Database container deployment on Kubernetes
Kubernetes is an open-source container orchestration platform that automatically manages infrastructure resources and schedules tasks for containerized applications at scale. Kubernetes achieves automation with a declarative model that decouples the application from the infrastructure. The administrator provides Kubernetes the desired state of an application, and Kubernetes deploys the application and works to maintain that desired state. This frees the administrator to update the application as business needs evolve, without worrying about the implementation details.
An application consists of resources, which are stateful objects that you create from Kubernetes resource types. Kubernetes provides access to resource types through the Kubernetes API, an HTTP API that exposes resource types as endpoints. The most common way to create a resource is with a YAML-formatted manifest file that defines the desired state of the resource. You use the kubectl command-line tool to request a resource instance of that type from the Kubernetes API. In addition to the default resource types, you can extend the Kubernetes API and define your own resource types as a Custom Resource Definition (CRD).
To manage the infrastructure, Kubernetes uses a host to run the control plane, and designates one or more hosts as worker nodes. The control plane is a collection of services and controllers that maintain the desired state of Kubernetes objects and schedule tasks on worker nodes. Worker nodes complete tasks that the control plane assigns. Just as you can create a CRD to extend the Kubernetes API, you can create a custom controller that maintains the state of your custom resources (CR) created from the CRD.
VerticaDB custom resource definition and custom controller
The VerticaDB CRD extends the Kubernetes API so that you can create custom resources that deploy an Eon Mode database as a StatefulSet. Additionally, the VerticaDB operator is a custom controller that maintains the desired state of your CR and automates lifecycle tasks. The result is a self-healing, highly-available, and scalable Eon Mode database that requires minimal manual intervention.
To simplify deployment, the database packages the CRD and the operator in Helm charts. A Helm chart bundles manifest files into a single package to create multiple resource type objects with a single command.
Custom resource definition architecture
The database CRD creates a StatefulSet, a workload resource type that persists data with ephemeral Kubernetes objects. The following diagram describes the database CRD architecture:
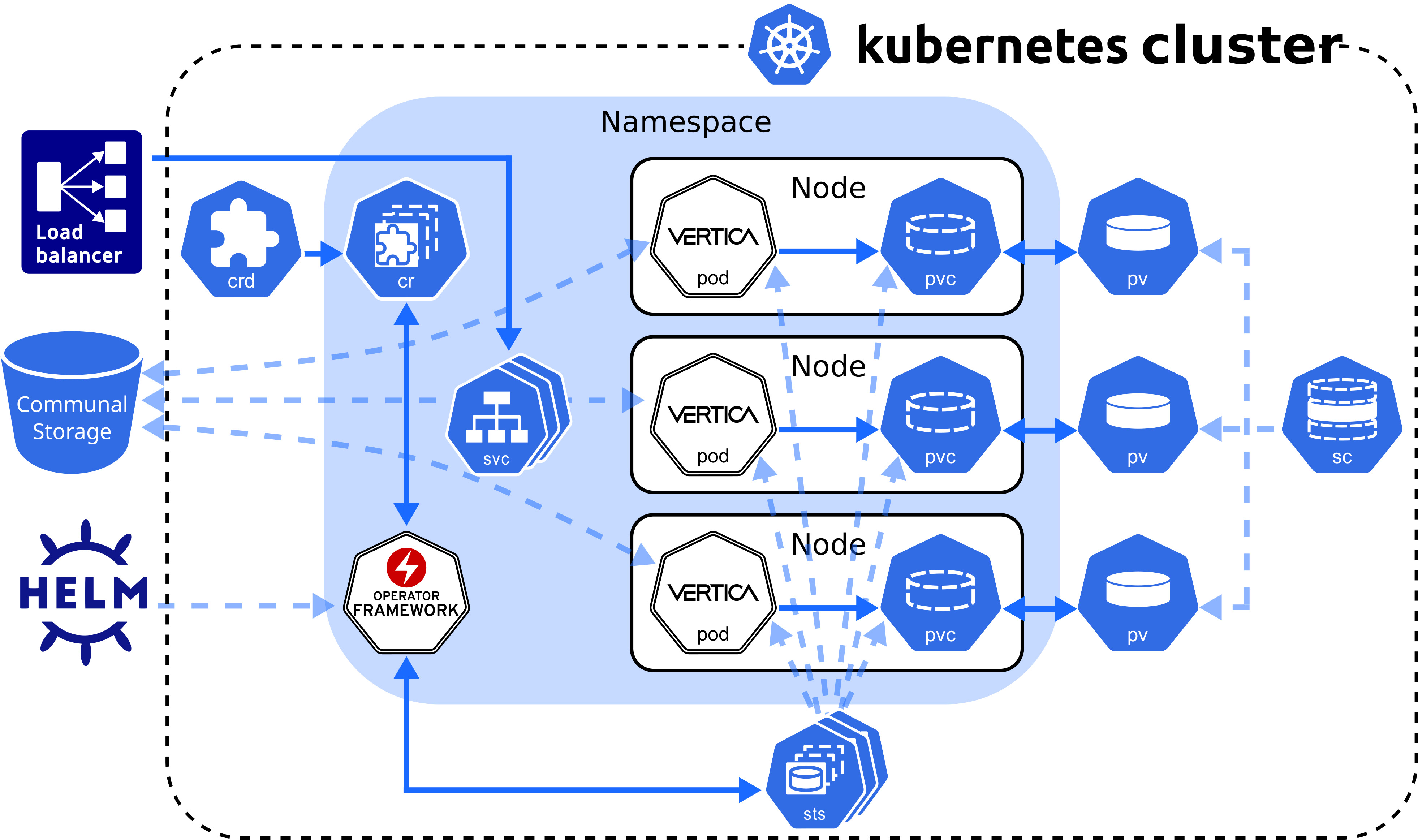
VerticaDB operator
The VerticaDB operator is a cluster-scoped custom controller that maintains the state of custom objects and automates administrator tasks across all namespaces in the cluster. The operator watches objects and compares their current state to the desired state declared in the custom resource. When the current state does not match the desired state, the operator works to restore the objects to the desired state.
In addition to state maintenance, the operator:
-
Installs Vertica
-
Creates an Eon Mode database
-
Upgrades Vertica
-
Revives an existing Eon Mode database
-
Restarts and reschedules DOWN pods
-
Scales subclusters
-
Manages services for pods
-
Monitors pod health
-
Handles load balancing for internal and external traffic
To validate changes to the custom resource, the operator queries the admission controller, a webhook that provides rules for mutable states in a custom resource.
The operator and admission controller are available with Helm charts, kubectl command-line tool, or through OperatorHub.io. For details about installing the operator and the admission controller with both methods, see Installing the VerticaDB operator.
Database pod
A pod is essentially a wrapper around one or more logically grouped containers. A database pod in the default configuration consists of two containers: the database server container that runs the main database process, and the Node Management Agent (NMA) container.
The NMA runs in a sidecar container, which is a container that contributes to the pod's main process, the database server. The database pod runs a single process per container to align each process lifetime with its container lifetime. This alignment provides the following benefits:
- Accurate health checks. A container can have only one health check, so performing a health check on a container with multiple running processes might return inaccurate results.
- Granular Kubernetes probe control. Kubernetes sets probes at the container level. If the database container runs multiple processes, the NMA process might interfere with the probe that you set for the database server process. This interference is not an issue with single-process containers.
- Simplified monitoring. A container with multiple processes has multiple states, which complicates monitoring. A container with a single process returns a single state.
- Easier troubleshooting. If a container runs multiple processes and crashes, it might be difficult to determine which failure caused the crash. Running one process per container makes it easier to pinpoint issues.
When a database pod launches, the NMA process starts and prepares the configuration files for the database server process. After the server container retrieves environment information from the NMA configuration files, the database server process is ready.
All containers in the database pod consume the host node resources in a shared execution environment. In addition to sharing resources, a pod extends the container to interact with Kubernetes services. For example, you can assign labels to associate pods to other objects, and you can implement affinity rules to schedule pods on specific host nodes.
DNS names provide continuity between pod lifecycles. Each pod is assigned an ordered and stable DNS name that is unique within its cluster. When a database pod fails, the rescheduled pod uses the same DNS name as its predecessor. If a pod needs to persist data between lifecycles, you can mount a custom volume in its filesystem.
Rescheduled pods require information about the environment to become part of the cluster. This information is provided by the Downward API. Environment information, such as the superuser password Secret, is mounted in the /etc/podinfo directory.
NMA sidecar
The NMA sidecar exposes a REST API that the VerticaDB operator uses to administer your cluster. This container runs the same image as the database server process, specified by the spec.image parameter setting in the VerticaDB custom resource definition.
The NMA sidecar is designed to consume minimal resources, but because the database size determines the amount of resources consumed by some NMA operations, there are no default resource limits. This prevents failures that result from inadequate available resources.
Running the NMA in a sidecar enables idiomatic Kubernetes logging, which sends all logs to STDOUT and STDERR on the host node. In addition, the kubectl logs command accepts a container name, so you can specify a container name during log collection.
Sidecar logger
The database server process writes log messages to a catalog file named vertica.log. However, idiomatic Kubernetes practices send log messages to STDOUT and STDERR on the host node for log aggregation.
vertica-logger sidecar image aligns the database server logging with the Kubernetes convention. You can run this image in a sidecar, and it retrieves logs from vertica.log and sends them to the container's STDOUT and STDERR stream. If your sidecar logger needs to persist data, you can mount a custom volume in the filesystem.
For implementation details, see VerticaDB custom resource definition.
Persistent storage
A pod is an ephemeral, immutable object that requires access to external storage to persist data between lifecycles. To persist data, the operator uses the following API resource types:
-
StorageClass: Represents an external storage provider. You must create a StorageClass object separately from your custom resource and set this value with the
local.storageClassNameconfiguration parameter. -
PersistentVolume (PV): A unit of storage that mounts in a pod to persist data. You dynamically or statically provision PVs. Each PV references a StorageClass.
-
PersistentVolumeClaim (PVC): The resource type that a pod uses to describe its StorageClass and storage requirements. When you delete a VerticaDB CR, its PVC is deleted.
A pod mounts a PV in its filesystem to persist data, but a PV is not associated with a pod by default. However, the pod is associated with a PVC that includes a StorageClass in its storage requirements. When a pod requests storage with a PVC, the operator observes this request and then searches for a PV that meets the storage requirements. If the operator locates a PV, it binds the PVC to the PV and mounts the PV as a volume in the pod. If the operator does not locate a PV, it must either dynamically provision one, or the administrator must manually provision one before the operator can bind it to a pod.
PVs persist data because they exist independently of the pod life cycle. When a pod fails or is rescheduled, it has no effect on the PV. When you delete a VerticaDB, the VerticaDB operator automatically deletes any PVCs associated with that VerticaDB instance.
For additional details about StorageClass, PersistentVolume, and PersistentVolumeClaim, see the Kubernetes documentation.
StorageClass requirements
The StorageClass affects how the database server environment and operator function. For optimum performance, consider the following:
-
If you do not set the
local.storageClassNameconfiguration parameter, the operator uses the default storage class. If you use the default storage class, confirm that it meets storage requirements for a production workload. -
Select a StorageClass that uses a recommended storage format type as its
fsType. -
Use dynamic volume provisioning. The operator requires on-demand volume provisioning to create PVs as needed.
Local volume mounts
The operator mounts a single PVC in the /home/dbadmin/local-data/ directory of each pod to persist data. Each of the following subdirectories is a sub-path into the volume that backs the PVC:
-
/catalog: Optional subdirectory that you can create if your environment requires a catalog location that is separate from the local data. You can customize this path with thelocal.catalogPathparameter.
By default, the catalog is stored in the/datasubdirectory. -
/data: Stores any temporary files, and the catalog iflocal.catalogPathis not set. You can customize this path with thelocal.dataPathparameter. -
/depot: Improves depot warming in a rescheduled pod. You can customize this path with thelocal.depotPathparameter.Note
You can change the volume type for the/depotwith thelocal.depotVolumeparameter. By default, this parameter is set toPersistentVolume, and the operator creates the/depotsub-path. Iflocal.depotVolumeis not set toPersistentVolume, the operator does not create the sub-path. -
/opt/vertica/config: Persists the contents of the configuration directory between restarts. -
/opt/vertica/log: Persists log files between pod restarts. -
/tmp/scrutinize: Target location for the final scruitinize tar file and any additional files generated during scrutinize diagnositics collection.
Note
Kubernetes assigns each custom resource a unique identifier. The volume mount paths include the unique identifier between the mount point and the subdirectory. For example, the full path to the/data directory is /home/dbadmin/local-data/uid/data.
By default, each path mounted in the /local-data directory is owned by the user or group specified by the operator. To customize the user or group, set the podSecurityContext custom resource definition parameter.
Custom volume mounts
You might need to persist data between pod lifecycles in one of the following scenarios:
-
An external process performs a task that requires long-term access to the database server data.
-
Your custom resource includes a sidecar container in the database pod.
You can mount a custom volume in the database pod or sidecar filesystem. To mount a custom volume in the database pod, add the definition in the spec section of the CR. To mount the custom volume in the sidecar, add it in an element of the sidecars array.
The CR requires that you provide the volume type and a name for each custom volume. The CR accepts any Kubernetes volume type. The volumeMounts.name value identifies the volume within the CR, and has the following requirements and restrictions:
-
It must match the
volumes.nameparameter setting. -
It must be unique among all volumes in the
/local-data,/podinfo, or/licensingmounted directories.
For instructions on how to mount a custom volume in either the database server container or in a sidecar, see VerticaDB custom resource definition.
Service objects
OpenText™ Analytics Database on Kubernetes provides two service objects: a headless service that requires no configuration to maintain DNS records and ordered names for each pod, and a load-balancing service that manages internal traffic and external client requests for the pods in your cluster.
Load-balancing services
Each subcluster uses a single load-balancing service object. You can manually assign a name to a load-balancing service object with the subclusters[i].serviceName parameter in the custom resource. Assigning a name is useful when you want to:
-
Direct traffic from a single client to multiple subclusters.
-
Scale subclusters by workload with more flexibility.
-
Identify subclusters by a custom service object name.
To configure the type of service object, use the subclusters[i].serviceType parameter in the custom resource to define a Kubernetes service type. The following service types are supported:
-
ClusterIP: The default service type. This service provides internal load balancing, and sets a stable IP and port that is accessible from within the subcluster only.
-
NodePort: Provides external client access. You can specify a port number for each host node in the subcluster to open for client connections.
-
LoadBalancer: Uses a cloud provider load balancer to create NodePort and ClusterIP services as needed. For details about implementation, see the Kubernetes documentation and your cloud provider documentation.
Important
To prevent performance issues during heavy network traffic, it is recommended that you set--proxy-mode to iptables for your Kubernetes cluster.
Because native load balancing interferes with the Kubernetes service object, it is recommended that you allow the Kubernetes services to manage load balancing for the subcluster. You can configure the native load balancer within the Kubernetes cluster, but you receive unexpected results. For example, if you set the database load-balancing policy to ROUNDROBIN, the load balancing appears random.
For additional details about Kubernetes services, see the official Kubernetes documentation.
Security considerations
OpenText™ Analytics Database on Kubernetes supports both TLS and mTLS for communications between resource objects. You must manually configure TLS in your environment. For details, see TLS protocol.
Important
After the database is created in Kubernetes, do not change the tls mode for server TLS Configuration toVERIFY_CA or VERIFY_FULL, as this may cause the database to go down and be difficult to recover.
The VerticaDB operator manages changes to the certificates. If you update an existing certificate, the operator replaces the certificate in the database server container. If you add or delete a certificate, the operator reschedules the pod with the new configuration.
The subsequent sections detail internal and external connections that require TLS for secure communications.
Admission controller webhook certificates
The VerticaDB operator Helm chart includes the admission controller, a webhook that communicates with the Kubernetes API server to validate changes to a resource object. Because the API server communicates over HTTPS only, you must configure TLS certificates to authenticate communications between the API server and the webhook.
The method you use to install the VerticaDB operator determines how you manage TLS certificates for the admission controller:
- Helm charts: In the default configuration, the operator generates self-signed certificates. You can add custom certificates with the
webhook.certSourceHelm chart parameter. - kubectl: The operator generates self-signed certificates.
- OperatorHub.io: Runs on the Operator Lifecycle Manager (OLM) and automatically creates and mounts a self-signed certificate for the webhook. This installation method does not require additional action.
For details about each installation method, see Installing the VerticaDB operator.
Node Management Agent certificates
The Node Management Agent (NMA) exposes a REST API for cluster administration. OpenText™ Analytics Database on Kubernetes manages NMA certificates differently than a non-Kubernetes environment. Non-Kubernetes deployments use the TLS configuration generated by the install_vertica script, but OpenText™ Analytics Database on Kubernetes uses TLS certificates that are provided when a database server pod starts.
You have the following options to provide TLS certificates at startup:
- The VerticaDB operator generates production-safe, self-signed certificates for the NMA. This is the default configuration.
- You can add custom certificates with the
nmaTLSSecretcustom resource parameter.
Communal storage certificates
Supported storage locations authenticate requests with a self-signed certificate authority (CA) bundle. For TLS configuration details for each provider, see Configuring communal storage.
Client-server certificates
You might require multiple certificates to authenticate external client connections to the load-balancing service object. You can mount one or more custom certificates in the database server container with the certSecrets custom resource parameter. Each certificate is mounted in the container at /certs/cert-name/key.
For details, see VerticaDB custom resource definition.
Prometheus metrics certificates
The database integrates with Prometheus to scrape metrics about the VerticaDB operator and the server process. The operator and server export metrics independently from one another, and each set of metrics requires a different TLS configuration.
The operator SDK framework enforces role-based access control (RBAC) to the metrics with a proxy sidecar that uses self-signed certificates to authenticate requests for authorized service accounts. If you run Prometheus outside of Kubernetes, you cannot authenticate with a service account, so you must provide the proxy sidecar with custom TLS certificates.
The database server exports metrics with the HTTPS service. This service requires client, server, and CA certificates to configure mutual mode TLS for a secure connection.
For details about both the operator and server metrics, see Prometheus integration.
System configuration
As a best practice, make system configurations on the host node so that pods inherit those settings from the host node. This strategy eliminates the need to provide each pod a privileged security context to make system configurations on the host.
To manually configure host nodes, refer to the following sections:
The superuser account—historically, the dbadmin account—must use one of the authentication techniques described in Dbadmin authentication access.