This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
SQL analytics
For details about supported functions, see Analytic Functions.
Vertica analytics are SQL functions based on the ANSI 99 standard. These functions handle complex analysis and reporting tasks—for example:
-
Rank the longest-standing customers in a particular state.
-
Calculate the moving average of retail volume over a specified time.
-
Find the highest score among all students in the same grade.
-
Compare the current sales bonus that salespersons received against their previous bonus.
Analytic functions return aggregate results but they do not group the result set. They return the group value multiple times, once per record. You can sort group values, or partitions, using a window ORDER BY clause, but the order affects only the function result set, not the entire query result set.
For details about supported functions, see Analytic functions.
1 - Invoking analytic functions
You invoke analytic functions as follows:.
You invoke analytic functions as follows:
analytic-function(arguments) OVER(
[ window-partition-clause ]
[ window-order-clause [ window-frame-clause ] ]
)
An analytic function's OVER clause contains up to three sub-clauses, which specify how to partition and sort function input, and how to frame input with respect to the current row. Function input is the result set that the query returns after it evaluates FROM, WHERE, GROUP BY, and HAVING clauses.
Note
Each function has its own OVER clause requirements. For example, some analytic functions do not support window order and window frame clauses.
For syntax details, see Analytic functions.
Function execution
An analytic function executes as follows:
- Takes the input rows that the query returns after it performs all joins, and evaluates
FROM, WHERE, GROUP BY, and HAVING clauses.
- Groups input rows according to the window partition (
PARTITION BY) clause. If this clause is omitted, all input rows are treated as a single partition.
- Sorts rows within each partition according to window order (
ORDER BY) clause.
- If the
OVER clause includes a window order clause, the function checks for a window frame clause and executes it as it processes each input row. If the OVER clause omits a window frame clause, the function treats the entire partition as a window frame.
Restrictions
-
Analytic functions are allowed only in a query's SELECT and ORDER BY clauses.
-
Analytic functions cannot be nested. For example, the following query throws an error:
=> SELECT MEDIAN(RANK() OVER(ORDER BY sal) OVER()).
2 - Analytic functions versus aggregate functions
Like aggregate functions, analytic functions return aggregate results, but analytics do not group the result set.
Like aggregate functions, analytic functions return aggregate results, but analytics do not group the result set. Instead, they return the group value multiple times with each record, allowing further analysis.
Analytic queries generally run faster and use fewer resources than aggregate queries.
|
Aggregate functions |
Analytic functions |
|
Return a single summary value. |
Return the same number of rows as the input. |
Define the groups of rows on which they operate through the SQL GROUP BY clause. |
Define the groups of rows on which they operate through window partition and window frame clauses. |
Examples
The examples below contrast the aggregate function
COUNT with its analytic counterpart
COUNT. The examples use the employees table as defined below:
CREATE TABLE employees(emp_no INT, dept_no INT);
INSERT INTO employees VALUES(1, 10);
INSERT INTO employees VALUES(2, 30);
INSERT INTO employees VALUES(3, 30);
INSERT INTO employees VALUES(4, 10);
INSERT INTO employees VALUES(5, 30);
INSERT INTO employees VALUES(6, 20);
INSERT INTO employees VALUES(7, 20);
INSERT INTO employees VALUES(8, 20);
INSERT INTO employees VALUES(9, 20);
INSERT INTO employees VALUES(10, 20);
INSERT INTO employees VALUES(11, 20);
COMMIT;
When you query this table, the following result set returns:
=> SELECT * FROM employees ORDER BY emp_no;
emp_no | dept_no
--------+---------
1 | 10
2 | 30
3 | 30
4 | 10
5 | 30
6 | 20
7 | 20
8 | 20
9 | 20
10 | 20
11 | 20
(11 rows)
Below, two queries use the COUNT function to count the number of employees in each department. The query on the left uses aggregate function
COUNT; the query on the right uses analytic function
COUNT:
|
Aggregate COUNT |
Analytics COUNT |
=> SELECT dept_no, COUNT(*) AS emp_count
FROM employees
GROUP BY dept_no ORDER BY dept_no;
|
=> SELECT emp_no, dept_no, COUNT(*) OVER(
PARTITION BY dept_no
ORDER BY emp_no) AS emp_count
FROM employees;
|
dept_no | emp_count
---------+-----------
10 | 2
20 | 6
30 | 3
(3 rows)
|
emp_no | dept_no | emp_count
--------+---------+-----------
1 | 10 | 1
4 | 10 | 2
------------------------------
6 | 20 | 1
7 | 20 | 2
8 | 20 | 3
9 | 20 | 4
10 | 20 | 5
11 | 20 | 6
------------------------------
2 | 30 | 1
3 | 30 | 2
5 | 30 | 3
(11 rows)
|
Aggregate function
COUNT returns one row per department for the number of employees in that department. |
Within each dept_no partition analytic function
COUNT returns a cumulative count of employees. The count is ordered by emp_no, as specified by the ORDER BY clause. |
See also
3 - Window partitioning
Optionally specified in a function's OVER clause, a partition (PARTITION BY) clause groups input rows before the function processes them.
Optionally specified in a function's OVER clause, a partition (PARTITION BY) clause groups input rows before the function processes them. Window partitioning using PARTITION NODES or PARTITION BEST is similar to an aggregate function's GROUP BY clause, except it returns exactly one result row per input row. Window partitioning using PARTITION ROW allows you to provide single-row partitions of input, allowing you to use window partitioning on 1:N transform functions. If you omit the window partition clause, the function treats all input rows as a single partition.
Specifying window partitioning
You specify window partitioning in the function's OVER clause, as follows:
{ PARTITION BY expression[,...]
| PARTITION BEST
| PARTITION NODES
| PARTITION ROW
| PARTITION LEFT JOIN }
For syntax details, see Window partition clause.
Examples
The examples in this topic use the allsales schema defined in Invoking analytic functions.
CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT);
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
The following query calculates the median of sales within each state. The analytic function is computed per partition and starts over again at the beginning of the next partition.
=> SELECT state, name, sales, MEDIAN(sales)
OVER (PARTITION BY state) AS median from allsales;
The results are grouped into partitions for MA (35) and NY (20) under the median column.
state | name | sales | median
-------+------+-------+--------
NY | C | 15 | 20
NY | B | 20 | 20
NY | F | 40 | 20
-------------------------------
MA | G | 10 | 35
MA | D | 20 | 35
MA | E | 50 | 35
MA | A | 60 | 35
(7 rows)
The following query calculates the median of total sales among states. When you use OVER() with no parameters, there is one partition—the entire input:
=> SELECT state, sum(sales), median(SUM(sales))
OVER () AS median FROM allsales GROUP BY state;
state | sum | median
-------+-----+--------
NY | 75 | 107.5
MA | 140 | 107.5
(2 rows)
Sales larger than median (evaluation order)
Analytic functions are evaluated after all other clauses except the query's final SQL ORDER BY clause. So a query that asks for all rows with sales larger than the median returns an error because the WHERE clause is applied before the analytic function and column m does not yet exist:
=> SELECT name, sales, MEDIAN(sales) OVER () AS m
FROM allsales WHERE sales > m;
ERROR 2624: Column "m" does not exist
You can work around this by placing in a subquery the predicate WHERE sales > m:
=> SELECT * FROM
(SELECT name, sales, MEDIAN(sales) OVER () AS m FROM allsales) sq
WHERE sales > m;
name | sales | m
------+-------+----
F | 40 | 20
E | 50 | 20
A | 60 | 20
(3 rows)
For more examples, see Analytic query examples.
4 - Window ordering
Window ordering specifies how to sort rows that are supplied to the function.
Window ordering specifies how to sort rows that are supplied to the function. You specify window ordering through an ORDER BY clause in the function's OVER clause, as shown below. If the OVER clause includes a window partition clause, rows are sorted within each partition. An window order clause also creates a default window frame if none is explicitly specified.
The window order clause only specifies order within a window result set. The query can have its own
ORDER BY clause outside the OVER clause. This has precedence over the window order clause and orders the final result set.
Specifying window order
You specify a window frame in the analytic function's OVER clause, as shown below:
ORDER BY { expression [ ASC | DESC [ NULLS { FIRST | LAST | AUTO } ] ]
}[,...]
For syntax details, see Window order clause.
Analytic function usage
Analytic aggregation functions such as
SUM support window order clauses.
Required Usage
The following functions require a window order clause:
Invalid Usage
You cannot use a window order clause with the following functions:
Examples
The examples below use the allsales table schema:
CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT);
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
Example 1
The following query orders sales inside each state partition:
=> SELECT state, sales, name, RANK() OVER(
PARTITION BY state ORDER BY sales) AS RANK
FROM allsales;
state | sales | name | RANK
-------+-------+------+----------
MA | 10 | G | 1
MA | 20 | D | 2
MA | 50 | E | 3
MA | 60 | A | 4
---------------------------------
NY | 15 | C | 1
NY | 20 | B | 2
NY | 40 | F | 3
(7 rows)
Example 2
The following query's final ORDER BY clause sorts results by name:
=> SELECT state, sales, name, RANK() OVER(
PARTITION BY state ORDER BY sales) AS RANK
FROM allsales ORDER BY name;
state | sales | name | RANK
-------+-------+------+----------
MA | 60 | A | 4
NY | 20 | B | 2
NY | 15 | C | 1
MA | 20 | D | 2
MA | 50 | E | 3
NY | 40 | F | 3
MA | 10 | G | 1
(7 rows)
5 - Window framing
The window frame of an analytic function comprises a set of rows relative to the row that is currently being evaluated by the function.
The window frame of an analytic function comprises a set of rows relative to the row that is currently being evaluated by the function. After the analytic function processes that row and its window frame, Vertica advances the current row and adjusts the frame boundaries accordingly. If the OVER clause also specifies a partition, Vertica also checks that frame boundaries do not cross partition boundaries. This process repeats until the function evaluates the last row of the last partition.
Specifying a window frame
You specify a window frame in the analytic function's OVER clause, as follows:
{ ROWS | RANGE } { BETWEEN start-point AND end-point } | start-point
start-point | end-point:
{ UNBOUNDED {PRECEDING | FOLLOWING}
| CURRENT ROW
| constant-value {PRECEDING | FOLLOWING}}
start-point and end-point specify the window frame's offset from the current row. Keywords ROWS and RANGE specify whether the offset is physical or logical. If you specify only a start point, Vertica creates a window from that point to the current row.
For syntax details, see Window frame clause.
Requirements
In order to specify a window frame, the OVER must also specify a window order (ORDER BY) clause. If the OVER clause includes a window order clause but omits specifying a window frame, the function creates a default frame that extends from the first row in the current partition to the current row. This is equivalent to the following clause:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
Window aggregate functions
Analytic functions that support window frames are called window aggregates. They return information such as moving averages and cumulative results. To use the following functions as window (analytic) aggregates, instead of basic aggregates, the OVER clause must specify a window order clause and, optionally, a window frame clause. If the OVER clause omits specifying a window frame, the function creates a default window frame as described earlier.
The following analytic functions support window frames:
A window aggregate with an empty OVER clause creates no window frame. The function is used as a reporting function, where all input is treated as a single partition.
5.1 - Windows with a physical offset (ROWS)
The keyword ROWS in a window frame clause specifies window dimensions as the number of rows relative to the current row.
The keyword ROWS in a window frame clause specifies window dimensions as the number of rows relative to the current row. The value can be INTEGER data type only.
Note
The value returned by an analytic function with a physical offset is liable to produce nondeterministic results unless the ordering expression results in a unique ordering. To achieve unique ordering, the
window order clause might need to specify multiple columns.
Examples
The examples on this page use the emp table schema:
CREATE TABLE emp(deptno INT, sal INT, empno INT);
INSERT INTO emp VALUES(10,101,1);
INSERT INTO emp VALUES(10,104,4);
INSERT INTO emp VALUES(20,100,11);
INSERT INTO emp VALUES(20,109,7);
INSERT INTO emp VALUES(20,109,6);
INSERT INTO emp VALUES(20,109,8);
INSERT INTO emp VALUES(20,110,10);
INSERT INTO emp VALUES(20,110,9);
INSERT INTO emp VALUES(30,102,2);
INSERT INTO emp VALUES(30,103,3);
INSERT INTO emp VALUES(30,105,5);
COMMIT;
The following query invokes COUNT to count the current row and the rows preceding it, up to two rows:
SELECT deptno, sal, empno, COUNT(*) OVER
(PARTITION BY deptno ORDER BY sal ROWS BETWEEN 2 PRECEDING AND CURRENT ROW)
AS count FROM emp;
The OVER clause contains three components:
-
Window partition clause PARTITION BY deptno
-
Order by clause ORDER BY sal
-
Window frame clause ROWS BETWEEN 2 PRECEDING AND CURRENT ROW . This clause defines window dimensions as extending from the current row through the two rows that precede it.
The query returns results that are divided into three partitions, indicated below as red lines. Within the second partition (deptno=20), COUNT processes the window frame clause as follows:
-
Creates the first window (green box). This window comprises a single row, as the current row (blue box) is also the the partition's first row. Thus, the value in the count column shows the number of rows in the current window, which is 1:

-
After COUNT processes the partition's first row, it resets the current row to the partition's second row. The window now spans the current row and the row above it, so COUNT returns a value of 2:

-
After COUNT processes the partition's second row, it resets the current row to the partition's third row. The window now spans the current row and the two rows above it, so COUNT returns a value of 3:
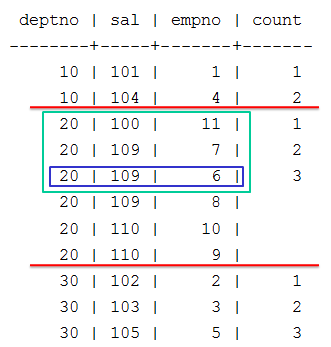
-
Thereafter, COUNT continues to process the remaining partition rows and moves the window accordingly, but the window dimensions (ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) remain unchanged as three rows. Accordingly, the value in the count column also remains unchanged (3):


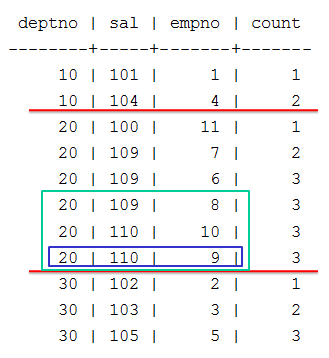
5.2 - Windows with a logical offset (RANGE)
The RANGE keyword defines an analytic window frame as a logical offset from the current row.
The RANGE keyword defines an analytic window frame as a logical offset from the current row.
Note
The value returned by an analytic function with a logical offset is always deterministic.
For each row, an analytic function uses the window order clause (ORDER_BY) column or expression to calculate window frame dimensions as follows:
-
Within the current partition, evaluates the ORDER_BY value of the current row against the ORDER_BY values of contiguous rows.
-
Determines which of these rows satisfy the specified range requirements relative to the current row.
-
Creates a window frame that includes only those rows.
-
Executes on the current window.
Example
This example uses the table property_sales, which contains data about neighborhood home sales:
=> SELECT property_key, neighborhood, sell_price FROM property_sales ORDER BY neighborhood, sell_price;
property_key | neighborhood | sell_price
--------------+---------------+------------
10918 | Jamaica Plain | 353000
10921 | Jamaica Plain | 450000
10927 | Jamaica Plain | 450000
10922 | Jamaica Plain | 474000
10919 | Jamaica Plain | 515000
10917 | Jamaica Plain | 675000
10924 | Jamaica Plain | 675000
10920 | Jamaica Plain | 705000
10923 | Jamaica Plain | 710000
10926 | Jamaica Plain | 875000
10925 | Jamaica Plain | 900000
10930 | Roslindale | 300000
10928 | Roslindale | 422000
10932 | Roslindale | 450000
10929 | Roslindale | 485000
10931 | Roslindale | 519000
10938 | West Roxbury | 479000
10933 | West Roxbury | 550000
10937 | West Roxbury | 550000
10934 | West Roxbury | 574000
10935 | West Roxbury | 598000
10936 | West Roxbury | 615000
10939 | West Roxbury | 720000
(23 rows)
The analytic function AVG can obtain the average of proximate selling prices within each neighborhood. The following query calculates for each home the average sale for all other neighborhood homes whose selling price was $50k higher or lower:
=> SELECT property_key, neighborhood, sell_price, AVG(sell_price) OVER(
PARTITION BY neighborhood ORDER BY sell_price
RANGE BETWEEN 50000 PRECEDING and 50000 FOLLOWING)::int AS comp_sales
FROM property_sales ORDER BY neighborhood;
property_key | neighborhood | sell_price | comp_sales
--------------+---------------+------------+------------
10918 | Jamaica Plain | 353000 | 353000
10927 | Jamaica Plain | 450000 | 458000
10921 | Jamaica Plain | 450000 | 458000
10922 | Jamaica Plain | 474000 | 472250
10919 | Jamaica Plain | 515000 | 494500
10917 | Jamaica Plain | 675000 | 691250
10924 | Jamaica Plain | 675000 | 691250
10920 | Jamaica Plain | 705000 | 691250
10923 | Jamaica Plain | 710000 | 691250
10926 | Jamaica Plain | 875000 | 887500
10925 | Jamaica Plain | 900000 | 887500
10930 | Roslindale | 300000 | 300000
10928 | Roslindale | 422000 | 436000
10932 | Roslindale | 450000 | 452333
10929 | Roslindale | 485000 | 484667
10931 | Roslindale | 519000 | 502000
10938 | West Roxbury | 479000 | 479000
10933 | West Roxbury | 550000 | 568000
10937 | West Roxbury | 550000 | 568000
10934 | West Roxbury | 574000 | 577400
10935 | West Roxbury | 598000 | 577400
10936 | West Roxbury | 615000 | 595667
10939 | West Roxbury | 720000 | 720000
(23 rows)
AVG processes this query as follows:
-
AVG evaluates row 1 of the first partition (Jamaica Plain), but finds no sales within $50k of this row's sell_price, ($353k). AVG creates a window that includes this row only, and returns an average of 353k for row 1:
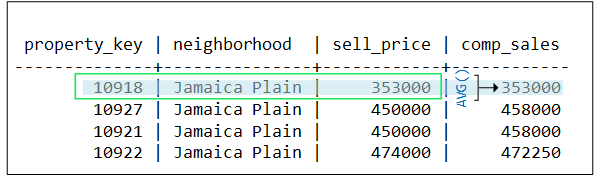
-
AVG evaluates row 2 and finds three sell_price values within $50k of the current row. AVG creates a window that includes these three rows, and returns an average of 458k for row 2:
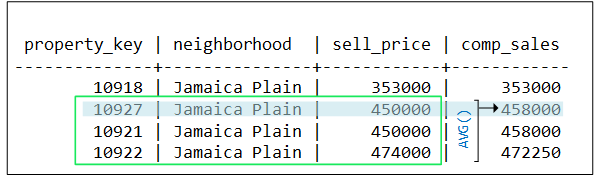
-
AVG evaluates row 3 and finds the same three sell_price values within $50k of the current row. AVG creates a window identical to the one before, and returns the same average of 458k for row 3:
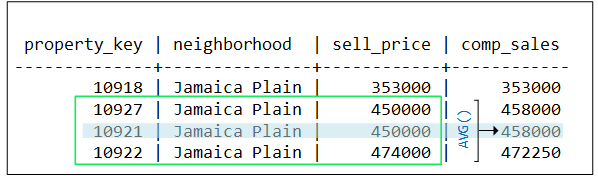
-
AVG evaluates row 4 and finds four sell_price values within $50k of the current row. AVG expands its window to include rows 2 through 5, and returns an average of $472.25k for row 4:
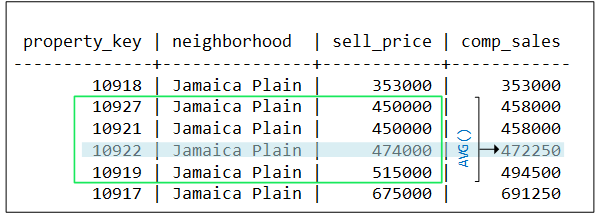
-
In similar fashion, AVG evaluates the remaining rows in this partition. When the function evaluates the first row of the second partition (Roslindale), it resets the window as follows:
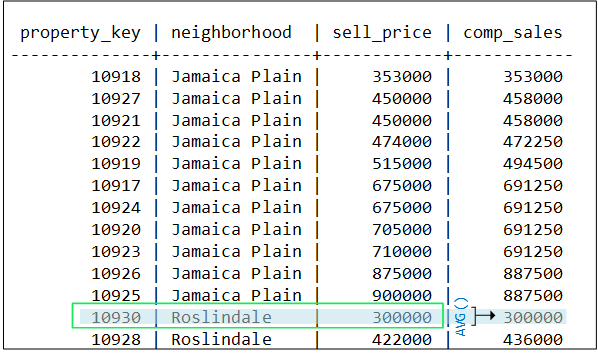
Restrictions
If RANGE specifies a constant value, that value's data type and the window's ORDER BY data type must be the same. The following exceptions apply:
-
RANGE can specify INTERVAL Year to Month if the window order clause data type is one of following: TIMESTAMP, TIMESTAMP WITH TIMEZONE, or DATE. TIME and TIME WITH TIMEZONE are not supported.
-
RANGE can specify INTERVAL Day to Second if the window order clause data is one of following: TIMESTAMP, TIMESTAMP WITH TIMEZONE, DATE, TIME, or TIME WITH TIMEZONE.
The window order clause must specify one of the following data types: NUMERIC, DATE/TIME, FLOAT or INTEGER. This requirement is ignored if the window specifies one of following frames:
-
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
-
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING
-
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
5.3 - Reporting aggregates
Some of the analytic functions that take the window-frame-clause are the reporting aggregates.
Some of the analytic functions that take the window-frame-clause are the reporting aggregates. These functions let you compare a partition's aggregate values with detail rows, taking the place of correlated subqueries or joins.
If you use a window aggregate with an empty OVER() clause, the analytic function is used as a reporting function, where the entire input is treated as a single partition.
About standard deviation and variance functions
With standard deviation functions, a low standard deviation indicates that the data points tend to be very close to the mean, whereas high standard deviation indicates that the data points are spread out over a large range of values.
Standard deviation is often graphed and a distributed standard deviation creates the classic bell curve.
Variance functions measure how far a set of numbers is spread out.
Examples
Think of the window for reporting aggregates as a window defined as UNBOUNDED PRECEDING and UNBOUNDED FOLLOWING. The omission of a window-order-clause makes all rows in the partition also the window (reporting aggregates).
=> SELECT deptno, sal, empno, COUNT(sal)
OVER (PARTITION BY deptno) AS COUNT FROM emp;
deptno | sal | empno | count
--------+-----+-------+-------
10 | 101 | 1 | 2
10 | 104 | 4 | 2
------------------------------
20 | 110 | 10 | 6
20 | 110 | 9 | 6
20 | 109 | 7 | 6
20 | 109 | 6 | 6
20 | 109 | 8 | 6
20 | 100 | 11 | 6
------------------------------
30 | 105 | 5 | 3
30 | 103 | 3 | 3
30 | 102 | 2 | 3
(11 rows)
If the OVER() clause in the above query contained a window-order-clause (for example, ORDER BY sal), it would become a moving window (window aggregate) query with a default window of RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:
=> SELECT deptno, sal, empno, COUNT(sal) OVER (PARTITION BY deptno ORDER BY sal) AS COUNT FROM emp;
deptno | sal | empno | count
--------+-----+-------+-------
10 | 101 | 1 | 1
10 | 104 | 4 | 2
------------------------------
20 | 100 | 11 | 1
20 | 109 | 7 | 4
20 | 109 | 6 | 4
20 | 109 | 8 | 4
20 | 110 | 10 | 6
20 | 110 | 9 | 6
------------------------------
30 | 102 | 2 | 1
30 | 103 | 3 | 2
30 | 105 | 5 | 3
(11 rows)
What about LAST_VALUE?
You might wonder why you couldn't just use the LAST_VALUE() analytic function.
For example, for each employee, get the highest salary in the department:
=> SELECT deptno, sal, empno,LAST_VALUE(empno) OVER (PARTITION BY deptno ORDER BY sal) AS lv FROM emp;

Due to default window semantics, LAST_VALUE does not always return the last value of a partition. If you omit the window-frame-clause from the analytic clause, LAST_VALUE operates on this default window. Results, therefore, can seem non-intuitive because the function does not return the bottom of the current partition. It returns the bottom of the window, which continues to change along with the current input row being processed.
Remember the default window:
OVER (PARTITION BY deptno ORDER BY sal)
is the same as:
OVER(PARTITION BY deptno ORDER BY salROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
If you want to return the last value of a partition, use UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
=> SELECT deptno, sal, empno, LAST_VALUE(empno)
OVER (PARTITION BY deptno ORDER BY sal
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS lv
FROM emp;

Vertica recommends that you use LAST_VALUE with the window-order-clause to produce deterministic results.
In the following example, empno 6, 7, and 8 have the same salary, so they are in adjacent rows. empno 8 appears first in this case but the order is not guaranteed.

Notice in the output above, the last value is 7, which is the last row from the partition deptno = 20. If the rows have a different order, then the function returns a different value:

Now the last value is 6, which is the last row from the partition deptno = 20. The solution is to add a unique key to the sort order. Even if the order of the query changes, the result will always be the same, and so deterministic.
=> SELECT deptno, sal, empno, LAST_VALUE(empno)
OVER (PARTITION BY deptno ORDER BY sal, empno
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) as lv
FROM emp;

Notice how the rows are now ordered by empno, the last value stays at 8, and it does not matter the order of the query.
6 - Named windows
An analytic function's OVER clause can reference a named window, which encapsulates one or more window clauses: a window partition (PARTITION BY) clause and (optionally) a window order (ORDER BY) clause.
An analytic function's OVER clause can reference a named window, which encapsulates one or more window clauses: a window partition (PARTITION BY) clause and (optionally) a window order (ORDER BY) clause. Named windows can be useful when you write queries that invoke multiple analytic functions with similar OVER clause syntax—for example, they use the same partition clauses.
A query names a window as follows:
WINDOW window-name AS ( window-partition-clause [window-order-clause] );
The same query can name and reference multiple windows. All window names must be unique within the same query.
Examples
The following query invokes two analytic functions,
RANK and
DENSE_RANK. Because the two functions use the same partition and order clauses, the query names a window w that specifies both clauses. The two functions reference this window as follows:
=> SELECT employee_region region, employee_key, annual_salary,
RANK() OVER w Rank,
DENSE_RANK() OVER w "Dense Rank"
FROM employee_dimension WINDOW w AS (PARTITION BY employee_region ORDER BY annual_salary);
region | employee_key | annual_salary | Rank | Dense Rank
----------------------------------+--------------+---------------+------+------------
West | 5248 | 1200 | 1 | 1
West | 6880 | 1204 | 2 | 2
West | 5700 | 1214 | 3 | 3
West | 9857 | 1218 | 4 | 4
West | 6014 | 1218 | 4 | 4
West | 9221 | 1220 | 6 | 5
West | 7646 | 1222 | 7 | 6
West | 6621 | 1222 | 7 | 6
West | 6488 | 1224 | 9 | 7
West | 7659 | 1226 | 10 | 8
West | 7432 | 1226 | 10 | 8
West | 9905 | 1226 | 10 | 8
West | 9021 | 1228 | 13 | 9
West | 7855 | 1228 | 13 | 9
West | 7119 | 1230 | 15 | 10
...
If the named window omits an order clause, the query's OVER clauses can specify their own order clauses. For example, you can modify the previous query so each function uses a different order clause. The named window is defined so it includes only a partition clause:
=> SELECT employee_region region, employee_key, annual_salary,
RANK() OVER (w ORDER BY annual_salary DESC) Rank,
DENSE_RANK() OVER (w ORDER BY annual_salary ASC) "Dense Rank"
FROM employee_dimension WINDOW w AS (PARTITION BY employee_region);
region | employee_key | annual_salary | Rank | Dense Rank
----------------------------------+--------------+---------------+------+------------
West | 5248 | 1200 | 2795 | 1
West | 6880 | 1204 | 2794 | 2
West | 5700 | 1214 | 2793 | 3
West | 6014 | 1218 | 2791 | 4
West | 9857 | 1218 | 2791 | 4
West | 9221 | 1220 | 2790 | 5
West | 6621 | 1222 | 2788 | 6
West | 7646 | 1222 | 2788 | 6
West | 6488 | 1224 | 2787 | 7
West | 7432 | 1226 | 2784 | 8
West | 9905 | 1226 | 2784 | 8
West | 7659 | 1226 | 2784 | 8
West | 7855 | 1228 | 2782 | 9
West | 9021 | 1228 | 2782 | 9
West | 7119 | 1230 | 2781 | 10
...
Similarly, an OVER clause specifies a named window can also specify a window frame clause, provided the named window includes an order clause. This can be useful inasmuch as you cannot define a named windows to include a window frame clause.
For example, the following query defines a window that encapsulates partitioning and order clauses. The OVER clause invokes this window and also includes a window frame clause:
=> SELECT deptno, sal, empno, COUNT(*) OVER (w ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS count
FROM emp WINDOW w AS (PARTITION BY deptno ORDER BY sal);
deptno | sal | empno | count
--------+-----+-------+-------
10 | 101 | 1 | 1
10 | 104 | 4 | 2
20 | 100 | 11 | 1
20 | 109 | 8 | 2
20 | 109 | 6 | 3
20 | 109 | 7 | 3
20 | 110 | 10 | 3
20 | 110 | 9 | 3
30 | 102 | 2 | 1
30 | 103 | 3 | 2
30 | 105 | 5 | 3
(11 rows)
Recursive window references
A WINDOW clause can reference another window that is already named. For example, because named window w1 is defined before w2, the WINDOW clause that defines w2 can reference w1:
=> SELECT RANK() OVER(w1 ORDER BY sal DESC), RANK() OVER w2
FROM EMP WINDOW w1 AS (PARTITION BY deptno), w2 AS (w1 ORDER BY sal);
Restrictions
7 - Analytic query examples
The topics in this section show how to use analytic queries for calculations.
The topics in this section show how to use analytic queries for calculations.
7.1 - Calculating a median value
A median is a numerical value that separates the higher half of a sample from the lower half.
A median is a numerical value that separates the higher half of a sample from the lower half. For example, you can retrieve the median of a finite list of numbers by arranging all observations from lowest value to highest value and then picking the middle one.
If the number of observations is even, then there is no single middle value; the median is the mean (average) of the two middle values.
The following example uses this table:
CREATE TABLE allsales(state VARCHAR(20), name VARCHAR(20), sales INT);
INSERT INTO allsales VALUES('MA', 'A', 60);
INSERT INTO allsales VALUES('NY', 'B', 20);
INSERT INTO allsales VALUES('NY', 'C', 15);
INSERT INTO allsales VALUES('MA', 'D', 20);
INSERT INTO allsales VALUES('MA', 'E', 50);
INSERT INTO allsales VALUES('NY', 'F', 40);
INSERT INTO allsales VALUES('MA', 'G', 10);
COMMIT;
You can use the analytic function
MEDIAN to calculate the median of all sales in this table. In the following query, the function's OVER clause is empty, so the query returns the same aggregated value for each row of the result set:
=> SELECT name, sales, MEDIAN(sales) OVER() AS median FROM allsales;
name | sales | median
------+-------+--------
G | 10 | 20
C | 15 | 20
D | 20 | 20
B | 20 | 20
F | 40 | 20
E | 50 | 20
A | 60 | 20
(7 rows)
You can modify this query to group sales by state and obtain the median for each one. To do so, include a window partition clause in the OVER clause:
=> SELECT state, name, sales, MEDIAN(sales) OVER(partition by state) AS median FROM allsales;
state | name | sales | median
-------+------+-------+--------
MA | G | 10 | 35
MA | D | 20 | 35
MA | E | 50 | 35
MA | A | 60 | 35
NY | C | 15 | 20
NY | B | 20 | 20
NY | F | 40 | 20
(7 rows)
7.2 - Getting price differential for two stocks
The following subquery selects out two stocks of interest.
The following subquery selects out two stocks of interest. The outer query uses the LAST_VALUE() and OVER() components of analytics, with IGNORE NULLS.
Schema
DROP TABLE Ticks CASCADE;
CREATE TABLE Ticks (ts TIMESTAMP, Stock varchar(10), Bid float);
INSERT INTO Ticks VALUES('2011-07-12 10:23:54', 'abc', 10.12);
INSERT INTO Ticks VALUES('2011-07-12 10:23:58', 'abc', 10.34);
INSERT INTO Ticks VALUES('2011-07-12 10:23:59', 'abc', 10.75);
INSERT INTO Ticks VALUES('2011-07-12 10:25:15', 'abc', 11.98);
INSERT INTO Ticks VALUES('2011-07-12 10:25:16', 'abc');
INSERT INTO Ticks VALUES('2011-07-12 10:25:22', 'xyz', 45.16);
INSERT INTO Ticks VALUES('2011-07-12 10:25:27', 'xyz', 49.33);
INSERT INTO Ticks VALUES('2011-07-12 10:31:12', 'xyz', 65.25);
INSERT INTO Ticks VALUES('2011-07-12 10:31:15', 'xyz');
COMMIT;
Ticks table
=> SELECT * FROM ticks;
ts | stock | bid
---------------------+-------+-------
2011-07-12 10:23:59 | abc | 10.75
2011-07-12 10:25:22 | xyz | 45.16
2011-07-12 10:23:58 | abc | 10.34
2011-07-12 10:25:27 | xyz | 49.33
2011-07-12 10:23:54 | abc | 10.12
2011-07-12 10:31:15 | xyz |
2011-07-12 10:25:15 | abc | 11.98
2011-07-12 10:25:16 | abc |
2011-07-12 10:31:12 | xyz | 65.25
(9 rows)
Query
=> SELECT ts, stock, bid, last_value(price1 IGNORE NULLS)
OVER(ORDER BY ts) - last_value(price2 IGNORE NULLS)
OVER(ORDER BY ts) as price_diff
FROM
(SELECT ts, stock, bid,
CASE WHEN stock = 'abc' THEN bid ELSE NULL END AS price1,
CASE WHEN stock = 'xyz' then bid ELSE NULL END AS price2
FROM ticks
WHERE stock IN ('abc','xyz')
) v1
ORDER BY ts;
ts | stock | bid | price_diff
---------------------+-------+-------+------------
2011-07-12 10:23:54 | abc | 10.12 |
2011-07-12 10:23:58 | abc | 10.34 |
2011-07-12 10:23:59 | abc | 10.75 |
2011-07-12 10:25:15 | abc | 11.98 |
2011-07-12 10:25:16 | abc | |
2011-07-12 10:25:22 | xyz | 45.16 | -33.18
2011-07-12 10:25:27 | xyz | 49.33 | -37.35
2011-07-12 10:31:12 | xyz | 65.25 | -53.27
2011-07-12 10:31:15 | xyz | | -53.27
(9 rows)
7.3 - Calculating the moving average
Calculating the moving average is useful to get an estimate about the trends in a data set.
Calculating the moving average is useful to get an estimate about the trends in a data set. The moving average is the average of any subset of numbers over a period of time. For example, if you have retail data that spans over ten years, you could calculate a three year moving average, a four year moving average, and so on. This example calculates a 40-second moving average of bids for one stock. This examples uses the
ticks table schema.
Query
=> SELECT ts, bid, AVG(bid)
OVER(ORDER BY ts
RANGE BETWEEN INTERVAL '40 seconds'
PRECEDING AND CURRENT ROW)
FROM ticks
WHERE stock = 'abc'
GROUP BY bid, ts
ORDER BY ts;
ts | bid | ?column?
---------------------+-------+------------------
2011-07-12 10:23:54 | 10.12 | 10.12
2011-07-12 10:23:58 | 10.34 | 10.23
2011-07-12 10:23:59 | 10.75 | 10.4033333333333
2011-07-12 10:25:15 | 11.98 | 11.98
2011-07-12 10:25:16 | | 11.98
(5 rows)
DROP TABLE Ticks CASCADE;
CREATE TABLE Ticks (ts TIMESTAMP, Stock varchar(10), Bid float);
INSERT INTO Ticks VALUES('2011-07-12 10:23:54', 'abc', 10.12);
INSERT INTO Ticks VALUES('2011-07-12 10:23:58', 'abc', 10.34);
INSERT INTO Ticks VALUES('2011-07-12 10:23:59', 'abc', 10.75);
INSERT INTO Ticks VALUES('2011-07-12 10:25:15', 'abc', 11.98);
INSERT INTO Ticks VALUES('2011-07-12 10:25:16', 'abc');
INSERT INTO Ticks VALUES('2011-07-12 10:25:22', 'xyz', 45.16);
INSERT INTO Ticks VALUES('2011-07-12 10:25:27', 'xyz', 49.33);
INSERT INTO Ticks VALUES('2011-07-12 10:31:12', 'xyz', 65.25);
INSERT INTO Ticks VALUES('2011-07-12 10:31:15', 'xyz');
COMMIT;
7.4 - Getting latest bid and ask results
The following query fills in missing NULL values to create a full book order showing latest bid and ask price and size, by vendor id.
The following query fills in missing NULL values to create a full book order showing latest bid and ask price and size, by vendor id. Original rows have values for (typically) one price and one size, so use last_value with "ignore nulls" to find the most recent non-null value for the other pair each time there is an entry for the ID. Sequenceno provides a unique total ordering.
Schema:
=> CREATE TABLE bookorders(
vendorid VARCHAR(100),
date TIMESTAMP,
sequenceno INT,
askprice FLOAT,
asksize INT,
bidprice FLOAT,
bidsize INT);
=> INSERT INTO bookorders VALUES('3325XPK','2011-07-12 10:23:54', 1, 10.12, 55, 10.23, 59);
=> INSERT INTO bookorders VALUES('3345XPZ','2011-07-12 10:23:55', 2, 10.55, 58, 10.75, 57);
=> INSERT INTO bookorders VALUES('445XPKF','2011-07-12 10:23:56', 3, 10.22, 43, 54);
=> INSERT INTO bookorders VALUES('445XPKF','2011-07-12 10:23:57', 3, 10.22, 59, 10.25, 61);
=> INSERT INTO bookorders VALUES('3425XPY','2011-07-12 10:23:58', 4, 11.87, 66, 11.90, 66);
=> INSERT INTO bookorders VALUES('3727XVK','2011-07-12 10:23:59', 5, 11.66, 51, 11.67, 62);
=> INSERT INTO bookorders VALUES('5325XYZ','2011-07-12 10:24:01', 6, 15.05, 44, 15.10, 59);
=> INSERT INTO bookorders VALUES('3675XVS','2011-07-12 10:24:05', 7, 15.43, 47, 58);
=> INSERT INTO bookorders VALUES('8972VUG','2011-07-12 10:25:15', 8, 14.95, 52, 15.11, 57);
COMMIT;
Query:
=> SELECT
sequenceno Seq,
date "Time",
vendorid ID,
LAST_VALUE (bidprice IGNORE NULLS)
OVER (PARTITION BY vendorid ORDER BY sequenceno
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS "Bid Price",
LAST_VALUE (bidsize IGNORE NULLS)
OVER (PARTITION BY vendorid ORDER BY sequenceno
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS "Bid Size",
LAST_VALUE (askprice IGNORE NULLS)
OVER (PARTITION BY vendorid ORDER BY sequenceno
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS "Ask Price",
LAST_VALUE (asksize IGNORE NULLS)
OVER (PARTITION BY vendorid order by sequenceno
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW )
AS "Ask Size"
FROM bookorders
ORDER BY sequenceno;
Seq | Time | ID | Bid Price | Bid Size | Ask Price | Ask Size
-----+---------------------+---------+-----------+----------+-----------+----------
1 | 2011-07-12 10:23:54 | 3325XPK | 10.23 | 59 | 10.12 | 55
2 | 2011-07-12 10:23:55 | 3345XPZ | 10.75 | 57 | 10.55 | 58
3 | 2011-07-12 10:23:57 | 445XPKF | 10.25 | 61 | 10.22 | 59
3 | 2011-07-12 10:23:56 | 445XPKF | 54 | | 10.22 | 43
4 | 2011-07-12 10:23:58 | 3425XPY | 11.9 | 66 | 11.87 | 66
5 | 2011-07-12 10:23:59 | 3727XVK | 11.67 | 62 | 11.66 | 51
6 | 2011-07-12 10:24:01 | 5325XYZ | 15.1 | 59 | 15.05 | 44
7 | 2011-07-12 10:24:05 | 3675XVS | 58 | | 15.43 | 47
8 | 2011-07-12 10:25:15 | 8972VUG | 15.11 | 57 | 14.95 | 52
(9 rows)
8 - Event-based windows
Add index entries.
Event-based windows let you break time series data into windows that border on significant events within the data. This is especially relevant in financial data where analysis often focuses on specific events as triggers to other activity.
Vertica provides two event-based window functions that are not part of the SQL-99 standard:
-
CONDITIONAL_CHANGE_EVENT assigns an event window number to each row, starting from 0, and increments by 1 when the result of evaluating the argument expression on the current row differs from that on the previous row. This function is similar to the analytic function
ROW_NUMBER, which assigns a unique number, sequentially, starting from 1, to each row within a partition.
-
CONDITIONAL_TRUE_EVENT assigns an event window number to each row, starting from 0, and increments the number by 1 when the result of the boolean argument expression evaluates true.
Both functions are described in greater detail below.
Note
CONDITIONAL_CHANGE_EVENT and
CONDITIONAL_TRUE_EVENT do not support
window framing.
Example schema
The examples on this page use the following schema:
CREATE TABLE TickStore3 (ts TIMESTAMP, symbol VARCHAR(8), bid FLOAT);
CREATE PROJECTION TickStore3_p (ts, symbol, bid) AS SELECT * FROM TickStore3 ORDER BY ts, symbol, bid UNSEGMENTED ALL NODES;
INSERT INTO TickStore3 VALUES ('2009-01-01 03:00:00', 'XYZ', 10.0);
INSERT INTO TickStore3 VALUES ('2009-01-01 03:00:03', 'XYZ', 11.0);
INSERT INTO TickStore3 VALUES ('2009-01-01 03:00:06', 'XYZ', 10.5);
INSERT INTO TickStore3 VALUES ('2009-01-01 03:00:09', 'XYZ', 11.0);
COMMIT;
Using CONDITIONAL_CHANGE_EVENT
The analytical function CONDITIONAL_CHANGE_EVENT returns a sequence of integers indicating event window numbers, starting from 0. The function increments the event window number when the result of evaluating the function expression on the current row differs from the previous value.
In the following example, the first query returns all records from the TickStore3 table. The second query uses the CONDITIONAL_CHANGE_EVENT function on the bid column. Since each bid row value is different from the previous value, the function increments the window ID from 0 to 3:
SELECT ts, symbol, bidFROM Tickstore3 ORDER BY ts; |
|
SELECT CONDITIONAL_CHANGE_EVENT(bid)
OVER(ORDER BY ts) FROM Tickstore3;
|
ts | symbol | bid
---------------------+--------+------
2009-01-01 03:00:00 | XYZ | 10
2009-01-01 03:00:03 | XYZ | 11
2009-01-01 03:00:06 | XYZ | 10.5
2009-01-01 03:00:09 | XYZ | 11
(4 rows)
|
==> |
ts | symbol | bid | cce
---------------------+--------+------+-----
2009-01-01 03:00:00 | XYZ | 10 | 0
2009-01-01 03:00:03 | XYZ | 11 | 1
2009-01-01 03:00:06 | XYZ | 10.5 | 2
2009-01-01 03:00:09 | XYZ | 11 | 3
(4 rows)
|
The following figure is a graphical illustration of the change in the bid price. Each value is different from its previous one, so the window ID increments for each time slice:
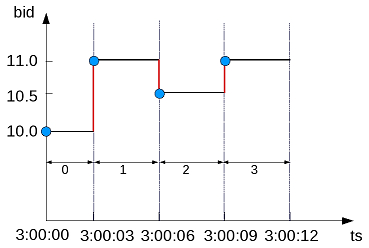
So the window ID starts at 0 and increments at every change in from the previous value.
In this example, the bid price changes from $10 to $11 in the second row, but then stays the same. CONDITIONAL_CHANGE_EVENT increments the event window ID in row 2, but not subsequently:
SELECT ts, symbol, bidFROM Tickstore3 ORDER BY ts; |
|
SELECT CONDITIONAL_CHANGE_EVENT(bid)
OVER(ORDER BY ts) FROM Tickstore3;
|
ts | symbol | bid
---------------------+--------+------
2009-01-01 03:00:00 | XYZ | 10
2009-01-01 03:00:03 | XYZ | 11
2009-01-01 03:00:06 | XYZ | 11
2009-01-01 03:00:09 | XYZ | 11
|
==> |
ts | symbol | bid | cce
---------------------+--------+------+-----
2009-01-01 03:00:00 | XYZ | 10 | 0
2009-01-01 03:00:03 | XYZ | 11 | 1
2009-01-01 03:00:06 | XYZ | 11 | 1
2009-01-01 03:00:09 | XYZ | 11 | 1
|
The following figure is a graphical illustration of the change in the bid price at 3:00:03 only. The price stays the same at 3:00:06 and 3:00:09, so the window ID remains at 1 for each time slice after the change:

Using CONDITIONAL_TRUE_EVENT
Like CONDITIONAL_CHANGE_EVENT, the analytic function CONDITIONAL_TRUE_EVENT also returns a sequence of integers indicating event window numbers, starting from 0. The two functions differ as follows:
In the following example, the first query returns all records from the TickStore3 table. The second query uses CONDITIONAL_TRUE_EVENT to test whether the current bid is greater than a given value (10.6). Each time the expression tests true, the function increments the window ID. The first time the function increments the window ID is on row 2, when the value is 11. The expression tests false for the next row (value is not greater than 10.6), so the function does not increment the event window ID. In the final row, the expression is true for the given condition, and the function increments the window:
SELECT ts, symbol, bidFROM Tickstore3 ORDER BY ts; |
|
SELECT CONDITIONAL_TRUE_EVENT(bid > 10.6)
OVER(ORDER BY ts) FROM Tickstore3;
|
ts | symbol | bid
---------------------+--------+------
2009-01-01 03:00:00 | XYZ | 10
2009-01-01 03:00:03 | XYZ | 11
2009-01-01 03:00:06 | XYZ | 10.5
2009-01-01 03:00:09 | XYZ | 11
|
==> |
ts | symbol | bid | cte---------------------+--------+------+-----
2009-01-01 03:00:00 | XYZ | 10 | 0
2009-01-01 03:00:03 | XYZ | 11 | 1
2009-01-01 03:00:06 | XYZ | 10.5 | 1
2009-01-01 03:00:09 | XYZ | 11 | 2
|
The following figure is a graphical illustration that shows the bid values and window ID changes. Because the bid value is greater than $10.6 on only the second and fourth time slices (3:00:03 and 3:00:09), the window ID returns <0,1,1,2>:
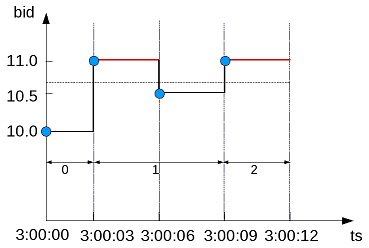
In the following example, the first query returns all records from the TickStore3 table, ordered by the tickstore values (ts). The second query uses CONDITIONAL_TRUE_EVENT to increment the window ID each time the bid value is greater than 10.6. The first time the function increments the event window ID is on row 2, where the value is 11. The window ID then increments each time after that, because the expression (bid > 10.6) tests true for each time slice:
SELECT ts, symbol, bidFROM Tickstore3 ORDER BY ts; |
|
SELECT CONDITIONAL_TRUE_EVENT(bid > 10.6)
OVER(ORDER BY ts) FROM Tickstore3;
|
ts | symbol | bid
---------------------+--------+------
2009-01-01 03:00:00 | XYZ | 10
2009-01-01 03:00:03 | XYZ | 11
2009-01-01 03:00:06 | XYZ | 11
2009-01-01 03:00:09 | XYZ | 11
|
==> |
ts | symbol | bid | cte
---------------------+--------+------+-----
2009-01-01 03:00:00 | XYZ | 10 | 0
2009-01-01 03:00:03 | XYZ | 11 | 1
2009-01-01 03:00:06 | XYZ | 11 | 2
2009-01-01 03:00:09 | XYZ | 11 | 3
|
The following figure is a graphical illustration that shows the bid values and window ID changes. The bid value is greater than 10.6 on the second time slice (3:00:03) and remains for the remaining two time slices. The function increments the event window ID each time because the expression tests true:
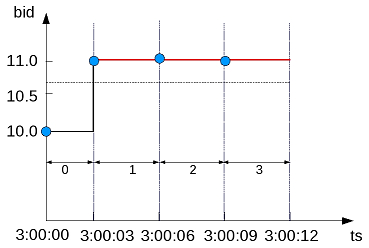
Advanced use of event-based windows
In event-based window functions, the condition expression accesses values from the current row only. To access a previous value, you can use a more powerful event-based window that allows the window event condition to include previous data points. For example, analytic function LAG(x, n) retrieves the value of column x in the nth to last input record. In this case, LAG shares the OVER specifications of the CONDITIONAL_CHANGE_EVENT or CONDITIONAL_TRUE_EVENT function expression.
In the following example, the first query returns all records from the TickStore3 table. The second query uses CONDITIONAL_TRUE_EVENT with the LAG function in its boolean expression. In this case, CONDITIONAL_TRUE_EVENT increments the event window ID each time the bid value on the current row is less than the previous value. The first time CONDITIONAL_TRUE_EVENT increments the window ID starts on the third time slice, when the expression tests true. The current value (10.5) is less than the previous value. The window ID is not incremented in the last row because the final value is greater than the previous row:
SELECT ts, symbol, bidFROM Tickstore3 ORDER BY ts; |
SELECT CONDITIONAL_TRUE_EVENT(bid < LAG(bid))
OVER(ORDER BY ts) FROM Tickstore;
|
ts | symbol | bid
---------------------+--------+------
2009-01-01 03:00:00 | XYZ | 10
2009-01-01 03:00:03 | XYZ | 11
2009-01-01 03:00:06 | XYZ | 10.5
2009-01-01 03:00:09 | XYZ | 11
|
ts | symbol | bid | cte
---------------------+--------+------+-----
2009-01-01 03:00:00 | XYZ | 10 | 0
2009-01-01 03:00:03 | XYZ | 11 | 0
2009-01-01 03:00:06 | XYZ | 10.5 | 1
2009-01-01 03:00:09 | XYZ | 11 | 1
|
The following figure illustrates the second query above. When the bid price is less than the previous value, the window ID gets incremented, which occurs only in the third time slice (3:00:06):
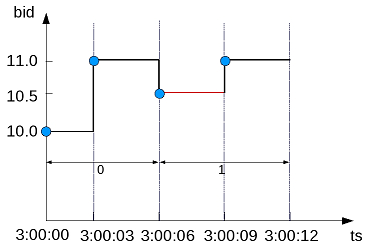
See also
9 - Sessionization with event-based windows
Sessionization, a special case of event-based windows, is a feature often used to analyze click streams, such as identifying web browsing sessions from recorded web clicks.
Sessionization, a special case of event-based windows, is a feature often used to analyze click streams, such as identifying web browsing sessions from recorded web clicks.
In Vertica, given an input clickstream table, where each row records a Web page click made by a particular user (or IP address), the sessionization computation attempts to identify Web browsing sessions from the recorded clicks by grouping the clicks from each user based on the time-intervals between the clicks. If two clicks from the same user are made too far apart in time, as defined by a time-out threshold, the clicks are treated as though they are from two different browsing sessions.
Example Schema
The examples in this topic use the following WebClicks schema to represent a simple clickstream table:
CREATE TABLE WebClicks(userId INT, timestamp TIMESTAMP);
INSERT INTO WebClicks VALUES (1, '2009-12-08 3:00:00 pm');
INSERT INTO WebClicks VALUES (1, '2009-12-08 3:00:25 pm');
INSERT INTO WebClicks VALUES (1, '2009-12-08 3:00:45 pm');
INSERT INTO WebClicks VALUES (1, '2009-12-08 3:01:45 pm');
INSERT INTO WebClicks VALUES (2, '2009-12-08 3:02:45 pm');
INSERT INTO WebClicks VALUES (2, '2009-12-08 3:02:55 pm');
INSERT INTO WebClicks VALUES (2, '2009-12-08 3:03:55 pm');
COMMIT;
The input table WebClicks contains the following rows:
=> SELECT * FROM WebClicks;
userId | timestamp
--------+---------------------
1 | 2009-12-08 15:00:00
1 | 2009-12-08 15:00:25
1 | 2009-12-08 15:00:45
1 | 2009-12-08 15:01:45
2 | 2009-12-08 15:02:45
2 | 2009-12-08 15:02:55
2 | 2009-12-08 15:03:55
(7 rows)
In the following query, sessionization performs computation on the SELECT list columns, showing the difference between the current and previous timestamp value using LAG(). It evaluates to true and increments the window ID when the difference is greater than 30 seconds.
=> SELECT userId, timestamp,
CONDITIONAL_TRUE_EVENT(timestamp - LAG(timestamp) > '30 seconds')
OVER(PARTITION BY userId ORDER BY timestamp) AS session FROM WebClicks;
userId | timestamp | session
--------+---------------------+---------
1 | 2009-12-08 15:00:00 | 0
1 | 2009-12-08 15:00:25 | 0
1 | 2009-12-08 15:00:45 | 0
1 | 2009-12-08 15:01:45 | 1
2 | 2009-12-08 15:02:45 | 0
2 | 2009-12-08 15:02:55 | 0
2 | 2009-12-08 15:03:55 | 1
(7 rows)
In the output, the session column contains the window ID from the CONDITIONAL_TRUE_EVENT function. The window ID evaluates to true on row 4 (timestamp 15:01:45), and the ID that follows row 4 is zero because it is the start of a new partition (for user ID 2), and that row does not evaluate to true until the last line in the output.
You might want to give users different time-out thresholds. For example, one user might have a slower network connection or be multi-tasking, while another user might have a faster connection and be focused on a single Web site, doing a single task.
To compute an adaptive time-out threshold based on the last 2 clicks, use CONDITIONAL_TRUE_EVENT with LAG to return the average time between the last 2 clicks with a grace period of 3 seconds:
=> SELECT userId, timestamp, CONDITIONAL_TRUE_EVENT(timestamp - LAG(timestamp) >
(LAG(timestamp, 1) - LAG(timestamp, 3)) / 2 + '3 seconds')
OVER(PARTITION BY userId ORDER BY timestamp) AS session
FROM WebClicks;
userId | timestamp | session
--------+---------------------+---------
2 | 2009-12-08 15:02:45 | 0
2 | 2009-12-08 15:02:55 | 0
2 | 2009-12-08 15:03:55 | 0
1 | 2009-12-08 15:00:00 | 0
1 | 2009-12-08 15:00:25 | 0
1 | 2009-12-08 15:00:45 | 0
1 | 2009-12-08 15:01:45 | 1
(7 rows)
Note
You cannot define a moving window in time series data. For example, if the query is evaluating the first row and there’s no data, it will be the current row. If you have a lag of 2, no results are returned until the third row.
See also





