This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Routing JDBC queries directly to a single node
The JDBC driver has the ability to route queries directly to a single node using a special connection called a Routable Connection.
The JDBC driver has the ability to route queries directly to a single node using a special connection called a Routable Connection. This feature is ideal for high-volume "short" requests that return a small number of results that all exist on a single node. The common scenario for using this feature is to do high-volume lookups on data that is identified with a unique key. Routable queries typically provide lower latency and use less system resources than distributed queries. However, the data being queried must be segmented in such a way that the JDBC client can determine on which node the data resides.
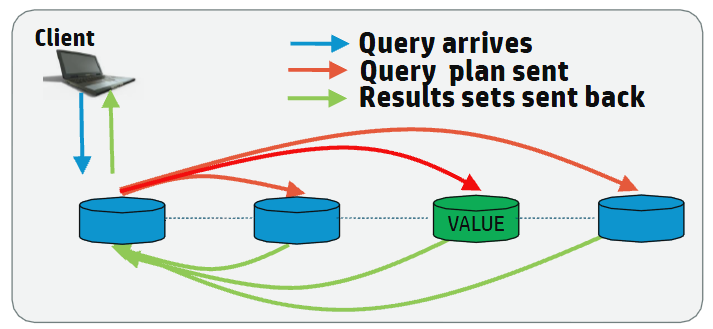
Vertica Typical Analytic Query
Typical analytic queries require dense computation on data across all nodes in the cluster and benefit from having all nodes involved in the planning and execution of the queries.
Vertica Routable Query API Query
For high-volume queries that return a single or a few rows of data, it is more efficient to execute the query on the single node that contains the data.
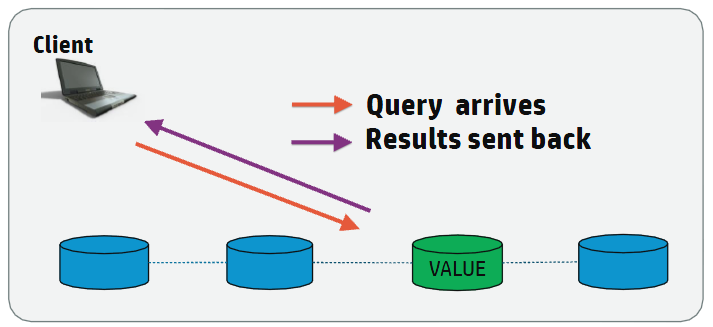
To effectively route a request to a single node, the client must determine the specific node on which the data resides. For the client to be able to determine the correct node, the table must be segmented by one or more columns. For example, if you segment a table on a Primary Key (PK) column, then the client can determine on which node the data resides based on the Primary Key and directly connect to that node to quickly fulfill the request.
The Routable Query API provides two classes for performing routable queries: VerticaRoutableExecutor and VGet. VerticaRoutableExecutor provides a more expressive SQL-based API while VGet provides a more structured API for programmatic access.
-
The VerticaRoutableExecutor class allows you to use traditional SQL with a reduced feature set to query data on a single node.
For joins, the table must be joined on a key column that exists in each table you are joining, and the tables must be segmented on that key. However, this is not true for unsegmented tables, which can always be joined (since all the data in an unsegmented table is available on all nodes).
-
The VGet class does not use traditional SQL syntax. Instead, it uses a data structure that you build by defining predicates and predicate expressions and outputs and output expressions. This class is ideal for doing Key/Value type lookups on single tables.
The data structure used for querying the table must provide a predicate for each segmented column defined in the projection for the table. You must provide, at a minimum, a predicate with a constant value for each segmented column. For example, an id with a value of 12234 if the table is segmented only on the id column. You can also specify additional predicates for the other, non-segmented, columns in the table. Predicates act like a SQL WHERE clause and multiple predicates/predicate expressions apply together with a SQL AND modifier. Predicates must be defined with a constant value. Predicate expressions can be used to refine the query and can contain any arbitrary SQL expressions (such as less than, greater than, and so on) for any of the non-segmented columns in the table.
Java documentation for all classes and methods in the JDBC Driver is available in the Vertica JDBC documentation.
Note
The JDBC Routable Query API is read-only and requires JDK 1.6 or greater.
1 - Creating tables and projections for use with the routable query API
For routable queries, the client must determine the appropriate node to get the data.
For routable queries, the client must determine the appropriate node to get the data. The client does this by comparing all projections available for the table, and determining the best projection to use to find the single node that contains data. You must create a projection segmented by the key column(s) on at least one table to take full advantage of the routable query API. Other tables that join to this table must either have an unsegmented projection, or a projection segmented as described below.
Note
Tables must be segmented by hash for routable queries. See
Hash segmentation clause. Other segmentation types are not supported.
Creating tables for use with routable queries
To create a table that can be used with the routable query API, segment (by hash) the table on a uniformly distributed column. Typically, you segment on a primary key. For faster lookups, sort the projection on the same columns on which you segmented. For example, to create a table that is well suited to routable queries:
CREATE TABLE users (
id INT NOT NULL PRIMARY KEY,
username VARCHAR(32),
email VARCHAR(64),
business_unit VARCHAR(16))
ORDER BY id
SEGMENTED BY HASH(id)
ALL NODES;
This table is segmented based on the id column (and ordered by id to make lookups faster). To build a query for this table using the routable query API, you only need to provide a single predicate for the id column which returns a single row when queried.
However, you might add multiple columns to the segmentation clause. For example:
CREATE TABLE users2 (
id INT NOT NULL PRIMARY KEY,
username VARCHAR(32),
email VARCHAR(64),
business_unit VARCHAR(16))
ORDER BY id, business_unit
SEGMENTED BY HASH(id, business_unit)
ALL NODES;
In this case, you need to provide two predicates when querying the users2 table, as it is segmented on two columns, id and business_unit. However, if you know both id and business_unit when you perform the queries, then it is beneficial to segment on both columns, as it makes it easier for the client to determine that this projection is the best projection to use to determine the correct node.
Designing tables for single-node JOINs
If you plan to use the VerticaRoutableExecutor class and join tables during routable queries, then you must segment all tables being joined by the same segmentation key. Typically this key is a primary/foreign key on all the tables being joined. For example, the customer_key may be the primary key in a customers dimension table, and the same key is a foreign key in a sales fact table. Projections for a VerticaRoutableExecutor query using these tables must be segmented by hash on the customer key in each table.
If you want to join with small dimension tables, such as date dimensions, then it may be appropriate to make those tables unsegmented so that the date_dimension data exists on all nodes. It is important to note that when joining unsegmented tables, you still must specify a segmented table in the createRoutableExecutor() call.
Verifying existing projections for tables
If tables are already segmented by hash (for example, on an ID column), then you can determine what predicates are needed to query the table by using the Vertica function
GET_PROJECTIONS to view that table's projections. For example:
=> SELECT GET_PROJECTIONS ('users');
...
Projection Name: [Segmented] [Seg Cols] [# of Buddies] [Buddy Projections] [Safe] [UptoDate] [Stats]
----------------------------------------------------------------------------------------------------
public.users_b1 [Segmented: Yes] [Seg Cols: "public.users.id"] [K: 1] [public.users_b0] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
public.users_b0 [Segmented: Yes] [Seg Cols: "public.users.id"] [K: 1] [public.users_b1] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
For each projection, only the public.users.id column is specified, indicating your query predicate should include this column.
If the table is segmented on multiple columns, for example id and business_unit, then you need to provide both columns as predicates to the routable query.
2 - Creating a connection for routable queries
The JDBC Routable Query API provides the VerticaRoutableConnection (details are available in the JDBC Documentation) interface to connect to a cluster and allow for Routable Queries.
The JDBC Routable Query API provides the VerticaRoutableConnection (details are available in the JDBC documentation interface to connect to a cluster and allow for Routable Queries. This interface provides advanced routing capabilities beyond those of a normal VerticaConnection. The VerticaRoutableConnection provides access to the VerticaRoutableExecutor and VGet classes. See Defining the query for routable queries using the VerticaRoutableExecutor class and Defining the query for routable queries using the VGet class respectively.
You enable access to this class by setting the EnableRoutableQueries JDBC connection property to true.
The VerticaRoutableConnection maintains an internal pool of connections and a cache of table metadata that is shared by all VerticaRoutableExecutor/VGet objects that are produced by the connection's createRoutableExecutor()/prepareGet() method. It is also a fully-fledged JDBC connection on its own and supports all the functionality that a VerticaConnection supports. When this connection is closed, all pooled connections managed by this VerticaRoutableConnection and all child objects are closed too. The connection pool and metadata is only used by child Routable Query operations.
Example:
You can create the connection using a JDBC DataSource:
com.vertica.jdbc.DataSource jdbcSettings = new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("exampleDB");
jdbcSettings.setHost("v_vmart_node0001.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
conn = (VerticaRoutableConnection)jdbcSettings.getConnection();
You can also create the connection using a connection string and the DriverManager.getConnection() method:
String connectionString = "jdbc:vertica://v_vmart_node0001.example.com:5433/exampleDB?user=dbadmin&password=&EnableRoutableQueries=true";
VerticaRoutableConnection conn = (VerticaRoutableConnection) DriverManager.getConnection(connectionString);
Both methods result in a conn connection object that is identical.
Note
Avoid opening many VerticaRoutableConnection connections because this connection maintains its own private pool of connections which are not shared with other connections. Instead, your application should use a single connection and issue multiple queries through that connection.
In addition to the setEnableRoutableQueries property that the Routable Query API adds to the Vertica JDBC connection class, the API also adds additional properties. The complete list is below.
-
EnableRoutableQueries: Enables Routable Query lookup capability. Default is false.
-
FailOnMultiNodePlans: If the plan requires more than one node, and FailOnMultiNodePlans is true, then the query fails. If it is set to false then a warning is generated and the query continues. However, latency is greatly increased as the Routable Query must first determine the data is on multiple nodes, then a normal query is run using traditional (all node) execution and execution. Defaults to true. Note that this failure cannot occur on simple calls using only predicates and constant values.
-
MetadataCacheLifetime: The time in seconds to keep projection metadata. The API caches metadata about the projection used for the query (such as projections). The cache is used on subsequent queries to reduce response time. The default is 300 seconds.
-
MaxPooledConnections: Cluster-wide maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Default 20.
-
MaxPooledConnectionsPerNode: Per-node maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Default 5.
3 - Defining the query for routable queries using the VerticaRoutableExecutor class
Use the VerticaRoutableExecutor class to access table data directly from a single node.
Use the VerticaRoutableExecutor class to access table data directly from a single node. VerticaRoutableExecutor directly queries Vertica only on the node that has all the data needed for the query, avoiding the distributed planning and execution costs associated with Vertica query execution. You can use VerticaRoutableExecutor to join tables or use a GROUP BY clause, as these operations are not possible using VGet.
When using the VerticaRoutableExecutor class, the following rules apply:
- If joining tables, all tables being joined must be segmented (by hash) on the same set of columns referenced in the join predicate, unless the table to join is unsegmented.
- Multiple conditions in a join WHERE clause must be AND'd together. Using OR in the WHERE clause causes the query to degenerate to a multi-node plan. You can specify OR, IN list, or range conditions on columns outside the join condition if the data exists on the same node.
- You can only execute a single statement per request. Chained SQL statements are not permitted.
- Your query can be used in a driver-generated subquery to help determine whether the query can execute on a single node. Therefore, you cannot include the semi-colon at the end of the statement and you cannot include SQL comments using double-dashes (
--), as these cause the driver-generated query to fail.
You create a VerticaRoutableExecutor by calling the createRoutableExecutor method on a connection object:
createRoutableExecutor( schema-name, table-name )
For example:
VerticaRoutableConnection conn;
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
String table = "customers";
VerticaRoutableExecutor q = conn.createRoutableExecutor(null, table);
...
}...
If schema-name is set to null, then the search path is used to find the table.
VerticaRoutableExecutor methods
VerticaRoutableExecutor has the following methods:
For details on this class, see the JDBC documentation.
Execute
execute( query-string, { column, value | map } )
Runs the query.
query-string |
The query to execute |
column, value |
The column and value when the lookup is done on a single value. For example:
String column = "customer_key";
Integer value = 1;
ResultSet rs = q.execute(query, column, value)
|
map |
A Java map of the column names and corresponding values if the lookup is done on one or more columns. For example: ResultSet rs = q.execute(query, map);. The table must have at least one projection segmented by a set of columns that exactly match the columns in the map. Each column defined in the map can have only one value. For example:
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
map.put("another_key", 42);
ResultSet rs = q.execute(query, map);
|
The following requirements apply:
-
The query to execute must use regular SQL that complies with the rules of the VerticaRoutableExecutor class. For example, you can add limits and sorts, or use aggregate functions, provided the data exists on a single node.
-
The JDBC client uses the column/value or map arguments to determine on which node to execute the query. The content of the query must use the same values that you provide in the column/value or map arguments.
-
The following data types cannot be used as column values: * INTERVAL * TIMETZ * TIMESTAMPTZ
Also, if a table is segmented on any columns with the following data types then the table cannot be queried with the routable query API:
The driver does not verify the syntax of the query before it sends the query to the server. If your expression is incorrect, then the query fails.
Close
close()
Closes this VerticaRoutableExecutor by releasing resources used by this VerticaRoutableExecutor. It does not close the parent JDBC connection to Vertica.
getWarnings
getWarnings()
Retrieves the first warning reported by calls on this VerticaRoutableExecutor. Additional warnings are chained and can be accessed with the JDBC method getNextWarning().
Example
The following example shows how to use VerticaRoutableExecutor to execute a query using both a JOIN clause and an aggregate function with a GROUP BY clause. The example also shows how to create a customer and sales table, and segment the tables so they can be joined using the VerticaRoutableExecutor class. This example uses the date_dimension table in the VMart schema to show how to join data on unsegmented tables.
-
Create the customers table to store customer details, and then create projections that are segmented on the table's customer_key column:
=> CREATE TABLE customers (customer_key INT, customer_name VARCHAR(128), customer_email VARCHAR(128));
=> CREATE PROJECTION cust_proj_b0 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES;
=> CREATE PROJECTION cust_proj_b1 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 1;
=> CREATE PROJECTION cust_proj_b2 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 2;
=> SELECT start_refresh();
-
Create the sales table, then create projections that are segmented on its customer_key column. Because the customer and sales tables are segmented on the same key, you can join them later with the VerticaRoutableExecutor routable query lookup.
=> CREATE TABLE sales (sale_key INT, customer_key INT, date_key INT, sales_amount FLOAT);
=> CREATE PROJECTION sales_proj_b0 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES;
=> CREATE PROJECTION sales_proj_b1 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 1;
=> CREATE PROJECTION sales_proj_b2 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 2;
=> SELECT start_refresh();
-
Add some sample data:
=> INSERT INTO customers VALUES (1, 'Fred', 'fred@example.com');
=> INSERT INTO customers VALUES (2, 'Sue', 'Sue@example.com');
=> INSERT INTO customers VALUES (3, 'Dave', 'Dave@example.com');
=> INSERT INTO customers VALUES (4, 'Ann', 'Ann@example.com');
=> INSERT INTO customers VALUES (5, 'Jamie', 'Jamie@example.com');
=> COMMIT;
=> INSERT INTO sales VALUES(1, 1, 1, '100.00');
=> INSERT INTO sales VALUES(2, 2, 2, '200.00');
=> INSERT INTO sales VALUES(3, 3, 3, '300.00');
=> INSERT INTO sales VALUES(4, 4, 4, '400.00');
=> INSERT INTO sales VALUES(5, 5, 5, '400.00');
=> INSERT INTO sales VALUES(6, 1, 15, '500.00');
=> INSERT INTO sales VALUES(7, 1, 15, '400.00');
=> INSERT INTO sales VALUES(8, 1, 35, '300.00');
=> INSERT INTO sales VALUES(9, 1, 35, '200.00');
=> COMMIT;
-
Create an unsegmented projection of the VMart date_dimension table for use in this example. Call the meta-function START_REFRESH to unsegment the existing data:
=> CREATE PROJECTION date_dim AS SELECT * FROM date_dimension UNSEGMENTED ALL NODES;
=> SELECT start_refresh();
Using the customer, sales, and date_dimension data, you can now create a routable query lookup that uses joins and a group by to query the customers table and return the total number of purchases per day for a given customer:
import java.sql.*;
import java.util.HashMap;
import java.util.Map;
import com.vertica.jdbc.kv.*;
public class verticaKV_doc {
public static void main(String[] args) {
com.vertica.jdbc.DataSource jdbcSettings
= new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("VMart");
jdbcSettings.setHost("vertica.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setFailOnMultiNodePlans(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
String table = "customers";
VerticaRoutableExecutor q = conn.createRoutableExecutor(null, table);
String query = "select d.date, SUM(s.sales_amount) as Total ";
query += " from customers as c";
query += " join sales as s ";
query += " on s.customer_key = c.customer_key ";
query += " join date_dimension as d ";
query += " on d.date_key = s.date_key ";
query += " where c.customer_key = " + map.get("customer_key");
query += " group by (d.date) order by Total DESC";
ResultSet rs = q.execute(query, map);
while(rs.next()) {
System.out.print("Date: " + rs.getString("date") + ": ");
System.out.println("Amount: " + rs.getString("Total"));
}
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The example code produces output like this:
Date: 2012-01-15: Amount: 900.0
Date: 2012-02-04: Amount: 500.0
Date: 2012-01-01: Amount: 100.0
Note
Your output might be different, because the VMart schema randomly generates dates in the date_dimension table.
4 - Defining the query for routable queries using the VGet class
The VGet class is used to access table data directly from a single node when you do not need to join the data or use a group by clause.
The VGet class is used to access table data directly from a single node when you do not need to join the data or use a group by clause. Like VerticaRoutableExecutor, VGet directly queries Vertica nodes that have the data needed for the query, avoiding the distributed planning and execution costs associated with a normal Vertica execution. However, VGet does not use SQL. Instead, you define predicates and values to perform key/value type lookups on a single table. VGet is especially suited to key/value-type lookups on single tables.
You create a VGet by calling the prepareGet method on a connection object:
prepareGet( schema-name, { table-name | projection-name } )
For example:
VerticaRoutableConnection conn;
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
System.out.println("Connected.");
VGet get = conn.prepareGet("public", "users");
...
}...
VGet operations span multiple JDBC connections (and multiple Vertica sessions) and do not honor the parent connection's transaction semantics. If consistency is required across multiple executions, the parent VerticaRoutableConnection's consistent read API can be used to guarantee all operations occur at the same epoch.
VGet is thread safe, but all methods are synchronized, so threads that share a VGet instance are never run in parallel. For better parallelism, each thread should have its own VGet instance. Different VGet instances that operate on the same table share pooled connections and metadata in a manner that enables a high degree of parallelism.
VGet methods
VGet has the following methods:
By default, VGet fetches all columns of all rows that satisfy the logical AND of predicates passed via the addPredicate method. You can further customize the get operation with the following methods: addOutputColumn, addOutputExpression, addPredicateExpression, addSortColumn, and setLimit.
addPredicate
addPredicate(string, object)
Adds a predicate column and a constant value to the query. You must include a predicate for each column on which the table is segmented. The predicate acts as the query WHERE clause. Multiple addPredicate method calls are joined by AND modifiers. The VGet retains this value after each call to execute. To remove it, use clearPredicates.
The following data types cannot be used as column values. Also, if a table is segmented on any columns with these data types then the table cannot be queried with the Routable Query API:
addPredicateExpression
addPredicateExpression(string)
Accepts arbitrary SQL expressions that operate on the table's columns as input to the query. Predicate expressions and predicates are joined by AND modifiers. You can use segmented columns in predicate expressions, but they must also be specified as a regular predicate with addPredicate. The VGet retains this value after each call to execute. To remove it, use clearPredicates.
The driver does not verify the syntax of the expression before it sends it to the server. If your expression is incorrect then the query fails.
addOutputColumn
addOutputColumn(string)
Adds a column to be included in the output. By default the query runs as SELECT * and you do not need to define any output columns to return the data. If you add output columns then you must add all the columns to be returned. The VGet retains this value after each call to execute. To remove it, use clearOutputs.
addOutputExpression
addOutputExpression(string)
Accepts arbitrary SQL expressions that operate on the table's columns as output. The VGet retains this value after each call to execute. To remove it, use ClearOutputs.
The following restrictions apply:
-
The driver does not verify the syntax of the expression before it sends it to the server. If your expression is incorrect then the query fails.
-
addOutputExpression is not supported when querying flex tables. If you use addOutputExpression on a flex table query, then a SQLFeatureNotSupportedException is thrown.
addSortColumn
addSortColumn(string, SortOrder)
Adds a sort order to an output column. The output column can be either the one returned by the default query (SELECT *) or one of the columns defined in addSortColumn or addOutputExpress. You can defined multiple sort columns.
setLimit
setLimit(int)
Sets a limit on the number of results returned. A limit of 0 is unlimited.
clearPredicates
clearPredicates()
Removes predicates that were added by addPredicate and addPredicateExpression.
clearOutputs
clearOutputs()
Removes outputs added by addOutputColumn and addOutputExpression.
clearSortColumns
clearSortColumns()
Removes sort columns previously added by addSortColumn.
Execute
execute()
Runs the query. Care must be taken to ensure that the predicate columns exist on the table and projection used by VGet, and that the expressions do not require multiple nodes to execute. If an expression is sufficiently complex as to require more than one node to execute, execute throws a SQLException if the FailOnMultiNodePlans connection property is true.
Close
close()
Closes this VGet by releasing resources used by this VGet. It does not close the parent JDBC connection to Vertica.
getWarnings
getWarnings()
Retrieves the first warning reported by calls on this VGet. Additional warnings are chained and can be accessed with the JDBC method getNextWarning.
Example
The following code queries the users table that is defined in Creating tables and projections for use with the routable query API. The table defines an id column that is segmented by hash.
import java.sql.*;
import com.vertica.jdbc.kv.*;
public class verticaKV2 {
public static void main(String[] args) {
com.vertica.jdbc.DataSource jdbcSettings
= new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("exampleDB");
jdbcSettings.setHost("v_vmart_node0001.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
System.out.println("Connected.");
VGet get = conn.prepareGet("public", "users");
get.addPredicate("id", 5);
ResultSet rs = get.execute();
rs.next();
System.out.println("ID: " +
rs.getString("id"));
System.out.println("Username: "
+ rs.getString("username"));
System.out.println("Email: "
+ rs.getString("email"));
System.out.println("Closing Connection.");
conn.close();
} catch (SQLException e) {
System.out.println("Error! Stacktrace:");
e.printStackTrace();
}
}
}
This code produces the following output:
Connected.
ID: 5
Username: userE
Email: usere@example.com
Closing Connection.
5 - Routable query performance and troubleshooting
This topic details performance considerations and common issues you might encounter when using the routable query API.
This topic details performance considerations and common issues you might encounter when using the routable query API.
Using resource pools with routable queries
Individual routable queries are serviced quickly since they directly access a single node and return only one or a few rows of data. However, by default, Vertica resource pools use an AUTO setting for the execution parallelism parameter. When set to AUTO, the setting is determined by the number of CPU cores available and generally results in multi-threaded execution of queries in the resource pool. It is not efficient to create parallel threads on the server because routable query operations return data so quickly and routable query operations only use a single thread to find a row. To prevent the server from opening unneeded processing threads, you should create a specific resource pool for routable query clients. Consider the following settings for the resource pool you use for routable queries:
-
Set execution parallelism to 1 to force single-threaded queries. This setting improves routable query performance.
-
Use CPU affinity to limit the resource pool to a specific CPU or CPU set. The setting ensures that the routable queries have resources available to them, but it also prevents routable queries from significantly impacting performance on the system for other general queries.
-
If you do not set a CPU affinity for the resource pool, consider setting the maximum concurrency value of the resource pool to a setting that ensures good performance for routable queries, but does not negatively impact the performance of general queries.
Because a VerticaRoutableConnection opens an internal pool of connections, it is important to configure MaxPooledConnections and MaxPooledConnectionsPerNode appropriately for your cluster size and the amount of simultaneous client connections. It is possible to impact normal database connections if you are overloading the cluster with VerticaRoutableConnections.
The initial connection to the initiator node discovers all other nodes in the cluster. The internal-pool connections are not opened until a VerticaRoutableExecutor or VGet query is sent. All VerticaRoutableExecutors/VGets in a connection object use connections from the internal pool and are limited by the MaxPooledConnections settings. Connections remain open until they are closed so a new connection can be opened elsewhere if the connection limit has been reached.
Troubleshooting routable queries
Routable query issues generally fall into two categories:
Predicate Requirements
You must provide the same number of predicates that correspond to the columns of the table segmented by hash. To determine the segmented columns, call the Vertica function
GET_PROJECTIONS. You must provide a predicate for each column displayed in the Seg Cols field.
For VGet, this means you must use addPredicate() to add each of the columns. For VerticaRoutableExecutor, this means you must provide all of the predicates and values in the map sent to execute().
Multi-node Failures
It is possible to define the correct number of predicates, but still have a failure because multiple nodes contain the data. This failure occurs because the projection's data is not segmented in such a way that the data being queried is contained on a single node. Enable logging for the connection and view the logs to verify the projection being used. If the client is not picking the correct projection, then try to query the projection directly by specifying the projection instead of the table in the create/prepare statement, for example:
Additionally, you can use the EXPLAIN command in vsql to help determine if your query can run in single node. EXPLAIN can help you understand why the query is being run as single or multi-node.
6 - Pre-segmenting data using VHash
The VHash class is an implementation of the Vertica hash function for use with JDBC client applications.
The VHash class is an implementation of the Vertica hash function for use with JDBC client applications.
Hash segmentation in Vertica allows you to segment a projection based on a built-in hash function. The built-in hash function provides even data distribution across some or all nodes in a cluster, resulting in optimal query execution.
Suppose you have several million rows of values spread across thousands of CSV files. Assume that you already have a table segmented by hash. Before you load the values into your database, you probably want to know to which node a particular value loads. For this reason, using VHash can be particularly helpful, by allowing you to pre-segment your data before loading.
The following example shows the VHash class hashing the first column of a file named "testFile.csv". The name of the first column in this file is meterId.
Segment the data using VHash
This example demonstrates how you can read the testFile.csv file from the local file system and run a hash function on the meteterId column. Using the database metadata from a projection, you can then pre-segment the individual rows in the file based on the hash value of meterId.
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.UnsupportedEncodingException;
import java.util.*;
import java.io.IOException;
import java.sql.*;
import com.vertica.jdbc.kv.VHash;
public class VerticaKVDoc {
final Map<String, FileOutputStream> files;
final Map<String, List<Long>> nodeToHashList;
String segmentationMetadata;
List<String> lines;
public static void main(String[] args) throws Exception {
try {
Class.forName("com.vertica.jdbc.Driver");
} catch (ClassNotFoundException e) {
System.err.println("Could not find the JDBC driver class.");
e.printStackTrace();
return;
}
Properties myProp = new Properties();
myProp.put("user", "username");
myProp.put("password", "password");
VerticaKVDoc ex = new VerticaKVDoc();
// Read in the data from a CSV file.
ex.readLinesFromFile("C:\\testFile.csv");
try (Connection conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:portNumber/databaseName", myProp)) {
// Compute the hashes and create FileOutputStreams.
ex.prepareForHashing(conn);
}
// Write to files.
ex.writeLinesToFiles();
}
public VerticaKVDoc() {
files = new HashMap<String, FileOutputStream>();
nodeToHashList = new HashMap<String, List<Long>>();
}
public void prepareForHashing(Connection conn) throws SQLException,
FileNotFoundException {
// Send a query to Vertica to return the projection segments.
try (ResultSet rs = conn.createStatement().executeQuery(
"SELECT get_projection_segments('public.projectionName')")) {
rs.next();
segmentationMetadata = rs.getString(1);
}
// Initialize the data files.
try (ResultSet rs = conn.createStatement().executeQuery(
"SELECT node_name FROM nodes")) {
while (rs.next()) {
String node = rs.getString(1);
files.put(node, new FileOutputStream(node + ".csv"));
}
}
}
public void writeLinesToFiles() throws UnsupportedEncodingException,
IOException {
for (String line : lines) {
long hashedValue = VHash.hashLong(getMeterIdFromLine(line));
// Write the row data to that node's data file.
String node = VHash.getNodeFor(segmentationMetadata, hashedValue);
FileOutputStream fos = files.get(node);
fos.write(line.getBytes("UTF-8"));
}
}
private long getMeterIdFromLine(String line) {
// In our file, "meterId" is the name of the first column in the file.
return Long.parseLong(line.split(",")[0]);
}
public void readLinesFromFile(String filename) throws IOException {
lines = new ArrayList<String>();
String line;
try (BufferedReader reader = new BufferedReader(
new FileReader(filename))) {
while ((line = reader.readLine()) != null) {
lines.add(line);
}
}
}
}