Configuring rack locality
Note
This feature is supported only for reading ORC and Parquet data on co-located clusters. It is only meaningful on Hadoop clusters that span multiple racks.When possible, when planning a query Vertica automatically uses database nodes that are co-located with the HDFS nodes that contain the data. Moving query execution closer to the data reduces network latency and can improve performance. This behavior, called node locality, requires no additional configuration.
When Vertica is co-located on only a subset of HDFS nodes, sometimes there is no database node that is co-located with the data. However, performance is usually better if a query uses a database node in the same rack. If configured with information about Hadoop rack structure, Vertica attempts to use a database node in the same rack as the data to be queried.
For example, the following diagram illustrates a Hadoop cluster with three racks each containing three data nodes. (Typical production systems have more data nodes per rack.) In each rack, Vertica is co-located on one node.
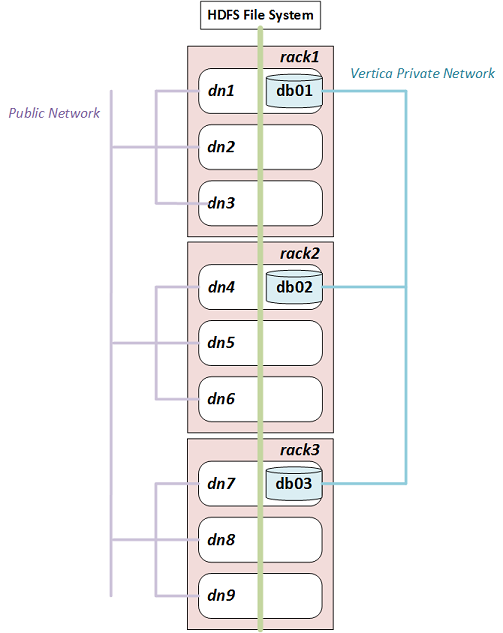
If you configure rack locality, Vertica uses db01 to query data on dn1, dn2, or dn3, and uses db02 and db03 for data on rack2 and rack3 respectively. Because HDFS replicates data, any given data block can exist in more than one rack. If a data block is replicated on dn2, dn3, and dn6, for example, Vertica uses either db01 or db02 to query it.
Hadoop components are rack-aware, so configuration files describing rack structure already exist in the Hadoop cluster. To use this information in Vertica, configure fault groups that describe this rack structure. Vertica uses fault groups in query planning.
Configuring fault groups
Vertica uses Fault groups to describe physical cluster layout. Because your database nodes are co-located on HDFS nodes, Vertica can use the information about the physical layout of the HDFS cluster.
Tip
For best results, ensure that each Hadoop rack contains at least one co-located Vertica node.Hadoop stores its cluster-layout data in a topology mapping file in HADOOP_CONF_DIR. On HortonWorks the file is typically named topology_mappings.data. On Cloudera it is typically named topology.map. Use the data in this file to create an input file for the fault-group script. For more information about the format of this file, see Creating a fault group input file.
Following is an example topology mapping file for the cluster illustrated previously:
[network_topology]
dn1.example.com=/rack1
10.20.41.51=/rack1
dn2.example.com=/rack1
10.20.41.52=/rack1
dn3.example.com=/rack1
10.20.41.53=/rack1
dn4.example.com=/rack2
10.20.41.71=/rack2
dn5.example.com=/rack2
10.20.41.72=/rack2
dn6.example.com=/rack2
10.20.41.73=/rack2
dn7.example.com=/rack3
10.20.41.91=/rack3
dn8.example.com=/rack3
10.20.41.92=/rack3
dn9.example.com=/rack3
10.20.41.93=/rack3
From this data, you can create the following input file describing the Vertica subset of this cluster:
/rack1 /rack2 /rack3
/rack1 = db01
/rack2 = db02
/rack3 = db03
This input file tells Vertica that the database node "db01" is on rack1, "db02" is on rack2, and "db03" is on rack3. In creating this file, ignore Hadoop data nodes that are not also Vertica nodes.
After you create the input file, run the fault-group tool:
$ python /opt/vertica/scripts/fault_group_ddl_generator.py dbName input_file > fault_group_ddl.sql
The output of this script is a SQL file that creates the fault groups. Execute it following the instructions in Creating fault groups.
You can review the new fault groups with the following statement:
=> SELECT member_name,node_address,parent_name FROM fault_groups
INNER JOIN nodes ON member_name=node_name ORDER BY parent_name;
member_name | node_address | parent_name
-------------------------+--------------+-------------
db01 | 10.20.41.51 | /rack1
db02 | 10.20.41.71 | /rack2
db03 | 10.20.41.91 | /rack3
(3 rows)
Working with multi-level racks
A Hadoop cluster can use multi-level racks. For example, /west/rack-w1, /west/rack-2, and /west/rack-w3 might be served from one data center, while /east/rack-e1, /east/rack-e2, and /east/rack-e3 are served from another. Use the following format for entries in the input file for the fault-group script:
/west /east
/west = /rack-w1 /rack-w2 /rack-w3
/east = /rack-e1 /rack-e2 /rack-e3
/rack-w1 = db01
/rack-w2 = db02
/rack-w3 = db03
/rack-e1 = db04
/rack-e2 = db05
/rack-e3 = db06
Do not create entries using the full rack path, such as /west/rack-w1.
Auditing results
To see how much data can be loaded with rack locality, use EXPLAIN with the query and look for statements like the following in the output:
100% of ORC data including co-located data can be loaded with rack locality.