To monitor real-time flow of data through a query plan and its individual paths, query the following system tables:
EXECUTION_ENGINE_PROFILES and
QUERY_PLAN_PROFILES. These tables provides data on how Vertica executed a query plan and its individual paths:
-
EXECUTION_ENGINE_PROFILESsummarizes query execution runs. -
QUERY_PLAN_PROFILESshows the real-time flow of data, and the time and resources consumed for each query plan path.
Each query plan path has a unique ID, as shown in the following
EXPLAIN output fragment.
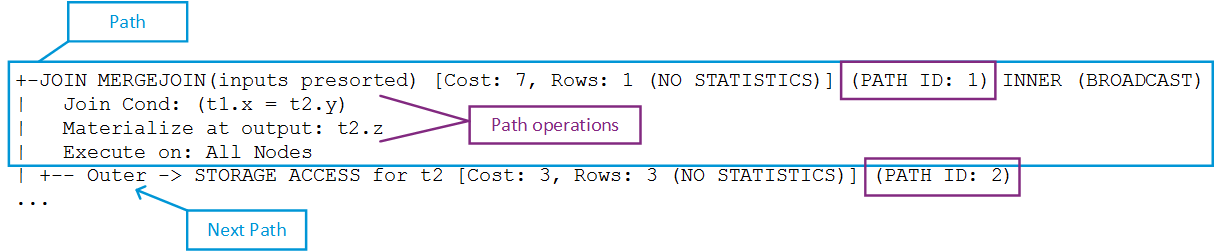
Both tables provide path-specific data. For example, QUERY_PLAN_PROFILES provides high-level data for each path, which includes:
-
Length of a query operation execution
-
How much memory that path's operation consumed
-
Size of data sent/received over the network
For example, you might observe that a GROUP BY HASH operation executed in 0.2 seconds using 100MB of memory.
Requirements
Real-time profiling minimally requires the ID of the transaction to monitor. If the transaction includes multiple statements, you also need the statement ID. You can get statement and transaction IDs by issuing
PROFILE on the query to profile. You can then use these identifiers to query system tables EXECUTION_ENGINE_PROFILES and QUERY_PLAN_PROFILES.
For more information, see Profiling single statements.