This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Partitioning tables
Data partitioning is defined as a table property, and is implemented on all projections of that table.
Data partitioning is defined as a table property, and is implemented on all projections of that table. On all load, refresh, and recovery operations, the Vertica Tuple Mover automatically partitions data into separate ROS containers. Each ROS container contains data for a single partition or partition group; depending on space requirements, a partition or partition group can span multiple ROS containers.
For example, it is common to partition data by time slices. If a table contains decades of data, you can partition it by year. If the table contains only one year of data, you can partition it by month.
Logical divisions of data can significantly improve query execution. For example, if you query a table on a column that is in the table's partition clause, the query optimizer can quickly isolate the relevant ROS containers (see Partition pruning).
Partitions can also facilitate DML operations. For example, given a table that is partitioned by months, you might drop all data for the oldest month when a new month begins. In this case, Vertica can easily identify the ROS containers that store the partition data to drop. For details, see Managing partitions.
1 - Defining partitions
You can specify partitioning for new and existing tables:.
You can specify partitioning for new and existing tables:
1.1 - Partitioning a new table
Use CREATE TABLE to partition a new table, as specified by the PARTITION BY clause:.
Use CREATE TABLE to partition a new table, as specified by the PARTITION BY clause:
CREATE TABLE table-name... PARTITION BY partition-expression [ GROUP BY group-expression ] [ REORGANIZE ];
The following statements create the store_orders table and load data into it. The CREATE TABLE statement includes a simple partition clause that specifies to partition data by year:
=> CREATE TABLE public.store_orders
(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date
)
UNSEGMENTED ALL NODES
PARTITION BY YEAR(order_date);
CREATE TABLE
=> COPY store_orders FROM '/home/dbadmin/export_store_orders_data.txt';
41834
As COPY loads the new table data into ROS storage, the Tuple Mover executes the table's partition clause by dividing orders for each year into separate partitions, and consolidating these partitions in ROS containers.
In this case, the Tuple Mover creates four partition keys for the loaded data—2017, 2016, 2015, and 2014—and divides the data into separate ROS containers accordingly:
=> SELECT dump_table_partition_keys('store_orders');
... Partition keys on node v_vmart_node0001
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 1
Partition keys: 2017
Storage [ROS container]
No of partition keys: 1
Partition keys: 2016
Storage [ROS container]
No of partition keys: 1
Partition keys: 2015
Storage [ROS container]
No of partition keys: 1
Partition keys: 2014
Partition keys on node v_vmart_node0002
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 1
Partition keys: 2017
...
(1 row)
As new data is loaded into store_orders, the Tuple Mover merges it into the appropriate partitions, creating partition keys as needed for new years.
1.2 - Partitioning existing table data
Use ALTER TABLE to partition or repartition an existing table, as specified by the PARTITION BY clause:.
Use ALTER TABLE to partition or repartition an existing table, as specified by the PARTITION BY clause:
ALTER TABLE table-name PARTITION BY partition-expression [ GROUP BY group-expression ] [ REORGANIZE ];
For example, you might repartition the store_orders table, defined earlier. The following ALTER TABLE divides all store_orders data into monthly partitions for each year, each partition key identifying the order date year and month:
=> ALTER TABLE store_orders
PARTITION BY EXTRACT(YEAR FROM order_date)*100 + EXTRACT(MONTH FROM order_date)
GROUP BY EXTRACT(YEAR from order_date)*100 + EXTRACT(MONTH FROM order_date);
NOTICE 8364: The new partitioning scheme will produce partitions in 42 physical storage containers per projection
WARNING 6100: Using PARTITION expression that returns a Numeric value
HINT: This PARTITION expression may cause too many data partitions. Use of an expression that returns a more accurate value, such as a regular VARCHAR or INT, is encouraged
WARNING 4493: Queries using table "store_orders" may not perform optimally since the data may not be repartitioned in accordance with the new partition expression
HINT: Use "ALTER TABLE public.store_orders REORGANIZE;" to repartition the data
After executing this statement, Vertica drops existing partition keys. However, the partition clause omits REORGANIZE, so existing data remains stored according to the previous partition clause. This can put table partitioning in an inconsistent state and adversely affect query performance, DROP_PARTITIONS, and node recovery. In this case, you must explicitly request Vertica to reorganize existing data into new partitions, in one of the following ways:
-
Issue ALTER TABLE...REORGANIZE:
ALTER TABLE table-name REORGANIZE;
-
Call the Vertica meta-function PARTITION_TABLE.
For example:
=> ALTER TABLE store_orders REORGANIZE;
NOTICE 4785: Started background repartition table task
ALTER TABLE
ALTER TABLE...REORGANIZE and PARTITION_TABLE operate identically: both split any ROS containers where partition keys do not conform with the new partition clause. On executing its next mergeout, the Tuple Mover merges partitions into the appropriate ROS containers.
1.3 - Partition grouping
Partition groups consolidate partitions into logical subsets that minimize use of ROS storage.
Partition groups consolidate partitions into logical subsets that minimize use of ROS storage. Reducing the number of ROS containers to store partitioned data helps facilitate DML operations such as DELETE and UPDATE, and avoid ROS pushback. For example, you can group date partitions by year. By doing so, the Tuple Mover allocates ROS containers for each year group, and merges individual partitions into these ROS containers accordingly.
Creating partition groups
You create partition groups by qualifying the PARTITION BY clause with a GROUP BY clause:
ALTER TABLE table-name PARTITION BY partition-expression [ GROUP BY group-expression ]
The GROUP BY clause specifies how to consolidate partition keys into groups, where each group is identified by a unique partition group key. For example, the following
ALTER TABLE statement specifies to repartition the store_orders table (shown in Partitioning a new table) by order dates, grouping partition keys by year. The group expression—DATE_TRUNC('year', (order_date)::DATE)—uses the partition expression order_date::DATE to generate partition group keys:
=> ALTER TABLE store_orders
PARTITION BY order_date::DATE GROUP BY DATE_TRUNC('year', (order_date)::DATE) REORGANIZE;
NOTICE 8364: The new partitioning scheme will produce partitions in 4 physical storage containers per projection
NOTICE 4785: Started background repartition table task
In this case, the order_date column dates span four years. The Tuple Mover creates four partition group keys, and merges store_orders partitions into group-specific ROS storage containers accordingly:
=> SELECT DUMP_TABLE_PARTITION_KEYS('store_orders');
...
Partition keys on node v_vmart_node0001
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 173
Partition keys: 2017-01-02 2017-01-03 2017-01-04 ... 2017-09-25 2017-09-26 2017-09-27
Storage [ROS container]
No of partition keys: 212
Partition keys: 2016-01-01 2016-01-04 2016-01-05 ... 2016-11-23 2016-11-24 2016-11-25
Storage [ROS container]
No of partition keys: 213
Partition keys: 2015-01-01 2015-01-02 2015-01-05 ... 2015-11-23 2015-11-24 2015-11-25
2015-11-26 2015-11-27
Storage [ROS container]
No of partition keys: 211
Partition keys: 2014-01-01 2014-01-02 2014-01-03 ... 2014-11-25 2014-11-26 2014-11-27
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 173
...
Caution
This example demonstrates how partition grouping can facilitate more efficient use of ROS storage. However, grouping all partitions into several large and static ROS containers can adversely affect performance, especially for a table that is subject to frequent DML operations. Frequent load operations in particular can incur considerable merge overhead, which, in turn, reduces performance.
Vertica recommends that you use
CALENDAR_HIERARCHY_DAY, as a partition clause's group expression. This function automatically groups DATE partition keys into a dynamic hierarchy of years, months, and days. Doing so helps minimize merge-related issues. For details, see Hierarchical partitioning.
Managing partitions within groups
You can use various partition management functions, such as
DROP_PARTITIONS or
MOVE_PARTITIONS_TO_TABLE, to target a range of order dates within a given partition group, or across multiple partition groups. In the previous example, each group contains partition keys of different dates within a given year. You can use DROP_PARTITIONS to drop order dates that span two years, 2014 and 2015:
=> SELECT DROP_PARTITIONS('store_orders', '2014-05-30', '2015-01-15', 'true');
2 - Hierarchical partitioning
Hierarchical partitions organize data into partition groups for more efficient storage. For example, you can have separate partitions for recent months while grouping older months together by year, reducing the number of ROS files Vertica uses.
Hierarchical partitions organize data into partition groups for more efficient storage. When partitioning by date, the oldest partitions are grouped by year, more recent partitions are grouped by month, and the most recent partitions remain ungrouped. Grouping is dynamic: as recent data ages, the Tuple Mover merges those partitions into month groups, and eventually into year groups. Hierarchical partitioning reduces the number of ROS files Vertica uses and thus reduces ROS pushback.
Use the CALENDAR_HIERARCHY_DAY function as the partitioning GROUP BY expression in a table's PARTITION BY clause, as in the following example:
=> CREATE TABLE public.store_orders(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date )
PARTITION BY order_date::DATE
GROUP BY CALENDAR_HIERARCHY_DAY(order_date::DATE, 3, 2);
Managing timestamped data
Partition consolidation strategies are especially important for managing timestamped data, where the number of partitions can quickly escalate and risk ROS pushback. For example, the following statements create the store_orders table and load data into it. The CREATE TABLE statement includes a simple partition clause that partitions data by date:
=> DROP TABLE IF EXISTS public.store_orders CASCADE;
=> CREATE TABLE public.store_orders(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date )
UNSEGMENTED ALL NODES PARTITION BY order_date::DATE;
=> COPY store_orders FROM '/home/dbadmin/export_store_orders_data.txt';
As COPY loads the new table data into ROS storage, it executes this table's partition clause by dividing daily orders into separate partitions, where each partition requires its own ROS container:
=> SELECT COUNT (DISTINCT ros_id) NumROS, node_name FROM PARTITIONS
WHERE projection_name ilike '%store_orders_super%'
GROUP BY node_name ORDER BY node_name;
NumROS | node_name
--------+------------------
809 | v_vmart_node0001
809 | v_vmart_node0002
809 | v_vmart_node0003
(3 rows)
This is far above the recommended maximum of 50 partitions per projection. This number is also close to the default system limit of 1024 ROS containers per projection, risking ROS pushback in the near future.
You can approach this problem in several ways:
-
Consolidate table data into larger partitions—for example, partition by month instead of day. However, partitioning data at this level might limit effective use of partition management functions.
-
Regularly archive older partitions, and thereby minimize the number of accumulated partitions. However, this requires an extra layer of data management, and also inhibits access to historical data.
Alternatively, you can use CALENDAR_HIERARCHY_DAY to automatically merge partitions into a date-based hierarchy of partition groups. Each partition group is stored in its own set of ROS containers, apart from other groups. You specify this function in the table partition clause as follows:
PARTITION BY partition-expression
GROUP BY CALENDAR_HIERARCHY_DAY( partition-expression [, active-months[, active-years] ] )
For example, given the previous table, you can repartition it as follows:
=> ALTER TABLE public.store_orders
PARTITION BY order_date::DATE
GROUP BY CALENDAR_HIERARCHY_DAY(order_date::DATE, 2, 2) REORGANIZE;
The partition expression must match the expression used in the GROUP BY expression. When using CALENDAR_HIERARCHY_DAY, the expression must be a DATE.
Important
The CALENDAR_HIERARCHY_DAY algorithm assumes that most table activity is focused on recent dates. Setting active-years and active-months to a low number ≥ 2 serves to isolate most merge activity to date-specific containers, and incurs minimal overhead. Vertica recommends that you use the default setting of 2 for active-years and active-months. For most users, these settings achieve an optimal balance between ROS storage and performance.
As a best practice, never set active-years and active-months to 0.
Grouping DATE data hierarchically
CALENDAR_HIERARCHY_DAY creates hierarchies of partition groups and merges partitions into the appropriate groups. It does so by evaluating the partition expression of each table row with the following algorithm, to determine its partition group key:
GROUP BY (
CASE WHEN DATEDIFF('YEAR', , NOW()::TIMESTAMPTZ(6)) >=
THEN DATE_TRUNC('YEAR', ::DATE)
WHEN DATEDIFF('MONTH', , NOW()::TIMESTAMPTZ(6)) >=
THEN DATE_TRUNC('MONTH', ::DATE)
ELSE DATE_TRUNC('DAY', ::DATE) END);
In this example, the algorithm compares order_date in each row to the current date as follows:
-
Determines if order_date is in an inactive year. If it is, the row is merged into a ROS container for that year.
-
Otherwise, for an active year, CALENDAR_HIERARCHY_DAY evaluates order_date to determine if it is in an inactive month. If it is, the row is merged into a ROS container for that month.
-
Otherwise, for an active month, the row is merged into a ROS container for that day. Any rows where order_date is a future date is treated in the same way.
For example, if the current date is 2017-09-26, CALENDAR_HIERARCHY_DAY resolves active-years and active-months to the following date spans:
-
active-years: 2016-01-01 to 2017-12-31. Partitions in active years are grouped into monthly ROS containers or are merged into daily ROS containers. Partitions from earlier years are regarded as inactive and merged into yearly ROS containers.
-
active-months: 2017-08-01 to 2017-09-30. Partitions in active months are merged into daily ROS containers.
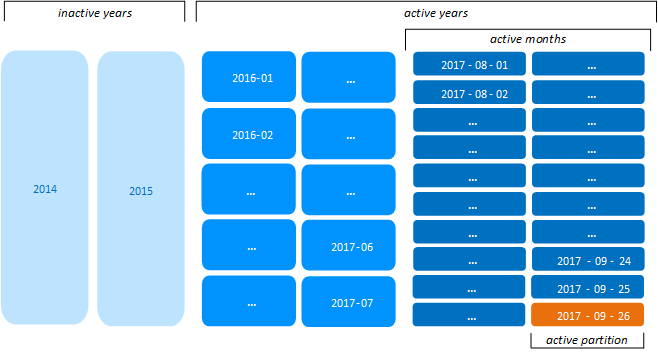
Now, the total number of ROS containers is reduced to 40 per projection:
=> SELECT COUNT (DISTINCT ros_id) NumROS, node_name FROM PARTITIONS
WHERE projection_name ilike '%store_orders_super%'
GROUP BY node_name ORDER BY node_name;
NumROS | node_name
--------+------------------
40 | v_vmart_node0001
40 | v_vmart_node0002
40 | v_vmart_node0003
(3 rows)
Regardless of how the Tuple Mover groups and merges partitions, it always identifies one or more partitions or partition groups as active. For details, see Active and inactive partitions.
Dynamic regrouping
As shown earlier, CALENDAR_HIERARCHY_DAY references the current date when it creates partition group keys and merges partitions. As the calendar advances, the Tuple Mover reevaluates the partition group keys of tables that are partitioned with this function, and moves partitions as needed to different ROS containers.
Thus, given the previous example, on 2017-10-01 the Tuple Mover creates a monthly ROS container for August partitions. All partition keys between 2017-08-01 and 2017-08-31 are merged into the new ROS container 2017-08:
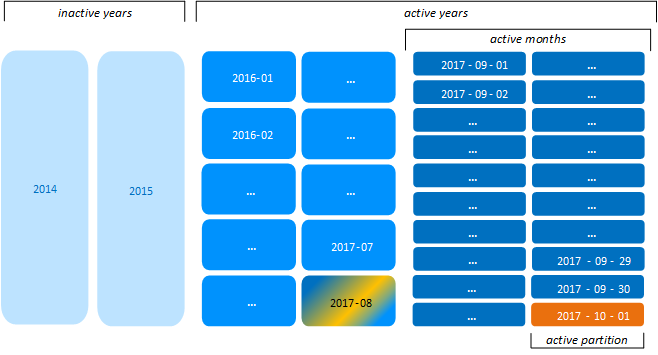
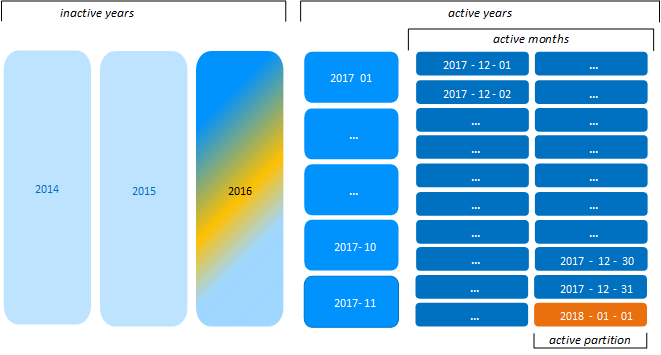
Likewise, on 2018-01-01, the Tuple Mover creates a ROS container for 2016 partitions. All partition keys between 2016-01-01 and 2016-12-31 that were previously grouped by month are merged into the new yearly ROS container:
Caution
After older partitions are grouped into months and years, any partition operation that acts on a subset of older partition groups is likely to split ROS containers into smaller ROS containers for each partition—for example,
MOVE_PARTITIONS_TO_TABLE, where
force-split is set to true. These operations can lead to ROS pushback. If you anticipate frequent partition operations on hierarchically grouped partitions,
consider modifying the partition expression so partitions are grouped no higher than months.
Customizing partition group hierarchies
Vertica provides a single function, CALENDAR_HIERARCHY_DAY, to facilitate hierarchical partitioning. Vertica stores the GROUP BY clause as a CASE statement that you can edit to suit your own requirements.
For example, Vertica stores the store_orders partition clause as follows:
=> SELECT EXPORT_TABLES('','store_orders');
...
CREATE TABLE public.store_orders ( ... )
...
PARTITION BY ((store_orders.order_date)::date)
GROUP BY (
CASE WHEN ("datediff"('year', (store_orders.order_date)::date, ((now())::timestamptz(6))::date) >= 2)
THEN (date_trunc('year', (store_orders.order_date)::date))::date
WHEN ("datediff"('month', (store_orders.order_date)::date, ((now())::timestamptz(6))::date) >= 2)
THEN (date_trunc('month', (store_orders.order_date)::date))::date
ELSE (store_orders.order_date)::date END);
You can modify the CASE statement to customize the hierarchy of partition groups. For example, the following CASE statement creates a hierarchy of months, days, and hours:
=> ALTER TABLE store_orders
PARTITION BY (store_orders.order_date)
GROUP BY (
CASE
WHEN DATEDIFF('MONTH', store_orders.order_date, NOW()::TIMESTAMPTZ(6)) >= 2
THEN DATE_TRUNC('MONTH', store_orders.order_date::DATE)
WHEN DATEDIFF('DAY', store_orders.order_date, NOW()::TIMESTAMPTZ(6)) >= 2
THEN DATE_TRUNC('DAY', store_orders.order_date::DATE)
ELSE DATE_TRUNC('hour', store_orders.order_date::DATE) END);
Alternatively, you can write a user-defined SQL function to partition values in different ways. The following example defines a function that partitions timestamps by hour:
=> CREATE OR REPLACE FUNCTION public.My_Calendar_By_Hour
( tsz timestamp(0)
, p1 int
, p2 int
)
return timestamp(0)
as
begin
return (case
when datediff('day', trunc(tsz, 'hh'), now() at time zone 'utc') > p1
then date_trunc('month', trunc(tsz, 'hh'))
when datediff('day', trunc(tsz, 'hh'), now() at time zone 'utc') > p2
then date_trunc('day' , trunc(tsz, 'hh'))
else date_trunc('hour' , trunc(tsz, 'hh'))
end);
end;
You can then use this function in the partition clause:
=> ALTER TABLE store_orders
PARTITION BY ((col2 at time zone 'utc')::timestamp(0))
GROUP BY My_Calendar_By_Hour((col2 at time zone 'utc')::timestamp(0), 31, 1)
REORGANIZE;
3 - Partitioning and segmentation
In Vertica, partitioning and segmentation are separate concepts and achieve different goals to localize data:.
In Vertica, partitioning and segmentation are separate concepts and achieve different goals to localize data:
-
Segmentation refers to organizing and distributing data across cluster nodes for fast data purges and query performance. Segmentation aims to distribute data evenly across multiple database nodes so all nodes participate in query execution. You specify segmentation with the
CREATE PROJECTION statement's hash segmentation clause.
-
Partitioning specifies how to organize data within individual nodes for distributed computing. Node partitions let you easily identify data you wish to drop and help reclaim disk space. You specify partitioning with the
CREATE TABLE statement's PARTITION BY clause.
For example: partitioning data by year makes sense for retaining and dropping annual data. However, segmenting the same data by year would be inefficient, because the node holding data for the current year would likely answer far more queries than the other nodes.
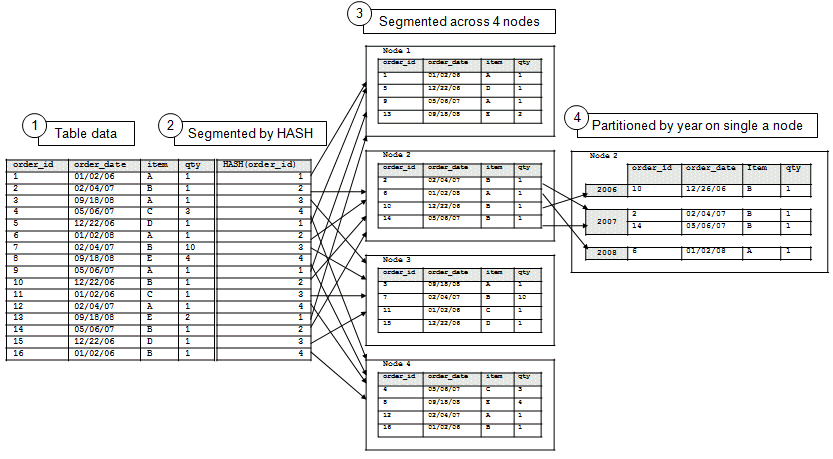
The following diagram illustrates the flow of segmentation and partitioning on a four-node database cluster:
-
Example table data
-
Data segmented by HASH(order_id)
-
Data segmented by hash across four nodes
-
Data partitioned by year on a single node
While partitioning occurs on all four nodes, the illustration shows partitioned data on one node for simplicity.
See also
4 - Managing partitions
You can manage partitions with the following operations:.
You can manage partitions with the following operations:
4.1 - Dropping partitions
Use the DROP_PARTITIONS function to drop one or more partition keys for a given table.
Use the DROP_PARTITIONS function to drop one or more partition keys for a given table. You can specify a single partition key or a range of partition keys.
For example, the table shown in Partitioning a new table is partitioned by column order_date:
=> CREATE TABLE public.store_orders
(
order_no int,
order_date timestamp NOT NULL,
shipper varchar(20),
ship_date date
)
PARTITION BY YEAR(order_date);
Given this table definition, Vertica creates a partition key for each unique order_date year—in this case, 2017, 2016, 2015, and 2014—and divides the data into separate ROS containers accordingly.
The following DROP_PARTITIONS statement drops from table store_orders all order records associated with partition key 2014:
=> SELECT DROP_PARTITIONS ('store_orders', 2014, 2014);
Partition dropped
Splitting partition groups
If a table partition clause includes a GROUP BY clause, partitions are consolidated in the ROS by their partition group keys. DROP_PARTITIONS can then specify a range of partition keys within a given partition group, or across multiple partition groups. In either case, the drop operation requires Vertica to split the ROS containers that store these partitions. To do so, the function's force_split parameter must be set to true.
For example, the store_orders table shown above can be repartitioned with a GROUP BY clause as follows:
=> ALTER TABLE store_orders
PARTITION BY order_date::DATE GROUP BY DATE_TRUNC('year', (order_date)::DATE) REORGANIZE;
With all 2014 order records having been dropped earlier, order_date values now span three years—2017, 2016, and 2015. Accordingly, the Tuple Mover creates three partition group keys for each year, and designates one or more ROS containers for each group. It then merges store_orders partitions into the appropriate groups.
The following DROP_PARTITIONS statement specifies to drop order dates that span two years, 2014 and 2015:
=> SELECT DROP_PARTITIONS('store_orders', '2015-05-30', '2016-01-16', 'true');
Partition dropped
The drop operation requires Vertica to drop partitions from two partition groups—2015 and 2016. These groups span at least two ROS containers, which must be split in order to remove the target partitions. Accordingly, the function's force_split parameter is set to true.
Scheduling partition drops
If your hardware has fixed disk space, you might need to configure a regular process to roll out old data by dropping partitions.
For example, if you have only enough space to store data for a fixed number of days, configure Vertica to drop the oldest partition keys. To do so, create a time-based job scheduler such as cron to schedule dropping the partition keys during low-load periods.
If the ingest rate for data has peaks and valleys, you can use two techniques to manage how you drop partition keys:
- Set up a process to check the disk space on a regular (daily) basis. If the percentage of used disk space exceeds a certain threshold—for example, 80%—drop the oldest partition keys.
- Add an artificial column in a partition that increments based on a metric like row count. For example, that column might increment each time the row count increases by 100 rows. Set up a process that queries this column on a regular (daily) basis. If the value in the new column exceeds a certain threshold—for example, 100—drop the oldest partition keys, and set the column value back to 0.
Table locking
DROP_PARTITIONS requires an exclusive D lock on the target table. This lock is only compatible with I-lock operations, so only table load operations such as INSERT and COPY are allowed during drop partition operations.
4.2 - Archiving partitions
You can move partitions from one table to another with the Vertica function MOVE_PARTITIONS_TO_TABLE.
You can move partitions from one table to another with the Vertica function
MOVE_PARTITIONS_TO_TABLE. This function is useful for archiving old partitions, as part of the following procedure:
-
Identify the partitions to archive, and move them to a temporary staging table with
MOVE_PARTITIONS_TO_TABLE.
-
Back up the staging table.
-
Drop the staging table.
You restore archived partitions at any time.
Move partitions to staging tables
You archive historical data by identifying the partitions you wish to remove from a table. You then move each partition (or group of partitions) to a temporary staging table.
Before calling MOVE_PARTITIONS_TO_TABLE:
- Refresh all out-of-date projections.
The following recommendations apply to staging tables:
-
To facilitate the backup process, create a unique schema for the staging table of each archiving operation.
-
Specify new names for staging tables. This ensures that they do not contain partitions from previous move operations.
If the table does not exist, Vertica creates a table from the source table's definition, by calling
CREATE TABLE with LIKE and INCLUDING PROJECTIONS clause. The new table inherits ownership from the source table. For details, see Replicating a table.
-
Use staging names that enable other users to easily identify partition contents. For example, if a table is partitioned by dates, use a name that specifies a date or date range.
In the following example, MOVE_PARTITIONS_TO_TABLE specifies to move a single partition to the staging table partn_backup.tradfes_200801.
=> SELECT MOVE_PARTITIONS_TO_TABLE (
'prod_trades',
'200801',
'200801',
'partn_backup.trades_200801');
MOVE_PARTITIONS_TO_TABLE
-------------------------------------------------
1 distinct partition values moved at epoch 15.
(1 row)
Back up the staging table
After you create a staging table, you archive it through an object-level backup using a
vbr configuration file. For detailed information, see Backing up and restoring the database.
Important
Vertica recommends performing a full database backup before the object-level backup, as a precaution against data loss. You can only restore object-level backups to the original database.
Drop the staging tables
After the backup is complete, you can drop the staging table as described in Dropping tables.
Restoring archived partitions
You can restore partitions that you previously moved to an intermediate table, archived as an object-level backup, and then dropped.
Note
Restoring an archived partition requires that the original table definition is unchanged since the partition was archived and dropped. If the table definition changed, you can restore an archived partition with INSERT...SELECT statements, which are not described here.
These are the steps to restoring archived partitions:
-
Restore the backup of the intermediate table you saved when you moved one or more partitions to archive (see Archiving partitions).
-
Move the restored partitions from the intermediate table to the original table.
-
Drop the intermediate table.
4.3 - Swapping partitions
SWAP_PARTITIONS_BETWEEN_TABLES combines the operations of DROP_PARTITIONS and MOVE_PARTITIONS_TO_TABLE as a single transaction.
SWAP_PARTITIONS_BETWEEN_TABLES combines the operations of DROP_PARTITIONS and MOVE_PARTITIONS_TO_TABLE as a single transaction. SWAP_PARTITIONS_BETWEEN_TABLES is useful if you regularly load partitioned data from one table into another and need to refresh partitions in the second table.
For example, you might have a table of revenue that is partitioned by date, and you routinely move data into it from a staging table. Occasionally, the staging table contains data for dates that are already in the target table. In this case, you must first remove partitions from the target table for those dates, then replace them with the corresponding partitions from the staging table. You can accomplish both tasks with a single call to SWAP_PARTITIONS_BETWEEN_TABLES.
By wrapping the drop and move operations within a single transaction, SWAP_PARTITIONS_BETWEEN_TABLES maintains integrity of the swapped data. If any task in the swap operation fails, the entire operation fails and is rolled back.
Example
The following example creates two partitioned tables and then swaps certain partitions between them.
Both tables have the same definition and have partitions for various year values. You swap the partitions where year = 2008 and year = 2009. Both tables have at least two rows to swap.
-
Create the customer_info table:
=> CREATE TABLE customer_info (
customer_id INT NOT NULL,
first_name VARCHAR(25),
last_name VARCHAR(35),
city VARCHAR(25),
year INT NOT NULL)
ORDER BY last_name
PARTITION BY year;
-
Insert data into the customer_info table:
INSERT INTO customer_info VALUES
(1,'Joe','Smith','Denver',2008),
(2,'Bob','Jones','Boston',2008),
(3,'Silke','Muller','Frankfurt',2007),
(4,'Simone','Bernard','Paris',2014),
(5,'Vijay','Kumar','New Delhi',2010);
OUTPUT
--------
5
(1 row)
=> COMMIT;
-
View the table data:
=> SELECT * FROM customer_info ORDER BY year DESC;
customer_id | first_name | last_name | city | year
-------------+------------+-----------+-----------+------
4 | Simone | Bernard | Paris | 2014
5 | Vijay | Kumar | New Delhi | 2010
2 | Bob | Jones | Boston | 2008
1 | Joe | Smith | Denver | 2008
3 | Silke | Muller | Frankfurt | 2007
(5 rows)
-
Create a second table, member_info, that has the same definition as customer_info:
=> CREATE TABLE member_info LIKE customer_info INCLUDING PROJECTIONS;
CREATE TABLE
-
Insert data into the member_info table:
=> INSERT INTO member_info VALUES
(1,'Jane','Doe','Miami',2001),
(2,'Mike','Brown','Chicago',2014),
(3,'Patrick','OMalley','Dublin',2008),
(4,'Ana','Lopez','Madrid',2009),
(5,'Mike','Green','New York',2008);
OUTPUT
--------
5
(1 row)
=> COMMIT;
COMMIT
-
View the data in the member_info table:
=> SELECT * FROM member_info ORDER BY year DESC;
customer_id | first_name | last_name | city | year
-------------+------------+-----------+----------+------
2 | Mike | Brown | Chicago | 2014
4 | Ana | Lopez | Madrid | 2009
5 | Mike | Green | New York | 2008
3 | Patrick | OMalley | Dublin | 2008
1 | Jane | Doe | Miami | 2001
(5 rows)
-
To swap the partitions, run the SWAP_PARTITIONS_BETWEEN_TABLES function:
=> SELECT SWAP_PARTITIONS_BETWEEN_TABLES('customer_info', 2008, 2009, 'member_info');
SWAP_PARTITIONS_BETWEEN_TABLES
----------------------------------------------------------------------------------------------
1 partition values from table customer_info and 2 partition values from table member_info are swapped at epoch 1045.
(1 row)
-
Query both tables to confirm that they swapped their respective 2008 and 2009 records:
=> SELECT * FROM customer_info ORDER BY year DESC;
customer_id | first_name | last_name | city | year
-------------+------------+-----------+-----------+------
4 | Simone | Bernard | Paris | 2014
5 | Vijay | Kumar | New Delhi | 2010
4 | Ana | Lopez | Madrid | 2009
3 | Patrick | OMalley | Dublin | 2008
5 | Mike | Green | New York | 2008
3 | Silke | Muller | Frankfurt | 2007
(6 rows)
=> SELECT * FROM member_info ORDER BY year DESC;
customer_id | first_name | last_name | city | year
-------------+------------+-----------+---------+------
2 | Mike | Brown | Chicago | 2014
2 | Bob | Jones | Boston | 2008
1 | Joe | Smith | Denver | 2008
1 | Jane | Doe | Miami | 2001
(4 rows)
4.4 - Minimizing partitions
By default, Vertica supports up to 1024 ROS containers to store partitions for a given projection (see Projection Parameters).
By default, Vertica supports up to 1024 ROS containers to store partitions for a given projection (see Projection parameters). A ROS container contains data that share the same partition key, or the same partition group key. Depending on the amount of data per partition, a partition or partition group can span multiple ROS containers.
Given this limit, it is inadvisable to partition a table on highly granular data—for example, on a TIMESTAMP column. Doing so can generate a very high number of partitions. If the number of partitions requires more than 1024 ROS containers, Vertica issues a ROS pushback warning and refuses to load more table data. A large number of ROS containers also can adversely affect DML operations such as DELETE, which requires Vertica to open all ROS containers.
In practice, it is unlikely you will approach this maximum. For optimal performance, Vertica recommends that the number of ungrouped partitions range between 10 and 20, and not exceed 50. This range is typically compatible with most business requirements.
You can also reduce the number of ROS containers by grouping partitions. For more information, see Partition grouping and Hierarchical partitioning.
4.5 - Viewing partition storage data
Vertica provides various ways to view how your table partitions are organized and stored:.
Vertica provides various ways to view how your table partitions are organized and stored:
Querying PARTITIONS table
The following table and projection definitions partition store_order data on order dates, and groups together partitions of the same year:
=> CREATE TABLE public.store_orders
(order_no int, order_date timestamp NOT NULL, shipper varchar(20), ship_date date)
PARTITION BY ((order_date)::date) GROUP BY (date_trunc('year', (order_date)::date));
=> CREATE PROJECTION public.store_orders_super
AS SELECT order_no, order_date, shipper, ship_date FROM store_orders
ORDER BY order_no, order_date, shipper, ship_date UNSEGMENTED ALL NODES;
=> COPY store_orders FROM '/home/dbadmin/export_store_orders_data.txt';
After loading data into this table, you can query the PARTITIONS table to determine how many ROS containers store the grouped partitions for projection store_orders_unseg, across all nodes. Each node has eight ROS containers, each container storing partitions of one partition group:
=> SELECT COUNT (partition_key) NumPartitions, ros_id, node_name FROM PARTITIONS
WHERE projection_name ilike 'store_orders%' GROUP BY ros_id, node_name ORDER BY node_name, NumPartitions;
NumPartitions | ros_id | node_name
---------------+-------------------+------------------
173 | 45035996274562779 | v_vmart_node0001
211 | 45035996274562791 | v_vmart_node0001
212 | 45035996274562783 | v_vmart_node0001
213 | 45035996274562787 | v_vmart_node0001
173 | 49539595901916471 | v_vmart_node0002
211 | 49539595901916483 | v_vmart_node0002
212 | 49539595901916475 | v_vmart_node0002
213 | 49539595901916479 | v_vmart_node0002
173 | 54043195529286985 | v_vmart_node0003
211 | 54043195529286997 | v_vmart_node0003
212 | 54043195529286989 | v_vmart_node0003
213 | 54043195529286993 | v_vmart_node0003
(12 rows)
Dumping partition keys
Vertica provides several functions that let you inspect how individual partitions are stored on the cluster, at several levels:
Given the previous table and projection, DUMP_PROJECTION_PARTITION_KEYS shows the contents of four ROS containers on each node:
=> SELECT DUMP_PROJECTION_PARTITION_KEYS('store_orders_super');
...
Partition keys on node v_vmart_node0001
Projection 'store_orders_super'
Storage [ROS container]
No of partition keys: 173
Partition keys: 2017-01-02 2017-01-03 2017-01-04 2017-01-05 2017-01-06 2017-01-09 2017-01-10
2017-01-11 2017-01-12 2017-01-13 2017-01-16 2017-01-17 2017-01-18 2017-01-19 2017-01-20 2017-01-23
2017-01-24 2017-01-25 2017-01-26 2017-01-27 2017-02-01 2017-02-02 2017-02-03 2017-02-06 2017-02-07
2017-02-08 2017-02-09 2017-02-10 2017-02-13 2017-02-14 2017-02-15 2017-02-16 2017-02-17 2017-02-20
...
2017-09-01 2017-09-04 2017-09-05 2017-09-06 2017-09-07 2017-09-08 2017-09-11 2017-09-12 2017-09-13
2017-09-14 2017-09-15 2017-09-18 2017-09-19 2017-09-20 2017-09-21 2017-09-22 2017-09-25 2017-09-26 2017-09-27
Storage [ROS container]
No of partition keys: 212
Partition keys: 2016-01-01 2016-01-04 2016-01-05 2016-01-06 2016-01-07 2016-01-08 2016-01-11
2016-01-12 2016-01-13 2016-01-14 2016-01-15 2016-01-18 2016-01-19 2016-01-20 2016-01-21 2016-01-22
2016-01-25 2016-01-26 2016-01-27 2016-02-01 2016-02-02 2016-02-03 2016-02-04 2016-02-05 2016-02-08
2016-02-09 2016-02-10 2016-02-11 2016-02-12 2016-02-15 2016-02-16 2016-02-17 2016-02-18 2016-02-19
...
2016-11-01 2016-11-02 2016-11-03 2016-11-04 2016-11-07 2016-11-08 2016-11-09 2016-11-10 2016-11-11
2016-11-14 2016-11-15 2016-11-16 2016-11-17 2016-11-18 2016-11-21 2016-11-22 2016-11-23 2016-11-24 2016-11-25
Storage [ROS container]
No of partition keys: 213
Partition keys: 2015-01-01 2015-01-02 2015-01-05 2015-01-06 2015-01-07 2015-01-08 2015-01-09
2015-01-12 2015-01-13 2015-01-14 2015-01-15 2015-01-16 2015-01-19 2015-01-20 2015-01-21 2015-01-22
2015-01-23 2015-01-26 2015-01-27 2015-02-02 2015-02-03 2015-02-04 2015-02-05 2015-02-06 2015-02-09
2015-02-10 2015-02-11 2015-02-12 2015-02-13 2015-02-16 2015-02-17 2015-02-18 2015-02-19 2015-02-20
...
2015-11-02 2015-11-03 2015-11-04 2015-11-05 2015-11-06 2015-11-09 2015-11-10 2015-11-11 2015-11-12
2015-11-13 2015-11-16 2015-11-17 2015-11-18 2015-11-19 2015-11-20 2015-11-23 2015-11-24 2015-11-25
2015-11-26 2015-11-27
Storage [ROS container]
No of partition keys: 211
Partition keys: 2014-01-01 2014-01-02 2014-01-03 2014-01-06 2014-01-07 2014-01-08 2014-01-09
2014-01-10 2014-01-13 2014-01-14 2014-01-15 2014-01-16 2014-01-17 2014-01-20 2014-01-21 2014-01-22
2014-01-23 2014-01-24 2014-01-27 2014-02-03 2014-02-04 2014-02-05 2014-02-06 2014-02-07 2014-02-10
2014-02-11 2014-02-12 2014-02-13 2014-02-14 2014-02-17 2014-02-18 2014-02-19 2014-02-20 2014-02-21
...
2014-11-04 2014-11-05 2014-11-06 2014-11-07 2014-11-10 2014-11-11 2014-11-12 2014-11-13 2014-11-14
2014-11-17 2014-11-18 2014-11-19 2014-11-20 2014-11-21 2014-11-24 2014-11-25 2014-11-26 2014-11-27
Storage [ROS container]
No of partition keys: 173
...
5 - Active and inactive partitions
Partitioned tables in the same database can be subject to different distributions of update and load activity.
The Tuple Mover assumes that all loads and updates to a partitioned table are targeted to one or more partitions that it identifies as active. In general, the partitions with the largest partition keys—typically, the most recently created partitions—are regarded as active. As the partition ages, its workload typically shrinks and becomes mostly read-only.
Setting active partition count
You can specify how many partitions are active for partitioned tables at two levels, in ascending order of precedence:
-
Configuration parameter ActivePartitionCount determines how many partitions are active for partitioned tables in the database. By default, ActivePartitionCount is set to 1. The Tuple Mover applies this setting to all tables that do not set their own active partition count.
-
Individual tables can supersede ActivePartitionCount by setting their own active partition count with CREATE TABLE and ALTER TABLE.
Partitioned tables in the same database can be subject to different distributions of update and load activity. When these differences are significant, it might make sense for some tables to set their own active partition counts.
For example, table store_orders is partitioned by month and gets its active partition count from configuration parameter ActivePartitionCount. If the parameter is set to 1, the Tuple Mover identifes the latest month—typically, the current one—as the table's active partition. If store_orders is subject to frequent activity on data for the current month and the one before it, you might want the table to supersede the configuration parameter, and set its active partition count to 2:
ALTER TABLE public.store_orders SET ACTIVEPARTITIONCOUNT 2;
Note
For tables partitioned by non-temporal attributes, set its active partition count to reflect the number of partitions that are subject to a high level of activity—for example, frequent loads or queries.
Identifying the active partition
The Tuple Mover typically identifies the active partition as the one most recently created. Vertica uses the following algorithm to determine which partitions are older than others:
-
If partition X was created before partition Y, partition X is older.
-
If partitions X and Y were created at the same time, but partition X was last updated before partition Y, partition X is older.
-
If partitions X and Y were created and last updated at the same time, the partition with the smaller key is older.
You can obtain the active partitions for a table by joining system tables
PARTITIONS and
STRATA and querying on its projections. For example, the following query gets the active partition for projection store_orders_super:
=> SELECT p.node_name, p.partition_key, p.ros_id, p.ros_size_bytes, p.ros_row_count, ROS_container_count
FROM partitions p JOIN strata s ON p.partition_key = s.stratum_key AND p.node_name=s.node_name
WHERE p.projection_name = 'store_orders_super' ORDER BY p.node_name, p.partition_key;
node_name | partition_key | ros_id | ros_size_bytes | ros_row_count | ROS_container_count
------------------+---------------+-------------------+----------------+---------------+---------------------
v_vmart_node0001 | 2017-09-01 | 45035996279322851 | 6905 | 960 | 1
v_vmart_node0002 | 2017-09-01 | 49539595906590663 | 6905 | 960 | 1
v_vmart_node0003 | 2017-09-01 | 54043195533961159 | 6905 | 960 | 1
(3 rows)
Active partition groups
If a table's partition clause includes a GROUP BY expression, Vertica applies the table's active partition count to its largest partition group key, and regards all the partitions in that group as active. If you group partitions with Vertica meta-function
CALENDAR_HIERARCHY_DAY, the most recent date partitions are also grouped by day. Thus, the largest partition group key and largest partition key are identical. In effect, this means that only the most recent partitions are active.
For more information about partition grouping, see Partition grouping and Hierarchical partitioning.
6 - Partition pruning
If a query predicate specifies a partitioning expression, the query optimizer evaluates the predicate against the containers of the partitioned data.
If a query predicate specifies a partitioning expression, the query optimizer evaluates the predicate against the ROS containers of the partitioned data. Each ROS container maintains the minimum and maximum values of its partition key data. The query optimizer uses this metadata to determine which ROS containers it needs to execute the query, and omits, or prunes, the remaining containers from the query plan. By minimizing the number of ROS containers that it must scan, the query optimizer enables faster execution of the query.
For example, a table might be partitioned by year as follows:
=> CREATE TABLE ... PARTITION BY EXTRACT(year FROM date);
Given this table definition, its projection data is partitioned into ROS containers according to year, one for each year—in this case, 2007, 2008, 2009.
The following query specifies the partition expression date:
=> SELECT ... WHERE date = '12-2-2009';
Given this query, the ROS containers that contain data for 2007 and 2008 fall outside the boundaries of the requested year (2009). The query optimizer prunes these containers from the query plan before the query executes:
Examples
Assume a table that is partitioned by time and will use queries that restrict data on time.
=> CREATE TABLE time ( tdate DATE NOT NULL, tnum INTEGER)
PARTITION BY EXTRACT(year FROM tdate);
=> CREATE PROJECTION time_p (tdate, tnum) AS
=> SELECT * FROM time ORDER BY tdate, tnum UNSEGMENTED ALL NODES;
Note
Projection sort order has no effect on partition pruning.
=> INSERT INTO time VALUES ('03/15/04' , 1);
=> INSERT INTO time VALUES ('03/15/05' , 2);
=> INSERT INTO time VALUES ('03/15/06' , 3);
=> INSERT INTO time VALUES ('03/15/06' , 4);
The data inserted in the previous series of commands are loaded into three ROS containers, one per year, as that is how the data is partitioned:
=> SELECT * FROM time ORDER BY tnum;
tdate | tnum
------------+------
2004-03-15 | 1 --ROS1 (min 03/01/04, max 03/15/04)
2005-03-15 | 2 --ROS2 (min 03/15/05, max 03/15/05)
2006-03-15 | 3 --ROS3 (min 03/15/06, max 03/15/06)
2006-03-15 | 4 --ROS3 (min 03/15/06, max 03/15/06)
(4 rows)
Here's what happens when you query the time table:
-
In this query, Vertica can omit container ROS2 because it is only looking for year 2004:
=> SELECT COUNT(*) FROM time WHERE tdate = '05/07/2004';
-
In the next query, Vertica can omit two containers, ROS1 and ROS3:
=> SELECT COUNT(*) FROM time WHERE tdate = '10/07/2005';
-
The following query has an additional predicate on the tnum column for which no minimum/maximum values are maintained. In addition, the use of logical operator OR is not supported, so no ROS elimination occurs:
=> SELECT COUNT(*) FROM time WHERE tdate = '05/07/2004' OR tnum = 7;