This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Automatically consume data from Kafka with a scheduler
Vertica offers a scheduler that loads streamed messages from one or more Kafka topics.
Vertica offers a scheduler that loads streamed messages from one or more Kafka topics. Automatically loading streaming data has a number of advantages over manually using COPY:
-
The streamed data automatically appears in your database. The frequency with which new data appears in your database is governed by the scheduler's frame duration.
-
The scheduler provides an exactly-once consumption process. The schedulers manage offsets for you so that each message sent by Kafka is consumed once.
-
You can configure backup schedulers to provide high-availability. Should the primary scheduler fail for some reason, the backup scheduler automatically takes over loading data.
-
The scheduler manages resources for the data load. You control its resource usage through the settings on the resource pool you assign to it . When loading manually, you must take into account the resources your load consumes.
There are a few drawbacks to using a scheduler which may make it unsuitable for your needs. You may find that schedulers do not offer the flexibility you need for your load process. For example, schedulers cannot perform business logic during the load transaction. If you need to perform this sort of processing, you are better off creating your own load process. This process would periodically run COPY statements to load data from Kafka. Then it would perform the business logic processing you need before committing the transaction.
For information on job scheduler requirements, refer to Apache Kafka integrations.
What the job scheduler does
The scheduler is responsible for scheduling loads of data from Kafka. The scheduler's basic unit of processing is a frame, which is a period of time. Within each frame, the scheduler assigns a slice of time for each active microbatch to run. Each microbatch is responsible for loading data from a single source. Once the frame ends, the scheduler starts the next frame. The scheduler continues this process until you stop it.
The anatomy of a scheduler
Each scheduler has several groups of settings, each of which control an aspect of the data load. These groups are:
-
The scheduler itself, which defines the configuration schema, frame duration, and resource pool.
-
Clusters, which define the hosts in the Kafka cluster that the scheduler contacts to load data. Each scheduler can contain multiple clusters, allowing you to load data from multiple Kafka clusters with a single scheduler.
-
Sources, which define the Kafka topics and partitions in those topics to read data from.
-
Targets, which define the tables in Vertica that will receive the data. These tables can be traditional Vertica database tables, or they can be flex tables.
-
Load specs, which define setting Vertica uses while loading the data. These settings include the parsers and filters Vertica needs to use to load the data. For example, if you are reading a Kafka topic that is in Avro format, your load spec needs to specify the Avro parser and schema.
-
Microbatches, which represent an individual segment of a data load from a Kafka stream. They combine the definitions for your cluster, source, target, and load spec that you create using the other vkconfig tools. The scheduler uses all of the information in the microbatch to execute COPY statements using the KafkaSource UDL function to transfer data from Kafka to Vertica. The statistics on each microbatch's load is stored in the stream_microbatch_history table.
The vkconfig script
You use a Linux command-line script named vkconfig to create, configure, and run schedulers. This script is installed on your Vertica hosts along with the Vertica server in the following path:
/opt/vertica/packages/kafka/bin/vkconfig
Note
You can install and use the vkconfig utility on a non-Vertica host. You may want to do this if:
The easiest way to install vkconfig on a host is to install the Vertica server RPM. You must use the RPM that matches the version of Vertica installed on your database cluster. Do not create a database after installing the RPM. The vkconfig utility and its associated files will be in the /opt/vertica/packages/kafka/bin directory on the host.
The vkconfig script contains multiple tools. The first argument to the vkconfig script is always the tool you want to use. Each tool performs one function, such as changing one group of settings (such as clusters or sources) or starting and stopping the scheduler. For example, to create or configure a scheduler, you use the command:
$ /opt/vertica/packages/kafka/bin/vkconfig scheduler other options...
What happens when you create a scheduler
When you create a new scheduler, the vkconfig script takes the following steps:
-
Creates a new Vertica schema using the name you specified for the scheduler. You use this name to identify the scheduler during configuration.
-
Creates the tables needed to manage the Kafka data load in the newly-created schema. See Data streaming schema tables for more information.
Validating schedulers
When you create or configure a scheduler, it validates the following settings:
-
Confirms that all brokers in the specified cluster exist.
-
Connects to the specified host or hosts and retrieves the list of all brokers in the Kafka cluster. Getting this list always ensures that the scheduler has an up-to-date list of all the brokers. If the host is part of a cluster that has already been defined, the scheduler cancels the configuration.
-
Confirms that the specified source exists. If the source no longer exists, the source is disabled.
-
Retrieves the number of partitions in the source. If the number of partitions retrieved from the source is different than the partitions value saved by the scheduler, Vertica updates the scheduler with the number of partitions retrieved from the source in the cluster.
You can disable validation using the --validation-type option in the vkconfig script's scheduler tool. See Scheduler tool options for more information.
Synchronizing schedulers
By default, the scheduler automatically synchronizes its configuration and source information with Kafka host clusters. You can configure the synchronization interval using the --config-refresh scheduler utility option. Each interval, the scheduler:
You can configure synchronization settings using the --auto-sync option using the vkconfig script's scheduler tool. Scheduler tool options for details.
Launching a scheduler
You use the vkconfig script's launch tool to launch a scheduler.
When you launch a scheduler, it collects data from your sources, starting at the specified offset. You can view the stream_microbatch_history table to see what the scheduler is doing at any given time.
To learn how to create, configure, and launch a scheduler, see Setting up a scheduler in this guide.
You can also choose to bypass the scheduler. For example, you might want to do a single load with a specific range of offsets. For more information, see Manually consume data from Kafka in this guide.
If the Vertica cluster goes down, the scheduler attempts to reconnect and fails. You must relaunch the scheduler when the cluster is restarted.
Managing a running scheduler
When you launch a scheduler from the command line, it runs in the foreground. It will run until you kill it (or the host shuts down). Usually, you want to start the scheduler as a daemon process that starts it when the host operating system starts, or after the Vertica database has started.
You shut down a running scheduler using the vkconfig script's shutdown tool. See Shutdown tool options for details.
You can change most of a scheduler's settings (adding or altering clusters, sources, targets, and microbatches for example) while it is running. The scheduler automatically acts on the configuration updates.
Launching multiple job schedulers for high availability
For high availability, you can launch two or more identical schedulers that target the same configuration schema. You differentiate the schedulers using the launch tool's --instance-name option (see Launch tool options).
The active scheduler loads data and maintains an S lock on the stream_lock table. The scheduler not in use remains in stand-by mode until the active scheduler fails or is disabled. If the active scheduler fails, the backup scheduler immediately obtains the lock on the stream_lock table, and takes over loading data from Kafka where the failed scheduler left off.
Managing messages rejected during automatic loads
Vertica rejects messages during automatic loads using the parser definition, which is required in the microbatch load spec.
The scheduler creates a rejection table to store rejected messages for each microbatch automatically. To manually specify a rejection table, use the --rejection-schema and --rejection-table microbatch utility options when creating the microbatch. Query the stream_microbatches table to return the rejection schema and table for a microbatch.
For additional details about how Vertica handles rejected data, see Handling messy data.
Passing options to the scheduler's JVM
The scheduler uses a Java Virtual Machine to connect to Vertica via JDBC. You can pass command-line options to the JVM through a Linux environment variable named VKCONFIG_JVM_OPTS. This option is useful when configuring a scheduler to use TLS/SSL encryption when connecting to Vertica. See Configuring your scheduler for TLS connections for more information.
Viewing schedulers from the MC
You can view the status of Kafka jobs from the MC. For more information, refer to Viewing load history.
1 - Setting up a scheduler
You set up a scheduler using the Linux command line.
Note
This document describes how to create and launch a scheduler in a Linux environment. For details about creating a containerized scheduler, see
Containerized Kafka Scheduler.
You set up a scheduler using the Linux command line. Usually you perform the configuration on the host where you want your scheduler to run. It can be one of your Vertica hosts, or a separate host where you have installed the vkconfig utility (see The vkconfig Script for more information).
The steps to launch a scheduler are explained in the following sections. These sections will use the example of loading web log data (hits on a web site) from Kafka into a Vertica table.
Create a config file (optional)
Many of the arguments you supply to the vkconfig script while creating a scheduler do not change. For example, you often need to pass a username and password to Vertica to authorize the changes to be made in the database. Adding the username and password to each call to vkconfig is tedious and error-prone.
Instead, you can pass the vkconfig utility a configuration file using the --conf option that specifies these arguments for you. It can save you a lot of typing and frustration.
The config file is a text file with a keyword=value pair on each line. Each keyword is a vkconfig command-line option, such as the ones listed in Common vkconfig script options.
The following example shows a config file named weblog.conf that will be used to define a scheduler named weblog_sched. This config file is used throughout the rest of this example.
# The configuraton options for the weblog_sched scheduler.
username=dbadmin
password=mypassword
dbhost=vertica01.example.com
dbport=5433
config-schema=weblog_sched
Add the vkconfig directory to your path (optional)
The vkconfig script is located in the /opt/vertica/packages/kafka/bin directory. Typing this path for each call to vkconfig is tedious. You can add vkconfig to your search path for your current Linux session using the following command:
$ export PATH=/opt/vertica/packages/kafka/bin:$PATH
For the rest of your session, you are able to call vkconfig without specifying its entire path:
$ vkconfig
Invalid tool
Valid options are scheduler, cluster, source, target, load-spec, microbatch, sync, launch,
shutdown, help
If you want to make this setting permanent, add the export statement to your ~/.profile file. The rest of this example assumes that you have added this directory to your shell's search path.
Create a resource pool for your scheduler
Vertica recommends that you always create a resource pool specifically for each scheduler. Schedulers assume that they have exclusive use of their assigned resource pool. Using a separate pool for a scheduler lets you fine-tune its impact on your Vertica cluster's performance. You create resource pools with CREATE RESOURCE POOL.
The following resource pool settings play an important role when creating your scheduler's resource pool:
-
PLANNEDCONCURRENCY determines the number of microbatches (COPY statements) that the scheduler sends to Vertica simultaneously.
-
EXECUTIONPARALLELISM determines the maximum number of threads that each node creates to process a microbatch's partitions.
-
QUEUETIMEOUT provides manual control over resource timings. Set this to 0 to allow the scheduler to manage timings.
See Managing scheduler resources and performance for detailed information about these settings and how to fine-tune a resource pool for your scheduler.
The following CREATE RESOURCE POOL statement creates a resource pool that loads 1 microbatch and processes 1 partition:
=> CREATE RESOURCE POOL weblog_pool
MEMORYSIZE '10%'
PLANNEDCONCURRENCY 1
EXECUTIONPARALLELISM 1
QUEUETIMEOUT 0;
If you do not create and assign a resource pool for your scheduler, it uses a portion of the GENERAL resource pool. Vertica recommends that you do not use the GENERAL pool for schedulers in production environments. This fallback to the GENERAL pool is intended as a convenience when you test your scheduler configuration. When you are ready to deploy your scheduler, create a resource pool that you tuned to its specific needs. Each time that you start a scheduler that is using the GENERAL pool, the vkconfig utility displays a warning message.
Not allocating enough resources to your schedulers can result in errors. For example, you might get OVERSHOT DEADLINE FOR FRAME errors if the scheduler is unable to load data from all topics in a data frame.
See Resource pool architecture for more information about resource pools.
Create the scheduler
Vertica includes a default scheduler named stream_config. You can use this scheduler or create a new scheduler using the vkconfig script's scheduler tool with the --create and --config-schema options:
$ vkconfig scheduler --create --config-schema scheduler_name --conf conf_file
The --create and --config-schema options are the only ones required to add a scheduler with default options. This command creates a new schema in Vertica that holds the scheduler's configuration. See What Happens When You Create a Scheduler for details on the creation of the scheduler's schema.
You can use additional configuration parameters to further customize your scheduler. See Scheduler tool options for more information.
The following example:
-
Creates a scheduler named weblog_sched using the --config-schema option.
-
Grants privileges to configure and run the scheduler to the Vertica user named kafka_user with the --operator option. The dbadmin user must specify additional privileges separately.
-
Specifies a frame duration of seven minutes with the --frame-duration option. For more information about picking a frame duration, see Choosing a frame duration.
-
Sets the resource pool that the scheduler uses to the weblog_pool created earlier:
$ vkconfig scheduler --create --config-schema weblog_sched --operator kafka_user \
--frame-duration '00:07:00' --resource-pool weblog_pool --conf weblog.conf
Note
Technically, the previous example doesn't need to supply the --config-schema argument because it is set in the weblog.conf file. It appears in this example for clarity. There's no harm in supplying it on the command line as well as in the configuration file, as long as the values match. If they do not match, the value given on the command line takes priority.
Create a cluster
You must associate at least one Kafka cluster with your scheduler. Schedulers can access more than one Kafka cluster. To create a cluster, you supply a name for the cluster and host names and ports the Kafka cluster's brokers.
When you create a cluster, the scheduler attempts to validate it by connecting to the Kafka cluster. If it successfully connects, the scheduler automatically retrieves the list of all brokers in the cluster. Therefore, you do not have to list every single broker in the --hosts parameter.
The following example creates a cluster named kafka_weblog, with two Kafka broker hosts: kafka01 and kafka03 in the example.com domain. The Kafka brokers are running on port 9092.
$ vkconfig cluster --create --cluster kafka_weblog \
--hosts kafka01.example.com:9092,kafka03.example.com:9092 --conf weblog.conf
See Cluster tool options for more information.
Create a source
Next, create at least one source for your scheduler to read. The source defines the Kafka topic the scheduler loads data from as well as the number of partitions the topic contains.
To create and associate a source with a configured scheduler, use the source tool. When you create a source, Vertica connects to the Kafka cluster to verify that the topic exists. So, before you create the source, make sure that the topic already exists in your Kafka cluster. Because Vertica verifies the existence of the topic, you must supply the previously-defined cluster name using the --cluster option.
The following example creates a source for the Kafka topic named web_hits on the cluster created in the previous step. This topic has a single partition.
$ vkconfig source --create --cluster kafka_weblog --source web_hits --partitions 1 --conf weblog.conf
Note
The --partitions parameter is the number of partitions to load, not a list of individual partitions. For example, if you set this parameter to 3, the scheduler will load data from partitions 0, 1, and 2.
See Source tool options for more information.
Create a data table
Before you can create a target for your scheduler, you must create a target table in your Vertica database. This is the table Vertica uses to store the data the scheduler loads from Kafka. You must decide which type of table to create for your target:
-
A standard Vertica database table, which you create using the CREATE TABLE statement. This type of table stores data efficiently. However, you must ensure that its columns match the data format of the messages in Kafka topic you are loading. You cannot load complex types of data into a standard Vertica table.
-
A flex table, which you create using CREATE FLEXIBLE TABLE. A flex table is less efficient than a standard Vertica database table. However, it is flexible enough to deal with data whose schema varies and changes. It also can load most complex data types that (such as maps and lists) that standard Vertica tables cannot.
Important
Avoid having columns with primary key restrictions in your target table. The scheduler stops loading data if it encounters a row that has a value which violates this restriction. If you must have a primary key restricted column, try to filter out any redundant values for that column in the streamed data before is it loaded by the scheduler.
The data in this example is in a set format, so the best table to use is a standard Vertica table. The following example creates a table named web_hits to hold four columns of data. This table is located in the public schema.
=> CREATE TABLE web_hits (ip VARCHAR(16), url VARCHAR(256), date DATETIME, user_agent VARCHAR(1024));
Note
You do not need to create a rejection table to store rejected messages. The scheduler creates the rejection table automatically.
Create a target
Once you have created your target table, you can create your scheduler's target. The target tells your scheduler where to store the data it retrieves from Kafka. This table must exist when you create your target. You use the vkconfig script's target tool with the --target-schema and --target_table options to specify the Vertica target table's schema and name. The following example adds a target for the table created in the previous step.
$ vkconfig target --create --target-schema public --target-table web_hits --conf weblog.conf
See Target tool options for more information.
Create a load spec
The scheduler's load spec provides parameters that Vertica uses when parsing the data loaded from Kafka. The most important option is --parser which sets the parser that Vertica uses to parse the data. You have three parser options:
In this example, the data being loaded from Kafka is in JSON format. The following command creates a load spec named weblog_load and sets the parser to KafkaJSONParser.
$ vkconfig load-spec --create --parser KafkaJSONParser --load-spec weblog_load --conf weblog.conf
See Load spec tool options for more information.
Create a microbatch
The microbatch combines all of the settings added to the scheduler so far to define the individual COPY statements that the scheduler uses to load data from Kafka.
The following example uses all of the settings created in the previous examples to create a microbatch called weblog.
$ vkconfig microbatch --create --microbatch weblog --target-schema public --target-table web_hits \
--add-source web_hits --add-source-cluster kafka_weblog --load-spec weblog_load \
--conf weblog.conf
For microbatches that might benefit from a reduced transaction size, consider using the --max-parallelism option when creating the microbatch. This option splits a single microbatch with multiple partitions into the specified number of simultaneous COPY statements consisting of fewer partitions.
See Microbatch tool options for more information about --max-parallelism and other options.
Launch the scheduler
Once you've created at least one microbatch, you can run your scheduler. You start your scheduler using the launch tool, passing it the name of the scheduler's schema. The scheduler begins scheduling microbatch loads for every enabled microbatch defined in its schema.
The following example launches the weblog scheduler defined in the previous steps. It uses the nohup command to prevent the scheduler being killed when the user logs out, and redirects stdout and stderr to prevent a nohup.out file from being created.
$ nohup vkconfig launch --conf weblog.conf >/dev/null 2>&1 &
Important
Vertica does not recommend specifying a password on the command line. Passwords on the command line can be exposed by the system's list of processes, which shows the command line for each process. Instead, put the password in a configuration file. Make sure the configuration file's permissions only allow it to be read by the user.
See Launch tool options for more information.
Checking that the scheduler is running
Once you have launched your scheduler, you can verify that it is running by querying the stream_microbatch_history table in the scheduler's schema. This table lists the results of each microbatch the scheduler has run.
For example, this query lists the microbatch name, the start and end times of the microbatch, the start and end offset of the batch, and why the batch ended. The results are ordered to start from when the scheduler was launched:
=> SELECT microbatch, batch_start, batch_end, start_offset,
end_offset, end_reason
FROM weblog_sched.stream_microbatch_history
ORDER BY batch_start DESC LIMIT 10;
microbatch | batch_start | batch_end | start_offset | end_offset | end_reason
------------+----------------------------+----------------------------+--------------+------------+---------------
weblog | 2017-10-04 09:30:19.100752 | 2017-10-04 09:30:20.455739 | -2 | 34931 | END_OF_STREAM
weblog | 2017-10-04 09:30:49.161756 | 2017-10-04 09:30:49.873389 | 34931 | 34955 | END_OF_STREAM
weblog | 2017-10-04 09:31:19.25731 | 2017-10-04 09:31:22.203173 | 34955 | 35274 | END_OF_STREAM
weblog | 2017-10-04 09:31:49.299119 | 2017-10-04 09:31:50.669889 | 35274 | 35555 | END_OF_STREAM
weblog | 2017-10-04 09:32:19.43153 | 2017-10-04 09:32:20.7519 | 35555 | 35852 | END_OF_STREAM
weblog | 2017-10-04 09:32:49.397684 | 2017-10-04 09:32:50.091675 | 35852 | 36142 | END_OF_STREAM
weblog | 2017-10-04 09:33:19.449274 | 2017-10-04 09:33:20.724478 | 36142 | 36444 | END_OF_STREAM
weblog | 2017-10-04 09:33:49.481563 | 2017-10-04 09:33:50.068068 | 36444 | 36734 | END_OF_STREAM
weblog | 2017-10-04 09:34:19.661624 | 2017-10-04 09:34:20.639078 | 36734 | 37036 | END_OF_STREAM
weblog | 2017-10-04 09:34:49.612355 | 2017-10-04 09:34:50.121824 | 37036 | 37327 | END_OF_STREAM
(10 rows)
2 - Choosing a frame duration
One key setting for your scheduler is its frame duration.
One key setting for your scheduler is its frame duration. The duration sets the amount of time the scheduler has to run all of the microbatches you have defined for it. This setting has significant impact on how data is loaded from Apache Kafka.
What happens during each frame
To understand the right frame duration, you first need to understand what happens during each frame.
The frame duration is split among the microbatches you add to your scheduler. In addition, there is some overhead in each frame that takes some time away from processing the microbatches. Within each microbatch, there is also some overhead which reduces the time the microbatch spends loading data from Kafka. The following diagram shows roughly how each frame is divided:

As you can see, only a portion of the time in the frame is spent actually loading the streaming data.
How the scheduler prioritizes microbatches
To start with, the scheduler evenly divides the time in the frame among the microbatches. It then runs each microbatch in turn.
In each microbatch, the bulk of the time is dedicated to loading data using a COPY statement. This statement loads data using the KafkaSource UDL. It runs until one of two conditions occurs:
-
It reaches the ends of the data streams for the topics and partitions you defined for the microbatch. In this case, the microbatch completes processing early.
-
It reaches a timeout set by the scheduler.
As the scheduler processes frames, it notes which microbatches finish early. It then schedules them to run first in the next frame. Arranging the microbatches in this manner lets the scheduler allocate more of the time in the frame to the microbatches that are spending the most time loading data (and perhaps have not had enough time to reach the end of their data streams).
For example, consider the following diagram. During the first frame, the scheduler evenly divides the time between the microbatches. Microbatch #2 uses all of the time allocated to it (as indicated by the filled-in area), while the other microbatches do not. In the next frame, the scheduler rearranges the microbatches so that microbatches that finished early go first. It also allocates less time to the microbatches that ran for a shorter period. Assuming these microbatches finish early again, the scheduler is able to give the rest of the time in the frame to microbatch #2. This shifting of priorities continues while the scheduler runs. If one topic sees a spike in traffic, the scheduler compensates by giving the microbatch reading from that topic more time.

What happens if the frame duration is too short
If you make the scheduler's frame duration too short, microbatches may not have enough time to load all of the data in the data streams they are responsible for reading. In the worst case, a microbatch could fall further behind when reading a high-volume topic during each frame. If left unaddressed, this issue could result in messages never being loaded, as they age out of the data stream before the microbatch has a chance to read them.
In extreme cases, the scheduler may not be able to run each microbatch during each frame. This problem can occur if the frame duration is so short that much of is spent in overhead tasks such committing data and preparing to run microbatches. The COPY statement that each microbatch runs to load data from Kafka has a minimum duration of 1 second. Add to this the overhead of processing data loads. In general, if the frame duration is shorter than 2 seconds times the number of microbatches in the scheduler, then some microbatches may not get a chance to run in each frame.
If the scheduler runs out of time during a frame to run each microbatch, it compensates during the next frame by giving priority to the microbatches that didn't run in the prior frame. This strategy makes sure each microbatch gets a chance to load data. However, it cannot address the root cause of the problem. Your best solution is to increase the frame duration to give each microbatch enough time to load data during each frame.
What happens if the frame duration is too long
One downside of a long frame duration is increased data latency. This latency is the time between when Kafka sends data out and when that data becomes available for queries in your database. A longer frame duration means that there is more time between each execution of a microbatch. That translates into more time between the data in your database being updated.
Depending on your application, this latency may not be important. When determining your frame duration, consider whether having the data potentially delayed up to the entire length of the frame duration will cause an issue.
Another issue to consider when using a long frame duration is the time it takes to shut down the scheduler. The scheduler does not shut down until the current COPY statement completes. Depending on the length of your frame duration, this process might take a few minutes.
The minimum frame duration
At a minimum, allocate two seconds for each microbatch you add to your scheduler. The vkconfig utility warns you if your frame duration is shorter than this lower limit. In most cases, you want your frame duration to be longer. Two seconds per microbatch leaves little time for data to actually load.
Balancing frame duration requirements
To determine the best frame duration for your deployment, consider how sensitive you are to data latency. If you are not performing time-sensitive queries against the data streaming in from Kafka, you can afford to have the default 5 minute or even longer frame duration. If you need a shorter data latency, then consider the volume of data being read from Kafka. High volumes of data, or data that has significant spikes in traffic can cause problems if you have a short frame duration.
Using different schedulers for different needs
Suppose you are loading streaming data from a few Kafka topics that you want to query with low latency and other topics that have a high volume but which you can afford more latency. Choosing a "middle of the road" frame duration in this situation may not meet either need. A better solution is to use multiple schedulers: create one scheduler with a shorter frame duration that reads just the topics that you need to query with low latency. Then create another scheduler that has a longer frame duration to load data from the high-volume topics.
For example, suppose you are loading streaming data from an Internet of Things (IOT) sensor network via Kafka into Vertica. You use the most of this data to periodically generate reports and update dashboard displays. Neither of these use cases are particularly time sensitive. However, three of the topics you are loading from do contain time-sensitive data (system failures, intrusion detection, and loss of connectivity) that must trigger immediate alerts.
In this case, you can create one scheduler with a frame duration of 5 minutes or more to read most of the topics that contain the non-critical data. Then create a second scheduler with a frame duration of at least 6 seconds (but preferably longer) that loads just the data from the three time-sensitive topics. The volume of data in these topics is hopefully low enough that having a short frame duration will not cause problems.
3 - Managing scheduler resources and performance
Your scheduler's performance is impacted by the number of microbatches in your scheduler, partitions in each microbatch, and nodes in your Vertica cluster.
Your scheduler's performance is impacted by the number of microbatches in your scheduler, partitions in each microbatch, and nodes in your Vertica cluster. Use resource pools to allocate a subset of system resources for your scheduler, and fine-tune those resources to optimize automatic loads into Vertica.
The following sections provide details about scheduler resource pool configurations and processing scenarios.
Schedulers and resource pools
Vertica recommends that you always create a resource pool specifically for each scheduler. Schedulers assume that they have exclusive use of their assigned resource pool. Using a separate pool for a scheduler lets you fine-tune its impact on your Vertica cluster's performance. You create resource pools with CREATE RESOURCE POOL.
If you do not create and assign a resource pool for your scheduler, it uses a portion of the GENERAL resource pool. Vertica recommends that you do not use the GENERAL pool for schedulers in production environments. This fallback to the GENERAL pool is intended as a convenience when you test your scheduler configuration. When you are ready to deploy your scheduler, create a resource pool that you tuned to its specific needs. Each time that you start a scheduler that is using the GENERAL pool, the vkconfig utility displays a warning message.
Not allocating enough resources to your schedulers can result in errors. For example, you might get OVERSHOT DEADLINE FOR FRAME errors if the scheduler is unable to load data from all topics in a data frame.
See Resource pool architecture for more information about resource pools.
Key resource pool settings
A microbatch is a unit of work that processes the partitions of a single Kafka topic within the duration of a frame. The following resource pool settings play an important role in how Vertica loads microbatches and processes partitions:
- PLANNEDCONCURRENCY determines the number of microbatches (COPY statements) the scheduler sends to Vertica simultaneously. At the start of each frame, the scheduler creates the number of scheduler threads specified by PLANNEDCONCURRENCY. Each scheduler thread connects to Vertica and loads one microbatch at a time. If there are more microbatches than scheduler threads, the scheduler queues the extra microbatches and loads them as threads become available.
- EXECUTIONPARALLELISM determines the maximum number of threads each node creates to process a microbatch's partitions. When a microbatch is loaded into Vertica, its partitions are distributed evenly among the nodes in the cluster. During each frame, a node creates a maximum of one thread for each partition. Each thread reads from one partition at a time until processing completes, or the frame ends. If there are more partitions than threads across all nodes, remaining partitions are processed as threads become available.
- QUEUETIMEOUT provides manual control over resource timings. Set the resource pool parameter QUEUETIMEOUT to 0 to allow the scheduler to manage timings. After all of the microbatches are processed, the scheduler waits for the remainder of the frame to process the next microbatch. A properly sized configuration includes rest time to plan for traffic surges. See Choosing a frame duration for information about the impacts of frame duration size.
For example, the following CREATE RESOURCE POOL statement creates a resource pool named weblogs_pool that loads 2 microbatches simultaneously. Each node in the Vertica cluster creates 10 threads per microbatch to process partitions:
=> CREATE RESOURCE POOL weblogs_pool
MEMORYSIZE '10%'
PLANNEDCONCURRENCY 2
EXECUTIONPARALLELISM 10
QUEUETIMEOUT 0;
For a three-node Vertica cluster, weblogs_pool provides resources for each node to create up to 10 threads to process partitions, or 30 total threads per microbatch.
Loading multiple microbatches concurrently
In some circumstances, you might have more microbatches in your scheduler than available PLANNEDCONCURRENCY. The following images illustrate how the scheduler loads microbatches into a single Vertica node when there are not enough scheduler threads to load each microbatch simultaneously. The resource pool's PLANNEDCONCURRENCY (PC) is set to 2, but the scheduler must load three microbatches: A, B, and C. For simplicity, EXECUTIONPARALLELISM (EP) is set to 1.
To begin, the scheduler loads microbatch A and microbatch B while microbatch C waits:
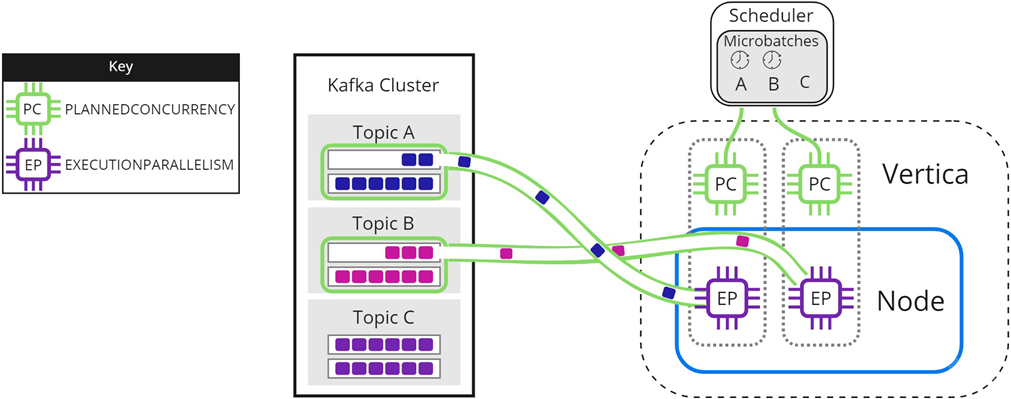
When either microbatch finishes loading, the scheduler loads any remaining microbatches. In the following image, microbatch A is completely loaded into Vertica. The scheduler continues to load microbatch B, and uses the newly available scheduler thread to load microbatch C:
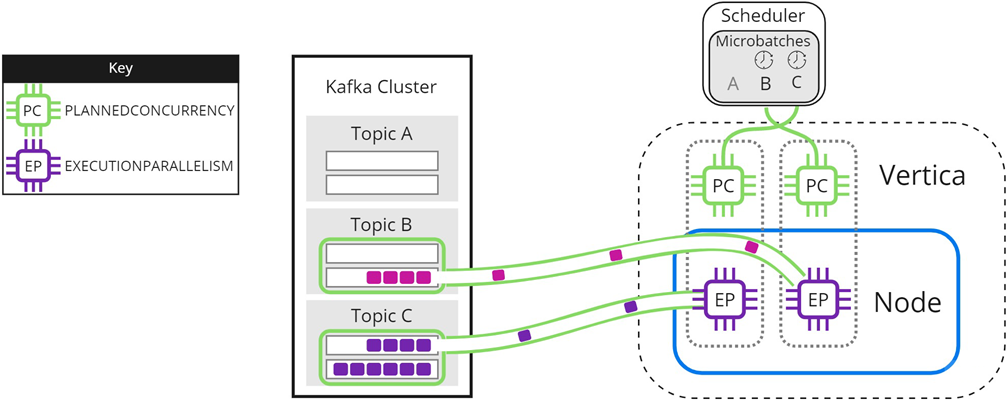
The scheduler continues sending data until all microbatches are loaded into Vertica, or the frame ends.
Experiment with PLANNEDCONCURRENCY to optimize performance. Note that setting it too high might create too many connections at the beginning of each frame, resulting in scalability stress on Vertica or Kafka. Setting PLANNEDCONCURRENCY too low does not take full advantage of the multiprocessing power of Vertica.
Parallel processing within Vertica
The resource pool setting EXECUTIONPARALLELISM limits the number of threads each Vertica node creates to process partitions. The following image illustrates how a three-node Vertica cluster processes a topic with nine partitions, when there is not enough EXECUTIONPARALLELISM to create one thread per partition. The partitions are distributed evenly among Node 1, Node 2, and Node 3 in the Vertica cluster. The scheduler's resource pool has PLANNEDCONCURRENCY (PC) set to 1 and EXECUTIONPARALLELISM (EP) set to 2, so each node creates a maximum of 2 threads when the scheduler loads microbatch A. Each thread reads from one partition at a time. Partitions that are not assigned a thread must wait for processing:
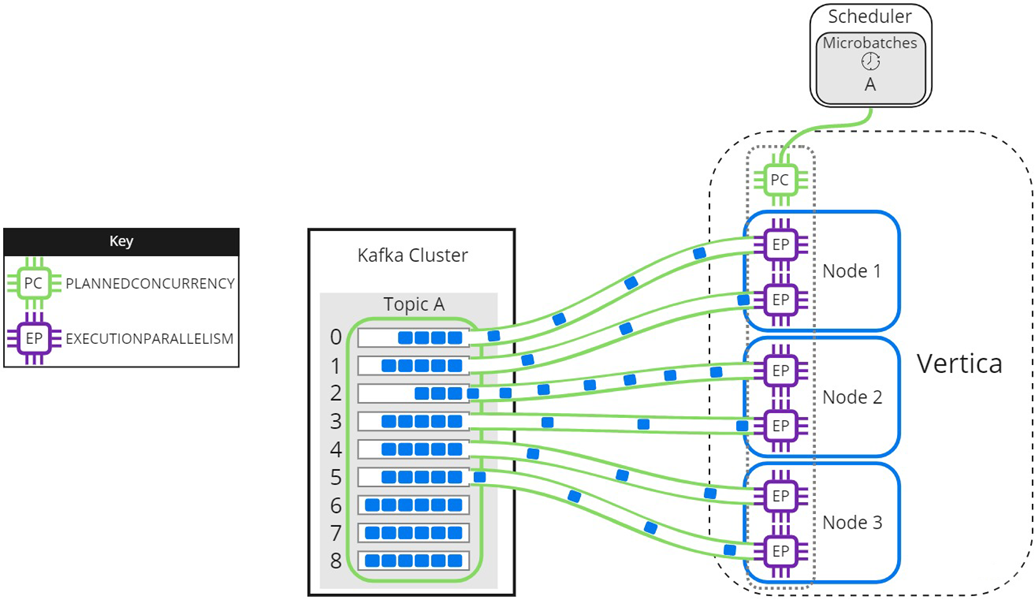
As threads finish processing their assigned partitions, the remaining partitions are distributed to threads as they become available:
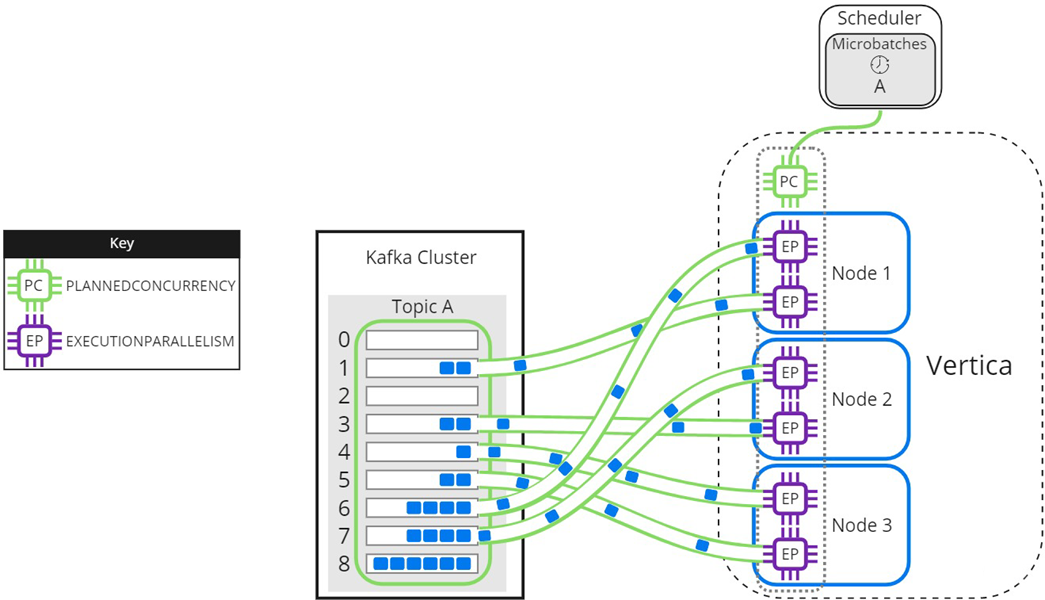
When setting the EXECUTIONPARALLELISM on your scheduler's resource pool, consider the number of partitions across all microbatches in the scheduler.
Loading partitioned topics concurrently
Single topics with multiple partitions might benefit from increased parallel loading or a reduced transaction size. The --max-parallelism microbatch utility option enables you to dynamically split a topic with multiple partitions into multiple, load-balanced microbatches that each consist of a subset of the original microbatch's partitions. The scheduler loads the dynamically split microbatches simultaneously using the PLANNEDCONCURRENCY available in its resource pool.
The EXECUTIONPARALLELISM setting in the scheduler's resource pool determines the maximum number of threads each node creates to process its portion of a single microbatch's partitions. Splitting a microbatch enables each node to create more threads for the same unit of work. When there is enough PLANNEDCONCURRENCY and the number of partitions assigned per node is greater than the EXECUTIONPARALLELISM setting in the scheduler's resource pool, use --max-parallelism to split the microbatch and create more threads per node to process more partitions in parallel.
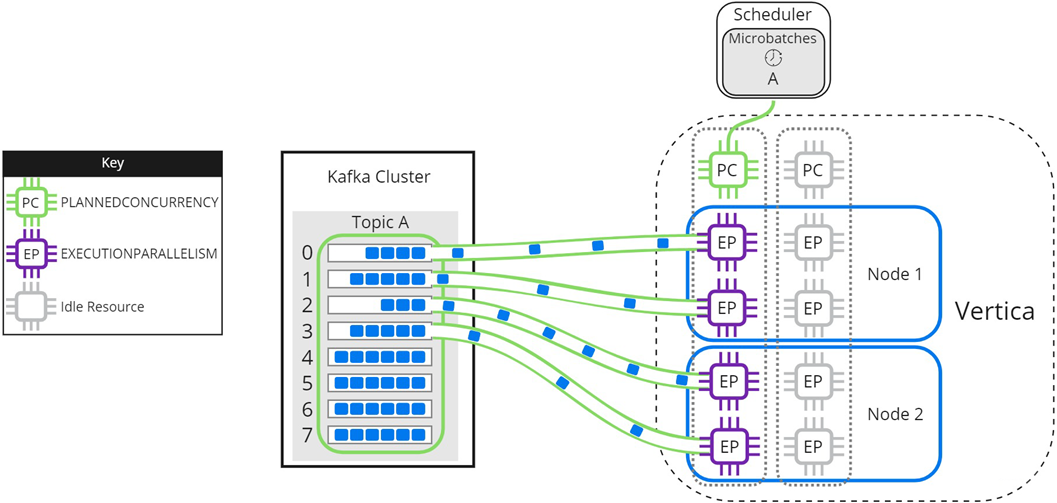
The following image illustrates how a two-node Vertica cluster loads and processes microbatch A using a resource pool with PLANNEDCONCURRENCY (PC) set to 2, and EXECUTIONPARALLELISM (EP) set to 2. Because the scheduler is loading only one microbatch, there is 1 scheduler thread left unused. Each node creates 2 threads per scheduler thread to process its assigned partitions:
Setting microbatch A's --max-parallelism option to 2 enables the scheduler to dynamically split microbatch A into 2 smaller microbatches, A1 and A2. Because there are 2 available scheduler threads, the subset microbatches are loaded into Vertica simultaneously. Each node creates 2 threads per scheduler thread to process partitions for microbatches A1 and A2:
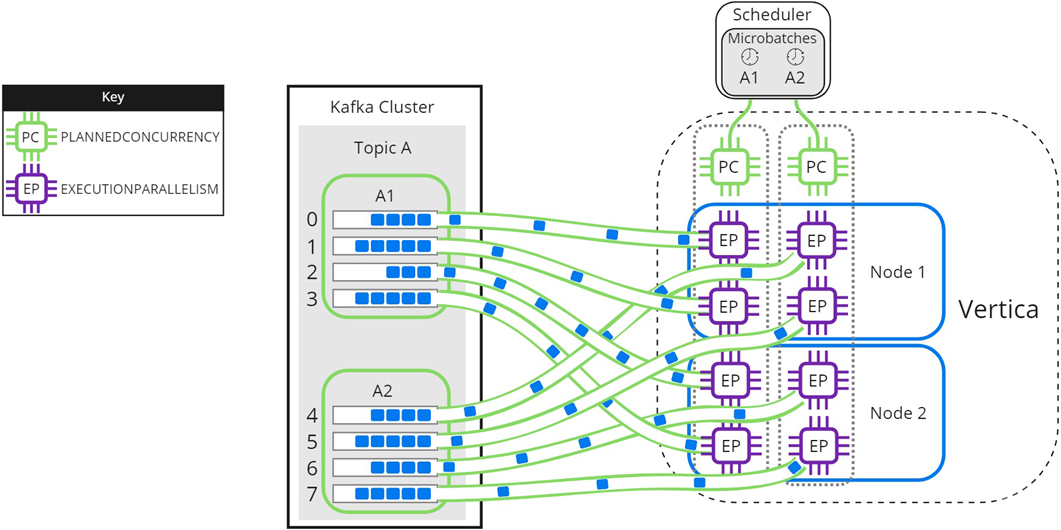
Use --max-parallelism to prevent bottlenecks in microbatches consisting of high-volume Kafka topics. It also provides faster loads for microbatches that require additional processing, such as text indexing.
4 - Using connection load balancing with the Kafka scheduler
You supply the scheduler with the name of a Vertica node in the --dbhost option or the dbhost entry in your configuration file.
You supply the scheduler with the name of a Vertica node in the --dbhost option or the dbhost entry in your configuration file. The scheduler connects to this node to initiate all of the statements it executes to load data from Kafka. For example, each time it executes a microbatch, the scheduler connects to the same node to run the COPY statement. Having a single node act as the initiator node for all of the scheduler's actions can affect the performance of the node, and in turn the database as a whole.
To avoid a single node becoming a bottleneck, you can use connection load balancing to spread the load of running the scheduler's statements across multiple nodes in your database. Connection load balancing distributes client connections among the nodes in a load balancing group. See About native connection load balancing for an overview of this feature.
Enabling connection load balancing for a scheduler is a two-step process:
-
Choose or create a load balancing policy for your scheduler.
-
Enable load balancing in the scheduler.
Choosing or creating a load balancing policy for the scheduler
A connecting load balancing policy redirects incoming connections in from a specific set of network addresses to a group of nodes. If your database already defines a suitable load balancing policy, you can use it instead of creating one specifically for your scheduler.
If your database does not have a suitable policy, create one. Have your policy redirect connections coming from the IP addresses of hosts running Kafka schedulers to a group of nodes in your database. The group of nodes that you select will act as the initiators for the statements that the scheduler executes.
Important
In an
Eon Mode database, only include nodes that are part of a
primary subcluster in the scheduler's load balancing group. These nodes are the most efficient for loading data.
The following example demonstrates setting up a load balancing policy for all three nodes in a three-node database. The scheduler runs on node 1 in the database, so the source address range (192.168.110.0/24) of the routing rule covers the IP addresses of the nodes in the database. The last step of the example verifies that connections from the first node (IP address 10.20.110.21) are load balanced.
=> SELECT node_name,node_address,node_address_family FROM v_catalog.nodes;
node_name | node_address | node_address_family
------------------+--------------+----------------------
v_vmart_node0001 | 10.20.110.21 | ipv4
v_vmart_node0002 | 10.20.110.22 | ipv4
v_vmart_node0003 | 10.20.110.23 | ipv4
(4 rows)
=> CREATE NETWORK ADDRESS node01 ON v_vmart_node0001 WITH '10.20.110.21';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS node02 ON v_vmart_node0002 WITH '10.20.110.22';
CREATE NETWORK ADDRESS
=> CREATE NETWORK ADDRESS node03 on v_vmart_node0003 WITH '10.20.110.23';
CREATE NETWORK ADDRESS
=> CREATE LOAD BALANCE GROUP kafka_scheduler_group WITH ADDRESS node01,node02,node03;
CREATE LOAD BALANCE GROUP
=> CREATE ROUTING RULE kafka_scheduler_rule ROUTE
'10.20.110.0/24' TO kafka_scheduler_group;
CREATE ROUTING RULE
=> SELECT describe_load_balance_decision('10.20.110.21');
describe_load_balance_decision
--------------------------------------------------------------------------------
Describing load balance decision for address [10.20.110.21]
Load balance cache internal version id (node-local): [2]
Considered rule [kafka_scheduler_rule] source ip filter [10.20.110.0/24]...
input address matches this rule
Matched to load balance group [kafka_scheduler_group] the group has policy [ROUNDROBIN]
number of addresses [3]
(0) LB Address: [10.20.110.21]:5433
(1) LB Address: [10.20.110.22]:5433
(2) LB Address: [10.20.110.23]:5433
Chose address at position [1]
Routing table decision: Success. Load balance redirect to: [10.20.110.23] port [5433]
(1 row)
Important
Be careful if you run your scheduler on a Vertica node and have either set its dbhost name to localhost or are not specifying a value (which means dbhost defaults to localhost). Connections to localhost use the loopback IP address 127.0.0.1 instead of the node's primary network address. If you create a load balancing routing rule that redirects incoming connections from the node's IP address range, it will not apply to connections made using localhost. The best solution is to use the node's IP address or FQDN as the dbhost setting.
If your scheduler connects to Vertica from an IP address that no routing rule applies to, you will see messages similar to the following in the vertica.log:
[Session] <INFO> Load balance request from client address ::1 had decision:
Classic load balancing considered, but either the policy was NONE or no target was
available. Details: [NONE or invalid]
<LOG> @v_vmart_node0001: 00000/5789: Connection load balance request
refused by server
Enabling load balancing in the scheduler
Clients must opt-in to load balancing for Vertica to apply the connection load balancing policies to the connection. For example, you must pass the -C flag to the vsql command for your interactive session to be load balanced.
The scheduler uses the Java JDBC library to connect to Vertica. To have the scheduler opt-in to load balancing, you must set the JDBC library's ConnectionLoadBalance option to 1. See Load balancing in JDBC for details.
Use the vkconfig script's --jdbc-opt option, or add the jdbc-opt option to your configuration file to set the ConnectionLoadBalance option. For example, to start the scheduler from the command line using a configuration file named weblog.conf, use the command:
$ nohup vkconfig launch --conf weblog.conf --jdbc-opt ConnectionLoadBalance=1 >/dev/null 2>&1 &
To permanently enable load balancing, you can add the load balancing option to your configuration file. The following example shows the weblog.conf file from the example in Setting up a scheduler configured to use connection load balancing.
username=dbadmin
password=mypassword
dbhost=10.20.110.21
dbport=5433
config-schema=weblog_sched
jdbc-opt=ConnectionLoadBalance=1
You can check whether the scheduler's connections are being load balanced by querying the SESSIONS table:
=> SELECT node_name, user_name, client_label FROM V_MONITOR.SESSIONS;
node_name | user_name | client_label
------------------+-----------+-------------------------------------------
v_vmart_node0001 | dbadmin | vkstream_weblog_sched_leader_persistent_4
v_vmart_node0001 | dbadmin |
v_vmart_node0002 | dbadmin | vkstream_weblog_sched_lane-worker-0_0_8
v_vmart_node0003 | dbadmin | vkstream_weblog_sched_VDBLogger_0_9
(4 rows)
In the client_labels column, the scheduler's connections have labels starting with vkstream (the row without a client label is an interactive session). You can see that the three connections the scheduler has opened all go to different nodes.
5 - Limiting loads using offsets
Kafka maintains a user-configurable backlog of messages.
Kafka maintains a user-configurable backlog of messages. By default, a newly-created scheduler reads all of the messages in a Kafka topic, including all of the messages in the backlog, not just the messages that are streamed out after the scheduler starts. Often, this is what you want.
In some cases, however, you may want to stream just a section of a source into a table. For example, suppose you want to analyze the web traffic of your e-commerce site starting at specific date and time. However, your Kafka topic contains web access records from much further back in time than you want to analyze. In this case, you can use an offset to stream just the data you want into Vertica for analysis.
Another common use case is when you have already loaded data some from Kafka manually (see Manually consume data from Kafka). Now you want to stream all of the newly-arriving data. By default, your scheduler ill reload all of the previously loaded data (assuming it is still available from Kafka). You can use an offset to tell your scheduler to start automatically loading data at the point where your manual data load left off.
Configuring a scheduler to start streaming from an offset
The vkconfig script's microbatch tool has an --offset option that lets you specify the index of the message in the source where you want the scheduler to begin loading. This option accepts a comma-separated list of index values. You must supply one index value for each partition in the source unless you use the --partition option. This option lets you choose the partitions the offsets apply to. The scheduler cannot be running when you set an offset in the microbatch.
If your microbatch defines more than one cluster, use the --cluster option to select which one the offset option applies to. Similarly, if your microbatch has more than one source, you must select one using the --source option.
For example, suppose you want to load just the last 1000 messages from a source named web_hits. To make things easy, suppose the source contains just a single partition, and the microbatch defines just a single cluster and single topic.
Your first task is to determine the current offset of the end of the stream. You can do this on one of the Kafka nodes by calling the GetOffsetShell class with the time parameter set to -1 (the end of the topic):
$ path to kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell \
--broker-list kafka01:9092,kafka03:9092 --time -1 \
--topic web_hits
{metadata.broker.list=kafka01:9092,kafka03:9092, request.timeout.ms=1000,
client.id=GetOffsetShell, security.protocol=PLAINTEXT}
web_hits:0:8932
You can also use GetOffsetShell to find the offset in the stream that occurs before a timestamp.
In the above example, the web_hits topic's single partition has an ending offset of 8932. If we want to load the last 1000 messages from the source, we need to set the microbatch's offset to 8932 - 1001 or 7931.
Note
The start of an offset is inclusive in the Vertica COPY statement. Kafka's native starting offset is exclusive. Therefore, you must add one to the offset to get the correct number of messages.
With the offset calculated, you are ready to set it in the microbatch's configuration. The following example:
$ vkconfig shutdown --conf weblog.conf
$ vkconfig microbatch --microbatch weblog --update --conf weblog.conf --offset 7931
$ nohup vkconfig launch --conf weblog.conf >/dev/null 2>&1 &
If the target table was empty or truncated before the scheduler started, it will have 1000 rows in the table in it (until more messages are streamed through the source):
=> select count(*) from web_hits;
count
-------
1000
(1 row)
Note
The last example assumes that the offset values for the last 1000 messages in the Kafka topic were assigned consecutively. This assumption is not always be true. A Kafka topic can have gaps in its offset numbering for a variety of reasons. Offsets refer to the key value assigned to a message by Kafka, not its position in the topic.
6 - Updating schedulers after Vertica upgrades
A scheduler is only compatible with the version of Vertica that created it.
A scheduler is only compatible with the version of Vertica that created it. Between Vertica versions, the scheduler's configuration schema or the UDx function the scheduler calls may change. After you upgrade Vertica, you must update your schedulers to account for these changes.
When you upgrade Vertica to a new major version or service pack, use the vkconfig scheduler tool's --upgrade option to update your scheduler. If you do not update a scheduler, you receive an error message if you try to launch it. For example:
$ nohup vkconfig launch --conf weblog.conf >/dev/null 2>&1 &
com.vertica.solutions.kafka.exception.FatalException: Configured scheduler schema and current
scheduler configuration schema version do not match. Upgrade configuration by running:
vkconfig scheduler --upgrade
at com.vertica.solutions.kafka.scheduler.StreamCoordinator.assertVersion(StreamCoordinator.java:64)
at com.vertica.solutions.kafka.scheduler.StreamCoordinator.run(StreamCoordinator.java:125)
at com.vertica.solutions.kafka.Launcher.run(Launcher.java:205)
at com.vertica.solutions.kafka.Launcher.main(Launcher.java:258)
Scheduler instance failed. Check log file. Check log file.
$ vkconfig scheduler --upgrade --conf weblog.conf
Checking if UPGRADE necessary...
UPGRADE required, running UPGRADE...
UPGRADE completed successfully, now the scheduler configuration schema version is v8.1.1
$ nohup vkconfig launch --conf weblog.conf >/dev/null 2>&1 &
. . .