This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Developing user-defined extensions (UDxs)
The primary strengths of UDxs are:.
User-defined extensions (UDxs) are functions contained in external libraries that are developed in C++, Python, Java, or R using the Vertica SDK. The external libraries are defined in the Vertica catalog using the CREATE LIBRARY statement. They are best suited for analytic operations that are difficult to perform in SQL, or that need to be performed frequently enough that their speed is a major concern.
The primary strengths of UDxs are:
-
They can be used anywhere an internal function can be used.
-
They take full advantage of Vertica's distributed computing features. The extensions usually execute in parallel on each node in the cluster.
-
They are distributed to all nodes by Vertica. You only need to copy the library to the initiator node.
-
All of the complicated aspects of developing a distributed piece of analytic code are handled for you by Vertica. Your main programming task is to read in data, process it, and then write it out using the Vertica SDK APIs.
There are a few things to keep in mind about developing UDxs:
-
UDxs can be developed in the programming languages C++, Python, Java, and R. (Not all UDx types support all languages.)
-
UDxs written in Java always run in fenced mode, because the Java Virtual Machine that executes Java programs cannot run directly within the Vertica process.
-
UDxs written in Python and R always run in fenced mode.
-
UDxs developed in C++ have the option of running in unfenced mode, which means they load and run directly in the Vertica database process. This option provides the lowest overhead and highest speed. However, any bugs in the UDx's code can cause database instability. You must thoroughly test any UDxs you intend to run in unfenced mode before deploying them in a live environment. Consider whether the performance boost of running a C++ UDx unfenced is worth the potential database instability that a buggy UDx can cause.
-
Because a UDx runs on the Vertica cluster, it can take processor time and memory away from the database processes. A UDx that consumes large amounts of computing resources can negatively impact database performance.
Types of UDxs
Vertica supports five types of user-defined extensions:
-
User-defined scalar functions (UDSFs) take in a single row of data and return a single value. These functions can be used anywhere a native function can be used, except CREATE TABLE BY PARTITION and SEGMENTED BY expressions. UDSFs can be developed in C++, Python, Java, and R.
-
User-defined aggregate functions (UDAF) allow you to create custom Aggregate functions specific to your needs. They read one column of data, and return one output column. UDAFs can be developed in C++.
-
User-defined analytic functions (UDAnF) are similar to UDSFs, in that they read a row of data and return a single row. However, the function can read input rows independently of outputting rows, so that the output values can be calculated over several input rows. The function can be used with the query's OVER() clause to partition rows. UDAnFs can be developed in C++ and Java.
-
User-defined transform functions (UDTFs) operate on table partitions (as specified by the query's OVER() clause) and return zero or more rows of data. The data they return can be an entirely new table, unrelated to the schema of the input table, with its own ordering and segmentation expressions. They can only be used in the SELECT list of a query. UDTFs can be developed in C++, Python, Java, and R.
To optimize query performance, you can use live aggregate projections to pre-aggregate the data that a UDTF returns. For more information, see Pre-aggregating UDTF results.
-
User-defined load allows you to create custom sources, filters, and parsers to load data. These extensions can be used in COPY statements. UDLs can be developed C++, Java and Python.
While each UDx type has a unique base class, developing them is similar in many ways. Different UDx types can also share the same library.
Structure
Each UDx type consists of two primary classes. The main class does the actual work (a transformation, an aggregation, and so on). The class usually has at least three methods: one to set up, one to tear down (release reserved resources), and one to do the work. Sometimes additional methods are defined.
The main processing method receives an instance of the ServerInterface class as an argument. This object is used by the underlying Vertica SDK code to make calls back into the Vertica process, for example to allocate memory. You can use this class to write to the server log during UDx execution.
The second class is a singleton factory. It defines one method that produces instances of the first class, and might define other methods to manage parameters.
When implementing a UDx you must subclass both classes.
Conventions
The C++, Python, and Java APIs are nearly identical. Where possible, this documentation describes these interfaces without respect to language. Documentation specific to C++, Python, or Java is covered in language-specific sections.
Because some documentation is language-independent, it is not always possible to use ideal, language-based terminology. This documentation uses the term "method" to refer to a Java method or a C++ member function.
See also
Loading UDxs
1 - Developing with the Vertica SDK
Before you can write a user-defined extension you must set up a development environment.
Before you can write a user-defined extension you must set up a development environment. After you do so, a good test is to download, build, and run the published examples.
In addition to covering how to set up your environment, this section covers general information about working with the Vertica SDK, including language-specific considerations.
1.1 - Setting up a development environment
Before you start developing your UDx, you need to configure your development and test environments.
Before you start developing your UDx, you need to configure your development and test environments. Development and test environments must use the same operating system and Vertica version as the production environment.
For additional language-specific requirements, see the following topics:
Development environment options
The language that you use to develop your UDx determines the setup options and requirements for your development environment. C++ developers can use the C++ UDx container, and all developers can use a non-production Vertica environment.
C++ UDx container
C++ developers can develop with the C++ UDx container. The UDx-container GitHub repository provides the tools to build a container that packages the binaries, libraries, and compilers required to develop C++ Vertica extensions. The C++ UDx container has the following build options:
For requirement, build, and test details, see the repository README.
Non-production Vertica environments
You can use a node in a non-production Vertica database or another machine that runs the same operating system and Vertica version as your production environment. For specific requirements and dependencies, refer to Operating System Requirements and Language Requirements.
Test environment options
To test your UDx, you need access to a non-production Vertica database. You have the following options:
- Install a single-node Vertica database on your development machine.
- Download and build a containerized test environment.
Containerized test environments
Vertica provides the following containerized options to simplify your test environment setup:
1.2 - Downloading and running UDx example code
You can download all of the examples shown in this documentation, and many more, from the Vertica GitHub repository.
You can download all of the examples shown in this documentation, and many more, from the Vertica GitHub repository. This repository includes examples of all types of UDxs.
You can download the examples in either of two ways:
-
Download the ZIP file. Extract the contents of the file into a directory.
-
Clone the repository. Using a terminal window, run the following command:
$ git clone https://github.com/vertica/UDx-Examples.git
The repository includes a makefile that you can use to compile the C++ and Java examples. It also includes .sql files that load and use the examples. See the README file for instructions on compiling and running the examples. To compile the examples you will need g++ or a JDK and make. See Setting up a development environment for related information.
Running the examples not only helps you understand how a UDx works, but also helps you ensure your development environment is properly set up to compile UDx libraries.
See also
1.3 - C++ SDK
The Vertica SDK supports writing both fenced and unfenced UDxs in C++ 11.
The Vertica SDK supports writing both fenced and unfenced UDxs in C++ 11. You can download, compile, and run the examples; see Downloading and running UDx example code. Running the examples is a good way to verify that your development environment has all needed libraries.
If you do not have access to a Vertica test environment, you can install Vertica on your development machine and run a single node. Each time you rebuild your UDx library, you need to re-install it into Vertica. The following diagram illustrates the typical development cycle.

This section covers C++-specific topics that apply to all UDx types. For information that applies to all languages, see Arguments and return values, UDx parameters, Errors, warnings, and logging, Handling cancel requests and the sections for specific UDx types. For full API documentation, see the C++ SDK Documentation.
1.3.1 - Setting up the C++ SDK
The Vertica C++ Software Development Kit (SDK) is distributed as part of the server installation.
The Vertica C++ Software Development Kit (SDK) is distributed as part of the server installation. It contains the source and header files you need to create your UDx library. For examples that you can compile and run, see Downloading and running UDx example code.
Requirements
At a minimum, install the following on your development machine:
-
gcc version 8 or higher. Vertica has not tested UDx builds with versions higher than 9.
-
g++ and its associated toolchain, such as ld. Some Linux distributions package g++ separately from gcc.
-
A copy of the Vertica SDK.
Note
The Vertica binaries are compiled using the default version of g++ installed on the supported Linux platforms.
You must compile with a std flag value of c++11 or later.
The following optional software packages can simplify development:
-
make, or some other build-management tool.
-
gdb, or some other debugger.
-
Valgrind, or similar tools that detect memory leaks.
If you want to use any third-party libraries, such as statistical analysis libraries, you need to install them on your development machine. If you do not statically link these libraries into your UDx library, you must install them on every node in the cluster. See Compiling your C++ library for details.
SDK files
The SDK files are located in the sdk subdirectory under the root Vertica server directory (usually,
/opt/vertica/sdk). This directory contains a subdirectory, include, which contains the headers and source files needed to compile UDx libraries.
There are two files in the include directory you need when compiling your UDx:
-
Vertica.h is the main header file for the SDK. Your UDx code needs to include this file in order to find the SDK's definitions.
-
Vertica.cpp contains support code that needs to be compiled into the UDx library.
Much of the Vertica SDK API is defined in the VerticaUDx.h header file (which is included by the Vertica.h file). If you're curious, you might want to review the contents of this file in addition to reading the API documentation.
Finding the current SDK version
You must develop your UDx using the same SDK version as the database in which you plan to use it. To display the SDK version currently installed on your system, run the following command in vsql:
=> SELECT sdk_version();
Running the examples
You can download the examples from the GitHub repository (see Downloading and running UDx example code). Compiling and running the examples helps you to ensure that your development environment is properly set up.
To compile all of the examples, including the Java examples, issue the following command in the Java-and-C++ directory under the examples directory:
$ make
Note
To compile the examples, you must have a g++ development environment installed. To install a g++ development environment on Red Hat systems, run yum install gcc gcc-c++ make.
1.3.2 - Compiling your C++ library
GNU g++ is the only supported compiler for compiling UDx libraries.
GNU g++ is the only supported compiler for compiling UDx libraries. Always compile your UDx code on the same version of Linux that you use on your Vertica cluster.
When compiling your library, you must always:
-
Compile with a -std flag value of c++11 or later.
-
Pass the -shared and -fPIC flags to the linker. The simplest method is to just pass these flags to g++ when you compile and link your library.
-
Use the -Wno-unused-value flag to suppress warnings when macro arguments are not used. If you do not use this flag, you may get "left-hand operand of comma has no effect" warnings.
-
Compile sdk/include/Vertica.cpp and link it into your library. This file contains support routines that help your UDx communicate with Vertica. The easiest way to do this is to include it in the g++ command to compile your library. Vertica supplies this file as C++ source rather than a library to limit library compatibility issues.
-
Add the Vertica SDK include directory in the include search path using the g++ -I flag.
The SDK examples include a working makefile. See Downloading and running UDx example code.
Example of compiling a UDx
The following command compiles a UDx contained in a single source file named MyUDx.cpp into a shared library named MyUDx.so:
g++ -I /opt/vertica/sdk/include -Wall -shared -Wno-unused-value \
-fPIC -o MyUDx.so MyUDx.cpp /opt/vertica/sdk/include/Vertica.cpp
Important
Vertica only supports UDx development on 64-bit architectures.
After you debug your UDx, you are ready to deploy it. Recompile your UDx using the -O3 flag to enable compiler optimization.
You can add additional source files to your library by adding them to the command line. You can also compile them separately and then link them together.
Tip
The examples subdirectory in the Vertica SDK directory contains a make file that you can use as starting point for your own UDx project.
Handling external libraries
You must link your UDx library to any supporting libraries that your UDx code relies on.These libraries might be either ones you developed or others provided by third parties. You have two options for linking:
-
Statically link the support libraries into your UDx. The benefit of this method is that your UDx library does not rely on external files. Having a single UDx library file simplifies deployment because you just transfer a single file to your Vertica cluster. This method's main drawback is that it increases the size of your UDx library file.
-
Dynamically link the library to your UDx. You must sometimes use dynamic linking if a third-party library does not allow static linking. In this case, you must copy the libraries to your Vertica cluster in addition to your UDx library file.
1.3.3 - Adding metadata to C++ libraries
For example, the following code demonstrates adding metadata to the Add2Ints example (see C++ Example: Add2Ints).
You can add metadata, such as author name, the version of the library, a description of your library, and so on to your library. This metadata lets you track the version of your function that is deployed on a Vertica Analytic Database cluster and lets third-party users of your function know who created the function. Your library's metadata appears in the USER_LIBRARIES system table after your library has been loaded into the Vertica Analytic Database catalog.
You declare the metadata for your library by calling the RegisterLibrary() function in one of the source files for your UDx. If there is more than one function call in the source files for your UDx, whichever gets interpreted last as Vertica Analytic Database loads the library is used to determine the library's metadata.
The RegisterLibrary() function takes eight string parameters:
RegisterLibrary(author,
library_build_tag,
library_version,
library_sdk_version,
source_url,
description,
licenses_required,
signature);
-
author contains whatever name you want associated with the creation of the library (your own name or your company's name for example).
-
library_build_tag is a string you want to use to represent the specific build of the library (for example, the SVN revision number or a timestamp of when the library was compiled). This is useful for tracking instances of your library as you are developing them.
-
library_version is the version of your library. You can use whatever numbering or naming scheme you want.
-
library_sdk_version is the version of the Vertica Analytic Database SDK Library for which you've compiled the library.
Note
This field isn't used to determine whether a library is compatible with a version of the Vertica Analytic Database server. The version of the Vertica Analytic Database SDK you use to compile your library is embedded in the library when you compile it. It is this information that Vertica Analytic Database server uses to determine if your library is compatible with it.
-
source_url is a URL where users of your function can find more information about it. This can be your company's website, the GitHub page hosting your library's source code, or whatever site you like.
-
description is a concise description of your library.
-
licenses_required is a placeholder for licensing information. You must pass an empty string for this value.
-
signature is a placeholder for a signature that will authenticate your library. You must pass an empty string for this value.
For example, the following code demonstrates adding metadata to the Add2Ints example (see C++ example: Add2Ints).
// Register the factory with Vertica
RegisterFactory(Add2IntsFactory);
// Register the library's metadata.
RegisterLibrary("Whizzo Analytics Ltd.",
"1234",
"2.0",
"7.0.0",
"http://www.example.com/add2ints",
"Add 2 Integer Library",
"",
"");
Loading the library and querying the USER_LIBRARIES system table shows the metadata supplied in the call to RegisterLibrary():
=> CREATE LIBRARY add2intslib AS '/home/dbadmin/add2ints.so';
CREATE LIBRARY
=> \x
Expanded display is on.
=> SELECT * FROM USER_LIBRARIES WHERE lib_name = 'add2intslib';
-[ RECORD 1 ]-----+----------------------------------------
schema_name | public
lib_name | add2intslib
lib_oid | 45035996273869808
author | Whizzo Analytics Ltd.
owner_id | 45035996273704962
lib_file_name | public_add2intslib_45035996273869808.so
md5_sum | 732c9e145d447c8ac6e7304313d3b8a0
sdk_version | v7.0.0-20131105
revision | 125200
lib_build_tag | 1234
lib_version | 2.0
lib_sdk_version | 7.0.0
source_url | http://www.example.com/add2ints
description | Add 2 Integer Library
licenses_required |
signature |
1.3.4 - C++ SDK data types
The Vertica SDK has typedefs and classes for representing Vertica data types within your UDx code.
The Vertica SDK has typedefs and classes for representing Vertica data types within your UDx code. Using these typedefs ensures data type compatibility between the data your UDx processes and generates and the Vertica database. The following table describes some of the typedefs available. Consult the C++ SDK Documentation for a complete list, as well as lists of helper functions to convert and manipulate these data types.
For information about SDK support for complex data types, see Complex Types as Arguments and Return Values.
|
Type Definition |
Description |
|
Interval |
A Vertica interval |
|
IntervalYM |
A Vertica year-to-month interval. |
|
Timestamp |
A Vertica timestamp |
|
vint |
A standard Vertica 64-bit integer |
|
vbool |
A Boolean value in Vertica |
|
vbool_null |
A null value for a Boolean data types |
|
vfloat |
A Vertica floating point value |
|
VString |
String data types (such as varchar and char)
Note: Do not use a VString object to hold an intermediate result. Use a std::string or char[] instead.
|
|
VNumeric |
Fixed-point data types from Vertica |
|
VUuid |
A Vertica universally unique identifier |
Notes
-
When making some Vertica SDK API calls (such as VerticaType::getNumericLength()) on objects, make sure they have the correct data type. To minimize overhead and improve performance, most of the APIs do not check the data types of the objects on which they are called. Calling a function on an incorrect data type can result in an error.
-
You cannot create instances of VString or VNumeric yourself. You can manipulate the values of existing objects of these classes that Vertica passes to your UDx, and extract values from them. However, only Vertica can instantiate these classes.
1.3.5 - Resource use for C++ UDxs
Your UDxs consume at least a small amount of memory by instantiating classes and creating local variables.
Your UDxs consume at least a small amount of memory by instantiating classes and creating local variables. This basic memory usage by UDxs is small enough that you do not need to be concerned about it.
If your UDx needs to allocate more than one or two megabytes of memory for data structures, or requires access to additional resources such as files, you must inform Vertica about its resource use. Vertica can then ensure that the resources your UDx requires are available before running a query that uses it. Even moderate memory use (10MB per invocation of a UDx, for example) can become an issue if there are many simultaneous queries that call it.
Note
If your UDx allocates its own memory, you must make
absolutely sure it properly frees it. Failing to free even a single byte of allocated memory can have significant consequences at scale. Instead of having your code allocate its own memory, you should use the C++
vt_alloc macro, which uses Vertica's own memory manager to allocate and track memory. This memory is guaranteed to be properly disposed of when your UDx completes execution. See
Allocating resources for UDxs for more information.
1.3.5.1 - Allocating resources for UDxs
You have two options for allocating memory and file handles for your user-defined extensions (UDxs):.
You have two options for allocating memory and file handles for your user-defined extensions (UDxs):
-
Use Vertica SDK macros to allocate resources. This is the best method, since it uses Vertica's own resource manager, and guarantees that resources used by your UDx are reclaimed. See Allocating resources with the SDK macros.
-
While not the recommended option, you can allocate resources in your UDxs yourself using standard C++ methods (instantiating objects using new, allocating memory blocks using malloc(), etc.). You must manually free these resources before your UDx exits.
Note
You must be extremely careful if you choose to allocate your own resources in your UDx. Failing to free resources properly will have significant negative impact, especially if your UDx is running in unfenced mode.
Whichever method you choose, you usually allocate resources in a function named setup() in your UDx class. This function is called after your UDx function object is instantiated, but before Vertica calls it to process data.
If you allocate memory on your own in the setup() function, you must free it in a corresponding function named destroy(). This function is called after your UDx has performed all of its processing. This function is also called if your UDx returns an error (see Handling errors).
Note
Always use the setup() and destroy() functions to allocate and free resources instead of your own constructors and destructors. The memory for your UDx object is allocated from one of Vertica's own memory pools. Vertica always calls your UDx's destroy() function before it deallocates the object's memory. There is no guarantee that your UDx's destructor is will be called before the object is deallocated. Using the destroy() function ensures that your UDx has a chance to free its allocated resources before it is destroyed.
The following code fragment demonstrates allocating and freeing memory using a setup() and destroy() function.
class MemoryAllocationExample : public ScalarFunction
{
public:
uint64* myarray;
// Called before running the UDF to allocate memory used throughout
// the entire UDF processing.
virtual void setup(ServerInterface &srvInterface, const SizedColumnTypes
&argTypes)
{
try
{
// Allocate an array. This memory is directly allocated, rather than
// letting Vertica do it. Remember to properly calculate the amount
// of memory you need based on the data type you are allocating.
// This example divides 500MB by 8, since that's the number of
// bytes in a 64-bit unsigned integer.
myarray = new uint64[1024 * 1024 * 500 / 8];
}
catch (std::bad_alloc &ba)
{
// Always check for exceptions caused by failed memory
// allocations.
vt_report_error(1, "Couldn't allocate memory :[%s]", ba.what());
}
}
// Called after the UDF has processed all of its information. Use to free
// any allocated resources.
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes
&argTypes)
{
// srvInterface.log("RowNumber processed %d records", *count_ptr);
try
{
// Properly dispose of the allocated memory.
delete[] myarray;
}
catch (std::bad_alloc &ba)
{
// Always check for exceptions caused by failed memory
// allocations.
vt_report_error(1, "Couldn't free memory :[%s]", ba.what());
}
}
1.3.5.2 - Allocating resources with the SDK macros
The Vertica SDK provides three macros to allocate memory:.
The Vertica SDK provides three macros to allocate memory:
-
vt_alloc allocates a block of memory to fit a specific data type (vint, struct, etc.).
-
vt_allocArray allocates a block of memory to hold an array of a specific data type.
-
vt_allocSize allocates an arbitrarily-sized block of memory.
All of these macros allocate their memory from memory pools managed by Vertica. The main benefit of allowing Vertica to manage your UDx's memory is that the memory is automatically reclaimed after your UDx has finished. This ensures there is no memory leaks in your UDx.
Because Vertica frees this memory automatically, do not attempt to free any of the memory you allocate through any of these macros. Attempting to free this memory results in run-time errors.
1.3.5.3 - Informing Vertica of resource requirements
When you run your UDx in fenced mode, Vertica monitors its use of memory and file handles.
When you run your UDx in fenced mode, Vertica monitors its use of memory and file handles. If your UDx uses more than a few megabytes of memory or any file handles, it should tell Vertica about its resource requirements. Knowing the resource requirements of your UDx allows Vertica to determine whether it can run the UDx immediately or needs to queue the request until enough resources become available to run it.
Determining how much memory your UDx requires can be difficult in some cases. For example, if your UDx extracts unique data elements from a data set, there is potentially no bound on the number of data items. In this case, a useful technique is to run your UDx in a test environment and monitor its memory use on a node as it handles several differently-sized queries, then extrapolate its memory use based on the worst-case scenario it may face in your production environment. In all cases, it's usually a good idea to add a safety margin to the amount of memory you tell Vertica your UDx uses.
Note
The information on your UDx's resource needs that you pass to Vertica is used when planning the query execution. There is no way to change the amount of resources your UDx requests from Vertica while the UDx is actually running.
Your UDx informs Vertica of its resource needs by implementing the getPerInstanceResources() function in its factory class (see Vertica::UDXFactory::getPerInstanceResources() in the SDK documentation). If your UDx's factory class implements this function, Vertica calls it to determine the resources your UDx requires.
The getPerInstanceResources() function receives an instance of the Vertica::VResources struct. This struct contains fields that set the amount of memory and the number of file handles your UDx needs. By default, the Vertica server allocates zero bytes of memory and 100 file handles for each instance of your UDx.
Your implementation of the getPerInstanceResources() function sets the fields in the VResources struct based on the maximum resources your UDx may consume for each instance of the UDx function. So, if your UDx's processBlock() function creates a data structure that uses at most 100MB of memory, your UDx must set the VResources.scratchMemory field to at least 104857600 (the number of bytes in 100MB). Leave yourself a safety margin by increasing the number beyond what your UDx should normally consume. In this example, allocating 115000000 bytes (just under 110MB) is a good idea.
The following ScalarFunctionFactory class demonstrates calling getPerInstanceResources() to inform Vertica about the memory requirements of the MemoryAllocationExample class shown in Allocating resources for UDxs. It tells Vertica that the UDSF requires 510MB of memory (which is a bit more than the UDSF actually allocates, to be on the safe size).
class MemoryAllocationExampleFactory : public ScalarFunctionFactory
{
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface
&srvInterface)
{
return vt_createFuncObj(srvInterface.allocator, MemoryAllocationExample);
}
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
// Tells Vertica the amount of resources that this UDF uses.
virtual void getPerInstanceResources(ServerInterface &srvInterface,
VResources &res)
{
res.scratchMemory += 1024LL * 1024 * 510; // request 510MB of memory
}
};
1.3.5.4 - Setting memory limits for fenced-mode UDxs
Vertica calls a fenced-mode UDx's implementation of Vertica::UDXFactory::getPerInstanceResources() to determine if there are enough free resources to run the query containing the UDx (see Informing [%=Vertica.DBMS_SHORT%] of Resource Requirements).
Vertica calls a fenced-mode UDx's implementation of Vertica::UDXFactory::getPerInstanceResources() to determine if there are enough free resources to run the query containing the UDx (see Informing Vertica of resource requirements). Since these reports are not generated by actual memory use, they can be inaccurate. Once started by Vertica, a UDx could allocate far more memory or file handles than it reported it needs.
The FencedUDxMemoryLimitMB configuration parameter lets you create an absolute memory limit for UDxs. Any attempt by a UDx to allocate more memory than this limit results in a bad_alloc exception. For an example of setting FencedUDxMemoryLimitMB, see How resource limits are enforced.
1.3.5.5 - How resource limits are enforced
Before running a query, Vertica determines how much memory it requires to run.
Before running a query, Vertica determines how much memory it requires to run. If the query contains a fenced-mode UDx which implements the getPerInstanceResources() function in its factory class, Vertica calls it to determine the amount of memory the UDx needs and adds this to the total required for the query. Based on these requirements, Vertica decides how to handle the query:
-
If the total amount of memory required (including the amount that the UDxs report that they need) is larger than the session's MEMORYCAP or resource pool's MAXMEMORYSIZE setting, Vertica rejects the query. For more information about resource pools, see Resource pool architecture.
-
If the amount of memory is below the limit set by the session and resource pool limits, but there is currently not enough free memory to run the query, Vertica queues it until enough resources become available.
-
If there are enough free resources to run the query, Vertica executes it.
Note
Vertica has no other way to determine the amount of resources a UDx requires other than the values it reports using the
getPerInstanceResources() function. A UDx could use more resources than it claims, which could cause performance issues for other queries that are denied resources. You can set an absolute limit on the amount of memory UDxs can allocate. See
Setting memory limits for fenced-mode UDxs for more information.
If the process executing your UDx attempts to allocate more memory than the limit set by the FencedUDxMemoryLimitMB configuration parameter, it receives a bad_alloc exception. For more information about FencedUDxMemoryLimitMB, see Setting memory limits for fenced-mode UDxs.
Below is the output of loading a UDSF that consumes 500MB of memory, then changing the memory settings to cause out-of-memory errors. The MemoryAllocationExample UDSF in the following example is just the Add2Ints UDSF example altered as shown in Allocating resources for UDxs and Informing Vertica of resource requirements to allocate 500MB of RAM.
=> CREATE LIBRARY mylib AS '/home/dbadmin/MemoryAllocationExample.so';
CREATE LIBRARY
=> CREATE FUNCTION usemem AS NAME 'MemoryAllocationExampleFactory' LIBRARY mylib
-> FENCED;
CREATE FUNCTION
=> SELECT usemem(1,2);
usemem
--------
3
(1 row)
The following statements demonstrate setting the session's MEMORYCAP to lower than the amount of memory that the UDSF reports it uses. This causes Vertica to return an error before it executes the UDSF.
=> SET SESSION MEMORYCAP '100M';
SET
=> SELECT usemem(1,2);
ERROR 3596: Insufficient resources to execute plan on pool sysquery
[Request exceeds session memory cap: 520328KB > 102400KB]
=> SET SESSION MEMORYCAP = default;
SET
The resource pool can also prevent a UDx from running if it requires more memory than is available in the pool. The following statements demonstrate the effect of creating and using a resource pool that has too little memory for the UDSF to run. Similar to the session's MAXMEMORYCAP limit, the pool's MAXMEMORYSIZE setting prevents Vertica from executing the query containing the UDSF.
=> CREATE RESOURCE POOL small MEMORYSIZE '100M' MAXMEMORYSIZE '100M';
CREATE RESOURCE POOL
=> SET SESSION RESOURCE POOL small;
SET
=> CREATE TABLE ExampleTable(a int, b int);
CREATE TABLE
=> INSERT /*+direct*/ INTO ExampleTable VALUES (1,2);
OUTPUT
--------
1
(1 row)
=> SELECT usemem(a, b) FROM ExampleTable;
ERROR 3596: Insufficient resources to execute plan on pool small
[Request Too Large:Memory(KB) Exceeded: Requested = 523136, Free = 102400 (Limit = 102400, Used = 0)]
=> DROP RESOURCE POOL small; --Dropping the pool resets the session's pool
DROP RESOURCE POOL
Finally, setting the FencedUDxMemoryLimitMB configuration parameter to lower than the UDx actually allocates results in the UDx throwing an exception. This is a different case than either of the previous two examples, since the query actually executes. The UDx's code needs to catch and handle the exception. In this example, it uses the vt_report_error macro to report the error back to Vertica and exit.
=> ALTER DATABASE DEFAULT SET FencedUDxMemoryLimitMB = 300;
=> SELECT usemem(1,2);
ERROR 3412: Failure in UDx RPC call InvokeSetup(): Error calling setup() in
User Defined Object [usemem] at [MemoryAllocationExample.cpp:32], error code:
1, message: Couldn't allocate memory :[std::bad_alloc]
=> ALTER DATABASE DEFAULT SET FencedUDxMemoryLimitMB = -1;
=> SELECT usemem(1,2);
usemem
--------
3
(1 row)
See also
1.4 - Java SDK
The Vertica SDK supports writing Java UDxs of all types except aggregate functions.
The Vertica SDK supports writing Java UDxs of all types except aggregate functions. All Java UDxs are fenced.
You can download, compile, and run the examples; see Downloading and running UDx example code. Running the examples is a good way to verify that your development environment has all needed libraries.
If you do not have access to a Vertica test environment, you can install Vertica on your development machine and run a single node. Each time you rebuild your UDx library, you need to re-install it into Vertica. The following diagram illustrates the typical development cycle.

This section covers Java-specific topics that apply to all UDx types. For information that applies to all languages, see Arguments and return values, UDx parameters, Errors, warnings, and logging, Handling cancel requests and the sections for specific UDx types. For full API documentation, see the Java SDK Documentation.
1.4.1 - Setting up the Java SDK
The Vertica Java Software Development Kit (SDK) is distributed as part of the server installation.
The Vertica Java Software Development Kit (SDK) is distributed as part of the server installation. It contains the source and JAR files you need to create your UDx library. For examples that you can compile and run, see Downloading and running UDx example code.
Requirements
At a minimum, install the following on your development machine:
Optionally, you can simplify development with a build-management tool, such as make.
SDK files
To use the SDK you need two files from the Java support package:
-
/opt/vertica/bin/VerticaSDK.jar contains the Vertica Java SDK and other supporting files.
-
/opt/vertica/sdk/BuildInfo.java contains version information about the SDK. You must compile this file and include it within your Java UDx JAR files.
If you are not doing your development on a database node, you can copy these two files from one of the database nodes to your development system.
The BuildInfo.java and VerticaSDK.jar files that you use to compile your UDx must be from the same SDK version. Both files must also match the version of the SDK files on your Vertica hosts. Versioning is only an issue if you are not compiling your UDxs on a Vertica host. If you are compiling on a separate development system, always refresh your copies of these two files and recompile your UDxs just before deploying them.
Finding the current SDK version
You must develop your UDx using the same SDK version as the database in which you plan to use it. To display the SDK version currently installed on your system, run the following command in vsql:
=> SELECT sdk_version();
Compiling BuildInfo.java
You need to compile the BuildInfo.java file into a class file, so you can include it in your Java UDx JAR library. If you are using a Vertica node as a development system, you can either:
-
Copy the BuildInfo.java file to another location on your host.
-
If you have root privileges, compile the BuildInfo.java file in place. (Only the root user has privileges to write files to the /opt/vertica/sdk directory.)
Compile the file using the following command. Replace path with the path to the file and output-directory with the directory where you will compile your UDxs.
$ javac -classpath /opt/vertica/bin/VerticaSDK.jar \
/path/BuildInfo.java -d output-directory
If you use an IDE such as Eclipse, you can include the BuildInfo.java file in your project instead of compiling it separately. You must also add the VerticaSDK.jar file to the project's build path. See your IDE's documentation for details on how to include files and libraries in your projects.
Running the examples
You can download the examples from the GitHub repository (see Downloading and running UDx example code). Compiling and running the examples helps you to ensure that your development environment is properly set up.
If you have not already done so, set the JAVA_HOME environment variable to your JDK (not JRE) directory.
To compile all of the examples, including the Java examples, issue the following command in the Java-and-C++ directory under the examples directory:
$ make
To compile only the Java examples, issue the following command in the Java-and-C++ directory under the examples directory:
$ make JavaFunctions
1.4.2 - Compiling and packaging a Java library
Before you can use your Java UDx, you need to compile it and package it into a JAR file.
Before you can use your Java UDx, you need to compile it and package it into a JAR file.
The SDK examples include a working makefile. See Downloading and running UDx example code.
Compile your Java UDx
You must include the SDK JAR file in the CLASSPATH when you compile your Java UDx source files so the Java compiler can resolve the Vertica API calls. If you are using the command-line Java compiler on a host in your database cluster, enter this command:
$ javac -classpath /opt/vertica/bin/VerticaSDK.jar factorySource.java \
[functionSource.java...] -d output-directory
If all of your source files are in the same directory, you can use *.java on the command line instead of listing the files individually.
If you are using an IDE, verify that a copy of the VerticaSDK.jar file is in the build path.
UDx class file organization
After you compile your UDx, you must package its class files and the BuildInfo.class file into a JAR file.
Note
You can package as many UDxs as you want into the same JAR file. Bundling your UDxs together saves you from having to load multiple libraries.
To use the jar command packaged as part of the JDK, you must organize your UDx class files into a directory structure matching your class package structure. For example, suppose your UDx's factory class has a fully-qualified name of com.mycompany.udfs.Add2ints. In this case, your class files must be in the directory hierarchy com/mycompany/udfs relative to your project's base directory. In addition, you must have a copy of the BuildInfo.class file in the path com/vertica/sdk so that it can be included in the JAR file. This class must appear in your JAR file to indicate the SDK version that was used to compile your Java UDx.
The JAR file for the Add2ints UDSF example has the following directory structure after compilation:
com/vertica/sdk/BuildInfo.class
com/mycompany/example/Add2intsFactory.class
com/mycompany/example/Add2intsFactory$Add2ints.class
Package your UDx into a JAR file
To create a JAR file from the command line:
-
Change to the root directory of your project.
-
Use the jar command to package the BuildInfo.class file and all of the classes in your UDx:
# jar -cvf libname.jar com/vertica/sdk/BuildInfo.class \
packagePath/*.class
When you type this command, libname is the filename you have chosen for your JAR file (choose whatever name you like), and packagePath is the path to the directory containing your UDx's class files.
-
For example, to package the files from the Add2ints example, you use the command:
# jar -cvf Add2intsLib.jar com/vertica/sdk/BuildInfo.class \
com/mycompany/example/*.class
-
More simply, if you compiled BuildInfo.class and your class files into the same root directory, you can use the following command:
# jar -cvf Add2intsLib.jar .
You must include all of the class files that make up your UDx in your JAR file. Your UDx always consists of at least two classes (the factory class and the function class). Even if you defined your function class as an inner class of your factory class, Java generates a separate class file for the inner class.
After you package your UDx into a JAR file, you are ready to deploy it to your Vertica database.
1.4.3 - Handling Java UDx dependencies
If your Java UDx relies on one or more external libraries, you can handle the dependencies in one of three ways:.
If your Java UDx relies on one or more external libraries, you can handle the dependencies in one of three ways:
-
Bundle the JAR files into your UDx JAR file using a tool such as One-JAR or Eclipse Runnable JAR Export Wizard.
-
Unpack the JAR file and then repack its contents in your UDx's JAR file.
-
Copy the libraries to your Vertica cluster in addition to your UDx library.Then, use the DEPENDS keyword of the CREATE LIBRARY statement to tell Vertica that the UDx library depends on the external libraries. This keyword acts as a library-specific CLASSPATH setting. Vertica distributes the support libraries to all of the nodes in the cluster and sets the class path for the UDx so it can find them.
If your UDx depends on native libraries (SO files), use the DEPENDS keyword to specify their path. When you call System.loadLibrary in your UDx (which you must do before using a native library), this function uses the DEPENDS path to find them. You do not need to also set the LD_LIBRARY_PATH environment variable.
External library example
The following example demonstrates using an external library with a Java UDx.
The following sample code defines a simple class, named VowelRemover. It contains a single method, named removevowels, that removes all of the vowels (the letters a, e, i, o u, and y) from a string.
package com.mycompany.libs;
public class VowelRemover {
public String removevowels(String input) {
return input.replaceAll("(?i)[aeiouy]", "");
}
};
You can compile this class and package it into a JAR file with the following commands:
$ javac -g com/mycompany/libs/VowelRemover.java
$ jar cf mycompanylibs.jar com/mycompany/libs/VowelRemover.class
The following code defines a Java UDSF, named DeleteVowels, that uses the library defined in the preceding example code. DeleteVowels accepts a single VARCHAR as input, and returns a VARCHAR.
package com.mycompany.udx;
// Import the support class created earlier
import com.mycompany.libs.VowelRemover;
// Import the Vertica SDK
import com.vertica.sdk.*;
public class DeleteVowelsFactory extends ScalarFunctionFactory {
@Override
public ScalarFunction createScalarFunction(ServerInterface arg0) {
return new DeleteVowels();
}
@Override
public void getPrototype(ServerInterface arg0, ColumnTypes argTypes,
ColumnTypes returnTypes) {
// Accept a single string and return a single string.
argTypes.addVarchar();
returnTypes.addVarchar();
}
@Override
public void getReturnType(ServerInterface srvInterface,
SizedColumnTypes argTypes,
SizedColumnTypes returnType){
returnType.addVarchar(
// Output will be no larger than the input.
argTypes.getColumnType(0).getStringLength(), "RemovedVowels");
}
public class DeleteVowels extends ScalarFunction
{
@Override
public void processBlock(ServerInterface arg0, BlockReader argReader,
BlockWriter resWriter) throws UdfException, DestroyInvocation {
// Create an instance of the VowelRemover object defined in
// the library.
VowelRemover remover = new VowelRemover();
do {
String instr = argReader.getString(0);
// Call the removevowels method defined in the library.
resWriter.setString(remover.removevowels(instr));
resWriter.next();
} while (argReader.next());
}
}
}
Use the following commands to build the example UDSF and package it into a JAR:
-
The first javac command compiles the SDK’s BuildInfo class. Vertica requires all UDx libraries to contain this class. The javac command’s -d option outputs the class file in the directory structure of your UDSF’s source.
-
The second javac command compiles the UDSF class. It adds the previously-created mycompanylibs.jar file to the class path so compiler can find the the VowelRemover class.
-
The jar command packages the BuildInfo and the classes for the UDx library together.
$ javac -g -cp /opt/vertica/bin/VerticaSDK.jar\
/opt/vertica/sdk/com/vertica/sdk/BuildInfo.java -d .
$ javac -g -cp mycompanylibs.jar:/opt/vertica/bin/VerticaSDK.jar\
com/mycompany/udx/DeleteVowelsFactory.java
$ jar cf DeleteVowelsLib.jar com/mycompany/udx/*.class \
com/vertica/sdk/*.class
To install the UDx library, you must copy both of the JAR files to a node in the Vertica cluster. Then, connect to the node to execute the CREATE LIBRARY statement.
The following example demonstrates how to load the UDx library after you copy the JAR files to the home directory of the dbadmin user. The DEPENDS keyword tells Vertica that the UDx library depends on the mycompanylibs.jar file.
=> CREATE LIBRARY DeleteVowelsLib AS
'/home/dbadmin/DeleteVowelsLib.jar' DEPENDS '/home/dbadmin/mycompanylibs.jar'
LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE FUNCTION deleteVowels AS language 'java' NAME
'com.mycompany.udx.DeleteVowelsFactory' LIBRARY DeleteVowelsLib;
CREATE FUNCTION
=> SELECT deleteVowels('I hate vowels!');
deleteVowels
--------------
ht vwls!
(1 row)
1.4.4 - Java and Vertica data types
The Vertica Java SDK converts Vertica's native data types into the appropriate Java data type.
The Vertica Java SDK converts Vertica's native data types into the appropriate Java data type. The following table lists the Vertica data types and their corresponding Java data types.
|
Vertica Data Type |
Java Data Type |
|
INTEGER |
long |
|
FLOAT |
double |
|
NUMERIC |
com.vertica.sdk.VNumeric |
|
DATE |
java.sql.Date |
|
CHAR, VARCHAR, LONG VARCHAR |
com.vertica.sdk.VString |
|
BINARY, VARBINARY, LONG VARBINARY |
com.vertica.sdk.VString |
|
TIMESTAMP |
java.sql.Timestamp |
Note
Some Vertica data types are not supported.
Setting BINARY, VARBINARY, and LONG VARBINARY values
The Vertica BINARY, VARBINARY, and LONG VARBINARY data types are converted as the Java UDx SDK 's VString class. You can also set the value of a column with one of these data types with a ByteBuffer object (or a byte array wrapped in a ByteBuffer) using the PartitionWriter.setStringBytes() method. See the Java API UDx entry for PartitionWriter.setStringBytes() for more information.
Timestamps and time zones
When the SDK converts a Vertica timestamp into a Java timestamp, it uses the time zone of the JVM. If the JVM is running in a different time zone than the one used by Vertica, the results can be confusing.
Vertica stores timestamps in the database in UTC. (If a database time zone is set, the conversion is done at query time.) To prevent errors from the JVM time zone, add the following code to the processing method of your UDx:
TimeZone.setDefault(TimeZone.getTimeZone("UTC"));
Strings
The Java SDK contains a class named StringUtils that assists you when manipulating string data. One of its more useful features is its getStringBytes() method. This method extracts bytes from a String in a way that prevents the creation of invalid strings. If you attempt to extract a substring that would split part of a multi-byte UTF-8 character, getStringBytes() truncates it to the nearest whole character.
1.4.5 - Handling NULL values
Your UDxs must be prepared to handle NULL values.
Your UDxs must be prepared to handle NULL values. These values usually must be handled separately from regular values.
Reading NULL values
Your UDx reads data from instances of the the BlockReader or PartitionReader classes. If the value of a column is NULL, the methods you use to get data (such as getLong) return a Java null reference. If you attempt to use the value without checking for NULL, the Java runtime will throw a null pointer exception.
You can test for null values before reading columns by using the data-type-specific methods (such as isLongNull, isDoubleNull, and isBooleanNull). For example, to test whether the INTEGER first column of your UDx's input is a NULL, you would use the statement:
// See if the Long value in column 0 is a NULL
if (inputReader.isLongNull(0)) {
// value is null
. . .
Writing NULL values
You output NULL values using type-specific methods on the BlockWriter and PartitionWriter classes (such as setLongNull and setStringNull). These methods take the column number to receive the NULL value. In addition, the PartitionWriter class has data-type specific set value methods (such as setLongValue and setStringValue). If you pass these methods a value, they set the output column to that value. If you pass them a Java null reference, they set the output column to NULL.
1.4.6 - Adding metadata to Java UDx libraries
To add metadata to your Java UDx library, you create a subclass of the UDXLibrary class that contains your library's metadata.
You can add metadata, such as author name, the version of the library, a description of your library, and so on to your library. This metadata lets you track the version of your function that is deployed on a Vertica Analytic Database cluster and lets third-party users of your function know who created the function. Your library's metadata appears in the USER_LIBRARIES system table after your library has been loaded into the Vertica Analytic Database catalog.
To add metadata to your Java UDx library, you create a subclass of the UDXLibrary class that contains your library's metadata. You then include this class within your JAR file. When you load your class into the Vertica Analytic Database catalog using the CREATE LIBRARY statement, looks for a subclass of UDXLibrary for the library's metadata.
In your subclass of UDXLibrary, you need to implement eight getters that return String values containing the library's metadata. The getters in this class are:
-
getAuthor() returns the name you want associated with the creation of the library (your own name or your company's name for example).
-
getLibraryBuildTag() returns whatever String you want to use to represent the specific build of the library (for example, the SVN revision number or a timestamp of when the library was compiled). This is useful for tracking instances of your library as you are developing them.
-
getLibraryVersion() returns the version of your library. You can use whatever numbering or naming scheme you want.
-
getLibrarySDKVersion() returns the version of the Vertica Analytic Database SDK Library for which you've compiled the library.
Note
This field isn't used to determine whether a library is compatible with a version of the Vertica Analytic Database server. The version of the Vertica Analytic Database SDK you use to compile your library is embedded in the library when you compile it. It is this information that Vertica Analytic Database server uses to determine if your library is compatible with it.
-
getSourceUrl() returns a URL where users of your function can find more information about it. This can be your company's website, the GitHub page hosting your library's source code, or whatever site you like.
-
getDescription() returns a concise description of your library.
-
getLicensesRequired() returns a placeholder for licensing information. You must pass an empty string for this value.
-
getSignature() returns a placeholder for a signature that will authenticate your library. You must pass an empty string for this value.
For example, the following code demonstrates creating a UDXLibrary subclass to be included in the Add2Ints UDSF example JAR file (see /opt/vertica/sdk/examples/JavaUDx/ScalarFunctions on any Vertica node).
// Import the UDXLibrary class to hold the metadata
import com.vertica.sdk.UDXLibrary;
public class Add2IntsLibrary extends UDXLibrary
{
// Return values for the metadata about this library.
@Override public String getAuthor() {return "Whizzo Analytics Ltd.";}
@Override public String getLibraryBuildTag() {return "1234";}
@Override public String getLibraryVersion() {return "1.0";}
@Override public String getLibrarySDKVersion() {return "7.0.0";}
@Override public String getSourceUrl() {
return "http://example.com/add2ints";
}
@Override public String getDescription() {
return "My Awesome Add 2 Ints Library";
}
@Override public String getLicensesRequired() {return "";}
@Override public String getSignature() {return "";}
}
When the library containing the Add2IntsLibrary class loaded, the metadata appears in the USER_LIBRARIES system table:
=> CREATE LIBRARY JavaAdd2IntsLib AS :libfile LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE FUNCTION JavaAdd2Ints as LANGUAGE 'JAVA' name 'com.mycompany.example.Add2IntsFactory' library JavaAdd2IntsLib;
CREATE FUNCTION
=> \x
Expanded display is on.
=> SELECT * FROM USER_LIBRARIES WHERE lib_name = 'JavaAdd2IntsLib';
-[ RECORD 1 ]-----+---------------------------------------------
schema_name | public
lib_name | JavaAdd2IntsLib
lib_oid | 45035996273869844
author | Whizzo Analytics Ltd.
owner_id | 45035996273704962
lib_file_name | public_JavaAdd2IntsLib_45035996273869844.jar
md5_sum | f3bfc76791daee95e4e2c0f8a8d2737f
sdk_version | v7.0.0-20131105
revision | 125200
lib_build_tag | 1234
lib_version | 1.0
lib_sdk_version | 7.0.0
source_url | http://example.com/add2ints
description | My Awesome Add 2 Ints Library
licenses_required |
signature |
1.4.7 - Java UDx resource management
Java Virtual Machines (JVMs) allocate a set amount of memory when they start.
Java Virtual Machines (JVMs) allocate a set amount of memory when they start. This set memory allocation complicates memory management for Java UDxs, because memory cannot be dynamically allocated and freed by the UDx as it is processing data. This is differs from C++ UDxs which can dynamically allocate resources.
To control the amount of memory consumed by Java UDxs, Vertica has a memory pool named jvm that it uses to allocate memory for JVMs. If this memory pool is exhausted, queries that call Java UDxs block until enough memory in the pool becomes free to start a new JVM.
By default, the jvm pool has:
-
no memory of its own assigned to it, so it borrows memory from the GENERAL pool.
-
its MAXMEMORYSIZE set to either 10% of system memory or 2GB, whichever is smaller.
-
its PLANNEDCONCURRENCY set to AUTO, so that it inherits the GENERAL pool's PLANNEDCONCURRENCY setting.
You can view the current settings for the jvm pool by querying the RESOURCE_POOLS table:
=> SELECT MAXMEMORYSIZE,PLANNEDCONCURRENCY FROM V_CATALOG.RESOURCE_POOLS WHERE NAME = 'jvm';
MAXMEMORYSIZE | PLANNEDCONCURRENCY
---------------+--------------------
10% | AUTO
When a SQL statement calls a Java UDx, Vertica checks if the jvm memory pool has enough memory to start a new JVM instance to execute the function call. Vertica starts each new JVM with its heap memory size set to approximately the jvm pool's MAXMEMORYSIZE parameter divided by its PLANNEDCONCURRENCY parameter. If the memory pool does not contain enough memory, the query blocks until another JVM exits and return their memory to the pool.
If your Java UDx attempts to consume more memory than has been allocated to the JVM's heap size, it exits with a memory error. You can attempt to resolve this issue by:
-
increasing the jvm pool's MAXMEMORYSIZE parameter.
-
decreasing the jvm pool's PLANNEDCONCURRENCY parameter.
-
changing your Java UDx's code to consume less memory.
Adjusting the jvm pool
When adjusting the jvm pool to your needs, you must consider two factors:
You can learn the amount of memory your Java UDx needs using several methods. For example, your code can use Java's Runtime class to get an estimate of the total memory it has allocated and then log the value using ServerInterface.log(). (An instance of this class is passed to your UDx.) If you have multiple Java UDxs in your database, set the jvm pool memory size based on the UDx that uses the most memory.
The number of concurrent sessions that need to run Java UDxs may not be the same as the global PLANNEDCONCURRENCY setting. For example, you may have just a single user who runs a Java UDx, which means you can lower the jvm pool's PLANNEDCONCURRENCY setting to 1.
When you have an estimate for the amount of RAM and the number of concurrent user sessions that need to run Java UDXs, you can adjust the jvm pool to an appropriate size. Set the pool's MAXMEMORYSIZE to the maximum amount of RAM needed by the most demanding Java UDx multiplied by the number of concurrent user sessions that need to run Java UDxs. Set the pool's PLANNEDCONCURENCY to the numebr of simultaneous user sessions that need to run Java UDxs.
For example, suppose your Java UDx requires up to 4GB of memory to run and you expect up to two user sessions use Java UDx's. You would use the following command to adjust the jvm pool:
=> ALTER RESOURCE POOL jvm MAXMEMORYSIZE '8G' PLANNEDCONCURRENCY 2;
The MEMORYSIZE is set to 8GB, which is the 4GB maximum memory use by the Java UDx multiplied by the 2 concurrent user sessions.
Note
The PLANNEDCONCURRENCY value is not the number of calls to Java UDx that you expect to happen simultaneously. Instead, it is the number of concurrently open user sessions that call Java UDxs at any time during the session. See below for more information.
See Managing workloads for more information on tuning the jvm and other resource pools.
Freeing JVM memory
The first time users call a Java UDx during their session, Vertica allocates memory from the jvm pool and starts a new JVM. This JVM remains running for as long as the user's session is open so it can process other Java UDx calls. Keeping the JVM running lowers the overhead of executing multiple Java UDxs by the same session. If the JVM did not remain open, each call to a Java UDx would require additional time for Vertica to allocate resources and start a new JVM. However, having the JVM remain open means that the JVM's memory remains allocated for the life of the session whether or not it will be used again.
If the jvm memory pool is depleted, queries containing Java UDxs either block until memory becomes available or eventually fail due a lack of resources. If you find queries blocking or failing for this reason, you can allocate more memory to the jvm pool and increase its PLANNEDCONCURRENCY. Another option is to ask users to call the RELEASE_JVM_MEMORY function when they no longer need to run Java UDxs. This function closes any JVM belonging to the user's session and returns its allocated memory to the jvm memory pool.
The following example demonstrates querying V_MONITOR.SESSIONS to find the memory allocated to JVMs by all sessions. It also demonstrates how the memory is allocated by a call to a Java UDx, and then freed by calling RELEASE_JVM_MEMORY.
=> SELECT USER_NAME,EXTERNAL_MEMORY_KB FROM V_MONITOR.SESSIONS;
user_name | external_memory_kb
-----------+---------------
dbadmin | 0
(1 row)
=> -- Call a Java UDx
=> SELECT add2ints(123,456);
add2ints
----------
579
(1 row)
=> -- JVM is now running and memory is allocated to it.
=> SELECT USER_NAME,EXTERNAL_MEMORY_KB FROM V_MONITOR.SESSIONS;
USER_NAME | EXTERNAL_MEMORY_KB
-----------+---------------
dbadmin | 79705
(1 row)
=> -- Shut down the JVM and deallocate memory
=> SELECT RELEASE_JVM_MEMORY();
RELEASE_JVM_MEMORY
-----------------------------------------
Java process killed and memory released
(1 row)
=> SELECT USER_NAME,EXTERNAL_MEMORY_KB FROM V_MONITOR.SESSIONS;
USER_NAME | EXTERNAL_MEMORY_KB
-----------+---------------
dbadmin | 0
(1 row)
In rare cases, you may need to close all JVMs. For example, you may need to free memory for an important query, or several instances of a Java UDx may be taking too long to complete. You can use the RELEASE_ALL_JVM_MEMORY to close all of the JVMs in all user sessions:
=> SELECT USER_NAME,EXTERNAL_MEMORY_KB FROM V_MONITOR.SESSIONS;
USER_NAME | EXTERNAL_MEMORY_KB
-------------+---------------
ExampleUser | 79705
dbadmin | 79705
(2 rows)
=> SELECT RELEASE_ALL_JVM_MEMORY();
RELEASE_ALL_JVM_MEMORY
-----------------------------------------------------------------------------
Close all JVM sessions command sent. Check v_monitor.sessions for progress.
(1 row)
=> SELECT USER_NAME,EXTERNAL_MEMORY_KB FROM V_MONITOR.SESSIONS;
USER_NAME | EXTERNAL_MEMORY_KB
-----------+---------------
dbadmin | 0
(1 row)
Caution
This function terminates all JVMs, including ones that are currently executing Java UDXs. This will cause any query that is currently executing a Java UDx to return an error.
Notes
-
The jvm resource pool is used only to allocate memory for the Java UDx function calls in a statement. The rest of the resources required by the SQL statement come from other memory pools.
-
The first time a Java UDx is called, Vertica starts a JVM to execute some Java methods to get metadata about the UDx during the query planning phase. The memory for this JVM is also taken from the jvm memory pool.
1.5 - Python SDK
The Vertica SDK supports writing UDxs of some types in Python 3.
The Vertica SDK supports writing UDxs of some types in Python 3.
The Python SDK does not require any additional system configuration or header files. This low overhead allows you to develop and deploy new capabilities to your Vertica cluster in a short amount of time.
The following workflow is typical for the Python SDK:

Because Python has an interpreter, you do not have to compile your program before loading the UDx in Vertica. However, you should expect to do some debugging of your code after you create your function and begin testing it in Vertica.
When Vertica calls your UDx, it starts a side process that manages the interaction between the server and the Python interpreter.
This section covers Python-specific topics that apply to all UDx types. For information that applies to all languages, see Arguments and return values, UDx parameters, Errors, warnings, and logging, Handling cancel requests and the sections for specific UDx types. For full API documentation, see the Python SDK.
Important
Your UDx must be able to run with the version of Python bundled with Vertica. You can find this with /opt/vertica/sbin/python3 --version. You cannot change the version used by the Vertica Python interpreter.
1.5.1 - Setting up a Python development environment
To avoid problems when loading and executing your UDxs, develop your UDxs using the same version of Python that Vertica uses.
To avoid problems when loading and executing your UDxs, develop your UDxs using the same version of Python that Vertica uses. To do this without changing your environment for projects that might require other Python versions, you can use a Python virtual environment (venv). You can install libraries that your UDx depends on into your venv and use that path when you create your UDx library with CREATE LIBRARY.
Setting up venv
Set up venv using the Python version bundled with Vertica. If you have direct access to a database node, you can use that Python binary directly to create your venv:
$ /opt/vertica/sbin/python3 -m venv /path/to/new/environment
The result is a directory with a default environment, including a site-packages directory:
$ ls venv/lib/
python3.9
$ ls venv/lib/python3.9/
site-packages
If your UDx depends on libraries that are not packaged with Vertica, install them into this directory:
$ source venv/bin/activate
(venv) $ pip install numpy
...
The lib/python3.9/site-packages directory now contains the installed library. The change affects only your virtual environment.
UDx imports
Your UDx code must import, in addition to any libraries you add, the vertica_sdk library:
# always required:
import vertica_sdk
# other libs:
import numpy as np
# ...
The vertica_sdk library is included as a part of the Vertica server. You do not need to add it to site-packages or declare it as a dependency.
Deployment
For libraries you add, you must declare dependencies when using CREATE LIBRARY. This declaration allows Vertica to find the libraries and distribute them to all database nodes. You can supply a path instead of enumerating the libraries:
=> CREATE OR REPLACE LIBRARY pylib AS
'/path/to/udx/add2ints.py'
DEPENDS '/path/to/new/environment/lib/python3.9/site-packages/*'
LANGUAGE 'Python';
=> CREATE OR REPLACE FUNCTION add2ints AS LANGUAGE 'Python'
NAME 'add2ints_factory' LIBRARY pylib;
CREATE LIBRARY copies the UDx and the contents of the DEPENDS path and stores them with the database. Vertica then distributes copies to all database nodes.
1.5.2 - Python and Vertica data types
The Vertica Python SDK converts native Vertica data types into the appropriate Python data types.
The Vertica Python SDK converts native Vertica data types into the appropriate Python data types. The following table describes some of the data type conversions. Consult the Python SDK for a complete list, as well as lists of helper functions to convert and manipulate these data types.
For information about SDK support for complex data types, see Complex Types as Arguments and Return Values.
|
Vertica Data Type |
Python Data Type |
|
INTEGER |
int |
|
FLOAT |
float |
|
NUMERIC |
decimal.Decimal |
|
DATE |
datetime.date |
|
CHAR, VARCHAR, LONG VARCHAR |
string (UTF-8 encoded) |
|
BINARY, VARBINARY, LONG VARBINARY |
binary |
|
TIMESTAMP |
datetime.datetime |
|
TIME |
datetime.time |
|
ARRAY |
list
Note: Nested ARRAY types are also converted into lists.
|
|
ROW |
collections.OrderedDict
Note: Nested ROW types are also converted into collections.OrderedDicts.
|
Note
Some Vertica data types are not supported in Python. For a list of all Vertica data types, see
Data types.
1.6 - R SDK
The Vertica R SDK extends the capabilities of the Vertica Analytic Database so you can leverage additional R libraries.
The Vertica R SDK extends the capabilities of the Vertica Analytic Database so you can leverage additional R libraries. Before you can begin developing User Defined Extensions (UDxs) in R, you must install the R Language Pack for Vertica on each of the nodes in your cluster. The R SDK supports scalar and transform functions in fenced mode. Other UDx types are not supported.
The following workflow is typical for the R SDK:

You can find detailed documentation of all of the classes in the Vertica R SDK.
1.6.1 - Installing/upgrading the R language pack for Vertica
To create R UDxs in Vertica, install the R Language Pack package that matches your server version.
To create R UDxs in Vertica, install the R Language Pack package that matches your server version. The R Language Pack includes the R runtime and associated libraries for interfacing with Vertica. You must use this version of the R runtime; you cannot upgrade it.
You must install the R Language Pack on each node in the cluster. The Vertica R Language Pack must be the only R Language Pack installed on the node.
Vertica R language pack prerequisites
The R Language Pack package requires a number of packages for installation and execution. The names of these dependencies vary among Linux distributions. For Vertica-supported Linux platforms the packages are:
-
RHEL/CentOS: libgfortran, xz-libs, libgomp
-
SUSE Linux Enterprise Server: libgfortran, liblzma5, libgomp1
-
Debian/Ubuntu: libgfortran, liblzma5, libgomp1
-
Amazon Linux 2023: libgfortran, xz-libs, libgomp
Vertica requires version 5 of the libgfortran library later than 8.3.0 to create R extensions. The libgfortran library is included by default with the devtool and gcc packages.
Installing the Vertica R language pack
If you use your operating systems package manager, rather than the rpm or dpkg command, for installation, you do not need to manually install the R Language Pack. The native package managers for each supported Linux version are:
-
Download the R language package by browsing to the Vertica website.
-
On the Support tab, select Customer Downloads.
-
When prompted, log in using your Micro Focus credentials.
-
Located and select the vertica-R-lang_version.rpm or vertica-R-lang_version.deb file for your server version. The R language package version must match your server version to three decimal points.
-
Install the package as root or using sudo:
-
RHEL/CentOS
$ yum install vertica-R-lang-<version>.rpm
-
SUSE Linux Enterprise Server
$ zypper install vertica-R-lang-<version>.rpm
-
Debian
$ apt-get install ./vertica-R-lang_<version>.deb
-
Amazon Linux 2023
$ yum install vertica-R-lang-<version>.AMZN.rpm
The installer puts the R binary in /opt/vertica/R.
Upgrading the Vertica R language pack
When upgrading, some R packages you have manually installed may not work and may have to be reinstalled. If you do not update your package(s), then R returns an error if the package cannot be used. Instructions for upgrading these packages are below.
Note
The R packages provided in the R Language Pack are automatically upgraded and do not need to be reinstalled.
-
You must uninstall the R Language package before upgrading Vertica. Any additional R packages you manually installed remain in /opt/vertica/R and are not removed when you uninstall the package.
-
Upgrade your server package as detailed in Upgrading Vertica to a New Version.
-
After the server package has been updated, install the new R Language package on each host.
If you have installed additional R packages, on each node:
-
As root run /opt/vertica/R/bin/R and issue the command:
> update.packages(checkBuilt=TRUE)
-
Select a CRAN mirror from the list displayed.
-
You are prompted to update each package that has an update available for it. You must update any packages that you manually installed and are not compatible with the current version of R in the R Language Pack.
Do NOT update:
The packages you selected to be updated are installed. Quit R with the command:
> quit()
Vertica UDx functions written in R do not need to be compiled and you do not need to reload your Vertica-R libraries and functions after an upgrade.
1.6.2 - R packages
The Vertica R Language Pack includes the following R packages in addition to the default packages bundled with R:.
The Vertica R Language Pack includes the following R packages in addition to the default packages bundled with R:
-
Rcpp
-
RInside
-
IpSolve
-
lpSolveAPI
You can install additional R packages not included in the Vertica R Language Pack by using one of two methods. You must install the same packages on all nodes.
Installing R packages
You can install additional R packages by using one of the two following methods.
Using the install.packages() R command:
$ sudo /opt/vertica/R/bin/R
> install.packages("Zelig");
Using CMD INSTALL:
/opt/vertica/R/bin/R CMD INSTALL <path-to-package-tgz>
The installed packages are located in: /opt/vertica/R/library.
1.6.3 - R and Vertica data types
The following data types are supported when passing data to/from an R UDx:.
The following data types are supported when passing data to/from an R UDx:
|
Vertica Data Type |
R Data Type |
|
BOOLEAN |
logical |
|
DATE, DATETIME, SMALLDATETIME, TIME, TIMESTAMP, TIMESTAMPTZ, TIMETZ |
numeric |
|
DOUBLE PRECISION, FLOAT, REAL |
numeric |
|
BIGINT, DECIMAL, INT, NUMERIC, NUMBER, MONEY |
numeric |
|
BINARY, VARBINARY |
character |
|
CHAR, VARCHAR |
character |
NULL values in Vertica are translated to R NA values when sent to the R function. R NA values are translated into Vertica null values when returned from the R function to Vertica.
Important
When specifying LONG VARCHAR or LONG VARBINARY data types, include the space between the two words. For example, datatype = c("long varchar").
1.6.4 - Adding metadata to R libraries
The following example shows how to add metadata to an R UDx.
You can add metadata, such as author name, the version of the library, a description of your library, and so on to your library. This metadata lets you track the version of your function that is deployed on a Vertica Analytic Database cluster and lets third-party users of your function know who created the function. Your library's metadata appears in the USER_LIBRARIES system table after your library has been loaded into the Vertica Analytic Database catalog.
You declare the metadata for your library by calling the RegisterLibrary() function in one of the source files for your UDx. If there is more than one function call in the source files for your UDx, whichever gets interpreted last as Vertica Analytic Database loads the library is used to determine the library's metadata.
The RegisterLibrary() function takes eight string parameters:
RegisterLibrary(author,
library_build_tag,
library_version,
library_sdk_version,
source_url,
description,
licenses_required,
signature);
-
author contains whatever name you want associated with the creation of the library (your own name or your company's name for example).
-
library_build_tag is a string you want to use to represent the specific build of the library (for example, the SVN revision number or a timestamp of when the library was compiled). This is useful for tracking instances of your library as you are developing them.
-
library_version is the version of your library. You can use whatever numbering or naming scheme you want.
-
library_sdk_version is the version of the Vertica Analytic Database SDK Library for which you've compiled the library.
Note
This field isn't used to determine whether a library is compatible with a version of the Vertica Analytic Database server. The version of the Vertica Analytic Database SDK you use to compile your library is embedded in the library when you compile it. It is this information that Vertica Analytic Database server uses to determine if your library is compatible with it.
-
source_url is a URL where users of your function can find more information about it. This can be your company's website, the GitHub page hosting your library's source code, or whatever site you like.
-
description is a concise description of your library.
-
licenses_required is a placeholder for licensing information. You must pass an empty string for this value.
-
signature is a placeholder for a signature that will authenticate your library. You must pass an empty string for this value.
The following example shows how to add metadata to an R UDx.
RegisterLibrary("Speedy Analytics Ltd.",
"1234",
"1.0",
"8.1.0",
"http://www.example.com/sales_tax_calculator.R",
"Sales Tax R Library",
"",
"")
Loading the library and querying the USER_LIBRARIES system table shows the metadata supplied in the call to RegisterLibrary:
=> CREATE LIBRARY rLib AS '/home/dbadmin/sales_tax_calculator.R' LANGUAGE 'R';
CREATE LIBRARY
=> SELECT * FROM USER_LIBRARIES WHERE lib_name = 'rLib';
-[ RECORD 1 ]-----+---------------------------------------------------------
schema_name | public
lib_name | rLib
lib_oid | 45035996273708350
author | Speedy Analytics Ltd.
owner_id | 45035996273704962
lib_file_name | rLib_02552872a35d9352b4907d3fcd03cf9700a0000000000d3e.R
md5_sum | 30da555537c4d93c352775e4f31332d2
sdk_version |
revision |
lib_build_tag | 1234
lib_version | 1.0
lib_sdk_version | 8.1.0
source_url | http://www.example.com/sales_tax_calculator.R
description | Sales Tax R Library
licenses_required |
signature |
dependencies |
is_valid | t
sal_storage_id | 02552872a35d9352b4907d3fcd03cf9700a0000000000d3e
1.6.5 - Setting null input and volatility behavior for R functions
Vertica supports defining volatility and null-input settings for UDxs written in R.
Vertica supports defining volatility and null-input settings for UDxs written in R. Both settings aid in the performance of your R function.
Volatility settings
Volatility settings describe the behavior of the function to the Vertica optimizer. For example, if you have identical rows of input data and you know the UDx is immutable, then you can define the UDx as IMMUTABLE. This tells the Vertica optimizer that it can return a cached value for subsequent identical rows on which the function is called rather than having the function run on each identical row.
To indicate your UDx's volatility, set the volatility parameter of your R factory function to one of the following values:
|
Value |
Description |
VOLATILE |
Repeated calls to the function with the same arguments always result in different values. Vertica always calls volatile functions for each invocation. |
IMMUTABLE |
Calls to the function with the same arguments always results in the same return value. |
STABLE |
Repeated calls to the function with the same arguments within the same statement returns the same output. For example, a function that returns the current user name is stable because the user cannot change within a statement. The user name could change between statements. |
DEFAULT_VOLATILITY |
The default volatility. This is the same as VOLATILE. |
If you do not define a volatility, then the function is considered to be VOLATILE.
The following example sets the volatility to STABLE in the multiplyTwoIntsFactory function:
multiplyTwoIntsFactory <- function() {
list(name = multiplyTwoInts,
udxtype = c("scalar"),
intype = c("float","float"),
outtype = c("float"),
volatility = c("stable"),
parametertypecallback = multiplyTwoIntsParameters)
}
Null input setting determine how to respond to rows that have null input. For example, you can choose to return null if any inputs are null rather than calling the function and having the function deal with a NULL input.
To indicate how your UDx reacts to NULL input, set the strictness parameter of your R factory function to one of the following values:
|
Value |
Description |
|
CALLED_ON_NULL_INPUT |
The function must be called, even if one or more arguments are NULL. |
|
RETURN_NULL_ON_NULL_INPUT |
The function always returns a NULL value if any of its arguments are NULL. |
|
STRICT |
A synonym for RETURN_NULL_ON_NULL_INPUT |
|
DEFAULT_STRICTNESS |
The default strictness setting. This is the same as CALLED_ON_NULL_INPUT. |
If you do not define a null input behavior, then the function is called on every row of data regardless of the presence of NULL values.
The following example sets the NULL input behavior to STRICT in the multiplyTwoIntsFactory function:
multiplyTwoIntsFactory <- function() {
list(name = multiplyTwoInts,
udxtype = c("scalar"),
intype = c("float","float"),
outtype = c("float"),
strictness = c("strict"),
parametertypecallback = multiplyTwoIntsParameters)
}
1.7 - Debugging tips
The following tips can help you debug your UDx before deploying it in a production environment.
The following tips can help you debug your UDx before deploying it in a production environment.
Use a single node for initial debugging
You can attach to the Vertica process using a debugger such as gdb to debug your UDx code. Doing this in a multi-node environment, however, is very difficult. Therefore, consider setting up a single-node Vertica test environment to initially debug your UDx.
Use logging
Each UDx has an associated ServerInterface instance. The ServerInterface provides functions to write to the Vertica log and, in the C++ API only, a system table. See Logging for more information.
2 - Arguments and return values
For all UDx types except load (UDL), the factory class declares the arguments and return type of the associated function.
For all UDx types except load (UDL), the factory class declares the arguments and return type of the associated function. Factories have two methods for this purpose:
-
getPrototype() (required): declares input and output types
-
getReturnType() (sometimes required): declares the return types, including length and precision, when applicable
The getPrototype() method receives two ColumnTypes parameters, one for input and one for output. The factory in C++ example: string tokenizer takes a single input string and returns a string:
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)
{
argTypes.addVarchar();
returnType.addVarchar();
}
The ColumnTypes class provides "add" methods for each supported type, like addVarchar(). This class supports complex types with the addArrayType() and addRowType() methods; see Complex Types as Arguments. If your function is polymorphic, you can instead call addAny(). You are then responsible for validating your inputs and outputs. For more information about implementing polymorphic UDxs, see Creating a polymorphic UDx.
The getReturnType() method computes a maximum length for the returned value. If your UDx returns a sized column (a return data type whose length can vary, such as a VARCHAR), a value that requires precision, or more than one value, implement this factory method. (Some UDx types require you to implement it.)
The input is a SizedColumnTypes containing the input argument types along with their lengths. Depending on the input types, add one of the following to the output types:
-
CHAR, (LONG) VARCHAR, BINARY, and (LONG) VARBINARY: return the maximum length.
-
NUMERIC types: specify the precision and scale.
-
TIME and TIMESTAMP values (with or without timezone): specify precision.
-
INTERVAL YEAR TO MONTH: specify range.
-
INTERVAL DAY TO SECOND: specify precision and range.
-
ARRAY: specify the maximum number of array elements.
In the case of the string tokenizer, the output is a VARCHAR and the function determines its maximum length:
// Tell Vertica what our return string length will be, given the input
// string length
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
// Error out if we're called with anything but 1 argument
if (inputTypes.getColumnCount() != 1)
vt_report_error(0, "Function only accepts 1 argument, but %zu provided", inputTypes.getColumnCount());
int input_len = inputTypes.getColumnType(0).getStringLength();
// Our output size will never be more than the input size
outputTypes.addVarchar(input_len, "words");
}
Complex types as arguments and return values
The ColumnTypes class supports ARRAY and ROW types. Arrays have elements and rows have fields, both of which have types that you need to describe. To work with complex types, you build ColumnTypes objects for the array or row and then add them to the ColumnTypes objects representing the function inputs and outputs.
In the following example, the input to a transform function is an array of orders, which are rows, and the output is the individual rows with their positions in the array. An order consists of a shipping address (VARCHAR) and an array of product IDs (INT).
The factory's getPrototype() method first creates ColumnTypes for the array and row elements and then calls addArrayType() and addRowType() using them:
void getPrototype(ServerInterface &srv,
ColumnTypes &argTypes,
ColumnTypes &retTypes)
{
// item ID (int), to be used in an array
ColumnTypes itemIdProto;
itemIdProto.addInt();
// row: order = address (varchar) + array of previously-created item IDs
ColumnTypes orderProto;
orderProto.addVarchar(); /* address */
orderProto.addArrayType(itemIdProto); /* array of item ID */
/* argument (input) is array of orders */
argTypes.addArrayType(orderProto);
/* return values: index in the array, order */
retTypes.addInt(); /* index of element */
retTypes.addRowType(orderProto); /* element return type */
}
The arguments include a sized type (the VARCHAR). The getReturnType() method uses a similar approach, using the Fields class to build the two fields in the order.
void getReturnType(ServerInterface &srv,
const SizedColumnTypes &argTypes,
SizedColumnTypes &retTypes)
{
Fields itemIdElementFields;
itemIdElementFields.addInt("item_id");
Fields orderFields;
orderFields.addVarchar(32, "address");
orderFields.addArrayType(itemIdElementFields[0], "item_id");
// optional third arg: max length, default unbounded
/* declare return type */
retTypes.addInt("index");
static_cast<Fields &>(retTypes).addRowType(orderFields, "element");
/* NOTE: presumably we have verified that the arguments match the prototype, so really we could just do this: */
retTypes.addInt("index");
retTypes.addArg(argTypes.getColumnType(0).getElementType(), "element");
}
To access complex types in the UDx processing method, use the ArrayReader, ArrayWriter, StructReader, and StructWriter classes.
See C++ example: using complex types for a polymorphic function that uses arrays.
The factory's getPrototype() method first uses makeType() and addType() methods to create and construct ColumnTypes for the row and its elements. The method then calls addType() methods to add these constructed ColumnTypes to the arg_types and return_type objects:
def getPrototype(self, srv_interface, arg_types, return_type):
# item ID (int), to be used in an array
itemIdProto = vertica_sdk.ColumnTypes.makeInt()
# row (order): address (varchar) + array of previously-created item IDs
orderProtoFields = vertica_sdk.ColumnTypes.makeEmpty()
orderProtoFields.addVarchar() # address
orderProtoFields.addArrayType(itemIdProto) # array of item ID
orderProto = vertica_sdk.ColumnTypes.makeRowType(orderProtoFields)
# argument (input): array of orders
arg_types.addArrayType(orderProto)
# return values: index in the array, order
return_type.addInt(); # index of element
return_type.addRowType(orderProto); # element return type
The factory's getReturnType() method creates SizedColumnTypes with the makeInt() and makeEmpty() methods and then builds two row fields with the addVarchar() and addArrayType() methods. Note that the addArrayType() method specifies the maximum number of array elements as 1024. getReturnType() then adds these constructed SizedColumnTypes to the object representing the return type.
def getReturnType(self, srv_interface, arg_types, return_type):
itemsIdElementField = vertica_sdk.SizedColumnTypes.makeInt("item_id")
orderFields = vertica_sdk.SizedColumnTypes.makeEmpty()
orderFields.addVarchar(32, "address")
orderFields.addArrayType(itemIdElementField, 1024, "item_ids")
# declare return type
return_type.addInt("index")
return_type.addRowType(orderFields, "element")
'''
NOTE: presumably we have verified that the arguments match the prototype, so really we could just do this:
return_type.addInt("index")
return_type.addArrayType(argTypes.getColumnType(0).getElementType(), "element")
'''
To access complex types in the UDx processing method, use the ArrayReader, ArrayWriter, RowReader, and RowWriter classes. For details, see Python SDK.
See Python example: matrix multiplication for a scalar function that uses complex types.
Handling different numbers and types of arguments
You can create UDxs that handle multiple signatures, or even accept all arguments supplied to them by the user, using either overloading or polymorphism.
You can overload your UDx by assigning the same SQL function name to multiple factory classes, each of which defines a unique function signature. When a user uses the function name in a query, Vertica tries to match the signature of the function call to the signatures declared by the factory's getPrototype() method. This is the best technique to use if your UDx needs to accept a few different signatures (for example, accepting two required and one optional argument).
Alternatively, you can write a polymorphic function, writing one factory method instead of several and declaring that it accepts any number and type of arguments. When a user uses the function name in a query, Vertica calls your function regardless of the signature. In exchange for this flexibility, your UDx's main "process" method has to determine whether it can accept the arguments and emit errors if not.
All UDx types can use polymorphic inputs. Transform functions and analytic functions can also use polymorphic outputs. This means that getPrototype() can declare a return type of "any" and set the actual return type at runtime. For example, a function that returns the largest value in an input would return the same type as the input type.
2.1 - Overloading your UDx
You may want your UDx to accept several different signatures (sets of arguments).
You may want your UDx to accept several different signatures (sets of arguments). For example, you might want your UDx to accept:
-
One or more optional arguments.
-
One or more arguments that can be one of several data types.
-
Completely distinct signatures (either all INTEGER or all VARCHAR, for example).
You can create a function with this behavior by creating several factory classes, each of which accepts a different signature (the number and data types of arguments). You can then associate a single SQL function name with all of them. You can use the same SQL function name to refer to multiple factory classes as long as the signature defined by each factory is unique. When a user calls your UDx, Vertica matches the number and types of arguments supplied by the user to the arguments accepted by each of your function's factory classes. If one matches, Vertica uses it to instantiate a function class to process the data.
Multiple factory classes can instantiate the same function class, so you can re-use one function class that is able to process multiple sets of arguments and then create factory classes for each of the function signatures. You can also create multiple function classes if you want.
See the C++ example: overloading your UDx and Java example: overloading your UDx examples.
2.1.1 - C++ example: overloading your UDx
The following example code demonstrates creating a user-defined scalar function (UDSF) that adds two or three integers together.
The following example code demonstrates creating a user-defined scalar function (UDSF) that adds two or three integers together. The Add2or3ints class is prepared to handle two or three arguments. The processBlock() function checks the number of arguments that have been passed to it, and adds all two or three of them together. It also exits with an error message if it has been called with less than 2 or more than 3 arguments. In theory, this should never happen, since Vertica only calls the UDSF if the user's function call matches a signature on one of the factory classes you create for your function. In practice, it is a good idea to perform this sanity checking, in case your (or someone else's) factory class inaccurately reports a set of arguments your function class cannot handle.
#include "Vertica.h"
using namespace Vertica;
using namespace std;
// a ScalarFunction that accepts two or three
// integers and adds them together.
class Add2or3ints : public Vertica::ScalarFunction
{
public:
virtual void processBlock(Vertica::ServerInterface &srvInterface,
Vertica::BlockReader &arg_reader,
Vertica::BlockWriter &res_writer)
{
const size_t numCols = arg_reader.getNumCols();
// Ensure that only two or three parameters are passed in
if ( numCols < 2 || numCols > 3)
vt_report_error(0, "Function only accept 2 or 3 arguments, "
"but %zu provided", arg_reader.getNumCols());
// Add two integers together
do {
const vint a = arg_reader.getIntRef(0);
const vint b = arg_reader.getIntRef(1);
vint c = 0;
// Check for third argument, add it in if it exists.
if (numCols == 3)
c = arg_reader.getIntRef(2);
res_writer.setInt(a+b+c);
res_writer.next();
} while (arg_reader.next());
}
};
// This factory accepts function calls with two integer arguments.
class Add2intsFactory : public Vertica::ScalarFunctionFactory
{
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface
&srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, Add2or3ints); }
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{ // Accept 2 integer values
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
};
RegisterFactory(Add2intsFactory);
// This factory defines a function that accepts 3 ints.
class Add3intsFactory : public Vertica::ScalarFunctionFactory
{
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface
&srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, Add2or3ints); }
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{ // accept 3 integer values
argTypes.addInt();
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
};
RegisterFactory(Add3intsFactory);
The example has two ScalarFunctionFactory classes, one for each signature that the function accepts (two integers and three integers). There is nothing unusual about these factory classes, except that their implementation of ScalarFunctionFactory::createScalarFunction() both create Add2or3ints objects.
The final step is to bind the same SQL function name to both factory classes. You can assign multiple factories to the same SQL function, as long as the signatures defined by each factory's getPrototype() implementation are different.
=> CREATE LIBRARY add2or3IntsLib AS '/home/dbadmin/Add2or3Ints.so';
CREATE LIBRARY
=> CREATE FUNCTION add2or3Ints as NAME 'Add2intsFactory' LIBRARY add2or3IntsLib FENCED;
CREATE FUNCTION
=> CREATE FUNCTION add2or3Ints as NAME 'Add3intsFactory' LIBRARY add2or3IntsLib FENCED;
CREATE FUNCTION
=> SELECT add2or3Ints(1,2);
add2or3Ints
-------------
3
(1 row)
=> SELECT add2or3Ints(1,2,4);
add2or3Ints
-------------
7
(1 row)
=> SELECT add2or3Ints(1,2,3,4); -- Will generate an error
ERROR 3467: Function add2or3Ints(int, int, int, int) does not exist, or
permission is denied for add2or3Ints(int, int, int, int)
HINT: No function matches the given name and argument types. You may
need to add explicit type casts
The error message in response to the final call to the add2or3Ints function was generated by Vertica, since it could not find a factory class associated with add2or3Ints that accepted four integer arguments. To expand add2or3Ints further, you could create another factory class that accepted this signature, and either change the Add2or3ints ScalarFunction class or create a totally different class to handle adding more integers together. However, adding more classes to accept each variation in the arguments quickly becomes overwhelming. In that case, you should consider creating a polymorphic UDx.
2.1.2 - Java example: overloading your UDx
The following example code demonstrates creating a user-defined scalar function (UDSF) that adds two or three integers together.
The following example code demonstrates creating a user-defined scalar function (UDSF) that adds two or three integers together. The Add2or3ints class is prepared to handle two or three arguments. It checks the number of arguments that have been passed to it, and adds all two or three of them together. The processBlock() method checks whether it has been called with less than 2 or more than 3 arguments. In theory, this should never happen, since Vertica only calls the UDSF if the user's function call matches a signature on one of the factory classes you create for your function. In practice, it is a good idea to perform this sanity checking, in case your (or someone else's) factory class reports that your function class accepts a set of arguments that it actually does not.
// You need to specify the full package when creating functions based on
// the classes in your library.
package com.mycompany.multiparamexample;
// Import the entire Vertica SDK
import com.vertica.sdk.*;
// This ScalarFunction accepts two or three integer arguments. It tests
// the number of input columns to determine whether to read two or three
// arguments as input.
public class Add2or3ints extends ScalarFunction
{
@Override
public void processBlock(ServerInterface srvInterface,
BlockReader argReader,
BlockWriter resWriter)
throws UdfException, DestroyInvocation
{
// See how many arguments were passed in
int numCols = argReader.getNumCols();
// Return an error if less than two or more than 3 aerguments
// were given. This error only occurs if a Factory class that
// accepts the wrong number of arguments instantiates this
// class.
if (numCols < 2 || numCols > 3) {
throw new UdfException(0,
"Must supply 2 or 3 integer arguments");
}
// Process all of the rows of input.
do {
// Get the first two integer arguments from the BlockReader
long a = argReader.getLong(0);
long b = argReader.getLong(1);
// Assume no third argument.
long c = 0;
// Get third argument value if it exists
if (numCols == 3) {
c = argReader.getLong(2);
}
// Process the arguments and come up with a result. For this
// example, just add the three arguments together.
long result = a+b+c;
// Write the integer output value.
resWriter.setLong(result);
// Advance the output BlocKWriter to the next row.
resWriter.next();
// Continue processing input rows until there are no more.
} while (argReader.next());
}
}
The main difference between the Add2ints class and the Add2or3ints class is the inclusion of a section that gets the number of arguments by calling BlockReader.getNumCols(). This class also tests the number of columns it received from Vertica to ensure it is in the range it is prepared to handle. This test will only fail if you create a ScalarFunctionFactory whose getPrototype() method defines a signature that accepts less than two or more than three arguments. This is not really necessary in this simple example, but for a more complicated class it is a good idea to test the number of columns and data types that Vertica passed your function class.
Within the do loop, Add2or3ints uses a default value of zero if Vertica sent it two input columns. Otherwise, it retrieves the third value and adds that to the other two. Your own class needs to use default values for missing input columns or alter its processing in some other way to handle the variable columns.
You must define your function class in its own source file, rather than as an inner class of one of your factory classes since Java does not allow the instantiation of an inner class from outside its containing class. You factory class has to be available for instantiation by multiple factory classes.
Once you have created a function class or classes, you create a factory class for each signature you want your function class to handle. These factory classes can call individual function classes, or they can all call the same class that is prepared to accept multiple sets of arguments.
The following example's createScalarFunction() method instantiates a member of the Add2or3ints class.
// You will need to specify the full package when creating functions based on
// the classes in your library.
package com.mycompany.multiparamexample;
// Import the entire Vertica SDK
import com.vertica.sdk.*;
public class Add2intsFactory extends ScalarFunctionFactory
{
@Override
public void getPrototype(ServerInterface srvInterface,
ColumnTypes argTypes,
ColumnTypes returnType)
{
// Accept two integers as input
argTypes.addInt();
argTypes.addInt();
// writes one integer as output
returnType.addInt();
}
@Override
public ScalarFunction createScalarFunction(ServerInterface srvInterface)
{
// Instantiate the class that can handle either 2 or 3 integers.
return new Add2or3ints();
}
}
The following ScalarFunctionFactory subclass accepts three integers as input. It, too, instantiates a member of the Add2or3ints class to process the function call:
// You will need to specify the full package when creating functions based on
// the classes in your library.
package com.mycompany.multiparamexample;
// Import the entire Vertica SDK
import com.vertica.sdk.*;
public class Add3intsFactory extends ScalarFunctionFactory
{
@Override
public void getPrototype(ServerInterface srvInterface,
ColumnTypes argTypes,
ColumnTypes returnType)
{
// Accepts three integers as input
argTypes.addInt();
argTypes.addInt();
argTypes.addInt();
// Returns a single integer
returnType.addInt();
}
@Override
public ScalarFunction createScalarFunction(ServerInterface srvInterface)
{
// Instantiates the Add2or3ints ScalarFunction class, which is able to
// handle eitehr 2 or 3 integers as arguments.
return new Add2or3ints();
}
}
The factory classes and the function class or classes they call must be packaged into the same JAR file (see Compiling and packaging a Java library for details). If a host in the database cluster has the JDK installed on it, you could use the following commands to compile and package the example:
$ cd pathToJavaProject$ javac -classpath /opt/vertica/bin/VerticaSDK.jar \
> com/mycompany/multiparamexample/*.java
$ jar -cvf Add2or3intslib.jar com/vertica/sdk/BuildInfo.class \
> com/mycompany/multiparamexample/*.class
added manifest
adding: com/vertica/sdk/BuildInfo.class(in = 1202) (out= 689)(deflated 42%)
adding: com/mycompany/multiparamexample/Add2intsFactory.class(in = 677) (out= 366)(deflated 45%)
adding: com/mycompany/multiparamexample/Add2or3ints.class(in = 919) (out= 601)(deflated 34%)
adding: com/mycompany/multiparamexample/Add3intsFactory.class(in = 685) (out= 369)(deflated 46%)
Once you have packaged your overloaded UDx, you deploy it the same way as you do a regular UDx, except you use multiple CREATE FUNCTION statements to define the function, once for each factory class.
=> CREATE LIBRARY add2or3intslib as '/home/dbadmin/Add2or3intslib.jar'
-> language 'Java';
CREATE LIBRARY
=> CREATE FUNCTION add2or3ints as LANGUAGE 'Java' NAME 'com.mycompany.multiparamexample.Add2intsFactory' LIBRARY add2or3intslib;
CREATE FUNCTION
=> CREATE FUNCTION add2or3ints as LANGUAGE 'Java' NAME 'com.mycompany.multiparamexample.Add3intsFactory' LIBRARY add2or3intslib;
CREATE FUNCTION
You call the overloaded function the same way you call any other function.
=> SELECT add2or3ints(2,3);
add2or3ints
-------------
5
(1 row)
=> SELECT add2or3ints(2,3,4);
add2or3ints
-------------
9
(1 row)
=> SELECT add2or3ints(2,3,4,5);
ERROR 3457: Function add2or3ints(int, int, int, int) does not exist, or permission is denied for add2or3ints(int, int, int, int)
HINT: No function matches the given name and argument types. You may need to add explicit type casts
The last error was generated by Vertica, not the UDx code. It returns an error if it cannot find a factory class whose signature matches the function call's signature.
Creating an overloaded UDx is useful if you want your function to accept a limited set of potential arguments. If you want to create a more flexible function, you can create a polymorphic function.
2.2 - Creating a polymorphic UDx
Polymorphic UDxs accept any number and type of argument that the user supplies.
Polymorphic UDxs accept any number and type of argument that the user supplies. Transform functions (UDTFs), analytic functions (UDAnFs), and aggregate functions (UDAFs) can define their output return types at runtime, usually based on the input arguments. For example, a UDTF that adds two numbers could return an integer or a float, depending on the input types.
Vertica does not check the number or types of argument that the user passes to the UDx—it just passes the UDx all of the arguments supplied by the user. It is up to your polymorphic UDx's main processing function (for example, processBlock() in user-defined scalar functions) to examine the number and types of arguments it received and determine if it can handle them. UDxs support up to 9800 arguments.
Polymorphic UDxs are more flexible than using multiple factory classes for your function (see Overloading your UDx). They also allow you to write more concise code, instead of writing versions for each data type. The tradeoff is that your polymorphic function needs to perform more work to determine whether it can process its arguments.
Your polymorphic UDx declares that it accepts any number of arguments in its factory's getPrototype() function by calling the addAny() function on the ColumnTypes object that defines its arguments, as follows:
// C++ example
void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
argTypes.addAny(); // Must be only argument type.
returnType.addInt(); // or whatever the function returns
}
This "any parameter" argument type is the only one that your function can declare. You cannot define required arguments and then call addAny() to declare the rest of the signature as optional. If your function has requirements for the arguments it accepts, your process() function must enforce them.
The getPrototype() example shown previously accepts any type and declares that it returns an integer. The following example shows a version of the method that defers resolving the return type until runtime. You can only use the "any" return type for transform and analytic functions.
void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
argTypes.addAny();
returnType.addAny(); // type determined at runtime
}
If you use polymorphic return types, you must also define getReturnType() in your factory. This function is called at runtime to determine the actual return type. See C++ example: PolyNthValue for an example.
Polymorphic UDxs and schema search paths
If a user does not supply a schema name as part of a UDx call, Vertica searches each schema in the schema search path for a function whose name and signature match the function call. See Setting search paths for more information about schema search paths.
Because polymorphic UDxs do not have specific signatures associated with them, Vertica initially skips them when searching for a function to handle the function call. If none of the schemas in the search path contain a UDx whose name and signature match the function call, Vertica searches the schema search path again for a polymorphic UDx whose name matches the function name in the function call.
This behavior gives precedence to a UDx whose signature exactly matches the function call. It allows you to create a "catch-all" polymorphic UDx that Vertica calls only when none of the non-polymorphic UDxs with the same name have matching signatures.
This behavior may cause confusion if your users expect the first polymorphic function in the schema search path to handle a function call. To avoid confusion, you should:
-
Avoid using the same name for different UDxs. You should always uniquely name UDxs unless you intend to create an overloaded UDx with multiple signatures.
-
When you cannot avoid having UDxs with the same name in different schemas, always supply the schema name as part of the function call. Using the schema name prevents ambiguity and ensures that Vertica uses the correct UDx to process your function calls.
2.2.1 - C++ example: PolyNthValue
The PolyNthValue example is an analytic function that returns the value in the Nth row in each partition in its input.
The PolyNthValue example is an analytic function that returns the value in the Nth row in each partition in its input. This function is a generalization of FIRST_VALUE [analytic] and LAST_VALUE [analytic].
The values can be of any primitive data type.
For the complete source code, see PolymorphicNthValue.cpp in the examples (in /opt/vertica/sdk/examples/AnalyticFunctions/).
Loading and using the example
Load the library and create the function as follows:
=> CREATE LIBRARY AnalyticFunctions AS '/home/dbadmin/AnalyticFns.so';
CREATE LIBRARY
=> CREATE ANALYTIC FUNCTION poly_nth_value AS LANGUAGE 'C++'
NAME 'PolyNthValueFactory' LIBRARY AnalyticFunctions;
CREATE ANALYTIC FUNCTION
Consider a table of scores for different test groups:
=> SELECT cohort, score FROM trials;
cohort | score
--------+-------
1 | 9
1 | 8
1 | 7
3 | 3
3 | 2
3 | 1
2 | 4
2 | 5
2 | 6
(9 rows)
Call the function in a query that uses an OVER clause to partition the data. This example returns the second-highest score in each cohort:
=> SELECT cohort, score, poly_nth_value(score USING PARAMETERS n=2) OVER (PARTITION BY cohort) AS nth_value
FROM trials;
cohort | score | nth_value
--------+-------+-----------
1 | 9 | 8
1 | 8 | 8
1 | 7 | 8
3 | 3 | 2
3 | 2 | 2
3 | 1 | 2
2 | 4 | 5
2 | 5 | 5
2 | 6 | 5
(9 rows)
Factory implementation
The factory declares that the class is polymorphic, and then sets the return type based on the input type. Two factory methods specify the argument and return types.
Use the getPrototype() method to declare that the analytic function takes and returns any type:
void getPrototype(ServerInterface &srvInterface, ColumnTypes &argTypes, ColumnTypes &returnType)
{
// This function supports any argument data type
argTypes.addAny();
// Output data type will be the same as the argument data type
// We will specify that in getReturnType()
returnType.addAny();
}
The getReturnType() method is called at runtime. This is where you set the return type based on the input type:
void getReturnType(ServerInterface &srvInterface, const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
// This function accepts only one argument
// Complain if we find a different number
std::vector<size_t> argCols;
inputTypes.getArgumentColumns(argCols); // get argument column indices
if (argCols.size() != 1)
{
vt_report_error(0, "Only one argument is expected but %s provided",
argCols.size()? std::to_string(argCols.size()).c_str() : "none");
}
// Define output type the same as argument type
outputTypes.addArg(inputTypes.getColumnType(argCols[0]), inputTypes.getColumnName(argCols[0]));
}
Function implementation
The analytic function itself is type-agnostic:
void processPartition(ServerInterface &srvInterface, AnalyticPartitionReader &inputReader,
AnalyticPartitionWriter &outputWriter)
{
try {
const SizedColumnTypes &inTypes = inputReader.getTypeMetaData();
std::vector<size_t> argCols; // Argument column indexes.
inTypes.getArgumentColumns(argCols);
vint currentRow = 1;
bool nthRowExists = false;
// Find the value of the n-th row
do {
if (currentRow == this->n) {
nthRowExists = true;
break;
} else {
currentRow++;
}
} while (inputReader.next());
if (nthRowExists) {
do {
// Return n-th value
outputWriter.copyFromInput(0 /*dest column*/, inputReader,
argCols[0] /*source column*/);
} while (outputWriter.next());
} else {
// The partition has less than n rows
// Return NULL value
do {
outputWriter.setNull(0);
} while (outputWriter.next());
}
} catch(std::exception& e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while processing partition: [%s]", e.what());
}
}
};
2.2.2 - Java example: AddAnyInts
The following example shows an implementation of a Java ScalarFunction that adds together two or more integers.
The following example shows an implementation of a Java ScalarFunction that adds together two or more integers.
For the complete source code, see AddAnyIntsInfo.java in the examples (in /opt/vertica/sdk/examples/JavaUDx/ScalarFunctions).
Loading and using the example
Load the library and create the function as follows:
=> CREATE LIBRARY JavaScalarFunctions AS '/home/dbadmin/JavaScalarLib.jar' LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE FUNCTION addAnyInts AS LANGUAGE 'Java' NAME 'com.vertica.JavaLibs.AddAnyIntsInfo'
LIBRARY JavaScalarFunctions;
CREATE FUNCTION
Call the function with two or more integer arguments:
=> SELECT addAnyInts(1,2);
addAnyInts
------------
3
(1 row)
=> SELECT addAnyInts(1,2,3,40,50,60,70,80,900);
addAnyInts
------------
1206
(1 row)
Calling the function with too few arguments, or with non-integer arguments, produces errors that are generated from the processBlock() method. It is up to your UDx to ensure that the user supplies the correct number and types of arguments to your function and exit with an error if it cannot process them.
Function implementation
Most of the work in the example is done by the processBlock() method. It performs two checks on the arguments that have been passed in through the BlockReader object:
It is up to your polymorphic UDx to determine that all of the input passed to it is valid.
Once the processBlock() method validates its arguments, it loops over them, adding them together.
@Override
public void processBlock(ServerInterface srvInterface,
BlockReader arg_reader,
BlockWriter res_writer)
throws UdfException, DestroyInvocation
{
SizedColumnTypes inTypes = arg_reader.getTypeMetaData();
ArrayList<Integer> argCols = new ArrayList<Integer>(); // Argument column indexes.
inTypes.getArgumentColumns(argCols);
// While we have inputs to process
do {
long sum = 0;
for (int i = 0; i < argCols.size(); ++i){
long a = arg_reader.getLong(i);
sum += a;
}
res_writer.setLong(sum);
res_writer.next();
} while (arg_reader.next());
}
}
Factory implementation
The factory declares the number and type of arguments in the getPrototype() function.
@Override
public void getPrototype(ServerInterface srvInterface,
ColumnTypes argTypes,
ColumnTypes returnType)
{
argTypes.addAny();
returnType.addInt();
}
2.2.3 - R example: kmeansPoly
The following example shows an implementation of a Transform Function (UDTF) that performs kmeans clustering on one or more input columns.
The following example shows an implementation of a Transform Function (UDTF) that performs kmeans clustering on one or more input columns.
kmeansPoly <- function(v.data.frame,v.param.list) {
# Computes clusters using the kmeans algorithm.
#
# Input: A dataframe and a list of parameters.
# Output: A dataframe with one column that tells the cluster to which each data
# point belongs.
# Args:
# v.data.frame: The data from Vertica cast as an R data frame.
# v.param.list: List of function parameters.
#
# Returns:
# The cluster associated with each data point.
# Ensure k is not null.
if(!is.null(v.param.list[['k']])) {
number_of_clusters <- as.numeric(v.param.list[['k']])
} else {
stop("k cannot be NULL! Please use a valid value.")
}
# Run the kmeans algorithm.
kmeans_clusters <- kmeans(v.data.frame, number_of_clusters)
final.output <- data.frame(kmeans_clusters$cluster)
return(final.output)
}
kmeansFactoryPoly <- function() {
# This function tells Vertica the name of the R function,
# and the polymorphic parameters.
list(name=kmeansPoly, udxtype=c("transform"), intype=c("any"),
outtype=c("int"), parametertypecallback=kmeansParameters)
}
kmeansParameters <- function() {
# Callback function for the parameter types.
function.parameters <- data.frame(datatype=rep(NA, 1), length=rep(NA,1),
scale=rep(NA,1), name=rep(NA,1))
function.parameters[1,1] = "int"
function.parameters[1,4] = "k"
return(function.parameters)
}
The polymorphic R function declares it accepts any number of arguments in its factory function by specifying "any" as the argument to the intype parameter and optionally the outtype parameter. If you define "any" argument for intype or outtype, then it is the only type that your function can declare for the respective parameter. You cannot define required arguments and then call "any" to declare the rest of the signature as optional. If your function has requirements for the arguments it accepts, your process function must enforce them.
The outtypecallback method is used to indicate the argument types and sizes it has been called with, and is expected to indicate the types and sizes that the function returns. The outtypecallback method can also be used to check for unsupported types and/or number of arguments. For example, the function may require only integers, with no more than 10 of them.
You assign a SQL name to your polymorphic UDx using the same statement you use to assign one to a non-polymorphic UDx. The following statements show how you load and call the polymorphic function from the example.
=> CREATE LIBRARY rlib2 AS '/home/dbadmin/R_UDx/poly_kmeans.R' LANGUAGE 'R';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION kmeansPoly AS LANGUAGE 'R' name 'kmeansFactoryPoly' LIBRARY rlib2;
CREATE FUNCTION
=> SELECT spec, kmeansPoly(sl,sw,pl,pw USING PARAMETERS k = 3)
OVER(PARTITION BY spec) AS Clusters
FROM iris;
spec | Clusters
-----------------+----------
Iris-setosa | 1
Iris-setosa | 1
Iris-setosa | 1
Iris-setosa | 1
.
.
.
(150 rows)
3 - UDx parameters
Parameters let you define arguments for your UDxs that remain constant across all of the rows processed by the SQL statement that calls your UDx.
Parameters let you define arguments for your UDxs that remain constant across all of the rows processed by the SQL statement that calls your UDx. Typically, your UDxs accept arguments that come from columns in a SQL statement. For example, in the following SQL statement, the arguments a and b to the add2ints UDSF change value for each row processed by the SELECT statement:
=> SELECT a, b, add2ints(a,b) AS 'sum' FROM example;
a | b | sum
---+----+-----
1 | 2 | 3
3 | 4 | 7
5 | 6 | 11
7 | 8 | 15
9 | 10 | 19
(5 rows)
Parameters remain constant for all the rows your UDx processes. You can also make parameters optional so that if the user does not supply it, your UDx uses a default value. For example, the following example demonstrates calling a UDSF named add2intsWithConstant that has a single parameter value named constant whose value is added to each the arguments supplied in each row of input:
=> SELECT a, b, add2intsWithConstant(a, b USING PARAMETERS constant=42)
AS 'a+b+42' from example;
a | b | a+b+42
---+----+--------
1 | 2 | 45
3 | 4 | 49
5 | 6 | 53
7 | 8 | 57
9 | 10 | 61
(5 rows)
Note
When calling a UDx with parameters, there is no comma between the last argument and the USING PARAMETERS clause.
The topics in this section explain how to develop UDxs that accept parameters.
3.1 - Defining UDx parameters
You define the parameters that your UDx accepts in its factory class (ScalarFunctionFactory, AggregateFunctionFactory, and so on) by implementing getParameterType().
You define the parameters that your UDx accepts in its factory class (ScalarFunctionFactory, AggregateFunctionFactory, and so on) by implementing getParameterType(). This method is similar to getReturnType(): you call data-type-specific methods on a SizedColumnTypes object that is passed in as a parameter. Each function call sets the name, data type, and width or precision (if the data type requires it) of the parameter.
Note
Parameter names in the __param-name__ format are reserved for internal use.
Setting parameter properties (C++ only)
When you add parameters to the getParameterType() function using the C++ API, you can also set properties for each parameter. For example, you can define a parameter as being required by the UDx. Doing so lets the Vertica server know that every UDx invocation must provide the specified parameter, or the query fails.
By passing an object to the SizedColumnTypes::Properties class, you can define the following four parameter properties:
|
Parameter |
Type |
Description |
visible |
BOOLEAN |
If set to TRUE, the parameter appears in the USER_FUNCTION_PARAMETERS table. You may want to set this to FALSE to declare a parameter for internal use only. |
required |
BOOLEAN |
If set to TRUE:
- The parameter is required when invoking the UDx.
- Invoking the UDx without supplying the parameter results in an error, and the UDx does not run.
|
canBeNull |
BOOLEAN |
If set to TRUE, the parameter can have a NULL value.
If set to FALSE, make sure that the supplied parameter does not contain a NULL value when invoking the UDx. Otherwise, an error results, and the UDx does not run.
|
comment |
VARCHAR(128) |
A comment to describe the parameter.
If you exceed the 128 character limit, Vertica generates an error when you run the CREATE_FUNCTION command. Additionally, if you replace the existing function definition in the comment parameter, make sure that the new definition does not exceed 128 characters. Otherwise, you delete all existing entries in the USER_FUNCTION_PARAMETERS table related to the UDx.
|
Setting parameter properties (R only)
When using parameters in your R UDx, you must specify a field in the factory function called parametertypecallback. This field points to the callback function that defines the parameters expected by the function. The callback function defines a four-column data frame with the following properties:
|
Parameter |
Type |
Description |
datatype |
VARCHAR(128) |
The data type of the parameter. |
length |
INTEGER |
The dimension of the parameter. |
scale |
INTEGER |
The proportional dimensions of the parameter. |
name |
VARCHAR(128) |
The name of the parameter. |
If any of the columns are left blank (or the parametertypecallback function is omitted), then Vertica uses default values.
For more information, see Parametertypecallback function.
Redacting UDx parameters
If a parameter name meets any of the following criteria, its value is automatically redacted from logs and system tables like QUERY_REQUESTS:
3.2 - Getting parameter values in UDxs
Your UDx uses the parameter values it declared in its factory class (see Defining the Parameters Your UDx Accepts) in its function class's processing method (for example, processBlock() or processPartition()).
Your UDx uses the parameter values it declared in its factory class (see Defining UDx parameters) in its function class's processing method (for example, processBlock() or processPartition()). It gets its parameter values from a ParamReader object, which is available from the ServerInterface object that is passed to your processing method. Reading parameters from this object is similar to reading argument values from BlockReader or PartitionReader objects: you call a data-type-specific function with the name of the parameter to retrieve its value. For example, in C++:
// Get the parameter reader from the ServerInterface to see if there are supplied parameters.
ParamReader paramReader = srvInterface.getParamReader();
// Get the value of an int parameter named constant.
const vint constant = paramReader.getIntRef("constant");
Note
String data values do not have any of their escape characters processed before they are passed to your function. Therefore, your function may need to process the escape sequences itself if it needs to operate on unescaped character values.
Using parameters in the factory class
In addition to using parameters in your UDx function class, you can also access the parameters in the factory class. You may want to access the parameters to let the user control the input or output values of your function in some way. For example, your UDx can have a parameter that lets the user choose to have your UDx return a single- or double-precision value. The process of accessing parameters in the factory class is the same as accessing it in the function class: get a ParamReader object from the ServerInterface's getParamReader() method, them read the parameter values.
Testing whether the user supplied parameter values
Unlike its handling of arguments, Vertica does not immediately return an error if a user's function call does not include a value for a parameter defined by your UDx's factory class. This means that your function can attempt to read a parameter value that the user did not supply. If it does so, by default Vertica returns a non-existent parameter warning to the user, and the query containing the function call continues.
If you want your parameter to be optional, you can test whether the user supplied a value for the parameter before attempting to access its value. Your function determines if a value exists for a particular parameter by calling the ParamReader's containsParameter() method with the parameter's name. If this call returns true, your function can safely retrieve the value. If this call returns false, your UDx can use a default value or change its processing in some other way to compensate for not having the parameter value. As long as your UDx does not try to access the non-existent parameter value, Vertica does not generate an error or warning about missing parameters.
Note
If the user passes your UDx a parameter that it has not defined, by default Vertica issues a warning that the parameter is not used. It still executes the SQL statement, ignoring the parameter. You can change this behavior by altering the
StrictUDxParameterChecking configuration parameter.
See C++ example: defining parameters for an example.
3.3 - Calling UDxs with parameters
You pass parameters to a UDx by adding a USING PARAMETERS clause in the function call after the last argument.
You pass parameters to a UDx by adding a USING PARAMETERS clause in the function call after the last argument.
-
Do not insert a comma between the last argument and the USING PARAMETERS clause.
-
After the USING PARAMETERS clause, add one or more parameter definitions, in the following form:
<parameter name> = <parameter value>
-
Separate parameter definitions by commas.
Parameter values can be a constant expression (for example 1234 + SQRT(5678)). You cannot use volatile functions (such as RANDOM) in the expression, because they do not return a constant value. If you do supply a volatile expression as a parameter value, by default, Vertica returns an incorrect parameter type warning. Vertica then tries to run the UDx without the parameter value. If the UDx requires the parameter, it returns its own error, which cancels the query.
Calling a UDx with a single parameter
The following example demonstrates how you can call the Add2intsWithConstant UDSF example shown in C++ example: defining parameters:
=> SELECT a, b, Add2intsWithConstant(a, b USING PARAMETERS constant=42) AS 'a+b+42' from example;
a | b | a+b+42
---+----+--------
1 | 2 | 45
3 | 4 | 49
5 | 6 | 53
7 | 8 | 57
9 | 10 | 61
(5 rows)
To remove the first instance of the number 3, you can call the RemoveSymbol UDSF example:
=> SELECT '3re3mo3ve3sy3mb3ol' original_string, RemoveSymbol('3re3mo3ve3sy3mb3ol' USING PARAMETERS symbol='3');
original_string | RemoveSymbol
--------------------+-------------------
3re3mo3ve3sy3mb3ol | re3mo3ve3sy3mb3ol
(1 row)
Calling a UDx with multiple parameters
The following example shows how you can call a version of the tokenize UDTF. This UDTF includes parameters to limit the shortest allowed word and force the words to be output in uppercase. Separate multiple parameters with commas.
=> SELECT url, tokenize(description USING PARAMETERS minLength=4, uppercase=true) OVER (partition by url) FROM T;
url | words
-----------------+-----------
www.amazon.com | ONLINE
www.amazon.com | RETAIL
www.amazon.com | MERCHANT
www.amazon.com | PROVIDER
www.amazon.com | CLOUD
www.amazon.com | SERVICES
www.dell.com | LEADING
www.dell.com | PROVIDER
www.dell.com | COMPUTER
www.dell.com | HARDWARE
www.vertica.com | WORLD'S
www.vertica.com | FASTEST
www.vertica.com | ANALYTIC
www.vertica.com | DATABASE
(16 rows)
The following example calls the RemoveSymbol UDSF. By changing the value of the optional parameter, n, you can remove all instances of the number 3:
=> SELECT '3re3mo3ve3sy3mb3ol' original_string, RemoveSymbol('3re3mo3ve3sy3mb3ol' USING PARAMETERS symbol='3', n=6);
original_string | RemoveSymbol
--------------------+--------------
3re3mo3ve3sy3mb3ol | removesymbol
(1 row)
Calling a UDx with optional or incorrect parameters
You can optionally add the Add2intsWithConstant UDSF's constant parameter. Calling this constraint without the parameter does not return an error or warning:
=> SELECT a,b,Add2intsWithConstant(a, b) AS 'sum' FROM example;
a | b | sum
---+----+-----
1 | 2 | 3
3 | 4 | 7
5 | 6 | 11
7 | 8 | 15
9 | 10 | 19
(5 rows)
Although calling a UDx with incorrect parameters generates a warning, by default, the query still runs. For further information on setting the behavior of your UDx when you supply incorrect parameters, see Specifying the behavior of passing unregistered parameters.
=> SELECT a, b, add2intsWithConstant(a, b USING PARAMETERS wrongparam=42) AS 'result' from example;
WARNING 4332: Parameter wrongparam was not registered by the function and cannot
be coerced to a definite data type
a | b | result
---+----+--------
1 | 2 | 3
3 | 4 | 7
5 | 6 | 11
7 | 8 | 15
9 | 10 | 19
(5 rows)
3.4 - Specifying the behavior of passing unregistered parameters
By default, Vertica issues a warning message when you pass a UDx an unregistered parameter.
By default, Vertica issues a warning message when you pass a UDx an unregistered parameter. An unregistered parameter is one that you did not declare in the getParameterType() method.
You can control the behavior of your UDx when you pass it an unregistered parameter by altering the StrictUDxParameterChecking configuration parameter.
Unregistered parameter behavior settings
You can specify the behavior of your UDx in response to one or more unregistered parameters. To do so, set the StrictUDxParameterChecking configuration parameter to one of the following values:
-
0: Allows unregistered parameters to be accessible to the UDx. The ParamReader class's getType() method determines the data type of the unregistered parameter. Vertica does not display any warning or error message.
-
1 (default): Ignores the unregistered parameter and allows the function to run. Vertica displays a warning message.
-
2: Returns an error and does not allow the function to run.
Examples
The following examples demonstrate the behavior you can specify using different values with the StrictUDxParameterChecking parameter.
View the current value of StrictUDxParameterChecking
To view the current value of the StrictUDxParameterChecking configuration parameter, run the following query:
=> \x
Expanded display is on.
=> SELECT * FROM configuration_parameters WHERE parameter_name = 'StrictUDxParameterChecking';
-[ RECORD 1 ]-----------------+------------------------------------------------------------------
node_name | ALL
parameter_name | StrictUDxParameterChecking
current_value | 1
restart_value | 1
database_value | 1
default_value | 1
current_level | DATABASE
restart_level | DATABASE
is_mismatch | f
groups |
allowed_levels | DATABASE
superuser_only | f
change_under_support_guidance | f
change_requires_restart | f
description | Sets the behavior to deal with undeclared UDx function parameters
Change the value of StrictUDxParameterChecking
You can change the value of the StrictUDxParameterChecking configuration parameter at the database, node, or session level. For example, you can change the value to '0' to specify that unregistered parameters can pass to the UDx without displaying a warning or error message:
=> ALTER DATABASE DEFAULT SET StrictUDxParameterChecking = 0;
ALTER DATABASE
Invalid parameter behavior with RemoveSymbol
The following example demonstrates how to call the RemoveSymbol UDSF example. The RemoveSymbol UDSF has a required parameter, symbol, and an optional parameter, n. In this case, you do not use the optional parameter.
If you pass both symbol and an additional parameter called wrongParam, which is not declared in the UDx, the behavior of the UDx changes corresponding to the value of StrictUDxParameterChecking.
When you set StrictUDxParameterChecking to '0', the UDx runs normally without a warning. Additionally, wrongParam becomes accessible to the UDx through the ParamReader object of the ServerInterface object:
=> ALTER DATABASE DEFAULT SET StrictUDxParameterChecking = 0;
ALTER DATABASE
=> SELECT '3re3mo3ve3sy3mb3ol' original_string, RemoveSymbol('3re3mo3ve3sy3mb3ol' USING PARAMETERS symbol='3', wrongParam='x');
original_string | RemoveSymbol
--------------------+-------------------
3re3mo3ve3sy3mb3ol | re3mo3ve3sy3mb3ol
(1 row)
When you set StrictUDxParameterChecking to '1', the UDx ignores wrongParam and runs normally. However, it also issues a warning message:
=> ALTER DATABASE DEFAULT SET StrictUDxParameterChecking = 1;
ALTER DATABASE
=> SELECT '3re3mo3ve3sy3mb3ol' original_string, RemoveSymbol('3re3mo3ve3sy3mb3ol' USING PARAMETERS symbol='3', wrongParam='x');
WARNING 4320: Parameter wrongParam was not registered by the function and cannot be coerced to a definite data type
original_string | RemoveSymbol
--------------------+-------------------
3re3mo3ve3sy3mb3ol | re3mo3ve3sy3mb3ol
(1 row)
When you set StrictUDxParameterChecking to '2', the UDx encounters an error when it tries to call wrongParam and does not run. Instead, it generates an error message:
=> ALTER DATABASE DEFAULT SET StrictUDxParameterChecking = 2;
ALTER DATABASE
=> SELECT '3re3mo3ve3sy3mb3ol' original_string, RemoveSymbol('3re3mo3ve3sy3mb3ol' USING PARAMETERS symbol='3', wrongParam='x');
ERROR 0: Parameter wrongParam was not registered by the function
3.5 - User-defined session parameters
User-defined session parameters allow you to write more generalized parameters than what Vertica provides.
User-defined session parameters allow you to write more generalized parameters than what Vertica provides. You can configure user-defined session parameters in these ways:
A user-defined session parameter can be passed into any type of UDx supported by Vertica. You can also set parameters for your UDx at the session level. By specifying a user-defined session parameter, you can have the state of a parameter saved continuously. Vertica saves the state of the parameter even when the UDx is invoked multiple times during a single session.
The RowCount example uses a user-defined session parameter. This parameter counts the total number of rows processed by the UDx each time it runs. RowCount then displays the aggregate number of rows processed for all executions. See C++ example: using session parameters and Java example: using session parameters for implementations.
Viewing the user-defined session parameter
Enter the following command to see the value of all session parameters:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+---------+-----+-------
(0 rows)
No value has been set, so the table is empty. Now, execute the UDx:
=> SELECT RowCount(5,5);
RowCount
----------
10
(1 row)
Again, enter the command to see the value of the session parameter:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+-----------+----------+-------
public | UDSession | rowcount | 1
(1 row)
The library column shows the name of the library containing the UDx. This is the name set with CREATE LIBRARY. Because the UDx has processed one row, the value of the rowcount session parameter is now 1. Running the UDx two more times should increment the value twice.
=> SELECT RowCount(10,10);
RowCount
----------
20
(1 row)
=> SELECT RowCount(15,15);
RowCount
----------
30
(1 row)
You have now executed the UDx three times, obtaining the sum of 5 + 5, 10 + 10, and 15 + 15. Now, check the value of rowcount.
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+-----------+----------+-------
public | UDSession | rowcount | 3
(1 row)
Altering the user-defined session parameter
You can also manually alter the value of rowcount. To do so, enter the following command:
=> ALTER SESSION SET UDPARAMETER FOR UDSession rowcount = 25;
ALTER SESSION
Check the value of RowCount:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+-----------+----------+-------
public | UDSession | rowcount | 25
(1 row)
Clearing the user-defined session parameter
From the client:
To clear the current value of rowcount, enter the following command:
=> ALTER SESSION CLEAR UDPARAMETER FOR UDSession rowcount;
ALTER SESSION
Verify that rowcount has been cleared:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+---------+-----+-------
(0 rows)
Through the UDx in C++:
You can set the session parameter to clear through the UDx itself. For example, to clear rowcount when its value reaches 10 or greater, do the following:
-
Remove the following line from the destroy() method in the RowCount class:
udParams.getUDSessionParamWriter("library").getStringRef("rowCount").copy(i_as_string);
-
Replace the removed line from the destroy() method with the following code:
if (rowCount < 10)
{
udParams.getUDSessionParamWriter("library").getStringRef("rowCount").copy(i_as_string);
}
else
{
udParams.getUDSessionParamWriter("library").clearParameter("rowCount");
}
-
To see the UDx clear the session parameter, set rowcount to a value of 9:
=> ALTER SESSION SET UDPARAMETER FOR UDSession rowcount = 9;
ALTER SESSION
-
Check the value of rowcount:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+-----------+----------+-------
public | UDSession | rowcount | 9
(1 row)
-
Invoke RowCount so that its value becomes 10:
=> SELECT RowCount(15,15);
RowCount
----------
30
(1 row)
-
Check the value of rowcount again. Because the value has reached 10, the threshold specified in the UDx, expect that rowcount is cleared:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+---------+-----+-------
(0 rows)
As expected, RowCount is cleared.
Through the UDx in Java:
-
Remove the following lines from the destroy() method in the RowCount class:
udParams.getUDSessionParamWriter("library").setString("rowCount", Integer.toString(rowCount));
srvInterface.log("RowNumber processed %d records", count);
-
Replace the removed lines from the destroy() method with the following code:
if (rowCount < 10)
{
udParams.getUDSessionParamWriter("library").setString("rowCount", Integer.toString(rowCount));
srvInterface.log("RowNumber processed %d records", count);
}
else
{
udParams.getUDSessionParamWriter("library").clearParameter("rowCount");
}
-
To see the UDx clear the session parameter, set rowcount to a value of 9:
=> ALTER SESSION SET UDPARAMETER FOR UDSession rowcount = 9;
ALTER SESSION
-
Check the value of rowcount:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+-----------+----------+-------
public | UDSession | rowcount | 9
(1 row)
-
Invoke RowCount so that its value becomes 10:
=> SELECT RowCount(15,15);
RowCount
----------
30
(1 row)
-
Check the value of rowcount. Since the value has reached 10, the threshold specified in the UDx, expect that rowcount is cleared:
=> SHOW SESSION UDPARAMETER all;
schema | library | key | value
--------+---------+-----+-------
(0 rows)
As expected, rowcount is cleared.
Read-only and hidden session parameters
If you don't want a parameter to be set anywhere except in the UDx, you can make it read-only. If, additionally, you don't want a parameter to be visible in the client, you can make it hidden.
To make a parameter read-only, meaning that it cannot be set in the client, but can be viewed, add a single underscore before the parameter's name. For example, to make rowCount read-only, change all instances in the UDx of "rowCount" to "_rowCount".
To make a parameter hidden, meaning that it cannot be viewed in the client nor set, add two underscores before the parameter's name. For example, to make rowCount hidden, change all instances in the UDx of "rowCount" to "__rowCount".
Redacted parameters
If a parameter name meets any of the following criteria, its value is automatically redacted from logs and system tables like QUERY_REQUESTS:
See also
Kafka user-defined session parameters
3.6 - C++ example: defining parameters
The following code fragment demonstrates adding a single parameter to the C++ add2ints UDSF example.
The following code fragment demonstrates adding a single parameter to the C++ add2ints UDSF example. The getParameterType() function defines a single integer parameter that is named constant.
class Add2intsWithConstantFactory : public ScalarFunctionFactory
{
// Return an instance of Add2ints to perform the actual addition.
virtual ScalarFunction *createScalarFunction(ServerInterface &interface)
{
// Calls the vt_createFuncObj to create the new Add2ints class instance.
return vt_createFuncObj(interface.allocator, Add2intsWithConstant);
}
// Report the argument and return types to Vertica.
virtual void getPrototype(ServerInterface &interface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
// Takes two ints as inputs, so add ints to the argTypes object.
argTypes.addInt();
argTypes.addInt();
// Returns a single int.
returnType.addInt();
}
// Defines the parameters for this UDSF. Works similarly to defining arguments and return types.
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes)
{
// One int parameter named constant.
parameterTypes.addInt("constant");
}
};
RegisterFactory(Add2intsWithConstantFactory);
See the Vertica SDK entry for SizedColumnTypes for a full list of the data-type-specific functions you can call to define parameters.
The following code fragment demonstrates using the parameter value. The Add2intsWithConstant class defines a function that adds two integer values. If the user supplies it, the function also adds the value of the optional integer parameter named constant.
/**
* A UDSF that adds two numbers together with a constant value.
*
*/
class Add2intsWithConstant : public ScalarFunction
{
public:
// Processes a block of data sent by Vertica.
virtual void processBlock(ServerInterface &srvInterface,
BlockReader &arg_reader,
BlockWriter &res_writer)
{
try
{
// The default value for the constant parameter is 0.
vint constant = 0;
// Get the parameter reader from the ServerInterface to see if there are supplied parameters.
ParamReader paramReader = srvInterface.getParamReader();
// See if the user supplied the constant parameter.
if (paramReader.containsParameter("constant"))
// There is a parameter, so get its value.
constant = paramReader.getIntRef("constant");
// While we have input to process:
do
{
// Read the two integer input parameters by calling the BlockReader.getIntRef class function.
const vint a = arg_reader.getIntRef(0);
const vint b = arg_reader.getIntRef(1);
// Add arguments plus constant.
res_writer.setInt(a+b+constant);
// Finish writing the row, and advance to the next output row.
res_writer.next();
// Continue looping until there are no more input rows.
}
while (arg_reader.next());
}
catch (exception& e)
{
// Standard exception. Quit.
vt_report_error(0, "Exception while processing partition: %s",
e.what());
}
}
};
3.7 - C++ example: using session parameters
The RowCount example uses a user-defined session parameter, also called RowCount.
The RowCount example uses a user-defined session parameter, also called RowCount. This parameter counts the total number of rows processed by the UDx each time it runs. RowCount then displays the aggregate number of rows processed for all executions.
#include <string>
#include <sstream>
#include <iostream>
#include "Vertica.h"
#include "VerticaUDx.h"
using namespace Vertica;
class RowCount : public Vertica::ScalarFunction
{
private:
int rowCount;
int count;
public:
virtual void setup(Vertica::ServerInterface &srvInterface, const Vertica::SizedColumnTypes &argTypes) {
ParamReader pSessionParams = srvInterface.getUDSessionParamReader("library");
std::string rCount = pSessionParams.containsParameter("rowCount")?
pSessionParams.getStringRef("rowCount").str(): "0";
rowCount=atoi(rCount.c_str());
}
virtual void processBlock(Vertica::ServerInterface &srvInterface, Vertica::BlockReader &arg_reader, Vertica::BlockWriter &res_writer) {
count = 0;
if(arg_reader.getNumCols() != 2)
vt_report_error(0, "Function only accepts two arguments, but %zu provided", arg_reader.getNumCols());
do {
const Vertica::vint a = arg_reader.getIntRef(0);
const Vertica::vint b = arg_reader.getIntRef(1);
res_writer.setInt(a+b);
count++;
res_writer.next();
} while (arg_reader.next());
srvInterface.log("count %d", count);
}
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes &argTypes, SessionParamWriterMap &udParams) {
rowCount = rowCount + count;
std:ostringstream s;
s << rowCount;
const std::string i_as_string(s.str());
udParams.getUDSessionParamWriter("library").getStringRef("rowCount").copy(i_as_string);
}
};
class RowCountsInfo : public Vertica::ScalarFunctionFactory {
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface &srvInterface)
{ return Vertica::vt_createFuncObject<RowCount>(srvInterface.allocator);
}
virtual void getPrototype(Vertica::ServerInterface &srvInterface, Vertica::ColumnTypes &argTypes, Vertica::ColumnTypes &returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
};
RegisterFactory(RowCountsInfo);
3.8 - Java example: defining parameters
The following code fragment demonstrates adding a single parameter to the Java add2ints UDSF example.
The following code fragment demonstrates adding a single parameter to the Java add2ints UDSF example. The getParameterType() method defines a single integer parameter that is named constant.
package com.mycompany.example;
import com.vertica.sdk.*;
public class Add2intsWithConstantFactory extends ScalarFunctionFactory
{
@Override
public void getPrototype(ServerInterface srvInterface,
ColumnTypes argTypes,
ColumnTypes returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
@Override
public void getReturnType(ServerInterface srvInterface,
SizedColumnTypes argTypes,
SizedColumnTypes returnType)
{
returnType.addInt("sum");
}
// Defines the parameters for this UDSF. Works similarly to defining
// arguments and return types.
public void getParameterType(ServerInterface srvInterface,
SizedColumnTypes parameterTypes)
{
// One INTEGER parameter named constant
parameterTypes.addInt("constant");
}
@Override
public ScalarFunction createScalarFunction(ServerInterface srvInterface)
{
return new Add2intsWithConstant();
}
}
See the Vertica Java SDK entry for SizedColumnTypes for a full list of the data-type-specific methods you can call to define parameters.
3.9 - Java example: using session parameters
The RowCount example uses a user-defined session parameter, also called RowCount.
The RowCount example uses a user-defined session parameter, also called RowCount. This parameter counts the total number of rows processed by the UDx each time it runs. RowCount then displays the aggregate number of rows processed for all executions.
package com.mycompany.example;
import com.vertica.sdk.*;
public class RowCountFactory extends ScalarFunctionFactory {
@Override
public void getPrototype(ServerInterface srvInterface, ColumnTypes argTypes, ColumnTypes returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
public class RowCount extends ScalarFunction {
private Integer count;
private Integer rowCount;
// In the setup method, you look for the rowCount parameter. If it doesn't exist, it is created.
// Look in the default namespace which is "library," but it could be anything else, most likely "public" if not "library".
@Override
public void setup(ServerInterface srvInterface, SizedColumnTypes argTypes) {
count = new Integer(0);
ParamReader pSessionParams = srvInterface.getUDSessionParamReader("library");
String rCount = pSessionParams.containsParameter("rowCount")?
pSessionParams.getString("rowCount"): "0";
rowCount = Integer.parseInt(rCount);
}
@Override
public void processBlock(ServerInterface srvInterface, BlockReader arg_reader, BlockWriter res_writer)
throws UdfException, DestroyInvocation {
do {
++count;
long a = arg_reader.getLong(0);
long b = arg_reader.getLong(1);
res_writer.setLong(a+b);
res_writer.next();
} while (arg_reader.next());
}
@Override
public void destroy(ServerInterface srvInterface, SizedColumnTypes argTypes, SessionParamWriterMap udParams){
rowCount = rowCount+count;
udParams.getUDSessionParamWriter("library").setString("rowCount", Integer.toString(rowCount));
srvInterface.log("RowNumber processed %d records", count);
}
}
@Override
public ScalarFunction createScalarFunction(ServerInterface srvInterface){
return new RowCount();
}
}
4 - Errors, warnings, and logging
The SDK provides several ways for a UDx to report errors, warnings, and other messages.
The SDK provides several ways for a UDx to report errors, warnings, and other messages. For a UDx written in C++ or Python, use the messaging APIs described in Sending messages. UDxs in all languages can halt execution with an error, as explained in Handling errors.
UDxs can also write messages to the Vertica log, and UDxs written in C++ can write messages to a system table.
4.1 - Sending messages
A UDx can handle a problem by reporting an error and terminating execution, but in some cases you might want to send a warning and proceed.
A UDx can handle a problem by reporting an error and terminating execution, but in some cases you might want to send a warning and proceed. For example, a UDx might ignore or use a default for an unexpected input and report that it did so. The C++ and Python messaging APIs support reporting messages at different severity levels.
A UDx has access to a ServerInterface instance. This class has the following methods for reporting messages, in order of severity:
Each method produces messages with the following components:
-
ID code: an identification code, any integer. This code does not interact with Vertica error codes.
-
Message string: a succinct description of the issue.
-
Optional details string: provides more contextual information.
-
Optional hint string: provides other guidance.
Duplicate messages are condensed into a single report if they have the same code and message string, even if the details and hint strings differ.
Constructing messages
The UDx should report errors immediately, usually during a process call. For all other message types, record information during processing and call the reporting methods from the UDx's destroy method. The other reporting methods do not produce output if called during processing.
The process of constructing messages is language-specific.
C++
Each ServerInterface reporting method takes a ClientMessage argument. The ClientMessage class has the following methods to set the code and message, detail, and hint:
-
makeMessage: sets the ID code and message string.
-
setDetail: sets the optional detail string.
-
setHint: sets the optional hint string.
These method calls can be chained to simplify creating and passing the message.
All strings support printf-style arguments and formatting.
In the following example, a function records issues in processBlock and reports them in destroy:
class PositiveIdentity : public Vertica::ScalarFunction
{
public:
using ScalarFunction::destroy;
bool hitNotice = false;
virtual void processBlock(Vertica::ServerInterface &srvInterface,
Vertica::BlockReader &arg_reader,
Vertica::BlockWriter &res_writer)
{
do {
const Vertica::vint a = arg_reader.getIntRef(0);
if (a < 0 && a != vint_null) {
hitNotice = true;
res_writer.setInt(null);
} else {
res_writer.setInt(a);
}
res_writer.next();
} while (arg_reader.next());
}
virtual void destroy(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes) override
{
if (hitNotice) {
ClientMessage msg = ClientMessage::makeMessage(100, "Passed negative argument")
.setDetail("Value set to null");
srvInterface.reportNotice(msg);
}
}
}
Python
Each ServerInterface reporting method has the following positional and keyword arguments:
-
idCode: integer ID code, positional argument.
-
message: message text, positional argument.
-
hint: optional hint text, keyword argument.
-
detail: optional detail text, keyword argument.
All arguments support str.format() and f-string formatting.
In the following example, a function records issues in processBlock and reports them in destroy:
class PositiveIdentity(vertica_sdk.ScalarFunction):
def __init__(self):
self.hitNotice = False
def processBlock(self, server_interface, arg_reader, res_writer):
while True:
arg = arg_reader.getInt(0)
if arg < 0 and arg is not None:
self.hitNotice = True
res_writer.setNull()
else:
res_writer.setInt(arg)
res_writer.next()
if not arg_reader.next():
break
def destroy(self, srv, argType):
if self.hitNotice:
srv.reportNotice(100, "Passed negative arguement", detail="Value set to null")
return
API
Before calling a ServerInterface reporting method, construct and populate a message with the ClientMessage class.
The ServerInterface API provides the following methods for reporting messages:
// ClientMessage methods
template<typename... Argtypes>
static ClientMessage makeMessage(int errorcode, const char *fmt, Argtypes&&... args);
template <typename... Argtypes>
ClientMessage & setDetail(const char *fmt, Argtypes&&... args);
template <typename... Argtypes>
ClientMessage & setHint(const char *fmt, Argtypes&&... args);
// ServerInterface reporting methods
virtual void reportError(ClientMessage msg);
virtual void reportInfo(ClientMessage msg);
virtual void reportNotice(ClientMessage msg);
virtual void reportWarning(ClientMessage msg);
The ServerInterface API provides the following methods for reporting messages:
def reportError(self, code, text, hint='', detail=''):
def reportInfo(self, code, text, hint='', detail=''):
def reportNotice(self, code, text, hint='', detail=''):
def reportWarning(self, code, text, hint='', detail=''):
4.2 - Handling errors
If your UDx encounters an unrecoverable error, it should report the error and terminate.
If your UDx encounters an unrecoverable error, it should report the error and terminate. How you do this depends on the language:
-
C++: Consider using the API described in Sending messages, which is more expressive than the error-handling described in this topic. Alternatively, you can use the vt_report_error macro to report an error and exit. The macro takes two parameters: an error number and an error message string. Both the error number and message appear in the error that Vertica reports to the user. The error number is not defined by Vertica. You can use whatever value that you wish.
-
Java: Instantiate and throw a UdfException, which takes a numeric code and a message string to report to the user.
-
Python: Consider using the API described in Sending messages, which is more expressive than the error-handling described in this topic. Alternatively, raise an exception built into the Python language; the SDK does not include a UDx-specific exception.
-
R: Use stop to halt execution with a message.
An exception or halt causes the transaction containing the function call to be rolled back.
The following examples demonstrate error-handling:
The following function divides two integers. To prevent division by zero, it tests the second parameter and fails if it is zero:
class Div2ints : public ScalarFunction
{
public:
virtual void processBlock(ServerInterface &srvInterface,
BlockReader &arg_reader,
BlockWriter &res_writer)
{
// While we have inputs to process
do
{
const vint a = arg_reader.getIntRef(0);
const vint b = arg_reader.getIntRef(1);
if (b == 0)
{
vt_report_error(1,"Attempted divide by zero");
}
res_writer.setInt(a/b);
res_writer.next();
}
while (arg_reader.next());
}
};
Loading and invoking the function demonstrates how the error appears to the user. Fenced and unfenced modes use different error numbers.
=> CREATE LIBRARY Div2IntsLib AS '/home/dbadmin/Div2ints.so';
CREATE LIBRARY
=> CREATE FUNCTION div2ints AS LANGUAGE 'C++' NAME 'Div2intsInfo' LIBRARY Div2IntsLib;
CREATE FUNCTION
=> SELECT div2ints(25, 5);
div2ints
----------
5
(1 row)
=> SELECT * FROM MyTable;
a | b
----+---
12 | 6
7 | 0
12 | 2
18 | 9
(4 rows)
=> SELECT * FROM MyTable WHERE div2ints(a, b) > 2;
ERROR 3399: Error in calling processBlock() for User Defined Scalar Function
div2ints at Div2ints.cpp:21, error code: 1, message: Attempted divide by zero
In the following example, if either of the arguments is NULL, the processBlock() method throws an exception:
@Override
public void processBlock(ServerInterface srvInterface,
BlockReader argReader,
BlockWriter resWriter)
throws UdfException, DestroyInvocation
{
do {
// Test for NULL value. Throw exception if one occurs.
if (argReader.isLongNull(0) || argReader.isLongNull(1) ) {
// No nulls allowed. Throw exception
throw new UdfException(1234, "Cannot add a NULL value");
}
When your UDx throws an exception, the side process running your UDx reports the error back to Vertica and exits. Vertica displays the error message contained in the exception and a stack trace to the user:
=> SELECT add2ints(2, NULL);
ERROR 3399: Failure in UDx RPC call InvokeProcessBlock(): Error in User Defined Object [add2ints], error code: 1234
com.vertica.sdk.UdfException: Cannot add a NULL value
at com.example.Add2intsFactory$Add2ints.processBlock(Add2intsFactory.java:37)
at com.vertica.udxfence.UDxExecContext.processBlock(UDxExecContext.java:700)
at com.vertica.udxfence.UDxExecContext.run(UDxExecContext.java:173)
at java.lang.Thread.run(Thread.java:662)
In this example, if one of the arguments is less than 100, then the Python UDx throws an error:
while(True):
# Example of error checking best practices.
product_id = block_reader.getInt(2)
if product_id < 100:
raise ValueError("Invalid Product ID")
An error generates a message like the following:
=> SELECT add2ints(prod_cost, sale_price, product_id) FROM bunch_of_numbers;
ERROR 3399: Failure in UDx RPC call InvokeProcessBlock(): Error calling processBlock() in User Defined Object [add2ints]
at [/udx/PythonInterface.cpp:168], error code: 0,
message: Error [/udx/PythonInterface.cpp:385] function ['call_method']
(Python error type [<class 'ValueError'>])
Traceback (most recent call last):
File "/home/dbadmin/py_db/v_py_db_node0001_catalog/Libraries/02fc4af0ace6f91eefa74baecf3ef76000a0000000004fc4/pylib_02fc4af0ace6f91eefa74baecf3ef76000a0000000004fc4.py",
line 13, in processBlock
raise ValueError("Invalid Product ID")
ValueError: Invalid Product ID
In this example, if the third column of the data frame does not match the specified Product ID, then the R UDx throws an error:
Calculate_Cost_w_Tax <- function(input.data.frame) {
# Must match the Product ID 11444
if ( !is.numeric(input.data.frame[, 3]) == 11444 ) {
stop("Invalid Product ID!")
} else {
cost_w_tax <- data.frame(input.data.frame[, 1] * input.data.frame[, 2])
}
return(cost_w_tax)
}
Calculate_Cost_w_TaxFactory <- function() {
list(name=Calculate_Cost_w_Tax,
udxtype=c("scalar"),
intype=c("float","float", "float"),
outtype=c("float"))
}
An error generates a message like the following:
=> SELECT Calculate_Cost_w_Tax(item_price, tax_rate, prod_id) FROM Inventory_Sales_Data;
vsql:sql_test_multiply.sql:21: ERROR 3399: Failure in UDx RPC call InvokeProcessBlock():
Error calling processBlock() in User Defined Object [mul] at
[/udx/RInterface.cpp:1308],
error code: 0, message: Exception in processBlock :Invalid Product ID!
To report additional diagnostic information about the error, you can write messages to a log file before throwing the exception (see Logging).
Your UDx must not consume exceptions that it did not throw. Intercepting server exceptions can lead to database instability.
4.3 - Logging
Each UDx written in C++, Java, or Python has an associated instance of ServerInterface.
Each UDx written in C++, Java, or Python has an associated instance of ServerInterface. The ServerInterface class provides a function to write to the Vertica log, and the C++ implementation also provides a function to log events in a system table.
Writing messages to the Vertica log
You can write to log files using the ServerInterface.log() function. The function acts similarly to printf(), taking a formatted string and an optional set of values and writing the string to the log file. Where the message is written depends on whether your function runs in fenced mode or unfenced mode:
-
Functions running in unfenced mode write their messages into the
vertica.log file in the catalog directory.
-
Functions running in fenced mode write their messages into a log file named UDxLogs/UDxFencedProcesses.log in the catalog directory.
To help identify your function's output, Vertica adds the SQL function name bound to your UDx to the log message.
The following example logs a UDx's input values:
virtual void processBlock(ServerInterface &srvInterface,
BlockReader &argReader,
BlockWriter &resWriter)
{
try {
// While we have inputs to process
do {
if (argReader.isNull(0) || argReader.isNull(1)) {
resWriter.setNull();
} else {
const vint a = argReader.getIntRef(0);
const vint b = argReader.getIntRef(1);
srvInterface.log("got a: %d and b: %d", (int) a, (int) b);
resWriter.setInt(a+b);
}
resWriter.next();
} while (argReader.next());
} catch(std::exception& e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while processing block: [%s]", e.what());
}
}
@Override
public void processBlock(ServerInterface srvInterface,
BlockReader argReader,
BlockWriter resWriter)
throws UdfException, DestroyInvocation
{
do {
// Get the two integer arguments from the BlockReader
long a = argReader.getLong(0);
long b = argReader.getLong(1);
// Log the input values
srvInterface.log("Got values a=%d and b=%d", a, b);
long result = a+b;
resWriter.setLong(result);
resWriter.next();
} while (argReader.next());
}
}
def processBlock(self, server_interface, arg_reader, res_writer):
server_interface.log("Python UDx - Adding 2 ints!")
while(True):
first_int = block_reader.getInt(0)
second_int = block_reader.getInt(1)
block_writer.setInt(first_int + second_int)
server_interface.log("Values: first_int is {} second_int is {}".format(first_int, second_int))
block_writer.next()
if not block_reader.next():
break
The log() function generates entries in the log file like the following:
$ tail /home/dbadmin/py_db/v_py_db_node0001_catalog/UDxLogs/UDxFencedProcesses.log
07:52:12.862 [Python-v_py_db_node0001-7524:0x206c-40575] 0x7f70eee2f780 PythonExecContext::processBlock
07:52:12.862 [Python-v_py_db_node0001-7524:0x206c-40575] 0x7f70eee2f780 [UserMessage] add2ints - Python UDx - Adding 2 ints!
07:52:12.862 [Python-v_py_db_node0001-7524:0x206c-40575] 0x7f70eee2f780 [UserMessage] add2ints - Values: first_int is 100 second_int is 100
For details on viewing the Vertica log files, see Monitoring log files.
Writing messages to the UDX_EVENTS table (C++ only)
In the C++ API, you can write messages to the UDX_EVENTS system table instead of or in addition to writing to the log. Writing to a system table allows you to collect events from all nodes in one place.
You can write to this table using the ServerInterface.logEvent() function. The function takes one argument, a map. The map is written into the __RAW__ column of the table as a Flex VMap. The following example shows how the Parquet exporter creates and logs this map.
// Log exported parquet file details to v_monitor.udx_events
std::map<std::string, std::string> details;
details["file"] = escapedPath;
details["created"] = create_timestamp_;
details["closed"] = close_timestamp_;
details["rows"] = std::to_string(num_rows_in_file);
details["row_groups"] = std::to_string(num_row_groups_in_file);
details["size_mb"] = std::to_string((double)outputStream->Tell()/(1024*1024));
srvInterface.logEvent(details);
You can select individual fields from the VMap as in the following example.
=> SELECT __RAW__['file'] FROM UDX_EVENTS;
__RAW__
-----------------------------------------------------------------------------
/tmp/export_tmpzLkrKq3a/450c4213-v_vmart_node0001-139770732459776-0.parquet
/tmp/export_tmpzLkrKq3a/9df1c797-v_vmart_node0001-139770860660480-0.parquet
(2 rows)
Alternatively, you can define a view to make it easier to query fields directly, as columns. See Monitoring exports for an example.
5 - Handling cancel requests
Users of your UDx might cancel the operation while it is running.
Users of your UDx might cancel the operation while it is running. How Vertica handles the cancellation of the query and your UDx depends on whether your UDx is running in fenced or unfenced mode:
-
If your UDx is running in unfenced mode, Vertica either stops the function when it requests a new block of input or output, or waits until your function completes running and discards the results.
-
If your UDx is running in Fenced and unfenced modes, Vertica kills the zygote process that is running your function if it continues processing past a timeout.
In addition, you can implement the cancel() method in any UDx to perform any necessary additional work. Vertica calls your function when a query is canceled. This cancellation can occur at any time during your UDx's lifetime, from setup() through destroy().
You can check for cancellation before starting an expensive operation by calling isCanceled().
5.1 - Implementing the cancel callback
Your UDx can implement a cancel() callback function.
Your UDx can implement a cancel() callback function. Vertica calls this function if the query that invoked the UDx has been canceled.
You usually implement this function to perform an orderly shutdown of any additional processing that your UDx spawned. For example, you can have your cancel() function shut down threads that your UDx has spawned or signal a third-party library that it needs to stop processing and exit. Your cancel() function should leave your UDx's function class ready to be destroyed, because Vertica calls the UDx's destroy() function after the cancel() function has exited.
A UDx's default cancel() behavior is to do nothing.
The contract for cancel() is:
-
Vertica will call cancel() at most once per UDx instance.
-
Vertica can call cancel() concurrently with any other method of the UDx object except the constructor and destructor.
-
Vertica can call cancel() from another thread, so implementations should be thread-safe.
-
Vertica will call cancel() for either an explicit user cancellation or an error in the query.
-
Vertica does not guarantee that cancel() will run to completion. Long-running cancellations might be aborted.
The call to cancel() is not synchronized in any way with your UDx's other functions. If you need your processing function to exit before your cancel() function performs some action (killing threads, for example), you must have the two function synchronize their actions.
Vertica always calls destroy() if it called setup(). Cancellation does not prevent destruction.
See C++ example: cancelable UDSource for an example that implements cancel().
5.2 - Checking for cancellation during execution
You can call the isCanceled() method to check for user cancellation.
You can call the isCanceled() method to check for user cancellation. Typically you check for cancellation from the method that does the main processing in your UDx before beginning expensive operations. If isCanceled() returns true, the query has been canceled and your method should exit immediately to prevent it from wasting CPU time. If your UDx is not running fenced mode, Vertica cannot halt your function and has to wait for it to finish. If it is running in fenced mode, Vertica eventually kills the side process running it.
See C++ example: cancelable UDSource for an example that uses isCanceled().
5.3 - C++ example: cancelable UDSource
The FifoSource example, found in filelib.cpp in the SDK examples, demonstrates use of cancel() and isCanceled().
The FifoSource example, found in filelib.cpp in the SDK examples, demonstrates use of cancel() and isCanceled(). This source reads from a named pipe. Unlike reads from files, reads from pipes can block. Therefore, we need to be able to cancel a load from this source.
To manage cancellation, the UDx uses a pipe, a data channel used for inter-process communication. A process can write data to the write end of the pipe, and it remains available until another process reads it from the read end of the pipe. This example doesn't pass data through this pipe; rather, it uses the pipe to manage cancellation, as explained further below. In addition to the pipe's two file descriptors (one for each end), the UDx creates a file descriptor for the file to read from. The setup() function creates the pipe and then opens the file.
virtual void setup(ServerInterface &srvInterface) {
// cancelPipe is a pipe used only for checking cancellation
if (pipe(cancelPipe)) {
vt_report_error(0, "Error opening control structure");
}
// handle to the named pipe from which we read data
namedPipeFd = open(filename.c_str(), O_RDONLY | O_NONBLOCK);
if (namedPipeFd < 0) {
vt_report_error(0, "Error opening fifo [%s]", filename.c_str());
}
}
We now have three file descriptors: namedPipeFd, cancelPipe[PIPE_READ], and cancelPipe[PIPE_WRITE]. Each of these must eventually be closed.
This UDx uses the poll() system call to wait either for data to arrive from the named pipe (namedPipeFd) or for a cancellation (cancelPipe[PIPE_READ]). The process() function polls, checks for results, checks for cancellation, writes output if needed, and returns.
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &output) {
struct pollfd pollfds[2] = {
{ namedPipeFd, POLLIN, 0 },
{ cancelPipe[PIPE_READ], POLLIN, 0 }
};
if (poll(pollfds, 2, -1) < 0) {
vt_report_error(1, "Error reading [%s]", filename.c_str());
}
if (pollfds[1].revents & (POLLIN | POLLHUP)) {
/* This can only happen after cancel() has been called */
VIAssert(isCanceled());
return DONE;
}
VIAssert(pollfds[PIPE_READ].revents & (POLLIN | POLLHUP));
const ssize_t amount = read(namedPipeFd, output.buf + output.offset, output.size - output.offset);
if (amount < 0) {
vt_report_error(1, "Error reading from fifo [%s]", filename.c_str());
}
if (amount == 0 || isCanceled()) {
return DONE;
} else {
output.offset += amount;
return OUTPUT_NEEDED;
}
}
If the query is canceled, the cancel() function closes the write end of the pipe. The next time process() polls for input, it finds no input on the read end of the pipe and exits. Otherwise, it continues. The function also calls isCanceled() to check for cancellation before returning OUTPUT_NEEDED, the signal that it has filled its buffer and is waiting for it to be processed downstream.
The cancel() function does only the work needed to interrupt a call to process(). Cleanup that is always needed, not just for cancellation, is instead done in destroy() or the destructor. The cancel() function closes the write end of the pipe. (The helper function will be shown later.)
virtual void cancel(ServerInterface &srvInterface) {
closeIfNeeded(cancelPipe[PIPE_WRITE]);
}
It is not safe to close the named pipe in cancel(), because closing it could create a race condition if another process (like another query) were to reuse the file descriptor number for a new descriptor before the UDx finishes. Instead we close it, and the read end of the pipe, in destroy().
virtual void destroy(ServerInterface &srvInterface) {
closeIfNeeded(namedPipeFd);
closeIfNeeded(cancelPipe[PIPE_READ]);
}
It is not safe to close the write end of the pipe in destroy(), because cancel() closes it and can be called concurrently with destroy(). Therefore, we close it in the destructor.
~FifoSource() {
closeIfNeeded(cancelPipe[PIPE_WRITE]);
}
The UDx uses a helper function, closeIfNeeded(), to make sure each file descriptor is closed exactly once.
void closeIfNeeded(int &fd) {
if (fd >= 0) {
close(fd);
fd = -1;
}
}
6 - Aggregate functions (UDAFs)
Aggregate functions perform an operation on a set of values and return one value.
Aggregate functions perform an operation on a set of values and return one value. Vertica provides standard built-in aggregate functions such as AVG, MAX, and MIN. User-defined aggregate functions (UDAFs) provide similar functionality:
-
Support a single input column (or set) of values and provide a single output column.
-
Support RLE decompression. RLE input is decompressed before it is sent to a UDAF.
-
Support use with GROUP BY and HAVING clauses. Only columns appearing in the GROUP BY clause can be selected.
Restrictions
The following restrictions apply to UDAFs:
6.1 - AggregateFunction class
The AggregateFunction class performs the aggregation.
The AggregateFunction class performs the aggregation. It computes values on each database node where relevant data is stored and then combines the results from the nodes. You must implement the following methods:
-
initAggregate() - Initializes the class, defines variables, and sets the starting value for the variables. This function must be idempotent.
-
aggregate() - The main aggregation operation, executed on each node.
-
combine() - If multiple invocations of aggregate() are needed, Vertica calls combine() to combine all the sub-aggregations into a final aggregation. Although this method might not be called, you must define it.
-
terminate() - Terminates the function and returns the result as a column.
Important
The aggregate() function might not operate on the complete input set all at once. For this reason, initAggregate() must be idempotent.
The AggregateFunction class also provides optional methods that you can implement to allocate and free resources: setup() and destroy(). You should use these methods to allocate and deallocate resources that you do not allocate through the UDAF API (see Allocating resources for UDxs for details).
API
Aggregate functions are supported for C++ only.
The AggregateFunction API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
virtual void initAggregate(ServerInterface &srvInterface, IntermediateAggs &aggs)=0;
void aggregate(ServerInterface &srvInterface, BlockReader &arg_reader,
IntermediateAggs &aggs);
virtual void combine(ServerInterface &srvInterface, IntermediateAggs &aggs_output,
MultipleIntermediateAggs &aggs_other)=0;
virtual void terminate(ServerInterface &srvInterface, BlockWriter &res_writer,
IntermediateAggs &aggs);
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes &argTypes);
6.2 - AggregateFunctionFactory class
The AggregateFunctionFactory class specifies metadata information such as the argument and return types of your aggregate function.
The AggregateFunctionFactory class specifies metadata information such as the argument and return types of your aggregate function. It also instantiates your AggregateFunction subclass. Your subclass must implement the following methods:
-
getPrototype() - Defines the number of parameters and data types accepted by the function. There is a single parameter for aggregate functions.
-
getIntermediateTypes() - Defines the intermediate variable(s) used by the function. These variables are used when combining the results of aggregate() calls.
-
getReturnType() - Defines the type of the output column.
Your function may also implement getParameterType(), which defines the names and types of parameters that this function uses.
Vertica uses this data when you call the CREATE AGGREGATE FUNCTION SQL statement to add the function to the database catalog.
API
Aggregate functions are supported for C++ only.
The AggregateFunctionFactory API provides the following methods for extension by subclasses:
virtual AggregateFunction *
createAggregateFunction ServerInterface &srvInterface)=0;
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)=0;
virtual void getIntermediateTypes(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes, SizedColumnTypes &intermediateTypeMetaData)=0;
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes, SizedColumnTypes &returnType)=0;
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
6.3 - UDAF performance in statements containing a GROUP BY clause
You may see slower-than-expected performance from your UDAF if the SQL statement calling it also contains a GROUP BY Clause.
You may see slower-than-expected performance from your UDAF if the SQL statement calling it also contains a GROUP BY clause. For example:
=> SELECT a, MYUDAF(b) FROM sampletable GROUP BY a;
In statements like this one, Vertica does not consolidate row data together before calling your UDAF's aggregate() method. Instead, it calls aggregate() once for each row of data. Usually, the overhead of having Vertica consolidate the row data is greater than the overhead of calling aggregate() for each row of data. However, if your UDAF's aggregate() method has significant overhead, then you might notice an impact on your UDAF's performance.
For example, suppose aggregate() allocates memory. When called in a statement with a GROUP BY clause, it performs this memory allocation for each row of data. Because memory allocation is a relatively expensive process, this allocation can impact the overall performance of your UDAF and the query.
There are two ways you can address UDAF performance in a statement containing a GROUP BY clause:
-
Reduce the overhead of each call to aggregate(). If possible, move any allocation or other setup operations to the UDAF's setup() function.
-
Declare a special parameter that tells Vertica to group row data together when calling a UDAF. This technique is explained below.
Using the _minimizeCallCount parameter
Your UDAF can tell Vertica to always batch row data together to reduce the number of calls to its aggregate() method. To trigger this behavior, your UDAF must declare an integer parameter named _minimizeCallCount. You do not need to set a value for this parameter in your SQL statement. The fact that your UDAF declares this parameter triggers Vertica to group row data together when calling aggregate().
You declare the _minimizeCallCount parameter the same way you declare other UDx parameters. See UDx parameters for more information.
Important
Always test the performance of your UDAF before and after implementing the _minimizeCallCount parameter to ensure that it improves performance. You might find that the overhead of having Vertica group row data for your UDAF is greater than the cost of the repeated calls to aggregate().
6.4 - C++ example: average
The Average aggregate function created in this example computes the average of values in a column.
The Average aggregate function created in this example computes the average of values in a column.
You can find the source code used in this example on the Vertica GitHub page.
Loading the example
Use CREATE LIBRARY and CREATE AGGREGATE FUNCTION to declare the function:
=> CREATE LIBRARY AggregateFunctions AS
'/opt/vertica/sdk/examples/build/AggregateFunctions.so';
CREATE LIBRARY
=> CREATE aggregate function ag_avg AS LANGUAGE 'C++'
name 'AverageFactory' library AggregateFunctions;
CREATE AGGREGATE FUNCTION
Using the example
Use the function as part of a SELECT statement:
=> SELECT * FROM average;
id | count
----+---------
A | 8
B | 3
C | 6
D | 2
E | 9
F | 7
G | 5
H | 4
I | 1
(9 rows)
=> SELECT ag_avg(count) FROM average;
ag_avg
--------
5
(1 row)
AggregateFunction implementation
This example adds the input argument values in the aggregate() method and keeps a counter of the number of values added. The server runs aggregate() on every node and different data chunks, and combines all the individually added values and counters in the combine() method. Finally, the average value is computed in the terminate() method by dividing the total sum by the total number of values processed.
For this discussion, assume the following environment:
-
A three-node Vertica cluster
-
A table column that contains nine values that are evenly distributed across the nodes. Schematically, the nodes look like the following figure:

The function uses sum and count variables. Sum contains the sum of the values, and count contains the count of values.
First, initAggregate() initializes the variables and sets their values to zero.
virtual void initAggregate(ServerInterface &srvInterface,
IntermediateAggs &aggs)
{
try {
VNumeric &sum = aggs.getNumericRef(0);
sum.setZero();
vint &count = aggs.getIntRef(1);
count = 0;
}
catch(std::exception &e) {
vt_ report_ error(0, "Exception while initializing intermediate aggregates: [% s]", e.what());
}
}
The aggregate() function reads the block of data on each node and calculates partial aggregates.
void aggregate(ServerInterface &srvInterface,
BlockReader &argReader,
IntermediateAggs &aggs)
{
try {
VNumeric &sum = aggs.getNumericRef(0);
vint &count = aggs.getIntRef(1);
do {
const VNumeric &input = argReader.getNumericRef(0);
if (!input.isNull()) {
sum.accumulate(&input);
count++;
}
} while (argReader.next());
} catch(std::exception &e) {
vt_ report_ error(0, " Exception while processing aggregate: [% s]", e.what());
}
}
Each completed instance of the aggregate() function returns multiple partial aggregates for sum and count. The following figure illustrates this process using the aggregate() function:
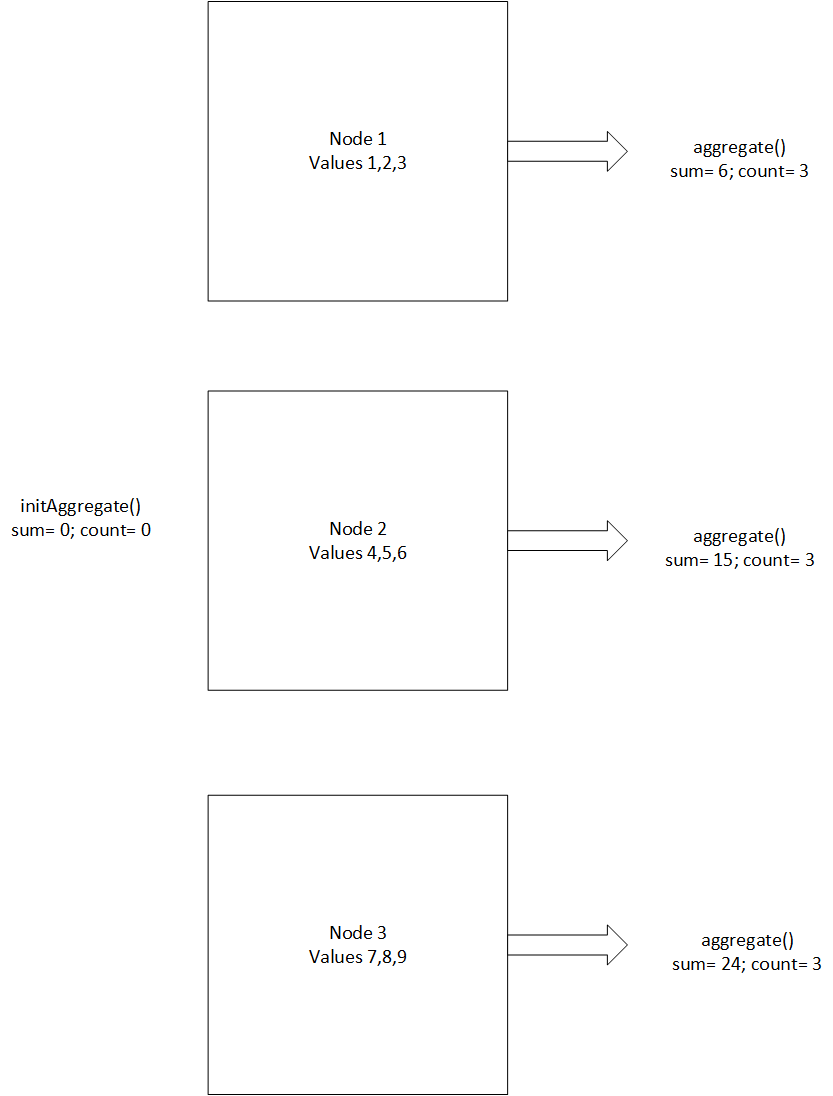
The combine() function puts together the partial aggregates calculated by each instance of the average function.
virtual void combine(ServerInterface &srvInterface,
IntermediateAggs &aggs,
MultipleIntermediateAggs &aggsOther)
{
try {
VNumeric &mySum = aggs.getNumericRef(0);
vint &myCount = aggs.getIntRef(1);
// Combine all the other intermediate aggregates
do {
const VNumeric &otherSum = aggsOther.getNumericRef(0);
const vint &otherCount = aggsOther.getIntRef(1);
// Do the actual accumulation
mySum.accumulate(&otherSum);
myCount += otherCount;
} while (aggsOther.next());
} catch(std::exception &e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while combining intermediate aggregates: [%s]", e.what());
}
}
The following figure shows how each partial aggregate is combined:
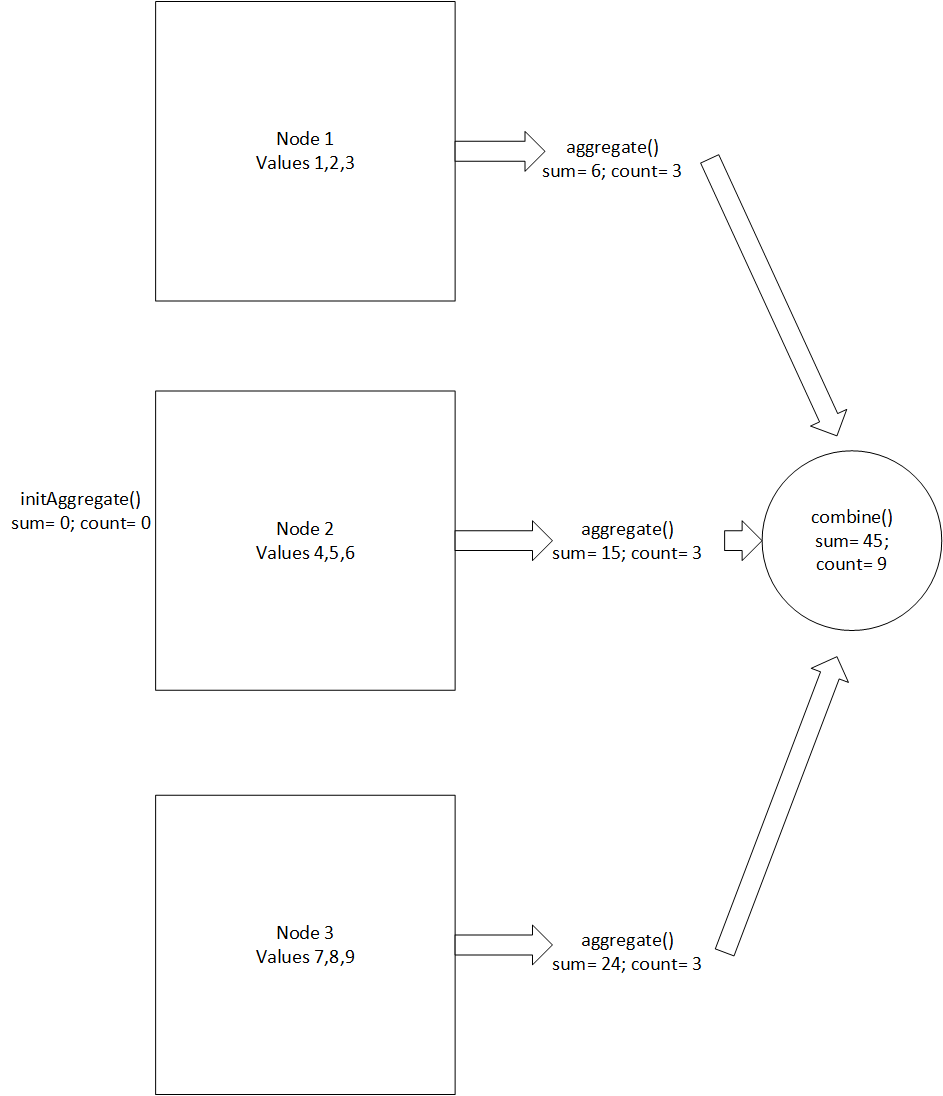
After all input has been evaluated by the aggregate() function Vertica calls the terminate() function. It returns the average to the caller.
virtual void terminate(ServerInterface &srvInterface,
BlockWriter &resWriter,
IntermediateAggs &aggs)
{
try {
const int32 MAX_INT_PRECISION = 20;
const int32 prec = Basics::getNumericWordCount(MAX_INT_PRECISION);
uint64 words[prec];
VNumeric count(words,prec,0/*scale*/);
count.copy(aggs.getIntRef(1));
VNumeric &out = resWriter.getNumericRef();
if (count.isZero()) {
out.setNull();
} else
const VNumeric &sum = aggs.getNumericRef(0);
out.div(&sum, &count);
}
}
The following figure shows the implementation of the terminate() function:
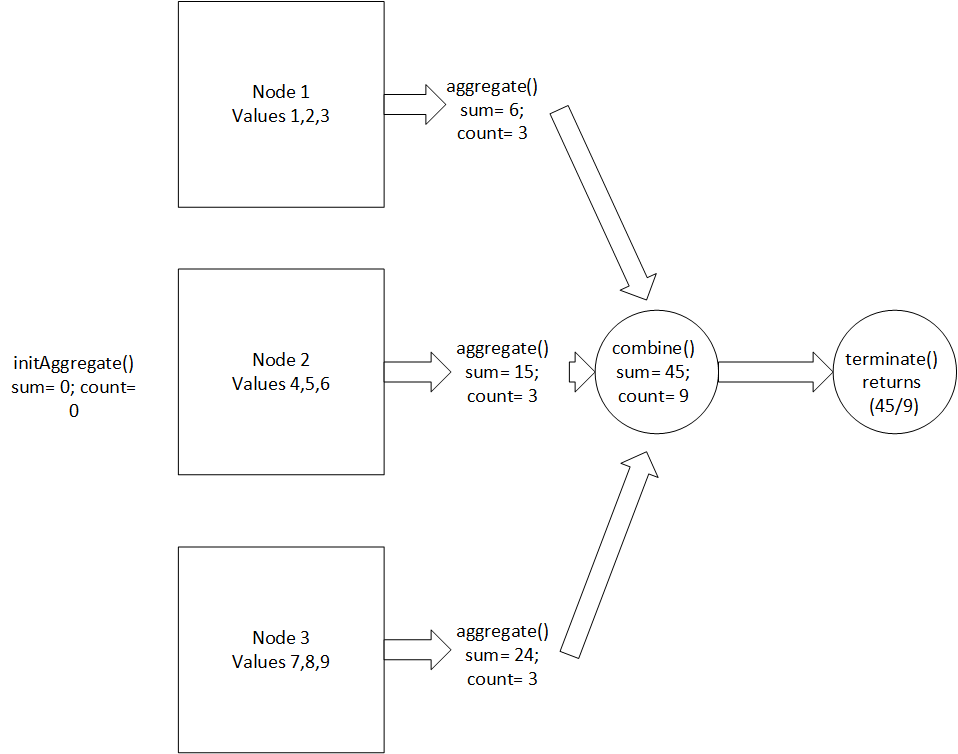
AggregateFunctionFactory implementation
The getPrototype() function allows you to define the variables that are sent to your aggregate function and returned to Vertica after your aggregate function runs. The following example accepts and returns a numeric value:
virtual void getPrototype(ServerInterface &srvfloaterface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
argTypes.addNumeric();
returnType.addNumeric();
}
The getIntermediateTypes() function defines any intermediate variables that you use in your aggregate function. Intermediate variables are values used to pass data among multiple invocations of an aggregate function. They are used to combine results until a final result can be computed. In this example, there are two results - total (numeric) and count (int).
virtual void getIntermediateTypes(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &intermediateTypeMetaData)
{
const VerticaType &inType = inputTypes.getColumnType(0);
intermediateTypeMetaData.addNumeric(interPrec, inType.getNumericScale());
intermediateTypeMetaData.addInt();
}
The getReturnType() function defines the output data type:
virtual void getReturnType(ServerInterface &srvfloaterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
const VerticaType &inType = inputTypes.getColumnType(0);
outputTypes.addNumeric(inType.getNumericPrecision(),
inType.getNumericScale());
}
7 - Analytic functions (UDAnFs)
User-defined analytic functions (UDAnFs) are used for analytics.
User-defined analytic functions (UDAnFs) are used for analytics. See SQL analytics for an overview of Vertica's built-in analytics. Like user-defined scalar functions (UDSFs), UDAnFs must output a single value for each row of data read and can have no more than 9800 arguments.
Unlike UDSFs, the UDAnF's input reader and output reader can be advanced independently. This feature lets you create analytic functions where the output value is calculated over multiple rows of data. By advancing the reader and writer independently, you can create functions similar to the built-in analytic functions such as LAG, which uses data from prior rows to output a value for the current row.
7.1 - AnalyticFunction class
The AnalyticFunction class performs the analytic processing.
The AnalyticFunction class performs the analytic processing. Your subclass must define the processPartition() method to perform the operation. It may define methods to set up and tear down the function.
The processPartition() method reads a partition of data, performs some sort of processing, and outputs a single value for each input row.
Vertica calls processPartition() once for each partition of data. It supplies the partition using an AnalyticPartitionReader object from which you read its input data. In addition, there is a unique method on this object named isNewOrderByKey(), which returns a Boolean value indicating whether your function has seen a row with the same ORDER BY key (or keys). This method is very useful for analytic functions (such as the example RANK function) which need to handle rows with identical ORDER BY keys differently than rows with different ORDER BY keys.
Note
You can specify multiple ORDER BY columns in the SQL query you use to call your UDAnF. The isNewOrderByKey method returns true if any of the ORDER BY keys are different than the previous row.
Once your method has finished processing the row of data, you advance it to the next row of input by calling next() on AnalyticPartitionReader.
Your method writes its output value using an AnalyticPartitionWriter object that Vertica supplies as a parameter to processPartition(). This object has data-type-specific methods to write the output value (such as setInt()). After setting the output value, call next() on AnalyticPartitionWriter to advance to the next row in the output.
Note
You must be sure that your function produces a row of output for each row of input in the partition. You must also not output more rows than are in the partition, otherwise the zygote size process (if running in
Fenced and unfenced modes) or Vertica itself could generate an out of bounds error.
Setting up and tearing down
The AnalyticFunction class defines two additional methods that you can optionally implement to allocate and free resources: setup() and destroy(). You should use these methods to allocate and deallocate resources that you do not allocate through the UDx API (see Allocating resources for UDxs for details).
API
The AnalyticFunction API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
virtual void processPartition (ServerInterface &srvInterface,
AnalyticPartitionReader &input_reader,
AnalyticPartitionWriter &output_writer)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes &argTypes);
The AnalyticFunction API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface, SizedColumnTypes argTypes);
public abstract void processPartition (ServerInterface srvInterface,
AnalyticPartitionReader input_reader, AnalyticPartitionWriter output_writer)
throws UdfException, DestroyInvocation;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface, SizedColumnTypes argTypes);
7.2 - AnalyticFunctionFactory class
The AnalyticFunctionFactory class tells Vertica metadata about your UDAnF: its number of parameters and their data types, as well as the data type of its return value.
The AnalyticFunctionFactory class tells Vertica metadata about your UDAnF: its number of parameters and their data types, as well as the data type of its return value. It also instantiates a subclass of AnalyticFunction.
Your AnalyticFunctionFactory subclass must implement the following methods:
-
getPrototype() describes the input parameters and output value of your function. You set these values by calling functions on two ColumnTypes objects that are passed to your method.
-
createAnalyticFunction() supplies an instance of your AnalyticFunction that Vertica can call to process a UDAnF function call.
-
getReturnType() provides details about your function's output. This method is where you set the width of the output value if your function returns a variable-width value (such as VARCHAR) or the precision of the output value if it has a settable precision (such as TIMESTAMP).
API
The AnalyticFunctionFactory API provides the following methods for extension by subclasses:
virtual AnalyticFunction * createAnalyticFunction (ServerInterface &srvInterface)=0;
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)=0;
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes, SizedColumnTypes &returnType)=0;
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
The AnalyticFunctionFactory API provides the following methods for extension by subclasses:
public abstract AnalyticFunction createAnalyticFunction (ServerInterface srvInterface);
public abstract void getPrototype(ServerInterface srvInterface, ColumnTypes argTypes, ColumnTypes returnType);
public abstract void getReturnType(ServerInterface srvInterface, SizedColumnTypes argTypes,
SizedColumnTypes returnType) throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
7.3 - C++ example: rank
The Rank analytic function ranks rows based on how they are ordered.
The Rank analytic function ranks rows based on how they are ordered. A Java version of this UDx is included in /opt/vertica/sdk/examples.
Loading and using the example
The following example shows how to load the function into Vertica. It assumes that the AnalyticFunctions.so library that contains the function has been copied to the dbadmin user's home directory on the initiator node.
=> CREATE LIBRARY AnalyticFunctions AS '/home/dbadmin/AnalyticFunctions.so';
CREATE LIBRARY
=> CREATE ANALYTIC FUNCTION an_rank AS LANGUAGE 'C++'
NAME 'RankFactory' LIBRARY AnalyticFunctions;
CREATE ANALYTIC FUNCTION
An example of running this rank function, named an_rank, is:
=> SELECT * FROM hits;
site | date | num_hits
-----------------+------------+----------
www.example.com | 2012-01-02 | 97
www.vertica.com | 2012-01-01 | 343435
www.example.com | 2012-01-01 | 123
www.example.com | 2012-01-04 | 112
www.vertica.com | 2012-01-02 | 503695
www.vertica.com | 2012-01-03 | 490387
www.example.com | 2012-01-03 | 123
(7 rows)
=> SELECT site,date,num_hits,an_rank()
OVER (PARTITION BY site ORDER BY num_hits DESC)
AS an_rank FROM hits;
site | date | num_hits | an_rank
-----------------+------------+----------+---------
www.example.com | 2012-01-03 | 123 | 1
www.example.com | 2012-01-01 | 123 | 1
www.example.com | 2012-01-04 | 112 | 3
www.example.com | 2012-01-02 | 97 | 4
www.vertica.com | 2012-01-02 | 503695 | 1
www.vertica.com | 2012-01-03 | 490387 | 2
www.vertica.com | 2012-01-01 | 343435 | 3
(7 rows)
As with the built-in RANK analytic function, rows that have the same value for the ORDER BY column (num_hits in this example) have the same rank, but the rank continues to increase, so that the next row that has a different ORDER BY key gets a rank value based on the number of rows that preceded it.
AnalyticFunction implementation
The following code defines an AnalyticFunction subclass named Rank. It is based on example code distributed in the examples directory of the SDK.
/**
* User-defined analytic function: Rank - works mostly the same as SQL-99 rank
* with the ability to define as many order by columns as desired
*
*/
class Rank : public AnalyticFunction
{
virtual void processPartition(ServerInterface &srvInterface,
AnalyticPartitionReader &inputReader,
AnalyticPartitionWriter &outputWriter)
{
// Always use a top-level try-catch block to prevent exceptions from
// leaking back to Vertica or the fenced-mode side process.
try {
rank = 1; // The rank to assign a row
rowCount = 0; // Number of rows processed so far
do {
rowCount++;
// Do we have a new order by row?
if (inputReader.isNewOrderByKey()) {
// Yes, so set rank to the total number of rows that have been
// processed. Otherwise, the rank remains the same value as
// the previous iteration.
rank = rowCount;
}
// Write the rank
outputWriter.setInt(0, rank);
// Move to the next row of the output
outputWriter.next();
} while (inputReader.next()); // Loop until no more input
} catch(exception& e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while processing partition: %s", e.what());
}
}
private:
vint rank, rowCount;
};
In this example, the processPartition() method does not actually read any of the data from the input row; it just advances through the rows. It does not need to read data; it just counts the rows that have been read and determine whether those rows have the same ORDER BY key as the previous row. If the current row is a new ORDER BY key, then the rank is set to the total number of rows that have been processed. If the current row has the same ORDER BY value as the previous row, then the rank remains the same.
Note that the function has a top-level try-catch block. All of your UDx functions should always have one to prevent stray exceptions from being passed back to Vertica (if you run the function unfenced) or the side process.
AnalyticFunctionFactory implementation
The following code defines the AnalyticFunctionFactory that corresponds with the Rank analytic function.
class RankFactory : public AnalyticFunctionFactory
{
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)
{
returnType.addInt();
}
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
outputTypes.addInt();
}
virtual AnalyticFunction *createAnalyticFunction(ServerInterface
&srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, Rank); }
};
The first method defined by the RankFactory subclass, getPrototype(), sets the data type of the return value. Because the Rank UDAnF does not read input, it does not define any arguments by calling methods on the ColumnTypes object passed in the argTypes parameter.
The next method is getReturnType(). If your function returns a data type that needs to define a width or precision, your implementation of the getReturnType() method calls a method on the SizedColumnType object passed in as a parameter to tell Vertica the width or precision. Rank returns a fixed-width data type (an INTEGER) so it does not need to set the precision or width of its output; it just calls addInt() to report its output data type.
Finally, RankFactory defines the createAnalyticFunction() method that returns an instance of the AnalyticFunction class that Vertica can call. This code is mostly boilerplate. All you need to do is add the name of your analytic function class in the call to vt_createFuncObj(), which takes care of allocating the object for you.
8 - Scalar functions (UDSFs)
A user-defined scalar function (UDSF) returns a single value for each row of data it reads.
A user-defined scalar function (UDSF) returns a single value for each row of data it reads. You can use a UDSF anywhere you can use a built-in Vertica function. You usually develop a UDSF to perform data manipulations that are too complex or too slow to perform using SQL statements and functions. UDSFs also let you use analytic functions provided by third-party libraries within Vertica while still maintaining high performance.
A UDSF returns a single column. You can automatically return multiple values in a ROW. A ROW is a group of property-value pairs. In the following example, div_with_rem is a UDSF that performs a division operation, returning the quotient and remainder as integers:
=> SELECT div_with_rem(18,5);
div_with_rem
------------------------------
{"quotient":3,"remainder":3}
(1 row)
A ROW returned from a UDSF cannot be used as an argument to COUNT.
Alternatively, you can construct a complex return value yourself, as described in Complex Types as Arguments.
Your UDSF must return a value for every input row (unless it generates an error; see Handling errors for details). Failure to return a value for an input row results in incorrect results and potentially destabilizes the Vertica server if not run in Fenced and unfenced modes.
A UDSF can have up to 9800 arguments.
8.1 - ScalarFunction class
The ScalarFunction class is the heart of a UDSF.
The ScalarFunction class is the heart of a UDSF. Your subclass must define the processBlock() method to perform the scalar operation. It may define methods to set up and tear down the function.
For scalar functions written in C++, you can provide information that can help with query optimization. See Improving query performance (C++ only).
The processBlock() method carries out all of the processing that you want your UDSF to perform. When a user calls your function in a SQL statement, Vertica bundles together the data from the function parameters and passes it to processBlock() .
The input and output of the processBlock() method are supplied by objects of the BlockReader and BlockWriter classes. They define methods that you use to read the input data and write the output data for your UDSF.
The majority of the work in developing a UDSF is writing processBlock(). This is where all of the processing in your function occurs. Your UDSF should follow this basic pattern:
-
Read in a set of arguments from the BlockReader object using data-type-specific methods.
-
Process the data in some manner.
-
Output the resulting value using one of the BlockWriter class's data-type-specific methods.
-
Advance to the next row of output and input by calling BlockWriter.next() and BlockReader.next().
This process continues until there are no more rows of data to be read (BlockReader.next() returns false).
You must make sure that processBlock() reads all of the rows in its input and outputs a single value for each row. Failure to do so can corrupt the data structures that Vertica reads to get the output of your UDSF. The only exception to this rule is if your processBlock() function reports an error back to Vertica (see Handling errors). In that case, Vertica does not attempt to read the incomplete result set generated by the UDSF.
Setting up and tearing down
The ScalarFunction class defines two additional methods that you can optionally implement to allocate and free resources: setup() and destroy(). You should use these methods to allocate and deallocate resources that you do not allocate through the UDx API (see Allocating resources for UDxs for details).
Notes
-
While the name you choose for your ScalarFunction subclass does not have to match the name of the SQL function you will later assign to it, Vertica considers making the names the same a best practice.
-
Do not assume that your function will be called from the same thread that instantiated it.
-
The same instance of your ScalarFunction subclass can be called on to process multiple blocks of data.
-
The rows of input sent to processBlock() are not guaranteed to be any particular order.
-
Writing too many output rows can cause Vertica to emit an out-of-bounds error.
API
The ScalarFunction API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
virtual void processBlock(ServerInterface &srvInterface,
BlockReader &arg_reader, BlockWriter &res_writer)=0;
virtual void getOutputRange (ServerInterface &srvInterface,
ValueRangeReader &inRange, ValueRangeWriter &outRange)
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes &argTypes);
The ScalarFunction API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface, SizedColumnTypes argTypes);
public abstract void processBlock(ServerInterface srvInterface, BlockReader arg_reader,
BlockWriter res_writer) throws UdfException, DestroyInvocation;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface, SizedColumnTypes argTypes);
The ScalarFunction API provides the following methods for extension by subclasses:
def setup(self, server_interface, col_types)
def processBlock(self, server_interface, block_reader, block_writer)
def destroy(self, server_interface, col_types)
Implement the Main function API to define a scalar function:
FunctionName <- function(input.data.frame, parameters.data.frame) {
# Computations
# The function must return a data frame.
return(output.data.frame)
}
8.2 - ScalarFunctionFactory class
The ScalarFunctionFactory class tells Vertica metadata about your UDSF: its number of parameters and their data types, as well as the data type of its return value.
The ScalarFunctionFactory class tells Vertica metadata about your UDSF: its number of parameters and their data types, as well as the data type of its return value. It also instantiates a subclass of ScalarFunction.
Methods
You must implement the following methods in your ScalarFunctionFactory subclass:
-
createScalarFunction() instantiates a ScalarFunction subclass. If writing in C++, you can call the vt_createFuncObj macro with the name of the ScalarFunction subclass. This macro takes care of allocating and instantiating the class for you.
-
getPrototype() tells Vertica about the parameters and return type(s) for your UDSF. In addition to a ServerInterface object, this method gets two ColumnTypes objects. All you need to do in this function is to call class functions on these two objects to build the list of parameters and the return value type(s). If you return more than one value, the results are packaged into a ROW type.
After defining your factory class, you need to call the RegisterFactory macro. This macro instantiates a member of your factory class, so Vertica can interact with it and extract the metadata it contains about your UDSF.
Declaring return values
If your function returns a sized column (a return data type whose length can vary, such as a VARCHAR), a value that requires precision, or more than one value, you must implement getReturnType(). This method is called by Vertica to find the length or precision of the data being returned in each row of the results. The return value of this method depends on the data type your processBlock() method returns:
-
CHAR, (LONG) VARCHAR, BINARY, and (LONG) VARBINARY return the maximum length.
-
NUMERIC types specify the precision and scale.
-
TIME and TIMESTAMP values (with or without timezone) specify precision.
-
INTERVAL YEAR TO MONTH specifies range.
-
INTERVAL DAY TO SECOND specifies precision and range.
-
ARRAY types specify the maximum number of elements.
If your UDSF does not return one of these data types and returns a single value, it does not need a getReturnType() method.
The input to the getReturnType() method is a SizedColumnTypes object that contains the input argument types along with their lengths. This object will be passed to an instance of your processBlock() function. Your implementation of getReturnType() must extract the data types and lengths from this input and determine the length or precision of the output rows. It then saves this information in another instance of the SizedColumnTypes class.
API
The ScalarFunctionFactory API provides the following methods for extension by subclasses:
virtual ScalarFunction * createScalarFunction(ServerInterface &srvInterface)=0;
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)=0;
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes, SizedColumnTypes &returnType);
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
The ScalarFunctionFactory API provides the following methods for extension by subclasses:
public abstract ScalarFunction createScalarFunction(ServerInterface srvInterface);
public abstract void getPrototype(ServerInterface srvInterface, ColumnTypes argTypes, ColumnTypes returnType);
public void getReturnType(ServerInterface srvInterface, SizedColumnTypes argTypes,
SizedColumnTypes returnType) throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
The ScalarFunctionFactory API provides the following methods for extension by subclasses:
def createScalarFunction(self, srv)
def getPrototype(self, srv_interface, arg_types, return_type)
def getReturnType(self, srv_interface, arg_types, return_type)
Implement the Factory function API to define a scalar function factory:
FunctionNameFactory <- function() {
list(name = FunctionName,
udxtype = c("scalar"),
intype = c("int"),
outtype = c("int"))
}
8.3 - Setting null input and volatility behavior
Normally, Vertica calls your UDSF for every row of data in the query.
Normally, Vertica calls your UDSF for every row of data in the query. There are some cases where Vertica can avoid executing your UDSF. You can tell Vertica when it can skip calling your function and just supply a return value itself by changing your function's volatility and strictness settings.
-
Your function's volatility indicates whether it always returns the same output value when passed the same arguments. Depending on its behavior, Vertica can cache the arguments and the return value. If the user calls the UDSF with the same set of arguments, Vertica returns the cached value instead of calling your UDSF.
-
Your function's strictness indicates how it reacts to NULL arguments. If it always returns NULL when any argument is NULL, Vertica can just return NULL without having to call the function. This optimization also saves you work, because you do not need to test for and handle null arguments in your UDSF code.
You indicate the volatility and null handling of your function by setting the vol and strict fields in your ScalarFunctionFactory class's constructor.
Volatility settings
To indicate your function's volatility, set the vol field to one of the following values:
|
Value |
Description |
VOLATILE |
Repeated calls to the function with the same arguments always result in different values. Vertica always calls volatile functions for each invocation. |
IMMUTABLE |
Calls to the function with the same arguments always results in the same return value. |
STABLE |
Repeated calls to the function with the same arguments within the same statement returns the same output. For example, a function that returns the current user name is stable because the user cannot change within a statement. The user name could change between statements. |
DEFAULT_VOLATILITY |
The default volatility. This is the same as VOLATILE. |
Example
The following example shows a version of the Add2ints example factory class that makes the function immutable.
class Add2intsImmutableFactory : public Vertica::ScalarFunctionFactory
{
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface &srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, Add2ints); }
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
public:
Add2intsImmutableFactory() {vol = IMMUTABLE;}
};
RegisterFactory(Add2intsImmutableFactory);
The following example demonstrates setting the Add2IntsFactory's vol field to IMMUTABLE to tell Vertica it can cache the arguments and return value.
public class Add2IntsFactory extends ScalarFunctionFactory {
@Override
public void getPrototype(ServerInterface srvInterface, ColumnTypes argTypes, ColumnTypes returnType){
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
@Override
public ScalarFunction createScalarFunction(ServerInterface srvInterface){
return new Add2Ints();
}
// Class constructor
public Add2IntsFactory() {
// Tell Vertica that the same set of arguments will always result in the
// same return value.
vol = volatility.IMMUTABLE;
}
}
To indicate how your function reacts to NULL input, set the strictness field to one of the following values.
|
Value |
Description |
|
CALLED_ON_NULL_INPUT |
The function must be called, even if one or more arguments are NULL. |
|
RETURN_NULL_ON_NULL_INPUT |
The function always returns a NULL value if any of its arguments are NULL. |
|
STRICT |
A synonym for RETURN_NULL_ON_NULL_INPUT |
|
DEFAULT_STRICTNESS |
The default strictness setting. This is the same as CALLED_ON_NULL_INPUT. |
Example
The following C++ example demonstrates setting the null behavior of Add2ints so Vertica does not call the function with NULL values.
class Add2intsNullOnNullInputFactory : public Vertica::ScalarFunctionFactory
{
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface &srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, Add2ints); }
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt();
}
public:
Add2intsNullOnNullInputFactory() {strict = RETURN_NULL_ON_NULL_INPUT;}
};
RegisterFactory(Add2intsNullOnNullInputFactory);
8.4 - Improving query performance (C++ only)
When evaluating a query, Vertica can take advantage of available information about the ranges of values.
When evaluating a query, Vertica can take advantage of available information about the ranges of values. For example, if data is partitioned and a query restricts output by the partitioned value, Vertica can ignore partitions that cannot possibly contain data that would satisfy the query. Similarly, for a scalar function, Vertica can skip processing rows in the data where the value returned from the function cannot possibly affect the results.
Consider a table with millions of rows of data on customer orders and a scalar function that computes the total price paid for everything in an order. A query uses a WHERE clause to restrict results to orders above a given value. A scalar function is called on a block of data; if no rows within that block could produce the target value, skipping the processing of the block could improve query performance.
A scalar function written in C++ can implement the getOutputRange method. Before calling processBlock, Vertica calls getOutputRange to determine the minimum and maximum return values from this block given the input ranges. It then decides whether to call processBlock to perform the computations.
The Add2Ints example implements this function. The minimum output value is the sum of the smallest values of each of the two inputs, and the maximum output is the sum of the largest values of each of the inputs. This function does not consider individual rows. Consider the following inputs:
a | b
------+------
21 | 92
500 | 19
111 | 11
The smallest values of the two inputs are 21 and 11, so the function reports 32 as the low end of the output range. The largest input values are 500 and 92, so it reports 592 as the high end of the output range. 592 is larger than the value returned for any of the input rows and 32 is smaller than any row's return value.
The purpose of getOutputRange is to quickly eliminate calls where outputs would definitely be out of range. For example, if the query included "WHERE Add2Ints(a,b) > 600", this block of data could be skipped. There can still be cases where, after calling getOutputRange, processBlock returns no results. If the query included "WHERE Add2Ints(a,b) > 500", getOutputRange would not eliminate this block of data.
Add2Ints implements getOutputRange as follows:
/*
* This method computes the output range for this scalar function from
* the ranges of its inputs in a single invocation.
*
* The input ranges are retrieved via inRange
* The output range is returned via outRange
*/
virtual void getOutputRange(Vertica::ServerInterface &srvInterface,
Vertica::ValueRangeReader &inRange,
Vertica::ValueRangeWriter &outRange)
{
if (inRange.hasBounds(0) && inRange.hasBounds(1)) {
// Input ranges have bounds defined
if (inRange.isNull(0) || inRange.isNull(1)) {
// At least one range has only NULL values.
// Output range can only have NULL values.
outRange.setNull();
outRange.setHasBounds();
return;
} else {
// Compute output range
const vint& a1LoBound = inRange.getIntRefLo(0);
const vint& a2LoBound = inRange.getIntRefLo(1);
outRange.setIntLo(a1LoBound + a2LoBound);
const vint& a1UpBound = inRange.getIntRefUp(0);
const vint& a2UpBound = inRange.getIntRefUp(1);
outRange.setIntUp(a1UpBound + a2UpBound);
}
} else {
// Input ranges are unbounded. No output range can be defined
return;
}
if (!inRange.canHaveNulls(0) && !inRange.canHaveNulls(1)) {
// There cannot be NULL values in the output range
outRange.setCanHaveNulls(false);
}
// Let Vertica know that the output range is bounded
outRange.setHasBounds();
}
If getOutputRange produces an error, Vertica issues a warning and does not call the method again for the current query.
8.5 - C++ example: Add2Ints
The following example shows a basic subclass of ScalarFunction called Add2ints.
The following example shows a basic subclass of ScalarFunction called Add2ints. As the name implies, it adds two integers together, returning a single integer result.
For the complete source code, see /opt/vertica/sdk/examples/ScalarFunctions/Add2Ints.cpp. Java and Python versions of this UDx are included in /opt/vertica/sdk/examples.
Loading and using the example
Use CREATE LIBRARY to load the library containing the function, and then use CREATE FUNCTION (scalar) to declare the function as in the following example:
=> CREATE LIBRARY ScalarFunctions AS '/home/dbadmin/examples/ScalarFunctions.so';
=> CREATE FUNCTION add2ints AS LANGUAGE 'C++' NAME 'Add2IntsFactory' LIBRARY ScalarFunctions;
The following example shows how to use this function:
=> SELECT Add2Ints(27,15);
Add2ints
----------
42
(1 row)
=> SELECT * FROM MyTable;
a | b
-----+----
7 | 0
12 | 2
12 | 6
18 | 9
1 | 1
58 | 4
450 | 15
(7 rows)
=> SELECT * FROM MyTable WHERE Add2ints(a, b) > 20;
a | b
-----+----
18 | 9
58 | 4
450 | 15
(3 rows)
Function implementation
A scalar function does its computation in the processBlock method:
class Add2Ints : public ScalarFunction
{
public:
/*
* This method processes a block of rows in a single invocation.
*
* The inputs are retrieved via argReader
* The outputs are returned via resWriter
*/
virtual void processBlock(ServerInterface &srvInterface,
BlockReader &argReader,
BlockWriter &resWriter)
{
try {
// While we have inputs to process
do {
if (argReader.isNull(0) || argReader.isNull(1)) {
resWriter.setNull();
} else {
const vint a = argReader.getIntRef(0);
const vint b = argReader.getIntRef(1);
resWriter.setInt(a+b);
}
resWriter.next();
} while (argReader.next());
} catch(std::exception& e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while processing block: [%s]", e.what());
}
}
// ...
};
Implementing getOutputRange, which is optional, allows your function to skip rows where the result would not be within a target range. For example, if a WHERE clause restricts the query results to those in a certain range, calling the function for cases that could not possibly be in that range is unnecessary.
/*
* This method computes the output range for this scalar function from
* the ranges of its inputs in a single invocation.
*
* The input ranges are retrieved via inRange
* The output range is returned via outRange
*/
virtual void getOutputRange(Vertica::ServerInterface &srvInterface,
Vertica::ValueRangeReader &inRange,
Vertica::ValueRangeWriter &outRange)
{
if (inRange.hasBounds(0) && inRange.hasBounds(1)) {
// Input ranges have bounds defined
if (inRange.isNull(0) || inRange.isNull(1)) {
// At least one range has only NULL values.
// Output range can only have NULL values.
outRange.setNull();
outRange.setHasBounds();
return;
} else {
// Compute output range
const vint& a1LoBound = inRange.getIntRefLo(0);
const vint& a2LoBound = inRange.getIntRefLo(1);
outRange.setIntLo(a1LoBound + a2LoBound);
const vint& a1UpBound = inRange.getIntRefUp(0);
const vint& a2UpBound = inRange.getIntRefUp(1);
outRange.setIntUp(a1UpBound + a2UpBound);
}
} else {
// Input ranges are unbounded. No output range can be defined
return;
}
if (!inRange.canHaveNulls(0) && !inRange.canHaveNulls(1)) {
// There cannot be NULL values in the output range
outRange.setCanHaveNulls(false);
}
// Let Vertica know that the output range is bounded
outRange.setHasBounds();
}
Factory implementation
The factory instantiates a member of the class (createScalarFunction), and also describes the function's inputs and outputs (getPrototype):
class Add2IntsFactory : public ScalarFunctionFactory
{
// return an instance of Add2Ints to perform the actual addition.
virtual ScalarFunction *createScalarFunction(ServerInterface &interface)
{ return vt_createFuncObject<Add2Ints>(interface.allocator); }
// This function returns the description of the input and outputs of the
// Add2Ints class's processBlock function. It stores this information in
// two ColumnTypes objects, one for the input parameters, and one for
// the return value.
virtual void getPrototype(ServerInterface &interface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
argTypes.addInt();
argTypes.addInt();
// Note that ScalarFunctions *always* return a single value.
returnType.addInt();
}
};
The RegisterFactory macro
Use the RegisterFactory macro to register a UDx. This macro instantiates the factory class and makes the metadata it contains available for Vertica to access. To call this macro, pass it the name of your factory class:
RegisterFactory(Add2IntsFactory);
8.6 - Python example: currency_convert
The currency_convert scalar function reads two values from a table, a currency and a value.
The currency_convert scalar function reads two values from a table, a currency and a value. It then converts the item's value to USD, returning a single float result.
You can find more UDx examples in the Vertica Github repository, https://github.com/vertica/UDx-Examples.
UDSF Python code
import vertica_sdk
import decimal
rates2USD = {'USD': 1.000,
'EUR': 0.89977,
'GBP': 0.68452,
'INR': 67.0345,
'AUD': 1.39187,
'CAD': 1.30335,
'ZAR': 15.7181,
'XXX': -1.0000}
class currency_convert(vertica_sdk.ScalarFunction):
"""Converts a money column to another currency
Returns a value in USD.
"""
def __init__(self):
pass
def setup(self, server_interface, col_types):
pass
def processBlock(self, server_interface, block_reader, block_writer):
while(True):
currency = block_reader.getString(0)
try:
rate = decimal.Decimal(rates2USD[currency])
except KeyError:
server_interface.log("ERROR: {} not in dictionary.".format(currency))
# Scalar functions always need a value to move forward to the
# next input row. Therefore, we need to assign it a value to
# move beyond the error.
currency = 'XXX'
rate = decimal.Decimal(rates2USD[currency])
starting_value = block_reader.getNumeric(1)
converted_value = decimal.Decimal(starting_value / rate)
block_writer.setNumeric(converted_value)
block_writer.next()
if not block_reader.next():
break
def destroy(self, server_interface, col_types):
pass
class currency_convert_factory(vertica_sdk.ScalarFunctionFactory):
def createScalarFunction(self, srv):
return currency_convert()
def getPrototype(self, srv_interface, arg_types, return_type):
arg_types.addVarchar()
arg_types.addNumeric()
return_type.addNumeric()
def getReturnType(self, srv_interface, arg_types, return_type):
return_type.addNumeric(9,4)
Load the function and library
Create the library and the function.
=> CREATE LIBRARY pylib AS '/home/dbadmin/python_udx/currency_convert/currency_convert.py' LANGUAGE 'Python';
CREATE LIBRARY
=> CREATE FUNCTION currency_convert AS LANGUAGE 'Python' NAME 'currency_convert_factory' LIBRARY pylib fenced;
CREATE FUNCTION
Querying data with the function
The following query shows how you can run a query with the UDSF.
=> SELECT product, currency_convert(currency, value) AS cost_in_usd
FROM items;
product | cost_in_usd
--------------+-------------
Shoes | 133.4008
Soccer Ball | 110.2817
Coffee | 13.5190
Surfboard | 176.2593
Hockey Stick | 76.7177
Car | 17000.0000
Software | 10.4424
Hamburger | 7.5000
Fish | 130.4272
Cattle | 269.2367
(10 rows)
8.7 - Python example: validate_url
The validate_url scalar function reads a string from a table, a URL.
The validate_url scalar function reads a string from a table, a URL. It then validates if the URL is responsive, returning a status code or a string indicating the attempt failed.
You can find more UDx examples in the Vertica Github repository, https://github.com/vertica/UDx-Examples.
UDSF Python code
import vertica_sdk
import urllib.request
import time
class validate_url(vertica_sdk.ScalarFunction):
"""Validates HTTP requests.
Returns the status code of a webpage. Pages that cannot be accessed return
"Failed to load page."
"""
def __init__(self):
pass
def setup(self, server_interface, col_types):
pass
def processBlock(self, server_interface, arg_reader, res_writer):
# Writes a string to the UDx log file.
server_interface.log("Validating webpage accessibility - UDx")
while(True):
url = arg_reader.getString(0)
try:
status = urllib.request.urlopen(url).getcode()
# Avoid overwhelming web servers -- be nice.
time.sleep(2)
except (ValueError, urllib.error.HTTPError, urllib.error.URLError):
status = 'Failed to load page'
res_writer.setString(str(status))
res_writer.next()
if not arg_reader.next():
# Stop processing when there are no more input rows.
break
def destroy(self, server_interface, col_types):
pass
class validate_url_factory(vertica_sdk.ScalarFunctionFactory):
def createScalarFunction(self, srv):
return validate_url()
def getPrototype(self, srv_interface, arg_types, return_type):
arg_types.addVarchar()
return_type.addChar()
def getReturnType(self, srv_interface, arg_types, return_type):
return_type.addChar(20)
Load the function and library
Create the library and the function.
=> CREATE OR REPLACE LIBRARY pylib AS 'webpage_tester/validate_url.py' LANGUAGE 'Python';
=> CREATE OR REPLACE FUNCTION validate_url AS LANGUAGE 'Python' NAME 'validate_url_factory' LIBRARY pylib fenced;
Querying data with the function
The following query shows how you can run a query with the UDSF.
=> SELECT url, validate_url(url) AS url_status FROM webpages;
url | url_status
-----------------------------------------------+----------------------
http://www.vertica.com/documentation/vertica/ | 200
http://www.google.com/ | 200
http://www.mass.gov.com/ | Failed to load page
http://www.espn.com | 200
http://blah.blah.blah.blah | Failed to load page
http://www.vertica.com/ | 200
(6 rows)
8.8 - Python example: matrix multiplication
Python UDxs can accept and return complex types.
Python UDxs can accept and return complex types. The MatrixMultiply class multiplies input matrices and returns the resulting matrix product. These matrices are represented as two-dimensional arrays. In order to perform the matrix multiplication operation, the number of columns in the first input matrix must equal the number of rows in the second input matrix.
The complete source code is in /opt/vertica/sdk/examples/python/ScalarFunctions.py.
Loading and using the example
Load the library and create the function as follows:
=> CREATE OR REPLACE LIBRARY ScalarFunctions AS '/home/dbadmin/examples/python/ScalarFunctions.py' LANGUAGE 'Python';
=> CREATE FUNCTION MatrixMultiply AS LANGUAGE 'Python' NAME 'matrix_multiply_factory' LIBRARY ScalarFunctions;
You can create input matrices and then call the function, for example:
=> CREATE TABLE mn (id INTEGER, data ARRAY[ARRAY[INTEGER, 3], 2]);
CREATE TABLE
=> CREATE TABLE np (id INTEGER, data ARRAY[ARRAY[INTEGER, 2], 3]);
CREATE TABLE
=> COPY mn FROM STDIN PARSER fjsonparser();
{"id": 1, "data": [[1, 2, 3], [4, 5, 6]] }
{"id": 2, "data": [[7, 8, 9], [10, 11, 12]] }
\.
=> COPY np FROM STDIN PARSER fjsonparser();
{"id": 1, "data": [[0, 0], [0, 0], [0, 0]] }
{"id": 2, "data": [[1, 1], [1, 1], [1, 1]] }
{"id": 3, "data": [[2, 0], [0, 2], [2, 0]] }
\.
=> SELECT mn.id, np.id, MatrixMultiply(mn.data, np.data) FROM mn CROSS JOIN np ORDER BY 1, 2;
id | id | MatrixMultiply
---+----+-------------------
1 | 1 | [[0,0],[0,0]]
1 | 2 | [[6,6],[15,15]]
1 | 3 | [[8,4],[20,10]]
2 | 1 | [[0,0],[0,0]]
2 | 2 | [[24,24],[33,33]]
2 | 3 | [[32,16],[44,22]]
(6 rows)
Setup
All Python UDxs must import the Vertica SDK library:
Factory implementation
The getPrototype() method declares that the function arguments and return type must all be two-dimensional arrays, represented as arrays of integer arrays:
def getPrototype(self, srv_interface, arg_types, return_type):
array1dtype = vertica_sdk.ColumnTypes.makeArrayType(vertica_sdk.ColumnTypes.makeInt())
arg_types.addArrayType(array1dtype)
arg_types.addArrayType(array1dtype)
return_type.addArrayType(array1dtype)
getReturnType() validates that the product matrix has the same number of rows as the first input matrix and the same number of columns as the second input matrix:
def getReturnType(self, srv_interface, arg_types, return_type):
(_, a1type) = arg_types[0]
(_, a2type) = arg_types[1]
m = a1type.getArrayBound()
p = a2type.getElementType().getArrayBound()
return_type.addArrayType(vertica_sdk.SizedColumnTypes.makeArrayType(vertica_sdk.SizedColumnTypes.makeInt(), p), m)
Function implementation
The processBlock() method is called with a BlockReader and a BlockWriter, named arg_reader and res_writer respectively. To access elements of the input arrays, the method uses ArrayReader instances. The arrays are nested, so an ArrayReader must be instantiated for both the outer and inner arrays. List comprehension simplifies the process of reading the input arrays into lists. The method performs the computation and then uses an ArrayWriter instance to construct the product matrix.
def processBlock(self, server_interface, arg_reader, res_writer):
while True:
lmat = [[cell.getInt(0) for cell in row.getArrayReader(0)] for row in arg_reader.getArrayReader(0)]
rmat = [[cell.getInt(0) for cell in row.getArrayReader(0)] for row in arg_reader.getArrayReader(1)]
omat = [[0 for c in range(len(rmat[0]))] for r in range(len(lmat))]
for i in range(len(lmat)):
for j in range(len(rmat[0])):
for k in range(len(rmat)):
omat[i][j] += lmat[i][k] * rmat[k][j]
res_writer.setArray(omat)
res_writer.next()
if not arg_reader.next():
break
8.9 - R example: SalesTaxCalculator
The SalesTaxCalculator scalar function reads a float and a varchar from a table, an item's price and the state abbreviation.
The SalesTaxCalculator scalar function reads a float and a varchar from a table, an item's price and the state abbreviation. It then uses the state abbreviation to find the sales tax rate from a list and calculates the item's price including the state's sales tax, returning the total cost of the item.
You can find more UDx examples in the Vertica Github repository, https://github.com/vertica/UDx-Examples.
Load the function and library
Create the library and the function.
=> CREATE OR REPLACE LIBRARY rLib AS 'sales_tax_calculator.R' LANGUAGE 'R';
CREATE LIBRARY
=> CREATE OR REPLACE FUNCTION SalesTaxCalculator AS LANGUAGE 'R' NAME 'SalesTaxCalculatorFactory' LIBRARY rLib FENCED;
CREATE FUNCTION
Querying data with the function
The following query shows how you can run a query with the UDSF.
=> SELECT item, state_abbreviation,
price, SalesTaxCalculator(price, state_abbreviation) AS Price_With_Sales_Tax
FROM inventory;
item | state_abbreviation | price | Price_With_Sales_Tax
-------------+--------------------+-------+---------------------
Scarf | AZ | 6.88 | 7.53016
Software | MA | 88.31 | 96.655295
Soccer Ball | MS | 12.55 | 13.735975
Beads | LA | 0.99 | 1.083555
Baseball | TN | 42.42 | 46.42869
Cheese | WI | 20.77 | 22.732765
Coffee Mug | MA | 8.99 | 9.839555
Shoes | TN | 23.99 | 26.257055
(8 rows)
UDSF R code
SalesTaxCalculator <- function(input.data.frame) {
# Not a complete list of states in the USA, but enough to get the idea.
state.sales.tax <- list(ma = 0.0625,
az = 0.087,
la = 0.0891,
tn = 0.0945,
wi = 0.0543,
ms = 0.0707)
for ( state_abbreviation in input.data.frame[, 2] ) {
# Ensure state abbreviations are lowercase.
lower_state <- tolower(state_abbreviation)
# Check if the state is in our state.sales.tax list.
if (is.null(state.sales.tax[[lower_state]])) {
stop("State is not in our small sample!")
} else {
sales.tax.rate <- state.sales.tax[[lower_state]]
item.price <- input.data.frame[, 1]
# Calculate the price including sales tax.
price.with.sales.tax <- (item.price) + (item.price * sales.tax.rate)
}
}
return(price.with.sales.tax)
}
SalesTaxCalculatorFactory <- function() {
list(name = SalesTaxCalculator,
udxtype = c("scalar"),
intype = c("float", "varchar"),
outtype = c("float"))
}
8.10 - R example: kmeans
The KMeans_User scalar function reads any number of columns from a table, the observations.
The KMeans_User scalar function reads any number of columns from a table, the observations. It then uses the observations and the two parameters when applying the kmeans clustering algorithm to the data, returning an integer value associated with the cluster of the row.
You can find more UDx examples in the Vertica Github repository, https://github.com/vertica/UDx-Examples.
Load the function and library
Create the library and the function:
=> CREATE OR REPLACE LIBRARY rLib AS 'kmeans.R' LANGUAGE 'R';
CREATE LIBRARY
=> CREATE OR REPLACE FUNCTION KMeans_User AS LANGUAGE 'R' NAME 'KMeans_UserFactory' LIBRARY rLib FENCED;
CREATE FUNCTION
Querying data with the function
The following query shows how you can run a query with the UDSF:
=> SELECT spec,
KMeans_User(sl, sw, pl, pw USING PARAMETERS clusters = 3, nstart = 20)
FROM iris;
spec | KMeans_User
-----------------+-------------
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
Iris-setosa | 2
.
.
.
(150 rows)
UDSF R code
KMeans_User <- function(input.data.frame, parameters.data.frame) {
# Take the clusters and nstart parameters passed by the user and assign them
# to variables in the function.
if ( is.null(parameters.data.frame[['clusters']]) ) {
stop("NULL value for clusters! clusters cannot be NULL.")
} else {
clusters.value <- parameters.data.frame[['clusters']]
}
if ( is.null(parameters.data.frame[['nstart']]) ) {
stop("NULL value for nstart! nstart cannot be NULL.")
} else {
nstart.value <- parameters.data.frame[['nstart']]
}
# Apply the algorithm to the data.
kmeans.clusters <- kmeans(input.data.frame[, 1:length(input.data.frame)],
clusters.value, nstart = nstart.value)
final.output <- data.frame(kmeans.clusters$cluster)
return(final.output)
}
KMeans_UserFactory <- function() {
list(name = KMeans_User,
udxtype = c("scalar"),
# Since this is a polymorphic function the intype must be any
intype = c("any"),
outtype = c("int"),
parametertypecallback=KMeansParameters)
}
KMeansParameters <- function() {
parameters <- list(datatype = c("int", "int"),
length = c("NA", "NA"),
scale = c("NA", "NA"),
name = c("clusters", "nstart"))
return(parameters)
}
8.11 - C++ example: using complex types
UDxs can accept and return complex types.
UDxs can accept and return complex types. The ArraySlice example takes an array and two indices as inputs and returns an array containing only the values in that range. Because array elements can be of any type, the function is polymorphic.
The complete source code is in /opt/vertica/sdk/examples/ScalarFunctions/ArraySlice.cpp.
Loading and using the example
Load the library and create the function as follows:
=> CREATE OR REPLACE LIBRARY ScalarFunctions AS '/home/dbadmin/examplesUDSF.so';
=> CREATE FUNCTION ArraySlice AS
LANGUAGE 'C++' NAME 'ArraySliceFactory' LIBRARY ScalarFunctions;
Create some data and call the function on it as follows:
=> CREATE TABLE arrays (id INTEGER, aa ARRAY[INTEGER]);
COPY arrays FROM STDIN;
1|[]
2|[1,2,3]
3|[5,4,3,2,1]
\.
=> CREATE TABLE slices (b INTEGER, e INTEGER);
COPY slices FROM STDIN;
0|2
1|3
2|4
\.
=> SELECT id, b, e, ArraySlice(aa, b, e) AS slice FROM arrays, slices;
id | b | e | slice
----+---+---+-------
1 | 0 | 2 | []
1 | 1 | 3 | []
1 | 2 | 4 | []
2 | 0 | 2 | [1,2]
2 | 1 | 3 | [2,3]
2 | 2 | 4 | [3]
3 | 0 | 2 | [5,4]
3 | 1 | 3 | [4,3]
3 | 2 | 4 | [3,2]
(9 rows)
Factory implementation
Because the function is polymorphic, getPrototype() declares that the inputs and outputs can be of any type, and type enforcement must be done elsewhere:
void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes,
ColumnTypes &returnType) override
{
/*
* This is a polymorphic function that accepts any array
* and returns an array of the same type
*/
argTypes.addAny();
returnType.addAny();
}
The factory validates input types and determines the return type in getReturnType():
void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes,
SizedColumnTypes &returnType) override
{
/*
* Three arguments: (array, slicebegin, sliceend)
* Validate manually since the prototype accepts any arguments.
*/
if (argTypes.size() != 3) {
vt_report_error(0, "Three arguments (array, slicebegin, sliceend) expected");
} else if (!argTypes[0].getType().isArrayType()) {
vt_report_error(1, "Argument 1 is not an array");
} else if (!argTypes[1].getType().isInt()) {
vt_report_error(2, "Argument 2 (slicebegin) is not an integer)");
} else if (!argTypes[2].getType().isInt()) {
vt_report_error(3, "Argument 3 (sliceend) is not an integer)");
}
/* return type is the same as the array arg type, copy it over */
returnType.push_back(argTypes[0]);
}
Function implementation
The processBlock() method is called with a BlockReader and a BlockWriter. The first argument is an array. To access elements of the array, the method uses an ArrayReader. Similarly, it uses an ArrayWriter to construct the output.
void processBlock(ServerInterface &srvInterface,
BlockReader &argReader,
BlockWriter &resWriter) override
{
do {
if (argReader.isNull(0) || argReader.isNull(1) || argReader.isNull(2)) {
resWriter.setNull();
} else {
Array::ArrayReader argArray = argReader.getArrayRef(0);
const vint slicebegin = argReader.getIntRef(1);
const vint sliceend = argReader.getIntRef(2);
Array::ArrayWriter outArray = resWriter.getArrayRef(0);
if (slicebegin < sliceend) {
for (int i = 0; i < slicebegin && argArray->hasData(); i++) {
argArray->next();
}
for (int i = slicebegin; i < sliceend && argArray->hasData(); i++) {
outArray->copyFromInput(*argArray);
outArray->next();
argArray->next();
}
}
outArray.commit(); /* finalize the written array elements */
}
resWriter.next();
} while (argReader.next());
}
8.12 - C++ example: returning multiple values
When writing a UDSF, you can specify more than one return value.
When writing a UDSF, you can specify more than one return value. If you specify multiple values, Vertica packages them into a single ROW as a return value. You can query fields in the ROW or the entire ROW.
The following example implements a function named div (division) that returns two integers, the quotient and the remainder.
This example shows one way to return a ROW from a UDSF. Returning multiple values and letting Vertica build the ROW is convenient when inputs and outputs are all of primitive types. You can also work directly with the complex types, as described in Complex Types as Arguments and illustrated in C++ example: using complex types.
Loading and using the example
Load the library and create the function as follows:
=> CREATE OR REPLACE LIBRARY ScalarFunctions AS '/home/dbadmin/examplesUDSF.so';
=> CREATE FUNCTION div AS
LANGUAGE 'C++' NAME 'DivFactory' LIBRARY ScalarFunctions;
Create some data and call the function on it as follows:
=> CREATE TABLE D (a INTEGER, b INTEGER);
COPY D FROM STDIN DELIMITER ',';
10,0
10,1
10,2
10,3
10,4
10,5
\.
=> SELECT a, b, Div(a, b), (Div(a, b)).quotient, (Div(a, b)).remainder FROM D;
a | b | Div | quotient | remainder
----+---+------------------------------------+----------+-----------
10 | 0 | {"quotient":null,"remainder":null} | |
10 | 1 | {"quotient":10,"remainder":0} | 10 | 0
10 | 2 | {"quotient":5,"remainder":0} | 5 | 0
10 | 3 | {"quotient":3,"remainder":1} | 3 | 1
10 | 4 | {"quotient":2,"remainder":2} | 2 | 2
10 | 5 | {"quotient":2,"remainder":0} | 2 | 0
(6 rows)
Factory implementation
The factory declares the two return values in getPrototype() and in getReturnType(). The factory is otherwise unremarkable.
void getPrototype(ServerInterface &interface,
ColumnTypes &argTypes,
ColumnTypes &returnType) override
{
argTypes.addInt();
argTypes.addInt();
returnType.addInt(); /* quotient */
returnType.addInt(); /* remainder */
}
void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes,
SizedColumnTypes &returnType) override
{
returnType.addInt("quotient");
returnType.addInt("remainder");
}
Function implementation
The function writes two output values in processBlock(). The number of values here must match the factory declarations.
class Div : public ScalarFunction {
void processBlock(Vertica::ServerInterface &srvInterface,
Vertica::BlockReader &argReader,
Vertica::BlockWriter &resWriter) override
{
do {
if (argReader.isNull(0) || argReader.isNull(1) || (argReader.getIntRef(1) == 0)) {
resWriter.setNull(0);
resWriter.setNull(1);
} else {
const vint dividend = argReader.getIntRef(0);
const vint divisor = argReader.getIntRef(1);
resWriter.setInt(0, dividend / divisor);
resWriter.setInt(1, dividend % divisor);
}
resWriter.next();
} while (argReader.next());
}
};
8.13 - C++ example: calling a UDSF from a check constraint
This example shows you the C++ code needed to create a UDSF that can be called by a check constraint.
This example shows you the C++ code needed to create a UDSF that can be called by a check constraint. The name of the sample function is LargestSquareBelow. The sample function determines the largest number whose square is less than the number in the subject column. For example, if the number in the column is 1000, the largest number whose square is less than 1000 is 31 (961).
Important
A UDSF used within a check constraint must be immutable, and the constraint must handle null values properly. Otherwise, the check constraint might not work as you intended. In addition, Vertica evaluates the predicate of an enabled check constraint on every row that is loaded or updated, so consider performance in writing your function.
For information on check constraints, see Check constraints.
Loading and using the example
The following example shows how you can create and load a library named MySqLib, using CREATE LIBRARY. Adjust the library path in this example to the absolute path and file name for the location where you saved the shared object LargestSquareBelow.
Create the library:
=> CREATE OR REPLACE LIBRARY MySqLib AS '/home/dbadmin/LargestSquareBelow.so';
After you create and load the library, add the function to the catalog using the CREATE FUNCTION (scalar) statement:
=> CREATE OR REPLACE FUNCTION largestSqBelow AS LANGUAGE 'C++' NAME 'LargestSquareBelowInfo' LIBRARY MySqLib;
Next, include the UDSF in a check constraint:
=> CREATE TABLE squaretest(
ceiling INTEGER UNIQUE,
CONSTRAINT chk_sq CHECK (largestSqBelow(ceiling) < ceiling*ceiling)
);
Add data to the table, squaretest:
=> COPY squaretest FROM stdin DELIMITER ','NULL'null';
-1
null
0
1
1000
1000000
1000001
\.
Your output should be similar to the following sample, based upon the data you use:
=> SELECT ceiling, largestSqBelow(ceiling)
FROM squaretest ORDER BY ceiling;
ceiling | largestSqBelow
---------+----------------
|
-1 |
0 |
1 | 0
1000 | 31
1000000 | 999
1000001 | 1000
(7 rows)
ScalarFunction implementation
This ScalarFunction implementation does the processing work for a UDSF that determines the largest number whose square is less than the number input.
#include "Vertica.h"
/*
* ScalarFunction implementation for a UDSF that
* determines the largest number whose square is less than
* the number input.
*/
class LargestSquareBelow : public Vertica::ScalarFunction
{
public:
/*
* This function does all of the actual processing for the UDSF.
* The inputs are retrieved via arg_reader
* The outputs are returned via arg_writer
*
*/
virtual void processBlock(Vertica::ServerInterface &srvInterface,
Vertica::BlockReader &arg_reader,
Vertica::BlockWriter &res_writer)
{
if (arg_reader.getNumCols() != 1)
vt_report_error(0, "Function only accept 1 argument, but %zu provided", arg_reader.getNumCols());
// While we have input to process
do {
// Read the input parameter by calling the
// BlockReader.getIntRef class function
const Vertica::vint a = arg_reader.getIntRef(0);
Vertica::vint res;
//Determine the largest square below the number
if ((a != Vertica::vint_null) && (a > 0))
{
res = (Vertica::vint)sqrt(a - 1);
}
else
res = Vertica::vint_null;
//Call BlockWriter.setInt to store the output value,
//which is the largest square
res_writer.setInt(res);
//Write the row and advance to the next output row
res_writer.next();
//Continue looping until there are no more input rows
} while (arg_reader.next());
}
};
ScalarFunctionFactory implementation
This ScalarFunctionFactory implementation does the work of handling input and output, and marks the function as immutable (a requirement if you plan to use the UDSF within a check constraint).
class LargestSquareBelowInfo : public Vertica::ScalarFunctionFactory
{
//return an instance of LargestSquareBelow to perform the computation.
virtual Vertica::ScalarFunction *createScalarFunction(Vertica::ServerInterface &srvInterface)
//Call the vt_createFuncObj to create the new LargestSquareBelow class instance.
{ return Vertica::vt_createFuncObject<LargestSquareBelow>(srvInterface.allocator); }
/*
* This function returns the description of the input and outputs of the
* LargestSquareBelow class's processBlock function. It stores this information in
* two ColumnTypes objects, one for the input parameter, and one for
* the return value.
*/
virtual void getPrototype(Vertica::ServerInterface &srvInterface,
Vertica::ColumnTypes &argTypes,
Vertica::ColumnTypes &returnType)
{
// Takes one int as input, so adds int to the argTypes object
argTypes.addInt();
// Returns a single int, so add a single int to the returnType object.
// ScalarFunctions always return a single value.
returnType.addInt();
}
public:
// the function cannot be called within a check constraint unless the UDx author
// certifies that the function is immutable:
LargestSquareBelowInfo() { vol = Vertica::IMMUTABLE; }
};
The RegisterFactory macro
Use the RegisterFactory macro to register a ScalarFunctionFactory subclass. This macro instantiates the factory class and makes the metadata it contains available for Vertica to access. To call this macro, pass it the name of your factory class.
RegisterFactory(LargestSquareBelowInfo);
9 - Transform functions (UDTFs)
A user-defined transform function (UDTF) lets you transform a table of data into another table.
A user-defined transform function (UDTF) lets you transform a table of data into another table. It reads one or more arguments (treated as a row of data), and returns zero or more rows of data consisting of one or more columns. A UDTF can produce any number of rows as output. However, each row it outputs must be complete. Advancing to the next row without having added a value for each column produces incorrect results.
The schema of the output table does not need to correspond to the schema of the input table—they can be totally different. The UDTF can return any number of output rows for each row of input.
Unless a UDTF is marked as one-to-many in its factory function, it can only be used in a SELECT list that contains the UDTF call and a required OVER clause. A multi-phase UDTF can make use of partition columns (PARTITION BY), but other UDTFs cannot.
UDTFs are run after GROUP BY, but before the final ORDER BY, when used in conjunction with GROUP BY and ORDER BY in a statement. The ORDER BY clause may contain only columns or expressions that are in a window partition clause (see Window partitioning).
UDTFs can take up to 9800 parameters (input columns). Attempts to pass more parameters to a UDTF return an error.
9.1 - TransformFunction class
The TransformFunction class is where you perform the data-processing, transforming input rows into output rows.
The TransformFunction class is where you perform the data-processing, transforming input rows into output rows. Your subclass must define the processPartition() method. It may define methods to set up and tear down the function.
The processPartition() method carries out all of the processing that you want your UDTF to perform. When a user calls your function in a SQL statement, Vertica bundles together the data from the function parameters and passes it to processPartition().
The input and output of the processPartition() method are supplied by objects of the PartitionReader and PartitionWriter classes. They define methods that you use to read the input data and write the output data for your UDTF.
A UDTF does not necessarily operate on a single row the way a UDSF does. A UDTF can read any number of rows and write output at any time.
Consider the following guidelines when implementing processPartition():
-
Extract the input parameters by calling data-type-specific functions in the PartitionReader object to extract each input parameter. Each of these functions takes a single parameter: the column number in the input row that you want to read. Your function might need to handle NULL values.
-
When writing output, your UDTF must supply values for all of the output columns you defined in your factory. Similarly to reading input columns, the PartitionWriter object has functions for writing each type of data to the output row.
-
Use PartitionReader.next() to determine if there is more input to process, and exit when the input is exhausted.
-
In some cases, you might want to determine the number and types of parameters using PartitionReader's getNumCols() and getTypeMetaData() functions, instead of just hard-coding the data types of the columns in the input row. This is useful if you want your TransformFunction to be able to process input tables with different schemas. You can then use different TransformFunctionFactory classes to define multiple function signatures that call the same TransformFunction class. See Overloading your UDx for more information.
Setting up and tearing down
The TransformFunction class defines two additional methods that you can optionally implement to allocate and free resources: setup() and destroy(). You should use these methods to allocate and deallocate resources that you do not allocate through the UDx API (see Allocating resources for UDxs for details).
API
The TransformFunction API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
virtual void processPartition(ServerInterface &srvInterface,
PartitionReader &input_reader, PartitionWriter &output_writer)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
The PartitionReader and PartitionWriter classes provide getters and setters for column values, along with next() to iterate through partitions. See the API reference documentation for details.
The TransformFunction API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface, SizedColumnTypes argTypes);
public abstract void processPartition(ServerInterface srvInterface,
PartitionReader input_reader, PartitionWriter input_writer)
throws UdfException, DestroyInvocation;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface, SizedColumnTypes argTypes);
The PartitionReader and PartitionWriter classes provide getters and setters for column values, along with next() to iterate through partitions. See the API reference documentation for details.
The TransformFunction API provides the following methods for extension by subclasses:
def setup(self, server_interface, col_types)
def processPartition(self, server_interface, partition_reader, partition_writer)
def destroy(self, server_interface, col_types)
The PartitionReader and PartitionWriter classes provide getters and setters for column values, along with next() to iterate through partitions. See the API reference documentation for details.
Implement the Main function API to define a transform function:
FunctionName <- function(input.data.frame, parameters.data.frame) {
# Computations
# The function must return a data frame.
return(output.data.frame)
}
9.2 - TransformFunctionFactory class
The TransformFunctionFactory class tells Vertica metadata about your UDTF: its number of parameters and their data types, as well as function properties and the data type of the return value.
The TransformFunctionFactory class tells Vertica metadata about your UDTF: its number of parameters and their data types, as well as function properties and the data type of the return value. It also instantiates a subclass of TransformFunction.
You must implement the following methods in your TransformFunctionFactory:
-
getPrototype() returns two ColumnTypes objects that describe the columns your UDTF takes as input and returns as output.
-
getReturnType() tells Vertica details about the output values: the width of variable-sized data types (such as VARCHAR) and the precision of data types that have settable precision (such as TIMESTAMP). You can also set the names of the output columns using this function. While this method is optional for UDxs that return single values, you must implement it for UDTFs.
-
createTransformFunction() instantiates your TransformFunction subclass.
For UDTFs written in C++ and Python, you can implement the getTransformFunctionProperties() method to set transform function class properties, including:
isExploder: By default False, indicates whether a single-phase UDTF performs a transform from one input row to a result set of N rows, often called a one-to-many transform. If set to True, each partition to the UDTF must consist of exactly one input row. When a UDTF is labeled as one-to-many, Vertica is able to optimize query plans and users can write SELECT queries that include any expression and do not require an OVER clause. For more information about UDTF partitioning options and instructions on how to set this class property, see Partitioning options for UDTFs. See Python example: explode for an in-depth example detailing a one-to-many UDTF.
For transform functions written in C++, you can provide information that can help with query optimization. See Improving query performance (C++ only).
API
The TransformFunctionFactory API provides the following methods for extension by subclasses:
virtual TransformFunction *
createTransformFunction (ServerInterface &srvInterface)=0;
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)=0;
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes,
SizedColumnTypes &returnType)=0;
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
virtual void getTransformFunctionProperties(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes,
Properties &properties);
The TransformFunctionFactory API provides the following methods for extension by subclasses:
public abstract TransformFunction createTransformFunction(ServerInterface srvInterface);
public abstract void getPrototype(ServerInterface srvInterface, ColumnTypes argTypes, ColumnTypes returnType);
public abstract void getReturnType(ServerInterface srvInterface, SizedColumnTypes argTypes,
SizedColumnTypes returnType) throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
The TransformFunctionFactory API provides the following methods for extension by subclasses:
def createTransformFunction(self, srv)
def getPrototype(self, srv_interface, arg_types, return_type)
def getReturnType(self, srv_interface, arg_types, return_type)
def getParameterType(self, server_interface, parameterTypes)
def getTransformFunctionProperties(self, server_interface, arg_types)
Implement the Factory function API to define a transform function factory:
FunctionNameFactory <- function() {
list(name = FunctionName,
udxtype = c("scalar"),
intype = c("int"),
outtype = c("int"))
}
9.3 - MultiPhaseTransformFunctionFactory class
Multi-phase UDTFs let you break your data processing into multiple steps.
Multi-phase UDTFs let you break your data processing into multiple steps. Using this feature, your UDTFs can perform processing in a way similar to Hadoop or other MapReduce frameworks. You can use the first phase to break down and gather data, and then use subsequent phases to process the data. For example, the first phase of your UDTF could extract specific types of user interactions from a web server log stored in the column of a table, and subsequent phases could perform analysis on those interactions.
Multi-phase UDTFs also let you decide where processing should occur: locally on each node, or throughout the cluster. If your multi-phase UDTF is like a MapReduce process, you want the first phase of your multi-phase UDTF to process data that is stored locally on the node where the instance of the UDTF is running. This prevents large segments of data from being copied around the Vertica cluster. Depending on the type of processing being performed in later phases, you may choose to have the data segmented and distributed across the Vertica cluster.
Each phase of the UDTF is the same as a traditional (single-phase) UDTF: it receives a table as input, and generates a table as output. The schema for each phase's output does not have to match its input, and each phase can output as many or as few rows as it wants.
You create a subclass of TransformFunction to define the processing performed by each stage. If you already have a TransformFunction from a single-phase UDTF that performs the processing you want a phase of your multi-phase UDTF to perform, you can easily adapt it to work within the multi-phase UDTF.
What makes a multi-phase UDTF different from a traditional UDTF is the factory class you use. You define a multi-phase UDTF using a subclass of MultiPhaseTransformFunctionFactory, rather than the TransformFunctionFactory. This special factory class acts as a container for all of the phases in your multi-step UDTF. It provides Vertica with the input and output requirements of the entire multi-phase UDTF (through the getPrototype() function), and a list of all the phases in the UDTF.
Within your subclass of the MultiPhaseTransformFunctionFactory class, you define one or more subclasses of TransformFunctionPhase. These classes fill the same role as the TransformFunctionFactory class for each phase in your multi-phase UDTF. They define the input and output of each phase and create instances of their associated TransformFunction classes to perform the processing for each phase of the UDTF. In addition to these subclasses, your MultiPhaseTransformFunctionFactory includes fields that provide a handle to an instance of each of the TransformFunctionPhase subclasses.
Note
The
MultiPhaseTransformFunctionFactory and
TransformFunctionPhase classes do not support the
isExploder class property.
API
The MultiPhaseTransformFunctionFactory class extends TransformFunctionFactory The API provides the following additional methods for extension by subclasses:
virtual void getPhases(ServerInterface &srvInterface,
std::vector< TransformFunctionPhase * > &phases)=0;
If using this factory you must also extend TransformFunctionPhase. See the SDK reference documentation.
The MultiPhaseTransformFunctionFactory class extends TransformFunctionFactory. The API provides the following methods for extension by subclasses:
public abstract void getPhases(ServerInterface srvInterface,
Vector< TransformFunctionPhase > phases);
If using this factory you must also extend TransformFunctionPhase. See the SDK reference documentation.
The TransformFunctionFactory class extends TransformFunctionFactory. For each phase, the factory must define a class that extends TransformFunctionPhase.
The factory adds the following method:
TransformFunctionPhase has the following methods:
def createTransformFunction(cls, srv)
def getReturnType(self, srv_interface, input_types, output_types)
9.4 - Improving query performance (C++ only)
When evaluating a query, the Vertica optimizer might sort its input to improve performance.
When evaluating a query, the Vertica optimizer might sort its input to improve performance. If a function already returns sorted data, this means the optimizer is doing extra work. A transform function written in C++ can declare how the data it returns is sorted, and the optimizer can take advantage of that information.
A transform function does the actual sorting in the function's processPartition() method. To take advantage of this optimization, sorts must be ascending. You need not sort all columns, but you must return the sorted column or columns first.
You can declare how the function sorts its output in the factory's getReturnType() method.
Caution
If the sorting declared in the factory does not match the sorting provided by the function, query results can be incorrect.
The PolyTopKPerPartition example sorts input columns and returns a given number of rows:
=> SELECT polykSort(14, a, b, c) OVER (ORDER BY a, b, c)
AS (sort1,sort2,sort3) FROM observations ORDER BY 1,2,3;
sort1 | sort2 | sort3
-------+-------+-------
1 | 1 | 1
1 | 1 | 2
1 | 1 | 3
1 | 2 | 1
1 | 2 | 2
1 | 3 | 1
1 | 3 | 2
1 | 3 | 3
1 | 3 | 4
2 | 1 | 1
2 | 1 | 2
2 | 2 | 3
2 | 2 | 34
2 | 3 | 5
(14 rows)
The factory declares this sorting in getReturnType() by setting the isSortedBy property on each column. Each SizedColumnType has an associated Properties object where this value can be set:
virtual void getReturnType(ServerInterface &srvInterface, const SizedColumnTypes &inputTypes, SizedColumnTypes &outputTypes)
{
vector<size_t> argCols; // Argument column indexes.
inputTypes.getArgumentColumns(argCols);
size_t colIdx = 0;
for (vector<size_t>::iterator i = argCols.begin() + 1; i < argCols.end(); i++)
{
SizedColumnTypes::Properties props;
props.isSortedBy = true;
std::stringstream cname;
cname << "col" << colIdx++;
outputTypes.addArg(inputTypes.getColumnType(*i), cname.str(), props);
}
}
You can see the effects of this optimization by reviewing the EXPLAIN plans for queries with and without this setting. The following output shows the query plan for polyk, the unsorted version. Note the cost for sorting:
=> EXPLAN SELECT polyk(14, a, b, c) OVER (ORDER BY a, b, c)
FROM observations ORDER BY 1,2,3;
Access Path:
+-SORT [Cost: 2K, Rows: 10K] (PATH ID: 1)
| Order: col0 ASC, col1 ASC, col2 ASC
| +---> ANALYTICAL [Cost: 2K, Rows: 10K] (PATH ID: 2)
| | Analytic Group
| | Functions: polyk()
| | Group Sort: observations.a ASC NULLS LAST, observations.b ASC NULLS LAST, observations.c ASC NULLS LAST
| | +---> STORAGE ACCESS for observations [Cost: 2K, Rows: 10K]
(PATH ID: 3)
| | | Projection: public.observations_super
| | | Materialize: observations.a, observations.b, observations.c
The query plan for the sorted version omits this step (and cost) and starts with the analytical step (the second step in the previous plan):
=> EXPLAN SELECT polykSort(14, a, b, c) OVER (ORDER BY a, b, c)
FROM observations ORDER BY 1,2,3;
Access Path:
+-ANALYTICAL [Cost: 2K, Rows: 10K] (PATH ID: 2)
| Analytic Group
| Functions: polykSort()
| Group Sort: observations.a ASC NULLS LAST, observations.b ASC NULLS LAST, observations.c ASC NULLS LAST
| +---> STORAGE ACCESS for observations [Cost: 2K, Rows: 10K] (PATH ID: 3)
| | Projection: public.observations_super
| | Materialize: observations.a, observations.b, observations.c
9.5 - Partitioning options for UDTFs
Depending on the application, a UDTF might require the input data to be partitioned in a specific way.
Depending on the application, a UDTF might require the input data to be partitioned in a specific way. For example, a UDTF that processes a web server log file to count the number of hits referred by each partner web site needs to have its input partitioned by a referrer column. However, in other cases—such as a string tokenizer—the sort order of the data does not matter. Vertica provides partition options for both of these types of UDTFs.
Data sort required
In cases where a specific sort order is required, the window partitioning clause in the query that calls the UDTF should use a PARTITION BY clause. Each node in the cluster partitions the data it stores, sends some of these partitions off to other nodes, and then consolidates the partitions it receives from other nodes and runs an instance of the UDTF to process them.
For example, the following UDTF partitions the input data by store ID and then computes the count of each distinct array element in each partition:
=> SELECT * FROM orders;
storeID | productIDs
---------+-----------------------
1 | [101,102,103]
1 | [102,104]
1 | [101,102,102,201,203]
2 | [101,202,203,202,203]
2 | [203]
2 | []
(6 rows)
=> SELECT storeID, CountElements(productIDs) OVER (PARTITION BY storeID) FROM orders;
storeID | element_count
--------+---------------------------
1 | {"element":101,"count":2}
1 | {"element":102,"count":4}
1 | {"element":103,"count":1}
1 | {"element":104,"count":1}
1 | {"element":201,"count":1}
1 | {"element":202,"count":1}
2 | {"element":101,"count":1}
2 | {"element":202,"count":2}
2 | {"element":203,"count":3}
(9 rows)
No sort needed
Some UDTFs, such as Explode, do not need to partition input data in a particular way. In these cases, you can specify that each UDTF instance process only the data that is stored locally by the node on which it is running. By eliminating the overhead of partitioning data and the cost of sort and merge operations, processing can be much more efficient.
You can use the following window partition options for UDTFs that do not require a specific data partitioning:
-
PARTITION ROW: For single-phase UDTFs where each partition is one input row, allows users to write SELECT queries that include any expression. The UDTF calls the processPartition() method once per input row. UDTFs of this type, often called one-to-many transforms, can be explicitly marked as such with the exploder class property in the TransformFunctionFactory class. This class property helps Vertica optimize query plans and removes the need for an OVER clause. See One to Many UDTFs for details on how to set this class property for UDTFs written in C++ and Python.
-
PARTITION BEST: For thread-safe UDTFs only, optimizes performance through multi-threaded queries across multiple nodes. The UDTF calls the processPartition() method once per thread per node.
-
PARTITION NODES: Optimizes performance of single-threaded queries across multiple nodes. The UDTF calls the processPartition() method once per node.
For more information about these partition options, see Window partitioning.
One-to-many UDTFs
To mark a UDTF as one-to-many, you must set the isExploder class property to True within the getTransformFunctionProperties() method. Whether a UDTF is marked as one-to-many can be determined by the transform function's arguments and parameters, for example:
void getFunctionProperties(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes,
Properties &properties) override
{
if (argTypes.getColumnCount() > 1) {
properties.isExploder = false;
}
else {
properties.isExploder = true;
}
}
To mark a UDTF as one-to-many, you must set the is_exploder class property to True within the getTransformFunctionProperties() method. Whether a UDTF is marked as one-to-many can be determined by the transform function's arguments and parameters, for example:
def getFunctionProperties(cls, server_interface, arg_types):
props = vertica_sdk.TransformFunctionFactory.Properties()
if arg_types.getColumnCount() != 1:
props.is_exploder = False
else:
props.is_exploder = True
return props
If the exploder class property is set to True, the OVER clause is by default OVER(PARTITION ROW). This allows users to call the UDTF without specifying an OVER clause:
=> SELECT * FROM reviews;
id | sentence
----+--------------------------------------
1 | Customer service was slow
2 | Product is exactly what I needed
3 | Price is a bit high
4 | Highly recommended
(4 rows)
=> SELECT tokenize(sentence) FROM reviews;
tokens
-------------
Customer
service
was
slow
Product
...
bit
high
Highly
recommended
(17 rows)
Note
If a user writes an OVER clause with PARTITION BY for a function marked as one-to-many, the function replaces the OVER clause with OVER(PARTITION ROW) and emits a notice to the user.
One-to-many UDTFs also support any expression in the SELECT clause, unlike UDTFs that use either the PARTITION BEST or the PARTITION NODES clause:
=> SELECT id, tokenize(sentence) FROM reviews;
id | tokens
----+-------------
1 | Customer
1 | service
1 | was
1 | respond
2 | Product
...
3 | high
4 | Highly
4 | recommended
(17 rows)
For an in-depth example detailing a one-to-many UDTF, see Python example: explode.
See also
9.6 - C++ example: string tokenizer
The following example shows a subclass of TransformFunction named StringTokenizer.
The following example shows a subclass of TransformFunction named StringTokenizer. It defines a UDTF that reads a table containing an INTEGER ID column and a VARCHAR column. It breaks the text in the VARCHAR column into tokens (individual words). It returns a table containing each token, the row it occurred in, and its position within the string.
Loading and using the example
The following example shows how to load the function into Vertica. It assumes that the TransformFunctions.so library that contains the function has been copied to the dbadmin user's home directory on the initiator node.
=> CREATE LIBRARY TransformFunctions AS
'/home/dbadmin/TransformFunctions.so';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION tokenize
AS LANGUAGE 'C++' NAME 'TokenFactory' LIBRARY TransformFunctions;
CREATE TRANSFORM FUNCTION
You can then use it from SQL statements, for example:
=> CREATE TABLE T (url varchar(30), description varchar(2000));
CREATE TABLE
=> INSERT INTO T VALUES ('www.amazon.com','Online retail merchant and provider of cloud services');
OUTPUT
--------
1
(1 row)
=> INSERT INTO T VALUES ('www.vertica.com','World''s fastest analytic database');
OUTPUT
--------
1
(1 row)
=> COMMIT;
COMMIT
=> -- Invoke the UDTF
=> SELECT url, tokenize(description) OVER (partition by url) FROM T;
url | words
-----------------+-----------
www.amazon.com | Online
www.amazon.com | retail
www.amazon.com | merchant
www.amazon.com | and
www.amazon.com | provider
www.amazon.com | of
www.amazon.com | cloud
www.amazon.com | services
www.vertica.com | World's
www.vertica.com | fastest
www.vertica.com | analytic
www.vertica.com | database
(12 rows)
Notice that the number of rows and columns in the result table are different than the input table. This is one of the strengths of a UDTF.
The following code shows the StringTokenizer class.
class StringTokenizer : public TransformFunction
{
virtual void processPartition(ServerInterface &srvInterface,
PartitionReader &inputReader,
PartitionWriter &outputWriter)
{
try {
if (inputReader.getNumCols() != 1)
vt_report_error(0, "Function only accepts 1 argument, but %zu provided", inputReader.getNumCols());
do {
const VString &sentence = inputReader.getStringRef(0);
// If input string is NULL, then output is NULL as well
if (sentence.isNull())
{
VString &word = outputWriter.getStringRef(0);
word.setNull();
outputWriter.next();
}
else
{
// Otherwise, let's tokenize the string and output the words
std::string tmp = sentence.str();
std::istringstream ss(tmp);
do
{
std::string buffer;
ss >> buffer;
// Copy to output
if (!buffer.empty()) {
VString &word = outputWriter.getStringRef(0);
word.copy(buffer);
outputWriter.next();
}
} while (ss);
}
} while (inputReader.next() && !isCanceled());
} catch(std::exception& e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while processing partition: [%s]", e.what());
}
}
};
The processPartition() function in this example follows a pattern that you will follow in your own UDTF: it loops over all rows in the table partition that Vertica sends it, processing each row and checking for cancellation before advancing. For UDTFs you do not have to actually process every row. You can exit your function without having read all of the input without any issues. You may choose to do this if your UDTF is performing some sort search or some other operation where it can determine that the rest of the input is unneeded.
In this example, processPartition() first extracts the VString containing the text from the PartitionReader object. The VString class represents a Vertica string value (VARCHAR or CHAR). If there is input, it then tokenizes it and adds it to the output using the PartitionWriter object.
Similarly to reading input columns, the PartitionWriter class has functions for writing each type of data to the output row. In this case, the example calls the PartitionWriter object's getStringRef() function to allocate a new VString object to hold the token to output for the first column, and then copies the token's value into the VString.
The following code shows the factory class.
class TokenFactory : public TransformFunctionFactory
{
// Tell Vertica that we take in a row with 1 string, and return a row with 1 string
virtual void getPrototype(ServerInterface &srvInterface, ColumnTypes &argTypes, ColumnTypes &returnType)
{
argTypes.addVarchar();
returnType.addVarchar();
}
// Tell Vertica what our return string length will be, given the input
// string length
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
// Error out if we're called with anything but 1 argument
if (inputTypes.getColumnCount() != 1)
vt_report_error(0, "Function only accepts 1 argument, but %zu provided", inputTypes.getColumnCount());
int input_len = inputTypes.getColumnType(0).getStringLength();
// Our output size will never be more than the input size
outputTypes.addVarchar(input_len, "words");
}
virtual TransformFunction *createTransformFunction(ServerInterface &srvInterface)
{ return vt_createFuncObject<StringTokenizer>(srvInterface.allocator); }
};
In this example:
-
The UDTF takes a VARCHAR column as input. To define the input column, getPrototype() calls addVarchar() on the ColumnTypes object that represents the input table.
-
The UDTF returns a VARCHAR as output. The getPrototype() function calls addVarchar() to define the output table.
This example must return the maximum length of the VARCHAR output column. It sets the length to the length of the input string. This is a safe value, because the output will never be longer than the input string. It also sets the name of the VARCHAR output column to "words".
Note
You are not required to supply a name for an output column in this function. However, it is a best practice to do so. If you do not name an output column, getReturnType() sets the column name to "". The SQL statements that call your UDTF must provide aliases for any unnamed columns to access them or else they return an error. From a usability standpoint, it is easier for you to supply the column names here once. The alternative is to force all of the users of your function to supply their own column names for each call to the UDTF.
The implementation of the createTransformFunction() function in the example is boilerplate code. It just calls the vt_returnFuncObj macro with the name of the TransformFunction class associated with this factory class. This macro takes care of instantiating a copy of the TransformFunction class that Vertica can use to process data.
The RegisterFactory macro
The final step in creating your UDTF is to call the RegisterFactory macro. This macro ensures that your factory class is instantiated when Vertica loads the shared library containing your UDTF. Having your factory class instantiated is the only way that Vertica can find your UDTF and determine what its inputs and outputs are.
The RegisterFactory macro just takes the name of your factory class:
RegisterFactory(TokenFactory);
9.7 - Python example: string tokenizer
The following example shows a transform function that breaks an input string into tokens (based on whitespace).
The following example shows a transform function that breaks an input string into tokens (based on whitespace). It is similar to the tokenizer examples for C++ and Java.
Loading and using the example
Create the library and function:
=> CREATE LIBRARY pyudtf AS '/home/dbadmin/udx/tokenize.py' LANGUAGE 'Python';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION tokenize AS NAME 'StringTokenizerFactory' LIBRARY pyudtf;
CREATE TRANSFORM FUNCTION
You can then use the function in SQL statements, for example:
=> CREATE TABLE words (w VARCHAR);
CREATE TABLE
=> COPY words FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> this is a test of the python udtf
>> \.
=> SELECT tokenize(w) OVER () FROM words;
token
----------
this
is
a
test
of
the
python
udtf
(8 rows)
Setup
All Python UDxs must import the Vertica SDK.
UDTF Python code
The following code defines the tokenizer and its factory.
class StringTokenizer(vertica_sdk.TransformFunction):
"""
Transform function which tokenizes its inputs.
For each input string, each of the whitespace-separated tokens of that
string is produced as output.
"""
def processPartition(self, server_interface, input, output):
while True:
for token in input.getString(0).split():
output.setString(0, token)
output.next()
if not input.next():
break
class StringTokenizerFactory(vertica_sdk.TransformFunctionFactory):
def getPrototype(self, server_interface, arg_types, return_type):
arg_types.addVarchar()
return_type.addVarchar()
def getReturnType(self, server_interface, arg_types, return_type):
return_type.addColumn(arg_types.getColumnType(0), "tokens")
def createTransformFunction(cls, server_interface):
return StringTokenizer()
9.8 - R example: log tokenizer
The LogTokenizer transform function reads a varchar from a table, a log message.
The LogTokenizer transform function reads a varchar from a table, a log message. It then tokenizes each of the log messages, returning each of the tokens.
You can find more UDx examples in the Vertica Github repository, https://github.com/vertica/UDx-Examples.
Load the function and library
Create the library and the function.
=> CREATE OR REPLACE LIBRARY rLib AS 'log_tokenizer.R' LANGUAGE 'R';
CREATE LIBRARY
=> CREATE OR REPLACE TRANSFORM FUNCTION LogTokenizer AS LANGUAGE 'R' NAME 'LogTokenizerFactory' LIBRARY rLib FENCED;
CREATE FUNCTION
Querying data with the function
The following query shows how you can run a query with the UDTF.
=> SELECT machine,
LogTokenizer(error_log USING PARAMETERS spliton = ' ') OVER(PARTITION BY machine)
FROM error_logs;
machine | Token
---------+---------
node001 | ERROR
node001 | 345
node001 | -
node001 | Broken
node001 | pipe
node001 | WARN
node001 | -
node001 | Nearly
node001 | filled
node001 | disk
node002 | ERROR
node002 | 111
node002 | -
node002 | Flooded
node002 | roads
node003 | ERROR
node003 | 222
node003 | -
node003 | Plain
node003 | old
node003 | broken
(21 rows)
UDTF R code
LogTokenizer <- function(input.data.frame, parameters.data.frame) {
# Take the spliton parameter passed by the user and assign it to a variable
# in the function so we can use that as our tokenizer.
if ( is.null(parameters.data.frame[['spliton']]) ) {
stop("NULL value for spliton! Token cannot be NULL.")
} else {
split.on <- as.character(parameters.data.frame[['spliton']])
}
# Tokenize the string.
tokens <- vector(length=0)
for ( string in input.data.frame[, 1] ) {
tokenized.string <- strsplit(string, split.on)
for ( token in tokenized.string ) {
tokens <- append(tokens, token)
}
}
final.output <- data.frame(tokens)
return(final.output)
}
LogTokenizerFactory <- function() {
list(name = LogTokenizer,
udxtype = c("transform"),
intype = c("varchar"),
outtype = c("varchar"),
outtypecallback=LogTokenizerReturn,
parametertypecallback=LogTokenizerParameters)
}
LogTokenizerParameters <- function() {
parameters <- list(datatype = c("varchar"),
length = c("NA"),
scale = c("NA"),
name = c("spliton"))
return(parameters)
}
LogTokenizerReturn <- function(arg.data.frame, parm.data.frame) {
output.return.type <- data.frame(datatype = rep(NA,1),
length = rep(NA,1),
scale = rep(NA,1),
name = rep(NA,1))
output.return.type$datatype <- c("varchar")
output.return.type$name <- c("Token")
return(output.return.type)
}
9.9 - C++ example: multi-phase indexer
The following code fragment is from the InvertedIndex UDTF example distributed with the Vertica SDK.
The following code fragment is from the InvertedIndex UDTF example distributed with the Vertica SDK. It demonstrates subclassing the MultiPhaseTransformFunctionFactory including two TransformFunctionPhase subclasses that define the two phases in this UDTF.
class InvertedIndexFactory : public MultiPhaseTransformFunctionFactory
{
public:
/**
* Extracts terms from documents.
*/
class ForwardIndexPhase : public TransformFunctionPhase
{
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
// Sanity checks on input we've been given.
// Expected input: (doc_id INTEGER, text VARCHAR)
vector<size_t> argCols;
inputTypes.getArgumentColumns(argCols);
if (argCols.size() < 2 ||
!inputTypes.getColumnType(argCols.at(0)).isInt() ||
!inputTypes.getColumnType(argCols.at(1)).isVarchar())
vt_report_error(0, "Function only accepts two arguments"
"(INTEGER, VARCHAR))");
// Output of this phase is:
// (term_freq INTEGER) OVER(PBY term VARCHAR OBY doc_id INTEGER)
// Number of times term appears within a document.
outputTypes.addInt("term_freq");
// Add analytic clause columns: (PARTITION BY term ORDER BY doc_id).
// The length of any term is at most the size of the entire document.
outputTypes.addVarcharPartitionColumn(
inputTypes.getColumnType(argCols.at(1)).getStringLength(),
"term");
// Add order column on the basis of the document id's data type.
outputTypes.addOrderColumn(inputTypes.getColumnType(argCols.at(0)),
"doc_id");
}
virtual TransformFunction *createTransformFunction(ServerInterface
&srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, ForwardIndexBuilder); }
};
/**
* Constructs terms' posting lists.
*/
class InvertedIndexPhase : public TransformFunctionPhase
{
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
// Sanity checks on input we've been given.
// Expected input:
// (term_freq INTEGER) OVER(PBY term VARCHAR OBY doc_id INTEGER)
vector<size_t> argCols;
inputTypes.getArgumentColumns(argCols);
vector<size_t> pByCols;
inputTypes.getPartitionByColumns(pByCols);
vector<size_t> oByCols;
inputTypes.getOrderByColumns(oByCols);
if (argCols.size() != 1 || pByCols.size() != 1 || oByCols.size() != 1 ||
!inputTypes.getColumnType(argCols.at(0)).isInt() ||
!inputTypes.getColumnType(pByCols.at(0)).isVarchar() ||
!inputTypes.getColumnType(oByCols.at(0)).isInt())
vt_report_error(0, "Function expects an argument (INTEGER) with "
"analytic clause OVER(PBY VARCHAR OBY INTEGER)");
// Output of this phase is:
// (term VARCHAR, doc_id INTEGER, term_freq INTEGER, corp_freq INTEGER).
outputTypes.addVarchar(inputTypes.getColumnType(
pByCols.at(0)).getStringLength(),"term");
outputTypes.addInt("doc_id");
// Number of times term appears within the document.
outputTypes.addInt("term_freq");
// Number of documents where the term appears in.
outputTypes.addInt("corp_freq");
}
virtual TransformFunction *createTransformFunction(ServerInterface
&srvInterface)
{ return vt_createFuncObj(srvInterface.allocator, InvertedIndexBuilder); }
};
ForwardIndexPhase fwardIdxPh;
InvertedIndexPhase invIdxPh;
virtual void getPhases(ServerInterface &srvInterface,
std::vector<TransformFunctionPhase *> &phases)
{
fwardIdxPh.setPrepass(); // Process documents wherever they're originally stored.
phases.push_back(&fwardIdxPh);
phases.push_back(&invIdxPh);
}
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
// Expected input: (doc_id INTEGER, text VARCHAR).
argTypes.addInt();
argTypes.addVarchar();
// Output is: (term VARCHAR, doc_id INTEGER, term_freq INTEGER, corp_freq INTEGER)
returnType.addVarchar();
returnType.addInt();
returnType.addInt();
returnType.addInt();
}
};
RegisterFactory(InvertedIndexFactory);
Most of the code in this example is similar to the code in a TransformFunctionFactory class:
-
Both TransformFunctionPhase subclasses implement the getReturnType() function, which describes the output of each stage. This is the similar to the getReturnType() function from the TransformFunctionFactory class. However, this function also lets you control how the data is partitioned and ordered between each phase of your multi-phase UDTF.
The first phase calls SizedColumnTypes::addVarcharPartitionColumn() (rather than just addVarcharColumn()) to set the phase's output table to be partitioned by the column containing the extracted words. It also calls SizedColumnTypes::addOrderColumn() to order the output table by the document ID column. It calls this function instead of one of the data-type-specific functions (such as addIntOrderColumn()) so it can pass the data type of the original column through to the output column.
Note
Any order by column or partition by column set by the final phase of the UDTF in its getReturnType() function is ignored. Its output is returned to the initiator node rather than partitioned and reordered then sent to another phase.
-
The MultiPhaseTransformFunctionFactory class implements the getPrototype() function, that defines the schemas for the input and output of the multi-phase UDTF. This function is the same as the TransformFunctionFactory::getPrototype() function.
The unique function implemented by the MultiPhaseTransformFunctionFactory class is getPhases(). This function defines the order in which the phases are executed. The fields that represent the phases are pushed into this vector in the order they should execute.
The MultiPhaseTransformFunctionFactory.getPhases() function is also where you flag the first phase of the UDTF as operating on data stored locally on the node (called a "pre-pass" phase) rather than on data partitioned across all nodes. Using this option increases the efficiency of your multi-phase UDTF by avoiding having to move significant amounts of data around the Vertica cluster.
Note
Only the first phase of your UDTF can be a pre-pass phase. You cannot have multiple pre-pass phases, and no later phase can be a pre-pass phase.
To mark the first phase as pre-pass, you call the TransformFunctionPhase::setPrepass() function of the first phase's TransformFunctionPhase instance from within the getPhase() function.
Notes
-
You need to ensure that the output schema of each phase matches the input schema expected by the next phase. In the example code, each TransformFunctionPhase::getReturnType() implementation performs a sanity check on its input and output schemas. Your TransformFunction subclasses can also perform these checks in their processPartition() function.
-
There is no built-in limit on the number of phases that your multi-phase UDTF can have. However, more phases use more resources. When running in fenced mode, Vertica may terminate UDTFs that use too much memory. See Resource use for C++ UDxs.
9.10 - Python example: multi-phase calculation
The following example shows a multi-phase transform function that computes the average value on a column of numbers in an input table.
The following example shows a multi-phase transform function that computes the average value on a column of numbers in an input table. It first defines two transform functions, and then defines a factory that creates the phases using them.
See AvgMultiPhaseUDT.py in the examples distribution for the complete code.
Loading and using the example
Create the library and function:
=> CREATE LIBRARY pylib_avg AS '/home/dbadmin/udx/AvgMultiPhaseUDT.py' LANGUAGE 'Python';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION myAvg AS NAME 'MyAvgFactory' LIBRARY pylib_avg;
CREATE TRANSFORM FUNCTION
You can then use the function in SELECT statements:
=> CREATE TABLE IF NOT EXISTS numbers(num FLOAT);
CREATE TABLE
=> COPY numbers FROM STDIN delimiter ',';
1
2
3
4
\.
=> SELECT myAvg(num) OVER() FROM numbers;
average | ignored_rows | total_rows
---------+--------------+------------
2.5 | 0 | 4
(1 row)
Setup
All Python UDxs must import the Vertica SDK. This example also imports another library.
import vertica_sdk
import math
A multi-phase transform function must define two or more TransformFunction subclasses to be used in the phases. This example uses two classes: LocalCalculation, which does calculations on local partitions, and GlobalCalculation, which aggregates the results of all LocalCalculation instances to calculate a final result.
In both functions, the calculation is done in the processPartition() function:
class LocalCalculation(vertica_sdk.TransformFunction):
"""
This class is the first phase and calculates the local values for sum, ignored_rows and total_rows.
"""
def setup(self, server_interface, col_types):
server_interface.log("Setup: Phase0")
self.local_sum = 0.0
self.ignored_rows = 0
self.total_rows = 0
def processPartition(self, server_interface, input, output):
server_interface.log("Process Partition: Phase0")
while True:
self.total_rows += 1
if input.isNull(0) or math.isinf(input.getFloat(0)) or math.isnan(input.getFloat(0)):
# Null, Inf, or Nan is ignored
self.ignored_rows += 1
else:
self.local_sum += input.getFloat(0)
if not input.next():
break
output.setFloat(0, self.local_sum)
output.setInt(1, self.ignored_rows)
output.setInt(2, self.total_rows)
output.next()
class GlobalCalculation(vertica_sdk.TransformFunction):
"""
This class is the second phase and aggregates the values for sum, ignored_rows and total_rows.
"""
def setup(self, server_interface, col_types):
server_interface.log("Setup: Phase1")
self.global_sum = 0.0
self.ignored_rows = 0
self.total_rows = 0
def processPartition(self, server_interface, input, output):
server_interface.log("Process Partition: Phase1")
while True:
self.global_sum += input.getFloat(0)
self.ignored_rows += input.getInt(1)
self.total_rows += input.getInt(2)
if not input.next():
break
average = self.global_sum / (self.total_rows - self.ignored_rows)
output.setFloat(0, average)
output.setInt(1, self.ignored_rows)
output.setInt(2, self.total_rows)
output.next()
Multi-phase factory
A MultiPhaseTransformFunctionFactory ties together the individual functions as phases. The factory defines a TransformFunctionPhase for each function. Each phase defines createTransformFunction(), which calls the constructor for the corresponding TransformFunction, and getReturnType().
The first phase, LocalPhase, follows.
class MyAvgFactory(vertica_sdk.MultiPhaseTransformFunctionFactory):
""" Factory class """
class LocalPhase(vertica_sdk.TransformFunctionPhase):
""" Phase 1 """
def getReturnType(self, server_interface, input_types, output_types):
# sanity check
number_of_cols = input_types.getColumnCount()
if (number_of_cols != 1 or not input_types.getColumnType(0).isFloat()):
raise ValueError("Function only accepts one argument (FLOAT))")
output_types.addFloat("local_sum");
output_types.addInt("ignored_rows");
output_types.addInt("total_rows");
def createTransformFunction(cls, server_interface):
return LocalCalculation()
The second phase, GlobalPhase, does not check its inputs because the first phase already did. As with the first phase, createTransformFunction merely constructs and returns the corresponding TransformFunction.
class GlobalPhase(vertica_sdk.TransformFunctionPhase):
""" Phase 2 """
def getReturnType(self, server_interface, input_types, output_types):
output_types.addFloat("average");
output_types.addInt("ignored_rows");
output_types.addInt("total_rows");
def createTransformFunction(cls, server_interface):
return GlobalCalculation()
After defining the TransformFunctionPhase subclasses, the factory instantiates them and chains them together in getPhases().
ph0Instance = LocalPhase()
ph1Instance = GlobalPhase()
def getPhases(cls, server_interface):
cls.ph0Instance.setPrepass()
phases = [cls.ph0Instance, cls.ph1Instance]
return phases
9.11 - Python example: count elements
The following example details a UDTF that takes a partition of arrays, computes the count of each distinct array element in the partition, and outputs each element and its count as a row value.
The following example details a UDTF that takes a partition of arrays, computes the count of each distinct array element in the partition, and outputs each element and its count as a row value. You can call the function on tables that contain multiple partitions of arrays.
The complete source code is in /opt/vertica/sdk/examples/python/TransformFunctions.py.
Loading and using the example
Load the library and create the transform function as follows:
=> CREATE OR REPLACE LIBRARY TransformFunctions AS '/home/dbadmin/examples/python/TransformFunctions.py' LANGUAGE 'Python';
=> CREATE TRANSFORM FUNCTION CountElements AS LANGUAGE 'Python' NAME 'countElementsUDTFactory' LIBRARY TransformFunctions;
You can create some data and then call the function on it, for example:
=> CREATE TABLE orders (storeID int, productIDs array[int]);
CREATE TABLE
=> INSERT INTO orders VALUES
(1, array[101, 102, 103]),
(1, array[102, 104]),
(1, array[101, 102, 102, 201, 203]),
(2, array[101, 202, 203, 202, 203]),
(2, array[203]),
(2, array[]);
OUTPUT
--------
6
(1 row)
=> COMMIT;
COMMIT
=> SELECT storeID, CountElements(productIDs) OVER (PARTITION BY storeID) FROM orders;
storeID | element_count
--------+---------------------------
1 | {"element":101,"count":2}
1 | {"element":102,"count":4}
1 | {"element":103,"count":1}
1 | {"element":104,"count":1}
1 | {"element":201,"count":1}
1 | {"element":202,"count":1}
2 | {"element":101,"count":1}
2 | {"element":202,"count":2}
2 | {"element":203,"count":3}
(9 rows)
Setup
All Python UDxs must import the Vertica SDK library:
Factory implementation
The getPrototype() method declares that the inputs and outputs can be of any type, which means that type enforcement must be done elsewhere:
def getPrototype(self, srv_interface, arg_types, return_type):
arg_types.addAny()
return_type.addAny()
getReturnType() validates that the only argument to the function is an array and that the return type is a row with 'element' and 'count' fields:
def getReturnType(self, srv_interface, arg_types, return_type):
if arg_types.getColumnCount() != 1:
srv_interface.reportError(1, 'countElements UDT should take exactly one argument')
if not arg_types.getColumnType(0).isArrayType():
srv_interface.reportError(2, 'Argument to countElements UDT should be an ARRAY')
retRowFields = vertica_sdk.SizedColumnTypes.makeEmpty()
retRowFields.addColumn(arg_types.getColumnType(0).getElementType(), 'element')
retRowFields.addInt('count')
return_type.addRowType(retRowFields, 'element_count')
The countElementsUDTFactory class also contains a createTransformFunction() method that instantiates and returns the transform function.
Function implementation
The processBlock() method is called with a BlockReader and a BlockWriter, named arg_reader and res_writer respectively. The function loops through all the input arrays in a partition and uses a dictionary to collect the frequency of each element. To access elements of each input array, the method instantiates an ArrayReader. After collecting the element counts, the function writes each element and its count to a row. This process is repeated for each partition.
def processPartition(self, srv_interface, arg_reader, res_writer):
elemCounts = dict()
# Collect element counts for entire partition
while (True):
if not arg_reader.isNull(0):
arr = arg_reader.getArray(0)
for elem in arr:
elemCounts[elem] = elemCounts.setdefault(elem, 0) + 1
if not arg_reader.next():
break
# Write at least one value for each partition
if len(elemCounts) == 0:
elemCounts[None] = 0
# Write out element counts as (element, count) pairs
for pair in elemCounts.items():
res_writer.setRow(0, pair)
res_writer.next()
9.12 - Python example: explode
The following example details a UDTF that accepts a one-dimensional array as input and outputs each element of the array as a separate row, similar to functions commonly known as EXPLODE.
The following example details a UDTF that accepts a one-dimensional array as input and outputs each element of the array as a separate row, similar to functions commonly known as EXPLODE. Because this UDTF always accepts one array as input, you can explicitly mark it as a one-to-many UDTF in the factory function, which helps Vertica optimize query plans and allows users to write SELECT queries that include any expression and do not require an OVER clause.
The complete source code is in /opt/vertica/sdk/examples/python/TransformFunctions.py.
Loading and using the example
Load the library and create the transform function as follows:
=> CREATE OR REPLACE LIBRARY PyTransformFunctions AS '/opt/vertica/sdk/examples/python/TransformFunctions.py' LANGUAGE 'Python';
CREATE LIBRARY
=> CREATE TRANSFORM FUNCTION py_explode AS LANGUAGE 'Python' NAME 'ExplodeFactory' LIBRARY TransformFunctions;
CREATE TRANSFORM FUNCTION
You can then use the function in SQL statements, for example:
=> CREATE TABLE reviews (id INTEGER PRIMARY KEY, sentiment VARCHAR(16), review ARRAY[VARCHAR(16), 32]);
CREATE TABLE
=> INSERT INTO reviews VALUES(1, 'Very Negative', string_to_array('This was the worst restaurant I have ever had the misfortune of eating at' USING PARAMETERS collection_delimiter = ' ')),
(2, 'Neutral', string_to_array('This restaurant is pretty decent' USING PARAMETERS collection_delimiter = ' ')),
(3, 'Very Positive', string_to_array('Best restaurant in the Western Hemisphere' USING PARAMETERS collection_delimiter = ' ')),
(4, 'Positive', string_to_array('Prices low for the area' USING PARAMETERS collection_delimiter = ' '));
OUTPUT
--------
4
(1 row)
=> COMMIT;
COMMIT
=> SELECT id, sentiment, py_explode(review) FROM reviews; --no OVER clause because "is_exploder = True", see below
id | sentiment | element
----+---------------+------------
1 | Very Negative | This
1 | Very Negative | was
1 | Very Negative | the
1 | Very Negative | worst
1 | Very Negative | restaurant
1 | Very Negative | I
1 | Very Negative | have
...
3 | Very Positive | Western
3 | Very Positive | Hemisphere
4 | Positive | Prices
4 | Positive | low
4 | Positive | for
4 | Positive | the
4 | Positive | area
(30 rows)
Setup
All Python UDxs must import the Vertica SDK library:
Factory implementation
The following code shows the ExplodeFactory class.
class ExplodeFactory(vertica_sdk.TransformFunctionFactory):
def getPrototype(self, srv_interface, arg_types, return_type):
arg_types.addAny()
return_type.addAny()
def getTransformFunctionProperties(cls, server_interface, arg_types):
props = vertica_sdk.TransformFunctionFactory.Properties()
props.is_exploder = True
return props
def getReturnType(self, srv_interface, arg_types, return_type):
if arg_types.getColumnCount() != 1:
srv_interface.reportError(1, 'explode UDT should take exactly one argument')
if not arg_types.getColumnType(0).isArrayType():
srv_interface.reportError(2, 'Argument to explode UDT should be an ARRAY')
return_type.addColumn(arg_types.getColumnType(0).getElementType(), 'element')
def createTransformFunction(cls, server_interface):
return Explode()
In this example:
-
The getTransformFunctionProperties method sets the is_exploder class property to True, explicitly marking the UDTF as one-to-many. This indicates that the function uses an OVER(PARTITION ROW) clause by default and thereby removes the need to specify an OVER clause when calling the UDTF. With is_exploder set to True, users can write SELECT queries that include any expression, unlike queries that use PARTITION BEST or PARTITION NODES.
-
The getReturnType method verifies that the input contains only one argument and is of type ARRAY. The method also sets the return type to that of the elements in the input array.
Function implementation
The following code shows the Explode class:
class Explode(vertica_sdk.TransformFunction):
"""
Transform function that turns an array into one row
for each array element.
"""
def processPartition(self, srv_interface, arg_reader, res_writer):
while True:
arr = arg_reader.getArrayReader(0)
for elt in arr:
res_writer.copyRow(elt)
res_writer.next()
if not arg_reader.next():
break;
The processPartition() method accepts a single row of the input data, processes each element of the array, and then breaks the loop. The method accesses the elements of the array with an ArrayReader object and then uses an ArrayWriter object to write each element of the array to a separate output row. The UDTF calls processPartition() for each row of the input data.
See also
10 - User-defined load (UDL)
COPY offers extensive options and settings to control how to load data.
COPY offers extensive options and settings to control how to load data. However, you may find that these options do not suit the type of data load that you want to perform. The user-defined load (UDL) feature lets you develop one or more functions that change how the COPY statement operates. You can create custom libraries using the Vertica SDK to handle various steps in the loading process. .
You use three types of UDL functions during development, one for each stage of the data-load process:
-
User-defined source (UDSource): Controls how COPY obtains the data it loads into the database. For example, COPY might obtain data by fetching it through HTTP or cURL. Up to one UDSource reads data from a file or input stream. Your UDSource can read from more than one source, but COPY invokes only one UDSource.
API support: C++, Java.
-
User-defined filter (UDFilter): Preprocesses the data. For example, a filter might unzip a file or convert UTF-16 to UTF-8. You can chain multiple user-defined filters together, for example unzipping and then converting.
API support: C++, Java, Python.
-
User-defined parser (UDParser): Up to one parser parses the data into tuples that are ready to be inserted into a table. For example, a parser could extract data from an XML-like format. You can optionally define a user-defined chunker (UDChunker, C++ only), to have the parser perform parallel parsing.
API support: C++, Java, Python.
After the final step, COPY inserts the data into a table, or rejects it if the format is incorrect.
10.1 - User-defined source
A user-defined source allows you to process a source of data using a method that is not built into Vertica.
A user-defined source allows you to process a source of data using a method that is not built into Vertica. For example, you can write a user-defined source to access the data from an HTTP source using cURL. While a given COPY statement can use specify only one user-defined source statement, the source function itself can pull data from multiple sources.
The
UDSource class acquires data from an external source. It reads data from an input stream and produces an output stream to be filtered and parsed. If you implement a UDSource, you must also implement a corresponding
SourceFactory.
10.1.1 - UDSource class
You can subclass the UDSource class when you need to load data from a source type that COPY does not already support.
You can subclass the UDSource class when you need to load data from a source type that COPY does not already support.
Each instance of your UDSource subclass reads from a single data source. Examples of a single data source are a single file or the results of a single function call to a RESTful web application.
UDSource methods
Your UDSource subclass must override process() or processWithMetadata():
Note
processWithMetadata() is available only for user-defined extensions (UDxs) written in the C++ programming language.
-
process() reads the raw input stream as one large file. If there are any errors or failures, the entire load fails.
-
processWithMetadata() is useful when the data source has metadata about record boundaries available in some structured format that's separate from the data payload. With this interface, the source emits a record length for each record in addition to the data.
By implementing processWithMetadata() instead of process() in each phase, you can retain this record length metadata throughout the load stack, which enables a more efficient parse that can recover from errors on a per-message basis, rather than a per-file or per-source basis. KafkaSource and the Kafka parsers (KafkaAvroParser, KafkaJSONParser, and KafkaParser) use this mechanism to support per-Kafka-message rejections when individual Kafka messages are cannot be parsed.
Note
To implement processWithMetadata(), you must override useSideChannel() to return true.
Additionally, you can override the other UDSource class methods.
Source execution
The following sections detail the execution sequence each time a user-defined source is called. The following example overrides the process() method.
Setting Up
COPY calls setup() before the first time it calls process(). Use setup() to perform any necessary setup steps to access the data source. This method establishes network connections, opens files, and similar tasks that need to be performed before the UDSource can read data from the data source. Your object might be destroyed and re-created during use, so make sure that your object is restartable.
Processing a Source
COPY calls process() repeatedly during query execution to read data and write it to the DataBuffer passed as a parameter. This buffer is then passed to the first filter.
If the source runs out of input, or fills the output buffer, it must return the value StreamState.OUTPUT_NEEDED. When Vertica gets this return value, it will call the method again. This second call occurs after the output buffer has been processed by the next stage in the data-load process. Returning StreamState.DONE indicates that all of the data from the source has been read.
The user can cancel the load operation, which aborts reading.
Tearing Down
COPY calls destroy() after the last time that process() is called. This method frees any resources reserved by the setup() or process() methods, such as file handles or network connections that the setup() method allocated.
Accessors
A source can define two accessors, getSize() and getUri().
COPY might call getSize() to estimate the number of bytes of data to be read before calling process(). This value is an estimate only and is used to indicate the file size in the LOAD_STREAMS table. Because Vertica can call this method before calling setup(), getSize() must not rely on any resources allocated by setup().
This method should not leave any resources open. For example, do not save any file handles opened by getSize() for use by the process() method. Doing so can exhaust the available resources, because Vertica calls getSize() on all instances of your UDSource subclass before any data is loaded. If many data sources are being opened, these open file handles could use up the system's supply of file handles. Thus, none would remain available to perform the actual data load.
Vertica calls getUri() during execution to update status information about which resources are currently being loaded. It returns the URI of the data source being read by this UDSource.
API
The UDSource API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface);
virtual bool useSideChannel();
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &output)=0;
virtual StreamState processWithMetadata(ServerInterface &srvInterface, DataBuffer &output, LengthBuffer &output_lengths)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface);
virtual vint getSize();
virtual std::string getUri();
The UDSource API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface) throws UdfException;
public abstract StreamState process(ServerInterface srvInterface, DataBuffer output) throws UdfException;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface) throws UdfException;
public Integer getSize();
public String getUri();
10.1.2 - SourceFactory class
If you write a source, you must also write a source factory.
If you write a source, you must also write a source factory. Your subclass of the SourceFactory class is responsible for:
-
Performing the initial validation of the parameters passed to your UDSource.
-
Setting up any data structures your UDSource instances need to perform their work. This information can include recording which nodes will read which data source.
-
Creating one instance of your UDSource subclass for each data source (or portion thereof) that your function reads on each host.
The simplest source factory creates one UDSource instance per data source per executor node. You can also use multiple concurrent UDSource instances on each node. This behavior is called concurrent load. To support both options, SourceFactory has two versions of the method that creates the sources. You must implement exactly one of them.
Source factories are singletons. Your subclass must be stateless, with no fields containing data. The subclass also must not modify any global variables.
SourceFactory methods
The SourceFactory class defines several methods. Your class must override prepareUDSources(); it may override the other methods.
Setting up
Vertica calls plan() once on the initiator node to perform the following tasks:
-
Check the parameters the user supplied to the function call in the COPY statement and provide error messages if there are any issues. You can read the parameters by getting a ParamReader object from the instance of ServerInterface passed into the plan() method.
-
Decide which hosts in the cluster will read the data source. How you divide up the work depends on the source your function is reading. Some sources can be split across many hosts, such as a source that reads data from many URLs. Others, such as an individual local file on a host's file system, can be read only by a single specified host.
You store the list of hosts to read the data source by calling the setTargetNodes() method on the NodeSpecifyingPlanContext object. This object is passed into your plan() method.
-
Store any information that the individual hosts need to process the data sources in the NodeSpecifyingPlanContext instance passed to the plan() method. For example, you could store assignments that tell each host which data sources to process. The plan() method runs only on the initiator node, and the prepareUDSources() method runs on each host reading from a data source. Therefore, this object is the only means of communication between them.
You store data in the NodeSpecifyingPlanContext by getting a ParamWriter object from the getWriter() method. You then write parameters by calling methods on the ParamWriter such as setString().
Note
ParamWriter offers the ability to store only simple data types. For complex types, you must serialize the data in some manner and store it as a string or long string.
Creating sources
Vertica calls prepareUDSources() on all hosts that the plan() method selected to load data. This call instantiates and returns a list of UDSource subclass instances. If you are not using concurrent load, return one UDSource for each of the sources that the host is assigned to process. If you are using concurrent load, use the version of the method that takes an ExecutorPlanContext as a parameter, and return as many sources as you can use. Your factory must implement exactly one of these methods.
Note
In the C++ API, the function that supports concurrent load is named prepareUDSourcesExecutor(). In the Java API the class provides two overloads of prepareUDSources().
For concurrent load, you can find out how many threads are available on the node to run UDSource instances by calling getLoadConcurrency() on the ExecutorPlanContext that is passed in.
Defining parameters
Implement getParameterTypes() to define the names and types of parameters that your source uses. Vertica uses this information to warn callers about unknown or missing parameters. Vertica ignores unknown parameters and uses default values for missing parameters. While you should define the types and parameters for your function, you are not required to override this method.
Requesting threads for concurrent load
When a source factory creates sources on an executor node, by default, it creates one thread per source. If your sources can use multiple threads, implement getDesiredThreads(). Vertica calls this method before it calls prepareUDSources(), so you can also use it to decide how many sources to create. Return the number of threads your factory can use for sources. The maximum number of available threads is passed in, so you can take that into account. The value your method returns is a hint, not a guarantee; each executor node determines the number of threads to allocate. The FilePortionSourceFactory example implements this method; see C++ example: concurrent load.
You can allow your source to have control over parallelism, meaning that it can divide a single input into multiple load streams, by implementing isSourceApportionable(). Returning true from this method does not guarantee that the source will apportion the load. However, returning false indicates that it will not try to do so. See Apportioned load for more information.
Often, a SourceFactory that implements getDesiredThreads() also uses apportioned load. However, using apportioned load is not a requirement. A source reading from Kafka streams, for example, could use multiple threads without ssapportioning.
API
The SourceFactory API provides the following methods for extension by subclasses:
virtual void plan(ServerInterface &srvInterface, NodeSpecifyingPlanContext &planCtxt);
// must implement exactly one of prepareUDSources() or prepareUDSourcesExecutor()
virtual std::vector< UDSource * > prepareUDSources(ServerInterface &srvInterface,
NodeSpecifyingPlanContext &planCtxt);
virtual std::vector< UDSource * > prepareUDSourcesExecutor(ServerInterface &srvInterface,
ExecutorPlanContext &planCtxt);
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
virtual bool isSourceApportionable();
ssize_t getDesiredThreads(ServerInterface &srvInterface,
ExecutorPlanContext &planContext);
After creating your SourceFactory, you must register it with the RegisterFactory macro.
The SourceFactory API provides the following methods for extension by subclasses:
public void plan(ServerInterface srvInterface, NodeSpecifyingPlanContext planCtxt)
throws UdfException;
// must implement one overload of prepareUDSources()
public ArrayList< UDSource > prepareUDSources(ServerInterface srvInterface,
NodeSpecifyingPlanContext planCtxt)
throws UdfException;
public ArrayList< UDSource > prepareUDSources(ServerInterface srvInterface,
ExecutorPlanContext planCtxt)
throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
public boolean isSourceApportionable();
public int getDesiredThreads(ServerInterface srvInterface,
ExecutorPlanContext planCtxt)
throws UdfException;
10.1.3 - C++ example: CurlSource
The CurlSource example allows you to use cURL to open and read in a file over HTTP.
The CurlSource example allows you to use cURL to open and read in a file over HTTP. The example provided is part of: /opt/vertica/sdk/examples/SourceFunctions/cURL.cpp.
Source implementation
This example uses the helper library available in /opt/vertica/sdk/examples/HelperLibraries/.
CurlSource loads the data in chunks. If the parser encounters an EndOfFile marker, then the process() method returns DONE. Otherwise, the method returns OUTPUT_NEEDED and processes another chunk of data. The functions included in the helper library (such as url_fread() and url_fopen()) are based on examples that come with the libcurl library. For an example, see http://curl.haxx.se/libcurl/c/fopen.html.
The setup() function opens a file handle and the destroy() function closes it. Both use functions from the helper library.
class CurlSource : public UDSource {private:
URL_FILE *handle;
std::string url;
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &output) {
output.offset = url_fread(output.buf, 1, output.size, handle);
return url_feof(handle) ? DONE : OUTPUT_NEEDED;
}
public:
CurlSource(std::string url) : url(url) {}
void setup(ServerInterface &srvInterface) {
handle = url_fopen(url.c_str(),"r");
}
void destroy(ServerInterface &srvInterface) {
url_fclose(handle);
}
};
Factory implementation
CurlSourceFactory produces CurlSource instances.
class CurlSourceFactory : public SourceFactory {public:
virtual void plan(ServerInterface &srvInterface,
NodeSpecifyingPlanContext &planCtxt) {
std::vector<std::string> args = srvInterface.getParamReader().getParamNames();
/* Check parameters */
if (args.size() != 1 || find(args.begin(), args.end(), "url") == args.end()) {
vt_report_error(0, "You must provide a single URL.");
}
/* Populate planData */
planCtxt.getWriter().getStringRef("url").copy(
srvInterface.getParamReader().getStringRef("url"));
/* Assign Nodes */
std::vector<std::string> executionNodes = planCtxt.getClusterNodes();
while (executionNodes.size() > 1) executionNodes.pop_back();
// Only run on the first node in the list.
planCtxt.setTargetNodes(executionNodes);
}
virtual std::vector<UDSource*> prepareUDSources(ServerInterface &srvInterface,
NodeSpecifyingPlanContext &planCtxt) {
std::vector<UDSource*> retVal;
retVal.push_back(vt_createFuncObj(srvInterface.allocator, CurlSource,
planCtxt.getReader().getStringRef("url").str()));
return retVal;
}
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes) {
parameterTypes.addVarchar(65000, "url");
}
};
RegisterFactory(CurlSourceFactory);
10.1.4 - C++ example: concurrent load
The FilePortionSource example demonstrates the use of concurrent load.
The FilePortionSource example demonstrates the use of concurrent load. This example is a refinement of the FileSource example. Each input file is divided into portions and distributed to FilePortionSource instances. The source accepts a list of offsets at which to break the input into portions; if offsets are not provided, the source divides the input dynamically.
Concurrent load is handled in the factory, so this discussion focuses on FilePortionSourceFactory. The full code for the example is located in /opt/vertica/sdk/examples/ApportionLoadFunctions. The distribution also includes a Java version of this example.
Loading and using the example
Load and use the FilePortionSource example as follows.
=> CREATE LIBRARY FilePortionLib AS '/home/dbadmin/FP.so';
=> CREATE SOURCE FilePortionSource AS LANGUAGE 'C++'
-> NAME 'FilePortionSourceFactory' LIBRARY FilePortionLib;
=> COPY t WITH SOURCE FilePortionSource(file='g1/*.dat', nodes='initiator,e0,e1', offsets = '0,380000,820000');
=> COPY t WITH SOURCE FilePortionSource(file='g2/*.dat', nodes='e0,e1,e2', local_min_portion_size = 2097152);
Implementation
Concurrent load affects the source factory in two places, getDesiredThreads() and prepareUDSourcesExecutor().
getDesiredThreads()
The getDesiredThreads() member function determines the number of threads to request. Vertica calls this member function on each executor node before calling prepareUDSourcesExecutor().
The function begins by breaking an input file path, which might be a glob, into individual paths. This discussion omits those details. If apportioned load is not being used, then the function allocates one source per file.
virtual ssize_t getDesiredThreads(ServerInterface &srvInterface,
ExecutorPlanContext &planCtxt) {
const std::string filename = srvInterface.getParamReader().getStringRef("file").str();
std::vector<std::string> paths;
// expand the glob - at least one thread per source.
...
// figure out how to assign files to sources
const std::string nodeName = srvInterface.getCurrentNodeName();
const size_t nodeId = planCtxt.getWriter().getIntRef(nodeName);
const size_t numNodes = planCtxt.getTargetNodes().size();
if (!planCtxt.canApportionSource()) {
/* no apportioning, so the number of files is the final number of sources */
std::vector<std::string> *expanded =
vt_createFuncObject<std::vector<std::string> >(srvInterface.allocator, paths);
/* save expanded paths so we don't have to compute expansion again */
planCtxt.getWriter().setPointer("expanded", expanded);
return expanded->size();
}
// ...
If the source can be apportioned, then getDesiredThreads() uses the offsets that were passed as arguments to the factory to divide the file into portions. It then allocates portions to available nodes. This function does not actually assign sources directly; this work is done to determine how many threads to request.
else if (srvInterface.getParamReader().containsParameter("offsets")) {
// if the offsets are specified, then we will have a fixed number of portions per file.
// Round-robin assign offsets to nodes.
// ...
/* Construct the portions that this node will actually handle.
* This isn't changing (since the offset assignments are fixed),
* so we'll build the Portion objects now and make them available
* to prepareUDSourcesExecutor() by putting them in the ExecutorContext.
*
* We don't know the size of the last portion, since it depends on the file
* size. Rather than figure it out here we will indicate it with -1 and
* defer that to prepareUDSourcesExecutor().
*/
std::vector<Portion> *portions =
vt_createFuncObject<std::vector<Portion>>(srvInterface.allocator);
for (std::vector<size_t>::const_iterator offset = offsets.begin();
offset != offsets.end(); ++offset) {
Portion p(*offset);
p.is_first_portion = (offset == offsets.begin());
p.size = (offset + 1 == offsets.end() ? -1 : (*(offset + 1) - *offset));
if ((offset - offsets.begin()) % numNodes == nodeId) {
portions->push_back(p);
srvInterface.log("FilePortionSource: assigning portion %ld: [offset = %lld, size = %lld]",
offset - offsets.begin(), p.offset, p.size);
}
}
The function now has all the portions and thus the number of portions:
planCtxt.getWriter().setPointer("portions", portions);
/* total number of threads we want is the number of portions per file, which is fixed */
return portions->size() * expanded->size();
} // end of "offsets" parameter
If offsets were not provided, the function divides the file into portions dynamically, one portion per thread. This discussion omits the details of this computation. There is no point in requesting more threads than are available, so the function calls getMaxAllowedThreads() on the PlanContext (an argument to the function) to set an upper bound:
if (portions->size() >= planCtxt.getMaxAllowedThreads()) {
return paths.size();
}
See the full example for the details of how this function divides the file into portions.
This function uses the vt_createFuncObject template to create objects. Vertica calls the destructors of returned objects created using this macro, but it does not call destructors for other objects like vectors. You must call these destructors yourself to avoid memory leaks. In this example, these calls are made in prepareUDSourcesExecutor().
prepareUDSourcesExecutor()
The prepareUDSourcesExecutor() member function, like getDesiredThreads(), has separate blocks of code depending on whether offsets are provided. In both cases, the function breaks input into portions and creates UDSource instances for them.
If the function is called with offsets, prepareUDSourcesExecutor() calls prepareCustomizedPortions(). This function follows.
/* prepare portions as determined via the "offsets" parameter */
void prepareCustomizedPortions(ServerInterface &srvInterface,
ExecutorPlanContext &planCtxt,
std::vector<UDSource *> &sources,
const std::vector<std::string> &expandedPaths,
std::vector<Portion> &portions) {
for (std::vector<std::string>::const_iterator filename = expandedPaths.begin();
filename != expandedPaths.end(); ++filename) {
/*
* the "portions" vector contains the portions which were generated in
* "getDesiredThreads"
*/
const size_t fileSize = getFileSize(*filename);
for (std::vector<Portion>::const_iterator portion = portions.begin();
portion != portions.end(); ++portion) {
Portion fportion(*portion);
if (fportion.size == -1) {
/* as described above, this means from the offset to the end */
fportion.size = fileSize - portion->offset;
sources.push_back(vt_createFuncObject<FilePortionSource>(srvInterface.allocator,
*filename, fportion));
} else if (fportion.size > 0) {
sources.push_back(vt_createFuncObject<FilePortionSource>(srvInterface.allocator,
*filename, fportion));
}
}
}
}
If prepareUDSourcesExecutor() is called without offsets, then it must decide how many portions to create.
The base case is to use one portion per source. However, if extra threads are available, the function divides the input into more portions so that a source can process them concurrently. Then prepareUDSourcesExecutor() calls prepareGeneratedPortions() to create the portions. This function begins by calling getLoadConcurrency() on the plan context to find out how many threads are available.
void prepareGeneratedPortions(ServerInterface &srvInterface,
ExecutorPlanContext &planCtxt,
std::vector<UDSource *> &sources,
std::map<std::string, Portion> initialPortions) {
if ((ssize_t) initialPortions.size() >= planCtxt.getLoadConcurrency()) {
/* all threads will be used, don't bother splitting into portions */
for (std::map<std::string, Portion>::const_iterator file = initialPortions.begin();
file != initialPortions.end(); ++file) {
sources.push_back(vt_createFuncObject<FilePortionSource>(srvInterface.allocator,
file->first, file->second));
} // for
return;
} // if
// Now we can split files to take advantage of potentially-unused threads.
// First sort by size (descending), then we will split the largest first.
// details elided...
}
See the source code for the full implementation of this example.
10.1.5 - Java example: FileSource
The example shown in this section is a simple UDL Source function named FileSource, This function loads data from files stored on the host's file system (similar to the standard COPY statement).
The example shown in this section is a simple UDL Source function named FileSource, This function loads data from files stored on the host's file system (similar to the standard COPY statement). To call FileSource, you must supply a parameter named file that contains the absolute path to one or more files on the host file system. You can specify multiple files as a comma-separated list.
The FileSource function also accepts an optional parameter, named nodes, that indicates which nodes should load the files. If you do not supply this parameter, the function defaults to loading data on the initiator node only. Because this example is simple, the nodes load only the files from their own file systems. Any files in the file parameter must exist on all of the hosts in the nodes parameter. The FileSource UDSource attempts to load all of the files in the file parameter on all of the hosts in the nodes parameter.
Generating files
You can use the following Python script to generate files and distribute them to hosts in your Vertica cluster. With these files, you can experiment with the example UDSource function. Running the function requires passwordless-SSH logins to copy the files to the other hosts. Therefore, you must run the script using the database administrator account on one of your database hosts.
#!/usr/bin/python
# Save this file as UDLDataGen.py
import string
import random
import sys
import os
# Read in the dictionary file to provide random words. Assumes the words
# file is located in /usr/share/dict/words
wordFile = open("/usr/share/dict/words")
wordDict = []
for line in wordFile:
if len(line) > 6:
wordDict.append(line.strip())
MAXSTR = 4 # Maximum number of words to concatentate
NUMROWS = 1000 # Number of rows of data to generate
#FILEPATH = '/tmp/UDLdata.txt' # Final filename to use for UDL source
TMPFILE = '/tmp/UDLtemp.txt' # Temporary filename.
# Generate a random string by concatenating several words together. Max
# number of words set by MAXSTR
def randomWords():
words = [random.choice(wordDict) for n in xrange(random.randint(1, MAXSTR))]
sentence = " ".join(words)
return sentence
# Create a temporary data file that will be moved to a node. Number of
# rows for the file is set by NUMROWS. Adds the name of the node which will
# get the file, to show which node loaded the data.
def generateFile(node):
outFile = open(TMPFILE, 'w')
for line in xrange(NUMROWS):
outFile.write('{0}|{1}|{2}\n'.format(line,randomWords(),node))
outFile.close()
# Copy the temporary file to a node. Only works if passwordless SSH login
# is enabled, which it is for the database administrator account on
# Vertica hosts.
def copyFile(fileName,node):
os.system('scp "%s" "%s:%s"' % (TMPFILE, node, fileName) )
# Loop through the comma-separated list of nodes given in the first
# parameter, creating and copying data files whose full comma-separated
# paths are passed in the second parameter
for node in [x.strip() for x in sys.argv[1].split(',')]:
for fileName in [y.strip() for y in sys.argv[2].split(',')]:
print "generating file", fileName, "for", node
generateFile(node)
print "Copying file to",node
copyFile(fileName,node)
You call this script by giving it a comma-separated list of hosts to receive the files and a comma-separated list of absolute paths of files to generate. For example:
$ python UDLDataGen.py v_vmart_node0001,v_vmart_node0002,v_vmart_node0003 /tmp/UDLdata01.txt,/tmp/UDLdata02.txt,UDLdata03.txt
This script generates files that contain a thousand rows of columns delimited with the pipe character (|). These columns contain an index value, a set of random words, and the node for which the file was generated, as shown in the following output sample:
0|megabits embanks|v_vmart_node0001
1|unneatly|v_vmart_node0001
2|self-precipitation|v_vmart_node0001
3|antihistamine scalados Vatter|v_vmart_node0001
Loading and using the example
Load and use the FileSource UDSource as follows:
=> --Load library and create the source function
=> CREATE LIBRARY JavaLib AS '/home/dbadmin/JavaUDlLib.jar'
-> LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE SOURCE File as LANGUAGE 'JAVA' NAME
-> 'com.mycompany.UDL.FileSourceFactory' LIBRARY JavaLib;
CREATE SOURCE FUNCTION
=> --Create a table to hold the data loaded from files
=> CREATE TABLE t (i integer, text VARCHAR, node VARCHAR);
CREATE TABLE
=> -- Copy a single file from the currently host using the FileSource
=> COPY t SOURCE File(file='/tmp/UDLdata01.txt');
Rows Loaded
-------------
1000
(1 row)
=> --See some of what got loaded.
=> SELECT * FROM t WHERE i < 5 ORDER BY i;
i | text | node
---+-------------------------------+-----------------
0 | megabits embanks | v_vmart_node0001
1 | unneatly | v_vmart_node0001
2 | self-precipitation | v_vmart_node0001
3 | antihistamine scalados Vatter | v_vmart_node0001
4 | fate-menaced toilworn | v_vmart_node0001
(5 rows)
=> TRUNCATE TABLE t;
TRUNCATE TABLE
=> -- Now load a file from three hosts. All of these hosts must have a file
=> -- named /tmp/UDLdata01.txt, each with different data
=> COPY t SOURCE File(file='/tmp/UDLdata01.txt',
-> nodes='v_vmart_node0001,v_vmart_node0002,v_vmart_node0003');
Rows Loaded
-------------
3000
(1 row)
=> --Now see what has been loaded
=> SELECT * FROM t WHERE i < 5 ORDER BY i,node ;
i | text | node
---+-------------------------------------------------+--------
0 | megabits embanks | v_vmart_node0001
0 | nimble-eyed undupability frowsier | v_vmart_node0002
0 | Circean nonrepellence nonnasality | v_vmart_node0003
1 | unneatly | v_vmart_node0001
1 | floatmaker trabacolos hit-in | v_vmart_node0002
1 | revelrous treatableness Halleck | v_vmart_node0003
2 | self-precipitation | v_vmart_node0001
2 | whipcords archipelagic protodonatan copycutter | v_vmart_node0002
2 | Paganalian geochemistry short-shucks | v_vmart_node0003
3 | antihistamine scalados Vatter | v_vmart_node0001
3 | swordweed touristical subcommanders desalinized | v_vmart_node0002
3 | batboys | v_vmart_node0003
4 | fate-menaced toilworn | v_vmart_node0001
4 | twice-wanted cirrocumulous | v_vmart_node0002
4 | doon-head-clock | v_vmart_node0003
(15 rows)
=> TRUNCATE TABLE t;
TRUNCATE TABLE
=> --Now copy from several files on several hosts
=> COPY t SOURCE File(file='/tmp/UDLdata01.txt,/tmp/UDLdata02.txt,/tmp/UDLdata03.txt'
-> ,nodes='v_vmart_node0001,v_vmart_node0002,v_vmart_node0003');
Rows Loaded
-------------
9000
(1 row)
=> SELECT * FROM t WHERE i = 0 ORDER BY node ;
i | text | node
---+---------------------------------------------+--------
0 | Awolowo Mirabilis D'Amboise | v_vmart_node0001
0 | sortieing Divisionism selfhypnotization | v_vmart_node0001
0 | megabits embanks | v_vmart_node0001
0 | nimble-eyed undupability frowsier | v_vmart_node0002
0 | thiaminase hieroglypher derogated soilborne | v_vmart_node0002
0 | aurigraphy crocket stenocranial | v_vmart_node0002
0 | Khulna pelmets | v_vmart_node0003
0 | Circean nonrepellence nonnasality | v_vmart_node0003
0 | matterate protarsal | v_vmart_node0003
(9 rows)
Parser implementation
The following code shows the source of the FileSource class that reads a file from the host file system. The constructor, which is called by FileSourceFactory.prepareUDSources(), gets the absolute path for the file containing the data to be read. The setup() method opens the file and the destroy() method closes it. The process() method reads from the file into a buffer provided by the instance of the DataBuffer class passed to it as a parameter. If the read operation filled the output buffer, it returns OUTPUT_NEEDED. This value tells Vertica to call the method again after the next stage of the load has processed the output buffer. If the read did not fill the output buffer, then process() returns DONE to indicate it has finished processing the data source.
package com.mycompany.UDL;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.RandomAccessFile;
import com.vertica.sdk.DataBuffer;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.State.StreamState;
import com.vertica.sdk.UDSource;
import com.vertica.sdk.UdfException;
public class FileSource extends UDSource {
private String filename; // The file for this UDSource to read
private RandomAccessFile reader; // handle to read from file
// The constructor just stores the absolute filename of the file it will
// read.
public FileSource(String filename) {
super();
this.filename = filename;
}
// Called before Vertica starts requesting data from the data source.
// In this case, setup needs to open the file and save to the reader
// property.
@Override
public void setup(ServerInterface srvInterface ) throws UdfException{
try {
reader = new RandomAccessFile(new File(filename), "r");
} catch (FileNotFoundException e) {
// In case of any error, throw a UDfException. This will terminate
// the data load.
String msg = e.getMessage();
throw new UdfException(0, msg);
}
}
// Called after data has been loaded. In this case, close the file handle.
@Override
public void destroy(ServerInterface srvInterface ) throws UdfException {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
String msg = e.getMessage();
throw new UdfException(0, msg);
}
}
}
@Override
public StreamState process(ServerInterface srvInterface, DataBuffer output)
throws UdfException {
// Read up to the size of the buffer provided in the DataBuffer.buf
// property. Here we read directly from the file handle into the
// buffer.
long offset;
try {
offset = reader.read(output.buf,output.offset,
output.buf.length-output.offset);
} catch (IOException e) {
// Throw an exception in case of any errors.
String msg = e.getMessage();
throw new UdfException(0, msg);
}
// Update the number of bytes processed so far by the data buffer.
output.offset +=offset;
// See end of data source has been reached, or less data was read
// than can fit in the buffer
if(offset == -1 || offset < output.buf.length) {
// No more data to read.
return StreamState.DONE;
}else{
// Tell Vertica to call again when buffer has been emptied
return StreamState.OUTPUT_NEEDED;
}
}
}
Factory implementation
The following code is a modified version of the example Java UDsource function provided in the Java UDx support package. You can find the full example in /opt/vertica/sdk/examples/JavaUDx/UDLFuctions/com/vertica/JavaLibs/FileSourceFactory.java. Its override of the plan() method verifies that the user supplied the required file parameter. If the user also supplied the optional nodes parameter, this method verifies that the nodes exist in the Vertica cluster. If there is a problem with either parameter, the method throws an exception to return an error to the user. If there are no issues with the parameters, the plan() method stores their values in the plan context object.
package com.mycompany.UDL;
import java.util.ArrayList;
import java.util.Vector;
import com.vertica.sdk.NodeSpecifyingPlanContext;
import com.vertica.sdk.ParamReader;
import com.vertica.sdk.ParamWriter;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.SizedColumnTypes;
import com.vertica.sdk.SourceFactory;
import com.vertica.sdk.UDSource;
import com.vertica.sdk.UdfException;
public class FileSourceFactory extends SourceFactory {
// Called once on the initiator host to do initial setup. Checks
// parameters and chooses which nodes will do the work.
@Override
public void plan(ServerInterface srvInterface,
NodeSpecifyingPlanContext planCtxt) throws UdfException {
String nodes; // stores the list of nodes that will load data
// Get copy of the parameters the user supplied to the UDSource
// function call.
ParamReader args = srvInterface.getParamReader();
// A list of nodes that will perform work. This gets saved as part
// of the plan context.
ArrayList<String> executionNodes = new ArrayList<String>();
// First, ensure the user supplied the file parameter
if (!args.containsParameter("file")) {
// Withut a file parameter, we cannot continue. Throw an
// exception that will be caught by the Java UDx framework.
throw new UdfException(0, "You must supply a file parameter");
}
// If the user specified nodes to read the file, parse the
// comma-separated list and save. Otherwise, assume just the
// Initiator node has the file to read.
if (args.containsParameter("nodes")) {
nodes = args.getString("nodes");
// Get list of nodes in cluster, to ensure that the node the
// user specified actually exists. The list of nodes is available
// from the planCTxt (plan context) object,
ArrayList<String> clusterNodes = planCtxt.getClusterNodes();
// Parse the string parameter "nodes" which
// is a comma-separated list of node names.
String[] nodeNames = nodes.split(",");
for (int i = 0; i < nodeNames.length; i++){
// See if the node the user gave us actually exists
if(clusterNodes.contains(nodeNames[i]))
// Node exists. Add it to list of nodes.
executionNodes.add(nodeNames[i]);
else{
// User supplied node that doesn't exist. Throw an
// exception so the user is notified.
String msg = String.format("Specified node '%s' but no" +
" node by that name is available. Available nodes "
+ "are \"%s\".",
nodeNames[i], clusterNodes.toString());
throw new UdfException(0, msg);
}
}
} else {
// User did not supply a list of node names. Assume the initiator
// is the only host that will read the file. The srvInterface
// instance passed to this method has a getter for the current
// node.
executionNodes.add(srvInterface.getCurrentNodeName());
}
// Set the target node(s) in the plan context
planCtxt.setTargetNodes(executionNodes);
// Set parameters for each node reading data that tells it which
// files it will read. In this simple example, just tell it to
// read all of the files the user passed in the file parameter
String files = args.getString("file");
// Get object to write parameters into the plan context object.
ParamWriter nodeParams = planCtxt.getWriter();
// Loop through list of execution nodes, and add a parameter to plan
// context named for each node performing the work, which tells it the
// list of files it will process. Each node will look for a
// parameter named something like "filesForv_vmart_node0002" in its
// prepareUDSources() method.
for (int i = 0; i < executionNodes.size(); i++) {
nodeParams.setString("filesFor" + executionNodes.get(i), files);
}
}
// Called on each host that is reading data from a source. This method
// returns an array of UDSource objects that process each source.
@Override
public ArrayList<UDSource> prepareUDSources(ServerInterface srvInterface,
NodeSpecifyingPlanContext planCtxt) throws UdfException {
// An array to hold the UDSource subclasses that we instaniate
ArrayList<UDSource> retVal = new ArrayList<UDSource>();
// Get the list of files this node is supposed to process. This was
// saved by the plan() method in the plancontext
String myName = srvInterface.getCurrentNodeName();
ParamReader params = planCtxt.getReader();
String fileNames = params.getString("filesFor" + myName);
// Note that you can also be lazy and directly grab the parameters
// the user passed to the UDSource functon in the COPY statement directly
// by getting parameters from the ServerInterface object. I.e.:
//String fileNames = srvInterface.getParamReader().getString("file");
// Split comma-separated list into a single list.
String[] fileList = fileNames.split(",");
for (int i = 0; i < fileList.length; i++){
// Instantiate a FileSource object (which is a subclass of UDSource)
// to read each file. The constructor for FileSource takes the
// file name of the
retVal.add(new FileSource(fileList[i]));
}
// Return the collection of FileSource objects. They will be called,
// in turn, to read each of the files.
return retVal;
}
// Declares which parameters that this factory accepts.
@Override
public void getParameterType(ServerInterface srvInterface,
SizedColumnTypes parameterTypes) {
parameterTypes.addVarchar(65000, "file");
parameterTypes.addVarchar(65000, "nodes");
}
}
10.2 - User-defined filter
User-defined filter functions allow you to manipulate data obtained from a source in various ways.
User-defined filter functions allow you to manipulate data obtained from a source in various ways. For example, a filter can:
-
Process a compressed file in a compression format not natively supported by Vertica.
-
Take UTF-16-encoded data and transcode it to UTF-8 encoding.
-
Perform search-and-replace operations on data before it is loaded into Vertica.
You can also process data through multiple filters before it is loaded into Vertica. For instance, you could unzip a file compressed with GZip, convert the content from UTF-16 to UTF-8, and finally search and replace certain text strings.
If you implement a UDFilter, you must also implement a corresponding FilterFactory.
See UDFilter class and FilterFactory class for API details.
10.2.1 - UDFilter class
The UDFilter class is responsible for reading raw input data from a source and preparing it to be loaded into Vertica or processed by a parser.
The UDFilter class is responsible for reading raw input data from a source and preparing it to be loaded into Vertica or processed by a parser. This preparation may involve decompression, re-encoding, or any other sort of binary manipulation.
A UDFilter is instantiated by a corresponding FilterFactory on each host in the Vertica cluster that is performing filtering for the data source.
UDFilter methods
Your UDFilter subclass must override process() or processWithMetadata():
Note
processWithMetadata() is available only for user-defined extensions (UDxs) written in the C++ programming language.
-
process() reads the raw input stream as one large file. If there are any errors or failures, the entire load fails.
You can implement process() when the upstream source implements processWithMetadata(), but it might result in parsing errors.
-
processWithMetadata() is useful when the data source has metadata about record boundaries available in some structured format that's separate from the data payload. With this interface, the source emits a record length for each record in addition to the data.
By implementing processWithMetadata() instead of process() in each phase, you can retain this record length metadata throughout the load stack, which enables a more efficient parse that can recover from errors on a per-message basis, rather than a per-file or per-source basis. KafkaSource and the Kafka parsers (KafkaAvroParser, KafkaJSONParser, and KafkaParser) use this mechanism to support per-Kafka-message rejections when individual Kafka messages are corrupted.
Using processWithMetadata() with your UDFilter subclass enables you to write an internal filter that integrates the record length metadata from the source into the data stream, producing a single byte stream with boundary information to help parsers extract and process individual messages. KafkaInsertDelimeters and KafkaInsertLengths use this mechanism to insert message boundary information into Kafka data streams.
Note
To implement processWithMetadata(), you must override useSideChannel() to return true.
Optionally, you can override other UDFilter class methods.
Filter execution
The following sections detail the execution sequence each time a user-defined filter is called. The following example overrides the process() method.
Setting Up
COPY calls setup() before the first time it calls process(). Use setup() to perform any necessary setup steps that your filter needs to operate, such as initializing data structures to be used during filtering. Your object might be destroyed and re-created during use, so make sure that your object is restartable.
Filtering Data
COPY calls process() repeatedly during query execution to filter data. The method receives two instances of the DataBuffer class among its parameters, an input and an output buffer. Your implementation should read from the input buffer, manipulate it in some manner (such as decompressing it), and write the result to the output. A one-to-one correlation between the number of bytes your implementation reads and the number it writes might not exist. The process() method should process data until it either runs out of data to read or runs out of space in the output buffer. When one of these conditions occurs, your method should return one of the following values defined by StreamState:
-
OUTPUT_NEEDED if the filter needs more room in its output buffer.
-
INPUT_NEEDED if the filter has run out of input data (but the data source has not yet been fully processed).
-
DONE if the filter has processed all of the data in the data source.
-
KEEP_GOING if the filter cannot proceed for an extended period of time. The method will be called again, so do not block indefinitely. If you do, then you prevent your user from canceling the query.
Before returning, your process() method must set the offset property in each DataBuffer. In the input buffer, set it to the number of bytes that the method successfully read. In the output buffer, set it to the number of bytes the method wrote. Setting these properties allows the next call to process() to resume reading and writing data at the correct points in the buffers.
Your process() method also needs to check the InputState object passed to it to determine if there is more data in the data source. When this object is equal to END_OF_FILE, then the data remaining in the input data is the last data in the data source. Once it has processed all of the remaining data, process() must return DONE.
Tearing Down
COPY calls destroy() after the last time it calls process(). This method frees any resources reserved by the setup() or process() methods. Vertica calls this method after the process() method indicates it has finished filtering all of the data in the data stream.
If there are still data sources that have not yet been processed, Vertica may later call setup() on the object again. On subsequent calls Vertica directs the method to filter the data in a new data stream. Therefore, your destroy() method should leave an object of your UDFilter subclass in a state where the setup() method can prepare it to be reused.
API
The UDFilter API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface);
virtual bool useSideChannel();
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &input, InputState input_state, DataBuffer &output)=0;
virtual StreamState processWithMetadata(ServerInterface &srvInterface, DataBuffer &input,
LengthBuffer &input_lengths, InputState input_state, DataBuffer &output, LengthBuffer &output_lengths)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface);
The UDFilter API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface) throws UdfException;
public abstract StreamState process(ServerInterface srvInterface, DataBuffer input,
InputState input_state, DataBuffer output)
throws UdfException;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface) throws UdfException;
The UDFilter API provides the following methods for extension by subclasses:
class PyUDFilter(vertica_sdk.UDFilter):
def __init__(self):
pass
def setup(self, srvInterface):
pass
def process(self, srvInterface, inputbuffer, outputbuffer, inputstate):
# User process data here, and put into outputbuffer.
return StreamState.DONE
10.2.2 - FilterFactory class
If you write a filter, you must also write a filter factory to produce filter instances.
If you write a filter, you must also write a filter factory to produce filter instances. To do so, subclass the FilterFactory class.
Your subclass performs the initial validation and planning of the function execution and instantiates UDFilter objects on each host that will be filtering data.
Filter factories are singletons. Your subclass must be stateless, with no fields containing data. The subclass also must not modify any global variables.
FilterFactory methods
The FilterFactory class defines the following methods. Your subclass must override the prepare() method. It may override the other methods.
Setting up
Vertica calls plan() once on the initiator node, to perform the following tasks:
-
Check any parameters that have been passed from the function call in the COPY statement and error messages if there are any issues. You read the parameters by getting a ParamReader object from the instance of ServerInterface passed into your plan() method.
-
Store any information that the individual hosts need in order to filter data in the PlanContext instance passed as a parameter. For example, you could store details of the input format that the filter will read and output the format that the filter should produce. The plan() method runs only on the initiator node, and the prepare() method runs on each host reading from a data source. Therefore, this object is the only means of communication between them.
You store data in the PlanContext by getting a ParamWriter object from the getWriter() method. You then write parameters by calling methods on the ParamWriter such as setString.
Note
ParamWriter offers only the ability to store simple data types. For complex types, you need to serialize the data in some manner and store it as a string or long string.
Creating filters
Vertica calls prepare() to create and initialize your filter. It calls this method once on each node that will perform filtering. Vertica automatically selects the best nodes to complete the work based on available resources. You cannot specify the nodes on which the work is done.
Defining parameters
Implement getParameterTypes() to define the names and types of parameters that your filter uses. Vertica uses this information to warn callers about unknown or missing parameters. Vertica ignores unknown parameters and uses default values for missing parameters. While you should define the types and parameters for your function, you are not required to override this method.
API
The FilterFactory API provides the following methods for extension by subclasses:
virtual void plan(ServerInterface &srvInterface, PlanContext &planCtxt);
virtual UDFilter * prepare(ServerInterface &srvInterface, PlanContext &planCtxt)=0;
virtual void getParameterType(ServerInterface &srvInterface, SizedColumnTypes ¶meterTypes);
After creating your FilterFactory, you must register it with the RegisterFactory macro.
The FilterFactory API provides the following methods for extension by subclasses:
public void plan(ServerInterface srvInterface, PlanContext planCtxt)
throws UdfException;
public abstract UDFilter prepare(ServerInterface srvInterface, PlanContext planCtxt)
throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
The FilterFactory API provides the following methods for extension by subclasses:
class PyFilterFactory(vertica_sdk.SourceFactory):
def __init__(self):
pass
def plan(self):
pass
def prepare(self, planContext):
#User implement the function to create PyUDSources.
pass
10.2.3 - Java example: ReplaceCharFilter
The example in this section demonstrates creating a UDFilter that replaces any occurrences of a character in the input stream with another character in the output stream.
The example in this section demonstrates creating a UDFilter that replaces any occurrences of a character in the input stream with another character in the output stream. This example is highly simplified and assumes the input stream is ASCII data.
Always remember that the input and output streams in a UDFilter are actually binary data. If you are performing character transformations using a UDFilter, convert the data stream from a string of bytes into a properly encoded string. For example, your input stream might consist of UTF-8 encoded text. If so, be sure to transform the raw binary being read from the buffer into a UTF string before manipulating it.
Loading and using the example
The example UDFilter has two required parameters. The from_char parameter specifies the character to be replaced, and the to_char parameter specifies the replacement character. Load and use the ReplaceCharFilter UDFilter as follows:
=> CREATE LIBRARY JavaLib AS '/home/dbadmin/JavaUDlLib.jar'
->LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE FILTER ReplaceCharFilter as LANGUAGE 'JAVA'
->name 'com.mycompany.UDL.ReplaceCharFilterFactory' library JavaLib;
CREATE FILTER FUNCTION
=> CREATE TABLE t (text VARCHAR);
CREATE TABLE
=> COPY t FROM STDIN WITH FILTER ReplaceCharFilter(from_char='a', to_char='z');
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Mary had a little lamb
>> a man, a plan, a canal, Panama
>> \.
=> SELECT * FROM t;
text
--------------------------------
Mzry hzd z little lzmb
z mzn, z plzn, z cznzl, Pznzmz
(2 rows)
=> --Calling the filter with incorrect parameters returns errors
=> COPY t from stdin with filter ReplaceCharFilter();
ERROR 3399: Failure in UDx RPC call InvokePlanUDL(): Error in User Defined Object [
ReplaceCharFilter], error code: 0
com.vertica.sdk.UdfException: You must supply two parameters to ReplaceChar: 'from_char' and 'to_char'
at com.vertica.JavaLibs.ReplaceCharFilterFactory.plan(ReplaceCharFilterFactory.java:22)
at com.vertica.udxfence.UDxExecContext.planUDFilter(UDxExecContext.java:889)
at com.vertica.udxfence.UDxExecContext.planCurrentUDLType(UDxExecContext.java:865)
at com.vertica.udxfence.UDxExecContext.planUDL(UDxExecContext.java:821)
at com.vertica.udxfence.UDxExecContext.run(UDxExecContext.java:242)
at java.lang.Thread.run(Thread.java:662)
Parser implementation
The ReplaceCharFilter class reads the data stream, replacing each occurrence of a user-specified character with another character.
package com.vertica.JavaLibs;
import com.vertica.sdk.DataBuffer;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.State.InputState;
import com.vertica.sdk.State.StreamState;
import com.vertica.sdk.UDFilter;
public class ReplaceCharFilter extends UDFilter {
private byte[] fromChar;
private byte[] toChar;
public ReplaceCharFilter(String fromChar, String toChar){
// Stores the from char and to char as byte arrays. This is
// not a robust method of doing this, but works for this simple
// example.
this.fromChar= fromChar.getBytes();
this.toChar=toChar.getBytes();
}
@Override
public StreamState process(ServerInterface srvInterface, DataBuffer input,
InputState input_state, DataBuffer output) {
// Check if there is no more input and the input buffer has been completely
// processed. If so, filtering is done.
if (input_state == InputState.END_OF_FILE && input.buf.length == 0) {
return StreamState.DONE;
}
// Get current position in the input buffer
int offset = output.offset;
// Determine how many bytes to process. This is either until input
// buffer is exhausted or output buffer is filled
int limit = Math.min((input.buf.length - input.offset),
(output.buf.length - output.offset));
for (int i = input.offset; i < limit; i++) {
// This example just replaces each instance of from_char
// with to_char. It does not consider things such as multi-byte
// UTF-8 characters.
if (input.buf[i] == fromChar[0]) {
output.buf[i+offset] = toChar[0];
} else {
// Did not find from_char, so copy input to the output
output.buf[i+offset]=input.buf[i];
}
}
input.offset += limit;
output.offset += input.offset;
if (input.buf.length - input.offset < output.buf.length - output.offset) {
return StreamState.INPUT_NEEDED;
} else {
return StreamState.OUTPUT_NEEDED;
}
}
}
Factory implementation
ReplaceCharFilterFactory requires two parameters (from_char and to_char). The plan() method verifies that these parameters exist and are single-character strings. The method then stores them in the plan context. The prepare() method gets the parameter values and passes them to the ReplaceCharFilter objects, which it instantiates, to perform the filtering.
package com.vertica.JavaLibs;
import java.util.ArrayList;
import java.util.Vector;
import com.vertica.sdk.FilterFactory;
import com.vertica.sdk.PlanContext;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.SizedColumnTypes;
import com.vertica.sdk.UDFilter;
import com.vertica.sdk.UdfException;
public class ReplaceCharFilterFactory extends FilterFactory {
// Run on the initiator node to perform varification and basic setup.
@Override
public void plan(ServerInterface srvInterface,PlanContext planCtxt)
throws UdfException {
ArrayList<String> args =
srvInterface.getParamReader().getParamNames();
// Ensure user supplied two arguments
if (!(args.contains("from_char") && args.contains("to_char"))) {
throw new UdfException(0, "You must supply two parameters" +
" to ReplaceChar: 'from_char' and 'to_char'");
}
// Verify that the from_char is a single character.
String fromChar = srvInterface.getParamReader().getString("from_char");
if (fromChar.length() != 1) {
String message = String.format("Replacechar expects a single " +
"character in the 'from_char' parameter. Got length %d",
fromChar.length());
throw new UdfException(0, message);
}
// Save the from character in the plan context, to be read by
// prepare() method.
planCtxt.getWriter().setString("fromChar",fromChar);
// Ensure to character parameter is a single characater
String toChar = srvInterface.getParamReader().getString("to_char");
if (toChar.length() != 1) {
String message = String.format("Replacechar expects a single "
+ "character in the 'to_char' parameter. Got length %d",
toChar.length());
throw new UdfException(0, message);
}
// Save the to character in the plan data
planCtxt.getWriter().setString("toChar",toChar);
}
// Called on every host that will filter data. Must instantiate the
// UDFilter subclass.
@Override
public UDFilter prepare(ServerInterface srvInterface, PlanContext planCtxt)
throws UdfException {
// Get data stored in the context by the plan() method.
String fromChar = planCtxt.getWriter().getString("fromChar");
String toChar = planCtxt.getWriter().getString("toChar");
// Instantiate a filter object to perform filtering.
return new ReplaceCharFilter(fromChar, toChar);
}
// Describe the parameters accepted by this filter.
@Override
public void getParameterType(ServerInterface srvInterface,
SizedColumnTypes parameterTypes) {
parameterTypes.addVarchar(1, "from_char");
parameterTypes.addVarchar(1, "to_char");
}
}
10.2.4 - C++ example: converting encoding
The following example shows how you can convert encoding for a file from one type to another by converting UTF-16 encoded data to UTF-8.
The following example shows how you can convert encoding for a file from one type to another by converting UTF-16 encoded data to UTF-8. You can find this example in the SDK at /opt/vertica/sdk/examples/FilterFunctions/IConverter.cpp.
Filter implementation
class Iconverter : public UDFilter{
private:
std::string fromEncoding, toEncoding;
iconv_t cd; // the conversion descriptor opened
uint converted; // how many characters have been converted
protected:
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &input,
InputState input_state, DataBuffer &output)
{
char *input_buf = (char *)input.buf + input.offset;
char *output_buf = (char *)output.buf + output.offset;
size_t inBytesLeft = input.size - input.offset, outBytesLeft = output.size - output.offset;
// end of input
if (input_state == END_OF_FILE && inBytesLeft == 0)
{
// Gnu libc iconv doc says, it is good practice to finalize the
// outbuffer for stateful encodings (by calling with null inbuffer).
//
// http://www.gnu.org/software/libc/manual/html_node/Generic-Conversion-Interface.html
iconv(cd, NULL, NULL, &output_buf, &outBytesLeft);
// output buffer can be updated by this operation
output.offset = output.size - outBytesLeft;
return DONE;
}
size_t ret = iconv(cd, &input_buf, &inBytesLeft, &output_buf, &outBytesLeft);
// if conversion is successful, we ask for more input, as input has not reached EOF.
StreamState retStatus = INPUT_NEEDED;
if (ret == (size_t)(-1))
{
// seen an error
switch (errno)
{
case E2BIG:
// input size too big, not a problem, ask for more output.
retStatus = OUTPUT_NEEDED;
break;
case EINVAL:
// input stops in the middle of a byte sequence, not a problem, ask for more input
retStatus = input_state == END_OF_FILE ? DONE : INPUT_NEEDED;
break;
case EILSEQ:
// invalid sequence seen, throw
// TODO: reporting the wrong byte position
vt_report_error(1, "Invalid byte sequence when doing %u-th conversion", converted);
case EBADF:
// something wrong with descriptor, throw
vt_report_error(0, "Invalid descriptor");
default:
vt_report_error(0, "Uncommon Error");
break;
}
}
else converted += ret;
// move position pointer
input.offset = input.size - inBytesLeft;
output.offset = output.size - outBytesLeft;
return retStatus;
}
public:
Iconverter(const std::string &from, const std::string &to)
: fromEncoding(from), toEncoding(to), converted(0)
{
// note "to encoding" is first argument to iconv...
cd = iconv_open(to.c_str(), from.c_str());
if (cd == (iconv_t)(-1))
{
// error when creating converters.
vt_report_error(0, "Error initializing iconv: %m");
}
}
~Iconverter()
{
// free iconv resources;
iconv_close(cd);
}
};
Factory implementation
class IconverterFactory : public FilterFactory{
public:
virtual void plan(ServerInterface &srvInterface,
PlanContext &planCtxt) {
std::vector<std::string> args = srvInterface.getParamReader().getParamNames();
/* Check parameters */
if (!(args.size() == 0 ||
(args.size() == 1 && find(args.begin(), args.end(), "from_encoding")
!= args.end()) || (args.size() == 2
&& find(args.begin(), args.end(), "from_encoding") != args.end()
&& find(args.begin(), args.end(), "to_encoding") != args.end()))) {
vt_report_error(0, "Invalid arguments. Must specify either no arguments, or "
"'from_encoding' alone, or 'from_encoding' and 'to_encoding'.");
}
/* Populate planData */
// By default, we do UTF16->UTF8, and x->UTF8
VString from_encoding = planCtxt.getWriter().getStringRef("from_encoding");
VString to_encoding = planCtxt.getWriter().getStringRef("to_encoding");
from_encoding.copy("UTF-16");
to_encoding.copy("UTF-8");
if (args.size() == 2)
{
from_encoding.copy(srvInterface.getParamReader().getStringRef("from_encoding"));
to_encoding.copy(srvInterface.getParamReader().getStringRef("to_encoding"));
}
else if (args.size() == 1)
{
from_encoding.copy(srvInterface.getParamReader().getStringRef("from_encoding"));
}
if (!from_encoding.length()) {
vt_report_error(0, "The empty string is not a valid from_encoding value");
}
if (!to_encoding.length()) {
vt_report_error(0, "The empty string is not a valid to_encoding value");
}
}
virtual UDFilter* prepare(ServerInterface &srvInterface,
PlanContext &planCtxt) {
return vt_createFuncObj(srvInterface.allocator, Iconverter,
planCtxt.getReader().getStringRef("from_encoding").str(),
planCtxt.getReader().getStringRef("to_encoding").str());
}
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes) {
parameterTypes.addVarchar(32, "from_encoding");
parameterTypes.addVarchar(32, "to_encoding");
}
};
RegisterFactory(IconverterFactory);
10.3 - User-defined parser
A parser takes a stream of bytes and passes a corresponding sequence of tuples to the Vertica load process.
A parser takes a stream of bytes and passes a corresponding sequence of tuples to the Vertica load process. You can use user-defined parser functions to parse:
For example, you can load a CSV file using a specific CSV library. See the Vertica SDK for two CSV examples.
COPY supports a single user-defined parser that you can use with a user-defined source and zero or more instances of a user-defined filter. If you implement a UDParser class, you must also implement a corresponding ParserFactory.
Sometimes, you can improve the performance of your parser by adding a chunker. A chunker divides up the input and uses multiple threads to parse it. Chunkers are available only in the C++ API. For details, see Cooperative parse and UDChunker class. Under special circumstances you can further improve performance by using apportioned load, an approach where multiple Vertica nodes parse the input.
10.3.1 - UDParser class
You can subclass the UDParser class when you need to parse data that is in a format that the COPY statement's native parser cannot handle.
You can subclass the UDParser class when you need to parse data that is in a format that the COPY statement's native parser cannot handle.
During parser execution, Vertica always calls three methods: setup(), process(), and destroy(). It might also call getRejectedRecord().
UDParser constructor
The UDParser class performs important initialization required by all subclasses, including initializing the StreamWriter object used by the parser. Therefore, your constructor must call super().
UDParser methods
Your UDParser subclass must override process() or processWithMetadata():
Note
processWithMetadata() is available only for user-defined extensions (UDxs) written in the C++ programming language.
-
process() reads the raw input stream as one large file. If there are any errors or failures, the entire load fails. You can implement process() with a source or filter that implements processWithMetadata(), but it might result in parsing errors.
You can implement process() when the upstream source or filter implements processWithMetadata(), but it might result in parsing errors.
-
processWithMetadata() is useful when the data source has metadata about record boundaries available in some structured format that's separate from the data payload. With this interface, the source emits a record length for each record in addition to the data.
By implementing processWithMetadata() instead of process() in each phase, you can retain this record length metadata throughout the load stack, which enables a more efficient parse that can recover from errors on a per-message basis, rather than a per-file or per-source basis. KafkaSource and Kafka parsers (KafkaAvroParser, KafkaJSONParser, and KafkaParser) use this mechanism to support per-Kafka-message rejections when individual Kafka messages are corrupted.
Note
To implement processWithMetadata(), you must override useSideChannel() to return true.
Additionally, you must override getRejectedRecord() to return information about rejected records.
Optionally, you can override the other UDParser class methods.
Parser execution
The following sections detail the execution sequence each time a user-defined parser is called. The following example overrides the process() method.
Setting up
COPY calls setup() before the first time it calls process(). Use setup() to perform any initial setup tasks that your parser needs to parse data. This setup includes retrieving parameters from the class context structure or initializing data structures for use during filtering. Vertica calls this method before calling the process() method for the first time. Your object might be destroyed and re-created during use, so make sure that your object is restartable.
Parsing
COPY calls process() repeatedly during query execution. Vertica passes this method a buffer of data to parse into columns and rows and one of the following input states defined by InputState:
-
OK: currently at the start of or in the middle of a stream
-
END_OF_FILE: no further data is available.
-
END_OF_CHUNK: the current data ends on a record boundary and the parser should consume all of it before returning. This input state only occurs when using a chunker.
-
START_OF_PORTION: the input does not start at the beginning of a source. The parser should find the first end-of-record mark. This input state only occurs when using apportioned load.You can use the getPortion() method to access the offset and size of the portion.
-
END_OF_PORTION: the source has reached the end of its portion. The parser should finish processing the last record it started and advance no further. This input state only occurs when using apportioned load.
The parser must reject any data that it cannot parse, so that Vertica can report the rejection and write the rejected data to files.
The process() method must parse as much data as it can from the input buffer. The buffer might not end on a row boundary. Therefore, it might have to stop parsing in the middle of a row of input and ask for more data. The input can contain null bytes, if the source file contains them, and is not automatically null-terminated.
A parser has an associated StreamWriter object, which performs the actual writing of the data. When your parser extracts a column value, it uses one of the type-specific methods on StreamWriter to write that value to the output stream. See Writing Data for more information about these methods.
A single call to process() might write several rows of data. When your parser finishes processing a row of data, it must call next() on its StreamWriter to advance the output stream to a new row. (Usually a parser finishes processing a row because it encounters an end-of-row marker.)
When your process() method reaches the end of the buffer, it tells Vertica its current state by returning one of the following values defined by StreamState:
-
INPUT_NEEDED: the parser has reached the end of the buffer and needs more data to parse.
-
DONE: the parser has reached the end of the input data stream.
-
REJECT: the parser has rejected the last row of data it read (see Rejecting Rows).
Tearing down
COPY calls destroy() after the last time that process() is called. It frees any resources reserved by the setup() or process() method.
Vertica calls this method after the process() method indicates it has completed parsing the data source. However, sometimes data sources that have not yet been processed might remain. In such cases, Vertica might later call setup() on the object again and have it parse the data in a new data stream. Therefore, write your destroy() method so that it leaves an instance of your UDParser subclass in a state where setup() can be safely called again.
Reporting rejections
If process() rejects a row, Vertica calls getRejectedRecord() to report it. Usually, this method returns an instance of the RejectedRecord class with details of the rejected row.
Writing data
A parser has an associated StreamWriter object, which you access by calling getStreamWriter(). In your process() implementation, use the
setType() methods on the StreamWriter object to write values in a row to specific column indexes. Verify that the data types you write match the data types expected by the schema.
The following example shows how you can write a value of type long to the fourth column (index 3) in the current row:
StreamWriter writer = getStreamWriter();
...
writer.setLongValue(3, 98.6);
StreamWriter provides methods for all the basic types, such as setBooleanValue(), setStringValue(), and so on. See the API documentation for a complete list of StreamWriter methods, including options that take primitive types or explicitly set entries to null.
Rejecting rows
If your parser finds data it cannot parse, it should reject the row by:
-
Saving details about the rejected row data and the reason for the rejection. These pieces of information can be directly stored in a RejectedRecord object, or in fields on your UDParser subclass, until they are needed.
-
Updating the row's position in the input buffer by updating input.offset so it can resume parsing with the next row.
-
Signaling that it has rejected a row by returning with the value StreamState.REJECT.
-
Returning an instance of the RejectedRecord class with the details about the rejected row.
Breaking up large loads
Vertica provides two ways to break up large loads. Apportioned load allows you to distribute a load among several database nodes. Cooperative parse (C++ only) allows you to distribute a load among several threads on one node.
API
The UDParser API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface, SizedColumnTypes &returnType);
virtual bool useSideChannel();
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &input, InputState input_state)=0;
virtual StreamState processWithMetadata(ServerInterface &srvInterface, DataBuffer &input,
LengthBuffer &input_lengths, InputState input_state)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface, SizedColumnTypes &returnType);
virtual RejectedRecord getRejectedRecord();
The UDParser API provides the following methods for extension by subclasses:
public void setup(ServerInterface srvInterface, SizedColumnTypes returnType)
throws UdfException;
public abstract StreamState process(ServerInterface srvInterface,
DataBuffer input, InputState input_state)
throws UdfException, DestroyInvocation;
protected void cancel(ServerInterface srvInterface);
public void destroy(ServerInterface srvInterface, SizedColumnTypes returnType)
throws UdfException;
public RejectedRecord getRejectedRecord() throws UdfException;
A UDParser uses a StreamWriter to write its output. StreamWriter provides methods for all the basic types, such as setBooleanValue(), setStringValue(), and so on. In the Java API this class also provides the setValue() method, which automatically sets the data type.
The methods described so far write single column values. StreamWriter also provides a method to write a complete row from a map. The setRowFromMap() method takes a map of column names and values and writes all the values into their corresponding columns. This method does not define new columns but instead writes values only to existing columns. The JsonParser example uses this method to write arbitrary JSON input. (See Java example: JSON parser.)
Note
The setRowFromMap() method does not automatically advance the input to the next line; you must call next(). You can thus read a row and then override selected column values.
setRowsFromMap() also populates any VMap ('raw') column of Flex Tables (see Flex tables) with the entire provided map. For most cases, setRowsFromMap() is the appropriate way to populate a Flex Table. However, you can also generate a VMap value into a specified column using setVMap(), similar to other setValue() methods.
The setRowFromMap() method automatically coerces the input values into the types defined for those columns using an associated TypeCoercion. In most cases, using the default implementation (StandardTypeCoercion) is appropriate.
TypeCoercion uses policies to govern its behavior. For example, the FAIL_INVALID_INPUT_VALUE policy means invalid input is treated as an error instead of using a null value. Errors are caught and handled as rejections (see "Rejecting Rows" in User-defined parser). Policies also govern whether input that is too long is truncated. Use the setPolicy() method on the parser's TypeCoercion to set policies. See the API documentation for supported values.
You might need to customize type coercion beyond setting these policies. To do so, subclass one of the provided implementations of TypeCoercion and override the
asType() methods. Such customization could be necessary if your parser reads objects that come from a third-party library. A parser handling geo-coordinates, for example, might override asLong to translate inputs like "40.4397N" into numbers. See the Vertica API documentation for a list of implementations.
The UDParser API provides the following methods for extension by subclasses:
class PyUDParser(vertica_sdk.UDSource):
def __init__(self):
pass
def setup(srvInterface, returnType):
pass
def process(self, srvInterface, inputbuffer, inputstate, streamwriter):
# User implement process function.
# User reads data from inputbuffer and parse the data.
# Rows are emitted via the streamwriter argument
return StreamState.DONE
In Python, the process() method requires both an input buffer and an output buffer (see InputBuffer and OutputBuffer APIs). The input buffer represents the source of the information that you want to parse. The output buffer delivers the filtered information to Vertica.
In the event the filter rejects a record, use the method REJECT() to identify the rejected data and the reason for the rejection.
10.3.2 - UDChunker class
You can subclass the UDChunker class to allow your parser to support Cooperative Parse.
You can subclass the UDChunker class to allow your parser to support Cooperative parse. This class is available only in the C++ API.
Fundamentally, a UDChunker is a very simplistic parser. Like UDParser, it has the following three methods: setup(), process(), and destroy(). You must override process(); you may override the others. This class has one additional method, alignPortion(), which you must implement if you want to enable Apportioned load for your UDChunker.
Setting up and tearing down
As with UDParser, you can define initialization and cleanup code for your chunker. Vertica calls setup() before the first call to process() and destroy() after the last call to process(). Your object might be reused among multiple load sources, so make sure that setup() completely initializes all fields.
Chunking
Vertica calls process() to divide an input into chunks that can be parsed independently. The method takes an input buffer and an indicator of the input state:
-
OK: the input buffer begins at the start of or in the middle of a stream.
-
END_OF_FILE: no further data is available.
-
END_OF_PORTION: the source has reached the end of its portion. This state occurs only when using apportioned load.
If the input state is END_OF_FILE, the chunker should set the input.offset marker to input.size and return DONE. Returning INPUT_NEEDED is an error.
If the input state is OK, the chunker should read data from the input buffer and find record boundaries. If it finds the end of at least one record, it should align the input.offset marker with the byte after the end of the last record in the buffer and return CHUNK_ALIGNED. For example, if the input is "abc~def" and "~" is a record terminator, this method should set input.offset to 4, the position of "d". If process() reaches the end of the input without finding a record boundary, it should return INPUT_NEEDED.
You can divide the input into smaller chunks, but consuming all available records in the input can have better performance. For example, a chunker could scan backwards from the end of the input to find a record terminator, which might be the last of many records in the input, and return it all as one chunk without scanning through the rest of the input.
If the input state is END_OF_PORTION, the chunker should behave as it does for an input state of OK, except that it should also set a flag. When called again, it should find the first record in the next portion and align the chunk to that record.
The input data can contain null bytes, if the source file contains them. The input argument is not automatically null-terminated.
The process() method must not block indefinitely. If this method cannot proceed for an extended period of time, it should return KEEP_GOING. Failing to return KEEP_GOING has several consequences, such as preventing your user from being able to cancel the query.
See C++ example: delimited parser and chunker for an example of the process() method using chunking.
Aligning portions
If your chunker supports apportioned load, implement the alignPortion() method. Vertica calls this method one or more times, before calling process(), to align the input offset with the beginning of the first complete chunk in the portion. The method takes an input buffer and an indicator of the input state:
-
START_OF_PORTION: the beginning of the buffer corresponds to the start of the portion. You can use the getPortion() method to access the offset and size of the portion.
-
OK: the input buffer is in the middle of a portion.
-
END_OF_PORTION: the end of the buffer corresponds to the end of the portion or beyond the end of a portion.
-
END_OF_FILE: no further data is available.
The method should scan from the beginning of the buffer to the start of the first complete record. It should set input.offset to this position and return one of the following values:
-
DONE, if it found a chunk. input.offset is the first byte of the chunk.
-
INPUT_NEEDED, if the input buffer does not contain the start of any chunk. It is an error to return this from an input state of END_OF_FILE.
-
REJECT, if the portion (not buffer) does not contain the start of any chunk.
API
The UDChunker API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
SizedColumnTypes &returnType);
virtual StreamState alignPortion(ServerInterface &srvInterface,
DataBuffer &input, InputState state);
virtual StreamState process(ServerInterface &srvInterface,
DataBuffer &input, InputState input_state)=0;
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface,
SizedColumnTypes &returnType);
10.3.3 - ParserFactory class
If you write a parser, you must also write a factory to produce parser instances.
If you write a parser, you must also write a factory to produce parser instances. To do so, subclass the ParserFactory class.
Parser factories are singletons. Your subclass must be stateless, with no fields containing data. Your subclass also must not modify any global variables.
The ParserFactory class defines the following methods. Your subclass must override the prepare() method. It may override the other methods.
Setting up
Vertica calls plan() once on the initiator node to perform the following tasks:
-
Check any parameters that have been passed from the function call in the COPY statement and error messages if there are any issues. You read the parameters by getting a ParamReader object from the instance of ServerInterface passed into your plan() method.
-
Store any information that the individual hosts need in order to parse the data. For example, you could store parameters in the PlanContext instance passed in through the planCtxt parameter. The plan() method runs only on the initiator node, and the prepareUDSources() method runs on each host reading from a data source. Therefore, this object is the only means of communication between them.
You store data in the PlanContext by getting a ParamWriter object from the getWriter() method. You then write parameters by calling methods on the ParamWriter such as setString.
Note
ParamWriter offers only the ability to store simple data types. For complex types, you need to serialize the data in some manner and store it as a string or long string.
Creating parsers
Vertica calls prepare() on each node to create and initialize your parser, using data stored by the plan() method.
Defining parameters
Implement getParameterTypes() to define the names and types of parameters that your parser uses. Vertica uses this information to warn callers about unknown or missing parameters. Vertica ignores unknown parameters and uses default values for missing parameters. While you should define the types and parameters for your function, you are not required to override this method.
Defining parser outputs
Implement getParserReturnType() to define the data types of the table columns that the parser outputs. If applicable, getParserReturnType() also defines the size, precision, or scale of the data types. Usually, this method reads data types of the output table from the argType and perColumnParamReader arguments and verifies that it can output the appropriate data types. If getParserReturnType() is prepared to output the data types, it calls methods on the SizedColumnTypes object passed in the returnType argument. In addition to the data type of the output column, your method should also specify any additional information about the column's data type:
-
For binary and string data types (such as CHAR, VARCHAR, and LONG VARBINARY), specify its maximum length.
-
For NUMERIC types, specify its precision and scale.
-
For Time/Timestamp types (with or without time zone), specify its precision (-1 means unspecified).
-
For ARRAY types, specify the maximum number of elements.
-
For all other types, no length or precision specification is required.
Supporting cooperative parse
To support Cooperative parse, implement prepareChunker() and return an instance of your UDChunker subclass. If isChunkerApportionable() returns true, then it is an error for this method to return null.
Cooperative parse is currently supported only in the C++ API.
Supporting apportioned load
To support Apportioned load, your parser, chunker, or both must support apportioning. To indicate that the parser can apportion a load, implement isParserApportionable() and return true. To indicate that the chunker can apportion a load, implement isChunkerApportionable() and return true.
The isChunkerApportionable() method takes a ServerInterface as an argument, so you have access to the parameters supplied in the COPY statement. You might need this information if the user can specify a record delimiter, for example. Return true from this method if and only if the factory can create a chunker for this input.
API
The ParserFactory API provides the following methods for extension by subclasses:
virtual void plan(ServerInterface &srvInterface, PerColumnParamReader &perColumnParamReader, PlanContext &planCtxt);
virtual UDParser * prepare(ServerInterface &srvInterface, PerColumnParamReader &perColumnParamReader,
PlanContext &planCtxt, const SizedColumnTypes &returnType)=0;
virtual void getParameterType(ServerInterface &srvInterface, SizedColumnTypes ¶meterTypes);
virtual void getParserReturnType(ServerInterface &srvInterface, PerColumnParamReader &perColumnParamReader,
PlanContext &planCtxt, const SizedColumnTypes &argTypes,
SizedColumnTypes &returnType);
virtual bool isParserApportionable();
// C++ API only:
virtual bool isChunkerApportionable(ServerInterface &srvInterface);
virtual UDChunker * prepareChunker(ServerInterface &srvInterface, PerColumnParamReader &perColumnParamReader,
PlanContext &planCtxt, const SizedColumnTypes &returnType);
If you are using Apportioned load to divide a single input into multiple load streams, implement isParserApportionable() and/or isChunkerApportionable() and return true. Returning true from these methods does not guarantee that Verticawill apportion the load. However, returning false from both indicates that it will not try to do so.
If you are using Cooperative parse, implement prepareChunker() and return an instance of your UDChunker subclass. Cooperative parse is supported only for the C++ API.
Vertica calls the prepareChunker() method only for unfenced functions. This method is not available when you use the function in fenced mode.
If you want your chunker to be available for apportioned load, implement isChunkerApportionable() and return true.
After creating your ParserFactory, you must register it with the RegisterFactory macro.
The ParserFactory API provides the following methods for extension by subclasses:
public void plan(ServerInterface srvInterface, PerColumnParamReader perColumnParamReader, PlanContext planCtxt)
throws UdfException;
public abstract UDParser prepare(ServerInterface srvInterface, PerColumnParamReader perColumnParamReader,
PlanContext planCtxt, SizedColumnTypes returnType)
throws UdfException;
public void getParameterType(ServerInterface srvInterface, SizedColumnTypes parameterTypes);
public void getParserReturnType(ServerInterface srvInterface, PerColumnParamReader perColumnParamReader,
PlanContext planCtxt, SizedColumnTypes argTypes, SizedColumnTypes returnType)
throws UdfException;
The ParserFactory API provides the following methods for extension by subclasses:
class PyParserFactory(vertica_sdk.SourceFactory):
def __init__(self):
pass
def plan(self):
pass
def prepareUDSources(self, srvInterface):
# User implement the function to create PyUDParser.
pass
10.3.4 - C++ example: BasicIntegerParser
The BasicIntegerParser example parses a string of integers separated by non-numeric characters.
The BasicIntegerParser example parses a string of integers separated by non-numeric characters. For a version of this parser that uses continuous load, see C++ example: ContinuousIntegerParser.
Loading and using the example
Load and use the BasicIntegerParser example as follows.
=> CREATE LIBRARY BasicIntegerParserLib AS '/home/dbadmin/BIP.so';
=> CREATE PARSER BasicIntegerParser AS
LANGUAGE 'C++' NAME 'BasicIntegerParserFactory' LIBRARY BasicIntegerParserLib;
=> CREATE TABLE t (i integer);
=> COPY t FROM stdin WITH PARSER BasicIntegerParser();
0
1
2
3
4
5
\.
Implementation
The BasicIntegerParser class implements only the process() method from the API. (It also implements a helper method for type conversion.) This method processes each line of input, looking for numbers on each line. When it advances to a new line it moves the input.offset marker and checks the input state. It then writes the output.
virtual StreamState process(ServerInterface &srvInterface, DataBuffer &input,
InputState input_state) {
// WARNING: This implementation is not trying for efficiency.
// It is trying for simplicity, for demonstration purposes.
size_t start = input.offset;
const size_t end = input.size;
do {
bool found_newline = false;
size_t numEnd = start;
for (; numEnd < end; numEnd++) {
if (input.buf[numEnd] < '0' || input.buf[numEnd] > '9') {
found_newline = true;
break;
}
}
if (!found_newline) {
input.offset = start;
if (input_state == END_OF_FILE) {
// If we're at end-of-file,
// emit the last integer (if any) and return DONE.
if (start != end) {
writer->setInt(0, strToInt(input.buf + start, input.buf + numEnd));
writer->next();
}
return DONE;
} else {
// Otherwise, we need more data.
return INPUT_NEEDED;
}
}
writer->setInt(0, strToInt(input.buf + start, input.buf + numEnd));
writer->next();
start = numEnd + 1;
} while (true);
}
};
In the factory, the plan() method is a no-op; there are no parameters to check. The prepare() method instantiates the parser using the macro provided by the SDK:
virtual UDParser* prepare(ServerInterface &srvInterface,
PerColumnParamReader &perColumnParamReader,
PlanContext &planCtxt,
const SizedColumnTypes &returnType) {
return vt_createFuncObject<BasicIntegerParser>(srvInterface.allocator);
}
The getParserReturnType() method declares the single output:
virtual void getParserReturnType(ServerInterface &srvInterface,
PerColumnParamReader &perColumnParamReader,
PlanContext &planCtxt,
const SizedColumnTypes &argTypes,
SizedColumnTypes &returnType) {
// We only and always have a single integer column
returnType.addInt(argTypes.getColumnName(0));
}
As for all UDxs written in C++, the example ends by registering its factory:
RegisterFactory(BasicIntegerParserFactory);
10.3.5 - C++ example: ContinuousIntegerParser
The ContinuousIntegerParser example is a variation of BasicIntegerParser.
The ContinuousIntegerParser example is a variation of BasicIntegerParser. Both examples parse integers from input strings. ContinuousIntegerParser uses Continuous load to read data.
Loading and using the example
Load the ContinuousIntegerParser example as follows.
=> CREATE LIBRARY ContinuousIntegerParserLib AS '/home/dbadmin/CIP.so';
=> CREATE PARSER ContinuousIntegerParser AS
LANGUAGE 'C++' NAME 'ContinuousIntegerParserFactory'
LIBRARY ContinuousIntegerParserLib;
Use it in the same way that you use BasicIntegerParser. See C++ example: BasicIntegerParser.
Implementation
ContinuousIntegerParser is a subclass of ContinuousUDParser. Subclasses of ContinuousUDParser place the processing logic in the run() method.
virtual void run() {
// This parser assumes a single-column input, and
// a stream of ASCII integers split by non-numeric characters.
size_t pos = 0;
size_t reserved = cr.reserve(pos+1);
while (!cr.isEof() || reserved == pos + 1) {
while (reserved == pos + 1 && isdigit(*ptr(pos))) {
pos++;
reserved = cr.reserve(pos + 1);
}
std::string st(ptr(), pos);
writer->setInt(0, strToInt(st));
writer->next();
while (reserved == pos + 1 && !isdigit(*ptr(pos))) {
pos++;
reserved = cr.reserve(pos + 1);
}
cr.seek(pos);
pos = 0;
reserved = cr.reserve(pos + 1);
}
}
};
For a more complex example of a ContinuousUDParser, see ExampleDelimitedParser in the examples. (See Downloading and running UDx example code.) ExampleDelimitedParser uses a chunker; see C++ example: delimited parser and chunker.
10.3.6 - Java example: numeric text
This NumericTextParser example parses integer values spelled out in words rather than digits (for example "one two three" for one-hundred twenty three).
This NumericTextParser example parses integer values spelled out in words rather than digits (for example "one two three" for one-hundred twenty three). The parser:
-
Accepts a single parameter to set the character that separates columns in a row of data. The separator defaults to the pipe (|) character.
-
Ignores extra spaces and the capitalization of the words used to spell out the digits.
-
Recognizes the digits using the following words: zero, one, two, three, four, five, six, seven, eight, nine.
-
Assumes that the words spelling out an integer are separated by at least one space.
-
Rejects any row of data that cannot be completely parsed into integers.
-
Generates an error, if the output table has a non-integer column.
Loading and using the example
Load and use the parser as follows:
=> CREATE LIBRARY JavaLib AS '/home/dbadmin/JavaLib.jar' LANGUAGE 'JAVA';
CREATE LIBRARY
=> CREATE PARSER NumericTextParser AS LANGUAGE 'java'
-> NAME 'com.myCompany.UDParser.NumericTextParserFactory'
-> LIBRARY JavaLib;
CREATE PARSER FUNCTION
=> CREATE TABLE t (i INTEGER);
CREATE TABLE
=> COPY t FROM STDIN WITH PARSER NumericTextParser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> One
>> Two
>> One Two Three
>> \.
=> SELECT * FROM t ORDER BY i;
i
-----
1
2
123
(3 rows)
=> DROP TABLE t;
DROP TABLE
=> -- Parse multi-column input
=> CREATE TABLE t (i INTEGER, j INTEGER);
CREATE TABLE
=> COPY t FROM stdin WITH PARSER NumericTextParser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> One | Two
>> Two | Three
>> One Two Three | four Five Six
>> \.
=> SELECT * FROM t ORDER BY i;
i | j
-----+-----
1 | 2
2 | 3
123 | 456
(3 rows)
=> TRUNCATE TABLE t;
TRUNCATE TABLE
=> -- Use alternate separator character
=> COPY t FROM STDIN WITH PARSER NumericTextParser(separator='*');
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> Five * Six
>> seven * eight
>> nine * one zero
>> \.
=> SELECT * FROM t ORDER BY i;
i | j
---+----
5 | 6
7 | 8
9 | 10
(3 rows)
=> TRUNCATE TABLE t;
TRUNCATE TABLE
=> -- Rows containing data that does not parse into digits is rejected.
=> DROP TABLE t;
DROP TABLE
=> CREATE TABLE t (i INTEGER);
CREATE TABLE
=> COPY t FROM STDIN WITH PARSER NumericTextParser();
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> One Zero Zero
>> Two Zero Zero
>> Three Zed Zed
>> Four Zero Zero
>> Five Zed Zed
>> \.
SELECT * FROM t ORDER BY i;
i
-----
100
200
400
(3 rows)
=> -- Generate an error by trying to copy into a table with a non-integer column
=> DROP TABLE t;
DROP TABLE
=> CREATE TABLE t (i INTEGER, j VARCHAR);
CREATE TABLE
=> COPY t FROM STDIN WITH PARSER NumericTextParser();
vsql:UDParse.sql:94: ERROR 3399: Failure in UDx RPC call
InvokeGetReturnTypeParser(): Error in User Defined Object [NumericTextParser],
error code: 0
com.vertica.sdk.UdfException: Column 2 of output table is not an Int
at com.myCompany.UDParser.NumericTextParserFactory.getParserReturnType
(NumericTextParserFactory.java:70)
at com.vertica.udxfence.UDxExecContext.getReturnTypeParser(
UDxExecContext.java:1464)
at com.vertica.udxfence.UDxExecContext.getReturnTypeParser(
UDxExecContext.java:768)
at com.vertica.udxfence.UDxExecContext.run(UDxExecContext.java:236)
at java.lang.Thread.run(Thread.java:662)
Parser implementation
The following code implements the parser.
package com.myCompany.UDParser;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
import com.vertica.sdk.DataBuffer;
import com.vertica.sdk.DestroyInvocation;
import com.vertica.sdk.RejectedRecord;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.State.InputState;
import com.vertica.sdk.State.StreamState;
import com.vertica.sdk.StreamWriter;
import com.vertica.sdk.UDParser;
import com.vertica.sdk.UdfException;
public class NumericTextParser extends UDParser {
private String separator; // Holds column separator character
// List of strings that we accept as digits.
private List<String> numbers = Arrays.asList("zero", "one",
"two", "three", "four", "five", "six", "seven",
"eight", "nine");
// Hold information about the last rejected row.
private String rejectedReason;
private String rejectedRow;
// Constructor gets the separator character from the Factory's prepare()
// method.
public NumericTextParser(String sepparam) {
super();
this.separator = sepparam;
}
// Called to perform the actual work of parsing. Gets a buffer of bytes
// to turn into tuples.
@Override
public StreamState process(ServerInterface srvInterface, DataBuffer input,
InputState input_state) throws UdfException, DestroyInvocation {
int i=input.offset; // Current position in the input buffer
// Flag to indicate whether we just found the end of a row.
boolean lastCharNewline = false;
// Buffer to hold the row of data being read.
StringBuffer line = new StringBuffer();
//Continue reading until end of buffer.
for(; i < input.buf.length; i++){
// Loop through input until we find a linebreak: marks end of row
char inchar = (char) input.buf[i];
// Note that this isn't a robust way to find rows. It should
// accept a user-defined row separator. Also, the following
// assumes ASCII line break metheods, which isn't a good idea
// in the UTF world. But it is good enough for this simple example.
if (inchar != '\n' && inchar != '\r') {
// Keep adding to a line buffer until a full row of data is read
line.append(inchar);
lastCharNewline = false; // Last character not a new line
} else {
// Found a line break. Process the row.
lastCharNewline = true; // indicate we got a complete row
// Update the position in the input buffer. This is updated
// whether the row is successfully processed or not.
input.offset = i+1;
// Call procesRow to extract values and write tuples to the
// output. Returns false if there was an error.
if (!processRow(line)) {
// Processing row failed. Save bad row to rejectedRow field
// and return to caller indicating a rejected row.
rejectedRow = line.toString();
// Update position where we processed the data.
return StreamState.REJECT;
}
line.delete(0, line.length()); // clear row buffer
}
}
// At this point, process() has finished processing the input buffer.
// There are two possibilities: need to get more data
// from the input stream to finish processing, or there is
// no more data to process. If at the end of the input stream and
// the row was not terminated by a linefeed, it may need
// to process the last row.
if (input_state == InputState.END_OF_FILE && lastCharNewline) {
// End of input and it ended on a newline. Nothing more to do
return StreamState.DONE;
} else if (input_state == InputState.END_OF_FILE && !lastCharNewline) {
// At end of input stream but didn't get a final newline. Need to
// process the final row that was read in, then exit for good.
if (line.length() == 0) {
// Nothing to process. Done parsing.
return StreamState.DONE;
}
// Need to parse the last row, not terminated by a linefeed. This
// can occur if the file being read didn't have a final line break.
if (processRow(line)) {
return StreamState.DONE;
} else {
// Processing last row failed. Save bad row to rejectedRow field
// and return to caller indicating a rejected row.
rejectedRow = line.toString();
// Tell Vertica the entire buffer was processed so it won't
// call again to have the line processed.
input.offset = input.buf.length;
return StreamState.REJECT;
}
} else {
// Stream is not fully read, so tell Vertica to send more. If
// process() didn't get a complete row before it hit the end of the
// input buffer, it will end up re-processing that segment again
// when more data is added to the buffer.
return StreamState.INPUT_NEEDED;
}
}
// Breaks a row into columns, then parses the content of the
// columns. Returns false if there was an error parsing the
// row, in which case it sets the rejected row to the input
// line. Returns true if the row was successfully read.
private boolean processRow(StringBuffer line)
throws UdfException, DestroyInvocation {
String[] columns = line.toString().split(Pattern.quote(separator));
// Loop through the columns, decoding their contents
for (int col = 0; col < columns.length; col++) {
// Call decodeColumn to extract value from this column
Integer colval = decodeColumn(columns[col]);
if (colval == null) {
// Could not parse one of the columns. Indicate row should
// be rejected.
return false;
}
// Column parsed OK. Write it to the output. writer is a field
// provided by the parent class. Since this parser only accepts
// integers, there is no need to verify that data type of the parsed
// data matches the data type of the column being written. In your
// UDParsers, you may want to perform this verification.
writer.setLong(col,colval);
}
// Done with the row of data. Advance output to next row.
// Note that this example does not verify that all of the output columns
// have values assigned to them. If there are missing values at the
// end of a row, they get automatically get assigned a default value
// (0 for integers). This isn't a robust solution. Your UDParser
// should perform checks here to handle this situation and set values
// (such as null) when appropriate.
writer.next();
return true; // Successfully processed the row.
}
// Gets a string with text numerals, i.e. "One Two Five Seven" and turns
// it into an integer value, i.e. 1257. Returns null if the string could not
// be parsed completely into numbers.
private Integer decodeColumn(String text) {
int value = 0; // Hold the value being parsed.
// Split string into individual words. Eat extra spaces.
String[] words = text.toLowerCase().trim().split("\\s+");
// Loop through the words, matching them against the list of
// digit strings.
for (int i = 0; i < words.length; i++) {
if (numbers.contains(words[i])) {
// Matched a digit. Add the it to the value.
int digit = numbers.indexOf(words[i]);
value = (value * 10) + digit;
} else {
// The string didn't match one of the accepted string values
// for digits. Need to reject the row. Set the rejected
// reason string here so it can be incorporated into the
// rejected reason object.
//
// Note that this example does not handle null column values.
// In most cases, you want to differentiate between an
// unparseable column value and a missing piece of input
// data. This example just rejects the row if there is a missing
// column value.
rejectedReason = String.format(
"Could not parse '%s' into a digit",words[i]);
return null;
}
}
return value;
}
// Vertica calls this method if the parser rejected a row of data
// to find out what went wrong and add to the proper logs. Just gathers
// information stored in fields and returns it in an object.
@Override
public RejectedRecord getRejectedRecord() throws UdfException {
return new RejectedRecord(rejectedReason,rejectedRow.toCharArray(),
rejectedRow.length(), "\n");
}
}
ParserFactory implementation
The following code implements the parser factory.
NumericTextParser accepts a single optional parameter named separator. This parameter is defined in the getParameterType() method, and the plan() method stores its value. NumericTextParser outputs only integer values. Therefore, if the output table contains a column whose data type is not integer, the getParserReturnType() method throws an exception.
package com.myCompany.UDParser;
import java.util.regex.Pattern;
import com.vertica.sdk.ParamReader;
import com.vertica.sdk.ParamWriter;
import com.vertica.sdk.ParserFactory;
import com.vertica.sdk.PerColumnParamReader;
import com.vertica.sdk.PlanContext;
import com.vertica.sdk.ServerInterface;
import com.vertica.sdk.SizedColumnTypes;
import com.vertica.sdk.UDParser;
import com.vertica.sdk.UdfException;
import com.vertica.sdk.VerticaType;
public class NumericTextParserFactory extends ParserFactory {
// Called once on the initiator host to check the parameters and set up the
// context data that hosts performing processing will need later.
@Override
public void plan(ServerInterface srvInterface,
PerColumnParamReader perColumnParamReader,
PlanContext planCtxt) {
String separator = "|"; // assume separator is pipe character
// See if a parameter was given for column separator
ParamReader args = srvInterface.getParamReader();
if (args.containsParameter("separator")) {
separator = args.getString("separator");
if (separator.length() > 1) {
throw new UdfException(0,
"Separator parameter must be a single character");
}
if (Pattern.quote(separator).matches("[a-zA-Z]")) {
throw new UdfException(0,
"Separator parameter cannot be a letter");
}
}
// Save separator character in the Plan Data
ParamWriter context = planCtxt.getWriter();
context.setString("separator", separator);
}
// Define the data types of the output table that the parser will return.
// Mainly, this just ensures that all of the columns in the table which
// is the target of the data load are integer.
@Override
public void getParserReturnType(ServerInterface srvInterface,
PerColumnParamReader perColumnParamReader,
PlanContext planCtxt,
SizedColumnTypes argTypes,
SizedColumnTypes returnType) {
// Get access to the output table's columns
for (int i = 0; i < argTypes.getColumnCount(); i++ ) {
if (argTypes.getColumnType(i).isInt()) {
// Column is integer... add it to the output
returnType.addInt(argTypes.getColumnName(i));
} else {
// Column isn't an int, so throw an exception.
// Technically, not necessary since the
// UDx framework will automatically error out when it sees a
// Discrepancy between the type in the target table and the
// types declared by this method. Throwing this exception will
// provide a clearer error message to the user.
String message = String.format(
"Column %d of output table is not an Int", i + 1);
throw new UdfException(0, message);
}
}
}
// Instantiate the UDParser subclass named NumericTextParser. Passes the
// separator characetr as a paramter to the constructor.
@Override
public UDParser prepare(ServerInterface srvInterface,
PerColumnParamReader perColumnParamReader, PlanContext planCtxt,
SizedColumnTypes returnType) throws UdfException {
// Get the separator character from the context
String separator = planCtxt.getReader().getString("separator");
return new NumericTextParser(separator);
}
// Describe the parameters accepted by this parser.
@Override
public void getParameterType(ServerInterface srvInterface,
SizedColumnTypes parameterTypes) {
parameterTypes.addVarchar(1, "separator");
}
}
10.3.7 - Java example: JSON parser
The JSON Parser consumes a stream of JSON objects.
The JSON Parser consumes a stream of JSON objects. Each object must be well formed and on a single line in the input. Use line breaks to delimit the objects. The parser uses the field names as keys in a map, which become column names in the table. You can find the code for this example in /opt/vertica/packages/flextable/examples. This directory also contains an example data file.
This example uses the setRowFromMap() method to write data.
Loading and using the example
Load the library and define the JSON parser, using the third-party library (gson-2.2.4.jar) as follows. See the comments in JsonParser.java for a download URL:
=> CREATE LIBRARY json
-> AS '/opt/vertica/packages/flextable/examples/java/output/json.jar'
-> DEPENDS '/opt/vertica/bin/gson-2.2.4.jar' language 'java';
CREATE LIBRARY
=> CREATE PARSER JsonParser AS LANGUAGE 'java'
-> NAME 'com.vertica.flex.JsonParserFactory' LIBRARY json;
CREATE PARSER FUNCTION
You can now define a table and then use the JSON parser to load data into it, as follows:
=> CREATE TABLE mountains(name varchar(64), type varchar(32), height integer);
CREATE TABLE
=> COPY mountains FROM '/opt/vertica/packages/flextable/examples/mountains.json'
-> WITH PARSER JsonParser();
-[ RECORD 1 ]--
Rows Loaded | 2
=> SELECT * from mountains;
-[ RECORD 1 ]--------
name | Everest
type | mountain
height | 29029
-[ RECORD 2 ]--------
name | Mt St Helens
type | volcano
height |
The data file contains a value (hike_safety) that was not loaded because the table definition did not include that column. The data file follows:
{ "name": "Everest", "type":"mountain", "height": 29029, "hike_safety": 34.1 }
{ "name": "Mt St Helens", "type": "volcano", "hike_safety": 15.4 }
Implementation
The following code shows the process() method from JsonParser.java. The parser attempts to read the input into a Map. If the read is successful, the JSON Parser calls setRowFromMap():
@Override
public StreamState process(ServerInterface srvInterface, DataBuffer input,
InputState inputState) throws UdfException, DestroyInvocation {
clearReject();
StreamWriter output = getStreamWriter();
while (input.offset < input.buf.length) {
ByteBuffer lineBytes = consumeNextLine(input, inputState);
if (lineBytes == null) {
return StreamState.INPUT_NEEDED;
}
String lineString = StringUtils.newString(lineBytes);
try {
Map<String,Object> map = gson.fromJson(lineString, parseType);
if (map == null) {
continue;
}
output.setRowFromMap(map);
// No overrides needed, so just call next() here.
output.next();
} catch (Exception ex) {
setReject(lineString, ex);
return StreamState.REJECT;
}
}
}
The factory, JsonParserFactory.java, instantiates and returns a parser in the prepare() method. No additional setup is required.
10.3.8 - C++ example: delimited parser and chunker
The ExampleDelimitedUDChunker class divides an input at delimiter characters.
The ExampleDelimitedUDChunker class divides an input at delimiter characters. You can use this chunker with any parser that understands delimited input. ExampleDelimitedParser is a ContinuousUDParser subclass that uses this chunker.
Loading and using the example
Load and use the example as follows.
=> CREATE LIBRARY ExampleDelimitedParserLib AS '/home/dbadmin/EDP.so';
=> CREATE PARSER ExampleDelimitedParser AS
LANGUAGE 'C++' NAME 'DelimitedParserFrameworkExampleFactory'
LIBRARY ExampleDelimitedParserLib;
=> COPY t FROM stdin WITH PARSER ExampleDelimitedParser();
0
1
2
3
4
5
6
7
8
9
\.
Chunker implementation
This chunker supports apportioned load. The alignPortion() method finds the beginning of the first complete record in the current portion and aligns the input buffer with it. The record terminator is passed as an argument and set in the constructor.
StreamState ExampleDelimitedUDChunker::alignPortion(
ServerInterface &srvInterface,
DataBuffer &input, InputState state)
{
/* find the first record terminator. Its record belongs to the previous portion */
void *buf = reinterpret_cast<void *>(input.buf + input.offset);
void *term = memchr(buf, recordTerminator, input.size - input.offset);
if (term) {
/* record boundary found. Align to the start of the next record */
const size_t chunkSize = reinterpret_cast<size_t>(term) - reinterpret_cast<size_t>(buf);
input.offset += chunkSize
+ sizeof(char) /* length of record terminator */;
/* input.offset points at the start of the first complete record in the portion */
return DONE;
} else if (state == END_OF_FILE || state == END_OF_PORTION) {
return REJECT;
} else {
VIAssert(state == START_OF_PORTION || state == OK);
return INPUT_NEEDED;
}
}
The process() method has to account for chunks that span portion boundaries. If the previous call was at the end of a portion, the method set a flag. The code begins by checking for and handling that condition. The logic is similar to that of alignPortion(), so the example calls it to do part of the division.
StreamState ExampleDelimitedUDChunker::process(
ServerInterface &srvInterface,
DataBuffer &input,
InputState input_state)
{
const size_t termLen = 1;
const char *terminator = &recordTerminator;
if (pastPortion) {
/*
* Previous state was END_OF_PORTION, and the last chunk we will produce
* extends beyond the portion we started with, into the next portion.
* To be consistent with alignPortion(), that means finding the first
* record boundary, and setting the chunk to be at that boundary.
* Fortunately, this logic is identical to aligning the portion (with
* some slight accounting for END_OF_FILE)!
*/
const StreamState findLastTerminator = alignPortion(srvInterface, input);
switch (findLastTerminator) {
case DONE:
return DONE;
case INPUT_NEEDED:
if (input_state == END_OF_FILE) {
/* there is no more input where we might find a record terminator */
input.offset = input.size;
return DONE;
}
return INPUT_NEEDED;
default:
VIAssert("Invalid return state from alignPortion()");
}
return findLastTerminator;
}
Now the method looks for the delimiter. If the input began at the end of a portion, it sets the flag.
size_t ret = input.offset, term_index = 0;
for (size_t index = input.offset; index < input.size; ++index) {
const char c = input.buf[index];
if (c == terminator[term_index]) {
++term_index;
if (term_index == termLen) {
ret = index + 1;
term_index = 0;
}
continue;
} else if (term_index > 0) {
index -= term_index;
}
term_index = 0;
}
if (input_state == END_OF_PORTION) {
/*
* Regardless of whether or not a record was found, the next chunk will extend
* into the next portion.
*/
pastPortion = true;
}
Finally, process() moves the input offset and returns.
// if we were able to find some rows, move the offset to point at the start of the next (potential) row, or end of block
if (ret > input.offset) {
input.offset = ret;
return CHUNK_ALIGNED;
}
if (input_state == END_OF_FILE) {
input.offset = input.size;
return DONE;
}
return INPUT_NEEDED;
}
Factory implementation
The file ExampleDelimitedParser.cpp defines a factory that uses this UDChunker. The chunker supports apportioned load, so the factory implements isChunkerApportionable():
virtual bool isChunkerApportionable(ServerInterface &srvInterface) {
ParamReader params = srvInterface.getParamReader();
if (params.containsParameter("disable_chunker") && params.getBoolRef("d\
isable_chunker")) {
return false;
} else {
return true;
}
}
The prepareChunker() method creates the chunker:
virtual UDChunker* prepareChunker(ServerInterface &srvInterface,
PerColumnParamReader &perColumnParamReade\
r,
PlanContext &planCtxt,
const SizedColumnTypes &returnType)
{
ParamReader params = srvInterface.getParamReader();
if (params.containsParameter("disable_chunker") && params.getBoolRef("d\
isable_chunker")) {
return NULL;
}
std::string recordTerminator("\n");
ParamReader args(srvInterface.getParamReader());
if (args.containsParameter("record_terminator")) {
recordTerminator = args.getStringRef("record_terminator").str();
}
return vt_createFuncObject<ExampleDelimitedUDChunker>(srvInterface.allo\
cator,
recordTerminator[0]);
}
10.3.9 - Python example: complex types JSON parser
The following example details a UDParser that takes a JSON object and parses it into complex types.
The following example details a UDParser that takes a JSON object and parses it into complex types. For this example, the parser assumes the input data are arrays of rows with two integer fields. The input records should be separated by newline characters. If any row fields aren't specified by the JSON input, the function parses those fields as NULL.
The source code for this UDParser also contains a factory method for parsing rows that have an integer and an array of integer fields. The implementation of the parser is independent of the return type in the factory, so you can create factories with different return types that all point to the ComplexJsonParser() class in the prepare() method. The complete source code is in /opt/vertica/sdk/examples/python/UDParsers.py.
Loading and using the example
Load the library and create the parser as follows:
=> CREATE OR REPLACE LIBRARY UDParsers AS '/home/dbadmin/examples/python/UDParsers.py' LANGUAGE 'Python';
=> CREATE PARSER ComplexJsonParser AS LANGUAGE 'Python' NAME 'ArrayJsonParserFactory' LIBRARY UDParsers;
You can now define a table and then use the JSON parser to load data into it, for example:
=> CREATE TABLE orders (a bool, arr array[row(a int, b int)]);
CREATE TABLE
=> COPY orders (arr) FROM STDIN WITH PARSER ComplexJsonParser();
[]
[{"a":1, "b":10}]
[{"a":1, "b":10}, {"a":null, "b":10}]
[{"a":1, "b":10},{"a":10, "b":20}]
[{"a":1, "b":10}, {"a":null, "b":null}]
[{"a":1, "b":2}, {"a":3, "b":4}, {"a":5, "b":6}, {"a":7, "b":8}, {"a":9, "b":10}, {"a":11, "b":12}, {"a":13, "b":14}]
\.
=> SELECT * FROM orders;
a | arr
--+--------------------------------------------------------------------------
| []
| [{"a":1,"b":10}]
| [{"a":1,"b":10},{"a":null,"b":10}]
| [{"a":1,"b":10},{"a":10,"b":20}]
| [{"a":1,"b":10},{"a":null,"b":null}]
| [{"a":1,"b":2},{"a":3,"b":4},{"a":5,"b":6},{"a":7,"b":8},{"a":9,"b":10},{"a":11,"b":12},{"a":13,"b":14}]
(6 rows)
Setup
All Python UDxs must import the Vertica SDK library. ComplexJsonParser() also requires the json library.
import vertica_sdk
import json
Factory implementation
The prepare() method instantiates and returns a parser:
def prepare(self, srvInterface, perColumnParamReader, planCtxt, returnType):
return ComplexJsonParser()
getParserReturnType() declares that the return type must be an array of rows that each have two integer fields:
def getParserReturnType(self, rvInterface, perColumnParamReader, planCtxt, argTypes, returnType):
fieldTypes = vertica_sdk.SizedColumnTypes.makeEmpty()
fieldTypes.addInt('a')
fieldTypes.addInt('b')
returnType.addArrayType(vertica_sdk.SizedColumnTypes.makeRowType(fieldTypes, 'elements'), 64, 'arr')
Parser implementation
The process() method reads in data with an InputBuffer and then splits that input data on the newline character. The method then passes the processed data to the writeRows() method. writeRows() turns each data row into a JSON object, checks the type of that JSON object, and then writes the appropriate value or object to the output.
class ComplexJsonParser(vertica_sdk.UDParser):
leftover = ''
def process(self, srvInterface, input_buffer, input_state, writer):
input_buffer.setEncoding('utf-8')
self.count = 0
rec = self.leftover + input_buffer.read()
row_lst = rec.split('\n')
self.leftover = row_lst[-1]
self.writeRows(row_lst[:-1], writer)
if input_state == InputState.END_OF_FILE:
self.writeRows([self.leftover], writer)
return StreamState.DONE
else:
return StreamState.INPUT_NEEDED
def writeRows(self, str_lst, writer):
for s in str_lst:
stripped = s.strip()
if len(stripped) == 0:
return
elif len(stripped) > 1 and stripped[0:2] == "//":
continue
jsonValue = json.loads(stripped)
if type(jsonValue) is list:
writer.setArray(0, jsonValue)
elif jsonValue is None:
writer.setNull(0)
else:
writer.setRow(0, jsonValue)
writer.next()
10.4 - Load parallelism
Vertica can divide the work of loading data, taking advantage of parallelism to speed up the operation.
Vertica can divide the work of loading data, taking advantage of parallelism to speed up the operation. Vertica supports several types of parallelism:
-
Distributed load: Vertica distributes files in a multi-file load to several nodes to load in parallel, instead of loading all of them on a single node. Vertica manages distributed load; you do not need to do anything special in your UDL.
-
Cooperative parse: A source being loaded on a single node uses multi-threading to parallelize the parse. Cooperative parse divides a load at execution time, based on how threads are scheduled. You must enable cooperative parse in your parser. See Cooperative parse.
-
Apportioned load: Vertica divides a single large file or other single source into segments, which it assigns to several nodes to load in parallel. Apportioned load divides the load at planning time, based on available nodes and cores on each node. You must enable apportioned load in your source and parser. See Apportioned load.
You can support both cooperative parse and apportioned load in the same UDL. Vertica decides which to use for each load operation and might use both. See Combining cooperative parse and apportioned load.
10.4.1 - Cooperative parse
By default, Vertica parses a data source in a single thread on one database node.
By default, Vertica parses a data source in a single thread on one database node. You can optionally use cooperative parse to parse a source using multiple threads on a node. More specifically, data from a source passes through a chunker that groups blocks from the source stream into logical units. These chunks can be parsed in parallel. The chunker divides the input into pieces that can be individually parsed, and the parser then parses them concurrently. Cooperative parse is available only for unfenced UDxs. (See Fenced and unfenced modes.)
To use cooperative parse, a chunker must be able to locate end-of-record markers in the input. Locating these markers might not be possible in all input formats.
Chunkers are created by parser factories. At load time, Vertica first calls the UDChunker to divide the input into chunks and then calls the UDParser to parse each chunk.
You can use cooperative parse and apportioned load independently or together. See Combining cooperative parse and apportioned load.
How Vertica divides a load
When Vertica receives data from a source, it calls the chunker's process() method repeatedly. A chunker is, essentially, a lightweight parser; instead of parsing, the process() method divides the input into chunks.
After the chunker has finished dividing the input into chunks, Vertica sends those chunks to as many parsers as are available, calling the process() method on the parser.
Implementing cooperative parse
To implement cooperative parse, perform the following actions:
-
Subclass UDChunker and implement process().
-
In your ParserFactory, implement prepareChunker() to return a UDChunker.
See C++ example: delimited parser and chunker for a UDChunker that also supports apportioned load.
10.4.2 - Apportioned load
A parser can use more than one database node to load a single input source in parallel.
A parser can use more than one database node to load a single input source in parallel. This approach is referred to as apportioned load. Among the parsers built into Vertica, the default (delimited) parser supports apportioned load.
Apportioned load, like cooperative parse, requires an input that can be divided at record boundaries. The difference is that cooperative parse does a sequential scan to find record boundaries, while apportioned load first jumps (seeks) to a given position and then scans. Some formats, like generic XML, do not support seeking.
To use apportioned load, you must ensure that the source is reachable by all participating database nodes. You typically use apportioned load with distributed file systems.
It is possible for a parser to not support apportioned load directly but to have a chunker that supports apportioning.
You can use apportioned load and cooperative parse independently or together. See Combining cooperative parse and apportioned load.
How Vertica apportions a load
If both the parser and its source support apportioning, then you can specify that a single input is to be distributed to multiple database nodes for loading. The SourceFactory breaks the input into portions and assigns them to execution nodes. Each Portion consists of an offset into the input and a size. Vertica distributes the portions and their parameters to the execution nodes. A source factory running on each node produces a UDSource for the given portion.
The UDParser first determines where to start parsing:
-
If the portion is the first one in the input, the parser advances to the offset and begins parsing.
-
If the portion is not the first, the parser advances to the offset and then scans until it finds the end of a record. Because records can break across portions, parsing begins after the first record-end encountered.
The parser must complete a record, which might require it to read past the end of the portion. The parser is responsible for parsing all records that begin in the assigned portion, regardless of where they end. Most of this work occurs within the process() method of the parser.
Sometimes, a portion contains nothing to be parsed by its assigned node. For example, suppose you have a record that begins in portion 1, runs through all of portion 2, and ends in portion 3. The parser assigned to portion 1 parses the record, and the parser assigned to portion 3 starts after that record. The parser assigned to portion 2, however, has no record starting within its portion.
If the load also uses Cooperative parse, then after apportioning the load and before parsing, Vertica divides portions into chunks for parallel loading.
Implementing apportioned load
To implement apportioned load, perform the following actions in the source, the parser, and their factories.
In your SourceFactory subclass:
-
Implement isSourceApportionable() and return true.
-
Implement plan() to determine portion size, designate portions, and assign portions to execution nodes. To assign portions to particular executors, pass the information using the parameter writer on the plan context (PlanContext::getWriter()).
-
Implement prepareUDSources(). Vertica calls this method on each execution node with the plan context created by the factory. This method returns the UDSource instances to be used for this node's assigned portions.
-
If sources can take advantage of parallelism, you can implement getDesiredThreads() to request a number of threads for each source. See SourceFactory class for more information about this method.
In your UDSource subclass, implement process() as you would for any other source, using the assigned portion. You can retrieve this portion with getPortion().
In your ParserFactory subclass:
-
Implement isParserApportionable() and return true.
-
If your parser uses a UDChunker that supports apportioned load, implement isChunkerApportionable().
In your UDParser subclass:
-
Write your UDParser subclass to operate on portions rather than whole sources. You can do so by handling the stream states PORTION_START and PORTION_END, or by using the ContinuousUDParser API. Your parser must scan for the beginning of the portion, find the first record boundary after that position, and parse to the end of the last record beginning in that portion. Be aware that this behavior might require that the parser read beyond the end of the portion.
-
Handle the special case of a portion containing no record start by returning without writing any output.
In your UDChunker subclass, implement alignPortion(). See Aligning Portions.
Example
The SDK provides a C++ example of apportioned load in the ApportionLoadFunctions directory:
Use these classes together. You could also use FilePortionSource with the built-in delimited parser.
The following example shows how you can load the libraries and create the functions in the database:
=> CREATE LIBRARY FilePortionSourceLib as '/home/dbadmin/FP.so';
=> CREATE LIBRARY DelimFilePortionParserLib as '/home/dbadmin/Delim.so';
=> CREATE SOURCE FilePortionSource AS
LANGUAGE 'C++' NAME 'FilePortionSourceFactory' LIBRARY FilePortionSourceLib;
=> CREATE PARSER DelimFilePortionParser AS
LANGUAGE 'C++' NAME 'DelimFilePortionParserFactory' LIBRARY DelimFilePortionParserLib;
The following example shows how you can use the source and parser to load data:
=> COPY t WITH SOURCE FilePortionSource(file='g1/*.dat') PARSER DelimFilePortionParser(delimiter = '|',
record_terminator = '~');
10.4.3 - Combining cooperative parse and apportioned load
You can enable both Cooperative Parse and Apportioned Load in the same parser, allowing Vertica to decide how to load data.
You can enable both Cooperative parse and Apportioned load in the same parser, allowing Vertica to decide how to load data.
Deciding how to divide a load
Vertica uses apportioned load, where possible, at query-planning time. It decides whether to also use cooperative parse at execution time.
Apportioned load requires SourceFactory support. Given a suitable UDSource, at planning time Vertica calls the isParserApportionable() method on the ParserFactory. If this method returns true, Vertica apportions the load.
If isParserApportionable() returns false but isChunkerApportionable() returns true, then a chunker is available for cooperative parse and that chunker supports apportioned load. Vertica apportions the load.
If neither of these methods returns true, then Vertica does not apportion the load.
At execution time, Vertica first checks whether the load is running in unfenced mode and proceeds only if it is. Cooperative parse is not supported in fenced mode.
If the load is not apportioned, and more than one thread is available, Vertica uses cooperative parse.
If the load is apportioned, and exactly one thread is available, Vertica uses cooperative parse if and only if the parser is not apportionable. In this case, the chunker is apportionable but the parser is not.
If the load is apportioned, and more than one thread is available, and the chunker is apportionable, Vertica uses cooperative parse.
If Vertica uses cooperative parse but prepareChunker() does not return a UDChunker instance, Vertica reports an error.
Executing apportioned, cooperative loads
If a load uses both apportioned load and cooperative parse, Vertica uses the SourceFactory to break the input into portions. It then assigns the portions to execution nodes. See How Vertica Apportions a Load.
On the execution node, Vertica calls the chunker's alignPortion() method to align the input with portion boundaries. (This step is skipped for the first portion, which by definition is already aligned at the beginning.) This step is necessary because a parser using apportioned load sometimes has to read beyond the end of the portion, so a chunker needs to find the end point.
After aligning the portion, Vertica calls the chunker's process() method repeatedly. See How Vertica Divides a Load.
The chunks found by the chunker are then sent to the parser's process() method for processing in the usual way.
10.5 - Continuous load
The ContinuousUDSource, ContinuousUDFilter, and ContinuousUDParser classes allow you to write and process data as needed instead of having to iterate through the data.
The ContinuousUDSource, ContinuousUDFilter, and ContinuousUDParser classes allow you to write and process data as needed instead of having to iterate through the data. The Python API does not support continuous load.
Each class includes the following functions:
-
initialize() - Invoked before run(). You can optionally override this function to perform setup and initialization.
-
run() - Processes the data.
-
deinitialize() - Invoked after run() has returned. You can optionally override this function to perform tear-down and destruction.
Do not override the setup(), process(), and destroy() functions that are inherited from parent classes.
You can use the yield() function to yield control back to the server during idle or busy loops so the server can check for status changes or query cancellations.
These three classes use associated ContinuousReader and ContinuousWriter classes to read input data and write output data.
ContinuousUDSource API (C++)
The ContinuousUDSource class extends UDSource and adds the following methods for extension by subclasses:
virtual void initialize(ServerInterface &srvInterface);
virtual void run();
virtual void deinitialize(ServerInterface &srvInterface);
ContinuousUDFilter API (C++)
The ContinuousUDFilter class extends UDFilter and adds the following methods for extension by subclasses:
virtual void initialize(ServerInterface &srvInterface);
virtual void run();
virtual void deinitialize(ServerInterface &srvInterface);
ContinuousUDParser API
The ContinuousUDParser class extends UDParser and adds the following methods for extension by subclasses:
virtual void initialize(ServerInterface &srvInterface);
virtual void run();
virtual void deinitialize(ServerInterface &srvInterface);
The ContinuousUDParser class extends UDParser and adds the following methods for extension by subclasses:
public void initialize(ServerInterface srvInterface, SizedColumnTypes returnType);
public abstract void run() throws UdfException;
public void deinitialize(ServerInterface srvInterface, SizedColumnTypes returnType);
See the API documentation for additional utility methods.
10.6 - Buffer classes
Buffer classes are used as handles to the raw data stream for all UDL functions.
Buffer classes are used as handles to the raw data stream for all UDL functions. The C++ and Java APIs use a single DataBuffer class for both input and output. The Python API has two classes, InputBuffer and OutputBuffer.
DataBuffer API (C++, java)
The DataBuffer class has a pointer to a buffer and size, and an offset indicating how much of the stream has been consumed.
/**
* A contiguous in-memory buffer of char *
*/
struct DataBuffer {
/// Pointer to the start of the buffer
char * buf;
/// Size of the buffer in bytes
size_t size;
/// Number of bytes that have been processed by the UDL
size_t offset;
};
The DataBuffer class has an offset indicating how much of the stream has been consumed. Because Java is a language whose strings require attention to character encodings, the UDx must decode or encode buffers. A parser can interact with the stream by accessing the buffer directly.
/**
* DataBuffer is a a contiguous in-memory buffer of data.
*/
public class DataBuffer {
/**
* The buffer of data.
*/
public byte[] buf;
/**
* An offset into the buffer that is typically used to track progress
* through the DataBuffer. For example, a UDParser advances the
* offset as it consumes data from the DataBuffer.
*/
public int offset;}
The Python InputBuffer and OutputBuffer classes replace the DataBuffer class in the C++ and Java APIs.
The InputBuffer class decodes and translates raw data streams depending on the specified encoding. Python natively supports a wide range of languages and codecs. The InputBuffer is an argument to the process() method for both UDFilters and UDParsers. A user interacts with the UDL's data stream by calling methods of the InputBuffer
If you do not specify a value for setEncoding(), Vertica assumes a value of NONE.
class InputBuffer:
def getSize(self):
...
def getOffset(self):
...
def setEncoding(self, encoding):
"""
Set the encoding of the data contained in the underlying buffer
"""
pass
def peek(self, length = None):
"""
Copy data from the input buffer into Python.
If no encoding has been specified, returns a Bytes object containing raw data.
Otherwise, returns data decoded into an object corresponding to the specified encoding
(for example, 'utf-8' would return a string).
If length is None, returns all available data.
If length is not None then the length of the returned object is at most what is requested.
This method does not advance the buffer offset.
"""
pass
def read(self, length = None):
"""
See peek().
This method does the same thing as peek(), but it also advances the
buffer offset by the number of bytes consumed.
"""
pass
# Advances the DataBuffer offset by a number of bytes equal to the result
# of calling "read" with the same arguments.
def advance(self, length = None):
"""
Advance the buffer offset by the number of bytes indicated by
the length and encoding arguments. See peek().
Returns the new offset.
"""
pass
OutputBuffer class
The OutputBuffer class encodes and outputs data from Python to Vertica. The OutputBuffer is an argument to the process() method for both UDFilters and UDParsers. A user interacts with the UDL's data stream by calling methods of the OutputBuffer to manipulate and encode data.
The write() method transfers all data from the Python client to Vertica. The output buffer can accept any size object. If a user writes an object to the OutputBuffer larger than Vertica can immediately process, Vertica stores the overflow. During the next call to process(),Vertica checks for leftover data. If there is any, Vertica copies it to the DataBuffer before determining whether it needs to call process() from the Python UDL.
If you do not specify a value for setEncoding(), Vertica assumes a value of NONE.
class OutputBuffer:
def setEncoding(self, encoding):
"""
Specify the encoding of the data which will be written to the underlying buffer
"""
pass
def write(self, data):
"""
Transfer bytes from the data object into Vertica.
If an encoding was specified via setEncoding(), the data object will be converted to bytes using the specified encoding.
Otherwise, the data argument is expected to be a Bytes object and is copied to the underlying buffer.
"""
pass