This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Enterprise Mode concepts
In an Enterprise Mode Vertica database, the physical architecture is designed to move data as close as possible to computing resources.
In an Enterprise Mode Vertica database, the physical architecture is designed to move data as close as possible to computing resources. This architecture differs from a cluster running in Eon Mode which is described in Eon Mode concepts.
The data in an Enterprise Mode database is spread among the nodes in the database. Ideally, the data is evenly distributed to ensure that each node has an equal amount of the analytic workload.

Hybrid data store
When running in Enterprise Mode, Vertica stores data on the database in read optimized store (ROS) containers. ROS data is segmented, sorted, and compressed for high optimization. To avoid fragmentation of data among many small ROS containers, Vertica periodically executes a mergeout operation, which consolidates ROS data into fewer and larger containers.
Data redundancy
In Enterprise Mode, each node of the Vertica database stores and operates on data locally. Without some form of redundancy, the loss of a node would force your database to shut down, as some of its data would be unavailable to service queries.
You usually choose to have your Enterprise Mode database store data redundantly to prevent data loss and service interruptions should a node shut down. See K-safety in an Enterprise Mode database for details.
1 - K-safety in an Enterprise Mode database
K-safety sets the fault tolerance in your Enterprise Mode database cluster.
K-safety sets the fault tolerance in your Enterprise Mode database cluster. The value K represents the number of times the data in the database cluster is replicated. These replicas allow other nodes to take over query processing for any failed nodes.
In Vertica, the value of K can be zero (0), one (1), or two (2). If a database with a K-safety of one (K=1) loses a node, the database continues to run normally. Potentially, the database could continue running if additional nodes fail, as long as at least one other node in the cluster has a copy of the failed node's data. Increasing K-safety to 2 ensures that Vertica can run normally if any two nodes fail. When the failed node or nodes return and successfully recover, they can participate in database operations again.
Note
If the number of failed nodes exceeds the K value, some the data may become unavailable. In this case, the database is considered unsafe and automatically shuts down. However, if every data segment is available on at least one functioning cluster node Vertica continues to run safely.
Potentially, up to half the nodes in a database with a K-safety of 1 could fail without causing the database to shut down. As long as the data on each failed node is available from another active node, the database continues to run.
Note
If half or more of the nodes in the database cluster fail, the database automatically shuts down even if all of the data in the database is available from replicas. This behavior prevents issues due to network partitioning.
Note
The physical schema design must meet certain requirements. To create designs that are K-safe, Vertica recommends using the
Database Designer.
Buddy projections
In order to determine the value of K-safety, Vertica creates buddy projections, which are copies of segmented projections distributed across database nodes. (See Segmented projections and Unsegmented projections.) Vertica distributes segments that contain the same data to different nodes. This ensures that if a node goes down, all the data is available on the remaining nodes.
K-Safety example
This diagram above shows a 5-node cluster with a K-safety level of 1. Each node contains buddy projections for the data stored in the next higher node (node 1 has buddy projections for node 2, node 2 has buddy projections for node 3, and so on). If any of the nodes fail, the database continues to run. The database will have lower performance because one of the nodes must handle its own workload and the workload of the failed node.
The diagram below shows a failure of Node 2. In this case, Node 1 handles processing for Node 2 since it contains a replica of node 2's data. Node 1 also continues to perform its own processing. The fault tolerance of the database falls from 1 to 0, since a single node failure could cause the database to become unsafe. In this example, if either Node 1 or Node 3 fails, the database becomes unsafe because not all of its data is available. If Node 1 fails,Node 2's data is no longer be available. If Node 3 fails, its data is no longer available, because node 2 is down and could not use the buddy projection. In this case, nodes 1 and 3 are considered critical nodes. In a database with a K-safety level of 1, the node that contains the buddy projection of a failed node, and the node whose buddy projections are on the failed node, always become critical nodes.
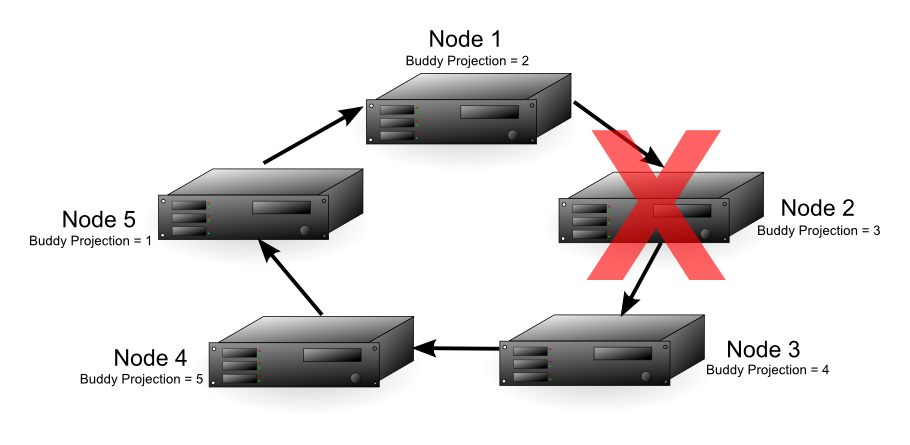
With Node 2 down, either node 4 or 5 could fail and the database still has all of its data available. The diagram below shows that if node 4 fails, node 3 can use its buddy projections to fill in for it. In this case, any further loss of nodes results in a database shutdown, since all the nodes in the cluster are now critical nodes. In addition, if one more node were to fail, half or more of the nodes would be down, requiring Vertica to automatically shut down, no matter if all of the data were available or not.
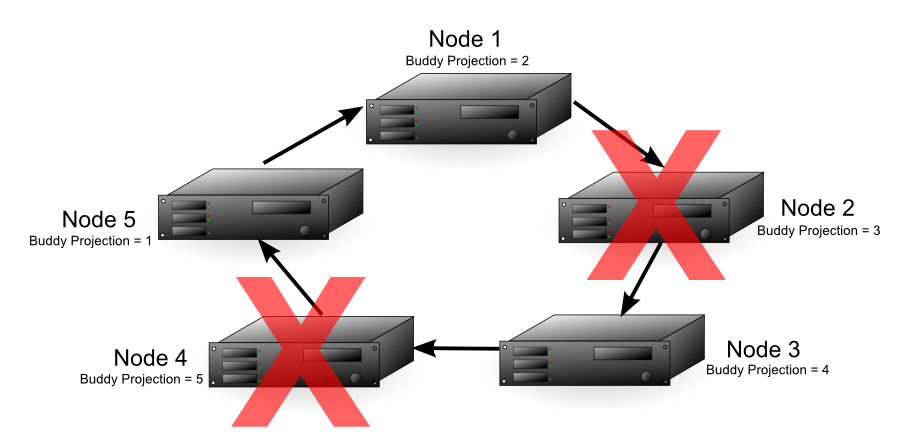
In a database with a K-safety level of 2, Node 2 and any other node in the cluster could fail and the database continues running. The diagram below shows that each node in the cluster contains buddy projections for both of its neighbors (for example, Node 1 contains buddy projections for Node 5 and Node 2). In this case, nodes 2 and 3 could fail and the database continues running. Node 1 could fill in for Node 2 and Node 4 could fill in for Node 3. Due to the requirement that half or more nodes in the cluster be available in order for the database to continue running, the cluster could not continue running if node 5 failed, even though nodes 1 and 4 both have buddy projections for its data.
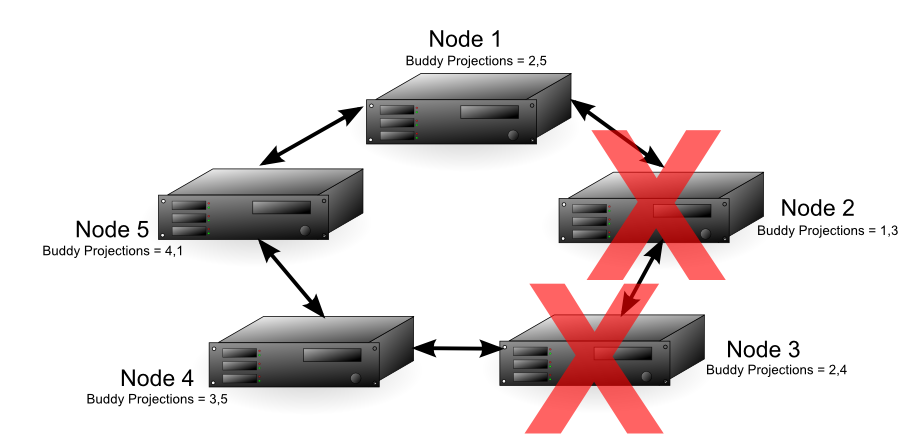
Note
Vertica requires that more than half of all nodes in a cluster must always be available; otherwise, it views the database as being in an unsafe state and shuts it down. Thus, in the previous example, the cluster cannot continue running if Node 5 fails, even though nodes 1 and 4 have buddy projections for its data.
Monitoring K-safety
You can access System Tables to monitor and log various aspects of Vertica operation. Use the
SYSTEM table to monitor information related to K-safety, such as:
-
NODE_COUNT: Number of nodes in the cluster
-
NODE_DOWN_COUNT: Number of nodes in the cluster that are currently down
-
CURRENT_FAULT_TOLERANCE: The K-safety level
2 - High availability with projections
To ensure high availability and recovery for database clusters of three or more nodes, Vertica:.
To ensure high availability and recovery for database clusters of three or more nodes, Vertica:
-
Replicates small, unsegmented projections
-
Creates buddy projections for large, segmented projections.
Replication (unsegmented projections)
When it creates projections, Database Designer replicates them, creating and storing duplicates of these projections on all nodes in the database.
Replication ensures:
-
Distributed query execution across multiple nodes.
-
High availability and recovery. In a K-safe database, replicated projections serve as buddy projections. This means that you can use a replicated projection on any node for recovery.
Note
We recommend you use Database Designer to create your physical schema. If you choose not to, be sure to segment all large tables across all database nodes, and replicate small, unsegmented table projections on all database nodes.
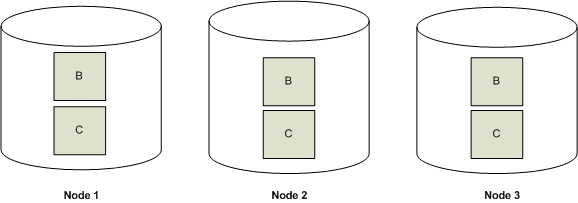
The following illustration shows two projections, B and C, replicated across a three node cluster.
Buddy projections (segmented projections)
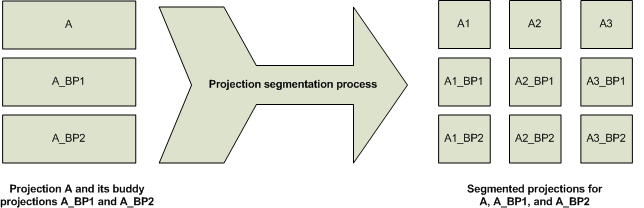
Vertica creates buddy projections which are copies of segmented projections that are distributed across database nodes (see Segmented projections.) Vertica distributes segments that contain the same data to different nodes. This ensures that if a node goes down, all the data is available on the remaining nodes. Vertica distributes segments to different nodes by using offsets. For example, segments that comprise the first buddy projection (A_BP1) are offset from projection A by one node, and segments from the second buddy projection (A_BP2) are offset from projection A by two nodes.
The following diagram shows the segmentation for a projection called A and its buddy projections, A_BP1 and A_BP2, for a three node cluster.
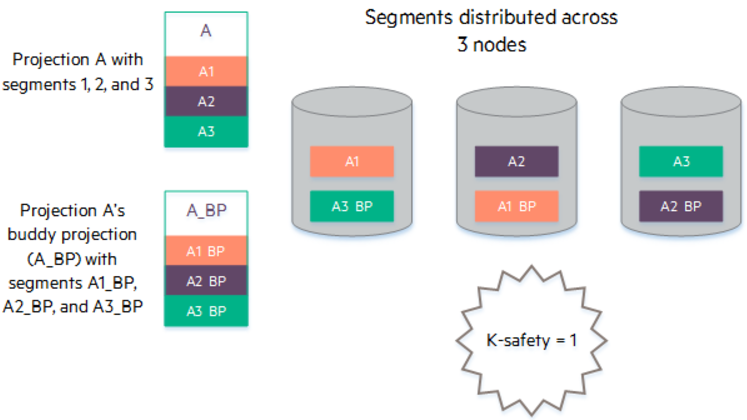
The following diagram shows how Vertica uses offsets to ensure that every node has a full set of data for the projection.
How result sets are stored
Vertica duplicates table columns on all nodes in the cluster to ensure high availability and recovery. Thus, if one node goes down in a K-Safe environment, the database continues to operate using duplicate data on the remaining nodes. Once the failed node resumes its normal operation, it automatically recovers its lost objects and data by querying other nodes.
Vertica compresses and encodes data to greatly reduce the storage space. It also operates on the encoded data whenever possible to avoid the cost of decoding. This combination of compression and encoding optimizes disk space while maximizing query performance.
Vertica stores table columns as projections. This enables you to optimize the stored data for specific queries and query sets. Vertica provides two methods for storing data:
3 - High availability with fault groups
Use fault groups to reduce the risk of correlated failures inherent in your physical environment.
Use fault groups to reduce the risk of correlated failures inherent in your physical environment. Correlated failures occur when two or more nodes fail as a result of a single failure. For example, such failures can occur due to problems with shared resources such as power loss, networking issues, or storage.
Vertica minimizes the risk of correlated failures by letting you define fault groups on your cluster. Vertica then uses the fault groups to distribute data segments across the cluster, so the database continues running if a single failure event occurs.
Note
If your cluster layout is managed by a single network switch, a switch failure can be a single point of failure. Fault groups cannot help with single-point failures.
Vertica supports complex, hierarchical fault groups of different shapes and sizes. You can integrate fault groups with elastic cluster and large cluster arrangements to add cluster flexibility and reliability.
Making Vertica aware of cluster topology with fault groups
You can also use fault groups to make Vertica aware of the topology of the cluster on which your Vertica database is running. Making Vertica aware of your cluster's topology is required when using terrace routing, which can significantly reduce message buffering on a large cluster database.
Automatic fault groups
When you configure a cluster of 120 nodes or more, Vertica automatically creates fault groups around control nodes. Control nodes are a subset of cluster nodes that manage spread (control messaging). Vertica places nodes that share a control node in the same fault group. See Large cluster for details.
User-defined fault groups
Define your own default groups if:
Example cluster topology
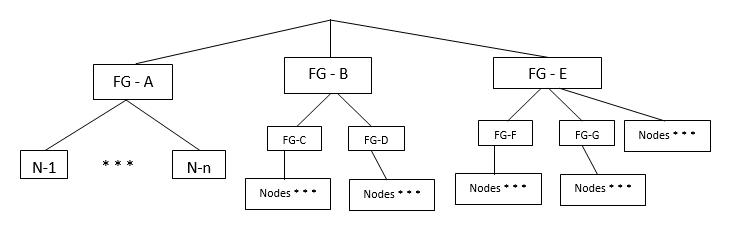
The following diagram provides an example of hierarchical fault groups configured on a single cluster:
-
Fault group FG–A contains nodes only.
-
Fault group FG-B (parent) contains child fault groups FG-C and FG-D. Each child fault group also contain nodes.
-
Fault group FG–E (parent) contains child fault groups FG-F and FG-G. The parent fault group FG–E also contains nodes.
How to create fault groups
Before you define fault groups, you must have a thorough knowledge of your physical cluster layout. Fault groups require careful planning.
To define fault groups, create an input file of your cluster arrangement. Then, pass the file to a script supplied by Vertica, and the script returns the SQL statements you need to run. See Fault Groups for details.