This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Accessing kerberized HDFS data
If your Hortonworks or Cloudera Hadoop cluster uses Kerberos authentication to restrict access to HDFS, Vertica must be granted access.
If your Hortonworks or Cloudera Hadoop cluster uses Kerberos authentication to restrict access to HDFS, Vertica must be granted access. If you use Kerberos authentication for your Vertica database, and database users have HDFS access, then you can configure Vertica to use the same principals to authenticate. However, not all Hadoop administrators want to grant access to all database users, preferring to manage access in other ways. In addition, not all Vertica databases use Kerberos.
Vertica provides the following options for accessing Kerberized Hadoop clusters:
-
Using Vertica Kerberos principals.
-
Using Hadoop proxy users combined with Vertica users.
-
Using a user-specified delegation token which grants access to HDFS. Delegation tokens are issued by the Hadoop cluster.
Proxy users and delegation tokens both use a session parameter to manage identities. Vertica need not be Kerberized when using either of these methods.
Vertica does not support Kerberos for MapR.
To test your Kerberos configuration, see Verifying HDFS configuration.
1 - Using Kerberos with Vertica
If you use Kerberos for your Vertica cluster and your principals have access to HDFS, then you can configure Vertica to use the same credentials for HDFS.
If you use Kerberos for your Vertica cluster and your principals have access to HDFS, then you can configure Vertica to use the same credentials for HDFS.
Vertica authenticates with Hadoop in two ways that require different configurations:
-
User Authentication—On behalf of the user, by passing along the user's existing Kerberos credentials. This method is also called user impersonation. Actions performed on behalf of particular users, like executing queries, generally use user authentication.
-
Vertica Authentication—On behalf of system processes that access ROS data or the catalog, by using a special Kerberos credential stored in a keytab file.
Note
Vertica and Hadoop must use the same Kerberos server or servers (KDCs).
Vertica can interact with more than one Kerberos realm. To configure multiple realms, see Multi-realm Support.
Vertica attempts to automatically refresh Hadoop tokens before they expire. See Token expiration.
User authentication
To use Vertica with Kerberos and Hadoop, the client user first authenticates with one of the Kerberos servers (Key Distribution Center, or KDC) being used by the Hadoop cluster. A user might run kinit or sign in to Active Directory, for example.
A user who authenticates to a Kerberos server receives a Kerberos ticket. At the beginning of a client session, Vertica automatically retrieves this ticket. Vertica then uses this ticket to get a Hadoop token, which Hadoop uses to grant access. Vertica uses this token to access HDFS, such as when executing a query on behalf of the user. When the token expires, Vertica automatically renews it, also renewing the Kerberos ticket if necessary.
The user must have been granted permission to access the relevant files in HDFS. This permission is checked the first time Vertica reads HDFS data.
Vertica can use multiple KDCs serving multiple Kerberos realms, if proper cross-realm trust has been set up between realms.
Vertica authentication
Automatic processes, such as the Tuple Mover or the processes that access Eon Mode communal storage, do not log in the way users do. Instead, Vertica uses a special identity (principal) stored in a keytab file on every database node. (This approach is also used for Vertica clusters that use Kerberos but do not use Hadoop.) After you configure the keytab file, Vertica uses the principal residing there to automatically obtain and maintain a Kerberos ticket, much as in the client scenario. In this case, the client does not interact with Kerberos.
Each Vertica node uses its own principal; it is common to incorporate the name of the node into the principal name. You can either create one keytab per node, containing only that node's principal, or you can create a single keytab containing all the principals and distribute the file to all nodes. Either way, the node uses its principal to get a Kerberos ticket and then uses that ticket to get a Hadoop token.
When creating HDFS storage locations Vertica uses the principal in the keytab file, not the principal of the user issuing the CREATE LOCATION statement. The HCatalog Connector sometimes uses the principal in the keytab file, depending on how Hive authenticates users.
Configuring users and the keytab file
If you have not already configured Kerberos authentication for Vertica, follow the instructions in Configure Vertica for Kerberos authentication. Of particular importance for Hadoop integration:
-
Create one Kerberos principal per node.
-
Place the keytab files in the same location on each database node and set configuration parameter KerberosKeytabFile to that location.
-
Set KerberosServiceName to the name of the principal. (See Inform Vertica about the Kerberos principal.)
If you are using the HCatalog Connector, follow the additional steps in Configuring security in the HCatalog Connector documentation.
If you are using HDFS storage locations, give all node principals read and write permission to the HDFS directory you will use as a storage location.
2 - Proxy users and delegation tokens
An alternative to granting HDFS access to individual Vertica users is to use delegation tokens, either directly or with a proxy user.
An alternative to granting HDFS access to individual Vertica users is to use delegation tokens, either directly or with a proxy user. In this configuration, Vertica accesses HDFS on behalf of some other (Hadoop) user. The Hadoop users need not be Vertica users at all.
In Vertica, you can either specify the name of the Hadoop user to act on behalf of (doAs), or you can directly use a Kerberos delegation token that you obtain from HDFS (Bring Your Own Delegation Token). In the doAs case, Vertica obtains a delegation token for that user, so both approaches ultimately use delegation tokens to access files in HDFS.
Use the HadoopImpersonationConfig session parameter to specify a user or delegation token to use for HDFS access. Each session can use a different user and can use either doAs or a delegation token. The value of HadoopImpersonationConfig is a set of JSON objects.
To use delegation tokens of either type (more specifically, when HadoopImpersonationConfig is set), you must access HDFS through WebHDFS.
2.1 - User impersonation (doAs)
You can use user impersonation to access data in an HDFS cluster from Vertica.
You can use user impersonation to access data in an HDFS cluster from Vertica. This approach is called "doAs" (for "do as") because Vertica uses a single proxy user on behalf of another (Hadoop) user. The impersonated Hadoop user does not need to also be a Vertica user.
In the following illustration, Alice is a Hadoop user but not a Vertica user. She connects to Vertica as the proxy user, vertica-etl. In her session, Vertica obtains a delegation token (DT) on behalf of the doAs user (Alice), and uses that delegation token to access HDFS.
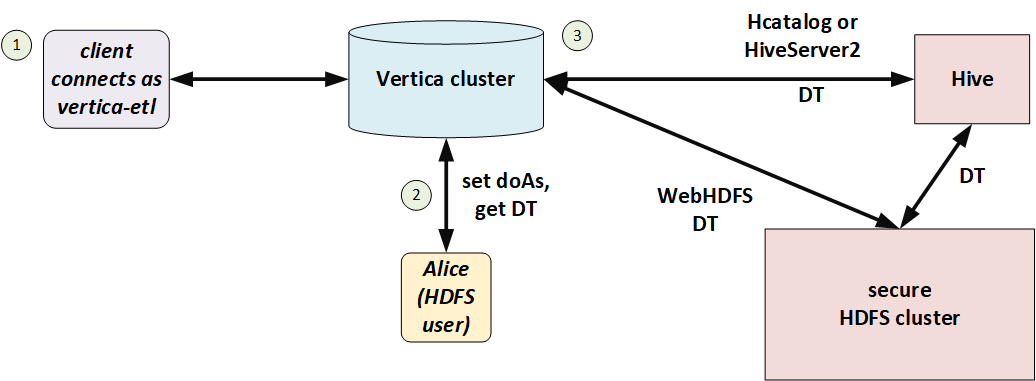
You can use doAs with or without Kerberos, so long as HDFS and Vertica match. If HDFS uses Kerberos then Vertica must too.
User configuration
The Hadoop administrator must create a proxy user and allow it to access HDFS on behalf of other users. Set values in core-site.xml as in the following example:
<name>hadoop.proxyuser.vertica-etl.users</name>
<value>*</value>
<name>hadoop.proxyuser.vertica-etl.hosts</name>
<value>*</value>
In Vertica, create a corresponding user.
Session configuration
To make requests on behalf of a Hadoop user, first set the HadoopImpersonationConfig session parameter to specify the user and HDFS cluster. Vertica will access HDFS as that user until the session ends or you change the parameter.
The value of this session parameter is a collection of JSON objects. Each object specifies an HDFS cluster and a Hadoop user. For the cluster, you can specify either a name service or an individual name node. If you are using HA name node, then you must either use a name service or specify all name nodes. HadoopImpersonationConfig format describes the full JSON syntax.
The following example shows access on behalf of two different users. The users "stephanie" and "bob" are Hadoop users, not Vertica users. "vertica-etl" is a Vertica user.
$ vsql -U vertica-etl
=> ALTER SESSION SET
HadoopImpersonationConfig = '[{"nameservice":"hadoopNS", "doAs":"stephanie"}]';
=> COPY nation FROM 'webhdfs:///user/stephanie/nation.dat';
=> ALTER SESSION SET
HadoopImpersonationConfig = '[{"nameservice":"hadoopNS", "doAs":"bob"}, {"authority":"hadoop2:50070", "doAs":"rob"}]';
=> COPY nation FROM 'webhdfs:///user/bob/nation.dat';
Vertica uses Hadoop delegation tokens, obtained from the name node, to impersonate Hadoop users. In a long-running session, a token could expire. Vertica attempts to renew tokens automatically; see Token expiration.
Testing the configuration
You can use the HADOOP_IMPERSONATION_CONFIG_CHECK function to test your HDFS delegation tokens and HCATALOGCONNECTOR_CONFIG_CHECK to test your HCatalog Connector delegation token.
2.2 - Bring your own delegation token
Instead of creating a proxy user and giving it access to HDFS for use with doAs, you can give Vertica a Hadoop delegation token to use.
Instead of creating a proxy user and giving it access to HDFS for use with doAs, you can give Vertica a Hadoop delegation token to use. You must obtain this delegation token from the Hadoop name node. In this model, security is handled entirely on the Hadoop side, with Vertica just passing along a token. Vertica may or may not be Kerberized.
A typical workflow is:
-
In an ETL front end, a user submits a query.
-
The ETL system uses authentication and authorization services to verify that the user has sufficient permission to run the query.
-
The ETL system requests a delegation token for the user from the name node.
-
The ETL system makes a client connection to Vertica, sets the delegation token for the session, and runs the query.
When using a delegation token, clients can connect as any Vertica user. No proxy user is required.
In the following illustration, Bob has a Hadoop-issued delegation token. He connects to Vertica and Vertica uses that delegation token to access files in HDFS.
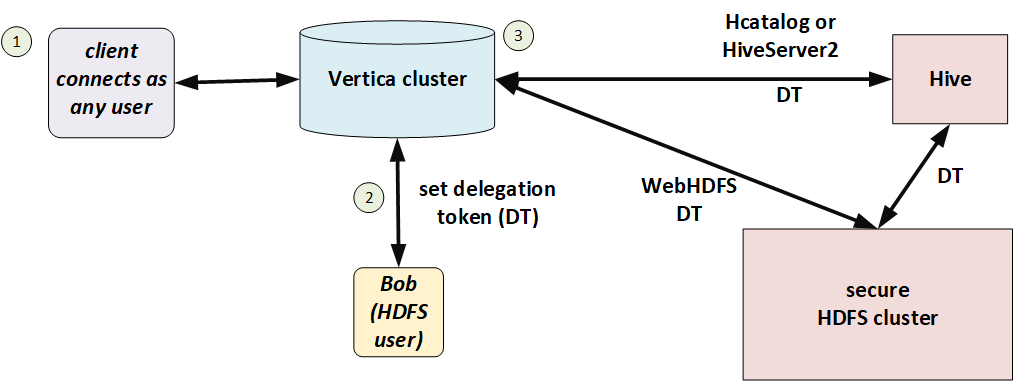
Session configuration
Set the HadoopImpersonationConfig session parameter to specify the delegation token and HDFS cluster. Vertica will access HDFS using that delegation token until the session ends, the token expires, or you change the parameter.
The value of this session parameter is a collection of JSON objects. Each object specifies a delegation token ("token") in WebHDFS format and an HDFS name service or name node. HadoopImpersonationConfig format describes the full JSON syntax.
The following example shows access on behalf of two different users. The users "stephanie" and "bob" are Hadoop users, not Vertica users. "dbuser1" is a Vertica user with no special privileges.
$ vsql -U dbuser1
=> ALTER SESSION SET
HadoopImpersonationConfig ='[{"authority":"hadoop1:50070","token":"JAAGZGJldGwxBmRiZXRsMQCKAWDXJgB9igFg-zKEfY4gao4BmhSJYtXiWqrhBHbbUn4VScNg58HWQxJXRUJIREZTIGRlbGVnYXRpb24RMTAuMjAuMTAwLjU0OjgwMjA"}]';
=> COPY nation FROM 'webhdfs:///user/stephanie/nation.dat';
=> ALTER SESSION SET
HadoopImpersonationConfig ='[{"authority":"hadoop1:50070","token":"HgADdG9tA3RvbQCKAWDXJgAoigFg-zKEKI4gaI4BmhRoOUpq_jPxrVhZ1NSMnodAQnhUthJXRUJIREZTIGRlbGVnYXRpb24RMTAuMjAuMTAwLjU0OjgwMjA"}]';
=> COPY nation FROM 'webhdfs:///user/bob/nation.dat';
You can use the WebHDFS REST API to get delegation tokens:
$ curl -s --noproxy "*" --negotiate -u: -X GET "http://hadoop1:50070/webhdfs/v1/?op=GETDELEGATIONTOKEN"
Vertica does not, and cannot, renew delegation tokens when they expire. You must either keep sessions shorter than token lifetime or implement a renewal scheme.
Delegation tokens and the HCatalog Connector
HiveServer2 uses a different format for delegation tokens. To use the HCatalog Connector, therefore, you must set two delegation tokens, one as usual (authority) and one for HiveServer2 (schema). The HCatalog Connector uses the schema token to access metadata and the authority token to access data. The schema name is the same Hive schema you specified in CREATE HCATALOG SCHEMA. The following example shows how to use these two delegation tokens.
$ vsql -U dbuser1
-- set delegation token for user and HiveServer2
=> ALTER SESSION SET
HadoopImpersonationConfig='[
{"nameservice":"hadoopNS","token":"JQAHcmVsZWFzZQdyZWxlYXNlAIoBYVJKrYSKAWF2VzGEjgmzj_IUCIrI9b8Dqu6awFTHk5nC-fHB8xsSV0VCSERGUyBkZWxlZ2F0aW9uETEwLjIwLjQyLjEwOTo4MDIw"},
{"schema":"access","token":"UwAHcmVsZWFzZQdyZWxlYXNlL2hpdmUvZW5nLWc5LTEwMC52ZXJ0aWNhY29ycC5jb21AVkVSVElDQUNPUlAuQ09NigFhUkmyTooBYXZWNk4BjgETFKN2xPURn19Yq9tf-0nekoD51TZvFUhJVkVfREVMRUdBVElPTl9UT0tFThZoaXZlc2VydmVyMkNsaWVudFRva2Vu"}]';
-- uses HiveServer2 token to get metadata
=> CREATE HCATALOG SCHEMA access WITH hcatalog_schema 'access';
-- uses both tokens
=> SELECT * FROM access.t1;
--uses only HiveServer2 token
=> SELECT * FROM hcatalog_tables;
HiveServer2 does not provide a REST API for delegation tokens like WebHDFS does. See Getting a HiveServer2 delegation token for some tips.
Testing the configuration
You can use the HADOOP_IMPERSONATION_CONFIG_CHECK function to test your HDFS delegation tokens and HCATALOGCONNECTOR_CONFIG_CHECK to test your HCatalog Connector delegation token.
2.3 - Getting a HiveServer2 delegation token
To acccess Hive metadata using HiveServer2, you need a special delegation token.
To acccess Hive metadata using HiveServer2, you need a special delegation token. (See Bring your own delegation token.) HiveServer2 does not provide an easy way to get this token, unlike the REST API that grants HDFS (data) delegation tokens.
The following utility code shows a way to get this token. You will need to modify this code for your own cluster; in particular, change the value of the connectURL static.
import java.io.FileWriter;
import java.io.PrintStream;
import java.io.PrintWriter;
import java.io.StringWriter;
import java.io.Writer;
import java.security.PrivilegedExceptionAction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.shims.Utils;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hive.jdbc.HiveConnection;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
public class JDBCTest {
public static final String driverName = "org.apache.hive.jdbc.HiveDriver";
public static String connectURL = "jdbc:hive2://node2.cluster0.example.com:2181,node1.cluster0.example.com:2181,node3.cluster0.example.com:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2";
public static String schemaName = "hcat";
public static String verticaUser = "condor";
public static String proxyUser = "condor-2";
public static String krb5conf = "/home/server/kerberos/krb5.conf";
public static String realm = "EXAMPLE.COM";
public static String keytab = "/home/server/kerberos/kt.keytab";
public static void main(String[] args) {
if (args.length < 7) {
System.out.println(
"Usage: JDBCTest <jdbc_url> <hive_schema> <kerberized_user> <proxy_user> <krb5_conf> <krb_realm> <krb_keytab>");
System.exit(1);
}
connectURL = args[0];
schemaName = args[1];
verticaUser = args[2];
proxyUser = args[3];
krb5conf = args[4];
realm = args[5];
keytab = args[6];
System.out.println("connectURL: " + connectURL);
System.out.println("schemaName: " + schemaName);
System.out.println("verticaUser: " + verticaUser);
System.out.println("proxyUser: " + proxyUser);
System.out.println("krb5conf: " + krb5conf);
System.out.println("realm: " + realm);
System.out.println("keytab: " + keytab);
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
System.out.println("Found HiveServer2 JDBC driver");
} catch (ClassNotFoundException e) {
System.out.println("Couldn't find HiveServer2 JDBC driver");
}
try {
Configuration conf = new Configuration();
System.setProperty("java.security.krb5.conf", krb5conf);
conf.set("hadoop.security.authentication", "kerberos");
UserGroupInformation.setConfiguration(conf);
dtTest();
} catch (Throwable e) {
Writer stackString = new StringWriter();
e.printStackTrace(new PrintWriter(stackString));
System.out.println(e);
System.out.printf("Error occurred when connecting to HiveServer2 with [%s]: %s\n%s\n",
new Object[] { connectURL, e.getMessage(), stackString.toString() });
}
}
private static void dtTest() throws Exception {
UserGroupInformation user = UserGroupInformation.loginUserFromKeytabAndReturnUGI(verticaUser + "@" + realm, keytab);
user.doAs(new PrivilegedExceptionAction() {
public Void run() throws Exception {
System.out.println("In doas: " + UserGroupInformation.getLoginUser());
Connection con = DriverManager.getConnection(JDBCTest.connectURL);
System.out.println("Connected to HiveServer2");
JDBCTest.showUser(con);
System.out.println("Getting delegation token for user");
String token = ((HiveConnection) con).getDelegationToken(JDBCTest.proxyUser, "hive/_HOST@" + JDBCTest.realm);
System.out.println("Got token: " + token);
System.out.println("Closing original connection");
con.close();
System.out.println("Setting delegation token in UGI");
Utils.setTokenStr(Utils.getUGI(), token, "hiveserver2ClientToken");
con = DriverManager.getConnection(JDBCTest.connectURL + ";auth=delegationToken");
System.out.println("Connected to HiveServer2 with delegation token");
JDBCTest.showUser(con);
con.close();
JDBCTest.writeDTJSON(token);
return null;
}
});
}
private static void showUser(Connection con) throws Exception {
String sql = "select current_user()";
Statement stmt = con.createStatement();
ResultSet res = stmt.executeQuery(sql);
StringBuilder result = new StringBuilder();
while (res.next()) {
result.append(res.getString(1));
}
System.out.println("\tcurrent_user: " + result.toString());
}
private static void writeDTJSON(String token) {
JSONArray arr = new JSONArray();
JSONObject obj = new JSONObject();
obj.put("schema", schemaName);
obj.put("token", token);
arr.add(obj);
try {
FileWriter fileWriter = new FileWriter("hcat_delegation.json");
fileWriter.write(arr.toJSONString());
fileWriter.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Following is an example call and its output:
$ java -cp hs2token.jar JDBCTest 'jdbc:hive2://test.example.com:10000/default;principal=hive/_HOST@EXAMPLE.COM' "default" "testuser" "test" "/etc/krb5.conf" "EXAMPLE.COM" "/test/testuser.keytab"
connectURL: jdbc:hive2://test.example.com:10000/default;principal=hive/_HOST@EXAMPLE.COM
schemaName: default
verticaUser: testuser
proxyUser: test
krb5conf: /etc/krb5.conf
realm: EXAMPLE.COM
keytab: /test/testuser.keytab
Found HiveServer2 JDBC driver
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
In doas: testuser@EXAMPLE.COM (auth:KERBEROS)
Connected to HiveServer2
current_user: testuser
Getting delegation token for user
Got token: JQAEdGVzdARoaXZlB3JlbGVhc2WKAWgvBOwzigFoUxFwMwKOAgMUHfqJ5ma7_27LiePN8C7MxJ682bsVSElWRV9ERUxFR0FUSU9OX1RPS0VOFmhpdmVzZXJ2ZXIyQ2xpZW50VG9rZW4
Closing original connection
Setting delegation token in UGI
Connected to HiveServer2 with delegation token
current_user: testuser
2.4 - HadoopImpersonationConfig format
The value of the HadoopImpersonationConfig session parameter is a set of one or more JSON objects.
The value of the HadoopImpersonationConfig session parameter is a set of one or more JSON objects. Each object describes one doAs user or delegation token for one Hadoop destination. You must use WebHDFS, not LibHDFS++, to use impersonation.
Syntax
[ { ("doAs" | "token"): value,
("nameservice" | "authority" | "schema"): value} [,...]
]
Properties
doAs |
The name of a Hadoop user to impersonate. |
token |
A delegation token to use for HDFS access. |
nameservice |
A Hadoop name service. All access to this name service uses the doAs user or delegation token. |
authority |
A name node authority. All access to this authority uses the doAs user or delegation token. If the name node fails over to another name node, the doAs user or delegation token does not automatically apply to the failover name node. If you are using HA name node, use nameservice instead of authority or include objects for every name node. |
schema |
A Hive schema, for use with the HCatalog Connector. Vertica uses this object's doAs user or token to access Hive metadata only. For data access you must also specify a name service or authority object, just like for all other data access. |
Examples
In the following example of doAs, Bob is a Hadoop user and vertica-etl is a Kerberized proxy user.
$ kinit vertica-etl -kt /home/dbadmin/vertica-etl.keytab
$ vsql -U vertica-etl
=> ALTER SESSION SET
HadoopImpersonationConfig = '[{"nameservice":"hadoopNS", "doAs":"Bob"}]';
=> COPY nation FROM 'webhdfs:///user/bob/nation.dat';
In the following example, the current Vertica user (it doesn't matter who that is) uses a Hadoop delegation token. This token belongs to Alice, but you never specify the user name here. Instead, you use it to get the delegation token from Hadoop.
$ vsql -U dbuser1
=> ALTER SESSION SET
HadoopImpersonationConfig ='[{"nameservice":"hadoopNS","token":"JAAGZGJldGwxBmRiZXRsMQCKAWDXJgB9igFg-zKEfY4gao4BmhSJYtXiWqrhBHbbUn4VScNg58HWQxJXRUJIREZTIGRlbGVnYXRpb24RMTAuMjAuMTAwLjU0OjgwMjA"}]';
=> COPY nation FROM 'webhdfs:///user/alice/nation.dat';
In the following example, "authority" specifies the (single) name node on a Hadoop cluster that does not use high availability.
$ vsql -U dbuser1
=> ALTER SESSION SET
HadoopImpersonationConfig ='[{"authority":"hadoop1:50070", "doAs":"Stephanie"}]';
=> COPY nation FROM 'webhdfs://hadoop1:50070/user/stephanie/nation.dat';
To access data in Hive you need to specify two delegation tokens. The first, for a name service or authority, is for data access as usual. The second is for the HiveServer2 metadata for the schema. HiveServer2 requires a delegation token in WebHDFS format. The schema name is the Hive schema you specify with CREATE HCATALOG SCHEMA.
$ vsql -U dbuser1
-- set delegation token for user and HiveServer2
=> ALTER SESSION SET
HadoopImpersonationConfig='[
{"nameservice":"hadoopNS","token":"JQAHcmVsZWFzZQdyZWxlYXNlAIoBYVJKrYSKAWF2VzGEjgmzj_IUCIrI9b8Dqu6awFTHk5nC-fHB8xsSV0VCSERGUyBkZWxlZ2F0aW9uETEwLjIwLjQyLjEwOTo4MDIw"},
{"schema":"access","token":"UwAHcmVsZWFzZQdyZWxlYXNlL2hpdmUvZW5nLWc5LTEwMC52ZXJ0aWNhY29ycC5jb21AVkVSVElDQUNPUlAuQ09NigFhUkmyTooBYXZWNk4BjgETFKN2xPURn19Yq9tf-0nekoD51TZvFUhJVkVfREVMRUdBVElPTl9UT0tFThZoaXZlc2VydmVyMkNsaWVudFRva2Vu"}]';
-- uses HiveServer2 token to get metadata
=> CREATE HCATALOG SCHEMA access WITH hcatalog_schema 'access';
-- uses both tokens
=> SELECT * FROM access.t1;
--uses only HiveServer2 token
=> SELECT * FROM hcatalog_tables;
Each object in the HadoopImpersonationConfig collection specifies one connection to one Hadoop cluster. You can add as many connections as you like, including to more than one Hadoop cluster. The following example shows delegation tokens for two different Hadoop clusters. Vertica uses the correct token for each cluster when connecting.
$ vsql -U dbuser1
=> ALTER SESSION SET
HadoopImpersonationConfig ='[
{"nameservice":"productionNS","token":"JAAGZGJldGwxBmRiZXRsMQCKAWDXJgB9igFg-zKEfY4gao4BmhSJYtXiWqrhBHbbUn4VScNg58HWQxJXRUJIREZTIGRlbGVnYXRpb24RMTAuMjAuMTAwLjU0OjgwMjA"},
{"nameservice":"testNS", "token":"HQAHcmVsZWFzZQdyZWxlYXNlAIoBYVJKrYSKAWF2VzGEjgmzj_IUCIrI9b8Dqu6awFTHk5nC-fHB8xsSV0VCSERGUyBkZWxlZ2F0aW9uETEwLjIwLjQyLjEwOTo4MDIw"}]';
=> COPY clicks FROM 'webhdfs://productionNS/data/clickstream.dat';
=> COPY testclicks FROM 'webhdfs://testNS/data/clickstream.dat';
3 - Token expiration
Vertica uses Hadoop tokens when using Kerberos tickets (Using Kerberos from [%=Vertica.DBMS_SHORT%]) or doAs (User Impersonation (doAs)).
Vertica uses Hadoop tokens when using Kerberos tickets (Using Kerberos with Vertica) or doAs (User impersonation (doAs)). Vertica attempts to automatically refresh Hadoop tokens before they expire, but you can also set a minimum refresh frequency if you prefer. Use the HadoopFSTokenRefreshFrequency configuration parameter to specify the frequency in seconds:
=> ALTER DATABASE exampledb SET HadoopFSTokenRefreshFrequency = '86400';
If the current age of the token is greater than the value specified in this parameter, Vertica refreshes the token before accessing data stored in HDFS.
Vertica does not refresh delegation tokens (Bring your own delegation token).