This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Aggregate functions (UDAFs)
Aggregate functions perform an operation on a set of values and return one value.
Aggregate functions perform an operation on a set of values and return one value. Vertica provides standard built-in aggregate functions such as AVG, MAX, and MIN. User-defined aggregate functions (UDAFs) provide similar functionality:
-
Support a single input column (or set) of values and provide a single output column.
-
Support RLE decompression. RLE input is decompressed before it is sent to a UDAF.
-
Support use with GROUP BY and HAVING clauses. Only columns appearing in the GROUP BY clause can be selected.
Restrictions
The following restrictions apply to UDAFs:
1 - AggregateFunction class
The AggregateFunction class performs the aggregation.
The AggregateFunction class performs the aggregation. It computes values on each database node where relevant data is stored and then combines the results from the nodes. You must implement the following methods:
-
initAggregate() - Initializes the class, defines variables, and sets the starting value for the variables. This function must be idempotent.
-
aggregate() - The main aggregation operation, executed on each node.
-
combine() - If multiple invocations of aggregate() are needed, Vertica calls combine() to combine all the sub-aggregations into a final aggregation. Although this method might not be called, you must define it.
-
terminate() - Terminates the function and returns the result as a column.
Important
The aggregate() function might not operate on the complete input set all at once. For this reason, initAggregate() must be idempotent.
The AggregateFunction class also provides optional methods that you can implement to allocate and free resources: setup() and destroy(). You should use these methods to allocate and deallocate resources that you do not allocate through the UDAF API (see Allocating resources for UDxs for details).
API
Aggregate functions are supported for C++ only.
The AggregateFunction API provides the following methods for extension by subclasses:
virtual void setup(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes);
virtual void initAggregate(ServerInterface &srvInterface, IntermediateAggs &aggs)=0;
void aggregate(ServerInterface &srvInterface, BlockReader &arg_reader,
IntermediateAggs &aggs);
virtual void combine(ServerInterface &srvInterface, IntermediateAggs &aggs_output,
MultipleIntermediateAggs &aggs_other)=0;
virtual void terminate(ServerInterface &srvInterface, BlockWriter &res_writer,
IntermediateAggs &aggs);
virtual void cancel(ServerInterface &srvInterface);
virtual void destroy(ServerInterface &srvInterface, const SizedColumnTypes &argTypes);
2 - AggregateFunctionFactory class
The AggregateFunctionFactory class specifies metadata information such as the argument and return types of your aggregate function.
The AggregateFunctionFactory class specifies metadata information such as the argument and return types of your aggregate function. It also instantiates your AggregateFunction subclass. Your subclass must implement the following methods:
-
getPrototype() - Defines the number of parameters and data types accepted by the function. There is a single parameter for aggregate functions.
-
getIntermediateTypes() - Defines the intermediate variable(s) used by the function. These variables are used when combining the results of aggregate() calls.
-
getReturnType() - Defines the type of the output column.
Your function may also implement getParameterType(), which defines the names and types of parameters that this function uses.
Vertica uses this data when you call the CREATE AGGREGATE FUNCTION SQL statement to add the function to the database catalog.
API
Aggregate functions are supported for C++ only.
The AggregateFunctionFactory API provides the following methods for extension by subclasses:
virtual AggregateFunction *
createAggregateFunction ServerInterface &srvInterface)=0;
virtual void getPrototype(ServerInterface &srvInterface,
ColumnTypes &argTypes, ColumnTypes &returnType)=0;
virtual void getIntermediateTypes(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes, SizedColumnTypes &intermediateTypeMetaData)=0;
virtual void getReturnType(ServerInterface &srvInterface,
const SizedColumnTypes &argTypes, SizedColumnTypes &returnType)=0;
virtual void getParameterType(ServerInterface &srvInterface,
SizedColumnTypes ¶meterTypes);
3 - UDAF performance in statements containing a GROUP BY clause
You may see slower-than-expected performance from your UDAF if the SQL statement calling it also contains a GROUP BY Clause.
You may see slower-than-expected performance from your UDAF if the SQL statement calling it also contains a GROUP BY clause. For example:
=> SELECT a, MYUDAF(b) FROM sampletable GROUP BY a;
In statements like this one, Vertica does not consolidate row data together before calling your UDAF's aggregate() method. Instead, it calls aggregate() once for each row of data. Usually, the overhead of having Vertica consolidate the row data is greater than the overhead of calling aggregate() for each row of data. However, if your UDAF's aggregate() method has significant overhead, then you might notice an impact on your UDAF's performance.
For example, suppose aggregate() allocates memory. When called in a statement with a GROUP BY clause, it performs this memory allocation for each row of data. Because memory allocation is a relatively expensive process, this allocation can impact the overall performance of your UDAF and the query.
There are two ways you can address UDAF performance in a statement containing a GROUP BY clause:
-
Reduce the overhead of each call to aggregate(). If possible, move any allocation or other setup operations to the UDAF's setup() function.
-
Declare a special parameter that tells Vertica to group row data together when calling a UDAF. This technique is explained below.
Using the _minimizeCallCount parameter
Your UDAF can tell Vertica to always batch row data together to reduce the number of calls to its aggregate() method. To trigger this behavior, your UDAF must declare an integer parameter named _minimizeCallCount. You do not need to set a value for this parameter in your SQL statement. The fact that your UDAF declares this parameter triggers Vertica to group row data together when calling aggregate().
You declare the _minimizeCallCount parameter the same way you declare other UDx parameters. See UDx parameters for more information.
Important
Always test the performance of your UDAF before and after implementing the _minimizeCallCount parameter to ensure that it improves performance. You might find that the overhead of having Vertica group row data for your UDAF is greater than the cost of the repeated calls to aggregate().
4 - C++ example: average
The Average aggregate function created in this example computes the average of values in a column.
The Average aggregate function created in this example computes the average of values in a column.
You can find the source code used in this example on the Vertica GitHub page.
Loading the example
Use CREATE LIBRARY and CREATE AGGREGATE FUNCTION to declare the function:
=> CREATE LIBRARY AggregateFunctions AS
'/opt/vertica/sdk/examples/build/AggregateFunctions.so';
CREATE LIBRARY
=> CREATE aggregate function ag_avg AS LANGUAGE 'C++'
name 'AverageFactory' library AggregateFunctions;
CREATE AGGREGATE FUNCTION
Using the example
Use the function as part of a SELECT statement:
=> SELECT * FROM average;
id | count
----+---------
A | 8
B | 3
C | 6
D | 2
E | 9
F | 7
G | 5
H | 4
I | 1
(9 rows)
=> SELECT ag_avg(count) FROM average;
ag_avg
--------
5
(1 row)
AggregateFunction implementation
This example adds the input argument values in the aggregate() method and keeps a counter of the number of values added. The server runs aggregate() on every node and different data chunks, and combines all the individually added values and counters in the combine() method. Finally, the average value is computed in the terminate() method by dividing the total sum by the total number of values processed.
For this discussion, assume the following environment:
-
A three-node Vertica cluster
-
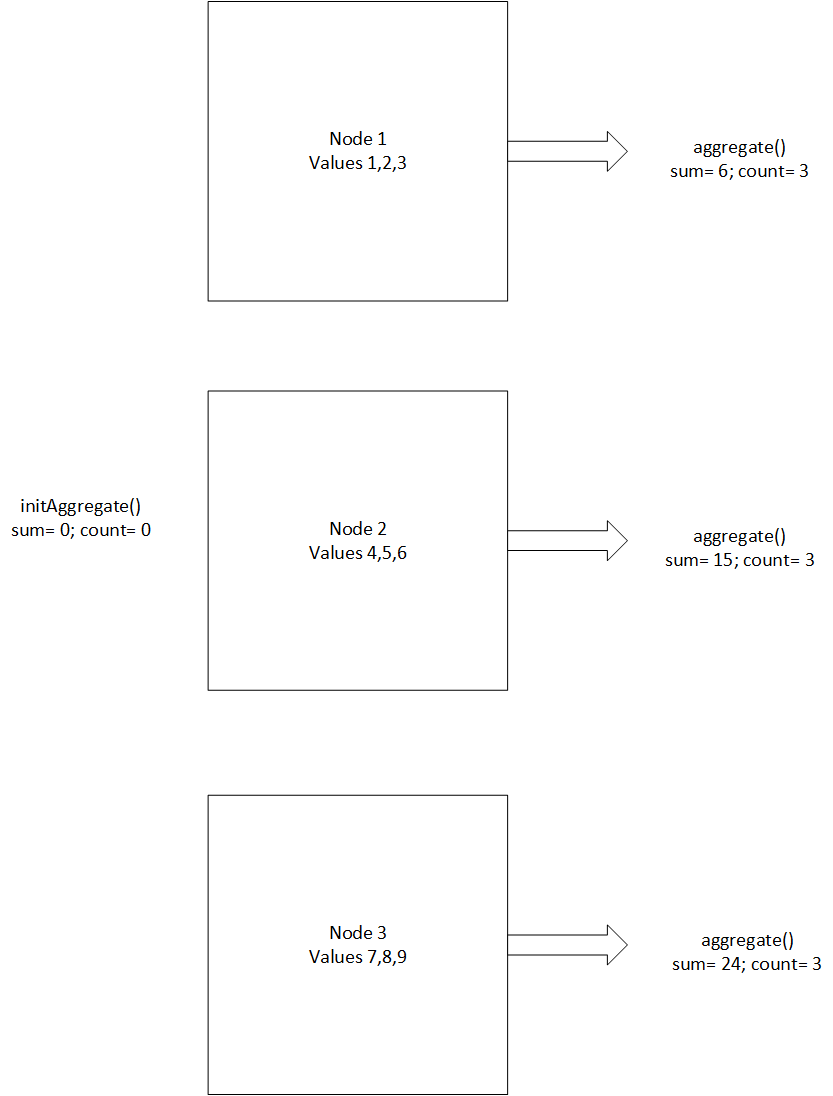
A table column that contains nine values that are evenly distributed across the nodes. Schematically, the nodes look like the following figure:

The function uses sum and count variables. Sum contains the sum of the values, and count contains the count of values.
First, initAggregate() initializes the variables and sets their values to zero.
virtual void initAggregate(ServerInterface &srvInterface,
IntermediateAggs &aggs)
{
try {
VNumeric &sum = aggs.getNumericRef(0);
sum.setZero();
vint &count = aggs.getIntRef(1);
count = 0;
}
catch(std::exception &e) {
vt_ report_ error(0, "Exception while initializing intermediate aggregates: [% s]", e.what());
}
}
The aggregate() function reads the block of data on each node and calculates partial aggregates.
void aggregate(ServerInterface &srvInterface,
BlockReader &argReader,
IntermediateAggs &aggs)
{
try {
VNumeric &sum = aggs.getNumericRef(0);
vint &count = aggs.getIntRef(1);
do {
const VNumeric &input = argReader.getNumericRef(0);
if (!input.isNull()) {
sum.accumulate(&input);
count++;
}
} while (argReader.next());
} catch(std::exception &e) {
vt_ report_ error(0, " Exception while processing aggregate: [% s]", e.what());
}
}
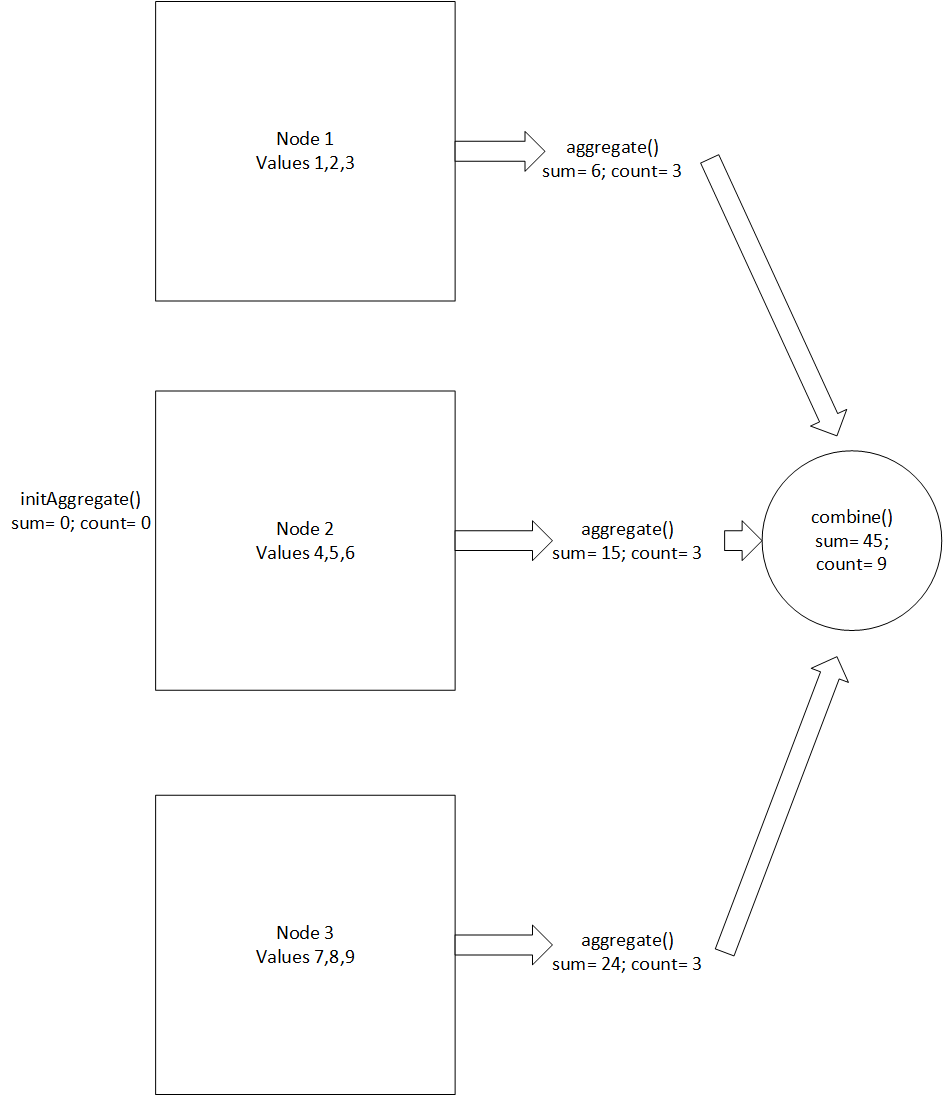
Each completed instance of the aggregate() function returns multiple partial aggregates for sum and count. The following figure illustrates this process using the aggregate() function:
The combine() function puts together the partial aggregates calculated by each instance of the average function.
virtual void combine(ServerInterface &srvInterface,
IntermediateAggs &aggs,
MultipleIntermediateAggs &aggsOther)
{
try {
VNumeric &mySum = aggs.getNumericRef(0);
vint &myCount = aggs.getIntRef(1);
// Combine all the other intermediate aggregates
do {
const VNumeric &otherSum = aggsOther.getNumericRef(0);
const vint &otherCount = aggsOther.getIntRef(1);
// Do the actual accumulation
mySum.accumulate(&otherSum);
myCount += otherCount;
} while (aggsOther.next());
} catch(std::exception &e) {
// Standard exception. Quit.
vt_report_error(0, "Exception while combining intermediate aggregates: [%s]", e.what());
}
}
The following figure shows how each partial aggregate is combined:
After all input has been evaluated by the aggregate() function Vertica calls the terminate() function. It returns the average to the caller.
virtual void terminate(ServerInterface &srvInterface,
BlockWriter &resWriter,
IntermediateAggs &aggs)
{
try {
const int32 MAX_INT_PRECISION = 20;
const int32 prec = Basics::getNumericWordCount(MAX_INT_PRECISION);
uint64 words[prec];
VNumeric count(words,prec,0/*scale*/);
count.copy(aggs.getIntRef(1));
VNumeric &out = resWriter.getNumericRef();
if (count.isZero()) {
out.setNull();
} else
const VNumeric &sum = aggs.getNumericRef(0);
out.div(&sum, &count);
}
}
The following figure shows the implementation of the terminate() function:
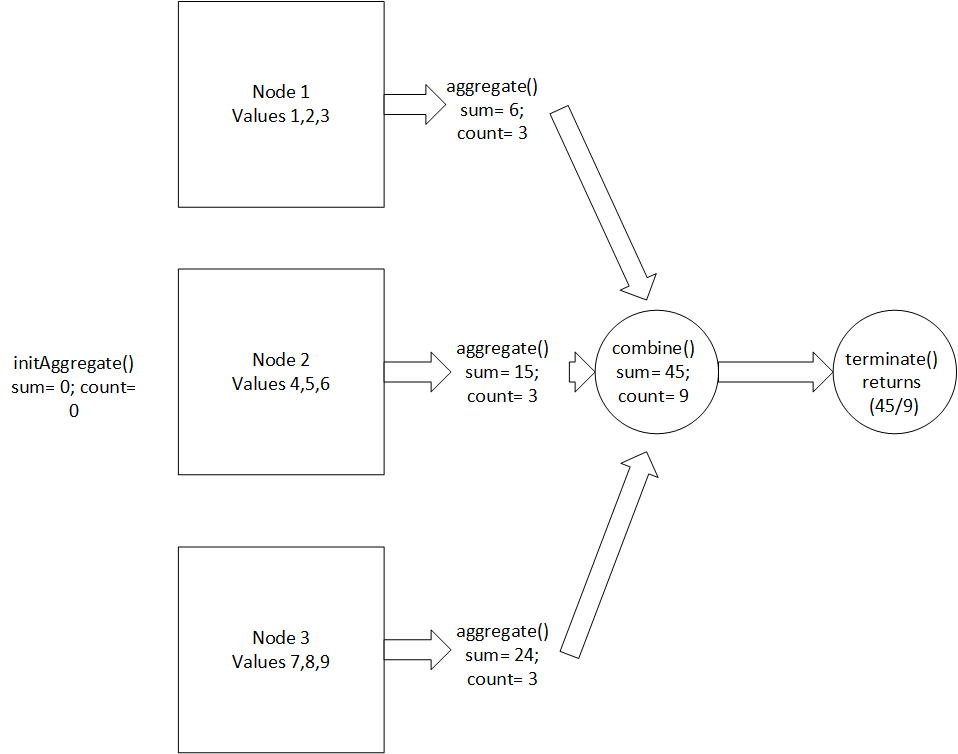
AggregateFunctionFactory implementation
The getPrototype() function allows you to define the variables that are sent to your aggregate function and returned to Vertica after your aggregate function runs. The following example accepts and returns a numeric value:
virtual void getPrototype(ServerInterface &srvfloaterface,
ColumnTypes &argTypes,
ColumnTypes &returnType)
{
argTypes.addNumeric();
returnType.addNumeric();
}
The getIntermediateTypes() function defines any intermediate variables that you use in your aggregate function. Intermediate variables are values used to pass data among multiple invocations of an aggregate function. They are used to combine results until a final result can be computed. In this example, there are two results - total (numeric) and count (int).
virtual void getIntermediateTypes(ServerInterface &srvInterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &intermediateTypeMetaData)
{
const VerticaType &inType = inputTypes.getColumnType(0);
intermediateTypeMetaData.addNumeric(interPrec, inType.getNumericScale());
intermediateTypeMetaData.addInt();
}
The getReturnType() function defines the output data type:
virtual void getReturnType(ServerInterface &srvfloaterface,
const SizedColumnTypes &inputTypes,
SizedColumnTypes &outputTypes)
{
const VerticaType &inType = inputTypes.getColumnType(0);
outputTypes.addNumeric(inType.getNumericPrecision(),
inType.getNumericScale());
}