This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Java
The Vertica JDBC driver provides you with a standard JDBC API.
The Vertica JDBC driver provides you with a standard JDBC API. If you have accessed other databases using JDBC, you should find accessing Vertica familiar. This section explains how to use the JDBC to connect your Java application to Vertica.
Prerequisites
You must install the JDBC client driver before creating Java client applications.
1 - JDBC feature support
The Vertica JDBC driver complies with the JDBC 4.0 standards (although it does not implement all of the optional features in them).
The Vertica JDBC driver complies with the JDBC 4.0 standards (although it does not implement all of the optional features in them). Your application can use the DatabaseMetaData class to determine if the driver supports a particular feature it wants to use. In addition, the driver implements the Wrapper interface, which lets your client code discover Vertica-specific extensions to the JDBC standard classes, such as VerticaConnection and VerticaStatement classes.
Some important facts to keep in mind when using the Vertica JDBC driver:
-
Cursors are forward only and are not scrollable. Result sets cannot be updated.
-
A connection supports executing a single statement at any time. If you want to execute multiple statements simultaneously, you must open multiple connections.
-
CallableStatement is supported as of the version 12.0.0 of the client driver.
Multiple SQL statement support
The Vertica JDBC driver can execute strings containing multiple statements. For example:
stmt.executeUpdate("CREATE TABLE t(a INT);INSERT INTO t VALUES(10);");
Only the Statement interface supports executing strings containing multiple SQL statements. You cannot use multiple statement strings with PreparedStatement. COPY statements that copy a file from a host file system work in a multiple statement string. However, client COPY statements (COPY FROM STDIN) do not work.
Multiple batch conversion to COPY statements
The Vertica JDBC driver converts all batch inserts into Vertica COPY statements. If you turn off your JDBC connection's AutoCommit property, the JDBC driver uses a single COPY statement to load data from sequential batch inserts which can improve load performance by reducing overhead. See Batch inserts using JDBC prepared statements for details.
JDBC version
The version of JDBC is determined by the version of the JVM. A JVM version of 8 or higher uses JDBC 4.2.
Multiple active result sets (MARS)
The Vertica JDBC driver supports Multiple active result sets (MARS). MARS allows the execution of multiple queries on a single connection. While ResultBufferSize sends the results of a query directly to the client, MARS stores the results first on the server. Once query execution has finished and all of the results have been stored, you can make a retrieval request to the server to have rows returned to the client.
2 - Creating and configuring a connection
Before your Java application can interact with Vertica, it must create a connection.
Before your Java application can interact with Vertica, it must create a connection. Connecting to Vertica using JDBC is similar to connecting to most other databases.
Importing SQL packages
Before creating a connection, you must import the Java SQL packages. A simple way to do so is to import the entire package using a wildcard:
You may also want to import the Properties class. You can use an instance of this class to pass connection properties when instantiating a connection, rather than encoding everything within the connection string:
import java.util.Properties;
Applications can run in a Java 6 or later JVM. If so, then the JVM automatically loads the Vertica JDBC 4.0-compatible driver without requiring the call to Class.forName. However, making this call does not adversely affect the process. Thus, if you want your application to be compatible with both Java 5 and Java 6 (or later) JVMs, it can still call Class.forName.
Opening the connection
With SQL packages imported, you are ready to create your connection by calling the DriverManager.getConnection() method. You supply this method with at least the following information:
-
The IP address or host name of a node in the database cluster.
You can provide an IPv4 address, IPv6 address, or host name.
In mixed IPv4/IPv6 networks, the DNS server configuration determines which IP version address is sent first. Use the PreferredAddressFamily option to force the connection to use either IPv4 or IPv6.
-
Port number for the database
-
Username of a database user account
-
Password of the user (if the user has a password)
The first three parameters are always supplied as part of the connection string, a URL that tells the JDBC driver where to find the database. The format of the connection string is (/databaseName is optional):
jdbc:vertica://VerticaHost:portNumber/databaseName
The first portion of the connection string selects the Vertica JDBC driver, followed by the location of the database.
You can provide the last two parameters, username and password, to the JDBC driver, in one of three ways:
-
As part of the connection string. The parameters are encoded similarly to URL parameters:
"jdbc:vertica://VerticaHost:portNumber/databaseName?user=username&password=password"
-
As separate parameters to DriverManager.getConnection():
Connection conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:portNumber/databaseName",
"username", "password");
-
In a Properties object:
Properties myProp = new Properties();
myProp.put("user", "username");
myProp.put("password", "password");
Connection conn = .getConnection(
"jdbc:vertica://VerticaHost:portNumber/databaseName", myProp);
Of these three methods, the Properties object is the most flexible because it makes passing additional connection properties to the getConnection() method easy. See Connection Properties and Setting and getting connection property values for more information about the additional connection properties.
If there is any problem establishing a connection to the database, the getConnection() method throws a SQLException on one of its subclasses. To prevent an exception, enclose the method within a try-catch block, as shown in the following complete example of establishing a connection.
import java.sql.*;
import java.util.Properties;
public class VerySimpleVerticaJDBCExample {
public static void main(String[] args) {
/*
* If your client needs to run under a Java 5 JVM, It will use the older
* JDBC 3.0-compliant driver, which requires you manually load the
* driver using Class.forname
*/
/*
* try { Class.forName("com.vertica.jdbc.Driver"); } catch
* (ClassNotFoundException e) { // Could not find the driver class.
* Likely an issue // with finding the .jar file.
* System.err.println("Could not find the JDBC driver class.");
* e.printStackTrace(); return; // Bail out. We cannot do anything
* further. }
*/
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("password", "vertica");
myProp.put("loginTimeout", "35");
myProp.put("KeystorePath", "c:/keystore/keystore.jks");
myProp.put("KeystorePassword", "keypwd");
myProp.put("TrustStorePath", "c:/truststore/localstore.jks");
myProp.put("TrustStorePassword", "trustpwd");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://V_vmart_node0001.example.com:5433/vmart", myProp);
System.out.println("Connected!");
conn.close();
} catch (SQLTransientConnectionException connException) {
// There was a potentially temporary network error
// Could automatically retry a number of times here, but
// instead just report error and exit.
System.out.print("Network connection issue: ");
System.out.print(connException.getMessage());
System.out.println(" Try again later!");
return;
} catch (SQLInvalidAuthorizationSpecException authException) {
// Either the username or password was wrong
System.out.print("Could not log into database: ");
System.out.print(authException.getMessage());
System.out.println(" Check the login credentials and try again.");
return;
} catch (SQLException e) {
// Catch-all for other exceptions
e.printStackTrace();
}
}
}
Creating a connection with a keystore and truststore
You can create secure connections with your JDBC client driver using a keystore and a truststore. For more information on security within Vertica, refer to Security and authentication.
For examples and instructions on how to generate (or import external) certificates in Vertica, see Generating TLS certificates and keys.
To view your keys and certificates in Vertica, see CERTIFICATES and CRYPTOGRAPHIC_KEYS.
-
Generate your own self-signed certificate or use an existing CA (certificate authority) certificate as the root CA. For information on this process, refer to the Schannel documentation.
-
Optional: Generate or import an intermediate CA certificate signed by your root CA. While not required, having an intermediate CA can be useful for testing and debugging your connection.
-
Generate and sign (or import) a server certificate for Vertica.
-
Use ALTER TLS CONFIGURATION to configure Vertica to use client/server TLS for new connections. For more information, see Configuring client-server TLS.
For Server Mode (no client-certificate verification):
=> ALTER TLS CONFIGURATION server TLSMODE 'ENABLE';
=> ALTER TLS CONFIGURATION server CERTIFICATE server_cert;
For Mutual Mode (client-certificate verification of varying strictness depending on the TLSMODE):
=> ALTER TLS CONFIGURATION server TLSMODE 'TRY_VERIFY';
=> ALTER TLS CONFIGURATION server CERTIFICATE server_cert ADD CA CERTIFICATES ca_cert;
-
Optionally, you can disable all non-SSL connections with CREATE AUTHENTICATION.
=> CREATE AUTHENTICATION no_tls METHOD 'reject' HOST NO TLS '0.0.0.0/0';
=> CREATE AUTHENTICATION no_tls METHOD 'reject' HOST NO TLS '::/128';
-
Generate and sign a certificate for your client using the same CA that signed your server certificate.
-
Convert your chain of pem certificates to a single pkcs 12 file.
-
Import the client key and chain into a keystore JKS file from your pkcs12 file. For information on using the keytool command interface, refer to the Java documentation.
$ keytool -importkeystore -srckeystore -alias my_alias -srcstoretype PKCS12 -srcstorepass my_password -noprompt -deststorepass my_password -destkeypass my_password -destkeystore /tmp/keystore.jks
-
Import the CA into a truststore JKS file.
$ keytool -import -file certs/intermediate_ca.pem -alias my_alias -trustcacerts -keystore /tmp/truststore.jks -storepass my_truststore_password -noprompt
Usage considerations
-
When you disconnect a user session, any uncommitted transactions are automatically rolled back.
-
If your database is not compliant with your Vertica license terms, Vertica issues a SQLWarning when you establish the connection to the database. You can retrieve this warning using the Connection.getWarnings() method. See Managing licenses for more information about complying with your license terms.
2.1 - JDBC connection properties
You use connection properties to configure the connection between your JDBC client application and your Vertica database.
You use connection properties to configure the connection between your JDBC client application and your Vertica database. The properties provide the basic information about the connections, such as the server name and port number to use to connect to your database. They also let you tune the performance of your connection and enable logging.
You can set a connection property in one of the following ways:
-
Include the property name and value as part of the connection string you pass to the method DriverManager.getConnection().
-
Set the properties in a Properties object, and then pass it to the method DriverManager.getConnection().
-
Use the method VerticaConnection.setProperty(). With this approach, you can change only those connection properties that remain changeable after the connection has been established.
Also, some standard JDBC connection properties have getters and setters on the Connection interface, such as Connection.setAutoCommit().
Connection properties
The properties in the following table can only be set before you open the connection to the database. Two of them are required for every connection.
|
Property |
Description |
|
BinaryTransfer |
Boolean value that determines which mode Vertica uses when connecting to a JDBC client:
Binary transfer is generally more efficient at reading data from a server to a JDBC client and typically requires less bandwidth than text transfer. However, when transferring a large number of small values, binary transfer may use more bandwidth.
The data output by both modes is identical with the following exceptions for certain data types:
-
FLOAT: Binary transfer has slightly better precision.
-
TIMESTAMPTZ: Binary transfer can fail to get the session time zone and default to the local time zone, while text transfer reliably uses the session time zone.
-
NUMERIC: Binary transfer is forcibly disabled for NUMERIC data by the server for Vertica 11.0.2+.
|
|
ConnSettings |
A string containing SQL statements that the JDBC driver automatically runs after it connects to the database. You can use this property to set the locale or schema search path, or perform other configuration that the connection requires. |
|
Label |
Sets a label for the connection on the server. This value appears in the client_label column of the SESSIONS system table.
Default: jdbc-driver-version-random_number
|
|
SSL |
When set to true, use SSL to encrypt the connection to the server. Vertica must be configured to handle SSL connections before you can establish an SSL-encrypted connection to it. See TLS protocol. This property has been deprecated in favor of the TLSmode property.
Default: false
|
|
TLSmode |
TLSmode identifies the security level that Vertica applies to the JDBC connection. Vertica must be configured to handle TLS connections before you can establish an encrypted connection to it. See TLS protocol for details. Valid values are:
-
disable: JDBC connects using plain text and implements no security measures.
-
require: JDBC connects using TLS without verifying the CA certificate.
-
verify-ca: JDBC connects using TLS and confirms that the server certificate has been signed by the certificate authority. This setting is equivalent to the deprecated ssl=true property.
-
verify-full: JDBC connects using TLS, confirms that the server certificate has been signed by the certificate authority, and verifies that the host name matches the name provided in the server certificate.
If this property and the SSL property are set, this property takes precedence.
Default: disable
|
|
HostnameVerifier |
If TLSmode is set to verify-full, this property the fully qualified domain name of the verifier that you want to confirm the host name. |
|
Password |
Required (for non-OAuth connections), the password to use to log into the database. |
|
User |
Required (for non-OAuth connections), the database user name to use to connect to the database. |
|
ConnectionLoadBalance |
A Boolean value indicating whether the client is willing to have its connection redirected to another host in the Vertica database. This setting has an effect only if the server has also enabled connection load balancing. See About native connection load balancing for more information about native connection load balancing.
Default: false
|
|
BackupServerNode |
A string containing the host name or IP address of one or more hosts in the database. If the connection to the host specified in the connection string times out, the client attempts to connect to any host named in this string.The host name or IP address can also include a colon followed by the port number for the database. If no port number is specified, the client uses the standard port number ( 5433) . Separate multiple host name or IP address entries with commas. |
|
PreferredAddressFamily |
The IP version to use if the client and server have both IPv4 and IPv6 addresses and you have provided a host name, one of the following:
-
ipv4: Connect to the server using IPv4.
-
ipv6: Connect to the server using IPv6.
-
none: Use the IP address provided by the DNS server.
Default: none
|
|
KeyStorePath |
The path to a .JKS file containing your private keys and their corresponding certificate chains. For information on creating a keystore, refer to documentation for your development environment. For information on creating a keystore, refer to the Java documentation. |
|
KeyStorePassword |
The password protecting the keystore file. If individual keys are also encrypted, the keystore file password must match the password for a key within the keystore. |
|
TrustStorePath |
The path to a .JKS truststore file containing certificates from authorities you trust. |
|
TrustStorePassword |
The password protecting the truststore file. |
|
workload |
The name of the workload for the session. For details, see Workload routing. |
OAuth connection properties
The following connection properties pertain to OAuth in JDBC.
|
Property |
Description |
|
oauthaccesstoken |
Required if oauthrefreshtoken is unspecified, an OAuth token that authorizes a user to the database. |
|
oauthrefreshtoken |
Deprecated
Use oauthaccesstoken instead. Token refresh should be handled by the client application separately.
Required if oauthaccesstoken is unspecified, a token used to obtain a new access token when their old one expires.
Either OAuthAccessToken or OAuthRefreshToken must be set (programmatically or manually) to authenticate to Vertica with OAuth authentication.
You can omit both OAuthAccessToken and OAuthRefreshToken only if you authenticate to your identity provider directly with single sign-on through the client driver, which requires the machine running the ODBC driver to have access to a web browser.
For details on the different methods for retrieving access tokens, see Retrieving access tokens.
If you set this parameter, you must also set the OAuthClientSecret connection property.
In cases where introspection fails (e.g. when the access token expires), Vertica responds to the request with an error. If introspection fails and OAuthRefreshToken is specified, the driver attempts to refresh and silently retrieve a new access token. Otherwise, the driver passes error to the client application.
|
|
oauthclientsecret |
Deprecated
Use oauthaccesstoken instead. Token refresh should be handled by the client application separately.
The secret provided by your identity provider for your client. |
|
oauthtruststorepath |
Deprecated
This property is deprecated, but will still be necessary if your environment requires custom CA certificates for the driver to connect to your identity provider. Versions with this property removed will not require the driver to connect to the identity provider.
The path to a custom truststore. If unspecified, JDBC uses the default system truststore. |
|
oauthtruststorepassword |
Deprecated
This property is deprecated, but will still be necessary if your environment requires custom CA certificates for the driver to connect to your identity provider. Versions with this property removed will not require the driver to connect to the identity provider.
The password to the truststore.
|
Timeout properties
With the following parameters, you can specify various timeouts for each step and the overall connection of JDBC to your Vertica database.
|
Property |
Description |
|
LoginTimeout |
The number of seconds Vertica waits for the client to log in to the database before throwing a SQLException.
Default: 0 (no timeout)
|
|
LoginNodeTimeout |
The number of seconds the JDBC client waits before attempting to connect to the next node if the Vertica process is running, but does not respond. The "next" node is determined by the either the BackupServerNode connection property or DNS resolution. If you only provide a single IP address, the JDBC client returns an error.
A timeout value of 0 instructs JDBC to wait indefinitely for an error/a successful connection rather than attempt to connect to another node.
Default: 0 (no timeout)
|
|
LoginNetworkTimeout |
The number of seconds the JDBC client has to establish a TCP connection to a Vertica node. A typical use case for this property is to let JDBC connect to another node if the system is down for maintenance and modifying the JDBC application's connection string is infeasible.
Default: 0 (no timeout)
|
|
NetworkTimeout |
The number of milliseconds for the server to reply to a request after the client has established a connection with the database.
Default: 0
|
The relationship between these properties and the role they play when JDBC attempts to connect to a Vertica database is illustrated in the following diagram:

General properties
The following properties can be set after the connection is established. None of these properties are required.
|
Property |
Description |
|
AutoCommit |
Controls whether the connection automatically commits transactions. Set this parameter to false to prevent the connection from automatically committing its transactions. You often want to do this when you are bulk loading multiple batches of data and you want the ability to roll back all of the loads if an error occurs.
Set After Connection: Connection.setAutoCommit()
Default: true
|
|
DirectBatchInsert |
Deprecated, always set to true. |
|
DisableCopyLocal |
When set to true, disables file-based COPY LOCAL operations, including copying data from local files and using local files to store data and exceptions. You can use this property to prevent users from writing to and copying from files on a Vertica host, including an MC host.
Default: false
|
|
MultipleActiveResultSets |
Allows more than one active result set on a single connection via MultipleActiveResultSets (MARS).
If both MultipleActiveResultSets and ResultBufferSize are turned on, MultipleActiveResultSets takes precedence. The connection does not provide an error, however ResultBufferSize is ignored.
Set After Connection: VerticaConnection.setProperty()
Default: false
|
|
ReadOnly |
When set to true, makes the data connection read-only. Any queries attempting to update the database using a read-only connection cause a SQLException.
Set After Connection: Connection.setReadOnly()
Default: false
|
|
ResultBufferSize |
Sets the size of the buffer the Vertica JDBC driver uses to temporarily store result sets. A value of 0 means ResultBufferSize is turned off.
Note: This property was named maxLRSMemory in previous versions of the Vertica JDBC driver.
Set After Connection: VerticaConnection.setProperty()
Default: 8912 (8KB)
|
|
SearchPath |
Sets the schema search path for the connection. This value is a string containing a comma-separated list of schema names. See Setting Search Paths for more information on the schema search path.
Set After Connection: VerticaConnection.setProperty()
Default: "$user", public, v_catalog, v_monitor, v_internal
|
|
ThreePartNaming |
A Boolean value that controls how DatabaseMetaData reports the catalog name. When set to true, the database name is returned as the catalog name in the database metadata. When set to false, NULL is returned as the catalog name.
Enable this option if your client software is set up to get the catalog name from the database metadata for use in a three-part name reference.
Set After Connection: VerticaConnection.setProperty()
Default: true
|
|
TransactionIsolation |
Sets the isolation level of the transactions that use the connection. See Changing the transaction isolation level for details.
Note: In previous versions of the Vertica JDBC driver, this property was only available using a getter and setter on the PGConnection object. You can now set it in the same way as other connection properties.
Set After Connection: Connection.setTransactionIsolation()
Default: TRANSACTION_READ_COMMITTED
|
Logging properties
The properties that control client logging must be set before the connection is opened. None of these properties are required, and none can be changed after the Connection object has been instantiated.
|
Property |
Description |
|
LogLevel |
Sets the type of information logged by the JDBC driver. The value is set to one of the following values:
-
"DEBUG"
-
"ERROR"
-
"TRACE"
-
"WARNING"
-
"INFO"
-
"OFF"
Default: "OFF"
|
|
LogNameSpace |
Restricts logging to just messages generated by a specific packages. Valid values are:
-
com.vertica — All messages generated by the JDBC driver
-
com.vertica.jdbc — All messages generated by the top-level JDBC API
-
com.vertica.jdbc.kv — A ll messages generated by the JDBC KV API)
-
com.vertica.jdbc.core — Connection and statement settings
-
com.vertica.jdbc.io — Client/server protocol messages
-
com.vertica.jdbc.util — Miscellaneous utilities
-
com.vertica.jdbc.dataengine — Query execution and result set iteration
-
com.vertica.dataengine — Query execution and result set iteration
|
|
LogPath |
The path for the log file.
Default: The current working directory
|
Kerberos connection parameters
Use the following parameters to set the service and host name principals for client authentication using Kerberos.
|
Parameters |
Description |
|
JAASConfigName |
Provides the name of the JAAS configuration that contains the JAAS Krb5LoginModule and its settings
Default: verticajdbc
|
|
KerberosServiceName |
Provides the service name portion of the Vertica Kerberos principal, for example: vertichost@EXAMPLE.COM
Default: vertica
|
|
KerberosHostname |
Provides the instance or host name portion of the Vertica Kerberos principal, for example: verticaosEXAMPLE.COM
Default: Value specified in the servername connection string property
|
Routable connection API connection parameters
Use the following parameters to set properties to enable and configure the connection for Routable Connection lookups.
|
Parameters |
Description |
|
EnableRoutableQueries |
Enables Routable Connection lookup. See Routing JDBC queries directly to a single node
Default: false
|
|
FailOnMultiNodePlans |
If the query plan requires more than one node, then the query fails. Only applicable when EnableRoutableQueries = true.
Default: true
|
|
MetadataCacheLifetime |
The time in seconds to keep projection metadata. Only applicable when EnableRoutableQueries = true.
Default:
|
|
MaxPooledConnections |
Cluster-wide maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Only applicable when EnableRoutableQueries = true.
Default: 20
|
MaxPooledConnections
PerNode |
Per-node maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Only applicable when EnableRoutableQueries = true.
Default: 5
|
Note
You can also use VerticaConnection.setProperty() method to set properties that have standard JDBC Connection setters, such as AutoCommit.
For information about manipulating these attributes, see Setting and getting connection property values.
2.2 - Setting and getting connection property values
When creating a connection to Vertica, you can set connection properties by:.
You can set a connection property in one of the following ways:
-
Include the property name and value as part of the connection string you pass to the method DriverManager.getConnection().
-
Set the properties in a Properties object, and then pass it to the method DriverManager.getConnection().
-
Use the method VerticaConnection.setProperty(). With this approach, you can change only those connection properties that remain changeable after the connection has been established.
Also, some standard JDBC connection properties have getters and setters on the Connection interface, such as Connection.setAutoCommit().
Setting properties when connecting
When creating a connection to Vertica, you can set connection properties by:
Connection string properties
You can specify connection properties in the connection string with the same URL parameter format used for usernames and passwords. For example, the following string enables a TLS connection:
"jdbc:vertica://VerticaHost:5433/db?user=UserName&password=Password&TLSmode=require"
Setting a host name using the setProperty() method overrides the host name set in a connection string. If this occurs, Vertica might not be able to connect to a host. For example, using the connection string above, the following overrides the VerticaHost name:
Properties props = new Properties();
props.setProperty("dataSource", dataSourceURL);
props.setProperty("database", database);
props.setProperty("user", user);
props.setProperty("password", password);
ps.setProperty("jdbcDriver", jdbcDriver);
props.setProperty("hostName", "NonVertica_host");
However, if a new connection or override connection is needed, you can enter a valid host name in the hostname properties object.
The NonVertica_host hostname overrides VerticaHost name in the connection string. To avoid this issue, comment out the props.setProperty("hostName", "NonVertica_host");line:
//props.setProperty("hostName", "NonVertica_host");
Properties object
To set connection properties with the Properties object passed to the getConnection() call:
-
Import the java.util.Properties class to instantiate a Properties object.
-
Use the put() method to add name-value pairs to the object.
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
myProp.put("LoginTimeout", "35");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:/ExampleDB", myProp);
} catch (SQLException e) {
e.printStackTrace();
}
Note
The data type of all of the values you set in the Properties object are strings, regardless of the property value's data type.
Getting and setting properties after connecting
After you establish a connection with Vertica, you can use the VerticaConnection methods getProperty() and setProperty() to set the values of some connection properties, respectively.
The VerticaConnection.getProperty() method lets you get the value of some connection properties. Use this method to change the value for properties that can be set after you establish a connection with Vertica.
Because these methods are Vertica-specific, you must cast your Connection object to the VerticaConnection interface with one of the following methods:
The following example demonstrates getting and setting the value of the ReadOnly property.
import java.sql.*;
import java.util.Properties;
import com.vertica.jdbc.*;
public class SetConnectionProperties {
public static void main(String[] args) {
// Note: If your application needs to run under Java 5, you need to
// load the JDBC driver using Class.forName() here.
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
// Set ReadOnly to true initially
myProp.put("ReadOnly", "true");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// Show state of the ReadOnly property. This was set at the
// time the connection was created.
System.out.println("ReadOnly state: "
+ ((VerticaConnection) conn).getProperty(
"ReadOnly"));
// Change it and show it again
((VerticaConnection) conn).setProperty("ReadOnly", false);
System.out.println("ReadOnly state is now: " +
((VerticaConnection) conn).getProperty(
"ReadOnly"));
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
When run, the example prints the following on the standard output:
ReadOnly state: true
ReadOnly state is now: false
2.3 - Configuring TLS for JDBC clients
To configure TLS for JDBC clients:.
To configure TLS for JDBC clients:
Setting keystore/truststore properties
You can set the keystore and truststore properties in the following ways, each with their own pros and cons:
-
At the driver level.
-
At the JVM level.
Driver-level configuration
If you use tools like DbVizualizer with many connections, configure the keystore and truststore with the JDBC connection properties. This does, however, expose these values in the connection string:
-
KeyStorePath
-
KeyStorePassword
-
TrustStorePath
-
TrustStorePassword
For example:
Properties props = new Properties();
props.setProperty("KeyStorePath", keystorepath);
props.setProperty("KeyStorePassword", keystorepassword);
props.setProperty("TrustStorePath", truststorepath);
props.setProperty("TrustStorePassword", truststorepassword);
JVM-level configuration
Setting keystore and truststore parameters at the JVM level excludes them from the connection string, which may be more accommodating for environments with more stringent security requirements:
For example:
System.setProperty("javax.net.ssl.keyStore","clientKeyStore.key");
System.setProperty("javax.net.ssl.trustStore","clientTrustStore.key");
System.setProperty("javax.net.ssl.keyStorePassword","new_keystore_password")
System.setProperty("javax.net.ssl.trustStorePassword","new_truststore_password");
Set the TLSmode connection property
You can set the TLSmode connection property to determine how certificates are handled. TLSmode is disabled by default.
TLSmode identifies the security level that Vertica applies to the JDBC connection. Vertica must be configured to handle TLS connections before you can establish an encrypted connection to it. See TLS protocol for details. Valid values are:
-
disable: JDBC connects using plain text and implements no security measures.
-
require: JDBC connects using TLS without verifying the CA certificate.
-
verify-ca: JDBC connects using TLS and confirms that the server certificate has been signed by the certificate authority. This setting is equivalent to the deprecated ssl=true property.
-
verify-full: JDBC connects using TLS, confirms that the server certificate has been signed by the certificate authority, and verifies that the host name matches the name provided in the server certificate.
If this property and the SSL property are set, this property takes precedence.
For example, to configure JDBC to connect to the server with TLS without verifying the CA certificate, you can set the TLSmode property to 'require' with the method VerticaConnection.setProperty():
Properties props = new Properties();
props.setProperty("TLSmode", "verify-full");
Run the SSL debug utility
After configuring TLS, you can run the following for a debugging utility:
$ java -Djavax.net.debug=ssl
You can use several debug specifiers (options) with the debug utility. The specifiers help narrow the scope of the debugging information that is returned. For example, you could specify one of the options that prints handshake messages or session activity.
For information on the debug utility and its options, see Debugging Utilities in the Oracle document, JSSE Reference Guide.
For information on interpreting debug information, refer to the Oracle document, Debugging SSL/TLS Connections.
2.4 - Setting and returning a client connection label
The JDBC Client has a method to set and return the client connection label: getClientInfo() and setClientInfo(). You can use these methods with the SQL Functions GET_CLIENT_LABEL and SET_CLIENT_LABEL.
When you use these two methods, make sure you pass the string value APPLICATIONNAME to both the setter and getter methods.
Use setClientInfo() to create a client label, and use getClientInfo() to return the client label:
import java.sql.*;
import java.util.Properties;
public class ClientLabelJDBC {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("password", "");
myProp.put("loginTimeout", "35");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://example.com:5433/mydb", myProp);
System.out.println("Connected!");
conn.setClientInfo("APPLICATIONNAME", "JDBC Client - Data Load");
System.out.println("New Conn label: " + conn.getClientInfo("APPLICATIONNAME"));
conn.close();
} catch (SQLTransientConnectionException connException) {
// There was a potentially temporary network error
// Could automatically retry a number of times here, but
// instead just report error and exit.
System.out.print("Network connection issue: ");
System.out.print(connException.getMessage());
System.out.println(" Try again later!");
return;
} catch (SQLInvalidAuthorizationSpecException authException) {
// Either the username or password was wrong
System.out.print("Could not log into database: ");
System.out.print(authException.getMessage());
System.out.println(" Check the login credentials and try again.");
return;
} catch (SQLException e) {
// Catch-all for other exceptions
e.printStackTrace();
}
}
}
When you run this method, it prints the following result to the standard output:
Connected!
New Conn Label: JDBC Client - Data Load
2.5 - Setting the locale for JDBC sessions
You set the locale for a connection while opening it by including a SET LOCALE statement in the ConnSettings property, or by executing a SET LOCALE statement at any time after opening the connection.
You set the locale for a connection while opening it by including a SET LOCALE statement in the ConnSettings property, or by executing a SET LOCALE statement at any time after opening the connection. Changing the locale of a Connection object affects all of the Statement objects you instantiated using it.
You can get the locale by executing a SHOW LOCALE query. The following example demonstrates setting the locale using ConnSettings and executing a statement, as well as getting the locale:
import java.sql.*;
import java.util.Properties;
public class GetAndSetLocale {
public static void main(String[] args) {
// If running under a Java 5 JVM, you need to load the JDBC driver
// using Class.forname here
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
// Set Locale to true en_GB on connection. After the connection
// is established, the JDBC driver runs the statements in the
// ConnSettings property.
myProp.put("ConnSettings", "SET LOCALE TO en_GB");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// Execute a query to get the locale. The results should
// show "en_GB" as the locale, since it was set by the
// conn settings property.
Statement stmt = conn.createStatement();
ResultSet rs = null;
rs = stmt.executeQuery("SHOW LOCALE");
System.out.print("Query reports that Locale is set to: ");
while (rs.next()) {
System.out.println(rs.getString(2).trim());
}
// Now execute a query to set locale.
stmt.execute("SET LOCALE TO en_US");
// Run query again to get locale.
rs = stmt.executeQuery("SHOW LOCALE");
System.out.print("Query now reports that Locale is set to: ");
while (rs.next()) {
System.out.println(rs.getString(2).trim());
}
// Clean up
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Running the above example displays the following on the system console:
Query reports that Locale is set to: en_GB (LEN)
Query now reports that Locale is set to: en_US (LEN)
Notes:
-
JDBC applications use a UTF-16 character set encoding and are responsible for converting any non-UTF-16 encoded data to UTF-16. Failing to convert the data can result in errors or the data being stored incorrectly.
-
The JDBC driver converts UTF-16 data to UTF-8 when passing to the Vertica server and converts data sent by Vertica server from UTF-8 to UTF-16 .
2.6 - Changing the transaction isolation level
Changing the transaction isolation level lets you choose how transactions prevent interference from other transactions.
Changing the transaction isolation level lets you choose how transactions prevent interference from other transactions. By default, the JDBC driver matches the transaction isolation level of the Vertica server. The Vertica default transaction isolation level is READ_COMMITTED, which means any changes made by a transaction cannot be read by any other transaction until after they are committed. This prevents a transaction from reading data inserted by another transaction that is later rolled back.
Vertica also supports the SERIALIZABLE transaction isolation level. This level locks tables to prevent queries from having the results of their WHERE clauses changed by other transactions. Locking tables can have a performance impact, since only one transaction is able to access the table at a time.
A transaction retains its isolation level until it completes, even if the session's isolation level changes during the transaction. Vertica internal processes (such as the Tuple Mover and refresh operations) and DDL operations always run at the SERIALIZABLE isolation level to ensure consistency.
You can change the transaction isolation level connection property after the connection has been established using the Connection object's setter (setTransactionIsolation()) and getter (getTransactionIsolation()). The value for transaction isolation property is an integer. The Connection interface defines constants to help you set the value in a more intuitive manner:
|
Constant |
Value |
Connection.TRANSACTION_READ_COMMITTED |
2 |
Connection.TRANSACTION_SERIALIZABLE |
8 |
Note
The Connection interface also defines several other transaction isolation constants (READ_UNCOMMITTED and REPEATABLE_READ). Since Vertica does not support these isolation levels, they are converted to READ_COMMITTED and SERIALIZABLE, respectively.
The following example demonstrates setting the transaction isolation level to SERIALIZABLE.
import java.sql.*;
import java.util.Properties;
public class SetTransactionIsolation {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// Get default transaction isolation
System.out.println("Transaction Isolation Level: "
+ conn.getTransactionIsolation());
// Set transaction isolation to SERIALIZABLE
conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
// Get the transaction isolation again
System.out.println("Transaction Isolation Level: "
+ conn.getTransactionIsolation());
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Running the example results in the following being printed out to the console:
Transaction Isolation Level: 2Transaction Isolation Level: 8
2.7 - JDBC connection pools
A pooling data source uses a collection of persistent connections in order to reduce the overhead of repeatedly opening network connections between the client and server.
A pooling data source uses a collection of persistent connections in order to reduce the overhead of repeatedly opening network connections between the client and server. Opening a new connection for each request is more costly for both the server and the client than keeping a small pool of connections open constantly, ready to be used by new requests. When a request comes in, one of the pre-existing connections in the pool is assigned to it. Only if there are no free connections in the pool is a new connection created. Once the request is complete, the connection returns to the pool and waits to service another request.
The Vertica JDBC driver supports connection pooling as defined in the JDBC 4.0 standard. If you are using a J2EE-based application server in conjunction with Vertica, it should already have a built-in data pooling feature. All that is required is that the application server work with the PooledConnection interface implemented by Vertica's JDBC driver. An application server's pooling feature is usually well-tuned for the works loads that the server is designed to handle. See your application server's documentation for details on how to work with pooled connections. Normally, using pooled connections should be transparent in your code—you will just open connections and the application server will worry about the details of pooling them.
If you are not using an application server, or your application server does not offer connection pooling that is compatible with Vertica, you can use a third-party pooling library, such as the open-source c3p0 or DBCP libraries, to implement connection pooling.
Note
The Vertica Analytic Database client driver's native connection load balancing feature works with third-party connection pooling supplied by application servers and third-party pooling libraries. See
Load balancing in JDBC for more information.
2.8 - Load balancing in JDBC
To enable native load balancing on your client, set the ConnectionLoadBalance connection parameter to true.
Native connection load balancing
Native connection load balancing helps spread the overhead caused by client connections on the hosts in the Vertica database. Both the server and the client must enable native connection load balancing. If enabled by both, then when the client initially connects to a host in the database, the host picks a host to handle the client connection from a list of the currently up hosts in the database, and informs the client which host it has chosen.
If the initially-contacted host does not choose itself to handle the connection, the client disconnects, then opens a second connection to the host selected by the first host. The connection process to this second host proceeds as usual—if SSL is enabled, then SSL negotiations begin, otherwise the client begins the authentication process. See About native connection load balancing for details.
To enable native load balancing on your client, set the ConnectionLoadBalance connection parameter to true. The following example demonstrates:
import java.sql.*;
import java.util.Properties;
import java.sql.*;
import java.util.Properties;
public class JDBCLoadingBalanceExample {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("password", "example_password123");
myProp.put("loginTimeout", "35");
myProp.put("ConnectionLoadBalance", "1");
Connection conn;
for (int x = 1; x <= 4; x++) {
try {
System.out.print("Connect attempt #" + x + "...");
conn = DriverManager.getConnection(
"jdbc:vertica://node01.example.com:5433/vmart", myProp);
Statement stmt = conn.createStatement();
// Set the load balance policy to round robin before testing the database's load balancing.
stmt.execute("SELECT SET_LOAD_BALANCE_POLICY('ROUNDROBIN');");
// Query system to table to see what node we are connected to. Assume a single row
// in response set.
ResultSet rs = stmt.executeQuery("SELECT node_name FROM v_monitor.current_session;");
rs.next();
System.out.println("Connected to node " + rs.getString(1).trim());
conn.close();
} catch (SQLTransientConnectionException connException) {
// There was a potentially temporary network error
// Could automatically retry a number of times here, but
// instead just report error and exit.
System.out.print("Network connection issue: ");
System.out.print(connException.getMessage());
System.out.println(" Try again later!");
return;
} catch (SQLInvalidAuthorizationSpecException authException) {
// Either the username or password was wrong
System.out.print("Could not log into database: ");
System.out.print(authException.getMessage());
System.out.println(" Check the login credentials and try again.");
return;
} catch (SQLException e) {
// Catch-all for other exceptions
e.printStackTrace();
}
}
}
}
Running the previous example produces the following output:
Connect attempt #1...Connected to node v_vmart_node0002
Connect attempt #2...Connected to node v_vmart_node0003
Connect attempt #3...Connected to node v_vmart_node0001
Connect attempt #4...Connected to node v_vmart_node0002
Hostname-based load balancing
You can load balance workloads by resolving a single hostname to multiple IP addresses. When you specify the hostname for the DriverManager.getConnection() method, the hostname resolves to a random listed IP address from the each connection.
For example, the hostname verticahost.example.com has the following entries in etc/hosts:
192.0.2.0 verticahost.example.com
192.0.2.1 verticahost.example.com
192.0.2.2 verticahost.example.com
Specifying verticahost.example.com as the connection for DriverManager.getConnection() randomly resolves to one of the listed IP address.
2.9 - JDBC connection failover
When run, the example outputs output similar to the following on the system console:.
If a client application attempts to connect to a host in the Vertica cluster that is down, the connection attempt fails when using the default connection configuration. This failure usually returns an error to the user. The user must either wait until the host recovers and retry the connection or manually edit the connection settings to choose another host.
Due to Vertica Analytic Database's distributed architecture, you usually do not care which database host handles a client application's connection. You can use the client driver's connection failover feature to prevent the user from getting connection errors when the host specified in the connection settings is unreachable. The JDBC driver gives you several ways to let the client driver automatically attempt to connect to a different host if the one specified in the connection parameters is unreachable:
-
Configure your DNS server to return multiple IP addresses for a host name. When you use this host name in the connection settings, the client attempts to connect to the first IP address from the DNS lookup. If the host at that IP address is unreachable, the client tries to connect to the second IP, and so on until it either manages to connect to a host or it runs out of IP addresses.
-
Supply a list of backup hosts for the client driver to try if the primary host you specify in the connection parameters is unreachable.
-
(JDBC only) Use driver-specific connection properties to manage timeouts before attempting to connect to the next node.
For all methods, the process of failover is transparent to the client application (other than specifying the list of backup hosts, if you choose to use the list method of failover). If the primary host is unreachable, the client driver automatically tries to connect to other hosts.
Failover only applies to the initial establishment of the client connection. If the connection breaks, the driver does not automatically try to reconnect to another host in the database.
Choosing a failover method
You usually choose to use one of the two failover methods. However, they do work together. If your DNS server returns multiple IP addresses and you supply a list of backup hosts, the client first tries all of the IPs returned by the DNS server, then the hosts in the backup list.
Note
If a host name in the backup host list resolves to multiple IP addresses, the client does not try all of them. It just tries the first IP address in the list.
The DNS method of failover centralizes the configuration client failover. As you add new nodes to your Vertica Analytic Database cluster, you can choose to add them to the failover list by editing the DNS server settings. All client systems that use the DNS server to connect to Vertica Analytic Database automatically use connection failover without having to change any settings. However, this method does require administrative access to the DNS server that all clients use to connect to the Vertica Analytic Database cluster. This may not be possible in your organization.
Using the backup server list is easier than editing the DNS server settings. However, it decentralizes the failover feature. You may need to update the application settings on each client system if you make changes to your Vertica Analytic Database cluster.
Using DNS failover
To use DNS failover, you need to change your DNS server's settings to map a single host name to multiple IP addresses of hosts in your Vertica Analytic Database cluster. You then have all client applications use this host name to connect to Vertica Analytic Database.
You can choose to have your DNS server return as many IP addresses for the host name as you want. In smaller clusters, you may choose to have it return the IP addresses of all of the hosts in your cluster. However, for larger clusters, you should consider choosing a subset of the hosts to return. Otherwise there can be a long delay as the client driver tries unsuccessfully to connect to each host in a database that is down.
Using the backup host list
To enable backup list-based connection failover, your client application has to specify at least one IP address or host name of a host in the BackupServerNode parameter. The host name or IP can optionally be followed by a colon and a port number. If not supplied, the driver defaults to the standard Vertica port number (5433). To list multiple hosts, separate them by a comma.
The following example demonstrates setting the BackupServerNode connection parameter to specify additional hosts for the connection attempt. The connection string intentionally has a non-existent node, so that the initial connection fails. The client driver has to resort to trying the backup hosts to establish a connection to Vertica.
import java.sql.*;
import java.util.Properties;
public class ConnectionFailoverExample {
public static void main(String[] args) {
// Assume using JDBC 4.0 driver on JVM 6+. No driver loading needed.
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("password", "vertica");
// Set two backup hosts to be used if connecting to the first host
// fails. All of these hosts will be tried in order until the connection
// succeeds or all of the connections fail.
myProp.put("BackupServerNode", "VerticaHost02,VerticaHost03");
Connection conn;
try {
// The connection string is set to try to connect to a known
// bad host (in this case, a host that never existed).
// The database name is optional.
conn = DriverManager.getConnection(
"jdbc:vertica://BadVerticaHost:5433/vmart", myProp);
System.out.println("Connected!");
// Query system to table to see what node we are connected to.
// Assume a single row in response set.
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery(
"SELECT node_name FROM v_monitor.current_session;");
rs.next();
System.out.println("Connected to node " + rs.getString(1).trim());
// Done with connection.
conn.close();
} catch (SQLException e) {
// Catch-all for other exceptions
e.printStackTrace();
}
}
}
When run, the example outputs output similar to the following on the system console:
Connected!
Connected to node v_vmart_node0002
Notice that the connection was made to the first node in the backup list (node 2).
Specifying connection timeouts
LoginTimeout controls the timeout for JDBC to establish establish a TCP connection with a node and log in to Vertica.
LoginNodeTimeout controls the timeout for JDBC to log in to the Vertica database. After the specified timeout, JDBC attempts to connect to the "next" node, which is determined by either the connection property BackupServerNode or DNS resolution. This is useful if the node is up, but something is wrong with the Vertica process.
LoginNetworkTimeout controls the timeout for JDBC to establish a TCP connection to a Vertica node. If you do not set this connection property, if the node to which the JDBC client attempts to connect is down, the JDBC client will wait "indefinitely," but practically, the system default timeout of 70 seconds is used. A typical use case for LoginNetworkTimeout is to let JDBC connect to another node if the current Vertica node is down for maintenance and modifying the JDBC application's connection string is infeasible.
NetworkTimeout controls the timeout for Vertica to respond to a request from a client after it has established a connection and logged in to the database.
To set these parameters in a connection string:
# LoginTimeout is 30 seconds, LoginNodeTimeout is 10 seconds, LoginNetworkTimeout is 2 seconds, NetworkTimeout is 0.5 seconds
Connection conn = DriverManager.getConnection("jdbc:vertica://VerticaHost:5433/verticadb?user=dbadmin&loginTimeout=30&loginNodeTimeout=10"&loginNetworkTimeout=2&networkTimeout=500");
To set these parameters as a connection property:
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("loginTimeout", "30"); // overall connection timeout is 30 seconds to make sure it is not too small for failover
myProp.put("loginNodeTimeout", "10"); // JDBC waits 10 seconds before attempting to connect to the next node if the Vertica process is running but does not respond
myProp.put("loginNetworkTimeout", "2"); // node connection timeout is 2 seconds
myProp.put("networkTimeout", "500"); // after the client has logged in, Vertica has 0.5 seconds to respond to each request
Connection conn = DriverManager.getConnection("jdbc:vertica://VerticaHost:5433/verticadb", myProp);
Interaction with load balancing
When native connection load balancing is enabled, the additional servers specified in the BackupServerNode connection parameter are only used for the initial connection to a Vertica host. If host redirects the client to another host in the database cluster to handle its connection request, the second connection does not use the backup node list. This is rarely an issue, since native connection load balancing is aware of which nodes are currently up in the database.
See Load balancing in JDBC for more information.
3 - JDBC data types
The JDBC driver transparently converts most Vertica data types to the appropriate Java data type.
The JDBC driver transparently converts most Vertica data types to the appropriate Java data type. In a few cases, a Vertica data type cannot be directly translated to a Java data type; these exceptions are explained in this section.
3.1 - The VerticaTypes class
JDBC does not support all of the data types that Vertica supports.
JDBC does not support all of the data types that Vertica supports. The Vertica JDBC client driver contains an additional class named VerticaTypes that helps you handle identifying these Vertica-specific data types. It contains constants that you can use in your code to specify Vertica data types. This class defines two different categories of data types:
-
Vertica's 13 types of interval values. This class contains constant properties for each of these types. You can use these constants to select a specific interval type when instantiating members of the VerticaDayTimeInterval and VerticaYearMonthInterval classes:
// Create a day to second interval.
VerticaDayTimeInterval dayInt = new VerticaDayTimeInterval(
VerticaTypes.INTERVAL_DAY_TO_SECOND, 10, 0, 5, 40, 0, 0, false);
// Create a year to month interval.
VerticaYearMonthInterval monthInt = new VerticaYearMonthInterval(
VerticaTypes.INTERVAL_YEAR_TO_MONTH, 10, 6, false);
-
Vertica UUID data type. One way you can use the VerticaTypes.UUID is to query a table's metadata to see if a column is a UUID. See UUID values for an example.
See the JDBC documentation for more information on this class.
3.2 - Numeric data alias conversion
The Vertica server supports data type aliases for integer, float and numeric types.
The Vertica server supports data type aliases for integer, float and numeric types. The JDBC driver reports these as its basic data types (BIGINT, DOUBLE PRECISION, and NUMERIC), as follows:
|
Vertica Server Types and Aliases |
Vertica JDBC Type |
|
INTEGER
INT
INT8
BIGINT
SMALLINT
TINYINT
|
BIGINT |
|
DOUBLE PRECISION
FLOAT5
FLOAT8
REAL
|
DOUBLE PRECISION |
|
DECIMAL
NUMERIC
NUMBER
MONEY
|
NUMERIC |
If a client application retrieves the values into smaller data types, Vertica JDBC driver does not check for overflows. The following example demonstrates the results of this overflow.
import java.sql.*;
import java.util.Properties;
public class JDBCDataTypes {
public static void main(String[] args) {
// If running under a Java 5 JVM, use you need to load the JDBC driver
// using Class.forname here
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/VMart",
myProp);
Statement statement = conn.createStatement();
// Create a table that will hold a row of different types of
// numeric data.
statement.executeUpdate(
"DROP TABLE IF EXISTS test_all_types cascade");
statement.executeUpdate("CREATE TABLE test_all_types ("
+ "c0 INTEGER, c1 TINYINT, c2 DECIMAL, "
+ "c3 MONEY, c4 DOUBLE PRECISION, c5 REAL)");
// Add a row of values to it.
statement.executeUpdate("INSERT INTO test_all_types VALUES("
+ "111111111111, 444, 55555555555.5555, "
+ "77777777.77, 88888888888888888.88, "
+ "10101010.10101010101010)");
// Query the new table to get the row back as a result set.
ResultSet rs = statement
.executeQuery("SELECT * FROM test_all_types");
// Get the metadata about the row, including its data type.
ResultSetMetaData md = rs.getMetaData();
// Loop should only run once...
while (rs.next()) {
// Print out the data type used to defined the column, followed
// by the values retrieved using several different retrieval
// methods.
String[] vertTypes = new String[] {"INTEGER", "TINYINT",
"DECIMAL", "MONEY", "DOUBLE PRECISION", "REAL"};
for (int x=1; x<7; x++) {
System.out.println("\n\nColumn " + x + " (" + vertTypes[x-1]
+ ")");
System.out.println("\tgetColumnType()\t\t"
+ md.getColumnType(x));
System.out.println("\tgetColumnTypeName()\t"
+ md.getColumnTypeName(x));
System.out.println("\tgetShort()\t\t"
+ rs.getShort(x));
System.out.println("\tgetLong()\t\t" + rs.getLong(x));
System.out.println("\tgetInt()\t\t" + rs.getInt(x));
System.out.println("\tgetByte()\t\t" + rs.getByte(x));
}
}
rs.close();
statement.executeUpdate("drop table test_all_types cascade");
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The above example prints the following on the console when run:
Column 1 (INTEGER)
getColumnType() -5
getColumnTypeName() BIGINT
getShort() 455
getLong() 111111111111
getInt() -558038585
getByte() -57
Column 2 (TINYINT)
getColumnType() -5
getColumnTypeName() BIGINT
getShort() 444
getLong() 444
getInt() 444
getByte() -68
Column 3 (DECIMAL)
getColumnType() 2
getColumnTypeName() NUMERIC
getShort() -1
getLong() 55555555555
getInt() 2147483647
getByte() -1
Column 4 (MONEY)
getColumnType() 2
getColumnTypeName() NUMERIC
getShort() -13455
getLong() 77777777
getInt() 77777777
getByte() 113
Column 5 (DOUBLE PRECISION)
getColumnType() 8
getColumnTypeName() DOUBLE PRECISION
getShort() -1
getLong() 88888888888888900
getInt() 2147483647
getByte() -1
Column 6 (REAL)
getColumnType() 8
getColumnTypeName() DOUBLE PRECISION
getShort() 8466
getLong() 10101010
getInt() 10101010
getByte() 18
3.3 - Using intervals with JDBC
The JDBC standard does not contain a data type for intervals (the duration between two points in time).
The JDBC standard does not contain a data type for intervals (the duration between two points in time). To handle Vertica's INTERVAL data type, you must use JDBC's database-specific object type.
When reading an interval value from a result set, use the ResultSet.getObject() method to retrieve the value, and then cast it to one of the Vertica interval classes: VerticaDayTimeInterval (which represents all ten types of day/time intervals) or VerticaYearMonthInterval (which represents all three types of year/month intervals).
Note
The units interval style is not supported. Do not use the
SET INTERVALSTYLE statement to change the interval style in your client applications.
Using intervals in batch inserts
When inserting batches into tables that contain interval data, you must create instances of the VerticaDayTimeInterval or VerticaYearMonthInterval classes to hold the data you want to insert. You set values either when calling the class's constructor, or afterwards using setters. You then insert your interval values using the PreparedStatement.setObject() method. You can also use the .setString() method, passing it a string in "DD**HH:MM:SS" or "YY-MM" format.
The following example demonstrates inserting data into a table containing a day/time interval and a year/month interval:
import java.sql.*;
import java.util.Properties;
// You need to import the Vertica JDBC classes to be able to instantiate
// the interval classes.
import com.vertica.jdbc.*;
public class IntervalDemo {
public static void main(String[] args) {
// If running under a Java 5 JVM, use you need to load the JDBC driver
// using Class.forname here
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/VMart", myProp);
// Create table for interval values
Statement stmt = conn.createStatement();
stmt.execute("DROP TABLE IF EXISTS interval_demo");
stmt.executeUpdate("CREATE TABLE interval_demo("
+ "DayInt INTERVAL DAY TO SECOND, "
+ "MonthInt INTERVAL YEAR TO MONTH)");
// Insert data into interval columns using
// VerticaDayTimeInterval and VerticaYearMonthInterval
// classes.
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO interval_demo VALUES(?,?)");
// Create instances of the Vertica classes that represent
// intervals.
VerticaDayTimeInterval dayInt = new VerticaDayTimeInterval(10, 0,
5, 40, 0, 0, false);
VerticaYearMonthInterval monthInt = new VerticaYearMonthInterval(
10, 6, false);
// These objects can also be manipulated using setters.
dayInt.setHour(7);
// Add the interval values to the batch
((VerticaPreparedStatement) pstmt).setObject(1, dayInt);
((VerticaPreparedStatement) pstmt).setObject(2, monthInt);
pstmt.addBatch();
// Set another row from strings.
// Set day interval in "days HH:MM:SS" format
pstmt.setString(1, "10 10:10:10");
// Set year to month value in "MM-YY" format
pstmt.setString(2, "12-09");
pstmt.addBatch();
// Execute the batch to insert the values.
try {
pstmt.executeBatch();
} catch (SQLException e) {
System.out.println("Error message: " + e.getMessage());
}
Reading interval values
You read an interval value from a result set using the ResultSet.getObject() method, and cast the object to the appropriate Vertica object class: VerticaDayTimeInterval for day/time intervals or VerticaYearMonthInterval for year/month intervals. This is easy to do if you know that the column contains an interval, and you know what type of interval it is. If your application cannot assume the structure of the data in the result set it reads in, you can test whether a column contains a database-specific object type, and if so, determine whether the object belongs to either the VerticaDayTimeInterval or VerticaYearMonthInterval classes.
// Retrieve the interval values inserted by previous demo.
// Query the table to get the row back as a result set.
ResultSet rs = stmt.executeQuery("SELECT * FROM interval_demo");
// If you do not know the types of data contained in the result set,
// you can read its metadata to determine the type, and use
// additional information to determine the interval type.
ResultSetMetaData md = rs.getMetaData();
while (rs.next()) {
for (int x = 1; x <= md.getColumnCount(); x++) {
// Get data type from metadata
int colDataType = md.getColumnType(x);
// You can get the type in a string:
System.out.println("Column " + x + " is a "
+ md.getColumnTypeName(x));
// Normally, you'd have a switch statement here to
// handle all sorts of column types, but this example is
// simplified to just handle database-specific types
if (colDataType == Types.OTHER) {
// Column contains a database-specific type. Determine
// what type of interval it is. Assuming it is an
// interval...
Object columnVal = rs.getObject(x);
if (columnVal instanceof VerticaDayTimeInterval) {
// We know it is a date time interval
VerticaDayTimeInterval interval =
(VerticaDayTimeInterval) columnVal;
// You can use the getters to access the interval's
// data
System.out.print("Column " + x + "'s value is ");
System.out.print(interval.getDay() + " Days ");
System.out.print(interval.getHour() + " Hours ");
System.out.println(interval.getMinute()
+ " Minutes");
} else if (columnVal instanceof VerticaYearMonthInterval) {
VerticaYearMonthInterval interval =
(VerticaYearMonthInterval) columnVal;
System.out.print("Column " + x + "'s value is ");
System.out.print(interval.getYear() + " Years ");
System.out.println(interval.getMonth() + " Months");
} else {
System.out.println("Not an interval.");
}
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The example prints the following to the console:
Column 1 is a INTERVAL DAY TO SECOND
Column 1's value is 10 Days 7 Hours 5 Minutes
Column 2 is a INTERVAL YEAR TO MONTH
Column 2's value is 10 Years 6 Months
Column 1 is a INTERVAL DAY TO SECOND
Column 1's value is 10 Days 10 Hours 10 Minutes
Column 2 is a INTERVAL YEAR TO MONTH
Column 2's value is 12 Years 9 Months
Another option is to use database metadata to find columns that contain intervals.
// Determine the interval data types by examining the database
// metadata.
DatabaseMetaData dbmd = conn.getMetaData();
ResultSet dbMeta = dbmd.getColumns(null, null, "interval_demo", null);
int colcount = 0;
while (dbMeta.next()) {
// Get the metadata type for a column.
int javaType = dbMeta.getInt("DATA_TYPE");
System.out.println("Column " + ++colcount + " Type name is " +
dbMeta.getString("TYPE_NAME"));
if(javaType == Types.OTHER) {
// The SQL_DATETIME_SUB column in the metadata tells you
// Specifically which subtype of interval you have.
// The VerticaDayTimeInterval.isDayTimeInterval()
// methods tells you if that value is a day time.
//
int intervalType = dbMeta.getInt("SQL_DATETIME_SUB");
if(VerticaDayTimeInterval.isDayTimeInterval(intervalType)) {
// Now you know it is one of the 10 day/time interval types.
// When you select this column you can cast to
// VerticaDayTimeInterval.
// You can get more specific by checking intervalType
// against each of the 10 constants directly, but
// they all are represented by the same object.
System.out.println("column " + colcount + " is a " +
"VerticaDayTimeInterval intervalType = "
+ intervalType);
} else if(VerticaYearMonthInterval.isYearMonthInterval(
intervalType)) {
//now you know it is one of the 3 year/month intervals,
//and you can select the column and cast to
// VerticaYearMonthInterval
System.out.println("column " + colcount + " is a " +
"VerticaDayTimeInterval intervalType = "
+ intervalType);
} else {
System.out.println("Not an interval type.");
}
}
}
3.4 - UUID values
UUID is a core data type in Vertica.
UUID is a core data type in Vertica. However, it is not a core Java data type. You must use the java.util.UUID class to represent UUID values in your Java code. The JDBC driver does not translate values from Vertica to non-core Java data types. Therefore, you must send UUID values to Vertica using generic object methods such as PreparedStatement.setObject(). You also use generic object methods (such as ResultSet.getObject()) to retrieve UUID values from Vertica. You then cast the retrieved objects as a member of the java.util.UUID class.
The following example code demonstrates inserting UUID values into and retrieving UUID values from Vertica.
package jdbc_uuid_example;
import java.sql.*;
import java.util.Properties;
public class VerticaUUIDExample {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "dbadmin");
myProp.put("password", "");
Connection conn;
try {
conn = DriverManager.getConnection("jdbc:vertica://doch01:5433/VMart",
myProp);
Statement stmt = conn.createStatement();
// Create a table with a UUID column and a VARCHAR column.
stmt.execute("DROP TABLE IF EXISTS UUID_TEST CASCADE;");
stmt.execute("CREATE TABLE UUID_TEST (id UUID, description VARCHAR(25));");
// Prepare a statement to insert a UUID and a string into the table.
PreparedStatement ps = conn.prepareStatement("INSERT INTO UUID_TEST VALUES(?,?)");
java.util.UUID uuid; // Holds the UUID value.
for (Integer x = 0; x < 10; x++) {
// Generate a random uuid
uuid = java.util.UUID.randomUUID();
// Set the UUID value by calling setObject.
ps.setObject(1, uuid);
// Set the String value to indicate which UUID this is.
ps.setString(2, "UUID #" + x);
ps.execute();
}
// Query the uuid
ResultSet rs = stmt.executeQuery("SELECT * FROM UUID_TEST ORDER BY description ASC");
while (rs.next()) {
// Cast the object from the result set as a UUID.
uuid = (java.util.UUID) rs.getObject(1);
System.out.println(rs.getString(2) + " : " + uuid.toString());
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The previous example prints output similar to the following:
UUID #0 : 67b6dcb6-c28c-4965-b9f7-5c830a04664d
UUID #1 : 485d3835-2887-4233-b003-392254fa97e0
UUID #2 : 81421f51-c803-473d-8cfc-2c184582a117
UUID #3 : bec8b86a-b650-47b0-852c-8229155332d9
UUID #4 : 8ae5e3ec-d143-4ef7-8901-24f6d0483abf
UUID #5 : 669696ce-5e86-4e87-b8d0-a937f5fc18d7
UUID #6 : 19609ec9-ec56-4444-9cfe-ad2b8de537dd
UUID #7 : 97182e1d-5c7e-4da1-9922-67e804fde173
UUID #8 : c76c3a2b-a9ef-4d65-b2fb-7c637f872b3c
UUID #9 : 3cbbcd26-c177-4277-b3df-bf4d9389f69d
Determining whether a column has a UUID data type
JDBC does not support the UUID data type. This limitation means you cannot use the usual ResultSetMetaData.getColumnType() method to determine column's data type is UUID. Calling this method on a UUID column returns Types.OTHER. This value is also to identify interval columns. You can use two ways to determine if a column contains UUIDs:
-
Use ResultSetMetaData.getColumnTypeName() to get the name of the column's data type. For UUID columns, this method returns the value "Uuid" as a String.
-
Query the table's metadata to get the SQL data type of the column. If this value is equal to VerticaTypes.UUID, the column's data type is UUID.
The following example demonstrates both of these techniques:
// This example assumes you already have a database connection
// and result set from a query on a table that may contain a UUID.
// Get the metadata of the result set to get the column definitions
ResultSetMetaData meta = rs.getMetaData();
int colcount;
int maxcol = meta.getColumnCount();
System.out.println("Using column metadata:");
for (colcount = 1; colcount < maxcol; colcount++) {
// .getColumnType() always returns "OTHER" for UUID columns.
if (meta.getColumnType(colcount) == Types.OTHER) {
// To determine that it is a UUID column, test the name of the column type.
if (meta.getColumnTypeName(colcount).equalsIgnoreCase("uuid")) {
// It's a UUID column
System.out.println("Column "+ colcount + " is UUID");
}
}
}
// You can also query the table's metadata to find its column types and compare
// it to the VerticaType.UUID constant to see if it is a UUID column.
System.out.println("Using table metadata:");
DatabaseMetaData dbmd = conn.getMetaData();
// Get the metdata for the previously-created test table.
ResultSet tableMeta = dbmd.getColumns(null, null, "UUID_TEST", null);
colcount = 0;
// Each row in the result set has metadata that describes a single column.
while (tableMeta.next()) {
colcount++;
// The SQL_DATA_TYPE column holds the Vertica database data type. You compare
// this value to the VerticvaTypes.UUID constant to see if it is a UUID.
if (tableMeta.getInt("SQL_DATA_TYPE") == VerticaTypes.UUID) {
// Column is a UUID data type...
System.out.println("Column " + colcount + " is a UUID column.");
}
}
This example prints the following to the console if it is run after running the prior example:
Using column metadata:
Column 1 is UUID
Using table metadata:
Column 1 is a UUID column.
3.5 - Complex types in JDBC
The results of a java.sql query are stored in a ResultSet.
The results of a java.sql query are stored in a ResultSet. If the ResultSet contains a column of complex type, you can retrieve it with one of the following:
-
For columns of type ARRAY, SET, or MAP, use getArray(), which returns a java.sql.Array.
-
For columns of type ROW, use getObject(), which returns a java.sql.Struct.
Type conversion table
The objects java.sql.Array and java.sql.Struct each have their own API for accessing complex type data. In each case, the data is returned as java.lang.Object and will need to be type cast to a Java type. The exact Java type to expect depends on the Vertica type used in the complex type definition, as shown in this type conversion table:
|
java.sql Type |
Vertica Type |
Java Type |
BIT |
BOOL |
java.lang.Boolean |
BIGINT |
INT |
java.lang.Long |
DOUBLE |
FLOAT |
java.lang.Double |
CHAR |
CHAR |
java.lang.String |
VARCHAR |
VARCHAR |
java.lang.String |
LONGVARCHAR |
LONGVARCHAR |
java.lang.String |
DATE |
DATE |
java.sql.Date |
TIME |
TIME |
java.sql.Time |
TIME |
TIMETZ |
java.sql.Time |
TIMESTAMP |
TIMESTAMP |
java.sql.Timestamp |
TIMESTAMP |
TIMESTAMPTZ |
com.vertica.dsi.dataengine.utilities.TimestampTz |
getIntervalRange(oid, typmod) |
INTERVAL |
com.vertica.jdbc.VerticaDayTimeInterval |
getIntervalRange(oid, typmod) |
INTERVALYM |
com.vertica.jdbc.VerticaYearMonthInterval |
BINARY |
BINARY |
byte[] |
VARBINARY |
VARBINARY |
byte[] |
LONGVARBINARY |
LONGVARBINARY |
byte[] |
NUMERIC |
NUMERIC |
java.math.BigDecimal |
TYPE_SQL_GUID |
UUID |
java.util.UUID |
ARRAY |
ARRAY |
java.lang.Object[] |
ARRAY |
SET |
java.lang.Object[] |
STRUCT |
ROW |
java.sql.Struct |
ARRAY |
MAP |
java.lang.Object[] |
ARRAY, SET, and MAP columns
For example, the following methods run queries that return an ARRAY of some Vertica type, which is then type cast to an array of its corresponding Java type by the JDBC driver when retrieved with getArray(). This particular example starts with ARRAY[INT] and ARRAY[FLOAT], so they are type cast to Long[] and Double[], respectively, as determined by the type conversion table.
-
getArrayResultSetExample() shows how the ARRAY can be processed as a java.sql.ResultSet. This example uses getResultSet() which returns the underlying array as another ResultSet. You can use this underlying ResultSet to:
-
getArrayObjectExample() shows how the ARRAY can be processed as a native Java array. This example uses getArray() which returns the underlying array as an Object array rather than a ResultSet. This has the following implications:
package com.vertica.jdbc.test.samples;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.Array;
import java.sql.Struct;
public class ComplexTypesArraySamples
{
/**
* Executes a query and gets a java.sql.Array from the ResultSet. It then uses the Array#getResultSet
* method to get a ResultSet containing the contents of the array.
* @param conn A Connection to a Vertica database
* @throws SQLException
*/
public static void getArrayResultSetExample (Connection conn) throws SQLException {
Statement stmt = conn.createStatement();
final String queryText = "SELECT ARRAY[ARRAY[1,2,3],ARRAY[4,5,6],ARRAY[7,8,9]]::ARRAY[ARRAY[INT]] as array";
final String targetColumnName = "array";
System.out.println ("queryText: " + queryText);
ResultSet rs = stmt.executeQuery(queryText);
int targetColumnId = rs.findColumn (targetColumnName);
while (rs.next ()) {
Array currentSqlArray = rs.getArray (targetColumnId);
ResultSet level1ResultSet = currentSqlArray.getResultSet();
if (level1ResultSet != null) {
while (level1ResultSet.next ()) {
// The first column of the result set holds the row index
int i = level1ResultSet.getInt(1) - 1;
Array level2SqlArray = level1ResultSet.getArray (2);
Object level2Object = level2SqlArray.getArray ();
// For this ARRAY[INT], the driver returns a Long[]
assert (level2Object instanceof Long[]);
Long [] level2Array = (Long [])level2Object;
System.out.println (" level1Object [" + i + "]: " + level2SqlArray.toString () + " (" + level2SqlArray.getClass() + ")");
for (int j = 0; j < level2Array.length; j++) {
System.out.println (" Value [" + i + ", " + j + "]: " + level2Array[j] + " (" + level2Array[j].getClass() + ")");
}
}
}
}
}
/**
* Executes a query and gets a java.sql.Array from the ResultSet. It then uses the Array#getArray
* method to get the contents of the array as a Java Object [].
* @param conn A Connection to a Vertica database
* @throws SQLException
*/
public static void getArrayObjectExample (Connection conn) throws SQLException {
Statement stmt = conn.createStatement();
final String queryText = "SELECT ARRAY[ARRAY[0.0,0.1,0.2],ARRAY[1.0,1.1,1.2],ARRAY[2.0,2.1,2.2]]::ARRAY[ARRAY[FLOAT]] as array";
final String targetColumnName = "array";
System.out.println ("queryText: " + queryText);
ResultSet rs = stmt.executeQuery(queryText);
int targetColumnId = rs.findColumn (targetColumnName);
while (rs.next ()) {
// Get the java.sql.Array from the result set
Array currentSqlArray = rs.getArray (targetColumnId);
// Get the internal Java Object implementing the array
Object level1ArrayObject = currentSqlArray.getArray ();
if (level1ArrayObject != null) {
// All returned instances are Object[]
assert (level1ArrayObject instanceof Object[]);
Object [] level1Array = (Object [])level1ArrayObject;
System.out.println ("Vertica driver returned a: " + level1Array.getClass());
for (int i = 0; i < level1Array.length; i++) {
Object level2Object = level1Array[i];
// For this ARRAY[FLOAT], the driver returns a Double[]
assert (level2Object instanceof Double[]);
Double [] level2Array = (Double [])level2Object;
for (int j = 0; j < level2Array.length; j++) {
System.out.println (" Value [" + i + ", " + j + "]: " + level2Array[j] + " (" + level2Array[j].getClass() + ")");
}
}
}
}
}
}
The output of getArrayResultSetExample() shows that the Vertica column type ARRAY[INT] is type cast to Long[]:
queryText: SELECT ARRAY[ARRAY[1,2,3],ARRAY[4,5,6],ARRAY[7,8,9]]::ARRAY[ARRAY[INT]] as array
level1Object [0]: [1,2,3] (class com.vertica.jdbc.jdbc42.S42Array)
Value [0, 0]: 1 (class java.lang.Long)
Value [0, 1]: 2 (class java.lang.Long)
Value [0, 2]: 3 (class java.lang.Long)
level1Object [1]: [4,5,6] (class com.vertica.jdbc.jdbc42.S42Array)
Value [1, 0]: 4 (class java.lang.Long)
Value [1, 1]: 5 (class java.lang.Long)
Value [1, 2]: 6 (class java.lang.Long)
level1Object [2]: [7,8,9] (class com.vertica.jdbc.jdbc42.S42Array)
Value [2, 0]: 7 (class java.lang.Long)
Value [2, 1]: 8 (class java.lang.Long)
Value [2, 2]: 9 (class java.lang.Long)
The output of getArrayObjectExample() shows that the Vertica column type ARRAY[FLOAT] is type cast to Double[]:
queryText: SELECT ARRAY[ARRAY[0.0,0.1,0.2],ARRAY[1.0,1.1,1.2],ARRAY[2.0,2.1,2.2]]::ARRAY[ARRAY[FLOAT]] as array
Vertica driver returned a: class [Ljava.lang.Object;
Value [0, 0]: 0.0 (class java.lang.Double)
Value [0, 1]: 0.1 (class java.lang.Double)
Value [0, 2]: 0.2 (class java.lang.Double)
Value [1, 0]: 1.0 (class java.lang.Double)
Value [1, 1]: 1.1 (class java.lang.Double)
Value [1, 2]: 1.2 (class java.lang.Double)
Value [2, 0]: 2.0 (class java.lang.Double)
Value [2, 1]: 2.1 (class java.lang.Double)
Value [2, 2]: 2.2 (class java.lang.Double)
ROW columns
Calling getObject() on a java.sql.ResultSet that contains a column of type ROW retrieves the column as a java.sql.Struct which contains an Object[] (itself retrievable with getAttributes()).
Each element of the Object[] represents an attribute from the struct, and each attribute has a corresponding Java type shown in the type conversion table above.
This example defines a ROW with the following attributes:
Name | Value | Vertica Type | Java Type
-----------------------------------------------------------
name | Amy | VARCHAR | String
date | '07/10/2021' | DATE | java.sql.Date
id | 5 | INT | java.lang.Long
current | false | BOOLEAN | java.lang.Boolean
package com.vertica.jdbc.test.samples;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.Array;
import java.sql.Struct;
public class ComplexTypesSamples
{
/**
* Executes a query and gets a java.sql.Struct from the ResultSet. It then uses the Struct#getAttributes
* method to get the contents of the struct as a Java Object [].
* @param conn A Connection to a Vertica database
* @throws SQLException
*/
public static void getRowExample (Connection conn) throws SQLException {
Statement stmt = conn.createStatement();
final String queryText = "SELECT ROW('Amy', '07/10/2021'::Date, 5, false) as rowExample(name, date, id, current)";
final String targetColumnName = "rowExample";
System.out.println ("queryText: " + queryText);
ResultSet rs = stmt.executeQuery(queryText);
int targetColumnId = rs.findColumn (targetColumnName);
while (rs.next ()) {
// Get the java.sql.Array from the result set
Object currentObject = rs.getObject (targetColumnId);
assert (currentObject instanceof Struct);
Struct rowStruct = (Struct)currentObject;
Object[] attributes = rowStruct.getAttributes();
// attributes.length should be 4 based on the queryText
assert (attributes.length == 4);
assert (attributes[0] instanceof String);
assert (attributes[1] instanceof java.sql.Date);
assert (attributes[2] instanceof java.lang.Long);
assert (attributes[3] instanceof java.lang.Boolean);
System.out.println ("attributes[0]: " + attributes[0] + " (" + attributes[0].getClass().getName() +")");
System.out.println ("attributes[1]: " + attributes[1] + " (" + attributes[1].getClass().getName() +")");
System.out.println ("attributes[2]: " + attributes[2] + " (" + attributes[2].getClass().getName() +")");
System.out.println ("attributes[3]: " + attributes[3] + " (" + attributes[3].getClass().getName() +")");
}
}
}
The output of getRowExample() shows the attribute of each element and its corresponding Java type:
queryText: SELECT ROW('Amy', '07/10/2021'::Date, 5, false) as rowExample(name, date, id, current)
attributes[0]: Amy (java.lang.String)
attributes[1]: 2021-07-10 (java.sql.Date)
attributes[2]: 5 (java.lang.Long)
attributes[3]: false (java.lang.Boolean)
3.6 - Date types in JDBC
For the purposes of this page, a is defined as a date with a year that exceeds 9999.
Converting a date to a string
For the purposes of this page, a large date is defined as a date with a year that exceeds 9999.
If your database doesn't contain any large dates, then you can reliably call toString() to convert the dates to strings.
Otherwise, if your database contains large dates, you should use java.text.SimpleDateFormat and its format() method:
-
Define a String format with java.text.SimpleDateFormat. The number of characters in yyyy in the format defines the minimum number of characters to use in the date.
-
Call SimpleDateFormat.format() to convert the java.sql.Date object to a String.
Examples
For example, the following method returns a string when passed a java.sql.Date object as an argument. Here, the year part of the format, YYYY indicates that this format is compatible with all dates with at least four characters in its year.
#import java.sql.Date;
private String convertDate (Date date) {
SimpleDateFormat dateFormat = new SimpleDateFormat ("yyyy-MM-dd");
return dateFormat.format (date);
}
4 - Executing queries through JDBC
To run a query through JDBC:.
To run a query through JDBC:
-
Connect with the Vertica database. See Creating and configuring a connection.
-
Run the query.
The method you use to run the query depends on the type of query you want to run:
Executing DDL (data definition language) queries
To run DDL queries, such as CREATE TABLE and COPY, use the Statement.execute() method. You get an instance of this class by calling the createStatement method of your connection object.
The following example creates an instance of the Statement class and uses it to execute a CREATE TABLE and a COPY query:
Statement stmt = conn.createStatement();
stmt.execute("CREATE TABLE address_book (Last_Name char(50) default ''," +
"First_Name char(50),Email char(50),Phone_Number char(50))");
stmt.execute("COPY address_book FROM 'address.dat' DELIMITER ',' NULL 'null'");
Executing queries that return result sets
Use the Statement class's executeQuery method to execute queries that return a result set, such as SELECT. To get the data from the result set, use methods such as getInt, getString, and getDouble to access column values depending upon the data types of columns in the result set. Use ResultSet.next to advance to the next row of the data set.
ResultSet rs = null;
rs = stmt.executeQuery("SELECT First_Name, Last_Name FROM address_book");
int x = 1;
while(rs.next()){
System.out.println(x + ". " + rs.getString(1).trim() + " "
+ rs.getString(2).trim());
x++;
}
Note
The Vertica JDBC driver does not support scrollable cursors. You can only read forwards through the result set.
Executing DML (data manipulation language) queries using executeUpdate
Use the executeUpdate method for DML SQL queries that change data in the database, such as INSERT, UPDATE and DELETE which do not return a result set.
stmt.executeUpdate("INSERT INTO address_book " +
"VALUES ('Ben-Shachar', 'Tamar', 'tamarrow@example.com'," +
"'555-380-6466')");
stmt.executeUpdate("INSERT INTO address_book (First_Name, Email) " +
"VALUES ('Pete','pete@example.com')");
Note
The Vertica JDBC driver's Statement class supports executing multiple statements in the SQL string you pass to the execute method. The PreparedStatement class does not support using multiple statements in a single execution.
Executing stored procedures
You can create and execute stored procedures with CallableStatements.
To create a stored procedure:
Statement st = conn.createStatement();
String createSimpleSp = "CREATE OR REPLACE PROCEDURE raiseInt(IN x INT) LANGUAGE PLvSQL AS $$ " +
"BEGIN" +
"RAISE INFO 'x = %', x;" +
"END;" +
"$$;";
st.execute(createSimpleSp);
To call a stored procedure:
String spCall = "CALL raiseInt (?)";
CallableStatement stmt = conn.prepareCall(spCall);
stmt.setInt(1, 42);
Stored procedures do not yet support OUT parameters. Instead, you can return and retrieve execution information with RAISE and getWarnings() respectively:
System.out.println(stmt.getWarnings().toString());
5 - Canceling JDBC queries
You can cancel JDBC queries with the Statement.cancel() method.
You can cancel JDBC queries with the Statement.cancel() method.
The following example creates a table jdbccanceltest and runs two queries, canceling the first:
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
import java.sql.ResultSet;
import java.sql.Array;
import java.sql.Struct;
public class CancelSamples
{
/**
* Sets up a large test table, queries its contents and cancels the query.
* @param conn A connection to a Vertica database
* @throws SQLException
*/
public static void sampleCancelTest(Connection conn) throws SQLException
{
setup(conn);
try
{
runQueryAndCancel(conn);
runSecondQuery(conn);
}
finally
{
cleanup(conn);
}
}
// Set up table used in test.
private static void setup(Connection conn) throws SQLException
{
System.out.println("Creating and loading table...");
Statement stmt = conn.createStatement();
String queryText = "DROP TABLE IF EXISTS jdbccanceltest";
stmt.execute(queryText);
queryText = "CREATE TABLE jdbccanceltest(id INTEGER, time TIMESTAMP)";
stmt.execute(queryText);
queryText = "INSERT INTO jdbccanceltest SELECT row_number() OVER(), slice_time "
+ "FROM(SELECT slice_time FROM("
+ "SELECT '2021-01-01'::timestamp s UNION ALL SELECT '2022-01-01'::timestamp s"
+ ") sq TIMESERIES slice_time AS '1 second' OVER(ORDER BY s)) sq2";
stmt.execute(queryText);
}
/**
* Execute a long-running query and cancel it.
* @param conn A connection to a Vertica database
* @throws SQLException
*/
private static void runQueryAndCancel(Connection conn) throws SQLException
{
System.out.println("Running and canceling query...");
Statement stmt = conn.createStatement();
String queryText = "select id, time from jdbccanceltest";
ResultSet rs = stmt.executeQuery(queryText);
int i=0;
stmt.cancel();
try
{
while (rs.next()) ;
i++;
}
catch (SQLException e)
{
System.out.println("Query canceled after retrieving " + i + " rows");
System.out.println(e.getMessage());
}
}
/**
* Run a simple query to demonstrate that it can be run after
* the previous query was canceled.
* @param conn A connection to a Vertica database
* @throws SQLException
*/
private static void runSecondQuery(Connection conn) throws SQLException
{
String queryText = "select 1 from dual";
Statement stmt = conn.createStatement();
try
{
ResultSet rs = stmt.executeQuery(queryText);
while (rs.next()) ;
}
catch (SQLException e)
{
System.out.println(e.getMessage());
System.out.println("warning: no exception should have been thrown on query after cancel");
}
}
/**
* Clean up table used in test.
* @param conn A connetion to a Vertica database
* @throws SQLException
*/
private static void cleanup(Connection conn) throws SQLException
{
String queryText = "drop table if exists jdbccanceltest";
Statement stmt = conn.createStatement();
stmt.execute(queryText);
}
}
6 - Loading data through JDBC
You can use any of the following methods to load data via the JDBC interface:.
You can use any of the following methods to load data via the JDBC interface:
-
Executing a SQL INSERT statement to insert a single row directly.
-
Batch loading data using a prepared statement.
-
Bulk loading data from files or streams using COPY.
The following sections explain in detail how you load data using JDBC.
6.1 - Using a single row insert
The simplest way to insert data into a table is to use the SQL INSERT statement.
The simplest way to insert data into a table is to use the SQL INSERT statement. You can use this statement by instantiating a member of the Statement class, and use its executeUpdate() method to run your SQL statement.
The following code fragment demonstrates how you can create a Statement object and use it to insert data into a table named address_book:
Statement stmt = conn.createStatement();
stmt.executeUpdate("INSERT INTO address_book " +
"VALUES ('Smith', 'John', 'jsmith@example.com', " +
"'555-123-4567')");
This method has a few drawbacks: you need convert your data to string and escape any special characters in your data. A better way to insert data is to use prepared statements. See Batch inserts using JDBC prepared statements.
6.2 - Batch inserts using JDBC prepared statements
You can load batches of data into Vertica using prepared INSERT statements—server-side statements that you set up once, and then call repeatedly.
You can load batches of data into Vertica using prepared INSERT statements—server-side statements that you set up once, and then call repeatedly. You instantiate a member of the PreparedStatement class with a SQL statement that contains question mark placeholders for data. For example:
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO customers(last, first, id) VALUES(?,?,?)");
You then set the parameters using data-type-specific methods on the PreparedStatement object, such as setString() and setInt(). Once your parameters are set, call the addBatch() method to add the row to the batch. When you have a complete batch of data ready, call the executeBatch() method to execute the insert batch.
Behind the scenes, the batch insert is converted into a COPY statement. When the connection's AutoCommit parameter is disabled, Vertica keeps the COPY statement open and uses it to load subsequent batches until the transaction is committed, the cursor is closed, or your application executes anything else (or executes any statement using another Statement or PreparedStatement object). Using a single COPY statement for multiple batch inserts makes loading data more efficient. If you are loading multiple batches, you should disable the AutoCommit property of the database to take advantage of this increased efficiency.
When performing batch inserts, experiment with various batch and row sizes to determine the settings that provide the best performance.
The following example demonstrates using a prepared statement to batch insert data.
import java.sql.*;
import java.util.Properties;
public class BatchInsertExample {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
//Set streamingBatchInsert to True to enable streaming mode for batch inserts.
//myProp.put("streamingBatchInsert", "True");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// establish connection and make a table for the data.
Statement stmt = conn.createStatement();
// Set AutoCommit to false to allow Vertica to reuse the same
// COPY statement
conn.setAutoCommit(false);
// Drop table and recreate.
stmt.execute("DROP TABLE IF EXISTS customers CASCADE");
stmt.execute("CREATE TABLE customers (CustID int, Last_Name"
+ " char(50), First_Name char(50),Email char(50), "
+ "Phone_Number char(12))");
// Some dummy data to insert.
String[] firstNames = new String[] { "Anna", "Bill", "Cindy",
"Don", "Eric" };
String[] lastNames = new String[] { "Allen", "Brown", "Chu",
"Dodd", "Estavez" };
String[] emails = new String[] { "aang@example.com",
"b.brown@example.com", "cindy@example.com",
"d.d@example.com", "e.estavez@example.com" };
String[] phoneNumbers = new String[] { "123-456-7890",
"555-444-3333", "555-867-5309",
"555-555-1212", "781-555-0000" };
// Create the prepared statement
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO customers (CustID, Last_Name, " +
"First_Name, Email, Phone_Number)" +
" VALUES(?,?,?,?,?)");
// Add rows to a batch in a loop. Each iteration adds a
// new row.
for (int i = 0; i < firstNames.length; i++) {
// Add each parameter to the row.
pstmt.setInt(1, i + 1);
pstmt.setString(2, lastNames[i]);
pstmt.setString(3, firstNames[i]);
pstmt.setString(4, emails[i]);
pstmt.setString(5, phoneNumbers[i]);
// Add row to the batch.
pstmt.addBatch();
}
try {
// Batch is ready, execute it to insert the data
pstmt.executeBatch();
} catch (SQLException e) {
System.out.println("Error message: " + e.getMessage());
return; // Exit if there was an error
}
// Commit the transaction to close the COPY command
conn.commit();
// Print the resulting table.
ResultSet rs = null;
rs = stmt.executeQuery("SELECT CustID, First_Name, "
+ "Last_Name FROM customers ORDER BY CustID");
while (rs.next()) {
System.out.println(rs.getInt(1) + " - "
+ rs.getString(2).trim() + " "
+ rs.getString(3).trim());
}
// Cleanup
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The result of running the example code is:
1 - Anna Allen
2 - Bill Brown
3 - Cindy Chu
4 - Don Dodd
5 - Eric Estavez
Streaming batch inserts
By default, Vertica performs batch inserts by caching each row and inserting the cache when the user calls the executeBatch() method. Vertica also supports streaming batch inserts. A streaming batch insert adds a row to the database each time the user calls addBatch(). Streaming batch inserts improve database performance by allowing parallel processing and reducing memory demands.
Note
Once you begin a streaming batch insert, you cannot make other JDBC calls that require client-server communication until you have executed the batch or closed or rolled back the connection.
To enable streaming batch inserts, set the streamingBatchInsert property to True. The preceding code sample includes a line enabling streamingBatchInsert mode. Remove the // comment marks to enable this line and activate streaming batch inserts.
The following table explains the various batch insert methods and how their behavior differs between default batch insert mode and streaming batch insert mode.
|
Method |
Default Batch Insert Behavior |
Streaming Batch Insert Behavior |
addBatch() |
Adds a row to the row cache. |
Inserts a row into the database. |
executeBatch() |
Adds the contents of the row cache to the database in a single action. |
Sends an end-of-batch message to the server and returns an array of integers indicating the success or failure of each addBatch() attempt. |
clearBatch() |
Clears the row cache without inserting any rows. |
Not supported. Triggers an exception if used when streaming batch inserts are enabled. |
Notes
-
Using the PreparedStatement.setFloat() method can cause rounding errors. If precision is important, use the .setDouble() method instead.
-
The PreparedStatement object caches the connection's AutoCommit property when the statement is prepared. Later changes to the AutoCommit property have no effect on the prepared statement.
6.2.1 - Error handling during batch loads
When loading individual batches, you can find how many rows were accepted and what rows were rejected (see Identifying Accepted and Rejected Rows for details).
When loading individual batches, you can find how many rows were accepted and what rows were rejected (see Identifying Accepted and Rejected Rows for details). If you have disabled the AutoCommit connection setting, other errors (such as disk space errors, for example) do not occur while inserting individual batches. This behavior is caused by having a single SQL COPY statement perform the loading of multiple consecutive batches (which makes the load process more efficient). It is only when the COPY statement closes that the batched data is committed and Vertica reports other types of errors.
Therefore, your bulk loading application should be prepared to check for errors when the COPY statement closes. You can trigger the COPY statement to close by:
-
ending the batch load transaction by calling Connection.commit()
-
closing the statement using Statement.close()
-
setting the connection's AutoCommit property to true before inserting the last batch in the load
Note
The COPY statement also closes if you execute any non-insert statement or execute any statement using a different Statement or PreparedStatement object. Ending the COPY statement using either of these methods can lead to confusion and a harder-to-maintain application, since you would need to handle batch load errors in a non-batch load statement. You should explicitly end the COPY statement at the end of your batch load and handle any errors at that time.
6.2.2 - Identifying accepted and rejected rows (JDBC)
The return value of PreparedStatement.executeBatch is an integer array containing the success or failure status of inserting each row.
The return value of PreparedStatement.executeBatch is an integer array containing the success or failure status of inserting each row. A value 1 means the row was accepted and a value of -3 means that the row was rejected. In the case where an exception occurred during the batch execution, you can also get the array using BatchUpdateException.getUpdateCounts().
The following example extends the example shown in Batch inserts using JDBC prepared statements to retrieve this array and display the results the batch load.
import java.sql.*;
import java.util.Arrays;
import java.util.Properties;
public class BatchInsertErrorHandlingExample {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
Connection conn;
// establish connection and make a table for the data.
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// Disable auto commit
conn.setAutoCommit(false);
// Create a statement
Statement stmt = conn.createStatement();
// Drop table and recreate.
stmt.execute("DROP TABLE IF EXISTS customers CASCADE");
stmt.execute("CREATE TABLE customers (CustID int, Last_Name"
+ " char(50), First_Name char(50),Email char(50), "
+ "Phone_Number char(12))");
// Some dummy data to insert. The one row won't insert because
// the phone number is too long for the phone column.
String[] firstNames = new String[] { "Anna", "Bill", "Cindy",
"Don", "Eric" };
String[] lastNames = new String[] { "Allen", "Brown", "Chu",
"Dodd", "Estavez" };
String[] emails = new String[] { "aang@example.com",
"b.brown@example.com", "cindy@example.com",
"d.d@example.com", "e.estavez@example.com" };
String[] phoneNumbers = new String[] { "123-456-789",
"555-444-3333", "555-867-53093453453",
"555-555-1212", "781-555-0000" };
// Create the prepared statement
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO customers (CustID, Last_Name, " +
"First_Name, Email, Phone_Number)" +
" VALUES(?,?,?,?,?)");
// Add rows to a batch in a loop. Each iteration adds a
// new row.
for (int i = 0; i < firstNames.length; i++) {
// Add each parameter to the row.
pstmt.setInt(1, i + 1);
pstmt.setString(2, lastNames[i]);
pstmt.setString(3, firstNames[i]);
pstmt.setString(4, emails[i]);
pstmt.setString(5, phoneNumbers[i]);
// Add row to the batch.
pstmt.addBatch();
}
// Integer array to hold the results of inserting
// the batch. Will contain an entry for each row,
// indicating success or failure.
int[] batchResults = null;
try {
// Batch is ready, execute it to insert the data
batchResults = pstmt.executeBatch();
} catch (BatchUpdateException e) {
// We expect an exception here, since one of the
// inserted phone numbers is too wide for its column. All of the
// rest of the rows will be inserted.
System.out.println("Error message: " + e.getMessage());
// Batch results isn't set due to exception, but you
// can get it from the exception object.
//
// In your own code, you shouldn't assume the a batch
// exception occurred, since exceptions can be thrown
// by the server for a variety of reasons.
batchResults = e.getUpdateCounts();
}
// You should also be prepared to catch SQLExceptions in your own
// application code, to handle dropped connections and other general
// problems.
// Commit the transaction
conn.commit();
// Print the array holding the results of the batch insertions.
System.out.println("Return value from inserting batch: "
+ Arrays.toString(batchResults));
// Print the resulting table.
ResultSet rs = null;
rs = stmt.executeQuery("SELECT CustID, First_Name, "
+ "Last_Name FROM customers ORDER BY CustID");
while (rs.next()) {
System.out.println(rs.getInt(1) + " - "
+ rs.getString(2).trim() + " "
+ rs.getString(3).trim());
}
// Cleanup
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Running the above example produces the following output on the console:
Error message: [Vertica][VJDBC](100172) One or more rows were rejected by the server.Return value from inserting batch: [1, 1, -3, 1, 1]
1 - Anna Allen
2 - Bill Brown
4 - Don Dodd
5 - Eric Estavez
Notice that the third row failed to insert because its phone number is too long for the Phone_Number column. All of the rest of the rows in the batch (including those after the error) were correctly inserted.
Note
It is more efficient for you to ensure that the data you are inserting is the correct data type and width for the table column you are inserting it into than to handle exceptions after the fact.
6.2.3 - Rolling back batch loads on the server
Batch loads always insert all of their data, even if one or more rows is rejected.
Batch loads always insert all of their data, even if one or more rows is rejected. Only the rows that caused errors in a batch are not loaded. When the database connection's AutoCommit property is true, batches automatically commit their transactions when they complete, so once the batch finishes loading, the data is committed.
In some cases, you may want all of the data in a batch to be successfully inserted—none of the data should be committed if an error occurs. The best way to accomplish this is to turn off the database connection's AutoCommit property to prevent batches from automatically committing themselves. Then, if a batch encounters an error, you can roll back the transaction after catching the BatchUpdateException caused by the insertion error.
The following example demonstrates performing a rollback if any error occurs when loading a batch.
import java.sql.*;
import java.util.Arrays;
import java.util.Properties;
public class RollbackBatchOnError {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "ExampleUser");
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",
myProp);
// Disable auto-commit. This will allow you to roll back a
// a batch load if there is an error.
conn.setAutoCommit(false);
// establish connection and make a table for the data.
Statement stmt = conn.createStatement();
// Drop table and recreate.
stmt.execute("DROP TABLE IF EXISTS customers CASCADE");
stmt.execute("CREATE TABLE customers (CustID int, Last_Name"
+ " char(50), First_Name char(50),Email char(50), "
+ "Phone_Number char(12))");
// Some dummy data to insert. The one row won't insert because
// the phone number is too long for the phone column.
String[] firstNames = new String[] { "Anna", "Bill", "Cindy",
"Don", "Eric" };
String[] lastNames = new String[] { "Allen", "Brown", "Chu",
"Dodd", "Estavez" };
String[] emails = new String[] { "aang@example.com",
"b.brown@example.com", "cindy@example.com",
"d.d@example.com", "e.estavez@example.com" };
String[] phoneNumbers = new String[] { "123-456-789",
"555-444-3333", "555-867-53094535", "555-555-1212",
"781-555-0000" };
// Create the prepared statement
PreparedStatement pstmt = conn.prepareStatement(
"INSERT INTO customers (CustID, Last_Name, " +
"First_Name, Email, Phone_Number) "+
"VALUES(?,?,?,?,?)");
// Add rows to a batch in a loop. Each iteration adds a
// new row.
for (int i = 0; i < firstNames.length; i++) {
// Add each parameter to the row.
pstmt.setInt(1, i + 1);
pstmt.setString(2, lastNames[i]);
pstmt.setString(3, firstNames[i]);
pstmt.setString(4, emails[i]);
pstmt.setString(5, phoneNumbers[i]);
// Add row to the batch.
pstmt.addBatch();
}
// Integer array to hold the results of inserting
// the batch. Will contain an entry for each row,
// indicating success or failure.
int[] batchResults = null;
try {
// Batch is ready, execute it to insert the data
batchResults = pstmt.executeBatch();
// If we reach here, we inserted the batch without errors.
// Commit it.
System.out.println("Batch insert successful. Committing.");
conn.commit();
} catch (BatchUpdateException e) {
System.out.println("Error message: " + e.getMessage());
// Batch results isn't set due to exception, but you
// can get it from the exception object.
batchResults = e.getUpdateCounts();
// Roll back the batch transaction.
System.out.println("Rolling back batch insertion");
conn.rollback();
}
catch (SQLException e) {
// General SQL errors, such as connection issues, throw
// SQLExceptions. Your application should do something more
// than just print a stack trace,
e.printStackTrace();
}
System.out.println("Return value from inserting batch: "
+ Arrays.toString(batchResults));
System.out.println("Customers table contains:");
// Print the resulting table.
ResultSet rs = null;
rs = stmt.executeQuery("SELECT CustID, First_Name, "
+ "Last_Name FROM customers ORDER BY CustID");
while (rs.next()) {
System.out.println(rs.getInt(1) + " - "
+ rs.getString(2).trim() + " "
+ rs.getString(3).trim());
}
// Cleanup
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
Running the above example prints the following on the system console:
Error message: [Vertica][VJDBC](100172) One or more rows were rejected by the server.Rolling back batch insertion
Return value from inserting batch: [1, 1, -3, 1, 1]
Customers table contains:
The return values indicate whether each rows was successfully inserted. The value 1 means the row inserted without any issues, and a -3 indicates the row failed to insert.
The customers table is empty since the batch insert was rolled back due to the error caused by the third column.
6.3 - Bulk loading using the COPY statement
One of the fastest ways to load large amounts of data into Vertica at once (bulk loading) is to use the COPY statement.
One of the fastest ways to load large amounts of data into Vertica at once (bulk loading) is to use the COPY statement. This statement loads data from a file stored on a Vertica host (or in a data stream) into a table in the database. You can pass the COPY statement parameters that define the format of the data in the file, how the data is to be transformed as it is loaded, how to handle errors, and how the data should be loaded. See the COPY documentation for details.
Important
In databases that were created in versions of Vertica ≤ 9.2, COPY supports the DIRECT option, which specifies to load data directly into ROS rather than WOS. Use this option when loading large (>100MB) files into the database; otherwise, the load is liable to fill the WOS. When this occurs, the Tuple Mover must perform a
moveout operation on the WOS data. It is more efficient to directly load into ROS and avoid forcing a moveout.
In databases created in Vertica 9.3, Vertica ignores load options and hints and always uses a load method of DIRECT. Databases created in versions ≥ 10.0 no longer support WOS and moveout operations; all data is always loaded directly into ROS.
Only a superuser can use COPY to copy a file stored on a host, so you must connect to the database with a superuser account. If you want to have a non-superuser user bulk-load data, you can use COPY to load from a stream on the host (such as STDIN) rather than a file or stream data from the client (see Streaming data via JDBC). You can also perform a standard batch insert using a prepared statement, which uses the COPY statement in the background to load the data.
Note
When using COPY parameter
ON ANY NODE, confirm that the source file is identical on all nodes. Using different files can produce inconsistent results.
The following example demonstrates using the COPY statement through the JDBC to load a file name customers.txt into a new database table. This file must be stored on the database host to which your application connects—in this example, a host named VerticaHost.
import java.sql.*;
import java.util.Properties;
import com.vertica.jdbc.*;
public class COPYFromFile {
public static void main(String[] args) {
Properties myProp = new Properties();
myProp.put("user", "ExampleAdmin"); // Must be superuser
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",myProp);
// Disable AutoCommit
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
// Create a table to hold data.
stmt.execute("DROP TABLE IF EXISTS customers;");
stmt.execute("CREATE TABLE IF NOT EXISTS customers (Last_Name char(50) "
+ "NOT NULL, First_Name char(50),Email char(50), "
+ "Phone_Number char(15))");
// Use the COPY command to load data. Use ENFORCELENGTH to reject
// strings too wide for their columns.
boolean result = stmt.execute("COPY customers FROM "
+ " '/data/customers.txt' ENFORCELENGTH");
// Determine if execution returned a count value, or a full result
// set.
if (result) {
System.out.println("Got result set");
} else {
// Count will usually return the count of rows inserted.
System.out.println("Got count");
int rowCount = stmt.getUpdateCount();
System.out.println("Number of accepted rows = " + rowCount);
}
// Commit the data load
conn.commit();
} catch (SQLException e) {
System.out.print("Error: ");
System.out.println(e.toString());
}
}
}
The example prints the following out to the system console when run (assuming that the customers.txt file contained two million valid rows):
Number of accepted rows = 2000000
6.4 - Streaming data via JDBC
There are two options to stream data from a file on the client to your Vertica database:.
There are two options to stream data from a file on the client to your Vertica database:
The topics in this section explain how to use these options.
6.4.1 - Using VerticaCopyStream
The VerticaCopyStream class lets you stream data from the client system to a Vertica database.
The VerticaCopyStream class lets you stream data from the client system to a Vertica database. It lets you use COPY directly without first copying the data to a host in the database cluster. Using COPY to load data from the host requires superuser privileges to access the host's file system. The COPY statement used to load data from a stream does not require superuser privileges, so your client can connect with any user account that has INSERT privileges on the target table.
To copy streams into the database:
-
Disable the database connections AutoCommit connection parameter.
-
Instantiate a VerticaCopyStreamObject, passing it at least the database connection objects and a string containing a COPY statement to load the data. This statement must copy data from the STDIN into your table. You can use any parameters that are appropriate for your data load.
Note
The VerticaCopyStreamObject constructor optionally takes a single InputStream object, or a List of InputStream objects. This option lets you pre-populate the list of streams to be copied into the database.
-
Call VerticaCopyStreamObject.start() to start the COPY statement and begin streaming the data in any streams you have already added to the VerticaCopyStreamObject.
-
Call VerticaCopyStreamObject.addStream() to add additional streams to the list of streams to send to the database. You can then call VerticaCopyStreamObject.execute() to stream them to the server.
-
Optionally, call VerticaCopyStreamObject.getRejects() to get a list of rejected rows from the last .execute() call. The list of rejects is reset by each call to .execute() or .finish().
Note
If you used either the REJECTED DATA or EXCEPTIONS options in the COPY statement you passed to VerticaCopyStreamObject the object in step 2, .getRejects() returns an empty list. You can only use one method of tracking the rejected rows at a time.
-
When you are finished adding streams, call VerticaCopyStreamObject.finish() to send any remaining streams to the database and close the COPY statement.
-
Call Connection.commit() to commit the loaded data.
Getting rejected rows
The VerticaCopyStreamObject.getRejects() method returns a List containing the row numbers of rows that were rejected after the previous .execute() method call. Each call to .execute() clears the list of rejected rows, so you need to call .getRejects() after each call to .execute(). Since .start() and .finish() also call .execute() to send any pending streams to the server, you should also call .getRejects() after these methods as well.
The following example demonstrates loading the content of five text files stored on the client system into a table.
import java.io.File;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.Statement;
import java.util.Iterator;
import java.util.List;
import java.util.Properties;
import com.vertica.jdbc.VerticaConnection;
import com.vertica.jdbc.VerticaCopyStream;
public class CopyMultipleStreamsExample {
public static void main(String[] args) {
// Note: If running on Java 5, you need to call Class.forName
// to manually load the JDBC driver.
// Set up the properties of the connection
Properties myProp = new Properties();
myProp.put("user", "ExampleUser"); // Must be superuser
myProp.put("password", "password123");
// When performing bulk loads, you should always disable the
// connection's AutoCommit property to ensure the loads happen as
// efficiently as possible by reusing the same COPY command and
// transaction.
myProp.put("AutoCommit", "false");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB", myProp);
Statement stmt = conn.createStatement();
// Create a table to receive the data
stmt.execute("DROP TABLE IF EXISTS customers");
stmt.execute("CREATE TABLE customers (Last_Name char(50), "
+ "First_Name char(50),Email char(50), "
+ "Phone_Number char(15))");
// Prepare the query to insert from a stream. This query must use
// the COPY statement to load data from STDIN. Unlike copying from
// a file on the host, you do not need superuser privileges to
// copy a stream. All your user account needs is INSERT privileges
// on the target table.
String copyQuery = "COPY customers FROM STDIN "
+ "DELIMITER '|' ENFORCELENGTH";
// Create an instance of the stream class. Pass in the
// connection and the query string.
VerticaCopyStream stream = new VerticaCopyStream(
(VerticaConnection) conn, copyQuery);
// Keep running count of the number of rejects
int totalRejects = 0;
// start() starts the stream process, and opens the COPY command.
stream.start();
// If you added streams to VerticaCopyStream before calling start(),
// You should check for rejects here (see below). The start() method
// calls execute() to send any pre-queued streams to the server
// once the COPY statement has been created.
// Simple for loop to load 5 text files named customers-1.txt to
// customers-5.txt
for (int loadNum = 1; loadNum <= 5; loadNum++) {
// Prepare the input file stream. Read from a local file.
String filename = "C:\\Data\\customers-" + loadNum + ".txt";
System.out.println("\n\nLoading file: " + filename);
File inputFile = new File(filename);
FileInputStream inputStream = new FileInputStream(inputFile);
// Add stream to the VerticaCopyStream
stream.addStream(inputStream);
// call execute() to load the newly added stream. You could
// add many streams and call execute once to load them all.
// Which method you choose depends mainly on whether you want
// the ability to check the number of rejections as the load
// progresses so you can stop if the number of rejects gets too
// high. Also, high numbers of InputStreams could create a
// resource issue on your client system.
stream.execute();
// Show any rejects from this execution of the stream load
// getRejects() returns a List containing the
// row numbers of rejected rows.
List<Long> rejects = stream.getRejects();
// The size of the list gives you the number of rejected rows.
int numRejects = rejects.size();
totalRejects += numRejects;
System.out.println("Number of rows rejected in load #"
+ loadNum + ": " + numRejects);
// List all of the rows that were rejected.
Iterator<Long> rejit = rejects.iterator();
long linecount = 0;
while (rejit.hasNext()) {
System.out.print("Rejected row #" + ++linecount);
System.out.println(" is row " + rejit.next());
}
}
// Finish closes the COPY command. It returns the number of
// rows inserted.
long results = stream.finish();
System.out.println("Finish returned " + results);
// If you added any streams that hadn't been executed(),
// you should also check for rejects here, since finish()
// calls execute() to
// You can also get the number of rows inserted using
// getRowCount().
System.out.println("Number of rows accepted: "
+ stream.getRowCount());
System.out.println("Total number of rows rejected: " + totalRejects);
// Commit the loaded data
conn.commit();
} catch (Exception e) {
e.printStackTrace();
}
}
}
Running the above example on some sample data results in the following output:
Loading file: C:\Data\customers-1.txtNumber of rows rejected in load #1: 3
Rejected row #1 is row 3
Rejected row #2 is row 7
Rejected row #3 is row 51
Loading file: C:\Data\customers-2.txt
Number of rows rejected in load #2: 5Rejected row #1 is row 4143
Rejected row #2 is row 6132
Rejected row #3 is row 9998
Rejected row #4 is row 10000
Rejected row #5 is row 10050
Loading file: C:\Data\customers-3.txt
Number of rows rejected in load #3: 9
Rejected row #1 is row 14142
Rejected row #2 is row 16131
Rejected row #3 is row 19999
Rejected row #4 is row 20001
Rejected row #5 is row 20005
Rejected row #6 is row 20049
Rejected row #7 is row 20056
Rejected row #8 is row 20144
Rejected row #9 is row 20236
Loading file: C:\Data\customers-4.txt
Number of rows rejected in load #4: 8
Rejected row #1 is row 23774
Rejected row #2 is row 24141
Rejected row #3 is row 25906
Rejected row #4 is row 26130
Rejected row #5 is row 27317
Rejected row #6 is row 28121
Rejected row #7 is row 29321
Rejected row #8 is row 29998
Loading file: C:\Data\customers-5.txt
Number of rows rejected in load #5: 1
Rejected row #1 is row 39997
Finish returned 39995
Number of rows accepted: 39995
Total number of rows rejected: 26
Note
The above example shows a simple load process that targets one node in the Vertica cluster. It is more efficient to simultaneously load multiple streams to multiple database nodes. Doing so greatly improves performance because it spreads the processing for the load across the cluster.
6.4.2 - Using COPY LOCAL with JDBC
To use COPY LOCAL with JDBC, just execute a COPY LOCAL statement with the path to the source file on the client system.
To use COPY LOCAL with JDBC, just execute a COPY LOCAL statement with the path to the source file on the client system. This method is simpler than using the VerticaCopyStream class (details on the class are available in the JDBC documentation. However, you may prefer using VerticaCopyStream if you have many files to copy to the database or if your data comes from a source other than a file (streamed over a network connection, for example).
You can use COPY LOCAL in a multiple-statement query. However, you should always make it the first statement in the query. You should not use it multiple times in the same query.
The following example code demonstrates using COPY LOCAL to copy a file from the client to the database. It is the same as the code shown in Bulk loading using the COPY statement, except for the use of the LOCAL option in the COPY statement, and the path to the data file is on the client system, rather than on the server.
Note
The exceptions/rejections files are created on the client machine when the exceptions and rejected data modifiers are specified on the copy local command. Specify a local path and filename for these modifiers when executing a COPY LOCAL query from the driver.
import java.sql.*;
import java.util.Properties;
public class COPYLocal {
public static void main(String[] args) {
// Note: If using Java 5, you must call Class.forName to load the
// JDBC driver.
Properties myProp = new Properties();
myProp.put("user", "ExampleUser"); // Do not need to superuser
myProp.put("password", "password123");
Connection conn;
try {
conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:5433/ExampleDB",myProp);
// Disable AutoCommit
conn.setAutoCommit(false);
Statement stmt = conn.createStatement();
// Create a table to hold data.
stmt.execute("DROP TABLE IF EXISTS customers;");
stmt.execute("CREATE TABLE IF NOT EXISTS customers (Last_Name char(50) "
+ "NOT NULL, First_Name char(50),Email char(50), "
+ "Phone_Number char(15))");
// Use the COPY command to load data. Load directly into ROS, since
// this load could be over 100MB. Use ENFORCELENGTH to reject
// strings too wide for their columns.
boolean result = stmt.execute("COPY customers FROM LOCAL "
+ " 'C:\\Data\\customers.txt' DIRECT ENFORCELENGTH");
// Determine if execution returned a count value, or a full result
// set.
if (result) {
System.out.println("Got result set");
} else {
// Count will usually return the count of rows inserted.
System.out.println("Got count");
int rowCount = stmt.getUpdateCount();
System.out.println("Number of accepted rows = " + rowCount);
}
conn.close();
} catch (SQLException e) {
System.out.print("Error: ");
System.out.println(e.toString());
}
}
}
The result of running this code appears below. In this case, the customers.txt file contains 10000 rows, seven of which get rejected because they contain data too wide to fit into their database columns.
Got countNumber of accepted rows = 9993
7 - Handling errors
When the Vertica JDBC driver encounters an error, it throws a SQLException or one of its subclasses.
When the Vertica JDBC driver encounters an error, it throws a SQLException or one of its subclasses. The specific subclass it throws depends on the type of error that has occurred. Most of the JDBC method calls can result in several different types of errors, in response to which the JDBC driver throws a specific SQLException subclass. Your client application can choose how to react to the error based on the specific exception that the JDBC driver threw.
Note
The specific SQLException subclasses were introduced in the JDBC 4.0 standard.
The hierarchy of SQLException subclasses is arranged to help your client application determine what actions it can take in response to an error condition. For example:
-
The JDBC driver throws SQLTransientException subclasses when the cause of the error may be a temporary condition, such as a timeout error (SQLTimeoutException) or a connection issue (SQLTransientConnectionIssue). Your client application can choose to retry the operation without making any sort of attempt to remedy the error, since it may not reoccur.
-
The JDBC driver throws SQLNonTransientException subclasses when the client needs to take some action before it could retry the operation. For example, executing a statement with a SQL syntax error results in the JDBC driver throwing the a SQLSyntaxErrorException (a subclass of SQLNonTransientException). Often, your client application just has to report these errors back to the user and have him or her resolve them. For example, if the user supplied your application with a SQL statement that triggered a SQLSyntaxErrorException, it could prompt the user to fix the SQL error.
SeeSQLState mapping to Java exception classes for a list Java exceptions thrown by the JDBC driver.
7.1 - SQLState mapping to Java exception classes
|
SQLSTATE Class or Value |
Description |
Java Exception Class |
|
Class 00 |
Successful Completion |
SQLException |
|
Class 01 |
Warning |
SQLException |
|
Class 02 |
No Data |
SQLException |
|
Class 03 |
SQL Statement Not Yet Complete |
SQLException |
|
Class 08 |
Client Connection Exception |
SQLNonTransientConnectionException |
|
Class 09 |
Triggered Action Exception |
SQLException |
|
Class 0A |
Feature Not Supported |
SQLFeatureNotSupportedException |
|
Class 0B |
Invalid Transaction Initiation |
SQLException |
|
Class 0F |
Locator Exception |
SQLException |
|
Class 0L |
Invalid Grantor |
SQLException |
|
Class 0P |
Invalid Role Specification |
SQLException |
|
Class 20 |
Case Not Found |
SQLException |
|
Class 21 |
Cardinality Violation |
SQLException |
|
Class 22 |
Data Exception |
SQLDataException |
|
22V21 |
INVALID_EPOCH |
SQLNonTransientException |
|
Class 23 |
Integrity Constraint Violation |
SQLIntegrityConstraintViolationException |
|
Class 24 |
Invalid Cursor State |
SQLException |
|
Class 25 |
Invalid Transaction State |
SQLTransactionRollbackException |
|
Class 26 |
Invalid SQL Statement Name |
SQLException |
|
Class 27 |
Triggered Data Change Violation |
SQLException |
|
Class 28 |
Invalid Authorization Specification |
SQLInvalidAuthorizationException |
|
Class 2B |
Dependent Privilege Descriptors Still Exist |
SQLDataException |
|
Class 2D |
Invalid Transaction Termination |
SQLException |
|
Class 2F |
SQL Routine Exception |
SQLException |
|
Class 34 |
Invalid Cursor Name |
SQLException |
|
Class 38 |
External Routine Exception |
SQLException |
|
Class 39 |
External Routine Invocation Exception |
SQLException |
|
Class 3B |
Savepoint Exception |
SQLException |
|
Class 3D |
Invalid Catalog Name |
SQLException |
|
Class 3F |
Invalid Schema Name |
SQLException |
|
Class 40 |
Transaction Rollback |
SQLTransactionRollbackException |
|
Class 42 |
Syntax Error or Access Rule Violation |
SQLClientSyntaxErrorException |
|
Class 44 |
WITH CHECK OPTION Violation |
SQLException |
|
Class 53 |
Insufficient Resources |
SQLTransientException |
|
53300 |
TOO_MANY_CONNECTIONS |
SQLTransientConnectionException |
|
Class 54 |
Program Limit Exceeded |
SQLNonTransientException |
|
Class 55 |
Object Not In Prerequisite State |
SQLNonTransientException |
|
55V03 |
LOCK_NOT_AVAILABLE |
SQLTransactionRollbackException |
|
Class 57 |
Operator Intervention |
SQLTransientException |
|
57V01 |
ADMIN_SHUTDOWN |
SQLNonTransientConnectionException |
|
57V02 |
CRASH_SHUTDOWN |
SQLNonTransientConnectionException |
|
57V03 |
CANNOT_CONNECT_NOW |
SQLNonTransientConnectionException |
|
Class 58 |
System Error |
SQLException |
|
Class V0 |
PL/vSQL errors |
SQLException |
|
Class V1 |
Vertica-specific multi-node errors class |
SQLException |
|
Class V2 |
Vertica-specific miscellaneous errors class |
SQLException |
|
V2000 |
AUTH_FAILED |
SQLInvalidAuthorizationException |
|
Class VC |
Configuration File Error |
SQLNonTransientException |
|
Class VD |
DB Designer errors |
SQLNonTransientException |
|
Class VP |
User procedure errors |
SQLNonTransientException |
|
Class VX |
Internal Error |
SQLException |
8 - Routing JDBC queries directly to a single node
The JDBC driver has the ability to route queries directly to a single node using a special connection called a Routable Connection.
The JDBC driver has the ability to route queries directly to a single node using a special connection called a Routable Connection. This feature is ideal for high-volume "short" requests that return a small number of results that all exist on a single node. The common scenario for using this feature is to do high-volume lookups on data that is identified with a unique key. Routable queries typically provide lower latency and use less system resources than distributed queries. However, the data being queried must be segmented in such a way that the JDBC client can determine on which node the data resides.
Vertica Typical Analytic Query
Typical analytic queries require dense computation on data across all nodes in the cluster and benefit from having all nodes involved in the planning and execution of the queries.
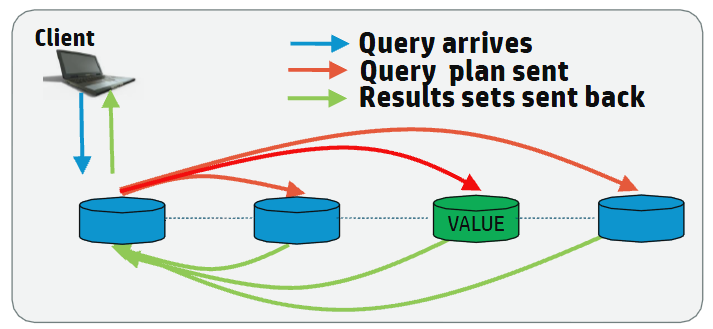
Vertica Routable Query API Query
For high-volume queries that return a single or a few rows of data, it is more efficient to execute the query on the single node that contains the data.
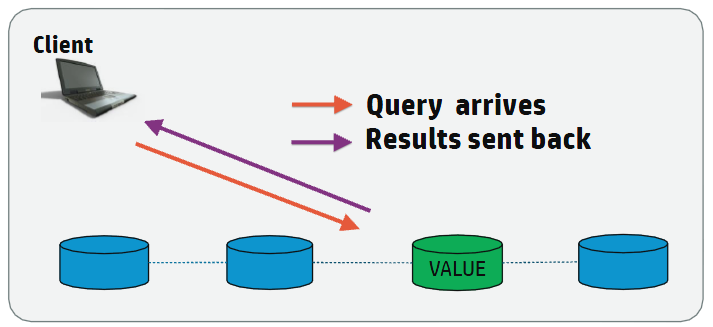
To effectively route a request to a single node, the client must determine the specific node on which the data resides. For the client to be able to determine the correct node, the table must be segmented by one or more columns. For example, if you segment a table on a Primary Key (PK) column, then the client can determine on which node the data resides based on the Primary Key and directly connect to that node to quickly fulfill the request.
The Routable Query API provides two classes for performing routable queries: VerticaRoutableExecutor and VGet. VerticaRoutableExecutor provides a more expressive SQL-based API while VGet provides a more structured API for programmatic access.
-
The VerticaRoutableExecutor class allows you to use traditional SQL with a reduced feature set to query data on a single node.
For joins, the table must be joined on a key column that exists in each table you are joining, and the tables must be segmented on that key. However, this is not true for unsegmented tables, which can always be joined (since all the data in an unsegmented table is available on all nodes).
-
The VGet class does not use traditional SQL syntax. Instead, it uses a data structure that you build by defining predicates and predicate expressions and outputs and output expressions. This class is ideal for doing Key/Value type lookups on single tables.
The data structure used for querying the table must provide a predicate for each segmented column defined in the projection for the table. You must provide, at a minimum, a predicate with a constant value for each segmented column. For example, an id with a value of 12234 if the table is segmented only on the id column. You can also specify additional predicates for the other, non-segmented, columns in the table. Predicates act like a SQL WHERE clause and multiple predicates/predicate expressions apply together with a SQL AND modifier. Predicates must be defined with a constant value. Predicate expressions can be used to refine the query and can contain any arbitrary SQL expressions (such as less than, greater than, and so on) for any of the non-segmented columns in the table.
Java documentation for all classes and methods in the JDBC Driver is available in the Vertica JDBC documentation.
Note
The JDBC Routable Query API is read-only and requires JDK 1.6 or greater.
8.1 - Creating tables and projections for use with the routable query API
For routable queries, the client must determine the appropriate node to get the data.
For routable queries, the client must determine the appropriate node to get the data. The client does this by comparing all projections available for the table, and determining the best projection to use to find the single node that contains data. You must create a projection segmented by the key column(s) on at least one table to take full advantage of the routable query API. Other tables that join to this table must either have an unsegmented projection, or a projection segmented as described below.
Note
Tables must be segmented by hash for routable queries. See
Hash segmentation clause. Other segmentation types are not supported.
Creating tables for use with routable queries
To create a table that can be used with the routable query API, segment (by hash) the table on a uniformly distributed column. Typically, you segment on a primary key. For faster lookups, sort the projection on the same columns on which you segmented. For example, to create a table that is well suited to routable queries:
CREATE TABLE users (
id INT NOT NULL PRIMARY KEY,
username VARCHAR(32),
email VARCHAR(64),
business_unit VARCHAR(16))
ORDER BY id
SEGMENTED BY HASH(id)
ALL NODES;
This table is segmented based on the id column (and ordered by id to make lookups faster). To build a query for this table using the routable query API, you only need to provide a single predicate for the id column which returns a single row when queried.
However, you might add multiple columns to the segmentation clause. For example:
CREATE TABLE users2 (
id INT NOT NULL PRIMARY KEY,
username VARCHAR(32),
email VARCHAR(64),
business_unit VARCHAR(16))
ORDER BY id, business_unit
SEGMENTED BY HASH(id, business_unit)
ALL NODES;
In this case, you need to provide two predicates when querying the users2 table, as it is segmented on two columns, id and business_unit. However, if you know both id and business_unit when you perform the queries, then it is beneficial to segment on both columns, as it makes it easier for the client to determine that this projection is the best projection to use to determine the correct node.
Designing tables for single-node JOINs
If you plan to use the VerticaRoutableExecutor class and join tables during routable queries, then you must segment all tables being joined by the same segmentation key. Typically this key is a primary/foreign key on all the tables being joined. For example, the customer_key may be the primary key in a customers dimension table, and the same key is a foreign key in a sales fact table. Projections for a VerticaRoutableExecutor query using these tables must be segmented by hash on the customer key in each table.
If you want to join with small dimension tables, such as date dimensions, then it may be appropriate to make those tables unsegmented so that the date_dimension data exists on all nodes. It is important to note that when joining unsegmented tables, you still must specify a segmented table in the createRoutableExecutor() call.
Verifying existing projections for tables
If tables are already segmented by hash (for example, on an ID column), then you can determine what predicates are needed to query the table by using the Vertica function
GET_PROJECTIONS to view that table's projections. For example:
=> SELECT GET_PROJECTIONS ('users');
...
Projection Name: [Segmented] [Seg Cols] [# of Buddies] [Buddy Projections] [Safe] [UptoDate] [Stats]
----------------------------------------------------------------------------------------------------
public.users_b1 [Segmented: Yes] [Seg Cols: "public.users.id"] [K: 1] [public.users_b0] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
public.users_b0 [Segmented: Yes] [Seg Cols: "public.users.id"] [K: 1] [public.users_b1] [Safe: Yes] [UptoDate: Yes] [Stats: RowCounts]
For each projection, only the public.users.id column is specified, indicating your query predicate should include this column.
If the table is segmented on multiple columns, for example id and business_unit, then you need to provide both columns as predicates to the routable query.
8.2 - Creating a connection for routable queries
The JDBC Routable Query API provides the VerticaRoutableConnection (details are available in the JDBC Documentation) interface to connect to a cluster and allow for Routable Queries.
The JDBC Routable Query API provides the VerticaRoutableConnection (details are available in the JDBC documentation interface to connect to a cluster and allow for Routable Queries. This interface provides advanced routing capabilities beyond those of a normal VerticaConnection. The VerticaRoutableConnection provides access to the VerticaRoutableExecutor and VGet classes. See Defining the query for routable queries using the VerticaRoutableExecutor class and Defining the query for routable queries using the VGet class respectively.
You enable access to this class by setting the EnableRoutableQueries JDBC connection property to true.
The VerticaRoutableConnection maintains an internal pool of connections and a cache of table metadata that is shared by all VerticaRoutableExecutor/VGet objects that are produced by the connection's createRoutableExecutor()/prepareGet() method. It is also a fully-fledged JDBC connection on its own and supports all the functionality that a VerticaConnection supports. When this connection is closed, all pooled connections managed by this VerticaRoutableConnection and all child objects are closed too. The connection pool and metadata is only used by child Routable Query operations.
Example:
You can create the connection using a JDBC DataSource:
com.vertica.jdbc.DataSource jdbcSettings = new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("exampleDB");
jdbcSettings.setHost("v_vmart_node0001.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
conn = (VerticaRoutableConnection)jdbcSettings.getConnection();
You can also create the connection using a connection string and the DriverManager.getConnection() method:
String connectionString = "jdbc:vertica://v_vmart_node0001.example.com:5433/exampleDB?user=dbadmin&password=&EnableRoutableQueries=true";
VerticaRoutableConnection conn = (VerticaRoutableConnection) DriverManager.getConnection(connectionString);
Both methods result in a conn connection object that is identical.
Note
Avoid opening many VerticaRoutableConnection connections because this connection maintains its own private pool of connections which are not shared with other connections. Instead, your application should use a single connection and issue multiple queries through that connection.
In addition to the setEnableRoutableQueries property that the Routable Query API adds to the Vertica JDBC connection class, the API also adds additional properties. The complete list is below.
-
EnableRoutableQueries: Enables Routable Query lookup capability. Default is false.
-
FailOnMultiNodePlans: If the plan requires more than one node, and FailOnMultiNodePlans is true, then the query fails. If it is set to false then a warning is generated and the query continues. However, latency is greatly increased as the Routable Query must first determine the data is on multiple nodes, then a normal query is run using traditional (all node) execution and execution. Defaults to true. Note that this failure cannot occur on simple calls using only predicates and constant values.
-
MetadataCacheLifetime: The time in seconds to keep projection metadata. The API caches metadata about the projection used for the query (such as projections). The cache is used on subsequent queries to reduce response time. The default is 300 seconds.
-
MaxPooledConnections: Cluster-wide maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Default 20.
-
MaxPooledConnectionsPerNode: Per-node maximum number of connections to keep in the VerticaRoutableConnection’s internal pool. Default 5.
8.3 - Defining the query for routable queries using the VerticaRoutableExecutor class
Use the VerticaRoutableExecutor class to access table data directly from a single node.
Use the VerticaRoutableExecutor class to access table data directly from a single node. VerticaRoutableExecutor directly queries Vertica only on the node that has all the data needed for the query, avoiding the distributed planning and execution costs associated with Vertica query execution. You can use VerticaRoutableExecutor to join tables or use a GROUP BY clause, as these operations are not possible using VGet.
When using the VerticaRoutableExecutor class, the following rules apply:
- If joining tables, all tables being joined must be segmented (by hash) on the same set of columns referenced in the join predicate, unless the table to join is unsegmented.
- Multiple conditions in a join WHERE clause must be AND'd together. Using OR in the WHERE clause causes the query to degenerate to a multi-node plan. You can specify OR, IN list, or range conditions on columns outside the join condition if the data exists on the same node.
- You can only execute a single statement per request. Chained SQL statements are not permitted.
- Your query can be used in a driver-generated subquery to help determine whether the query can execute on a single node. Therefore, you cannot include the semi-colon at the end of the statement and you cannot include SQL comments using double-dashes (
--), as these cause the driver-generated query to fail.
You create a VerticaRoutableExecutor by calling the createRoutableExecutor method on a connection object:
createRoutableExecutor( schema-name, table-name )
For example:
VerticaRoutableConnection conn;
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
String table = "customers";
VerticaRoutableExecutor q = conn.createRoutableExecutor(null, table);
...
}...
If schema-name is set to null, then the search path is used to find the table.
VerticaRoutableExecutor methods
VerticaRoutableExecutor has the following methods:
For details on this class, see the JDBC documentation.
Execute
execute( query-string, { column, value | map } )
Runs the query.
query-string |
The query to execute |
column, value |
The column and value when the lookup is done on a single value. For example:
String column = "customer_key";
Integer value = 1;
ResultSet rs = q.execute(query, column, value)
|
map |
A Java map of the column names and corresponding values if the lookup is done on one or more columns. For example: ResultSet rs = q.execute(query, map);. The table must have at least one projection segmented by a set of columns that exactly match the columns in the map. Each column defined in the map can have only one value. For example:
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
map.put("another_key", 42);
ResultSet rs = q.execute(query, map);
|
The following requirements apply:
-
The query to execute must use regular SQL that complies with the rules of the VerticaRoutableExecutor class. For example, you can add limits and sorts, or use aggregate functions, provided the data exists on a single node.
-
The JDBC client uses the column/value or map arguments to determine on which node to execute the query. The content of the query must use the same values that you provide in the column/value or map arguments.
-
The following data types cannot be used as column values: * INTERVAL * TIMETZ * TIMESTAMPTZ
Also, if a table is segmented on any columns with the following data types then the table cannot be queried with the routable query API:
The driver does not verify the syntax of the query before it sends the query to the server. If your expression is incorrect, then the query fails.
Close
close()
Closes this VerticaRoutableExecutor by releasing resources used by this VerticaRoutableExecutor. It does not close the parent JDBC connection to Vertica.
getWarnings
getWarnings()
Retrieves the first warning reported by calls on this VerticaRoutableExecutor. Additional warnings are chained and can be accessed with the JDBC method getNextWarning().
Example
The following example shows how to use VerticaRoutableExecutor to execute a query using both a JOIN clause and an aggregate function with a GROUP BY clause. The example also shows how to create a customer and sales table, and segment the tables so they can be joined using the VerticaRoutableExecutor class. This example uses the date_dimension table in the VMart schema to show how to join data on unsegmented tables.
-
Create the customers table to store customer details, and then create projections that are segmented on the table's customer_key column:
=> CREATE TABLE customers (customer_key INT, customer_name VARCHAR(128), customer_email VARCHAR(128));
=> CREATE PROJECTION cust_proj_b0 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES;
=> CREATE PROJECTION cust_proj_b1 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 1;
=> CREATE PROJECTION cust_proj_b2 AS SELECT * FROM customers SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 2;
=> SELECT start_refresh();
-
Create the sales table, then create projections that are segmented on its customer_key column. Because the customer and sales tables are segmented on the same key, you can join them later with the VerticaRoutableExecutor routable query lookup.
=> CREATE TABLE sales (sale_key INT, customer_key INT, date_key INT, sales_amount FLOAT);
=> CREATE PROJECTION sales_proj_b0 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES;
=> CREATE PROJECTION sales_proj_b1 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 1;
=> CREATE PROJECTION sales_proj_b2 AS SELECT * FROM sales SEGMENTED BY HASH (customer_key) ALL NODES OFFSET 2;
=> SELECT start_refresh();
-
Add some sample data:
=> INSERT INTO customers VALUES (1, 'Fred', 'fred@example.com');
=> INSERT INTO customers VALUES (2, 'Sue', 'Sue@example.com');
=> INSERT INTO customers VALUES (3, 'Dave', 'Dave@example.com');
=> INSERT INTO customers VALUES (4, 'Ann', 'Ann@example.com');
=> INSERT INTO customers VALUES (5, 'Jamie', 'Jamie@example.com');
=> COMMIT;
=> INSERT INTO sales VALUES(1, 1, 1, '100.00');
=> INSERT INTO sales VALUES(2, 2, 2, '200.00');
=> INSERT INTO sales VALUES(3, 3, 3, '300.00');
=> INSERT INTO sales VALUES(4, 4, 4, '400.00');
=> INSERT INTO sales VALUES(5, 5, 5, '400.00');
=> INSERT INTO sales VALUES(6, 1, 15, '500.00');
=> INSERT INTO sales VALUES(7, 1, 15, '400.00');
=> INSERT INTO sales VALUES(8, 1, 35, '300.00');
=> INSERT INTO sales VALUES(9, 1, 35, '200.00');
=> COMMIT;
-
Create an unsegmented projection of the VMart date_dimension table for use in this example. Call the meta-function START_REFRESH to unsegment the existing data:
=> CREATE PROJECTION date_dim AS SELECT * FROM date_dimension UNSEGMENTED ALL NODES;
=> SELECT start_refresh();
Using the customer, sales, and date_dimension data, you can now create a routable query lookup that uses joins and a group by to query the customers table and return the total number of purchases per day for a given customer:
import java.sql.*;
import java.util.HashMap;
import java.util.Map;
import com.vertica.jdbc.kv.*;
public class verticaKV_doc {
public static void main(String[] args) {
com.vertica.jdbc.DataSource jdbcSettings
= new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("VMart");
jdbcSettings.setHost("vertica.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setFailOnMultiNodePlans(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
Map<String, Object> map = new HashMap<String, Object>();
map.put("customer_key", 1);
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
String table = "customers";
VerticaRoutableExecutor q = conn.createRoutableExecutor(null, table);
String query = "select d.date, SUM(s.sales_amount) as Total ";
query += " from customers as c";
query += " join sales as s ";
query += " on s.customer_key = c.customer_key ";
query += " join date_dimension as d ";
query += " on d.date_key = s.date_key ";
query += " where c.customer_key = " + map.get("customer_key");
query += " group by (d.date) order by Total DESC";
ResultSet rs = q.execute(query, map);
while(rs.next()) {
System.out.print("Date: " + rs.getString("date") + ": ");
System.out.println("Amount: " + rs.getString("Total"));
}
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
The example code produces output like this:
Date: 2012-01-15: Amount: 900.0
Date: 2012-02-04: Amount: 500.0
Date: 2012-01-01: Amount: 100.0
Note
Your output might be different, because the VMart schema randomly generates dates in the date_dimension table.
8.4 - Defining the query for routable queries using the VGet class
The VGet class is used to access table data directly from a single node when you do not need to join the data or use a group by clause.
The VGet class is used to access table data directly from a single node when you do not need to join the data or use a group by clause. Like VerticaRoutableExecutor, VGet directly queries Vertica nodes that have the data needed for the query, avoiding the distributed planning and execution costs associated with a normal Vertica execution. However, VGet does not use SQL. Instead, you define predicates and values to perform key/value type lookups on a single table. VGet is especially suited to key/value-type lookups on single tables.
You create a VGet by calling the prepareGet method on a connection object:
prepareGet( schema-name, { table-name | projection-name } )
For example:
VerticaRoutableConnection conn;
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
System.out.println("Connected.");
VGet get = conn.prepareGet("public", "users");
...
}...
VGet operations span multiple JDBC connections (and multiple Vertica sessions) and do not honor the parent connection's transaction semantics. If consistency is required across multiple executions, the parent VerticaRoutableConnection's consistent read API can be used to guarantee all operations occur at the same epoch.
VGet is thread safe, but all methods are synchronized, so threads that share a VGet instance are never run in parallel. For better parallelism, each thread should have its own VGet instance. Different VGet instances that operate on the same table share pooled connections and metadata in a manner that enables a high degree of parallelism.
VGet methods
VGet has the following methods:
By default, VGet fetches all columns of all rows that satisfy the logical AND of predicates passed via the addPredicate method. You can further customize the get operation with the following methods: addOutputColumn, addOutputExpression, addPredicateExpression, addSortColumn, and setLimit.
addPredicate
addPredicate(string, object)
Adds a predicate column and a constant value to the query. You must include a predicate for each column on which the table is segmented. The predicate acts as the query WHERE clause. Multiple addPredicate method calls are joined by AND modifiers. The VGet retains this value after each call to execute. To remove it, use clearPredicates.
The following data types cannot be used as column values. Also, if a table is segmented on any columns with these data types then the table cannot be queried with the Routable Query API:
addPredicateExpression
addPredicateExpression(string)
Accepts arbitrary SQL expressions that operate on the table's columns as input to the query. Predicate expressions and predicates are joined by AND modifiers. You can use segmented columns in predicate expressions, but they must also be specified as a regular predicate with addPredicate. The VGet retains this value after each call to execute. To remove it, use clearPredicates.
The driver does not verify the syntax of the expression before it sends it to the server. If your expression is incorrect then the query fails.
addOutputColumn
addOutputColumn(string)
Adds a column to be included in the output. By default the query runs as SELECT * and you do not need to define any output columns to return the data. If you add output columns then you must add all the columns to be returned. The VGet retains this value after each call to execute. To remove it, use clearOutputs.
addOutputExpression
addOutputExpression(string)
Accepts arbitrary SQL expressions that operate on the table's columns as output. The VGet retains this value after each call to execute. To remove it, use ClearOutputs.
The following restrictions apply:
-
The driver does not verify the syntax of the expression before it sends it to the server. If your expression is incorrect then the query fails.
-
addOutputExpression is not supported when querying flex tables. If you use addOutputExpression on a flex table query, then a SQLFeatureNotSupportedException is thrown.
addSortColumn
addSortColumn(string, SortOrder)
Adds a sort order to an output column. The output column can be either the one returned by the default query (SELECT *) or one of the columns defined in addSortColumn or addOutputExpress. You can defined multiple sort columns.
setLimit
setLimit(int)
Sets a limit on the number of results returned. A limit of 0 is unlimited.
clearPredicates
clearPredicates()
Removes predicates that were added by addPredicate and addPredicateExpression.
clearOutputs
clearOutputs()
Removes outputs added by addOutputColumn and addOutputExpression.
clearSortColumns
clearSortColumns()
Removes sort columns previously added by addSortColumn.
Execute
execute()
Runs the query. Care must be taken to ensure that the predicate columns exist on the table and projection used by VGet, and that the expressions do not require multiple nodes to execute. If an expression is sufficiently complex as to require more than one node to execute, execute throws a SQLException if the FailOnMultiNodePlans connection property is true.
Close
close()
Closes this VGet by releasing resources used by this VGet. It does not close the parent JDBC connection to Vertica.
getWarnings
getWarnings()
Retrieves the first warning reported by calls on this VGet. Additional warnings are chained and can be accessed with the JDBC method getNextWarning.
Example
The following code queries the users table that is defined in Creating tables and projections for use with the routable query API. The table defines an id column that is segmented by hash.
import java.sql.*;
import com.vertica.jdbc.kv.*;
public class verticaKV2 {
public static void main(String[] args) {
com.vertica.jdbc.DataSource jdbcSettings
= new com.vertica.jdbc.DataSource();
jdbcSettings.setDatabase("exampleDB");
jdbcSettings.setHost("v_vmart_node0001.example.com");
jdbcSettings.setUserID("dbadmin");
jdbcSettings.setPassword("password");
jdbcSettings.setEnableRoutableQueries(true);
jdbcSettings.setPort((short) 5433);
VerticaRoutableConnection conn;
try {
conn = (VerticaRoutableConnection)
jdbcSettings.getConnection();
System.out.println("Connected.");
VGet get = conn.prepareGet("public", "users");
get.addPredicate("id", 5);
ResultSet rs = get.execute();
rs.next();
System.out.println("ID: " +
rs.getString("id"));
System.out.println("Username: "
+ rs.getString("username"));
System.out.println("Email: "
+ rs.getString("email"));
System.out.println("Closing Connection.");
conn.close();
} catch (SQLException e) {
System.out.println("Error! Stacktrace:");
e.printStackTrace();
}
}
}
This code produces the following output:
Connected.
ID: 5
Username: userE
Email: usere@example.com
Closing Connection.
8.5 - Routable query performance and troubleshooting
This topic details performance considerations and common issues you might encounter when using the routable query API.
This topic details performance considerations and common issues you might encounter when using the routable query API.
Using resource pools with routable queries
Individual routable queries are serviced quickly since they directly access a single node and return only one or a few rows of data. However, by default, Vertica resource pools use an AUTO setting for the execution parallelism parameter. When set to AUTO, the setting is determined by the number of CPU cores available and generally results in multi-threaded execution of queries in the resource pool. It is not efficient to create parallel threads on the server because routable query operations return data so quickly and routable query operations only use a single thread to find a row. To prevent the server from opening unneeded processing threads, you should create a specific resource pool for routable query clients. Consider the following settings for the resource pool you use for routable queries:
-
Set execution parallelism to 1 to force single-threaded queries. This setting improves routable query performance.
-
Use CPU affinity to limit the resource pool to a specific CPU or CPU set. The setting ensures that the routable queries have resources available to them, but it also prevents routable queries from significantly impacting performance on the system for other general queries.
-
If you do not set a CPU affinity for the resource pool, consider setting the maximum concurrency value of the resource pool to a setting that ensures good performance for routable queries, but does not negatively impact the performance of general queries.
Because a VerticaRoutableConnection opens an internal pool of connections, it is important to configure MaxPooledConnections and MaxPooledConnectionsPerNode appropriately for your cluster size and the amount of simultaneous client connections. It is possible to impact normal database connections if you are overloading the cluster with VerticaRoutableConnections.
The initial connection to the initiator node discovers all other nodes in the cluster. The internal-pool connections are not opened until a VerticaRoutableExecutor or VGet query is sent. All VerticaRoutableExecutors/VGets in a connection object use connections from the internal pool and are limited by the MaxPooledConnections settings. Connections remain open until they are closed so a new connection can be opened elsewhere if the connection limit has been reached.
Troubleshooting routable queries
Routable query issues generally fall into two categories:
Predicate Requirements
You must provide the same number of predicates that correspond to the columns of the table segmented by hash. To determine the segmented columns, call the Vertica function
GET_PROJECTIONS. You must provide a predicate for each column displayed in the Seg Cols field.
For VGet, this means you must use addPredicate() to add each of the columns. For VerticaRoutableExecutor, this means you must provide all of the predicates and values in the map sent to execute().
Multi-node Failures
It is possible to define the correct number of predicates, but still have a failure because multiple nodes contain the data. This failure occurs because the projection's data is not segmented in such a way that the data being queried is contained on a single node. Enable logging for the connection and view the logs to verify the projection being used. If the client is not picking the correct projection, then try to query the projection directly by specifying the projection instead of the table in the create/prepare statement, for example:
Additionally, you can use the EXPLAIN command in vsql to help determine if your query can run in single node. EXPLAIN can help you understand why the query is being run as single or multi-node.
8.6 - Pre-segmenting data using VHash
The VHash class is an implementation of the Vertica hash function for use with JDBC client applications.
The VHash class is an implementation of the Vertica hash function for use with JDBC client applications.
Hash segmentation in Vertica allows you to segment a projection based on a built-in hash function. The built-in hash function provides even data distribution across some or all nodes in a cluster, resulting in optimal query execution.
Suppose you have several million rows of values spread across thousands of CSV files. Assume that you already have a table segmented by hash. Before you load the values into your database, you probably want to know to which node a particular value loads. For this reason, using VHash can be particularly helpful, by allowing you to pre-segment your data before loading.
The following example shows the VHash class hashing the first column of a file named "testFile.csv". The name of the first column in this file is meterId.
Segment the data using VHash
This example demonstrates how you can read the testFile.csv file from the local file system and run a hash function on the meteterId column. Using the database metadata from a projection, you can then pre-segment the individual rows in the file based on the hash value of meterId.
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.UnsupportedEncodingException;
import java.util.*;
import java.io.IOException;
import java.sql.*;
import com.vertica.jdbc.kv.VHash;
public class VerticaKVDoc {
final Map<String, FileOutputStream> files;
final Map<String, List<Long>> nodeToHashList;
String segmentationMetadata;
List<String> lines;
public static void main(String[] args) throws Exception {
try {
Class.forName("com.vertica.jdbc.Driver");
} catch (ClassNotFoundException e) {
System.err.println("Could not find the JDBC driver class.");
e.printStackTrace();
return;
}
Properties myProp = new Properties();
myProp.put("user", "username");
myProp.put("password", "password");
VerticaKVDoc ex = new VerticaKVDoc();
// Read in the data from a CSV file.
ex.readLinesFromFile("C:\\testFile.csv");
try (Connection conn = DriverManager.getConnection(
"jdbc:vertica://VerticaHost:portNumber/databaseName", myProp)) {
// Compute the hashes and create FileOutputStreams.
ex.prepareForHashing(conn);
}
// Write to files.
ex.writeLinesToFiles();
}
public VerticaKVDoc() {
files = new HashMap<String, FileOutputStream>();
nodeToHashList = new HashMap<String, List<Long>>();
}
public void prepareForHashing(Connection conn) throws SQLException,
FileNotFoundException {
// Send a query to Vertica to return the projection segments.
try (ResultSet rs = conn.createStatement().executeQuery(
"SELECT get_projection_segments('public.projectionName')")) {
rs.next();
segmentationMetadata = rs.getString(1);
}
// Initialize the data files.
try (ResultSet rs = conn.createStatement().executeQuery(
"SELECT node_name FROM nodes")) {
while (rs.next()) {
String node = rs.getString(1);
files.put(node, new FileOutputStream(node + ".csv"));
}
}
}
public void writeLinesToFiles() throws UnsupportedEncodingException,
IOException {
for (String line : lines) {
long hashedValue = VHash.hashLong(getMeterIdFromLine(line));
// Write the row data to that node's data file.
String node = VHash.getNodeFor(segmentationMetadata, hashedValue);
FileOutputStream fos = files.get(node);
fos.write(line.getBytes("UTF-8"));
}
}
private long getMeterIdFromLine(String line) {
// In our file, "meterId" is the name of the first column in the file.
return Long.parseLong(line.split(",")[0]);
}
public void readLinesFromFile(String filename) throws IOException {
lines = new ArrayList<String>();
String line;
try (BufferedReader reader = new BufferedReader(
new FileReader(filename))) {
while ((line = reader.readLine()) != null) {
lines.add(line);
}
}
}
}
9 - Timezones and daylight savings time
When using JDBC to query TimeTZ and TimestampTZ values, the JVM and session timezones must match to get accurate results.
When building Java applications that query TimeTZ and TimestampTZ values, the JVM and session must use the same timezone to get accurate results. In particular, the CURRENT_TIME and CURRENT_TIMESTAMP functions can return different values if the following conditions are met:
- The JVM and session timezones are different
- One of the timezones is one where daylight savings time is in effect
The following example demonstrates how to query for the current timestamp:
- The
run() method sets the JVM timezone to US/Eastern.
US/Eastern is then passed to the getConnection() method, which sets the session timezone.- The
printCurrentTimeAndTimeStamp() method executes the CURRENT_TIME and CURRENT_TIMESTAMP functions, which return TimeTZ and TimestampTZ, respectively. These values should match because the JVM and session use the same timezone.
private Connection getConnection(String timezone) throws SQLException {
final String host = "host";
final String port = "5433";
final String dbName = "database";
Properties jdbcOptions = new Properties();
jdbcOptions.put("User", "Your Username");
jdbcOptions.put("Password", "Your Password");
// Use the ConnSettings connection property to ensure the session's timezone
// matches the JVM's timezone
jdbcOptions.put("ConnSettings", "SET TIMEZONE TO '" + timezone + "'");
return DriverManager.getConnection(
"jdbc:vertica://" + host + ":" + port + "/" + dbName, jdbcOptions);
}
private void printCurrentTimeAndTimeStamp(Connection conn) throws SQLException
{
Statement st = conn.createStatement();
String queryString = "SELECT CURRENT_TIME(0) AS time , CURRENT_TIMESTAMP(0) AS timestamp";
ResultSet rs = st.executeQuery(queryString);
rs.next();
String timeValue = rs.getString("time");
String timestampValue = rs.getString("timestamp");
System.out.println("CURRENT_TIME(): " + timeValue);
System.out.println("CURRENT_TIMESTAMP(): " + timestampValue);
}
public void run() throws SQLException
{
final String timezone = "US/Eastern";
// set JVM timezone
TimeZone.setDefault(TimeZone.getTimeZone(timezone));
Connection conn = getConnection(timezone);
try {
printCurrentTimeAndTimeStamp(conn);
} finally {
conn.close();
}
}