This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Sequences
Sequences can be used to set the default values of columns to sequential integer values.
Sequences can be used to set the default values of columns to sequential integer values. Sequences guarantee uniqueness, and help avoid constraint enforcement problems and overhead. Sequences are especially useful for primary key columns.
While sequence object values are guaranteed to be unique, they are not guaranteed to be contiguous. For example, two nodes can increment a sequence at different rates. The node with a heavier processing load increments the sequence, but the values are not contiguous with those being incremented on a node with less processing. For details, see Distributing sequences.
Vertica supports the following sequence types:
- Named sequences are database objects that generates unique numbers in sequential ascending or descending order. Named sequences are defined independently through CREATE SEQUENCE statements, and are managed independently of the tables that reference them. A table can set the default values of one or more columns to named sequences.
- IDENTITY column sequences increment or decrement column's value as new rows are added. Unlike named sequences, IDENTITY sequence types are defined in a table's DDL, so they do not persist independently of that table. A table can contain only one IDENTITY column.
1 - Sequence types compared
The following table lists the differences between the two sequence types:.
The following table lists the differences between the two sequence types:
|
Supported Behavior |
Named Sequence |
IDENTITY |
|
Default cache value 250K |
• |
• |
|
Set initial cache |
• |
• |
|
Define start value |
• |
• |
|
Specify increment unit |
• |
• |
|
Exists as an independent object |
• |
|
|
Exists only as part of table |
|
• |
|
Create as column constraint |
|
• |
|
Requires name |
• |
|
|
Use in expressions |
• |
|
|
Unique across tables |
• |
|
|
Change parameters |
• |
|
|
Move to different schema |
• |
|
|
Set to increment or decrement |
• |
|
|
Grant privileges to object |
• |
|
|
Specify minimum value |
• |
|
|
Specify maximum value |
• |
|
2 - Named sequences
Named sequences are sequences that are defined by CREATE SEQUENCE.
Named sequences are sequences that are defined by CREATE SEQUENCE. Unlike IDENTITY sequences, which are defined in a table's DDL, you create a named sequence as an independent object, and then set it as the default value of a table column.
Named sequences are used most often when an application requires a unique identifier in a table or an expression. After a named sequence returns a value, it never returns the same value again in the same session.
2.1 - Creating and using named sequences
You create a named sequence with CREATE SEQUENCE.
You create a named sequence with
CREATE SEQUENCE. The statement requires only a sequence name; all other parameters are optional. To create a sequence, a user must have CREATE privileges on a schema that contains the sequence.
The following example creates an ascending named sequence, my_seq, starting at the value 100:
=> CREATE SEQUENCE my_seq START 100;
CREATE SEQUENCE
Incrementing and decrementing a sequence
When you create a named sequence object, you can also specify its increment or decrement value by setting its INCREMENT parameter. If you omit this parameter, as in the previous example, the default is set to 1.
You increment or decrement a sequence by calling the function
NEXTVAL on it—either directly on the sequence itself, or indirectly by adding new rows to a table that references the sequence. When called for the first time on a new sequence, NEXTVAL initializes the sequence to its start value. Vertica also creates a cache for the sequence. Subsequent NEXTVAL calls on the sequence increment its value.
The following call to NEXTVAL initializes the new my_seq sequence to 100:
=> SELECT NEXTVAL('my_seq');
nextval
---------
100
(1 row)
Getting a sequence's current value
You can obtain the current value of a sequence by calling
CURRVAL on it. For example:
=> SELECT CURRVAL('my_seq');
CURRVAL
---------
100
(1 row)
Note
CURRVAL returns an error if you call it on a new sequence that has not yet been initialized by NEXTVAL, or an existing sequence that has not yet been accessed in a new session. For example:
=> CREATE SEQUENCE seq2;
CREATE SEQUENCE
=> SELECT currval('seq2');
ERROR 4700: Sequence seq2 has not been accessed in the session
Referencing sequences in tables
A table can set the default values of any column to a named sequence. The table creator must have the following privileges: SELECT on the sequence, and USAGE on its schema.
In the following example, column id gets its default values from named sequence my_seq:
=> CREATE TABLE customer(id INTEGER DEFAULT my_seq.NEXTVAL,
lname VARCHAR(25),
fname VARCHAR(25),
membership_card INTEGER
);
For each row that you insert into table customer, the sequence invokes the NEXTVAL function to set the value of the id column. For example:
=> INSERT INTO customer VALUES (default, 'Carr', 'Mary', 87432);
=> INSERT INTO customer VALUES (default, 'Diem', 'Nga', 87433);
=> COMMIT;
For each row, the insert operation invokes NEXTVAL on the sequence my_seq, which increments the sequence to 101 and 102, and sets the id column to those values:
=> SELECT * FROM customer;
id | lname | fname | membership_card
-----+-------+-------+-----------------
101 | Carr | Mary | 87432
102 | Diem | Nga | 87433
(1 row)
2.2 - Distributing sequences
When you create a sequence, its CACHE parameter determines the number of sequence values each node maintains during a session.
When you create a sequence, its CACHE parameter determines the number of sequence values each node maintains during a session. The default cache value is 250K, so each node reserves 250,000 values per session for each sequence. The default cache size provides an efficient means for large insert or copy operations.
If sequence caching is set to a low number, nodes are liable to request a new set of cache values more frequently. While it supplies a new cache, Vertica must lock the catalog. Until Vertica releases the lock, other database activities such as table inserts are blocked, which can adversely affect overall performance.
When a new session starts, node caches are initially empty. By default, the initiator node requests and reserves cache for all nodes in a cluster. You can change this default so each node requests its own cache, by setting configuration parameter ClusterSequenceCacheMode to 0.
For information on how Vertica requests and distributes cache among all nodes in a cluster, refer to Sequence caching.
Effects of distributed sessions
Vertica distributes a session across all nodes. The first time a cluster node calls the function NEXTVAL on a sequence to increment (or decrement) its value, the node requests its own cache of sequence values. The node then maintains that cache for the current session. As other nodes call NEXTVAL, they too create and maintain their own cache of sequence values.
During a session, nodes call NEXTVAL independently and at different frequencies. Each node uses its own cache to populate the sequence. All sequence values are guaranteed to be unique, but can be out of order with a NEXTVAL statement executed on another node. As a result, sequence values are often non-contiguous.
In all cases, increments a sequence only once per row. Thus, if the same sequence is referenced by multiple columns, NEXTVAL sets all columns in that row to the same value. This applies to rows of joined tables.
Calculating sequences
Vertica calculates the current value of a sequence as follows:
-
At the end of every statement, the state of all sequences used in the session is returned to the initiator node.
-
The initiator node calculates the maximum
CURRVAL of each sequence across all states on all nodes.
-
This maximum value is used as CURRVAL in subsequent statements until another NEXTVAL is invoked.
Losing sequence values
Sequence values in cache can be lost in the following situations:
-
If a statement fails after NEXTVAL is called (thereby consuming a sequence value from the cache), the value is lost.
-
If a disconnect occurs (for example, dropped session), any remaining values in cache that have not been returned through NEXTVAL are lost.
-
When the initiator node distributes a new block of cache to each node where one or more nodes has not used up its current cache allotment. For information on this scenario, refer to Sequence caching.
You can recover lost sequence values by using ALTER SEQUENCE...RESTART, which resets the sequence to the specified value in the next session.
Caution
Using ALTER SEQUENCE to set a sequence start value below its
current value can result in duplicate keys.
2.3 - Altering sequences
ALTER SEQUENCE can change sequences in two ways:.
ALTER SEQUENCE can change sequences in two ways:
- Changes values that control sequence behavior—for example, its start value and range of minimum and maximum values. These changes take effect only when you start a new database session.
- Changes sequence name, schema, or ownership. These changes take effect immediately.
Note
The same ALTER SEQUENCE statement cannot make both types of changes.
Changing sequence behavior
ALTER SEQUENCE can change one or more sequence attributes through the following parameters:
|
These parameters... |
Control... |
INCREMENT |
How much to increment or decrement the sequence on each call to NEXTVAL. |
MINVALUE/MAXVALUE |
Range of valid integers. |
RESTART |
Sequence value on its next call to NEXTVAL. |
CACHE/NO CACHE |
How many sequence numbers are pre-allocated and stored in memory for faster access. |
CYCLE/NO CYCLE |
Whether the sequence wraps when its minimum or maximum values are reached. |
These changes take effect only when you start a new database session. For example, if you create a named sequence my_sequence that starts at 10 and increments by 1 (the default), each sequence call to NEXTVAL increments its value by 1:
=> CREATE SEQUENCE my_sequence START 10;
=> SELECT NEXTVAL('my_sequence');
nextval
---------
10
(1 row)
=> SELECT NEXTVAL('my_sequence');
nextval
---------
11
(1 row)
The following ALTER SEQUENCE statement specifies to restart the sequence at 50:
=>ALTER SEQUENCE my_sequence RESTART WITH 50;
However, this change has no effect in the current session. The next call to NEXTVAL increments the sequence to 12:
=> SELECT NEXTVAL('my_sequence');
NEXTVAL
---------
12
(1 row)
The sequence restarts at 50 only after you start a new database session:
=> \q
$ vsql
Welcome to vsql, the Vertica Analytic Database interactive terminal.
=> SELECT NEXTVAL('my_sequence');
NEXTVAL
---------
50
(1 row)
Changing sequence name, schema, and ownership
You can use ALTER SEQUENCE to make the following changes to a sequence:
Each of these changes requires separate ALTER SEQUENCE statements. These changes take effect immediately.
For example, the following statement renames a sequence from my_seq to serial:
=> ALTER SEQUENCE s1.my_seq RENAME TO s1.serial;
This statement moves sequence s1.serial to schema s2:
=> ALTER SEQUENCE s1.my_seq SET SCHEMA TO s2;
The following statement reassigns ownership of s2.serial to another user:
=> ALTER SEQUENCE s2.serial OWNER TO bertie;
Note
Only a superuser or the sequence owner can change its ownership. Reassignment does not transfer grants from the original owner to the new owner. Grants made by the original owner are dropped.
2.4 - Dropping sequences
Use DROP SEQUENCE to remove a named sequence.
Use
DROP SEQUENCE to remove a named sequence. For example:
=> DROP SEQUENCE my_sequence;
You cannot drop a sequence if one of the following conditions is true:
-
Other objects depend on the sequence. DROP SEQUENCE does not support cascade operations.
-
A column's DEFAULT expression references the sequence. Before dropping the sequence, you must remove all column references to it.
3 - IDENTITY sequences
IDENTITY (synonymous with AUTO_INCREMENT) columns are defined with a sequence that automatically increments column values as new rows are added.
IDENTITY (synonymous with AUTO_INCREMENT) columns are defined with a sequence that automatically increments column values as new rows are added. You define an IDENTITY column in a table as follows:
CREATE TABLE table-name...
(column-name {IDENTITY | AUTO_INCREMENT}
( [ cache-size | start, increment [, cache-size ] ] )
Settings
start |
First value to set for this column.
Default: 1
|
increment |
Positive or negative integer that specifies how much to increment or decrement the sequence on each new row insertion from the previous row value, by default set to 1. To decrement sequence values, specify a negative value.
Note
The actual amount by which column values are incremented or decremented might be larger than the increment setting, unless sequence caching is disabled.
Default: 1
|
cache-size |
How many unique numbers each node caches per session. A value of 0 or 1 disables sequence caching. For details, see Sequence caching.
Default: 250,000
|
Managing settings
Like named sequences, you can manage an IDENTITY column with ALTER SEQUENCE—for example, reset its start integer. Two exceptions apply: because the sequence is defined as part of a table column, you cannot change the sequence name or schema. You can query the SEQUENCES system table for the name of an IDENTITY column's sequence. This name is automatically created when you define the table, and conforms to the following convention:
table-name_col-name_seq
For example, you can change the maximum value of an IDENTITY column that is defined in the testAutoId table:
=> SELECT * FROM sequences WHERE identity_table_name = 'testAutoId';
-[ RECORD 1 ]-------+-------------------------
sequence_schema | public
sequence_name | testAutoId_autoIdCol_seq
owner_name | dbadmin
identity_table_name | testAutoId
session_cache_count | 250000
allow_cycle | f
output_ordered | f
increment_by | 1
minimum | 1
maximum | 1000
current_value | 1
sequence_schema_id | 45035996273704980
sequence_id | 45035996274278950
owner_id | 45035996273704962
identity_table_id | 45035996274278948
=> ALTER SEQUENCE testAutoId_autoIdCol_seq maxvalue 10000;
ALTER SEQUENCE
This change, like other changes to a sequence, take effect only when you start a new database session. One exception applies: changes to the sequence owner take effect immediately.
You can obtain the last value generated for an IDENTITY column by calling LAST_INSERT_ID.
Restrictions
The following restrictions apply to IDENTITY columns:
- A table can contain only one IDENTITY column.
- IDENTITY column values automatically increment before the current transaction is committed; rolling back the transaction does not revert the change.
- You cannot change the value of an IDENTITY column.
Examples
The following example shows how to use the IDENTITY column-constraint to create a table with an ID column. The ID column has an initial value of 1. It is incremented by 1 every time a row is inserted.
-
Create table Premium_Customer:
=> CREATE TABLE Premium_Customer(
ID IDENTITY(1,1),
lname VARCHAR(25),
fname VARCHAR(25),
store_membership_card INTEGER
);
=> INSERT INTO Premium_Customer (lname, fname, store_membership_card )
VALUES ('Gupta', 'Saleem', 475987);
The IDENTITY column has a seed of 1, which specifies the value for the first row loaded into the table, and an increment of 1, which specifies the value that is added to the IDENTITY value of the previous row.
-
Confirm the row you added and see the ID value:
=> SELECT * FROM Premium_Customer;
ID | lname | fname | store_membership_card
----+-------+--------+-----------------------
1 | Gupta | Saleem | 475987
(1 row)
-
Add another row:
=> INSERT INTO Premium_Customer (lname, fname, store_membership_card)
VALUES ('Lee', 'Chen', 598742);
-
Call the Vertica function LAST_INSERT_ID. The function returns value 2 because you previously inserted a new customer (Chen Lee), and this value is incremented each time a row is inserted:
=> SELECT LAST_INSERT_ID();
last_insert_id
----------------
2
(1 row)
-
View all the ID values in the Premium_Customer table:
=> SELECT * FROM Premium_Customer;
ID | lname | fname | store_membership_card
----+-------+--------+-----------------------
1 | Gupta | Saleem | 475987
2 | Lee | Chen | 598742
(2 rows)
The next three examples illustrate the three valid ways to use IDENTITY arguments.
The first example uses a cache of 100, and the defaults for start value (1) and increment value (1):
=> CREATE TABLE t1(x IDENTITY(100), y INT);
The next example specifies the start and increment values as 1, and defaults to a cache value of 250,000:
=> CREATE TABLE t2(y IDENTITY(1,1), x INT);
The third example specifies start and increment values of 1, and a cache value of 100:
=> CREATE TABLE t3(z IDENTITY(1,1,100), zx INT);
4 - Sequence caching
Caching is similar for all sequence types: named sequences and IDENTITY column sequences.
Caching is similar for all sequence types: named sequences and IDENTITY column sequences. To allocate cache among the nodes in a cluster for a given sequence, Vertica uses the following process.
- By default, when a session begins, the cluster initiator node requests cache for itself and other nodes in the cluster.
- The initiator node distributes cache to other nodes when it distributes the execution plan.
- Because the initiator node requests caching for all nodes, only the initiator locks the global catalog for the cache request.
This approach is optimal for handling large INSERT-SELECT and COPY operations. The following figure shows how the initiator request and distributes cache for a named sequence in a three-node cluster, where caching for that sequence is set to 250 K:
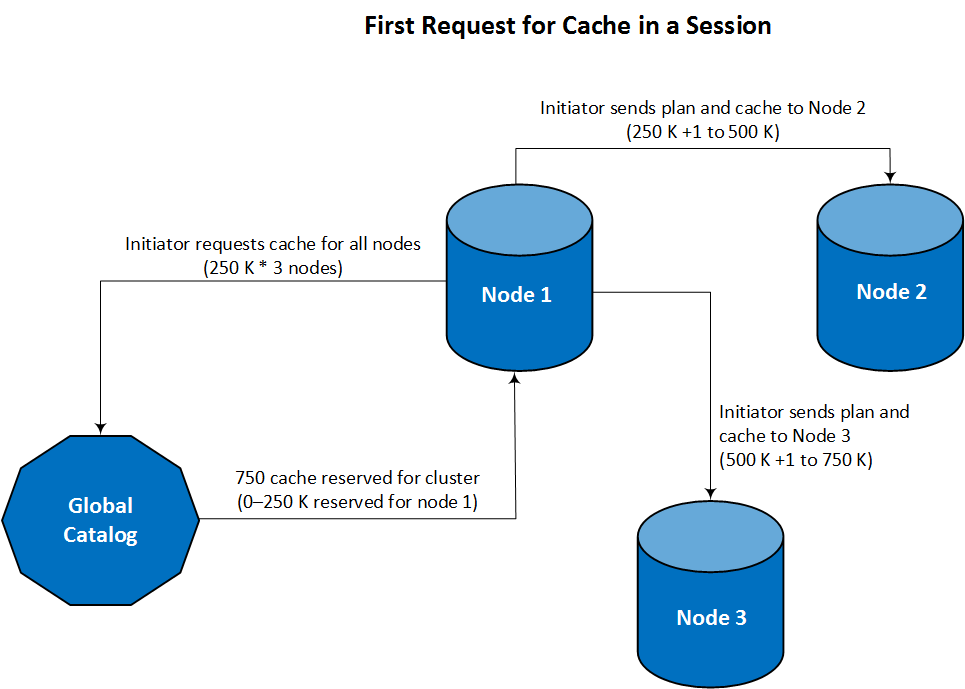
Nodes run out of cache at different times. While executing the same query, nodes individually request additional cache as needed.
For new queries in the same session, the initiator might have an empty cache if it used all of its cache to execute the previous query execution. In this case, the initiator requests cache for all nodes.
Configuring sequence caching
You can change how nodes obtain sequence caches by setting the configuration parameter ClusterSequenceCacheMode to 0 (disabled). When this parameter is set to 0, all nodes in the cluster request their own cache and catalog lock. However, for initial large INSERT-SELECT and COPY operations, when the cache is empty for all nodes, each node requests cache at the same time. These multiple requests result in simultaneous locks on the global catalog, which can adversely affect performance. For this reason, ClusterSequenceCacheMode should remain set to its default value of 1 (enabled).
The following example compares how different settings of ClusterSequenceCacheMode affect how Vertica manages sequence caching. The example assumes a three-node cluster, 250 K caches for each node (the default), and sequence ID values that increment by 1.
|
Workflow step |
ClusterSequenceCacheMode = 1 |
ClusterSequenceCacheMode = 0 |
|
1 |
Cache is empty for all nodes.
Initiator node requests 250 K cache for each node.
|
Cache is empty for all nodes.
Each node, including initiator, requests its own 250 K cache.
|
|
2 |
Blocks of cache are distributed to each node as follows:
Each node begins to use its cache as it processes sequence updates.
|
|
3 |
Initiator node and node 3 run out of cache.
Node 2 only uses 250 K +1 to 400 K, 100 K of cache remains from 400 K +1 to 500 K.
|
|
4 |
Executing same statement:
-
As each node uses up its cache, it requests a new cache allocation.
-
If node 2 never uses its cache, the 100-K unused cache becomes a gap in sequence IDs.
Executing a new statement in same session, if initiator node cache is empty:
-
It requests and distributes new cache blocks for all nodes.
-
Nodes receive a new cache before the old cache is used, creating a gap in ID sequencing.
|
Executing same or new statement:
-
As each node uses up its cache, it requests a new cache allocation.
-
If node 2 never uses its cache, the 100 K unused cache becomes a gap in sequence IDs.
|