This is the multi-page printable view of this section.
Click here to print.
Return to the regular view of this page.
Architecture
Understanding how Vertica works helps you effectively design, build, operate, and maintain a Vertica database.
Understanding how Vertica works helps you effectively design, build, operate, and maintain a Vertica database. This section assumes that you are familiar with the basic concepts and terminology of relational database management systems and SQL.
Column storage
Vertica stores data in a column format so it can be queried for best performance. Compared to row-based storage, column storage reduces disk I/O, making it ideal for read-intensive workloads. Vertica reads only the columns needed to answer the query. Columns are encoded and compressed to further improve performance.
Vertica uses a number of different encoding strategies, depending on column data type, table cardinality, and sort order. Encoding increases performance because there is less disk I/O during query execution. In addition, you can store more data in less space.
Compression allows a column store to occupy substantially less storage than a row store. In a column store, every value stored in a projection column has the same data type. This greatly facilitates compression, particularly in sorted columns. In a row store, each value of a row can have a different data type, resulting in a much less effective use of compression. The efficient storage methods that Vertica uses allow you to maintain more historical data in physical storage.
Projections
A projection consists of a set of columns with the same sort order, defined by a column to sort by or a sequence of columns by which to sort. Like an index or materialized view in a traditional database, a projection accelerates query processing. When you write queries in terms of the original tables, the query uses the projections to return query results. For more information, see Projections.
Projections are distributed and replicated across nodes in your cluster, ensuring that if one node becomes unavailable, another copy of the data remains available. This redundancy is called K-safety.
Automatic data replication, failover, and recovery provide for active redundancy, which increases performance. Nodes recover automatically by querying the system.
Eon and Enterprise Modes
A Vertica database runs in one of two modes: Eon or Enterprise. Both modes can be deployed on-premises or in the cloud. In Eon Mode, compute and storage are separate; the database uses shared communal storage, and you can add or remove nodes or subclusters based on demand. In Enterprise Mode, each database node has a share of the data and queries are distributed to take advantage of data locality. Understanding the differences between these modes is key. See Eon vs. Enterprise Mode.
1 - Eon vs. Enterprise Mode
A Vertica database runs in one of two modes: Eon or Enterprise.
A Vertica database runs in one of two modes: Eon or Enterprise. Both modes can be deployed on-premises or in the cloud. Understanding the difference between these two modes is key. If you are deploying a Vertica database, you must decide which mode to run it in early in your deployment planning. If you are using an already-deployed Vertica database, you should understand how each mode affects loading and querying data.
Vertica databases running in Eon and Enterprise modes store their data differently:
These different storage methods lead to a number of important differences between the two modes.
Storage overview
Eon Mode stores data in a shared object store called communal storage:

When deployed in a cloud environment, Vertica stores its data in a cloud-based storage container, such as an AWS S3 bucket. When deployed on-premises, Vertica stores data in a locally-deployed object store, such as a Pure Storage FlashBlade appliance. Separating the persistent data storage from the compute resources (the nodes that load data and process queries) provides flexibility.
Enterprise Mode stores data across the filesystems of the database nodes:

Each node is responsible for storing and processing a portion of the data. The data is co-located on the nodes in both cloud-based and on-premises databases to provide resiliency in the event of node failure. Having the data located close to the computing power offers a different set of advantages. When a node is added to the cluster, or comes back online after being unavailable, it automatically queries other nodes to update its local data.
Key advantages of each mode
The different ways Eon Mode and Enterprise Mode store data give each mode an advantage in different environments. The following table summarizes these differences. For details, see Eon vs. Enterprise Mode.
|
Chief advantages of... |
Where database mode is... |
|
Eon |
Enterprise |
|
Cloud |
-
Easily scaled up or down to meet changing workloads and reduce costs.
-
Workloads can be isolated to a subcluster of nodes.
-
Virtually no limits on database size. Most cloud providers offer essentially unlimited data storage (for a price).
|
Works in most cloud platforms. Eon Mode works in specific cloud providers. |
|
On‑premises |
-
Workloads can be isolated to a subset of nodes called a subcluster.
-
Can increase storage without adding nodes (and, if the object store supports hot plugging, without downtime).
|
No additional hardware needed beyond the servers that make up the database cluster. |
Eon Mode and Enterprise Mode databases have roughly the same performance in the same environment when properly configured.
An Eon Mode database typically enables caching data from communal storage on a node's local depot, which the node uses to process queries. With depot caching enabled, query performance on an Eon Mode database is equivalent to an Enterprise Mode database, where each node stores a portion of the database locally. In both cases, nodes access locally-stored data to resolve queries.
To further improve performance, you can enable depot warming on an Eon Mode database. When depot warming is enabled, a node that is undergoing startup preemptively loads its depot with frequently queried and pinned data. When the node completes startup and begins to execute queries, its depot already contains much of the data it needs to process those queries. This reduces the need to fetch data from communal storage, and expedites query performance accordingly.
Query performance in an Eon Mode database is liable to decline if its depot is too small. A small depot increases the chance that a query will require data that is not in the depot. That results in nodes having to retrieve data from communal storage more frequently.
Note
When comparing a cloud-based Eon Mode database to an on-premises Enterprise Mode database, performance differences are typically due to the overall performance impact of a shared cloud-based virtual environment compared to on-premises dedicated hardware. An Enterprise Mode database running in the same cloud would have the same performance as the Eon Mode, in most cases.
Installation
An Eon Mode database must have an object store to store its data communally. An Enterprise Mode database does not require any additional storage hardware beyond the storage installed on its nodes. Depending on the environment you've chosen for your Vertica database (especially if you are installing on-premises), the need to configure an object store may make your installation a bit more complex.
Because Enterprise Mode does not need additional hardware for data storage, it can be a bit simpler to install. An on-premises Eon Mode install needs additional hardware and additional configuration for the object store that provides the communal storage.
Enterprise Mode is especially useful for development environments because it does not require additional hardware beyond the nodes you use to run it. You can even create a single-node Enterprise Mode database, either on physical hardware or on a virtual machine. You can download a preconfigured single-node Enterprise Mode virtual machine that is ready to run. See Vertica community edition (CE) for more information.
Deploying an Eon Mode database in a cloud environment is usually simpler than an on-premises install. The cloud environments provide their own object store for you. For example, when you deploy an Eon Mode database in Amazon's AWS, you just need to create an S3 bucket for the communal data store. You then provide the S3 URL to Vertica when creating the database. There is no need to install and configure a separate data store.
Deploying an Enterprise Mode database in the cloud is similar to installing one on-premises. The virtual machines you create in the cloud must have enough local storage to store your database's data.
Workload isolation
You often want to prevent intensive workloads from interfering with other potentially time-sensitive workloads. For example, you may want to isolate ETL workloads from querying workloads. Groups of users that rely on real-time analytics can be isolated from groups that are running batched reports.

Eon Mode databases offer the best workload isolation option. It allows you to create groups of nodes called subclusters that isolate workloads. A query only runs on the nodes in a single subcluster. It does not affect nodes outside the subcluster. You can assign different groups of users a different subcluster to use.
In an Eon Mode database, subclusters and scalability work hand in hand. You often add, remove, stop, and start entire subclusters of nodes, rather than scaling nodes individually.
Enterprise Mode does not offer subclusters to isolate workloads. You can use features such as resource pools and other settings to give specific queries priority and access to more resources. However, these features do not truly isolate workloads as subclusters do. See Managing workloads for an explanation of managing workloads using these features.
Scalability
You can scale a Vertica database by adding or removing nodes to meet changing analytic needs. Scalability is usually more important in cloud environments where you are paying by the hour for each node in your database. If your database isn't busy, there is no reason to have underused nodes costing you money. You can reduce the number of nodes in your database during quiet times (weekends and holidays, for example) to save money.
Scalability is usually less important for on-premises installations. There are limited additional costs involved in having nodes running when they are not fully in use.
An Enterprise Mode database scales less efficiently than an Eon Mode one. When an Enterprise Mode database scales, it must re-segment (rebalance) its data to be spread among the new number of nodes.

Rebalancing is an expensive operation. When scaling the database up, Vertica must break up files and physically move a percentage of the data from the original nodes to the new nodes. When scaling down, Vertica must move the data off of the nodes that are being removed and distribute it among the remaining nodes. The database is not available during rebalancing. This process can take 12, 24, or even 36 hours to complete, depending on the size of the database. After scaling up an Enterprise Mode database, queries should run faster because each node is responsible for less data. Therefore, each node has less work to do to process each query. Scaling down an Enterprise Mode database usually has the opposite effect—queries will run slower. See Elastic cluster for more information on scaling an Enterprise Mode database.
Eon Mode databases scale more efficiently because data storage is separate from the computing resources.

When you scale up an Eon Mode database, the database's data does not need to be re-segmented. Instead, the additional nodes subscribe to preexisting segments (called shards) of data in communal storage. When expanding the cluster, Vertica rebalances the shards assigned to each node, rather than physically splitting the data storage and moving in between nodes. The new nodes prepare to process queries by retrieving data from the communal storage to fill their depots (a local cache of data from the communal storage). The database remains available while scaling and the process takes minutes rather than hours to complete.
Note
Node subscriptions are slightly more complicated than shown in the previous diagram. To ensure
K-safety, each node actually subscribes to a second shard (or shards, if there are more shards than nodes) to act as a backup in case the node subscribing to those shards goes down. See
Shards and subscriptions for details.
If the number of shards in the communal storage is equal to or higher than the new number of nodes (as shown in the previous diagram), then query performance improves after expanding the cluster. Each node is responsible for processing less data, so the same queries will run faster after you scale the cluster up.
You can also scale your database up to improve query throughput. Query throughput improves the number of queries processed by your database in parallel. You usually care about query throughput when your workload contains many, shorter-running queries ("dashboard queries"). To improve throughput, add more nodes to your database in a new subcluster. The subcluster isolates queries run by clients connected to it from the other nodes in the database. Subclusters work independently and in parallel. Isolating the workloads means that your database runs more queries simultaneously.

If a subcluster contains more nodes than the number of shards in communal storage, multiple nodes subscribe to the same shard. In this case, Vertica uses a feature called elastic crunch scaling to execute the query faster. Vertica divides the responsibility for the data in each shard between the subscribing nodes. Each node only needs to process a subset of the data in the shard it subscribes to. Having less data to process means that each node usually finishes its part of the query faster. This often translates into the query finishing its executing sooner.
Important
Always make the number of nodes in your Eon Mode subclusters a multiple of the number of shards in the database, or an even divisor of the number of shards. For example, in a six-shard database, your subclusters should have three, six, or twelve shards. Vertica recommends you never have more than two shards per node.
A mismatch between the number of shards and the number of nodes can impact performance. For example, suppose you have a six-shard database. If you expand a subcluster from three to five nodes, one node would still be the only subscriber for two shards. This means that node has to do twice the work of the other nodes in the subcluster during queries. In this case, you see no benefit from adding the two new nodes, because the node subscribing to two shards becomes a bottleneck.
Scaling down an Eon Mode database works similarly. Shutting down entire subclusters reduced your database's query throughput. If you remove nodes from a subcluster, the remaining nodes subscribe to any shards that do not have a subscriber. This process is fast, and the database remains running while it is happening.
Expandability
As you load more data into your database, you may eventually need to expand its data storage. Because Eon Mode databases separate compute from storage, you often expand its storage without changing the number of nodes.
In a cloud environment, you usually do not have a limit on storage. For example, an AWS S3 bucket can store as much data as you want. As long as you are willing to pay for additional storage charges, you do not have to worry about expanding your database's storage.
When you install Eon Mode on-premises, how you expand storage depends on the object store you are using. For example, Pure Storage FlashBlades support hot plugging new blades to add additional storage. This feature lets you expand the storage in your Eon Mode database with no downtime.

In most cases, you usually query a subset of the data in your database (called the working data set). Eon Mode's decoupling of compute and storage let you size your compute (the number of nodes in your database) to the working data set and your desired performance rather than to the entire data set.
For example, if you are performing time series analysis in which the active data set is usually the last 30 days, you can size your cluster to manage 30 days' worth of data. Data older than 30 days simply grows in communal storage. The only reason you need to add more nodes to your Eon Mode database is to meet additional workloads. On the other hand, if you want very high performance on a small data set, you can add as many nodes as you need to obtain the performance you want.
In an Enterprise Mode database, nodes are responsible for storage as well as compute. Because of the tight coupling between compute and storage, the best way to expand storage in an Enterprise Mode database is to add new nodes. As mentioned in the Scalability section, adding nodes to an Enterprise Mode database requires rebalancing the existing data in the database.
Due to the disruption rebalancing causes to the database, you usually expand the storage in an Enterprise Mode database infrequently. When you do expand its storage, you usually add significant amounts of storage to allow for future growth.
Adding nodes to increase storage has the downside that you may be adding compute power to your cluster that isn't really necessary. For example, suppose you are performing time-series analysis that focuses on recent data and your current cluster offers you enough query performance to meet your needs. However, you need to add additional storage to keep historical data. In this case, adding new nodes to your database for additional storage adds computing power you really don't need. Your queries may run a bit faster. However, the slight benefit of faster results probably does not justify the costs of adding more computing power.
2 - Eon Mode concepts
Eon Mode separates the computational processes from the communal storage layer of your database.
Eon Mode separates the computational processes from the communal storage layer of your database. This separation gives you the ability to store your data in a single location (such as S3 on AWS or Pure Storage) and elastically vary the number of compute nodes connected to that location according to your computational needs. You can adjust the size of your cluster without interrupting analytic workloads, adding or removing nodes as the volume of work changes
The following topics explain how Eon Mode works.
2.1 - Eon Mode architecture
Eon Mode separates the computational resources from the storage layer of your database.
Eon Mode separates the computational resources from the storage layer of your database. This separation gives you the ability to store your data in a single location. You can elastically vary the number of nodes connected to that location according to your computational needs. Adjusting the size of your cluster does not interrupt analytic workloads.
You can create an Eon Mode database either in a cloud environment, or on‑premises on your own systems.
Eon Mode is suited to a range of needs and data volumes. Because compute and storage are separate, you can scale them separately.
Communal storage
Instead of storing data locally, Eon Mode uses a single communal storage location for all data and the catalog (metadata). Communal storage is the database's centralized storage location, shared among the database nodes. Communal storage is based on an object store, such as Amazon's S3 in the cloud or a PureStorage FlashBlade appliance in an on-premises deployment. In either case, Vertica relies on the object store to maintain the durable copy of the data.
Communal storage has the following properties:
-
Communal storage in the cloud is more resilient and less susceptible to data loss due to storage failures than storage on disk on individual machines.
-
Any data can be read by any node using the same path.
-
Capacity is not limited by disk space on nodes.
-
Because data is stored communally, you can elastically scale your cluster to meet changing demands. If the data were stored locally on the nodes, adding or removing nodes would require moving significant amounts of data between nodes to either move it off of nodes that are being removed, or onto newly-created nodes.
Communal storage locations are listed in the STORAGE_LOCATIONS system table with a SHARING_TYPE of COMMUNAL.
Within communal storage, data is divided into portions called shards. Shards are how Vertica divides the data among the nodes in the database. Nodes subscribe to particular shards, with subscriptions balanced among the nodes. When loading or querying data, each node is responsible for the data in the shards it subscribes to. See Shards and subscriptions for more information.
Depot storage
A potential drawback of communal storage is its speed, especially in cloud environments. Accessing data from a shared cloud location is slower than reading it from local disk. Also, the connection to communal storage can become a bottleneck if many nodes are reading data from it at once. To improve data access speed, the nodes in an Eon Mode database maintain a local disk cache of data called the depot. When executing a query, the nodes first check whether the data it needs is in the depot. If it is, then the node finishes the query using the local copy of the data. If the data is not in the depot, the node fetches the data from communal storage, and saves a copy in the depot.
The node stores newly-loaded data in the depot before sending it to communal storage. See Loading Data below for more details.
By default, Vertica sets the maximum size of the depot to be 60% of the total disk space of the filesystem that stores the depot. You can adjust the size of the depot if you wish. Vertica limits the size of the depot to a maximum of 80% of the filesystem that contains it. This upper limit ensures enough disk space for other uses, such as temporary files that Vertica creates during data loads.
Each node also stores a local copy of the database catalog.
Loading data
In Eon Mode, COPY statements usually write to read optimized store (ROS) files in a node's depot to improve performance. The COPY statement segments, sorts, and compresses for high optimization. Before the statement commits, Vertica ships the ROS files to communal storage.
Because a load is buffered in the depot on the node executing the load, the size of your depot limits the amount of data you can load in a single operation. Unless you perform multiple loads in parallel sessions, you are unlikely to encounter this limit.
Note
If your data loads do overflow the amount of space in your database's depot, you can tell Vertica to bypass the depot and load data directly into communal storage. You enable direct writes to communal storage by setting the UseDepotForWrites configuration parameter to 0. See
Eon Mode parameters for more information. Once you have completed your large data load, switch this parameter back to 1 to re-enable writing to the depot.
At load time, the participating nodes write files to the depot and synchronously send them to communal storage. The data is also sent to all nodes that subscribe to the shard into which the data is being loaded. This mechanism of sending data to peers at load time improves performance if a node goes down, because the cache of the peers who take over for the down node is already warm. The file compaction mechanism (mergeout) puts its output files into the cache and also uploads them to the communal storage.
The following diagram shows the flow of data during a COPY statement.

Querying data
Vertica uses a slightly different process to plan queries in Eon Mode to incorporate the sharding mechanism and remote storage. Instead of using a fixed-segmentation scheme to distribute data to each node, Vertica uses the sharding mechanism to segment the data into a specific number of shards that at least one (and usually more) nodes subscribes to. When the optimizer selects a projection, the layout for the projection is determined by the participating subscriptions for the session. The optimizer generates query plans that are equivalent to those in Enterprise Mode. It selects one of the nodes that subscribes to each shard to participate in query execution.
Vertica first tries to use data in the depot to resolve a query. When the data in the depot cannot resolve the query, Vertica reads from the communal storage. You could see an impact on query performance when a substantial number of your queries read from the communal storage. If this is the case, then you should consider re-sizing your depot or use depot system tables to get a better idea of what is causing the issue. You can use ALTER_LOCATION_SIZE to change depot size.
Workload isolation and scaling
Eon Mode lets you define subclusters that divide up your nodes to isolate workloads from one another. You can also use subclusters to ensure that scaling down your cluster does not result in Vertica going into read-only mode to maintain data integrity. See Subclusters for more information.
2.2 - Shards and subscriptions
In Eon Mode, Vertica stores data communally in a shared data storage location (for example, in S3 when running on AWS).
In Eon Mode, Vertica stores data communally in a shared data storage location (for example, in S3 when running on AWS). All nodes are capable of accessing all of the data in the communal storage location. In order for nodes to divide the work of processing queries, Vertica must divide the data between them in some way. It breaks the data in communal storage into segments called shards. Each node in your database subscribes to a subset of the shards in the communal storage location. The shards in your communal storage location are similar to a collection of segmented projections in an Enterprise Mode database.
When K-safety is 1 or higher (high availability), each shard has more than one node subscribing to it in each subcluster. One of the subscribers is responsible for executing queries involving the shard. The other subscribers act as backups. If the main subscriber shuts down or is stopped, then another subscriber takes its place. See Data integrity and high availability in an Eon Mode database for more information.

Each shard in the database has a primary subscriber. This subscriber is a primary node that maintains the data in the shard by planning Tuple Mover operations on it. This node can delegate executing these actions to another node in the database cluster. See Tuple mover for more information about these operations. If the primary subscriber node is stopped or goes down, Vertica chooses another primary node that subscribes to the shard as the shard's primary subscriber. If all of the primary nodes that subscribe to a shard go down or are stopped, your database goes into read-only mode to maintain data integrity. Any primary node that is the sole subscriber to a shard is a critical node.
A special type of shard called a replica shard stores metadata for unsegmented projections. Replica shards exist on all nodes.
You define the number of shards when you create your database. For the best performance, the number of shards you choose should be no greater than 2× the number of nodes. At most, you should limit the shard-to-node ratio to no greater than 3:1. MC warns you to take all aspects of shard count into consideration. The number of shards should always be a multiple (or an even divisor) of the number of nodes in your database. See Choosing the Number of Shards and the Initial Node Count for more information.
After database creation, you can change the number of shards in your database with RESHARD_DATABASE. See Change the number of shards in the database for details.
For efficiency, Vertica transfers metadata about shards directly between database nodes. This peer-to-peer transfer applies only to metadata; the actual data that is stored on each node gets copied from communal storage to the node's depot as needed.
2.3 - Subclusters
Because Eon Mode separates compute and storage, you can create subclusters within your cluster to isolate work.
Because Eon Mode separates compute and storage, you can create subclusters within your cluster to isolate work. For example, you might want to dedicate some nodes to loading data and others to executing queries. Or you might want to create subclusters for dedicated groups of users (who might have different priorities). You can also use subclusters to organize nodes into groups for easily scaling your cluster up and down.
Every node in your Eon Mode database must belong to a subcluster. This requirement means your database must always have at least one subcluster. When you create a new Eon Mode database, Vertica creates a subcluster named default_subcluster that contains the nodes you create on database creation. If you add nodes to your database without assigning them to a subcluster, Vertica adds them to the default subcluster. You can choose to designate another subcluster as the default subcluster, or rename default_subcluster to something more descriptive. See Altering subcluster settings for more information.
Using subclusters for work isolation
Database administrators are often concerned about workload management. Intense analytics queries can consume so many resources that they interfere with other important database tasks, such as data loading. Subclusters help you prevent resource issues by isolating workloads from one another.
In Eon Mode, by default, queries only run on nodes in the subcluster that contains the initiator node. For example, consider the two subclusters shown in the following diagram. If you are connected to Node 4, your queries would run on nodes 4 through 9.
Similarly, queries started on Node 1 only run on nodes 1 through 3.
This isolation lets you configure your database cluster to prevent workloads from interfering with each other. You can assign subclusters to specific tasks such as loading data, performing in-depth analytics, and short-running dashboard queries. You can also create subclusters for different groups in your organization, so their workloads do not interfere with one another. You can tune the settings of each subcluster (resource pools, for example) to match their specific workloads.
Subcluster types
There are two types of subclusters: primary and secondary.
Primary subclusters form the core of your Vertica database. They are responsible for planning the maintenance of the data in the communal storage. Your primary subclusters must always be running. If all of your primary subclusters shut down, your database shuts down because it cannot maintain the data in communal storage without a primary subcluster.
Usually, you have just a single primary subcluster in your database. You can choose to have multiple primary subclusters. Additional primary subclusters can make your database more resilient to having primary nodes fail. However, additional primary subclusters make your database less scalable. You usually do not dynamically add or remove nodes from primary subclusters or shut them down to scale your database. In most cases, a single primary subcluster is enough.
Secondary subclusters are designed for dynamic scaling: you add and remove or start and stop these subclusters based on your analytic needs. They are not essential for maintaining your database's data. So, you can easily add, remove, and scale up or down secondary subclusters without impacting the database's ability to run normally.
The nodes in the subcluster inherit their primary or secondary status from the subcluster that contains them; primary subclusters contain primary nodes and secondary subclusters contain secondary nodes.
Subcluster types and elastic scaling
The most important difference between primary and secondary subclusters is their impact on how Vertica determines whether the database is K-Safe and has a quorum. Vertica only considers the nodes in primary subclusters when determining whether all of the shards in the database have a subscribing node. It also only considers primary nodes when determining whether more than half the nodes in the database are running (also known as having a quorum of primary nodes). If either of these conditions is not met, the database goes into read-only mode to prevent data corruption. See Data integrity and high availability in an Eon Mode database for more information about how Vertica maintains data integrity.
Vertica does not consider the secondary nodes when determining whether the database has shard coverage or a quorum of nodes. This fact makes secondary subclusters perfect for managing groups of nodes that you plan to expand and reduce dynamically. You can stop or remove an entire subcluster of secondary nodes without forcing the database into read-only mode.
Minimum subcluster size for K-safe databases
In a K-safe database, subclusters must have at least three nodes in order to operate. Each subcluster tries to maintain subscriptions to all shards in the database. If a subcluster has less than three nodes, it cannot maintain redundant shard coverage where each shard has at least two subscribers in the subcluster. Without redundant coverage, the subcluster cannot continue processing queries if it loses a node. Vertica returns an error if you attempt to rebalance shards in a subcluster with less than three nodes in a K-safe database.
See also
2.4 - Elasticity
Elasticity refers to the ability for you adjust your database to changing workload demands by adding or removing nodes.
Elasticity refers to the ability for you adjust your database to changing workload demands by adding or removing nodes. When your database experiences high demand, you can add new nodes or start stopped nodes to increase the amount of compute available. When your database experiences lower demands (such as during holidays or weekends) you can stop or terminate nodes to save money. You can also gradually add nodes over time as your database demands grow.
All nodes in an Eon Mode database belong to a subcluster. By choosing which subclusters get new nodes, you can affect how the new nodes impact your database. There are two goals you can achieve when adding nodes to your database:
-
Improve query throughput: higher throughput means your database processes more queries simultaneously. You often want to improve throughput when you have a workload of "dashboard queries": many relatively short-running queries. In this case, speeding up the processing of individual queries is not as important as having more queries run in parallel.
-
Improve query performance: higher query performance means that your complex in-depth analytic queries complete faster.
Scaling for query throughput
To scale for query throughput, add additional nodes to your database in one or more new subclusters. Subclusters independently process queries: a query only runs on the nodes in the subcluster containing the initiator node. By adding one or more subclusters, your database can process more queries at the same time. For the best performance, add the same number of nodes to each new subcluster as there are shards in the database. For example, if you have 6 shards in your database, add 6 nodes to each new subcluster you create.
To take advantage of the improved throughput offered by the new subclusters, clients must connect to them. The best way to ensure your users take advantage of the subclusters you have added for throughput scaling is to create connection load balancing policies that spread client connections across the all nodes in all of these subclusters. See Connection load balancing policies for more information.
Subclusters also organize nodes into groups that can easily be stopped or started together. This feature makes expanding and shrinking your database easier. See Starting and stopping subclusters for details.
To improve the performance of individual queries in a subcluster, add more nodes to it. Queries perform faster when there is more computing power available to process them.
Adding nodes is especially effective if your subcluster has less nodes than there are shards in the database. In this case, nodes are responsible for processing data in multiple shards. When you add more nodes, the newly-added nodes take over responsibility for some of the shards. With less data to process, each node finishes their part of the query faster, resulting in better overall performance. For the best performance, make the number of nodes in the subcluster an even divisor of (or equal to) the number of shards in the database. For example, in a 12-shard database, make the number of nodes in the subcluster 3, 6, or 12.
You can further improve query performance by adding more nodes than there are shards in the database. When nodes outnumber shards, multiple nodes in the subcluster subscribe to the same shard. In this case, when processing a query, Vertica uses a feature called elastic crunch scaling (ECS) to have all of the nodes in the subcluster take part in the query. ECS assigns a subset of the data in each shard to the shard's subscribers. For example, in six-node subcluster in a a three-shard database, each shard has two subscribers. ECS assigns each of the subscribers half of the data in the shard to process during queries. In most cases, with less data to process, the nodes finish executing the query faster. When adding more nodes than shards to a subcluster, make the number of nodes a multiple of the number of shards to ensure an even distribution. For example, in a three-shard database, make the number of nodes in the subcluster 6, 9, 12, and so on.
Using different subclusters for different query types
You do not have to choose one form of elasticity over the other in your database. You can create a group of subclusters to improve query throughput and one or more subclusters that improve query performance. The difference between the two subcluster types is mainly the number of subclusters you create and the number of nodes they contain. To improve throughput, add a multiple subclusters that contain a number of nodes that is equal to or less than the number of shards in the database. The more subclusters you add, the greater the throughput you achieve. To improve query performance, add one or more subclusters where the number of nodes is a multiple of the number of shards in the database.
Once you have created your set of subclusters, you must have clients connect to the correct subcluster for the types of queries they will run. For clients executing frequent, simple dashboard queries, create a connection load balancing policy that connects them to nodes in the throughput scaling subclusters. For clients running more complex analytic queries, create another load balancing policy that connects them to nodes in the performance scaling subcluster.
For details on scaling your Eon Mode database, see Scaling your Eon Mode database.
2.5 - Data integrity and high availability in an Eon Mode database
The nodes in your Eon Mode database's are responsible for maintaining the data in your database.
The nodes in your Eon Mode database's primary subclusters are responsible for maintaining the data in your database. These nodes (collectively called the database's primary nodes) plan the Tuple Mover mergeout operations that manage the data in the shards. They can also execute these operations if they are the best candidate to do so (see The Tuple Mover in Eon Mode Databases).
The primary nodes can be spread across multiple primary subclusters—they all work together to maintain the data in the shards. The health of the primary nodes is key for your database to continue running normally.
The nodes in secondary subclusters do not plan Tuple Mover operations. They can execute Tuple Mover mergeout operations if a primary node assigns it to them. Your database cluster can lose all of its secondary nodes and still maintain the data in the shards.
Maintaining data integrity the is top goal of your database. If your database loses too many primary nodes, it cannot safely process data. In this case, it goes into read-only mode to prevent data inconsistency or corruption.
High availability (having the database continue running even if individual nodes are lost) is another goal of Vertica. It has several redundancy features to help it prevent downtime. With these features enabled, your database continues to run even if it loses one or more primary nodes.
There are two requirements for the database to continue normal operations: maintaining quorum, and maintaining shard coverage.
Maintaining quorum
The basic requirement for the primary nodes in your Eon Mode database is maintaining a quorum of primary nodes running at all times. To maintain quorum, more than half of the primary nodes (50% plus 1) must be up. For example, in a database with 6 primary nodes, at least 4 of them must be up. If half or more of the primary nodes are down, your database goes into read-only mode to prevent potential data integrity issues. In a database with 6 primary nodes, the database goes into read-only if it loses 3 or more of them. See Read-Only Mode below.
Vertica only counts the primary nodes that are currently part of the database when determining whether the database has quorum. Removing primary nodes cannot result in a loss of quorum. During the removal process, Vertica adjusts the node count to prevent the loss of quorum.
At a minimum, your Eon Mode database must have at least one primary node to function. In most cases, it needs more than one. See Minimum Node Requirements for Eon Mode Database Operation below.
Maintaining shard coverage
In order to continue to process data, your database must be able to maintain the data in its shards. To maintain the data, each shard must have a subscribing primary node that is responsible for running the Tuple Mover on it. This requirement is called having shard coverage. If one or more shards do not have a primary node maintaining its data, your database loses shard coverage and goes into read-only mode (explained below) to prevent possible data integrity issues.
The measure of how resilient your Eon Mode database is to losing a primary node is called its K-safety level. The value K is the number of redundant shard subscriptions your Eon Mode database cluster maintains. It also represents the number of primary nodes in your database that can fail and still be able to run safely. In many cases, your database can lose more than K nodes and still continue to run normally, as long as it maintains shard coverage.
Vertica recommends that your database always have a K-safety value of 1 (K=1). In a K=1 database, each shard has two subscribers: a primary subscriber that is responsible for the shard, and a secondary subscriber that can fill in if the primary subscriber is lost. The primary subscriber is responsible for running the Tuple Mover on the data in the shard. The secondary subscriber maintains a copy of the shard's catalog metadata. so it can fill in if the primary subscriber is lost.
If a shard's primary subscriber fails, the secondary subscriber fills in for it. Because it does not maintain a separate depot for its secondary subscription, the secondary subscriber always directly accesses the shard's data in communal storage. This direct access impacts your database's performance while a secondary subscriber fills in for a primary subscriber. For this reason, always restart or replace a down primary node as soon as possible.
With primary and secondary subscribers in a K=1 database, the loss of a single primary node does not affect the database's ability to process and maintain data. However, if the secondary subscriber fails while standing in for the primary subscriber, your database would lose shard coverage. and be forced to go into read-only mode.
Elastic K-safety
Vertica uses a feature called elastic K-safety to help limit the possibility of shard coverage loss. By default, if either the primary or secondary subscriber to a shard fails, Vertica subscribes an additional primary node to the shard. This subscription takes time to be established, as the newly-subscribed node must get a copy of the shard's metadata. If the shard's sole subscriber fails while the new subscriber is getting the shard's metadata, the database loses shard coverage and can shut down. Once the newly-subscribed node gets a copy of the metadata, it is able to take over maintenance of the shard in case the other subscriber fails. At this point, your database once again has two subscribers for the shard.
Once the down nodes recover and rejoin the subcluster, Vertica removes the subscriptions it added for elastic K-safety. Once all of the nodes rejoin the cluster, the shard subscriptions are the same as they were before the node loss.
With elastic K-safety, your database could manage to maintain shard coverage through the gradual loss of primary nodes, up to the point that it loses quorum. As long as there is enough time for newly-subscribed nodes to gather the shard's metadata, your database is able to maintain shard coverage. However, your database could still be forced into read-only mode due to loss of shard coverage if it lost the primary and secondary subscribers to a shard before a new primary node could complete the process of subscribing to the shard.
Note
Vertica stops adding new subscriptions when your database gets close to losing quorum. It continues to add new subscriptions if your cluster has more than N ÷ 2 + K + 1 primary nodes up, where N is the total number of primary nodes in the database. For example, if you have 10 primary nodes in your K=1 database, Vertica adds new subscriptions as long as the number of primary nodes that are up is greater than 7 (10 ÷ 2 + 1 + 1). If the number of up primary nodes falls to 6 in this database, adding an additional subscription does not make sense. Losing another primary node would force the database to shut down due to a loss of quorum.
Database read-only mode
If your database loses either quorum or primary shard coverage, it goes into read-only mode. This mode prevents potential data corruption that could result when too many nodes are down or unable to reach other nodes in the database. Read-only mode prevents changes being made to the database that require updates to the global catalog.
DML and DDL in read-only mode
In read-only mode, statements that change the global catalog (such as most DML and DDL statements) fail with an error message. For example, executing DDL statements such as CREATE TABLE while the database is in read-only mode results in the following error:
=> CREATE TABLE t (a INTEGER, b VARCHAR);
ERROR 10428: Transaction commit aborted since the database is currently in read-only mode
HINT: Commits will be restored when the database restores the quorum
DML statements such as COPY return a different error. Vertica stops them from executing before they perform any work:
=> COPY warehouse_dimension from stdin;
ERROR 10422: Running DML statements is not possible in read-only mode
HINT: Running DMLs will be restored when the database restores the quorum
By returning the error early, Vertica avoids performing all of the work required to load data, only to fail when it tries to commit the transaction.
DDL and DML statements that do not affect the global catalog still work. For example, you can create a local temporary table and load data into it while the database is in read-only mode.
Queries in read-only mode
Queries can run on any subcluster that has shard coverage. For example, suppose you have an Eon Mode database with a 3-node primary and a 3-node secondary subcluster. If two of the primary nodes go down, the database loses quorum and goes into read-only mode. The primary subcluster also loses shard coverage, because two of its nodes are down. The remaining node does not have a subscription to at least some of the shards. In this case, queries on the remaining primary node (except for some system table queries) always fail:
=> SELECT * FROM warehouse_dimension;
ERROR 9099: Cannot find participating nodes to run the query
The secondary subcluster still has shard coverage so you can execute queries on it.
Monitoring read-only mode
Besides noticing DML and DDL statements returning errors, you can determine whether the database has gone into read-only mode by monitoring system tables:
-
The NODES system table has a column named is_readonly that becomes true for all nodes when the database is in read-only mode.
=> SELECT node_name, node_state, is_primary, is_readonly, subcluster_name FROM nodes;
node_name | node_state | is_primary | is_readonly | subcluster_name
----------------------+------------+------------+-------------+--------------------
v_verticadb_node0001 | UP | t | t | default_subcluster
v_verticadb_node0002 | DOWN | t | t | default_subcluster
v_verticadb_node0003 | DOWN | t | t | default_subcluster
v_verticadb_node0004 | UP | f | t | analytics
v_verticadb_node0005 | UP | f | t | analytics
v_verticadb_node0006 | UP | f | t | analytics
(6 rows)
-
When the database goes into read-only mode, every node that is still up in the database records a Cluster Read-only event (event code 20). You can find these events by querying the event monitoring system tables such as ACTIVE_EVENTS:
=> \x
Expanded display is on.
=> SELECT * FROM ACTIVE_EVENTS WHERE event_code = 20;
-[ RECORD 1 ]-------------+--------------------------------------------------------------------------
node_name | v_verticadb_node0001
event_code | 20
event_id | 0
event_severity | Critical
event_posted_timestamp | 2021-11-22 15:57:24.514475+00
event_expiration | 2089-12-10 19:11:31.514475+00
event_code_description | Cluster Read-only
event_problem_description | Cluster cannot perform updates due to quorum loss and can only be queried
reporting_node | v_verticadb_node0001
event_sent_to_channels | Vertica Log
event_posted_count | 1
-[ RECORD 2 ]-------------+--------------------------------------------------------------------------
node_name | v_verticadb_node0004
event_code | 20
event_id | 0
event_severity | Critical
event_posted_timestamp | 2021-11-22 15:57:24.515022+00
event_expiration | 2089-12-10 19:11:31.515022+00
event_code_description | Cluster Read-only
event_problem_description | Cluster cannot perform updates due to quorum loss and can only be queried
reporting_node | v_verticadb_node0004
event_sent_to_channels | Vertica Log
event_posted_count | 1
-[ RECORD 3 ]-------------+--------------------------------------------------------------------------
node_name | v_verticadb_node0005
event_code | 20
event_id | 0
event_severity | Critical
event_posted_timestamp | 2021-11-22 15:57:24.515019+00
event_expiration | 2089-12-10 19:11:31.515019+00
event_code_description | Cluster Read-only
event_problem_description | Cluster cannot perform updates due to quorum loss and can only be queried
reporting_node | v_verticadb_node0005
event_sent_to_channels | Vertica Log
event_posted_count | 1
-[ RECORD 4 ]-------------+--------------------------------------------------------------------------
node_name | v_verticadb_node0006
event_code | 20
event_id | 0
event_severity | Critical
event_posted_timestamp | 2021-11-22 15:57:24.515172+00
event_expiration | 2089-12-10 19:11:31.515172+00
event_code_description | Cluster Read-only
event_problem_description | Cluster cannot perform updates due to quorum loss and can only be queried
reporting_node | v_verticadb_node0006
event_sent_to_channels | Vertica Log
event_posted_count | 1
See Monitoring events.
Recover from read-only mode
To recover from read-only mode, restart the down nodes. Restarting the nodes resolves loss of quorum or loss of primary shard coverage that caused the database to go into read-only mode.
Once the down nodes restart and rejoin the database, Vertica restarts on the nodes that were in read-only mode. This step is necessary to allow the nodes to resubscribe to their shards. During this restart, client connections to these nodes will drop. For example, users connected via vsql to one of the nodes where Vertica is restarting see the message:
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Succeeded.
Users using vsql to connect to nodes as Vertica restarts see the message:
vsql: FATAL 4149: Node startup/recovery in progress. Not yet ready
to accept connections
Once Vertica restarts on the nodes, the database resumes normal operation.
When Vertica sets the K-safety value in an Eon Mode database
When you have three or more primary nodes in your database, Vertica automatically sets the database's K-safety to 1 (K=1). It also automatically configures shard subscriptions so that each node can act as a backup for another node, as described in Maintaining Shard Coverage.
This behavior is different than an Enterprise Mode database, where you must design your database's physical schema to meet several criteria before you can have Vertica mark the database as K-safe. See Difference Between Enterprise Mode and Eon Mode K-safe Designs below for details.
Note
Databases with less than three primary nodes have no data redundancy (K=0). Vertica recommends you only use a database with less than three primary nodes for testing.
Minimum node requirements for Eon Mode database operation
The K-safety level of your database determines the minimum number of primary nodes it must have:
- When K=0, your database must have at least 1 primary node. Setting K to 0 allows you to have a single-node Eon Mode database. Note that in a K=0 database, the loss of a primary node will result in the database going into read-only mode.
- When K=1 (the most common case), your database must have at least three primary nodes. This number of primary nodes allows Vertica to maintain data integrity if a primary node goes down.
- If you want to manually set the K-safe value to 2 (see Difference Between Enterprise Mode and Eon Mode K-safe Designs below) you must have at least 5 primary nodes.
Vertica prevents you from removing primary nodes if your cluster would fall below the lower limit for your database's K-safety setting. If you want to remove nodes in a database at this lower limit, you must lower the K-safety level using the MARK_DESIGN_KSAFE function and then call REBALANCE_SHARDS.
Critical nodes and subclusters
Vertica designates any node or subcluster in the database whose loss would cause the database to go into read-only mode as critical. For example, in an Eon Mode database, when a primary node goes down, nodes with secondary subscriptions to its shards take over maintaining the shards' data. These nodes become critical. Their loss would cause the database to lose shard coverage and be forced to go into read-only mode.
Note
When elastic K-safety is enabled (which is the default) Vertica subscribes additional primary nodes to a down primary node's shards. After these nodes finish subscribing by getting a copy of the shard's metadata, they are ready to fill in if the secondary subscriber also goes down. When this happens, the node filling in for the down node is no longer considered critical.
Vertica maintains a list of critical nodes and subclusters in two system tables: CRITICAL_NODES and CRITICAL_SUBCLUSTERS. Before stopping nodes or subclusters, check these tables to ensure the node or subcluster you intend to stop is not critical.
Difference between Enterprise Mode and Eon Mode K-safe designs
In an Enterprise Mode database, you use the MARK_DESIGN_KSAFE function to enable high availability in your database. You call this function after you have designed your database's physical schema to meet all the requirements for K-safe design (often, by running the database designer). If you attempt to mark your database as K-safe when the physical schema does not support the level K-safety you pass to MARK_DESIGN_KSAFE, it returns an error. See Designing segmented projections for K-safety for more information.
In Eon Mode, you do not need to use the MARK_DESIGN_KSAFE because Vertica automatically makes the database K-safe when you have three or more primary nodes. You can use this function to change the K-safety level of your database. In an Eon Mode database, this function changes how Vertica configures shard subscriptions. You can call MARK_DESIGN_KSAFE with any level of K-safety you want. It only has an effect when you call REBALANCE_SHARDS to update the shard subscriptions for the nodes in your database.
Note
Usually, you do not use a K-safety value of greater than 1 in a cloud-based Eon Mode database. Adding replacement nodes to a cluster is easy in a cloud environment.
2.6 - Stopping, starting, terminating, and reviving Eon Mode database clusters
If you do not need your Eon Mode database for a period of time, you can choose to stop or terminate its cluster.
If you do not need your Eon Mode database for a period of time, you can choose to stop or terminate its cluster. Stopping or terminating the cluster saves you money when running in cloud environments.
Stopping and starting a database cluster
When you stop your database cluster, you shut down the nodes in the cluster. Shutting down the cluster is an additional step beyond just shutting down the database. When you shut down the cluster in cloud environments, the node's instances no longer run but are still defined in the cloud platform. You can quickly restart the cluster and database when you need to use it again.
Stopping the database cluster is the best option to use when you will not need it for a short to medium time frame. For example, if no one accesses your database on weekends or holidays, you may consider stopping the cluster.
You save money when you shut down your database cluster in cloud environments. Stopped clusters do not consume expensive CPU resources. Stopped clusters can still cost you money, however. If you configured your nodes with persistent local storage, your cloud provider usually still charges a small amount to maintain that storage space.
Terminating and reviving a database cluster
Terminating a database cluster frees up the resources used by the database cluster's nodes.
On a cloud platform, terminating the database cluster deletes the node's virtual machine instances. The database's data and catalog remain stored in communal storage. You can restart the database by reviving it. When you revive a database, you provision a new database cluster and configure it to use the database's data and metadata stored in communal storage.
In an on-premises Eon Mode database, terminating the database cluster usually means shutting down the database and then repurposing the hardware that the nodes ran on.
Terminating the database cluster is the best option for when you will not need the database for an extended period (or if you are unsure whether you will ever need the database again). As long as you do not delete the communal storage location, you can get your database running again by reviving it.
To revive a database, you create a new Vertica Eon Mode cluster and configure it to use the database's communal storage location. The easiest way to revive a database in the cloud is to use the Management Console. It provisions a new Eon Mode cluster for you, and then revives the database onto it.
Reviving a database takes longer than starting a stopped database. Even if you use the MC to automate the process, provisioning a new set of nodes takes much longer than just restarting stopped nodes. When the new nodes start for the first time, they must load data from communal storage from scratch.
Terminating the database cluster can save you more money over simply stopping the database when the database's nodes have persistent local storage. Cloud providers usually charge you a small recurring fee for the space consumed by persistent local storage on the nodes.
See also
3 - Enterprise Mode concepts
In an Enterprise Mode Vertica database, the physical architecture is designed to move data as close as possible to computing resources.
In an Enterprise Mode Vertica database, the physical architecture is designed to move data as close as possible to computing resources. This architecture differs from a cluster running in Eon Mode which is described in Eon Mode concepts.
The data in an Enterprise Mode database is spread among the nodes in the database. Ideally, the data is evenly distributed to ensure that each node has an equal amount of the analytic workload.
Hybrid data store
When running in Enterprise Mode, Vertica stores data on the database in read optimized store (ROS) containers. ROS data is segmented, sorted, and compressed for high optimization. To avoid fragmentation of data among many small ROS containers, Vertica periodically executes a mergeout operation, which consolidates ROS data into fewer and larger containers.
Data redundancy
In Enterprise Mode, each node of the Vertica database stores and operates on data locally. Without some form of redundancy, the loss of a node would force your database to shut down, as some of its data would be unavailable to service queries.
You usually choose to have your Enterprise Mode database store data redundantly to prevent data loss and service interruptions should a node shut down. See K-safety in an Enterprise Mode database for details.
3.1 - K-safety in an Enterprise Mode database
K-safety sets the fault tolerance in your Enterprise Mode database cluster.
K-safety sets the fault tolerance in your Enterprise Mode database cluster. The value K represents the number of times the data in the database cluster is replicated. These replicas allow other nodes to take over query processing for any failed nodes.
In Vertica, the value of K can be zero (0), one (1), or two (2). If a database with a K-safety of one (K=1) loses a node, the database continues to run normally. Potentially, the database could continue running if additional nodes fail, as long as at least one other node in the cluster has a copy of the failed node's data. Increasing K-safety to 2 ensures that Vertica can run normally if any two nodes fail. When the failed node or nodes return and successfully recover, they can participate in database operations again.
Note
If the number of failed nodes exceeds the K value, some the data may become unavailable. In this case, the database is considered unsafe and automatically shuts down. However, if every data segment is available on at least one functioning cluster node Vertica continues to run safely.
Potentially, up to half the nodes in a database with a K-safety of 1 could fail without causing the database to shut down. As long as the data on each failed node is available from another active node, the database continues to run.
Note
If half or more of the nodes in the database cluster fail, the database automatically shuts down even if all of the data in the database is available from replicas. This behavior prevents issues due to network partitioning.
Note
The physical schema design must meet certain requirements. To create designs that are K-safe, Vertica recommends using the
Database Designer.
Buddy projections
In order to determine the value of K-safety, Vertica creates buddy projections, which are copies of segmented projections distributed across database nodes. (See Segmented projections and Unsegmented projections.) Vertica distributes segments that contain the same data to different nodes. This ensures that if a node goes down, all the data is available on the remaining nodes.
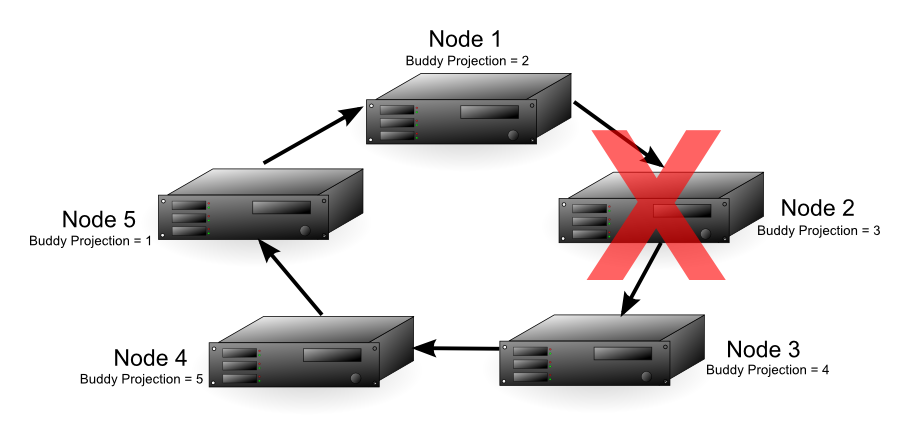
K‑Safety example
This diagram above shows a 5-node cluster with a K-safety level of 1. Each node contains buddy projections for the data stored in the next higher node (node 1 has buddy projections for node 2, node 2 has buddy projections for node 3, and so on). If any of the nodes fail, the database continues to run. The database will have lower performance because one of the nodes must handle its own workload and the workload of the failed node.
The diagram below shows a failure of Node 2. In this case, Node 1 handles processing for Node 2 since it contains a replica of node 2's data. Node 1 also continues to perform its own processing. The fault tolerance of the database falls from 1 to 0, since a single node failure could cause the database to become unsafe. In this example, if either Node 1 or Node 3 fails, the database becomes unsafe because not all of its data is available. If Node 1 fails,Node 2's data is no longer be available. If Node 3 fails, its data is no longer available, because node 2 is down and could not use the buddy projection. In this case, nodes 1 and 3 are considered critical nodes. In a database with a K-safety level of 1, the node that contains the buddy projection of a failed node, and the node whose buddy projections are on the failed node, always become critical nodes.
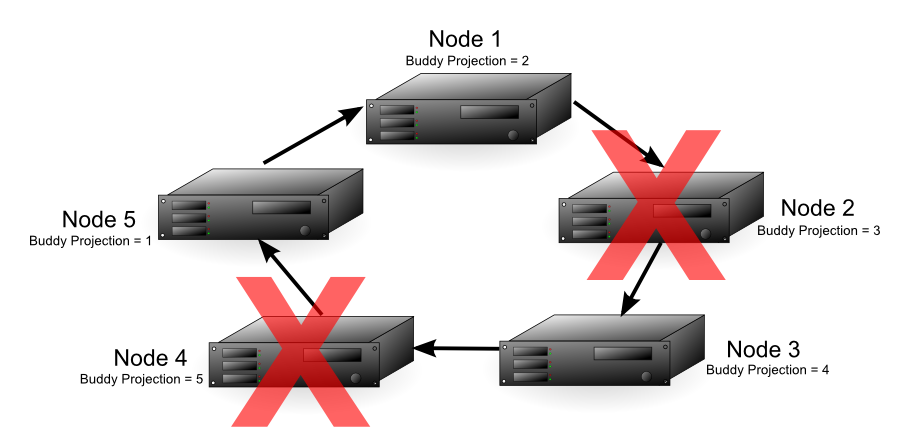
With Node 2 down, either node 4 or 5 could fail and the database still has all of its data available. The diagram below shows that if node 4 fails, node 3 can use its buddy projections to fill in for it. In this case, any further loss of nodes results in a database shutdown, since all the nodes in the cluster are now critical nodes. In addition, if one more node were to fail, half or more of the nodes would be down, requiring Vertica to automatically shut down, no matter if all of the data were available or not.
In a database with a K-safety level of 2, Node 2 and any other node in the cluster could fail and the database continues running. The diagram below shows that each node in the cluster contains buddy projections for both of its neighbors (for example, Node 1 contains buddy projections for Node 5 and Node 2). In this case, nodes 2 and 3 could fail and the database continues running. Node 1 could fill in for Node 2 and Node 4 could fill in for Node 3. Due to the requirement that half or more nodes in the cluster be available in order for the database to continue running, the cluster could not continue running if node 5 failed, even though nodes 1 and 4 both have buddy projections for its data.
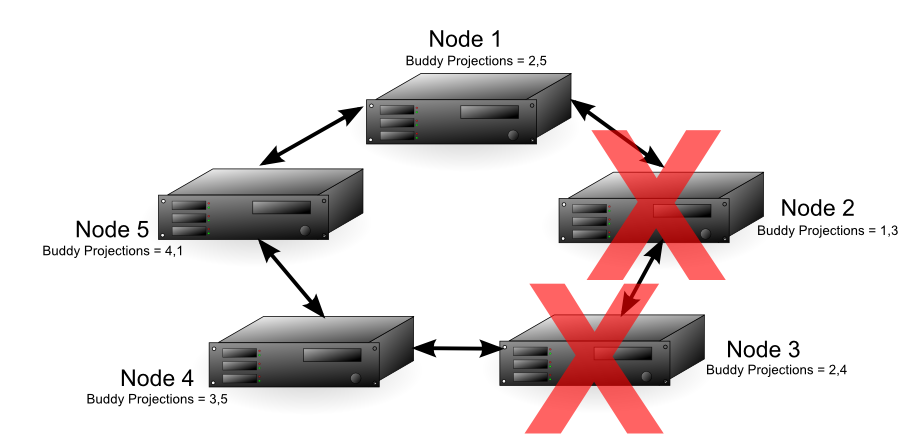
Note
Vertica requires that more than half of all nodes in a cluster must always be available; otherwise, it views the database as being in an unsafe state and shuts it down. Thus, in the previous example, the cluster cannot continue running if Node 5 fails, even though nodes 1 and 4 have buddy projections for its data.
Monitoring K‑safety
You can access System Tables to monitor and log various aspects of Vertica operation. Use the
SYSTEM table to monitor information related to K‑safety, such as:
-
NODE_COUNT: Number of nodes in the cluster
-
NODE_DOWN_COUNT: Number of nodes in the cluster that are currently down
-
CURRENT_FAULT_TOLERANCE: The K‑safety level
3.2 - High availability with projections
To ensure high availability and recovery for database clusters of three or more nodes, Vertica:.
To ensure high availability and recovery for database clusters of three or more nodes, Vertica:
-
Replicates small, unsegmented projections
-
Creates buddy projections for large, segmented projections.
Replication (unsegmented projections)
When it creates projections, Database Designer replicates them, creating and storing duplicates of these projections on all nodes in the database.
Replication ensures:
-
Distributed query execution across multiple nodes.
-
High availability and recovery. In a K-safe database, replicated projections serve as buddy projections. This means that you can use a replicated projection on any node for recovery.
Note
We recommend you use Database Designer to create your physical schema. If you choose not to, be sure to segment all large tables across all database nodes, and replicate small, unsegmented table projections on all database nodes.
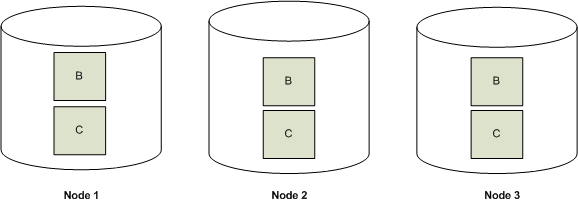
The following illustration shows two projections, B and C, replicated across a three node cluster.
Buddy projections (segmented projections)
Vertica creates buddy projections which are copies of segmented projections that are distributed across database nodes (see Segmented projections.) Vertica distributes segments that contain the same data to different nodes. This ensures that if a node goes down, all the data is available on the remaining nodes. Vertica distributes segments to different nodes by using offsets. For example, segments that comprise the first buddy projection (A_BP1) are offset from projection A by one node, and segments from the second buddy projection (A_BP2) are offset from projection A by two nodes.
The following diagram shows the segmentation for a projection called A and its buddy projections, A_BP1 and A_BP2, for a three node cluster.

The following diagram shows how Vertica uses offsets to ensure that every node has a full set of data for the projection.

How result sets are stored
Vertica duplicates table columns on all nodes in the cluster to ensure high availability and recovery. Thus, if one node goes down in a K-Safe environment, the database continues to operate using duplicate data on the remaining nodes. Once the failed node resumes its normal operation, it automatically recovers its lost objects and data by querying other nodes.
Vertica compresses and encodes data to greatly reduce the storage space. It also operates on the encoded data whenever possible to avoid the cost of decoding. This combination of compression and encoding optimizes disk space while maximizing query performance.
Vertica stores table columns as projections. This enables you to optimize the stored data for specific queries and query sets. Vertica provides two methods for storing data:
3.3 - High availability with fault groups
Use fault groups to reduce the risk of correlated failures inherent in your physical environment.
Use fault groups to reduce the risk of correlated failures inherent in your physical environment. Correlated failures occur when two or more nodes fail as a result of a single failure. For example, such failures can occur due to problems with shared resources such as power loss, networking issues, or storage.
Vertica minimizes the risk of correlated failures by letting you define fault groups on your cluster. Vertica then uses the fault groups to distribute data segments across the cluster, so the database continues running if a single failure event occurs.
Note
If your cluster layout is managed by a single network switch, a switch failure can be a single point of failure. Fault groups cannot help with single-point failures.
Vertica supports complex, hierarchical fault groups of different shapes and sizes. You can integrate fault groups with elastic cluster and large cluster arrangements to add cluster flexibility and reliability.
Making Vertica aware of cluster topology with fault groups
You can also use fault groups to make Vertica aware of the topology of the cluster on which your Vertica database is running. Making Vertica aware of your cluster's topology is required when using terrace routing, which can significantly reduce message buffering on a large cluster database.
Automatic fault groups
When you configure a cluster of 120 nodes or more, Vertica automatically creates fault groups around control nodes. Control nodes are a subset of cluster nodes that manage spread (control messaging). Vertica places nodes that share a control node in the same fault group. See Large cluster for details.
User-defined fault groups
Define your own default groups if:
Example cluster topology
The following diagram provides an example of hierarchical fault groups configured on a single cluster:
-
Fault group FG–A contains nodes only.
-
Fault group FG-B (parent) contains child fault groups FG-C and FG-D. Each child fault group also contain nodes.
-
Fault group FG–E (parent) contains child fault groups FG-F and FG-G. The parent fault group FG–E also contains nodes.
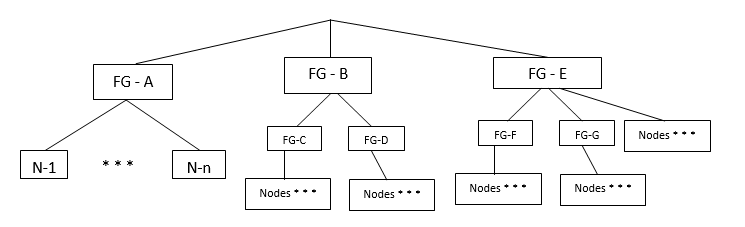
How to create fault groups
Before you define fault groups, you must have a thorough knowledge of your physical cluster layout. Fault groups require careful planning.
To define fault groups, create an input file of your cluster arrangement. Then, pass the file to a script supplied by Vertica, and the script returns the SQL statements you need to run. See Fault Groups for details.