HCatalog 连接器工作原理
规划访问 Hive 表中数据的查询时,启动程序节点上的 Vertica HCatalog 连接器将联系 Hadoop 群集中的 HiveServer2(或 WebHCat),以确定该表是否存在。如果该表存在,连接器将从元存储数据库检索该表的元数据,以便查询规划可以继续。查询执行时,Vertica 群集中的所有节点直接从 HDFS 检索完成查询所必需的数据。然后,它们使用 Hive SerDe 类提取数据,以便查询可以执行。访问 ORC 或 Parquet 格式的数据时,HCatalog 连接器使用 Vertica 的内部读取器(而不是 Hive SerDe 类)来处理这些格式。
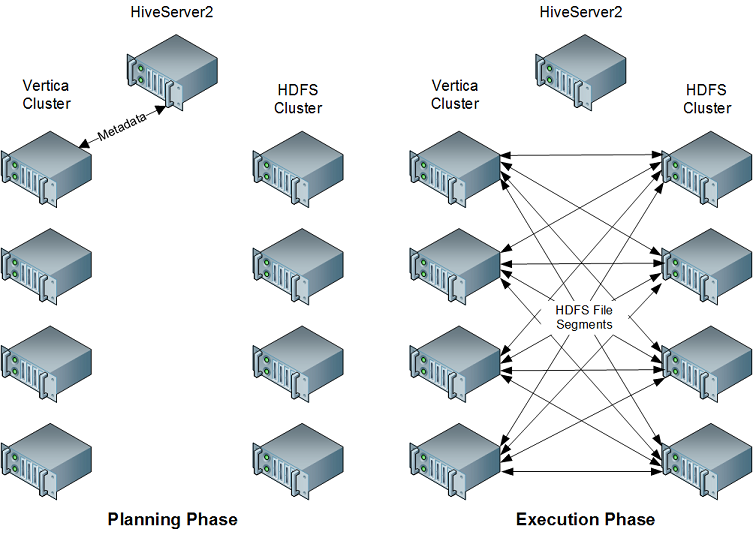
这种方法利用了 Vertica 和 Hadoop 的并行性。此外,HCatalog 连接器还通过直接执行数据检索和提取,降低了查询对 Hadoop 群集的影响。
对于采用 Optimized Columnar Row (ORC) 或 Parquet 格式且不使用复杂类型的文件,HCatalog 连接器将创建外部表并使用 ORC 或 Parquet 读取器,而不是使用 Java SerDe。如果 Hive 在写入数据时使用自定义 Hive 分区位置,您可以指示这些读取器访问该位置。默认情况下,系统会关闭这些额外的检查以提高性能。