This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Managing workloads
You can also use resource pools to manage resources assigned to running queries.
Vertica's resource management scheme allows diverse, concurrent workloads to run efficiently on the database. For basic operations, Vertica pre-configures the built-in GENERAL pool based on RAM and machine cores. You can customize the General pool to handle specific concurrency requirements.
You can also define new resource pools that you configure to limit memory usage, concurrency, and query priority. You can then optionally assign each database user to use a specific resource pool, which controls memory resources used by their requests.
User-defined pools are useful if you have competing resource requirements across different classes of workloads. Example scenarios include:
-
A large batch job takes up all server resources, leaving small jobs that update a web page without enough resources. This can degrade user experience.
In this scenario, create a resource pool to handle web page requests and ensure users get resources they need. Another option is to create a limited resource pool for the batch job, so the job cannot use up all system resources.
-
An application has lower priority than other applications and you want to limit the amount of memory and number of concurrent users for the low-priority application.
In this scenario, create a resource pool with an upper limit on the query's memory and associate the pool with users of the low-priority application.
You can also use resource pools to manage resources assigned to running queries. You can assign a run-time priority to a resource pool, as well as a threshold to assign different priorities to queries with different durations. See Managing resources at query run time for more information.
Enterprise Mode and Eon Mode
In Enterprise Mode, there is one global set of resource pools for the entire database. In Eon Mode, you can allocate resources globally or per subcluster. See Managing workload resources in an Eon Mode database for more information.
1 - Resource manager
On a single-user environment, the system can devote all resources to a single query, getting the most efficient execution for that one query.
On a single-user environment, the system can devote all resources to a single query, getting the most efficient execution for that one query. More likely, your environment needs to run several queries at once, which can cause tension between providing each query the maximum amount of resources (fastest run time) and serving multiple queries simultaneously with a reasonable run time.
The Vertica Resource Manager lets you resolve this tension, while ensuring that every query is eventually serviced and that true system limits are respected at all times.
For example, when the system experiences resource pressure, the Resource Manager might queue queries until the resources become available or a timeout value is reached. In addition, when you configure various Resource Manager settings, you can tune each query's target memory based on the expected number of concurrent queries running against the system.
Resource manager impact on query execution
The Resource Manager impacts individual query execution in various ways. When a query is submitted to the database, the following series of events occur:
-
The query is parsed, optimized to determine an execution plan, and distributed to the participating nodes.
-
The Resource Manager is invoked on each node to estimate resources required to run the query and compare that with the resources currently in use. One of the following will occur:
-
If the memory required by the query alone would exceed the machine's physical memory, the query is rejected - it cannot possibly run. Outside of significantly under-provisioned nodes, this case is very unlikely.
-
If the resource requirements are not currently available, the query is queued. The query will remain on the queue until either sufficient resources are freed up and the query runs or the query times out and is rejected.
-
Otherwise the query is allowed to run.
-
The query starts running when all participating nodes allow it to run.
Note
Once the query is running, the Resource Manager further manages resource allocation using
RUNTIMEPRIORITY and
RUNTIMEPRIORITYTHRESHOLD parameters for the resource pool
. See
Managing resources at query run time for more information.
Apportioning resources for a specific query and the maximum number of queries allowed to run depends on the resource pool configuration. See Resource pool architecture.
On each node, no resources are reserved or held while the query is in the queue. However, multi-node queries queued on some nodes will hold resources on the other nodes. Vertica makes every effort to avoid deadlocks in this situation.
2 - Resource pool architecture
The Resource Manager handles resources as one or more resource pools, which are a pre-allocated subset of the system resources with an associated queue.
The Resource Manager handles resources as one or more resource pools, which are a pre-allocated subset of the system resources with an associated queue.
In Enterprise Mode, there is one global set of resource pools that apply to all subclusters in the entire database. In Eon Mode, you can allocate resources globally or per subcluster. Global-level resource pools apply to all subclusters. Subcluster-level resource pools allow you to fine-tune resources for the type of workloads that the subcluster does. If you have both global- and subcluster-level resource pool settings, you can override any memory-related global setting for that subcluster. Global settings are applied to subclusters that do not have subcluster-level resource pool settings. See Managing workload resources in an Eon Mode database for more information about fine-tuning resource pools per subcluster.
Vertica is preconfigured with a set of Built-in pools that allocate resources to different request types, where the GENERAL pool allows for a certain concurrency level based on the RAM and cores in the machines.
Modifying and creating resource pools
You can configure the built-in GENERAL pool based on actual concurrency and performance requirements, as described in Built-in pools. You can also create custom pools to handle various classes of workloads and optionally restrict user requests to your custom pools.
You create and modify user-defined resource pools with
CREATE RESOURCE POOL and
ALTER RESOURCE POOL, respectively. You can configure these resource pools for memory usage, concurrency, and queue priority. You can also restrict a database user or user session to use a specific resource pool. Doing so allows you to control how memory, CPU, and other resources are allocated.
The following graphic illustrates what database operations are executed in which resource pool. Only three built-in pools are shown.
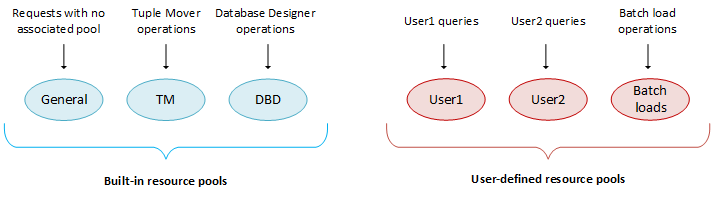
2.1 - Defining secondary resource pools
You can define secondary resource pools to which running queries can cascade if they exceed their primary pool's RUNTIMECAP .
You can define secondary resource pools to which running queries can cascade if they exceed their primary pool's RUNTIMECAP .
Identifying a secondary pool
Secondary resource pools designate a place where queries that exceed the RUNTIMECAP of the pool on which they are running can continue execution. If a query exceeds a pool's RUNTIMECAP, the query can cascade to a pool with a larger RUNTIMECAP instead of returning with an error. When a query cascades to another pool, the original pool regains the memory used by that query.
Unlike a user's primary resource pool, which requires USAGE privileges, Vertica does not check for user privileges on secondary resource pools. Thus, a user whose query cascades to a secondary resource pool requires no USAGE privileges on that resource pool.
You can define a secondary pool so it queues long-running queries if the pool lacks sufficient memory to handle that query immediately, by setting two parameters:
Eon Mode restrictions
In Eon Mode, you can associate user-defined resource pools with a subcluster. The following restrictions apply:
-
Global resource pools can cascade only to other global resource pools.
-
A subcluster resource pool can cascade to a global resource pool, or to another subcluster-specific resource pool that belongs to the same subcluster. If a subcluster-specific resource pool cascades to a user-defined resource pool that exists on both the global and subcluster level, the subcluster-level resource pool has priority. For example:
=> CREATE RESOURCE POOL billing1;
=> CREATE RESOURCE POOL billing1 FOR CURRENT SUBCLUSTER;
=> CREATE RESOURCE POOL billing2 FOR CURRENT SUBCLUSTER CASCADE TO billing1;
WARNING 9613: Resource pool billing1 both exists at both subcluster level and global level, assuming subcluster level
CREATE RESOURCE POOL
Query cascade path
Vertica routes queries to a secondary pool when the RUNTIMECAP on an initial pool is reached. Vertica then checks the secondary pool's RUNTIMECAP value. If the secondary pool's RUNTIMECAP is greater than the initial pool's value, the query executes on the secondary pool. If the secondary pool's RUNTIMECAP is less than or equal to the initial pool's value, Vertica retries the query on the next pool in the chain until it finds a pool on which the RUNTIMECAP is greater than the initial pool's value. If the secondary pool does not have sufficient resources available to execute the query at that time, SELECT queries may re-queue, re-plan, and abort on that pool. Other types of queries will fail due to insufficient resources. If no appropriate secondary pool exists for a query, the query will error out.
The following diagram demonstrates the path a query takes to execution.
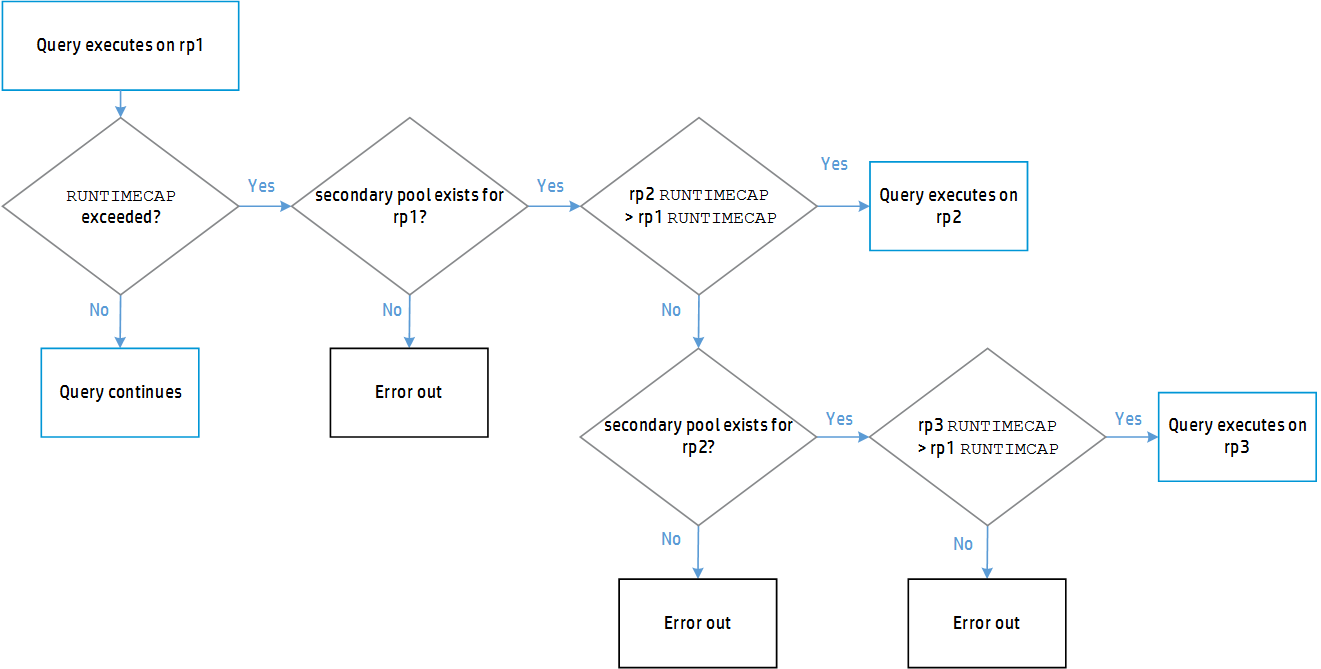
Query execution time allocation
After Vertica finds an appropriate pool on which to run the query, it continues to execute that query uninterrupted. The query now has the difference of the two pools' RUNTIMECAP limits in which to complete:
query execution time allocation = rp2 RUNTIMECAP - rp1 RUNTIMECAP
Using CASCADE TO
As a superuser, you can identify an existing resource pool—either user-defined pool or the GENERAL pool—by using the CASCADE TO parameter in the CREATE RESOURCE POOL or ALTER RESOURCE POOL statement.
In the following example, two resource pools are created and associated with a user as follows:
- The
shortUserQueries resource pool is created with a one-minute RUNTIMECAP
- The
userOverflow resource pool is created with a RUNTIMECAP of five minutes.
shortUserQueries is modified with ALTER RESOURCE POOL...CASCADE to use userOverflow to handle queries that require more than one minute to process.- The user
molly is created and configured to use shortUserQueries to handle that user's queries.
Given this scenario, queries issued by molly are initially directed to shortUserQueries for handling; queries that require more than one minute of processing time automatically cascade to the userOverflow pool to complete execution. Using the secondary pool frees up space in the primary pool, which is configured to handle short queries:
=> CREATE RESOURCE POOL shortUserQueries RUNTIMECAP '1 minutes'
=> CREATE RESOURCE POOL userOverflow RUNTIMECAP '5 minutes';
=> ALTER RESOURCE POOL shortUserQueries CASCADE TO userOverflow;
=> CREATE USER molly RESOURCE POOL shortUserQueries;
If desired, you can modify this scenario so userOverflow can queue long-running queries until it is available to handle them, by setting the PRIORITY and QUEUETIMEOUT parameters:
=> ALTER RESOURCE POOL userOverflow PRIORITY HOLD QUEUETIMEOUT '10 minutes';
In this scenario, a query that cascades to userOverflow can be queued up to 10 minutes until userOverflow acquires the memory it requires to handle it. After 10 minutes elapse, the query is rejected and returns with an error.
Dropping a secondary pool
If you try to drop a resource pool that is the secondary pool for another resource pool, Vertica returns an error. The error lists the resource pools that depend on the secondary pool you tried to drop. To drop a secondary resource pool, first set the CASCADE TO parameter to DEFAULT on the primary resource pool, and then drop the secondary pool.
For example, you can drop resource pool rp2, which is a secondary pool for rp1, as follows:
=> ALTER RESOURCE POOL rp1 CASCADE TO DEFAULT;
=> DROP RESOURCE POOL rp2;
Secondary pool parameter dependencies
In general, a secondary pool's parameters are applied to an incoming query. In the case of RUNTIMEPRIORITY , the following dependencies apply:
-
If the RUNTIMEPRIORITYTHRESHOLD timer was not started when the query was running in the primary pool, the query adopts the secondary resource pools' RUNTIMEPRIORITY when it cascades. This happens either when the RUNTIMEPRIORITYTHRESHOLD is not set for the primary pool or the RUNTIMEPRIORITY is set to HIGH for the primary pool.
-
If the RUNTIMEPRIORITYTHRESHOLD was reached in the primary pool, the query adopts the secondary resource pools' RUNTIMEPRIORITY when it cascades.
-
If the RUNTIMEPRIORITYTHRESHOLD was not reached in the primary pool and the secondary pool has no threshold, the query adopts the new pool's RUNTIMEPRIORITY when it cascades.
-
If the RUNTIMEPRIORITYTHRESHOLD was not reached in the primary pool and the secondary pool has a threshold set.
-
If the primary pool's RUNTIMEPRIORITYTHRESHOLD is greater than or equal to the secondary pool's RUNTIMEPRIORITYTHRESHOLD , the query adopts the secondary pool's RUNTIMEPRIORITY after the query reaches the RUNTIMEPRIORITYTHRESHOLD of the primary pool.
For example:
RUNTIMECAP of primary pool = 5 sec
RUNTIMEPRIORITYTHRESHOLD of primary pool = 8 sec
RUNTIMTPRIORITYTHRESHOLD of secondary pool = 7 sec
In this case, the query runs for 5 seconds on the primary pool and then cascades to the secondary pool. After another 3 seconds, 8 seconds total, the query adopts the RUNTIMEPRIORITY of the secondary pool.
-
If the primary pool's RUNTIMEPRIORITYTHRESHOLD is less than the secondary pool's RUNTIMEPRIORITYTHRESHOLD, the query adopts the secondary pool's RUNTIMEPRIORITY after the query reaches the RUNTIMEPRIORITYTHRESHOLD of the secondary pool.
In this case, the query runs for 5 seconds on the primary pool and then cascades to the secondary pool. After another 7 seconds, 12 seconds total, the query adopts the RUNTIMEPRIORITY of the secondary pool:
RUNTIMECAP of primary pool = 5 sec
RUNTIMEPRIORITYTHRESHOLD of primary pool = 8 sec
RUNTIMTPRIORITYTHRESHOLD of secondary pool = 12 se
CASCADE errors
A query that cascades to a secondary resource pool typically returns with an error in the following cases:
2.2 - Querying resource pool settings
You can use the following to get information about resource pools:.
You can use the following to get information about resource pools:
For runtime information about resource pools, see Monitoring resource pools.
Querying resource pool settings
The following example queries various settings of two internal resource pools, GENERAL and TM:
=> SELECT name, subcluster_oid, subcluster_name, maxmemorysize, memorysize, runtimepriority, runtimeprioritythreshold, queuetimeout
FROM RESOURCE_POOLS WHERE name IN('general', 'tm');
name | subcluster_oid | subcluster_name | maxmemorysize | memorysize | runtimepriority | runtimeprioritythreshold | queuetimeout
---------+----------------+-----------------+---------------+------------+-----------------+--------------------------+--------------
general | 0 | | Special: 95% | | MEDIUM | 2 | 00:05
tm | 0 | | | 3G | MEDIUM | 60 | 00:05
(2 rows)
Viewing overrides to global resource pools
In Eon Mode, you can query SUBCLUSTER_RESOURCE_POOL_OVERRIDES in the system tables to view any overrides to global resource pools for individual subclusters. The following query shows an override that sets MEMORYSIZE and MAXMEMORYSIZE for the built-in resource pool TM to 0% in the analytics_1 subcluster. These settings prevent the subcluster from performing Tuple Mover mergeout tasks.
=> SELECT * FROM SUBCLUSTER_RESOURCE_POOL_OVERRIDES;
pool_oid | name | subcluster_oid | subcluster_name | memorysize | maxmemorysize | maxquerymemorysize
-------------------+------+-------------------+-----------------+------------+---------------+--------------------
45035996273705058 | tm | 45035996273843504 | analytics_1 | 0% | 0% |
(1 row)
2.3 - User resource allocation
You can allocate resources to users in two ways:.
You can allocate resources to users in two ways:
- Customize allocation of resources for individual users by setting the appropriate user parameters.
- Assign users to a resource pool. This resource pool is used to process all queries from its assigned users, allocating resources as set by resource pool parameters.
The two methods can complement each other. For example, you can set the RUNTIMECAP parameter in the user-defined resource pool user_rp to 20 minutes. This setting applies to the queries of all users who are assigned to user_rp, including user Bob:
=> ALTER RESOURCE POOL user_rp RUNTIMECAP '20 minutes';
ALTER RESOURCE POOL
=> GRANT USAGE ON RESOURCE POOL user_rp to Bob;
GRANT PRIVILEGE
=> ALTER USER Bob RESOURCE POOL pool user_rp;
ALTER USER
When Vertica directs any query from user Bob to the user_rp resource pool for processing, it allocates resources to the query as configured in the resource pool, including RUNTIMECAP. Accordingly, queries in user_rp that do not complete execution within 20 minutes cascade to a secondary resource pool (if one is designated), or return to Bob with an error.
You can also edit Bob's user profile by setting its user-level parameter RUNTIMECAP to 10 minutes:
=> ALTER USER Bob RUNTIMECAP '10 minutes';
ALTER USER
On receiving queries from Bob after this change, the resource pool compares the two RUNTIMECAP settings—its own, and Bob's profile setting—and applies the shorter of the two. If you subsequently reassign Bob to another resource pool, the same logic applies, where the new resource pool continues to apply the shorter of the two RUNTIMECAP settings.
Precedence of user resource pools
Resource pools can be assigned to users at three levels, in ascending order of precedence:
-
Default user resource pool, set in configuration parameter DefaultResourcePoolForUsers. When a database user is created with CREATE USER, Vertica automatically sets the new user's profile to use this resource pool unless the CREATE USER statement specifies otherwise.
Important
By default, DefaultResourcePoolForUsers is set to the GENERAL resource pool, on which all new users have USAGE privileges. If you reconfigure DefaultResourcePoolForUsers to specify a user-defined resource pool, be sure that new users have USAGE privileges on it.
-
User resource pool, set in the user's profile by CREATE USER or ALTER USER with its RESOURCE POOL parameter. If you try to drop a user's resource pool, Vertica checks whether it can assign that user to the default user resource pool. If the user cannot be assigned to this resource pool—typically, for lack of USAGE privileges—Vertica rolls back the drop operation.
-
Current user session resource pool, set by SET SESSION RESOURCE_POOL.
In all cases, users must have USAGE privileges on their assigned resource pool; otherwise, they cannot log in to the database.
Resource pool usage in Eon Mode
In an Eon Mode database, you can assign a given resource pool to a subcluster, and then configure user profiles to use that resource pool. When users connect to a subcluster, Vertica determines which resource pool handles their queries as follows:
- If a user's resource pool and the subcluster resource pool are the same, then the subcluster resource pool handles queries from that user.
- If a user's resource pool and the subcluster resource pool are different, and the user has privileges on the default user resource pool, then that resource pool handles queries from the user.
- If a user's resource pool and the subcluster resource pool are different, and the user lacks privileges on the default user resource pool, then no resource pool is available on any node to handle queries from that user, and the queries return with an error.
Examples
For examples of different use cases for managing user resources, see Managing workloads with resource pools and user profiles.
2.4 - Query budgeting
Before it can execute a query, Vertica devises a query plan, which it sends to each node that will participate in executing the query.
Before it can execute a query, Vertica devises a query plan, which it sends to each node that will participate in executing the query. The Resource Manager evaluates the plan on each node and estimates how much memory and concurrency the node needs to execute its part of the query. This is the query budget, which Vertica stores in the query_budget_kb column of system table
V_MONITOR.RESOURCE_POOL_STATUS.
A query budget is based on several parameter settings of the resource pool where the query will execute:
-
MEMORYSIZE
-
MAXMEMORYSIZE
-
PLANNEDCONCURRENCY
You can modify MAXMEMORYSIZE and PLANNEDCONCURRENCY for the GENERAL resource pool with
ALTER RESOURCE POOL. This resource pool typically executes queries that are not assigned to a user-defined resource pool. You can set all three parameters for any user-defined resource pool when you create it with
CREATE RESOURCE POOL, or later with
ALTER RESOURCE POOL.
Important
You can also limit how much memory that a pool can allocate at runtime to its queries, by setting parameter
MAXQUERYMEMORYSIZE on that pool. For more information, see
CREATE RESOURCE POOL.
Computing the GENERAL pool query budget
Vertica calculates query budgets in the GENERAL pool with the following formula:
queryBudget = queuingThresholdPool / PLANNEDCONCURRENCY
Note
Vertica calculates the GENERAL pool's queuing threshold as 95 percent of its MAXMEMORYSIZE setting.
Computing query budgets for user-defined resource pools
For user-defined resource pools, Vertica uses the following algorithm:
-
If MEMORYSIZE is set to 0 and MAXMEMORYSIZE is not set:
queryBudget = queuingThresholdGeneralPool / PLANNEDCONCURRENCY
-
If MEMORYSIZE is set to 0 and MAXMEMORYSIZE is set to a non-default value:
query-budget = queuingThreshold / PLANNEDCONCURRENCY
Note
Vertica calculates a user-defined pool's queuing threshold as 95 percent of its MAXMEMORYSIZE setting.
-
If MEMORYSIZE is set to a non-default value:
queryBudget = MEMORYSIZE / PLANNEDCONCURRENCY
By carefully tuning a resource pool's MEMORYSIZE and PLANNEDCONCURRENCY parameters, you can control how much memory can be budgeted for queries.
Caution
Query budgets do not typically require tuning, However, if you reduce the MAXMEMORYSIZE because you need memory for other purposes, be aware that doing so also reduces the query budget. Reducing the query budget negatively impacts the query performance, particularly if the queries are complex.
To maintain the original query budget for the resource pool, be sure to reduce parameters MAXMEMORYSIZE and PLANNEDCONCURRENCY together.
See also
Do You Need to Put Your Query on a Budget? in the Vertica User Community.
3 - Managing resources at query run time
The Resource Manager estimates the resources required for queries to run, and then prioritizes them.
The Resource Manager estimates the resources required for queries to run, and then prioritizes them. You can control how the Resource Manager prioritizes query execution in several ways:
3.1 - Setting runtime priority for the resource pool
For each resource pool, you can manage resources that are assigned to queries that are already running.
For each resource pool, you can manage resources that are assigned to queries that are already running. You assign each resource pool a runtime priority of HIGH, MEDIUM, or LOW. These settings determine the amount of runtime resources (such as CPU and I/O bandwidth) assigned to queries in the resource pool when they run. Queries in a resource pool with a HIGH priority are assigned greater runtime resources than those in resource pools with MEDIUM or LOW runtime priorities.
Prioritizing queries within a resource pool
While runtime priority helps to manage resources for the resource pool, there may be instances where you want some flexibility within a resource pool. For instance, you may want to ensure that very short queries run at a high priority, while also ensuring that all other queries run at a medium or low priority.
The Resource Manager allows you this flexibility by letting you set a runtime priority threshold for the resource pool. With this threshold, you specify a time limit (in seconds) by which a query must finish before it is assigned the runtime priority of the resource pool. All queries begin running with a HIGH priority; once a query's duration exceeds the time limit specified in the runtime priority threshold, it is assigned the runtime priority of the resource pool.
Setting runtime priority and runtime priority threshold
You specify runtime priority and runtime priority threshold by setting two resource pool parameters with
CREATE RESOURCE POOL or
ALTER RESOURCE POOL:
-
RUNTIMEPRIORITY
-
RUNTIMEPRIORITYTHRESHOLD
3.2 - Changing runtime priority of a running query
CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY lets you to change a query's runtime priority.
CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY lets you to change a query's runtime priority. You can change the runtime priority of a query that is already executing.
This function takes two arguments:
-
The query's transaction ID, obtained from the system table
SESSIONS
-
The desired priority, one of the following string values: HIGH, MEDIUM, or LOW
Restrictions
Superusers can change the runtime priority of any query to any priority level. The following restrictions apply to other users:
Procedure
Changing a query's runtime priority is a two-step procedure:
-
Get the query's transaction ID by querying the system table
SESSIONS. For example, the following statement returns information about all running queries:
=> SELECT transaction_id, runtime_priority, transaction_description from SESSIONS;
-
Run `CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY```, specifying the query's transaction ID and desired runtime priority:
=> SELECT CHANGE_CURRENT_STATEMENT_RUNTIME_PRIORITY(45035996273705748, 'low')
3.3 - Manually moving queries to different resource pools
If you are the database administrator, you can move queries to another resource pool mid-execution using the MOVE_STATEMENT_TO_RESOURCE_POOL meta-function.
If you are the database administrator, you can move queries to another resource pool mid-execution using the MOVE_STATEMENT_TO_RESOURCE_POOL meta-function.
You might want to use this feature if a single query is using a large amount of resources, preventing smaller queries from executing.
What happens when a query moves to a different resource pool
When a query is moved from one resource pool to another, it continues executing, provided the target pool has enough resources to accommodate the incoming query. If sufficient resources cannot be assigned in the target pool on at least one node, Vertica cancels the query and attempts to re-plan the query. If Vertica cannot re-plan the query, the query is canceled indefinitely.
When you successfully move a query to a target resource pool, its resources will be accounted for by the target pool and released on the first pool.
If you move a query to a resource pool with PRIORITY HOLD, Vertica cancels the query and queues it on the target pool. This cancellation remains in effect until you change the PRIORITY or move the query to another pool without PRIORITY HOLD. You can use this option if you want to store long-running queries for later use.
You can view the RESOURCE_ACQUISITIONS or RESOURCE_POOL_STATUS system tables to determine if the target pool can accommodate the query you want to move. Be aware that the system tables may change between the time you query the tables and the time you invoke the MOVE_STATEMENT_TO_RESOURCE_POOL meta-function.
When a query successfully moves from one resource pool to another mid-execution, it executes until the greater of the existing and new RUNTIMECAP is reached. For example, if the RUNTIMECAP on the initial pool is greater than that on the target pool, the query can execute until the initial RUNTIMECAP is reached.
When a query successfully moves from one resource pool to another mid-execution the CPU affinity will change.
Using the MOVE_STATEMENT_TO_RESOURCE_POOL function
To manually move a query from its current resource pool to another resource pool, use the MOVE_STATEMENT_TO_RESOURCE_POOL meta-function. Provide the session id, transaction id, statement id, and target resource pool name, as shown:
=> SELECT MOVE_STATEMENT_TO_RESOURCE_POOL ('v_vmart_node0001.example.-31427:0x82fbm', 45035996273711993, 1, 'my_target_pool');
See also:
4 - Restoring resource manager defaults
System table RESOURCE_POOL_DEFAULTS stores default values for all parameters for all built-in and user-defined resource pools.
System table RESOURCE_POOL_DEFAULTS stores default values for all parameters for all built-in and user-defined resource pools.
If you have changed the value of any parameter in any of your resource pools and want to restore it to its default, you can simply alter the table and set the parameter to DEFAULT. For example, the following statement sets the RUNTIMEPRIORITY for the resource pool sysquery back to its default value:
=> ALTER RESOURCE POOL sysquery RUNTIMEPRIORITY DEFAULT;
5 - Best practices for managing workload resources
This section provides general guidelines and best practices on how to set up and tune resource pools for various common scenarios.
This section provides general guidelines and best practices on how to set up and tune resource pools for various common scenarios.
Note
The exact settings for resource pool parameters are heavily dependent on your query mix, data size, hardware configuration, and concurrency requirements. Vertica recommends performing your own experiments to determine the optimal configuration for your system.
5.1 - Basic principles for scalability and concurrency tuning
A Vertica database runs on a cluster of commodity hardware.
A Vertica database runs on a cluster of commodity hardware. All loads and queries running against the database take up system resources, such as CPU, memory, disk I/O bandwidth, file handles, and so forth. The performance (run time) of a given query depends on how much resource it has been allocated.
When running more than one query concurrently on the system, both queries are sharing the resources; therefore, each query could take longer to run than if it was running by itself. In an efficient and scalable system, if a query takes up all the resources on the machine and runs in X time, then running two such queries would double the run time of each query to 2X. If the query runs in > 2X, the system is not linearly scalable, and if the query runs in < 2X then the single query was wasteful in its use of resources. Note that the above is true as long as the query obtains the minimum resources necessary for it to run and is limited by CPU cycles. Instead, if the system becomes bottlenecked so the query does not get enough of a particular resource to run, then the system has reached a limit. In order to increase concurrency in such cases, the system must be expanded by adding more of that resource.
In practice, Vertica should achieve near linear scalability in run times, with increasing concurrency, until a system resource limit is reached. When adequate concurrency is reached without hitting bottlenecks, then the system can be considered as ideally sized for the workload.
Note
Typically Vertica queries on segmented tables run on multiple (likely all) nodes of the cluster. Adding more nodes generally improves the run time of the query almost linearly.
5.2 - Setting a runtime limit for queries
You can set a limit for the amount of time a query is allowed to run.
You can set a limit for the amount of time a query is allowed to run. You can set this limit at three levels, listed in descending order of precedence:
-
The resource pool to which the user is assigned.
-
User profile with RUNTIMECAP configuredby
CREATE USER/
ALTER USER
-
Session queries, set by
SET SESSION RUNTIMECAP
In all cases, you set the runtime limit with an interval value that does not exceed one year. When you set runtime limit at multiple levels, Vertica always uses the shortest value. If a runtime limit is set for a non-superuser, that user cannot set any session to a longer runtime limit. Superusers can set the runtime limit for other users and for their own sessions, to any value up to one year, inclusive.
Example
user1 is assigned to the ad_hoc_queries resource pool:
=> CREATE USER user1 RESOURCE POOL ad_hoc_queries;
RUNTIMECAP for user1 is set to 1 hour:
=> ALTER USER user1 RUNTIMECAP '60 minutes';
RUNTIMECAP for the ad_hoc_queries resource pool is set to 30 minutes:
=> ALTER RESOURCE POOL ad_hoc_queries RUNTIMECAP '30 minutes';
In this example, Vertica terminates user1's queries if they exceed 30 minutes. Although the user1's runtime limit is set to one hour, the pool on which the query runs, which has a 30-minute runtime limit, has precedence.
Note
If a secondary pool for the ad_hoc_queries pool is specified using the CASCADE TO function, the query executes on that pool when the RUNTIMECAP on the ad_hoc_queries pool is surpassed.
See also
5.3 - Handling session socket blocking
A session socket can be blocked while awaiting client input or output for a given query.
A session socket can be blocked while awaiting client input or output for a given query. Session sockets are typically blocked for numerous reasons—for example, when the Vertica execution engine transmits data to the client, or a
COPY LOCAL operation awaits load data from the client.
In rare cases, a session socket can remain indefinitely blocked. For example, a query times out on the client, which tries to forcibly cancel the query, or relies on the session RUNTIMECAP setting to terminate it. In either case, if the query ends while awaiting messages or data, the socket can remain blocked and the session hang until it is forcibly closed.
Configuring a grace period
You can configure the system with a grace period, during which a lagging client or server can catch up and deliver a pending response. If the socket is blocked for a continuous period that exceeds the grace period setting, the server shuts down the socket and throws a fatal error. The session is then terminated. If no grace period is set, the query can maintain its block on the socket indefinitely.
You should set the session grace period high enough to cover an acceptable range of latency and avoid closing sessions prematurely—for example, normal client-side delays in responding to the server. Very large load operations might require you to adjust the session grace period as needed.
You can set the grace period at four levels, listed in descending order of precedence:
-
Session (highest)
-
User
-
Node
-
Database
Setting grace periods for the database and nodes
At the database and node levels, you set the grace period to any interval up to 20 days, through configuration parameter BlockedSocketGracePeriod:
-
ALTER DATABASE db-name SET BlockedSocketGracePeriod = 'interval';
-
ALTER NODE node-name SET BlockedSocketGracePeriod = 'interval';
By default, the grace period for both levels is set to an empty string, which allows unlimited blocking.
Setting grace periods for users and sessions
You can set the grace period for individual users and for a given session, as follows:
A user can set a session to any interval equal to or less than the grace period set for that user. Superusers can set the grace period for other users, and for their own sessions, to any value up to 20 days, inclusive.
Examples
Superuser dbadmin sets the database grace period to 6 hours. This limit only applies to non-superusers. dbadmin can sets the session grace period for herself to any value up to 20 days—in this case, 10 hours:
=> ALTER DATABASE VMart SET BlockedSocketGracePeriod = '6 hours';
ALTER DATABASE
=> SHOW CURRENT BlockedSocketGracePeriod;
level | name | setting
----------+--------------------------+---------
DATABASE | BlockedSocketGracePeriod | 6 hours
(1 row)
=> SET SESSION GRACEPERIOD '10 hours';
SET
=> SHOW GRACEPERIOD;
name | setting
-------------+---------
graceperiod | 10:00
(1 row)
dbadmin creates user user777 created with no grace period setting. Thus, the effective grace period for user777 is derived from the database setting of BlockedSocketGracePeriod, which is 6 hours. Any attempt by user777 to set the session grace period to a value greater than 6 hours returns with an error:
=> CREATE USER user777;
=> \c - user777
You are now connected as user "user777".
=> SHOW GRACEPERIOD;
name | setting
-------------+---------
graceperiod | 06:00
(1 row)
=> SET SESSION GRACEPERIOD '7 hours';
ERROR 8175: The new period 07:00 would exceed the database limit of 06:00
dbadmin sets a grace period of 5 minutes for user777. Now, user777 can set the session grace period to any value equal to or less than the user-level setting:
=> \c
You are now connected as user "dbadmin".
=> ALTER USER user777 GRACEPERIOD '5 minutes';
ALTER USER
=> \c - user777
You are now connected as user "user777".
=> SET SESSION GRACEPERIOD '6 minutes';
ERROR 8175: The new period 00:06 would exceed the user limit of 00:05
=> SET SESSION GRACEPERIOD '4 minutes';
SET
5.4 - Managing workloads with resource pools and user profiles
The scenarios in this section describe common workload-management issues, and provide solutions with examples.
The scenarios in this section describe common workload-management issues, and provide solutions with examples.
5.4.1 - Periodic batch loads
You do batch loads every night, or occasionally (infrequently) during the day.
Scenario
You do batch loads every night, or occasionally (infrequently) during the day. When loads are running, it is acceptable to reduce resource usage by queries, but at all other times you want all resources to be available to queries.
Solution
Create a separate resource pool for loads with a higher priority than the preconfigured setting on the build-in GENERAL pool.
In this scenario, nightly loads get preference when borrowing memory from the GENERAL pool. When loads are not running, all memory is automatically available for queries.
Example
Create a resource pool that has higher priority than the GENERAL pool:
-
Create resource pool load_pool with PRIORITY set to 10:
=> CREATE RESOURCE POOL load_pool PRIORITY 10;
-
Modify user load_user to use the new resource pool:
=> ALTER USER load_user RESOURCE POOL load_pool;
5.4.2 - CEO query
The CEO runs a report every Monday at 9AM, and you want to be sure that the report always runs.
Scenario
The CEO runs a report every Monday at 9AM, and you want to be sure that the report always runs.
Solution
To ensure that a certain query or class of queries always gets resources, you could create a dedicated pool for it as follows:
-
Using the PROFILE command, run the query that the CEO runs every week to determine how much memory should be allocated:
=> PROFILE SELECT DISTINCT s.product_key, p.product_description
-> FROM store.store_sales_fact s, public.product_dimension p
-> WHERE s.product_key = p.product_key AND s.product_version = p.product_version
-> AND s.store_key IN (
-> SELECT store_key FROM store.store_dimension
-> WHERE store_state = 'MA')
-> ORDER BY s.product_key;
-
At the end of the query, the system returns a notice with resource usage:
NOTICE: Statement is being profiled.HINT: select * from v_monitor.execution_engine_profiles where
transaction_id=45035996273751349 and statement_id=6;
NOTICE: Initiator memory estimate for query: [on pool general: 1723648 KB,
minimum: 355920 KB]
-
Create a resource pool with MEMORYSIZE reported by the above hint to ensure that the CEO query has at least this memory reserved for it:
=> CREATE RESOURCE POOL ceo_pool MEMORYSIZE '1800M' PRIORITY 10;
CREATE RESOURCE POOL
=> \x
Expanded display is on.
=> SELECT * FROM resource_pools WHERE name = 'ceo_pool';
-[ RECORD 1 ]-------+-------------
name | ceo_pool
is_internal | f
memorysize | 1800M
maxmemorysize |
priority | 10
queuetimeout | 300
plannedconcurrency | 4
maxconcurrency |
singleinitiator | f
-
Assuming the CEO report user already exists, associate this user with the above resource pool using ALTER USER statement.
=> ALTER USER ceo_user RESOURCE POOL ceo_pool;
-
Issue the following command to confirm that the ceo_user is associated with the ceo_pool:
=> SELECT * FROM users WHERE user_name ='ceo_user';
-[ RECORD 1 ]-+------------------
user_id | 45035996273713548
user_name | ceo_user
is_super_user | f
resource_pool | ceo_pool
memory_cap_kb | unlimited
If the CEO query memory usage is too large, you can ask the Resource Manager to reduce it to fit within a certain budget. See Query budgeting.
5.4.3 - Preventing runaway queries
Joe, a business analyst often runs big reports in the middle of the day that take up the whole machine's resources.You want to prevent Joe from using more than 100MB of memory, and you want to also limit Joe's queries to run for less than 2 hours.
Scenario
Joe, a business analyst often runs big reports in the middle of the day that take up the whole machine's resources.You want to prevent Joe from using more than 100MB of memory, and you want to also limit Joe's queries to run for less than 2 hours.
Solution
User resource allocation provides a solution to this scenario. To restrict the amount of memory Joe can use at one time, set a MEMORYCAP for Joe to 100MB using the ALTER USER command. To limit the amount of time that Joe's query can run, set a RUNTIMECAP to 2 hours using the same command. If any query run by Joe takes up more than its cap, Vertica rejects the query.
If you have a whole class of users whose queries you need to limit, you can also create a resource pool for them and set RUNTIMECAP for the resource pool. When you move these users to the resource pool, Vertica limits all queries for these users to the RUNTIMECAP you specified for the resource pool.
Example
=> ALTER USER analyst_user MEMORYCAP '100M' RUNTIMECAP '2 hours';
If Joe attempts to run a query that exceeds 100MB, the system returns an error that the request exceeds the memory session limit, such as the following example:
\i vmart_query_04.sqlvsql:vmart_query_04.sql:12: ERROR: Insufficient resources to initiate plan
on pool general [Request exceeds memory session limit: 137669KB > 102400KB]
Only the system database administrator (dbadmin) can increase only the MEMORYCAP setting. Users cannot increase their own MEMORYCAP settings and will see an error like the following if they attempt to edit their MEMORYCAP or RUNTIMECAP settings:
ALTER USER analyst_user MEMORYCAP '135M';
ROLLBACK: permission denied
5.4.4 - Restricting resource usage of ad hoc query application
You recently made your data warehouse available to a large group of users who are inexperienced with SQL.
Scenario
You recently made your data warehouse available to a large group of users who are inexperienced with SQL. Some users run reports that operate on a large number of rows and overwhelm the system. You want to throttle system usage by these users.
Solution
-
Create a resource pool for ad hoc applications where MAXMEMORYSIZE is equal to MEMORYSIZE. This prevents queries in that resource pool from borrowing resources from the GENERAL pool. Also, set RUNTIMECAP to limit the maximum duration of ad hoc queries:
=> CREATE RESOURCE POOL adhoc_pool
MEMORYSIZE '200M'
MAXMEMORYSIZE '200M'
RUNTIMECAP '20 seconds'
PRIORITY 0
QUEUETIMEOUT 300
PLANNEDCONCURRENCY 4;
=> SELECT pool_name, memory_size_kb, queueing_threshold_kb
FROM V_MONITOR.RESOURCE_POOL_STATUS WHERE pool_name='adhoc_pool';
pool_name | memory_size_kb | queueing_threshold_kb
------------+----------------+-----------------------
adhoc_pool | 204800 | 153600
(1 row)
-
Associate this resource pool with database users who use the application to connect to the database.
=> ALTER USER app1_user RESOURCE POOL adhoc_pool;
5.4.5 - Setting a hard limit on concurrency for an application
For billing purposes, analyst Jane would like to impose a hard limit on concurrency for this application.
Scenario
For billing purposes, analyst Jane would like to impose a hard limit on concurrency for this application. How can she achieve this?
Solution
The simplest solution is to create a separate resource pool for the users of that application and set its MAXCONCURRENCY to the desired concurrency level. Any queries beyond MAXCONCURRENCY are queued.
Tip
Vertica recommends leaving PLANNEDCONCURRENCY to the default level so the queries get their maximum amount of resources. The system as a whole thus runs with the highest efficiency.
Example
In this example, there are four billing users associated with the billing pool. The objective is to set a hard limit on the resource pool so a maximum of three concurrent queries can be executed at one time. All other queries will queue and complete as resources are freed.
=> CREATE RESOURCE POOL billing_pool MAXCONCURRENCY 3 QUEUETIMEOUT 2;
=> CREATE USER bill1_user RESOURCE POOL billing_pool;
=> CREATE USER bill2_user RESOURCE POOL billing_pool;
=> CREATE USER bill3_user RESOURCE POOL billing_pool;
=> CREATE USER bill4_user RESOURCE POOL billing_pool;
=> \x
Expanded display is on.
=> select maxconcurrency,queuetimeout from resource_pools where name = 'billing_pool';
maxconcurrency | queuetimeout
----------------+--------------
3 | 2
(1 row)
> SELECT reason, resource_type, rejection_count FROM RESOURCE_REJECTIONS
WHERE pool_name = 'billing_pool' AND node_name ilike '%node0001';
reason | resource_type | rejection_count
---------------------------------------+---------------+-----------------
Timedout waiting for resource request | Queries | 16
(1 row)
If queries are running and do not complete in the allotted time (default timeout setting is 5 minutes), the next query requested gets an error similar to the following:
ERROR: Insufficient resources to initiate plan on pool billing_pool [Timedout waiting for resource request: Request exceeds limits:
Queries Exceeded: Requested = 1, Free = 0 (Limit = 3, Used = 3)]
The table below shows that there are three active queries on the billing pool.
=> SELECT pool_name, thread_count, open_file_handle_count, memory_inuse_kb FROM RESOURCE_ACQUISITIONS
WHERE pool_name = 'billing_pool';
pool_name | thread_count | open_file_handle_count | memory_inuse_kb
--------------+--------------+------------------------+-----------------
billing_pool | 4 | 5 | 132870
billing_pool | 4 | 5 | 132870
billing_pool | 4 | 5 | 132870
(3 rows)
5.4.6 - Handling mixed workloads: batch versus interactive
You have a web application with an interactive portal.
Scenario
You have a web application with an interactive portal. Sometimes when IT is running batch reports, the web page takes a long time to refresh and users complain, so you want to provide a better experience to your web site users.
Solution
The principles learned from the previous scenarios can be applied to solve this problem. The basic idea is to segregate the queries into two groups associated with different resource pools. The prerequisite is that there are two distinct database users issuing the different types of queries. If this is not the case, do consider this a best practice for application design.
**Method 1
**Create a dedicated pool for the web page refresh queries where you:
-
Size the pool based on the average resource needs of the queries and expected number of concurrent queries issued from the portal.
-
Associate this pool with the database user that runs the web site queries. SeeCEO query for information about creating a dedicated pool.
This ensures that the web site queries always run and never queue behind the large batch jobs. Leave the batch jobs to run off the GENERAL pool.
For example, the following pool is based on the average resources needed for the queries running from the web and the expected number of concurrent queries. It also has a higher PRIORITY to the web queries over any running batch jobs and assumes the queries are being tuned to take 250M each:
=> CREATE RESOURCE POOL web_pool
MEMORYSIZE '250M'
MAXMEMORYSIZE NONE
PRIORITY 10
MAXCONCURRENCY 5
PLANNEDCONCURRENCY 1;
**Method 2
**Create a resource pool with fixed memory size. This limits the amount of memory available to batch reports so memory is always left over for other purposes. For details, see Restricting resource usage of ad hoc query application.
For example:
=> CREATE RESOURCE POOL batch_pool
MEMORYSIZE '4G'
MAXMEMORYSIZE '4G'
MAXCONCURRENCY 10;
The same principle can be applied if you have three or more distinct classes of workloads.
5.4.7 - Setting priorities on queries issued by different users
You want user queries from one department to have a higher priority than queries from another department.
Scenario
You want user queries from one department to have a higher priority than queries from another department.
Solution
The solution is similar to the mixed workload case. In this scenario, you do not limit resource usage; you set different priorities. To do so, create two different pools, each with MEMORYSIZE=0% and a different PRIORITY parameter. Both pools borrow from the GENERAL pool, however when competing for resources, the priority determine the order in which each pool's request is granted. For example:
=> CREATE RESOURCE POOL dept1_pool PRIORITY 5;
=> CREATE RESOURCE POOL dept2_pool PRIORITY 8;
If you find this solution to be insufficient, or if one department's queries continuously starves another department’s users, you can add a reservation for each pool by setting MEMORYSIZE so some memory is guaranteed to be available for each department.
For example, both resources use the GENERAL pool for memory, so you can allocate some memory to each resource pool by using ALTER RESOURCE POOL to change MEMORYSIZE for each pool:
=> ALTER RESOURCE POOL dept1_pool MEMORYSIZE '100M';
=> ALTER RESOURCE POOL dept2_pool MEMORYSIZE '150M';
5.4.8 - Continuous load and query
You want your application to run continuous load streams, but many have up concurrent query streams.
Scenario
You want your application to run continuous load streams, but many have up concurrent query streams. You want to ensure that performance is predictable.
Solution
The solution to this scenario depends on your query mix. In all cases, the following approach applies:
-
Determine the number of continuous load streams required. This may be related to the desired load rate if a single stream does not provide adequate throughput, or may be more directly related to the number of sources of data to load. Create a dedicated resource pool for the loads, and associate it with the database user that will perform them. See CREATE RESOURCE POOL for details.
In general, concurrency settings for the load pool should be less than the number of cores per node. Unless the source processes are slow, it is more efficient to dedicate more memory per load, and have additional loads queue. Adjust the load pool's QUEUETIMEOUT setting if queuing is expected.
-
Run the load workload for a while and observe whether the load performance is as expected. If the Tuple Mover is not tuned adequately to cover the load behavior, see Managing the tuple mover.
-
If there is more than one kind of query in the system—for example, some queries must be answered quickly for interactive users, while others are part of a batch reporting process—follow the guidelines in Handling mixed workloads: batch versus interactive.
-
Let the queries run and observe performance. If some classes of queries do not perform as desired, then you might need to tune the GENERAL pool as outlined in Restricting resource usage of ad hoc query application, or create more dedicated resource pools for those queries. For more information, see CEO query and Handling mixed workloads: batch versus interactive.
See the sections on Managing workloads and CREATE RESOURCE POOL for information on obtaining predictable results in mixed workload environments.
5.4.9 - Prioritizing short queries at run time
You recently created a resource pool for users who are inexperienced with SQL and who frequently run ad hoc reports.
Scenario
You recently created a resource pool for users who are inexperienced with SQL and who frequently run ad hoc reports. Until now, you managed resource allocation by creating a resource pool where MEMORYSIZE and MAXMEMORYSIZE are equal. This prevented queries in that resource pool from borrowing resources from the GENERAL pool. Now you want to manage resources at run time and prioritize short queries so they are never queued as a result of limited run-time resources.
Solution
For example:
=> ALTER RESOURCE POOL ad_hoc_pool RUNTIMEPRIORITY medium RUNTIMEPRIORITYTHRESHOLD 5;
Because RUNTIMEPRIORITYTHRESHOLD is set to 5, all queries in resource pool ad_hoc_pool that complete within 5 seconds run at high priority. Queries that exceeds 5 seconds drop down to the RUNTIMEPRIORITY assigned to the resource pool, MEDIUM.
5.4.10 - Dropping the runtime priority of long queries
You want most queries in a resource pool to run at a HIGH runtime priority; however, you'd like to be able to drop jobs longer than 1 hour to a lower priority.
Scenario
You want most queries in a resource pool to run at a HIGH runtime priority; however, you'd like to be able to drop jobs longer than 1 hour to a lower priority.
Solution
Set the RUNTIMEPRIORITY for the resource pool to LOW and set the RUNTIMEPRIORITYTHRESHOLD to a number that cuts off only the longest jobs.
Example
To ensure that all queries with a duration of more than 3600 seconds (1 hour) are assigned a low runtime priority, modify the resource pool as follows:
=> ALTER RESOURCE POOL ad_hoc_pool RUNTIMEPRIORITY low RUNTIMEPRIORITYTHRESHOLD 3600;
5.5 - Tuning built-in pools
The scenarios in this section describe how to tune built-in pools.
The scenarios in this section describe how to tune built-in pools.
5.5.1 - Restricting Vertica to take only 60% of memory
You have a single node application that embeds Vertica, and some portion of the RAM needs to be devoted to the application process.
Scenario
You have a single node application that embeds Vertica, and some portion of the RAM needs to be devoted to the application process. In this scenario, you want to limit Vertica to use only 60% of the available RAM.
Solution
Set the MAXMEMORYSIZE parameter of the GENERAL pool to the desired memory size. See Resource pool architecture for a discussion on resource limits.
5.5.2 - Tuning for recovery
You have a large database that contains a single large table with two projections, and with default settings, recovery is taking too long.
Scenario
You have a large database that contains a single large table with two projections, and with default settings, recovery is taking too long. You want to give recovery more memory to improve speed.
Solution
Set PLANNEDCONCURRENCY and MAXCONCURRENCY in the RECOVERY pool to 1, so recovery can take as much memory as possible from the GENERAL pool and run only one thread at once.
Caution
This setting can slow down other queries in your system.
5.5.3 - Tuning for refresh
When a operation is running, system performance is affected and user queries are rejected.
Scenario
When a refresh operation is running, system performance is affected and user queries are rejected. You want to reduce the memory usage of the refresh job.
Solution
Set MEMORYSIZE in the REFRESH pool to a fixed value. The Resource Manager then tunes the refresh query to only use this amount of memory.
Important
Remember to reset MEMORYSIZE in the REFRESH pool to 0% after the refresh operation completes, so memory can be used for other operations.
5.5.4 - Tuning tuple mover pool settings
During heavy load operations, you occasionally notice spikes in the number of ROS containers.
Scenario 1
During heavy load operations, you occasionally notice spikes in the number of ROS containers. You would like the Tuple Mover to perform mergeout more aggressively to consolidate ROS containers, and avoid ROS pushback.
Solution
Use ALTER RESOURCE POOL to increase the setting of MAXCONCURRENCY in the TM resource pools. This setting determines how many threads are available for mergeout. By default , this parameter is set to 7. Vertica allocates half the threads to active partitions, and the remaining half to active and inactive partitions as needed. If MAXCONCURRENCY is set to an uneven integer, Vertica rounds up to favor active partitions.
For example, if you increase MAXCONCURRENCY to 9, then Vertica allocates five threads exclusively to active partitions, and allocates the remaining four threads to active and inactive partitions.
Scenario 2
You have a secondary subcluster that is dedicated to time-sensitive analytic queries. You want to limit any other workloads on this subcluster that could interfere with it processing queries while also freeing up memory to perform queries.
By default, each subcluster has a built-in TM resource pool for Tuple Mover operations that makes it eligible to execute Tuple Mover mergeout operations. The TM pool consumes memory that could be used for queries. In addition, the mergeout operation could add a slight overhead to your subcluster's processing. You want to reallocate the memory consumed by the TM pool, and prevent the subcluster from running mergeout operations.
Solution
Use ALTER RESOURCE POOL to override the global TM resource pool for the secondary subcluster, and set both its MAXMEMORYSIZE and MEMORYSIZE to 0. This allows you to use the memory consumed by the global TM pool for use running analytic queries and prevents the subcluster being assigned TM mergeout operations to execute.
5.5.5 - Tuning for machine learning
A large number of machine learning functions are running, and you want to give them more memory to improve performance.
Scenario
A large number of machine learning functions are running, and you want to give them more memory to improve performance.
Solution
Vertica executes machine learning functions in the BLOBDATA resource pool. To improve performance of machine learning functions and avoid spilling queries to disk, increase the pool's MAXMEMORYSIZE setting with ALTER RESOURCE POOL.
For more about tuning query budgets, see Query budgeting.
See also
5.6 - Reducing query run time
Query run time depends on the complexity of the query, the number of operators in the plan, data volumes, and projection design.
Query run time depends on the complexity of the query, the number of operators in the plan, data volumes, and projection design. I/O or CPU bottlenecks can cause queries to run slower than expected. You can often remedy high CPU usage with better projection design. High I/O can often be traced to contention caused by joins and sorts that spill to disk. However, no single solution addresses all queries that incur high CPU or I/O usage. You must analyze and tune each queryindividually.
You can evaluate a slow-running query in two ways:
Examining the query plan can reveal one or more of the following:
-
Suboptimal projection sort order
-
Predicate evaluation on an unsorted or unencoded column
-
Use of GROUPBY HASH instead of GROUPBY PIPE
Profiling
Vertica provides profiling mechanisms that help you evaluate database performance at different levels. For example, you can collect profiling data for a single statement, a single session, or for all sessions on all nodes. For details, see Profiling database performance.
5.7 - Managing workload resources in an Eon Mode database
You primarily control workloads in an Eon Mode database using subclusters.
You primarily control workloads in an Eon Mode database using subclusters. For example, you can create subclusters for specific use cases, such as ETL or query workloads, or you can create subclusters for different groups of users to isolate workloads. Within each subcluster, you can create individual resource pools to optimize resource allocation according to workload. See Managing subclusters for more information about how Vertica uses subclusters.
Global and subcluster-specific resource pools
You can define global resource pool allocations that affect all nodes in the database. You can also create resource pool allocations at the subcluster level. If you create both, the subcluster-level settings override the global settings.
Note
The GENERAL pool requires at least 25% of available memory to function properly. If you attempt to set MEMORYSIZE for a user-defined resource pool to more than 75%, Vertica returns an error.
You can use this feature to remove global resource pools that the subcluster does not need. Additionally, you can create a resource pool with settings that are adequate for most subclusters, and then tailor the settings for specific subclusters as needed.
Optimizing ETL and query subclusters
Overriding resource pool settings at the subcluster level allows you to isolate built-in and user-defined resource pools and optimize them by workload. You often assign specific roles to different subclusters:
-
Subclusters dedicated to ETL workloads and DDL statements that alter the database.
-
Subclusters dedicated to running in-depth, long-running analytics queries. These queries need more resources allocated for the best performance.
-
Subclusters that run many short-running "dashboard" queries that you want to finish quickly and run in parallel.
After you define the type of queries executed by each subcluster, you can create a subcluster-specific resource pool that is optimized to improve efficiency for that workload.
The following scenario optimizes 3 subclusters by workload:
-
etl: A subcluster that performs ETL that you want to optimize for Tuple Mover operations.
-
dashboard: A subcluster that you want to designate for short-running queries executed by a large number of users to refresh a web page.
-
analytics: A subcluster that you want to designate for long-running queries.
See Best practices for managing workload resources for additional scenarios about resource pool tuning.
Vertica chooses the subcluster that has the most ROS containers involved in a mergeout operation in its depot to execute a mergeout (see The Tuple Mover in Eon Mode Databases). Often, a subcluster performing ETL will be the best candidate to perform a mergeout because the data it loaded is involved in the mergeout. You can choose to improve the performance of mergeout operations on a subcluster by altering the TM pool's MAXCONCURRENCY setting to increase the number of threads available for mergeout operations. You cannot change this setting at the subcluster level, so you must set it globally:
=> ALTER RESOURCE POOL TM MAXCONCURRENCY 10;
See Tuning tuple mover pool settings for additional information about Tuple Mover resources.
By default, secondary subclusters have memory allocated to Tuple Mover resource pools. This pool setting allows Vertica to assign mergeout operations to the subcluster, which can add a small overhead. If you primarily use a secondary subcluster for queries, the best practice is to reclaim the memory used by the TM pool and prevent mergeout operations being assigned to the subcluster.
To optimize your dashboard query secondary subcluster, set their TM pool's MEMORYSIZE and MAXMEMORYSIZE settings to 0:
=> ALTER RESOURCE POOL TM FOR SUBCLUSTER dashboard MEMORYSIZE '0%'
MAXMEMORYSIZE '0%';
Important
Do not set the TM pool's MEMORYSIZE and MAXMEMORYSIZE settings to 0 on
primary subclusters. They must always be able to run the Tuple Mover.
To confirm the overrides, query the SUBCLUSTER_RESOURCE_POOL_OVERRIDES table:
=> SELECT pool_oid, name, subcluster_name, memorysize, maxmemorysize
FROM SUBCLUSTER_RESOURCE_POOL_OVERRIDES;
pool_oid | name | subcluster_name | memorysize | maxmemorysize
-------------------+------+-----------------+------------+---------------
45035996273705046 | tm | dashboard | 0% | 0%
(1 row)
To optimize the dashboard subcluster for short-running queries on a web page, create a dash_pool subcluster-level resource pool that uses 70% of the subcluster's memory. Additionally, increase PLANNEDCONCURRENCY to use all of the machine's logical cores, and limit EXECUTIONPARALLELISM to no more than half of the machine's available cores:
=> CREATE RESOURCE POOL dash_pool FOR SUBCLUSTER dashboard
MEMORYSIZE '70%'
PLANNEDCONCURRENCY 16
EXECUTIONPARALLELISM 8;
To optimize the analytics subcluster for long-running queries, create an analytics_pool subcluster-level resource pool that uses 60% of the subcluster's memory. In this scenario, you cannot allocate more memory to this pool because the nodes in this subcluster still have memory assigned to their TM pools. Additionally, set EXECUTIONPARALLELISM to AUTO to use all cores available on the node to process a query, and limit PLANNEDCONCURRENCY to no more than 8 concurrent queries:
=> CREATE RESOURCE POOL analytics_pool FOR SUBCLUSTER analytics
MEMORYSIZE '60%'
EXECUTIONPARALLELISM AUTO
PLANNEDCONCURRENCY 8;
6 - Managing system resource usage
You can use the SQL Monitoring APIs (system tables) to track overall resource usage on your cluster.
You can use the Using system tables to track overall resource usage on your cluster. These and the other system tables are described in the Vertica system tables.
If your queries are experiencing errors due to resource unavailability, you can use the following system tables to obtain more details:
When requests for resources of a certain type are being rejected, do one of the following:
-
Increase the resources available on the node by adding more memory, more disk space, and so on. See Managing disk space.
-
Reduce the demand for the resource by reducing the number of users on the system (see Managing sessions), rescheduling operations, and so on.
The LAST_REJECTED_VALUE field in RESOURCE_REJECTIONS indicates the cause of the problem. For example:
-
The message Usage of a single requests exceeds high limit means that the system does not have enough of the resource available for the single request. A common example occurs when the file handle limit is set too low and you are loading a table with a large number of columns.
-
The message Timed out or Canceled waiting for resource reservation usually means that there is too much contention for the resource because the hardware platform cannot support the number of concurrent users using it.
6.1 - Managing sessions
Vertica provides several methods for database administrators to view and control sessions.
Vertica provides several methods for database administrators to view and control sessions. The methods vary according to the type of session:
-
External (user) sessions are initiated by vsql or programmatic (ODBC or JDBC) connections and have associated client state.
-
Internal (system) sessions are initiated by Vertica and have no client state.
Configuring maximum sessions
The maximum number of per-node user sessions is set by the configuration parameter MaxClientSessions parameter, by default 50. You can set MaxClientSessions parameter to any value between 0 and 1000. In addition to this maximum, Vertica also allows up to five administrative sessions per node.
For example:
=> ALTER DATABASE DEFAULT SET MaxClientSessions = 100;
Note
If you use the Administration Tools "Connect to Database" option, Vertica will attempt connections to other nodes if a local connection does not succeed. These cases can result in more successful "Connect to Database" commands than you would expect given the MaxClientSessions value.
Viewing sessions
The system table
SESSIONS contains detailed information about user sessions and returns one row per session. Superusers have unrestricted access to all database metadata. Access for other users varies according to their privileges.
Interrupting and closing sessions
You can interrupt a running statement with the Vertica function
INTERRUPT_STATEMENT. Interrupting a running statement returns a session to an idle state:
Closing a user session interrupts the session and disposes of all state related to the session, including client socket connections for the target sessions. The following Vertica functions close one or more user sessions:
SELECT statements that call these functions return after the interrupt or close message is delivered to all nodes. The function might return before Vertica completes execution of the interrupt or close operation. Thus, there might be a delay after the statement returns and the interrupt or close takes effect throughout the cluster. To determine if the session or transaction ended, query the SESSIONS system table.
In order to shut down a database, you must first close all user sessions. For more about database shutdown, see Stopping the database.
6.2 - Managing load streams
You can use system table LOAD_STREAMS to monitor data as it is loaded on your cluster.
You can use system table LOAD_STREAMS to monitor data as it is loaded on your cluster. Several columns in this table showmetrics for each load stream on each node, including the following:
|
Column name |
Value... |
ACCEPTED_ROW_COUNT |
Increases during parsing, up to the maximum number of rows in the input file. |
PARSE_COMPLETE_PERCENT |
Remains zero (0) until all named pipes return an EOF. While COPY awaits an EOF from multiple pipes, it can appear to be hung. However, before canceling the COPY statement, check your system CPU and disk accesses to determine if any activity is in progress.
In a typical load, the PARSE_COMPLETE_PERCENT value can either increase slowly or jump quickly to 100%, if you are loading from named pipes or STDIN.
|
SORT_COMPLETE_PERCENT |
Remains at 0 when loading from named pipes or STDIN. After PARSE_COMPLETE_PERCENT reaches 100 percent, SORT_COMPLETE_PERCENT increases to 100 percent. |
Depending on the data sizes, a significant lag can occur between the time PARSE_COMPLETE_PERCENT reaches 100 percent and the time SORT_COMPLETE_PERCENT begins to increase.