S3, HDFS, GCS, and Azure file systems.
Records information about events involving the S3, HDFS, GCS, and Azure file systems.
Events are logged if they take longer to complete than the threshold specified by UDFSSlowRequestThreshold (default 1000ms).
HTTP requests are logged if they take longer to complete than the threshold specified by HTTPSlowRequestThreshold (default 500ms), or if they produce errors or are retries. HTTP requests are logged only for S3.
|
Column Name |
Data Type |
Description |
|
START_TIME |
TIMESTAMPTZ |
Event start time |
|
END_TIME |
TIMESTAMPTZ |
Event end time |
|
NODE_NAME |
VARCHAR |
Name of the node that reported the event |
|
SESSION_ID |
VARCHAR |
Identifies the event session, unique within the cluster at any point in time but can be reused when the session closes. |
|
USER_ID |
INTEGER |
Identifies the event user. |
|
TRANSACTION_ID* |
INTEGER |
Identifies the event transaction within the SESSION_ID-specified session, if any; otherwise NULL. |
|
STATEMENT_ID* |
INTEGER |
Uniquely identifies the current statement, if any; otherwise NULL. |
|
REQUEST_ID* |
INTEGER |
Uniquely identifies the event request in the user session. |
|
FILESYSTEM |
VARCHAR |
Name of the file system, such as S3 |
|
PATH |
VARCHAR |
Complete file path |
|
EVENT |
VARCHAR |
An event type, such as HttpRequestAttempt, or a function call, such as virtual size_t SAL::S3FileOperator::read(void*, size_t) |
|
STATUS |
VARCHAR |
Status of the event: OK, CANCEL, or FAIL |
|
DESCRIPTION |
VARCHAR |
Other event details. Depending on the event type, this column can be plain text or JSON. |
|
ACTIVITY |
VARCHAR |
Points to the component that was active and logged the event, for internal use only. |
|
PLAN_ID |
VARCHAR |
Uniquely identifies the node-specific Optimizer plan for this event. |
|
OPERATOR_ID |
INTEGER |
Identifier assigned by the Execution Engine operator instance that performs the work |
* In combination, TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identify an event within a given session.
Privileges
Superuser
8.2.124 - UDFS_OPS_PER_HOUR
This table summarizes the S3 file system statistics for each hour.
This table summarizes the S3 file system statistics for each hour.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node the file system is on. |
|
FILESYSTEM |
VARCHAR |
Name of the file system, such as S3. |
|
START_TIME |
TIMESTAMP |
Start time for statistics gathering. |
|
END_TIME |
TIMESTAMP |
Stop time for statistics gathering. |
|
AVG_OPERATIONS_PER_SECOND |
INTEGER |
Average number of operations per second during the specified hour. |
|
AVG_ERRORS_PER_SECOND |
INTEGER |
Average number of errors per second during the specified hour. |
|
RETRIES |
INTEGER |
Number of retry events during the specified hour. |
|
METADATA_READS |
INTEGER |
Number of requests to write metadata during the specified hour. For example, S3 POST and DELETE requests are metadata writes. |
|
METADATA_WRITES |
INTEGER |
Number of requests to write metadata during the specified hour. For example, S3 POST and DELETE requests are metadata writes. |
|
DATA_READS |
INTEGER |
Number of read operations, such as S3 GET requests to download files, during the specified hour. |
|
DATA_WRITES |
INTEGER |
Number of write operations, such as S3 PUT requests to upload files, during the specified hour. |
|
UPSTREAM_BYTES |
INTEGER |
Number of bytes received during the specified hour. |
|
DOWNSTREAM_BYTES |
INTEGER |
Number of bytes sent during the specified hour. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM UDFS_OPS_PER_HOUR;
-[ RECORD 1 ]-------------+--------------------
node_name | e1
filesystem | S3
start_time | 2018-04-06 04:00:00
end_time | 2018-04-06 04:00:00
avg_operations_per_second | 0
avg_errors_per_second | 0
retries | 0
metadata_reads | 0
metadata_writes | 0
data_reads | 0
data_writes | 0
upstream_bytes | 0
downstream_bytes | 0
...
See also
UDFS_OPS_PER_MINUTE
8.2.125 - UDFS_OPS_PER_MINUTE
This table summarizes the S3 file system statistics for each minute.
This table summarizes the S3 file system statistics for each minute.
|
Column Name |
Data Type |
Description |
|
NODE_NAME |
VARCHAR |
Name of the node the file system is on. |
|
FILESYSTEM |
VARCHAR |
Name of the file system, such as S3. |
|
START_TIME |
TIMESTAMP |
Start time for statistics gathering. |
|
END_TIME |
TIMESTAMP |
Stop time for statistics gathering. |
|
AVG_OPERATIONS_PER_SECOND |
INTEGER |
Average number of operations per second during the specified minute. |
|
AVG_ERRORS_PER_SECOND |
INTEGER |
Average number of errors per second during the specified minute. |
|
RETRIES |
INTEGER |
Number of retry events during the specified minute. |
|
METADATA_READS |
INTEGER |
Number of requests to write metadata during the specified minute. For example, S3 POST and DELETE requests are metadata writes. |
|
METADATA_WRITES |
INTEGER |
Number of requests to write metadata during the specified minute. For example, S3 POST and DELETE requests are metadata writes. |
|
DATA_READS |
INTEGER |
Number of read operations, such as S3 GET requests to download files, during the specified minute. |
|
DATA_WRITES |
INTEGER |
Number of write operations, such as S3 PUT requests to upload files, during the specified minute. |
|
UPSTREAM_BYTES |
INTEGER |
Number of bytes received during the specified minute. |
|
DOWNSTREAM_BYTES |
INTEGER |
Number of bytes sent during the specified minute. |
Examples
=> \x
Expanded display is on.
=> SELECT * FROM UDFS_OPS_PER_MINUTE;
-[ RECORD 1 ]-------------+--------------------
node_name | e1
filesystem | S3
start_time | 2018-04-06 04:17:00
end_time | 2018-04-06 04:18:00
avg_operations_per_second | 0
avg_errors_per_second | 0
retries | 0
metadata_reads | 0
metadata_writes | 0
data_reads | 0
data_writes | 0
upstream_bytes | 0
downstream_bytes | 0
...
See also
UDFS_OPS_PER_HOUR
8.2.126 - UDFS_STATISTICS
Records aggregate information about operations on file systems and object-stores.
Records aggregate information about operations on file systems and object stores. For access through LibHDFS++, the table records information about metadata but not data.
An operation can be made up of many individual read, write, or retry requests. SUCCESSFUL_OPERATIONS and FAILED_OPERATIONS count operations; the other counters count individual requests. When an operation finishes, one of the OPERATIONS counters is incremented once, but several other counters could be incremented several times each.
|
Column Name |
Data Type |
Description |
|
FILESYSTEM |
VARCHAR |
Name of the file system, such as S3 or Libhdfs++. |
|
SUCCESSFUL_OPERATIONS |
INTEGER |
Number of successful operations. |
|
FAILED_OPERATIONS |
INTEGER |
Number of failed operations. |
|
RETRIES |
INTEGER |
Number of retry events. |
|
METADATA_READS |
INTEGER |
Number of requests to read metadata. For example, S3 list bucket and HEAD requests are metadata reads. |
|
METADATA_WRITES |
INTEGER |
Number of requests to write metadata. For example, S3 POST and DELETE requests are metadata writes. |
|
DATA_READS |
INTEGER |
Number of read operations, such as S3 GET requests to download files. |
|
DATA_WRITES |
INTEGER |
Number of write operations, such as S3 PUT requests to upload files. |
|
DOWNSTREAM_BYTES |
INTEGER |
Number of bytes received. |
|
UPSTREAM_BYTES |
INTEGER |
Number of bytes sent. |
|
OPEN_FILES |
INTEGER |
Number of files that are currently open. |
|
MAPPED_FILES |
INTEGER |
Number of files that are currently mapped. On S3 file systems, this is the number of streaming connections for reading data. On other file systems, this value is 0. |
|
READING |
INTEGER |
The number of read operations that are currently running. |
|
WRITING |
INTEGER |
The number of write operations that are currently running. |
|
TOTAL_REQUEST_DURATION_MS |
INTEGER |
Accumulated HTTP request duration, in milliseconds. This information is recorded only for S3 and GCS. |
|
OVERALL_AVERAGE_LATENCY_MS |
INTEGER |
Average HTTP request duration, in milliseconds. This value is TOTAL_REQUEST_DURATION_MS divided by the sum of SUCCESSFUL_OPERATIONS and FAILED_OPERATIONS (rounded). This value is set only for S3 and GCS. |
|
OVERALL_DOWNSTREAM_THROUGHPUT_MB_S |
FLOAT |
HTTP request downstream throughput in megabytes per second (MB/s). This value is DOWNSTREAM_BYTES divided by TOTAL_REQUEST_DURATION_MS. This value is set only for S3 and GCS. |
|
OVERALL_UPSTREAM_THROUGHPUT_MB_S |
FLOAT |
HTTP request upstream throughput in megabytes per second (MB/s). This value is UPSTREAM_BYTES divided by TOTAL_REQUEST_DURATION_MS. This value is set only for S3 and GCS. |
Examples
The following query gets the total number of metadata RPCs for Libhdfs++ operations:
=> SELECT SUM(metadata_reads) FROM UDFS_STATISTICS WHERE filesystem = 'Libhdfs++';
8.2.127 - UDX_EVENTS
Records information about events raised from the execution of user-defined extensions.
Records information about events raised from the execution of user-defined extensions.
A UDx populates the __RAW__ column using ServerInterface::logEvent() (C++ only). VMap support is provided by Flex Tables, which must not be disabled.
In combination, TRANSACTION_ID, STATEMENT_ID, and REQUEST_ID uniquely identify an event within a given session.
|
Column Name |
Data Type |
Description |
|
REPORT_TIME |
TIMESTAMPTZ |
Time the event occurred. |
|
NODE_NAME |
VARCHAR |
Name of the node that reported the event |
|
SESSION_ID |
VARCHAR |
Identifies the event session, unique within the cluster at any point in time but can be reused when the session closes. |
|
USER_ID |
INTEGER |
Identifies the user running the UDx. |
|
USER_NAME |
VARCHAR |
Identifies the user running the UDx. |
|
TRANSACTION_ID |
INTEGER |
Identifies the event transaction within the SESSION_ID-specified session, if any; otherwise NULL. |
|
STATEMENT_ID |
INTEGER |
Uniquely identifies the current statement, if any; otherwise NULL. |
|
REQUEST_ID |
INTEGER |
Uniquely identifies the event request in the user session. |
|
UDX_NAME |
VARCHAR |
Name of the UDx, as specified in the corresponding CREATE FUNCTION statement. |
|
__RAW__ |
VARBINARY |
VMap containing UDx-specific values. See the documentation of individual UDXs for supported fields. |
8.2.128 - UDX_FENCED_PROCESSES
Provides information about processes Vertica uses to run user-defined extensions in fenced mode.
Provides information about processes Vertica uses to run user-defined extensions in fenced mode.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
PROCESS_TYPE |
VARCHAR |
Indicates what kind of side process this row is for and can be one of the following values:
-
UDxZygoteProcess — Master process that creates worker side processes, as needed, for queries. There will be, at most, 1 UP UDxZygoteProcess for each Vertica instance.
-
UDxSideProcess — Indicates that the process is a worker side process. There could be many UDxSideProcesses, depending on how many sessions there are, how many queries, and so on.
|
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
LANGUAGE |
VARCHAR |
The language of the UDx. For example 'R' or 'C++'; |
MAX_MEMORY_JAVA_KB |
INTEGER |
The maximum amount of memory in KB that can be used for the Java heap file on the node. |
PID |
INTEGER |
Linux process identifier of the side process (UDxSideProcess). |
PORT |
VARCHAR |
For Vertica internal use. The TCP port that the side process is listening on. |
STATUS |
VARCHAR |
Set to UP or DOWN, depending on whether the process is alive or not.
After a process fails, Vertica restarts it only on demand. So after a process failure, there might be periods of time when no side processes run.
|
Privileges
None
8.2.129 - USER_LIBRARIES
Lists the user libraries that are currently loaded.
Lists the user libraries that are currently loaded. These libraries contain user-defined extensions (UDxs) that provide additional analytic functions.
|
Column Name |
Data Type |
Description |
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the library. |
SCHEMA_NAME |
VARCHAR(8192) |
The name of the schema containing the library.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
LIB_NAME |
VARCHAR(8192) |
The name of the library. |
LIB_OID |
INTEGER |
The object ID of the library. |
AUTHOR |
VARCHAR(8192) |
The creator of the library file. |
OWNER_ID |
INTEGER |
The object ID of the library's owner. |
LIB_FILE_NAME |
VARCHAR(8192) |
The name of the shared library file. |
MD5_SUM |
VARCHAR(8192) |
The MD5 checksum of the library file, used to verify that the file was correctly copied to each node.
Note
This use of MD5 is not for cryptographic or authentication purposes. For information on authenticating with MD5 see Hash authentication.
|
SDK_VERSION |
VARCHAR(8192) |
The version of the Vertica SDK used to compile the library. |
REVISION |
VARCHAR(8192) |
The revision of the Vertica SDK used to compile the library. |
LIB_BUILD_TAG |
VARCHAR(8192) |
Internal information set by library developer to track the when the library was compiled. |
LIB_VERSION |
VARCHAR(8192) |
The version of the library. |
LIB_SDK_VERSION |
VARCHAR(8192) |
The version of the Vertica SDK intended for use with the library. The developer sets this value manually. This value may differ from the values in the SDK_VERSION and REVISION, which are set automatically during compilation. |
SOURCE_URL |
VARCHAR(8192) |
A URL that contains information about the library. |
DESCRIPTION |
VARCHAR(8192) |
A description of the library. |
LICENSES_REQUIRED |
VARCHAR(8192) |
The licenses required to use the library. |
SIGNATURE |
VARCHAR(8192) |
The signature used to sign the library for validation. |
DEPENDENCIES |
VARCHAR (8192) |
External libraries on which this library depends. These libraries are maintained by Vertica, just like the user libraries themselves. |
8.2.130 - USER_LIBRARY_MANIFEST
Lists user-defined functions contained in all loaded user libraries.
Lists user-defined functions contained in all loaded user libraries.
|
Column Name |
Data Type |
Description |
NAMESPACE_NAME |
VARCHAR |
For Eon Mode databases, name of the namespace that contains the function. |
SCHEMA_NAME |
VARCHAR |
Name of the schema that contains the function.
If the schema belongs to a non-default namespace in an Eon Mode database, the schema name is front-qualified with the name of the schema's namespace. For example, n1.s refers to schema s in namespace n1.
|
LIB_NAME |
VARCHAR |
The name of the library containing the UDF. |
LIB_OID |
INTEGER |
The object ID of the library containing the function. |
OBJ_NAME |
VARCHAR |
The name of the constructor class in the library for a function. |
OBJ_TYPE |
VARCHAR |
The type of user defined function (scalar function, transform function) |
ARG_TYPES |
VARCHAR |
A comma-delimited list of data types of the function's parameters. |
RETURN_TYPE |
VARCHAR |
A comma-delimited list of data types of the function's return values. |
Privileges
None
8.2.131 - USER_SESSIONS
Returns user session history on the system.
Returns user session history on the system.
|
Column Name |
Data Type |
Description |
NODE_NAME |
VARCHAR |
Name of the node that is reporting the requested information. |
USER_NAME |
VARCHAR |
Name of the user at the time Vertica recorded the session. |
SESSION_ID |
VARCHAR |
Identifier for this session. This identifier is unique within the cluster at any point in time but can be reused when the session closes. |
TRANSACTION_ID |
VARCHAR |
Identifier for the transaction within the session, if any. If a session is active but no transaction has begun, TRANSACTION_ID returns NULL. |
STATEMENT_ID |
VARCHAR |
Unique numeric ID for the currently-running statement. NULL indicates that no statement is currently being processed. The combination of TRANSACTION_ID and STATEMENT_ID uniquely identifies a statement within a session. |
RUNTIME_PRIORITY |
VARCHAR |
Determines the amount of run-time resources (CPU, I/O bandwidth) the Resource Manager should dedicate to queries already running in the resource pool. Valid values are:
Queries with a HIGH run-time priority are given more CPU and I/O resources than those with a MEDIUM or LOW run-time priority.
|
SESSION_START_TIMESTAMP |
TIMESTAMPTZ |
Value of session at beginning of history interval. |
SESSION_END_TIMESTAMP |
TIMESTAMPTZ |
Value of session at end of history interval. |
IS_ACTIVE |
BOOLEAN |
Denotes if the operation is executing. |
CLIENT_OS_HOSTNAME |
VARCHAR |
The hostname of the client as reported by their operating system. |
CLIENT_HOSTNAME |
VARCHAR |
The IP address and port of the TCP socket from which the client connection was made; NULL if the session is internal.
Vertica accepts either IPv4 or IPv6 connections from a client machine. If the client machine contains mappings for both IPv4 and IPv6, the server randomly chooses one IP address family to make a connection. This can cause the CLIENT_HOSTNAME column to display either IPv4 or IPv6 values, based on which address family the server chooses.
|
CLIENT_PID |
INTEGER |
Linux process identifier of the client process that issued this connection.
Note: The client process could be on a different machine from the server.
|
CLIENT_LABEL |
VARCHAR |
User-specified label for the client connection that can be set when using ODBC. See Label in DSN Parameters. |
SSL_STATE |
VARCHAR |
Indicates if Vertica used Secure Socket Layer (SSL) for a particular session. Possible values are:
-
None – Vertica did not use SSL.
-
Server – Sever authentication was used, so the client could authenticate the server.
-
Mutual – Both the server and the client authenticated one another through mutual authentication.
See Implementing Security and TLS protocol.
|
AUTHENTICATION_METHOD |
VARCHAR |
Type of client authentication used for a particular session, if known. Possible values are:
-
Unknown
-
Trust
-
Reject
-
Kerberos
-
Password
-
MD5
-
LDAP
-
Kerberos-GSS
-
Ident
See Security and authentication and Configuring client authentication.
|
CLIENT_TYPE |
VARCHAR |
The type of client from which the connection was made. Possible client type values:
-
ADO.NET Driver
-
ODBC Driver
-
JDBC Driver
-
vsql
|
CLIENT_VERSION |
VARCHAR |
Returns the client version. |
CLIENT_OS |
VARCHAR |
Returns the client operating system. |
CLIENT_OS_USER_NAME |
VARCHAR |
The name of the user that logged into, or attempted to log into, the database. This is logged even when the login attempt is unsuccessful. |
Privileges
Non-superuser: No explicit privileges required. You only see records for tables that you have privileges to view.
See also