使用二等分 k-means 对数据进行分层聚类
此二等分 k-means 示例使用名为 agar_dish_training 和 agar_dish_testing 的两个小数据集。使用 agar_dish_training 数据集中的数字数据,可以将数据聚类到 k 群集。然后,使用生成的二等分 k-means 模型,您可以在 agar_dish_testing 上运行 APPLY_BISECTING_KMEANS,并将数据分配给在您的训练模型中创建的群集。与常规 k-means(Vertica 中也提供)不同,二等分 k-means 允许您使用小于或等于 k 的任意数量的群集进行预测。因此,如果您使用 k=5 训练模型,但后来决定使用 k=2 进行预测,则无需重新训练该模型;只需运行 k=2 的 APPLY_BISECTING_KMEANS。
开始示例之前,请加载机器学习示例数据。 对于这个示例,加载 agar_dish_training.csv 和 agar_dish_testing.csv。
将训练数据聚类成 k 个群集来训练模型
-
使用 agar_dish_training 表数据创建名为 agar_dish_bkmeans 的二等分 k-means 模型。
=> SELECT BISECTING_KMEANS('agar_dish_bkmeans', 'agar_dish_training', '*', 5 USING PARAMETERS exclude_columns='id', key_columns='id', output_view='agar_1_view'); BISECTING_KMEANS ------------------ Finished. (1 row)此示例创建一个名为 agar_dish_bkmeans 的模型和一个包含模型结果的名为 agar_1_view 的视图。运行聚类算法时,您可能会得到略有不同的结果。这是因为 BISECTING_KMEANS 使用随机数来生成最佳群集。
-
查看 agar_1_view 的输出:
=> SELECT * FROM agar_1_view; id | cluster_id -----+------------ 2 | 4 5 | 4 7 | 4 9 | 4...在这里,我们可以看到 agar_dish_training 表中每个点的 ID 以及它被分配到了哪个群集。
-
由于我们将群集数量指定为 5,因此通过计算每个群集中的数据点数来验证该函数是否创建了五个群集。
=> SELECT cluster_id, COUNT(cluster_id) as Total_count FROM agar_1_view GROUP BY cluster_id; cluster_id | Total_count ------------+------------- 5 | 76 7 | 73 8 | 74 4 | 72 6 | 80 (5 rows)您可能想知道为什么 cluster_id 不从 0 或 1 开始。这是因为二等分 k-means 算法生成的群集比 k-means 多很多,然后输出 k 的指定值所需的群集。我们稍后会看到为什么这很有用。
您现在已成功将
agar_dish_training.csv中的数据聚类为五个不同的群集。
生成您的模型的摘要
使用 GET_MODEL_SUMMARY 函数查看 agar_dish_bkmeans 的摘要输出。
```
=> SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='agar_dish_bkmeans');
======
BKTree
======
```
```
center_id| x | y | withinss |totWithinss|bisection_level|cluster_size|parent|left_child|right_child
---------+--------+--------+----------+-----------+---------------+------------+------+----------+-----------
0 |-3.59450|-3.59371|6008.46192|6008.46192 | 0 | 375 | | 1 | 2
1 |-6.47574|-6.48280|336.41161 |1561.29110 | 1 | 156 | 0 | 5 | 6
2 |-1.54210|-1.53574|1224.87949|1561.29110 | 1 | 219 | 0 | 3 | 4
3 |-2.54088|-2.53830|317.34228 | 665.83744 | 2 | 147 | 2 | 7 | 8
4 | 0.49708| 0.51116| 12.08355 | 665.83744 | 2 | 72 | 2 | |
5 |-7.48119|-7.52577| 12.38904 | 354.80922 | 3 | 76 | 1 | |
6 |-5.52057|-5.49197| 12.99436 | 354.80922 | 3 | 80 | 1 | |
7 |-1.56238|-1.50561| 12.63924 | 61.31633 | 4 | 73 | 3 | |
8 |-3.50616|-3.55703| 11.21015 | 61.31633 | 4 | 74 | 3 | |
```
```
=======
Metrics
=======
Measure | Value
-----------------------------------------------------+----------
Total sum of squares |6008.46192
Total within-cluster sum of squares | 61.31633
Between-cluster sum of squares |5947.14559
Between-cluster sum of squares / Total sum of squares| 98.97950
Sum of squares for cluster 1, center_id 5 | 12.38904
Sum of squares for cluster 2, center_id 6 | 12.99436
Sum of squares for cluster 3, center_id 7 | 12.63924
Sum of squares for cluster 4, center_id 8 | 11.21015
Sum of squares for cluster 5, center_id 4 | 12.08355
===========
call_string
===========
bisecting_kmeans('agar_dish_bkmeans', 'agar_dish_training', '*', 5
USING PARAMETERS exclude_columns='id', bisection_iterations=1, split_method='SUM_SQUARES', min_divisible_cluster_size=2, distance_method='euclidean', kmeans_center_init_method='kmeanspp', kmeans_epsilon=0.0001, kmeans_max_iterations=10, output_view=''agar_1_view'', key_columns=''id'')
===============
Additional Info
===============
Name |Value
---------------------+-----
num_of_clusters | 5
dimensions_of_dataset| 2
num_of_clusters_found| 5
height_of_BKTree | 4
(1 row)
```
在这里,我们可以看到训练过程中通过对 k-means 进行二等分创建的所有中间群集的详细信息、一些用于评估聚类质量的指标(平方和越低越好)、训练算法的具体参数,以及有关数据算法的一些常规信息。
使用二等分 k-means 模型对测试数据进行聚类
使用刚刚创建的二等分 k-means 模型 agar_dish_bkmeans,您可以将 agar_dish_testing 中的点分配给群集中心。
-
使用 agar_dish_testing 表作为输入表,使用 agar_dish_bkmeans 模型作为群集中心,创建一个名为 bkmeans_results 的表。仅向 APPLY_BISECTING_KMEANS 函数中的实参添加相关特征列。
=> CREATE TABLE bkmeans_results_k5 AS (SELECT id, APPLY_BISECTING_KMEANS(x, y USING PARAMETERS model_name='agar_dish_bkmeans', number_clusters=5) AS cluster_id FROM agar_dish_testing); => SELECT cluster_id, COUNT(cluster_id) as Total_count FROM bkmeans_results_k5 GROUP BY cluster_id; cluster_id | Total_count ------------+------------- 5 | 24 4 | 28 6 | 20 8 | 26 7 | 27 (5 rows)bkmeans_results_k5 表显示 agar_dish_bkmeans 模型对 agar_dish_testing 数据进行了正确聚类。
-
使用二等分 k-means 的真正优势在于,它创建的模型可以将数据聚类到小于或等于训练它的 k 的任意数量的群集中。现在,无需重新训练模型,您可以将上述测试数据聚类为 3 个群集而不是 5 个群集:
=> CREATE TABLE bkmeans_results_k3 AS (SELECT id, APPLY_BISECTING_KMEANS(x, y USING PARAMETERS model_name='agar_dish_bkmeans', number_clusters=3) AS cluster_id FROM agar_dish_testing); => SELECT cluster_id, COUNT(cluster_id) as Total_count FROM bkmeans_results_k3 GROUP BY cluster_id; cluster_id | Total_count ------------+------------- 4 | 28 3 | 53 1 | 44 (3 rows)
使用经过训练的二等分 k-means 模型进行预测
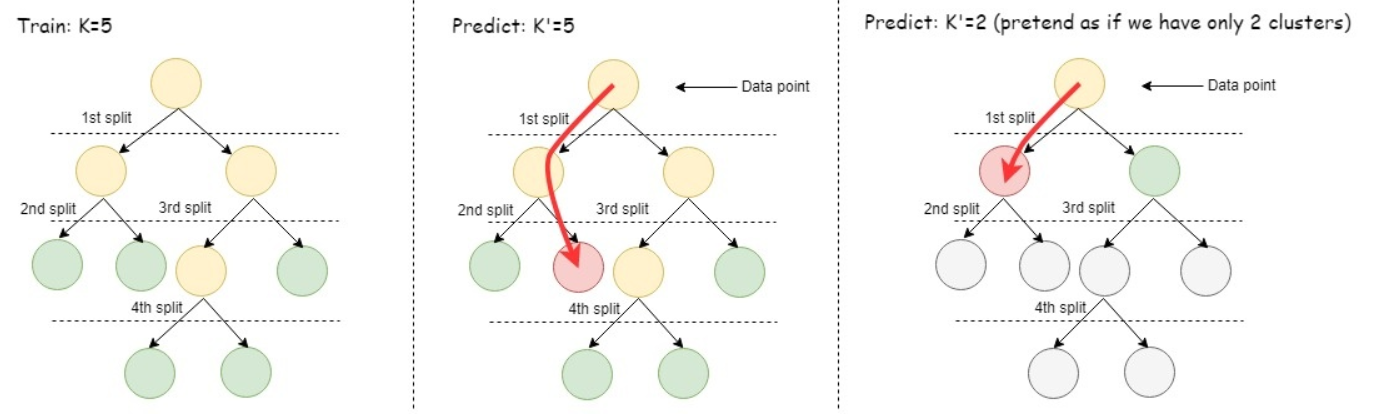
为了使用经过训练的模型对数据进行聚类,二等分 k-means 算法首先将传入数据点与根群集节点的子群集中心进行比较。该算法找出数据点与这些中心中的哪个中心离得最近。然后,将该数据点与离根最近的子节点的子群集中心进行比较。预测过程继续迭代,直到到达叶群集节点。最后,将该点分配给最近的叶群集。下图简单说明了二等分 k-means 算法的训练过程和预测过程。使用二等分 k-means 的一个优点是,您可以使用从 2 到训练模型的最大 k 值范围内的任何 k 值来进行预测。
下图中的模型使用 k=5 训练。中间的图显示如何使用模型预测 k=5 的情况,换句话说,在有 5 个叶群集的层次结构级别中,将传入的数据点匹配到具有最接近值的中心。右图显示如何使用模型预测 k=2 的情况,也就是说,先在只有两个群集的级别将传入的数据点与叶群集进行比较,然后将数据点匹配到这两个群集中心中较近的一个。这种方法比使用 k-means 进行预测快。