Managing scheduler resources and performance
Your scheduler's performance is impacted by the number of microbatches in your scheduler, partitions in each microbatch, and nodes in your Vertica cluster. Use resource pools to allocate a subset of system resources for your scheduler, and fine-tune those resources to optimize automatic loads into Vertica.
The following sections provide details about scheduler resource pool configurations and processing scenarios.
Schedulers and resource pools
Vertica recommends that you always create a resource pool specifically for each scheduler. Schedulers assume that they have exclusive use of their assigned resource pool. Using a separate pool for a scheduler lets you fine-tune its impact on your Vertica cluster's performance. You create resource pools with CREATE RESOURCE POOL.
If you do not create and assign a resource pool for your scheduler, it uses a portion of the GENERAL resource pool. Vertica recommends that you do not use the GENERAL pool for schedulers in production environments. This fallback to the GENERAL pool is intended as a convenience when you test your scheduler configuration. When you are ready to deploy your scheduler, create a resource pool that you tuned to its specific needs. Each time that you start a scheduler that is using the GENERAL pool, the vkconfig utility displays a warning message.
Not allocating enough resources to your schedulers can result in errors. For example, you might get OVERSHOT DEADLINE FOR FRAME errors if the scheduler is unable to load data from all topics in a data frame.
See Resource pool architecture for more information about resource pools.
Key resource pool settings
A microbatch is a unit of work that processes the partitions of a single Kafka topic within the duration of a frame. The following resource pool settings play an important role in how Vertica loads microbatches and processes partitions:
- PLANNEDCONCURRENCY determines the number of microbatches (COPY statements) the scheduler sends to Vertica simultaneously. At the start of each frame, the scheduler creates the number of scheduler threads specified by PLANNEDCONCURRENCY. Each scheduler thread connects to Vertica and loads one microbatch at a time. If there are more microbatches than scheduler threads, the scheduler queues the extra microbatches and loads them as threads become available.
- EXECUTIONPARALLELISM determines the maximum number of threads each node creates to process a microbatch's partitions. When a microbatch is loaded into Vertica, its partitions are distributed evenly among the nodes in the cluster. During each frame, a node creates a maximum of one thread for each partition. Each thread reads from one partition at a time until processing completes, or the frame ends. If there are more partitions than threads across all nodes, remaining partitions are processed as threads become available.
- QUEUETIMEOUT provides manual control over resource timings. Set the resource pool parameter QUEUETIMEOUT to 0 to allow the scheduler to manage timings. After all of the microbatches are processed, the scheduler waits for the remainder of the frame to process the next microbatch. A properly sized configuration includes rest time to plan for traffic surges. See Choosing a frame duration for information about the impacts of frame duration size.
For example, the following CREATE RESOURCE POOL statement creates a resource pool named weblogs_pool that loads 2 microbatches simultaneously. Each node in the Vertica cluster creates 10 threads per microbatch to process partitions:
=> CREATE RESOURCE POOL weblogs_pool
MEMORYSIZE '10%'
PLANNEDCONCURRENCY 2
EXECUTIONPARALLELISM 10
QUEUETIMEOUT 0;
For a three-node Vertica cluster, weblogs_pool provides resources for each node to create up to 10 threads to process partitions, or 30 total threads per microbatch.
Loading multiple microbatches concurrently
In some circumstances, you might have more microbatches in your scheduler than available PLANNEDCONCURRENCY. The following images illustrate how the scheduler loads microbatches into a single Vertica node when there are not enough scheduler threads to load each microbatch simultaneously. The resource pool's PLANNEDCONCURRENCY (PC) is set to 2, but the scheduler must load three microbatches: A, B, and C. For simplicity, EXECUTIONPARALLELISM (EP) is set to 1.
To begin, the scheduler loads microbatch A and microbatch B while microbatch C waits:
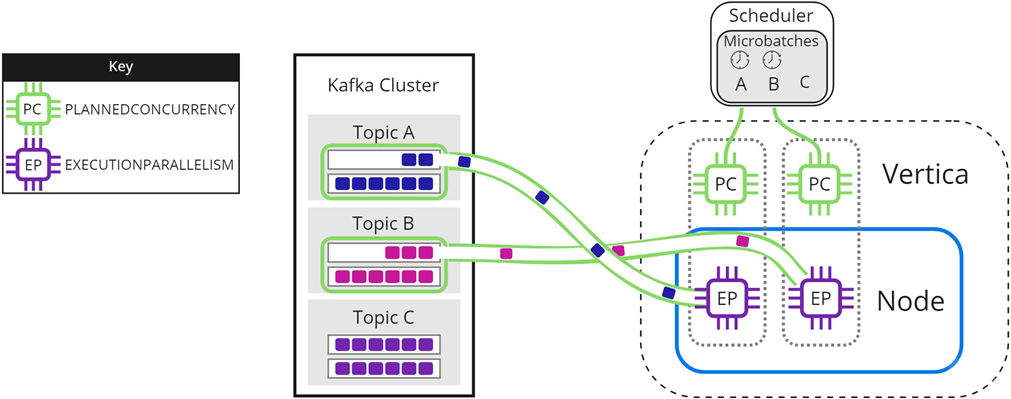
When either microbatch finishes loading, the scheduler loads any remaining microbatches. In the following image, microbatch A is completely loaded into Vertica. The scheduler continues to load microbatch B, and uses the newly available scheduler thread to load microbatch C:
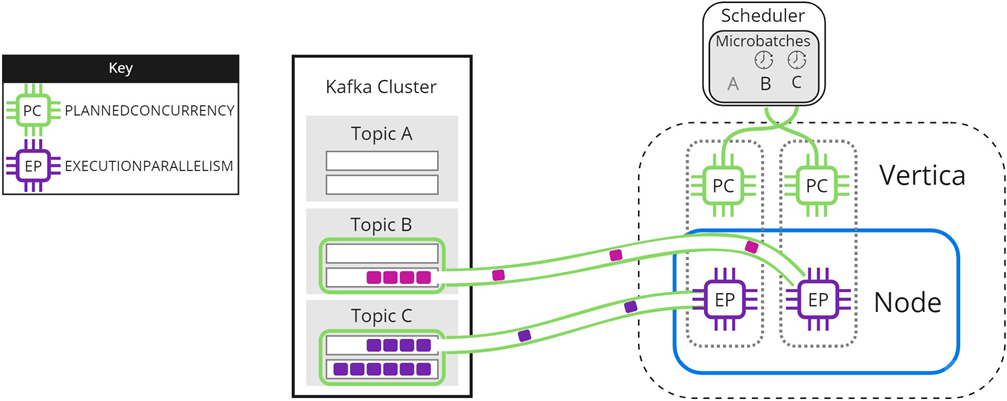
The scheduler continues sending data until all microbatches are loaded into Vertica, or the frame ends.
Experiment with PLANNEDCONCURRENCY to optimize performance. Note that setting it too high might create too many connections at the beginning of each frame, resulting in scalability stress on Vertica or Kafka. Setting PLANNEDCONCURRENCY too low does not take full advantage of the multiprocessing power of Vertica.
Parallel processing within Vertica
The resource pool setting EXECUTIONPARALLELISM limits the number of threads each Vertica node creates to process partitions. The following image illustrates how a three-node Vertica cluster processes a topic with nine partitions, when there is not enough EXECUTIONPARALLELISM to create one thread per partition. The partitions are distributed evenly among Node 1, Node 2, and Node 3 in the Vertica cluster. The scheduler's resource pool has PLANNEDCONCURRENCY (PC) set to 1 and EXECUTIONPARALLELISM (EP) set to 2, so each node creates a maximum of 2 threads when the scheduler loads microbatch A. Each thread reads from one partition at a time. Partitions that are not assigned a thread must wait for processing:
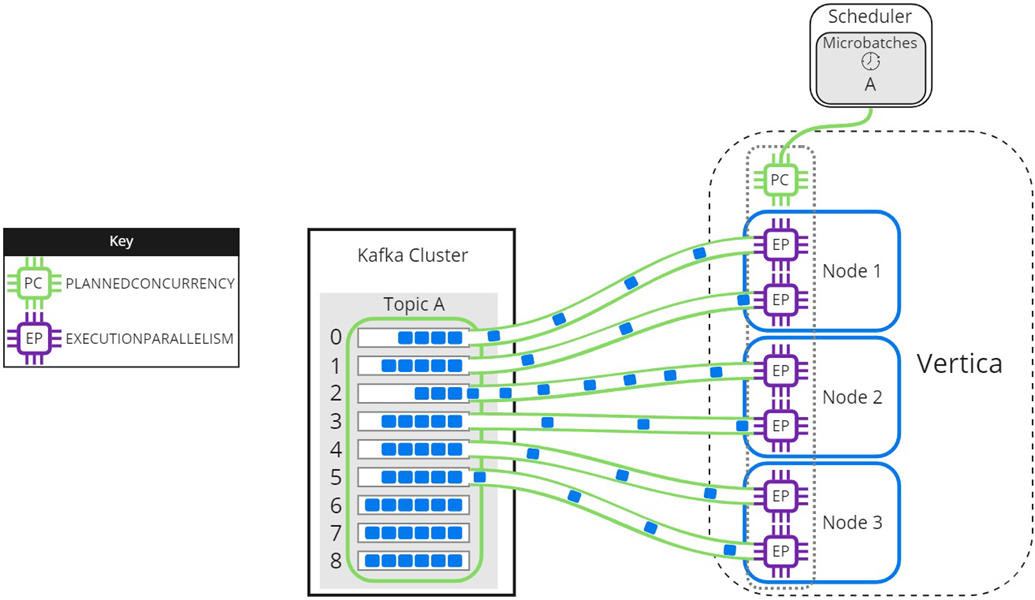
As threads finish processing their assigned partitions, the remaining partitions are distributed to threads as they become available:
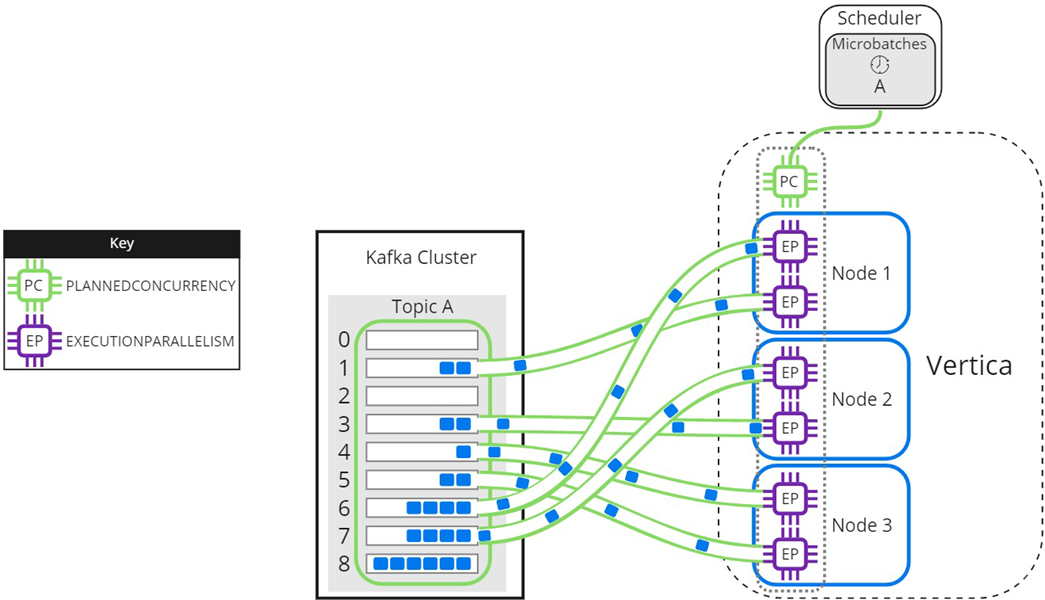
When setting the EXECUTIONPARALLELISM on your scheduler's resource pool, consider the number of partitions across all microbatches in the scheduler.
Loading partitioned topics concurrently
Single topics with multiple partitions might benefit from increased parallel loading or a reduced transaction size. The --max-parallelism microbatch utility option enables you to dynamically split a topic with multiple partitions into multiple, load-balanced microbatches that each consist of a subset of the original microbatch's partitions. The scheduler loads the dynamically split microbatches simultaneously using the PLANNEDCONCURRENCY available in its resource pool.
The EXECUTIONPARALLELISM setting in the scheduler's resource pool determines the maximum number of threads each node creates to process its portion of a single microbatch's partitions. Splitting a microbatch enables each node to create more threads for the same unit of work. When there is enough PLANNEDCONCURRENCY and the number of partitions assigned per node is greater than the EXECUTIONPARALLELISM setting in the scheduler's resource pool, use --max-parallelism to split the microbatch and create more threads per node to process more partitions in parallel.
The following image illustrates how a two-node Vertica cluster loads and processes microbatch A using a resource pool with PLANNEDCONCURRENCY (PC) set to 2, and EXECUTIONPARALLELISM (EP) set to 2. Because the scheduler is loading only one microbatch, there is 1 scheduler thread left unused. Each node creates 2 threads per scheduler thread to process its assigned partitions:
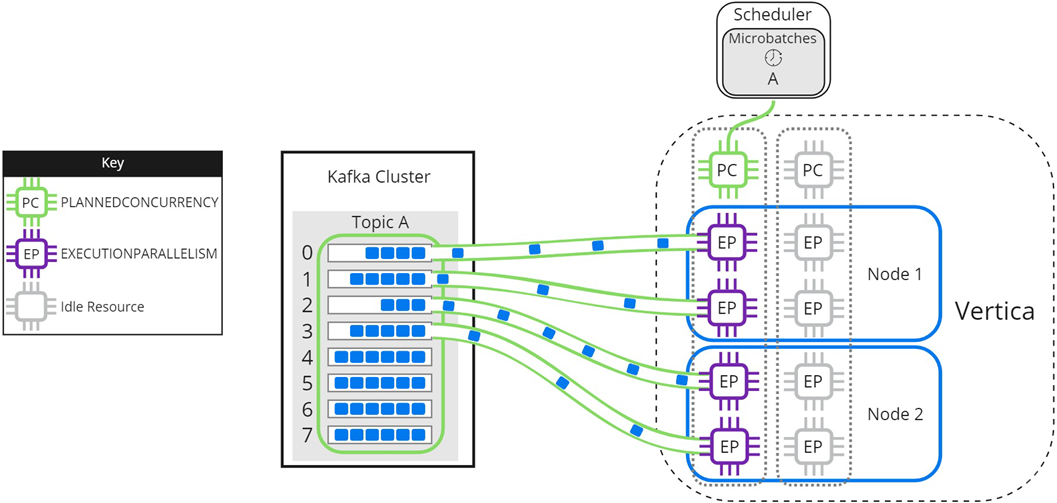
Setting microbatch A's --max-parallelism option to 2 enables the scheduler to dynamically split microbatch A into 2 smaller microbatches, A1 and A2. Because there are 2 available scheduler threads, the subset microbatches are loaded into Vertica simultaneously. Each node creates 2 threads per scheduler thread to process partitions for microbatches A1 and A2:
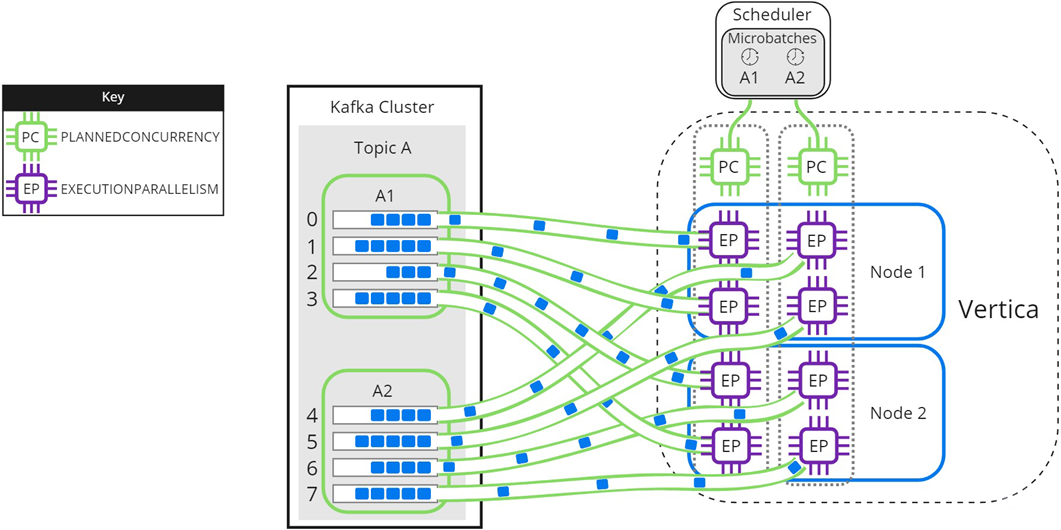
Use --max-parallelism to prevent bottlenecks in microbatches consisting of high-volume Kafka topics. It also provides faster loads for microbatches that require additional processing, such as text indexing.