This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Using external models with Vertica
To give you the utmost in machine learning flexibility and scalability, Vertica supports importing, exporting, and predicting with PMML and TensorFlow models.
To give you the utmost in machine learning flexibility and scalability, Vertica supports importing, exporting, and predicting with PMML and TensorFlow models.
The machine learning configuration parameter MaxModelSizeKB sets the maximum size of a model that can be imported into Vertica.
Support for PMML models
Vertica supports the import and export of machine learning models in Predictive Model Markup Language (PMML) format. Support for this platform-independent model format allows you to use models trained on other platforms to predict on data stored in your Vertica database. You can also use Vertica as your model repository. Vertica supports PMML version 4.4.1.
With the PREDICT_PMML function, you can use a PMML model archived in Vertica to run prediction on data stored in the Vertica database. For more information, see Using PMML models.
For details on the PMML models, tags, and attributes that Vertica supports, see PMML features and attributes.
Support for TensorFlow models
Vertica now supports importing trained TensorFlow models, and using those models to do prediction in Vertica on data stored in the Vertica database. Vertica supports TensorFlow models trained in TensorFlow version 1.15.
The PREDICT_TENSORFLOW and PREDICT_TENSORFLOW_SCALAR functions let you predict on data in Vertica with TensorFlow models.
For additional information, see TensorFlow models.
Additional external model support
The following functions support both PMML and TensorFlow models:
1 - TensorFlow models
Tensorflow is a framework for creating neural networks.
Tensorflow is a framework for creating neural networks. It implements basic linear algebra and multi-variable calculus operations in a scalable fashion, and allows users to easily chain these operations into a computation graph.
Vertica supports importing, exporting, and making predictions with TensorFlow 1.x and 2.x models trained outside of Vertica.
In-database TensorFlow integration with Vertica offers several advantages:
-
Your models live inside your database, so you never have to move your data to make predictions.
-
The volume of data you can handle is limited only by the size of your Vertica database, which makes Vertica particularly well-suited for machine learning on Big Data.
-
Vertica offers in-database model management, so you can store as many models as you want.
-
Imported models are portable and can be exported for use elsewhere.
When you run a TensorFlow model to predict on data in the database, Vertica calls a TensorFlow process to run the model. This allows Vertica to support any model you can create and train using TensorFlow. Vertica just provides the inputs - your data in the Vertica database - and stores the outputs.
1.1 - TensorFlow integration and directory structure
This page covers importing Tensorflow models into Vertica, making predictions on data in the Vertica database, and exporting the model for use on another Vertica cluster or a third-party platform.
This page covers importing Tensorflow models into Vertica, making predictions on data in the Vertica database, and exporting the model for use on another Vertica cluster or a third-party platform.
For a start-to-finish example through each operation, see TensorFlow example.
Vertica supports models created with either TensorFlow 1.x and 2.x, but 2.x is strongly recommended.
To use TensorFlow with Vertica, install the TFIntegration UDX package on any node. You only need to do this once:
$ /opt/vertica/bin/admintools -t install_package -d database_name -p 'password' --package TFIntegration
Directory and file structure for TensorFlow models
Before importing your models, you should have a separate directory for each model that contains each of the following files. Note that Vertica uses the directory name as the model name when you import it:
For example, a tf_models directory that contains two models, tf_mnist_estimator and tf_mnist_keras, has the following layout:
tf_models/
├── tf_mnist_estimator
│ ├── mnist_estimator.pb
│ └── tf_model_desc.json
└── tf_mnist_keras
├── mnist_keras.pb
└── tf_model_desc.json
You can generate both of these files for a given TensorFlow 2 (TF2) model with the freeze_tf2_model.py script included in the Machine-Learning-Examples GitHub repository and in the opt/vertica/packages/TFIntegration/examples directory in the Vertica database. The script accepts three arguments:
model-path- Path to a saved TF2 model directory.
folder-name- (Optional) Name of the folder to which the frozen model is saved; by default,
frozen_tfmodel.
column-type- (Optional) Integer, either 0 or 1, that signifies whether the input and output columns for the model are primitive or complex types. Use a value of 0 (default) for primitive types, or 1 for complex.
For example, the following call outputs the frozen tf_autoencoder model, which accepts complex input/output columns, into the frozen_autoencoder folder:
$ python3 ./freeze_tf2_model.py path/to/tf_autoencoder frozen_autoencoder 1
tf_model_desc.json
The tf_model_desc.json file forms the bridge between TensorFlow and Vertica. It describes the structure of the model so that Vertica can correctly match up its inputs and outputs to input/output tables.
Notice that the freeze_tf2_model.py script automatically generates this file for your TensorFlow 2 model, and this generated file can often be used as-is. For more complex models or use cases, you might have to edit this file. For a detailed breakdown of each field, see tf_model_desc.json overview.
Importing TensorFlow models into Vertica
To import TensorFlow models, use IMPORT_MODELS with the category 'TENSORFLOW'.
Import a single model. Keep in mind that the Vertica database uses the directory name as the model name:
select IMPORT_MODELS ( '/path/tf_models/tf_mnist_keras' USING PARAMETERS category='TENSORFLOW');
import_models
---------------
Success
(1 row)
Import all models in the directory (where each model has its own directory) with a wildcard (*):
select IMPORT_MODELS ('/path/tf_models/*' USING PARAMETERS category='TENSORFLOW');
import_models
---------------
Success
(1 row)
Make predictions with an imported TensorFlow model
After importing your TensorFlow model, you can use the model to predict on data in a Vertica table. Vertica provides two functions for making predictions with imported TensorFlow models: PREDICT_TENSORFLOW and PREDICT_TENSORFLOW_SCALAR.
The function you choose depends on whether you specified a column-type of 0 or 1 when calling the freeze_tf2_model.py script. If column-type was 0, meaning the model accepts primitive input and output types, use PREDICT_TENSORFLOW to make predictions; otherwise, use PREDICT_TENSORFLOW_SCALAR, as your model should accept complex input and output types.
Using PREDICT_TENSORFLOW
The PREDICT_TENSORFLOW function is different from the other predict functions in that it does not accept any parameters that affect the input columns such as "exclude_columns" or "id_column"; rather, the function always predicts on all the input columns provided. However, it does accept a num_passthru_cols parameter which allows the user to "skip" some number of input columns, as shown below.
The OVER(PARTITION BEST) clause tells Vertica to parallelize the operation across multiple nodes. See Window partition clause for details:
=> select PREDICT_TENSORFLOW (*
USING PARAMETERS model_name='tf_mnist_keras', num_passthru_cols=1)
OVER(PARTITION BEST) FROM tf_mnist_test_images;
--example output, the skipped columns are displayed as the first columns of the output
ID | col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9
----+------+------+------+------+------+------+------+------+------+------
1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
6 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0
...
Using PREDICT_TENSORFLOW_SCALAR
The PREDICT_TENSORFLOW_SCALAR function accepts one input column of type ROW, where each field corresponds to an input tensor. It returns one output column of type ROW, where each field corresponds to an output tensor. This complex type support can simplify the process for making predictions on data with many input features.
For instance, the MNIST handwritten digit classification dataset contains 784 input features for each input row, one feature for each pixel in the images of handwritten digits. The PREDICT_TENSORFLOW function requires that each of these input features are contained in a separate input column. By encapsulating these features into a single ARRAY, the PREDICT_TENSORFLOW_SCALAR function only needs a single input column of type ROW, where the pixel values are the array elements for an input field:
--Each array for the "image" field has 784 elements.
=> SELECT * FROM mnist_train;
id | inputs
---+---------------------------------------------
1 | {"image":[0, 0, 0,..., 244, 222, 210,...]}
2 | {"image":[0, 0, 0,..., 185, 84, 223,...]}
3 | {"image":[0, 0, 0,..., 133, 254, 78,...]}
...
In this case, the function output consists of a single opeartion with one tensor. The value of this field is an array of ten elements, which are all zero except for the element whose index is the predicted digit:
=> SELECT id, PREDICT_TENSORFLOW_SCALAR(inputs USING PARAMETERS model_name='tf_mnist_ct') FROM mnist_test;
id | PREDICT_TENSORFLOW_SCALAR
----+-------------------------------------------------------------------
1 | {"prediction:0":["0", "0", "0", "0", "1", "0", "0", "0", "0", "0"]}
2 | {"prediction:0":["0", "1", "0", "0", "0", "0", "0", "0", "0", "0"]}
3 | {"prediction:0":["0", "0", "0", "0", "0", "0", "0", "1", "0", "0"]}
...
Exporting TensorFlow models
Vertica exports the model as a frozen graph, which can then be re-imported at any time. Keep in mind that models that are saved as a frozen graph cannot be trained further.
Use EXPORT_MODELS to export TensorFlow models. For example, to export the tf_mnist_keras model to the /path/to/export/to directory:
=> SELECT EXPORT_MODELS ('/path/to/export/to', 'tf_mnist_keras');
export_models
---------------
Success
(1 row)
When you export a TensorFlow model, the Vertica database creates and uses the specified directory to store files that describe the model:
$ ls tf_mnist_keras/
crc.json metadata.json mnist_keras.pb model.json tf_model_desc.json
The .pb and tf_model_desc.json files describe the model, and the rest are organizational files created by the Vertica database.
|
File Name |
Purpose |
model_name.pb |
Frozen graph of the model. |
tf_model_desc.json |
Describes the model. |
crc.json |
Keeps track of files in this directory and their sizes. It is used for importing models. |
metadata.json |
Contains Vertica version, model type, and other information. |
model.json |
More verbose version of tf_model_desc.json. |
See also
1.2 - TensorFlow example
Vertica uses the TFIntegration UDX package to integrate with TensorFlow.
Vertica uses the TFIntegration UDX package to integrate with TensorFlow. You can train your models outside of your Vertica database, then import them to Vertica and make predictions on your data.
TensorFlow scripts and datasets are included in the GitHub repository under Machine-Learning-Examples/TensorFlow.
The example below creates a Keras (a TensorFlow API) neural network model trained on the MNIST handwritten digit classification dataset, the layers of which are shown below.
The data is fed through each layer from top to bottom, and each layer modifies the input before returning a score. In this example, the data passed in is a set of images of handwritten Arabic numerals and the output would be the probability of the input image being a particular digit:
inputs = keras.Input(shape=(28, 28, 1), name="image")
x = layers.Conv2D(32, 5, activation="relu")(inputs)
x = layers.MaxPooling2D(2)(x)
x = layers.Conv2D(64, 5, activation="relu")(x)
x = layers.MaxPooling2D(2)(x)
x = layers.Flatten()(x)
x = layers.Dense(10, activation='softmax', name='OUTPUT')(x)
tfmodel = keras.Model(inputs, x)
For more information on how TensorFlow interacts with your Vertica database and how to import more complex models, see TensorFlow integration and directory structure.
Prepare a TensorFlow model for Vertica
The following procedures take place outside of Vertica.
Train and save a TensorFlow model
-
Install TensorFlow 2.
-
Train your model. For this particular example, you can run train_simple_model.py to train and save the model. Otherwise, and more generally, you can manually train your model in Python and then save it:
$ mymodel.save('my_saved_model_dir')
-
Run the freeze_tf2_model.py script included in the Machine-Learning-Examples repository or in opt/vertica/packages/TFIntegration/examples, specifying your model, an output directory (optional, defaults to frozen_tfmodel), and the input and output column type (0 for primitive, 1 for complex).
This script transforms your saved model into the Vertica-compatible frozen graph format and creates the tf_model_desc.json file, which describes how Vertica should translate its tables to TensorFlow tensors:
$ ./freeze_tf2_model.py path/to/tf/model frozen_model_dir 0
Import TensorFlow models and make predictions in Vertica
-
If you haven't already, as dbadmin, install the TFIntegration UDX package on any node. You only need to do this once.
$ /opt/vertica/bin/admintools -t install_package -d database_name -p 'password' --package TFIntegration
-
Copy the the directory to any node in your Vertica cluster and import the model:
=> SELECT IMPORT_MODELS('path/to/frozen_model_dir' USING PARAMETERS category='TENSORFLOW');
-
Import the dataset you want to make a prediction on. For this example:
-
Copy the Machine-Learning-Examples/TensorFlow/data directory to any node on your Vertica cluster.
-
From that data directory, run the SQL script load_tf_data.sql to load the MNIST dataset:
$ vsql -f load_tf_data.sql
-
Make a prediction with your model on your dataset with PREDICT_TENSORFLOW. In this example, the model is used to classify the images of handwritten numbers in the MNIST dataset:
=> SELECT PREDICT_TENSORFLOW (*
USING PARAMETERS model_name='tf_mnist_keras', num_passthru_cols=1)
OVER(PARTITION BEST) FROM tf_mnist_test_images;
--example output, the skipped columns are displayed as the first columns of the output
ID | col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9
----+------+------+------+------+------+------+------+------+------+------
1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0
3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0
6 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0
...
Note
Because a
column-type of 0 was used when calling the
freeze_tf2_model.py script, the PREDICT_TENSORFLOW function must be used to make predictions. If
column-type was 1, meaning the model accepts complex input and output types, predictions must be made with the
PREDICT_TENSORFLOW_SCALAR function.
-
To export the model with EXPORT_MODELS:
=> SELECT EXPORT_MODELS('/path/to/export/to', 'tf_mnist_keras');
EXPORT_MODELS
---------------
Success
(1 row)
Note
While you cannot continue training a TensorFlow model after you export it from Vertica, you can use it to predict on data in another Vertica cluster, or outside Vertica on another platform.
TensorFlow 1 (deprecated)
-
Install TensorFlow 1.15 with Python 3.7 or below.
-
Run train_save_model.py in Machine-Learning-Examples/TensorFlow/tf1 to train and save the model in TensorFlow and frozen graph formats.
Note
Vertica does not supply a script to save and freeze TensorFlow 1 models that use complex column types.
See also
1.3 - tf_model_desc.json overview
Before importing your externally trained TensorFlow models, you must:.
Before importing your externally trained TensorFlow models, you must:
-
save the model in frozen graph (.pb) format
-
create tf_model_desc.json, which describes to your Vertica database how to map its inputs and outputs to input/output tables
Conveniently, the script freeze_tf2_model.py included in the TensorFlow directory of the Machine-Learning-Examples repository (and in opt/vertica/packages/TFIntegration/examples) will do both of these automatically. In most cases, the generated tf_model_desc.json can be used as-is, but for more complex datasets and use cases, you might need to edit it.
The contents of the tf_model_desc.json file depend on whether you provide a column-type of 0 or 1 when calling the freeze_tf2_model.py script. If column-type is 0, the imported model accepts primitive input and output columns. If it is 1, the model accepts complex input and output columns.
Models that accept primitive types
The following tf_model_desc.json is generated from the MNIST handwriting dataset used by the TensorFlow example.
{
"frozen_graph": "mnist_keras.pb",
"input_desc": [
{
"op_name": "image_input",
"tensor_map": [
{
"idx": 0,
"dim": [
1,
28,
28,
1
],
"col_start": 0
}
]
}
],
"output_desc": [
{
"op_name": "OUTPUT/Softmax",
"tensor_map": [
{
"idx": 0,
"dim": [
1,
10
],
"col_start": 0
}
]
}
]
}
This file describes the structure of the model's inputs and outputs. It must contain a frozen_graph field that matches the filename of the .pb model, an input_desc field, and an output_desc field.
input_desc and output_desc: the descriptions of the input and output nodes in the TensorFlow graph. Each of these include the following fields:
-
op_name: the name of the operation node which is set when creating and training the model. You can typically retrieve the names of these parameters from tfmodel.inputs and tfmodel.outputs. For example:
$ print({t.name:t for t in tfmodel.inputs})
{'image_input:0': <tf.Tensor 'image_input:0' shape=(?, 28, 28, 1) dtype=float32>}
$ print({t.name:t for t in tfmodel.outputs})
{'OUTPUT/Softmax:0': <tf.Tensor 'OUTPUT/Softmax:0' shape=(?, 10) dtype=float32>}
In this case, the respective values for op_name would be the following.
For a more detailed example of this process, review the code for freeze_tf2_model.py.
-
tensor_map: how to map the tensor to Vertica columns, which can be specified with the following:
-
idx: the index of the output tensor under the given operation (should be 0 for the first output, 1 for the second output, etc.).
-
dim: the vector holding the dimensions of the tensor; it provides the number of columns.
-
col_start (only used if col_idx is not specified): the starting column index. When used with dim, it specifies a range of indices of Vertica columns starting at col_start and ending at col_start+flattend_tensor_dimension. Vertica starts at the column specified by the index col_start and gets the next flattened_tensor_dimension columns.
-
col_idx: the indices in the Vertica columns corresponding to the flattened tensors. This allows you explicitly specify the indices of the Vertica columns that couldn't otherwise be specified as a simple range with col_start and dim (e.g. 1, 3, 5, 7).
-
data_type (not shown): the data type of the input or output, one of the following:
-
TF_FLOAT (default)
-
TF_DOUBLE
-
TF_INT8
-
TF_INT16
-
TF_INT32
-
TF_INT64
Below is a more complex example that includes multiple inputs and outputs:
{
"input_desc": [
{
"op_name": "input1",
"tensor_map": [
{
"idx": 0,
"dim": [
4
],
"col_idx": [
0,
1,
2,
3
]
},
{
"idx": 1,
"dim": [
2,
2
],
"col_start": 4
}
]
},
{
"op_name": "input2",
"tensor_map": [
{
"idx": 0,
"dim": [],
"col_idx": [
8
]
},
{
"idx": 1,
"dim": [
2
],
"col_start": 9
}
]
}
],
"output_desc": [
{
"op_name": "output",
"tensor_map": [
{
"idx": 0,
"dim": [
2
],
"col_start": 0
}
]
}
]
}
Models that accept complex types
The following tf_model_desc.json is generated from a model that inputs and outputs complex type columns:
{
"column_type": "complex",
"frozen_graph": "frozen_graph.pb",
"input_tensors": [
{
"name": "x:0",
"data_type": "int32",
"dims": [
-1,
1
]
},
{
"name": "x_1:0",
"data_type": "int32",
"dims": [
-1,
2
]
}
],
"output_tensors": [
{
"name": "Identity:0",
"data_type": "float32",
"dims": [
-1,
1
]
},
{
"name": "Identity_1:0",
"data_type": "float32",
"dims": [
-1,
2
]
}
]
}
As with models that accept primitive types, this file describes the structure of the model's inputs and outputs and contains a frozen_graph field that matches the filename of the .pb model. However, instead of an input_desc field and an output_desc field, models with complex types have an input_tensors field and an output_tensors field, as well as a column_type field.
-
column_type: specifies that the model accepts input and output columns of complex types. When imported into Vertica, the model must make predictions using the PREDICT_TENSORFLOW_SCALAR function.
-
input_tensors and output_tensors: the descriptions of the input and output tensors in the TensorFlow graph. Each of these fields include the following sub-fields:
-
name: the name of the tensor for which information is listed. The name is in the format of operation:tensor-number, where operation is the operation that contains the tensor and tensor-number is the index of the tensor under the given operation.
-
data_type: the data type of the elements in the input or output tensor, one of the following:
-
TF_FLOAT (default)
-
TF_DOUBLE
-
TF_INT8
-
TF_INT16
-
TF_INT32
-
TF_INT64
-
dims: the dimensions of the tensor. Each input/output tensor is contained in a 1D ARRAY in the input/output ROW column.
See also
2 - Using PMML models
Vertica can import, export, and make predictions with PMML models of version 4.4 and below.
Vertica can import, export, and make predictions with PMML models of version 4.4 and below.
2.1 - Exporting Vertica models in PMML format
You can take advantage of the built-in distributed algorithms in Vertica to train machine learning models.
You can take advantage of the built-in distributed algorithms in Vertica to train machine learning models. There might be cases in which you want to use these models for prediction outside Vertica, for example on an edge node. You can export certain Vertica models in PMML format and use them for prediction using a library or platform that supports reading and evaluating PMML models. Vertica supports the export of the following Vertica model types into PMML format: KMEANS, LINEAR_REGRESSION, LOGISTIC_REGRESSION, RF_CLASSIFIER, RF_REGRESSOR, XGB_CLASSIFIER, and XGB_REGRESSOR.
Here is an example for training a model in Vertica and then exporting it in PMML format. The following diagram shows the workflow of the example. We use vsql to run this example.
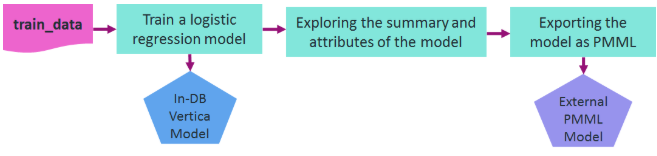
Let's assume that you want to train a logistic regression model on the data in a relation named 'patients' in order to predict the second attack of patients given their treatment and trait anxiety.
After training, the model is shown in a system table named V_CATALOG.MODELS which lists the archived ML models in Vertica.
=> -- Training a logistic regression model on a training_data
=> SELECT logistic_reg('myModel', 'patients', 'second_attack', 'treatment, trait_anxiety');
logistic_reg
---------------------------
Finished in 5 iterations
(1 row)
=> -- Looking at the models table
=> SELECT model_name, schema_name, category, model_type, create_time, size FROM models;
model_name | schema_name | category | model_type | create_time | size
------------+-------------+----------------+---------------------+-------------------------------+------
myModel | public | VERTICA_MODELS | LOGISTIC_REGRESSION | 2020-07-28 00:05:18.441958-04 | 1845
(1 row)
You can look at the summary of the model using the GET_MODEL_SUMMARY function.
=> -- Looking at the summary of the model
=> \t
Showing only tuples.
=> SELECT get_model_summary(USING PARAMETERS model_name='myModel');
=======
details
=======
predictor |coefficient|std_err |z_value |p_value
-------------+-----------+--------+--------+--------
Intercept | -6.36347 | 3.21390|-1.97998| 0.04771
treatment | -1.02411 | 1.17108|-0.87450| 0.38185
trait_anxiety| 0.11904 | 0.05498| 2.16527| 0.03037
==============
regularization
==============
type| lambda
----+--------
none| 1.00000
===========
call_string
===========
logistic_reg('public.myModel', 'patients', '"second_attack"', 'treatment, trait_anxiety'
USING PARAMETERS optimizer='newton', epsilon=1e-06, max_iterations=100, regularization='none', lambda=1, alpha=0.5)
===============
Additional Info
===============
Name |Value
------------------+-----
iteration_count | 5
rejected_row_count| 0
accepted_row_count| 20
You can also retrieve the model's attributes using the GET_MODEL_ATTRIBUTE function.
=> \t
Tuples only is off.
=> -- The list of the attributes of the model
=> SELECT get_model_attribute(USING PARAMETERS model_name='myModel');
attr_name | attr_fields | #_of_rows
--------------------+---------------------------------------------------+-----------
details | predictor, coefficient, std_err, z_value, p_value | 3
regularization | type, lambda | 1
iteration_count | iteration_count | 1
rejected_row_count | rejected_row_count | 1
accepted_row_count | accepted_row_count | 1
call_string | call_string | 1
(6 rows)
=> -- Returning the coefficients of the model in a tabular format
=> SELECT get_model_attribute(USING PARAMETERS model_name='myModel', attr_name='details');
predictor | coefficient | std_err | z_value | p_value
---------------+-------------------+--------------------+--------------------+--------------------
Intercept | -6.36346994178182 | 3.21390452471434 | -1.97998101463435 | 0.0477056620380991
treatment | -1.02410605239327 | 1.1710801464903 | -0.874496980810833 | 0.381847663704613
trait_anxiety | 0.119044916668605 | 0.0549791755747139 | 2.16527285875412 | 0.0303667955962211
(3 rows)
You can use the EXPORT_MODELS function in a simple statement to export the model in PMML format, as shown below.
=> -- Exporting the model as PMML
=> SELECT export_models('/data/username/temp', 'myModel' USING PARAMETERS category='PMML');
export_models
---------------
Success
(1 row)
See also
2.2 - Importing and predicting with PMML models
As a Vertica user, you can train ML models in other platforms, convert them to standard PMML format, and then import them into Vertica for in-database prediction on data stored in Vertica relations.
As a Vertica user, you can train ML models in other platforms, convert them to standard PMML format, and then import them into Vertica for in-database prediction on data stored in Vertica relations.
Here is an example of how to import a PMML model trained in Spark. The following diagram shows the workflow of the example.

You can use the IMPORT_MODELS function in a simple statement to import the PMML model. The imported model then appears in a system table named V_CATALOG.MODELS which lists the archived ML models in Vertica.
=> -- importing the PMML model trained and generated in Spark
=> SELECT import_models('/data/username/temp/spark_logistic_reg' USING PARAMETERS category='PMML');
import_models
---------------
Success
(1 row)
=> -- Looking at the models table=> SELECT model_name, schema_name, category, model_type, create_time, size FROM models;
model_name | schema_name | category | model_type | create_time | size
--------------------+-------------+----------+-----------------------+-------------------------------+------
spark_logistic_reg | public | PMML | PMML_REGRESSION_MODEL | 2020-07-28 00:12:29.389709-04 | 5831
(1 row)
You can look at the summary of the model using GET_MODEL_SUMMARY function.
=> \t
Showing only tuples.
=> SELECT get_model_summary(USING PARAMETERS model_name='spark_logistic_reg');
=============
function_name
=============
classification
===========
data_fields
===========
name |dataType| optype
-------+--------+-----------
field_0| double |continuous
field_1| double |continuous
field_2| double |continuous
field_3| double |continuous
field_4| double |continuous
field_5| double |continuous
field_6| double |continuous
field_7| double |continuous
field_8| double |continuous
target | string |categorical
==========
predictors
==========
name |exponent|coefficient
-------+--------+-----------
field_0| 1 | -0.23318
field_1| 1 | 0.73623
field_2| 1 | 0.29964
field_3| 1 | 0.12809
field_4| 1 | -0.66857
field_5| 1 | 0.51675
field_6| 1 | -0.41026
field_7| 1 | 0.30829
field_8| 1 | -0.17788
===============
Additional Info
===============
Name | Value
-------------+--------
is_supervised| 1
intercept |-1.20173
You can also retrieve the model's attributes using the GET_MODEL_ATTRIBUTE function.
=> \t
Tuples only is off.
=> -- The list of the attributes of the PMML model
=> SELECT get_model_attribute(USING PARAMETERS model_name='spark_logistic_reg');
attr_name | attr_fields | #_of_rows
---------------+-----------------------------+-----------
is_supervised | is_supervised | 1
function_name | function_name | 1
data_fields | name, dataType, optype | 10
intercept | intercept | 1
predictors | name, exponent, coefficient | 9
(5 rows)
=> -- The coefficients of the PMML model
=> SELECT get_model_attribute(USING PARAMETERS model_name='spark_logistic_reg', attr_name='predictors');
name | exponent | coefficient
---------+----------+--------------------
field_0 | 1 | -0.2331769167607
field_1 | 1 | 0.736227459496199
field_2 | 1 | 0.29963728232024
field_3 | 1 | 0.128085369856188
field_4 | 1 | -0.668573096260048
field_5 | 1 | 0.516750679584637
field_6 | 1 | -0.41025989394959
field_7 | 1 | 0.308289533913736
field_8 | 1 | -0.177878773139411
(9 rows)
You can then use the PREDICT_PMML function to apply the imported model on a relation for in-database prediction. The internal parameters of the model can be matched to the column names of the input relation by their names or their listed position. Direct input values can also be fed to the function as displayed below.
=> -- Using the imported PMML model for scoring direct input values
=> SELECT predict_pmml(1.5,0.5,2,1,0.75,4.2,3.1,0.9,1.1
username(> USING PARAMETERS model_name='spark_logistic_reg', match_by_pos=true);
predict_pmml
--------------
1
(1 row)
=> -- Using the imported PMML model for scoring samples in a table
=> SELECT predict_pmml(* USING PARAMETERS model_name='spark_logistic_reg') AS prediction
=> FROM test_data;
prediction
------------
1
0
(2 rows)
See also
2.3 - PMML features and attributes
Using External Models With Vertica gives an overview of the features Vertica supports for working with external models.
To be compatible with Vertica, PMML models must conform to the following:
The following table lists supported PMML tags and attributes.