配置机架位置
注意
仅当读取共置群集上的 ORC 和 Parquet 数据时,才支持此功能。它仅对跨多个机架的 Hadoop 群集有意义。如果可能,在规划查询时,Vertica 会自动使用与包含数据的 HDFS 节点共置的数据库节点。将查询执行移到更靠近数据的位置可以减少网络延迟并提高性能。这种称为节点定位的行为不需要额外的配置。
当 Vertica 仅共置于 HDFS 节点的子集上时,有时没有与数据共置的数据库节点。但是,如果查询使用同一机架中的数据库节点,性能通常会更好。如果配置了有关 Hadoop 机架结构的信息,Vertica 会尝试使用与要查询的数据位于同一机架中的数据库节点。
例如,下图说明了具有三个机架的 Hadoop 群集,每个机架包含三个数据节点。(典型的生产系统在每个机架上会有更多的数据节点。)在每个机架中,Vertica 共置于一个节点上。
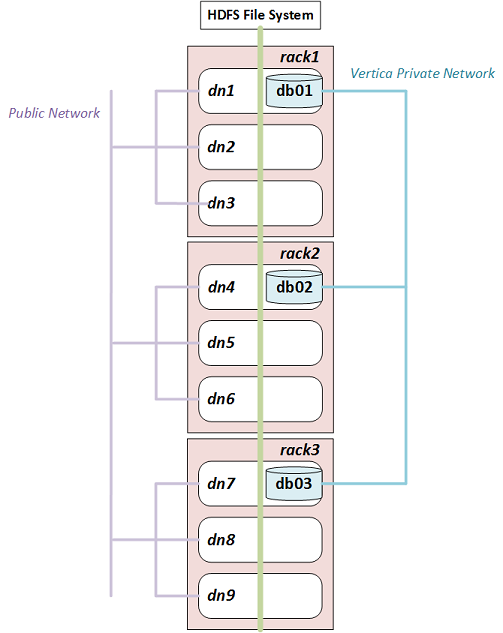
如果您配置了机架位置,则 Vertica 使用 db01 查询 dn1、dn2 或 dn3 上的数据,使用 db02 和 db03 分别查询 rack2 和 rack3 上的数据。因为 HDFS 会复制数据,所以任何给定的数据块都可以存在于多个机架中。例如,如果在 dn2、dn3 和 dn6 上复制数据块,Vertica 将使用 db01 或 db02 来查询它。
Hadoop 组件是机架感知的,因此描述机架结构的配置文件已经存在于 Hadoop 群集中。要在 Vertica 中使用此信息,请配置描述此机架结构的故障组。Vertica 在查询计划中使用故障组。
配置故障组
Vertica 使用 容错组 来描述物理群集布局。由于您的数据库节点共置在 HDFS 节点上,因此 Vertica 可以使用有关 HDFS 群集物理布局的信息。
提示
为获得最佳结果,请确保每个 Hadoop 机架至少包含一个共置的 Vertica 节点。Hadoop 将其群集布局数据存储在 HADOOP_CONF_DIR 中的拓扑映射文件中。在 HortonWorks 上,该文件通常命名为 topology_mappings.data。在 Cloudera 上,它通常命名为 topology.map。使用此文件中的数据为故障组脚本创建输入文件。有关此文件格式的详细信息,请参阅创建容错组输入文件。
以下是前面说明的群集的拓扑映射文件示例:
[network_topology]
dn1.example.com=/rack1
10.20.41.51=/rack1
dn2.example.com=/rack1
10.20.41.52=/rack1
dn3.example.com=/rack1
10.20.41.53=/rack1
dn4.example.com=/rack2
10.20.41.71=/rack2
dn5.example.com=/rack2
10.20.41.72=/rack2
dn6.example.com=/rack2
10.20.41.73=/rack2
dn7.example.com=/rack3
10.20.41.91=/rack3
dn8.example.com=/rack3
10.20.41.92=/rack3
dn9.example.com=/rack3
10.20.41.93=/rack3
根据这些数据,您可以创建以下输入文件来描述该群集的 Vertica 子集:
/rack1 /rack2 /rack3
/rack1 = db01
/rack2 = db02
/rack3 = db03
此输入文件告知 Vertica 数据库节点 "db01" 在 rack1 上,"db02" 在 rack2 上,"db03" 在 rack3 上。在创建此文件时,忽略那些不是 Vertica 节点的 Hadoop 数据节点。
创建输入文件后,运行故障组工具:
$ python /opt/vertica/scripts/fault_group_ddl_generator.py dbName input_file > fault_group_ddl.sql
此脚本的输出是创建故障组的 SQL 文件。按照创建容错组中的说明执行。
您可以使用以下语句查看新的故障组:
=> SELECT member_name,node_address,parent_name FROM fault_groups
INNER JOIN nodes ON member_name=node_name ORDER BY parent_name;
member_name | node_address | parent_name
-------------------------+--------------+-------------
db01 | 10.20.41.51 | /rack1
db02 | 10.20.41.71 | /rack2
db03 | 10.20.41.91 | /rack3
(3 rows)
使用多层机架
Hadoop 群集可以使用多层机架。例如,/west/rack-w1、/west/rack-2 和 /west/rack-w3 可能由一个数据中心提供服务,而 /east/rack-e1、/east/rack-e2 和 /east /rack-e3 由另一个数据中心提供服务。对故障组脚本输入文件中的条目使用以下格式:
/west /east
/west = /rack-w1 /rack-w2 /rack-w3
/east = /rack-e1 /rack-e2 /rack-e3
/rack-w1 = db01
/rack-w2 = db02
/rack-w3 = db03
/rack-e1 = db04
/rack-e2 = db05
/rack-e3 = db06
不要使用完整的机架路径(例如 /west/rack-w1)创建条目。
审核结果
要查看机架位置可以加载多少数据,请在查询中使用 EXPLAIN 并在输出中查找如下语句:
100% of ORC data including co-located data can be loaded with rack locality.